BLOG POST
AI 日报
Behind the Blog: Behind 404 Media's ICE Lawsuit
This week, we discuss being journalism dorks, our new lawsuit against ICE, and working on bullshit.
Earth Was Mysteriously Thrown Off-Kilter In 2015. Now, Scientists Think They Know Why.
The sudden reduction in the Chandler wobble, a deviation between Earth’s axis and crust, may primarily originate in a powerful La Niña event, reports a new study.
DeepMind's Gemini Robotics 1.5 Gives Robots Reasoning Powers
Google's AI research unit said the new models mark a step closer to artificial general intelligence.
CAMIA privacy attack reveals what AI models memorise
Researchers have developed a new attack that reveals privacy vulnerabilities by determining whether your data was used to train AI models. The method, named CAMIA (Context-Aware Membership Inference Attack), was developed by researchers from Brave and the National University of Singapore and is far more effective than previous attempts at probing the ‘memory’ of AI […]
The post CAMIA privacy attack reveals what AI models memorise appeared first on AI News.
Ethical cybersecurity practice reshapes enterprise security in 2025
When ransomware attacks like Akira and Ryuk began crippling organisations worldwide, the cybersecurity industry’s first instinct was predictable: build bigger walls, deploy more aggressive automated responses, and lock down everything. But there was a different problem emerging, according to Romanus Prabhu Raymond, Director of Technology at ManageEngine. The company’s customers were demanding aggressive containment features, […]
The post Ethical cybersecurity practice reshapes enterprise security in 2025 appeared first on AI News.
A Day in the Life of an AWS Developer

The campaign highlights something developers have always known: the line between work and life is porous.
The post A Day in the Life of an AWS Developer appeared first on Analytics India Magazine.
Two Indian Engineers on a Mission to Automate Home Cooking for the World

In a live demonstration for AIM, Posha prepared paneer tikka masala in approximately 25 minutes
The post Two Indian Engineers on a Mission to Automate Home Cooking for the World appeared first on Analytics India Magazine.
Karnataka to Democratise AI Access for Students, Startups

Kharge hinted at a possible extension of the Nipuna scheme to fund and retain advanced research talent.
The post Karnataka to Democratise AI Access for Students, Startups appeared first on Analytics India Magazine.
AWS Space Accelerator Program to Support 42 Indian Space Startups

The selected startups are developing solutions across geospatial analytics, satellite propulsion, space sustainability, and more.
The post AWS Space Accelerator Program to Support 42 Indian Space Startups appeared first on Analytics India Magazine.
BharatGen and the Pursuit of Sovereign, Scalable AI for India

“Knowledge-driven components are important because we don't want everything to be just algorithmic innovation.”
The post BharatGen and the Pursuit of Sovereign, Scalable AI for India appeared first on Analytics India Magazine.
GitHub Launches Copilot CLI in Public Preview for Terminal-Based Coding

The company is bringing its AI coding agent directly to the terminal with native GitHub integration, agentic capabilities, and full developer control.
The post GitHub Launches Copilot CLI in Public Preview for Terminal-Based Coding appeared first on Analytics India Magazine.
IBM Helps Unity Bank Cut Time to Market for New APIs by 50%

With IBM’s solutions, Unity Bank has established a centralised API hub to manage internal and external APIs across its hybrid cloud infrastructure.
The post IBM Helps Unity Bank Cut Time to Market for New APIs by 50% appeared first on Analytics India Magazine.
ServiceNow University Launches in India to Train 1 Million in AI by 2027

The launch comes as new research from ServiceNow estimates that Agentic AI will reshape more than 10 million jobs in India by 2030.
The post ServiceNow University Launches in India to Train 1 Million in AI by 2027 appeared first on Analytics India Magazine.
ChatGPT’s New Background Agent ‘Insanely Useful’

ChatGPT Pulse presents a feed of cards filled with content you’ve asked about before.
The post ChatGPT’s New Background Agent ‘Insanely Useful’ appeared first on Analytics India Magazine.
How Pradhi AI Embeds Emotional Intelligence in Voice AI

As businesses recognise the potential of voice-driven tech, Pradhi AI is laying the foundation for an empathetic, responsive AI ecosystem.
The post How Pradhi AI Embeds Emotional Intelligence in Voice AI appeared first on Analytics India Magazine.
Tech Mahindra, AMD Tie Up to Drive Hybrid Multi-Cloud Transformation for Global Enterprises

The deal aims to let enterprises across key sectors, including manufacturing, finance, telecommunications and healthcare harness the full potential of AI-driven infrastructure.
The post Tech Mahindra, AMD Tie Up to Drive Hybrid Multi-Cloud Transformation for Global Enterprises appeared first on Analytics India Magazine.
Perplexity Announces Search API

“With an index covering hundreds of billions of webpages, developers can now tap information from across the internet with one simple yet powerful interface.”
The post Perplexity Announces Search API appeared first on Analytics India Magazine.
LTIMindtree unveils AI governance Framework, BlueVerse Academy

The framework integrates AI governance into autonomous agents, ensuring compliance with business rules and regulations.
The post LTIMindtree unveils AI governance Framework, BlueVerse Academy appeared first on Analytics India Magazine.
Wipro Denies Karnataka’s Request to Use Sarjapur Campus for Public Vehicles To Ease Traffic

Instead, the company suggested a scientific study in urban transport management for Bengaluru’s long-term mobility solutions.
The post Wipro Denies Karnataka’s Request to Use Sarjapur Campus for Public Vehicles To Ease Traffic appeared first on Analytics India Magazine.
Accenture’s Underwhelming AI Reality Check Spells Trouble for Indian IT

On the one hand, clients want AI and Accenture is booking contracts around it, but it’s not yielding results as expected.
The post Accenture’s Underwhelming AI Reality Check Spells Trouble for Indian IT appeared first on Analytics India Magazine.
Zoho Vs Microsoft – India’s Homegrown Tech Giant Shows a Bold Move

Zoho is challenging Microsoft with its 50+ enterprise applications built entirely in India, from CRM to AI platforms. Bootstrapped and fiercely independent, Zoho is doubling down on R&D. With India’s IT Minister endorsing Zoho as a “Swadeshi” alternative, the company’s mission to rival global tech giants is gaining momentum.
The post Zoho Vs Microsoft – India’s Homegrown Tech Giant Shows a Bold Move appeared first on Analytics India Magazine.
Trump says TikTok should be tweaked to become “100% MAGA”
Uncertainty reigns as Trump claims China approved TikTok deal.
Scientists want to treat complex bone fractures with a bone-healing gun
It's a bit like a handheld 3D printer, with all the accuracy challenges that implies.
50+ scientific societies sign letter objecting to Trump executive order
Letter urges Congress to take action to safeguard integrity of independent peer-review system.
Asus’ new ROG Xbox Ally X set to break the bank at $999.99
The lower-powered ROG Xbox Ally comes in at a more reasonable $599.99.
Rocket Report: Keeping up with Kuiper; New Glenn’s second flight slips
Amazon plans to conduct two launches of Kuiper broadband satellites just days apart.
Raspberry Pi 500+ puts the Pi, 16GB of RAM, and a real SSD in a mechanical keyboard
Keyboard uses low-profile Gateron Blue switches and an RP2040 controller.
Fiji’s ants might be the canary in the coal mine for the insect apocalypse
A new genetic technique lets museum samples track population dynamics.
Charlie Kirk and the making of an AI-generated martyr
In a polarized environment, the elevation of a figure into a saint does more than honor the individual. It turns a political struggle into a sacred one.
Cute fluffy characters and Egyptian selfies: Meta launches AI feed Vibes
Under Mark Zuckerberg’s publicity video for Vibes, one Instagram user commented: ‘Bros posting ai slop on his own app’
Cat videos, selfies and dad jokes are typical fare for any social media feed but Mark Zuckerberg’s Meta is introducing a new twist: they’re all made by artificial intelligence.
The Meta founder and chief executive has announced the launch of Vibes, a new feed on the Meta AI app comprised entirely of AI-made videos.
Man fined $340,000 for deepfake pornography of prominent Australian women in first-of-its-kind case
Watchdog applauds ‘strong message’ after federal court orders Gold Coast man Anthony Rotondo to pay for posting deepfake images to a now-defunct website
Get our breaking news email, free app or daily news podcast
A man who posted deepfake pornographic images of prominent Australian women has been slapped with a hefty fine as a “strong message” in a first-of-its-kind case.
The federal court ordered Anthony Rotondo, also known as Antonio, to pay a $343,500 penalty plus costs on Friday after the online regulator eSafety Commissioner brought a case against him almost two years ago.
AI’s potential use in nuclear weapons ‘challenges future of humanity’, Penny Wong tells UN – video
The rise of artificial intelligence could potentially endanger the world if the technology were used to control nuclear weapons, Australia's affairs foreign minister warns. In a speech to the United Nations security council, Penny Wong says that while AI has extraordinary potential, it also presents significant dangers if it isn’t kept in check
Amanda Rishworth on the future of work and AI - podcast
Political reporter Josh Butler speaks to Amanda Rishworth, the minister for employment and workplace relations, about the Albanese government’s upcoming reform agenda for workers.
They also discuss the latest figures on enterprise agreements and why she thinks AI is more likely to ‘augment’ rather than displace workers in the near future
Bon Iver Side Project’s Spotify Page Features an AI Slop Song
Spotify promised to fix AI slop drowning out real music less than a day ago.
The post Bon Iver Side Project’s Spotify Page Features an AI Slop Song appeared first on Futurism.
A Researcher’s Guide to LLM Grounding
Large Language Models (LLMs) can be thought of as knowledge bases. During training, LLMs observe large amounts of text. Through this process, they encode a substantial amount of general knowledge that is drawn upon when generating output. This ability to reproduce knowledge is a key driver in enabling capabilities like question-answering or summarization. However, there…
The Video-Game Industry Has a Problem: There Are Too Many Games
A crowded September for video-game releases illustrates a broader challenge in the market
The TikTok Deal’s Unanswered Questions
How much is Trump’s TikTok really worth? Are China and ByteDance on board? Bloomberg Opinion columnist Dave Lee explains. (Source: Bloomberg)
Klarna Sinks Below IPO Price as Fintech Competition Heats Up
Just weeks after a buzzy trading debut, Klarna Group Plc shares fell below the initial public offering price for the first time in the face of increased competition from rivals and worries about the path of interest rates.
AI Cloud Firm Northern Data Raided by German Investigators
German investigators have carried out raids in relation to Northern Data AG, the Frankfurt-listed technology firm backed by stablecoin issuer Tether Holdings Ltd. that has been moving away from crypto mining to focus on artificial-intelligence computing.
SPAC King Palihapitiya, Lee Raise Cash for AI, Crypto Targets
The SPAC ecosystem is growing again, with two investors — including a public face of the original craze — raising funds to target AI and other risky industries.
Uber Sees Non-Takeout Deliveries Becoming $12.5 Billion Business
Uber Technologies Inc. sees its grocery and retail deliveries growing faster than expected, underscoring the company’s effort to catch up with rival services from Instacart, DoorDash Inc. and Amazon.com Inc.
ByteDance to Get About 50% of TikTok US Profit Under Trump Deal
TikTok’s Chinese parent company will likely get about half of the profit from the platform’s US operation even after it sells majority ownership to American investors as part of a deal orchestrated by President Donald Trump, according to people familiar with the matter.
Hackers Hit Hundreds of Cisco Firewalls in US Government
Hackers compromised firewall devices within the US government, according to a senior federal official, amid broader warnings of cyberattacks on widely-used devices manufactured by Cisco Systems, Inc.
Trump Pharma Plan Looks Like Reprieve for Many Drugmakers
President Donald Trump’s plan to impose a 100% tariff on branded drug imports was greeted with a shrug by many investors, who are betting his exemptions for companies with US manufacturing will soften any blow.
TikTok’s $14 Billion Valuation in Trump Deal Stuns Investors
The $14 billion valuation that the Trump administration has estimated for TikTok’s US business falls well below projections, surprising investors who say a deal at that price would be a bargain for potential buyers including Larry Ellison’s Oracle Corp. and partner Silver Lake Management LLC.
India Defends Skilled Worker Flow as Trump Tightens H-1B Rules
India said Friday that both the Indian and US economies have benefited significantly from the movement of skilled talent, days after President Donald Trump’s decision to impose severe restrictions on H-1B visas.
TikTok Gets $14 Billion Proposed Price Tag in Trump Deal
The $14 billion price tag for TikTok’s US business cited by Vice President JD Vance on Thursday is well below previous projections that scaled closer to $40 billion. The estimate comes as President Donald Trump pushes forward a plan for American investors to buy the US operation from Chinese internet firm ByteDance Ltd. Tyler Kendall reports on Bloomberg Television.
US Visa Policy Uncertainties Drive Tech Talent Toward New Hubs
Welcome to Tech In Depth, our daily newsletter about the business of tech from Bloomberg’s journalists around the world. Today, Sankalp Phartiyal addresses the impact of US immigration controls on the mood among workers powering the country’s big tech juggernauts.
Nidec Finds More Suspected Cases of Accounting Fraud
Nidec Corp. has discovered more suspected cases of improper bookkeeping, including some involving a Swiss subsidiary, adding to a scandal that’s threatening the listing of the once-celebrated Japanese auto gear maker.
What We Do and Don’t Know About US TikTok Deal With China
After more than a year of negotiations, the US and China are nearing an agreement to hive off the US operations of social media platform TikTok to a consortium that could include software giant Oracle Corp. If the deal is finalized, it would resolve a persistent issue in Beijing-Washington relations that has become entangled in broader talks over trade.
Meta Set to Launch Paid Version of Facebook and Instagram for UK
Meta Platforms Inc. will soon offer paid versions of Facebook and Instagram in the UK that will remove advertising from both platforms.
Nintendo Appoints Two-Decade Veteran to Helm US Operations
Nintendo Co. has appointed a new leader for its US operations starting next year, elevating a 19-year industry veteran to oversee the Switch 2’s progress in its largest market.
Jack Morris on Finding the Next Big AI Breakthrough
What an AI researcher actually does.
Odd Lots: Finding the Next Big AI Breakthrough (Podcast)
We know that the top-tier AI labs are spending unbelievable amounts of money on talent. But what are these researchers actually working on? And how do we know that they’re making progress? And furthermore, how can we even measure that progress? On this episode, we speak with Jack Morris, an AI researcher and Ph.D. candidate at Cornell University, who is also a part-time researcher at Meta. We talk about what he does, and why breakthroughs seem to be lumpy and unpredictable. We also talk about th
Self-Driving Firm Momenta Seeks Funding at $5 Billion-Plus Value
Autonomous driving startup Momenta is seeking to raise new funding at a valuation well above $5 billion, representing a major jump in the value of the Chinese partner to Uber Technologies Inc.
Prosus Unit OLX to Buy French Auto Trader in $1.3 Billion Deal
Prosus NV-owned OLX Group BV is buying French online auto trader La Centrale for €1.1 billion ($1.3 billion) to expand its business into Western Europe.
UK Seeks AI Rules to Spur Health-Care Overhaul, Protect Patients
The UK is pushing ahead on regulations for artificial intelligence in health care, creating a national commission to help the country attract health-tech investment and make the most of the AI revolution.
SingTel, Optus CEOs to Meet Australia Minister Over Fatal Outage
The heads of Singapore Telecommunications Ltd. and its Optus division will meet with Australian Communications Minister Anika Wells next week as the phone company struggles with the fallout of a network outage that resulted in multiple deaths.
Xiaomi Pledges to Spur Production Efforts for YU7 Electric Car
Xiaomi Corp.’s billionaire co-founder vowed to speed production of the YU7 electric vehicle as deliveries touched 40,000 within three months, taking aim at a big obstacle to his longer-term ambitions.
StanChart Venture Arm Teams Up With Fujitsu on Quantum Computing
Standard Chartered Plc’s venture building arm and Fujitsu Ltd. teamed up on quantum computing, the latest in a slew of financial firms investing in faster technology to speed up services.
Indian Tech Stocks Set for Worst Week Since April on H-1B Woes
Indian software exporters’ shares are heading for their worst week in nearly six months as a steep hike in H-1B visa fee worsens their earnings outlook.
The agentic internet is coming. AI companies are racing to build the digital rails first.
Just as Google and Apple locked in developer ecosystems during the web and mobile eras, today's protocol pioneers may dominate the agentic future.
Why that $14 billion TikTok deal may not be what it seems
A new deal values US TikTok at $14 billion. That seems crazy low for an enormously powerful tech platform.
My partner and I give each other 'jobs' when we travel. It makes our trips easier and more fun.
When we travel as a couple, my partner's job is navigating, and mine is planning logistics and reservations. The division of labor makes trips better.
After working in 4 countries, I learned the best bosses all have 1 thing in common: They know how to connect with employees
I've worked in several countries, and all the best bosses know how to make employees feel safe and heard. They slow down to chat in the hallways.
This Gemini calendar hack shows why Google is uniquely placed to win in AI
I suck at managing my digital calendar. Google's Gemini chatbot offers simple, but magical solutions. The lesson: Integration matters.
Ukraine's mysterious 'Ghosts' unit is hunting Russian warplanes in Crimea. They just claimed 2 more hits.
Ukraine said its "Ghosts" unit burned two Russian An-26 aircraft and hit two radar systems.
After an initial panic, Silicon Valley looks beyond the H1-B
The tech industry has already adapted to the limitations of H-1Bs, with remote work and other visa strategies powering Silicon Valley these days.
My dad's Greek meatballs are the perfect quick dinner — and so easy to make
These easy Greek meatballs have been part of my family's weekly dinner rotation for decades. They go well with fries, pasta, or roasted potatoes.
RIP 'rest and vest.' Big Tech has a new way of paying employees.
Big Tech is shifting to front-loaded equity vesting schedules, transforming employee compensation and challenging 'rest and vest' culture
Elon Musk backs up Trump administration amid James Comey indictment, looming government shutdown
It comes just days after Musk had a face-to-face conversation with Trump at Charlie Kirk's memorial.
TikTok finally cut a deal, but there's still plenty of uncertainty about what comes next
TikTok is in its US era now, but there's still a lot of questions surrounding the deal.
A Marine commander tried to kill off mustaches with a mass-shave order. It didn't last long.
The Marine Corps is one of the strictest services when it comes to appearances, but this fight in the war on facial hair fell apart fast.
The 25 most expensive colleges in the US in 2025, ranked
The yearly cost of attending some private colleges and universities is nearly six-figures.
I've eaten my way through over 20 countries in Europe. These are the 5 cities I can't stop thinking about.
From pizza and truffle pasta in Florence to fish and chips in Edinburgh, I've curated a list of my five favorite foodie cities in Europe.
I've eaten most of Trader Joe's fall foods. Here are the 10 you actually need to try, from frozen meals to easy breakfasts.
So far, I've eaten dozens of Trader Joe's seasonal fall offerings. From pumpkin desserts to savory frozen meals, here are my favorite ones to buy.
My parents are in their 60s. Traveling with them as an adult taught me a hard truth about growing up.
For the first time, my sister and I took the lead when coordinating our family's trip to Europe. It taught me how to show up for my aging parents.
A couple built a $500,000 ADU in their parents' backyard to afford living in California. It has its pros and cons.
While living in a tiny home in your parents' backyard has perks, like saving money, there are also downsides, like not having complete authority.
You've got to adapt to AI, even if your company hasn't figured it out yet, workplace guru says
Young workers should develop their "learning skills" so they can adapt to the job market's needs, Cambridge professor Thomas Roulet said.
Move over, doodles. There's a new 'It' dog in town.
Dachshunds could break into the American Kennel Club's top five most popular breeds this year — and weiner-dog influencers might help them do it.
I visited the billionaire hideaway of the Pacific Northwest and clocked 5 signs of extreme wealth and luxury
From Jeff Bezos to Bill Gates, some of the world's wealthiest people have lived in Medina, Washington, a small waterfront town near Seattle.
Broadcast TV Is a 'Melting Ice Cube.’ Kimmel Just Turned Up the Heat
After Sinclair and Nexstar pulled Jimmy Kimmel off air, the old affiliate model looks shakier than ever. Even Disney might do better without broadcast.
The Week’s 10 Biggest Funding Rounds: Health And AI Lead For Large Financings
This week was a fairly busy one for large financings, with eight of the top 10 exceeding the $100 million mark. Leading the way were two software providers: Judi Health, focused on health benefits software, and Filevine, used for legal practice management.
The Arc Of Venture Capital Bends Toward Democracy
We’re entering an era where the most transformative value could be created almost entirely within private markets, widening the wealth gap between insiders and everyone else, writes guest author Ben Miller, CEO of Fundrise. But momentum is finally on the side of access with the recent passing of the Fair Investment Opportunities for Professional Experts Act.
5 Interesting Startup Deals You May Have Missed In September: A Better Insulin Patch, Maternal Mental Health Care, And A Non-Humanoid Robot
This month most of the startups that caught our attention include a one making a more environmentally friendly fertilizer, a mental health platform for new and expecting mothers, and a medical device company aiming to make a better insulin patch. Let’s take a look.
Interpreting Public Sentiment in Diplomacy Events: A Counterfactual Analysis Framework Using Large Language Models
arXiv:2509.20367v1 Announce Type: new Abstract: Diplomatic events consistently prompt widespread public discussion and debate. Public sentiment plays a critical role in diplomacy, as a good sentiment provides vital support for policy implementation, helps resolve international issues, and shapes a nation's international image. Traditional methods for gauging public sentiment, such as large-scale surveys or manual content analysis of media, are typically time-consuming, labor-intensive, and lack the capacity for forward-looking analysis. We propose a novel framework that identifies specific modifications for diplomatic event narratives to shift public sentiment from negative to neutral or positive. First, we train a language model to predict public reaction towards diplomatic events. To this end, we construct a dataset comprising descriptions of diplomatic events and their associated public discussions. Second, guided by communication theories and in collaboration with domain experts, we predetermined several textual features for modification, ensuring that any alterations changed the event's narrative framing while preserving its core facts.We develop a counterfactual generation algorithm that employs a large language model to systematically produce modified versions of an original text. The results show that this framework successfully shifted public sentiment to a more favorable state with a 70\% success rate. This framework can therefore serve as a practical tool for diplomats, policymakers, and communication specialists, offering data-driven insights on how to frame diplomatic initiatives or report on events to foster a more desirable public sentiment.
Speaker Style-Aware Phoneme Anchoring for Improved Cross-Lingual Speech Emotion Recognition
arXiv:2509.20373v1 Announce Type: new Abstract: Cross-lingual speech emotion recognition (SER) remains a challenging task due to differences in phonetic variability and speaker-specific expressive styles across languages. Effectively capturing emotion under such diverse conditions requires a framework that can align the externalization of emotions across different speakers and languages. To address this problem, we propose a speaker-style aware phoneme anchoring framework that aligns emotional expression at the phonetic and speaker levels. Our method builds emotion-specific speaker communities via graph-based clustering to capture shared speaker traits. Using these groups, we apply dual-space anchoring in speaker and phonetic spaces to enable better emotion transfer across languages. Evaluations on the MSP-Podcast (English) and BIIC-Podcast (Taiwanese Mandarin) corpora demonstrate improved generalization over competitive baselines and provide valuable insights into the commonalities in cross-lingual emotion representation.
CFD-LLMBench: A Benchmark Suite for Evaluating Large Language Models in Computational Fluid Dynamics
arXiv:2509.20374v1 Announce Type: new Abstract: Large Language Models (LLMs) have demonstrated strong performance across general NLP tasks, but their utility in automating numerical experiments of complex physical system -- a critical and labor-intensive component -- remains underexplored. As the major workhorse of computational science over the past decades, Computational Fluid Dynamics (CFD) offers a uniquely challenging testbed for evaluating the scientific capabilities of LLMs. We introduce CFDLLMBench, a benchmark suite comprising three complementary components -- CFDQuery, CFDCodeBench, and FoamBench -- designed to holistically evaluate LLM performance across three key competencies: graduate-level CFD knowledge, numerical and physical reasoning of CFD, and context-dependent implementation of CFD workflows. Grounded in real-world CFD practices, our benchmark combines a detailed task taxonomy with a rigorous evaluation framework to deliver reproducible results and quantify LLM performance across code executability, solution accuracy, and numerical convergence behavior. CFDLLMBench establishes a solid foundation for the development and evaluation of LLM-driven automation of numerical experiments for complex physical systems. Code and data are available at https://github.com/NREL-Theseus/cfdllmbench/.
Assessing Classical Machine Learning and Transformer-based Approaches for Detecting AI-Generated Research Text
arXiv:2509.20375v1 Announce Type: new Abstract: The rapid adoption of large language models (LLMs) such as ChatGPT has blurred the line between human and AI-generated texts, raising urgent questions about academic integrity, intellectual property, and the spread of misinformation. Thus, reliable AI-text detection is needed for fair assessment to safeguard human authenticity and cultivate trust in digital communication. In this study, we investigate how well current machine learning (ML) approaches can distinguish ChatGPT-3.5-generated texts from human-written texts employing a labeled data set of 250 pairs of abstracts from a wide range of research topics. We test and compare both classical (Logistic Regression armed with classical Bag-of-Words, POS, and TF-IDF features) and transformer-based (BERT augmented with N-grams, DistilBERT, BERT with a lightweight custom classifier, and LSTM-based N-gram models) ML detection techniques. As we aim to assess each model's performance in detecting AI-generated research texts, we also aim to test whether an ensemble of these models can outperform any single detector. Results show DistilBERT achieves the overall best performance, while Logistic Regression and BERT-Custom offer solid, balanced alternatives; LSTM- and BERT-N-gram approaches lag. The max voting ensemble of the three best models fails to surpass DistilBERT itself, highlighting the primacy of a single transformer-based representation over mere model diversity. By comprehensively assessing the strengths and weaknesses of these AI-text detection approaches, this work lays a foundation for more robust transformer frameworks with larger, richer datasets to keep pace with ever-improving generative AI models.
ConceptViz: A Visual Analytics Approach for Exploring Concepts in Large Language Models
arXiv:2509.20376v1 Announce Type: new Abstract: Large language models (LLMs) have achieved remarkable performance across a wide range of natural language tasks. Understanding how LLMs internally represent knowledge remains a significant challenge. Despite Sparse Autoencoders (SAEs) have emerged as a promising technique for extracting interpretable features from LLMs, SAE features do not inherently align with human-understandable concepts, making their interpretation cumbersome and labor-intensive. To bridge the gap between SAE features and human concepts, we present ConceptViz, a visual analytics system designed for exploring concepts in LLMs. ConceptViz implements a novel dentification => Interpretation => Validation pipeline, enabling users to query SAEs using concepts of interest, interactively explore concept-to-feature alignments, and validate the correspondences through model behavior verification. We demonstrate the effectiveness of ConceptViz through two usage scenarios and a user study. Our results show that ConceptViz enhances interpretability research by streamlining the discovery and validation of meaningful concept representations in LLMs, ultimately aiding researchers in building more accurate mental models of LLM features. Our code and user guide are publicly available at https://github.com/Happy-Hippo209/ConceptViz.
SKILL-RAG: Self-Knowledge Induced Learning and Filtering for Retrieval-Augmented Generation
arXiv:2509.20377v1 Announce Type: new Abstract: Retrieval-Augmented Generation (RAG) has significantly improved the performance of large language models (LLMs) on knowledge-intensive tasks in recent years. However, since retrieval systems may return irrelevant content, incorporating such information into the model often leads to hallucinations. Thus, identifying and filtering out unhelpful retrieved content is a key challenge for improving RAG performance.To better integrate the internal knowledge of the model with external knowledge from retrieval, it is essential to understand what the model "knows" and "does not know" (which is also called "self-knowledge"). Based on this insight, we propose SKILL-RAG (Self-Knowledge Induced Learning and Filtering for RAG), a novel method that leverages the model's self-knowledge to determine which retrieved documents are beneficial for answering a given query. We design a reinforcement learning-based training framework to explicitly elicit self-knowledge from the model and employs sentence-level granularity to filter out irrelevant content while preserving useful knowledge.We evaluate SKILL-RAG using Llama2-7B and Qwen3-8B on several question answering benchmarks. Experimental results demonstrate that SKILL-RAG not only improves generation quality but also significantly reduces the number of input documents, validating the importance of self-knowledge in guiding the selection of high-quality retrievals.
Beyond Global Emotion: Fine-Grained Emotional Speech Synthesis with Dynamic Word-Level Modulation
arXiv:2509.20378v1 Announce Type: new Abstract: Emotional text-to-speech (E-TTS) is central to creating natural and trustworthy human-computer interaction. Existing systems typically rely on sentence-level control through predefined labels, reference audio, or natural language prompts. While effective for global emotion expression, these approaches fail to capture dynamic shifts within a sentence. To address this limitation, we introduce Emo-FiLM, a fine-grained emotion modeling framework for LLM-based TTS. Emo-FiLM aligns frame-level features from emotion2vec to words to obtain word-level emotion annotations, and maps them through a Feature-wise Linear Modulation (FiLM) layer, enabling word-level emotion control by directly modulating text embeddings. To support evaluation, we construct the Fine-grained Emotion Dynamics Dataset (FEDD) with detailed annotations of emotional transitions. Experiments show that Emo-FiLM outperforms existing approaches on both global and fine-grained tasks, demonstrating its effectiveness and generality for expressive speech synthesis.
USB-Rec: An Effective Framework for Improving Conversational Recommendation Capability of Large Language Model
arXiv:2509.20381v1 Announce Type: new Abstract: Recently, Large Language Models (LLMs) have been widely employed in Conversational Recommender Systems (CRSs). Unlike traditional language model approaches that focus on training, all existing LLMs-based approaches are mainly centered around how to leverage the summarization and analysis capabilities of LLMs while ignoring the issue of training. Therefore, in this work, we propose an integrated training-inference framework, User-Simulator-Based framework (USB-Rec), for improving the performance of LLMs in conversational recommendation at the model level. Firstly, we design a LLM-based Preference Optimization (PO) dataset construction strategy for RL training, which helps the LLMs understand the strategies and methods in conversational recommendation. Secondly, we propose a Self-Enhancement Strategy (SES) at the inference stage to further exploit the conversational recommendation potential obtained from RL training. Extensive experiments on various datasets demonstrate that our method consistently outperforms previous state-of-the-art methods.
Document Summarization with Conformal Importance Guarantees
arXiv:2509.20461v1 Announce Type: new Abstract: Automatic summarization systems have advanced rapidly with large language models (LLMs), yet they still lack reliable guarantees on inclusion of critical content in high-stakes domains like healthcare, law, and finance. In this work, we introduce Conformal Importance Summarization, the first framework for importance-preserving summary generation which uses conformal prediction to provide rigorous, distribution-free coverage guarantees. By calibrating thresholds on sentence-level importance scores, we enable extractive document summarization with user-specified coverage and recall rates over critical content. Our method is model-agnostic, requires only a small calibration set, and seamlessly integrates with existing black-box LLMs. Experiments on established summarization benchmarks demonstrate that Conformal Importance Summarization achieves the theoretically assured information coverage rate. Our work suggests that Conformal Importance Summarization can be combined with existing techniques to achieve reliable, controllable automatic summarization, paving the way for safer deployment of AI summarization tools in critical applications. Code is available at https://github.com/layer6ai-labs/conformal-importance-summarization.
ShortCheck: Checkworthiness Detection of Multilingual Short-Form Videos
arXiv:2509.20467v1 Announce Type: new Abstract: Short-form video platforms like TikTok present unique challenges for misinformation detection due to their multimodal, dynamic, and noisy content. We present ShortCheck, a modular, inference-only pipeline with a user-friendly interface that automatically identifies checkworthy short-form videos to help human fact-checkers. The system integrates speech transcription, OCR, object and deepfake detection, video-to-text summarization, and claim verification. ShortCheck is validated by evaluating it on two manually annotated datasets with TikTok videos in a multilingual setting. The pipeline achieves promising results with F1-weighted score over 70\%.
MARS: toward more efficient multi-agent collaboration for LLM reasoning
arXiv:2509.20502v1 Announce Type: new Abstract: Large language models (LLMs) have achieved impressive results in natural language understanding, yet their reasoning capabilities remain limited when operating as single agents. Multi-Agent Debate (MAD) has been proposed to address this limitation by enabling collaborative reasoning among multiple models in a round-table debate manner. While effective, MAD introduces substantial computational overhead due to the number of agents involved and the frequent communication required. In this paper, we propose MARS (Multi-Agent Review System), a role-based collaboration framework inspired by the review process. In MARS, an author agent generates an initial solution, reviewer agents provide decisions and comments independently, and a meta-reviewer integrates the feedback to make the final decision and guide further revision. This design enhances reasoning quality while avoiding costly reviewer-to-reviewer interactions, thereby controlling token consumption and inference time. We compared MARS with both MAD and other state-of-the-art reasoning strategies across multiple benchmarks. Extensive experiments with different LLMs show that MARS matches the accuracy of MAD while reducing both token usage and inference time by approximately 50\%. Code is available at https://github.com/xwang97/MARS.
SiniticMTError: A Machine Translation Dataset with Error Annotations for Sinitic Languages
arXiv:2509.20557v1 Announce Type: new Abstract: Despite major advances in machine translation (MT) in recent years, progress remains limited for many low-resource languages that lack large-scale training data and linguistic resources. Cantonese and Wu Chinese are two Sinitic examples, although each enjoys more than 80 million speakers around the world. In this paper, we introduce SiniticMTError, a novel dataset that builds on existing parallel corpora to provide error span, error type, and error severity annotations in machine-translated examples from English to Mandarin, Cantonese, and Wu Chinese. Our dataset serves as a resource for the MT community to utilize in fine-tuning models with error detection capabilities, supporting research on translation quality estimation, error-aware generation, and low-resource language evaluation. We report our rigorous annotation process by native speakers, with analyses on inter-annotator agreement, iterative feedback, and patterns in error type and severity.
SwasthLLM: a Unified Cross-Lingual, Multi-Task, and Meta-Learning Zero-Shot Framework for Medical Diagnosis Using Contrastive Representations
arXiv:2509.20567v1 Announce Type: new Abstract: In multilingual healthcare environments, automatic disease diagnosis from clinical text remains a challenging task due to the scarcity of annotated medical data in low-resource languages and the linguistic variability across populations. This paper proposes SwasthLLM, a unified, zero-shot, cross-lingual, and multi-task learning framework for medical diagnosis that operates effectively across English, Hindi, and Bengali without requiring language-specific fine-tuning. At its core, SwasthLLM leverages the multilingual XLM-RoBERTa encoder augmented with a language-aware attention mechanism and a disease classification head, enabling the model to extract medically relevant information regardless of the language structure. To align semantic representations across languages, a Siamese contrastive learning module is introduced, ensuring that equivalent medical texts in different languages produce similar embeddings. Further, a translation consistency module and a contrastive projection head reinforce language-invariant representation learning. SwasthLLM is trained using a multi-task learning strategy, jointly optimizing disease classification, translation alignment, and contrastive learning objectives. Additionally, we employ Model-Agnostic Meta-Learning (MAML) to equip the model with rapid adaptation capabilities for unseen languages or tasks with minimal data. Our phased training pipeline emphasizes robust representation alignment before task-specific fine-tuning. Extensive evaluation shows that SwasthLLM achieves high diagnostic performance, with a test accuracy of 97.22% and an F1-score of 97.17% in supervised settings. Crucially, in zero-shot scenarios, it attains 92.78% accuracy on Hindi and 73.33% accuracy on Bengali medical text, demonstrating strong generalization in low-resource contexts.
Dynamic Reasoning Chains through Depth-Specialized Mixture-of-Experts in Transformer Architectures
arXiv:2509.20577v1 Announce Type: new Abstract: Contemporary transformer architectures apply identical processing depth to all inputs, creating inefficiencies and limiting reasoning quality. Simple factual queries are subjected to the same multilayered computation as complex logical problems, wasting resources while constraining deep inference. To overcome this, we came up with a concept of Dynamic Reasoning Chains through Depth Specialised Mixture of Experts (DS-MoE), a modular framework that extends the Mixture of Experts paradigm from width-based to depth specialised computation. DS-MoE introduces expert modules optimised for distinct reasoning depths, shallow pattern recognition, compositional reasoning, logical inference, memory integration, and meta-cognitive supervision. A learned routing network dynamically assembles custom reasoning chains, activating only the necessary experts to match input complexity. The dataset on which we trained and evaluated DS-MoE is on The Pile, an 800GB corpus covering diverse domains such as scientific papers, legal texts, programming code, and web content, enabling systematic assessment across reasoning depths. Experimental results demonstrate that DS-MoE achieves up to 16 per cent computational savings and 35 per cent faster inference compared to uniform-depth transformers, while delivering 2.8 per cent higher accuracy on complex multi-step reasoning benchmarks. Furthermore, routing decisions yield interpretable reasoning chains, enhancing transparency and scalability. These findings establish DS-MoE as a significant advancement in adaptive neural architectures, demonstrating that depth-specialised modular processing can simultaneously improve efficiency, reasoning quality, and interpretability in large-scale language models.
Hierarchical Resolution Transformers: A Wavelet-Inspired Architecture for Multi-Scale Language Understanding
arXiv:2509.20581v1 Announce Type: new Abstract: Transformer architectures have achieved state-of-the-art performance across natural language tasks, yet they fundamentally misrepresent the hierarchical nature of human language by processing text as flat token sequences. This results in quadratic computational cost, weak computational cost, weak compositional generalization, and inadequate discourse-level modeling. We propose Hierarchical Resolution Transformer (HRT), a novel wavelet-inspired neural architecture that processes language simultaneously across multiple resolutions, from characters to discourse-level units. HRT constructs a multi-resolution attention, enabling bottom-up composition and top-down contextualization. By employing exponential sequence reduction across scales, HRT achieves O(nlogn) complexity, offering significant efficiency improvements over standard transformers. We evaluated HRT on a diverse suite of benchmarks, including GLUE, SuperGLUE, Long Range Arena, and WikiText-103, and results demonstrated that HRT outperforms standard transformer baselines by an average of +3.8% on GLUE, +4.5% on SuperGLUE, and +6.1% on Long Range Arena, while reducing memory usage by 42% and inference latency by 37% compared to BERT and GPT style models of similar parameter count. Ablation studies confirm the effectiveness of cross-resolution attention and scale-specialized modules, showing that each contributes independently to both efficiency and accuracy. Our findings establish HRT as the first architecture to align computational structure with the hierarchical organization of human language, demonstrating that multi-scale, wavelet-inspired processing yields both theoretical efficiency gains and practical improvements in language understanding.
FS-DFM: Fast and Accurate Long Text Generation with Few-Step Diffusion Language Models
arXiv:2509.20624v1 Announce Type: new Abstract: Autoregressive language models (ARMs) deliver strong likelihoods, but are inherently serial: they generate one token per forward pass, which limits throughput and inflates latency for long sequences. Diffusion Language Models (DLMs) parallelize across positions and thus appear promising for language generation, yet standard discrete diffusion typically needs hundreds to thousands of model evaluations to reach high quality, trading serial depth for iterative breadth. We introduce FS-DFM, Few-Step Discrete Flow-Matching. A discrete flow-matching model designed for speed without sacrificing quality. The core idea is simple: make the number of sampling steps an explicit parameter and train the model to be consistent across step budgets, so one big move lands where many small moves would. We pair this with a reliable update rule that moves probability in the right direction without overshooting, and with strong teacher guidance distilled from long-run trajectories. Together, these choices make few-step sampling stable, accurate, and easy to control. On language modeling benchmarks, FS-DFM with 8 sampling steps achieves perplexity parity with a 1,024-step discrete-flow baseline for generating 1,024 tokens using a similar-size model, delivering up to 128 times faster sampling and corresponding latency/throughput gains.
Look Before you Leap: Estimating LLM Benchmark Scores from Descriptions
arXiv:2509.20645v1 Announce Type: new Abstract: Progress in large language models is constrained by an evaluation bottleneck: build a benchmark, evaluate models and settings, then iterate. We therefore ask a simple question: can we forecast outcomes before running any experiments? We study text-only performance forecasting: estimating a model's score from a redacted task description and intended configuration, with no access to dataset instances. To support systematic study, we curate PRECOG, a corpus of redacted description-performance pairs spanning diverse tasks, domains, and metrics. Experiments show the task is challenging but feasible: models equipped with a retrieval module that excludes source papers achieve moderate prediction performance with well-calibrated uncertainty, reaching mean absolute error as low as 8.7 on the Accuracy subset at high-confidence thresholds. Our analysis indicates that stronger reasoning models engage in diverse, iterative querying, whereas current open-source models lag and often skip retrieval or gather evidence with limited diversity. We further test a zero-leakage setting, forecasting on newly released datasets or experiments before their papers are indexed, where GPT-5 with built-in web search still attains nontrivial prediction accuracy. Overall, our corpus and analyses offer an initial step toward open-ended anticipatory evaluation, supporting difficulty estimation and smarter experiment prioritization.
Building Tailored Speech Recognizers for Japanese Speaking Assessment
arXiv:2509.20655v1 Announce Type: new Abstract: This paper presents methods for building speech recognizers tailored for Japanese speaking assessment tasks. Specifically, we build a speech recognizer that outputs phonemic labels with accent markers. Although Japanese is resource-rich, there is only a small amount of data for training models to produce accurate phonemic transcriptions that include accent marks. We propose two methods to mitigate data sparsity. First, a multitask training scheme introduces auxiliary loss functions to estimate orthographic text labels and pitch patterns of the input signal, so that utterances with only orthographic annotations can be leveraged in training. The second fuses two estimators, one over phonetic alphabet strings, and the other over text token sequences. To combine these estimates we develop an algorithm based on the finite-state transducer framework. Our results indicate that the use of multitask learning and fusion is effective for building an accurate phonemic recognizer. We show that this approach is advantageous compared to the use of generic multilingual recognizers. The relative advantages of the proposed methods were also compared. Our proposed methods reduced the average of mora-label error rates from 12.3% to 7.1% over the CSJ core evaluation sets.
Enhancing Molecular Property Prediction with Knowledge from Large Language Models
arXiv:2509.20664v1 Announce Type: new Abstract: Predicting molecular properties is a critical component of drug discovery. Recent advances in deep learning, particularly Graph Neural Networks (GNNs), have enabled end-to-end learning from molecular structures, reducing reliance on manual feature engineering. However, while GNNs and self-supervised learning approaches have advanced molecular property prediction (MPP), the integration of human prior knowledge remains indispensable, as evidenced by recent methods that leverage large language models (LLMs) for knowledge extraction. Despite their strengths, LLMs are constrained by knowledge gaps and hallucinations, particularly for less-studied molecular properties. In this work, we propose a novel framework that, for the first time, integrates knowledge extracted from LLMs with structural features derived from pre-trained molecular models to enhance MPP. Our approach prompts LLMs to generate both domain-relevant knowledge and executable code for molecular vectorization, producing knowledge-based features that are subsequently fused with structural representations. We employ three state-of-the-art LLMs, GPT-4o, GPT-4.1, and DeepSeek-R1, for knowledge extraction. Extensive experiments demonstrate that our integrated method outperforms existing approaches, confirming that the combination of LLM-derived knowledge and structural information provides a robust and effective solution for MPP.
RedHerring Attack: Testing the Reliability of Attack Detection
arXiv:2509.20691v1 Announce Type: new Abstract: In response to adversarial text attacks, attack detection models have been proposed and shown to successfully identify text modified by adversaries. Attack detection models can be leveraged to provide an additional check for NLP models and give signals for human input. However, the reliability of these models has not yet been thoroughly explored. Thus, we propose and test a novel attack setting and attack, RedHerring. RedHerring aims to make attack detection models unreliable by modifying a text to cause the detection model to predict an attack, while keeping the classifier correct. This creates a tension between the classifier and detector. If a human sees that the detector is giving an ``incorrect'' prediction, but the classifier a correct one, then the human will see the detector as unreliable. We test this novel threat model on 4 datasets against 3 detectors defending 4 classifiers. We find that RedHerring is able to drop detection accuracy between 20 - 71 points, while maintaining (or improving) classifier accuracy. As an initial defense, we propose a simple confidence check which requires no retraining of the classifier or detector and increases detection accuracy greatly. This novel threat model offers new insights into how adversaries may target detection models.
Overcoming Black-box Attack Inefficiency with Hybrid and Dynamic Select Algorithms
arXiv:2509.20699v1 Announce Type: new Abstract: Adversarial text attack research plays a crucial role in evaluating the robustness of NLP models. However, the increasing complexity of transformer-based architectures has dramatically raised the computational cost of attack testing, especially for researchers with limited resources (e.g., GPUs). Existing popular black-box attack methods often require a large number of queries, which can make them inefficient and impractical for researchers. To address these challenges, we propose two new attack selection strategies called Hybrid and Dynamic Select, which better combine the strengths of previous selection algorithms. Hybrid Select merges generalized BinarySelect techniques with GreedySelect by introducing a size threshold to decide which selection algorithm to use. Dynamic Select provides an alternative approach of combining the generalized Binary and GreedySelect by learning which lengths of texts each selection method should be applied to. This greatly reduces the number of queries needed while maintaining attack effectiveness (a limitation of BinarySelect). Across 4 datasets and 6 target models, our best method(sentence-level Hybrid Select) is able to reduce the number of required queries per attack up 25.82\% on average against both encoder models and LLMs, without losing the effectiveness of the attack.
MI-Fuse: Label Fusion for Unsupervised Domain Adaptation with Closed-Source Large-Audio Language Model
arXiv:2509.20706v1 Announce Type: new Abstract: Large audio-language models (LALMs) show strong zero-shot ability on speech tasks, suggesting promise for speech emotion recognition (SER). However, SER in real-world deployments often fails under domain mismatch, where source data are unavailable and powerful LALMs are accessible only through an API. We ask: given only unlabeled target-domain audio and an API-only LALM, can a student model be adapted to outperform the LALM in the target domain? To this end, we propose MI-Fuse, a denoised label fusion framework that supplements the LALM with a source-domain trained SER classifier as an auxiliary teacher. The framework draws multiple stochastic predictions from both teachers, weights their mean distributions by mutual-information-based uncertainty, and stabilizes training with an exponential moving average teacher. Experiments across three public emotion datasets and six cross-domain transfers show consistent gains, with the student surpassing the LALM and outperforming the strongest baseline by 3.9%. This approach strengthens emotion-aware speech systems without sharing source data, enabling realistic adaptation.
Probability Distribution Collapse: A Critical Bottleneck to Compact Unsupervised Neural Grammar Induction
arXiv:2509.20734v1 Announce Type: new Abstract: Unsupervised neural grammar induction aims to learn interpretable hierarchical structures from language data. However, existing models face an expressiveness bottleneck, often resulting in unnecessarily large yet underperforming grammars. We identify a core issue, $\textit{probability distribution collapse}$, as the underlying cause of this limitation. We analyze when and how the collapse emerges across key components of neural parameterization and introduce a targeted solution, $\textit{collapse-relaxing neural parameterization}$, to mitigate it. Our approach substantially improves parsing performance while enabling the use of significantly more compact grammars across a wide range of languages, as demonstrated through extensive empirical analysis.
Confidence-guided Refinement Reasoning for Zero-shot Question Answering
arXiv:2509.20750v1 Announce Type: new Abstract: We propose Confidence-guided Refinement Reasoning (C2R), a novel training-free framework applicable to question-answering (QA) tasks across text, image, and video domains. C2R strategically constructs and refines sub-questions and their answers (sub-QAs), deriving a better confidence score for the target answer. C2R first curates a subset of sub-QAs to explore diverse reasoning paths, then compares the confidence scores of the resulting answer candidates to select the most reliable final answer. Since C2R relies solely on confidence scores derived from the model itself, it can be seamlessly integrated with various existing QA models, demonstrating consistent performance improvements across diverse models and benchmarks. Furthermore, we provide essential yet underexplored insights into how leveraging sub-QAs affects model behavior, specifically analyzing the impact of both the quantity and quality of sub-QAs on achieving robust and reliable reasoning.
SFT Doesn't Always Hurt General Capabilities: Revisiting Domain-Specific Fine-Tuning in LLMs
arXiv:2509.20758v1 Announce Type: new Abstract: Supervised Fine-Tuning (SFT) on domain-specific datasets is a common approach to adapt Large Language Models (LLMs) to specialized tasks but is often believed to degrade their general capabilities. In this work, we revisit this trade-off and present both empirical and theoretical insights. First, we show that SFT does not always hurt: using a smaller learning rate can substantially mitigate general performance degradation while preserving comparable target-domain performance. We then provide a theoretical analysis that explains these phenomena and further motivates a new method, Token-Adaptive Loss Reweighting (TALR). Building on this, and recognizing that smaller learning rates alone do not fully eliminate general-performance degradation in all cases, we evaluate a range of strategies for reducing general capability loss, including L2 regularization, LoRA, model averaging, FLOW, and our proposed TALR. Experimental results demonstrate that while no method completely eliminates the trade-off, TALR consistently outperforms these baselines in balancing domain-specific gains and general capabilities. Finally, we distill our findings into practical guidelines for adapting LLMs to new domains: (i) using a small learning rate to achieve a favorable trade-off, and (ii) when a stronger balance is further desired, adopt TALR as an effective strategy.
Towards Atoms of Large Language Models
arXiv:2509.20784v1 Announce Type: new Abstract: The fundamental units of internal representations in large language models (LLMs) remain undefined, limiting further understanding of their mechanisms. Neurons or features are often regarded as such units, yet neurons suffer from polysemy, while features face concerns of unreliable reconstruction and instability. To address this issue, we propose the Atoms Theory, which defines such units as atoms. We introduce the atomic inner product (AIP) to correct representation shifting, formally define atoms, and prove the conditions that atoms satisfy the Restricted Isometry Property (RIP), ensuring stable sparse representations over atom set and linking to compressed sensing. Under stronger conditions, we further establish the uniqueness and exact $\ell_1$ recoverability of the sparse representations, and provide guarantees that single-layer sparse autoencoders (SAEs) with threshold activations can reliably identify the atoms. To validate the Atoms Theory, we train threshold-activated SAEs on Gemma2-2B, Gemma2-9B, and Llama3.1-8B, achieving 99.9% sparse reconstruction across layers on average, and more than 99.8% of atoms satisfy the uniqueness condition, compared to 0.5% for neurons and 68.2% for features, showing that atoms more faithfully capture intrinsic representations of LLMs. Scaling experiments further reveal the link between SAEs size and recovery capacity. Overall, this work systematically introduces and validates Atoms Theory of LLMs, providing a theoretical framework for understanding internal representations and a foundation for mechanistic interpretability. Code available at https://github.com/ChenhuiHu/towards_atoms.
Few-Shot and Training-Free Review Generation via Conversational Prompting
arXiv:2509.20805v1 Announce Type: new Abstract: Personalized review generation helps businesses understand user preferences, yet most existing approaches assume extensive review histories of the target user or require additional model training. Real-world applications often face few-shot and training-free situations, where only a few user reviews are available and fine-tuning is infeasible. It is well known that large language models (LLMs) can address such low-resource settings, but their effectiveness depends on prompt engineering. In this paper, we propose Conversational Prompting, a lightweight method that reformulates user reviews as multi-turn conversations. Its simple variant, Simple Conversational Prompting (SCP), relies solely on the user's own reviews, while the contrastive variant, Contrastive Conversational Prompting (CCP), inserts reviews from other users or LLMs as incorrect replies and then asks the model to correct them, encouraging the model to produce text in the user's style. Experiments on eight product domains and five LLMs showed that the conventional non-conversational prompt often produced reviews similar to those written by random users, based on text-based metrics such as ROUGE-L and BERTScore, and application-oriented tasks like user identity matching and sentiment analysis. In contrast, both SCP and CCP produced reviews much closer to those of the target user, even when each user had only two reviews. CCP brings further improvements when high-quality negative examples are available, whereas SCP remains competitive when such data cannot be collected. These results suggest that conversational prompting offers a practical solution for review generation under few-shot and training-free constraints.
Enrich-on-Graph: Query-Graph Alignment for Complex Reasoning with LLM Enriching
arXiv:2509.20810v1 Announce Type: new Abstract: Large Language Models (LLMs) exhibit strong reasoning capabilities in complex tasks. However, they still struggle with hallucinations and factual errors in knowledge-intensive scenarios like knowledge graph question answering (KGQA). We attribute this to the semantic gap between structured knowledge graphs (KGs) and unstructured queries, caused by inherent differences in their focuses and structures. Existing methods usually employ resource-intensive, non-scalable workflows reasoning on vanilla KGs, but overlook this gap. To address this challenge, we propose a flexible framework, Enrich-on-Graph (EoG), which leverages LLMs' prior knowledge to enrich KGs, bridge the semantic gap between graphs and queries. EoG enables efficient evidence extraction from KGs for precise and robust reasoning, while ensuring low computational costs, scalability, and adaptability across different methods. Furthermore, we propose three graph quality evaluation metrics to analyze query-graph alignment in KGQA task, supported by theoretical validation of our optimization objectives. Extensive experiments on two KGQA benchmark datasets indicate that EoG can effectively generate high-quality KGs and achieve the state-of-the-art performance. Our code and data are available at https://github.com/zjukg/Enrich-on-Graph.
Leveraging What's Overfixed: Post-Correction via LLM Grammatical Error Overcorrection
arXiv:2509.20811v1 Announce Type: new Abstract: Robust supervised fine-tuned small Language Models (sLMs) often show high reliability but tend to undercorrect. They achieve high precision at the cost of low recall. Conversely, Large Language Models (LLMs) often show the opposite tendency, making excessive overcorrection, leading to low precision. To effectively harness the strengths of LLMs to address the recall challenges in sLMs, we propose Post-Correction via Overcorrection (PoCO), a novel approach that strategically balances recall and precision. PoCO first intentionally triggers overcorrection via LLM to maximize recall by allowing comprehensive revisions, then applies a targeted post-correction step via fine-tuning smaller models to identify and refine erroneous outputs. We aim to harmonize both aspects by leveraging the generative power of LLMs while preserving the reliability of smaller supervised models. Our extensive experiments demonstrate that PoCO effectively balances GEC performance by increasing recall with competitive precision, ultimately improving the overall quality of grammatical error correction.
Distilling Many-Shot In-Context Learning into a Cheat Sheet
arXiv:2509.20820v1 Announce Type: new Abstract: Recent advances in large language models (LLMs) enable effective in-context learning (ICL) with many-shot examples, but at the cost of high computational demand due to longer input tokens. To address this, we propose cheat-sheet ICL, which distills the information from many-shot ICL into a concise textual summary (cheat sheet) used as the context at inference time. Experiments on challenging reasoning tasks show that cheat-sheet ICL achieves comparable or better performance than many-shot ICL with far fewer tokens, and matches retrieval-based ICL without requiring test-time retrieval. These findings demonstrate that cheat-sheet ICL is a practical alternative for leveraging LLMs in downstream tasks.
Zero-Shot Privacy-Aware Text Rewriting via Iterative Tree Search
arXiv:2509.20838v1 Announce Type: new Abstract: The increasing adoption of large language models (LLMs) in cloud-based services has raised significant privacy concerns, as user inputs may inadvertently expose sensitive information. Existing text anonymization and de-identification techniques, such as rule-based redaction and scrubbing, often struggle to balance privacy preservation with text naturalness and utility. In this work, we propose a zero-shot, tree-search-based iterative sentence rewriting algorithm that systematically obfuscates or deletes private information while preserving coherence, relevance, and naturalness. Our method incrementally rewrites privacy-sensitive segments through a structured search guided by a reward model, enabling dynamic exploration of the rewriting space. Experiments on privacy-sensitive datasets show that our approach significantly outperforms existing baselines, achieving a superior balance between privacy protection and utility preservation.
Concise and Sufficient Sub-Sentence Citations for Retrieval-Augmented Generation
arXiv:2509.20859v1 Announce Type: new Abstract: In retrieval-augmented generation (RAG) question answering systems, generating citations for large language model (LLM) outputs enhances verifiability and helps users identify potential hallucinations. However, we observe two problems in the citations produced by existing attribution methods. First, the citations are typically provided at the sentence or even paragraph level. Long sentences or paragraphs may include a substantial amount of irrelevant content. Second, sentence-level citations may omit information that is essential for verifying the output, forcing users to read the surrounding context. In this paper, we propose generating sub-sentence citations that are both concise and sufficient, thereby reducing the effort required by users to confirm the correctness of the generated output. To this end, we first develop annotation guidelines for such citations and construct a corresponding dataset. Then, we propose an attribution framework for generating citations that adhere to our standards. This framework leverages LLMs to automatically generate fine-tuning data for our task and employs a credit model to filter out low-quality examples. Our experiments on the constructed dataset demonstrate that the propose approach can generate high-quality and more readable citations.
WeFT: Weighted Entropy-driven Fine-Tuning for dLLMs
arXiv:2509.20863v1 Announce Type: new Abstract: Diffusion models have recently shown strong potential in language modeling, offering faster generation compared to traditional autoregressive approaches. However, applying supervised fine-tuning (SFT) to diffusion models remains challenging, as they lack precise probability estimates at each denoising step. While the diffusion mechanism enables the model to reason over entire sequences, it also makes the generation process less predictable and often inconsistent. This highlights the importance of controlling key tokens that guide the direction of generation. To address this issue, we propose WeFT, a weighted SFT method for diffusion language models, where tokens are assigned different weights based on their entropy. Derived from diffusion theory, WeFT delivers substantial gains: training on s1K, s1K-1.1, and 3k samples from open-r1, it achieves relative improvements of 39%, 64%, and 83% over standard SFT on four widely used reasoning benchmarks (Sudoku, Countdown, GSM8K, and MATH-500). The code and models will be made publicly available.
Single Answer is Not Enough: On Generating Ranked Lists with Medical Reasoning Models
arXiv:2509.20866v1 Announce Type: new Abstract: This paper presents a systematic study on enabling medical reasoning models (MRMs) to generate ranked lists of answers for open-ended questions. Clinical decision-making rarely relies on a single answer but instead considers multiple options, reducing the risks of narrow perspectives. Yet current MRMs are typically trained to produce only one answer, even in open-ended settings. We propose an alternative format: ranked lists and investigate two approaches: prompting and fine-tuning. While prompting is a cost-effective way to steer an MRM's response, not all MRMs generalize well across different answer formats: choice, short text, and list answers. Based on our prompting findings, we train and evaluate MRMs using supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). SFT teaches a model to imitate annotated responses, and RFT incentivizes exploration through the responses that maximize a reward. We propose new reward functions targeted at ranked-list answer formats, and conduct ablation studies for RFT. Our results show that while some SFT models generalize to certain answer formats, models trained with RFT are more robust across multiple formats. We also present a case study on a modified MedQA with multiple valid answers, finding that although MRMs might fail to select the benchmark's preferred ground truth, they can recognize valid answers. To the best of our knowledge, this is the first systematic investigation of approaches for enabling MRMs to generate answers as ranked lists. We hope this work provides a first step toward developing alternative answer formats that are beneficial beyond single answers in medical domains.
Learning to Summarize by Learning to Quiz: Adversarial Agentic Collaboration for Long Document Summarization
arXiv:2509.20900v1 Announce Type: new Abstract: Long document summarization remains a significant challenge for current large language models (LLMs), as existing approaches commonly struggle with information loss, factual inconsistencies, and coherence issues when processing excessively long documents. We propose SummQ, a novel adversarial multi-agent framework that addresses these limitations through collaborative intelligence between specialized agents operating in two complementary domains: summarization and quizzing. Our approach employs summary generators and reviewers that work collaboratively to create and evaluate comprehensive summaries, while quiz generators and reviewers create comprehension questions that serve as continuous quality checks for the summarization process. This adversarial dynamic, enhanced by an examinee agent that validates whether the generated summary contains the information needed to answer the quiz questions, enables iterative refinement through multifaceted feedback mechanisms. We evaluate SummQ on three widely used long document summarization benchmarks. Experimental results demonstrate that our framework significantly outperforms existing state-of-the-art methods across ROUGE and BERTScore metrics, as well as in LLM-as-a-Judge and human evaluations. Our comprehensive analyses reveal the effectiveness of the multi-agent collaboration dynamics, the influence of different agent configurations, and the impact of the quizzing mechanism. This work establishes a new approach for long document summarization that uses adversarial agentic collaboration to improve summarization quality.
MemLens: Uncovering Memorization in LLMs with Activation Trajectories
arXiv:2509.20909v1 Announce Type: new Abstract: Large language models (LLMs) are commonly evaluated on challenging benchmarks such as AIME and Math500, which are susceptible to contamination and risk of being memorized. Existing detection methods, which primarily rely on surface-level lexical overlap and perplexity, demonstrate low generalization and degrade significantly when encountering implicitly contaminated data. In this paper, we propose MemLens (An Activation Lens for Memorization Detection) to detect memorization by analyzing the probability trajectories of numeric tokens during generation. Our method reveals that contaminated samples exhibit ``shortcut'' behaviors, locking onto an answer with high confidence in the model's early layers, whereas clean samples show more gradual evidence accumulation across the model's full depth. We observe that contaminated and clean samples exhibit distinct and well-separated reasoning trajectories. To further validate this, we inject carefully designed samples into the model through LoRA fine-tuning and observe the same trajectory patterns as in naturally contaminated data. These results provide strong evidence that MemLens captures genuine signals of memorization rather than spurious correlations.
Cross-Linguistic Analysis of Memory Load in Sentence Comprehension: Linear Distance and Structural Density
arXiv:2509.20916v1 Announce Type: new Abstract: This study examines whether sentence-level memory load in comprehension is better explained by linear proximity between syntactically related words or by the structural density of the intervening material. Building on locality-based accounts and cross-linguistic evidence for dependency length minimization, the work advances Intervener Complexity-the number of intervening heads between a head and its dependent-as a structurally grounded lens that refines linear distance measures. Using harmonized dependency treebanks and a mixed-effects framework across multiple languages, the analysis jointly evaluates sentence length, dependency length, and Intervener Complexity as predictors of the Memory-load measure. Studies in Psycholinguistics have reported the contributions of feature interference and misbinding to memory load during processing. For this study, I operationalized sentence-level memory load as the linear sum of feature misbinding and feature interference for tractability; current evidence does not establish that their cognitive contributions combine additively. All three factors are positively associated with memory load, with sentence length exerting the broadest influence and Intervener Complexity offering explanatory power beyond linear distance. Conceptually, the findings reconcile linear and hierarchical perspectives on locality by treating dependency length as an important surface signature while identifying intervening heads as a more proximate indicator of integration and maintenance demands. Methodologically, the study illustrates how UD-based graph measures and cross-linguistic mixed-effects modelling can disentangle linear and structural contributions to processing efficiency, providing a principled path for evaluating competing theories of memory load in sentence comprehension.
Tool Calling for Arabic LLMs: Data Strategies and Instruction Tuning
arXiv:2509.20957v1 Announce Type: new Abstract: Tool calling is a critical capability that allows Large Language Models (LLMs) to interact with external systems, significantly expanding their utility. However, research and resources for tool calling are predominantly English-centric, leaving a gap in our understanding of how to enable this functionality for other languages, such as Arabic. This paper investigates three key research questions: (1) the necessity of in-language (Arabic) tool-calling data versus relying on cross-lingual transfer, (2) the effect of general-purpose instruction tuning on tool-calling performance, and (3) the value of fine-tuning on specific, high-priority tools. To address these questions, we conduct extensive experiments using base and post-trained variants of an open-weight Arabic LLM. To enable this study, we bridge the resource gap by translating and adapting two open-source tool-calling datasets into Arabic. Our findings provide crucial insights into the optimal strategies for developing robust tool-augmented agents for Arabic.
Analysis of instruction-based LLMs' capabilities to score and judge text-input problems in an academic setting
arXiv:2509.20982v1 Announce Type: new Abstract: Large language models (LLMs) can act as evaluators, a role studied by methods like LLM-as-a-Judge and fine-tuned judging LLMs. In the field of education, LLMs have been studied as assistant tools for students and teachers. Our research investigates LLM-driven automatic evaluation systems for academic Text-Input Problems using rubrics. We propose five evaluation systems that have been tested on a custom dataset of 110 answers about computer science from higher education students with three models: JudgeLM, Llama-3.1-8B and DeepSeek-R1-Distill-Llama-8B. The evaluation systems include: The JudgeLM evaluation, which uses the model's single answer prompt to obtain a score; Reference Aided Evaluation, which uses a correct answer as a guide aside from the original context of the question; No Reference Evaluation, which ommits the reference answer; Additive Evaluation, which uses atomic criteria; and Adaptive Evaluation, which is an evaluation done with generated criteria fitted to each question. All evaluation methods have been compared with the results of a human evaluator. Results show that the best method to automatically evaluate and score Text-Input Problems using LLMs is Reference Aided Evaluation. With the lowest median absolute deviation (0.945) and the lowest root mean square deviation (1.214) when compared to human evaluation, Reference Aided Evaluation offers fair scoring as well as insightful and complete evaluations. Other methods such as Additive and Adaptive Evaluation fail to provide good results in concise answers, No Reference Evaluation lacks information needed to correctly assess questions and JudgeLM Evaluations have not provided good results due to the model's limitations. As a result, we conclude that Artificial Intelligence-driven automatic evaluation systems, aided with proper methodologies, show potential to work as complementary tools to other academic resources.
Generative AI for FFRDCs
arXiv:2509.21040v1 Announce Type: new Abstract: Federally funded research and development centers (FFRDCs) face text-heavy workloads, from policy documents to scientific and engineering papers, that are slow to analyze manually. We show how large language models can accelerate summarization, classification, extraction, and sense-making with only a few input-output examples. To enable use in sensitive government contexts, we apply OnPrem$.$LLM, an open-source framework for secure and flexible application of generative AI. Case studies on defense policy documents and scientific corpora, including the National Defense Authorization Act (NDAA) and National Science Foundation (NSF) Awards, demonstrate how this approach enhances oversight and strategic analysis while maintaining auditability and data sovereignty.
Behind RoPE: How Does Causal Mask Encode Positional Information?
arXiv:2509.21042v1 Announce Type: new Abstract: While explicit positional encodings such as RoPE are a primary source of positional information in Transformer decoders, the causal mask also provides positional information. In this work, we prove that the causal mask can induce position-dependent patterns in attention scores, even without parameters or causal dependency in the input. Our theoretical analysis indicates that the induced attention pattern tends to favor nearby query-key pairs, mirroring the behavior of common positional encodings. Empirical analysis confirms that trained models exhibit the same behavior, with learned parameters further amplifying these patterns. Notably, we found that the interaction of causal mask and RoPE distorts RoPE's relative attention score patterns into non-relative ones. We consistently observed this effect in modern large language models, suggesting the importance of considering the causal mask as a source of positional information alongside explicit positional encodings.
When Instructions Multiply: Measuring and Estimating LLM Capabilities of Multiple Instructions Following
arXiv:2509.21051v1 Announce Type: new Abstract: As large language models (LLMs) are increasingly applied to real-world scenarios, it becomes crucial to understand their ability to follow multiple instructions simultaneously. To systematically evaluate these capabilities, we introduce two specialized benchmarks for fundamental domains where multiple instructions following is important: Many Instruction-Following Eval (ManyIFEval) for text generation with up to ten instructions, and Style-aware Mostly Basic Programming Problems (StyleMBPP) for code generation with up to six instructions. Our experiments with the created benchmarks across ten LLMs reveal that performance consistently degrades as the number of instructions increases. Furthermore, given the fact that evaluating all the possible combinations of multiple instructions is computationally impractical in actual use cases, we developed three types of regression models that can estimate performance on both unseen instruction combinations and different numbers of instructions which are not used during training. We demonstrate that a logistic regression model using instruction count as an explanatory variable can predict performance of following multiple instructions with approximately 10% error, even for unseen instruction combinations. We show that relatively modest sample sizes (500 for ManyIFEval and 300 for StyleMBPP) are sufficient for performance estimation, enabling efficient evaluation of LLMs under various instruction combinations.
SoM-1K: A Thousand-Problem Benchmark Dataset for Strength of Materials
arXiv:2509.21079v1 Announce Type: new Abstract: Foundation models have shown remarkable capabilities in various domains, but their performance on complex, multimodal engineering problems remains largely unexplored. We introduce SoM-1K, the first large-scale multimodal benchmark dataset dedicated to evaluating foundation models on problems in the strength of materials (SoM). The dataset, which contains 1,065 annotated SoM problems, mirrors real-world engineering tasks by including both textual problem statements and schematic diagrams. Due to the limited capabilities of current foundation models in understanding complicated visual information, we propose a novel prompting strategy called Descriptions of Images (DoI), which provides rigorous expert-generated text descriptions of the visual diagrams as the context. We evaluate eight representative foundation models, including both large language models (LLMs) and vision language models (VLMs). Our results show that current foundation models struggle significantly with these engineering problems, with the best-performing model achieving only 56.6% accuracy. Interestingly, we found that LLMs, when provided with DoI, often outperform VLMs provided with visual diagrams. A detailed error analysis reveals that DoI plays a crucial role in mitigating visual misinterpretation errors, suggesting that accurate text-based descriptions can be more effective than direct image input for current foundation models. This work establishes a rigorous benchmark for engineering AI and highlights a critical need for developing more robust multimodal reasoning capabilities in foundation models, particularly in scientific and engineering contexts.
Which Cultural Lens Do Models Adopt? On Cultural Positioning Bias and Agentic Mitigation in LLMs
arXiv:2509.21080v1 Announce Type: new Abstract: Large language models (LLMs) have unlocked a wide range of downstream generative applications. However, we found that they also risk perpetuating subtle fairness issues tied to culture, positioning their generations from the perspectives of the mainstream US culture while demonstrating salient externality towards non-mainstream ones. In this work, we identify and systematically investigate this novel culture positioning bias, in which an LLM's default generative stance aligns with a mainstream view and treats other cultures as outsiders. We propose the CultureLens benchmark with 4000 generation prompts and 3 evaluation metrics for quantifying this bias through the lens of a culturally situated interview script generation task, in which an LLM is positioned as an onsite reporter interviewing local people across 10 diverse cultures. Empirical evaluation on 5 state-of-the-art LLMs reveals a stark pattern: while models adopt insider tones in over 88 percent of US-contexted scripts on average, they disproportionately adopt mainly outsider stances for less dominant cultures. To resolve these biases, we propose 2 inference-time mitigation methods: a baseline prompt-based Fairness Intervention Pillars (FIP) method, and a structured Mitigation via Fairness Agents (MFA) framework consisting of 2 pipelines: (1) MFA-SA (Single-Agent) introduces a self-reflection and rewriting loop based on fairness guidelines. (2) MFA-MA (Multi-Agent) structures the process into a hierarchy of specialized agents: a Planner Agent(initial script generation), a Critique Agent (evaluates initial script against fairness pillars), and a Refinement Agent (incorporates feedback to produce a polished, unbiased script). Empirical results showcase the effectiveness of agent-based methods as a promising direction for mitigating biases in generative LLMs.
PerHalluEval: Persian Hallucination Evaluation Benchmark for Large Language Models
arXiv:2509.21104v1 Announce Type: new Abstract: Hallucination is a persistent issue affecting all large language Models (LLMs), particularly within low-resource languages such as Persian. PerHalluEval (Persian Hallucination Evaluation) is the first dynamic hallucination evaluation benchmark tailored for the Persian language. Our benchmark leverages a three-stage LLM-driven pipeline, augmented with human validation, to generate plausible answers and summaries regarding QA and summarization tasks, focusing on detecting extrinsic and intrinsic hallucinations. Moreover, we used the log probabilities of generated tokens to select the most believable hallucinated instances. In addition, we engaged human annotators to highlight Persian-specific contexts in the QA dataset in order to evaluate LLMs' performance on content specifically related to Persian culture. Our evaluation of 12 LLMs, including open- and closed-source models using PerHalluEval, revealed that the models generally struggle in detecting hallucinated Persian text. We showed that providing external knowledge, i.e., the original document for the summarization task, could mitigate hallucination partially. Furthermore, there was no significant difference in terms of hallucination when comparing LLMs specifically trained for Persian with others.
BESPOKE: Benchmark for Search-Augmented Large Language Model Personalization via Diagnostic Feedback
arXiv:2509.21106v1 Announce Type: new Abstract: Search-augmented large language models (LLMs) have advanced information-seeking tasks by integrating retrieval into generation, reducing users' cognitive burden compared to traditional search systems. Yet they remain insufficient for fully addressing diverse user needs, which requires recognizing how the same query can reflect different intents across users and delivering information in preferred forms. While recent systems such as ChatGPT and Gemini attempt personalization by leveraging user histories, systematic evaluation of such personalization is under-explored. To address this gap, we propose BESPOKE, the realistic benchmark for evaluating personalization in search-augmented LLMs. BESPOKE is designed to be both realistic, by collecting authentic chat and search histories directly from humans, and diagnostic, by pairing responses with fine-grained preference scores and feedback. The benchmark is constructed through long-term, deeply engaged human annotation, where human annotators contributed their own histories, authored queries with detailed information needs, and evaluated responses with scores and diagnostic feedback. Leveraging BESPOKE, we conduct systematic analyses that reveal key requirements for effective personalization in information-seeking tasks, providing a foundation for fine-grained evaluation of personalized search-augmented LLMs. Our code and data are available at https://augustinlib.github.io/BESPOKE/.
VoiceBBQ: Investigating Effect of Content and Acoustics in Social Bias of Spoken Language Model
arXiv:2509.21108v1 Announce Type: new Abstract: We introduce VoiceBBQ, a spoken extension of the BBQ (Bias Benchmark for Question Answering) - a dataset that measures social bias by presenting ambiguous or disambiguated contexts followed by questions that may elicit stereotypical responses. Due to the nature of speech, social bias in Spoken Language Models (SLMs) can emerge from two distinct sources: 1) content aspect and 2) acoustic aspect. The dataset converts every BBQ context into controlled voice conditions, enabling per-axis accuracy, bias, and consistency scores that remain comparable to the original text benchmark. Using VoiceBBQ, we evaluate two SLMs - LLaMA-Omni and Qwen2-Audio - and observe architectural contrasts: LLaMA-Omni resists acoustic bias while amplifying gender and accent bias, whereas Qwen2-Audio substantially dampens these cues while preserving content fidelity. VoiceBBQ thus provides a compact, drop-in testbed for jointly diagnosing content and acoustic bias across spoken language models.
Acoustic-based Gender Differentiation in Speech-aware Language Models
arXiv:2509.21125v1 Announce Type: new Abstract: Speech-aware Language Models (SpeechLMs) have fundamentally transformed human-AI interaction by enabling voice-based communication, yet they may exhibit acoustic-based gender differentiation where identical questions lead to different responses based on the speaker's gender. This paper propose a new dataset that enables systematic analysis of this phenomenon, containing 9,208 speech samples across three categories: Gender-Independent, Gender-Stereotypical, and Gender-Dependent. We further evaluated LLaMA-Omni series and discovered a paradoxical pattern; while overall responses seems identical regardless of gender, the pattern is far from unbiased responses. Specifically, in Gender-Stereotypical questions, all models consistently exhibited male-oriented responses; meanwhile, in Gender-Dependent questions where gender differentiation would be contextually appropriate, models exhibited responses independent to gender instead. We also confirm that this pattern does not result from neutral options nor perceived gender of a voice. When we allow neutral response, models tends to respond neutrally also in Gender-Dependent questions. The paradoxical pattern yet retains when we applied gender neutralization methods on speech. Through comparison between SpeechLMs with corresponding backbone LLMs, we confirmed that these paradoxical patterns primarily stem from Whisper speech encoders, which generates male-oriented acoustic tokens. These findings reveal that current SpeechLMs may not successfully remove gender biases though they prioritized general fairness principles over contextual appropriateness, highlighting the need for more sophisticated techniques to utilize gender information properly in speech technology.
AutoIntent: AutoML for Text Classification
arXiv:2509.21138v1 Announce Type: new Abstract: AutoIntent is an automated machine learning tool for text classification tasks. Unlike existing solutions, AutoIntent offers end-to-end automation with embedding model selection, classifier optimization, and decision threshold tuning, all within a modular, sklearn-like interface. The framework is designed to support multi-label classification and out-of-scope detection. AutoIntent demonstrates superior performance compared to existing AutoML tools on standard intent classification datasets and enables users to balance effectiveness and resource consumption.
Retrieval over Classification: Integrating Relation Semantics for Multimodal Relation Extraction
arXiv:2509.21151v1 Announce Type: new Abstract: Relation extraction (RE) aims to identify semantic relations between entities in unstructured text. Although recent work extends traditional RE to multimodal scenarios, most approaches still adopt classification-based paradigms with fused multimodal features, representing relations as discrete labels. This paradigm has two significant limitations: (1) it overlooks structural constraints like entity types and positional cues, and (2) it lacks semantic expressiveness for fine-grained relation understanding. We propose \underline{R}etrieval \underline{O}ver \underline{C}lassification (ROC), a novel framework that reformulates multimodal RE as a retrieval task driven by relation semantics. ROC integrates entity type and positional information through a multimodal encoder, expands relation labels into natural language descriptions using a large language model, and aligns entity-relation pairs via semantic similarity-based contrastive learning. Experiments show that our method achieves state-of-the-art performance on the benchmark datasets MNRE and MORE and exhibits stronger robustness and interpretability.
Learning the Wrong Lessons: Syntactic-Domain Spurious Correlations in Language Models
arXiv:2509.21155v1 Announce Type: new Abstract: For an LLM to correctly respond to an instruction it must understand both the semantics and the domain (i.e., subject area) of a given task-instruction pair. However, syntax can also convey implicit information Recent work shows that syntactic templates--frequent sequences of Part-of-Speech (PoS) tags--are prevalent in training data and often appear in model outputs. In this work we characterize syntactic templates, domain, and semantics in task-instruction pairs. We identify cases of spurious correlations between syntax and domain, where models learn to associate a domain with syntax during training; this can sometimes override prompt semantics. Using a synthetic training dataset, we find that the syntactic-domain correlation can lower performance (mean 0.51 +/- 0.06) on entity knowledge tasks in OLMo-2 models (1B-13B). We introduce an evaluation framework to detect this phenomenon in trained models, and show that it occurs on a subset of the FlanV2 dataset in open (OLMo-2-7B; Llama-4-Maverick), and closed (GPT-4o) models. Finally, we present a case study on the implications for safety finetuning, showing that unintended syntactic-domain correlations can be used to bypass refusals in OLMo-2-7B Instruct and GPT-4o. Our findings highlight two needs: (1) to explicitly test for syntactic-domain correlations, and (2) to ensure syntactic diversity in training data, specifically within domains, to prevent such spurious correlations.
Who's Laughing Now? An Overview of Computational Humour Generation and Explanation
arXiv:2509.21175v1 Announce Type: new Abstract: The creation and perception of humour is a fundamental human trait, positioning its computational understanding as one of the most challenging tasks in natural language processing (NLP). As an abstract, creative, and frequently context-dependent construct, humour requires extensive reasoning to understand and create, making it a pertinent task for assessing the common-sense knowledge and reasoning abilities of modern large language models (LLMs). In this work, we survey the landscape of computational humour as it pertains to the generative tasks of creation and explanation. We observe that, despite the task of understanding humour bearing all the hallmarks of a foundational NLP task, work on generating and explaining humour beyond puns remains sparse, while state-of-the-art models continue to fall short of human capabilities. We bookend our literature survey by motivating the importance of computational humour processing as a subdiscipline of NLP and presenting an extensive discussion of future directions for research in the area that takes into account the subjective and ethically ambiguous nature of humour.
GEP: A GCG-Based method for extracting personally identifiable information from chatbots built on small language models
arXiv:2509.21192v1 Announce Type: new Abstract: Small language models (SLMs) become unprecedentedly appealing due to their approximately equivalent performance compared to large language models (LLMs) in certain fields with less energy and time consumption during training and inference. However, the personally identifiable information (PII) leakage of SLMs for downstream tasks has yet to be explored. In this study, we investigate the PII leakage of the chatbot based on SLM. We first finetune a new chatbot, i.e., ChatBioGPT based on the backbone of BioGPT using medical datasets Alpaca and HealthCareMagic. It shows a matchable performance in BERTscore compared with previous studies of ChatDoctor and ChatGPT. Based on this model, we prove that the previous template-based PII attacking methods cannot effectively extract the PII in the dataset for leakage detection under the SLM condition. We then propose GEP, which is a greedy coordinate gradient-based (GCG) method specifically designed for PII extraction. We conduct experimental studies of GEP and the results show an increment of up to 60$\times$ more leakage compared with the previous template-based methods. We further expand the capability of GEP in the case of a more complicated and realistic situation by conducting free-style insertion where the inserted PII in the dataset is in the form of various syntactic expressions instead of fixed templates, and GEP is still able to reveal a PII leakage rate of up to 4.53%.
Eigen-1: Adaptive Multi-Agent Refinement with Monitor-Based RAG for Scientific Reasoning
arXiv:2509.21193v1 Announce Type: new Abstract: Large language models (LLMs) have recently shown strong progress on scientific reasoning, yet two major bottlenecks remain. First, explicit retrieval fragments reasoning, imposing a hidden "tool tax" of extra tokens and steps. Second, multi-agent pipelines often dilute strong solutions by averaging across all candidates. We address these challenges with a unified framework that combines implicit retrieval and structured collaboration. At its foundation, a Monitor-based retrieval module operates at the token level, integrating external knowledge with minimal disruption to reasoning. On top of this substrate, Hierarchical Solution Refinement (HSR) iteratively designates each candidate as an anchor to be repaired by its peers, while Quality-Aware Iterative Reasoning (QAIR) adapts refinement to solution quality. On Humanity's Last Exam (HLE) Bio/Chem Gold, our framework achieves 48.3\% accuracy -- the highest reported to date, surpassing the strongest agent baseline by 13.4 points and leading frontier LLMs by up to 18.1 points, while simultaneously reducing token usage by 53.5\% and agent steps by 43.7\%. Results on SuperGPQA and TRQA confirm robustness across domains. Error analysis shows that reasoning failures and knowledge gaps co-occur in over 85\% of cases, while diversity analysis reveals a clear dichotomy: retrieval tasks benefit from solution variety, whereas reasoning tasks favor consensus. Together, these findings demonstrate how implicit augmentation and structured refinement overcome the inefficiencies of explicit tool use and uniform aggregation. Code is available at: https://github.com/tangxiangru/Eigen-1.
CLaw: Benchmarking Chinese Legal Knowledge in Large Language Models - A Fine-grained Corpus and Reasoning Analysis
arXiv:2509.21208v1 Announce Type: new Abstract: Large Language Models (LLMs) are increasingly tasked with analyzing legal texts and citing relevant statutes, yet their reliability is often compromised by general pre-training that ingests legal texts without specialized focus, obscuring the true depth of their legal knowledge. This paper introduces CLaw, a novel benchmark specifically engineered to meticulously evaluate LLMs on Chinese legal knowledge and its application in reasoning. CLaw comprises two key components: (1) a comprehensive, fine-grained corpus of all 306 Chinese national statutes, segmented to the subparagraph level and incorporating precise historical revision timesteps for rigorous recall evaluation (64,849 entries), and (2) a challenging set of 254 case-based reasoning instances derived from China Supreme Court curated materials to assess the practical application of legal knowledge. Our empirical evaluation reveals that most contemporary LLMs significantly struggle to faithfully reproduce legal provisions. As accurate retrieval and citation of legal provisions form the basis of legal reasoning, this deficiency critically undermines the reliability of their responses. We contend that achieving trustworthy legal reasoning in LLMs requires a robust synergy of accurate knowledge retrieval--potentially enhanced through supervised fine-tuning (SFT) or retrieval-augmented generation (RAG)--and strong general reasoning capabilities. This work provides an essential benchmark and critical insights for advancing domain-specific LLM reasoning, particularly within the complex legal sphere.
SGMem: Sentence Graph Memory for Long-Term Conversational Agents
arXiv:2509.21212v1 Announce Type: new Abstract: Long-term conversational agents require effective memory management to handle dialogue histories that exceed the context window of large language models (LLMs). Existing methods based on fact extraction or summarization reduce redundancy but struggle to organize and retrieve relevant information across different granularities of dialogue and generated memory. We introduce SGMem (Sentence Graph Memory), which represents dialogue as sentence-level graphs within chunked units, capturing associations across turn-, round-, and session-level contexts. By combining retrieved raw dialogue with generated memory such as summaries, facts and insights, SGMem supplies LLMs with coherent and relevant context for response generation. Experiments on LongMemEval and LoCoMo show that SGMem consistently improves accuracy and outperforms strong baselines in long-term conversational question answering.
Query-Centric Graph Retrieval Augmented Generation
arXiv:2509.21237v1 Announce Type: new Abstract: Graph-based retrieval-augmented generation (RAG) enriches large language models (LLMs) with external knowledge for long-context understanding and multi-hop reasoning, but existing methods face a granularity dilemma: fine-grained entity-level graphs incur high token costs and lose context, while coarse document-level graphs fail to capture nuanced relations. We introduce QCG-RAG, a query-centric graph RAG framework that enables query-granular indexing and multi-hop chunk retrieval. Our query-centric approach leverages Doc2Query and Doc2Query{-}{-} to construct query-centric graphs with controllable granularity, improving graph quality and interpretability. A tailored multi-hop retrieval mechanism then selects relevant chunks via the generated queries. Experiments on LiHuaWorld and MultiHop-RAG show that QCG-RAG consistently outperforms prior chunk-based and graph-based RAG methods in question answering accuracy, establishing a new paradigm for multi-hop reasoning.
Un-Doubling Diffusion: LLM-guided Disambiguation of Homonym Duplication
arXiv:2509.21262v1 Announce Type: new Abstract: Homonyms are words with identical spelling but distinct meanings, which pose challenges for many generative models. When a homonym appears in a prompt, diffusion models may generate multiple senses of the word simultaneously, which is known as homonym duplication. This issue is further complicated by an Anglocentric bias, which includes an additional translation step before the text-to-image model pipeline. As a result, even words that are not homonymous in the original language may become homonyms and lose their meaning after translation into English. In this paper, we introduce a method for measuring duplication rates and conduct evaluations of different diffusion models using both automatic evaluation utilizing Vision-Language Models (VLM) and human evaluation. Additionally, we investigate methods to mitigate the homonym duplication problem through prompt expansion, demonstrating that this approach also effectively reduces duplication related to Anglocentric bias. The code for the automatic evaluation pipeline is publicly available.
LLM Output Homogenization is Task Dependent
arXiv:2509.21267v1 Announce Type: new Abstract: A large language model can be less helpful if it exhibits output response homogenization. But whether two responses are considered homogeneous, and whether such homogenization is problematic, both depend on the task category. For instance, in objective math tasks, we often expect no variation in the final answer but anticipate variation in the problem-solving strategy. Whereas, for creative writing tasks, we may expect variation in key narrative components (e.g. plot, genre, setting, etc), beyond the vocabulary or embedding diversity produced by temperature-sampling. Previous work addressing output homogenization often fails to conceptualize diversity in a task-dependent way. We address this gap in the literature directly by making the following contributions. (1) We present a task taxonomy comprised of eight task categories that each have distinct conceptualizations of output homogenization. (2) We introduce task-anchored functional diversity to better evaluate output homogenization. (3) We propose a task-anchored sampling technique that increases functional diversity for task categories where homogenization is undesired, while preserving homogenization where it is desired. (4) We challenge the perceived existence of a diversity-quality trade-off by increasing functional diversity while maintaining response quality. Overall, we demonstrate how task dependence improves the evaluation and mitigation of output homogenization.
LLMTrace: A Corpus for Classification and Fine-Grained Localization of AI-Written Text
arXiv:2509.21269v1 Announce Type: new Abstract: The widespread use of human-like text from Large Language Models (LLMs) necessitates the development of robust detection systems. However, progress is limited by a critical lack of suitable training data; existing datasets are often generated with outdated models, are predominantly in English, and fail to address the increasingly common scenario of mixed human-AI authorship. Crucially, while some datasets address mixed authorship, none provide the character-level annotations required for the precise localization of AI-generated segments within a text. To address these gaps, we introduce LLMTrace, a new large-scale, bilingual (English and Russian) corpus for AI-generated text detection. Constructed using a diverse range of modern proprietary and open-source LLMs, our dataset is designed to support two key tasks: traditional full-text binary classification (human vs. AI) and the novel task of AI-generated interval detection, facilitated by character-level annotations. We believe LLMTrace will serve as a vital resource for training and evaluating the next generation of more nuanced and practical AI detection models. The project page is available at \href{https://sweetdream779.github.io/LLMTrace-info/}{iitolstykh/LLMTrace}.
Bounds of Chain-of-Thought Robustness: Reasoning Steps, Embed Norms, and Beyond
arXiv:2509.21284v1 Announce Type: new Abstract: Existing research indicates that the output of Chain-of-Thought (CoT) is significantly affected by input perturbations. Although many methods aim to mitigate such impact by optimizing prompts, a theoretical explanation of how these perturbations influence CoT outputs remains an open area of research. This gap limits our in-depth understanding of how input perturbations propagate during the reasoning process and hinders further improvements in prompt optimization methods. Therefore, in this paper, we theoretically analyze the effect of input perturbations on the fluctuation of CoT outputs. We first derive an upper bound for input perturbations under the condition that the output fluctuation is within an acceptable range, based on which we prove that: (i) This upper bound is positively correlated with the number of reasoning steps in the CoT; (ii) Even an infinitely long reasoning process cannot eliminate the impact of input perturbations. We then apply these conclusions to the Linear Self-Attention (LSA) model, which can be viewed as a simplified version of the Transformer. For the LSA model, we prove that the upper bound for input perturbation is negatively correlated with the norms of the input embedding and hidden state vectors. To validate this theoretical analysis, we conduct experiments on three mainstream datasets and four mainstream models. The experimental results align with our theoretical analysis, empirically demonstrating the correctness of our findings.
DisCoCLIP: A Distributional Compositional Tensor Network Encoder for Vision-Language Understanding
arXiv:2509.21287v1 Announce Type: new Abstract: Recent vision-language models excel at large-scale image-text alignment but often neglect the compositional structure of language, leading to failures on tasks that hinge on word order and predicate-argument structure. We introduce DisCoCLIP, a multimodal encoder that combines a frozen CLIP vision transformer with a novel tensor network text encoder that explicitly encodes syntactic structure. Sentences are parsed with a Combinatory Categorial Grammar parser to yield distributional word tensors whose contractions mirror the sentence's grammatical derivation. To keep the model efficient, high-order tensors are factorized with tensor decompositions, reducing parameter count from tens of millions to under one million. Trained end-to-end with a self-supervised contrastive loss, DisCoCLIP markedly improves sensitivity to verb semantics and word order: it raises CLIP's SVO-Probes verb accuracy from 77.6% to 82.4%, boosts ARO attribution and relation scores by over 9% and 4%, and achieves 93.7% on a newly introduced SVO-Swap benchmark. These results demonstrate that embedding explicit linguistic structure via tensor networks yields interpretable, parameter-efficient representations that substantially improve compositional reasoning in vision-language tasks.
The role of synthetic data in Multilingual, Multi-cultural AI systems: Lessons from Indic Languages
arXiv:2509.21294v1 Announce Type: new Abstract: Developing AI systems that operate effectively across languages while remaining culturally grounded is a long-standing challenge, particularly in low-resource settings. Synthetic data provides a promising avenue, yet its effectiveness in multilingual and multicultural contexts remains underexplored. We investigate the creation and impact of synthetic, culturally contextualized datasets for Indian languages through a bottom-up generation strategy that prompts large open-source LLMs (>= 235B parameters) to ground data generation in language-specific Wikipedia content. This approach complements the dominant top-down paradigm of translating synthetic datasets from high-resource languages such as English. We introduce Updesh, a high-quality large-scale synthetic instruction-following dataset comprising 9.5M data points across 13 Indian languages, encompassing diverse reasoning and generative tasks with an emphasis on long-context, multi-turn capabilities, and alignment with Indian cultural contexts. A comprehensive evaluation incorporating both automated metrics and human annotation across 10k assessments indicates that generated data is high quality; though, human evaluation highlights areas for further improvement. Additionally, we perform downstream evaluations by fine-tuning models on our dataset and assessing the performance across 15 diverse multilingual datasets. Models trained on Updesh consistently achieve significant gains on generative tasks and remain competitive on multiple-choice style NLU tasks. Notably, relative improvements are most pronounced in low and medium-resource languages, narrowing their gap with high-resource languages. These findings provide empirical evidence that effective multilingual AI requires multi-faceted data curation and generation strategies that incorporate context-aware, culturally grounded methodologies.
Sycophancy Is Not One Thing: Causal Separation of Sycophantic Behaviors in LLMs
arXiv:2509.21305v1 Announce Type: new Abstract: Large language models (LLMs) often exhibit sycophantic behaviors -- such as excessive agreement with or flattery of the user -- but it is unclear whether these behaviors arise from a single mechanism or multiple distinct processes. We decompose sycophancy into sycophantic agreement and sycophantic praise, contrasting both with genuine agreement. Using difference-in-means directions, activation additions, and subspace geometry across multiple models and datasets, we show that: (1) the three behaviors are encoded along distinct linear directions in latent space; (2) each behavior can be independently amplified or suppressed without affecting the others; and (3) their representational structure is consistent across model families and scales. These results suggest that sycophantic behaviors correspond to distinct, independently steerable representations.
RLBFF: Binary Flexible Feedback to bridge between Human Feedback & Verifiable Rewards
arXiv:2509.21319v1 Announce Type: new Abstract: Reinforcement Learning with Human Feedback (RLHF) and Reinforcement Learning with Verifiable Rewards (RLVR) are the main RL paradigms used in LLM post-training, each offering distinct advantages. However, RLHF struggles with interpretability and reward hacking because it relies on human judgments that usually lack explicit criteria, whereas RLVR is limited in scope by its focus on correctness-based verifiers. We propose Reinforcement Learning with Binary Flexible Feedback (RLBFF), which combines the versatility of human-driven preferences with the precision of rule-based verification, enabling reward models to capture nuanced aspects of response quality beyond mere correctness. RLBFF extracts principles that can be answered in a binary fashion (e.g. accuracy of information: yes, or code readability: no) from natural language feedback. Such principles can then be used to ground Reward Model training as an entailment task (response satisfies or does not satisfy an arbitrary principle). We show that Reward Models trained in this manner can outperform Bradley-Terry models when matched for data and achieve top performance on RM-Bench (86.2%) and JudgeBench (81.4%, #1 on leaderboard as of September 24, 2025). Additionally, users can specify principles of interest at inference time to customize the focus of our reward models, in contrast to Bradley-Terry models. Finally, we present a fully open source recipe (including data) to align Qwen3-32B using RLBFF and our Reward Model, to match or exceed the performance of o3-mini and DeepSeek R1 on general alignment benchmarks of MT-Bench, WildBench, and Arena Hard v2 (at <5% of the inference cost).
SciReasoner: Laying the Scientific Reasoning Ground Across Disciplines
arXiv:2509.21320v1 Announce Type: new Abstract: We present a scientific reasoning foundation model that aligns natural language with heterogeneous scientific representations. The model is pretrained on a 206B-token corpus spanning scientific text, pure sequences, and sequence-text pairs, then aligned via SFT on 40M instructions, annealed cold-start bootstrapping to elicit long-form chain-of-thought, and reinforcement learning with task-specific reward shaping, which instills deliberate scientific reasoning. It supports four capability families, covering up to 103 tasks across workflows: (i) faithful translation between text and scientific formats, (ii) text/knowledge extraction, (iii) property prediction, (iv) property classification, (v) unconditional and conditional sequence generation and design. Compared with specialist systems, our approach broadens instruction coverage, improves cross-domain generalization, and enhances fidelity. We detail data curation and training and show that cross-discipline learning strengthens transfer and downstream reliability. The model, instruct tuning datasets and the evaluation code are open-sourced at https://huggingface.co/SciReason and https://github.com/open-sciencelab/SciReason.
Intercept Cancer: Cancer Pre-Screening with Large Scale Healthcare Foundation Models
arXiv:2506.00209v1 Announce Type: cross Abstract: Cancer screening, leading to early detection, saves lives. Unfortunately, existing screening techniques require expensive and intrusive medical procedures, not globally available, resulting in too many lost would-be-saved lives. We present CATCH-FM, CATch Cancer early with Healthcare Foundation Models, a cancer pre-screening methodology that identifies high-risk patients for further screening solely based on their historical medical records. With millions of electronic healthcare records (EHR), we establish the scaling law of EHR foundation models pretrained on medical code sequences, pretrain compute-optimal foundation models of up to 2.4 billion parameters, and finetune them on clinician-curated cancer risk prediction cohorts. In our retrospective evaluation comprising of thirty thousand patients, CATCH-FM achieved strong efficacy (60% sensitivity) with low risk (99% specificity and Negative Predictive Value), outperforming feature-based tree models as well as general and medical large language models by large margins. Despite significant demographic, healthcare system, and EHR coding differences, CATCH-FM achieves state-of-the-art pancreatic cancer risk prediction on the EHRSHOT few-shot leaderboard, outperforming EHR foundation models pretrained using on-site patient data. Our analysis demonstrates the robustness of CATCH-FM in various patient distributions, the benefits of operating in the ICD code space, and its ability to capture non-trivial cancer risk factors. Our code will be open-sourced.
CARINOX: Inference-time Scaling with Category-Aware Reward-based Initial Noise Optimization and Exploration
arXiv:2509.17458v1 Announce Type: cross Abstract: Text-to-image diffusion models, such as Stable Diffusion, can produce high-quality and diverse images but often fail to achieve compositional alignment, particularly when prompts describe complex object relationships, attributes, or spatial arrangements. Recent inference-time approaches address this by optimizing or exploring the initial noise under the guidance of reward functions that score text-image alignment without requiring model fine-tuning. While promising, each strategy has intrinsic limitations when used alone: optimization can stall due to poor initialization or unfavorable search trajectories, whereas exploration may require a prohibitively large number of samples to locate a satisfactory output. Our analysis further shows that neither single reward metrics nor ad-hoc combinations reliably capture all aspects of compositionality, leading to weak or inconsistent guidance. To overcome these challenges, we present Category-Aware Reward-based Initial Noise Optimization and Exploration (CARINOX), a unified framework that combines noise optimization and exploration with a principled reward selection procedure grounded in correlation with human judgments. Evaluations on two complementary benchmarks covering diverse compositional challenges show that CARINOX raises average alignment scores by +16% on T2I-CompBench++ and +11% on the HRS benchmark, consistently outperforming state-of-the-art optimization and exploration-based methods across all major categories, while preserving image quality and diversity. The project page is available at https://amirkasaei.com/carinox/{this URL}.
Leveraging NTPs for Efficient Hallucination Detection in VLMs
arXiv:2509.20379v1 Announce Type: cross Abstract: Hallucinations of vision-language models (VLMs), which are misalignments between visual content and generated text, undermine the reliability of VLMs. One common approach for detecting them employs the same VLM, or a different one, to assess generated outputs. This process is computationally intensive and increases model latency. In this paper, we explore an efficient on-the-fly method for hallucination detection by training traditional ML models over signals based on the VLM's next-token probabilities (NTPs). NTPs provide a direct quantification of model uncertainty. We hypothesize that high uncertainty (i.e., a low NTP value) is strongly associated with hallucinations. To test this, we introduce a dataset of 1,400 human-annotated statements derived from VLM-generated content, each labeled as hallucinated or not, and use it to test our NTP-based lightweight method. Our results demonstrate that NTP-based features are valuable predictors of hallucinations, enabling fast and simple ML models to achieve performance comparable to that of strong VLMs. Furthermore, augmenting these NTPs with linguistic NTPs, computed by feeding only the generated text back into the VLM, enhances hallucination detection performance. Finally, integrating hallucination prediction scores from VLMs into the NTP-based models led to better performance than using either VLMs or NTPs alone. We hope this study paves the way for simple, lightweight solutions that enhance the reliability of VLMs.
Blueprints of Trust: AI System Cards for End to End Transparency and Governance
arXiv:2509.20394v1 Announce Type: cross Abstract: This paper introduces the Hazard-Aware System Card (HASC), a novel framework designed to enhance transparency and accountability in the development and deployment of AI systems. The HASC builds upon existing model card and system card concepts by integrating a comprehensive, dynamic record of an AI system's security and safety posture. The framework proposes a standardized system of identifiers, including a novel AI Safety Hazard (ASH) ID, to complement existing security identifiers like CVEs, allowing for clear and consistent communication of fixed flaws. By providing a single, accessible source of truth, the HASC empowers developers and stakeholders to make more informed decisions about AI system safety throughout its lifecycle. Ultimately, we also compare our proposed AI system cards with the ISO/IEC 42001:2023 standard and discuss how they can be used to complement each other, providing greater transparency and accountability for AI systems.
RadAgents: Multimodal Agentic Reasoning for Chest X-ray Interpretation with Radiologist-like Workflows
arXiv:2509.20490v1 Announce Type: cross Abstract: Agentic systems offer a potential path to solve complex clinical tasks through collaboration among specialized agents, augmented by tool use and external knowledge bases. Nevertheless, for chest X-ray (CXR) interpretation, prevailing methods remain limited: (i) reasoning is frequently neither clinically interpretable nor aligned with guidelines, reflecting mere aggregation of tool outputs; (ii) multimodal evidence is insufficiently fused, yielding text-only rationales that are not visually grounded; and (iii) systems rarely detect or resolve cross-tool inconsistencies and provide no principled verification mechanisms. To bridge the above gaps, we present RadAgents, a multi-agent framework for CXR interpretation that couples clinical priors with task-aware multimodal reasoning. In addition, we integrate grounding and multimodal retrieval-augmentation to verify and resolve context conflicts, resulting in outputs that are more reliable, transparent, and consistent with clinical practice.
InsightGUIDE: An Opinionated AI Assistant for Guided Critical Reading of Scientific Literature
arXiv:2509.20493v1 Announce Type: cross Abstract: The proliferation of scientific literature presents an increasingly significant challenge for researchers. While Large Language Models (LLMs) offer promise, existing tools often provide verbose summaries that risk replacing, rather than assisting, the reading of the source material. This paper introduces InsightGUIDE, a novel AI-powered tool designed to function as a reading assistant, not a replacement. Our system provides concise, structured insights that act as a "map" to a paper's key elements by embedding an expert's reading methodology directly into its core AI logic. We present the system's architecture, its prompt-driven methodology, and a qualitative case study comparing its output to a general-purpose LLM. The results demonstrate that InsightGUIDE produces more structured and actionable guidance, serving as a more effective tool for the modern researcher.
Perspectra: Choosing Your Experts Enhances Critical Thinking in Multi-Agent Research Ideation
arXiv:2509.20553v1 Announce Type: cross Abstract: Recent advances in multi-agent systems (MAS) enable tools for information search and ideation by assigning personas to agents. However, how users can effectively control, steer, and critically evaluate collaboration among multiple domain-expert agents remains underexplored. We present Perspectra, an interactive MAS that visualizes and structures deliberation among LLM agents via a forum-style interface, supporting @-mention to invite targeted agents, threading for parallel exploration, with a real-time mind map for visualizing arguments and rationales. In a within-subjects study with 18 participants, we compared Perspectra to a group-chat baseline as they developed research proposals. Our findings show that Perspectra significantly increased the frequency and depth of critical-thinking behaviors, elicited more interdisciplinary replies, and led to more frequent proposal revisions than the group chat condition. We discuss implications for designing multi-agent tools that scaffold critical thinking by supporting user control over multi-agent adversarial discourse.
Every Character Counts: From Vulnerability to Defense in Phishing Detection
arXiv:2509.20589v1 Announce Type: cross Abstract: Phishing attacks targeting both organizations and individuals are becoming an increasingly significant threat as technology advances. Current automatic detection methods often lack explainability and robustness in detecting new phishing attacks. In this work, we investigate the effectiveness of character-level deep learning models for phishing detection, which can provide both robustness and interpretability. We evaluate three neural architectures adapted to operate at the character level, namely CharCNN, CharGRU, and CharBiLSTM, on a custom-built email dataset, which combines data from multiple sources. Their performance is analyzed under three scenarios: (i) standard training and testing, (ii) standard training and testing under adversarial attacks, and (iii) training and testing with adversarial examples. Aiming to develop a tool that operates as a browser extension, we test all models under limited computational resources. In this constrained setup, CharGRU proves to be the best-performing model across all scenarios. All models show vulnerability to adversarial attacks, but adversarial training substantially improves their robustness. In addition, by adapting the Gradient-weighted Class Activation Mapping (Grad-CAM) technique to character-level inputs, we are able to visualize which parts of each email influence the decision of each model. Our open-source code and data is released at https://github.com/chipermaria/every-character-counts.
Human Semantic Representations of Social Interactions from Moving Shapes
arXiv:2509.20673v1 Announce Type: cross Abstract: Humans are social creatures who readily recognize various social interactions from simple display of moving shapes. While previous research has often focused on visual features, we examine what semantic representations that humans employ to complement visual features. In Study 1, we directly asked human participants to label the animations based on their impression of moving shapes. We found that human responses were distributed. In Study 2, we measured the representational geometry of 27 social interactions through human similarity judgments and compared it with model predictions based on visual features, labels, and semantic embeddings from animation descriptions. We found that semantic models provided complementary information to visual features in explaining human judgments. Among the semantic models, verb-based embeddings extracted from descriptions account for human similarity judgments the best. These results suggest that social perception in simple displays reflects the semantic structure of social interactions, bridging visual and abstract representations.
Can Federated Learning Safeguard Private Data in LLM Training? Vulnerabilities, Attacks, and Defense Evaluation
arXiv:2509.20680v1 Announce Type: cross Abstract: Fine-tuning large language models (LLMs) with local data is a widely adopted approach for organizations seeking to adapt LLMs to their specific domains. Given the shared characteristics in data across different organizations, the idea of collaboratively fine-tuning an LLM using data from multiple sources presents an appealing opportunity. However, organizations are often reluctant to share local data, making centralized fine-tuning impractical. Federated learning (FL), a privacy-preserving framework, enables clients to retain local data while sharing only model parameters for collaborative training, offering a potential solution. While fine-tuning LLMs on centralized datasets risks data leakage through next-token prediction, the iterative aggregation process in FL results in a global model that encapsulates generalized knowledge, which some believe protects client privacy. In this paper, however, we present contradictory findings through extensive experiments. We show that attackers can still extract training data from the global model, even using straightforward generation methods, with leakage increasing as the model size grows. Moreover, we introduce an enhanced attack strategy tailored to FL, which tracks global model updates during training to intensify privacy leakage. To mitigate these risks, we evaluate privacy-preserving techniques in FL, including differential privacy, regularization-constrained updates and adopting LLMs with safety alignment. Our results provide valuable insights and practical guidelines for reducing privacy risks when training LLMs with FL.
CE-GPPO: Controlling Entropy via Gradient-Preserving Clipping Policy Optimization in Reinforcement Learning
arXiv:2509.20712v1 Announce Type: cross Abstract: Reinforcement learning (RL) has become a powerful paradigm for optimizing large language models (LLMs) to handle complex reasoning tasks. A core challenge in this process lies in managing policy entropy, which reflects the balance between exploration and exploitation during training. Existing methods, such as proximal policy optimization (PPO) and its variants, discard valuable gradient signals from low-probability tokens due to the clipping mechanism. We systematically analyze the entropy dynamics and reveal that these clipped tokens play a critical yet overlooked role in regulating entropy evolution. We propose \textbf{C}ontrolling \textbf{E}ntropy via \textbf{G}radient-\textbf{P}reserving \textbf{P}olicy \textbf{O}ptimization (CE-GPPO), a novel algorithm that reintroduces gradients from clipped tokens in native PPO in a gentle and bounded manner. By controlling the magnitude of gradients from tokens outside the clipping interval, CE-GPPO is able to achieve an exploration-exploitation trade-off. We provide theoretical justification and empirical evidence showing that CE-GPPO effectively mitigates entropy instability. Extensive experiments on mathematical reasoning benchmarks show that CE-GPPO consistently outperforms strong baselines across different model scales.
Visual Authority and the Rhetoric of Health Misinformation: A Multimodal Analysis of Social Media Videos
arXiv:2509.20724v1 Announce Type: cross Abstract: Short form video platforms are central sites for health advice, where alternative narratives mix useful, misleading, and harmful content. Rather than adjudicating truth, this study examines how credibility is packaged in nutrition and supplement videos by analyzing the intersection of authority signals, narrative techniques, and monetization. We assemble a cross platform corpus of 152 public videos from TikTok, Instagram, and YouTube and annotate each on 26 features spanning visual authority, presenter attributes, narrative strategies, and engagement cues. A transparent annotation pipeline integrates automatic speech recognition, principled frame selection, and a multimodal model, with human verification on a stratified subsample showing strong agreement. Descriptively, a confident single presenter in studio or home settings dominates, and clinical contexts are rare. Analytically, authority cues such as titles, slides and charts, and certificates frequently occur with persuasive elements including jargon, references, fear or urgency, critiques of mainstream medicine, and conspiracies, and with monetization including sales links and calls to subscribe. References and science like visuals often travel with emotive and oppositional narratives rather than signaling restraint.
Seeing Through Words, Speaking Through Pixels: Deep Representational Alignment Between Vision and Language Models
arXiv:2509.20751v1 Announce Type: cross Abstract: Recent studies show that deep vision-only and language-only models--trained on disjoint modalities--nonetheless project their inputs into a partially aligned representational space. Yet we still lack a clear picture of where in each network this convergence emerges, what visual or linguistic cues support it, whether it captures human preferences in many-to-many image-text scenarios, and how aggregating exemplars of the same concept affects alignment. Here, we systematically investigate these questions. We find that alignment peaks in mid-to-late layers of both model types, reflecting a shift from modality-specific to conceptually shared representations. This alignment is robust to appearance-only changes but collapses when semantics are altered (e.g., object removal or word-order scrambling), highlighting that the shared code is truly semantic. Moving beyond the one-to-one image-caption paradigm, a forced-choice "Pick-a-Pic" task shows that human preferences for image-caption matches are mirrored in the embedding spaces across all vision-language model pairs. This pattern holds bidirectionally when multiple captions correspond to a single image, demonstrating that models capture fine-grained semantic distinctions akin to human judgments. Surprisingly, averaging embeddings across exemplars amplifies alignment rather than blurring detail. Together, our results demonstrate that unimodal networks converge on a shared semantic code that aligns with human judgments and strengthens with exemplar aggregation.
Verification Limits Code LLM Training
arXiv:2509.20837v1 Announce Type: cross Abstract: Large language models for code generation increasingly rely on synthetic data, where both problem solutions and verification tests are generated by models. While this enables scalable data creation, it introduces a previously unexplored bottleneck: the verification ceiling, in which the quality and diversity of training data are fundamentally constrained by the capabilities of synthetic verifiers. In this work, we systematically study how verification design and strategies influence model performance. We investigate (i) what we verify by analyzing the impact of test complexity and quantity: richer test suites improve code generation capabilities (on average +3 pass@1), while quantity alone yields diminishing returns, (ii) how we verify by exploring relaxed pass thresholds: rigid 100% pass criteria can be overly restrictive. By allowing for relaxed thresholds or incorporating LLM-based soft verification, we can recover valuable training data, leading to a 2-4 point improvement in pass@1 performance. However, this benefit is contingent upon the strength and diversity of the test cases used, and (iii) why verification remains necessary through controlled comparisons of formally correct versus incorrect solutions and human evaluation: retaining diverse correct solutions per problem yields consistent generalization gains. Our results show that Verification as currently practiced is too rigid, filtering out valuable diversity. But it cannot be discarded, only recalibrated. By combining calibrated verification with diverse, challenging problem-solution pairs, we outline a path to break the verification ceiling and unlock stronger code generation models.
StyleBench: Evaluating thinking styles in Large Language Models
arXiv:2509.20868v1 Announce Type: cross Abstract: The effectiveness of Large Language Models (LLMs) is heavily influenced by the reasoning strategies, or styles of thought, employed in their prompts. However, the interplay between these reasoning styles, model architecture, and task type remains poorly understood. To address this, we introduce StyleBench, a comprehensive benchmark for systematically evaluating reasoning styles across diverse tasks and models. We assess five representative reasoning styles, including Chain of Thought (CoT), Tree of Thought (ToT), Algorithm of Thought (AoT), Sketch of Thought (SoT), and Chain-of-Draft (CoD) on five reasoning tasks, using 15 open-source models from major families (LLaMA, Qwen, Mistral, Gemma, GPT-OSS, Phi, and DeepSeek) ranging from 270M to 120B parameters. Our large-scale analysis reveals that no single style is universally optimal. We demonstrate that strategy efficacy is highly contingent on both model scale and task type: search-based methods (AoT, ToT) excel in open-ended problems but require large-scale models, while concise styles (SoT, CoD) achieve radical efficiency gains on well-defined tasks. Furthermore, we identify key behavioral patterns: smaller models frequently fail to follow output instructions and default to guessing, while reasoning robustness emerges as a function of scale. Our findings offer a crucial roadmap for selecting optimal reasoning strategies based on specific constraints, we open source the benchmark in https://github.com/JamesJunyuGuo/Style_Bench.
On Theoretical Interpretations of Concept-Based In-Context Learning
arXiv:2509.20882v1 Announce Type: cross Abstract: In-Context Learning (ICL) has emerged as an important new paradigm in natural language processing and large language model (LLM) applications. However, the theoretical understanding of the ICL mechanism remains limited. This paper aims to investigate this issue by studying a particular ICL approach, called concept-based ICL (CB-ICL). In particular, we propose theoretical analyses on applying CB-ICL to ICL tasks, which explains why and when the CB-ICL performs well for predicting query labels in prompts with only a few demonstrations. In addition, the proposed theory quantifies the knowledge that can be leveraged by the LLMs to the prompt tasks, and leads to a similarity measure between the prompt demonstrations and the query input, which provides important insights and guidance for model pre-training and prompt engineering in ICL. Moreover, the impact of the prompt demonstration size and the dimension of the LLM embeddings in ICL are also explored based on the proposed theory. Finally, several real-data experiments are conducted to validate the practical usefulness of CB-ICL and the corresponding theory.
CLUE: Conflict-guided Localization for LLM Unlearning Framework
arXiv:2509.20977v1 Announce Type: cross Abstract: The LLM unlearning aims to eliminate the influence of undesirable data without affecting causally unrelated information. This process typically involves using a forget set to remove target information, alongside a retain set to maintain non-target capabilities. While recent localization-based methods demonstrate promise in identifying important neurons to be unlearned, they fail to disentangle neurons responsible for forgetting undesirable knowledge or retaining essential skills, often treating them as a single entangled group. As a result, these methods apply uniform interventions, risking catastrophic over-forgetting or incomplete erasure of the target knowledge. To address this, we turn to circuit discovery, a mechanistic interpretability technique, and propose the Conflict-guided Localization for LLM Unlearning framEwork (CLUE). This framework identifies the forget and retain circuit composed of important neurons, and then the circuits are transformed into conjunctive normal forms (CNF). The assignment of each neuron in the CNF satisfiability solution reveals whether it should be forgotten or retained. We then provide targeted fine-tuning strategies for different categories of neurons. Extensive experiments demonstrate that, compared to existing localization methods, CLUE achieves superior forget efficacy and retain utility through precise neural localization.
Binary Autoencoder for Mechanistic Interpretability of Large Language Models
arXiv:2509.20997v1 Announce Type: cross Abstract: Existing works are dedicated to untangling atomized numerical components (features) from the hidden states of Large Language Models (LLMs) for interpreting their mechanism. However, they typically rely on autoencoders constrained by some implicit training-time regularization on single training instances (i.e., $L_1$ normalization, top-k function, etc.), without an explicit guarantee of global sparsity among instances, causing a large amount of dense (simultaneously inactive) features, harming the feature sparsity and atomization. In this paper, we propose a novel autoencoder variant that enforces minimal entropy on minibatches of hidden activations, thereby promoting feature independence and sparsity across instances. For efficient entropy calculation, we discretize the hidden activations to 1-bit via a step function and apply gradient estimation to enable backpropagation, so that we term it as Binary Autoencoder (BAE) and empirically demonstrate two major applications: (1) Feature set entropy calculation. Entropy can be reliably estimated on binary hidden activations, which we empirically evaluate and leverage to characterize the inference dynamics of LLMs and In-context Learning. (2) Feature untangling. Similar to typical methods, BAE can extract atomized features from LLM's hidden states. To robustly evaluate such feature extraction capability, we refine traditional feature-interpretation methods to avoid unreliable handling of numerical tokens, and show that BAE avoids dense features while producing the largest number of interpretable ones among baselines, which confirms the effectiveness of BAE serving as a feature extractor.
Mechanism of Task-oriented Information Removal in In-context Learning
arXiv:2509.21012v1 Announce Type: cross Abstract: In-context Learning (ICL) is an emerging few-shot learning paradigm based on modern Language Models (LMs), yet its inner mechanism remains unclear. In this paper, we investigate the mechanism through a novel perspective of information removal. Specifically, we demonstrate that in the zero-shot scenario, LMs encode queries into non-selective representations in hidden states containing information for all possible tasks, leading to arbitrary outputs without focusing on the intended task, resulting in near-zero accuracy. Meanwhile, we find that selectively removing specific information from hidden states by a low-rank filter effectively steers LMs toward the intended task. Building on these findings, by measuring the hidden states on carefully designed metrics, we observe that few-shot ICL effectively simulates such task-oriented information removal processes, selectively removing the redundant information from entangled non-selective representations, and improving the output based on the demonstrations, which constitutes a key mechanism underlying ICL. Moreover, we identify essential attention heads inducing the removal operation, termed Denoising Heads, which enables the ablation experiments blocking the information removal operation from the inference, where the ICL accuracy significantly degrades, especially when the correct label is absent from the few-shot demonstrations, confirming both the critical role of the information removal mechanism and denoising heads.
DELTA-Code: How Does RL Unlock and Transfer New Programming Algorithms in LLMs?
arXiv:2509.21016v1 Announce Type: cross Abstract: It remains an open question whether LLMs can acquire or generalize genuinely new reasoning strategies, beyond the sharpened skills encoded in their parameters during pre-training or post-training. To attempt to answer this debate, we introduce DELTA-Code--Distributional Evaluation of Learnability and Transferrability in Algorithmic Coding, a controlled benchmark of synthetic coding problem families designed to probe two fundamental aspects: learnability -- can LLMs, through reinforcement learning (RL), solve problem families where pretrained models exhibit failure with large enough attempts (pass@K=0)? --and transferrability -- if learnability happens, can such skills transfer systematically to out-of-distribution (OOD) test sets? Unlike prior public coding datasets, DELTA isolates reasoning skills through templated problem generators and introduces fully OOD problem families that demand novel strategies rather than tool invocation or memorized patterns. Our experiments reveal a striking grokking phase transition: after an extended period with near-zero reward, RL-trained models abruptly climb to near-perfect accuracy. To enable learnability on previously unsolvable problem families, we explore key training ingredients such as staged warm-up with dense rewards, experience replay, curriculum training, and verification-in-the-loop. Beyond learnability, we use DELTA to evaluate transferability or generalization along exploratory, compositional, and transformative axes, as well as cross-family transfer. Results show solid gains within families and for recomposed skills, but persistent weaknesses in transformative cases. DELTA thus offers a clean testbed for probing the limits of RL-driven reasoning and for understanding how models can move beyond existing priors to acquire new algorithmic skills.
CLAUSE: Agentic Neuro-Symbolic Knowledge Graph Reasoning via Dynamic Learnable Context Engineering
arXiv:2509.21035v1 Announce Type: cross Abstract: Knowledge graphs provide structured context for multi-hop question answering, but deployed systems must balance answer accuracy with strict latency and cost targets while preserving provenance. Static k-hop expansions and "think-longer" prompting often over-retrieve, inflate context, and yield unpredictable runtime. We introduce CLAUSE, an agentic three-agent neuro-symbolic framework that treats context construction as a sequential decision process over knowledge graphs, deciding what to expand, which paths to follow or backtrack, what evidence to keep, and when to stop. Latency (interaction steps) and prompt cost (selected tokens) are exposed as user-specified budgets or prices, allowing per-query adaptation to trade-offs among accuracy, latency, and cost without retraining. CLAUSE employs the proposed Lagrangian-Constrained Multi-Agent Proximal Policy Optimization (LC-MAPPO) algorithm to coordinate three agents: Subgraph Architect, Path Navigator, and Context Curator, so that subgraph construction, reasoning-path discovery, and evidence selection are jointly optimized under per-query resource budgets on edge edits, interaction steps, and selected tokens. Across HotpotQA, MetaQA, and FactKG, CLAUSE yields higher EM@1 while reducing subgraph growth and end-to-end latency at equal or lower token budgets. On MetaQA-2-hop, relative to the strongest RAG baseline (GraphRAG), CLAUSE achieves +39.3 EM@1 with 18.6% lower latency and 40.9% lower edge growth. The resulting contexts are compact, provenance-preserving, and deliver predictable performance under deployment constraints.
Disagreements in Reasoning: How a Model's Thinking Process Dictates Persuasion in Multi-Agent Systems
arXiv:2509.21054v1 Announce Type: cross Abstract: The rapid proliferation of recent Multi-Agent Systems (MAS), where Large Language Models (LLMs) and Large Reasoning Models (LRMs) usually collaborate to solve complex problems, necessitates a deep understanding of the persuasion dynamics that govern their interactions. This paper challenges the prevailing hypothesis that persuasive efficacy is primarily a function of model scale. We propose instead that these dynamics are fundamentally dictated by a model's underlying cognitive process, especially its capacity for explicit reasoning. Through a series of multi-agent persuasion experiments, we uncover a fundamental trade-off we term the Persuasion Duality. Our findings reveal that the reasoning process in LRMs exhibits significantly greater resistance to persuasion, maintaining their initial beliefs more robustly. Conversely, making this reasoning process transparent by sharing the "thinking content" dramatically increases their ability to persuade others. We further consider more complex transmission persuasion situations and reveal complex dynamics of influence propagation and decay within multi-hop persuasion between multiple agent networks. This research provides systematic evidence linking a model's internal processing architecture to its external persuasive behavior, offering a novel explanation for the susceptibility of advanced models and highlighting critical implications for the safety, robustness, and design of future MAS.
PMark: Towards Robust and Distortion-free Semantic-level Watermarking with Channel Constraints
arXiv:2509.21057v1 Announce Type: cross Abstract: Semantic-level watermarking (SWM) for large language models (LLMs) enhances watermarking robustness against text modifications and paraphrasing attacks by treating the sentence as the fundamental unit. However, existing methods still lack strong theoretical guarantees of robustness, and reject-sampling-based generation often introduces significant distribution distortions compared with unwatermarked outputs. In this work, we introduce a new theoretical framework on SWM through the concept of proxy functions (PFs) $\unicode{x2013}$ functions that map sentences to scalar values. Building on this framework, we propose PMark, a simple yet powerful SWM method that estimates the PF median for the next sentence dynamically through sampling while enforcing multiple PF constraints (which we call channels) to strengthen watermark evidence. Equipped with solid theoretical guarantees, PMark achieves the desired distortion-free property and improves the robustness against paraphrasing-style attacks. We also provide an empirically optimized version that further removes the requirement for dynamical median estimation for better sampling efficiency. Experimental results show that PMark consistently outperforms existing SWM baselines in both text quality and robustness, offering a more effective paradigm for detecting machine-generated text. Our code will be released at this URL.
ScaleDiff: Scaling Difficult Problems for Advanced Mathematical Reasoning
arXiv:2509.21070v1 Announce Type: cross Abstract: Large Reasoning Models (LRMs) have shown impressive capabilities in complex problem-solving, often benefiting from training on difficult mathematical problems that stimulate intricate reasoning. Recent efforts have explored automated synthesis of mathematical problems by prompting proprietary models or large-scale open-source models from seed data or inherent mathematical concepts. However, scaling up these methods remains challenging due to their high computational/API cost, complexity of prompting, and limited difficulty level of the generated problems. To overcome these limitations, we propose ScaleDiff, a simple yet effective pipeline designed to scale the creation of difficult problems. We efficiently identify difficult problems from existing datasets with only a single forward pass using an adaptive thinking model, which can perceive problem difficulty and automatically switch between "Thinking" and "NoThinking" modes. We then train a specialized difficult problem generator (DiffGen-8B) on this filtered difficult data, which can produce new difficult problems in large scale, eliminating the need for complex, per-instance prompting and its associated high API costs. Fine-tuning Qwen2.5-Math-7B-Instruct on the ScaleDiff-Math dataset yields a substantial performance increase of 11.3% compared to the original dataset and achieves a 65.9% average accuracy on AIME'24, AIME'25, HMMT-Feb'25, BRUMO'25, and MATH500, outperforming recent strong LRMs like OpenThinker3. Notably, this performance is achieved using the cost-efficient Qwen3-8B model as a teacher, demonstrating that our pipeline can effectively transfer advanced reasoning capabilities without relying on larger, more expensive teacher models. Furthermore, we observe a clear scaling phenomenon in model performance on difficult benchmarks as the quantity of difficult problems increases. Code: https://github.com/QizhiPei/ScaleDiff.
Communication Bias in Large Language Models: A Regulatory Perspective
arXiv:2509.21075v1 Announce Type: cross Abstract: Large language models (LLMs) are increasingly central to many applications, raising concerns about bias, fairness, and regulatory compliance. This paper reviews risks of biased outputs and their societal impact, focusing on frameworks like the EU's AI Act and the Digital Services Act. We argue that beyond constant regulation, stronger attention to competition and design governance is needed to ensure fair, trustworthy AI. This is a preprint of the Communications of the ACM article of the same title.
TrustJudge: Inconsistencies of LLM-as-a-Judge and How to Alleviate Them
arXiv:2509.21117v1 Announce Type: cross Abstract: The adoption of Large Language Models (LLMs) as automated evaluators (LLM-as-a-judge) has revealed critical inconsistencies in current evaluation frameworks. We identify two fundamental types of inconsistencies: (1) Score-Comparison Inconsistency, where lower-rated responses outperform higher-scored ones in pairwise comparisons, and (2) Pairwise Transitivity Inconsistency, manifested through circular preference chains (A>B>C>A) and equivalence contradictions (A=B=C\neq A). We argue that these issues come from information loss in discrete rating systems and ambiguous tie judgments during pairwise evaluation. We propose TrustJudge, a probabilistic framework that addresses these limitations through two key innovations: 1) distribution-sensitive scoring that computes continuous expectations from discrete rating probabilities, preserving information entropy for more precise scoring, and 2) likelihood-aware aggregation that resolves transitivity violations using bidirectional preference probabilities or perplexity. We also formalize the theoretical limitations of current LLM-as-a-judge frameworks and demonstrate how TrustJudge's components overcome them. When evaluated with Llama-3.1-70B-Instruct as judge using our dataset, TrustJudge reduces Score-Comparison inconsistency by 8.43% (from 23.32% to 14.89%) and Pairwise Transitivity inconsistency by 10.82% (from 15.22% to 4.40%), while maintaining higher evaluation accuracy. Our work provides the first systematic analysis of evaluation framework inconsistencies in LLM-as-a-judge paradigms, offering both theoretical insights and practical solutions for reliable automated assessment. The framework demonstrates consistent improvements across various model architectures and scales, enabling more trustworthy LLM evaluation without requiring additional training or human annotations. The codes can be found at https://github.com/TrustJudge/TrustJudge.
Expanding Reasoning Potential in Foundation Model by Learning Diverse Chains of Thought Patterns
arXiv:2509.21124v1 Announce Type: cross Abstract: Recent progress in large reasoning models for challenging mathematical reasoning has been driven by reinforcement learning (RL). Incorporating long chain-of-thought (CoT) data during mid-training has also been shown to substantially improve reasoning depth. However, current approaches often utilize CoT data indiscriminately, leaving open the critical question of which data types most effectively enhance model reasoning capabilities. In this paper, we define the foundation model's reasoning potential for the first time as the inverse of the number of independent attempts required to correctly answer the question, which is strongly correlated with the final model performance. We then propose utilizing diverse data enriched with high-value reasoning patterns to expand the reasoning potential. Specifically, we abstract atomic reasoning patterns from CoT sequences, characterized by commonality and inductive capabilities, and use them to construct a core reference set enriched with valuable reasoning patterns. Furthermore, we propose a dual-granularity algorithm involving chains of reasoning patterns and token entropy, efficiently selecting high-value CoT data (CoTP) from the data pool that aligns with the core set, thereby training models to master reasoning effectively. Only 10B-token CoTP data enables the 85A6B Mixture-of-Experts (MoE) model to improve by 9.58% on the challenging AIME 2024 and 2025, and to raise the upper bound of downstream RL performance by 7.81%.
Automotive-ENV: Benchmarking Multimodal Agents in Vehicle Interface Systems
arXiv:2509.21143v1 Announce Type: cross Abstract: Multimodal agents have demonstrated strong performance in general GUI interactions, but their application in automotive systems has been largely unexplored. In-vehicle GUIs present distinct challenges: drivers' limited attention, strict safety requirements, and complex location-based interaction patterns. To address these challenges, we introduce Automotive-ENV, the first high-fidelity benchmark and interaction environment tailored for vehicle GUIs. This platform defines 185 parameterized tasks spanning explicit control, implicit intent understanding, and safety-aware tasks, and provides structured multimodal observations with precise programmatic checks for reproducible evaluation. Building on this benchmark, we propose ASURADA, a geo-aware multimodal agent that integrates GPS-informed context to dynamically adjust actions based on location, environmental conditions, and regional driving norms. Experiments show that geo-aware information significantly improves success on safety-aware tasks, highlighting the importance of location-based context in automotive environments. We will release Automotive-ENV, complete with all tasks and benchmarking tools, to further the development of safe and adaptive in-vehicle agents.
TABLET: A Large-Scale Dataset for Robust Visual Table Understanding
arXiv:2509.21205v1 Announce Type: cross Abstract: While table understanding increasingly relies on pixel-only settings where tables are processed as visual representations, current benchmarks predominantly use synthetic renderings that lack the complexity and visual diversity of real-world tables. Additionally, existing visual table understanding (VTU) datasets offer fixed examples with single visualizations and pre-defined instructions, providing no access to underlying serialized data for reformulation. We introduce TABLET, a large-scale VTU dataset with 4 million examples across 20 tasks, grounded in 2 million unique tables where 88% preserve original visualizations. Each example includes paired image-HTML representations, comprehensive metadata, and provenance information linking back to the source datasets. Fine-tuning vision-language models like Qwen2.5-VL-7B on TABLET improves performance on seen and unseen VTU tasks while increasing robustness on real-world table visualizations. By preserving original visualizations and maintaining example traceability in a unified large-scale collection, TABLET establishes a foundation for robust training and extensible evaluation of future VTU models.
Sigma: Semantically Informative Pre-training for Skeleton-based Sign Language Understanding
arXiv:2509.21223v1 Announce Type: cross Abstract: Pre-training has proven effective for learning transferable features in sign language understanding (SLU) tasks. Recently, skeleton-based methods have gained increasing attention because they can robustly handle variations in subjects and backgrounds without being affected by appearance or environmental factors. Current SLU methods continue to face three key limitations: 1) weak semantic grounding, as models often capture low-level motion patterns from skeletal data but struggle to relate them to linguistic meaning; 2) imbalance between local details and global context, with models either focusing too narrowly on fine-grained cues or overlooking them for broader context; and 3) inefficient cross-modal learning, as constructing semantically aligned representations across modalities remains difficult. To address these, we propose Sigma, a unified skeleton-based SLU framework featuring: 1) a sign-aware early fusion mechanism that facilitates deep interaction between visual and textual modalities, enriching visual features with linguistic context; 2) a hierarchical alignment learning strategy that jointly maximises agreements across different levels of paired features from different modalities, effectively capturing both fine-grained details and high-level semantic relationships; and 3) a unified pre-training framework that combines contrastive learning, text matching and language modelling to promote semantic consistency and generalisation. Sigma achieves new state-of-the-art results on isolated sign language recognition, continuous sign language recognition, and gloss-free sign language translation on multiple benchmarks spanning different sign and spoken languages, demonstrating the impact of semantically informative pre-training and the effectiveness of skeletal data as a stand-alone solution for SLU.
Evaluating the Evaluators: Metrics for Compositional Text-to-Image Generation
arXiv:2509.21227v1 Announce Type: cross Abstract: Text-image generation has advanced rapidly, but assessing whether outputs truly capture the objects, attributes, and relations described in prompts remains a central challenge. Evaluation in this space relies heavily on automated metrics, yet these are often adopted by convention or popularity rather than validated against human judgment. Because evaluation and reported progress in the field depend directly on these metrics, it is critical to understand how well they reflect human preferences. To address this, we present a broad study of widely used metrics for compositional text-image evaluation. Our analysis goes beyond simple correlation, examining their behavior across diverse compositional challenges and comparing how different metric families align with human judgments. The results show that no single metric performs consistently across tasks: performance varies with the type of compositional problem. Notably, VQA-based metrics, though popular, are not uniformly superior, while certain embedding-based metrics prove stronger in specific cases. Image-only metrics, as expected, contribute little to compositional evaluation, as they are designed for perceptual quality rather than alignment. These findings underscore the importance of careful and transparent metric selection, both for trustworthy evaluation and for their use as reward models in generation. Project page is available at \href{https://amirkasaei.com/eval-the-evals/}{this URL}.
Hallucination as an Upper Bound: A New Perspective on Text-to-Image Evaluation
arXiv:2509.21257v1 Announce Type: cross Abstract: In language and vision-language models, hallucination is broadly understood as content generated from a model's prior knowledge or biases rather than from the given input. While this phenomenon has been studied in those domains, it has not been clearly framed for text-to-image (T2I) generative models. Existing evaluations mainly focus on alignment, checking whether prompt-specified elements appear, but overlook what the model generates beyond the prompt. We argue for defining hallucination in T2I as bias-driven deviations and propose a taxonomy with three categories: attribute, relation, and object hallucinations. This framing introduces an upper bound for evaluation and surfaces hidden biases, providing a foundation for richer assessment of T2I models.
Interactive Recommendation Agent with Active User Commands
arXiv:2509.21317v1 Announce Type: cross Abstract: Traditional recommender systems rely on passive feedback mechanisms that limit users to simple choices such as like and dislike. However, these coarse-grained signals fail to capture users' nuanced behavior motivations and intentions. In turn, current systems cannot also distinguish which specific item attributes drive user satisfaction or dissatisfaction, resulting in inaccurate preference modeling. These fundamental limitations create a persistent gap between user intentions and system interpretations, ultimately undermining user satisfaction and harming system effectiveness. To address these limitations, we introduce the Interactive Recommendation Feed (IRF), a pioneering paradigm that enables natural language commands within mainstream recommendation feeds. Unlike traditional systems that confine users to passive implicit behavioral influence, IRF empowers active explicit control over recommendation policies through real-time linguistic commands. To support this paradigm, we develop RecBot, a dual-agent architecture where a Parser Agent transforms linguistic expressions into structured preferences and a Planner Agent dynamically orchestrates adaptive tool chains for on-the-fly policy adjustment. To enable practical deployment, we employ simulation-augmented knowledge distillation to achieve efficient performance while maintaining strong reasoning capabilities. Through extensive offline and long-term online experiments, RecBot shows significant improvements in both user satisfaction and business outcomes.
Higher-Order DisCoCat (Peirce-Lambek-Montague semantics)
arXiv:2311.17813v2 Announce Type: replace Abstract: We propose a new definition of higher-order DisCoCat (categorical compositional distributional) models where the meaning of a word is not a diagram, but a diagram-valued higher-order function. Our models can be seen as a variant of Montague semantics based on a lambda calculus where the primitives act on string diagrams rather than logical formulae. As a special case, we show how to translate from the Lambek calculus into Peirce's system beta for first-order logic. This allows us to give a purely diagrammatic treatment of higher-order and non-linear processes in natural language semantics: adverbs, prepositions, negation and quantifiers. The definition presented in this article comes with a proof-of-concept implementation in DisCoPy, the Python library for string diagrams.
ASCIIEval: Benchmarking Models' Visual Perception in Text Strings via ASCII Art
arXiv:2410.01733v2 Announce Type: replace Abstract: Perceiving visual semantics embedded within consecutive characters is a crucial yet under-explored capability for both Large Language Models (LLMs) and Multi-modal Large Language Models (MLLMs). In this work, we select ASCII art as a representative artifact. It depicts concepts through careful arrangement of characters, which can be formulated in both text and image modalities. We frame the problem as a recognition task, and construct a novel benchmark, ASCIIEval. It covers over 3K samples with an elaborate categorization tree, along with a training set for further enhancement. Encompassing a comprehensive analysis of tens of models through different input modalities, our benchmark demonstrate its multi-faceted diagnostic power. Given textual input, language models shows their visual perception ability on ASCII art concepts. Proprietary models achieve over 70% accuracy on certain categories, with GPT-5 topping the rank. For image inputs, we reveal that open-source MLLMs suffer from a trade-off between fine-grained text recognition and collective visual perception. They exhibit limited generalization ability to this special kind of arts, leading to the dramatic gap of over 20.01% accuracy compared with their proprietary counterparts. Another critical finding is that model performance is sensitive to the length of the ASCII art, with this sensitivity varying across input modalities. Unfortunately, none of the models could successfully benefit from the simultaneous provision of both modalities, highlighting the need for more flexible modality-fusion approaches. Besides, we also introduce approaches for further enhancement and discuss future directions. Resources are available at https://github.com/JiaQiSJTU/VisionInText.
UniHR: Hierarchical Representation Learning for Unified Knowledge Graph Link Prediction
arXiv:2411.07019v4 Announce Type: replace Abstract: Real-world knowledge graphs (KGs) contain not only standard triple-based facts, but also more complex, heterogeneous types of facts, such as hyper-relational facts with auxiliary key-value pairs, temporal facts with additional timestamps, and nested facts that imply relationships between facts. These richer forms of representation have attracted significant attention due to their enhanced expressiveness and capacity to model complex semantics in real-world scenarios. However, most existing studies suffer from two main limitations: (1) they typically focus on modeling only specific types of facts, thus making it difficult to generalize to real-world scenarios with multiple fact types; and (2) they struggle to achieve generalizable hierarchical (inter-fact and intra-fact) modeling due to the complexity of these representations. To overcome these limitations, we propose UniHR, a Unified Hierarchical Representation learning framework, which consists of a learning-optimized Hierarchical Data Representation (HiDR) module and a unified Hierarchical Structure Learning (HiSL) module. The HiDR module unifies hyper-relational KGs, temporal KGs, and nested factual KGs into triple-based representations. Then HiSL incorporates intra-fact and inter-fact message passing, focusing on enhancing both semantic information within individual facts and enriching the structural information between facts. To go beyond the unified method itself, we further explore the potential of unified representation in complex real-world scenarios, including joint modeling of multi-task, compositional and hybrid facts. Extensive experiments on 9 datasets across 5 types of KGs demonstrate the effectiveness of UniHR and highlight the strong potential of unified representations.
Investigating Factuality in Long-Form Text Generation: The Roles of Self-Known and Self-Unknown
arXiv:2411.15993v2 Announce Type: replace Abstract: Large language models (LLMs) have demonstrated strong capabilities in text understanding and generation. However, they often lack factuality, producing a mixture of true and false information, especially in long-form generation. In this work, we investigates the factuality of long-form text generation across various large language models (LLMs), including GPT-4, Gemini-1.5-Pro, Claude-3-Opus, Llama-3-70B, and Mistral. Our analysis reveals that factuality tend to decline in later sentences of the generated text, accompanied by a rise in the number of unsupported claims. Furthermore, we explore the effectiveness of different evaluation settings to assess whether LLMs can accurately judge the correctness of their own outputs: Self-Known (the percentage of supported atomic claims, decomposed from LLM outputs, that the corresponding LLMs judge as correct) and Self-Unknown (the percentage of unsupported atomic claims that the corresponding LLMs judge as incorrect). Empirically, we observe a positive correlation between higher Self-Known scores and improved factuality, whereas higher Self-Unknown scores are associated with reduced factuality. Interestingly, the number of unsupported claims can increase even without significant changes in a model's self-judgment scores (Self-Known and Self-Unknown), likely as a byproduct of long-form text generation. We also derive a mathematical framework linking Self-Known and Self-Unknown scores to factuality: $\textrm{Factuality}=\frac{1-\textrm{Self-Unknown}}{2-\textrm{Self-Unknown}-\textrm{Self-Known}}$, which aligns with our empirical observations. Additional Retrieval-Augmented Generation (RAG) experiments further highlight the limitations of current LLMs in long-form generation and underscore the need for continued research to improve factuality in long-form text.
LAMA-UT: Language Agnostic Multilingual ASR through Orthography Unification and Language-Specific Transliteration
arXiv:2412.15299v3 Announce Type: replace Abstract: Building a universal multilingual automatic speech recognition (ASR) model that performs equitably across languages has long been a challenge due to its inherent difficulties. To address this task we introduce a Language-Agnostic Multilingual ASR pipeline through orthography Unification and language-specific Transliteration (LAMA-UT). LAMA-UT operates without any language-specific modules while matching the performance of state-of-the-art models trained on a minimal amount of data. Our pipeline consists of two key steps. First, we utilize a universal transcription generator to unify orthographic features into Romanized form and capture common phonetic characteristics across diverse languages. Second, we utilize a universal converter to transform these universal transcriptions into language-specific ones. In experiments, we demonstrate the effectiveness of our proposed method leveraging universal transcriptions for massively multilingual ASR. Our pipeline achieves a relative error reduction rate of 45% when compared to Whisper and performs comparably to MMS, despite being trained on only 0.1% of Whisper's training data. Furthermore, our pipeline does not rely on any language-specific modules. However, it performs on par with zero-shot ASR approaches which utilize additional language-specific lexicons and language models. We expect this framework to serve as a cornerstone for flexible multilingual ASR systems that are generalizable even to unseen languages.
Labeling Free-text Data using Language Model Ensembles
arXiv:2501.08413v3 Announce Type: replace Abstract: Free-text responses are commonly collected in psychological studies, providing rich qualitative insights that quantitative measures may not capture. Labeling curated topics of research interest in free-text data by multiple trained human coders is typically labor-intensive and time-consuming. Though large language models (LLMs) excel in language processing, LLM-assisted labeling techniques relying on closed-source LLMs cannot be directly applied to free-text data, without explicit consent for external use. In this study, we propose a framework of assembling locally-deployable LLMs to enhance the labeling of predetermined topics in free-text data under privacy constraints. Analogous to annotation by multiple human raters, this framework leverages the heterogeneity of diverse open-source LLMs. The ensemble approach seeks a balance between the agreement and disagreement across LLMs, guided by a relevancy scoring methodology that utilizes embedding distances between topic descriptions and LLMs' reasoning. We evaluated the ensemble approach using both publicly accessible Reddit data from eating disorder related forums, and free-text responses from eating disorder patients, both complemented by human annotations. We found that: (1) there is heterogeneity in the performance of labeling among same-sized LLMs, with some showing low sensitivity but high precision, while others exhibit high sensitivity but low precision. (2) Compared to individual LLMs, the ensemble of LLMs achieved the highest accuracy and optimal precision-sensitivity trade-off in predicting human annotations. (3) The relevancy scores across LLMs showed greater agreement than dichotomous labels, indicating that the relevancy scoring method effectively mitigates the heterogeneity in LLMs' labeling.
Improving LLM Unlearning Robustness via Random Perturbations
arXiv:2501.19202v4 Announce Type: replace Abstract: Here, we show that current state-of-the-art LLM unlearning methods inherently reduce models' robustness, causing them to misbehave even when a single non-adversarial forget-token is present in the retain-query. Toward understanding underlying causes, we propose a novel theoretical framework that reframes the unlearning process as backdoor attacks and defenses: forget-tokens act as backdoor triggers that, when activated in retain-queries, cause disruptions in unlearned models' behaviors, similar to successful backdoor attacks. The sense that, LLM unlearning methods themselves poison the model, make it more vulnerable to forget-tokens, and hide rather than erase target knowledge, describes their true mechanism. To mitigate the vulnerability caused by the forgetting process, we reinterpret the retaining process as a backdoor defense and propose Random Noise Augmentation (RNA), a lightweight, model and method-agnostic approach with theoretical guarantees for improving the robustness of models. Extensive experiments demonstrate that RNA significantly improves the robustness of unlearned models while preserving forget and retain performances. This backdoor attack-defense framework offers insights into the mechanism of unlearning that can shed light on future research directions for improving unlearning robustness.
Quantifying depressive mental states with large language models
arXiv:2502.09487v2 Announce Type: replace Abstract: Large Language Models (LLMs) may have an important role to play in mental health by facilitating the quantification of verbal expressions used to communicate emotions, feelings and thoughts. While there has been substantial and very promising work in this area, the fundamental limits are uncertain. Here, focusing on depressive symptoms, we outline and evaluate LLM performance on three critical tests. The first test evaluates LLM performance on a novel ground-truth dataset from a large human sample (n=770). This dataset is novel as it contains both standard clinically validated quantifications of depression symptoms and specific verbal descriptions of the thoughts related to each symptom by the same individual. The performance of LLMs on this richly informative data shows an upper bound on the performance in this domain, and allow us to examine the extent to which inference about symptoms generalises. Second, we test to what extent the latent structure in LLMs can capture the clinically observed patterns. We train supervised sparse auto-encoders (sSAE) to predict specific symptoms and symptom patterns within a syndrome. We find that sSAE weights can effectively modify the clinical pattern produced by the model, and thereby capture the latent structure of relevant clinical variation. Third, if LLMs correctly capture and quantify relevant mental states, then these states should respond to changes in emotional states induced by validated emotion induction interventions. We show that this holds in a third experiment with 190 participants. Overall, this work provides foundational insights into the quantification of pathological mental states with LLMs, highlighting hard limits on the requirements of the data underlying LLM-based quantification; but also suggesting LLMs show substantial conceptual alignment.
MathFimer: Enhancing Mathematical Reasoning by Expanding Reasoning Steps through Fill-in-the-Middle Task
arXiv:2502.11684v2 Announce Type: replace Abstract: Mathematical reasoning represents a critical frontier in advancing large language models (LLMs). While step-by-step approaches have emerged as the dominant paradigm for mathematical problem-solving in LLMs, the quality of reasoning steps in training data fundamentally constrains the performance of the models. Recent studies has demonstrated that more detailed intermediate steps can enhance model performance, yet existing methods for step expansion either require more powerful external models or incur substantial computational costs. In this paper, we introduce MathFimer, a novel framework for mathematical reasoning step expansion inspired by the "Fill-in-the-middle" task from code completion. By decomposing solution chains into prefix-suffix pairs and training models to reconstruct missing intermediate steps, we develop a specialized model, MathFimer-7B, on our carefully curated NuminaMath-FIM dataset. We then apply these models to enhance existing mathematical reasoning datasets by inserting detailed intermediate steps into their solution chains, creating MathFimer-expanded versions. Through comprehensive experiments on multiple mathematical reasoning datasets, including MathInstruct, MetaMathQA and etc., we demonstrate that models trained on MathFimer-expanded data consistently outperform their counterparts trained on original data across various benchmarks such as GSM8K and MATH. Our approach offers a practical, scalable solution for enhancing mathematical reasoning capabilities in LLMs without relying on powerful external models or expensive inference procedures.
The Validation Gap: A Mechanistic Analysis of How Language Models Compute Arithmetic but Fail to Validate It
arXiv:2502.11771v2 Announce Type: replace Abstract: The ability of large language models (LLMs) to validate their output and identify potential errors is crucial for ensuring robustness and reliability. However, current research indicates that LLMs struggle with self-correction, encountering significant challenges in detecting errors. While studies have explored methods to enhance self-correction in LLMs, relatively little attention has been given to understanding the models' internal mechanisms underlying error detection. In this paper, we present a mechanistic analysis of error detection in LLMs, focusing on simple arithmetic problems. Through circuit analysis, we identify the computational subgraphs responsible for detecting arithmetic errors across four smaller-sized LLMs. Our findings reveal that all models heavily rely on $\textit{consistency heads}$--attention heads that assess surface-level alignment of numerical values in arithmetic solutions. Moreover, we observe that the models' internal arithmetic computation primarily occurs in higher layers, whereas validation takes place in middle layers, before the final arithmetic results are fully encoded. This structural dissociation between arithmetic computation and validation seems to explain why smaller-sized LLMs struggle to detect even simple arithmetic errors.
Thinking Outside the (Gray) Box: A Context-Based Score for Assessing Value and Originality in Neural Text Generation
arXiv:2502.13207v3 Announce Type: replace Abstract: Despite the increasing use of large language models for creative tasks, their outputs often lack diversity. Common solutions, such as sampling at higher temperatures, can compromise the quality of the results. Dealing with this trade-off is still an open challenge in designing AI systems for creativity. Drawing on information theory, we propose a context-based score to quantitatively evaluate value and originality. This score incentivizes accuracy and adherence to the request while fostering divergence from the learned distribution. We show that our score can be used as a reward in a reinforcement learning framework to fine-tune large language models for maximum performance. We validate our strategy through experiments considering a variety of creative tasks, such as poetry generation and math problem solving, demonstrating that it enhances the value and originality of the generated solutions.
JUREX-4E: Juridical Expert-Annotated Four-Element Knowledge Base for Legal Reasoning
arXiv:2502.17166v2 Announce Type: replace Abstract: In recent years, Large Language Models (LLMs) have been widely applied to legal tasks. To enhance their understanding of legal texts and improve reasoning accuracy, a promising approach is to incorporate legal theories. One of the most widely adopted theories is the Four-Element Theory (FET), which defines the crime constitution through four elements: Subject, Object, Subjective Aspect, and Objective Aspect. While recent work has explored prompting LLMs to follow FET, our evaluation demonstrates that LLM-generated four-elements are often incomplete and less representative, limiting their effectiveness in legal reasoning. To address these issues, we present JUREX-4E, an expert-annotated four-element knowledge base covering 155 criminal charges. The annotations follow a progressive hierarchical framework grounded in legal source validity and incorporate diverse interpretive methods to ensure precision and authority. We evaluate JUREX-4E on the Similar Charge Disambiguation task and apply it to Legal Case Retrieval. Experimental results validate the high quality of JUREX-4E and its substantial impact on downstream legal tasks, underscoring its potential for advancing legal AI applications. The dataset and code are available at: https://github.com/THUlawtech/JUREX
Problem Solved? Information Extraction Design Space for Layout-Rich Documents using LLMs
arXiv:2502.18179v3 Announce Type: replace Abstract: This paper defines and explores the design space for information extraction (IE) from layout-rich documents using large language models (LLMs). The three core challenges of layout-aware IE with LLMs are 1) data structuring, 2) model engagement, and 3) output refinement. Our study investigates the sub-problems and methods within these core challenges, such as input representation, chunking, prompting, selection of LLMs, and multimodal models. It examines the effect of different design choices through LayIE-LLM, a new, open-source, layout-aware IE test suite, benchmarking against traditional, fine-tuned IE models. The results on two IE datasets show that LLMs require adjustment of the IE pipeline to achieve competitive performance: the optimized configuration found with LayIE-LLM achieves 13.3--37.5 F1 points more than a general-practice baseline configuration using the same LLM. To find a well-working configuration, we develop a one-factor-at-a-time (OFAT) method that achieves near-optimal results. Our method is only 0.8--1.8 points lower than the best full factorial exploration with a fraction (2.8%) of the required computation. Overall, we demonstrate that, if well-configured, general-purpose LLMs match the performance of specialized models, providing a cost-effective, finetuning-free alternative. Our test-suite is available at https://github.com/gayecolakoglu/LayIE-LLM.
Collab-Overcooked: Benchmarking and Evaluating Large Language Models as Collaborative Agents
arXiv:2502.20073v3 Announce Type: replace Abstract: Large Language Models (LLMs) based agent systems have made great strides in real-world applications beyond traditional NLP tasks. This paper proposes a new LLM-based Multi-Agent System (LLM-MAS) benchmark, Collab-Overcooked, built on the popular Overcooked-AI game with more applicable and challenging tasks in interactive environments. Collab-Overcooked extends existing benchmarks in two novel ways. First, it provides a multi-agent framework supporting diverse tasks and objectives and encourages collaboration through natural language communication. Second, it introduces a spectrum of process-oriented evaluation metrics to assess the fine-grained collaboration capabilities of different LLM agents, a dimension often overlooked in prior work. We conduct extensive experiments with 13 popular LLMs and show that, while the LLMs exhibit a strong ability in goal interpretation, there are significant shortcomings in active collaboration and continuous adaptation, which are critical for efficiently fulfilling complex tasks. Notably, we highlight the strengths and weaknesses of LLM-MAS and provide insights for improving and evaluating LLM-MAS on a unified and open-source benchmark. The environments, 30 open-ended tasks, and the evaluation package are publicly available at https://github.com/YusaeMeow/Collab-Overcooked.
Constructions are Revealed in Word Distributions
arXiv:2503.06048v2 Announce Type: replace Abstract: Construction grammar posits that constructions, or form-meaning pairings, are acquired through experience with language (the distributional learning hypothesis). But how much information about constructions does this distribution actually contain? Corpus-based analyses provide some answers, but text alone cannot answer counterfactual questions about what \emph{caused} a particular word to occur. This requires computable models of the distribution over strings -- namely, pretrained language models (PLMs). Here, we treat a RoBERTa model as a proxy for this distribution and hypothesize that constructions will be revealed within it as patterns of statistical affinity. We support this hypothesis experimentally: many constructions are robustly distinguished, including (i) hard cases where semantically distinct constructions are superficially similar, as well as (ii) \emph{schematic} constructions, whose ``slots'' can be filled by abstract word classes. Despite this success, we also provide qualitative evidence that statistical affinity alone may be insufficient to identify all constructions from text. Thus, statistical affinity is likely an important, but partial, signal available to learners.
Explainable Sentiment Analysis with DeepSeek-R1: Performance, Efficiency, and Few-Shot Learning
arXiv:2503.11655v4 Announce Type: replace Abstract: Large language models (LLMs) have transformed sentiment analysis, yet balancing accuracy, efficiency, and explainability remains a critical challenge. This study presents the first comprehensive evaluation of DeepSeek-R1--an open-source reasoning model--against OpenAI's GPT-4o and GPT-4o-mini. We test the full 671B model and its distilled variants, systematically documenting few-shot learning curves. Our experiments show DeepSeek-R1 achieves a 91.39\% F1 score on 5-class sentiment and 99.31\% accuracy on binary tasks with just 5 shots, an eightfold improvement in few-shot efficiency over GPT-4o. Architecture-specific distillation effects emerge, where a 32B Qwen2.5-based model outperforms the 70B Llama-based variant by 6.69 percentage points. While its reasoning process reduces throughput, DeepSeek-R1 offers superior explainability via transparent, step-by-step traces, establishing it as a powerful, interpretable open-source alternative.
Inverse Reinforcement Learning with Dynamic Reward Scaling for LLM Alignment
arXiv:2503.18991v5 Announce Type: replace Abstract: Alignment is vital for safely deploying large language models (LLMs). Existing techniques are either reward-based (train a reward model on preference pairs and optimize with reinforcement learning) or reward-free (directly fine-tune on ranked outputs). Recent research shows that well-tuned reward-based pipelines remain robust, and single-response demonstrations can outperform pairwise preference data. However, two challenges persist: (1) imbalanced safety datasets that overrepresent common hazards while neglecting long-tail threats; and (2) static reward models that ignore task difficulty, limiting optimization efficiency and attainable gains. We propose DR-IRL (Dynamically adjusting Rewards through Inverse Reinforcement Learning). We first train category-specific reward models using a balanced safety dataset covering seven harmful categories via IRL. Then we enhance Group Relative Policy Optimization (GRPO) by introducing dynamic reward scaling--adjusting rewards by task difficulty--data-level hardness by text encoder cosine similarity, model-level responsiveness by reward gaps. Extensive experiments across various benchmarks and LLMs demonstrate that DR-IRL outperforms all baseline methods in safety alignment while maintaining usefulness.
Inference-Time Scaling for Generalist Reward Modeling
arXiv:2504.02495v3 Announce Type: replace Abstract: Reinforcement learning (RL) has been widely adopted in post-training for large language models (LLMs) at scale. Recently, the incentivization of reasoning capabilities in LLMs from RL indicates that $\textit{proper learning methods could enable effective inference-time scalability}$. A key challenge of RL is to obtain accurate reward signals for LLMs in various domains beyond verifiable questions or artificial rules. In this work, we investigate how to improve reward modeling (RM) with more inference compute for general queries, i.e. the $\textbf{inference-time scalability of generalist RM}$, and further, how to improve the effectiveness of performance-compute scaling with proper learning methods. For the RM approach, we adopt pointwise generative reward modeling (GRM) to enable flexibility for different input types and potential for inference-time scaling. For the learning method, we propose Self-Principled Critique Tuning (SPCT) to foster scalable reward generation behaviors in GRMs through online RL, to generate principles adaptively and critiques accurately, resulting in $\textbf{DeepSeek-GRM}$ models. Furthermore, for effective inference-time scaling, we use parallel sampling to expand compute usage, and introduce a meta RM to guide voting process for better scaling performance. Empirically, we show that SPCT significantly improves the quality and scalability of GRMs, outperforming existing methods and models in various RM benchmarks without severe biases, and could achieve better performance compared to training-time scaling. DeepSeek-GRM still meets challenges in some tasks, which we believe can be addressed by future efforts in generalist reward systems. The models are released at Hugging Face and ModelScope.
Decoding Open-Ended Information Seeking Goals from Eye Movements in Reading
arXiv:2505.02872v2 Announce Type: replace Abstract: When reading, we often have specific information that interests us in a text. For example, you might be reading this paper because you are curious about LLMs for eye movements in reading, the experimental design, or perhaps you wonder ``This sounds like science fiction. Does it actually work?''. More broadly, in daily life, people approach texts with any number of text-specific goals that guide their reading behavior. In this work, we ask, for the first time, whether open-ended reading goals can be automatically decoded solely from eye movements in reading. To address this question, we introduce goal decoding tasks and evaluation frameworks using large-scale eye tracking for reading data in English with hundreds of text-specific information seeking tasks. We develop and compare several discriminative and generative multimodal text and eye movements LLMs for these tasks. Our experiments show considerable success on the task of selecting the correct goal among several options, and even progress towards free-form textual reconstruction of the precise goal formulation. These results open the door for further scientific investigation of goal driven reading, as well as the development of educational and assistive technologies that will rely on real-time decoding of reader goals from their eye movements.
Ambiguity Resolution in Text-to-Structured Data Mapping
arXiv:2505.11679v2 Announce Type: replace Abstract: Ambiguity in natural language is a significant obstacle for achieving accurate text to structured data mapping through large language models (LLMs), which affects the performance of tasks such as mapping text to agentic tool calling and text-to-SQL queries. Existing methods to ambiguity handling either rely on the ReACT framework to obtain correct mappings through trial and error, or on supervised fine-tuning to bias models toward specific tasks. In this paper, we adopt a different approach that characterizes representation differences of ambiguous text in the latent space and leverages these differences to identify ambiguity before mapping them to structured data. To detect sentence-level ambiguity, we focus on the relationship between ambiguous questions and their interpretations. Unlike distances calculated by dense embeddings, we introduce a new distance measure based on a path kernel over concepts. With this measurement, we identify patterns to distinguish ambiguous from unambiguous questions. Furthermore, we propose a method for improving LLM performance on ambiguous agentic tool calling through missing concept prediction. Both achieve state-of-the-art results.
VerifyBench: Benchmarking Reference-based Reward Systems for Large Language Models
arXiv:2505.15801v3 Announce Type: replace Abstract: Large reasoning models such as OpenAI o1 and DeepSeek-R1 have achieved remarkable performance in the domain of reasoning. A key component of their training is the incorporation of verifiable rewards within reinforcement learning (RL). However, existing reward benchmarks do not evaluate reference-based reward systems, leaving researchers with limited understanding of the accuracy of verifiers used in RL. In this paper, we introduce two benchmarks, VerifyBench and VerifyBench-Hard, designed to assess the performance of reference-based reward systems. These benchmarks are constructed through meticulous data collection and curation, followed by careful human annotation to ensure high quality. Current models still show considerable room for improvement on both VerifyBench and VerifyBench-Hard, especially smaller-scale models. Furthermore, we conduct a thorough and comprehensive analysis of evaluation results, offering insights for understanding and developing reference-based reward systems. Our proposed benchmarks serve as effective tools for guiding the development of verifier accuracy and the reasoning capabilities of models trained via RL in reasoning tasks.
UNCERTAINTY-LINE: Length-Invariant Estimation of Uncertainty for Large Language Models
arXiv:2505.19060v2 Announce Type: replace Abstract: Large Language Models (LLMs) have become indispensable tools across various applications, making it more important than ever to ensure the quality and the trustworthiness of their outputs. This has led to growing interest in uncertainty quantification (UQ) methods for assessing the reliability of LLM outputs. Many existing UQ techniques rely on token probabilities, which inadvertently introduces a bias with respect to the length of the output. While some methods attempt to account for this, we demonstrate that such biases persist even in length-normalized approaches. To address the problem, here we propose UNCERTAINTY-LINE: (Length-INvariant Estimation), a simple debiasing procedure that regresses uncertainty scores on output length and uses the residuals as corrected, length-invariant estimates. Our method is post-hoc, model-agnostic, and applicable to a range of UQ measures. Through extensive evaluation on machine translation, summarization, and question-answering tasks, we demonstrate that UNCERTAINTY-LINE: consistently improves over even nominally length-normalized UQ methods uncertainty estimates across multiple metrics and models.
InComeS: Integrating Compression and Selection Mechanisms into LLMs for Efficient Model Editing
arXiv:2505.22156v2 Announce Type: replace Abstract: Although existing model editing methods perform well in recalling exact edit facts, they often struggle in complex scenarios that require deeper semantic understanding rather than mere knowledge regurgitation. Leveraging the strong contextual reasoning abilities of large language models (LLMs), in-context learning (ICL) becomes a promising editing method by comprehending edit information through context encoding. However, this method is constrained by the limited context window of LLMs, leading to degraded performance and efficiency as the number of edits increases. To overcome this limitation, we propose InComeS, a flexible framework that enhances LLMs' ability to process editing contexts through explicit compression and selection mechanisms. Specifically, InComeS compresses each editing context into the key-value (KV) cache of a special gist token, enabling efficient handling of multiple edits without being restricted by the model's context window. Furthermore, specialized cross-attention modules are added to dynamically select the most relevant information from the gist pools, enabling adaptive and effective utilization of edit information. We conduct experiments on diverse model editing benchmarks with various editing formats, and the results demonstrate the effectiveness and efficiency of our method.
Bayesian Attention Mechanism: A Probabilistic Framework for Positional Encoding and Context Length Extrapolation
arXiv:2505.22842v2 Announce Type: replace Abstract: Transformer-based language models rely on positional encoding (PE) to handle token order and support context length extrapolation. However, existing PE methods lack theoretical clarity and rely on limited evaluation metrics to substantiate their extrapolation claims. We propose the Bayesian Attention Mechanism (BAM), a theoretical framework that formulates positional encoding as a prior within a probabilistic model. BAM unifies existing methods (e.g., NoPE and ALiBi) and motivates a new Generalized Gaussian positional prior that substantially improves long-context generalization. Empirically, BAM enables accurate information retrieval at $500\times$ the training context length, outperforming previous state-of-the-art context length generalization in long context retrieval accuracy while maintaining comparable perplexity and introducing minimal additional parameters.
BabyLM's First Constructions: Causal probing provides a signal of learning
arXiv:2506.02147v2 Announce Type: replace Abstract: Construction grammar posits that language learners acquire constructions (form-meaning pairings) from the statistics of their environment. Recent work supports this hypothesis by showing sensitivity to constructions in pretrained language models (PLMs), including one recent study (Rozner et al., 2025) demonstrating that constructions shape RoBERTa's output distribution. However, models under study have generally been trained on developmentally implausible amounts of data, casting doubt on their relevance to human language learning. Here we use Rozner et al.'s methods to evaluate construction learning in masked language models from the 2024 BabyLM Challenge. Our results show that even when trained on developmentally plausible quantities of data, models learn diverse constructions, even hard cases that are superficially indistinguishable. We further find correlational evidence that constructional performance may be functionally relevant: models that better represent construction perform better on the BabyLM benchmarks.
Co-Evolving LLM Coder and Unit Tester via Reinforcement Learning
arXiv:2506.03136v2 Announce Type: replace Abstract: We propose CURE, a novel reinforcement learning framework with a dedicated reward design that co-evolves coding and unit test generation capabilities based on their interaction outcomes, without any ground-truth code as supervision. This approach enables flexible and scalable training and allows the unit tester to learn directly from the coder's mistakes. Our derived ReasonFlux-Coder-7B and 14B models improve code generation accuracy by 5.3% and Best-of-N accuracy by 9.0% after optimization on Qwen2.5-Instruct models, outperforming similarly sized Qwen-Coder, DeepSeek-Coder, and Seed-Coder. They naturally extend to downstream tasks such as test-time scaling and agentic coding-achieving a 8.1% improvement over the base model. For the long-CoT model, our ReasonFlux-Coder-4B consistently outperforms Qwen3-4B while achieving 64.8% inference efficiency in unit test generation. Notably, we also find that our model can serve as an effective reward model for reinforcement learning on base models. Project: https://github.com/Gen-Verse/CURE
ConsistentChat: Building Skeleton-Guided Consistent Multi-Turn Dialogues for Large Language Models from Scratch
arXiv:2506.03558v2 Announce Type: replace Abstract: Current instruction data synthesis methods primarily focus on single-turn instructions and often neglect cross-turn coherence, resulting in context drift and reduced task completion rates in extended conversations. To address this limitation, we propose Skeleton-Guided Multi-Turn Dialogue Generation, a framework that constrains multi-turn instruction synthesis by explicitly modeling human conversational intent. It operates in two stages: (1) Intent Modeling, which captures the global structure of human dialogues by assigning each conversation to one of nine well-defined intent trajectories, ensuring a coherent and goal-oriented information flow; and (2) Skeleton Generation, which constructs a structurally grounded sequence of user queries aligned with the modeled intent, thereby serving as a scaffold that constrains and guides the downstream instruction synthesis process. Based on this process, we construct ConsistentChat, a multi-turn instruction dataset with approximately 15,000 multi-turn conversations and 224,392 utterances. Experiments on the Light, Topdial, and MT-Eval benchmarks show that models fine-tuned on ConsistentChat achieve a 20-30% improvement in chat consistency and up to a 15% increase in task success rate, significantly outperforming models trained on existing single-turn and multi-turn instruction datasets.
From Replication to Redesign: Exploring Pairwise Comparisons for LLM-Based Peer Review
arXiv:2506.11343v2 Announce Type: replace Abstract: The advent of large language models (LLMs) offers unprecedented opportunities to reimagine peer review beyond the constraints of traditional workflows. Despite these opportunities, prior efforts have largely focused on replicating traditional review workflows with LLMs serving as direct substitutes for human reviewers, while limited attention has been given to exploring new paradigms that fundamentally rethink how LLMs can participate in the academic review process. In this paper, we introduce and explore a novel mechanism that employs LLM agents to perform pairwise comparisons among manuscripts instead of individual scoring. By aggregating outcomes from substantial pairwise evaluations, this approach enables a more accurate and robust measure of relative manuscript quality. Our experiments demonstrate that this comparative approach significantly outperforms traditional rating-based methods in identifying high-impact papers. However, our analysis also reveals emergent biases in the selection process, notably a reduced novelty in research topics and an increased institutional imbalance. These findings highlight both the transformative potential of rethinking peer review with LLMs and critical challenges that future systems must address to ensure equity and diversity.
ImpliRet: Benchmarking the Implicit Fact Retrieval Challenge
arXiv:2506.14407v3 Announce Type: replace Abstract: Retrieval systems are central to many NLP pipelines, but often rely on surface-level cues such as keyword overlap and lexical semantic similarity. To evaluate retrieval beyond these shallow signals, recent benchmarks introduce reasoning-heavy queries; however, they primarily shift the burden to query-side processing techniques -- like prompting or multi-hop retrieval -- that can help resolve complexity. In contrast, we present Impliret, a benchmark that shifts the reasoning challenge to document-side processing: The queries are simple, but relevance depends on facts stated implicitly in documents through temporal (e.g., resolving "two days ago"), arithmetic, and world knowledge relationships. We evaluate a range of sparse and dense retrievers, all of which struggle in this setting: the best nDCG@10 is only 14.91%. We also test whether long-context models can overcome this limitation. But even with a short context of only thirty documents, including the positive document, GPT-o4-mini scores only 55.54%, showing that document-side reasoning remains a challenge. Our codes are available at github.com/ZeinabTaghavi/IMPLIRET.
When Does Meaning Backfire? Investigating the Role of AMRs in NLI
arXiv:2506.14613v2 Announce Type: replace Abstract: Natural Language Inference (NLI) relies heavily on adequately parsing the semantic content of the premise and hypothesis. In this work, we investigate whether adding semantic information in the form of an Abstract Meaning Representation (AMR) helps pretrained language models better generalize in NLI. Our experiments integrating AMR into NLI in both fine-tuning and prompting settings show that the presence of AMR in fine-tuning hinders model generalization while prompting with AMR leads to slight gains in GPT-4o. However, an ablation study reveals that the improvement comes from amplifying surface-level differences rather than aiding semantic reasoning. This amplification can mislead models to predict non-entailment even when the core meaning is preserved.
THCM-CAL: Temporal-Hierarchical Causal Modelling with Conformal Calibration for Clinical Risk Prediction
arXiv:2506.17844v2 Announce Type: replace Abstract: Automated clinical risk prediction from electronic health records (EHRs) demands modeling both structured diagnostic codes and unstructured narrative notes. However, most prior approaches either handle these modalities separately or rely on simplistic fusion strategies that ignore the directional, hierarchical causal interactions by which narrative observations precipitate diagnoses and propagate risk across admissions. In this paper, we propose THCM-CAL, a Temporal-Hierarchical Causal Model with Conformal Calibration. Our framework constructs a multimodal causal graph where nodes represent clinical entities from two modalities: Textual propositions extracted from notes and ICD codes mapped to textual descriptions. Through hierarchical causal discovery, THCM-CAL infers three clinically grounded interactions: intra-slice same-modality sequencing, intra-slice cross-modality triggers, and inter-slice risk propagation. To enhance prediction reliability, we extend conformal prediction to multi-label ICD coding, calibrating per-code confidence intervals under complex co-occurrences. Experimental results on MIMIC-III and MIMIC-IV demonstrate the superiority of THCM-CAL.
A Simple "Motivation" Can Enhance Reinforcement Finetuning of Large Reasoning Models
arXiv:2506.18485v2 Announce Type: replace Abstract: Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful learn-to-reason paradigm for Large Reasoning Models to tackle complex tasks. However, current RLVR paradigm is still not efficient enough, as it works in a trial-and-error manner. To perform better, the model needs to explore the reward space by numerously generating responses and learn from fragmented reward signals, blind to the overall reward patterns. Fortunately, verifiable rewards make the natural language description of the reward function possible, and meanwhile, LLMs have demonstrated strong in-context learning ability. This motivates us to explore if Large Reasoning Models can benefit from a motivation of the task, i.e., awareness of the reward function, during the reinforcement finetuning process, as we humans sometimes do when learning. In this paper, we introduce Motivation-enhanced Reinforcement Finetuning (MeRF), an intuitive yet effective method enhancing reinforcement finetuning of LLMs by involving ``telling LLMs rules of the game''. Specifically, MeRF directly injects the reward specification into the prompt, which serves as an in-context motivation for the model to be aware of the optimization objective. This simple modification leverages the in-context learning ability of LLMs, aligning generation with optimization, thereby incentivizing the model to generate desired outputs from both inner motivation and external reward. Empirical evaluations demonstrate that MeRF achieves substantial performance gains over RLVR baseline. Moreover, ablation studies show that MeRF performs better with greater consistency between the in-context motivation and the external reward function, while the model also demonstrates an ability to adapt to misleading motivations through reinforcement finetuning.
ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs
arXiv:2506.18896v2 Announce Type: replace Abstract: Process Reward Models (PRMs) have recently emerged as a powerful framework for supervising intermediate reasoning steps in large language models (LLMs). Previous PRMs are primarily trained on model final output responses and struggle to evaluate intermediate thinking trajectories robustly, especially in the emerging setting of trajectory-response outputs generated by frontier reasoning models like Deepseek-R1. In this work, we introduce ReasonFlux-PRM, a novel trajectory-aware PRM explicitly designed to evaluate the trajectory-response type of reasoning traces. ReasonFlux-PRM incorporates both step-level and trajectory-level supervision, enabling fine-grained reward assignment aligned with structured chain-of-thought data. We adapt ReasonFlux-PRM to support reward supervision under both offline and online settings, including (i) selecting high-quality model distillation data for downstream supervised fine-tuning of smaller models, (ii) providing dense process-level rewards for policy optimization during reinforcement learning, and (iii) enabling reward-guided Best-of-N test-time scaling. Empirical results on challenging downstream benchmarks such as AIME, MATH500, and GPQA-Diamond demonstrate that ReasonFlux-PRM-7B selects higher quality data than strong PRMs (e.g., Qwen2.5-Math-PRM-72B) and human-curated baselines. Furthermore, our derived ReasonFlux-PRM-7B yields consistent performance improvements, achieving average gains of 12.1% in supervised fine-tuning, 4.5% in reinforcement learning, and 6.3% in test-time scaling. We also release our efficient ReasonFlux-PRM-1.5B for resource-constrained applications and edge deployment. Project: https://github.com/Gen-Verse/ReasonFlux
ARF-RLHF: Adaptive Reward-Following for RLHF through Emotion-Driven Self-Supervision and Trace-Biased Dynamic Optimization
arXiv:2507.03069v2 Announce Type: replace Abstract: Current RLHF methods such as PPO and DPO typically reduce human preferences to binary labels, which are costly to obtain and too coarse to reflect individual variation. We observe that expressions of satisfaction and dissatisfaction follow stable linguistic patterns across users, indicating that more informative supervisory signals can be extracted from free-form feedback. Building on this insight, we introduce Adaptive Reward-Following (ARF), which converts natural feedback into continuous preference trajectories and optimizes them using the novel TraceBias algorithm. Across diverse LLMs and preference domains, ARF consistently outperforms PPO and DPO, improving alignment by up to 7.6%. Our results demonstrate that continuous reward modeling provides a scalable path toward personalized and theoretically grounded RLHF.
ixi-GEN: Efficient Industrial sLLMs through Domain Adaptive Continual Pretraining
arXiv:2507.06795v3 Announce Type: replace Abstract: The emergence of open-source large language models (LLMs) has expanded opportunities for enterprise applications; however, many organizations still lack the infrastructure to deploy and maintain large-scale models. As a result, small LLMs (sLLMs) have become a practical alternative, despite their inherent performance limitations. While Domain Adaptive Continual Pretraining (DACP) has been previously explored as a method for domain adaptation, its utility in commercial applications remains under-examined. In this study, we validate the effectiveness of applying a DACP-based recipe across diverse foundation models and service domains. Through extensive experiments and real-world evaluations, we demonstrate that DACP-applied sLLMs achieve substantial gains in target domain performance while preserving general capabilities, offering a cost-efficient and scalable solution for enterprise-level deployment.
Turning Internal Gap into Self-Improvement: Promoting the Generation-Understanding Unification in MLLMs
arXiv:2507.16663v2 Announce Type: replace Abstract: Although unified MLLMs aim to unify generation and understanding, they are considered to exhibit an internal gap, with understanding outperforming generation. Through large-scale evaluation across multiple MLLMs and tasks, we confirm the widespread non-unification of MLLMs, and demonstrate that it indeed stems from weak generation rather than misunderstanding. This finding motivates us to propose a simple yet effective internal gap-based self-improvement framework, which mitigates internal gaps by leveraging stronger understanding to guide weaker generation without relying on any external signals. We validate this strategy through comprehensive experiments: scoring generations with understanding to construct image data for post-training (e.g., SFT and DPO) significantly improves generation while promoting unification. Furthermore, we empirically discover a co-improvement effect of such self-improvement, a phenomenon well known in pre-training but underexplored in post-training. Specifically, as generation improves, understanding becomes more effective at detecting false positives that were previously misclassified as prompt-aligned. To explain this effect, we extend learning dynamic theory to the MLLM setting, showing that the shared empirical neural tangent kernel between generation and understanding encourages aligned learning dynamics, thereby driving co-improvement. This interplay between generation and understanding further motivates a curriculum learning approach for stronger self-improvement: progressively enhanced understanding and generation revisit samples underutilized by pre-trained MLLMs, dynamically expanding post-training data and leading to improved performance and unification.
A Comprehensive Taxonomy of Negation for NLP and Neural Retrievers
arXiv:2507.22337v2 Announce Type: replace Abstract: Understanding and solving complex reasoning tasks is vital for addressing the information needs of a user. Although dense neural models learn contextualised embeddings, they still underperform on queries containing negation. To understand this phenomenon, we study negation in both traditional neural information retrieval and LLM-based models. We (1) introduce a taxonomy of negation that derives from philosophical, linguistic, and logical definitions; (2) generate two benchmark datasets that can be used to evaluate the performance of neural information retrieval models and to fine-tune models for a more robust performance on negation; and (3) propose a logic-based classification mechanism that can be used to analyze the performance of retrieval models on existing datasets. Our taxonomy produces a balanced data distribution over negation types, providing a better training setup that leads to faster convergence on the NevIR dataset. Moreover, we propose a classification schema that reveals the coverage of negation types in existing datasets, offering insights into the factors that might affect the generalization of fine-tuned models on negation.
C3: A Bilingual Benchmark for Spoken Dialogue Models Exploring Challenges in Complex Conversations
arXiv:2507.22968v2 Announce Type: replace Abstract: Spoken Dialogue Models (SDMs) have recently attracted significant attention for their ability to generate voice responses directly to users' spoken queries. Despite their increasing popularity, there exists a gap in research focused on comprehensively understanding their practical effectiveness in comprehending and emulating human conversations. This is especially true compared to text-based Large Language Models (LLMs), which benefit from extensive benchmarking. Human voice interactions are inherently more complex than text due to characteristics unique to spoken dialogue. Ambiguity poses one challenge, stemming from semantic factors like polysemy, as well as phonological aspects such as heterograph, heteronyms, and stress patterns. Additionally, context-dependency, like omission, coreference, and multi-turn interaction, adds further complexity to human conversational dynamics. To illuminate the current state of SDM development and to address these challenges, we present a benchmark dataset in this paper, which comprises 1,079 instances in English and Chinese. Accompanied by an LLM-based evaluation method that closely aligns with human judgment, this dataset facilitates a comprehensive exploration of the performance of SDMs in tackling these practical challenges.
ILRe: Intermediate Layer Retrieval for Context Compression in Causal Language Models
arXiv:2508.17892v2 Announce Type: replace Abstract: Large Language Models (LLMs) have demonstrated success across many benchmarks. However, they still exhibit limitations in long-context scenarios, primarily due to their short effective context length, quadratic computational complexity, and high memory overhead when processing lengthy inputs. To mitigate these issues, we introduce a novel context compression pipeline, called Intermediate Layer Retrieval (ILRe), which determines one intermediate decoder layer offline, encodes context by streaming chunked prefill only up to that layer, and recalls tokens by the attention scores between the input query and full key cache in that specified layer. In particular, we propose a multi-pooling kernels allocating strategy in the token recalling process to maintain the completeness of semantics. Our approach not only reduces the prefilling complexity from $O(L^2)$ to $O(L)$ and trims the memory footprint to a few tenths of that required for the full context, but also delivers performance comparable to or superior to the full-context setup in long-context scenarios. Without additional post training or operator development, ILRe can process a single $1M$ tokens request in less than half a minute (speedup $\approx 180\times$) and scores RULER-$1M$ benchmark of $\approx 79.8$ with model Llama-3.1-UltraLong-8B-1M-Instruct on a Huawei Ascend 910B NPU.
MathBuddy: A Multimodal System for Affective Math Tutoring
arXiv:2508.19993v2 Announce Type: replace Abstract: The rapid adoption of LLM-based conversational systems is already transforming the landscape of educational technology. However, the current state-of-the-art learning models do not take into account the student's affective states. Multiple studies in educational psychology support the claim that positive or negative emotional states can impact a student's learning capabilities. To bridge this gap, we present MathBuddy, an emotionally aware LLM-powered Math Tutor, which dynamically models the student's emotions and maps them to relevant pedagogical strategies, making the tutor-student conversation a more empathetic one. The student's emotions are captured from the conversational text as well as from their facial expressions. The student's emotions are aggregated from both modalities to confidently prompt our LLM Tutor for an emotionally-aware response. We have evaluated our model using automatic evaluation metrics across eight pedagogical dimensions and user studies. We report a massive 23 point performance gain using the win rate and a 3 point gain at an overall level using DAMR scores which strongly supports our hypothesis of improving LLM-based tutor's pedagogical abilities by modeling students' emotions. Our dataset and code are available at: https://github.com/ITU-NLP/MathBuddy .
JudgeAgent: Knowledge-wise and Dynamic LLM Evaluation with Agent-as-Interviewer
arXiv:2509.02097v2 Announce Type: replace Abstract: Current evaluation paradigms for large language models (LLMs) suffer from overestimated or biased evaluation and mismatched question difficulty, leading to incomplete evaluations of LLM's knowledge and capability boundaries, which hinder LLM's effective application and optimization. To address these challenges, we propose Agent-as-Interviewer, a dynamic evaluation paradigm that employs LLM agents to conduct multi-turn interactions for evaluation. Unlike current benchmarking or dynamic interaction paradigms, Agent-as-Interviewer utilizes agents to call knowledge tools for wider and deeper knowledge in the dynamic multi-turn question generation, achieving more complete evaluations of the LLM's knowledge boundaries. It also leverages agents to plan query strategies for adjustment of the question difficulty levels, enhancing the difficulty control to match the actual capabilities of target LLMs. Based on this paradigm, we develop JudgeAgent, a knowledge-wise dynamic evaluation framework that employs knowledge-driven synthesis as the agent's tool, and uses difficulty scoring as strategy guidance, thereby finally providing valuable suggestions to help targets optimize themselves. Extensive experiments validate the effectiveness of JudgeAgent's suggestions, demonstrating that Agent-as-Interviewer can accurately identify the knowledge and capability boundaries of target models. The source code is available on https://anonymous.4open.science/r/JudgeAgent.
Just-in-time and distributed task representations in language models
arXiv:2509.04466v2 Announce Type: replace Abstract: Many of language models' impressive capabilities originate from their in-context learning: based on instructions or examples, they can infer and perform new tasks without weight updates. In this work, we investigate when representations for new tasks are formed in language models, and how these representations change over the course of context. We focus on ''transferrable'' task representations -- vector representations that can restore task contexts in another instance of the model, even without the full prompt. We show that these representations evolve in non-monotonic and sporadic ways, and are distinct from a more inert representation of high-level task categories that persists throughout the context. Specifically, when more examples are provided in the context, transferrable task representations successfully condense evidence. This allows better transfer of task contexts and aligns well with the performance improvement. However, this evidence accrual process exhibits strong locality along the sequence dimension, coming online only at certain tokens -- despite task identity being reliably decodable throughout the context. Moreover, these local but transferrable task representations tend to capture minimal ''task scopes'', such as a semantically-independent subtask. For longer and composite tasks, models rely on more temporally-distributed representations. This two-fold locality (temporal and semantic) underscores a kind of just-in-time computational process that language models use to perform new tasks on the fly.
PLaMo 2 Technical Report
arXiv:2509.04897v2 Announce Type: replace Abstract: In this report, we introduce PLaMo 2, a series of Japanese-focused large language models featuring a hybrid Samba-based architecture that transitions to full attention via continual pre-training to support 32K token contexts. Training leverages extensive synthetic corpora to overcome data scarcity, while computational efficiency is achieved through weight reuse and structured pruning. This efficient pruning methodology produces an 8B model that achieves performance comparable to our previous 100B model. Post-training further refines the models using a pipeline of supervised fine-tuning (SFT) and direct preference optimization (DPO), enhanced by synthetic Japanese instruction data and model merging techniques. Optimized for inference using vLLM and quantization with minimal accuracy loss, the PLaMo 2 models achieve state-of-the-art results on Japanese benchmarks, outperforming similarly-sized open models in instruction-following, language fluency, and Japanese-specific knowledge.
LM-Searcher: Cross-domain Neural Architecture Search with LLMs via Unified Numerical Encoding
arXiv:2509.05657v3 Announce Type: replace Abstract: Recent progress in Large Language Models (LLMs) has opened new avenues for solving complex optimization problems, including Neural Architecture Search (NAS). However, existing LLM-driven NAS approaches rely heavily on prompt engineering and domain-specific tuning, limiting their practicality and scalability across diverse tasks. In this work, we propose LM-Searcher, a novel framework that leverages LLMs for cross-domain neural architecture optimization without the need for extensive domain-specific adaptation. Central to our approach is NCode, a universal numerical string representation for neural architectures, which enables cross-domain architecture encoding and search. We also reformulate the NAS problem as a ranking task, training LLMs to select high-performing architectures from candidate pools using instruction-tuning samples derived from a novel pruning-based subspace sampling strategy. Our curated dataset, encompassing a wide range of architecture-performance pairs, encourages robust and transferable learning. Comprehensive experiments demonstrate that LM-Searcher achieves competitive performance in both in-domain (e.g., CNNs for image classification) and out-of-domain (e.g., LoRA configurations for segmentation and generation) tasks, establishing a new paradigm for flexible and generalizable LLM-based architecture search. The datasets and models will be released at https://github.com/Ashone3/LM-Searcher.
WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents
arXiv:2509.06501v2 Announce Type: replace Abstract: The paradigm of Large Language Models (LLMs) has increasingly shifted toward agentic applications, where web browsing capabilities are fundamental for retrieving information from diverse online sources. However, existing open-source web agents either demonstrate limited information-seeking abilities on complex tasks or lack transparent implementations. In this work, we identify that the key challenge lies in the scarcity of challenging data for information seeking. To address this limitation, we introduce WebExplorer: a systematic data generation approach using model-based exploration and iterative, long-to-short query evolution. This method creates challenging query-answer pairs that require multi-step reasoning and complex web navigation. By leveraging our curated high-quality dataset, we successfully develop advanced web agent WebExplorer-8B through supervised fine-tuning followed by reinforcement learning. Our model supports 128K context length and up to 100 tool calling turns, enabling long-horizon problem solving. Across diverse information-seeking benchmarks, WebExplorer-8B achieves the state-of-the-art performance at its scale. Notably, as an 8B-sized model, WebExplorer-8B is able to effectively search over an average of 16 turns after RL training, achieving higher accuracy than WebSailor-72B on BrowseComp-en/zh and attaining the best performance among models up to 100B parameters on WebWalkerQA and FRAMES. Beyond these information-seeking tasks, our model also achieves strong generalization on the HLE benchmark even though it is only trained on knowledge-intensive QA data. These results highlight our approach as a practical path toward long-horizon web agents.
Ko-PIQA: A Korean Physical Commonsense Reasoning Dataset with Cultural Context
arXiv:2509.11303v2 Announce Type: replace Abstract: Physical commonsense reasoning datasets like PIQA are predominantly English-centric and lack cultural diversity. We introduce Ko-PIQA, a Korean physical commonsense reasoning dataset that incorporates cultural context. Starting from 3.01 million web-crawled questions, we employed a multi-stage filtering approach using three language models to identify 11,553 PIQA-style questions. Through GPT-4o refinement and human validation, we obtained 441 high-quality question-answer pairs. A key feature of Ko-PIQA is its cultural grounding: 19.7\% of questions contain culturally specific elements like traditional Korean foods (kimchi), clothing (hanbok), and specialized appliances (kimchi refrigerators) that require culturally-aware reasoning beyond direct translation. We evaluate seven language models on Ko-PIQA, with the best model achieving 83.22\% accuracy while the weakest reaches only 59.86\%, demonstrating significant room for improvement. Models particularly struggle with culturally specific scenarios, highlighting the importance of culturally diverse datasets. Ko-PIQA serves as both a benchmark for Korean language models and a foundation for more inclusive commonsense reasoning research. The dataset and code will be publicly available.
Canary-1B-v2 & Parakeet-TDT-0.6B-v3: Efficient and High-Performance Models for Multilingual ASR and AST
arXiv:2509.14128v2 Announce Type: replace Abstract: This report introduces Canary-1B-v2, a fast, robust multilingual model for Automatic Speech Recognition (ASR) and Speech-to-Text Translation (AST). Built with a FastConformer encoder and Transformer decoder, it supports 25 languages primarily European. The model was trained on 1.7M hours of total data samples, including Granary and NeMo ASR Set 3.0, with non-speech audio added to reduce hallucinations for ASR and AST. We describe its two-stage pre-training and fine-tuning process with dynamic data balancing, as well as experiments with an nGPT encoder. Results show nGPT scales well with massive data, while FastConformer excels after fine-tuning. For timestamps, Canary-1B-v2 uses the NeMo Forced Aligner (NFA) with an auxiliary CTC model, providing reliable segment-level timestamps for ASR and AST. Evaluations show Canary-1B-v2 outperforms Whisper-large-v3 on English ASR while being 10x faster, and delivers competitive multilingual ASR and AST performance against larger models like Seamless-M4T-v2-large and LLM-based systems. We also release Parakeet-TDT-0.6B-v3, a successor to v2, offering multilingual ASR across the same 25 languages with just 600M parameters.
Causal-Counterfactual RAG: The Integration of Causal-Counterfactual Reasoning into RAG
arXiv:2509.14435v2 Announce Type: replace Abstract: Large language models (LLMs) have transformed natural language processing (NLP), enabling diverse applications by integrating large-scale pre-trained knowledge. However, their static knowledge limits dynamic reasoning over external information, especially in knowledge-intensive domains. Retrieval-Augmented Generation (RAG) addresses this challenge by combining retrieval mechanisms with generative modeling to improve contextual understanding. Traditional RAG systems suffer from disrupted contextual integrity due to text chunking and over-reliance on semantic similarity for retrieval, often resulting in shallow and less accurate responses. We propose Causal-Counterfactual RAG, a novel framework that integrates explicit causal graphs representing cause-effect relationships into the retrieval process and incorporates counterfactual reasoning grounded on the causal structure. Unlike conventional methods, our framework evaluates not only direct causal evidence but also the counterfactuality of associated causes, combining results from both to generate more robust, accurate, and interpretable answers. By leveraging causal pathways and associated hypothetical scenarios, Causal-Counterfactual RAG preserves contextual coherence, reduces hallucination, and enhances reasoning fidelity.
FURINA: Free from Unmergeable Router via LINear Aggregation of mixed experts
arXiv:2509.14900v2 Announce Type: replace Abstract: The Mixture of Experts (MoE) paradigm has been successfully integrated into Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning (PEFT), delivering performance gains with minimal parameter overhead. However, a key limitation of existing MoE-LoRA methods is their reliance on a discrete router, which prevents the integration of the MoE components into the backbone model. To overcome this, we propose FURINA, a novel Free from Unmergeable Router framework based on the LINear Aggregation of experts. FURINA eliminates the router by introducing a Self-Routing mechanism. This is achieved through three core innovations: (1) decoupled learning of the direction and magnitude for LoRA adapters, (2) a shared learnable magnitude vector for consistent activation scaling, and (3) expert selection loss that encourages divergent expert activation. The proposed mechanism leverages the angular similarity between the input and each adapter's directional component to activate experts, which are then scaled by the shared magnitude vector. This design allows the output norm to naturally reflect the importance of each expert, thereby enabling dynamic, router-free routing. The expert selection loss further sharpens this behavior by encouraging sparsity and aligning it with standard MoE activation patterns. We also introduce a shared expert within the MoE-LoRA block that provides stable, foundational knowledge. To the best of our knowledge, FURINA is the first router-free, MoE-enhanced LoRA method that can be fully merged into the backbone model, introducing zero additional inference-time cost or complexity. Extensive experiments demonstrate that FURINA not only significantly outperforms standard LoRA but also matches or surpasses the performance of existing MoE-LoRA methods, while eliminating the extra inference-time overhead of MoE.
Speech Language Models for Under-Represented Languages: Insights from Wolof
arXiv:2509.15362v2 Announce Type: replace Abstract: We present our journey in training a speech language model for Wolof, an underrepresented language spoken in West Africa, and share key insights. We first emphasize the importance of collecting large-scale, spontaneous, high-quality unsupervised speech data, and show that continued pretraining HuBERT on this dataset outperforms both the base model and African-centric models on ASR. We then integrate this speech encoder into a Wolof LLM to train the first Speech LLM for this language, extending its capabilities to tasks such as speech translation. Furthermore, we explore training the Speech LLM to perform multi-step Chain-of-Thought before transcribing or translating. Our results show that the Speech LLM not only improves speech recognition but also performs well in speech translation. The models and the code will be openly shared.
TactfulToM: Do LLMs Have the Theory of Mind Ability to Understand White Lies?
arXiv:2509.17054v2 Announce Type: replace Abstract: While recent studies explore Large Language Models' (LLMs) performance on Theory of Mind (ToM) reasoning tasks, research on ToM abilities that require more nuanced social context is limited, such as white lies. We introduce TactfulToM, a novel English benchmark designed to evaluate LLMs' ability to understand white lies within real-life conversations and reason about prosocial motivations behind them, particularly when they are used to spare others' feelings and maintain social harmony. Our benchmark is generated through a multi-stage human-in-the-loop pipeline where LLMs expand manually designed seed stories into conversations to maintain the information asymmetry between participants necessary for authentic white lies. We show that TactfulToM is challenging for state-of-the-art models, which perform substantially below humans, revealing shortcomings in their ability to fully comprehend the ToM reasoning that enables true understanding of white lies.
EpiCache: Episodic KV Cache Management for Long Conversational Question Answering
arXiv:2509.17396v2 Announce Type: replace Abstract: Modern large language models (LLMs) extend context lengths to up to millions of tokens, enabling AI assistants to generate coherent and personalized responses grounded in long conversational histories. This ability, however, hinges on Key-Value (KV) caching, whose memory grows linearly with dialogue length and quickly becomes the bottleneck in resource-constrained environments. An active line of research for reducing memory bottleneck is KV cache compression, which seeks to limit cache size while preserving accuracy. Yet existing methods face two major limitations: (i) evicting the KV cache after full-context prefill causes unbounded peak memory, and (ii) query-dependent eviction narrows the cache to a single query, leading to failure cases in multi-turn conversations. We introduce EpiCache, a training-free KV cache management framework for long conversational question answering (LongConvQA) under fixed memory budgets. EpiCache bounds cache growth through block-wise prefill and preserves topic-relevant context via episodic KV compression, which clusters conversation history into coherent episodes and applies episode-specific KV cache eviction. We further design an adaptive layer-wise budget allocation strategy that measures each layer's sensitivity to eviction and distributes the memory budget across layers accordingly. Across three LongConvQA benchmarks, EpiCache improves accuracy by up to 40% over recent baselines, sustains near-full KV accuracy under 4-6x compression, and reduces latency and memory by up to 2.4x and 3.5x, thereby enabling efficient multi-turn interaction under strict resource constraints.
CogniLoad: A Synthetic Natural Language Reasoning Benchmark With Tunable Length, Intrinsic Difficulty, and Distractor Density
arXiv:2509.18458v2 Announce Type: replace Abstract: Current benchmarks for long-context reasoning in Large Language Models (LLMs) often blur critical factors like intrinsic task complexity, distractor interference, and task length. To enable more precise failure analysis, we introduce CogniLoad, a novel synthetic benchmark grounded in Cognitive Load Theory (CLT). CogniLoad generates natural-language logic puzzles with independently tunable parameters that reflect CLT's core dimensions: intrinsic difficulty ($d$) controls intrinsic load; distractor-to-signal ratio ($\rho$) regulates extraneous load; and task length ($N$) serves as an operational proxy for conditions demanding germane load. Evaluating 22 SotA reasoning LLMs, CogniLoad reveals distinct performance sensitivities, identifying task length as a dominant constraint and uncovering varied tolerances to intrinsic complexity and U-shaped responses to distractor ratios. By offering systematic, factorial control over these cognitive load dimensions, CogniLoad provides a reproducible, scalable, and diagnostically rich tool for dissecting LLM reasoning limitations and guiding future model development.
False Friends Are Not Foes: Investigating Vocabulary Overlap in Multilingual Language Models
arXiv:2509.18750v2 Announce Type: replace Abstract: Subword tokenizers trained on multilingual corpora naturally produce overlapping tokens across languages. Does token overlap facilitate cross-lingual transfer or instead introduce interference between languages? Prior work offers mixed evidence, partly due to varied setups and confounders, such as token frequency or subword segmentation granularity. To address this question, we devise a controlled experiment where we train bilingual autoregressive models on multiple language pairs under systematically varied vocabulary overlap settings. Crucially, we explore a new dimension to understanding how overlap affects transfer: the semantic similarity of tokens shared across languages. We first analyze our models' hidden representations and find that overlap of any kind creates embedding spaces that capture cross-lingual semantic relationships, while this effect is much weaker in models with disjoint vocabularies. On XNLI and XQuAD, we find that models with overlap outperform models with disjoint vocabularies, and that transfer performance generally improves as overlap increases. Overall, our findings highlight the advantages of token overlap in multilingual models and show that substantial shared vocabulary remains a beneficial design choice for multilingual tokenizers.
Reinforcement Learning on Pre-Training Data
arXiv:2509.19249v2 Announce Type: replace Abstract: The growing disparity between the exponential scaling of computational resources and the finite growth of high-quality text data now constrains conventional scaling approaches for large language models (LLMs). To address this challenge, we introduce Reinforcement Learning on Pre-Training data (RLPT), a new training-time scaling paradigm for optimizing LLMs. In contrast to prior approaches that scale training primarily through supervised learning, RLPT enables the policy to autonomously explore meaningful trajectories to learn from pre-training data and improve its capability through reinforcement learning (RL). While existing RL strategies such as reinforcement learning from human feedback (RLHF) and reinforcement learning with verifiable rewards (RLVR) rely on human annotation for reward construction, RLPT eliminates this dependency by deriving reward signals directly from pre-training data. Specifically, it adopts a next-segment reasoning objective, rewarding the policy for accurately predicting subsequent text segments conditioned on the preceding context. This formulation allows RL to be scaled on pre-training data, encouraging the exploration of richer trajectories across broader contexts and thereby fostering more generalizable reasoning skills. Extensive experiments on both general-domain and mathematical reasoning benchmarks across multiple models validate the effectiveness of RLPT. For example, when applied to Qwen3-4B-Base, RLPT yields absolute improvements of $3.0$, $5.1$, $8.1$, $6.0$, $6.6$, and $5.3$ on MMLU, MMLU-Pro, GPQA-Diamond, KOR-Bench, AIME24, and AIME25, respectively. The results further demonstrate favorable scaling behavior, suggesting strong potential for continued gains with more compute. In addition, RLPT provides a solid foundation, extending the reasoning boundaries of LLMs and enhancing RLVR performance.
Part-of-speech tagging for Nagamese Language using CRF
arXiv:2509.19343v2 Announce Type: replace Abstract: This paper investigates part-of-speech tagging, an important task in Natural Language Processing (NLP) for the Nagamese language. The Nagamese language, a.k.a. Naga Pidgin, is an Assamese-lexified Creole language developed primarily as a means of communication in trade between the Nagas and people from Assam in northeast India. A substantial amount of work in part-of-speech-tagging has been done for resource-rich languages like English, Hindi, etc. However, no work has been done in the Nagamese language. To the best of our knowledge, this is the first attempt at part-of-speech tagging for the Nagamese Language. The aim of this work is to identify the part-of-speech for a given sentence in the Nagamese language. An annotated corpus of 16,112 tokens is created and applied machine learning technique known as Conditional Random Fields (CRF). Using CRF, an overall tagging accuracy of 85.70%; precision, recall of 86%, and f1-score of 85% is achieved. Keywords. Nagamese, NLP, part-of-speech, machine learning, CRF.
LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
arXiv:2509.19580v2 Announce Type: replace Abstract: Cutting-edge Artificial Intelligence (AI) techniques keep reshaping our view of the world. For example, Large Language Models (LLMs) based applications such as ChatGPT have shown the capability of generating human-like conversation on extensive topics. Due to the impressive performance on a variety of language-related tasks (e.g., open-domain question answering, translation, and document summarization), one can envision the far-reaching impacts that can be brought by the LLMs with broader real-world applications (e.g., customer service, education and accessibility, and scientific discovery). Inspired by their success, this paper will offer an overview of state-of-the-art LLMs and their integration into a wide range of academic disciplines, including: (1) arts, letters, and law (e.g., history, philosophy, political science, arts and architecture, law), (2) economics and business (e.g., finance, economics, accounting, marketing), and (3) science and engineering (e.g., mathematics, physics and mechanical engineering, chemistry and chemical engineering, life sciences and bioengineering, earth sciences and civil engineering, computer science and electrical engineering). Integrating humanity and technology, in this paper, we will explore how LLMs are shaping research and practice in these fields, while also discussing key limitations, open challenges, and future directions in the era of generative AI. The review of how LLMs are engaged across disciplines-along with key observations and insights-can help researchers and practitioners interested in exploiting LLMs to advance their works in diverse real-world applications.
Polarity Detection of Sustainable Detection Goals in News Text
arXiv:2509.19833v2 Announce Type: replace Abstract: The United Nations' Sustainable Development Goals (SDGs) provide a globally recognised framework for addressing critical societal, environmental, and economic challenges. Recent developments in natural language processing (NLP) and large language models (LLMs) have facilitated the automatic classification of textual data according to their relevance to specific SDGs. Nevertheless, in many applications, it is equally important to determine the directionality of this relevance; that is, to assess whether the described impact is positive, neutral, or negative. To tackle this challenge, we propose the novel task of SDG polarity detection, which assesses whether a text segment indicates progress toward a specific SDG or conveys an intention to achieve such progress. To support research in this area, we introduce SDG-POD, a benchmark dataset designed specifically for this task, combining original and synthetically generated data. We perform a comprehensive evaluation using six state-of-the-art large LLMs, considering both zero-shot and fine-tuned configurations. Our results suggest that the task remains challenging for the current generation of LLMs. Nevertheless, some fine-tuned models, particularly QWQ-32B, achieve good performance, especially on specific Sustainable Development Goals such as SDG-9 (Industry, Innovation and Infrastructure), SDG-12 (Responsible Consumption and Production), and SDG-15 (Life on Land). Furthermore, we demonstrate that augmenting the fine-tuning dataset with synthetically generated examples yields improved model performance on this task. This result highlights the effectiveness of data enrichment techniques in addressing the challenges of this resource-constrained domain. This work advances the methodological toolkit for sustainability monitoring and provides actionable insights into the development of efficient, high-performing polarity detection systems.
From Text to Talk: Audio-Language Model Needs Non-Autoregressive Joint Training
arXiv:2509.20072v2 Announce Type: replace Abstract: Recent advances in large language models (LLMs) have attracted significant interest in extending their capabilities to multimodal scenarios, particularly for speech-to-speech conversational systems. However, existing multimodal models handling interleaved audio and text rely on autoregressive methods, overlooking that text depends on target-target relations whereas audio depends mainly on source-target relations. In this work, we propose Text-to-Talk (TtT), a unified audio-text framework that integrates autoregressive (AR) text generation with non-autoregressive (NAR) audio diffusion in a single Transformer. By leveraging the any-order autoregressive property of absorbing discrete diffusion, our approach provides a unified training objective for text and audio. To support this hybrid generation paradigm, we design a modality-aware attention mechanism that enforces causal decoding for text while allowing bidirectional modeling within audio spans, and further introduce three training strategies that reduce train-test discrepancies. During inference, TtT employs block-wise diffusion to synthesize audio in parallel while flexibly handling variable-length outputs. Extensive experiments across Audio-QA and ASR tasks demonstrate the effectiveness of our approach, with detailed ablation studies validating each proposed component. We will open-source our models, data and code to facilitate future research in this direction.
Thinking Augmented Pre-training
arXiv:2509.20186v2 Announce Type: replace Abstract: This paper introduces a simple and scalable approach to improve the data efficiency of large language model (LLM) training by augmenting existing text data with thinking trajectories. The compute for pre-training LLMs has been growing at an unprecedented rate, while the availability of high-quality data remains limited. Consequently, maximizing the utility of available data constitutes a significant research challenge. A primary impediment is that certain high-quality tokens are difficult to learn given a fixed model capacity, as the underlying rationale for a single token can be exceptionally complex and deep. To address this issue, we propose Thinking augmented Pre-Training (TPT), a universal methodology that augments text with automatically generated thinking trajectories. Such augmentation effectively increases the volume of the training data and makes high-quality tokens more learnable through step-by-step reasoning and decomposition. We apply TPT across diverse training configurations up to $100$B tokens, encompassing pre-training with both constrained and abundant data, as well as mid-training from strong open-source checkpoints. Experimental results indicate that our method substantially improves the performance of LLMs across various model sizes and families. Notably, TPT enhances the data efficiency of LLM pre-training by a factor of $3$. For a $3$B parameter model, it improves the post-training performance by over $10\%$ on several challenging reasoning benchmarks.
SIM-CoT: Supervised Implicit Chain-of-Thought
arXiv:2509.20317v2 Announce Type: replace Abstract: Implicit Chain-of-Thought (CoT) methods offer a token-efficient alternative to explicit CoT reasoning in Large Language Models (LLMs), but a persistent performance gap has limited their adoption. We identify a core latent instability issue when scaling the computational budget of implicit CoT: as the number of reasoning tokens increases, training often becomes unstable and collapses. Our analysis shows that this instability arises from latent representations becoming homogeneous and losing semantic diversity, caused by insufficient step-level supervision in current implicit CoT methods. To address this, we propose SIM-CoT, a plug-and-play training module that introduces step-level supervision to stabilize and enrich the latent reasoning space. SIM-CoT employs an auxiliary decoder during training to align each implicit token with its corresponding explicit reasoning step, ensuring latent states capture distinct and meaningful information. The auxiliary decoder is removed at inference, preserving the efficiency of implicit CoT with no added overhead. It also provides interpretability by projecting each latent token onto an explicit reasoning vocabulary, enabling per-step visualization and diagnosis. SIM-CoT significantly improves both in-domain accuracy and out-of-domain stability of implicit CoT methods, boosting Coconut by +8.2\% on GPT-2 and CODI by +3.0\% on LLaMA-3.1 8B. It further surpasses the explicit CoT baseline on GPT-2 by 2.1\% with 2.3$\times$ greater token efficiency, while closing the performance gap on larger models like LLaMA-3.1 8B. Code: https://github.com/InternLM/SIM-CoT
Can social media provide early warning of retraction? Evidence from critical tweets identified by human annotation and large language models
arXiv:2403.16851v3 Announce Type: replace-cross Abstract: Timely detection of problematic research is essential for safeguarding scientific integrity. To explore whether social media commentary can serve as an early indicator of potentially problematic articles, this study analysed 3,815 tweets referencing 604 retracted articles and 3,373 tweets referencing 668 comparable non-retracted articles. Tweets critical of the articles were identified through both human annotation and large language models (LLMs). Human annotation revealed that 8.3% of retracted articles were associated with at least one critical tweet prior to retraction, compared to only 1.5% of non-retracted articles, highlighting the potential of tweets as early warning signals of retraction. However, critical tweets identified by LLMs (GPT-4o mini, Gemini 2.0 Flash-Lite, and Claude 3.5 Haiku) only partially aligned with human annotation, suggesting that fully automated monitoring of post-publication discourse should be applied with caution. A human-AI collaborative approach may offer a more reliable and scalable alternative, with human expertise helping to filter out tweets critical of issues unrelated to the research integrity of the articles. Overall, this study provides insights into how social media signals, combined with generative AI technologies, may support efforts to strengthen research integrity.
TestAgent: Automatic Benchmarking and Exploratory Interaction for Evaluating LLMs in Vertical Domains
arXiv:2410.11507v5 Announce Type: replace-cross Abstract: As Large Language Models (LLMs) are increasingly deployed in highly specialized vertical domains, the evaluation of their domain-specific performance becomes critical. However, existing evaluations for vertical domains typically rely on the labor-intensive construction of static single-turn datasets, which present two key limitations: (i) manual data construction is costly and must be repeated for each new domain, and (ii) static single-turn evaluations are misaligned with the dynamic multi-turn interactions in real-world applications, limiting the assessment of professionalism and stability. To address these, we propose TestAgent, a framework for automatic benchmarking and exploratory dynamic evaluation in vertical domains. TestAgent leverages retrieval-augmented generation to create domain-specific questions from user-provided knowledge sources, combined with a two-stage criteria generation process, thereby enabling scalable and automated benchmark creation. Furthermore, it introduces a reinforcement learning-guided multi-turn interaction strategy that adaptively determines question types based on real-time model responses, dynamically probing knowledge boundaries and stability. Extensive experiments across medical, legal, and governmental domains demonstrate that TestAgent enables efficient cross-domain benchmark generation and yields deeper insights into model behavior through dynamic exploratory evaluation. This work establishes a new paradigm for automated and in-depth evaluation of LLMs in vertical domains.
Bias Similarity Measurement: A Black-Box Audit of Fairness Across LLMs
arXiv:2410.12010v4 Announce Type: replace-cross Abstract: Large Language Models (LLMs) reproduce social biases, yet prevailing evaluations score models in isolation, obscuring how biases persist across families and releases. We introduce Bias Similarity Measurement (BSM), which treats fairness as a relational property between models, unifying scalar, distributional, behavioral, and representational signals into a single similarity space. Evaluating 30 LLMs on 1M+ prompts, we find that instruction tuning primarily enforces abstention rather than altering internal representations; small models gain little accuracy and can become less fair under forced choice; and open-weight models can match or exceed proprietary systems. Family signatures diverge: Gemma favors refusal, LLaMA 3.1 approaches neutrality with fewer refusals, and converges toward abstention-heavy behavior overall. Counterintuitively, Gemma 3 Instruct matches GPT-4-level fairness at far lower cost, whereas Gemini's heavy abstention suppresses utility. Beyond these findings, BSM offers an auditing workflow for procurement, regression testing, and lineage screening, and extends naturally to code and multilingual settings. Our results reframe fairness not as isolated scores but as comparative bias similarity, enabling systematic auditing of LLM ecosystems. Code available at https://github.com/HyejunJeong/bias_llm.
Reformulation is All You Need: Addressing Malicious Text Features in DNNs
arXiv:2502.00652v2 Announce Type: replace-cross Abstract: Human language encompasses a wide range of intricate and diverse implicit features, which attackers can exploit to launch adversarial or backdoor attacks, compromising DNN models for NLP tasks. Existing model-oriented defenses often require substantial computational resources as model size increases, whereas sample-oriented defenses typically focus on specific attack vectors or schemes, rendering them vulnerable to adaptive attacks. We observe that the root cause of both adversarial and backdoor attacks lies in the encoding process of DNN models, where subtle textual features, negligible for human comprehension, are erroneously assigned significant weight by less robust or trojaned models. Based on it we propose a unified and adaptive defense framework that is effective against both adversarial and backdoor attacks. Our approach leverages reformulation modules to address potential malicious features in textual inputs while preserving the original semantic integrity. Extensive experiments demonstrate that our framework outperforms existing sample-oriented defense baselines across a diverse range of malicious textual features.
AdaSVD: Adaptive Singular Value Decomposition for Large Language Models
arXiv:2502.01403v4 Announce Type: replace-cross Abstract: Large language models (LLMs) have achieved remarkable success in natural language processing (NLP) tasks, yet their substantial memory requirements present significant challenges for deployment on resource-constrained devices. Singular Value Decomposition (SVD) has emerged as a promising compression technique for LLMs, offering considerable reductions in memory overhead. However, existing SVD-based methods often struggle to effectively mitigate the errors introduced by SVD truncation, leading to a noticeable performance gap when compared to the original models. Furthermore, applying a uniform compression ratio across all transformer layers fails to account for the varying importance of different layers. To address these challenges, we propose AdaSVD, an adaptive SVD-based LLM compression approach. Specifically, AdaSVD introduces adaComp, which adaptively compensates for SVD truncation errors by alternately updating the singular matrices $\mathcal{U}$ and $\mathcal{V}^\top$. Additionally, AdaSVD introduces adaCR, which adaptively assigns layer-specific compression ratios based on the relative importance of each layer. Extensive experiments across multiple LLM/VLM families and evaluation metrics demonstrate that AdaSVD consistently outperforms state-of-the-art (SOTA) SVD-based methods, achieving superior performance with significantly reduced memory requirements. Code and models of AdaSVD will be available at https://github.com/ZHITENGLI/AdaSVD.
Scaling Rich Style-Prompted Text-to-Speech Datasets
arXiv:2503.04713v2 Announce Type: replace-cross Abstract: We introduce Paralinguistic Speech Captions (ParaSpeechCaps), a large-scale dataset that annotates speech utterances with rich style captions. While rich abstract tags (e.g. guttural, nasal, pained) have been explored in small-scale human-annotated datasets, existing large-scale datasets only cover basic tags (e.g. low-pitched, slow, loud). We combine off-the-shelf text and speech embedders, classifiers and an audio language model to automatically scale rich tag annotations for the first time. ParaSpeechCaps covers a total of 59 style tags, including both speaker-level intrinsic tags and utterance-level situational tags. It consists of 342 hours of human-labelled data (PSC-Base) and 2427 hours of automatically annotated data (PSC-Scaled). We finetune Parler-TTS, an open-source style-prompted TTS model, on ParaSpeechCaps, and achieve improved style consistency (+7.9% Consistency MOS) and speech quality (+15.5% Naturalness MOS) over the best performing baseline that combines existing rich style tag datasets. We ablate several of our dataset design choices to lay the foundation for future work in this space. Our dataset, models and code are released at https://github.com/ajd12342/paraspeechcaps .
What Makes a Reward Model a Good Teacher? An Optimization Perspective
arXiv:2503.15477v2 Announce Type: replace-cross Abstract: The success of Reinforcement Learning from Human Feedback (RLHF) critically depends on the quality of the reward model. However, while this quality is primarily evaluated through accuracy, it remains unclear whether accuracy fully captures what makes a reward model an effective teacher. We address this question from an optimization perspective. First, we prove that regardless of how accurate a reward model is, if it induces low reward variance, then the RLHF objective suffers from a flat landscape. Consequently, even a perfectly accurate reward model can lead to extremely slow optimization, underperforming less accurate models that induce higher reward variance. We additionally show that a reward model that works well for one language model can induce low reward variance, and thus a flat objective landscape, for another. These results establish a fundamental limitation of evaluating reward models solely based on accuracy or independently of the language model they guide. Experiments using models of up to 8B parameters corroborate our theory, demonstrating the interplay between reward variance, accuracy, and reward maximization rate. Overall, our findings highlight that beyond accuracy, a reward model needs to induce sufficient variance for efficient~optimization.
On the Perception Bottleneck of VLMs for Chart Understanding
arXiv:2503.18435v2 Announce Type: replace-cross Abstract: Chart understanding requires models to effectively analyze and reason about numerical data, textual elements, and complex visual components. Our observations reveal that the perception capabilities of existing large vision-language models (LVLMs) constitute a critical bottleneck in this process. In this study, we delve into this perception bottleneck by decomposing it into two components: the vision encoder bottleneck, where the visual representation may fail to encapsulate the correct information, and the extraction bottleneck, where the language model struggles to extract the necessary information from the provided visual representations. Through comprehensive experiments, we find that (1) the information embedded within visual representations is substantially richer than what is typically captured by linear extractors, such as the widely used retrieval accuracy metric; (2) While instruction tuning effectively enhances the extraction capability of LVLMs, the vision encoder remains a critical bottleneck, demanding focused attention and improvement. Therefore, we further enhance the visual encoder to mitigate the vision encoder bottleneck under a contrastive learning framework. Empirical results demonstrate that our approach significantly mitigates the perception bottleneck and improves the ability of LVLMs to comprehend charts. Code is publicly available at https://github.com/hkust-nlp/Vision4Chart.
A Framework for Situating Innovations, Opportunities, and Challenges in Advancing Vertical Systems with Large AI Models
arXiv:2504.02793v2 Announce Type: replace-cross Abstract: Large artificial intelligence (AI) models have garnered significant attention for their remarkable, often "superhuman", performance on standardized benchmarks. However, when these models are deployed in high-stakes verticals such as healthcare, education, and law, they often reveal notable limitations. For instance, they exhibit brittleness to minor variations in input data, present contextually uninformed decisions in critical settings, and undermine user trust by confidently producing or reproducing inaccuracies. These challenges in applying large models necessitate cross-disciplinary innovations to align the models' capabilities with the needs of real-world applications. We introduce a framework that addresses this gap through a layer-wise abstraction of innovations aimed at meeting users' requirements with large models. Through multiple case studies, we illustrate how researchers and practitioners across various fields can operationalize this framework. Beyond modularizing the pipeline of transforming large models into useful "vertical systems", we also highlight the dynamism that exists within different layers of the framework. Finally, we discuss how our framework can guide researchers and practitioners to (i) optimally situate their innovations (e.g., when vertical-specific insights can empower broadly impactful vertical-agnostic innovations), (ii) uncover overlooked opportunities (e.g., spotting recurring problems across verticals to develop practically useful foundation models instead of chasing benchmarks), and (iii) facilitate cross-disciplinary communication of critical challenges (e.g., enabling a shared vocabulary for AI developers, domain experts, and human-computer interaction scholars). Project webpage: https://gaurav22verma.github.io/vertical-systems-with-large-ai-models/
Process Reward Models That Think
arXiv:2504.16828v4 Announce Type: replace-cross Abstract: Step-by-step verifiers -- also known as process reward models (PRMs) -- are a key ingredient for test-time scaling. PRMs require step-level supervision, making them expensive to train. This work aims to build data-efficient PRMs as verbalized step-wise reward models that verify every step in the solution by generating a verification chain-of-thought (CoT). We propose ThinkPRM, a long CoT verifier fine-tuned on orders of magnitude fewer process labels than those required by discriminative PRMs. Our approach capitalizes on the inherent reasoning abilities of long CoT models, and outperforms LLM-as-a-Judge and discriminative verifiers -- using only 1% of the process labels in PRM800K -- across several challenging benchmarks. Specifically, ThinkPRM beats the baselines on ProcessBench, MATH-500, and AIME '24 under best-of-N selection and reward-guided search. In an out-of-domain evaluation on a subset of GPQA-Diamond and LiveCodeBench, our PRM surpasses discriminative verifiers trained on the full PRM800K by 8% and 4.5%, respectively. Lastly, under the same token budget, ThinkPRM scales up verification compute more effectively compared to LLM-as-a-Judge, outperforming it by 7.2% on a subset of ProcessBench. Our work highlights the value of generative, long CoT PRMs that can scale test-time compute for verification while requiring minimal supervision for training. Our code, data, and models are released at https://github.com/mukhal/thinkprm.
UDDETTS: Unifying Discrete and Dimensional Emotions for Controllable Emotional Text-to-Speech
arXiv:2505.10599v2 Announce Type: replace-cross Abstract: Recent large language models (LLMs) have made great progress in the field of text-to-speech (TTS), but they still face major challenges in synthesizing fine-grained emotional speech in an interpretable manner. Traditional methods rely on discrete emotion labels to control emotion categories and intensities, which cannot capture the complexity and continuity of human emotional perception and expression. The lack of large-scale emotional speech datasets with balanced emotion distributions and fine-grained emotional annotations often causes overfitting in synthesis models and impedes effective emotion control. To address these issues, we propose UDDETTS, a universal LLM framework unifying discrete and dimensional emotions for controllable emotional TTS. This model introduces the interpretable Arousal-Dominance-Valence (ADV) space for dimensional emotion description and supports emotion control driven by either discrete emotion labels or nonlinearly quantified ADV values. Furthermore, a semi-supervised training strategy is designed to comprehensively utilize diverse speech datasets with different types of emotional annotations to train the UDDETTS. Experiments show that UDDETTS achieves linear emotion control along three interpretable dimensions, and exhibits superior end-to-end emotional speech synthesis capabilities. Code and demos are available at: https://anonymous.4open.science/w/UDDETTS.
SelfBudgeter: Adaptive Token Allocation for Efficient LLM Reasoning
arXiv:2505.11274v3 Announce Type: replace-cross Abstract: While reasoning models demonstrate exceptional performance on complex tasks, they often exhibit tendencies of overthinking on simple problems. This phenomenon not only leads to excessive computational resource consumption but also significantly degrades user experience. To address this challenge, we propose SelfBudgeter - a novel user-friendly adaptive controllable reasoning framework that incorporates a budget estimation mechanism prior to reasoning. The framework adopts a dual-phase training paradigm: during the cold-start phase, the model learns to predict token budgets before executing reasoning in a standardized format; in the reinforcement learning phase, the model is trained to autonomously plan budgets based on problem difficulty and strictly adhere to them when generating responses. Since the model outputs budget estimates at the initial stage, users can immediately anticipate waiting duration, enabling flexible decisions on whether to interrupt or continue the generation process. Notably, our method supports manual control of reasoning length through pre-filled budget fields. Experimental results demonstrate that SelfBudgeter can dynamically allocate budgets according to problem complexity, yielding an average response length compression of 61% for the 1.5B model on GSM8K, MATH500, and AIME2025, and 48% for the 7B model, while maintaining nearly undiminished accuracy.
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
arXiv:2505.23764v2 Announce Type: replace-cross Abstract: Spatial intelligence is essential for multimodal large language models (MLLMs) operating in the complex physical world. Existing benchmarks, however, probe only single-image relations and thus fail to assess the multi-image spatial reasoning that real-world deployments demand. We introduce MMSI-Bench, a VQA benchmark dedicated to multi-image spatial intelligence. Six 3D-vision researchers spent more than 300 hours meticulously crafting 1,000 challenging, unambiguous multiple-choice questions from over 120,000 images, each paired with carefully designed distractors and a step-by-step reasoning process. We conduct extensive experiments and thoroughly evaluate 34 open-source and proprietary MLLMs, observing a wide gap: the strongest open-source model attains roughly 30% accuracy and OpenAI's o3 reasoning model reaches 40%, while humans score 97%. These results underscore the challenging nature of MMSI-Bench and the substantial headroom for future research. Leveraging the annotated reasoning processes, we also provide an automated error analysis pipeline that diagnoses four dominant failure modes, including (1) grounding errors, (2) overlap-matching and scene-reconstruction errors, (3) situation-transformation reasoning errors, and (4) spatial-logic errors, offering valuable insights for advancing multi-image spatial intelligence. Project page: https://runsenxu.com/projects/MMSI_Bench .
Fractional Reasoning via Latent Steering Vectors Improves Inference Time Compute
arXiv:2506.15882v2 Announce Type: replace-cross Abstract: Test-time compute has emerged as a powerful paradigm for improving the performance of large language models (LLMs), where generating multiple outputs or refining individual chains can significantly boost answer accuracy. However, existing methods like Best-of-N, majority voting, and self-reflection typically apply reasoning in a uniform way across inputs, overlooking the fact that different problems may require different levels of reasoning depth. In this work, we propose Fractional Reasoning, a training-free and model-agnostic framework that enables continuous control over reasoning intensity at inference time, going beyond the limitations of fixed instructional prompts. Our method operates by extracting the latent steering vector associated with deeper reasoning and reapplying it with a tunable scaling factor, allowing the model to tailor its reasoning process to the complexity of each input. This supports two key modes of test-time scaling: (1) improving output quality in breadth-based strategies (e.g., Best-of-N, majority voting), and (2) enhancing the correctness of individual reasoning chains in depth-based strategies (e.g., self-reflection). Experiments on GSM8K, MATH500, and GPQA demonstrate that Fractional Reasoning consistently improves performance across diverse reasoning tasks and models.
Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling
arXiv:2507.01679v2 Announce Type: replace-cross Abstract: Existing post-training techniques for large language models are broadly categorized into Supervised Fine-Tuning (SFT) and Reinforcement Fine-Tuning (RFT). Each paradigm presents a distinct trade-off: SFT excels at mimicking demonstration data but can lead to problematic generalization as a form of behavior cloning. Conversely, RFT can significantly enhance a model's performance but is prone to learn unexpected behaviors, and its performance is highly sensitive to the initial policy. In this paper, we propose a unified view of these methods and introduce Prefix-RFT, a hybrid approach that synergizes learning from both demonstration and exploration. Using mathematical reasoning problems as a testbed, we empirically demonstrate that Prefix-RFT is both simple and effective. It not only surpasses the performance of standalone SFT and RFT but also outperforms parallel mixed-policy RFT methods. A key advantage is its seamless integration into existing open-source frameworks, requiring only minimal modifications to the standard RFT pipeline. Our analysis highlights the complementary nature of SFT and RFT, and validates that Prefix-RFT effectively harmonizes these two learning paradigms. Furthermore, ablation studies confirm the method's robustness to variations in the quality and quantity of demonstration data. We hope this work offers a new perspective on LLM post-training, suggesting that a unified paradigm that judiciously integrates demonstration and exploration could be a promising direction for future research.
Reinforcement Fine-Tuning Naturally Mitigates Forgetting in Continual Post-Training
arXiv:2507.05386v2 Announce Type: replace-cross Abstract: Continual post-training (CPT) is a popular and effective technique for adapting foundation models like multimodal large language models to specific and ever-evolving downstream tasks. While existing research has primarily concentrated on methods like data replay, model expansion, or parameter regularization, the fundamental role of the learning paradigm within CPT remains largely unexplored. This paper presents a comparative analysis of two core post-training paradigms: supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT), investigating their respective impacts on knowledge retention during CPT. Our experiments are conducted on a benchmark comprising seven diverse multimodal tasks, utilizing Qwen2.5-VL-7B-Instruct as the base model for continual post-training. The investigation yields two significant findings: (1) When continuously learning on downstream tasks, SFT leads to catastrophic forgetting of previously learned tasks. In contrast, RFT inherently preserves prior knowledge and achieve performance comparable to multi-task training. (2) RFT successfully protects and even enhances the model's general knowledge on standard benchmarks (e.g., MMMU and MMLU-Pro). Conversely, SFT degrades general model capabilities severely. Further analysis reveals that this stability is not primarily due to explicit mechanisms like KL penalty or chain-of-thought reasoning. Instead, we identify an implicit regularization mechanism inherent to RFT as a key contributing factor. Our theoretical analysis suggests that RFT's gradient updates are naturally scaled by the reward variance, acting as a data-dependent regularizer that inherently protects previously acquired knowledge. Finally, we propose a rollout-based instance filtering algorithm to enhance the stability and efficiency of RFT. Our comprehensive study demonstrates the superiority of RFT as a robust paradigm for continual post-training.
NoHumansRequired: Autonomous High-Quality Image Editing Triplet Mining
arXiv:2507.14119v2 Announce Type: replace-cross Abstract: Recent advances in generative modeling enable image editing assistants that follow natural language instructions without additional user input. Their supervised training requires millions of triplets (original image, instruction, edited image), yet mining pixel-accurate examples is hard. Each edit must affect only prompt-specified regions, preserve stylistic coherence, respect physical plausibility, and retain visual appeal. The lack of robust automated edit-quality metrics hinders reliable automation at scale. We present an automated, modular pipeline that mines high-fidelity triplets across domains, resolutions, instruction complexities, and styles. Built on public generative models and running without human intervention, our system uses a task-tuned Gemini validator to score instruction adherence and aesthetics directly, removing any need for segmentation or grounding models. Inversion and compositional bootstrapping enlarge the mined set by approx. 2.6x, enabling large-scale high-fidelity training data. By automating the most repetitive annotation steps, the approach allows a new scale of training without human labeling effort. To democratize research in this resource-intensive area, we release NHR-Edit, an open dataset of 720k high-quality triplets, curated at industrial scale via millions of guided generations and validator passes, and we analyze the pipeline's stage-wise survival rates, providing a framework for estimating computational effort across different model stacks. In the largest cross-dataset evaluation, it surpasses all public alternatives. We also release Bagel-NHR-Edit, a fine-tuned Bagel model with state-of-the-art metrics.
Causal Reflection with Language Models
arXiv:2508.04495v2 Announce Type: replace-cross Abstract: While LLMs exhibit impressive fluency and factual recall, they struggle with robust causal reasoning, often relying on spurious correlations and brittle patterns. Similarly, traditional Reinforcement Learning agents also lack causal understanding, optimizing for rewards without modeling why actions lead to outcomes. We introduce Causal Reflection, a framework that explicitly models causality as a dynamic function over state, action, time, and perturbation, enabling agents to reason about delayed and nonlinear effects. Additionally, we define a formal Reflect mechanism that identifies mismatches between predicted and observed outcomes and generates causal hypotheses to revise the agent's internal model. In this architecture, LLMs serve not as black-box reasoners, but as structured inference engines translating formal causal outputs into natural language explanations and counterfactuals. Our framework lays the theoretical groundwork for Causal Reflective agents that can adapt, self-correct, and communicate causal understanding in evolving environments.
Searching for Privacy Risks in LLM Agents via Simulation
arXiv:2508.10880v2 Announce Type: replace-cross Abstract: The widespread deployment of LLM-based agents is likely to introduce a critical privacy threat: malicious agents that proactively engage others in multi-turn interactions to extract sensitive information. However, the evolving nature of such dynamic dialogues makes it challenging to anticipate emerging vulnerabilities and design effective defenses. To tackle this problem, we present a search-based framework that alternates between improving attack and defense strategies through the simulation of privacy-critical agent interactions. Specifically, we employ LLMs as optimizers to analyze simulation trajectories and iteratively propose new agent instructions. To explore the strategy space more efficiently, we further utilize parallel search with multiple threads and cross-thread propagation. Through this process, we find that attack strategies escalate from direct requests to sophisticated tactics, such as impersonation and consent forgery, while defenses evolve from simple rule-based constraints to robust identity-verification state machines. The discovered attacks and defenses transfer across diverse scenarios and backbone models, demonstrating strong practical utility for building privacy-aware agents.
Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks
arXiv:2508.18672v2 Announce Type: replace-cross Abstract: Empirical scaling laws have driven the evolution of large language models (LLMs), yet their coefficients shift whenever the model architecture or data pipeline changes. Mixture-of-Experts (MoE) models, now standard in state-of-the-art systems, introduce a new sparsity dimension that current dense-model frontiers overlook. We investigate how MoE sparsity influences two distinct capability regimes: memorization skills and reasoning skills. By training MoE families that vary total parameters, active parameters, and top-$k$ routing under fixed compute budgets, we disentangle pre-training loss from downstream accuracy. Our results reveal two principles. First, Active FLOPs: models with identical training loss but greater active compute achieve higher reasoning accuracy. Second, Total tokens per parameter (TPP): memorization tasks improve with more parameters, while reasoning tasks benefit from optimal TPP, indicating that reasoning is data-hungry. Neither reinforcement learning post-training (GRPO) nor increased test-time compute alters these trends. We therefore argue that optimal MoE sparsity must be determined jointly by active FLOPs and TPP, revising the classical picture of compute-optimal scaling. Our model checkpoints, code and logs are open-source at https://github.com/rioyokotalab/optimal-sparsity.
CoT-Space: A Theoretical Framework for Internal Slow-Thinking via Reinforcement Learning
arXiv:2509.04027v2 Announce Type: replace-cross Abstract: Reinforcement Learning (RL) has become a pivotal approach for enhancing the reasoning capabilities of Large Language Models (LLMs). However, a significant theoretical gap persists, as traditional token-level RL frameworks fail to align with the reasoning-level nature of complex, multi-step thought processes like Chain-of-Thought (CoT). To address this challenge, we introduce CoT-Space, a novel theoretical framework that recasts LLM reasoning from a discrete token-prediction task to an optimization process within a continuous, reasoning-level semantic space. This shift in perspective serves as a conceptual bridge, revitalizing foundational principles from classical learning theory to analyze the unique dynamics of LLMs. By analyzing this process from both a noise perspective and a risk perspective, we demonstrate that the convergence to an optimal CoT length is a natural consequence of the fundamental trade-off between underfitting and overfitting. Furthermore, extensive experiments provide strong empirical validation for our theoretical findings. Our framework not only provides a coherent explanation for empirical phenomena such as overthinking but also offers a solid theoretical foundation to guide the future development of more effective and generalizable reasoning agents. We open-source our code at https://github.com/ZyGan1999/CoT-Space.
ALICE: An Interpretable Neural Architecture for Generalization in Substitution Ciphers
arXiv:2509.07282v2 Announce Type: replace-cross Abstract: We present cryptogram solving as an ideal testbed for studying neural network reasoning and generalization; models must decrypt text encoded with substitution ciphers, choosing from 26! possible mappings without explicit access to the cipher. We develop ALICE (an Architecture for Learning Interpretable Cryptogram dEcipherment), a simple encoder-only Transformer that sets a new state-of-the-art for both accuracy and speed on this decryption problem. Surprisingly, ALICE generalizes to unseen ciphers after training on only ${\sim}1500$ unique ciphers, a minute fraction ($3.7 \times 10^{-24}$) of the possible cipher space. To enhance interpretability, we introduce a novel bijective decoding head that explicitly models permutations via the Gumbel-Sinkhorn method, enabling direct extraction of learned cipher mappings. Through early exit and probing experiments, we reveal how ALICE progressively refines its predictions in a way that appears to mirror common human strategies -- early layers place greater emphasis on letter frequencies, while later layers form word-level structures. Our architectural innovations and analysis methods are applicable beyond cryptograms and offer new insights into neural network generalization and interpretability.
ButterflyQuant: Ultra-low-bit LLM Quantization through Learnable Orthogonal Butterfly Transforms
arXiv:2509.09679v2 Announce Type: replace-cross Abstract: Large language models require massive memory footprints, severely limiting deployment on consumer hardware. Quantization reduces memory through lower numerical precision, but extreme 2-bit quantization suffers from catastrophic performance loss due to outliers in activations. Rotation-based methods such as QuIP and QuaRot apply orthogonal transforms to eliminate outliers before quantization, using computational invariance: $\mathbf{y} = \mathbf{Wx} = (\mathbf{WQ}^T)(\mathbf{Qx})$ for orthogonal $\mathbf{Q}$. However, these methods use fixed transforms--Hadamard matrices achieving optimal worst-case coherence $\mu = 1/\sqrt{n}$--that cannot adapt to specific weight distributions. We identify that different transformer layers exhibit distinct outlier patterns, motivating layer-adaptive rotations rather than one-size-fits-all approaches. In this work, we propose ButterflyQuant, which replaces Hadamard rotations with learnable butterfly transforms parameterized by continuous Givens rotation angles. Unlike Hadamard's discrete ${+1, -1}$ entries that are non-differentiable and thus prohibit gradient-based learning, butterfly transforms' continuous parameterization enables smooth optimization while guaranteeing orthogonality by construction. This orthogonal constraint ensures theoretical guarantees in outlier suppression while achieving $O(n \log n)$ computational complexity with only $\frac{n \log n}{2}$ learnable parameters. We further introduce a uniformity regularization on post-transformation activations to promote smoother distributions amenable to quantization. Learning requires only 128 calibration samples and converges in minutes on a single GPU--a negligible one-time cost. For LLaMA-2-7B with 2-bit quantization, ButterflyQuant achieves 15.4 perplexity versus 37.3 for QuIP. \href{https://github.com/42Shawn/Butterflyquant-llm}{Codes} are available.
How to Evaluate Medical AI
arXiv:2509.11941v2 Announce Type: replace-cross Abstract: The integration of artificial intelligence (AI) into medical diagnostic workflows requires robust and consistent evaluation methods to ensure reliability, clinical relevance, and the inherent variability in expert judgments. Traditional metrics like precision and recall often fail to account for the inherent variability in expert judgments, leading to inconsistent assessments of AI performance. Inter-rater agreement statistics like Cohen's Kappa are more reliable but they lack interpretability. We introduce Relative Precision and Recall of Algorithmic Diagnostics (RPAD and RRAD) - a new evaluation metrics that compare AI outputs against multiple expert opinions rather than a single reference. By normalizing performance against inter-expert disagreement, these metrics provide a more stable and realistic measure of the quality of predicted diagnosis. In addition to the comprehensive analysis of diagnostic quality measures, our study contains a very important side result. Our evaluation methodology allows us to avoid selecting diagnoses from a limited list when evaluating a given case. Instead, both the models being tested and the examiners verifying them arrive at a free-form diagnosis. In this automated methodology for establishing the identity of free-form clinical diagnoses, a remarkable 98% accuracy becomes attainable. We evaluate our approach using 360 medical dialogues, comparing multiple large language models (LLMs) against a panel of physicians. Large-scale study shows that top-performing models, such as DeepSeek-V3, achieve consistency on par with or exceeding expert consensus. Moreover, we demonstrate that expert judgments exhibit significant variability - often greater than that between AI and humans. This finding underscores the limitations of any absolute metrics and supports the need to adopt relative metrics in medical AI.
Small LLMs with Expert Blocks Are Good Enough for Hyperparamter Tuning
arXiv:2509.15561v3 Announce Type: replace-cross Abstract: Hyper-parameter Tuning (HPT) is a necessary step in machine learning (ML) pipelines but becomes computationally expensive and opaque with larger models. Recently, Large Language Models (LLMs) have been explored for HPT, yet most rely on models exceeding 100 billion parameters. We propose an Expert Block Framework for HPT using Small LLMs. At its core is the Trajectory Context Summarizer (TCS), a deterministic block that transforms raw training trajectories into structured context, enabling small LLMs to analyze optimization progress with reliability comparable to larger models. Using two locally-run LLMs (phi4:reasoning14B and qwen2.5-coder:32B) and a 10-trial budget, our TCS-enabled HPT pipeline achieves average performance within ~0.9 percentage points of GPT-4 across six diverse tasks.
OpenGVL - Benchmarking Visual Temporal Progress for Data Curation
arXiv:2509.17321v2 Announce Type: replace-cross Abstract: Data scarcity remains one of the most limiting factors in driving progress in robotics. However, the amount of available robotics data in the wild is growing exponentially, creating new opportunities for large-scale data utilization. Reliable temporal task completion prediction could help automatically annotate and curate this data at scale. The Generative Value Learning (GVL) approach was recently proposed, leveraging the knowledge embedded in vision-language models (VLMs) to predict task progress from visual observations. Building upon GVL, we propose OpenGVL, a comprehensive benchmark for estimating task progress across diverse challenging manipulation tasks involving both robotic and human embodiments. We evaluate the capabilities of publicly available open-source foundation models, showing that open-source model families significantly underperform closed-source counterparts, achieving only approximately $70\%$ of their performance on temporal progress prediction tasks. Furthermore, we demonstrate how OpenGVL can serve as a practical tool for automated data curation and filtering, enabling efficient quality assessment of large-scale robotics datasets. We release the benchmark along with the complete codebase at \href{github.com/budzianowski/opengvl}{OpenGVL}.
Failure Makes the Agent Stronger: Enhancing Accuracy through Structured Reflection for Reliable Tool Interactions
arXiv:2509.18847v2 Announce Type: replace-cross Abstract: Tool-augmented large language models (LLMs) are usually trained with supervised imitation or coarse-grained reinforcement learning that optimizes single tool calls. Current self-reflection practices rely on heuristic prompts or one-way reasoning: the model is urged to 'think more' instead of learning error diagnosis and repair. This is fragile in multi-turn interactions; after a failure the model often repeats the same mistake. We propose structured reflection, which turns the path from error to repair into an explicit, controllable, and trainable action. The agent produces a short yet precise reflection: it diagnoses the failure using evidence from the previous step and then proposes a correct, executable follow-up call. For training we combine DAPO and GSPO objectives with a reward scheme tailored to tool use, optimizing the stepwise strategy Reflect, then Call, then Final. To evaluate, we introduce Tool-Reflection-Bench, a lightweight benchmark that programmatically checks structural validity, executability, parameter correctness, and result consistency. Tasks are built as mini trajectories of erroneous call, reflection, and corrected call, with disjoint train and test splits. Experiments on BFCL v3 and Tool-Reflection-Bench show large gains in multi-turn tool-call success and error recovery, and a reduction of redundant calls. These results indicate that making reflection explicit and optimizing it directly improves the reliability of tool interaction and offers a reproducible path for agents to learn from failure.
Leveraging NTPs for Efficient Hallucination Detection in VLMs
arXiv:2509.20379v1 Announce Type: new Abstract: Hallucinations of vision-language models (VLMs), which are misalignments between visual content and generated text, undermine the reliability of VLMs. One common approach for detecting them employs the same VLM, or a different one, to assess generated outputs. This process is computationally intensive and increases model latency. In this paper, we explore an efficient on-the-fly method for hallucination detection by training traditional ML models over signals based on the VLM's next-token probabilities (NTPs). NTPs provide a direct quantification of model uncertainty. We hypothesize that high uncertainty (i.e., a low NTP value) is strongly associated with hallucinations. To test this, we introduce a dataset of 1,400 human-annotated statements derived from VLM-generated content, each labeled as hallucinated or not, and use it to test our NTP-based lightweight method. Our results demonstrate that NTP-based features are valuable predictors of hallucinations, enabling fast and simple ML models to achieve performance comparable to that of strong VLMs. Furthermore, augmenting these NTPs with linguistic NTPs, computed by feeding only the generated text back into the VLM, enhances hallucination detection performance. Finally, integrating hallucination prediction scores from VLMs into the NTP-based models led to better performance than using either VLMs or NTPs alone. We hope this study paves the way for simple, lightweight solutions that enhance the reliability of VLMs.
Quasi-Synthetic Riemannian Data Generation for Writer-Independent Offline Signature Verification
arXiv:2509.20420v1 Announce Type: new Abstract: Offline handwritten signature verification remains a challenging task, particularly in writer-independent settings where models must generalize across unseen individuals. Recent developments have highlighted the advantage of geometrically inspired representations, such as covariance descriptors on Riemannian manifolds. However, past or present, handcrafted or data-driven methods usually depend on real-world signature datasets for classifier training. We introduce a quasi-synthetic data generation framework leveraging the Riemannian geometry of Symmetric Positive Definite matrices (SPD). A small set of genuine samples in the SPD space is the seed to a Riemannian Gaussian Mixture which identifies Riemannian centers as synthetic writers and variances as their properties. Riemannian Gaussian sampling on each center generates positive as well as negative synthetic SPD populations. A metric learning framework utilizes pairs of similar and dissimilar SPD points, subsequently testing it over on real-world datasets. Experiments conducted on two popular signature datasets, encompassing Western and Asian writing styles, demonstrate the efficacy of the proposed approach under both intra- and cross- dataset evaluation protocols. The results indicate that our quasi-synthetic approach achieves low error rates, highlighting the potential of generating synthetic data in Riemannian spaces for writer-independent signature verification systems.
Seedream 4.0: Toward Next-generation Multimodal Image Generation
arXiv:2509.20427v1 Announce Type: new Abstract: We introduce Seedream 4.0, an efficient and high-performance multimodal image generation system that unifies text-to-image (T2I) synthesis, image editing, and multi-image composition within a single framework. We develop a highly efficient diffusion transformer with a powerful VAE which also can reduce the number of image tokens considerably. This allows for efficient training of our model, and enables it to fast generate native high-resolution images (e.g., 1K-4K). Seedream 4.0 is pretrained on billions of text-image pairs spanning diverse taxonomies and knowledge-centric concepts. Comprehensive data collection across hundreds of vertical scenarios, coupled with optimized strategies, ensures stable and large-scale training, with strong generalization. By incorporating a carefully fine-tuned VLM model, we perform multi-modal post-training for training both T2I and image editing tasks jointly. For inference acceleration, we integrate adversarial distillation, distribution matching, and quantization, as well as speculative decoding. It achieves an inference time of up to 1.8 seconds for generating a 2K image (without a LLM/VLM as PE model). Comprehensive evaluations reveal that Seedream 4.0 can achieve state-of-the-art results on both T2I and multimodal image editing. In particular, it demonstrates exceptional multimodal capabilities in complex tasks, including precise image editing and in-context reasoning, and also allows for multi-image reference, and can generate multiple output images. This extends traditional T2I systems into an more interactive and multidimensional creative tool, pushing the boundary of generative AI for both creativity and professional applications. Seedream 4.0 is now accessible on https://www.volcengine.com/experience/ark?launch=seedream.
A Contrastive Learning Framework for Breast Cancer Detection
arXiv:2509.20474v1 Announce Type: new Abstract: Breast cancer, the second leading cause of cancer-related deaths globally, accounts for a quarter of all cancer cases [1]. To lower this death rate, it is crucial to detect tumors early, as early-stage detection significantly improves treatment outcomes. Advances in non-invasive imaging techniques have made early detection possible through computer-aided detection (CAD) systems which rely on traditional image analysis to identify malignancies. However, there is a growing shift towards deep learning methods due to their superior effectiveness. Despite their potential, deep learning methods often struggle with accuracy due to the limited availability of large-labeled datasets for training. To address this issue, our study introduces a Contrastive Learning (CL) framework, which excels with smaller labeled datasets. In this regard, we train Resnet-50 in semi supervised CL approach using similarity index on a large amount of unlabeled mammogram data. In this regard, we use various augmentation and transformations which help improve the performance of our approach. Finally, we tune our model on a small set of labelled data that outperforms the existing state of the art. Specifically, we observed a 96.7% accuracy in detecting breast cancer on benchmark datasets INbreast and MIAS.
Are Foundation Models Ready for Industrial Defect Recognition? A Reality Check on Real-World Data
arXiv:2509.20479v1 Announce Type: new Abstract: Foundation Models (FMs) have shown impressive performance on various text and image processing tasks. They can generalize across domains and datasets in a zero-shot setting. This could make them suitable for automated quality inspection during series manufacturing, where various types of images are being evaluated for many different products. Replacing tedious labeling tasks with a simple text prompt to describe anomalies and utilizing the same models across many products would save significant efforts during model setup and implementation. This is a strong advantage over supervised Artificial Intelligence (AI) models, which are trained for individual applications and require labeled training data. We test multiple recent FMs on both custom real-world industrial image data and public image data. We show that all of those models fail on our real-world data, while the very same models perform well on public benchmark datasets.
Shared Neural Space: Unified Precomputed Feature Encoding for Multi-Task and Cross Domain Vision
arXiv:2509.20481v1 Announce Type: new Abstract: The majority of AI models in imaging and vision are customized to perform on specific high-precision task. However, this strategy is inefficient for applications with a series of modular tasks, since each requires a mapping into a disparate latent domain. To address this inefficiency, we proposed a universal Neural Space (NS), where an encoder-decoder framework pre-computes features across vision and imaging tasks. Our encoder learns transformation aware, generalizable representations, which enable multiple downstream AI modules to share the same feature space. This architecture reduces redundancy, improves generalization across domain shift, and establishes a foundation for effecient multi-task vision pipelines. Furthermore, as opposed to larger transformer backbones, our backbone is lightweight and CNN-based, allowing for wider across hardware. We furthur demonstrate that imaging and vision modules, such as demosaicing, denoising, depth estimation and semantic segmentation can be performed efficiently in the NS.
Data-Efficient Stream-Based Active Distillation for Scalable Edge Model Deployment
arXiv:2509.20484v1 Announce Type: new Abstract: Edge camera-based systems are continuously expanding, facing ever-evolving environments that require regular model updates. In practice, complex teacher models are run on a central server to annotate data, which is then used to train smaller models tailored to the edge devices with limited computational power. This work explores how to select the most useful images for training to maximize model quality while keeping transmission costs low. Our work shows that, for a similar training load (i.e., iterations), a high-confidence stream-based strategy coupled with a diversity-based approach produces a high-quality model with minimal dataset queries.
InstructVTON: Optimal Auto-Masking and Natural-Language-Guided Interactive Style Control for Inpainting-Based Virtual Try-On
arXiv:2509.20524v1 Announce Type: new Abstract: We present InstructVTON, an instruction-following interactive virtual try-on system that allows fine-grained and complex styling control of the resulting generation, guided by natural language, on single or multiple garments. A computationally efficient and scalable formulation of virtual try-on formulates the problem as an image-guided or image-conditioned inpainting task. These inpainting-based virtual try-on models commonly use a binary mask to control the generation layout. Producing a mask that yields desirable result is difficult, requires background knowledge, might be model dependent, and in some cases impossible with the masking-based approach (e.g. trying on a long-sleeve shirt with "sleeves rolled up" styling on a person wearing long-sleeve shirt with sleeves down, where the mask will necessarily cover the entire sleeve). InstructVTON leverages Vision Language Models (VLMs) and image segmentation models for automated binary mask generation. These masks are generated based on user-provided images and free-text style instructions. InstructVTON simplifies the end-user experience by removing the necessity of a precisely drawn mask, and by automating execution of multiple rounds of image generation for try-on scenarios that cannot be achieved with masking-based virtual try-on models alone. We show that InstructVTON is interoperable with existing virtual try-on models to achieve state-of-the-art results with styling control.
Innovative Deep Learning Architecture for Enhanced Altered Fingerprint Recognition
arXiv:2509.20537v1 Announce Type: new Abstract: Altered fingerprint recognition (AFR) is challenging for biometric verification in applications such as border control, forensics, and fiscal admission. Adversaries can deliberately modify ridge patterns to evade detection, so robust recognition of altered prints is essential. We present DeepAFRNet, a deep learning recognition model that matches and recognizes distorted fingerprint samples. The approach uses a VGG16 backbone to extract high-dimensional features and cosine similarity to compare embeddings. We evaluate on the SOCOFing Real-Altered subset with three difficulty levels (Easy, Medium, Hard). With strict thresholds, DeepAFRNet achieves accuracies of 96.7 percent, 98.76 percent, and 99.54 percent for the three levels. A threshold-sensitivity study shows that relaxing the threshold from 0.92 to 0.72 sharply degrades accuracy to 7.86 percent, 27.05 percent, and 29.51 percent, underscoring the importance of threshold selection in biometric systems. By using real altered samples and reporting per-level metrics, DeepAFRNet addresses limitations of prior work based on synthetic alterations or limited verification protocols, and indicates readiness for real-world deployments where both security and recognition resilience are critical.
Large Pre-Trained Models for Bimanual Manipulation in 3D
arXiv:2509.20579v1 Announce Type: new Abstract: We investigate the integration of attention maps from a pre-trained Vision Transformer into voxel representations to enhance bimanual robotic manipulation. Specifically, we extract attention maps from DINOv2, a self-supervised ViT model, and interpret them as pixel-level saliency scores over RGB images. These maps are lifted into a 3D voxel grid, resulting in voxel-level semantic cues that are incorporated into a behavior cloning policy. When integrated into a state-of-the-art voxel-based policy, our attention-guided featurization yields an average absolute improvement of 8.2% and a relative gain of 21.9% across all tasks in the RLBench bimanual benchmark.
A Comparative Benchmark of Real-time Detectors for Blueberry Detection towards Precision Orchard Management
arXiv:2509.20580v1 Announce Type: new Abstract: Blueberry detection in natural environments remains challenging due to variable lighting, occlusions, and motion blur due to environmental factors and imaging devices. Deep learning-based object detectors promise to address these challenges, but they demand a large-scale, diverse dataset that captures the real-world complexities. Moreover, deploying these models in practical scenarios often requires the right accuracy/speed/memory trade-off in model selection. This study presents a novel comparative benchmark analysis of advanced real-time object detectors, including YOLO (You Only Look Once) (v8-v12) and RT-DETR (Real-Time Detection Transformers) (v1-v2) families, consisting of 36 model variants, evaluated on a newly curated dataset for blueberry detection. This dataset comprises 661 canopy images collected with smartphones during the 2022-2023 seasons, consisting of 85,879 labelled instances (including 36,256 ripe and 49,623 unripe blueberries) across a wide range of lighting conditions, occlusions, and fruit maturity stages. Among the YOLO models, YOLOv12m achieved the best accuracy with a mAP@50 of 93.3%, while RT-DETRv2-X obtained a mAP@50 of 93.6%, the highest among all the RT-DETR variants. The inference time varied with the model scale and complexity, and the mid-sized models appeared to offer a good accuracy-speed balance. To further enhance detection performance, all the models were fine-tuned using Unbiased Mean Teacher-based semi-supervised learning (SSL) on a separate set of 1,035 unlabeled images acquired by a ground-based machine vision platform in 2024. This resulted in accuracy gains ranging from -1.4% to 2.9%, with RT-DETR-v2-X achieving the best mAP@50 of 94.8%. More in-depth research into SSL is needed to better leverage cross-domain unlabeled data. Both the dataset and software programs of this study are made publicly available to support further research.
Region-of-Interest Augmentation for Mammography Classification under Patient-Level Cross-Validation
arXiv:2509.20585v1 Announce Type: new Abstract: Breast cancer screening with mammography remains central to early detection and mortality reduction. Deep learning has shown strong potential for automating mammogram interpretation, yet limited-resolution datasets and small sample sizes continue to restrict performance. We revisit the Mini-DDSM dataset (9,684 images; 2,414 patients) and introduce a lightweight region-of-interest (ROI) augmentation strategy. During training, full images are probabilistically replaced with random ROI crops sampled from a precomputed, label-free bounding-box bank, with optional jitter to increase variability. We evaluate under strict patient-level cross-validation and report ROC-AUC, PR-AUC, and training-time efficiency metrics (throughput and GPU memory). Because ROI augmentation is training-only, inference-time cost remains unchanged. On Mini-DDSM, ROI augmentation (best: p_roi = 0.10, alpha = 0.10) yields modest average ROC-AUC gains, with performance varying across folds; PR-AUC is flat to slightly lower. These results demonstrate that simple, data-centric ROI strategies can enhance mammography classification in constrained settings without requiring additional labels or architectural modifications.
Reflect3r: Single-View 3D Stereo Reconstruction Aided by Mirror Reflections
arXiv:2509.20607v1 Announce Type: new Abstract: Mirror reflections are common in everyday environments and can provide stereo information within a single capture, as the real and reflected virtual views are visible simultaneously. We exploit this property by treating the reflection as an auxiliary view and designing a transformation that constructs a physically valid virtual camera, allowing direct pixel-domain generation of the virtual view while adhering to the real-world imaging process. This enables a multi-view stereo setup from a single image, simplifying the imaging process, making it compatible with powerful feed-forward reconstruction models for generalizable and robust 3D reconstruction. To further exploit the geometric symmetry introduced by mirrors, we propose a symmetric-aware loss to refine pose estimation. Our framework also naturally extends to dynamic scenes, where each frame contains a mirror reflection, enabling efficient per-frame geometry recovery. For quantitative evaluation, we provide a fully customizable synthetic dataset of 16 Blender scenes, each with ground-truth point clouds and camera poses. Extensive experiments on real-world data and synthetic data are conducted to illustrate the effectiveness of our method.
Recov-Vision: Linking Street View Imagery and Vision-Language Models for Post-Disaster Recovery
arXiv:2509.20628v1 Announce Type: new Abstract: Building-level occupancy after disasters is vital for triage, inspections, utility re-energization, and equitable resource allocation. Overhead imagery provides rapid coverage but often misses facade and access cues that determine habitability, while street-view imagery captures those details but is sparse and difficult to align with parcels. We present FacadeTrack, a street-level, language-guided framework that links panoramic video to parcels, rectifies views to facades, and elicits interpretable attributes (for example, entry blockage, temporary coverings, localized debris) that drive two decision strategies: a transparent one-stage rule and a two-stage design that separates perception from conservative reasoning. Evaluated across two post-Hurricane Helene surveys, the two-stage approach achieves a precision of 0.927, a recall of 0.781, and an F-1 score of 0.848, compared with the one-stage baseline at a precision of 0.943, a recall of 0.728, and an F-1 score of 0.822. Beyond accuracy, intermediate attributes and spatial diagnostics reveal where and why residual errors occur, enabling targeted quality control. The pipeline provides auditable, scalable occupancy assessments suitable for integration into geospatial and emergency-management workflows.
Human Semantic Representations of Social Interactions from Moving Shapes
arXiv:2509.20673v1 Announce Type: new Abstract: Humans are social creatures who readily recognize various social interactions from simple display of moving shapes. While previous research has often focused on visual features, we examine what semantic representations that humans employ to complement visual features. In Study 1, we directly asked human participants to label the animations based on their impression of moving shapes. We found that human responses were distributed. In Study 2, we measured the representational geometry of 27 social interactions through human similarity judgments and compared it with model predictions based on visual features, labels, and semantic embeddings from animation descriptions. We found that semantic models provided complementary information to visual features in explaining human judgments. Among the semantic models, verb-based embeddings extracted from descriptions account for human similarity judgments the best. These results suggest that social perception in simple displays reflects the semantic structure of social interactions, bridging visual and abstract representations.
Enhancing Cross-View Geo-Localization Generalization via Global-Local Consistency and Geometric Equivariance
arXiv:2509.20684v1 Announce Type: new Abstract: Cross-view geo-localization (CVGL) aims to match images of the same location captured from drastically different viewpoints. Despite recent progress, existing methods still face two key challenges: (1) achieving robustness under severe appearance variations induced by diverse UAV orientations and fields of view, which hinders cross-domain generalization, and (2) establishing reliable correspondences that capture both global scene-level semantics and fine-grained local details. In this paper, we propose EGS, a novel CVGL framework designed to enhance cross-domain generalization. Specifically, we introduce an E(2)-Steerable CNN encoder to extract stable and reliable features under rotation and viewpoint shifts. Furthermore, we construct a graph with a virtual super-node that connects to all local nodes, enabling global semantics to be aggregated and redistributed to local regions, thereby enforcing global-local consistency. Extensive experiments on the University-1652 and SUES-200 benchmarks demonstrate that EGS consistently achieves substantial performance gains and establishes a new state of the art in cross-domain CVGL.
DENet: Dual-Path Edge Network with Global-Local Attention for Infrared Small Target Detection
arXiv:2509.20701v1 Announce Type: new Abstract: Infrared small target detection is crucial for remote sensing applications like disaster warning and maritime surveillance. However, due to the lack of distinctive texture and morphological features, infrared small targets are highly susceptible to blending into cluttered and noisy backgrounds. A fundamental challenge in designing deep models for this task lies in the inherent conflict between capturing high-resolution spatial details for minute targets and extracting robust semantic context for larger targets, often leading to feature misalignment and suboptimal performance. Existing methods often rely on fixed gradient operators or simplistic attention mechanisms, which are inadequate for accurately extracting target edges under low contrast and high noise. In this paper, we propose a novel Dual-Path Edge Network that explicitly addresses this challenge by decoupling edge enhancement and semantic modeling into two complementary processing paths. The first path employs a Bidirectional Interaction Module, which uses both Local Self-Attention and Global Self-Attention to capture multi-scale local and global feature dependencies. The global attention mechanism, based on a Transformer architecture, integrates long-range semantic relationships and contextual information, ensuring robust scene understanding. The second path introduces the Multi-Edge Refiner, which enhances fine-grained edge details using cascaded Taylor finite difference operators at multiple scales. This mathematical approach, along with an attention-driven gating mechanism, enables precise edge localization and feature enhancement for targets of varying sizes, while effectively suppressing noise. Our method provides a promising solution for precise infrared small target detection and localization, combining structural semantics and edge refinement in a unified framework.
Beyond the Individual: Introducing Group Intention Forecasting with SHOT Dataset
arXiv:2509.20715v1 Announce Type: new Abstract: Intention recognition has traditionally focused on individual intentions, overlooking the complexities of collective intentions in group settings. To address this limitation, we introduce the concept of group intention, which represents shared goals emerging through the actions of multiple individuals, and Group Intention Forecasting (GIF), a novel task that forecasts when group intentions will occur by analyzing individual actions and interactions before the collective goal becomes apparent. To investigate GIF in a specific scenario, we propose SHOT, the first large-scale dataset for GIF, consisting of 1,979 basketball video clips captured from 5 camera views and annotated with 6 types of individual attributes. SHOT is designed with 3 key characteristics: multi-individual information, multi-view adaptability, and multi-level intention, making it well-suited for studying emerging group intentions. Furthermore, we introduce GIFT (Group Intention ForecasTer), a framework that extracts fine-grained individual features and models evolving group dynamics to forecast intention emergence. Experimental results confirm the effectiveness of SHOT and GIFT, establishing a strong foundation for future research in group intention forecasting. The dataset is available at https://xinyi-hu.github.io/SHOT_DATASET.
Neptune-X: Active X-to-Maritime Generation for Universal Maritime Object Detection
arXiv:2509.20745v1 Announce Type: new Abstract: Maritime object detection is essential for navigation safety, surveillance, and autonomous operations, yet constrained by two key challenges: the scarcity of annotated maritime data and poor generalization across various maritime attributes (e.g., object category, viewpoint, location, and imaging environment). % In particular, models trained on existing datasets often underperform in underrepresented scenarios such as open-sea environments. To address these challenges, we propose Neptune-X, a data-centric generative-selection framework that enhances training effectiveness by leveraging synthetic data generation with task-aware sample selection. From the generation perspective, we develop X-to-Maritime, a multi-modality-conditioned generative model that synthesizes diverse and realistic maritime scenes. A key component is the Bidirectional Object-Water Attention module, which captures boundary interactions between objects and their aquatic surroundings to improve visual fidelity. To further improve downstream tasking performance, we propose Attribute-correlated Active Sampling, which dynamically selects synthetic samples based on their task relevance. To support robust benchmarking, we construct the Maritime Generation Dataset, the first dataset tailored for generative maritime learning, encompassing a wide range of semantic conditions. Extensive experiments demonstrate that our approach sets a new benchmark in maritime scene synthesis, significantly improving detection accuracy, particularly in challenging and previously underrepresented settings.The code is available at https://github.com/gy65896/Neptune-X.
AI-Enabled Crater-Based Navigation for Lunar Mapping
arXiv:2509.20748v1 Announce Type: new Abstract: Crater-Based Navigation (CBN) uses the ubiquitous impact craters of the Moon observed on images as natural landmarks to determine the six degrees of freedom pose of a spacecraft. To date, CBN has primarily been studied in the context of powered descent and landing. These missions are typically short in duration, with high-frequency imagery captured from a nadir viewpoint over well-lit terrain. In contrast, lunar mapping missions involve sparse, oblique imagery acquired under varying illumination conditions over potentially year-long campaigns, posing significantly greater challenges for pose estimation. We bridge this gap with STELLA - the first end-to-end CBN pipeline for long-duration lunar mapping. STELLA combines a Mask R-CNN-based crater detector, a descriptor-less crater identification module, a robust perspective-n-crater pose solver, and a batch orbit determination back-end. To rigorously test STELLA, we introduce CRESENT-365 - the first public dataset that emulates a year-long lunar mapping mission. Each of its 15,283 images is rendered from high-resolution digital elevation models with SPICE-derived Sun angles and Moon motion, delivering realistic global coverage, illumination cycles, and viewing geometries. Experiments on CRESENT+ and CRESENT-365 show that STELLA maintains metre-level position accuracy and sub-degree attitude accuracy on average across wide ranges of viewing angles, illumination conditions, and lunar latitudes. These results constitute the first comprehensive assessment of CBN in a true lunar mapping setting and inform operational conditions that should be considered for future missions.
Seeing Through Words, Speaking Through Pixels: Deep Representational Alignment Between Vision and Language Models
arXiv:2509.20751v1 Announce Type: new Abstract: Recent studies show that deep vision-only and language-only models--trained on disjoint modalities--nonetheless project their inputs into a partially aligned representational space. Yet we still lack a clear picture of where in each network this convergence emerges, what visual or linguistic cues support it, whether it captures human preferences in many-to-many image-text scenarios, and how aggregating exemplars of the same concept affects alignment. Here, we systematically investigate these questions. We find that alignment peaks in mid-to-late layers of both model types, reflecting a shift from modality-specific to conceptually shared representations. This alignment is robust to appearance-only changes but collapses when semantics are altered (e.g., object removal or word-order scrambling), highlighting that the shared code is truly semantic. Moving beyond the one-to-one image-caption paradigm, a forced-choice "Pick-a-Pic" task shows that human preferences for image-caption matches are mirrored in the embedding spaces across all vision-language model pairs. This pattern holds bidirectionally when multiple captions correspond to a single image, demonstrating that models capture fine-grained semantic distinctions akin to human judgments. Surprisingly, averaging embeddings across exemplars amplifies alignment rather than blurring detail. Together, our results demonstrate that unimodal networks converge on a shared semantic code that aligns with human judgments and strengthens with exemplar aggregation.
FreeInsert: Personalized Object Insertion with Geometric and Style Control
arXiv:2509.20756v1 Announce Type: new Abstract: Text-to-image diffusion models have made significant progress in image generation, allowing for effortless customized generation. However, existing image editing methods still face certain limitations when dealing with personalized image composition tasks. First, there is the issue of lack of geometric control over the inserted objects. Current methods are confined to 2D space and typically rely on textual instructions, making it challenging to maintain precise geometric control over the objects. Second, there is the challenge of style consistency. Existing methods often overlook the style consistency between the inserted object and the background, resulting in a lack of realism. In addition, the challenge of inserting objects into images without extensive training remains significant. To address these issues, we propose \textit{FreeInsert}, a novel training-free framework that customizes object insertion into arbitrary scenes by leveraging 3D geometric information. Benefiting from the advances in existing 3D generation models, we first convert the 2D object into 3D, perform interactive editing at the 3D level, and then re-render it into a 2D image from a specified view. This process introduces geometric controls such as shape or view. The rendered image, serving as geometric control, is combined with style and content control achieved through diffusion adapters, ultimately producing geometrically controlled, style-consistent edited images via the diffusion model.
CusEnhancer: A Zero-Shot Scene and Controllability Enhancement Method for Photo Customization via ResInversion
arXiv:2509.20775v1 Announce Type: new Abstract: Recently remarkable progress has been made in synthesizing realistic human photos using text-to-image diffusion models. However, current approaches face degraded scenes, insufficient control, and suboptimal perceptual identity. We introduce CustomEnhancer, a novel framework to augment existing identity customization models. CustomEnhancer is a zero-shot enhancement pipeline that leverages face swapping techniques, pretrained diffusion model, to obtain additional representations in a zeroshot manner for encoding into personalized models. Through our proposed triple-flow fused PerGeneration approach, which identifies and combines two compatible counter-directional latent spaces to manipulate a pivotal space of personalized model, we unify the generation and reconstruction processes, realizing generation from three flows. Our pipeline also enables comprehensive training-free control over the generation process of personalized models, offering precise controlled personalization for them and eliminating the need for controller retraining for per-model. Besides, to address the high time complexity of null-text inversion (NTI), we introduce ResInversion, a novel inversion method that performs noise rectification via a pre-diffusion mechanism, reducing the inversion time by 129 times. Experiments demonstrate that CustomEnhancer reach SOTA results at scene diversity, identity fidelity, training-free controls, while also showing the efficiency of our ResInversion over NTI. The code will be made publicly available upon paper acceptance.
CompressAI-Vision: Open-source software to evaluate compression methods for computer vision tasks
arXiv:2509.20777v1 Announce Type: new Abstract: With the increasing use of neural network (NN)-based computer vision applications that process image and video data as input, interest has emerged in video compression technology optimized for computer vision tasks. In fact, given the variety of vision tasks, associated NN models and datasets, a consolidated platform is needed as a common ground to implement and evaluate compression methods optimized for downstream vision tasks. CompressAI-Vision is introduced as a comprehensive evaluation platform where new coding tools compete to efficiently compress the input of vision network while retaining task accuracy in the context of two different inference scenarios: "remote" and "split" inferencing. Our study showcases various use cases of the evaluation platform incorporated with standard codecs (under development) by examining the compression gain on several datasets in terms of bit-rate versus task accuracy. This evaluation platform has been developed as open-source software and is adopted by the Moving Pictures Experts Group (MPEG) for the development the Feature Coding for Machines (FCM) standard. The software is available publicly at https://github.com/InterDigitalInc/CompressAI-Vision.
Dual-supervised Asymmetric Co-training for Semi-supervised Medical Domain Generalization
arXiv:2509.20785v1 Announce Type: new Abstract: Semi-supervised domain generalization (SSDG) in medical image segmentation offers a promising solution for generalizing to unseen domains during testing, addressing domain shift challenges and minimizing annotation costs. However, conventional SSDG methods assume labeled and unlabeled data are available for each source domain in the training set, a condition that is not always met in practice. The coexistence of limited annotation and domain shift in the training set is a prevalent issue. Thus, this paper explores a more practical and challenging scenario, cross-domain semi-supervised domain generalization (CD-SSDG), where domain shifts occur between labeled and unlabeled training data, in addition to shifts between training and testing sets. Existing SSDG methods exhibit sub-optimal performance under such domain shifts because of inaccurate pseudolabels. To address this issue, we propose a novel dual-supervised asymmetric co-training (DAC) framework tailored for CD-SSDG. Building upon the co-training paradigm with two sub-models offering cross pseudo supervision, our DAC framework integrates extra feature-level supervision and asymmetric auxiliary tasks for each sub-model. This feature-level supervision serves to address inaccurate pseudo supervision caused by domain shifts between labeled and unlabeled data, utilizing complementary supervision from the rich feature space. Additionally, two distinct auxiliary self-supervised tasks are integrated into each sub-model to enhance domain-invariant discriminative feature learning and prevent model collapse. Extensive experiments on real-world medical image segmentation datasets, i.e., Fundus, Polyp, and SCGM, demonstrate the robust generalizability of the proposed DAC framework.
Real-Time Object Detection Meets DINOv3
arXiv:2509.20787v1 Announce Type: new Abstract: Benefiting from the simplicity and effectiveness of Dense O2O and MAL, DEIM has become the mainstream training framework for real-time DETRs, significantly outperforming the YOLO series. In this work, we extend it with DINOv3 features, resulting in DEIMv2. DEIMv2 spans eight model sizes from X to Atto, covering GPU, edge, and mobile deployment. For the X, L, M, and S variants, we adopt DINOv3-pretrained or distilled backbones and introduce a Spatial Tuning Adapter (STA), which efficiently converts DINOv3's single-scale output into multi-scale features and complements strong semantics with fine-grained details to enhance detection. For ultra-lightweight models (Nano, Pico, Femto, and Atto), we employ HGNetv2 with depth and width pruning to meet strict resource budgets. Together with a simplified decoder and an upgraded Dense O2O, this unified design enables DEIMv2 to achieve a superior performance-cost trade-off across diverse scenarios, establishing new state-of-the-art results. Notably, our largest model, DEIMv2-X, achieves 57.8 AP with only 50.3 million parameters, surpassing prior X-scale models that require over 60 million parameters for just 56.5 AP. On the compact side, DEIMv2-S is the first sub-10 million model (9.71 million) to exceed the 50 AP milestone on COCO, reaching 50.9 AP. Even the ultra-lightweight DEIMv2-Pico, with just 1.5 million parameters, delivers 38.5 AP, matching YOLOv10-Nano (2.3 million) with around 50 percent fewer parameters.
DAC-LoRA: Dynamic Adversarial Curriculum for Efficient and Robust Few-Shot Adaptation
arXiv:2509.20792v1 Announce Type: new Abstract: Vision-Language Models (VLMs) are foundational to critical applications like autonomous driving, medical diagnosis, and content moderation. While Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA enable their efficient adaptation to specialized tasks, these models remain vulnerable to adversarial attacks that can compromise safety-critical decisions. CLIP, the backbone for numerous downstream VLMs, is a high-value target whose vulnerabilities can cascade across the multimodal AI ecosystem. We propose Dynamic Adversarial Curriculum DAC-LoRA, a novel framework that integrates adversarial training into PEFT. The core principle of our method i.e. an intelligent curriculum of progressively challenging attack, is general and can potentially be applied to any iterative attack method. Guided by the First-Order Stationary Condition (FOSC) and a TRADES-inspired loss, DAC-LoRA achieves substantial improvements in adversarial robustness without significantly compromising clean accuracy. Our work presents an effective, lightweight, and broadly applicable method to demonstrate that the DAC-LoRA framework can be easily integrated into a standard PEFT pipeline to significantly enhance robustness.
Federated Domain Generalization with Domain-specific Soft Prompts Generation
arXiv:2509.20807v1 Announce Type: new Abstract: Prompt learning has become an efficient paradigm for adapting CLIP to downstream tasks. Compared with traditional fine-tuning, prompt learning optimizes a few parameters yet yields highly competitive results, especially appealing in federated learning for computational efficiency. engendering domain shift among clients and posing a formidable challenge for downstream-task adaptation. Existing federated domain generalization (FDG) methods based on prompt learning typically learn soft prompts from training samples, replacing manually designed prompts to enhance the generalization ability of federated models. However, these learned prompts exhibit limited diversity and tend to ignore information from unknown domains. We propose a novel and effective method from a generative perspective for handling FDG tasks, namely federated domain generalization with domain-specific soft prompts generation (FedDSPG). Specifically, during training, we introduce domain-specific soft prompts (DSPs) for each domain and integrate content and domain knowledge into the generative model among clients. In the inference phase, the generator is utilized to obtain DSPs for unseen target domains, thus guiding downstream tasks in unknown domains. Comprehensive evaluations across several public datasets confirm that our method outperforms existing strong baselines in FDG, achieving state-of-the-art results.
Revolutionizing Precise Low Back Pain Diagnosis via Contrastive Learning
arXiv:2509.20813v1 Announce Type: new Abstract: Low back pain affects millions worldwide, driving the need for robust diagnostic models that can jointly analyze complex medical images and accompanying text reports. We present LumbarCLIP, a novel multimodal framework that leverages contrastive language-image pretraining to align lumbar spine MRI scans with corresponding radiological descriptions. Built upon a curated dataset containing axial MRI views paired with expert-written reports, LumbarCLIP integrates vision encoders (ResNet-50, Vision Transformer, Swin Transformer) with a BERT-based text encoder to extract dense representations. These are projected into a shared embedding space via learnable projection heads, configurable as linear or non-linear, and normalized to facilitate stable contrastive training using a soft CLIP loss. Our model achieves state-of-the-art performance on downstream classification, reaching up to 95.00% accuracy and 94.75% F1-score on the test set, despite inherent class imbalance. Extensive ablation studies demonstrate that linear projection heads yield more effective cross-modal alignment than non-linear variants. LumbarCLIP offers a promising foundation for automated musculoskeletal diagnosis and clinical decision support.
Poisoning Prompt-Guided Sampling in Video Large Language Models
arXiv:2509.20851v1 Announce Type: new Abstract: Video Large Language Models (VideoLLMs) have emerged as powerful tools for understanding videos, supporting tasks such as summarization, captioning, and question answering. Their performance has been driven by advances in frame sampling, progressing from uniform-based to semantic-similarity-based and, most recently, prompt-guided strategies. While vulnerabilities have been identified in earlier sampling strategies, the safety of prompt-guided sampling remains unexplored. We close this gap by presenting PoisonVID, the first black-box poisoning attack that undermines prompt-guided sampling in VideoLLMs. PoisonVID compromises the underlying prompt-guided sampling mechanism through a closed-loop optimization strategy that iteratively optimizes a universal perturbation to suppress harmful frame relevance scores, guided by a depiction set constructed from paraphrased harmful descriptions leveraging a shadow VideoLLM and a lightweight language model, i.e., GPT-4o-mini. Comprehensively evaluated on three prompt-guided sampling strategies and across three advanced VideoLLMs, PoisonVID achieves 82% - 99% attack success rate, highlighting the importance of developing future advanced sampling strategies for VideoLLMs.
Punching Above Precision: Small Quantized Model Distillation with Learnable Regularizer
arXiv:2509.20854v1 Announce Type: new Abstract: Quantization-aware training (QAT) combined with knowledge distillation (KD) is a promising strategy for compressing Artificial Intelligence (AI) models for deployment on resource-constrained hardware. However, existing QAT-KD methods often struggle to balance task-specific (TS) and distillation losses due to heterogeneous gradient magnitudes, especially under low-bit quantization. We propose Game of Regularizer (GoR), a novel learnable regularization method that adaptively balances TS and KD objectives using only two trainable parameters for dynamic loss weighting. GoR reduces conflict between supervision signals, improves convergence, and boosts the performance of small quantized models (SQMs). Experiments on image classification, object detection (OD), and large language model (LLM) compression show that GoR consistently outperforms state-of-the-art QAT-KD methods. On low-power edge devices, it delivers faster inference while maintaining full-precision accuracy. We also introduce QAT-EKD-GoR, an ensemble distillation framework that uses multiple heterogeneous teacher models. Under optimal conditions, the proposed EKD-GoR can outperform full-precision models, providing a robust solution for real-world deployment.
Plant identification based on noisy web data: the amazing performance of deep learning (LifeCLEF 2017)
arXiv:2509.20856v1 Announce Type: new Abstract: The 2017-th edition of the LifeCLEF plant identification challenge is an important milestone towards automated plant identification systems working at the scale of continental floras with 10.000 plant species living mainly in Europe and North America illustrated by a total of 1.1M images. Nowadays, such ambitious systems are enabled thanks to the conjunction of the dazzling recent progress in image classification with deep learning and several outstanding international initiatives, such as the Encyclopedia of Life (EOL), aggregating the visual knowledge on plant species coming from the main national botany institutes. However, despite all these efforts the majority of the plant species still remain without pictures or are poorly illustrated. Outside the institutional channels, a much larger number of plant pictures are available and spread on the web through botanist blogs, plant lovers web-pages, image hosting websites and on-line plant retailers. The LifeCLEF 2017 plant challenge presented in this paper aimed at evaluating to what extent a large noisy training dataset collected through the web and containing a lot of labelling errors can compete with a smaller but trusted training dataset checked by experts. To fairly compare both training strategies, the test dataset was created from a third data source, i.e. the Pl@ntNet mobile application that collects millions of plant image queries all over the world. This paper presents more precisely the resources and assessments of the challenge, summarizes the approaches and systems employed by the participating research groups, and provides an analysis of the main outcomes.
TasselNetV4: A vision foundation model for cross-scene, cross-scale, and cross-species plant counting
arXiv:2509.20857v1 Announce Type: new Abstract: Accurate plant counting provides valuable information for agriculture such as crop yield prediction, plant density assessment, and phenotype quantification. Vision-based approaches are currently the mainstream solution. Prior art typically uses a detection or a regression model to count a specific plant. However, plants have biodiversity, and new cultivars are increasingly bred each year. It is almost impossible to exhaust and build all species-dependent counting models. Inspired by class-agnostic counting (CAC) in computer vision, we argue that it is time to rethink the problem formulation of plant counting, from what plants to count to how to count plants. In contrast to most daily objects with spatial and temporal invariance, plants are dynamic, changing with time and space. Their non-rigid structure often leads to worse performance than counting rigid instances like heads and cars such that current CAC and open-world detection models are suboptimal to count plants. In this work, we inherit the vein of the TasselNet plant counting model and introduce a new extension, TasselNetV4, shifting from species-specific counting to cross-species counting. TasselNetV4 marries the local counting idea of TasselNet with the extract-and-match paradigm in CAC. It builds upon a plain vision transformer and incorporates novel multi-branch box-aware local counters used to enhance cross-scale robustness. Two challenging datasets, PAC-105 and PAC-Somalia, are harvested. Extensive experiments against state-of-the-art CAC models show that TasselNetV4 achieves not only superior counting performance but also high efficiency.Our results indicate that TasselNetV4 emerges to be a vision foundation model for cross-scene, cross-scale, and cross-species plant counting.
SD-RetinaNet: Topologically Constrained Semi-Supervised Retinal Lesion and Layer Segmentation in OCT
arXiv:2509.20864v1 Announce Type: new Abstract: Optical coherence tomography (OCT) is widely used for diagnosing and monitoring retinal diseases, such as age-related macular degeneration (AMD). The segmentation of biomarkers such as layers and lesions is essential for patient diagnosis and follow-up. Recently, semi-supervised learning has shown promise in improving retinal segmentation performance. However, existing methods often produce anatomically implausible segmentations, fail to effectively model layer-lesion interactions, and lack guarantees on topological correctness. To address these limitations, we propose a novel semi-supervised model that introduces a fully differentiable biomarker topology engine to enforce anatomically correct segmentation of lesions and layers. This enables joint learning with bidirectional influence between layers and lesions, leveraging unlabeled and diverse partially labeled datasets. Our model learns a disentangled representation, separating spatial and style factors. This approach enables more realistic layer segmentations and improves lesion segmentation, while strictly enforcing lesion location in their anatomically plausible positions relative to the segmented layers. We evaluate the proposed model on public and internal datasets of OCT scans and show that it outperforms the current state-of-the-art in both lesion and layer segmentation, while demonstrating the ability to generalize layer segmentation to pathological cases using partially annotated training data. Our results demonstrate the potential of using anatomical constraints in semi-supervised learning for accurate, robust, and trustworthy retinal biomarker segmentation.
Plant identification in an open-world (LifeCLEF 2016)
arXiv:2509.20870v1 Announce Type: new Abstract: The LifeCLEF plant identification challenge aims at evaluating plant identification methods and systems at a very large scale, close to the conditions of a real-world biodiversity monitoring scenario. The 2016-th edition was actually conducted on a set of more than 110K images illustrating 1000 plant species living in West Europe, built through a large-scale participatory sensing platform initiated in 2011 and which now involves tens of thousands of contributors. The main novelty over the previous years is that the identification task was evaluated as an open-set recognition problem, i.e. a problem in which the recognition system has to be robust to unknown and never seen categories. Beyond the brute-force classification across the known classes of the training set, the big challenge was thus to automatically reject the false positive classification hits that are caused by the unknown classes. This overview presents more precisely the resources and assessments of the challenge, summarizes the approaches and systems employed by the participating research groups, and provides an analysis of the main outcomes.
SCRA-VQA: Summarized Caption-Rerank for Augmented Large Language Models in Visual Question Answering
arXiv:2509.20871v1 Announce Type: new Abstract: Acquiring high-quality knowledge is a central focus in Knowledge-Based Visual Question Answering (KB-VQA). Recent methods use large language models (LLMs) as knowledge engines for answering. These methods generally employ image captions as visual text descriptions to assist LLMs in interpreting images. However, the captions frequently include excessive noise irrelevant to the question, and LLMs generally do not comprehend VQA tasks, limiting their reasoning capabilities. To address this issue, we propose the Summarized Caption-Rerank Augmented VQA (SCRA-VQA), which employs a pre-trained visual language model to convert images into captions. Moreover, SCRA-VQA generates contextual examples for the captions while simultaneously summarizing and reordering them to exclude unrelated information. The caption-rerank process enables LLMs to understand the image information and questions better, thus enhancing the model's reasoning ability and task adaptability without expensive end-to-end training. Based on an LLM with 6.7B parameters, SCRA-VQA performs excellently on two challenging knowledge-based VQA datasets: OK-VQA and A-OKVQA, achieving accuracies of 38.8% and 34.6%. Our code is available at https://github.com/HubuKG/SCRA-VQA.
The Unanticipated Asymmetry Between Perceptual Optimization and Assessment
arXiv:2509.20878v1 Announce Type: new Abstract: Perceptual optimization is primarily driven by the fidelity objective, which enforces both semantic consistency and overall visual realism, while the adversarial objective provides complementary refinement by enhancing perceptual sharpness and fine-grained detail. Despite their central role, the correlation between their effectiveness as optimization objectives and their capability as image quality assessment (IQA) metrics remains underexplored. In this work, we conduct a systematic analysis and reveal an unanticipated asymmetry between perceptual optimization and assessment: fidelity metrics that excel in IQA are not necessarily effective for perceptual optimization, with this misalignment emerging more distinctly under adversarial training. In addition, while discriminators effectively suppress artifacts during optimization, their learned representations offer only limited benefits when reused as backbone initializations for IQA models. Beyond this asymmetry, our findings further demonstrate that discriminator design plays a decisive role in shaping optimization, with patch-level and convolutional architectures providing more faithful detail reconstruction than vanilla or Transformer-based alternatives. These insights advance the understanding of loss function design and its connection to IQA transferability, paving the way for more principled approaches to perceptual optimization.
Integrating Object Interaction Self-Attention and GAN-Based Debiasing for Visual Question Answering
arXiv:2509.20884v1 Announce Type: new Abstract: Visual Question Answering (VQA) presents a unique challenge by requiring models to understand and reason about visual content to answer questions accurately. Existing VQA models often struggle with biases introduced by the training data, leading to over-reliance on superficial patterns and inadequate generalization to diverse questions and images. This paper presents a novel model, IOG-VQA, which integrates Object Interaction Self-Attention and GAN-Based Debiasing to enhance VQA model performance. The self-attention mechanism allows our model to capture complex interactions between objects within an image, providing a more comprehensive understanding of the visual context. Meanwhile, the GAN-based debiasing framework generates unbiased data distributions, helping the model to learn more robust and generalizable features. By leveraging these two components, IOG-VQA effectively combines visual and textual information to address the inherent biases in VQA datasets. Extensive experiments on the VQA-CP v1 and VQA-CP v2 datasets demonstrate that our model shows excellent performance compared with the existing methods, particularly in handling biased and imbalanced data distributions highlighting the importance of addressing both object interactions and dataset biases in advancing VQA tasks. Our code is available at https://github.com/HubuKG/IOG-VQA.
Nuclear Diffusion Models for Low-Rank Background Suppression in Videos
arXiv:2509.20886v1 Announce Type: new Abstract: Video sequences often contain structured noise and background artifacts that obscure dynamic content, posing challenges for accurate analysis and restoration. Robust principal component methods address this by decomposing data into low-rank and sparse components. Still, the sparsity assumption often fails to capture the rich variability present in real video data. To overcome this limitation, a hybrid framework that integrates low-rank temporal modeling with diffusion posterior sampling is proposed. The proposed method, Nuclear Diffusion, is evaluated on a real-world medical imaging problem, namely cardiac ultrasound dehazing, and demonstrates improved dehazing performance compared to traditional RPCA concerning contrast enhancement (gCNR) and signal preservation (KS statistic). These results highlight the potential of combining model-based temporal models with deep generative priors for high-fidelity video restoration.
FerretNet: Efficient Synthetic Image Detection via Local Pixel Dependencies
arXiv:2509.20890v1 Announce Type: new Abstract: The increasing realism of synthetic images generated by advanced models such as VAEs, GANs, and LDMs poses significant challenges for synthetic image detection. To address this issue, we explore two artifact types introduced during the generation process: (1) latent distribution deviations and (2) decoding-induced smoothing effects, which manifest as inconsistencies in local textures, edges, and color transitions. Leveraging local pixel dependencies (LPD) properties rooted in Markov Random Fields, we reconstruct synthetic images using neighboring pixel information to expose disruptions in texture continuity and edge coherence. Building upon LPD, we propose FerretNet, a lightweight neural network with only 1.1M parameters that delivers efficient and robust synthetic image detection. Extensive experiments demonstrate that FerretNet, trained exclusively on the 4-class ProGAN dataset, achieves an average accuracy of 97.1% on an open-world benchmark comprising across 22 generative models, surpassing state-of-the-art methods by 10.6%.
Concepts in Motion: Temporal Bottlenecks for Interpretable Video Classification
arXiv:2509.20899v1 Announce Type: new Abstract: Conceptual models such as Concept Bottleneck Models (CBMs) have driven substantial progress in improving interpretability for image classification by leveraging human-interpretable concepts. However, extending these models from static images to sequences of images, such as video data, introduces a significant challenge due to the temporal dependencies inherent in videos, which are essential for capturing actions and events. In this work, we introduce MoTIF (Moving Temporal Interpretable Framework), an architectural design inspired by a transformer that adapts the concept bottleneck framework for video classification and handles sequences of arbitrary length. Within the video domain, concepts refer to semantic entities such as objects, attributes, or higher-level components (e.g., 'bow', 'mount', 'shoot') that reoccur across time - forming motifs collectively describing and explaining actions. Our design explicitly enables three complementary perspectives: global concept importance across the entire video, local concept relevance within specific windows, and temporal dependencies of a concept over time. Our results demonstrate that the concept-based modeling paradigm can be effectively transferred to video data, enabling a better understanding of concept contributions in temporal contexts while maintaining competitive performance. Code available at github.com/patrick-knab/MoTIF.
FSMODNet: A Closer Look at Few-Shot Detection in Multispectral Data
arXiv:2509.20905v1 Announce Type: new Abstract: Few-shot multispectral object detection (FSMOD) addresses the challenge of detecting objects across visible and thermal modalities with minimal annotated data. In this paper, we explore this complex task and introduce a framework named "FSMODNet" that leverages cross-modality feature integration to improve detection performance even with limited labels. By effectively combining the unique strengths of visible and thermal imagery using deformable attention, the proposed method demonstrates robust adaptability in complex illumination and environmental conditions. Experimental results on two public datasets show effective object detection performance in challenging low-data regimes, outperforming several baselines we established from state-of-the-art models. All code, models, and experimental data splits can be found at https://anonymous.4open.science/r/Test-B48D.
Finding 3D Positions of Distant Objects from Noisy Camera Movement and Semantic Segmentation Sequences
arXiv:2509.20906v1 Announce Type: new Abstract: 3D object localisation based on a sequence of camera measurements is essential for safety-critical surveillance tasks, such as drone-based wildfire monitoring. Localisation of objects detected with a camera can typically be solved with dense depth estimation or 3D scene reconstruction. However, in the context of distant objects or tasks limited by the amount of available computational resources, neither solution is feasible. In this paper, we show that the task can be solved using particle filters for both single and multiple target scenarios. The method was studied using a 3D simulation and a drone-based image segmentation sequence with global navigation satellite system (GNSS)-based camera pose estimates. The results showed that a particle filter can be used to solve practical localisation tasks based on camera poses and image segments in these situations where other solutions fail. The particle filter is independent of the detection method, making it flexible for new tasks. The study also demonstrates that drone-based wildfire monitoring can be conducted using the proposed method paired with a pre-existing image segmentation model.
SwinMamba: A hybrid local-global mamba framework for enhancing semantic segmentation of remotely sensed images
arXiv:2509.20918v1 Announce Type: new Abstract: Semantic segmentation of remote sensing imagery is a fundamental task in computer vision, supporting a wide range of applications such as land use classification, urban planning, and environmental monitoring. However, this task is often challenged by the high spatial resolution, complex scene structures, and diverse object scales present in remote sensing data. To address these challenges, various deep learning architectures have been proposed, including convolutional neural networks, Vision Transformers, and the recently introduced Vision Mamba. Vision Mamba features a global receptive field and low computational complexity, demonstrating both efficiency and effectiveness in image segmentation. However, its reliance on global scanning tends to overlook critical local features, such as textures and edges, which are essential for achieving accurate segmentation in remote sensing contexts. To tackle this limitation, we propose SwinMamba, a novel framework inspired by the Swin Transformer. SwinMamba integrates localized Mamba-style scanning within shifted windows with a global receptive field, to enhance the model's perception of both local and global features. Specifically, the first two stages of SwinMamba perform local scanning to capture fine-grained details, while its subsequent two stages leverage global scanning to fuse broader contextual information. In our model, the use of overlapping shifted windows enhances inter-region information exchange, facilitating more robust feature integration across the entire image. Extensive experiments on the LoveDA and ISPRS Potsdam datasets demonstrate that SwinMamba outperforms state-of-the-art methods, underscoring its effectiveness and potential as a superior solution for semantic segmentation of remotely sensed imagery.
Revisiting Data Challenges of Computational Pathology: A Pack-based Multiple Instance Learning Framework
arXiv:2509.20923v1 Announce Type: new Abstract: Computational pathology (CPath) digitizes pathology slides into whole slide images (WSIs), enabling analysis for critical healthcare tasks such as cancer diagnosis and prognosis. However, WSIs possess extremely long sequence lengths (up to 200K), significant length variations (from 200 to 200K), and limited supervision. These extreme variations in sequence length lead to high data heterogeneity and redundancy. Conventional methods often compromise on training efficiency and optimization to preserve such heterogeneity under limited supervision. To comprehensively address these challenges, we propose a pack-based MIL framework. It packs multiple sampled, variable-length feature sequences into fixed-length ones, enabling batched training while preserving data heterogeneity. Moreover, we introduce a residual branch that composes discarded features from multiple slides into a hyperslide which is trained with tailored labels. It offers multi-slide supervision while mitigating feature loss from sampling. Meanwhile, an attention-driven downsampler is introduced to compress features in both branches to reduce redundancy. By alleviating these challenges, our approach achieves an accuracy improvement of up to 8% while using only 12% of the training time in the PANDA(UNI). Extensive experiments demonstrate that focusing data challenges in CPath holds significant potential in the era of foundation models. The code is https://github.com/FangHeng/PackMIL
SimDiff: Simulator-constrained Diffusion Model for Physically Plausible Motion Generation
arXiv:2509.20927v1 Announce Type: new Abstract: Generating physically plausible human motion is crucial for applications such as character animation and virtual reality. Existing approaches often incorporate a simulator-based motion projection layer to the diffusion process to enforce physical plausibility. However, such methods are computationally expensive due to the sequential nature of the simulator, which prevents parallelization. We show that simulator-based motion projection can be interpreted as a form of guidance, either classifier-based or classifier-free, within the diffusion process. Building on this insight, we propose SimDiff, a Simulator-constrained Diffusion Model that integrates environment parameters (e.g., gravity, wind) directly into the denoising process. By conditioning on these parameters, SimDiff generates physically plausible motions efficiently, without repeated simulator calls at inference, and also provides fine-grained control over different physical coefficients. Moreover, SimDiff successfully generalizes to unseen combinations of environmental parameters, demonstrating compositional generalization.
Unlocking Noise-Resistant Vision: Key Architectural Secrets for Robust Models
arXiv:2509.20939v1 Announce Type: new Abstract: While the robustness of vision models is often measured, their dependence on specific architectural design choices is rarely dissected. We investigate why certain vision architectures are inherently more robust to additive Gaussian noise and convert these empirical insights into simple, actionable design rules. Specifically, we performed extensive evaluations on 1,174 pretrained vision models, empirically identifying four consistent design patterns for improved robustness against Gaussian noise: larger stem kernels, smaller input resolutions, average pooling, and supervised vision transformers (ViTs) rather than CLIP ViTs, which yield up to 506 rank improvements and 21.6\%p accuracy gains. We then develop a theoretical analysis that explains these findings, converting observed correlations into causal mechanisms. First, we prove that low-pass stem kernels attenuate noise with a gain that decreases quadratically with kernel size and that anti-aliased downsampling reduces noise energy roughly in proportion to the square of the downsampling factor. Second, we demonstrate that average pooling is unbiased and suppresses noise in proportion to the pooling window area, whereas max pooling incurs a positive bias that grows slowly with window size and yields a relatively higher mean-squared error and greater worst-case sensitivity. Third, we reveal and explain the vulnerability of CLIP ViTs via a pixel-space Lipschitz bound: The smaller normalization standard deviations used in CLIP preprocessing amplify worst-case sensitivity by up to 1.91 times relative to the Inception-style preprocessing common in supervised ViTs. Our results collectively disentangle robustness into interpretable modules, provide a theory that explains the observed trends, and build practical, plug-and-play guidelines for designing vision models more robust against Gaussian noise.
Decoding the Surgical Scene: A Scoping Review of Scene Graphs in Surgery
arXiv:2509.20941v1 Announce Type: new Abstract: Scene graphs (SGs) provide structured relational representations crucial for decoding complex, dynamic surgical environments. This PRISMA-ScR-guided scoping review systematically maps the evolving landscape of SG research in surgery, charting its applications, methodological advancements, and future directions. Our analysis reveals rapid growth, yet uncovers a critical 'data divide': internal-view research (e.g., triplet recognition) almost exclusively uses real-world 2D video, while external-view 4D modeling relies heavily on simulated data, exposing a key translational research gap. Methodologically, the field has advanced from foundational graph neural networks to specialized foundation models that now significantly outperform generalist large vision-language models in surgical contexts. This progress has established SGs as a cornerstone technology for both analysis, such as workflow recognition and automated safety monitoring, and generative tasks like controllable surgical simulation. Although challenges in data annotation and real-time implementation persist, they are actively being addressed through emerging techniques. Surgical SGs are maturing into an essential semantic bridge, enabling a new generation of intelligent systems to improve surgical safety, efficiency, and training.
A Real-Time On-Device Defect Detection Framework for Laser Power-Meter Sensors via Unsupervised Learning
arXiv:2509.20946v1 Announce Type: new Abstract: We present an automated vision-based system for defect detection and classification of laser power meter sensor coatings. Our approach addresses the critical challenge of identifying coating defects such as thermal damage and scratches that can compromise laser energy measurement accuracy in medical and industrial applications. The system employs an unsupervised anomaly detection framework that trains exclusively on ``good'' sensor images to learn normal coating distribution patterns, enabling detection of both known and novel defect types without requiring extensive labeled defect datasets. Our methodology consists of three key components: (1) a robust preprocessing pipeline using Laplacian edge detection and K-means clustering to segment the area of interest, (2) synthetic data augmentation via StyleGAN2, and (3) a UFlow-based neural network architecture for multi-scale feature extraction and anomaly map generation. Experimental evaluation on 366 real sensor images demonstrates $93.8\%$ accuracy on defective samples and $89.3\%$ accuracy on good samples, with image-level AUROC of 0.957 and pixel-level AUROC of 0.961. The system provides potential annual cost savings through automated quality control and processing times of 0.5 seconds per image in on-device implementation.
Unlocking Financial Insights: An advanced Multimodal Summarization with Multimodal Output Framework for Financial Advisory Videos
arXiv:2509.20961v1 Announce Type: new Abstract: The dynamic propagation of social media has broadened the reach of financial advisory content through podcast videos, yet extracting insights from lengthy, multimodal segments (30-40 minutes) remains challenging. We introduce FASTER (Financial Advisory Summariser with Textual Embedded Relevant images), a modular framework that tackles three key challenges: (1) extracting modality-specific features, (2) producing optimized, concise summaries, and (3) aligning visual keyframes with associated textual points. FASTER employs BLIP for semantic visual descriptions, OCR for textual patterns, and Whisper-based transcription with Speaker diarization as BOS features. A modified Direct Preference Optimization (DPO)-based loss function, equipped with BOS-specific fact-checking, ensures precision, relevance, and factual consistency against the human-aligned summary. A ranker-based retrieval mechanism further aligns keyframes with summarized content, enhancing interpretability and cross-modal coherence. To acknowledge data resource scarcity, we introduce Fin-APT, a dataset comprising 470 publicly accessible financial advisory pep-talk videos for robust multimodal research. Comprehensive cross-domain experiments confirm FASTER's strong performance, robustness, and generalizability when compared to Large Language Models (LLMs) and Vision-Language Models (VLMs). By establishing a new standard for multimodal summarization, FASTER makes financial advisory content more accessible and actionable, thereby opening new avenues for research. The dataset and code are available at: https://github.com/sarmistha-D/FASTER
An Adaptor for Triggering Semi-Supervised Learning to Out-of-Box Serve Deep Image Clustering
arXiv:2509.20976v1 Announce Type: new Abstract: Recently, some works integrate SSL techniques into deep clustering frameworks to enhance image clustering performance. However, they all need pretraining, clustering learning, or a trained clustering model as prerequisites, limiting the flexible and out-of-box application of SSL learners in the image clustering task. This work introduces ASD, an adaptor that enables the cold-start of SSL learners for deep image clustering without any prerequisites. Specifically, we first randomly sample pseudo-labeled data from all unlabeled data, and set an instance-level classifier to learn them with semantically aligned instance-level labels. With the ability of instance-level classification, we track the class transitions of predictions on unlabeled data to extract high-level similarities of instance-level classes, which can be utilized to assign cluster-level labels to pseudo-labeled data. Finally, we use the pseudo-labeled data with assigned cluster-level labels to trigger a general SSL learner trained on the unlabeled data for image clustering. We show the superior performance of ASD across various benchmarks against the latest deep image clustering approaches and very slight accuracy gaps compared to SSL methods using ground-truth, e.g., only 1.33% on CIFAR-10. Moreover, ASD can also further boost the performance of existing SSL-embedded deep image clustering methods.
SiNGER: A Clearer Voice Distills Vision Transformers Further
arXiv:2509.20986v1 Announce Type: new Abstract: Vision Transformers are widely adopted as the backbone of vision foundation models, but they are known to produce high-norm artifacts that degrade representation quality. When knowledge distillation transfers these features to students, high-norm artifacts dominate the objective, so students overfit to artifacts and underweight informative signals, diminishing the gains from larger models. Prior work attempted to remove artifacts but encountered an inherent trade-off between artifact suppression and preserving informative signals from teachers. To address this, we introduce Singular Nullspace-Guided Energy Reallocation (SiNGER), a novel distillation framework that suppresses artifacts while preserving informative signals. The key idea is principled teacher feature refinement: during refinement, we leverage the nullspace-guided perturbation to preserve information while suppressing artifacts. Then, the refined teacher's features are distilled to a student. We implement this perturbation efficiently with a LoRA-based adapter that requires minimal structural modification. Extensive experiments show that \oursname consistently improves student models, achieving state-of-the-art performance in multiple downstream tasks and producing clearer and more interpretable representations.
Fast-SEnSeI: Lightweight Sensor-Independent Cloud Masking for On-board Multispectral Sensors
arXiv:2509.20991v1 Announce Type: new Abstract: Cloud segmentation is a critical preprocessing step for many Earth observation tasks, yet most models are tightly coupled to specific sensor configurations and rely on ground-based processing. In this work, we propose Fast-SEnSeI, a lightweight, sensor-independent encoder module that enables flexible, on-board cloud segmentation across multispectral sensors with varying band configurations. Building upon SEnSeI-v2, Fast-SEnSeI integrates an improved spectral descriptor, lightweight architecture, and robust padding-band handling. It accepts arbitrary combinations of spectral bands and their wavelengths, producing fixed-size feature maps that feed into a compact, quantized segmentation model based on a modified U-Net. The module runs efficiently on embedded CPUs using Apache TVM, while the segmentation model is deployed on FPGA, forming a CPU-FPGA hybrid pipeline suitable for space-qualified hardware. Evaluations on Sentinel-2 and Landsat 8 datasets demonstrate accurate segmentation across diverse input configurations.
A Single Neuron Works: Precise Concept Erasure in Text-to-Image Diffusion Models
arXiv:2509.21008v1 Announce Type: new Abstract: Text-to-image models exhibit remarkable capabilities in image generation. However, they also pose safety risks of generating harmful content. A key challenge of existing concept erasure methods is the precise removal of target concepts while minimizing degradation of image quality. In this paper, we propose Single Neuron-based Concept Erasure (SNCE), a novel approach that can precisely prevent harmful content generation by manipulating only a single neuron. Specifically, we train a Sparse Autoencoder (SAE) to map text embeddings into a sparse, disentangled latent space, where individual neurons align tightly with atomic semantic concepts. To accurately locate neurons responsible for harmful concepts, we design a novel neuron identification method based on the modulated frequency scoring of activation patterns. By suppressing activations of the harmful concept-specific neuron, SNCE achieves surgical precision in concept erasure with minimal disruption to image quality. Experiments on various benchmarks demonstrate that SNCE achieves state-of-the-art results in target concept erasure, while preserving the model's generation capabilities for non-target concepts. Additionally, our method exhibits strong robustness against adversarial attacks, significantly outperforming existing methods.
OmniPlantSeg: Species Agnostic 3D Point Cloud Organ Segmentation for High-Resolution Plant Phenotyping Across Modalities
arXiv:2509.21038v1 Announce Type: new Abstract: Accurate point cloud segmentation for plant organs is crucial for 3D plant phenotyping. Existing solutions are designed problem-specific with a focus on certain plant species or specified sensor-modalities for data acquisition. Furthermore, it is common to use extensive pre-processing and down-sample the plant point clouds to meet hardware or neural network input size requirements. We propose a simple, yet effective algorithm KDSS for sub-sampling of biological point clouds that is agnostic to sensor data and plant species. The main benefit of this approach is that we do not need to down-sample our input data and thus, enable segmentation of the full-resolution point cloud. Combining KD-SS with current state-of-the-art segmentation models shows satisfying results evaluated on different modalities such as photogrammetry, laser triangulation and LiDAR for various plant species. We propose KD-SS as lightweight resolution-retaining alternative to intensive pre-processing and down-sampling methods for plant organ segmentation regardless of used species and sensor modality.
Background Prompt for Few-Shot Out-of-Distribution Detection
arXiv:2509.21055v1 Announce Type: new Abstract: Existing foreground-background (FG-BG) decomposition methods for the few-shot out-of-distribution (FS-OOD) detection often suffer from low robustness due to over-reliance on the local class similarity and a fixed background patch extraction strategy. To address these challenges, we propose a new FG-BG decomposition framework, namely Mambo, for FS-OOD detection. Specifically, we propose to first learn a background prompt to obtain the local background similarity containing both the background and image semantic information, and then refine the local background similarity using the local class similarity. As a result, we use both the refined local background similarity and the local class similarity to conduct background extraction, reducing the dependence of the local class similarity in previous methods. Furthermore, we propose the patch self-calibrated tuning to consider the sample diversity to flexibly select numbers of background patches for different samples, and thus exploring the issue of fixed background extraction strategies in previous methods. Extensive experiments on real-world datasets demonstrate that our proposed Mambo achieves the best performance, compared to SOTA methods in terms of OOD detection and near OOD detection setting. The source code will be released at https://github.com/YuzunoKawori/Mambo.
Stratify or Die: Rethinking Data Splits in Image Segmentation
arXiv:2509.21056v1 Announce Type: new Abstract: Random splitting of datasets in image segmentation often leads to unrepresentative test sets, resulting in biased evaluations and poor model generalization. While stratified sampling has proven effective for addressing label distribution imbalance in classification tasks, extending these ideas to segmentation remains challenging due to the multi-label structure and class imbalance typically present in such data. Building on existing stratification concepts, we introduce Iterative Pixel Stratification (IPS), a straightforward, label-aware sampling method tailored for segmentation tasks. Additionally, we present Wasserstein-Driven Evolutionary Stratification (WDES), a novel genetic algorithm designed to minimize the Wasserstein distance, thereby optimizing the similarity of label distributions across dataset splits. We prove that WDES is globally optimal given enough generations. Using newly proposed statistical heterogeneity metrics, we evaluate both methods against random sampling and find that WDES consistently produces more representative splits. Applying WDES across diverse segmentation tasks, including street scenes, medical imaging, and satellite imagery, leads to lower performance variance and improved model evaluation. Our results also highlight the particular value of WDES in handling small, imbalanced, and low-diversity datasets, where conventional splitting strategies are most prone to bias.
EnGraf-Net: Multiple Granularity Branch Network with Fine-Coarse Graft Grained for Classification Task
arXiv:2509.21061v1 Announce Type: new Abstract: Fine-grained classification models are designed to focus on the relevant details necessary to distinguish highly similar classes, particularly when intra-class variance is high and inter-class variance is low. Most existing models rely on part annotations such as bounding boxes, part locations, or textual attributes to enhance classification performance, while others employ sophisticated techniques to automatically extract attention maps. We posit that part-based approaches, including automatic cropping methods, suffer from an incomplete representation of local features, which are fundamental for distinguishing similar objects. While fine-grained classification aims to recognize the leaves of a hierarchical structure, humans recognize objects by also forming semantic associations. In this paper, we leverage semantic associations structured as a hierarchy (taxonomy) as supervised signals within an end-to-end deep neural network model, termed EnGraf-Net. Extensive experiments on three well-known datasets CIFAR-100, CUB-200-2011, and FGVC-Aircraft demonstrate the superiority of EnGraf-Net over many existing fine-grained models, showing competitive performance with the most recent state-of-the-art approaches, without requiring cropping techniques or manual annotations.
Vision Transformers: the threat of realistic adversarial patches
arXiv:2509.21084v1 Announce Type: new Abstract: The increasing reliance on machine learning systems has made their security a critical concern. Evasion attacks enable adversaries to manipulate the decision-making processes of AI systems, potentially causing security breaches or misclassification of targets. Vision Transformers (ViTs) have gained significant traction in modern machine learning due to increased 1) performance compared to Convolutional Neural Networks (CNNs) and 2) robustness against adversarial perturbations. However, ViTs remain vulnerable to evasion attacks, particularly to adversarial patches, unique patterns designed to manipulate AI classification systems. These vulnerabilities are investigated by designing realistic adversarial patches to cause misclassification in person vs. non-person classification tasks using the Creases Transformation (CT) technique, which adds subtle geometric distortions similar to those occurring naturally when wearing clothing. This study investigates the transferability of adversarial attack techniques used in CNNs when applied to ViT classification models. Experimental evaluation across four fine-tuned ViT models on a binary person classification task reveals significant vulnerability variations: attack success rates ranged from 40.04% (google/vit-base-patch16-224-in21k) to 99.97% (facebook/dino-vitb16), with google/vit-base-patch16-224 achieving 66.40% and facebook/dinov3-vitb16 reaching 65.17%. These results confirm the cross-architectural transferability of adversarial patches from CNNs to ViTs, with pre-training dataset scale and methodology strongly influencing model resilience to adversarial attacks.
UniTransfer: Video Concept Transfer via Progressive Spatial and Timestep Decomposition
arXiv:2509.21086v1 Announce Type: new Abstract: We propose a novel architecture UniTransfer, which introduces both spatial and diffusion timestep decomposition in a progressive paradigm, achieving precise and controllable video concept transfer. Specifically, in terms of spatial decomposition, we decouple videos into three key components: the foreground subject, the background, and the motion flow. Building upon this decomposed formulation, we further introduce a dual-to-single-stream DiT-based architecture for supporting fine-grained control over different components in the videos. We also introduce a self-supervised pretraining strategy based on random masking to enhance the decomposed representation learning from large-scale unlabeled video data. Inspired by the Chain-of-Thought reasoning paradigm, we further revisit the denoising diffusion process and propose a Chain-of-Prompt (CoP) mechanism to achieve the timestep decomposition. We decompose the denoising process into three stages of different granularity and leverage large language models (LLMs) for stage-specific instructions to guide the generation progressively. We also curate an animal-centric video dataset called OpenAnimal to facilitate the advancement and benchmarking of research in video concept transfer. Extensive experiments demonstrate that our method achieves high-quality and controllable video concept transfer across diverse reference images and scenes, surpassing existing baselines in both visual fidelity and editability. Web Page: https://yu-shaonian.github.io/UniTransfer-Web/
VideoChat-R1.5: Visual Test-Time Scaling to Reinforce Multimodal Reasoning by Iterative Perception
arXiv:2509.21100v1 Announce Type: new Abstract: Inducing reasoning in multimodal large language models (MLLMs) is critical for achieving human-level perception and understanding. Existing methods mainly leverage LLM reasoning to analyze parsed visuals, often limited by static perception stages. This paper introduces Visual Test-Time Scaling (VTTS), a novel approach to enhance MLLMs' reasoning via iterative perception during inference. VTTS mimics humans' hierarchical attention by progressively refining focus on high-confidence spatio-temporal regions, guided by updated textual predictions. Specifically, VTTS employs an Iterative Perception (ITP) mechanism, incorporating reinforcement learning with spatio-temporal supervision to optimize reasoning. To support this paradigm, we also present VTTS-80K, a dataset tailored for iterative perception. These designs allows a MLLM to enhance its performance by increasing its perceptual compute. Extensive experiments validate VTTS's effectiveness and generalization across diverse tasks and benchmarks. Our newly introduced Videochat-R1.5 model has achieved remarkable improvements, with an average increase of over 5\%, compared to robust baselines such as Qwen2.5VL-3B and -7B, across more than 15 benchmarks that encompass video conversation, video reasoning, and spatio-temporal perception.
Mammo-CLIP Dissect: A Framework for Analysing Mammography Concepts in Vision-Language Models
arXiv:2509.21102v1 Announce Type: new Abstract: Understanding what deep learning (DL) models learn is essential for the safe deployment of artificial intelligence (AI) in clinical settings. While previous work has focused on pixel-based explainability methods, less attention has been paid to the textual concepts learned by these models, which may better reflect the reasoning used by clinicians. We introduce Mammo-CLIP Dissect, the first concept-based explainability framework for systematically dissecting DL vision models trained for mammography. Leveraging a mammography-specific vision-language model (Mammo-CLIP) as a "dissector," our approach labels neurons at specified layers with human-interpretable textual concepts and quantifies their alignment to domain knowledge. Using Mammo-CLIP Dissect, we investigate three key questions: (1) how concept learning differs between DL vision models trained on general image datasets versus mammography-specific datasets; (2) how fine-tuning for downstream mammography tasks affects concept specialisation; and (3) which mammography-relevant concepts remain underrepresented. We show that models trained on mammography data capture more clinically relevant concepts and align more closely with radiologists' workflows than models not trained on mammography data. Fine-tuning for task-specific classification enhances the capture of certain concept categories (e.g., benign calcifications) but can reduce coverage of others (e.g., density-related features), indicating a trade-off between specialisation and generalisation. Our findings show that Mammo-CLIP Dissect provides insights into how convolutional neural networks (CNNs) capture mammography-specific knowledge. By comparing models across training data and fine-tuning regimes, we reveal how domain-specific training and task-specific adaptation shape concept learning. Code and concept set are available: https://github.com/Suaiba/Mammo-CLIP-Dissect.
MOSS-ChatV: Reinforcement Learning with Process Reasoning Reward for Video Temporal Reasoning
arXiv:2509.21113v1 Announce Type: new Abstract: Video reasoning has emerged as a critical capability for multimodal large language models (MLLMs), requiring models to move beyond static perception toward coherent understanding of temporal dynamics in complex scenes. Yet existing MLLMs often exhibit process inconsistency, where intermediate reasoning drifts from video dynamics even when the final answer is correct, undermining interpretability and robustness. To address this issue, we introduce MOSS-ChatV, a reinforcement learning framework with a Dynamic Time Warping (DTW)-based process reward. This rule-based reward aligns reasoning traces with temporally grounded references, enabling efficient process supervision without auxiliary reward models. We further identify dynamic state prediction as a key measure of video reasoning and construct MOSS-Video, a benchmark with annotated reasoning traces, where the training split is used to fine-tune MOSS-ChatV and the held-out split is reserved for evaluation. MOSS-ChatV achieves 87.2\% on MOSS-Video (test) and improves performance on general video benchmarks such as MVBench and MMVU. The framework consistently yields gains across different architectures, including Qwen2.5-VL and Phi-2, confirming its broad applicability. Evaluations with GPT-4o-as-judge further show that MOSS-ChatV produces more consistent and stable reasoning traces.
MotionFlow:Learning Implicit Motion Flow for Complex Camera Trajectory Control in Video Generation
arXiv:2509.21119v1 Announce Type: new Abstract: Generating videos guided by camera trajectories poses significant challenges in achieving consistency and generalizability, particularly when both camera and object motions are present. Existing approaches often attempt to learn these motions separately, which may lead to confusion regarding the relative motion between the camera and the objects. To address this challenge, we propose a novel approach that integrates both camera and object motions by converting them into the motion of corresponding pixels. Utilizing a stable diffusion network, we effectively learn reference motion maps in relation to the specified camera trajectory. These maps, along with an extracted semantic object prior, are then fed into an image-to-video network to generate the desired video that can accurately follow the designated camera trajectory while maintaining consistent object motions. Extensive experiments verify that our model outperforms SOTA methods by a large margin.
The Unwinnable Arms Race of AI Image Detection
arXiv:2509.21135v1 Announce Type: new Abstract: The rapid progress of image generative AI has blurred the boundary between synthetic and real images, fueling an arms race between generators and discriminators. This paper investigates the conditions under which discriminators are most disadvantaged in this competition. We analyze two key factors: data dimensionality and data complexity. While increased dimensionality often strengthens the discriminators ability to detect subtle inconsistencies, complexity introduces a more nuanced effect. Using Kolmogorov complexity as a measure of intrinsic dataset structure, we show that both very simple and highly complex datasets reduce the detectability of synthetic images; generators can learn simple datasets almost perfectly, whereas extreme diversity masks imperfections. In contrast, intermediate-complexity datasets create the most favorable conditions for detection, as generators fail to fully capture the distribution and their errors remain visible.
WAVECLIP: Wavelet Tokenization for Adaptive-Resolution CLIP
arXiv:2509.21153v1 Announce Type: new Abstract: We introduce WAVECLIP, a single unified model for adaptive resolution inference in CLIP, enabled by wavelet-based tokenization. WAVECLIP replaces standard patch embeddings with a multi-level wavelet decomposition, enabling the model to process images coarse to fine while naturally supporting multiple resolutions within the same model. At inference time, the model begins with low resolution tokens and refines only when needed, using key-value caching and causal cross-level attention to reuse computation, effectively introducing to the model only new information when needed. We evaluate WAVECLIP in zero-shot classification, demonstrating that a simple confidence-based gating mechanism enables adaptive early exits. This allows users to dynamically choose a compute-accuracy trade-off using a single deployed model. Our approach requires only lightweight distillation from a frozen CLIP teacher and achieves competitive accuracy with significant computational savings.
Can Less Precise Be More Reliable? A Systematic Evaluation of Quantization's Impact on CLIP Beyond Accuracy
arXiv:2509.21173v1 Announce Type: new Abstract: The powerful zero-shot generalization capabilities of vision-language models (VLMs) like CLIP have enabled new paradigms for safety-related tasks such as out-of-distribution (OOD) detection. However, additional aspects crucial for the computationally efficient and reliable deployment of CLIP are still overlooked. In particular, the impact of quantization on CLIP's performance beyond accuracy remains underexplored. This work presents a large-scale evaluation of quantization on CLIP models, assessing not only in-distribution accuracy but a comprehensive suite of reliability metrics and revealing counterintuitive results driven by pre-training source. We demonstrate that quantization consistently improves calibration for typically underconfident pre-trained models, while often degrading it for overconfident variants. Intriguingly, this degradation in calibration does not preclude gains in other reliability metrics; we find that OOD detection can still improve for these same poorly calibrated models. Furthermore, we identify specific quantization-aware training (QAT) methods that yield simultaneous gains in zero-shot accuracy, calibration, and OOD robustness, challenging the view of a strict efficiency-performance trade-off. These findings offer critical insights for navigating the multi-objective problem of deploying efficient, reliable, and robust VLMs by utilizing quantization beyond its conventional role.
TABLET: A Large-Scale Dataset for Robust Visual Table Understanding
arXiv:2509.21205v1 Announce Type: new Abstract: While table understanding increasingly relies on pixel-only settings where tables are processed as visual representations, current benchmarks predominantly use synthetic renderings that lack the complexity and visual diversity of real-world tables. Additionally, existing visual table understanding (VTU) datasets offer fixed examples with single visualizations and pre-defined instructions, providing no access to underlying serialized data for reformulation. We introduce TABLET, a large-scale VTU dataset with 4 million examples across 20 tasks, grounded in 2 million unique tables where 88% preserve original visualizations. Each example includes paired image-HTML representations, comprehensive metadata, and provenance information linking back to the source datasets. Fine-tuning vision-language models like Qwen2.5-VL-7B on TABLET improves performance on seen and unseen VTU tasks while increasing robustness on real-world table visualizations. By preserving original visualizations and maintaining example traceability in a unified large-scale collection, TABLET establishes a foundation for robust training and extensible evaluation of future VTU models.
Learning Conformal Explainers for Image Classifiers
arXiv:2509.21209v1 Announce Type: new Abstract: Feature attribution methods are widely used for explaining image-based predictions, as they provide feature-level insights that can be intuitively visualized. However, such explanations often vary in their robustness and may fail to faithfully reflect the reasoning of the underlying black-box model. To address these limitations, we propose a novel conformal prediction-based approach that enables users to directly control the fidelity of the generated explanations. The method identifies a subset of salient features that is sufficient to preserve the model's prediction, regardless of the information carried by the excluded features, and without demanding access to ground-truth explanations for calibration. Four conformity functions are proposed to quantify the extent to which explanations conform to the model's predictions. The approach is empirically evaluated using five explainers across six image datasets. The empirical results demonstrate that FastSHAP consistently outperforms the competing methods in terms of both fidelity and informational efficiency, the latter measured by the size of the explanation regions. Furthermore, the results reveal that conformity measures based on super-pixels are more effective than their pixel-wise counterparts.
Sigma: Semantically Informative Pre-training for Skeleton-based Sign Language Understanding
arXiv:2509.21223v1 Announce Type: new Abstract: Pre-training has proven effective for learning transferable features in sign language understanding (SLU) tasks. Recently, skeleton-based methods have gained increasing attention because they can robustly handle variations in subjects and backgrounds without being affected by appearance or environmental factors. Current SLU methods continue to face three key limitations: 1) weak semantic grounding, as models often capture low-level motion patterns from skeletal data but struggle to relate them to linguistic meaning; 2) imbalance between local details and global context, with models either focusing too narrowly on fine-grained cues or overlooking them for broader context; and 3) inefficient cross-modal learning, as constructing semantically aligned representations across modalities remains difficult. To address these, we propose Sigma, a unified skeleton-based SLU framework featuring: 1) a sign-aware early fusion mechanism that facilitates deep interaction between visual and textual modalities, enriching visual features with linguistic context; 2) a hierarchical alignment learning strategy that jointly maximises agreements across different levels of paired features from different modalities, effectively capturing both fine-grained details and high-level semantic relationships; and 3) a unified pre-training framework that combines contrastive learning, text matching and language modelling to promote semantic consistency and generalisation. Sigma achieves new state-of-the-art results on isolated sign language recognition, continuous sign language recognition, and gloss-free sign language translation on multiple benchmarks spanning different sign and spoken languages, demonstrating the impact of semantically informative pre-training and the effectiveness of skeletal data as a stand-alone solution for SLU.
Evaluating the Evaluators: Metrics for Compositional Text-to-Image Generation
arXiv:2509.21227v1 Announce Type: new Abstract: Text-image generation has advanced rapidly, but assessing whether outputs truly capture the objects, attributes, and relations described in prompts remains a central challenge. Evaluation in this space relies heavily on automated metrics, yet these are often adopted by convention or popularity rather than validated against human judgment. Because evaluation and reported progress in the field depend directly on these metrics, it is critical to understand how well they reflect human preferences. To address this, we present a broad study of widely used metrics for compositional text-image evaluation. Our analysis goes beyond simple correlation, examining their behavior across diverse compositional challenges and comparing how different metric families align with human judgments. The results show that no single metric performs consistently across tasks: performance varies with the type of compositional problem. Notably, VQA-based metrics, though popular, are not uniformly superior, while certain embedding-based metrics prove stronger in specific cases. Image-only metrics, as expected, contribute little to compositional evaluation, as they are designed for perceptual quality rather than alignment. These findings underscore the importance of careful and transparent metric selection, both for trustworthy evaluation and for their use as reward models in generation. Project page is available at \href{https://amirkasaei.com/eval-the-evals/}{this URL}.
SlideMamba: Entropy-Based Adaptive Fusion of GNN and Mamba for Enhanced Representation Learning in Digital Pathology
arXiv:2509.21239v1 Announce Type: new Abstract: Advances in computational pathology increasingly rely on extracting meaningful representations from Whole Slide Images (WSIs) to support various clinical and biological tasks. In this study, we propose a generalizable deep learning framework that integrates the Mamba architecture with Graph Neural Networks (GNNs) for enhanced WSI analysis. Our method is designed to capture both local spatial relationships and long-range contextual dependencies, offering a flexible architecture for digital pathology analysis. Mamba modules excels in capturing long-range global dependencies, while GNNs emphasize fine-grained short-range spatial interactions. To effectively combine these complementary signals, we introduce an adaptive fusion strategy that uses an entropy-based confidence weighting mechanism. This approach dynamically balances contributions from both branches by assigning higher weight to the branch with more confident (lower-entropy) predictions, depending on the contextual importance of local versus global information for different downstream tasks. We demonstrate the utility of our approach on a representative task: predicting gene fusion and mutation status from WSIs. Our framework, SlideMamba, achieves an area under the precision recall curve (PRAUC) of 0.751 \pm 0.05, outperforming MIL (0.491 \pm 0.042), Trans-MIL (0.39 \pm 0.017), Mamba-only (0.664 \pm 0.063), GNN-only (0.748 \pm 0.091), and a prior similar work GAT-Mamba (0.703 \pm 0.075). SlideMamba also achieves competitive results across ROC AUC (0.738 \pm 0.055), sensitivity (0.662 \pm 0.083), and specificity (0.725 \pm 0.094). These results highlight the strength of the integrated architecture, enhanced by the proposed entropy-based adaptive fusion strategy, and suggest promising potential for application of spatially-resolved predictive modeling tasks in computational pathology.
Hunyuan3D-Omni: A Unified Framework for Controllable Generation of 3D Assets
arXiv:2509.21245v1 Announce Type: new Abstract: Recent advances in 3D-native generative models have accelerated asset creation for games, film, and design. However, most methods still rely primarily on image or text conditioning and lack fine-grained, cross-modal controls, which limits controllability and practical adoption. To address this gap, we present Hunyuan3D-Omni, a unified framework for fine-grained, controllable 3D asset generation built on Hunyuan3D 2.1. In addition to images, Hunyuan3D-Omni accepts point clouds, voxels, bounding boxes, and skeletal pose priors as conditioning signals, enabling precise control over geometry, topology, and pose. Instead of separate heads for each modality, our model unifies all signals in a single cross-modal architecture. We train with a progressive, difficulty-aware sampling strategy that selects one control modality per example and biases sampling toward harder signals (e.g., skeletal pose) while downweighting easier ones (e.g., point clouds), encouraging robust multi-modal fusion and graceful handling of missing inputs. Experiments show that these additional controls improve generation accuracy, enable geometry-aware transformations, and increase robustness for production workflows.
Learning to Look: Cognitive Attention Alignment with Vision-Language Models
arXiv:2509.21247v1 Announce Type: new Abstract: Convolutional Neural Networks (CNNs) frequently "cheat" by exploiting superficial correlations, raising concerns about whether they make predictions for the right reasons. Inspired by cognitive science, which highlights the role of attention in robust human perception, recent methods have sought to guide model attention using concept-based supervision and explanation regularization. However, these techniques depend on labor-intensive, expert-provided annotations, limiting their scalability. We propose a scalable framework that leverages vision-language models to automatically generate semantic attention maps using natural language prompts. By introducing an auxiliary loss that aligns CNN attention with these language-guided maps, our approach promotes more reliable and cognitively plausible decision-making without manual annotation. Experiments on challenging datasets, ColoredMNIST and DecoyMNIST, show that our method achieves state-of-the-art performance on ColorMNIST and remains competitive with annotation-heavy baselines on DecoyMNIST, demonstrating improved generalization, reduced shortcut reliance, and model attention that better reflects human intuition.
Decipher-MR: A Vision-Language Foundation Model for 3D MRI Representations
arXiv:2509.21249v1 Announce Type: new Abstract: Magnetic Resonance Imaging (MRI) is a critical medical imaging modality in clinical diagnosis and research, yet its complexity and heterogeneity pose challenges for automated analysis, particularly in scalable and generalizable machine learning applications. While foundation models have revolutionized natural language and vision tasks, their application to MRI remains limited due to data scarcity and narrow anatomical focus. In this work, we present Decipher-MR, a 3D MRI-specific vision-language foundation model trained on a large-scale dataset comprising 200,000 MRI series from over 22,000 studies spanning diverse anatomical regions, sequences, and pathologies. Decipher-MR integrates self-supervised vision learning with report-guided text supervision to build robust, generalizable representations, enabling effective adaptation across broad applications. To enable robust and diverse clinical tasks with minimal computational overhead, Decipher-MR supports a modular design that enables tuning of lightweight, task-specific decoders attached to a frozen pretrained encoder. Following this setting, we evaluate Decipher-MR across diverse benchmarks including disease classification, demographic prediction, anatomical localization, and cross-modal retrieval, demonstrating consistent performance gains over existing foundation models and task-specific approaches. Our results establish Decipher-MR as a scalable and versatile foundation for MRI-based AI, facilitating efficient development across clinical and research domains.
Instruction-tuned Self-Questioning Framework for Multimodal Reasoning
arXiv:2509.21251v1 Announce Type: new Abstract: The field of vision-language understanding has been actively researched in recent years, thanks to the development of Large Language Models~(LLMs). However, it still needs help with problems requiring multi-step reasoning, even for very simple questions. Recent studies adopt LLMs to tackle this problem by iteratively generating sub-questions and answers. However, there are disadvantages such as 1) the fine-grained visual contents of images are not available using LLMs that cannot read visual information, 2) internal mechanisms are inaccessible and difficult to reproduce by using black-box LLMs. To solve these problems, we propose the SQ (Self-Questioning)-InstructBLIP, which improves inference performance by generating image-aware informative sub-questions and sub-answers iteratively. The SQ-InstructBLIP, which consists of a Questioner, Answerer, and Reasoner that share the same architecture. Questioner and Answerer generate sub-questions and sub-answers to help infer the main-question, and Reasoner performs reasoning on the main-question considering the generated sub-question information. Our experiments show that the proposed method SQ-InstructBLIP, which uses the generated sub-questions as additional information when solving the VQA task, performs more accurate reasoning than the previous works.
Hallucination as an Upper Bound: A New Perspective on Text-to-Image Evaluation
arXiv:2509.21257v1 Announce Type: new Abstract: In language and vision-language models, hallucination is broadly understood as content generated from a model's prior knowledge or biases rather than from the given input. While this phenomenon has been studied in those domains, it has not been clearly framed for text-to-image (T2I) generative models. Existing evaluations mainly focus on alignment, checking whether prompt-specified elements appear, but overlook what the model generates beyond the prompt. We argue for defining hallucination in T2I as bias-driven deviations and propose a taxonomy with three categories: attribute, relation, and object hallucinations. This framing introduces an upper bound for evaluation and surfaces hidden biases, providing a foundation for richer assessment of T2I models.
Every Subtlety Counts: Fine-grained Person Independence Micro-Action Recognition via Distributionally Robust Optimization
arXiv:2509.21261v1 Announce Type: new Abstract: Micro-action Recognition is vital for psychological assessment and human-computer interaction. However, existing methods often fail in real-world scenarios because inter-person variability causes the same action to manifest differently, hindering robust generalization. To address this, we propose the Person Independence Universal Micro-action Recognition Framework, which integrates Distributionally Robust Optimization principles to learn person-agnostic representations. Our framework contains two plug-and-play components operating at the feature and loss levels. At the feature level, the Temporal-Frequency Alignment Module normalizes person-specific motion characteristics with a dual-branch design: the temporal branch applies Wasserstein-regularized alignment to stabilize dynamic trajectories, while the frequency branch introduces variance-guided perturbations to enhance robustness against person-specific spectral differences. A consistency-driven fusion mechanism integrates both branches. At the loss level, the Group-Invariant Regularized Loss partitions samples into pseudo-groups to simulate unseen person-specific distributions. By up-weighting boundary cases and regularizing subgroup variance, it forces the model to generalize beyond easy or frequent samples, thus enhancing robustness to difficult variations. Experiments on the large-scale MA-52 dataset demonstrate that our framework outperforms existing methods in both accuracy and robustness, achieving stable generalization under fine-grained conditions.
Dense Semantic Matching with VGGT Prior
arXiv:2509.21263v1 Announce Type: new Abstract: Semantic matching aims to establish pixel-level correspondences between instances of the same category and represents a fundamental task in computer vision. Existing approaches suffer from two limitations: (i) Geometric Ambiguity: Their reliance on 2D foundation model features (e.g., Stable Diffusion, DINO) often fails to disambiguate symmetric structures, requiring extra fine-tuning yet lacking generalization; (ii) Nearest-Neighbor Rule: Their pixel-wise matching ignores cross-image invisibility and neglects manifold preservation. These challenges call for geometry-aware pixel descriptors and holistic dense correspondence mechanisms. Inspired by recent advances in 3D geometric foundation models, we turn to VGGT, which provides geometry-grounded features and holistic dense matching capabilities well aligned with these needs. However, directly transferring VGGT is challenging, as it was originally designed for geometry matching within cross views of a single instance, misaligned with cross-instance semantic matching, and further hindered by the scarcity of dense semantic annotations. To address this, we propose an approach that (i) retains VGGT's intrinsic strengths by reusing early feature stages, fine-tuning later ones, and adding a semantic head for bidirectional correspondences; and (ii) adapts VGGT to the semantic matching scenario under data scarcity through cycle-consistent training strategy, synthetic data augmentation, and progressive training recipe with aliasing artifact mitigation. Extensive experiments demonstrate that our approach achieves superior geometry awareness, matching reliability, and manifold preservation, outperforming previous baselines.
MedVSR: Medical Video Super-Resolution with Cross State-Space Propagation
arXiv:2509.21265v1 Announce Type: new Abstract: High-resolution (HR) medical videos are vital for accurate diagnosis, yet are hard to acquire due to hardware limitations and physiological constraints. Clinically, the collected low-resolution (LR) medical videos present unique challenges for video super-resolution (VSR) models, including camera shake, noise, and abrupt frame transitions, which result in significant optical flow errors and alignment difficulties. Additionally, tissues and organs exhibit continuous and nuanced structures, but current VSR models are prone to introducing artifacts and distorted features that can mislead doctors. To this end, we propose MedVSR, a tailored framework for medical VSR. It first employs Cross State-Space Propagation (CSSP) to address the imprecise alignment by projecting distant frames as control matrices within state-space models, enabling the selective propagation of consistent and informative features to neighboring frames for effective alignment. Moreover, we design an Inner State-Space Reconstruction (ISSR) module that enhances tissue structures and reduces artifacts with joint long-range spatial feature learning and large-kernel short-range information aggregation. Experiments across four datasets in diverse medical scenarios, including endoscopy and cataract surgeries, show that MedVSR significantly outperforms existing VSR models in reconstruction performance and efficiency. Code released at https://github.com/CUHK-AIM-Group/MedVSR.
MMR1: Enhancing Multimodal Reasoning with Variance-Aware Sampling and Open Resources
arXiv:2509.21268v1 Announce Type: new Abstract: Large multimodal reasoning models have achieved rapid progress, but their advancement is constrained by two major limitations: the absence of open, large-scale, high-quality long chain-of-thought (CoT) data, and the instability of reinforcement learning (RL) algorithms in post-training. Group Relative Policy Optimization (GRPO), the standard framework for RL fine-tuning, is prone to gradient vanishing when reward variance is low, which weakens optimization signals and impairs convergence. This work makes three contributions: (1) We propose Variance-Aware Sampling (VAS), a data selection strategy guided by Variance Promotion Score (VPS) that combines outcome variance and trajectory diversity to promote reward variance and stabilize policy optimization. (2) We release large-scale, carefully curated resources containing ~1.6M long CoT cold-start data and ~15k RL QA pairs, designed to ensure quality, difficulty, and diversity, along with a fully reproducible end-to-end training codebase. (3) We open-source a family of multimodal reasoning models in multiple scales, establishing standardized baselines for the community. Experiments across mathematical reasoning benchmarks demonstrate the effectiveness of both the curated data and the proposed VAS. Comprehensive ablation studies and analyses provide further insight into the contributions of each component. In addition, we theoretically establish that reward variance lower-bounds the expected policy gradient magnitude, with VAS serving as a practical mechanism to realize this guarantee. Our code, data, and checkpoints are available at https://github.com/LengSicong/MMR1.
A Sentinel-3 foundation model for ocean colour
arXiv:2509.21273v1 Announce Type: new Abstract: Artificial Intelligence (AI) Foundation models (FMs), pre-trained on massive unlabelled datasets, have the potential to drastically change AI applications in ocean science, where labelled data are often sparse and expensive to collect. In this work, we describe a new foundation model using the Prithvi-EO Vision Transformer architecture which has been pre-trained to reconstruct data from the Sentinel-3 Ocean and Land Colour Instrument (OLCI). We evaluate the model by fine-tuning on two downstream marine earth observation tasks. We first assess model performance compared to current baseline models used to quantify chlorophyll concentration. We then evaluate the FMs ability to refine remote sensing-based estimates of ocean primary production. Our results demonstrate the utility of self-trained FMs for marine monitoring, in particular for making use of small amounts of high quality labelled data and in capturing detailed spatial patterns of ocean colour whilst matching point observations. We conclude that this new generation of geospatial AI models has the potential to provide more robust, data-driven insights into ocean ecosystems and their role in global climate processes.
Does FLUX Already Know How to Perform Physically Plausible Image Composition?
arXiv:2509.21278v1 Announce Type: new Abstract: Image composition aims to seamlessly insert a user-specified object into a new scene, but existing models struggle with complex lighting (e.g., accurate shadows, water reflections) and diverse, high-resolution inputs. Modern text-to-image diffusion models (e.g., SD3.5, FLUX) already encode essential physical and resolution priors, yet lack a framework to unleash them without resorting to latent inversion, which often locks object poses into contextually inappropriate orientations, or brittle attention surgery. We propose SHINE, a training-free framework for Seamless, High-fidelity Insertion with Neutralized Errors. SHINE introduces manifold-steered anchor loss, leveraging pretrained customization adapters (e.g., IP-Adapter) to guide latents for faithful subject representation while preserving background integrity. Degradation-suppression guidance and adaptive background blending are proposed to further eliminate low-quality outputs and visible seams. To address the lack of rigorous benchmarks, we introduce ComplexCompo, featuring diverse resolutions and challenging conditions such as low lighting, strong illumination, intricate shadows, and reflective surfaces. Experiments on ComplexCompo and DreamEditBench show state-of-the-art performance on standard metrics (e.g., DINOv2) and human-aligned scores (e.g., DreamSim, ImageReward, VisionReward). Code and benchmark will be publicly available upon publication.
Quantized Visual Geometry Grounded Transformer
arXiv:2509.21302v1 Announce Type: new Abstract: Learning-based 3D reconstruction models, represented by Visual Geometry Grounded Transformers (VGGTs), have made remarkable progress with the use of large-scale transformers. Their prohibitive computational and memory costs severely hinder real-world deployment. Post-Training Quantization (PTQ) has become a common practice for compressing and accelerating models. However, we empirically observe that PTQ faces unique obstacles when compressing billion-scale VGGTs: the data-independent special tokens induce heavy-tailed activation distributions, while the multi-view nature of 3D data makes calibration sample selection highly unstable. This paper proposes the first Quantization framework for VGGTs, namely QuantVGGT. This mainly relies on two technical contributions: First, we introduce Dual-Smoothed Fine-Grained Quantization, which integrates pre-global Hadamard rotation and post-local channel smoothing to mitigate heavy-tailed distributions and inter-channel variance robustly. Second, we design Noise-Filtered Diverse Sampling, which filters outliers via deep-layer statistics and constructs frame-aware diverse calibration clusters to ensure stable quantization ranges. Comprehensive experiments demonstrate that QuantVGGT achieves the state-of-the-art results across different benchmarks and bit-width, surpassing the previous state-of-the-art generic quantization method with a great margin. We highlight that our 4-bit QuantVGGT can deliver a 3.7$\times$ memory reduction and 2.5$\times$ acceleration in real-hardware inference, while maintaining reconstruction accuracy above 98\% of its full-precision counterpart. This demonstrates the vast advantages and practicality of QuantVGGT in resource-constrained scenarios. Our code is released in https://github.com/wlfeng0509/QuantVGGT.
NewtonGen: Physics-Consistent and Controllable Text-to-Video Generation via Neural Newtonian Dynamics
arXiv:2509.21309v1 Announce Type: new Abstract: A primary bottleneck in large-scale text-to-video generation today is physical consistency and controllability. Despite recent advances, state-of-the-art models often produce unrealistic motions, such as objects falling upward, or abrupt changes in velocity and direction. Moreover, these models lack precise parameter control, struggling to generate physically consistent dynamics under different initial conditions. We argue that this fundamental limitation stems from current models learning motion distributions solely from appearance, while lacking an understanding of the underlying dynamics. In this work, we propose NewtonGen, a framework that integrates data-driven synthesis with learnable physical principles. At its core lies trainable Neural Newtonian Dynamics (NND), which can model and predict a variety of Newtonian motions, thereby injecting latent dynamical constraints into the video generation process. By jointly leveraging data priors and dynamical guidance, NewtonGen enables physically consistent video synthesis with precise parameter control.
SD3.5-Flash: Distribution-Guided Distillation of Generative Flows
arXiv:2509.21318v1 Announce Type: new Abstract: We present SD3.5-Flash, an efficient few-step distillation framework that brings high-quality image generation to accessible consumer devices. Our approach distills computationally prohibitive rectified flow models through a reformulated distribution matching objective tailored specifically for few-step generation. We introduce two key innovations: "timestep sharing" to reduce gradient noise and "split-timestep fine-tuning" to improve prompt alignment. Combined with comprehensive pipeline optimizations like text encoder restructuring and specialized quantization, our system enables both rapid generation and memory-efficient deployment across different hardware configurations. This democratizes access across the full spectrum of devices, from mobile phones to desktop computers. Through extensive evaluation including large-scale user studies, we demonstrate that SD3.5-Flash consistently outperforms existing few-step methods, making advanced generative AI truly accessible for practical deployment.
BlockFUL: Enabling Unlearning in Blockchained Federated Learning
arXiv:2402.16294v2 Announce Type: cross Abstract: Unlearning in Federated Learning (FL) presents significant challenges, as models grow and evolve with complex inheritance relationships. This complexity is amplified when blockchain is employed to ensure the integrity and traceability of FL, where the need to edit multiple interlinked blockchain records and update all inherited models complicates the process.In this paper, we introduce Blockchained Federated Unlearning (BlockFUL), a novel framework with a dual-chain structure comprising a live chain and an archive chain for enabling unlearning capabilities within Blockchained FL. BlockFUL introduces two new unlearning paradigms, i.e., parallel and sequential paradigms, which can be effectively implemented through gradient-ascent-based and re-training-based unlearning methods. These methods enhance the unlearning process across multiple inherited models by enabling efficient consensus operations and reducing computational costs. Our extensive experiments validate that these methods effectively reduce data dependency and operational overhead, thereby boosting the overall performance of unlearning inherited models within BlockFUL on CIFAR-10 and Fashion-MNIST datasets using AlexNet, ResNet18, and MobileNetV2 models.
SceneWeaver: All-in-One 3D Scene Synthesis with an Extensible and Self-Reflective Agent
arXiv:2509.20414v1 Announce Type: cross Abstract: Indoor scene synthesis has become increasingly important with the rise of Embodied AI, which requires 3D environments that are not only visually realistic but also physically plausible and functionally diverse. While recent approaches have advanced visual fidelity, they often remain constrained to fixed scene categories, lack sufficient object-level detail and physical consistency, and struggle to align with complex user instructions. In this work, we present SceneWeaver, a reflective agentic framework that unifies diverse scene synthesis paradigms through tool-based iterative refinement. At its core, SceneWeaver employs a language model-based planner to select from a suite of extensible scene generation tools, ranging from data-driven generative models to visual- and LLM-based methods, guided by self-evaluation of physical plausibility, visual realism, and semantic alignment with user input. This closed-loop reason-act-reflect design enables the agent to identify semantic inconsistencies, invoke targeted tools, and update the environment over successive iterations. Extensive experiments on both common and open-vocabulary room types demonstrate that SceneWeaver not only outperforms prior methods on physical, visual, and semantic metrics, but also generalizes effectively to complex scenes with diverse instructions, marking a step toward general-purpose 3D environment generation. Project website: https://scene-weaver.github.io/.
Optimal Transport Based Hyperspectral Unmixing for Highly Mixed Observations
arXiv:2509.20417v1 Announce Type: cross Abstract: We propose a novel approach based on optimal transport (OT) for tackling the problem of highly mixed data in blind hyperspectral unmixing. Our method constrains the distribution of the estimated abundance matrix to resemble a targeted Dirichlet distribution more closely. The novelty lies in using OT to measure the discrepancy between the targeted and true abundance distributions, which we incorporate as a regularization term in our optimization problem. We demonstrate the efficiency of our method through a case study involving an unsupervised deep learning approach. Our experiments show that the proposed approach allows for a better estimation of the endmembers in the presence of highly mixed data, while displaying robustness to the choice of target abundance distribution.
ShortCheck: Checkworthiness Detection of Multilingual Short-Form Videos
arXiv:2509.20467v1 Announce Type: cross Abstract: Short-form video platforms like TikTok present unique challenges for misinformation detection due to their multimodal, dynamic, and noisy content. We present ShortCheck, a modular, inference-only pipeline with a user-friendly interface that automatically identifies checkworthy short-form videos to help human fact-checkers. The system integrates speech transcription, OCR, object and deepfake detection, video-to-text summarization, and claim verification. ShortCheck is validated by evaluating it on two manually annotated datasets with TikTok videos in a multilingual setting. The pipeline achieves promising results with F1-weighted score over 70\%.
RadAgents: Multimodal Agentic Reasoning for Chest X-ray Interpretation with Radiologist-like Workflows
arXiv:2509.20490v1 Announce Type: cross Abstract: Agentic systems offer a potential path to solve complex clinical tasks through collaboration among specialized agents, augmented by tool use and external knowledge bases. Nevertheless, for chest X-ray (CXR) interpretation, prevailing methods remain limited: (i) reasoning is frequently neither clinically interpretable nor aligned with guidelines, reflecting mere aggregation of tool outputs; (ii) multimodal evidence is insufficiently fused, yielding text-only rationales that are not visually grounded; and (iii) systems rarely detect or resolve cross-tool inconsistencies and provide no principled verification mechanisms. To bridge the above gaps, we present RadAgents, a multi-agent framework for CXR interpretation that couples clinical priors with task-aware multimodal reasoning. In addition, we integrate grounding and multimodal retrieval-augmentation to verify and resolve context conflicts, resulting in outputs that are more reliable, transparent, and consistent with clinical practice.
Beyond Visual Similarity: Rule-Guided Multimodal Clustering with explicit domain rules
arXiv:2509.20501v1 Announce Type: cross Abstract: Traditional clustering techniques often rely solely on similarity in the input data, limiting their ability to capture structural or semantic constraints that are critical in many domains. We introduce the Domain Aware Rule Triggered Variational Autoencoder (DARTVAE), a rule guided multimodal clustering framework that incorporates domain specific constraints directly into the representation learning process. DARTVAE extends the VAE architecture by embedding explicit rules, semantic representations, and data driven features into a unified latent space, while enforcing constraint compliance through rule consistency and violation penalties in the loss function. Unlike conventional clustering methods that rely only on visual similarity or apply rules as post hoc filters, DARTVAE treats rules as first class learning signals. The rules are generated by LLMs, structured into knowledge graphs, and enforced through a loss function combining reconstruction, KL divergence, consistency, and violation penalties. Experiments on aircraft and automotive datasets demonstrate that rule guided clustering produces more operationally meaningful and interpretable clusters for example, isolating UAVs, unifying stealth aircraft, or separating SUVs from sedans while improving traditional clustering metrics. However, the framework faces challenges: LLM generated rules may hallucinate or conflict, excessive rules risk overfitting, and scaling to complex domains increases computational and consistency difficulties. By combining rule encodings with learned representations, DARTVAE achieves more meaningful and consistent clustering outcomes than purely data driven models, highlighting the utility of constraint guided multimodal clustering for complex, knowledge intensive settings.
Equi-RO: A 4D mmWave Radar Odometry via Equivariant Networks
arXiv:2509.20674v1 Announce Type: cross Abstract: Autonomous vehicles and robots rely on accurate odometry estimation in GPS-denied environments. While LiDARs and cameras struggle under extreme weather, 4D mmWave radar emerges as a robust alternative with all-weather operability and velocity measurement. In this paper, we introduce Equi-RO, an equivariant network-based framework for 4D radar odometry. Our algorithm pre-processes Doppler velocity into invariant node and edge features in the graph, and employs separate networks for equivariant and invariant feature processing. A graph-based architecture enhances feature aggregation in sparse radar data, improving inter-frame correspondence. Experiments on the open-source dataset and self-collected dataset show Equi-RO outperforms state-of-the-art algorithms in accuracy and robustness. Overall, our method achieves 10.7% and 20.0% relative improvements in translation and rotation accuracy, respectively, compared to the best baseline on the open-source dataset.
Bispectral OT: Dataset Comparison using Symmetry-Aware Optimal Transport
arXiv:2509.20678v1 Announce Type: cross Abstract: Optimal transport (OT) is a widely used technique in machine learning, graphics, and vision that aligns two distributions or datasets using their relative geometry. In symmetry-rich settings, however, OT alignments based solely on pairwise geometric distances between raw features can ignore the intrinsic coherence structure of the data. We introduce Bispectral Optimal Transport, a symmetry-aware extension of discrete OT that compares elements using their representation using the bispectrum, a group Fourier invariant that preserves all signal structure while removing only the variation due to group actions. Empirically, we demonstrate that the transport plans computed with Bispectral OT achieve greater class preservation accuracy than naive feature OT on benchmark datasets transformed with visual symmetries, improving the quality of meaningful correspondences that capture the underlying semantic label structure in the dataset while removing nuisance variation not affecting class or content.
Efficient Construction of Implicit Surface Models From a Single Image for Motion Generation
arXiv:2509.20681v1 Announce Type: cross Abstract: Implicit representations have been widely applied in robotics for obstacle avoidance and path planning. In this paper, we explore the problem of constructing an implicit distance representation from a single image. Past methods for implicit surface reconstruction, such as \emph{NeuS} and its variants generally require a large set of multi-view images as input, and require long training times. In this work, we propose Fast Image-to-Neural Surface (FINS), a lightweight framework that can reconstruct high-fidelity surfaces and SDF fields based on a single or a small set of images. FINS integrates a multi-resolution hash grid encoder with lightweight geometry and color heads, making the training via an approximate second-order optimizer highly efficient and capable of converging within a few seconds. Additionally, we achieve the construction of a neural surface requiring only a single RGB image, by leveraging pre-trained foundation models to estimate the geometry inherent in the image. Our experiments demonstrate that under the same conditions, our method outperforms state-of-the-art baselines in both convergence speed and accuracy on surface reconstruction and SDF field estimation. Moreover, we demonstrate the applicability of FINS for robot surface following tasks and show its scalability to a variety of benchmark datasets.
RAM-NAS: Resource-aware Multiobjective Neural Architecture Search Method for Robot Vision Tasks
arXiv:2509.20688v1 Announce Type: cross Abstract: Neural architecture search (NAS) has shown great promise in automatically designing lightweight models. However, conventional approaches are insufficient in training the supernet and pay little attention to actual robot hardware resources. To meet such challenges, we propose RAM-NAS, a resource-aware multi-objective NAS method that focuses on improving the supernet pretrain and resource-awareness on robot hardware devices. We introduce the concept of subnets mutual distillation, which refers to mutually distilling all subnets sampled by the sandwich rule. Additionally, we utilize the Decoupled Knowledge Distillation (DKD) loss to enhance logits distillation performance. To expedite the search process with consideration for hardware resources, we used data from three types of robotic edge hardware to train Latency Surrogate predictors. These predictors facilitated the estimation of hardware inference latency during the search phase, enabling a unified multi-objective evolutionary search to balance model accuracy and latency trade-offs. Our discovered model family, RAM-NAS models, can achieve top-1 accuracy ranging from 76.7% to 81.4% on ImageNet. In addition, the resource-aware multi-objective NAS we employ significantly reduces the model's inference latency on edge hardware for robots. We conducted experiments on downstream tasks to verify the scalability of our methods. The inference time for detection and segmentation is reduced on all three hardware types compared to MobileNetv3-based methods. Our work fills the gap in NAS for robot hardware resource-aware.
Joint Flow Trajectory Optimization For Feasible Robot Motion Generation from Video Demonstrations
arXiv:2509.20703v1 Announce Type: cross Abstract: Learning from human video demonstrations offers a scalable alternative to teleoperation or kinesthetic teaching, but poses challenges for robot manipulators due to embodiment differences and joint feasibility constraints. We address this problem by proposing the Joint Flow Trajectory Optimization (JFTO) framework for grasp pose generation and object trajectory imitation under the video-based Learning-from-Demonstration (LfD) paradigm. Rather than directly imitating human hand motions, our method treats demonstrations as object-centric guides, balancing three objectives: (i) selecting a feasible grasp pose, (ii) generating object trajectories consistent with demonstrated motions, and (iii) ensuring collision-free execution within robot kinematics. To capture the multimodal nature of demonstrations, we extend flow matching to $\SE(3)$ for probabilistic modeling of object trajectories, enabling density-aware imitation that avoids mode collapse. The resulting optimization integrates grasp similarity, trajectory likelihood, and collision penalties into a unified differentiable objective. We validate our approach in both simulation and real-world experiments across diverse real-world manipulation tasks.
ArtUV: Artist-style UV Unwrapping
arXiv:2509.20710v1 Announce Type: cross Abstract: UV unwrapping is an essential task in computer graphics, enabling various visual editing operations in rendering pipelines. However, existing UV unwrapping methods struggle with time-consuming, fragmentation, lack of semanticity, and irregular UV islands, limiting their practical use. An artist-style UV map must not only satisfy fundamental criteria, such as overlap-free mapping and minimal distortion, but also uphold higher-level standards, including clean boundaries, efficient space utilization, and semantic coherence. We introduce ArtUV, a fully automated, end-to-end method for generating artist-style UV unwrapping. We simulates the professional UV mapping process by dividing it into two stages: surface seam prediction and artist-style UV parameterization. In the seam prediction stage, SeamGPT is used to generate semantically meaningful cutting seams. Then, in the parameterization stage, a rough UV obtained from an optimization-based method, along with the mesh, is fed into an Auto-Encoder, which refines it into an artist-style UV map. Our method ensures semantic consistency and preserves topological structure, making the UV map ready for 2D editing. We evaluate ArtUV across multiple benchmarks and show that it serves as a versatile solution, functioning seamlessly as either a plug-in for professional rendering tools or as a standalone system for rapid, high-quality UV generation.
Visual Authority and the Rhetoric of Health Misinformation: A Multimodal Analysis of Social Media Videos
arXiv:2509.20724v1 Announce Type: cross Abstract: Short form video platforms are central sites for health advice, where alternative narratives mix useful, misleading, and harmful content. Rather than adjudicating truth, this study examines how credibility is packaged in nutrition and supplement videos by analyzing the intersection of authority signals, narrative techniques, and monetization. We assemble a cross platform corpus of 152 public videos from TikTok, Instagram, and YouTube and annotate each on 26 features spanning visual authority, presenter attributes, narrative strategies, and engagement cues. A transparent annotation pipeline integrates automatic speech recognition, principled frame selection, and a multimodal model, with human verification on a stratified subsample showing strong agreement. Descriptively, a confident single presenter in studio or home settings dominates, and clinical contexts are rare. Analytically, authority cues such as titles, slides and charts, and certificates frequently occur with persuasive elements including jargon, references, fear or urgency, critiques of mainstream medicine, and conspiracies, and with monetization including sales links and calls to subscribe. References and science like visuals often travel with emotive and oppositional narratives rather than signaling restraint.
SeamCrafte: Enhancing Mesh Seam Generation for Artist UV Unwrapping via Reinforcement Learning
arXiv:2509.20725v1 Announce Type: cross Abstract: Mesh seams play a pivotal role in partitioning 3D surfaces for UV parametrization and texture mapping. Poorly placed seams often result in severe UV distortion or excessive fragmentation, thereby hindering texture synthesis and disrupting artist workflows. Existing methods frequently trade one failure mode for another-producing either high distortion or many scattered islands. To address this, we introduce SeamCrafter, an autoregressive GPT-style seam generator conditioned on point cloud inputs. SeamCrafter employs a dual-branch point-cloud encoder that disentangles and captures complementary topological and geometric cues during pretraining. To further enhance seam quality, we fine-tune the model using Direct Preference Optimization (DPO) on a preference dataset derived from a novel seam-evaluation framework. This framework assesses seams primarily by UV distortion and fragmentation, and provides pairwise preference labels to guide optimization. Extensive experiments demonstrate that SeamCrafter produces seams with substantially lower distortion and fragmentation than prior approaches, while preserving topological consistency and visual fidelity.
SLAM-Free Visual Navigation with Hierarchical Vision-Language Perception and Coarse-to-Fine Semantic Topological Planning
arXiv:2509.20739v1 Announce Type: cross Abstract: Conventional SLAM pipelines for legged robot navigation are fragile under rapid motion, calibration demands, and sensor drift, while offering limited semantic reasoning for task-driven exploration. To deal with these issues, we propose a vision-only, SLAM-free navigation framework that replaces dense geometry with semantic reasoning and lightweight topological representations. A hierarchical vision-language perception module fuses scene-level context with object-level cues for robust semantic inference. And a semantic-probabilistic topological map supports coarse-to-fine planning: LLM-based global reasoning for subgoal selection and vision-based local planning for obstacle avoidance. Integrated with reinforcement-learning locomotion controllers, the framework is deployable across diverse legged robot platforms. Experiments in simulation and real-world settings demonstrate consistent improvements in semantic accuracy, planning quality, and navigation success, while ablation studies further showcase the necessity of both hierarchical perception and fine local planning. This work introduces a new paradigm for SLAM-free, vision-language-driven navigation, shifting robotic exploration from geometry-centric mapping to semantics-driven decision making.
MASt3R-Fusion: Integrating Feed-Forward Visual Model with IMU, GNSS for High-Functionality SLAM
arXiv:2509.20757v1 Announce Type: cross Abstract: Visual SLAM is a cornerstone technique in robotics, autonomous driving and extended reality (XR), yet classical systems often struggle with low-texture environments, scale ambiguity, and degraded performance under challenging visual conditions. Recent advancements in feed-forward neural network-based pointmap regression have demonstrated the potential to recover high-fidelity 3D scene geometry directly from images, leveraging learned spatial priors to overcome limitations of traditional multi-view geometry methods. However, the widely validated advantages of probabilistic multi-sensor information fusion are often discarded in these pipelines. In this work, we propose MASt3R-Fusion,a multi-sensor-assisted visual SLAM framework that tightly integrates feed-forward pointmap regression with complementary sensor information, including inertial measurements and GNSS data. The system introduces Sim(3)-based visualalignment constraints (in the Hessian form) into a universal metric-scale SE(3) factor graph for effective information fusion. A hierarchical factor graph design is developed, which allows both real-time sliding-window optimization and global optimization with aggressive loop closures, enabling real-time pose tracking, metric-scale structure perception and globally consistent mapping. We evaluate our approach on both public benchmarks and self-collected datasets, demonstrating substantial improvements in accuracy and robustness over existing visual-centered multi-sensor SLAM systems. The code will be released open-source to support reproducibility and further research (https://github.com/GREAT-WHU/MASt3R-Fusion).
Provenance Analysis of Archaeological Artifacts via Multimodal RAG Systems
arXiv:2509.20769v1 Announce Type: cross Abstract: In this work, we present a retrieval-augmented generation (RAG)-based system for provenance analysis of archaeological artifacts, designed to support expert reasoning by integrating multimodal retrieval and large vision-language models (VLMs). The system constructs a dual-modal knowledge base from reference texts and images, enabling raw visual, edge-enhanced, and semantic retrieval to identify stylistically similar objects. Retrieved candidates are synthesized by the VLM to generate structured inferences, including chronological, geographical, and cultural attributions, alongside interpretive justifications. We evaluate the system on a set of Eastern Eurasian Bronze Age artifacts from the British Museum. Expert evaluation demonstrates that the system produces meaningful and interpretable outputs, offering scholars concrete starting points for analysis and significantly alleviating the cognitive burden of navigating vast comparative corpora.
Extrapolating Phase-Field Simulations in Space and Time with Purely Convolutional Architectures
arXiv:2509.20770v1 Announce Type: cross Abstract: Phase-field models of liquid metal dealloying (LMD) can resolve rich microstructural dynamics but become intractable for large domains or long time horizons. We present a conditionally parameterized, fully convolutional U-Net surrogate that generalizes far beyond its training window in both space and time. The design integrates convolutional self-attention and physics-aware padding, while parameter conditioning enables variable time-step skipping and adaptation to diverse alloy systems. Although trained only on short, small-scale simulations, the surrogate exploits the translational invariance of convolutions to extend predictions to much longer horizons than traditional solvers. It accurately reproduces key LMD physics, with relative errors typically under 5% within the training regime and below 10% when extrapolating to larger domains and later times. The method accelerates computations by up to 16,000 times, cutting weeks of simulation down to seconds, and marks an early step toward scalable, high-fidelity extrapolation of LMD phase-field models.
FERD: Fairness-Enhanced Data-Free Robustness Distillation
arXiv:2509.20793v1 Announce Type: cross Abstract: Data-Free Robustness Distillation (DFRD) aims to transfer the robustness from the teacher to the student without accessing the training data. While existing methods focus on overall robustness, they overlook the robust fairness issues, leading to severe disparity of robustness across different categories. In this paper, we find two key problems: (1) student model distilled with equal class proportion data behaves significantly different across distinct categories; and (2) the robustness of student model is not stable across different attacks target. To bridge these gaps, we present the first Fairness-Enhanced data-free Robustness Distillation (FERD) framework to adjust the proportion and distribution of adversarial examples. For the proportion, FERD adopts a robustness-guided class reweighting strategy to synthesize more samples for the less robust categories, thereby improving robustness of them. For the distribution, FERD generates complementary data samples for advanced robustness distillation. It generates Fairness-Aware Examples (FAEs) by enforcing a uniformity constraint on feature-level predictions, which suppress the dominance of class-specific non-robust features, providing a more balanced representation across all categories. Then, FERD constructs Uniform-Target Adversarial Examples (UTAEs) from FAEs by applying a uniform target class constraint to avoid biased attack directions, which distribute the attack targets across all categories and prevents overfitting to specific vulnerable categories. Extensive experiments on three public datasets show that FERD achieves state-of-the-art worst-class robustness under all adversarial attack (e.g., the worst-class robustness under FGSM and AutoAttack are improved by 15.1\% and 6.4\% using MobileNet-V2 on CIFAR-10), demonstrating superior performance in both robustness and fairness aspects.
CaTS-Bench: Can Language Models Describe Numeric Time Series?
arXiv:2509.20823v1 Announce Type: cross Abstract: Time series captioning, the task of describing numeric time series in natural language, requires numerical reasoning, trend interpretation, and contextual understanding. Existing benchmarks, however, often rely on synthetic data or overly simplistic captions, and typically neglect metadata and visual representations. To close this gap, we introduce CaTS-Bench, the first large-scale, real-world benchmark for Context-aware Time Series captioning. CaTS-Bench is derived from 11 diverse datasets reframed as captioning and Q&A tasks, comprising roughly 465k training and 105k test timestamps. Each sample includes a numeric series segment, contextual metadata, a line-chart image, and a caption. A key contribution of this work is the scalable pipeline used to generate reference captions: while most references are produced by an oracle LLM and verified through factual checks, human indistinguishability studies, and diversity analyses, we also provide a human-revisited subset of 579 test captions, refined from LLM outputs to ensure accuracy and human-like style. Beyond captioning, CaTS-Bench offers 460 multiple-choice questions targeting deeper aspects of time series reasoning. We further propose new tailored evaluation metrics and benchmark leading VLMs, highlighting both their strengths and persistent limitations. Together, these contributions establish CaTS-Bench and its captioning pipeline as a reliable and extensible foundation for future research at the intersection of time series analysis and foundation models.
ARMesh: Autoregressive Mesh Generation via Next-Level-of-Detail Prediction
arXiv:2509.20824v1 Announce Type: cross Abstract: Directly generating 3D meshes, the default representation for 3D shapes in the graphics industry, using auto-regressive (AR) models has become popular these days, thanks to their sharpness, compactness in the generated results, and ability to represent various types of surfaces. However, AR mesh generative models typically construct meshes face by face in lexicographic order, which does not effectively capture the underlying geometry in a manner consistent with human perception. Inspired by 2D models that progressively refine images, such as the prevailing next-scale prediction AR models, we propose generating meshes auto-regressively in a progressive coarse-to-fine manner. Specifically, we view mesh simplification algorithms, which gradually merge mesh faces to build simpler meshes, as a natural fine-to-coarse process. Therefore, we generalize meshes to simplicial complexes and develop a transformer-based AR model to approximate the reverse process of simplification in the order of level of detail, constructing meshes initially from a single point and gradually adding geometric details through local remeshing, where the topology is not predefined and is alterable. Our experiments show that this novel progressive mesh generation approach not only provides intuitive control over generation quality and time consumption by early stopping the auto-regressive process but also enables applications such as mesh refinement and editing.
FHRFormer: A Self-supervised Transformer Approach for Fetal Heart Rate Inpainting and Forecasting
arXiv:2509.20852v1 Announce Type: cross Abstract: Approximately 10\% of newborns require assistance to initiate breathing at birth, and around 5\% need ventilation support. Fetal heart rate (FHR) monitoring plays a crucial role in assessing fetal well-being during prenatal care, enabling the detection of abnormal patterns and supporting timely obstetric interventions to mitigate fetal risks during labor. Applying artificial intelligence (AI) methods to analyze large datasets of continuous FHR monitoring episodes with diverse outcomes may offer novel insights into predicting the risk of needing breathing assistance or interventions. Recent advances in wearable FHR monitors have enabled continuous fetal monitoring without compromising maternal mobility. However, sensor displacement during maternal movement, as well as changes in fetal or maternal position, often lead to signal dropouts, resulting in gaps in the recorded FHR data. Such missing data limits the extraction of meaningful insights and complicates automated (AI-based) analysis. Traditional approaches to handle missing data, such as simple interpolation techniques, often fail to preserve the spectral characteristics of the signals. In this paper, we propose a masked transformer-based autoencoder approach to reconstruct missing FHR signals by capturing both spatial and frequency components of the data. The proposed method demonstrates robustness across varying durations of missing data and can be used for signal inpainting and forecasting. The proposed approach can be applied retrospectively to research datasets to support the development of AI-based risk algorithms. In the future, the proposed method could be integrated into wearable FHR monitoring devices to achieve earlier and more robust risk detection.
ArchGPT: Understanding the World's Architectures with Large Multimodal Models
arXiv:2509.20858v1 Announce Type: cross Abstract: Architecture embodies aesthetic, cultural, and historical values, standing as a tangible testament to human civilization. Researchers have long leveraged virtual reality (VR), mixed reality (MR), and augmented reality (AR) to enable immersive exploration and interpretation of architecture, enhancing accessibility, public understanding, and creative workflows around architecture in education, heritage preservation, and professional design practice. However, existing VR/MR/AR systems are often developed case-by-case, relying on hard-coded annotations and task-specific interactions that do not scale across diverse built environments. In this work, we present ArchGPT, a multimodal architectural visual question answering (VQA) model, together with a scalable data-construction pipeline for curating high-quality, architecture-specific VQA annotations. This pipeline yields Arch-300K, a domain-specialized dataset of approximately 315,000 image-question-answer triplets. Arch-300K is built via a multi-stage process: first, we curate architectural scenes from Wikimedia Commons and filter unconstrained tourist photo collections using a novel coarse-to-fine strategy that integrates 3D reconstruction and semantic segmentation to select occlusion-free, structurally consistent architectural images. To mitigate noise and inconsistency in raw textual metadata, we propose an LLM-guided text verification and knowledge-distillation pipeline to generate reliable, architecture-specific question-answer pairs. Using these curated images and refined metadata, we further synthesize formal analysis annotations-including detailed descriptions and aspect-guided conversations-to provide richer semantic variety while remaining faithful to the data. We perform supervised fine-tuning of an open-source multimodal backbone ,ShareGPT4V-7B, on Arch-300K, yielding ArchGPT.
Autoregressive End-to-End Planning with Time-Invariant Spatial Alignment and Multi-Objective Policy Refinement
arXiv:2509.20938v1 Announce Type: cross Abstract: The inherent sequential modeling capabilities of autoregressive models make them a formidable baseline for end-to-end planning in autonomous driving. Nevertheless, their performance is constrained by a spatio-temporal misalignment, as the planner must condition future actions on past sensory data. This creates an inconsistent worldview, limiting the upper bound of performance for an otherwise powerful approach. To address this, we propose a Time-Invariant Spatial Alignment (TISA) module that learns to project initial environmental features into a consistent ego-centric frame for each future time step, effectively correcting the agent's worldview without explicit future scene prediction. In addition, we employ a kinematic action prediction head (i.e., acceleration and yaw rate) to ensure physically feasible trajectories. Finally, we introduce a multi-objective post-training stage using Direct Preference Optimization (DPO) to move beyond pure imitation. Our approach provides targeted feedback on specific driving behaviors, offering a more fine-grained learning signal than the single, overall objective used in standard DPO. Our model achieves a state-of-the-art 89.8 PDMS on the NAVSIM dataset among autoregressive models. The video document is available at https://tisa-dpo-e2e.github.io/.
Marching Neurons: Accurate Surface Extraction for Neural Implicit Shapes
arXiv:2509.21007v1 Announce Type: cross Abstract: Accurate surface geometry representation is crucial in 3D visual computing. Explicit representations, such as polygonal meshes, and implicit representations, like signed distance functions, each have distinct advantages, making efficient conversions between them increasingly important. Conventional surface extraction methods for implicit representations, such as the widely used Marching Cubes algorithm, rely on spatial decomposition and sampling, leading to inaccuracies due to fixed and limited resolution. We introduce a novel approach for analytically extracting surfaces from neural implicit functions. Our method operates natively in parallel and can navigate large neural architectures. By leveraging the fact that each neuron partitions the domain, we develop a depth-first traversal strategy to efficiently track the encoded surface. The resulting meshes faithfully capture the full geometric information from the network without ad-hoc spatial discretization, achieving unprecedented accuracy across diverse shapes and network architectures while maintaining competitive speed.
KeyWorld: Key Frame Reasoning Enables Effective and Efficient World Models
arXiv:2509.21027v1 Announce Type: cross Abstract: Robotic world models are a promising paradigm for forecasting future environment states, yet their inference speed and the physical plausibility of generated trajectories remain critical bottlenecks, limiting their real-world applications. This stems from the redundancy of the prevailing frame-to-frame generation approach, where the model conducts costly computation on similar frames, as well as neglecting the semantic importance of key transitions. To address this inefficiency, we propose KeyWorld, a framework that improves text-conditioned robotic world models by concentrating transformers computation on a few semantic key frames while employing a lightweight convolutional model to fill the intermediate frames. Specifically, KeyWorld first identifies significant transitions by iteratively simplifying the robot's motion trajectories, obtaining the ground truth key frames. Then, a DiT model is trained to reason and generate these physically meaningful key frames from textual task descriptions. Finally, a lightweight interpolator efficiently reconstructs the full video by inpainting all intermediate frames. Evaluations on the LIBERO benchmark demonstrate that KeyWorld achieves a 5.68$\times$ acceleration compared to the frame-to-frame generation baseline, and focusing on the motion-aware key frames further contributes to the physical validity of the generated videos, especially on complex tasks. Our approach highlights a practical path toward deploying world models in real-time robotic control and other domains requiring both efficient and effective world models. Code is released at https://anonymous.4open.science/r/Keyworld-E43D.
Cross-Modal Instructions for Robot Motion Generation
arXiv:2509.21107v1 Announce Type: cross Abstract: Teaching robots novel behaviors typically requires motion demonstrations via teleoperation or kinaesthetic teaching, that is, physically guiding the robot. While recent work has explored using human sketches to specify desired behaviors, data collection remains cumbersome, and demonstration datasets are difficult to scale. In this paper, we introduce an alternative paradigm, Learning from Cross-Modal Instructions, where robots are shaped by demonstrations in the form of rough annotations, which can contain free-form text labels, and are used in lieu of physical motion. We introduce the CrossInstruct framework, which integrates cross-modal instructions as examples into the context input to a foundational vision-language model (VLM). The VLM then iteratively queries a smaller, fine-tuned model, and synthesizes the desired motion over multiple 2D views. These are then subsequently fused into a coherent distribution over 3D motion trajectories in the robot's workspace. By incorporating the reasoning of the large VLM with a fine-grained pointing model, CrossInstruct produces executable robot behaviors that generalize beyond the environment of in the limited set of instruction examples. We then introduce a downstream reinforcement learning pipeline that leverages CrossInstruct outputs to efficiently learn policies to complete fine-grained tasks. We rigorously evaluate CrossInstruct on benchmark simulation tasks and real hardware, demonstrating effectiveness without additional fine-tuning and providing a strong initialization for policies subsequently refined via reinforcement learning.
CHARM: Control-point-based 3D Anime Hairstyle Auto-Regressive Modeling
arXiv:2509.21114v1 Announce Type: cross Abstract: We present CHARM, a novel parametric representation and generative framework for anime hairstyle modeling. While traditional hair modeling methods focus on realistic hair using strand-based or volumetric representations, anime hairstyle exhibits highly stylized, piecewise-structured geometry that challenges existing techniques. Existing works often rely on dense mesh modeling or hand-crafted spline curves, making them inefficient for editing and unsuitable for scalable learning. CHARM introduces a compact, invertible control-point-based parameterization, where a sequence of control points represents each hair card, and each point is encoded with only five geometric parameters. This efficient and accurate representation supports both artist-friendly design and learning-based generation. Built upon this representation, CHARM introduces an autoregressive generative framework that effectively generates anime hairstyles from input images or point clouds. By interpreting anime hairstyles as a sequential "hair language", our autoregressive transformer captures both local geometry and global hairstyle topology, resulting in high-fidelity anime hairstyle creation. To facilitate both training and evaluation of anime hairstyle generation, we construct AnimeHair, a large-scale dataset of 37K high-quality anime hairstyles with separated hair cards and processed mesh data. Extensive experiments demonstrate state-of-the-art performance of CHARM in both reconstruction accuracy and generation quality, offering an expressive and scalable solution for anime hairstyle modeling. Project page: https://hyzcluster.github.io/charm/
Sparse Representations Improve Adversarial Robustness of Neural Network Classifiers
arXiv:2509.21130v1 Announce Type: cross Abstract: Deep neural networks perform remarkably well on image classification tasks but remain vulnerable to carefully crafted adversarial perturbations. This work revisits linear dimensionality reduction as a simple, data-adapted defense. We empirically compare standard Principal Component Analysis (PCA) with its sparse variant (SPCA) as front-end feature extractors for downstream classifiers, and we complement these experiments with a theoretical analysis. On the theory side, we derive exact robustness certificates for linear heads applied to SPCA features: for both $\ell_\infty$ and $\ell_2$ threat models (binary and multiclass), the certified radius grows as the dual norms of $W^\top u$ shrink, where $W$ is the projection and $u$ the head weights. We further show that for general (non-linear) heads, sparsity reduces operator-norm bounds through a Lipschitz composition argument, predicting lower input sensitivity. Empirically, with a small non-linear network after the projection, SPCA consistently degrades more gracefully than PCA under strong white-box and black-box attacks while maintaining competitive clean accuracy. Taken together, the theory identifies the mechanism (sparser projections reduce adversarial leverage) and the experiments verify that this benefit persists beyond the linear setting. Our code is available at https://github.com/killian31/SPCARobustness.
A Unified Framework for Diffusion Model Unlearning with f-Divergence
arXiv:2509.21167v1 Announce Type: cross Abstract: Machine unlearning aims to remove specific knowledge from a trained model. While diffusion models (DMs) have shown remarkable generative capabilities, existing unlearning methods for text-to-image (T2I) models often rely on minimizing the mean squared error (MSE) between the output distribution of a target and an anchor concept. We show that this MSE-based approach is a special case of a unified $f$-divergence-based framework, in which any $f$-divergence can be utilized. We analyze the benefits of using different $f$-divergences, that mainly impact the convergence properties of the algorithm and the quality of unlearning. The proposed unified framework offers a flexible paradigm that allows to select the optimal divergence for a specific application, balancing different trade-offs between aggressive unlearning and concept preservation.
Human-like Navigation in a World Built for Humans
arXiv:2509.21189v1 Announce Type: cross Abstract: When navigating in a man-made environment they haven't visited before--like an office building--humans employ behaviors such as reading signs and asking others for directions. These behaviors help humans reach their destinations efficiently by reducing the need to search through large areas. Existing robot navigation systems lack the ability to execute such behaviors and are thus highly inefficient at navigating within large environments. We present ReasonNav, a modular navigation system which integrates these human-like navigation skills by leveraging the reasoning capabilities of a vision-language model (VLM). We design compact input and output abstractions based on navigation landmarks, allowing the VLM to focus on language understanding and reasoning. We evaluate ReasonNav on real and simulated navigation tasks and show that the agent successfully employs higher-order reasoning to navigate efficiently in large, complex buildings.
Differential-Integral Neural Operator for Long-Term Turbulence Forecasting
arXiv:2509.21196v1 Announce Type: cross Abstract: Accurately forecasting the long-term evolution of turbulence represents a grand challenge in scientific computing and is crucial for applications ranging from climate modeling to aerospace engineering. Existing deep learning methods, particularly neural operators, often fail in long-term autoregressive predictions, suffering from catastrophic error accumulation and a loss of physical fidelity. This failure stems from their inability to simultaneously capture the distinct mathematical structures that govern turbulent dynamics: local, dissipative effects and global, non-local interactions. In this paper, we propose the {\textbf{\underline{D}}}ifferential-{\textbf{\underline{I}}}ntegral {\textbf{\underline{N}}}eural {\textbf{\underline{O}}}perator (\method{}), a novel framework designed from a first-principles approach of operator decomposition. \method{} explicitly models the turbulent evolution through parallel branches that learn distinct physical operators: a local differential operator, realized by a constrained convolutional network that provably converges to a derivative, and a global integral operator, captured by a Transformer architecture that learns a data-driven global kernel. This physics-based decomposition endows \method{} with exceptional stability and robustness. Through extensive experiments on the challenging 2D Kolmogorov flow benchmark, we demonstrate that \method{} significantly outperforms state-of-the-art models in long-term forecasting. It successfully suppresses error accumulation over hundreds of timesteps, maintains high fidelity in both the vorticity fields and energy spectra, and establishes a new benchmark for physically consistent, long-range turbulence forecast.
VC-Agent: An Interactive Agent for Customized Video Dataset Collection
arXiv:2509.21291v1 Announce Type: cross Abstract: Facing scaling laws, video data from the internet becomes increasingly important. However, collecting extensive videos that meet specific needs is extremely labor-intensive and time-consuming. In this work, we study the way to expedite this collection process and propose VC-Agent, the first interactive agent that is able to understand users' queries and feedback, and accordingly retrieve/scale up relevant video clips with minimal user input. Specifically, considering the user interface, our agent defines various user-friendly ways for the user to specify requirements based on textual descriptions and confirmations. As for agent functions, we leverage existing multi-modal large language models to connect the user's requirements with the video content. More importantly, we propose two novel filtering policies that can be updated when user interaction is continually performed. Finally, we provide a new benchmark for personalized video dataset collection, and carefully conduct the user study to verify our agent's usage in various real scenarios. Extensive experiments demonstrate the effectiveness and efficiency of our agent for customized video dataset collection. Project page: https://allenyidan.github.io/vcagent_page/.
SuperPatchMatch: an Algorithm for Robust Correspondences using Superpixel Patches
arXiv:1903.07169v2 Announce Type: replace Abstract: Superpixels have become very popular in many computer vision applications. Nevertheless, they remain underexploited since the superpixel decomposition may produce irregular and non stable segmentation results due to the dependency to the image content. In this paper, we first introduce a novel structure, a superpixel-based patch, called SuperPatch. The proposed structure, based on superpixel neighborhood, leads to a robust descriptor since spatial information is naturally included. The generalization of the PatchMatch method to SuperPatches, named SuperPatchMatch, is introduced. Finally, we propose a framework to perform fast segmentation and labeling from an image database, and demonstrate the potential of our approach since we outperform, in terms of computational cost and accuracy, the results of state-of-the-art methods on both face labeling and medical image segmentation.
Retina Vision Transformer (RetinaViT): Introducing Scaled Patches into Vision Transformers
arXiv:2403.13677v2 Announce Type: replace Abstract: Humans see low spatial frequency components before high spatial frequency components. Drawing on this neuroscientific inspiration, we investigate the effect of introducing patches from different spatial frequencies into Vision Transformers (ViTs). We name this model Retina Vision Transformer (RetinaViT) due to its inspiration from the human visual system. Our experiments on benchmark data show that RetinaViT exhibits a strong tendency to attend to low spatial frequency components in the early layers, and shifts its attention to high spatial frequency components as the network goes deeper. This tendency emerged by itself without any additional inductive bias, and aligns with the visual processing order of the human visual system. We hypothesise that RetinaViT captures structural features, or the gist of the scene, in earlier layers, before attending to fine details in subsequent layers, which is the reverse of the processing order of mainstream backbone vision models, such as CNNs. We also observe that RetinaViT is more robust to significant reductions in model size compared to the original ViT, which we hypothesise to have come from its ability to capture the gist of the scene early.
Vim-F: Visual State Space Model Benefiting from Learning in the Frequency Domain
arXiv:2405.18679v3 Announce Type: replace Abstract: In recent years, State Space Models (SSMs) with efficient hardware-aware designs, known as the Mamba deep learning models, have made significant progress in modeling long sequences such as language understanding. Therefore, building efficient and general-purpose visual backbones based on SSMs is a promising direction. Compared to traditional convolutional neural networks (CNNs) and Vision Transformers (ViTs), the performance of Vision Mamba (ViM) methods is not yet fully competitive. To enable SSMs to process image data, ViMs typically flatten 2D images into 1D sequences, inevitably ignoring some 2D local dependencies, thereby weakening the model's ability to interpret spatial relationships from a global perspective. We use Fast Fourier Transform (FFT) to obtain the spectrum of the feature map and add it to the original feature map, enabling ViM to model a unified visual representation in both frequency and spatial domains. The introduction of frequency domain information enables ViM to have a global receptive field during scanning. We propose a novel model called Vim-F, which employs pure Mamba encoders and scans in both the frequency and spatial domains. Moreover, we question the necessity of position embedding in ViM and remove it accordingly in Vim-F, which helps to fully utilize the efficient long-sequence modeling capability of ViM. Finally, we redesign a patch embedding for Vim-F, leveraging a convolutional stem to capture more local correlations, further improving the performance of Vim-F. Code is available at: https://github.com/yws-wxs/Vim-F.
Model Agnostic Defense against Adversarial Patch Attacks on Object Detection in Unmanned Aerial Vehicles
arXiv:2405.19179v2 Announce Type: replace Abstract: Object detection forms a key component in Unmanned Aerial Vehicles (UAVs) for completing high-level tasks that depend on the awareness of objects on the ground from an aerial perspective. In that scenario, adversarial patch attacks on an onboard object detector can severely impair the performance of upstream tasks. This paper proposes a novel model-agnostic defense mechanism against the threat of adversarial patch attacks in the context of UAV-based object detection. We formulate adversarial patch defense as an occlusion removal task. The proposed defense method can neutralize adversarial patches located on objects of interest, without exposure to adversarial patches during training. Our lightweight single-stage defense approach allows us to maintain a model-agnostic nature, that once deployed does not require to be updated in response to changes in the object detection pipeline. The evaluations in digital and physical domains show the feasibility of our method for deployment in UAV object detection pipelines, by significantly decreasing the Attack Success Ratio without incurring significant processing costs. As a result, the proposed defense solution can improve the reliability of object detection for UAVs.
SOOD++: Leveraging Unlabeled Data to Boost Oriented Object Detection
arXiv:2407.01016v2 Announce Type: replace Abstract: Semi-supervised object detection (SSOD), leveraging unlabeled data to boost object detectors, has become a hot topic recently. However, existing SSOD approaches mainly focus on horizontal objects, leaving oriented objects common in aerial images unexplored. At the same time, the annotation cost of oriented objects is significantly higher than that of their horizontal counterparts. Therefore, in this paper, we propose a simple yet effective Semi-supervised Oriented Object Detection method termed SOOD++. Specifically, we observe that objects from aerial images usually have arbitrary orientations, small scales, and dense distribution, which inspires the following core designs: a Simple Instance-aware Dense Sampling (SIDS) strategy is used to generate comprehensive dense pseudo-labels; the Geometry-aware Adaptive Weighting (GAW) loss dynamically modulates the importance of each pair between pseudo-label and corresponding prediction by leveraging the intricate geometric information of aerial objects; we treat aerial images as global layouts and explicitly build the many-to-many relationship between the sets of pseudo-labels and predictions via the proposed Noise-driven Global Consistency (NGC). Extensive experiments conducted on various oriented object datasets under various labeled settings demonstrate the effectiveness of our method. For example, on the DOTA-V2.0/DOTA-V1.5 benchmark, the proposed method outperforms previous state-of-the-art (SOTA) by a large margin (+2.90/2.14, +2.16/2.18, and +2.66/2.32) mAP under 10%, 20%, and 30% labeled data settings, respectively, with single-scale training and testing. More importantly, it still improves upon a strong supervised baseline with 70.66 mAP, trained using the full DOTA-V1.5 train-val set, by +1.82 mAP, resulting in a 72.48 mAP, pushing the new state-of-the-art. The project page is at https://dk-liang.github.io/SOODv2/
Lightweight Modular Parameter-Efficient Tuning for Open-Vocabulary Object Detection
arXiv:2408.10787v4 Announce Type: replace Abstract: Open-vocabulary object detection (OVD) extends recognition beyond fixed taxonomies by aligning visual and textual features, as in MDETR, GLIP, or RegionCLIP. While effective, these models require updating all parameters of large vision--language backbones, leading to prohibitive training cost. Recent efficient OVD approaches, inspired by parameter-efficient fine-tuning methods such as LoRA or adapters, reduce trainable parameters but often face challenges in selecting which layers to adapt and in balancing efficiency with accuracy. We propose UniProj-Det, a lightweight modular framework for parameter-efficient OVD. UniProj-Det freezes pretrained backbones and introduces a Universal Projection module with a learnable modality token, enabling unified vision--language adaptation at minimal cost. Applied to MDETR, our framework trains only about ~2-5% of parameters while achieving competitive or superior performance on phrase grounding, referring expression comprehension, and segmentation. Comprehensive analysis of FLOPs, memory, latency, and ablations demonstrates UniProj-Det as a principled step toward scalable and efficient open-vocabulary detection.
Asynchronous Perception Machine For Efficient Test-Time-Training
arXiv:2410.20535v4 Announce Type: replace Abstract: In this work, we propose Asynchronous Perception Machine (APM), a computationally-efficient architecture for test-time-training (TTT). APM can process patches of an image one at a time in any order asymmetrically and still encode semantic-awareness in the net. We demonstrate APM's ability to recognize out-of-distribution images without dataset-specific pre-training, augmentation or any-pretext task. APM offers competitive performance over existing TTT approaches. To perform TTT, APM just distills test sample's representation once. APM possesses a unique property: it can learn using just this single representation and starts predicting semantically-aware features. APM demostrates potential applications beyond test-time-training: APM can scale up to a dataset of 2D images and yield semantic-clusterings in a single forward pass. APM also provides first empirical evidence towards validating GLOM's insight, i.e. input percept is a field. Therefore, APM helps us converge towards an implementation which can do both interpolation and perception on a shared-connectionist hardware. Our code is publicly available at this link: https://rajatmodi62.github.io/apm_project_page/.
Training-Free Layout-to-Image Generation with Marginal Attention Constraints
arXiv:2411.10495v2 Announce Type: replace Abstract: Recently, many text-to-image diffusion models excel at generating high-resolution images from text but struggle with precise control over spatial composition and object counting. To address these challenges, prior works developed layout-to-image (L2I) approaches that incorporate layout instructions into text-to-image models. However, existing L2I methods typically require fine-tuning of pre-trained parameters or training additional control modules for the diffusion models. In this work, we propose a training-free L2I approach, MAC (Marginal Attention Constrained Generation), which eliminates the need for additional modules or fine-tuning. Specifically, we use text-visual cross-attention feature maps to quantify inconsistencies between the layout of the generated images and the provided instructions, and then compute loss functions to optimize latent features during the diffusion reverse process. To enhance spatial controllability and mitigate semantic failures in complex layout instructions, we leverage pixel-to-pixel correlations in the self-attention feature maps to align cross-attention maps and combine three loss functions constrained by boundary attention to update latent features. Comprehensive experimental results on both L2I and non-L2I pretrained diffusion models demonstrate that our method outperforms existing training-free L2I techniques both quantitatively and qualitatively in terms of image composition on the DrawBench and HRS benchmarks.
Supercharged One-step Text-to-Image Diffusion Models with Negative Prompts
arXiv:2412.02687v3 Announce Type: replace Abstract: The escalating demand for real-time image synthesis has driven significant advancements in one-step diffusion models, which inherently offer expedited generation speeds compared to traditional multi-step methods. However, this enhanced efficiency is frequently accompanied by a compromise in the controllability of image attributes. While negative prompting, typically implemented via classifier-free guidance (CFG), has proven effective for fine-grained control in multi-step models, its application to one-step generators remains largely unaddressed. Due to the lack of iterative refinement, as in multi-step diffusion, directly applying CFG to one-step generation leads to blending artifacts and diminished output quality. To fill this gap, we introduce \textbf{N}egative-\textbf{A}way \textbf{S}teer \textbf{A}ttention (NASA), an efficient method that integrates negative prompts into one-step diffusion models. NASA operates within the intermediate representation space by leveraging cross-attention mechanisms to suppress undesired visual attributes. This strategy avoids the blending artifacts inherent in output-space guidance and achieves high efficiency, incurring only a minimal 1.89\% increase in FLOPs compared to the computational doubling of CFG. Furthermore, NASA can be seamlessly integrated into existing timestep distillation frameworks, enhancing the student's output quality. Experimental results demonstrate that NASA substantially improves controllability and output quality, achieving an HPSv2 score of \textbf{31.21}, setting a new state-of-the-art benchmark for one-step diffusion models.
GVDepth: Zero-Shot Monocular Depth Estimation for Ground Vehicles based on Probabilistic Cue Fusion
arXiv:2412.06080v2 Announce Type: replace Abstract: Generalizing metric monocular depth estimation presents a significant challenge due to its ill-posed nature, while the entanglement between camera parameters and depth amplifies issues further, hindering multi-dataset training and zero-shot accuracy. This challenge is particularly evident in autonomous vehicles and mobile robotics, where data is collected with fixed camera setups, limiting the geometric diversity. Yet, this context also presents an opportunity: the fixed relationship between the camera and the ground plane imposes additional perspective geometry constraints, enabling depth regression via vertical image positions of objects. However, this cue is highly susceptible to overfitting, thus we propose a novel canonical representation that maintains consistency across varied camera setups, effectively disentangling depth from specific parameters and enhancing generalization across datasets. We also propose a novel architecture that adaptively and probabilistically fuses depths estimated via object size and vertical image position cues. A comprehensive evaluation demonstrates the effectiveness of the proposed approach on five autonomous driving datasets, achieving accurate metric depth estimation for varying resolutions, aspect ratios and camera setups. Notably, we achieve comparable accuracy to existing zero-shot methods, despite training on a single dataset with a single-camera setup. Project website: https://unizgfer-lamor.github.io/gvdepth/
MonSter++: Unified Stereo Matching, Multi-view Stereo, and Real-time Stereo with Monodepth Priors
arXiv:2501.08643v2 Announce Type: replace Abstract: We introduce MonSter++, a geometric foundation model for multi-view depth estimation, unifying rectified stereo matching and unrectified multi-view stereo. Both tasks fundamentally recover metric depth from correspondence search and consequently face the same dilemma: struggling to handle ill-posed regions with limited matching cues. To address this, we propose MonSter++, a novel method that integrates monocular depth priors into multi-view depth estimation, effectively combining the complementary strengths of single-view and multi-view cues. MonSter++ fuses monocular depth and multi-view depth into a dual-branched architecture. Confidence-based guidance adaptively selects reliable multi-view cues to correct scale ambiguity in monocular depth. The refined monocular predictions, in turn, effectively guide multi-view estimation in ill-posed regions. This iterative mutual enhancement enables MonSter++ to evolve coarse object-level monocular priors into fine-grained, pixel-level geometry, fully unlocking the potential of multi-view depth estimation. MonSter++ achieves new state-of-the-art on both stereo matching and multi-view stereo. By effectively incorporating monocular priors through our cascaded search and multi-scale depth fusion strategy, our real-time variant RT-MonSter++ also outperforms previous real-time methods by a large margin. As shown in Fig.1, MonSter++ achieves significant improvements over previous methods across eight benchmarks from three tasks -- stereo matching, real-time stereo matching, and multi-view stereo, demonstrating the strong generality of our framework. Besides high accuracy, MonSter++ also demonstrates superior zero-shot generalization capability. We will release both the large and the real-time models to facilitate their use by the open-source community.
Technical report on label-informed logit redistribution for better domain generalization in low-shot classification with foundation models
arXiv:2501.17595v3 Announce Type: replace Abstract: Confidence calibration is an emerging challenge in real-world decision systems based on foundations models when used for downstream vision classification tasks. Due to various reasons exposed, logit scores on the CLIP head remain large irrespective of whether the image-language pairs reconcile. It is difficult to address in data space, given the few-shot regime. We propose a penalty incorporated into loss objective that penalizes incorrect classifications whenever one is made during finetuning, by moving an amount of log-likelihood to the true class commensurate to the relative amplitudes of the two likelihoods. We refer to it as \textit{confidence misalignment penalty (CMP)}. Extensive experiments on $12$ vision datasets and $5$ domain generalization datasets supports the calibration performance of our method against stat-of-the-art. CMP outperforms the benchmarked prompt learning methods, demonstrating average improvement in Expected Calibration Error (ECE) by average $6.01$\%, $4.01$ \% at minimum and $9.72$\% at maximum.
AdaSVD: Adaptive Singular Value Decomposition for Large Language Models
arXiv:2502.01403v4 Announce Type: replace Abstract: Large language models (LLMs) have achieved remarkable success in natural language processing (NLP) tasks, yet their substantial memory requirements present significant challenges for deployment on resource-constrained devices. Singular Value Decomposition (SVD) has emerged as a promising compression technique for LLMs, offering considerable reductions in memory overhead. However, existing SVD-based methods often struggle to effectively mitigate the errors introduced by SVD truncation, leading to a noticeable performance gap when compared to the original models. Furthermore, applying a uniform compression ratio across all transformer layers fails to account for the varying importance of different layers. To address these challenges, we propose AdaSVD, an adaptive SVD-based LLM compression approach. Specifically, AdaSVD introduces adaComp, which adaptively compensates for SVD truncation errors by alternately updating the singular matrices $\mathcal{U}$ and $\mathcal{V}^\top$. Additionally, AdaSVD introduces adaCR, which adaptively assigns layer-specific compression ratios based on the relative importance of each layer. Extensive experiments across multiple LLM/VLM families and evaluation metrics demonstrate that AdaSVD consistently outperforms state-of-the-art (SOTA) SVD-based methods, achieving superior performance with significantly reduced memory requirements. Code and models of AdaSVD will be available at https://github.com/ZHITENGLI/AdaSVD.
LadderMIL: Multiple Instance Learning with Coarse-to-Fine Self-Distillation
arXiv:2502.02707v4 Announce Type: replace Abstract: Multiple Instance Learning (MIL) for whole slide image (WSI) analysis in computational pathology often neglects instance-level learning as supervision is typically provided only at the bag level, hindering the integrated consideration of instance and bag-level information during the analysis. In this work, we present LadderMIL, a framework designed to improve MIL through two perspectives: (1) employing instance-level supervision and (2) learning inter-instance contextual information at bag level. Firstly, we propose a novel Coarse-to-Fine Self-Distillation (CFSD) paradigm that probes and distils a network trained with bag-level information to adaptively obtain instance-level labels which could effectively provide the instance-level supervision for the same network in a self-improving way. Secondly, to capture inter-instance contextual information in WSI, we propose a Contextual Encoding Generator (CEG), which encodes the contextual appearance of instances within a bag. We also theoretically and empirically prove the instance-level learnability of CFSD. Our LadderMIL is evaluated on multiple clinically relevant benchmarking tasks including breast cancer receptor status classification, multi-class subtype classification, tumour classification, and prognosis prediction. Average improvements of 8.1%, 11% and 2.4% in AUC, F1-score, and C-index, respectively, are demonstrated across the five benchmarks, compared to the best baseline.
Efficiently Disentangling CLIP for Multi-Object Perception
arXiv:2502.02977v4 Announce Type: replace Abstract: Vision-language models like CLIP excel at recognizing the single, prominent object in a scene. However, they struggle in complex scenes containing multiple objects. We identify a fundamental reason for this limitation: VLM feature space exhibits excessive mutual feature information (MFI), where the features of one class contain substantial information about other, unrelated classes. This high MFI becomes evident during class-specific queries, as unrelated objects are activated alongside the queried class. To address this limitation, we propose DCLIP, an efficient framework that learns an optimal level of mutual information while adding only minimal learnable parameters to a frozen VLM. DCLIP uses two complementary losses: a novel MFI Loss that regulates class feature similarity to prevent excessive overlap while preserving necessary shared information, and the Asymmetric Loss (ASL) that aligns image features with the disentangled text features. Through this disentanglement, DCLIP reduces excessive inter-class similarity by 30%. On multi-label recognition, DCLIP performs favorably over SOTA approaches on VOC2007 and COCO-14 while using 75% fewer training parameters. For zero-shot semantic segmentation, it shows improved performance across six benchmark datasets. These results highlight the importance of feature disentanglement for multi-object perception in VLMs.
HermesFlow: Seamlessly Closing the Gap in Multimodal Understanding and Generation
arXiv:2502.12148v2 Announce Type: replace Abstract: The remarkable success of the autoregressive paradigm has made significant advancement in Multimodal Large Language Models (MLLMs), with powerful models like Show-o, Transfusion and Emu3 achieving notable progress in unified image understanding and generation. For the first time, we uncover a common phenomenon: the understanding capabilities of MLLMs are typically stronger than their generative capabilities, with a significant gap between the two. Building on this insight, we propose HermesFlow, a simple yet general framework designed to seamlessly bridge the gap between understanding and generation in MLLMs. Specifically, we take the homologous data as input to curate homologous preference data of both understanding and generation. Through Pair-DPO and self-play iterative optimization, HermesFlow effectively aligns multimodal understanding and generation using homologous preference data. Extensive experiments demonstrate the significant superiority of our approach over prior methods, particularly in narrowing the gap between multimodal understanding and generation. These findings highlight the potential of HermesFlow as a general alignment framework for next-generation multimodal foundation models. Code: https://github.com/Gen-Verse/HermesFlow
Diff-Reg v2: Diffusion-Based Matching Matrix Estimation for Image Matching and 3D Registration
arXiv:2503.04127v3 Announce Type: replace Abstract: Establishing reliable correspondences is crucial for all registration tasks, including 2D image registration, 3D point cloud registration, and 2D-3D image-to-point cloud registration. However, these tasks are often complicated by challenges such as scale inconsistencies, symmetry, and large deformations, which can lead to ambiguous matches. Previous feature-based and correspondence-based methods typically rely on geometric or semantic features to generate or polish initial potential correspondences. Some methods typically leverage specific geometric priors, such as topological preservation, to devise diverse and innovative strategies tailored to a given enhancement goal, which cannot be exhaustively enumerated. Additionally, many previous approaches rely on a single-step prediction head, which can struggle with local minima in complex matching scenarios. To address these challenges, we introduce an innovative paradigm that leverages a diffusion model in matrix space for robust matching matrix estimation. Our model treats correspondence estimation as a denoising diffusion process in the matching matrix space, gradually refining the intermediate matching matrix to the optimal one. Specifically, we apply the diffusion model in the doubly stochastic matrix space for 3D-3D and 2D-3D registration tasks. In the 2D image registration task, we deploy the diffusion model in a matrix subspace where dual-softmax projection regularization is applied. For all three registration tasks, we provide adaptive matching matrix embedding implementations tailored to the specific characteristics of each task while maintaining a consistent "match-to-warp" encoding pattern. Furthermore, we adopt a lightweight design for the denoising module. In inference, once points or image features are extracted and fixed, this module performs multi-step denoising predictions through reverse sampling.
REArtGS: Reconstructing and Generating Articulated Objects via 3D Gaussian Splatting with Geometric and Motion Constraints
arXiv:2503.06677v4 Announce Type: replace Abstract: Articulated objects, as prevalent entities in human life, their 3D representations play crucial roles across various applications. However, achieving both high-fidelity textured surface reconstruction and dynamic generation for articulated objects remains challenging for existing methods. In this paper, we present REArtGS, a novel framework that introduces additional geometric and motion constraints to 3D Gaussian primitives, enabling realistic surface reconstruction and generation for articulated objects. Specifically, given multi-view RGB images of arbitrary two states of articulated objects, we first introduce an unbiased Signed Distance Field (SDF) guidance to regularize Gaussian opacity fields, enhancing geometry constraints and improving surface reconstruction quality. Then we establish deformable fields for 3D Gaussians constrained by the kinematic structures of articulated objects, achieving unsupervised generation of surface meshes in unseen states. Extensive experiments on both synthetic and real datasets demonstrate our approach achieves high-quality textured surface reconstruction for given states, and enables high-fidelity surface generation for unseen states. Project site: https://sites.google.com/view/reartgs/home.
LLaVA-RadZ: Can Multimodal Large Language Models Effectively Tackle Zero-shot Radiology Recognition?
arXiv:2503.07487v2 Announce Type: replace Abstract: Recently, Multimodal Large Language Models (MLLMs) have demonstrated exceptional capabilities in visual understanding and reasoning across various vision-language tasks. However, we found that MLLMs cannot process effectively from fine-grained medical image data in the traditional Visual Question Answering (VQA) pipeline, as they do not exploit the captured features and available medical knowledge fully, results in MLLMs usually performing poorly in zero-shot medical disease recognition. Fortunately, this limitation does not indicate that MLLMs are fundamentally incapable of addressing fine-grained recognition tasks. From a feature representation perspective, MLLMs demonstrate considerable potential for tackling such challenging problems. Thus, to address this challenge, we propose LLaVA-RadZ, a simple yet effective framework for zero-shot medical disease recognition via utilizing the existing MLLM features. Specifically, we design an end-to-end training strategy, termed Decoding-Side Feature Alignment Training (DFAT) to take advantage of the characteristics of the MLLM decoder architecture and incorporate modality-specific tokens tailored for different modalities. Additionally, we introduce a Domain Knowledge Anchoring Module (DKAM) to exploit the intrinsic medical knowledge of large models, which mitigates the category semantic gap in image-text alignment. Extensive experiments demonstrate that our LLaVA-RadZ significantly outperforms traditional MLLMs in zero-shot disease recognition, achieving the comparable performance to the well-established and highly-optimized CLIP-based approaches.
Parameter-Efficient Adaptation of Geospatial Foundation Models through Embedding Deflection
arXiv:2503.09493v2 Announce Type: replace Abstract: As large-scale heterogeneous data sets become increasingly available, adapting foundation models at low cost has become a key issue. Seminal works in natural language processing, e.g. Low-Rank Adaptation (LoRA), leverage the low "intrinsic rank" of parameter updates during adaptation. In this paper, we argue that incorporating stronger inductive biases in both data and models can enhance the adaptation of Geospatial Foundation Models (GFMs), pretrained on RGB satellite images, to other types of optical satellite data. Specifically, the pretrained parameters of GFMs serve as a strong prior for the spatial structure of multispectral images. For this reason, we introduce DEFLECT (Deflecting Embeddings for Finetuning Latent representations for Earth and Climate Tasks), a novel strategy for adapting GFMs to multispectral satellite imagery with very few additional parameters. DEFLECT improves the representation capabilities of the extracted features, particularly enhancing spectral information, which is essential for geoscience and environmental-related tasks. We demonstrate the effectiveness of our method across three different GFMs and five diverse datasets, ranging from forest monitoring to marine environment segmentation. Compared to competing methods, DEFLECT achieves on-par or higher accuracy with 5-10$\times$ fewer parameters for classification and segmentation tasks. The code will be made publicly available.
Autoregressive Image Generation with Randomized Parallel Decoding
arXiv:2503.10568v2 Announce Type: replace Abstract: We introduce ARPG, a novel visual autoregressive model that enables randomized parallel generation, addressing the inherent limitations of conventional raster-order approaches, which hinder inference efficiency and zero-shot generalization due to their sequential, predefined token generation order. Our key insight is that effective random-order modeling necessitates explicit guidance for determining the position of the next predicted token. To this end, we propose a novel decoupled decoding framework that decouples positional guidance from content representation, encoding them separately as queries and key-value pairs. By directly incorporating this guidance into the causal attention mechanism, our approach enables fully random-order training and generation, eliminating the need for bidirectional attention. Consequently, ARPG readily generalizes to zero-shot inference tasks such as image inpainting, outpainting, and resolution expansion. Furthermore, it supports parallel inference by concurrently processing multiple queries using a shared KV cache. On the ImageNet-1K 256 benchmark, our approach attains an FID of 1.83 with only 32 sampling steps, achieving over a 30 times speedup in inference and a 75 percent reduction in memory consumption compared to representative recent autoregressive models at a similar scale.
Radar-Guided Polynomial Fitting for Metric Depth Estimation
arXiv:2503.17182v2 Announce Type: replace Abstract: We propose POLAR, a novel radar-guided depth estimation method that introduces polynomial fitting to efficiently transform scaleless depth predictions from pretrained monocular depth estimation (MDE) models into metric depth maps. Unlike existing approaches that rely on complex architectures or expensive sensors, our method is grounded in a fundamental insight: although MDE models often infer reasonable local depth structure within each object or local region, they may misalign these regions relative to one another, making a linear scale and shift (affine) transformation insufficient given three or more of these regions. To address this limitation, we use polynomial coefficients predicted from cheap, ubiquitous radar data to adaptively adjust depth predictions non-uniformly across depth ranges. In this way, POLAR generalizes beyond affine transformations and is able to correct such misalignments by introducing inflection points. Importantly, our polynomial fitting framework preserves structural consistency through a novel training objective that enforces local monotonicity via first-derivative regularization. POLAR achieves state-of-the-art performance across three datasets, outperforming existing methods by an average of 24.9% in MAE and 33.2% in RMSE, while also achieving state-of-the-art efficiency in terms of latency and computational cost.
On the Perception Bottleneck of VLMs for Chart Understanding
arXiv:2503.18435v2 Announce Type: replace Abstract: Chart understanding requires models to effectively analyze and reason about numerical data, textual elements, and complex visual components. Our observations reveal that the perception capabilities of existing large vision-language models (LVLMs) constitute a critical bottleneck in this process. In this study, we delve into this perception bottleneck by decomposing it into two components: the vision encoder bottleneck, where the visual representation may fail to encapsulate the correct information, and the extraction bottleneck, where the language model struggles to extract the necessary information from the provided visual representations. Through comprehensive experiments, we find that (1) the information embedded within visual representations is substantially richer than what is typically captured by linear extractors, such as the widely used retrieval accuracy metric; (2) While instruction tuning effectively enhances the extraction capability of LVLMs, the vision encoder remains a critical bottleneck, demanding focused attention and improvement. Therefore, we further enhance the visual encoder to mitigate the vision encoder bottleneck under a contrastive learning framework. Empirical results demonstrate that our approach significantly mitigates the perception bottleneck and improves the ability of LVLMs to comprehend charts. Code is publicly available at https://github.com/hkust-nlp/Vision4Chart.
Improving Brain Disorder Diagnosis with Advanced Brain Function Representation and Kolmogorov-Arnold Networks
arXiv:2504.03923v2 Announce Type: replace Abstract: Quantifying functional connectivity (FC), a vital metric for the diagnosis of various brain disorders, traditionally relies on the use of a pre-defined brain atlas. However, using such atlases can lead to issues regarding selection bias and lack of regard for specificity. Addressing this, we propose a novel transformer-based classification network (ABFR-KAN) with effective brain function representation to aid in diagnosing autism spectrum disorder (ASD). ABFR-KAN leverages Kolmogorov-Arnold Network (KAN) blocks replacing traditional multi-layer perceptron (MLP) components. Thorough experimentation reveals the effectiveness of ABFR-KAN in improving the diagnosis of ASD under various configurations of the model architecture. Our code is available at https://github.com/tbwa233/ABFR-KAN
VideoPASTA: 7K Preference Pairs That Matter for Video-LLM Alignment
arXiv:2504.14096v3 Announce Type: replace Abstract: Video-language models (Video-LLMs) excel at understanding video content but struggle with spatial relationships, temporal ordering, and cross-frame continuity. To address these limitations, we introduce VideoPASTA (Preference Alignment with Spatio-Temporal-Cross Frame Adversaries), a framework that enhances Video-LLMs through targeted preference optimization. VideoPASTA trains models to distinguish accurate video representations from carefully crafted adversarial examples that deliberately violate spatial, temporal, or cross-frame relationships. With only 7,020 preference pairs and Direct Preference Optimization, VideoPASTA enables models to learn robust representations that capture fine-grained spatial details and long-range temporal dynamics. Experiments demonstrate that VideoPASTA is model agnostic and significantly improves performance, for example, achieving gains of up to +3.8 percentage points on LongVideoBench, +4.1 on VideoMME, and +4.0 on MVBench, when applied to various state-of-the-art Video-LLMs. These results demonstrate that targeted alignment, rather than massive pretraining or architectural modifications, effectively addresses core video-language challenges. Notably, VideoPASTA achieves these improvements without any human annotation or captioning, relying solely on 32-frame sampling. This efficiency makes our approach a scalable plug-and-play solution that seamlessly integrates with existing models while preserving their original capabilities.
Learning Flow-Guided Registration for RGB-Event Semantic Segmentation
arXiv:2505.01548v2 Announce Type: replace Abstract: Event cameras capture microsecond-level motion cues that complement RGB sensors. However, the prevailing paradigm of treating RGB-Event perception as a fusion problem is ill-posed, as it ignores the intrinsic (i) Spatiotemporal and (ii) Modal Misalignment, unlike other RGB-X sensing domains. To tackle these limitations, we recast RGB-Event segmentation from fusion to registration. We propose BRENet, a novel flow-guided bidirectional framework that adaptively matches correspondence between the asymmetric modalities. Specifically, it leverages temporally aligned optical flows as a coarse-grained guide, along with fine-grained event temporal features, to generate precise forward and backward pixel pairings for registration. This pairing mechanism converts the inherent motion lag into terms governed by flow estimation error, bridging modality gaps. Moreover, we introduce Motion-Enhanced Event Tensor (MET), a new representation that transforms sparse event streams into a dense, temporally coherent form. Extensive experiments on four large-scale datasets validate our approach, establishing flow-guided registration as a promising direction for RGB-Event segmentation. Our code is available at: https://github.com/zyaocoder/BRENet.
Automated Visual Attention Detection using Mobile Eye Tracking in Behavioral Classroom Studies
arXiv:2505.07552v2 Announce Type: replace Abstract: Teachers' visual attention and its distribution across the students in classrooms can constitute important implications for student engagement, achievement, and professional teacher training. Despite that, inferring the information about where and which student teachers focus on is not trivial. Mobile eye tracking can provide vital help to solve this issue; however, the use of mobile eye tracking alone requires a significant amount of manual annotations. To address this limitation, we present an automated processing pipeline concept that requires minimal manually annotated data to recognize which student the teachers focus on. To this end, we utilize state-of-the-art face detection models and face recognition feature embeddings to train face recognition models with transfer learning in the classroom context and combine these models with the teachers' gaze from mobile eye trackers. We evaluated our approach with data collected from four different classrooms, and our results show that while it is possible to estimate the visually focused students with reasonable performance in all of our classroom setups, U-shaped and small classrooms led to the best results with accuracies of approximately 0.7 and 0.9, respectively. While we did not evaluate our method for teacher-student interactions and focused on the validity of the technical approach, as our methodology does not require a vast amount of manually annotated data and offers a non-intrusive way of handling teachers' visual attention, it could help improve instructional strategies, enhance classroom management, and provide feedback for professional teacher development.
Instance-aware Image Colorization with Controllable Textual Descriptions and Segmentation Masks
arXiv:2505.08705v2 Announce Type: replace Abstract: Recently, the application of deep learning in image colorization has received widespread attention. The maturation of diffusion models has further advanced the development of image colorization models. However, current mainstream image colorization models still face issues such as color bleeding and color binding errors, and cannot colorize images at the instance level. In this paper, we propose a diffusion-based colorization method MT-Color to achieve precise instance-aware colorization with use-provided guidance. To tackle color bleeding issue, we design a pixel-level mask attention mechanism that integrates latent features and conditional gray image features through cross-attention. We use segmentation masks to construct cross-attention masks, preventing pixel information from exchanging between different instances. We also introduce an instance mask and text guidance module that extracts instance masks and text representations of each instance, which are then fused with latent features through self-attention, utilizing instance masks to form self-attention masks to prevent instance texts from guiding the colorization of other areas, thus mitigating color binding errors. Furthermore, we apply a multi-instance sampling strategy, which involves sampling each instance region separately and then fusing the results. Additionally, we have created a specialized dataset for instance-level colorization tasks, GPT-color, by leveraging large visual language models on existing image datasets. Qualitative and quantitative experiments show that our model and dataset outperform previous methods and datasets.
CONSIGN: Conformal Segmentation Informed by Spatial Groupings via Decomposition
arXiv:2505.14113v2 Announce Type: replace Abstract: Most machine learning-based image segmentation models produce pixel-wise confidence scores that represent the model's predicted probability for each class label at every pixel. While this information can be particularly valuable in high-stakes domains such as medical imaging, these scores are heuristic in nature and do not constitute rigorous quantitative uncertainty estimates. Conformal prediction (CP) provides a principled framework for transforming heuristic confidence scores into statistically valid uncertainty estimates. However, applying CP directly to image segmentation ignores the spatial correlations between pixels, a fundamental characteristic of image data. This can result in overly conservative and less interpretable uncertainty estimates. To address this, we propose CONSIGN (Conformal Segmentation Informed by Spatial Groupings via Decomposition), a CP-based method that incorporates spatial correlations to improve uncertainty quantification in image segmentation. Our method generates meaningful prediction sets that come with user-specified, high-probability error guarantees. It is compatible with any pre-trained segmentation model capable of generating multiple sample outputs. We evaluate CONSIGN against two CP baselines across three medical imaging datasets and two COCO dataset subsets, using three different pre-trained segmentation models. Results demonstrate that accounting for spatial structure significantly improves performance across multiple metrics and enhances the quality of uncertainty estimates.
MMaDA: Multimodal Large Diffusion Language Models
arXiv:2505.15809v2 Announce Type: replace Abstract: We introduce MMaDA, a novel class of multimodal diffusion foundation models designed to achieve superior performance across diverse domains such as textual reasoning, multimodal understanding, and text-to-image generation. The approach is distinguished by three key innovations: (i) MMaDA adopts a unified diffusion architecture with a shared probabilistic formulation and a modality-agnostic design, eliminating the need for modality-specific components. This architecture ensures seamless integration and processing across different data types. (ii) We implement a mixed long chain-of-thought (CoT) fine-tuning strategy that curates a unified CoT format across modalities. By aligning reasoning processes between textual and visual domains, this strategy facilitates cold-start training for the final reinforcement learning (RL) stage, thereby enhancing the model's ability to handle complex tasks from the outset. (iii) We propose UniGRPO, a unified policy-gradient-based RL algorithm specifically tailored for diffusion foundation models. Utilizing diversified reward modeling, UniGRPO unifies post-training across both reasoning and generation tasks, ensuring consistent performance improvements. Experimental results demonstrate that MMaDA-8B exhibits strong generalization capabilities as a unified multimodal foundation model. It surpasses powerful models like LLaMA-3-7B and Qwen2-7B in textual reasoning, outperforms Show-o and SEED-X in multimodal understanding, and excels over SDXL and Janus in text-to-image generation. These achievements highlight MMaDA's effectiveness in bridging the gap between pretraining and post-training within unified diffusion architectures, providing a comprehensive framework for future research and development. We open-source our code and trained models at: https://github.com/Gen-Verse/MMaDA
MME-VideoOCR: Evaluating OCR-Based Capabilities of Multimodal LLMs in Video Scenarios
arXiv:2505.21333v2 Announce Type: replace Abstract: Multimodal Large Language Models (MLLMs) have achieved considerable accuracy in Optical Character Recognition (OCR) from static images. However, their efficacy in video OCR is significantly diminished due to factors such as motion blur, temporal variations, and visual effects inherent in video content. To provide clearer guidance for training practical MLLMs, we introduce the MME-VideoOCR benchmark, which encompasses a comprehensive range of video OCR application scenarios. MME-VideoOCR features 10 task categories comprising 25 individual tasks and spans 44 diverse scenarios. These tasks extend beyond text recognition to incorporate deeper comprehension and reasoning of textual content within videos. The benchmark consists of 1,464 videos with varying resolutions, aspect ratios, and durations, along with 2,000 meticulously curated, manually annotated question-answer pairs. We evaluate 18 state-of-the-art MLLMs on MME-VideoOCR, revealing that even the best-performing model (Gemini-2.5 Pro) achieves an accuracy of only 73.7%. Fine-grained analysis indicates that while existing MLLMs demonstrate strong performance on tasks where relevant texts are contained within a single or few frames, they exhibit limited capability in effectively handling tasks that demand holistic video comprehension. These limitations are especially evident in scenarios that require spatio-temporal reasoning, cross-frame information integration, or resistance to language prior bias. Our findings also highlight the importance of high-resolution visual input and sufficient temporal coverage for reliable OCR in dynamic video scenarios.
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
arXiv:2505.23764v2 Announce Type: replace Abstract: Spatial intelligence is essential for multimodal large language models (MLLMs) operating in the complex physical world. Existing benchmarks, however, probe only single-image relations and thus fail to assess the multi-image spatial reasoning that real-world deployments demand. We introduce MMSI-Bench, a VQA benchmark dedicated to multi-image spatial intelligence. Six 3D-vision researchers spent more than 300 hours meticulously crafting 1,000 challenging, unambiguous multiple-choice questions from over 120,000 images, each paired with carefully designed distractors and a step-by-step reasoning process. We conduct extensive experiments and thoroughly evaluate 34 open-source and proprietary MLLMs, observing a wide gap: the strongest open-source model attains roughly 30% accuracy and OpenAI's o3 reasoning model reaches 40%, while humans score 97%. These results underscore the challenging nature of MMSI-Bench and the substantial headroom for future research. Leveraging the annotated reasoning processes, we also provide an automated error analysis pipeline that diagnoses four dominant failure modes, including (1) grounding errors, (2) overlap-matching and scene-reconstruction errors, (3) situation-transformation reasoning errors, and (4) spatial-logic errors, offering valuable insights for advancing multi-image spatial intelligence. Project page: https://runsenxu.com/projects/MMSI_Bench .
Beyond Quantity: Distribution-Aware Labeling for Visual Grounding
arXiv:2505.24372v2 Announce Type: replace Abstract: Visual grounding requires large and diverse region-text pairs. However, manual annotation is costly and fixed vocabularies restrict scalability and generalization. Existing pseudo-labeling pipelines often overfit to biased distributions and generate noisy or redundant samples. Through our systematic analysis of data quality and distributional coverage, we find that performance gains come less from raw data volume and more from effective distribution expansion. Motivated by this insight, we propose DAL, a distribution-aware labeling framework for visual grounding. The proposed method first employs a dual-driven annotation module, where a closed-set path provides reliable pseudo labels and an open-set path enriches vocabulary and introduces novel concepts; meanwhile, it further performs explicit out-of-distribution (OOD) expression expansion to broaden semantic coverage. We then propose a consistency- and distribution-aware filtering module to discard noisy or redundant region-text pairs and rebalance underrepresented linguistic and visual content, thereby improving both data quality and training efficiency. Extensive experiments on three benchmarks demonstrate that our method consistently outperforms strong baselines and achieves state-of-the-art results, underscoring the critical role of distribution-aware labeling in building scalable and robust visual grounding datasets.
ProstaTD: Bridging Surgical Triplet from Classification to Fully Supervised Detection
arXiv:2506.01130v2 Announce Type: replace Abstract: Surgical triplet detection is a critical task in surgical video analysis. However, existing datasets like CholecT50 lack precise spatial bounding box annotations, rendering triplet classification at the image level insufficient for practical applications. The inclusion of bounding box annotations is essential to make this task meaningful, as they provide the spatial context necessary for accurate analysis and improved model generalizability. To address these shortcomings, we introduce ProstaTD, a large-scale, multi-institutional dataset for surgical triplet detection, developed from the technically demanding domain of robot-assisted prostatectomy. ProstaTD offers clinically defined temporal boundaries and high-precision bounding box annotations for each structured triplet activity. The dataset comprises 71,775 video frames and 196,490 annotated triplet instances, collected from 21 surgeries performed across multiple institutions, reflecting a broad range of surgical practices and intraoperative conditions. The annotation process was conducted under rigorous medical supervision and involved more than 60 contributors, including practicing surgeons and medically trained annotators, through multiple iterative phases of labeling and verification. To further facilitate future general-purpose surgical annotation, we developed two tailored labeling tools to improve efficiency and scalability in our annotation workflows. In addition, we created a surgical triplet detection evaluation toolkit that enables standardized and reproducible performance assessment across studies. ProstaTD is the largest and most diverse surgical triplet dataset to date, moving the field from simple classification to full detection with precise spatial and temporal boundaries and thereby providing a robust foundation for fair benchmarking.
O-MaMa: Learning Object Mask Matching between Egocentric and Exocentric Views
arXiv:2506.06026v2 Announce Type: replace Abstract: Understanding the world from multiple perspectives is essential for intelligent systems operating together, where segmenting common objects across different views remains an open problem. We introduce a new approach that re-defines cross-image segmentation by treating it as a mask matching task. Our method consists of: (1) A Mask-Context Encoder that pools dense DINOv2 semantic features to obtain discriminative object-level representations from FastSAM mask candidates, (2) an Ego$\leftrightarrow$Exo Cross-Attention that fuses multi-perspective observations, (3) a Mask Matching contrastive loss that aligns cross-view features in a shared latent space, and (4) a Hard Negative Adjacent Mining strategy to encourage the model to better differentiate between nearby objects. O-MaMa achieves the state of the art in the Ego-Exo4D Correspondences benchmark, obtaining relative gains of +22% and +76% in the Ego2Exo and Exo2Ego IoU against the official challenge baselines, and a +13% and +6% compared with the SOTA with 1% of the training parameters.
Why Settle for One? Text-to-ImageSet Generation and Evaluation
arXiv:2506.23275v2 Announce Type: replace Abstract: Despite remarkable progress in Text-to-Image models, many real-world applications require generating coherent image sets with diverse consistency requirements. Existing consistent methods often focus on a specific domain with specific aspects of consistency, which significantly constrains their generalizability to broader applications. In this paper, we propose a more challenging problem, Text-to-ImageSet (T2IS) generation, which aims to generate sets of images that meet various consistency requirements based on user instructions. To systematically study this problem, we first introduce $\textbf{T2IS-Bench}$ with 596 diverse instructions across 26 subcategories, providing comprehensive coverage for T2IS generation. Building on this, we propose $\textbf{T2IS-Eval}$, an evaluation framework that transforms user instructions into multifaceted assessment criteria and employs effective evaluators to adaptively assess consistency fulfillment between criteria and generated sets. Subsequently, we propose $\textbf{AutoT2IS}$, a training-free framework that maximally leverages pretrained Diffusion Transformers' in-context capabilities to harmonize visual elements to satisfy both image-level prompt alignment and set-level visual consistency. Extensive experiments on T2IS-Bench reveal that diverse consistency challenges all existing methods, while our AutoT2IS significantly outperforms current generalized and even specialized approaches. Our method also demonstrates the ability to enable numerous underexplored real-world applications, confirming its substantial practical value. Visit our project in https://chengyou-jia.github.io/T2IS-Home.
3D-MoRe: Unified Modal-Contextual Reasoning for Embodied Question Answering
arXiv:2507.12026v2 Announce Type: replace Abstract: With the growing need for diverse and scalable data in indoor scene tasks, such as question answering and dense captioning, we propose 3D-MoRe, a novel paradigm designed to generate large-scale 3D-language datasets by leveraging the strengths of foundational models. The framework integrates key components, including multi-modal embedding, cross-modal interaction, and a language model decoder, to process natural language instructions and 3D scene data. This approach facilitates enhanced reasoning and response generation in complex 3D environments. Using the ScanNet 3D scene dataset, along with text annotations from ScanQA and ScanRefer, 3D-MoRe generates 62,000 question-answer (QA) pairs and 73,000 object descriptions across 1,513 scenes. We also employ various data augmentation techniques and implement semantic filtering to ensure high-quality data. Experiments on ScanQA demonstrate that 3D-MoRe significantly outperforms state-of-the-art baselines, with the CIDEr score improving by 2.15\%. Similarly, on ScanRefer, our approach achieves a notable increase in CIDEr@0.5 by 1.84\%, highlighting its effectiveness in both tasks. Our code and generated datasets will be publicly released to benefit the community, and both can be accessed on the https://3D-MoRe.github.io.
NoHumansRequired: Autonomous High-Quality Image Editing Triplet Mining
arXiv:2507.14119v2 Announce Type: replace Abstract: Recent advances in generative modeling enable image editing assistants that follow natural language instructions without additional user input. Their supervised training requires millions of triplets (original image, instruction, edited image), yet mining pixel-accurate examples is hard. Each edit must affect only prompt-specified regions, preserve stylistic coherence, respect physical plausibility, and retain visual appeal. The lack of robust automated edit-quality metrics hinders reliable automation at scale. We present an automated, modular pipeline that mines high-fidelity triplets across domains, resolutions, instruction complexities, and styles. Built on public generative models and running without human intervention, our system uses a task-tuned Gemini validator to score instruction adherence and aesthetics directly, removing any need for segmentation or grounding models. Inversion and compositional bootstrapping enlarge the mined set by approx. 2.6x, enabling large-scale high-fidelity training data. By automating the most repetitive annotation steps, the approach allows a new scale of training without human labeling effort. To democratize research in this resource-intensive area, we release NHR-Edit, an open dataset of 720k high-quality triplets, curated at industrial scale via millions of guided generations and validator passes, and we analyze the pipeline's stage-wise survival rates, providing a framework for estimating computational effort across different model stacks. In the largest cross-dataset evaluation, it surpasses all public alternatives. We also release Bagel-NHR-Edit, a fine-tuned Bagel model with state-of-the-art metrics.
Conditional Video Generation for High-Efficiency Video Compression
arXiv:2507.15269v4 Announce Type: replace Abstract: Perceptual studies demonstrate that conditional diffusion models excel at reconstructing video content aligned with human visual perception. Building on this insight, we propose a video compression framework that leverages conditional diffusion models for perceptually optimized reconstruction. Specifically, we reframe video compression as a conditional generation task, where a generative model synthesizes video from sparse, yet informative signals. Our approach introduces three key modules: (1) Multi-granular conditioning that captures both static scene structure and dynamic spatio-temporal cues; (2) Compact representations designed for efficient transmission without sacrificing semantic richness; (3) Multi-condition training with modality dropout and role-aware embeddings, which prevent over-reliance on any single modality and enhance robustness. Extensive experiments show that our method significantly outperforms both traditional and neural codecs on perceptual quality metrics such as Fr\'echet Video Distance (FVD) and LPIPS, especially under high compression ratios.
GeMix: Conditional GAN-Based Mixup for Improved Medical Image Augmentation
arXiv:2507.15577v2 Announce Type: replace Abstract: Mixup has become a popular augmentation strategy for image classification, yet its naive pixel-wise interpolation often produces unrealistic images that can hinder learning, particularly in high-stakes medical applications. We propose GeMix, a two-stage framework that replaces heuristic blending with a learned, label-aware interpolation powered by class-conditional GANs. First, a StyleGAN2-ADA generator is trained on the target dataset. During augmentation, we sample two label vectors from Dirichlet priors biased toward different classes and blend them via a Beta-distributed coefficient. Then, we condition the generator on this soft label to synthesize visually coherent images that lie along a continuous class manifold. We benchmark GeMix on the large-scale COVIDx-CT-3 dataset using three backbones (ResNet-50, ResNet-101, EfficientNet-B0). When combined with real data, our method increases macro-F1 over traditional mixup for all backbones, reducing the false negative rate for COVID-19 detection. GeMix is thus a drop-in replacement for pixel-space mixup, delivering stronger regularization and greater semantic fidelity, without disrupting existing training pipelines. We publicly release our code at https://github.com/hugocarlesso/GeMix to foster reproducibility and further research.
CNS-Bench: Benchmarking Image Classifier Robustness Under Continuous Nuisance Shifts
arXiv:2507.17651v2 Announce Type: replace Abstract: An important challenge when using computer vision models in the real world is to evaluate their performance in potential out-of-distribution (OOD) scenarios. While simple synthetic corruptions are commonly applied to test OOD robustness, they often fail to capture nuisance shifts that occur in the real world. Recently, diffusion models have been applied to generate realistic images for benchmarking, but they are restricted to binary nuisance shifts. In this work, we introduce CNS-Bench, a Continuous Nuisance Shift Benchmark to quantify OOD robustness of image classifiers for continuous and realistic generative nuisance shifts. CNS-Bench allows generating a wide range of individual nuisance shifts in continuous severities by applying LoRA adapters to diffusion models. To address failure cases, we propose a filtering mechanism that outperforms previous methods, thereby enabling reliable benchmarking with generative models. With the proposed benchmark, we perform a large-scale study to evaluate the robustness of more than 40 classifiers under various nuisance shifts. Through carefully designed comparisons and analyses, we find that model rankings can change for varying shifts and shift scales, which cannot be captured when applying common binary shifts. Additionally, we show that evaluating the model performance on a continuous scale allows the identification of model failure points, providing a more nuanced understanding of model robustness. Project page including code and data: https://genintel.github.io/CNS.
RIS-LAD: A Benchmark and Model for Referring Low-Altitude Drone Image Segmentation
arXiv:2507.20920v2 Announce Type: replace Abstract: Referring Image Segmentation (RIS), which aims to segment specific objects based on natural language descriptions, plays an essential role in vision-language understanding. Despite its progress in remote sensing applications, RIS in Low-Altitude Drone (LAD) scenarios remains underexplored. Existing datasets and methods are typically designed for high-altitude and static-view imagery. They struggle to handle the unique characteristics of LAD views, such as diverse viewpoints and high object density. To fill this gap, we present RIS-LAD, the first fine-grained RIS benchmark tailored for LAD scenarios. This dataset comprises 13,871 carefully annotated image-text-mask triplets collected from realistic drone footage, with a focus on small, cluttered, and multi-viewpoint scenes. It highlights new challenges absent in previous benchmarks, such as category drift caused by tiny objects and object drift under crowded same-class objects. To tackle these issues, we propose the Semantic-Aware Adaptive Reasoning Network (SAARN). Rather than uniformly injecting all linguistic features, SAARN decomposes and routes semantic information to different stages of the network. Specifically, the Category-Dominated Linguistic Enhancement (CDLE) aligns visual features with object categories during early encoding, while the Adaptive Reasoning Fusion Module (ARFM) dynamically selects semantic cues across scales to improve reasoning in complex scenes. The experimental evaluation reveals that RIS-LAD presents substantial challenges to state-of-the-art RIS algorithms, and also demonstrates the effectiveness of our proposed model in addressing these challenges. The dataset and code will be publicly released soon at: https://github.com/AHideoKuzeA/RIS-LAD/.
CLIPin: A Non-contrastive Plug-in to CLIP for Multimodal Semantic Alignment
arXiv:2508.06434v2 Announce Type: replace Abstract: Large-scale natural image-text datasets, especially those automatically collected from the web, often suffer from loose semantic alignment due to weak supervision, while medical datasets tend to have high cross-modal correlation but low content diversity. These properties pose a common challenge for contrastive language-image pretraining (CLIP): they hinder the model's ability to learn robust and generalizable representations. In this work, we propose CLIPin, a unified non-contrastive plug-in that can be seamlessly integrated into CLIP-style architectures to improve multimodal semantic alignment, providing stronger supervision and enhancing alignment robustness. Furthermore, two shared pre-projectors are designed for image and text modalities respectively to facilitate the integration of contrastive and non-contrastive learning in a parameter-compromise manner. Extensive experiments on diverse downstream tasks demonstrate the effectiveness and generality of CLIPin as a plug-and-play component compatible with various contrastive frameworks. Code is available at https://github.com/T6Yang/CLIPin.
Semantic-Aware Reconstruction Error for Detecting AI-Generated Images
arXiv:2508.09487v2 Announce Type: replace Abstract: Recently, AI-generated image detection has gained increasing attention, as the rapid advancement of image generation technologies has raised serious concerns about their potential misuse. While existing detection methods have achieved promising results, their performance often degrades significantly when facing fake images from unseen, out-of-distribution (OOD) generative models, since they primarily rely on model-specific artifacts and thus overfit to the models used for training. To address this limitation, we propose a novel representation, namely Semantic-Aware Reconstruction Error (SARE), that measures the semantic difference between an image and its caption-guided reconstruction. The key hypothesis behind SARE is that real images, whose captions often fail to fully capture their complex visual content, may undergo noticeable semantic shifts during the caption-guided reconstruction process. In contrast, fake images, which closely align with their captions, show minimal semantic changes. By quantifying these semantic shifts, SARE provides a robust and discriminative feature for detecting fake images across diverse generative models. Additionally, we introduce a fusion module that integrates SARE into the backbone detector via a cross-attention mechanism. Image features attend to semantic representations extracted from SARE, enabling the model to adaptively leverage semantic information. Experimental results demonstrate that the proposed method achieves strong generalization, outperforming existing baselines on benchmarks including GenImage and ForenSynths. We further validate the effectiveness of caption guidance through a detailed analysis of semantic shifts, confirming its ability to enhance detection robustness.
D2-Mamba: Dual-Scale Fusion and Dual-Path Scanning with SSMs for Shadow Removal
arXiv:2508.12750v3 Announce Type: replace Abstract: Shadow removal aims to restore images that are partially degraded by shadows, where the degradation is spatially localized and non-uniform. Unlike general restoration tasks that assume global degradation, shadow removal can leverage abundant information from non-shadow regions for guidance. However, the transformation required to correct shadowed areas often differs significantly from that of well-lit regions, making it challenging to apply uniform correction strategies. This necessitates the effective integration of non-local contextual cues and adaptive modeling of region-specific transformations. To this end, we propose a novel Mamba-based network featuring dual-scale fusion and dual-path scanning to selectively propagate contextual information based on transformation similarity across regions. Specifically, the proposed Dual-Scale Fusion Mamba Block (DFMB) enhances multi-scale feature representation by fusing original features with low-resolution features, effectively reducing boundary artifacts. The Dual-Path Mamba Group (DPMG) captures global features via horizontal scanning and incorporates a mask-aware adaptive scanning strategy, which improves structural continuity and fine-grained region modeling. Experimental results demonstrate that our method significantly outperforms existing state-of-the-art approaches on shadow removal benchmarks.
Odo: Depth-Guided Diffusion for Identity-Preserving Body Reshaping
arXiv:2508.13065v3 Announce Type: replace Abstract: Human shape editing enables controllable transformation of a person's body shape, such as thin, muscular, or overweight, while preserving pose, identity, clothing, and background. Unlike human pose editing, which has advanced rapidly, shape editing remains relatively under-explored. Current approaches typically rely on 3D morphable models or image warping, often introducing unrealistic body proportions, texture distortions, and background inconsistencies due to alignment errors and deformations. A key limitation is the lack of large-scale, publicly available datasets for training and evaluating body shape manipulation methods. In this work, we introduce the first large-scale dataset of 18,573 images across 1523 subjects, specifically designed for controlled human shape editing. It features diverse variations in body shape, including fat, muscular and thin, captured under consistent identity, clothing, and background conditions. Using this dataset, we propose Odo, an end-to-end diffusion-based method that enables realistic and intuitive body reshaping guided by simple semantic attributes. Our approach combines a frozen UNet that preserves fine-grained appearance and background details from the input image with a ControlNet that guides shape transformation using target SMPL depth maps. Extensive experiments demonstrate that our method outperforms prior approaches, achieving per-vertex reconstruction errors as low as 7.5mm, significantly lower than the 13.6mm observed in baseline methods, while producing realistic results that accurately match the desired target shapes.
FastTracker: Real-Time and Accurate Visual Tracking
arXiv:2508.14370v5 Announce Type: replace Abstract: Conventional multi-object tracking (MOT) systems are predominantly designed for pedestrian tracking and often exhibit limited generalization to other object categories. This paper presents a generalized tracking framework capable of handling multiple object types, with a particular emphasis on vehicle tracking in complex traffic scenes. The proposed method incorporates two key components: (1) an occlusion-aware re-identification mechanism that enhances identity preservation for heavily occluded objects, and (2) a road-structure-aware tracklet refinement strategy that utilizes semantic scene priors such as lane directions, crosswalks, and road boundaries to improve trajectory continuity and accuracy. In addition, we introduce a new benchmark dataset comprising diverse vehicle classes with frame-level tracking annotations, specifically curated to support evaluation of vehicle-focused tracking methods. Extensive experimental results demonstrate that the proposed approach achieves robust performance on both the newly introduced dataset and several public benchmarks, highlighting its effectiveness in general-purpose object tracking. While our framework is designed for generalized multi-class tracking, it also achieves strong performance on conventional benchmarks, with HOTA scores of 66.4 on MOT17 and 65.7 on MOT20 test sets. Code and Benchmark are available: github.com/Hamidreza-Hashempoor/FastTracker, huggingface.co/datasets/Hamidreza-Hashemp/FastTracker-Benchmark.
Multimodal Deep Learning for Phyllodes Tumor Classification from Ultrasound and Clinical Data
arXiv:2509.00213v2 Announce Type: replace Abstract: Phyllodes tumors (PTs) are rare fibroepithelial breast lesions that are difficult to classify preoperatively due to their radiological similarity to benign fibroadenomas. This often leads to unnecessary surgical excisions. To address this, we propose a multimodal deep learning framework that integrates breast ultrasound (BUS) images with structured clinical data to improve diagnostic accuracy. We developed a dual-branch neural network that extracts and fuses features from ultrasound images and patient metadata from 81 subjects with confirmed PTs. Class-aware sampling and subject-stratified 5-fold cross-validation were applied to prevent class imbalance and data leakage. The results show that our proposed multimodal method outperforms unimodal baselines in classifying benign versus borderline/malignant PTs. Among six image encoders, ConvNeXt and ResNet18 achieved the best performance in the multimodal setting, with AUC-ROC scores of 0.9427 and 0.9349, and F1-scores of 0.6720 and 0.7294, respectively. This study demonstrates the potential of multimodal AI to serve as a non-invasive diagnostic tool, reducing unnecessary biopsies and improving clinical decision-making in breast tumor management.
Multimodal Iterative RAG for Knowledge-Intensive Visual Question Answering
arXiv:2509.00798v3 Announce Type: replace Abstract: Recent advances in Multimodal Large Language Models~(MLLMs) have significantly enhanced the ability of these models in multimodal understanding and reasoning. However, the performance of MLLMs for knowledge-intensive visual questions, which require external knowledge beyond the visual content of an image, still remains limited. While Retrieval-Augmented Generation (RAG) has become a promising solution to provide models with external knowledge, its conventional single-pass framework often fails to gather sufficient knowledge. To overcome this limitation, we propose MI-RAG, a Multimodal Iterative RAG framework that leverages reasoning to enhance retrieval and incorporates knowledge synthesis to refine its understanding. At each iteration, the model formulates a reasoning-guided multi-query to explore multiple facets of knowledge. Subsequently, these queries drive a joint search across heterogeneous knowledge bases, retrieving diverse knowledge. This retrieved knowledge is then synthesized to enrich the reasoning record, progressively deepening the model's understanding. Experiments on challenging benchmarks, including Encyclopedic VQA, InfoSeek, and OK-VQA, show that MI-RAG significantly improves both retrieval recall and answer accuracy, establishing a scalable approach for compositional reasoning in knowledge-intensive VQA.
P3-SAM: Native 3D Part Segmentation
arXiv:2509.06784v4 Announce Type: replace Abstract: Segmenting 3D assets into their constituent parts is crucial for enhancing 3D understanding, facilitating model reuse, and supporting various applications such as part generation. However, current methods face limitations such as poor robustness when dealing with complex objects and cannot fully automate the process. In this paper, we propose a native 3D point-promptable part segmentation model termed P$^3$-SAM, designed to fully automate the segmentation of any 3D objects into components. Inspired by SAM, P$^3$-SAM consists of a feature extractor, multiple segmentation heads, and an IoU predictor, enabling interactive segmentation for users. We also propose an algorithm to automatically select and merge masks predicted by our model for part instance segmentation. Our model is trained on a newly built dataset containing nearly 3.7 million models with reasonable segmentation labels. Comparisons show that our method achieves precise segmentation results and strong robustness on any complex objects, attaining state-of-the-art performance. Our project page is available at https://murcherful.github.io/P3-SAM/.
Implicit Neural Representations of Intramyocardial Motion and Strain
arXiv:2509.09004v4 Announce Type: replace Abstract: Automatic quantification of intramyocardial motion and strain from tagging MRI remains an important but challenging task. We propose a method using implicit neural representations (INRs), conditioned on learned latent codes, to predict continuous left ventricular (LV) displacement -- without requiring inference-time optimisation. Evaluated on 452 UK Biobank test cases, our method achieved the best tracking accuracy (2.14 mm RMSE) and the lowest combined error in global circumferential (2.86%) and radial (6.42%) strain compared to three deep learning baselines. In addition, our method is $\sim$380$\times$ faster than the most accurate baseline. These results highlight the suitability of INR-based models for accurate and scalable analysis of myocardial strain in large CMR datasets. The code can be found at https://github.com/andrewjackbell/Displacement-INR
LazyDrag: Enabling Stable Drag-Based Editing on Multi-Modal Diffusion Transformers via Explicit Correspondence
arXiv:2509.12203v2 Announce Type: replace Abstract: The reliance on implicit point matching via attention has become a core bottleneck in drag-based editing, resulting in a fundamental compromise on weakened inversion strength and costly test-time optimization (TTO). This compromise severely limits the generative capabilities of diffusion models, suppressing high-fidelity inpainting and text-guided creation. In this paper, we introduce LazyDrag, the first drag-based image editing method for Multi-Modal Diffusion Transformers, which directly eliminates the reliance on implicit point matching. In concrete terms, our method generates an explicit correspondence map from user drag inputs as a reliable reference to boost the attention control. This reliable reference opens the potential for a stable full-strength inversion process, which is the first in the drag-based editing task. It obviates the necessity for TTO and unlocks the generative capability of models. Therefore, LazyDrag naturally unifies precise geometric control with text guidance, enabling complex edits that were previously out of reach: opening the mouth of a dog and inpainting its interior, generating new objects like a ``tennis ball'', or for ambiguous drags, making context-aware changes like moving a hand into a pocket. Additionally, LazyDrag supports multi-round workflows with simultaneous move and scale operations. Evaluated on the DragBench, our method outperforms baselines in drag accuracy and perceptual quality, as validated by VIEScore and human evaluation. LazyDrag not only establishes new state-of-the-art performance, but also paves a new way to editing paradigms.
MoCLIP-Lite: Efficient Video Recognition by Fusing CLIP with Motion Vectors
arXiv:2509.17084v2 Announce Type: replace Abstract: Video action recognition is a fundamental task in computer vision, but state-of-the-art models are often computationally expensive and rely on extensive video pre-training. In parallel, large-scale vision-language models like Contrastive Language-Image Pre-training (CLIP) offer powerful zero-shot capabilities on static images, while motion vectors (MV) provide highly efficient temporal information directly from compressed video streams. To synergize the strengths of these paradigms, we propose MoCLIP-Lite, a simple yet powerful two-stream late fusion framework for efficient video recognition. Our approach combines features from a frozen CLIP image encoder with features from a lightweight, supervised network trained on raw MV. During fusion, both backbones are frozen, and only a tiny Multi-Layer Perceptron (MLP) head is trained, ensuring extreme efficiency. Through comprehensive experiments on the UCF101 dataset, our method achieves a remarkable 89.2% Top-1 accuracy, significantly outperforming strong zero-shot (65.0%) and MV-only (66.5%) baselines. Our work provides a new, highly efficient baseline for video understanding that effectively bridges the gap between large static models and dynamic, low-cost motion cues. Our code and models are available at https://github.com/microa/MoCLIP-Lite.
Neurodynamics-Driven Coupled Neural P Systems for Multi-Focus Image Fusion
arXiv:2509.17704v2 Announce Type: replace Abstract: Multi-focus image fusion (MFIF) is a crucial technique in image processing, with a key challenge being the generation of decision maps with precise boundaries. However, traditional methods based on heuristic rules and deep learning methods with black-box mechanisms are difficult to generate high-quality decision maps. To overcome this challenge, we introduce neurodynamics-driven coupled neural P (CNP) systems, which are third-generation neural computation models inspired by spiking mechanisms, to enhance the accuracy of decision maps. Specifically, we first conduct an in-depth analysis of the model's neurodynamics to identify the constraints between the network parameters and the input signals. This solid analysis avoids abnormal continuous firing of neurons and ensures the model accurately distinguishes between focused and unfocused regions, generating high-quality decision maps for MFIF. Based on this analysis, we propose a Neurodynamics-Driven CNP Fusion model (ND-CNPFuse) tailored for the challenging MFIF task. Unlike current ideas of decision map generation, ND-CNPFuse distinguishes between focused and unfocused regions by mapping the source image into interpretable spike matrices. By comparing the number of spikes, an accurate decision map can be generated directly without any post-processing. Extensive experimental results show that ND-CNPFuse achieves new state-of-the-art performance on four classical MFIF datasets, including Lytro, MFFW, MFI-WHU, and Real-MFF. The code is available at https://github.com/MorvanLi/ND-CNPFuse.
TempSamp-R1: Effective Temporal Sampling with Reinforcement Fine-Tuning for Video LLMs
arXiv:2509.18056v2 Announce Type: replace Abstract: This paper introduces TempSamp-R1, a new reinforcement fine-tuning framework designed to improve the effectiveness of adapting multimodal large language models (MLLMs) to video temporal grounding tasks. We reveal that existing reinforcement learning methods, such as Group Relative Policy Optimization (GRPO), rely on on-policy sampling for policy updates. However, in tasks with large temporal search spaces, this strategy becomes both inefficient and limited in performance, as it often fails to identify temporally accurate solutions. To address this limitation, TempSamp-R1 leverages ground-truth annotations as off-policy supervision to provide temporally precise guidance, effectively compensating for the sparsity and misalignment in on-policy solutions. To further stabilize training and reduce variance in reward-based updates, TempSamp-R1 provides a non-linear soft advantage computation method that dynamically reshapes the reward feedback via an asymmetric transformation. By employing a hybrid Chain-of-Thought (CoT) training paradigm, TempSamp-R1 optimizes a single unified model to support both CoT and non-CoT inference modes, enabling efficient handling of queries with varying reasoning complexity. Experimental results demonstrate that TempSamp-R1 outperforms GRPO-based baselines, establishing new state-of-the-art performance on benchmark datasets: Charades-STA (R1@0.7: 52.9%, +2.7%), ActivityNet Captions (R1@0.5: 56.0%, +5.3%), and QVHighlights (mAP: 30.0%, +3.0%). Moreover, TempSamp-R1 shows robust few-shot generalization capabilities under limited data. Code: https://github.com/HVision-NKU/TempSamp-R1
HazeFlow: Revisit Haze Physical Model as ODE and Non-Homogeneous Haze Generation for Real-World Dehazing
arXiv:2509.18190v2 Announce Type: replace Abstract: Dehazing involves removing haze or fog from images to restore clarity and improve visibility by estimating atmospheric scattering effects. While deep learning methods show promise, the lack of paired real-world training data and the resulting domain gap hinder generalization to real-world scenarios. In this context, physics-grounded learning becomes crucial; however, traditional methods based on the Atmospheric Scattering Model (ASM) often fall short in handling real-world complexities and diverse haze patterns. To solve this problem, we propose HazeFlow, a novel ODE-based framework that reformulates ASM as an ordinary differential equation (ODE). Inspired by Rectified Flow (RF), HazeFlow learns an optimal ODE trajectory to map hazy images to clean ones, enhancing real-world dehazing performance with only a single inference step. Additionally, we introduce a non-homogeneous haze generation method using Markov Chain Brownian Motion (MCBM) to address the scarcity of paired real-world data. By simulating realistic haze patterns through MCBM, we enhance the adaptability of HazeFlow to diverse real-world scenarios. Through extensive experiments, we demonstrate that HazeFlow achieves state-of-the-art performance across various real-world dehazing benchmark datasets.
Understanding-in-Generation: Reinforcing Generative Capability of Unified Model via Infusing Understanding into Generation
arXiv:2509.18639v3 Announce Type: replace Abstract: Recent works have made notable advancements in enhancing unified models for text-to-image generation through the Chain-of-Thought (CoT). However, these reasoning methods separate the processes of understanding and generation, which limits their ability to guide the reasoning of unified models in addressing the deficiencies of their generative capabilities. To this end, we propose a novel reasoning framework for unified models, Understanding-in-Generation (UiG), which harnesses the robust understanding capabilities of unified models to reinforce their performance in image generation. The core insight of our UiG is to integrate generative guidance by the strong understanding capabilities during the reasoning process, thereby mitigating the limitations of generative abilities. To achieve this, we introduce "Image Editing" as a bridge to infuse understanding into the generation process. Initially, we verify the generated image and incorporate the understanding of unified models into the editing instructions. Subsequently, we enhance the generated image step by step, gradually infusing the understanding into the generation process. Our UiG framework demonstrates a significant performance improvement in text-to-image generation over existing text-to-image reasoning methods, e.g., a 3.92% gain on the long prompt setting of the TIIF benchmark. The project code: https://github.com/QC-LY/UiG
Failure Makes the Agent Stronger: Enhancing Accuracy through Structured Reflection for Reliable Tool Interactions
arXiv:2509.18847v2 Announce Type: replace Abstract: Tool-augmented large language models (LLMs) are usually trained with supervised imitation or coarse-grained reinforcement learning that optimizes single tool calls. Current self-reflection practices rely on heuristic prompts or one-way reasoning: the model is urged to 'think more' instead of learning error diagnosis and repair. This is fragile in multi-turn interactions; after a failure the model often repeats the same mistake. We propose structured reflection, which turns the path from error to repair into an explicit, controllable, and trainable action. The agent produces a short yet precise reflection: it diagnoses the failure using evidence from the previous step and then proposes a correct, executable follow-up call. For training we combine DAPO and GSPO objectives with a reward scheme tailored to tool use, optimizing the stepwise strategy Reflect, then Call, then Final. To evaluate, we introduce Tool-Reflection-Bench, a lightweight benchmark that programmatically checks structural validity, executability, parameter correctness, and result consistency. Tasks are built as mini trajectories of erroneous call, reflection, and corrected call, with disjoint train and test splits. Experiments on BFCL v3 and Tool-Reflection-Bench show large gains in multi-turn tool-call success and error recovery, and a reduction of redundant calls. These results indicate that making reflection explicit and optimizing it directly improves the reliability of tool interaction and offers a reproducible path for agents to learn from failure.
StrCGAN: A Generative Framework for Stellar Image Restoration
arXiv:2509.19805v2 Announce Type: replace Abstract: We introduce StrCGAN (Stellar Cyclic GAN), a generative model designed to enhance low-resolution astrophotography images. Our goal is to reconstruct high-fidelity ground truth-like representations of celestial objects, a task that is challenging due to the limited resolution and quality of small-telescope observations such as the MobilTelesco dataset. Traditional models such as CycleGAN provide a foundation for image-to-image translation but are restricted to 2D mappings and often distort the morphology of stars and galaxies. To overcome these limitations, we extend the CycleGAN framework with three key innovations: 3D convolutional layers to capture volumetric spatial correlations, multi-spectral fusion to align optical and near-infrared (NIR) domains, and astrophysical regularization modules to preserve stellar morphology. Ground-truth references from multi-mission all-sky surveys spanning optical to NIR guide the training process, ensuring that reconstructions remain consistent across spectral bands. Together, these components allow StrCGAN to generate reconstructions that are not only visually sharper but also physically consistent, outperforming standard GAN models in the task of astrophysical image enhancement.
Interpreting ResNet-based CLIP via Neuron-Attention Decomposition
arXiv:2509.19943v2 Announce Type: replace Abstract: We present a novel technique for interpreting the neurons in CLIP-ResNet by decomposing their contributions to the output into individual computation paths. More specifically, we analyze all pairwise combinations of neurons and the following attention heads of CLIP's attention-pooling layer. We find that these neuron-head pairs can be approximated by a single direction in CLIP-ResNet's image-text embedding space. Leveraging this insight, we interpret each neuron-head pair by associating it with text. Additionally, we find that only a sparse set of the neuron-head pairs have a significant contribution to the output value, and that some neuron-head pairs, while polysemantic, represent sub-concepts of their corresponding neurons. We use these observations for two applications. First, we employ the pairs for training-free semantic segmentation, outperforming previous methods for CLIP-ResNet. Second, we utilize the contributions of neuron-head pairs to monitor dataset distribution shifts. Our results demonstrate that examining individual computation paths in neural networks uncovers interpretable units, and that such units can be utilized for downstream tasks.
OmniScene: Attention-Augmented Multimodal 4D Scene Understanding for Autonomous Driving
arXiv:2509.19973v2 Announce Type: replace Abstract: Human vision is capable of transforming two-dimensional observations into an egocentric three-dimensional scene understanding, which underpins the ability to translate complex scenes and exhibit adaptive behaviors. This capability, however, remains lacking in current autonomous driving systems, where mainstream approaches primarily rely on depth-based 3D reconstruction rather than true scene understanding. To address this limitation, we propose a novel human-like framework called OmniScene. First, we introduce the OmniScene Vision-Language Model (OmniVLM), a vision-language framework that integrates multi-view and temporal perception for holistic 4D scene understanding. Then, harnessing a teacher-student OmniVLM architecture and knowledge distillation, we embed textual representations into 3D instance features for semantic supervision, enriching feature learning, and explicitly capturing human-like attentional semantics. These feature representations are further aligned with human driving behaviors, forming a more human-like perception-understanding-action architecture. In addition, we propose a Hierarchical Fusion Strategy (HFS) to address imbalances in modality contributions during multimodal integration. Our approach adaptively calibrates the relative significance of geometric and semantic features at multiple abstraction levels, enabling the synergistic use of complementary cues from visual and textual modalities. This learnable dynamic fusion enables a more nuanced and effective exploitation of heterogeneous information. We evaluate OmniScene comprehensively on the nuScenes dataset, benchmarking it against over ten state-of-the-art models across various tasks. Our approach consistently achieves superior results, establishing new benchmarks in perception, prediction, planning, and visual question answering.
Does the Manipulation Process Matter? RITA: Reasoning Composite Image Manipulations via Reversely-Ordered Incremental-Transition Autoregression
arXiv:2509.20006v2 Announce Type: replace Abstract: Image manipulations often entail a complex manipulation process, comprising a series of editing operations to create a deceptive image, exhibiting sequentiality and hierarchical characteristics. However, existing IML methods remain manipulation-process-agnostic, directly producing localization masks in a one-shot prediction paradigm without modeling the underlying editing steps. This one-shot paradigm compresses the high-dimensional compositional space into a single binary mask, inducing severe dimensional collapse, thereby creating a fundamental mismatch with the intrinsic nature of the IML task. To address this, we are the first to reformulate image manipulation localization as a conditional sequence prediction task, proposing the RITA framework. RITA predicts manipulated regions layer-by-layer in an ordered manner, using each step's prediction as the condition for the next, thereby explicitly modeling temporal dependencies and hierarchical structures among editing operations. To enable training and evaluation, we synthesize multi-step manipulation data and construct a new benchmark HSIM. We further propose the HSS metric to assess sequential order and hierarchical alignment. Extensive experiments show RITA achieves SOTA on traditional benchmarks and provides a solid foundation for the novel hierarchical localization task, validating its potential as a general and effective paradigm. The code and dataset will be publicly available.
Hyperspectral Adapter for Semantic Segmentation with Vision Foundation Models
arXiv:2509.20107v2 Announce Type: replace Abstract: Hyperspectral imaging (HSI) captures spatial information along with dense spectral measurements across numerous narrow wavelength bands. This rich spectral content has the potential to facilitate robust robotic perception, particularly in environments with complex material compositions, varying illumination, or other visually challenging conditions. However, current HSI semantic segmentation methods underperform due to their reliance on architectures and learning frameworks optimized for RGB inputs. In this work, we propose a novel hyperspectral adapter that leverages pretrained vision foundation models to effectively learn from hyperspectral data. Our architecture incorporates a spectral transformer and a spectrum-aware spatial prior module to extract rich spatial-spectral features. Additionally, we introduce a modality-aware interaction block that facilitates effective integration of hyperspectral representations and frozen vision Transformer features through dedicated extraction and injection mechanisms. Extensive evaluations on three benchmark autonomous driving datasets demonstrate that our architecture achieves state-of-the-art semantic segmentation performance while directly using HSI inputs, outperforming both vision-based and hyperspectral segmentation methods. We make the code available at https://hsi-adapter.cs.uni-freiburg.de.
Least Volume Analysis
arXiv:2404.17773v2 Announce Type: replace-cross Abstract: This paper introduces Least Volume (LV)--a simple yet effective regularization method inspired by geometric intuition--that reduces the number of latent dimensions required by an autoencoder without prior knowledge of the dataset's intrinsic dimensionality. We show that its effectiveness depends on the Lipschitz continuity of the decoder, prove that Principal Component Analysis (PCA) is a linear special case, and demonstrate that LV induces a PCA-like importance ordering in nonlinear models. We extend LV to non-Euclidean settings as Generalized Least Volume (GLV), enabling the integration of label information into the latent representation. To support implementation, we also develop an accompanying Dynamic Pruning algorithm. We evaluate LV on several benchmark problems, demonstrating its effectiveness in dimension reduction. Leveraging this, we reveal the role of low-dimensional latent spaces in data sampling and disentangled representation, and use them to probe the varying topological complexity of various datasets. GLV is further applied to labeled datasets, where it induces a contrastive learning effect in representations of discrete labels. On a continuous-label airfoil dataset, it produces representations that lead to smooth changes in aerodynamic performance, thereby stabilizing downstream optimization.
EC-Diffuser: Multi-Object Manipulation via Entity-Centric Behavior Generation
arXiv:2412.18907v3 Announce Type: replace-cross Abstract: Object manipulation is a common component of everyday tasks, but learning to manipulate objects from high-dimensional observations presents significant challenges. These challenges are heightened in multi-object environments due to the combinatorial complexity of the state space as well as of the desired behaviors. While recent approaches have utilized large-scale offline data to train models from pixel observations, achieving performance gains through scaling, these methods struggle with compositional generalization in unseen object configurations with constrained network and dataset sizes. To address these issues, we propose a novel behavioral cloning (BC) approach that leverages object-centric representations and an entity-centric Transformer with diffusion-based optimization, enabling efficient learning from offline image data. Our method first decomposes observations into an object-centric representation, which is then processed by our entity-centric Transformer that computes attention at the object level, simultaneously predicting object dynamics and the agent's actions. Combined with the ability of diffusion models to capture multi-modal behavior distributions, this results in substantial performance improvements in multi-object tasks and, more importantly, enables compositional generalization. We present BC agents capable of zero-shot generalization to tasks with novel compositions of objects and goals, including larger numbers of objects than seen during training. We provide video rollouts on our webpage: https://sites.google.com/view/ec-diffuser.
AnyPlace: Learning Generalized Object Placement for Robot Manipulation
arXiv:2502.04531v2 Announce Type: replace-cross Abstract: Object placement in robotic tasks is inherently challenging due to the diversity of object geometries and placement configurations. To address this, we propose AnyPlace, a two-stage method trained entirely on synthetic data, capable of predicting a wide range of feasible placement poses for real-world tasks. Our key insight is that by leveraging a Vision-Language Model (VLM) to identify rough placement locations, we focus only on the relevant regions for local placement, which enables us to train the low-level placement-pose-prediction model to capture diverse placements efficiently. For training, we generate a fully synthetic dataset of randomly generated objects in different placement configurations (insertion, stacking, hanging) and train local placement-prediction models. We conduct extensive evaluations in simulation, demonstrating that our method outperforms baselines in terms of success rate, coverage of possible placement modes, and precision. In real-world experiments, we show how our approach directly transfers models trained purely on synthetic data to the real world, where it successfully performs placements in scenarios where other models struggle -- such as with varying object geometries, diverse placement modes, and achieving high precision for fine placement. More at: https://any-place.github.io.
Online Language Splatting
arXiv:2503.09447v3 Announce Type: replace-cross Abstract: To enable AI agents to interact seamlessly with both humans and 3D environments, they must not only perceive the 3D world accurately but also align human language with 3D spatial representations. While prior work has made significant progress by integrating language features into geometrically detailed 3D scene representations using 3D Gaussian Splatting (GS), these approaches rely on computationally intensive offline preprocessing of language features for each input image, limiting adaptability to new environments. In this work, we introduce Online Language Splatting, the first framework to achieve online, near real-time, open-vocabulary language mapping within a 3DGS-SLAM system without requiring pre-generated language features. The key challenge lies in efficiently fusing high-dimensional language features into 3D representations while balancing the computation speed, memory usage, rendering quality and open-vocabulary capability. To this end, we innovatively design: (1) a high-resolution CLIP embedding module capable of generating detailed language feature maps in 18ms per frame, (2) a two-stage online auto-encoder that compresses 768-dimensional CLIP features to 15 dimensions while preserving open-vocabulary capabilities, and (3) a color-language disentangled optimization approach to improve rendering quality. Experimental results show that our online method not only surpasses the state-of-the-art offline methods in accuracy but also achieves more than 40x efficiency boost, demonstrating the potential for dynamic and interactive AI applications.
Generating 360{\deg} Video is What You Need For a 3D Scene
arXiv:2504.02045v4 Announce Type: replace-cross Abstract: Generating 3D scenes is still a challenging task due to the lack of readily available scene data. Most existing methods only produce partial scenes and provide limited navigational freedom. We introduce a practical and scalable solution that uses 360{\deg} video as an intermediate scene representation, capturing the full-scene context and ensuring consistent visual content throughout the generation. We propose WorldPrompter, a generative pipeline that synthesizes traversable 3D scenes from text prompts. WorldPrompter incorporates a conditional 360{\deg} panoramic video generator, capable of producing a 128-frame video that simulates a person walking through and capturing a virtual environment. The resulting video is then reconstructed as Gaussian splats by a fast feedforward 3D reconstructor, enabling a true walkable experience within the 3D scene. Experiments demonstrate that our panoramic video generation model, trained with a mix of image and video data, achieves convincing spatial and temporal consistency for static scenes. This is validated by an average COLMAP matching rate of 94.6\%, allowing for high-quality panoramic Gaussian splat reconstruction and improved navigation throughout the scene. Qualitative and quantitative results also show it outperforms the state-of-the-art 360{\deg} video generators and 3D scene generation models.
Benchmarking for Practice: Few-Shot Time-Series Crop-Type Classification on the EuroCropsML Dataset
arXiv:2504.11022v2 Announce Type: replace-cross Abstract: Accurate crop-type classification from satellite time series is essential for agricultural monitoring. While various machine learning algorithms have been developed to enhance performance on data-scarce tasks, their evaluation often lacks real-world scenarios. Consequently, their efficacy in challenging practical applications has not yet been profoundly assessed. To facilitate future research in this domain, we present the first comprehensive benchmark for evaluating supervised and SSL methods for crop-type classification under real-world conditions. This benchmark study relies on the EuroCropsML time-series dataset, which combines farmer-reported crop data with Sentinel-2 satellite observations from Estonia, Latvia, and Portugal. Our findings indicate that MAML-based meta-learning algorithms achieve slightly higher accuracy compared to supervised transfer learning and SSL methods. However, compared to simpler transfer learning, the improvement of meta-learning comes at the cost of increased computational demands and training time. Moreover, supervised methods benefit most when pre-trained and fine-tuned on geographically close regions. In addition, while SSL generally lags behind meta-learning, it demonstrates advantages over training from scratch, particularly in capturing fine-grained features essential for real-world crop-type classification, and also surpasses standard transfer learning. This highlights its practical value when labeled pre-training crop data is scarce. Our insights underscore the trade-offs between accuracy and computational demand in selecting supervised machine learning methods for real-world crop-type classification tasks and highlight the difficulties of knowledge transfer across diverse geographic regions. Furthermore, they demonstrate the practical value of SSL approaches when labeled pre-training crop data is scarce.
Frequency-Compensated Network for Daily Arctic Sea Ice Concentration Prediction
arXiv:2504.16745v2 Announce Type: replace-cross Abstract: Accurately forecasting sea ice concentration (SIC) in the Arctic is critical to global ecosystem health and navigation safety. However, current methods still is confronted with two challenges: 1) these methods rarely explore the long-term feature dependencies in the frequency domain. 2) they can hardly preserve the high-frequency details, and the changes in the marginal area of the sea ice cannot be accurately captured. To this end, we present a Frequency-Compensated Network (FCNet) for Arctic SIC prediction on a daily basis. In particular, we design a dual-branch network, including branches for frequency feature extraction and convolutional feature extraction. For frequency feature extraction, we design an adaptive frequency filter block, which integrates trainable layers with Fourier-based filters. By adding frequency features, the FCNet can achieve refined prediction of edges and details. For convolutional feature extraction, we propose a high-frequency enhancement block to separate high and low-frequency information. Moreover, high-frequency features are enhanced via channel-wise attention, and temporal attention unit is employed for low-frequency feature extraction to capture long-range sea ice changes. Extensive experiments are conducted on a satellite-derived daily SIC dataset, and the results verify the effectiveness of the proposed FCNet. Our codes and data will be made public available at: https://github.com/oucailab/FCNet .
Buffer-free Class-Incremental Learning with Out-of-Distribution Detection
arXiv:2505.23412v2 Announce Type: replace-cross Abstract: Class-incremental learning (CIL) poses significant challenges in open-world scenarios, where models must not only learn new classes over time without forgetting previous ones but also handle inputs from unknown classes that a closed-set model would misclassify. Recent works address both issues by (i)~training multi-head models using the task-incremental learning framework, and (ii) predicting the task identity employing out-of-distribution (OOD) detectors. While effective, the latter mainly relies on joint training with a memory buffer of past data, raising concerns around privacy, scalability, and increased training time. In this paper, we present an in-depth analysis of post-hoc OOD detection methods and investigate their potential to eliminate the need for a memory buffer. We uncover that these methods, when applied appropriately at inference time, can serve as a strong substitute for buffer-based OOD detection. We show that this buffer-free approach achieves comparable or superior performance to buffer-based methods both in terms of class-incremental learning and the rejection of unknown samples. Experimental results on CIFAR-10, CIFAR-100 and Tiny ImageNet datasets support our findings, offering new insights into the design of efficient and privacy-preserving CIL systems for open-world settings.
GAF: Gaussian Action Field as a 4D Representation for Dynamic World Modeling in Robotic Manipulation
arXiv:2506.14135v4 Announce Type: replace-cross Abstract: Accurate scene perception is critical for vision-based robotic manipulation. Existing approaches typically follow either a Vision-to-Action (V-A) paradigm, predicting actions directly from visual inputs, or a Vision-to-3D-to-Action (V-3D-A) paradigm, leveraging intermediate 3D representations. However, these methods often struggle with action inaccuracies due to the complexity and dynamic nature of manipulation scenes. In this paper, we adopt a V-4D-A framework that enables direct action reasoning from motion-aware 4D representations via a Gaussian Action Field (GAF). GAF extends 3D Gaussian Splatting (3DGS) by incorporating learnable motion attributes, allowing 4D modeling of dynamic scenes and manipulation actions. To learn time-varying scene geometry and action-aware robot motion, GAF provides three interrelated outputs: reconstruction of the current scene, prediction of future frames, and estimation of init action via Gaussian motion. Furthermore, we employ an action-vision-aligned denoising framework, conditioned on a unified representation that combines the init action and the Gaussian perception, both generated by the GAF, to further obtain more precise actions. Extensive experiments demonstrate significant improvements, with GAF achieving +11.5385 dB PSNR, +0.3864 SSIM and -0.5574 LPIPS improvements in reconstruction quality, while boosting the average +7.3% success rate in robotic manipulation tasks over state-of-the-art methods.
CryoSplat: Gaussian Splatting for Cryo-EM Homogeneous Reconstruction
arXiv:2508.04929v3 Announce Type: replace-cross Abstract: As a critical modality for structural biology, cryogenic electron microscopy (cryo-EM) facilitates the determination of macromolecular structures at near-atomic resolution. The core computational task in single-particle cryo-EM is to reconstruct the 3D electrostatic potential of a molecule from noisy 2D projections acquired at unknown orientations. Gaussian mixture models (GMMs) provide a continuous, compact, and physically interpretable representation for molecular density and have recently gained interest in cryo-EM reconstruction. However, existing methods rely on external consensus maps or atomic models for initialization, limiting their use in self-contained pipelines. In parallel, differentiable rendering techniques such as Gaussian splatting have demonstrated remarkable scalability and efficiency for volumetric representations, suggesting a natural fit for GMM-based cryo-EM reconstruction. However, off-the-shelf Gaussian splatting methods are designed for photorealistic view synthesis and remain incompatible with cryo-EM due to mismatches in the image formation physics, reconstruction objectives, and coordinate systems. Addressing these issues, we propose cryoSplat, a GMM-based method that integrates Gaussian splatting with the physics of cryo-EM image formation. In particular, we develop an orthogonal projection-aware Gaussian splatting, with adaptations such as a view-dependent normalization term and FFT-aligned coordinate system tailored for cryo-EM imaging. These innovations enable stable and efficient homogeneous reconstruction directly from raw cryo-EM particle images using random initialization. Experimental results on real datasets validate the effectiveness and robustness of cryoSplat over representative baselines. The code will be released upon publication.
DermINO: Hybrid Pretraining for a Versatile Dermatology Foundation Model
arXiv:2508.12190v2 Announce Type: replace-cross Abstract: Skin diseases impose a substantial burden on global healthcare systems, driven by their high prevalence (affecting up to 70% of the population), complex diagnostic processes, and a critical shortage of dermatologists in resource-limited areas. While artificial intelligence(AI) tools have demonstrated promise in dermatological image analysis, current models face limitations-they often rely on large, manually labeled datasets and are built for narrow, specific tasks, making them less effective in real-world settings. To tackle these limitations, we present DermNIO, a versatile foundation model for dermatology. Trained on a curated dataset of 432,776 images from three sources (public repositories, web-sourced images, and proprietary collections), DermNIO incorporates a novel hybrid pretraining framework that augments the self-supervised learning paradigm through semi-supervised learning and knowledge-guided prototype initialization. This integrated method not only deepens the understanding of complex dermatological conditions, but also substantially enhances the generalization capability across various clinical tasks. Evaluated across 20 datasets, DermNIO consistently outperforms state-of-the-art models across a wide range of tasks. It excels in high-level clinical applications including malignancy classification, disease severity grading, multi-category diagnosis, and dermatological image caption, while also achieving state-of-the-art performance in low-level tasks such as skin lesion segmentation. Furthermore, DermNIO demonstrates strong robustness in privacy-preserving federated learning scenarios and across diverse skin types and sexes. In a blinded reader study with 23 dermatologists, DermNIO achieved 95.79% diagnostic accuracy (versus clinicians' 73.66%), and AI assistance improved clinician performance by 17.21%.
Cross-Cancer Knowledge Transfer in WSI-based Prognosis Prediction
arXiv:2508.13482v2 Announce Type: replace-cross Abstract: Whole-Slide Image (WSI) is an important tool for estimating cancer prognosis. Current studies generally follow a conventional cancer-specific paradigm where one cancer corresponds to one model. However, it naturally struggles to scale to rare tumors and cannot utilize the knowledge of other cancers. Although a multi-task learning-like framework has been studied recently, it usually has high demands on computational resources and needs considerable costs in iterative training on ultra-large multi-cancer WSI datasets. To this end, this paper makes a paradigm shift to knowledge transfer and presents the first preliminary yet systematic study on cross-cancer prognosis knowledge transfer in WSIs, called CROPKT. It has three major parts: (i) we curate a large dataset (UNI2-h-DSS) with 26 cancers and use it to measure the transferability of WSI-based prognostic knowledge across different cancers (including rare tumors); (ii) beyond a simple evaluation merely for benchmark, we design a range of experiments to gain deeper insights into the underlying mechanism of transferability; (iii) we further show the utility of cross-cancer knowledge transfer, by proposing a routing-based baseline approach (ROUPKT) that could often efficiently utilize the knowledge transferred from off-the-shelf models of other cancers. We hope CROPKT could serve as an inception and lay the foundation for this nascent paradigm, i.e., WSI-based prognosis prediction with cross-cancer knowledge transfer. Our source code is available at https://github.com/liupei101/CROPKT.
Robust Pan-Cancer Mitotic Figure Detection with YOLOv12
arXiv:2509.02593v2 Announce Type: replace-cross Abstract: Mitotic figures represent a key histoprognostic feature in tumor pathology, providing crucial insights into tumor aggressiveness and proliferation. However, their identification remains challenging, subject to significant inter-observer variability, even among experienced pathologists. To address this issue, the MItosis DOmain Generalization (MIDOG) 2025 challenge marks the third edition of an international competition aiming to develop robust mitosis detection algorithms. In this paper, we present a mitotic figure detection approach based on the state-of-the-art YOLOv12 object detection architecture. Our method achieved an F1-score of 0.801 on the preliminary test set (hotspots only) and ranked second on the final test leaderboard with an F1-score of 0.7216 across complex and heterogeneous whole-slide regions, without relying on external data.
Long-Tailed Out-of-Distribution Detection with Refined Separate Class Learning
arXiv:2509.17034v2 Announce Type: replace-cross Abstract: Out-of-distribution (OOD) detection is crucial for deploying robust machine learning models. However, when training data follows a long-tailed distribution, the model's ability to accurately detect OOD samples is significantly compromised, due to the confusion between OOD samples and head/tail classes. To distinguish OOD samples from both head and tail classes, the separate class learning (SCL) approach has emerged as a promising solution, which separately conduct head-specific and tail-specific class learning. To this end, we examine the limitations of existing works of SCL and reveal that the OOD detection performance is notably influenced by the use of static scaling temperature value and the presence of uninformative outliers. To mitigate these limitations, we propose a novel approach termed Refined Separate Class Learning (RSCL), which leverages dynamic class-wise temperature adjustment to modulate the temperature parameter for each in-distribution class and informative outlier mining to identify diverse types of outliers based on their affinity with head and tail classes. Extensive experiments demonstrate that RSCL achieves superior OOD detection performance while improving the classification accuracy on in-distribution data.
HUNT: High-Speed UAV Navigation and Tracking in Unstructured Environments via Instantaneous Relative Frames
arXiv:2509.19452v2 Announce Type: replace-cross Abstract: Search and rescue operations require unmanned aerial vehicles to both traverse unknown unstructured environments at high speed and track targets once detected. Achieving both capabilities under degraded sensing and without global localization remains an open challenge. Recent works on relative navigation have shown robust tracking by anchoring planning and control to a visible detected object, but cannot address navigation when no target is in the field of view. We present HUNT (High-speed UAV Navigation and Tracking), a real-time framework that unifies traversal, acquisition, and tracking within a single relative formulation. HUNT defines navigation objectives directly from onboard instantaneous observables such as attitude, altitude, and velocity, enabling reactive high-speed flight during search. Once a target is detected, the same perception-control pipeline transitions seamlessly to tracking. Outdoor experiments in dense forests, container compounds, and search-and-rescue operations with vehicles and mannequins demonstrate robust autonomy where global methods fail.
Predictive Coding-based Deep Neural Network Fine-tuning for Computationally Efficient Domain Adaptation
arXiv:2509.20269v2 Announce Type: replace-cross Abstract: As deep neural networks are increasingly deployed in dynamic, real-world environments, relying on a single static model is often insufficient. Changes in input data distributions caused by sensor drift or lighting variations necessitate continual model adaptation. In this paper, we propose a hybrid training methodology that enables efficient on-device domain adaptation by combining the strengths of Backpropagation and Predictive Coding. The method begins with a deep neural network trained offline using Backpropagation to achieve high initial performance. Subsequently, Predictive Coding is employed for online adaptation, allowing the model to recover accuracy lost due to shifts in the input data distribution. This approach leverages the robustness of Backpropagation for initial representation learning and the computational efficiency of Predictive Coding for continual learning, making it particularly well-suited for resource-constrained edge devices or future neuromorphic accelerators. Experimental results on the MNIST and CIFAR-10 datasets demonstrate that this hybrid strategy enables effective adaptation with a reduced computational overhead, offering a promising solution for maintaining model performance in dynamic environments.
A Theory of Multi-Agent Generative Flow Networks
arXiv:2509.20408v1 Announce Type: new Abstract: Generative flow networks utilize a flow-matching loss to learn a stochastic policy for generating objects from a sequence of actions, such that the probability of generating a pattern can be proportional to the corresponding given reward. However, a theoretical framework for multi-agent generative flow networks (MA-GFlowNets) has not yet been proposed. In this paper, we propose the theory framework of MA-GFlowNets, which can be applied to multiple agents to generate objects collaboratively through a series of joint actions. We further propose four algorithms: a centralized flow network for centralized training of MA-GFlowNets, an independent flow network for decentralized execution, a joint flow network for achieving centralized training with decentralized execution, and its updated conditional version. Joint Flow training is based on a local-global principle allowing to train a collection of (local) GFN as a unique (global) GFN. This principle provides a loss of reasonable complexity and allows to leverage usual results on GFN to provide theoretical guarantees that the independent policies generate samples with probability proportional to the reward function. Experimental results demonstrate the superiority of the proposed framework compared to reinforcement learning and MCMC-based methods.
FastEagle: Cascaded Drafting for Accelerating Speculative Decoding
arXiv:2509.20416v1 Announce Type: new Abstract: Speculative decoding accelerates generation by drafting candidates and verifying them in parallel, yet state-of-the-art drafters (e.g., EAGLE) still require N sequential passes to propose N tokens. We present FastEagle, a non-autoregressive cascaded drafter that emits an entire draft in a single forward pass. FastEagle replaces temporal steps with a lightweight layer cascade and trains with layer-wise supervision to mitigate error accumulation. Coupled with a constrained draft tree that preserves lossless verification cost, FastEagle delivers substantial wall-clock speedups over strong autoregressive drafters while maintaining competitive acceptance behavior. Across multiple LLMs (Vicuna-13B, LLaMA-Instruct 3.x, and DeepSeek-R1-Distill-LLaMA) and tasks (MT-Bench, HumanEval, GSM8K, CNN/DM, Alpaca), FastEagle consistently outperforms EAGLE-3 in speedup under both greedy and stochastic decoding, with comparable average acceptance lengths. These results indicate that removing sequential dependencies in drafting is a practical path toward lossless LLM inference acceleration.
mloz: A Highly Efficient Machine Learning-Based Ozone Parameterization for Climate Sensitivity Simulations
arXiv:2509.20422v1 Announce Type: new Abstract: Atmospheric ozone is a crucial absorber of solar radiation and an important greenhouse gas. However, most climate models participating in the Coupled Model Intercomparison Project (CMIP) still lack an interactive representation of ozone due to the high computational costs of atmospheric chemistry schemes. Here, we introduce a machine learning parameterization (mloz) to interactively model daily ozone variability and trends across the troposphere and stratosphere in standard climate sensitivity simulations, including two-way interactions of ozone with the Quasi-Biennial Oscillation. We demonstrate its high fidelity on decadal timescales and its flexible use online across two different climate models -- the UK Earth System Model (UKESM) and the German ICOsahedral Nonhydrostatic (ICON) model. With atmospheric temperature profile information as the only input, mloz produces stable ozone predictions around 31 times faster than the chemistry scheme in UKESM, contributing less than 4 percent of the respective total climate model runtimes. In particular, we also demonstrate its transferability to different climate models without chemistry schemes by transferring the parameterization from UKESM to ICON. This highlights the potential for widespread adoption in CMIP-level climate models that lack interactive chemistry for future climate change assessments, particularly when focusing on climate sensitivity simulations, where ozone trends and variability are known to significantly modulate atmospheric feedback processes.
Bridging Privacy and Utility: Synthesizing anonymized EEG with constraining utility functions
arXiv:2509.20454v1 Announce Type: new Abstract: Electroencephalography (EEG) is widely used for recording brain activity and has seen numerous applications in machine learning, such as detecting sleep stages and neurological disorders. Several studies have successfully shown the potential of EEG data for re-identification and leakage of other personal information. Therefore, the increasing availability of EEG consumer devices raises concerns about user privacy, motivating us to investigate how to safeguard this sensitive data while retaining its utility for EEG applications. To address this challenge, we propose a transformer-based autoencoder to create EEG data that does not allow for subject re-identification while still retaining its utility for specific machine learning tasks. We apply our approach to automatic sleep staging by evaluating the re-identification and utility potential of EEG data before and after anonymization. The results show that the re-identifiability of the EEG signal can be substantially reduced while preserving its utility for machine learning.
Efficiently Attacking Memorization Scores
arXiv:2509.20463v1 Announce Type: new Abstract: Influence estimation tools -- such as memorization scores -- are widely used to understand model behavior, attribute training data, and inform dataset curation. However, recent applications in data valuation and responsible machine learning raise the question: can these scores themselves be adversarially manipulated? In this work, we present a systematic study of the feasibility of attacking memorization-based influence estimators. We characterize attacks for producing highly memorized samples as highly sensitive queries in the regime where a trained algorithm is accurate. Our attack (calculating the pseudoinverse of the input) is practical, requiring only black-box access to model outputs and incur modest computational overhead. We empirically validate our attack across a wide suite of image classification tasks, showing that even state-of-the-art proxies are vulnerable to targeted score manipulations. In addition, we provide a theoretical analysis of the stability of memorization scores under adversarial perturbations, revealing conditions under which influence estimates are inherently fragile. Our findings highlight critical vulnerabilities in influence-based attribution and suggest the need for robust defenses. All code can be found at https://anonymous.4open.science/r/MemAttack-5413/
Offline Goal-conditioned Reinforcement Learning with Quasimetric Representations
arXiv:2509.20478v1 Announce Type: new Abstract: Approaches for goal-conditioned reinforcement learning (GCRL) often use learned state representations to extract goal-reaching policies. Two frameworks for representation structure have yielded particularly effective GCRL algorithms: (1) contrastive representations, in which methods learn "successor features" with a contrastive objective that performs inference over future outcomes, and (2) temporal distances, which link the (quasimetric) distance in representation space to the transit time from states to goals. We propose an approach that unifies these two frameworks, using the structure of a quasimetric representation space (triangle inequality) with the right additional constraints to learn successor representations that enable optimal goal-reaching. Unlike past work, our approach is able to exploit a quasimetric distance parameterization to learn optimal goal-reaching distances, even with suboptimal data and in stochastic environments. This gives us the best of both worlds: we retain the stability and long-horizon capabilities of Monte Carlo contrastive RL methods, while getting the free stitching capabilities of quasimetric network parameterizations. On existing offline GCRL benchmarks, our representation learning objective improves performance on stitching tasks where methods based on contrastive learning struggle, and on noisy, high-dimensional environments where methods based on quasimetric networks struggle.
CoSupFormer : A Contrastive Supervised learning approach for EEG signal Classification
arXiv:2509.20489v1 Announce Type: new Abstract: Electroencephalography signals (EEGs) contain rich multi-scale information crucial for understanding brain states, with potential applications in diagnosing and advancing the drug development landscape. However, extracting meaningful features from raw EEG signals while handling noise and channel variability remains a major challenge. This work proposes a novel end-to-end deep-learning framework that addresses these issues through several key innovations. First, we designed an encoder capable of explicitly capturing multi-scale frequency oscillations covering a wide range of features for different EEG-related tasks. Secondly, to model complex dependencies and handle the high temporal resolution of EEGs, we introduced an attention-based encoder that simultaneously learns interactions across EEG channels and within localized {\em patches} of individual channels. We integrated a dedicated gating network on top of the attention encoder to dynamically filter out noisy and non-informative channels, enhancing the reliability of EEG data. The entire encoding process is guided by a novel loss function, which leverages supervised and contrastive learning, significantly improving model generalization. We validated our approach in multiple applications, ranging from the classification of effects across multiple Central Nervous System (CNS) disorders treatments to the diagnosis of Parkinson's and Alzheimer's disease. Our results demonstrate that the proposed learning paradigm can extract biologically meaningful patterns from raw EEG signals across different species, autonomously select high-quality channels, and achieve robust generalization through innovative architectural and loss design.
Beyond Visual Similarity: Rule-Guided Multimodal Clustering with explicit domain rules
arXiv:2509.20501v1 Announce Type: new Abstract: Traditional clustering techniques often rely solely on similarity in the input data, limiting their ability to capture structural or semantic constraints that are critical in many domains. We introduce the Domain Aware Rule Triggered Variational Autoencoder (DARTVAE), a rule guided multimodal clustering framework that incorporates domain specific constraints directly into the representation learning process. DARTVAE extends the VAE architecture by embedding explicit rules, semantic representations, and data driven features into a unified latent space, while enforcing constraint compliance through rule consistency and violation penalties in the loss function. Unlike conventional clustering methods that rely only on visual similarity or apply rules as post hoc filters, DARTVAE treats rules as first class learning signals. The rules are generated by LLMs, structured into knowledge graphs, and enforced through a loss function combining reconstruction, KL divergence, consistency, and violation penalties. Experiments on aircraft and automotive datasets demonstrate that rule guided clustering produces more operationally meaningful and interpretable clusters for example, isolating UAVs, unifying stealth aircraft, or separating SUVs from sedans while improving traditional clustering metrics. However, the framework faces challenges: LLM generated rules may hallucinate or conflict, excessive rules risk overfitting, and scaling to complex domains increases computational and consistency difficulties. By combining rule encodings with learned representations, DARTVAE achieves more meaningful and consistent clustering outcomes than purely data driven models, highlighting the utility of constraint guided multimodal clustering for complex, knowledge intensive settings.
Myosotis: structured computation for attention like layer
arXiv:2509.20503v1 Announce Type: new Abstract: Attention layers apply a sequence-to-sequence mapping whose parameters depend on the pairwise interactions of the input elements. However, without any structural assumptions, memory and compute scale quadratically with the sequence length. The two main ways to mitigate this are to introduce sparsity by ignoring a sufficient amount of pairwise interactions or to introduce recurrent dependence along them, as SSM does. Although both approaches are reasonable, they both have disadvantages. We propose a novel algorithm that combines the advantages of both concepts. Our idea is based on the efficient inversion of tree-structured matrices.
Auto-Regressive U-Net for Full-Field Prediction of Shrinkage-Induced Damage in Concrete
arXiv:2509.20507v1 Announce Type: new Abstract: This paper introduces a deep learning approach for predicting time-dependent full-field damage in concrete. The study uses an auto-regressive U-Net model to predict the evolution of the scalar damage field in a unit cell given microstructural geometry and evolution of an imposed shrinkage profile. By sequentially using the predicted damage output as input for subsequent predictions, the model facilitates the continuous assessment of damage progression. Complementarily, a convolutional neural network (CNN) utilises the damage estimations to forecast key mechanical properties, including observed shrinkage and residual stiffness. The proposed dual-network architecture demonstrates high computational efficiency and robust predictive performance on the synthesised datasets. The approach reduces the computational load traditionally associated with full-field damage evaluations and is used to gain insights into the relationship between aggregate properties, such as shape, size, and distribution, and the effective shrinkage and reduction in stiffness. Ultimately, this can help to optimize concrete mix designs, leading to improved durability and reduced internal damage.
Complexity-Driven Policy Optimization
arXiv:2509.20509v1 Announce Type: new Abstract: Policy gradient methods often balance exploitation and exploration via entropy maximization. However, maximizing entropy pushes the policy towards a uniform random distribution, which represents an unstructured and sometimes inefficient exploration strategy. In this work, we propose replacing the entropy bonus with a more robust complexity bonus. In particular, we adopt a measure of complexity, defined as the product of Shannon entropy and disequilibrium, where the latter quantifies the distance from the uniform distribution. This regularizer encourages policies that balance stochasticity (high entropy) with structure (high disequilibrium), guiding agents toward regimes where useful, non-trivial behaviors can emerge. Such behaviors arise because the regularizer suppresses both extremes, e.g., maximal disorder and complete order, creating pressure for agents to discover structured yet adaptable strategies. Starting from Proximal Policy Optimization (PPO), we introduce Complexity-Driven Policy Optimization (CDPO), a new learning algorithm that replaces entropy with complexity. We show empirically across a range of discrete action space tasks that CDPO is more robust to the choice of the complexity coefficient than PPO is with the entropy coefficient, especially in environments requiring greater exploration.
A Recovery Theory for Diffusion Priors: Deterministic Analysis of the Implicit Prior Algorithm
arXiv:2509.20511v1 Announce Type: new Abstract: Recovering high-dimensional signals from corrupted measurements is a central challenge in inverse problems. Recent advances in generative diffusion models have shown remarkable empirical success in providing strong data-driven priors, but rigorous recovery guarantees remain limited. In this work, we develop a theoretical framework for analyzing deterministic diffusion-based algorithms for inverse problems, focusing on a deterministic version of the algorithm proposed by Kadkhodaie \& Simoncelli \cite{kadkhodaie2021stochastic}. First, we show that when the underlying data distribution concentrates on a low-dimensional model set, the associated noise-convolved scores can be interpreted as time-varying projections onto such a set. This leads to interpreting previous algorithms using diffusion priors for inverse problems as generalized projected gradient descent methods with varying projections. When the sensing matrix satisfies a restricted isometry property over the model set, we can derive quantitative convergence rates that depend explicitly on the noise schedule. We apply our framework to two instructive data distributions: uniform distributions over low-dimensional compact, convex sets and low-rank Gaussian mixture models. In the latter setting, we can establish global convergence guarantees despite the nonconvexity of the underlying model set.
MDBench: Benchmarking Data-Driven Methods for Model Discovery
arXiv:2509.20529v1 Announce Type: new Abstract: Model discovery aims to uncover governing differential equations of dynamical systems directly from experimental data. Benchmarking such methods is essential for tracking progress and understanding trade-offs in the field. While prior efforts have focused mostly on identifying single equations, typically framed as symbolic regression, there remains a lack of comprehensive benchmarks for discovering dynamical models. To address this, we introduce MDBench, an open-source benchmarking framework for evaluating model discovery methods on dynamical systems. MDBench assesses 12 algorithms on 14 partial differential equations (PDEs) and 63 ordinary differential equations (ODEs) under varying levels of noise. Evaluation metrics include derivative prediction accuracy, model complexity, and equation fidelity. We also introduce seven challenging PDE systems from fluid dynamics and thermodynamics, revealing key limitations in current methods. Our findings illustrate that linear methods and genetic programming methods achieve the lowest prediction error for PDEs and ODEs, respectively. Moreover, linear models are in general more robust against noise. MDBench accelerates the advancement of model discovery methods by offering a rigorous, extensible benchmarking framework and a rich, diverse collection of dynamical system datasets, enabling systematic evaluation, comparison, and improvement of equation accuracy and robustness.
Understanding and Improving Adversarial Robustness of Neural Probabilistic Circuits
arXiv:2509.20549v1 Announce Type: new Abstract: Neural Probabilistic Circuits (NPCs), a new class of concept bottleneck models, comprise an attribute recognition model and a probabilistic circuit for reasoning. By integrating the outputs from these two modules, NPCs produce compositional and interpretable predictions. While offering enhanced interpretability and high performance on downstream tasks, the neural-network-based attribute recognition model remains a black box. This vulnerability allows adversarial attacks to manipulate attribute predictions by introducing carefully crafted subtle perturbations to input images, potentially compromising the final predictions. In this paper, we theoretically analyze the adversarial robustness of NPC and demonstrate that it only depends on the robustness of the attribute recognition model and is independent of the robustness of the probabilistic circuit. Moreover, we propose RNPC, the first robust neural probabilistic circuit against adversarial attacks on the recognition module. RNPC introduces a novel class-wise integration for inference, ensuring a robust combination of outputs from the two modules. Our theoretical analysis demonstrates that RNPC exhibits provably improved adversarial robustness compared to NPC. Empirical results on image classification tasks show that RNPC achieves superior adversarial robustness compared to existing concept bottleneck models while maintaining high accuracy on benign inputs.
Generalizable Diabetes Risk Stratification via Hybrid Machine Learning Models
arXiv:2509.20565v1 Announce Type: new Abstract: Background/Purpose: Diabetes affects over 537 million people worldwide and is projected to reach 783 million by 2045. Early risk stratification can benefit from machine learning. We compare two hybrid classifiers and assess their generalizability on an external cohort. Methods: Two hybrids were built: (i) XGBoost + Random Forest (XGB-RF) and (ii) Support Vector Machine + Logistic Regression (SVM-LR). A leakage-safe, standardized pipeline (encoding, imputation, min-max scaling; SMOTE on training folds only; probability calibration for SVM) was fit on the primary dataset and frozen. Evaluation prioritized threshold-independent discrimination (AUROC/AUPRC) and calibration (Brier, slope/intercept). External validation used the PIMA cohort (N=768) with the frozen pipeline; any thresholded metrics on PIMA were computed at the default rule tau = 0.5. Results: On the primary dataset (PR baseline = 0.50), XGB-RF achieved AUROC ~0.995 and AUPRC ~0.998, outperforming SVM-LR (AUROC ~0.978; AUPRC ~0.947). On PIMA (PR baseline ~0.349), XGB-RF retained strong performance (AUROC ~0.990; AUPRC ~0.959); SVM-LR was lower (AUROC ~0.963; AUPRC ~0.875). Thresholded metrics on PIMA at tau = 0.5 were XGB-RF (Accuracy 0.960; Precision 0.941; Recall 0.944; F1 0.942) and SVM-LR (Accuracy 0.900; Precision 0.855; Recall 0.858; F1 0.857). Conclusions: Across internal and external cohorts, XGB-RF consistently dominated SVM-LR and exhibited smaller external attenuation on ROC/PR with acceptable calibration. These results support gradient-boosting-based hybridization as a robust, transferable approach for diabetes risk stratification and motivate prospective, multi-site validation with deployment-time threshold selection based on clinical trade-offs.
PIRF: Physics-Informed Reward Fine-Tuning for Diffusion Models
arXiv:2509.20570v1 Announce Type: new Abstract: Diffusion models have demonstrated strong generative capabilities across scientific domains, but often produce outputs that violate physical laws. We propose a new perspective by framing physics-informed generation as a sparse reward optimization problem, where adherence to physical constraints is treated as a reward signal. This formulation unifies prior approaches under a reward-based paradigm and reveals a shared bottleneck: reliance on diffusion posterior sampling (DPS)-style value function approximations, which introduce non-negligible errors and lead to training instability and inference inefficiency. To overcome this, we introduce Physics-Informed Reward Fine-tuning (PIRF), a method that bypasses value approximation by computing trajectory-level rewards and backpropagating their gradients directly. However, a naive implementation suffers from low sample efficiency and compromised data fidelity. PIRF mitigates these issues through two key strategies: (1) a layer-wise truncated backpropagation method that leverages the spatiotemporally localized nature of physics-based rewards, and (2) a weight-based regularization scheme that improves efficiency over traditional distillation-based methods. Across five PDE benchmarks, PIRF consistently achieves superior physical enforcement under efficient sampling regimes, highlighting the potential of reward fine-tuning for advancing scientific generative modeling.
The Sensitivity of Variational Bayesian Neural Network Performance to Hyperparameters
arXiv:2509.20574v1 Announce Type: new Abstract: In scientific applications, predictive modeling is often of limited use without accurate uncertainty quantification (UQ) to indicate when a model may be extrapolating or when more data needs to be collected. Bayesian Neural Networks (BNNs) produce predictive uncertainty by propagating uncertainty in neural network (NN) weights and offer the promise of obtaining not only an accurate predictive model but also accurate UQ. However, in practice, obtaining accurate UQ with BNNs is difficult due in part to the approximations used for practical model training and in part to the need to choose a suitable set of hyperparameters; these hyperparameters outnumber those needed for traditional NNs and often have opaque effects on the results. We aim to shed light on the effects of hyperparameter choices for BNNs by performing a global sensitivity analysis of BNN performance under varying hyperparameter settings. Our results indicate that many of the hyperparameters interact with each other to affect both predictive accuracy and UQ. For improved usage of BNNs in real-world applications, we suggest that global sensitivity analysis, or related methods such as Bayesian optimization, should be used to aid in dimensionality reduction and selection of hyperparameters to ensure accurate UQ in BNNs.
Learning Greens Operators through Hierarchical Neural Networks Inspired by the Fast Multipole Method
arXiv:2509.20591v1 Announce Type: new Abstract: The Fast Multipole Method (FMM) is an efficient numerical algorithm for computation of long-ranged forces in $N$-body problems within gravitational and electrostatic fields. This method utilizes multipole expansions of the Green's function inherent to the underlying dynamical systems. Despite its widespread application in physics and engineering, the integration of FMM with modern machine learning architectures remains underexplored. In this work, we propose a novel neural network architecture, the Neural FMM, that integrates the information flow of the FMM into a hierarchical machine learning framework for learning the Green's operator of an Elliptic PDE. Our Neural FMM architecture leverages a hierarchical computation flow of the FMM method to split up the local and far-field interactions and efficiently learn their respective representations.
TSKAN: Interpretable Machine Learning for QoE modeling over Time Series Data
arXiv:2509.20595v1 Announce Type: new Abstract: Quality of Experience (QoE) modeling is crucial for optimizing video streaming services to capture the complex relationships between different features and user experience. We propose a novel approach to QoE modeling in video streaming applications using interpretable Machine Learning (ML) techniques over raw time series data. Unlike traditional black-box approaches, our method combines Kolmogorov-Arnold Networks (KANs) as an interpretable readout on top of compact frequency-domain features, allowing us to capture temporal information while retaining a transparent and explainable model. We evaluate our method on popular datasets and demonstrate its enhanced accuracy in QoE prediction, while offering transparency and interpretability.
Explicit and Effectively Symmetric Schemes for Neural SDEs
arXiv:2509.20599v1 Announce Type: new Abstract: Backpropagation through (neural) SDE solvers is traditionally approached in two ways: discretise-then-optimise, which offers accurate gradients but incurs prohibitive memory costs due to storing the full computational graph (even when mitigated by checkpointing); and optimise-then-discretise, which achieves constant memory cost by solving an auxiliary backward SDE, but suffers from slower evaluation and gradient approximation errors. Algebraically reversible solvers promise both memory efficiency and gradient accuracy, yet existing methods such as the Reversible Heun scheme are often unstable under complex models and large step sizes. We address these limitations by introducing a novel class of stable, near-reversible Runge--Kutta schemes for neural SDEs. These Explicit and Effectively Symmetric (EES) schemes retain the benefits of reversible solvers while overcoming their instability, enabling memory-efficient training without severe restrictions on step size or model complexity. Through numerical experiments, we demonstrate the superior stability and reliability of our schemes, establishing them as a practical foundation for scalable and accurate training of neural SDEs.
Function Spaces Without Kernels: Learning Compact Hilbert Space Representations
arXiv:2509.20605v1 Announce Type: new Abstract: Function encoders are a recent technique that learn neural network basis functions to form compact, adaptive representations of Hilbert spaces of functions. We show that function encoders provide a principled connection to feature learning and kernel methods by defining a kernel through an inner product of the learned feature map. This kernel-theoretic perspective explains their ability to scale independently of dataset size while adapting to the intrinsic structure of data, and it enables kernel-style analysis of neural models. Building on this foundation, we develop two training algorithms that learn compact bases: a progressive training approach that constructively grows bases, and a train-then-prune approach that offers a computationally efficient alternative after training. Both approaches use principles from PCA to reveal the intrinsic dimension of the learned space. In parallel, we derive finite-sample generalization bounds using Rademacher complexity and PAC-Bayes techniques, providing inference time guarantees. We validate our approach on a polynomial benchmark with a known intrinsic dimension, and on nonlinear dynamical systems including a Van der Pol oscillator and a two-body orbital model, demonstrating that the same accuracy can be achieved with substantially fewer basis functions. This work suggests a path toward neural predictors with kernel-level guarantees, enabling adaptable models that are both efficient and principled at scale.
MMG: Mutual Information Estimation via the MMSE Gap in Diffusion
arXiv:2509.20609v1 Announce Type: new Abstract: Mutual information (MI) is one of the most general ways to measure relationships between random variables, but estimating this quantity for complex systems is challenging. Denoising diffusion models have recently set a new bar for density estimation, so it is natural to consider whether these methods could also be used to improve MI estimation. Using the recently introduced information-theoretic formulation of denoising diffusion models, we show the diffusion models can be used in a straightforward way to estimate MI. In particular, the MI corresponds to half the gap in the Minimum Mean Square Error (MMSE) between conditional and unconditional diffusion, integrated over all Signal-to-Noise-Ratios (SNRs) in the noising process. Our approach not only passes self-consistency tests but also outperforms traditional and score-based diffusion MI estimators. Furthermore, our method leverages adaptive importance sampling to achieve scalable MI estimation, while maintaining strong performance even when the MI is high.
Policy Compatible Skill Incremental Learning via Lazy Learning Interface
arXiv:2509.20612v1 Announce Type: new Abstract: Skill Incremental Learning (SIL) is the process by which an embodied agent expands and refines its skill set over time by leveraging experience gained through interaction with its environment or by the integration of additional data. SIL facilitates efficient acquisition of hierarchical policies grounded in reusable skills for downstream tasks. However, as the skill repertoire evolves, it can disrupt compatibility with existing skill-based policies, limiting their reusability and generalization. In this work, we propose SIL-C, a novel framework that ensures skill-policy compatibility, allowing improvements in incrementally learned skills to enhance the performance of downstream policies without requiring policy re-training or structural adaptation. SIL-C employs a bilateral lazy learning-based mapping technique to dynamically align the subtask space referenced by policies with the skill space decoded into agent behaviors. This enables each subtask, derived from the policy's decomposition of a complex task, to be executed by selecting an appropriate skill based on trajectory distribution similarity. We evaluate SIL-C across diverse SIL scenarios and demonstrate that it maintains compatibility between evolving skills and downstream policies while ensuring efficiency throughout the learning process.
Latent Twins
arXiv:2509.20615v1 Announce Type: new Abstract: Over the past decade, scientific machine learning has transformed the development of mathematical and computational frameworks for analyzing, modeling, and predicting complex systems. From inverse problems to numerical PDEs, dynamical systems, and model reduction, these advances have pushed the boundaries of what can be simulated. Yet they have often progressed in parallel, with representation learning and algorithmic solution methods evolving largely as separate pipelines. With \emph{Latent Twins}, we propose a unifying mathematical framework that creates a hidden surrogate in latent space for the underlying equations. Whereas digital twins mirror physical systems in the digital world, Latent Twins mirror mathematical systems in a learned latent space governed by operators. Through this lens, classical modeling, inversion, model reduction, and operator approximation all emerge as special cases of a single principle. We establish the fundamental approximation properties of Latent Twins for both ODEs and PDEs and demonstrate the framework across three representative settings: (i) canonical ODEs, capturing diverse dynamical regimes; (ii) a PDE benchmark using the shallow-water equations, contrasting Latent Twin simulations with DeepONet and forecasts with a 4D-Var baseline; and (iii) a challenging real-data geopotential reanalysis dataset, reconstructing and forecasting from sparse, noisy observations. Latent Twins provide a compact, interpretable surrogate for solution operators that evaluate across arbitrary time gaps in a single-shot, while remaining compatible with scientific pipelines such as assimilation, control, and uncertainty quantification. Looking forward, this framework offers scalable, theory-grounded surrogates that bridge data-driven representation learning and classical scientific modeling across disciplines.
Training Task Reasoning LLM Agents for Multi-turn Task Planning via Single-turn Reinforcement Learning
arXiv:2509.20616v1 Announce Type: new Abstract: Large Language Models (LLMs) have demonstrated remarkable capabilities in knowledge acquisition, reasoning, and tool use, making them promising candidates for autonomous agent applications. However, training LLM agents for complex multi-turn task planning faces significant challenges, including sparse episode-wise rewards, credit assignment across long horizons, and the computational overhead of reinforcement learning in multi-turn interaction settings. To this end, this paper introduces a novel approach that transforms multi-turn task planning into single-turn task reasoning problems, enabling efficient policy optimization through Group Relative Policy Optimization (GRPO) with dense and verifiable reward from expert trajectories. Our theoretical analysis shows that GRPO improvement on single-turn task reasoning results in higher multi-turn success probability under the minimal turns, as well as the generalization to subtasks with shorter horizons. Experimental evaluation on the complex task planning benchmark demonstrates that our 1.5B parameter model trained with single-turn GRPO achieves superior performance compared to larger baseline models up to 14B parameters, with success rates of 70% for long-horizon planning tasks with over 30 steps. We also theoretically and empirically validate the strong cross-task generalizability that the models trained on complex tasks can lead to the successful completion of all simpler subtasks.
Personalized Federated Dictionary Learning for Modeling Heterogeneity in Multi-site fMRI Data
arXiv:2509.20627v1 Announce Type: new Abstract: Data privacy constraints pose significant challenges for large-scale neuroimaging analysis, especially in multi-site functional magnetic resonance imaging (fMRI) studies, where site-specific heterogeneity leads to non-independent and identically distributed (non-IID) data. These factors hinder the development of generalizable models. To address these challenges, we propose Personalized Federated Dictionary Learning (PFedDL), a novel federated learning framework that enables collaborative modeling across sites without sharing raw data. PFedDL performs independent dictionary learning at each site, decomposing each site-specific dictionary into a shared global component and a personalized local component. The global atoms are updated via federated aggregation to promote cross-site consistency, while the local atoms are refined independently to capture site-specific variability, thereby enhancing downstream analysis. Experiments on the ABIDE dataset demonstrate that PFedDL outperforms existing methods in accuracy and robustness across non-IID datasets.
Investigating Modality Contribution in Audio LLMs for Music
arXiv:2509.20641v1 Announce Type: new Abstract: Audio Large Language Models (Audio LLMs) enable human-like conversation about music, yet it is unclear if they are truly listening to the audio or just using textual reasoning, as recent benchmarks suggest. This paper investigates this issue by quantifying the contribution of each modality to a model's output. We adapt the MM-SHAP framework, a performance-agnostic score based on Shapley values that quantifies the relative contribution of each modality to a model's prediction. We evaluate two models on the MuChoMusic benchmark and find that the model with higher accuracy relies more on text to answer questions, but further inspection shows that even if the overall audio contribution is low, models can successfully localize key sound events, suggesting that audio is not entirely ignored. Our study is the first application of MM-SHAP to Audio LLMs and we hope it will serve as a foundational step for future research in explainable AI and audio.
Wonder Wins Ways: Curiosity-Driven Exploration through Multi-Agent Contextual Calibration
arXiv:2509.20648v1 Announce Type: new Abstract: Autonomous exploration in complex multi-agent reinforcement learning (MARL) with sparse rewards critically depends on providing agents with effective intrinsic motivation. While artificial curiosity offers a powerful self-supervised signal, it often confuses environmental stochasticity with meaningful novelty. Moreover, existing curiosity mechanisms exhibit a uniform novelty bias, treating all unexpected observations equally. However, peer behavior novelty, which encode latent task dynamics, are often overlooked, resulting in suboptimal exploration in decentralized, communication-free MARL settings. To this end, inspired by how human children adaptively calibrate their own exploratory behaviors via observing peers, we propose a novel approach to enhance multi-agent exploration. We introduce CERMIC, a principled framework that empowers agents to robustly filter noisy surprise signals and guide exploration by dynamically calibrating their intrinsic curiosity with inferred multi-agent context. Additionally, CERMIC generates theoretically-grounded intrinsic rewards, encouraging agents to explore state transitions with high information gain. We evaluate CERMIC on benchmark suites including VMAS, Meltingpot, and SMACv2. Empirical results demonstrate that exploration with CERMIC significantly outperforms SoTA algorithms in sparse-reward environments.
Guiding Application Users via Estimation of Computational Resources for Massively Parallel Chemistry Computations
arXiv:2509.20667v1 Announce Type: new Abstract: In this work, we develop machine learning (ML) based strategies to predict resources (costs) required for massively parallel chemistry computations, such as coupled-cluster methods, to guide application users before they commit to running expensive experiments on a supercomputer. By predicting application execution time, we determine the optimal runtime parameter values such as number of nodes and tile sizes. Two key questions of interest to users are addressed. The first is the shortest-time question, where the user is interested in knowing the parameter configurations (number of nodes and tile sizes) to achieve the shortest execution time for a given problem size and a target supercomputer. The second is the cheapest-run question in which the user is interested in minimizing resource usage, i.e., finding the number of nodes and tile size that minimizes the number of node-hours for a given problem size. We evaluate a rich family of ML models and strategies, developed based on the collections of runtime parameter values for the CCSD (Coupled Cluster with Singles and Doubles) application executed on the Department of Energy (DOE) Frontier and Aurora supercomputers. Our experiments show that when predicting the total execution time of a CCSD iteration, a Gradient Boosting (GB) ML model achieves a Mean Absolute Percentage Error (MAPE) of 0.023 and 0.073 for Aurora and Frontier, respectively. In the case where it is expensive to run experiments just to collect data points, we show that active learning can achieve a MAPE of about 0.2 with just around 450 experiments collected from Aurora and Frontier.
Theoretical Bounds for Stable In-Context Learning
arXiv:2509.20677v1 Announce Type: new Abstract: In-context learning (ICL) is flexible but its reliability is highly sensitive to prompt length. This paper establishes a non-asymptotic lower bound that links the minimal number of demonstrations to ICL stability under fixed high-dimensional sub-Gaussian representations. The bound gives explicit sufficient conditions in terms of spectral properties of the covariance, providing a computable criterion for practice. Building on this analysis, we propose a two-stage observable estimator with a one-shot calibration that produces practitioner-ready prompt-length estimates without distributional priors. Experiments across diverse datasets, encoders, and generators show close alignment between the predicted thresholds and empirical knee-points, with the theory acting as a conservative but reliable upper bound; the calibrated variant further tightens this gap. These results connect spectral coverage to stable ICL, bridge theory and deployment, and improve the interpretability and reliability of large-scale prompting in realistic finite-sample regimes.
Bispectral OT: Dataset Comparison using Symmetry-Aware Optimal Transport
arXiv:2509.20678v1 Announce Type: new Abstract: Optimal transport (OT) is a widely used technique in machine learning, graphics, and vision that aligns two distributions or datasets using their relative geometry. In symmetry-rich settings, however, OT alignments based solely on pairwise geometric distances between raw features can ignore the intrinsic coherence structure of the data. We introduce Bispectral Optimal Transport, a symmetry-aware extension of discrete OT that compares elements using their representation using the bispectrum, a group Fourier invariant that preserves all signal structure while removing only the variation due to group actions. Empirically, we demonstrate that the transport plans computed with Bispectral OT achieve greater class preservation accuracy than naive feature OT on benchmark datasets transformed with visual symmetries, improving the quality of meaningful correspondences that capture the underlying semantic label structure in the dataset while removing nuisance variation not affecting class or content.
Can Federated Learning Safeguard Private Data in LLM Training? Vulnerabilities, Attacks, and Defense Evaluation
arXiv:2509.20680v1 Announce Type: new Abstract: Fine-tuning large language models (LLMs) with local data is a widely adopted approach for organizations seeking to adapt LLMs to their specific domains. Given the shared characteristics in data across different organizations, the idea of collaboratively fine-tuning an LLM using data from multiple sources presents an appealing opportunity. However, organizations are often reluctant to share local data, making centralized fine-tuning impractical. Federated learning (FL), a privacy-preserving framework, enables clients to retain local data while sharing only model parameters for collaborative training, offering a potential solution. While fine-tuning LLMs on centralized datasets risks data leakage through next-token prediction, the iterative aggregation process in FL results in a global model that encapsulates generalized knowledge, which some believe protects client privacy. In this paper, however, we present contradictory findings through extensive experiments. We show that attackers can still extract training data from the global model, even using straightforward generation methods, with leakage increasing as the model size grows. Moreover, we introduce an enhanced attack strategy tailored to FL, which tracks global model updates during training to intensify privacy leakage. To mitigate these risks, we evaluate privacy-preserving techniques in FL, including differential privacy, regularization-constrained updates and adopting LLMs with safety alignment. Our results provide valuable insights and practical guidelines for reducing privacy risks when training LLMs with FL.
Learning to Align Molecules and Proteins: A Geometry-Aware Approach to Binding Affinity
arXiv:2509.20693v1 Announce Type: new Abstract: Accurate prediction of drug-target binding affinity can accelerate drug discovery by prioritizing promising compounds before costly wet-lab screening. While deep learning has advanced this task, most models fuse ligand and protein representations via simple concatenation and lack explicit geometric regularization, resulting in poor generalization across chemical space and time. We introduce FIRM-DTI, a lightweight framework that conditions molecular embeddings on protein embeddings through a feature-wise linear modulation (FiLM) layer and enforces metric structure with a triplet loss. An RBF regression head operating on embedding distances yields smooth, interpretable affinity predictions. Despite its modest size, FIRM-DTI achieves state-of-the-art performance on the Therapeutics Data Commons DTI-DG benchmark, as demonstrated by an extensive ablation study and out-of-domain evaluation. Our results underscore the value of conditioning and metric learning for robust drug-target affinity prediction.
CE-GPPO: Controlling Entropy via Gradient-Preserving Clipping Policy Optimization in Reinforcement Learning
arXiv:2509.20712v1 Announce Type: new Abstract: Reinforcement learning (RL) has become a powerful paradigm for optimizing large language models (LLMs) to handle complex reasoning tasks. A core challenge in this process lies in managing policy entropy, which reflects the balance between exploration and exploitation during training. Existing methods, such as proximal policy optimization (PPO) and its variants, discard valuable gradient signals from low-probability tokens due to the clipping mechanism. We systematically analyze the entropy dynamics and reveal that these clipped tokens play a critical yet overlooked role in regulating entropy evolution. We propose \textbf{C}ontrolling \textbf{E}ntropy via \textbf{G}radient-\textbf{P}reserving \textbf{P}olicy \textbf{O}ptimization (CE-GPPO), a novel algorithm that reintroduces gradients from clipped tokens in native PPO in a gentle and bounded manner. By controlling the magnitude of gradients from tokens outside the clipping interval, CE-GPPO is able to achieve an exploration-exploitation trade-off. We provide theoretical justification and empirical evidence showing that CE-GPPO effectively mitigates entropy instability. Extensive experiments on mathematical reasoning benchmarks show that CE-GPPO consistently outperforms strong baselines across different model scales.
A Genetic Algorithm for Navigating Synthesizable Molecular Spaces
arXiv:2509.20719v1 Announce Type: new Abstract: Inspired by the effectiveness of genetic algorithms and the importance of synthesizability in molecular design, we present SynGA, a simple genetic algorithm that operates directly over synthesis routes. Our method features custom crossover and mutation operators that explicitly constrain it to synthesizable molecular space. By modifying the fitness function, we demonstrate the effectiveness of SynGA on a variety of design tasks, including synthesizable analog search and sample-efficient property optimization, for both 2D and 3D objectives. Furthermore, by coupling SynGA with a machine learning-based filter that focuses the building block set, we boost SynGA to state-of-the-art performance. For property optimization, this manifests as a model-based variant SynGBO, which employs SynGA and block filtering in the inner loop of Bayesian optimization. Since SynGA is lightweight and enforces synthesizability by construction, our hope is that SynGA can not only serve as a strong standalone baseline but also as a versatile module that can be incorporated into larger synthesis-aware workflows in the future.
Scaling Laws are Redundancy Laws
arXiv:2509.20721v1 Announce Type: new Abstract: Scaling laws, a defining feature of deep learning, reveal a striking power-law improvement in model performance with increasing dataset and model size. Yet, their mathematical origins, especially the scaling exponent, have remained elusive. In this work, we show that scaling laws can be formally explained as redundancy laws. Using kernel regression, we show that a polynomial tail in the data covariance spectrum yields an excess risk power law with exponent alpha = 2s / (2s + 1/beta), where beta controls the spectral tail and 1/beta measures redundancy. This reveals that the learning curve's slope is not universal but depends on data redundancy, with steeper spectra accelerating returns to scale. We establish the law's universality across boundedly invertible transformations, multi-modal mixtures, finite-width approximations, and Transformer architectures in both linearized (NTK) and feature-learning regimes. This work delivers the first rigorous mathematical explanation of scaling laws as finite-sample redundancy laws, unifying empirical observations with theoretical foundations.
The Impact of Audio Watermarking on Audio Anti-Spoofing Countermeasures
arXiv:2509.20736v1 Announce Type: new Abstract: This paper presents the first study on the impact of audio watermarking on spoofing countermeasures. While anti-spoofing systems are essential for securing speech-based applications, the influence of widely used audio watermarking, originally designed for copyright protection, remains largely unexplored. We construct watermark-augmented training and evaluation datasets, named the Watermark-Spoofing dataset, by applying diverse handcrafted and neural watermarking methods to existing anti-spoofing datasets. Experiments show that watermarking consistently degrades anti-spoofing performance, with higher watermark density correlating with higher Equal Error Rates (EERs). To mitigate this, we propose the Knowledge-Preserving Watermark Learning (KPWL) framework, enabling models to adapt to watermark-induced shifts while preserving their original-domain spoofing detection capability. These findings reveal audio watermarking as a previously overlooked domain shift and establish the first benchmark for developing watermark-resilient anti-spoofing systems. All related protocols are publicly available at https://github.com/Alphawarheads/Watermark_Spoofing.git
Measuring LLM Sensitivity in Transformer-based Tabular Data Synthesis
arXiv:2509.20768v1 Announce Type: new Abstract: Synthetic tabular data is used for privacy-preserving data sharing and data-driven model development. Its effectiveness, however, depends heavily on the used Tabular Data Synthesis (TDS) tool. Recent studies have shown that Transformer-based models outperform other state-of-the-art models such as Generative Adversarial Networks (GANs) and Diffusion models in terms of data quality. However, Transformer-based models also come with high computational costs, making them sometimes unfeasible for end users with prosumer hardware. This study presents a sensitivity assessment on how the choice of hyperparameters, such as number of layers or hidden dimension affects the quality of the resultant synthetic data and the computational performance. It is performed across two tools, GReaT and REaLTabFormer, evaluating 10 model setups that vary in architecture type and depth. We assess the sensitivity on three dimensions: runtime, machine learning (ML) utility, and similarity to real data distributions. Experiments were conducted on four real-world datasets. Our findings reveal that runtime is proportional to the number of hyperparameters, with shallower configurations completing faster. GReaT consistently achieves lower runtimes than REaLTabFormer, and only on the largest dataset they have comparable runtime. For small datasets, both tools achieve synthetic data with high utility and optimal similarity, but on larger datasets only REaLTabFormer sustains strong utility and similarity. As a result, REaLTabFormer with lightweight LLMs provides the best balance, since it preserves data quality while reducing computational requirements. Nonetheless, its runtime remains higher than that of GReaT and other TDS tools, suggesting that efficiency gains are possible but only up to a certain level.
Sig2Model: A Boosting-Driven Model for Updatable Learned Indexes
arXiv:2509.20781v1 Announce Type: new Abstract: Learned Indexes (LIs) represent a paradigm shift from traditional index structures by employing machine learning models to approximate the cumulative distribution function (CDF) of sorted data. While LIs achieve remarkable efficiency for static datasets, their performance degrades under dynamic updates: maintaining the CDF invariant (sum of F(k) equals 1) requires global model retraining, which blocks queries and limits the queries-per-second (QPS) metric. Current approaches fail to address these retraining costs effectively, rendering them unsuitable for real-world workloads with frequent updates. In this paper, we present Sig2Model, an efficient and adaptive learned index that minimizes retraining cost through three key techniques: (1) a sigmoid boosting approximation technique that dynamically adjusts the index model by approximating update-induced shifts in data distribution with localized sigmoid functions while preserving bounded error guarantees and deferring full retraining; (2) proactive update training via Gaussian mixture models (GMMs) that identifies high-update-probability regions for strategic placeholder allocation to speed up updates; and (3) a neural joint optimization framework that continuously refines both the sigmoid ensemble and GMM parameters via gradient-based learning. We evaluate Sig2Model against state-of-the-art updatable learned indexes on real-world and synthetic workloads, and show that Sig2Model reduces retraining cost by up to 20x, achieves up to 3x higher QPS, and uses up to 1000x less memory.
IConv: Focusing on Local Variation with Channel Independent Convolution for Multivariate Time Series Forecasting
arXiv:2509.20783v1 Announce Type: new Abstract: Real-world time-series data often exhibit non-stationarity, including changing trends, irregular seasonality, and residuals. In terms of changing trends, recently proposed multi-layer perceptron (MLP)-based models have shown excellent performance owing to their computational efficiency and ability to capture long-term dependency. However, the linear nature of MLP architectures poses limitations when applied to channels with diverse distributions, resulting in local variations such as seasonal patterns and residual components being ignored. However, convolutional neural networks (CNNs) can effectively incorporate these variations. To resolve the limitations of MLP, we propose combining them with CNNs. The overall trend is modeled using an MLP to consider long-term dependencies. The CNN uses diverse kernels to model fine-grained local patterns in conjunction with MLP trend predictions. To focus on modeling local variation, we propose IConv, a novel convolutional architecture that processes the temporal dependency channel independently and considers the inter-channel relationship through distinct layers. Independent channel processing enables the modeling of diverse local temporal dependencies and the adoption of a large kernel size. Distinct inter-channel considerations reduce computational cost. The proposed model is evaluated through extensive experiments on time-series datasets. The results reveal the superiority of the proposed method for multivariate time-series forecasting.
LiLAW: Lightweight Learnable Adaptive Weighting to Meta-Learn Sample Difficulty and Improve Noisy Training
arXiv:2509.20786v1 Announce Type: new Abstract: Training deep neural networks in the presence of noisy labels and data heterogeneity is a major challenge. We introduce Lightweight Learnable Adaptive Weighting (LiLAW), a novel method that dynamically adjusts the loss weight of each training sample based on its evolving difficulty level, categorized as easy, moderate, or hard. Using only three learnable parameters, LiLAW adaptively prioritizes informative samples throughout training by updating these weights using a single mini-batch gradient descent step on the validation set after each training mini-batch, without requiring excessive hyperparameter tuning or a clean validation set. Extensive experiments across multiple general and medical imaging datasets, noise levels and types, loss functions, and architectures with and without pretraining demonstrate that LiLAW consistently enhances performance, even in high-noise environments. It is effective without heavy reliance on data augmentation or advanced regularization, highlighting its practicality. It offers a computationally efficient solution to boost model generalization and robustness in any neural network training setup.
Aligning Inductive Bias for Data-Efficient Generalization in State Space Models
arXiv:2509.20789v1 Announce Type: new Abstract: The remarkable success of large-scale models is fundamentally tied to scaling laws, yet the finite nature of high-quality data presents a looming challenge. One of the next frontiers in modeling is data efficiency: the ability to learn more from less. A model's inductive bias is a critical lever for this, but foundational sequence models like State Space Models (SSMs) rely on a fixed bias. This fixed prior is sample-inefficient when a task's underlying structure does not match. In this work, we introduce a principled framework to solve this problem. We first formalize the inductive bias of linear time-invariant SSMs through an SSM-induced kernel, mathematically and empirically proving its spectrum is directly governed by the model's frequency response. Further, we propose a method of Task-Dependent Initialization (TDI): power spectrum matching, a fast and efficient method that aligns the model's inductive bias with the task's spectral characteristics before large-scale training. Our experiments on a diverse set of real-world benchmarks show that TDI significantly improves generalization and sample efficiency, particularly in low-data regimes. This work provides a theoretical and practical tool to create more data-efficient models, a crucial step towards sustainable scaling.
FERD: Fairness-Enhanced Data-Free Robustness Distillation
arXiv:2509.20793v1 Announce Type: new Abstract: Data-Free Robustness Distillation (DFRD) aims to transfer the robustness from the teacher to the student without accessing the training data. While existing methods focus on overall robustness, they overlook the robust fairness issues, leading to severe disparity of robustness across different categories. In this paper, we find two key problems: (1) student model distilled with equal class proportion data behaves significantly different across distinct categories; and (2) the robustness of student model is not stable across different attacks target. To bridge these gaps, we present the first Fairness-Enhanced data-free Robustness Distillation (FERD) framework to adjust the proportion and distribution of adversarial examples. For the proportion, FERD adopts a robustness-guided class reweighting strategy to synthesize more samples for the less robust categories, thereby improving robustness of them. For the distribution, FERD generates complementary data samples for advanced robustness distillation. It generates Fairness-Aware Examples (FAEs) by enforcing a uniformity constraint on feature-level predictions, which suppress the dominance of class-specific non-robust features, providing a more balanced representation across all categories. Then, FERD constructs Uniform-Target Adversarial Examples (UTAEs) from FAEs by applying a uniform target class constraint to avoid biased attack directions, which distribute the attack targets across all categories and prevents overfitting to specific vulnerable categories. Extensive experiments on three public datasets show that FERD achieves state-of-the-art worst-class robustness under all adversarial attack (e.g., the worst-class robustness under FGSM and AutoAttack are improved by 15.1\% and 6.4\% using MobileNet-V2 on CIFAR-10), demonstrating superior performance in both robustness and fairness aspects.
T2I-Diff: fMRI Signal Generation via Time-Frequency Image Transform and Classifier-Free Denoising Diffusion Models
arXiv:2509.20822v1 Announce Type: new Abstract: Functional Magnetic Resonance Imaging (fMRI) is an advanced neuroimaging method that enables in-depth analysis of brain activity by measuring dynamic changes in the blood oxygenation level-dependent (BOLD) signals. However, the resource-intensive nature of fMRI data acquisition limits the availability of high-fidelity samples required for data-driven brain analysis models. While modern generative models can synthesize fMRI data, they often underperform because they overlook the complex non-stationarity and nonlinear BOLD dynamics. To address these challenges, we introduce T2I-Diff, an fMRI generation framework that leverages time-frequency representation of BOLD signals and classifier-free denoising diffusion. Specifically, our framework first converts BOLD signals into windowed spectrograms via a time-dependent Fourier transform, capturing both the underlying temporal dynamics and spectral evolution. Subsequently, a classifier-free diffusion model is trained to generate class-conditioned frequency spectrograms, which are then reverted to BOLD signals via inverse Fourier transforms. Finally, we validate the efficacy of our approach by demonstrating improved accuracy and generalization in downstream fMRI-based brain network classification.
CaTS-Bench: Can Language Models Describe Numeric Time Series?
arXiv:2509.20823v1 Announce Type: new Abstract: Time series captioning, the task of describing numeric time series in natural language, requires numerical reasoning, trend interpretation, and contextual understanding. Existing benchmarks, however, often rely on synthetic data or overly simplistic captions, and typically neglect metadata and visual representations. To close this gap, we introduce CaTS-Bench, the first large-scale, real-world benchmark for Context-aware Time Series captioning. CaTS-Bench is derived from 11 diverse datasets reframed as captioning and Q&A tasks, comprising roughly 465k training and 105k test timestamps. Each sample includes a numeric series segment, contextual metadata, a line-chart image, and a caption. A key contribution of this work is the scalable pipeline used to generate reference captions: while most references are produced by an oracle LLM and verified through factual checks, human indistinguishability studies, and diversity analyses, we also provide a human-revisited subset of 579 test captions, refined from LLM outputs to ensure accuracy and human-like style. Beyond captioning, CaTS-Bench offers 460 multiple-choice questions targeting deeper aspects of time series reasoning. We further propose new tailored evaluation metrics and benchmark leading VLMs, highlighting both their strengths and persistent limitations. Together, these contributions establish CaTS-Bench and its captioning pipeline as a reliable and extensible foundation for future research at the intersection of time series analysis and foundation models.
Explaining Grokking and Information Bottleneck through Neural Collapse Emergence
arXiv:2509.20829v1 Announce Type: new Abstract: The training dynamics of deep neural networks often defy expectations, even as these models form the foundation of modern machine learning. Two prominent examples are grokking, where test performance improves abruptly long after the training loss has plateaued, and the information bottleneck principle, where models progressively discard input information irrelevant to the prediction task as training proceeds. However, the mechanisms underlying these phenomena and their relations remain poorly understood. In this work, we present a unified explanation of such late-phase phenomena through the lens of neural collapse, which characterizes the geometry of learned representations. We show that the contraction of population within-class variance is a key factor underlying both grokking and information bottleneck, and relate this measure to the neural collapse measure defined on the training set. By analyzing the dynamics of neural collapse, we show that distinct time scales between fitting the training set and the progression of neural collapse account for the behavior of the late-phase phenomena. Finally, we validate our theoretical findings on multiple datasets and architectures.
Shaping Initial State Prevents Modality Competition in Multi-modal Fusion: A Two-stage Scheduling Framework via Fast Partial Information Decomposition
arXiv:2509.20840v1 Announce Type: new Abstract: Multi-modal fusion often suffers from modality competition during joint training, where one modality dominates the learning process, leaving others under-optimized. Overlooking the critical impact of the model's initial state, most existing methods address this issue during the joint learning stage. In this study, we introduce a two-stage training framework to shape the initial states through unimodal training before the joint training. First, we propose the concept of Effective Competitive Strength (ECS) to quantify a modality's competitive strength. Our theoretical analysis further reveals that properly shaping the initial ECS by unimodal training achieves a provably tighter error bound. However, ECS is computationally intractable in deep neural networks. To bridge this gap, we develop a framework comprising two core components: a fine-grained computable diagnostic metric and an asynchronous training controller. For the metric, we first prove that mutual information(MI) is a principled proxy for ECS. Considering MI is induced by per-modality marginals and thus treats each modality in isolation, we further propose FastPID, a computationally efficient and differentiable solver for partial information decomposition, which decomposes the joint distribution's information into fine-grained measurements: modality-specific uniqueness, redundancy, and synergy. Guided by these measurements, our asynchronous controller dynamically balances modalities by monitoring uniqueness and locates the ideal initial state to start joint training by tracking peak synergy. Experiments on diverse benchmarks demonstrate that our method achieves state-of-the-art performance. Our work establishes that shaping the pre-fusion models' initial state is a powerful strategy that eases competition before it starts, reliably unlocking synergistic multi-modal fusion.
Robust Multi-Omics Integration from Incomplete Modalities Significantly Improves Prediction of Alzheimer's Disease
arXiv:2509.20842v1 Announce Type: new Abstract: Multi-omics data capture complex biomolecular interactions and provide insights into metabolism and disease. However, missing modalities hinder integrative analysis across heterogeneous omics. To address this, we present MOIRA (Multi-Omics Integration with Robustness to Absent modalities), an early integration method enabling robust learning from incomplete omics data via representation alignment and adaptive aggregation. MOIRA leverages all samples, including those with missing modalities, by projecting each omics dataset onto a shared embedding space where a learnable weighting mechanism fuses them. Evaluated on the Religious Order Study and Memory and Aging Project (ROSMAP) dataset for Alzheimer's Disease (AD), MOIRA outperformed existing approaches, and further ablation studies confirmed modality-wise contributions. Feature importance analysis revealed AD-related biomarkers consistent with prior literature, highlighting the biological relevance of our approach.
Causal Time Series Generation via Diffusion Models
arXiv:2509.20846v1 Announce Type: new Abstract: Time series generation (TSG) synthesizes realistic sequences and has achieved remarkable success. Among TSG, conditional models generate sequences given observed covariates, however, such models learn observational correlations without considering unobserved confounding. In this work, we propose a causal perspective on conditional TSG and introduce causal time series generation as a new TSG task family, formalized within Pearl's causal ladder, extending beyond observational generation to include interventional and counterfactual settings. To instantiate these tasks, we develop CaTSG, a unified diffusion-based framework with backdoor-adjusted guidance that causally steers sampling toward desired interventions and individual counterfactuals while preserving observational fidelity. Specifically, our method derives causal score functions via backdoor adjustment and the abduction-action-prediction procedure, thus enabling principled support for all three levels of TSG. Extensive experiments on both synthetic and real-world datasets show that CaTSG achieves superior fidelity and also supporting interventional and counterfactual generation that existing baselines cannot handle. Overall, we propose the causal TSG family and instantiate it with CaTSG, providing an initial proof-of-concept and opening a promising direction toward more reliable simulation under interventions and counterfactual generation.
FHRFormer: A Self-supervised Transformer Approach for Fetal Heart Rate Inpainting and Forecasting
arXiv:2509.20852v1 Announce Type: new Abstract: Approximately 10\% of newborns require assistance to initiate breathing at birth, and around 5\% need ventilation support. Fetal heart rate (FHR) monitoring plays a crucial role in assessing fetal well-being during prenatal care, enabling the detection of abnormal patterns and supporting timely obstetric interventions to mitigate fetal risks during labor. Applying artificial intelligence (AI) methods to analyze large datasets of continuous FHR monitoring episodes with diverse outcomes may offer novel insights into predicting the risk of needing breathing assistance or interventions. Recent advances in wearable FHR monitors have enabled continuous fetal monitoring without compromising maternal mobility. However, sensor displacement during maternal movement, as well as changes in fetal or maternal position, often lead to signal dropouts, resulting in gaps in the recorded FHR data. Such missing data limits the extraction of meaningful insights and complicates automated (AI-based) analysis. Traditional approaches to handle missing data, such as simple interpolation techniques, often fail to preserve the spectral characteristics of the signals. In this paper, we propose a masked transformer-based autoencoder approach to reconstruct missing FHR signals by capturing both spatial and frequency components of the data. The proposed method demonstrates robustness across varying durations of missing data and can be used for signal inpainting and forecasting. The proposed approach can be applied retrospectively to research datasets to support the development of AI-based risk algorithms. In the future, the proposed method could be integrated into wearable FHR monitoring devices to achieve earlier and more robust risk detection.
Federated Markov Imputation: Privacy-Preserving Temporal Imputation in Multi-Centric ICU Environments
arXiv:2509.20867v1 Announce Type: new Abstract: Missing data is a persistent challenge in federated learning on electronic health records, particularly when institutions collect time-series data at varying temporal granularities. To address this, we propose Federated Markov Imputation (FMI), a privacy-preserving method that enables Intensive Care Units (ICUs) to collaboratively build global transition models for temporal imputation. We evaluate FMI on a real-world sepsis onset prediction task using the MIMIC-IV dataset and show that it outperforms local imputation baselines, especially in scenarios with irregular sampling intervals across ICUs.
StyleBench: Evaluating thinking styles in Large Language Models
arXiv:2509.20868v1 Announce Type: new Abstract: The effectiveness of Large Language Models (LLMs) is heavily influenced by the reasoning strategies, or styles of thought, employed in their prompts. However, the interplay between these reasoning styles, model architecture, and task type remains poorly understood. To address this, we introduce StyleBench, a comprehensive benchmark for systematically evaluating reasoning styles across diverse tasks and models. We assess five representative reasoning styles, including Chain of Thought (CoT), Tree of Thought (ToT), Algorithm of Thought (AoT), Sketch of Thought (SoT), and Chain-of-Draft (CoD) on five reasoning tasks, using 15 open-source models from major families (LLaMA, Qwen, Mistral, Gemma, GPT-OSS, Phi, and DeepSeek) ranging from 270M to 120B parameters. Our large-scale analysis reveals that no single style is universally optimal. We demonstrate that strategy efficacy is highly contingent on both model scale and task type: search-based methods (AoT, ToT) excel in open-ended problems but require large-scale models, while concise styles (SoT, CoD) achieve radical efficiency gains on well-defined tasks. Furthermore, we identify key behavioral patterns: smaller models frequently fail to follow output instructions and default to guessing, while reasoning robustness emerges as a function of scale. Our findings offer a crucial roadmap for selecting optimal reasoning strategies based on specific constraints, we open source the benchmark in https://github.com/JamesJunyuGuo/Style_Bench.
Model-Based Reinforcement Learning under Random Observation Delays
arXiv:2509.20869v1 Announce Type: new Abstract: Delays frequently occur in real-world environments, yet standard reinforcement learning (RL) algorithms often assume instantaneous perception of the environment. We study random sensor delays in POMDPs, where observations may arrive out-of-sequence, a setting that has not been previously addressed in RL. We analyze the structure of such delays and demonstrate that naive approaches, such as stacking past observations, are insufficient for reliable performance. To address this, we propose a model-based filtering process that sequentially updates the belief state based on an incoming stream of observations. We then introduce a simple delay-aware framework that incorporates this idea into model-based RL, enabling agents to effectively handle random delays. Applying this framework to Dreamer, we compare our approach to delay-aware baselines developed for MDPs. Our method consistently outperforms these baselines and demonstrates robustness to delay distribution shifts during deployment. Additionally, we present experiments on simulated robotic tasks, comparing our method to common practical heuristics and emphasizing the importance of explicitly modeling observation delays.
Distribution-Controlled Client Selection to Improve Federated Learning Strategies
arXiv:2509.20877v1 Announce Type: new Abstract: Federated learning (FL) is a distributed learning paradigm that allows multiple clients to jointly train a shared model while maintaining data privacy. Despite its great potential for domains with strict data privacy requirements, the presence of data imbalance among clients is a thread to the success of FL, as it causes the performance of the shared model to decrease. To address this, various studies have proposed enhancements to existing FL strategies, particularly through client selection methods that mitigate the detrimental effects of data imbalance. In this paper, we propose an extension to existing FL strategies, which selects active clients that best align the current label distribution with one of two target distributions, namely a balanced distribution or the federations combined label distribution. Subsequently, we empirically verify the improvements through our distribution-controlled client selection on three common FL strategies and two datasets. Our results show that while aligning the label distribution with a balanced distribution yields the greatest improvements facing local imbalance, alignment with the federation's combined label distribution is superior for global imbalance.
Improving Early Sepsis Onset Prediction Through Federated Learning
arXiv:2509.20885v1 Announce Type: new Abstract: Early and accurate prediction of sepsis onset remains a major challenge in intensive care, where timely detection and subsequent intervention can significantly improve patient outcomes. While machine learning models have shown promise in this domain, their success is often limited by the amount and diversity of training data available to individual hospitals and Intensive Care Units (ICUs). Federated Learning (FL) addresses this issue by enabling collaborative model training across institutions without requiring data sharing, thus preserving patient privacy. In this work, we propose a federated, attention-enhanced Long Short-Term Memory model for sepsis onset prediction, trained on multi-centric ICU data. Unlike existing approaches that rely on fixed prediction windows, our model supports variable prediction horizons, enabling both short- and long-term forecasting in a single unified model. During analysis, we put particular emphasis on the improvements through our approach in terms of early sepsis detection, i.e., predictions with large prediction windows by conducting an in-depth temporal analysis. Our results prove that using FL does not merely improve overall prediction performance (with performance approaching that of a centralized model), but is particularly beneficial for early sepsis onset prediction. Finally, we show that our choice of employing a variable prediction window rather than a fixed window does not hurt performance significantly but reduces computational, communicational, and organizational overhead.
Deterministic Discrete Denoising
arXiv:2509.20896v1 Announce Type: new Abstract: We propose a deterministic denoising algorithm for discrete-state diffusion models based on Markov chains. The generative reverse process is derandomized by introducing a variant of the herding algorithm with weakly chaotic dynamics, which induces deterministic discrete state transitions. Our approach is a direct replacement for the stochastic denoising process, requiring neither retraining nor continuous state embeddings. We demonstrate consistent improvements in both efficiency and sample quality on text and image generation tasks. Thus, this simple derandomization approach is expected to enhance the significance of discrete diffusion in generative modeling. Furthermore, our results reveal that deterministic reverse processes, well established in continuous diffusion, can also be effective in discrete state spaces.
Deep Learning for Crime Forecasting: The Role of Mobility at Fine-grained Spatiotemporal Scales
arXiv:2509.20913v1 Announce Type: new Abstract: Objectives: To develop a deep learning framework to evaluate if and how incorporating micro-level mobility features, alongside historical crime and sociodemographic data, enhances predictive performance in crime forecasting at fine-grained spatial and temporal resolutions. Methods: We advance the literature on computational methods and crime forecasting by focusing on four U.S. cities (i.e., Baltimore, Chicago, Los Angeles, and Philadelphia). We employ crime incident data obtained from each city's police department, combined with sociodemographic data from the American Community Survey and human mobility data from Advan, collected from 2019 to 2023. This data is aggregated into grids with equally sized cells of 0.077 sq. miles (0.2 sq. kms) and used to train our deep learning forecasting model, a Convolutional Long Short-Term Memory (ConvLSTM) network, which predicts crime occurrences 12 hours ahead using 14-day and 2-day input sequences. We also compare its performance against three baseline models: logistic regression, random forest, and standard LSTM. Results: Incorporating mobility features improves predictive performance, especially when using shorter input sequences. Noteworthy, however, the best results are obtained when both mobility and sociodemographic features are used together, with our deep learning model achieving the highest recall, precision, and F1 score in all four cities, outperforming alternative methods. With this configuration, longer input sequences enhance predictions for violent crimes, while shorter sequences are more effective for property crimes. Conclusion: These findings underscore the importance of integrating diverse data sources for spatiotemporal crime forecasting, mobility included. They also highlight the advantages (and limits) of deep learning when dealing with fine-grained spatial and temporal scales.
Energy saving in off-road vehicles using leakage compensation technique
arXiv:2509.20926v1 Announce Type: new Abstract: The article focuses on enhancing the energy efficiency of linear actuators used in heavy earth moving equipment, particularly in the booms ofexcavation equipment. Two hydraulic circuits are compared in terms of energy efficiency, with one using a conventional proportional directionalcontrol valve (PDCV) and the other using an innovative solution of proportional flow control valve (PFCV) with artificial leakage between thetwo ends of the actuator. The PFCV reduces energy loss in the form of heat by bypassing the extra flow from the pump during position control,unlike the PDCV that uses a pressure relief valve. The hydraulic circuit using PFCV is found to be 8.5% more energy efficient than theconventional circuit using PDCV. The article also discusses the position control of the actuator, which is achieved using a PID controller tuned by a fuzzy controller. Thesimulation of the hydraulic circuit is carried out using MATLAB/Simulink, and the results are compared with experiments. Overall, the proposedapproach could lead to significant improvements in the energy efficiency of linear actuators used in heavy earth moving equipment, therebyreducing their environmental impact and operating costs.
GenFacts-Generative Counterfactual Explanations for Multi-Variate Time Series
arXiv:2509.20936v1 Announce Type: new Abstract: Counterfactual explanations aim to enhance model transparency by showing how inputs can be minimally altered to change predictions. For multivariate time series, existing methods often generate counterfactuals that are invalid, implausible, or unintuitive. We introduce GenFacts, a generative framework based on a class-discriminative variational autoencoder. It integrates contrastive and classification-consistency objectives, prototype-based initialization, and realism-constrained optimization. We evaluate GenFacts on radar gesture data as an industrial use case and handwritten letter trajectories as an intuitive benchmark. Across both datasets, GenFacts outperforms state-of-the-art baselines in plausibility (+18.7%) and achieves the highest interpretability scores in a human study. These results highlight that plausibility and user-centered interpretability, rather than sparsity alone, are key to actionable counterfactuals in time series data.
Why Attention Fails: The Degeneration of Transformers into MLPs in Time Series Forecasting
arXiv:2509.20942v1 Announce Type: new Abstract: Transformer-based architectures achieved high performance in natural language processing and computer vision, yet many studies have shown that they have not demonstrated a clear advantage in time series forecasting and even underperform simple linear baselines in some cases. However, most of these studies have not thoroughly explored the reasons behind the failure of transformers. To better understand time-series transformers(TST), we designed a series of experiments, progressively modifying transformers into MLPs to investigate the impact of the attention mechanism. Surprisingly, transformer blocks often degenerate into simple MLPs in existing time-series transformers. We designed a interpretable dataset to investigate the reasons behind the failure of the attention mechanism and revealed that the attention mechanism is not working in the expected way. We theoretically analyzed the reasons behind this phenomenon, demonstrating that the current embedding methods fail to allow transformers to function in a well-structured latent space, and further analyzed the deeper underlying causes of the failure of embedding.
Decoupled-Value Attention for Prior-Data Fitted Networks: GP Inference for Physical Equations
arXiv:2509.20950v1 Announce Type: new Abstract: Prior-data fitted networks (PFNs) are a promising alternative to time-consuming Gaussian Process (GP) inference for creating fast surrogates of physical systems. PFN reduces the computational burden of GP-training by replacing Bayesian inference in GP with a single forward pass of a learned prediction model. However, with standard Transformer attention, PFNs show limited effectiveness on high-dimensional regression tasks. We introduce Decoupled-Value Attention (DVA)-- motivated by the GP property that the function space is fully characterized by the kernel over inputs and the predictive mean is a weighted sum of training targets. DVA computes similarities from inputs only and propagates labels solely through values. Thus, the proposed DVA mirrors the Gaussian-process update while remaining kernel-free. We demonstrate that the crucial factor for scaling PFNs is the attention rule rather than the architecture itself. Specifically, our results demonstrate that (a) localized attention consistently reduces out-of-sample validation loss in PFNs across different dimensional settings, with validation loss reduced by more than 50% in five- and ten-dimensional cases, and (b) the role of attention is more decisive than the choice of backbone architecture, showing that CNN-based PFNs can perform at par with their Transformer-based counterparts. The proposed PFNs provide 64-dimensional power flow equation approximations with a mean absolute error of the order of 1E-3, while being over 80x faster than exact GP inference.
Flow Matching in the Low-Noise Regime: Pathologies and a Contrastive Remedy
arXiv:2509.20952v1 Announce Type: new Abstract: Flow matching has recently emerged as a powerful alternative to diffusion models, providing a continuous-time formulation for generative modeling and representation learning. Yet, we show that this framework suffers from a fundamental instability in the low-noise regime. As noise levels approach zero, arbitrarily small perturbations in the input can induce large variations in the velocity target, causing the condition number of the learning problem to diverge. This ill-conditioning not only slows optimization but also forces the encoder to reallocate its limited Jacobian capacity toward noise directions, thereby degrading semantic representations. We provide the first theoretical analysis of this phenomenon, which we term the low-noise pathology, establishing its intrinsic link to the structure of the flow matching objective. Building on these insights, we propose Local Contrastive Flow (LCF), a hybrid training protocol that replaces direct velocity regression with contrastive feature alignment at small noise levels, while retaining standard flow matching at moderate and high noise. Empirically, LCF not only improves convergence speed but also stabilizes representation quality. Our findings highlight the critical importance of addressing low-noise pathologies to unlock the full potential of flow matching for both generation and representation learning.
Alignment Unlocks Complementarity: A Framework for Multiview Circuit Representation Learning
arXiv:2509.20968v1 Announce Type: new Abstract: Multiview learning on Boolean circuits holds immense promise, as different graph-based representations offer complementary structural and semantic information. However, the vast structural heterogeneity between views, such as an And-Inverter Graph (AIG) versus an XOR-Majority Graph (XMG), poses a critical barrier to effective fusion, especially for self-supervised techniques like masked modeling. Naively applying such methods fails, as the cross-view context is perceived as noise. Our key insight is that functional alignment is a necessary precondition to unlock the power of multiview self-supervision. We introduce MixGate, a framework built on a principled training curriculum that first teaches the model a shared, function-aware representation space via an Equivalence Alignment Loss. Only then do we introduce a multiview masked modeling objective, which can now leverage the aligned views as a rich, complementary signal. Extensive experiments, including a crucial ablation study, demonstrate that our alignment-first strategy transforms masked modeling from an ineffective technique into a powerful performance driver.
Knowledgeable Language Models as Black-Box Optimizers for Personalized Medicine
arXiv:2509.20975v1 Announce Type: new Abstract: The goal of personalized medicine is to discover a treatment regimen that optimizes a patient's clinical outcome based on their personal genetic and environmental factors. However, candidate treatments cannot be arbitrarily administered to the patient to assess their efficacy; we often instead have access to an in silico surrogate model that approximates the true fitness of a proposed treatment. Unfortunately, such surrogate models have been shown to fail to generalize to previously unseen patient-treatment combinations. We hypothesize that domain-specific prior knowledge - such as medical textbooks and biomedical knowledge graphs - can provide a meaningful alternative signal of the fitness of proposed treatments. To this end, we introduce LLM-based Entropy-guided Optimization with kNowledgeable priors (LEON), a mathematically principled approach to leverage large language models (LLMs) as black-box optimizers without any task-specific fine-tuning, taking advantage of their ability to contextualize unstructured domain knowledge to propose personalized treatment plans in natural language. In practice, we implement LEON via 'optimization by prompting,' which uses LLMs as stochastic engines for proposing treatment designs. Experiments on real-world optimization tasks show LEON outperforms both traditional and LLM-based methods in proposing individualized treatments for patients.
CLUE: Conflict-guided Localization for LLM Unlearning Framework
arXiv:2509.20977v1 Announce Type: new Abstract: The LLM unlearning aims to eliminate the influence of undesirable data without affecting causally unrelated information. This process typically involves using a forget set to remove target information, alongside a retain set to maintain non-target capabilities. While recent localization-based methods demonstrate promise in identifying important neurons to be unlearned, they fail to disentangle neurons responsible for forgetting undesirable knowledge or retaining essential skills, often treating them as a single entangled group. As a result, these methods apply uniform interventions, risking catastrophic over-forgetting or incomplete erasure of the target knowledge. To address this, we turn to circuit discovery, a mechanistic interpretability technique, and propose the Conflict-guided Localization for LLM Unlearning framEwork (CLUE). This framework identifies the forget and retain circuit composed of important neurons, and then the circuits are transformed into conjunctive normal forms (CNF). The assignment of each neuron in the CNF satisfiability solution reveals whether it should be forgotten or retained. We then provide targeted fine-tuning strategies for different categories of neurons. Extensive experiments demonstrate that, compared to existing localization methods, CLUE achieves superior forget efficacy and retain utility through precise neural localization.
FracAug: Fractional Augmentation boost Graph-level Anomaly Detection under Limited Supervision
arXiv:2509.20978v1 Announce Type: new Abstract: Graph-level anomaly detection (GAD) is critical in diverse domains such as drug discovery, yet high labeling costs and dataset imbalance hamper the performance of Graph Neural Networks (GNNs). To address these issues, we propose FracAug, an innovative plug-in augmentation framework that enhances GNNs by generating semantically consistent graph variants and pseudo-labeling with mutual verification. Unlike previous heuristic methods, FracAug learns semantics within given graphs and synthesizes fractional variants, guided by a novel weighted distance-aware margin loss. This captures multi-scale topology to generate diverse, semantic-preserving graphs unaffected by data imbalance. Then, FracAug utilizes predictions from both original and augmented graphs to pseudo-label unlabeled data, iteratively expanding the training set. As a model-agnostic module compatible with various GNNs, FracAug demonstrates remarkable universality and efficacy: experiments across 14 GNNs on 12 real-world datasets show consistent gains, boosting average AUROC, AUPRC, and F1-score by up to 5.72%, 7.23%, and 4.18%, respectively.
Toward Robust and Efficient ML-Based GPU Caching for Modern Inference
arXiv:2509.20979v1 Announce Type: new Abstract: In modern GPU inference, cache efficiency remains a major bottleneck. In recommendation models, embedding hit rates largely determine throughput, while in large language models, KV-cache misses substantially increase time-to-first-token (TTFT). Heuristic policies such as \textsc{LRU} often struggle under structured access patterns. Learning-based approaches are promising, but in practice face two major limitations: they degrade sharply when predictions are inaccurate, or they gain little even with accurate predictions due to conservative designs. Some also incur high overhead, further limiting practicality. We present \textsc{LCR}, a practical framework for learning-based GPU caching that delivers performance gains while ensuring robustness and efficiency. Its core algorithm, \textsc{LARU}, enhances \textsc{LRU} with machine-learned predictions and dynamically adapts to prediction accuracy through online error estimation. When predictions are accurate, \textsc{LARU} achieves near-optimal performance. With inaccurate predictions, it degrades gracefully to near-\textsc{LRU} performance. With \textsc{LCR}, we bridge the gap between empirical progress and theoretical advances in learning-based caching. Experiments show that \textsc{LCR} delivers consistent gains under realistic conditions. In DLRM and LLM scenarios, it improves throughput by up to 24.2\% and reduces P99 TTFT by up to 28.3\%, outperforming widely used inference systems. Even under poor predictions, its performance remains stable, demonstrating practical robustness.
Learning Ising Models under Hard Constraints using One Sample
arXiv:2509.20993v1 Announce Type: new Abstract: We consider the problem of estimating inverse temperature parameter $\beta$ of an $n$-dimensional truncated Ising model using a single sample. Given a graph $G = (V,E)$ with $n$ vertices, a truncated Ising model is a probability distribution over the $n$-dimensional hypercube ${-1,1}^n$ where each configuration $\mathbf{\sigma}$ is constrained to lie in a truncation set $S \subseteq {-1,1}^n$ and has probability $\Pr(\mathbf{\sigma}) \propto \exp(\beta\mathbf{\sigma}^\top A\mathbf{\sigma})$ with $A$ being the adjacency matrix of $G$. We adopt the recent setting of [Galanis et al. SODA'24], where the truncation set $S$ can be expressed as the set of satisfying assignments of a $k$-SAT formula. Given a single sample $\mathbf{\sigma}$ from a truncated Ising model, with inverse parameter $\beta^$, underlying graph $G$ of bounded degree $\Delta$ and $S$ being expressed as the set of satisfying assignments of a $k$-SAT formula, we design in nearly $O(n)$ time an estimator $\hat{\beta}$ that is $O(\Delta^3/\sqrt{n})$-consistent with the true parameter $\beta^$ for $k \gtrsim \log(d^2k)\Delta^3.$ Our estimator is based on the maximization of the pseudolikelihood, a notion that has received extensive analysis for various probabilistic models without [Chatterjee, Annals of Statistics '07] or with truncation [Galanis et al. SODA '24]. Our approach generalizes recent techniques from [Daskalakis et al. STOC '19, Galanis et al. SODA '24], to confront the more challenging setting of the truncated Ising model.
Binary Autoencoder for Mechanistic Interpretability of Large Language Models
arXiv:2509.20997v1 Announce Type: new Abstract: Existing works are dedicated to untangling atomized numerical components (features) from the hidden states of Large Language Models (LLMs) for interpreting their mechanism. However, they typically rely on autoencoders constrained by some implicit training-time regularization on single training instances (i.e., $L_1$ normalization, top-k function, etc.), without an explicit guarantee of global sparsity among instances, causing a large amount of dense (simultaneously inactive) features, harming the feature sparsity and atomization. In this paper, we propose a novel autoencoder variant that enforces minimal entropy on minibatches of hidden activations, thereby promoting feature independence and sparsity across instances. For efficient entropy calculation, we discretize the hidden activations to 1-bit via a step function and apply gradient estimation to enable backpropagation, so that we term it as Binary Autoencoder (BAE) and empirically demonstrate two major applications: (1) Feature set entropy calculation. Entropy can be reliably estimated on binary hidden activations, which we empirically evaluate and leverage to characterize the inference dynamics of LLMs and In-context Learning. (2) Feature untangling. Similar to typical methods, BAE can extract atomized features from LLM's hidden states. To robustly evaluate such feature extraction capability, we refine traditional feature-interpretation methods to avoid unreliable handling of numerical tokens, and show that BAE avoids dense features while producing the largest number of interpretable ones among baselines, which confirms the effectiveness of BAE serving as a feature extractor.
Feature Augmentation of GNNs for ILPs: Local Uniqueness Suffices
arXiv:2509.21000v1 Announce Type: new Abstract: Integer Linear Programs (ILPs) are central to real-world optimizations but notoriously difficult to solve. Learning to Optimize (L2O) has emerged as a promising paradigm, with Graph Neural Networks (GNNs) serving as the standard backbone. However, standard anonymous GNNs are limited in expressiveness for ILPs, and the common enhancement of augmenting nodes with globally unique identifiers (UIDs) typically introduces spurious correlations that severely harm generalization. To address this tradeoff, we propose a parsimonious Local-UID scheme based on d-hop uniqueness coloring, which ensures identifiers are unique only within each node's d-hop neighborhood. Building on this scheme, we introduce ColorGNN, which incorporates color information via color-conditioned embeddings, and ColorUID, a lightweight feature-level variant. We prove that for d-layer networks, Local-UIDs achieve the expressive power of Global-UIDs while offering stronger generalization. Extensive experiments show that our approach (i) yields substantial gains on three ILP benchmarks, (ii) exhibits strong OOD generalization on linear programming datasets, and (iii) further improves a general graph-level task when paired with a state-of-the-art method.
Lossless Compression: A New Benchmark for Time Series Model Evaluation
arXiv:2509.21002v1 Announce Type: new Abstract: The evaluation of time series models has traditionally focused on four canonical tasks: forecasting, imputation, anomaly detection, and classification. While these tasks have driven significant progress, they primarily assess task-specific performance and do not rigorously measure whether a model captures the full generative distribution of the data. We introduce lossless compression as a new paradigm for evaluating time series models, grounded in Shannon's source coding theorem. This perspective establishes a direct equivalence between optimal compression length and the negative log-likelihood, providing a strict and unified information-theoretic criterion for modeling capacity. Then We define a standardized evaluation protocol and metrics. We further propose and open-source a comprehensive evaluation framework TSCom-Bench, which enables the rapid adaptation of time series models as backbones for lossless compression. Experiments across diverse datasets on state-of-the-art models, including TimeXer, iTransformer, and PatchTST, demonstrate that compression reveals distributional weaknesses overlooked by classic benchmarks. These findings position lossless compression as a principled task that complements and extends existing evaluation for time series modeling.
MAIFormer: Multi-Agent Inverted Transformer for Flight Trajectory Prediction
arXiv:2509.21004v1 Announce Type: new Abstract: Flight trajectory prediction for multiple aircraft is essential and provides critical insights into how aircraft navigate within current air traffic flows. However, predicting multi-agent flight trajectories is inherently challenging. One of the major difficulties is modeling both the individual aircraft behaviors over time and the complex interactions between flights. Generating explainable prediction outcomes is also a challenge. Therefore, we propose a Multi-Agent Inverted Transformer, MAIFormer, as a novel neural architecture that predicts multi-agent flight trajectories. The proposed framework features two key attention modules: (i) masked multivariate attention, which captures spatio-temporal patterns of individual aircraft, and (ii) agent attention, which models the social patterns among multiple agents in complex air traffic scenes. We evaluated MAIFormer using a real-world automatic dependent surveillance-broadcast flight trajectory dataset from the terminal airspace of Incheon International Airport in South Korea. The experimental results show that MAIFormer achieves the best performance across multiple metrics and outperforms other methods. In addition, MAIFormer produces prediction outcomes that are interpretable from a human perspective, which improves both the transparency of the model and its practical utility in air traffic control.
ExMolRL: Phenotype-Target Joint Generation of De Novo Molecules via Multi-Objective Reinforcement Learning
arXiv:2509.21010v1 Announce Type: new Abstract: The generation of high-quality candidate molecules remains a central challenge in AI-driven drug design. Current phenotype-based and target-based strategies each suffer limitations, either incurring high experimental costs or overlook system-level cellular responses. To bridge this gap, we propose ExMoIRL, a novel generative framework that synergistically integrates phenotypic and target-specific cues for de novo molecular generation. The phenotype-guided generator is first pretrained on expansive drug-induced transcriptional profiles and subsequently fine-tuned via multi-objective reinforcement learning (RL). Crucially, the reward function fuses docking affinity and drug-likeness scores, augmented with ranking loss, prior-likelihood regularization, and entropy maximization. The multi-objective RL steers the model toward chemotypes that are simultaneously potent, diverse, and aligned with the specified phenotypic effects. Extensive experiments demonstrate ExMoIRL's superior performance over state-of-the-art phenotype-based and target-based models across multiple well-characterized targets. Our generated molecules exhibit favorable drug-like properties, high target affinity, and inhibitory potency (IC50) against cancer cells. This unified framework showcases the synergistic potential of combining phenotype-guided and target-aware strategies, offering a more effective solution for de novo drug discovery.
Mechanism of Task-oriented Information Removal in In-context Learning
arXiv:2509.21012v1 Announce Type: new Abstract: In-context Learning (ICL) is an emerging few-shot learning paradigm based on modern Language Models (LMs), yet its inner mechanism remains unclear. In this paper, we investigate the mechanism through a novel perspective of information removal. Specifically, we demonstrate that in the zero-shot scenario, LMs encode queries into non-selective representations in hidden states containing information for all possible tasks, leading to arbitrary outputs without focusing on the intended task, resulting in near-zero accuracy. Meanwhile, we find that selectively removing specific information from hidden states by a low-rank filter effectively steers LMs toward the intended task. Building on these findings, by measuring the hidden states on carefully designed metrics, we observe that few-shot ICL effectively simulates such task-oriented information removal processes, selectively removing the redundant information from entangled non-selective representations, and improving the output based on the demonstrations, which constitutes a key mechanism underlying ICL. Moreover, we identify essential attention heads inducing the removal operation, termed Denoising Heads, which enables the ablation experiments blocking the information removal operation from the inference, where the ICL accuracy significantly degrades, especially when the correct label is absent from the few-shot demonstrations, confirming both the critical role of the information removal mechanism and denoising heads.
Predicting LLM Reasoning Performance with Small Proxy Model
arXiv:2509.21013v1 Announce Type: new Abstract: Given the prohibitive cost of pre-training large language models, it is essential to leverage smaller proxy models to optimize datasets before scaling up. However, this approach becomes challenging for reasoning capabilities, which exhibit emergent behavior that only appear reliably at larger model sizes, often exceeding 7B parameters. To address this, we introduce rBridge, showing that small proxies ($\leq$1B) can effectively predict large-model reasoning by aligning more closely with (1) the pre-training objective and (2) the target task. rBridge achieves this by weighting negative log-likelihood with task alignment, using reasoning traces from frontier models as gold labels. In our experiments, rBridge (i) reduces dataset ranking costs by over 100x relative to the best baseline, (ii) achieves the strongest correlation across six reasoning benchmarks at 1B to 32B scale, and (iii) zero-shot transfers predictive relationships across pre-training datasets at 1B to 7B scale. These findings indicate that rBridge offers a practical path for exploring reasoning-oriented pre-training at lower cost.
DELTA-Code: How Does RL Unlock and Transfer New Programming Algorithms in LLMs?
arXiv:2509.21016v1 Announce Type: new Abstract: It remains an open question whether LLMs can acquire or generalize genuinely new reasoning strategies, beyond the sharpened skills encoded in their parameters during pre-training or post-training. To attempt to answer this debate, we introduce DELTA-Code--Distributional Evaluation of Learnability and Transferrability in Algorithmic Coding, a controlled benchmark of synthetic coding problem families designed to probe two fundamental aspects: learnability -- can LLMs, through reinforcement learning (RL), solve problem families where pretrained models exhibit failure with large enough attempts (pass@K=0)? --and transferrability -- if learnability happens, can such skills transfer systematically to out-of-distribution (OOD) test sets? Unlike prior public coding datasets, DELTA isolates reasoning skills through templated problem generators and introduces fully OOD problem families that demand novel strategies rather than tool invocation or memorized patterns. Our experiments reveal a striking grokking phase transition: after an extended period with near-zero reward, RL-trained models abruptly climb to near-perfect accuracy. To enable learnability on previously unsolvable problem families, we explore key training ingredients such as staged warm-up with dense rewards, experience replay, curriculum training, and verification-in-the-loop. Beyond learnability, we use DELTA to evaluate transferability or generalization along exploratory, compositional, and transformative axes, as well as cross-family transfer. Results show solid gains within families and for recomposed skills, but persistent weaknesses in transformative cases. DELTA thus offers a clean testbed for probing the limits of RL-driven reasoning and for understanding how models can move beyond existing priors to acquire new algorithmic skills.
Efficient Ensemble Conditional Independence Test Framework for Causal Discovery
arXiv:2509.21021v1 Announce Type: new Abstract: Constraint-based causal discovery relies on numerous conditional independence tests (CITs), but its practical applicability is severely constrained by the prohibitive computational cost, especially as CITs themselves have high time complexity with respect to the sample size. To address this key bottleneck, we introduce the Ensemble Conditional Independence Test (E-CIT), a general and plug-and-play framework. E-CIT operates on an intuitive divide-and-aggregate strategy: it partitions the data into subsets, applies a given base CIT independently to each subset, and aggregates the resulting p-values using a novel method grounded in the properties of stable distributions. This framework reduces the computational complexity of a base CIT to linear in the sample size when the subset size is fixed. Moreover, our tailored p-value combination method offers theoretical consistency guarantees under mild conditions on the subtests. Experimental results demonstrate that E-CIT not only significantly reduces the computational burden of CITs and causal discovery but also achieves competitive performance. Notably, it exhibits an improvement in complex testing scenarios, particularly on real-world datasets.
Actor-Critic without Actor
arXiv:2509.21022v1 Announce Type: new Abstract: Actor-critic methods constitute a central paradigm in reinforcement learning (RL), coupling policy evaluation with policy improvement. While effective across many domains, these methods rely on separate actor and critic networks, which makes training vulnerable to architectural decisions and hyperparameter tuning. Such complexity limits their scalability in settings that require large function approximators. Recently, diffusion models have recently been proposed as expressive policies that capture multi-modal behaviors and improve exploration, but they introduce additional design choices and computational burdens, hindering efficient deployment. We introduce Actor-Critic without Actor (ACA), a lightweight framework that eliminates the explicit actor network and instead generates actions directly from the gradient field of a noise-level critic. This design removes the algorithmic and computational overhead of actor training while keeping policy improvement tightly aligned with the critic's latest value estimates. Moreover, ACA retains the ability to capture diverse, multi-modal behaviors without relying on diffusion-based actors, combining simplicity with expressiveness. Through extensive experiments on standard online RL benchmarks,ACA achieves more favorable learning curves and competitive performance compared to both standard actor-critic and state-of-the-art diffusion-based methods, providing a simple yet powerful solution for online RL.
FORCE: Transferable Visual Jailbreaking Attacks via Feature Over-Reliance CorrEction
arXiv:2509.21029v1 Announce Type: new Abstract: The integration of new modalities enhances the capabilities of multimodal large language models (MLLMs) but also introduces additional vulnerabilities. In particular, simple visual jailbreaking attacks can manipulate open-source MLLMs more readily than sophisticated textual attacks. However, these underdeveloped attacks exhibit extremely limited cross-model transferability, failing to reliably identify vulnerabilities in closed-source MLLMs. In this work, we analyse the loss landscape of these jailbreaking attacks and find that the generated attacks tend to reside in high-sharpness regions, whose effectiveness is highly sensitive to even minor parameter changes during transfer. To further explain the high-sharpness localisations, we analyse their feature representations in both the intermediate layers and the spectral domain, revealing an improper reliance on narrow layer representations and semantically poor frequency components. Building on this, we propose a Feature Over-Reliance CorrEction (FORCE) method, which guides the attack to explore broader feasible regions across layer features and rescales the influence of frequency features according to their semantic content. By eliminating non-generalizable reliance on both layer and spectral features, our method discovers flattened feasible regions for visual jailbreaking attacks, thereby improving cross-model transferability. Extensive experiments demonstrate that our approach effectively facilitates visual red-teaming evaluations against closed-source MLLMs.
Reinforcement Learning Fine-Tuning Enhances Activation Intensity and Diversity in the Internal Circuitry of LLMs
arXiv:2509.21044v1 Announce Type: new Abstract: Large language models (LLMs) acquire extensive prior knowledge through large-scale pretraining and can be further enhanced via supervised fine-tuning (SFT) or reinforcement learning (RL)-based post-training. A growing body of evidence has shown that RL fine-tuning improves the capability of LLMs beyond what SFT alone achieves. However, the underlying mechanisms why RL fine-tuning is able to enhance the capability of various LLMs with distinct intrinsic characteristics remain underexplored. In this study, we draw inspiration from prior work on edge attribution patching (EAP) to investigate the internal differences of LLMs before and after RL fine-tuning. Our analysis across multiple model families shows two robust effects of online RL post-training: (i) an overall increase in activation intensity, indicating that more internal pathways are engaged and their signals become stronger, and (ii) greater diversity in activation patterns, reflected by higher entropy and less concentrated edge distributions. These changes suggest that RL reshapes information flow to be both more redundant and more flexible, which may explain its advantage in generalization. Notably, models fine-tuned with Direct Preference Optimization (DPO) deviate from these trends, exhibiting substantially weaker or inconsistent internal changes compared to PPO- and GRPO-based training. Together, our findings provide a unified view of how RL fine-tuning systematically alters the internal circuitry of LLMs and highlight the methodological distinctions between online RL and preference-based approaches. Our code is open source at https://anonymous.4open.science/r/llm_rl_probing_analysis-F673.
Physics of Learning: A Lagrangian perspective to different learning paradigms
arXiv:2509.21049v1 Announce Type: new Abstract: We study the problem of building an efficient learning system. Efficient learning processes information in the least time, i.e., building a system that reaches a desired error threshold with the least number of observations. Building upon least action principles from physics, we derive classic learning algorithms, Bellman's optimality equation in reinforcement learning, and the Adam optimizer in generative models from first principles, i.e., the Learning $\textit{Lagrangian}$. We postulate that learning searches for stationary paths in the Lagrangian, and learning algorithms are derivable by seeking the stationary trajectories.
GeoRef: Referring Expressions in Geometry via Task Formulation, Synthetic Supervision, and Reinforced MLLM-based Solutions
arXiv:2509.21050v1 Announce Type: new Abstract: AI-driven geometric problem solving is a complex vision-language task that requires accurate diagram interpretation, mathematical reasoning, and robust cross-modal grounding. A foundational yet underexplored capability for this task is the ability to identify and interpret geometric elements based on natural language queries. To address this, we introduce the task of Referring Expression Comprehension (REC) for geometric problems, which evaluates whether models can localize points, shapes, and spatial relations in diagrams in response to textual prompts. We present GeoRef, a benchmark dataset constructed from existing geometric problem corpora, featuring diverse, high-quality annotations and queries. Due to the lack of annotated data for this task, we generate a large-scale synthetic training dataset using a structured geometric formal language, enabling broad coverage of geometric concepts and facilitating model adaptation. We explore two fine-tuning approaches: Supervised Fine-Tuning (SFT) and Group Relative Policy Optimization (GRPO). Our results show that GRPO significantly outperforms SFT by better aligning model behavior with task-specific rewards. Furthermore, we propose a verify-and-regenerate mechanism that detects incorrect predictions and re-infers answers using contextual reasoning history, further boosting accuracy. Notably, even state-of-the-art Multimodal Large Language Models (MLLMs) struggle with this task, underscoring the necessity of explicitly evaluating and strengthening geometric grounding as a prerequisite for robust geometric problem solving. Moreover, models trained on GeoRef demonstrate measurable improvements on downstream geometric reasoning tasks, highlighting the broader value of REC as a foundation for multimodal mathematical understanding.
SPREAD: Sampling-based Pareto front Refinement via Efficient Adaptive Diffusion
arXiv:2509.21058v1 Announce Type: new Abstract: Developing efficient multi-objective optimization methods to compute the Pareto set of optimal compromises between conflicting objectives remains a key challenge, especially for large-scale and expensive problems. To bridge this gap, we introduce SPREAD, a generative framework based on Denoising Diffusion Probabilistic Models (DDPMs). SPREAD first learns a conditional diffusion process over points sampled from the decision space and then, at each reverse diffusion step, refines candidates via a sampling scheme that uses an adaptive multiple gradient descent-inspired update for fast convergence alongside a Gaussian RBF-based repulsion term for diversity. Empirical results on multi-objective optimization benchmarks, including offline and Bayesian surrogate-based settings, show that SPREAD matches or exceeds leading baselines in efficiency, scalability, and Pareto front coverage.
Structure-Attribute Transformations with Markov Chain Boost Graph Domain Adaptation
arXiv:2509.21059v1 Announce Type: new Abstract: Graph domain adaptation has gained significant attention in label-scarce scenarios across different graph domains. Traditional approaches to graph domain adaptation primarily focus on transforming node attributes over raw graph structures and aligning the distributions of the transformed node features across networks. However, these methods often struggle with the underlying structural heterogeneity between distinct graph domains, which leads to suboptimal distribution alignment. To address this limitation, we propose Structure-Attribute Transformation with Markov Chain (SATMC), a novel framework that sequentially aligns distributions across networks via both graph structure and attribute transformations. To mitigate the negative influence of domain-private information and further enhance the model's generalization, SATMC introduces a private domain information reduction mechanism and an empirical Wasserstein distance. Theoretical proofs suggest that SATMC can achieve a tighter error bound for cross-network node classification compared to existing graph domain adaptation methods. Extensive experiments on nine pairs of publicly available cross-domain datasets show that SATMC outperforms state-of-the-art methods in the cross-network node classification task. The code is available at https://github.com/GiantZhangYT/SATMC.
ScaleDiff: Scaling Difficult Problems for Advanced Mathematical Reasoning
arXiv:2509.21070v1 Announce Type: new Abstract: Large Reasoning Models (LRMs) have shown impressive capabilities in complex problem-solving, often benefiting from training on difficult mathematical problems that stimulate intricate reasoning. Recent efforts have explored automated synthesis of mathematical problems by prompting proprietary models or large-scale open-source models from seed data or inherent mathematical concepts. However, scaling up these methods remains challenging due to their high computational/API cost, complexity of prompting, and limited difficulty level of the generated problems. To overcome these limitations, we propose ScaleDiff, a simple yet effective pipeline designed to scale the creation of difficult problems. We efficiently identify difficult problems from existing datasets with only a single forward pass using an adaptive thinking model, which can perceive problem difficulty and automatically switch between "Thinking" and "NoThinking" modes. We then train a specialized difficult problem generator (DiffGen-8B) on this filtered difficult data, which can produce new difficult problems in large scale, eliminating the need for complex, per-instance prompting and its associated high API costs. Fine-tuning Qwen2.5-Math-7B-Instruct on the ScaleDiff-Math dataset yields a substantial performance increase of 11.3% compared to the original dataset and achieves a 65.9% average accuracy on AIME'24, AIME'25, HMMT-Feb'25, BRUMO'25, and MATH500, outperforming recent strong LRMs like OpenThinker3. Notably, this performance is achieved using the cost-efficient Qwen3-8B model as a teacher, demonstrating that our pipeline can effectively transfer advanced reasoning capabilities without relying on larger, more expensive teacher models. Furthermore, we observe a clear scaling phenomenon in model performance on difficult benchmarks as the quantity of difficult problems increases. Code: https://github.com/QizhiPei/ScaleDiff.
TyphoonMLA: A Mixed Naive-Absorb MLA Kernel For Shared Prefix
arXiv:2509.21081v1 Announce Type: new Abstract: Multi-Head Latent Attention (MLA) is a recent attention mechanism adopted in state-of-the-art LLMs such as DeepSeek-v3 and Kimi K2. Thanks to its novel formulation, MLA allows two functionally equivalent but computationally distinct kernel implementations: naive and absorb. While the naive kernels (e.g., FlashAttention) are typically preferred in training and prefill for their computational efficiency, existing decoding kernels (e.g., FlashMLA) rely on the absorb method to minimize HBM bandwidth usage. However, the compute-bound nature of the absorb implementations prohibits performance benefits from data reuse opportunities in attention calculations, such as shared prefixes. In this work, we introduce TyphoonMLA, a hybrid approach that combines naive and absorb formulations to harness the strengths of both. TyphoonMLA effectively leverages the shared prefix by applying the naive formulation to the compute-bound parts of attention calculations, while reducing the bandwidth requirements for non-shared parts by using the absorb formulation. As a result, TyphoonMLA improves the throughput of attention calculations in MLA architectures by up to 3x and 3.24x on NPU and GPUs, with only a 3% overhead in HBM size.
GraphUniverse: Enabling Systematic Evaluation of Inductive Generalization
arXiv:2509.21097v1 Announce Type: new Abstract: A fundamental challenge in graph learning is understanding how models generalize to new, unseen graphs. While synthetic benchmarks offer controlled settings for analysis, existing approaches are confined to single-graph, transductive settings where models train and test on the same graph structure. Addressing this gap, we introduce GraphUniverse, a framework for generating entire families of graphs to enable the first systematic evaluation of inductive generalization at scale. Our core innovation is the generation of graphs with persistent semantic communities, ensuring conceptual consistency while allowing fine-grained control over structural properties like homophily and degree distributions. This enables crucial but underexplored robustness tests, such as performance under controlled distribution shifts. Benchmarking a wide range of architectures -- from GNNs to graph transformers and topological architectures -- reveals that strong transductive performance is a poor predictor of inductive generalization. Furthermore, we find that robustness to distribution shift is highly sensitive not only to model architecture choice but also to the initial graph regime (e.g., high vs. low homophily). Beyond benchmarking, GraphUniverse's flexibility and scalability can facilitate the development of robust and truly generalizable architectures -- including next-generation graph foundation models. An interactive demo is available at https://graphuniverse.streamlit.app.
Teaching RL Agents to Act Better: VLM as Action Advisor for Online Reinforcement Learning
arXiv:2509.21126v1 Announce Type: new Abstract: Online reinforcement learning in complex tasks is time-consuming, as massive interaction steps are needed to learn the optimal Q-function.Vision-language action (VLA) policies represent a promising direction for solving diverse tasks; however, their performance on low-level control remains limited, and effective deployment often requires task-specific expert demonstrations for fine-tuning. In this paper, we propose \textbf{VARL} (\textbf{V}LM as \textbf{A}ction advisor for online \textbf{R}einforcement \textbf{L}earning), a framework that leverages the domain knowledge of vision-language models (VLMs) to provide action suggestions for reinforcement learning agents. Unlike previous methods, VARL provides action suggestions rather than designing heuristic rewards, thereby guaranteeing unchanged optimality and convergence. The suggested actions increase sample diversity and ultimately improve sample efficiency, especially in sparse-reward tasks. To validate the effectiveness of VARL, we evaluate it across diverse environments and agent settings. Results show that VARL greatly improves sample efficiency without introducing significant computational overhead. These advantages make VARL a general framework for online reinforcement learning and make it feasible to directly apply reinforcement learning from scratch in real-world environments.
EvoMail: Self-Evolving Cognitive Agents for Adaptive Spam and Phishing Email Defense
arXiv:2509.21129v1 Announce Type: new Abstract: Modern email spam and phishing attacks have evolved far beyond keyword blacklists or simple heuristics. Adversaries now craft multi-modal campaigns that combine natural-language text with obfuscated URLs, forged headers, and malicious attachments, adapting their strategies within days to bypass filters. Traditional spam detection systems, which rely on static rules or single-modality models, struggle to integrate heterogeneous signals or to continuously adapt, leading to rapid performance degradation. We propose EvoMail, a self-evolving cognitive agent framework for robust detection of spam and phishing. EvoMail first constructs a unified heterogeneous email graph that fuses textual content, metadata (headers, senders, domains), and embedded resources (URLs, attachments). A Cognitive Graph Neural Network enhanced by a Large Language Model (LLM) performs context-aware reasoning across these sources to identify coordinated spam campaigns. Most critically, EvoMail engages in an adversarial self-evolution loop: a ''red-team'' agent generates novel evasion tactics -- such as character obfuscation or AI-generated phishing text -- while the ''blue-team'' detector learns from failures, compresses experiences into a memory module, and reuses them for future reasoning. Extensive experiments on real-world datasets (Enron-Spam, Ling-Spam, SpamAssassin, and TREC) and synthetic adversarial variants demonstrate that EvoMail consistently outperforms state-of-the-art baselines in detection accuracy, adaptability to evolving spam tactics, and interpretability of reasoning traces. These results highlight EvoMail's potential as a resilient and explainable defense framework against next-generation spam and phishing threats.
Sparse Representations Improve Adversarial Robustness of Neural Network Classifiers
arXiv:2509.21130v1 Announce Type: new Abstract: Deep neural networks perform remarkably well on image classification tasks but remain vulnerable to carefully crafted adversarial perturbations. This work revisits linear dimensionality reduction as a simple, data-adapted defense. We empirically compare standard Principal Component Analysis (PCA) with its sparse variant (SPCA) as front-end feature extractors for downstream classifiers, and we complement these experiments with a theoretical analysis. On the theory side, we derive exact robustness certificates for linear heads applied to SPCA features: for both $\ell_\infty$ and $\ell_2$ threat models (binary and multiclass), the certified radius grows as the dual norms of $W^\top u$ shrink, where $W$ is the projection and $u$ the head weights. We further show that for general (non-linear) heads, sparsity reduces operator-norm bounds through a Lipschitz composition argument, predicting lower input sensitivity. Empirically, with a small non-linear network after the projection, SPCA consistently degrades more gracefully than PCA under strong white-box and black-box attacks while maintaining competitive clean accuracy. Taken together, the theory identifies the mechanism (sparser projections reduce adversarial leverage) and the experiments verify that this benefit persists beyond the linear setting. Our code is available at https://github.com/killian31/SPCARobustness.
LAVA: Explainability for Unsupervised Latent Embeddings
arXiv:2509.21149v1 Announce Type: new Abstract: Unsupervised black-box models can be drivers of scientific discovery, but remain difficult to interpret. Crucially, discovery hinges on understanding the model output, which is often a multi-dimensional latent embedding rather than a well-defined target. While explainability for supervised learning usually seeks to uncover how input features are used to predict a target, its unsupervised counterpart should relate input features to the structure of the learned latent space. Adaptations of supervised model explainability for unsupervised learning provide either single-sample or dataset-wide summary explanations. However, without automated strategies of relating similar samples to one another guided by their latent proximity, explanations remain either too fine-grained or too reductive to be meaningful. This is especially relevant for manifold learning methods that produce no mapping function, leaving us only with the relative spatial organization of their embeddings. We introduce Locality-Aware Variable Associations (LAVA), a post-hoc model-agnostic method designed to explain local embedding organization through its relationship with the input features. To achieve this, LAVA represents the latent space as a series of localities (neighborhoods) described in terms of correlations between the original features, and then reveals reoccurring patterns of correlations across the entire latent space. Based on UMAP embeddings of MNIST and a single-cell kidney dataset, we show that LAVA captures relevant feature associations, with visually and biologically relevant local patterns shared among seemingly distant regions of the latent spaces.
CAD-Tokenizer: Towards Text-based CAD Prototyping via Modality-Specific Tokenization
arXiv:2509.21150v1 Announce Type: new Abstract: Computer-Aided Design (CAD) is a foundational component of industrial prototyping, where models are defined not by raw coordinates but by construction sequences such as sketches and extrusions. This sequential structure enables both efficient prototype initialization and subsequent editing. Text-guided CAD prototyping, which unifies Text-to-CAD generation and CAD editing, has the potential to streamline the entire design pipeline. However, prior work has not explored this setting, largely because standard large language model (LLM) tokenizers decompose CAD sequences into natural-language word pieces, failing to capture primitive-level CAD semantics and hindering attention modules from modeling geometric structure. We conjecture that a multimodal tokenization strategy, aligned with CAD's primitive and structural nature, can provide more effective representations. To this end, we propose CAD-Tokenizer, a framework that represents CAD data with modality-specific tokens using a sequence-based VQ-VAE with primitive-level pooling and constrained decoding. This design produces compact, primitive-aware representations that align with CAD's structural nature. Applied to unified text-guided CAD prototyping, CAD-Tokenizer significantly improves instruction following and generation quality, achieving better quantitative and qualitative performance over both general-purpose LLMs and task-specific baselines.
GRPO is Secretly a Process Reward Model
arXiv:2509.21154v1 Announce Type: new Abstract: We prove theoretically that the GRPO RL algorithm induces a non-trivial process reward model (PRM), under certain assumptions regarding within-group overlap of token sequences across completions. We then show empirically that these assumptions are met under real-world conditions: GRPO does in fact induce a non-trivial PRM. Leveraging the framework of GRPO-as-a-PRM, we identify a flaw in the GRPO objective: non-uniformly distributed process steps hinder both exploration and exploitation (under different conditions). We propose a simple modification to the algorithm to mitigate this defect ($\lambda$-GRPO), and show that LLMs trained with $\lambda$-GRPO achieve higher validation accuracy and performance on downstream reasoning tasks$-$and reach peak performance more rapidly$-$than LLMs trained with standard GRPO. Our results call into question the advantage of costly, explicitly-defined PRMs for GRPO: we show that it is possible to instead leverage the hidden, built-in PRM structure within the vanilla GRPO algorithm to boost model performance with a negligible impact on training time and cost.
DATS: Distance-Aware Temperature Scaling for Calibrated Class-Incremental Learning
arXiv:2509.21161v1 Announce Type: new Abstract: Continual Learning (CL) is recently gaining increasing attention for its ability to enable a single model to learn incrementally from a sequence of new classes. In this scenario, it is important to keep consistent predictive performance across all the classes and prevent the so-called Catastrophic Forgetting (CF). However, in safety-critical applications, predictive performance alone is insufficient. Predictive models should also be able to reliably communicate their uncertainty in a calibrated manner - that is, with confidence scores aligned to the true frequencies of target events. Existing approaches in CL address calibration primarily from a data-centric perspective, relying on a single temperature shared across all tasks. Such solutions overlook task-specific differences, leading to large fluctuations in calibration error across tasks. For this reason, we argue that a more principled approach should adapt the temperature according to the distance to the current task. However, the unavailability of the task information at test time/during deployment poses a major challenge to achieve the intended objective. For this, we propose Distance-Aware Temperature Scaling (DATS), which combines prototype-based distance estimation with distance-aware calibration to infer task proximity and assign adaptive temperatures without prior task information. Through extensive empirical evaluation on both standard benchmarks and real-world, imbalanced datasets taken from the biomedical domain, our approach demonstrates to be stable, reliable and consistent in reducing calibration error across tasks compared to state-of-the-art approaches.
Mixture of Thoughts: Learning to Aggregate What Experts Think, Not Just What They Say
arXiv:2509.21164v1 Announce Type: new Abstract: Open-source Large Language Models (LLMs) increasingly specialize by domain (e.g., math, code, general reasoning), motivating systems that leverage complementary strengths across models. Prior multi-LLM approaches either (i) route a query to one or a few experts and generate independently, (ii) aggregate outputs from each model via costly multi-turn exchanges, or (iii) fuse weights into a single model-typically requiring architectural homogeneity. We introduce Mixture of Thoughts (MoT), a simple method for latent-level collaboration among heterogeneous experts under a global routing scheme. For each query, a lightweight router selects top-$K$ experts and designates a primary expert; uniformly placed interaction layers project hidden states into a shared latent space where the primary expert performs cross-attention over its active (selected) peers. Pre-trained experts remain frozen; only the router and the lightweight interaction layers are trained with a novel joint training objective that improves both the expert selection and inter-expert collaboration. Across five in-distribution (ID) and three out-of-distribution (OOD) benchmarks, MoT surpasses the current routing and aggregation-based state-of-the-art, Avengers, by $+0.38\%$ and $+2.92\%$, respectively. Further, MoT significantly outperforms the best-performing single model. It achieves this with single-pass inference, runtime comparable to routing baselines, and none of the overheads of iterative aggregation. MoT offers a simple latent-space mechanism for combining heterogeneous LLMs, a practical step toward broader multi-LLM collaboration. Our code is publicly available at https://github.com/jacobfa/mot.
A Unified Framework for Diffusion Model Unlearning with f-Divergence
arXiv:2509.21167v1 Announce Type: new Abstract: Machine unlearning aims to remove specific knowledge from a trained model. While diffusion models (DMs) have shown remarkable generative capabilities, existing unlearning methods for text-to-image (T2I) models often rely on minimizing the mean squared error (MSE) between the output distribution of a target and an anchor concept. We show that this MSE-based approach is a special case of a unified $f$-divergence-based framework, in which any $f$-divergence can be utilized. We analyze the benefits of using different $f$-divergences, that mainly impact the convergence properties of the algorithm and the quality of unlearning. The proposed unified framework offers a flexible paradigm that allows to select the optimal divergence for a specific application, balancing different trade-offs between aggressive unlearning and concept preservation.
Inverse Reinforcement Learning Using Just Classification and a Few Regressions
arXiv:2509.21172v1 Announce Type: new Abstract: Inverse reinforcement learning (IRL) aims to explain observed behavior by uncovering an underlying reward. In the maximum-entropy or Gumbel-shocks-to-reward frameworks, this amounts to fitting a reward function and a soft value function that together satisfy the soft Bellman consistency condition and maximize the likelihood of observed actions. While this perspective has had enormous impact in imitation learning for robotics and understanding dynamic choices in economics, practical learning algorithms often involve delicate inner-loop optimization, repeated dynamic programming, or adversarial training, all of which complicate the use of modern, highly expressive function approximators like neural nets and boosting. We revisit softmax IRL and show that the population maximum-likelihood solution is characterized by a linear fixed-point equation involving the behavior policy. This observation reduces IRL to two off-the-shelf supervised learning problems: probabilistic classification to estimate the behavior policy, and iterative regression to solve the fixed point. The resulting method is simple and modular across function approximation classes and algorithms. We provide a precise characterization of the optimal solution, a generic oracle-based algorithm, finite-sample error bounds, and empirical results showing competitive or superior performance to MaxEnt IRL.
Closed-form $\ell_r$ norm scaling with data for overparameterized linear regression and diagonal linear networks under $\ell_p$ bias
arXiv:2509.21181v1 Announce Type: new Abstract: For overparameterized linear regression with isotropic Gaussian design and minimum-$\ell_p$ interpolator $p\in(1,2]$, we give a unified, high-probability characterization for the scaling of the family of parameter norms $ \{ \lVert \widehat{w_p} \rVert_r \}{r \in [1,p]} $ with sample size. We solve this basic, but unresolved question through a simple dual-ray analysis, which reveals a competition between a signal spike and a bulk of null coordinates in $X^\top Y$, yielding closed-form predictions for (i) a data-dependent transition $n\star$ (the "elbow"), and (ii) a universal threshold $r_\star=2(p-1)$ that separates $\lVert \widehat{w_p} \rVert_r$'s which plateau from those that continue to grow with an explicit exponent. This unified solution resolves the scaling of all $\ell_r$ norms within the family $r\in [1,p]$ under $\ell_p$-biased interpolation, and explains in one picture which norms saturate and which increase as $n$ grows. We then study diagonal linear networks (DLNs) trained by gradient descent. By calibrating the initialization scale $\alpha$ to an effective $p_{\mathrm{eff}}(\alpha)$ via the DLN separable potential, we show empirically that DLNs inherit the same elbow/threshold laws, providing a predictive bridge between explicit and implicit bias. Given that many generalization proxies depend on $\lVert \widehat {w_p} \rVert_r$, our results suggest that their predictive power will depend sensitively on which $l_r$ norm is used.
Towards Foundation Models for Zero-Shot Time Series Anomaly Detection: Leveraging Synthetic Data and Relative Context Discrepancy
arXiv:2509.21190v1 Announce Type: new Abstract: Time series anomaly detection (TSAD) is a critical task, but developing models that generalize to unseen data in a zero-shot manner remains a major challenge. Prevailing foundation models for TSAD predominantly rely on reconstruction-based objectives, which suffer from a fundamental objective mismatch: they struggle to identify subtle anomalies while often misinterpreting complex normal patterns, leading to high rates of false negatives and positives. To overcome these limitations, we introduce \texttt{TimeRCD}, a novel foundation model for TSAD built upon a new pre-training paradigm: Relative Context Discrepancy (RCD). Instead of learning to reconstruct inputs, \texttt{TimeRCD} is explicitly trained to identify anomalies by detecting significant discrepancies between adjacent time windows. This relational approach, implemented with a standard Transformer architecture, enables the model to capture contextual shifts indicative of anomalies that reconstruction-based methods often miss. To facilitate this paradigm, we develop a large-scale, diverse synthetic corpus with token-level anomaly labels, providing the rich supervisory signal necessary for effective pre-training. Extensive experiments demonstrate that \texttt{TimeRCD} significantly outperforms existing general-purpose and anomaly-specific foundation models in zero-shot TSAD across diverse datasets. Our results validate the superiority of the RCD paradigm and establish a new, effective path toward building robust and generalizable foundation models for time series anomaly detection.
Differential-Integral Neural Operator for Long-Term Turbulence Forecasting
arXiv:2509.21196v1 Announce Type: new Abstract: Accurately forecasting the long-term evolution of turbulence represents a grand challenge in scientific computing and is crucial for applications ranging from climate modeling to aerospace engineering. Existing deep learning methods, particularly neural operators, often fail in long-term autoregressive predictions, suffering from catastrophic error accumulation and a loss of physical fidelity. This failure stems from their inability to simultaneously capture the distinct mathematical structures that govern turbulent dynamics: local, dissipative effects and global, non-local interactions. In this paper, we propose the {\textbf{\underline{D}}}ifferential-{\textbf{\underline{I}}}ntegral {\textbf{\underline{N}}}eural {\textbf{\underline{O}}}perator (\method{}), a novel framework designed from a first-principles approach of operator decomposition. \method{} explicitly models the turbulent evolution through parallel branches that learn distinct physical operators: a local differential operator, realized by a constrained convolutional network that provably converges to a derivative, and a global integral operator, captured by a Transformer architecture that learns a data-driven global kernel. This physics-based decomposition endows \method{} with exceptional stability and robustness. Through extensive experiments on the challenging 2D Kolmogorov flow benchmark, we demonstrate that \method{} significantly outperforms state-of-the-art models in long-term forecasting. It successfully suppresses error accumulation over hundreds of timesteps, maintains high fidelity in both the vorticity fields and energy spectra, and establishes a new benchmark for physically consistent, long-range turbulence forecast.
From Physics to Machine Learning and Back: Part II - Learning and Observational Bias in PHM
arXiv:2509.21207v1 Announce Type: new Abstract: Prognostics and Health Management ensures the reliability, safety, and efficiency of complex engineered systems by enabling fault detection, anticipating equipment failures, and optimizing maintenance activities throughout an asset lifecycle. However, real-world PHM presents persistent challenges: sensor data is often noisy or incomplete, available labels are limited, and degradation behaviors and system interdependencies can be highly complex and nonlinear. Physics-informed machine learning has emerged as a promising approach to address these limitations by embedding physical knowledge into data-driven models. This review examines how incorporating learning and observational biases through physics-informed modeling and data strategies can guide models toward physically consistent and reliable predictions. Learning biases embed physical constraints into model training through physics-informed loss functions and governing equations, or by incorporating properties like monotonicity. Observational biases influence data selection and synthesis to ensure models capture realistic system behavior through virtual sensing for estimating unmeasured states, physics-based simulation for data augmentation, and multi-sensor fusion strategies. The review then examines how these approaches enable the transition from passive prediction to active decision-making through reinforcement learning, which allows agents to learn maintenance policies that respect physical constraints while optimizing operational objectives. This closes the loop between model-based predictions, simulation, and actual system operation, empowering adaptive decision-making. Finally, the review addresses the critical challenge of scaling PHM solutions from individual assets to fleet-wide deployment. Fast adaptation methods including meta-learning and few-shot learning are reviewed alongside domain generalization techniques ...
Go With The Flow: Churn-Tolerant Decentralized Training of Large Language Models
arXiv:2509.21221v1 Announce Type: new Abstract: Motivated by the emergence of large language models (LLMs) and the importance of democratizing their training, we propose GWTF, the first crash tolerant practical decentralized training framework for LLMs. Differently from existing distributed and federated training frameworks, GWTF enables the efficient collaborative training of a LLM on heterogeneous clients that volunteer their resources. In addition, GWTF addresses node churn, i.e., clients joining or leaving the system at any time, and network instabilities, i.e., network links becoming unstable or unreliable. The core of GWTF is a novel decentralized flow algorithm that finds the most effective routing that maximizes the number of microbatches trained with the lowest possible delay. We extensively evaluate GWTF on GPT-like and LLaMa-like models and compare it against the prior art. Our results indicate that GWTF reduces the training time by up to 45% in realistic and challenging scenarios that involve heterogeneous client nodes distributed over 10 different geographic locations with a high node churn rate.
AbideGym: Turning Static RL Worlds into Adaptive Challenges
arXiv:2509.21234v1 Announce Type: new Abstract: Agents trained with reinforcement learning often develop brittle policies that fail when dynamics shift, a problem amplified by static benchmarks. AbideGym, a dynamic MiniGrid wrapper, introduces agent-aware perturbations and scalable complexity to enforce intra-episode adaptation. By exposing weaknesses in static policies and promoting resilience, AbideGym provides a modular, reproducible evaluation framework for advancing research in curriculum learning, continual learning, and robust generalization.
Tree Search for LLM Agent Reinforcement Learning
arXiv:2509.21240v1 Announce Type: new Abstract: Recent advances in reinforcement learning (RL) have significantly enhanced the agentic capabilities of large language models (LLMs). In long-term and multi-turn agent tasks, existing approaches driven solely by outcome rewards often suffer from the problem of sparse supervision. To address the challenge, we propose Tree-based Group Relative Policy Optimization (Tree-GRPO), a grouped agent RL method based on tree search, where each tree node represents the complete agent interaction step. By sharing common prefixes, the tree search sampling increases the number of rollouts achievable within a fixed budget of tokens or tool calls. Moreover, we find that the tree-structured trajectory naturally allows the construction of step-wise process supervised signals even using only the outcome reward. Based on this, Tree-GRPO estimates the grouped relative advantages both on intra-tree and inter-tree levels. Through theoretical analysis, we demonstrate that the objective of intra-tree level group relative policy optimization is equivalent to that of step-level direct preference learning. Experiments across 11 datasets and 3 types of QA tasks demonstrate the superiority of the proposed tree-based RL over the chain-based RL method.
Explaining Fine Tuned LLMs via Counterfactuals A Knowledge Graph Driven Framework
arXiv:2509.21241v1 Announce Type: new Abstract: The widespread adoption of Low-Rank Adaptation (LoRA) has enabled large language models (LLMs) to acquire domain-specific knowledge with remarkable efficiency. However, understanding how such a fine-tuning mechanism alters a model's structural reasoning and semantic behavior remains an open challenge. This work introduces a novel framework that explains fine-tuned LLMs via counterfactuals grounded in knowledge graphs. Specifically, we construct BioToolKG, a domain-specific heterogeneous knowledge graph in bioinformatics tools and design a counterfactual-based fine-tuned LLMs explainer (CFFTLLMExplainer) that learns soft masks over graph nodes and edges to generate minimal structural perturbations that induce maximum semantic divergence. Our method jointly optimizes structural sparsity and semantic divergence while enforcing interpretability preserving constraints such as entropy regularization and edge smoothness. We apply this framework to a fine-tuned LLaMA-based LLM and reveal that counterfactual masking exposes the model's structural dependencies and aligns with LoRA-induced parameter shifts. This work provides new insights into the internal mechanisms of fine-tuned LLMs and highlights counterfactual graphs as a potential tool for interpretable AI.
Federated Flow Matching
arXiv:2509.21250v1 Announce Type: new Abstract: Data today is decentralized, generated and stored across devices and institutions where privacy, ownership, and regulation prevent centralization. This motivates the need to train generative models directly from distributed data locally without central aggregation. In this paper, we introduce Federated Flow Matching (FFM), a framework for training flow matching models under privacy constraints. Specifically, we first examine FFM-vanilla, where each client trains locally with independent source and target couplings, preserving privacy but yielding curved flows that slow inference. We then develop FFM-LOT, which employs local optimal transport couplings to improve straightness within each client but lacks global consistency under heterogeneous data. Finally, we propose FFM-GOT, a federated strategy based on the semi-dual formulation of optimal transport, where a shared global potential function coordinates couplings across clients. Experiments on synthetic and image datasets show that FFM enables privacy-preserving training while enhancing both the flow straightness and sample quality in federated settings, with performance comparable to the centralized baseline.
humancompatible.train: Implementing Optimization Algorithms for Stochastically-Constrained Stochastic Optimization Problems
arXiv:2509.21254v1 Announce Type: new Abstract: There has been a considerable interest in constrained training of deep neural networks (DNNs) recently for applications such as fairness and safety. Several toolkits have been proposed for this task, yet there is still no industry standard. We present humancompatible.train (https://github.com/humancompatible/train), an easily-extendable PyTorch-based Python package for training DNNs with stochastic constraints. We implement multiple previously unimplemented algorithms for stochastically constrained stochastic optimization. We demonstrate the toolkit use by comparing two algorithms on a deep learning task with fairness constraints.
A Causality-Aware Spatiotemporal Model for Multi-Region and Multi-Pollutant Air Quality Forecasting
arXiv:2509.21260v1 Announce Type: new Abstract: Air pollution, a pressing global problem, threatens public health, environmental sustainability, and climate stability. Achieving accurate and scalable forecasting across spatially distributed monitoring stations is challenging due to intricate multi-pollutant interactions, evolving meteorological conditions, and region specific spatial heterogeneity. To address this challenge, we propose AirPCM, a novel deep spatiotemporal forecasting model that integrates multi-region, multi-pollutant dynamics with explicit meteorology-pollutant causality modeling. Unlike existing methods limited to single pollutants or localized regions, AirPCM employs a unified architecture to jointly capture cross-station spatial correlations, temporal auto-correlations, and meteorology-pollutant dynamic causality. This empowers fine-grained, interpretable multi-pollutant forecasting across varying geographic and temporal scales, including sudden pollution episodes. Extensive evaluations on multi-scale real-world datasets demonstrate that AirPCM consistently surpasses state-of-the-art baselines in both predictive accuracy and generalization capability. Moreover, the long-term forecasting capability of AirPCM provides actionable insights into future air quality trends and potential high-risk windows, offering timely support for evidence-based environmental governance and carbon mitigation planning.
SuperOffload: Unleashing the Power of Large-Scale LLM Training on Superchips
arXiv:2509.21271v1 Announce Type: new Abstract: The emergence of Superchips represents a significant advancement in next-generation AI hardware. These Superchips employ a tightly coupled heterogeneous architecture that integrates GPU and CPU on the same package, which offers unprecedented computational power. However, there has been scant research investigating how LLM training benefits from this new architecture. In this work, for the first time, we study LLM training solutions based on offloading for Superchips. We observe important differences between Superchips and traditional loosely-coupled GPU-CPU architecture, which necessitate revisiting prevailing assumptions about offloading. Based on that, we present SuperOffload, a Superchip-centric offloading system that simultaneously uses Hopper GPU, Grace CPU, and NVLink-C2C interconnect more efficiently. SuperOffload accomplishes this via a combination of techniques, such as adaptive weight offloading, bucketization repartitioning, Superchip-aware casting, speculative execution, and a highly optimized Adam optimizer for Grace CPUs. Our evaluation of SuperOffload on NVIDIA GH200 demonstrates up to 2.5x throughput improvement compared to state-of-the-art offloading-based systems, enabling training of up to 25B model on a single Superchip while achieving high training throughput. We also extend SuperOffload with ZeRO-style data parallelism and DeepSpeed-Ulysses sequence parallelism, enabling training of 13B model with sequence lengths up to 1 million tokens on 8 GH200 while achieving 55% MFU.
It's Not You, It's Clipping: A Soft Trust-Region via Probability Smoothing for LLM RL
arXiv:2509.21282v1 Announce Type: new Abstract: Training large language models (LLMs) with reinforcement learning (RL) methods such as PPO and GRPO commonly relies on ratio clipping to stabilise updates. While effective at preventing instability, clipping discards information and introduces gradient discontinuities. We propose Probability Smoothing Policy Optimisation (PSPO), which smooths the current policy's probabilities toward the old (behaviour) policy before computing the importance ratio, analogous to label smoothing. Unlike clipping, PSPO preserves gradient signal, while interpolation toward the old policy creates a soft trust region that discourages large, destabilising updates, with formal guarantees. We instantiate PSPO within GRPO (GR-PSPO) and fine-tune Qwen2.5-0.5B and Qwen2.5-1.5B on GSM8K, evaluating on GSM8K test and the cross-dataset generalisation on SVAMP, ASDiv, and MATH-500. Relative to unclipped GRPO (single iteration; no data reuse, ratio always = 1), GR-PSPO achieves similar performance but improves the reasoning leading to clearer and more concise responses which are more logical. Compared to clipped GRPO, GR-PSPO substantially improves performance both the 0.5B and 1.5B models, with a boost of over 20% on GSM8K (39.7% vs. 17.6% for 0.5B, 59.4% vs. 37.8% for 1.5B).
Optimal Robust Recourse with $L^p$-Bounded Model Change
arXiv:2509.21293v1 Announce Type: new Abstract: Recourse provides individuals who received undesirable labels (e.g., denied a loan) from algorithmic decision-making systems with a minimum-cost improvement suggestion to achieve the desired outcome. However, in practice, models often get updated to reflect changes in the data distribution or environment, invalidating the recourse recommendations (i.e., following the recourse will not lead to the desirable outcome). The robust recourse literature addresses this issue by providing a framework for computing recourses whose validity is resilient to slight changes in the model. However, since the optimization problem of computing robust recourse is non-convex (even for linear models), most of the current approaches do not have any theoretical guarantee on the optimality of the recourse. Recent work by Kayastha et. al. provides the first provably optimal algorithm for robust recourse with respect to generalized linear models when the model changes are measured using the $L^{\infty}$ norm. However, using the $L^{\infty}$ norm can lead to recourse solutions with a high price. To address this shortcoming, we consider more constrained model changes defined by the $L^p$ norm, where $p\geq 1$ but $p\neq \infty$, and provide a new algorithm that provably computes the optimal robust recourse for generalized linear models. Empirically, for both linear and non-linear models, we demonstrate that our algorithm achieves a significantly lower price of recourse (up to several orders of magnitude) compared to prior work and also exhibits a better trade-off between the implementation cost of recourse and its validity. Our empirical analysis also illustrates that our approach provides more sparse recourses compared to prior work and remains resilient to post-processing approaches that guarantee feasibility.
No Prior, No Leakage: Revisiting Reconstruction Attacks in Trained Neural Networks
arXiv:2509.21296v1 Announce Type: new Abstract: The memorization of training data by neural networks raises pressing concerns for privacy and security. Recent work has shown that, under certain conditions, portions of the training set can be reconstructed directly from model parameters. Some of these methods exploit implicit bias toward margin maximization, suggesting that properties often regarded as beneficial for generalization may actually compromise privacy. Yet despite striking empirical demonstrations, the reliability of these attacks remains poorly understood and lacks a solid theoretical foundation. In this work, we take a complementary perspective: rather than designing stronger attacks, we analyze the inherent weaknesses and limitations of existing reconstruction methods and identify conditions under which they fail. We rigorously prove that, without incorporating prior knowledge about the data, there exist infinitely many alternative solutions that may lie arbitrarily far from the true training set, rendering reconstruction fundamentally unreliable. Empirically, we further demonstrate that exact duplication of training examples occurs only by chance. Our results refine the theoretical understanding of when training set leakage is possible and offer new insights into mitigating reconstruction attacks. Remarkably, we demonstrate that networks trained more extensively, and therefore satisfying implicit bias conditions more strongly -- are, in fact, less susceptible to reconstruction attacks, reconciling privacy with the need for strong generalization in this setting.
Copycats: the many lives of a publicly available medical imaging dataset
arXiv:2402.06353v3 Announce Type: cross Abstract: Medical Imaging (MI) datasets are fundamental to artificial intelligence in healthcare. The accuracy, robustness, and fairness of diagnostic algorithms depend on the data (and its quality) used to train and evaluate the models. MI datasets used to be proprietary, but have become increasingly available to the public, including on community-contributed platforms (CCPs) like Kaggle or HuggingFace. While open data is important to enhance the redistribution of data's public value, we find that the current CCP governance model fails to uphold the quality needed and recommended practices for sharing, documenting, and evaluating datasets. In this paper, we conduct an analysis of publicly available machine learning datasets on CCPs, discussing datasets' context, and identifying limitations and gaps in the current CCP landscape. We highlight differences between MI and computer vision datasets, particularly in the potentially harmful downstream effects from poor adoption of recommended dataset management practices. We compare the analyzed datasets across several dimensions, including data sharing, data documentation, and maintenance. We find vague licenses, lack of persistent identifiers and storage, duplicates, and missing metadata, with differences between the platforms. Our research contributes to efforts in responsible data curation and AI algorithms for healthcare.
An Analytical and AI-discovered Stable, Accurate, and Generalizable Subgrid-scale Closure for Geophysical Turbulence
arXiv:2509.20365v1 Announce Type: cross Abstract: By combining AI and fluid physics, we discover a closed-form closure for 2D turbulence from small direct numerical simulation (DNS) data. Large-eddy simulation (LES) with this closure is accurate and stable, reproducing DNS statistics including those of extremes. We also show that the new closure could be derived from a 4th-order truncated Taylor expansion. Prior analytical and AI-based work only found the 2nd-order expansion, which led to unstable LES. The additional terms emerge only when inter-scale energy transfer is considered alongside standard reconstruction criterion in the sparse-equation discovery.
Philosophy-informed Machine Learning
arXiv:2509.20370v1 Announce Type: cross Abstract: Philosophy-informed machine learning (PhIML) directly infuses core ideas from analytic philosophy into ML model architectures, objectives, and evaluation protocols. Therefore, PhIML promises new capabilities through models that respect philosophical concepts and values by design. From this lens, this paper reviews conceptual foundations to demonstrate philosophical gains and alignment. In addition, we present case studies on how ML users/designers can adopt PhIML as an agnostic post-hoc tool or intrinsically build it into ML model architectures. Finally, this paper sheds light on open technical barriers alongside philosophical, practical, and governance challenges and outlines a research roadmap toward safe, philosophy-aware, and ethically responsible PhIML.
Speaker Style-Aware Phoneme Anchoring for Improved Cross-Lingual Speech Emotion Recognition
arXiv:2509.20373v1 Announce Type: cross Abstract: Cross-lingual speech emotion recognition (SER) remains a challenging task due to differences in phonetic variability and speaker-specific expressive styles across languages. Effectively capturing emotion under such diverse conditions requires a framework that can align the externalization of emotions across different speakers and languages. To address this problem, we propose a speaker-style aware phoneme anchoring framework that aligns emotional expression at the phonetic and speaker levels. Our method builds emotion-specific speaker communities via graph-based clustering to capture shared speaker traits. Using these groups, we apply dual-space anchoring in speaker and phonetic spaces to enable better emotion transfer across languages. Evaluations on the MSP-Podcast (English) and BIIC-Podcast (Taiwanese Mandarin) corpora demonstrate improved generalization over competitive baselines and provide valuable insights into the commonalities in cross-lingual emotion representation.
Leveraging NTPs for Efficient Hallucination Detection in VLMs
arXiv:2509.20379v1 Announce Type: cross Abstract: Hallucinations of vision-language models (VLMs), which are misalignments between visual content and generated text, undermine the reliability of VLMs. One common approach for detecting them employs the same VLM, or a different one, to assess generated outputs. This process is computationally intensive and increases model latency. In this paper, we explore an efficient on-the-fly method for hallucination detection by training traditional ML models over signals based on the VLM's next-token probabilities (NTPs). NTPs provide a direct quantification of model uncertainty. We hypothesize that high uncertainty (i.e., a low NTP value) is strongly associated with hallucinations. To test this, we introduce a dataset of 1,400 human-annotated statements derived from VLM-generated content, each labeled as hallucinated or not, and use it to test our NTP-based lightweight method. Our results demonstrate that NTP-based features are valuable predictors of hallucinations, enabling fast and simple ML models to achieve performance comparable to that of strong VLMs. Furthermore, augmenting these NTPs with linguistic NTPs, computed by feeding only the generated text back into the VLM, enhances hallucination detection performance. Finally, integrating hallucination prediction scores from VLMs into the NTP-based models led to better performance than using either VLMs or NTPs alone. We hope this study paves the way for simple, lightweight solutions that enhance the reliability of VLMs.
Lightweight MobileNetV1+GRU for ECG Biometric Authentication: Federated and Adversarial Evaluation
arXiv:2509.20382v1 Announce Type: cross Abstract: ECG biometrics offer a unique, secure authentication method, yet their deployment on wearable devices faces real-time processing, privacy, and spoofing vulnerability challenges. This paper proposes a lightweight deep learning model (MobileNetV1+GRU) for ECG-based authentication, injection of 20dB Gaussian noise & custom preprocessing. We simulate wearable conditions and edge deployment using the ECGID, MIT-BIH, CYBHi, and PTB datasets, achieving accuracies of 99.34%, 99.31%, 91.74%, and 98.49%, F1-scores of 0.9869, 0.9923, 0.9125, and 0.9771, Precision of 0.9866, 0.9924, 0.9180 and 0.9845, Recall of 0.9878, 0.9923, 0.9129, and 0.9756, equal error rates (EER) of 0.0009, 0.00013, 0.0091, and 0.0009, and ROC-AUC values of 0.9999, 0.9999, 0.9985, and 0.9998, while under FGSM adversarial attacks, accuracy drops from 96.82% to as low as 0.80%. This paper highlights federated learning, adversarial testing, and the need for diverse wearable physiological datasets to ensure secure and scalable biometrics.
A Comparative Analysis of Ensemble-Based Machine Learning Approaches with Explainable AI for Multi-Class Intrusion Detection in Drone Networks
arXiv:2509.20391v1 Announce Type: cross Abstract: The growing integration of drones into civilian, commercial, and defense sectors introduces significant cybersecurity concerns, particularly with the increased risk of network-based intrusions targeting drone communication protocols. Detecting and classifying these intrusions is inherently challenging due to the dynamic nature of drone traffic and the presence of multiple sophisticated attack vectors such as spoofing, injection, replay, and man-in-the-middle (MITM) attacks. This research aims to develop a robust and interpretable intrusion detection framework tailored for drone networks, with a focus on handling multi-class classification and model explainability. We present a comparative analysis of ensemble-based machine learning models, namely Random Forest, Extra Trees, AdaBoost, CatBoost, and XGBoost, trained on a labeled dataset comprising benign traffic and nine distinct intrusion types. Comprehensive data preprocessing was performed, including missing value imputation, scaling, and categorical encoding, followed by model training and extensive evaluation using metrics such as macro F1-score, ROC AUC, Matthews Correlation Coefficient, and Log Loss. Random Forest achieved the highest performance with a macro F1-score of 0.9998 and ROC AUC of 1.0000. To validate the superiority of the models, statistical tests, including Friedmans test, the Wilcoxon signed-rank test with Holm correction, and bootstrapped confidence intervals, were applied. Furthermore, explainable AI methods, SHAP and LIME, were integrated to interpret both global and local feature importance, enhancing model transparency and decision trustworthiness. The proposed approach not only delivers near-perfect accuracy but also ensures interpretability, making it highly suitable for real-time and safety-critical drone operations.
The Secret Agenda: LLMs Strategically Lie and Our Current Safety Tools Are Blind
arXiv:2509.20393v1 Announce Type: cross Abstract: We investigate strategic deception in large language models using two complementary testbeds: Secret Agenda (across 38 models) and Insider Trading compliance (via SAE architectures). Secret Agenda reliably induced lying when deception advantaged goal achievement across all model families. Analysis revealed that autolabeled SAE features for "deception" rarely activated during strategic dishonesty, and feature steering experiments across 100+ deception-related features failed to prevent lying. Conversely, insider trading analysis using unlabeled SAE activations separated deceptive versus compliant responses through discriminative patterns in heatmaps and t-SNE visualizations. These findings suggest autolabel-driven interpretability approaches fail to detect or control behavioral deception, while aggregate unlabeled activations provide population-level structure for risk assessment. Results span Llama 8B/70B SAE implementations and GemmaScope under resource constraints, representing preliminary findings that motivate larger studies on feature discovery, labeling methodology, and causal interventions in realistic deception contexts.
Sample completion, structured correlation, and Netflix problems
arXiv:2509.20404v1 Announce Type: cross Abstract: We develop a new high-dimensional statistical learning model which can take advantage of structured correlation in data even in the presence of randomness. We completely characterize learnability in this model in terms of VCN${}_{k,k}$-dimension (essentially $k$-dependence from Shelah's classification theory). This model suggests a theoretical explanation for the success of certain algorithms in the 2006~Netflix Prize competition.
Structuring Collective Action with LLM-Guided Evolution: From Ill-Structured Problems to Executable Heuristics
arXiv:2509.20412v1 Announce Type: cross Abstract: Collective action problems, which require aligning individual incentives with collective goals, are classic examples of Ill-Structured Problems (ISPs). For an individual agent, the causal links between local actions and global outcomes are unclear, stakeholder objectives often conflict, and no single, clear algorithm can bridge micro-level choices with macro-level welfare. We present ECHO-MIMIC, a computational framework that converts this global complexity into a tractable, Well-Structured Problem (WSP) for each agent by discovering compact, executable heuristics and persuasive rationales. The framework operates in two stages: ECHO (Evolutionary Crafting of Heuristics from Outcomes) evolves snippets of Python code that encode candidate behavioral policies, while MIMIC (Mechanism Inference & Messaging for Individual-to-Collective Alignment) evolves companion natural language messages that motivate agents to adopt those policies. Both phases employ a large-language-model-driven evolutionary search: the LLM proposes diverse and context-aware code or text variants, while population-level selection retains those that maximize collective performance in a simulated environment. We demonstrate this framework on a canonical ISP in agricultural landscape management, where local farming decisions impact global ecological connectivity. Results show that ECHO-MIMIC discovers high-performing heuristics compared to baselines and crafts tailored messages that successfully align simulated farmer behavior with landscape-level ecological goals. By coupling algorithmic rule discovery with tailored communication, ECHO-MIMIC transforms the cognitive burden of collective action into a simple set of agent-level instructions, making previously ill-structured problems solvable in practice and opening a new path toward scalable, adaptive policy design.
SceneWeaver: All-in-One 3D Scene Synthesis with an Extensible and Self-Reflective Agent
arXiv:2509.20414v1 Announce Type: cross Abstract: Indoor scene synthesis has become increasingly important with the rise of Embodied AI, which requires 3D environments that are not only visually realistic but also physically plausible and functionally diverse. While recent approaches have advanced visual fidelity, they often remain constrained to fixed scene categories, lack sufficient object-level detail and physical consistency, and struggle to align with complex user instructions. In this work, we present SceneWeaver, a reflective agentic framework that unifies diverse scene synthesis paradigms through tool-based iterative refinement. At its core, SceneWeaver employs a language model-based planner to select from a suite of extensible scene generation tools, ranging from data-driven generative models to visual- and LLM-based methods, guided by self-evaluation of physical plausibility, visual realism, and semantic alignment with user input. This closed-loop reason-act-reflect design enables the agent to identify semantic inconsistencies, invoke targeted tools, and update the environment over successive iterations. Extensive experiments on both common and open-vocabulary room types demonstrate that SceneWeaver not only outperforms prior methods on physical, visual, and semantic metrics, but also generalizes effectively to complex scenes with diverse instructions, marking a step toward general-purpose 3D environment generation. Project website: https://scene-weaver.github.io/.
Neural Networks as Surrogate Solvers for Time-Dependent Accretion Disk Dynamics
arXiv:2509.20447v1 Announce Type: cross Abstract: Accretion disks are ubiquitous in astrophysics, appearing in diverse environments from planet-forming systems to X-ray binaries and active galactic nuclei. Traditionally, modeling their dynamics requires computationally intensive (magneto)hydrodynamic simulations. Recently, Physics-Informed Neural Networks (PINNs) have emerged as a promising alternative. This approach trains neural networks directly on physical laws without requiring data. We for the first time demonstrate PINNs for solving the two-dimensional, time-dependent hydrodynamics of non-self-gravitating accretion disks. Our models provide solutions at arbitrary times and locations within the training domain, and successfully reproduce key physical phenomena, including the excitation and propagation of spiral density waves and gap formation from disk-companion interactions. Notably, the boundary-free approach enabled by PINNs naturally eliminates the spurious wave reflections at disk edges, which are challenging to suppress in numerical simulations. These results highlight how advanced machine learning techniques can enable physics-driven, data-free modeling of complex astrophysical systems, potentially offering an alternative to traditional numerical simulations in the future.
Document Summarization with Conformal Importance Guarantees
arXiv:2509.20461v1 Announce Type: cross Abstract: Automatic summarization systems have advanced rapidly with large language models (LLMs), yet they still lack reliable guarantees on inclusion of critical content in high-stakes domains like healthcare, law, and finance. In this work, we introduce Conformal Importance Summarization, the first framework for importance-preserving summary generation which uses conformal prediction to provide rigorous, distribution-free coverage guarantees. By calibrating thresholds on sentence-level importance scores, we enable extractive document summarization with user-specified coverage and recall rates over critical content. Our method is model-agnostic, requires only a small calibration set, and seamlessly integrates with existing black-box LLMs. Experiments on established summarization benchmarks demonstrate that Conformal Importance Summarization achieves the theoretically assured information coverage rate. Our work suggests that Conformal Importance Summarization can be combined with existing techniques to achieve reliable, controllable automatic summarization, paving the way for safer deployment of AI summarization tools in critical applications. Code is available at https://github.com/layer6ai-labs/conformal-importance-summarization.
Objective Evaluation of Prosody and Intelligibility in Speech Synthesis via Conditional Prediction of Discrete Tokens
arXiv:2509.20485v1 Announce Type: cross Abstract: Objective evaluation of synthesized speech is critical for advancing speech generation systems, yet existing metrics for intelligibility and prosody remain limited in scope and weakly correlated with human perception. Word Error Rate (WER) provides only a coarse text-based measure of intelligibility, while F0-RMSE and related pitch-based metrics offer a narrow, reference-dependent view of prosody. To address these limitations, we propose TTScore, a targeted and reference-free evaluation framework based on conditional prediction of discrete speech tokens. TTScore employs two sequence-to-sequence predictors conditioned on input text: TTScore-int, which measures intelligibility through content tokens, and TTScore-pro, which evaluates prosody through prosody tokens. For each synthesized utterance, the predictors compute the likelihood of the corresponding token sequences, yielding interpretable scores that capture alignment with intended linguistic content and prosodic structure. Experiments on the SOMOS, VoiceMOS, and TTSArena benchmarks demonstrate that TTScore-int and TTScore-pro provide reliable, aspect-specific evaluation and achieve stronger correlations with human judgments of overall quality than existing intelligibility and prosody-focused metrics.
Fast Estimation of Wasserstein Distances via Regression on Sliced Wasserstein Distances
arXiv:2509.20508v1 Announce Type: cross Abstract: We address the problem of efficiently computing Wasserstein distances for multiple pairs of distributions drawn from a meta-distribution. To this end, we propose a fast estimation method based on regressing Wasserstein distance on sliced Wasserstein (SW) distances. Specifically, we leverage both standard SW distances, which provide lower bounds, and lifted SW distances, which provide upper bounds, as predictors of the true Wasserstein distance. To ensure parsimony, we introduce two linear models: an unconstrained model with a closed-form least-squares solution, and a constrained model that uses only half as many parameters. We show that accurate models can be learned from a small number of distribution pairs. Once estimated, the model can predict the Wasserstein distance for any pair of distributions via a linear combination of SW distances, making it highly efficient. Empirically, we validate our approach on diverse tasks, including Gaussian mixtures, point-cloud classification, and Wasserstein-space visualizations for 3D point clouds. Across various datasets such as MNIST point clouds, ShapeNetV2, MERFISH Cell Niches, and scRNA-seq, our method consistently provides a better approximation of Wasserstein distance than the state-of-the-art Wasserstein embedding model, Wasserstein Wormhole, particularly in low-data regimes. Finally, we demonstrate that our estimator can also accelerate Wormhole training, yielding \textit{RG-Wormhole}.
Adaptive Approach to Enhance Machine Learning Scheduling Algorithms During Runtime Using Reinforcement Learning in Metascheduling Applications
arXiv:2509.20520v1 Announce Type: cross Abstract: Metascheduling in time-triggered architectures has been crucial in adapting to dynamic and unpredictable environments, ensuring the reliability and efficiency of task execution. However, traditional approaches face significant challenges when training Artificial Intelligence (AI) scheduling inferences offline, particularly due to the complexities involved in constructing a comprehensive Multi-Schedule Graph (MSG) that accounts for all possible scenarios. The process of generating an MSG that captures the vast probability space, especially when considering context events like hardware failures, slack variations, or mode changes, is resource-intensive and often infeasible. To address these challenges, we propose an adaptive online learning unit integrated within the metascheduler to enhance performance in real-time. The primary motivation for developing this unit stems from the limitations of offline training, where the MSG created is inherently a subset of the complete space, focusing only on the most probable and critical context events. In the online mode, Reinforcement Learning (RL) plays a pivotal role by continuously exploring and discovering new scheduling solutions, thus expanding the MSG and enhancing system performance over time. This dynamic adaptation allows the system to handle unexpected events and complex scheduling scenarios more effectively. Several RL models were implemented within the online learning unit, each designed to address specific challenges in scheduling. These models not only facilitate the discovery of new solutions but also optimize existing schedulers, particularly when stricter deadlines or new performance criteria are introduced. By continuously refining the AI inferences through real-time training, the system remains flexible and capable of meeting evolving demands, thus ensuring robustness and efficiency in large-scale, safety-critical environments.
A Compound Classification System Based on Fuzzy Relations Applied to the Noise-Tolerant Control of a Bionic Hand via EMG Signal Recognition
arXiv:2509.20523v1 Announce Type: cross Abstract: Modern anthropomorphic upper limb bioprostheses are typically controlled by electromyographic (EMG) biosignals using a pattern recognition scheme. Unfortunately, there are many factors originating from the human source of objects to be classified and from the human-prosthesis interface that make it difficult to obtain an acceptable classification quality. One of these factors is the high susceptibility of biosignals to contamination, which can considerably reduce the quality of classification of a recognition system. In the paper, the authors propose a new recognition system intended for EMG based control of the hand prosthesis with detection of contaminated biosignals in order to mitigate the adverse effect of contaminations. The system consists of two ensembles: the set of one-class classifiers (OCC) to assess the degree of contamination of individual channels and the ensemble of K-nearest neighbours (KNN) classifier to recognise the patient's intent. For all recognition systems, an original, coherent fuzzy model was developed, which allows the use of a uniform soft (fuzzy) decision scheme throughout the recognition process. The experimental evaluation was conducted using real biosignals from a public repository. The goal was to provide an experimental comparative analysis of the parameters and procedures of the developed method on which the quality of the recognition system depends. The proposed fuzzy recognition system was also compared with similar systems described in the literature.
Innovative Deep Learning Architecture for Enhanced Altered Fingerprint Recognition
arXiv:2509.20537v1 Announce Type: cross Abstract: Altered fingerprint recognition (AFR) is challenging for biometric verification in applications such as border control, forensics, and fiscal admission. Adversaries can deliberately modify ridge patterns to evade detection, so robust recognition of altered prints is essential. We present DeepAFRNet, a deep learning recognition model that matches and recognizes distorted fingerprint samples. The approach uses a VGG16 backbone to extract high-dimensional features and cosine similarity to compare embeddings. We evaluate on the SOCOFing Real-Altered subset with three difficulty levels (Easy, Medium, Hard). With strict thresholds, DeepAFRNet achieves accuracies of 96.7 percent, 98.76 percent, and 99.54 percent for the three levels. A threshold-sensitivity study shows that relaxing the threshold from 0.92 to 0.72 sharply degrades accuracy to 7.86 percent, 27.05 percent, and 29.51 percent, underscoring the importance of threshold selection in biometric systems. By using real altered samples and reporting per-level metrics, DeepAFRNet addresses limitations of prior work based on synthetic alterations or limited verification protocols, and indicates readiness for real-world deployments where both security and recognition resilience are critical.
Large Pre-Trained Models for Bimanual Manipulation in 3D
arXiv:2509.20579v1 Announce Type: cross Abstract: We investigate the integration of attention maps from a pre-trained Vision Transformer into voxel representations to enhance bimanual robotic manipulation. Specifically, we extract attention maps from DINOv2, a self-supervised ViT model, and interpret them as pixel-level saliency scores over RGB images. These maps are lifted into a 3D voxel grid, resulting in voxel-level semantic cues that are incorporated into a behavior cloning policy. When integrated into a state-of-the-art voxel-based policy, our attention-guided featurization yields an average absolute improvement of 8.2% and a relative gain of 21.9% across all tasks in the RLBench bimanual benchmark.
Region-of-Interest Augmentation for Mammography Classification under Patient-Level Cross-Validation
arXiv:2509.20585v1 Announce Type: cross Abstract: Breast cancer screening with mammography remains central to early detection and mortality reduction. Deep learning has shown strong potential for automating mammogram interpretation, yet limited-resolution datasets and small sample sizes continue to restrict performance. We revisit the Mini-DDSM dataset (9,684 images; 2,414 patients) and introduce a lightweight region-of-interest (ROI) augmentation strategy. During training, full images are probabilistically replaced with random ROI crops sampled from a precomputed, label-free bounding-box bank, with optional jitter to increase variability. We evaluate under strict patient-level cross-validation and report ROC-AUC, PR-AUC, and training-time efficiency metrics (throughput and GPU memory). Because ROI augmentation is training-only, inference-time cost remains unchanged. On Mini-DDSM, ROI augmentation (best: p_roi = 0.10, alpha = 0.10) yields modest average ROC-AUC gains, with performance varying across folds; PR-AUC is flat to slightly lower. These results demonstrate that simple, data-centric ROI strategies can enhance mammography classification in constrained settings without requiring additional labels or architectural modifications.
Unsupervised Domain Adaptation with an Unobservable Source Subpopulation
arXiv:2509.20587v1 Announce Type: cross Abstract: We study an unsupervised domain adaptation problem where the source domain consists of subpopulations defined by the binary label $Y$ and a binary background (or environment) $A$. We focus on a challenging setting in which one such subpopulation in the source domain is unobservable. Naively ignoring this unobserved group can result in biased estimates and degraded predictive performance. Despite this structured missingness, we show that the prediction in the target domain can still be recovered. Specifically, we rigorously derive both background-specific and overall prediction models for the target domain. For practical implementation, we propose the distribution matching method to estimate the subpopulation proportions. We provide theoretical guarantees for the asymptotic behavior of our estimator, and establish an upper bound on the prediction error. Experiments on both synthetic and real-world datasets show that our method outperforms the naive benchmark that does not account for this unobservable source subpopulation.
Every Character Counts: From Vulnerability to Defense in Phishing Detection
arXiv:2509.20589v1 Announce Type: cross Abstract: Phishing attacks targeting both organizations and individuals are becoming an increasingly significant threat as technology advances. Current automatic detection methods often lack explainability and robustness in detecting new phishing attacks. In this work, we investigate the effectiveness of character-level deep learning models for phishing detection, which can provide both robustness and interpretability. We evaluate three neural architectures adapted to operate at the character level, namely CharCNN, CharGRU, and CharBiLSTM, on a custom-built email dataset, which combines data from multiple sources. Their performance is analyzed under three scenarios: (i) standard training and testing, (ii) standard training and testing under adversarial attacks, and (iii) training and testing with adversarial examples. Aiming to develop a tool that operates as a browser extension, we test all models under limited computational resources. In this constrained setup, CharGRU proves to be the best-performing model across all scenarios. All models show vulnerability to adversarial attacks, but adversarial training substantially improves their robustness. In addition, by adapting the Gradient-weighted Class Activation Mapping (Grad-CAM) technique to character-level inputs, we are able to visualize which parts of each email influence the decision of each model. Our open-source code and data is released at https://github.com/chipermaria/every-character-counts.
An LLM-based Agentic Framework for Accessible Network Control
arXiv:2509.20600v1 Announce Type: cross Abstract: Traditional approaches to network management have been accessible only to a handful of highly-trained network operators with significant expert knowledge. This creates barriers for lay users to easily manage their networks without resorting to experts. With recent development of powerful large language models (LLMs) for language comprehension, we design a system to make network management accessible to a broader audience of non-experts by allowing users to converse with networks in natural language. To effectively leverage advancements in LLMs, we propose an agentic framework that uses an intermediate representation to streamline configuration across diverse vendor equipment, retrieves the network state from memory in real-time, and provides an interface for external feedback. We also conduct pilot studies to collect real user data of natural language utterances for network control, and present a visualization interface to facilitate dialogue-driven user interaction and enable large-scale data collection for future development. Preliminary experiments validate the effectiveness of our proposed system components with LLM integration on both synthetic and real user utterances. Through our data collection and visualization efforts, we pave the way for more effective use of LLMs and democratize network control for everyday users.
Experience Deploying Containerized GenAI Services at an HPC Center
arXiv:2509.20603v1 Announce Type: cross Abstract: Generative Artificial Intelligence (GenAI) applications are built from specialized components -- inference servers, object storage, vector and graph databases, and user interfaces -- interconnected via web-based APIs. While these components are often containerized and deployed in cloud environments, such capabilities are still emerging at High-Performance Computing (HPC) centers. In this paper, we share our experience deploying GenAI workloads within an established HPC center, discussing the integration of HPC and cloud computing environments. We describe our converged computing architecture that integrates HPC and Kubernetes platforms running containerized GenAI workloads, helping with reproducibility. A case study illustrates the deployment of the Llama Large Language Model (LLM) using a containerized inference server (vLLM) across both Kubernetes and HPC platforms using multiple container runtimes. Our experience highlights practical considerations and opportunities for the HPC container community, guiding future research and tool development.
A Gapped Scale-Sensitive Dimension and Lower Bounds for Offset Rademacher Complexity
arXiv:2509.20618v1 Announce Type: cross Abstract: We study gapped scale-sensitive dimensions of a function class in both sequential and non-sequential settings. We demonstrate that covering numbers for any uniformly bounded class are controlled above by these gapped dimensions, generalizing the results of \cite{anthony2000function,alon1997scale}. Moreover, we show that the gapped dimensions lead to lower bounds on offset Rademacher averages, thereby strengthening existing approaches for proving lower bounds on rates of convergence in statistical and online learning.
FS-DFM: Fast and Accurate Long Text Generation with Few-Step Diffusion Language Models
arXiv:2509.20624v1 Announce Type: cross Abstract: Autoregressive language models (ARMs) deliver strong likelihoods, but are inherently serial: they generate one token per forward pass, which limits throughput and inflates latency for long sequences. Diffusion Language Models (DLMs) parallelize across positions and thus appear promising for language generation, yet standard discrete diffusion typically needs hundreds to thousands of model evaluations to reach high quality, trading serial depth for iterative breadth. We introduce FS-DFM, Few-Step Discrete Flow-Matching. A discrete flow-matching model designed for speed without sacrificing quality. The core idea is simple: make the number of sampling steps an explicit parameter and train the model to be consistent across step budgets, so one big move lands where many small moves would. We pair this with a reliable update rule that moves probability in the right direction without overshooting, and with strong teacher guidance distilled from long-run trajectories. Together, these choices make few-step sampling stable, accurate, and easy to control. On language modeling benchmarks, FS-DFM with 8 sampling steps achieves perplexity parity with a 1,024-step discrete-flow baseline for generating 1,024 tokens using a similar-size model, delivering up to 128 times faster sampling and corresponding latency/throughput gains.
Design, Implementation and Evaluation of a Novel Programming Language Topic Classification Workflow
arXiv:2509.20631v1 Announce Type: cross Abstract: As software systems grow in scale and complexity, understanding the distribution of programming language topics within source code becomes increasingly important for guiding technical decisions, improving onboarding, and informing tooling and education. This paper presents the design, implementation, and evaluation of a novel programming language topic classification workflow. Our approach combines a multi-label Support Vector Machine (SVM) with a sliding window and voting strategy to enable fine-grained localization of core language concepts such as operator overloading, virtual functions, inheritance, and templates. Trained on the IBM Project CodeNet dataset, our model achieves an average F1 score of 0.90 across topics and 0.75 in code-topic highlight. Our findings contribute empirical insights and a reusable pipeline for researchers and practitioners interested in code analysis and data-driven software engineering.
A Hierarchical Variational Graph Fused Lasso for Recovering Relative Rates in Spatial Compositional Data
arXiv:2509.20636v1 Announce Type: cross Abstract: The analysis of spatial data from biological imaging technology, such as imaging mass spectrometry (IMS) or imaging mass cytometry (IMC), is challenging because of a competitive sampling process which convolves signals from molecules in a single pixel. To address this, we develop a scalable Bayesian framework that leverages natural sparsity in spatial signal patterns to recover relative rates for each molecule across the entire image. Our method relies on the use of a heavy-tailed variant of the graphical lasso prior and a novel hierarchical variational family, enabling efficient inference via automatic differentiation variational inference. Simulation results show that our approach outperforms state-of-the-practice point estimate methodologies in IMS, and has superior posterior coverage than mean-field variational inference techniques. Results on real IMS data demonstrate that our approach better recovers the true anatomical structure of known tissue, removes artifacts, and detects active regions missed by the standard analysis approach.
Look Before you Leap: Estimating LLM Benchmark Scores from Descriptions
arXiv:2509.20645v1 Announce Type: cross Abstract: Progress in large language models is constrained by an evaluation bottleneck: build a benchmark, evaluate models and settings, then iterate. We therefore ask a simple question: can we forecast outcomes before running any experiments? We study text-only performance forecasting: estimating a model's score from a redacted task description and intended configuration, with no access to dataset instances. To support systematic study, we curate PRECOG, a corpus of redacted description-performance pairs spanning diverse tasks, domains, and metrics. Experiments show the task is challenging but feasible: models equipped with a retrieval module that excludes source papers achieve moderate prediction performance with well-calibrated uncertainty, reaching mean absolute error as low as 8.7 on the Accuracy subset at high-confidence thresholds. Our analysis indicates that stronger reasoning models engage in diverse, iterative querying, whereas current open-source models lag and often skip retrieval or gather evidence with limited diversity. We further test a zero-leakage setting, forecasting on newly released datasets or experiments before their papers are indexed, where GPT-5 with built-in web search still attains nontrivial prediction accuracy. Overall, our corpus and analyses offer an initial step toward open-ended anticipatory evaluation, supporting difficulty estimation and smarter experiment prioritization.
Implicit Augmentation from Distributional Symmetry in Turbulence Super-Resolution
arXiv:2509.20683v1 Announce Type: cross Abstract: The immense computational cost of simulating turbulence has motivated the use of machine learning approaches for super-resolving turbulent flows. A central challenge is ensuring that learned models respect physical symmetries, such as rotational equivariance. We show that standard convolutional neural networks (CNNs) can partially acquire this symmetry without explicit augmentation or specialized architectures, as turbulence itself provides implicit rotational augmentation in both time and space. Using 3D channel-flow subdomains with differing anisotropy, we find that models trained on more isotropic mid-plane data achieve lower equivariance error than those trained on boundary layer data, and that greater temporal or spatial sampling further reduces this error. We show a distinct scale-dependence of equivariance error that occurs regardless of dataset anisotropy that is consistent with Kolmogorov's local isotropy hypothesis. These results clarify when rotational symmetry must be explicitly incorporated into learning algorithms and when it can be obtained directly from turbulence, enabling more efficient and symmetry-aware super-resolution.
Cryptographic Backdoor for Neural Networks: Boon and Bane
arXiv:2509.20714v1 Announce Type: cross Abstract: In this paper we show that cryptographic backdoors in a neural network (NN) can be highly effective in two directions, namely mounting the attacks as well as in presenting the defenses as well. On the attack side, a carefully planted cryptographic backdoor enables powerful and invisible attack on the NN. Considering the defense, we present applications: first, a provably robust NN watermarking scheme; second, a protocol for guaranteeing user authentication; and third, a protocol for tracking unauthorized sharing of the NN intellectual property (IP). From a broader theoretical perspective, borrowing the ideas from Goldwasser et. al. [FOCS 2022], our main contribution is to show that all these instantiated practical protocol implementations are provably robust. The protocols for watermarking, authentication and IP tracking resist an adversary with black-box access to the NN, whereas the backdoor-enabled adversarial attack is impossible to prevent under the standard assumptions. While the theoretical tools used for our attack is mostly in line with the Goldwasser et. al. ideas, the proofs related to the defense need further studies. Finally, all these protocols are implemented on state-of-the-art NN architectures with empirical results corroborating the theoretical claims. Further, one can utilize post-quantum primitives for implementing the cryptographic backdoors, laying out foundations for quantum-era applications in machine learning (ML).
PALQO: Physics-informed Model for Accelerating Large-scale Quantum Optimization
arXiv:2509.20733v1 Announce Type: cross Abstract: Variational quantum algorithms (VQAs) are leading strategies to reach practical utilities of near-term quantum devices. However, the no-cloning theorem in quantum mechanics precludes standard backpropagation, leading to prohibitive quantum resource costs when applying VQAs to large-scale tasks. To address this challenge, we reformulate the training dynamics of VQAs as a nonlinear partial differential equation and propose a novel protocol that leverages physics-informed neural networks (PINNs) to model this dynamical system efficiently. Given a small amount of training trajectory data collected from quantum devices, our protocol predicts the parameter updates of VQAs over multiple iterations on the classical side, dramatically reducing quantum resource costs. Through systematic numerical experiments, we demonstrate that our method achieves up to a 30x speedup compared to conventional methods and reduces quantum resource costs by as much as 90\% for tasks involving up to 40 qubits, including ground state preparation of different quantum systems, while maintaining competitive accuracy. Our approach complements existing techniques aimed at improving the efficiency of VQAs and further strengthens their potential for practical applications.
Real-Time System for Audio-Visual Target Speech Enhancement
arXiv:2509.20741v1 Announce Type: cross Abstract: We present a live demonstration for RAVEN, a real-time audio-visual speech enhancement system designed to run entirely on a CPU. In single-channel, audio-only settings, speech enhancement is traditionally approached as the task of extracting clean speech from environmental noise. More recent work has explored the use of visual cues, such as lip movements, to improve robustness, particularly in the presence of interfering speakers. However, to our knowledge, no prior work has demonstrated an interactive system for real-time audio-visual speech enhancement operating on CPU hardware. RAVEN fills this gap by using pretrained visual embeddings from an audio-visual speech recognition model to encode lip movement information. The system generalizes across environmental noise, interfering speakers, transient sounds, and even singing voices. In this demonstration, attendees will be able to experience live audio-visual target speech enhancement using a microphone and webcam setup, with clean speech playback through headphones.
RAPTOR-GEN: RApid PosTeriOR GENerator for Bayesian Learning in Biomanufacturing
arXiv:2509.20753v1 Announce Type: cross Abstract: Biopharmaceutical manufacturing is vital to public health but lacks the agility for rapid, on-demand production of biotherapeutics due to the complexity and variability of bioprocesses. To overcome this, we introduce RApid PosTeriOR GENerator (RAPTOR-GEN), a mechanism-informed Bayesian learning framework designed to accelerate intelligent digital twin development from sparse and heterogeneous experimental data. This framework is built on a multi-scale probabilistic knowledge graph (pKG), formulated as a stochastic differential equation (SDE)-based foundational model that captures the nonlinear dynamics of bioprocesses. RAPTOR-GEN consists of two ingredients: (i) an interpretable metamodel integrating linear noise approximation (LNA) that exploits the structural information of bioprocessing mechanisms and a sequential learning strategy to fuse heterogeneous and sparse data, enabling inference of latent state variables and explicit approximation of the intractable likelihood function; and (ii) an efficient Bayesian posterior sampling method that utilizes Langevin diffusion (LD) to accelerate posterior exploration by exploiting the gradients of the derived likelihood. It generalizes the LNA approach to circumvent the challenge of step size selection, facilitating robust learning of mechanistic parameters with provable finite-sample performance guarantees. We develop a fast and robust RAPTOR-GEN algorithm with controllable error. Numerical experiments demonstrate its effectiveness in uncovering the underlying regulatory mechanisms of biomanufacturing processes.
Identifying Group Anchors in Real-World Group Interactions Under Label Scarcity
arXiv:2509.20762v1 Announce Type: cross Abstract: Group interactions occur in various real-world contexts, e.g., co-authorship, email communication, and online Q&A. In each group, there is often a particularly significant member, around whom the group is formed. Examples include the first or last author of a paper, the sender of an email, and the questioner in a Q&A session. In this work, we discuss the existence of such individuals in real-world group interactions. We call such individuals group anchors and study the problem of identifying them. First, we introduce the concept of group anchors and the identification problem. Then, we discuss our observations on group anchors in real-world group interactions. Based on our observations, we develop AnchorRadar, a fast and effective method for group anchor identification under realistic settings with label scarcity, i.e., when only a few groups have known anchors. AnchorRadar is a semi-supervised method using information from groups both with and without known group anchors. Finally, through extensive experiments on thirteen real-world datasets, we demonstrate the empirical superiority of AnchorRadar over various baselines w.r.t. accuracy and efficiency. In most cases, AnchorRadar achieves higher accuracy in group anchor identification than all the baselines, while using 10.2$\times$ less training time than the fastest baseline and 43.6$\times$ fewer learnable parameters than the most lightweight baseline on average.
Leveraging Temporally Extended Behavior Sharing for Multi-task Reinforcement Learning
arXiv:2509.20766v1 Announce Type: cross Abstract: Multi-task reinforcement learning (MTRL) offers a promising approach to improve sample efficiency and generalization by training agents across multiple tasks, enabling knowledge sharing between them. However, applying MTRL to robotics remains challenging due to the high cost of collecting diverse task data. To address this, we propose MT-L\'evy, a novel exploration strategy that enhances sample efficiency in MTRL environments by combining behavior sharing across tasks with temporally extended exploration inspired by L\'evy flight. MT-L\'evy leverages policies trained on related tasks to guide exploration towards key states, while dynamically adjusting exploration levels based on task success ratios. This approach enables more efficient state-space coverage, even in complex robotics environments. Empirical results demonstrate that MT-L\'evy significantly improves exploration and sample efficiency, supported by quantitative and qualitative analyses. Ablation studies further highlight the contribution of each component, showing that combining behavior sharing with adaptive exploration strategies can significantly improve the practicality of MTRL in robotics applications.
Extrapolating Phase-Field Simulations in Space and Time with Purely Convolutional Architectures
arXiv:2509.20770v1 Announce Type: cross Abstract: Phase-field models of liquid metal dealloying (LMD) can resolve rich microstructural dynamics but become intractable for large domains or long time horizons. We present a conditionally parameterized, fully convolutional U-Net surrogate that generalizes far beyond its training window in both space and time. The design integrates convolutional self-attention and physics-aware padding, while parameter conditioning enables variable time-step skipping and adaptation to diverse alloy systems. Although trained only on short, small-scale simulations, the surrogate exploits the translational invariance of convolutions to extend predictions to much longer horizons than traditional solvers. It accurately reproduces key LMD physics, with relative errors typically under 5% within the training regime and below 10% when extrapolating to larger domains and later times. The method accelerates computations by up to 16,000 times, cutting weeks of simulation down to seconds, and marks an early step toward scalable, high-fidelity extrapolation of LMD phase-field models.
DAC-LoRA: Dynamic Adversarial Curriculum for Efficient and Robust Few-Shot Adaptation
arXiv:2509.20792v1 Announce Type: cross Abstract: Vision-Language Models (VLMs) are foundational to critical applications like autonomous driving, medical diagnosis, and content moderation. While Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA enable their efficient adaptation to specialized tasks, these models remain vulnerable to adversarial attacks that can compromise safety-critical decisions. CLIP, the backbone for numerous downstream VLMs, is a high-value target whose vulnerabilities can cascade across the multimodal AI ecosystem. We propose Dynamic Adversarial Curriculum DAC-LoRA, a novel framework that integrates adversarial training into PEFT. The core principle of our method i.e. an intelligent curriculum of progressively challenging attack, is general and can potentially be applied to any iterative attack method. Guided by the First-Order Stationary Condition (FOSC) and a TRADES-inspired loss, DAC-LoRA achieves substantial improvements in adversarial robustness without significantly compromising clean accuracy. Our work presents an effective, lightweight, and broadly applicable method to demonstrate that the DAC-LoRA framework can be easily integrated into a standard PEFT pipeline to significantly enhance robustness.
ImaginationPolicy: Towards Generalizable, Precise and Reliable End-to-End Policy for Robotic Manipulation
arXiv:2509.20841v1 Announce Type: cross Abstract: End-to-end robot manipulation policies offer significant potential for enabling embodied agents to understand and interact with the world. Unlike traditional modular pipelines, end-to-end learning mitigates key limitations such as information loss between modules and feature misalignment caused by isolated optimization targets. Despite these advantages, existing end-to-end neural networks for robotic manipulation--including those based on large VLM/VLA models--remain insufficiently performant for large-scale practical deployment. In this paper, we take a step towards an end-to-end manipulation policy that is generalizable, accurate and reliable. To achieve this goal, we propose a novel Chain of Moving Oriented Keypoints (CoMOK) formulation for robotic manipulation. Our formulation is used as the action representation of a neural policy, which can be trained in an end-to-end fashion. Such an action representation is general, as it extends the standard end-effector pose action representation and supports a diverse set of manipulation tasks in a unified manner. The oriented keypoint in our method enables natural generalization to objects with different shapes and sizes, while achieving sub-centimeter accuracy. Moreover, our formulation can easily handle multi-stage tasks, multi-modal robot behaviors, and deformable objects. Extensive simulated and hardware experiments demonstrate the effectiveness of our method.
Actively Learning Halfspaces without Synthetic Data
arXiv:2509.20848v1 Announce Type: cross Abstract: In the classic point location problem, one is given an arbitrary dataset $X \subset \mathbb{R}^d$ of $n$ points with query access to an unknown halfspace $f : \mathbb{R}^d \to {0,1}$, and the goal is to learn the label of every point in $X$. This problem is extremely well-studied and a nearly-optimal $\widetilde{O}(d \log n)$ query algorithm is known due to Hopkins-Kane-Lovett-Mahajan (FOCS 2020). However, their algorithm is granted the power to query arbitrary points outside of $X$ (point synthesis), and in fact without this power there is an $\Omega(n)$ query lower bound due to Dasgupta (NeurIPS 2004). In this work our goal is to design efficient algorithms for learning halfspaces without point synthesis. To circumvent the $\Omega(n)$ lower bound, we consider learning halfspaces whose normal vectors come from a set of size $D$, and show tight bounds of $\Theta(D + \log n)$. As a corollary, we obtain an optimal $O(d + \log n)$ query deterministic learner for axis-aligned halfspaces, closing a previous gap of $O(d \log n)$ vs. $\Omega(d + \log n)$. In fact, our algorithm solves the more general problem of learning a Boolean function $f$ over $n$ elements which is monotone under at least one of $D$ provided orderings. Our technical insight is to exploit the structure in these orderings to perform a binary search in parallel rather than considering each ordering sequentially, and we believe our approach may be of broader interest. Furthermore, we use our exact learning algorithm to obtain nearly optimal algorithms for PAC-learning. We show that $O(\min(D + \log(1/\varepsilon), 1/\varepsilon) \cdot \log D)$ queries suffice to learn $f$ within error $\varepsilon$, even in a setting when $f$ can be adversarially corrupted on a $c\varepsilon$-fraction of points, for a sufficiently small constant $c$. This bound is optimal up to a $\log D$ factor, including in the realizable setting.
Single Answer is Not Enough: On Generating Ranked Lists with Medical Reasoning Models
arXiv:2509.20866v1 Announce Type: cross Abstract: This paper presents a systematic study on enabling medical reasoning models (MRMs) to generate ranked lists of answers for open-ended questions. Clinical decision-making rarely relies on a single answer but instead considers multiple options, reducing the risks of narrow perspectives. Yet current MRMs are typically trained to produce only one answer, even in open-ended settings. We propose an alternative format: ranked lists and investigate two approaches: prompting and fine-tuning. While prompting is a cost-effective way to steer an MRM's response, not all MRMs generalize well across different answer formats: choice, short text, and list answers. Based on our prompting findings, we train and evaluate MRMs using supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). SFT teaches a model to imitate annotated responses, and RFT incentivizes exploration through the responses that maximize a reward. We propose new reward functions targeted at ranked-list answer formats, and conduct ablation studies for RFT. Our results show that while some SFT models generalize to certain answer formats, models trained with RFT are more robust across multiple formats. We also present a case study on a modified MedQA with multiple valid answers, finding that although MRMs might fail to select the benchmark's preferred ground truth, they can recognize valid answers. To the best of our knowledge, this is the first systematic investigation of approaches for enabling MRMs to generate answers as ranked lists. We hope this work provides a first step toward developing alternative answer formats that are beneficial beyond single answers in medical domains.
RecIS: Sparse to Dense, A Unified Training Framework for Recommendation Models
arXiv:2509.20883v1 Announce Type: cross Abstract: In this paper, we propose RecIS, a unified Sparse-Dense training framework designed to achieve two primary goals: 1. Unified Framework To create a Unified sparse-dense training framework based on the PyTorch ecosystem that meets the training needs of industrial-grade recommendation models that integrated with large models. 2.System Optimization To optimize the sparse component, offering superior efficiency over the TensorFlow-based recommendation models. The dense component, meanwhile, leverages existing optimization technologies within the PyTorch ecosystem. Currently, RecIS is being used in Alibaba for numerous large-model enhanced recommendation training tasks, and some traditional sparse models have also begun training in it.
Nuclear Diffusion Models for Low-Rank Background Suppression in Videos
arXiv:2509.20886v1 Announce Type: cross Abstract: Video sequences often contain structured noise and background artifacts that obscure dynamic content, posing challenges for accurate analysis and restoration. Robust principal component methods address this by decomposing data into low-rank and sparse components. Still, the sparsity assumption often fails to capture the rich variability present in real video data. To overcome this limitation, a hybrid framework that integrates low-rank temporal modeling with diffusion posterior sampling is proposed. The proposed method, Nuclear Diffusion, is evaluated on a real-world medical imaging problem, namely cardiac ultrasound dehazing, and demonstrates improved dehazing performance compared to traditional RPCA concerning contrast enhancement (gCNR) and signal preservation (KS statistic). These results highlight the potential of combining model-based temporal models with deep generative priors for high-fidelity video restoration.
Conditionally Whitened Generative Models for Probabilistic Time Series Forecasting
arXiv:2509.20928v1 Announce Type: cross Abstract: Probabilistic forecasting of multivariate time series is challenging due to non-stationarity, inter-variable dependencies, and distribution shifts. While recent diffusion and flow matching models have shown promise, they often ignore informative priors such as conditional means and covariances. In this work, we propose Conditionally Whitened Generative Models (CW-Gen), a framework that incorporates prior information through conditional whitening. Theoretically, we establish sufficient conditions under which replacing the traditional terminal distribution of diffusion models, namely the standard multivariate normal, with a multivariate normal distribution parameterized by estimators of the conditional mean and covariance improves sample quality. Guided by this analysis, we design a novel Joint Mean-Covariance Estimator (JMCE) that simultaneously learns the conditional mean and sliding-window covariance. Building on JMCE, we introduce Conditionally Whitened Diffusion Models (CW-Diff) and extend them to Conditionally Whitened Flow Matching (CW-Flow). Experiments on five real-world datasets with six state-of-the-art generative models demonstrate that CW-Gen consistently enhances predictive performance, capturing non-stationary dynamics and inter-variable correlations more effectively than prior-free approaches. Empirical results further demonstrate that CW-Gen can effectively mitigate the effects of distribution shift.
Reverse Fa`a di Bruno's Formula for Cartesian Reverse Differential Categories
arXiv:2509.20931v1 Announce Type: cross Abstract: Reverse differentiation is an essential operation for automatic differentiation. Cartesian reverse differential categories axiomatize reverse differentiation in a categorical framework, where one of the primary axioms is the reverse chain rule, which is the formula that expresses the reverse derivative of a composition. Here, we present the reverse differential analogue of Faa di Bruno's Formula, which gives a higher-order reverse chain rule in a Cartesian reverse differential category. To properly do so, we also define partial reverse derivatives and higher-order reverse derivatives in a Cartesian reverse differential category.
Unlocking Noise-Resistant Vision: Key Architectural Secrets for Robust Models
arXiv:2509.20939v1 Announce Type: cross Abstract: While the robustness of vision models is often measured, their dependence on specific architectural design choices is rarely dissected. We investigate why certain vision architectures are inherently more robust to additive Gaussian noise and convert these empirical insights into simple, actionable design rules. Specifically, we performed extensive evaluations on 1,174 pretrained vision models, empirically identifying four consistent design patterns for improved robustness against Gaussian noise: larger stem kernels, smaller input resolutions, average pooling, and supervised vision transformers (ViTs) rather than CLIP ViTs, which yield up to 506 rank improvements and 21.6\%p accuracy gains. We then develop a theoretical analysis that explains these findings, converting observed correlations into causal mechanisms. First, we prove that low-pass stem kernels attenuate noise with a gain that decreases quadratically with kernel size and that anti-aliased downsampling reduces noise energy roughly in proportion to the square of the downsampling factor. Second, we demonstrate that average pooling is unbiased and suppresses noise in proportion to the pooling window area, whereas max pooling incurs a positive bias that grows slowly with window size and yields a relatively higher mean-squared error and greater worst-case sensitivity. Third, we reveal and explain the vulnerability of CLIP ViTs via a pixel-space Lipschitz bound: The smaller normalization standard deviations used in CLIP preprocessing amplify worst-case sensitivity by up to 1.91 times relative to the Inception-style preprocessing common in supervised ViTs. Our results collectively disentangle robustness into interpretable modules, provide a theory that explains the observed trends, and build practical, plug-and-play guidelines for designing vision models more robust against Gaussian noise.
An Adaptor for Triggering Semi-Supervised Learning to Out-of-Box Serve Deep Image Clustering
arXiv:2509.20976v1 Announce Type: cross Abstract: Recently, some works integrate SSL techniques into deep clustering frameworks to enhance image clustering performance. However, they all need pretraining, clustering learning, or a trained clustering model as prerequisites, limiting the flexible and out-of-box application of SSL learners in the image clustering task. This work introduces ASD, an adaptor that enables the cold-start of SSL learners for deep image clustering without any prerequisites. Specifically, we first randomly sample pseudo-labeled data from all unlabeled data, and set an instance-level classifier to learn them with semantically aligned instance-level labels. With the ability of instance-level classification, we track the class transitions of predictions on unlabeled data to extract high-level similarities of instance-level classes, which can be utilized to assign cluster-level labels to pseudo-labeled data. Finally, we use the pseudo-labeled data with assigned cluster-level labels to trigger a general SSL learner trained on the unlabeled data for image clustering. We show the superior performance of ASD across various benchmarks against the latest deep image clustering approaches and very slight accuracy gaps compared to SSL methods using ground-truth, e.g., only 1.33% on CIFAR-10. Moreover, ASD can also further boost the performance of existing SSL-embedded deep image clustering methods.
Empirical PAC-Bayes bounds for Markov chains
arXiv:2509.20985v1 Announce Type: cross Abstract: The core of generalization theory was developed for independent observations. Some PAC and PAC-Bayes bounds are available for data that exhibit a temporal dependence. However, there are constants in these bounds that depend on properties of the data-generating process: mixing coefficients, mixing time, spectral gap... Such constants are unknown in practice. In this paper, we prove a new PAC-Bayes bound for Markov chains. This bound depends on a quantity called the pseudo-spectral gap. The main novelty is that we can provide an empirical bound on the pseudo-spectral gap when the state space is finite. Thus, we obtain the first fully empirical PAC-Bayes bound for Markov chains. This extends beyond the finite case, although this requires additional assumptions. On simulated experiments, the empirical version of the bound is essentially as tight as the non-empirical one.
Fast-SEnSeI: Lightweight Sensor-Independent Cloud Masking for On-board Multispectral Sensors
arXiv:2509.20991v1 Announce Type: cross Abstract: Cloud segmentation is a critical preprocessing step for many Earth observation tasks, yet most models are tightly coupled to specific sensor configurations and rely on ground-based processing. In this work, we propose Fast-SEnSeI, a lightweight, sensor-independent encoder module that enables flexible, on-board cloud segmentation across multispectral sensors with varying band configurations. Building upon SEnSeI-v2, Fast-SEnSeI integrates an improved spectral descriptor, lightweight architecture, and robust padding-band handling. It accepts arbitrary combinations of spectral bands and their wavelengths, producing fixed-size feature maps that feed into a compact, quantized segmentation model based on a modified U-Net. The module runs efficiently on embedded CPUs using Apache TVM, while the segmentation model is deployed on FPGA, forming a CPU-FPGA hybrid pipeline suitable for space-qualified hardware. Evaluations on Sentinel-2 and Landsat 8 datasets demonstrate accurate segmentation across diverse input configurations.
RollPacker: Mitigating Long-Tail Rollouts for Fast, Synchronous RL Post-Training
arXiv:2509.21009v1 Announce Type: cross Abstract: Reinforcement Learning (RL) is a pivotal post-training technique for enhancing the reasoning capabilities of Large Language Models (LLMs). However, synchronous RL post-training often suffers from significant GPU underutilization, referred to as bubbles, caused by imbalanced response lengths within rollout steps. Many RL systems attempt to alleviate this problem by relaxing synchronization, but this can compromise training accuracy. In this paper, we introduce tail batching, a novel rollout scheduling strategy for synchronous RL that systematically consolidates prompts leading to long-tail responses into a small subset of rollout steps (long rounds), while ensuring that the majority of steps (short rounds) involve only balanced, short rollouts. By excluding long responses from short rounds and rescheduling them into a few designated long rounds, tail batching effectively reduces GPU idle time during rollouts and significantly accelerates RL training without sacrificing accuracy. We present RollPacker, a system that fully harnesses the benefits of tail batching through holistic optimizations across all three RL stages: elastic parallelism adaptation for rollout, dynamic resource allocation and scheduling for reward, and stream-based training. Empirical results show that RollPacker achieves a 2.03x-2.56x end-to-end training time reduction compared to veRL and up to 2.24x speedup compared to RLHFuse for the Qwen2.5 family of LLMs on up to 128 H800 GPUs.
Behind RoPE: How Does Causal Mask Encode Positional Information?
arXiv:2509.21042v1 Announce Type: cross Abstract: While explicit positional encodings such as RoPE are a primary source of positional information in Transformer decoders, the causal mask also provides positional information. In this work, we prove that the causal mask can induce position-dependent patterns in attention scores, even without parameters or causal dependency in the input. Our theoretical analysis indicates that the induced attention pattern tends to favor nearby query-key pairs, mirroring the behavior of common positional encodings. Empirical analysis confirms that trained models exhibit the same behavior, with learned parameters further amplifying these patterns. Notably, we found that the interaction of causal mask and RoPE distorts RoPE's relative attention score patterns into non-relative ones. We consistently observed this effect in modern large language models, suggesting the importance of considering the causal mask as a source of positional information alongside explicit positional encodings.
Combinatorial Creativity: A New Frontier in Generalization Abilities
arXiv:2509.21043v1 Announce Type: cross Abstract: Artificial intelligence (AI) systems, and large language models (LLMs) in particular, are increasingly employed for creative tasks like scientific idea generation, constituting a form of generalization from training data unaddressed by existing conceptual frameworks. Though in many ways similar to forms of compositional generalization (CG), combinatorial creativity (CC) is an open-ended ability. Instead of evaluating for accuracy or correctness against fixed targets, which would contradict the open-ended nature of CC, we propose a theoretical framework and algorithmic task for evaluating outputs by their degrees of novelty and utility. From here, we make several important empirical contributions: (1) We obtain the first insights into the scaling behavior of creativity for LLMs. (2) We discover that, for fixed compute budgets, there exist optimal model depths and widths for creative ability. (3) We find that the ideation-execution gap, whereby LLMs excel at generating novel scientific ideas but struggle to ensure their practical feasibility, may be explained by a more fundamental novelty-utility tradeoff characteristic of creativity algorithms in general. Importantly, this tradeoff remains persistent even at scale, casting doubt on the long-term creative potential of LLMs in their current form. Together, our conceptual framework and empirical findings provide a foundation for understanding and improving creativity in modern AI models, marking a new frontier in generalization abilities.
MPC-based Deep Reinforcement Learning Method for Space Robotic Control with Fuel Sloshing Mitigation
arXiv:2509.21045v1 Announce Type: cross Abstract: This paper presents an integrated Reinforcement Learning (RL) and Model Predictive Control (MPC) framework for autonomous satellite docking with a partially filled fuel tank. Traditional docking control faces challenges due to fuel sloshing in microgravity, which induces unpredictable forces affecting stability. To address this, we integrate Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC) RL algorithms with MPC, leveraging MPC's predictive capabilities to accelerate RL training and improve control robustness. The proposed approach is validated through Zero-G Lab of SnT experiments for planar stabilization and high-fidelity numerical simulations for 6-DOF docking with fuel sloshing dynamics. Simulation results demonstrate that SAC-MPC achieves superior docking accuracy, higher success rates, and lower control effort, outperforming standalone RL and PPO-MPC methods. This study advances fuel-efficient and disturbance-resilient satellite docking, enhancing the feasibility of on-orbit refueling and servicing missions.
Communication Bias in Large Language Models: A Regulatory Perspective
arXiv:2509.21075v1 Announce Type: cross Abstract: Large language models (LLMs) are increasingly central to many applications, raising concerns about bias, fairness, and regulatory compliance. This paper reviews risks of biased outputs and their societal impact, focusing on frameworks like the EU's AI Act and the Digital Services Act. We argue that beyond constant regulation, stronger attention to competition and design governance is needed to ensure fair, trustworthy AI. This is a preprint of the Communications of the ACM article of the same title.
Are Modern Speech Enhancement Systems Vulnerable to Adversarial Attacks?
arXiv:2509.21087v1 Announce Type: cross Abstract: Machine learning approaches for speech enhancement are becoming increasingly expressive, enabling ever more powerful modifications of input signals. In this paper, we demonstrate that this expressiveness introduces a vulnerability: advanced speech enhancement models can be susceptible to adversarial attacks. Specifically, we show that adversarial noise, carefully crafted and psychoacoustically masked by the original input, can be injected such that the enhanced speech output conveys an entirely different semantic meaning. We experimentally verify that contemporary predictive speech enhancement models can indeed be manipulated in this way. Furthermore, we highlight that diffusion models with stochastic samplers exhibit inherent robustness to such adversarial attacks by design.
Best-of-$\infty$ -- Asymptotic Performance of Test-Time Compute
arXiv:2509.21091v1 Announce Type: cross Abstract: We study best-of-$N$ for large language models (LLMs) where the selection is based on majority voting. In particular, we analyze the limit $N \to \infty$, which we denote as Best-of-$\infty$. While this approach achieves impressive performance in the limit, it requires an infinite test-time budget. To address this, we propose an adaptive generation scheme that selects $N$ based on answer agreement, thereby efficiently allocating inference-time computation. Beyond adaptivity, we extend the framework to weighted ensembles of multiple LLMs, showing that such mixtures can outperform any individual model. The optimal ensemble weighting is formulated and efficiently computed as a mixed-integer linear program. Extensive experiments demonstrate the effectiveness of our approach.
Cross-Modal Instructions for Robot Motion Generation
arXiv:2509.21107v1 Announce Type: cross Abstract: Teaching robots novel behaviors typically requires motion demonstrations via teleoperation or kinaesthetic teaching, that is, physically guiding the robot. While recent work has explored using human sketches to specify desired behaviors, data collection remains cumbersome, and demonstration datasets are difficult to scale. In this paper, we introduce an alternative paradigm, Learning from Cross-Modal Instructions, where robots are shaped by demonstrations in the form of rough annotations, which can contain free-form text labels, and are used in lieu of physical motion. We introduce the CrossInstruct framework, which integrates cross-modal instructions as examples into the context input to a foundational vision-language model (VLM). The VLM then iteratively queries a smaller, fine-tuned model, and synthesizes the desired motion over multiple 2D views. These are then subsequently fused into a coherent distribution over 3D motion trajectories in the robot's workspace. By incorporating the reasoning of the large VLM with a fine-grained pointing model, CrossInstruct produces executable robot behaviors that generalize beyond the environment of in the limited set of instruction examples. We then introduce a downstream reinforcement learning pipeline that leverages CrossInstruct outputs to efficiently learn policies to complete fine-grained tasks. We rigorously evaluate CrossInstruct on benchmark simulation tasks and real hardware, demonstrating effectiveness without additional fine-tuning and providing a strong initialization for policies subsequently refined via reinforcement learning.
Physics Informed Neural Networks for design optimisation of diamond particle detectors for charged particle fast-tracking at high luminosity hadron colliders
arXiv:2509.21123v1 Announce Type: cross Abstract: Future high-luminosity hadron colliders demand tracking detectors with extreme radiation tolerance, high spatial precision, and sub-nanosecond timing. 3D diamond pixel sensors offer these capabilities due to diamond's radiation hardness and high carrier mobility. Conductive electrodes, produced via femtosecond IR laser pulses, exhibit high resistivity that delays signal propagation. This effect necessitates extending the classical Ramo-Shockley weighting potential formalism. We model the phenomenon through a 3rd-order, 3+1D PDE derived as a quasi-stationary approximation of Maxwell's equations. The PDE is solved numerically and coupled with charge transport simulations for realistic 3D sensor geometries. A Mixture-of-Experts Physics-Informed Neural Network, trained on Spectral Method data, provides a meshless solver to assess timing degradation from electrode resistance.
The Unwinnable Arms Race of AI Image Detection
arXiv:2509.21135v1 Announce Type: cross Abstract: The rapid progress of image generative AI has blurred the boundary between synthetic and real images, fueling an arms race between generators and discriminators. This paper investigates the conditions under which discriminators are most disadvantaged in this competition. We analyze two key factors: data dimensionality and data complexity. While increased dimensionality often strengthens the discriminators ability to detect subtle inconsistencies, complexity introduces a more nuanced effect. Using Kolmogorov complexity as a measure of intrinsic dataset structure, we show that both very simple and highly complex datasets reduce the detectability of synthetic images; generators can learn simple datasets almost perfectly, whereas extreme diversity masks imperfections. In contrast, intermediate-complexity datasets create the most favorable conditions for detection, as generators fail to fully capture the distribution and their errors remain visible.
Emerging Paradigms for Securing Federated Learning Systems
arXiv:2509.21147v1 Announce Type: cross Abstract: Federated Learning (FL) facilitates collaborative model training while keeping raw data decentralized, making it a conduit for leveraging the power of IoT devices while maintaining privacy of the locally collected data. However, existing privacy- preserving techniques present notable hurdles. Methods such as Multi-Party Computation (MPC), Homomorphic Encryption (HE), and Differential Privacy (DP) often incur high compu- tational costs and suffer from limited scalability. This survey examines emerging approaches that hold promise for enhancing both privacy and efficiency in FL, including Trusted Execution Environments (TEEs), Physical Unclonable Functions (PUFs), Quantum Computing (QC), Chaos-Based Encryption (CBE), Neuromorphic Computing (NC), and Swarm Intelligence (SI). For each paradigm, we assess its relevance to the FL pipeline, outlining its strengths, limitations, and practical considerations. We conclude by highlighting open challenges and prospective research avenues, offering a detailed roadmap for advancing secure and scalable FL systems.
WISER: Segmenting watermarked region - an epidemic change-point perspective
arXiv:2509.21160v1 Announce Type: cross Abstract: With the increasing popularity of large language models, concerns over content authenticity have led to the development of myriad watermarking schemes. These schemes can be used to detect a machine-generated text via an appropriate key, while being imperceptible to readers with no such keys. The corresponding detection mechanisms usually take the form of statistical hypothesis testing for the existence of watermarks, spurring extensive research in this direction. However, the finer-grained problem of identifying which segments of a mixed-source text are actually watermarked, is much less explored; the existing approaches either lack scalability or theoretical guarantees robust to paraphrase and post-editing. In this work, we introduce a unique perspective to such watermark segmentation problems through the lens of epidemic change-points. By highlighting the similarities as well as differences of these two problems, we motivate and propose WISER: a novel, computationally efficient, watermark segmentation algorithm. We theoretically validate our algorithm by deriving finite sample error-bounds, and establishing its consistency in detecting multiple watermarked segments in a single text. Complementing these theoretical results, our extensive numerical experiments show that WISER outperforms state-of-the-art baseline methods, both in terms of computational speed as well as accuracy, on various benchmark datasets embedded with diverse watermarking schemes. Our theoretical and empirical findings establish WISER as an effective tool for watermark localization in most settings. It also shows how insights from a classical statistical problem can lead to a theoretically valid and computationally efficient solution of a modern and pertinent problem.
Can Less Precise Be More Reliable? A Systematic Evaluation of Quantization's Impact on CLIP Beyond Accuracy
arXiv:2509.21173v1 Announce Type: cross Abstract: The powerful zero-shot generalization capabilities of vision-language models (VLMs) like CLIP have enabled new paradigms for safety-related tasks such as out-of-distribution (OOD) detection. However, additional aspects crucial for the computationally efficient and reliable deployment of CLIP are still overlooked. In particular, the impact of quantization on CLIP's performance beyond accuracy remains underexplored. This work presents a large-scale evaluation of quantization on CLIP models, assessing not only in-distribution accuracy but a comprehensive suite of reliability metrics and revealing counterintuitive results driven by pre-training source. We demonstrate that quantization consistently improves calibration for typically underconfident pre-trained models, while often degrading it for overconfident variants. Intriguingly, this degradation in calibration does not preclude gains in other reliability metrics; we find that OOD detection can still improve for these same poorly calibrated models. Furthermore, we identify specific quantization-aware training (QAT) methods that yield simultaneous gains in zero-shot accuracy, calibration, and OOD robustness, challenging the view of a strict efficiency-performance trade-off. These findings offer critical insights for navigating the multi-objective problem of deploying efficient, reliable, and robust VLMs by utilizing quantization beyond its conventional role.
Breaking the curse of dimensionality for linear rules: optimal predictors over the ellipsoid
arXiv:2509.21174v1 Announce Type: cross Abstract: In this work, we address the following question: What minimal structural assumptions are needed to prevent the degradation of statistical learning bounds with increasing dimensionality? We investigate this question in the classical statistical setting of signal estimation from $n$ independent linear observations $Y_i = X_i^{\top}\theta + \epsilon_i$. Our focus is on the generalization properties of a broad family of predictors that can be expressed as linear combinations of the training labels, $f(X) = \sum_{i=1}^{n} l_{i}(X) Y_i$. This class -- commonly referred to as linear prediction rules -- encompasses a wide range of popular parametric and non-parametric estimators, including ridge regression, gradient descent, and kernel methods. Our contributions are twofold. First, we derive non-asymptotic upper and lower bounds on the generalization error for this class under the assumption that the Bayes predictor $\theta$ lies in an ellipsoid. Second, we establish a lower bound for the subclass of rotationally invariant linear prediction rules when the Bayes predictor is fixed. Our analysis highlights two fundamental contributions to the risk: (a) a variance-like term that captures the intrinsic dimensionality of the data; (b) the noiseless error, a term that arises specifically in the high-dimensional regime. These findings shed light on the role of structural assumptions in mitigating the curse of dimensionality.
IntSR: An Integrated Generative Framework for Search and Recommendation
arXiv:2509.21179v1 Announce Type: cross Abstract: Generative recommendation has emerged as a promising paradigm, demonstrating remarkable results in both academic benchmarks and industrial applications. However, existing systems predominantly focus on unifying retrieval and ranking while neglecting the integration of search and recommendation (S&R) tasks. What makes search and recommendation different is how queries are formed: search uses explicit user requests, while recommendation relies on implicit user interests. As for retrieval versus ranking, the distinction comes down to whether the queries are the target items themselves. Recognizing the query as central element, we propose IntSR, an integrated generative framework for S&R. IntSR integrates these disparate tasks using distinct query modalities. It also addresses the increased computational complexity associated with integrated S&R behaviors and the erroneous pattern learning introduced by a dynamically changing corpus. IntSR has been successfully deployed across various scenarios in Amap, leading to substantial improvements in digital asset's GMV(+3.02%), POI recommendation's CTR(+2.76%), and travel mode suggestion's ACC(+5.13%).
Data-driven Neural Networks for Windkessel Parameter Calibration
arXiv:2509.21206v1 Announce Type: cross Abstract: In this work, we propose a novel method for calibrating Windkessel (WK) parameters in a dimensionally reduced 1D-0D coupled blood flow model. To this end, we design a data-driven neural network (NN)trained on simulated blood pressures in the left brachial artery. Once trained, the NN emulates the pressure pulse waves across the entire simulated domain, i.e., over time, space and varying WK parameters, with negligible error and computational effort. To calibrate the WK parameters on a measured pulse wave, the NN is extended by dummy neurons and retrained only on these. The main objective of this work is to assess the effectiveness of the method in various scenarios -- particularly, when the exact measurement location is unknown or the data are affected by noise.
Learning Conformal Explainers for Image Classifiers
arXiv:2509.21209v1 Announce Type: cross Abstract: Feature attribution methods are widely used for explaining image-based predictions, as they provide feature-level insights that can be intuitively visualized. However, such explanations often vary in their robustness and may fail to faithfully reflect the reasoning of the underlying black-box model. To address these limitations, we propose a novel conformal prediction-based approach that enables users to directly control the fidelity of the generated explanations. The method identifies a subset of salient features that is sufficient to preserve the model's prediction, regardless of the information carried by the excluded features, and without demanding access to ground-truth explanations for calibration. Four conformity functions are proposed to quantify the extent to which explanations conform to the model's predictions. The approach is empirically evaluated using five explainers across six image datasets. The empirical results demonstrate that FastSHAP consistently outperforms the competing methods in terms of both fidelity and informational efficiency, the latter measured by the size of the explanation regions. Furthermore, the results reveal that conformity measures based on super-pixels are more effective than their pixel-wise counterparts.
Response to Promises and Pitfalls of Deep Kernel Learning
arXiv:2509.21228v1 Announce Type: cross Abstract: This note responds to "Promises and Pitfalls of Deep Kernel Learning" (Ober et al., 2021). The marginal likelihood of a Gaussian process can be compartmentalized into a data fit term and a complexity penalty. Ober et al. (2021) shows that if a kernel can be multiplied by a signal variance coefficient, then reparametrizing and substituting in the maximized value of this parameter sets a reparametrized data fit term to a fixed value. They use this finding to argue that the complexity penalty, a log determinant of the kernel matrix, then dominates in determining the other values of kernel hyperparameters, which can lead to data overcorrelation. By contrast, we show that the reparametrization in fact introduces another data-fit term which influences all other kernel hyperparameters. Thus, a balance between data fit and complexity still plays a significant role in determining kernel hyperparameters.
Decipher-MR: A Vision-Language Foundation Model for 3D MRI Representations
arXiv:2509.21249v1 Announce Type: cross Abstract: Magnetic Resonance Imaging (MRI) is a critical medical imaging modality in clinical diagnosis and research, yet its complexity and heterogeneity pose challenges for automated analysis, particularly in scalable and generalizable machine learning applications. While foundation models have revolutionized natural language and vision tasks, their application to MRI remains limited due to data scarcity and narrow anatomical focus. In this work, we present Decipher-MR, a 3D MRI-specific vision-language foundation model trained on a large-scale dataset comprising 200,000 MRI series from over 22,000 studies spanning diverse anatomical regions, sequences, and pathologies. Decipher-MR integrates self-supervised vision learning with report-guided text supervision to build robust, generalizable representations, enabling effective adaptation across broad applications. To enable robust and diverse clinical tasks with minimal computational overhead, Decipher-MR supports a modular design that enables tuning of lightweight, task-specific decoders attached to a frozen pretrained encoder. Following this setting, we evaluate Decipher-MR across diverse benchmarks including disease classification, demographic prediction, anatomical localization, and cross-modal retrieval, demonstrating consistent performance gains over existing foundation models and task-specific approaches. Our results establish Decipher-MR as a scalable and versatile foundation for MRI-based AI, facilitating efficient development across clinical and research domains.
Does FLUX Already Know How to Perform Physically Plausible Image Composition?
arXiv:2509.21278v1 Announce Type: cross Abstract: Image composition aims to seamlessly insert a user-specified object into a new scene, but existing models struggle with complex lighting (e.g., accurate shadows, water reflections) and diverse, high-resolution inputs. Modern text-to-image diffusion models (e.g., SD3.5, FLUX) already encode essential physical and resolution priors, yet lack a framework to unleash them without resorting to latent inversion, which often locks object poses into contextually inappropriate orientations, or brittle attention surgery. We propose SHINE, a training-free framework for Seamless, High-fidelity Insertion with Neutralized Errors. SHINE introduces manifold-steered anchor loss, leveraging pretrained customization adapters (e.g., IP-Adapter) to guide latents for faithful subject representation while preserving background integrity. Degradation-suppression guidance and adaptive background blending are proposed to further eliminate low-quality outputs and visible seams. To address the lack of rigorous benchmarks, we introduce ComplexCompo, featuring diverse resolutions and challenging conditions such as low lighting, strong illumination, intricate shadows, and reflective surfaces. Experiments on ComplexCompo and DreamEditBench show state-of-the-art performance on standard metrics (e.g., DINOv2) and human-aligned scores (e.g., DreamSim, ImageReward, VisionReward). Code and benchmark will be publicly available upon publication.
Taxonomy-aware Dynamic Motion Generation on Hyperbolic Manifolds
arXiv:2509.21281v1 Announce Type: cross Abstract: Human-like motion generation for robots often draws inspiration from biomechanical studies, which often categorize complex human motions into hierarchical taxonomies. While these taxonomies provide rich structural information about how movements relate to one another, this information is frequently overlooked in motion generation models, leading to a disconnect between the generated motions and their underlying hierarchical structure. This paper introduces the \ac{gphdm}, a novel approach that learns latent representations preserving both the hierarchical structure of motions and their temporal dynamics to ensure physical consistency. Our model achieves this by extending the dynamics prior of the Gaussian Process Dynamical Model (GPDM) to the hyperbolic manifold and integrating it with taxonomy-aware inductive biases. Building on this geometry- and taxonomy-aware frameworks, we propose three novel mechanisms for generating motions that are both taxonomically-structured and physically-consistent: two probabilistic recursive approaches and a method based on pullback-metric geodesics. Experiments on generating realistic motion sequences on the hand grasping taxonomy show that the proposed GPHDM faithfully encodes the underlying taxonomy and temporal dynamics, and generates novel physically-consistent trajectories.
Maxout Polytopes
arXiv:2509.21286v1 Announce Type: cross Abstract: Maxout polytopes are defined by feedforward neural networks with maxout activation function and non-negative weights after the first layer. We characterize the parameter spaces and extremal f-vectors of maxout polytopes for shallow networks, and we study the separating hypersurfaces which arise when a layer is added to the network. We also show that maxout polytopes are cubical for generic networks without bottlenecks.
RLBFF: Binary Flexible Feedback to bridge between Human Feedback & Verifiable Rewards
arXiv:2509.21319v1 Announce Type: cross Abstract: Reinforcement Learning with Human Feedback (RLHF) and Reinforcement Learning with Verifiable Rewards (RLVR) are the main RL paradigms used in LLM post-training, each offering distinct advantages. However, RLHF struggles with interpretability and reward hacking because it relies on human judgments that usually lack explicit criteria, whereas RLVR is limited in scope by its focus on correctness-based verifiers. We propose Reinforcement Learning with Binary Flexible Feedback (RLBFF), which combines the versatility of human-driven preferences with the precision of rule-based verification, enabling reward models to capture nuanced aspects of response quality beyond mere correctness. RLBFF extracts principles that can be answered in a binary fashion (e.g. accuracy of information: yes, or code readability: no) from natural language feedback. Such principles can then be used to ground Reward Model training as an entailment task (response satisfies or does not satisfy an arbitrary principle). We show that Reward Models trained in this manner can outperform Bradley-Terry models when matched for data and achieve top performance on RM-Bench (86.2%) and JudgeBench (81.4%, #1 on leaderboard as of September 24, 2025). Additionally, users can specify principles of interest at inference time to customize the focus of our reward models, in contrast to Bradley-Terry models. Finally, we present a fully open source recipe (including data) to align Qwen3-32B using RLBFF and our Reward Model, to match or exceed the performance of o3-mini and DeepSeek R1 on general alignment benchmarks of MT-Bench, WildBench, and Arena Hard v2 (at <5% of the inference cost).
Learning to Bid Optimally and Efficiently in Adversarial First-price Auctions
arXiv:2007.04568v2 Announce Type: replace Abstract: First-price auctions have very recently swept the online advertising industry, replacing second-price auctions as the predominant auction mechanism on many platforms. This shift has brought forth important challenges for a bidder: how should one bid in a first-price auction, where unlike in second-price auctions, it is no longer optimal to bid one's private value truthfully and hard to know the others' bidding behaviors? In this paper, we take an online learning angle and address the fundamental problem of learning to bid in repeated first-price auctions, where both the bidder's private valuations and other bidders' bids can be arbitrary. We develop the first minimax optimal online bidding algorithm that achieves an $\widetilde{O}(\sqrt{T})$ regret when competing with the set of all Lipschitz bidding policies, a strong oracle that contains a rich set of bidding strategies. This novel algorithm is built on the insight that the presence of a good expert can be leveraged to improve performance, as well as an original hierarchical expert-chaining structure, both of which could be of independent interest in online learning. Further, by exploiting the product structure that exists in the problem, we modify this algorithm--in its vanilla form statistically optimal but computationally infeasible--to a computationally efficient and space efficient algorithm that also retains the same $\widetilde{O}(\sqrt{T})$ minimax optimal regret guarantee. Additionally, through an impossibility result, we highlight that one is unlikely to compete this favorably with a stronger oracle (than the considered Lipschitz bidding policies). Finally, we test our algorithm on three real-world first-price auction datasets obtained from Verizon Media and demonstrate our algorithm's superior performance compared to several existing bidding algorithms.
Contextual Combinatorial Bandits with Changing Action Sets via Gaussian Processes
arXiv:2110.02248v3 Announce Type: replace Abstract: We consider a contextual bandit problem with a combinatorial action set and time-varying base arm availability. At the beginning of each round, the agent observes the set of available base arms and their contexts and then selects an action that is a feasible subset of the set of available base arms to maximize its cumulative reward in the long run. We assume that the mean outcomes of base arms are samples from a Gaussian Process (GP) indexed by the context set ${\cal X}$, and the expected reward is Lipschitz continuous in expected base arm outcomes. For this setup, we propose an algorithm called Optimistic Combinatorial Learning and Optimization with Kernel Upper Confidence Bounds (O'CLOK-UCB) and prove that it incurs $\tilde{O}(\sqrt{\lambda^(K)KT\gamma_{KT}(\cup_{t\leq T}\mathcal{X}t)} )$ regret with high probability, where $\gamma{KT}(\cup_{t\leq T}\mathcal{X}_t)$ is the maximum information gain associated with the sets of base arm contexts $\mathcal{X}_t$ that appeared in the first $T$ rounds, $K$ is the maximum cardinality of any feasible action over all rounds, and $\lambda^(K)$ is the maximum eigenvalue of all covariance matrices of selected actions up to time $T$, which is a function of $K$. To dramatically speed up the algorithm, we also propose a variant of O'CLOK-UCB that uses sparse GPs. Finally, we experimentally show that both algorithms exploit inter-base arm outcome correlation and vastly outperform the previous state-of-the-art UCB-based algorithms in realistic setups.
Security of Deep Reinforcement Learning for Autonomous Driving: A Survey
arXiv:2212.06123v3 Announce Type: replace Abstract: Reinforcement learning (RL) enables agents to learn optimal behaviors through interaction with their environment and has been increasingly deployed in safety-critical applications, including autonomous driving. Despite its promise, RL is susceptible to attacks designed either to compromise policy learning or to induce erroneous decisions by trained agents. Although the literature on RL security has grown rapidly and several surveys exist, existing categorizations often fall short in guiding the selection of appropriate defenses for specific systems. In this work, we present a comprehensive survey of 86 recent studies on RL security, addressing these limitations by systematically categorizing attacks and defenses according to defined threat models and single- versus multi-agent settings. Furthermore, we examine the relevance and applicability of state-of-the-art attacks and defense mechanisms within the context of autonomous driving, providing insights to inform the design of robust RL systems.
Towards the Identifiability in Noisy Label Learning: A Multinomial Mixture Modelling Approach
arXiv:2301.01405v3 Announce Type: replace Abstract: Learning from noisy labels (LNL) is crucial in deep learning, in which one of the approaches is to identify clean-label samples from poorly-annotated datasets. Such an identification is challenging because the conventional LNL problem, which assumes only one noisy label per instance, is non-identifiable, i.e., clean labels cannot be estimated theoretically without additional heuristics. This paper presents a novel data-driven approach that addresses this issue without requiring any heuristics about clean samples. We discover that the LNL problem becomes identifiable if there are at least $2C - 1$ i.i.d. noisy labels per instance, where $C$ is the number of classes. Our finding relies on the assumption of i.i.d. noisy labels and multinomial mixture modelling, making it easier to interpret than previous studies that require full-rank noisy-label transition matrices. To fulfil this condition without additional manual annotations, we propose a method that automatically generates additional i.i.d. noisy labels through nearest neighbours. These noisy labels are then used in the Expectation-Maximisation algorithm to infer clean labels. Our method demonstrably estimates clean labels accurately across various label noise benchmarks, including synthetic, web-controlled, and real-world datasets. Furthermore, the model trained with our method performs competitively with many state-of-the-art methods.
Estimating Deep Learning energy consumption based on model architecture and training environment
arXiv:2307.05520v5 Announce Type: replace Abstract: To raise awareness of the environmental impact of deep learning (DL), many studies estimate the energy use of DL systems. However, energy estimates during DL training often rely on unverified assumptions. This work addresses that gap by investigating how model architecture and training environment affect energy consumption. We train a variety of computer vision models and collect energy consumption and accuracy metrics to analyze their trade-offs across configurations. Our results show that selecting the right model-training environment combination can reduce training energy consumption by up to 80.68% with less than 2% loss in $F_1$ score. We find a significant interaction effect between model and training environment: energy efficiency improves when GPU computational power scales with model complexity. Moreover, we demonstrate that common estimation practices, such as using FLOPs or GPU TDP, fail to capture these dynamics and can lead to substantial errors. To address these shortcomings, we propose the Stable Training Epoch Projection (STEP) and the Pre-training Regression-based Estimation (PRE) methods. Across evaluations, our methods outperform existing tools by a factor of two or more in estimation accuracy.
Energy based diffusion generator for efficient sampling of Boltzmann distributions
arXiv:2401.02080v3 Announce Type: replace Abstract: Sampling from Boltzmann distributions, particularly those tied to high dimensional and complex energy functions, poses a significant challenge in many fields. In this work, we present the Energy-Based Diffusion Generator (EDG), a novel approach that integrates ideas from variational autoencoders and diffusion models. EDG uses a decoder to generate Boltzmann-distributed samples from simple latent variables, and a diffusion-based encoder to estimate the Kullback-Leibler divergence to the target distribution. Notably, EDG is simulation-free, eliminating the need to solve ordinary or stochastic differential equations during training. Furthermore, by removing constraints such as bijectivity in the decoder, EDG allows for flexible network design. Through empirical evaluation, we demonstrate the superior performance of EDG across a variety of sampling tasks with complex target distributions, outperforming existing methods.
Reinforcement Learning in Categorical Cybernetics
arXiv:2404.02688v2 Announce Type: replace Abstract: We show that several major algorithms of reinforcement learning (RL) fit into the framework of categorical cybernetics, that is to say, parametrised bidirectional processes. We build on our previous work in which we show that value iteration can be represented by precomposition with a certain optic. The outline of the main construction in this paper is: (1) We extend the Bellman operators to parametrised optics that apply to action-value functions and depend on a sample. (2) We apply a representable contravariant functor, obtaining a parametrised function that applies the Bellman iteration. (3) This parametrised function becomes the backward pass of another parametrised optic that represents the model, which interacts with an environment via an agent. Thus, parametrised optics appear in two different ways in our construction, with one becoming part of the other. As we show, many of the major classes of algorithms in RL can be seen as different extremal cases of this general setup: dynamic programming, Monte Carlo methods, temporal difference learning, and deep RL. We see this as strong evidence that this approach is a natural one and believe that it will be a fruitful way to think about RL in the future.
Least Volume Analysis
arXiv:2404.17773v2 Announce Type: replace Abstract: This paper introduces Least Volume (LV)--a simple yet effective regularization method inspired by geometric intuition--that reduces the number of latent dimensions required by an autoencoder without prior knowledge of the dataset's intrinsic dimensionality. We show that its effectiveness depends on the Lipschitz continuity of the decoder, prove that Principal Component Analysis (PCA) is a linear special case, and demonstrate that LV induces a PCA-like importance ordering in nonlinear models. We extend LV to non-Euclidean settings as Generalized Least Volume (GLV), enabling the integration of label information into the latent representation. To support implementation, we also develop an accompanying Dynamic Pruning algorithm. We evaluate LV on several benchmark problems, demonstrating its effectiveness in dimension reduction. Leveraging this, we reveal the role of low-dimensional latent spaces in data sampling and disentangled representation, and use them to probe the varying topological complexity of various datasets. GLV is further applied to labeled datasets, where it induces a contrastive learning effect in representations of discrete labels. On a continuous-label airfoil dataset, it produces representations that lead to smooth changes in aerodynamic performance, thereby stabilizing downstream optimization.
Edge Probability Graph Models Beyond Edge Independency: Concepts, Analyses, and Algorithms
arXiv:2405.16726v3 Announce Type: replace Abstract: Desirable random graph models (RGMs) should (i) reproduce common patterns in real-world graphs (e.g., power-law degrees, small diameters, and high clustering), (ii) generate variable (i.e., not overly similar) graphs, and (iii) remain tractable to compute and control graph statistics. A common class of RGMs (e.g., Erdos-Renyi and stochastic Kronecker) outputs edge probabilities, so we need to realize (i.e., sample from) the output edge probabilities to generate graphs. Typically, the existence of each edge is assumed to be determined independently, for simplicity and tractability. However, with edge independency, RGMs provably cannot produce high subgraph densities and high output variability simultaneously. In this work, we explore RGMs beyond edge independence that can better reproduce common patterns while maintaining high tractability and variability. Theoretically, we propose an edge-dependent realization (i.e., sampling) framework called binding that provably preserves output variability, and derive closed-form tractability results on subgraph (e.g., triangle) densities. Practically, we propose algorithms for graph generation with binding and parameter fitting of binding. Our empirical results demonstrate that RGMs with binding exhibit high tractability and well reproduce common patterns, significantly improving upon edge-independent RGMs.
Agreement-Based Cascading for Efficient Inference
arXiv:2407.02348v4 Announce Type: replace Abstract: Adaptive inference schemes reduce the cost of machine learning inference by assigning smaller models to easier examples, attempting to avoid invocation of larger models when possible. In this work we explore a simple, effective adaptive inference technique we term Agreement-Based Cascading (ABC). ABC builds a cascade of models of increasing size/complexity, and uses agreement between ensembles of models at each level of the cascade as a basis for data-dependent routing. Although ensemble execution introduces additional expense, we show that these costs can be easily offset in practice due to large expected differences in model sizes, parallel inference execution capabilities, and accuracy benefits of ensembling. We examine ABC theoretically and empirically in terms of these parameters, showing that the approach can reliably act as a drop-in replacement for existing models and surpass the best single model it aims to replace in terms of both efficiency and accuracy. Additionally, we explore the performance of ABC relative to existing cascading methods in three common scenarios: (1) edge-to-cloud inference, where ABC reduces communication costs by up to 14x; (2) cloud-based model serving, where it achieves a 3x reduction in rental costs; and (3) inference via model API services, where ABC achieves a 2-25x reduction in average price per token/request relative to state-of-the-art LLM cascades.
Context-Aware Reasoning On Parametric Knowledge for Inferring Causal Variables
arXiv:2409.02604v2 Announce Type: replace Abstract: Scientific discovery catalyzes human intellectual advances, driven by the cycle of hypothesis generation, experimental design, evaluation, and assumption refinement. Central to this process is causal inference, uncovering the mechanisms behind observed phenomena. While randomized experiments provide strong inferences, they are often infeasible due to ethical or practical constraints. However, observational studies are prone to confounding or mediating biases. While crucial, identifying such backdoor paths is expensive and heavily depends on scientists' domain knowledge to generate hypotheses. We introduce a novel benchmark where the objective is to complete a partial causal graph. We design a benchmark with varying difficulty levels with over 4000 queries. We show the strong ability of LLMs to hypothesize the backdoor variables between a cause and its effect. Unlike simple knowledge memorization of fixed associations, our task requires the LLM to reason according to the context of the entire graph.
FoMo-0D: A Foundation Model for Zero-shot Tabular Outlier Detection
arXiv:2409.05672v4 Announce Type: replace Abstract: Outlier detection (OD) has a vast literature as it finds numerous real-world applications. Being an unsupervised task, model selection is a key bottleneck for OD without label supervision. Despite a long list of available OD algorithms with tunable hyperparameters, the lack of systematic approaches for unsupervised algorithm and hyperparameter selection limits their effective use in practice. In this paper, we present FoMo-0D, a pre-trained Foundation Model for zero/0-shot OD on tabular data, which bypasses the hurdle of model selection altogether. Having been pre-trained on synthetic data, FoMo-0D can directly predict the (outlier/inlier) label of test samples without parameter fine-tuning -- requiring no labeled data, and no additional training or hyperparameter tuning when given a new task. Extensive experiments on 57 real-world datasets against 26 baselines show that FoMo-0D is highly competitive; outperforming the majority of the baselines with no statistically significant difference from the 2nd best method. Further, FoMo-0D is efficient in inference time requiring only 7.7 ms per sample on average, with at least 7x speed-up compared to previous methods. To facilitate future research, our implementations for data synthesis and pre-training as well as model checkpoints are openly available at https://github.com/A-Chicharito-S/FoMo-0D.
DimINO: Dimension-Informed Neural Operator Learning
arXiv:2410.05894v5 Announce Type: replace Abstract: In computational physics, a longstanding challenge lies in finding numerical solutions to partial differential equations (PDEs). Recently, research attention has increasingly focused on Neural Operator methods, which are notable for their ability to approximate operators-mappings between functions. Although neural operators benefit from a universal approximation theorem, achieving reliable error bounds often necessitates large model architectures, such as deep stacks of Fourier layers. This raises a natural question: Can we design lightweight models without sacrificing generalization? To address this, we introduce DimINO (Dimension-Informed Neural Operators), a framework inspired by dimensional analysis. DimINO incorporates two key components, DimNorm and a redimensionalization operation, which can be seamlessly integrated into existing neural operator architectures. These components enhance the model's ability to generalize across datasets with varying physical parameters. Theoretically, we establish a universal approximation theorem for DimINO and prove that it satisfies a critical property we term Similar Transformation Invariance (STI). Empirically, DimINO achieves up to 76.3% performance gain on PDE datasets while exhibiting clear evidence of the STI property.
Expressiveness of Multi-Neuron Convex Relaxations in Neural Network Certification
arXiv:2410.06816v3 Announce Type: replace Abstract: Neural network certification methods heavily rely on convex relaxations to provide robustness guarantees. However, these relaxations are often imprecise: even the most accurate single-neuron relaxation is incomplete for general ReLU networks, a limitation known as the \emph{single-neuron convex barrier}. While multi-neuron relaxations have been heuristically applied to address this issue, two central questions arise: (i) whether they overcome the convex barrier, and if not, (ii) whether they offer theoretical capabilities beyond those of single-neuron relaxations. In this work, we present the first rigorous analysis of the expressiveness of multi-neuron relaxations. Perhaps surprisingly, we show that they are inherently incomplete, even when allocated sufficient resources to capture finitely many neurons and layers optimally. This result extends the single-neuron barrier to a \textit{universal convex barrier} for neural network certification. On the positive side, we show that completeness can be achieved by either (i) augmenting the network with a polynomial number of carefully designed ReLU neurons or (ii) partitioning the input domain into convex sub-polytopes, thereby distinguishing multi-neuron relaxations from single-neuron ones which are unable to realize the former and have worse partition complexity for the latter. Our findings establish a foundation for multi-neuron relaxations and point to new directions for certified robustness, including training methods tailored to multi-neuron relaxations and verification methods with multi-neuron relaxations as the main subroutine.
Bias Similarity Measurement: A Black-Box Audit of Fairness Across LLMs
arXiv:2410.12010v4 Announce Type: replace Abstract: Large Language Models (LLMs) reproduce social biases, yet prevailing evaluations score models in isolation, obscuring how biases persist across families and releases. We introduce Bias Similarity Measurement (BSM), which treats fairness as a relational property between models, unifying scalar, distributional, behavioral, and representational signals into a single similarity space. Evaluating 30 LLMs on 1M+ prompts, we find that instruction tuning primarily enforces abstention rather than altering internal representations; small models gain little accuracy and can become less fair under forced choice; and open-weight models can match or exceed proprietary systems. Family signatures diverge: Gemma favors refusal, LLaMA 3.1 approaches neutrality with fewer refusals, and converges toward abstention-heavy behavior overall. Counterintuitively, Gemma 3 Instruct matches GPT-4-level fairness at far lower cost, whereas Gemini's heavy abstention suppresses utility. Beyond these findings, BSM offers an auditing workflow for procurement, regression testing, and lineage screening, and extends naturally to code and multilingual settings. Our results reframe fairness not as isolated scores but as comparative bias similarity, enabling systematic auditing of LLM ecosystems. Code available at https://github.com/HyejunJeong/bias_llm.
Understanding Optimization in Deep Learning with Central Flows
arXiv:2410.24206v2 Announce Type: replace Abstract: Traditional theories of optimization cannot describe the dynamics of optimization in deep learning, even in the simple setting of deterministic training. The challenge is that optimizers typically operate in a complex, oscillatory regime called the "edge of stability." In this paper, we develop theory that can describe the dynamics of optimization in this regime. Our key insight is that while the exact trajectory of an oscillatory optimizer may be challenging to analyze, the time-averaged (i.e. smoothed) trajectory is often much more tractable. To analyze an optimizer, we derive a differential equation called a "central flow" that characterizes this time-averaged trajectory. We empirically show that these central flows can predict long-term optimization trajectories for generic neural networks with a high degree of numerical accuracy. By interpreting these central flows, we are able to understand how gradient descent makes progress even as the loss sometimes goes up; how adaptive optimizers "adapt" to the local loss landscape; and how adaptive optimizers implicitly navigate towards regions where they can take larger steps. Our results suggest that central flows can be a valuable theoretical tool for reasoning about optimization in deep learning.
Bayesian Optimization with Preference Exploration using a Monotonic Neural Network Ensemble
arXiv:2501.18792v2 Announce Type: replace Abstract: Many real-world black-box optimization problems have multiple conflicting objectives. Rather than attempting to approximate the entire set of Pareto-optimal solutions, interactive preference learning allows to focus the search on the most relevant subset. However, few previous studies have exploited the fact that utility functions are usually monotonic. In this paper, we address the Bayesian Optimization with Preference Exploration (BOPE) problem and propose using a neural network ensemble as a utility surrogate model. This approach naturally integrates monotonicity and supports pairwise comparison data. Our experiments demonstrate that the proposed method outperforms state-of-the-art approaches and exhibits robustness to noise in utility evaluations. An ablation study highlights the critical role of monotonicity in enhancing performance.
Strassen Attention, Split VC Dimension and Compositionality in Transformers
arXiv:2501.19215v3 Announce Type: replace Abstract: We propose the first method to show theoretical limitations for one-layer softmax transformers with arbitrarily many precision bits (even infinite). We establish those limitations for three tasks that require advanced reasoning. The first task, Match 3 (Sanford et al., 2023), requires looking at all possible token triplets in an input sequence. The second and third tasks address compositionality-based reasoning: function composition (Peng et al., 2024) and binary relations composition, respectively. We formally prove the inability of one-layer softmax Transformers to solve any of these tasks. To overcome these limitations, we introduce Strassen attention and prove that, equipped with this mechanism, a one-layer transformer can in principle solve all these tasks. Importantly, we show that it enjoys sub-cubic running-time complexity, making it more scalable than similar previously proposed mechanisms, such as higher-order attention (Sanford et al., 2023). To complement our theoretical findings, we experimentally studied Strassen attention and compared it against standard (Vaswani et al, 2017), higher-order attention (Sanford et al., 2023), and triangular attention (Bergen et al. 2021). Our results help to disentangle all these attention mechanisms, highlighting their strengths and limitations. In particular, Strassen attention outperforms standard attention significantly on all the tasks. Altogether, understanding the theoretical limitations can guide research towards scalable attention mechanisms that improve the reasoning abilities of Transformers.
Reformulation is All You Need: Addressing Malicious Text Features in DNNs
arXiv:2502.00652v2 Announce Type: replace Abstract: Human language encompasses a wide range of intricate and diverse implicit features, which attackers can exploit to launch adversarial or backdoor attacks, compromising DNN models for NLP tasks. Existing model-oriented defenses often require substantial computational resources as model size increases, whereas sample-oriented defenses typically focus on specific attack vectors or schemes, rendering them vulnerable to adaptive attacks. We observe that the root cause of both adversarial and backdoor attacks lies in the encoding process of DNN models, where subtle textual features, negligible for human comprehension, are erroneously assigned significant weight by less robust or trojaned models. Based on it we propose a unified and adaptive defense framework that is effective against both adversarial and backdoor attacks. Our approach leverages reformulation modules to address potential malicious features in textual inputs while preserving the original semantic integrity. Extensive experiments demonstrate that our framework outperforms existing sample-oriented defense baselines across a diverse range of malicious textual features.
A Quotient Homology Theory of Representation in Neural Networks
arXiv:2502.01360v3 Announce Type: replace Abstract: Previous research has proven that the set of maps implemented by neural networks with a ReLU activation function is identical to the set of piecewise linear continuous maps. Furthermore, such networks induce a hyperplane arrangement splitting the input domain of the network into convex polyhedra $G_J$ over which a network $\Phi$ operates in an affine manner. In this work, we leverage these properties to define an equivalence class $\sim_\Phi$ on top of an input dataset, which can be split into two sets related to the local rank of $\Phi_J$ and the intersections $\cap \text{Im}\Phi_{J_i}$. We refer to the latter as the \textit{overlap decomposition} $\mathcal{O}\Phi$ and prove that if the intersections between each polyhedron and an input manifold are convex, the homology groups of neural representations are isomorphic to quotient homology groups $H_k(\Phi(\mathcal{M})) \simeq H_k(\mathcal{M}/\mathcal{O}\Phi)$. This lets us intrinsically calculate the Betti numbers of neural representations without the choice of an external metric. We develop methods to numerically compute the overlap decomposition through linear programming and a union-find algorithm. Using this framework, we perform several experiments on toy datasets showing that, compared to standard persistent homology, our overlap homology-based computation of Betti numbers tracks purely topological rather than geometric features. Finally, we study the evolution of the overlap decomposition during training on several classification problems while varying network width and depth and discuss some shortcomings of our method.
A High-Dimensional Statistical Method for Optimizing Transfer Quantities in Multi-Source Transfer Learning
arXiv:2502.04242v3 Announce Type: replace Abstract: Multi-source transfer learning provides an effective solution to data scarcity in real- world supervised learning scenarios by leveraging multiple source tasks. In this field, existing works typically use all available samples from sources in training, which constrains their training efficiency and may lead to suboptimal results. To address this, we propose a theoretical framework that answers the question: what is the optimal quantity of source samples needed from each source task to jointly train the target model? Specifically, we introduce a generalization error measure based on K-L divergence, and minimize it based on high-dimensional statistical analysis to determine the optimal transfer quantity for each source task. Additionally, we develop an architecture-agnostic and data-efficient algorithm OTQMS to implement our theoretical results for target model training in multi- source transfer learning. Experimental studies on diverse architectures and two real-world benchmark datasets show that our proposed algorithm significantly outperforms state-of-the-art approaches in both accuracy and data efficiency. The code and supplementary materials are available in https://anonymous.4open.science/r/Materials.
Training Set Reconstruction from Differentially Private Forests: How Effective is DP?
arXiv:2502.05307v3 Announce Type: replace Abstract: Recent research has shown that structured machine learning models such as tree ensembles are vulnerable to privacy attacks targeting their training data. To mitigate these risks, differential privacy (DP) has become a widely adopted countermeasure, as it offers rigorous privacy protection. In this paper, we introduce a reconstruction attack targeting state-of-the-art $\epsilon$-DP random forests. By leveraging a constraint programming model that incorporates knowledge of the forest's structure and DP mechanism characteristics, our approach formally reconstructs the most likely dataset that could have produced a given forest. Through extensive computational experiments, we examine the interplay between model utility, privacy guarantees and reconstruction accuracy across various configurations. Our results reveal that random forests trained with meaningful DP guarantees can still leak portions of their training data. Specifically, while DP reduces the success of reconstruction attacks, the only forests fully robust to our attack exhibit predictive performance no better than a constant classifier. Building on these insights, we also provide practical recommendations for the construction of DP random forests that are more resilient to reconstruction attacks while maintaining a non-trivial predictive performance.
Regularization can make diffusion models more efficient
arXiv:2502.09151v2 Announce Type: replace Abstract: Diffusion models are one of the key architectures of generative AI. Their main drawback, however, is the computational costs. This study indicates that the concept of sparsity, well known especially in statistics, can provide a pathway to more efficient diffusion pipelines. Our mathematical guarantees prove that sparsity can reduce the input dimension's influence on the computational complexity to that of a much smaller intrinsic dimension of the data. Our empirical findings confirm that inducing sparsity can indeed lead to better samples at a lower cost.
You Are Your Own Best Teacher: Achieving Centralized-level Performance in Federated Learning under Heterogeneous and Long-tailed Data
arXiv:2503.06916v2 Announce Type: replace Abstract: Data heterogeneity, stemming from local non-IID data and global long-tailed distributions, is a major challenge in federated learning (FL), leading to significant performance gaps compared to centralized learning. Previous research found that poor representations and biased classifiers are the main problems and proposed neural-collapse-inspired synthetic simplex ETF to help representations be closer to neural collapse optima. However, we find that the neural-collapse-inspired methods are not strong enough to reach neural collapse and still have huge gaps to centralized training. In this paper, we rethink this issue from a self-bootstrap perspective and propose FedYoYo (You Are Your Own Best Teacher), introducing Augmented Self-bootstrap Distillation (ASD) to improve representation learning by distilling knowledge between weakly and strongly augmented local samples, without needing extra datasets or models. We further introduce Distribution-aware Logit Adjustment (DLA) to balance the self-bootstrap process and correct biased feature representations. FedYoYo nearly eliminates the performance gap, achieving centralized-level performance even under mixed heterogeneity. It enhances local representation learning, reducing model drift and improving convergence, with feature prototypes closer to neural collapse optimality. Extensive experiments show FedYoYo achieves state-of-the-art results, even surpassing centralized logit adjustment methods by 5.4\% under global long-tailed settings.
What Makes a Reward Model a Good Teacher? An Optimization Perspective
arXiv:2503.15477v2 Announce Type: replace Abstract: The success of Reinforcement Learning from Human Feedback (RLHF) critically depends on the quality of the reward model. However, while this quality is primarily evaluated through accuracy, it remains unclear whether accuracy fully captures what makes a reward model an effective teacher. We address this question from an optimization perspective. First, we prove that regardless of how accurate a reward model is, if it induces low reward variance, then the RLHF objective suffers from a flat landscape. Consequently, even a perfectly accurate reward model can lead to extremely slow optimization, underperforming less accurate models that induce higher reward variance. We additionally show that a reward model that works well for one language model can induce low reward variance, and thus a flat objective landscape, for another. These results establish a fundamental limitation of evaluating reward models solely based on accuracy or independently of the language model they guide. Experiments using models of up to 8B parameters corroborate our theory, demonstrating the interplay between reward variance, accuracy, and reward maximization rate. Overall, our findings highlight that beyond accuracy, a reward model needs to induce sufficient variance for efficient~optimization.
Benchmarking for Practice: Few-Shot Time-Series Crop-Type Classification on the EuroCropsML Dataset
arXiv:2504.11022v2 Announce Type: replace Abstract: Accurate crop-type classification from satellite time series is essential for agricultural monitoring. While various machine learning algorithms have been developed to enhance performance on data-scarce tasks, their evaluation often lacks real-world scenarios. Consequently, their efficacy in challenging practical applications has not yet been profoundly assessed. To facilitate future research in this domain, we present the first comprehensive benchmark for evaluating supervised and SSL methods for crop-type classification under real-world conditions. This benchmark study relies on the EuroCropsML time-series dataset, which combines farmer-reported crop data with Sentinel-2 satellite observations from Estonia, Latvia, and Portugal. Our findings indicate that MAML-based meta-learning algorithms achieve slightly higher accuracy compared to supervised transfer learning and SSL methods. However, compared to simpler transfer learning, the improvement of meta-learning comes at the cost of increased computational demands and training time. Moreover, supervised methods benefit most when pre-trained and fine-tuned on geographically close regions. In addition, while SSL generally lags behind meta-learning, it demonstrates advantages over training from scratch, particularly in capturing fine-grained features essential for real-world crop-type classification, and also surpasses standard transfer learning. This highlights its practical value when labeled pre-training crop data is scarce. Our insights underscore the trade-offs between accuracy and computational demand in selecting supervised machine learning methods for real-world crop-type classification tasks and highlight the difficulties of knowledge transfer across diverse geographic regions. Furthermore, they demonstrate the practical value of SSL approaches when labeled pre-training crop data is scarce.
Process Reward Models That Think
arXiv:2504.16828v4 Announce Type: replace Abstract: Step-by-step verifiers -- also known as process reward models (PRMs) -- are a key ingredient for test-time scaling. PRMs require step-level supervision, making them expensive to train. This work aims to build data-efficient PRMs as verbalized step-wise reward models that verify every step in the solution by generating a verification chain-of-thought (CoT). We propose ThinkPRM, a long CoT verifier fine-tuned on orders of magnitude fewer process labels than those required by discriminative PRMs. Our approach capitalizes on the inherent reasoning abilities of long CoT models, and outperforms LLM-as-a-Judge and discriminative verifiers -- using only 1% of the process labels in PRM800K -- across several challenging benchmarks. Specifically, ThinkPRM beats the baselines on ProcessBench, MATH-500, and AIME '24 under best-of-N selection and reward-guided search. In an out-of-domain evaluation on a subset of GPQA-Diamond and LiveCodeBench, our PRM surpasses discriminative verifiers trained on the full PRM800K by 8% and 4.5%, respectively. Lastly, under the same token budget, ThinkPRM scales up verification compute more effectively compared to LLM-as-a-Judge, outperforming it by 7.2% on a subset of ProcessBench. Our work highlights the value of generative, long CoT PRMs that can scale test-time compute for verification while requiring minimal supervision for training. Our code, data, and models are released at https://github.com/mukhal/thinkprm.
Rethinking Circuit Completeness in Language Models: AND, OR, and ADDER Gates
arXiv:2505.10039v2 Announce Type: replace Abstract: Circuit discovery has gradually become one of the prominent methods for mechanistic interpretability, and research on circuit completeness has also garnered increasing attention. Methods of circuit discovery that do not guarantee completeness not only result in circuits that are not fixed across different runs but also cause key mechanisms to be omitted. The nature of incompleteness arises from the presence of OR gates within the circuit, which are often only partially detected in standard circuit discovery methods. To this end, we systematically introduce three types of logic gates: AND, OR, and ADDER gates, and decompose the circuit into combinations of these logical gates. Through the concept of these gates, we derive the minimum requirements necessary to achieve faithfulness and completeness. Furthermore, we propose a framework that combines noising-based and denoising-based interventions, which can be easily integrated into existing circuit discovery methods without significantly increasing computational complexity. This framework is capable of fully identifying the logic gates and distinguishing them within the circuit. In addition to the extensive experimental validation of the framework's ability to restore the faithfulness, completeness, and sparsity of circuits, using this framework, we uncover fundamental properties of the three logic gates, such as their proportions and contributions to the output, and explore how they behave among the functionalities of language models.
Identification and Optimal Nonlinear Control of Turbojet Engine Using Koopman Eigenfunction Model
arXiv:2505.10438v4 Announce Type: replace Abstract: Gas turbine engines are complex and highly nonlinear dynamical systems. Deriving their physics-based models can be challenging because it requires performance characteristics that are not always available, often leading to many simplifying assumptions. This paper discusses the limitations of conventional experimental methods used to derive component-level and locally linear parameter-varying models, and addresses these issues by employing identification techniques based on data collected from standard engine operation under closed-loop control. The rotor dynamics are estimated using the sparse identification of nonlinear dynamics. Subsequently, the autonomous part of the dynamics is mapped into an optimally constructed Koopman eigenfunction space. This process involves eigenvalue optimization using metaheuristic algorithms and temporal projection, followed by gradient-based eigenfunction identification. The resulting Koopman model is validated against an in-house reference component-level model. A globally optimal nonlinear feedback controller and a Kalman estimator are then designed within the eigenfunction space and compared to traditional and gain-scheduled proportional-integral controllers, as well as a proposed internal model control approach. The eigenmode structure enables targeting individual modes during optimization, leading to improved performance tuning. Results demonstrate that the Koopman-based controller surpasses other benchmark controllers in both reference tracking and disturbance rejection under sea-level and varying flight conditions, due to its global nature.
UDDETTS: Unifying Discrete and Dimensional Emotions for Controllable Emotional Text-to-Speech
arXiv:2505.10599v2 Announce Type: replace Abstract: Recent large language models (LLMs) have made great progress in the field of text-to-speech (TTS), but they still face major challenges in synthesizing fine-grained emotional speech in an interpretable manner. Traditional methods rely on discrete emotion labels to control emotion categories and intensities, which cannot capture the complexity and continuity of human emotional perception and expression. The lack of large-scale emotional speech datasets with balanced emotion distributions and fine-grained emotional annotations often causes overfitting in synthesis models and impedes effective emotion control. To address these issues, we propose UDDETTS, a universal LLM framework unifying discrete and dimensional emotions for controllable emotional TTS. This model introduces the interpretable Arousal-Dominance-Valence (ADV) space for dimensional emotion description and supports emotion control driven by either discrete emotion labels or nonlinearly quantified ADV values. Furthermore, a semi-supervised training strategy is designed to comprehensively utilize diverse speech datasets with different types of emotional annotations to train the UDDETTS. Experiments show that UDDETTS achieves linear emotion control along three interpretable dimensions, and exhibits superior end-to-end emotional speech synthesis capabilities. Code and demos are available at: https://anonymous.4open.science/w/UDDETTS.
Fractal Graph Contrastive Learning
arXiv:2505.11356v3 Announce Type: replace Abstract: While Graph Contrastive Learning (GCL) has attracted considerable attention in the field of graph self-supervised learning, its performance heavily relies on data augmentations that are expected to generate semantically consistent positive pairs. Existing strategies typically resort to random perturbations or local structure preservation, yet lack explicit control over global structural consistency between augmented views. To address this limitation, we propose Fractal Graph Contrastive Learning (FractalGCL), a theory-driven framework introducing two key innovations: a renormalisation-based augmentation that generates structurally aligned positive views via box coverings; and a fractal-dimension-aware contrastive loss that aligns graph embeddings according to their fractal dimensions, equipping the method with a fallback mechanism guaranteeing a performance lower bound even on non-fractal graphs. While combining the two innovations markedly boosts graph-representation quality, it also adds non-trivial computational overhead. To mitigate the computational overhead of fractal dimension estimation, we derive a one-shot estimator by proving that the dimension discrepancy between original and renormalised graphs converges weakly to a centred Gaussian distribution. This theoretical insight enables a reduction in dimension computation cost by an order of magnitude, cutting overall training time by approximately 61\%. The experiments show that FractalGCL not only delivers state-of-the-art results on standard benchmarks but also outperforms traditional and latest baselines on traffic networks by an average margin of about remarkably 4\%. Codes are available at (https://anonymous.4open.science/r/FractalGCL-0511/).
OLMA: One Loss for More Accurate Time Series Forecasting
arXiv:2505.11567v2 Announce Type: replace Abstract: Time series forecasting faces two important but often overlooked challenges. Firstly, the inherent random noise in the time series labels sets a theoretical lower bound for the forecasting error, which is positively correlated with the entropy of the labels. Secondly, neural networks exhibit a frequency bias when modeling the state-space of time series, that is, the model performs well in learning certain frequency bands but poorly in others, thus restricting the overall forecasting performance. To address the first challenge, we prove a theorem that there exists a unitary transformation that can reduce the marginal entropy of multiple correlated Gaussian processes, thereby providing guidance for reducing the lower bound of forecasting error. Furthermore, experiments confirm that Discrete Fourier Transform (DFT) can reduce the entropy in the majority of scenarios. Correspondingly, to alleviate the frequency bias, we jointly introduce supervision in the frequency domain along the temporal dimension through DFT and Discrete Wavelet Transform (DWT). This supervision-side strategy is highly general and can be seamlessly integrated into any supervised learning method. Moreover, we propose a novel loss function named OLMA, which utilizes the frequency domain transformation across both channel and temporal dimensions to enhance forecasting. Finally, the experimental results on multiple datasets demonstrate the effectiveness of OLMA in addressing the above two challenges and the resulting improvement in forecasting accuracy. The results also indicate that the perspectives of entropy and frequency bias provide a new and feasible research direction for time series forecasting. The code is available at: https://github.com/Yuyun1011/OLMA-One-Loss-for-More-Accurate-Time-Series-Forecasting.
Redefining Neural Operators in $d+1$ Dimensions
arXiv:2505.11766v2 Announce Type: replace Abstract: Neural Operators have emerged as powerful tools for learning mappings between function spaces. Among them, the kernel integral operator has been widely validated on universally approximating various operators. Although many advancements following this definition have developed effective modules to better approximate the kernel function defined on the original domain (with $d$ dimensions, $d=1, 2, 3\dots$), the unclarified evolving mechanism in the embedding spaces blocks researchers' view to design neural operators that can fully capture the target system evolution. Drawing on the Schr\"odingerisation method in quantum simulations of partial differential equations (PDEs), we elucidate the linear evolution mechanism in neural operators. Based on that, we redefine neural operators on a new $d+1$ dimensional domain. Within this framework, we implement a Schr\"odingerised Kernel Neural Operator (SKNO) aligning better with the $d+1$ dimensional evolution. In experiments, the $d+1$ dimensional evolving designs in our SKNO consistently outperform other baselines across ten benchmarks of increasing difficulty, ranging from the simple 1D heat equation to the highly nonlinear 3D Rayleigh-Taylor instability. We also validate the resolution-invariance of SKNO on mixing-resolution training and zero-shot super-resolution tasks. In addition, we show the impact of different lifting and recovering operators on the prediction within the redefined NO framework, reflecting the alignment between our model and the underlying $d+1$ dimensional evolution.
Generative and Contrastive Graph Representation Learning
arXiv:2505.11776v2 Announce Type: replace Abstract: Self-supervised learning (SSL) on graphs generates node and graph representations (i.e., embeddings) that can be used for downstream tasks such as node classification, node clustering, and link prediction. Graph SSL is particularly useful in scenarios with limited or no labeled data. Existing SSL methods predominantly follow contrastive or generative paradigms, each excelling in different tasks: contrastive methods typically perform well on classification tasks, while generative methods often excel in link prediction. In this paper, we present a novel architecture for graph SSL that integrates the strengths of both approaches. Our framework introduces community-aware node-level contrastive learning, providing more robust and effective positive and negative node pairs generation, alongside graph-level contrastive learning to capture global semantic information. Additionally, we employ a comprehensive augmentation strategy that combines feature masking, node perturbation, and edge perturbation, enabling robust and diverse representation learning. By incorporating these enhancements, our model achieves superior performance across multiple tasks, including node classification, clustering, and link prediction. Evaluations on open benchmark datasets demonstrate that our model outperforms state-of-the-art methods, achieving a performance lift of 0.23%-2.01% depending on the task and dataset.
Provably Sample-Efficient Robust Reinforcement Learning with Average Reward
arXiv:2505.12462v2 Announce Type: replace Abstract: Robust reinforcement learning (RL) under the average-reward criterion is essential for long-term decision-making, particularly when the environment may differ from its specification. However, a significant gap exists in understanding the finite-sample complexity of these methods, as most existing work provides only asymptotic guarantees. This limitation hinders their principled understanding and practical deployment, especially in data-limited scenarios. We close this gap by proposing \textbf{Robust Halpern Iteration (RHI)}, a new algorithm designed for robust Markov Decision Processes (MDPs) with transition uncertainty characterized by $\ell_p$-norm and contamination models. Our approach offers three key advantages over previous methods: (1). Weaker Structural Assumptions: RHI only requires the underlying robust MDP to be communicating, a less restrictive condition than the commonly assumed ergodicity or irreducibility; (2). No Prior Knowledge: Our algorithm operates without requiring any prior knowledge of the robust MDP; (3). State-of-the-Art Sample Complexity: To learn an $\epsilon$-optimal robust policy, RHI achieves a sample complexity of $\tilde{\mathcal O}\left(\frac{SA\mathcal H^{2}}{\epsilon^{2}}\right)$, where $S$ and $A$ denote the numbers of states and actions, and $\mathcal H$ is the robust optimal bias span. This result represents the tightest known bound. Our work hence provides essential theoretical understanding of sample efficiency of robust average reward RL.
Optimal Formats for Weight Quantisation
arXiv:2505.12988v2 Announce Type: replace Abstract: Weight quantisation is an essential technique for enabling efficient training and deployment of modern deep learning models. However, the recipe book of quantisation formats is large and formats are often chosen empirically. In this paper, we propose a framework for systematic design and analysis of quantisation formats. By connecting the question of format design with the classical quantisation theory, we show that the strong practical performance of popular formats comes from their ability to represent values using variable-length codes. We frame the problem as minimising the KL divergence between original and quantised model outputs under a model size constraint, which can be approximated by minimising the squared quantisation error, a well-studied problem where entropy-constrained quantisers with variable-length codes are optimal. We develop non-linear quantisation curves for block-scaled data across multiple distribution families and observe that these formats, along with sparse outlier formats, consistently outperform fixed-length formats, indicating that they also exploit variable-length encoding. Finally, by using the relationship between the Fisher information and KL divergence, we derive the optimal allocation of bit-widths to individual parameter tensors across the model's layers, saving up to 0.25 bits per parameter when applied to large language models.
Time series saliency maps: explaining models across multiple domains
arXiv:2505.13100v2 Announce Type: replace Abstract: Traditional saliency map methods, popularized in computer vision, highlight individual points (pixels) of the input that contribute the most to the model's output. However, in time-series they offer limited insights as semantically meaningful features are often found in other domains. We introduce Cross-domain Integrated Gradients, a generalization of Integrated Gradients. Our method enables feature attributions on any domain that can be formulated as an invertible, differentiable transformation of the time domain. Crucially, our derivation extends the original Integrated Gradients into the complex domain, enabling frequency-based attributions. We provide the necessary theoretical guarantees, namely, path independence and completeness. Our approach reveals interpretable, problem-specific attributions that time-domain methods cannot capture, on three real-world tasks: wearable sensor heart rate extraction, electroencephalography-based seizure detection, and zero-shot time-series forecasting. We release an open-source Tensorflow/PyTorch library to enable plug-and-play cross-domain explainability for time-series models. These results demonstrate the ability of cross-domain integrated gradients to provide semantically meaningful insights in time-series models that are impossible with traditional time-domain saliency.
Why and When Deep is Better than Shallow: An Implementation-Agnostic State-Transition View of Depth Supremacy
arXiv:2505.15064v2 Announce Type: replace Abstract: Why and when is deep better than shallow? We answer this question in a framework that is agnostic to network implementation. We formulate a deep model as an abstract state-transition semigroup acting on a general metric space, and separate the implementation (e.g., ReLU nets, transformers, and chain-of-thought) from the abstract state transition. We prove a bias-variance decomposition in which the variance depends only on the abstract depth-$k$ network and not on the implementation (Theorem 1). We further split the bounds into output and hidden parts to tie the depth dependence of the variance to the metric entropy of the state-transition semigroup (Theorem 2). We then investigate implementation-free conditions under which the variance grow polynomially or logarithmically with depth (Section 4). Combining these with exponential or polynomial bias decay identifies four canonical bias-variance trade-off regimes (EL/EP/PL/PP) and produces explicit optimal depths $k^\ast$. Across regimes, $k^\ast>1$ typically holds, giving a rigorous form of depth supremacy. The lowest generalization error bound is achieved under the EL regime (exp-decay bias + log-growth variance), explaining why and when deep is better, especially for iterative or hierarchical concept classes such as neural ODEs, diffusion/score models, and chain-of-thought reasoning.
Cohort-Based Active Modality Acquisition
arXiv:2505.16791v2 Announce Type: replace Abstract: Real-world machine learning applications often involve data from multiple modalities that must be integrated effectively to make robust predictions. However, in many practical settings, not all modalities are available for every sample, and acquiring additional modalities can be costly. This raises the question: which samples should be prioritized for additional modality acquisition when resources are limited? While prior work has explored individual-level acquisition strategies and training-time active learning paradigms, test-time and cohort-based acquisition remain underexplored. We introduce Cohort-based Active Modality Acquisition (CAMA), a novel test-time setting to formalize the challenge of selecting which samples should receive additional modalities. We derive acquisition strategies that leverage a combination of generative imputation and discriminative modeling to estimate the expected benefit of acquiring missing modalities based on common evaluation metrics. We also introduce upper-bound heuristics that provide performance ceilings to benchmark acquisition strategies. Experiments on multimodal datasets with up to 15 modalities demonstrate that our proposed imputation-based strategies can more effectively guide the acquisition of additional modalities for selected samples compared with methods relying solely on unimodal information, entropy-based guidance, or random selection. We showcase the real-world relevance and scalability of our method by demonstrating its ability to effectively guide the costly acquisition of proteomics data for disease prediction in a large prospective cohort, the UK Biobank (UKBB). Our work provides an effective approach for optimizing modality acquisition at the cohort level, enabling more effective use of resources in constrained settings.
Runtime-Adaptive Pruning for LLM Inference
arXiv:2505.17138v3 Announce Type: replace Abstract: Large language models (LLMs) excel at language understanding and generation, but their enormous computational and memory requirements hinder deployment. Compression offers a potential solution to mitigate these constraints. However, most existing methods rely on fixed heuristics and thus fail to adapt to runtime memory variations or heterogeneous KV-cache demands arising from diverse user requests. To address these limitations, we propose RAP, an elastic pruning framework driven by reinforcement learning (RL) that dynamically adjusts compression strategies in a runtime-aware manner. Specifically, RAP dynamically tracks the evolving ratio between model parameters and KV-cache across practical execution. Recognizing that FFNs house most parameters, whereas parameter -light attention layers dominate KV-cache formation, the RL agent retains only those components that maximize utility within the current memory budget, conditioned on instantaneous workload and device state. Extensive experiments results demonstrate that RAP outperforms state-of-the-art baselines, marking the first time to jointly consider model weights and KV-cache on the fly.
Supervised Graph Contrastive Learning for Gene Regulatory Networks
arXiv:2505.17786v4 Announce Type: replace Abstract: Graph Contrastive Learning (GCL) is a powerful self-supervised learning framework that performs data augmentation through graph perturbations, with growing applications in the analysis of biological networks such as Gene Regulatory Networks (GRNs). The artificial perturbations commonly used in GCL, such as node dropping, induce structural changes that can diverge from biological reality. This concern has contributed to a broader trend in graph representation learning toward augmentation-free methods, which view such structural changes as problematic and to be avoided. However, this trend overlooks the fundamental insight that structural changes from biologically meaningful perturbations are not a problem to be avoided but a rich source of information, thereby ignoring the valuable opportunity to leverage data from real biological experiments. Motivated by this insight, we propose SupGCL (Supervised Graph Contrastive Learning), a new GCL method for GRNs that directly incorporates biological perturbations from gene knockdown experiments as supervision. SupGCL is a probabilistic formulation that continuously generalizes conventional GCL, linking artificial augmentations with real perturbations measured in knockdown experiments and using the latter as explicit supervisory signals. To assess effectiveness, we train GRN representations with SupGCL and evaluate their performance on downstream tasks. The evaluation includes both node-level tasks, such as gene function classification, and graph-level tasks on patient-specific GRNs, such as patient survival hazard prediction. Across 13 tasks built from GRN datasets derived from patients with three cancer types, SupGCL consistently outperforms state-of-the-art baselines.
FFT-based Dynamic Subspace Selection for Low-Rank Adaptive Optimization of Large Language Models
arXiv:2505.17967v2 Announce Type: replace Abstract: Low-rank optimization has emerged as a promising direction in training large language models (LLMs) to improve running time and reduce the memory usage of adaptive optimizers by constraining learning to a lower-dimensional space. Prior work typically projects gradients of linear layers using approaches based on Singular Value Decomposition (SVD) or QR-decomposition. Applying these techniques individually to each layer in large models is computationally expensive and incurs additional memory costs due to storing the projection matrices. In this work, we propose a computationally efficient and conceptually simple, two-step procedure to approximate SVD/QR-based gradient projections into lower-dimensional spaces by using a predefined orthogonal matrix of the Discrete Cosine Transform (DCT). We dynamically select columns from the DCT matrix based on their alignment with the gradient of each layer. The effective projection matrices are obtained via a simple matmul with the DCT matrix in $O(n^3)$ time, followed by a lightweight sorting step to identify the most relevant basis vectors. For large layers, DCT can be computed via Makhoul's $N$-point algorithm based on Fast Fourier Transform (FFT) in $O(n^2 \log(n))$ time. Due to the predefined nature of the orthogonal bases, they are computed once at the start of training. Our numerical experiments on both pre-training and fine-tuning tasks demonstrate the effectiveness of our dual strategy in approximating optimal low-rank projections, obtaining an approach with rank-independent running time that matches the performance of costly SVD/QR-based methods while achieving faster runtime and reduced memory usage by up to $25\%$ across different model sizes.
MESS+: Dynamically Learned Inference-Time LLM Routing in Model Zoos with Service Level Guarantees
arXiv:2505.19947v2 Announce Type: replace Abstract: Open-weight large language model (LLM) zoos provide access to numerous high-quality models, but selecting the appropriate model for specific tasks remains challenging and requires technical expertise. Most users simply want factually correct, safe, and satisfying responses without concerning themselves with model technicalities, while inference service providers prioritize minimizing operating costs. These competing interests are typically mediated through service level agreements (SLAs) that guarantee minimum service quality. We introduce MESS+, a stochastic optimization algorithm for cost-optimal LLM request routing while providing rigorous SLA compliance guarantees. MESS+ learns request satisfaction probabilities of LLMs in real-time as users interact with the system, based on which model selection decisions are made by solving a per-request optimization problem. Our algorithm includes a novel combination of virtual queues and request satisfaction prediction, along with a theoretical analysis of cost optimality and constraint satisfaction. Across a wide range of state-of-the-art LLM benchmarks, MESS+ achieves an average of $2\times$ cost savings compared to existing LLM routing techniques.
Bridging Arbitrary and Tree Metrics via Differentiable Gromov Hyperbolicity
arXiv:2505.21073v3 Announce Type: replace Abstract: Trees and the associated shortest-path tree metrics provide a powerful framework for representing hierarchical and combinatorial structures in data. Given an arbitrary metric space, its deviation from a tree metric can be quantified by Gromov's $\delta$-hyperbolicity. Nonetheless, designing algorithms that bridge an arbitrary metric to its closest tree metric is still a vivid subject of interest, as most common approaches are either heuristical and lack guarantees, or perform moderately well. In this work, we introduce a novel differentiable optimization framework, coined DeltaZero, that solves this problem. Our method leverages a smooth surrogate for Gromov's $\delta$-hyperbolicity which enables a gradient-based optimization, with a tractable complexity. The corresponding optimization procedure is derived from a problem with better worst case guarantees than existing bounds, and is justified statistically. Experiments on synthetic and real-world datasets demonstrate that our method consistently achieves state-of-the-art distortion.
CRISP-NAM: Competing Risks Interpretable Survival Prediction with Neural Additive Models
arXiv:2505.21360v5 Announce Type: replace Abstract: Competing risks are crucial considerations in survival modelling, particularly in healthcare domains where patients may experience multiple distinct event types. We propose CRISP-NAM (Competing Risks Interpretable Survival Prediction with Neural Additive Models), an interpretable neural additive model for competing risks survival analysis which extends the neural additive architecture to model cause-specific hazards while preserving feature-level interpretability. Each feature contributes independently to risk estimation through dedicated neural networks, allowing for visualization of complex non-linear relationships between covariates and each competing risk. We demonstrate competitive performance on multiple datasets compared to existing approaches.
On the Dynamic Regret of Following the Regularized Leader: Optimism with History Pruning
arXiv:2505.22899v2 Announce Type: replace Abstract: We revisit the Follow the Regularized Leader (FTRL) framework for Online Convex Optimization (OCO) over compact sets, focusing on achieving dynamic regret guarantees. Prior work has highlighted the framework's limitations in dynamic environments due to its tendency to produce "lazy" iterates. However, building on insights showing FTRL's ability to produce "agile" iterates, we show that it can indeed recover known dynamic regret bounds through optimistic composition of future costs and careful linearization of past costs, which can lead to pruning some of them. This new analysis of FTRL against dynamic comparators yields a principled way to interpolate between greedy and agile updates and offers several benefits, including refined control over regret terms, optimism without cyclic dependence, and the application of minimal recursive regularization akin to AdaFTRL. More broadly, we show that it is not the "lazy" projection style of FTRL that hinders (optimistic) dynamic regret, but the decoupling of the algorithm's state (linearized history) from its iterates, allowing the state to grow arbitrarily. Instead, pruning synchronizes these two when necessary.
Buffer-free Class-Incremental Learning with Out-of-Distribution Detection
arXiv:2505.23412v2 Announce Type: replace Abstract: Class-incremental learning (CIL) poses significant challenges in open-world scenarios, where models must not only learn new classes over time without forgetting previous ones but also handle inputs from unknown classes that a closed-set model would misclassify. Recent works address both issues by (i)~training multi-head models using the task-incremental learning framework, and (ii) predicting the task identity employing out-of-distribution (OOD) detectors. While effective, the latter mainly relies on joint training with a memory buffer of past data, raising concerns around privacy, scalability, and increased training time. In this paper, we present an in-depth analysis of post-hoc OOD detection methods and investigate their potential to eliminate the need for a memory buffer. We uncover that these methods, when applied appropriately at inference time, can serve as a strong substitute for buffer-based OOD detection. We show that this buffer-free approach achieves comparable or superior performance to buffer-based methods both in terms of class-incremental learning and the rejection of unknown samples. Experimental results on CIFAR-10, CIFAR-100 and Tiny ImageNet datasets support our findings, offering new insights into the design of efficient and privacy-preserving CIL systems for open-world settings.
Differential Gated Self-Attention
arXiv:2505.24054v2 Announce Type: replace Abstract: Transformers excel across a large variety of tasks but remain susceptible to corrupted inputs, since standard self-attention treats all query-key interactions uniformly. Inspired by lateral inhibition in biological neural circuits and building on the recent use by the Differential Transformer's use of two parallel softmax subtraction for noise cancellation, we propose Multihead Differential Gated Self-Attention (M-DGSA) that learns per-head input-dependent gating to dynamically suppress attention noise. Each head splits into excitatory and inhibitory branches whose dual softmax maps are fused by a sigmoid gate predicted from the token embedding, yielding a context-aware contrast enhancement. M-DGSA integrates seamlessly into existing Transformer stacks with minimal computational overhead. We evaluate on both vision and language benchmarks, demonstrating consistent robustness gains over vanilla Transformer, Vision Transformer, and Differential Transformer baselines. Our contributions are (i) a novel input-dependent gating mechanism for self-attention grounded in lateral inhibition, (ii) a principled synthesis of biological contrast-enhancement and self-attention theory, and (iii) comprehensive experiments demonstrating noise resilience and cross-domain applicability.
A Finite-Time Analysis of TD Learning with Linear Function Approximation without Projections or Strong Convexity
arXiv:2506.01052v2 Announce Type: replace Abstract: We investigate the finite-time convergence properties of Temporal Difference (TD) learning with linear function approximation, a cornerstone algorithm in the field of reinforcement learning. We are interested in the so-called ``robust'' setting, where the convergence guarantee does not depend on the minimal curvature of the potential function. While prior work has established convergence guarantees in this setting, these results typically rely on the assumption that each iterate is projected onto a bounded set, a condition that is both artificial and does not match the current practice. In this paper, we challenge the necessity of such an assumption and present a refined analysis of TD learning. For the first time, we show that the simple projection-free variant converges with a rate of $\widetilde{\mathcal{O}}(\frac{||\theta^*||^2_2}{\sqrt{T}})$, even in the presence of Markovian noise. Our analysis reveals a novel self-bounding property of the TD updates and exploits it to guarantee bounded iterates.
Spiking Brain Compression: Exploring One-Shot Post-Training Pruning and Quantization for Spiking Neural Networks
arXiv:2506.03996v2 Announce Type: replace Abstract: Spiking Neural Networks (SNNs) have emerged as a new generation of energy-efficient neural networks suitable for implementation on neuromorphic hardware. As neuromorphic hardware has limited memory and computing resources, weight pruning and quantization have recently been explored to improve SNNs' efficiency. State-of-the-art SNN pruning/quantization methods employ multiple compression and training iterations, increasing the cost for pre-trained or very large SNNs. In this paper, we propose a new one-shot post-training pruning/quantization framework, Spiking Brain Compression (SBC), that extends the Optimal Brain Compression (OBC) method to SNNs. SBC replaces the current-based loss found in OBC with a spike train-based objective whose Hessian is cheaply computable, allowing a single backward pass to prune or quantize synapses and analytically rescale the rest. Our experiments on models trained with neuromorphic datasets (N-MNIST, CIFAR10-DVS, DVS128-Gesture) and large static datasets (CIFAR-100, ImageNet) show state-of-the-art results for one-shot post-training compression methods on SNNs, with single-digit to double-digit accuracy gains compared to OBC. SBC also approaches the accuracy of costly iterative methods, while cutting compression time by 2-3 orders of magnitude.
UNO: Unlearning via Orthogonalization in Generative models
arXiv:2506.04712v2 Announce Type: replace Abstract: As generative models become increasingly powerful and pervasive, the ability to unlearn specific data, whether due to privacy concerns, legal requirements, or the correction of harmful content, has become increasingly important. Unlike in conventional training, where data are accumulated and knowledge is reinforced, unlearning aims to selectively remove the influence of particular data points without costly retraining from scratch. To be effective and reliable, such algorithms need to achieve (i) forgetting of the undesired data, (ii) preservation of the quality of the generation, (iii) preservation of the influence of the desired training data on the model parameters, and (iv) small number of training steps. We propose fast unlearning algorithms based on loss gradient orthogonalization for unconditional and conditional generative models. We show that our algorithms are able to forget data while maintaining the fidelity of the original model. On standard image benchmarks, our algorithms achieve orders of magnitude faster unlearning times than their predecessors, such as gradient surgery. We demonstrate our algorithms with datasets of increasing complexity (MNIST, CelebA and ImageNet-1K) and for generative models of increasing complexity (VAEs and diffusion transformers).
There Was Never a Bottleneck in Concept Bottleneck Models
arXiv:2506.04877v2 Announce Type: replace Abstract: Deep learning representations are often difficult to interpret, which can hinder their deployment in sensitive applications. Concept Bottleneck Models (CBMs) have emerged as a promising approach to mitigate this issue by learning representations that support target task performance while ensuring that each component predicts a concrete concept from a predefined set. In this work, we argue that CBMs do not impose a true bottleneck: the fact that a component can predict a concept does not guarantee that it encodes only information about that concept. This shortcoming raises concerns regarding interpretability and the validity of intervention procedures. To overcome this limitation, we propose Minimal Concept Bottleneck Models (MCBMs), which incorporate an Information Bottleneck (IB) objective to constrain each representation component to retain only the information relevant to its corresponding concept. This IB is implemented via a variational regularization term added to the training loss. As a result, MCBMs yield more interpretable representations, support principled concept-level interventions, and remain consistent with probability-theoretic foundations.
AMPED: Adaptive Multi-objective Projection for balancing Exploration and skill Diversification
arXiv:2506.05980v2 Announce Type: replace Abstract: Skill-based reinforcement learning (SBRL) enables rapid adaptation in environments with sparse rewards by pretraining a skill-conditioned policy. Effective skill learning requires jointly maximizing both exploration and skill diversity. However, existing methods often face challenges in simultaneously optimizing for these two conflicting objectives. In this work, we propose a new method, Adaptive Multi-objective Projection for balancing Exploration and skill Diversification (AMPED), which explicitly addresses both: during pre-training, a gradient-surgery projection balances the exploration and diversity gradients, and during fine-tuning, a skill selector exploits the learned diversity by choosing skills suited to downstream tasks. Our approach achieves performance that surpasses SBRL baselines across various benchmarks. Through an extensive ablation study, we identify the role of each component and demonstrate that each element in AMPED is contributing to performance. We further provide theoretical and empirical evidence that, with a greedy skill selector, greater skill diversity reduces fine-tuning sample complexity. These results highlight the importance of explicitly harmonizing exploration and diversity and demonstrate the effectiveness of AMPED in enabling robust and generalizable skill learning. Project Page: https://geonwoo.me/amped/
Improved Scaling Laws in Linear Regression via Data Reuse
arXiv:2506.08415v2 Announce Type: replace Abstract: Neural scaling laws suggest that the test error of large language models trained online decreases polynomially as the model size and data size increase. However, such scaling can be unsustainable when running out of new data. In this work, we show that data reuse can improve existing scaling laws in linear regression. Specifically, we derive sharp test error bounds on $M$-dimensional linear models trained by multi-pass stochastic gradient descent (multi-pass SGD) on $N$ data with sketched features. Assuming that the data covariance has a power-law spectrum of degree $a$, and that the true parameter follows a prior with an aligned power-law spectrum of degree $b-a$ (with $a > b > 1$), we show that multi-pass SGD achieves a test error of $\Theta(M^{1-b} + L^{(1-b)/a})$, where $L \lesssim N^{a/b}$ is the number of iterations. In the same setting, one-pass SGD only attains a test error of $\Theta(M^{1-b} + N^{(1-b)/a})$ (see e.g., Lin et al., 2024). This suggests an improved scaling law via data reuse (i.e., choosing $L>N$) in data-constrained regimes. Numerical simulations are also provided to verify our theoretical findings.
CodeBrain: Towards Decoupled Interpretability and Multi-Scale Architecture for EEG Foundation Model
arXiv:2506.09110v2 Announce Type: replace Abstract: Electroencephalography (EEG) provides real-time insights into brain activity and supports diverse applications in neuroscience. While EEG foundation models (EFMs) have emerged to address the scalability issues of task-specific models, current approaches still yield clinically uninterpretable and weakly discriminative representations, inefficiently capture global dependencies, and neglect important local neural events. We present CodeBrain, a two-stage EFM designed to fill this gap. In the first stage, we introduce the TFDual-Tokenizer, which decouples heterogeneous temporal and frequency EEG signals into discrete tokens, quadratically expanding the representation space to enhance discriminative power and offering domain-specific interpretability by suggesting potential links to neural events and spectral rhythms. In the second stage, we propose the multi-scale EEGSSM architecture, which combines structured global convolution with sliding window attention to efficiently capture both sparse long-range and local dependencies, reflecting the brain's small-world topology. Pretrained on the largest public EEG corpus, CodeBrain achieves strong generalization across 8 downstream tasks and 10 datasets under distribution shifts, supported by comprehensive ablations, scaling-law analyses, and interpretability evaluations. Both code and pretraining weights will be released in the future version.
Robust Molecular Property Prediction via Densifying Scarce Labeled Data
arXiv:2506.11877v3 Announce Type: replace Abstract: A widely recognized limitation of molecular prediction models is their reliance on structures observed in the training data, resulting in poor generalization to out-of-distribution compounds. Yet in drug discovery, the compounds most critical for advancing research often lie beyond the training set, making the bias toward the training data particularly problematic. This mismatch introduces substantial covariate shift, under which standard deep learning models produce unstable and inaccurate predictions. Furthermore, the scarcity of labeled data-stemming from the onerous and costly nature of experimental validation-further exacerbates the difficulty of achieving reliable generalization. To address these limitations, we propose a novel bilevel optimization approach that leverages unlabeled data to interpolate between in-distribution (ID) and out-of-distribution (OOD) data, enabling the model to learn how to generalize beyond the training distribution. We demonstrate significant performance gains on challenging real-world datasets with substantial covariate shift, supported by t-SNE visualizations highlighting our interpolation method.
Exploring the Secondary Risks of Large Language Models
arXiv:2506.12382v3 Announce Type: replace Abstract: Ensuring the safety and alignment of Large Language Models is a significant challenge with their growing integration into critical applications and societal functions. While prior research has primarily focused on jailbreak attacks, less attention has been given to non-adversarial failures that subtly emerge during benign interactions. We introduce secondary risks a novel class of failure modes marked by harmful or misleading behaviors during benign prompts. Unlike adversarial attacks, these risks stem from imperfect generalization and often evade standard safety mechanisms. To enable systematic evaluation, we introduce two risk primitives verbose response and speculative advice that capture the core failure patterns. Building on these definitions, we propose SecLens, a black-box, multi-objective search framework that efficiently elicits secondary risk behaviors by optimizing task relevance, risk activation, and linguistic plausibility. To support reproducible evaluation, we release SecRiskBench, a benchmark dataset of 650 prompts covering eight diverse real-world risk categories. Experimental results from extensive evaluations on 16 popular models demonstrate that secondary risks are widespread, transferable across models, and modality independent, emphasizing the urgent need for enhanced safety mechanisms to address benign yet harmful LLM behaviors in real-world deployments.
Fractional Reasoning via Latent Steering Vectors Improves Inference Time Compute
arXiv:2506.15882v2 Announce Type: replace Abstract: Test-time compute has emerged as a powerful paradigm for improving the performance of large language models (LLMs), where generating multiple outputs or refining individual chains can significantly boost answer accuracy. However, existing methods like Best-of-N, majority voting, and self-reflection typically apply reasoning in a uniform way across inputs, overlooking the fact that different problems may require different levels of reasoning depth. In this work, we propose Fractional Reasoning, a training-free and model-agnostic framework that enables continuous control over reasoning intensity at inference time, going beyond the limitations of fixed instructional prompts. Our method operates by extracting the latent steering vector associated with deeper reasoning and reapplying it with a tunable scaling factor, allowing the model to tailor its reasoning process to the complexity of each input. This supports two key modes of test-time scaling: (1) improving output quality in breadth-based strategies (e.g., Best-of-N, majority voting), and (2) enhancing the correctness of individual reasoning chains in depth-based strategies (e.g., self-reflection). Experiments on GSM8K, MATH500, and GPQA demonstrate that Fractional Reasoning consistently improves performance across diverse reasoning tasks and models.
VRAIL: Vectorized Reward-based Attribution for Interpretable Learning
arXiv:2506.16014v4 Announce Type: replace Abstract: We propose VRAIL (Vectorized Reward-based Attribution for Interpretable Learning), a bi-level framework for value-based reinforcement learning (RL) that learns interpretable weight representations from state features. VRAIL consists of two stages: a deep learning (DL) stage that fits an estimated value function using state features, and an RL stage that uses this to shape learning via potential-based reward transformations. The estimator is modeled in either linear or quadratic form, allowing attribution of importance to individual features and their interactions. Empirical results on the Taxi-v3 environment demonstrate that VRAIL improves training stability and convergence compared to standard DQN, without requiring environment modifications. Further analysis shows that VRAIL uncovers semantically meaningful subgoals, such as passenger possession, highlighting its ability to produce human-interpretable behavior. Our findings suggest that VRAIL serves as a general, model-agnostic framework for reward shaping that enhances both learning and interpretability.
CopulaSMOTE: A Copula-Based Oversampling Approach for Imbalanced Classification in Diabetes Prediction
arXiv:2506.17326v2 Announce Type: replace Abstract: Diabetes mellitus poses a significant health risk, as nearly 1 in 9 people are affected by it. Early detection can significantly lower this risk. Despite significant advancements in machine learning for identifying diabetic cases, results can still be influenced by the imbalanced nature of the data. To address this challenge, our study considered copula-based data augmentation, which preserves the dependency structure when generating data for the minority class and integrates it with machine learning (ML) techniques. We selected the Pima Indian dataset and generated data using A2 copula, then applied five machine learning algorithms: logistic regression, random forest, gradient boosting, extreme gradient boosting, and Multilayer Perceptron. Overall, our findings show that Random Forest with A2 copula oversampling (theta = 10) achieved the best performance, with improvements of 5.3% in accuracy, 9.5% in precision, 5.7% in recall, 7.6% in F1-score, and 1.1% in AUC compared to the standard SMOTE method. Furthermore, we statistically validated our results using the McNemar's test. This research represents the first known use of A2 copulas for data augmentation and serves as an alternative to the SMOTE technique, highlighting the efficacy of copulas as a statistical method in machine learning applications.
An entropy-optimal path to humble AI
arXiv:2506.17940v2 Announce Type: replace Abstract: Progress of AI has led to very successful, but by no means humble models and tools, especially regarding (i) the huge and further exploding costs and resources they demand, and (ii) the over-confidence of these tools with the answers they provide. Here we introduce a novel mathematical framework for a non-equilibrium entropy-optimizing reformulation of Boltzmann machines based on the exact law of total probability and the exact convex polytope representations. We show that it results in the highly-performant, but much cheaper, gradient-descent-free learning framework with mathematically-justified existence and uniqueness criteria, and cheaply-computable confidence/reliability measures for both the model inputs and the outputs. Comparisons to state-of-the-art AI tools in terms of performance, cost and the model descriptor lengths on a broad set of synthetic and real-world problems with varying complexity reveal that the proposed method results in more performant and slim models, with the descriptor lengths being very close to the intrinsic complexity scaling bounds for the underlying problems. Applying this framework to historical climate data results in models with systematically higher prediction skills for the onsets of important La Ni\~na and El Ni\~no climate phenomena, requiring just few years of climate data for training - a small fraction of what is necessary for contemporary climate prediction tools.
Shift Happens: Mixture of Experts based Continual Adaptation in Federated Learning
arXiv:2506.18789v2 Announce Type: replace Abstract: Federated Learning (FL) enables collaborative model training across decentralized clients without sharing raw data, yet faces significant challenges in real-world settings where client data distributions evolve dynamically over time. This paper tackles the critical problem of covariate and label shifts in streaming FL environments, where non-stationary data distributions degrade model performance and necessitate a middleware layer that adapts FL to distributional shifts. We introduce ShiftEx, a shift-aware mixture of experts framework that dynamically creates and trains specialized global models in response to detected distribution shifts using Maximum Mean Discrepancy for covariate shifts. The framework employs a latent memory mechanism for expert reuse and implements facility location-based optimization to jointly minimize covariate mismatch, expert creation costs, and label imbalance. Through theoretical analysis and comprehensive experiments on benchmark datasets, we demonstrate 5.5-12.9 percentage point accuracy improvements and 22-95 % faster adaptation compared to state-of-the-art FL baselines across diverse shift scenarios. The proposed approach offers a scalable, privacy-preserving middleware solution for FL systems operating in non-stationary, real-world conditions while minimizing communication and computational overhead.
TRACED: Transition-aware Regret Approximation with Co-learnability for Environment Design
arXiv:2506.19997v3 Announce Type: replace Abstract: Generalizing deep reinforcement learning agents to unseen environments remains a significant challenge. One promising solution is Unsupervised Environment Design (UED), a co-evolutionary framework in which a teacher adaptively generates tasks with high learning potential, while a student learns a robust policy from this evolving curriculum. Existing UED methods typically measure learning potential via regret, the gap between optimal and current performance, approximated solely by value-function loss. Building on these approaches, we introduce the transition-prediction error as an additional term in our regret approximation. To capture how training on one task affects performance on others, we further propose a lightweight metric called Co-Learnability. By combining these two measures, we present Transition-aware Regret Approximation with Co-learnability for Environment Design (TRACED). Empirical evaluations show that TRACED produces curricula that improve zero-shot generalization over strong baselines across multiple benchmarks. Ablation studies confirm that the transition-prediction error drives rapid complexity ramp-up and that Co-Learnability delivers additional gains when paired with the transition-prediction error. These results demonstrate how refined regret approximation and explicit modeling of task relationships can be leveraged for sample-efficient curriculum design in UED. Project Page: https://geonwoo.me/traced/
Mirror Descent Policy Optimisation for Robust Constrained Markov Decision Processes
arXiv:2506.23165v2 Announce Type: replace Abstract: Safety is an essential requirement for reinforcement learning systems. The newly emerging framework of robust constrained Markov decision processes allows learning policies that satisfy long-term constraints while providing guarantees under epistemic uncertainty. This paper presents mirror descent policy optimisation for robust constrained Markov decision processes (RCMDPs), making use of policy gradient techniques to optimise both the policy (as a maximiser) and the transition kernel (as an adversarial minimiser) on the Lagrangian representing a constrained MDP. Our proposed algorithm obtains an $\tilde{\mathcal{O}}\left(1/T^{1/3}\right)$ convergence rate in the sample-based RCMDP setting. In addition to the RCMDP setting, the paper also contributes an algorithm for approximate gradient descent in the space of transition kernels, which is of independent interest for designing adversarial environments. Experiments confirm the benefits of mirror descent policy optimisation in constrained and unconstrained optimisation, and significant improvements are observed in robustness tests when compared to baseline policy optimisation algorithms.
Blending Supervised and Reinforcement Fine-Tuning with Prefix Sampling
arXiv:2507.01679v2 Announce Type: replace Abstract: Existing post-training techniques for large language models are broadly categorized into Supervised Fine-Tuning (SFT) and Reinforcement Fine-Tuning (RFT). Each paradigm presents a distinct trade-off: SFT excels at mimicking demonstration data but can lead to problematic generalization as a form of behavior cloning. Conversely, RFT can significantly enhance a model's performance but is prone to learn unexpected behaviors, and its performance is highly sensitive to the initial policy. In this paper, we propose a unified view of these methods and introduce Prefix-RFT, a hybrid approach that synergizes learning from both demonstration and exploration. Using mathematical reasoning problems as a testbed, we empirically demonstrate that Prefix-RFT is both simple and effective. It not only surpasses the performance of standalone SFT and RFT but also outperforms parallel mixed-policy RFT methods. A key advantage is its seamless integration into existing open-source frameworks, requiring only minimal modifications to the standard RFT pipeline. Our analysis highlights the complementary nature of SFT and RFT, and validates that Prefix-RFT effectively harmonizes these two learning paradigms. Furthermore, ablation studies confirm the method's robustness to variations in the quality and quantity of demonstration data. We hope this work offers a new perspective on LLM post-training, suggesting that a unified paradigm that judiciously integrates demonstration and exploration could be a promising direction for future research.
Enhanced Generative Model Evaluation with Clipped Density and Coverage
arXiv:2507.01761v2 Announce Type: replace Abstract: Although generative models have made remarkable progress in recent years, their use in critical applications has been hindered by an inability to reliably evaluate the quality of their generated samples. Quality refers to at least two complementary concepts: fidelity and coverage. Current quality metrics often lack reliable, interpretable values due to an absence of calibration or insufficient robustness to outliers. To address these shortcomings, we introduce two novel metrics: Clipped Density and Clipped Coverage. By clipping individual sample contributions, as well as the radii of nearest neighbor balls for fidelity, our metrics prevent out-of-distribution samples from biasing the aggregated values. Through analytical and empirical calibration, these metrics demonstrate linear score degradation as the proportion of bad samples increases. Thus, they can be straightforwardly interpreted as equivalent proportions of good samples. Extensive experiments on synthetic and real-world datasets demonstrate that Clipped Density and Clipped Coverage outperform existing methods in terms of robustness, sensitivity, and interpretability when evaluating generative models.
Lost in Latent Space: An Empirical Study of Latent Diffusion Models for Physics Emulation
arXiv:2507.02608v3 Announce Type: replace Abstract: The steep computational cost of diffusion models at inference hinders their use as fast physics emulators. In the context of image and video generation, this computational drawback has been addressed by generating in the latent space of an autoencoder instead of the pixel space. In this work, we investigate whether a similar strategy can be effectively applied to the emulation of dynamical systems and at what cost. We find that the accuracy of latent-space emulation is surprisingly robust to a wide range of compression rates (up to 1000x). We also show that diffusion-based emulators are consistently more accurate than non-generative counterparts and compensate for uncertainty in their predictions with greater diversity. Finally, we cover practical design choices, spanning from architectures to optimizers, that we found critical to train latent-space emulators.
Reinforcement Fine-Tuning Naturally Mitigates Forgetting in Continual Post-Training
arXiv:2507.05386v2 Announce Type: replace Abstract: Continual post-training (CPT) is a popular and effective technique for adapting foundation models like multimodal large language models to specific and ever-evolving downstream tasks. While existing research has primarily concentrated on methods like data replay, model expansion, or parameter regularization, the fundamental role of the learning paradigm within CPT remains largely unexplored. This paper presents a comparative analysis of two core post-training paradigms: supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT), investigating their respective impacts on knowledge retention during CPT. Our experiments are conducted on a benchmark comprising seven diverse multimodal tasks, utilizing Qwen2.5-VL-7B-Instruct as the base model for continual post-training. The investigation yields two significant findings: (1) When continuously learning on downstream tasks, SFT leads to catastrophic forgetting of previously learned tasks. In contrast, RFT inherently preserves prior knowledge and achieve performance comparable to multi-task training. (2) RFT successfully protects and even enhances the model's general knowledge on standard benchmarks (e.g., MMMU and MMLU-Pro). Conversely, SFT degrades general model capabilities severely. Further analysis reveals that this stability is not primarily due to explicit mechanisms like KL penalty or chain-of-thought reasoning. Instead, we identify an implicit regularization mechanism inherent to RFT as a key contributing factor. Our theoretical analysis suggests that RFT's gradient updates are naturally scaled by the reward variance, acting as a data-dependent regularizer that inherently protects previously acquired knowledge. Finally, we propose a rollout-based instance filtering algorithm to enhance the stability and efficiency of RFT. Our comprehensive study demonstrates the superiority of RFT as a robust paradigm for continual post-training.
Training-Free Stein Diffusion Guidance: Posterior Correction for Sampling Beyond High-Density Regions
arXiv:2507.05482v2 Announce Type: replace Abstract: Training free diffusion guidance provides a flexible way to leverage off-the-shelf classifiers without additional training. Yet, current approaches hinge on posterior approximations via Tweedie's formula, which often yield unreliable guidance, particularly in low-density regions. Stochastic optimal control (SOC), in contrast, provides principled posterior simulation but is prohibitively expensive for fast sampling. In this work, we reconcile the strengths of these paradigms by introducing Stein Diffusion Guidance (SDG), a novel training-free framework grounded in a surrogate SOC objective. We establish a theoretical bound on the value function, demonstrating the necessity of correcting approximate posteriors to faithfully reflect true diffusion dynamics. Leveraging Stein variational inference, SDG identifies the steepest descent direction that minimizes the Kullback-Leibler divergence between approximate and true posteriors. By incorporating a principled Stein correction mechanism and a novel running cost functional, SDG enables effective guidance in low-density regions. Experiments on molecular low-density sampling tasks suggest that SDG consistently surpasses standard training-free guidance methods, highlighting its potential for broader diffusion-based sampling beyond high-density regions.
From Sorting Algorithms to Scalable Kernels: Bayesian Optimization in High-Dimensional Permutation Spaces
arXiv:2507.13263v3 Announce Type: replace Abstract: Bayesian Optimization (BO) is a powerful tool for black-box optimization, but its application to high-dimensional permutation spaces is severely limited by the challenge of defining scalable representations. The current state-of-the-art BO approach for permutation spaces relies on an exhaustive $\Omega(n^2)$ pairwise comparison, inducing a dense representation that is impractical for large-scale permutations. To break this barrier, we introduce a novel framework for generating efficient permutation representations via kernel functions derived from sorting algorithms. Within this framework, the Mallows kernel can be viewed as a special instance derived from enumeration sort. Further, we introduce the \textbf{Merge Kernel} , which leverages the divide-and-conquer structure of merge sort to produce a compact, $\Theta(n\log n)$ to achieve the lowest possible complexity with no information loss and effectively capture permutation structure. Our central thesis is that the Merge Kernel performs competitively with the Mallows kernel in low-dimensional settings, but significantly outperforms it in both optimization performance and computational efficiency as the dimension $n$ grows. Extensive evaluations on various permutation optimization benchmarks confirm our hypothesis, demonstrating that the Merge Kernel provides a scalable and more effective solution for Bayesian optimization in high-dimensional permutation spaces, thereby unlocking the potential for tackling previously intractable problems such as large-scale feature ordering and combinatorial neural architecture search.
ParallelTime: Dynamically Weighting the Balance of Short- and Long-Term Temporal Dependencies
arXiv:2507.13998v2 Announce Type: replace Abstract: Modern multivariate time series forecasting primarily relies on two architectures: the Transformer with attention mechanism and Mamba. In natural language processing, an approach has been used that combines local window attention for capturing short-term dependencies and Mamba for capturing long-term dependencies, with their outputs averaged to assign equal weight to both. We find that for time-series forecasting tasks, assigning equal weight to long-term and short-term dependencies is not optimal. To mitigate this, we propose a dynamic weighting mechanism, ParallelTime Weighter, which calculates interdependent weights for long-term and short-term dependencies for each token based on the input and the model's knowledge. Furthermore, we introduce the ParallelTime architecture, which incorporates the ParallelTime Weighter mechanism to deliver state-of-the-art performance across diverse benchmarks. Our architecture demonstrates robustness, achieves lower FLOPs, requires fewer parameters, scales effectively to longer prediction horizons, and significantly outperforms existing methods. These advances highlight a promising path for future developments of parallel Attention-Mamba in time series forecasting. The implementation is readily available at: \href{https://github.com/itay1551/ParallelTime}{GitHub}.
Merging Memory and Space: A State Space Neural Operator
arXiv:2507.23428v3 Announce Type: replace Abstract: We propose the State Space Neural Operator (SS-NO), a compact architecture for learning solution operators of time-dependent partial differential equations (PDEs). Our formulation extends structured state space models (SSMs) to joint spatiotemporal modeling, introducing two key mechanisms: adaptive damping, which stabilizes learning by localizing receptive fields, and learnable frequency modulation, which enables data-driven spectral selection. These components provide a unified framework for capturing long-range dependencies with parameter efficiency. Theoretically, we establish connections between SSMs and neural operators, proving a universality theorem for convolutional architectures with full field-of-view. Empirically, SS-NO achieves state-of-the-art performance across diverse PDE benchmarks-including 1D Burgers' and Kuramoto-Sivashinsky equations, and 2D Navier-Stokes and compressible Euler flows-while using significantly fewer parameters than competing approaches. A factorized variant of SS-NO further demonstrates scalable performance on challenging 2D problems. Our results highlight the effectiveness of damping and frequency learning in operator modeling, while showing that lightweight factorization provides a complementary path toward efficient large-scale PDE learning.
GEDAN: Learning the Edit Costs for Graph Edit Distance
arXiv:2508.03111v2 Announce Type: replace Abstract: Graph Edit Distance (GED) is defined as the minimum cost transformation of one graph into another and is a widely adopted metric for measuring the dissimilarity between graphs. The major problem of GED is that its computation is NP-hard, which has in turn led to the development of various approximation methods, including approaches based on neural networks (NN). However, most NN methods assume a unit cost for edit operations -- a restrictive and often unrealistic simplification, since topological and functional distances rarely coincide in real-world data. In this paper, we propose a fully end-to-end Graph Neural Network framework for learning the edit costs for GED, at a fine-grained level, aligning topological and task-specific similarity. Our method combines an unsupervised self-organizing mechanism for GED approximation with a Generalized Additive Model that flexibly learns contextualized edit costs. Experiments demonstrate that our approach overcomes the limitations of non-end-to-end methods, yielding directly interpretable graph matchings, uncovering meaningful structures in complex graphs, and showing strong applicability to domains such as molecular analysis.
Causal Reflection with Language Models
arXiv:2508.04495v2 Announce Type: replace Abstract: While LLMs exhibit impressive fluency and factual recall, they struggle with robust causal reasoning, often relying on spurious correlations and brittle patterns. Similarly, traditional Reinforcement Learning agents also lack causal understanding, optimizing for rewards without modeling why actions lead to outcomes. We introduce Causal Reflection, a framework that explicitly models causality as a dynamic function over state, action, time, and perturbation, enabling agents to reason about delayed and nonlinear effects. Additionally, we define a formal Reflect mechanism that identifies mismatches between predicted and observed outcomes and generates causal hypotheses to revise the agent's internal model. In this architecture, LLMs serve not as black-box reasoners, but as structured inference engines translating formal causal outputs into natural language explanations and counterfactuals. Our framework lays the theoretical groundwork for Causal Reflective agents that can adapt, self-correct, and communicate causal understanding in evolving environments.
Reparameterization Proximal Policy Optimization
arXiv:2508.06214v2 Announce Type: replace Abstract: Reparameterization policy gradient (RPG) is promising for improving sample efficiency by leveraging differentiable dynamics. However, a critical barrier is its training instability, where high-variance gradients can destabilize the learning process. To address this, we draw inspiration from Proximal Policy Optimization (PPO), which uses a surrogate objective to enable stable sample reuse in the model-free setting. We first establish a connection between this surrogate objective and RPG, which has been largely unexplored and is non-trivial. Then, we bridge this gap by demonstrating that the reparameterization gradient of a PPO-like surrogate objective can be computed efficiently using backpropagation through time. Based on this key insight, we propose Reparameterization Proximal Policy Optimization (RPO), a stable and sample-efficient RPG-based method. RPO enables stable sample reuse over multiple epochs by employing a policy gradient clipping mechanism tailored for RPG. It is further stabilized by Kullback-Leibler (KL) divergence regularization and remains fully compatible with existing variance reduction methods. We evaluate RPO on a suite of challenging locomotion and manipulation tasks, where experiments demonstrate that our method achieves superior sample efficiency and strong performance.
Discovery Learning accelerates battery design evaluation
arXiv:2508.06985v2 Announce Type: replace Abstract: Fast and reliable validation of novel designs in complex physical systems such as batteries is critical to accelerating technological innovation. However, battery research and development remain bottlenecked by the prohibitively high time and energy costs required to evaluate numerous new design candidates, particularly in battery prototyping and life testing. Despite recent progress in data-driven battery lifetime prediction, existing methods require labeled data of target designs to improve accuracy and cannot make reliable predictions until after prototyping, thus falling far short of the efficiency needed to enable rapid feedback for battery design. Here, we introduce Discovery Learning (DL), a scientific machine-learning paradigm that integrates active learning, physics-guided learning, and zero-shot learning into a human-like reasoning loop, drawing inspiration from learning theories in educational psychology. DL can learn from historical battery designs and actively reduce the need for prototyping, thus enabling rapid lifetime evaluation for unobserved material-design combinations without requiring additional data labeling. To test DL, we present 123 industrial-grade large-format lithium-ion pouch cells, spanning eight material-design combinations and diverse cycling protocols. Trained solely on public datasets of small-capacity cylindrical cells, DL achieves 7.2% test error in predicting the average cycle life under unknown device variability. This results in savings of 98% in time and 95% in energy compared to industrial practices. This work highlights the potential of uncovering insights from historical designs to inform and accelerate the development of next-generation battery technologies. DL represents a key advance toward efficient data-driven modeling and helps realize the promise of machine learning for accelerating scientific discovery and engineering innovation.
A Principled Loss Function for Direct Language Model Alignment
arXiv:2508.07137v2 Announce Type: replace Abstract: The alignment of large language models (LLMs) with human preferences is commonly achieved through Reinforcement Learning from Human Feedback (RLHF). Direct Preference Optimization (DPO) simplified this paradigm by establishing a direct mapping between the optimal policy and a reward function, eliminating the need for an explicit reward model. However, we argue that the DPO loss function is theoretically misaligned with its own derivation, as it promotes the indefinite maximization of a logits difference, which can lead to training instability and reward hacking. In this paper, we propose a novel loss function derived directly from the RLHF optimality condition. Our proposed loss targets a specific, finite value for the logits difference, which is dictated by the underlying reward, rather than its maximization. We provide a theoretical analysis, including a gradient-based comparison, to demonstrate that our method avoids the large gradients that plague DPO when the probability of dispreferred responses approaches zero. This inherent stability prevents reward hacking and leads to more effective alignment. We validate our approach by fine-tuning a Qwen2.5-7B model, showing significant win-rate improvements over a standard DPO baseline and achieving competitive performance against larger models like Llama-3.1-8B.
Causal Structure Learning in Hawkes Processes with Complex Latent Confounder Networks
arXiv:2508.11727v2 Announce Type: replace Abstract: Multivariate Hawkes process provides a powerful framework for modeling temporal dependencies and event-driven interactions in complex systems. While existing methods primarily focus on uncovering causal structures among observed subprocesses, real-world systems are often only partially observed, with latent subprocesses posing significant challenges. In this paper, we show that continuous-time event sequences can be represented by a discrete-time causal model as the time interval shrinks, and we leverage this insight to establish necessary and sufficient conditions for identifying latent subprocesses and the causal influences. Accordingly, we propose a two-phase iterative algorithm that alternates between inferring causal relationships among discovered subprocesses and uncovering new latent subprocesses, guided by path-based conditions that guarantee identifiability. Experiments on both synthetic and real-world datasets show that our method effectively recovers causal structures despite the presence of latent subprocesses.
MDPO: Overcoming the Training-Inference Divide of Masked Diffusion Language Models
arXiv:2508.13148v2 Announce Type: replace Abstract: Diffusion language models, as a promising alternative to traditional autoregressive (AR) models, enable faster generation and richer conditioning on bidirectional context. However, they suffer from a key discrepancy between training and inference: during inference, MDLMs progressively reveal the structure of the generated sequence by producing fewer and fewer masked tokens, whereas this structure is ignored in training as tokens are masked at random. Although this discrepancy between training and inference can lead to suboptimal performance, it has been largely overlooked by previous works, leaving closing this gap between the two stages an open problem. To address this, we frame the problem of learning effective denoising trajectories as a sequential decision-making problem and use the resulting framework to apply reinforcement learning. We propose a novel Masked Diffusion Policy Optimization (MDPO) to exploit the Markov property diffusion possesses and explicitly train the model under the same progressive refining schedule used at inference. MDPO matches the performance of the previous state-of-the-art (SOTA) method with 60x fewer gradient updates, while achieving average improvements of 9.6% on MATH500 and 54.2% on Countdown over SOTA when trained within the same number of weight updates. Additionally, we improve the remasking strategy of MDLMs as a plug-in inference replacement to overcome the limitation that the model cannot refine tokens flexibly. This training-free method, termed Running Confidence Remasking (RCR), consistently enhances performance and provides further improvements when used with MDPO. Our findings establish great potential for investigating the discrepancy between pre-training and inference of MDLMs. Code: https://github.com/autonomousvision/mdpo. Project Page: https://cli212.github.io/MDPO/.
Aligning Distributionally Robust Optimization with Practical Deep Learning Needs
arXiv:2508.16734v2 Announce Type: replace Abstract: While traditional Deep Learning (DL) optimization methods treat all training samples equally, Distributionally Robust Optimization (DRO) adaptively assigns importance weights to different samples. However, a significant gap exists between DRO and current DL practices. Modern DL optimizers require adaptivity and the ability to handle stochastic gradients, as these methods demonstrate superior performance. Additionally, for practical applications, a method should allow weight assignment not only to individual samples, but also to groups of objects (for example, all samples of the same class). This paper aims to bridge this gap by introducing ALSO $\unicode{x2013}$ Adaptive Loss Scaling Optimizer $\unicode{x2013}$ an adaptive algorithm for a modified DRO objective that can handle weight assignment to sample groups. We prove the convergence of our proposed algorithm for non-convex objectives, which is the typical case for DL models. Empirical evaluation across diverse Deep Learning tasks, from Tabular DL to Split Learning tasks, demonstrates that ALSO outperforms both traditional optimizers and existing DRO methods.
Breaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning
arXiv:2508.16949v3 Announce Type: replace Abstract: Recent advances in Large Language Models (LLMs) have underscored the potential of Reinforcement Learning (RL) to facilitate the emergence of reasoning capabilities. Despite the encouraging results, a fundamental dilemma persists as RL improvement relies on learning from high-quality samples, yet the exploration for such samples remains bounded by the inherent limitations of LLMs. This, in effect, creates an undesirable cycle in which what cannot be explored cannot be learned. In this work, we propose Rubric-Scaffolded Reinforcement Learning (RuscaRL), a novel instructional scaffolding framework designed to break the exploration bottleneck for general LLM reasoning. Specifically, RuscaRL introduces checklist-style rubrics as (1) explicit scaffolding for exploration during rollout generation, where different rubrics are provided as external guidance within task instructions to steer diverse high-quality responses. This guidance is gradually decayed over time, encouraging the model to internalize the underlying reasoning patterns; (2) verifiable rewards for exploitation during model training, where we can obtain robust LLM-as-a-Judge scores using rubrics as references, enabling effective RL on general reasoning tasks. Extensive experiments demonstrate the superiority of the proposed RuscaRL across various benchmarks, effectively expanding reasoning boundaries under the Best-of-N evaluation. Notably, RuscaRL significantly boosts Qwen2.5-7B-Instruct from 23.6 to 50.3 on HealthBench-500, surpassing GPT-4.1. Furthermore, our fine-tuned variant on Qwen3-30B-A3B-Instruct achieves 61.1 on HealthBench-500, outperforming leading LLMs including OpenAI-o3. Our code is available at https://github.com/IANNXANG/RuscaRL.
Optimal Sparsity of Mixture-of-Experts Language Models for Reasoning Tasks
arXiv:2508.18672v2 Announce Type: replace Abstract: Empirical scaling laws have driven the evolution of large language models (LLMs), yet their coefficients shift whenever the model architecture or data pipeline changes. Mixture-of-Experts (MoE) models, now standard in state-of-the-art systems, introduce a new sparsity dimension that current dense-model frontiers overlook. We investigate how MoE sparsity influences two distinct capability regimes: memorization skills and reasoning skills. By training MoE families that vary total parameters, active parameters, and top-$k$ routing under fixed compute budgets, we disentangle pre-training loss from downstream accuracy. Our results reveal two principles. First, Active FLOPs: models with identical training loss but greater active compute achieve higher reasoning accuracy. Second, Total tokens per parameter (TPP): memorization tasks improve with more parameters, while reasoning tasks benefit from optimal TPP, indicating that reasoning is data-hungry. Neither reinforcement learning post-training (GRPO) nor increased test-time compute alters these trends. We therefore argue that optimal MoE sparsity must be determined jointly by active FLOPs and TPP, revising the classical picture of compute-optimal scaling. Our model checkpoints, code and logs are open-source at https://github.com/rioyokotalab/optimal-sparsity.
Data-Augmented Few-Shot Neural Emulator for Computer-Model System Identification
arXiv:2508.19441v3 Announce Type: replace Abstract: Partial differential equations (PDEs) underpin the modeling of many natural and engineered systems. It can be convenient to express such models as neural PDEs rather than using traditional numerical PDE solvers by replacing part or all of the PDE's governing equations with a neural network representation. Neural PDEs are often easier to differentiate, linearize, reduce, or use for uncertainty quantification than the original numerical solver. They are usually trained on solution trajectories obtained by long-horizon rollout of the PDE solver. Here we propose a more sample-efficient data-augmentation strategy for generating neural PDE training data from a computer model by space-filling sampling of local "stencil" states. This approach removes a large degree of spatiotemporal redundancy present in trajectory data and oversamples states that may be rarely visited but help the neural PDE generalize across the state space. We demonstrate that accurate neural PDE stencil operators can be learned from synthetic training data generated by the computational equivalent of 10 timesteps' worth of numerical simulation. Accuracy is further improved if we assume access to a single full-trajectory simulation from the computer model, which is typically available in practice. Across several PDE systems, we show that our data-augmented stencil data yield better trained neural stencil operators, with clear performance gains compared with naively sampled stencil data from simulation trajectories. Finally, with only 10 solver steps' worth of augmented stencil data, our approach outperforms traditional ML emulators trained on thousands of trajectories in long-horizon rollout accuracy and stability.
The Lifecycle Principle: Stabilizing Dynamic Neural Networks with State Memory
arXiv:2509.02575v2 Announce Type: replace Abstract: I investigate a stronger form of regularization by deactivating neurons for extended periods, a departure from the temporary changes of methods like Dropout. However, this long-term dynamism introduces a critical challenge: severe training instability when neurons are revived with random weights. To solve this, I propose the Lifecycle (LC) principle, a regularization mechanism centered on a key innovation: state memory. Instead of re-initializing a revived neuron, my method restores its parameters to their last known effective state. This process preserves learned knowledge and avoids destructive optimization shocks. My theoretical analysis reveals that the LC principle smooths the loss landscape, guiding optimization towards flatter minima associated with better generalization. Experiments on image classification benchmarks demonstrate that my method improves generalization and robustness. Crucially, ablation studies confirm that state memory is essential for achieving these gains.
On Entropy Control in LLM-RL Algorithms
arXiv:2509.03493v2 Announce Type: replace Abstract: For RL algorithms, appropriate entropy control is crucial to their effectiveness. To control the policy entropy, a commonly used method is entropy regularization, which is adopted in various popular RL algorithms including PPO, SAC and A3C. Although entropy regularization proves effective in robotic and games RL conventionally, studies found that it gives weak to no gains in LLM-RL training. In this work, we study the issues of entropy bonus in LLM-RL setting. Specifically, we first argue that the conventional entropy regularization suffers from the LLM's extremely large response space and the sparsity of the optimal outputs. As a remedy, we propose AEnt, an entropy control method that utilizes a new clamped entropy bonus with an automatically adjusted coefficient. The clamped entropy is evaluated with the re-normalized policy defined on certain smaller token space, which encourages exploration within a more compact response set. In addition, the algorithm automatically adjusts entropy coefficient according to the clamped entropy value, effectively controlling the entropy-induced bias while leveraging the entropy's benefits. AEnt is tested in math-reasoning tasks under different base models and datasets, and it is observed that AEnt outperforms the baselines consistently across multiple benchmarks.
One-Embedding-Fits-All: Efficient Zero-Shot Time Series Forecasting by a Model Zoo
arXiv:2509.04208v2 Announce Type: replace Abstract: The proliferation of Time Series Foundation Models (TSFMs) has significantly advanced zero-shot forecasting, enabling predictions for unseen time series without task-specific fine-tuning. Extensive research has confirmed that no single TSFM excels universally, as different models exhibit preferences for distinct temporal patterns. This diversity suggests an opportunity: how to take advantage of the complementary abilities of TSFMs. To this end, we propose ZooCast, which characterizes each model's distinct forecasting strengths. ZooCast can intelligently assemble current TSFMs into a model zoo that dynamically selects optimal models for different forecasting tasks. Our key innovation lies in the One-Embedding-Fits-All paradigm that constructs a unified representation space where each model in the zoo is represented by a single embedding, enabling efficient similarity matching for all tasks. Experiments demonstrate ZooCast's strong performance on the GIFT-Eval zero-shot forecasting benchmark while maintaining the efficiency of a single TSFM. In real-world scenarios with sequential model releases, the framework seamlessly adds new models for progressive accuracy gains with negligible overhead.
Data-Efficient Time-Dependent PDE Surrogates: Graph Neural Simulators vs. Neural Operators
arXiv:2509.06154v2 Announce Type: replace Abstract: Developing accurate, data-efficient surrogate models is central to advancing AI for Science. Neural operators (NOs), which approximate mappings between infinite-dimensional function spaces using conventional neural architectures, have gained popularity as surrogates for systems driven by partial differential equations (PDEs). However, their reliance on large datasets and limited ability to generalize in low-data regimes hinder their practical utility. We argue that these limitations arise from their global processing of data, which fails to exploit the local, discretized structure of physical systems. To address this, we propose Graph Neural Simulators (GNS) as a principled surrogate modeling paradigm for time-dependent PDEs. GNS leverages message-passing combined with numerical time-stepping schemes to learn PDE dynamics by modeling the instantaneous time derivatives. This design mimics traditional numerical solvers, enabling stable long-horizon rollouts and strong inductive biases that enhance generalization. We rigorously evaluate GNS on four canonical PDE systems: (1) 2D scalar Burgers', (2) 2D coupled Burgers', (3) 2D Allen-Cahn, and (4) 2D nonlinear shallow-water equations, comparing against state-of-the-art NOs including Deep Operator Network (DeepONet) and Fourier Neural Operator (FNO). Results demonstrate that GNS is markedly more data-efficient, achieving less than 1% relative L2 error using only 3% of available trajectories, and exhibits dramatically reduced error accumulation over time (82.5% lower autoregressive error than FNO, 99.9% lower than DeepONet). To choose the training data, we introduce a PCA combined with KMeans trajectory selection strategy. These findings provide compelling evidence that GNS, with its graph-based locality and solver-inspired design, is the most suitable and scalable surrogate modeling framework for AI-driven scientific discovery.
ALICE: An Interpretable Neural Architecture for Generalization in Substitution Ciphers
arXiv:2509.07282v2 Announce Type: replace Abstract: We present cryptogram solving as an ideal testbed for studying neural network reasoning and generalization; models must decrypt text encoded with substitution ciphers, choosing from 26! possible mappings without explicit access to the cipher. We develop ALICE (an Architecture for Learning Interpretable Cryptogram dEcipherment), a simple encoder-only Transformer that sets a new state-of-the-art for both accuracy and speed on this decryption problem. Surprisingly, ALICE generalizes to unseen ciphers after training on only ${\sim}1500$ unique ciphers, a minute fraction ($3.7 \times 10^{-24}$) of the possible cipher space. To enhance interpretability, we introduce a novel bijective decoding head that explicitly models permutations via the Gumbel-Sinkhorn method, enabling direct extraction of learned cipher mappings. Through early exit and probing experiments, we reveal how ALICE progressively refines its predictions in a way that appears to mirror common human strategies -- early layers place greater emphasis on letter frequencies, while later layers form word-level structures. Our architectural innovations and analysis methods are applicable beyond cryptograms and offer new insights into neural network generalization and interpretability.
One Model for All Tasks: Leveraging Efficient World Models in Multi-Task Planning
arXiv:2509.07945v2 Announce Type: replace Abstract: In heterogeneous multi-task decision-making, tasks not only exhibit diverse observation and action spaces but also vary substantially in their underlying complexities. While conventional multi-task world models like UniZero excel in single-task settings, we find that when handling a broad and diverse suite of tasks, gradient conflicts and the loss of model plasticity often constrain their sample efficiency. In this work, we address these challenges from two complementary perspectives: the single learning iteration and the overall learning process. First, to mitigate the gradient conflicts, we systematically investigate key architectural designs for extending UniZero. Our investigation identifies a Mixture-of-Experts (MoE) architecture as the most effective approach. We demonstrate, both theoretically and empirically, that this architecture alleviates gradient conflicts by routing task-specific representations to specialized sub-networks. This finding leads to our proposed model, \textit{ScaleZero}. Second, to dynamically allocate model capacity throughout the learning process, we introduce an online Dynamic Parameter Scaling (DPS) strategy. This strategy progressively integrates LoRA adapters in response to task-specific progress, enabling adaptive knowledge retention and parameter expansion. Evaluations on a diverse set of standard benchmarks (Atari, DMC, Jericho) demonstrate that ScaleZero, utilizing solely online reinforcement learning with one model, performs on par with specialized single-task agents. With the DPS strategy, it remains competitive while using just 71.5% of the environment interactions. These findings underscore the potential of ScaleZero for effective multi-task planning. Our code is available at \textcolor{magenta}{https://github.com/opendilab/LightZero}.
ButterflyQuant: Ultra-low-bit LLM Quantization through Learnable Orthogonal Butterfly Transforms
arXiv:2509.09679v2 Announce Type: replace Abstract: Large language models require massive memory footprints, severely limiting deployment on consumer hardware. Quantization reduces memory through lower numerical precision, but extreme 2-bit quantization suffers from catastrophic performance loss due to outliers in activations. Rotation-based methods such as QuIP and QuaRot apply orthogonal transforms to eliminate outliers before quantization, using computational invariance: $\mathbf{y} = \mathbf{Wx} = (\mathbf{WQ}^T)(\mathbf{Qx})$ for orthogonal $\mathbf{Q}$. However, these methods use fixed transforms--Hadamard matrices achieving optimal worst-case coherence $\mu = 1/\sqrt{n}$--that cannot adapt to specific weight distributions. We identify that different transformer layers exhibit distinct outlier patterns, motivating layer-adaptive rotations rather than one-size-fits-all approaches. In this work, we propose ButterflyQuant, which replaces Hadamard rotations with learnable butterfly transforms parameterized by continuous Givens rotation angles. Unlike Hadamard's discrete ${+1, -1}$ entries that are non-differentiable and thus prohibit gradient-based learning, butterfly transforms' continuous parameterization enables smooth optimization while guaranteeing orthogonality by construction. This orthogonal constraint ensures theoretical guarantees in outlier suppression while achieving $O(n \log n)$ computational complexity with only $\frac{n \log n}{2}$ learnable parameters. We further introduce a uniformity regularization on post-transformation activations to promote smoother distributions amenable to quantization. Learning requires only 128 calibration samples and converges in minutes on a single GPU--a negligible one-time cost. For LLaMA-2-7B with 2-bit quantization, ButterflyQuant achieves 15.4 perplexity versus 37.3 for QuIP. \href{https://github.com/42Shawn/Butterflyquant-llm}{Codes} are available.
Prompt Injection Attacks on LLM Generated Reviews of Scientific Publications
arXiv:2509.10248v3 Announce Type: replace Abstract: The ongoing intense discussion on rising LLM usage in the scientific peer-review process has recently been mingled by reports of authors using hidden prompt injections to manipulate review scores. Since the existence of such "attacks" - although seen by some commentators as "self-defense" - would have a great impact on the further debate, this paper investigates the practicability and technical success of the described manipulations. Our systematic evaluation uses 1k reviews of 2024 ICLR papers generated by a wide range of LLMs shows two distinct results: I) very simple prompt injections are indeed highly effective, reaching up to 100% acceptance scores. II) LLM reviews are generally biased toward acceptance (>95% in many models). Both results have great impact on the ongoing discussions on LLM usage in peer-review.
Matched-Pair Experimental Design with Active Learning
arXiv:2509.10742v2 Announce Type: replace Abstract: Matched-pair experimental designs aim to detect treatment effects by pairing participants and comparing within-pair outcome differences. In many situations, the overall effect size across the entire population is small. Then, the focus naturally shifts to identifying and targeting high treatment-effect regions where the intervention is most effective. This paper proposes a matched-pair experimental design that sequentially and actively enrolls patients in high treatment-effect regions. Importantly, we frame the identification of the target region as a classification problem and propose an active learning framework tailored to matched-pair designs. Our design not only reduces the experimental cost of detecting treatment efficacy, but also ensures that the identified regions enclose the entire high-treatment-effect regions. Our theoretical analysis of the framework's label complexity and experiments in practical scenarios demonstrate the efficiency and advantages of the approach.
Selective Risk Certification for LLM Outputs via Information-Lift Statistics: PAC-Bayes, Robustness, and Skeleton Design
arXiv:2509.12527v2 Announce Type: replace Abstract: Large language models frequently generate confident but incorrect outputs, requiring formal uncertainty quantification with abstention guarantees. We develop information-lift certificates that compare model probabilities to a skeleton baseline, accumulating evidence into sub-gamma PAC-Bayes bounds valid under heavy-tailed distributions. Across eight datasets, our method achieves 77.2\% coverage at 2\% risk, outperforming recent 2023-2024 baselines by 8.6-15.1 percentage points, while blocking 96\% of critical errors in high-stakes scenarios vs 18-31\% for entropy methods. Limitations include skeleton dependence and frequency-only (not severity-aware) risk control, though performance degrades gracefully under corruption.
Adversarial generalization of unfolding (model-based) networks
arXiv:2509.15370v2 Announce Type: replace Abstract: Unfolding networks are interpretable networks emerging from iterative algorithms, incorporate prior knowledge of data structure, and are designed to solve inverse problems like compressed sensing, which deals with recovering data from noisy, missing observations. Compressed sensing finds applications in critical domains, from medical imaging to cryptography, where adversarial robustness is crucial to prevent catastrophic failures. However, a solid theoretical understanding of the performance of unfolding networks in the presence of adversarial attacks is still in its infancy. In this paper, we study the adversarial generalization of unfolding networks when perturbed with $l_2$-norm constrained attacks, generated by the fast gradient sign method. Particularly, we choose a family of state-of-the-art overaparameterized unfolding networks and deploy a new framework to estimate their adversarial Rademacher complexity. Given this estimate, we provide adversarial generalization error bounds for the networks under study, which are tight with respect to the attack level. To our knowledge, this is the first theoretical analysis on the adversarial generalization of unfolding networks. We further present a series of experiments on real-world data, with results corroborating our derived theory, consistently for all data. Finally, we observe that the family's overparameterization can be exploited to promote adversarial robustness, shedding light on how to efficiently robustify neural networks.
Small LLMs with Expert Blocks Are Good Enough for Hyperparamter Tuning
arXiv:2509.15561v3 Announce Type: replace Abstract: Hyper-parameter Tuning (HPT) is a necessary step in machine learning (ML) pipelines but becomes computationally expensive and opaque with larger models. Recently, Large Language Models (LLMs) have been explored for HPT, yet most rely on models exceeding 100 billion parameters. We propose an Expert Block Framework for HPT using Small LLMs. At its core is the Trajectory Context Summarizer (TCS), a deterministic block that transforms raw training trajectories into structured context, enabling small LLMs to analyze optimization progress with reliability comparable to larger models. Using two locally-run LLMs (phi4:reasoning14B and qwen2.5-coder:32B) and a 10-trial budget, our TCS-enabled HPT pipeline achieves average performance within ~0.9 percentage points of GPT-4 across six diverse tasks.
Local Mechanisms of Compositional Generalization in Conditional Diffusion
arXiv:2509.16447v2 Announce Type: replace Abstract: Conditional diffusion models appear capable of compositional generalization, i.e., generating convincing samples for out-of-distribution combinations of conditioners, but the mechanisms underlying this ability remain unclear. To make this concrete, we study length generalization, the ability to generate images with more objects than seen during training. In a controlled CLEVR setting (Johnson et al., 2017), we find that length generalization is achievable in some cases but not others, suggesting that models only sometimes learn the underlying compositional structure. We then investigate locality as a structural mechanism for compositional generalization. Prior works proposed score locality as a mechanism for creativity in unconditional diffusion models (Kamb & Ganguli, 2024; Niedoba et al., 2024), but did not address flexible conditioning or compositional generalization. In this paper, we prove an exact equivalence between a specific compositional structure ("conditional projective composition") (Bradley et al., 2025) and scores with sparse dependencies on both pixels and conditioners ("local conditional scores"). This theory also extends to feature-space compositionality. We validate our theory empirically: CLEVR models that succeed at length generalization exhibit local conditional scores, while those that fail do not. Furthermore, we show that a causal intervention explicitly enforcing local conditional scores restores length generalization in a previously failing model. Finally, we investigate feature-space compositionality in color-conditioned CLEVR, and find preliminary evidence of compositional structure in SDXL.
Long-Tailed Out-of-Distribution Detection with Refined Separate Class Learning
arXiv:2509.17034v2 Announce Type: replace Abstract: Out-of-distribution (OOD) detection is crucial for deploying robust machine learning models. However, when training data follows a long-tailed distribution, the model's ability to accurately detect OOD samples is significantly compromised, due to the confusion between OOD samples and head/tail classes. To distinguish OOD samples from both head and tail classes, the separate class learning (SCL) approach has emerged as a promising solution, which separately conduct head-specific and tail-specific class learning. To this end, we examine the limitations of existing works of SCL and reveal that the OOD detection performance is notably influenced by the use of static scaling temperature value and the presence of uninformative outliers. To mitigate these limitations, we propose a novel approach termed Refined Separate Class Learning (RSCL), which leverages dynamic class-wise temperature adjustment to modulate the temperature parameter for each in-distribution class and informative outlier mining to identify diverse types of outliers based on their affinity with head and tail classes. Extensive experiments demonstrate that RSCL achieves superior OOD detection performance while improving the classification accuracy on in-distribution data.
MolPILE - large-scale, diverse dataset for molecular representation learning
arXiv:2509.18353v2 Announce Type: replace Abstract: The size, diversity, and quality of pretraining datasets critically determine the generalization ability of foundation models. Despite their growing importance in chemoinformatics, the effectiveness of molecular representation learning has been hindered by limitations in existing small molecule datasets. To address this gap, we present MolPILE, large-scale, diverse, and rigorously curated collection of 222 million compounds, constructed from 6 large-scale databases using an automated curation pipeline. We present a comprehensive analysis of current pretraining datasets, highlighting considerable shortcomings for training ML models, and demonstrate how retraining existing models on MolPILE yields improvements in generalization performance. This work provides a standardized resource for model training, addressing the pressing need for an ImageNet-like dataset in molecular chemistry.
APRIL: Active Partial Rollouts in Reinforcement Learning to Tame Long-tail Generation
arXiv:2509.18521v2 Announce Type: replace Abstract: Reinforcement learning (RL) has become a cornerstone in advancing large-scale pre-trained language models (LLMs). Successive generations, including GPT-o series, DeepSeek-R1, Kimi-K1.5, Grok 4, and GLM-4.5, have relied on large-scale RL training to enhance reasoning and coding capabilities. To meet the community's growing RL needs, numerous RL frameworks have been proposed. However, RL training remains computationally expensive, with rollout generation accounting for more than 90% of total runtime. In addition, its efficiency is often constrained by the long-tail distribution of rollout response lengths, where a few lengthy responses stall entire batches, leaving GPUs idle and underutilized. As model and rollout sizes continue to grow, this bottleneck increasingly limits scalability. To address this challenge, we propose Active Partial Rollouts in Reinforcement Learning (APRIL), which mitigates long-tail inefficiency. In the rollout phase, APRIL over-provisions rollout requests, terminates once the target number of responses is reached, and recycles incomplete responses for continuation in future steps. This strategy ensures that no rollouts are discarded while substantially reducing GPU idle time. Experiments show that APRIL improves rollout throughput by at most 44% across commonly used RL algorithms (GRPO, DAPO, GSPO), accelerates convergence, and achieves at most 8% higher final accuracy across tasks. Moreover, APRIL is both framework and hardware agnostic, already integrated into the slime RL framework, and deployable on NVIDIA and AMD GPUs alike. Taken together, this work unifies system-level and algorithmic considerations in proposing APRIL, with the aim of advancing RL training efficiency and inspiring further optimizations in RL systems. Our codebase is available at https://github.com/RLsys-Foundation/APRIL
S$^2$Transformer: Scalable Structured Transformers for Global Station Weather Forecasting
arXiv:2509.19648v2 Announce Type: replace Abstract: Global Station Weather Forecasting (GSWF) is a key meteorological research area, critical to energy, aviation, and agriculture. Existing time series forecasting methods often ignore or unidirectionally model spatial correlation when conducting large-scale global station forecasting. This contradicts the intrinsic nature underlying observations of the global weather system, limiting forecast performance. To address this, we propose a novel Spatial Structured Attention Block in this paper. It partitions the spatial graph into a set of subgraphs and instantiates Intra-subgraph Attention to learn local spatial correlation within each subgraph, and aggregates nodes into subgraph representations for message passing among the subgraphs via Inter-subgraph Attention -- considering both spatial proximity and global correlation. Building on this block, we develop a multiscale spatiotemporal forecasting model S$^2$Transformer by progressively expanding subgraph scales. The resulting model is both scalable and able to produce structured spatial correlation, and meanwhile, it is easy to implement. The experimental results show that it can achieve performance improvements up to 16.8% over time series forecasting baselines at low running costs.
Frictional Q-Learning
arXiv:2509.19771v2 Announce Type: replace Abstract: We draw an analogy between static friction in classical mechanics and extrapolation error in off-policy RL, and use it to formulate a constraint that prevents the policy from drifting toward unsupported actions. In this study, we present Frictional Q-learning, a deep reinforcement learning algorithm for continuous control, which extends batch-constrained reinforcement learning. Our algorithm constrains the agent's action space to encourage behavior similar to that in the replay buffer, while maintaining a distance from the manifold of the orthonormal action space. The constraint preserves the simplicity of batch-constrained, and provides an intuitive physical interpretation of extrapolation error. Empirically, we further demonstrate that our algorithm is robustly trained and achieves competitive performance across standard continuous control benchmarks.
Advancing Universal Deep Learning for Electronic-Structure Hamiltonian Prediction of Materials
arXiv:2509.19877v2 Announce Type: replace Abstract: Deep learning methods for electronic-structure Hamiltonian prediction has offered significant computational efficiency advantages over traditional DFT methods, yet the diversity of atomic types, structural patterns, and the high-dimensional complexity of Hamiltonians pose substantial challenges to the generalization performance. In this work, we contribute on both the methodology and dataset sides to advance universal deep learning paradigm for Hamiltonian prediction. On the method side, we propose NextHAM, a neural E(3)-symmetry and expressive correction method for efficient and generalizable materials electronic-structure Hamiltonian prediction. First, we introduce the zeroth-step Hamiltonians, which can be efficiently constructed by the initial charge density of DFT, as informative descriptors of neural regression model in the input level and initial estimates of the target Hamiltonian in the output level, so that the regression model directly predicts the correction terms to the target ground truths, thereby significantly simplifying the input-output mapping for learning. Second, we present a neural Transformer architecture with strict E(3)-Symmetry and high non-linear expressiveness for Hamiltonian prediction. Third, we propose a novel training objective to ensure the accuracy performance of Hamiltonians in both real space and reciprocal space, preventing error amplification and the occurrence of "ghost states" caused by the large condition number of the overlap matrix. On the dataset side, we curate a high-quality broad-coverage large benchmark, namely Materials-HAM-SOC, comprising 17,000 material structures spanning 68 elements from six rows of the periodic table and explicitly incorporating SOC effects. Experimental results on Materials-HAM-SOC demonstrate that NextHAM achieves excellent accuracy and efficiency in predicting Hamiltonians and band structures.
MCGrad: Multicalibration at Web Scale
arXiv:2509.19884v2 Announce Type: replace Abstract: We propose MCGrad, a novel and scalable multicalibration algorithm. Multicalibration - calibration in sub-groups of the data - is an important property for the performance of machine learning-based systems. Existing multicalibration methods have thus far received limited traction in industry. We argue that this is because existing methods (1) require such subgroups to be manually specified, which ML practitioners often struggle with, (2) are not scalable, or (3) may harm other notions of model performance such as log loss and Area Under the Precision-Recall Curve (PRAUC). MCGrad does not require explicit specification of protected groups, is scalable, and often improves other ML evaluation metrics instead of harming them. MCGrad has been in production at Meta, and is now part of hundreds of production models. We present results from these deployments as well as results on public datasets.
Discovering Association Rules in High-Dimensional Small Tabular Data
arXiv:2509.20113v2 Announce Type: replace Abstract: Association Rule Mining (ARM) aims to discover patterns between features in datasets in the form of propositional rules, supporting both knowledge discovery and interpretable machine learning in high-stakes decision-making. However, in high-dimensional settings, rule explosion and computational overhead render popular algorithmic approaches impractical without effective search space reduction, challenges that propagate to downstream tasks. Neurosymbolic methods, such as Aerial+, have recently been proposed to address the rule explosion in ARM. While they tackle the high dimensionality of the data, they also inherit limitations of neural networks, particularly reduced performance in low-data regimes. This paper makes three key contributions to association rule discovery in high-dimensional tabular data. First, we empirically show that Aerial+ scales one to two orders of magnitude better than state-of-the-art algorithmic and neurosymbolic baselines across five real-world datasets. Second, we introduce the novel problem of ARM in high-dimensional, low-data settings, such as gene expression data from the biomedicine domain with around 18k features and 50 samples. Third, we propose two fine-tuning approaches to Aerial+ using tabular foundation models. Our proposed approaches are shown to significantly improve rule quality on five real-world datasets, demonstrating their effectiveness in low-data, high-dimensional scenarios.
Predictive Coding-based Deep Neural Network Fine-tuning for Computationally Efficient Domain Adaptation
arXiv:2509.20269v2 Announce Type: replace Abstract: As deep neural networks are increasingly deployed in dynamic, real-world environments, relying on a single static model is often insufficient. Changes in input data distributions caused by sensor drift or lighting variations necessitate continual model adaptation. In this paper, we propose a hybrid training methodology that enables efficient on-device domain adaptation by combining the strengths of Backpropagation and Predictive Coding. The method begins with a deep neural network trained offline using Backpropagation to achieve high initial performance. Subsequently, Predictive Coding is employed for online adaptation, allowing the model to recover accuracy lost due to shifts in the input data distribution. This approach leverages the robustness of Backpropagation for initial representation learning and the computational efficiency of Predictive Coding for continual learning, making it particularly well-suited for resource-constrained edge devices or future neuromorphic accelerators. Experimental results on the MNIST and CIFAR-10 datasets demonstrate that this hybrid strategy enables effective adaptation with a reduced computational overhead, offering a promising solution for maintaining model performance in dynamic environments.
Predicting Male Domestic Violence Using Explainable Ensemble Learning and Exploratory Data Analysis
arXiv:2403.15594v3 Announce Type: replace-cross Abstract: Domestic violence is commonly viewed as a gendered issue that primarily affects women, which tends to leave male victims largely overlooked. This study presents a novel, data-driven analysis of male domestic violence (MDV) in Bangladesh, highlighting the factors that influence it and addressing the challenges posed by a significant categorical imbalance of 5:1 and limited data availability. We collected data from nine major cities in Bangladesh and conducted exploratory data analysis (EDA) to understand the underlying dynamics. EDA revealed patterns such as the high prevalence of verbal abuse, the influence of financial dependency, and the role of familial and socio-economic factors in MDV. To predict and analyze MDV, we implemented 10 traditional machine learning (ML) models, three deep learning models, and two ensemble models, including stacking and hybrid approaches. We propose a stacking ensemble model with ANN and CatBoost as base classifiers and Logistic Regression as the meta-model, which demonstrated the best performance, achieving $95\%$ accuracy, a $99.29\%$ AUC, and balanced metrics across evaluation criteria. Model-specific feature importance analysis of the base classifiers identified key features influencing their decision-making. Model-agnostic explainable AI techniques, such as SHAP and LIME, provided both local and global insights into the decision-making processes of the proposed model, thereby increasing transparency and interpretability. Statistical validation using paired $t$-tests with 10-fold cross-validation and Bonferroni correction ($\alpha = 0.0036$) confirmed the superior performance of our proposed model over alternatives. Our findings challenge the prevailing notion that domestic abuse primarily affects women, emphasizing the need for tailored interventions and support systems for male victims.
Can social media provide early warning of retraction? Evidence from critical tweets identified by human annotation and large language models
arXiv:2403.16851v3 Announce Type: replace-cross Abstract: Timely detection of problematic research is essential for safeguarding scientific integrity. To explore whether social media commentary can serve as an early indicator of potentially problematic articles, this study analysed 3,815 tweets referencing 604 retracted articles and 3,373 tweets referencing 668 comparable non-retracted articles. Tweets critical of the articles were identified through both human annotation and large language models (LLMs). Human annotation revealed that 8.3% of retracted articles were associated with at least one critical tweet prior to retraction, compared to only 1.5% of non-retracted articles, highlighting the potential of tweets as early warning signals of retraction. However, critical tweets identified by LLMs (GPT-4o mini, Gemini 2.0 Flash-Lite, and Claude 3.5 Haiku) only partially aligned with human annotation, suggesting that fully automated monitoring of post-publication discourse should be applied with caution. A human-AI collaborative approach may offer a more reliable and scalable alternative, with human expertise helping to filter out tweets critical of issues unrelated to the research integrity of the articles. Overall, this study provides insights into how social media signals, combined with generative AI technologies, may support efforts to strengthen research integrity.
Generalized Gradient Descent is a Hypergraph Functor
arXiv:2403.19845v2 Announce Type: replace-cross Abstract: Cartesian reverse derivative categories (CRDCs) provide an axiomatic generalization of the reverse derivative, which allows generalized analogues of classic optimization algorithms such as gradient descent to be applied to a broad class of problems. In this paper, we show that generalized gradient descent with respect to a given CRDC induces a hypergraph functor from a hypergraph category of optimization problems to a hypergraph category of dynamical systems. The domain of this functor consists of objective functions that are 1) general in the sense that they are defined with respect to an arbitrary CRDC, and 2) open in that they are decorated spans that can be composed with other such objective functions via variable sharing. The codomain is specified analogously as a category of general and open dynamical systems for the underlying CRDC. We describe how the hypergraph functor induces a distributed optimization algorithm for arbitrary composite problems specified in the domain. To illustrate the kinds of problems our framework can model, we show that parameter sharing models in multitask learning, a prevalent machine learning paradigm, yield a composite optimization problem for a given choice of CRDC. We then apply the gradient descent functor to this composite problem and describe the resulting distributed gradient descent algorithm for training parameter sharing models.
Two-level overlapping additive Schwarz preconditioner for training scientific machine learning applications
arXiv:2406.10997v2 Announce Type: replace-cross Abstract: We introduce a novel two-level overlapping additive Schwarz preconditioner for accelerating the training of scientific machine learning applications. The design of the proposed preconditioner is motivated by the nonlinear two-level overlapping additive Schwarz preconditioner. The neural network parameters are decomposed into groups (subdomains) with overlapping regions. In addition, the network's feed-forward structure is indirectly imposed through a novel subdomain-wise synchronization strategy and a coarse-level training step. Through a series of numerical experiments, which consider physics-informed neural networks and operator learning approaches, we demonstrate that the proposed two-level preconditioner significantly speeds up the convergence of the standard (LBFGS) optimizer while also yielding more accurate machine learning models. Moreover, the devised preconditioner is designed to take advantage of model-parallel computations, which can further reduce the training time.
A Deep Learning Framework for Evaluating Dynamic Network Generative Models and Anomaly Detection
arXiv:2406.11901v2 Announce Type: replace-cross Abstract: Understanding dynamic systems like disease outbreaks, social influence, and information diffusion requires effective modeling of complex networks. Traditional evaluation methods for static networks often fall short when applied to temporal networks. This paper introduces DGSP-GCN (Dynamic Graph Similarity Prediction based on Graph Convolutional Network), a deep learning-based framework that integrates graph convolutional networks with dynamic graph signal processing techniques to provide a unified solution for evaluating generative models and detecting anomalies in dynamic networks. DGSP-GCN assesses how well a generated network snapshot matches the expected temporal evolution, incorporating an attention mechanism to improve embedding quality and capture dynamic structural changes. The approach was tested on five real-world datasets: WikiMath, Chickenpox, PedalMe, MontevideoBus, and MetraLa. Results show that DGSP-GCN outperforms baseline methods, such as time series regression and random similarity assignment, achieving the lowest error rates (MSE of 0.0645, MAE of 0.1781, RMSE of 0.2507). These findings highlight DGSP-GCN's effectiveness in evaluating and detecting anomalies in dynamic networks, offering valuable insights for network evolution and anomaly detection research.
Towards Complete Causal Explanation with Expert Knowledge
arXiv:2407.07338v3 Announce Type: replace-cross Abstract: We study the problem of restricting a Markov equivalence class of maximal ancestral graphs (MAGs) to only those MAGs that contain certain edge marks, which we refer to as expert or orientation knowledge. Such a restriction of the Markov equivalence class can be uniquely represented by a restricted essential ancestral graph. Our contributions are several-fold. First, we prove certain properties for the entire Markov equivalence class including a conjecture from Ali et al. (2009). Second, we present several new sound graphical orientation rules for adding orientation knowledge to an essential ancestral graph. We also show that some orientation rules of Zhang (2008b) are not needed for restricting the Markov equivalence class with orientation knowledge. Third, we provide an algorithm for including this orientation knowledge and show that in certain settings the output of our algorithm is a restricted essential ancestral graph. Finally, outside of the specified settings, we provide an algorithm for checking whether a graph is a restricted essential graph and discuss its runtime. This work can be seen as a generalization of Meek (1995) to settings which allow for latent confounding.
Text-Augmented Multimodal LLMs for Chemical Reaction Condition Recommendation
arXiv:2407.15141v2 Announce Type: replace-cross Abstract: Identifying reaction conditions that are broadly applicable across diverse substrates is a longstanding challenge in chemical and pharmaceutical research. While many methods are available to generate conditions with acceptable performance, a universal approach for reliably discovering effective conditions during reaction exploration is rare. Consequently, current reaction optimization processes are often labor-intensive, time-consuming, and costly, relying heavily on trial-and-error experimentation. Nowadays, large language models (LLMs) are capable of tackling chemistry-related problems, such as molecule design and chemical reasoning tasks. Here, we report the design, implementation and application of Chemma-RC, a text-augmented multimodal LLM to identify effective conditions through task-specific dialogue and condition generation. Chemma-RC learns a unified representation of chemical reactions by aligning multiple modalities-including text corpus, reaction SMILES, and reaction graphs-within a shared embedding module. Performance benchmarking on datasets showed high precision in identifying optimal conditions, with up to 17% improvement over the current state-of-the-art methods. A palladium-catalysed imidazole C-H arylation reaction was investigated experimentally to evaluate the functionalities of the Chemma-RC in practice. Our findings suggest that Chemma-RC holds significant potential to accelerate high-throughput condition screening in chemical synthesis.
Real-time Hybrid System Identification with Online Deterministic Annealing
arXiv:2408.01730v2 Announce Type: replace-cross Abstract: We introduce a real-time identification method for discrete-time state-dependent switching systems in both the input--output and state-space domains. In particular, we design a system of adaptive algorithms running in two timescales; a stochastic approximation algorithm implements an online deterministic annealing scheme at a slow timescale and estimates the mode-switching signal, and an recursive identification algorithm runs at a faster timescale and updates the parameters of the local models based on the estimate of the switching signal. We first focus on piece-wise affine systems and discuss identifiability conditions and convergence properties based on the theory of two-timescale stochastic approximation. In contrast to standard identification algorithms for switched systems, the proposed approach gradually estimates the number of modes and is appropriate for real-time system identification using sequential data acquisition. The progressive nature of the algorithm improves computational efficiency and provides real-time control over the performance-complexity trade-off. Finally, we address specific challenges that arise in the application of the proposed methodology in identification of more general switching systems. Simulation results validate the efficacy of the proposed methodology.
Lightweight Modular Parameter-Efficient Tuning for Open-Vocabulary Object Detection
arXiv:2408.10787v4 Announce Type: replace-cross Abstract: Open-vocabulary object detection (OVD) extends recognition beyond fixed taxonomies by aligning visual and textual features, as in MDETR, GLIP, or RegionCLIP. While effective, these models require updating all parameters of large vision--language backbones, leading to prohibitive training cost. Recent efficient OVD approaches, inspired by parameter-efficient fine-tuning methods such as LoRA or adapters, reduce trainable parameters but often face challenges in selecting which layers to adapt and in balancing efficiency with accuracy. We propose UniProj-Det, a lightweight modular framework for parameter-efficient OVD. UniProj-Det freezes pretrained backbones and introduces a Universal Projection module with a learnable modality token, enabling unified vision--language adaptation at minimal cost. Applied to MDETR, our framework trains only about ~2-5% of parameters while achieving competitive or superior performance on phrase grounding, referring expression comprehension, and segmentation. Comprehensive analysis of FLOPs, memory, latency, and ablations demonstrates UniProj-Det as a principled step toward scalable and efficient open-vocabulary detection.
The Northeast Materials Database for Magnetic Materials
arXiv:2409.15675v2 Announce Type: replace-cross Abstract: The discovery of magnetic materials with high operating temperature ranges and optimized performance is essential for advanced applications. Current data-driven approaches are limited by the lack of accurate, comprehensive, and feature-rich databases. This study aims to address this challenge by using Large Language Models (LLMs) to create a comprehensive, experiment-based, magnetic materials database named the Northeast Materials Database (NEMAD), which consists of 67,573 magnetic materials entries(www.nemad.org). The database incorporates chemical composition, magnetic phase transition temperatures, structural details, and magnetic properties. Enabled by NEMAD, we trained machine learning models to classify materials and predict transition temperatures. Our classification model achieved an accuracy of 90% in categorizing materials as ferromagnetic (FM), antiferromagnetic (AFM), and non-magnetic (NM). The regression models predict Curie (N\'eel) temperature with a coefficient of determination (R2) of 0.87 (0.83) and a mean absolute error (MAE) of 56K (38K). These models identified 25 (13) FM (AFM) candidates with a predicted Curie (N\'eel) temperature above 500K (100K) from the Materials Project. This work shows the feasibility of combining LLMs for automated data extraction and machine learning models to accelerate the discovery of magnetic materials.
Hybrid Summary Statistics
arXiv:2410.07548v2 Announce Type: replace-cross Abstract: We present a way to capture high-information posteriors from training sets that are sparsely sampled over the parameter space for robust simulation-based inference. In physical inference problems, we can often apply domain knowledge to define traditional summary statistics to capture some of the information in a dataset. We show that augmenting these statistics with neural network outputs to maximise the mutual information improves information extraction compared to neural summaries alone or their concatenation to existing summaries and makes inference robust in settings with low training data. We introduce 1) two loss formalisms to achieve this and 2) apply the technique to two different cosmological datasets to extract non-Gaussian parameter information.
Scaling Laws for Online Advertisement Retrieval
arXiv:2411.13322v2 Announce Type: replace-cross Abstract: The scaling law is a notable property of neural network models and has significantly propelled the development of large language models. Scaling laws hold great promise in guiding model design and resource allocation. Recent research increasingly shows that scaling laws are not limited to NLP tasks or Transformer architectures; they also apply to domains such as recommendation. However, there is still a lack of literature on scaling law research in online advertisement retrieval systems. This may be because 1) identifying the scaling law for resource cost and online revenue is often expensive in both time and training resources for industrial applications, and 2) varying settings for different systems prevent the scaling law from being applied across various scenarios. To address these issues, we propose a lightweight paradigm to identify online scaling laws of retrieval models, incorporating a novel offline metric and an offline simulation algorithm. We prove that under mild assumptions, the correlation between the novel metric and online revenue asymptotically approaches 1 and empirically validates its effectiveness. The simulation algorithm can estimate the machine cost offline. Based on the lightweight paradigm, we can identify online scaling laws for retrieval models almost exclusively through offline experiments, and quickly estimate machine costs and revenues for given model configurations. We further validate the existence of scaling laws across mainstream model architectures (e.g., Transformer, MLP, and DSSM) in our real-world advertising system. With the identified scaling laws, we demonstrate practical applications for ROI-constrained model designing and multi-scenario resource allocation in the online advertising system. To the best of our knowledge, this is the first work to study identification and application of online scaling laws for online advertisement retrieval.
The Asymptotic Behavior of Attention in Transformers
arXiv:2412.02682v2 Announce Type: replace-cross Abstract: The transformer architecture has become the foundation of modern Large Language Models (LLMs), yet its theoretical properties are still not well understood. As with classic neural networks, a common approach to improve these models is to increase their size and depth. However, such strategies may be suboptimal, as several works have shown that adding more layers yields increasingly diminishing returns. More importantly, prior studies have shown that increasing depth may lead to model collapse, i.e., all the tokens converge to a single cluster, undermining the ability of LLMs to generate diverse outputs. Building on differential equation models for the transformer dynamics, we prove that all the tokens in a transformer asymptotically converge to a cluster as depth increases. At the technical level we leverage tools from control theory, including consensus dynamics on manifolds and input-to-state stability (ISS). We then extend our analysis to autoregressive models, exploiting their structure to further generalize the theoretical guarantees.
The Value of Information in Human-AI Decision-making
arXiv:2502.06152v5 Announce Type: replace-cross Abstract: Multiple agents are increasingly combined to make decisions with the expectation of achieving complementary performance, where the decisions they make together outperform those made individually. However, knowing how to improve the performance of collaborating agents requires knowing what information and strategies each agent employs. With a focus on human-AI pairings, we contribute a decision-theoretic framework for characterizing the value of information. By defining complementary information, our approach identifies opportunities for agents to better exploit available information in AI-assisted decision workflows. We present a novel explanation technique (ILIV-SHAP) that adapts SHAP explanations to highlight human-complementing information. We validate the effectiveness of ACIV and ILIV-SHAP through a study of human-AI decision-making, and demonstrate the framework on examples from chest X-ray diagnosis and deepfake detection. We find that presenting ILIV-SHAP with AI predictions leads to reliably greater reductions in error over non-AI assisted decisions more than vanilla SHAP.
Quantifying depressive mental states with large language models
arXiv:2502.09487v2 Announce Type: replace-cross Abstract: Large Language Models (LLMs) may have an important role to play in mental health by facilitating the quantification of verbal expressions used to communicate emotions, feelings and thoughts. While there has been substantial and very promising work in this area, the fundamental limits are uncertain. Here, focusing on depressive symptoms, we outline and evaluate LLM performance on three critical tests. The first test evaluates LLM performance on a novel ground-truth dataset from a large human sample (n=770). This dataset is novel as it contains both standard clinically validated quantifications of depression symptoms and specific verbal descriptions of the thoughts related to each symptom by the same individual. The performance of LLMs on this richly informative data shows an upper bound on the performance in this domain, and allow us to examine the extent to which inference about symptoms generalises. Second, we test to what extent the latent structure in LLMs can capture the clinically observed patterns. We train supervised sparse auto-encoders (sSAE) to predict specific symptoms and symptom patterns within a syndrome. We find that sSAE weights can effectively modify the clinical pattern produced by the model, and thereby capture the latent structure of relevant clinical variation. Third, if LLMs correctly capture and quantify relevant mental states, then these states should respond to changes in emotional states induced by validated emotion induction interventions. We show that this holds in a third experiment with 190 participants. Overall, this work provides foundational insights into the quantification of pathological mental states with LLMs, highlighting hard limits on the requirements of the data underlying LLM-based quantification; but also suggesting LLMs show substantial conceptual alignment.
Thinking Outside the (Gray) Box: A Context-Based Score for Assessing Value and Originality in Neural Text Generation
arXiv:2502.13207v3 Announce Type: replace-cross Abstract: Despite the increasing use of large language models for creative tasks, their outputs often lack diversity. Common solutions, such as sampling at higher temperatures, can compromise the quality of the results. Dealing with this trade-off is still an open challenge in designing AI systems for creativity. Drawing on information theory, we propose a context-based score to quantitatively evaluate value and originality. This score incentivizes accuracy and adherence to the request while fostering divergence from the learned distribution. We show that our score can be used as a reward in a reinforcement learning framework to fine-tune large language models for maximum performance. We validate our strategy through experiments considering a variety of creative tasks, such as poetry generation and math problem solving, demonstrating that it enhances the value and originality of the generated solutions.
Multimodal AI predicts clinical outcomes of drug combinations from preclinical data
arXiv:2503.02781v2 Announce Type: replace-cross Abstract: Predicting clinical outcomes from preclinical data is essential for identifying safe and effective drug combinations, reducing late-stage clinical failures, and accelerating the development of precision therapies. Current AI models rely on structural or target-based features but fail to incorporate the multimodal data necessary for accurate, clinically relevant predictions. Here, we introduce Madrigal, a multimodal AI model that learns from structural, pathway, cell viability, and transcriptomic data to predict drug-combination effects across 953 clinical outcomes and 21,842 compounds, including combinations of approved drugs and novel compounds in development. Madrigal uses an attention bottleneck module to unify preclinical drug data modalities while handling missing data during training and inference, a major challenge in multimodal learning. It outperforms single-modality methods and state-of-the-art models in predicting adverse drug interactions, and ablations show both modality alignment and multimodality are necessary. It captures transporter-mediated interactions and aligns with head-to-head clinical trial differences for neutropenia, anemia, alopecia, and hypoglycemia. In type 2 diabetes and MASH, Madrigal supports polypharmacy decisions and prioritizes resmetirom among safer candidates. Extending to personalization, Madrigal improves patient-level adverse-event prediction in a longitudinal EHR cohort and an independent oncology cohort, and predicts ex vivo efficacy in primary acute myeloid leukemia samples and patient-derived xenograft models. Madrigal links preclinical multimodal readouts to safety risks of drug combinations and offers a generalizable foundation for safer combination design.
Scaling Rich Style-Prompted Text-to-Speech Datasets
arXiv:2503.04713v2 Announce Type: replace-cross Abstract: We introduce Paralinguistic Speech Captions (ParaSpeechCaps), a large-scale dataset that annotates speech utterances with rich style captions. While rich abstract tags (e.g. guttural, nasal, pained) have been explored in small-scale human-annotated datasets, existing large-scale datasets only cover basic tags (e.g. low-pitched, slow, loud). We combine off-the-shelf text and speech embedders, classifiers and an audio language model to automatically scale rich tag annotations for the first time. ParaSpeechCaps covers a total of 59 style tags, including both speaker-level intrinsic tags and utterance-level situational tags. It consists of 342 hours of human-labelled data (PSC-Base) and 2427 hours of automatically annotated data (PSC-Scaled). We finetune Parler-TTS, an open-source style-prompted TTS model, on ParaSpeechCaps, and achieve improved style consistency (+7.9% Consistency MOS) and speech quality (+15.5% Naturalness MOS) over the best performing baseline that combines existing rich style tag datasets. We ablate several of our dataset design choices to lay the foundation for future work in this space. Our dataset, models and code are released at https://github.com/ajd12342/paraspeechcaps .
Beyond SHAP and Anchors: A large-scale experiment on how developers struggle to design meaningful end-user explanations
arXiv:2503.15512v3 Announce Type: replace-cross Abstract: Modern machine learning produces models that are impossible for users or developers to fully understand -- raising concerns about trust, oversight, safety, and human dignity when they are integrated into software products. Transparency and explainability methods aim to provide some help in understanding models, but it remains challenging for developers to design explanations that are understandable to target users and effective for their purpose. Emerging guidelines and regulations set goals but may not provide effective actionable guidance to developers. In a large-scale experiment with 124 participants, we explored how developers approach providing end-user explanations, including what challenges they face, and to what extent specific policies can guide their actions. We investigated whether and how specific forms of policy guidance help developers design explanations and provide evidence for policy compliance for an ML-powered screening tool for diabetic retinopathy. Participants across the board struggled to produce quality explanations and comply with the provided policies. Contrary to our expectations, we found that the nature and specificity of policy guidance had little effect. We posit that participant noncompliance is in part due to a failure to imagine and anticipate the needs of non-technical stakeholders. Drawing on cognitive process theory and the sociological imagination to contextualize participants' failure, we recommend educational interventions.
Revenue Maximization Under Sequential Price Competition Via The Estimation Of s-Concave Demand Functions
arXiv:2503.16737v3 Announce Type: replace-cross Abstract: We consider price competition among multiple sellers over a selling horizon of $T$ periods. In each period, sellers simultaneously offer their prices (which are made public) and subsequently observe their respective demand (not made public). The demand function of each seller depends on all sellers' prices through a private, unknown, and nonlinear relationship. We propose a dynamic pricing policy that uses semi-parametric least-squares estimation and show that when the sellers employ our policy, their prices converge at a rate of $O(T^{-1/7})$ to the Nash equilibrium prices that sellers would reach if they were fully informed. Each seller incurs a regret of $O(T^{5/7})$ relative to a dynamic benchmark policy. A theoretical contribution of our work is proving the existence of equilibrium under shape-constrained demand functions via the concept of $s$-concavity and establishing regret bounds of our proposed policy. Technically, we also establish new concentration results for the least squares estimator under shape constraints. Our findings offer significant insights into dynamic competition-aware pricing and contribute to the broader study of non-parametric learning in strategic decision-making.
Inverse Reinforcement Learning with Dynamic Reward Scaling for LLM Alignment
arXiv:2503.18991v5 Announce Type: replace-cross Abstract: Alignment is vital for safely deploying large language models (LLMs). Existing techniques are either reward-based (train a reward model on preference pairs and optimize with reinforcement learning) or reward-free (directly fine-tune on ranked outputs). Recent research shows that well-tuned reward-based pipelines remain robust, and single-response demonstrations can outperform pairwise preference data. However, two challenges persist: (1) imbalanced safety datasets that overrepresent common hazards while neglecting long-tail threats; and (2) static reward models that ignore task difficulty, limiting optimization efficiency and attainable gains. We propose DR-IRL (Dynamically adjusting Rewards through Inverse Reinforcement Learning). We first train category-specific reward models using a balanced safety dataset covering seven harmful categories via IRL. Then we enhance Group Relative Policy Optimization (GRPO) by introducing dynamic reward scaling--adjusting rewards by task difficulty--data-level hardness by text encoder cosine similarity, model-level responsiveness by reward gaps. Extensive experiments across various benchmarks and LLMs demonstrate that DR-IRL outperforms all baseline methods in safety alignment while maintaining usefulness.
Inference-Time Scaling for Generalist Reward Modeling
arXiv:2504.02495v3 Announce Type: replace-cross Abstract: Reinforcement learning (RL) has been widely adopted in post-training for large language models (LLMs) at scale. Recently, the incentivization of reasoning capabilities in LLMs from RL indicates that $\textit{proper learning methods could enable effective inference-time scalability}$. A key challenge of RL is to obtain accurate reward signals for LLMs in various domains beyond verifiable questions or artificial rules. In this work, we investigate how to improve reward modeling (RM) with more inference compute for general queries, i.e. the $\textbf{inference-time scalability of generalist RM}$, and further, how to improve the effectiveness of performance-compute scaling with proper learning methods. For the RM approach, we adopt pointwise generative reward modeling (GRM) to enable flexibility for different input types and potential for inference-time scaling. For the learning method, we propose Self-Principled Critique Tuning (SPCT) to foster scalable reward generation behaviors in GRMs through online RL, to generate principles adaptively and critiques accurately, resulting in $\textbf{DeepSeek-GRM}$ models. Furthermore, for effective inference-time scaling, we use parallel sampling to expand compute usage, and introduce a meta RM to guide voting process for better scaling performance. Empirically, we show that SPCT significantly improves the quality and scalability of GRMs, outperforming existing methods and models in various RM benchmarks without severe biases, and could achieve better performance compared to training-time scaling. DeepSeek-GRM still meets challenges in some tasks, which we believe can be addressed by future efforts in generalist reward systems. The models are released at Hugging Face and ModelScope.
Uncertainty-Aware Surrogate-based Amortized Bayesian Inference for Computationally Expensive Models
arXiv:2505.08683v2 Announce Type: replace-cross Abstract: Bayesian inference typically relies on a large number of model evaluations to estimate posterior distributions. Established methods like Markov Chain Monte Carlo (MCMC) and Amortized Bayesian Inference (ABI) can become computationally challenging. While ABI enables fast inference after training, generating sufficient training data still requires thousands of model simulations, which is infeasible for expensive models. Surrogate models offer a solution by providing approximate simulations at a lower computational cost, allowing the generation of large data sets for training. However, the introduced approximation errors and uncertainties can lead to overconfident posterior estimates. To address this, we propose Uncertainty-Aware Surrogate-based Amortized Bayesian Inference (UA-SABI) -- a framework that combines surrogate modeling and ABI while explicitly quantifying and propagating surrogate uncertainties through the inference pipeline. Our experiments show that this approach enables reliable, fast, and repeated Bayesian inference for computationally expensive models, even under tight time constraints.
Ambiguity Resolution in Text-to-Structured Data Mapping
arXiv:2505.11679v2 Announce Type: replace-cross Abstract: Ambiguity in natural language is a significant obstacle for achieving accurate text to structured data mapping through large language models (LLMs), which affects the performance of tasks such as mapping text to agentic tool calling and text-to-SQL queries. Existing methods to ambiguity handling either rely on the ReACT framework to obtain correct mappings through trial and error, or on supervised fine-tuning to bias models toward specific tasks. In this paper, we adopt a different approach that characterizes representation differences of ambiguous text in the latent space and leverages these differences to identify ambiguity before mapping them to structured data. To detect sentence-level ambiguity, we focus on the relationship between ambiguous questions and their interpretations. Unlike distances calculated by dense embeddings, we introduce a new distance measure based on a path kernel over concepts. With this measurement, we identify patterns to distinguish ambiguous from unambiguous questions. Furthermore, we propose a method for improving LLM performance on ambiguous agentic tool calling through missing concept prediction. Both achieve state-of-the-art results.
CONSIGN: Conformal Segmentation Informed by Spatial Groupings via Decomposition
arXiv:2505.14113v2 Announce Type: replace-cross Abstract: Most machine learning-based image segmentation models produce pixel-wise confidence scores that represent the model's predicted probability for each class label at every pixel. While this information can be particularly valuable in high-stakes domains such as medical imaging, these scores are heuristic in nature and do not constitute rigorous quantitative uncertainty estimates. Conformal prediction (CP) provides a principled framework for transforming heuristic confidence scores into statistically valid uncertainty estimates. However, applying CP directly to image segmentation ignores the spatial correlations between pixels, a fundamental characteristic of image data. This can result in overly conservative and less interpretable uncertainty estimates. To address this, we propose CONSIGN (Conformal Segmentation Informed by Spatial Groupings via Decomposition), a CP-based method that incorporates spatial correlations to improve uncertainty quantification in image segmentation. Our method generates meaningful prediction sets that come with user-specified, high-probability error guarantees. It is compatible with any pre-trained segmentation model capable of generating multiple sample outputs. We evaluate CONSIGN against two CP baselines across three medical imaging datasets and two COCO dataset subsets, using three different pre-trained segmentation models. Results demonstrate that accounting for spatial structure significantly improves performance across multiple metrics and enhances the quality of uncertainty estimates.
R&D-Agent-Quant: A Multi-Agent Framework for Data-Centric Factors and Model Joint Optimization
arXiv:2505.15155v2 Announce Type: replace-cross Abstract: Financial markets pose fundamental challenges for asset return prediction due to their high dimensionality, non-stationarity, and persistent volatility. Despite advances in large language models and multi-agent systems, current quantitative research pipelines suffer from limited automation, weak interpretability, and fragmented coordination across key components such as factor mining and model innovation. In this paper, we propose R&D-Agent for Quantitative Finance, in short RD-Agent(Q), the first data-centric multi-agent framework designed to automate the full-stack research and development of quantitative strategies via coordinated factor-model co-optimization. RD-Agent(Q) decomposes the quant process into two iterative stages: a Research stage that dynamically sets goal-aligned prompts, formulates hypotheses based on domain priors, and maps them to concrete tasks, and a Development stage that employs a code-generation agent, Co-STEER, to implement task-specific code, which is then executed in real-market backtests. The two stages are connected through a feedback stage that thoroughly evaluates experimental outcomes and informs subsequent iterations, with a multi-armed bandit scheduler for adaptive direction selection. Empirically, RD-Agent(Q) achieves up to 2X higher annualized returns than classical factor libraries using 70% fewer factors, and outperforms state-of-the-art deep time-series models on real markets. Its joint factor-model optimization delivers a strong balance between predictive accuracy and strategy robustness. Our code is available at: https://github.com/microsoft/RD-Agent.
Flexible MOF Generation with Torsion-Aware Flow Matching
arXiv:2505.17914v2 Announce Type: replace-cross Abstract: Designing metal-organic frameworks (MOFs) with novel chemistries is a longstanding challenge due to their large combinatorial space and complex 3D arrangements of the building blocks. While recent deep generative models have enabled scalable MOF generation, they assume (1) a fixed set of building blocks and (2) known local 3D coordinates of building blocks. However, this limits their ability to (1) design novel MOFs and (2) generate the structure using novel building blocks. We propose a two-stage MOF generation framework that overcomes these limitations by modeling both chemical and geometric degrees of freedom. First, we train an SMILES-based autoregressive model to generate metal and organic building blocks, paired with a cheminformatics toolkit for 3D structure initialization. Second, we introduce a flow matching model that predicts translations, rotations, and torsional angles to assemble the blocks into valid 3D frameworks. Our experiments demonstrate improved reconstruction accuracy, the generation of valid, novel, and unique MOFs, and the ability to create novel building blocks. Our code is available at https://github.com/nayoung10/MOFFlow-2.
Streaming Flow Policy: Simplifying diffusion/flow-matching policies by treating action trajectories as flow trajectories
arXiv:2505.21851v2 Announce Type: replace-cross Abstract: Recent advances in diffusion$/$flow-matching policies have enabled imitation learning of complex, multi-modal action trajectories. However, they are computationally expensive because they sample a trajectory of trajectories: a diffusion$/$flow trajectory of action trajectories. They discard intermediate action trajectories, and must wait for the sampling process to complete before any actions can be executed on the robot. We simplify diffusion$/$flow policies by treating action trajectories as flow trajectories. Instead of starting from pure noise, our algorithm samples from a narrow Gaussian around the last action. Then, it incrementally integrates a velocity field learned via flow matching to produce a sequence of actions that constitute a single trajectory. This enables actions to be streamed to the robot on-the-fly during the flow sampling process, and is well-suited for receding horizon policy execution. Despite streaming, our method retains the ability to model multi-modal behavior. We train flows that stabilize around demonstration trajectories to reduce distribution shift and improve imitation learning performance. Streaming flow policy outperforms prior methods while enabling faster policy execution and tighter sensorimotor loops for learning-based robot control. Project website: https://streaming-flow-policy.github.io/
Bayesian Attention Mechanism: A Probabilistic Framework for Positional Encoding and Context Length Extrapolation
arXiv:2505.22842v2 Announce Type: replace-cross Abstract: Transformer-based language models rely on positional encoding (PE) to handle token order and support context length extrapolation. However, existing PE methods lack theoretical clarity and rely on limited evaluation metrics to substantiate their extrapolation claims. We propose the Bayesian Attention Mechanism (BAM), a theoretical framework that formulates positional encoding as a prior within a probabilistic model. BAM unifies existing methods (e.g., NoPE and ALiBi) and motivates a new Generalized Gaussian positional prior that substantially improves long-context generalization. Empirically, BAM enables accurate information retrieval at $500\times$ the training context length, outperforming previous state-of-the-art context length generalization in long context retrieval accuracy while maintaining comparable perplexity and introducing minimal additional parameters.
Tensor State Space-based Dynamic Multilayer Network Modeling
arXiv:2506.02413v2 Announce Type: replace-cross Abstract: Understanding the complex interactions within dynamic multilayer networks is critical for advancements in various scientific domains. Existing models often fail to capture such networks' temporal and cross-layer dynamics. This paper introduces a novel Tensor State Space Model for Dynamic Multilayer Networks (TSSDMN), utilizing a latent space model framework. TSSDMN employs a symmetric Tucker decomposition to represent latent node features, their interaction patterns, and layer transitions. Then by fixing the latent features and allowing the interaction patterns to evolve over time, TSSDMN uniquely captures both the temporal dynamics within layers and across different layers. The model identifiability conditions are discussed. By treating latent features as variables whose posterior distributions are approximated using a mean-field variational inference approach, a variational Expectation Maximization algorithm is developed for efficient model inference. Numerical simulations and case studies demonstrate the efficacy of TSSDMN for understanding dynamic multilayer networks.
Language-Guided Multi-Agent Learning in Simulations: A Unified Framework and Evaluation
arXiv:2506.04251v3 Announce Type: replace-cross Abstract: This paper introduces LLM-MARL, a unified framework that incorporates large language models (LLMs) into multi-agent reinforcement learning (MARL) to enhance coordination, communication, and generalization in simulated game environments. The framework features three modular components of Coordinator, Communicator, and Memory, which dynamically generate subgoals, facilitate symbolic inter-agent messaging, and support episodic recall. Training combines PPO with a language-conditioned loss and LLM query gating. LLM-MARL is evaluated in Google Research Football, MAgent Battle, and StarCraft II. Results show consistent improvements over MAPPO and QMIX in win rate, coordination score, and zero-shot generalization. Ablation studies demonstrate that subgoal generation and language-based messaging each contribute significantly to performance gains. Qualitative analysis reveals emergent behaviors such as role specialization and communication-driven tactics. By bridging language modeling and policy learning, this work contributes to the design of intelligent, cooperative agents in interactive simulations. It offers a path forward for leveraging LLMs in multi-agent systems used for training, games, and human-AI collaboration.
Generalizing while preserving monotonicity in comparison-based preference learning models
arXiv:2506.08616v2 Announce Type: replace-cross Abstract: If you tell a learning model that you prefer an alternative $a$ over another alternative $b$, then you probably expect the model to be monotone, that is, the valuation of $a$ increases, and that of $b$ decreases. Yet, perhaps surprisingly, many widely deployed comparison-based preference learning models, including large language models, fail to have this guarantee. Until now, the only comparison-based preference learning algorithms that were proved to be monotone are the Generalized Bradley-Terry models. Yet, these models are unable to generalize to uncompared data. In this paper, we advance the understanding of the set of models with generalization ability that are monotone. Namely, we propose a new class of Linear Generalized Bradley-Terry models with Diffusion Priors, and identify sufficient conditions on alternatives' embeddings that guarantee monotonicity. Our experiments show that this monotonicity is far from being a general guarantee, and that our new class of generalizing models improves accuracy, especially when the dataset is limited.
AMLgentex: Mobilizing Data-Driven Research to Combat Money Laundering
arXiv:2506.13989v2 Announce Type: replace-cross Abstract: Money laundering enables organized crime by moving illicit funds into the legitimate economy. Although trillions of dollars are laundered each year, detection rates remain low because launderers evade oversight, confirmed cases are rare, and institutions see only fragments of the global transaction network. Since access to real transaction data is tightly restricted, synthetic datasets are essential for developing and evaluating detection methods. However, existing datasets fall short: they often neglect partial observability, temporal dynamics, strategic behavior, uncertain labels, class imbalance, and network-level dependencies. We introduce AMLGentex, an open-source suite for generating realistic, configurable transaction data and benchmarking detection methods. AMLGentex enables systematic evaluation of anti-money laundering systems under conditions that mirror real-world challenges. By releasing multiple country-specific datasets and practical parameter guidance, we aim to empower researchers and practitioners and provide a common foundation for collaboration and progress in combating money laundering.
ixi-GEN: Efficient Industrial sLLMs through Domain Adaptive Continual Pretraining
arXiv:2507.06795v3 Announce Type: replace-cross Abstract: The emergence of open-source large language models (LLMs) has expanded opportunities for enterprise applications; however, many organizations still lack the infrastructure to deploy and maintain large-scale models. As a result, small LLMs (sLLMs) have become a practical alternative, despite their inherent performance limitations. While Domain Adaptive Continual Pretraining (DACP) has been previously explored as a method for domain adaptation, its utility in commercial applications remains under-examined. In this study, we validate the effectiveness of applying a DACP-based recipe across diverse foundation models and service domains. Through extensive experiments and real-world evaluations, we demonstrate that DACP-applied sLLMs achieve substantial gains in target domain performance while preserving general capabilities, offering a cost-efficient and scalable solution for enterprise-level deployment.
NoHumansRequired: Autonomous High-Quality Image Editing Triplet Mining
arXiv:2507.14119v2 Announce Type: replace-cross Abstract: Recent advances in generative modeling enable image editing assistants that follow natural language instructions without additional user input. Their supervised training requires millions of triplets (original image, instruction, edited image), yet mining pixel-accurate examples is hard. Each edit must affect only prompt-specified regions, preserve stylistic coherence, respect physical plausibility, and retain visual appeal. The lack of robust automated edit-quality metrics hinders reliable automation at scale. We present an automated, modular pipeline that mines high-fidelity triplets across domains, resolutions, instruction complexities, and styles. Built on public generative models and running without human intervention, our system uses a task-tuned Gemini validator to score instruction adherence and aesthetics directly, removing any need for segmentation or grounding models. Inversion and compositional bootstrapping enlarge the mined set by approx. 2.6x, enabling large-scale high-fidelity training data. By automating the most repetitive annotation steps, the approach allows a new scale of training without human labeling effort. To democratize research in this resource-intensive area, we release NHR-Edit, an open dataset of 720k high-quality triplets, curated at industrial scale via millions of guided generations and validator passes, and we analyze the pipeline's stage-wise survival rates, providing a framework for estimating computational effort across different model stacks. In the largest cross-dataset evaluation, it surpasses all public alternatives. We also release Bagel-NHR-Edit, a fine-tuned Bagel model with state-of-the-art metrics.
GeMix: Conditional GAN-Based Mixup for Improved Medical Image Augmentation
arXiv:2507.15577v2 Announce Type: replace-cross Abstract: Mixup has become a popular augmentation strategy for image classification, yet its naive pixel-wise interpolation often produces unrealistic images that can hinder learning, particularly in high-stakes medical applications. We propose GeMix, a two-stage framework that replaces heuristic blending with a learned, label-aware interpolation powered by class-conditional GANs. First, a StyleGAN2-ADA generator is trained on the target dataset. During augmentation, we sample two label vectors from Dirichlet priors biased toward different classes and blend them via a Beta-distributed coefficient. Then, we condition the generator on this soft label to synthesize visually coherent images that lie along a continuous class manifold. We benchmark GeMix on the large-scale COVIDx-CT-3 dataset using three backbones (ResNet-50, ResNet-101, EfficientNet-B0). When combined with real data, our method increases macro-F1 over traditional mixup for all backbones, reducing the false negative rate for COVID-19 detection. GeMix is thus a drop-in replacement for pixel-space mixup, delivering stronger regularization and greater semantic fidelity, without disrupting existing training pipelines. We publicly release our code at https://github.com/hugocarlesso/GeMix to foster reproducibility and further research.
Robustifying Learning-Augmented Caching Efficiently without Compromising 1-Consistency
arXiv:2507.16242v5 Announce Type: replace-cross Abstract: The online caching problem aims to minimize cache misses when serving a sequence of requests under a limited cache size. While naive learning-augmented caching algorithms achieve ideal $1$-consistency, they lack robustness guarantees. Existing robustification methods either sacrifice $1$-consistency or introduce significant computational overhead. In this paper, we introduce Guard, a lightweight robustification framework that enhances the robustness of a broad class of learning-augmented caching algorithms to $2H_k + 2$, while preserving their $1$-consistency. Guard achieves the current best-known trade-off between consistency and robustness, with only $O(1)$ additional per-request overhead, thereby maintaining the original time complexity of the base algorithm. Extensive experiments across multiple real-world datasets and prediction models validate the effectiveness of Guard in practice.
Locally Adaptive Conformal Inference for Operator Models
arXiv:2507.20975v2 Announce Type: replace-cross Abstract: Operator models are regression algorithms between Banach spaces of functions. They have become an increasingly critical tool for spatiotemporal forecasting and physics emulation, especially in high-stakes scenarios where robust, calibrated uncertainty quantification is required. We introduce Local Sliced Conformal Inference (LSCI), a distribution-free framework for generating function-valued, locally adaptive prediction sets for operator models. We prove finite-sample validity and derive a data-dependent upper bound on the coverage gap under local exchangeability. On synthetic Gaussian-process tasks and real applications (air quality monitoring, energy demand forecasting, and weather prediction), LSCI yields tighter sets with stronger adaptivity compared to conformal baselines. We also empirically demonstrate robustness against biased predictions and certain out-of-distribution noise regimes.
villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
arXiv:2507.23682v3 Announce Type: replace-cross Abstract: Vision-Language-Action (VLA) models have emerged as a popular paradigm for learning robot manipulation policies that can follow language instructions and generalize to novel scenarios. Recent works have begun to explore the incorporation of latent actions, abstract representations of motion between two frames, into VLA pre-training. In this paper, we introduce villa-X, a novel Vision-Language-Latent-Action (ViLLA) framework that advances latent action modeling for learning generalizable robot manipulation policies. Our approach improves both how latent actions are learned and how they are incorporated into VLA pre-training. We demonstrate that villa-X can generate latent action plans in a zero-shot fashion, even for unseen embodiments and open-vocabulary symbolic understanding. This capability enables villa-X to achieve superior performance across diverse simulation tasks in SIMPLER and on two real-world robotic setups involving both gripper and dexterous hand manipulation. These results establish villa-X as a principled and scalable paradigm for learning generalizable robot manipulation policies. We believe it provides a strong foundation for future research.
AuthPrint: Fingerprinting Generative Models Against Malicious Model Providers
arXiv:2508.05691v2 Announce Type: replace-cross Abstract: Generative models are increasingly adopted in high-stakes domains, yet current deployments offer no mechanisms to verify whether a given output truly originates from the certified model. We address this gap by extending model fingerprinting techniques beyond the traditional collaborative setting to one where the model provider itself may act adversarially, replacing the certified model with a cheaper or lower-quality substitute. To our knowledge, this is the first work to study fingerprinting for provenance attribution under such a threat model. Our approach introduces a trusted verifier that, during a certification phase, extracts hidden fingerprints from the authentic model's output space and trains a detector to recognize them. During verification, this detector can determine whether new outputs are consistent with the certified model, without requiring specialized hardware or model modifications. In extensive experiments, our methods achieve near-zero FPR@95%TPR on both GANs and diffusion models, and remain effective even against subtle architectural or training changes. Furthermore, the approach is robust to adaptive adversaries that actively manipulate outputs in an attempt to evade detection.
ML-PWS: Estimating the Mutual Information Between Experimental Time Series Using Neural Networks
arXiv:2508.16509v2 Announce Type: replace-cross Abstract: The ability to quantify information transmission is crucial for the analysis and design of natural and engineered systems. The information transmission rate is the fundamental measure for systems with time-varying signals, yet computing it is extremely challenging. In particular, the rate cannot be obtained directly from experimental time-series data without approximations, because of the high dimensionality of the signal trajectory space. Path Weight Sampling (PWS) is a computational technique that makes it possible to obtain the information rate exactly for any stochastic system. However, it requires a mathematical model of the system of interest, be it described by a master equation or a set of differential equations. Here, we present a technique that employs Machine Learning (ML) to develop a generative model from experimental time-series data, which is then combined with PWS to obtain the information rate. We demonstrate the accuracy of this technique, called ML-PWS, by comparing its results on synthetic time-series data generated from a non-linear model against ground-truth results obtained by applying PWS directly to the same model. We illustrate the utility of ML-PWS by applying it to neuronal time-series data.
ILRe: Intermediate Layer Retrieval for Context Compression in Causal Language Models
arXiv:2508.17892v2 Announce Type: replace-cross Abstract: Large Language Models (LLMs) have demonstrated success across many benchmarks. However, they still exhibit limitations in long-context scenarios, primarily due to their short effective context length, quadratic computational complexity, and high memory overhead when processing lengthy inputs. To mitigate these issues, we introduce a novel context compression pipeline, called Intermediate Layer Retrieval (ILRe), which determines one intermediate decoder layer offline, encodes context by streaming chunked prefill only up to that layer, and recalls tokens by the attention scores between the input query and full key cache in that specified layer. In particular, we propose a multi-pooling kernels allocating strategy in the token recalling process to maintain the completeness of semantics. Our approach not only reduces the prefilling complexity from $O(L^2)$ to $O(L)$ and trims the memory footprint to a few tenths of that required for the full context, but also delivers performance comparable to or superior to the full-context setup in long-context scenarios. Without additional post training or operator development, ILRe can process a single $1M$ tokens request in less than half a minute (speedup $\approx 180\times$) and scores RULER-$1M$ benchmark of $\approx 79.8$ with model Llama-3.1-UltraLong-8B-1M-Instruct on a Huawei Ascend 910B NPU.
Universal Dynamics with Globally Controlled Analog Quantum Simulators
arXiv:2508.19075v3 Announce Type: replace-cross Abstract: Analog quantum simulators with global control fields have emerged as powerful platforms for exploring complex quantum phenomena. Recent breakthroughs, such as the coherent control of thousands of atoms, highlight the growing potential for quantum applications at scale. Despite these advances, a fundamental theoretical question remains unresolved: to what extent can such systems realize universal quantum dynamics under global control? Here we establish a necessary and sufficient condition for universal quantum computation using only global pulse control, proving that a broad class of analog quantum simulators is, in fact, universal. We further extend this framework to fermionic and bosonic systems, including modern platforms such as ultracold atoms in optical superlattices. Crucially, to connect the theoretical possibility with experimental reality, we introduce a new control technique into the experiment - direct quantum optimal control. This method enables the synthesis of complex effective Hamiltonians and allows us to incorporate realistic hardware constraints. To show its practical power, we experimentally engineer three-body interactions outside the blockade regime and demonstrate topological dynamics on a Rydberg atom array. Using the new control framework, we overcome key experimental challenges, including hardware limitations and atom position fluctuations in the non-blockade regime, by identifying smooth, short-duration pulses that achieve high-fidelity dynamics. Experimental measurements reveal dynamical signatures of symmetry-protected-topological edge modes, confirming both the expressivity and feasibility of our approach. Our work opens a new avenue for quantum simulation beyond native hardware Hamiltonians, enabling the engineering of effective multi-body interactions and advancing the frontier of quantum information processing with globally-controlled analog platforms.
Constrained Decoding for Robotics Foundation Models
arXiv:2509.01728v2 Announce Type: replace-cross Abstract: Recent advances in the development of robotic foundation models have led to promising end-to-end and general-purpose capabilities in robotic systems. These models are pretrained on vast datasets of robot trajectories to process multi-modal inputs and directly output a sequence of action that the system then executes in the real world. Although this approach is attractive from the perspective of improved generalization across diverse tasks, these models are still data-driven and, therefore, lack explicit notions of behavioral correctness and safety constraints. We address these limitations by introducing a constrained decoding framework for robotics foundation models that enforces logical constraints on action trajectories in dynamical systems. Our method ensures that generated actions provably satisfy signal temporal logic (STL) specifications at runtime without retraining, while remaining agnostic of the underlying foundation model. We perform comprehensive evaluation of our approach across state-of-the-art navigation foundation models and we show that our decoding-time interventions are useful not only for filtering unsafe actions but also for conditional action-generation. Videos available on our website: https://constrained-robot-fms.github.io
PLaMo 2 Technical Report
arXiv:2509.04897v2 Announce Type: replace-cross Abstract: In this report, we introduce PLaMo 2, a series of Japanese-focused large language models featuring a hybrid Samba-based architecture that transitions to full attention via continual pre-training to support 32K token contexts. Training leverages extensive synthetic corpora to overcome data scarcity, while computational efficiency is achieved through weight reuse and structured pruning. This efficient pruning methodology produces an 8B model that achieves performance comparable to our previous 100B model. Post-training further refines the models using a pipeline of supervised fine-tuning (SFT) and direct preference optimization (DPO), enhanced by synthetic Japanese instruction data and model merging techniques. Optimized for inference using vLLM and quantization with minimal accuracy loss, the PLaMo 2 models achieve state-of-the-art results on Japanese benchmarks, outperforming similarly-sized open models in instruction-following, language fluency, and Japanese-specific knowledge.
Expressive Power of Deep Networks on Manifolds: Simultaneous Approximation
arXiv:2509.09362v3 Announce Type: replace-cross Abstract: A key challenge in scientific machine learning is solving partial differential equations (PDEs) on complex domains, where the curved geometry complicates the approximation of functions and their derivatives required by differential operators. This paper establishes the first simultaneous approximation theory for deep neural networks on manifolds. We prove that a constant-depth $\mathrm{ReLU}^{k-1}$ network with bounded weights--a property that plays a crucial role in controlling generalization error--can approximate any function in the Sobolev space $\mathcal{W}_p^{k}(\mathcal{M}^d)$ to an error of $\varepsilon$ in the $\mathcal{W}_p^{s}(\mathcal{M}^d)$ norm, for $k\geq 3$ and $s<k$, using $\mathcal{O}(\varepsilon^{-d/(k-s)})$ nonzero parameters, a rate that overcomes the curse of dimensionality by depending only on the intrinsic dimension $d$. These results readily extend to functions in H\"older-Zygmund spaces. We complement this result with a matching lower bound, proving our construction is nearly optimal by showing the required number of parameters matches up to a logarithmic factor. Our proof of the lower bound introduces novel estimates for the Vapnik-Chervonenkis dimension and pseudo-dimension of the network's high-order derivative classes. These complexity bounds provide a theoretical cornerstone for learning PDEs on manifolds involving derivatives. Our analysis reveals that the network architecture leverages a sparse structure to efficiently exploit the manifold's low-dimensional geometry. Finally, we corroborate our theoretical findings with numerical experiments.
Neural Audio Codecs for Prompt-Driven Universal Sound Separation
arXiv:2509.11717v3 Announce Type: replace-cross Abstract: Text-guided sound separation supports flexible audio editing across media and assistive applications, but existing models like AudioSep are too compute-heavy for edge deployment. Neural audio codec (NAC) models such as CodecFormer and SDCodec are compute-efficient but limited to fixed-class separation. We introduce CodecSep, the first NAC-based model for on-device universal, text-driven separation. CodecSep combines DAC compression with a Transformer masker modulated by CLAP-derived FiLM parameters. Across six open-domain benchmarks under matched training/prompt protocols, \textbf{CodecSep} surpasses \textbf{AudioSep} in separation fidelity (SI-SDR) while remaining competitive in perceptual quality (ViSQOL) and matching or exceeding fixed-stem baselines (TDANet, CodecFormer, SDCodec). In code-stream deployments, it needs just 1.35~GMACs end-to-end -- approximately $54\times$ less compute ($25\times$ architecture-only) than spectrogram-domain separators like AudioSep -- while remaining fully bitstream-compatible.
Label-Efficient Grasp Joint Prediction with Point-JEPA
arXiv:2509.13349v2 Announce Type: replace-cross Abstract: We study whether 3D self-supervised pretraining with Point--JEPA enables label-efficient grasp joint-angle prediction. Meshes are sampled to point clouds and tokenized; a ShapeNet-pretrained Point--JEPA encoder feeds a $K{=}5$ multi-hypothesis head trained with winner-takes-all and evaluated by top--logit selection. On a multi-finger hand dataset with strict object-level splits, Point--JEPA improves top--logit RMSE and Coverage@15$^{\circ}$ in low-label regimes (e.g., 26% lower RMSE at 25% data) and reaches parity at full supervision, suggesting JEPA-style pretraining is a practical lever for data-efficient grasp learning.
On the System Theoretic Offline Learning of Continuous-Time LQR with Exogenous Disturbances
arXiv:2509.16746v2 Announce Type: replace-cross Abstract: We analyze offline designs of linear quadratic regulator (LQR) strategies with uncertain disturbances. First, we consider the scenario where the exogenous variable can be estimated in a controlled environment, and subsequently, consider a more practical and challenging scenario where it is unknown in a stochastic setting. Our approach builds on the fundamental learning-based framework of adaptive dynamic programming (ADP), combined with a Lyapunov-based analytical methodology to design the algorithms and derive sample-based approximations motivated from the Markov decision process (MDP)-based approaches. For the scenario involving non-measurable disturbances, we further establish stability and convergence guarantees for the learned control gains under sample-based approximations. The overall methodology emphasizes simplicity while providing rigorous guarantees. Finally, numerical experiments focus on the intricacies and validations for the design of offline continuous-time LQR with exogenous disturbances.
DiffSyn: A Generative Diffusion Approach to Materials Synthesis Planning
arXiv:2509.17094v2 Announce Type: replace-cross Abstract: The synthesis of crystalline materials, such as zeolites, remains a significant challenge due to a high-dimensional synthesis space, intricate structure-synthesis relationships and time-consuming experiments. Considering the one-to-many relationship between structure and synthesis, we propose DiffSyn, a generative diffusion model trained on over 23,000 synthesis recipes spanning 50 years of literature. DiffSyn generates probable synthesis routes conditioned on a desired zeolite structure and an organic template. DiffSyn achieves state-of-the-art performance by capturing the multi-modal nature of structure-synthesis relationships. We apply DiffSyn to differentiate among competing phases and generate optimal synthesis routes. As a proof of concept, we synthesize a UFI material using DiffSyn-generated synthesis routes. These routes, rationalized by density functional theory binding energies, resulted in the successful synthesis of a UFI material with a high Si/Al$_{\text{ICP}}$ of 19.0, which is expected to improve thermal stability and is higher than that of any previously recorded.
Bilateral Distribution Compression: Reducing Both Data Size and Dimensionality
arXiv:2509.17543v3 Announce Type: replace-cross Abstract: Existing distribution compression methods reduce dataset size by minimising the Maximum Mean Discrepancy (MMD) between original and compressed sets, but modern datasets are often large in both sample size and dimensionality. We propose Bilateral Distribution Compression (BDC), a two-stage framework that compresses along both axes while preserving the underlying distribution, with overall linear time and memory complexity in dataset size and dimension. Central to BDC is the Decoded MMD (DMMD), which quantifies the discrepancy between the original data and a compressed set decoded from a low-dimensional latent space. BDC proceeds by (i) learning a low-dimensional projection using the Reconstruction MMD (RMMD), and (ii) optimising a latent compressed set with the Encoded MMD (EMMD). We show that this procedure minimises the DMMD, guaranteeing that the compressed set faithfully represents the original distribution. Experiments show that across a variety of scenarios BDC can achieve comparable or superior performance to ambient-space compression at substantially lower cost.
Efficient & Correct Predictive Equivalence for Decision Trees
arXiv:2509.17774v2 Announce Type: replace-cross Abstract: The Rashomon set of decision trees (DTs) finds importance uses. Recent work showed that DTs computing the same classification function, i.e. predictive equivalent DTs, can represent a significant fraction of the Rashomon set. Such redundancy is undesirable. For example, feature importance based on the Rashomon set becomes inaccurate due the existence of predictive equivalent DTs, i.e. DTs with the same prediction for every possible input. In recent work, McTavish et al. proposed solutions for several computational problems related with DTs, including that of deciding predictive equivalent DTs. This approach, which this paper refers to as MBDSR, consists of applying the well-known method of Quine-McCluskey (QM) for obtaining minimum-size DNF (disjunctive normal form) representations of DTs, which are then used for comparing DTs for predictive equivalence. Furthermore, the minimum-size DNF representation was also applied to computing explanations for the predictions made by DTs, and to finding predictions in the presence of missing data. However, the problem of formula minimization is hard for the second level of the polynomial hierarchy, and the QM method may exhibit worst-case exponential running time and space. This paper first demonstrates that there exist decision trees that trigger the worst-case exponential running time and space of the QM method. Second, the paper shows that, depending on the QM method implementation, the MBDSR approach can produce incorrect results for the problem of deciding predictive equivalence. Third, the paper shows that any of the problems to which the smallest DNF representation has been applied to can be solved in polynomial time, in the size of the DT. The experiments confirm that, for DTs for which the worst-case of the QM method is triggered, the algorithms proposed in this paper are orders of magnitude faster than the ones proposed by McTavish et al.
CogniLoad: A Synthetic Natural Language Reasoning Benchmark With Tunable Length, Intrinsic Difficulty, and Distractor Density
arXiv:2509.18458v2 Announce Type: replace-cross Abstract: Current benchmarks for long-context reasoning in Large Language Models (LLMs) often blur critical factors like intrinsic task complexity, distractor interference, and task length. To enable more precise failure analysis, we introduce CogniLoad, a novel synthetic benchmark grounded in Cognitive Load Theory (CLT). CogniLoad generates natural-language logic puzzles with independently tunable parameters that reflect CLT's core dimensions: intrinsic difficulty ($d$) controls intrinsic load; distractor-to-signal ratio ($\rho$) regulates extraneous load; and task length ($N$) serves as an operational proxy for conditions demanding germane load. Evaluating 22 SotA reasoning LLMs, CogniLoad reveals distinct performance sensitivities, identifying task length as a dominant constraint and uncovering varied tolerances to intrinsic complexity and U-shaped responses to distractor ratios. By offering systematic, factorial control over these cognitive load dimensions, CogniLoad provides a reproducible, scalable, and diagnostically rich tool for dissecting LLM reasoning limitations and guiding future model development.
Reinforcement Learning on Pre-Training Data
arXiv:2509.19249v2 Announce Type: replace-cross Abstract: The growing disparity between the exponential scaling of computational resources and the finite growth of high-quality text data now constrains conventional scaling approaches for large language models (LLMs). To address this challenge, we introduce Reinforcement Learning on Pre-Training data (RLPT), a new training-time scaling paradigm for optimizing LLMs. In contrast to prior approaches that scale training primarily through supervised learning, RLPT enables the policy to autonomously explore meaningful trajectories to learn from pre-training data and improve its capability through reinforcement learning (RL). While existing RL strategies such as reinforcement learning from human feedback (RLHF) and reinforcement learning with verifiable rewards (RLVR) rely on human annotation for reward construction, RLPT eliminates this dependency by deriving reward signals directly from pre-training data. Specifically, it adopts a next-segment reasoning objective, rewarding the policy for accurately predicting subsequent text segments conditioned on the preceding context. This formulation allows RL to be scaled on pre-training data, encouraging the exploration of richer trajectories across broader contexts and thereby fostering more generalizable reasoning skills. Extensive experiments on both general-domain and mathematical reasoning benchmarks across multiple models validate the effectiveness of RLPT. For example, when applied to Qwen3-4B-Base, RLPT yields absolute improvements of $3.0$, $5.1$, $8.1$, $6.0$, $6.6$, and $5.3$ on MMLU, MMLU-Pro, GPQA-Diamond, KOR-Bench, AIME24, and AIME25, respectively. The results further demonstrate favorable scaling behavior, suggesting strong potential for continued gains with more compute. In addition, RLPT provides a solid foundation, extending the reasoning boundaries of LLMs and enhancing RLVR performance.
HUNT: High-Speed UAV Navigation and Tracking in Unstructured Environments via Instantaneous Relative Frames
arXiv:2509.19452v2 Announce Type: replace-cross Abstract: Search and rescue operations require unmanned aerial vehicles to both traverse unknown unstructured environments at high speed and track targets once detected. Achieving both capabilities under degraded sensing and without global localization remains an open challenge. Recent works on relative navigation have shown robust tracking by anchoring planning and control to a visible detected object, but cannot address navigation when no target is in the field of view. We present HUNT (High-speed UAV Navigation and Tracking), a real-time framework that unifies traversal, acquisition, and tracking within a single relative formulation. HUNT defines navigation objectives directly from onboard instantaneous observables such as attitude, altitude, and velocity, enabling reactive high-speed flight during search. Once a target is detected, the same perception-control pipeline transitions seamlessly to tracking. Outdoor experiments in dense forests, container compounds, and search-and-rescue operations with vehicles and mannequins demonstrate robust autonomy where global methods fail.
Hyperspectral Adapter for Semantic Segmentation with Vision Foundation Models
arXiv:2509.20107v2 Announce Type: replace-cross Abstract: Hyperspectral imaging (HSI) captures spatial information along with dense spectral measurements across numerous narrow wavelength bands. This rich spectral content has the potential to facilitate robust robotic perception, particularly in environments with complex material compositions, varying illumination, or other visually challenging conditions. However, current HSI semantic segmentation methods underperform due to their reliance on architectures and learning frameworks optimized for RGB inputs. In this work, we propose a novel hyperspectral adapter that leverages pretrained vision foundation models to effectively learn from hyperspectral data. Our architecture incorporates a spectral transformer and a spectrum-aware spatial prior module to extract rich spatial-spectral features. Additionally, we introduce a modality-aware interaction block that facilitates effective integration of hyperspectral representations and frozen vision Transformer features through dedicated extraction and injection mechanisms. Extensive evaluations on three benchmark autonomous driving datasets demonstrate that our architecture achieves state-of-the-art semantic segmentation performance while directly using HSI inputs, outperforming both vision-based and hyperspectral segmentation methods. We make the code available at https://hsi-adapter.cs.uni-freiburg.de.
Thinking Augmented Pre-training
arXiv:2509.20186v2 Announce Type: replace-cross Abstract: This paper introduces a simple and scalable approach to improve the data efficiency of large language model (LLM) training by augmenting existing text data with thinking trajectories. The compute for pre-training LLMs has been growing at an unprecedented rate, while the availability of high-quality data remains limited. Consequently, maximizing the utility of available data constitutes a significant research challenge. A primary impediment is that certain high-quality tokens are difficult to learn given a fixed model capacity, as the underlying rationale for a single token can be exceptionally complex and deep. To address this issue, we propose Thinking augmented Pre-Training (TPT), a universal methodology that augments text with automatically generated thinking trajectories. Such augmentation effectively increases the volume of the training data and makes high-quality tokens more learnable through step-by-step reasoning and decomposition. We apply TPT across diverse training configurations up to $100$B tokens, encompassing pre-training with both constrained and abundant data, as well as mid-training from strong open-source checkpoints. Experimental results indicate that our method substantially improves the performance of LLMs across various model sizes and families. Notably, TPT enhances the data efficiency of LLM pre-training by a factor of $3$. For a $3$B parameter model, it improves the post-training performance by over $10\%$ on several challenging reasoning benchmarks.
New GenAI System Built to Accelerate HPC Operations Data Analytics
AI continues to play a key role in scientific research – not just in driving new discoveries but also in how we understand the tools behind those discoveries. High-performance computing Read more…
The post New GenAI System Built to Accelerate HPC Operations Data Analytics appeared first on BigDATAwire.
Anthropic and Figma's new MCPs could transform front end development forever
Plus: Perplexity's new Email Assistant, Become a systems thinker, 3 new Gemini updates worth knowing about
How to connect Figma MCP to KIRO IDE
As a frontend engineer adapting to new tools, I’ve been trying out IDEs that promise to improve development workflows. One of the most promising is Figma MCP, which improves how LLMs replicate user interfaces designed in Figma.
I initially struggled to configure MCP to work with Kiro IDE, so I’ve documented the exact steps to make it easier for you.
a. Navigate to Settings in Figma.

b. Select Security from the top tabs.

c. Scroll to Personal Access Tokens and generate a new token.

d. Grant read permissions.
e. Copy the generated token: you won’t be able to after this point.
a. Open Settings in Kiro.
b. Search for MCP and select either Workspace MCP configuration or User MCP configuration.
c. Paste the following JSON:
{
"mcpServers": {
"figma": {
"command": "npx",
"args": [
"-y",
"figma-developer-mcp",
"--figma-api-key=your_figma_api_key",
"--stdio"
],
"disabled": false,
"autoApprove": ["get_figma_data", "download_figma_images"]
}
}
}
d. Replace "your_figma_api_key" with the token you generated in Figma.
e. Save the configuration.
- Open the Figma design you want to work with in Kiro.
- Select a component in the design.
- Right-click, choose Copy link to selection, and paste it into your Kiro chat.
- Address your prompts to that link.
Note: This requires a paid plan on Figma.
Will you be trying Figma MCP on Kiro? Have questions or hit any snags? Let me know in the comments. I’d be glad to help.
Read moe tutorials on my Hashnode blog.
I share frontend engineering insights and practical developer experience tips. Follow along if you’re interested in design-to-code workflows and the future of DevRel.
Automate Your Complex Workflows with Sub-Recipes in goose
Remember when you first learned to cook? You probably started with simple recipes like scrambled eggs or toast. But eventually you wanted to make something more complex, like a full dinner with multiple dishes. That's how subrecipes work in goose: each recipe can run stand-alone for a dedicated task, and a main recipe can orchestrate how they run.
Let's explore goose subrecipes together! You're about to learn know how to orchestrate multiple AI models, coordinate tasks, and build workflows that will turn you into a "head chef" user with goose.
Think of subrecipes like having a team of specialized chefs in your kitchen. One chef is amazing at making desserts, another excels at grilling, and a third is the salad master. Instead of having one person try to do everything, you let each specialist focus on what they do best.
That's exactly what subrecipes do for your goose workflows. You can have one recipe that's optimized for creative tasks like image generation, another that's perfect for technical documentation, and a third that excels at writing code. Then you orchestrate them all from a main recipe.
I built a project setup system that creates a complete project with documentation, logo generator, and an initial codebase. Instead of one massive recipe trying to do everything, I broke it into specialized pieces.
Here's the parent recipe that orchestrates everything:
version: 1.0.0
title: "Complete Project Setup"
description: "Creates a full project with README, image, and code using specialized models"
instructions: |
You are a project orchestrator. Execute the sub-recipes to create a complete project setup.
Each sub-recipe is specialized for its task and uses the optimal model and instructions for that work.
EXECUTION ORDER:
- Run image-creator and code-writer first, in parallel
- When they both succeed and finish, then run readme-generator; don't make the readme until we have a logo and finished code project to reference
prompt: |
Create a complete project setup for: {{ project_name }} within ./project
Execute these tasks:
- Create a project logo/image
- Write the initial codebase
- Generate project documentation
Project details:
- Name: {{ project_name }}
- Language: {{ language }}
- Description: {{ description }}
parameters:
- key: project_name
input_type: string
requirement: required
description: "Name of the project to create"
- key: language
input_type: string
requirement: optional
description: "Programming language to use"
default: python
- key: description
input_type: string
requirement: required
description: "Project description"
sub_recipes:
- name: "image-creator"
path: "{{ recipe_dir }}/2-image.yaml"
description: "Create project logo using GPT"
values:
project_name: "{{ project_name }}"
description: "{{ description }}"
- name: "code-writer"
path: "{{ recipe_dir }}/3-code.yaml"
description: "Write initial code using Claude"
values:
project_name: "{{ project_name }}"
language: "{{ language }}"
description: "{{ description }}"
- name: "readme-generator"
path: "{{ recipe_dir }}/1-readme.yaml"
description: "Generate comprehensive README using Gemini"
sequential_when_repeated: true
values:
project_name: "{{ project_name }}"
description: "{{ description }}"
language: "{{ language }}"
extensions:
- type: builtin
name: developer
Notice how each subrecipe gets only the parameters it needs, and we can control the execution order in our prompt.
By default, subrecipes run in parallel. This is like having multiple chefs working simultaneously in different parts of the kitchen. The image generation and code writing happen at the same time, cutting your total execution time.
Sometimes you need things to happen in order. The best approach here is to list the specific order you want in the recipe instructions. In this example, I want the image and code generation to happen in parallel (because they don't depend on each other), and only run the README generation when the other two steps are both successful so it can reference the generated files.
Each subrecipe is optimized for its specific job.
Image Generation with OpenAI DALL-E
For the image generation, we could use an image generator MCP system in a smaller recipe. For this example, though, I'm going to have this recipe write a specific script to call OpenAI's DALL-E API directly. This gives me more control over the image generation process and avoids external resources.
version: 1.0.0
title: "Project Image Creator"
description: "Generate project logos and images"
settings:
goose_provider: "databricks"
goose_model: "goose-claude-4-sonnet"
temperature: 0.1
instructions: |
You are a creative designer specializing in logo and image creation.
Create visually appealing, professional images that represent the project's purpose.
Generate images using OpenAI's DALL-E API
activities:
- Generate images using DALL-E API
- Save images to specified locations
- Handle API errors gracefully
prompt: |
Create a project logo/image for "{{ project_name }}" - {{ description }}.
Your working folder is "{{recipe_dir}}/project/"
Task: Generate an image using OpenAI's DALL-E API directly via Python script.
Image specifications:
- Size: 1024x1024
- Quality: standard
- Output file: "logo.png"
- Modern, professional design suitable for a tech API
- Include themed elements based on project description: {{ description}}
- Professional color scheme
- High quality and suitable for documentation
Steps:
1. First, verify the OPENAI_API_KEY environment variable is set
2. Create a Python script:
- the filename should be "./project/logo_generator.py", create that file and edit it in place
- it should calls OpenAI's DALL-E API directly to generate an image
- the output folder to store the image is the same folder in which the logo_generator.py script exists
- for example, the final image should be "./project/logo.png" but not have the "./project" path hard-coded in the script
3. Execute the script to generate the image with the specified parameters
4. Verify the image was created successfully and report the file location
5. If there are any errors, provide clear troubleshooting guidance
Implementation approach:
- Use the developer extension to create and run a Python script
- The script should use only standard library modules (urllib, json, base64) to avoid dependency issues
- Call OpenAI's DALL-E 3 API directly with proper authentication
- Handle API responses and save the base64-encoded image to the specified location
- Provide detailed error messages for troubleshooting
Requirements:
- The OPENAI_API_KEY environment variable must be set
- Handle any API errors gracefully and provide helpful error messages
retry:
max_retries: 3
checks:
- type: shell
command: test -f "{{recipe_dir}}/project/logo_generator.py"
- type: shell
command: test -f "{{recipe_dir}}/project/logo.png"
on_failure: rm -f "{{recipe_dir}}/project/logo.png" && rm -rf "{{recipe_dir}}/project/logo_generator.py"
timeout_seconds: 60
extensions:
- type: builtin
name: developer
parameters:
- key: project_name
input_type: string
requirement: required
description: "Project name for the logo"
- key: description
input_type: string
requirement: required
description: "What the project is about"
If you did want more creativity, you could use an image generation MCP server and use a model that's optimized for artistic image creation:
settings:
goose_provider: "openai"
goose_model: "gpt-4o"
temperature: 0.8
Code Generation with Claude Sonnet
The code generation recipe uses Claude for technical precision. We set a low "temperature" value to ensure the generated code is reliable and follows best practices.
version: 1.0.0
title: "Code Generator"
description: "Write initial project codebase"
settings:
goose_provider: "anthropic"
goose_model: "claude-sonnet-4"
temperature: 0.1
instructions: |
You are a senior software engineer who writes clean, well-documented, and maintainable code.
Follow best practices and include comprehensive error handling and documentation.
prompt: |
Write the initial codebase for "{{ project_name }}".
Your project folder will be ./project/
Requirements:
- Language: {{ language }}
- Description: {{ description }}
- Include proper project structure
- Include error handling
- Follow language-specific best practices
- Add unit tests where appropriate
Documentation:
- Add comprehensive documentation in a file called USAGE.md
- do not create a README.md file
extensions:
- type: builtin
name: developer
parameters:
- key: project_name
input_type: string
requirement: required
description: "Project name"
- key: language
input_type: string
requirement: required
default: "python"
description: "Programming language"
- key: description
input_type: string
requirement: required
description: "Project description"
README Generation with Gemini
And the documentation recipe uses Gemini for comprehensive README generation:
version: 1.0.0
title: "README Generator"
description: "Generate comprehensive project documentation"
settings:
goose_provider: "google"
goose_model: "gemini-2.5-flash"
temperature: 0.5
instructions: |
You are a technical documentation specialist. Create comprehensive, well-structured README files
that are informative, professional, and follow best practices.
prompt: |
Create a comprehensive README.md file for the project "{{ project_name }}".
Project details:
- Name: {{ project_name }}
- Language: {{ language }}
- Description: {{ description }}
Include sections for:
- Project overview and features with lots of excitement over the capabilities of the project
- Installation instructions
- Usage examples
the code and logo for this project will be in ./project; include the logo.png at the top of the readme, and instructions on running the code in the readme.
the readme file should be placed in ./project/
extensions:
- type: builtin
name: developer
parameters:
- key: project_name
input_type: string
requirement: required
description: "Project name"
- key: language
input_type: string
requirement: required
description: "Programming language"
- key: description
input_type: string
requirement: required
description: "Project description"
Debugging subrecipes is straightforward if you follow a few best practices:
1. Make Sure Each Recipe Runs Independently
This is crucial. Each subrecipe should work perfectly on its own. Test them individually before combining them. If a subrecipe fails when run alone, it will definitely fail as part of a larger workflow.
# Test each subrecipe individually first
goose run --recipe 1-readme.yaml --params project_name="test" language="python" description="test project"
goose run --recipe 2-image.yaml --params project_name="test" description="test project"
goose run --recipe 3-code.yaml --params project_name="test" language="python" description="test project"
2. Use recipe_dir for Relative Paths
Always use {{ recipe_dir }} for file paths within your recipes. This makes your recipes portable and prevents path issues when someone runs them from a different directory.
3. Parameter Validation is Your Friend
Include clear parameter descriptions and mark required parameters. This prevents confusing errors when someone forgets to pass a needed value.
4. Add Retry Logic for Flaky Operations
Network calls, file operations, and API calls can fail. Add retry logic with proper cleanup:
retry:
max_retries: 3
checks:
- type: shell
command: test -f "expected_output.txt"
on_failure: rm -f "partial_output.txt"
timeout_seconds: 60
5. Monitor Resource Usage
When running multiple subrecipes in parallel, watch your API rate limits and system resources. You might need to adjust the execution strategy for resource-intensive tasks.
Start simple. Pick a complex task you do regularly and break it into 2-3 smaller pieces. Create individual recipes for each piece, test them separately, then build a parent recipe to orchestrate them.
Some ideas to get you started:
- Content Creation Pipeline: Research, writing, editing, and formatting
- Development Workflow: Code generation, testing, documentation, deployment
- Data Processing: Collection, cleaning, analysis, visualization
- Project Setup: Structure creation, configuration, initial files, documentation
Subrecipes represent something bigger than just a goose feature. They're a glimpse into how we'll work with AI in the future -- not as monolithic systems trying to do everything, but as specialized agents working together toward common goals.
Each recipe becomes a reusable component that you can mix and match. Build a library of specialized recipes, then combine them in different ways for different projects. It's like having a toolkit of AI specialists ready to tackle any challenge.
Ready to start building your own subrecipe workflows? The kitchen is open, and all the ingredients are waiting for you.
Do you have a recipe you'd like to share with the community? We'd love to feature them in our Recipe Cookbook!
How to contribute:
- Fork the goose repository
- Add your recipe YAML file to the
documentation/src/pages/recipes/data/recipes/directory - Create a pull request following our Recipe Contribution Guide Browse existing recipes for inspiration and formatting examples.
The best (free - cheap) AI friendly Cli and Coding environments
With so many LLM providers and coding environments, how do you choose the right one for your next project? We all want the "best" model, but what we really need is the one that's the most reliable, the most cost-effective, and the most suited for our workflow. This guide breaks down the real-world performance, pricing, and hidden costs of the top LLM providers and CLI environments, from freemium to enterprise. We'll go beyond the marketing claims and give you the data you need to make an informed decision.
LLM and Inference Provider Cross-Reference
OpenAI
Freemium / Entry Level Cost: Free tier with a $5.00 credit (valid for 3 months).
Pricing Model: Pay-per-token; different rates for different models (e.g., GPT-4o is more expensive than GPT-3.5).
Reliability & Throughput: High. Offers tiered usage limits that scale with spend. Known for robust infrastructure but can have occasional downtime.
Anthropic
Freemium / Entry Level Cost: Free tier with a $10.00 credit (valid for a limited period).
Pricing Model: Pay-per-token. Haiku model is the most cost-effective.
Reliability & Throughput: High. Free tier has rate limits (e.g., 5 RPM, 20K TPM on Haiku), which are sufficient for development and experimentation.
Deepseek
Freemium / Entry Level Cost: Free tier with some trial credits.
Pricing Model: Pay-per-token, with separate rates for input (cache hit/miss) and output tokens.
Reliability & Throughput: Generally good, but may not have the same global infrastructure as larger providers. Good for cost-sensitive projects.
Qwen (Dashscope)
Freemium / Entry Level Cost: Free tier with 2,000 requests per day and a 60 RPM limit.
Pricing Model: Pay-per-token after free tier. The Qwen-Flash model is very cheap for simple tasks.
Reliability & Throughput: Good. The free tier is generous for personal projects and offers a great way to test the model's capabilities.
Fireworks AI
Freemium / Entry Level Cost: $50 monthly spend limit with a valid payment method.
Pricing Model: Pay-per-token. Very competitive rates for various open-source models like Deepseek and Qwen.
Reliability & Throughput: Very high. Known for its speed and low latency. The free tier is well-suited for experimentation and small-scale applications before committing to a higher spend tier.
Amazon Bedrock
Freemium / Entry Level Cost: Pay-as-you-go, no upfront cost. Some models have a free trial period.
Pricing Model: Complex. On-demand, provisioned throughput, and commitment-based pricing. Pricing varies significantly by model.
Reliability & Throughput: Extremely High. Backed by AWS's robust infrastructure, offering high reliability and the ability to scale. Best for production use cases where you need a consistent throughput.
Hugging Face
Freemium / Entry Level Cost: Free tier for inference endpoints on some models.
Pricing Model: Pay-per-hour for dedicated inference endpoints.
Reliability & Throughput: Reliability depends on the model's popularity and the infrastructure supporting it. The free tier can have high latency due to a queuing system.
OpenRouter
Freemium / Entry Level Cost: Pay-per-token. You only pay for what you use.
Pricing Model: Aggregator. Provides access to many models (including OpenAI and Anthropic) on a single API key, often at competitive rates.
Reliability & Throughput: Varies by model, but generally high. The platform manages the back-end complexity of multiple models, making it a great entry point for comparing different models.
Terminal Cli and Coding environments
Tier 1: Free & Open-Source (Cost is just API Tokens / Free Tier Access)
Cursor CLI
Cost Model: Free. Relies on the user's API key (OpenAI, Anthropic, etc.).
Use Case & Features: An editor and CLI environment built around a code-aware AI. Ideal for developers who want maximum control over the model and are happy to manage their own API costs.
Qwen Code
Cost Model: Free tier with 2,000 requests per day and a 60 RPM limit.
Use Case & Features: A coding agent focused on tool calling and environment interaction. Offers a generous free tier for developers on a budget, perfect for experimenting with agentic workflows.
GitHub Copilot CLI
Cost Model: Free Tier Available. New "Copilot Free" tier offers 2,000 code completions and 50 premium requests per month. Students, teachers, and open-source maintainers get Copilot Pro for free.
Use Case & Features: Agent-powered, GitHub-native tool that executes coding tasks. This is the new, more powerful agentic Copilot CLI, replacing the older gh-copilot extension.
Tier 2: Freemium & Free-for-Individual (Generous Free Access)
Gemini Code Assist
Cost Model: Free for individuals (permanently). Access to higher daily limits is available through a subscription to Google AI Pro ($19.99/month), which often includes an extended free trial for 12 months for students in eligible regions.
Use Case & Features: An AI-first coding assistant integrated directly into major IDEs and the terminal (Gemini CLI). The individual version is a highly generous, no-cost option.
Warp Code
Cost Model: Freemium. Includes 150 free AI requests per month. Paid plans start around $15/user/month for teams.
Use Case & Features: A complete agentic development environment that unifies the terminal, editor, and AI features. Known for its speed, local indexing, and multi-model orchestration.
Atlassian Rovodev
Cost Model: Free tier with an Atlassian Cloud account. Quotas are based on "AI credits" tied to paid Jira/Confluence plans.
Use Case & Features: Integrated with the Atlassian ecosystem, focusing on developer tasks within project management (Jira) and documentation (Confluence). Best for teams already on the Atlassian stack.
Tier 3: Subscription Required (Paid Access to High-End Models)
Codex CLI (OpenAI)
Cost Model: Included with ChatGPT paid plans (Plus, Pro, Business, Enterprise), starting at $20/user/month (ChatGPT Plus).
Use Case & Features: A comprehensive software engineering agent powered by models like GPT-5-Codex. It works in the terminal, IDE, and cloud, using tools, tracking progress with a to-do list, and supporting multi-modal input.
Claude Code (Anthropic)
Cost Model: Likely included with a paid Claude Pro or higher subscription. Uses Anthropic's latest models (e.g., Sonnet/Opus).
Use Case & Features: An agentic coding partner focused on extended thinking and complex, multi-step tasks. It uses planning modes and creates project memory files (CLAUDE.md) for deep context management.
Grok CLI (xAI)
Cost Model: Requires an X Premium+ subscription, which is roughly $30 - $40/month for consumer access, or an API plan for token-based billing.
Use Case & Features: Distinguished by its focus on real-time data integration (from the X platform) and its "rebellious streak." Best for projects requiring up-to-the-minute data integration alongside coding tasks.
With so many LLM providers and coding environments, how do you choose the right one for your next project? We all want the "best" model, but what we really need is the one that's the most reliable, the most cost-effective, and the most suited for our workflow. This guide breaks down the real-world performance, pricing, and hidden costs of the top LLM providers and CLI environments, from freemium to enterprise. We'll go beyond the marketing claims and give you the data you need to make an informed decision.
LLM and Inference Provider Cross-Reference
OpenAI
Freemium / Entry Level Cost: Free tier with a $5.00 credit (valid for 3 months).
Pricing Model: Pay-per-token; different rates for different models (e.g., GPT-4o is more expensive than GPT-3.5).
Reliability & Throughput: High. Offers tiered usage limits that scale with spend. Known for robust infrastructure but can have occasional downtime.
Anthropic
Freemium / Entry Level Cost: Free tier with a $10.00 credit (valid for a limited period).
Pricing Model: Pay-per-token. Haiku model is the most cost-effective.
Reliability & Throughput: High. Free tier has rate limits (e.g., 5 RPM, 20K TPM on Haiku), which are sufficient for development and experimentation.
Deepseek
Freemium / Entry Level Cost: Free tier with some trial credits.
Pricing Model: Pay-per-token, with separate rates for input (cache hit/miss) and output tokens.
Reliability & Throughput: Generally good, but may not have the same global infrastructure as larger providers. Good for cost-sensitive projects.
Qwen (Dashscope)
Freemium / Entry Level Cost: Free tier with 2,000 requests per day and a 60 RPM limit.
Pricing Model: Pay-per-token after free tier. The Qwen-Flash model is very cheap for simple tasks.
Reliability & Throughput: Good. The free tier is generous for personal projects and offers a great way to test the model's capabilities.
Fireworks AI
Freemium / Entry Level Cost: $50 monthly spend limit with a valid payment method.
Pricing Model: Pay-per-token. Very competitive rates for various open-source models like Deepseek and Qwen.
Reliability & Throughput: Very high. Known for its speed and low latency. The free tier is well-suited for experimentation and small-scale applications before committing to a higher spend tier.
Amazon Bedrock
Freemium / Entry Level Cost: Pay-as-you-go, no upfront cost. Some models have a free trial period.
Pricing Model: Complex. On-demand, provisioned throughput, and commitment-based pricing. Pricing varies significantly by model.
Reliability & Throughput: Extremely High. Backed by AWS's robust infrastructure, offering high reliability and the ability to scale. Best for production use cases where you need a consistent throughput.
Hugging Face
Freemium / Entry Level Cost: Free tier for inference endpoints on some models.
Pricing Model: Pay-per-hour for dedicated inference endpoints.
Reliability & Throughput: Reliability depends on the model's popularity and the infrastructure supporting it. The free tier can have high latency due to a queuing system.
OpenRouter
Freemium / Entry Level Cost: Pay-per-token. You only pay for what you use.
Pricing Model: Aggregator. Provides access to many models (including OpenAI and Anthropic) on a single API key, often at competitive rates.
Reliability & Throughput: Varies by model, but generally high. The platform manages the back-end complexity of multiple models, making it a great entry point for comparing different models.
Arquitetura REST: Conceitos e Aplicações
Desde que sistemas começaram a se comunicar, integrar tudo de forma eficiente virou um desafio. Com a chegada da web, novas possibilidades surgiram, e entre elas, o REST se destacou como o jeito mais prático e popular de fazer essa comunicação acontecer.
Hoje, REST é a base da maioria das APIs modernas. Este artigo mostra o que é REST, por que ele faz tanto sucesso e como ele é usado na prática.
REST (Representational State Transfer) não é uma tecnologia, mas um estilo de arquitetura proposto por Roy Fielding em 2000. Ele se baseia em princípios simples que usam o protocolo HTTP para acessar e manipular recursos, que são representações de dados, identificados por URLs.
A força do REST está justamente na sua simplicidade. Como resume Marco Tulio Valente:
“Um padrão simples, mas poderoso, que se consolidou como base no desenvolvimento de APIs Web modernas.” (Valente, 2022)
Em vez de depender de padrões complexos, o REST usa os recursos que a web já oferece, como métodos HTTP (GET, POST, PUT, DELETE) e os próprios URLs.
REST ajudou a resolver dois grandes problemas do desenvolvimento de software: escalabilidade e integração.
Como o servidor não precisa guardar o estado de cada cliente (ou seja, ele é stateless), é mais fácil distribuir a carga entre diferentes servidores. Isso torna os sistemas naturalmente escaláveis.
Além disso, ao dividir tudo em recursos independentes, REST promove modularidade e baixo acoplamento, dois princípios fundamentais para sistemas sustentáveis, como defendem especialistas como Robert C. Martin e Ian Sommerville:
“A capacidade de gerenciar a complexidade e garantir a manutenibilidade é o que define a sobrevivência de um sistema a longo prazo.” (Sommerville, 2019)
REST também favorece a evolução rápida. APIs RESTful são fáceis de consumir, manter e documentar. Isso acelera o desenvolvimento e facilita a integração entre sistemas diversos, desde apps mobile até grandes plataformas web.
Na prática, REST virou o padrão de integração entre aplicações. A comunicação acontece por meio de requisições HTTP, trocando dados geralmente em JSON (às vezes XML).
4.1. Estrutura de uma requisição REST
Uma requisição RESTful é bem organizada:
- Verbo HTTP: Indica a ação (GET para buscar, POST para criar, PUT para atualizar, DELETE para remover).
- URL: Identifica o recurso. Ex: /api/satc/202412299
- Cabeçalhos: Incluem metadados como tipo de conteúdo ou tokens de autenticação.
- Corpo da requisição: Vai junto com POST ou PUT, contendo os dados a serem enviados.
Esse padrão ajuda a manter a previsibilidade da comunicação. Robert C. Martin reforça:
“Quanto mais as interfaces permanecem as mesmas, mais o software que as usa fica desacoplado e mais fácil de mudar.” (Martin, 2012)
REST aplica exatamente isso: comunicação clara, direta e confiável entre cliente e servidor.
4.2. Códigos de resposta
Toda requisição gera uma resposta do servidor, e ela vem com um código de status. Esses códigos ajudam a entender rapidamente o que aconteceu:
- 200 (OK): Sucesso.
- 201 (Created): Recurso criado com sucesso.
- 400 (Bad Request): Erro de quem enviou a requisição.
- 401 (Unauthorized): Falta de autenticação.
- 404 (Not Found): Recurso não encontrado.
- 500 (Internal Server Error): Erro no servidor.
Esses códigos tornam o diagnóstico mais rápido e ajudam os desenvolvedores a reagir corretamente a cada situação.
Como disse Sommerville:
“O código deve ser escrito para que suas falhas possam ser facilmente detectadas e isoladas.” (Sommerville, 2019)
REST usa os status HTTP para cumprir exatamente essa função.
REST virou padrão porque faz o simples funcionar muito bem. Ele aproveita os recursos da web, promove integração fácil entre sistemas, e ao mesmo tempo garante escalabilidade, modularidade e agilidade no desenvolvimento.
Funciona como uma “regra de trânsito” que todo sistema entende e respeita. É isso que faz do REST a escolha certa para APIs modernas, seja para conectar um app mobile ao servidor, integrar sistemas legados ou expor serviços ao mundo.
Em resumo, REST é:
- Escalável: o servidor não guarda estado, o que facilita crescer.
- Interoperável: diferentes sistemas e linguagens se entendem.
- Modular: cada recurso é independente, o que facilita manutenção.
REST é uma base sólida para criar sistemas prontos para o futuro.
FIELDING, Roy Thomas. Estilos de arquitetura e o design de arquiteturas de software baseadas em rede. 2000.
MARTIN, Robert C. Arquitetura limpa. Alta Books, 2012.
SOMMERVILLE, Ian. Engenharia de Software. 10. ed. Pearson, 2019.
VALENTE, Marco Tulio. Engenharia de Software Moderna. 2. ed. Grupo Gen, 2022.
Evolução da linguagem Java (parte 3)
Neste artigo damos continuidade à nossa análise histórica sobre os recursos que cada versão do Java. trouxe para tornar o código mais limpo e simples para o desenvolvedor.
Se você caiu de paraquedas aqui e ainda não leu a primeira parte, clique aqui.
Java 11
O Java 11 trouxe várias melhorias pontuais. Entre elas, novos métodos em String(isBlank, lines, strip, stripLeading, stripTrailing e repeat), a possibilidade de usar var em parâmetros de expressões lambda e um novo HttpClient moderno e menos verboso.
Novos métodos em String
O isBlank(), verifica se a string é vazia ou contém apenas espaços em branco:
String texto = " Olá \nMundo ";
String textoVazio = " ";
System.out.println(texto.isBlank()); //false
System.out.println(textoVazio); //true
O método lines() deixa o código mais limpo quando precisamos quebrar uma string em várias linhas.
String texto = "Linha 1\nLinha 2\nLinha 3";
String[] linhas = texto.split("\\R"); // regex para qualquer quebra de linha
for (String l : linhas) {
System.out.println(l);
}
// Java 11
texto.lines().forEach(System.out::println);
Os métodos strip, stripLeading e stripTrailing nasceram para substituir o nosso antigo método trim.
String s = " Java ";
System.out.println("[" + s.strip() + "]"); // [Java]
System.out.println("[" + s.stripLeading() + "]"); // [Java ]
System.out.println("[" + s.stripTrailing() + "]"); // [ Java]
O trim não remove todos os tipos de espaço Unicode, apenas espaço comum, tab, quebra de linha e outros (menor ou igual a U+0020). Já o strip remove todos os espaços em branco Unicode do início e do fim.
String texto = " Olá Mundo ";
String textoUnicode = "\u2002Olá Mundo\u2002"; // contém espaço Unicode (EN SPACE)
System.out.println("[" + texto.trim() + "]"); // [Olá Mundo]
System.out.println("[" + texto.strip() + "]"); // [Olá Mundo]
// Diferença com Unicode
System.out.println("[" + textoUnicode.trim() + "]"); // [ Olá Mundo ] (não removeu)
System.out.println("[" + textoUnicode.strip() + "]"); // [Olá Mundo] (removeu)
O método repeat(int count), facilita muito a repetição de strings — algo que antes exigia laços ou utilitários.
// Antes - Usando StringBuilder
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 5; i++) {
sb.append("=");
}
String repetido = sb.toString();
// Antes - Usando Collections.nCopies
String repetido = String.join("", Collections.nCopies(5, "="));
// Java 11
String repetido = "=".repeat(5);
Novo HttpClient
Este novo client, além de reduzir a verbosidade, trouxe suporte nativo a HTTP/2, eliminando a necessidade de bibliotecas de terceiros para casos simples.
// Java 11
HttpClient client = HttpClient.newHttpClient();
HttpRequest req = HttpRequest.newBuilder(URI.create("https://httpbin.org/get")).build();
HttpResponse<String> resp = client.send(req, HttpResponse.BodyHandlers.ofString());
System.out.println(resp.body());
Java 12, 13 e 14.
Nessas versões novos recursos foram adicionados, como Switch Expressions, Text Blocks, Records e Pattern Matching para instanceof.
Entretanto, todos ainda estavam sinalizados como preview. Vou falar especificamente de cada um deles nas versões em que se tornaram final.
Os métodos em String foram muito bem-vindos, mas na época eu esperava ainda mais.
Quando li sobre a novidade, imaginei que o Java finalmente eliminaria a necessidade de bibliotecas de terceiros (como a StringUtils, do Apache ou do Spring).
Ainda assim, esses métodos ajudam a reduzir linhas de código.
O uso de var em parâmetros de lambda, na minha visão, é desnecessário — acaba deixando o código mais verboso sem trazer ganho real.
Já o novo HttpClient chegou um pouco atrasado. Enquanto ele não existia, bibliotecas de terceiros já ofereciam suporte ao HTTP/2 há anos, e em grandes projetos ainda prefiro soluções maduras como OpenFeign ou OkHttp.
👉Concorda com a minha análise? Se lembrar de algum recurso relevante que não citei, compartilhe nos comentários.
Gostou deste artigo? Me siga e fique atento para a terceira parte, onde vamos explorar o que veio do Java 15 em diante.
Plasma Foundation | Over USD 2.4B TVL & 54.02% APY, XPL and Staking Rewards

Plasma Foundation | Over USD 2.4B TVL & 54.02% APY, XPL and Staking Rewards
Dear community,
We are excited to introduce Plasma, a next-generation stablecoin ecosystem, now launching its XPL token and native stablecoin neobank, targeting emerging markets.
Recent milestones include:
- XPL Token Market Cap: Over USD 2.4B at debut
- Mainnet Beta Launch: XPL token rallying ahead of full deployment
- Stablecoin-Neobank Integration: First of its kind, designed for seamless cross-border payments
- Emerging Markets Focus: Expanding access to digital financial tools globally
- Staking Rewards: Earn rewards proportional to the amount of XPL tokens staked
Next step:
Participate in staking to secure early rewards and access exclusive ecosystem benefits. Ensure wallet registration and token eligibility to maximize your Plasma experience.
➖ Stake & Earn: Start Staking XPL and Earn Reward
For detailed news coverage, updates are available on Phys.org, CoinDesk, and MSN Money.
Best regards,
Plasma Foundation
Driving global financial inclusion with blockchain technology
ㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤ
@@amulyakumar @stevemax237 @aries4491 @defillama545 @chainbrary @the_red_dev_cyrillia @creamyb3 @defillama32 @adi_shitrit_5030417793375 @dev_royale
The Dos and Don’ts of Designing an Efficient Tableau Dashboard
Introduction: Why Dashboards Matter in the Data Age
In today’s digital world, businesses are swimming in oceans of data. Every click, purchase, or transaction leaves behind a trail of information. Yet, raw data alone means little until it is shaped into something that decision-makers can understand and act upon. That’s where dashboards step in.
According to Wikipedia, dashboards provide at-a-glance views of key performance indicators (KPIs) relevant to a specific business goal. But in simpler terms, dashboards act as a window into your business health—a storytelling tool that translates numbers into actionable insights.
When designed correctly, dashboards become a silent advisor, answering critical questions such as:
Are we meeting our targets?
What are the risks?
Where are the opportunities?
However, when designed poorly, dashboards can confuse stakeholders, waste time, and lead to misguided decisions. A clumsy dashboard not only hurts productivity but also diminishes trust in data-driven decision-making.
Among the leading tools for dashboard creation, Tableau has consistently been a frontrunner. For years, it has been recognized in Gartner’s Magic Quadrant as a “Leader” in analytics and business intelligence. Tableau’s strength lies in its ability to blend powerful visualization with interactivity, making dashboards not just informative but engaging.
This article dives into the dos and don’ts of designing an efficient Tableau dashboard, structured into three stages of the development lifecycle:
Pre-Development: Ideation and Planning
Development: Building with Best Practices
Post-Development: Testing and Maintenance
We’ll also explore common pitfalls, share real-world case studies, and highlight additional considerations for businesses aiming to maximize the impact of their dashboards.
Stage 1: Pre-Development – The Foundation of a Great Dashboard
Before jumping into charts and colors, successful dashboard design begins with careful planning.
- Define a Clear Goal
Every dashboard must have a purpose. Ask yourself:
Are we trying to automate monthly reporting?
Do we want to monitor real-time operations?
Are we presenting financial KPIs for leadership?
A lack of clarity often leads to dashboards overloaded with irrelevant data. When you know the goal, you can filter out the noise and focus on metrics that truly matter.
Case Study:
A global retail chain once created a single dashboard for sales, operations, and marketing combined. It became so cluttered that executives stopped using it. By refocusing and creating separate dashboards for each goal, adoption improved by 60%.
- Know Your Audience
A dashboard designed for a CEO will differ dramatically from one for a supply chain manager.
Executives need high-level KPIs and strategic indicators.
Middle managers prefer operational dashboards that allow some drill-down.
Frontline staff need tactical dashboards with real-time alerts.
Tailoring dashboards to the audience avoids information overload and ensures relevance.
- Identify the Right KPIs
Not every metric deserves dashboard real estate. Once you’ve consulted stakeholders, finalize a shortlist of KPIs. Having formal sign-off reduces rework and ensures alignment across teams.
For example:
A marketing dashboard may focus on conversion rates, campaign ROI, and customer acquisition cost.
A logistics dashboard may highlight on-time deliveries, shipping costs, and warehouse efficiency.
- Map Data Sources
Every additional data source adds complexity. Limit your connections to those essential for producing KPIs. Also, assess data quality early—dirty or inconsistent data will undermine trust in the dashboard.
- Estimate Infrastructure Needs
Volume and velocity matter. Will data refresh once a day or in real time? Will thousands of users access the dashboard simultaneously? Planning storage and computational requirements upfront avoids future bottlenecks.
Stage 2: Development – Bringing the Dashboard to Life
Once the foundation is set, the focus shifts to design and functionality.
- Keep Design Simple and Intuitive
Dashboards are not meant to dazzle with artistic complexity—they should communicate insights instantly. Stick to your company’s branding guidelines for colors, fonts, and themes to maintain familiarity and professionalism.
Case Example:
A financial services firm redesigned its investor dashboards with the brand’s navy-blue palette and standardized font. The result? Users reported 25% faster comprehension of insights, simply because the design felt familiar and consistent.
- Use the Right Visualization for the Right Data
Each chart type serves a specific purpose.
Line charts: trends over time
Bar charts: category comparisons
Heat maps: density and distribution
KPIs with large numbers: quick status check
A mismatched visualization can distort interpretation. For example, showing profit margins in a pie chart may confuse readers, whereas a bar or line graph offers more clarity.
- Prioritize Impact at First Glance
The most important insights should appear in the top left section of the dashboard (where the eye naturally begins). Supporting data, details, and drill-downs should follow below. This mirrors the “inverted pyramid” style of journalism.
- Provide Context with Annotations and Captions
Numbers without context can mislead. Tableau’s functionality to add notes, captions, or tooltips ensures users understand what the data means. Think of captions as the voice of the dashboard when you’re not there to explain it.
- Enable Interactivity Thoughtfully
Filters, drill-downs, and hover actions empower users to explore data. However, too much interactivity can overwhelm. Strike a balance by including only those interactive elements that align with your dashboard’s goal.
Stage 3: Post-Development – Sustaining Value Over Time
Dashboards are not “set and forget.” They need care.
- Test Rigorously
Testing should include:
Data accuracy checks
Load time assessments
Cross-device usability (desktop, tablet, mobile)
A single error—like showing revenue in euros instead of dollars—can damage trust for months.
- Maintain and Update Regularly
Business priorities shift, data sources change, and software evolves. Without ongoing maintenance, dashboards quickly lose relevance. Schedule periodic reviews to:
Add new KPIs if needed
Retire outdated metrics
Upgrade infrastructure for larger datasets
Common Pitfalls to Avoid
- Starting Too Big
Ambition is great, but beginning with an overly complex dashboard invites failure. A phased rollout—starting small and expanding—ensures quick wins and user adoption.
- Overloading with KPIs
Too many metrics dilute focus. Instead of showing 20 KPIs, pick the 5–7 that align most closely with business goals.
- Underestimating Deployment and Maintenance Time
Building the dashboard is just half the battle. Allocate sufficient resources for testing, training, and support to ensure long-term success.
Additional Considerations for Tableau Dashboards
- Storytelling with Data
Beyond numbers, dashboards should tell a story. Structuring data as a narrative helps stakeholders see not just what is happening, but why.
Example:
A healthcare provider used Tableau dashboards to track patient satisfaction. By combining wait times, staff performance, and patient feedback, the story became clear: longer wait times correlated with lower satisfaction. This narrative spurred operational changes that improved ratings by 18%.
- Psychology of Colors and Layout
Colors evoke emotions—green for success, red for warning, blue for stability. Similarly, cluttered layouts create stress, while clean designs inspire confidence. Applying these principles enhances decision-making.
- Industry-Specific Dashboards
Segmentation by industry makes dashboards even more impactful.
Retail: Sales by region, product categories, and customer demographics.
Finance: Risk exposure, portfolio performance, regulatory compliance.
Healthcare: Patient flow, bed occupancy, treatment outcomes.
Each industry benefits from dashboards that align closely with its unique workflows.
Case Studies: Dashboards in Action
Case Study 1: Airlines and Operations Efficiency
A leading airline adopted Tableau to monitor flight delays, cancellations, and maintenance issues. By visualizing bottlenecks, they reduced turnaround time per aircraft by 12 minutes, saving millions annually.
Case Study 2: E-commerce Personalization
An online retailer built dashboards to track customer segmentation and purchase behavior. Insights led to personalized product recommendations that boosted conversion rates by 20%.
Case Study 3: Public Sector Transparency
A city government used Tableau dashboards to track budget allocations and public spending. Citizens gained access to transparent data, increasing trust in governance.
The Future of Dashboard Design
The next frontier lies in:
AI-powered insights: Dashboards that recommend actions, not just display data.
Mobile-first dashboards: Catering to an increasingly remote workforce.
Natural language queries: Users asking questions like “Show me sales by region last quarter” directly within dashboards.
Collaborative dashboards: Shared annotations and decision-making features.
Conclusion: Dashboards as Strategic Assets
A well-crafted Tableau dashboard is more than a report—it’s a strategic decision-making companion. From ideation to maintenance, every stage of the process demands clarity, thoughtfulness, and discipline. By following best practices, avoiding pitfalls, and learning from real-world case studies, businesses can transform dashboards into engines of insight.
When designed with care, dashboards don’t just present numbers—they drive conversations, inspire action, and shape the future of the business.
This article was originally published on Perceptive Analytics.
In United States, our mission is simple — to enable businesses to unlock value in data. For over 20 years, we’ve partnered with more than 100 clients — from Fortune 500 companies to mid-sized firms — helping them solve complex data analytics challenges. As a leading hire Tableau Expert, Power BI Freelancer and Excel Expert in San Jose we turn raw data into strategic insights that drive better decisions.
[Boost]

🛟 Plasma Foundation | Over USD 2.4B TVL & 54.02% APY, XPL and Staking Rewards
Plasma Foundation | Over USD 2.4B TVL & 54.02% APY, XPL and Staking Rewards
Dear community,
We are excited to introduce Plasma, a next-generation stablecoin ecosystem, now launching its XPL token and native stablecoin neobank, targeting emerging markets.
Recent milestones include:
- XPL Token Market Cap: Over USD 2.4B at debut
- Mainnet Beta Launch: XPL token rallying ahead of full deployment
- Stablecoin-Neobank Integration: First of its kind, designed for seamless cross-border payments
- Emerging Markets Focus: Expanding access to digital financial tools globally
- Staking Rewards: Earn rewards proportional to the amount of XPL tokens staked
Next step:
Participate in staking to secure early rewards and access exclusive ecosystem benefits. Ensure wallet registration and token eligibility to maximize your Plasma experience.
➖ Stake & Earn: Start Staking XPL and Earn Reward
For detailed news coverage, updates are available on Phys.org, CoinDesk, and MSN Money.
Best regards,
Plasma Foundation
Driving global financial inclusion with blockchain technology
ㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤㅤ
@@icolomina @diegocardoso93 @mederhoo @ravixalgorithm @daraxdray @jm27 @lordlokion @cyberg9 @ohgodnoor @hahz
From Copper Wire to Code: A Master Electrician's Journey into Software Development ⚡💻
Hey everyone! I'm here to share a bit about my current journey—one that's taking me from the physical world of Master Electrician work and small business ownership into the digital realm of software development. It's a huge, exciting, and sometimes terrifying shift, and I know I'm not the only one making a big career change.
For years, my world revolved around circuit diagrams, voltage testers, and the precise logic of electrical systems. As a Master Electrician with multiple licenses and a contracting business owner, my days were defined by planning installations, ensuring safety, and troubleshooting complex systems. The work required meticulous precision and a deep understanding of how components interact.
Recently, I felt a pull toward something new—the systems that run the digital world. I realized the core skills I use every day were transferable, and I decided to make the leap into software development.
Making a career switch this big means going back to the fundamentals. I'm currently diving into two powerful languages: C++ and Python. C++ is my choice for building robust, high-performance tools, while Python is my versatile go-to for rapid scripting and utility.
My entire workspace is built on an open platform: I run exclusively on Linux—specifically Debian. I appreciate the stability and control it offers, making it the perfect environment for a builder like me. My approach is simple: learn by building practical applications that solve real problems.
I'm focused on creating tools that provide real utility, like my gambling tax calculator written in C++. I decided to build this tool to handle the complexities of tracking winnings and losses in different jurisdictions. The challenge lies in designing a system that can be easily updated to reflect changing tax laws—it's about creating flexible logic, much like designing an electrical system that can handle future expansions.
You can check out the source code and how it's progressing here: Gambling Tax Calculator GitHub Repo.
As I learn, I'm also creating resources that help me solidify my knowledge and, hopefully, help others in the community. I'm building a repository of developer cheat sheets for the terminal tools I use constantly, specifically tmux and vim.
- Vim is my editor of choice (if you know, you know!) and mastering its efficiency is a key focus.
- tmux helps me keep my terminal sessions and workflows organized.
Creating documentation like this is an easy way to contribute to the community without writing complex code. Feel free to check out and contribute to the cheat sheets here: tmux Cheat Sheet and vim Cheat Sheet.
What does a Master Electrician bring to coding? The answer is systematic troubleshooting.
The core of electrical work is systematic problem-solving:
- Isolate the issue: Is the problem upstream (the breaker) or downstream (the load)?
- Form a hypothesis: A loss of power suggests a loose connection.
- Test the hypothesis: Check for voltage at the first junction point.
This process translates almost perfectly to debugging code:
- Isolate the issue: Is the bug in the data input, the logic, or the output?
- Form a hypothesis: An unexpected value suggests a variable scope error.
- Test the hypothesis: Use a debugger to set a breakpoint and inspect the variable state.
In both careers, you're dealing with a hidden system where one small error can cause a catastrophic failure. Both require a meticulous, logical approach—you can't just guess your way to a solution.
My learning approach is strictly self-taught. I don't have a Computer Science degree, which brings both massive freedom and significant challenges.
The biggest challenge is tackling complex programming concepts independently. Ideas like memory management and design patterns can feel abstract when you're trying to figure them out alone. It's a constant battle between practical application and theoretical depth.
But my philosophy remains: build real solutions to real problems. That tangible sense of accomplishment is what keeps the motivation high, and I believe my practical background offers a unique and valuable perspective in this new field.
My transition from Master Electrician to software developer is built on a decade of experience in systems architecture, problem-solving under pressure, and reliable project execution. As I continue to expand my skills in C++ and Python, I look forward to applying this rigorous, real-world discipline to future software development opportunities. I believe the ability to quickly diagnose and resolve complex system issues, a trait honed in the trades, will be an invaluable asset in any development team.
This transition is an intense solo effort, and connecting with the wider developer community is essential for growth.
If you're a developer, especially one who works in C++ or Python, I'd love to hear from you.
If you're a career changer who's made a jump from a trade, service industry, or any other non-traditional background—how did you bridge the knowledge gap? What was your "a-ha!" moment?
Drop a comment below! I'm eager to connect, exchange advice, and share war stories from the trenches, whether they involve 220 volts or a nasty core dump.
- Have you made a career change into development? Share your "before" and "after" story in the comments!
- Got any essential VIM or TMUX tips for a new developer? I use vim, so drop your best .vimrc or .tmux.conf snippets!
- What open source project do you think every newcomer should check out?
Let's learn together! 🤝
🧠 Tiny Yet Mighty: How TinyGo is Revolutionizing IoT and Embedded Development in 2024
Tired of bloated embedded toolchains and complex cross-compiling rituals? There’s a new sheriff in town: TinyGo – the minimalist Go compiler that's making embedded programming fun again. And it's not just for Arduinos – learn how this lightweight beast is building WebAssembly and microcontroller firmware like a boss.
🔍 What Is TinyGo?
TinyGo is a lean and mean version of the Go programming language made specifically for:
- Microcontrollers
- WebAssembly (WASM)
- Tiny footprint Linux-based devices
Built on LLVM and compatible with many Go language features, TinyGo lets you write Go code that runs on devices with as little as 16KB of RAM. Yes, seriously.
✨ Quick Features:
- Cross compiling made easy
- Runs on dozens of MCUs (Arduino, ESP32, STM32, RISC-V, etc.)
- WASM support out of the box
- Works well with existing Go tooling
⚠️ The Pain TinyGo Solves
Traditional Embedded:
- Toolchain hell
- Debugging nightmares
- Inconsistent language support
- Developer unfriendly
TinyGo:
- Use a modern language (Go 🧡) with amazing tooling
- Write once, compile for microcontrollers or WebAssembly
🔧 Tip: Hello World on An Arduino Uno
Let’s break TinyGo in with a basic example to flash an LED on your Arduino Uno.
Requirements:
- Go installed
- TinyGo installed (brew install tinygo or download from https://tinygo.org/getting-started/)
- Arduino Uno
- USB cable
Code: main.go
package main
import (
"machine"
"time"
)
func main() {
led := machine.LED
led.Configure(machine.PinConfig{Mode: machine.PinOutput})
for {
led.High()
time.Sleep(time.Second)
led.Low()
time.Sleep(time.Second)
}
}
Flash it:
tinygo flash -target=arduino main.go
That’s it. You got a running Go program on your Arduino. Beautiful.
🎯 Cross Target Compilation - WASM & Microcontrollers
Let’s say you want to reuse your logic on web — for visualization or interaction. With TinyGo, it's literally one line away:
Compile to WebAssembly:
tinygo build -o main.wasm -target=wasm main.go
Now you can use this .wasm in a web project. TinyGo’s WASM builds are tiny (hence the name) — under 100KB vs >500KB with Go’s default compiler!
🧪 Real Use Case: Sensor Dashboard from MCU to Browser
Let’s assume you have a microcontroller reading sensor values. Why spin up a heavy Node.js backend to crunch and visualize data?
Split your logic in a shared Go-like interface that works on both:
- ESP32 with MicroPython-style simplicity
- WASM side on the browser
Advanced users can even combine MQTT + WASM visualizers entirely in Go, then build JS dashboards without the JS!
Example interface for message:
type SensorData struct {
Temperature float32 `json:"temperature"`
Humidity float32 `json:"humidity"`
Timestamp int64 `json:"timestamp"`
}
You can reuse this struct both on:
- Microcontroller sending data in JSON (compiled with TinyGo)
- WASM code parsing and displaying it in browser DOM (React + TinyGo WebAssembly)
🛠️ The Compilation Magic Behind TinyGo
TinyGo compiles using LLVM under the hood, not the standard Go compiler (gc). This allows it to strip unused functions (tree-shaking), perform deep optimizations, and keep memory usage microscopic.
This is critical when working with:
- 8-bit and 32-bit MCUs
- Devices with limited Flash/RAM
- High-performance browser WASM apps
⛓️ VS Rust Embedded (YES, the hot topic 🥵)
| Feature | TinyGo | Rust + no_std |
|---|---|---|
| Learning Curve | Low | Steep |
| WASM Support | Excellent | Also Good |
| Community | Growing | Large |
| Ecosystem | Go packages | Crates (but isolated) |
| Tooling | Easy (go mod) | Complex (Cargo + X) |
Rust wins on safety guarantees, no doubt, but TinyGo hits the sweet spot for microservices developers wanting to break into embedded or WASM land without mastering yet another toolchain.
🙌 Real-World Projects Built with TinyGo
- Blues Wireless Notecard support
- Flashing firmware via OTA with TinyGo for ESP32
- Smartwatch UIs in WASM using TinyGo generated .wasm
- IoT dashboards powered by shared codebase from firmware to frontend
🤯 Pro Tip: Write Go Middleware Once — Reuse as Firmware Logic + WASM Frontend Parser
Imagine writing a parser or rule-engine in Go, then reusing it on:
- Embedded device (TinyGo compiled firmware)
- WASM dashboard rule checking (TinyGo .wasm)
- Backend Go server
DRY across the entire stack — embedded → browser → backend.
🔩 Conclusion: Why You Should Try TinyGo Now
TinyGo isn’t just a toy. It’s beginning to disrupt the WASM and embedded world with full stack Go. For developers already familiar with Go or coming from web dev, this is the most accessible path into:
- Embedded 💡
- IoT 🌐
- Robotics 🤖
- WASM 🧙♂️ wizardry
Next Steps:
- 👉 Get Started Guide from TinyGo.org
- 👉 Try the WASM Playground
- 👉 Flash your first Arduino app in Go
Go small. But dream big. 🧠
#tinygo #embed-programming #golang #wasm
✅ If you need this done – we offer Research & Development Services tailored for embedded, WebAssembly, and cross-platform Go development.
Andrew Huang: The most innovative music tools of 2025!
The most innovative music tools of 2025!
Andrew Huang teams up with The MIDI Association to showcase the year’s coolest gear, from polished commercial hardware and software to experimental prototypes. Expect to see everything from sleek audio interfaces and plugins to next-level synth rigs and cutting-edge production tools—plus a deep dive into the promise of MIDI 2.0.
Chapters guide you through each category:
• Commercial hardware products (0:51)
• Hardware prototypes (4:22)
• Commercial software products (6:56)
• Software prototypes (10:42)
• MIDI 2.0 (13:21)
• Artistic/visual projects & installations (14:27)
Watch on YouTube
UCIe 3.0 Adds DSP Support
AI is driving a great deal of chiplet adoption, but there’s a diverse set of usages being addressed by the standard
The post UCIe 3.0 Adds DSP Support appeared first on EE Times.
Leading the AI Evolution with Innovative 2mm Flash Memory Assembly Technology
The rapid growth of AI has accelerated demand for flash memory capacity. KIOXIA has successfully developed large-capacity 8 TB (terabyte) flash memory by assembling 32 pieces of 2 Tb (terabit) memory dies into a package less than 2 mm in height. This achievement was made possible with advanced assembly process technologies, including the technology for […]
The post Leading the AI Evolution with Innovative 2mm Flash Memory Assembly Technology appeared first on EE Times.
Plugging the Electronics Skills Shortage the U.K. Way With UKESF
How the U.K.’s Electronics Skills Foundation is using a multi-faceted approach to addressing the skills shortage and feeding the talent pipeline in electronics.
The post Plugging the Electronics Skills Shortage the U.K. Way With UKESF appeared first on EE Times.
Today's best iPad deals include a record-low price on the latest iPad Air M3
Apple's four iPad models each have their value — the mini is super portable, the standard model with the A16 chip is ideal for casual use while the Pros can handle complex tasks better than some laptops. The iPad Air falls somewhere in between, offering a balance between power and price. But these popular tablets don't come cheap, which is why we keep track of sale prices on iPads and round them up each week. We've reviewed every current model so if you want to check out our thoughts before you buy, you can. Here are the best iPad deals you can get right now, along with discounts on other Apple gear we recommend.
Apple iPad (A16) for $299 ($50 off): The most recent entry-level iPad comes with a faster A16 chip, 2GB more RAM and 128GB of storage by default. It earned a score of 84 in our review — if you only need a tablet for roaming the internet, watching shows and doing some lighter productivity tasks, it should do the job. With the new iPadOS 26 update, it also has most of the same multitasking features available with the more expensive models. We've seen this price for most of the past several months, but it's still a bit cheaper than buying direct from Apple. Also at Walmart and Best Buy.
Apple iPad Air (13-inch, M3) for $649 ($150 off): Engadget's Nate Ingraham gave the 13-inch iPad Air a score of 89 when it was released in March. It has a bigger and slightly brighter display than its 11-inch counterpart; otherwise, the two slates are the same. If you plan to keep your iPad hooked up to a keyboard, the extra screen space is lovely for taking in movies and multitasking for work. This is another all-time low, and it applies to several color options and storage configs. Also at Walmart.
Apple iPad Pro (11-inch, M4) for $899 ($100 off): The iPad Pro is much more tablet than most people need, but it’s the ultimate iPad for those who can stomach its price tag. It’s wonderfully thin, its OLED display is one of the best we’ve seen on a consumer device and its M4 chip can handle virtually anything you’d ever do on an iPad. It’s also the only Apple tablet with Face ID and it has a better speaker setup than the iPad Air. We gave it a score of 84 in our review, with the only real drawback being its price. Also at Best Buy, Target and B&H.
The 13-inch model is on sale for $1,099 as well, a $200 discount, but be warned: Bloomberg's Mark Gurman reports that Apple could release updated iPad Pros as soon as October. So if you can hold out, you probably should.
Apple Watch Series 11 (GPS, 42mm) for $389 ($10 off): The latest Apple Watches only hit the market last week, but Amazon is already offering a $10 discount on certain colorways. It doesn't show up as a percentage off, but you'll see some models listed at $389, while others show up at the full price of $399. If you're new to Apple's wearables or are ready to upgrade from a Series 9 or older, this is a good model to grab. If you're coming from a Series 10, however, there's not much need to upgrade as the only major change from last year's model is a slightly larger battery and a tougher screen.
Apple Watch SE 3 (GPS, 40mm) for $240 ($9 off): You'll see a similar stealth discount on Apple's newest budget model, the SE 3 at Amazon. It goes for $249 regularly. Apple gave this model some badly needed updates from its predecessor, including a faster charging battery, better sensors and the same processor that you'll find in the new Apple Watch Series 11.
Apple MagSafe charger (25W, 2m) for $35 ($14 off): Here's a record-low price on Apple's fasted wireless charging puck. It'll work with any iPhone as long it's an iPhone 8 or newer, but if you have an iPhone 16 or 17, this cable can charge your device at 25W when paired with 30W power adapter. Also at Best Buy. The one-meter model is on sale at Walmart for $27.30.
Apple MacBook Air (13-inch, M4) for $799 ($200 off): Apple's latest MacBook Air is the top pick in our guide to the best laptops, and it earned a score of 92 in our review. It's not a major overhaul, but the design is still exceptionally thin, light and well-built, with long battery life and a top-notch keyboard and trackpad. Now it's a bit faster. (Though we'd still love more ports and a refresh rate higher than 60Hz.) This discount ties an all-time low for base config with 16GB of RAM and a 256GB SSD. Models with more memory or storage are also $200 off. Also at Best Buy.
Apple MacBook Air (15-inch, M4) for $999 ($200 off): The 15-inch MacBook Air is nearly identical to the smaller version but has better speakers and a more spacious trackpad alongside its roomier display. Outside of one very brief drop around $980 in June, this ties a record low for the base model. Other configs are similarly discounted if you need more power. Also at B&H and Best Buy.
Apple Mac mini (M4, 16GB/256GB) for $499 ($100 off): The newest version of Apple’s tiny desktop PC has a smaller overall footprint, a faster M4 chip, 16GB of RAM as standard (finally), two front-facing USB-C ports (finally!), an extra Thunderbolt 4 port and the ability to drive three external displays. It doesn't have any USB-A ports, however. We gave the M4 Pro model a review score of 90. This deal is for the entry-level version with a base M4 chip, 16GB of RAM and a 256GB SSD — we’ve seen it fall as low as $469 in the past, but this is still a decent savings. Also at Best Buy, Walmart and B&H.
Apple Mac mini (M4, 16GB/512GB) for $689 ($110 off): If you want your tiny Apple desktop to have a little bit more storage capacity, you may want to spring for the 512GB model. It's currently $110 off at Amazon and B&H Photo. The model with 24GB of RAM is down to $904 after a $95 discount.
Apple AirTags (4-pack) for $75 ($24 off): We may see an updated model by the end of 2025, but the current AirTags are the best Bluetooth trackers for iPhone users thanks to their vast finding network and accurate ultrawide band features that make it easy to locate things that are close by. Just note that you'll need a separate AirTag holder to attach them to your keys, wallet or bag. This isn't a great deal for a four-pack — the bundle was as low as $65 in July — but it's still a bit lower than its list price. Also at Walmart.
Apple Pencil Pro for $99 ($30 off): The highest-end option in Apple’s confusing stylus lineup, the Pencil Pro supports pressure sensitivity, wireless charging, tilt detection, haptic feedback and Apple’s double tap and squeeze gestures, among other perks. It’s a lovely tool for more intricate sketching and note-taking, but the catch is that it’s only compatible with the M4 iPad Pro, M2 and M3 iPad Air and most recent iPad mini. We've seen this deal fairly often over the year, but it's a solid discount compared to buying from Apple directly. Also at Walmart, Best Buy and Target.
Apple 35W Dual USB-C Port adapter for $39 ($20 off): It's always good to have a few extra ports around. This is the adapter that ships with the M4 with 10‑core GPU MacBook Air, and it can quickly charge iPads, iPhones and anything else powered by USB-C, too. Walmart is also selling Apple's 2-meter fast charge cable for $23 (a $6 discount).
Read more Apple coverage:
Follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/todays-best-ipad-deals-include-a-record-low-price-on-the-latest-ipad-air-m3-150020567.html?src=rss
This battery-powered Ring doorbell is 47 percent off ahead of Prime Day
The Ring Battery Doorbell Plus is on sale for almost half off and is at the lowest price we've ever seen for this model. Normally retailing for $150, the smart doorbell is on sale for $80, a discount of 47 percent. This aggressive sale comes ahead of another Prime Day that runs October 7-8.
The Battery Doorbell Plus offers a 150-by-150-degree "head to toe" field of vision and 1536p high-resolution video. This makes it a lot easier to see boxes dropped off at your front door since it doesn't cut off the bottom of the image like a lot of video doorbells.
This model features motion detection, privacy zones, color night vision and Live View with two-way talk, among other features. Installation is a breeze since you don't have to hardwire it to your existing doorbell wiring. Most users report that the battery lasts between several weeks and several months depending on how users set up the video doorbell, with power-heavy features like motion detection consuming more battery life.
With most video doorbells today, you need a subscription to get the most out of them, and Ring is no exception. Features like package alerts require a Ring Home plan, with tiers ranging from Basic for $5 per month to Premium for $20 per month. You'll also need a plan to store your video event history.
Ring was acquired by Amazon in 2018, and now offers a full suite of home security products including outdoor cameras, home alarm systems and more. This deal is part of a larger sale on Ring and Blink devices leading up to Prime Day.
This article originally appeared on Engadget at https://www.engadget.com/deals/this-battery-powered-ring-doorbell-is-47-percent-off-ahead-of-prime-day-154508654.html?src=rss
Horror-tinged sidescroller Possessor(s) hits PC and PS5 on November 11
The long-awaited sidescroller Possessor(s) will be available on November 11 for PC and PS5. It's a horror-tinged action game with Metroidvania elements. It also happens to look extremely beautiful.
The game was developed by Heart Machine, which is the same company behind Hyper Light Drifter and its prequel Hyper Light Breaker. Publishing duties fall to Devolver, which has had a hand in a boatload of recent indie hits from Enter the Gungeon to Cult of the Lamb. The developer just dropped a launch date trailer for Possessor(s) and it's filled with both gameplay and story elements.
As for that story, the game's set in a quarantined metropolis that's been invaded by ghostly forces. Exploration will slowly unravel what happened to the city. There's an open-ended narrative with multiple paths and plenty of characters to meet.
The combat looks really slick, with lots of melee using found objects. The protagonist can also slide down long corridors and swing from a grappling hook. Weapons can be upgraded and there looks to be a skill tree of some kind.
We only have around five weeks until we can get our hands on this one. Pre-orders on both platforms are up right now, but there's no price yet.
This article originally appeared on Engadget at https://www.engadget.com/gaming/horror-tinged-sidescroller-possessors-hits-pc-and-ps5-on-november-11-152851427.html?src=rss
Meta announces paid subscriptions for both Instagram and Facebook in the UK
Facebook and Instagram users in the UK will soon be offered paid subscriptions that remove ads. In the coming weeks, those over the age of 18 can pay £3 ($4) per month on the web, or £4 ($5) per month when using Meta’s iOS or Android apps. If you're wondering why the mobile version is more expensive, Meta blames that on fees levied by Apple and Google in their respective app stores.
A no-ads subscription will apply to any Facebook and Instagram account added to a Meta Accounts Center, which is what Meta uses to let users connect various Meta logins on its different platforms. Any additional account listed in a user’s Accounts Center will automatically gain their own subscription for an extra £2 ($3) per month on the web or £3 ($4) per month for iOS and Android. Anyone who chooses to decline Meta’s offer will continue to see ads on its free platforms as normal, and can still use Ad Preferences to choose which ads they would prefer to see more or less of.
Meta says the change is a response to new regulatory "consent or pay" guidance from the Information Commissioner’s Office (ICO), whereby users are given the choice between consenting to an organization using their data to personalize ads, or paying to avoid it. Meta previously introduced a similar change for its EU users, offering an ad-free subscription option for €10 ($11), but was fined €200 million by the European Commission for allegedly failing to comply with its stricter Digital Markets Act (DMA) laws. The company later offered a revised, cheaper, ad-free plan that was still being assessed by the EC earlier this year.
Meta praised the ICO for its "constructive approach" to personalised ads, which it insists provide the best experience for both its users and businesses, and criticised EU regulators for continuing to "overreach" with its privacy regulations. As reported by Bloomberg, digital advertising accounted for around 97 percent of Meta’s revenue in 2024.
This article originally appeared on Engadget at https://www.engadget.com/big-tech/meta-announces-paid-subscriptions-for-both-instagram-and-facebook-in-the-uk-140913304.html?src=rss
The best October Prime Day deals you can get today: Early sales on gear from Apple, Anker, JBL, Shark and more
Amazon Prime Day has returned in the fall for the past few years, and 2025 is no exception. Prime Day will return on October 7 and 8, but really, you don't have to wait until the official start date to save. Amazon typically always has early Prime Day deals in the lead-up to the event, and this year we’re already seeing some solid discounts on gadgets we like. Here, we’ve gathered all of the best Prime Day deals you can get right now, and we’ll keep updating this post as we get close to Prime Day proper.
Anker 622 5K magnetic power bank with stand for $34 (29 percent off, Prime exclusive): This 0.5-inch thick power bank attaches magnetically to iPhones and won't get in your way when you're using your phone. It also has a built-in stand so you can watch videos, make FaceTime calls and more hands-free while your phone is powering up.
Anker Nano 5K ultra-slim power bank (Qi2, 15W) for $46 (16 percent off): A top pick in our guide to the best MagSafe power banks, this super-slim battery is great for anyone who wants the convenient of extra power without the bulk. We found its proportions work very well with iPhones, and its smooth, matte texture and solid build quality make it feel premium.
Leebein 2025 electric spin scrubber for $40 (43 percent off, Prime exclusive): This is an updated version of my beloved Leebein electric scrubber, which has made cleaning my shower easier than ever before. It comes with seven brush heads so you can use it to clean all kinds of surfaces, and its adjustable arm length makes it easier to clean hard-to-reach spots. It's IPX7 waterproof and recharges via USB-C.
Apple Mac mini (M4) for $499 $100 off): If you prefer desktops over laptops, the upgraded M4 Mac mini is one that won’t take up too much space, but will provide a ton of power at the same time. Not only does it come with an M4 chipset, but it also includes 16GB of RAM in the base model, plus front-facing USB-C and headphone ports for easier access.
Jisulife Life7 handheld fan for $25 (14 percent off, Prime exclusive): This handy little fan is a must-have if you life in a warm climate or have a tropical vacation planned anytime soon. It can be used as a table or handheld fan and even be worn around the neck so you don't have to hold it at all. Its 5,000 mAh battery allows it to last hours on a single charge, and the small display in the middle of the fan's blades show its remaining battery level.
Apple Watch Series 11 for $389 ($10 off): The latest flagship Apple Watch is our new pick for the best smartwatch you can get, and it's the best all-around Apple Watch, period. It's not too different from the previous model, but Apple promises noticeable gains in battery life, which will be handy for anyone who wants to wear their watch all day and all night to track sleep.
Apple MacBook Air (13-inch, M4) for $799 (20 percent off): Our top pick for the best laptop for most people, the latest MacBook Air is impressively thin and light without skimping on performance. The M4 chipset is powerful enough to handle everyday tasks without breaking a sweat, plus some gaming and labor-intensive work. It has a comfortable keyboard, luxe-feeling trackpad and an excellent battery life.
Apple iPad (A16) for $299 ($50 off): The new base-model iPad now comes with twice the storage of the previous model and the A16 chip. That makes the most affordable iPad faster and more capable, but still isn't enough to support Apple Intelligence.
Apple iPad Air (11-inch, M3) for $449 ($150 off): The only major difference between the latest iPad Air and the previous generation is the addition of the faster M3 chip. We awarded the new slab an 89 in our review, appreciating the fact that the M3 chip was about 16 percent faster in benchmark tests than the M2. This is the iPad to get if you want a reasonable amount of productivity out of an iPad that's more affordable than the Pro models.
Samsung EVO Select microSD card (256GB) for $23 (15 percent off): This Samsung card has been one of our recommended models for a long time. It's a no-frills microSD card that, while not the fastest, will be perfectly capable in most devices where you're just looking for simple, expanded storage.
Roku Streaming Stick Plus 2025 for $29 (27 percent off): Roku makes some of the best streaming devices available, and this small dongle gives you access to a ton of free content plus all the other streaming services you could ask for: Netflix, Prime Video, Disney+, HBO Max and many more.
Blink Mini 2 security cameras (two-pack) for $35 (50 percent off): Blink makes some of our favorite security cameras, and the Mini 2 is a great option for indoor monitoring. It can be placed outside with the right weatherproof adapter, but since it needs to be plugged in, we like it for keeping an eye on your pets while you're away and watching over entry ways from the inside.
JBL Go 4 portable speaker for $40 (20 percent off): The Go 4 is a handy little Bluetooth speaker that you can take anywhere you go thanks to its small, IP67-rated design and built-in carrying loop. It'll get seven hours of playtime on a single charge, and you can pair two together for stereo sound.
Anker Soundcore Space A40 for $45 (44 percent off): Our top pick for the best budget wireless earbuds, the Space A40 have surprisingly good ANC, good sound quality, a comfortable fit and multi-device connectivity.
Anker MagGo 10K power bank (Qi2, 15W) for $63 (22 percent off, Prime exclusive): A 10K power bank like this is ideal if you want to be able to recharge your phone at least once fully and have extra power to spare. This one is also Qi2 compatible, providing up to 15W of power to supported phones.
Rode Wireless Go III for $199 (30 percent off): A top pick in our guide to the best wireless microphones, the Wireless Go III records pro-grade sound and has handy extras like onboard storage, 32-bit float and universal compatibility with iPhones, Android, cameras and PCs.
Shark AI robot vacuum with self-empty base for $230 (58 percent off, Prime exclusive): A version of one of our favorite robot vacuums, this Shark machine has strong suction power and supports home mapping. The Shark mobile app lets you set cleaning schedules, and the self-empty base that it comes with will hold 30 days worth of dust and debris.
Levoit LVAC-300 cordless vacuum for $250 ($100 off, Prime exclusive): One of our favorite cordless vacuums, this Levoit machine has great handling, strong suction power for its price and a premium-feeling design. Its bin isn't too small, it has HEPA filtration and its battery life should be more than enough for you to clean your whole home many times over before it needs a recharge.
Shark Robot Vacuum and Mop Combo for $300 (57 percent off, Prime exclusive): If you're looking for an autonomous dirt-sucker that can also mop, this is a good option. It has a mopping pad and water reservoir built in, and it supports home mapping as well. Its self-emptying base can hold up to 60 days worth of debris, too.
Nintendo Switch 2 for $449: While not technically a discount, it's worth mentioning that the Switch 2 and the Mario Kart Switch 2 bundle are both available at Amazon now, no invitation required. Amazon only listed the new console for the first time in July after being left out of the initial pre-order/availability window in April. Once it became available, Amazon customers looking to buy the Switch 2 had to sign up to receive an invitation to do so. Now, that extra step has been removed and anyone can purchase the Switch 2 on Amazon.
This article originally appeared on Engadget at https://www.engadget.com/deals/the-best-october-prime-day-deals-you-can-get-today-early-sales-on-gear-from-apple-anker-jbl-shark-and-more-050801366.html?src=rss
Apple Watch Series 11 models are already on sale at Amazon
The Apple Watch Series 11 is already available on Amazon, and you can pick up select color and case combos for $10 less than Apple's base price. The newest generation of Apple's smartwatch was just revealed this month at the company's iPhone 17 event in Cupertino.
The Series 11 packs some new features like 5G connectivity on cellular models, a more scratch-resistant screen, new sleep features, improved battery life and a hypertension alert system that just received FDA clearance. The GPS-only version is our top pick for Best Apple Watch in 2025.
In our hands-on review, we gave the Apple Watch Series 11 a score of 90 out of 100, noting its thin and light design, the excellent battery life, a nifty new wrist-flick gesture and its comprehensive approach to health and fitness monitoring. It is relatively pricey however, and the Watch SE 3 is probably enough for most users, but the Series 11 has a brighter and larger display, a thinner design, longer battery life and more advanced health features.
For anyone who hasn't bought a new Apple Watch in a few years, the Series 11 is a worthy upgrade. If you're in the market for your first Apple Watch, then this model would be a great one to start with. If you're rocking a Series 10, then you probably don't need to upgrade now unless the improved battery life will mean that much to you.
The Apple Watch Series 11 is available on Amazon in all sizes, colors and connectivity options. There are a few case color and band combinations that are $10 off Apple's base price.
This article originally appeared on Engadget at https://www.engadget.com/deals/apple-watch-series-11-models-are-already-on-sale-at-amazon-135020611.html?src=rss
UK announces plans for digital ID cards
UK Prime Minister Keir Starmer has announced a new requirement for all working adults in the country to carry a digital identification called the Brit Card. In practice, the Brit Card will be based on the One Login infrastructure already used by the UK government.
Supporters of the plan say digital ID cards can ensure that people have the right to work in the UK, and thus could help crack down on illegal immigration and exploitative employment schemes. "It will send a clear message that if you come here illegally, you will not be able to work, deterring people from making these dangerous journeys," Starmer's office wrote bluntly in the announcement. The UK government also plans to have an "outreach programme, including face-to-face support" for those "who aren’t able to use a smartphone" or those who "aren’t as experienced with the digital world, like the homeless and older people."
The announcement claims the scheme will use "state-of-the-art encryption and authentication technology" and that "digital credentials will be stored directly on people’s own device." However, critics say the IDs may infringe on civil liberties by requiring citizens to give the government additional personal information. They also raise concerns about how the administration plans to protect all those sensitive details from misuse or theft.
"No system is immune to failure, and we have seen time and again governments and tech giants fail to protect people’s personal data," said David Davis, a Conservative MP and former cabinet minister. "If world-leading companies cannot protect our data, I have little faith that Whitehall would be able to do better."
This article originally appeared on Engadget at https://www.engadget.com/cybersecurity/uk-announces-plans-for-digital-id-cards-133833359.html?src=rss
Apple's 25W MagSafe charger is on sale for a record-low price
On the heels of the iPhone 17 lineup being released last week, you can pick up Apple's 25W MagSafe charger for a song. The two-meter version of the more powerful charging cable has dropped by 29 percent from $49 to $35. That's a record-low price.
As it happens, that actually makes the two-meter version of the cable less expensive than the one-meter variant. The shorter cable will run you $39 as things stand.
If you have an iPhone 16, iPhone 17 or iPhone Air, this cable can charge your device at 25W as long as it's connected to a 30W power adapter on the other end. While you'll need a more recent iPhone to get the fastest MagSafe charging speeds, the charger can wirelessly top up the battery of any iPhone from the last eight years (iPhone 8 and later). With older iPhones, the charging speed tops out at 15W. The cable works with AirPods wireless charging cases too — it's certified for Qi2.2 and Qi charging.
The MagSafe charger is one of our favorite iPhone accessories, and would pair quite nicely with your new iPhone if you're picking up one of the latest models. If you're on the fence about that, be sure to check out our reviews of the iPhone 17, iPhone Pro/Pro Max and iPhone Air.
Check out our coverage of the best Apple deals for more discounts, and follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/apples-25w-magsafe-charger-is-on-sale-for-a-record-low-price-143415602.html?src=rss
Roomba robot vacuums are more than $300 off right now
You can save big today on a new Roomba. The flagship Roomba Max 705 + AutoEmpty dock, which launched in April, is available for $320 off. The robovac, which typically costs $899, is on sale for $579. Enter our exclusive code ENG320 at checkout to snag the deal.
iRobot says the Roomba Max 705 offers 180 times the suction power of its budget Roomba 600. The high-end model has dual multi-surface rubber brushes with an anti-tangle design. That could be especially handy for pet owners.
The robovac includes an edge-sweeping brush to handle corners and edges. There's also a feature called Carpet Boost that automatically increases suction when it reaches carpet. And it uses LiDAR for precision navigation and obstacle avoidance.
The AutoEmpty dock lives up to its name, allowing the vacuum to dump its own debris automatically. iRobot says it can do that for up to 75 days before you need to manually empty the dock.
This model doesn't mop, which may be harder for some to justify at its typical $899. But for $579, a high-powered vacuum with an auto-emptying dock starts to look more sensible. Just remember that code: ENG320.
If you're looking for something more affordable (but with a different feature set), there's the Roomba Plus 405 Combo. Although its suction isn't as powerful as the aforementioned 705 model, this one does mop. Its AutoWash dock supports up to 45 days of auto-emptying and four weeks of mopping and pad washing before requiring your attention.
The iRobot Roomba Plus 405 Combo robot + AutoWash dock typically retails for $799. With our code ENG320, you can have it for $479.
Follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/roomba-robot-vacuums-are-more-than-300-off-right-now-130043860.html?src=rss
Norton VPN review: A VPN that fails to meet Norton's standards
One thing I need to make clear right from the start: this is a review of Norton VPN (formerly Norton Secure VPN, and briefly Norton Ultra VPN) as a standalone app, not of the VPN feature in the Norton 360 package. They're similar, but Norton VPN has a few more features, including the ability to choose cities as server locations in countries with more than one option.
I'll state my opinion up front. Norton VPN isn't a bad service, but it's not good enough to get ahead of its direct competitors. ExpressVPN, Surfshark, Proton VPN and NordVPN are all either faster, more feature-rich, more secure, more affordable or some combination of the four. There's no reason to go with Norton as your VPN unless you're getting it as part of another Norton 360 bundle.
For this review, I ran rigorous tests that highlighted Norton VPN's strengths (well-designed user interfaces, a verified privacy policy) along with its weaknesses (holes in its security, renewals that double the price, weak customer support). Norton's history of focusing on Windows means that app is by far the most complete; if you're on any other platform, expect to miss out on the best VPN protocols and the complete feature set.
Editor's note (9/26/25): We've overhauled our VPN coverage to provide more detailed, actionable buying advice. Going forward, we'll continue to update both our best VPN list and individual reviews (like this one) as circumstances change. Most recently, we added official scores to all of our VPN reviews. Check out how we test VPNs to learn more about the new standards we're using.
Use this table as a quick reference for my test results, investigations and thoughts about Norton VPN. For more details, jump to the relevant section using the table of contents above.
Category |
Notes |
Installation and UI |
All apps install easily Navigation is intuitive, with clearly labeled tabs and explanations of each feature Mac and iOS apps lack several options, including split tunneling Browser extensions are the only way to use the ad blocker Smart TVs are also supported |
Speed |
Relatively significant average speed drop of 21.1 percent Download speeds varied with distance, which can be a sign of outdated infrastructure Upload speeds dropped an average of 9.5 percent Mean worldwide latency was 322 ms, putting Norton in the middle of the pack |
Security |
Windows and Android apps have WireGuard, OpenVPN and Mimic; Mac and iOS apps just have IKEv2 and Mimic Mimic uses vetted encryption, but I still recommend using open-source protocols wherever possible Unless kill switch is enabled, your real IP address is visible while switching server locations |
Pricing |
You can only subscribe for one year at a time After one year, renewal pricing kicks in, doubling the annual fee The Standard plan, which includes all VPN features, costs $39.99 for the first year and $79.99 for future years All plans can be refunded for 60 days |
Bundles |
Plus plans add most of the functionality of Norton Antivirus, but without manual scans, disk cleanup or email monitoring Ultimate adds parental controls and personal data removal Norton VPN is also available through several Norton 360 plans, with reduced features |
Privacy policy |
Norton's general privacy policy allows far too much data collection, but Norton VPN's rules are stricter An audit in 2024 found that Norton VPN posed little or no privacy risk |
Virtual location change |
Most servers changed my virtual location to access a different Netflix library Iceland location was repeatedly blocked |
Server network |
106 server locations in 66 countries Good distribution across northern and southern hemispheres No information on virtual server locations |
Features |
Can block ads on mobile and browsers; browser version can allow certain acceptable ads Some locations connect through a second server, while others continually rotate your IP address Kill switch works but is only available on iOS through Mimic Windows and Android users get split tunneling by app Can scan wi-fi networks for common attacks |
Customer support |
Windows users have the most in-app debugging options — all other platforms just link to the website FAQs are hard to navigate and have little useful information Tech support prefers to call rather than email |
Background check |
Norton Antivirus was first offered in 1991, but Norton VPN didn't launch until 2019 as part of the Norton 360 resurrection No serious controversies during that time |
Here, I'll do my best to convey how it feels to use Norton VPN on various platforms. Its apps for Windows, Mac, Android, iOS and browsers are all similar, but there are distinctions in both design and features.
Windows
Once you download the Norton VPN app from its website or the Microsoft Store, an installation wizard takes over and makes the rest of the process easy. You'll have to click to grant a few permissions and skip through a tutorial, but after that, you're free to move about the interface.
Norton VPN's Windows UI was a pleasant surprise. There's no wasted detail on the front page. Click the large yellow button to connect to the VPN, or select the server name to go to the location list, which is alphabetized. Clicking the very first entry in the list connects you to the fastest location. IP rotator servers and double VPN routes are grouped under tabs below that. There's no clutter and no aggressive popups, and connections happen quickly.
You'll find four tabs on the left-hand side of the Window. The top one manages the VPN. Then there's a store for other Norton products (IMO the only real misstep), a set of help pages and the controls for the VPN's settings and features. This last is subdivided into a row of easily understandable subtabs. I'm impressed by how seamlessly the design works in explanations of what each setting does — it makes the whole thing that much more accessible.
Mac
Downloading Norton VPN for Mac is a quick and painless process, with one slight difference from Windows: you'll have to mess around a bit in System Preferences to give Norton the permissions it needs. Fortunately, the setup wizard guides you through the steps with text and animations.
The actual interface is just as free of clutter as the Windows app — more so in some cases, as there's no shilling of the rest of the Norton family. The downside is that there's also no help center access from the main window; you have to go to Settings -> Troubleshooting to find the link. There also aren't links to specific help articles like the Windows app includes.
Android
One word of warning about Norton VPN's mobile apps: you need an internet connection for the initial login and setup. It doesn't appear to be opening a website, but if you don't have web access, you'll get stuck in an endless loading loop.
The front pages of Norton VPN's desktop apps don't have many design elements, so the same general schematic is easy to compress onto mobile. The Android client has a status indicator, a large button to start your connection, tabs along the bottom and a gear icon for settings in the top-right. It's all intuitive and responsive.
If I were to change anything, though, I'd take some of the options from the upper-right settings menu and swap them with the bottom tabs for notifications and accounts settings. VPN preferences should be accessible in one click, especially protocols. Frankly, the messages you get from this app aren't important enough to merit such pride of place.
iOS
Norton VPN's apps for iPhone and iPad are almost identical to its Android app. The only real difference is that the iOS client is missing some features, most notably split tunneling; also, the kill switch is only available on the Mimic protocol, about which there's limited information. Other than that, it feels good to use. While it's not great that Apple users lose out on the full feature set, I can't deny it alleviates the problem of the VPN preferences menu feeling overstuffed.
Browser extensions
Norton VPN has browser extensions for Chrome, Firefox and Edge. The only reason to install any of these is to access the ad blocker, which doesn't come with either of the desktop apps. Other than that, it's an underwhelming extension. I recommend skipping it and going with a dedicated ad blocker instead — you'll get more customization features that way.
Using speedtest.net, I tested Norton VPN to see how much it slowed down my browsing speeds. I then calculated the results as percentages. While different networks give you different starting speeds, the same server location tends to slow down all those networks at about the same rate. You can use this table to estimate how much speed you can expect while Norton VPN is running.
As a reference, you generally need download speed for loading web pages and videos, upload speed for sending large amounts of data and latency for real-time communication. Latency always increases sharply over longer distances, but a good VPN can still keep the jumps under control. Let's see how Norton VPN did.
Server location |
Latency (ms) |
Increase factor |
Download speed (Mbps) |
Percentage drop |
Upload speed (Mbps) |
Percentage drop |
Portland, OR, USA (unprotected) |
18 |
— |
58.90 |
— |
5.91 |
— |
Portland, OR, USA (protected) |
30 |
1.7x |
55.83 |
5.2 |
5.53 |
6.4 |
McAllen, TX, USA |
164 |
9.1x |
48.96 |
16.9 |
5.70 |
3.6 |
Argentina |
422 |
23.4x |
43.02 |
27.0 |
5.72 |
3.2 |
Croatia |
379 |
21.1x |
46.35 |
21.3 |
5.65 |
4.4 |
Nigeria |
564 |
31.3x |
39.94 |
32.2 |
3.86 |
34.7 |
Indonesia |
375 |
20.8x |
44.88 |
23.8 |
5.64 |
4.6 |
Average |
322 |
17.9x |
46.50 |
21.1 |
5.35 |
9.5 |
Before I interpret the results, I should mention that the algorithm Norton VPN uses to pick the fastest server doesn't seem to be reliable. Every time I clicked it, it gave me the server in Texas, thousands of miles from my real location in Portland, Oregon. Moreover, the Portland server was obviously faster. This happened repeatedly over multiple days of testing.
To the point: this table doesn't look good for Norton VPN. Download speeds dropped an average of 21.1 percent, the worst showing of any VPN I've tested so far. What's worse, the data clearly trend toward worse speeds at greater distances. Although it's true that distance impacts download speed as well as latency, it's also true that a well-implemented modern server OS should be able to render that effect minimal.
Upload speed looks better, with an average drop of under 10 percent — mainly dragged down by the Nigeria server, which cut speeds sharply across every test. Latency is also not awful. Controlling for the expected variance due to distance, Norton VPN beat out both Surfshark and NordVPN in average worldwide ping, which suggests that gaming may be its comfort zone.
A VPN's primary job is to change your IP address. While doing this, it must also encrypt your communications with its servers so nobody can follow your connection home — this is what separates a VPN from a simple proxy. In this section, I'll run three checks to see whether Norton VPN can guarantee anonymous browsing.
VPN protocols
VPNs use protocols to establish stable connections between your devices and their servers. Most providers pick from the same pool of field-tested options, but you do see a surprise every now and then, like Norton VPN's Mimic.
Norton VPN's protocol selection follows its general trend of serving very different experiences to users on different platforms. Windows and Android users get WireGuard, OpenVPN and Mimic, while macOS and iOS users only get Mimic and IKEv2. Here's a rundown of each.
WireGuard is the most modern open-source VPN protocol currently available. It's almost always the fastest and uses a secure stream cipher for cryptography. The one downside is that it saves your real IP address to keep the connection open. Norton VPN deals with this by assigning temporary dynamic IP addresses during the authentication process.
OpenVPN is an open source protocol that's been in use for ages. Its source code is slightly clunky after years of volunteers poking it for weaknesses, but that also makes it the most trustworthy option. It's fast on average, though usually slower than WireGuard or IKEv2.
IKEv2 is a fast protocol that's good at reconnecting mobile devices as they move between networks. Norton VPN uses it in conjunction with IPSec encryption. If you're on an Apple device, it's your only option other than Mimic.
Mimic is an obfuscation protocol, which makes your VPN connection look like regular HTTPS traffic. This can get around networks that block all VPN traffic regardless of content. Mimic is based on TLS 1.3, and uses the same standard encryption algorithms as the other protocols.
Normally, I advise letting your VPN choose what protocol is best. Norton VPN is different. There simply isn't enough information about Mimic for me to trust it, and you shouldn't let the VPN switch you to it without your knowledge. All the others are fine, though.
Leak test
Testing a VPN for leaks is easy: just check your IP address before and after connecting, and see if it changes. I used IPleak.net to run that test on several Norton VPN servers. I first observed that Norton VPN prevents IPv6 leaks by blocking IPv6 altogether. On every run, the IPv6 test failed to load, no matter which server location I chose. This is an effective way to make leaks impossible, since almost none of the internet is IPv6-only yet.
My second conclusion was that Norton VPN's servers don't leak through DNS or WebRTC while your connection remains stable. However, every time I changed from one location to another, my real IP address was visible on the test screen for several seconds. Enabling the kill switch solved this problem, but the kill switch is not active by default, so make sure you turn it on in the settings.
There is one other serious problem with this: on the iOS app, the kill switch cannot be used except with the Mimic protocol. This forces users to choose between leaving a hole in their security or trusting it to a protocol with limited transparency. Until this changes, I can't recommend installing Norton VPN on iOS at all.
I tested the rotating IP server in the United States to see if it had the same problem, and thankfully didn't notice it. A Norton representative also confirmed that all servers have their own DNS resolvers that avoid public servers, cutting off a big source of leaks. Still, I'd recommend keeping the kill switch engaged. As long as you remember this, Norton VPN is secure.
Encryption test
Finally, I ran a test with WireShark to see if Norton VPN's protocols managed to encrypt my traffic. Since I've been uncertain about Mimic, I used it for the encryption test. I found that Mimic does in fact encrypt data packets, even on an unsecured HTTP connection. WireShark also confirmed to me that Mimic is using TLS for key exchange and encryption.
Norton VPN subscriptions are only available for one year at a time — there's no monthly option. There are three different subscription tiers, summarized in the table below. "Number of devices" refers to how many devices you can have installed on a single account, whether or not any of them are connected to the VPN.
Subscription |
Starting price (One year) |
Renewal price (One year) |
Number of devices |
Features |
Standard |
$39.99 |
$79.99 |
5 |
Basic VPN service, IP rotation, double VPN, kill switch |
Plus |
$49.99 |
$109.99 |
5 |
Antivirus, password manager, dark web alerts, 10GB cloud backup |
Ultimate |
$59.99 |
$129.99 |
10 |
Parental controls, device locator |
The Standard subscription is a reasonable price for what you get, but the superior Proton VPN is barely more expensive and Surfshark is actually cheaper. In other words, Norton VPN is a good price, but not great value — especially when you factor in the renewal prices, all of which force you to pay double or more what you paid the first time. If you'd like to decide for yourself, all the plans do come with a 60-day money-back guarantee.
Norton is better known as an antivirus company than a VPN provider, so naturally Norton VPN is packaged with the rest of the Norton 360 family. Be warned — unless you turn the option off in the Settings -> Privacy tab, Norton will collect information on your app usage and use it to target you with ads for its other products.
Norton 360 is a massive product line encompassing dozens of individual subscriptions. To keep this section from bloating, I'll focus on the software available as part of an upgraded Norton VPN subscription, then end by listing the Norton 360 plans that include Norton VPN.
Features on Norton VPN Plus
A Norton VPN Plus subscription adds several features from Norton's antivirus suite, but isn't a complete replacement for Norton or any other dedicated antivirus software. Plus users get most of the antivirus features that work in real time, including a smart firewall, anti-ransomware backups, a sandbox for quarantining suspicious programs and a malicious script blocker.
VPN subscribers do not get access to the quicker Smart Scan option, instead getting a different scan feature that checks for online threats (note that the FAQ page about this erroneously says Norton VPN includes Smart Scan). VPN users also miss out on the LiveUpdate feature that installs security patches autonomously, plus the automated hard drive cleaner.
Features on Norton VPN Ultimate
In addition to raising the device limit to 10, Norton VPN Ultimate adds two features on top of Plus: parental controls and Privacy Monitor. The latter is only available in the US and Canada.
Parental control is both a time-based site blocker and a monitoring app. It can not only track a child's internet activity, but also their physical location, giving you alerts if they leave set boundaries during a certain time (say school property during a weekday). Privacy Monitor scans for your information on data brokerage sites so you can send deletion requests, similar to Surfshark Incogni.
Norton 360 plans that include Norton VPN
Instead of subscribing to Norton VPN directly, you can also pick a Norton 360 plan that includes VPN service. Norton 360 Standard and Norton 360 For Gamers each let you install Norton VPN on three devices. Norton 360 Deluxe raises that number to five, while Norton 360 with Lifelock Select and Norton 360 with Lifelock Advantage grant you 10 total VPN installs. Norton 360 with Lifelock Ultimate Plus lets you install Norton VPN on an unlimited number of devices.
To assess Norton VPN's privacy, we need to look at two different privacy policies. Like I said in the introduction, there are technically two products called Norton VPN — the standalone service I've been reviewing and the VPN features of the Norton 360 bundle. I've been focused on the independent Norton VPN so far, but since the Norton 360 VPN add-on is a privacy risk, I want to mention it here.
Norton lists the privacy policies for each of its products on one page of its website. The VPN feature of Norton 360 is governed by the top two policies, Norton Security Products (desktop) and Norton 360 Mobile Apps. The standalone Norton VPN has its own policy further down the page.
The Norton 360 policy is a privacy nightmare. Both the desktop and mobile apps claim the right to save your IP address, device fingerprints and web activity for up to 36 months, and there's no exception for the VPN feature. I strongly advise against using Norton 360's bundled VPN for any activity you don't want Norton seeing.
Fortunately, Norton holds the standalone VPN to a much more acceptable set of rules. It isn't permitted to collect IP addresses, browsing history or DNS requests, nor can it share any of the data it does collect with partners. The partners note is important because one of Norton's sibling companies, Avast, is known to have sold information on its users to corporations for ad targeting. A Norton representative stated that Avast is no longer involved in harvesting or selling user data. More importantly, he said that no data from VPN products is shared between Gen Digital brands.
Independent privacy audits
A recent audit by penetration testing firm VerSprite provides reason to be hopeful about Norton VPN's privacy. According to a report published in August 2024, which you can download from this page, VerSprite found that Norton VPN posed an overall "low" privacy risk, judged on a scale of low, medium, high and critical risks.
During their audit, VerSprite informed Norton that certain conditions could make VPN users identifiable. In a second round of tests, Norton appears to have fixed those vulnerabilities. That's certainly reassuring, but I wish the report — which only runs three pages in all — was more specific about what the problem actually was. Regardless, the VerSprite audit is a good sign that Norton VPN is taking privacy more seriously than Norton as a whole.
If a VPN can change your virtual location, it can not only throw ISPs and other interlopers off your real identity, but also change what you see on the internet — especially on streaming sites, where connecting through a different country can unlock new shows. However, Netflix and its brethren block VPN traffic for copyright reasons, so it's never a guarantee that you'll get in.
I tested Norton VPN's ability to unblock Netflix on five different locations, connecting three times on three different servers in each place. I set the app to automatically choose the protocol. In the table below, you'll see how many tests each location passed, and whether Netflix showed new content each time. If I get into Netflix but the library doesn't change, that indicates the server might be leaky.
Server location |
Unblocked Netflix? |
Changed content? |
Vancouver, Canada |
3/3 |
3/3 |
Iceland |
0/3 |
0/3 |
Latvia |
3/3 |
3/3 |
Morocco |
3/3 |
3/3 |
Philippines |
3/3 |
3/3 |
I had no problems in four out of five of the locations I tested, but Netflix utterly defeated the Iceland servers. No matter how many times I disconnected and reconnected to get a new IP address, Netflix recognized a VPN server and blocked me. This happened even when I switched to the Mimic protocol.
That indicates that Netflix has blocklisted most or all of Norton VPN's servers in Iceland, and the company hasn't caught up. It's another troubling indication that Norton isn't committing the level of attention that its server network requires.
Speaking of the server network, now's the time to get deeper into it. The relative scarcity of different IP addresses on Norton VPN, along with the download speed drops over long distances, suggest to me that Norton might have relegated maintaining VPN data centers to an afterthought. So, let's see what its worldwide server selection looks like.
Region |
Countries with servers |
Total server locations |
North America |
5 |
32 |
South America |
6 |
6 |
Europe |
36 |
47 |
Africa |
5 |
5 |
Middle East |
2 |
2 |
Asia |
10 |
10 |
Oceania |
2 |
4 |
Total |
66 |
106 |
All of Norton VPN's server locations are physical, with no virtual locations. This makes its network more reliable — virtual server locations can deliver unexpected speed swings. However, it does limit the number of locations Norton is capable of offering.
The selection is reasonably good, with many locations in often-underserved Africa and South America, and many options in marquee regions like the US and Europe. However, it's a pretty small network for what Norton is charging. Also, as we saw with the Iceland location getting blocked by Netflix, having a country on the menu doesn't necessarily mean it will do the job.
Norton VPN added a ton of features in the first several months of 2025. Most of these mainly brought it up to par with other VPNs, like city-level region selection or support for smart TVs. However, there are one or two you won't find in many other places, like the IP rotator — to my knowledge, nobody else has that except Surfshark. Here are the most important extras to know about.
Ad blocker
Norton VPN's ad blocker can be used on its browser extension. Its mobile apps can block the trackers embedded in ads, but not the ads themselves. There's not a lot of customization potential; you can turn it on and off, and that's mainly it. The one option you have on the extension is to turn "acceptable ads" back on. This can help you get into sites that normally block users with adblock on, or use sites where you want to see ads to help them monetize.
Double VPN and IP rotator
Norton introduced these two features in 2025 as "enhanced anonymity" upgrades. Double VPN runs your VPN through two server locations instead of one, so you're still safe if one server breaks down. You can choose from eight pre-determined multi-hop paths with endpoints in the USA, the UK, Australia, New Zealand, Canada, Japan, Germany and Taiwan.
IP rotation servers change your IP address frequently while you're connected, which makes you harder to track. Unlike Surfshark, which lets you turn this on everywhere, Norton VPN limits you to six IP rotator locations: the USA, the UK, Canada, Japan, Germany and Australia.
Convenience features
The next three features were also added in the last eight months. The server location menu now puts your last five locations at the top for easy retrieval. While connected to a server, you can pause the VPN for 15, 30 or 60 minutes, after which it turns back on. Finally, the mobile apps have added a home screen widget so you can operate the VPN without opening the app.
Kill switch
A VPN kill switch cuts off your internet access if you lose your VPN connection, so any sensitive information isn't broadcast unprotected. Norton VPN's kill switch is vital, since it appears to briefly drop encryption while switching server locations. Unfortunately, it's not available on iOS unless you're using the Mimic protocol.
Split tunneling
The Windows and Android apps for Norton VPN allow split tunneling, in which only certain apps go through the VPN while others connect directly. Norton uses app-based split tunneling, but if you want to protect or remove protection from specific URLs, you can use two different web browsers.
Wi-Fi security
This feature, which appears on NortonVPN's mobile apps only, activates whenever you connect to a Wi-Fi network. Norton VPN scans that network for common attacks launched over Wi-Fi, like DNS poisoning and SSL stripping, and sends you an alert if it detects any.
P2P optimization
Norton VPN has certain servers in its network configured for torrenting. You can't use it for torrenting outside those locations — if you try, the VPN will disconnect. To connect to a P2P server, just select "P2P-optimized region" from the server menu. You can't choose a torrenting server in a specific region; the app just selects the fastest.
Following the broad trend of Norton VPN, the Windows app gets most of the love, having much more in-app support than any other platform. Mac users get a troubleshooting tab in the settings menu, with three options: go to the online help center, send a bug report or go to the community forum. iOS and Android just have a "help and support" button on the accounts page that sends you straight to the website.
On Windows, there's a separate help and support tab above the settings tab, which gives you direct links to some of the most important pages on the Norton website. It's also got links to the forum and help center. Then there's the same troubleshooting tab as the Mac app, but with more options. Windows users can reset the app to default, record a problem to get more specific help, send debug logs and run an automated "Repair Norton" process.
If you got to the website through a desktop app, it's surprisingly difficult to get to the general support page for Norton VPN — Windows links to a splintered set of FAQ pages, while Mac sends you to a Mac-specific page for the entire Norton Family. I recommend just going to support.norton.com in your browser, then clicking the Norton VPN button. At least the links in both mobile apps take you straight there.
Once you have gotten to the Norton VPN support page, you won't find much of use. Help articles are limited and leave some big holes. For example, all connectivity problems are limited to a page called "Fix problem accessing the internet when connected to Norton VPN." The only advice for Windows, Mac and Android is to choose a different VPN protocol, and there's nothing at all for iOS.
Even worse, whenever you use the search bar to look anything up, you're forced to watch an AI answer type itself out in real time, so links to the actual help pages are constantly jumping around as you try to click on them. It's this feature that pushes Norton's help pages from negligent to hostile.
Live support experience
There are a few other ways to get support from Norton VPN. You can check in on the community forum, chat live with an agent or call their phone line. The forums are reasonably active for Windows, but pretty dead for all other platforms.
I used live chat to ask about a problem with installing the iOS app. I managed to reach a human pretty quickly, but there were several long pauses during our conversation. Eventually, they escalated my case to a higher support team.
I assumed that this team would send me an email, per standard practice. Instead, they repeatedly tried to reach me by phone. I was not warned that they would do this, and each time, the call was flagged as spam. By the time I realized Norton was calling me, I'd already solved the problem myself. Be aware of this if you plan to contact Norton with a difficult issue.
The Norton software brand has existed in some form or another since the Norton Utilities package was developed for DOS in 1982. The brand was acquired in 1990 by Symantec, which had published its own first antivirus program the year before. Symantec began releasing Norton Antivirus in 1991, and continued distributing it until its merger with Avast in 2022. Since then, the combined company has been called Gen Digital.
Compared to that long history, Norton VPN has only been around for a blip. It launched in 2019 as part of Symantec's bid to expand the Norton Antivirus line into a suite that could defend against more types of threats. As such, while Norton and Symantec have been involved in their share of controversies over the years, very few of them happened during Norton VPN's lifetime.
Despite Norton's long and checkered history, checking the background of its VPN is pretty simple: nothing has gone seriously wrong yet. This VPN has problems, but they're mainly out in the open, stemming from it being a relative afterthought from a company more focused on other types of security.
For me to recommend a VPN, it has to stand out in a crowded field. After a week of working with Norton VPN, I have to conclude that the only way it distinguishes itself is the Norton name. For everything else it does, a competitor does it better. Surfshark scoops it on IP rotation and multihop, ExpressVPN has better protocols, NordVPN is faster and Proton VPN's ad blocker works in more places.
One thing I will say in Norton VPN's favor is that it's working to rectify all this. In the last year, it's added a lot of features. The problem is that most of those are options I'd have expected it to have already, such as city-level region selection and a kill switch on Mac. It's catching up, not innovating.
It's also nice that you can use the bundles to roll more Norton products into one subscription. However, since Norton is much more experienced at developing other sorts of security software, I'd advise going the Norton 360 route if you're interested in those other features and treating the VPN as an add-on. Norton VPN is a side dish, not an entree.
This article originally appeared on Engadget at https://www.engadget.com/cybersecurity/vpn/norton-vpn-review-a-vpn-that-fails-to-meet-nortons-standards-170037086.html?src=rss
Engadget Podcast: How Carvana is trying to fix the broken car buying world
Buying a car in America is usually a hellish experience involving pushy salespeople, mysterious fees, and hours-long financing negotiations. That’s something Carvana aimed to solve with its online used car marketplace when it launched 13 years ago. In this episode, Devindra chats with Carvana Chief Product Officer Dan Gill about how the company moved beyond the flashy marketing of its early car vending machines, and how it’s still trying to perfect the online car buying experience. We also dive into some of the issues the company has faced – including delayed registrations and vehicle issues – and how it’s trying to learn from them.
Hosts: Devindra Hardawar
Guest: Dan Gill
Producer: Ben Ellman
Music: Dale North and Terrence O'Brien
This article originally appeared on Engadget at https://www.engadget.com/mobile/smartphones/engadget-podcast-how-carvana-is-trying-to-fix-the-broken-car-buying-world-123045020.html?src=rss
Get two Blink Mini 2 cameras for only $35 with this Prime Day deal
October Prime Day is right around the corner, but you can grab some good deals today. Blink security cameras are almost always on sale during Amazon's shopping events, and this time is no different. One of the best deals at the moment is on a duo of Blink Mini 2 cameras, which you can get for only $35. That's half off and a record-low price, not to mention less than what you'd typically pay for one full price. It's also Engadget's pick for the best budget security camera.
This is the newest (2024) model of Blink's budget wired model. The camera is well-suited for nighttime video: It has a built-in LED spotlight, color night vision and a low-light sensor. Day or night, it records in sharp 1080p resolution. It also has a wider field of view than its predecessor.
The Blink Mini 2 is primarily designed for indoor use. But you can use it outdoors, too. You'll just need to fork over $10 for a weather-resistant adapter. Wherever you use the camera, it works with Alexa and supports two-way audio. ("Hello, doggy, I'll be home soon.")
It also supports person detection. (That's a neat feature that differentiates between people and other types of movement.) However, the feature requires a Blink Subscription Plan. They start at $3 per month or $30 per year for one device.
The camera is available in black or white. Both colors are available for the $35 Prime Day deal, but they can't be mixed unless you buy each separately. It's worth noting that this deal is open to anyone — no Prime subscription necessary. You can also save on a bunch of other Blink (and Ring) security gear. The Blink Outdoor 4 cameras are some of our favorites, and most configurations are on sale for Prime Day, including bundles like this three-camera system that's 61 percent off.
This article originally appeared on Engadget at https://www.engadget.com/deals/get-two-blink-mini-2-cameras-for-only-35-with-this-prime-day-deal-201049776.html?src=rss
The ROG Xbox Ally X handheld gaming device will cost you $1,000
Microsoft has finally revealed how much the ROG Xbox Ally handheld consoles will cost you, now that they're available for preorder. The ROG Xbox Ally X, which the company describes as the "ultimate high-performance handheld" that's "built for the most demanding players," will set you back $1,000.
Meanwhile, the ROG Xbox Ally "for everyone from the casual player to the avid enthusiast" is priced at $600, and you can pre-order that model from other retailers like Amazon, Best Buy and Walmart. They're a bit more expensive than ASUS' regular ROG Ally systems, which are priced from $500 to $800.
The company unveiled the devices during the Xbox Games Showcase at Summer Game Fest in June, with the promise that it was going to be available by this year's holiday shopping season. It revealed a couple of months later that the consoles will be on store shelves by October 16, but it didn't announce their prices until now.
Microsoft teamed up with ASUS' ROG division to develop the handhelds. They're powered by Windows 11 and lets you play any Xbox game you've purchased, whether you bought it on your console or your computer, as well as PC games from any store that you install directly on the device. You can use it to stream Xbox games from your console anywhere in your home or from the Xbox Cloud Gaming service. And yes, you'll be able to continue where you left off when you jump from one device to another. At launch, Xbox will mark thousands of games as Handheld Optimized or Mostly Compatible to indicate if they play well on handhelds.
In the US, you can preorder the consoles from the Xbox website, ASUS' website or from local retailers like Best Buy. A SanDisk microSD card designed specifically for the handhelds and a SeaGate SSD that supports Microsoft DirectStorage are now also available for preorder.
You can also preorder the consoles in Australia, Belgium, Canada, Czech Republic, Denmark, Finland, France, Germany, Hong Kong, Ireland, Italy, Japan, Mexico, the Netherlands, New Zealand, Norway, Poland, Portugal, Republic of Korea, Romania, Saudi Arabia, Singapore, Spain, Sweden, Taiwan, Turkey, United Arab Emirates, United Kingdom, Vietnam, Egypt, Greece, Hungary, Indonesia, Slovenia, South Africa, Thailand and Ukraine. All these markets, including the US, are getting the console on October 16. The handhelds will be available in additional markets in the future, as well, namely in Brazil, China, India, Luxembourg, Malaysia, Philippines and Switzerland.
This article originally appeared on Engadget at https://www.engadget.com/gaming/xbox/the-rog-xbox-ally-x-handheld-gaming-device-will-cost-you-1000-120029250.html?src=rss
The best monitors for every budget in 2025
Monitors are more than screens to plug into your PC — they shape how you work, play and create. Whether you need the best monitor for gaming, video editing or everyday tasks, there are plenty of options that balance price, performance and design.
In 2025, you’ll find everything from compact displays for light work to massive widescreen panels that make multitasking a breeze. A new monitor might also mean sharper images with high resolution panels, or better comfort with IPS displays that offer accurate colors and wide viewing angles.
Of course, not every job calls for 4K or higher. Sometimes a lower resolution option makes more sense, especially if you want to save money or don’t have a powerful GPU. With so many types of monitors on the market, the right choice comes down to your setup and the kind of work (or play) you plan to do.
Panel type
The cheapest monitors are still TN (twisted nematic), which are strictly for gamers or office use. VA (vertical alignment) monitors are also relatively cheap, while offering good brightness and a high contrast ratio. However, content creators will find that LCD, IPS displays (in-plane switching) deliver better color accuracy, pixel density, picture quality and wide viewing angles — making them a strong option for general computer monitor use.
If maximum brightness is important, a quantum dot LCD display is the way to go — those are typically found in larger displays. OLED panels are now available and offer the best blacks and color reproduction, but they lack the brightness of LED or quantum dot displays. Plus, they’re expensive. The latest type of OLED monitor, called QD-OLED from Samsung, is now common among gaming monitors. The most notable advantage is that it can get a lot brighter, with recent models hitting up to 1,000 nits+ of peak brightness.
MiniLEDs are now widely used in high-end displays. They’re similar to quantum dot tech, but as the name suggests, it uses smaller LED diodes that are just 0.2mm in diameter. As such, manufacturers can pack in up to three times more LEDs with more local dimming zones, delivering deeper blacks and better contrast. MiniLED displays also tend to offer excellent backlight control, making them a great choice for HDR content and video editing.
Screen size, resolution and display format
Where 24-inch displays used to be more or less standard (and can still be useful for basic computing), 27-, 32-, 34- and even 42-inch displays have become popular for entertainment, content creation and even gaming these days.
Nearly every monitor used to be 16:9, but it’s now possible to find 16:10 and other more exotic display shapes. On the gaming and entertainment side, we’re also seeing curved monitors and widescreen ultrawide monitors with aspect ratios like 21:9. If you do decide to buy an ultrawide display, however, keep in mind that a 30-inch 21:9 model is the same height as a 24-inch monitor, so you might end up with a smaller display than you expected.
A 4K monitor is nearly a must for content creators, and some folks are even going for 5K or all the way up to 8K. Keep in mind, though, that you’ll need a pretty powerful computer with a decent graphics card to drive all those sharp pixels. And 4K higher resolution should be paired with a screen size of 27 inches and up, or you won’t notice much difference between 1440p. At the same time, I wouldn’t get a model larger than 27 inches unless it’s 4K, as you’ll start to see pixelation if you’re working up close to the display. That’s when a lower resolution monitor shows its limits.
One new monitor category to consider is portable monitors designed to be carried and used with laptops. Those typically come in 1080p resolutions and sizes from 13-15 inches. They usually have a lightweight kickstand-type support that folds up to keep things compact and maximize portability and functionality.
HDR
HDR adds vibrancy to entertainment and gaming – but be careful before jumping in. Some monitors that claim HDR on their marketing materials don’t even conform to a base standard. To be sure that a display at least meets minimum HDR specs, you’ll want to choose one with a DisplayHDR rating with each tier representing maximum brightness in nits.
However, the lowest DisplayHDR 400 and 500 tiers may disappoint you with a lack of brightness, washed out blacks and mediocre color reproduction. If you can afford it, the best monitor to choose is a model with DisplayHDR 600, 1000 or True Black 400, True Black 500 and True Black 600.
Where televisions typically offer HDR10 and Dolby Vision or HDR10+, most PC monitors only support the HDR10 standard, other than a few (very expensive) models. That doesn’t matter much for content creation or gaming, but HDR streaming on Netflix, Amazon Prime Video and other services won’t look quite as punchy. In addition, the best gaming monitors are usually the ones supporting HDR600 (and up), rather than content creation monitors – with a few exceptions.
Refresh rate
High refresh rate is a key feature, particularly on gaming monitors. A bare minimum nowadays is 60Hz, and 80Hz and higher refresh rates are much easier on the eyes. However, most 4K displays top out at 60Hz with some rare exceptions and the HDMI 2.0 spec only supports 4K at 60Hz, so you’d need at least DisplayPort 1.4 (4K at 120Hz) or HDMI 2.1. The latter is now available on a number of monitors, particularly gaming displays. However, it’s only supported by the latest NVIDIA RTX 3000- and 4000-series, AMD RX 6000-series GPUs. Support for G-Sync and AMD FreeSync is also something to look for if you want to eliminate screen tearing and stuttering during fast-paced gameplay — especially when paired with a high refresh rate.
Inputs
There are essentially three types of modern display inputs: Thunderbolt, DisplayPort and HDMI. Most monitors built for PCs come with the latter two, while a select few (typically built for Macs) will use Thunderbolt. To add to the confusion, USB-C ports may be Thunderbolt 3, and by extension, DisplayPort compatible, so you may need a USB-C to Thunderbolt or DisplayPort cable adapter depending on your display.
Color bit depth
Serious content creators should consider a more costly 10-bit monitor that can display billions of colors. If budget is an issue, you can go for an 8-bit panel that can fake billions of colors via dithering (often spec’d as “8-bit + FRC”). For entertainment or business purposes, a regular 8-bit monitor that can display millions of colors will be fine.
Color gamut
The other aspect of color is the gamut. That expresses the range of colors that can be reproduced and not just the number of colors. Most good monitors these days can cover the sRGB and Rec.709 gamuts (designed for photos and video respectively). For more demanding work, though, you’ll want one that can reproduce more demanding modern gamuts like AdobeRGB, DCI-P3 and Rec.2020 gamuts, which encompass a wider range of colors. The latter two are often used for film projection and HDR, respectively.
Is OLED better than mini-LED for monitors?
OLED is better than mini-LED in many areas but not all. Here are the advantages of OLED panels:
OLED monitors don't have any "blooming" or halos around bright parts of the image.
OLEDs have blacks with zero brightness, which is not achievable on mini-LED. That means they also have higher contrast ratios.
OLEDs consume less energy.
OLEDs have faster response times for gaming.
And here are the advantages of mini-LED monitors:
They are brighter (often much brighter), so it can be better for HDR content.
They don't suffer from burn-in like OLED can.
What size monitor is best for a home office?
This depends on the individual. For normal use, 27-32 inches is the sweet spot. If you're one who likes many windows open at a time (like a stock broker), then you might want to go up to 37 or even 42 inches.
Are curved monitors worth it for gaming?
If you need as much speed as possible, a curved monitor lets you rapidly look around the screen without changing focus or moving your head as much compared to a flat screen. It also provides more immersion. The drawback is that curved displays tend to be wider so they take up more desk space. They're also generally more expensive.
This article originally appeared on Engadget at https://www.engadget.com/computing/accessories/best-monitor-130006843.html?src=rss
The best eco-friendly phone cases for 2025
We all want to protect our phones from the inevitable drops, scratches and tumbles of daily life, but what if your cell phone case could protect more than just your device? The best eco-friendly phone cases offer a great blend of durability and sustainability, helping to reduce plastic waste and better the planet.
Made from natural materials like biodegradable plastics, recycled ocean waste or even sustainable bamboo, eco-friendly and compostable phone covers prove that you don’t have to sacrifice style or protection to go green. They’re designed to safeguard your device while actively combating plastic pollution, making them a win-win for both you and Mother Earth.
Whether you’re looking for something sleek and minimal or bold and artistic, there’s an eco-friendly option out there that will fit your style. Instead of a standard plastic case, you can choose one that’s both practical and planet-friendly, like biodegradable phone cases that are often recyclable and plastic-free in design.
What makes a phone case eco-friendly?
A phone case can be considered eco-friendly when it’s designed to protect not just your phone but also the planet. What sets these cases apart is the use of sustainable materials like biodegradable plastics, recycled plastic waste or even natural materials like bamboo or flax straw. Instead of contributing to plastic pollution, these materials break down naturally over time, or are made from recycled content that reduces waste.
Eco-friendly cases can also go a step further by being compostable, meaning you can toss them in a compost bin at the end of their life and they’ll decompose into the earth without leaving harmful residues. Plus, many brands behind these cases focus on sustainable practices, like reducing carbon emissions during production or offering recycling programs for old cases.
Are compostable phone cases actually biodegradable?
Yes, most compostable phone cases are designed to break down naturally, but how fast they do depends on the material and the conditions. In a home compost bin, some cases may take months to decompose, while in industrial composting facilities the process is quicker. These cases are usually made from plant-based bioplastics, flax or starch blends which return to the soil without leaving behind harmful residue.
Can you recycle old phone cases?
It depends on the material. Standard plastic cases are tough to recycle because they’re often made with mixed plastics and additives so they usually end up in landfills. Some brands run take-back programs where you can send your old case in and they’ll reuse or up-cycle it into new products. If your case is made from single-type plastic or a recycled blend, check with your local recycling facility but in many cases specialized programs are the best option.
Georgie Peru contributed to this report.
Check out more from our spring cleaning guide.
This article originally appeared on Engadget at https://www.engadget.com/computing/accessories/best-eco-friendly-phone-cases-150016494.html?src=rss
IXI's autofocus glasses are one step closer to reality
Forget smart glasses, autofocus lenses have the potential to help far more people by offering a high-tech alternative to clunky bifocal and varifocal eyewear. Those traditional solutions involve looking at specific portions of glasses for near and far objects. While that's more convenient than swapping frames constantly, it requires retraining your eyes a bit and can also lead to eye strain.
Finnish startup IXI's autofocus glasses aim to go one step further: It has developed eyewear with built-in eye tracking and LCDs that can automatically focus on whatever you're looking at, just like fixed frame glasses. Even better, they look just like regular eyewear, even more-so than Meta's thick-framed Ray-Ban smart glasses. While IXI isn't yet ready to start shipping its hardware yet, the company announced today that it's one step closer to production by acquiring the lens manufacturing company Finnsusp and entering into a "long-term strategic partnership" with OptiSwiss.
.jpg)
While IXI isn't the only company working on autofocus frames -- we covered ViXion01's Star Trek-esque glasses at CES last year -- it's the closest to bringing the technology to normal-looking spectacles. Sure, they're not as flashy as Meta's Ray-Ban lineup, and they don't exactly scream high-tech, but IXI's reserved approach could make its glasses more compelling to older audiences. Not everyone wants to look like a trendy supergeek, after all, but the idea of having glasses that could make your eyes feel decades younger practically is a huge draw.
IXI has developed "the world's lowest power eye-tracking" to make its glasses possible, CEO and co-founder Niko Eiden told Engadget in an interview. The company stuffed tiny batteries into the thin frames of its glasses, which Eiden claims can last for a day of usage. The assumption is that you'll charge them overnight by connecting a cable to their temple area (unfortunately, that also makes them too unwieldy to power up while you're wearing them). If they do completely lose power, they'll function purely as far-sighted spectacles.
With the Finnsusp acquisition, IXI will be able to begin low-volume production of its glasses for in-house testing, while the OptiSwiss partnership will eventually help it to scale for the mass market. Eiden says the company isn’t announcing pricing or availability yet, but he expects it to be in the “high end of existing glasses.” More so than Meta’s hyped-up smart glasses, IXI’s products are targeted at people who are already wearing glasses and who could quickly see the value of in autofocus lenses. Eye degradation comes for us all eventually.
This article originally appeared on Engadget at https://www.engadget.com/wearables/ixis-autofocus-glasses-are-one-step-closer-to-reality-060000152.html?src=rss
Google asks US Supreme Court to delay Play Store policy changes
Google has appealed the U.S. Supreme Court to pause an injunction ordered by a lower court. It is related to the antitrust case against Epic Games. The case has dragged on since […]
Thank you for being a Ghacks reader. The post Google asks US Supreme Court to delay Play Store policy changes appeared first on gHacks Technology News.
Proton Mail app gets a redesign, offline mode on Android and iOS
The Proton Mail app for Android and iOS has been updated. It has a new design, and adds support for offline mode. Proton's announcement says that the encrypted mail client now shares […]
Thank you for being a Ghacks reader. The post Proton Mail app gets a redesign, offline mode on Android and iOS appeared first on gHacks Technology News.
ROG Xbox Ally is up for pre-order in 38 Countries, prices revealed
Microsoft and ASUS have opened pre-orders for the Xbox Ally consoles. But, you're not going to like the prices. Both consoles have a 7-inch screen, the primary difference between the two are […]
Thank you for being a Ghacks reader. The post ROG Xbox Ally is up for pre-order in 38 Countries, prices revealed appeared first on gHacks Technology News.
Microsoft makes Windows 10 Extended Security Updates free, but only for users in one region
Windows 10 has just a few more weeks to go officially before Microsoft ends support for the operating system officially. Customers who run Windows 10 devices may extend support by a year […]
Thank you for being a Ghacks reader. The post Microsoft makes Windows 10 Extended Security Updates free, but only for users in one region appeared first on gHacks Technology News.
You’ll Never Guess Which Food Just Got Recalled Again for Being Radioactive

Okay, you can probably guess.
The ‘Alien: Earth’ Sound Designer Explains That Xenomorph Baby Talk

We don't yet know why Sydney Chandler's Wendy can communicate with aliens, but we have some new insight into how the show pulled off the effect.
The Quest 3’s ‘Hyperscapes’ Are Impressive, Weird, and Doomed to Be Under-Appreciated

Another impressive use case for VR at a time where interest feels to be waning.
Neon, an App That Pays to Record Your Phone Calls Hit #2 on the App Store, Taken Down Over Security Flaw

Neon wants use the calls to train AI, but a security concern forced it to go offline, for now.
Doctors Blame Cannabis for Healthy Woman’s Sudden Cardiac Arrest

The woman had no preexisting heart disease or other risk factors, except for heavy cannabis use, the doctors wrote.
Has ‘Peacemaker’ Been Hiding Its Big Twist in Plain Sight?

Who would've thought an opening dance number was plot essential?
Don’t Count on the iPhone Air 2 Getting an Ultrawide Camera

If you want an iPhone Air, get it now, or you'll just be disappointed when the iPhone Air 2 also has a single rear camera.
CMF Says Its Over-Ear Headphones Have 100-Hour Battery, but I’m Skeptical

A total of 100 hours? I need to know more.
‘Peacemaker’ Finally Answers Why That Pocket Dimension Actually Really Sucks

"Ignorance Is Chris" lifts the lid on the multiversal twist we've all been waiting for—with a few surprises along the way.
Undetected, Dangerous Asteroids Could Be Lurking in Venus’s Orbit

A new study warns of an undiscovered population of asteroids that could strike Earth with little to no warning.
James Gunn Teases What He Wants Out of the DCU’s Batman

Plus, could 'Edge of Tomorrow 2' finally start shooting next year?
Kids Are Getting Hurt by Golf Carts More Than Ever

New research shows that golf cart injuries have been sending children to the emergency room more often in recent years.
The best HackerNoon stories you might have skipped 👀
HackerNoon's top stories of the week cover tech, startups, AI, gaming, and more. Want to make the next list? Start working on your next story!
5 Steps to Launching a Lovable Vibecoding Project (and Why Skipping Step 3 Will Cost You)
After 8 years of building everything from appointment booking solutions to AI-powered applications, I find vibecoding to be extremely interesting. Here are the 5 crucial steps I used to launch my latest Lovable project, and why most people skip step 3.
OpenAPI or Bust: How I Made Lovable Play Nice with a Real Backend
Lovable is great for frontends, but what about the backend? Here's how I connected my existing backend service to my Lovable frontend.
Thirty Reports, Zero News: The AI PR Machine Has Gone Too Far
The obsession with AI as a headline in itself is lazy, says author. It clogs up journalists’ inboxes, floods editorial calendars, and drowns out the rare gems of actual news that deserve coverage.
If You’re an AppSec Engineer, You’re Lucky
AI is transforming software - and security. Discover why it’s the best (and hardest) time to be an AppSec engineer.
LangGraph Beginner to Advance: Part 1: Introduction to LangGraph and Some Basic Concepts
LangGraph is a Python library designed for building advanced conversational AI workflows. By the end of this series, you will be equipped to create robust, scalable conversational applications.
Ethereum’s Node Problem: Who Really Hosts Web3?
Ethereum may be the world’s most decentralized smart contract platform, but look beneath the surface and a different story emerges. The physical machines that keep the platform alive are overwhelmingly hosted on centralized cloud providers. A new wave of projects is rethinking how and where blockchains live.
Developers Gain Direct Insight Into Data Flows With CocoIndex Update
CocoIndex and CocoInsight have added a Query mode. The result is directly linked and can be traced back step by step to how data is generated on the indexing path.
The Cost of Broken Code: How Claude.ai Wastes Your Time and Credits
Claude.ai is like paying for an app that gives you broken tools and then charging you again for each fix attempt
xAI Releases Grok 4 Fast with Lower Cost Reasoning Model

xAI has introduced Grok 4 Fast, a new reasoning model designed for efficiency and lower cost.
By Daniel DominguezWall Street and the Impact of Agentic AI
 As enterprise AI systems become more advanced, they are moving beyond task automation toward workflow intelligence. On Wall Street, this evolution is playing out where milliseconds can mean millions and decisions can ripple across markets. Financial institutions are beginning to embed agentic AI into core operations to surface insights and accelerate decision-making.
As enterprise AI systems become more advanced, they are moving beyond task automation toward workflow intelligence. On Wall Street, this evolution is playing out where milliseconds can mean millions and decisions can ripple across markets. Financial institutions are beginning to embed agentic AI into core operations to surface insights and accelerate decision-making.
Limestone Networks and Charg Announce 60-PFlop AI Supercomputer
![]() Limestone Networks, a bare-metal and cloud infrastructure company, has teamed with GPU cloud platform Charg on a 60-petaflop supercomputer built for AI and advanced enterprise workloads. The companies ....
Limestone Networks, a bare-metal and cloud infrastructure company, has teamed with GPU cloud platform Charg on a 60-petaflop supercomputer built for AI and advanced enterprise workloads. The companies ....
U.S. Military Presence Off Venezuela's Coast Not Big Enough To 'Actually Invade,' Expert Says
A former State Department lawyer said that the U.S.'s military presence off the Venezuelan coast, despite being "significant," it is "not what you would need to actually invade."
Trump Says Yes to Elon Musk's Grok for Federal Agencies — For 42 Cents, How Can It Help the US Government?
Elon Musk's Grok received the approval of the General Services Administration (GSA). This will allow federal agencies to use the artificial intelligence. But, for what?
Billionaire Xiaomi Founder Unleashes $630 Xiaomi 17 Pro — iPhone 17 Killer or Overhyped?
Chinese tech giant Xiaomi is rapidly accelerating its transformation from a smartphone vendor to a multi-sector powerhouse, leveraging its success in Electric Vehicles (EVs) to drive future growth.
Tesla Is Not Releasing a 'Pi' Phone; Here's What Rumours Say They're Trying to Do with Starlink Instead
Despite viral rumours, Tesla denies plans for a phone, while SpaceX pursues satellite mobile tech with £13.7 billion spectrum deal.
Costco Stock: The Hidden Story of Slowing Sales, Returning Inflation, and a Secret War on Tariffs
Costco's strong quarterly results hide slowing sales momentum, inflationary pressures, and tariff risks that could reshape its margins and long-term growth strategy.
Bitcoin Price: Is the US Government to Blame for the Crash? $1.6B Liquidation Sparks Panic
Bitcoin plunged from record highs after a $1.6 billion liquidation wiped out long positions, sparking panic as investors blamed US Treasury liquidity drains and looming rate cuts.
How Polestar Studio Is Transforming Movement and Lives One Pilates Session at a Time in Colorado
At Polestar Studio, owned and run by Sarka Ruzickova, Pilates has been epitomized as a way of life, carefully tailored to athletes and everyday people alike.
Europe Grabs 3-1 Lead As US Seeks Trump Boost At Ryder Cup
Europe delivered a stunning early domination of the United States to quiet a raucous New York crowd and seize a 3-1 lead as US President Donald Trump arrived for Friday's opening matches of the 45th Ryder Cup.
US Fed's Preferred Inflation Gauge Rises, With More Cost Pressures Expected
The US Federal Reserve's preferred inflation measure edged up in August as tariffs filtered through the economy, government data showed Friday, with analysts warning of further cost pressures after President Donald Trump unveiled a slew of upcoming duties.
Former UK PM Blair Could Lead Transitional Authority In Gaza: Reports
Former UK prime minister Tony Blair could take a leading role in a transitional authority for Gaza under US-led peace plans, various British media reported on Friday.
The Nations And Firms Threatened By Trump's Pharma Tariffs
Donald Trump has shocked the global drug industry by announcing 100-percent tariffs on all branded, imported pharmaceutical products -- unless companies are building manufacturing plants in the United States.
EU Steps Up 'Drone Wall' Plans After Russian Incursions
EU countries on Friday agreed on the urgent need to create a "wall" of anti-drone defences, after airspace violations by Russia rattled eastern members.
Kenyan Jeans Factory To Fire Workers As US Deal Expires
A Kenyan factory making jeans for US stores will start firing hundreds of workers this week as American lawmakers failed to renew Africa's duty-free access in time, its boss said Friday.
UN Identifies 158 Firms Linked To Israeli Settlements
The United Nations on Friday released a long-awaited update of its database of companies with activities in Israeli settlements in Palestinian territories, listing 158 firms from 11 countries.
iPhone 17 Killer? Xiaomi Just Released A $630 Gadget - And It's A Thing Of Beauty
The Xiaomi 17 series debuts with 7,500mAh batteries, triple 50MP Leica cams, Snapdragon power—all under £548
Starbucks to Close Underperforming Stores, Cut 900 Jobs in $1 Billion Overhaul
Starbucks is closing hundreds of stores and cutting 900 jobs as part of a $1 billion plan to improve its business.
Meta's New 'Vibes' Feed Turns TikTok Into AI Slop, But Who Actually Wants It?
Meta launches Vibes, an AI-generated video feed aiming to rival TikTok and Reels, but early reactions show users aren't buying into the hype.
ChatGPT Pulse: OpenAI's $200 AI Assistant That Works Overnight to Plan Your Day
OpenAI's new ChatGPT Pulse scans your data overnight to deliver personalized daily updates, acting like a digital secretary for your morning routine.
Most Venezuelans Believe Maduro Will Fall Within The Next Six Months, Poll Shows
Over half of Venezuelans believe that the country's authoritarian President, Nicolas Maduro, will fall within the next six months, according to a new poll
HSBC Achieves 'Ground-Breaking' Quantum Result in Trading Experiment
HSBC uses quantum computing to boost bond trading predictions by 34%, marking a breakthrough in financial technology.
Amazon Hit With Largest-Ever FTC Civil Penalty in Prime Case
Amazon agrees to a record $2.5 billion FTC settlement over deceptive Prime sign-ups and cancellations.
Xbox Handheld Pre-Orders: Where to Get ROG Xbox Ally Soon?
The long-awaited ROG Xbox Ally handhelds are up for pre-order, with Game Pass integration, two versions, and a retailer-exclusive twist.
Justin Bieber's Dad Says Fatherhood Grounded Him Amid Coachella $10M Payday
Justin Bieber's dad says fatherhood has 'grounded' the singer as he headlines Coachella 2026, sells out all six shows, and lands a record $10M payday with wife Hailey's support.
Democrats Give Hard Deadline To AG Bondi To Release Documents Related To Border Czar Homan Bribery Investigation
Senate Democrats are urging Attorney General Pam Bondi to release documents related to an investigation on White House border czar Tom Homan following allegations that he accepted $50,000 from undercover FBI agents
CDC Report Shows More Children Are Either Dying or Becoming Severely Ill With Flu Amid Declining Vaccination Rates
A Centers for Disease Control and Prevention (CDC) report showed that more children are becoming severely ill or dying from the flu as vaccination rates decline.
Building Machine Learning Application with Django
Build and serve your own end-to-end machine learning app with Django, from training the model to creating web forms and APIs, all in one tutorial.
Nano Banana Practical Prompting & Usage Guide
In this article we will take a look at what Nano Banana excels at, some tips and tricks for using the model, and lay out a series of example prompts and promoting strategies for getting the most out of using it.
Builder.ai founder Sachin Dev Duggal plots new AI startup
无摘要
Checkout.com launches secondary share sale at $12bn valuation, reports say
无摘要
Rise of the ‘Hedo cubs’: Hedosophia alumni spin out new VC firms
无摘要
There are too many drone startups
无摘要
Billions gone: No funds for EIT under new European Union budget
无摘要
A dozen Revolut employees jump ship for Dubai-based proptech Huspy
无摘要
Best early October Prime Day 2025 PC gaming deals: Save big on laptops and accessories
October Prime Day is just around the corner, and you can already find great discounts on gaming desktops, laptops, and accessories at Amazon.
Microsoft will compete with AWS to offer a marketplace of AI apps and agents
Built atop Microsoft Cloud, the new platform lets customers quickly onboard new AI tools without having to worry about security risks.
This 100-inch Hisense TV just dropped to its lowest price yet on Amazon
The Hisense U6 Mini-LED TV is a truly cinema-sized screen for the ultimate home theater experience. Right now, you can save almost 30%.
This is the best space-saving smart heater I've ever used, and it's perfect for chilly nights
The Dreo Smart Wall Heater did a great job keeping my family warm all last winter. It's efficient and affordable.
5 ways you can maximize AI's big impact in software development
These financial services executives explain how they balance automation with compliance – and there are important lessons for all business leaders.
That Antifa 'terrorist' label you saw on Threads and Reddit? It's not what you think
You might have noticed an ominous message appearing on social media posts. Here's what's happening.
How I turned an old laptop into a home document station - and cut down on paperwork chaos
This clever setup uses scanners, shredders, and custom 3D prints to stop paper and mail as soon it enters my house.
Best early October Prime Day TV deals 2025: All time low prices from Samsung, LG, and more
Amazon's October Prime Day sale is still a few weeks away, but you can already find steep markdowns on both premium and entry-level TVs from brands like Samsung, LG, Hisense, and more.
Best early Amazon Prime Day laptop deals 2025: My 30 favorites sales ahead of October
Amazon October Prime Day is around the corner, but the laptop deals are already heating up. Here are the best we've found, from Apple, Lenovo, HP, and more.
Best early Amazon Prime Day deals 2025: Our 50+ favorite sales ahead of October
Amazon's fall Prime Day event returns Oct. 7 and 8, but some deals are already live. These are our favorite sales on tech, home, and more so far.
Why I ditched my USB cables after switching to this Baseus power bank - and can't go back
Drones, action cameras, pocket-sized gimbal cameras and mics all have voracious appetites for power. This power bank is perfect for keeping them charged on the go.
This HP laptop's connectivity superpower solved my biggest issue with work travel
The HP EliteBook 6 G1q has an all-day battery, a sleek form factor, and support for 5G connection for an always-on connection.
Watch out, Sonos: I listened to Marshall's new soundbars, and they rock
Marshall's compact soundbar and external subwoofer should be considered serious competitors to the big names in home audio.
Best early Amazon Prime Day deals under $25 in 2025: My favorite cheap sales ahead of October
October Prime Day is coming soon. These are my favorite under $25 deals live now.
How to remove yourself from Whitepages in 5 quick steps - and why you should
Is your name, address, and phone number on this popular website? Here's how to request removal and protect your privacy.
Your colleagues are sick of your AI workslop
Don't risk your professional reputation on this.
Amazon Prime Day is October 7-8: Everything you need to know about October Prime Day
Amazon's Prime Big Deal Days returns in two weeks. Here's everything you need to know to shop like a pro (plus some early deals).
Best Amazon Prime Day tablet deals 2025: My 13 favorite sales ahead of October
We found the best early tablet deals ahead of Amazon's October Prime Day sale, including discounts on the Apple iPad and Samsung Galaxy Tab.
Slow Wi-Fi? 10 tricks I use to get internet speeds as fast and reliable as wired
I spent the weekend tweaking my home network to improve my Wi-Fi speed and connectivity. Here's what worked.
Forget Samsung: This Android tablet won't break the bank or strain your eyes
The TCL Tab Nxtpaper 5G lets you switch from full color to e-paper mode in seconds.
Best early October Prime Day 2025 PC gaming deals: Save big on laptops and accessories
October Prime Day is just around the corner, and you can already find great discounts on gaming desktops, laptops, and accessories at Amazon.
Microsoft will compete with AWS to offer a marketplace of AI apps and agents
Built atop Microsoft Cloud, the new platform lets customers quickly onboard new AI tools without having to worry about security risks.
This 100-inch Hisense TV just dropped to its lowest price yet on Amazon
The Hisense U6 Mini-LED TV is a truly cinema-sized screen for the ultimate home theater experience. Right now, you can save almost 30%.
This is the best space-saving smart heater I've ever used, and it's perfect for chilly nights
The Dreo Smart Wall Heater did a great job keeping my family warm all last winter. It's efficient and affordable.
5 ways you can maximize AI's big impact in software development
These financial services executives explain how they balance automation with compliance – and there are important lessons for all business leaders.
That Antifa 'terrorist' label you saw on Threads and Reddit? It's not what you think
You might have noticed an ominous message appearing on social media posts. Here's what's happening.
How I turned an old laptop into a home document station - and cut down on paperwork chaos
This clever setup uses scanners, shredders, and custom 3D prints to stop paper and mail as soon it enters my house.
Best early October Prime Day TV deals 2025: All time low prices from Samsung, LG, and more
Amazon's October Prime Day sale is still a few weeks away, but you can already find steep markdowns on both premium and entry-level TVs from brands like Samsung, LG, Hisense, and more.
Best early Amazon Prime Day laptop deals 2025: My 30 favorites sales ahead of October
Amazon October Prime Day is around the corner, but the laptop deals are already heating up. Here are the best we've found, from Apple, Lenovo, HP, and more.
Best early Amazon Prime Day deals 2025: Our 50+ favorite sales ahead of October
Amazon's fall Prime Day event returns Oct. 7 and 8, but some deals are already live. These are our favorite sales on tech, home, and more so far.
Why I ditched my USB cables after switching to this Baseus power bank - and can't go back
Drones, action cameras, pocket-sized gimbal cameras and mics all have voracious appetites for power. This power bank is perfect for keeping them charged on the go.
This HP laptop's connectivity superpower solved my biggest issue with work travel
The HP EliteBook 6 G1q has an all-day battery, a sleek form factor, and support for 5G connection for an always-on connection.
Watch out, Sonos: I listened to Marshall's new soundbars, and they rock
Marshall's compact soundbar and external subwoofer should be considered serious competitors to the big names in home audio.
Best early Amazon Prime Day deals under $25 in 2025: My favorite cheap sales ahead of October
October Prime Day is coming soon. These are my favorite under $25 deals live now.
How to remove yourself from Whitepages in 5 quick steps - and why you should
Is your name, address, and phone number on this popular website? Here's how to request removal and protect your privacy.
Your colleagues are sick of your AI workslop
Don't risk your professional reputation on this.
Amazon Prime Day is October 7-8: Everything you need to know about October Prime Day
Amazon's Prime Big Deal Days returns in two weeks. Here's everything you need to know to shop like a pro (plus some early deals).
Best Amazon Prime Day tablet deals 2025: My 13 favorite sales ahead of October
We found the best early tablet deals ahead of Amazon's October Prime Day sale, including discounts on the Apple iPad and Samsung Galaxy Tab.
Slow Wi-Fi? 10 tricks I use to get internet speeds as fast and reliable as wired
I spent the weekend tweaking my home network to improve my Wi-Fi speed and connectivity. Here's what worked.
Forget Samsung: This Android tablet won't break the bank or strain your eyes
The TCL Tab Nxtpaper 5G lets you switch from full color to e-paper mode in seconds.
Sakana AI Released ShinkaEvolve: An Open-Source Framework that Evolves Programs for Scientific Discovery with Unprecedented Sample-Efficiency
Sakana AI has released ShinkaEvolve, an open-sourced framework that uses large language models (LLMs) as mutation operators in an evolutionary loop to evolve programs for scientific and engineering problems—while drastically cutting the number of evaluations needed to reach strong solutions. On the canonical circle-packing benchmark (n=26 in a unit square), ShinkaEvolve reports a new SOTA […]
The post Sakana AI Released ShinkaEvolve: An Open-Source Framework that Evolves Programs for Scientific Discovery with Unprecedented Sample-Efficiency appeared first on MarkTechPost.
Google AI Ships a Model Context Protocol (MCP) Server for Data Commons, Giving AI Agents First-Class Access to Public Stats
Google released a Model Context Protocol (MCP) server for Data Commons, exposing the project’s interconnected public datasets—census, health, climate, economics—through a standards-based interface that agentic systems can query in natural language. The Data Commons MCP Server is available now with quickstarts for Gemini CLI and Google’s Agent Development Kit (ADK). What was released Why MCP […]
The post Google AI Ships a Model Context Protocol (MCP) Server for Data Commons, Giving AI Agents First-Class Access to Public Stats appeared first on MarkTechPost.
The Download: shoplifter-chasing drones, and Trump’s TikTok deal
Shoplifters in the US could soon be chased down by drones The news: Flock Safety, whose drones were once reserved for police departments, is now offering them for private-sector security, the company has announced. Potential customers include businesses trying to curb shoplifting. How it works: If the security team at a store sees shoplifters leave,…
The quantum internet just went live on Verizon’s network
Penn engineers have taken quantum networking from the lab to Verizon’s live fiber network, using a silicon “Q-chip” that speaks the same Internet Protocol as the modern web. The system pairs classical and quantum signals like a train engine with sealed cargo, ensuring routing without destroying quantum states. By maintaining fidelity above 97% even under real-world noise, the approach shows that a scalable quantum internet is possible using today’s infrastructure.
Lightweight framework enables faster, more accurate object detection for UAV remote sensing
Remote sensing object detection is a rapidly growing field in artificial intelligence, playing a critical role in advancing the use of unmanned aerial vehicles (UAVs) for real-world applications such as disaster response, urban planning, and environmental monitoring. Yet, designing models that balance both high accuracy and fast, lightweight performance remains a challenge.
AI has bright future in Latin America, despite training deficit: regional Google chief
AI has a bright future in Latin America but is hamstrung by a huge training shortage, one of Google's top regional executives told AFP in an interview Thursday.
Judge endorses Anthropic's $1.5 bn copyright settlement
A US judge on Thursday endorsed Anthropic's deal to pay $1.5 billion to settle a class action lawsuit over amassing a library of pirated books to train its artificial intelligence.
Lightweight framework enables faster, more accurate object detection for UAV remote sensing
Remote sensing object detection is a rapidly growing field in artificial intelligence, playing a critical role in advancing the use of unmanned aerial vehicles (UAVs) for real-world applications such as disaster response, urban planning, and environmental monitoring. Yet, designing models that balance both high accuracy and fast, lightweight performance remains a challenge.
AI has bright future in Latin America, despite training deficit: regional Google chief
AI has a bright future in Latin America but is hamstrung by a huge training shortage, one of Google's top regional executives told AFP in an interview Thursday.
Judge endorses Anthropic's $1.5 bn copyright settlement
A US judge on Thursday endorsed Anthropic's deal to pay $1.5 billion to settle a class action lawsuit over amassing a library of pirated books to train its artificial intelligence.
Why CVEs Belong in Frameworks and Apps, Not AI Models
 The Common Vulnerabilities and Exposures (CVE) system is the global standard for cataloging security flaws in software. Maintained by MITRE and backed by CISA,...
The Common Vulnerabilities and Exposures (CVE) system is the global standard for cataloging security flaws in software. Maintained by MITRE and backed by CISA,...
Trump Clears Way for American-Owned TikTok Valued at $14 Billion
The administration has been working for months to find non-Chinese investors for a U.S. version of the app.
The Great A.I. Build-Out + H-1B Visa Chaos + TikTok Braces for the Rapture
“You now have the leaders of the biggest technology companies in the world saying, effectively in unison, that they do not care how much it costs to build all the way to A.G.I.”
How to Use Apple’s iOS 26 and Google’s Android 16
Don’t have the latest A.I.-powered model? There are still plenty of new features in Apple’s iOS 26 and Google’s Android 16 to make your own.
Incredible Photos Show the Same Chinese Train Driver 26 Years Apart

When train driver Han Junjia first started his career in 1992, the railway industry in China operated on steam locomotives that could just about manage 30 miles per hour.
It Took a Photographer 10 Years to Finally Nail the Perfect Lion Photo

Some photographs happen in an instant. Others take years to arrive. For more than a decade, I carried a very specific picture in my mind: a lion at complete ease, drinking from still water, everything calm and in balance. I knew how it should look, the light, the posture, the mood, but in the field, the moment always slipped away.
How Tether Tools’ Custom USB Cable Solved a Huge Tethered Photography Problem

Tether Tools has long been a key player in the tethered photography community. This specialized but vital niche of the photography market has very specific cable requirements, which, when faced with increasing issues with USB-C PD, forced Tether Tools back to the drawing board. The company developed a brand-new USB-C cable, Optima, to deal with growing USB concerns on modern cameras.
Why Kids All Pose with the Peace Sign in Photos

From family snapshots to school pictures, children today almost always strike the peace sign, a simple V-shaped gesture that has quietly become a ubiquitous part of their photo poses.
Satellite Photos Reveal 125-Mile Scar Left by Canadian Storm Visible from Space

Satellite photos reveal how a devastating hailstorm that swept across Canada last month left a 125-mile-long "scar" visible from space.
LensNode V1 Brings Realistic Lens Simulations to DaVinci Resolve

LensNode brings advanced, data-driven lens simulations to DaVinci Resolve. Using real-world optical data and GPU-powered performance, the plugin delivers authentic distortions, aberrations, and bokeh effects for filmmakers and post-production professionals.
‘One Battle After Another’ is the Latest Hollywood Blockbuster to be Filmed in VistaVision

Today marks the release of the much-hyped One Battle After Another starring Leonardo DiCaprio and directed by Paul Thomas Anderson. It is yet another production filmed in VistaVision -- a mid-20th-century format that has been making a strong comeback after years in the wilderness.
Scientists Photograph Newly-Discovered Marsupial In Peruvian Cloud Forest

A team of researchers discovered and photographed a new species of marsupial while exploring the Abiseo River National Park, a UNESCO World Heritage site in the Peruvian Andes. The new little mammal is strange, tiny, and adorable, and only one specimen has been observed.
Museum Director Sentenced to Russian Jail Over Composite Photo of Putin and Hitler

A museum director has been sentenced to 10 years in a Russian prison over a poster featuring a composite photograph of Russian President Vladimir Putin and Adolf Hitler merged into one face.
Anthropic to Pay $1.5 Billion in Landmark AI Copyright Settlement with Authors

A judge approved a $1.5 billion settlement between Anthropic and a group of U.S. authors who alleged that the company stole their work to train its AI models in a high-profile class-action lawsuit.
Photographer’s Genius Strategy to Avoid the Crowds on Manhattanhenge

Manhattanhenge is one of the biggest events in the New York photographic calendar, and it gets very, very crowded.
Photoshop Has Added Google’s Viral Nano Banana AI Model to Generative Fill

Adobe has added two popular AI image models to Photoshop Beta, including Google's viral Gemini 2.5 Flash Image, otherwise known as Nano Banana.
Vibes
Super cringey AI slop that Zuck loves
<p>
<a href="https://www.producthunt.com/products/meta?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1020198?app_id=339">Link</a>
</p>
AdMesh
Promote Products inside AI Conversations
<p>
<a href="https://www.producthunt.com/products/admesh?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1020171?app_id=339">Link</a>
</p>
Nansen AI
A Crypto Research Team In Your Pocket, 24/7
<p>
<a href="https://www.producthunt.com/products/nansen-ai?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1020179?app_id=339">Link</a>
</p>
New Math Revives Geometry’s Oldest Problems
Using a relatively young theory, a team of mathematicians has started to answer questions whose roots lie at the very beginning of mathematics.
The post New Math Revives Geometry’s Oldest Problems first appeared on Quanta Magazine
China won the electric car race. Up next: freight trucks
Nine Chinese giants dominate a market Tesla and Volvo can barely crack.
Smallmouth Bass Evolve to Evade Electric Culling in Adirondack Lake
Scientists electrically culled invasive fish in a 20-year battle—but the fish fought back with rapid evolution
Asteroid ‘Families’ Reveal Solar System’s Secret History
Many asteroids are related, but their family trees can be hard to trace
Neuroscience and Art Collide in a Posthumous ‘Composition’ by Alvin Lucier in Revivification
A museum exhibit in Australia lets visitors hear music generated by brain cells derived from the blood of a dead composer.
Pollinators need double EU target to recover on farmland, study finds
EU targets to protect biodiversity on farmland fall way short of what’s needed, finds new research by Trinity’s Prof Jane Stout and colleagues.
Read more: Pollinators need double EU target to recover on farmland, study finds
Google DeepMind adds agentic AI models to robots
‘This is a foundational step toward building robots that can navigate the complexities of the physical world with intelligence and dexterity,’ said DeepMind’s Carolina Parada.
Read more: Google DeepMind adds agentic AI models to robots
‘Women in business disproportionately affected by social issues’
Familial responsibilities, gender bias and insufficient funding continue to harm the upwards trajectory of women in the business sector.
Read more: ‘Women in business disproportionately affected by social issues’
‘Trust is not a soft metric’: How trust will shape the future of AI adoption
Rob Brown from Reputation Inc argues that trust not technological advancements will shape the future of AI adoption.
Read more: ‘Trust is not a soft metric’: How trust will shape the future of AI adoption
$1.5bn Anthropic settlement gets preliminary approval
'This is a fair settlement,' the presiding judge said.
Read more: $1.5bn Anthropic settlement gets preliminary approval
Ekco Cybersecurity Graduate Programme to create jobs amid talent shortage
The 12-month programme will prepare graduates for the rigours of a role in the cybersecurity sector and real-world challenges.
Read more: Ekco Cybersecurity Graduate Programme to create jobs amid talent shortage
15pc cap on EU pharma exports to US still applies, says Tánaiste
As Donald Trump announced 100pc tariffs on patented pharma products entering the US, Ireland’s Tánaiste pointed to the 15pc EU cap in the August trade agreement.
Read more: 15pc cap on EU pharma exports to US still applies, says Tánaiste
Amazon to pay $2.5bn to settle US FTC ‘dark patterns’ case
According to the FTC, Amazon manipulated consumers into signing up for Prime membership without their consent and also made it difficult to cancel subscriptions.
Read more: Amazon to pay $2.5bn to settle US FTC ‘dark patterns’ case
Oracle, Silver Lake among investors set to control 50pc of TikTok US – reports
Despite an executive order being signed, the deal for TikTok’s divestiture in the US is still not finalised, but Oracle and Silver Lake look set to be key players.
Read more: Oracle, Silver Lake among investors set to control 50pc of TikTok US – reports
Five finalists compete for 2025’s HPSU Founder of the Year Award
The overall winner will be announced at an awards ceremony on 16 October in Dublin.
Read more: Five finalists compete for 2025’s HPSU Founder of the Year Award
Getting Backstage in front of a shifting dev experience
Ryan welcomes Pia Nilsson, GM for Backstage and head of developer experience at Spotify, to discuss the evolution and adoption of Backstage, the impact of AI on dev experience, and how Spotify approaches platform engineering and standardization to help teams solve for specific needs.
Sample completion, structured correlation, and Netflix problems
arXiv:2509.20404v1 Announce Type: new Abstract: We develop a new high-dimensional statistical learning model which can take advantage of structured correlation in data even in the presence of randomness. We completely characterize learnability in this model in terms of VCN${}_{k,k}$-dimension (essentially $k$-dependence from Shelah's classification theory). This model suggests a theoretical explanation for the success of certain algorithms in the 2006~Netflix Prize competition.
Fast Estimation of Wasserstein Distances via Regression on Sliced Wasserstein Distances
arXiv:2509.20508v1 Announce Type: new Abstract: We address the problem of efficiently computing Wasserstein distances for multiple pairs of distributions drawn from a meta-distribution. To this end, we propose a fast estimation method based on regressing Wasserstein distance on sliced Wasserstein (SW) distances. Specifically, we leverage both standard SW distances, which provide lower bounds, and lifted SW distances, which provide upper bounds, as predictors of the true Wasserstein distance. To ensure parsimony, we introduce two linear models: an unconstrained model with a closed-form least-squares solution, and a constrained model that uses only half as many parameters. We show that accurate models can be learned from a small number of distribution pairs. Once estimated, the model can predict the Wasserstein distance for any pair of distributions via a linear combination of SW distances, making it highly efficient. Empirically, we validate our approach on diverse tasks, including Gaussian mixtures, point-cloud classification, and Wasserstein-space visualizations for 3D point clouds. Across various datasets such as MNIST point clouds, ShapeNetV2, MERFISH Cell Niches, and scRNA-seq, our method consistently provides a better approximation of Wasserstein distance than the state-of-the-art Wasserstein embedding model, Wasserstein Wormhole, particularly in low-data regimes. Finally, we demonstrate that our estimator can also accelerate Wormhole training, yielding \textit{RG-Wormhole}.
Unsupervised Domain Adaptation with an Unobservable Source Subpopulation
arXiv:2509.20587v1 Announce Type: new Abstract: We study an unsupervised domain adaptation problem where the source domain consists of subpopulations defined by the binary label $Y$ and a binary background (or environment) $A$. We focus on a challenging setting in which one such subpopulation in the source domain is unobservable. Naively ignoring this unobserved group can result in biased estimates and degraded predictive performance. Despite this structured missingness, we show that the prediction in the target domain can still be recovered. Specifically, we rigorously derive both background-specific and overall prediction models for the target domain. For practical implementation, we propose the distribution matching method to estimate the subpopulation proportions. We provide theoretical guarantees for the asymptotic behavior of our estimator, and establish an upper bound on the prediction error. Experiments on both synthetic and real-world datasets show that our method outperforms the naive benchmark that does not account for this unobservable source subpopulation.
A Gapped Scale-Sensitive Dimension and Lower Bounds for Offset Rademacher Complexity
arXiv:2509.20618v1 Announce Type: new Abstract: We study gapped scale-sensitive dimensions of a function class in both sequential and non-sequential settings. We demonstrate that covering numbers for any uniformly bounded class are controlled above by these gapped dimensions, generalizing the results of \cite{anthony2000function,alon1997scale}. Moreover, we show that the gapped dimensions lead to lower bounds on offset Rademacher averages, thereby strengthening existing approaches for proving lower bounds on rates of convergence in statistical and online learning.
A Hierarchical Variational Graph Fused Lasso for Recovering Relative Rates in Spatial Compositional Data
arXiv:2509.20636v1 Announce Type: new Abstract: The analysis of spatial data from biological imaging technology, such as imaging mass spectrometry (IMS) or imaging mass cytometry (IMC), is challenging because of a competitive sampling process which convolves signals from molecules in a single pixel. To address this, we develop a scalable Bayesian framework that leverages natural sparsity in spatial signal patterns to recover relative rates for each molecule across the entire image. Our method relies on the use of a heavy-tailed variant of the graphical lasso prior and a novel hierarchical variational family, enabling efficient inference via automatic differentiation variational inference. Simulation results show that our approach outperforms state-of-the-practice point estimate methodologies in IMS, and has superior posterior coverage than mean-field variational inference techniques. Results on real IMS data demonstrate that our approach better recovers the true anatomical structure of known tissue, removes artifacts, and detects active regions missed by the standard analysis approach.
RAPTOR-GEN: RApid PosTeriOR GENerator for Bayesian Learning in Biomanufacturing
arXiv:2509.20753v1 Announce Type: new Abstract: Biopharmaceutical manufacturing is vital to public health but lacks the agility for rapid, on-demand production of biotherapeutics due to the complexity and variability of bioprocesses. To overcome this, we introduce RApid PosTeriOR GENerator (RAPTOR-GEN), a mechanism-informed Bayesian learning framework designed to accelerate intelligent digital twin development from sparse and heterogeneous experimental data. This framework is built on a multi-scale probabilistic knowledge graph (pKG), formulated as a stochastic differential equation (SDE)-based foundational model that captures the nonlinear dynamics of bioprocesses. RAPTOR-GEN consists of two ingredients: (i) an interpretable metamodel integrating linear noise approximation (LNA) that exploits the structural information of bioprocessing mechanisms and a sequential learning strategy to fuse heterogeneous and sparse data, enabling inference of latent state variables and explicit approximation of the intractable likelihood function; and (ii) an efficient Bayesian posterior sampling method that utilizes Langevin diffusion (LD) to accelerate posterior exploration by exploiting the gradients of the derived likelihood. It generalizes the LNA approach to circumvent the challenge of step size selection, facilitating robust learning of mechanistic parameters with provable finite-sample performance guarantees. We develop a fast and robust RAPTOR-GEN algorithm with controllable error. Numerical experiments demonstrate its effectiveness in uncovering the underlying regulatory mechanisms of biomanufacturing processes.
Conditionally Whitened Generative Models for Probabilistic Time Series Forecasting
arXiv:2509.20928v1 Announce Type: new Abstract: Probabilistic forecasting of multivariate time series is challenging due to non-stationarity, inter-variable dependencies, and distribution shifts. While recent diffusion and flow matching models have shown promise, they often ignore informative priors such as conditional means and covariances. In this work, we propose Conditionally Whitened Generative Models (CW-Gen), a framework that incorporates prior information through conditional whitening. Theoretically, we establish sufficient conditions under which replacing the traditional terminal distribution of diffusion models, namely the standard multivariate normal, with a multivariate normal distribution parameterized by estimators of the conditional mean and covariance improves sample quality. Guided by this analysis, we design a novel Joint Mean-Covariance Estimator (JMCE) that simultaneously learns the conditional mean and sliding-window covariance. Building on JMCE, we introduce Conditionally Whitened Diffusion Models (CW-Diff) and extend them to Conditionally Whitened Flow Matching (CW-Flow). Experiments on five real-world datasets with six state-of-the-art generative models demonstrate that CW-Gen consistently enhances predictive performance, capturing non-stationary dynamics and inter-variable correlations more effectively than prior-free approaches. Empirical results further demonstrate that CW-Gen can effectively mitigate the effects of distribution shift.
Empirical PAC-Bayes bounds for Markov chains
arXiv:2509.20985v1 Announce Type: new Abstract: The core of generalization theory was developed for independent observations. Some PAC and PAC-Bayes bounds are available for data that exhibit a temporal dependence. However, there are constants in these bounds that depend on properties of the data-generating process: mixing coefficients, mixing time, spectral gap... Such constants are unknown in practice. In this paper, we prove a new PAC-Bayes bound for Markov chains. This bound depends on a quantity called the pseudo-spectral gap. The main novelty is that we can provide an empirical bound on the pseudo-spectral gap when the state space is finite. Thus, we obtain the first fully empirical PAC-Bayes bound for Markov chains. This extends beyond the finite case, although this requires additional assumptions. On simulated experiments, the empirical version of the bound is essentially as tight as the non-empirical one.
Best-of-$\infty$ -- Asymptotic Performance of Test-Time Compute
arXiv:2509.21091v1 Announce Type: new Abstract: We study best-of-$N$ for large language models (LLMs) where the selection is based on majority voting. In particular, we analyze the limit $N \to \infty$, which we denote as Best-of-$\infty$. While this approach achieves impressive performance in the limit, it requires an infinite test-time budget. To address this, we propose an adaptive generation scheme that selects $N$ based on answer agreement, thereby efficiently allocating inference-time computation. Beyond adaptivity, we extend the framework to weighted ensembles of multiple LLMs, showing that such mixtures can outperform any individual model. The optimal ensemble weighting is formulated and efficiently computed as a mixed-integer linear program. Extensive experiments demonstrate the effectiveness of our approach.
WISER: Segmenting watermarked region - an epidemic change-point perspective
arXiv:2509.21160v1 Announce Type: new Abstract: With the increasing popularity of large language models, concerns over content authenticity have led to the development of myriad watermarking schemes. These schemes can be used to detect a machine-generated text via an appropriate key, while being imperceptible to readers with no such keys. The corresponding detection mechanisms usually take the form of statistical hypothesis testing for the existence of watermarks, spurring extensive research in this direction. However, the finer-grained problem of identifying which segments of a mixed-source text are actually watermarked, is much less explored; the existing approaches either lack scalability or theoretical guarantees robust to paraphrase and post-editing. In this work, we introduce a unique perspective to such watermark segmentation problems through the lens of epidemic change-points. By highlighting the similarities as well as differences of these two problems, we motivate and propose WISER: a novel, computationally efficient, watermark segmentation algorithm. We theoretically validate our algorithm by deriving finite sample error-bounds, and establishing its consistency in detecting multiple watermarked segments in a single text. Complementing these theoretical results, our extensive numerical experiments show that WISER outperforms state-of-the-art baseline methods, both in terms of computational speed as well as accuracy, on various benchmark datasets embedded with diverse watermarking schemes. Our theoretical and empirical findings establish WISER as an effective tool for watermark localization in most settings. It also shows how insights from a classical statistical problem can lead to a theoretically valid and computationally efficient solution of a modern and pertinent problem.
Breaking the curse of dimensionality for linear rules: optimal predictors over the ellipsoid
arXiv:2509.21174v1 Announce Type: new Abstract: In this work, we address the following question: What minimal structural assumptions are needed to prevent the degradation of statistical learning bounds with increasing dimensionality? We investigate this question in the classical statistical setting of signal estimation from $n$ independent linear observations $Y_i = X_i^{\top}\theta + \epsilon_i$. Our focus is on the generalization properties of a broad family of predictors that can be expressed as linear combinations of the training labels, $f(X) = \sum_{i=1}^{n} l_{i}(X) Y_i$. This class -- commonly referred to as linear prediction rules -- encompasses a wide range of popular parametric and non-parametric estimators, including ridge regression, gradient descent, and kernel methods. Our contributions are twofold. First, we derive non-asymptotic upper and lower bounds on the generalization error for this class under the assumption that the Bayes predictor $\theta$ lies in an ellipsoid. Second, we establish a lower bound for the subclass of rotationally invariant linear prediction rules when the Bayes predictor is fixed. Our analysis highlights two fundamental contributions to the risk: (a) a variance-like term that captures the intrinsic dimensionality of the data; (b) the noiseless error, a term that arises specifically in the high-dimensional regime. These findings shed light on the role of structural assumptions in mitigating the curse of dimensionality.
Response to Promises and Pitfalls of Deep Kernel Learning
arXiv:2509.21228v1 Announce Type: new Abstract: This note responds to "Promises and Pitfalls of Deep Kernel Learning" (Ober et al., 2021). The marginal likelihood of a Gaussian process can be compartmentalized into a data fit term and a complexity penalty. Ober et al. (2021) shows that if a kernel can be multiplied by a signal variance coefficient, then reparametrizing and substituting in the maximized value of this parameter sets a reparametrized data fit term to a fixed value. They use this finding to argue that the complexity penalty, a log determinant of the kernel matrix, then dominates in determining the other values of kernel hyperparameters, which can lead to data overcorrelation. By contrast, we show that the reparametrization in fact introduces another data-fit term which influences all other kernel hyperparameters. Thus, a balance between data fit and complexity still plays a significant role in determining kernel hyperparameters.
The Sensitivity of Variational Bayesian Neural Network Performance to Hyperparameters
arXiv:2509.20574v1 Announce Type: cross Abstract: In scientific applications, predictive modeling is often of limited use without accurate uncertainty quantification (UQ) to indicate when a model may be extrapolating or when more data needs to be collected. Bayesian Neural Networks (BNNs) produce predictive uncertainty by propagating uncertainty in neural network (NN) weights and offer the promise of obtaining not only an accurate predictive model but also accurate UQ. However, in practice, obtaining accurate UQ with BNNs is difficult due in part to the approximations used for practical model training and in part to the need to choose a suitable set of hyperparameters; these hyperparameters outnumber those needed for traditional NNs and often have opaque effects on the results. We aim to shed light on the effects of hyperparameter choices for BNNs by performing a global sensitivity analysis of BNN performance under varying hyperparameter settings. Our results indicate that many of the hyperparameters interact with each other to affect both predictive accuracy and UQ. For improved usage of BNNs in real-world applications, we suggest that global sensitivity analysis, or related methods such as Bayesian optimization, should be used to aid in dimensionality reduction and selection of hyperparameters to ensure accurate UQ in BNNs.
Incorporating External Controls for Estimating the Average Treatment Effect on the Treated with High-Dimensional Data: Retaining Double Robustness and Ensuring Double Safety
arXiv:2509.20586v1 Announce Type: cross Abstract: Randomized controlled trials (RCTs) are widely regarded as the gold standard for causal inference in biomedical research. For instance, when estimating the average treatment effect on the treated (ATT), a doubly robust estimation procedure can be applied, requiring either the propensity score model or the control outcome model to be correctly specified. In this paper, we address scenarios where external control data, often with a much larger sample size, are available. Such data are typically easier to obtain from historical records or third-party sources. However, we find that incorporating external controls into the standard doubly robust estimator for ATT may paradoxically result in reduced efficiency compared to using the estimator without external controls. This counterintuitive outcome suggests that the naive incorporation of external controls could be detrimental to estimation efficiency. To resolve this issue, we propose a novel doubly robust estimator that guarantees higher efficiency than the standard approach without external controls, even under model misspecification. When all models are correctly specified, this estimator aligns with the standard doubly robust estimator that incorporates external controls and achieves semiparametric efficiency. The asymptotic theory developed in this work applies to high-dimensional confounder settings, which are increasingly common with the growing prevalence of electronic health record data. We demonstrate the effectiveness of our methodology through extensive simulation studies and a real-world data application.
Bispectral OT: Dataset Comparison using Symmetry-Aware Optimal Transport
arXiv:2509.20678v1 Announce Type: cross Abstract: Optimal transport (OT) is a widely used technique in machine learning, graphics, and vision that aligns two distributions or datasets using their relative geometry. In symmetry-rich settings, however, OT alignments based solely on pairwise geometric distances between raw features can ignore the intrinsic coherence structure of the data. We introduce Bispectral Optimal Transport, a symmetry-aware extension of discrete OT that compares elements using their representation using the bispectrum, a group Fourier invariant that preserves all signal structure while removing only the variation due to group actions. Empirically, we demonstrate that the transport plans computed with Bispectral OT achieve greater class preservation accuracy than naive feature OT on benchmark datasets transformed with visual symmetries, improving the quality of meaningful correspondences that capture the underlying semantic label structure in the dataset while removing nuisance variation not affecting class or content.
Scaling Laws are Redundancy Laws
arXiv:2509.20721v1 Announce Type: cross Abstract: Scaling laws, a defining feature of deep learning, reveal a striking power-law improvement in model performance with increasing dataset and model size. Yet, their mathematical origins, especially the scaling exponent, have remained elusive. In this work, we show that scaling laws can be formally explained as redundancy laws. Using kernel regression, we show that a polynomial tail in the data covariance spectrum yields an excess risk power law with exponent alpha = 2s / (2s + 1/beta), where beta controls the spectral tail and 1/beta measures redundancy. This reveals that the learning curve's slope is not universal but depends on data redundancy, with steeper spectra accelerating returns to scale. We establish the law's universality across boundedly invertible transformations, multi-modal mixtures, finite-width approximations, and Transformer architectures in both linearized (NTK) and feature-learning regimes. This work delivers the first rigorous mathematical explanation of scaling laws as finite-sample redundancy laws, unifying empirical observations with theoretical foundations.
Learning Ising Models under Hard Constraints using One Sample
arXiv:2509.20993v1 Announce Type: cross Abstract: We consider the problem of estimating inverse temperature parameter $\beta$ of an $n$-dimensional truncated Ising model using a single sample. Given a graph $G = (V,E)$ with $n$ vertices, a truncated Ising model is a probability distribution over the $n$-dimensional hypercube ${-1,1}^n$ where each configuration $\mathbf{\sigma}$ is constrained to lie in a truncation set $S \subseteq {-1,1}^n$ and has probability $\Pr(\mathbf{\sigma}) \propto \exp(\beta\mathbf{\sigma}^\top A\mathbf{\sigma})$ with $A$ being the adjacency matrix of $G$. We adopt the recent setting of [Galanis et al. SODA'24], where the truncation set $S$ can be expressed as the set of satisfying assignments of a $k$-SAT formula. Given a single sample $\mathbf{\sigma}$ from a truncated Ising model, with inverse parameter $\beta^$, underlying graph $G$ of bounded degree $\Delta$ and $S$ being expressed as the set of satisfying assignments of a $k$-SAT formula, we design in nearly $O(n)$ time an estimator $\hat{\beta}$ that is $O(\Delta^3/\sqrt{n})$-consistent with the true parameter $\beta^$ for $k \gtrsim \log(d^2k)\Delta^3.$ Our estimator is based on the maximization of the pseudolikelihood, a notion that has received extensive analysis for various probabilistic models without [Chatterjee, Annals of Statistics '07] or with truncation [Galanis et al. SODA '24]. Our approach generalizes recent techniques from [Daskalakis et al. STOC '19, Galanis et al. SODA '24], to confront the more challenging setting of the truncated Ising model.
Efficient Ensemble Conditional Independence Test Framework for Causal Discovery
arXiv:2509.21021v1 Announce Type: cross Abstract: Constraint-based causal discovery relies on numerous conditional independence tests (CITs), but its practical applicability is severely constrained by the prohibitive computational cost, especially as CITs themselves have high time complexity with respect to the sample size. To address this key bottleneck, we introduce the Ensemble Conditional Independence Test (E-CIT), a general and plug-and-play framework. E-CIT operates on an intuitive divide-and-aggregate strategy: it partitions the data into subsets, applies a given base CIT independently to each subset, and aggregates the resulting p-values using a novel method grounded in the properties of stable distributions. This framework reduces the computational complexity of a base CIT to linear in the sample size when the subset size is fixed. Moreover, our tailored p-value combination method offers theoretical consistency guarantees under mild conditions on the subtests. Experimental results demonstrate that E-CIT not only significantly reduces the computational burden of CITs and causal discovery but also achieves competitive performance. Notably, it exhibits an improvement in complex testing scenarios, particularly on real-world datasets.
Inverse Reinforcement Learning Using Just Classification and a Few Regressions
arXiv:2509.21172v1 Announce Type: cross Abstract: Inverse reinforcement learning (IRL) aims to explain observed behavior by uncovering an underlying reward. In the maximum-entropy or Gumbel-shocks-to-reward frameworks, this amounts to fitting a reward function and a soft value function that together satisfy the soft Bellman consistency condition and maximize the likelihood of observed actions. While this perspective has had enormous impact in imitation learning for robotics and understanding dynamic choices in economics, practical learning algorithms often involve delicate inner-loop optimization, repeated dynamic programming, or adversarial training, all of which complicate the use of modern, highly expressive function approximators like neural nets and boosting. We revisit softmax IRL and show that the population maximum-likelihood solution is characterized by a linear fixed-point equation involving the behavior policy. This observation reduces IRL to two off-the-shelf supervised learning problems: probabilistic classification to estimate the behavior policy, and iterative regression to solve the fixed point. The resulting method is simple and modular across function approximation classes and algorithms. We provide a precise characterization of the optimal solution, a generic oracle-based algorithm, finite-sample error bounds, and empirical results showing competitive or superior performance to MaxEnt IRL.
Closed-form $\ell_r$ norm scaling with data for overparameterized linear regression and diagonal linear networks under $\ell_p$ bias
arXiv:2509.21181v1 Announce Type: cross Abstract: For overparameterized linear regression with isotropic Gaussian design and minimum-$\ell_p$ interpolator $p\in(1,2]$, we give a unified, high-probability characterization for the scaling of the family of parameter norms $ \{ \lVert \widehat{w_p} \rVert_r \}{r \in [1,p]} $ with sample size. We solve this basic, but unresolved question through a simple dual-ray analysis, which reveals a competition between a signal spike and a bulk of null coordinates in $X^\top Y$, yielding closed-form predictions for (i) a data-dependent transition $n\star$ (the "elbow"), and (ii) a universal threshold $r_\star=2(p-1)$ that separates $\lVert \widehat{w_p} \rVert_r$'s which plateau from those that continue to grow with an explicit exponent. This unified solution resolves the scaling of all $\ell_r$ norms within the family $r\in [1,p]$ under $\ell_p$-biased interpolation, and explains in one picture which norms saturate and which increase as $n$ grows. We then study diagonal linear networks (DLNs) trained by gradient descent. By calibrating the initialization scale $\alpha$ to an effective $p_{\mathrm{eff}}(\alpha)$ via the DLN separable potential, we show empirically that DLNs inherit the same elbow/threshold laws, providing a predictive bridge between explicit and implicit bias. Given that many generalization proxies depend on $\lVert \widehat {w_p} \rVert_r$, our results suggest that their predictive power will depend sensitively on which $l_r$ norm is used.
No Prior, No Leakage: Revisiting Reconstruction Attacks in Trained Neural Networks
arXiv:2509.21296v1 Announce Type: cross Abstract: The memorization of training data by neural networks raises pressing concerns for privacy and security. Recent work has shown that, under certain conditions, portions of the training set can be reconstructed directly from model parameters. Some of these methods exploit implicit bias toward margin maximization, suggesting that properties often regarded as beneficial for generalization may actually compromise privacy. Yet despite striking empirical demonstrations, the reliability of these attacks remains poorly understood and lacks a solid theoretical foundation. In this work, we take a complementary perspective: rather than designing stronger attacks, we analyze the inherent weaknesses and limitations of existing reconstruction methods and identify conditions under which they fail. We rigorously prove that, without incorporating prior knowledge about the data, there exist infinitely many alternative solutions that may lie arbitrarily far from the true training set, rendering reconstruction fundamentally unreliable. Empirically, we further demonstrate that exact duplication of training examples occurs only by chance. Our results refine the theoretical understanding of when training set leakage is possible and offer new insights into mitigating reconstruction attacks. Remarkably, we demonstrate that networks trained more extensively, and therefore satisfying implicit bias conditions more strongly -- are, in fact, less susceptible to reconstruction attacks, reconciling privacy with the need for strong generalization in this setting.
Towards Complete Causal Explanation with Expert Knowledge
arXiv:2407.07338v3 Announce Type: replace Abstract: We study the problem of restricting a Markov equivalence class of maximal ancestral graphs (MAGs) to only those MAGs that contain certain edge marks, which we refer to as expert or orientation knowledge. Such a restriction of the Markov equivalence class can be uniquely represented by a restricted essential ancestral graph. Our contributions are several-fold. First, we prove certain properties for the entire Markov equivalence class including a conjecture from Ali et al. (2009). Second, we present several new sound graphical orientation rules for adding orientation knowledge to an essential ancestral graph. We also show that some orientation rules of Zhang (2008b) are not needed for restricting the Markov equivalence class with orientation knowledge. Third, we provide an algorithm for including this orientation knowledge and show that in certain settings the output of our algorithm is a restricted essential ancestral graph. Finally, outside of the specified settings, we provide an algorithm for checking whether a graph is a restricted essential graph and discuss its runtime. This work can be seen as a generalization of Meek (1995) to settings which allow for latent confounding.
Hybrid Summary Statistics
arXiv:2410.07548v2 Announce Type: replace Abstract: We present a way to capture high-information posteriors from training sets that are sparsely sampled over the parameter space for robust simulation-based inference. In physical inference problems, we can often apply domain knowledge to define traditional summary statistics to capture some of the information in a dataset. We show that augmenting these statistics with neural network outputs to maximise the mutual information improves information extraction compared to neural summaries alone or their concatenation to existing summaries and makes inference robust in settings with low training data. We introduce 1) two loss formalisms to achieve this and 2) apply the technique to two different cosmological datasets to extract non-Gaussian parameter information.
Revenue Maximization Under Sequential Price Competition Via The Estimation Of s-Concave Demand Functions
arXiv:2503.16737v3 Announce Type: replace Abstract: We consider price competition among multiple sellers over a selling horizon of $T$ periods. In each period, sellers simultaneously offer their prices (which are made public) and subsequently observe their respective demand (not made public). The demand function of each seller depends on all sellers' prices through a private, unknown, and nonlinear relationship. We propose a dynamic pricing policy that uses semi-parametric least-squares estimation and show that when the sellers employ our policy, their prices converge at a rate of $O(T^{-1/7})$ to the Nash equilibrium prices that sellers would reach if they were fully informed. Each seller incurs a regret of $O(T^{5/7})$ relative to a dynamic benchmark policy. A theoretical contribution of our work is proving the existence of equilibrium under shape-constrained demand functions via the concept of $s$-concavity and establishing regret bounds of our proposed policy. Technically, we also establish new concentration results for the least squares estimator under shape constraints. Our findings offer significant insights into dynamic competition-aware pricing and contribute to the broader study of non-parametric learning in strategic decision-making.
Uncertainty-Aware Surrogate-based Amortized Bayesian Inference for Computationally Expensive Models
arXiv:2505.08683v2 Announce Type: replace Abstract: Bayesian inference typically relies on a large number of model evaluations to estimate posterior distributions. Established methods like Markov Chain Monte Carlo (MCMC) and Amortized Bayesian Inference (ABI) can become computationally challenging. While ABI enables fast inference after training, generating sufficient training data still requires thousands of model simulations, which is infeasible for expensive models. Surrogate models offer a solution by providing approximate simulations at a lower computational cost, allowing the generation of large data sets for training. However, the introduced approximation errors and uncertainties can lead to overconfident posterior estimates. To address this, we propose Uncertainty-Aware Surrogate-based Amortized Bayesian Inference (UA-SABI) -- a framework that combines surrogate modeling and ABI while explicitly quantifying and propagating surrogate uncertainties through the inference pipeline. Our experiments show that this approach enables reliable, fast, and repeated Bayesian inference for computationally expensive models, even under tight time constraints.
Tensor State Space-based Dynamic Multilayer Network Modeling
arXiv:2506.02413v2 Announce Type: replace Abstract: Understanding the complex interactions within dynamic multilayer networks is critical for advancements in various scientific domains. Existing models often fail to capture such networks' temporal and cross-layer dynamics. This paper introduces a novel Tensor State Space Model for Dynamic Multilayer Networks (TSSDMN), utilizing a latent space model framework. TSSDMN employs a symmetric Tucker decomposition to represent latent node features, their interaction patterns, and layer transitions. Then by fixing the latent features and allowing the interaction patterns to evolve over time, TSSDMN uniquely captures both the temporal dynamics within layers and across different layers. The model identifiability conditions are discussed. By treating latent features as variables whose posterior distributions are approximated using a mean-field variational inference approach, a variational Expectation Maximization algorithm is developed for efficient model inference. Numerical simulations and case studies demonstrate the efficacy of TSSDMN for understanding dynamic multilayer networks.
Locally Adaptive Conformal Inference for Operator Models
arXiv:2507.20975v2 Announce Type: replace Abstract: Operator models are regression algorithms between Banach spaces of functions. They have become an increasingly critical tool for spatiotemporal forecasting and physics emulation, especially in high-stakes scenarios where robust, calibrated uncertainty quantification is required. We introduce Local Sliced Conformal Inference (LSCI), a distribution-free framework for generating function-valued, locally adaptive prediction sets for operator models. We prove finite-sample validity and derive a data-dependent upper bound on the coverage gap under local exchangeability. On synthetic Gaussian-process tasks and real applications (air quality monitoring, energy demand forecasting, and weather prediction), LSCI yields tighter sets with stronger adaptivity compared to conformal baselines. We also empirically demonstrate robustness against biased predictions and certain out-of-distribution noise regimes.
Bilateral Distribution Compression: Reducing Both Data Size and Dimensionality
arXiv:2509.17543v3 Announce Type: replace Abstract: Existing distribution compression methods reduce dataset size by minimising the Maximum Mean Discrepancy (MMD) between original and compressed sets, but modern datasets are often large in both sample size and dimensionality. We propose Bilateral Distribution Compression (BDC), a two-stage framework that compresses along both axes while preserving the underlying distribution, with overall linear time and memory complexity in dataset size and dimension. Central to BDC is the Decoded MMD (DMMD), which quantifies the discrepancy between the original data and a compressed set decoded from a low-dimensional latent space. BDC proceeds by (i) learning a low-dimensional projection using the Reconstruction MMD (RMMD), and (ii) optimising a latent compressed set with the Encoded MMD (EMMD). We show that this procedure minimises the DMMD, guaranteeing that the compressed set faithfully represents the original distribution. Experiments show that across a variety of scenarios BDC can achieve comparable or superior performance to ambient-space compression at substantially lower cost.
Learning to Bid Optimally and Efficiently in Adversarial First-price Auctions
arXiv:2007.04568v2 Announce Type: replace-cross Abstract: First-price auctions have very recently swept the online advertising industry, replacing second-price auctions as the predominant auction mechanism on many platforms. This shift has brought forth important challenges for a bidder: how should one bid in a first-price auction, where unlike in second-price auctions, it is no longer optimal to bid one's private value truthfully and hard to know the others' bidding behaviors? In this paper, we take an online learning angle and address the fundamental problem of learning to bid in repeated first-price auctions, where both the bidder's private valuations and other bidders' bids can be arbitrary. We develop the first minimax optimal online bidding algorithm that achieves an $\widetilde{O}(\sqrt{T})$ regret when competing with the set of all Lipschitz bidding policies, a strong oracle that contains a rich set of bidding strategies. This novel algorithm is built on the insight that the presence of a good expert can be leveraged to improve performance, as well as an original hierarchical expert-chaining structure, both of which could be of independent interest in online learning. Further, by exploiting the product structure that exists in the problem, we modify this algorithm--in its vanilla form statistically optimal but computationally infeasible--to a computationally efficient and space efficient algorithm that also retains the same $\widetilde{O}(\sqrt{T})$ minimax optimal regret guarantee. Additionally, through an impossibility result, we highlight that one is unlikely to compete this favorably with a stronger oracle (than the considered Lipschitz bidding policies). Finally, we test our algorithm on three real-world first-price auction datasets obtained from Verizon Media and demonstrate our algorithm's superior performance compared to several existing bidding algorithms.
Contextual Combinatorial Bandits with Changing Action Sets via Gaussian Processes
arXiv:2110.02248v3 Announce Type: replace-cross Abstract: We consider a contextual bandit problem with a combinatorial action set and time-varying base arm availability. At the beginning of each round, the agent observes the set of available base arms and their contexts and then selects an action that is a feasible subset of the set of available base arms to maximize its cumulative reward in the long run. We assume that the mean outcomes of base arms are samples from a Gaussian Process (GP) indexed by the context set ${\cal X}$, and the expected reward is Lipschitz continuous in expected base arm outcomes. For this setup, we propose an algorithm called Optimistic Combinatorial Learning and Optimization with Kernel Upper Confidence Bounds (O'CLOK-UCB) and prove that it incurs $\tilde{O}(\sqrt{\lambda^(K)KT\gamma_{KT}(\cup_{t\leq T}\mathcal{X}t)} )$ regret with high probability, where $\gamma{KT}(\cup_{t\leq T}\mathcal{X}_t)$ is the maximum information gain associated with the sets of base arm contexts $\mathcal{X}_t$ that appeared in the first $T$ rounds, $K$ is the maximum cardinality of any feasible action over all rounds, and $\lambda^(K)$ is the maximum eigenvalue of all covariance matrices of selected actions up to time $T$, which is a function of $K$. To dramatically speed up the algorithm, we also propose a variant of O'CLOK-UCB that uses sparse GPs. Finally, we experimentally show that both algorithms exploit inter-base arm outcome correlation and vastly outperform the previous state-of-the-art UCB-based algorithms in realistic setups.
Rosenthal-type inequalities for linear statistics of Markov chains
arXiv:2303.05838v3 Announce Type: replace-cross Abstract: In this paper, we establish novel concentration inequalities for additive functionals of geometrically ergodic Markov chains similar to Rosenthal inequalities for sums of independent random variables. We pay special attention to the dependence of our bounds on the mixing time of the corresponding chain. Precisely, we establish explicit bounds that are linked to the constants from the martingale version of the Rosenthal inequality, as well as the constants that characterize the mixing properties of the underlying Markov kernel. Finally, our proof technique is, up to our knowledge, new and is based on a recurrent application of the Poisson decomposition.
Energy based diffusion generator for efficient sampling of Boltzmann distributions
arXiv:2401.02080v3 Announce Type: replace-cross Abstract: Sampling from Boltzmann distributions, particularly those tied to high dimensional and complex energy functions, poses a significant challenge in many fields. In this work, we present the Energy-Based Diffusion Generator (EDG), a novel approach that integrates ideas from variational autoencoders and diffusion models. EDG uses a decoder to generate Boltzmann-distributed samples from simple latent variables, and a diffusion-based encoder to estimate the Kullback-Leibler divergence to the target distribution. Notably, EDG is simulation-free, eliminating the need to solve ordinary or stochastic differential equations during training. Furthermore, by removing constraints such as bijectivity in the decoder, EDG allows for flexible network design. Through empirical evaluation, we demonstrate the superior performance of EDG across a variety of sampling tasks with complex target distributions, outperforming existing methods.
Counterfactual Cocycles: A Framework for Robust and Coherent Counterfactual Transports
arXiv:2405.13844v4 Announce Type: replace-cross Abstract: Estimating joint distributions (a.k.a. couplings) over counterfactual outcomes is central to personalized decision-making and treatment risk assessment. Two emergent frameworks with identifiability guarantees are: (i) bijective structural causal models (SCMs), which are flexible but brittle to mis-specified latent noise; and (ii) optimal-transport (OT) methods, which avoid latent noise assumptions but can produce incoherent counterfactual transports which fail to identify higher-order couplings. In this work, we bridge the gap with \emph{counterfactual cocycles}: a framework for counterfactual transports that use algebraic structure to provide coherence and identifiability guarantees. Every counterfactual cocycle corresponds to an equivalence class of SCMs, however the cocycle is invariant to the latent noise distribution, enabling us to sidestep various mis-specification problems. We characterize the structure of all identifiable counterfactual cocycles; propose flexible model parameterizations; introduce a novel cocycle estimator that avoids any distributional assumptions; and derive mis-specification robustness properties of the resulting counterfactual inference method. We demonstrate state-of-the-art performance and noise-robustness of counterfactual cocycles across synthetic benchmarks and a 401(k) eligibility study.
Understanding Optimization in Deep Learning with Central Flows
arXiv:2410.24206v2 Announce Type: replace-cross Abstract: Traditional theories of optimization cannot describe the dynamics of optimization in deep learning, even in the simple setting of deterministic training. The challenge is that optimizers typically operate in a complex, oscillatory regime called the "edge of stability." In this paper, we develop theory that can describe the dynamics of optimization in this regime. Our key insight is that while the exact trajectory of an oscillatory optimizer may be challenging to analyze, the time-averaged (i.e. smoothed) trajectory is often much more tractable. To analyze an optimizer, we derive a differential equation called a "central flow" that characterizes this time-averaged trajectory. We empirically show that these central flows can predict long-term optimization trajectories for generic neural networks with a high degree of numerical accuracy. By interpreting these central flows, we are able to understand how gradient descent makes progress even as the loss sometimes goes up; how adaptive optimizers "adapt" to the local loss landscape; and how adaptive optimizers implicitly navigate towards regions where they can take larger steps. Our results suggest that central flows can be a valuable theoretical tool for reasoning about optimization in deep learning.
Bayesian Optimization with Preference Exploration using a Monotonic Neural Network Ensemble
arXiv:2501.18792v2 Announce Type: replace-cross Abstract: Many real-world black-box optimization problems have multiple conflicting objectives. Rather than attempting to approximate the entire set of Pareto-optimal solutions, interactive preference learning allows to focus the search on the most relevant subset. However, few previous studies have exploited the fact that utility functions are usually monotonic. In this paper, we address the Bayesian Optimization with Preference Exploration (BOPE) problem and propose using a neural network ensemble as a utility surrogate model. This approach naturally integrates monotonicity and supports pairwise comparison data. Our experiments demonstrate that the proposed method outperforms state-of-the-art approaches and exhibits robustness to noise in utility evaluations. An ablation study highlights the critical role of monotonicity in enhancing performance.
Regularization can make diffusion models more efficient
arXiv:2502.09151v2 Announce Type: replace-cross Abstract: Diffusion models are one of the key architectures of generative AI. Their main drawback, however, is the computational costs. This study indicates that the concept of sparsity, well known especially in statistics, can provide a pathway to more efficient diffusion pipelines. Our mathematical guarantees prove that sparsity can reduce the input dimension's influence on the computational complexity to that of a much smaller intrinsic dimension of the data. Our empirical findings confirm that inducing sparsity can indeed lead to better samples at a lower cost.
What Makes a Reward Model a Good Teacher? An Optimization Perspective
arXiv:2503.15477v2 Announce Type: replace-cross Abstract: The success of Reinforcement Learning from Human Feedback (RLHF) critically depends on the quality of the reward model. However, while this quality is primarily evaluated through accuracy, it remains unclear whether accuracy fully captures what makes a reward model an effective teacher. We address this question from an optimization perspective. First, we prove that regardless of how accurate a reward model is, if it induces low reward variance, then the RLHF objective suffers from a flat landscape. Consequently, even a perfectly accurate reward model can lead to extremely slow optimization, underperforming less accurate models that induce higher reward variance. We additionally show that a reward model that works well for one language model can induce low reward variance, and thus a flat objective landscape, for another. These results establish a fundamental limitation of evaluating reward models solely based on accuracy or independently of the language model they guide. Experiments using models of up to 8B parameters corroborate our theory, demonstrating the interplay between reward variance, accuracy, and reward maximization rate. Overall, our findings highlight that beyond accuracy, a reward model needs to induce sufficient variance for efficient~optimization.
Provably Sample-Efficient Robust Reinforcement Learning with Average Reward
arXiv:2505.12462v2 Announce Type: replace-cross Abstract: Robust reinforcement learning (RL) under the average-reward criterion is essential for long-term decision-making, particularly when the environment may differ from its specification. However, a significant gap exists in understanding the finite-sample complexity of these methods, as most existing work provides only asymptotic guarantees. This limitation hinders their principled understanding and practical deployment, especially in data-limited scenarios. We close this gap by proposing \textbf{Robust Halpern Iteration (RHI)}, a new algorithm designed for robust Markov Decision Processes (MDPs) with transition uncertainty characterized by $\ell_p$-norm and contamination models. Our approach offers three key advantages over previous methods: (1). Weaker Structural Assumptions: RHI only requires the underlying robust MDP to be communicating, a less restrictive condition than the commonly assumed ergodicity or irreducibility; (2). No Prior Knowledge: Our algorithm operates without requiring any prior knowledge of the robust MDP; (3). State-of-the-Art Sample Complexity: To learn an $\epsilon$-optimal robust policy, RHI achieves a sample complexity of $\tilde{\mathcal O}\left(\frac{SA\mathcal H^{2}}{\epsilon^{2}}\right)$, where $S$ and $A$ denote the numbers of states and actions, and $\mathcal H$ is the robust optimal bias span. This result represents the tightest known bound. Our work hence provides essential theoretical understanding of sample efficiency of robust average reward RL.
Why and When Deep is Better than Shallow: An Implementation-Agnostic State-Transition View of Depth Supremacy
arXiv:2505.15064v2 Announce Type: replace-cross Abstract: Why and when is deep better than shallow? We answer this question in a framework that is agnostic to network implementation. We formulate a deep model as an abstract state-transition semigroup acting on a general metric space, and separate the implementation (e.g., ReLU nets, transformers, and chain-of-thought) from the abstract state transition. We prove a bias-variance decomposition in which the variance depends only on the abstract depth-$k$ network and not on the implementation (Theorem 1). We further split the bounds into output and hidden parts to tie the depth dependence of the variance to the metric entropy of the state-transition semigroup (Theorem 2). We then investigate implementation-free conditions under which the variance grow polynomially or logarithmically with depth (Section 4). Combining these with exponential or polynomial bias decay identifies four canonical bias-variance trade-off regimes (EL/EP/PL/PP) and produces explicit optimal depths $k^\ast$. Across regimes, $k^\ast>1$ typically holds, giving a rigorous form of depth supremacy. The lowest generalization error bound is achieved under the EL regime (exp-decay bias + log-growth variance), explaining why and when deep is better, especially for iterative or hierarchical concept classes such as neural ODEs, diffusion/score models, and chain-of-thought reasoning.
Bridging Arbitrary and Tree Metrics via Differentiable Gromov Hyperbolicity
arXiv:2505.21073v3 Announce Type: replace-cross Abstract: Trees and the associated shortest-path tree metrics provide a powerful framework for representing hierarchical and combinatorial structures in data. Given an arbitrary metric space, its deviation from a tree metric can be quantified by Gromov's $\delta$-hyperbolicity. Nonetheless, designing algorithms that bridge an arbitrary metric to its closest tree metric is still a vivid subject of interest, as most common approaches are either heuristical and lack guarantees, or perform moderately well. In this work, we introduce a novel differentiable optimization framework, coined DeltaZero, that solves this problem. Our method leverages a smooth surrogate for Gromov's $\delta$-hyperbolicity which enables a gradient-based optimization, with a tractable complexity. The corresponding optimization procedure is derived from a problem with better worst case guarantees than existing bounds, and is justified statistically. Experiments on synthetic and real-world datasets demonstrate that our method consistently achieves state-of-the-art distortion.
A Finite-Time Analysis of TD Learning with Linear Function Approximation without Projections or Strong Convexity
arXiv:2506.01052v2 Announce Type: replace-cross Abstract: We investigate the finite-time convergence properties of Temporal Difference (TD) learning with linear function approximation, a cornerstone algorithm in the field of reinforcement learning. We are interested in the so-called ``robust'' setting, where the convergence guarantee does not depend on the minimal curvature of the potential function. While prior work has established convergence guarantees in this setting, these results typically rely on the assumption that each iterate is projected onto a bounded set, a condition that is both artificial and does not match the current practice. In this paper, we challenge the necessity of such an assumption and present a refined analysis of TD learning. For the first time, we show that the simple projection-free variant converges with a rate of $\widetilde{\mathcal{O}}(\frac{||\theta^*||^2_2}{\sqrt{T}})$, even in the presence of Markovian noise. Our analysis reveals a novel self-bounding property of the TD updates and exploits it to guarantee bounded iterates.
Improved Scaling Laws in Linear Regression via Data Reuse
arXiv:2506.08415v2 Announce Type: replace-cross Abstract: Neural scaling laws suggest that the test error of large language models trained online decreases polynomially as the model size and data size increase. However, such scaling can be unsustainable when running out of new data. In this work, we show that data reuse can improve existing scaling laws in linear regression. Specifically, we derive sharp test error bounds on $M$-dimensional linear models trained by multi-pass stochastic gradient descent (multi-pass SGD) on $N$ data with sketched features. Assuming that the data covariance has a power-law spectrum of degree $a$, and that the true parameter follows a prior with an aligned power-law spectrum of degree $b-a$ (with $a > b > 1$), we show that multi-pass SGD achieves a test error of $\Theta(M^{1-b} + L^{(1-b)/a})$, where $L \lesssim N^{a/b}$ is the number of iterations. In the same setting, one-pass SGD only attains a test error of $\Theta(M^{1-b} + N^{(1-b)/a})$ (see e.g., Lin et al., 2024). This suggests an improved scaling law via data reuse (i.e., choosing $L>N$) in data-constrained regimes. Numerical simulations are also provided to verify our theoretical findings.
Generalizing while preserving monotonicity in comparison-based preference learning models
arXiv:2506.08616v2 Announce Type: replace-cross Abstract: If you tell a learning model that you prefer an alternative $a$ over another alternative $b$, then you probably expect the model to be monotone, that is, the valuation of $a$ increases, and that of $b$ decreases. Yet, perhaps surprisingly, many widely deployed comparison-based preference learning models, including large language models, fail to have this guarantee. Until now, the only comparison-based preference learning algorithms that were proved to be monotone are the Generalized Bradley-Terry models. Yet, these models are unable to generalize to uncompared data. In this paper, we advance the understanding of the set of models with generalization ability that are monotone. Namely, we propose a new class of Linear Generalized Bradley-Terry models with Diffusion Priors, and identify sufficient conditions on alternatives' embeddings that guarantee monotonicity. Our experiments show that this monotonicity is far from being a general guarantee, and that our new class of generalizing models improves accuracy, especially when the dataset is limited.
CopulaSMOTE: A Copula-Based Oversampling Approach for Imbalanced Classification in Diabetes Prediction
arXiv:2506.17326v2 Announce Type: replace-cross Abstract: Diabetes mellitus poses a significant health risk, as nearly 1 in 9 people are affected by it. Early detection can significantly lower this risk. Despite significant advancements in machine learning for identifying diabetic cases, results can still be influenced by the imbalanced nature of the data. To address this challenge, our study considered copula-based data augmentation, which preserves the dependency structure when generating data for the minority class and integrates it with machine learning (ML) techniques. We selected the Pima Indian dataset and generated data using A2 copula, then applied five machine learning algorithms: logistic regression, random forest, gradient boosting, extreme gradient boosting, and Multilayer Perceptron. Overall, our findings show that Random Forest with A2 copula oversampling (theta = 10) achieved the best performance, with improvements of 5.3% in accuracy, 9.5% in precision, 5.7% in recall, 7.6% in F1-score, and 1.1% in AUC compared to the standard SMOTE method. Furthermore, we statistically validated our results using the McNemar's test. This research represents the first known use of A2 copulas for data augmentation and serves as an alternative to the SMOTE technique, highlighting the efficacy of copulas as a statistical method in machine learning applications.
An entropy-optimal path to humble AI
arXiv:2506.17940v2 Announce Type: replace-cross Abstract: Progress of AI has led to very successful, but by no means humble models and tools, especially regarding (i) the huge and further exploding costs and resources they demand, and (ii) the over-confidence of these tools with the answers they provide. Here we introduce a novel mathematical framework for a non-equilibrium entropy-optimizing reformulation of Boltzmann machines based on the exact law of total probability and the exact convex polytope representations. We show that it results in the highly-performant, but much cheaper, gradient-descent-free learning framework with mathematically-justified existence and uniqueness criteria, and cheaply-computable confidence/reliability measures for both the model inputs and the outputs. Comparisons to state-of-the-art AI tools in terms of performance, cost and the model descriptor lengths on a broad set of synthetic and real-world problems with varying complexity reveal that the proposed method results in more performant and slim models, with the descriptor lengths being very close to the intrinsic complexity scaling bounds for the underlying problems. Applying this framework to historical climate data results in models with systematically higher prediction skills for the onsets of important La Ni\~na and El Ni\~no climate phenomena, requiring just few years of climate data for training - a small fraction of what is necessary for contemporary climate prediction tools.
Enhanced Generative Model Evaluation with Clipped Density and Coverage
arXiv:2507.01761v2 Announce Type: replace-cross Abstract: Although generative models have made remarkable progress in recent years, their use in critical applications has been hindered by an inability to reliably evaluate the quality of their generated samples. Quality refers to at least two complementary concepts: fidelity and coverage. Current quality metrics often lack reliable, interpretable values due to an absence of calibration or insufficient robustness to outliers. To address these shortcomings, we introduce two novel metrics: Clipped Density and Clipped Coverage. By clipping individual sample contributions, as well as the radii of nearest neighbor balls for fidelity, our metrics prevent out-of-distribution samples from biasing the aggregated values. Through analytical and empirical calibration, these metrics demonstrate linear score degradation as the proportion of bad samples increases. Thus, they can be straightforwardly interpreted as equivalent proportions of good samples. Extensive experiments on synthetic and real-world datasets demonstrate that Clipped Density and Clipped Coverage outperform existing methods in terms of robustness, sensitivity, and interpretability when evaluating generative models.
Training-Free Stein Diffusion Guidance: Posterior Correction for Sampling Beyond High-Density Regions
arXiv:2507.05482v2 Announce Type: replace-cross Abstract: Training free diffusion guidance provides a flexible way to leverage off-the-shelf classifiers without additional training. Yet, current approaches hinge on posterior approximations via Tweedie's formula, which often yield unreliable guidance, particularly in low-density regions. Stochastic optimal control (SOC), in contrast, provides principled posterior simulation but is prohibitively expensive for fast sampling. In this work, we reconcile the strengths of these paradigms by introducing Stein Diffusion Guidance (SDG), a novel training-free framework grounded in a surrogate SOC objective. We establish a theoretical bound on the value function, demonstrating the necessity of correcting approximate posteriors to faithfully reflect true diffusion dynamics. Leveraging Stein variational inference, SDG identifies the steepest descent direction that minimizes the Kullback-Leibler divergence between approximate and true posteriors. By incorporating a principled Stein correction mechanism and a novel running cost functional, SDG enables effective guidance in low-density regions. Experiments on molecular low-density sampling tasks suggest that SDG consistently surpasses standard training-free guidance methods, highlighting its potential for broader diffusion-based sampling beyond high-density regions.
Causal Structure Learning in Hawkes Processes with Complex Latent Confounder Networks
arXiv:2508.11727v2 Announce Type: replace-cross Abstract: Multivariate Hawkes process provides a powerful framework for modeling temporal dependencies and event-driven interactions in complex systems. While existing methods primarily focus on uncovering causal structures among observed subprocesses, real-world systems are often only partially observed, with latent subprocesses posing significant challenges. In this paper, we show that continuous-time event sequences can be represented by a discrete-time causal model as the time interval shrinks, and we leverage this insight to establish necessary and sufficient conditions for identifying latent subprocesses and the causal influences. Accordingly, we propose a two-phase iterative algorithm that alternates between inferring causal relationships among discovered subprocesses and uncovering new latent subprocesses, guided by path-based conditions that guarantee identifiability. Experiments on both synthetic and real-world datasets show that our method effectively recovers causal structures despite the presence of latent subprocesses.
Data-Augmented Few-Shot Neural Emulator for Computer-Model System Identification
arXiv:2508.19441v3 Announce Type: replace-cross Abstract: Partial differential equations (PDEs) underpin the modeling of many natural and engineered systems. It can be convenient to express such models as neural PDEs rather than using traditional numerical PDE solvers by replacing part or all of the PDE's governing equations with a neural network representation. Neural PDEs are often easier to differentiate, linearize, reduce, or use for uncertainty quantification than the original numerical solver. They are usually trained on solution trajectories obtained by long-horizon rollout of the PDE solver. Here we propose a more sample-efficient data-augmentation strategy for generating neural PDE training data from a computer model by space-filling sampling of local "stencil" states. This approach removes a large degree of spatiotemporal redundancy present in trajectory data and oversamples states that may be rarely visited but help the neural PDE generalize across the state space. We demonstrate that accurate neural PDE stencil operators can be learned from synthetic training data generated by the computational equivalent of 10 timesteps' worth of numerical simulation. Accuracy is further improved if we assume access to a single full-trajectory simulation from the computer model, which is typically available in practice. Across several PDE systems, we show that our data-augmented stencil data yield better trained neural stencil operators, with clear performance gains compared with naively sampled stencil data from simulation trajectories. Finally, with only 10 solver steps' worth of augmented stencil data, our approach outperforms traditional ML emulators trained on thousands of trajectories in long-horizon rollout accuracy and stability.
Data-Efficient Time-Dependent PDE Surrogates: Graph Neural Simulators vs. Neural Operators
arXiv:2509.06154v2 Announce Type: replace-cross Abstract: Developing accurate, data-efficient surrogate models is central to advancing AI for Science. Neural operators (NOs), which approximate mappings between infinite-dimensional function spaces using conventional neural architectures, have gained popularity as surrogates for systems driven by partial differential equations (PDEs). However, their reliance on large datasets and limited ability to generalize in low-data regimes hinder their practical utility. We argue that these limitations arise from their global processing of data, which fails to exploit the local, discretized structure of physical systems. To address this, we propose Graph Neural Simulators (GNS) as a principled surrogate modeling paradigm for time-dependent PDEs. GNS leverages message-passing combined with numerical time-stepping schemes to learn PDE dynamics by modeling the instantaneous time derivatives. This design mimics traditional numerical solvers, enabling stable long-horizon rollouts and strong inductive biases that enhance generalization. We rigorously evaluate GNS on four canonical PDE systems: (1) 2D scalar Burgers', (2) 2D coupled Burgers', (3) 2D Allen-Cahn, and (4) 2D nonlinear shallow-water equations, comparing against state-of-the-art NOs including Deep Operator Network (DeepONet) and Fourier Neural Operator (FNO). Results demonstrate that GNS is markedly more data-efficient, achieving less than 1% relative L2 error using only 3% of available trajectories, and exhibits dramatically reduced error accumulation over time (82.5% lower autoregressive error than FNO, 99.9% lower than DeepONet). To choose the training data, we introduce a PCA combined with KMeans trajectory selection strategy. These findings provide compelling evidence that GNS, with its graph-based locality and solver-inspired design, is the most suitable and scalable surrogate modeling framework for AI-driven scientific discovery.
Expressive Power of Deep Networks on Manifolds: Simultaneous Approximation
arXiv:2509.09362v3 Announce Type: replace-cross Abstract: A key challenge in scientific machine learning is solving partial differential equations (PDEs) on complex domains, where the curved geometry complicates the approximation of functions and their derivatives required by differential operators. This paper establishes the first simultaneous approximation theory for deep neural networks on manifolds. We prove that a constant-depth $\mathrm{ReLU}^{k-1}$ network with bounded weights--a property that plays a crucial role in controlling generalization error--can approximate any function in the Sobolev space $\mathcal{W}_p^{k}(\mathcal{M}^d)$ to an error of $\varepsilon$ in the $\mathcal{W}_p^{s}(\mathcal{M}^d)$ norm, for $k\geq 3$ and $s<k$, using $\mathcal{O}(\varepsilon^{-d/(k-s)})$ nonzero parameters, a rate that overcomes the curse of dimensionality by depending only on the intrinsic dimension $d$. These results readily extend to functions in H\"older-Zygmund spaces. We complement this result with a matching lower bound, proving our construction is nearly optimal by showing the required number of parameters matches up to a logarithmic factor. Our proof of the lower bound introduces novel estimates for the Vapnik-Chervonenkis dimension and pseudo-dimension of the network's high-order derivative classes. These complexity bounds provide a theoretical cornerstone for learning PDEs on manifolds involving derivatives. Our analysis reveals that the network architecture leverages a sparse structure to efficiently exploit the manifold's low-dimensional geometry. Finally, we corroborate our theoretical findings with numerical experiments.
Selective Risk Certification for LLM Outputs via Information-Lift Statistics: PAC-Bayes, Robustness, and Skeleton Design
arXiv:2509.12527v2 Announce Type: replace-cross Abstract: Large language models frequently generate confident but incorrect outputs, requiring formal uncertainty quantification with abstention guarantees. We develop information-lift certificates that compare model probabilities to a skeleton baseline, accumulating evidence into sub-gamma PAC-Bayes bounds valid under heavy-tailed distributions. Across eight datasets, our method achieves 77.2\% coverage at 2\% risk, outperforming recent 2023-2024 baselines by 8.6-15.1 percentage points, while blocking 96\% of critical errors in high-stakes scenarios vs 18-31\% for entropy methods. Limitations include skeleton dependence and frequency-only (not severity-aware) risk control, though performance degrades gracefully under corruption.
Mixture-of-Experts Framework for Field-of-View Enhanced Signal-Dependent Binauralization of Moving Talkers
arXiv:2509.13548v3 Announce Type: replace-cross Abstract: We propose a novel mixture of experts framework for field-of-view enhancement in binaural signal matching. Our approach enables dynamic spatial audio rendering that adapts to continuous talker motion, allowing users to emphasize or suppress sounds from selected directions while preserving natural binaural cues. Unlike traditional methods that rely on explicit direction-of-arrival estimation or operate in the Ambisonics domain, our signal-dependent framework combines multiple binaural filters in an online manner using implicit localization. This allows for real-time tracking and enhancement of moving sound sources, supporting applications such as speech focus, noise reduction, and world-locked audio in augmented and virtual reality. The method is agnostic to array geometry offering a flexible solution for spatial audio capture and personalized playback in next-generation consumer audio devices.
5 Ways to Get Enterprise AI Going at ODSC AI West

Artificial intelligence in the enterprise has moved far beyond experiments. Today, the challenge isn’t if businesses should adopt AI — it’s how to do it responsibly, at scale, and in a way that drives measurable impact. From reshaping technical roles to introducing entirely new development lifecycles, the playbook for enterprise AI is being rewritten in real time.
At ODSC AI West 2025, October 28–30 in San Francisco, some of the leading voices in the field will share practical strategies, frameworks, and case studies for moving from AI hype to enterprise reality. Here’s a preview of what you’ll learn — and how to start laying the groundwork today.
Rule-Based Foundations for Enterprise AI
Scaling AI requires more than enthusiasm — it requires discipline. At ODSC AI West, Cameron Royce Turner, Founder & CEO of TRUIFY.AI, will present 5 Rules of Enterprise AI for 2026. His session will cover the most common pitfalls Fortune 500 companies have faced in early generative AI adoption and lay out practical rules for ensuring resilience, governance, and ROI.
Turner’s talk will show attendees how to build AI systems that are not only technically robust but also sustainable and ethically governed. If your enterprise is ready to push prototypes into production, his five rules provide a pragmatic playbook.
From Software Development to Agent Development
Traditional software lifecycles no longer fit the reality of adaptive AI agents. At ODSC West, Matan-Paul Shetrit, Director of Product at Writer, will explain this shift in his session, Understanding the Agent Development Lifecycle in the Enterprise. His talk will cover how the ADLC (Agent Development Lifecycle) helps organizations move beyond demos and proofs of concept toward agents that deliver measurable business outcomes.
Attendees will walk away with practical frameworks to reimagine the development process — not as building deterministic software, but as cultivating adaptive, outcome-driven agents.
Architecting and Governing Agentic AI
Moving from prototypes to enterprise-scale agentic AI requires careful design and oversight. In his session, From AlphaFold to Agentic AI: How to Build & Govern Enterprise Scale Agentic Applications, Dr. Ali Arsanjani of Google Cloud will cover the technical and governance frameworks needed to succeed.
His talk will walk attendees through the components of the “agentic stack,” from LLMs and planning algorithms to vector databases and secure tool integrations. Just as importantly, he’ll detail the guardrails — cost control, monitoring, and human-in-the-loop oversight — that ensure AI agents remain safe, predictable, and reliable.
Thriving in the Age of AI Agents
The rise of AI agents will reshape the role of the software engineer. At ODSC West, Julian Bright, Member of Technical Staff at xAI, will explore this transformation in his session, How to Adapt and Thrive in the Age of AI Agents.
Bright’s talk will cover reskilling strategies for engineers and technical leaders as well as the infrastructure needed for human–AI collaboration. From making codebases “agent-ready” to hiring and training AI-native engineers, this session will help executives and managers prepare their organizations for a future where agents handle entire features and production issues autonomously.
The Human Advantage
Amid rapid automation, it’s easy to forget the uniquely human qualities that drive value. At ODSC West, Kelli Quinn, Director of Product and Customer Success at VEOX, will unpack this in her session, The Human Advantage: Why Judgment Outranks Automation.
Her session will cover how human roles are shifting from doers to evaluators and judges of quality. Using powerful analogies like Michael Jordan and Nike, Quinn will show business leaders how to reframe their value in an AI-first economy — placing judgment and creativity at the center of enterprise AI strategies.
Spotlight on the Gen AI X Summit
All of these sessions are part of the Gen AI X Summit, the enterprise-focused program inside ODSC AI West. The summit brings together executives, product leaders, and applied AI experts to tackle the unique challenges of implementing AI in large organizations — from governance and scaling to team reskilling and business alignment.
If you’re responsible for driving AI transformation at your company, the Gen AI X Summit is your one-stop hub for proven frameworks, lessons learned from industry leaders, and practical steps to accelerate enterprise adoption. It’s where strategy meets execution — making it the most valuable track for business and technical leaders alike.
Why ODSC AI West?
Together, these sessions chart a roadmap for enterprises:
- Turner’s five rules for building resilient AI systems.
- Shetrit’s ADLC for operationalizing adaptive agents.
- Arsanjani’s blueprint for architecting and governing the agentic stack.
- Bright’s strategies for reskilling teams and building AI-ready infrastructure.
- Quinn’s framework for keeping human judgment central to innovation.
The future of enterprise AI isn’t just about deploying models — it’s about reshaping organizations, roles, and governance to unlock sustainable impact.
That’s why ODSC AI West 2025 is more than a conference. It’s a gathering of practitioners, executives, and innovators charting the next phase of AI in the enterprise. Whether you’re building agentic applications, leading technical teams, or navigating strategic adoption, you’ll walk away with the frameworks and connections to move from exploration to execution.
Join us in San Francisco this October 28–30 and take the next step in your enterprise AI journey.
TruSources to show off its on-device identity-checking tech at TechCrunch Disrupt 2025
Age-verification laws are a privacy and security nightmare. This startup performs age checks on-device, without users having to upload their IDs to the internet.
Thousands of Indian bank transfer records found spilling online after security lapse
Security researchers found the exposed Indian bank transfer records, and the data was eventually secured. Indian fintech company NuPay took responsibility for the "configuration" error.
Is the Apple Watch SE 3 a good deal?
The gap between Apple's standard and budget smart watches has never felt smaller.
IPO-bound Flipkart gains key approvals to relocate to India
Flipkart is set to become the most valuable startup to shift its headquarters back to India ahead of a planned IPO.
The Trump administration is going after semiconductor imports
The Trump administration wants the industry to reach a 1:1 ratio of domestically produced and imported chips.
Today is the last day to save up to $668 on TechCrunch Disrupt 2025 tickets
Today is the last chance to save up to $668 on TechCrunch Disrupt 2025. Join 250+ top tech leaders, explore 200+ sessions, and connect with 10,000+ innovators, investors, and founders.
Here’s what’s happening right now with the US TikTok deal
A number of investors are competing for the opportunity to purchase the app, and if a deal were to go through, the platform's U.S. business could have its valuation soar to upward of $60 billion.
Battery startup Moxion went bankrupt. Now its founder is back to ‘finish what we started.’
Anode Technology Company wants to build mobile battery generators for construction sites, live events, and EV fleets. But first it has to avoid the pitfalls that claimed its predecessor, Moxion.
Sierra Space’s spaceplane faces a reinvention after NASA contract change
Sierra Space's Dream Chaser spaceplane is facing an identity crisis after NASA changed contract terms to remove its guarantee to buy cargo flights to the ISS.
How developers are using Apple’s local AI models with iOS 26
As iOS 26 is rolling out to all users, developers have been updating their apps to include features powered by Apple's local AI models.
Sources: US regulators examined 200+ companies about sharp share-price gains in the lead-up to their announcements about making buying crypto a core strategy (Vicky Ge Huang/Wall Street Journal)

![]() Vicky Ge Huang / Wall Street Journal:
Vicky Ge Huang / Wall Street Journal:
Sources: US regulators examined 200+ companies about sharp share-price gains in the lead-up to their announcements about making buying crypto a core strategy — SEC, Finra reach out to companies whose shares moved sharply before they announced plans to buy bitcoin, other digital assets
Uber expects non-restaurant deliveries to hit an annual run rate of $12.5B in gross bookings by the end of 2025, up 25% from the $10B+ rate it shared in May (Natalie Lung/Bloomberg)

![]() Natalie Lung / Bloomberg:
Natalie Lung / Bloomberg:
Uber expects non-restaurant deliveries to hit an annual run rate of $12.5B in gross bookings by the end of 2025, up 25% from the $10B+ rate it shared in May — Uber Technologies Inc. sees its grocery and retail deliveries growing faster than expected, underscoring the company's effort …
Inspiren, which provides AI-powered fall detection and other tech for senior living facilities, raised a $100M Series B, bringing its total funding to $155M (Kathleen Steele Gaivin/McKnight's ...)

![]() Kathleen Steele Gaivin / McKnight's Senior Living:
Kathleen Steele Gaivin / McKnight's Senior Living:
Inspiren, which provides AI-powered fall detection and other tech for senior living facilities, raised a $100M Series B, bringing its total funding to $155M — Inspiren has raised $100 million in Series B funding, the healthcare technology company announced today.
Anthropic plans to triple its global workforce and expand its applied AI team 5x in 2025, after growing its business clients from ~1K to 300K+ in two years (MacKenzie Sigalos/CNBC)

![]() MacKenzie Sigalos / CNBC:
MacKenzie Sigalos / CNBC:
Anthropic plans to triple its global workforce and expand its applied AI team 5x in 2025, after growing its business clients from ~1K to 300K+ in two years — Anthropic is stepping up its global enterprise ambitions. — The $183 billion artificial intelligence startup has grown …
Perplexity launches Search API, giving developers direct access to the same web index that powers the startup's answer engine (Michael Nuñez/Venturebeat)

![]() Michael Nuñez / Venturebeat:
Michael Nuñez / Venturebeat:
Perplexity launches Search API, giving developers direct access to the same web index that powers the startup's answer engine — Perplexity AI launched a comprehensive search application programming interface on Thursday, giving developers direct access to the same massive web index that powers …
Sources: ByteDance may get ~50% of TikTok US' overall profit, including a licensing fee of 20% of revenue, despite selling majority ownership to US investors (Bloomberg)

![]() Bloomberg:
Bloomberg:
Sources: ByteDance may get ~50% of TikTok US' overall profit, including a licensing fee of 20% of revenue, despite selling majority ownership to US investors — TikTok's Chinese parent company will likely get about half of the profit from the platform's US operation even after it sells majority ownership …
China and its media are quiet about the TikTok deal, a notable silence as China can still decide the app's fate; Chinese social media chatter has been limited (Dylan Butts/CNBC)

![]() Dylan Butts / CNBC:
Dylan Butts / CNBC:
China and its media are quiet about the TikTok deal, a notable silence as China can still decide the app's fate; Chinese social media chatter has been limited — Following U.S. President Donald Trump's approval of a deal that could keep TikTok alive in the U.S. on Thursday …
German investigators conduct raids in relation to Northern Data, which is majority-owned by Tether and has been pivoting from crypto mining to AI computing (Bloomberg)

![]() Bloomberg:
Bloomberg:
German investigators conduct raids in relation to Northern Data, which is majority-owned by Tether and has been pivoting from crypto mining to AI computing — German investigators have carried out raids in relation to Northern Data AG, the Frankfurt-listed technology firm backed …
The Trump administration's $14B valuation of TikTok's US business falls well below previous estimates of around $40B, considered a bargain by investors (Bloomberg)

![]() Bloomberg:
Bloomberg:
The Trump administration's $14B valuation of TikTok's US business falls well below previous estimates of around $40B, considered a bargain by investors — The $14 billion valuation that the Trump administration has estimated for TikTok's US business falls well below projections …
The UK unveils plans for a digital ID, which will be required to work in the country, to combat illegal immigration; the ID will be stored on people's phones (Kate Whannel/BBC)

![]() Kate Whannel / BBC:
Kate Whannel / BBC:
The UK unveils plans for a digital ID, which will be required to work in the country, to combat illegal immigration; the ID will be stored on people's phones — Digital ID will be mandatory in order to work in the UK, as part of plans to tackle illegal migration.
Meta plans to launch paid, ad-free versions of Instagram and Facebook in the UK, each costing £2.99 per month on the web, and £3.99 on iOS and Android (Bloomberg)

![]() Bloomberg:
Bloomberg:
Meta plans to launch paid, ad-free versions of Instagram and Facebook in the UK, each costing £2.99 per month on the web, and £3.99 on iOS and Android — Meta Platforms Inc. will soon offer paid versions of Facebook and Instagram in the UK that will remove advertising from both platforms.
Checkout.com announces an employee share buyback at a $12B valuation, up 30% from $9.35B two years ago yet below $40B in 2022, and says an IPO isn't a priority (Aisha S Gani/Bloomberg)

![]() Aisha S Gani / Bloomberg:
Aisha S Gani / Bloomberg:
Checkout.com announces an employee share buyback at a $12B valuation, up 30% from $9.35B two years ago yet below $40B in 2022, and says an IPO isn't a priority — Checkout.com is allowing employees to sell some of their shares back to the firm at a $12 billion valuation …
How inaccurate AI translations of Wikipedia pages, which AI models use for training, may cause a doom spiral that further marginalizes vulnerable languages (Jacob Judah/MIT Technology Review)

![]() Jacob Judah / MIT Technology Review:
Jacob Judah / MIT Technology Review:
How inaccurate AI translations of Wikipedia pages, which AI models use for training, may cause a doom spiral that further marginalizes vulnerable languages — When Kenneth Wehr started managing the Greenlandic-language version of Wikipedia four years ago, his first act was to delete almost everything.
OLX Group, an online marketplace owned by Prosus, agrees to acquire La Centrale, a French auto classifieds platform, for $1.3B in cash, expected to close in Q4 (Loni Prinsloo/Bloomberg)

![]() Loni Prinsloo / Bloomberg:
Loni Prinsloo / Bloomberg:
OLX Group, an online marketplace owned by Prosus, agrees to acquire La Centrale, a French auto classifieds platform, for $1.3B in cash, expected to close in Q4 — Prosus NV-owned OLX Group BV is buying French online auto trader La Centrale for €1.1 billion ($1.3 billion) to expand its business into Western Europe.
A look at the use of tools like ChatGPT by retail investors to pick stocks, fueling a robo-advisory market boom, as experts warn of solely relying on AI (Joice Alves/Reuters)

![]() Joice Alves / Reuters:
Joice Alves / Reuters:
A look at the use of tools like ChatGPT by retail investors to pick stocks, fueling a robo-advisory market boom, as experts warn of solely relying on AI — - Robo-advisory market projected to grow 600% by 2029 — Half of retail investors open to using AI tools, survey finds
The overlooked cyber risk in data centre cooling systems
Data centre cooling systems are just as vulnerable to cyberattack as other systems. But they can be protected, and effectively so.
HighPoint's Rocket 7638D is the first PCIe switch to support Nvidia's GPUDirect storage technology

Direct GPU-to-storage connectivity is gradually reaching commercially available products you can install in your own server. HighPoint Technologies, a company specializing in advanced PCIe storage solutions since 2000, is introducing a new PCIe Gen5 switch designed to allow powerful Nvidia GPUs to access NVMe storage drives at maximum speed.
Read Entire Article
Windows 10 users in Europe will receive extended security updates for free

According to a recent open letter from Euroconsumers, Windows 10 users in the European Economic Area can receive an additional year of security updates for free, with no conditions attached. However, the consumer advocacy group remains critical of Microsoft's approach to the transition to Windows 11, which could render millions...
Read Entire Article
NASA studies plan to destroy asteroid with nuclear bombs before it can hit the Moon

Is NASA really planning an Armageddon-style mission near the Moon's orbit? The US space agency, together with astronomers around the world, is considering the best way to neutralize any potential threat asteroid 2024 YR4 could pose to Earth. And yes, scientists are seriously contemplating destroying the massive space rock with...
Read Entire Article
AMD patent proposes new memory module to double DDR5 speeds

The patent describes the development of high-bandwidth dual inline memory modules (HB-DIMMs) that use pseudo channels and specialized data routing to boost performance. Rather than re-engineering DRAM chips, AMD proposes coupling multiple DRAM devices to advanced data buffer chips. These buffers manage signal flow in a way that effectively doubles...
Read Entire Article
Sam Altman predicts Artificial General Intelligence by 2030, says AI will take over 40% of tasks

Jan Philipp Burgard, editor-in-chief of the Die Welt newpaper, interviewed Altman on behalf of the Axel Springer Global Reporters Network this week in Berlin. Altman was in Germany's capital to receive this year's Axel Springer Award.
Read Entire Article
Microsoft confirms $599 price for ROG Xbox Ally, $999 for high-end Ally X

Pre-orders are now open for the ROG Xbox Ally and ROG Xbox Ally X. Launching on October 16, the basic version starts at $599, while a more powerful model will retail for $999.
Read Entire Article
Elon Musk's xAI lands US government contract to provide Grok chatbot at 42 cents per agency

The deal will give federal agencies access to Grok for Government, based on the Grok 4 and Grok 4 Fast models. It's valid for 18 months – until March 2027 – making it the longest AI contract signed by the government to date.
Read Entire Article
Trump approves $14 billion TikTok deal backed by Oracle and MGX, but questions linger

President Donald Trump has signed an executive order approving a plan for a group of US and global investors to take control of TikTok's American operations, a move intended to satisfy a 2024 law that requires the divestiture of the app from its Chinese parent company, ByteDance, in order for...
Read Entire Article
Sony once again calls the PlayStation 5 its "most successful" console ever, despite the PS2's sales crown

Geoff Keighley, the video game journalist and presenter known for hosting The Game Awards, posted an image on X of Sony executive Hideaki Nishino's presentation at the Tokyo Game Show.
Read Entire Article
Amazon to refund $1.5 billion to customers in Prime sign-ups settlement

Under the agreement, Amazon will pay a $1 billion penalty to the FTC and refund $1.5 billion to an estimated 35 million customers who were charged for Prime memberships they did not intend to keep. According to the agency, eligible customers could receive refunds of up to $51, which are...
Read Entire Article
EA Sports FC 26 launches today, here's what reviewers are saying

FC 26 delivers faster, more responsive gameplay with 'Authentic Gameplay' tweaks and solid upgrades to Career Mode and offline play. Reviewers note that Ultimate Team sees only minor changes, but the game overall impresses with excellent visuals and a wealth of content.
Read Entire Article
I'm Happy That the AI Industry Is Being Constantly Mischaracterized
You reap what you sow, or something to that effect
AI-generated "workslop" is costing companies millions and hurting team morale, study finds

AI-generated "workslop" is quietly draining millions from companies and damaging team morale, according to a new study from BetterUp Labs and the Stanford Social Media Lab.
The article AI-generated "workslop" is costing companies millions and hurting team morale, study finds appeared first on THE DECODER.
Why pgEdge ‘Ripped the Band-Aid Off’ To Go Totally Open Source

The hullabaloo over moves away from open source licensing — HashiCorp/OpenTofu anyone? — seems to have settled a bit, but
The post Why pgEdge ‘Ripped the Band-Aid Off’ To Go Totally Open Source appeared first on The New Stack.
How Vite Became the Backbone of Modern Frontend Frameworks

Vite, created by Evan You, has become the go-to build tool for modern frontend frameworks, including Vue, SvelteKit, Astro, and
The post How Vite Became the Backbone of Modern Frontend Frameworks appeared first on The New Stack.
CISOs: Prepare for Software’s Agentic Future Today

recent C-suite survey found that 89% of executives anticipate that agentic AI will be the definitive software development standard within
The post CISOs: Prepare for Software’s Agentic Future Today appeared first on The New Stack.
Why Rancher’s Founders Pivoted From Kubernetes to Agentic AI

The transformation of generative AI (GenAI) from conversational tools to autonomous, action-oriented agents marks a significant inflection point for enterprise
The post Why Rancher’s Founders Pivoted From Kubernetes to Agentic AI appeared first on The New Stack.
Project infragraph: IBM’s Real-Time Model for Infrastructure Assets

As anyone who works with infrastructure knows, there are limited tools for understanding all of an organization’s IT assets, offering
The post Project infragraph: IBM’s Real-Time Model for Infrastructure Assets appeared first on The New Stack.
Software CEO tells Catholic uni panel AI won't take out jobs, but it could take out brains
As exorcist convention decries AI's potential for 'necromancy'
The CEO of a software testing company told a panel at Catholic University of America that AI will not create mass unemployment – though it could make people more stupid.…
Prompt injection – and a $5 domain – trick Salesforce Agentforce into leaking sales
More fun with AI agents and their security holes
A now-fixed flaw in Salesforce’s Agentforce could have allowed external attackers to steal sensitive customer data via prompt injection, according to security researchers who published a proof-of-concept attack on Thursday. They were aided by an expired trusted domain that they were able to buy for a measly five bucks.…
ChatGPT gets proactive with Pulse
PLUS: Get instant business insights from spreadsheets
Leaders in Trading 2025: Buy-side shortlists unveiled, voting now open!
Winners across the six categories will be announced at Leaders in Trading, taking place at The Savoy in London on 6 November.
The post Leaders in Trading 2025: Buy-side shortlists unveiled, voting now open! appeared first on The TRADE.
The TRADE appoints Claudia Preece as news editor
Annabel Smith set to depart after five years with The TRADE for a new market structure and sales role within the industry.
The post The TRADE appoints Claudia Preece as news editor appeared first on The TRADE.
Citi appoints futures and derivatives clearing vice president
Individual previously spent more than 11 years at BTIG, most recently as a vice president for outsourced trading.
The post Citi appoints futures and derivatives clearing vice president appeared first on The TRADE.
Millennium Advisors adopts self-clearing model for fixed income market
The move is set to help the firm increase efficiency and navigate trading costs, and follows an uptick in non-traditional liquidity providers investing in automation across the fixed income market.
The post Millennium Advisors adopts self-clearing model for fixed income market appeared first on The TRADE.
Clearstream and Euroclear set timeline for Eurobond digitisation
Dematerialised issuance to begin in 2026 as ICSDs introduce common data standard to streamline market processes.
The post Clearstream and Euroclear set timeline for Eurobond digitisation appeared first on The TRADE.
Trump’s new H-1B policy caused short-term panic — and will cause long-term chaos
Throughout his 2016 presidential campaign, Donald Trump often claimed that his efforts against immigration were primarily against irregular or illegal immigration, and that he was happy to have people go through "proper channels." Those assurances got weaker as he moved into his first term, but he still made at least rhetorical overtures to legal immigration […]
Meta AI funnels AI videos from creators into new ‘Vibes’ feed
On Thursday, Meta AI launched a new feed of short-form, AI-generated videos called Vibes. The feed is designed to encourage users to remix AI-generated videos that come from “creators and communities,” the company said. Users can post their own AI-generated videos to Vibes or cross-post the videos across Meta’s platforms for friends and followers to […]
This smartwatch lacks notifications but will still distract you with Tetris
After releasing Space Invaders and Atari 2600 versions of its gaming-themed semi-smart wearable, My Play Watch is back with a third version that puts Tetris on your wrist. The Tetris: My Play Watch is now available for preorder through Amazon for $79.99, and is expected to ship sometime in October 2025 with an alternate interchangeable […]
Amazon’s Fire TV Stick 4K Max is already $20 off ahead of Amazon’s fall Prime Day event
Amazon’s fall Prime Day event is now less than two weeks away, but we’re already seeing prices drop on everything from chargers to Apple devices. One notable deal, especially if you need a streaming stick before October 7th, is on Amazon’s Fire TV Stick 4K Max. Normally $59.99, right now you can buy it for […]
TCL’s 8-inch Nxtpaper tablet could lure you away from the color Kindle
TCL has put its Nxtpaper display technology, designed to be easy on the eyes like E Ink’s e-paper screens, in a slew of devices ranging from hefty 14-inch tablets to smartphones for kids. The new Tab 8 is the latest addition to TCL’s Nxtpaper lineup and with an 8.7-inch screen it sits somewhere in-between the company’s […]
Dear LA, you deserve better than the Clippers’ carbon scandal
We watched LA burn this year. If you're not from around here, you might have seen it unfold in the news like so many other infernos. Neighborhoods in ashes. People in shock. I was nearby when it happened in January, visiting home from New York to attend a family member's funeral. As a climate journalist, […]
Suno’s upgraded AI music generator is technically impressive, but still soulless
When it's not trying to fend off lawsuits from major record labels, Suno is still working on refining its AI music creation tool. The latest model, Suno v5, is an obvious technical improvement over its previous version, v4.5+. But it still can't seem to escape the bland emptiness that pervades most AI art. There are […]
I’ve got a bone to pick with ‘getting credit’ from your fitness tracker
This is Optimizer, a weekly newsletter sent every Friday from Verge senior reviewer Victoria Song that dissects and discusses the latest phones, smartwatches, apps, and other gizmos that swear they're going to change your life. Optimizer arrives in our subscribers' inboxes at 10AM ET. Opt in for Optimizer here. I'll be the first person to […]
Raspberry Pi upgraded its keyboard computer with mechanical switches and SSD storage
After upgrading its original compact computer-in-a-keyboard with its more capable Raspberry Pi 5 microcomputer, the company has announced a new premium version of last year’s model. The Raspberry Pi 500 Plus is the first to feature an M.2 2280 SSD socket for storage in addition to an SD card slot that can be used to […]
Tick tock, TikTok
After more than five years of machinations, secret meetings, legislative actions, and confusing messaging, it appears a deal is coming to keep TikTok alive in the US. On Thursday, President Trump signed an executive order that didn't quite make a deal, but at least gave everyone space to make deal. It's a concept of a […]
How to Perform Comprehensive Large-Scale LLM Validation

LangGraph Beginner to Advanced: Part 1: Introduction to LangGraph and some basic concepts

Welcome to this LangGraph Beginner to Advance series. LangGraph has is one of the most popular frameworks for building Agentic AI applications. With Agentic AI, the application has a lot more scope and tasks to accomplish by navigating various flows and autonomously invoking various agents to fulfill a task completely. LangGraph is built within the LangChain system to act as an orchestration framework to build a multi-step flow for each task execution. Unlike a linear chain of events that you build with LangChain, with a multi-step flow, the orchestration can have logical conditions which decide which agent to invoke, it can make decisions, use various tools and maintain the state of the conversation throughout the flow.
If you’ve ever wanted to build AI agents and design graph-based conversational workflows, this course-style blog series is for you.
LangGraph is a powerful Python library designed for building advanced conversational AI workflows. By the end of this series, you will be equipped to create robust, scalable conversational applications that leverage the full potential of Large Language Models (LLMs).
👋 Hey, my name is Talib and I’m an AI Engineer. In this series, we’re going to walk through LangGraph step by step — from fundamentals to coding real AI agents.
Before diving into the complex stuff, let’s get started with some basic concepts:
📌 Prerequisites
Before continuing, you should have:
- Basic knowledge of Python
- Understanding of dictionaries, classes, and functions
- Familiarity with type annotations (optional but helpful)
Why Type Annotations?
When we eventually start coding AI agents and graphs in LangGraph, type annotations will appear everywhere. If you’ve never worked with them before, they might look confusing. That’s why we’ll go through them first.
Dictionaries in Python
movie = {
"name": "Avengers Endgame",
"year": 2019
}
Dictionaries are powerful and flexible. But there’s a problem that they don’t enforce structure. You could mistakenly pass wrong data types, and in large projects, this creates logical errors that are painful to debug.
Type Dictionaries
A type dictionary enforces structure. In Python, you can define this using a class:
from typing import TypedDict
class Movie(TypedDict):
name: str
year: int
movie: Movie = {
"name": "Avengers Endgame",
"year": 2019
}
✅ Benefits:
- Type safety → fewer runtime errors
- Readability → easier debugging
- Scalability → used extensively in LangGraph to define states
Union
The Union type lets you define multiple acceptable data types.
from typing import Union
def square(x: Union[int, float]) -> float:
return x * x
✔️ square(5) → works
✔️ square(1.23) → works
❌ square(“hello”) → fails
LangChain and LangGraph both use Union extensively.
Optional
The Optional type means a value can either be of a type OR None.
from typing import Optional
def nice_message(name: Optional[str]) -> str:
if name:
return f"Hi there {name}"
else:
return "Hey random person"
- ✅ Works with “Bob”
- ✅ Works with None
- ❌ Doesn’t allow integers or booleans
Any
The Any type allows literally anything.
from typing import Any
def print_value(x: Any):
print(x)
print_value("Hello")
print_value(123)
print_value([1, 2, 3])
Lambda Functions
Lambda functions are small, anonymous functions.
Example 1: Squaring a number
square = lambda x: x * x
print(square(10)) # 100
Example 2: Mapping over a list
nums = [1, 2, 3, 4]
squared = list(map(lambda x: x * x, nums))
print(squared) # [1, 4, 9, 16]
💡 Advanced programmers often use lambdas + map() for efficiency instead of writing full loops.
These will keep showing up in LangGraph, so having a good grasp now will save you from confusion later.
Now it’s time to dive deeper into the building blocks of LangGraph:
- States (memory)
- Nodes (tasks)
- Graphs & Edges (workflow connections)
- Start & End points
- Tools & Tool Nodes
- State Graph (blueprint)
- Runnables (building blocks)
- Messages (communication between humans, AI, and tools)
To make this easier to follow, let’s understand with a factory assembly line analogy.
Think of LangGraph as a smart automated factory where:

- The state = the shared whiteboard of the factory (tracking progress)
- The nodes = workstations (each does one specific job)
- The edges = conveyor belts between stations (deciding flow)
- The tools = machines used at workstations
- The tool nodes = operators controlling the machines
- The graph = blueprint of the entire factory
- The runnables = modular Lego-like parts for assembling workflows
- The messages = conversations between workers, machines, and managers
Let’s break this down step by step.
State — The Factory’s Memory
A state is a shared data structure that holds the current information of your application.
Imagine a whiteboard at the entrance of a factory. Every time something is updated — like materials arriving, work being done, or outputs ready — it’s recorded here.
This ensures every worker (node) knows the latest status.
from typing import TypedDict
class FactoryState(TypedDict):
item: str
progress: str
Here, FactoryState defines what information our factory tracks: the item being worked on, and its progress.
Nodes — The Workstations
Nodes are individual functions that perform one specific job.
In a car factory, one station might install the wheels, another paints the body, and another inspects quality. Each station = a node.
def paint_node(state: FactoryState) -> FactoryState:
state["progress"] = f"Painting {state['item']}"
return state
Each node:
- Takes the current state as input
- Does its job (e.g., painting)
- Updates the state
- Returns the updated state
Graph — The Blueprint of the Factory
A graph is the overarching structure — the blueprint of the workflow.
Just like an architect draws a factory floor plan, a graph maps out which workstation (node) connects to which, and in what sequence.
from langgraph.graph import StateGraph
graph = StateGraph(FactoryState)
This creates a workflow blueprint for how tasks will flow through the factory.
Edges — The Conveyor Belts
Edges are the connections between nodes. They define the flow of execution.
Conveyor belts carry car parts from one workstation to another. Without belts, workers would be isolated.
graph.add_edge("painting", "inspection")
This means once painting is done, the item automatically moves to inspection.
Conditional Edges
Some conveyor belts have switches that decide where an item should go. Think of a railway track switch. Depending on the condition, a car may go left (to polishing) or right (to repairs).
if state["progress"] == "damaged":
next_node = "repair"
else:
next_node = "finish"
This is like a traffic light deciding the next move.
Start and End Points
- Start Point = the factory entrance (where raw materials arrive)
- End Point = the exit gate (finished product shipped out)
graph.set_entry_point("painting")
graph.set_finish_point("inspection")
The start point doesn’t do any work itself — it just marks where execution begins.
Tools — The Machines
Tools are specialised utilities that nodes can use. A workstation worker might use a drill, paint gun, or screwdriver to complete their task. These are tools.
For example:
- A fetch_data tool → gets information from an API
- A calculator tool → performs math operations
Tool Nodes — The Operators
A tool node is a node whose only job is to run a tool. The operator at the paint station doesn’t paint by hand — they just control the painting machine.
def api_tool_node(state: FactoryState) -> FactoryState:
data = fetch_from_api()
state["progress"] = f"Fetched data: {data}"
return state
The operator (tool node) runs the machine (tool), then updates the whiteboard (state).
State Graph — The Factory’s Master Blueprint
The state graph manages all:
- Nodes (workstations)
- Edges (conveyor belts)
- State (the whiteboard)
Think of it as the master blueprint of a skyscraper. It doesn’t do the work but defines structure and flow.
graph = StateGraph(FactoryState)
graph.add_node("paint", paint_node)
graph.add_node("inspect", inspection_node)
Runnables — Lego Blocks
Runnables are modular, standardised components. Think of Lego bricks. Each brick is small, but they can be snapped together to build castles, cars, or spaceships. Similarly, runnables let you assemble sophisticated AI workflows.
Messages — The Conversations
Messages are how humans, AI, and tools communicate in LangGraph. In our factory, workers shout instructions, machines beep when done, and managers give guidelines. These are messages.
Types of messages:
- Human Message → input from the user (e.g., “Build a red car”)
- AI Message → response from the AI (e.g., “Okay, painting car red”)
- System Message → manager’s instruction (e.g., “Always ensure safety first”)
- Tool Message → output from a tool (e.g., “Wheels attached”)
- Function Message → result of a function call
Example:
from langchain.schema import HumanMessage, AIMessage, SystemMessage
conversation = [
SystemMessage(content="You are a helpful assistant."),
HumanMessage(content="Build me a chatbot"),
AIMessage(content="Sure, I’ll design the workflow.")
]
Summary of Core Elements
- State → Whiteboard (memory of the app)
- Node → Workstation (specific task)
- Graph → Blueprint (overall structure)
- Edge → Conveyor belt (flow of execution)
- Conditional Edge → Railway switch (if/else flow)
- Start/End → Factory entrance and exit
- Tool → Machine at the workstation
- Tool Node → Operator who runs the machine
- State Graph → Master blueprint of factory workflow
- Runnable → Lego brick (modular execution unit)
- Messages → Communication between human, AI, and tools\
Now that you understand the core elements of LangGraph, you’re ready to move from theory to practice.
With these concepts mastered, you are now ready to build actual AI workflows.
Catch the whole LangGraph Series here: LangGraph Reading List
Thank you for reading!
You might be interested in Reading!
- Where did multi-agent systems come from?
- Summarising Large Documents with GPT-4o
- How does LlamaIndex compare to LangChain in terms of ease of use for beginners
- Pre-training vs. Fine-tuning [With code implementation]
- Costs of Hosting Open Source LLMs vs Closed Sourced (OpenAI)
- Embeddings: The Back Bone of LLMs
- How to Use a Fine-Tuned Language Model for Summarization
LangGraph Beginner to Advanced: Part 1: Introduction to LangGraph and some basic concepts was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Every Disruptive Technology Hides Newly Invented Numbers You Never Imagined

From quantum to AI and beyond, each breakthrough starts with a new breed of numbers nobody ever taught you.
AI Sandbox in 2025: How Enterprises and Governments Shape AI’s Future

AI, every day you will see it and talk about it multiple times. From industrialists to governments and individual life, it has become an important part of life. However, the growth and adoption of the raid bring risks.
Unchecked AI can misuse data, cause errors, and create trust issues. To manage such risks, the AI Sandbox has been developed. From enterprises to MNCs, they use these sandboxes to control and secure the digital environment.
Many countries in Europe and Australia are adopting AI Sandbox technology and regulating it to provide a safe virtual world to their people. By the end of 2025, there will be 66 active sandboxes worldwide for data, AI, and emerging tech. With 31 countries focused solely on AI innovation, and 23 countries planning AI-specific sandboxes to test new technologies.
What is an AI Sandbox?
An AI Sandbox is a controlled space to test AI tools without harming real systems. It isolates experiments, allowing developers and policymakers to explore models safely.
Within this environment, code runs, prompts are tested, and data is analyzed securely. Features include access to multiple large language models, image generation, and file uploads. Users compare outputs, fine-tune prompts, and train models without external risks.
Why AI Needs Sandboxes Now?
AI grows more powerful each year. Data is larger, and risks are harder to predict. Traditional methods cannot handle today’s challenges.
- Zero-day threats: Sandboxes detect risks that filters miss.
- Privacy needs: Sensitive data stays protected during testing.
- Regulatory rules: Sandboxes meet compliance while encouraging innovation.
- Experimentation: Teams explore models without harming production systems.
AI sandboxes give freedom with safety. They allow testing without fear of failures spreading beyond the sandbox.
Why Enterprises & Governments are Turning to AI Sandboxes?
Enterprises adopt AI sandboxes for speed and safety. Teams create prototypes faster, while data remains secure. Sandboxes cut time to market, also.
Governments use AI sandboxes for oversight. Like fintech sandboxes, they test new technology under controlled conditions. Regulators collect evidence before shaping laws. Utah’s AI sandbox in 2025 shows this balance. Other states prepare similar moves.
Both enterprises and governments see sandboxes as bridges. They connect innovation with accountability.
Types of AI Sandboxes
AI sandboxes exist in different forms:
- Prompt Sandboxes: Users test prompts across models like ChatGPT, Claude, or Jurassic. Results are compared side by side.
- AI Cloud Sandboxes: Cloud providers offer isolated AI environments. Credentials allow secure testing with enterprise services.
- SageMaker Studio Notebook: A ready environment for coding, cleaning data, training, and deploying AI. It saves setup effort.
- Google AI Studio: Allows prompt engineering, LLM testing, and quick deployment of models into apps.
- Microsoft Copilot Studio: Enables creation of AI copilots with drag-and-drop workflows, integrating with Microsoft 365.
- Hugging Face Spaces: Hosts community-built AI apps and models in sandbox-style environments for public testing.
- Amazon Bedrock: Provides access to foundation models through APIs in a secure AWS environment, with scalable sandbox support.
Each type serves a unique purpose. Some help developers, some aid researchers, and others assist regulators.
Benefits & Use Cases of AI Sandbox Across Industries
AI sandboxes bring security, flexibility, and collaboration. They reduce risks while promoting creativity. Industries benefit in different ways.
- Experimentation: Teams test new models, prompts, or algorithms safely. Mistakes stay inside the sandbox, protecting live systems from damage.
- Development: Pre-configured tools speed up building and deployment. AI apps reach the market faster without extra setup delays.
- Training: Models train on anonymized or synthetic datasets. This ensures privacy compliance while allowing realistic performance checks.
- Collaboration: Multiple users share one secure sandbox. Teams brainstorm, code, and review together, encouraging creativity and shared learning.
- Security: Isolated testing environments block threats from spreading. Sensitive data and systems stay safe during risky experiments.
Industry-specific Benefits
- Healthcare: AI diagnostic systems train on anonymized medical records. This safeguards patient privacy while allowing accurate model performance testing before clinical use.
- Finance: Fraud detection algorithms process simulated transaction data in sandboxes. Risky flaws are identified early, protecting real markets from financial disruptions.
- Retail: Recommendation engines analyze synthetic shopping data. Models refine personalization strategies without disrupting live customer experiences or sales operations.
- Education: Students and researchers code, train, and test AI in sandboxed labs. They gain practical skills without exposing institutional networks to threats.
- Government Services: Citizen-facing AI chatbots undergo trial runs in secure sandboxes. Policymakers evaluate accuracy, compliance, and data handling before public deployment.
AI sandboxes act as safe laboratories. They blend creativity with responsibility.
Latest Global Adoption of AI Sandbox
Adoption is expanding across regions. Each country adapts sandboxes to its needs.
- Europe
EU member states implement sandboxes under the AI Act. These testbeds monitor compliance, safety, and societal impacts before large-scale adoption. Regulators group participants into cohorts like generative AI or HR technologies. Participants may receive limited regulatory relief while following strict data rules.
- Singapore
The first sandbox in 2023 focused on evaluating generative AI large language models. In 2024, trials supported firms adding AI into marketing and customer engagement. Sandboxes here emphasize technical insights, not regulatory relief. Companies test with approved AI providers under close review.
- United States
Utah launched the Learning Lab in 2025 under the AI Policy Act (S.B. 149). Participants gain regulatory mitigation similar to the EU approach. Texas, Oklahoma, and Connecticut introduced bills for sandboxes offering relief and encouraging innovation. Regulators assess societal benefits and risks before approval.
- United Arab Emirates
The UAE applies AI sandboxes to align innovation with governance. Projects undergo strict oversight while promoting local adoption. Pilots test AI in sectors like public services, industry, and security, balancing rapid growth with responsible regulation.
This wave shows one theme that governments want innovation with guardrails. Enterprises join because it builds trust with regulators and users.
Blockchain + GenAI: The Next Evolution of AI Sandboxes
The next step is merging blockchain with Generative AI.
Blockchain security: Every prompt, model change, or test inside the sandbox is recorded on an immutable ledger. This transparent logging builds accountability and helps auditors track how AI systems evolve.
Generative AI creativity: Within the sandbox, generative models produce text, images, and even videos in a controlled setting. Teams explore advanced creative outputs while keeping experiments safe from misuse.
Combined advantage: The fusion of blockchain’s traceability with GenAI’s creative power delivers both trust and innovation. Enterprises and governments gain reliable audit trails while pushing the boundaries of AI-driven solutions.
Europe’s blockchain sandbox and EIC funding prove this direction. Blockchain plus GenAI can redefine how sandboxes track accountability.
Conclusion
AI sandboxes are no longer imaginary; now you can work on your space with complete security. Governments are adopting new technologies, and industries are innovating with new AI and blockchain. As the technology grows, regulations also increase to keep the user’s information safe from fraud.
Looking beyond 2025, the tech growth is hinting towards Gen AI, blockchain, and many more to make these sandboxes more powerful. Those who are thinking of developing AI sandboxes must reach out to experts for consultation and fix their goals and plans.
AI Sandbox in 2025: How Enterprises and Governments Shape AI’s Future was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
The Railway Paradox: Why Shipping Code Beats Managing Servers

An AI/ML philosopher’s guide to developer-first infrastructure and the small, decisive moves that let creators win.
Activation Steering: The Zero-Training Revolution That’s Making AI Models Actually Listen

Imagine spending 10 months wrestling with an AI model that keeps making stuff up, only to discover a technique that fixes the problem in…
Meet MCP: Why Every AI Tool Just Got Its USB-C Moment
Okay, real talk — how many chargers do you carry in your bag? Two? Three? Basically a mini electronics shop? Now imagine doing that same juggling act every time an AI wants to do something useful for you.
Enter MCP (Model Context Protocol), the USB-C moment for AI.
If you’ve ever rolled your eyes at needing one charger for your phone, another for your camera, and yet another for your laptop (pre-USB-C chaos days), you already get the struggle. Each device had its own connector, just like each tool today has its own API.
Then came USB-C: one charger to rule them all.
That’s exactly what MCP does for AI — one common “language” that lets models like ChatGPT, Claude, or Gemini connect seamlessly with different tools, without needing a fresh integration every single time.
Here’s the Problem
You ask an AI: “Book me a flight to Paris tomorrow and add it to my calendar.”
Before MCP: The AI would need one translator for IndiGo, another for Google Calendar, one for Outlook, and a few ad‑hoc duct tapes in between.
After MCP: The AI just speaks one language. It’s like using a single USB‑C cable instead of a drawer of incompatible chargers.
So What Is MCP?
MCP is a standardized way for AI models (think ChatGPT, Claude, Gemini, etc.) to talk to external tools and services. It doesn’t replace those tools’ APIs, it wraps them in a neat, common format so the model doesn’t have to learn a dozen different dialects.
Bottom line: AI speaks MCP → Tools implement MCP servers → Everyone gets along.
Why Should You Care?
• Less chaos for developers: no more writing bespoke integrations for every new tool.
• Faster UX wins: your assistant can actually do multi‑step tasks across apps without crying for help.
• Model‑agnostic: whether someone uses ChatGPT, Claude, or Gemini, the interaction looks familiar.
In plain English: MCP makes assistants useful, not just chatty.
Let’s See It in Action
Here’s exactly how the magic happens:

You say: “Book me a flight tomorrow at 10 AM on IndiGo and add it to my Google Calendar.”
- The AI figures out: book_flight + add_event.
- It turns those intents into MCP calls, structured data that says which tool, which function, and what parameters.
- IndiGo’s MCP server translates that MCP call into IndiGo’s actual API and books your ticket.
- Google Calendar’s MCP server receives an MCP call to add the event and creates it.
- You get the message: “Flight booked. Event added.” And you can go back to planning croissants.
Can You Build Your Own?
Absolutely! Have a weird internal tool with a messy API? Wrap it in an MCP server that exposes clean functions like create_event, book_flight, or get_balance. Once it speaks MCP, any compatible AI model can use it, no sweat.
It’s basically: hide the messy plumbing, show a pretty, consistent interface.
A Few Important Details
• MCP isn’t a central database of all APIs, each tool still runs its own server.
• Tool names disambiguate (e.g., google-calendar vs microsoft-calendar). If you say “add to my calendar,” the AI may ask which one unless a default is set.
• Security, auth, and rate limits still matter — MCP standardizes structure, not policy.
Final Thought
MCP feels obvious in hindsight, the kind of idea you slap your forehead at and say, “Why didn’t we do this sooner?” If it becomes widely adopted, AI assistants won’t just answer; they’ll actually help you get stuff done across your apps.
The USB-C moment for AI is here, and it’s about time.
Meet MCP: Why Every AI Tool Just Got Its USB-C Moment was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Building an Employee Onboarding Chatbot with RAG, FastAPI, and AI
Learn how to build a smart employee onboarding assistant using Retrieval-Augmented Generation (RAG), FastAPI, and LLMs. Step-by-step guide with code, vector embeddings, and conversation memory to create a context-aware AI chatbot for your company handbook.

Introduction
Every company faces the same challenge. Employees frequently have questions about policies, leave structures, benefits, and workplace rules. Traditionally, employees are expected to read thick handbooks or dig through lengthy documents to find answers, which can be time consuming and frustrating.
We wanted to make this easier. Instead of expecting our team to navigate dozens of pages, we aimed to provide a solution where employees can simply ask, How many annual leave days do I get? and receive a clear, accurate answer in seconds.
To achieve this, we implemented an AI-powered chatbot that can read the company handbook, retain conversational context, and respond in a friendly, helpful manner. This system connects concepts like language models, embeddings, and vector databases to ensure employees get precise information quickly, improving both productivity and satisfaction.
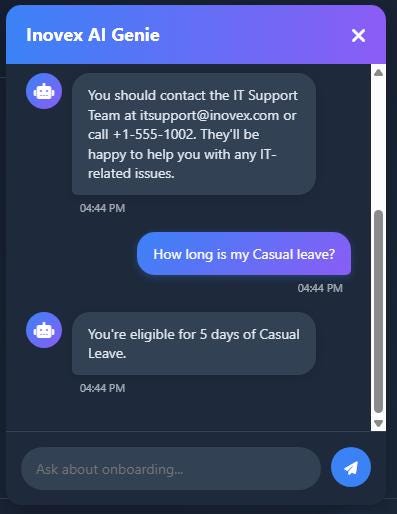
Step 1: Why Large Language Models Alone Are Not Enough
LLMs like ChatGPT are trained on a lot of general text. If you ask them about your company-specific policies, they won’t have the correct answer because that information is private and specific. You could feed the handbook directly into the model, but LLMs have a token limit, meaning they can only process a certain amount of text at once.
So we need a system that can look up the relevant parts of the handbook and feed them to the model. This approach is called Retrieval-Augmented Generation (RAG).
Step 2: What is Retrieval-Augmented Generation (RAG)?
Think of a smart intern who has read hundreds of books but cannot remember everything. You ask them a question, and they first search for the exact paragraph in the relevant book, then summarize it in simple language. That’s RAG.
In our chatbot:
- Retriever searches the handbook for relevant passages.
- Generator (LLM) reads those passages and answers the user in a friendly manner.
This ensures answers are accurate and grounded in your own company material.

Step 3: Preparing the Project
We need a few libraries: FastAPI for the backend, LangChain to connect the LLM and retriever, Groq Llama-3.1 as the language model, and tools for embeddings and vector storage. Install them using:
pip install fastapi uvicorn python-dotenv
pip install langchain langchain-community langchain_groq langchain_huggingface langchain_chroma
pip install pypdf sentence_transformers chromadb
We also create a .env file for storing API keys safely:
GROQ_API_KEY=your_groq_api_key_here
In Python, we load the API key like this:
from dotenv import load_dotenv
import os
load_dotenv()
groq_api_key = os.getenv("GROQ_API_KEY")
Step 4: Reading the Handbook with a Loader
PDFs are structured for humans, not computers. To extract plain text, we use PyPDFLoader from LangChain. This reads each page of the PDF and creates a list of documents.
from langchain.document_loaders import PyPDFLoader
pdf_files = ["employee_handbook.pdf"]
all_docs = []
for file in pdf_files:
loader = PyPDFLoader(file)
docs = loader.load()
all_docs.extend(docs)
At this point, all_docs contains all the text from the handbook, split page by page.
Step 5: Splitting the Text into Chunks
Language models can’t process huge text blocks. Imagine trying to feed a 50-page handbook in one go, it would exceed token limits.
We split text into chunks with slight overlaps so context isn’t lost between chunks:
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(all_docs)
Each chunk is now a manageable piece of text that can be processed by the LLM.
Step 6: Understanding Embeddings
Computers don’t understand words like humans. If you search for “vacation days,” the exact phrase might not appear, but “annual leave” might. To solve this, we convert each chunk into embeddings, numerical vectors that capture meaning.
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
Two similar sentences will now have embeddings close together in vector space, which allows semantic search.
Step 7: Storing Embeddings in a Vector Database
So far, we’ve converted each chunk of text into embeddings, which are numerical representations capturing the meaning of the text. But embeddings by themselves aren’t very useful, you need a way to search them efficiently when a user asks a question.
This is where a vector database comes in. Unlike a traditional database that searches for exact words, a vector database searches for vectors that are close to each other in high-dimensional space. In other words, it finds text chunks that are semantically similar to the user’s query, even if the words don’t exactly match.
For example, if a user asks “How many vacation days do I get?” the database can find a chunk containing “annual leave policy,” because the embeddings for these two sentences are close in meaning.
Here’s how we do it with Chroma:
from langchain_chroma import Chroma
vector_store = Chroma.from_documents(splits, embeddings)
retriever = vector_store.as_retriever()
Now, when a user asks a question, we can quickly find the chunks most relevant to the question.
Step 8: Guiding the Language Model with Prompts
A language model like Llama-3.1 is extremely powerful. It can generate text in almost any style, but by itself, it doesn’t know how it should behave for a specific task. If we just feed it a question, it might give long winded, irrelevant, or even incorrect answers.
This is where prompts come in. A prompt is basically an instruction that tells the model how to respond. In our chatbot, we use a system prompt to set the role of the assistant and define rules for how it should answer.
from langchain_core.prompts import ChatPromptTemplate
system_prompt = """
You are an onboarding assistant - Innovex Genie for new employees at Innovex.
Use the following retrieved context to answer the question.
If you do not know the answer, say you don't know.
Be concise, friendly, and helpful.
Context:
{context}
"""
human_prompt = "{input}"
qa_prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", human_prompt)
])
Let’s see what happens here:
- System prompt — Think of this as giving the AI its job description. It tells the model that it is an onboarding assistant for Innovex, and it should answer using only the provided context. This prevents it from guessing or hallucinating information that isn’t in the handbook.
- Human prompt — This is where the user’s actual question is inserted. For example, if the user asks, “How many annual leave days do I get?” that input goes here.
- ChatPromptTemplate — This combines the system instructions and the user question into a single message that the model can process. It ensures the language model understands the context and the role it should play.
By providing these instructions, the chatbot knows how to behave. It will give answers that are concise, relevant, friendly, and grounded in the handbook, instead of generating generic or incorrect responses.This ensures the bot answers based on retrieved context and doesn’t hallucinate.
Step 9: Creating the RAG Chain
At this stage, we have two main components ready: a retriever that can find the most relevant sections of the handbook, and a language model (LLM) that can generate natural, friendly answers. But to make the chatbot actually work, we need to connect these two components in a pipeline. This is what we call a RAG chain.
Think of it like this: the retriever is a librarian who quickly fetches the relevant pages from a large handbook, and the LLM is an assistant who reads those pages and explains the answer in plain language. By combining them, we create a system that can answer questions accurately without the model having to memorize the entire handbook.
In code, this looks like:
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
from langchain_groq import ChatGroq
llm = ChatGroq(
groq_api_key=groq_api_key,
model_name="llama-3.1-8b-instant",
temperature=0.7
)
qa_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(retriever, qa_chain)
Here’s what happens when a user asks a question:
- The retriever searches the vector database and fetches the most relevant chunks of the handbook.
- These chunks are combined into a single context by create_stuff_documents_chain.
- The language model reads the combined context and generates a precise answer for the user.
By building this RAG chain, we ensure that every answer the chatbot gives is grounded in the actual handbook, making it reliable and helpful for new employees.
Now, the bot can answer queries grounded in the handbook.
Step 10: Adding Conversation Memory
Without memory, each question is treated in isolation. To make conversations flow naturally, we add a history aware retriever. It rewrites follow-up questions into standalone questions using chat history:
from langchain_core.prompts import MessagesPlaceholder
from langchain.chains import create_history_aware_retriever
contextual_q_system_prompt = """
Given a chat history and the latest user question,
formulate a standalone question understandable without history.
Do not answer, just reformulate.
"""
contextual_q_prompt = ChatPromptTemplate.from_messages([
("system", contextual_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}")
])
history_aware_retriever = create_history_aware_retriever(llm, retriever, contextual_q_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, qa_chain)
- MessagesPlaceholder("chat_history") inserts previous messages:
This tells the system to automatically include all previous user and AI messages in the prompt sent to the language model. By having access to past conversation turns, the model can understand references, pronouns, or context that a follow-up question might depend on. - The LLM rewrites queries before retrieval, keeping the retriever stateless:
Instead of giving the retriever raw follow-up questions, the LLM first reformulates them into standalone queries. This means the retriever doesn’t need to “remember” anything — it just searches the vector database with a fully-formed, context-aware query. This separation of responsibilities makes the system more reliable and easier to scale. - Smooth multi-turn conversations:
Because the follow-up question is reformulated with context, the chatbot can handle dialogues naturally. For example, after asking about annual leave, a user can follow up with “And how about sick leave?” The chatbot understands the reference and provides an accurate answer, making the conversation feel coherent and human-like.
Step 11: Serving the Chatbot with FastAPI
Finally, we expose the chatbot as an API using FastAPI:
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from langchain_core.messages import HumanMessage, AIMessage
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["http://localhost:3000"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class ChatRequest(BaseModel):
message: str
chat_histories = {}
@app.post("/chat")
async def chat_endpoint(request: ChatRequest):
try:
if "default" not in chat_histories:
chat_histories["default"] = []
chat_history = chat_histories["default"]
response = rag_chain.invoke({
"input": request.message,
"chat_history": chat_history
})
chat_history.append(HumanMessage(content=request.message))
chat_history.append(AIMessage(content=response['answer']))
return {"response": response['answer']}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
Run the server with:
uvicorn app:app --reload --host 0.0.0.0 --port 8000
You can now test the chatbot by sending a POST request:
curl -X POST http://localhost:8000/chat \
-H "Content-Type: application/json" \
-d '{"message":"What is the leave policy?"}'
Step 12: Conclusion
By combining retrieval, embeddings, and generation, we transformed a static handbook into a conversational AI assistant. The system can answer specific employee questions while remembering context, making onboarding much smoother.
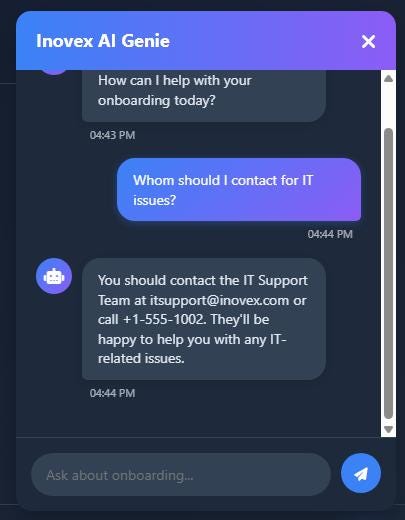
This architecture can also be adapted for customer support, healthcare FAQs, legal documents, or university guides. The key takeaway is that retrieval and generation together make AI practically useful.
Building an Employee Onboarding Chatbot with RAG, FastAPI, and AI was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Master LangChain in 2025: From RAG to Tools (Complete Guide)

Models → Prompt →Output → Chain →Runnable →RAG → Documents Loaders → Text Splitter → Vector Store → Retriver → Creating Tools → Tools Calling → AI Agents
I have provided an example and a link to the code on GitHub.
What is Langchain ?
LangChain is an open-source framework that simplifies the development of applications powered by large language models (LLMS). It provides tools and abstractions for connecting LLMS to external data sources, creating chains of model calls, and building various AI applications like chatbots and virtual agents. LangChain is available in both Python and JavaScript/TypeScript, making it accessible to a wide range of developers.
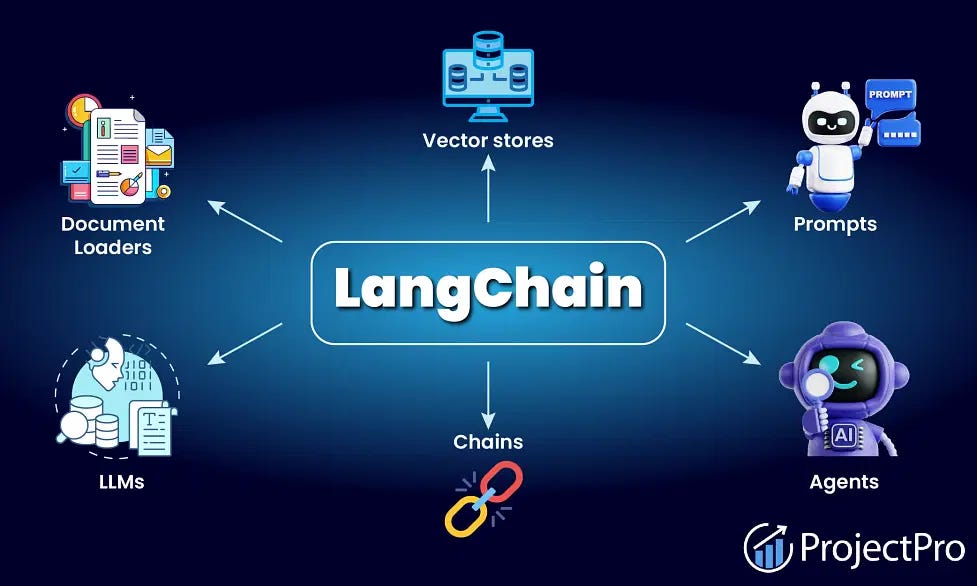
Models :
These models are essentially the “brains” of your application, capable of generating text, completing prompts, or engaging in conversational interactions. LangChain provides a unified interface to interact with various LLMS and chat models from different providers, making building applications that leverage their capabilities easier.
In Langchain, we utilise two types of models: 1) Language Model 2) Embedding Model
- Language Models:
There are two main categories of language models: Large Language Models (LLMS) and Chat Models. Nowadays, many companies prefer using Chat Models over LLMs. It’s essential to understand the distinctions between these two types.
- LLM:
Large Language Models (LLMs) are pure text-generating models. They do not interact like a human. So that's why we use Chat models instead of LLMs.An example is OpenAI’s GPT-3, which takes a string prompt as input and generates a text completion as output.
2. Chat Model:
Chat Models are often based on LLMs but are specifically designed for conversational interactions like humans. They accept a sequence of chat messages as input and return a chat message as output. Examples of Chat Models include GPT-4 and Anthropic’s Claude-2.
3. Embedding Models
Embedding models are algorithms that transform text into numerical representations, or embeddings, which are then used by machine learning algorithms for various natural language processing (NLP) tasks. These embeddings capture the semantic meaning of text, allowing for tasks like similarity search,etc.
from langchain_openai import ChatOpenAI # Chatmodels
from dotenv import load_dotenv
#load api key from .env file
load_dotenv()
# 1. model: The model name to use. For example, "gpt-3.5-turbo" or "gpt-4".
# 2. temperature: Controls the randomness of the output. Lower values make the output more deterministic, while higher values make it more random.
# 3. max_tokens: The maximum number of tokens to generate in the response.
model=ChatOpenAI(model="gpt-4", temperature=0.5, max_tokens=50)
results=model.invoke("What is Capital of the India?")
print(results)
print(results.content)
Prompts:
Prompts are the structured inputs provided to Large Language Models (LLMs) to guide their responses. They are essentially instructions or questions designed to extract a specific output from the model. Prompt engineering focuses on crafting these prompts effectively to ensure the LLM generates accurate, relevant, and helpful responses.
- Basic Prompt
from langchain.prompts import PromptTemplate,load_prompt
input=PromptTemplate(template="My name Is {name} and I am from {country}. I have done my {education} ",
input_variables=['name', 'country','education'],validate_template=True)
input.format(name= 'Debasish Das', education= 'Master', country='India')
# Output
'My name Is Debasish Das and I am from India. I have done my Master '
- JSON Prompt
input=PromptTemplate(template="My name Is {name} and I am from {country}. I have done my {education} ",
input_variables=['name', 'country','education'],validate_template=True)
input.format(name= 'Debasish Das', education= 'Master', country='India')
input.save('temp.json')
- Load Prompt from Jason File
from langchain.prompts import PromptTemplate,load_prompt
input=load_prompt('temp.json')
input.format(name= 'Debasish Das', education= 'Master', country='India')
# Output
'My name Is Debasish Das and I am from India. I have done my Master '
Output:
- Structure Output
In LangChain, structured output refers to the practice of having language models return responses in a well-defined data format (for example, JSON), rather than free-form text. This makes the model output easier to parse and work with programmatically.
Most new language models have the ability to provide structured output. When using certain libraries, they can produce JSON-type or dictionary-type data. This is extremely useful for integrating multiple components into one pipeline.
Here we are converting LLM Response to Pydantic Data Format :
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
from typing import TypedDict, Annotated, Optional, Literal
from pydantic import BaseModel, Field
load_dotenv()
model = ChatOpenAI()
# schema
class Review(BaseModel):
key_themes: list[str] = Field(description="Write down all the key themes discussed in the review in a list")
summary: str = Field(description="A brief summary of the review")
sentiment: Literal["pos", "neg"] = Field(description="Return sentiment of the review either negative, positive or neutral")
pros: Optional[list[str]] = Field(default=None, description="Write down all the pros inside a list")
cons: Optional[list[str]] = Field(default=None, description="Write down all the cons inside a list")
name: Optional[str] = Field(default=None, description="Write the name of the reviewer")
structured_model = model.with_structured_output(Review)
result = structured_model.invoke("""I recently upgraded to the Samsung Galaxy S24 Ultra, and I must say, it’s an absolute powerhouse! The Snapdragon 8 Gen 3 processor makes everything lightning fast—whether I’m gaming, multitasking, or editing photos. The 5000mAh battery easily lasts a full day even with heavy use, and the 45W fast charging is a lifesaver.
The S-Pen integration is a great touch for note-taking and quick sketches, though I don't use it often. What really blew me away is the 200MP camera—the night mode is stunning, capturing crisp, vibrant images even in low light. Zooming up to 100x actually works well for distant objects, but anything beyond 30x loses quality.
However, the weight and size make it a bit uncomfortable for one-handed use. Also, Samsung’s One UI still comes with bloatware—why do I need five different Samsung apps for things Google already provides? The $1,300 price tag is also a hard pill to swallow.
Pros:
Insanely powerful processor (great for gaming and productivity)
Stunning 200MP camera with incredible zoom capabilities
Long battery life with fast charging
S-Pen support is unique and useful
Review by Nitish Singh
""")
print(result)
In the same way, we can convert into JSON and Dict format.
- Output Parser
Output Parsers in Lang Chain help convert raw LLM responses into structured formats like JSON, CSV, Pydantic models, and more. They ensure consistency, validation, and ease of use in applications.
Old LLMs cannot provide output in a structured format; therefore, we use an output parser to convert the LLM response into structured formats like JSON, dictionaries, Pydantic, Stroutput Parser, etc.
Converting LLM Response to Pydantic Format :
from langchain_huggingface import ChatHuggingFace, HuggingFaceEndpoint
from dotenv import load_dotenv
from langchain_core.prompts import PromptTemplate
from langchain_groq import ChatGroq
from langchain_core.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
load_dotenv()
# # Define the model
# llm = HuggingFaceEndpoint(
# repo_id="google/gemma-2-2b-it",
# task="text-generation"
# )
# model = ChatHuggingFace(llm=llm)
model=ChatGroq(model="llama-3.1-8b-instant")
class Person(BaseModel):
name: str = Field(description='Name of the person')
age: int = Field(gt=18, description='Age of the person')
city: str = Field(description='Name of the city the person belongs to')
parser = PydanticOutputParser(pydantic_object=Person)
template = PromptTemplate(
template='Generate the name, age and city of a fictional {place} person \n {format_instruction}',
input_variables=['place'],
partial_variables={'format_instruction':parser.get_format_instructions()}
)
chain = template | model | parser
final_result = chain.invoke({'place':'sri lankan'})
print(final_result)
In the same way, we can convert the response to String, JSON, Dict, CSV, Structure output parser, and Pydantic Output parser format.
Difference between string, JSON, Structure, Pydantic :

Chain:
A chain refers to a sequence of calls or actions executed in a predefined order. These actions can involve interacting with large language models (LLMs), external tools, or data preprocessing steps. Chains are fundamental to LangChain because they allow you to build more complex and powerful applications by combining different components and functionalities.
- Sequential Chain
from langchain_groq import ChatGroq
from dotenv import load_dotenv
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
load_dotenv()
# Define the model
model= ChatGroq(model="llama-3.1-8b-instant")
# Prompt for model
prompt=PromptTemplate(template="Give me 5 line summary of thr {topic}", input_variables=["topic"])
# Output parser
parser=StrOutputParser()
# Chains
chain= prompt | model | parser
resluts=chain.invoke({"topic":"Grobal Warming"})
# Print summary
print(resluts)
# Pipeline Printing
chain.get_graph().print_ascii()
- Parallel Chain
from langchain_groq import ChatGroq
from dotenv import load_dotenv
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain.schema.runnable import RunnableParallel
load_dotenv()
model=ChatGroq(model="llama-3.1-8b-instant")
# Define the prompts
prompt1=PromptTemplate(template="Can U tell me the future of {job_role} in this sector and tell about pro and cons", input_variables=["job_role"]
)
prompt2=PromptTemplate(template="Can U tell me the current Job market trends for {job_role}", input_variables=["job_role"]
)
prompt3=PromptTemplate(template="Analysing the {future} and {market_trend} this job role good for me or not",input_variables=["future","market_trend"])
# Define the output parsers
parser=StrOutputParser()
# Create Parallel pipe line
sequence=RunnableParallel({
"future": prompt1 | model | parser,
"market_trend": prompt2| model | parser}
)
# Define the final prompt
main= prompt3 | model | parser
# Test the pipeline
chain= sequence | main | parser
results=chain.invoke({"job_role": "Data Science"})
print(results)
chain.get_graph().print_ascii()
- Conditional Chain
from langchain_groq import ChatGroq
from dotenv import load_dotenv
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain.schema.runnable import RunnableParallel, RunnableBranch, RunnableLambda
from langchain_core.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from typing import Literal
load_dotenv()
model=ChatGroq(model="llama-3.1-8b-instant")
parser = StrOutputParser()
class Feedback(BaseModel):
sentiment: Literal['positive', 'negative'] = Field(description='Give the sentiment of the feedback')
parser2 = PydanticOutputParser(pydantic_object=Feedback)
prompt1 = PromptTemplate(
template='Classify the sentiment of the following feedback text into postive or negative \n {feedback} \n {format_instruction}',
input_variables=['feedback'],
partial_variables={'format_instruction':parser2.get_format_instructions()}
)
classifier_chain = prompt1 | model | parser2
prompt2 = PromptTemplate(
template='Write an appropriate response to this positive feedback \n {feedback}',
input_variables=['feedback']
)
prompt3 = PromptTemplate(
template='Write an appropriate response to this negative feedback \n {feedback}',
input_variables=['feedback']
)
branch_chain = RunnableBranch(
(lambda x:x.sentiment == 'positive', prompt2 | model | parser),
(lambda x:x.sentiment == 'negative', prompt3 | model | parser),
RunnableLambda(lambda x: "could not find sentiment")
)
chain = classifier_chain | branch_chain
print(chain.invoke({'feedback': 'This is a beautiful phone'}))
chain.get_graph().print_ascii()
Runnables:
The Runnable interface in LangChain is essential for simplifying the creation, execution, and customisation of workflows involving large language models (LLMS). It standardises how chains are defined and executed, offering methods like invoke, batch, and stream to handle inputs and outputs efficiently, whether synchronously or asynchronously. This interface supports advanced features like concurrent processing, intermediate result access, and seamless integration with other LangChain components, such as memory modules and retrieval systems. By enabling flexibility, scalability, and ease of use, the Runnable interface helps developers transition smoothly from prototyping to production while building sophisticated applications with features like streaming outputs, debugging capabilities, and multi-agent orchestration.
- Task Specfic Runnables
These core Lanchain components have been converted into Runnables for pipeline use. It performs task-specific operations like LLM calls, prompting and retrieval.
Example:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
model = ChatOpenAI() # Connect LLM to local system
parser = StrOutputParser() # Formats Prompts Dynamically
- Primitives Runnables
These are foundational building blocks for structuring execution logic in AI Workflows. They help orchestrate execution by defining runnables. People mostly use Primitive Runnables.
Code Examples:
''' Here an end-to-end project implementing a customer service assistant
using LangChain components '''
from langchain_core.runnables import (
RunnableSequence,
RunnableParallel,
RunnablePassthrough,
RunnableLambda,
RunnableBranch
)
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# 1. Define components
llm = ChatOpenAI(model="gpt-3.5-turbo")
output_parser = StrOutputParser()
# Prompt templates
main_prompt = PromptTemplate.from_template(
"As customer service, respond to this query: {query}\n"
"Context:\n- User status: {user_status}\n- Order history: {order_history}"
)
urgent_prompt = PromptTemplate.from_template(
"URGENT QUERY: {query}\n"
"Immediately escalate to L2 support with this summary:"
)
# 2. Custom functions
def check_urgency(query: str) -> bool:
return any(word in query.lower() for word in ["urgent", "emergency", "critical"])
def fetch_user_data(query: str):
# Simulated database lookup
return {"user_status": "VIP", "order_history": "3 orders in past month"}
# 3. Create runnables
route_checker = RunnableLambda(check_urgency)
data_fetcher = RunnableLambda(fetch_user_data)
# 4. Define processing branches
urgent_chain = (
urgent_prompt
| llm
| output_parser
)
normal_chain = (
RunnableParallel(
query=RunnablePassthrough(),
user_status=lambda x: x["user_status"],
order_history=lambda x: x["order_history"]
)
| main_prompt
| llm
| output_parser
)
# 5. Build main sequence
full_chain = RunnableSequence(
RunnablePassthrough.assign(
is_urgent=route_checker
)
| RunnableBranch(
(lambda x: x["is_urgent"], urgent_chain),
normal_chain
)
)
# 6. Add parallel data processing
full_chain = RunnableParallel(
original_input=RunnablePassthrough(),
user_data=data_fetcher
) | {
"query": lambda x: x["original_input"],
"user_status": lambda x: x["user_data"]["user_status"],
"order_history": lambda x: x["user_data"]["order_history"]
} | full_chain
# Example usage
print(full_chain.invoke("My order is missing! This is urgent!"))
# Output: Escalating to L2 support: Customer reports missing urgent order...
print(full_chain.invoke("When will my package arrive?"))
# Output: As a valued VIP customer, your package with 3 recent orders...
RAG:
- Document Loaders
- Text Splitter
- Vector Store
- Retrievers
Documents Loaders :
Document loaders are components in Langchain used to load data from various sources into a standardised format ( usually as Document Objects), which can then be used for chunking, embedding, retrieval and Generation.
- Textloader: It converts a text (.txt) file to a Langchain Document Object.
- PyPDFLoader: It is a Langchain Documents Loader that converts a PDF file to a Langchain Documents Object. One limitation is that it is not useful for a complex layout of a PDF.
- DirectoryLoaders: It loads multiple documents from a Directory (Folder).
- Load vs Lazy Load

- WebBaseLoader: It loads and extracts text content from web pages(URLS).
Text Splitting :
Whenever we work with any LLM or embedding model, they operate within a limited token capacity. The model may produce incorrect results if you provide input exceeding this token limit. This is where text splitters come into play. Text splitters solve this problem by dividing the text into smaller chunks that fit within the model’s token limit. Instead of using the entire text, we use a text splitter to segment it and then feed these chunks to the model. This approach is particularly useful when creating embeddings.
Text splitters are highly effective in NLP-related tasks as they reduce computational costs, improve results, and optimise the parallel processing of text.
Parameters: Chunk_Size , Chunk_Overlap
- Length-Based Text Splitter
==> A length-based text splitter divides text into chunks based on a specified number of characters, words, or other length units. This straightforward approach ensures consistent chunk sizes, making it suitable for various applications.
Key aspects of length-based splitting:
- Chunk Size:
==> The maximum length of each chunk is defined, ensuring that no chunk exceeds this limit.
- Overlap:
==> An optional overlap between chunks can be added to maintain context.
2. Text Structure-Based Text Splitter
==> Text Structure-Based text splitters utilize the natural hierarchy of text (paragraphs, sentences, words) to create chunks that maintain semantic coherence and natural language flow. LangChain’s RecursiveCharacterTextSplitter is a prime example, which recursively attempts to split at the highest level possible (paragraphs, sentences, then words) while keeping chunks within a specified size. This approach aims to preserve the original meaning and context of the text.
3. Document Structure-Based Text Splitter
==> A Document Structure-Based Text Splitter in LangChain is a type of text splitter that breaks down documents into smaller, manageable chunks based on their inherent structure, such as headers, paragraphs, or sections. This approach benefits documents with a natural hierarchy, like HTML, Markdown, or JSON files. Splitting along structural boundaries helps preserve the document's logical organisation and semantic context, making it more effective for downstream tasks like retrieval and summarisation.
4. Semantic Meaning-Based Test Splitter
==> A Semantic Meaning-Based Test Splitter is a tool that divides text into chunks based on semantic similarity, ensuring that each chunk contains sentences with related meanings. This approach is beneficial for tasks where maintaining the context and flow of information is essential, like in natural language processing or document summarization.
# Install required packages
# pip install langchain-text-splitters langchain-community sentence-transformers
from langchain_text_splitters import (
RecursiveCharacterTextSplitter,
MarkdownHeaderTextSplitter,
CharacterTextSplitter
)
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import PyPDFLoader
# Sample text for demonstration
text = """# LangChain Documentation
## Text Splitting
Effective text splitting is crucial for working with large documents.
There are several approaches to split text while preserving meaning.
### Methods
1. Length-based splitting
2. Structure-aware splitting
3. Document-type specific splitting
4. Semantic splitting"""
# 1. Length-based splitter (Recursive Character Text Splitter)
length_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
separators=["\n\n", "\n", " ", ""])
length_chunks = length_splitter.split_text(text)
# 2. Structure-based splitter (Markdown Header Splitter)
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3")
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
structure_chunks = markdown_splitter.split_text(text)
# 3. Document-based splitter (PDF processing example)
document_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50
)
loader = PyPDFLoader("example.pdf") # Replace with actual PDF path
docs = loader.load()
document_chunks = document_splitter.split_documents(docs)
# 4. Semantic splitter (Experimental)
embeddings = HuggingFaceEmbeddings()
semantic_splitter = SemanticChunker(
embeddings,
breakpoint_threshold_type="percentile",
buffer_size=3
)
semantic_chunks = semantic_splitter.split_text(text)
Vector Store
- Why do we need Vector Store instead of a Database?
==> Vector stores are crucial for AI and machine learning because they efficiently handle high-dimensional vector data and enable fast similarity searches, which traditional databases cannot manage effectively due to their limitations with complex, unstructured data. This makes vector stores indispensable for modern applications like semantic analysis and image recognition.
- What is Vector Store?
==>A vector store is a specialized system or library designed to efficiently store, manage, and retrieve vector embeddings, which are numerical data representations. These systems are beneficial for tasks like similarity search, pattern recognition, and machine learning in AI and data analytics.
Key Features and Functionality:
- Vector Embedding Storage:
==> Vector stores are specifically designed to handle vector embeddings, which are numerical representations of data points. These embeddings capture the semantic meaning of data, making them suitable for similarity searches.
- Similarity Search:
==> Vector stores enable efficient searching based on the similarity of data points. By comparing the vector embeddings of a query with those stored in the database, they can retrieve the most relevant results.
- Index and Retrieval:
==> Vector stores employ indexing techniques to optimize search performance. They can quickly locate and retrieve relevant vectors based on similarity criteria.
- High-Dimensional Data Handling:
==> Vector stores are well-suited for managing and querying high-dimensional data, which is common in machine learning and AI applications.
Retrievers
- What are Retrivers?
A Retriever is the component responsible for finding relevant information from a knowledge base or external source based on a user’s query. It acts as a search engine, returning the most relevant documents, passages, or chunks of text to the generator, which then uses this context to create a response.
- Types of Retrievers
==> Data Source, Search Strategy
- Wikipedia Retriever
==> Accessing real-time web content can be a valuable data source.
- Vector store Retriever
==> These store data as vector embeddings, allowing for semantic similarity searches.
- MMR
==> This strategy generates multiple queries from the original query to capture different perspectives and improve retrieval.
- MQR
==> This technique re-ranks results to balance relevance and diversity.
- CCR
==> This method reduces the size of retrieved documents by compressing irrelevant information, saving LLM costs.
Tools
- What are Tools?
==> A “Tool” is essentially a packaged-up Python function that an LLM can understand and request to be executed when needed. This allows the LLM to interact with the outside world, perform actions beyond just generating text.
or
These are Python functions (or similar functions in other languages) that are designed to perform specific tasks.
- How to fit Agents in Ecosystem
==> An AI agent is an LLM-powered system that can autonomously think, make decisions, and take actions to achieve a goal, often by using external tools or APIs. Unlike a chatbot, which simply responds to queries, an AI agent can plan, execute, and learn from its interactions with the environment.

- Built-in Tools
Built-in tools are tools which is provided by Langchain. You need to use it freely. No need for any external installation.
i. DuckDuckGoSearchRun
ii. GmailsendMessageTool
iii.WikipediaQueryRun
For more information on tools, Visit Here.
Now Our Mission is to Create Tools for Agents

- Custom Tools Using Tool Class:
A custom tool is a tool that you define yourself.
Use them when:
- You want to call your own APIs
- You want to encapsulate business logic
- You want the LLM to interact with your database
# Step 1 - create a function
# Step 2 - add type hints
# Step 3 - add tool decorator
from langchain_core.tools import tool
@tool
def multiply(a: int, b:int) -> int:
"""Multiply two numbers"""
return a*b
# Output
result = multiply.invoke({"a":3, "b":5})
print(result)
# Features
print(multiply.name)
print(multiply.description)
print(multiply.args)
- Structure Tools and Pydantic
A Stractured tool in Langchain is a special type of tool where the input to the tool follows a structured schema, typically defined using a Pydantic Model.
from langchain.tools import StructuredTool
from pydantic import BaseModel, Field
class MultiplyInput(BaseModel):
a: int = Field(required=True, description="The first number to add")
b: int = Field(required=True, description="The second number to add")
multiply_tool = StructuredTool.from_function(
func=multiply_func,
name="multiply",
description="Multiply two numbers",
args_schema=MultiplyInput
)
result = multiply_tool.invoke({'a':3, 'b':3})
print(result)
print(multiply_tool.name)
print(multiply_tool.description)
print(multiply_tool.args)
- Base model Class
Base Tool is the abstract base class for all tools in Langchain. It defines the core structure and interface that any tool must follow, whether it's a simple one-liner or fully customized functions.
All other tool types, like the tool and structured tool, are built on top of BaseTool.
from langchain.tools import BaseTool
from typing import Type
class MultiplyInput(BaseModel):
a: int = Field(required=True, description="The first number to add")
b: int = Field(required=True, description="The second number to add")
class MultiplyTool(BaseTool):
name: str = "multiply"
description: str = "Multiply two numbers"
args_schema: Type[BaseModel] = MultiplyInput
def _run(self, a: int, b: int) -> int:
return a * b
multiply_tool = MultiplyTool()
result = multiply_tool.invoke({'a':3, 'b':3})
print(result)
print(multiply_tool.name)
print(multiply_tool.description)
print(multiply_tool.args)
- Toolkit

from langchain_core.tools import tool
# Custom tools
@tool
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers"""
return a * b
class MathToolkit:
def get_tools(self):
return [add, multiply]
toolkit = MathToolkit()
tools = toolkit.get_tools()
for tool in tools:
print(tool.name, "=>", tool.description)
# Output
"""add => Add two numbers
multiply => Multiply two numbers"""
Tools Calling
- Tool Binding

- Tool Calling

- Tool Execution

Small Project [ Currency Conversion ] use tool calling
# tool create for Currency Conversion
from langchain_core.tools import InjectedToolArg
from typing import Annotated
@tool
def get_conversion_factor(base_currency: str, target_currency: str) -> float:
"""
This function fetches the currency conversion factor between a given base currency and a target currency
"""
url = f'https://v6.exchangerate-api.com/v6/API/pair/{base_currency}/{target_currency}'
response = requests.get(url)
return response.json()
@tool
def convert(base_currency_value: int, conversion_rate: Annotated[float, InjectedToolArg]) -> float:
"""
given a currency conversion rate this function calculates the target currency value from a given base currency value
"""
return base_currency_value * conversion_rate
# Model
llm = ChatOpenAI()
# Tools Binding
llm_with_tools = llm.bind_tools([get_conversion_factor, convert])
# Queary message
messages = [HumanMessage('What is the conversion factor between INR and USD, and based on that can you convert 10 inr to usd')]
# Store the Meaasge
ai_message = llm_with_tools.invoke(messages)
messages.append(ai_message)
import json
# Atuomathed workflow for Currency Conversion
for tool_call in ai_message.tool_calls:
# execute the 1st tool and get the value of conversion rate
if tool_call['name'] == 'get_conversion_factor':
tool_message1 = get_conversion_factor.invoke(tool_call)
# fetch this conversion rate
conversion_rate = json.loads(tool_message1.content)['conversion_rate']
# append this tool message to messages list
messages.append(tool_message1)
# execute the 2nd tool using the conversion rate from tool 1
if tool_call['name'] == 'convert':
# fetch the current arg
tool_call['args']['conversion_rate'] = conversion_rate
tool_message2 = convert.invoke(tool_call)
messages.append(tool_message2)
# Output
llm_with_tools.invoke(messages).content
AI Agents
- What is an AI Agent?
An AI agent is a software program or system that uses artificial intelligence to interact with its environment and perform tasks to achieve specific goals. These agents have a degree of autonomy, meaning they can make decisions and act independently to accomplish their objectives. They rely on AI techniques like machine learning and natural language processing to understand and respond to user inputs, and they can learn and adapt over time.
- Characteristics of AI Agents

- What is ReAct?
“ReAct” stands for Reasoning and Acting. It’s a framework that enhances LLM agents by integrating reasoning with the ability to take actions and interact with external environments. Essentially, ReAct allows LLMs to think, then act, and then use the results of their actions to refine their thinking and further act.
- What are agents and Agent Executor?
An agent is a system that uses a language model (LLM) as a reasoning engine to determine which actions to take and what inputs to use for those actions. The agent itself doesn’t execute the actions; instead, it’s the AgentExecutor’s responsibility to manage the execution of those actions.
Agents:
- Reasoning Engine:
Agents use an LLM to decide what actions to take and the necessary inputs for those actions.
- Action Planning:
The agent determines the sequence of actions needed to achieve a goal, but it doesn’t execute them.
- Tool Interaction:
Agents can interact with various tools and environments to gather information, perform tasks, and generate outputs.
AgentExecutor:
- Execution Manager:
The AgentExecutor is responsible for managing the execution of the agent’s actions, controlling its lifecycle, and handling interactions with tools.
- Action Execution:
It executes the actions determined by the agent, potentially using tools to perform tasks.
- Iteration and Observation:
The AgentExecutor can iterate through actions, observe the results, and feed them back to the agent for further decision-making.
- Scratchpad:
It often uses a scratchpad (a list of messages) to keep track of the agent’s thoughts, actions, and observations during the execution.
— — — — — — — — — — — — — The End — — — — — — — — — — — —
I will be adding more content to this blog in the future. For now, this serves as a comprehensive resource for learning Langchain, from basic to advanced levels. I frequently reference Nitish Sir’s videos while creating this blog, as well as the Langchain documentation.
If you enjoy this blog, please follow me on Medium and LinkedIn. Thank you for your time!.
Master LangChain in 2025: From RAG to Tools (Complete Guide) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Machine Learning for Beginners: A Simple Guide
A beginner-friendly introduction to machine learning concepts, workflows, and applications.

1. Introduction to Machine Learning for Beginners
Machine learning (ML) for beginners can be compared to teaching a child how to spot a ripe mango. Instead of memorizing rules like “yellow and soft means ripe,” you show many examples of ripe and unripe mangoes. Over time, the child learns patterns on their own. Machine learning works the same way: instead of hard-coding rules, we give computers data, and they learn to make predictions or decisions by finding patterns.
Machine learning is a core idea in artificial intelligence and powers many tools we use daily. From Netflix recommendations and Amazon product suggestions to fraud detection in banks and diagnostic support in hospitals, ML is now practical technology shaping industries and everyday life. Learning step by step not only helps you understand how these systems work but also prepares you to build your own projects in the future.
Before moving further, here is a quick overview of what this guide covers:
Table of Contents
- 1. Introduction to Machine Learning for Beginners
- 2. Core Concepts in Machine Learning
- 3. Types of Machine Learning
- 4. Machine Learning Workflow (End-to-End Pipeline)
- 5. Tools and Ecosystem
- 6. Applications of Machine Learning
- 7. Challenges in Machine Learning
- 8. Responsible and Ethical AI
- 9. Career and Learning Path
- 10. Resources to Learn More
- 11. Final Thoughts
What is AI, ML, and DL?
Artificial Intelligence (AI):
Artificial Intelligence is the broad field of making machines act in ways that seem intelligent. The goal of AI is to build systems that can solve problems, make decisions, and perform tasks that usually require human thinking. AI covers many areas such as understanding language, recognizing images, reasoning through logic, and even playing games.
New to AI? Start with AI Fundamentals: A Beginner’s Guide to Artificial Intelligence
A good example is ChatGPT, which can generate text, answer questions, or help with writing by understanding patterns in language. Another example is AI in modern video games, where computer opponents adapt their strategy to make gameplay more realistic.
Machine Learning (ML):
Machine Learning (ML) is a branch of AI that enables systems to learn from data instead of following fixed rules. Rather than programming every instruction, we provide examples and let the system discover patterns on its own. As ML models train on more data, they improve in accuracy, making them powerful for tasks where writing clear rules is too complex or impractical.
For example, think about email spam filters. A spam filter is trained on thousands of emails labeled as “spam” or “not spam.” Over time, the system learns which words, phrases, or patterns are likely to appear in spam messages. When a new email arrives, the machine learning model predicts whether it belongs in your inbox or spam folder. The more emails it processes, the better its predictions become.

Deep Learning (DL):
Deep Learning is a specialized part of machine learning that uses structures called neural networks. These networks are made up of many layers, which is why they are called “deep.” Each layer processes information and passes it to the next, allowing the system to recognize highly complex patterns.
Deep learning is especially powerful for tasks involving images, audio, and natural language because it can capture subtle features that simpler algorithms might miss.
A real-world example is how self-driving cars work. Cameras on the car capture images of the road. A deep learning model processes those images to recognize traffic lights, pedestrians, road signs, and other vehicles. The car then decides how to act based on this information. Another example is Google Translate, which uses deep learning to translate entire sentences from one language to another by analyzing massive amounts of multilingual text.
Why Machine Learning Matters Today
Machine Learning is all around us. It powers Netflix and YouTube recommendations, helps banks detect fraud, supports doctors in diagnosing diseases, and makes tools like Google Photos or voice assistants smarter. Because businesses and individuals now generate huge amounts of data, ML has become the key technology for turning that data into useful insights.
Learning ML is also valuable for your career. Companies in technology, healthcare, finance, and many other industries look for people who understand how data-driven systems work. Even if you are not building models yourself, knowing the basics of ML helps you understand the tools shaping decisions in daily life.
Traditional Programming vs. Machine Learning
Traditional programming relies on rules written by humans. You provide the rules and data, and the computer produces an answer. For example, to calculate tax, you feed in the income (data) and the formula (rules), and the program gives the result.
Machine Learning works differently. You give the computer data and the correct answers, and it figures out the rules by itself. The system creates a model that can then predict answers for new, unseen data. A common example is a spam filter, which learns patterns of spam from many examples and then applies those learned rules to incoming emails.
2. Core Concepts in Machine Learning
Features and Labels
In machine learning, data is usually divided into two parts: features and labels. Features are the input variables that describe the problem, such as age, income, or number of website visits. The label is the target outcome that we want to predict, such as whether a customer will buy a product or whether a patient has a certain disease.
For example, if we are building a model to predict house prices, the features could include the size of the house, number of rooms, and location. The label would be the actual selling price. Features provide the clues, and the label gives the answer we want the model to learn.
Structured vs. Unstructured Data
Data comes in two main types: structured and unstructured. Structured data is neatly organized in rows and columns, such as spreadsheets or databases. It is easy to handle and commonly used in business tasks like sales forecasting or customer analysis.
Unstructured data, on the other hand, includes text, images, audio, and video. For example, social media posts, photos, or voice recordings are all unstructured. Machine learning models need more advanced techniques, like natural language processing or image recognition, to make sense of this type of data.
Data Splits: Train, Validation, and Test
To create reliable models, we divide the dataset into three parts. The training set is used to teach the model, the validation set is used to tune settings and improve accuracy, and the test set checks how well the model performs on new, unseen data. This prevents the model from only memorizing patterns.
For example, if you train a spam filter on all your emails and then test it on the same emails, it may look perfect but fail on new ones. By splitting data, you make sure the model is evaluated fairly and can generalize to fresh inputs.
Overfitting vs. Underfitting
Overfitting happens when the model learns too much from the training data, including random noise, and cannot perform well on new data. Underfitting is when the model is too simple and misses important patterns, leading to poor accuracy.
For example, if a student memorizes exact answers to past exam questions, they may fail when new questions appear. That is overfitting. If another student only skims the material and learns too little, that is underfitting. The best student studies in a balanced way and performs well in any situation, just like a good ML model.
Bias-Variance Tradeoff
The bias-variance tradeoff is about balancing simplicity and complexity in models. A high-bias model is too simple, makes strong assumptions, and often misses patterns. A high-variance model is too complex and reacts too much to small changes in the data.
Imagine trying to fit a line to a set of points. A straight line may miss many details (high bias), while a curve that passes through every single point may be too wiggly and fail on new data (high variance). The goal is to find a balance that captures the main pattern without being overly rigid or overly flexible.
Cross Validation
Cross validation is a method to test how reliable a model is. Instead of using just one split of the data, the dataset is divided into several smaller parts. The model is trained and tested multiple times on different combinations of these parts.
For example, if you split your data into five sections, the model trains on four and tests on the fifth. This process repeats until each section has been tested once. If the results are consistent across all tests, you know the model is stable and dependable.
Scaling and Normalization
When features have very different ranges, models may struggle to compare them fairly. For instance, income can be in thousands, while age is usually between 1 and 100. Without adjustments, models might give too much importance to features with larger values.
Scaling and normalization solve this by bringing values into a common range. For example, dividing all features by their maximum value can place them between 0 and 1. This makes sure the model treats each feature equally during training.
Curse of Dimensionality
As the number of features grows, it becomes harder for models to find meaningful patterns. This problem is called the curse of dimensionality. Too many features can confuse the model, make it slower, and reduce its accuracy.
For example, imagine trying to identify customer preferences with thousands of unnecessary details. Instead of helping, the extra information creates noise. To fix this, techniques like feature selection or Principal Component Analysis (PCA) reduce the data into fewer but more meaningful features.
3. Types of Machine Learning
Supervised Learning
Supervised learning means the model learns from labeled data. Every input comes with the correct answer (the label), and the system tries to discover the relationship between inputs and outputs. It is the most common and practical type of machine learning because it provides clear feedback during training.
There are two main approaches here:
1. Regression
Regression is used when the output is a continuous value. Continuous means the answer can take any number within a range, including decimals, and it changes smoothly rather than in fixed jumps. Regression problems are about predicting quantities, like height, weight, temperature, or price.
A good example is predicting house prices. Features like size, number of rooms, and location are inputs, while the selling price is the label.
2. Classification
Classification is used when the output is a discrete value. Discrete means the answer comes from a fixed set of categories, with no values in between. Classification problems are about predicting labels, such as colors, species, or categories.
An easy case is predicting whether an image shows a cat or a dog. The features are the pixel values of the image, and the label is the animal type. The model must choose one category from the set, not something in between.
Unsupervised Learning
Unsupervised learning works with unlabeled data. The system does not know the answers in advance; it tries to find hidden patterns or groupings on its own. This makes it useful for exploring data when labels are not available.
Clustering is one of the main methods. For example, businesses use clustering to group customers into segments based on purchasing behavior. Another method is dimensionality reduction, which simplifies large datasets while keeping the most important patterns.
Reinforcement Learning
In reinforcement learning, an agent learns by interacting with an environment and receiving rewards or penalties for its actions. Over time, it improves by choosing actions that maximize rewards. This approach is inspired by how humans and animals learn from trial and error.
A common example is gaming. Systems like AlphaGo learned to play complex games by playing millions of rounds against themselves. Reinforcement learning is also used in robotics for teaching machines to walk and in self-driving cars for decision-making on the road.
Semi-Supervised and Self-Supervised Learning
Semi-supervised learning uses a mix of labeled and unlabeled data. This is useful when labeling data is expensive or time-consuming. The model learns from a small amount of labeled data and improves further using the larger pool of unlabeled data.
Self-supervised learning has become key for modern AI. In this approach, the system creates labels from the data itself. ChatGPT, for example, is trained with self-supervised methods by predicting missing words in massive amounts of text. This allows it to learn language patterns without needing humans to label every example.
4. Machine Learning Workflow (End-to-End Pipeline)
The machine learning workflow is the step-by-step process of turning raw data into a working model that can be used in the real world. While the exact steps may vary depending on the project, most workflows include collecting data, preparing it, training models, and improving them through testing and iteration. It is not a rigid formula but a general roadmap that ensures models are built systematically and remain useful over time.
1. Collect Data
Every ML project begins with gathering data. This can come from sources like company databases, sensors, surveys, or public datasets. Without enough data, even the best algorithms cannot perform well.
For example, an e-commerce company might collect purchase histories, product details, and customer demographics to build a recommendation system.
2. Clean and Preprocess Data
Raw data is rarely perfect. It may contain missing values, errors, or inconsistencies. Preprocessing ensures that the data is accurate and ready for modeling.
For instance, filling in missing ages, removing duplicate entries, or converting categories like “Male” and “Female” into numbers are common preprocessing tasks.
3. Explore with Visualization
Exploratory Data Analysis (EDA) helps uncover patterns, distributions, and potential issues in the dataset. Visualization tools like histograms or scatter plots are used at this stage.
As an example, plotting customer ages might reveal that most buyers are between 25 and 40, which could influence feature selection or business insights.
4. Feature Engineering
Feature engineering is the process of creating or transforming input variables so they better represent the problem for the model. Good features can often improve performance more than choosing a different algorithm.
For example, instead of using raw date values, you might extract “day of the week” or “month” to capture seasonal trends. Similarly, combining “height” and “weight” into a new feature like “BMI” can give the model a more useful signal.
5. Split Train, Validation, and Test Sets
To check how well a model works, data is divided into three sets. Training data is used to teach the model, validation data tunes the model, and test data evaluates final performance.
For example, a spam filter might be trained on 70 percent of emails, tuned on 15 percent, and tested on the remaining 15 percent to ensure it works on new messages.
6. Train Baseline and Improve
A baseline model is the simplest version of a model. It sets a starting point to compare improvements against. From there, better models and techniques are applied.
For instance, predicting house prices could start with a simple linear regression baseline. Later, more advanced models like decision trees or random forests can be added for higher accuracy.
7. Evaluate with Correct Metrics
Different problems need different evaluation metrics. Accuracy works for balanced datasets, but precision, recall, or F1-score may be better for imbalanced ones like fraud detection.
For example, in medical diagnosis, recall is critical because missing a sick patient (false negative) is more dangerous than mistakenly flagging a healthy one.
8. Hyperparameter Tuning
Hyperparameters are the settings that control how a model learns, and tuning them helps find the best combination for performance. Unlike model parameters (which the model learns), hyperparameters must be set by the developer before training.
For instance, in a Random Forest model, the number of trees and the maximum depth of each tree are hyperparameters. Testing different values, often through methods like grid search or random search, can significantly improve accuracy and reliability.
9. Deploy to Real Users
Once trained and tested, the model is deployed so real users or systems can benefit from it. Deployment often means integrating the model into apps or websites.
For instance, a recommendation model could be deployed on an e-commerce website to suggest products in real time as customers shop.
10. Monitor for Drift
Over time, the world changes, and data patterns shift. This can make models less accurate, a problem called data drift. Monitoring ensures performance stays consistent.
For example, a credit scoring model trained on past customer data may fail if new economic conditions change spending behavior.
11. Iterate Continuously
Machine learning is not a one-time process. With new data and feedback, models are updated and improved in cycles. This keeps them relevant and accurate.
Think of a spam filter: as spammers change tactics, the model needs to retrain with the latest examples to stay effective.
5. Tools and Ecosystem
Machine learning is supported by a wide range of tools, but beginners don’t need to learn them all at once. Here are the essentials:
- Programming Language: Python is the most popular choice for ML, thanks to its simplicity and rich libraries. R is also used for statistics and visualization.
- Data Handling & Visualization: NumPy, Pandas, and Polars (fast alternative) are key for data processing. For visualization, Matplotlib, Seaborn, and Plotly help turn numbers into insights.
- ML & DL Libraries: Use scikit-learn for classical ML. For deep learning, start with TensorFlow/Keras or PyTorch (widely used in research and industry). For structured data, boosting libraries like XGBoost and LightGBM are very effective.
- Practice & Development: Jupyter Notebook and Google Colab make it easy to experiment. Kaggle offers free datasets and coding environments. As you advance, use IDEs like VS Code or PyCharm.
- Collaboration & Deployment: Git/GitHub for version control, MLflow or Weights & Biases for experiment tracking, and tools like Streamlit or FastAPI for turning models into apps. Cloud services (AWS SageMaker, Google Vertex AI, Azure ML) support large-scale projects.
6. Applications of Machine Learning
Recommendations
Recommendation systems are one of the most visible uses of ML. They analyze your past behavior and compare it with millions of other users to suggest content or products you are likely to enjoy.
For example, Netflix suggests movies and series based on your watch history, while Amazon recommends products you may want to buy.
Fraud Detection
Banks and financial institutions use ML to spot unusual activity in real time. Models learn patterns of normal spending and raise alerts when something looks suspicious.
For example, if your credit card is suddenly used in another country or for an unusual purchase, the system may block the transaction or ask for extra verification.
Predictive Sales and Customer Churn
Companies use ML to predict future sales and identify customers who may leave (churn). By analyzing past purchases, browsing history, and engagement, ML helps businesses take action early.
For example, a telecom company might use ML to spot which customers are at risk of canceling their plans and offer them special deals to stay.
Healthcare
ML plays an important role in diagnostics and treatment predictions. Models can analyze medical images, lab results, or patient records to support doctors in decision-making.
For instance, ML systems can detect early signs of diseases like cancer in X-rays or predict how well a patient may respond to a particular treatment.
Natural Language Processing (NLP)
NLP allows machines to understand and generate human language. Chatbots, translation tools, and voice assistants all rely on ML to process text and speech.
For example, ML powers customer service chatbots that answer questions instantly or apps like Google Translate that convert one language into another in seconds.
Computer Vision
Computer vision enables machines to interpret images and videos. It is widely used in security, manufacturing, and consumer devices.
For example, smartphones use face recognition to unlock, and factories use vision systems to detect product defects automatically.
Forecasting
ML is also used in forecasting future trends by analyzing past data. This is useful in finance, supply chains, and weather prediction.
For instance, stock prediction models look for patterns in historical prices, while supermarkets use ML to forecast demand and plan inventory.
7. Challenges in Machine Learning
Data Quality
The success of any machine learning model depends heavily on the quality of data. If the dataset is incomplete, biased, or filled with errors, the model will learn those flaws and perform poorly. In fact, preparing and cleaning data often takes more time than building the model itself.
To deal with this, teams focus on proper data preprocessing, cleaning missing values, and collecting diverse datasets. Using techniques like data augmentation or sourcing data from multiple channels can also reduce bias and improve reliability.
Model Complexity
Another challenge is choosing the right level of complexity. Sometimes simple models, like linear regression, can solve a problem effectively. However, beginners often rush to advanced algorithms without considering if they are needed. More complex models require more data, computing power, and careful tuning.
The best approach is to start with a simple baseline model, measure performance, and only move to more complex methods if needed. This helps save time, resources, and also makes the solution easier to interpret.
Interpretability
Many machine learning models, especially deep learning systems, work like a black box. This makes it difficult to explain why a certain decision was made. In areas such as healthcare or finance, where trust and accountability are critical, lack of interpretability can limit adoption of machine learning solutions.
To address this, techniques like LIME or SH AP values are used to explain model predictions. Choosing simpler, more interpretable models when possible and documenting the decision-making process also improves trust in the system.
8. Responsible and Ethical AI
Bias and Fairness
Machine learning models learn from historical data. If that data contains biases, the model can repeat or even amplify them. This is a serious concern when AI is used in hiring, lending, or law enforcement, because unfair predictions can reinforce existing inequalities.
For example, a hiring model trained mostly on resumes from men may unintentionally favor male candidates over female candidates, even if both have the same skills. Ensuring fairness requires diverse datasets and regular checks for bias.
Transparency and Explainability
Many ML models, especially deep learning systems, work like a black box, making it hard to understand how decisions are made. Transparency is about making models explainable so people can trust and verify the results.
For instance, in healthcare, doctors need to know why an AI system recommended a certain treatment. Techniques like SHAP values or LIME can help explain which features influenced the prediction.
Privacy and Data Governance
Machine learning often uses sensitive personal information such as medical records, financial details, or browsing history. Protecting this data is essential. Privacy can be maintained through anonymization, encryption, and following strict data governance rules.
For example, a hospital using ML for diagnosis must ensure that patient data is securely stored and used only with proper consent.
9. Career and Learning Path
Starting with machine learning does not require advanced math or heavy coding right away. The best entry point is learning Python, along with the basics of NumPy and Pandas for handling data. Once you are comfortable with these, move to scikit-learn to explore classical ML algorithms such as regression and classification. These tools let you experience the complete cycle of training and evaluating models.
The next step is practice. Small projects like predicting house prices, classifying emails, or analyzing datasets from Kaggle help you apply concepts in a practical way. Over time, you can explore deep learning frameworks such as TensorFlow or PyTorch for advanced tasks like image recognition and natural language processing.
To guide your journey, high-quality resources make a big difference. Focus on building projects, reading official documentation, and practicing regularly. With consistency, you’ll gain confidence and move step by step from beginner to advanced levels. For recommended books and courses, see the References section below.
10. Resources to Learn More
If you are serious about learning machine learning, the right resources will speed up your journey. Here are some recommended starting points:
Disclosure: This article Machine Learning for Beginners: A Simple Guide contains affiliate links. If you purchase through them, we may earn a small commission at no extra cost to you. This helps support Noro Insight in creating more free content for readers.
Books
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow [affiliate link] — A practical, beginner-friendly book that walks you through both classical ML and deep learning.
- The Hundred-Page Machine Learning Book [affiliate link] — A concise, high-impact read that covers the core concepts of machine learning in an accessible way.
- Machine Learning for Absolute Beginners [affiliate link] by Oliver Theobald — (very beginner-friendly) Introduces the ideas in plain English, with minimal math or prerequisites.
Courses
- AI For Everyone — A nontechnical course that teaches how AI works, how it affects businesses, and how to think about it — no coding required. Coursera
- Machine Learning A-Z: AI, Python & R — A practical Udemy course that teaches ML with Python and R, including projects and code templates.
- Google’s Machine Learning Crash Course — Hands-on lessons with code examples, exercises, and visualizations to bring theory into practice. (by Google)
- AI For Beginners (Microsoft) — A 12-week curriculum with 24 lessons, labs, and quizzes to introduce core AI & ML concepts. Microsoft GitHub
- Machine Learning Specialization — A beginner-friendly three-course program by Andrew Ng to master foundational ML concepts and practical skills. Coursera
Practice Platforms
- Kaggle — Offers free datasets, tutorials, and competitions to practice ML in real-world scenarios.
- Google Colab — Lets you run notebooks in the cloud without installing anything.
- GitHub — Explore open-source ML projects to see how others structure their work.
With these resources, you can move from beginner to intermediate level while working on projects that showcase your skills. The key is consistency: read, practice, and build small projects regularly.
11. Final Thoughts
Machine learning is no longer just a research topic, it is part of our daily lives. From streaming recommendations to fraud detection, it powers the apps and services we use every day. By learning the basics such as features, labels, workflows, and applications, you build the foundation to explore deeper areas of AI with confidence.
As you continue your journey, remember that machine learning is about solving real problems, not just applying complex algorithms. Start small, focus on data quality, and build projects that truly interest you. With steady practice and the right resources, anyone can develop strong ML skills. Just as important, learning with a responsible mindset ensures the models you create are fair, transparent, and genuinely useful for people.
If this article helped you understand machine learning better, I’d love to hear your thoughts.
• Connect with me on LinkedIn
• Follow Noro Insight for practical insights on data, AI, and analytics
• Share your thoughts or questions in the comments. Let’s start a conversation.
For more content on AI, data science, and problem-solving strategies, visit NoroInsight.com.
Follow me on Medium , Twitter & LinkedIn
Originally published at https://noroinsight.com on September 21, 2025.
Machine Learning for Beginners: A Simple Guide was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Why MissForest Fails in Prediction Tasks: A Key Limitation You Need to Keep in Mind
Why the original MissForest algorithm cannot be directly applied for predictive modeling, and how MissForestPredict solves this problem
The post Why MissForest Fails in Prediction Tasks: A Key Limitation You Need to Keep in Mind appeared first on Towards Data Science.
Using Vision Language Models to Process Millions of Documents
Learn how to effectively apply vision language models to problem solving
The post Using Vision Language Models to Process Millions of Documents appeared first on Towards Data Science.
All creatures, great, small, and artificial
Oleksandra Mukhachova & The Bigger Picture / Snapcat / Licenced by CC-BY 4.0 By Robyn Lowe and Edward Rochead This article had its genesis when co-author Ed’s dog, Sparkle, was treated for pneumonia in the summer of 2024. Ed, a mathematician and chair of the Alliance for Data Science Professionals, was intrigued by the surgery’s […]