BLOG POST
AI 日报
‘Find My Parking Cops’ Tracks Officers Handing Out Tickets All Around San Francisco
"Find My Parking Cops" pins the near-realtime locations of parking officers all over the city, and shows what they're issuing fines for, and how much.
A Vast ‘Cosmic Web’ Connects the Universe—Really. Now, We Can Emulate It.
An emulator called Effort.jl can drastically reduce computational time without sacrificing accuracy, which could help solve longstanding mysteries about the cosmos.
Podcast: We're Suing ICE. Here's Why
Our lawsuit against ICE; the rise of AI 'workslop'; Steam's malicious game problem; and Silk Song.
AI ‘Workslop’ Is Killing Productivity and Making Workers Miserable
AI slop is taking over workplaces. Workers said that they thought of their colleagues who filed low-quality AI work as "less creative, capable, and reliable than they did before receiving the output."
Florida Sues Hentai Site and High-Risk Payment Processor for Not Verifying Ages
Florida's attorney general claims Nutaku, Spicevids, and Segpay are in violation of the state's age verification law.
CBP Flew Drones to Help ICE 50 Times in Last Year
The drone flight log data, which stretches from March 2024 to March 2025, shows CBP flying its drones to support ICE and other agencies. CBP maintains multiple Predator drones and flew them over the recent anti-ICE protests in Los Angeles.
Steam Hosted Malware Game that Stole $32,000 from a Cancer Patient Live on Stream
Scammers stole the crypto from a Latvian streamer battling cancer and the wider security community rallied to make him whole.
Google Launches Model Context Protocol Server
The server simplifies the process of consuming data by eliminating the need for complex APIs.
Elon Musk xAI Launches Grok4 Fast
The new system is billed as a faster and more affordable version of its flagship Grok model.
Wayve's Self-Driving AI Tested in Tokyo
The Wayve-Nissan partnership is targeting a 2027 consumer launch, with Nvidia potentially investing $500 million in the AI start-up's next funding round.
Examining Nvidia and Intel's $5B Partnership
While creating opportunities for both vendors, the deal will likely put pressure on other chipmakers, such as AMD, and could be a motivating factor for the partnership.
How Creatio Is Redefining CRM for Financial Institutions
Two New England banks switched from Salesforce to Creatio, highlighting what executives say is the importance of personalized relationships between vendor and customer.
Can unified multimodal models align understanding and generation, without any captions?
Reconstruction alignment improves unified multimodal models
Generative AI in retail: Adoption comes at high security cost
The retail industry is among the leaders in generative AI adoption, but a new report highlights the security costs that accompany it. According to cybersecurity firm Netskope, the retail sector has all but universally adopted the technology, with 95% of organisations now using generative AI applications. That’s a huge jump from 73% just a year […]
The post Generative AI in retail: Adoption comes at high security cost appeared first on AI News.
OpenAI and Nvidia plan $100B chip deal for AI future
OpenAI and Nvidia have signed a letter of intent for a $100B partnership that could reshape how AI systems are trained and deployed. The plan calls for at least 10 gigawatts of Nvidia hardware to support OpenAI’s next-generation AI infrastructure, which will train and run future models aimed at superintelligence. To support the rollout, Nvidia […]
The post OpenAI and Nvidia plan $100B chip deal for AI future appeared first on AI News.
Governing the age of agentic AI: Balancing autonomy and accountability
Author: Rodrigo Coutinho, Co-Founder and AI Product Manager at OutSystems AI has moved beyond pilot projects and future promises. Today, it’s embedded in industries, with more than three-quarters of organisations (78%) now using AI in at least one business function. The next leap, however, is agentic AI: systems that don’t just provide insights or automate […]
The post Governing the age of agentic AI: Balancing autonomy and accountability appeared first on AI News.
Martin Frederik, Snowflake: Data quality is key to AI-driven growth
As companies race to implement AI, many are finding that project success hinges directly on the quality of their data. This dependency is causing many ambitious initiatives to stall, never making it beyond the experimental proof-of-concept stage. So, what’s the secret to turning these experiments into real revenue generators? AI News caught up with Martin […]
The post Martin Frederik, Snowflake: Data quality is key to AI-driven growth appeared first on AI News.
Agentic Vibe Coding Startup Emergent Secures $23 million in Series A funding

The platform experienced swift adoption, with Emergent exceeding $15 million in annual recurring revenue (ARR) within just 90 days.
The post Agentic Vibe Coding Startup Emergent Secures $23 million in Series A funding appeared first on Analytics India Magazine.
India’s Space Story Needs Its Own Elon Musk

For India to increase its share in the global space economy from 2-10% by 2033, private players need to take on more ambitious projects.
The post India’s Space Story Needs Its Own Elon Musk appeared first on Analytics India Magazine.
This Indian AI Startup is Using Google Veo 3 to Create Microdramas

Dashverse’s Raftaar has already crossed 1 million views on the company’s DashReels app.
The post This Indian AI Startup is Using Google Veo 3 to Create Microdramas appeared first on Analytics India Magazine.
Axtria, Kedaara Capital Announce $240 Mn Investment and Employee Buyback

This transaction provides liquidity to Axtria’s current and former employees, as well as to its early investors.
The post Axtria, Kedaara Capital Announce $240 Mn Investment and Employee Buyback appeared first on Analytics India Magazine.
Mangaluru Gears Up for ₹3,500 Cr Tech Park

At Mangaluru Technovanza 2025, Kharge urged venture capitalists to support Karnataka's goal of becoming a hub for India's entrepreneurs.
The post Mangaluru Gears Up for ₹3,500 Cr Tech Park appeared first on Analytics India Magazine.
AI Pushes Indian Tech SMEs to Rethink Survival Playbook

According to a Nasscom report, SMEs are expected to contribute 6–7% of India’s technology sector revenues in FY25, roughly $280 billion.
The post AI Pushes Indian Tech SMEs to Rethink Survival Playbook appeared first on Analytics India Magazine.
Snowflake, Salesforce, dbt Labs, BlackRock Launch Open Semantic Interchange to Standardise Data for AI

The initiative introduces a vendor-neutral semantic model specification designed to create consistency in how business logic is defined and shared across AI and business intelligence applications.
The post Snowflake, Salesforce, dbt Labs, BlackRock Launch Open Semantic Interchange to Standardise Data for AI appeared first on Analytics India Magazine.
BharatGen’s ‘Recipe’ for Building a Trillion Parameters Indic Model

The consortium insists sovereignty doesn’t mean shutting the door on global players.
The post BharatGen’s ‘Recipe’ for Building a Trillion Parameters Indic Model appeared first on Analytics India Magazine.
Carrier and SatSure Won the Best Firms Awards at Cypher 2025

The Best Firm Certification is not just a recognition of popularity. It is based on employee perspectives and structured evaluation of benefits, identity, purpose, and value.
The post Carrier and SatSure Won the Best Firms Awards at Cypher 2025 appeared first on Analytics India Magazine.
Minsky Awards for Excellence in AI 2025: Meet the Winners

The Minsky Awards for Excellence in AI 2025 recognised the most innovative companies, celebrating their groundbreaking contributions across sectors in artificial intelligence.
The post Minsky Awards for Excellence in AI 2025: Meet the Winners appeared first on Analytics India Magazine.
Indian Vibe Coding Startup Rocket.new Raises $15 Mn from Salesforce Ventures, Accel

Despite being only 16 weeks old, the platform has been used to create over half a million applications.
The post Indian Vibe Coding Startup Rocket.new Raises $15 Mn from Salesforce Ventures, Accel appeared first on Analytics India Magazine.
Storytelling is in the Creator’s Control with GenAI

“Democracy would not have been possible without storytelling being distributed.”
The post Storytelling is in the Creator’s Control with GenAI appeared first on Analytics India Magazine.
Alibaba Launches Qwen3-VL With Open Source Flagship Model

The focus is on moving visual AI from simple recognition towards deeper reasoning and execution.
The post Alibaba Launches Qwen3-VL With Open Source Flagship Model appeared first on Analytics India Magazine.
Cloudflare Open-Sources VibeSDK, Letting Developers Build Vibe Coding Platforms in One Click

The platform integrates LLMs for code generation, debugging, and real-time iteration.
The post Cloudflare Open-Sources VibeSDK, Letting Developers Build Vibe Coding Platforms in One Click appeared first on Analytics India Magazine.
Karnataka IT Minister Steers AI Past Bengaluru Into Panchayats and Tier-2 Cities

“I'd be a little more cautious and ensure that I push AI across different demographies and socio-economic backgrounds.”
The post Karnataka IT Minister Steers AI Past Bengaluru Into Panchayats and Tier-2 Cities appeared first on Analytics India Magazine.
From J.P. Morgan to Netflix to Meta: The H-1B Conversation Continues

The conversation about visas could be, in reality, a deliberation about where the future of technology will be built.
The post From J.P. Morgan to Netflix to Meta: The H-1B Conversation Continues appeared first on Analytics India Magazine.
RVAI Global Acquihires TYNYBAY to Build Agentic AI Services Platform

The deal combines RVAI’s enterprise AI consulting and talent solutions with TYNYBAY’s capabilities in autonomous workforce solutions and process orchestration.
The post RVAI Global Acquihires TYNYBAY to Build Agentic AI Services Platform appeared first on Analytics India Magazine.
India’s Gas-Powered Data Centres at Crossroads: Bridge Fuel or Wrong Turn?

Natural gas may seem a potential fuel for data centres, but higher costs and insufficient infrastructure pose challenges.
The post India’s Gas-Powered Data Centres at Crossroads: Bridge Fuel or Wrong Turn? appeared first on Analytics India Magazine.
OpenAI Envisions ‘Producing a Gigawatt of New AI Infrastructure Weekly’, says Sam Altman

The CEO outlined the company’s goals involving AI and computing power, as OpenAI announced five new data centre sites as part of the Stargate Project.
The post OpenAI Envisions ‘Producing a Gigawatt of New AI Infrastructure Weekly’, says Sam Altman appeared first on Analytics India Magazine.
Karnataka CM seeks Wipro’s support to cut ORR congestion by 30%

“Your support will go a long way in easing bottlenecks, enhancing commuter experience, and contributing to a more efficient and livable Bengaluru,” CM wrote.
The post Karnataka CM seeks Wipro’s support to cut ORR congestion by 30% appeared first on Analytics India Magazine.
TikTok’s US Future Shaped by Trump, Powered by Oracle and Murdoch

“Oracle will operate, retrain and continuously monitor the US algorithm to ensure content is free from improper manipulation or surveillance.”
The post TikTok’s US Future Shaped by Trump, Powered by Oracle and Murdoch appeared first on Analytics India Magazine.
TCS Expands AI Services with NVIDIA Partnership, Deepens Vodafone Idea Ties

The NVIDIA partnership centres on advancing global retail, whereas the collaboration with the telecom company aims to enhance customer experience.
The post TCS Expands AI Services with NVIDIA Partnership, Deepens Vodafone Idea Ties appeared first on Analytics India Magazine.
Amid H-1B Row, Can Remote Work Save Big Tech?

Firms may either go the remote work way or just pay up when they really want an employee in US.
The post Amid H-1B Row, Can Remote Work Save Big Tech? appeared first on Analytics India Magazine.
Satellites That ‘Think’ Could Change How India Responds to Disasters

SkyServe is building onboard processing for satellites, shortening the time between capturing an image and turning it into usable insights.
The post Satellites That ‘Think’ Could Change How India Responds to Disasters appeared first on Analytics India Magazine.
Developer Experience: The Unsung Hero Behind GenAI and Agentic AI Acceleration

DevEx is emerging as the invisible force that accelerates innovation, reduces
friction and translates experimentation into enterprise-grade outcomes.
The post Developer Experience: The Unsung Hero Behind GenAI and Agentic AI Acceleration appeared first on Analytics India Magazine.
Indian IT Majors Cut Visa Petitions by 44% in Four Years

A steep new US visa fee could reshape the global tech talent landscape while also bolstering India’s tech hubs.
The post Indian IT Majors Cut Visa Petitions by 44% in Four Years appeared first on Analytics India Magazine.
Healthtech Startup Zealthix Secures $1.1 Mn in Seed Funding Led by Unicorn India Ventures

The funding will fuel Zealthix’s expansion and technology enhancements aimed at digitising India’s healthcare ecosystem.
The post Healthtech Startup Zealthix Secures $1.1 Mn in Seed Funding Led by Unicorn India Ventures appeared first on Analytics India Magazine.
Cloudflare Pledges 1,111 Internship Spots for 2026

Beginning January 2026, select startups will be able to work from Cloudflare offices on certain days to collaborate with teams and peers.
The post Cloudflare Pledges 1,111 Internship Spots for 2026 appeared first on Analytics India Magazine.
Agnikul Cosmos Opens India’s First Large-Format Rocket 3D Printing Hub

This Chennai startup aims to speed up engine production and strengthen India’s private space ecosystem.
The post Agnikul Cosmos Opens India’s First Large-Format Rocket 3D Printing Hub appeared first on Analytics India Magazine.
OpenTelemetry Is Ageing Like Fine Wine

Enterprises and AI frameworks are embracing OpenTelemetry to standardise data, cut integration costs, and build trust in AI systems.
The post OpenTelemetry Is Ageing Like Fine Wine appeared first on Analytics India Magazine.
Why does OpenAI need six giant data centers?
OpenAI's new $400 billion announcement plan reveals both growing AI demand and circular investments.
Taiwan starts weaponizing chip access after US urged it to, expert says
South Africa has 60 days to meet with Taiwan to avoid export curbs.
The DHS has been quietly harvesting DNA from Americans for years
The DNA of nearly 2,000 US citizens has been entered into an FBI crime database.
Ford F-150 Lightnings are powering the grid in first residential V2G pilot
Sunrun, Ford, and BGE started the vehicle-to-grid test in July.
Supermicro server motherboards can be infected with unremovable malware
Baseboard management controller vulnerabilities make remote attacks possible.
Pennywise gets an origin story in Welcome to Derry trailer
Bill Skarsgård reprises his role as the murderous clown, and there are several Stephen King Easter eggs.
When “no” means “yes”: Why AI chatbots can’t process Persian social etiquette
New study examines how a helpful AI response could become a cultural disaster in Iran.
Disney decides it hasn’t angered people enough, announces Disney+ price hikes
In case you needed another reason to get rid of Disney+.
YouTube will restore channels banned for COVID and election misinformation
Alphabet blames the Biden administration for its moderation decisions.
FCC chairman unconvincingly claims he never threatened ABC station licenses
Brendan Carr would like you to reject the evidence of your eyes and ears.
Review: Apple’s iPhone Air is a bunch of small changes that add up to something big
An interesting iPhone despite throttling, worse battery, and single-lens camera.
Scientists catch a shark threesome on camera
"It was over quickly for both males, one after the other. The first took 63 seconds, the other 47."
Baby Steps is the most gloriously frustrating game I’ve ever struggled through
QWOP meets Death Stranding meets Getting Over It to form wonderfully surreal, unique game.
US uncovers 100,000 SIM cards that could have “shut down” NYC cell network
A "nation-state" is said to be involved.
NASA targeting early February for Artemis II mission to the Moon
"There is a desire for us to be the first to return to the surface of the Moon."
Judge lets construction on an offshore wind farm resume
Judge calls decision to stop construction “the height of arbitrary and capricious.”
Broadcom’s prohibitive VMware prices create a learning “barrier,” IT pro says
Public schools ran to VMware during the pandemic. Now they're running away.
Supreme Court lets Trump fire FTC Democrat despite 90-year-old precedent
Kagan dissent: Majority is giving Trump "full control" of independent agencies.
Google Play is getting a Gemini-powered AI Sidekick to help you in games
Here comes another screen overlay.
EU investigates Apple, Google, and Microsoft over handling of online scams
EU looks at Big Tech groups over handling of fake apps and search results.
Spectacle, weirdness and novelty: what early cinema tells us about the appeal of ‘AI slop’
Just as the gimmicky first films evolved into a sophisticated medium, will we look back on today’s AI-generated video as the beginnings of a new art form?
The US-UK tech prosperity deal carries promise but also peril for the general public
The deliberate alignment of AI systems with the values of corporations and individuals could sour the investment.
Air quality analysis reveals minimal changes after xAI data center opens in pollution-burdened Memphis neighborhood
Analysis of the air quality data available for southwest Memphis finds that pollution has long been quite bad, but the turbines powering an xAI data center have not made it much worse.
What happens when AI comes to the cotton fields
AI can help farmers be more effective and sustainable, but its use varies from state to state. A project in Georgia aims to bring the technology to the state’s cotton farmers.
Adviser to UK minister claimed AI firms would never have to compensate creatives
Exclusive: Kirsty Innes made statement in now-deleted post on X seven months before taking up role as Liz Kendall aide
A senior ministerial aide said AI companies would never have to compensate creatives for using their content to train their systems, in a statement that has alarmed campaigners demanding Labour deliver a fairer deal for musicians, artists and writers from the tech industry.
Kirsty Innes, recently appointed as a special adviser to Liz Kendall, the secretary of state for science, innovation and technology, said “whether or not you philosophically believe the big AI firms should compensate content creators, they in practice will never legally have to”.
AI investors are in for a rude awakening | Roger McNamee
There is a huge gap between investment and revenue from LLMs. Investors wrongly assume everyone will be a winner
By the end of this year, the tech industry will have invested about $717bon over three years into large language model (LLM) AI and the infrastructure needed to support it. While estimates for next year vary, it is possible that industry will invest a comparable amount. This suggests that the industry is receiving more capital than has been invested in the rest of the tech industry since the modern era began in 1956, the year the justice department’s consent decree with AT&T gave birth to Silicon Valley.
In a technology investing career that now spans 43 years, I have never seen a phenomenon remotely like large language model AI. Big Tech, journalists, politicians, CEOs and investors are all convinced that AI is an inevitable Next Big Thing that will change everything in our economy and society for the better.
‘Tentacles squelching wetly’: the human subtitle writers under threat from AI
Artificial intelligence is making steady advances into subtitling but, say its practitioners, it’s a vital service that needs a human to make it work
Is artificial intelligence going to destroy the SDH [subtitles for the deaf and hard of hearing] industry? It’s a valid question because, while SDH is the default subtitle format on most platforms, the humans behind it – as with all creative industries – are being increasingly devalued in the age of AI. “SDH is an art, and people in the industry have no idea. They think it’s just a transcription,” says Max Deryagin, chair of Subtle, a non-profit association of freelance subtitlers and translators.
The thinking is that AI should simplify the process of creating subtitles, but that is way off the mark, says Subtle committee member Meredith Cannella. “There’s an assumption that we now have to do less work because of AI tools. But I’ve been doing this now for about 14-15 years, and there hasn’t been much of a difference in how long it takes me to complete projects over the last five or six years.”
CEO Pumping Out Thousands of AI Slop Podcasts Says Her Critics Are “Luddites”
"We believe that in the near future half the people on the planet will be AI."
The post CEO Pumping Out Thousands of AI Slop Podcasts Says Her Critics Are “Luddites” appeared first on Futurism.
Former Facebook Exec Warns AI Industry Is Entirely Built on “Vibes”
"Things just don't grow that fast."
The post Former Facebook Exec Warns AI Industry Is Entirely Built on “Vibes” appeared first on Futurism.
Stan Lee Resuscitated for AI-Powered Hologram at Comic Con
Is this a form of elder abuse?
The post Stan Lee Resuscitated for AI-Powered Hologram at Comic Con appeared first on Futurism.
Racists Are Using AI to Spread Diabolical Anti-Immigrant Slop
Welcome to the future.
The post Racists Are Using AI to Spread Diabolical Anti-Immigrant Slop appeared first on Futurism.
Users Are Saying ChatGPT Has Been Lobotomized by a Secret New Update
"I just want it to stop lying."
The post Users Are Saying ChatGPT Has Been Lobotomized by a Secret New Update appeared first on Futurism.
A Startup Used AI to Make a Psychedelic Without the Trip
Mindstate Design Labs, backed by Silicon Valley power players, has created what its CEO calls “the least psychedelic psychedelic that’s psychoactive.”
OpenAI Teams Up With Oracle and SoftBank to Build 5 New Stargate Data Centers
The new sites will boost Stargate’s planned capacity to nearly 7 gigawatts—about equal to the output of seven large nuclear reactors.
Why One VC Thinks Quantum Is a Bigger Unlock Than AGI
Venture capitalist Alexa von Tobel is ready to bet on quantum computing—starting with hardware.
AI-powered smart bandage heals wounds 25% faster
A new wearable device, a-Heal, combines AI, imaging, and bioelectronics to speed up wound recovery. It continuously monitors wounds, diagnoses healing stages, and applies personalized treatments like medicine or electric fields. Preclinical tests showed healing about 25% faster than standard care, highlighting potential for chronic wound therapy.
Oracle Corporate Bond Sale Sparks Nearly $88 Billion in Demand
Oracle Corp. is seeking to borrow $15 billion from the US investment-grade bond market on Wednesday, the second-biggest debt sale this year, as the software maker ramps up its spending to meet the needs of the artificial intelligence boom.
Mercedes Replaces Technology Chief, Promotes CEO Ally
Mercedes-Benz Group AG is replacing its chief technology officer Markus Schäfer as the German luxury-car maker prepares for additional cost cuts.
Macquarie CEO Sees Deglobalization Spurring Infrastructure Bets
A rollback of globalization is creating new opportunities for infrastructure investing, according to the head of Macquarie Group Ltd.
Waymo Launches Enterprise Service for Employee and Event Rides
Waymo is launching a new product that lets businesses offer employee or event rides in its robotaxis, a move that could expand its user base while helping maximize usage of its cars on the road.
Drahi Said to Draw Interest in SFR Business in Breakup Push
Patrick Drahi’s Altice France SA has attracted interest from potential buyers for the enterprise unit of French carrier SFR, as the billionaire explores ways to pare the debt load of his telecom empire, people familiar with the matter said.
US Stocks Decline as Fading AI Gains Put Tech Rally in Doubt
US stocks resumed a decline Wednesday as gains driven by renewed pledges of spending in artificial intelligence faded.
SAP Strikes Deals With OpenAI, AWS for ‘Sovereign’ Service
SAP SE announced deals with OpenAI and Amazon Web Services to expand its “digital sovereignty” offerings to European governments.
Univision, Like Other Networks, Is Forced to Adapt to Trump Era
CEO Daniel Alegre steers a more centrist approach at Spanish-language broadcaster
Microsoft Partners With OpenAI Rival Anthropic on AI Copilot
Microsoft Corp. will start using artificial intelligence models from Anthropic to help power its workplace AI assistant, adding a significant partner to a product that has so far been predominantly driven by OpenAI.
Instagram Hits 3 Billion Users With Focus on Video, Messaging
Instagram has reached 3 billion monthly users, cementing the network as one of the most popular consumer apps of all time and leading parent Meta Platforms Inc. to put even more emphasis on the tools that keep driving growth: short-form video and private messaging.
Micron Forecast Fails to Satisfy Investors After AI-Fueled Rally
Micron Technology Inc. shares fell after a generally upbeat forecast from the memory-chip maker failed to impress investors, underscoring Wall Street’s lofty expectations following an extraordinary rally this year.
Tether Turns Stablecoin Dominance Into $500 Billion Valuation Play
Tether Holdings SA has weathered market meltdowns, regulatory troubles and an influx of new challengers. Now the crypto firm is chasing a roughly $500 billion valuation — a towering ambition, even in a private-market era awash with capital.
Why Oracle Has a Starring Role in Proposed TikTok Deal
The US and China are edging toward a deal to resolve the future of TikTok in the US, with Oracle Corp. cast in a starring role.
‘Most Prevalent’ Chinese Hacking Group Targets Tech, Law Firms
Suspected Chinese hackers are behind an ongoing cyber-espionage campaign against US technology companies and legal firms, stealing national security secrets often while remaining undetected, according to Alphabet Inc.’s Google.
Walmart’s India Payments App PhonePe Files for $1.5 Billion IPO
Walmart Inc.-backed PhonePe Ltd., India’s largest digital payments provider, has filed preliminary documents through the confidential route for an initial public offer, which may raise as much as $1.5 billion and value the fintech company at about $15 billion.
‘Frothy and Risky’ Rally in Profitless Tech Grows as Fed Eases
Bets that the Federal Reserve will continue cutting interest rates have fueled a rally in one of the riskiest corners of the technology sector, raising concerns about a potential reversal in the stocks.
UK Arrests Man During European Airports Cyberattack Probe
The UK’s National Crime Agency has arrested a man during its investigation into a cyberattack that disrupted check-ins and delayed flights at several major European airports over the weekend.
Cathie Wood Says Ark Can Cut Back on New Hires Thanks to AI
Developments in artificial intelligence mean fund manager Ark Investment Management LLC can get by with fewer human recruits, the disruptive technology investor’s founder Cathie Wood said.
Xi Urges Stability, Governance Focus to Spur Growth in Xinjiang
Chinese President Xi Jinping called on Xinjiang’s local government to make every effort to maintain social stability and strengthen governance, aiming to advance the autonomous region’s development.
Trustee of Bankrupt Northvolt Unit Says Board Liability Unlikely
The trustee for a unit of failed Swedish battery maker Northvolt AB said there is little basis to hold board directors personally liable, even as supplier claims of about 6.8 billion kronor ($720 million) remain unpaid.
Nvidia-Backed Cohere Valued at $7 Billion as New Capital Flows In
New investments in Canadian tech unicorn Cohere Inc. have brought its valuation to about $7 billion as businesses race to adopt artificial intelligence tools.
Alibaba Shares Soar After Hiking AI Budget Past $50 Billion
Alibaba Group Holding Ltd.’s shares surged to their highest in nearly four years after revealing plans to ramp up AI spending past an original $50 billion-plus target, joining tech leaders pledging ever-greater sums toward a global race for technological breakthroughs.
Oracle’s AI-Fueled Cash Crunch Sets Stage for Major Job Cuts
Welcome to Tech In Depth, our daily newsletter about the business of tech from Bloomberg’s journalists around the world. Today, Brody Ford looks at one of the downsides of Oracle’s leap into prominence as a provider of cloud computing for artificial intelligence work.
Review: Recent Apple Watch Buyers Won't Be Jealous of This Year's Models
The company’s latest smartwatches are geared toward new buyers and people with aging devices.
Pinewood.AI CEO Sees Opportunity in Trump’s Trade Wars
Pinewood Technologies Group Plc Chief Executive Officer Bill Berman said he sees an opportunity in US President Donald Trump’s tariffs and trade wars as the software company expands in the US.
Taiwan Weaponizes Chip Sector to Deter China on World Stage
For years, Taiwan has viewed its dominance in supplying countries with cutting-edge chips as a shield from Chinese aggression. Now, officials are testing out semiconductors as a diplomatic sword.
Breaking Down the Proposed US-China TikTok Deal
On today’s Big Take Asia podcast, we break down what the TikTok deal means for US-China relations and who gained the upper hand at the negotiating table.
Germany Courts Indian Talent After Trump Targets H-1B Visas
Germany is seeking to attract skilled Indian workers, its envoy said, as US President Donald Trump’s H-1B visa crackdown rattles India’s software industry and raises tensions with Washington.
Optus Outage Cut Off 480 Emergency Callers, Review Underway
Australian phone company Optus said last week’s network outage left some 480 customers unable to reach emergency services, as the Singapore Telecommunications Ltd.-owned business started an independent review into the fatal failure.
Alibaba Integrates Nvidia Robotics Software in Its AI Platform
Alibaba Group Holdings Ltd. is integrating Nvidia Corp.’s suite of artificial intelligence development tools for so-called physical AI into its cloud software platform.
I traveled 17 hours to Indonesia, but was immediately sent home because I'd made a simple mistake with my passport
I traveled 17 hours to Indonesia, but had to fly back home because my passport didn't have enough blank pages. I'll never make the same mistake again.
I'm a pediatrician and mom of 2. If your child has an activity every night after school, they're overbooked.
Dyan Hes is a pediatrician and mom of two. She says that over-scheduling kids and lead to stress. She recommends kid have at least one free night.
Sean Combs launched a jailhouse 'Free Game with Diddy' course to teach fellow inmates business skills: lawyers
Sean "Diddy" Combs' 6-week course was designed to teach "essential" business and entrepreneurship skills to fellow inmates, his lawyers said.
I visited Bentonville, Arkansas, where Walmart's new headquarters is expanding. The city was a tourist's dream.
I recently visited Bentonville, the home of Walmart, in northwest Arkansas. The city is modern and features many hiking and biking trails.
Costco is getting a traffic boost from opening early for executive members
Costco's decision to open stores early for executive members wasn't guaranteed to be a success, but so far it looks like a big win for the company.
Where does Trump vs. Kimmel go next?
Jimmy Kimmel is back on the air. Trump is threatening to sue. Don't tune out just yet. This story demands your attention.
Podcaster Theo Von tells DHS to take down a video celebrating deportations that features a clip of him
Von responded to the video, saying that his views on immigration are "more nuanced than this video allows."
Jimmy Kimmel's return represents a big, final test for Disney's Bob Iger before he heads for the exits
Disney CEO Bob Iger is set to step down at the end of next year, but the Jimmy Kimmel drama has created one final challenge for me.
Klarna chairman sent a stark post-IPO message to CEO: 'We're 10 years behind Revolut'
Klarna CEO Sebastian Siemiatkowski kicked off its internal conference for employees last week with a rap performance.
I left the US to live in Japan. While I loved my life there, I moved away after 5 years.
Ryan Cole left his ski bum life in Colorado for Japan in 2001. He loved life in Japan but couldn't live there forever and left five years later.
Cloudflare goes after Google's AI Overviews with a new license for 20% of the web
Cloudflare is enhancing robots.txt, giving website owners more control over how AI systems access their data.
China's booming EV industry flexed its muscles once again by breaking the record for the world's fastest car
BYD's Yangwang U9 "Xtreme" supercar recorded a blistering top speed of 496.22km/h (308 miles per hour) at a test track in Germany earlier this month.
I toured the only nuclear-missile submarine in the US open to the public. Take a look inside.
Armed with nuclear missiles, the USS Growler acted as a deterrent to keep other nations from using their nuclear weapons during the Cold War.
I email my 106-year-old grandmother every Friday. It's one of the most meaningful commitments I've ever made.
Two years ago, I started the tradition of emailing my grandma every week. Our messages help us stay connected despite the distance between us.
2 women who turned side hustles into businesses share 5 ways to overcome common mistakes
Tori Dunlap, host of the Financial Feminist podcast, said one of the best things she did for her startup was rebranding to fit her customer base.
I spent a night in Vancouver's 'castle in the city.' My $320 room was average, but the hotel was worth it.
The Fairmont Hotel Vancouver in British Columbia, Canada, looks like a castle. It has a history of war, royalty, and entertainment.
I bought a BYD Dolphin Surf and took it on a European road trip. I was surprised by how relaxing driving 1,000 miles in an EV was.
Rafael Verástegui and his wife took their new BYD on a 1,000 mile European roadtrip from Spain to Germany.
Barry Diller likes to give younger workers 'more responsibility than they qualify for' to see who succeeds
Billionaire IAC and Expedia Group chairman Barry Diller said he liked bringing in people "without any experience."
The US Army's recent drone wins hint at how far behind it is
Recent Army firsts like dropping a grenade from a drone have offered insight into the skill gaps facing the service as it ready for drone warfare.
This isn't your basic tiny home. It looks like a spaceship and comes with a sauna. See inside.
The Pebl Grand, designed by Hungary-based architecture studio Hello Wood, marries natural textures with a distinctly otherworldly feel.
A Former Apple Luminary Sets Out to Create the Ultimate GPU Software
Demand for AI chips is booming—and so is the need for software to run them. Chris Lattner’s startup Modular just raised $250 million to build the best developer tools for AI hardware.
OpenAI Teams Up With Oracle and SoftBank to Build 5 New Stargate Data Centers
The new sites will boost Stargate’s planned capacity to nearly 7 gigawatts—about equal to the output of seven large nuclear reactors.
Why One VC Thinks Quantum Is a Bigger Unlock Than AGI
Venture capitalist Alexa von Tobel is ready to bet on quantum computing—starting with hardware.
How Signal’s Meredith Whittaker Remembers SignalGate: ‘No Fucking Way’
The Signal Foundation president recalls where she was when she heard Trump cabinet officials had added a journalist to a highly sensitive group chat.
How Smaller Funds Can Access Top Deals In A Competitive Market
In today’s hyper-competitive VC landscape, small funds can still win — but only by changing their approach, writes Flint Capital GP Andrew Gershfeld, who points out that the real differentiators are trust, early involvement and strategic relationships.
AI Is Gorging On Venture Capital. This Is Why ‘Physical AI’ Is Next
In this guest commentary, Alberto Onetti, chairman of Mind the Bridge, shares the findings of the firm's Scaleup Summit San Francisco 2025 and discusses the AI sectors grabbing the majority of funding dollars, and shares what he sees coming in the next artificial intelligence wave.
Legal Tech Investment Hits All-Time High With Filevine Funding
Per Crunchbase data, companies in the legal and legal technology sectors have raised just over $2.4 billion so far in 2025 in seed through growth-stage funding. With over three months left in the year, it’s already the highest annual total on record.
Why OpenAI May Never Generate ROI
Unless infrastructure costs or compute requirements somehow plummet, writes guest author Eugene Malobrodsky, managing partner at One Way Ventures, the billions of realized profits are going into the pockets of the providers of GPUs, energy and other resources, not the foundation model providers.
What We’ve Learned Investing In Challenger Banks Across The Globe
Guest author Arjuna Costa of Flourish Ventures shares what he learned on his journey toward reshaping financial systems by scaling neobanks globally, and why Chime's successful Nasdaq debut proves that building consumer-first financial institutions is not only viable but necessary.
Dynamic Prompt Fusion for Multi-Task and Cross-Domain Adaptation in LLMs
arXiv:2509.18113v1 Announce Type: new Abstract: This study addresses the generalization limitations commonly observed in large language models under multi-task and cross-domain settings. Unlike prior methods such as SPoT, which depends on fixed prompt templates, our study introduces a unified multi-task learning framework with dynamic prompt scheduling mechanism. By introducing a prompt pool and a task-aware scheduling strategy, the method dynamically combines and aligns prompts for different tasks. This enhances the model's ability to capture semantic differences across tasks. During prompt fusion, the model uses task embeddings and a gating mechanism to finely control the prompt signals. This ensures alignment between prompt content and task-specific demands. At the same time, it builds flexible sharing pathways across tasks. In addition, the proposed optimization objective centers on joint multi-task learning. It incorporates an automatic learning strategy for scheduling weights, which effectively mitigates task interference and negative transfer. To evaluate the effectiveness of the method, a series of sensitivity experiments were conducted. These experiments examined the impact of prompt temperature parameters and task number variation. The results confirm the advantages of the proposed mechanism in maintaining model stability and enhancing transferability. Experimental findings show that the prompt scheduling method significantly improves performance on a range of language understanding and knowledge reasoning tasks. These results fully demonstrate its applicability and effectiveness in unified multi-task modeling and cross-domain adaptation.
GAUSS: Benchmarking Structured Mathematical Skills for Large Language Models
arXiv:2509.18122v1 Announce Type: new Abstract: We introduce \textbf{GAUSS} (\textbf{G}eneral \textbf{A}ssessment of \textbf{U}nderlying \textbf{S}tructured \textbf{S}kills in Mathematics), a benchmark that evaluates LLMs' mathematical abilities across twelve core skill dimensions, grouped into three domains: knowledge and understanding, problem solving and communication, and meta-skills and creativity. By categorizing problems according to cognitive skills and designing tasks that isolate specific abilities, GAUSS constructs comprehensive, fine-grained, and interpretable profiles of models' mathematical abilities. These profiles faithfully represent their underlying mathematical intelligence. To exemplify how to use the \textsc{GAUSS} benchmark, we have derived the skill profile of \textsc{GPT-5-thinking}, revealing its strengths and weaknesses as well as its differences relative to \textsc{o4-mini-high}, thereby underscoring the value of multidimensional, skill-based evaluation.
Event Causality Identification with Synthetic Control
arXiv:2509.18156v1 Announce Type: new Abstract: Event causality identification (ECI), a process that extracts causal relations between events from text, is crucial for distinguishing causation from correlation. Traditional approaches to ECI have primarily utilized linguistic patterns and multi-hop relational inference, risking false causality identification due to informal usage of causality and specious graphical inference. In this paper, we adopt the Rubin Causal Model to identify event causality: given two temporally ordered events, we see the first event as the treatment and the second one as the observed outcome. Determining their causality involves manipulating the treatment and estimating the resultant change in the likelihood of the outcome. Given that it is only possible to implement manipulation conceptually in the text domain, as a work-around, we try to find a twin for the protagonist from existing corpora. This twin should have identical life experiences with the protagonist before the treatment but undergoes an intervention of treatment. However, the practical difficulty of locating such a match limits its feasibility. Addressing this issue, we use the synthetic control method to generate such a twin' from relevant historical data, leveraging text embedding synthesis and inversion techniques. This approach allows us to identify causal relations more robustly than previous methods, including GPT-4, which is demonstrated on a causality benchmark, COPES-hard.
ZERA: Zero-init Instruction Evolving Refinement Agent - From Zero Instructions to Structured Prompts via Principle-based Optimization
arXiv:2509.18158v1 Announce Type: new Abstract: Automatic Prompt Optimization (APO) improves large language model (LLM) performance by refining prompts for specific tasks. However, prior APO methods typically focus only on user prompts, rely on unstructured feedback, and require large sample sizes and long iteration cycles-making them costly and brittle. We propose ZERA (Zero-init Instruction Evolving Refinement Agent), a novel framework that jointly optimizes both system and user prompts through principled, low-overhead refinement. ZERA scores prompts using eight generalizable criteria with automatically inferred weights, and revises prompts based on these structured critiques. This enables fast convergence to high-quality prompts using minimal examples and short iteration cycles. We evaluate ZERA across five LLMs and nine diverse datasets spanning reasoning, summarization, and code generation tasks. Experimental results demonstrate consistent improvements over strong baselines. Further ablation studies highlight the contribution of each component to more effective prompt construction. Our implementation including all prompts is publicly available at https://github.com/younatics/zera-agent.
Thinking in a Crowd: How Auxiliary Information Shapes LLM Reasoning
arXiv:2509.18163v1 Announce Type: new Abstract: The capacity of Large Language Models (LLMs) to reason is fundamental to their application in complex, knowledge-intensive domains. In real-world scenarios, LLMs are often augmented with external information that can be helpful, irrelevant, or even misleading. This paper investigates the causal impact of such auxiliary information on the reasoning process of LLMs with explicit step-by-step thinking capabilities. We introduce SciAux, a new dataset derived from ScienceQA, to systematically test the robustness of the model against these types of information. Our findings reveal a critical vulnerability: the model's deliberative "thinking mode" is a double-edged sword. While helpful context improves accuracy, misleading information causes a catastrophic drop in performance, which is amplified by the thinking process. Instead of conferring robustness, thinking reinforces the degree of error when provided with misinformation. This highlights that the challenge is not merely to make models "think", but to endow them with the critical faculty to evaluate the information upon which their reasoning is based. The SciAux dataset is available at https://huggingface.co/datasets/billhdzhao/SciAux.
SIRAG: Towards Stable and Interpretable RAG with A Process-Supervised Multi-Agent Framework
arXiv:2509.18167v1 Announce Type: new Abstract: Retrieval-Augmented Generation (RAG) enables large language models (LLMs) to access external knowledge sources, but the effectiveness of RAG relies on the coordination between the retriever and the generator. Since these components are developed independently, their interaction is often suboptimal: the retriever may return irrelevant or redundant documents, while the generator may fail to fully leverage retrieved evidence. In this work, we propose a process-supervised multi-agent framework to bridge the gap between retriever and generator. The framework introduces two lightweight agents: a Decision Maker, which determines when to continue retrieval or stop for answer generation, and a Knowledge Selector, which filters retrieved documents to retain only the most useful evidence. To provide fine-grained supervision, we employ an LLM-as-a-Judge that evaluates each intermediate action with process-level rewards, ensuring more accurate credit assignment than relying solely on final answer correctness. We further adopt a tree-structured rollout strategy to explore diverse reasoning paths, and train both agents with Proximal Policy Optimization (PPO) in an end-to-end manner. Experiments on single-hop and multi-hop question answering benchmarks show that our approach achieves higher accuracy, more stable convergence, and produces more interpretable reasoning trajectories compared with standard RAG baselines. Importantly, the proposed framework is modular and plug-and-play, requiring no modification to the retriever or generator, making it practical for real-world RAG applications.
ERFC: Happy Customers with Emotion Recognition and Forecasting in Conversation in Call Centers
arXiv:2509.18175v1 Announce Type: new Abstract: Emotion Recognition in Conversation has been seen to be widely applicable in call center analytics, opinion mining, finance, retail, healthcare, and other industries. In a call center scenario, the role of the call center agent is not just confined to receiving calls but to also provide good customer experience by pacifying the frustration or anger of the customers. This can be achieved by maintaining neutral and positive emotion from the agent. As in any conversation, the emotion of one speaker is usually dependent on the emotion of other speaker. Hence the positive emotion of an agent, accompanied with the right resolution will help in enhancing customer experience. This can change an unhappy customer to a happy one. Imparting the right resolution at right time becomes easier if the agent has the insight of the emotion of future utterances. To predict the emotions of the future utterances we propose a novel architecture, Emotion Recognition and Forecasting in Conversation. Our proposed ERFC architecture considers multi modalities, different attributes of emotion, context and the interdependencies of the utterances of the speakers in the conversation. Our intensive experiments on the IEMOCAP dataset have shown the feasibility of the proposed ERFC. This approach can provide a tremendous business value for the applications like call center, where the happiness of customer is utmost important.
Evaluating Large Language Models for Detecting Antisemitism
arXiv:2509.18293v1 Announce Type: new Abstract: Detecting hateful content is a challenging and important problem. Automated tools, like machine-learning models, can help, but they require continuous training to adapt to the ever-changing landscape of social media. In this work, we evaluate eight open-source LLMs' capability to detect antisemitic content, specifically leveraging in-context definition as a policy guideline. We explore various prompting techniques and design a new CoT-like prompt, Guided-CoT. Guided-CoT handles the in-context policy well, increasing performance across all evaluated models, regardless of decoding configuration, model sizes, or reasoning capability. Notably, Llama 3.1 70B outperforms fine-tuned GPT-3.5. Additionally, we examine LLM errors and introduce metrics to quantify semantic divergence in model-generated rationales, revealing notable differences and paradoxical behaviors among LLMs. Our experiments highlight the differences observed across LLMs' utility, explainability, and reliability.
Exploiting Tree Structure for Credit Assignment in RL Training of LLMs
arXiv:2509.18314v1 Announce Type: new Abstract: Reinforcement learning improves LLM reasoning, yet sparse delayed reward over long sequences makes token-level credit assignment the key bottleneck. We study the verifiable-reward setting, where the final answer is checkable and multiple responses can be drawn per prompt. Reasoning tasks in math and medical QA align with this setup, where only a few decision tokens significantly impact the outcome. PPO offers token-level advantages with a learned value model, but it is complex to train both the actor and critic models simultaneously, and it is not easily generalizable, as the token-level values from the critic model can make training prone to overfitting. GRPO is critic-free and supports verifiable rewards, but spreads a single sequence-level return across tokens and ignores branching. We introduce \textbf{Prefix-to-Tree (P2T)}, a simple procedure that converts a group of responses into a prefix tree and computes \emph{nonparametric} prefix values (V(s)) by aggregating descendant outcomes. Built on P2T, we propose \textbf{TEMPO} (\emph{\textbf{T}ree-\textbf{E}stimated \textbf{M}ean Prefix Value for \textbf{P}olicy \textbf{O}ptimization}), a critic-free algorithm that augments the group-relative outcome signal of GRPO with \emph{branch-gated} temporal-difference corrections derived from the tree. At non-branch tokens, the temporal-difference (TD) term is zero, so TEMPO reduces to GRPO; at branching tokens, it supplies precise token-level credit without a learned value network or extra judges/teachers. On Qwen3-1.7B/4B, TEMPO outperforms PPO and GRPO on in-distribution (MATH, MedQA) and out-of-distribution (GSM-HARD, AMC23, MedMCQA, MMLU-Medical) benchmarks, and reaches higher validation accuracy with roughly the same wall-clock time.
Brittleness and Promise: Knowledge Graph Based Reward Modeling for Diagnostic Reasoning
arXiv:2509.18316v1 Announce Type: new Abstract: Large language models (LLMs) show promise for diagnostic reasoning but often lack reliable, knowledge grounded inference. Knowledge graphs (KGs), such as the Unified Medical Language System (UMLS), offer structured biomedical knowledge that can support trustworthy reasoning. Prior approaches typically integrate KGs via retrieval augmented generation or fine tuning, inserting KG content into prompts rather than enabling structured reasoning. We explore an alternative paradigm: treating the LLM as a reward model of KG reasoning paths, where the model learns to judge whether a candidate path leads to correct diagnosis for a given patient input. This approach is inspired by recent work that leverages reward training to enhance model reasoning abilities, and grounded in computational theory, which suggests that verifying a solution is often easier than generating one from scratch. It also parallels physicians' diagnostic assessment, where they judge which sequences of findings and intermediate conditions most plausibly support a diagnosis. We first systematically evaluate five task formulation for knowledge path judging and eight training paradigm. Second, we test whether the path judging abilities generalize to downstream diagnostic tasks, including diagnosis summarization and medical question answering. Experiments with three open source instruct-tuned LLMs reveal both promise and brittleness: while specific reward optimization and distillation lead to strong path-judging performance, the transferability to downstream tasks remain weak. Our finding provides the first systematic assessment of "reward model style" reasoning over clinical KGs, offering insights into how structured, reward-based supervision influences diagnostic reasoning in GenAI systems for healthcare.
Speculate Deep and Accurate: Lossless and Training-Free Acceleration for Offloaded LLMs via Substitute Speculative Decoding
arXiv:2509.18344v1 Announce Type: new Abstract: The immense model sizes of large language models (LLMs) challenge deployment on memory-limited consumer GPUs. Although model compression and parameter offloading are common strategies to address memory limitations, compression can degrade quality, and offloading maintains quality but suffers from slow inference. Speculative decoding presents a promising avenue to accelerate parameter offloading, utilizing a fast draft model to propose multiple draft tokens, which are then verified by the target LLM in parallel with a single forward pass. This method reduces the time-consuming data transfers in forward passes that involve offloaded weight transfers. Existing methods often rely on pretrained weights of the same family, but require additional training to align with custom-trained models. Moreover, approaches that involve draft model training usually yield only modest speedups. This limitation arises from insufficient alignment with the target model, preventing higher token acceptance lengths. To address these challenges and achieve greater speedups, we propose SubSpec, a plug-and-play method to accelerate parameter offloading that is lossless and training-free. SubSpec constructs a highly aligned draft model by generating low-bit quantized substitute layers from offloaded target LLM portions. Additionally, our method shares the remaining GPU-resident layers and the KV-Cache, further reducing memory overhead and enhance alignment. SubSpec achieves a high average acceptance length, delivering 9.1x speedup for Qwen2.5 7B on MT-Bench (8GB VRAM limit) and an average of 12.5x speedup for Qwen2.5 32B on popular generation benchmarks (24GB VRAM limit).
Speech Vecalign: an Embedding-based Method for Aligning Parallel Speech Documents
arXiv:2509.18360v1 Announce Type: new Abstract: We present Speech Vecalign, a parallel speech document alignment method that monotonically aligns speech segment embeddings and does not depend on text transcriptions. Compared to the baseline method Global Mining, a variant of speech mining, Speech Vecalign produces longer speech-to-speech alignments. It also demonstrates greater robustness than Local Mining, another speech mining variant, as it produces less noise. We applied Speech Vecalign to 3,000 hours of unlabeled parallel English-German (En-De) speech documents from VoxPopuli, yielding about 1,000 hours of high-quality alignments. We then trained En-De speech-to-speech translation models on the aligned data. Speech Vecalign improves the En-to-De and De-to-En performance over Global Mining by 0.37 and 0.18 ASR-BLEU, respectively. Moreover, our models match or outperform SpeechMatrix model performance, despite using 8 times fewer raw speech documents.
Interactive Real-Time Speaker Diarization Correction with Human Feedback
arXiv:2509.18377v1 Announce Type: new Abstract: Most automatic speech processing systems operate in "open loop" mode without user feedback about who said what; yet, human-in-the-loop workflows can potentially enable higher accuracy. We propose an LLM-assisted speaker diarization correction system that lets users fix speaker attribution errors in real time. The pipeline performs streaming ASR and diarization, uses an LLM to deliver concise summaries to the users, and accepts brief verbal feedback that is immediately incorporated without disrupting interactions. Moreover, we develop techniques to make the workflow more effective: First, a split-when-merged (SWM) technique detects and splits multi-speaker segments that the ASR erroneously attributes to just a single speaker. Second, online speaker enrollments are collected based on users' diarization corrections, thus helping to prevent speaker diarization errors from occurring in the future. LLM-driven simulations on the AMI test set indicate that our system substantially reduces DER by 9.92% and speaker confusion error by 44.23%. We further analyze correction efficacy under different settings, including summary vs full transcript display, the number of online enrollments limitation, and correction frequency.
NormGenesis: Multicultural Dialogue Generation via Exemplar-Guided Social Norm Modeling and Violation Recovery
arXiv:2509.18395v1 Announce Type: new Abstract: Social norms govern culturally appropriate behavior in communication, enabling dialogue systems to produce responses that are not only coherent but also socially acceptable. We present NormGenesis, a multicultural framework for generating and annotating socially grounded dialogues across English, Chinese, and Korean. To model the dynamics of social interaction beyond static norm classification, we propose a novel dialogue type, Violation-to-Resolution (V2R), which models the progression of conversations following norm violations through recognition and socially appropriate repair. To improve pragmatic consistency in underrepresented languages, we implement an exemplar-based iterative refinement early in the dialogue synthesis process. This design introduces alignment with linguistic, emotional, and sociocultural expectations before full dialogue generation begins. Using this framework, we construct a dataset of 10,800 multi-turn dialogues annotated at the turn level for norm adherence, speaker intent, and emotional response. Human and LLM-based evaluations demonstrate that NormGenesis significantly outperforms existing datasets in refinement quality, dialogue naturalness, and generalization performance. We show that models trained on our V2R-augmented data exhibit improved pragmatic competence in ethically sensitive contexts. Our work establishes a new benchmark for culturally adaptive dialogue modeling and provides a scalable methodology for norm-aware generation across linguistically and culturally diverse languages.
Evaluating the Creativity of LLMs in Persian Literary Text Generation
arXiv:2509.18401v1 Announce Type: new Abstract: Large language models (LLMs) have demonstrated notable creative abilities in generating literary texts, including poetry and short stories. However, prior research has primarily centered on English, with limited exploration of non-English literary traditions and without standardized methods for assessing creativity. In this paper, we evaluate the capacity of LLMs to generate Persian literary text enriched with culturally relevant expressions. We build a dataset of user-generated Persian literary spanning 20 diverse topics and assess model outputs along four creativity dimensions-originality, fluency, flexibility, and elaboration-by adapting the Torrance Tests of Creative Thinking. To reduce evaluation costs, we adopt an LLM as a judge for automated scoring and validate its reliability against human judgments using intraclass correlation coefficients, observing strong agreement. In addition, we analyze the models' ability to understand and employ four core literary devices: simile, metaphor, hyperbole, and antithesis. Our results highlight both the strengths and limitations of LLMs in Persian literary text generation, underscoring the need for further refinement.
Developing an AI framework to automatically detect shared decision-making in patient-doctor conversations
arXiv:2509.18439v1 Announce Type: new Abstract: Shared decision-making (SDM) is necessary to achieve patient-centred care. Currently no methodology exists to automatically measure SDM at scale. This study aimed to develop an automated approach to measure SDM by using language modelling and the conversational alignment (CA) score. A total of 157 video-recorded patient-doctor conversations from a randomized multi-centre trial evaluating SDM decision aids for anticoagulation in atrial fibrillations were transcribed and segmented into 42,559 sentences. Context-response pairs and negative sampling were employed to train deep learning (DL) models and fine-tuned BERT models via the next sentence prediction (NSP) task. Each top-performing model was used to calculate four types of CA scores. A random-effects analysis by clinician, adjusting for age, sex, race, and trial arm, assessed the association between CA scores and SDM outcomes: the Decisional Conflict Scale (DCS) and the Observing Patient Involvement in Decision-Making 12 (OPTION12) scores. p-values were corrected for multiple comparisons with the Benjamini-Hochberg method. Among 157 patients (34% female, mean age 70 SD 10.8), clinicians on average spoke more words than patients (1911 vs 773). The DL model without the stylebook strategy achieved a recall@1 of 0.227, while the fine-tuned BERTbase (110M) achieved the highest recall@1 with 0.640. The AbsMax (18.36 SE7.74 p=0.025) and Max CA (21.02 SE7.63 p=0.012) scores generated with the DL without stylebook were associated with OPTION12. The Max CA score generated with the fine-tuned BERTbase (110M) was associated with the DCS score (-27.61 SE12.63 p=0.037). BERT model sizes did not have an impact the association between CA scores and SDM. This study introduces an automated, scalable methodology to measure SDM in patient-doctor conversations through explainable CA scores, with potential to evaluate SDM strategies at scale.
CogniLoad: A Synthetic Natural Language Reasoning Benchmark With Tunable Length, Intrinsic Difficulty, and Distractor Density
arXiv:2509.18458v1 Announce Type: new Abstract: Current benchmarks for long-context reasoning in Large Language Models (LLMs) often blur critical factors like intrinsic task complexity, distractor interference, and task length. To enable more precise failure analysis, we introduce CogniLoad, a novel synthetic benchmark grounded in Cognitive Load Theory (CLT). CogniLoad generates natural-language logic puzzles with independently tunable parameters that reflect CLT's core dimensions: intrinsic difficulty ($d$) controls intrinsic load; distractor-to-signal ratio ($\rho$) regulates extraneous load; and task length ($N$) serves as an operational proxy for conditions demanding germane load. Evaluating 22 SotA reasoning LLMs, CogniLoad reveals distinct performance sensitivities, identifying task length as a dominant constraint and uncovering varied tolerances to intrinsic complexity and U-shaped responses to distractor ratios. By offering systematic, factorial control over these cognitive load dimensions, CogniLoad provides a reproducible, scalable, and diagnostically rich tool for dissecting LLM reasoning limitations and guiding future model development.
LAWCAT: Efficient Distillation from Quadratic to Linear Attention with Convolution across Tokens for Long Context Modeling
arXiv:2509.18467v1 Announce Type: new Abstract: Although transformer architectures have achieved state-of-the-art performance across diverse domains, their quadratic computational complexity with respect to sequence length remains a significant bottleneck, particularly for latency-sensitive long-context applications. While recent linear-complexity alternatives are increasingly powerful, effectively training them from scratch is still resource-intensive. To overcome these limitations, we propose LAWCAT (Linear Attention with Convolution Across Time), a novel linearization framework designed to efficiently transfer the capabilities of pre-trained transformers into a performant linear attention architecture. LAWCAT integrates causal Conv1D layers to enhance local dependency modeling and employs normalized gated linear attention to improve generalization across varying context lengths. Our comprehensive evaluations demonstrate that, distilling Mistral-7B with only 1K-length sequences yields over 90\% passkey retrieval accuracy up to 22K tokens, significantly extending its effective context window. Similarly, Llama3.2-1B LAWCAT variant achieves competitive performance on S-NIAH 1\&2\&3 tasks (1K-8K context length) and BABILong benchmark (QA2\&QA3, 0K-16K context length), requiring less than 0.1\% pre-training tokens compared with pre-training models. Furthermore, LAWCAT exhibits faster prefill speeds than FlashAttention-2 for sequences exceeding 8K tokens. LAWCAT thus provides an efficient pathway to high-performance, long-context linear models suitable for edge deployment, reducing reliance on extensive long-sequence training data and computational resources.
Actions Speak Louder than Prompts: A Large-Scale Study of LLMs for Graph Inference
arXiv:2509.18487v1 Announce Type: new Abstract: Large language models (LLMs) are increasingly used for text-rich graph machine learning tasks such as node classification in high-impact domains like fraud detection and recommendation systems. Yet, despite a surge of interest, the field lacks a principled understanding of the capabilities of LLMs in their interaction with graph data. In this work, we conduct a large-scale, controlled evaluation across several key axes of variability to systematically assess the strengths and weaknesses of LLM-based graph reasoning methods in text-based applications. The axes include the LLM-graph interaction mode, comparing prompting, tool-use, and code generation; dataset domains, spanning citation, web-link, e-commerce, and social networks; structural regimes contrasting homophilic and heterophilic graphs; feature characteristics involving both short- and long-text node attributes; and model configurations with varying LLM sizes and reasoning capabilities. We further analyze dependencies by methodically truncating features, deleting edges, and removing labels to quantify reliance on input types. Our findings provide practical and actionable guidance. (1) LLMs as code generators achieve the strongest overall performance on graph data, with especially large gains on long-text or high-degree graphs where prompting quickly exceeds the token budget. (2) All interaction strategies remain effective on heterophilic graphs, challenging the assumption that LLM-based methods collapse under low homophily. (3) Code generation is able to flexibly adapt its reliance between structure, features, or labels to leverage the most informative input type. Together, these findings provide a comprehensive view of the strengths and limitations of current LLM-graph interaction modes and highlight key design principles for future approaches.
A Rhythm-Aware Phrase Insertion for Classical Arabic Poetry Composition
arXiv:2509.18514v1 Announce Type: new Abstract: This paper presents a methodology for inserting phrases in Arabic poems to conform to a specific rhythm using ByT5, a byte-level multilingual transformer-based model. Our work discusses a rule-based grapheme-to-beat transformation tailored for extracting the rhythm from fully diacritized Arabic script. Our approach employs a conditional denoising objective to fine-tune ByT5, where the model reconstructs masked words to match a target rhythm. We adopt a curriculum learning strategy, pre-training on a general Arabic dataset before fine-tuning on poetic dataset, and explore cross-lingual transfer from English to Arabic. Experimental results demonstrate that our models achieve high rhythmic alignment while maintaining semantic coherence. The proposed model has the potential to be used in co-creative applications in the process of composing classical Arabic poems.
Trace Is In Sentences: Unbiased Lightweight ChatGPT-Generated Text Detector
arXiv:2509.18535v1 Announce Type: new Abstract: The widespread adoption of ChatGPT has raised concerns about its misuse, highlighting the need for robust detection of AI-generated text. Current word-level detectors are vulnerable to paraphrasing or simple prompts (PSP), suffer from biases induced by ChatGPT's word-level patterns (CWP) and training data content, degrade on modified text, and often require large models or online LLM interaction. To tackle these issues, we introduce a novel task to detect both original and PSP-modified AI-generated texts, and propose a lightweight framework that classifies texts based on their internal structure, which remains invariant under word-level changes. Our approach encodes sentence embeddings from pre-trained language models and models their relationships via attention. We employ contrastive learning to mitigate embedding biases from autoregressive generation and incorporate a causal graph with counterfactual methods to isolate structural features from topic-related biases. Experiments on two curated datasets, including abstract comparisons and revised life FAQs, validate the effectiveness of our method.
CCQA: Generating Question from Solution Can Improve Inference-Time Reasoning in SLMs
arXiv:2509.18536v1 Announce Type: new Abstract: Recently, inference-time reasoning strategies have further improved the accuracy of large language models (LLMs), but their effectiveness on smaller models remains unclear. Based on the observation that conventional approaches often fail to improve performance in this context, we propose \textbf{C}ycle-\textbf{C}onsistency in \textbf{Q}uestion \textbf{A}nswering (CCQA), a novel reasoning method that can be effectively applied to SLMs. Inspired by cycle consistency, CCQA generates a question from each reasoning path and answer, evaluates each by its similarity to the original question, and then selects the candidate solution with the highest similarity score as the final response. Since conventional SLMs struggle to generate accurate questions from their own reasoning paths and answers, we employ a lightweight Flan-T5 model specialized for question generation to support this process efficiently. From the experimental results, it is verified that CCQA consistently outperforms existing state-of-the-art (SOTA) methods across eight models on mathematical and commonsense reasoning benchmarks. Furthermore, our method establishes a new practical baseline for efficient reasoning in SLMs. Source code can be found at https://github.com/scai-research/ccqa_official.
Prior-based Noisy Text Data Filtering: Fast and Strong Alternative For Perplexity
arXiv:2509.18577v1 Announce Type: new Abstract: As large language models (LLMs) are pretrained on massive web corpora, careful selection of data becomes essential to ensure effective and efficient learning. While perplexity (PPL)-based filtering has shown strong performance, it suffers from drawbacks: substantial time costs and inherent unreliability of the model when handling noisy or out-of-distribution samples. In this work, we propose a simple yet powerful alternative: a prior-based data filtering method that estimates token priors using corpus-level term frequency statistics, inspired by linguistic insights on word roles and lexical density. Our approach filters documents based on the mean and standard deviation of token priors, serving as a fast proxy to PPL while requiring no model inference. Despite its simplicity, the prior-based filter achieves the highest average performance across 20 downstream benchmarks, while reducing time cost by over 1000x compared to PPL-based filtering. We further demonstrate its applicability to symbolic languages such as code and math, and its dynamic adaptability to multilingual corpora without supervision
TsqLoRA: Towards Sensitivity and Quality Low-Rank Adaptation for Efficient Fine-Tuning
arXiv:2509.18585v1 Announce Type: new Abstract: Fine-tuning large pre-trained models for downstream tasks has become a fundamental approach in natural language processing. Fully fine-tuning all model parameters is computationally expensive and memory-intensive, especially in resource-constrained environments. Existing parameter-efficient fine-tuning methods reduce the number of trainable parameters but typically overlook the varying sensitivity of different model layers and the importance of training data. In this work, we propose TsqLoRA, a novel method that integrates data-quality-driven selection with sensitivity-aware low-rank adaptation, consisted of two main components: a quality-aware sampling mechanism for selecting the most informative training data, and a dynamic rank allocation module that adjusts the rank of each layer based on its sensitivity to parameter updates. The experimental results demonstrate that TsqLoRA improves fine-tuning efficiency while maintaining or even improving performance on a variety of NLP tasks. Our code will be available at https://github.com/Benjamin-Ricky/TsqLoRA.
UniECG: Understanding and Generating ECG in One Unified Model
arXiv:2509.18588v1 Announce Type: new Abstract: Recent unified models such as GPT-5 have achieved encouraging progress on vision-language tasks. However, these unified models typically fail to correctly understand ECG signals and provide accurate medical diagnoses, nor can they correctly generate ECG signals. To address these limitations, we propose UniECG, the first unified model for ECG capable of concurrently performing evidence-based ECG interpretation and text-conditioned ECG generation tasks. Through a decoupled two-stage training approach, the model first learns evidence-based interpretation skills (ECG-to-Text), and then injects ECG generation capabilities (Text-to-ECG) via latent space alignment. UniECG can autonomously choose to interpret or generate an ECG based on user input, significantly extending the capability boundaries of current ECG models. Our code and checkpoints will be made publicly available at https://github.com/PKUDigitalHealth/UniECG upon acceptance.
A Good Plan is Hard to Find: Aligning Models with Preferences is Misaligned with What Helps Users
arXiv:2509.18632v1 Announce Type: new Abstract: To assist users in complex tasks, LLMs generate plans: step-by-step instructions towards a goal. While alignment methods aim to ensure LLM plans are helpful, they train (RLHF) or evaluate (ChatbotArena) on what users prefer, assuming this reflects what helps them. We test this with Planorama: an interface where 126 users answer 300 multi-step questions with LLM plans. We get 4388 plan executions and 5584 comparisons to measure plan helpfulness (QA success) and user preferences on plans, and recreate the setup in agents and reward models to see if they simulate or prefer what helps users. We expose: 1) user/model preferences and agent success do not accurately predict which plans help users, so common alignment feedback can misalign with helpfulness; 2) this gap is not due to user-specific preferences, as users are similarly successful when using plans they prefer/disprefer; 3) surface-level cues like brevity and question similarity strongly link to preferences, but such biases fail to predict helpfulness. In all, we argue aligning helpful LLMs needs feedback from real user interactions, not just preferences of what looks helpful, so we discuss the plan NLP researchers can execute to solve this problem.
Consistency-Aware Parameter-Preserving Knowledge Editing Framework for Multi-Hop Question Answering
arXiv:2509.18655v1 Announce Type: new Abstract: Parameter-Preserving Knowledge Editing (PPKE) enables updating models with new or corrected information without retraining or parameter adjustment. Recent PPKE approaches based on knowledge graphs (KG) to extend knowledge editing (KE) capabilities to multi-hop question answering (MHQA). However, these methods often lack consistency, leading to knowledge contamination, unstable updates, and retrieval behaviors that fail to reflect the intended edits. Such inconsistencies undermine the reliability of PPKE in multi- hop reasoning. We present CAPE-KG, Consistency-Aware Parameter-Preserving Editing with Knowledge Graphs, a novel consistency-aware framework for PPKE on MHQA. CAPE-KG ensures KG construction, update, and retrieval are always aligned with the requirements of the MHQA task, maintaining coherent reasoning over both unedited and edited knowledge. Extensive experiments on the MQuAKE benchmark show accuracy improvements in PPKE performance for MHQA, demonstrating the effectiveness of addressing consistency in PPKE.
Analyzing Uncertainty of LLM-as-a-Judge: Interval Evaluations with Conformal Prediction
arXiv:2509.18658v1 Announce Type: new Abstract: LLM-as-a-judge has become a promising paradigm for using large language models (LLMs) to evaluate natural language generation (NLG), but the uncertainty of its evaluation remains underexplored. This lack of reliability may limit its deployment in many applications. This work presents the first framework to analyze the uncertainty by offering a prediction interval of LLM-based scoring via conformal prediction. Conformal prediction constructs continuous prediction intervals from a single evaluation run, and we design an ordinal boundary adjustment for discrete rating tasks. We also suggest a midpoint-based score within the interval as a low-bias alternative to raw model score and weighted average. We perform extensive experiments and analysis, which show that conformal prediction can provide valid prediction interval with coverage guarantees. We also explore the usefulness of interval midpoint and judge reprompting for better judgment.
MemOrb: A Plug-and-Play Verbal-Reinforcement Memory Layer for E-Commerce Customer Service
arXiv:2509.18713v1 Announce Type: new Abstract: Large Language Model-based agents(LLM-based agents) are increasingly deployed in customer service, yet they often forget across sessions, repeat errors, and lack mechanisms for continual self-improvement. This makes them unreliable in dynamic settings where stability and consistency are critical. To better evaluate these properties, we emphasize two indicators: task success rate as a measure of overall effectiveness, and consistency metrics such as Pass$^k$ to capture reliability across multiple trials. To address the limitations of existing approaches, we propose MemOrb, a lightweight and plug-and-play verbal reinforcement memory layer that distills multi-turn interactions into compact strategy reflections. These reflections are stored in a shared memory bank and retrieved to guide decision-making, without requiring any fine-tuning. Experiments show that MemOrb significantly improves both success rate and stability, achieving up to a 63 percentage-point gain in multi-turn success rate and delivering more consistent performance across repeated trials. Our results demonstrate that structured reflection is a powerful mechanism for enhancing long-term reliability of frozen LLM agents in customer service scenarios.
LOTUSDIS: A Thai far-field meeting corpus for robust conversational ASR
arXiv:2509.18722v1 Announce Type: new Abstract: We present LOTUSDIS, a publicly available Thai meeting corpus designed to advance far-field conversational ASR. The dataset comprises 114 hours of spontaneous, unscripted dialogue collected in 15-20 minute sessions with three participants, where overlapping speech is frequent and natural. Speech was recorded simultaneously by nine independent single-channel devices spanning six microphone types at distances from 0.12 m to 10 m, preserving the authentic effects of reverberation, noise, and device coloration without relying on microphone arrays. We provide standard train, dev, test splits and release a reproducible baseline system. We benchmarked several Whisper variants under zero-shot and fine-tuned conditions. Off-the-shelf models showed strong degradation with distance, confirming a mismatch between pre-training data and Thai far-field speech. Fine-tuning on LOTUSDIS dramatically improved robustness: a Thai Whisper baseline reduced overall WER from 64.3 to 38.3 and far-field WER from 81.6 to 49.5, with especially large gains on the most distant microphones. These results underscore the importance of distance-diverse training data for robust ASR. The corpus is available under CC-BY-SA 4.0. We also release training and evaluation scripts as a baseline system to promote reproducible research in this field.
Global-Recent Semantic Reasoning on Dynamic Text-Attributed Graphs with Large Language Models
arXiv:2509.18742v1 Announce Type: new Abstract: Dynamic Text-Attribute Graphs (DyTAGs), characterized by time-evolving graph interactions and associated text attributes, are prevalent in real-world applications. Existing methods, such as Graph Neural Networks (GNNs) and Large Language Models (LLMs), mostly focus on static TAGs. Extending these existing methods to DyTAGs is challenging as they largely neglect the recent-global temporal semantics: the recent semantic dependencies among interaction texts and the global semantic evolution of nodes over time. Furthermore, applying LLMs to the abundant and evolving text in DyTAGs faces efficiency issues. To tackle these challenges, we propose Dynamic Global-Recent Adaptive Semantic Processing (DyGRASP), a novel method that leverages LLMs and temporal GNNs to efficiently and effectively reason on DyTAGs. Specifically, we first design a node-centric implicit reasoning method together with a sliding window mechanism to efficiently capture recent temporal semantics. In addition, to capture global semantic dynamics of nodes, we leverage explicit reasoning with tailored prompts and an RNN-like chain structure to infer long-term semantics. Lastly, we intricately integrate the recent and global temporal semantics as well as the dynamic graph structural information using updating and merging layers. Extensive experiments on DyTAG benchmarks demonstrate DyGRASP's superiority, achieving up to 34% improvement in Hit@10 for destination node retrieval task. Besides, DyGRASP exhibits strong generalization across different temporal GNNs and LLMs.
False Friends Are Not Foes: Investigating Vocabulary Overlap in Multilingual Language Models
arXiv:2509.18750v1 Announce Type: new Abstract: Subword tokenizers trained on multilingual corpora naturally produce overlapping tokens across languages. Does token overlap facilitate cross-lingual transfer or instead introduce interference between languages? Prior work offers mixed evidence, partly due to varied setups and confounders, such as token frequency or subword segmentation granularity. To address this question, we devise a controlled experiment where we train bilingual autoregressive models on multiple language pairs under systematically varied vocabulary overlap settings. Crucially, we explore a new dimension to understanding how overlap affects transfer: the semantic similarity of tokens shared across languages. We first analyze our models' hidden representations and find that overlap of any kind creates embedding spaces that capture cross-lingual semantic relationships, while this effect is much weaker in models with disjoint vocabularies. On XNLI and XQuAD, we find that models with overlap outperform models with disjoint vocabularies, and that transfer performance generally improves as overlap increases. Overall, our findings highlight the advantages of token overlap in multilingual models and show that substantial shared vocabulary remains a beneficial design choice for multilingual tokenizers.
When Long Helps Short: How Context Length in Supervised Fine-tuning Affects Behavior of Large Language Models
arXiv:2509.18762v1 Announce Type: new Abstract: Large language models (LLMs) have achieved impressive performance across natural language processing (NLP) tasks. As real-world applications increasingly demand longer context windows, continued pretraining and supervised fine-tuning (SFT) on long-context data has become a common approach. While the effects of data length in continued pretraining have been extensively studied, their implications for SFT remain unclear. In this work, we systematically investigate how SFT data length influences LLM behavior on short-context tasks. Counterintuitively, we find that long-context SFT improves short-context performance, contrary to the commonly observed degradation from long-context pretraining. To uncover the underlying mechanisms of this phenomenon, we first decouple and analyze two key components, Multi-Head Attention (MHA) and Feed-Forward Network (FFN), and show that both independently benefit from long-context SFT. We further study their interaction and reveal a knowledge preference bias: long-context SFT promotes contextual knowledge, while short-context SFT favors parametric knowledge, making exclusive reliance on long-context SFT suboptimal. Finally, we demonstrate that hybrid training mitigates this bias, offering explainable guidance for fine-tuning LLMs.
Financial Risk Relation Identification through Dual-view Adaptation
arXiv:2509.18775v1 Announce Type: new Abstract: A multitude of interconnected risk events -- ranging from regulatory changes to geopolitical tensions -- can trigger ripple effects across firms. Identifying inter-firm risk relations is thus crucial for applications like portfolio management and investment strategy. Traditionally, such assessments rely on expert judgment and manual analysis, which are, however, subjective, labor-intensive, and difficult to scale. To address this, we propose a systematic method for extracting inter-firm risk relations using Form 10-K filings -- authoritative, standardized financial documents -- as our data source. Leveraging recent advances in natural language processing, our approach captures implicit and abstract risk connections through unsupervised fine-tuning based on chronological and lexical patterns in the filings. This enables the development of a domain-specific financial encoder with a deeper contextual understanding and introduces a quantitative risk relation score for transparency, interpretable analysis. Extensive experiments demonstrate that our method outperforms strong baselines across multiple evaluation settings.
AECBench: A Hierarchical Benchmark for Knowledge Evaluation of Large Language Models in the AEC Field
arXiv:2509.18776v1 Announce Type: new Abstract: Large language models (LLMs), as a novel information technology, are seeing increasing adoption in the Architecture, Engineering, and Construction (AEC) field. They have shown their potential to streamline processes throughout the building lifecycle. However, the robustness and reliability of LLMs in such a specialized and safety-critical domain remain to be evaluated. To address this challenge, this paper establishes AECBench, a comprehensive benchmark designed to quantify the strengths and limitations of current LLMs in the AEC domain. The benchmark defines 23 representative tasks within a five-level cognition-oriented evaluation framework encompassing Knowledge Memorization, Understanding, Reasoning, Calculation, and Application. These tasks were derived from authentic AEC practice, with scope ranging from codes retrieval to specialized documents generation. Subsequently, a 4,800-question dataset encompassing diverse formats, including open-ended questions, was crafted primarily by engineers and validated through a two-round expert review. Furthermore, an LLM-as-a-Judge approach was introduced to provide a scalable and consistent methodology for evaluating complex, long-form responses leveraging expert-derived rubrics. Through the evaluation of nine LLMs, a clear performance decline across five cognitive levels was revealed. Despite demonstrating proficiency in foundational tasks at the Knowledge Memorization and Understanding levels, the models showed significant performance deficits, particularly in interpreting knowledge from tables in building codes, executing complex reasoning and calculation, and generating domain-specific documents. Consequently, this study lays the groundwork for future research and development aimed at the robust and reliable integration of LLMs into safety-critical engineering practices.
Beyond the Leaderboard: Understanding Performance Disparities in Large Language Models via Model Diffing
arXiv:2509.18792v1 Announce Type: new Abstract: As fine-tuning becomes the dominant paradigm for improving large language models (LLMs), understanding what changes during this process is increasingly important. Traditional benchmarking often fails to explain why one model outperforms another. In this work, we use model diffing, a mechanistic interpretability approach, to analyze the specific capability differences between Gemma-2-9b-it and a SimPO-enhanced variant. Using crosscoders, we identify and categorize latent representations that differentiate the two models. We find that SimPO acquired latent concepts predominantly enhance safety mechanisms (+32.8%), multilingual capabilities (+43.8%), and instruction-following (+151.7%), while its additional training also reduces emphasis on model self-reference (-44.1%) and hallucination management (-68.5%). Our analysis shows that model diffing can yield fine-grained insights beyond leaderboard metrics, attributing performance gaps to concrete mechanistic capabilities. This approach offers a transparent and targeted framework for comparing LLMs.
MAPEX: A Multi-Agent Pipeline for Keyphrase Extraction
arXiv:2509.18813v1 Announce Type: new Abstract: Keyphrase extraction is a fundamental task in natural language processing. However, existing unsupervised prompt-based methods for Large Language Models (LLMs) often rely on single-stage inference pipelines with uniform prompting, regardless of document length or LLM backbone. Such one-size-fits-all designs hinder the full exploitation of LLMs' reasoning and generation capabilities, especially given the complexity of keyphrase extraction across diverse scenarios. To address these challenges, we propose MAPEX, the first framework that introduces multi-agent collaboration into keyphrase extraction. MAPEX coordinates LLM-based agents through modules for expert recruitment, candidate extraction, topic guidance, knowledge augmentation, and post-processing. A dual-path strategy dynamically adapts to document length: knowledge-driven extraction for short texts and topic-guided extraction for long texts. Extensive experiments on six benchmark datasets across three different LLMs demonstrate its strong generalization and universality, outperforming the state-of-the-art unsupervised method by 2.44\% and standard LLM baselines by 4.01\% in F1@5 on average. Code is available at https://github.com/NKU-LITI/MAPEX.
Are Smaller Open-Weight LLMs Closing the Gap to Proprietary Models for Biomedical Question Answering?
arXiv:2509.18843v1 Announce Type: new Abstract: Open-weight versions of large language models (LLMs) are rapidly advancing, with state-of-the-art models like DeepSeek-V3 now performing comparably to proprietary LLMs. This progression raises the question of whether small open-weight LLMs are capable of effectively replacing larger closed-source models. We are particularly interested in the context of biomedical question-answering, a domain we explored by participating in Task 13B Phase B of the BioASQ challenge. In this work, we compare several open-weight models against top-performing systems such as GPT-4o, GPT-4.1, Claude 3.5 Sonnet, and Claude 3.7 Sonnet. To enhance question answering capabilities, we use various techniques including retrieving the most relevant snippets based on embedding distance, in-context learning, and structured outputs. For certain submissions, we utilize ensemble approaches to leverage the diverse outputs generated by different models for exact-answer questions. Our results demonstrate that open-weight LLMs are comparable to proprietary ones. In some instances, open-weight LLMs even surpassed their closed counterparts, particularly when ensembling strategies were applied. All code is publicly available at https://github.com/evidenceprime/BioASQ-13b.
Multi-Hierarchical Feature Detection for Large Language Model Generated Text
arXiv:2509.18862v1 Announce Type: new Abstract: With the rapid advancement of large language model technology, there is growing interest in whether multi-feature approaches can significantly improve AI text detection beyond what single neural models achieve. While intuition suggests that combining semantic, syntactic, and statistical features should provide complementary signals, this assumption has not been rigorously tested with modern LLM-generated text. This paper provides a systematic empirical investigation of multi-hierarchical feature integration for AI text detection, specifically testing whether the computational overhead of combining multiple feature types is justified by performance gains. We implement MHFD (Multi-Hierarchical Feature Detection), integrating DeBERTa-based semantic analysis, syntactic parsing, and statistical probability features through adaptive fusion. Our investigation reveals important negative results: despite theoretical expectations, multi-feature integration provides minimal benefits (0.4-0.5% improvement) while incurring substantial computational costs (4.2x overhead), suggesting that modern neural language models may already capture most relevant detection signals efficiently. Experimental results on multiple benchmark datasets demonstrate that the MHFD method achieves 89.7% accuracy in in-domain detection and maintains 84.2% stable performance in cross-domain detection, showing modest improvements of 0.4-2.6% over existing methods.
Diversity Boosts AI-Generated Text Detection
arXiv:2509.18880v1 Announce Type: new Abstract: Detecting AI-generated text is an increasing necessity to combat misuse of LLMs in education, business compliance, journalism, and social media, where synthetic fluency can mask misinformation or deception. While prior detectors often rely on token-level likelihoods or opaque black-box classifiers, these approaches struggle against high-quality generations and offer little interpretability. In this work, we propose DivEye, a novel detection framework that captures how unpredictability fluctuates across a text using surprisal-based features. Motivated by the observation that human-authored text exhibits richer variability in lexical and structural unpredictability than LLM outputs, DivEye captures this signal through a set of interpretable statistical features. Our method outperforms existing zero-shot detectors by up to 33.2% and achieves competitive performance with fine-tuned baselines across multiple benchmarks. DivEye is robust to paraphrasing and adversarial attacks, generalizes well across domains and models, and improves the performance of existing detectors by up to 18.7% when used as an auxiliary signal. Beyond detection, DivEye provides interpretable insights into why a text is flagged, pointing to rhythmic unpredictability as a powerful and underexplored signal for LLM detection.
Extractive Fact Decomposition for Interpretable Natural Language Inference in one Forward Pass
arXiv:2509.18901v1 Announce Type: new Abstract: Recent works in Natural Language Inference (NLI) and related tasks, such as automated fact-checking, employ atomic fact decomposition to enhance interpretability and robustness. For this, existing methods rely on resource-intensive generative large language models (LLMs) to perform decomposition. We propose JEDI, an encoder-only architecture that jointly performs extractive atomic fact decomposition and interpretable inference without requiring generative models during inference. To facilitate training, we produce a large corpus of synthetic rationales covering multiple NLI benchmarks. Experimental results demonstrate that JEDI achieves competitive accuracy in distribution and significantly improves robustness out of distribution and in adversarial settings over models based solely on extractive rationale supervision. Our findings show that interpretability and robust generalization in NLI can be realized using encoder-only architectures and synthetic rationales. Code and data available at https://jedi.nicpopovic.com
DTW-Align: Bridging the Modality Gap in End-to-End Speech Translation with Dynamic Time Warping Alignment
arXiv:2509.18987v1 Announce Type: new Abstract: End-to-End Speech Translation (E2E-ST) is the task of translating source speech directly into target text bypassing the intermediate transcription step. The representation discrepancy between the speech and text modalities has motivated research on what is known as bridging the modality gap. State-of-the-art methods addressed this by aligning speech and text representations on the word or token level. Unfortunately, this requires an alignment tool that is not available for all languages. Although this issue has been addressed by aligning speech and text embeddings using nearest-neighbor similarity search, it does not lead to accurate alignments. In this work, we adapt Dynamic Time Warping (DTW) for aligning speech and text embeddings during training. Our experiments demonstrate the effectiveness of our method in bridging the modality gap in E2E-ST. Compared to previous work, our method produces more accurate alignments and achieves comparable E2E-ST results while being significantly faster. Furthermore, our method outperforms previous work in low resource settings on 5 out of 6 language directions.
Investigating Test-Time Scaling with Reranking for Machine Translation
arXiv:2509.19020v1 Announce Type: new Abstract: Scaling model parameters has become the de facto strategy for improving NLP systems, but it comes with substantial computational costs. Test-Time Scaling (TTS) offers an alternative by allocating more computation at inference: generating multiple candidates and selecting the best. While effective in tasks such as mathematical reasoning, TTS has not been systematically explored for machine translation (MT). In this paper, we present the first systematic study of TTS for MT, investigating a simple but practical best-of-N framework on WMT24 benchmarks. Our experiments cover six high-resource and one low-resource language pairs, five model sizes (3B-72B), and various TTS compute budget (N up to 1024). Our results show that a) For high-resource languages, TTS generally improves translation quality according to multiple neural MT evaluation metrics, and our human evaluation confirms these gains; b) Augmenting smaller models with large $N$ can match or surpass larger models at $N{=}1$ with more compute cost; c) Under fixed compute budgets, larger models are typically more efficient, and TTS can degrade quality due to metric blind spots in low-resource cases.
Charting a Decade of Computational Linguistics in Italy: The CLiC-it Corpus
arXiv:2509.19033v1 Announce Type: new Abstract: Over the past decade, Computational Linguistics (CL) and Natural Language Processing (NLP) have evolved rapidly, especially with the advent of Transformer-based Large Language Models (LLMs). This shift has transformed research goals and priorities, from Lexical and Semantic Resources to Language Modelling and Multimodality. In this study, we track the research trends of the Italian CL and NLP community through an analysis of the contributions to CLiC-it, arguably the leading Italian conference in the field. We compile the proceedings from the first 10 editions of the CLiC-it conference (from 2014 to 2024) into the CLiC-it Corpus, providing a comprehensive analysis of both its metadata, including author provenance, gender, affiliations, and more, as well as the content of the papers themselves, which address various topics. Our goal is to provide the Italian and international research communities with valuable insights into emerging trends and key developments over time, supporting informed decisions and future directions in the field.
Pathways of Thoughts: Multi-Directional Thinking for Long-form Personalized Question Answering
arXiv:2509.19094v1 Announce Type: new Abstract: Personalization is essential for adapting question answering (QA) systems to user-specific information needs, thereby improving both accuracy and user satisfaction. However, personalized QA remains relatively underexplored due to challenges such as inferring preferences from long, noisy, and implicit contexts, and generating responses that are simultaneously correct, contextually appropriate, and aligned with user expectations and background knowledge. To address these challenges, we propose Pathways of Thoughts (PoT), an inference-stage method that applies to any large language model (LLM) without requiring task-specific fine-tuning. The approach models the reasoning of an LLM as an iterative decision process, where the model dynamically selects among cognitive operations such as reasoning, revision, personalization, and clarification. This enables exploration of multiple reasoning trajectories, producing diverse candidate responses that capture different perspectives. PoT then aggregates and reweights these candidates according to inferred user preferences, yielding a final personalized response that benefits from the complementary strengths of diverse reasoning paths. Experiments on the LaMP-QA benchmark for personalized QA show that PoT consistently outperforms competitive baselines, achieving up to a 13.1% relative improvement. Human evaluation corroborates these results, with annotators preferring outputs from PoT in 66% of cases and reporting ties in only 15% of cases.
Are most sentences unique? An empirical examination of Chomskyan claims
arXiv:2509.19108v1 Announce Type: new Abstract: A repeated claim in linguistics is that the majority of linguistic utterances are unique. For example, Pinker (1994: 10), summarizing an argument by Noam Chomsky, states that "virtually every sentence that a person utters or understands is a brand-new combination of words, appearing for the first time in the history of the universe." With the increased availability of large corpora, this is a claim that can be empirically investigated. The current paper addresses the question by using the NLTK Python library to parse corpora of different genres, providing counts of exact string matches in each. Results show that while completely unique sentences are often the majority of corpora, this is highly constrained by genre, and that duplicate sentences are not an insignificant part of any individual corpus.
Human-Annotated NER Dataset for the Kyrgyz Language
arXiv:2509.19109v1 Announce Type: new Abstract: We introduce KyrgyzNER, the first manually annotated named entity recognition dataset for the Kyrgyz language. Comprising 1,499 news articles from the 24.KG news portal, the dataset contains 10,900 sentences and 39,075 entity mentions across 27 named entity classes. We show our annotation scheme, discuss the challenges encountered in the annotation process, and present the descriptive statistics. We also evaluate several named entity recognition models, including traditional sequence labeling approaches based on conditional random fields and state-of-the-art multilingual transformer-based models fine-tuned on our dataset. While all models show difficulties with rare entity categories, models such as the multilingual RoBERTa variant pretrained on a large corpus across many languages achieve a promising balance between precision and recall. These findings emphasize both the challenges and opportunities of using multilingual pretrained models for processing languages with limited resources. Although the multilingual RoBERTa model performed best, other multilingual models yielded comparable results. This suggests that future work exploring more granular annotation schemes may offer deeper insights for Kyrgyz language processing pipelines evaluation.
Context-Aware Hierarchical Taxonomy Generation for Scientific Papers via LLM-Guided Multi-Aspect Clustering
arXiv:2509.19125v1 Announce Type: new Abstract: The rapid growth of scientific literature demands efficient methods to organize and synthesize research findings. Existing taxonomy construction methods, leveraging unsupervised clustering or direct prompting of large language models (LLMs), often lack coherence and granularity. We propose a novel context-aware hierarchical taxonomy generation framework that integrates LLM-guided multi-aspect encoding with dynamic clustering. Our method leverages LLMs to identify key aspects of each paper (e.g., methodology, dataset, evaluation) and generates aspect-specific paper summaries, which are then encoded and clustered along each aspect to form a coherent hierarchy. In addition, we introduce a new evaluation benchmark of 156 expert-crafted taxonomies encompassing 11.6k papers, providing the first naturally annotated dataset for this task. Experimental results demonstrate that our method significantly outperforms prior approaches, achieving state-of-the-art performance in taxonomy coherence, granularity, and interpretability.
Anecdoctoring: Automated Red-Teaming Across Language and Place
arXiv:2509.19143v1 Announce Type: new Abstract: Disinformation is among the top risks of generative artificial intelligence (AI) misuse. Global adoption of generative AI necessitates red-teaming evaluations (i.e., systematic adversarial probing) that are robust across diverse languages and cultures, but red-teaming datasets are commonly US- and English-centric. To address this gap, we propose "anecdoctoring", a novel red-teaming approach that automatically generates adversarial prompts across languages and cultures. We collect misinformation claims from fact-checking websites in three languages (English, Spanish, and Hindi) and two geographies (US and India). We then cluster individual claims into broader narratives and characterize the resulting clusters with knowledge graphs, with which we augment an attacker LLM. Our method produces higher attack success rates and offers interpretability benefits relative to few-shot prompting. Results underscore the need for disinformation mitigations that scale globally and are grounded in real-world adversarial misuse.
Measuring AI "Slop" in Text
arXiv:2509.19163v1 Announce Type: new Abstract: AI "slop" is an increasingly popular term used to describe low-quality AI-generated text, but there is currently no agreed upon definition of this term nor a means to measure its occurrence. In this work, we develop a taxonomy of "slop" through interviews with experts in NLP, writing, and philosophy, and propose a set of interpretable dimensions for its assessment in text. Through span-level annotation, we find that binary "slop" judgments are (somewhat) subjective, but such determinations nonetheless correlate with latent dimensions such as coherence and relevance. Our framework can be used to evaluate AI-generated text in both detection and binary preference tasks, potentially offering new insights into the linguistic and stylistic factors that contribute to quality judgments.
Soft Tokens, Hard Truths
arXiv:2509.19170v1 Announce Type: new Abstract: The use of continuous instead of discrete tokens during the Chain-of-Thought (CoT) phase of reasoning LLMs has garnered attention recently, based on the intuition that a continuous mixture of discrete tokens could simulate a superposition of several reasoning paths simultaneously. Theoretical results have formally proven that continuous tokens have much greater expressivity and can solve specific problems more efficiently. However, practical use of continuous tokens has been limited by strong training difficulties: previous works either just use continuous tokens at inference time on a pre-trained discrete-token model, or must distill the continuous CoT from ground-truth discrete CoTs and face computational costs that limit the CoT to very few tokens. This is the first work introducing a scalable method to learn continuous CoTs via reinforcement learning (RL), without distilling from reference discrete CoTs. We use "soft" tokens: mixtures of tokens together with noise on the input embedding to provide RL exploration. Computational overhead is minimal, enabling us to learn continuous CoTs with hundreds of tokens. On math reasoning benchmarks with Llama and Qwen models up to 8B, training with continuous CoTs match discrete-token CoTs for pass@1 and surpass them for pass@32, showing greater CoT diversity. In systematic comparisons, the best-performing scenario is to train with continuous CoT tokens then use discrete tokens for inference, meaning the "soft" models can be deployed in a standard way. Finally, we show continuous CoT RL training better preserves the predictions of the base model on out-of-domain tasks, thus providing a softer touch to the base model.
Online Process Reward Leanring for Agentic Reinforcement Learning
arXiv:2509.19199v1 Announce Type: new Abstract: Large language models (LLMs) are increasingly trained with reinforcement learning (RL) as autonomous agents that reason and act over long horizons in interactive environments. However, sparse and sometimes unverifiable rewards make temporal credit assignment extremely challenging. Recent work attempts to integrate process supervision into agent learning but suffers from biased annotation, reward hacking, high-variance from overly fine-grained signals or failtures when state overlap is rare. We therefore introduce Online Process Reward Learning (OPRL), a general credit-assignment strategy for agentic RL that integrates seamlessly with standard on-policy algorithms without relying on additional rollouts or explicit step labels. In OPRL, we optimize an implicit process reward model (PRM) alternately with the agent's policy to transform trajectory preferences into implicit step rewards through a trajectory-based DPO objective. These step rewards are then used to compute step-level advantages, which are combined with episode-level advantages from outcome rewards for policy update, creating a self-reinforcing loop. Theoretical findings guarantee that the learned step rewards are consistent with trajectory preferences and act as potential-based shaping rewards, providing bounded gradients to stabilize training. Empirically, we evaluate OPRL on three distinct agent benmarks, including WebShop and VisualSokoban, as well as open-ended social interactions with unverfiable rewards in SOTOPIA. Crucially, OPRL shows superior performance over frontier LLMs and strong RL baselines across domains, achieving state-of-the-art results with higher sample-efficiency and lower variance during training. Further analysis also demonstrates the efficient exploration by OPRL using fewer actions, underscoring its potential for agentic learning in real-world scenarios.
Steering Multimodal Large Language Models Decoding for Context-Aware Safety
arXiv:2509.19212v1 Announce Type: new Abstract: Multimodal Large Language Models (MLLMs) are increasingly deployed in real-world applications, yet their ability to make context-aware safety decisions remains limited. Existing methods often fail to balance oversensitivity (unjustified refusals of benign queries) and undersensitivity (missed detection of visually grounded risks), leaving a persistent gap in safety alignment. To address this issue, we introduce Safety-aware Contrastive Decoding (SafeCoDe), a lightweight and model-agnostic decoding framework that dynamically adjusts token generation based on multimodal context. SafeCoDe operates in two stages: (1) a contrastive decoding mechanism that highlights tokens sensitive to visual context by contrasting real and Gaussian-noised images, and (2) a global-aware token modulation strategy that integrates scene-level reasoning with token-level adjustment to adapt refusals according to the predicted safety verdict. Extensive experiments across diverse MLLM architectures and safety benchmarks, covering undersensitivity, oversensitivity, and general safety evaluations, show that SafeCoDe consistently improves context-sensitive refusal behaviors while preserving model helpfulness.
Systematic Comparative Analysis of Large Pretrained Language Models on Contextualized Medication Event Extraction
arXiv:2509.19224v1 Announce Type: new Abstract: Attention-based models have become the leading approach in modeling medical language for Natural Language Processing (NLP) in clinical notes. These models outperform traditional techniques by effectively capturing contextual rep- resentations of language. In this research a comparative analysis is done amongst pre- trained attention based models namely Bert Base, BioBert, two variations of Bio+Clinical Bert, RoBerta, and Clinical Long- former on task related to Electronic Health Record (EHR) information extraction. The tasks from Track 1 of Harvard Medical School's 2022 National Clinical NLP Challenges (n2c2) are considered for this comparison, with the Contextualized Medication Event Dataset (CMED) given for these task. CMED is a dataset of unstructured EHRs and annotated notes that contain task relevant information about the EHRs. The goal of the challenge is to develop effective solutions for extracting contextual information related to patient medication events from EHRs using data driven methods. Each pre-trained model is fine-tuned and applied on CMED to perform medication extraction, medical event detection, and multi-dimensional medication event context classification. Pro- cessing methods are also detailed for breaking down EHRs for compatibility with the applied models. Performance analysis has been carried out using a script based on constructing medical terms from the evaluation portion of CMED with metrics including recall, precision, and F1-Score. The results demonstrate that models pre-trained on clinical data are more effective in detecting medication and medication events, but Bert Base, pre- trained on general domain data showed to be the most effective for classifying the context of events related to medications.
CompLLM: Compression for Long Context Q&A
arXiv:2509.19228v1 Announce Type: new Abstract: Large Language Models (LLMs) face significant computational challenges when processing long contexts due to the quadratic complexity of self-attention. While soft context compression methods, which map input text to smaller latent representations, have shown promise, their real-world adoption is limited. Existing techniques typically compress the context as a single unit, which leads to quadratic compression complexity and an inability to reuse computations across queries with overlapping contexts. In this work, we introduce CompLLM, a soft compression technique designed for practical deployment. Instead of processing the context holistically, CompLLM divides it into segments and compresses each one independently. This simple design choice yields three critical properties: efficiency, as the compression step scales linearly with the context length; scalability, enabling models trained on short sequences (e.g., 1k tokens) to generalize to contexts of 100k tokens; and reusability, allowing compressed segments to be cached and reused across different queries. Our experiments show that with a 2x compression rate, at high context lengths CompLLM speeds up Time To First Token (TTFT) by up to 4x and reduces the KV cache size by 50%. Furthermore, CompLLM achieves performance comparable to that obtained with the uncompressed context, and even surpasses it on very long sequences, demonstrating its effectiveness and practical utility.
Reinforcement Learning on Pre-Training Data
arXiv:2509.19249v1 Announce Type: new Abstract: The growing disparity between the exponential scaling of computational resources and the finite growth of high-quality text data now constrains conventional scaling approaches for large language models (LLMs). To address this challenge, we introduce Reinforcement Learning on Pre-Training data (RLPT), a new training-time scaling paradigm for optimizing LLMs. In contrast to prior approaches that scale training primarily through supervised learning, RLPT enables the policy to autonomously explore meaningful trajectories to learn from pre-training data and improve its capability through reinforcement learning (RL). While existing RL strategies such as reinforcement learning from human feedback (RLHF) and reinforcement learning with verifiable rewards (RLVR) rely on human annotation for reward construction, RLPT eliminates this dependency by deriving reward signals directly from pre-training data. Specifically, it adopts a next-segment reasoning objective, rewarding the policy for accurately predicting subsequent text segments conditioned on the preceding context. This formulation allows RL to be scaled on pre-training data, encouraging the exploration of richer trajectories across broader contexts and thereby fostering more generalizable reasoning skills. Extensive experiments on both general-domain and mathematical reasoning benchmarks across multiple models validate the effectiveness of RLPT. For example, when applied to Qwen3-4B-Base, RLPT yields absolute improvements of $3.0$, $5.1$, $8.1$, $6.0$, $6.6$, and $5.3$ on MMLU, MMLU-Pro, GPQA-Diamond, KOR-Bench, AIME24, and AIME25, respectively. The results further demonstrate favorable scaling behavior, suggesting strong potential for continued gains with more compute. In addition, RLPT provides a solid foundation, extending the reasoning boundaries of LLMs and enhancing RLVR performance.
Extracting Conceptual Spaces from LLMs Using Prototype Embeddings
arXiv:2509.19269v1 Announce Type: new Abstract: Conceptual spaces represent entities and concepts using cognitively meaningful dimensions, typically referring to perceptual features. Such representations are widely used in cognitive science and have the potential to serve as a cornerstone for explainable AI. Unfortunately, they have proven notoriously difficult to learn, although recent LLMs appear to capture the required perceptual features to a remarkable extent. Nonetheless, practical methods for extracting the corresponding conceptual spaces are currently still lacking. While various methods exist for extracting embeddings from LLMs, extracting conceptual spaces also requires us to encode the underlying features. In this paper, we propose a strategy in which features (e.g. sweetness) are encoded by embedding the description of a corresponding prototype (e.g. a very sweet food). To improve this strategy, we fine-tune the LLM to align the prototype embeddings with the corresponding conceptual space dimensions. Our empirical analysis finds this approach to be highly effective.
SloPalSpeech: A 2,8000-Hour Slovak Speech Corpus from Parliamentary Data
arXiv:2509.19270v1 Announce Type: new Abstract: Automatic Speech Recognition (ASR) for low-resource languages like Slovak is hindered by the scarcity of training data. To address this, we introduce SloPalSpeech, a new, large-scale Slovak ASR dataset containing 2,806 hours of speech from parliamentary proceedings. We developed a robust processing pipeline to align and segment long-form recordings into clean, 30-second audio-transcript pairs suitable for model training. We use this dataset to fine-tune several OpenAI Whisper models (small, medium, large-v3, and large-v3-turbo), achieving significant Word Error Rate (WER) reductions on standard Slovak benchmarks like Common Voice and FLEURS. For instance, the fine-tuned Whisper-small model's WER dropped by up to 70\%, approaching the baseline performance of the much larger Whisper-large-v3 model. To foster future research in low-resource speech recognition, we publicly release the complete SloPalSpeech dataset, the fully segmented transcripts (60 million words), and all our fine-tuned models.
WolBanking77: Wolof Banking Speech Intent Classification Dataset
arXiv:2509.19271v1 Announce Type: new Abstract: Intent classification models have made a lot of progress in recent years. However, previous studies primarily focus on high-resource languages datasets, which results in a gap for low-resource languages and for regions with a high rate of illiterate people where languages are more spoken than read or written. This is the case in Senegal, for example, where Wolof is spoken by around 90\% of the population, with an illiteracy rate of 42\% for the country. Wolof is actually spoken by more than 10 million people in West African region. To tackle such limitations, we release a Wolof Intent Classification Dataset (WolBanking77), for academic research in intent classification. WolBanking77 currently contains 9,791 text sentences in the banking domain and more than 4 hours of spoken sentences. Experiments on various baselines are conducted in this work, including text and voice state-of-the-art models. The results are very promising on this current dataset. This paper also provides detailed analyses of the contents of the data. We report baseline f1-score and word error rate metrics respectively on NLP and ASR models trained on WolBanking77 dataset and also comparisons between models. We plan to share and conduct dataset maintenance, updates and to release open-source code.
DRISHTIKON: A Multimodal Multilingual Benchmark for Testing Language Models' Understanding on Indian Culture
arXiv:2509.19274v1 Announce Type: new Abstract: We introduce DRISHTIKON, a first-of-its-kind multimodal and multilingual benchmark centered exclusively on Indian culture, designed to evaluate the cultural understanding of generative AI systems. Unlike existing benchmarks with a generic or global scope, DRISHTIKON offers deep, fine-grained coverage across India's diverse regions, spanning 15 languages, covering all states and union territories, and incorporating over 64,000 aligned text-image pairs. The dataset captures rich cultural themes including festivals, attire, cuisines, art forms, and historical heritage amongst many more. We evaluate a wide range of vision-language models (VLMs), including open-source small and large models, proprietary systems, reasoning-specialized VLMs, and Indic-focused models, across zero-shot and chain-of-thought settings. Our results expose key limitations in current models' ability to reason over culturally grounded, multimodal inputs, particularly for low-resource languages and less-documented traditions. DRISHTIKON fills a vital gap in inclusive AI research, offering a robust testbed to advance culturally aware, multimodally competent language technologies.
Safe-SAIL: Towards a Fine-grained Safety Landscape of Large Language Models via Sparse Autoencoder Interpretation Framework
arXiv:2509.18127v1 Announce Type: cross Abstract: Increasing deployment of large language models (LLMs) in real-world applications raises significant safety concerns. Most existing safety research focuses on evaluating LLM outputs or specific safety tasks, limiting their ability to ad- dress broader, undefined risks. Sparse Autoencoders (SAEs) facilitate interpretability research to clarify model behavior by explaining single-meaning atomic features decomposed from entangled signals. jHowever, prior applications on SAEs do not interpret features with fine-grained safety-related con- cepts, thus inadequately addressing safety-critical behaviors, such as generating toxic responses and violating safety regu- lations. For rigorous safety analysis, we must extract a rich and diverse set of safety-relevant features that effectively capture these high-risk behaviors, yet face two challenges: identifying SAEs with the greatest potential for generating safety concept-specific neurons, and the prohibitively high cost of detailed feature explanation. In this paper, we pro- pose Safe-SAIL, a framework for interpreting SAE features within LLMs to advance mechanistic understanding in safety domains. Our approach systematically identifies SAE with best concept-specific interpretability, explains safety-related neurons, and introduces efficient strategies to scale up the in- terpretation process. We will release a comprehensive toolkit including SAE checkpoints and human-readable neuron ex- planations, which supports empirical analysis of safety risks to promote research on LLM safety.
PiMoE: Token-Level Routing for Integrating High-Precision Computation and Reasoning
arXiv:2509.18169v1 Announce Type: cross Abstract: Complex systems typically rely on high-precision numerical computation to support decisions, but current large language models (LLMs) cannot yet incorporate such computations as an intrinsic and interpretable capability with existing architectures. Mainstream multi-agent approaches can leverage external experts, but inevitably introduce communication overhead and suffer from inefficient multimodal emergent capability and limited scalability. To this end, we propose PiMoE (Physically-isolated Mixture of Experts), a training and inference architecture for integrating computation and reasoning. Instead of the workflow paradigm of tool invocation, PiMoE endogenously integrates computational capabilities into neural networks after separately training experts, a text-to-computation module, and a router. At inference, the router directs computation and reasoning at the token level, thereby enabling iterative alternation within a single chain of thought. We evaluate PiMoE on two reasoning-computation tasks against LLM finetuning and the multi-agent system approaches. Results show that the PiMoE architecture achieves not only higher accuracy than directly finetuning LLMs but also significant improvements in response latency, token usage, and GPU energy consumption compared with mainstream multi-agent approaches. PiMoE offers an efficient, interpretable, and scalable paradigm for next-generation scientific or industrial intelligent systems.
TurnBack: A Geospatial Route Cognition Benchmark for Large Language Models through Reverse Route
arXiv:2509.18173v1 Announce Type: cross Abstract: Humans can interpret geospatial information through natural language, while the geospatial cognition capabilities of Large Language Models (LLMs) remain underexplored. Prior research in this domain has been constrained by non-quantifiable metrics, limited evaluation datasets and unclear research hierarchies. Therefore, we propose a large-scale benchmark and conduct a comprehensive evaluation of the geospatial route cognition of LLMs. We create a large-scale evaluation dataset comprised of 36000 routes from 12 metropolises worldwide. Then, we introduce PathBuilder, a novel tool for converting natural language instructions into navigation routes, and vice versa, bridging the gap between geospatial information and natural language. Finally, we propose a new evaluation framework and metrics to rigorously assess 11 state-of-the-art (SOTA) LLMs on the task of route reversal. The benchmark reveals that LLMs exhibit limitation to reverse routes: most reverse routes neither return to the starting point nor are similar to the optimal route. Additionally, LLMs face challenges such as low robustness in route generation and high confidence for their incorrect answers. Code\ \&\ Data available here: \href{https://github.com/bghjmn32/EMNLP2025_Turnback}{TurnBack.}
Baseer: A Vision-Language Model for Arabic Document-to-Markdown OCR
arXiv:2509.18174v1 Announce Type: cross Abstract: Arabic document OCR remains a challenging task due to the language's cursive script, diverse fonts, diacritics, and right-to-left orientation. While modern Multimodal Large Language Models (MLLMs) have advanced document understanding for high-resource languages, their performance on Arabic remains limited. In this work, we introduce Baseer, a vision-language model fine- tuned specifically for Arabic document OCR. Leveraging a large-scale dataset combining synthetic and real-world documents, Baseer is trained using a decoder-only fine-tuning strategy to adapt a pre-trained MLLM while preserving general visual features. We also present Misraj-DocOCR, a high-quality, expert-verified benchmark designed for rigorous evaluation of Arabic OCR systems. Our experiments show that Baseer significantly outperforms existing open-source and commercial solutions, achieving a WER of 0.25 and establishing a new state-of-the-art in the domain of Arabic document OCR. Our results highlight the benefits of domain-specific adaptation of general-purpose MLLMs and establish a strong baseline for high-accuracy OCR on morphologically rich languages like Arabic.
Conversational Orientation Reasoning: Egocentric-to-Allocentric Navigation with Multimodal Chain-of-Thought
arXiv:2509.18200v1 Announce Type: cross Abstract: Conversational agents must translate egocentric utterances (e.g., "on my right") into allocentric orientations (N/E/S/W). This challenge is particularly critical in indoor or complex facilities where GPS signals are weak and detailed maps are unavailable. While chain-of-thought (CoT) prompting has advanced reasoning in language and vision tasks, its application to multimodal spatial orientation remains underexplored. We introduce Conversational Orientation Reasoning (COR), a new benchmark designed for Traditional Chinese conversational navigation projected from real-world environments, addressing egocentric-to-allocentric reasoning in non-English and ASR-transcribed scenarios. We propose a multimodal chain-of-thought (MCoT) framework, which integrates ASR-transcribed speech with landmark coordinates through a structured three-step reasoning process: (1) extracting spatial relations, (2) mapping coordinates to absolute directions, and (3) inferring user orientation. A curriculum learning strategy progressively builds these capabilities on Taiwan-LLM-13B-v2.0-Chat, a mid-sized model representative of resource-constrained settings. Experiments show that MCoT achieves 100% orientation accuracy on clean transcripts and 98.1% with ASR transcripts, substantially outperforming unimodal and non-structured baselines. Moreover, MCoT demonstrates robustness under noisy conversational conditions, including ASR recognition errors and multilingual code-switching. The model also maintains high accuracy in cross-domain evaluation and resilience to linguistic variation, domain shift, and referential ambiguity. These findings highlight the potential of structured MCoT spatial reasoning as a path toward interpretable and resource-efficient embodied navigation.
The Illusion of Readiness: Stress Testing Large Frontier Models on Multimodal Medical Benchmarks
arXiv:2509.18234v1 Announce Type: cross Abstract: Large frontier models like GPT-5 now achieve top scores on medical benchmarks. But our stress tests tell a different story. Leading systems often guess correctly even when key inputs like images are removed, flip answers under trivial prompt changes, and fabricate convincing yet flawed reasoning. These aren't glitches; they expose how today's benchmarks reward test-taking tricks over medical understanding. We evaluate six flagship models across six widely used benchmarks and find that high leaderboard scores hide brittleness and shortcut learning. Through clinician-guided rubric evaluation, we show that benchmarks vary widely in what they truly measure yet are treated interchangeably, masking failure modes. We caution that medical benchmark scores do not directly reflect real-world readiness. If we want AI to earn trust in healthcare, we must demand more than leaderboard wins and must hold systems accountable for robustness, sound reasoning, and alignment with real medical demands.
Memory-QA: Answering Recall Questions Based on Multimodal Memories
arXiv:2509.18436v1 Announce Type: cross Abstract: We introduce Memory-QA, a novel real-world task that involves answering recall questions about visual content from previously stored multimodal memories. This task poses unique challenges, including the creation of task-oriented memories, the effective utilization of temporal and location information within memories, and the ability to draw upon multiple memories to answer a recall question. To address these challenges, we propose a comprehensive pipeline, Pensieve, integrating memory-specific augmentation, time- and location-aware multi-signal retrieval, and multi-memory QA fine-tuning. We created a multimodal benchmark to illustrate various real challenges in this task, and show the superior performance of Pensieve over state-of-the-art solutions (up to 14% on QA accuracy).
No Verifiable Reward for Prosody: Toward Preference-Guided Prosody Learning in TTS
arXiv:2509.18531v1 Announce Type: cross Abstract: Recent work reports gains in neural text-to-speech (TTS) with Group Relative Policy Optimization (GRPO). However, in the absence of a verifiable reward for \textit{prosody}, GRPO trained on transcription-oriented signals (CER/NLL) lowers error rates yet collapses prosody into monotone, unnatural speech; adding speaker-similarity further destabilizes training and degrades CER. We address this with an \textit{iterative Direct Preference Optimization (DPO)} scheme that uses only a few hundred human-labeled preference pairs per round to directly optimize prosodic naturalness while regularizing to the current model. On \textbf{KoCC-TTS}, a curated dataset of authentic Korean call center interactions capturing task-oriented dialogues, our method attains the highest human preference (ELO) with competitive CER, outperforming GRPO and strong commercial baselines. These results suggest that when prosody cannot be rewarded automatically, \textit{human preference optimization} offers a practical and data-efficient path to natural and robust TTS. The demo page is available at \href{https://tts.ch.dev}
HarmoniFuse: A Component-Selective and Prompt-Adaptive Framework for Multi-Task Speech Language Modeling
arXiv:2509.18570v1 Announce Type: cross Abstract: Recent advances in large language models have facilitated the development of unified speech language models (SLMs) capable of supporting multiple speech tasks within a shared architecture. However, tasks such as automatic speech recognition (ASR) and speech emotion recognition (SER) rely on distinct types of information: ASR primarily depends on linguistic content, whereas SER requires the integration of both linguistic and paralinguistic cues. Existing multitask SLMs typically adopt naive parameter sharing or prompt-based conditioning without explicitly modeling the differences in information composition required by each task. Such designs risk task interference and performance degradation, especially under limited data conditions. To address these limitations, we propose HarmoniFuse, a component-selective and prompt-adaptive framework for multi-task speech language modeling. HarmoniFuse is designed to harmonize heterogeneous task demands by selecting and fusing task-relevant components of speech representations. Specifically, it integrates a gated speech encoder to extract task-specific acoustic features and a prompt-adaptive dynamic fusion module to aggregate transformer layers based on task characteristics. In addition, a batch-interleaved training strategy enables leveraging separate ASR and SER datasets without requiring joint annotation. Experimental results demonstrate that HarmoniFuse improves both ASR and SER performance, offering a scalable and robust solution for multitask speech understanding under realistic data constraints.
Teaching Audio Models to Reason: A Unified Framework for Source- and Layer-wise Distillation
arXiv:2509.18579v1 Announce Type: cross Abstract: While large audio language models excel at tasks like ASR and emotion recognition, they still struggle with complex reasoning due to the modality gap between audio and text as well as the lack of structured intermediate supervision. To address this, we propose a unified knowledge distillation framework to transfer reasoning capabilities from a high-capacity textual teacher model to a student audio models while preserving its acoustic competence. Our method introduces two key dimensions: source-wise distillation, which leverages both textual and acoustic teachers to provide complementary modality-specific supervision; and layer-wise distillation, which aligns teacher signals with appropriate student layers to improve transfer efficiency. This dual-dimensional strategy enables fine-grained control over the distillation process, effectively bridging the gap between symbolic reasoning and speech representations. Experimental results show significant improvements in audio reasoning performance, demonstrating the effectiveness of our framework as a reasoning transfer solution for audio modeling.
OraPO: Oracle-educated Reinforcement Learning for Data-efficient and Factual Radiology Report Generation
arXiv:2509.18600v1 Announce Type: cross Abstract: Radiology report generation (RRG) aims to automatically produce clinically faithful reports from chest X-ray images. Prevailing work typically follows a scale-driven paradigm, by multi-stage training over large paired corpora and oversized backbones, making pipelines highly data- and compute-intensive. In this paper, we propose Oracle-educated GRPO {OraPO) with a FactScore-based reward (FactS) to tackle the RRG task under constrained budgets. OraPO enables single-stage, RL-only training by converting failed GRPO explorations on rare or difficult studies into direct preference supervision via a lightweight oracle step. FactS grounds learning in diagnostic evidence by extracting atomic clinical facts and checking entailment against ground-truth labels, yielding dense, interpretable sentence-level rewards. Together, OraPO and FactS create a compact and powerful framework that significantly improves learning efficiency on clinically challenging cases, setting the new SOTA performance on the CheXpert Plus dataset (0.341 in F1) with 2--3 orders of magnitude less training data using a small base VLM on modest hardware.
Agentic AutoSurvey: Let LLMs Survey LLMs
arXiv:2509.18661v1 Announce Type: cross Abstract: The exponential growth of scientific literature poses unprecedented challenges for researchers attempting to synthesize knowledge across rapidly evolving fields. We present \textbf{Agentic AutoSurvey}, a multi-agent framework for automated survey generation that addresses fundamental limitations in existing approaches. Our system employs four specialized agents (Paper Search Specialist, Topic Mining \& Clustering, Academic Survey Writer, and Quality Evaluator) working in concert to generate comprehensive literature surveys with superior synthesis quality. Through experiments on six representative LLM research topics from COLM 2024 categories, we demonstrate that our multi-agent approach achieves significant improvements over existing baselines, scoring 8.18/10 compared to AutoSurvey's 4.77/10. The multi-agent architecture processes 75--443 papers per topic (847 total across six topics) while targeting high citation coverage (often $\geq$80\% on 75--100-paper sets; lower on very large sets such as RLHF) through specialized agent orchestration. Our 12-dimension evaluation captures organization, synthesis integration, and critical analysis beyond basic metrics. These findings demonstrate that multi-agent architectures represent a meaningful advancement for automated literature survey generation in rapidly evolving scientific domains.
Pay More Attention To Audio: Mitigating Imbalance of Cross-Modal Attention in Large Audio Language Models
arXiv:2509.18816v1 Announce Type: cross Abstract: Large Audio-Language Models (LALMs) often suffer from audio-textual attention imbalance, prioritizing text over acoustic information, particularly in the multi-modal fusion layers of the Transformer architecture. This bias hinders their ability to fully utilize acoustic cues, causing suboptimal performance on audio reasoning tasks. To mitigate this, we propose \textbf{MATA}, a novel training-free method that dynamically pushes LALMs to pay \textbf{M}ore \textbf{A}ttention \textbf{T}o \textbf{A}udio tokens within the self-attention mechanism. Specifically, MATA intervenes post raw attention scoring, targeting only the last token in intermediate layers without introducing additional parameters or computational overhead. Experiments on the MMAU and MMAR benchmarks confirm MATA's effectiveness, with consistent performance gains. Notably, on MMAR, MATA enables an open-source model to surpass the proprietary Gemini 2.0 Flash for the first time. Our work provides an efficient solution to mitigate attention bias and opens a new research direction for enhancing the audio-processing capabilities of multi-modal models.
Failure Makes the Agent Stronger: Enhancing Accuracy through Structured Reflection for Reliable Tool Interactions
arXiv:2509.18847v1 Announce Type: cross Abstract: Tool-augmented large language models (LLMs) are usually trained with supervised imitation or coarse-grained reinforcement learning that optimizes single tool calls. Current self-reflection practices rely on heuristic prompts or one-way reasoning: the model is urged to 'think more' instead of learning error diagnosis and repair. This is fragile in multi-turn interactions; after a failure the model often repeats the same mistake. We propose structured reflection, which turns the path from error to repair into an explicit, controllable, and trainable action. The agent produces a short yet precise reflection: it diagnoses the failure using evidence from the previous step and then proposes a correct, executable follow-up call. For training we combine DAPO and GSPO objectives with a reward scheme tailored to tool use, optimizing the stepwise strategy Reflect, then Call, then Final. To evaluate, we introduce Tool-Reflection-Bench, a lightweight benchmark that programmatically checks structural validity, executability, parameter correctness, and result consistency. Tasks are built as mini trajectories of erroneous call, reflection, and corrected call, with disjoint train and test splits. Experiments on BFCL v3 and Tool-Reflection-Bench show large gains in multi-turn tool-call success and error recovery, and a reduction of redundant calls. These results indicate that making reflection explicit and optimizing it directly improves the reliability of tool interaction and offers a reproducible path for agents to learn from failure.
VIR-Bench: Evaluating Geospatial and Temporal Understanding of MLLMs via Travel Video Itinerary Reconstruction
arXiv:2509.19002v1 Announce Type: cross Abstract: Recent advances in multimodal large language models (MLLMs) have significantly enhanced video understanding capabilities, opening new possibilities for practical applications. Yet current video benchmarks focus largely on indoor scenes or short-range outdoor activities, leaving the challenges associated with long-distance travel largely unexplored. Mastering extended geospatial-temporal trajectories is critical for next-generation MLLMs, underpinning real-world tasks such as embodied-AI planning and navigation. To bridge this gap, we present VIR-Bench, a novel benchmark consisting of 200 travel videos that frames itinerary reconstruction as a challenging task designed to evaluate and push forward MLLMs' geospatial-temporal intelligence. Experimental results reveal that state-of-the-art MLLMs, including proprietary ones, struggle to achieve high scores, underscoring the difficulty of handling videos that span extended spatial and temporal scales. Moreover, we conduct an in-depth case study in which we develop a prototype travel-planning agent that leverages the insights gained from VIR-Bench. The agent's markedly improved itinerary recommendations verify that our evaluation protocol not only benchmarks models effectively but also translates into concrete performance gains in user-facing applications.
ColorBlindnessEval: Can Vision-Language Models Pass Color Blindness Tests?
arXiv:2509.19070v1 Announce Type: cross Abstract: This paper presents ColorBlindnessEval, a novel benchmark designed to evaluate the robustness of Vision-Language Models (VLMs) in visually adversarial scenarios inspired by the Ishihara color blindness test. Our dataset comprises 500 Ishihara-like images featuring numbers from 0 to 99 with varying color combinations, challenging VLMs to accurately recognize numerical information embedded in complex visual patterns. We assess 9 VLMs using Yes/No and open-ended prompts and compare their performance with human participants. Our experiments reveal limitations in the models' ability to interpret numbers in adversarial contexts, highlighting prevalent hallucination issues. These findings underscore the need to improve the robustness of VLMs in complex visual environments. ColorBlindnessEval serves as a valuable tool for benchmarking and improving the reliability of VLMs in real-world applications where accuracy is critical.
Citrus-V: Advancing Medical Foundation Models with Unified Medical Image Grounding for Clinical Reasoning
arXiv:2509.19090v1 Announce Type: cross Abstract: Medical imaging provides critical evidence for clinical diagnosis, treatment planning, and surgical decisions, yet most existing imaging models are narrowly focused and require multiple specialized networks, limiting their generalization. Although large-scale language and multimodal models exhibit strong reasoning and multi-task capabilities, real-world clinical applications demand precise visual grounding, multimodal integration, and chain-of-thought reasoning. We introduce Citrus-V, a multimodal medical foundation model that combines image analysis with textual reasoning. The model integrates detection, segmentation, and multimodal chain-of-thought reasoning, enabling pixel-level lesion localization, structured report generation, and physician-like diagnostic inference in a single framework. We propose a novel multimodal training approach and release a curated open-source data suite covering reasoning, detection, segmentation, and document understanding tasks. Evaluations demonstrate that Citrus-V outperforms existing open-source medical models and expert-level imaging systems across multiple benchmarks, delivering a unified pipeline from visual grounding to clinical reasoning and supporting precise lesion quantification, automated reporting, and reliable second opinions.
Finding My Voice: Generative Reconstruction of Disordered Speech for Automated Clinical Evaluation
arXiv:2509.19231v1 Announce Type: cross Abstract: We present ChiReSSD, a speech reconstruction framework that preserves children speaker's identity while suppressing mispronunciations. Unlike prior approaches trained on healthy adult speech, ChiReSSD adapts to the voices of children with speech sound disorders (SSD), with particular emphasis on pitch and prosody. We evaluate our method on the STAR dataset and report substantial improvements in lexical accuracy and speaker identity preservation. Furthermore, we automatically predict the phonetic content in the original and reconstructed pairs, where the proportion of corrected consonants is comparable to the percentage of correct consonants (PCC), a clinical speech assessment metric. Our experiments show Pearson correlation of 0.63 between automatic and human expert annotations, highlighting the potential to reduce the manual transcription burden. In addition, experiments on the TORGO dataset demonstrate effective generalization for reconstructing adult dysarthric speech. Our results indicate that disentangled, style-based TTS reconstruction can provide identity-preserving speech across diverse clinical populations.
Cross-Cultural Transfer of Commonsense Reasoning in LLMs: Evidence from the Arab World
arXiv:2509.19265v1 Announce Type: cross Abstract: Large language models (LLMs) often reflect Western-centric biases, limiting their effectiveness in diverse cultural contexts. Although some work has explored cultural alignment, the potential for cross-cultural transfer, using alignment in one culture to improve performance in others, remains underexplored. This paper investigates cross-cultural transfer of commonsense reasoning in the Arab world, where linguistic and historical similarities coexist with local cultural differences. Using a culturally grounded commonsense reasoning dataset covering 13 Arab countries, we evaluate lightweight alignment methods such as in-context learning and demonstration-based reinforcement (DITTO), alongside baselines like supervised fine-tuning and direct preference optimization. Our results show that merely 12 culture-specific examples from one country can improve performance in others by 10\% on average, within multilingual models. In addition, we demonstrate that out-of-culture demonstrations from Indonesia and US contexts can match or surpass in-culture alignment for MCQ reasoning, highlighting cultural commonsense transferability beyond the Arab world. These findings demonstrate that efficient cross-cultural alignment is possible and offer a promising approach to adapt LLMs to low-resource cultural settings.
LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via a Hybrid Architecture
arXiv:2409.02889v3 Announce Type: replace Abstract: Expanding the long-context capabilities of Multi-modal Large Language Models~(MLLMs) is critical for advancing video understanding and high-resolution image analysis. Achieving this requires systematic improvements in model architecture, data construction, and training strategies, particularly to address challenges such as performance degradation with increasing image counts and high computational costs. In this paper, we propose a hybrid architecture that integrates Mamba and Transformer blocks, introduce data construction methods that capture both temporal and spatial dependencies, and employ a progressive training strategy. Our released model, LongLLaVA (\textbf{Long}-Context \textbf{L}arge \textbf{L}anguage \textbf{a}nd \textbf{V}ision \textbf{A}ssistant), demonstrates an effective balance between efficiency and performance. LongLLaVA achieves competitive results across various benchmarks while maintaining high throughput and low memory consumption. Notably, it can process nearly one thousand images on a single A100 80GB GPU, underscoring its potential for a wide range of multi-modal applications.
GALLa: Graph Aligned Large Language Models for Improved Source Code Understanding
arXiv:2409.04183v4 Announce Type: replace Abstract: Programming languages possess rich semantic information - such as data flow - that is represented by graphs and not available from the surface form of source code. Recent code language models have scaled to billions of parameters, but model source code solely as text tokens while ignoring any other structural information. Conversely, models that do encode structural information of code make modifications to the Transformer architecture, limiting their scale and compatibility with pretrained LLMs. In this work, we take the best of both worlds with GALLa - Graph Aligned Large Language Models. GALLa utilizes graph neural networks and cross-modal alignment technologies to inject the structural information of code into LLMs as an auxiliary task during finetuning. This framework is both model-agnostic and task-agnostic, as it can be applied to any code LLM for any code downstream task, and requires the structural graph data only at training time from a corpus unrelated to the finetuning data, while incurring no cost at inference time over the baseline LLM. Experiments on five code tasks with seven different baseline LLMs ranging in size from 350M to 14B validate the effectiveness of GALLa, demonstrating consistent improvement over the baseline, even for powerful models such as LLaMA3 and Qwen2.5-Coder.
Enhancing Unsupervised Sentence Embeddings via Knowledge-Driven Data Augmentation and Gaussian-Decayed Contrastive Learning
arXiv:2409.12887v4 Announce Type: replace Abstract: Recently, using large language models (LLMs) for data augmentation has led to considerable improvements in unsupervised sentence embedding models. However, existing methods encounter two primary challenges: limited data diversity and high data noise. Current approaches often neglect fine-grained knowledge, such as entities and quantities, leading to insufficient diversity. Besides, unsupervised data frequently lacks discriminative information, and the generated synthetic samples may introduce noise. In this paper, we propose a pipeline-based data augmentation method via LLMs and introduce the Gaussian-decayed gradient-assisted Contrastive Sentence Embedding (GCSE) model to enhance unsupervised sentence embeddings. To tackle the issue of low data diversity, our pipeline utilizes knowledge graphs (KGs) to extract entities and quantities, enabling LLMs to generate more diverse samples. To address high data noise, the GCSE model uses a Gaussian-decayed function to limit the impact of false hard negative samples, enhancing the model's discriminative capability. Experimental results show that our approach achieves state-of-the-art performance in semantic textual similarity (STS) tasks, using fewer data samples and smaller LLMs, demonstrating its efficiency and robustness across various models.
Post-hoc Study of Climate Microtargeting on Social Media Ads with LLMs: Thematic Insights and Fairness Evaluation
arXiv:2410.05401v4 Announce Type: replace Abstract: Climate change communication on social media increasingly employs microtargeting strategies to effectively reach and influence specific demographic groups. This study presents a post-hoc analysis of microtargeting practices within climate campaigns by leveraging large language models (LLMs) to examine Meta (previously known as Facebook) advertisements. Our analysis focuses on two key aspects: demographic targeting and fairness. We evaluate the ability of LLMs to accurately predict the intended demographic targets, such as gender and age group. Furthermore, we instruct the LLMs to generate explanations for their classifications, providing transparent reasoning behind each decision. These explanations reveal the specific thematic elements used to engage different demographic segments, highlighting distinct strategies tailored to various audiences. Our findings show that young adults are primarily targeted through messages emphasizing activism and environmental consciousness, while women are engaged through themes related to caregiving roles and social advocacy. Additionally, we conduct a comprehensive fairness analysis to uncover biases in model predictions. We assess disparities in accuracy and error rates across demographic groups using established fairness metrics such as Demographic Parity, Equal Opportunity, and Predictive Equality. Our findings indicate that while LLMs perform well overall, certain biases exist, particularly in the classification of male audiences. The analysis of thematic explanations uncovers recurring patterns in messaging strategies tailored to various demographic groups, while the fairness analysis underscores the need for more inclusive targeting methods. This study provides a valuable framework for future research aimed at enhancing transparency, accountability, and inclusivity in social media-driven climate campaigns.
Exploring Model Kinship for Merging Large Language Models
arXiv:2410.12613v3 Announce Type: replace Abstract: Model merging has emerged as a key technique for enhancing the capabilities and efficiency of Large Language Models (LLMs). The open-source community has driven model evolution by iteratively merging existing models, yet a principled understanding of the gains and underlying factors in model merging remains limited. In this work, we study model evolution through iterative merging, drawing an analogy to biological evolution, and introduce the concept of model kinship, the degree of similarity or relatedness between LLMs. Through comprehensive empirical analysis, we show that model kinship is closely linked to the performance improvements achieved by merging, providing a useful criterion for selecting candidate models. Building on this insight, we propose a new model merging strategy: Top-k Greedy Merging with Model Kinship, which can improve benchmark performance. Specifically, we discover that incorporating model kinship as a guiding criterion enables continuous merging while mitigating performance degradation caused by local optima, thereby facilitating more effective model evolution. Code is available at https://github.com/zjunlp/ModelKinship.
Language Models as Causal Effect Generators
arXiv:2411.08019v2 Announce Type: replace Abstract: In this work, we present sequence-driven structural causal models (SD-SCMs), a framework for specifying causal models with user-defined structure and language-model-defined mechanisms. We characterize how an SD-SCM enables sampling from observational, interventional, and counterfactual distributions according to the desired causal structure. We then leverage this procedure to propose a new type of benchmark for causal inference methods, generating individual-level counterfactual data to test treatment effect estimation. We create an example benchmark consisting of thousands of datasets, and test a suite of popular estimation methods for average, conditional average, and individual treatment effect estimation. We find under this benchmark that (1) causal methods outperform non-causal methods and that (2) even state-of-the-art methods struggle with individualized effect estimation, suggesting this benchmark captures some inherent difficulties in causal estimation. Apart from generating data, this same technique can underpin the auditing of language models for (un)desirable causal effects, such as misinformation or discrimination. We believe SD-SCMs can serve as a useful tool in any application that would benefit from sequential data with controllable causal structure.
Compositional Phoneme Approximation for L1-Grounded L2 Pronunciation Training
arXiv:2411.10927v4 Announce Type: replace Abstract: Learners of a second language (L2) often map non-native phonemes with similar native-language (L1) phonemes, making conventional L2-focused training slow and effortful. To address this, we propose an L1-grounded pronunciation training method based on compositional phoneme approximation (CPA), a feature-based representation technique that approximates L2 sounds with sequences of L1 phonemes. Evaluations with 20 Korean non-native English speakers show that CPA-based training achieves a 76% in-box formant rate in acoustic analysis, over 20% relative improvement in phoneme recognition accuracy, and over 80% of speech being rated as more native-like, with minimal training.
Improving Low-Resource Sequence Labeling with Knowledge Fusion and Contextual Label Explanations
arXiv:2501.19093v3 Announce Type: replace Abstract: Sequence labeling remains a significant challenge in low-resource, domain-specific scenarios, particularly for character-dense languages like Chinese. Existing methods primarily focus on enhancing model comprehension and improving data diversity to boost performance. However, these approaches still struggle with inadequate model applicability and semantic distribution biases in domain-specific contexts. To overcome these limitations, we propose a novel framework that combines an LLM-based knowledge enhancement workflow with a span-based Knowledge Fusion for Rich and Efficient Extraction (KnowFREE) model. Our workflow employs explanation prompts to generate precise contextual interpretations of target entities, effectively mitigating semantic biases and enriching the model's contextual understanding. The KnowFREE model further integrates extension label features, enabling efficient nested entity extraction without relying on external knowledge during inference. Experiments on multiple Chinese domain-specific sequence labeling datasets demonstrate that our approach achieves state-of-the-art performance, effectively addressing the challenges posed by low-resource settings.
VLDBench Evaluating Multimodal Disinformation with Regulatory Alignment
arXiv:2502.11361v4 Announce Type: replace Abstract: Detecting disinformation that blends manipulated text and images has become increasingly challenging, as AI tools make synthetic content easy to generate and disseminate. While most existing AI safety benchmarks focus on single modality misinformation (i.e., false content shared without intent to deceive), intentional multimodal disinformation, such as propaganda or conspiracy theories that imitate credible news, remains largely unaddressed. We introduce the Vision-Language Disinformation Detection Benchmark (VLDBench), the first large-scale resource supporting both unimodal (text-only) and multimodal (text + image) disinformation detection. VLDBench comprises approximately 62,000 labeled text-image pairs across 13 categories, curated from 58 news outlets. Using a semi-automated pipeline followed by expert review, 22 domain experts invested over 500 hours to produce high-quality annotations with substantial inter-annotator agreement. Evaluations of state-of-the-art Large Language Models (LLMs) and Vision-Language Models (VLMs) on VLDBench show that incorporating visual cues improves detection accuracy by 5 to 35 percentage points over text-only models. VLDBench provides data and code for evaluation, fine-tuning, and robustness testing to support disinformation analysis. Developed in alignment with AI governance frameworks (e.g., the MIT AI Risk Repository), VLDBench offers a principled foundation for advancing trustworthy disinformation detection in multimodal media. Project: https://vectorinstitute.github.io/VLDBench/ Dataset: https://huggingface.co/datasets/vector-institute/VLDBench Code: https://github.com/VectorInstitute/VLDBench
Language Models Can Predict Their Own Behavior
arXiv:2502.13329v2 Announce Type: replace Abstract: The text produced by language models (LMs) can exhibit specific `behaviors,' such as a failure to follow alignment training, that we hope to detect and react to during deployment. Identifying these behaviors can often only be done post facto, i.e., after the entire text of the output has been generated. We provide evidence that there are times when we can predict how an LM will behave early in computation, before even a single token is generated. We show that probes trained on the internal representation of input tokens alone can predict a wide range of eventual behaviors over the entire output sequence. Using methods from conformal prediction, we provide provable bounds on the estimation error of our probes, creating precise early warning systems for these behaviors. The conformal probes can identify instances that will trigger alignment failures (jailbreaking) and instruction-following failures, without requiring a single token to be generated. An early warning system built on the probes reduces jailbreaking by 91%. Our probes also show promise in pre-emptively estimating how confident the model will be in its response, a behavior that cannot be detected using the output text alone. Conformal probes can preemptively estimate the final prediction of an LM that uses Chain-of-Thought (CoT) prompting, hence accelerating inference. When applied to an LM that uses CoT to perform text classification, the probes drastically reduce inference costs (65% on average across 27 datasets), with negligible accuracy loss. Encouragingly, probes generalize to unseen datasets and perform better on larger models, suggesting applicability to the largest of models in real-world settings.
Triangulating LLM Progress through Benchmarks, Games, and Cognitive Tests
arXiv:2502.14359v3 Announce Type: replace Abstract: We examine three evaluation paradigms: standard benchmarks (e.g., MMLU and BBH), interactive games (e.g., Signalling Games or Taboo), and cognitive tests (e.g., for working memory or theory of mind). First, we investigate which of the former two-benchmarks or games-is most effective at discriminating LLMs of varying quality. Then, inspired by human cognitive assessments, we compile a suite of targeted tests that measure cognitive abilities deemed essential for effective language use, and we investigate their correlation with model performance in benchmarks and games. Our analyses reveal that interactive games are superior to standard benchmarks in discriminating models. Causal and logical reasoning correlate with both static and interactive tests, while differences emerge regarding core executive functions and social/emotional skills, which correlate more with games. We advocate for the development of new interactive benchmarks and targeted cognitive tasks inspired by assessing human abilities but designed specifically for LLMs.
LightThinker: Thinking Step-by-Step Compression
arXiv:2502.15589v2 Announce Type: replace Abstract: Large language models (LLMs) have shown remarkable performance in complex reasoning tasks, but their efficiency is hindered by the substantial memory and computational costs associated with generating lengthy tokens. In this paper, we propose LightThinker, a novel method that enables LLMs to dynamically compress intermediate thoughts during reasoning. Inspired by human cognitive processes, LightThinker compresses verbose thought steps into compact representations and discards the original reasoning chains, thereby significantly reducing the number of tokens stored in the context window. This is achieved by training the model on when and how to perform compression through data construction, mapping hidden states to condensed gist tokens, and creating specialized attention masks. Additionally, we introduce the Dependency (Dep) metric to quantify the degree of compression by measuring the reliance on historical tokens during generation. Extensive experiments on four datasets and two models show that LightThinker reduces peak memory usage and inference time, while maintaining competitive accuracy. Our work provides a new direction for improving the efficiency of LLMs in complex reasoning tasks without sacrificing performance. Code is released at https://github.com/zjunlp/LightThinker.
Can LLMs Explain Themselves Counterfactually?
arXiv:2502.18156v2 Announce Type: replace Abstract: Explanations are an important tool for gaining insights into the behavior of ML models, calibrating user trust and ensuring regulatory compliance. Past few years have seen a flurry of post-hoc methods for generating model explanations, many of which involve computing model gradients or solving specially designed optimization problems. However, owing to the remarkable reasoning abilities of Large Language Model (LLMs), self-explanation, that is, prompting the model to explain its outputs has recently emerged as a new paradigm. In this work, we study a specific type of self-explanations, self-generated counterfactual explanations (SCEs). We design tests for measuring the efficacy of LLMs in generating SCEs. Analysis over various LLM families, model sizes, temperature settings, and datasets reveals that LLMs sometimes struggle to generate SCEs. Even when they do, their prediction often does not agree with their own counterfactual reasoning.
Anything Goes? A Crosslinguistic Study of (Im)possible Language Learning in LMs
arXiv:2502.18795v3 Announce Type: replace Abstract: Do language models (LMs) offer insights into human language learning? A common argument against this idea is that because their architecture and training paradigm are so vastly different from humans, LMs can learn arbitrary inputs as easily as natural languages. We test this claim by training LMs to model impossible and typologically unattested languages. Unlike previous work, which has focused exclusively on English, we conduct experiments on 12 languages from 4 language families with two newly constructed parallel corpora. Our results show that while GPT-2 small can largely distinguish attested languages from their impossible counterparts, it does not achieve perfect separation between all the attested languages and all the impossible ones. We further test whether GPT-2 small distinguishes typologically attested from unattested languages with different NP orders by manipulating word order based on Greenberg's Universal 20. We find that the model's perplexity scores do not distinguish attested vs. unattested word orders, while its performance on the generalization test does. These findings suggest that LMs exhibit some human-like inductive biases, though these biases are weaker than those found in human learners.
Promote, Suppress, Iterate: How Language Models Answer One-to-Many Factual Queries
arXiv:2502.20475v3 Announce Type: replace Abstract: To answer one-to-many factual queries (e.g., listing cities of a country), a language model (LM) must simultaneously recall knowledge and avoid repeating previous answers. How are these two subtasks implemented and integrated internally? Across multiple datasets, models, and prompt templates, we identify a promote-then-suppress mechanism: the model first recalls all answers, and then suppresses previously generated ones. Specifically, LMs use both the subject and previous answer tokens to perform knowledge recall, with attention propagating subject information and MLPs promoting the answers. Then, attention attends to and suppresses previous answer tokens, while MLPs amplify the suppression signal. Our mechanism is corroborated by extensive experimental evidence: in addition to using early decoding and causal tracing, we analyze how components use different tokens by introducing both Token Lens, which decodes aggregated attention updates from specified tokens, and a knockout method that analyzes changes in MLP outputs after removing attention to specified tokens. Overall, we provide new insights into how LMs' internal components interact with different input tokens to support complex factual recall. Code is available at https://github.com/Lorenayannnnn/how-lms-answer-one-to-many-factual-queries.
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
arXiv:2502.21074v3 Announce Type: replace Abstract: Chain-of-Thought (CoT) reasoning enhances Large Language Models (LLMs) by encouraging step-by-step reasoning in natural language. However, leveraging a latent continuous space for reasoning may offer benefits in terms of both efficiency and robustness. Prior implicit CoT methods attempt to bypass language completely by reasoning in continuous space but have consistently underperformed compared to the standard explicit CoT approach. We introduce CODI (Continuous Chain-of-Thought via Self-Distillation), a novel training framework that effectively compresses natural language CoT into continuous space. CODI jointly trains a teacher task (Explicit CoT) and a student task (Implicit CoT), distilling the reasoning ability from language into continuous space by aligning the hidden states of a designated token. Our experiments show that CODI is the first implicit CoT approach to match the performance of explicit CoT on GSM8k at the GPT-2 scale, achieving a 3.1x compression rate and outperforming the previous state-of-the-art by 28.2% in accuracy. CODI also demonstrates robustness, generalizable to complex datasets, and interpretability. These results validate that LLMs can reason effectively not only in natural language, but also in a latent continuous space. Code is available at https://github.com/zhenyi4/codi.
CaKE: Circuit-aware Editing Enables Generalizable Knowledge Learners
arXiv:2503.16356v2 Announce Type: replace Abstract: Knowledge Editing (KE) enables the modification of outdated or incorrect information in large language models (LLMs). While existing KE methods can update isolated facts, they often fail to generalize these updates to multi-hop reasoning tasks that rely on the modified knowledge. Through an analysis of reasoning circuits -- the neural pathways LLMs use for knowledge-based inference, we find that current layer-localized KE approaches (e.g., MEMIT, WISE), which edit only single or a few model layers, inadequately integrate updated knowledge into these reasoning pathways. To address this limitation, we present CaKE (Circuit-aware Knowledge Editing), a novel method that enhances the effective integration of updated knowledge in LLMs. By only leveraging a few curated data samples guided by our circuit-based analysis, CaKE stimulates the model to develop appropriate reasoning circuits for newly incorporated knowledge. Experiments show that CaKE enables more accurate and consistent use of edited knowledge across related reasoning tasks, achieving an average improvement of 20% in multi-hop reasoning accuracy on the MQuAKE dataset while requiring less memory than existing KE methods. We release the code and data in https://github.com/zjunlp/CaKE.
LookAhead Tuning: Safer Language Models via Partial Answer Previews
arXiv:2503.19041v2 Announce Type: replace Abstract: Fine-tuning enables large language models (LLMs) to adapt to specific domains, but often compromises their previously established safety alignment. To mitigate the degradation of model safety during fine-tuning, we introduce LookAhead Tuning, a lightweight and effective data-driven approach that preserves safety during fine-tuning. The method introduces two simple strategies that modify training data by previewing partial answer prefixes, thereby minimizing perturbations to the model's initial token distributions and maintaining its built-in safety mechanisms. Comprehensive experiments demonstrate that LookAhead Tuning effectively maintains model safety without sacrificing robust performance on downstream tasks. Our findings position LookAhead Tuning as a reliable and efficient solution for the safe and effective adaptation of LLMs.
Pandora: A Code-Driven Large Language Model Agent for Unified Reasoning Across Diverse Structured Knowledge
arXiv:2504.12734v2 Announce Type: replace Abstract: Unified Structured Knowledge Reasoning (USKR) aims to answer natural language questions (NLQs) by using structured sources such as tables, databases, and knowledge graphs in a unified way. Existing USKR methods either rely on employing task-specific strategies or custom-defined representations, which struggle to leverage the knowledge transfer between different SKR tasks or align with the prior of LLMs, thereby limiting their performance. This paper proposes a novel USKR framework named \textsc{Pandora}, which takes advantage of \textsc{Python}'s \textsc{Pandas} API to construct a unified knowledge representation for alignment with LLM pre-training. It employs an LLM to generate textual reasoning steps and executable Python code for each question. Demonstrations are drawn from a memory of training examples that cover various SKR tasks, facilitating knowledge transfer. Extensive experiments on four benchmarks involving three SKR tasks demonstrate that \textsc{Pandora} outperforms existing unified frameworks and competes effectively with task-specific methods.
Think in Safety: Unveiling and Mitigating Safety Alignment Collapse in Multimodal Large Reasoning Model
arXiv:2505.06538v3 Announce Type: replace Abstract: The rapid development of Multimodal Large Reasoning Models (MLRMs) has demonstrated broad application potential, yet their safety and reliability remain critical concerns that require systematic exploration. To address this gap, we conduct a comprehensive and systematic safety evaluation of 11 MLRMs across 5 benchmarks and unveil prevalent safety degradation phenomena in most advanced models. Moreover, our analysis reveals distinct safety patterns across different benchmarks: significant safety degradation is observed across jailbreak robustness benchmarks, whereas safety-awareness benchmarks demonstrate less pronounced degradation. In particular, the long thought process in some scenarios even enhances safety performance. Therefore, it is a potential approach to address safety issues in MLRMs by leveraging the intrinsic reasoning capabilities of the model to detect unsafe intent. To operationalize this insight, we construct a multimodal tuning dataset that incorporates a safety-oriented thought process. Experimental results from fine-tuning existing MLRMs with this dataset effectively enhances the safety on both jailbreak robustness and safety-awareness benchmarks. This study provides a new perspective for developing safe MLRMs. Our dataset is available at https://github.com/xinyuelou/Think-in-Safety.
Benchmarking Critical Questions Generation: A Challenging Reasoning Task for Large Language Models
arXiv:2505.11341v3 Announce Type: replace Abstract: The task of Critical Questions Generation (CQs-Gen) aims to foster critical thinking by enabling systems to generate questions that expose underlying assumptions and challenge the validity of argumentative reasoning structures. Despite growing interest in this area, progress has been hindered by the lack of suitable datasets and automatic evaluation standards. This paper presents a comprehensive approach to support the development and benchmarking of systems for this task. We construct the first large-scale dataset including ~5K manually annotated questions. We also investigate automatic evaluation methods and propose reference-based techniques as the strategy that best correlates with human judgments. Our zero-shot evaluation of 11 LLMs establishes a strong baseline while showcasing the difficulty of the task. Data and code plus a public leaderboard are provided to encourage further research, not only in terms of model performance, but also to explore the practical benefits of CQs-Gen for both automated reasoning and human critical thinking.
Disambiguation in Conversational Question Answering in the Era of LLMs and Agents: A Survey
arXiv:2505.12543v2 Announce Type: replace Abstract: Ambiguity remains a fundamental challenge in Natural Language Processing (NLP) due to the inherent complexity and flexibility of human language. With the advent of Large Language Models (LLMs), addressing ambiguity has become even more critical due to their expanded capabilities and applications. In the context of Conversational Question Answering (CQA), this paper explores the definition, forms, and implications of ambiguity for language driven systems, particularly in the context of LLMs. We define key terms and concepts, categorize various disambiguation approaches enabled by LLMs, and provide a comparative analysis of their advantages and disadvantages. We also explore publicly available datasets for benchmarking ambiguity detection and resolution techniques and highlight their relevance for ongoing research. Finally, we identify open problems and future research directions, especially in agentic settings, proposing areas for further investigation. By offering a comprehensive review of current research on ambiguities and disambiguation with LLMs, we aim to contribute to the development of more robust and reliable LLM-based systems.
JOLT-SQL: Joint Loss Tuning of Text-to-SQL with Confusion-aware Noisy Schema Sampling
arXiv:2505.14305v3 Announce Type: replace Abstract: Text-to-SQL, which maps natural language to SQL queries, has benefited greatly from recent advances in Large Language Models (LLMs). While LLMs offer various paradigms for this task, including prompting and supervised fine-tuning (SFT), SFT approaches still face challenges such as complex multi-stage pipelines and poor robustness to noisy schema information. To address these limitations, we present JOLT-SQL, a streamlined single-stage SFT framework that jointly optimizes schema linking and SQL generation via a unified loss. JOLT-SQL employs discriminative schema linking, enhanced by local bidirectional attention, alongside a confusion-aware noisy schema sampling strategy with selective attention to improve robustness under noisy schema conditions. Experiments on the Spider and BIRD benchmarks demonstrate that JOLT-SQL achieves state-of-the-art execution accuracy among comparable-size open-source models, while significantly improving both training and inference efficiency. Our code is available at https://github.com/Songjw133/JOLT-SQL.
Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study
arXiv:2505.15389v3 Announce Type: replace Abstract: Rapid deployment of vision-language models (VLMs) magnifies safety risks, yet most evaluations rely on artificial images. This study asks: How safe are current VLMs when confronted with meme images that ordinary users share? To investigate this question, we introduce MemeSafetyBench, a 50,430-instance benchmark pairing real meme images with both harmful and benign instructions. Using a comprehensive safety taxonomy and LLM-based instruction generation, we assess multiple VLMs across single and multi-turn interactions. We investigate how real-world memes influence harmful outputs, the mitigating effects of conversational context, and the relationship between model scale and safety metrics. Our findings demonstrate that VLMs are more vulnerable to meme-based harmful prompts than to synthetic or typographic images. Memes significantly increase harmful responses and decrease refusals compared to text-only inputs. Though multi-turn interactions provide partial mitigation, elevated vulnerability persists. These results highlight the need for ecologically valid evaluations and stronger safety mechanisms. MemeSafetyBench is publicly available at https://github.com/oneonlee/Meme-Safety-Bench.
Memorization or Reasoning? Exploring the Idiom Understanding of LLMs
arXiv:2505.16216v2 Announce Type: replace Abstract: Idioms have long posed a challenge due to their unique linguistic properties, which set them apart from other common expressions. While recent studies have leveraged large language models (LLMs) to handle idioms across various tasks, e.g., idiom-containing sentence generation and idiomatic machine translation, little is known about the underlying mechanisms of idiom processing in LLMs, particularly in multilingual settings. To this end, we introduce MIDAS, a new large-scale dataset of idioms in six languages, each paired with its corresponding meaning. Leveraging this resource, we conduct a comprehensive evaluation of LLMs' idiom processing ability, identifying key factors that influence their performance. Our findings suggest that LLMs rely not only on memorization, but also adopt a hybrid approach that integrates contextual cues and reasoning, especially when processing compositional idioms. This implies that idiom understanding in LLMs emerges from an interplay between internal knowledge retrieval and reasoning-based inference.
Large Language Models Implicitly Learn to See and Hear Just By Reading
arXiv:2505.17091v2 Announce Type: replace Abstract: This paper presents a fascinating find: By training an auto-regressive LLM model on text tokens, the text model inherently develops internally an ability to understand images and audio, thereby developing the ability to see and hear just by reading. Popular audio and visual LLM models fine-tune text LLM models to give text output conditioned on images and audio embeddings. On the other hand, our architecture takes in patches of images, audio waveforms or tokens as input. It gives us the embeddings or category labels typical of a classification pipeline. We show the generality of text weights in aiding audio classification for datasets FSD-50K and GTZAN. Further, we show this working for image classification on CIFAR-10 and Fashion-MNIST, as well on image patches. This pushes the notion of text-LLMs learning powerful internal circuits that can be utilized by activating necessary connections for various applications rather than training models from scratch every single time.
Large Language Models Do Multi-Label Classification Differently
arXiv:2505.17510v2 Announce Type: replace Abstract: Multi-label classification is prevalent in real-world settings, but the behavior of Large Language Models (LLMs) in this setting is understudied. We investigate how autoregressive LLMs perform multi-label classification, focusing on subjective tasks, by analyzing the output distributions of the models at each label generation step. We find that the initial probability distribution for the first label often does not reflect the eventual final output, even in terms of relative order and find LLMs tend to suppress all but one label at each generation step. We further observe that as model scale increases, their token distributions exhibit lower entropy and higher single-label confidence, but the internal relative ranking of the labels improves. Finetuning methods such as supervised finetuning and reinforcement learning amplify this phenomenon. We introduce the task of distribution alignment for multi-label settings: aligning LLM-derived label distributions with empirical distributions estimated from annotator responses in subjective tasks. We propose both zero-shot and supervised methods which improve both alignment and predictive performance over existing approaches. We find one method -- taking the max probability over all label generation distributions instead of just using the initial probability distribution -- improves both distribution alignment and overall F1 classification without adding any additional computation.
NileChat: Towards Linguistically Diverse and Culturally Aware LLMs for Local Communities
arXiv:2505.18383v3 Announce Type: replace Abstract: Enhancing the linguistic capabilities of Large Language Models (LLMs) to include low-resource languages is a critical research area. Current research directions predominantly rely on synthetic data generated by translating English corpora, which, while demonstrating promising linguistic understanding and translation abilities, often results in models aligned with source language culture. These models frequently fail to represent the cultural heritage and values of local communities. This work proposes a methodology to create both synthetic and retrieval-based pre-training data tailored to a specific community, considering its (i) language, (ii) cultural heritage, and (iii) cultural values. We demonstrate our methodology using Egyptian and Moroccan dialects as testbeds, chosen for their linguistic and cultural richness and current underrepresentation in LLMs. As a proof-of-concept, we develop NileChat, a 3B parameter Egyptian and Moroccan Arabic LLM adapted for Egyptian and Moroccan communities, incorporating their language, cultural heritage, and values. Our results on various understanding, translation, and cultural and values alignment benchmarks show that NileChat outperforms existing Arabic-aware LLMs of similar size and performs on par with larger models. This work addresses Arabic dialect in LLMs with a focus on cultural and values alignment via controlled synthetic data generation and retrieval-augmented pre-training for Moroccan Darija and Egyptian Arabic, including Arabizi variants, advancing Arabic NLP for low-resource communities. We share our methods, data, and models with the community to promote the inclusion and coverage of more diverse communities in cultural LLM development: https://github.com/UBC-NLP/nilechat .
Unraveling Misinformation Propagation in LLM Reasoning
arXiv:2505.18555v2 Announce Type: replace Abstract: Large Language Models (LLMs) have demonstrated impressive capabilities in reasoning, positioning them as promising tools for supporting human problem-solving. However, what happens when their performance is affected by misinformation, i.e., incorrect inputs introduced by users due to oversights or gaps in knowledge? Such misinformation is prevalent in real-world interactions with LLMs, yet how it propagates within LLMs' reasoning process remains underexplored. Focusing on mathematical reasoning, we present a comprehensive analysis of how misinformation affects intermediate reasoning steps and final answers. We also examine how effectively LLMs can correct misinformation when explicitly instructed to do so. Even with explicit instructions, LLMs succeed less than half the time in rectifying misinformation, despite possessing correct internal knowledge, leading to significant accuracy drops (10.02% - 72.20%), and the degradation holds with thinking models (4.30% - 19.97%). Further analysis shows that applying factual corrections early in the reasoning process most effectively reduces misinformation propagation, and fine-tuning on synthesized data with early-stage corrections significantly improves reasoning factuality. Our work offers a practical approach to mitigating misinformation propagation.
LiTEx: A Linguistic Taxonomy of Explanations for Understanding Within-Label Variation in Natural Language Inference
arXiv:2505.22848v3 Announce Type: replace Abstract: There is increasing evidence of Human Label Variation (HLV) in Natural Language Inference (NLI), where annotators assign different labels to the same premise-hypothesis pair. However, within-label variation--cases where annotators agree on the same label but provide divergent reasoning--poses an additional and mostly overlooked challenge. Several NLI datasets contain highlighted words in the NLI item as explanations, but the same spans on the NLI item can be highlighted for different reasons, as evidenced by free-text explanations, which offer a window into annotators' reasoning. To systematically understand this problem and gain insight into the rationales behind NLI labels, we introduce LITEX, a linguistically-informed taxonomy for categorizing free-text explanations. Using this taxonomy, we annotate a subset of the e-SNLI dataset, validate the taxonomy's reliability, and analyze how it aligns with NLI labels, highlights, and explanations. We further assess the taxonomy's usefulness in explanation generation, demonstrating that conditioning generation on LITEX yields explanations that are linguistically closer to human explanations than those generated using only labels or highlights. Our approach thus not only captures within-label variation but also shows how taxonomy-guided generation for reasoning can bridge the gap between human and model explanations more effectively than existing strategies.
Please Translate Again: Two Simple Experiments on Whether Human-Like Reasoning Helps Translation
arXiv:2506.04521v2 Announce Type: replace Abstract: Large Language Models (LLMs) demonstrate strong reasoning capabilities for many tasks, often by explicitly decomposing the task via Chain-of-Thought (CoT) reasoning. Recent work on LLM-based translation designs hand-crafted prompts to decompose translation, or trains models to incorporate intermediate steps. Translating Step-by-step (Briakou et al., 2024), for instance, introduces a multi-step prompt with decomposition and refinement of translation with LLMs, which achieved state-of-the-art results on WMT24 test data. In this work, we scrutinise this strategy's effectiveness. Empirically, we find no clear evidence that performance gains stem from explicitly decomposing the translation process via CoT, at least for the models on test; and we show prompting LLMs to 'translate again' and self-refine yields even better results than human-like step-by-step prompting. While the decomposition influences translation behaviour, faithfulness to the decomposition has both positive and negative effects on translation. Our analysis therefore suggests a divergence between the optimal translation strategies for humans and LLMs.
LaMP-Cap: Personalized Figure Caption Generation With Multimodal Figure Profiles
arXiv:2506.06561v4 Announce Type: replace Abstract: Figure captions are crucial for helping readers understand and remember a figure's key message. Many models have been developed to generate these captions, helping authors compose better quality captions more easily. Yet, authors almost always need to revise generic AI-generated captions to match their writing style and the domain's style, highlighting the need for personalization. Despite language models' personalization (LaMP) advances, these technologies often focus on text-only settings and rarely address scenarios where both inputs and profiles are multimodal. This paper introduces LaMP-Cap, a dataset for personalized figure caption generation with multimodal figure profiles. For each target figure, LaMP-Cap provides not only the needed inputs, such as figure images, but also up to three other figures from the same document--each with its image, caption, and figure-mentioning paragraphs--as a profile to characterize the context. Experiments with four LLMs show that using profile information consistently helps generate captions closer to the original author-written ones. Ablation studies reveal that images in the profile are more helpful than figure-mentioning paragraphs, highlighting the advantage of using multimodal profiles over text-only ones.
Combining Constrained and Unconstrained Decoding via Boosting: BoostCD and Its Application to Information Extraction
arXiv:2506.14901v2 Announce Type: replace Abstract: Many recent approaches to structured NLP tasks use an autoregressive language model $M$ to map unstructured input text $x$ to output text $y$ representing structured objects (such as tuples, lists, trees, code, etc.), where the desired output structure is enforced via constrained decoding. During training, these approaches do not require the model to be aware of the constraints, which are merely implicit in the training outputs $y$. This is advantageous as it allows for dynamic constraints without requiring retraining, but can lead to low-quality output during constrained decoding at test time. We overcome this problem with Boosted Constrained Decoding (BoostCD), which combines constrained and unconstrained decoding in two phases: Phase 1 decodes from the base model $M$ twice, in constrained and unconstrained mode, obtaining two weak predictions. In phase 2, a learned autoregressive boosted model combines the two weak predictions into one final prediction. The mistakes made by the base model with vs. without constraints tend to be complementary, which the boosted model learns to exploit for improved performance. We demonstrate the power of BoostCD by applying it to closed information extraction. Our model, BoostIE, outperforms prior approaches both in and out of distribution, addressing several common errors identified in those approaches.
A suite of allotaxonometric tools for the comparison of complex systems using rank-turbulence divergence
arXiv:2506.21808v2 Announce Type: replace Abstract: Describing and comparing complex systems requires principled, theoretically grounded tools. Built around the phenomenon of type turbulence, allotaxonographs provide map-and-list visual comparisons of pairs of heavy-tailed distributions. Allotaxonographs are designed to accommodate a wide range of instruments including rank- and probability-turbulence divergences, Jenson-Shannon divergence, and generalized entropy divergences. Here, we describe a suite of programmatic tools for rendering allotaxonographs for rank-turbulence divergence in Matlab, Javascript, and Python, all of which have different use cases.
Automating Steering for Safe Multimodal Large Language Models
arXiv:2507.13255v3 Announce Type: replace Abstract: Recent progress in Multimodal Large Language Models (MLLMs) has unlocked powerful cross-modal reasoning abilities, but also raised new safety concerns, particularly when faced with adversarial multimodal inputs. To improve the safety of MLLMs during inference, we introduce a modular and adaptive inference-time intervention technology, AutoSteer, without requiring any fine-tuning of the underlying model. AutoSteer incorporates three core components: (1) a novel Safety Awareness Score (SAS) that automatically identifies the most safety-relevant distinctions among the model's internal layers; (2) an adaptive safety prober trained to estimate the likelihood of toxic outputs from intermediate representations; and (3) a lightweight Refusal Head that selectively intervenes to modulate generation when safety risks are detected. Experiments on LLaVA-OV and Chameleon across diverse safety-critical benchmarks demonstrate that AutoSteer significantly reduces the Attack Success Rate (ASR) for textual, visual, and cross-modal threats, while maintaining general abilities. These findings position AutoSteer as a practical, interpretable, and effective framework for safer deployment of multimodal AI systems.
T-Detect: Tail-Aware Statistical Normalization for Robust Detection of Adversarial Machine-Generated Text
arXiv:2507.23577v2 Announce Type: replace Abstract: Large language models (LLMs) have shown the capability to generate fluent and logical content, presenting significant challenges to machine-generated text detection, particularly text polished by adversarial perturbations such as paraphrasing. Current zero-shot detectors often employ Gaussian distributions as statistical measure for computing detection thresholds, which falters when confronted with the heavy-tailed statistical artifacts characteristic of adversarial or non-native English texts. In this paper, we introduce T-Detect, a novel detection method that fundamentally redesigns the curvature-based detectors. Our primary innovation is the replacement of standard Gaussian normalization with a heavy-tailed discrepancy score derived from the Student's t-distribution. This approach is theoretically grounded in the empirical observation that adversarial texts exhibit significant leptokurtosis, rendering traditional statistical assumptions inadequate. T-Detect computes a detection score by normalizing the log-likelihood of a passage against the expected moments of a t-distribution, providing superior resilience to statistical outliers. We validate our approach on the challenging RAID benchmark for adversarial text and the comprehensive HART dataset. Experiments show that T-Detect provides a consistent performance uplift over strong baselines, improving AUROC by up to 3.9\% in targeted domains. When integrated into a two-dimensional detection framework (CT), our method achieves state-of-the-art performance, with an AUROC of 0.926 on the Books domain of RAID. Our contributions are a new, theoretically-justified statistical foundation for text detection, an ablation-validated method that demonstrates superior robustness, and a comprehensive analysis of its performance under adversarial conditions. Ours code are released at https://github.com/ResearAI/t-detect.
AI-Generated Text is Non-Stationary: Detection via Temporal Tomography
arXiv:2508.01754v2 Announce Type: replace Abstract: The field of AI-generated text detection has evolved from supervised classification to zero-shot statistical analysis. However, current approaches share a fundamental limitation: they aggregate token-level measurements into scalar scores, discarding positional information about where anomalies occur. Our empirical analysis reveals that AI-generated text exhibits significant non-stationarity, statistical properties vary by 73.8\% more between text segments compared to human writing. This discovery explains why existing detectors fail against localized adversarial perturbations that exploit this overlooked characteristic. We introduce Temporal Discrepancy Tomography (TDT), a novel detection paradigm that preserves positional information by reformulating detection as a signal processing task. TDT treats token-level discrepancies as a time-series signal and applies Continuous Wavelet Transform to generate a two-dimensional time-scale representation, capturing both the location and linguistic scale of statistical anomalies. On the RAID benchmark, TDT achieves 0.855 AUROC (7.1\% improvement over the best baseline). More importantly, TDT demonstrates robust performance on adversarial tasks, with 14.1\% AUROC improvement on HART Level 2 paraphrasing attacks. Despite its sophisticated analysis, TDT maintains practical efficiency with only 13\% computational overhead. Our work establishes non-stationarity as a fundamental characteristic of AI-generated text and demonstrates that preserving temporal dynamics is essential for robust detection.
Columbo: Expanding Abbreviated Column Names for Tabular Data Using Large Language Models
arXiv:2508.09403v3 Announce Type: replace Abstract: Expanding the abbreviated column names of tables, such as "esal" to "employee salary", is critical for many downstream NLP tasks for tabular data, such as NL2SQL, table QA, and keyword search. This problem arises in enterprises, domain sciences, government agencies, and more. In this paper, we make three contributions that significantly advance the state of the art. First, we show that the synthetic public data used by prior work has major limitations, and we introduce four new datasets in enterprise/science domains, with real-world abbreviations. Second, we show that accuracy measures used by prior work seriously undercount correct expansions, and we propose new synonym-aware measures that capture accuracy much more accurately. Finally, we develop Columbo, a powerful LLM-based solution that exploits context, rules, chain-of-thought reasoning, and token-level analysis. Extensive experiments show that Columbo significantly outperforms NameGuess, the current most advanced solution, by 4-29%, over five datasets. Columbo has been used in production on EDI, a major data lake for environmental sciences.
Reward-Shifted Speculative Sampling Is An Efficient Test-Time Weak-to-Strong Aligner
arXiv:2508.15044v3 Announce Type: replace Abstract: Aligning large language models (LLMs) with human preferences has become a critical step in their development. Recent research has increasingly focused on test-time alignment, where additional compute is allocated during inference to enhance LLM safety and reasoning capabilities. However, these test-time alignment techniques often incur substantial inference costs, limiting their practical application. We are inspired by the speculative sampling acceleration, which leverages a small draft model to efficiently predict future tokens, to address the efficiency bottleneck of test-time alignment. We introduce the reward-shifted speculative sampling (SSS) algorithm, in which the draft model is aligned with human preferences, while the target model remains unchanged. We theoretically demonstrate that the distributional shift between the aligned draft model and the unaligned target model can be exploited to recover the RLHF optimal solution without actually obtaining it, by modifying the acceptance criterion and bonus token distribution. Our algorithm achieves superior gold reward scores at a significantly reduced inference cost in test-time weak-to-strong alignment experiments, thereby validating both its effectiveness and efficiency.
Identifying and Answering Questions with False Assumptions: An Interpretable Approach
arXiv:2508.15139v2 Announce Type: replace Abstract: People often ask questions with false assumptions, a type of question that does not have regular answers. Answering such questions requires first identifying the false assumptions. Large Language Models (LLMs) often generate misleading answers to these questions because of hallucinations. In this paper, we focus on identifying and answering questions with false assumptions in several domains. We first investigate whether the problem reduces to fact verification. Then, we present an approach leveraging external evidence to mitigate hallucinations. Experiments with five LLMs demonstrate that (1) incorporating retrieved evidence is beneficial and (2) generating and validating atomic assumptions yields more improvements and provides an interpretable answer by pinpointing the false assumptions.
OpenWHO: A Document-Level Parallel Corpus for Health Translation in Low-Resource Languages
arXiv:2508.16048v4 Announce Type: replace Abstract: In machine translation (MT), health is a high-stakes domain characterised by widespread deployment and domain-specific vocabulary. However, there is a lack of MT evaluation datasets for low-resource languages in this domain. To address this gap, we introduce OpenWHO, a document-level parallel corpus of 2,978 documents and 26,824 sentences from the World Health Organization's e-learning platform. Sourced from expert-authored, professionally translated materials shielded from web-crawling, OpenWHO spans a diverse range of over 20 languages, of which nine are low-resource. Leveraging this new resource, we evaluate modern large language models (LLMs) against traditional MT models. Our findings reveal that LLMs consistently outperform traditional MT models, with Gemini 2.5 Flash achieving a +4.79 ChrF point improvement over NLLB-54B on our low-resource test set. Further, we investigate how LLM context utilisation affects accuracy, finding that the benefits of document-level translation are most pronounced in specialised domains like health. We release the OpenWHO corpus to encourage further research into low-resource MT in the health domain.
Linguistic Neuron Overlap Patterns to Facilitate Cross-lingual Transfer on Low-resource Languages
arXiv:2508.17078v2 Announce Type: replace Abstract: The current Large Language Models (LLMs) face significant challenges in improving their performance on low-resource languages and urgently need data-efficient methods without costly fine-tuning. From the perspective of language-bridge, we propose a simple yet effective method, namely BridgeX-ICL, to improve the zero-shot Cross-lingual In-Context Learning (X-ICL) for low-resource languages. Unlike existing works focusing on language-specific neurons, BridgeX-ICL explores whether sharing neurons can improve cross-lingual performance in LLMs. We construct neuron probe data from the ground-truth MUSE bilingual dictionaries, and define a subset of language overlap neurons accordingly to ensure full activation of these anchored neurons. Subsequently, we propose an HSIC-based metric to quantify LLMs' internal linguistic spectrum based on overlapping neurons, guiding optimal bridge selection. The experiments conducted on 4 cross-lingual tasks and 15 language pairs from 7 diverse families, covering both high-low and moderate-low pairs, validate the effectiveness of BridgeX-ICL and offer empirical insights into the underlying multilingual mechanisms of LLMs. The code is publicly available at https://github.com/xuyuemei/BridgeX-ICL.
T2R-bench: A Benchmark for Generating Article-Level Reports from Real World Industrial Tables
arXiv:2508.19813v4 Announce Type: replace Abstract: Extensive research has been conducted to explore the capabilities of large language models (LLMs) in table reasoning. However, the essential task of transforming tables information into reports remains a significant challenge for industrial applications. This task is plagued by two critical issues: 1) the complexity and diversity of tables lead to suboptimal reasoning outcomes; and 2) existing table benchmarks lack the capacity to adequately assess the practical application of this task. To fill this gap, we propose the table-to-report task and construct a bilingual benchmark named T2R-bench, where the key information flow from the tables to the reports for this task. The benchmark comprises 457 industrial tables, all derived from real-world scenarios and encompassing 19 industry domains as well as 4 types of industrial tables. Furthermore, we propose an evaluation criteria to fairly measure the quality of report generation. The experiments on 25 widely-used LLMs reveal that even state-of-the-art models like Deepseek-R1 only achieves performance with 62.71 overall score, indicating that LLMs still have room for improvement on T2R-bench.
PDTrim: Targeted Pruning for Prefill-Decode Disaggregation in Inference
arXiv:2509.04467v3 Announce Type: replace Abstract: Large Language Models (LLMs) demonstrate exceptional capabilities across various tasks, but their deployment is constrained by high computational and memory costs. Model pruning provides an effective means to alleviate these demands. However, existing methods often ignore the characteristics of prefill-decode (PD) disaggregation in practice. In this paper, we propose a novel pruning method for PD disaggregation inference, enabling more precise and efficient block and KV Cache pruning. Our approach constructs pruning and distillation sets to perform iterative block removal independently for the prefill and decode stages, obtaining better pruning solutions. Moreover, we introduce a token-aware cache pruning mechanism that retains all KV Cache in the prefill stage but selectively reuses entries for the first and last token sequences in selected layers during decode, reducing communication costs with minimal overhead. Extensive experiments demonstrate that our approach consistently achieves strong performance in both PD disaggregation and PD unified settings without disaggregation. Under the same (default) settings, our method achieves improved performance and faster inference, along with a 4.95$\times$ reduction in data transmission bandwidth consumption.
Mind the Gap: Evaluating Model- and Agentic-Level Vulnerabilities in LLMs with Action Graphs
arXiv:2509.04802v2 Announce Type: replace Abstract: As large language models transition to agentic systems, current safety evaluation frameworks face critical gaps in assessing deployment-specific risks. We introduce AgentSeer, an observability-based evaluation framework that decomposes agentic executions into granular action and component graphs, enabling systematic agentic-situational assessment. Through cross-model validation on GPT-OSS-20B and Gemini-2.0-flash using HarmBench single turn and iterative refinement attacks, we demonstrate fundamental differences between model-level and agentic-level vulnerability profiles. Model-level evaluation reveals baseline differences: GPT-OSS-20B (39.47% ASR) versus Gemini-2.0-flash (50.00% ASR), with both models showing susceptibility to social engineering while maintaining logic-based attack resistance. However, agentic-level assessment exposes agent-specific risks invisible to traditional evaluation. We discover "agentic-only" vulnerabilities that emerge exclusively in agentic contexts, with tool-calling showing 24-60% higher ASR across both models. Cross-model analysis reveals universal agentic patterns, agent transfer operations as highest-risk tools, semantic rather than syntactic vulnerability mechanisms, and context-dependent attack effectiveness, alongside model-specific security profiles in absolute ASR levels and optimal injection strategies. Direct attack transfer from model-level to agentic contexts shows degraded performance (GPT-OSS-20B: 57% human injection ASR; Gemini-2.0-flash: 28%), while context-aware iterative attacks successfully compromise objectives that failed at model-level, confirming systematic evaluation gaps. These findings establish the urgent need for agentic-situation evaluation paradigms, with AgentSeer providing the standardized methodology and empirical validation.
Seeing is Not Understanding: A Benchmark on Perception-Cognition Disparities in Large Language Models
arXiv:2509.11101v3 Announce Type: replace Abstract: With the rapid advancement of Multimodal Large Language Models (MLLMs), they have demonstrated exceptional capabilities across a variety of vision-language tasks. However, current evaluation benchmarks predominantly focus on objective visual question answering or captioning, inadequately assessing the models' ability to understand complex and subjective human emotions. To bridge this gap, we introduce EmoBench-Reddit, a novel, hierarchical benchmark for multimodal emotion understanding. The dataset comprises 350 meticulously curated samples from the social media platform Reddit, each containing an image, associated user-provided text, and an emotion category (sad, humor, sarcasm, happy) confirmed by user flairs. We designed a hierarchical task framework that progresses from basic perception to advanced cognition, with each data point featuring six multiple-choice questions and one open-ended question of increasing difficulty. Perception tasks evaluate the model's ability to identify basic visual elements (e.g., colors, objects), while cognition tasks require scene reasoning, intent understanding, and deep empathy integrating textual context. We ensured annotation quality through a combination of AI assistance (Claude 4) and manual verification.We conducted a comprehensive evaluation of nine leading MLLMs, including GPT-5, Gemini-2.5-pro, and GPT-4o, on EmoBench-Reddit.
Automated Generation of Research Workflows from Academic Papers: A Full-text Mining Framework
arXiv:2509.12955v2 Announce Type: replace Abstract: The automated generation of research workflows is essential for improving the reproducibility of research and accelerating the paradigm of "AI for Science". However, existing methods typically extract merely fragmented procedural components and thus fail to capture complete research workflows. To address this gap, we propose an end-to-end framework that generates comprehensive, structured research workflows by mining full-text academic papers. As a case study in the Natural Language Processing (NLP) domain, our paragraph-centric approach first employs Positive-Unlabeled (PU) Learning with SciBERT to identify workflow-descriptive paragraphs, achieving an F1-score of 0.9772. Subsequently, we utilize Flan-T5 with prompt learning to generate workflow phrases from these paragraphs, yielding ROUGE-1, ROUGE-2, and ROUGE-L scores of 0.4543, 0.2877, and 0.4427, respectively. These phrases are then systematically categorized into data preparation, data processing, and data analysis stages using ChatGPT with few-shot learning, achieving a classification precision of 0.958. By mapping categorized phrases to their document locations in the documents, we finally generate readable visual flowcharts of the entire research workflows. This approach facilitates the analysis of workflows derived from an NLP corpus and reveals key methodological shifts over the past two decades, including the increasing emphasis on data analysis and the transition from feature engineering to ablation studies. Our work offers a validated technical framework for automated workflow generation, along with a novel, process-oriented perspective for the empirical investigation of evolving scientific paradigms. Source code and data are available at: https://github.com/ZH-heng/research_workflow.
Toxicity Red-Teaming: Benchmarking LLM Safety in Singapore's Low-Resource Languages
arXiv:2509.15260v2 Announce Type: replace Abstract: The advancement of Large Language Models (LLMs) has transformed natural language processing; however, their safety mechanisms remain under-explored in low-resource, multilingual settings. Here, we aim to bridge this gap. In particular, we introduce \textsf{SGToxicGuard}, a novel dataset and evaluation framework for benchmarking LLM safety in Singapore's diverse linguistic context, including Singlish, Chinese, Malay, and Tamil. SGToxicGuard adopts a red-teaming approach to systematically probe LLM vulnerabilities in three real-world scenarios: \textit{conversation}, \textit{question-answering}, and \textit{content composition}. We conduct extensive experiments with state-of-the-art multilingual LLMs, and the results uncover critical gaps in their safety guardrails. By offering actionable insights into cultural sensitivity and toxicity mitigation, we lay the foundation for safer and more inclusive AI systems in linguistically diverse environments.\footnote{Link to the dataset: https://github.com/Social-AI-Studio/SGToxicGuard.} \textcolor{red}{Disclaimer: This paper contains sensitive content that may be disturbing to some readers.}
PolBiX: Detecting LLMs' Political Bias in Fact-Checking through X-phemisms
arXiv:2509.15335v2 Announce Type: replace Abstract: Large Language Models are increasingly used in applications requiring objective assessment, which could be compromised by political bias. Many studies found preferences for left-leaning positions in LLMs, but downstream effects on tasks like fact-checking remain underexplored. In this study, we systematically investigate political bias through exchanging words with euphemisms or dysphemisms in German claims. We construct minimal pairs of factually equivalent claims that differ in political connotation, to assess the consistency of LLMs in classifying them as true or false. We evaluate six LLMs and find that, more than political leaning, the presence of judgmental words significantly influences truthfulness assessment. While a few models show tendencies of political bias, this is not mitigated by explicitly calling for objectivism in prompts. Warning: This paper contains content that may be offensive or upsetting.
DivLogicEval: A Framework for Benchmarking Logical Reasoning Evaluation in Large Language Models
arXiv:2509.15587v2 Announce Type: replace Abstract: Logic reasoning in natural language has been recognized as an important measure of human intelligence for Large Language Models (LLMs). Popular benchmarks may entangle multiple reasoning skills and thus provide unfaithful evaluations on the logic reasoning skill. Meanwhile, existing logic reasoning benchmarks are limited in language diversity and their distributions are deviated from the distribution of an ideal logic reasoning benchmark, which may lead to biased evaluation results. This paper thereby proposes a new classical logic benchmark DivLogicEval, consisting of natural sentences composed of diverse statements in a counterintuitive way. To ensure a more reliable evaluation, we also introduce a new evaluation metric that mitigates the influence of bias and randomness inherent in LLMs. Through experiments, we demonstrate the extent to which logical reasoning is required to answer the questions in DivLogicEval and compare the performance of different popular LLMs in conducting logical reasoning.
RPG: A Repository Planning Graph for Unified and Scalable Codebase Generation
arXiv:2509.16198v2 Announce Type: replace Abstract: Large language models excel at function- and file-level code generation, yet generating complete repositories from scratch remains a fundamental challenge. This process demands coherent and reliable planning across proposal- and implementation-level stages, while natural language, due to its ambiguity and verbosity, is ill-suited for faithfully representing complex software structures. To address this, we introduce the Repository Planning Graph (RPG), a persistent representation that unifies proposal- and implementation-level planning by encoding capabilities, file structures, data flows, and functions in one graph. RPG replaces ambiguous natural language with an explicit blueprint, enabling long-horizon planning and scalable repository generation. Building on RPG, we develop ZeroRepo, a graph-driven framework for repository generation from scratch. It operates in three stages: proposal-level planning and implementation-level refinement to construct the graph, followed by graph-guided code generation with test validation. To evaluate this setting, we construct RepoCraft, a benchmark of six real-world projects with 1,052 tasks. On RepoCraft, ZeroRepo generates repositories averaging 36K Code Lines, roughly 3.9$\times$ the strongest baseline (Claude Code) and about 64$\times$ other baselines. It attains 81.5% functional coverage and a 69.7% pass rate, exceeding Claude Code by 27.3 and 35.8 percentage points, respectively. Further analysis shows that RPG models complex dependencies, enables progressively more sophisticated planning through near-linear scaling, and enhances LLM understanding of repositories, thereby accelerating agent localization.
Gender and Political Bias in Large Language Models: A Demonstration Platform
arXiv:2509.16264v2 Announce Type: replace Abstract: We present ParlAI Vote, an interactive system for exploring European Parliament debates and votes, and for testing LLMs on vote prediction and bias analysis. This platform connects debate topics, speeches, and roll-call outcomes, and includes rich demographic data such as gender, age, country, and political group. Users can browse debates, inspect linked speeches, compare real voting outcomes with predictions from frontier LLMs, and view error breakdowns by demographic group. Visualizing the EuroParlVote benchmark and its core tasks of gender classification and vote prediction, ParlAI Vote highlights systematic performance bias in state-of-the-art LLMs. The system unifies data, models, and visual analytics in a single interface, lowering the barrier for reproducing findings, auditing behavior, and running counterfactual scenarios. It supports research, education, and public engagement with legislative decision-making, while making clear both the strengths and the limitations of current LLMs in political analysis.
PruneCD: Contrasting Pruned Self Model to Improve Decoding Factuality
arXiv:2509.16598v2 Announce Type: replace Abstract: To mitigate the hallucination problem in large language models, DoLa exploits early exit logits from the same model as a contrastive prior. However, we found that these early exit logits tend to be flat, low in magnitude, and fail to reflect meaningful contrasts. To address this, we propose PruneCD, a novel contrastive decoding method that constructs the amateur model via layer pruning rather than early exit. This design leads to more informative and well-aligned logits, enabling more effective contrastive decoding. Through qualitative and quantitative analyses, we demonstrate that PruneCD consistently improves factuality with minimal inference overhead, offering a robust and practical approach to mitigating hallucinations in LLMs.
Can GRPO Boost Complex Multimodal Table Understanding?
arXiv:2509.16889v2 Announce Type: replace Abstract: Existing table understanding methods face challenges due to complex table structures and intricate logical reasoning. While supervised finetuning (SFT) dominates existing research, reinforcement learning (RL), such as Group Relative Policy Optimization (GRPO), has shown promise but struggled with low initial policy accuracy and coarse rewards in tabular contexts. In this paper, we introduce Table-R1, a three-stage RL framework that enhances multimodal table understanding through: (1) Warm-up that prompts initial perception and reasoning capabilities, (2) Perception Alignment GRPO (PA-GRPO), which employs continuous Tree-Edit-Distance Similarity (TEDS) rewards for recognizing table structures and contents, and (3) Hint-Completion GRPO (HC-GRPO), which utilizes fine-grained rewards of residual steps based on the hint-guided question. Extensive experiments demonstrate that Table-R1 can boost the model's table reasoning performance obviously on both held-in and held-out datasets, outperforming SFT and GRPO largely. Notably, Qwen2-VL-7B with Table-R1 surpasses larger specific table understanding models (e.g., Table-LLaVA 13B), even achieving comparable performance to the closed-source model GPT-4o on held-in datasets, demonstrating the efficacy of each stage of Table-R1 in overcoming initialization bottlenecks and reward sparsity, thereby advancing robust multimodal table understanding.
K-DeCore: Facilitating Knowledge Transfer in Continual Structured Knowledge Reasoning via Knowledge Decoupling
arXiv:2509.16929v2 Announce Type: replace Abstract: Continual Structured Knowledge Reasoning (CSKR) focuses on training models to handle sequential tasks, where each task involves translating natural language questions into structured queries grounded in structured knowledge. Existing general continual learning approaches face significant challenges when applied to this task, including poor generalization to heterogeneous structured knowledge and inefficient reasoning due to parameter growth as tasks increase. To address these limitations, we propose a novel CSKR framework, \textsc{K-DeCore}, which operates with a fixed number of tunable parameters. Unlike prior methods, \textsc{K-DeCore} introduces a knowledge decoupling mechanism that disentangles the reasoning process into task-specific and task-agnostic stages, effectively bridging the gaps across diverse tasks. Building on this foundation, \textsc{K-DeCore} integrates a dual-perspective memory consolidation mechanism for distinct stages and introduces a structure-guided pseudo-data synthesis strategy to further enhance the model's generalization capabilities. Extensive experiments on four benchmark datasets demonstrate the superiority of \textsc{K-DeCore} over existing continual learning methods across multiple metrics, leveraging various backbone large language models.
QWHA: Quantization-Aware Walsh-Hadamard Adaptation for Parameter-Efficient Fine-Tuning on Large Language Models
arXiv:2509.17428v2 Announce Type: replace Abstract: The demand for efficient deployment of large language models (LLMs) has driven interest in quantization, which reduces inference cost, and parameter-efficient fine-tuning (PEFT), which lowers training overhead. This motivated the development of quantization-aware PEFT to produce accurate yet efficient quantized models. In this setting, reducing quantization error prior to fine-tuning is crucial for achieving high model accuracy. However, existing methods that rely on low-rank adaptation suffer from limited representational capacity. Recent Fourier-related transform (FT)-based adapters offer greater representational power than low-rank adapters, but their direct integration into quantized models often results in ineffective error reduction and increased computational overhead. To overcome these limitations, we propose QWHA, a method that integrates FT-based adapters into quantized models by employing the Walsh-Hadamard Transform (WHT) as the transform kernel, together with a novel adapter initialization scheme incorporating adaptive parameter selection and value refinement. We demonstrate that QWHA effectively mitigates quantization errors while facilitating fine-tuning, and that its design substantially reduces computational cost. Experimental results show that QWHA consistently outperforms baselines in low-bit quantization accuracy and achieves significant training speedups over existing FT-based adapters. The code is available at https://github.com/vantaa89/qwha.
Breaking Token Into Concepts: Exploring Extreme Compression in Token Representation Via Compositional Shared Semantics
arXiv:2509.17737v2 Announce Type: replace Abstract: Standard language models employ unique, monolithic embeddings for each token, potentially limiting their ability to capture the multifaceted nature of word meanings. We investigate whether tokens can be more effectively represented through a compositional structure that accumulates diverse semantic facets. To explore this, we propose Aggregate Semantic Grouping (ASG), a novel approach leveraging Product Quantization (PQ). We apply ASG to standard transformer architectures (mBERT, XLM-R, mT5) and evaluate this representational scheme across diverse tasks (NLI, NER, QA), as well as a biomedical domain-specific benchmark (BC5CDR) using BioBERT. Our findings demonstrate that representing tokens compositionally via ASG achieves extreme compression in embedding parameters (0.4--0.5\%) while maintaining $>$95\% task performance relative to the base model, even in generative tasks and extends to both cross lingual transfer and domain-specific settings. These results validate the principle that tokens can be effectively modeled as combinations of shared semantic building blocks. ASG offers a simple yet concrete method for achieving this, showcasing how compositional representations can capture linguistic richness while enabling compact yet semantically rich models.
Fine-Grained Detection of AI-Generated Text Using Sentence-Level Segmentation
arXiv:2509.17830v2 Announce Type: replace Abstract: Generation of Artificial Intelligence (AI) texts in important works has become a common practice that can be used to misuse and abuse AI at various levels. Traditional AI detectors often rely on document-level classification, which struggles to identify AI content in hybrid or slightly edited texts designed to avoid detection, leading to concerns about the model's efficiency, which makes it hard to distinguish between human-written and AI-generated texts. A sentence-level sequence labeling model proposed to detect transitions between human- and AI-generated text, leveraging nuanced linguistic signals overlooked by document-level classifiers. By this method, detecting and segmenting AI and human-written text within a single document at the token-level granularity is achieved. Our model combines the state-of-the-art pre-trained Transformer models, incorporating Neural Networks (NN) and Conditional Random Fields (CRFs). This approach extends the power of transformers to extract semantic and syntactic patterns, and the neural network component to capture enhanced sequence-level representations, thereby improving the boundary predictions by the CRF layer, which enhances sequence recognition and further identification of the partition between Human- and AI-generated texts. The evaluation is performed on two publicly available benchmark datasets containing collaborative human and AI-generated texts. Our experimental comparisons are with zero-shot detectors and the existing state-of-the-art models, along with rigorous ablation studies to justify that this approach, in particular, can accurately detect the spans of AI texts in a completely collaborative text. All our source code and the processed datasets are available in our GitHub repository.
Improving Image Captioning Descriptiveness by Ranking and LLM-based Fusion
arXiv:2306.11593v2 Announce Type: replace-cross Abstract: State-of-The-Art (SoTA) image captioning models are often trained on the MicroSoft Common Objects in Context (MS-COCO) dataset, which contains human-annotated captions with an average length of approximately ten tokens. Although effective for general scene understanding, these short captions often fail to capture complex scenes and convey detailed information. Moreover, captioning models tend to exhibit bias towards the ``average'' caption, which captures only the more general aspects, thus overlooking finer details. In this paper, we present a novel approach to generate richer and more informative image captions by combining the captions generated from different SoTA captioning models. Our proposed method requires no additional model training: given an image, it leverages pre-trained models from the literature to generate the initial captions, and then ranks them using a newly introduced image-text-based metric, which we name BLIPScore. Subsequently, the top two captions are fused using a Large Language Model (LLM) to produce the final, more detailed description. Experimental results on the MS-COCO and Flickr30k test sets demonstrate the effectiveness of our approach in terms of caption-image alignment and hallucination reduction according to the ALOHa, CAPTURE, and Polos metrics. A subjective study lends additional support to these results, suggesting that the captions produced by our model are generally perceived as more consistent with human judgment. By combining the strengths of diverse SoTA models, our method enhances the quality and appeal of image captions, bridging the gap between automated systems and the rich and informative nature of human-generated descriptions. This advance enables the generation of more suitable captions for the training of both vision-language and captioning models.
Is Pre-training Truly Better Than Meta-Learning?
arXiv:2306.13841v2 Announce Type: replace-cross Abstract: In the context of few-shot learning, it is currently believed that a fixed pre-trained (PT) model, along with fine-tuning the final layer during evaluation, outperforms standard meta-learning algorithms. We re-evaluate these claims under an in-depth empirical examination of an extensive set of formally diverse datasets and compare PT to Model Agnostic Meta-Learning (MAML). Unlike previous work, we emphasize a fair comparison by using: the same architecture, the same optimizer, and all models trained to convergence. Crucially, we use a more rigorous statistical tool -- the effect size (Cohen's d) -- to determine the practical significance of the difference between a model trained with PT vs. a MAML. We then use a previously proposed metric -- the diversity coefficient -- to compute the average formal diversity of a dataset. Using this analysis, we demonstrate the following: 1. when the formal diversity of a data set is low, PT beats MAML on average and 2. when the formal diversity is high, MAML beats PT on average. The caveat is that the magnitude of the average difference between a PT vs. MAML using the effect size is low (according to classical statistical thresholds) -- less than 0.2. Nevertheless, this observation is contrary to the currently held belief that a pre-trained model is always better than a meta-learning model. Our extensive experiments consider 21 few-shot learning benchmarks, including the large-scale few-shot learning dataset Meta-Data set. We also show no significant difference between a MAML model vs. a PT model with GPT-2 on Openwebtext. We, therefore, conclude that a pre-trained model does not always beat a meta-learned model and that the formal diversity of a dataset is a driving factor.
MediSyn: A Generalist Text-Guided Latent Diffusion Model For Diverse Medical Image Synthesis
arXiv:2405.09806v5 Announce Type: replace-cross Abstract: Deep learning algorithms require extensive data to achieve robust performance. However, data availability is often restricted in the medical domain due to patient privacy concerns. Synthetic data presents a possible solution to these challenges. Recently, image generative models have found increasing use for medical applications but are often designed for singular medical specialties and imaging modalities, thus limiting their broader utility. To address this, we introduce MediSyn: a text-guided, latent diffusion model capable of generating synthetic images from 6 medical specialties and 10 image types. Through extensive experimentation, we first demonstrate that MediSyn quantitatively matches or surpasses the performance of specialist models. Second, we show that our synthetic images are realistic and exhibit strong alignment with their corresponding text prompts, as validated by a team of expert physicians. Third, we provide empirical evidence that our synthetic images are visually distinct from their corresponding real patient images. Finally, we demonstrate that in data-limited settings, classifiers trained solely on synthetic data or real data supplemented with synthetic data can outperform those trained solely on real data. Our findings highlight the immense potential of generalist image generative models to accelerate algorithmic research and development in medicine.
DOTA: Distributional Test-Time Adaptation of Vision-Language Models
arXiv:2409.19375v2 Announce Type: replace-cross Abstract: Vision-language foundation models (VLMs), such as CLIP, exhibit remarkable performance across a wide range of tasks. However, deploying these models can be unreliable when significant distribution gaps exist between training and test data, while fine-tuning for diverse scenarios is often costly. Cache-based test-time adapters offer an efficient alternative by storing representative test samples to guide subsequent classifications. Yet, these methods typically employ naive cache management with limited capacity, leading to severe catastrophic forgetting when samples are inevitably dropped during updates. In this paper, we propose DOTA (DistributiOnal Test-time Adaptation), a simple yet effective method addressing this limitation. Crucially, instead of merely memorizing individual test samples, DOTA continuously estimates the underlying distribution of the test data stream. Test-time posterior probabilities are then computed using these dynamically estimated distributions via Bayes' theorem for adaptation. This distribution-centric approach enables the model to continually learn and adapt to the deployment environment. Extensive experiments validate that DOTA significantly mitigates forgetting and achieves state-of-the-art performance compared to existing methods.
EMMA: End-to-End Multimodal Model for Autonomous Driving
arXiv:2410.23262v3 Announce Type: replace-cross Abstract: We introduce EMMA, an End-to-end Multimodal Model for Autonomous driving. Built upon a multi-modal large language model foundation like Gemini, EMMA directly maps raw camera sensor data into various driving-specific outputs, including planner trajectories, perception objects, and road graph elements. EMMA maximizes the utility of world knowledge from the pre-trained large language models, by representing all non-sensor inputs (e.g. navigation instructions and ego vehicle status) and outputs (e.g. trajectories and 3D locations) as natural language text. This approach allows EMMA to jointly process various driving tasks in a unified language space, and generate the outputs for each task using task-specific prompts. Empirically, we demonstrate EMMA's effectiveness by achieving state-of-the-art performance in motion planning on nuScenes as well as competitive results on the Waymo Open Motion Dataset (WOMD). EMMA also yields competitive results for camera-primary 3D object detection on the Waymo Open Dataset (WOD). We show that co-training EMMA with planner trajectories, object detection, and road graph tasks yields improvements across all three domains, highlighting EMMA's potential as a generalist model for autonomous driving applications. We hope that our results will inspire research to further evolve the state of the art in autonomous driving model architectures.
Large Vision-Language Model Alignment and Misalignment: A Survey Through the Lens of Explainability
arXiv:2501.01346v3 Announce Type: replace-cross Abstract: Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in processing both visual and textual information. However, the critical challenge of alignment between visual and textual representations is not fully understood. This survey presents a comprehensive examination of alignment and misalignment in LVLMs through an explainability lens. We first examine the fundamentals of alignment, exploring its representational and behavioral aspects, training methodologies, and theoretical foundations. We then analyze misalignment phenomena across three semantic levels: object, attribute, and relational misalignment. Our investigation reveals that misalignment emerges from challenges at multiple levels: the data level, the model level, and the inference level. We provide a comprehensive review of existing mitigation strategies, categorizing them into parameter-frozen and parameter-tuning approaches. Finally, we outline promising future research directions, emphasizing the need for standardized evaluation protocols and in-depth explainability studies.
Fine-Tuning is Subgraph Search: A New Lens on Learning Dynamics
arXiv:2502.06106v3 Announce Type: replace-cross Abstract: The study of mechanistic interpretability aims to reverse-engineer a model to explain its behaviors. While recent studies have focused on the static mechanism of a certain behavior, the learning dynamics inside a model remain to be explored. In this work, we develop a fine-tuning method for analyzing the mechanism behind learning. Inspired by the concept of intrinsic dimension, we view a model as a computational graph with redundancy for a specific task, and treat the fine-tuning process as a search for and optimization of a subgraph within this graph. Based on this hypothesis, we propose circuit-tuning, an algorithm that iteratively builds the subgraph for a specific task and updates the relevant parameters in a heuristic way. We first validate our hypothesis through a carefully designed experiment and provide a detailed analysis of the learning dynamics during fine-tuning. Subsequently, we conduct experiments on more complex tasks, demonstrating that circuit-tuning could strike a balance between the performance on the target task and the general capabilities. Our work offers a new analytical method for the dynamics of fine-tuning, provides new findings on the mechanisms behind the training process, and inspires the design of superior algorithms for the training of neural networks.
DeepResonance: Enhancing Multimodal Music Understanding via Music-centric Multi-way Instruction Tuning
arXiv:2502.12623v3 Announce Type: replace-cross Abstract: Recent advancements in music large language models (LLMs) have significantly improved music understanding tasks, which involve the model's ability to analyze and interpret various musical elements. These improvements primarily focused on integrating both music and text inputs. However, the potential of incorporating additional modalities such as images, videos and textual music features to enhance music understanding remains unexplored. To bridge this gap, we propose DeepResonance, a multimodal music understanding LLM fine-tuned via multi-way instruction tuning with multi-way aligned music, text, image, and video data. To this end, we construct Music4way-MI2T, Music4way-MV2T, and Music4way-Any2T, three 4-way training and evaluation datasets designed to enable DeepResonance to integrate both visual and textual music feature content. We also introduce multi-sampled ImageBind embeddings and a pre-LLM fusion Transformer to enhance modality fusion prior to input into text LLMs, tailoring for multi-way instruction tuning. Our model achieves state-of-the-art performances across six music understanding tasks, highlighting the benefits of the auxiliary modalities and the structural superiority of DeepResonance. We open-source the codes, models and datasets we constructed: github.com/sony/DeepResonance.
Union of Experts: Adapting Hierarchical Routing to Equivalently Decomposed Transformer
arXiv:2503.02495v3 Announce Type: replace-cross Abstract: Mixture-of-Experts (MoE) enhances model performance while maintaining computational efficiency, making it well-suited for large-scale applications. Conventional mixture-of-experts (MoE) architectures suffer from suboptimal coordination dynamics, where isolated expert operations expose the model to overfitting risks. Moreover, they have not been effectively extended to attention blocks, which limits further efficiency improvements. To tackle these issues, we propose Union-of-Experts (UoE), which decomposes the transformer model into an equivalent group of experts and applies a hierarchical routing mechanism to allocate input subspaces to specialized experts. Our approach advances MoE design with four key innovations: (1) Constructing expert groups by partitioning non-MoE models into functionally equivalent specialists (2) Developing a hierarchical routing paradigm that integrates patch-wise data selection and expert selection strategies. (3) Extending the MoE design to attention blocks. (4) Proposing a hardware-optimized parallelization scheme that exploits batched matrix multiplications for efficient expert computation. The experiments demonstrate that our UoE model surpasses Full Attention, state-of-the-art MoEs and efficient transformers in several tasks across image and natural language domains. In language modeling tasks, UoE achieves an average reduction of 2.38 in perplexity compared to the best-performing MoE method with only 76% of its FLOPs. In the Long Range Arena benchmark, it demonstrates an average score at least 0.68% higher than all comparison models, with only 50% of the FLOPs of the best MoE method. In image classification, it yields an average accuracy improvement of 1.75% over the best model while maintaining comparable FLOPs. The source codes are available at https://github.com/YujiaoYang-work/UoE.
A Survey on Sparse Autoencoders: Interpreting the Internal Mechanisms of Large Language Models
arXiv:2503.05613v3 Announce Type: replace-cross Abstract: Large Language Models (LLMs) have transformed natural language processing, yet their internal mechanisms remain largely opaque. Recently, mechanistic interpretability has attracted significant attention from the research community as a means to understand the inner workings of LLMs. Among various mechanistic interpretability approaches, Sparse Autoencoders (SAEs) have emerged as a promising method due to their ability to disentangle the complex, superimposed features within LLMs into more interpretable components. This paper presents a comprehensive survey of SAEs for interpreting and understanding the internal workings of LLMs. Our major contributions include: (1) exploring the technical framework of SAEs, covering basic architecture, design improvements, and effective training strategies; (2) examining different approaches to explaining SAE features, categorized into input-based and output-based explanation methods; (3) discussing evaluation methods for assessing SAE performance, covering both structural and functional metrics; and (4) investigating real-world applications of SAEs in understanding and manipulating LLM behaviors.
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning
arXiv:2503.19470v3 Announce Type: replace-cross Abstract: Large Language Models (LLMs) have shown remarkable capabilities in reasoning, exemplified by the success of OpenAI-o1 and DeepSeek-R1. However, integrating reasoning with external search processes remains challenging, especially for complex multi-hop questions requiring multiple retrieval steps. We propose ReSearch, a novel framework that trains LLMs to Reason with Search via reinforcement learning without using any supervised data on reasoning steps. Our approach treats search operations as integral components of the reasoning chain, where when and how to perform searches is guided by text-based thinking, and search results subsequently influence further reasoning. We train ReSearch on Qwen2.5-7B(-Instruct) and Qwen2.5-32B(-Instruct) models and conduct extensive experiments. Despite being trained on only one dataset, our models demonstrate strong generalizability across various benchmarks. Analysis reveals that ReSearch naturally elicits advanced reasoning capabilities such as reflection and self-correction during the reinforcement learning process.
Meta-Semantics Augmented Few-Shot Relational Learning
arXiv:2505.05684v3 Announce Type: replace-cross Abstract: Few-shot relational learning on knowledge graph (KGs) aims to perform reasoning over relations with only a few training examples. While current methods have focused primarily on leveraging specific relational information, rich semantics inherent in KGs have been largely overlooked. To bridge this gap, we propose PromptMeta, a novel prompted meta-learning framework that seamlessly integrates meta-semantics with relational information for few-shot relational learning. PromptMeta introduces two core innovations: (1) a Meta-Semantic Prompt (MSP) pool that learns and consolidates high-level meta-semantics shared across tasks, enabling effective knowledge transfer and adaptation to newly emerging relations; and (2) a learnable fusion mechanism that dynamically combines meta-semantics with task-specific relational information tailored to different few-shot tasks. Both components are optimized jointly with model parameters within a meta-learning framework. Extensive experiments and analyses on two real-world KG benchmarks validate the effectiveness of PromptMeta in adapting to new relations with limited supervision.
Beyond Input Activations: Identifying Influential Latents by Gradient Sparse Autoencoders
arXiv:2505.08080v2 Announce Type: replace-cross Abstract: Sparse Autoencoders (SAEs) have recently emerged as powerful tools for interpreting and steering the internal representations of large language models (LLMs). However, conventional approaches to analyzing SAEs typically rely solely on input-side activations, without considering the causal influence between each latent feature and the model's output. This work is built on two key hypotheses: (1) activated latents do not contribute equally to the construction of the model's output, and (2) only latents with high causal influence are effective for model steering. To validate these hypotheses, we propose Gradient Sparse Autoencoder (GradSAE), a simple yet effective method that identifies the most influential latents by incorporating output-side gradient information.
MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning
arXiv:2505.24846v2 Announce Type: replace-cross Abstract: Reward modeling is a key step in building safe foundation models when applying reinforcement learning from human feedback (RLHF) to align Large Language Models (LLMs). However, reward modeling based on the Bradley-Terry (BT) model assumes a global reward function, failing to capture the inherently diverse and heterogeneous human preferences. Hence, such oversimplification limits LLMs from supporting personalization and pluralistic alignment. Theoretically, we show that when human preferences follow a mixture distribution of diverse subgroups, a single BT model has an irreducible error. While existing solutions, such as multi-objective learning with fine-grained annotations, help address this issue, they are costly and constrained by predefined attributes, failing to fully capture the richness of human values. In this work, we introduce MiCRo, a two-stage framework that enhances personalized preference learning by leveraging large-scale binary preference datasets without requiring explicit fine-grained annotations. In the first stage, MiCRo introduces context-aware mixture modeling approach to capture diverse human preferences. In the second stage, MiCRo integrates an online routing strategy that dynamically adapts mixture weights based on specific context to resolve ambiguity, allowing for efficient and scalable preference adaptation with minimal additional supervision. Experiments on multiple preference datasets demonstrate that MiCRo effectively captures diverse human preferences and significantly improves downstream personalization.
Athena: Enhancing Multimodal Reasoning with Data-efficient Process Reward Models
arXiv:2506.09532v2 Announce Type: replace-cross Abstract: We present Athena-PRM, a multimodal process reward model (PRM) designed to evaluate the reward score for each step in solving complex reasoning problems. Developing high-performance PRMs typically demands significant time and financial investment, primarily due to the necessity for step-level annotations of reasoning steps. Conventional automated labeling methods, such as Monte Carlo estimation, often produce noisy labels and incur substantial computational costs. To efficiently generate high-quality process-labeled data, we propose leveraging prediction consistency between weak and strong completers as a criterion for identifying reliable process labels. Remarkably, Athena-PRM demonstrates outstanding effectiveness across various scenarios and benchmarks with just 5,000 samples. Furthermore, we also develop two effective strategies to improve the performance of PRMs: ORM initialization and up-sampling for negative data. We validate our approach in three specific scenarios: verification for test time scaling, direct evaluation of reasoning step correctness, and reward ranked fine-tuning. Our Athena-PRM consistently achieves superior performance across multiple benchmarks and scenarios. Notably, when using Qwen2.5-VL-7B as the policy model, Athena-PRM enhances performance by 10.2 points on WeMath and 7.1 points on MathVista for test time scaling. Furthermore, Athena-PRM sets the state-of-the-art (SoTA) results in VisualProcessBench and outperforms the previous SoTA by 3.9 F1-score, showcasing its robust capability to accurately assess the correctness of the reasoning step. Additionally, utilizing Athena-PRM as the reward model, we develop Athena-7B with reward ranked fine-tuning and outperforms baseline with a significant margin on five benchmarks.
When and How Long Did Therapy Happen? Soft-Supervising Temporal Localization Using Audio-Language Models
arXiv:2506.09707v3 Announce Type: replace-cross Abstract: Prolonged Exposure (PE) therapy is an effective treatment for post-traumatic stress disorder (PTSD), but evaluating therapist fidelity remains labor-intensive due to the need for manual review of session recordings. We present a method for the automatic temporal localization of key PE fidelity elements, identifying their start and stop times, directly from session audio and transcripts. Our approach fine-tunes a large pre-trained audio-language model, Qwen2-Audio, using Low-Rank Adaptation (LoRA) to process focused 30-second windows of audio-transcript input. Fidelity labels for three core protocol phases, therapist orientation (P1), imaginal exposure (P2), and post-imaginal processing (P3), are generated via LLM-based prompting and verified by trained raters. The model is trained to predict normalized boundary offsets using soft supervision guided by task-specific prompts. On a dataset of 308 real PE sessions, our best configuration (LoRA rank 8, 30s windows) achieves a mean absolute error (MAE) of 5.3s across tasks, within typical rater tolerance for timestamp review, enabling practical fidelity QC. We further analyze the effects of window size and LoRA rank, highlighting the importance of context granularity and model adaptation. This work introduces a privacy-preserving, scalable framework for fidelity tracking in PE therapy, with potential to support clinician training, supervision, and quality assurance.
RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning
arXiv:2506.11555v4 Announce Type: replace-cross Abstract: The integration of external knowledge through Retrieval-Augmented Generation (RAG) has become foundational in enhancing large language models (LLMs) for knowledge-intensive tasks. However, existing RAG paradigms often overlook the cognitive step of applying knowledge, leaving a gap between retrieved facts and task-specific reasoning. In this work, we introduce RAG+, a principled and modular extension that explicitly incorporates application-aware reasoning into the RAG pipeline. RAG+ constructs a dual corpus consisting of knowledge and aligned application examples, created either manually or automatically, and retrieves both jointly during inference. This design enables LLMs not only to access relevant information but also to apply it within structured, goal-oriented reasoning processes. Experiments across mathematical, legal, and medical domains, conducted on multiple models, demonstrate that RAG+ consistently outperforms standard RAG variants, achieving average improvements of 3-5%, and peak gains up to 13.5% in complex scenarios. By bridging retrieval with actionable application, RAG+ advances a more cognitively grounded framework for knowledge integration, representing a step toward more interpretable and capable LLMs.
LogicGuard: Improving Embodied LLM agents through Temporal Logic based Critics
arXiv:2507.03293v2 Announce Type: replace-cross Abstract: Large language models (LLMs) have shown promise in zero-shot and single step reasoning and decision making problems, but in long horizon sequential planning tasks, their errors compound, often leading to unreliable or inefficient behavior. We introduce LogicGuard, a modular actor-critic architecture in which an LLM actor is guided by a trajectory level LLM critic that communicates through Linear Temporal Logic (LTL). Our setup combines the reasoning strengths of language models with the guarantees of formal logic. The actor selects high-level actions from natural language observations, while the critic analyzes full trajectories and proposes new LTL constraints that shield the actor from future unsafe or inefficient behavior. LogicGuard supports both fixed safety rules and adaptive, learned constraints, and is model-agnostic: any LLM-based planner can serve as the actor, with LogicGuard acting as a logic-generating wrapper. We formalize planning as graph traversal under symbolic constraints, allowing LogicGuard to analyze failed or suboptimal trajectories and generate new temporal logic rules that improve future behavior. To demonstrate generality, we evaluate LogicGuard across two distinct settings: short-horizon general tasks and long-horizon specialist tasks. On the Behavior benchmark of 100 household tasks, LogicGuard increases task completion rates by 25% over a baseline InnerMonologue planner. On the Minecraft diamond-mining task, which is long-horizon and requires multiple interdependent subgoals, LogicGuard improves both efficiency and safety compared to SayCan and InnerMonologue. These results show that enabling LLMs to supervise each other through temporal logic yields more reliable, efficient and safe decision-making for both embodied agents.
Generative Medical Event Models Improve with Scale
arXiv:2508.12104v2 Announce Type: replace-cross Abstract: Realizing personalized medicine at scale calls for methods that distill insights from longitudinal patient journeys, which can be viewed as a sequence of medical events. Foundation models pretrained on large-scale medical event data represent a promising direction for scaling real-world evidence generation and generalizing to diverse downstream tasks. Using Epic Cosmos, a dataset with medical events from de-identified longitudinal health records for 16.3 billion encounters over 300 million unique patient records from 310 health systems, we introduce the Comet models, a family of decoder-only transformer models pretrained on 118 million patients representing 115 billion discrete medical events (151 billion tokens). We present the largest scaling-law study of medical event data, establishing a methodology for pretraining and revealing power-law scaling relationships for compute, tokens, and model size. Consequently, we pretrained a series of compute-optimal models with up to 1 billion parameters. Conditioned on a patient's real-world history, Comet autoregressively predicts the next medical event to simulate patient health timelines. We studied 78 real-world tasks, including diagnosis prediction, disease prognosis, and healthcare operations. Remarkably for a foundation model with generic pretraining and simulation-based inference, Comet generally outperformed or matched task-specific supervised models on these tasks, without requiring task-specific fine-tuning or few-shot examples. Comet's predictive power consistently improves as the model and pretraining scale. Our results show that Comet, a generative medical event foundation model, can effectively capture complex clinical dynamics, providing an extensible and generalizable framework to support clinical decision-making, streamline healthcare operations, and improve patient outcomes.
Retrieval Enhanced Feedback via In-context Neural Error-book
arXiv:2508.16313v4 Announce Type: replace-cross Abstract: Recent advancements in Large Language Models (LLMs) have significantly improved reasoning capabilities, with in-context learning (ICL) emerging as a key technique for adaptation without retraining. While previous works have focused on leveraging correct examples, recent research highlights the importance of learning from errors to enhance performance. However, existing methods lack a structured framework for analyzing and mitigating errors, particularly in Multimodal Large Language Models (MLLMs), where integrating visual and textual inputs adds complexity. To address this issue, we propose REFINE: Retrieval-Enhanced Feedback via In-context Neural Error-book, a teacher-student framework that systematically structures errors and provides targeted feedback. REFINE introduces three systematic queries to construct structured feedback -- Feed-Target, Feed-Check, and Feed-Path -- to enhance multimodal reasoning by prioritizing relevant visual information, diagnosing critical failure points, and formulating corrective actions. Unlike prior approaches that rely on redundant retrievals, REFINE optimizes structured feedback retrieval, improving inference efficiency, token usage, and scalability. Our results demonstrate substantial speedup, reduced computational costs, and successful generalization, highlighting REFINE's potential for enhancing multimodal reasoning.
Training Language Model Agents to Find Vulnerabilities with CTF-Dojo
arXiv:2508.18370v2 Announce Type: replace-cross Abstract: Large language models (LLMs) have demonstrated exceptional capabilities when trained within executable runtime environments, notably excelling at software engineering tasks through verified feedback loops. Yet, scalable and generalizable execution-grounded environments remain scarce, limiting progress in training more capable ML agents. We introduce CTF-Dojo, the first large-scale executable runtime tailored for training LLMs with verifiable feedback, featuring 658 fully functional Capture-The-Flag (CTF)-style challenges containerized in Docker with guaranteed reproducibility. To enable rapid scaling without manual intervention, we develop CTF-Forge, an automated pipeline that transforms publicly available artifacts into ready-to-use execution environments in minutes, eliminating weeks of expert configuration traditionally required. We trained LLM-based agents on just 486 high-quality, execution-verified trajectories from CTF-Dojo, achieving up to 11.6% absolute gains over strong baselines across three competitive benchmarks: InterCode-CTF, NYU CTF Bench, and Cybench. Our best-performing 32B model reaches 31.9% Pass@1, establishing a new open-weight state-of-the-art that rivals frontier models like DeepSeek-V3-0324 and Gemini-2.5-Flash. By framing CTF-style tasks as a benchmark for executable-agent learning, CTF-Dojo demonstrates that execution-grounded training signals are not only effective but pivotal in advancing high-performance ML agents without dependence on costly proprietary systems.
SoK: Large Language Model Copyright Auditing via Fingerprinting
arXiv:2508.19843v2 Announce Type: replace-cross Abstract: The broad capabilities and substantial resources required to train Large Language Models (LLMs) make them valuable intellectual property, yet they remain vulnerable to copyright infringement, such as unauthorized use and model theft. LLM fingerprinting, a non-intrusive technique that extracts and compares the distinctive features from LLMs to identify infringements, offers a promising solution to copyright auditing. However, its reliability remains uncertain due to the prevalence of diverse model modifications and the lack of standardized evaluation. In this SoK, we present the first comprehensive study of LLM fingerprinting. We introduce a unified framework and formal taxonomy that categorizes existing methods into white-box and black-box approaches, providing a structured overview of the state of the art. We further propose LeaFBench, the first systematic benchmark for evaluating LLM fingerprinting under realistic deployment scenarios. Built upon mainstream foundation models and comprising 149 distinct model instances, LeaFBench integrates 13 representative post-development techniques, spanning both parameter-altering methods (e.g., fine-tuning, quantization) and parameter-independent mechanisms (e.g., system prompts, RAG). Extensive experiments on LeaFBench reveal the strengths and weaknesses of existing methods, thereby outlining future research directions and critical open problems in this emerging field. The code is available at https://github.com/shaoshuo-ss/LeaFBench.
Clip Your Sequences Fairly: Enforcing Length Fairness for Sequence-Level RL
arXiv:2509.09177v2 Announce Type: replace-cross Abstract: We propose FSPO (Fair Sequence Policy Optimization), a sequence-level reinforcement learning method for LLMs that enforces length-fair clipping on the importance-sampling (IS) weight. We study RL methods with sequence-level IS and identify a mismatch when PPO/GRPO-style clipping is transplanted to sequences: a fixed clip range systematically reweights short vs.\ long responses, distorting the optimization direction. FSPO introduces a simple remedy: we clip the sequence log-IS ratio with a band that scales as $\sqrt{L}$. Theoretically, we formalize length fairness via a Length Reweighting Error (LRE) and prove that small LRE yields a cosine directional guarantee between the clipped and true updates. Empirically, FSPO flattens clip rates across length bins, stabilizes training, and outperforms all baselines across multiple evaluation datasets on Qwen3-8B-Base model.
Abduct, Act, Predict: Scaffolding Causal Inference for Automated Failure Attribution in Multi-Agent Systems
arXiv:2509.10401v2 Announce Type: replace-cross Abstract: Failure attribution in multi-agent systems -- pinpointing the exact step where a decisive error occurs -- is a critical yet unsolved challenge. Current methods treat this as a pattern recognition task over long conversation logs, leading to critically low step-level accuracy (below 17\%), which renders them impractical for debugging complex systems. Their core weakness is a fundamental inability to perform robust counterfactual reasoning: to determine if correcting a single action would have actually averted the task failure. To bridge this \emph{counterfactual inference gap}, we introduce Abduct-Act-Predict (A2P) Scaffolding, a novel agent framework that transforms failure attribution from pattern recognition into a structured causal inference task. A2P explicitly guides a large language model through a formal three-step reasoning process within a single inference pass: (1) Abduction, to infer the hidden root causes behind an agent's actions; (2) Action, to define a minimal corrective intervention; and (3) Prediction, to simulate the subsequent trajectory and verify if the intervention resolves the failure. This structured approach leverages the holistic context of the entire conversation while imposing a rigorous causal logic on the model's analysis. Our extensive experiments on the Who\&When benchmark demonstrate its efficacy. On the Algorithm-Generated dataset, A2P achieves 47.46\% step-level accuracy, a 2.85$\times$ improvement over the 16.67\% of the baseline. On the more complex Hand-Crafted dataset, it achieves 29.31\% step accuracy, a 2.43$\times$ improvement over the baseline's 12.07\%. By reframing the problem through a causal lens, A2P Scaffolding provides a robust, verifiable, and significantly more accurate solution for automated failure attribution. Ours code are released at https://github.com/ResearAI/A2P.
Privacy-Aware In-Context Learning for Large Language Models
arXiv:2509.13625v3 Announce Type: replace-cross Abstract: Large language models (LLMs) have significantly transformed natural language understanding and generation, but they raise privacy concerns due to potential exposure of sensitive information. Studies have highlighted the risk of information leakage, where adversaries can extract sensitive information embedded in the prompts. In this work, we introduce a novel private prediction framework for generating high-quality synthetic text with strong privacy guarantees. Our approach leverages the Differential Privacy (DP) framework to ensure worst-case theoretical bounds on information leakage without requiring any fine-tuning of the underlying models. The proposed method performs inference on private records and aggregates the resulting per-token output distributions. This enables the generation of longer and coherent synthetic text while maintaining privacy guarantees. Additionally, we propose a simple blending operation that combines private and public inference to further enhance utility. Empirical evaluations demonstrate that our approach outperforms previous state-of-the-art methods on in-context-learning (ICL) tasks, making it a promising direction for privacy-preserving text generation while maintaining high utility.
ViSpec: Accelerating Vision-Language Models with Vision-Aware Speculative Decoding
arXiv:2509.15235v3 Announce Type: replace-cross Abstract: Speculative decoding is a widely adopted technique for accelerating inference in large language models (LLMs), yet its application to vision-language models (VLMs) remains underexplored, with existing methods achieving only modest speedups (<1.5x). This gap is increasingly significant as multimodal capabilities become central to large-scale models. We hypothesize that large VLMs can effectively filter redundant image information layer by layer without compromising textual comprehension, whereas smaller draft models struggle to do so. To address this, we introduce Vision-Aware Speculative Decoding (ViSpec), a novel framework tailored for VLMs. ViSpec employs a lightweight vision adaptor module to compress image tokens into a compact representation, which is seamlessly integrated into the draft model's attention mechanism while preserving original image positional information. Additionally, we extract a global feature vector for each input image and augment all subsequent text tokens with this feature to enhance multimodal coherence. To overcome the scarcity of multimodal datasets with long assistant responses, we curate a specialized training dataset by repurposing existing datasets and generating extended outputs using the target VLM with modified prompts. Our training strategy mitigates the risk of the draft model exploiting direct access to the target model's hidden states, which could otherwise lead to shortcut learning when training solely on target model outputs. Extensive experiments validate ViSpec, achieving, to our knowledge, the first substantial speedup in VLM speculative decoding. Code is available at https://github.com/KangJialiang/ViSpec.
Small LLMs with Expert Blocks Are Good Enough for Hyperparamter Tuning
arXiv:2509.15561v2 Announce Type: replace-cross Abstract: Hyper-parameter Tuning (HPT) is a necessary step in machine learning (ML) pipelines but becomes computationally expensive and opaque with larger models. Recently, Large Language Models (LLMs) have been explored for HPT, yet most rely on models exceeding 100 billion parameters. We propose an Expert Block Framework for HPT using Small LLMs. At its core is the Trajectory Context Summarizer (TCS), a deterministic block that transforms raw training trajectories into structured context, enabling small LLMs to analyze optimization progress with reliability comparable to larger models. Using two locally-run LLMs (phi4:reasoning14B and qwen2.5-coder:32B) and a 10-trial budget, our TCS-enabled HPT pipeline achieves average performance within ~0.9 percentage points of GPT-4 across six diverse tasks.
Program Synthesis via Test-Time Transduction
arXiv:2509.17393v2 Announce Type: replace-cross Abstract: We introduce transductive program synthesis, a new formulation of the program synthesis task that explicitly leverages test inputs during synthesis. While prior approaches to program synthesis--whether based on natural language descriptions or input-output examples--typically aim to generalize from training examples, they often struggle with robustness, especially in real-world settings where training examples are limited and test inputs involve various edge cases. To address this, we propose a novel framework that improves robustness by treating synthesis as an active learning over a finite hypothesis class defined by programs' outputs. We use an LLM to predict outputs for selected test inputs and eliminate inconsistent hypotheses, where the inputs are chosen via a greedy maximin algorithm to minimize the number of LLM queries required. We evaluate our approach on four benchmarks: Playgol, MBPP+, 1D-ARC, and programmatic world modeling on MiniGrid. We demonstrate that our method significantly improves program synthesis in both accuracy and efficiency. We release our code at https://github.com/klee972/SYNTRA.
PolypSeg-GradCAM: Towards Explainable Computer-Aided Gastrointestinal Disease Detection Using U-Net Based Segmentation and Grad-CAM Visualization on the Kvasir Dataset
arXiv:2509.18159v1 Announce Type: new Abstract: Colorectal cancer (CRC) remains one of the leading causes of cancer-related morbidity and mortality worldwide, with gastrointestinal (GI) polyps serving as critical precursors according to the World Health Organization (WHO). Early and accurate segmentation of polyps during colonoscopy is essential for reducing CRC progression, yet manual delineation is labor-intensive and prone to observer variability. Deep learning methods have demonstrated strong potential for automated polyp analysis, but their limited interpretability remains a barrier to clinical adoption. In this study, we present PolypSeg-GradCAM, an explainable deep learning framework that integrates the U-Net architecture with Gradient-weighted Class Activation Mapping (Grad-CAM) for transparent polyp segmentation. The model was trained and evaluated on the Kvasir-SEG dataset of 1000 annotated endoscopic images. Experimental results demonstrate robust segmentation performance, achieving a mean Intersection over Union (IoU) of 0.9257 on the test set and consistently high Dice coefficients (F-score > 0.96) on training and validation sets. Grad-CAM visualizations further confirmed that predictions were guided by clinically relevant regions, enhancing transparency and trust in the model's decisions. By coupling high segmentation accuracy with interpretability, PolypSeg-GradCAM represents a step toward reliable, trustworthy AI-assisted colonoscopy and improved early colorectal cancer prevention.
PerceptronCARE: A Deep Learning-Based Intelligent Teleopthalmology Application for Diabetic Retinopathy Diagnosis
arXiv:2509.18160v1 Announce Type: new Abstract: Diabetic retinopathy is a leading cause of vision loss among adults and a major global health challenge, particularly in underserved regions. This study presents PerceptronCARE, a deep learning-based teleophthalmology application designed for automated diabetic retinopathy detection using retinal images. The system was developed and evaluated using multiple convolutional neural networks, including ResNet-18, EfficientNet-B0, and SqueezeNet, to determine the optimal balance between accuracy and computational efficiency. The final model classifies disease severity with an accuracy of 85.4%, enabling real-time screening in clinical and telemedicine settings. PerceptronCARE integrates cloud-based scalability, secure patient data management, and a multi-user framework, facilitating early diagnosis, improving doctor-patient interactions, and reducing healthcare costs. This study highlights the potential of AI-driven telemedicine solutions in expanding access to diabetic retinopathy screening, particularly in remote and resource-constrained environments.
Self Identity Mapping
arXiv:2509.18165v1 Announce Type: new Abstract: Regularization is essential in deep learning to enhance generalization and mitigate overfitting. However, conventional techniques often rely on heuristics, making them less reliable or effective across diverse settings. We propose Self Identity Mapping (SIM), a simple yet effective, data-intrinsic regularization framework that leverages an inverse mapping mechanism to enhance representation learning. By reconstructing the input from its transformed output, SIM reduces information loss during forward propagation and facilitates smoother gradient flow. To address computational inefficiencies, We instantiate SIM as $ \rho\text{SIM} $ by incorporating patch-level feature sampling and projection-based method to reconstruct latent features, effectively lowering complexity. As a model-agnostic, task-agnostic regularizer, SIM can be seamlessly integrated as a plug-and-play module, making it applicable to different network architectures and tasks. We extensively evaluate $\rho\text{SIM}$ across three tasks: image classification, few-shot prompt learning, and domain generalization. Experimental results show consistent improvements over baseline methods, highlighting $\rho\text{SIM}$'s ability to enhance representation learning across various tasks. We also demonstrate that $\rho\text{SIM}$ is orthogonal to existing regularization methods, boosting their effectiveness. Moreover, our results confirm that $\rho\text{SIM}$ effectively preserves semantic information and enhances performance in dense-to-dense tasks, such as semantic segmentation and image translation, as well as in non-visual domains including audio classification and time series anomaly detection. The code is publicly available at https://github.com/XiudingCai/SIM-pytorch.
MAGIA: Sensing Per-Image Signals from Single-Round Averaged Gradients for Label-Inference-Free Gradient Inversion
arXiv:2509.18170v1 Announce Type: new Abstract: We study gradient inversion in the challenging single round averaged gradient SAG regime where per sample cues are entangled within a single batch mean gradient. We introduce MAGIA a momentum based adaptive correction on gradient inversion attack a novel label inference free framework that senses latent per image signals by probing random data subsets. MAGIA objective integrates two core innovations 1 a closed form combinatorial rescaling that creates a provably tighter optimization bound and 2 a momentum based mixing of whole batch and subset losses to ensure reconstruction robustness. Extensive experiments demonstrate that MAGIA significantly outperforms advanced methods achieving high fidelity multi image reconstruction in large batch scenarios where prior works fail. This is all accomplished with a computational footprint comparable to standard solvers and without requiring any auxiliary information.
Baseer: A Vision-Language Model for Arabic Document-to-Markdown OCR
arXiv:2509.18174v1 Announce Type: new Abstract: Arabic document OCR remains a challenging task due to the language's cursive script, diverse fonts, diacritics, and right-to-left orientation. While modern Multimodal Large Language Models (MLLMs) have advanced document understanding for high-resource languages, their performance on Arabic remains limited. In this work, we introduce Baseer, a vision-language model fine- tuned specifically for Arabic document OCR. Leveraging a large-scale dataset combining synthetic and real-world documents, Baseer is trained using a decoder-only fine-tuning strategy to adapt a pre-trained MLLM while preserving general visual features. We also present Misraj-DocOCR, a high-quality, expert-verified benchmark designed for rigorous evaluation of Arabic OCR systems. Our experiments show that Baseer significantly outperforms existing open-source and commercial solutions, achieving a WER of 0.25 and establishing a new state-of-the-art in the domain of Arabic document OCR. Our results highlight the benefits of domain-specific adaptation of general-purpose MLLMs and establish a strong baseline for high-accuracy OCR on morphologically rich languages like Arabic.
A Deep Learning Approach for Spatio-Temporal Forecasting of InSAR Ground Deformation in Eastern Ireland
arXiv:2509.18176v1 Announce Type: new Abstract: Monitoring ground displacement is crucial for urban infrastructure stability and mitigating geological hazards. However, forecasting future deformation from sparse Interferometric Synthetic Aperture Radar (InSAR) time-series data remains a significant challenge. This paper introduces a novel deep learning framework that transforms these sparse point measurements into a dense spatio-temporal tensor. This methodological shift allows, for the first time, the direct application of advanced computer vision architectures to this forecasting problem. We design and implement a hybrid Convolutional Neural Network and Long-Short Term Memory (CNN-LSTM) model, specifically engineered to simultaneously learn spatial patterns and temporal dependencies from the generated data tensor. The model's performance is benchmarked against powerful machine learning baselines, Light Gradient Boosting Machine and LASSO regression, using Sentinel-1 data from eastern Ireland. Results demonstrate that the proposed architecture provides significantly more accurate and spatially coherent forecasts, establishing a new performance benchmark for this task. Furthermore, an interpretability analysis reveals that baseline models often default to simplistic persistence patterns, highlighting the necessity of our integrated spatio-temporal approach to capture the complex dynamics of ground deformation. Our findings confirm the efficacy and potential of spatio-temporal deep learning for high-resolution deformation forecasting.
A Framework for Generating Artificial Datasets to Validate Absolute and Relative Position Concepts
arXiv:2509.18177v1 Announce Type: new Abstract: In this paper, we present the Scrapbook framework, a novel methodology designed to generate extensive datasets for probing the learned concepts of artificial intelligence (AI) models. The framework focuses on fundamental concepts such as object recognition, absolute and relative positions, and attribute identification. By generating datasets with a large number of questions about individual concepts and a wide linguistic variation, the Scrapbook framework aims to validate the model's understanding of these basic elements before tackling more complex tasks. Our experimental findings reveal that, while contemporary models demonstrate proficiency in recognizing and enumerating objects, they encounter challenges in comprehending positional information and addressing inquiries with additional constraints. Specifically, the MobileVLM-V2 model showed significant answer disagreements and plausible wrong answers, while other models exhibited a bias toward affirmative answers and struggled with questions involving geometric shapes and positional information, indicating areas for improvement in understanding and consistency. The proposed framework offers a valuable instrument for generating diverse and comprehensive datasets, which can be utilized to systematically assess and enhance the performance of AI models.
The Describe-Then-Generate Bottleneck: How VLM Descriptions Alter Image Generation Outcomes
arXiv:2509.18179v1 Announce Type: new Abstract: With the increasing integration of multimodal AI systems in creative workflows, understanding information loss in vision-language-vision pipelines has become important for evaluating system limitations. However, the degradation that occurs when visual content passes through textual intermediation remains poorly quantified. In this work, we provide empirical analysis of the describe-then-generate bottleneck, where natural language serves as an intermediate representation for visual information. We generated 150 image pairs through the describe-then-generate pipeline and applied existing metrics (LPIPS, SSIM, and color distance) to measure information preservation across perceptual, structural, and chromatic dimensions. Our evaluation reveals that 99.3% of samples exhibit substantial perceptual degradation and 91.5% demonstrate significant structural information loss, providing empirical evidence that the describe-then-generate bottleneck represents a measurable and consistent limitation in contemporary multimodal systems.
AI-Derived Structural Building Intelligence for Urban Resilience: An Application in Saint Vincent and the Grenadines
arXiv:2509.18182v1 Announce Type: new Abstract: Detailed structural building information is used to estimate potential damage from hazard events like cyclones, floods, and landslides, making them critical for urban resilience planning and disaster risk reduction. However, such information is often unavailable in many small island developing states (SIDS) in climate-vulnerable regions like the Caribbean. To address this data gap, we present an AI-driven workflow to automatically infer rooftop attributes from high-resolution satellite imagery, with Saint Vincent and the Grenadines as our case study. Here, we compare the utility of geospatial foundation models combined with shallow classifiers against fine-tuned deep learning models for rooftop classification. Furthermore, we assess the impact of incorporating additional training data from neighboring SIDS to improve model performance. Our best models achieve F1 scores of 0.88 and 0.83 for roof pitch and roof material classification, respectively. Combined with local capacity building, our work aims to provide SIDS with novel capabilities to harness AI and Earth Observation (EO) data to enable more efficient, evidence-based urban governance.
VLA-LPAF: Lightweight Perspective-Adaptive Fusion for Vision-Language-Action to Enable More Unconstrained Robotic Manipulation
arXiv:2509.18183v1 Announce Type: new Abstract: The Visual-Language-Action (VLA) models can follow text instructions according to visual observations of the surrounding environment. This ability to map multimodal inputs to actions is derived from the training of the VLA model on extensive standard demonstrations. These visual observations captured by third-personal global and in-wrist local cameras are inevitably varied in number and perspective across different environments, resulting in significant differences in the visual features. This perspective heterogeneity constrains the generality of VLA models. In light of this, we first propose the lightweight module VLA-LPAF to foster the perspective adaptivity of VLA models using only 2D data. VLA-LPAF is finetuned using images from a single view and fuses other multiview observations in the latent space, which effectively and efficiently bridge the gap caused by perspective inconsistency. We instantiate our VLA-LPAF framework with the VLA model RoboFlamingo to construct RoboFlamingo-LPAF. Experiments show that RoboFlamingo-LPAF averagely achieves around 8% task success rate improvement on CALVIN, 15% on LIBERO, and 30% on a customized simulation benchmark. We also demonstrate the developed viewadaptive characteristics of the proposed RoboFlamingo-LPAF through real-world tasks.
URNet: Uncertainty-aware Refinement Network for Event-based Stereo Depth Estimation
arXiv:2509.18184v1 Announce Type: new Abstract: Event cameras provide high temporal resolution, high dynamic range, and low latency, offering significant advantages over conventional frame-based cameras. In this work, we introduce an uncertainty-aware refinement network called URNet for event-based stereo depth estimation. Our approach features a local-global refinement module that effectively captures fine-grained local details and long-range global context. Additionally, we introduce a Kullback-Leibler (KL) divergence-based uncertainty modeling method to enhance prediction reliability. Extensive experiments on the DSEC dataset demonstrate that URNet consistently outperforms state-of-the-art (SOTA) methods in both qualitative and quantitative evaluations.
Visionerves: Automatic and Reproducible Hybrid AI for Peripheral Nervous System Recognition Applied to Endometriosis Cases
arXiv:2509.18185v1 Announce Type: new Abstract: Endometriosis often leads to chronic pelvic pain and possible nerve involvement, yet imaging the peripheral nerves remains a challenge. We introduce Visionerves, a novel hybrid AI framework for peripheral nervous system recognition from multi-gradient DWI and morphological MRI data. Unlike conventional tractography, Visionerves encodes anatomical knowledge through fuzzy spatial relationships, removing the need for selection of manual ROIs. The pipeline comprises two phases: (A) automatic segmentation of anatomical structures using a deep learning model, and (B) tractography and nerve recognition by symbolic spatial reasoning. Applied to the lumbosacral plexus in 10 women with (confirmed or suspected) endometriosis, Visionerves demonstrated substantial improvements over standard tractography, with Dice score improvements of up to 25% and spatial errors reduced to less than 5 mm. This automatic and reproducible approach enables detailed nerve analysis and paves the way for non-invasive diagnosis of endometriosis-related neuropathy, as well as other conditions with nerve involvement.
V-SenseDrive: A Privacy-Preserving Road Video and In-Vehicle Sensor Fusion Framework for Road Safety & Driver Behaviour Modelling
arXiv:2509.18187v1 Announce Type: new Abstract: Road traffic accidents remain a major public health challenge, particularly in countries with heterogeneous road conditions, mixed traffic flow, and variable driving discipline, such as Pakistan. Reliable detection of unsafe driving behaviours is a prerequisite for improving road safety, enabling advanced driver assistance systems (ADAS), and supporting data driven decisions in insurance and fleet management. Most of existing datasets originate from the developed countries with limited representation of the behavioural diversity observed in emerging economies and the driver's face recording voilates the privacy preservation. We present V-SenseDrive, the first privacy-preserving multimodal driver behaviour dataset collected entirely within the Pakistani driving environment. V-SenseDrive combines smartphone based inertial and GPS sensor data with synchronized road facing video to record three target driving behaviours (normal, aggressive, and risky) on multiple types of roads, including urban arterials, secondary roads, and motorways. Data was gathered using a custom Android application designed to capture high frequency accelerometer, gyroscope, and GPS streams alongside continuous video, with all sources precisely time aligned to enable multimodal analysis. The focus of this work is on the data acquisition process, covering participant selection, driving scenarios, environmental considerations, and sensor video synchronization techniques. The dataset is structured into raw, processed, and semantic layers, ensuring adaptability for future research in driver behaviour classification, traffic safety analysis, and ADAS development. By representing real world driving in Pakistan, V-SenseDrive fills a critical gap in the global landscape of driver behaviour datasets and lays the groundwork for context aware intelligent transportation solutions.
Qianfan-VL: Domain-Enhanced Universal Vision-Language Models
arXiv:2509.18189v1 Announce Type: new Abstract: We present Qianfan-VL, a series of multimodal large language models ranging from 3B to 70B parameters, achieving state-of-the-art performance through innovative domain enhancement techniques. Our approach employs multi-stage progressive training and high-precision data synthesis pipelines, which prove to be critical technologies for enhancing domain-specific capabilities while maintaining strong general performance. Qianfan-VL achieves comparable results to leading open-source models on general benchmarks, with state-of-the-art performance on benchmarks such as CCBench, SEEDBench IMG, ScienceQA, and MMStar. The domain enhancement strategy delivers significant advantages in OCR and document understanding, validated on both public benchmarks (OCRBench 873, DocVQA 94.75%) and in-house evaluations. Notably, Qianfan-VL-8B and 70B variants incorporate long chain-of-thought capabilities, demonstrating superior performance on mathematical reasoning (MathVista 78.6%) and logical inference tasks. All models are trained entirely on Baidu's Kunlun P800 chips, validating the capability of large-scale AI infrastructure to train SOTA-level multimodal models with over 90% scaling efficiency on 5000 chips for a single task. This work establishes an effective methodology for developing domain-enhanced multimodal models suitable for diverse enterprise deployment scenarios.
HazeFlow: Revisit Haze Physical Model as ODE and Non-Homogeneous Haze Generation for Real-World Dehazing
arXiv:2509.18190v1 Announce Type: new Abstract: Dehazing involves removing haze or fog from images to restore clarity and improve visibility by estimating atmospheric scattering effects. While deep learning methods show promise, the lack of paired real-world training data and the resulting domain gap hinder generalization to real-world scenarios. In this context, physics-grounded learning becomes crucial; however, traditional methods based on the Atmospheric Scattering Model (ASM) often fall short in handling real-world complexities and diverse haze patterns. To solve this problem, we propose HazeFlow, a novel ODE-based framework that reformulates ASM as an ordinary differential equation (ODE). Inspired by Rectified Flow (RF), HazeFlow learns an optimal ODE trajectory to map hazy images to clean ones, enhancing real-world dehazing performance with only a single inference step. Additionally, we introduce a non-homogeneous haze generation method using Markov Chain Brownian Motion (MCBM) to address the scarcity of paired real-world data. By simulating realistic haze patterns through MCBM, we enhance the adaptability of HazeFlow to diverse real-world scenarios. Through extensive experiments, we demonstrate that HazeFlow achieves state-of-the-art performance across various real-world dehazing benchmark datasets.
TinyEcoWeedNet: Edge Efficient Real-Time Aerial Agricultural Weed Detection
arXiv:2509.18193v1 Announce Type: new Abstract: Deploying deep learning models in agriculture is difficult because edge devices have limited resources, but this work presents a compressed version of EcoWeedNet using structured channel pruning, quantization-aware training (QAT), and acceleration with NVIDIA's TensorRT on the Jetson Orin Nano. Despite the challenges of pruning complex architectures with residual shortcuts, attention mechanisms, concatenations, and CSP blocks, the model size was reduced by up to 68.5% and computations by 3.2 GFLOPs, while inference speed reached 184 FPS at FP16, 28.7% faster than the baseline. On the CottonWeedDet12 dataset, the pruned EcoWeedNet with a 39.5% pruning ratio outperformed YOLO11n and YOLO12n (with only 20% pruning), achieving 83.7% precision, 77.5% recall, and 85.9% mAP50, proving it to be both efficient and effective for precision agriculture.
Learning Contrastive Multimodal Fusion with Improved Modality Dropout for Disease Detection and Prediction
arXiv:2509.18284v1 Announce Type: new Abstract: As medical diagnoses increasingly leverage multimodal data, machine learning models are expected to effectively fuse heterogeneous information while remaining robust to missing modalities. In this work, we propose a novel multimodal learning framework that integrates enhanced modalities dropout and contrastive learning to address real-world limitations such as modality imbalance and missingness. Our approach introduces learnable modality tokens for improving missingness-aware fusion of modalities and augments conventional unimodal contrastive objectives with fused multimodal representations. We validate our framework on large-scale clinical datasets for disease detection and prediction tasks, encompassing both visual and tabular modalities. Experimental results demonstrate that our method achieves state-of-the-art performance, particularly in challenging and practical scenarios where only a single modality is available. Furthermore, we show its adaptability through successful integration with a recent CT foundation model. Our findings highlight the effectiveness, efficiency, and generalizability of our approach for multimodal learning, offering a scalable, low-cost solution with significant potential for real-world clinical applications. The code is available at https://github.com/omron-sinicx/medical-modality-dropout.
Rethinking Pulmonary Embolism Segmentation: A Study of Current Approaches and Challenges with an Open Weight Model
arXiv:2509.18308v1 Announce Type: new Abstract: In this study, we curated a densely annotated in-house dataset comprising 490 CTPA scans. Using this dataset, we systematically evaluated nine widely used segmentation architectures from both the CNN and Vision Transformer (ViT) families, initialized with either pretrained or random weights, under a unified testing framework as a performance audit. Our study leads to several important observations: (1) 3D U-Net with a ResNet encoder remains a highly effective architecture for PE segmentation; (2) 3D models are particularly well-suited to this task given the morphological characteristics of emboli; (3) CNN-based models generally yield superior performance compared to their ViT-based counterparts in PE segmentation; (4) classification-based pretraining, even on large PE datasets, can adversely impact segmentation performance compared to training from scratch, suggesting that PE classification and segmentation may rely on different sets of discriminative features; (5) different model architectures show a highly consistent pattern of segmentation performance when trained on the same data; and (6) while central and large emboli can be segmented with satisfactory accuracy, distal emboli remain challenging due to both task complexity and the scarcity of high-quality datasets. Besides these findings, our best-performing model achieves a mean Dice score of 0.7131 for segmentation. It detects 181 emboli with 49 false positives and 28 false negatives from 60 in-house testing scans. Its generalizability is further validated on public datasets.
Improving Handshape Representations for Sign Language Processing: A Graph Neural Network Approach
arXiv:2509.18309v1 Announce Type: new Abstract: Handshapes serve a fundamental phonological role in signed languages, with American Sign Language employing approximately 50 distinct shapes. However,computational approaches rarely model handshapes explicitly, limiting both recognition accuracy and linguistic analysis.We introduce a novel graph neural network that separates temporal dynamics from static handshape configurations. Our approach combines anatomically-informed graph structures with contrastive learning to address key challenges in handshape recognition, including subtle interclass distinctions and temporal variations. We establish the first benchmark for structured handshape recognition in signing sequences, achieving 46% accuracy across 37 handshape classes (with baseline methods achieving 25%).
Influence of Classification Task and Distribution Shift Type on OOD Detection in Fetal Ultrasound
arXiv:2509.18326v1 Announce Type: new Abstract: Reliable out-of-distribution (OOD) detection is important for safe deployment of deep learning models in fetal ultrasound amidst heterogeneous image characteristics and clinical settings. OOD detection relies on estimating a classification model's uncertainty, which should increase for OOD samples. While existing research has largely focused on uncertainty quantification methods, this work investigates the impact of the classification task itself. Through experiments with eight uncertainty quantification methods across four classification tasks, we demonstrate that OOD detection performance significantly varies with the task, and that the best task depends on the defined ID-OOD criteria; specifically, whether the OOD sample is due to: i) an image characteristic shift or ii) an anatomical feature shift. Furthermore, we reveal that superior OOD detection does not guarantee optimal abstained prediction, underscoring the necessity to align task selection and uncertainty strategies with the specific downstream application in medical image analysis.
OrthoLoC: UAV 6-DoF Localization and Calibration Using Orthographic Geodata
arXiv:2509.18350v1 Announce Type: new Abstract: Accurate visual localization from aerial views is a fundamental problem with applications in mapping, large-area inspection, and search-and-rescue operations. In many scenarios, these systems require high-precision localization while operating with limited resources (e.g., no internet connection or GNSS/GPS support), making large image databases or heavy 3D models impractical. Surprisingly, little attention has been given to leveraging orthographic geodata as an alternative paradigm, which is lightweight and increasingly available through free releases by governmental authorities (e.g., the European Union). To fill this gap, we propose OrthoLoC, the first large-scale dataset comprising 16,425 UAV images from Germany and the United States with multiple modalities. The dataset addresses domain shifts between UAV imagery and geospatial data. Its paired structure enables fair benchmarking of existing solutions by decoupling image retrieval from feature matching, allowing isolated evaluation of localization and calibration performance. Through comprehensive evaluation, we examine the impact of domain shifts, data resolutions, and covisibility on localization accuracy. Finally, we introduce a refinement technique called AdHoP, which can be integrated with any feature matcher, improving matching by up to 95% and reducing translation error by up to 63%. The dataset and code are available at: https://deepscenario.github.io/OrthoLoC.
A Single Image Is All You Need: Zero-Shot Anomaly Localization Without Training Data
arXiv:2509.18354v1 Announce Type: new Abstract: Anomaly detection in images is typically addressed by learning from collections of training data or relying on reference samples. In many real-world scenarios, however, such training data may be unavailable, and only the test image itself is provided. We address this zero-shot setting by proposing a single-image anomaly localization method that leverages the inductive bias of convolutional neural networks, inspired by Deep Image Prior (DIP). Our method is named Single Shot Decomposition Network (SSDnet). Our key assumption is that natural images often exhibit unified textures and patterns, and that anomalies manifest as localized deviations from these repetitive or stochastic patterns. To learn the deep image prior, we design a patch-based training framework where the input image is fed directly into the network for self-reconstruction, rather than mapping random noise to the image as done in DIP. To avoid the model simply learning an identity mapping, we apply masking, patch shuffling, and small Gaussian noise. In addition, we use a perceptual loss based on inner-product similarity to capture structure beyond pixel fidelity. Our approach needs no external training data, labels, or references, and remains robust in the presence of noise or missing pixels. SSDnet achieves 0.99 AUROC and 0.60 AUPRC on MVTec-AD and 0.98 AUROC and 0.67 AUPRC on the fabric dataset, outperforming state-of-the-art methods. The implementation code will be released at https://github.com/mehrdadmoradi124/SSDnet
Align Where the Words Look: Cross-Attention-Guided Patch Alignment with Contrastive and Transport Regularization for Bengali Captioning
arXiv:2509.18369v1 Announce Type: new Abstract: Grounding vision--language models in low-resource languages remains challenging, as they often produce fluent text about the wrong objects. This stems from scarce paired data, translation pivots that break alignment, and English-centric pretraining that ignores target-language semantics. We address this with a compute-aware Bengali captioning pipeline trained on LaBSE-verified EN--BN pairs and 110k bilingual-prompted synthetic images. A frozen MaxViT yields stable visual patches, a Bengali-native mBART-50 decodes, and a lightweight bridge links the modalities. Our core novelty is a tri-loss objective: Patch-Alignment Loss (PAL) aligns real and synthetic patch descriptors using decoder cross-attention, InfoNCE enforces global real--synthetic separation, and Sinkhorn-based OT ensures balanced fine-grained patch correspondence. This PAL+InfoNCE+OT synergy improves grounding, reduces spurious matches, and drives strong gains on Flickr30k-1k (BLEU-4 12.29, METEOR 27.98, BERTScore-F1 71.20) and MSCOCO-1k (BLEU-4 12.00, METEOR 28.14, BERTScore-F1 75.40), outperforming strong CE baselines and narrowing the real--synthetic centroid gap by 41%.
TinyBEV: Cross Modal Knowledge Distillation for Efficient Multi Task Bird's Eye View Perception and Planning
arXiv:2509.18372v1 Announce Type: new Abstract: We present TinyBEV, a unified, camera only Bird's Eye View (BEV) framework that distills the full-stack capabilities of a large planning-oriented teacher (UniAD [19]) into a compact, real-time student model. Unlike prior efficient camera only baselines such as VAD[23] and VADv2[7], TinyBEV supports the complete autonomy stack 3D detection, HD-map segmentation, motion forecasting, occupancy prediction, and goal-directed planning within a streamlined 28M-parameter backbone, achieving a 78% reduction in parameters over UniAD [19]. Our model-agnostic, multi-stage distillation strategy combines feature-level, output-level, and adaptive region-aware supervision to effectively transfer high-capacity multi-modal knowledge to a lightweight BEV representation. On nuScenes[4], Tiny-BEV achieves 39.0 mAP for detection, 1.08 minADE for motion forecasting, and a 0.32 collision rate, while running 5x faster (11 FPS) and requiring only camera input. These results demonstrate that full-stack driving intelligence can be retained in resource-constrained settings, bridging the gap between large-scale, multi-modal perception-planning models and deployment-ready real-time autonomy.
BlurBall: Joint Ball and Motion Blur Estimation for Table Tennis Ball Tracking
arXiv:2509.18387v1 Announce Type: new Abstract: Motion blur reduces the clarity of fast-moving objects, posing challenges for detection systems, especially in racket sports, where balls often appear as streaks rather than distinct points. Existing labeling conventions mark the ball at the leading edge of the blur, introducing asymmetry and ignoring valuable motion cues correlated with velocity. This paper introduces a new labeling strategy that places the ball at the center of the blur streak and explicitly annotates blur attributes. Using this convention, we release a new table tennis ball detection dataset. We demonstrate that this labeling approach consistently enhances detection performance across various models. Furthermore, we introduce BlurBall, a model that jointly estimates ball position and motion blur attributes. By incorporating attention mechanisms such as Squeeze-and-Excitation over multi-frame inputs, we achieve state-of-the-art results in ball detection. Leveraging blur not only improves detection accuracy but also enables more reliable trajectory prediction, benefiting real-time sports analytics.
MVP: Motion Vector Propagation for Zero-Shot Video Object Detection
arXiv:2509.18388v1 Announce Type: new Abstract: Running a large open-vocabulary (Open-vocab) detector on every video frame is accurate but expensive. We introduce a training-free pipeline that invokes OWLv2 only on fixed-interval keyframes and propagates detections to intermediate frames using compressed-domain motion vectors (MV). A simple 3x3 grid aggregation of motion vectors provides translation and uniform-scale updates, augmented with an area-growth check and an optional single-class switch. The method requires no labels, no fine-tuning, and uses the same prompt list for all open-vocabulary methods. On ILSVRC2015-VID (validation dataset), our approach (MVP) attains mAP@0.5=0.609 and mAP@[0.5:0.95]=0.316. At loose intersection-over-union (IoU) thresholds it remains close to framewise OWLv2-Large (0.747/0.721 at 0.2/0.3 versus 0.784/0.780), reflecting that coarse localization is largely preserved. Under the same keyframe schedule, MVP outperforms tracker-based propagation (MOSSE, KCF, CSRT) at mAP@0.5. A supervised reference (YOLOv12x) reaches 0.631 at mAP@0.5 but requires labeled training, whereas our method remains label-free and open-vocabulary. These results indicate that compressed-domain propagation is a practical way to reduce detector invocations while keeping strong zero-shot coverage in videos. Our code and models are available at https://github.com/microa/MVP.
Improving the color accuracy of lighting estimation models
arXiv:2509.18390v1 Announce Type: new Abstract: Advances in high dynamic range (HDR) lighting estimation from a single image have opened new possibilities for augmented reality (AR) applications. Predicting complex lighting environments from a single input image allows for the realistic rendering and compositing of virtual objects. In this work, we investigate the color robustness of such methods -- an often overlooked yet critical factor for achieving visual realism. While most evaluations conflate color with other lighting attributes (e.g., intensity, direction), we isolate color as the primary variable of interest. Rather than introducing a new lighting estimation algorithm, we explore whether simple adaptation techniques can enhance the color accuracy of existing models. Using a novel HDR dataset featuring diverse lighting colors, we systematically evaluate several adaptation strategies. Our results show that preprocessing the input image with a pre-trained white balance network improves color robustness, outperforming other strategies across all tested scenarios. Notably, this approach requires no retraining of the lighting estimation model. We further validate the generality of this finding by applying the technique to three state-of-the-art lighting estimation methods from recent literature.
Check Field Detection Agent (CFD-Agent) using Multimodal Large Language and Vision Language Models
arXiv:2509.18405v1 Announce Type: new Abstract: Checks remain a foundational instrument in the financial ecosystem, facilitating substantial transaction volumes across institutions. However, their continued use also renders them a persistent target for fraud, underscoring the importance of robust check fraud detection mechanisms. At the core of such systems lies the accurate identification and localization of critical fields, such as the signature, magnetic ink character recognition (MICR) line, courtesy amount, legal amount, payee, and payer, which are essential for subsequent verification against reference checks belonging to the same customer. This field-level detection is traditionally dependent on object detection models trained on large, diverse, and meticulously labeled datasets, a resource that is scarce due to proprietary and privacy concerns. In this paper, we introduce a novel, training-free framework for automated check field detection, leveraging the power of a vision language model (VLM) in conjunction with a multimodal large language model (MLLM). Our approach enables zero-shot detection of check components, significantly lowering the barrier to deployment in real-world financial settings. Quantitative evaluation of our model on a hand-curated dataset of 110 checks spanning multiple formats and layouts demonstrates strong performance and generalization capability. Furthermore, this framework can serve as a bootstrap mechanism for generating high-quality labeled datasets, enabling the development of specialized real-time object detection models tailored to institutional needs.
Losing the Plot: How VLM responses degrade on imperfect charts
arXiv:2509.18425v1 Announce Type: new Abstract: Vision language models (VLMs) show strong results on chart understanding, yet existing benchmarks assume clean figures and fact based queries. Real world charts often contain distortions and demand reasoning beyond simple matching. We evaluate ChatGPT 4o, Claude Sonnet 4, and Gemini 2.5 Pro, finding sharp performance drops under corruption or occlusion, with hallucinations such as value fabrication, trend misinterpretation, and entity confusion becoming more frequent. Models remain overconfident in degraded settings, generating plausible but unsupported explanations. To address this gap, we introduce CHART NOISe(Chart Hallucinations, Answers, and Reasoning Testing on Noisy and Occluded Input Selections), a dataset combining chart corruptions, occlusions, and exam style multiple choice questions inspired by Korea's CSAT English section. A key innovation is prompt reverse inconsistency, where models contradict themselves when asked to confirm versus deny the same statement. Our contributions are threefold: (1) benchmarking state of the art VLMs, exposing systematic vulnerabilities in chart reasoning; (2) releasing CHART NOISe, the first dataset unifying corruption, occlusion, and reverse inconsistency; and (3) proposing baseline mitigation strategies such as quality filtering and occlusion detection. Together, these efforts establish a rigorous testbed for advancing robustness and reliability in chart understanding.
CPT-4DMR: Continuous sPatial-Temporal Representation for 4D-MRI Reconstruction
arXiv:2509.18427v1 Announce Type: new Abstract: Four-dimensional MRI (4D-MRI) is an promising technique for capturing respiratory-induced motion in radiation therapy planning and delivery. Conventional 4D reconstruction methods, which typically rely on phase binning or separate template scans, struggle to capture temporal variability, complicate workflows, and impose heavy computational loads. We introduce a neural representation framework that considers respiratory motion as a smooth, continuous deformation steered by a 1D surrogate signal, completely replacing the conventional discrete sorting approach. The new method fuses motion modeling with image reconstruction through two synergistic networks: the Spatial Anatomy Network (SAN) encodes a continuous 3D anatomical representation, while a Temporal Motion Network (TMN), guided by Transformer-derived respiratory signals, produces temporally consistent deformation fields. Evaluation using a free-breathing dataset of 19 volunteers demonstrates that our template- and phase-free method accurately captures both regular and irregular respiratory patterns, while preserving vessel and bronchial continuity with high anatomical fidelity. The proposed method significantly improves efficiency, reducing the total processing time from approximately five hours required by conventional discrete sorting methods to just 15 minutes of training. Furthermore, it enables inference of each 3D volume in under one second. The framework accurately reconstructs 3D images at any respiratory state, achieves superior performance compared to conventional methods, and demonstrates strong potential for application in 4D radiation therapy planning and real-time adaptive treatment.
An Analysis of Kalman Filter based Object Tracking Methods for Fast-Moving Tiny Objects
arXiv:2509.18451v1 Announce Type: new Abstract: Unpredictable movement patterns and small visual mark make precise tracking of fast-moving tiny objects like a racquetball one of the challenging problems in computer vision. This challenge is particularly relevant for sport robotics applications, where lightweight and accurate tracking systems can improve robot perception and planning capabilities. While Kalman filter-based tracking methods have shown success in general object tracking scenarios, their performance degrades substantially when dealing with rapidly moving objects that exhibit irregular bouncing behavior. In this study, we evaluate the performance of five state-of-the-art Kalman filter-based tracking methods-OCSORT, DeepOCSORT, ByteTrack, BoTSORT, and StrongSORT-using a custom dataset containing 10,000 annotated racquetball frames captured at 720p-1280p resolution. We focus our analysis on two critical performance factors: inference speed and update frequency per image, examining how these parameters affect tracking accuracy and reliability for fast-moving tiny objects. Our experimental evaluation across four distinct scenarios reveals that DeepOCSORT achieves the lowest tracking error with an average ADE of 31.15 pixels compared to ByteTrack's 114.3 pixels, while ByteTrack demonstrates the fastest processing at 26.6ms average inference time versus DeepOCSORT's 26.8ms. However, our results show that all Kalman filter-based trackers exhibit significant tracking drift with spatial errors ranging from 3-11cm (ADE values: 31-114 pixels), indicating fundamental limitations in handling the unpredictable motion patterns of fast-moving tiny objects like racquetballs. Our analysis demonstrates that current tracking approaches require substantial improvements, with error rates 3-4x higher than standard object tracking benchmarks, highlighting the need for specialized methodologies for fast-moving tiny object tracking applications.
MoCrop: Training Free Motion Guided Cropping for Efficient Video Action Recognition
arXiv:2509.18473v1 Announce Type: new Abstract: We introduce MoCrop, a motion-aware adaptive cropping module for efficient video action recognition in the compressed domain. MoCrop uses motion vectors that are available in H.264 video to locate motion-dense regions and produces a single clip-level crop that is applied to all I-frames at inference. The module is training free, adds no parameters, and can be plugged into diverse backbones. A lightweight pipeline that includes denoising & merge (DM), Monte Carlo sampling (MCS), and adaptive cropping (AC) via a motion-density submatrix search yields robust crops with negligible overhead. On UCF101, MoCrop improves accuracy or reduces compute. With ResNet-50, it delivers +3.5% Top-1 accuracy at equal FLOPs (attention setting), or +2.4% Top-1 accuracy with 26.5% fewer FLOPs (efficiency setting). Applied to CoViAR, it reaches 89.2% Top-1 accuracy at the original cost and 88.5% Top-1 accuracy while reducing compute from 11.6 to 8.5 GFLOPs. Consistent gains on MobileNet-V3, EfficientNet-B1, and Swin-B indicate strong generality and make MoCrop practical for real-time deployment in the compressed domain. Our code and models are available at https://github.com/microa/MoCrop.
Codebook-Based Adaptive Feature Compression With Semantic Enhancement for Edge-Cloud Systems
arXiv:2509.18481v1 Announce Type: new Abstract: Coding images for machines with minimal bitrate and strong analysis performance is key to effective edge-cloud systems. Several approaches deploy an image codec and perform analysis on the reconstructed image. Other methods compress intermediate features using entropy models and subsequently perform analysis on the decoded features. Nevertheless, these methods both perform poorly under low-bitrate conditions, as they retain many redundant details or learn over-concentrated symbol distributions. In this paper, we propose a Codebook-based Adaptive Feature Compression framework with Semantic Enhancement, named CAFC-SE. It maps continuous visual features to discrete indices with a codebook at the edge via Vector Quantization (VQ) and selectively transmits them to the cloud. The VQ operation that projects feature vectors onto the nearest visual primitives enables us to preserve more informative visual patterns under low-bitrate conditions. Hence, CAFC-SE is less vulnerable to low-bitrate conditions. Extensive experiments demonstrate the superiority of our method in terms of rate and accuracy.
MK-UNet: Multi-kernel Lightweight CNN for Medical Image Segmentation
arXiv:2509.18493v1 Announce Type: new Abstract: In this paper, we introduce MK-UNet, a paradigm shift towards ultra-lightweight, multi-kernel U-shaped CNNs tailored for medical image segmentation. Central to MK-UNet is the multi-kernel depth-wise convolution block (MKDC) we design to adeptly process images through multiple kernels, while capturing complex multi-resolution spatial relationships. MK-UNet also emphasizes the images salient features through sophisticated attention mechanisms, including channel, spatial, and grouped gated attention. Our MK-UNet network, with a modest computational footprint of only 0.316M parameters and 0.314G FLOPs, represents not only a remarkably lightweight, but also significantly improved segmentation solution that provides higher accuracy over state-of-the-art (SOTA) methods across six binary medical imaging benchmarks. Specifically, MK-UNet outperforms TransUNet in DICE score with nearly 333$\times$ and 123$\times$ fewer parameters and FLOPs, respectively. Similarly, when compared against UNeXt, MK-UNet exhibits superior segmentation performance, improving the DICE score up to 6.7% margins while operating with 4.7$\times$ fewer #Params. Our MK-UNet also outperforms other recent lightweight networks, such as MedT, CMUNeXt, EGE-UNet, and Rolling-UNet, with much lower computational resources. This leap in performance, coupled with drastic computational gains, positions MK-UNet as an unparalleled solution for real-time, high-fidelity medical diagnostics in resource-limited settings, such as point-of-care devices. Our implementation is available at https://github.com/SLDGroup/MK-UNet.
BridgeSplat: Bidirectionally Coupled CT and Non-Rigid Gaussian Splatting for Deformable Intraoperative Surgical Navigation
arXiv:2509.18501v1 Announce Type: new Abstract: We introduce BridgeSplat, a novel approach for deformable surgical navigation that couples intraoperative 3D reconstruction with preoperative CT data to bridge the gap between surgical video and volumetric patient data. Our method rigs 3D Gaussians to a CT mesh, enabling joint optimization of Gaussian parameters and mesh deformation through photometric supervision. By parametrizing each Gaussian relative to its parent mesh triangle, we enforce alignment between Gaussians and mesh and obtain deformations that can be propagated back to update the CT. We demonstrate BridgeSplat's effectiveness on visceral pig surgeries and synthetic data of a human liver under simulation, showing sensible deformations of the preoperative CT on monocular RGB data. Code, data, and additional resources can be found at https://maxfehrentz.github.io/ct-informed-splatting/ .
Source-Free Domain Adaptive Semantic Segmentation of Remote Sensing Images with Diffusion-Guided Label Enrichment
arXiv:2509.18502v1 Announce Type: new Abstract: Research on unsupervised domain adaptation (UDA) for semantic segmentation of remote sensing images has been extensively conducted. However, research on how to achieve domain adaptation in practical scenarios where source domain data is inaccessible namely, source-free domain adaptation (SFDA) remains limited. Self-training has been widely used in SFDA, which requires obtaining as many high-quality pseudo-labels as possible to train models on target domain data. Most existing methods optimize the entire pseudo-label set to obtain more supervisory information. However, as pseudo-label sets often contain substantial noise, simultaneously optimizing all labels is challenging. This limitation undermines the effectiveness of optimization approaches and thus restricts the performance of self-training. To address this, we propose a novel pseudo-label optimization framework called Diffusion-Guided Label Enrichment (DGLE), which starts from a few easily obtained high-quality pseudo-labels and propagates them to a complete set of pseudo-labels while ensuring the quality of newly generated labels. Firstly, a pseudo-label fusion method based on confidence filtering and super-resolution enhancement is proposed, which utilizes cross-validation of details and contextual information to obtain a small number of high-quality pseudo-labels as initial seeds. Then, we leverage the diffusion model to propagate incomplete seed pseudo-labels with irregular distributions due to its strong denoising capability for randomly distributed noise and powerful modeling capacity for complex distributions, thereby generating complete and high-quality pseudo-labels. This method effectively avoids the difficulty of directly optimizing the complete set of pseudo-labels, significantly improves the quality of pseudo-labels, and thus enhances the model's performance in the target domain.
Hyperbolic Coarse-to-Fine Few-Shot Class-Incremental Learning
arXiv:2509.18504v1 Announce Type: new Abstract: In the field of machine learning, hyperbolic space demonstrates superior representation capabilities for hierarchical data compared to conventional Euclidean space. This work focuses on the Coarse-To-Fine Few-Shot Class-Incremental Learning (C2FSCIL) task. Our study follows the Knowe approach, which contrastively learns coarse class labels and subsequently normalizes and freezes the classifier weights of learned fine classes in the embedding space. To better interpret the "coarse-to-fine" paradigm, we propose embedding the feature extractor into hyperbolic space. Specifically, we employ the Poincar\'e ball model of hyperbolic space, enabling the feature extractor to transform input images into feature vectors within the Poincar\'e ball instead of Euclidean space. We further introduce hyperbolic contrastive loss and hyperbolic fully-connected layers to facilitate model optimization and classification in hyperbolic space. Additionally, to enhance performance under few-shot conditions, we implement maximum entropy distribution in hyperbolic space to estimate the probability distribution of fine-class feature vectors. This allows generation of augmented features from the distribution to mitigate overfitting during training with limited samples. Experiments on C2FSCIL benchmarks show that our method effectively improves both coarse and fine class accuracies.
GeoRemover: Removing Objects and Their Causal Visual Artifacts
arXiv:2509.18538v1 Announce Type: new Abstract: Towards intelligent image editing, object removal should eliminate both the target object and its causal visual artifacts, such as shadows and reflections. However, existing image appearance-based methods either follow strictly mask-aligned training and fail to remove these causal effects which are not explicitly masked, or adopt loosely mask-aligned strategies that lack controllability and may unintentionally over-erase other objects. We identify that these limitations stem from ignoring the causal relationship between an object's geometry presence and its visual effects. To address this limitation, we propose a geometry-aware two-stage framework that decouples object removal into (1) geometry removal and (2) appearance rendering. In the first stage, we remove the object directly from the geometry (e.g., depth) using strictly mask-aligned supervision, enabling structure-aware editing with strong geometric constraints. In the second stage, we render a photorealistic RGB image conditioned on the updated geometry, where causal visual effects are considered implicitly as a result of the modified 3D geometry. To guide learning in the geometry removal stage, we introduce a preference-driven objective based on positive and negative sample pairs, encouraging the model to remove objects as well as their causal visual artifacts while avoiding new structural insertions. Extensive experiments demonstrate that our method achieves state-of-the-art performance in removing both objects and their associated artifacts on two popular benchmarks. The code is available at https://github.com/buxiangzhiren/GeoRemover.
SEGA: A Transferable Signed Ensemble Gaussian Black-Box Attack against No-Reference Image Quality Assessment Models
arXiv:2509.18546v1 Announce Type: new Abstract: No-Reference Image Quality Assessment (NR-IQA) models play an important role in various real-world applications. Recently, adversarial attacks against NR-IQA models have attracted increasing attention, as they provide valuable insights for revealing model vulnerabilities and guiding robust system design. Some effective attacks have been proposed against NR-IQA models in white-box settings, where the attacker has full access to the target model. However, these attacks often suffer from poor transferability to unknown target models in more realistic black-box scenarios, where the target model is inaccessible. This work makes the first attempt to address the challenge of low transferability in attacking NR-IQA models by proposing a transferable Signed Ensemble Gaussian black-box Attack (SEGA). The main idea is to approximate the gradient of the target model by applying Gaussian smoothing to source models and ensembling their smoothed gradients. To ensure the imperceptibility of adversarial perturbations, SEGA further removes inappropriate perturbations using a specially designed perturbation filter mask. Experimental results on the CLIVE dataset demonstrate the superior transferability of SEGA, validating its effectiveness in enabling successful transfer-based black-box attacks against NR-IQA models.
HadaSmileNet: Hadamard fusion of handcrafted and deep-learning features for enhancing facial emotion recognition of genuine smiles
arXiv:2509.18550v1 Announce Type: new Abstract: The distinction between genuine and posed emotions represents a fundamental pattern recognition challenge with significant implications for data mining applications in social sciences, healthcare, and human-computer interaction. While recent multi-task learning frameworks have shown promise in combining deep learning architectures with handcrafted D-Marker features for smile facial emotion recognition, these approaches exhibit computational inefficiencies due to auxiliary task supervision and complex loss balancing requirements. This paper introduces HadaSmileNet, a novel feature fusion framework that directly integrates transformer-based representations with physiologically grounded D-Markers through parameter-free multiplicative interactions. Through systematic evaluation of 15 fusion strategies, we demonstrate that Hadamard multiplicative fusion achieves optimal performance by enabling direct feature interactions while maintaining computational efficiency. The proposed approach establishes new state-of-the-art results for deep learning methods across four benchmark datasets: UvA-NEMO (88.7 percent, +0.8), MMI (99.7 percent), SPOS (98.5 percent, +0.7), and BBC (100 percent, +5.0). Comprehensive computational analysis reveals 26 percent parameter reduction and simplified training compared to multi-task alternatives, while feature visualization demonstrates enhanced discriminative power through direct domain knowledge integration. The framework's efficiency and effectiveness make it particularly suitable for practical deployment in multimedia data mining applications that require real-time affective computing capabilities.
Event-guided 3D Gaussian Splatting for Dynamic Human and Scene Reconstruction
arXiv:2509.18566v1 Announce Type: new Abstract: Reconstructing dynamic humans together with static scenes from monocular videos remains difficult, especially under fast motion, where RGB frames suffer from motion blur. Event cameras exhibit distinct advantages, e.g., microsecond temporal resolution, making them a superior sensing choice for dynamic human reconstruction. Accordingly, we present a novel event-guided human-scene reconstruction framework that jointly models human and scene from a single monocular event camera via 3D Gaussian Splatting. Specifically, a unified set of 3D Gaussians carries a learnable semantic attribute; only Gaussians classified as human undergo deformation for animation, while scene Gaussians stay static. To combat blur, we propose an event-guided loss that matches simulated brightness changes between consecutive renderings with the event stream, improving local fidelity in fast-moving regions. Our approach removes the need for external human masks and simplifies managing separate Gaussian sets. On two benchmark datasets, ZJU-MoCap-Blur and MMHPSD-Blur, it delivers state-of-the-art human-scene reconstruction, with notable gains over strong baselines in PSNR/SSIM and reduced LPIPS, especially for high-speed subjects.
Live-E2T: Real-time Threat Monitoring in Video via Deduplicated Event Reasoning and Chain-of-Thought
arXiv:2509.18571v1 Announce Type: new Abstract: Real-time threat monitoring identifies threatening behaviors in video streams and provides reasoning and assessment of threat events through explanatory text. However, prevailing methodologies, whether based on supervised learning or generative models, struggle to concurrently satisfy the demanding requirements of real-time performance and decision explainability. To bridge this gap, we introduce Live-E2T, a novel framework that unifies these two objectives through three synergistic mechanisms. First, we deconstruct video frames into structured Human-Object-Interaction-Place semantic tuples. This approach creates a compact, semantically focused representation, circumventing the information degradation common in conventional feature compression. Second, an efficient online event deduplication and updating mechanism is proposed to filter spatio-temporal redundancies, ensuring the system's real time responsiveness. Finally, we fine-tune a Large Language Model using a Chain-of-Thought strategy, endow it with the capability for transparent and logical reasoning over event sequences to produce coherent threat assessment reports. Extensive experiments on benchmark datasets, including XD-Violence and UCF-Crime, demonstrate that Live-E2T significantly outperforms state-of-the-art methods in terms of threat detection accuracy, real-time efficiency, and the crucial dimension of explainability.
The Photographer Eye: Teaching Multimodal Large Language Models to See and Critique like Photographers
arXiv:2509.18582v1 Announce Type: new Abstract: While editing directly from life, photographers have found it too difficult to see simultaneously both the blue and the sky. Photographer and curator, Szarkowski insightfully revealed one of the notable gaps between general and aesthetic visual understanding: while the former focuses on identifying the factual element in an image (sky), the latter transcends such object identification, viewing it instead as an aesthetic component--a pure color block (blue). Such fundamental distinctions between general (detection, localization, etc.) and aesthetic (color, lighting, composition, etc.) visual understanding present a significant challenge for Multimodal Large Language Models (MLLMs). Although some recent works have made initial explorations, they are often limited to general and basic aesthetic commonsense. As a result, they frequently fall short in real-world scenarios (Fig. 1), which require extensive expertise--including photographic techniques, photo pre/post-processing knowledge, and more, to provide a detailed analysis and description. To fundamentally enhance the aesthetics understanding of MLLMs, we first introduce a novel dataset, PhotoCritique, derived from extensive discussions among professional photographers and enthusiasts, and characterized by the large scale, expertise, and diversity. Then, to better learn visual aesthetics from PhotoCritique, we furthur propose a novel model, PhotoEye, featuring a languageguided multi-view vision fusion mechanism to understand image aesthetics from multiple perspectives. Finally, we present a novel benchmark, PhotoBench, a comprehensive and professional benchmark for aesthetic visual understanding. On existing benchmarks and PhotoBench, our model demonstrates clear advantages over existing models.
Enhancing Video Object Segmentation in TrackRAD Using XMem Memory Network
arXiv:2509.18591v1 Announce Type: new Abstract: This paper presents an advanced tumor segmentation framework for real-time MRI-guided radiotherapy, designed for the TrackRAD2025 challenge. Our method leverages the XMem model, a memory-augmented architecture, to segment tumors across long cine-MRI sequences. The proposed system efficiently integrates memory mechanisms to track tumor motion in real-time, achieving high segmentation accuracy even under challenging conditions with limited annotated data. Unfortunately, the detailed experimental records have been lost, preventing us from reporting precise quantitative results at this stage. Nevertheless, From our preliminary impressions during development, the XMem-based framework demonstrated reasonable segmentation performance and satisfied the clinical real-time requirement. Our work contributes to improving the precision of tumor tracking during MRI-guided radiotherapy, which is crucial for enhancing the accuracy and safety of cancer treatments.
SSCM: A Spatial-Semantic Consistent Model for Multi-Contrast MRI Super-Resolution
arXiv:2509.18593v1 Announce Type: new Abstract: Multi-contrast Magnetic Resonance Imaging super-resolution (MC-MRI SR) aims to enhance low-resolution (LR) contrasts leveraging high-resolution (HR) references, shortening acquisition time and improving imaging efficiency while preserving anatomical details. The main challenge lies in maintaining spatial-semantic consistency, ensuring anatomical structures remain well-aligned and coherent despite structural discrepancies and motion between the target and reference images. Conventional methods insufficiently model spatial-semantic consistency and underuse frequency-domain information, which leads to poor fine-grained alignment and inadequate recovery of high-frequency details. In this paper, we propose the Spatial-Semantic Consistent Model (SSCM), which integrates a Dynamic Spatial Warping Module for inter-contrast spatial alignment, a Semantic-Aware Token Aggregation Block for long-range semantic consistency, and a Spatial-Frequency Fusion Block for fine structure restoration. Experiments on public and private datasets show that SSCM achieves state-of-the-art performance with fewer parameters while ensuring spatially and semantically consistent reconstructions.
OraPO: Oracle-educated Reinforcement Learning for Data-efficient and Factual Radiology Report Generation
arXiv:2509.18600v1 Announce Type: new Abstract: Radiology report generation (RRG) aims to automatically produce clinically faithful reports from chest X-ray images. Prevailing work typically follows a scale-driven paradigm, by multi-stage training over large paired corpora and oversized backbones, making pipelines highly data- and compute-intensive. In this paper, we propose Oracle-educated GRPO {OraPO) with a FactScore-based reward (FactS) to tackle the RRG task under constrained budgets. OraPO enables single-stage, RL-only training by converting failed GRPO explorations on rare or difficult studies into direct preference supervision via a lightweight oracle step. FactS grounds learning in diagnostic evidence by extracting atomic clinical facts and checking entailment against ground-truth labels, yielding dense, interpretable sentence-level rewards. Together, OraPO and FactS create a compact and powerful framework that significantly improves learning efficiency on clinically challenging cases, setting the new SOTA performance on the CheXpert Plus dataset (0.341 in F1) with 2--3 orders of magnitude less training data using a small base VLM on modest hardware.
Training-Free Multi-Style Fusion Through Reference-Based Adaptive Modulation
arXiv:2509.18602v1 Announce Type: new Abstract: We propose Adaptive Multi-Style Fusion (AMSF), a reference-based training-free framework that enables controllable fusion of multiple reference styles in diffusion models. Most of the existing reference-based methods are limited by (a) acceptance of only one style image, thus prohibiting hybrid aesthetics and scalability to more styles, and (b) lack of a principled mechanism to balance several stylistic influences. AMSF mitigates these challenges by encoding all style images and textual hints with a semantic token decomposition module that is adaptively injected into every cross-attention layer of an frozen diffusion model. A similarity-aware re-weighting module then recalibrates, at each denoising step, the attention allocated to every style component, yielding balanced and user-controllable blends without any fine-tuning or external adapters. Both qualitative and quantitative evaluations show that AMSF produces multi-style fusion results that consistently outperform the state-of-the-art approaches, while its fusion design scales seamlessly to two or more styles. These capabilities position AMSF as a practical step toward expressive multi-style generation in diffusion models.
MLF-4DRCNet: Multi-Level Fusion with 4D Radar and Camera for 3D Object Detection in Autonomous Driving
arXiv:2509.18613v1 Announce Type: new Abstract: The emerging 4D millimeter-wave radar, measuring the range, azimuth, elevation, and Doppler velocity of objects, is recognized for its cost-effectiveness and robustness in autonomous driving. Nevertheless, its point clouds exhibit significant sparsity and noise, restricting its standalone application in 3D object detection. Recent 4D radar-camera fusion methods have provided effective perception. Most existing approaches, however, adopt explicit Bird's-Eye-View fusion paradigms originally designed for LiDAR-camera fusion, neglecting radar's inherent drawbacks. Specifically, they overlook the sparse and incomplete geometry of radar point clouds and restrict fusion to coarse scene-level integration. To address these problems, we propose MLF-4DRCNet, a novel two-stage framework for 3D object detection via multi-level fusion of 4D radar and camera images. Our model incorporates the point-, scene-, and proposal-level multi-modal information, enabling comprehensive feature representation. It comprises three crucial components: the Enhanced Radar Point Encoder (ERPE) module, the Hierarchical Scene Fusion Pooling (HSFP) module, and the Proposal-Level Fusion Enhancement (PLFE) module. Operating at the point-level, ERPE densities radar point clouds with 2D image instances and encodes them into voxels via the proposed Triple-Attention Voxel Feature Encoder. HSFP dynamically integrates multi-scale voxel features with 2D image features using deformable attention to capture scene context and adopts pooling to the fused features. PLFE refines region proposals by fusing image features, and further integrates with the pooled features from HSFP. Experimental results on the View-of-Delft (VoD) and TJ4DRadSet datasets demonstrate that MLF-4DRCNet achieves the state-of-the-art performance. Notably, it attains performance comparable to LiDAR-based models on the VoD dataset.
Prompt-Guided Dual Latent Steering for Inversion Problems
arXiv:2509.18619v1 Announce Type: new Abstract: Inverting corrupted images into the latent space of diffusion models is challenging. Current methods, which encode an image into a single latent vector, struggle to balance structural fidelity with semantic accuracy, leading to reconstructions with semantic drift, such as blurred details or incorrect attributes. To overcome this, we introduce Prompt-Guided Dual Latent Steering (PDLS), a novel, training-free framework built upon Rectified Flow models for their stable inversion paths. PDLS decomposes the inversion process into two complementary streams: a structural path to preserve source integrity and a semantic path guided by a prompt. We formulate this dual guidance as an optimal control problem and derive a closed-form solution via a Linear Quadratic Regulator (LQR). This controller dynamically steers the generative trajectory at each step, preventing semantic drift while ensuring the preservation of fine detail without costly, per-image optimization. Extensive experiments on FFHQ-1K and ImageNet-1K under various inversion tasks, including Gaussian deblurring, motion deblurring, super-resolution and freeform inpainting, demonstrate that PDLS produces reconstructions that are both more faithful to the original image and better aligned with the semantic information than single-latent baselines.
Learning neuroimaging models from health system-scale data
arXiv:2509.18638v1 Announce Type: new Abstract: Neuroimaging is a ubiquitous tool for evaluating patients with neurological diseases. The global demand for magnetic resonance imaging (MRI) studies has risen steadily, placing significant strain on health systems, prolonging turnaround times, and intensifying physician burnout \cite{Chen2017-bt, Rula2024-qp-1}. These challenges disproportionately impact patients in low-resource and rural settings. Here, we utilized a large academic health system as a data engine to develop Prima, the first vision language model (VLM) serving as an AI foundation for neuroimaging that supports real-world, clinical MRI studies as input. Trained on over 220,000 MRI studies, Prima uses a hierarchical vision architecture that provides general and transferable MRI features. Prima was tested in a 1-year health system-wide study that included 30K MRI studies. Across 52 radiologic diagnoses from the major neurologic disorders, including neoplastic, inflammatory, infectious, and developmental lesions, Prima achieved a mean diagnostic area under the ROC curve of 92.0, outperforming other state-of-the-art general and medical AI models. Prima offers explainable differential diagnoses, worklist priority for radiologists, and clinical referral recommendations across diverse patient demographics and MRI systems. Prima demonstrates algorithmic fairness across sensitive groups and can help mitigate health system biases, such as prolonged turnaround times for low-resource populations. These findings highlight the transformative potential of health system-scale VLMs and Prima's role in advancing AI-driven healthcare.
Understanding-in-Generation: Reinforcing Generative Capability of Unified Model via Infusing Understanding into Generation
arXiv:2509.18639v1 Announce Type: new Abstract: Recent works have made notable advancements in enhancing unified models for text-to-image generation through the Chain-of-Thought (CoT). However, these reasoning methods separate the processes of understanding and generation, which limits their ability to guide the reasoning of unified models in addressing the deficiencies of their generative capabilities. To this end, we propose a novel reasoning framework for unified models, Understanding-in-Generation (UiG), which harnesses the robust understanding capabilities of unified models to reinforce their performance in image generation. The core insight of our UiG is to integrate generative guidance by the strong understanding capabilities during the reasoning process, thereby mitigating the limitations of generative abilities. To achieve this, we introduce "Image Editing" as a bridge to infuse understanding into the generation process. Initially, we verify the generated image and incorporate the understanding of unified models into the editing instructions. Subsequently, we enhance the generated image step by step, gradually infusing the understanding into the generation process. Our UiG framework demonstrates a significant performance improvement in text-to-image generation over existing text-to-image reasoning methods, e.g., a 3.92% gain on the long prompt setting of the TIIF benchmark. The project code: https://github.com/QC-LY/UiG
Zero-shot Monocular Metric Depth for Endoscopic Images
arXiv:2509.18642v1 Announce Type: new Abstract: Monocular relative and metric depth estimation has seen a tremendous boost in the last few years due to the sharp advancements in foundation models and in particular transformer based networks. As we start to see applications to the domain of endoscopic images, there is still a lack of robust benchmarks and high-quality datasets in that area. This paper addresses these limitations by presenting a comprehensive benchmark of state-of-the-art (metric and relative) depth estimation models evaluated on real, unseen endoscopic images, providing critical insights into their generalisation and performance in clinical scenarios. Additionally, we introduce and publish a novel synthetic dataset (EndoSynth) of endoscopic surgical instruments paired with ground truth metric depth and segmentation masks, designed to bridge the gap between synthetic and real-world data. We demonstrate that fine-tuning depth foundation models using our synthetic dataset boosts accuracy on most unseen real data by a significant margin. By providing both a benchmark and a synthetic dataset, this work advances the field of depth estimation for endoscopic images and serves as an important resource for future research. Project page, EndoSynth dataset and trained weights are available at https://github.com/TouchSurgery/EndoSynth.
LEAF-Mamba: Local Emphatic and Adaptive Fusion State Space Model for RGB-D Salient Object Detection
arXiv:2509.18683v1 Announce Type: new Abstract: RGB-D salient object detection (SOD) aims to identify the most conspicuous objects in a scene with the incorporation of depth cues. Existing methods mainly rely on CNNs, limited by the local receptive fields, or Vision Transformers that suffer from the cost of quadratic complexity, posing a challenge in balancing performance and computational efficiency. Recently, state space models (SSM), Mamba, have shown great potential for modeling long-range dependency with linear complexity. However, directly applying SSM to RGB-D SOD may lead to deficient local semantics as well as the inadequate cross-modality fusion. To address these issues, we propose a Local Emphatic and Adaptive Fusion state space model (LEAF-Mamba) that contains two novel components: 1) a local emphatic state space module (LE-SSM) to capture multi-scale local dependencies for both modalities. 2) an SSM-based adaptive fusion module (AFM) for complementary cross-modality interaction and reliable cross-modality integration. Extensive experiments demonstrate that the LEAF-Mamba consistently outperforms 16 state-of-the-art RGB-D SOD methods in both efficacy and efficiency. Moreover, our method can achieve excellent performance on the RGB-T SOD task, proving a powerful generalization ability.
Lightweight Vision Transformer with Window and Spatial Attention for Food Image Classification
arXiv:2509.18692v1 Announce Type: new Abstract: With the rapid development of society and continuous advances in science and technology, the food industry increasingly demands higher production quality and efficiency. Food image classification plays a vital role in enabling automated quality control on production lines, supporting food safety supervision, and promoting intelligent agricultural production. However, this task faces challenges due to the large number of parameters and high computational complexity of Vision Transformer models. To address these issues, we propose a lightweight food image classification algorithm that integrates a Window Multi-Head Attention Mechanism (WMHAM) and a Spatial Attention Mechanism (SAM). The WMHAM reduces computational cost by capturing local and global contextual features through efficient window partitioning, while the SAM adaptively emphasizes key spatial regions to improve discriminative feature representation. Experiments conducted on the Food-101 and Vireo Food-172 datasets demonstrate that our model achieves accuracies of 95.24% and 94.33%, respectively, while significantly reducing parameters and FLOPs compared with baseline methods. These results confirm that the proposed approach achieves an effective balance between computational efficiency and classification performance, making it well-suited for deployment in resource-constrained environments.
OSDA: A Framework for Open-Set Discovery and Automatic Interpretation of Land-cover in Remote Sensing Imagery
arXiv:2509.18693v1 Announce Type: new Abstract: Open-set land-cover analysis in remote sensing requires the ability to achieve fine-grained spatial localization and semantically open categorization. This involves not only detecting and segmenting novel objects without categorical supervision but also assigning them interpretable semantic labels through multimodal reasoning. In this study, we introduce OSDA, an integrated three-stage framework for annotation-free open-set land-cover discovery, segmentation, and description. The pipeline consists of: (1) precise discovery and mask extraction with a promptable fine-tuned segmentation model (SAM), (2) semantic attribution and contextual description via a two-phase fine-tuned multimodal large language model (MLLM), and (3) LLM-as-judge and manual scoring of the MLLMs evaluation. By combining pixel-level accuracy with high-level semantic understanding, OSDA addresses key challenges in open-world remote sensing interpretation. Designed to be architecture-agnostic and label-free, the framework supports robust evaluation across diverse satellite imagery without requiring manual annotation. Our work provides a scalable and interpretable solution for dynamic land-cover monitoring, showing strong potential for automated cartographic updating and large-scale earth observation analysis.
Overview of PlantCLEF 2021: cross-domain plant identification
arXiv:2509.18697v1 Announce Type: new Abstract: Automated plant identification has improved considerably thanks to recent advances in deep learning and the availability of training data with more and more field photos. However, this profusion of data concerns only a few tens of thousands of species, mainly located in North America and Western Europe, much less in the richest regions in terms of biodiversity such as tropical countries. On the other hand, for several centuries, botanists have systematically collected, catalogued and stored plant specimens in herbaria, especially in tropical regions, and recent efforts by the biodiversity informatics community have made it possible to put millions of digitised records online. The LifeCLEF 2021 plant identification challenge (or "PlantCLEF 2021") was designed to assess the extent to which automated identification of flora in data-poor regions can be improved by using herbarium collections. It is based on a dataset of about 1,000 species mainly focused on the Guiana Shield of South America, a region known to have one of the highest plant diversities in the world. The challenge was evaluated as a cross-domain classification task where the training set consisted of several hundred thousand herbarium sheets and a few thousand photos to allow learning a correspondence between the two domains. In addition to the usual metadata (location, date, author, taxonomy), the training data also includes the values of 5 morphological and functional traits for each species. The test set consisted exclusively of photos taken in the field. This article presents the resources and evaluations of the assessment carried out, summarises the approaches and systems used by the participating research groups and provides an analysis of the main results.
AGSwap: Overcoming Category Boundaries in Object Fusion via Adaptive Group Swapping
arXiv:2509.18699v1 Announce Type: new Abstract: Fusing cross-category objects to a single coherent object has gained increasing attention in text-to-image (T2I) generation due to its broad applications in virtual reality, digital media, film, and gaming. However, existing methods often produce biased, visually chaotic, or semantically inconsistent results due to overlapping artifacts and poor integration. Moreover, progress in this field has been limited by the absence of a comprehensive benchmark dataset. To address these problems, we propose \textbf{Adaptive Group Swapping (AGSwap)}, a simple yet highly effective approach comprising two key components: (1) Group-wise Embedding Swapping, which fuses semantic attributes from different concepts through feature manipulation, and (2) Adaptive Group Updating, a dynamic optimization mechanism guided by a balance evaluation score to ensure coherent synthesis. Additionally, we introduce \textbf{Cross-category Object Fusion (COF)}, a large-scale, hierarchically structured dataset built upon ImageNet-1K and WordNet. COF includes 95 superclasses, each with 10 subclasses, enabling 451,250 unique fusion pairs. Extensive experiments demonstrate that AGSwap outperforms state-of-the-art compositional T2I methods, including GPT-Image-1 using simple and complex prompts.
Overview of LifeCLEF Plant Identification task 2019: diving into data deficient tropical countries
arXiv:2509.18705v1 Announce Type: new Abstract: Automated identification of plants has improved considerably thanks to the recent progress in deep learning and the availability of training data. However, this profusion of data only concerns a few tens of thousands of species, while the planet has nearly 369K. The LifeCLEF 2019 Plant Identification challenge (or "PlantCLEF 2019") was designed to evaluate automated identification on the flora of data deficient regions. It is based on a dataset of 10K species mainly focused on the Guiana shield and the Northern Amazon rainforest, an area known to have one of the greatest diversity of plants and animals in the world. As in the previous edition, a comparison of the performance of the systems evaluated with the best tropical flora experts was carried out. This paper presents the resources and assessments of the challenge, summarizes the approaches and systems employed by the participating research groups, and provides an analysis of the main outcomes.
RSVG-ZeroOV: Exploring a Training-Free Framework for Zero-Shot Open-Vocabulary Visual Grounding in Remote Sensing Images
arXiv:2509.18711v1 Announce Type: new Abstract: Remote sensing visual grounding (RSVG) aims to localize objects in remote sensing images based on free-form natural language expressions. Existing approaches are typically constrained to closed-set vocabularies, limiting their applicability in open-world scenarios. While recent attempts to leverage generic foundation models for open-vocabulary RSVG, they overly rely on expensive high-quality datasets and time-consuming fine-tuning. To address these limitations, we propose \textbf{RSVG-ZeroOV}, a training-free framework that aims to explore the potential of frozen generic foundation models for zero-shot open-vocabulary RSVG. Specifically, RSVG-ZeroOV comprises three key stages: (i) Overview: We utilize a vision-language model (VLM) to obtain cross-attention\footnote[1]{In this paper, although decoder-only VLMs use self-attention over all tokens, we refer to the image-text interaction part as cross-attention to distinguish it from pure visual self-attention.}maps that capture semantic correlations between text queries and visual regions. (ii) Focus: By leveraging the fine-grained modeling priors of a diffusion model (DM), we fill in gaps in structural and shape information of objects, which are often overlooked by VLM. (iii) Evolve: A simple yet effective attention evolution module is introduced to suppress irrelevant activations, yielding purified segmentation masks over the referred objects. Without cumbersome task-specific training, RSVG-ZeroOV offers an efficient and scalable solution. Extensive experiments demonstrate that the proposed framework consistently outperforms existing weakly-supervised and zero-shot methods.
What Makes You Unique? Attribute Prompt Composition for Object Re-Identification
arXiv:2509.18715v1 Announce Type: new Abstract: Object Re-IDentification (ReID) aims to recognize individuals across non-overlapping camera views. While recent advances have achieved remarkable progress, most existing models are constrained to either single-domain or cross-domain scenarios, limiting their real-world applicability. Single-domain models tend to overfit to domain-specific features, whereas cross-domain models often rely on diverse normalization strategies that may inadvertently suppress identity-specific discriminative cues. To address these limitations, we propose an Attribute Prompt Composition (APC) framework, which exploits textual semantics to jointly enhance discrimination and generalization. Specifically, we design an Attribute Prompt Generator (APG) consisting of a Semantic Attribute Dictionary (SAD) and a Prompt Composition Module (PCM). SAD is an over-complete attribute dictionary to provide rich semantic descriptions, while PCM adaptively composes relevant attributes from SAD to generate discriminative attribute-aware features. In addition, motivated by the strong generalization ability of Vision-Language Models (VLM), we propose a Fast-Slow Training Strategy (FSTS) to balance ReID-specific discrimination and generalizable representation learning. Specifically, FSTS adopts a Fast Update Stream (FUS) to rapidly acquire ReID-specific discriminative knowledge and a Slow Update Stream (SUS) to retain the generalizable knowledge inherited from the pre-trained VLM. Through a mutual interaction, the framework effectively focuses on ReID-relevant features while mitigating overfitting. Extensive experiments on both conventional and Domain Generalized (DG) ReID datasets demonstrate that our framework surpasses state-of-the-art methods, exhibiting superior performances in terms of both discrimination and generalization. The source code is available at https://github.com/AWangYQ/APC.
Pre-training CLIP against Data Poisoning with Optimal Transport-based Matching and Alignment
arXiv:2509.18717v1 Announce Type: new Abstract: Recent studies have shown that Contrastive Language-Image Pre-training (CLIP) models are threatened by targeted data poisoning and backdoor attacks due to massive training image-caption pairs crawled from the Internet. Previous defense methods correct poisoned image-caption pairs by matching a new caption for each image. However, the matching process relies solely on the global representations of images and captions, overlooking fine-grained features of visual and textual features. It may introduce incorrect image-caption pairs and harm the CLIP pre-training. To address their limitations, we propose an Optimal Transport-based framework to reconstruct image-caption pairs, named OTCCLIP. We propose a new optimal transport-based distance measure between fine-grained visual and textual feature sets and re-assign new captions based on the proposed optimal transport distance. Additionally, to further reduce the negative impact of mismatched pairs, we encourage the inter- and intra-modality fine-grained alignment by employing optimal transport-based objective functions. Our experiments demonstrate that OTCCLIP can successfully decrease the attack success rates of poisoning attacks. Also, compared to previous methods, OTCCLIP significantly improves CLIP's zero-shot and linear probing performance trained on poisoned datasets.
Knowledge Transfer from Interaction Learning
arXiv:2509.18733v1 Announce Type: new Abstract: Current visual foundation models (VFMs) face a fundamental limitation in transferring knowledge from vision language models (VLMs), while VLMs excel at modeling cross-modal interactions through unified representation spaces, existing VFMs predominantly adopt result-oriented paradigms that neglect the underlying interaction processes. This representational discrepancy hinders effective knowledge transfer and limits generalization across diverse vision tasks. We propose Learning from Interactions (LFI), a cognitive-inspired framework that addresses this gap by explicitly modeling visual understanding as an interactive process. Our key insight is that capturing the dynamic interaction patterns encoded in pre-trained VLMs enables more faithful and efficient knowledge transfer to VFMs. The approach centers on two technical innovations, Interaction Queries, which maintain persistent relational structures across network layers, and interaction-based supervision, derived from the cross-modal attention mechanisms of VLMs. Comprehensive experiments demonstrate consistent improvements across multiple benchmarks, achieving 3.3 and 1.6mAP/2.4AP absolute gains on TinyImageNet classification and COCO detection/segmentation respectively, with minimal parameter overhead and faster convergence. The framework particularly excels in cross-domain settings, delivering 2.4 and 9.3 zero-shot improvements on PACS and VLCS. Human evaluations further confirm its cognitive alignment, outperforming result-oriented methods by 2.7 times in semantic consistency metrics.
HyPSAM: Hybrid Prompt-driven Segment Anything Model for RGB-Thermal Salient Object Detection
arXiv:2509.18738v1 Announce Type: new Abstract: RGB-thermal salient object detection (RGB-T SOD) aims to identify prominent objects by integrating complementary information from RGB and thermal modalities. However, learning the precise boundaries and complete objects remains challenging due to the intrinsic insufficient feature fusion and the extrinsic limitations of data scarcity. In this paper, we propose a novel hybrid prompt-driven segment anything model (HyPSAM), which leverages the zero-shot generalization capabilities of the segment anything model (SAM) for RGB-T SOD. Specifically, we first propose a dynamic fusion network (DFNet) that generates high-quality initial saliency maps as visual prompts. DFNet employs dynamic convolution and multi-branch decoding to facilitate adaptive cross-modality interaction, overcoming the limitations of fixed-parameter kernels and enhancing multi-modal feature representation. Moreover, we propose a plug-and-play refinement network (P2RNet), which serves as a general optimization strategy to guide SAM in refining saliency maps by using hybrid prompts. The text prompt ensures reliable modality input, while the mask and box prompts enable precise salient object localization. Extensive experiments on three public datasets demonstrate that our method achieves state-of-the-art performance. Notably, HyPSAM has remarkable versatility, seamlessly integrating with different RGB-T SOD methods to achieve significant performance gains, thereby highlighting the potential of prompt engineering in this field. The code and results of our method are available at: https://github.com/milotic233/HyPSAM.
TriFusion-AE: Language-Guided Depth and LiDAR Fusion for Robust Point Cloud Processing
arXiv:2509.18743v1 Announce Type: new Abstract: LiDAR-based perception is central to autonomous driving and robotics, yet raw point clouds remain highly vulnerable to noise, occlusion, and adversarial corruptions. Autoencoders offer a natural framework for denoising and reconstruction, but their performance degrades under challenging real-world conditions. In this work, we propose TriFusion-AE, a multimodal cross-attention autoencoder that integrates textual priors, monocular depth maps from multi-view images, and LiDAR point clouds to improve robustness. By aligning semantic cues from text, geometric (depth) features from images, and spatial structure from LiDAR, TriFusion-AE learns representations that are resilient to stochastic noise and adversarial perturbations. Interestingly, while showing limited gains under mild perturbations, our model achieves significantly more robust reconstruction under strong adversarial attacks and heavy noise, where CNN-based autoencoders collapse. We evaluate on the nuScenes-mini dataset to reflect realistic low-data deployment scenarios. Our multimodal fusion framework is designed to be model-agnostic, enabling seamless integration with any CNN-based point cloud autoencoder for joint representation learning.
COLT: Enhancing Video Large Language Models with Continual Tool Usage
arXiv:2509.18754v1 Announce Type: new Abstract: The success of Large Language Models (LLMs) has significantly propelled the research of video understanding. To harvest the benefits of well-trained expert models (i.e., tools), video LLMs prioritize the exploration of tool usage capabilities. Existing methods either prompt closed-source LLMs or employ the instruction tuning paradigm for tool-use fine-tuning. These methods, however, assume an established repository of fixed tools and struggle to generalize to real-world environments where tool data is perpetually evolving and streaming in. To this end, we propose to enhance open-source video LLMs with COntinuaL Tool usage (termed COLT), which automatically acquires tool-use ability in a successive tool stream without suffering 'catastrophic forgetting' of the past learned tools. Specifically, our COLT incorporates a learnable tool codebook as a tool-specific memory system. Then relevant tools are dynamically selected based on the similarity between user instruction and tool features within the codebook. To unleash the tool usage potential of video LLMs, we collect a video-centric tool-use instruction tuning dataset VideoToolBench. Extensive experiments on both previous video LLM benchmarks and the tool-use-specific VideoToolBench dataset demonstrate the state-of-the-art performance of our proposed COLT.
FixingGS: Enhancing 3D Gaussian Splatting via Training-Free Score Distillation
arXiv:2509.18759v1 Announce Type: new Abstract: Recently, 3D Gaussian Splatting (3DGS) has demonstrated remarkable success in 3D reconstruction and novel view synthesis. However, reconstructing 3D scenes from sparse viewpoints remains highly challenging due to insufficient visual information, which results in noticeable artifacts persisting across the 3D representation. To address this limitation, recent methods have resorted to generative priors to remove artifacts and complete missing content in under-constrained areas. Despite their effectiveness, these approaches struggle to ensure multi-view consistency, resulting in blurred structures and implausible details. In this work, we propose FixingGS, a training-free method that fully exploits the capabilities of the existing diffusion model for sparse-view 3DGS reconstruction enhancement. At the core of FixingGS is our distillation approach, which delivers more accurate and cross-view coherent diffusion priors, thereby enabling effective artifact removal and inpainting. In addition, we propose an adaptive progressive enhancement scheme that further refines reconstructions in under-constrained regions. Extensive experiments demonstrate that FixingGS surpasses existing state-of-the-art methods with superior visual quality and reconstruction performance. Our code will be released publicly.
Bi-VLM: Pushing Ultra-Low Precision Post-Training Quantization Boundaries in Vision-Language Models
arXiv:2509.18763v1 Announce Type: new Abstract: We address the critical gap between the computational demands of vision-language models and the possible ultra-low-bit weight precision (bitwidth $\leq2$ bits) we can use for higher efficiency. Our work is motivated by the substantial computational cost and memory requirements of VLMs, which restrict their applicability in hardware-constrained environments. We propose Bi-VLM, which separates model weights non-uniformly based on the Gaussian quantiles. Our formulation groups the model weights into outlier (salient) and multiple inlier (unsalient) subsets, ensuring that each subset contains a proportion of weights corresponding to its quantile in the distribution. We propose a saliency-aware hybrid quantization algorithm and use it to quantize weights by imposing different constraints on the scaler and binary matrices based on the saliency metric and compression objective. We have evaluated our approach on different VLMs. For the language model part of the VLM, our Bi-VLM outperforms the SOTA by 3%-47% on the visual question answering task in terms of four different benchmarks and three different models. For the overall VLM, our Bi-VLM outperforms the SOTA by 4%-45%. We also perform token pruning on the quantized models and observe that there is redundancy of image tokens 90% - 99% in the quantized models. This helps us to further prune the visual tokens to improve efficiency.
DiSSECT: Structuring Transfer-Ready Medical Image Representations through Discrete Self-Supervision
arXiv:2509.18765v1 Announce Type: new Abstract: Self-supervised learning (SSL) has emerged as a powerful paradigm for medical image representation learning, particularly in settings with limited labeled data. However, existing SSL methods often rely on complex architectures, anatomy-specific priors, or heavily tuned augmentations, which limit their scalability and generalizability. More critically, these models are prone to shortcut learning, especially in modalities like chest X-rays, where anatomical similarity is high and pathology is subtle. In this work, we introduce DiSSECT -- Discrete Self-Supervision for Efficient Clinical Transferable Representations, a framework that integrates multi-scale vector quantization into the SSL pipeline to impose a discrete representational bottleneck. This constrains the model to learn repeatable, structure-aware features while suppressing view-specific or low-utility patterns, improving representation transfer across tasks and domains. DiSSECT achieves strong performance on both classification and segmentation tasks, requiring minimal or no fine-tuning, and shows particularly high label efficiency in low-label regimes. We validate DiSSECT across multiple public medical imaging datasets, demonstrating its robustness and generalizability compared to existing state-of-the-art approaches.
Real-time Deer Detection and Warning in Connected Vehicles via Thermal Sensing and Deep Learning
arXiv:2509.18779v1 Announce Type: new Abstract: Deer-vehicle collisions represent a critical safety challenge in the United States, causing nearly 2.1 million incidents annually and resulting in approximately 440 fatalities, 59,000 injuries, and 10 billion USD in economic damages. These collisions also contribute significantly to declining deer populations. This paper presents a real-time detection and driver warning system that integrates thermal imaging, deep learning, and vehicle-to-everything communication to help mitigate deer-vehicle collisions. Our system was trained and validated on a custom dataset of over 12,000 thermal deer images collected in Mars Hill, North Carolina. Experimental evaluation demonstrates exceptional performance with 98.84 percent mean average precision, 95.44 percent precision, and 95.96 percent recall. The system was field tested during a follow-up visit to Mars Hill and readily sensed deer providing the driver with advanced warning. Field testing validates robust operation across diverse weather conditions, with thermal imaging maintaining between 88 and 92 percent detection accuracy in challenging scenarios where conventional visible light based cameras achieve less than 60 percent effectiveness. When a high probability threshold is reached sensor data sharing messages are broadcast to surrounding vehicles and roadside units via cellular vehicle to everything (CV2X) communication devices. Overall, our system achieves end to end latency consistently under 100 milliseconds from detection to driver alert. This research establishes a viable technological pathway for reducing deer-vehicle collisions through thermal imaging and connected vehicles.
Towards Application Aligned Synthetic Surgical Image Synthesis
arXiv:2509.18796v1 Announce Type: new Abstract: The scarcity of annotated surgical data poses a significant challenge for developing deep learning systems in computer-assisted interventions. While diffusion models can synthesize realistic images, they often suffer from data memorization, resulting in inconsistent or non-diverse samples that may fail to improve, or even harm, downstream performance. We introduce \emph{Surgical Application-Aligned Diffusion} (SAADi), a new framework that aligns diffusion models with samples preferred by downstream models. Our method constructs pairs of \emph{preferred} and \emph{non-preferred} synthetic images and employs lightweight fine-tuning of diffusion models to align the image generation process with downstream objectives explicitly. Experiments on three surgical datasets demonstrate consistent gains of $7$--$9\%$ in classification and $2$--$10\%$ in segmentation tasks, with the considerable improvements observed for underrepresented classes. Iterative refinement of synthetic samples further boosts performance by $4$--$10\%$. Unlike baseline approaches, our method overcomes sample degradation and establishes task-aware alignment as a key principle for mitigating data scarcity and advancing surgical vision applications.
A Kernel Space-based Multidimensional Sparse Model for Dynamic PET Image Denoising
arXiv:2509.18801v1 Announce Type: new Abstract: Achieving high image quality for temporal frames in dynamic positron emission tomography (PET) is challenging due to the limited statistic especially for the short frames. Recent studies have shown that deep learning (DL) is useful in a wide range of medical image denoising tasks. In this paper, we propose a model-based neural network for dynamic PET image denoising. The inter-frame spatial correlation and intra-frame structural consistency in dynamic PET are used to establish the kernel space-based multidimensional sparse (KMDS) model. We then substitute the inherent forms of the parameter estimation with neural networks to enable adaptive parameters optimization, forming the end-to-end neural KMDS-Net. Extensive experimental results from simulated and real data demonstrate that the neural KMDS-Net exhibits strong denoising performance for dynamic PET, outperforming previous baseline methods. The proposed method may be used to effectively achieve high temporal and spatial resolution for dynamic PET. Our source code is available at https://github.com/Kuangxd/Neural-KMDS-Net/tree/main.
Surgical Video Understanding with Label Interpolation
arXiv:2509.18802v1 Announce Type: new Abstract: Robot-assisted surgery (RAS) has become a critical paradigm in modern surgery, promoting patient recovery and reducing the burden on surgeons through minimally invasive approaches. To fully realize its potential, however, a precise understanding of the visual data generated during surgical procedures is essential. Previous studies have predominantly focused on single-task approaches, but real surgical scenes involve complex temporal dynamics and diverse instrument interactions that limit comprehensive understanding. Moreover, the effective application of multi-task learning (MTL) requires sufficient pixel-level segmentation data, which are difficult to obtain due to the high cost and expertise required for annotation. In particular, long-term annotations such as phases and steps are available for every frame, whereas short-term annotations such as surgical instrument segmentation and action detection are provided only for key frames, resulting in a significant temporal-spatial imbalance. To address these challenges, we propose a novel framework that combines optical flow-based segmentation label interpolation with multi-task learning. optical flow estimated from annotated key frames is used to propagate labels to adjacent unlabeled frames, thereby enriching sparse spatial supervision and balancing temporal and spatial information for training. This integration improves both the accuracy and efficiency of surgical scene understanding and, in turn, enhances the utility of RAS.
Hyper-Bagel: A Unified Acceleration Framework for Multimodal Understanding and Generation
arXiv:2509.18824v1 Announce Type: new Abstract: Unified multimodal models have recently attracted considerable attention for their remarkable abilities in jointly understanding and generating diverse content. However, as contexts integrate increasingly numerous interleaved multimodal tokens, the iterative processes of diffusion denoising and autoregressive decoding impose significant computational overhead. To address this, we propose Hyper-Bagel, a unified acceleration framework designed to simultaneously speed up both multimodal understanding and generation tasks. Our approach uses a divide-and-conquer strategy, employing speculative decoding for next-token prediction and a multi-stage distillation process for diffusion denoising. The framework delivers substantial performance gains, achieving over a 2x speedup in multimodal understanding. For generative tasks, our resulting lossless 6-NFE model yields a 16.67x speedup in text-to-image generation and a 22x speedup in image editing, all while preserving the high-quality output of the original model. We further develop a highly efficient 1-NFE model that enables near real-time interactive editing and generation. By combining advanced adversarial distillation with human feedback learning, this model achieves ultimate cost-effectiveness and responsiveness, making complex multimodal interactions seamless and instantaneous.
Benchmarking Vision-Language and Multimodal Large Language Models in Zero-shot and Few-shot Scenarios: A study on Christian Iconography
arXiv:2509.18839v1 Announce Type: new Abstract: This study evaluates the capabilities of Multimodal Large Language Models (LLMs) and Vision Language Models (VLMs) in the task of single-label classification of Christian Iconography. The goal was to assess whether general-purpose VLMs (CLIP and SigLIP) and LLMs, such as GPT-4o and Gemini 2.5, can interpret the Iconography, typically addressed by supervised classifiers, and evaluate their performance. Two research questions guided the analysis: (RQ1) How do multimodal LLMs perform on image classification of Christian saints? And (RQ2), how does performance vary when enriching input with contextual information or few-shot exemplars? We conducted a benchmarking study using three datasets supporting Iconclass natively: ArtDL, ICONCLASS, and Wikidata, filtered to include the top 10 most frequent classes. Models were tested under three conditions: (1) classification using class labels, (2) classification with Iconclass descriptions, and (3) few-shot learning with five exemplars. Results were compared against ResNet50 baselines fine-tuned on the same datasets. The findings show that Gemini-2.5 Pro and GPT-4o outperformed the ResNet50 baselines. Accuracy dropped significantly on the Wikidata dataset, where Siglip reached the highest accuracy score, suggesting model sensitivity to image size and metadata alignment. Enriching prompts with class descriptions generally improved zero-shot performance, while few-shot learning produced lower results, with only occasional and minimal increments in accuracy. We conclude that general-purpose multimodal LLMs are capable of classification in visually complex cultural heritage domains. These results support the application of LLMs as metadata curation tools in digital humanities workflows, suggesting future research on prompt optimization and the expansion of the study to other classification strategies and models.
ViG-LRGC: Vision Graph Neural Networks with Learnable Reparameterized Graph Construction
arXiv:2509.18840v1 Announce Type: new Abstract: Image Representation Learning is an important problem in Computer Vision. Traditionally, images were processed as grids, using Convolutional Neural Networks or as a sequence of visual tokens, using Vision Transformers. Recently, Vision Graph Neural Networks (ViG) have proposed the treatment of images as a graph of nodes; which provides a more intuitive image representation. The challenge is to construct a graph of nodes in each layer that best represents the relations between nodes and does not need a hyper-parameter search. ViG models in the literature depend on non-parameterized and non-learnable statistical methods that operate on the latent features of nodes to create a graph. This might not select the best neighborhood for each node. Starting from k-NN graph construction to HyperGraph Construction and Similarity-Thresholded graph construction, these methods lack the ability to provide a learnable hyper-parameter-free graph construction method. To overcome those challenges, we present the Learnable Reparameterized Graph Construction (LRGC) for Vision Graph Neural Networks. LRGC applies key-query attention between every pair of nodes; then uses soft-threshold reparameterization for edge selection, which allows the use of a differentiable mathematical model for training. Using learnable parameters to select the neighborhood removes the bias that is induced by any clustering or thresholding methods previously introduced in the literature. In addition, LRGC allows tuning the threshold in each layer to the training data since the thresholds are learnable through training and are not provided as hyper-parameters to the model. We demonstrate that the proposed ViG-LRGC approach outperforms state-of-the-art ViG models of similar sizes on the ImageNet-1k benchmark dataset.
Failure Makes the Agent Stronger: Enhancing Accuracy through Structured Reflection for Reliable Tool Interactions
arXiv:2509.18847v1 Announce Type: new Abstract: Tool-augmented large language models (LLMs) are usually trained with supervised imitation or coarse-grained reinforcement learning that optimizes single tool calls. Current self-reflection practices rely on heuristic prompts or one-way reasoning: the model is urged to 'think more' instead of learning error diagnosis and repair. This is fragile in multi-turn interactions; after a failure the model often repeats the same mistake. We propose structured reflection, which turns the path from error to repair into an explicit, controllable, and trainable action. The agent produces a short yet precise reflection: it diagnoses the failure using evidence from the previous step and then proposes a correct, executable follow-up call. For training we combine DAPO and GSPO objectives with a reward scheme tailored to tool use, optimizing the stepwise strategy Reflect, then Call, then Final. To evaluate, we introduce Tool-Reflection-Bench, a lightweight benchmark that programmatically checks structural validity, executability, parameter correctness, and result consistency. Tasks are built as mini trajectories of erroneous call, reflection, and corrected call, with disjoint train and test splits. Experiments on BFCL v3 and Tool-Reflection-Bench show large gains in multi-turn tool-call success and error recovery, and a reduction of redundant calls. These results indicate that making reflection explicit and optimizing it directly improves the reliability of tool interaction and offers a reproducible path for agents to learn from failure.
Attack for Defense: Adversarial Agents for Point Prompt Optimization Empowering Segment Anything Model
arXiv:2509.18891v1 Announce Type: new Abstract: Prompt quality plays a critical role in the performance of the Segment Anything Model (SAM), yet existing approaches often rely on heuristic or manually crafted prompts, limiting scalability and generalization. In this paper, we propose Point Prompt Defender, an adversarial reinforcement learning framework that adopts an attack-for-defense paradigm to automatically optimize point prompts. We construct a task-agnostic point prompt environment by representing image patches as nodes in a dual-space graph, where edges encode both physical and semantic distances. Within this environment, an attacker agent learns to activate a subset of prompts that maximally degrade SAM's segmentation performance, while a defender agent learns to suppress these disruptive prompts and restore accuracy. Both agents are trained using Deep Q-Networks with a reward signal based on segmentation quality variation. During inference, only the defender is deployed to refine arbitrary coarse prompt sets, enabling enhanced SAM segmentation performance across diverse tasks without retraining. Extensive experiments show that Point Prompt Defender effectively improves SAM's robustness and generalization, establishing a flexible, interpretable, and plug-and-play framework for prompt-based segmentation.
SmartWilds: Multimodal Wildlife Monitoring Dataset
arXiv:2509.18894v1 Announce Type: new Abstract: We present the first release of SmartWilds, a multimodal wildlife monitoring dataset. SmartWilds is a synchronized collection of drone imagery, camera trap photographs and videos, and bioacoustic recordings collected during summer 2025 at The Wilds safari park in Ohio. This dataset supports multimodal AI research for comprehensive environmental monitoring, addressing critical needs in endangered species research, conservation ecology, and habitat management. Our pilot deployment captured four days of synchronized monitoring across three modalities in a 220-acre pasture containing Pere David's deer, Sichuan takin, Przewalski's horses, as well as species native to Ohio, including bald eagles, white-tailed deer, and coyotes. We provide a comparative analysis of sensor modality performance, demonstrating complementary strengths for landuse patterns, species detection, behavioral analysis, and habitat monitoring. This work establishes reproducible protocols for multimodal wildlife monitoring while contributing open datasets to advance conservation computer vision research. Future releases will include synchronized GPS tracking data from tagged individuals, citizen science data, and expanded temporal coverage across multiple seasons.
RS3DBench: A Comprehensive Benchmark for 3D Spatial Perception in Remote Sensing
arXiv:2509.18897v1 Announce Type: new Abstract: In this paper, we introduce a novel benchmark designed to propel the advancement of general-purpose, large-scale 3D vision models for remote sensing imagery. While several datasets have been proposed within the realm of remote sensing, many existing collections either lack comprehensive depth information or fail to establish precise alignment between depth data and remote sensing images. To address this deficiency, we present a visual Benchmark for 3D understanding of Remotely Sensed images, dubbed RS3DBench. This dataset encompasses 54,951 pairs of remote sensing images and pixel-level aligned depth maps, accompanied by corresponding textual descriptions, spanning a broad array of geographical contexts. It serves as a tool for training and assessing 3D visual perception models within remote sensing image spatial understanding tasks. Furthermore, we introduce a remotely sensed depth estimation model derived from stable diffusion, harnessing its multimodal fusion capabilities, thereby delivering state-of-the-art performance on our dataset. Our endeavor seeks to make a profound contribution to the evolution of 3D visual perception models and the advancement of geographic artificial intelligence within the remote sensing domain. The dataset, models and code will be accessed on the https://rs3dbench.github.io.
DeblurSplat: SfM-free 3D Gaussian Splatting with Event Camera for Robust Deblurring
arXiv:2509.18898v1 Announce Type: new Abstract: In this paper, we propose the first Structure-from-Motion (SfM)-free deblurring 3D Gaussian Splatting method via event camera, dubbed DeblurSplat. We address the motion-deblurring problem in two ways. First, we leverage the pretrained capability of the dense stereo module (DUSt3R) to directly obtain accurate initial point clouds from blurred images. Without calculating camera poses as an intermediate result, we avoid the cumulative errors transfer from inaccurate camera poses to the initial point clouds' positions. Second, we introduce the event stream into the deblur pipeline for its high sensitivity to dynamic change. By decoding the latent sharp images from the event stream and blurred images, we can provide a fine-grained supervision signal for scene reconstruction optimization. Extensive experiments across a range of scenes demonstrate that DeblurSplat not only excels in generating high-fidelity novel views but also achieves significant rendering efficiency compared to the SOTAs in deblur 3D-GS.
Moir\'eNet: A Compact Dual-Domain Network for Image Demoir\'eing
arXiv:2509.18910v1 Announce Type: new Abstract: Moir\'e patterns arise from spectral aliasing between display pixel lattices and camera sensor grids, manifesting as anisotropic, multi-scale artifacts that pose significant challenges for digital image demoir\'eing. We propose Moir\'eNet, a convolutional neural U-Net-based framework that synergistically integrates frequency and spatial domain features for effective artifact removal. Moir\'eNet introduces two key components: a Directional Frequency-Spatial Encoder (DFSE) that discerns moir\'e orientation via directional difference convolution, and a Frequency-Spatial Adaptive Selector (FSAS) that enables precise, feature-adaptive suppression. Extensive experiments demonstrate that Moir\'eNet achieves state-of-the-art performance on public and actively used datasets while being highly parameter-efficient. With only 5.513M parameters, representing a 48% reduction compared to ESDNet-L, Moir\'eNet combines superior restoration quality with parameter efficiency, making it well-suited for resource-constrained applications including smartphone photography, industrial imaging, and augmented reality.
Frequency-Domain Decomposition and Recomposition for Robust Audio-Visual Segmentation
arXiv:2509.18912v1 Announce Type: new Abstract: Audio-visual segmentation (AVS) plays a critical role in multimodal machine learning by effectively integrating audio and visual cues to precisely segment objects or regions within visual scenes. Recent AVS methods have demonstrated significant improvements. However, they overlook the inherent frequency-domain contradictions between audio and visual modalities--the pervasively interfering noise in audio high-frequency signals vs. the structurally rich details in visual high-frequency signals. Ignoring these differences can result in suboptimal performance. In this paper, we rethink the AVS task from a deeper perspective by reformulating AVS task as a frequency-domain decomposition and recomposition problem. To this end, we introduce a novel Frequency-Aware Audio-Visual Segmentation (FAVS) framework consisting of two key modules: Frequency-Domain Enhanced Decomposer (FDED) module and Synergistic Cross-Modal Consistency (SCMC) module. FDED module employs a residual-based iterative frequency decomposition to discriminate modality-specific semantics and structural features, and SCMC module leverages a mixture-of-experts architecture to reinforce semantic consistency and modality-specific feature preservation through dynamic expert routing. Extensive experiments demonstrate that our FAVS framework achieves state-of-the-art performance on three benchmark datasets, and abundant qualitative visualizations further verify the effectiveness of the proposed FDED and SCMC modules. The code will be released as open source upon acceptance of the paper.
xAI-CV: An Overview of Explainable Artificial Intelligence in Computer Vision
arXiv:2509.18913v1 Announce Type: new Abstract: Deep learning has become the de facto standard and dominant paradigm in image analysis tasks, achieving state-of-the-art performance. However, this approach often results in "black-box" models, whose decision-making processes are difficult to interpret, raising concerns about reliability in critical applications. To address this challenge and provide human a method to understand how AI model process and make decision, the field of xAI has emerged. This paper surveys four representative approaches in xAI for visual perception tasks: (i) Saliency Maps, (ii) Concept Bottleneck Models (CBM), (iii) Prototype-based methods, and (iv) Hybrid approaches. We analyze their underlying mechanisms, strengths and limitations, as well as evaluation metrics, thereby providing a comprehensive overview to guide future research and applications.
LiDAR Point Cloud Image-based Generation Using Denoising Diffusion Probabilistic Models
arXiv:2509.18917v1 Announce Type: new Abstract: Autonomous vehicles (AVs) are expected to revolutionize transportation by improving efficiency and safety. Their success relies on 3D vision systems that effectively sense the environment and detect traffic agents. Among sensors AVs use to create a comprehensive view of surroundings, LiDAR provides high-resolution depth data enabling accurate object detection, safe navigation, and collision avoidance. However, collecting real-world LiDAR data is time-consuming and often affected by noise and sparsity due to adverse weather or sensor limitations. This work applies a denoising diffusion probabilistic model (DDPM), enhanced with novel noise scheduling and time-step embedding techniques to generate high-quality synthetic data for augmentation, thereby improving performance across a range of computer vision tasks, particularly in AV perception. These modifications impact the denoising process and the model's temporal awareness, allowing it to produce more realistic point clouds based on the projection. The proposed method was extensively evaluated under various configurations using the IAMCV and KITTI-360 datasets, with four performance metrics compared against state-of-the-art (SOTA) methods. The results demonstrate the model's superior performance over most existing baselines and its effectiveness in mitigating the effects of noisy and sparse LiDAR data, producing diverse point clouds with rich spatial relationships and structural detail.
Advancing Metallic Surface Defect Detection via Anomaly-Guided Pretraining on a Large Industrial Dataset
arXiv:2509.18919v1 Announce Type: new Abstract: The pretraining-finetuning paradigm is a crucial strategy in metallic surface defect detection for mitigating the challenges posed by data scarcity. However, its implementation presents a critical dilemma. Pretraining on natural image datasets such as ImageNet, faces a significant domain gap. Meanwhile, naive self-supervised pretraining on in-domain industrial data is often ineffective due to the inability of existing learning objectives to distinguish subtle defect patterns from complex background noise and textures. To resolve this, we introduce Anomaly-Guided Self-Supervised Pretraining (AGSSP), a novel paradigm that explicitly guides representation learning through anomaly priors. AGSSP employs a two-stage framework: (1) it first pretrains the model's backbone by distilling knowledge from anomaly maps, encouraging the network to capture defect-salient features; (2) it then pretrains the detector using pseudo-defect boxes derived from these maps, aligning it with localization tasks. To enable this, we develop a knowledge-enhanced method to generate high-quality anomaly maps and collect a large-scale industrial dataset of 120,000 images. Additionally, we present two small-scale, pixel-level labeled metallic surface defect datasets for validation. Extensive experiments demonstrate that AGSSP consistently enhances performance across various settings, achieving up to a 10\% improvement in mAP@0.5 and 11.4\% in mAP@0.5:0.95 compared to ImageNet-based models. All code, pretrained models, and datasets are publicly available at https://clovermini.github.io/AGSSP-Dev/.
Audio-Driven Universal Gaussian Head Avatars
arXiv:2509.18924v1 Announce Type: new Abstract: We introduce the first method for audio-driven universal photorealistic avatar synthesis, combining a person-agnostic speech model with our novel Universal Head Avatar Prior (UHAP). UHAP is trained on cross-identity multi-view videos. In particular, our UHAP is supervised with neutral scan data, enabling it to capture the identity-specific details at high fidelity. In contrast to previous approaches, which predominantly map audio features to geometric deformations only while ignoring audio-dependent appearance variations, our universal speech model directly maps raw audio inputs into the UHAP latent expression space. This expression space inherently encodes, both, geometric and appearance variations. For efficient personalization to new subjects, we employ a monocular encoder, which enables lightweight regression of dynamic expression variations across video frames. By accounting for these expression-dependent changes, it enables the subsequent model fine-tuning stage to focus exclusively on capturing the subject's global appearance and geometry. Decoding these audio-driven expression codes via UHAP generates highly realistic avatars with precise lip synchronization and nuanced expressive details, such as eyebrow movement, gaze shifts, and realistic mouth interior appearance as well as motion. Extensive evaluations demonstrate that our method is not only the first generalizable audio-driven avatar model that can account for detailed appearance modeling and rendering, but it also outperforms competing (geometry-only) methods across metrics measuring lip-sync accuracy, quantitative image quality, and perceptual realism.
SynapFlow: A Modular Framework Towards Large-Scale Analysis of Dendritic Spines
arXiv:2509.18926v1 Announce Type: new Abstract: Dendritic spines are key structural components of excitatory synapses in the brain. Given the size of dendritic spines provides a proxy for synaptic efficacy, their detection and tracking across time is important for studies of the neural basis of learning and memory. Despite their relevance, large-scale analyses of the structural dynamics of dendritic spines in 3D+time microscopy data remain challenging and labor-intense. Here, we present a modular machine learning-based pipeline designed to automate the detection, time-tracking, and feature extraction of dendritic spines in volumes chronically recorded with two-photon microscopy. Our approach tackles the challenges posed by biological data by combining a transformer-based detection module, a depth-tracking component that integrates spatial features, a time-tracking module to associate 3D spines across time by leveraging spatial consistency, and a feature extraction unit that quantifies biologically relevant spine properties. We validate our method on open-source labeled spine data, and on two complementary annotated datasets that we publish alongside this work: one for detection and depth-tracking, and one for time-tracking, which, to the best of our knowledge, is the first data of this kind. To encourage future research, we release our data, code, and pre-trained weights at https://github.com/pamelaosuna/SynapFlow, establishing a baseline for scalable, end-to-end analysis of dendritic spine dynamics.
No Labels Needed: Zero-Shot Image Classification with Collaborative Self-Learning
arXiv:2509.18938v1 Announce Type: new Abstract: While deep learning, including Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), has significantly advanced classification performance, its typical reliance on extensive annotated datasets presents a major obstacle in many practical scenarios where such data is scarce. Vision-language models (VLMs) and transfer learning with pre-trained visual models appear as promising techniques to deal with this problem. This paper proposes a novel zero-shot image classification framework that combines a VLM and a pre-trained visual model within a self-learning cycle. Requiring only the set of class names and no labeled training data, our method utilizes a confidence-based pseudo-labeling strategy to train a lightweight classifier directly on the test data, enabling dynamic adaptation. The VLM identifies high-confidence samples, and the pre-trained visual model enhances their visual representations. These enhanced features then iteratively train the classifier, allowing the system to capture complementary semantic and visual cues without supervision. Notably, our approach avoids VLM fine-tuning and the use of large language models, relying on the visual-only model to reduce the dependence on semantic representation. Experimental evaluations on ten diverse datasets demonstrate that our approach outperforms the baseline zero-shot method.
Seeing Through Reflections: Advancing 3D Scene Reconstruction in Mirror-Containing Environments with Gaussian Splatting
arXiv:2509.18956v1 Announce Type: new Abstract: Mirror-containing environments pose unique challenges for 3D reconstruction and novel view synthesis (NVS), as reflective surfaces introduce view-dependent distortions and inconsistencies. While cutting-edge methods such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) excel in typical scenes, their performance deteriorates in the presence of mirrors. Existing solutions mainly focus on handling mirror surfaces through symmetry mapping but often overlook the rich information carried by mirror reflections. These reflections offer complementary perspectives that can fill in absent details and significantly enhance reconstruction quality. To advance 3D reconstruction in mirror-rich environments, we present MirrorScene3D, a comprehensive dataset featuring diverse indoor scenes, 1256 high-quality images, and annotated mirror masks, providing a benchmark for evaluating reconstruction methods in reflective settings. Building on this, we propose ReflectiveGS, an extension of 3D Gaussian Splatting that utilizes mirror reflections as complementary viewpoints rather than simple symmetry artifacts, enhancing scene geometry and recovering absent details. Experiments on MirrorScene3D show that ReflectiveGaussian outperforms existing methods in SSIM, PSNR, LPIPS, and training speed, setting a new benchmark for 3D reconstruction in mirror-rich environments.
Generative data augmentation for biliary tract detection on intraoperative images
arXiv:2509.18958v1 Announce Type: new Abstract: Cholecystectomy is one of the most frequently performed procedures in gastrointestinal surgery, and the laparoscopic approach is the gold standard for symptomatic cholecystolithiasis and acute cholecystitis. In addition to the advantages of a significantly faster recovery and better cosmetic results, the laparoscopic approach bears a higher risk of bile duct injury, which has a significant impact on quality of life and survival. To avoid bile duct injury, it is essential to improve the intraoperative visualization of the bile duct. This work aims to address this problem by leveraging a deep-learning approach for the localization of the biliary tract from white-light images acquired during the surgical procedures. To this end, the construction and annotation of an image database to train the Yolo detection algorithm has been employed. Besides classical data augmentation techniques, the paper proposes Generative Adversarial Network (GAN) for the generation of a synthetic portion of the training dataset. Experimental results have been discussed along with ethical considerations.
Prompt-DAS: Annotation-Efficient Prompt Learning for Domain Adaptive Semantic Segmentation of Electron Microscopy Images
arXiv:2509.18973v1 Announce Type: new Abstract: Domain adaptive segmentation (DAS) of numerous organelle instances from large-scale electron microscopy (EM) is a promising way to enable annotation-efficient learning. Inspired by SAM, we propose a promptable multitask framework, namely Prompt-DAS, which is flexible enough to utilize any number of point prompts during the adaptation training stage and testing stage. Thus, with varying prompt configurations, Prompt-DAS can perform unsupervised domain adaptation (UDA) and weakly supervised domain adaptation (WDA), as well as interactive segmentation during testing. Unlike the foundation model SAM, which necessitates a prompt for each individual object instance, Prompt-DAS is only trained on a small dataset and can utilize full points on all instances, sparse points on partial instances, or even no points at all, facilitated by the incorporation of an auxiliary center-point detection task. Moreover, a novel prompt-guided contrastive learning is proposed to enhance discriminative feature learning. Comprehensive experiments conducted on challenging benchmarks demonstrate the effectiveness of the proposed approach over existing UDA, WDA, and SAM-based approaches.
VIR-Bench: Evaluating Geospatial and Temporal Understanding of MLLMs via Travel Video Itinerary Reconstruction
arXiv:2509.19002v1 Announce Type: new Abstract: Recent advances in multimodal large language models (MLLMs) have significantly enhanced video understanding capabilities, opening new possibilities for practical applications. Yet current video benchmarks focus largely on indoor scenes or short-range outdoor activities, leaving the challenges associated with long-distance travel largely unexplored. Mastering extended geospatial-temporal trajectories is critical for next-generation MLLMs, underpinning real-world tasks such as embodied-AI planning and navigation. To bridge this gap, we present VIR-Bench, a novel benchmark consisting of 200 travel videos that frames itinerary reconstruction as a challenging task designed to evaluate and push forward MLLMs' geospatial-temporal intelligence. Experimental results reveal that state-of-the-art MLLMs, including proprietary ones, struggle to achieve high scores, underscoring the difficulty of handling videos that span extended spatial and temporal scales. Moreover, we conduct an in-depth case study in which we develop a prototype travel-planning agent that leverages the insights gained from VIR-Bench. The agent's markedly improved itinerary recommendations verify that our evaluation protocol not only benchmarks models effectively but also translates into concrete performance gains in user-facing applications.
Unveiling Chain of Step Reasoning for Vision-Language Models with Fine-grained Rewards
arXiv:2509.19003v1 Announce Type: new Abstract: Chain of thought reasoning has demonstrated remarkable success in large language models, yet its adaptation to vision-language reasoning remains an open challenge with unclear best practices. Existing attempts typically employ reasoning chains at a coarse-grained level, which struggles to perform fine-grained structured reasoning and, more importantly, are difficult to evaluate the reward and quality of intermediate reasoning. In this work, we delve into chain of step reasoning for vision-language models, enabling assessing reasoning step quality accurately and leading to effective reinforcement learning and inference-time scaling with fine-grained rewards. We present a simple, effective, and fully transparent framework, including the step-level reasoning data, process reward model (PRM), and reinforcement learning training. With the proposed approaches, our models set strong baselines with consistent improvements on challenging vision-language benchmarks. More importantly, we conduct a thorough empirical analysis and ablation study, unveiling the impact of each component and several intriguing properties of inference-time scaling. We believe this paper serves as a baseline for vision-language models and offers insights into more complex multimodal reasoning. Our dataset, PRM, and code will be available at https://github.com/baaivision/CoS.
Weakly Supervised Food Image Segmentation using Vision Transformers and Segment Anything Model
arXiv:2509.19028v1 Announce Type: new Abstract: In this paper, we propose a weakly supervised semantic segmentation approach for food images which takes advantage of the zero-shot capabilities and promptability of the Segment Anything Model (SAM) along with the attention mechanisms of Vision Transformers (ViTs). Specifically, we use class activation maps (CAMs) from ViTs to generate prompts for SAM, resulting in masks suitable for food image segmentation. The ViT model, a Swin Transformer, is trained exclusively using image-level annotations, eliminating the need for pixel-level annotations during training. Additionally, to enhance the quality of the SAM-generated masks, we examine the use of image preprocessing techniques in combination with single-mask and multi-mask SAM generation strategies. The methodology is evaluated on the FoodSeg103 dataset, generating an average of 2.4 masks per image (excluding background), and achieving an mIoU of 0.54 for the multi-mask scenario. We envision the proposed approach as a tool to accelerate food image annotation tasks or as an integrated component in food and nutrition tracking applications.
A DyL-Unet framework based on dynamic learning for Temporally Consistent Echocardiographic Segmentation
arXiv:2509.19052v1 Announce Type: new Abstract: Accurate segmentation of cardiac anatomy in echocardiography is essential for cardiovascular diagnosis and treatment. Yet echocardiography is prone to deformation and speckle noise, causing frame-to-frame segmentation jitter. Even with high accuracy in single-frame segmentation, temporal instability can weaken functional estimates and impair clinical interpretability. To address these issues, we propose DyL-UNet, a dynamic learning-based temporal consistency U-Net segmentation architecture designed to achieve temporally stable and precise echocardiographic segmentation. The framework constructs an Echo-Dynamics Graph (EDG) through dynamic learning to extract dynamic information from videos. DyL-UNet incorporates multiple Swin-Transformer-based encoder-decoder branches for processing single-frame images. It further introduces Cardiac Phase-Dynamics Attention (CPDA) at the skip connections, which uses EDG-encoded dynamic features and cardiac-phase cues to enforce temporal consistency during segmentation. Extensive experiments on the CAMUS and EchoNet-Dynamic datasets demonstrate that DyL-UNet maintains segmentation accuracy comparable to existing methods while achieving superior temporal consistency, providing a reliable solution for automated clinical echocardiography.
ColorBlindnessEval: Can Vision-Language Models Pass Color Blindness Tests?
arXiv:2509.19070v1 Announce Type: new Abstract: This paper presents ColorBlindnessEval, a novel benchmark designed to evaluate the robustness of Vision-Language Models (VLMs) in visually adversarial scenarios inspired by the Ishihara color blindness test. Our dataset comprises 500 Ishihara-like images featuring numbers from 0 to 99 with varying color combinations, challenging VLMs to accurately recognize numerical information embedded in complex visual patterns. We assess 9 VLMs using Yes/No and open-ended prompts and compare their performance with human participants. Our experiments reveal limitations in the models' ability to interpret numbers in adversarial contexts, highlighting prevalent hallucination issues. These findings underscore the need to improve the robustness of VLMs in complex visual environments. ColorBlindnessEval serves as a valuable tool for benchmarking and improving the reliability of VLMs in real-world applications where accuracy is critical.
WaveletGaussian: Wavelet-domain Diffusion for Sparse-view 3D Gaussian Object Reconstruction
arXiv:2509.19073v1 Announce Type: new Abstract: 3D Gaussian Splatting (3DGS) has become a powerful representation for image-based object reconstruction, yet its performance drops sharply in sparse-view settings. Prior works address this limitation by employing diffusion models to repair corrupted renders, subsequently using them as pseudo ground truths for later optimization. While effective, such approaches incur heavy computation from the diffusion fine-tuning and repair steps. We present WaveletGaussian, a framework for more efficient sparse-view 3D Gaussian object reconstruction. Our key idea is to shift diffusion into the wavelet domain: diffusion is applied only to the low-resolution LL subband, while high-frequency subbands are refined with a lightweight network. We further propose an efficient online random masking strategy to curate training pairs for diffusion fine-tuning, replacing the commonly used, but inefficient, leave-one-out strategy. Experiments across two benchmark datasets, Mip-NeRF 360 and OmniObject3D, show WaveletGaussian achieves competitive rendering quality while substantially reducing training time.
3rd Place Report of LSVOS 2025 MeViS Track: Sa2VA-i: Improving Sa2VA Results with Consistent Training and Inference
arXiv:2509.19082v1 Announce Type: new Abstract: Sa2VA is a recent model for language-guided dense grounding in images and video that achieves state-of-the-art results on multiple segmentation benchmarks and that has become widely popular. However, we found that Sa2VA does not perform according to its full potential for referring video object segmentation tasks. We identify inconsistencies between training and inference procedures as the key factor holding it back. To mitigate this issue, we propose an improved version of Sa2VA, Sa2VA-i, that rectifies these issues and improves the results. In fact, Sa2VA-i sets a new state of the art for multiple video benchmarks and achieves improvements of up to +11.6 J&F on MeViS, +1.4 on Ref-YT-VOS, +3.3 on Ref-DAVIS and +4.1 on ReVOS using the same Sa2VA checkpoints. With our fixes, the Sa2VA-i-1B model even performs on par with the original Sa2VA-26B model on the MeViS benchmark. We hope that this work will show the importance of seemingly trivial implementation details and that it will provide valuable insights for the referring video segmentation field. We provide the code and updated models at https://github.com/kumuji/sa2va-i
Zero-Shot Multi-Spectral Learning: Reimagining a Generalist Multimodal Gemini 2.5 Model for Remote Sensing Applications
arXiv:2509.19087v1 Announce Type: new Abstract: Multi-spectral imagery plays a crucial role in diverse Remote Sensing applications including land-use classification, environmental monitoring and urban planning. These images are widely adopted because their additional spectral bands correlate strongly with physical materials on the ground, such as ice, water, and vegetation. This allows for more accurate identification, and their public availability from missions, such as Sentinel-2 and Landsat, only adds to their value. Currently, the automatic analysis of such data is predominantly managed through machine learning models specifically trained for multi-spectral input, which are costly to train and support. Furthermore, although providing a lot of utility for Remote Sensing, such additional inputs cannot be used with powerful generalist large multimodal models, which are capable of solving many visual problems, but are not able to understand specialized multi-spectral signals. To address this, we propose a training-free approach which introduces new multi-spectral data in a Zero-Shot-only mode, as inputs to generalist multimodal models, trained on RGB-only inputs. Our approach leverages the multimodal models' understanding of the visual space, and proposes to adapt to inputs to that space, and to inject domain-specific information as instructions into the model. We exemplify this idea with the Gemini2.5 model and observe strong Zero-Shot performance gains of the approach on popular Remote Sensing benchmarks for land cover and land use classification and demonstrate the easy adaptability of Gemini2.5 to new inputs. These results highlight the potential for geospatial professionals, working with non-standard specialized inputs, to easily leverage powerful multimodal models, such as Gemini2.5, to accelerate their work, benefiting from their rich reasoning and contextual capabilities, grounded in the specialized sensor data.
Citrus-V: Advancing Medical Foundation Models with Unified Medical Image Grounding for Clinical Reasoning
arXiv:2509.19090v1 Announce Type: new Abstract: Medical imaging provides critical evidence for clinical diagnosis, treatment planning, and surgical decisions, yet most existing imaging models are narrowly focused and require multiple specialized networks, limiting their generalization. Although large-scale language and multimodal models exhibit strong reasoning and multi-task capabilities, real-world clinical applications demand precise visual grounding, multimodal integration, and chain-of-thought reasoning. We introduce Citrus-V, a multimodal medical foundation model that combines image analysis with textual reasoning. The model integrates detection, segmentation, and multimodal chain-of-thought reasoning, enabling pixel-level lesion localization, structured report generation, and physician-like diagnostic inference in a single framework. We propose a novel multimodal training approach and release a curated open-source data suite covering reasoning, detection, segmentation, and document understanding tasks. Evaluations demonstrate that Citrus-V outperforms existing open-source medical models and expert-level imaging systems across multiple benchmarks, delivering a unified pipeline from visual grounding to clinical reasoning and supporting precise lesion quantification, automated reporting, and reliable second opinions.
Investigating Traffic Accident Detection Using Multimodal Large Language Models
arXiv:2509.19096v1 Announce Type: new Abstract: Traffic safety remains a critical global concern, with timely and accurate accident detection essential for hazard reduction and rapid emergency response. Infrastructure-based vision sensors offer scalable and efficient solutions for continuous real-time monitoring, facilitating automated detection of acci- dents directly from captured images. This research investigates the zero-shot capabilities of multimodal large language models (MLLMs) for detecting and describing traffic accidents using images from infrastructure cameras, thus minimizing reliance on extensive labeled datasets. Main contributions include: (1) Evaluation of MLLMs using the simulated DeepAccident dataset from CARLA, explicitly addressing the scarcity of diverse, realistic, infrastructure-based accident data through controlled simulations; (2) Comparative performance analysis between Gemini 1.5 and 2.0, Gemma 3 and Pixtral models in acci- dent identification and descriptive capabilities without prior fine-tuning; and (3) Integration of advanced visual analytics, specifically YOLO for object detection, Deep SORT for multi- object tracking, and Segment Anything (SAM) for instance segmentation, into enhanced prompts to improve model accuracy and explainability. Key numerical results show Pixtral as the top performer with an F1-score of 0.71 and 83% recall, while Gemini models gained precision with enhanced prompts (e.g., Gemini 1.5 rose to 90%) but suffered notable F1 and recall losses. Gemma 3 offered the most balanced performance with minimal metric fluctuation. These findings demonstrate the substantial potential of integrating MLLMs with advanced visual analytics techniques, enhancing their applicability in real-world automated traffic monitoring systems.
Track-On2: Enhancing Online Point Tracking with Memory
arXiv:2509.19115v1 Announce Type: new Abstract: In this paper, we consider the problem of long-term point tracking, which requires consistent identification of points across video frames under significant appearance changes, motion, and occlusion. We target the online setting, i.e. tracking points frame-by-frame, making it suitable for real-time and streaming applications. We extend our prior model Track-On into Track-On2, a simple and efficient transformer-based model for online long-term tracking. Track-On2 improves both performance and efficiency through architectural refinements, more effective use of memory, and improved synthetic training strategies. Unlike prior approaches that rely on full-sequence access or iterative updates, our model processes frames causally and maintains temporal coherence via a memory mechanism, which is key to handling drift and occlusions without requiring future frames. At inference, we perform coarse patch-level classification followed by refinement. Beyond architecture, we systematically study synthetic training setups and their impact on memory behavior, showing how they shape temporal robustness over long sequences. Through comprehensive experiments, Track-On2 achieves state-of-the-art results across five synthetic and real-world benchmarks, surpassing prior online trackers and even strong offline methods that exploit bidirectional context. These results highlight the effectiveness of causal, memory-based architectures trained purely on synthetic data as scalable solutions for real-world point tracking. Project page: https://kuis-ai.github.io/track_on2
KAMERA: Enhancing Aerial Surveys of Ice-associated Seals in Arctic Environments
arXiv:2509.19129v1 Announce Type: new Abstract: We introduce KAMERA: a comprehensive system for multi-camera, multi-spectral synchronization and real-time detection of seals and polar bears. Utilized in aerial surveys for ice-associated seals in the Bering, Chukchi, and Beaufort seas around Alaska, KAMERA provides up to an 80% reduction in dataset processing time over previous methods. Our rigorous calibration and hardware synchronization enable using multiple spectra for object detection. All collected data are annotated with metadata so they can be easily referenced later. All imagery and animal detections from a survey are mapped onto a world plane for accurate surveyed area estimates and quick assessment of survey results. We hope KAMERA will inspire other mapping and detection efforts in the scientific community, with all software, models, and schematics fully open-sourced.
NeuCODEX: Edge-Cloud Co-Inference with Spike-Driven Compression and Dynamic Early-Exit
arXiv:2509.19156v1 Announce Type: new Abstract: Spiking Neural Networks (SNNs) offer significant potential for enabling energy-efficient intelligence at the edge. However, performing full SNN inference at the edge can be challenging due to the latency and energy constraints arising from fixed and high timestep overheads. Edge-cloud co-inference systems present a promising solution, but their deployment is often hindered by high latency and feature transmission costs. To address these issues, we introduce NeuCODEX, a neuromorphic co-inference architecture that jointly optimizes both spatial and temporal redundancy. NeuCODEX incorporates a learned spike-driven compression module to reduce data transmission and employs a dynamic early-exit mechanism to adaptively terminate inference based on output confidence. We evaluated NeuCODEX on both static images (CIFAR10 and Caltech) and neuromorphic event streams (CIFAR10-DVS and N-Caltech). To demonstrate practicality, we prototyped NeuCODEX on ResNet-18 and VGG-16 backbones in a real edge-to-cloud testbed. Our proposed system reduces data transfer by up to 2048x and edge energy consumption by over 90%, while reducing end-to-end latency by up to 3x compared to edge-only inference, all with a negligible accuracy drop of less than 2%. In doing so, NeuCODEX enables practical, high-performance SNN deployment in resource-constrained environments.
RoSe: Robust Self-supervised Stereo Matching under Adverse Weather Conditions
arXiv:2509.19165v1 Announce Type: new Abstract: Recent self-supervised stereo matching methods have made significant progress, but their performance significantly degrades under adverse weather conditions such as night, rain, and fog. We identify two primary weaknesses contributing to this performance degradation. First, adverse weather introduces noise and reduces visibility, making CNN-based feature extractors struggle with degraded regions like reflective and textureless areas. Second, these degraded regions can disrupt accurate pixel correspondences, leading to ineffective supervision based on the photometric consistency assumption. To address these challenges, we propose injecting robust priors derived from the visual foundation model into the CNN-based feature extractor to improve feature representation under adverse weather conditions. We then introduce scene correspondence priors to construct robust supervisory signals rather than relying solely on the photometric consistency assumption. Specifically, we create synthetic stereo datasets with realistic weather degradations. These datasets feature clear and adverse image pairs that maintain the same semantic context and disparity, preserving the scene correspondence property. With this knowledge, we propose a robust self-supervised training paradigm, consisting of two key steps: robust self-supervised scene correspondence learning and adverse weather distillation. Both steps aim to align underlying scene results from clean and adverse image pairs, thus improving model disparity estimation under adverse weather effects. Extensive experiments demonstrate the effectiveness and versatility of our proposed solution, which outperforms existing state-of-the-art self-supervised methods. Codes are available at \textcolor{blue}{https://github.com/cocowy1/RoSe-Robust-Self-supervised-Stereo-Matching-under-Adverse-Weather-Conditions}.
YOLO-LAN: Precise Polyp Detection via Optimized Loss, Augmentations and Negatives
arXiv:2509.19166v1 Announce Type: new Abstract: Colorectal cancer (CRC), a lethal disease, begins with the growth of abnormal mucosal cell proliferation called polyps in the inner wall of the colon. When left undetected, polyps can become malignant tumors. Colonoscopy is the standard procedure for detecting polyps, as it enables direct visualization and removal of suspicious lesions. Manual detection by colonoscopy can be inconsistent and is subject to oversight. Therefore, object detection based on deep learning offers a better solution for a more accurate and real-time diagnosis during colonoscopy. In this work, we propose YOLO-LAN, a YOLO-based polyp detection pipeline, trained using M2IoU loss, versatile data augmentations and negative data to replicate real clinical situations. Our pipeline outperformed existing methods for the Kvasir-seg and BKAI-IGH NeoPolyp datasets, achieving mAP${50}$ of 0.9619, mAP${50:95}$ of 0.8599 with YOLOv12 and mAP${50}$ of 0.9540, mAP${50:95}$ of 0.8487 with YOLOv8 on the Kvasir-seg dataset. The significant increase is achieved in mAP$_{50:95}$ score, showing the precision of polyp detection. We show robustness based on polyp size and precise location detection, making it clinically relevant in AI-assisted colorectal screening.
The 1st Solution for MOSEv2 Challenge 2025: Long-term and Concept-aware Video Segmentation via SeC
arXiv:2509.19183v1 Announce Type: new Abstract: This technical report explores the MOSEv2 track of the LSVOS Challenge, which targets complex semi-supervised video object segmentation. By analysing and adapting SeC, an enhanced SAM-2 framework, we conduct a detailed study of its long-term memory and concept-aware memory, showing that long-term memory preserves temporal continuity under occlusion and reappearance, while concept-aware memory supplies semantic priors that suppress distractors; together, these traits directly benefit several MOSEv2's core challenges. Our solution achieves a JF score of 39.89% on the test set, ranking 1st in the MOSEv2 track of the LSVOS Challenge.
Reading Images Like Texts: Sequential Image Understanding in Vision-Language Models
arXiv:2509.19191v1 Announce Type: new Abstract: Vision-Language Models (VLMs) have demonstrated remarkable performance across a variety of real-world tasks. However, existing VLMs typically process visual information by serializing images, a method that diverges significantly from the parallel nature of human vision. Moreover, their opaque internal mechanisms hinder both deeper understanding and architectural innovation. Inspired by the dual-stream hypothesis of human vision, which distinguishes the "what" and "where" pathways, we deconstruct the visual processing in VLMs into object recognition and spatial perception for separate study. For object recognition, we convert images into text token maps and find that the model's perception of image content unfolds as a two-stage process from shallow to deep layers, beginning with attribute recognition and culminating in semantic disambiguation. For spatial perception, we theoretically derive and empirically verify the geometric structure underlying the positional representation in VLMs. Based on these findings, we introduce an instruction-agnostic token compression algorithm based on a plug-and-play visual decoder to improve decoding efficiency, and a RoPE scaling technique to enhance spatial reasoning. Through rigorous experiments, our work validates these analyses, offering a deeper understanding of VLM internals and providing clear principles for designing more capable future architectures.
Vision-Free Retrieval: Rethinking Multimodal Search with Textual Scene Descriptions
arXiv:2509.19203v1 Announce Type: new Abstract: Contrastively-trained Vision-Language Models (VLMs), such as CLIP, have become the standard approach for learning discriminative vision-language representations. However, these models often exhibit shallow language understanding, manifesting bag-of-words behaviour. These limitations are reinforced by their dual-encoder design, which induces a modality gap. Additionally, the reliance on vast web-collected data corpora for training makes the process computationally expensive and introduces significant privacy concerns. To address these limitations, in this work, we challenge the necessity of vision encoders for retrieval tasks by introducing a vision-free, single-encoder retrieval pipeline. Departing from the traditional text-to-image retrieval paradigm, we migrate to a text-to-text paradigm with the assistance of VLLM-generated structured image descriptions. We demonstrate that this paradigm shift has significant advantages, including a substantial reduction of the modality gap, improved compositionality, and better performance on short and long caption queries, all attainable with only a few hours of calibration on two GPUs. Additionally, substituting raw images with textual descriptions introduces a more privacy-friendly alternative for retrieval. To further assess generalisation and address some of the shortcomings of prior compositionality benchmarks, we release two benchmarks derived from Flickr30k and COCO, containing diverse compositional queries made of short captions, which we coin subFlickr and subCOCO. Our vision-free retriever matches and often surpasses traditional multimodal models. Importantly, our approach achieves state-of-the-art zero-shot performance on multiple retrieval and compositionality benchmarks, with models as small as 0.3B parameters. Code is available at: https://github.com/IoannaNti/LexiCLIP
Long Story Short: Disentangling Compositionality and Long-Caption Understanding in VLMs
arXiv:2509.19207v1 Announce Type: new Abstract: Contrastive vision-language models (VLMs) have made significant progress in binding visual and textual information, but understanding long, dense captions remains an open challenge. We hypothesize that compositionality, the capacity to reason about object-attribute bindings and inter-object relationships, is key to understanding longer captions. In this paper, we investigate the interaction between compositionality and long-caption understanding, asking whether training for one property enhances the other. We train and evaluate a range of models that target each of these capabilities. Our results reveal a bidirectional relationship: compositional training improves performance on long-caption retrieval, and training on long captions promotes compositionality. However, these gains are sensitive to data quality and model design. We find that training on poorly structured captions, or with limited parameter updates, fails to support generalization. Likewise, strategies that aim at retaining general alignment, such as freezing positional embeddings, do not improve compositional understanding. Overall, we find that compositional understanding and long-caption understanding are intertwined capabilities that can be jointly learned through training on dense, grounded descriptions. Despite these challenges, we show that models trained on high-quality, long-caption data can achieve strong performance in both tasks, offering practical guidance for improving VLM generalization.
Enabling Plant Phenotyping in Weedy Environments using Multi-Modal Imagery via Synthetic and Generated Training Data
arXiv:2509.19208v1 Announce Type: new Abstract: Accurate plant segmentation in thermal imagery remains a significant challenge for high throughput field phenotyping, particularly in outdoor environments where low contrast between plants and weeds and frequent occlusions hinder performance. To address this, we present a framework that leverages synthetic RGB imagery, a limited set of real annotations, and GAN-based cross-modality alignment to enhance semantic segmentation in thermal images. We trained models on 1,128 synthetic images containing complex mixtures of crop and weed plants in order to generate image segmentation masks for crop and weed plants. We additionally evaluated the benefit of integrating as few as five real, manually segmented field images within the training process using various sampling strategies. When combining all the synthetic images with a few labeled real images, we observed a maximum relative improvement of 22% for the weed class and 17% for the plant class compared to the full real-data baseline. Cross-modal alignment was enabled by translating RGB to thermal using CycleGAN-turbo, allowing robust template matching without calibration. Results demonstrated that combining synthetic data with limited manual annotations and cross-domain translation via generative models can significantly boost segmentation performance in complex field environments for multi-model imagery.
HyKid: An Open MRI Dataset with Expert-Annotated Multi-Structure and Choroid Plexus in Pediatric Hydrocephalus
arXiv:2509.19218v1 Announce Type: new Abstract: Evaluation of hydrocephalus in children is challenging, and the related research is limited by a lack of publicly available, expert-annotated datasets, particularly those with segmentation of the choroid plexus. To address this, we present HyKid, an open-source dataset from 48 pediatric patients with hydrocephalus. 3D MRIs were provided with 1mm isotropic resolution, which was reconstructed from routine low-resolution images using a slice-to-volume algorithm. Manually corrected segmentations of brain tissues, including white matter, grey matter, lateral ventricle, external CSF, and the choroid plexus, were provided by an experienced neurologist. Additionally, structured data was extracted from clinical radiology reports using a Retrieval-Augmented Generation framework. The strong correlation between choroid plexus volume and total CSF volume provided a potential biomarker for hydrocephalus evaluation, achieving excellent performance in a predictive model (AUC = 0.87). The proposed HyKid dataset provided a high-quality benchmark for neuroimaging algorithms development, and it revealed the choroid plexus-related features in hydrocephalus assessments. Our datasets are publicly available at https://www.synapse.org/Synapse:syn68544889.
MsFIN: Multi-scale Feature Interaction Network for Traffic Accident Anticipation
arXiv:2509.19227v1 Announce Type: new Abstract: With the widespread deployment of dashcams and advancements in computer vision, developing accident prediction models from the dashcam perspective has become critical for proactive safety interventions. However, two key challenges persist: modeling feature-level interactions among traffic participants (often occluded in dashcam views) and capturing complex, asynchronous multi-temporal behavioral cues preceding accidents. To deal with these two challenges, a Multi-scale Feature Interaction Network (MsFIN) is proposed for early-stage accident anticipation from dashcam videos. MsFIN has three layers for multi-scale feature aggregation, temporal feature processing and multi-scale feature post fusion, respectively. For multi-scale feature aggregation, a Multi-scale Module is designed to extract scene representations at short-term, mid-term and long-term temporal scales. Meanwhile, the Transformer architecture is leveraged to facilitate comprehensive feature interactions. Temporal feature processing captures the sequential evolution of scene and object features under causal constraints. In the multi-scale feature post fusion stage, the network fuses scene and object features across multiple temporal scales to generate a comprehensive risk representation. Experiments on DAD and DADA datasets show that MsFIN significantly outperforms state-of-the-art models with single-scale feature extraction in both prediction correctness and earliness. Ablation studies validate the effectiveness of each module in MsFIN, highlighting how the network achieves superior performance through multi-scale feature fusion and contextual interaction modeling.
DevFD: Developmental Face Forgery Detection by Learning Shared and Orthogonal LoRA Subspaces
arXiv:2509.19230v1 Announce Type: new Abstract: The rise of realistic digital face generation and manipulation poses significant social risks. The primary challenge lies in the rapid and diverse evolution of generation techniques, which often outstrip the detection capabilities of existing models. To defend against the ever-evolving new types of forgery, we need to enable our model to quickly adapt to new domains with limited computation and data while avoiding forgetting previously learned forgery types. In this work, we posit that genuine facial samples are abundant and relatively stable in acquisition methods, while forgery faces continuously evolve with the iteration of manipulation techniques. Given the practical infeasibility of exhaustively collecting all forgery variants, we frame face forgery detection as a continual learning problem and allow the model to develop as new forgery types emerge. Specifically, we employ a Developmental Mixture of Experts (MoE) architecture that uses LoRA models as its individual experts. These experts are organized into two groups: a Real-LoRA to learn and refine knowledge of real faces, and multiple Fake-LoRAs to capture incremental information from different forgery types. To prevent catastrophic forgetting, we ensure that the learning direction of Fake-LoRAs is orthogonal to the established subspace. Moreover, we integrate orthogonal gradients into the orthogonal loss of Fake-LoRAs, preventing gradient interference throughout the training process of each task. Experimental results under both the datasets and manipulation types incremental protocols demonstrate the effectiveness of our method.
Lavida-O: Elastic Masked Diffusion Models for Unified Multimodal Understanding and Generation
arXiv:2509.19244v1 Announce Type: new Abstract: We proposed Lavida-O, a unified multi-modal Masked Diffusion Model (MDM) capable of image understanding and generation tasks. Unlike existing multimodal diffsion language models such as MMaDa and Muddit which only support simple image-level understanding tasks and low-resolution image generation, Lavida-O exhibits many new capabilities such as object grounding, image-editing, and high-resolution (1024px) image synthesis. It is also the first unified MDM that uses its understanding capabilities to improve image generation and editing results through planning and iterative self-reflection. To allow effective and efficient training and sampling, Lavida-O ntroduces many novel techniques such as Elastic Mixture-of-Transformer architecture, universal text conditioning, and stratified sampling. \ours~achieves state-of-the-art performance on a wide range of benchmarks such as RefCOCO object grounding, GenEval text-to-image generation, and ImgEdit image editing, outperforming existing autoregressive and continuous diffusion models such as Qwen2.5-VL and FluxKontext-dev, while offering considerable speedup at inference.
ConViS-Bench: Estimating Video Similarity Through Semantic Concepts
arXiv:2509.19245v1 Announce Type: new Abstract: What does it mean for two videos to be similar? Videos may appear similar when judged by the actions they depict, yet entirely different if evaluated based on the locations where they were filmed. While humans naturally compare videos by taking different aspects into account, this ability has not been thoroughly studied and presents a challenge for models that often depend on broad global similarity scores. Large Multimodal Models (LMMs) with video understanding capabilities open new opportunities for leveraging natural language in comparative video tasks. We introduce Concept-based Video Similarity estimation (ConViS), a novel task that compares pairs of videos by computing interpretable similarity scores across a predefined set of key semantic concepts. ConViS allows for human-like reasoning about video similarity and enables new applications such as concept-conditioned video retrieval. To support this task, we also introduce ConViS-Bench, a new benchmark comprising carefully annotated video pairs spanning multiple domains. Each pair comes with concept-level similarity scores and textual descriptions of both differences and similarities. Additionally, we benchmark several state-of-the-art models on ConViS, providing insights into their alignment with human judgments. Our results reveal significant performance differences on ConViS, indicating that some concepts present greater challenges for estimating video similarity. We believe that ConViS-Bench will serve as a valuable resource for advancing research in language-driven video understanding.
Adversarially-Refined VQ-GAN with Dense Motion Tokenization for Spatio-Temporal Heatmaps
arXiv:2509.19252v1 Announce Type: new Abstract: Continuous human motion understanding remains a core challenge in computer vision due to its high dimensionality and inherent redundancy. Efficient compression and representation are crucial for analyzing complex motion dynamics. In this work, we introduce an adversarially-refined VQ-GAN framework with dense motion tokenization for compressing spatio-temporal heatmaps while preserving the fine-grained traces of human motion. Our approach combines dense motion tokenization with adversarial refinement, which eliminates reconstruction artifacts like motion smearing and temporal misalignment observed in non-adversarial baselines. Our experiments on the CMU Panoptic dataset provide conclusive evidence of our method's superiority, outperforming the dVAE baseline by 9.31% SSIM and reducing temporal instability by 37.1%. Furthermore, our dense tokenization strategy enables a novel analysis of motion complexity, revealing that 2D motion can be optimally represented with a compact 128-token vocabulary, while 3D motion's complexity demands a much larger 1024-token codebook for faithful reconstruction. These results establish practical deployment feasibility across diverse motion analysis applications. The code base for this work is available at https://github.com/TeCSAR-UNCC/Pose-Quantization.
Graph-Radiomic Learning (GrRAiL) Descriptor to Characterize Imaging Heterogeneity in Confounding Tumor Pathologies
arXiv:2509.19258v1 Announce Type: new Abstract: A significant challenge in solid tumors is reliably distinguishing confounding pathologies from malignant neoplasms on routine imaging. While radiomics methods seek surrogate markers of lesion heterogeneity on CT/MRI, many aggregate features across the region of interest (ROI) and miss complex spatial relationships among varying intensity compositions. We present a new Graph-Radiomic Learning (GrRAiL) descriptor for characterizing intralesional heterogeneity (ILH) on clinical MRI scans. GrRAiL (1) identifies clusters of sub-regions using per-voxel radiomic measurements, then (2) computes graph-theoretic metrics to quantify spatial associations among clusters. The resulting weighted graphs encode higher-order spatial relationships within the ROI, aiming to reliably capture ILH and disambiguate confounding pathologies from malignancy. To assess efficacy and clinical feasibility, GrRAiL was evaluated in n=947 subjects spanning three use cases: differentiating tumor recurrence from radiation effects in glioblastoma (GBM; n=106) and brain metastasis (n=233), and stratifying pancreatic intraductal papillary mucinous neoplasms (IPMNs) into no+low vs high risk (n=608). In a multi-institutional setting, GrRAiL consistently outperformed state-of-the-art baselines - Graph Neural Networks (GNNs), textural radiomics, and intensity-graph analysis. In GBM, cross-validation (CV) and test accuracies for recurrence vs pseudo-progression were 89% and 78% with >10% test-accuracy gains over comparators. In brain metastasis, CV and test accuracies for recurrence vs radiation necrosis were 84% and 74% (>13% improvement). For IPMN risk stratification, CV and test accuracies were 84% and 75%, showing >10% improvement.
Moving by Looking: Towards Vision-Driven Avatar Motion Generation
arXiv:2509.19259v1 Announce Type: new Abstract: The way we perceive the world fundamentally shapes how we move, whether it is how we navigate in a room or how we interact with other humans. Current human motion generation methods, neglect this interdependency and use task-specific ``perception'' that differs radically from that of humans. We argue that the generation of human-like avatar behavior requires human-like perception. Consequently, in this work we present CLOPS, the first human avatar that solely uses egocentric vision to perceive its surroundings and navigate. Using vision as the primary driver of motion however, gives rise to a significant challenge for training avatars: existing datasets have either isolated human motion, without the context of a scene, or lack scale. We overcome this challenge by decoupling the learning of low-level motion skills from learning of high-level control that maps visual input to motion. First, we train a motion prior model on a large motion capture dataset. Then, a policy is trained using Q-learning to map egocentric visual inputs to high-level control commands for the motion prior. Our experiments empirically demonstrate that egocentric vision can give rise to human-like motion characteristics in our avatars. For example, the avatars walk such that they avoid obstacles present in their visual field. These findings suggest that equipping avatars with human-like sensors, particularly egocentric vision, holds promise for training avatars that behave like humans.
OverLayBench: A Benchmark for Layout-to-Image Generation with Dense Overlaps
arXiv:2509.19282v1 Announce Type: new Abstract: Despite steady progress in layout-to-image generation, current methods still struggle with layouts containing significant overlap between bounding boxes. We identify two primary challenges: (1) large overlapping regions and (2) overlapping instances with minimal semantic distinction. Through both qualitative examples and quantitative analysis, we demonstrate how these factors degrade generation quality. To systematically assess this issue, we introduce OverLayScore, a novel metric that quantifies the complexity of overlapping bounding boxes. Our analysis reveals that existing benchmarks are biased toward simpler cases with low OverLayScore values, limiting their effectiveness in evaluating model performance under more challenging conditions. To bridge this gap, we present OverLayBench, a new benchmark featuring high-quality annotations and a balanced distribution across different levels of OverLayScore. As an initial step toward improving performance on complex overlaps, we also propose CreatiLayout-AM, a model fine-tuned on a curated amodal mask dataset. Together, our contributions lay the groundwork for more robust layout-to-image generation under realistic and challenging scenarios. Project link: https://mlpc-ucsd.github.io/OverLayBench.
Lyra: Generative 3D Scene Reconstruction via Video Diffusion Model Self-Distillation
arXiv:2509.19296v1 Announce Type: new Abstract: The ability to generate virtual environments is crucial for applications ranging from gaming to physical AI domains such as robotics, autonomous driving, and industrial AI. Current learning-based 3D reconstruction methods rely on the availability of captured real-world multi-view data, which is not always readily available. Recent advancements in video diffusion models have shown remarkable imagination capabilities, yet their 2D nature limits the applications to simulation where a robot needs to navigate and interact with the environment. In this paper, we propose a self-distillation framework that aims to distill the implicit 3D knowledge in the video diffusion models into an explicit 3D Gaussian Splatting (3DGS) representation, eliminating the need for multi-view training data. Specifically, we augment the typical RGB decoder with a 3DGS decoder, which is supervised by the output of the RGB decoder. In this approach, the 3DGS decoder can be purely trained with synthetic data generated by video diffusion models. At inference time, our model can synthesize 3D scenes from either a text prompt or a single image for real-time rendering. Our framework further extends to dynamic 3D scene generation from a monocular input video. Experimental results show that our framework achieves state-of-the-art performance in static and dynamic 3D scene generation.
VolSplat: Rethinking Feed-Forward 3D Gaussian Splatting with Voxel-Aligned Prediction
arXiv:2509.19297v1 Announce Type: new Abstract: Feed-forward 3D Gaussian Splatting (3DGS) has emerged as a highly effective solution for novel view synthesis. Existing methods predominantly rely on a pixel-aligned Gaussian prediction paradigm, where each 2D pixel is mapped to a 3D Gaussian. We rethink this widely adopted formulation and identify several inherent limitations: it renders the reconstructed 3D models heavily dependent on the number of input views, leads to view-biased density distributions, and introduces alignment errors, particularly when source views contain occlusions or low texture. To address these challenges, we introduce VolSplat, a new multi-view feed-forward paradigm that replaces pixel alignment with voxel-aligned Gaussians. By directly predicting Gaussians from a predicted 3D voxel grid, it overcomes pixel alignment's reliance on error-prone 2D feature matching, ensuring robust multi-view consistency. Furthermore, it enables adaptive control over Gaussian density based on 3D scene complexity, yielding more faithful Gaussian point clouds, improved geometric consistency, and enhanced novel-view rendering quality. Experiments on widely used benchmarks including RealEstate10K and ScanNet demonstrate that VolSplat achieves state-of-the-art performance while producing more plausible and view-consistent Gaussian reconstructions. In addition to superior results, our approach establishes a more scalable framework for feed-forward 3D reconstruction with denser and more robust representations, paving the way for further research in wider communities. The video results, code and trained models are available on our project page: https://lhmd.top/volsplat.
CAR-Flow: Condition-Aware Reparameterization Aligns Source and Target for Better Flow Matching
arXiv:2509.19300v1 Announce Type: new Abstract: Conditional generative modeling aims to learn a conditional data distribution from samples containing data-condition pairs. For this, diffusion and flow-based methods have attained compelling results. These methods use a learned (flow) model to transport an initial standard Gaussian noise that ignores the condition to the conditional data distribution. The model is hence required to learn both mass transport and conditional injection. To ease the demand on the model, we propose Condition-Aware Reparameterization for Flow Matching (CAR-Flow) -- a lightweight, learned shift that conditions the source, the target, or both distributions. By relocating these distributions, CAR-Flow shortens the probability path the model must learn, leading to faster training in practice. On low-dimensional synthetic data, we visualize and quantify the effects of CAR. On higher-dimensional natural image data (ImageNet-256), equipping SiT-XL/2 with CAR-Flow reduces FID from 2.07 to 1.68, while introducing less than 0.6% additional parameters.
Localized PCA-Net Neural Operators for Scalable Solution Reconstruction of Elliptic PDEs
arXiv:2509.18110v1 Announce Type: cross Abstract: Neural operator learning has emerged as a powerful approach for solving partial differential equations (PDEs) in a data-driven manner. However, applying principal component analysis (PCA) to high-dimensional solution fields incurs significant computational overhead. To address this, we propose a patch-based PCA-Net framework that decomposes the solution fields into smaller patches, applies PCA within each patch, and trains a neural operator in the reduced PCA space. We investigate two different patch-based approaches that balance computational efficiency and reconstruction accuracy: (1) local-to-global patch PCA, and (2) local-to-local patch PCA. The trade-off between computational cost and accuracy is analyzed, highlighting the advantages and limitations of each approach. Furthermore, within each approach, we explore two refinements for the most computationally efficient method: (i) introducing overlapping patches with a smoothing filter and (ii) employing a two-step process with a convolutional neural network (CNN) for refinement. Our results demonstrate that patch-based PCA significantly reduces computational complexity while maintaining high accuracy, reducing end-to-end pipeline processing time by a factor of 3.7 to 4 times compared to global PCA, thefore making it a promising technique for efficient operator learning in PDE-based systems.
Prompt Optimization Meets Subspace Representation Learning for Few-shot Out-of-Distribution Detection
arXiv:2509.18111v1 Announce Type: cross Abstract: The reliability of artificial intelligence (AI) systems in open-world settings depends heavily on their ability to flag out-of-distribution (OOD) inputs unseen during training. Recent advances in large-scale vision-language models (VLMs) have enabled promising few-shot OOD detection frameworks using only a handful of in-distribution (ID) samples. However, existing prompt learning-based OOD methods rely solely on softmax probabilities, overlooking the rich discriminative potential of the feature embeddings learned by VLMs trained on millions of samples. To address this limitation, we propose a novel context optimization (CoOp)-based framework that integrates subspace representation learning with prompt tuning. Our approach improves ID-OOD separability by projecting the ID features into a subspace spanned by prompt vectors, while projecting ID-irrelevant features into an orthogonal null space. To train such OOD detection framework, we design an easy-to-handle end-to-end learning criterion that ensures strong OOD detection performance as well as high ID classification accuracy. Experiments on real-world datasets showcase the effectiveness of our approach.
KM-GPT: An Automated Pipeline for Reconstructing Individual Patient Data from Kaplan-Meier Plots
arXiv:2509.18141v1 Announce Type: cross Abstract: Reconstructing individual patient data (IPD) from Kaplan-Meier (KM) plots provides valuable insights for evidence synthesis in clinical research. However, existing approaches often rely on manual digitization, which is error-prone and lacks scalability. To address these limitations, we develop KM-GPT, the first fully automated, AI-powered pipeline for reconstructing IPD directly from KM plots with high accuracy, robustness, and reproducibility. KM-GPT integrates advanced image preprocessing, multi-modal reasoning powered by GPT-5, and iterative reconstruction algorithms to generate high-quality IPD without manual input or intervention. Its hybrid reasoning architecture automates the conversion of unstructured information into structured data flows and validates data extraction from complex KM plots. To improve accessibility, KM-GPT is equipped with a user-friendly web interface and an integrated AI assistant, enabling researchers to reconstruct IPD without requiring programming expertise. KM-GPT was rigorously evaluated on synthetic and real-world datasets, consistently demonstrating superior accuracy. To illustrate its utility, we applied KM-GPT to a meta-analysis of gastric cancer immunotherapy trials, reconstructing IPD to facilitate evidence synthesis and biomarker-based subgroup analyses. By automating traditionally manual processes and providing a scalable, web-based solution, KM-GPT transforms clinical research by leveraging reconstructed IPD to enable more informed downstream analyses, supporting evidence-based decision-making.
MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe
arXiv:2509.18154v1 Announce Type: cross Abstract: Multimodal Large Language Models (MLLMs) are undergoing rapid progress and represent the frontier of AI development. However, their training and inference efficiency have emerged as a core bottleneck in making MLLMs more accessible and scalable. To address the challenges, we present MiniCPM-V 4.5, an 8B parameter model designed for high efficiency and strong performance. We introduce three core improvements in model architecture, data strategy and training method: a unified 3D-Resampler model architecture for highly compact encoding over images and videos, a unified learning paradigm for document knowledge and text recognition without heavy data engineering, and a hybrid reinforcement learning strategy for proficiency in both short and long reasoning modes. Comprehensive experimental results in OpenCompass evaluation show that MiniCPM-V 4.5 surpasses widely used proprietary models such as GPT-4o-latest, and significantly larger open-source models such as Qwen2.5-VL 72B. Notably, the strong performance is achieved with remarkable efficiency. For example, on the widely adopted VideoMME benchmark, MiniCPM-V 4.5 achieves state-of-the-art performance among models under 30B size, using just 46.7\% GPU memory cost and 8.7\% inference time of Qwen2.5-VL 7B.
Semantic-Aware Particle Filter for Reliable Vineyard Robot Localisation
arXiv:2509.18342v1 Announce Type: cross Abstract: Accurate localisation is critical for mobile robots in structured outdoor environments, yet LiDAR-based methods often fail in vineyards due to repetitive row geometry and perceptual aliasing. We propose a semantic particle filter that incorporates stable object-level detections, specifically vine trunks and support poles into the likelihood estimation process. Detected landmarks are projected into a birds eye view and fused with LiDAR scans to generate semantic observations. A key innovation is the use of semantic walls, which connect adjacent landmarks into pseudo-structural constraints that mitigate row aliasing. To maintain global consistency in headland regions where semantics are sparse, we introduce a noisy GPS prior that adaptively supports the filter. Experiments in a real vineyard demonstrate that our approach maintains localisation within the correct row, recovers from deviations where AMCL fails, and outperforms vision-based SLAM methods such as RTAB-Map.
Neural Network-Driven Direct CBCT-Based Dose Calculation for Head-and-Neck Proton Treatment Planning
arXiv:2509.18378v1 Announce Type: cross Abstract: Accurate dose calculation on cone beam computed tomography (CBCT) images is essential for modern proton treatment planning workflows, particularly when accounting for inter-fractional anatomical changes in adaptive treatment scenarios. Traditional CBCT-based dose calculation suffers from image quality limitations, requiring complex correction workflows. This study develops and validates a deep learning approach for direct proton dose calculation from CBCT images using extended Long Short-Term Memory (xLSTM) neural networks. A retrospective dataset of 40 head-and-neck cancer patients with paired planning CT and treatment CBCT images was used to train an xLSTM-based neural network (CBCT-NN). The architecture incorporates energy token encoding and beam's-eye-view sequence modelling to capture spatial dependencies in proton dose deposition patterns. Training utilized 82,500 paired beam configurations with Monte Carlo-generated ground truth doses. Validation was performed on 5 independent patients using gamma analysis, mean percentage dose error assessment, and dose-volume histogram comparison. The CBCT-NN achieved gamma pass rates of 95.1 $\pm$ 2.7% using 2mm/2% criteria. Mean percentage dose errors were 2.6 $\pm$ 1.4% in high-dose regions ($>$90% of max dose) and 5.9 $\pm$ 1.9% globally. Dose-volume histogram analysis showed excellent preservation of target coverage metrics (Clinical Target Volume V95% difference: -0.6 $\pm$ 1.1%) and organ-at-risk constraints (parotid mean dose difference: -0.5 $\pm$ 1.5%). Computation time is under 3 minutes without sacrificing Monte Carlo-level accuracy. This study demonstrates the proof-of-principle of direct CBCT-based proton dose calculation using xLSTM neural networks. The approach eliminates traditional correction workflows while achieving comparable accuracy and computational efficiency suitable for adaptive protocols.
Does Embodiment Matter to Biomechanics and Function? A Comparative Analysis of Head-Mounted and Hand-Held Assistive Devices for Individuals with Blindness and Low Vision
arXiv:2509.18391v1 Announce Type: cross Abstract: Visual assistive technologies, such as Microsoft Seeing AI, can improve access to environmental information for persons with blindness or low vision (pBLV). Yet, the physical and functional implications of different device embodiments remain unclear. In this study, 11 pBLV participants used Seeing AI on a hand-held smartphone and on a head-mounted ARx Vision system to perform six activities of daily living, while their movements were captured with Xsens motion capture. Functional outcomes included task time, success rate, and number of attempts, and biomechanical measures included joint range of motion, angular path length, working volume, and movement smoothness. The head-mounted system generally reduced upper-body movement and task time, especially for document-scanning style tasks, whereas the hand-held system yielded higher success rates for tasks involving small or curved text. These findings indicate that both embodiments are viable, but they differ in terms of physical demands and ease of use. Incorporating biomechanical measures into assistive technology evaluations can inform designs that optimise user experience by balancing functional efficiency, physical sustainability, and intuitive interaction.
Latent Action Pretraining Through World Modeling
arXiv:2509.18428v1 Announce Type: cross Abstract: Vision-Language-Action (VLA) models have gained popularity for learning robotic manipulation tasks that follow language instructions. State-of-the-art VLAs, such as OpenVLA and $\pi_{0}$, were trained on large-scale, manually labeled action datasets collected through teleoperation. More recent approaches, including LAPA and villa-X, introduce latent action representations that enable unsupervised pretraining on unlabeled datasets by modeling abstract visual changes between frames. Although these methods have shown strong results, their large model sizes make deployment in real-world settings challenging. In this work, we propose LAWM, a model-agnostic framework to pretrain imitation learning models in a self-supervised way, by learning latent action representations from unlabeled video data through world modeling. These videos can be sourced from robot recordings or videos of humans performing actions with everyday objects. Our framework is designed to be effective for transferring across tasks, environments, and embodiments. It outperforms models trained with ground-truth robotics actions and similar pretraining methods on the LIBERO benchmark and real-world setup, while being significantly more efficient and practical for real-world settings.
Zero-Shot Visual Deepfake Detection: Can AI Predict and Prevent Fake Content Before It's Created?
arXiv:2509.18461v1 Announce Type: cross Abstract: Generative adversarial networks (GANs) and diffusion models have dramatically advanced deepfake technology, and its threats to digital security, media integrity, and public trust have increased rapidly. This research explored zero-shot deepfake detection, an emerging method even when the models have never seen a particular deepfake variation. In this work, we studied self-supervised learning, transformer-based zero-shot classifier, generative model fingerprinting, and meta-learning techniques that better adapt to the ever-evolving deepfake threat. In addition, we suggested AI-driven prevention strategies that mitigated the underlying generation pipeline of the deepfakes before they occurred. They consisted of adversarial perturbations for creating deepfake generators, digital watermarking for content authenticity verification, real-time AI monitoring for content creation pipelines, and blockchain-based content verification frameworks. Despite these advancements, zero-shot detection and prevention faced critical challenges such as adversarial attacks, scalability constraints, ethical dilemmas, and the absence of standardized evaluation benchmarks. These limitations were addressed by discussing future research directions on explainable AI for deepfake detection, multimodal fusion based on image, audio, and text analysis, quantum AI for enhanced security, and federated learning for privacy-preserving deepfake detection. This further highlighted the need for an integrated defense framework for digital authenticity that utilized zero-shot learning in combination with preventive deepfake mechanisms. Finally, we highlighted the important role of interdisciplinary collaboration between AI researchers, cybersecurity experts, and policymakers to create resilient defenses against the rising tide of deepfake attacks.
Machine learning approach to single-shot multiparameter estimation for the non-linear Schr\"odinger equation
arXiv:2509.18479v1 Announce Type: cross Abstract: The nonlinear Schr\"odinger equation (NLSE) is a fundamental model for wave dynamics in nonlinear media ranging from optical fibers to Bose-Einstein condensates. Accurately estimating its parameters, which are often strongly correlated, from a single measurement remains a significant challenge. We address this problem by treating parameter estimation as an inverse problem and training a neural network to invert the NLSE mapping. We combine a fast numerical solver with a machine learning approach based on the ConvNeXt architecture and a multivariate Gaussian negative log-likelihood loss function. From single-shot field (density and phase) images, our model estimates three key parameters: the nonlinear coefficient $n_2$, the saturation intensity $I_{sat}$, and the linear absorption coefficient $\alpha$. Trained on 100,000 simulated images, the model achieves a mean absolute error of $3.22\%$ on 12,500 unseen test samples, demonstrating strong generalization and close agreement with ground-truth values. This approach provides an efficient route for characterizing nonlinear systems and has the potential to bridge theoretical modeling and experimental data when realistic noise is incorporated.
Differentiable Light Transport with Gaussian Surfels via Adapted Radiosity for Efficient Relighting and Geometry Reconstruction
arXiv:2509.18497v1 Announce Type: cross Abstract: Radiance fields have gained tremendous success with applications ranging from novel view synthesis to geometry reconstruction, especially with the advent of Gaussian splatting. However, they sacrifice modeling of material reflective properties and lighting conditions, leading to significant geometric ambiguities and the inability to easily perform relighting. One way to address these limitations is to incorporate physically-based rendering, but it has been prohibitively expensive to include full global illumination within the inner loop of the optimization. Therefore, previous works adopt simplifications that make the whole optimization with global illumination effects efficient but less accurate. In this work, we adopt Gaussian surfels as the primitives and build an efficient framework for differentiable light transport, inspired from the classic radiosity theory. The whole framework operates in the coefficient space of spherical harmonics, enabling both diffuse and specular materials. We extend the classic radiosity into non-binary visibility and semi-opaque primitives, propose novel solvers to efficiently solve the light transport, and derive the backward pass for gradient optimizations, which is more efficient than auto-differentiation. During inference, we achieve view-independent rendering where light transport need not be recomputed under viewpoint changes, enabling hundreds of FPS for global illumination effects, including view-dependent reflections using a spherical harmonics representation. Through extensive qualitative and quantitative experiments, we demonstrate superior geometry reconstruction, view synthesis and relighting than previous inverse rendering baselines, or data-driven baselines given relatively sparse datasets with known or unknown lighting conditions.
Dynamical Modeling of Behaviorally Relevant Spatiotemporal Patterns in Neural Imaging Data
arXiv:2509.18507v1 Announce Type: cross Abstract: High-dimensional imaging of neural activity, such as widefield calcium and functional ultrasound imaging, provide a rich source of information for understanding the relationship between brain activity and behavior. Accurately modeling neural dynamics in these modalities is crucial for understanding this relationship but is hindered by the high-dimensionality, complex spatiotemporal dependencies, and prevalent behaviorally irrelevant dynamics in these modalities. Existing dynamical models often employ preprocessing steps to obtain low-dimensional representations from neural image modalities. However, this process can discard behaviorally relevant information and miss spatiotemporal structure. We propose SBIND, a novel data-driven deep learning framework to model spatiotemporal dependencies in neural images and disentangle their behaviorally relevant dynamics from other neural dynamics. We validate SBIND on widefield imaging datasets, and show its extension to functional ultrasound imaging, a recent modality whose dynamical modeling has largely remained unexplored. We find that our model effectively identifies both local and long-range spatial dependencies across the brain while also dissociating behaviorally relevant neural dynamics. Doing so, SBIND outperforms existing models in neural-behavioral prediction. Overall, SBIND provides a versatile tool for investigating the neural mechanisms underlying behavior using imaging modalities.
Efficient Breast and Ovarian Cancer Classification via ViT-Based Preprocessing and Transfer Learning
arXiv:2509.18553v1 Announce Type: cross Abstract: Cancer is one of the leading health challenges for women, specifically breast and ovarian cancer. Early detection can help improve the survival rate through timely intervention and treatment. Traditional methods of detecting cancer involve manually examining mammograms, CT scans, ultrasounds, and other imaging types. However, this makes the process labor-intensive and requires the expertise of trained pathologists. Hence, making it both time-consuming and resource-intensive. In this paper, we introduce a novel vision transformer (ViT)-based method for detecting and classifying breast and ovarian cancer. We use a pre-trained ViT-Base-Patch16-224 model, which is fine-tuned for both binary and multi-class classification tasks using publicly available histopathological image datasets. Further, we use a preprocessing pipeline that converts raw histophological images into standardized PyTorch tensors, which are compatible with the ViT architecture and also help improve the model performance. We evaluated the performance of our model on two benchmark datasets: the BreakHis dataset for binary classification and the UBC-OCEAN dataset for five-class classification without any data augmentation. Our model surpasses existing CNN, ViT, and topological data analysis-based approaches in binary classification. For multi-class classification, it is evaluated against recent topological methods and demonstrates superior performance. Our study highlights the effectiveness of Vision Transformer-based transfer learning combined with efficient preprocessing in oncological diagnostics.
VLN-Zero: Rapid Exploration and Cache-Enabled Neurosymbolic Vision-Language Planning for Zero-Shot Transfer in Robot Navigation
arXiv:2509.18592v1 Announce Type: cross Abstract: Rapid adaptation in unseen environments is essential for scalable real-world autonomy, yet existing approaches rely on exhaustive exploration or rigid navigation policies that fail to generalize. We present VLN-Zero, a two-phase vision-language navigation framework that leverages vision-language models to efficiently construct symbolic scene graphs and enable zero-shot neurosymbolic navigation. In the exploration phase, structured prompts guide VLM-based search toward informative and diverse trajectories, yielding compact scene graph representations. In the deployment phase, a neurosymbolic planner reasons over the scene graph and environmental observations to generate executable plans, while a cache-enabled execution module accelerates adaptation by reusing previously computed task-location trajectories. By combining rapid exploration, symbolic reasoning, and cache-enabled execution, the proposed framework overcomes the computational inefficiency and poor generalization of prior vision-language navigation methods, enabling robust and scalable decision-making in unseen environments. VLN-Zero achieves 2x higher success rate compared to state-of-the-art zero-shot models, outperforms most fine-tuned baselines, and reaches goal locations in half the time with 55% fewer VLM calls on average compared to state-of-the-art models across diverse environments. Codebase, datasets, and videos for VLN-Zero are available at: https://vln-zero.github.io/.
Reconstruction of Optical Coherence Tomography Images from Wavelength-space Using Deep-learning
arXiv:2509.18783v1 Announce Type: cross Abstract: Conventional Fourier-domain Optical Coherence Tomography (FD-OCT) systems depend on resampling into wavenumber (k) domain to extract the depth profile. This either necessitates additional hardware resources or amplifies the existing computational complexity. Moreover, the OCT images also suffer from speckle noise, due to systemic reliance on low coherence interferometry. We propose a streamlined and computationally efficient approach based on Deep-Learning (DL) which enables reconstructing speckle-reduced OCT images directly from the wavelength domain. For reconstruction, two encoder-decoder styled networks namely Spatial Domain Convolution Neural Network (SD-CNN) and Fourier Domain CNN (FD-CNN) are used sequentially. The SD-CNN exploits the highly degraded images obtained by Fourier transforming the domain fringes to reconstruct the deteriorated morphological structures along with suppression of unwanted noise. The FD-CNN leverages this output to enhance the image quality further by optimization in Fourier domain (FD). We quantitatively and visually demonstrate the efficacy of the method in obtaining high-quality OCT images. Furthermore, we illustrate the computational complexity reduction by harnessing the power of DL models. We believe that this work lays the framework for further innovations in the realm of OCT image reconstruction.
Human-Interpretable Uncertainty Explanations for Point Cloud Registration
arXiv:2509.18786v1 Announce Type: cross Abstract: In this paper, we address the point cloud registration problem, where well-known methods like ICP fail under uncertainty arising from sensor noise, pose-estimation errors, and partial overlap due to occlusion. We develop a novel approach, Gaussian Process Concept Attribution (GP-CA), which not only quantifies registration uncertainty but also explains it by attributing uncertainty to well-known sources of errors in registration problems. Our approach leverages active learning to discover new uncertainty sources in the wild by querying informative instances. We validate GP-CA on three publicly available datasets and in our real-world robot experiment. Extensive ablations substantiate our design choices. Our approach outperforms other state-of-the-art methods in terms of runtime, high sample-efficiency with active learning, and high accuracy. Our real-world experiment clearly demonstrates its applicability. Our video also demonstrates that GP-CA enables effective failure-recovery behaviors, yielding more robust robotic perception.
DexSkin: High-Coverage Conformable Robotic Skin for Learning Contact-Rich Manipulation
arXiv:2509.18830v1 Announce Type: cross Abstract: Human skin provides a rich tactile sensing stream, localizing intentional and unintentional contact events over a large and contoured region. Replicating these tactile sensing capabilities for dexterous robotic manipulation systems remains a longstanding challenge. In this work, we take a step towards this goal by introducing DexSkin. DexSkin is a soft, conformable capacitive electronic skin that enables sensitive, localized, and calibratable tactile sensing, and can be tailored to varying geometries. We demonstrate its efficacy for learning downstream robotic manipulation by sensorizing a pair of parallel jaw gripper fingers, providing tactile coverage across almost the entire finger surfaces. We empirically evaluate DexSkin's capabilities in learning challenging manipulation tasks that require sensing coverage across the entire surface of the fingers, such as reorienting objects in hand and wrapping elastic bands around boxes, in a learning-from-demonstration framework. We then show that, critically for data-driven approaches, DexSkin can be calibrated to enable model transfer across sensor instances, and demonstrate its applicability to online reinforcement learning on real robots. Our results highlight DexSkin's suitability and practicality for learning real-world, contact-rich manipulation. Please see our project webpage for videos and visualizations: https://dex-skin.github.io/.
Text Slider: Efficient and Plug-and-Play Continuous Concept Control for Image/Video Synthesis via LoRA Adapters
arXiv:2509.18831v1 Announce Type: cross Abstract: Recent advances in diffusion models have significantly improved image and video synthesis. In addition, several concept control methods have been proposed to enable fine-grained, continuous, and flexible control over free-form text prompts. However, these methods not only require intensive training time and GPU memory usage to learn the sliders or embeddings but also need to be retrained for different diffusion backbones, limiting their scalability and adaptability. To address these limitations, we introduce Text Slider, a lightweight, efficient and plug-and-play framework that identifies low-rank directions within a pre-trained text encoder, enabling continuous control of visual concepts while significantly reducing training time, GPU memory consumption, and the number of trainable parameters. Furthermore, Text Slider supports multi-concept composition and continuous control, enabling fine-grained and flexible manipulation in both image and video synthesis. We show that Text Slider enables smooth and continuous modulation of specific attributes while preserving the original spatial layout and structure of the input. Text Slider achieves significantly better efficiency: 5$\times$ faster training than Concept Slider and 47$\times$ faster than Attribute Control, while reducing GPU memory usage by nearly 2$\times$ and 4$\times$, respectively.
Quantum Random Synthetic Skyrmion Texture Generation, a Qiskit Simulation
arXiv:2509.18947v1 Announce Type: cross Abstract: An integer winding, i.e., topological charge, is a characteristic of skyrmions, which are topologically nontrivial spin patterns in magnets. They emerge when smooth two-dimensional spin configurations are stabilized by conflicting interactions such as exchange, anisotropy, the Dzyaloshinskii-Moriya interaction, or geometric frustration. These nanoscale textures, which are typically a few to tens of nanometers in size, are strong 'particle-like' excitations because they are shielded by energy barriers connected to their topology. By exploiting their helicity, i.e., spin rotation angle or associated internal modes, as a two-level system, skyrmions can function as quantum bits or qubits. Two quantized helicity states of a nanometer-scale skyrmion encode the logical value states in a 'skyrmion qubit.' Interestingly, skyrmion qubits are topologically protected and macroscopic, i.e., they involve a large number of spins; however, external influences can still affect them. When the texture is tiny and disconnected, the helicity angle of the skyrmion becomes quantized. A qubit basis is made up of the lowest two energy eigenstates, i.e., symmetric or antisymmetric superpositions of opposite helicity, for example. Therefore, Skyrmion textures can provide valuable insights for different purposes. However, is it possible to synthetically generate skyrmion textures using quantum computing? This paper investigates the possibility and generates a few hundred different textures, producing sample comparisons from various types, which indicate a novel direction for skyrmion-based research based on quantum randomness and other criteria.
One-shot Embroidery Customization via Contrastive LoRA Modulation
arXiv:2509.18948v1 Announce Type: cross Abstract: Diffusion models have significantly advanced image manipulation techniques, and their ability to generate photorealistic images is beginning to transform retail workflows, particularly in presale visualization. Beyond artistic style transfer, the capability to perform fine-grained visual feature transfer is becoming increasingly important. Embroidery is a textile art form characterized by intricate interplay of diverse stitch patterns and material properties, which poses unique challenges for existing style transfer methods. To explore the customization for such fine-grained features, we propose a novel contrastive learning framework that disentangles fine-grained style and content features with a single reference image, building on the classic concept of image analogy. We first construct an image pair to define the target style, and then adopt a similarity metric based on the decoupled representations of pretrained diffusion models for style-content separation. Subsequently, we propose a two-stage contrastive LoRA modulation technique to capture fine-grained style features. In the first stage, we iteratively update the whole LoRA and the selected style blocks to initially separate style from content. In the second stage, we design a contrastive learning strategy to further decouple style and content through self-knowledge distillation. Finally, we build an inference pipeline to handle image or text inputs with only the style blocks. To evaluate our method on fine-grained style transfer, we build a benchmark for embroidery customization. Our approach surpasses prior methods on this task and further demonstrates strong generalization to three additional domains: artistic style transfer, sketch colorization, and appearance transfer.
Towards Robust LiDAR Localization: Deep Learning-based Uncertainty Estimation
arXiv:2509.18954v1 Announce Type: cross Abstract: LiDAR-based localization and SLAM often rely on iterative matching algorithms, particularly the Iterative Closest Point (ICP) algorithm, to align sensor data with pre-existing maps or previous scans. However, ICP is prone to errors in featureless environments and dynamic scenes, leading to inaccurate pose estimation. Accurately predicting the uncertainty associated with ICP is crucial for robust state estimation but remains challenging, as existing approaches often rely on handcrafted models or simplified assumptions. Moreover, a few deep learning-based methods for localizability estimation either depend on a pre-built map, which may not always be available, or provide a binary classification of localizable versus non-localizable, which fails to properly model uncertainty. In this work, we propose a data-driven framework that leverages deep learning to estimate the registration error covariance of ICP before matching, even in the absence of a reference map. By associating each LiDAR scan with a reliable 6-DoF error covariance estimate, our method enables seamless integration of ICP within Kalman filtering, enhancing localization accuracy and robustness. Extensive experiments on the KITTI dataset demonstrate the effectiveness of our approach, showing that it accurately predicts covariance and, when applied to localization using a pre-built map or SLAM, reduces localization errors and improves robustness.
Category-Level Object Shape and Pose Estimation in Less Than a Millisecond
arXiv:2509.18979v1 Announce Type: cross Abstract: Object shape and pose estimation is a foundational robotics problem, supporting tasks from manipulation to scene understanding and navigation. We present a fast local solver for shape and pose estimation which requires only category-level object priors and admits an efficient certificate of global optimality. Given an RGB-D image of an object, we use a learned front-end to detect sparse, category-level semantic keypoints on the target object. We represent the target object's unknown shape using a linear active shape model and pose a maximum a posteriori optimization problem to solve for position, orientation, and shape simultaneously. Expressed in unit quaternions, this problem admits first-order optimality conditions in the form of an eigenvalue problem with eigenvector nonlinearities. Our primary contribution is to solve this problem efficiently with self-consistent field iteration, which only requires computing a 4-by-4 matrix and finding its minimum eigenvalue-vector pair at each iterate. Solving a linear system for the corresponding Lagrange multipliers gives a simple global optimality certificate. One iteration of our solver runs in about 100 microseconds, enabling fast outlier rejection. We test our method on synthetic data and a variety of real-world settings, including two public datasets and a drone tracking scenario. Code is released at https://github.com/MIT-SPARK/Fast-ShapeAndPose.
Latent Danger Zone: Distilling Unified Attention for Cross-Architecture Black-box Attacks
arXiv:2509.19044v1 Announce Type: cross Abstract: Black-box adversarial attacks remain challenging due to limited access to model internals. Existing methods often depend on specific network architectures or require numerous queries, resulting in limited cross-architecture transferability and high query costs. To address these limitations, we propose JAD, a latent diffusion model framework for black-box adversarial attacks. JAD generates adversarial examples by leveraging a latent diffusion model guided by attention maps distilled from both a convolutional neural network (CNN) and a Vision Transformer (ViT) models. By focusing on image regions that are commonly sensitive across architectures, this approach crafts adversarial perturbations that transfer effectively between different model types. This joint attention distillation strategy enables JAD to be architecture-agnostic, achieving superior attack generalization across diverse models. Moreover, the generative nature of the diffusion framework yields high adversarial sample generation efficiency by reducing reliance on iterative queries. Experiments demonstrate that JAD offers improved attack generalization, generation efficiency, and cross-architecture transferability compared to existing methods, providing a promising and effective paradigm for black-box adversarial attacks.
FUNCanon: Learning Pose-Aware Action Primitives via Functional Object Canonicalization for Generalizable Robotic Manipulation
arXiv:2509.19102v1 Announce Type: cross Abstract: General-purpose robotic skills from end-to-end demonstrations often leads to task-specific policies that fail to generalize beyond the training distribution. Therefore, we introduce FunCanon, a framework that converts long-horizon manipulation tasks into sequences of action chunks, each defined by an actor, verb, and object. These chunks focus policy learning on the actions themselves, rather than isolated tasks, enabling compositionality and reuse. To make policies pose-aware and category-general, we perform functional object canonicalization for functional alignment and automatic manipulation trajectory transfer, mapping objects into shared functional frames using affordance cues from large vision language models. An object centric and action centric diffusion policy FuncDiffuser trained on this aligned data naturally respects object affordances and poses, simplifying learning and improving generalization ability. Experiments on simulated and real-world benchmarks demonstrate category-level generalization, cross-task behavior reuse, and robust sim2real deployment, showing that functional canonicalization provides a strong inductive bias for scalable imitation learning in complex manipulation domains. Details of the demo and supplemental material are available on our project website https://sites.google.com/view/funcanon.
MOIS-SAM2: Exemplar-based Segment Anything Model 2 for multilesion interactive segmentation of neurobromas in whole-body MRI
arXiv:2509.19277v1 Announce Type: cross Abstract: Background and Objectives: Neurofibromatosis type 1 is a genetic disorder characterized by the development of numerous neurofibromas (NFs) throughout the body. Whole-body MRI (WB-MRI) is the clinical standard for detection and longitudinal surveillance of NF tumor growth. Existing interactive segmentation methods fail to combine high lesion-wise precision with scalability to hundreds of lesions. This study proposes a novel interactive segmentation model tailored to this challenge. Methods: We introduce MOIS-SAM2, a multi-object interactive segmentation model that extends the state-of-the-art, transformer-based, promptable Segment Anything Model 2 (SAM2) with exemplar-based semantic propagation. MOIS-SAM2 was trained and evaluated on 119 WB-MRI scans from 84 NF1 patients acquired using T2-weighted fat-suppressed sequences. The dataset was split at the patient level into a training set and four test sets (one in-domain and three reflecting different domain shift scenarios, e.g., MRI field strength variation, low tumor burden, differences in clinical site and scanner vendor). Results: On the in-domain test set, MOIS-SAM2 achieved a scan-wise DSC of 0.60 against expert manual annotations, outperforming baseline 3D nnU-Net (DSC: 0.54) and SAM2 (DSC: 0.35). Performance of the proposed model was maintained under MRI field strength shift (DSC: 0.53) and scanner vendor variation (DSC: 0.50), and improved in low tumor burden cases (DSC: 0.61). Lesion detection F1 scores ranged from 0.62 to 0.78 across test sets. Preliminary inter-reader variability analysis showed model-to-expert agreement (DSC: 0.62-0.68), comparable to inter-expert agreement (DSC: 0.57-0.69). Conclusions: The proposed MOIS-SAM2 enables efficient and scalable interactive segmentation of NFs in WB-MRI with minimal user input and strong generalization, supporting integration into clinical workflows.
Evaluation Framework of Superpixel Methods with a Global Regularity Measure
arXiv:1903.07162v2 Announce Type: replace Abstract: In the superpixel literature, the comparison of state-of-the-art methods can be biased by the non-robustness of some metrics to decomposition aspects, such as the superpixel scale. Moreover, most recent decomposition methods allow to set a shape regularity parameter, which can have a substantial impact on the measured performances. In this paper, we introduce an evaluation framework, that aims to unify the comparison process of superpixel methods. We investigate the limitations of existing metrics, and propose to evaluate each of the three core decomposition aspects: color homogeneity, respect of image objects and shape regularity. To measure the regularity aspect, we propose a new global regularity measure (GR), which addresses the non-robustness of state-of-the-art metrics. We evaluate recent superpixel methods with these criteria, at several superpixel scales and regularity levels. The proposed framework reduces the bias in the comparison process of state-of-the-art superpixel methods. Finally, we demonstrate that the proposed GR measure is correlated with the performances of various applications.
ZoDIAC: Zoneout Dropout Injection Attention Calculation
arXiv:2206.14263v3 Announce Type: replace Abstract: In the past few years the transformer model has been utilized for a variety of tasks such as image captioning, image classification natural language generation, and natural language understanding. As a key component of the transformer model, self-attention calculates the attention values by mapping the relationships among the head elements of the source and target sequence, yet there is no explicit mechanism to refine and intensify the attention values with respect to the context of the input and target sequences. Based on this intuition, we introduce a novel refine and intensify attention mechanism that is called Zoneup Dropout Injection Attention Calculation (ZoDIAC), in which the intensities of attention values in the elements of the input source and target sequences are first refined using GELU and dropout and then intensified using a proposed zoneup process which includes the injection of a learned scalar factor. Our extensive experiments show that ZoDIAC achieves statistically significant higher scores under all image captioning metrics using various feature extractors in comparison to the conventional self-attention module in the transformer model on the MS-COCO dataset. Our proposed ZoDIAC attention modules can be used as a drop-in replacement for the attention components in all transformer models. The code for our experiments is publicly available at: https://github.com/zanyarz/zodiac
Improving Image Captioning Descriptiveness by Ranking and LLM-based Fusion
arXiv:2306.11593v2 Announce Type: replace Abstract: State-of-The-Art (SoTA) image captioning models are often trained on the MicroSoft Common Objects in Context (MS-COCO) dataset, which contains human-annotated captions with an average length of approximately ten tokens. Although effective for general scene understanding, these short captions often fail to capture complex scenes and convey detailed information. Moreover, captioning models tend to exhibit bias towards the ``average'' caption, which captures only the more general aspects, thus overlooking finer details. In this paper, we present a novel approach to generate richer and more informative image captions by combining the captions generated from different SoTA captioning models. Our proposed method requires no additional model training: given an image, it leverages pre-trained models from the literature to generate the initial captions, and then ranks them using a newly introduced image-text-based metric, which we name BLIPScore. Subsequently, the top two captions are fused using a Large Language Model (LLM) to produce the final, more detailed description. Experimental results on the MS-COCO and Flickr30k test sets demonstrate the effectiveness of our approach in terms of caption-image alignment and hallucination reduction according to the ALOHa, CAPTURE, and Polos metrics. A subjective study lends additional support to these results, suggesting that the captions produced by our model are generally perceived as more consistent with human judgment. By combining the strengths of diverse SoTA models, our method enhances the quality and appeal of image captions, bridging the gap between automated systems and the rich and informative nature of human-generated descriptions. This advance enables the generation of more suitable captions for the training of both vision-language and captioning models.
Fix your downsampling ASAP! Be natively more robust via Aliasing and Spectral Artifact free Pooling
arXiv:2307.09804v2 Announce Type: replace Abstract: Convolutional Neural Networks (CNNs) are successful in various computer vision tasks. From an image and signal processing point of view, this success is counter-intuitive, as the inherent spatial pyramid design of most CNNs is apparently violating basic signal processing laws, i.e. the Sampling Theorem in their downsampling operations. This issue has been broadly neglected until recent work in the context of adversarial attacks and distribution shifts showed that there is a strong correlation between the vulnerability of CNNs and aliasing artifacts induced by bandlimit-violating downsampling. As a remedy, we propose an alias-free downsampling operation in the frequency domain, denoted Frequency Low Cut Pooling (FLC Pooling) which we further extend to Aliasing and Sinc Artifact-free Pooling (ASAP). ASAP is alias-free and removes further artifacts from sinc-interpolation. Our experimental evaluation on ImageNet-1k, ImageNet-C and CIFAR datasets on various CNN architectures demonstrates that networks using FLC Pooling and ASAP as downsampling methods learn more stable features as measured by their robustness against common corruptions and adversarial attacks, while maintaining a clean accuracy similar to the respective baseline models.
Individualized Mapping of Aberrant Cortical Thickness via Stochastic Cortical Self-Reconstruction
arXiv:2403.06837v2 Announce Type: replace Abstract: Understanding individual differences in cortical structure is key to advancing diagnostics in neurology and psychiatry. Reference models aid in detecting aberrant cortical thickness, yet site-specific biases limit their direct application to unseen data, and region-wise averages prevent the detection of localized cortical changes. To address these limitations, we developed the Stochastic Cortical Self-Reconstruction (SCSR), a novel method that leverages deep learning to reconstruct cortical thickness maps at the vertex level without needing additional subject information. Trained on over 25,000 healthy individuals, SCSR generates highly individualized cortical reconstructions that can detect subtle thickness deviations. Our evaluations on independent test sets demonstrated that SCSR achieved significantly lower reconstruction errors and identified atrophy patterns that enabled better disease discrimination than established methods. It also hints at cortical thinning in preterm infants that went undetected by existing models, showcasing its versatility. Finally, SCSR excelled in mapping highly resolved cortical deviations of dementia patients from clinical data, highlighting its potential for supporting diagnosis in clinical practice.
MediSyn: A Generalist Text-Guided Latent Diffusion Model For Diverse Medical Image Synthesis
arXiv:2405.09806v5 Announce Type: replace Abstract: Deep learning algorithms require extensive data to achieve robust performance. However, data availability is often restricted in the medical domain due to patient privacy concerns. Synthetic data presents a possible solution to these challenges. Recently, image generative models have found increasing use for medical applications but are often designed for singular medical specialties and imaging modalities, thus limiting their broader utility. To address this, we introduce MediSyn: a text-guided, latent diffusion model capable of generating synthetic images from 6 medical specialties and 10 image types. Through extensive experimentation, we first demonstrate that MediSyn quantitatively matches or surpasses the performance of specialist models. Second, we show that our synthetic images are realistic and exhibit strong alignment with their corresponding text prompts, as validated by a team of expert physicians. Third, we provide empirical evidence that our synthetic images are visually distinct from their corresponding real patient images. Finally, we demonstrate that in data-limited settings, classifiers trained solely on synthetic data or real data supplemented with synthetic data can outperform those trained solely on real data. Our findings highlight the immense potential of generalist image generative models to accelerate algorithmic research and development in medicine.
REACT: Real-time Efficiency and Accuracy Compromise for Tradeoffs in Scene Graph Generation
arXiv:2405.16116v3 Announce Type: replace Abstract: Scene Graph Generation (SGG) is a task that encodes visual relationships between objects in images as graph structures. SGG shows significant promise as a foundational component for downstream tasks, such as reasoning for embodied agents. To enable real-time applications, SGG must address the trade-off between performance and inference speed. However, current methods tend to focus on one of the following: (1) improving relation prediction accuracy, (2) enhancing object detection accuracy, or (3) reducing latency, without aiming to balance all three objectives simultaneously. To address this limitation, we propose the Real-time Efficiency and Accuracy Compromise for Tradeoffs in Scene Graph Generation (REACT) architecture, which achieves the highest inference speed among existing SGG models, improving object detection accuracy without sacrificing relation prediction performance. Compared to state-of-the-art approaches, REACT is 2.7 times faster and improves object detection accuracy by 58\%. Furthermore, our proposal significantly reduces model size, with an average of 5.5x fewer parameters. The code is available at https://github.com/Maelic/SGG-Benchmark
Deep Spherical Superpixels
arXiv:2407.17354v2 Announce Type: replace Abstract: Over the years, the use of superpixel segmentation has become very popular in various applications, serving as a preprocessing step to reduce data size by adapting to the content of the image, regardless of its semantic content. While the superpixel segmentation of standard planar images, captured with a 90{\deg} field of view, has been extensively studied, there has been limited focus on dedicated methods to omnidirectional or spherical images, captured with a 360{\deg} field of view. In this study, we introduce the first deep learning-based superpixel segmentation approach tailored for omnidirectional images called DSS (for Deep Spherical Superpixels). Our methodology leverages on spherical CNN architectures and the differentiable K-means clustering paradigm for superpixels, to generate superpixels that follow the spherical geometry. Additionally, we propose to use data augmentation techniques specifically designed for 360{\deg} images, enabling our model to efficiently learn from a limited set of annotated omnidirectional data. Our extensive validation across two datasets demonstrates that taking into account the inherent circular geometry of such images into our framework improves the segmentation performance over traditional and deep learning-based superpixel methods. Our code is available online.
Your Turn: At Home Turning Angle Estimation for Parkinson's Disease Severity Assessment
arXiv:2408.08182v4 Announce Type: replace Abstract: People with Parkinson's Disease (PD) often experience progressively worsening gait, including changes in how they turn around, as the disease progresses. Existing clinical rating tools are not capable of capturing hour-by-hour variations of PD symptoms, as they are confined to brief assessments within clinic settings. Measuring gait turning angles continuously and passively is a component step towards using gait characteristics as sensitive indicators of disease progression in PD. This paper presents a deep learning-based approach to automatically quantify turning angles by extracting 3D skeletons from videos and calculating the rotation of hip and knee joints. We utilise state-of-the-art human pose estimation models, Fastpose and Strided Transformer, on a total of 1386 turning video clips from 24 subjects (12 people with PD and 12 healthy control volunteers), trimmed from a PD dataset of unscripted free-living videos in a home-like setting (Turn-REMAP). We also curate a turning video dataset, Turn-H3.6M, from the public Human3.6M human pose benchmark with 3D ground truth, to further validate our method. Previous gait research has primarily taken place in clinics or laboratories evaluating scripted gait outcomes, but this work focuses on free-living home settings where complexities exist, such as baggy clothing and poor lighting. Due to difficulties in obtaining accurate ground truth data in a free-living setting, we quantise the angle into the nearest bin $45^\circ$ based on the manual labelling of expert clinicians. Our method achieves a turning calculation accuracy of 41.6%, a Mean Absolute Error (MAE) of 34.7{\deg}, and a weighted precision WPrec of 68.3% for Turn-REMAP. This is the first work to explore the use of single monocular camera data to quantify turns by PD patients in a home setting.
Variational Bayes Gaussian Splatting
arXiv:2410.03592v2 Announce Type: replace Abstract: Recently, 3D Gaussian Splatting has emerged as a promising approach for modeling 3D scenes using mixtures of Gaussians. The predominant optimization method for these models relies on backpropagating gradients through a differentiable rendering pipeline, which struggles with catastrophic forgetting when dealing with continuous streams of data. To address this limitation, we propose Variational Bayes Gaussian Splatting (VBGS), a novel approach that frames training a Gaussian splat as variational inference over model parameters. By leveraging the conjugacy properties of multivariate Gaussians, we derive a closed-form variational update rule, allowing efficient updates from partial, sequential observations without the need for replay buffers. Our experiments show that VBGS not only matches state-of-the-art performance on static datasets, but also enables continual learning from sequentially streamed 2D and 3D data, drastically improving performance in this setting.
CrossEarth: Geospatial Vision Foundation Model for Domain Generalizable Remote Sensing Semantic Segmentation
arXiv:2410.22629v3 Announce Type: replace Abstract: The field of Remote Sensing Domain Generalization (RSDG) has emerged as a critical and valuable research frontier, focusing on developing models that generalize effectively across diverse scenarios. Despite the substantial domain gaps in RS images that are characterized by variabilities such as location, wavelength, and sensor type, research in this area remains underexplored: (1) Current cross-domain methods primarily focus on Domain Adaptation (DA), which adapts models to predefined domains rather than to unseen ones; (2) Few studies targeting the RSDG issue, especially for semantic segmentation tasks, where existing models are developed for specific unknown domains, struggling with issues of underfitting on other unknown scenarios; (3) Existing RS foundation models tend to prioritize in-domain performance over cross-domain generalization. To this end, we introduce the first vision foundation model for RSDG semantic segmentation, CrossEarth. CrossEarth demonstrates strong cross-domain generalization through a specially designed data-level Earth-Style Injection pipeline and a model-level Multi-Task Training pipeline. In addition, for the semantic segmentation task, we have curated an RSDG benchmark comprising 32 cross-domain settings across various regions, spectral bands, platforms, and climates, providing a comprehensive framework for testing the generalizability of future RSDG models. Extensive experiments on this benchmark demonstrate the superiority of CrossEarth over existing state-of-the-art methods.
EMMA: End-to-End Multimodal Model for Autonomous Driving
arXiv:2410.23262v3 Announce Type: replace Abstract: We introduce EMMA, an End-to-end Multimodal Model for Autonomous driving. Built upon a multi-modal large language model foundation like Gemini, EMMA directly maps raw camera sensor data into various driving-specific outputs, including planner trajectories, perception objects, and road graph elements. EMMA maximizes the utility of world knowledge from the pre-trained large language models, by representing all non-sensor inputs (e.g. navigation instructions and ego vehicle status) and outputs (e.g. trajectories and 3D locations) as natural language text. This approach allows EMMA to jointly process various driving tasks in a unified language space, and generate the outputs for each task using task-specific prompts. Empirically, we demonstrate EMMA's effectiveness by achieving state-of-the-art performance in motion planning on nuScenes as well as competitive results on the Waymo Open Motion Dataset (WOMD). EMMA also yields competitive results for camera-primary 3D object detection on the Waymo Open Dataset (WOD). We show that co-training EMMA with planner trajectories, object detection, and road graph tasks yields improvements across all three domains, highlighting EMMA's potential as a generalist model for autonomous driving applications. We hope that our results will inspire research to further evolve the state of the art in autonomous driving model architectures.
Superpixel Segmentation: A Long-Lasting Ill-Posed Problem
arXiv:2411.06478v2 Announce Type: replace Abstract: For many years, image over-segmentation into superpixels has been essential to computer vision pipelines, by creating homogeneous and identifiable regions of similar sizes. Such constrained segmentation problem would require a clear definition and specific evaluation criteria. However, the validation framework for superpixel methods, typically viewed as standard object segmentation, has rarely been thoroughly studied. In this work, we first take a step back to show that superpixel segmentation is fundamentally an ill-posed problem, due to the implicit regularity constraint on the shape and size of superpixels. We also demonstrate through a novel comprehensive study that the literature suffers from only evaluating certain aspects, sometimes incorrectly and with inappropriate metrics. Concurrently, recent deep learning-based superpixel methods mainly focus on the object segmentation task at the expense of regularity. In this ill-posed context, we show that we can achieve competitive results using a recent architecture like the Segment Anything Model (SAM), without dedicated training for the superpixel segmentation task. This leads to rethinking superpixel segmentation and the necessary properties depending on the targeted downstream task.
SparseDiT: Token Sparsification for Efficient Diffusion Transformer
arXiv:2412.06028v2 Announce Type: replace Abstract: Diffusion Transformers (DiT) are renowned for their impressive generative performance; however, they are significantly constrained by considerable computational costs due to the quadratic complexity in self-attention and the extensive sampling steps required. While advancements have been made in expediting the sampling process, the underlying architectural inefficiencies within DiT remain underexplored. We introduce SparseDiT, a novel framework that implements token sparsification across spatial and temporal dimensions to enhance computational efficiency while preserving generative quality. Spatially, SparseDiT employs a tri-segment architecture that allocates token density based on feature requirements at each layer: Poolingformer in the bottom layers for efficient global feature extraction, Sparse-Dense Token Modules (SDTM) in the middle layers to balance global context with local detail, and dense tokens in the top layers to refine high-frequency details. Temporally, SparseDiT dynamically modulates token density across denoising stages, progressively increasing token count as finer details emerge in later timesteps. This synergy between SparseDiT spatially adaptive architecture and its temporal pruning strategy enables a unified framework that balances efficiency and fidelity throughout the generation process. Our experiments demonstrate SparseDiT effectiveness, achieving a 55% reduction in FLOPs and a 175% improvement in inference speed on DiT-XL with similar FID score on 512x512 ImageNet, a 56% reduction in FLOPs across video generation datasets, and a 69% improvement in inference speed on PixArt-$\alpha$ on text-to-image generation task with a 0.24 FID score decrease. SparseDiT provides a scalable solution for high-quality diffusion-based generation compatible with sampling optimization techniques.
Token Preference Optimization with Self-Calibrated Visual-Anchored Rewards for Hallucination Mitigation
arXiv:2412.14487v4 Announce Type: replace Abstract: Direct Preference Optimization (DPO) has been demonstrated to be highly effective in mitigating hallucinations in Large Vision Language Models (LVLMs) by aligning their outputs more closely with human preferences. Despite the recent progress, existing methods suffer from two drawbacks: 1) Lack of scalable token-level rewards; and 2) Neglect of visual-anchored tokens. To this end, we propose a novel Token Preference Optimization model with self-calibrated rewards (dubbed as TPO), which adaptively attends to visual-correlated tokens without fine-grained annotations. Specifically, we introduce a token-level \emph{visual-anchored} \emph{reward} as the difference of the logistic distributions of generated tokens conditioned on the raw image and the corrupted one. In addition, to highlight the informative visual-anchored tokens, a visual-aware training objective is proposed to enhance more accurate token-level optimization. Extensive experimental results have manifested the state-of-the-art performance of the proposed TPO. For example, by building on top of LLAVA-1.5-7B, our TPO boosts the performance absolute improvement for hallucination benchmarks.
Injecting Explainability and Lightweight Design into Weakly Supervised Video Anomaly Detection Systems
arXiv:2412.20201v2 Announce Type: replace Abstract: Weakly Supervised Monitoring Anomaly Detection (WSMAD) utilizes weak supervision learning to identify anomalies, a critical task for smart city monitoring. However, existing multimodal approaches often fail to meet the real-time and interpretability requirements of edge devices due to their complexity. This paper presents TCVADS (Two-stage Cross-modal Video Anomaly Detection System), which leverages knowledge distillation and cross-modal contrastive learning to enable efficient, accurate, and interpretable anomaly detection on edge devices.TCVADS operates in two stages: coarse-grained rapid classification and fine-grained detailed analysis. In the first stage, TCVADS extracts features from video frames and inputs them into a time series analysis module, which acts as the teacher model. Insights are then transferred via knowledge distillation to a simplified convolutional network (student model) for binary classification. Upon detecting an anomaly, the second stage is triggered, employing a fine-grained multi-class classification model. This stage uses CLIP for cross-modal contrastive learning with text and images, enhancing interpretability and achieving refined classification through specially designed triplet textual relationships. Experimental results demonstrate that TCVADS significantly outperforms existing methods in model performance, detection efficiency, and interpretability, offering valuable contributions to smart city monitoring applications.
Large Vision-Language Model Alignment and Misalignment: A Survey Through the Lens of Explainability
arXiv:2501.01346v3 Announce Type: replace Abstract: Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in processing both visual and textual information. However, the critical challenge of alignment between visual and textual representations is not fully understood. This survey presents a comprehensive examination of alignment and misalignment in LVLMs through an explainability lens. We first examine the fundamentals of alignment, exploring its representational and behavioral aspects, training methodologies, and theoretical foundations. We then analyze misalignment phenomena across three semantic levels: object, attribute, and relational misalignment. Our investigation reveals that misalignment emerges from challenges at multiple levels: the data level, the model level, and the inference level. We provide a comprehensive review of existing mitigation strategies, categorizing them into parameter-frozen and parameter-tuning approaches. Finally, we outline promising future research directions, emphasizing the need for standardized evaluation protocols and in-depth explainability studies.
EventVL: Understand Event Streams via Multimodal Large Language Model
arXiv:2501.13707v2 Announce Type: replace Abstract: The event-based Vision-Language Model (VLM) recently has made good progress for practical vision tasks. However, most of these works just utilize CLIP for focusing on traditional perception tasks, which obstruct model understanding explicitly the sufficient semantics and context from event streams. To address the deficiency, we propose EventVL, the first generative event-based MLLM (Multimodal Large Language Model) framework for explicit semantic understanding. Specifically, to bridge the data gap for connecting different modalities semantics, we first annotate a large event-image/video-text dataset, containing almost 1.4 million high-quality pairs of data, which enables effective learning across various scenes, e.g., drive scene or human motion. After that, we design Event Spatiotemporal Representation to fully explore the comprehensive information by diversely aggregating and segmenting the event stream. To further promote a compact semantic space, Dynamic Semantic Alignment is introduced to improve and complete sparse semantic spaces of events. Extensive experiments show that our EventVL can significantly surpass existing MLLM baselines in event captioning and scene description generation tasks. We hope our research could contribute to the development of the event vision community.
Without Paired Labeled Data: End-to-End Self-Supervised Learning for Drone-view Geo-Localization
arXiv:2502.11381v4 Announce Type: replace Abstract: Drone-view Geo-Localization (DVGL) aims to achieve accurate localization of drones by retrieving the most relevant GPS-tagged satellite images. However, most existing methods heavily rely on strictly pre-paired drone-satellite images for supervised learning. When the target region shifts, new paired samples are typically required to adapt to the distribution changes. The high cost of annotation and the limited transferability of these methods significantly hinder the practical deployment of DVGL in open-world scenarios. To address these limitations, we propose a novel end-to-end self-supervised learning method with a shallow backbone network, called the dynamic memory-driven and neighborhood information learning (DMNIL) method. It employs a clustering algorithm to generate pseudo-labels and adopts a dual-path contrastive learning framework to learn discriminative intra-view representations. Furthermore, DMNIL incorporates two core modules, including the dynamic hierarchical memory learning (DHML) module and the information consistency evolution learning (ICEL) module. The DHML module combines short-term and long-term memory to enhance intra-view feature consistency and discriminability. Meanwhile, the ICEL module utilizes a neighborhood-driven dynamic constraint mechanism to systematically capture implicit cross-view semantic correlations, consequently improving cross-view feature alignment. To further stabilize and strengthen the self-supervised training process, a pseudo-label enhancement strategy is introduced to enhance the quality of pseudo supervision. Extensive experiments on three public benchmark datasets demonstrate that the proposed method consistently outperforms existing self-supervised methods and even surpasses several state-of-the-art supervised methods. Our code is available at https://github.com/ISChenawei/DMNIL.
JL1-CD: A New Benchmark for Remote Sensing Change Detection and a Robust Multi-Teacher Knowledge Distillation Framework
arXiv:2502.13407v4 Announce Type: replace Abstract: Change detection (CD) in remote sensing images plays a vital role in Earth observation. However, the scarcity of high-resolution, comprehensive open-source datasets and the difficulty in achieving robust performance across varying change types remain major challenges. To address these issues, we introduce JL1-CD, a large-scale, sub-meter CD dataset consisting of 5,000 image pairs. We further propose a novel Origin-Partition (O-P) strategy and integrate it into a Multi-Teacher Knowledge Distillation (MTKD) framework to enhance CD performance. The O-P strategy partitions the training set by Change Area Ratio (CAR) and trains specialized teacher models on each subset. The MTKD framework then distills complementary knowledge from these teachers into a single student model, enabling improved detection results across diverse CAR scenarios without additional inference cost. Our MTKD approach demonstrated strong performance in the 2024 ``Jilin-1'' Cup challenge, ranking first in the preliminary and second in the final rounds. Extensive experiments on the JL1-CD and SYSU-CD datasets show that the MTKD framework consistently improves the performance of CD models with various network architectures and parameter sizes, establishing new state-of-the-art results. Code and dataset are available at https://github.com/circleLZY/MTKD-CD.
SCoT: Straight Consistent Trajectory for Pre-Trained Diffusion Model Distillations
arXiv:2502.16972v3 Announce Type: replace Abstract: Pre-trained diffusion models are commonly used to generate clean data (e.g., images) from random noises, effectively forming pairs of noises and corresponding clean images. Distillation on these pre-trained models can be viewed as the process of constructing advanced trajectories within the pair to accelerate sampling. For instance, consistency model distillation develops consistent projection functions to regulate trajectories, although sampling efficiency remains a concern. Rectified flow method enforces straight trajectories to enable faster sampling, yet relies on numerical ODE solvers, which may introduce approximation errors. In this work, we bridge the gap between the consistency model and the rectified flow method by proposing a Straight Consistent Trajectory~(SCoT) model. SCoT enjoys the benefits of both approaches for fast sampling, producing trajectories with consistent and straight properties simultaneously. These dual properties are strategically balanced by targeting two critical objectives: (1) regulating the gradient of SCoT's mapping to a constant, (2) ensuring trajectory consistency. Extensive experimental results demonstrate the effectiveness and efficiency of SCoT.
HDM: Hybrid Diffusion Model for Unified Image Anomaly Detection
arXiv:2502.19200v2 Announce Type: replace Abstract: Image anomaly detection plays a vital role in applications such as industrial quality inspection and medical imaging, where it directly contributes to improving product quality and system reliability. However, existing methods often struggle with complex and diverse anomaly patterns. In particular, the separation between generation and discrimination tasks limits the effective coordination between anomaly sample generation and anomaly region detection. To address these challenges, we propose a novel hybrid diffusion model (HDM) that integrates generation and discrimination into a unified framework. The model consists of three key modules: the Diffusion Anomaly Generation Module (DAGM), the Diffusion Discriminative Module (DDM), and the Probability Optimization Module (POM). DAGM generates realistic and diverse anomaly samples, improving their representativeness. DDM then applies a reverse diffusion process to capture the differences between generated and normal samples, enabling precise anomaly region detection and localization based on probability distributions. POM refines the probability distributions during both the generation and discrimination phases, ensuring high-quality samples are used for training. Extensive experiments on multiple industrial image datasets demonstrate that our method outperforms state-of-the-art approaches, significantly improving both image-level and pixel-level anomaly detection performance, as measured by AUROC.
Leveraging Large Models to Evaluate Novel Content: A Case Study on Advertisement Creativity
arXiv:2503.00046v2 Announce Type: replace Abstract: Evaluating creativity is challenging, even for humans, not only because of its subjectivity but also because it involves complex cognitive processes. Inspired by work in marketing, we attempt to break down visual advertisement creativity into atypicality and originality. With fine-grained human annotations on these dimensions, we propose a suite of tasks specifically for such a subjective problem. We also evaluate the alignment between state-of-the-art (SoTA) vision language models (VLMs) and humans on our proposed benchmark, demonstrating both the promises and challenges of using VLMs for automatic creativity assessment.
STORM: Token-Efficient Long Video Understanding for Multimodal LLMs
arXiv:2503.04130v4 Announce Type: replace Abstract: Recent advances in video-based multimodal large language models (Video-LLMs) have significantly improved video understanding by processing videos as sequences of image frames. However, many existing methods treat frames independently in the vision backbone, lacking explicit temporal modeling, which limits their ability to capture dynamic patterns and efficiently handle long videos. To address these limitations, we introduce STORM (Spatiotemporal TOken Reduction for Multimodal LLMs), a novel architecture incorporating a dedicated temporal encoder between the image encoder and the LLM. Our temporal encoder leverages the Mamba State Space Model to integrate temporal information into image tokens, generating enriched representations that preserve inter-frame dynamics across the entire video sequence. This enriched encoding not only enhances video reasoning capabilities but also enables effective token reduction strategies, including test-time sampling and training-based temporal and spatial pooling, substantially reducing computational demands on the LLM without sacrificing key temporal information. By integrating these techniques, our approach simultaneously reduces training and inference latency while improving performance, enabling efficient and robust video understanding over extended temporal contexts. Extensive evaluations show that STORM achieves state-of-the-art results across various long video understanding benchmarks (more than 5% improvement on MLVU and LongVideoBench) while reducing the computation costs by up to $8\times$ and the decoding latency by 2.4-2.9$\times$ for the fixed numbers of input frames. Project page is available at https://research.nvidia.com/labs/lpr/storm
Latent Beam Diffusion Models for Generating Visual Sequences
arXiv:2503.20429v3 Announce Type: replace Abstract: While diffusion models excel at generating high-quality images from text prompts, they struggle with visual consistency when generating image sequences. Existing methods generate each image independently, leading to disjointed narratives - a challenge further exacerbated in non-linear storytelling, where scenes must connect beyond adjacent images. We introduce a novel beam search strategy for latent space exploration, enabling conditional generation of full image sequences with beam search decoding. In contrast to earlier methods that rely on fixed latent priors, our method dynamically samples past latents to search for an optimal sequence of latent representations, ensuring coherent visual transitions. As the latent denoising space is explored, the beam search graph is pruned with a cross-attention mechanism that efficiently scores search paths, prioritizing alignment with both textual prompts and visual context. Human and automatic evaluations confirm that BeamDiffusion outperforms other baseline methods, producing full sequences with superior coherence, visual continuity, and textual alignment.
Visual Chronicles: Using Multimodal LLMs to Analyze Massive Collections of Images
arXiv:2504.08727v3 Announce Type: replace Abstract: We present a system using Multimodal LLMs (MLLMs) to analyze a large database with tens of millions of images captured at different times, with the aim of discovering patterns in temporal changes. Specifically, we aim to capture frequent co-occurring changes ("trends") across a city over a certain period. Unlike previous visual analyses, our analysis answers open-ended queries (e.g., "what are the frequent types of changes in the city?") without any predetermined target subjects or training labels. These properties cast prior learning-based or unsupervised visual analysis tools unsuitable. We identify MLLMs as a novel tool for their open-ended semantic understanding capabilities. Yet, our datasets are four orders of magnitude too large for an MLLM to ingest as context. So we introduce a bottom-up procedure that decomposes the massive visual analysis problem into more tractable sub-problems. We carefully design MLLM-based solutions to each sub-problem. During experiments and ablation studies with our system, we find it significantly outperforms baselines and is able to discover interesting trends from images captured in large cities (e.g., "addition of outdoor dining,", "overpass was painted blue," etc.). See more results and interactive demos at https://boyangdeng.com/visual-chronicles.
SpinMeRound: Consistent Multi-View Identity Generation Using Diffusion Models
arXiv:2504.10716v2 Announce Type: replace Abstract: Despite recent progress in diffusion models, generating realistic head portraits from novel viewpoints remains a significant challenge. Most current approaches are constrained to limited angular ranges, predominantly focusing on frontal or near-frontal views. Moreover, although the recent emerging large-scale diffusion models have been proven robust in handling 3D scenes, they underperform on facial data, given their complex structure and the uncanny valley pitfalls. In this paper, we propose SpinMeRound, a diffusion-based approach designed to generate consistent and accurate head portraits from novel viewpoints. By leveraging a number of input views alongside an identity embedding, our method effectively synthesizes diverse viewpoints of a subject whilst robustly maintaining its unique identity features. Through experimentation, we showcase our model's generation capabilities in 360 head synthesis, while beating current state-of-the-art multiview diffusion models.
A Decade of Wheat Mapping for Lebanon
arXiv:2504.11366v4 Announce Type: replace Abstract: Wheat accounts for approximately 20% of the world's caloric intake, making it a vital component of global food security. Given this importance, mapping wheat fields plays a crucial role in enabling various stakeholders, including policy makers, researchers, and agricultural organizations, to make informed decisions regarding food security, supply chain management, and resource allocation. In this paper, we tackle the problem of accurately mapping wheat fields out of satellite images by introducing an improved pipeline for winter wheat segmentation, as well as presenting a case study on a decade-long analysis of wheat mapping in Lebanon. We integrate a Temporal Spatial Vision Transformer (TSViT) with Parameter-Efficient Fine Tuning (PEFT) and a novel post-processing pipeline based on the Fields of The World (FTW) framework. Our proposed pipeline addresses key challenges encountered in existing approaches, such as the clustering of small agricultural parcels in a single large field. By merging wheat segmentation with precise field boundary extraction, our method produces geometrically coherent and semantically rich maps that enable us to perform in-depth analysis such as tracking crop rotation pattern over years. Extensive evaluations demonstrate improved boundary delineation and field-level precision, establishing the potential of the proposed framework in operational agricultural monitoring and historical trend analysis. By allowing for accurate mapping of wheat fields, this work lays the foundation for a range of critical studies and future advances, including crop monitoring and yield estimation.
In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer
arXiv:2504.20690v3 Announce Type: replace Abstract: Instruction-based image editing enables precise modifications via natural language prompts, but existing methods face a precision-efficiency tradeoff: fine-tuning demands massive datasets (>10M) and computational resources, while training-free approaches suffer from weak instruction comprehension. We address this by proposing ICEdit, which leverages the inherent comprehension and generation abilities of large-scale Diffusion Transformers (DiTs) through three key innovations: (1) An in-context editing paradigm without architectural modifications; (2) Minimal parameter-efficient fine-tuning for quality improvement; (3) Early Filter Inference-Time Scaling, which uses VLMs to select high-quality noise samples for efficiency. Experiments show that ICEdit achieves state-of-the-art editing performance with only 0.1\% of the training data and 1\% trainable parameters compared to previous methods. Our approach establishes a new paradigm for balancing precision and efficiency in instructional image editing. Codes and demos can be found in https://river-zhang.github.io/ICEdit-gh-pages/.
PainFormer: a Vision Foundation Model for Automatic Pain Assessment
arXiv:2505.01571v5 Announce Type: replace Abstract: Pain is a manifold condition that impacts a significant percentage of the population. Accurate and reliable pain evaluation for the people suffering is crucial to developing effective and advanced pain management protocols. Automatic pain assessment systems provide continuous monitoring and support decision-making processes, ultimately aiming to alleviate distress and prevent functionality decline. This study introduces PainFormer, a vision foundation model based on multi-task learning principles trained simultaneously on 14 tasks/datasets with a total of 10.9 million samples. Functioning as an embedding extractor for various input modalities, the foundation model provides feature representations to the Embedding-Mixer, a transformer-based module that performs the final pain assessment. Extensive experiments employing behavioral modalities - including RGB, synthetic thermal, and estimated depth videos - and physiological modalities such as ECG, EMG, GSR, and fNIRS revealed that PainFormer effectively extracts high-quality embeddings from diverse input modalities. The proposed framework is evaluated on two pain datasets, BioVid and AI4Pain, and directly compared to 75 different methodologies documented in the literature. Experiments conducted in unimodal and multimodal settings demonstrate state-of-the-art performances across modalities and pave the way toward general-purpose models for automatic pain assessment. The foundation model's architecture (code) and weights are available at: https://github.com/GkikasStefanos/PainFormer.
Split Matching for Inductive Zero-shot Semantic Segmentation
arXiv:2505.05023v3 Announce Type: replace Abstract: Zero-shot Semantic Segmentation (ZSS) aims to segment categories that are not annotated during training. While fine-tuning vision-language models has achieved promising results, these models often overfit to seen categories due to the lack of supervision for unseen classes. As an alternative to fully supervised approaches, query-based segmentation has shown great latent in ZSS, as it enables object localization without relying on explicit labels. However, conventional Hungarian matching, a core component in query-based frameworks, needs full supervision and often misclassifies unseen categories as background in the setting of ZSS. To address this issue, we propose Split Matching (SM), a novel assignment strategy that decouples Hungarian matching into two components: one for seen classes in annotated regions and another for latent classes in unannotated regions (referred to as unseen candidates). Specifically, we partition the queries into seen and candidate groups, enabling each to be optimized independently according to its available supervision. To discover unseen candidates, we cluster CLIP dense features to generate pseudo masks and extract region-level embeddings using CLS tokens. Matching is then conducted separately for the two groups based on both class-level similarity and mask-level consistency. Additionally, we introduce a Multi-scale Feature Enhancement (MFE) module that refines decoder features through residual multi-scale aggregation, improving the model's ability to capture spatial details across resolutions. SM is the first to introduce decoupled Hungarian matching under the inductive ZSS setting, and achieves state-of-the-art performance on two standard benchmarks.
InstanceBEV: Unifying Instance and BEV Representation for 3D Panoptic Segmentation
arXiv:2505.13817v2 Announce Type: replace Abstract: BEV-based 3D perception has emerged as a focal point of research in end-to-end autonomous driving. However, existing BEV approaches encounter significant challenges due to the large feature space, complicating efficient modeling and hindering effective integration of global attention mechanisms. We propose a novel modeling strategy, called InstanceBEV, that synergistically combines the strengths of both map-centric approaches and object-centric approaches. Our method effectively extracts instance-level features within the BEV features, facilitating the implementation of global attention modeling in a highly compressed feature space, thereby addressing the efficiency challenges inherent in map-centric global modeling. Furthermore, our approach enables effective multi-task learning without introducing additional module. We validate the efficiency and accuracy of the proposed model through predicting occupancy, achieving 3D occupancy panoptic segmentation by combining instance information. Experimental results on the OCC3D-nuScenes dataset demonstrate that InstanceBEV, utilizing only 8 frames, achieves a RayPQ of 15.3 and a RayIoU of 38.2. This surpasses SparseOcc's RayPQ by 9.3% and RayIoU by 10.7%, showcasing the effectiveness of multi-task synergy.
Mitigating Hallucination in Large Vision-Language Models through Aligning Attention Distribution to Information Flow
arXiv:2505.14257v3 Announce Type: replace Abstract: Due to the unidirectional masking mechanism, Decoder-Only models propagate information from left to right. LVLMs (Large Vision-Language Models) follow the same architecture, with visual information gradually integrated into semantic representations during forward propagation. Through systematic analysis, we observe that the majority of the visual information is absorbed into the semantic representations. However, the model's attention distribution does not exhibit sufficient emphasis on semantic representations. This misalignment between the attention distribution and the actual information flow undermines the model's visual understanding ability and contributes to hallucinations. To address this issue, we enhance the model's visual understanding by leveraging the core information embedded in semantic representations. Specifically, we identify attention heads that focus on core semantic representations based on their attention distributions. Then, through a two-stage optimization paradigm, we propagate the advantages of these attention heads across the entire model, aligning the attention distribution with the actual information flow. We evaluate our method on three image captioning benchmarks using five different LVLMs, demonstrating its effectiveness in significantly reducing hallucinations. Further experiments reveal a trade-off between reduced hallucinations and richer details. Notably, our method allows for manual adjustment of the model's conservativeness, enabling flexible control to meet diverse real-world requirements.
Dual Data Alignment Makes AI-Generated Image Detector Easier Generalizable
arXiv:2505.14359v5 Announce Type: replace Abstract: Existing detectors are often trained on biased datasets, leading to the possibility of overfitting on non-causal image attributes that are spuriously correlated with real/synthetic labels. While these biased features enhance performance on the training data, they result in substantial performance degradation when applied to unbiased datasets. One common solution is to perform dataset alignment through generative reconstruction, matching the semantic content between real and synthetic images. However, we revisit this approach and show that pixel-level alignment alone is insufficient. The reconstructed images still suffer from frequency-level misalignment, which can perpetuate spurious correlations. To illustrate, we observe that reconstruction models tend to restore the high-frequency details lost in real images (possibly due to JPEG compression), inadvertently creating a frequency-level misalignment, where synthetic images appear to have richer high-frequency content than real ones. This misalignment leads to models associating high-frequency features with synthetic labels, further reinforcing biased cues. To resolve this, we propose Dual Data Alignment (DDA), which aligns both the pixel and frequency domains. Moreover, we introduce two new test sets: DDA-COCO, containing DDA-aligned synthetic images for testing detector performance on the most aligned dataset, and EvalGEN, featuring the latest generative models for assessing detectors under new generative architectures such as visual auto-regressive generators. Finally, our extensive evaluations demonstrate that a detector trained exclusively on DDA-aligned MSCOCO could improve across 8 diverse benchmarks by a non-trivial margin, showing a +7.2% on in-the-wild benchmarks, highlighting the improved generalizability of unbiased detectors. Our code is available at: https://github.com/roy-ch/Dual-Data-Alignment.
AvatarShield: Visual Reinforcement Learning for Human-Centric Synthetic Video Detection
arXiv:2505.15173v3 Announce Type: replace Abstract: Recent advances in Artificial Intelligence Generated Content have led to highly realistic synthetic videos, particularly in human-centric scenarios involving speech, gestures, and full-body motion, posing serious threats to information authenticity and public trust. Unlike DeepFake techniques that focus on localized facial manipulation, human-centric video generation methods can synthesize entire human bodies with controllable movements, enabling complex interactions with environments, objects, and even other people. However, existing detection methods largely overlook the growing risks posed by such full-body synthetic content. Meanwhile, a growing body of research has explored leveraging LLMs for interpretable fake detection, aiming to explain decisions in natural language. Yet these approaches heavily depend on supervised fine-tuning, which introduces limitations such as annotation bias, hallucinated supervision, and weakened generalization. To address these challenges, we propose AvatarShield, a novel multimodal human-centric synthetic video detection framework that eliminates the need for dense textual supervision by adopting Group Relative Policy Optimization, enabling LLMs to develop reasoning capabilities from simple binary labels. Our architecture combines a discrete vision tower for high-level semantic inconsistencies and a residual extractor for fine-grained artifact analysis. We further introduce FakeHumanVid, a large-scale benchmark containing 15K real and synthetic videos across nine state-of-the-art human generation methods driven by text, pose, or audio. Extensive experiments demonstrate that AvatarShield outperforms existing methods in both in-domain and cross-domain settings.
VIBE: Annotation-Free Video-to-Text Information Bottleneck Evaluation for TL;DR
arXiv:2505.17423v3 Announce Type: replace Abstract: Many decision-making tasks, where both accuracy and efficiency matter, still require human supervision. For example, tasks like traffic officers reviewing hour-long dashcam footage or researchers screening conference videos can benefit from concise summaries that reduce cognitive load and save time. Yet current vision-language models (VLMs) often produce verbose, redundant outputs that hinder task performance. Existing video caption evaluation depends on costly human annotations and overlooks the summaries' utility in downstream tasks. We address these gaps with Video-to-text Information Bottleneck Evaluation (VIBE), an annotation-free method that scores VLM outputs using two metrics: grounding (how well the summary aligns with visual content) and utility (how informative it is for the task). VIBE selects from randomly sampled VLM outputs by ranking them according to the two scores to support effective human decision-making. Human studies on LearningPaper24, SUTD-TrafficQA, and LongVideoBench show that summaries selected by VIBE consistently improve performance-boosting task accuracy by up to 61.23% and reducing response time by 75.77% compared to naive VLM summaries or raw video.
Do It Yourself: Learning Semantic Correspondence from Pseudo-Labels
arXiv:2506.05312v3 Announce Type: replace Abstract: Finding correspondences between semantically similar points across images and object instances is one of the everlasting challenges in computer vision. While large pre-trained vision models have recently been demonstrated as effective priors for semantic matching, they still suffer from ambiguities for symmetric objects or repeated object parts. We propose improving semantic correspondence estimation through 3D-aware pseudo-labeling. Specifically, we train an adapter to refine off-the-shelf features using pseudo-labels obtained via 3D-aware chaining, filtering wrong labels through relaxed cyclic consistency, and 3D spherical prototype mapping constraints. While reducing the need for dataset-specific annotations compared to prior work, we establish a new state-of-the-art on SPair-71k, achieving an absolute gain of over 4% and of over 7% compared to methods with similar supervision requirements. The generality of our proposed approach simplifies the extension of training to other data sources, which we demonstrate in our experiments.
Image Segmentation and Classification of E-waste for Training Robots for Waste Segregation
arXiv:2506.07122v2 Announce Type: replace Abstract: Industry partners provided a problem statement that involves classifying electronic waste using machine learning models that will be used by pick-and-place robots for waste segregation. This was achieved by taking common electronic waste items, such as a mouse and charger, unsoldering them, and taking pictures to create a custom dataset. Then state-of-the art YOLOv11 model was trained and run to achieve 70 mAP in real-time. Mask-RCNN model was also trained and achieved 41 mAP. The model can be integrated with pick-and-place robots to perform segregation of e-waste.
Gaussian Herding across Pens: An Optimal Transport Perspective on Global Gaussian Reduction for 3DGS
arXiv:2506.09534v2 Announce Type: replace Abstract: 3D Gaussian Splatting (3DGS) has emerged as a powerful technique for radiance field rendering, but it typically requires millions of redundant Gaussian primitives, overwhelming memory and rendering budgets. Existing compaction approaches address this by pruning Gaussians based on heuristic importance scores, without global fidelity guarantee. To bridge this gap, we propose a novel optimal transport perspective that casts 3DGS compaction as global Gaussian mixture reduction. Specifically, we first minimize the composite transport divergence over a KD- tree partition to produce a compact geometric representation, and then decouple appearance from geometry by fine-tuning color and opacity attributes with far fewer Gaussian primitives. Experiments on benchmark datasets show that our method (i) yields negligible loss in rendering quality (PSNR, SSIM, LPIPS) compared to vanilla 3DGS with only 10% Gaussians; and (ii) consistently outperforms state- of-the-art 3DGS compaction techniques. Notably, our method is applicable to any stage of vanilla or accelerated 3DGS pipelines, providing an efficient and agnostic pathway to lightweight neural rendering. The code is publicly available at https://github.com/DrunkenPoet/GHAP
WaveFormer: A Lightweight Transformer Model for sEMG-based Gesture Recognition
arXiv:2506.11168v2 Announce Type: replace Abstract: Human-machine interaction, particularly in prosthetic and robotic control, has seen progress with gesture recognition via surface electromyographic (sEMG) signals.However, classifying similar gestures that produce nearly identical muscle signals remains a challenge, often reducing classification accuracy. Traditional deep learning models for sEMG gesture recognition are large and computationally expensive, limiting their deployment on resource-constrained embedded systems. In this work, we propose WaveFormer, a lightweight transformer-based architecture tailored for sEMG gesture recognition. Our model integrates time-domain and frequency-domain features through a novel learnable wavelet transform, enhancing feature extraction. In particular, the WaveletConv module, a multi-level wavelet decomposition layer with depthwise separable convolution, ensures both efficiency and compactness. With just 3.1 million parameters, WaveFormer achieves 95% classification accuracy on the EPN612 dataset, outperforming larger models. Furthermore, when profiled on a laptop equipped with an Intel CPU, INT8 quantization achieves real-time deployment with a 6.75 ms inference latency.
Earth Observation Foundation Model PhilEO: Pretraining on the MajorTOM and FastTOM Datasets
arXiv:2506.14765v4 Announce Type: replace Abstract: Today, Earth Observation (EO) satellites generate massive volumes of data. To fully exploit this, it is essential to pretrain EO Foundation Models (FMs) on large unlabeled datasets, enabling efficient fine-tuning for downstream tasks with minimal labeled data. In this paper, we study scaling-up FMs: we train our models on the pretraining dataset MajorTOM 23TB which includes all regions, and the performance on average is competitive versus models pretrained on more specialized datasets which are substantially smaller and include only land. The additional data of oceans and ice do not decrease the performance on land-focused downstream tasks. These results indicate that large FMs trained on global datasets for a wider variety of downstream tasks can be useful for downstream applications that only require a subset of the information included in their training. The second contribution is the exploration of U-Net Convolutional Neural Network (CNN), Vision Transformers (ViT), and Mamba State-Space Models (SSM) as FMs. U-Net captures local correlations amongst pixels, while ViT and Mamba capture local and distant correlations. We develop various models using different architectures, including U-Net, ViT, and Mamba, and different number of parameters. We evaluate the FLoating-point OPerations (FLOPs) needed by the models. We fine-tune on the PhilEO Bench for different downstream tasks: roads, buildings, and land cover. For most n-shots for roads and buildings, U-Net 200M-2T outperforms the other models. Using Mamba, we achieve comparable results on the downstream tasks, with less computational expenses. We also compare with the recent FM TerraMind which we evaluate on PhilEO Bench.
Uncertainty-Aware Information Pursuit for Interpretable and Reliable Medical Image Analysis
arXiv:2506.16742v2 Announce Type: replace Abstract: To be adopted in safety-critical domains like medical image analysis, AI systems must provide human-interpretable decisions. Variational Information Pursuit (V-IP) offers an interpretable-by-design framework by sequentially querying input images for human-understandable concepts, using their presence or absence to make predictions. However, existing V-IP methods overlook sample-specific uncertainty in concept predictions, which can arise from ambiguous features or model limitations, leading to suboptimal query selection and reduced robustness. In this paper, we propose an interpretable and uncertainty-aware framework for medical imaging that addresses these limitations by accounting for upstream uncertainties in concept-based, interpretable-by-design models. Specifically, we introduce two uncertainty-aware models, EUAV-IP and IUAV-IP, that integrate uncertainty estimates into the V-IP querying process to prioritize more reliable concepts per sample. EUAV-IP skips uncertain concepts via masking, while IUAV-IP incorporates uncertainty into query selection implicitly for more informed and clinically aligned decisions. Our approach allows models to make reliable decisions based on a subset of concepts tailored to each individual sample, without human intervention, while maintaining overall interpretability. We evaluate our methods on five medical imaging datasets across four modalities: dermoscopy, X-ray, ultrasound, and blood cell imaging. The proposed IUAV-IP model achieves state-of-the-art accuracy among interpretable-by-design approaches on four of the five datasets, and generates more concise explanations by selecting fewer yet more informative concepts. These advances enable more reliable and clinically meaningful outcomes, enhancing model trustworthiness and supporting safer AI deployment in healthcare.
Exploring Image Generation via Mutually Exclusive Probability Spaces and Local Correlation Hypothesis
arXiv:2506.21731v2 Announce Type: replace Abstract: A common assumption in probabilistic generative models for image generation is that learning the global data distribution suffices to generate novel images via sampling. We investigate the limitation of this core assumption, namely that learning global distributions leads to memorization rather than generative behavior. We propose two theoretical frameworks, the Mutually Exclusive Probability Space (MEPS) and the Local Dependence Hypothesis (LDH), for investigation. MEPS arises from the observation that deterministic mappings (e.g. neural networks) involving random variables tend to reduce overlap coefficients among involved random variables, thereby inducing exclusivity. We further propose a lower bound in terms of the overlap coefficient, and introduce a Binary Latent Autoencoder (BL-AE) that encodes images into signed binary latent representations. LDH formalizes dependence within a finite observation radius, which motivates our $\gamma$-Autoregressive Random Variable Model ($\gamma$-ARVM). $\gamma$-ARVM is an autoregressive model, with a variable observation range $\gamma$, that predicts a histogram for the next token. Using $\gamma$-ARVM, we observe that as the observation range increases, autoregressive models progressively shift toward memorization. In the limit of global dependence, the model behaves as a pure memorizer when operating on the binary latents produced by our BL-AE. Comprehensive experiments and discussions support our investigation.
3D-ADAM: A Dataset for 3D Anomaly Detection in Additive Manufacturing
arXiv:2507.07838v2 Announce Type: replace Abstract: Surface defects are a primary source of yield loss in manufacturing, yet existing anomaly detection methods often fail in real-world deployment due to limited and unrepresentative datasets. To overcome this, we introduce 3D-ADAM, a 3D Anomaly Detection in Additive Manufacturing dataset, that is the first large-scale, industry-relevant dataset for RGB+3D surface defect detection in additive manufacturing. 3D-ADAM comprises 14,120 high-resolution scans of 217 unique parts, captured with four industrial depth sensors, and includes 27,346 annotated defects across 12 categories along with 27,346 annotations of machine element features in 16 classes. 3D-ADAM is captured in a real industrial environment and as such reflects real production conditions, including variations in part placement, sensor positioning, lighting, and partial occlusion. Benchmarking state-of-the-art models demonstrates that 3D-ADAM presents substantial challenges beyond existing datasets. Validation through expert labelling surveys with industry partners further confirms its industrial relevance. By providing this benchmark, 3D-ADAM establishes a foundation for advancing robust 3D anomaly detection capable of meeting manufacturing demands.
DWTGS: Rethinking Frequency Regularization for Sparse-view 3D Gaussian Splatting
arXiv:2507.15690v2 Announce Type: replace Abstract: Sparse-view 3D Gaussian Splatting (3DGS) presents significant challenges in reconstructing high-quality novel views, as it often overfits to the widely-varying high-frequency (HF) details of the sparse training views. While frequency regularization can be a promising approach, its typical reliance on Fourier transforms causes difficult parameter tuning and biases towards detrimental HF learning. We propose DWTGS, a framework that rethinks frequency regularization by leveraging wavelet-space losses that provide additional spatial supervision. Specifically, we supervise only the low-frequency (LF) LL subbands at multiple DWT levels, while enforcing sparsity on the HF HH subband in a self-supervised manner. Experiments across benchmarks show that DWTGS consistently outperforms Fourier-based counterparts, as this LF-centric strategy improves generalization and reduces HF hallucinations.
DATA: Domain-And-Time Alignment for High-Quality Feature Fusion in Collaborative Perception
arXiv:2507.18237v2 Announce Type: replace Abstract: Feature-level fusion shows promise in collaborative perception (CP) through balanced performance and communication bandwidth trade-off. However, its effectiveness critically relies on input feature quality. The acquisition of high-quality features faces domain gaps from hardware diversity and deployment conditions, alongside temporal misalignment from transmission delays. These challenges degrade feature quality with cumulative effects throughout the collaborative network. In this paper, we present the Domain-And-Time Alignment (DATA) network, designed to systematically align features while maximizing their semantic representations for fusion. Specifically, we propose a Consistency-preserving Domain Alignment Module (CDAM) that reduces domain gaps through proximal-region hierarchical downsampling and observability-constrained discriminator. We further propose a Progressive Temporal Alignment Module (PTAM) to handle transmission delays via multi-scale motion modeling and two-stage compensation. Building upon the aligned features, an Instance-focused Feature Aggregation Module (IFAM) is developed to enhance semantic representations. Extensive experiments demonstrate that DATA achieves state-of-the-art performance on three typical datasets, maintaining robustness with severe communication delays and pose errors. The code will be released at https://github.com/ChengchangTian/DATA.
LRQ-DiT: Log-Rotation Post-Training Quantization of Diffusion Transformers for Image and Video Generation
arXiv:2508.03485v3 Announce Type: replace Abstract: Diffusion Transformers (DiTs) have achieved impressive performance in text-to-image and text-to-video generation. However, their high computational cost and large parameter sizes pose significant challenges for usage in resource-constrained scenarios. Effective compression of models has become a crucial issue that urgently needs to be addressed. Post-training quantization (PTQ) is a promising solution to reduce memory usage and accelerate inference, but existing PTQ methods suffer from severe performance degradation under extreme low-bit settings. After experiments and analysis, we identify two key obstacles to low-bit PTQ for DiTs: (1) the weights of DiT models follow a Gaussian-like distribution with long tails, causing uniform quantization to poorly allocate intervals and leading to significant quantization errors. This issue has been observed in the linear layer weights of different DiT models, which deeply limits the performance. (2) two types of activation outliers in DiT models: (i) Mild Outliers with slightly elevated values, and (ii) Salient Outliers with large magnitudes concentrated in specific channels, which disrupt activation quantization. To address these issues, we propose LRQ-DiT, an efficient and accurate post-training quantization framework for image and video generation. First, we introduce Twin-Log Quantization (TLQ), a log-based method that allocates more quantization intervals to the intermediate dense regions, effectively achieving alignment with the weight distribution and reducing quantization errors. Second, we propose an Adaptive Rotation Scheme (ARS) that dynamically applies Hadamard or outlier-aware rotations based on activation fluctuation, effectively mitigating the impact of both types of outliers. Extensive experiments on various text-to-image and text-to-video DiT models demonstrate that LRQ-DiT preserves high generation quality.
PointAD+: Learning Hierarchical Representations for Zero-shot 3D Anomaly Detection
arXiv:2509.03277v2 Announce Type: replace Abstract: In this paper, we aim to transfer CLIP's robust 2D generalization capabilities to identify 3D anomalies across unseen objects of highly diverse class semantics. To this end, we propose a unified framework to comprehensively detect and segment 3D anomalies by leveraging both point- and pixel-level information. We first design PointAD, which leverages point-pixel correspondence to represent 3D anomalies through their associated rendering pixel representations. This approach is referred to as implicit 3D representation, as it focuses solely on rendering pixel anomalies but neglects the inherent spatial relationships within point clouds. Then, we propose PointAD+ to further broaden the interpretation of 3D anomalies by introducing explicit 3D representation, emphasizing spatial abnormality to uncover abnormal spatial relationships. Hence, we propose G-aggregation to involve geometry information to enable the aggregated point representations spatially aware. To simultaneously capture rendering and spatial abnormality, PointAD+ proposes hierarchical representation learning, incorporating implicit and explicit anomaly semantics into hierarchical text prompts: rendering prompts for the rendering layer and geometry prompts for the geometry layer. A cross-hierarchy contrastive alignment is further introduced to promote the interaction between the rendering and geometry layers, facilitating mutual anomaly learning. Finally, PointAD+ integrates anomaly semantics from both layers to capture the generalized anomaly semantics. During the test, PointAD+ can integrate RGB information in a plug-and-play manner and further improve its detection performance. Extensive experiments demonstrate the superiority of PointAD+ in ZS 3D anomaly detection across unseen objects with highly diverse class semantics, achieving a holistic understanding of abnormality.
PromptEnhancer: A Simple Approach to Enhance Text-to-Image Models via Chain-of-Thought Prompt Rewriting
arXiv:2509.04545v5 Announce Type: replace Abstract: Recent advancements in text-to-image (T2I) diffusion models have demonstrated remarkable capabilities in generating high-fidelity images. However, these models often struggle to faithfully render complex user prompts, particularly in aspects like attribute binding, negation, and compositional relationships. This leads to a significant mismatch between user intent and the generated output. To address this challenge, we introduce PromptEnhancer, a novel and universal prompt rewriting framework that enhances any pretrained T2I model without requiring modifications to its weights. Unlike prior methods that rely on model-specific fine-tuning or implicit reward signals like image-reward scores, our framework decouples the rewriter from the generator. We achieve this by training a Chain-of-Thought (CoT) rewriter through reinforcement learning, guided by a dedicated reward model we term the AlignEvaluator. The AlignEvaluator is trained to provide explicit and fine-grained feedback based on a systematic taxonomy of 24 key points, which are derived from a comprehensive analysis of common T2I failure modes. By optimizing the CoT rewriter to maximize the reward from our AlignEvaluator, our framework learns to generate prompts that are more precisely interpreted by T2I models. Extensive experiments on the HunyuanImage 2.1 model demonstrate that PromptEnhancer significantly improves image-text alignment across a wide range of semantic and compositional challenges. Furthermore, we introduce a new, high-quality human preference benchmark to facilitate future research in this direction.
TinyDef-DETR: A DETR-based Framework for Defect Detection in Transmission Lines from UAV Imagery
arXiv:2509.06035v5 Announce Type: replace Abstract: Automated defect detection from UAV imagery of transmission lines is a challenging task due to the small size, ambiguity, and complex backgrounds of defects. This paper proposes TinyDef-DETR, a DETR-based framework designed to achieve accurate and efficient detection of transmission line defects from UAV-acquired images. The model integrates four major components: an edge-enhanced ResNet backbone to strengthen boundary-sensitive representations, a stride-free space-to-depth module to enable detail-preserving downsampling, a cross-stage dual-domain multi-scale attention mechanism to jointly model global context and local cues, and a Focaler-Wise-SIoU regression loss to improve the localization of small and difficult targets. Together, these designs effectively mitigate the limitations of conventional detectors. Extensive experiments on both public and real-world datasets demonstrate that TinyDef-DETR achieves superior detection performance and strong generalization capability, while maintaining modest computational overhead. The accuracy and efficiency of TinyDef-DETR make it a suitable method for UAV-based transmission line defect detection, particularly in scenarios involving small and ambiguous targets.
MEGS$^{2}$: Memory-Efficient Gaussian Splatting via Spherical Gaussians and Unified Pruning
arXiv:2509.07021v2 Announce Type: replace Abstract: 3D Gaussian Splatting (3DGS) has emerged as a dominant novel-view synthesis technique, but its high memory consumption severely limits its applicability on edge devices. A growing number of 3DGS compression methods have been proposed to make 3DGS more efficient, yet most only focus on storage compression and fail to address the critical bottleneck of rendering memory. To address this problem, we introduce MEGS$^{2}$, a novel memory-efficient framework that tackles this challenge by jointly optimizing two key factors: the total primitive number and the parameters per primitive, achieving unprecedented memory compression. Specifically, we replace the memory-intensive spherical harmonics with lightweight, arbitrarily oriented spherical Gaussian lobes as our color representations. More importantly, we propose a unified soft pruning framework that models primitive-number and lobe-number pruning as a single constrained optimization problem. Experiments show that MEGS$^{2}$ achieves a 50% static VRAM reduction and a 40% rendering VRAM reduction compared to existing methods, while maintaining comparable rendering quality. Project page: https://megs-2.github.io/
LD-ViCE: Latent Diffusion Model for Video Counterfactual Explanations
arXiv:2509.08422v2 Announce Type: replace Abstract: Video-based AI systems are increasingly adopted in safety-critical domains such as autonomous driving and healthcare. However, interpreting their decisions remains challenging due to the inherent spatiotemporal complexity of video data and the opacity of deep learning models. Existing explanation techniques often suffer from limited temporal coherence, insufficient robustness, and a lack of actionable causal insights. Current counterfactual explanation methods typically do not incorporate guidance from the target model, reducing semantic fidelity and practical utility. We introduce Latent Diffusion for Video Counterfactual Explanations (LD-ViCE), a novel framework designed to explain the behavior of video-based AI models. Compared to previous approaches, LD-ViCE reduces the computational costs of generating explanations by operating in latent space using a state-of-the-art diffusion model, while producing realistic and interpretable counterfactuals through an additional refinement step. Our experiments demonstrate the effectiveness of LD-ViCE across three diverse video datasets, including EchoNet-Dynamic (cardiac ultrasound), FERV39k (facial expression), and Something-Something V2 (action recognition). LD-ViCE outperforms a recent state-of-the-art method, achieving an increase in R2 score of up to 68% while reducing inference time by half. Qualitative analysis confirms that LD-ViCE generates semantically meaningful and temporally coherent explanations, offering valuable insights into the target model behavior. LD-ViCE represents a valuable step toward the trustworthy deployment of AI in safety-critical domains.
Handling Multiple Hypotheses in Coarse-to-Fine Dense Image Matching
arXiv:2509.08805v2 Announce Type: replace Abstract: Dense image matching aims to find a correspondent for every pixel of a source image in a partially overlapping target image. State-of-the-art methods typically rely on a coarse-to-fine mechanism where a single correspondent hypothesis is produced per source location at each scale. In challenging cases -- such as at depth discontinuities or when the target image is a strong zoom-in of the source image -- the correspondents of neighboring source locations are often widely spread and predicting a single correspondent hypothesis per source location at each scale may lead to erroneous matches. In this paper, we investigate the idea of predicting multiple correspondent hypotheses per source location at each scale instead. We consider a beam search strategy to propagat multiple hypotheses at each scale and propose integrating these multiple hypotheses into cross-attention layers, resulting in a novel dense matching architecture called BEAMER. BEAMER learns to preserve and propagate multiple hypotheses across scales, making it significantly more robust than state-of-the-art methods, especially at depth discontinuities or when the target image is a strong zoom-in of the source image.
Diffusion-Based Action Recognition Generalizes to Untrained Domains
arXiv:2509.08908v3 Announce Type: replace Abstract: Humans can recognize the same actions despite large context and viewpoint variations, such as differences between species (walking in spiders vs. horses), viewpoints (egocentric vs. third-person), and contexts (real life vs movies). Current deep learning models struggle with such generalization. We propose using features generated by a Vision Diffusion Model (VDM), aggregated via a transformer, to achieve human-like action recognition across these challenging conditions. We find that generalization is enhanced by the use of a model conditioned on earlier timesteps of the diffusion process to highlight semantic information over pixel level details in the extracted features. We experimentally explore the generalization properties of our approach in classifying actions across animal species, across different viewing angles, and different recording contexts. Our model sets a new state-of-the-art across all three generalization benchmarks, bringing machine action recognition closer to human-like robustness. Project page: https://www.vision.caltech.edu/actiondiff. Code: https://github.com/frankyaoxiao/ActionDiff
LaV-CoT: Language-Aware Visual CoT with Multi-Aspect Reward Optimization for Real-World Multilingual VQA
arXiv:2509.10026v2 Announce Type: replace Abstract: As large vision language models (VLMs) advance, their capabilities in multilingual visual question answering (mVQA) have significantly improved. Chain-of-thought (CoT) reasoning has been proven to enhance interpretability and complex reasoning. However, most existing approaches rely primarily on textual CoT and provide limited support for multilingual multimodal reasoning, constraining their deployment in real-world applications. To address this gap, we introduce \textbf{LaV-CoT}, the first Language-aware Visual CoT framework with Multi-Aspect Reward Optimization. LaV-CoT incorporates an interpretable multi-stage reasoning pipeline consisting of Text Summary with Bounding Box (BBox), Language Identification, Spatial Object-level Captioning, and Step-by-step Logical Reasoning. Following this reasoning pipeline, we design an automated data curation method that generates multilingual CoT annotations through iterative generation, correction, and refinement, enabling scalable and high-quality training data. To improve reasoning and generalization, LaV-CoT adopts a two-stage training paradigm combining Supervised Fine-Tuning (SFT) with Language-aware Group Relative Policy Optimization (GRPO), guided by verifiable multi-aspect rewards including language consistency, structural accuracy, and semantic alignment. Extensive evaluations on public datasets including MMMB, Multilingual MMBench, and MTVQA show that LaV-CoT achieves up to ~9.5% accuracy improvements over open-source baselines of similar size and even surpasses models with 2$\times$ larger scales by ~2.6%. Moreover, LaV-CoT outperforms advanced proprietary models such as GPT-4o-0513 and Gemini-2.5-flash. We further conducted an online A/B test to validate our method on real-world data, highlighting its effectiveness for industrial deployment. Our code is available at this link: \href{https://github.com/HJNVR/LaV-CoT}
3D Human Pose and Shape Estimation from LiDAR Point Clouds: A Review
arXiv:2509.12197v2 Announce Type: replace Abstract: In this paper, we present a comprehensive review of 3D human pose estimation and human mesh recovery from in-the-wild LiDAR point clouds. We compare existing approaches across several key dimensions, and propose a structured taxonomy to classify these methods. Following this taxonomy, we analyze each method's strengths, limitations, and design choices. In addition, (i) we perform a quantitative comparison of the three most widely used datasets, detailing their characteristics; (ii) we compile unified definitions of all evaluation metrics; and (iii) we establish benchmark tables for both tasks on these datasets to enable fair comparisons and promote progress in the field. We also outline open challenges and research directions critical for advancing LiDAR-based 3D human understanding. Moreover, we maintain an accompanying webpage that organizes papers according to our taxonomy and continuously update it with new studies: https://github.com/valeoai/3D-Human-Pose-Shape-Estimation-from-LiDAR
MOCHA: Multi-modal Objects-aware Cross-arcHitecture Alignment
arXiv:2509.14001v2 Announce Type: replace Abstract: We introduce MOCHA (Multi-modal Objects-aware Cross-arcHitecture Alignment), a knowledge distillation approach that transfers region-level multimodal semantics from a large vision-language teacher (e.g., LLaVa) into a lightweight vision-only object detector student (e.g., YOLO). A translation module maps student features into a joint space, where the training of the student and translator is guided by a dual-objective loss that enforces both local alignment and global relational consistency. Unlike prior approaches focused on dense or global alignment, MOCHA operates at the object level, enabling efficient transfer of semantics without modifying the teacher or requiring textual input at inference. We validate our method across four personalized detection benchmarks under few-shot regimes. Results show consistent gains over baselines, with a +10.1 average score improvement. Despite its compact architecture, MOCHA reaches performance on par with larger multimodal models, proving its suitability for real-world deployment.
ViSpec: Accelerating Vision-Language Models with Vision-Aware Speculative Decoding
arXiv:2509.15235v3 Announce Type: replace Abstract: Speculative decoding is a widely adopted technique for accelerating inference in large language models (LLMs), yet its application to vision-language models (VLMs) remains underexplored, with existing methods achieving only modest speedups (<1.5x). This gap is increasingly significant as multimodal capabilities become central to large-scale models. We hypothesize that large VLMs can effectively filter redundant image information layer by layer without compromising textual comprehension, whereas smaller draft models struggle to do so. To address this, we introduce Vision-Aware Speculative Decoding (ViSpec), a novel framework tailored for VLMs. ViSpec employs a lightweight vision adaptor module to compress image tokens into a compact representation, which is seamlessly integrated into the draft model's attention mechanism while preserving original image positional information. Additionally, we extract a global feature vector for each input image and augment all subsequent text tokens with this feature to enhance multimodal coherence. To overcome the scarcity of multimodal datasets with long assistant responses, we curate a specialized training dataset by repurposing existing datasets and generating extended outputs using the target VLM with modified prompts. Our training strategy mitigates the risk of the draft model exploiting direct access to the target model's hidden states, which could otherwise lead to shortcut learning when training solely on target model outputs. Extensive experiments validate ViSpec, achieving, to our knowledge, the first substantial speedup in VLM speculative decoding. Code is available at https://github.com/KangJialiang/ViSpec.
AHA - Predicting What Matters Next: Online Highlight Detection Without Looking Ahead
arXiv:2509.16421v2 Announce Type: replace Abstract: Real-time understanding of continuous video streams is essential for intelligent agents operating in high-stakes environments, including autonomous vehicles, surveillance drones, and disaster response robots. Yet, most existing video understanding and highlight detection methods assume access to the entire video during inference, making them unsuitable for online or streaming scenarios. In particular, current models optimize for offline summarization, failing to support step-by-step reasoning needed for real-time decision-making. We introduce Aha, an autoregressive highlight detection framework that predicts the relevance of each video frame against a task described in natural language. Without accessing future video frames, Aha utilizes a multimodal vision-language model and lightweight, decoupled heads trained on a large, curated dataset of human-centric video labels. To enable scalability, we introduce the Dynamic SinkCache mechanism that achieves constant memory usage across infinite-length streams without degrading performance on standard benchmarks. This encourages the hidden representation to capture high-level task objectives, enabling effective frame-level rankings for informativeness, relevance, and uncertainty with respect to the natural language task. Aha achieves state-of-the-art (SOTA) performance on highlight detection benchmarks, surpassing even prior offline, full-context approaches and video-language models by +5.9% on TVSum and +8.3% on Mr. Hisum in mAP (mean Average Precision). We explore Aha's potential for real-world robotics applications given a task-oriented natural language input and a continuous, robot-centric video. Both experiments demonstrate Aha's potential effectiveness as a real-time reasoning module for downstream planning and long-horizon understanding.
3D Gaussian Flats: Hybrid 2D/3D Photometric Scene Reconstruction
arXiv:2509.16423v2 Announce Type: replace Abstract: Recent advances in radiance fields and novel view synthesis enable creation of realistic digital twins from photographs. However, current methods struggle with flat, texture-less surfaces, creating uneven and semi-transparent reconstructions, due to an ill-conditioned photometric reconstruction objective. Surface reconstruction methods solve this issue but sacrifice visual quality. We propose a novel hybrid 2D/3D representation that jointly optimizes constrained planar (2D) Gaussians for modeling flat surfaces and freeform (3D) Gaussians for the rest of the scene. Our end-to-end approach dynamically detects and refines planar regions, improving both visual fidelity and geometric accuracy. It achieves state-of-the-art depth estimation on ScanNet++ and ScanNetv2, and excels at mesh extraction without overfitting to a specific camera model, showing its effectiveness in producing high-quality reconstruction of indoor scenes.
Pain in 3D: Generating Controllable Synthetic Faces for Automated Pain Assessment
arXiv:2509.16727v2 Announce Type: replace Abstract: Automated pain assessment from facial expressions is crucial for non-communicative patients, such as those with dementia. Progress has been limited by two challenges: (i) existing datasets exhibit severe demographic and label imbalance due to ethical constraints, and (ii) current generative models cannot precisely control facial action units (AUs), facial structure, or clinically validated pain levels. We present 3DPain, a large-scale synthetic dataset specifically designed for automated pain assessment, featuring unprecedented annotation richness and demographic diversity. Our three-stage framework generates diverse 3D meshes, textures them with diffusion models, and applies AU-driven face rigging to synthesize multi-view faces with paired neutral and pain images, AU configurations, PSPI scores, and the first dataset-level annotations of pain-region heatmaps. The dataset comprises 82,500 samples across 25,000 pain expression heatmaps and 2,500 synthetic identities balanced by age, gender, and ethnicity. We further introduce ViTPain, a Vision Transformer based cross-modal distillation framework in which a heatmap-trained teacher guides a student trained on RGB images, enhancing accuracy, interpretability, and clinical reliability. Together, 3DPain and ViTPain establish a controllable, diverse, and clinically grounded foundation for generalizable automated pain assessment.
Min: Mixture of Noise for Pre-Trained Model-Based Class-Incremental Learning
arXiv:2509.16738v2 Announce Type: replace Abstract: Class Incremental Learning (CIL) aims to continuously learn new categories while retaining the knowledge of old ones. Pre-trained models (PTMs) show promising capabilities in CIL. However, existing approaches that apply lightweight fine-tuning to backbones still induce parameter drift, thereby compromising the generalization capability of pre-trained models. Parameter drift can be conceptualized as a form of noise that obscures critical patterns learned for previous tasks. However, recent researches have shown that noise is not always harmful. For example, the large number of visual patterns learned from pre-training can be easily abused by a single task, and introducing appropriate noise can suppress some low-correlation features, thus leaving a margin for future tasks. To this end, we propose learning beneficial noise for CIL guided by information theory and propose Mixture of Noise (Min), aiming to mitigate the degradation of backbone generalization from adapting new tasks. Specifically, task-specific noise is learned from high-dimension features of new tasks. Then, a set of weights is adjusted dynamically for optimal mixture of different task noise. Finally, Min embeds the beneficial noise into the intermediate features to mask the response of inefficient patterns. Extensive experiments on six benchmark datasets demonstrate that Min achieves state-of-the-art performance in most incremental settings, with particularly outstanding results in 50-steps incremental settings. This shows the significant potential for beneficial noise in continual learning. Code is available at https://github.com/ASCIIJK/MiN-NeurIPS2025.
L2M-Reg: Building-level Uncertainty-aware Registration of Outdoor LiDAR Point Clouds and Semantic 3D City Models
arXiv:2509.16832v2 Announce Type: replace Abstract: Accurate registration between LiDAR (Light Detection and Ranging) point clouds and semantic 3D city models is a fundamental topic in urban digital twinning and a prerequisite for downstream tasks, such as digital construction, change detection and model refinement. However, achieving accurate LiDAR-to-Model registration at individual building level remains challenging, particularly due to the generalization uncertainty in semantic 3D city models at the Level of Detail 2 (LoD2). This paper addresses this gap by proposing L2M-Reg, a plane-based fine registration method that explicitly accounts for model uncertainty. L2M-Reg consists of three key steps: establishing reliable plane correspondence, building a pseudo-plane-constrained Gauss-Helmert model, and adaptively estimating vertical translation. Experiments on three real-world datasets demonstrate that L2M-Reg is both more accurate and computationally efficient than existing ICP-based and plane-based methods. Overall, L2M-Reg provides a novel building-level solution regarding LiDAR-to-Model registration when model uncertainty is present.
SAM-DCE: Addressing Token Uniformity and Semantic Over-Smoothing in Medical Segmentation
arXiv:2509.16886v2 Announce Type: replace Abstract: The Segment Anything Model (SAM) demonstrates impressive zero-shot segmentation ability on natural images but encounters difficulties in medical imaging due to domain shifts, anatomical variability, and its reliance on user-provided prompts. Recent prompt-free adaptations alleviate the need for expert intervention, yet still suffer from limited robustness and adaptability, often overlooking the issues of semantic over-smoothing and token uniformity. We propose SAM-DCE, which balances local discrimination and global semantics while mitigating token uniformity, enhancing inter-class separability, and enriching mask decoding with fine-grained, consistent representations. Extensive experiments on diverse medical benchmarks validate its effectiveness.
Rethinking Evaluation of Infrared Small Target Detection
arXiv:2509.16888v2 Announce Type: replace Abstract: As an essential vision task, infrared small target detection (IRSTD) has seen significant advancements through deep learning. However, critical limitations in current evaluation protocols impede further progress. First, existing methods rely on fragmented pixel- and target-level specific metrics, which fails to provide a comprehensive view of model capabilities. Second, an excessive emphasis on overall performance scores obscures crucial error analysis, which is vital for identifying failure modes and improving real-world system performance. Third, the field predominantly adopts dataset-specific training-testing paradigms, hindering the understanding of model robustness and generalization across diverse infrared scenarios. This paper addresses these issues by introducing a hybrid-level metric incorporating pixel- and target-level performance, proposing a systematic error analysis method, and emphasizing the importance of cross-dataset evaluation. These aim to offer a more thorough and rational hierarchical analysis framework, ultimately fostering the development of more effective and robust IRSTD models. An open-source toolkit has be released to facilitate standardized benchmarking.
Penalizing Boundary Activation for Object Completeness in Diffusion Models
arXiv:2509.16968v2 Announce Type: replace Abstract: Diffusion models have emerged as a powerful technique for text-to-image (T2I) generation, creating high-quality, diverse images across various domains. However, a common limitation in these models is the incomplete display of objects, where fragments or missing parts undermine the model's performance in downstream applications. In this study, we conduct an in-depth analysis of the incompleteness issue and reveal that the primary factor behind incomplete object generation is the usage of RandomCrop during model training. This widely used data augmentation method, though enhances model generalization ability, disrupts object continuity during training. To address this, we propose a training-free solution that penalizes activation values at image boundaries during the early denoising steps. Our method is easily applicable to pre-trained Stable Diffusion models with minimal modifications and negligible computational overhead. Extensive experiments demonstrate the effectiveness of our method, showing substantial improvements in object integrity and image quality.
HyRF: Hybrid Radiance Fields for Memory-efficient and High-quality Novel View Synthesis
arXiv:2509.17083v2 Announce Type: replace Abstract: Recently, 3D Gaussian Splatting (3DGS) has emerged as a powerful alternative to NeRF-based approaches, enabling real-time, high-quality novel view synthesis through explicit, optimizable 3D Gaussians. However, 3DGS suffers from significant memory overhead due to its reliance on per-Gaussian parameters to model view-dependent effects and anisotropic shapes. While recent works propose compressing 3DGS with neural fields, these methods struggle to capture high-frequency spatial variations in Gaussian properties, leading to degraded reconstruction of fine details. We present Hybrid Radiance Fields (HyRF), a novel scene representation that combines the strengths of explicit Gaussians and neural fields. HyRF decomposes the scene into (1) a compact set of explicit Gaussians storing only critical high-frequency parameters and (2) grid-based neural fields that predict remaining properties. To enhance representational capacity, we introduce a decoupled neural field architecture, separately modeling geometry (scale, opacity, rotation) and view-dependent color. Additionally, we propose a hybrid rendering scheme that composites Gaussian splatting with a neural field-predicted background, addressing limitations in distant scene representation. Experiments demonstrate that HyRF achieves state-of-the-art rendering quality while reducing model size by over 20 times compared to 3DGS and maintaining real-time performance. Our project page is available at https://wzpscott.github.io/hyrf/.
Multi-scale Temporal Prediction via Incremental Generation and Multi-agent Collaboration
arXiv:2509.17429v2 Announce Type: replace Abstract: Accurate temporal prediction is the bridge between comprehensive scene understanding and embodied artificial intelligence. However, predicting multiple fine-grained states of a scene at multiple temporal scales is difficult for vision-language models. We formalize the Multi-Scale Temporal Prediction (MSTP) task in general and surgical scenes by decomposing multi-scale into two orthogonal dimensions: the temporal scale, forecasting states of humans and surgery at varying look-ahead intervals, and the state scale, modeling a hierarchy of states in general and surgical scenes. For example, in general scenes, states of contact relationships are finer-grained than states of spatial relationships. In surgical scenes, medium-level steps are finer-grained than high-level phases yet remain constrained by their encompassing phase. To support this unified task, we introduce the first MSTP Benchmark, featuring synchronized annotations across multiple state scales and temporal scales. We further propose a method, Incremental Generation and Multi-agent Collaboration (IG-MC), which integrates two key innovations. First, we present a plug-and-play incremental generation module that continuously synthesizes up-to-date visual previews at expanding temporal scales to inform multiple decision-making agents, keeping decisions and generated visuals synchronized and preventing performance degradation as look-ahead intervals lengthen. Second, we present a decision-driven multi-agent collaboration framework for multi-state prediction, comprising generation, initiation, and multi-state assessment agents that dynamically trigger and evaluate prediction cycles to balance global coherence and local fidelity.
EmbodiedSplat: Personalized Real-to-Sim-to-Real Navigation with Gaussian Splats from a Mobile Device
arXiv:2509.17430v2 Announce Type: replace Abstract: The field of Embodied AI predominantly relies on simulation for training and evaluation, often using either fully synthetic environments that lack photorealism or high-fidelity real-world reconstructions captured with expensive hardware. As a result, sim-to-real transfer remains a major challenge. In this paper, we introduce EmbodiedSplat, a novel approach that personalizes policy training by efficiently capturing the deployment environment and fine-tuning policies within the reconstructed scenes. Our method leverages 3D Gaussian Splatting (GS) and the Habitat-Sim simulator to bridge the gap between realistic scene capture and effective training environments. Using iPhone-captured deployment scenes, we reconstruct meshes via GS, enabling training in settings that closely approximate real-world conditions. We conduct a comprehensive analysis of training strategies, pre-training datasets, and mesh reconstruction techniques, evaluating their impact on sim-to-real predictivity in real-world scenarios. Experimental results demonstrate that agents fine-tuned with EmbodiedSplat outperform both zero-shot baselines pre-trained on large-scale real-world datasets (HM3D) and synthetically generated datasets (HSSD), achieving absolute success rate improvements of 20% and 40% on real-world Image Navigation task. Moreover, our approach yields a high sim-vs-real correlation (0.87-0.97) for the reconstructed meshes, underscoring its effectiveness in adapting policies to diverse environments with minimal effort. Project page: https://gchhablani.github.io/embodied-splat.
Hierarchical Neural Semantic Representation for 3D Semantic Correspondence
arXiv:2509.17431v2 Announce Type: replace Abstract: This paper presents a new approach to estimate accurate and robust 3D semantic correspondence with the hierarchical neural semantic representation. Our work has three key contributions. First, we design the hierarchical neural semantic representation (HNSR), which consists of a global semantic feature to capture high-level structure and multi-resolution local geometric features to preserve fine details, by carefully harnessing 3D priors from pre-trained 3D generative models. Second, we design a progressive global-to-local matching strategy, which establishes coarse semantic correspondence using the global semantic feature, then iteratively refines it with local geometric features, yielding accurate and semantically-consistent mappings. Third, our framework is training-free and broadly compatible with various pre-trained 3D generative backbones, demonstrating strong generalization across diverse shape categories. Our method also supports various applications, such as shape co-segmentation, keypoint matching, and texture transfer, and generalizes well to structurally diverse shapes, with promising results even in cross-category scenarios. Both qualitative and quantitative evaluations show that our method outperforms previous state-of-the-art techniques.
Multimodal Medical Image Classification via Synergistic Learning Pre-training
arXiv:2509.17492v2 Announce Type: replace Abstract: Multimodal pathological images are usually in clinical diagnosis, but computer vision-based multimodal image-assisted diagnosis faces challenges with modality fusion, especially in the absence of expert-annotated data. To achieve the modality fusion in multimodal images with label scarcity, we propose a novel ``pretraining + fine-tuning" framework for multimodal semi-supervised medical image classification. Specifically, we propose a synergistic learning pretraining framework of consistency, reconstructive, and aligned learning. By treating one modality as an augmented sample of another modality, we implement a self-supervised learning pre-train, enhancing the baseline model's feature representation capability. Then, we design a fine-tuning method for multimodal fusion. During the fine-tuning stage, we set different encoders to extract features from the original modalities and provide a multimodal fusion encoder for fusion modality. In addition, we propose a distribution shift method for multimodal fusion features, which alleviates the prediction uncertainty and overfitting risks caused by the lack of labeled samples. We conduct extensive experiments on the publicly available gastroscopy image datasets Kvasir and Kvasirv2. Quantitative and qualitative results demonstrate that the proposed method outperforms the current state-of-the-art classification methods. The code will be released at: https://github.com/LQH89757/MICS.
SimToken: A Simple Baseline for Referring Audio-Visual Segmentation
arXiv:2509.17537v2 Announce Type: replace Abstract: Referring Audio-Visual Segmentation (Ref-AVS) aims to segment specific objects in videos based on natural language expressions involving audio, vision, and text information. This task poses significant challenges in cross-modal reasoning and fine-grained object localization. In this paper, we propose a simple framework, SimToken, that integrates a multimodal large language model (MLLM) with the Segment Anything Model (SAM). The MLLM is guided to generate a special semantic token representing the referred object. This compact token, enriched with contextual information from all modalities, acts as a prompt to guide SAM to segment objectsacross video frames. To further improve semantic learning, we introduce a novel target-consistent semantic alignment loss that aligns token embeddings from different expressions but referring to the same object. Experiments on the Ref-AVS benchmark demonstrate that our approach achieves superior performance compared to existing methods.
Visual Instruction Pretraining for Domain-Specific Foundation Models
arXiv:2509.17562v2 Announce Type: replace Abstract: Modern computer vision is converging on a closed loop in which perception, reasoning and generation mutually reinforce each other. However, this loop remains incomplete: the top-down influence of high-level reasoning on the foundational learning of low-level perceptual features is not yet underexplored. This paper addresses this gap by proposing a new paradigm for pretraining foundation models in downstream domains. We introduce Visual insTruction Pretraining (ViTP), a novel approach that directly leverages reasoning to enhance perception. ViTP embeds a Vision Transformer (ViT) backbone within a Vision-Language Model and pretrains it end-to-end using a rich corpus of visual instruction data curated from target downstream domains. ViTP is powered by our proposed Visual Robustness Learning (VRL), which compels the ViT to learn robust and domain-relevant features from a sparse set of visual tokens. Extensive experiments on 16 challenging remote sensing and medical imaging benchmarks demonstrate that ViTP establishes new state-of-the-art performance across a diverse range of downstream tasks. The code is available at https://github.com/zcablii/ViTP.
Clothing agnostic Pre-inpainting Virtual Try-ON
arXiv:2509.17654v2 Announce Type: replace Abstract: With the development of deep learning technology, virtual try-on technology has become an important application value in the fields of e-commerce, fashion, and entertainment. The recently proposed Leffa has improved the texture distortion problem of diffu-sion-based models, but there are limitations in that the bottom detection inaccuracy and the existing clothing silhouette remain in the synthesis results. To solve this problem, this study proposes CaP-VTON (Clothing agnostic Pre-inpainting Virtual Try-ON). CaP-VTON has improved the naturalness and consistency of whole-body clothing syn-thesis by integrating multi-category masking based on Dress Code and skin inpainting based on Stable Diffusion. In particular, a generate skin module was introduced to solve the skin restoration problem that occurs when long-sleeved images are converted into short-sleeved or sleeveless ones, and high-quality restoration was implemented consider-ing the human body posture and color. As a result, CaP-VTON recorded 92.5%, which is 15.4% better than Leffa in short-sleeved synthesis accuracy, and showed the performance of consistently reproducing the style and shape of reference clothing in visual evaluation. These structures maintain model-agnostic properties and are applicable to various diffu-sion-based virtual inspection systems, and can contribute to applications that require high-precision virtual wearing, such as e-commerce, custom styling, and avatar creation.
Development and validation of an AI foundation model for endoscopic diagnosis of esophagogastric junction adenocarcinoma: a cohort and deep learning study
arXiv:2509.17660v2 Announce Type: replace Abstract: The early detection of esophagogastric junction adenocarcinoma (EGJA) is crucial for improving patient prognosis, yet its current diagnosis is highly operator-dependent. This paper aims to make the first attempt to develop an artificial intelligence (AI) foundation model-based method for both screening and staging diagnosis of EGJA using endoscopic images. In this cohort and learning study, we conducted a multicentre study across seven Chinese hospitals between December 28, 2016 and December 30, 2024. It comprises 12,302 images from 1,546 patients; 8,249 of them were employed for model training, while the remaining were divided into the held-out (112 patients, 914 images), external (230 patients, 1,539 images), and prospective (198 patients, 1,600 images) test sets for evaluation. The proposed model employs DINOv2 (a vision foundation model) and ResNet50 (a convolutional neural network) to extract features of global appearance and local details of endoscopic images for EGJA staging diagnosis. Our model demonstrates satisfactory performance for EGJA staging diagnosis across three test sets, achieving an accuracy of 0.9256, 0.8895, and 0.8956, respectively. In contrast, among representative AI models, the best one (ResNet50) achieves an accuracy of 0.9125, 0.8382, and 0.8519 on the three test sets, respectively; the expert endoscopists achieve an accuracy of 0.8147 on the held-out test set. Moreover, with the assistance of our model, the overall accuracy for the trainee, competent, and expert endoscopists improves from 0.7035, 0.7350, and 0.8147 to 0.8497, 0.8521, and 0.8696, respectively. To our knowledge, our model is the first application of foundation models for EGJA staging diagnosis and demonstrates great potential in both diagnostic accuracy and efficiency.
Adaptive Fast-and-Slow Visual Program Reasoning for Long-Form VideoQA
arXiv:2509.17743v2 Announce Type: replace Abstract: Large language models (LLMs) have shown promise in generating program workflows for visual tasks. However, previous approaches often rely on closed-source models, lack systematic reasoning, and struggle with long-form video question answering (videoQA). To address these challenges, we introduce the FS-VisPR framework, an adaptive visual program reasoning approach that balances fast reasoning for simple queries with slow reasoning for difficult ones. First, we design efficient visual modules (e.g., key clip retrieval and subtitle retrieval) to support long-form video tasks. Then, we construct a diverse and high-quality fast-slow reasoning dataset with a strong LLM to align open-source language models' ability to generate visual program workflows as FS-LLM. Next, we design a fast-slow reasoning framework with FS-LLM: Simple queries are directly solved by VideoLLMs, while difficult ones invoke visual program reasoning, motivated by human-like reasoning processes. During this process, low-confidence fast-thinking answers will trigger a second-stage slow-reasoning process, and a fallback mechanism to fast reasoning is activated if the program execution fails. Moreover, we improve visual programs through parameter search during both training and inference. By adjusting the parameters of the visual modules within the program, multiple variants are generated: during training, programs that yield correct answers are selected, while during inference, the program with the highest confidence result is applied. Experiments show that FS-VisPR improves both efficiency and reliability in visual program workflows. It achieves 50.4% accuracy on LVBench, surpassing GPT-4o, matching the performance of Qwen2.5VL-72B on VideoMME.
StableGuard: Towards Unified Copyright Protection and Tamper Localization in Latent Diffusion Models
arXiv:2509.17993v2 Announce Type: replace Abstract: The advancement of diffusion models has enhanced the realism of AI-generated content but also raised concerns about misuse, necessitating robust copyright protection and tampering localization. Although recent methods have made progress toward unified solutions, their reliance on post hoc processing introduces considerable application inconvenience and compromises forensic reliability. We propose StableGuard, a novel framework that seamlessly integrates a binary watermark into the diffusion generation process, ensuring copyright protection and tampering localization in Latent Diffusion Models through an end-to-end design. We develop a Multiplexing Watermark VAE (MPW-VAE) by equipping a pretrained Variational Autoencoder (VAE) with a lightweight latent residual-based adapter, enabling the generation of paired watermarked and watermark-free images. These pairs, fused via random masks, create a diverse dataset for training a tampering-agnostic forensic network. To further enhance forensic synergy, we introduce a Mixture-of-Experts Guided Forensic Network (MoE-GFN) that dynamically integrates holistic watermark patterns, local tampering traces, and frequency-domain cues for precise watermark verification and tampered region detection. The MPW-VAE and MoE-GFN are jointly optimized in a self-supervised, end-to-end manner, fostering a reciprocal training between watermark embedding and forensic accuracy. Extensive experiments demonstrate that StableGuard consistently outperforms state-of-the-art methods in image fidelity, watermark verification, and tampering localization.
Is Pre-training Truly Better Than Meta-Learning?
arXiv:2306.13841v2 Announce Type: replace-cross Abstract: In the context of few-shot learning, it is currently believed that a fixed pre-trained (PT) model, along with fine-tuning the final layer during evaluation, outperforms standard meta-learning algorithms. We re-evaluate these claims under an in-depth empirical examination of an extensive set of formally diverse datasets and compare PT to Model Agnostic Meta-Learning (MAML). Unlike previous work, we emphasize a fair comparison by using: the same architecture, the same optimizer, and all models trained to convergence. Crucially, we use a more rigorous statistical tool -- the effect size (Cohen's d) -- to determine the practical significance of the difference between a model trained with PT vs. a MAML. We then use a previously proposed metric -- the diversity coefficient -- to compute the average formal diversity of a dataset. Using this analysis, we demonstrate the following: 1. when the formal diversity of a data set is low, PT beats MAML on average and 2. when the formal diversity is high, MAML beats PT on average. The caveat is that the magnitude of the average difference between a PT vs. MAML using the effect size is low (according to classical statistical thresholds) -- less than 0.2. Nevertheless, this observation is contrary to the currently held belief that a pre-trained model is always better than a meta-learning model. Our extensive experiments consider 21 few-shot learning benchmarks, including the large-scale few-shot learning dataset Meta-Data set. We also show no significant difference between a MAML model vs. a PT model with GPT-2 on Openwebtext. We, therefore, conclude that a pre-trained model does not always beat a meta-learned model and that the formal diversity of a dataset is a driving factor.
GlaLSTM: A Concurrent LSTM Stream Framework for Glaucoma Detection via Biomarker Mining
arXiv:2408.15555v3 Announce Type: replace-cross Abstract: Glaucoma is a complex group of eye diseases marked by optic nerve damage, commonly linked to elevated intraocular pressure and biomarkers like retinal nerve fiber layer thickness. Understanding how these biomarkers interact is crucial for unraveling glaucoma's underlying mechanisms. In this paper, we propose GlaLSTM, a novel concurrent LSTM stream framework for glaucoma detection, leveraging latent biomarker relationships. Unlike traditional CNN-based models that primarily detect glaucoma from images, GlaLSTM provides deeper interpretability, revealing the key contributing factors and enhancing model transparency. This approach not only improves detection accuracy but also empowers clinicians with actionable insights, facilitating more informed decision-making. Experimental evaluations confirm that GlaLSTM surpasses existing state-of-the-art methods, demonstrating its potential for both advanced biomarker analysis and reliable glaucoma detection.
LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via a Hybrid Architecture
arXiv:2409.02889v3 Announce Type: replace-cross Abstract: Expanding the long-context capabilities of Multi-modal Large Language Models~(MLLMs) is critical for advancing video understanding and high-resolution image analysis. Achieving this requires systematic improvements in model architecture, data construction, and training strategies, particularly to address challenges such as performance degradation with increasing image counts and high computational costs. In this paper, we propose a hybrid architecture that integrates Mamba and Transformer blocks, introduce data construction methods that capture both temporal and spatial dependencies, and employ a progressive training strategy. Our released model, LongLLaVA (\textbf{Long}-Context \textbf{L}arge \textbf{L}anguage \textbf{a}nd \textbf{V}ision \textbf{A}ssistant), demonstrates an effective balance between efficiency and performance. LongLLaVA achieves competitive results across various benchmarks while maintaining high throughput and low memory consumption. Notably, it can process nearly one thousand images on a single A100 80GB GPU, underscoring its potential for a wide range of multi-modal applications.
DOTA: Distributional Test-Time Adaptation of Vision-Language Models
arXiv:2409.19375v2 Announce Type: replace-cross Abstract: Vision-language foundation models (VLMs), such as CLIP, exhibit remarkable performance across a wide range of tasks. However, deploying these models can be unreliable when significant distribution gaps exist between training and test data, while fine-tuning for diverse scenarios is often costly. Cache-based test-time adapters offer an efficient alternative by storing representative test samples to guide subsequent classifications. Yet, these methods typically employ naive cache management with limited capacity, leading to severe catastrophic forgetting when samples are inevitably dropped during updates. In this paper, we propose DOTA (DistributiOnal Test-time Adaptation), a simple yet effective method addressing this limitation. Crucially, instead of merely memorizing individual test samples, DOTA continuously estimates the underlying distribution of the test data stream. Test-time posterior probabilities are then computed using these dynamically estimated distributions via Bayes' theorem for adaptation. This distribution-centric approach enables the model to continually learn and adapt to the deployment environment. Extensive experiments validate that DOTA significantly mitigates forgetting and achieves state-of-the-art performance compared to existing methods.
Exploring Model Kinship for Merging Large Language Models
arXiv:2410.12613v3 Announce Type: replace-cross Abstract: Model merging has emerged as a key technique for enhancing the capabilities and efficiency of Large Language Models (LLMs). The open-source community has driven model evolution by iteratively merging existing models, yet a principled understanding of the gains and underlying factors in model merging remains limited. In this work, we study model evolution through iterative merging, drawing an analogy to biological evolution, and introduce the concept of model kinship, the degree of similarity or relatedness between LLMs. Through comprehensive empirical analysis, we show that model kinship is closely linked to the performance improvements achieved by merging, providing a useful criterion for selecting candidate models. Building on this insight, we propose a new model merging strategy: Top-k Greedy Merging with Model Kinship, which can improve benchmark performance. Specifically, we discover that incorporating model kinship as a guiding criterion enables continuous merging while mitigating performance degradation caused by local optima, thereby facilitating more effective model evolution. Code is available at https://github.com/zjunlp/ModelKinship.
CaKE: Circuit-aware Editing Enables Generalizable Knowledge Learners
arXiv:2503.16356v2 Announce Type: replace-cross Abstract: Knowledge Editing (KE) enables the modification of outdated or incorrect information in large language models (LLMs). While existing KE methods can update isolated facts, they often fail to generalize these updates to multi-hop reasoning tasks that rely on the modified knowledge. Through an analysis of reasoning circuits -- the neural pathways LLMs use for knowledge-based inference, we find that current layer-localized KE approaches (e.g., MEMIT, WISE), which edit only single or a few model layers, inadequately integrate updated knowledge into these reasoning pathways. To address this limitation, we present CaKE (Circuit-aware Knowledge Editing), a novel method that enhances the effective integration of updated knowledge in LLMs. By only leveraging a few curated data samples guided by our circuit-based analysis, CaKE stimulates the model to develop appropriate reasoning circuits for newly incorporated knowledge. Experiments show that CaKE enables more accurate and consistent use of edited knowledge across related reasoning tasks, achieving an average improvement of 20% in multi-hop reasoning accuracy on the MQuAKE dataset while requiring less memory than existing KE methods. We release the code and data in https://github.com/zjunlp/CaKE.
LookAhead Tuning: Safer Language Models via Partial Answer Previews
arXiv:2503.19041v2 Announce Type: replace-cross Abstract: Fine-tuning enables large language models (LLMs) to adapt to specific domains, but often compromises their previously established safety alignment. To mitigate the degradation of model safety during fine-tuning, we introduce LookAhead Tuning, a lightweight and effective data-driven approach that preserves safety during fine-tuning. The method introduces two simple strategies that modify training data by previewing partial answer prefixes, thereby minimizing perturbations to the model's initial token distributions and maintaining its built-in safety mechanisms. Comprehensive experiments demonstrate that LookAhead Tuning effectively maintains model safety without sacrificing robust performance on downstream tasks. Our findings position LookAhead Tuning as a reliable and efficient solution for the safe and effective adaptation of LLMs.
Disentangle and Regularize: Sign Language Production with Articulator-Based Disentanglement and Channel-Aware Regularization
arXiv:2504.06610v3 Announce Type: replace-cross Abstract: In this work, we propose DARSLP, a simple gloss-free, transformer-based sign language production (SLP) framework that directly maps spoken-language text to sign pose sequences. We first train a pose autoencoder that encodes sign poses into a compact latent space using an articulator-based disentanglement strategy, where features corresponding to the face, right hand, left hand, and body are modeled separately to promote structured and interpretable representation learning. Next, a non-autoregressive transformer decoder is trained to predict these latent representations from word-level text embeddings of the input sentence. To guide this process, we apply channel-aware regularization by aligning predicted latent distributions with priors extracted from the ground-truth encodings using a KL divergence loss. The contribution of each channel to the loss is weighted according to its associated articulator region, enabling the model to account for the relative importance of different articulators during training. Our approach does not rely on gloss supervision or pretrained models, and achieves state-of-the-art results on the PHOENIX14T and CSL-Daily datasets.
Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study
arXiv:2505.15389v3 Announce Type: replace-cross Abstract: Rapid deployment of vision-language models (VLMs) magnifies safety risks, yet most evaluations rely on artificial images. This study asks: How safe are current VLMs when confronted with meme images that ordinary users share? To investigate this question, we introduce MemeSafetyBench, a 50,430-instance benchmark pairing real meme images with both harmful and benign instructions. Using a comprehensive safety taxonomy and LLM-based instruction generation, we assess multiple VLMs across single and multi-turn interactions. We investigate how real-world memes influence harmful outputs, the mitigating effects of conversational context, and the relationship between model scale and safety metrics. Our findings demonstrate that VLMs are more vulnerable to meme-based harmful prompts than to synthetic or typographic images. Memes significantly increase harmful responses and decrease refusals compared to text-only inputs. Though multi-turn interactions provide partial mitigation, elevated vulnerability persists. These results highlight the need for ecologically valid evaluations and stronger safety mechanisms. MemeSafetyBench is publicly available at https://github.com/oneonlee/Meme-Safety-Bench.
Large Language Models Implicitly Learn to See and Hear Just By Reading
arXiv:2505.17091v2 Announce Type: replace-cross Abstract: This paper presents a fascinating find: By training an auto-regressive LLM model on text tokens, the text model inherently develops internally an ability to understand images and audio, thereby developing the ability to see and hear just by reading. Popular audio and visual LLM models fine-tune text LLM models to give text output conditioned on images and audio embeddings. On the other hand, our architecture takes in patches of images, audio waveforms or tokens as input. It gives us the embeddings or category labels typical of a classification pipeline. We show the generality of text weights in aiding audio classification for datasets FSD-50K and GTZAN. Further, we show this working for image classification on CIFAR-10 and Fashion-MNIST, as well on image patches. This pushes the notion of text-LLMs learning powerful internal circuits that can be utilized by activating necessary connections for various applications rather than training models from scratch every single time.
UltraBoneUDF: Self-supervised Bone Surface Reconstruction from Ultrasound Based on Neural Unsigned Distance Functions
arXiv:2505.17912v3 Announce Type: replace-cross Abstract: Bone surface reconstruction is an essential component of computer-assisted orthopedic surgery (CAOS), forming the foundation for preoperative planning and intraoperative guidance. Compared to traditional imaging modalities such as CT and MRI, ultrasound provides a radiation-free, and cost-effective alternative. While ultrasound offers new opportunities in CAOS, technical shortcomings continue to hinder its translation into surgery. In particular, due to the inherent limitations of ultrasound imaging, B-mode ultrasound typically capture only partial bone surfaces, posing major challenges for surface reconstruction. Existing reconstruction methods struggle with such incomplete data, leading to increased reconstruction errors and artifacts. Effective techniques for accurately reconstructing open bone surfaces from real-world 3D ultrasound volumes remain lacking. We propose UltraBoneUDF, a self-supervised framework specifically designed for reconstructing open bone surfaces from ultrasound data using neural unsigned distance functions (UDFs). In addition, we present a novel loss function based on local tangent plane optimization that substantially improves surface reconstruction quality. UltraBoneUDF and competing models are benchmarked on three open-source datasets and further evaluated through ablation studies. Results: Qualitative results highlight the limitations of the state-of-the-art methods for open bone surface reconstruction and demonstrate the effectiveness of UltraBoneUDF. Quantitatively, UltraBoneUDF significantly outperforms competing methods across all evaluated datasets for both open and closed bone surface reconstruction in terms of mean Chamfer distance error: 0.96 mm on the UltraBones100k dataset (28.9% improvement compared to the state-of-the-art), 0.21 mm on the OpenBoneCT dataset (40.0% improvement), and 0.18 mm on the ClosedBoneCT dataset (63.3% improvement).
Foresight: Adaptive Layer Reuse for Accelerated and High-Quality Text-to-Video Generation
arXiv:2506.00329v2 Announce Type: replace-cross Abstract: Diffusion Transformers (DiTs) achieve state-of-the-art results in text-to-image, text-to-video generation, and editing. However, their large model size and the quadratic cost of spatial-temporal attention over multiple denoising steps make video generation computationally expensive. Static caching mitigates this by reusing features across fixed steps but fails to adapt to generation dynamics, leading to suboptimal trade-offs between speed and quality. We propose Foresight, an adaptive layer-reuse technique that reduces computational redundancy across denoising steps while preserving baseline performance. Foresight dynamically identifies and reuses DiT block outputs for all layers across steps, adapting to generation parameters such as resolution and denoising schedules to optimize efficiency. Applied to OpenSora, Latte, and CogVideoX, Foresight achieves up to \latencyimprv end-to-end speedup, while maintaining video quality. The source code of Foresight is available at \href{https://github.com/STAR-Laboratory/foresight}{https://github.com/STAR-Laboratory/foresight}.
LaMP-Cap: Personalized Figure Caption Generation With Multimodal Figure Profiles
arXiv:2506.06561v4 Announce Type: replace-cross Abstract: Figure captions are crucial for helping readers understand and remember a figure's key message. Many models have been developed to generate these captions, helping authors compose better quality captions more easily. Yet, authors almost always need to revise generic AI-generated captions to match their writing style and the domain's style, highlighting the need for personalization. Despite language models' personalization (LaMP) advances, these technologies often focus on text-only settings and rarely address scenarios where both inputs and profiles are multimodal. This paper introduces LaMP-Cap, a dataset for personalized figure caption generation with multimodal figure profiles. For each target figure, LaMP-Cap provides not only the needed inputs, such as figure images, but also up to three other figures from the same document--each with its image, caption, and figure-mentioning paragraphs--as a profile to characterize the context. Experiments with four LLMs show that using profile information consistently helps generate captions closer to the original author-written ones. Ablation studies reveal that images in the profile are more helpful than figure-mentioning paragraphs, highlighting the advantage of using multimodal profiles over text-only ones.
Athena: Enhancing Multimodal Reasoning with Data-efficient Process Reward Models
arXiv:2506.09532v2 Announce Type: replace-cross Abstract: We present Athena-PRM, a multimodal process reward model (PRM) designed to evaluate the reward score for each step in solving complex reasoning problems. Developing high-performance PRMs typically demands significant time and financial investment, primarily due to the necessity for step-level annotations of reasoning steps. Conventional automated labeling methods, such as Monte Carlo estimation, often produce noisy labels and incur substantial computational costs. To efficiently generate high-quality process-labeled data, we propose leveraging prediction consistency between weak and strong completers as a criterion for identifying reliable process labels. Remarkably, Athena-PRM demonstrates outstanding effectiveness across various scenarios and benchmarks with just 5,000 samples. Furthermore, we also develop two effective strategies to improve the performance of PRMs: ORM initialization and up-sampling for negative data. We validate our approach in three specific scenarios: verification for test time scaling, direct evaluation of reasoning step correctness, and reward ranked fine-tuning. Our Athena-PRM consistently achieves superior performance across multiple benchmarks and scenarios. Notably, when using Qwen2.5-VL-7B as the policy model, Athena-PRM enhances performance by 10.2 points on WeMath and 7.1 points on MathVista for test time scaling. Furthermore, Athena-PRM sets the state-of-the-art (SoTA) results in VisualProcessBench and outperforms the previous SoTA by 3.9 F1-score, showcasing its robust capability to accurately assess the correctness of the reasoning step. Additionally, utilizing Athena-PRM as the reward model, we develop Athena-7B with reward ranked fine-tuning and outperforms baseline with a significant margin on five benchmarks.
A Rigorous Behavior Assessment of CNNs Using a Data-Domain Sampling Regime
arXiv:2507.03866v2 Announce Type: replace-cross Abstract: We present a data-domain sampling regime for quantifying CNNs' graphic perception behaviors. This regime lets us evaluate CNNs' ratio estimation ability in bar charts from three perspectives: sensitivity to training-test distribution discrepancies, stability to limited samples, and relative expertise to human observers. After analyzing 16 million trials from 800 CNNs models and 6,825 trials from 113 human participants, we arrived at a simple and actionable conclusion: CNNs can outperform humans and their biases simply depend on the training-test distance. We show evidence of this simple, elegant behavior of the machines when they interpret visualization images. osf.io/gfqc3 provides registration, the code for our sampling regime, and experimental results.
IMAIA: Interactive Maps AI Assistant for Travel Planning and Geo-Spatial Intelligence
arXiv:2507.06993v3 Announce Type: replace-cross Abstract: Map applications are still largely point-and-click, making it difficult to ask map-centric questions or connect what a camera sees to the surrounding geospatial context with view-conditioned inputs. We introduce IMAIA, an interactive Maps AI Assistant that enables natural-language interaction with both vector (street) maps and satellite imagery, and augments camera inputs with geospatial intelligence to help users understand the world. IMAIA comprises two complementary components. Maps Plus treats the map as first-class context by parsing tiled vector/satellite views into a grid-aligned representation that a language model can query to resolve deictic references (e.g., ``the flower-shaped building next to the park in the top-right''). Places AI Smart Assistant (PAISA) performs camera-aware place understanding by fusing image--place embeddings with geospatial signals (location, heading, proximity) to ground a scene, surface salient attributes, and generate concise explanations. A lightweight multi-agent design keeps latency low and exposes interpretable intermediate decisions. Across map-centric QA and camera-to-place grounding tasks, IMAIA improves accuracy and responsiveness over strong baselines while remaining practical for user-facing deployments. By unifying language, maps, and geospatial cues, IMAIA moves beyond scripted tools toward conversational mapping that is both spatially grounded and broadly usable.
Class-wise Balancing Data Replay for Federated Class-Incremental Learning
arXiv:2507.07712v2 Announce Type: replace-cross Abstract: Federated Class Incremental Learning (FCIL) aims to collaboratively process continuously increasing incoming tasks across multiple clients. Among various approaches, data replay has become a promising solution, which can alleviate forgetting by reintroducing representative samples from previous tasks. However, their performance is typically limited by class imbalance, both within the replay buffer due to limited global awareness and between replayed and newly arrived classes. To address this issue, we propose a class wise balancing data replay method for FCIL (FedCBDR), which employs a global coordination mechanism for class-level memory construction and reweights the learning objective to alleviate the aforementioned imbalances. Specifically, FedCBDR has two key components: 1) the global-perspective data replay module reconstructs global representations of prior task in a privacy-preserving manner, which then guides a class-aware and importance-sensitive sampling strategy to achieve balanced replay; 2) Subsequently, to handle class imbalance across tasks, the task aware temperature scaling module adaptively adjusts the temperature of logits at both class and instance levels based on task dynamics, which reduces the model's overconfidence in majority classes while enhancing its sensitivity to minority classes. Experimental results verified that FedCBDR achieves balanced class-wise sampling under heterogeneous data distributions and improves generalization under task imbalance between earlier and recent tasks, yielding a 2%-15% Top-1 accuracy improvement over six state-of-the-art methods.
Enhancing Video-Based Robot Failure Detection Using Task Knowledge
arXiv:2508.18705v2 Announce Type: replace-cross Abstract: Robust robotic task execution hinges on the reliable detection of execution failures in order to trigger safe operation modes, recovery strategies, or task replanning. However, many failure detection methods struggle to provide meaningful performance when applied to a variety of real-world scenarios. In this paper, we propose a video-based failure detection approach that uses spatio-temporal knowledge in the form of the actions the robot performs and task-relevant objects within the field of view. Both pieces of information are available in most robotic scenarios and can thus be readily obtained. We demonstrate the effectiveness of our approach on three datasets that we amend, in part, with additional annotations of the aforementioned task-relevant knowledge. In light of the results, we also propose a data augmentation method that improves performance by applying variable frame rates to different parts of the video. We observe an improvement from 77.9 to 80.0 in F1 score on the ARMBench dataset without additional computational expense and an additional increase to 81.4 with test-time augmentation. The results emphasize the importance of spatio-temporal information during failure detection and suggest further investigation of suitable heuristics in future implementations. Code and annotations are available.
mRadNet: A Compact Radar Object Detector with MetaFormer
arXiv:2509.16223v2 Announce Type: replace-cross Abstract: Frequency-modulated continuous wave radars have gained increasing popularity in the automotive industry. Its robustness against adverse weather conditions makes it a suitable choice for radar object detection in advanced driver assistance systems. These real-time embedded systems have requirements for the compactness and efficiency of the model, which have been largely overlooked in previous work. In this work, we propose mRadNet, a novel radar object detection model with compactness in mind. mRadNet employs a U-net style architecture with MetaFormer blocks, in which separable convolution and attention token mixers are used to capture both local and global features effectively. More efficient token embedding and merging strategies are introduced to further facilitate the lightweight design. The performance of mRadNet is validated on the CRUW dataset, improving state-of-the-art performance with the least number of parameters and FLOPs.
Towards Interpretable and Efficient Attention: Compressing All by Contracting a Few
arXiv:2509.16875v2 Announce Type: replace-cross Abstract: Attention mechanisms in Transformers have gained significant empirical success. Nonetheless, the optimization objectives underlying their forward pass are still unclear. Additionally, the quadratic complexity of self-attention is increasingly prohibitive. Unlike the prior work on addressing the interpretability or efficiency issue separately, we propose a unified optimization objective to alleviate both issues simultaneously. By unrolling the optimization over the objective, we derive an inherently interpretable and efficient attention mechanism, which compresses all tokens into low-dimensional structures by contracting a few representative tokens and then broadcasting the contractions back. This Contract-and-Broadcast Self-Attention (CBSA) mechanism can not only scale linearly but also generalize existing attention mechanisms as its special cases. Experiments further demonstrate comparable performance and even superior advantages of CBSA on several visual tasks. Code is available at this https URL.
A Chain-of-thought Reasoning Breast Ultrasound Dataset Covering All Histopathology Categories
arXiv:2509.17046v2 Announce Type: replace-cross Abstract: Breast ultrasound (BUS) is an essential tool for diagnosing breast lesions, with millions of examinations per year. However, publicly available high-quality BUS benchmarks for AI development are limited in data scale and annotation richness. In this work, we present BUS-CoT, a BUS dataset for chain-of-thought (CoT) reasoning analysis, which contains 11,439 images of 10,019 lesions from 4,838 patients and covers all 99 histopathology types. To facilitate research on incentivizing CoT reasoning, we construct the reasoning processes based on observation, feature, diagnosis and pathology labels, annotated and verified by experienced experts. Moreover, by covering lesions of all histopathology types, we aim to facilitate robust AI systems in rare cases, which can be error-prone in clinical practice.
Joint Memory Frequency and Computing Frequency Scaling for Energy-efficient DNN Inference
arXiv:2509.17970v2 Announce Type: replace-cross Abstract: Deep neural networks (DNNs) have been widely applied in diverse applications, but the problems of high latency and energy overhead are inevitable on resource-constrained devices. To address this challenge, most researchers focus on the dynamic voltage and frequency scaling (DVFS) technique to balance the latency and energy consumption by changing the computing frequency of processors. However, the adjustment of memory frequency is usually ignored and not fully utilized to achieve efficient DNN inference, which also plays a significant role in the inference time and energy consumption. In this paper, we first investigate the impact of joint memory frequency and computing frequency scaling on the inference time and energy consumption with a model-based and data-driven method. Then by combining with the fitting parameters of different DNN models, we give a preliminary analysis for the proposed model to see the effects of adjusting memory frequency and computing frequency simultaneously. Finally, simulation results in local inference and cooperative inference cases further validate the effectiveness of jointly scaling the memory frequency and computing frequency to reduce the energy consumption of devices.
Machine Learnability as a Measure of Order in Aperiodic Sequences
arXiv:2509.18103v1 Announce Type: new Abstract: Research on the distribution of prime numbers has revealed a dual character: deterministic in definition yet exhibiting statistical behavior reminiscent of random processes. In this paper we show that it is possible to use an image-focused machine learning model to measure the comparative regularity of prime number fields at specific regions of an Ulam spiral. Specifically, we demonstrate that in pure accuracy terms, models trained on blocks extracted from regions of the spiral in the vicinity of 500m outperform models trained on blocks extracted from the region representing integers lower than 25m. This implies existence of more easily learnable order in the former region than in the latter. Moreover, a detailed breakdown of precision and recall scores seem to imply that the model is favouring a different approach to classification in different regions of the spiral, focusing more on identifying prime patterns at lower numbers and more on eliminating composites at higher numbers. This aligns with number theory conjectures suggesting that at higher orders of magnitude we should see diminishing noise in prime number distributions, with averages (density, AP equidistribution) coming to dominate, while local randomness regularises after scaling by log x. Taken together, these findings point toward an interesting possibility: that machine learning can serve as a new experimental instrument for number theory. Notably, the method shows potential 1 for investigating the patterns in strong and weak primes for cryptographic purposes.
Data Valuation and Selection in a Federated Model Marketplace
arXiv:2509.18104v1 Announce Type: new Abstract: In the era of Artificial Intelligence (AI), marketplaces have become essential platforms for facilitating the exchange of data products to foster data sharing. Model transactions provide economic solutions in data marketplaces that enhance data reusability and ensure the traceability of data ownership. To establish trustworthy data marketplaces, Federated Learning (FL) has emerged as a promising paradigm to enable collaborative learning across siloed datasets while safeguarding data privacy. However, effective data valuation and selection from heterogeneous sources in the FL setup remain key challenges. This paper introduces a comprehensive framework centered on a Wasserstein-based estimator tailored for FL. The estimator not only predicts model performance across unseen data combinations but also reveals the compatibility between data heterogeneity and FL aggregation algorithms. To ensure privacy, we propose a distributed method to approximate Wasserstein distance without requiring access to raw data. Furthermore, we demonstrate that model performance can be reliably extrapolated under the neural scaling law, enabling effective data selection without full-scale training. Extensive experiments across diverse scenarios, such as label skew, mislabeled, and unlabeled sources, show that our approach consistently identifies high-performing data combinations, paving the way for more reliable FL-based model marketplaces.
BULL-ODE: Bullwhip Learning with Neural ODEs and Universal Differential Equations under Stochastic Demand
arXiv:2509.18105v1 Announce Type: new Abstract: We study learning of continuous-time inventory dynamics under stochastic demand and quantify when structure helps or hurts forecasting of the bullwhip effect. BULL-ODE compares a fully learned Neural ODE (NODE) that models the entire right-hand side against a physics-informed Universal Differential Equation (UDE) that preserves conservation and order-up-to structure while learning a small residual policy term. Classical supply chain models explain the bullwhip through control/forecasting choices and information sharing, while recent physics-informed and neural differential equation methods blend domain constraints with learned components. It is unclear whether structural bias helps or hinders forecasting under different demand regimes. We address this by using a single-echelon testbed with three demand regimes - AR(1) (autocorrelated), i.i.d. Gaussian, and heavy-tailed lognormal. Training is done on varying fractions of each trajectory, followed by evaluation of multi-step forecasts for inventory I, order rate O, and demand D. Across the structured regimes, UDE consistently generalizes better: with 90% of the training horizon, inventory RMSE drops from 4.92 (NODE) to 0.26 (UDE) under AR(1) and from 5.96 to 0.95 under Gaussian demand. Under heavy-tailed lognormal shocks, the flexibility of NODE is better. These trends persist as train18 ing data shrinks, with NODE exhibiting phase drift in extrapolation while UDE remains stable but underreacts to rare spikes. Our results provide concrete guidance: enforce structure when noise is light-tailed or temporally correlated; relax structure when extreme events dominate. Beyond inventory control, the results offer guidance for hybrid modeling in scientific and engineering systems: enforce known structure when conservation laws and modest noise dominate, and relax structure to capture extremes in settings where rare events drive dynamics.
Model-Based Transfer Learning for Real-Time Damage Assessment of Bridge Networks
arXiv:2509.18106v1 Announce Type: new Abstract: The growing use of permanent monitoring systems has increased data availability, offering new opportunities for structural assessment but also posing scalability challenges, especially across large bridge networks. Managing multiple structures requires tracking and comparing long-term behaviour efficiently. To address this, knowledge transfer between similar structures becomes essential. This study proposes a model-based transfer learning approach using neural network surrogate models, enabling a model trained on one bridge to be adapted to another with similar characteristics. These models capture shared damage mechanisms, supporting a scalable and generalizable monitoring framework. The method was validated using real data from two bridges. The transferred model was integrated into a Bayesian inference framework for continuous damage assessment based on modal features from monitoring data. Results showed high sensitivity to damage location, severity, and extent. This approach enhances real-time monitoring and enables cross-structure knowledge transfer, promoting smart monitoring strategies and improved resilience at the network level.
AdaMixT: Adaptive Weighted Mixture of Multi-Scale Expert Transformers for Time Series Forecasting
arXiv:2509.18107v1 Announce Type: new Abstract: Multivariate time series forecasting involves predicting future values based on historical observations. However, existing approaches primarily rely on predefined single-scale patches or lack effective mechanisms for multi-scale feature fusion. These limitations hinder them from fully capturing the complex patterns inherent in time series, leading to constrained performance and insufficient generalizability. To address these challenges, we propose a novel architecture named Adaptive Weighted Mixture of Multi-Scale Expert Transformers (AdaMixT). Specifically, AdaMixT introduces various patches and leverages both General Pre-trained Models (GPM) and Domain-specific Models (DSM) for multi-scale feature extraction. To accommodate the heterogeneity of temporal features, AdaMixT incorporates a gating network that dynamically allocates weights among different experts, enabling more accurate predictions through adaptive multi-scale fusion. Comprehensive experiments on eight widely used benchmarks, including Weather, Traffic, Electricity, ILI, and four ETT datasets, consistently demonstrate the effectiveness of AdaMixT in real-world scenarios.
Solve it with EASE
arXiv:2509.18108v1 Announce Type: new Abstract: This paper presents EASE (Effortless Algorithmic Solution Evolution), an open-source and fully modular framework for iterative algorithmic solution generation leveraging large language models (LLMs). EASE integrates generation, testing, analysis, and evaluation into a reproducible feedback loop, giving users full control over error handling, analysis, and quality assessment. Its architecture supports the orchestration of multiple LLMs in complementary roles-such as generator, analyst, and evaluator. By abstracting the complexity of prompt design and model management, EASE provides a transparent and extensible platform for researchers and practitioners to co-design algorithms and other generative solutions across diverse domains.
Machine Learning-Based Classification of Vessel Types in Straits Using AIS Tracks
arXiv:2509.18109v1 Announce Type: new Abstract: Accurate recognition of vessel types from Automatic Identification System (AIS) tracks is essential for safety oversight and combating illegal, unreported, and unregulated (IUU) activity. This paper presents a strait-scale, machine-learning pipeline that classifies moving vessels using only AIS data. We analyze eight days of historical AIS from the Danish Maritime Authority covering the Bornholm Strait in the Baltic Sea (January 22-30, 2025). After forward/backward filling voyage records, removing kinematic and geospatial outliers, and segmenting per-MMSI tracks while excluding stationary periods ($\ge 1$ h), we derive 31 trajectory-level features spanning kinematics (e.g., SOG statistics), temporal, geospatial (Haversine distances, spans), and ship-shape attributes computed from AIS A/B/C/D reference points (length, width, aspect ratio, bridge-position ratio). To avoid leakage, we perform grouped train/test splits by MMSI and use stratified 5-fold cross-validation. Across five classes (cargo, tanker, passenger, high-speed craft, fishing; N=1{,}910 trajectories; test=382), tree-based models dominate: a Random Forest with SMOTE attains 92.15% accuracy (macro-precision 94.11%, macro-recall 92.51%, macro-F1 93.27%) on the held-out test set, while a tuned RF reaches one-vs-rest ROC-AUC up to 0.9897. Feature-importance analysis highlights the bridge-position ratio and maximum SOG as the most discriminative signals; principal errors occur between cargo and tanker, reflecting similar transit behavior. We demonstrate operational value by backfilling missing ship types on unseen data and discuss improvements such as DBSCAN based trip segmentation and gradient-boosted ensembles to handle frequent-stop ferries and further lift performance. The results show that lightweight features over AIS trajectories enable real-time vessel type classification in straits.
Localized PCA-Net Neural Operators for Scalable Solution Reconstruction of Elliptic PDEs
arXiv:2509.18110v1 Announce Type: new Abstract: Neural operator learning has emerged as a powerful approach for solving partial differential equations (PDEs) in a data-driven manner. However, applying principal component analysis (PCA) to high-dimensional solution fields incurs significant computational overhead. To address this, we propose a patch-based PCA-Net framework that decomposes the solution fields into smaller patches, applies PCA within each patch, and trains a neural operator in the reduced PCA space. We investigate two different patch-based approaches that balance computational efficiency and reconstruction accuracy: (1) local-to-global patch PCA, and (2) local-to-local patch PCA. The trade-off between computational cost and accuracy is analyzed, highlighting the advantages and limitations of each approach. Furthermore, within each approach, we explore two refinements for the most computationally efficient method: (i) introducing overlapping patches with a smoothing filter and (ii) employing a two-step process with a convolutional neural network (CNN) for refinement. Our results demonstrate that patch-based PCA significantly reduces computational complexity while maintaining high accuracy, reducing end-to-end pipeline processing time by a factor of 3.7 to 4 times compared to global PCA, thefore making it a promising technique for efficient operator learning in PDE-based systems.
Prompt Optimization Meets Subspace Representation Learning for Few-shot Out-of-Distribution Detection
arXiv:2509.18111v1 Announce Type: new Abstract: The reliability of artificial intelligence (AI) systems in open-world settings depends heavily on their ability to flag out-of-distribution (OOD) inputs unseen during training. Recent advances in large-scale vision-language models (VLMs) have enabled promising few-shot OOD detection frameworks using only a handful of in-distribution (ID) samples. However, existing prompt learning-based OOD methods rely solely on softmax probabilities, overlooking the rich discriminative potential of the feature embeddings learned by VLMs trained on millions of samples. To address this limitation, we propose a novel context optimization (CoOp)-based framework that integrates subspace representation learning with prompt tuning. Our approach improves ID-OOD separability by projecting the ID features into a subspace spanned by prompt vectors, while projecting ID-irrelevant features into an orthogonal null space. To train such OOD detection framework, we design an easy-to-handle end-to-end learning criterion that ensures strong OOD detection performance as well as high ID classification accuracy. Experiments on real-world datasets showcase the effectiveness of our approach.
Large language models surpass domain-specific architectures for antepartum electronic fetal monitoring analysis
arXiv:2509.18112v1 Announce Type: new Abstract: Foundation models (FMs) and large language models (LLMs) demonstrate remarkable capabilities across diverse domains through training on massive datasets. These models have demonstrated exceptional performance in healthcare applications, yet their potential for electronic fetal monitoring (EFM)/cardiotocography (CTG) analysis, a critical technology for evaluating fetal well-being, remains largely underexplored. Antepartum CTG interpretation presents unique challenges due to the complex nature of fetal heart rate (FHR) patterns and uterine activity, requiring sophisticated analysis of long time-series data. The assessment of CTG is heavily based on subjective clinical interpretation, often leading to variability in diagnostic accuracy and deviation from timely pregnancy care. This study presents the first comprehensive comparison of state-of-the-art AI approaches for automated antepartum CTG analysis. We systematically compare time-series FMs and LLMs against established CTG-specific architectures. Our evaluation encompasses over 500 CTG recordings of varying durations reflecting real-world clinical recordings, providing robust performance benchmarks across different modelling paradigms. Our results demonstrate that fine-tuned LLMs achieve superior performance compared to both foundation models and domain-specific approaches, offering a promising alternative pathway for clinical CTG interpretation. These findings provide critical insights into the relative strengths of different AI methodologies for fetal monitoring applications and establish a foundation for future clinical AI development in prenatal care.
A Study of Skews, Imbalances, and Pathological Conditions in LLM Inference Deployment on GPU Clusters detectable from DPU
arXiv:2509.18114v1 Announce Type: new Abstract: Autoregressive inference in large transformer-based language models (LLMs) presents significant challenges for runtime efficiency, particularly during the decode phase where load imbalance across GPU shards can cause throughput degradation and latency spikes. A DPU-assisted framework leveraged by BlueField-3 Data Processing Units can enable real-time detection and mitigation of load imbalance in multi-node tensor-parallel inference. By offloading monitoring tasks to the DPU and analyzing GPU telemetry and inter-node communication patterns, the resulting system can provide actionable feedback to inference controllers and schedulers. The goal of this study is three-fold i) identify the reported skews/imbalances/pathological conditions that arise in muti-GPU execution of a) LLM tensor computing (both during training and inference), b) identify their impact on computational performance, and c) make a critical assessment if those can be tracked for potential mitigation from a DPU network.
Towards Scalable and Structured Spatiotemporal Forecasting
arXiv:2509.18115v1 Announce Type: new Abstract: In this paper, we propose a novel Spatial Balance Attention block for spatiotemporal forecasting. To strike a balance between obeying spatial proximity and capturing global correlation, we partition the spatial graph into a set of subgraphs and instantiate Intra-subgraph Attention to learn local spatial correlation within each subgraph; to capture the global spatial correlation, we further aggregate the nodes to produce subgraph representations and achieve message passing among the subgraphs via Inter-subgraph Attention. Building on the proposed Spatial Balance Attention block, we develop a multiscale spatiotemporal forecasting model by progressively increasing the subgraph scales. The resulting model is both scalable and able to produce structured spatial correlation, and meanwhile, it is easy to implement. We evaluate its efficacy and efficiency against the existing models on real-world spatiotemporal datasets from medium to large sizes. The experimental results show that it can achieve performance improvements up to 7.7% over the baseline methods at low running costs.
Amortized Latent Steering: Low-Cost Alternative to Test-Time Optimization
arXiv:2509.18116v1 Announce Type: new Abstract: Test-time optimization remains impractical at scale due to prohibitive inference costs\textemdash techniques like iterative refinement and multi-step verification can require $10$--$100\times$ more compute per query than standard decoding. Latent space test-time optimization methods like LatentSeek offer a more direct approach by steering hidden representations, but still demand expensive per-query optimization loops with multiple backward passes. We propose Amortized Latent Steering (ALS), which collapses this iterative optimization into a single offline-computed vector applied at constant cost during inference. ALS computes the mean difference between hidden states from successful versus unsuccessful generations, then uses this direction to calibrate the model's hidden representations: when decoding drifts away from the success manifold, ALS nudges activations back toward it. Across GSM8K and MATH-$500$ benchmarks, ALS achieves $2$--$5\times$ speedup over iterative methods while matching or surpassing greedy Chain-of-Thought (CoT) and Self-Consistency baselines, yielding up to 101\% improvement in efficiency--accuracy trade-off. These results show that much of latent optimization's benefit can be captured offline, making sophisticated reasoning techniques viable for production deployment. Code is available at~\href{https://anonymous.4open.science/r/steering-17F2}{https://anonymous.4open.science/r/steering-17F2}
Robust and continuous machine learning of usage habits to adapt digital interfaces to user needs
arXiv:2509.18117v1 Announce Type: new Abstract: The paper presents a machine learning approach to design digital interfaces that can dynamically adapt to different users and usage strategies. The algorithm uses Bayesian statistics to model users' browsing behavior, focusing on their habits rather than group preferences. It is distinguished by its online incremental learning, allowing reliable predictions even with little data and in the case of a changing environment. This inference method generates a task model, providing a graphical representation of navigation with the usage statistics of the current user. The algorithm learns new tasks while preserving prior knowledge. The theoretical framework is described, and simulations show the effectiveness of the approach in stationary and non-stationary environments. In conclusion, this research paves the way for adaptive systems that improve the user experience by helping them to better navigate and act on their interface.
Decentor-V: Lightweight ML Training on Low-Power RISC-V Edge Devices
arXiv:2509.18118v1 Announce Type: new Abstract: Modern IoT devices increasingly rely on machine learning solutions to process data locally. However, the lack of graphics processing units (GPUs) or dedicated accelerators on most platforms makes on-device training largely infeasible, often requiring cloud-based services to perform this task. This procedure often raises privacy-related concerns, and creates dependency on reliable and always-on connectivity. Federated Learning (FL) is a new trend that addresses these issues by enabling decentralized and collaborative training directly on devices, but it requires highly efficient optimization algorithms. L-SGD, a lightweight variant of stochastic gradient descent, has enabled neural network training on Arm Cortex-M Microcontroller Units (MCUs). This work extends L-SGD to RISC-V-based MCUs, an open and emerging architecture that still lacks robust support for on-device training. L-SGD was evaluated on both Arm and RISC-V platforms using 32-bit floating-point arithmetic, highlighting the performance impact of the absence of Floating-Point Units (FPUs) in RISC-V MCUs. To mitigate these limitations, we introduce an 8-bit quantized version of L-SGD for RISC-V, which achieves nearly 4x reduction in memory usage and a 2.2x speedup in training time, with negligible accuracy degradation.
MobileRL: Online Agentic Reinforcement Learning for Mobile GUI Agents
arXiv:2509.18119v1 Announce Type: new Abstract: Building general-purpose graphical user interface (GUI) agents has become increasingly promising with the progress in vision language models. However, developing effective mobile GUI agents with reinforcement learning (RL) remains challenging due to the heavy-tailed distribution of task difficulty and the inefficiency of large-scale environment sampling. We present an online agentic reinforcement learning framework MOBILERL to enhance GUI agents in mobile environments. Its core component is the Difficulty-Adaptive GRPO (ADAGRPO) algorithm. In ADAGRPO, we design difficulty-adaptive positive replay and failure curriculum filtering to adapt the model to different task difficulties. We introduce the shortest path reward adjustment strategy to reshape rewards concerning the task length in multi-turn agentic tasks. Those strategies jointly stabilize RL training, improve sample efficiency, and generate strong performance across diverse mobile apps and tasks. We apply MOBILERL to two open models (Qwen2.5-VL-7B-Instruct and GLM-4.1V-9B-Base). The resultant MOBILERL-9B model achieves state-of-the-art results in terms of success rates on both AndroidWorld (75.8%) and AndroidLab (46.8%). The MOBILERL framework is adopted in the AutoGLM products, and also open-sourced at https://github.com/THUDM/MobileRL.
A Coopetitive-Compatible Data Generation Framework for Cross-silo Federated Learning
arXiv:2509.18120v1 Announce Type: new Abstract: Cross-silo federated learning (CFL) enables organizations (e.g., hospitals or banks) to collaboratively train artificial intelligence (AI) models while preserving data privacy by keeping data local. While prior work has primarily addressed statistical heterogeneity across organizations, a critical challenge arises from economic competition, where organizations may act as market rivals, making them hesitant to participate in joint training due to potential utility loss (i.e., reduced net benefit). Furthermore, the combined effects of statistical heterogeneity and inter-organizational competition on organizational behavior and system-wide social welfare remain underexplored. In this paper, we propose CoCoGen, a coopetitive-compatible data generation framework, leveraging generative AI (GenAI) and potential game theory to model, analyze, and optimize collaborative learning under heterogeneous and competitive settings. Specifically, CoCoGen characterizes competition and statistical heterogeneity through learning performance and utility-based formulations and models each training round as a weighted potential game. We then derive GenAI-based data generation strategies that maximize social welfare. Experimental results on the Fashion-MNIST dataset reveal how varying heterogeneity and competition levels affect organizational behavior and demonstrate that CoCoGen consistently outperforms baseline methods.
Prediction of Coffee Ratings Based On Influential Attributes Using SelectKBest and Optimal Hyperparameters
arXiv:2509.18124v1 Announce Type: new Abstract: This study explores the application of supervised machine learning algorithms to predict coffee ratings based on a combination of influential textual and numerical attributes extracted from user reviews. Through careful data preprocessing including text cleaning, feature extraction using TF-IDF, and selection with SelectKBest, the study identifies key factors contributing to coffee quality assessments. Six models (Decision Tree, KNearest Neighbors, Multi-layer Perceptron, Random Forest, Extra Trees, and XGBoost) were trained and evaluated using optimized hyperparameters. Model performance was assessed primarily using F1-score, Gmean, and AUC metrics. Results demonstrate that ensemble methods (Extra Trees, Random Forest, and XGBoost), as well as Multi-layer Perceptron, consistently outperform simpler classifiers (Decision Trees and K-Nearest Neighbors) in terms of evaluation metrics such as F1 scores, G-mean and AUC. The findings highlight the essence of rigorous feature selection and hyperparameter tuning in building robust predictive systems for sensory product evaluation, offering a data driven approach to complement traditional coffee cupping by expertise of trained professionals.
NurseSchedRL: Attention-Guided Reinforcement Learning for Nurse-Patient Assignment
arXiv:2509.18125v1 Announce Type: new Abstract: Healthcare systems face increasing pressure to allocate limited nursing resources efficiently while accounting for skill heterogeneity, patient acuity, staff fatigue, and continuity of care. Traditional optimization and heuristic scheduling methods struggle to capture these dynamic, multi-constraint environments. I propose NurseSchedRL, a reinforcement learning framework for nurse-patient assignment that integrates structured state encoding, constrained action masking, and attention-based representations of skills, fatigue, and geographical context. NurseSchedRL uses Proximal Policy Optimization (PPO) with feasibility masks to ensure assignments respect real-world constraints, while dynamically adapting to patient arrivals and varying nurse availability. In simulation with realistic nurse and patient data, NurseSchedRL achieves improved scheduling efficiency, better alignment of skills to patient needs, and reduced fatigue compared to baseline heuristic and unconstrained RL approaches. These results highlight the potential of reinforcement learning for decision support in complex, high-stakes healthcare workforce management.
Anomaly Detection in Electric Vehicle Charging Stations Using Federated Learning
arXiv:2509.18126v1 Announce Type: new Abstract: Federated Learning (FL) is a decentralized training framework widely used in IoT ecosystems that preserves privacy by keeping raw data local, making it ideal for IoT-enabled cyber-physical systems with sensing and communication like Smart Grids (SGs), Connected and Automated Vehicles (CAV), and Electric Vehicle Charging Stations (EVCS). With the rapid expansion of electric vehicle infrastructure, securing these IoT-based charging stations against cyber threats has become critical. Centralized Intrusion Detection Systems (IDS) raise privacy concerns due to sensitive network and user data, making FL a promising alternative. However, current FL-based IDS evaluations overlook practical challenges such as system heterogeneity and non-IID data. To address these challenges, we conducted experiments to evaluate the performance of federated learning for anomaly detection in EV charging stations under system and data heterogeneity. We used FedAvg and FedAvgM, widely studied optimization approaches, to analyze their effectiveness in anomaly detection. Under IID settings, FedAvg achieves superior performance to centralized models using the same neural network. However, performance degrades with non-IID data and system heterogeneity. FedAvgM consistently outperforms FedAvg in heterogeneous settings, showing better convergence and higher anomaly detection accuracy. Our results demonstrate that FL can handle heterogeneity in IoT-based EVCS without significant performance loss, with FedAvgM as a promising solution for robust, privacy-preserving EVCS security.
Safe-SAIL: Towards a Fine-grained Safety Landscape of Large Language Models via Sparse Autoencoder Interpretation Framework
arXiv:2509.18127v1 Announce Type: new Abstract: Increasing deployment of large language models (LLMs) in real-world applications raises significant safety concerns. Most existing safety research focuses on evaluating LLM outputs or specific safety tasks, limiting their ability to ad- dress broader, undefined risks. Sparse Autoencoders (SAEs) facilitate interpretability research to clarify model behavior by explaining single-meaning atomic features decomposed from entangled signals. jHowever, prior applications on SAEs do not interpret features with fine-grained safety-related con- cepts, thus inadequately addressing safety-critical behaviors, such as generating toxic responses and violating safety regu- lations. For rigorous safety analysis, we must extract a rich and diverse set of safety-relevant features that effectively capture these high-risk behaviors, yet face two challenges: identifying SAEs with the greatest potential for generating safety concept-specific neurons, and the prohibitively high cost of detailed feature explanation. In this paper, we pro- pose Safe-SAIL, a framework for interpreting SAE features within LLMs to advance mechanistic understanding in safety domains. Our approach systematically identifies SAE with best concept-specific interpretability, explains safety-related neurons, and introduces efficient strategies to scale up the in- terpretation process. We will release a comprehensive toolkit including SAE checkpoints and human-readable neuron ex- planations, which supports empirical analysis of safety risks to promote research on LLM safety.
Accounting for Uncertainty in Machine Learning Surrogates: A Gauss-Hermite Quadrature Approach to Reliability Analysis
arXiv:2509.18128v1 Announce Type: new Abstract: Machine learning surrogates are increasingly employed to replace expensive computational models for physics-based reliability analysis. However, their use introduces epistemic uncertainty from model approximation errors, which couples with aleatory uncertainty in model inputs, potentially compromising the accuracy of reliability predictions. This study proposes a Gauss-Hermite quadrature approach to decouple these nested uncertainties and enable more accurate reliability analysis. The method evaluates conditional failure probabilities under aleatory uncertainty using First and Second Order Reliability Methods and then integrates these probabilities across realizations of epistemic uncertainty. Three examples demonstrate that the proposed approach maintains computational efficiency while yielding more trustworthy predictions than traditional methods that ignore model uncertainty.
Research on Metro Transportation Flow Prediction Based on the STL-GRU Combined Model
arXiv:2509.18130v1 Announce Type: new Abstract: In the metro intelligent transportation system, accurate transfer passenger flow prediction is a key link in optimizing operation plans and improving transportation efficiency. To further improve the theory of metro internal transfer passenger flow prediction and provide more reliable support for intelligent operation decisions, this paper innovatively proposes a metro transfer passenger flow prediction model that integrates the Seasonal and Trend decomposition using Loess (STL) method and Gated Recurrent Unit (GRU).In practical application, the model first relies on the deep learning library Keras to complete the construction and training of the GRU model, laying the foundation for subsequent prediction; then preprocesses the original metro card swiping data, uses the graph-based depth-first search algorithm to identify passengers' travel paths, and further constructs the transfer passenger flow time series; subsequently adopts the STL time series decomposition algorithm to decompose the constructed transfer passenger flow time series into trend component, periodic component and residual component, and uses the 3{\sigma} principle to eliminate and fill the outliers in the residual component, and finally completes the transfer passenger flow prediction.Taking the transfer passenger flow data of a certain metro station as the research sample, the validity of the model is verified. The results show that compared with Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and the combined model of STL time series decomposition method and Long Short-Term Memory (STL-LSTM), the STL-GRU combined prediction model significantly improves the prediction accuracy of transfer passenger flow on weekdays (excluding Fridays), Fridays and rest days, with the mean absolute percentage error (MAPE) of the prediction results reduced by at least 2.3, 1.36 and 6.42 percentage points respectively.
Two ways to knowledge?
arXiv:2509.18131v1 Announce Type: new Abstract: It is shown that the weight matrices of transformer-based machine learning applications to the solution of two representative physical applications show a random-like character which bears no directly recognizable link to the physical and mathematical structure of the physical problem under study. This suggests that machine learning and the scientific method may represent two distinct and potentially complementary paths to knowledge, even though a strict notion of explainability in terms of direct correspondence between network parameters and physical structures may remain out of reach. It is also observed that drawing a parallel between transformer operation and (generalized) path-integration techniques may account for the random-like nature of the weights, but still does not resolve the tension with explainability. We conclude with some general comments on the hazards of gleaning knowledge without the benefit of Insight.
Self-Evolving LLMs via Continual Instruction Tuning
arXiv:2509.18133v1 Announce Type: new Abstract: In real-world industrial settings, large language models (LLMs) must learn continually to keep pace with diverse and evolving tasks, requiring self-evolution to refine knowledge under dynamic data distributions. However, existing continual learning (CL) approaches, such as replay and parameter isolation, often suffer from catastrophic forgetting: training on new tasks degrades performance on earlier ones by overfitting to the new distribution and weakening generalization.We propose MoE-CL, a parameter-efficient adversarial mixture-of-experts framework for industrial-scale, self-evolving continual instruction tuning of LLMs. MoE-CL uses a dual-expert design: (1) a dedicated LoRA expert per task to preserve task-specific knowledge via parameter independence, mitigating forgetting; and (2) a shared LoRA expert to enable cross-task transfer. To prevent transferring task-irrelevant noise through the shared pathway, we integrate a task-aware discriminator within a GAN. The discriminator encourages the shared expert to pass only task-aligned information during sequential training. Through adversarial learning, the shared expert acquires generalized representations that mimic the discriminator, while dedicated experts retain task-specific details, balancing knowledge retention and cross-task generalization and thereby supporting self-evolution.Extensive experiments on the public MTL5 benchmark and an industrial Tencent3 benchmark validate the effectiveness of MoE-CL for continual instruction tuning. In real-world A/B testing for content compliance review on the Tencent Video platform, MoE-CL reduced manual review costs by 15.3%. These results demonstrate that MoE-CL is practical for large-scale industrial deployment where continual adaptation and stable transfer are critical.
A Weighted Gradient Tracking Privacy-Preserving Method for Distributed Optimization
arXiv:2509.18134v1 Announce Type: new Abstract: This paper investigates the privacy-preserving distributed optimization problem, aiming to protect agents' private information from potential attackers during the optimization process. Gradient tracking, an advanced technique for improving the convergence rate in distributed optimization, has been applied to most first-order algorithms in recent years. We first reveal the inherent privacy leakage risk associated with gradient tracking. Building upon this insight, we propose a weighted gradient tracking distributed privacy-preserving algorithm, eliminating the privacy leakage risk in gradient tracking using decaying weight factors. Then, we characterize the convergence of the proposed algorithm under time-varying heterogeneous step sizes. We prove the proposed algorithm converges precisely to the optimal solution under mild assumptions. Finally, numerical simulations validate the algorithm's effectiveness through a classical distributed estimation problem and the distributed training of a convolutional neural network.
SDGF: Fusing Static and Multi-Scale Dynamic Correlations for Multivariate Time Series Forecasting
arXiv:2509.18135v1 Announce Type: new Abstract: Inter-series correlations are crucial for accurate multivariate time series forecasting, yet these relationships often exhibit complex dynamics across different temporal scales. Existing methods are limited in modeling these multi-scale dependencies and struggle to capture their intricate and evolving nature. To address this challenge, this paper proposes a novel Static-Dynamic Graph Fusion network (SDGF), whose core lies in capturing multi-scale inter-series correlations through a dual-path graph structure learning approach. Specifically, the model utilizes a static graph based on prior knowledge to anchor long-term, stable dependencies, while concurrently employing Multi-level Wavelet Decomposition to extract multi-scale features for constructing an adaptively learned dynamic graph to capture associations at different scales. We design an attention-gated module to fuse these two complementary sources of information intelligently, and a multi-kernel dilated convolutional network is then used to deepen the understanding of temporal patterns. Comprehensive experiments on multiple widely used real-world benchmark datasets demonstrate the effectiveness of our proposed model.
From Parameters to Performance: A Data-Driven Study on LLM Structure and Development
arXiv:2509.18136v1 Announce Type: new Abstract: Large language models (LLMs) have achieved remarkable success across various domains, driving significant technological advancements and innovations. Despite the rapid growth in model scale and capability, systematic, data-driven research on how structural configurations affect performance remains scarce. To address this gap, we present a large-scale dataset encompassing diverse open-source LLM structures and their performance across multiple benchmarks. Leveraging this dataset, we conduct a systematic, data mining-driven analysis to validate and quantify the relationship between structural configurations and performance. Our study begins with a review of the historical development of LLMs and an exploration of potential future trends. We then analyze how various structural choices impact performance across benchmarks and further corroborate our findings using mechanistic interpretability techniques. By providing data-driven insights into LLM optimization, our work aims to guide the targeted development and application of future models. We will release our dataset at https://huggingface.co/datasets/DX0369/LLM-Structure-Performance-Dataset
LoRALib: A Standardized Benchmark for Evaluating LoRA-MoE Methods
arXiv:2509.18137v1 Announce Type: new Abstract: As a parameter efficient fine-tuning (PEFT) method, low-rank adaptation (LoRA) can save significant costs in storage and computing, but its strong adaptability to a single task is often accompanied by insufficient cross-task generalization capabilities. To improve this, existing work combines LoRA with mixture-of-experts (MoE) to enhance the model's adaptability through expert modules and routing mechanisms. However, existing LoRA-MoE methods lack unified standards in models, datasets, hyperparameters, and evaluation methods, making it difficult to conduct fair comparisons between different methods. To this end, we proposed a unified benchmark named LoRALib. Specifically, we standardized datasets from $40$ downstream tasks into a unified format, fine-tuned them using the same hyperparameters and obtained $680$ LoRA modules across $17$ model architectures. Based on this LoRA library, we conduct large-scale experiments on $3$ representative LoRA-MoE methods and different LoRA selection mechanisms using the open-sourced testing tool OpenCompass. Extensive experiments show that LoRAMoE performs best, and that prioritizing LoRAs relevant to the target task can further improve the performance of MoE. We hope these findings will inspire future work. Our datasets and LoRA library are available at https://huggingface.co/datasets/YaoLuzjut/LoRAOcean_dataset and https://huggingface.co/YaoLuzjut/models.
Rank-Induced PL Mirror Descent: A Rank-Faithful Second-Order Algorithm for Sleeping Experts
arXiv:2509.18138v1 Announce Type: new Abstract: We introduce a new algorithm, \emph{Rank-Induced Plackett--Luce Mirror Descent (RIPLM)}, which leverages the structural equivalence between the \emph{rank benchmark} and the \emph{distributional benchmark} established in \citet{BergamOzcanHsu2022}. Unlike prior approaches that operate on expert identities, RIPLM updates directly in the \emph{rank-induced Plackett--Luce (PL)} parameterization. This ensures that the algorithm's played distributions remain within the class of rank-induced distributions at every round, preserving the equivalence with the rank benchmark. To our knowledge, RIPLM is the first algorithm that is both (i) \emph{rank-faithful} and (ii) \emph{variance-adaptive} in the sleeping experts setting.
Comparative Analysis of FOLD-SE vs. FOLD-R++ in Binary Classification and XGBoost in Multi-Category Classification
arXiv:2509.18139v1 Announce Type: new Abstract: Recently, the demand for Machine Learning (ML) models that can balance accuracy, efficiency, and interpreability has grown significantly. Traditionally, there has been a tradeoff between accuracy and explainability in predictive models, with models such as Neural Networks achieving high accuracy on complex datasets while sacrificing internal transparency. As such, new rule-based algorithms such as FOLD-SE have been developed that provide tangible justification for predictions in the form of interpretable rule sets. The primary objective of this study was to compare FOLD-SE and FOLD-R++, both rule-based classifiers, in binary classification and evaluate how FOLD-SE performs against XGBoost, a widely used ensemble classifier, when applied to multi-category classification. We hypothesized that because FOLD-SE can generate a condensed rule set in a more explainable manner, it would lose upwards of an average of 3 percent in accuracy and F1 score when compared with XGBoost and FOLD-R++ in multiclass and binary classification, respectively. The research used data collections for classification, with accuracy, F1 scores, and processing time as the primary performance measures. Outcomes show that FOLD-SE is superior to FOLD-R++ in terms of binary classification by offering fewer rules but losing a minor percentage of accuracy and efficiency in processing time; in tasks that involve multi-category classifications, FOLD-SE is more precise and far more efficient compared to XGBoost, in addition to generating a comprehensible rule set. The results point out that FOLD-SE is a better choice for both binary tasks and classifications with multiple categories. Therefore, these results demonstrate that rule-based approaches like FOLD-SE can bridge the gap between explainability and performance, highlighting their potential as viable alternatives to black-box models in diverse classification tasks.
A Machine Learning Framework for Pathway-Driven Therapeutic Target Discovery in Metabolic Disorders
arXiv:2509.18140v1 Announce Type: new Abstract: Metabolic disorders, particularly type 2 diabetes mellitus (T2DM), represent a significant global health burden, disproportionately impacting genetically predisposed populations such as the Pima Indians (a Native American tribe from south central Arizona). This study introduces a novel machine learning (ML) framework that integrates predictive modeling with gene-agnostic pathway mapping to identify high-risk individuals and uncover potential therapeutic targets. Using the Pima Indian dataset, logistic regression and t-tests were applied to identify key predictors of T2DM, yielding an overall model accuracy of 78.43%. To bridge predictive analytics with biological relevance, we developed a pathway mapping strategy that links identified predictors to critical signaling networks, including insulin signaling, AMPK, and PPAR pathways. This approach provides mechanistic insights without requiring direct molecular data. Building upon these connections, we propose therapeutic strategies such as dual GLP-1/GIP receptor agonists, AMPK activators, SIRT1 modulators, and phytochemical, further validated through pathway enrichment analyses. Overall, this framework advances precision medicine by offering interpretable and scalable solutions for early detection and targeted intervention in metabolic disorders. The key contributions of this work are: (1) development of an ML framework combining logistic regression and principal component analysis (PCA) for T2DM risk prediction; (2) introduction of a gene-agnostic pathway mapping approach to generate mechanistic insights; and (3) identification of novel therapeutic strategies tailored for high-risk populations.
KM-GPT: An Automated Pipeline for Reconstructing Individual Patient Data from Kaplan-Meier Plots
arXiv:2509.18141v1 Announce Type: new Abstract: Reconstructing individual patient data (IPD) from Kaplan-Meier (KM) plots provides valuable insights for evidence synthesis in clinical research. However, existing approaches often rely on manual digitization, which is error-prone and lacks scalability. To address these limitations, we develop KM-GPT, the first fully automated, AI-powered pipeline for reconstructing IPD directly from KM plots with high accuracy, robustness, and reproducibility. KM-GPT integrates advanced image preprocessing, multi-modal reasoning powered by GPT-5, and iterative reconstruction algorithms to generate high-quality IPD without manual input or intervention. Its hybrid reasoning architecture automates the conversion of unstructured information into structured data flows and validates data extraction from complex KM plots. To improve accessibility, KM-GPT is equipped with a user-friendly web interface and an integrated AI assistant, enabling researchers to reconstruct IPD without requiring programming expertise. KM-GPT was rigorously evaluated on synthetic and real-world datasets, consistently demonstrating superior accuracy. To illustrate its utility, we applied KM-GPT to a meta-analysis of gastric cancer immunotherapy trials, reconstructing IPD to facilitate evidence synthesis and biomarker-based subgroup analyses. By automating traditionally manual processes and providing a scalable, web-based solution, KM-GPT transforms clinical research by leveraging reconstructed IPD to enable more informed downstream analyses, supporting evidence-based decision-making.
AdaSTI: Conditional Diffusion Models with Adaptive Dependency Modeling for Spatio-Temporal Imputation
arXiv:2509.18144v1 Announce Type: new Abstract: Spatio-temporal data abounds in domain like traffic and environmental monitoring. However, it often suffers from missing values due to sensor malfunctions, transmission failures, etc. Recent years have seen continued efforts to improve spatio-temporal data imputation performance. Recently diffusion models have outperformed other approaches in various tasks, including spatio-temporal imputation, showing competitive performance. Extracting and utilizing spatio-temporal dependencies as conditional information is vital in diffusion-based methods. However, previous methods introduce error accumulation in this process and ignore the variability of the dependencies in the noisy data at different diffusion steps. In this paper, we propose AdaSTI (Adaptive Dependency Model in Diffusion-based Spatio-Temporal Imputation), a novel spatio-temporal imputation approach based on conditional diffusion model. Inside AdaSTI, we propose a BiS4PI network based on a bi-directional S4 model for pre-imputation with the imputed result used to extract conditional information by our designed Spatio-Temporal Conditionalizer (STC)network. We also propose a Noise-Aware Spatio-Temporal (NAST) network with a gated attention mechanism to capture the variant dependencies across diffusion steps. Extensive experiments on three real-world datasets show that AdaSTI outperforms existing methods in all the settings, with up to 46.4% reduction in imputation error.
Early Prediction of Multi-Label Care Escalation Triggers in the Intensive Care Unit Using Electronic Health Records
arXiv:2509.18145v1 Announce Type: new Abstract: Intensive Care Unit (ICU) patients often present with complex, overlapping signs of physiological deterioration that require timely escalation of care. Traditional early warning systems, such as SOFA or MEWS, are limited by their focus on single outcomes and fail to capture the multi-dimensional nature of clinical decline. This study proposes a multi-label classification framework to predict Care Escalation Triggers (CETs), including respiratory failure, hemodynamic instability, renal compromise, and neurological deterioration, using the first 24 hours of ICU data. Using the MIMIC-IV database, CETs are defined through rule-based criteria applied to data from hours 24 to 72 (for example, oxygen saturation below 90, mean arterial pressure below 65 mmHg, creatinine increase greater than 0.3 mg/dL, or a drop in Glasgow Coma Scale score greater than 2). Features are extracted from the first 24 hours and include vital sign aggregates, laboratory values, and static demographics. We train and evaluate multiple classification models on a cohort of 85,242 ICU stays (80 percent training: 68,193; 20 percent testing: 17,049). Evaluation metrics include per-label precision, recall, F1-score, and Hamming loss. XGBoost, the best performing model, achieves F1-scores of 0.66 for respiratory, 0.72 for hemodynamic, 0.76 for renal, and 0.62 for neurologic deterioration, outperforming baseline models. Feature analysis shows that clinically relevant parameters such as respiratory rate, blood pressure, and creatinine are the most influential predictors, consistent with the clinical definitions of the CETs. The proposed framework demonstrates practical potential for early, interpretable clinical alerts without requiring complex time-series modeling or natural language processing.
ConceptFlow: Hierarchical and Fine-grained Concept-Based Explanation for Convolutional Neural Networks
arXiv:2509.18147v1 Announce Type: new Abstract: Concept-based interpretability for Convolutional Neural Networks (CNNs) aims to align internal model representations with high-level semantic concepts, but existing approaches largely overlook the semantic roles of individual filters and the dynamic propagation of concepts across layers. To address these limitations, we propose ConceptFlow, a concept-based interpretability framework that simulates the internal "thinking path" of a model by tracing how concepts emerge and evolve across layers. ConceptFlow comprises two key components: (i) concept attentions, which associate each filter with relevant high-level concepts to enable localized semantic interpretation, and (ii) conceptual pathways, derived from a concept transition matrix that quantifies how concepts propagate and transform between filters. Together, these components offer a unified and structured view of internal model reasoning. Experimental results demonstrate that ConceptFlow yields semantically meaningful insights into model reasoning, validating the effectiveness of concept attentions and conceptual pathways in explaining decision behavior. By modeling hierarchical conceptual pathways, ConceptFlow provides deeper insight into the internal logic of CNNs and supports the generation of more faithful and human-aligned explanations.
Sparse Training Scheme for Multimodal LLM
arXiv:2509.18150v1 Announce Type: new Abstract: Multimodal Large Language Models (MLLMs) have demonstrated outstanding performance across a variety of domains. However, training MLLMs is often inefficient due to the significantly longer input sequences introduced by multimodal data and the low utilization of inter-layer computations. To address this challenge, we shift the focus to the training process itself and propose a novel training-efficient framework based on sparse representations, termed the Sparse Training Scheme (STS). This scheme consists of two key components: the Visual Token Compressor, which reduces the information load by compressing visual tokens, and the Layer Dynamic Skipper, which mitigates the computational overhead by dynamically skipping unnecessary layers in the language model during both forward and backward passes. Our approach is broadly applicable to diverse MLLM architectures and has been extensively evaluated on multiple benchmarks, demonstrating its effectiveness and efficiency.
HyperNAS: Enhancing Architecture Representation for NAS Predictor via Hypernetwork
arXiv:2509.18151v1 Announce Type: new Abstract: Time-intensive performance evaluations significantly impede progress in Neural Architecture Search (NAS). To address this, neural predictors leverage surrogate models trained on proxy datasets, allowing for direct performance predictions for new architectures. However, these predictors often exhibit poor generalization due to their limited ability to capture intricate relationships among various architectures. In this paper, we propose HyperNAS, a novel neural predictor paradigm for enhancing architecture representation learning. HyperNAS consists of two primary components: a global encoding scheme and a shared hypernetwork. The global encoding scheme is devised to capture the comprehensive macro-structure information, while the shared hypernetwork serves as an auxiliary task to enhance the investigation of inter-architecture patterns. To ensure training stability, we further develop a dynamic adaptive multi-task loss to facilitate personalized exploration on the Pareto front. Extensive experiments across five representative search spaces, including ViTs, demonstrate the advantages of HyperNAS, particularly in few-shot scenarios. For instance, HyperNAS strikes new state-of-the-art results, with 97.60\% top-1 accuracy on CIFAR-10 and 82.4\% top-1 accuracy on ImageNet, using at least 5.0$\times$ fewer samples.
WLFM: A Well-Logs Foundation Model for Multi-Task and Cross-Well Geological Interpretation
arXiv:2509.18152v1 Announce Type: new Abstract: Well-log interpretation is fundamental for subsurface characterization but remains challenged by heterogeneous tool responses, noisy signals, and limited labels. We propose WLFM, a foundation model pretrained on multi-curve logs from 1200 wells, comprising three stages: tokenization of log patches into geological tokens, self-supervised pretraining with masked-token modeling and stratigraphy-aware contrastive learning, and multi-task adaptation with few-shot fine-tuning. WLFM consistently outperforms state-of-the-art baselines, achieving 0.0041 MSE in porosity estimation and 74.13\% accuracy in lithology classification, while WLFM-Finetune further improves to 0.0038 MSE and 78.10\% accuracy. Beyond predictive accuracy, WLFM exhibits emergent layer-awareness, learns a reusable geological vocabulary, and reconstructs masked curves with reasonable fidelity, though systematic offsets are observed in shallow and ultra-deep intervals. Although boundary detection is not explicitly evaluated here, clustering analyses suggest strong potential for future extension. These results establish WLFM as a scalable, interpretable, and transferable backbone for geological AI, with implications for multi-modal integration of logs, seismic, and textual data.
A deep reinforcement learning platform for antibiotic discovery
arXiv:2509.18153v1 Announce Type: new Abstract: Antimicrobial resistance (AMR) is projected to cause up to 10 million deaths annually by 2050, underscoring the urgent need for new antibiotics. Here we present ApexAmphion, a deep-learning framework for de novo design of antibiotics that couples a 6.4-billion-parameter protein language model with reinforcement learning. The model is first fine-tuned on curated peptide data to capture antimicrobial sequence regularities, then optimised with proximal policy optimization against a composite reward that combines predictions from a learned minimum inhibitory concentration (MIC) classifier with differentiable physicochemical objectives. In vitro evaluation of 100 designed peptides showed low MIC values (nanomolar range in some cases) for all candidates (100% hit rate). Moreover, 99 our of 100 compounds exhibited broad-spectrum antimicrobial activity against at least two clinically relevant bacteria. The lead molecules killed bacteria primarily by potently targeting the cytoplasmic membrane. By unifying generation, scoring and multi-objective optimization with deep reinforcement learning in a single pipeline, our approach rapidly produces diverse, potent candidates, offering a scalable route to peptide antibiotics and a platform for iterative steering toward potency and developability within hours.
MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe
arXiv:2509.18154v1 Announce Type: new Abstract: Multimodal Large Language Models (MLLMs) are undergoing rapid progress and represent the frontier of AI development. However, their training and inference efficiency have emerged as a core bottleneck in making MLLMs more accessible and scalable. To address the challenges, we present MiniCPM-V 4.5, an 8B parameter model designed for high efficiency and strong performance. We introduce three core improvements in model architecture, data strategy and training method: a unified 3D-Resampler model architecture for highly compact encoding over images and videos, a unified learning paradigm for document knowledge and text recognition without heavy data engineering, and a hybrid reinforcement learning strategy for proficiency in both short and long reasoning modes. Comprehensive experimental results in OpenCompass evaluation show that MiniCPM-V 4.5 surpasses widely used proprietary models such as GPT-4o-latest, and significantly larger open-source models such as Qwen2.5-VL 72B. Notably, the strong performance is achieved with remarkable efficiency. For example, on the widely adopted VideoMME benchmark, MiniCPM-V 4.5 achieves state-of-the-art performance among models under 30B size, using just 46.7\% GPU memory cost and 8.7\% inference time of Qwen2.5-VL 7B.
Developing Training Procedures for Piecewise-linear Spline Activation Functions in Neural Networks
arXiv:2509.18161v1 Announce Type: new Abstract: Activation functions in neural networks are typically selected from a set of empirically validated, commonly used static functions such as ReLU, tanh, or sigmoid. However, by optimizing the shapes of a network's activation functions, we can train models that are more parameter-efficient and accurate by assigning more optimal activations to the neurons. In this paper, I present and compare 9 training methodologies to explore dual-optimization dynamics in neural networks with parameterized linear B-spline activation functions. The experiments realize up to 94% lower end model error rates in FNNs and 51% lower rates in CNNs compared to traditional ReLU-based models. These gains come at the cost of additional development and training complexity as well as end model latency.
A Simple and Reproducible Hybrid Solver for a Truck-Drone VRP with Recharge
arXiv:2509.18162v1 Announce Type: new Abstract: We study last-mile delivery with one truck and one drone under explicit battery management: the drone flies at twice the truck speed; each sortie must satisfy an endurance budget; after every delivery the drone recharges on the truck before the next launch. We introduce a hybrid reinforcement learning (RL) solver that couples an ALNS-based truck tour (with 2/3-opt and Or-opt) with a small pointer/attention policy that schedules drone sorties. The policy decodes launch--serve--rendezvous triplets with hard feasibility masks for endurance and post-delivery recharge; a fast, exact timeline simulator enforces launch/recovery handling and computes the true makespan used by masked greedy/beam decoding. On Euclidean instances with $N{=}50$, $E{=}0.7$, and $R{=}0.1$, the method achieves an average makespan of \textbf{5.203}$\pm$0.093, versus \textbf{5.349}$\pm$0.038 for ALNS and \textbf{5.208}$\pm$0.124 for NN -- i.e., \textbf{2.73\%} better than ALNS on average and within \textbf{0.10\%} of NN. Per-seed, the RL scheduler never underperforms ALNS on the same instance and ties or beats NN on two of three seeds. A decomposition of the makespan shows the expected truck--wait trade-off across heuristics; the learned scheduler balances both to minimize the total completion time. We provide a config-first implementation with plotting and significance-test utilities to support replication.
DSFT: Inspiring Diffusion Large Language Models to Comprehend Mathematical and Logical Patterns
arXiv:2509.18164v1 Announce Type: new Abstract: Diffusion large language models (dLLMs) have emerged as a new architecture following auto regressive models. Their denoising process offers a powerful generative advantage, but they present significant challenges in learning and understanding numerically sensitive mathematical and order-sensitive logical tasks. Current training methods, including pre-training, fine-tuning, and reinforcement learning, focus primarily on improving general knowledge retention and reasoning abilities, but lack a comprehensive understanding of mathematical and logical patterns. We propose DSFT, a simple yet effective Diffusion SFT strategy, by adjusting the masking strategy and loss function, guiding models to understand mathematical and logical patterns. This strategy can be flexibly combined with pre-training, reinforcement learning, and other training methods. Validated on models such as LLaDA and Dream series, we prove that DSFT on small-scale data can achieve improvements of 5-10% and approximately 2% on mathematical and logical problems, respectively. This inspiring masking approach offers insights for future learning of specific patterns, which can be easily and efficiently combined with other training methods and applied to various dLLMs. Our code is publicly available at https://anonymous.4open.science/r/DSFT-0FFB/
MobiGPT: A Foundation Model for Mobile Wireless Networks
arXiv:2509.18166v1 Announce Type: new Abstract: With the rapid development of mobile communication technologies, future mobile networks will offer vast services and resources for commuting, production, daily life, and entertainment. Accurate and efficient forecasting of mobile data (e.g., cell traffic, user behavior, channel quality) helps operators monitor network state changes, orchestrate wireless resources, and schedule infrastructure and users, thereby improving supply efficiency and service quality. However, current forecasting paradigms rely on customized designs with tailored models for exclusive data types. Such approaches increase complexity and deployment costs under large-scale, heterogeneous networks involving base stations, users, and channels. In this paper, we design a foundation model for mobile data forecasting, MobiGPT, with a unified structure capable of forecasting three data types: base station traffic, user app usage, and channel quality. We propose a soft-prompt learning method to help the model understand features of different data types, and introduce a temporal masking mechanism to guide the model through three forecasting tasks: short-term prediction, long-term prediction, and distribution generation, supporting diverse optimization scenarios. Evaluations on real-world datasets with over 100,000 samples show that MobiGPT achieves accurate multi-type forecasting. Compared to existing models, it improves forecasting accuracy by 27.37%, 20.08%, and 7.27%, reflecting strong generalization. Moreover, MobiGPT exhibits superior zero/few-shot performance in unseen scenarios, with over 21.51% improvement, validating its strong transferability as a foundation model.
PiMoE: Token-Level Routing for Integrating High-Precision Computation and Reasoning
arXiv:2509.18169v1 Announce Type: new Abstract: Complex systems typically rely on high-precision numerical computation to support decisions, but current large language models (LLMs) cannot yet incorporate such computations as an intrinsic and interpretable capability with existing architectures. Mainstream multi-agent approaches can leverage external experts, but inevitably introduce communication overhead and suffer from inefficient multimodal emergent capability and limited scalability. To this end, we propose PiMoE (Physically-isolated Mixture of Experts), a training and inference architecture for integrating computation and reasoning. Instead of the workflow paradigm of tool invocation, PiMoE endogenously integrates computational capabilities into neural networks after separately training experts, a text-to-computation module, and a router. At inference, the router directs computation and reasoning at the token level, thereby enabling iterative alternation within a single chain of thought. We evaluate PiMoE on two reasoning-computation tasks against LLM finetuning and the multi-agent system approaches. Results show that the PiMoE architecture achieves not only higher accuracy than directly finetuning LLMs but also significant improvements in response latency, token usage, and GPU energy consumption compared with mainstream multi-agent approaches. PiMoE offers an efficient, interpretable, and scalable paradigm for next-generation scientific or industrial intelligent systems.
FedIA: A Plug-and-Play Importance-Aware Gradient Pruning Aggregation Method for Domain-Robust Federated Graph Learning on Node Classification
arXiv:2509.18171v1 Announce Type: new Abstract: Federated Graph Learning (FGL) under domain skew -- as observed on platforms such as \emph{Twitch Gamers} and multilingual \emph{Wikipedia} networks -- drives client models toward incompatible representations, rendering naive aggregation both unstable and ineffective. We find that the culprit is not the weighting scheme but the \emph{noisy gradient signal}: empirical analysis of baseline methods suggests that a vast majority of gradient dimensions can be dominated by domain-specific variance. We therefore shift focus from "aggregation-first" to a \emph{projection-first} strategy that denoises client updates \emph{before} they are combined. The proposed FedIA framework realises this \underline{I}mportance-\underline{A}ware idea through a two-stage, plug-and-play pipeline: (i) a server-side top-$\rho$ mask keeps only the most informative about 5% of coordinates, and (ii) a lightweight influence-regularised momentum weight suppresses outlier clients. FedIA adds \emph{no extra uplink traffic and only negligible server memory}, making it readily deployable. On both homogeneous (Twitch Gamers) and heterogeneous (Wikipedia) graphs, it yields smoother, more stable convergence and higher final accuracy than nine strong baselines. A convergence sketch further shows that dynamic projection maintains the optimal $\mathcal{O}(\sigma^{2}/\sqrt{T})$ rate.
SBVR: Summation of BitVector Representation for Efficient LLM Quantization
arXiv:2509.18172v1 Announce Type: new Abstract: With the advent of large language models (LLMs), numerous Post-Training Quantization (PTQ) strategies have been proposed to alleviate deployment barriers created by their enormous parameter counts. Quantization achieves compression by limiting the number of representable points in the data. Therefore, the key to achieving efficient quantization is selecting the optimal combination of representation points, or codes, for the given data. Existing PTQ solutions adopt two major approaches to this problem: Round-To-Nearest (RTN)-based methods and codebook-based methods. RTN-based methods map LLM weights onto uniformly distributed integer grids, failing to account for the Gaussian-like weight distribution of LLM weights. Codebook-based methods mitigate this issue by constructing distribution-aware codebooks; however, they suffer from random and strided memory access patterns, resulting in degraded inference speed that is exacerbated by the limited size of GPU L1 cache. To overcome these limitations, we propose a novel LLM quantization method, SBVR (Summation of BitVector Representation), that enables Gaussian-like code representation in a hardware-friendly manner for fast inference. SBVR maps weight values to non-uniform representation points whose distribution follows the actual distribution of LLM weights, enabling more accurate compression. Additionally, we design a custom CUDA kernel that allows matrix-vector multiplication directly in the SBVR format without decompression, thereby enabling high-performance execution of SBVR-compressed models. Our evaluations of SBVR on various models demonstrate state-of-the-art perplexity and accuracy benchmark performance while delivering a 2.21x- 3.04x end-to-end token-generation speedup over naive FP16 models in the 4-bit quantization regime.
TurnBack: A Geospatial Route Cognition Benchmark for Large Language Models through Reverse Route
arXiv:2509.18173v1 Announce Type: new Abstract: Humans can interpret geospatial information through natural language, while the geospatial cognition capabilities of Large Language Models (LLMs) remain underexplored. Prior research in this domain has been constrained by non-quantifiable metrics, limited evaluation datasets and unclear research hierarchies. Therefore, we propose a large-scale benchmark and conduct a comprehensive evaluation of the geospatial route cognition of LLMs. We create a large-scale evaluation dataset comprised of 36000 routes from 12 metropolises worldwide. Then, we introduce PathBuilder, a novel tool for converting natural language instructions into navigation routes, and vice versa, bridging the gap between geospatial information and natural language. Finally, we propose a new evaluation framework and metrics to rigorously assess 11 state-of-the-art (SOTA) LLMs on the task of route reversal. The benchmark reveals that LLMs exhibit limitation to reverse routes: most reverse routes neither return to the starting point nor are similar to the optimal route. Additionally, LLMs face challenges such as low robustness in route generation and high confidence for their incorrect answers. Code\ \&\ Data available here: \href{https://github.com/bghjmn32/EMNLP2025_Turnback}{TurnBack.}
Conversational Orientation Reasoning: Egocentric-to-Allocentric Navigation with Multimodal Chain-of-Thought
arXiv:2509.18200v1 Announce Type: new Abstract: Conversational agents must translate egocentric utterances (e.g., "on my right") into allocentric orientations (N/E/S/W). This challenge is particularly critical in indoor or complex facilities where GPS signals are weak and detailed maps are unavailable. While chain-of-thought (CoT) prompting has advanced reasoning in language and vision tasks, its application to multimodal spatial orientation remains underexplored. We introduce Conversational Orientation Reasoning (COR), a new benchmark designed for Traditional Chinese conversational navigation projected from real-world environments, addressing egocentric-to-allocentric reasoning in non-English and ASR-transcribed scenarios. We propose a multimodal chain-of-thought (MCoT) framework, which integrates ASR-transcribed speech with landmark coordinates through a structured three-step reasoning process: (1) extracting spatial relations, (2) mapping coordinates to absolute directions, and (3) inferring user orientation. A curriculum learning strategy progressively builds these capabilities on Taiwan-LLM-13B-v2.0-Chat, a mid-sized model representative of resource-constrained settings. Experiments show that MCoT achieves 100% orientation accuracy on clean transcripts and 98.1% with ASR transcripts, substantially outperforming unimodal and non-structured baselines. Moreover, MCoT demonstrates robustness under noisy conversational conditions, including ASR recognition errors and multilingual code-switching. The model also maintains high accuracy in cross-domain evaluation and resilience to linguistic variation, domain shift, and referential ambiguity. These findings highlight the potential of structured MCoT spatial reasoning as a path toward interpretable and resource-efficient embodied navigation.
Variational Task Vector Composition
arXiv:2509.18208v1 Announce Type: new Abstract: Task vectors capture how a model changes during fine-tuning by recording the difference between pre-trained and task-specific weights. The composition of task vectors, a key operator in task arithmetic, enables models to integrate knowledge from multiple tasks without incurring additional inference costs. In this paper, we propose variational task vector composition, where composition coefficients are taken as latent variables and estimated in a Bayesian inference framework. Unlike previous methods that operate at the task level, our framework focuses on sample-specific composition. Motivated by the observation of structural redundancy in task vectors, we introduce a Spike-and-Slab prior that promotes sparsity and preserves only the most informative components. To further address the high variance and sampling inefficiency in sparse, high-dimensional spaces, we develop a gated sampling mechanism that constructs a controllable posterior by filtering the composition coefficients based on both uncertainty and importance. This yields a more stable and interpretable variational framework by deterministically selecting reliable task components, reducing sampling variance while improving transparency and generalization. Experimental results demonstrate that our method consistently outperforms existing approaches across all datasets by selectively leveraging the most reliable and informative components in task vectors. These findings highlight the practical value of our approach, establishing a new standard for efficient and effective task vector composition.
MolPILE - large-scale, diverse dataset for molecular representation learning
arXiv:2509.18353v1 Announce Type: new Abstract: The size, diversity, and quality of pretraining datasets critically determine the generalization ability of foundation models. Despite their growing importance in chemoinformatics, the effectiveness of molecular representation learning has been hindered by limitations in existing small molecule datasets. To address this gap, we present MolPILE, large-scale, diverse, and rigorously curated collection of 222 million compounds, constructed from 6 large-scale databases using an automated curation pipeline. We present a comprehensive analysis of current pretraining datasets, highlighting considerable shortcomings for training ML models, and demonstrate how retraining existing models on MolPILE yields improvements in generalization performance. This work provides a standardized resource for model training, addressing the pressing need for an ImageNet-like dataset in molecular chemistry.
FastMTP: Accelerating LLM Inference with Enhanced Multi-Token Prediction
arXiv:2509.18362v1 Announce Type: new Abstract: As large language models (LLMs) become increasingly powerful, the sequential nature of autoregressive generation creates a fundamental throughput bottleneck that limits the practical deployment. While Multi-Token Prediction (MTP) has demonstrated remarkable benefits for model training efficiency and performance, its inherent potential for inference acceleration remains largely unexplored. This paper introduces FastMTP, a simple yet effective method that improves multi-step draft quality by aligning MTP training with its inference pattern, significantly enhancing speculative decoding performance. Our approach fine-tunes a single MTP head with position-shared weights on self-distilled data, enabling it to capture dependencies among consecutive future tokens and maintain high acceptance rates across multiple recursive draft steps. By integrating language-aware dynamic vocabulary compression into the MTP head, we further reduce computational overhead in the drafting process. Experimental results across seven diverse benchmarks demonstrate that FastMTP achieves an average of 2.03x speedup compared to standard next token prediction with lossless output quality, outperforming vanilla MTP by 82%. FastMTP requires only lightweight training and seamlessly integrates with existing inference frameworks, offering a practical and rapidly deployable solution for accelerating LLM inference.
Multi-Worker Selection based Distributed Swarm Learning for Edge IoT with Non-i.i.d. Data
arXiv:2509.18367v1 Announce Type: new Abstract: Recent advances in distributed swarm learning (DSL) offer a promising paradigm for edge Internet of Things. Such advancements enhance data privacy, communication efficiency, energy saving, and model scalability. However, the presence of non-independent and identically distributed (non-i.i.d.) data pose a significant challenge for multi-access edge computing, degrading learning performance and diverging training behavior of vanilla DSL. Further, there still lacks theoretical guidance on how data heterogeneity affects model training accuracy, which requires thorough investigation. To fill the gap, this paper first study the data heterogeneity by measuring the impact of non-i.i.d. datasets under the DSL framework. This then motivates a new multi-worker selection design for DSL, termed M-DSL algorithm, which works effectively with distributed heterogeneous data. A new non-i.i.d. degree metric is introduced and defined in this work to formulate the statistical difference among local datasets, which builds a connection between the measure of data heterogeneity and the evaluation of DSL performance. In this way, our M-DSL guides effective selection of multiple works who make prominent contributions for global model updates. We also provide theoretical analysis on the convergence behavior of our M-DSL, followed by extensive experiments on different heterogeneous datasets and non-i.i.d. data settings. Numerical results verify performance improvement and network intelligence enhancement provided by our M-DSL beyond the benchmarks.
GnnXemplar: Exemplars to Explanations - Natural Language Rules for Global GNN Interpretability
arXiv:2509.18376v1 Announce Type: new Abstract: Graph Neural Networks (GNNs) are widely used for node classification, yet their opaque decision-making limits trust and adoption. While local explanations offer insights into individual predictions, global explanation methods, those that characterize an entire class, remain underdeveloped. Existing global explainers rely on motif discovery in small graphs, an approach that breaks down in large, real-world settings where subgraph repetition is rare, node attributes are high-dimensional, and predictions arise from complex structure-attribute interactions. We propose GnnXemplar, a novel global explainer inspired from Exemplar Theory from cognitive science. GnnXemplar identifies representative nodes in the GNN embedding space, exemplars, and explains predictions using natural language rules derived from their neighborhoods. Exemplar selection is framed as a coverage maximization problem over reverse k-nearest neighbors, for which we provide an efficient greedy approximation. To derive interpretable rules, we employ a self-refining prompt strategy using large language models (LLMs). Experiments across diverse benchmarks show that GnnXemplar significantly outperforms existing methods in fidelity, scalability, and human interpretability, as validated by a user study with 60 participants.
Graph Enhanced Trajectory Anomaly Detection
arXiv:2509.18386v1 Announce Type: new Abstract: Trajectory anomaly detection is essential for identifying unusual and unexpected movement patterns in applications ranging from intelligent transportation systems to urban safety and fraud prevention. Existing methods only consider limited aspects of the trajectory nature and its movement space by treating trajectories as sequences of sampled locations, with sampling determined by positioning technology, e.g., GPS, or by high-level abstractions such as staypoints. Trajectories are analyzed in Euclidean space, neglecting the constraints and connectivity information of the underlying movement network, e.g., road or transit networks. The proposed Graph Enhanced Trajectory Anomaly Detection (GETAD) framework tightly integrates road network topology, segment semantics, and historical travel patterns to model trajectory data. GETAD uses a Graph Attention Network to learn road-aware embeddings that capture both physical attributes and transition behavior, and augments these with graph-based positional encodings that reflect the spatial layout of the road network. A Transformer-based decoder models sequential movement, while a multiobjective loss function combining autoregressive prediction and supervised link prediction ensures realistic and structurally coherent representations. To improve the robustness of anomaly detection, we introduce Confidence Weighted Negative Log Likelihood (CW NLL), an anomaly scoring function that emphasizes high-confidence deviations. Experiments on real-world and synthetic datasets demonstrate that GETAD achieves consistent improvements over existing methods, particularly in detecting subtle anomalies in road-constrained environments. These results highlight the benefits of incorporating graph structure and contextual semantics into trajectory modeling, enabling more precise and context-aware anomaly detection.
Towards Provable Emergence of In-Context Reinforcement Learning
arXiv:2509.18389v1 Announce Type: new Abstract: Typically, a modern reinforcement learning (RL) agent solves a task by updating its neural network parameters to adapt its policy to the task. Recently, it has been observed that some RL agents can solve a wide range of new out-of-distribution tasks without parameter updates after pretraining on some task distribution. When evaluated in a new task, instead of making parameter updates, the pretrained agent conditions its policy on additional input called the context, e.g., the agent's interaction history in the new task. The agent's performance increases as the information in the context increases, with the agent's parameters fixed. This phenomenon is typically called in-context RL (ICRL). The pretrained parameters of the agent network enable the remarkable ICRL phenomenon. However, many ICRL works perform the pretraining with standard RL algorithms. This raises the central question this paper aims to address: Why can the RL pretraining algorithm generate network parameters that enable ICRL? We hypothesize that the parameters capable of ICRL are minimizers of the pretraining loss. This work provides initial support for this hypothesis through a case study. In particular, we prove that when a Transformer is pretrained for policy evaluation, one of the global minimizers of the pretraining loss can enable in-context temporal difference learning.
Development of Deep Learning Optimizers: Approaches, Concepts, and Update Rules
arXiv:2509.18396v1 Announce Type: new Abstract: Deep learning optimizers are optimization algorithms that enable deep neural networks to learn. The effectiveness of learning is highly dependent on the optimizer employed in the training process. Alongside the rapid advancement of deep learning, a wide range of optimizers with different approaches have been developed. This study aims to provide a review of various optimizers that have been proposed and received attention in the literature. From Stochastic gradient descent to the most recent ones such as Momentum, AdamW, Sophia, and Muon in chronological order, optimizers are examined individually, and their distinctive features are highlighted in the study. The update rule of each optimizer is presented in detail, with an explanation of the associated concepts and variables. The techniques applied by these optimizers, their contributions to the optimization process, and their default hyperparameter settings are also discussed. In addition, insights are offered into the open challenges encountered in the optimization of deep learning models. Thus, a comprehensive resource is provided both for understanding the current state of optimizers and for identifying potential areas of future development.
Explicit Path CGR: Maintaining Sequence Fidelity in Geometric Representations
arXiv:2509.18408v1 Announce Type: new Abstract: We present a novel information-preserving Chaos Game Representation (CGR) method, also called Reverse-CGR (R-CGR), for biological sequence analysis that addresses the fundamental limitation of traditional CGR approaches - the loss of sequence information during geometric mapping. Our method introduces complete sequence recovery through explicit path encoding combined with rational arithmetic precision control, enabling perfect sequence reconstruction from stored geometric traces. Unlike purely geometric approaches, our reversibility is achieved through comprehensive path storage that maintains both positional and character information at each step. We demonstrate the effectiveness of R-CGR on biological sequence classification tasks, achieving competitive performance compared to traditional sequence-based methods while providing interpretable geometric visualizations. The approach generates feature-rich images suitable for deep learning while maintaining complete sequence information through explicit encoding, opening new avenues for interpretable bioinformatics analysis where both accuracy and sequence recovery are essential.
Diffusion Policies with Offline and Inverse Reinforcement Learning for Promoting Physical Activity in Older Adults Using Wearable Sensors
arXiv:2509.18433v1 Announce Type: new Abstract: Utilizing offline reinforcement learning (RL) with real-world clinical data is getting increasing attention in AI for healthcare. However, implementation poses significant challenges. Defining direct rewards is difficult, and inverse RL (IRL) struggles to infer accurate reward functions from expert behavior in complex environments. Offline RL also encounters challenges in aligning learned policies with observed human behavior in healthcare applications. To address challenges in applying offline RL to physical activity promotion for older adults at high risk of falls, based on wearable sensor activity monitoring, we introduce Kolmogorov-Arnold Networks and Diffusion Policies for Offline Inverse Reinforcement Learning (KANDI). By leveraging the flexible function approximation in Kolmogorov-Arnold Networks, we estimate reward functions by learning free-living environment behavior from low-fall-risk older adults (experts), while diffusion-based policies within an Actor-Critic framework provide a generative approach for action refinement and efficiency in offline RL. We evaluate KANDI using wearable activity monitoring data in a two-arm clinical trial from our Physio-feedback Exercise Program (PEER) study, emphasizing its practical application in a fall-risk intervention program to promote physical activity among older adults. Additionally, KANDI outperforms state-of-the-art methods on the D4RL benchmark. These results underscore KANDI's potential to address key challenges in offline RL for healthcare applications, offering an effective solution for activity promotion intervention strategies in healthcare.
MeshODENet: A Graph-Informed Neural Ordinary Differential Equation Neural Network for Simulating Mesh-Based Physical Systems
arXiv:2509.18445v1 Announce Type: new Abstract: The simulation of complex physical systems using a discretized mesh is a cornerstone of applied mechanics, but traditional numerical solvers are often computationally prohibitive for many-query tasks. While Graph Neural Networks (GNNs) have emerged as powerful surrogate models for mesh-based data, their standard autoregressive application for long-term prediction is often plagued by error accumulation and instability. To address this, we introduce MeshODENet, a general framework that synergizes the spatial reasoning of GNNs with the continuous-time modeling of Neural Ordinary Differential Equations. We demonstrate the framework's effectiveness and versatility on a series of challenging structural mechanics problems, including one- and two-dimensional elastic bodies undergoing large, non-linear deformations. The results demonstrate that our approach significantly outperforms baseline models in long-term predictive accuracy and stability, while achieving substantial computational speed-ups over traditional solvers. This work presents a powerful and generalizable approach for developing data-driven surrogates to accelerate the analysis and modeling of complex structural systems.
Fast Linear Solvers via AI-Tuned Markov Chain Monte Carlo-based Matrix Inversion
arXiv:2509.18452v1 Announce Type: new Abstract: Large, sparse linear systems are pervasive in modern science and engineering, and Krylov subspace solvers are an established means of solving them. Yet convergence can be slow for ill-conditioned matrices, so practical deployments usually require preconditioners. Markov chain Monte Carlo (MCMC)-based matrix inversion can generate such preconditioners and accelerate Krylov iterations, but its effectiveness depends on parameters whose optima vary across matrices; manual or grid search is costly. We present an AI-driven framework recommending MCMC parameters for a given linear system. A graph neural surrogate predicts preconditioning speed from $A$ and MCMC parameters. A Bayesian acquisition function then chooses the parameter sets most likely to minimise iterations. On a previously unseen ill-conditioned system, the framework achieves better preconditioning with 50\% of the search budget of conventional methods, yielding about a 10\% reduction in iterations to convergence. These results suggest a route for incorporating MCMC-based preconditioners into large-scale systems.
GluMind: Multimodal Parallel Attention and Knowledge Retention for Robust Cross-Population Blood Glucose Forecasting
arXiv:2509.18457v1 Announce Type: new Abstract: This paper proposes GluMind, a transformer-based multimodal framework designed for continual and long-term blood glucose forecasting. GluMind devises two attention mechanisms, including cross-attention and multi-scale attention, which operate in parallel and deliver accurate predictive performance. Cross-attention effectively integrates blood glucose data with other physiological and behavioral signals such as activity, stress, and heart rate, addressing challenges associated with varying sampling rates and their adverse impacts on robust prediction. Moreover, the multi-scale attention mechanism captures long-range temporal dependencies. To mitigate catastrophic forgetting, GluMind incorporates a knowledge retention technique into the transformer-based forecasting model. The knowledge retention module not only enhances the model's ability to retain prior knowledge but also boosts its overall forecasting performance. We evaluate GluMind on the recently released AIREADI dataset, which contains behavioral and physiological data collected from healthy people, individuals with prediabetes, and those with type 2 diabetes. We examine the performance stability and adaptability of GluMind in learning continuously as new patient cohorts are introduced. Experimental results show that GluMind consistently outperforms other state-of-the-art forecasting models, achieving approximately 15% and 9% improvements in root mean squared error (RMSE) and mean absolute error (MAE), respectively.
Probabilistic Geometric Principal Component Analysis with application to neural data
arXiv:2509.18469v1 Announce Type: new Abstract: Dimensionality reduction is critical across various domains of science including neuroscience. Probabilistic Principal Component Analysis (PPCA) is a prominent dimensionality reduction method that provides a probabilistic approach unlike the deterministic approach of PCA and serves as a connection between PCA and Factor Analysis (FA). Despite their power, PPCA and its extensions are mainly based on linear models and can only describe the data in a Euclidean coordinate system. However, in many neuroscience applications, data may be distributed around a nonlinear geometry (i.e., manifold) rather than lying in the Euclidean space. We develop Probabilistic Geometric Principal Component Analysis (PGPCA) for such datasets as a new dimensionality reduction algorithm that can explicitly incorporate knowledge about a given nonlinear manifold that is first fitted from these data. Further, we show how in addition to the Euclidean coordinate system, a geometric coordinate system can be derived for the manifold to capture the deviations of data from the manifold and noise. We also derive a data-driven EM algorithm for learning the PGPCA model parameters. As such, PGPCA generalizes PPCA to better describe data distributions by incorporating a nonlinear manifold geometry. In simulations and brain data analyses, we show that PGPCA can effectively model the data distribution around various given manifolds and outperforms PPCA for such data. Moreover, PGPCA provides the capability to test whether the new geometric coordinate system better describes the data than the Euclidean one. Finally, PGPCA can perform dimensionality reduction and learn the data distribution both around and on the manifold. These capabilities make PGPCA valuable for enhancing the efficacy of dimensionality reduction for analysis of high-dimensional data that exhibit noise and are distributed around a nonlinear manifold.
Discrete-time diffusion-like models for speech synthesis
arXiv:2509.18470v1 Announce Type: new Abstract: Diffusion models have attracted a lot of attention in recent years. These models view speech generation as a continuous-time process. For efficient training, this process is typically restricted to additive Gaussian noising, which is limiting. For inference, the time is typically discretized, leading to the mismatch between continuous training and discrete sampling conditions. Recently proposed discrete-time processes, on the other hand, usually do not have these limitations, may require substantially fewer inference steps, and are fully consistent between training/inference conditions. This paper explores some diffusion-like discrete-time processes and proposes some new variants. These include processes applying additive Gaussian noise, multiplicative Gaussian noise, blurring noise and a mixture of blurring and Gaussian noises. The experimental results suggest that discrete-time processes offer comparable subjective and objective speech quality to their widely popular continuous counterpart, with more efficient and consistent training and inference schemas.
Individualized non-uniform quantization for vector search
arXiv:2509.18471v1 Announce Type: new Abstract: Embedding vectors are widely used for representing unstructured data and searching through it for semantically similar items. However, the large size of these vectors, due to their high-dimensionality, creates problems for modern vector search techniques: retrieving large vectors from memory/storage is expensive and their footprint is costly. In this work, we present NVQ (non-uniform vector quantization), a new vector compression technique that is computationally and spatially efficient in the high-fidelity regime. The core in NVQ is to use novel parsimonious and computationally efficient nonlinearities for building non-uniform vector quantizers. Critically, these quantizers are \emph{individually} learned for each indexed vector. Our experimental results show that NVQ exhibits improved accuracy compared to the state of the art with a minimal computational cost.
SimpleFold: Folding Proteins is Simpler than You Think
arXiv:2509.18480v1 Announce Type: new Abstract: Protein folding models have achieved groundbreaking results typically via a combination of integrating domain knowledge into the architectural blocks and training pipelines. Nonetheless, given the success of generative models across different but related problems, it is natural to question whether these architectural designs are a necessary condition to build performant models. In this paper, we introduce SimpleFold, the first flow-matching based protein folding model that solely uses general purpose transformer blocks. Protein folding models typically employ computationally expensive modules involving triangular updates, explicit pair representations or multiple training objectives curated for this specific domain. Instead, SimpleFold employs standard transformer blocks with adaptive layers and is trained via a generative flow-matching objective with an additional structural term. We scale SimpleFold to 3B parameters and train it on approximately 9M distilled protein structures together with experimental PDB data. On standard folding benchmarks, SimpleFold-3B achieves competitive performance compared to state-of-the-art baselines, in addition SimpleFold demonstrates strong performance in ensemble prediction which is typically difficult for models trained via deterministic reconstruction objectives. Due to its general-purpose architecture, SimpleFold shows efficiency in deployment and inference on consumer-level hardware. SimpleFold challenges the reliance on complex domain-specific architectures designs in protein folding, opening up an alternative design space for future progress.
Physics-informed time series analysis with Kolmogorov-Arnold Networks under Ehrenfest constraints
arXiv:2509.18483v1 Announce Type: new Abstract: The prediction of quantum dynamical responses lies at the heart of modern physics. Yet, modeling these time-dependent behaviors remains a formidable challenge because quantum systems evolve in high-dimensional Hilbert spaces, often rendering traditional numerical methods computationally prohibitive. While large language models have achieved remarkable success in sequential prediction, quantum dynamics presents a fundamentally different challenge: forecasting the entire temporal evolution of quantum systems rather than merely the next element in a sequence. Existing neural architectures such as recurrent and convolutional networks often require vast training datasets and suffer from spurious oscillations that compromise physical interpretability. In this work, we introduce a fundamentally new approach: Kolmogorov Arnold Networks (KANs) augmented with physics-informed loss functions that enforce the Ehrenfest theorems. Our method achieves superior accuracy with significantly less training data: it requires only 5.4 percent of the samples (200) compared to Temporal Convolution Networks (3,700). We further introduce the Chain of KANs, a novel architecture that embeds temporal causality directly into the model design, making it particularly well-suited for time series modeling. Our results demonstrate that physics-informed KANs offer a compelling advantage over conventional black-box models, maintaining both mathematical rigor and physical consistency while dramatically reducing data requirements.
Hybrid Data can Enhance the Utility of Synthetic Data for Training Anti-Money Laundering Models
arXiv:2509.18499v1 Announce Type: new Abstract: Money laundering is a critical global issue for financial institutions. Automated Anti-money laundering (AML) models, like Graph Neural Networks (GNN), can be trained to identify illicit transactions in real time. A major issue for developing such models is the lack of access to training data due to privacy and confidentiality concerns. Synthetically generated data that mimics the statistical properties of real data but preserves privacy and confidentiality has been proposed as a solution. However, training AML models on purely synthetic datasets presents its own set of challenges. This article proposes the use of hybrid datasets to augment the utility of synthetic datasets by incorporating publicly available, easily accessible, and real-world features. These additions demonstrate that hybrid datasets not only preserve privacy but also improve model utility, offering a practical pathway for financial institutions to enhance AML systems.
APRIL: Active Partial Rollouts in Reinforcement Learning to tame long-tail generation
arXiv:2509.18521v1 Announce Type: new Abstract: Reinforcement learning (RL) has become a cornerstone in advancing large-scale pre-trained language models (LLMs). Successive generations, including GPT-o series, DeepSeek-R1, Kimi-K1.5, Grok 4, and GLM-4.5, have relied on large-scale RL training to enhance reasoning and coding capabilities. To meet the community's growing RL needs, numerous RL frameworks have been proposed. Most of these frameworks primarily rely on inference engines for rollout generation and training engines for policy updates. However, RL training remains computationally expensive, with rollout generation accounting for more than 90% of total runtime. In addition, its efficiency is often constrained by the long-tail distribution of rollout response lengths, where a few lengthy responses stall entire batches, leaving GPUs idle and underutilized. As model and rollout sizes continue to grow, this bottleneck increasingly limits scalability. To address this challenge, we propose Active Partial Rollouts in Reinforcement Learning (APRIL), which mitigates long-tail inefficiency. In the rollout phase, APRIL over-provisions rollout requests, terminates once the target number of responses is reached, and recycles incomplete responses for continuation in future steps. This strategy ensures that no rollouts are discarded while substantially reducing GPU idle time. Experiments show that APRIL improves rollout throughput by at most 44% across commonly used RL algorithms (GRPO, DAPO, GSPO), accelerates convergence, and achieves at most 8% higher final accuracy across tasks. Moreover, APRIL is both framework and hardware agnostic, already integrated into the slime RL framework, and deployable on NVIDIA and AMD GPUs alike. Taken together, this work unifies system-level and algorithmic considerations in proposing APRIL, with the aim of advancing RL training efficiency and inspiring further optimizations in RL systems.
Reverse-Complement Consistency for DNA Language Models
arXiv:2509.18529v1 Announce Type: new Abstract: A fundamental property of DNA is that the reverse complement (RC) of a sequence often carries identical biological meaning. However, state-of-the-art DNA language models frequently fail to capture this symmetry, producing inconsistent predictions for a sequence and its RC counterpart, which undermines their reliability. In this work, we introduce Reverse-Complement Consistency Regularization (RCCR), a simple and model-agnostic fine-tuning objective that directly penalizes the divergence between a model's prediction on a sequence and the aligned prediction on its reverse complement. We evaluate RCCR across three diverse backbones (Nucleotide Transformer, HyenaDNA, DNABERT-2) on a wide range of genomic tasks, including sequence classification, scalar regression, and profile prediction. Our experiments show that RCCR substantially improves RC robustness by dramatically reducing prediction flips and errors, all while maintaining or improving task accuracy compared to baselines such as RC data augmentation and test-time averaging. By integrating a key biological prior directly into the learning process, RCCR produces a single, intrinsically robust, and computationally efficient model fine-tuning recipe for diverse biology tasks.
Symphony-MoE: Harmonizing Disparate Pre-trained Models into a Coherent Mixture-of-Experts
arXiv:2509.18542v1 Announce Type: new Abstract: Mixture-of-Experts (MoE) models enable scalable performance by activating large parameter sets sparsely, minimizing computational overhead. To circumvent the prohibitive cost of training MoEs from scratch, recent work employs upcycling, reusing a single pre-trained dense model by replicating its feed-forward network (FFN) layers into experts. However, this limits expert diversity, as all experts originate from a single pre-trained dense model. This paper addresses this limitation by constructing powerful MoE models using experts sourced from multiple identically-architected but disparate pre-trained models (e.g., Llama2-Chat and Code Llama). A key challenge lies in the fact that these source models occupy disparate, dissonant regions of the parameter space, making direct upcycling prone to severe performance degradation. To overcome this, we propose Symphony-MoE, a novel two-stage framework designed to harmonize these models into a single, coherent expert mixture. First, we establish this harmony in a training-free manner: we construct a shared backbone via a layer-aware fusion strategy and, crucially, alleviate parameter misalignment among experts using activation-based functional alignment. Subsequently, a single lightweight stage of router training coordinates the entire architecture. Experiments demonstrate that our method successfully integrates experts from heterogeneous sources, achieving an MoE model that significantly surpasses baselines in multi-domain tasks and out-of-distribution generalization.
Global Minimizers of Sigmoid Contrastive Loss
arXiv:2509.18552v1 Announce Type: new Abstract: The meta-task of obtaining and aligning representations through contrastive pretraining is steadily gaining importance since its introduction in CLIP and ALIGN. In this paper we theoretically explain the advantages of synchronizing with trainable inverse temperature and bias under the sigmoid loss, as implemented in the recent SigLIP and SigLIP2 models of Google DeepMind. Temperature and bias can drive the loss function to zero for a rich class of configurations that we call $(\mathsf{m}, \mathsf{b}{\mathsf{rel}})$-Constellations. $(\mathsf{m}, \mathsf{b}{\mathsf{rel}})$-Constellations are a novel combinatorial object related to spherical codes and are parametrized by a margin $\mathsf{m}$ and relative bias $\mathsf{b}_{\mathsf{rel}}$. We use our characterization of constellations to theoretically justify the success of SigLIP on retrieval, to explain the modality gap present in SigLIP, and to identify the necessary dimension for producing high-quality representations. Finally, we propose a reparameterization of the sigmoid loss with explicit relative bias, which improves training dynamics in experiments with synthetic data.
Explainable Graph Neural Networks: Understanding Brain Connectivity and Biomarkers in Dementia
arXiv:2509.18568v1 Announce Type: new Abstract: Dementia is a progressive neurodegenerative disorder with multiple etiologies, including Alzheimer's disease, Parkinson's disease, frontotemporal dementia, and vascular dementia. Its clinical and biological heterogeneity makes diagnosis and subtype differentiation highly challenging. Graph Neural Networks (GNNs) have recently shown strong potential in modeling brain connectivity, but their limited robustness, data scarcity, and lack of interpretability constrain clinical adoption. Explainable Graph Neural Networks (XGNNs) have emerged to address these barriers by combining graph-based learning with interpretability, enabling the identification of disease-relevant biomarkers, analysis of brain network disruptions, and provision of transparent insights for clinicians. This paper presents the first comprehensive review dedicated to XGNNs in dementia research. We examine their applications across Alzheimer's disease, Parkinson's disease, mild cognitive impairment, and multi-disease diagnosis. A taxonomy of explainability methods tailored for dementia-related tasks is introduced, alongside comparisons of existing models in clinical scenarios. We also highlight challenges such as limited generalizability, underexplored domains, and the integration of Large Language Models (LLMs) for early detection. By outlining both progress and open problems, this review aims to guide future work toward trustworthy, clinically meaningful, and scalable use of XGNNs in dementia research.
Interaction Topological Transformer for Multiscale Learning in Porous Materials
arXiv:2509.18573v1 Announce Type: new Abstract: Porous materials exhibit vast structural diversity and support critical applications in gas storage, separations, and catalysis. However, predictive modeling remains challenging due to the multiscale nature of structure-property relationships, where performance is governed by both local chemical environments and global pore-network topology. These complexities, combined with sparse and unevenly distributed labeled data, hinder generalization across material families. We propose the Interaction Topological Transformer (ITT), a unified data-efficient framework that leverages novel interaction topology to capture materials information across multiple scales and multiple levels, including structural, elemental, atomic, and pairwise-elemental organization. ITT extracts scale-aware features that reflect both compositional and relational structure within complex porous frameworks, and integrates them through a built-in Transformer architecture that supports joint reasoning across scales. Trained using a two-stage strategy, i.e., self-supervised pretraining on 0.6 million unlabeled structures followed by supervised fine-tuning, ITT achieves state-of-the-art, accurate, and transferable predictions for adsorption, transport, and stability properties. This framework provides a principled and scalable path for learning-guided discovery in structurally and chemically diverse porous materials.
DS-Diffusion: Data Style-Guided Diffusion Model for Time-Series Generation
arXiv:2509.18584v1 Announce Type: new Abstract: Diffusion models are the mainstream approach for time series generation tasks. However, existing diffusion models for time series generation require retraining the entire framework to introduce specific conditional guidance. There also exists a certain degree of distributional bias between the generated data and the real data, which leads to potential model biases in downstream tasks. Additionally, the complexity of diffusion models and the latent spaces leads to an uninterpretable inference process. To address these issues, we propose the data style-guided diffusion model (DS-Diffusion). In the DS-Diffusion, a diffusion framework based on style-guided kernels is developed to avoid retraining for specific conditions. The time-information based hierarchical denoising mechanism (THD) is developed to reduce the distributional bias between the generated data and the real data. Furthermore, the generated samples can clearly indicate the data style from which they originate. We conduct comprehensive evaluations using multiple public datasets to validate our approach. Experimental results show that, compared to the state-of-the-art model such as ImagenTime, the predictive score and the discriminative score decrease by 5.56% and 61.55%, respectively. The distributional bias between the generated data and the real data is further reduced, the inference process is also more interpretable. Moreover, by eliminating the need to retrain the diffusion model, the flexibility and adaptability of the model to specific conditions are also enhanced.
Reflect before Act: Proactive Error Correction in Language Models
arXiv:2509.18607v1 Announce Type: new Abstract: Large Language Models (LLMs) have demonstrated remarkable capabilities in interactive decision-making tasks, but existing methods often struggle with error accumulation and lack robust self-correction mechanisms. We introduce "Reflect before Act" (REBACT), a novel approach that enhances LLM-based decision-making by introducing a critical reflect step prior to taking the next action. This approach allows for immediate error correction, ensuring smooth action path and adaptibity to environment feedback. We evaluate REBACT on three diverse interactive environments: ALFWorld, WebShop, and TextCraft. Our results demonstrate that REBACT significantly outperforms strong baselines, improving success rates by up to 24% on WebShop (achieving 61%), 6.72% on ALFWorld (achieving 98.51%), and 0.5% on TextCraft (achieving 99.5%) using Claude3.5-sonnet as the underlying LLM. Further analysis reveals that REBACT's performance improvements are achieved with only a few modification steps, demonstrating its computational efficiency.
Flow marching for a generative PDE foundation model
arXiv:2509.18611v1 Announce Type: new Abstract: Pretraining on large-scale collections of PDE-governed spatiotemporal trajectories has recently shown promise for building generalizable models of dynamical systems. Yet most existing PDE foundation models rely on deterministic Transformer architectures, which lack generative flexibility for many science and engineering applications. We propose Flow Marching, an algorithm that bridges neural operator learning with flow matching motivated by an analysis of error accumulation in physical dynamical systems, and we build a generative PDE foundation model on top of it. By jointly sampling the noise level and the physical time step between adjacent states, the model learns a unified velocity field that transports a noisy current state toward its clean successor, reducing long-term rollout drift while enabling uncertainty-aware ensemble generations. Alongside this core algorithm, we introduce a Physics-Pretrained Variational Autoencoder (P2VAE) to embed physical states into a compact latent space, and an efficient Flow Marching Transformer (FMT) that combines a diffusion-forcing scheme with latent temporal pyramids, achieving up to 15x greater computational efficiency than full-length video diffusion models and thereby enabling large-scale pretraining at substantially reduced cost. We curate a corpus of ~2.5M trajectories across 12 distinct PDE families and train suites of P2VAEs and FMTs at multiple scales. On downstream evaluation, we benchmark on unseen Kolmogorov turbulence with few-shot adaptation, demonstrate long-term rollout stability over deterministic counterparts, and present uncertainty-stratified ensemble results, highlighting the importance of generative PDE foundation models for real-world applications.
HyperAdapt: Simple High-Rank Adaptation
arXiv:2509.18629v1 Announce Type: new Abstract: Foundation models excel across diverse tasks, but adapting them to specialized applications often requires fine-tuning, an approach that is memory and compute-intensive. Parameter-efficient fine-tuning (PEFT) methods mitigate this by updating only a small subset of weights. In this paper, we introduce HyperAdapt, a parameter-efficient fine-tuning method that significantly reduces the number of trainable parameters compared to state-of-the-art methods like LoRA. Specifically, HyperAdapt adapts a pre-trained weight matrix by applying row- and column-wise scaling through diagonal matrices, thereby inducing a high-rank update while requiring only $n+m$ trainable parameters for an $n \times m$ matrix. Theoretically, we establish an upper bound on the rank of HyperAdapt's updates, and empirically, we confirm that it consistently induces high-rank transformations across model layers. Experiments on GLUE, arithmetic reasoning, and commonsense reasoning benchmarks with models up to 14B parameters demonstrate that HyperAdapt matches or nearly matches the performance of full fine-tuning and state-of-the-art PEFT methods while using orders of magnitude fewer trainable parameters.
Subspace Clustering of Subspaces: Unifying Canonical Correlation Analysis and Subspace Clustering
arXiv:2509.18653v1 Announce Type: new Abstract: We introduce a novel framework for clustering a collection of tall matrices based on their column spaces, a problem we term Subspace Clustering of Subspaces (SCoS). Unlike traditional subspace clustering methods that assume vectorized data, our formulation directly models each data sample as a matrix and clusters them according to their underlying subspaces. We establish conceptual links to Subspace Clustering and Generalized Canonical Correlation Analysis (GCCA), and clarify key differences that arise in this more general setting. Our approach is based on a Block Term Decomposition (BTD) of a third-order tensor constructed from the input matrices, enabling joint estimation of cluster memberships and partially shared subspaces. We provide the first identifiability results for this formulation and propose scalable optimization algorithms tailored to large datasets. Experiments on real-world hyperspectral imaging datasets demonstrate that our method achieves superior clustering accuracy and robustness, especially under high noise and interference, compared to existing subspace clustering techniques. These results highlight the potential of the proposed framework in challenging high-dimensional applications where structure exists beyond individual data vectors.
Towards Rational Pesticide Design with Graph Machine Learning Models for Ecotoxicology
arXiv:2509.18703v1 Announce Type: new Abstract: This research focuses on rational pesticide design, using graph machine learning to accelerate the development of safer, eco-friendly agrochemicals, inspired by in silico methods in drug discovery. With an emphasis on ecotoxicology, the initial contributions include the creation of ApisTox, the largest curated dataset on pesticide toxicity to honey bees. We conducted a broad evaluation of machine learning (ML) models for molecular graph classification, including molecular fingerprints, graph kernels, GNNs, and pretrained transformers. The results show that methods successful in medicinal chemistry often fail to generalize to agrochemicals, underscoring the need for domain-specific models and benchmarks. Future work will focus on developing a comprehensive benchmarking suite and designing ML models tailored to the unique challenges of pesticide discovery.
A Generalized Bisimulation Metric of State Similarity between Markov Decision Processes: From Theoretical Propositions to Applications
arXiv:2509.18714v1 Announce Type: new Abstract: The bisimulation metric (BSM) is a powerful tool for computing state similarities within a Markov decision process (MDP), revealing that states closer in BSM have more similar optimal value functions. While BSM has been successfully utilized in reinforcement learning (RL) for tasks like state representation learning and policy exploration, its application to multiple-MDP scenarios, such as policy transfer, remains challenging. Prior work has attempted to generalize BSM to pairs of MDPs, but a lack of rigorous analysis of its mathematical properties has limited further theoretical progress. In this work, we formally establish a generalized bisimulation metric (GBSM) between pairs of MDPs, which is rigorously proven with the three fundamental properties: GBSM symmetry, inter-MDP triangle inequality, and the distance bound on identical state spaces. Leveraging these properties, we theoretically analyse policy transfer, state aggregation, and sampling-based estimation in MDPs, obtaining explicit bounds that are strictly tighter than those derived from the standard BSM. Additionally, GBSM provides a closed-form sample complexity for estimation, improving upon existing asymptotic results based on BSM. Numerical results validate our theoretical findings and demonstrate the effectiveness of GBSM in multi-MDP scenarios.
LLM-Enhanced Self-Evolving Reinforcement Learning for Multi-Step E-Commerce Payment Fraud Risk Detection
arXiv:2509.18719v1 Announce Type: new Abstract: This paper presents a novel approach to e-commerce payment fraud detection by integrating reinforcement learning (RL) with Large Language Models (LLMs). By framing transaction risk as a multi-step Markov Decision Process (MDP), RL optimizes risk detection across multiple payment stages. Crafting effective reward functions, essential for RL model success, typically requires significant human expertise due to the complexity and variability in design. LLMs, with their advanced reasoning and coding capabilities, are well-suited to refine these functions, offering improvements over traditional methods. Our approach leverages LLMs to iteratively enhance reward functions, achieving better fraud detection accuracy and demonstrating zero-shot capability. Experiments with real-world data confirm the effectiveness, robustness, and resilience of our LLM-enhanced RL framework through long-term evaluations, underscoring the potential of LLMs in advancing industrial RL applications.
Theory of periodic convolutional neural network
arXiv:2509.18744v1 Announce Type: new Abstract: We introduce a novel convolutional neural network architecture, termed the \emph{periodic CNN}, which incorporates periodic boundary conditions into the convolutional layers. Our main theoretical contribution is a rigorous approximation theorem: periodic CNNs can approximate ridge functions depending on $d-1$ linear variables in a $d$-dimensional input space, while such approximation is impossible in lower-dimensional ridge settings ($d-2$ or fewer variables). This result establishes a sharp characterization of the expressive power of periodic CNNs. Beyond the theory, our findings suggest that periodic CNNs are particularly well-suited for problems where data naturally admits a ridge-like structure of high intrinsic dimension, such as image analysis on wrapped domains, physics-informed learning, and materials science. The work thus both expands the mathematical foundation of CNN approximation theory and highlights a class of architectures with surprising and practically relevant approximation capabilities.
MOMEMTO: Patch-based Memory Gate Model in Time Series Foundation Model
arXiv:2509.18751v1 Announce Type: new Abstract: Recently reconstruction-based deep models have been widely used for time series anomaly detection, but as their capacity and representation capability increase, these models tend to over-generalize, often reconstructing unseen anomalies accurately. Prior works have attempted to mitigate this by incorporating a memory architecture that stores prototypes of normal patterns. Nevertheless, these approaches suffer from high training costs and have yet to be effectively integrated with time series foundation models (TFMs). To address these challenges, we propose \textbf{MOMEMTO}, a TFM for anomaly detection, enhanced with a patch-based memory module to mitigate over-generalization. The memory module is designed to capture representative normal patterns from multiple domains and enables a single model to be jointly fine-tuned across multiple datasets through a multi-domain training strategy. MOMEMTO initializes memory items with latent representations from a pre-trained encoder, organizes them into patch-level units, and updates them via an attention mechanism. We evaluate our method using 23 univariate benchmark datasets. Experimental results demonstrate that MOMEMTO, as a single model, achieves higher scores on AUC and VUS metrics compared to baseline methods, and further enhances the performance of its backbone TFM, particularly in few-shot learning scenarios.
Diagonal Linear Networks and the Lasso Regularization Path
arXiv:2509.18766v1 Announce Type: new Abstract: Diagonal linear networks are neural networks with linear activation and diagonal weight matrices. Their theoretical interest is that their implicit regularization can be rigorously analyzed: from a small initialization, the training of diagonal linear networks converges to the linear predictor with minimal 1-norm among minimizers of the training loss. In this paper, we deepen this analysis showing that the full training trajectory of diagonal linear networks is closely related to the lasso regularization path. In this connection, the training time plays the role of an inverse regularization parameter. Both rigorous results and simulations are provided to illustrate this conclusion. Under a monotonicity assumption on the lasso regularization path, the connection is exact while in the general case, we show an approximate connection.
Probabilistic Machine Learning for Uncertainty-Aware Diagnosis of Industrial Systems
arXiv:2509.18810v1 Announce Type: new Abstract: Deep neural networks has been increasingly applied in fault diagnostics, where it uses historical data to capture systems behavior, bypassing the need for high-fidelity physical models. However, despite their competence in prediction tasks, these models often struggle with the evaluation of their confidence. This matter is particularly important in consistency-based diagnosis where decision logic is highly sensitive to false alarms. To address this challenge, this work presents a diagnostic framework that uses ensemble probabilistic machine learning to improve diagnostic characteristics of data driven consistency based diagnosis by quantifying and automating the prediction uncertainty. The proposed method is evaluated across several case studies using both ablation and comparative analyses, showing consistent improvements across a range of diagnostic metrics.
Training-Free Data Assimilation with GenCast
arXiv:2509.18811v1 Announce Type: new Abstract: Data assimilation is widely used in many disciplines such as meteorology, oceanography, and robotics to estimate the state of a dynamical system from noisy observations. In this work, we propose a lightweight and general method to perform data assimilation using diffusion models pre-trained for emulating dynamical systems. Our method builds on particle filters, a class of data assimilation algorithms, and does not require any further training. As a guiding example throughout this work, we illustrate our methodology on GenCast, a diffusion-based model that generates global ensemble weather forecasts.
Graph-based Clustering Revisited: A Relaxation of Kernel $k$-Means Perspective
arXiv:2509.18826v1 Announce Type: new Abstract: The well-known graph-based clustering methods, including spectral clustering, symmetric non-negative matrix factorization, and doubly stochastic normalization, can be viewed as relaxations of the kernel $k$-means approach. However, we posit that these methods excessively relax their inherent low-rank, nonnegative, doubly stochastic, and orthonormal constraints to ensure numerical feasibility, potentially limiting their clustering efficacy. In this paper, guided by our theoretical analyses, we propose \textbf{Lo}w-\textbf{R}ank \textbf{D}oubly stochastic clustering (\textbf{LoRD}), a model that only relaxes the orthonormal constraint to derive a probabilistic clustering results. Furthermore, we theoretically establish the equivalence between orthogonality and block diagonality under the doubly stochastic constraint. By integrating \textbf{B}lock diagonal regularization into LoRD, expressed as the maximization of the Frobenius norm, we propose \textbf{B-LoRD}, which further enhances the clustering performance. To ensure numerical solvability, we transform the non-convex doubly stochastic constraint into a linear convex constraint through the introduction of a class probability parameter. We further theoretically demonstrate the gradient Lipschitz continuity of our LoRD and B-LoRD enables the proposal of a globally convergent projected gradient descent algorithm for their optimization. Extensive experiments validate the effectiveness of our approaches. The code is publicly available at https://github.com/lwl-learning/LoRD.
Shared-Weights Extender and Gradient Voting for Neural Network Expansion
arXiv:2509.18842v1 Announce Type: new Abstract: Expanding neural networks during training is a promising way to augment capacity without retraining larger models from scratch. However, newly added neurons often fail to adjust to a trained network and become inactive, providing no contribution to capacity growth. We propose the Shared-Weights Extender (SWE), a novel method explicitly designed to prevent inactivity of new neurons by coupling them with existing ones for smooth integration. In parallel, we introduce the Steepest Voting Distributor (SVoD), a gradient-based method for allocating neurons across layers during deep network expansion. Our extensive benchmarking on four datasets shows that our method can effectively suppress neuron inactivity and achieve better performance compared to other expanding methods and baselines.
NGRPO: Negative-enhanced Group Relative Policy Optimization
arXiv:2509.18851v1 Announce Type: new Abstract: RLVR has enhanced the reasoning capabilities of Large Language Models (LLMs) across various tasks. However, GRPO, a representative RLVR algorithm, suffers from a critical limitation: when all responses within a group are either entirely correct or entirely incorrect, the model fails to learn from these homogeneous responses. This is particularly problematic for homogeneously incorrect groups, where GRPO's advantage function yields a value of zero, leading to null gradients and the loss of valuable learning signals. To overcome this issue, we propose NGRPO (Negative-enhanced Group Relative Policy Optimization), an algorithm designed to convert homogeneous errors into robust learning signals. First, NGRPO introduces Advantage Calibration. This mechanism hypothesizes the existence of a virtual maximum-reward sample during advantage calculation, thereby altering the mean and variance of rewards within a group and ensuring that the advantages for homogeneously incorrect samples are no longer zero. Second, NGRPO employs Asymmetric Clipping, which relaxes the update magnitude for positive samples while imposing stricter constraints on that of negative samples. This serves to stabilize the exploration pressure introduced by the advantage calibration. Our experiments on Qwen2.5-Math-7B demonstrate that NGRPO significantly outperforms baselines such as PPO, GRPO, DAPO, and PSR-NSR on mathematical benchmarks including MATH500, AMC23, and AIME2025. These results validate NGRPO's ability to learn from homogeneous errors, leading to stable and substantial improvements in mathematical reasoning. Our code is available at https://github.com/nangongrui-ngr/NGRPO.
Exploring Heterophily in Graph-level Tasks
arXiv:2509.18893v1 Announce Type: new Abstract: While heterophily has been widely studied in node-level tasks, its impact on graph-level tasks remains unclear. We present the first analysis of heterophily in graph-level learning, combining theoretical insights with empirical validation. We first introduce a taxonomy of graph-level labeling schemes, and focus on motif-based tasks within local structure labeling, which is a popular labeling scheme. Using energy-based gradient flow analysis, we reveal a key insight: unlike frequency-dominated regimes in node-level tasks, motif detection requires mixed-frequency dynamics to remain flexible across multiple spectral components. Our theory shows that motif objectives are inherently misaligned with global frequency dominance, demanding distinct architectural considerations. Experiments on synthetic datasets with controlled heterophily and real-world molecular property prediction support our findings, showing that frequency-adaptive model outperform frequency-dominated models. This work establishes a new theoretical understanding of heterophily in graph-level learning and offers guidance for designing effective GNN architectures.
Enhancing the Effectiveness and Durability of Backdoor Attacks in Federated Learning through Maximizing Task Distinction
arXiv:2509.18904v1 Announce Type: new Abstract: Federated learning allows multiple participants to collaboratively train a central model without sharing their private data. However, this distributed nature also exposes new attack surfaces. In particular, backdoor attacks allow attackers to implant malicious behaviors into the global model while maintaining high accuracy on benign inputs. Existing attacks usually rely on fixed patterns or adversarial perturbations as triggers, which tightly couple the main and backdoor tasks. This coupling makes them vulnerable to dilution by honest updates and limits their persistence under federated defenses. In this work, we propose an approach to decouple the backdoor task from the main task by dynamically optimizing the backdoor trigger within a min-max framework. The inner layer maximizes the performance gap between poisoned and benign samples, ensuring that the contributions of benign users have minimal impact on the backdoor. The outer process injects the adaptive triggers into the local model. We evaluate our method on both computer vision and natural language tasks, and compare it with six backdoor attack methods under six defense algorithms. Experimental results show that our method achieves good attack performance and can be easily integrated into existing backdoor attack techniques.
Tackling GNARLy Problems: Graph Neural Algorithmic Reasoning Reimagined through Reinforcement Learning
arXiv:2509.18930v1 Announce Type: new Abstract: Neural Algorithmic Reasoning (NAR) is a paradigm that trains neural networks to execute classic algorithms by supervised learning. Despite its successes, important limitations remain: inability to construct valid solutions without post-processing and to reason about multiple correct ones, poor performance on combinatorial NP-hard problems, and inapplicability to problems for which strong algorithms are not yet known. To address these limitations, we reframe the problem of learning algorithm trajectories as a Markov Decision Process, which imposes structure on the solution construction procedure and unlocks the powerful tools of imitation and reinforcement learning (RL). We propose the GNARL framework, encompassing the methodology to translate problem formulations from NAR to RL and a learning architecture suitable for a wide range of graph-based problems. We achieve very high graph accuracy results on several CLRS-30 problems, performance matching or exceeding much narrower NAR approaches for NP-hard problems and, remarkably, applicability even when lacking an expert algorithm.
Towards Privacy-Aware Bayesian Networks: A Credal Approach
arXiv:2509.18949v1 Announce Type: new Abstract: Bayesian networks (BN) are probabilistic graphical models that enable efficient knowledge representation and inference. These have proven effective across diverse domains, including healthcare, bioinformatics and economics. The structure and parameters of a BN can be obtained by domain experts or directly learned from available data. However, as privacy concerns escalate, it becomes increasingly critical for publicly released models to safeguard sensitive information in training data. Typically, released models do not prioritize privacy by design. In particular, tracing attacks from adversaries can combine the released BN with auxiliary data to determine whether specific individuals belong to the data from which the BN was learned. State-of-the-art protection tecniques involve introducing noise into the learned parameters. While this offers robust protection against tracing attacks, it significantly impacts the model's utility, in terms of both the significance and accuracy of the resulting inferences. Hence, high privacy may be attained at the cost of releasing a possibly ineffective model. This paper introduces credal networks (CN) as a novel solution for balancing the model's privacy and utility. After adapting the notion of tracing attacks, we demonstrate that a CN enables the masking of the learned BN, thereby reducing the probability of successful attacks. As CNs are obfuscated but not noisy versions of BNs, they can achieve meaningful inferences while safeguarding privacy. Moreover, we identify key learning information that must be concealed to prevent attackers from recovering the underlying BN. Finally, we conduct a set of numerical experiments to analyze how privacy gains can be modulated by tuning the CN hyperparameters. Our results confirm that CNs provide a principled, practical, and effective approach towards the development of privacy-aware probabilistic graphical models.
Lift What You Can: Green Online Learning with Heterogeneous Ensembles
arXiv:2509.18962v1 Announce Type: new Abstract: Ensemble methods for stream mining necessitate managing multiple models and updating them as data distributions evolve. Considering the calls for more sustainability, established methods are however not sufficiently considerate of ensemble members' computational expenses and instead overly focus on predictive capabilities. To address these challenges and enable green online learning, we propose heterogeneous online ensembles (HEROS). For every training step, HEROS chooses a subset of models from a pool of models initialized with diverse hyperparameter choices under resource constraints to train. We introduce a Markov decision process to theoretically capture the trade-offs between predictive performance and sustainability constraints. Based on this framework, we present different policies for choosing which models to train on incoming data. Most notably, we propose the novel $\zeta$-policy, which focuses on training near-optimal models at reduced costs. Using a stochastic model, we theoretically prove that our $\zeta$-policy achieves near optimal performance while using fewer resources compared to the best performing policy. In our experiments across 11 benchmark datasets, we find empiric evidence that our $\zeta$-policy is a strong contribution to the state-of-the-art, demonstrating highly accurate performance, in some cases even outperforming competitors, and simultaneously being much more resource-friendly.
Central Limit Theorems for Asynchronous Averaged Q-Learning
arXiv:2509.18964v1 Announce Type: new Abstract: This paper establishes central limit theorems for Polyak-Ruppert averaged Q-learning under asynchronous updates. We present a non-asymptotic central limit theorem, where the convergence rate in Wasserstein distance explicitly reflects the dependence on the number of iterations, state-action space size, the discount factor, and the quality of exploration. In addition, we derive a functional central limit theorem, showing that the partial-sum process converges weakly to a Brownian motion.
Otters: An Energy-Efficient SpikingTransformer via Optical Time-to-First-Spike Encoding
arXiv:2509.18968v1 Announce Type: new Abstract: Spiking neural networks (SNNs) promise high energy efficiency, particularly with time-to-first-spike (TTFS) encoding, which maximizes sparsity by emitting at most one spike per neuron. However, such energy advantage is often unrealized because inference requires evaluating a temporal decay function and subsequent multiplication with the synaptic weights. This paper challenges this costly approach by repurposing a physical hardware `bug', namely, the natural signal decay in optoelectronic devices, as the core computation of TTFS. We fabricated a custom indium oxide optoelectronic synapse, showing how its natural physical decay directly implements the required temporal function. By treating the device's analog output as the fused product of the synaptic weight and temporal decay, optoelectronic synaptic TTFS (named Otters) eliminates these expensive digital operations. To use the Otters paradigm in complex architectures like the transformer, which are challenging to train directly due to the sparsity issue, we introduce a novel quantized neural network-to-SNN conversion algorithm. This complete hardware-software co-design enables our model to achieve state-of-the-art accuracy across seven GLUE benchmark datasets and demonstrates a 1.77$\times$ improvement in energy efficiency over previous leading SNNs, based on a comprehensive analysis of compute, data movement, and memory access costs using energy measurements from a commercial 22nm process. Our work thus establishes a new paradigm for energy-efficient SNNs, translating fundamental device physics directly into powerful computational primitives. All codes and data are open source.
Learning From Simulators: A Theory of Simulation-Grounded Learning
arXiv:2509.18990v1 Announce Type: new Abstract: Simulation-Grounded Neural Networks (SGNNs) are predictive models trained entirely on synthetic data from mechanistic simulations. They have achieved state-of-the-art performance in domains where real-world labels are limited or unobserved, but lack a formal underpinning. We present the foundational theory of simulation-grounded learning. We show that SGNNs implement amortized Bayesian inference under a simulation prior and converge to the Bayes-optimal predictor. We derive generalization bounds under model misspecification and prove that SGNNs can learn unobservable scientific quantities that empirical methods provably cannot. We also formalize a novel form of mechanistic interpretability uniquely enabled by SGNNs: by attributing predictions to the simulated mechanisms that generated them, SGNNs yield posterior-consistent, scientifically grounded explanations. We provide numerical experiments to validate all theoretical predictions. SGNNs recover latent parameters, remain robust under mismatch, and outperform classical tools: in a model selection task, SGNNs achieve half the error of AIC in distinguishing mechanistic dynamics. These results establish SGNNs as a principled and practical framework for scientific prediction in data-limited regimes.
CR-Net: Scaling Parameter-Efficient Training with Cross-Layer Low-Rank Structure
arXiv:2509.18993v1 Announce Type: new Abstract: Low-rank architectures have become increasingly important for efficient large language model (LLM) pre-training, providing substantial reductions in both parameter complexity and memory/computational demands. Despite these advantages, current low-rank methods face three critical shortcomings: (1) compromised model performance, (2) considerable computational overhead, and (3) limited activation memory savings. To address these limitations, we propose Cross-layer Low-Rank residual Network (CR-Net), an innovative parameter-efficient framework inspired by our discovery that inter-layer activation residuals possess low-rank properties. CR-Net implements this insight through a dual-path architecture that efficiently reconstructs layer activations by combining previous-layer outputs with their low-rank differences, thereby maintaining high-rank information with minimal parameters. We further develop a specialized activation recomputation strategy tailored for CR-Net that dramatically reduces memory requirements. Extensive pre-training experiments across model scales from 60M to 7B parameters demonstrate that CR-Net consistently outperforms state-of-the-art low-rank frameworks while requiring fewer computational resources and less memory.
Theoretical Foundations of Representation Learning using Unlabeled Data: Statistics and Optimization
arXiv:2509.18997v1 Announce Type: new Abstract: Representation learning from unlabeled data has been extensively studied in statistics, data science and signal processing with a rich literature on techniques for dimension reduction, compression, multi-dimensional scaling among others. However, current deep learning models use new principles for unsupervised representation learning that cannot be easily analyzed using classical theories. For example, visual foundation models have found tremendous success using self-supervision or denoising/masked autoencoders, which effectively learn representations from massive amounts of unlabeled data. However, it remains difficult to characterize the representations learned by these models and to explain why they perform well for diverse prediction tasks or show emergent behavior. To answer these questions, one needs to combine mathematical tools from statistics and optimization. This paper provides an overview of recent theoretical advances in representation learning from unlabeled data and mentions our contributions in this direction.
Fully Learnable Neural Reward Machines
arXiv:2509.19017v1 Announce Type: new Abstract: Non-Markovian Reinforcement Learning (RL) tasks present significant challenges, as agents must reason over entire trajectories of state-action pairs to make optimal decisions. A common strategy to address this is through symbolic formalisms, such as Linear Temporal Logic (LTL) or automata, which provide a structured way to express temporally extended objectives. However, these approaches often rely on restrictive assumptions -- such as the availability of a predefined Symbol Grounding (SG) function mapping raw observations to high-level symbolic representations, or prior knowledge of the temporal task. In this work, we propose a fully learnable version of Neural Reward Machines (NRM), which can learn both the SG function and the automaton end-to-end, removing any reliance on prior knowledge. Our approach is therefore as easily applicable as classic deep RL (DRL) approaches, while being far more explainable, because of the finite and compact nature of automata. Furthermore, we show that by integrating Fully Learnable Reward Machines (FLNRM) with DRL, our method outperforms previous approaches based on Recurrent Neural Networks (RNNs).
OmniBridge: Unified Multimodal Understanding, Generation, and Retrieval via Latent Space Alignment
arXiv:2509.19018v1 Announce Type: new Abstract: Recent advances in multimodal large language models (LLMs) have led to significant progress in understanding, generation, and retrieval tasks. However, current solutions often treat these tasks in isolation or require training LLMs from scratch, resulting in high computational costs and limited generalization across modalities. In this work, we present OmniBridge, a unified and modular multimodal framework that supports vision-language understanding, generation, and retrieval within a unified architecture. OmniBridge adopts a language-centric design that reuses pretrained LLMs and introduces a lightweight bidirectional latent alignment module. To address the challenge of task interference, we propose a two-stage decoupled training strategy: supervised fine-tuning and latent space alignment for aligning LLM behavior with multimodal reasoning, and semantic-guided diffusion training to align cross-modal latent spaces via learnable query embeddings. Extensive experiments across a wide range of benchmarks demonstrate that OmniBridge achieves competitive or state-of-the-art performance in all three tasks. Moreover, our results highlight the effectiveness of latent space alignment for unifying multimodal modeling under a shared representation space. Code and models are released at https://github.com/xiao-xt/OmniBridge.
Improving Credit Card Fraud Detection through Transformer-Enhanced GAN Oversampling
arXiv:2509.19032v1 Announce Type: new Abstract: Detection of credit card fraud is an acute issue of financial security because transaction datasets are highly lopsided, with fraud cases being only a drop in the ocean. Balancing datasets using the most popular methods of traditional oversampling such as the Synthetic Minority Oversampling Technique (SMOTE) generally create simplistic synthetic samples that are not readily applicable to complex fraud patterns. Recent industry advances that include Conditional Tabular Generative Adversarial Networks (CTGAN) and Tabular Variational Autoencoders (TVAE) have demonstrated increased efficiency in tabular synthesis, yet all these models still exhibit issues with high-dimensional dependence modelling. Now we will present our hybrid approach where we use a Generative Adversarial Network (GAN) with a Transformer encoder block to produce realistic fraudulent transactions samples. The GAN architecture allows training realistic generators adversarial, and the Transformer allows the model to learn rich feature interactions by self-attention. Such a hybrid strategy overcomes the limitations of SMOTE, CTGAN, and TVAE by producing a variety of high-quality synthetic minority classes samples. We test our algorithm on the publicly-available Credit Card Fraud Detection dataset and compare it to conventional and generative resampling strategies with a variety of classifiers, such as Logistic Regression (LR), Random Forest (RF), Extreme Gradient Boosting (XGBoost), and Support Vector Machine (SVM). Findings indicate that our Transformer-based GAN shows substantial gains in Recall, F1-score and Area Under the Receiver Operating Characteristic Curve (AUC), which indicates that it is effective in overcoming the severe class imbalance inherent in the task of fraud detection.
Latent Danger Zone: Distilling Unified Attention for Cross-Architecture Black-box Attacks
arXiv:2509.19044v1 Announce Type: new Abstract: Black-box adversarial attacks remain challenging due to limited access to model internals. Existing methods often depend on specific network architectures or require numerous queries, resulting in limited cross-architecture transferability and high query costs. To address these limitations, we propose JAD, a latent diffusion model framework for black-box adversarial attacks. JAD generates adversarial examples by leveraging a latent diffusion model guided by attention maps distilled from both a convolutional neural network (CNN) and a Vision Transformer (ViT) models. By focusing on image regions that are commonly sensitive across architectures, this approach crafts adversarial perturbations that transfer effectively between different model types. This joint attention distillation strategy enables JAD to be architecture-agnostic, achieving superior attack generalization across diverse models. Moreover, the generative nature of the diffusion framework yields high adversarial sample generation efficiency by reducing reliance on iterative queries. Experiments demonstrate that JAD offers improved attack generalization, generation efficiency, and cross-architecture transferability compared to existing methods, providing a promising and effective paradigm for black-box adversarial attacks.
Beyond Backpropagation: Exploring Innovative Algorithms for Energy-Efficient Deep Neural Network Training
arXiv:2509.19063v1 Announce Type: new Abstract: The rising computational and energy demands of deep neural networks (DNNs), driven largely by backpropagation (BP), challenge sustainable AI development. This paper rigorously investigates three BP-free training methods: the Forward-Forward (FF), Cascaded-Forward (CaFo), and Mono-Forward (MF) algorithms, tracing their progression from foundational concepts to a demonstrably superior solution. A robust comparative framework was established: each algorithm was implemented on its native architecture (MLPs for FF and MF, a CNN for CaFo) and benchmarked against an equivalent BP-trained model. Hyperparameters were optimized with Optuna, and consistent early stopping criteria were applied based on validation performance, ensuring all models were optimally tuned before comparison. Results show that MF not only competes with but consistently surpasses BP in classification accuracy on its native MLPs. Its superior generalization stems from converging to a more favorable minimum in the validation loss landscape, challenging the assumption that global optimization is required for state-of-the-art results. Measured at the hardware level using the NVIDIA Management Library (NVML) API, MF reduces energy consumption by up to 41% and shortens training time by up to 34%, translating to a measurably smaller carbon footprint as estimated by CodeCarbon. Beyond this primary result, we present a hardware-level analysis that explains the efficiency gains: exposing FF's architectural inefficiencies, validating MF's computationally lean design, and challenging the assumption that all BP-free methods are inherently more memory-efficient. By documenting the evolution from FF's conceptual groundwork to MF's synthesis of accuracy and sustainability, this work offers a clear, data-driven roadmap for future energy-efficient deep learning.
Diffusion Bridge Variational Inference for Deep Gaussian Processes
arXiv:2509.19078v1 Announce Type: new Abstract: Deep Gaussian processes (DGPs) enable expressive hierarchical Bayesian modeling but pose substantial challenges for posterior inference, especially over inducing variables. Denoising diffusion variational inference (DDVI) addresses this by modeling the posterior as a time-reversed diffusion from a simple Gaussian prior. However, DDVI's fixed unconditional starting distribution remains far from the complex true posterior, resulting in inefficient inference trajectories and slow convergence. In this work, we propose Diffusion Bridge Variational Inference (DBVI), a principled extension of DDVI that initiates the reverse diffusion from a learnable, data-dependent initial distribution. This initialization is parameterized via an amortized neural network and progressively adapted using gradients from the ELBO objective, reducing the posterior gap and improving sample efficiency. To enable scalable amortization, we design the network to operate on the inducing inputs, which serve as structured, low-dimensional summaries of the dataset and naturally align with the inducing variables' shape. DBVI retains the mathematical elegance of DDVI, including Girsanov-based ELBOs and reverse-time SDEs,while reinterpreting the prior via a Doob-bridged diffusion process. We derive a tractable training objective under this formulation and implement DBVI for scalable inference in large-scale DGPs. Across regression, classification, and image reconstruction tasks, DBVI consistently outperforms DDVI and other variational baselines in predictive accuracy, convergence speed, and posterior quality.
Graph Neural Networks with Similarity-Navigated Probabilistic Feature Copying
arXiv:2509.19084v1 Announce Type: new Abstract: Graph Neural Networks (GNNs) have demonstrated remarkable success across various graph-based tasks. However, they face some fundamental limitations: feature oversmoothing can cause node representations to become indistinguishable in deeper networks, they struggle to effectively manage heterogeneous relationships where connected nodes differ significantly, and they process entire feature vectors as indivisible units, which limits flexibility. We seek to address these limitations. We propose AxelGNN, a novel GNN architecture inspired by Axelrod's cultural dissemination model that addresses these limitations through a unified framework. AxelGNN incorporates similarity-gated probabilistic interactions that adaptively promote convergence or divergence based on node similarity, implements trait-level copying mechanisms for fine-grained feature aggregation at the segment level, and maintains global polarization to preserve node distinctiveness across multiple representation clusters. The model's bistable convergence dynamics naturally handle both homophilic and heterophilic graphs within a single architecture. Extensive experiments on node classification and influence estimation benchmarks demonstrate that AxelGNN consistently outperforms or matches state-of-the-art GNN methods across diverse graph structures with varying homophily-heterophily characteristics.
Asymptotically Optimal Problem-Dependent Bandit Policies for Transfer Learning
arXiv:2509.19098v1 Announce Type: new Abstract: We study the non-contextual multi-armed bandit problem in a transfer learning setting: before any pulls, the learner is given N'_k i.i.d. samples from each source distribution nu'_k, and the true target distributions nu_k lie within a known distance bound d_k(nu_k, nu'_k) <= L_k. In this framework, we first derive a problem-dependent asymptotic lower bound on cumulative regret that extends the classical Lai-Robbins result to incorporate the transfer parameters (d_k, L_k, N'_k). We then propose KL-UCB-Transfer, a simple index policy that matches this new bound in the Gaussian case. Finally, we validate our approach via simulations, showing that KL-UCB-Transfer significantly outperforms the no-prior baseline when source and target distributions are sufficiently close.
Algorithms for Adversarially Robust Deep Learning
arXiv:2509.19100v1 Announce Type: new Abstract: Given the widespread use of deep learning models in safety-critical applications, ensuring that the decisions of such models are robust against adversarial exploitation is of fundamental importance. In this thesis, we discuss recent progress toward designing algorithms that exhibit desirable robustness properties. First, we discuss the problem of adversarial examples in computer vision, for which we introduce new technical results, training paradigms, and certification algorithms. Next, we consider the problem of domain generalization, wherein the task is to train neural networks to generalize from a family of training distributions to unseen test distributions. We present new algorithms that achieve state-of-the-art generalization in medical imaging, molecular identification, and image classification. Finally, we study the setting of jailbreaking large language models (LLMs), wherein an adversarial user attempts to design prompts that elicit objectionable content from an LLM. We propose new attacks and defenses, which represent the frontier of progress toward designing robust language-based agents.
DRO-REBEL: Distributionally Robust Relative-Reward Regression for Fast and Efficient LLM Alignment
arXiv:2509.19104v1 Announce Type: new Abstract: Reinforcement learning with human feedback (RLHF) has become crucial for aligning Large Language Models (LLMs) with human intent. However, existing offline RLHF approaches suffer from overoptimization, where models overfit to reward misspecification and drift from preferred behaviors observed during training. We introduce DRO-REBEL, a unified family of robust REBEL updates with type-$p$ Wasserstein, KL, and $\chi^2$ ambiguity sets. Using Fenchel duality, each update reduces to a simple relative-reward regression, preserving scalability and avoiding PPO-style clipping or auxiliary value networks. Under standard linear-reward and log-linear policy classes with a data-coverage condition, we establish $O(n^{-1/4})$ estimation bounds with tighter constants than prior DRO-DPO approaches, and recover the minimax-optimal $O(n^{-1/2})$ rate via a localized Rademacher complexity analysis. The same analysis closes the gap for Wasserstein-DPO and KL-DPO, showing both also attain optimal parametric rates. We derive practical SGD algorithms for all three divergences: gradient regularization (Wasserstein), importance weighting (KL), and a fast 1-D dual solve ($\chi^2$). Experiments on Emotion Alignment, the large-scale ArmoRM multi-objective benchmark, and HH-Alignment demonstrate strong worst-case robustness across unseen preference mixtures, model sizes, and data scales, with $\chi^2$-REBEL showing consistently strong empirical performance. A controlled radius--coverage study validates a no-free-lunch trade-off: radii shrinking faster than empirical divergence concentration rates achieve minimax-optimal parametric rates but forfeit coverage, while coverage-guaranteeing radii incur $O(n^{-1/4})$ rates.
Towards Practical Multi-label Causal Discovery in High-Dimensional Event Sequences via One-Shot Graph Aggregation
arXiv:2509.19112v1 Announce Type: new Abstract: Understanding causality in event sequences where outcome labels such as diseases or system failures arise from preceding events like symptoms or error codes is critical. Yet remains an unsolved challenge across domains like healthcare or vehicle diagnostics. We introduce CARGO, a scalable multi-label causal discovery method for sparse, high-dimensional event sequences comprising of thousands of unique event types. Using two pretrained causal Transformers as domain-specific foundation models for event sequences. CARGO infers in parallel, per sequence one-shot causal graphs and aggregates them using an adaptive frequency fusion to reconstruct the global Markov boundaries of labels. This two-stage approach enables efficient probabilistic reasoning at scale while bypassing the intractable cost of full-dataset conditional independence testing. Our results on a challenging real-world automotive fault prediction dataset with over 29,100 unique event types and 474 imbalanced labels demonstrate CARGO's ability to perform structured reasoning.
FedFiTS: Fitness-Selected, Slotted Client Scheduling for Trustworthy Federated Learning in Healthcare AI
arXiv:2509.19120v1 Announce Type: new Abstract: Federated Learning (FL) has emerged as a powerful paradigm for privacy-preserving model training, yet deployments in sensitive domains such as healthcare face persistent challenges from non-IID data, client unreliability, and adversarial manipulation. This paper introduces FedFiTS, a trust and fairness-aware selective FL framework that advances the FedFaSt line by combining fitness-based client election with slotted aggregation. FedFiTS implements a three-phase participation strategy-free-for-all training, natural selection, and slotted team participation-augmented with dynamic client scoring, adaptive thresholding, and cohort-based scheduling to balance convergence efficiency with robustness. A theoretical convergence analysis establishes bounds for both convex and non-convex objectives under standard assumptions, while a communication-complexity analysis shows reductions relative to FedAvg and other baselines. Experiments on diverse datasets-medical imaging (X-ray pneumonia), vision benchmarks (MNIST, FMNIST), and tabular agricultural data (Crop Recommendation)-demonstrate that FedFiTS consistently outperforms FedAvg, FedRand, and FedPow in accuracy, time-to-target, and resilience to poisoning attacks. By integrating trust-aware aggregation with fairness-oriented client selection, FedFiTS advances scalable and secure FL, making it well suited for real-world healthcare and cross-domain deployments.
Analysis on distribution and clustering of weight
arXiv:2509.19122v1 Announce Type: new Abstract: The study on architecture and parameter characteristics remains the hot topic in the research of large language models. In this paper we concern with the characteristics of weight which are used to analyze the correlations and differences between models. Two kinds of vectors-standard deviation vector and clustering vector-are proposed to describe features of models. In the first case, the weights are assumed to follow normal distribution. The standard deviation values of projection matrices are normalized to form Standard-Deviation Vector, representing the distribution characteristics of models. In the second case, the singular values from each weight projection matrix are extracted and grouped by K-Means algorithm. The grouped data with the same type matrix are combined as Clustering Vector to represent the correlation characteristics of models' weights. The study reveals that these two vectors can effectively distinguish between different models and clearly show the similarities among models of the same family. Moreover, after conducting LoRA fine-tuning with different datasets and models, it is found that the distribution of weights represented by standard deviation vector is directly influenced by the dataset, but the correlations between different weights represented by clustering vector remain unaffected and maintain a high consistency with the pre-trained model.
PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence Generatio
arXiv:2509.19128v1 Announce Type: new Abstract: Reinforcement Learning (RL) is increasingly utilized to enhance the reasoning capabilities of Large Language Models (LLMs). However, effectively scaling these RL methods presents significant challenges, primarily due to the difficulty in maintaining high AI accelerator utilization without generating stale, off-policy data that harms common RL algorithms. This paper introduces PipelineRL, an approach designed to achieve a superior trade-off between hardware efficiency and data on-policyness for LLM training. PipelineRL employs concurrent asynchronous data generation and model training, distinguished by the novel in-flight weight updates. This mechanism allows the LLM generation engine to receive updated model weights with minimal interruption during the generation of token sequences, thereby maximizing both the accelerator utilization and the freshness of training data. Experiments conducted on long-form reasoning tasks using 128 H100 GPUs demonstrate that PipelineRL achieves approximately $\sim 2x$ faster learning compared to conventional RL baselines while maintaining highly on-policy training data. A scalable and modular open-source implementation of PipelineRL is also released as a key contribution.
GSTM-HMU: Generative Spatio-Temporal Modeling for Human Mobility Understanding
arXiv:2509.19135v1 Announce Type: new Abstract: Human mobility traces, often recorded as sequences of check-ins, provide a unique window into both short-term visiting patterns and persistent lifestyle regularities. In this work we introduce GSTM-HMU, a generative spatio-temporal framework designed to advance mobility analysis by explicitly modeling the semantic and temporal complexity of human movement. The framework consists of four key innovations. First, a Spatio-Temporal Concept Encoder (STCE) integrates geographic location, POI category semantics, and periodic temporal rhythms into unified vector representations. Second, a Cognitive Trajectory Memory (CTM) adaptively filters historical visits, emphasizing recent and behaviorally salient events in order to capture user intent more effectively. Third, a Lifestyle Concept Bank (LCB) contributes structured human preference cues, such as activity types and lifestyle patterns, to enhance interpretability and personalization. Finally, task-oriented generative heads transform the learned representations into predictions for multiple downstream tasks. We conduct extensive experiments on four widely used real-world datasets, including Gowalla, WeePlace, Brightkite, and FourSquare, and evaluate performance on three benchmark tasks: next-location prediction, trajectory-user identification, and time estimation. The results demonstrate consistent and substantial improvements over strong baselines, confirming the effectiveness of GSTM-HMU in extracting semantic regularities from complex mobility data. Beyond raw performance gains, our findings also suggest that generative modeling provides a promising foundation for building more robust, interpretable, and generalizable systems for human mobility intelligence.
Efficient Reinforcement Learning by Reducing Forgetting with Elephant Activation Functions
arXiv:2509.19159v1 Announce Type: new Abstract: Catastrophic forgetting has remained a significant challenge for efficient reinforcement learning for decades (Ring 1994, Rivest and Precup 2003). While recent works have proposed effective methods to mitigate this issue, they mainly focus on the algorithmic side. Meanwhile, we do not fully understand what architectural properties of neural networks lead to catastrophic forgetting. This study aims to fill this gap by studying the role of activation functions in the training dynamics of neural networks and their impact on catastrophic forgetting in reinforcement learning setup. Our study reveals that, besides sparse representations, the gradient sparsity of activation functions also plays an important role in reducing forgetting. Based on this insight, we propose a new class of activation functions, elephant activation functions, that can generate both sparse outputs and sparse gradients. We show that by simply replacing classical activation functions with elephant activation functions in the neural networks of value-based algorithms, we can significantly improve the resilience of neural networks to catastrophic forgetting, thus making reinforcement learning more sample-efficient and memory-efficient.
Unveiling the Role of Learning Rate Schedules via Functional Scaling Laws
arXiv:2509.19189v1 Announce Type: new Abstract: Scaling laws have played a cornerstone role in guiding the training of large language models (LLMs). However, most existing works on scaling laws primarily focus on the final-step loss, overlooking the loss dynamics during the training process and, crucially, the impact of learning rate schedule (LRS). In this paper, we aim to bridge this gap by studying a teacher-student kernel regression setup trained via online stochastic gradient descent (SGD). Leveraging a novel intrinsic time viewpoint and stochastic differential equation (SDE) modeling of SGD, we introduce the Functional Scaling Law (FSL), which characterizes the evolution of population risk during the training process for general LRSs. Remarkably, the impact of the LRSs is captured through an explicit convolution-type functional term, making their effects fully tractable. To illustrate the utility of FSL, we analyze three widely used LRSs -- constant, exponential decay, and warmup-stable-decay (WSD) -- under both data-limited and compute-limited regimes. We provide theoretical justification for widely adopted empirical practices in LLMs pre-training such as (i) higher-capacity models are more data- and compute-efficient; (ii) learning rate decay can improve training efficiency; (iii) WSD-like schedules can outperform direct-decay schedules. Lastly, we explore the practical relevance of FSL as a surrogate model for fitting, predicting and optimizing the loss curves in LLM pre-training, with experiments conducted across model sizes ranging from 0.1B to 1B parameters. We hope our FSL framework can deepen the understanding of LLM pre-training dynamics and provide insights for improving large-scale model training.
A Validation Strategy for Deep Learning Models: Evaluating and Enhancing Robustness
arXiv:2509.19197v1 Announce Type: new Abstract: Data-driven models, especially deep learning classifiers often demonstrate great success on clean datasets. Yet, they remain vulnerable to common data distortions such as adversarial and common corruption perturbations. These perturbations can significantly degrade performance, thereby challenging the overall reliability of the models. Traditional robustness validation typically relies on perturbed test datasets to assess and improve model performance. In our framework, however, we propose a validation approach that extracts "weak robust" samples directly from the training dataset via local robustness analysis. These samples, being the most susceptible to perturbations, serve as an early and sensitive indicator of the model's vulnerabilities. By evaluating models on these challenging training instances, we gain a more nuanced understanding of its robustness, which informs targeted performance enhancement. We demonstrate the effectiveness of our approach on models trained with CIFAR-10, CIFAR-100, and ImageNet, highlighting how robustness validation guided by weak robust samples can drive meaningful improvements in model reliability under adversarial and common corruption scenarios.
PPG-Distill: Efficient Photoplethysmography Signals Analysis via Foundation Model Distillation
arXiv:2509.19215v1 Announce Type: new Abstract: Photoplethysmography (PPG) is widely used in wearable health monitoring, yet large PPG foundation models remain difficult to deploy on resource-limited devices. We present PPG-Distill, a knowledge distillation framework that transfers both global and local knowledge through prediction-, feature-, and patch-level distillation. PPG-Distill incorporates morphology distillation to preserve local waveform patterns and rhythm distillation to capture inter-patch temporal structures. On heart rate estimation and atrial fibrillation detection, PPG-Distill improves student performance by up to 21.8% while achieving 7X faster inference and reducing memory usage by 19X, enabling efficient PPG analysis on wearables
FedFusion: Federated Learning with Diversity- and Cluster-Aware Encoders for Robust Adaptation under Label Scarcity
arXiv:2509.19220v1 Announce Type: new Abstract: Federated learning in practice must contend with heterogeneous feature spaces, severe non-IID data, and scarce labels across clients. We present FedFusion, a federated transfer-learning framework that unifies domain adaptation and frugal labelling with diversity-/cluster-aware encoders (DivEn, DivEn-mix, DivEn-c). Labelled teacher clients guide learner clients via confidence-filtered pseudo-labels and domain-adaptive transfer, while clients maintain personalised encoders tailored to local data. To preserve global coherence under heterogeneity, FedFusion employs similarity-weighted classifier coupling (with optional cluster-wise averaging), mitigating dominance by data-rich sites and improving minority-client performance. The frugal-labelling pipeline combines self-/semi-supervised pretext training with selective fine-tuning, reducing annotation demands without sharing raw data. Across tabular and imaging benchmarks under IID, non-IID, and label-scarce regimes, FedFusion consistently outperforms state-of-the-art baselines in accuracy, robustness, and fairness while maintaining comparable communication and computation budgets. These results show that harmonising personalisation, domain adaptation, and label efficiency is an effective recipe for robust federated learning under real-world constraints.
Video Killed the Energy Budget: Characterizing the Latency and Power Regimes of Open Text-to-Video Models
arXiv:2509.19222v1 Announce Type: new Abstract: Recent advances in text-to-video (T2V) generation have enabled the creation of high-fidelity, temporally coherent clips from natural language prompts. Yet these systems come with significant computational costs, and their energy demands remain poorly understood. In this paper, we present a systematic study of the latency and energy consumption of state-of-the-art open-source T2V models. We first develop a compute-bound analytical model that predicts scaling laws with respect to spatial resolution, temporal length, and denoising steps. We then validate these predictions through fine-grained experiments on WAN2.1-T2V, showing quadratic growth with spatial and temporal dimensions, and linear scaling with the number of denoising steps. Finally, we extend our analysis to six diverse T2V models, comparing their runtime and energy profiles under default settings. Our results provide both a benchmark reference and practical insights for designing and deploying more sustainable generative video systems.
Study Design and Demystification of Physics Informed Neural Networks for Power Flow Simulation
arXiv:2509.19233v1 Announce Type: new Abstract: In the context of the energy transition, with increasing integration of renewable sources and cross-border electricity exchanges, power grids are encountering greater uncertainty and operational risk. Maintaining grid stability under varying conditions is a complex task, and power flow simulators are commonly used to support operators by evaluating potential actions before implementation. However, traditional physical solvers, while accurate, are often too slow for near real-time use. Machine learning models have emerged as fast surrogates, and to improve their adherence to physical laws (e.g., Kirchhoff's laws), they are often trained with embedded constraints which are also known as physics-informed or hybrid models. This paper presents an ablation study to demystify hybridization strategies, ranging from incorporating physical constraints as regularization terms or unsupervised losses, and exploring model architectures from simple multilayer perceptrons to advanced graph-based networks enabling the direct optimization of physics equations. Using our custom benchmarking pipeline for hybrid models called LIPS, we evaluate these models across four dimensions: accuracy, physical compliance, industrial readiness, and out-of-distribution generalization. The results highlight how integrating physical knowledge impacts performance across these criteria. All the implementations are reproducible and provided in the corresponding Github page.
Stability and Generalization of Adversarial Diffusion Training
arXiv:2509.19234v1 Announce Type: new Abstract: Algorithmic stability is an established tool for analyzing generalization. While adversarial training enhances model robustness, it often suffers from robust overfitting and an enlarged generalization gap. Although recent work has established the convergence of adversarial training in decentralized networks, its generalization properties remain unexplored. This work presents a stability-based generalization analysis of adversarial training under the diffusion strategy for convex losses. We derive a bound showing that the generalization error grows with both the adversarial perturbation strength and the number of training steps, a finding consistent with single-agent case but novel for decentralized settings. Numerical experiments on logistic regression validate these theoretical predictions.
What Characterizes Effective Reasoning? Revisiting Length, Review, and Structure of CoT
arXiv:2509.19284v1 Announce Type: new Abstract: Large reasoning models (LRMs) spend substantial test-time compute on long chain-of-thought (CoT) traces, but what characterizes an effective CoT remains unclear. While prior work reports gains from lengthening CoTs and increasing review (revisiting earlier steps) via appended wait tokens, recent studies suggest that shorter thinking can outperform longer traces. We therefore conduct a systematic evaluation across ten LRMs on math and scientific reasoning. Contrary to the "longer-is-better" narrative, we find that both naive CoT lengthening and increased review are associated with lower accuracy. As CoT unfolds step by step, token-level metrics can conflate verbosity with process quality. We introduce a graph view of CoT to extract structure and identify a single statistic-the Failed-Step Fraction (FSF), the fraction of steps in abandoned branches-that consistently outpredicts length and review ratio for correctness across models. To probe causality, we design two interventions. First, we rank candidate CoTs by each metric at test time, where FSF yields the largest pass@1 gains; second, we edit CoTs to remove failed branches, which significantly improves accuracy, indicating that failed branches bias subsequent reasoning. Taken together, these results characterize effective CoTs as those that fail less and support structure-aware test-time scaling over indiscriminately generating long CoT.
Leveraging Geometric Visual Illusions as Perceptual Inductive Biases for Vision Models
arXiv:2509.15156v1 Announce Type: cross Abstract: Contemporary deep learning models have achieved impressive performance in image classification by primarily leveraging statistical regularities within large datasets, but they rarely incorporate structured insights drawn directly from perceptual psychology. To explore the potential of perceptually motivated inductive biases, we propose integrating classic geometric visual illusions well-studied phenomena from human perception into standard image-classification training pipelines. Specifically, we introduce a synthetic, parametric geometric-illusion dataset and evaluate three multi-source learning strategies that combine illusion recognition tasks with ImageNet classification objectives. Our experiments reveal two key conceptual insights: (i) incorporating geometric illusions as auxiliary supervision systematically improves generalization, especially in visually challenging cases involving intricate contours and fine textures; and (ii) perceptually driven inductive biases, even when derived from synthetic stimuli traditionally considered unrelated to natural image recognition, can enhance the structural sensitivity of both CNN and transformer-based architectures. These results demonstrate a novel integration of perceptual science and machine learning and suggest new directions for embedding perceptual priors into vision model design.
A Cost-Benefit Analysis of On-Premise Large Language Model Deployment: Breaking Even with Commercial LLM Services
arXiv:2509.18101v1 Announce Type: cross Abstract: Large language models (LLMs) are becoming increasingly widespread. Organizations that want to use AI for productivity now face an important decision. They can subscribe to commercial LLM services or deploy models on their own infrastructure. Cloud services from providers such as OpenAI, Anthropic, and Google are attractive because they provide easy access to state-of-the-art models and are easy to scale. However, concerns about data privacy, the difficulty of switching service providers, and long-term operating costs have driven interest in local deployment of open-source models. This paper presents a cost-benefit analysis framework to help organizations determine when on-premise LLM deployment becomes economically viable compared to commercial subscription services. We consider the hardware requirements, operational expenses, and performance benchmarks of the latest open-source models, including Qwen, Llama, Mistral, and etc. Then we compare the total cost of deploying these models locally with the major cloud providers subscription fee. Our findings provide an estimated breakeven point based on usage levels and performance needs. These results give organizations a practical framework for planning their LLM strategies.
Dynamic Prompt Fusion for Multi-Task and Cross-Domain Adaptation in LLMs
arXiv:2509.18113v1 Announce Type: cross Abstract: This study addresses the generalization limitations commonly observed in large language models under multi-task and cross-domain settings. Unlike prior methods such as SPoT, which depends on fixed prompt templates, our study introduces a unified multi-task learning framework with dynamic prompt scheduling mechanism. By introducing a prompt pool and a task-aware scheduling strategy, the method dynamically combines and aligns prompts for different tasks. This enhances the model's ability to capture semantic differences across tasks. During prompt fusion, the model uses task embeddings and a gating mechanism to finely control the prompt signals. This ensures alignment between prompt content and task-specific demands. At the same time, it builds flexible sharing pathways across tasks. In addition, the proposed optimization objective centers on joint multi-task learning. It incorporates an automatic learning strategy for scheduling weights, which effectively mitigates task interference and negative transfer. To evaluate the effectiveness of the method, a series of sensitivity experiments were conducted. These experiments examined the impact of prompt temperature parameters and task number variation. The results confirm the advantages of the proposed mechanism in maintaining model stability and enhancing transferability. Experimental findings show that the prompt scheduling method significantly improves performance on a range of language understanding and knowledge reasoning tasks. These results fully demonstrate its applicability and effectiveness in unified multi-task modeling and cross-domain adaptation.
Energy-convergence trade off for the training of neural networks on bio-inspired hardware
arXiv:2509.18121v1 Announce Type: cross Abstract: The increasing deployment of wearable sensors and implantable devices is shifting AI processing demands to the extreme edge, necessitating ultra-low power for continuous operation. Inspired by the brain, emerging memristive devices promise to accelerate neural network training by eliminating costly data transfers between compute and memory. Though, balancing performance and energy efficiency remains a challenge. We investigate ferroelectric synaptic devices based on HfO2/ZrO2 superlattices and feed their experimentally measured weight updates into hardware-aware neural network simulations. Across pulse widths from 20 ns to 0.2 ms, shorter pulses lower per-update energy but require more training epochs while still reducing total energy without sacrificing accuracy. Classification accuracy using plain stochastic gradient descent (SGD) is diminished compared to mixed-precision SGD. We analyze the causes and propose a ``symmetry point shifting'' technique, addressing asymmetric updates and restoring accuracy. These results highlight a trade-off among accuracy, convergence speed, and energy use, showing that short-pulse programming with tailored training significantly enhances on-chip learning efficiency.
SPADE: A Large Language Model Framework for Soil Moisture Pattern Recognition and Anomaly Detection in Precision Agriculture
arXiv:2509.18123v1 Announce Type: cross Abstract: Accurate interpretation of soil moisture patterns is critical for irrigation scheduling and crop management, yet existing approaches for soil moisture time-series analysis either rely on threshold-based rules or data-hungry machine learning or deep learning models that are limited in adaptability and interpretability. In this study, we introduce SPADE (Soil moisture Pattern and Anomaly DEtection), an integrated framework that leverages large language models (LLMs) to jointly detect irrigation patterns and anomalies in soil moisture time-series data. SPADE utilizes ChatGPT-4.1 for its advanced reasoning and instruction-following capabilities, enabling zero-shot analysis without requiring task-specific annotation or fine-tuning. By converting time-series data into a textual representation and designing domain-informed prompt templates, SPADE identifies irrigation events, estimates net irrigation gains, detects, classifies anomalies, and produces structured, interpretable reports. Experiments were conducted on real-world soil moisture sensor data from commercial and experimental farms cultivating multiple crops across the United States. Results demonstrate that SPADE outperforms the existing method in anomaly detection, achieving higher recall and F1 scores and accurately classifying anomaly types. Furthermore, SPADE achieved high precision and recall in detecting irrigation events, indicating its strong capability to capture irrigation patterns accurately. SPADE's reports provide interpretability and usability of soil moisture analytics. This study highlights the potential of LLMs as scalable, adaptable tools for precision agriculture, which is capable of integrating qualitative knowledge and data-driven reasoning to produce actionable insights for accurate soil moisture monitoring and improved irrigation scheduling from soil moisture time-series data.
Pareto-optimal Tradeoffs Between Communication and Computation with Flexible Gradient Tracking
arXiv:2509.18129v1 Announce Type: cross Abstract: This paper addresses distributed optimization problems in non-i.i.d. scenarios, focusing on the interplay between communication and computation efficiency. To this end, we propose FlexGT, a flexible snapshot gradient tracking method with tunable numbers of local updates and neighboring communications in each round. Leveraging a unified convergence analysis framework, we prove that FlexGT achieves a linear or sublinear convergence rate depending on objective-specific properties--from (strongly) convex to nonconvex--and the above-mentioned tunable parameters. FlexGT is provably robust to the heterogeneity across nodes and attains the best-known communication and computation complexity among existing results. Moreover, we introduce an accelerated gossip-based variant, termed Acc-FlexGT, and show that with prior knowledge of the graph, it achieves a Pareto-optimal trade-off between communication and computation. Particularly, Acc-FlexGT achieves the optimal iteration complexity of $\tilde{\mathcal{O}} \left( L/\epsilon +L\sigma ^2/\left( n\epsilon^2 \sqrt{1-\sqrt{\rho _W}} \right) \right) $ for the nonconvex case, matching the existing lower bound up to a logarithmic factor, and improves the existing results for the strongly convex case by a factor of $\tilde{\mathcal{O}} \left( 1/\sqrt{\epsilon} \right)$, where $\epsilon$ is the targeted accuracy, $n$ the number of nodes, $L$ the Lipschitz constant, $\rho_W$ the spectrum gap of the graph, and $\sigma$ the stochastic gradient variance. Numerical examples are provided to demonstrate the effectiveness of the proposed methods.
Weight Mapping Properties of a Dual Tree Single Clock Adiabatic Capacitive Neuron
arXiv:2509.18143v1 Announce Type: cross Abstract: Dual Tree Single Clock (DTSC) Adiabatic Capacitive Neuron (ACN) circuits offer the potential for highly energy-efficient Artificial Neural Network (ANN) computation in full custom analog IC designs. The efficient mapping of Artificial Neuron (AN) abstract weights, extracted from the software-trained ANNs, onto physical ACN capacitance values has, however, yet to be fully researched. In this paper, we explore the unexpected hidden complexities, challenges and properties of the mapping, as well as, the ramifications for IC designers in terms accuracy, design and implementation. We propose an optimal, AN to ACN methodology, that promotes smaller chip sizes and improved overall classification accuracy, necessary for successful practical deployment. Using TensorFlow and Larq software frameworks, we train three different ANN networks and map their weights into the energy-efficient DTSC ACN capacitance value domain to demonstrate 100% functional equivalency. Finally, we delve into the impact of weight quantization on ACN performance using novel metrics related to practical IC considerations, such as IC floor space and comparator decision-making efficacy.
Augmenting Limited and Biased RCTs through Pseudo-Sample Matching-Based Observational Data Fusion Method
arXiv:2509.18148v1 Announce Type: cross Abstract: In the online ride-hailing pricing context, companies often conduct randomized controlled trials (RCTs) and utilize uplift models to assess the effect of discounts on customer orders, which substantially influences competitive market outcomes. However, due to the high cost of RCTs, the proportion of trial data relative to observational data is small, which only accounts for 0.65\% of total traffic in our context, resulting in significant bias when generalizing to the broader user base. Additionally, the complexity of industrial processes reduces the quality of RCT data, which is often subject to heterogeneity from potential interference and selection bias, making it difficult to correct. Moreover, existing data fusion methods are challenging to implement effectively in complex industrial settings due to the high dimensionality of features and the strict assumptions that are hard to verify with real-world data. To address these issues, we propose an empirical data fusion method called pseudo-sample matching. By generating pseudo-samples from biased, low-quality RCT data and matching them with the most similar samples from large-scale observational data, the method expands the RCT dataset while mitigating its heterogeneity. We validated the method through simulation experiments, conducted offline and online tests using real-world data. In a week-long online experiment, we achieved a 0.41\% improvement in profit, which is a considerable gain when scaled to industrial scenarios with hundreds of millions in revenue. In addition, we discuss the harm to model training, offline evaluation, and online economic benefits when the RCT data quality is not high, and emphasize the importance of improving RCT data quality in industrial scenarios. Further details of the simulation experiments can be found in the GitHub repository https://github.com/Kairong-Han/Pseudo-Matching.
Tensor Train Completion from Fiberwise Observations Along a Single Mode
arXiv:2509.18149v1 Announce Type: cross Abstract: Tensor completion is an extension of matrix completion aimed at recovering a multiway data tensor by leveraging a given subset of its entries (observations) and the pattern of observation. The low-rank assumption is key in establishing a relationship between the observed and unobserved entries of the tensor. The low-rank tensor completion problem is typically solved using numerical optimization techniques, where the rank information is used either implicitly (in the rank minimization approach) or explicitly (in the error minimization approach). Current theories concerning these techniques often study probabilistic recovery guarantees under conditions such as random uniform observations and incoherence requirements. However, if an observation pattern exhibits some low-rank structure that can be exploited, more efficient algorithms with deterministic recovery guarantees can be designed by leveraging this structure. This work shows how to use only standard linear algebra operations to compute the tensor train decomposition of a specific type of ``fiber-wise" observed tensor, where some of the fibers of a tensor (along a single specific mode) are either fully observed or entirely missing, unlike the usual entry-wise observations. From an application viewpoint, this setting is relevant when it is easier to sample or collect a multiway data tensor along a specific mode (e.g., temporal). The proposed completion method is fast and is guaranteed to work under reasonable deterministic conditions on the observation pattern. Through numerical experiments, we showcase interesting applications and use cases that illustrate the effectiveness of the proposed approach.
Surrogate Modelling of Proton Dose with Monte Carlo Dropout Uncertainty Quantification
arXiv:2509.18155v1 Announce Type: cross Abstract: Accurate proton dose calculation using Monte Carlo (MC) is computationally demanding in workflows like robust optimisation, adaptive replanning, and probabilistic inference, which require repeated evaluations. To address this, we develop a neural surrogate that integrates Monte Carlo dropout to provide fast, differentiable dose predictions along with voxelwise predictive uncertainty. The method is validated through a series of experiments, starting with a one-dimensional analytic benchmark that establishes accuracy, convergence, and variance decomposition. Two-dimensional bone-water phantoms, generated using TOPAS Geant4, demonstrate the method's behavior under domain heterogeneity and beam uncertainty, while a three-dimensional water phantom confirms scalability for volumetric dose prediction. Across these settings, we separate epistemic (model) from parametric (input) contributions, showing that epistemic variance increases under distribution shift, while parametric variance dominates at material boundaries. The approach achieves significant speedups over MC while retaining uncertainty information, making it suitable for integration into robust planning, adaptive workflows, and uncertainty-aware optimisation in proton therapy.
Learning Progression-Guided AI Evaluation of Scientific Models To Support Diverse Multi-Modal Understanding in NGSS Classroom
arXiv:2509.18157v1 Announce Type: cross Abstract: Learning Progressions (LPs) can help adjust instruction to individual learners needs if the LPs reflect diverse ways of thinking about a construct being measured, and if the LP-aligned assessments meaningfully measure this diversity. The process of doing science is inherently multi-modal with scientists utilizing drawings, writing and other modalities to explain phenomena. Thus, fostering deep science understanding requires supporting students in using multiple modalities when explaining phenomena. We build on a validated NGSS-aligned multi-modal LP reflecting diverse ways of modeling and explaining electrostatic phenomena and associated assessments. We focus on students modeling, an essential practice for building a deep science understanding. Supporting culturally and linguistically diverse students in building modeling skills provides them with an alternative mode of communicating their understanding, essential for equitable science assessment. Machine learning (ML) has been used to score open-ended modeling tasks (e.g., drawings), and short text-based constructed scientific explanations, both of which are time- consuming to score. We use ML to evaluate LP-aligned scientific models and the accompanying short text-based explanations reflecting multi-modal understanding of electrical interactions in high school Physical Science. We show how LP guides the design of personalized ML-driven feedback grounded in the diversity of student thinking on both assessment modes.
ZERA: Zero-init Instruction Evolving Refinement Agent - From Zero Instructions to Structured Prompts via Principle-based Optimization
arXiv:2509.18158v1 Announce Type: cross Abstract: Automatic Prompt Optimization (APO) improves large language model (LLM) performance by refining prompts for specific tasks. However, prior APO methods typically focus only on user prompts, rely on unstructured feedback, and require large sample sizes and long iteration cycles-making them costly and brittle. We propose ZERA (Zero-init Instruction Evolving Refinement Agent), a novel framework that jointly optimizes both system and user prompts through principled, low-overhead refinement. ZERA scores prompts using eight generalizable criteria with automatically inferred weights, and revises prompts based on these structured critiques. This enables fast convergence to high-quality prompts using minimal examples and short iteration cycles. We evaluate ZERA across five LLMs and nine diverse datasets spanning reasoning, summarization, and code generation tasks. Experimental results demonstrate consistent improvements over strong baselines. Further ablation studies highlight the contribution of each component to more effective prompt construction. Our implementation including all prompts is publicly available at https://github.com/younatics/zera-agent.
PolypSeg-GradCAM: Towards Explainable Computer-Aided Gastrointestinal Disease Detection Using U-Net Based Segmentation and Grad-CAM Visualization on the Kvasir Dataset
arXiv:2509.18159v1 Announce Type: cross Abstract: Colorectal cancer (CRC) remains one of the leading causes of cancer-related morbidity and mortality worldwide, with gastrointestinal (GI) polyps serving as critical precursors according to the World Health Organization (WHO). Early and accurate segmentation of polyps during colonoscopy is essential for reducing CRC progression, yet manual delineation is labor-intensive and prone to observer variability. Deep learning methods have demonstrated strong potential for automated polyp analysis, but their limited interpretability remains a barrier to clinical adoption. In this study, we present PolypSeg-GradCAM, an explainable deep learning framework that integrates the U-Net architecture with Gradient-weighted Class Activation Mapping (Grad-CAM) for transparent polyp segmentation. The model was trained and evaluated on the Kvasir-SEG dataset of 1000 annotated endoscopic images. Experimental results demonstrate robust segmentation performance, achieving a mean Intersection over Union (IoU) of 0.9257 on the test set and consistently high Dice coefficients (F-score > 0.96) on training and validation sets. Grad-CAM visualizations further confirmed that predictions were guided by clinically relevant regions, enhancing transparency and trust in the model's decisions. By coupling high segmentation accuracy with interpretability, PolypSeg-GradCAM represents a step toward reliable, trustworthy AI-assisted colonoscopy and improved early colorectal cancer prevention.
Self Identity Mapping
arXiv:2509.18165v1 Announce Type: cross Abstract: Regularization is essential in deep learning to enhance generalization and mitigate overfitting. However, conventional techniques often rely on heuristics, making them less reliable or effective across diverse settings. We propose Self Identity Mapping (SIM), a simple yet effective, data-intrinsic regularization framework that leverages an inverse mapping mechanism to enhance representation learning. By reconstructing the input from its transformed output, SIM reduces information loss during forward propagation and facilitates smoother gradient flow. To address computational inefficiencies, We instantiate SIM as $ \rho\text{SIM} $ by incorporating patch-level feature sampling and projection-based method to reconstruct latent features, effectively lowering complexity. As a model-agnostic, task-agnostic regularizer, SIM can be seamlessly integrated as a plug-and-play module, making it applicable to different network architectures and tasks. We extensively evaluate $\rho\text{SIM}$ across three tasks: image classification, few-shot prompt learning, and domain generalization. Experimental results show consistent improvements over baseline methods, highlighting $\rho\text{SIM}$'s ability to enhance representation learning across various tasks. We also demonstrate that $\rho\text{SIM}$ is orthogonal to existing regularization methods, boosting their effectiveness. Moreover, our results confirm that $\rho\text{SIM}$ effectively preserves semantic information and enhances performance in dense-to-dense tasks, such as semantic segmentation and image translation, as well as in non-visual domains including audio classification and time series anomaly detection. The code is publicly available at https://github.com/XiudingCai/SIM-pytorch.
A Deep Learning Approach for Spatio-Temporal Forecasting of InSAR Ground Deformation in Eastern Ireland
arXiv:2509.18176v1 Announce Type: cross Abstract: Monitoring ground displacement is crucial for urban infrastructure stability and mitigating geological hazards. However, forecasting future deformation from sparse Interferometric Synthetic Aperture Radar (InSAR) time-series data remains a significant challenge. This paper introduces a novel deep learning framework that transforms these sparse point measurements into a dense spatio-temporal tensor. This methodological shift allows, for the first time, the direct application of advanced computer vision architectures to this forecasting problem. We design and implement a hybrid Convolutional Neural Network and Long-Short Term Memory (CNN-LSTM) model, specifically engineered to simultaneously learn spatial patterns and temporal dependencies from the generated data tensor. The model's performance is benchmarked against powerful machine learning baselines, Light Gradient Boosting Machine and LASSO regression, using Sentinel-1 data from eastern Ireland. Results demonstrate that the proposed architecture provides significantly more accurate and spatially coherent forecasts, establishing a new performance benchmark for this task. Furthermore, an interpretability analysis reveals that baseline models often default to simplistic persistence patterns, highlighting the necessity of our integrated spatio-temporal approach to capture the complex dynamics of ground deformation. Our findings confirm the efficacy and potential of spatio-temporal deep learning for high-resolution deformation forecasting.
A Framework for Generating Artificial Datasets to Validate Absolute and Relative Position Concepts
arXiv:2509.18177v1 Announce Type: cross Abstract: In this paper, we present the Scrapbook framework, a novel methodology designed to generate extensive datasets for probing the learned concepts of artificial intelligence (AI) models. The framework focuses on fundamental concepts such as object recognition, absolute and relative positions, and attribute identification. By generating datasets with a large number of questions about individual concepts and a wide linguistic variation, the Scrapbook framework aims to validate the model's understanding of these basic elements before tackling more complex tasks. Our experimental findings reveal that, while contemporary models demonstrate proficiency in recognizing and enumerating objects, they encounter challenges in comprehending positional information and addressing inquiries with additional constraints. Specifically, the MobileVLM-V2 model showed significant answer disagreements and plausible wrong answers, while other models exhibited a bias toward affirmative answers and struggled with questions involving geometric shapes and positional information, indicating areas for improvement in understanding and consistency. The proposed framework offers a valuable instrument for generating diverse and comprehensive datasets, which can be utilized to systematically assess and enhance the performance of AI models.
Foam-Agent: An End-to-End Composable Multi-Agent Framework for Automating CFD Simulation in OpenFOAM
arXiv:2509.18178v1 Announce Type: cross Abstract: Computational Fluid Dynamics (CFD) is an essential simulation tool in engineering, yet its steep learning curve and complex manual setup create significant barriers. To address these challenges, we introduce Foam-Agent, a multi-agent framework that automates the entire end-to-end OpenFOAM workflow from a single natural language prompt. Our key innovations address critical gaps in existing systems: 1. An Comprehensive End-to-End Simulation Automation: Foam-Agent is the first system to manage the full simulation pipeline, including advanced pre-processing with a versatile Meshing Agent capable of handling external mesh files and generating new geometries via Gmsh, automatic generation of HPC submission scripts, and post-simulation visualization via ParaView. 2. Composable Service Architecture: Going beyond a monolithic agent, the framework uses Model Context Protocol (MCP) to expose its core functions as discrete, callable tools. This allows for flexible integration and use by other agentic systems, such as Claude-code, for more exploratory workflows. 3. High-Fidelity Configuration Generation: We achieve superior accuracy through a Hierarchical Multi-Index RAG for precise context retrieval and a dependency-aware generation process that ensures configuration consistency. Evaluated on a benchmark of 110 simulation tasks, Foam-Agent achieves an 88.2% success rate with Claude 3.5 Sonnet, significantly outperforming existing frameworks (55.5% for MetaOpenFOAM). Foam-Agent dramatically lowers the expertise barrier for CFD, demonstrating how specialized multi-agent systems can democratize complex scientific computing. The code is public at https://github.com/csml-rpi/Foam-Agent.
Synthesizing Attitudes, Predicting Actions (SAPA): Behavioral Theory-Guided LLMs for Ridesourcing Mode Choice Modeling
arXiv:2509.18181v1 Announce Type: cross Abstract: Accurate modeling of ridesourcing mode choices is essential for designing and implementing effective traffic management policies for reducing congestion, improving mobility, and allocating resources more efficiently. Existing models for predicting ridesourcing mode choices often suffer from limited predictive accuracy due to their inability to capture key psychological factors, and are further challenged by severe class imbalance, as ridesourcing trips comprise only a small fraction of individuals' daily travel. To address these limitations, this paper introduces the Synthesizing Attitudes, Predicting Actions (SAPA) framework, a hierarchical approach that uses Large Language Models (LLMs) to synthesize theory-grounded latent attitudes to predict ridesourcing choices. SAPA first uses an LLM to generate qualitative traveler personas from raw travel survey data and then trains a propensity-score model on demographic and behavioral features, enriched by those personas, to produce an individual-level score. Next, the LLM assigns quantitative scores to theory-driven latent variables (e.g., time and cost sensitivity), and a final classifier integrates the propensity score, latent-variable scores (with their interaction terms), and observable trip attributes to predict ridesourcing mode choice. Experiments on a large-scale, multi-year travel survey show that SAPA significantly outperforms state-of-the-art baselines, improving ridesourcing choice predictions by up to 75.9% in terms of PR-AUC on a held-out test set. This study provides a powerful tool for accurately predicting ridesourcing mode choices, and provides a methodology that is readily transferable to various applications.
AI-Derived Structural Building Intelligence for Urban Resilience: An Application in Saint Vincent and the Grenadines
arXiv:2509.18182v1 Announce Type: cross Abstract: Detailed structural building information is used to estimate potential damage from hazard events like cyclones, floods, and landslides, making them critical for urban resilience planning and disaster risk reduction. However, such information is often unavailable in many small island developing states (SIDS) in climate-vulnerable regions like the Caribbean. To address this data gap, we present an AI-driven workflow to automatically infer rooftop attributes from high-resolution satellite imagery, with Saint Vincent and the Grenadines as our case study. Here, we compare the utility of geospatial foundation models combined with shallow classifiers against fine-tuned deep learning models for rooftop classification. Furthermore, we assess the impact of incorporating additional training data from neighboring SIDS to improve model performance. Our best models achieve F1 scores of 0.88 and 0.83 for roof pitch and roof material classification, respectively. Combined with local capacity building, our work aims to provide SIDS with novel capabilities to harness AI and Earth Observation (EO) data to enable more efficient, evidence-based urban governance.
Joint Cooperative and Non-Cooperative Localization in WSNs with Distributed Scaled Proximal ADMM Algorithms
arXiv:2509.18213v1 Announce Type: cross Abstract: Cooperative and non-cooperative localization frequently arise together in wireless sensor networks, particularly when sensor positions are uncertain and targets are unable to communicate with the network. While joint processing can eliminate the delay in target estimation found in sequential approaches, it introduces complex variable coupling, posing challenges in both modeling and optimization. This paper presents a joint modeling approach that formulates cooperative and non-cooperative localization as a single optimization problem. To address the resulting coupling, we introduce auxiliary variables that enable structural decoupling and distributed computation. Building on this formulation, we develop the Scaled Proximal Alternating Direction Method of Multipliers for Joint Cooperative and Non-Cooperative Localization (SP-ADMM-JCNL). Leveraging the problem's structured design, we provide theoretical guarantees that the algorithm generates a sequence converging globally to the Karush-Kuhn-Tucker (KKT) point of the reformulated problem and further to a critical point of the original non-convex objective function, with a sublinear rate of O(1/T). Experiments on both synthetic and benchmark datasets demonstrate that SP-ADMM-JCNL achieves accurate and reliable localization performance.
nDNA -- the Semantic Helix of Artificial Cognition
arXiv:2509.18216v1 Announce Type: cross Abstract: As AI foundation models grow in capability, a deeper question emerges: What shapes their internal cognitive identity -- beyond fluency and output? Benchmarks measure behavior, but the soul of a model resides in its latent geometry. In this work, we propose Neural DNA (nDNA) as a semantic-genotypic representation that captures this latent identity through the intrinsic geometry of belief. At its core, nDNA is synthesized from three principled and indispensable dimensions of latent geometry: spectral curvature, which reveals the curvature of conceptual flow across layers; thermodynamic length, which quantifies the semantic effort required to traverse representational transitions through layers; and belief vector field, which delineates the semantic torsion fields that guide a model's belief directional orientations. Like biological DNA, it encodes ancestry, mutation, and semantic inheritance, found in finetuning and alignment scars, cultural imprints, and architectural drift. In naming it, we open a new field: Neural Genomics, where models are not just tools, but digital semantic organisms with traceable inner cognition. Modeling statement. We read AI foundation models as semantic fluid--dynamics: meaning is transported through layers like fluid in a shaped conduit; nDNA is the physics-grade readout of that flow -- a geometry-first measure of how meaning is bent, paid for, and pushed -- yielding a stable, coordinate-free neural DNA fingerprint tied to on-input behavior; with this fingerprint we cross into biology: tracing lineages across pretraining, fine-tuning, alignment, pruning, distillation, and merges; measuring inheritance between checkpoints; detecting drift as traits shift under new data or objectives; and, ultimately, studying the evolution of artificial cognition to compare models, diagnose risks, and govern change over time.
Multimodal Health Risk Prediction System for Chronic Diseases via Vision-Language Fusion and Large Language Models
arXiv:2509.18221v1 Announce Type: cross Abstract: With the rising global burden of chronic diseases and the multimodal and heterogeneous clinical data (medical imaging, free-text recordings, wearable sensor streams, etc.), there is an urgent need for a unified multimodal AI framework that can proactively predict individual health risks. We propose VL-RiskFormer, a hierarchical stacked visual-language multimodal Transformer with a large language model (LLM) inference head embedded in its top layer. The system builds on the dual-stream architecture of existing visual-linguistic models (e.g., PaLM-E, LLaVA) with four key innovations: (i) pre-training with cross-modal comparison and fine-grained alignment of radiological images, fundus maps, and wearable device photos with corresponding clinical narratives using momentum update encoders and debiased InfoNCE losses; (ii) a time fusion block that integrates irregular visit sequences into the causal Transformer decoder through adaptive time interval position coding; (iii) a disease ontology map adapter that injects ICD-10 codes into visual and textual channels in layers and infers comorbid patterns with the help of a graph attention mechanism. On the MIMIC-IV longitudinal cohort, VL-RiskFormer achieved an average AUROC of 0.90 with an expected calibration error of 2.7 percent.
Towards General Computer Control with Hierarchical Agents and Multi-Level Action Spaces
arXiv:2509.18230v1 Announce Type: cross Abstract: Controlling desktop applications via software remains a fundamental yet under-served problem. Existing multi-modal large language models (MLLMs) ingest screenshots and task instructions to generate keystrokes and mouse events, but they suffer from prohibitive inference latency, poor sample efficiency on long-horizon sparse-reward tasks, and infeasible on-device deployment. We introduce a lightweight hierarchical reinforcement learning framework, ComputerAgent, that formulates OS control as a two-level option process (manager and subpolicy), employs a triple-modal state encoder (screenshot, task ID, numeric state) to handle visual and contextual diversity, integrates meta-actions with an early-stop mechanism to reduce wasted interactions, and uses a compact vision backbone plus small policy networks for on-device inference (15M parameters). On a suite of 135 real-world desktop tasks, ComputerAgent attains 92.1% success on simple tasks (<8 steps) and 58.8% on hard tasks (>=8 steps), matching or exceeding 200B-parameter MLLM baselines on simple scenarios while reducing model size by over four orders of magnitude and halving inference time. These results demonstrate that hierarchical RL offers a practical, scalable alternative to monolithic MLLM-based automation for computer control.
The Illusion of Readiness: Stress Testing Large Frontier Models on Multimodal Medical Benchmarks
arXiv:2509.18234v1 Announce Type: cross Abstract: Large frontier models like GPT-5 now achieve top scores on medical benchmarks. But our stress tests tell a different story. Leading systems often guess correctly even when key inputs like images are removed, flip answers under trivial prompt changes, and fabricate convincing yet flawed reasoning. These aren't glitches; they expose how today's benchmarks reward test-taking tricks over medical understanding. We evaluate six flagship models across six widely used benchmarks and find that high leaderboard scores hide brittleness and shortcut learning. Through clinician-guided rubric evaluation, we show that benchmarks vary widely in what they truly measure yet are treated interchangeably, masking failure modes. We caution that medical benchmark scores do not directly reflect real-world readiness. If we want AI to earn trust in healthcare, we must demand more than leaderboard wins and must hold systems accountable for robustness, sound reasoning, and alignment with real medical demands.
PEEK: Guiding and Minimal Image Representations for Zero-Shot Generalization of Robot Manipulation Policies
arXiv:2509.18282v1 Announce Type: cross Abstract: Robotic manipulation policies often fail to generalize because they must simultaneously learn where to attend, what actions to take, and how to execute them. We argue that high-level reasoning about where and what can be offloaded to vision-language models (VLMs), leaving policies to specialize in how to act. We present PEEK (Policy-agnostic Extraction of Essential Keypoints), which fine-tunes VLMs to predict a unified point-based intermediate representation: 1. end-effector paths specifying what actions to take, and 2. task-relevant masks indicating where to focus. These annotations are directly overlaid onto robot observations, making the representation policy-agnostic and transferable across architectures. To enable scalable training, we introduce an automatic annotation pipeline, generating labeled data across 20+ robot datasets spanning 9 embodiments. In real-world evaluations, PEEK consistently boosts zero-shot generalization, including a 41.4x real-world improvement for a 3D policy trained only in simulation, and 2-3.5x gains for both large VLAs and small manipulation policies. By letting VLMs absorb semantic and visual complexity, PEEK equips manipulation policies with the minimal cues they need--where, what, and how. Website at https://peek-robot.github.io/.
Improving Handshape Representations for Sign Language Processing: A Graph Neural Network Approach
arXiv:2509.18309v1 Announce Type: cross Abstract: Handshapes serve a fundamental phonological role in signed languages, with American Sign Language employing approximately 50 distinct shapes. However,computational approaches rarely model handshapes explicitly, limiting both recognition accuracy and linguistic analysis.We introduce a novel graph neural network that separates temporal dynamics from static handshape configurations. Our approach combines anatomically-informed graph structures with contrastive learning to address key challenges in handshape recognition, including subtle interclass distinctions and temporal variations. We establish the first benchmark for structured handshape recognition in signing sequences, achieving 46% accuracy across 37 handshape classes (with baseline methods achieving 25%).
On Multi-entity, Multivariate Quickest Change Point Detection
arXiv:2509.18310v1 Announce Type: cross Abstract: We propose a framework for online Change Point Detection (CPD) from multi-entity, multivariate time series data, motivated by applications in crowd monitoring where traditional sensing methods (e.g., video surveillance) may be infeasible. Our approach addresses the challenge of detecting system-wide behavioral shifts in complex, dynamic environments where the number and behavior of individual entities may be uncertain or evolve. We introduce the concept of Individual Deviation from Normality (IDfN), computed via a reconstruction-error-based autoencoder trained on normal behavior. We aggregate these individual deviations using mean, variance, and Kernel Density Estimates (KDE) to yield a System-Wide Anomaly Score (SWAS). To detect persistent or abrupt changes, we apply statistical deviation metrics and the Cumulative Sum (CUSUM) technique to these scores. Our unsupervised approach eliminates the need for labeled data or feature extraction, enabling real-time operation on streaming input. Evaluations on both synthetic datasets and crowd simulations, explicitly designed for anomaly detection in group behaviors, demonstrate that our method accurately detects significant system-level changes, offering a scalable and privacy-preserving solution for monitoring complex multi-agent systems. In addition to this methodological contribution, we introduce new, challenging multi-entity multivariate time series datasets generated from crowd simulations in Unity and coupled nonlinear oscillators. To the best of our knowledge, there is currently no publicly available dataset of this type designed explicitly to evaluate CPD in complex collective and interactive systems, highlighting an essential gap that our work addresses.
Statistical Insight into Meta-Learning via Predictor Subspace Characterization and Quantification of Task Diversity
arXiv:2509.18349v1 Announce Type: cross Abstract: Meta-learning has emerged as a powerful paradigm for leveraging information across related tasks to improve predictive performance on new tasks. In this paper, we propose a statistical framework for analyzing meta-learning through the lens of predictor subspace characterization and quantification of task diversity. Specifically, we model the shared structure across tasks using a latent subspace and introduce a measure of diversity that captures heterogeneity across task-specific predictors. We provide both simulation-based and theoretical evidence indicating that achieving the desired prediction accuracy in meta-learning depends on the proportion of predictor variance aligned with the shared subspace, as well as on the accuracy of subspace estimation.
A Single Image Is All You Need: Zero-Shot Anomaly Localization Without Training Data
arXiv:2509.18354v1 Announce Type: cross Abstract: Anomaly detection in images is typically addressed by learning from collections of training data or relying on reference samples. In many real-world scenarios, however, such training data may be unavailable, and only the test image itself is provided. We address this zero-shot setting by proposing a single-image anomaly localization method that leverages the inductive bias of convolutional neural networks, inspired by Deep Image Prior (DIP). Our method is named Single Shot Decomposition Network (SSDnet). Our key assumption is that natural images often exhibit unified textures and patterns, and that anomalies manifest as localized deviations from these repetitive or stochastic patterns. To learn the deep image prior, we design a patch-based training framework where the input image is fed directly into the network for self-reconstruction, rather than mapping random noise to the image as done in DIP. To avoid the model simply learning an identity mapping, we apply masking, patch shuffling, and small Gaussian noise. In addition, we use a perceptual loss based on inner-product similarity to capture structure beyond pixel fidelity. Our approach needs no external training data, labels, or references, and remains robust in the presence of noise or missing pixels. SSDnet achieves 0.99 AUROC and 0.60 AUPRC on MVTec-AD and 0.98 AUROC and 0.67 AUPRC on the fabric dataset, outperforming state-of-the-art methods. The implementation code will be released at https://github.com/mehrdadmoradi124/SSDnet
G\"odel Test: Can Large Language Models Solve Easy Conjectures?
arXiv:2509.18383v1 Announce Type: cross Abstract: Recent announcements from frontier AI model labs have highlighted strong results on high-school and undergraduate math competitions. Yet it remains unclear whether large language models can solve new, simple conjectures in more advanced areas of mathematics. We propose the G\"odel Test: evaluating whether a model can produce correct proofs for very simple, previously unsolved conjectures. To this end, we study the performance of GPT-5 on five conjectures in combinatorial optimization. For each problem, we provided one or two source papers from which the conjecture arose, withheld our own conjecture, and then assessed the model's reasoning in detail. On the three easier problems, GPT-5 produced nearly correct solutions; for Problem 2 it even derived a different approximation guarantee that, upon checking, refuted our conjecture while providing a valid solution. The model failed on Problem 4, which required combining results from two papers. On Problem 5, a harder case without a validated conjecture, GPT-5 proposed the same algorithm we had in mind but failed in the analysis, suggesting the proof is more challenging than expected. Although our sample is small, the results point to meaningful progress on routine reasoning, occasional flashes of originality, and clear limitations when cross-paper synthesis is required. GPT-5 may represent an early step toward frontier models eventually passing the G\"odel Test.
Measurement Score-Based MRI Reconstruction with Automatic Coil Sensitivity Estimation
arXiv:2509.18402v1 Announce Type: cross Abstract: Diffusion-based inverse problem solvers (DIS) have recently shown outstanding performance in compressed-sensing parallel MRI reconstruction by combining diffusion priors with physical measurement models. However, they typically rely on pre-calibrated coil sensitivity maps (CSMs) and ground truth images, making them often impractical: CSMs are difficult to estimate accurately under heavy undersampling and ground-truth images are often unavailable. We propose Calibration-free Measurement Score-based diffusion Model (C-MSM), a new method that eliminates these dependencies by jointly performing automatic CSM estimation and self-supervised learning of measurement scores directly from k-space data. C-MSM reconstructs images by approximating the full posterior distribution through stochastic sampling over partial measurement posterior scores, while simultaneously estimating CSMs. Experiments on the multi-coil brain fastMRI dataset show that C-MSM achieves reconstruction performance close to DIS with clean diffusion priors -- even without access to clean training data and pre-calibrated CSMs.
Zero-Shot Transferable Solution Method for Parametric Optimal Control Problems
arXiv:2509.18404v1 Announce Type: cross Abstract: This paper presents a transferable solution method for optimal control problems with varying objectives using function encoder (FE) policies. Traditional optimization-based approaches must be re-solved whenever objectives change, resulting in prohibitive computational costs for applications requiring frequent evaluation and adaptation. The proposed method learns a reusable set of neural basis functions that spans the control policy space, enabling efficient zero-shot adaptation to new tasks through either projection from data or direct mapping from problem specifications. The key idea is an offline-online decomposition: basis functions are learned once during offline imitation learning, while online adaptation requires only lightweight coefficient estimation. Numerical experiments across diverse dynamics, dimensions, and cost structures show our method delivers near-optimal performance with minimal overhead when generalizing across tasks, enabling semi-global feedback policies suitable for real-time deployment.
Identifying birdsong syllables without labelled data
arXiv:2509.18412v1 Announce Type: cross Abstract: Identifying sequences of syllables within birdsongs is key to tackling a wide array of challenges, including bird individual identification and better understanding of animal communication and sensory-motor learning. Recently, machine learning approaches have demonstrated great potential to alleviate the need for experts to label long audio recordings by hand. However, they still typically rely on the availability of labelled data for model training, restricting applicability to a few species and datasets. In this work, we build the first fully unsupervised algorithm to decompose birdsong recordings into sequences of syllables. We first detect syllable events, then cluster them to extract templates --syllable representations-- before performing matching pursuit to decompose the recording as a sequence of syllables. We evaluate our automatic annotations against human labels on a dataset of Bengalese finch songs and find that our unsupervised method achieves high performance. We also demonstrate that our approach can distinguish individual birds within a species through their unique vocal signatures, for both Bengalese finches and another species, the great tit.
VoxGuard: Evaluating User and Attribute Privacy in Speech via Membership Inference Attacks
arXiv:2509.18413v1 Announce Type: cross Abstract: Voice anonymization aims to conceal speaker identity and attributes while preserving intelligibility, but current evaluations rely almost exclusively on Equal Error Rate (EER) that obscures whether adversaries can mount high-precision attacks. We argue that privacy should instead be evaluated in the low false-positive rate (FPR) regime, where even a small number of successful identifications constitutes a meaningful breach. To this end, we introduce VoxGuard, a framework grounded in differential privacy and membership inference that formalizes two complementary notions: User Privacy, preventing speaker re-identification, and Attribute Privacy, protecting sensitive traits such as gender and accent. Across synthetic and real datasets, we find that informed adversaries, especially those using fine-tuned models and max-similarity scoring, achieve orders-of-magnitude stronger attacks at low-FPR despite similar EER. For attributes, we show that simple transparent attacks recover gender and accent with near-perfect accuracy even after anonymization. Our results demonstrate that EER substantially underestimates leakage, highlighting the need for low-FPR evaluation, and recommend VoxGuard as a benchmark for evaluating privacy leakage.
Large-Scale, Longitudinal Study of Large Language Models During the 2024 US Election Season
arXiv:2509.18446v1 Announce Type: cross Abstract: The 2024 US presidential election is the first major contest to occur in the US since the popularization of large language models (LLMs). Building on lessons from earlier shifts in media (most notably social media's well studied role in targeted messaging and political polarization) this moment raises urgent questions about how LLMs may shape the information ecosystem and influence political discourse. While platforms have announced some election safeguards, how well they work in practice remains unclear. Against this backdrop, we conduct a large-scale, longitudinal study of 12 models, queried using a structured survey with over 12,000 questions on a near-daily cadence from July through November 2024. Our design systematically varies content and format, resulting in a rich dataset that enables analyses of the models' behavior over time (e.g., across model updates), sensitivity to steering, responsiveness to instructions, and election-related knowledge and "beliefs." In the latter half of our work, we perform four analyses of the dataset that (i) study the longitudinal variation of model behavior during election season, (ii) illustrate the sensitivity of election-related responses to demographic steering, (iii) interrogate the models' beliefs about candidates' attributes, and (iv) reveal the models' implicit predictions of the election outcome. To facilitate future evaluations of LLMs in electoral contexts, we detail our methodology, from question generation to the querying pipeline and third-party tooling. We also publicly release our dataset at https://huggingface.co/datasets/sarahcen/llm-election-data-2024
CogniLoad: A Synthetic Natural Language Reasoning Benchmark With Tunable Length, Intrinsic Difficulty, and Distractor Density
arXiv:2509.18458v1 Announce Type: cross Abstract: Current benchmarks for long-context reasoning in Large Language Models (LLMs) often blur critical factors like intrinsic task complexity, distractor interference, and task length. To enable more precise failure analysis, we introduce CogniLoad, a novel synthetic benchmark grounded in Cognitive Load Theory (CLT). CogniLoad generates natural-language logic puzzles with independently tunable parameters that reflect CLT's core dimensions: intrinsic difficulty ($d$) controls intrinsic load; distractor-to-signal ratio ($\rho$) regulates extraneous load; and task length ($N$) serves as an operational proxy for conditions demanding germane load. Evaluating 22 SotA reasoning LLMs, CogniLoad reveals distinct performance sensitivities, identifying task length as a dominant constraint and uncovering varied tolerances to intrinsic complexity and U-shaped responses to distractor ratios. By offering systematic, factorial control over these cognitive load dimensions, CogniLoad provides a reproducible, scalable, and diagnostically rich tool for dissecting LLM reasoning limitations and guiding future model development.
Robotic Skill Diversification via Active Mutation of Reward Functions in Reinforcement Learning During a Liquid Pouring Task
arXiv:2509.18463v1 Announce Type: cross Abstract: This paper explores how deliberate mutations of reward function in reinforcement learning can produce diversified skill variations in robotic manipulation tasks, examined with a liquid pouring use case. To this end, we developed a new reward function mutation framework that is based on applying Gaussian noise to the weights of the different terms in the reward function. Inspired by the cost-benefit tradeoff model from human motor control, we designed the reward function with the following key terms: accuracy, time, and effort. The study was performed in a simulation environment created in NVIDIA Isaac Sim, and the setup included Franka Emika Panda robotic arm holding a glass with a liquid that needed to be poured into a container. The reinforcement learning algorithm was based on Proximal Policy Optimization. We systematically explored how different configurations of mutated weights in the rewards function would affect the learned policy. The resulting policies exhibit a wide range of behaviours: from variations in execution of the originally intended pouring task to novel skills useful for unexpected tasks, such as container rim cleaning, liquid mixing, and watering. This approach offers promising directions for robotic systems to perform diversified learning of specific tasks, while also potentially deriving meaningful skills for future tasks.
End-Cut Preference in Survival Trees
arXiv:2509.18477v1 Announce Type: cross Abstract: The end-cut preference (ECP) problem, referring to the tendency to favor split points near the boundaries of a feature's range, is a well-known issue in CART (Breiman et al., 1984). ECP may induce highly imbalanced and biased splits, obscure weak signals, and lead to tree structures that are both unstable and difficult to interpret. For survival trees, we show that ECP also arises when using greedy search to select the optimal cutoff point by maximizing the log-rank test statistic. To address this issue, we propose a smooth sigmoid surrogate (SSS) approach, in which the hard-threshold indicator function is replaced by a smooth sigmoid function. We further demonstrate, both theoretically and through numerical illustrations, that SSS provides an effective remedy for mitigating or avoiding ECP.
Estimating Heterogeneous Causal Effect on Networks via Orthogonal Learning
arXiv:2509.18484v1 Announce Type: cross Abstract: Estimating causal effects on networks is important for both scientific research and practical applications. Unlike traditional settings that assume the Stable Unit Treatment Value Assumption (SUTVA), interference allows an intervention/treatment on one unit to affect the outcomes of others. Understanding both direct and spillover effects is critical in fields such as epidemiology, political science, and economics. Causal inference on networks faces two main challenges. First, causal effects are typically heterogeneous, varying with unit features and local network structure. Second, connected units often exhibit dependence due to network homophily, creating confounding between structural correlations and causal effects. In this paper, we propose a two-stage method to estimate heterogeneous direct and spillover effects on networks. The first stage uses graph neural networks to estimate nuisance components that depend on the complex network topology. In the second stage, we adjust for network confounding using these estimates and infer causal effects through a novel attention-based interference model. Our approach balances expressiveness and interpretability, enabling downstream tasks such as identifying influential neighborhoods and recovering the sign of spillover effects. We integrate the two stages using Neyman orthogonalization and cross-fitting, which ensures that errors from nuisance estimation contribute only at higher order. As a result, our causal effect estimates are robust to bias and misspecification in modeling causal effects under network dependencies.
Hyperbolic Coarse-to-Fine Few-Shot Class-Incremental Learning
arXiv:2509.18504v1 Announce Type: cross Abstract: In the field of machine learning, hyperbolic space demonstrates superior representation capabilities for hierarchical data compared to conventional Euclidean space. This work focuses on the Coarse-To-Fine Few-Shot Class-Incremental Learning (C2FSCIL) task. Our study follows the Knowe approach, which contrastively learns coarse class labels and subsequently normalizes and freezes the classifier weights of learned fine classes in the embedding space. To better interpret the "coarse-to-fine" paradigm, we propose embedding the feature extractor into hyperbolic space. Specifically, we employ the Poincar\'e ball model of hyperbolic space, enabling the feature extractor to transform input images into feature vectors within the Poincar\'e ball instead of Euclidean space. We further introduce hyperbolic contrastive loss and hyperbolic fully-connected layers to facilitate model optimization and classification in hyperbolic space. Additionally, to enhance performance under few-shot conditions, we implement maximum entropy distribution in hyperbolic space to estimate the probability distribution of fine-class feature vectors. This allows generation of augmented features from the distribution to mitigate overfitting during training with limited samples. Experiments on C2FSCIL benchmarks show that our method effectively improves both coarse and fine class accuracies.
Dynamical Modeling of Behaviorally Relevant Spatiotemporal Patterns in Neural Imaging Data
arXiv:2509.18507v1 Announce Type: cross Abstract: High-dimensional imaging of neural activity, such as widefield calcium and functional ultrasound imaging, provide a rich source of information for understanding the relationship between brain activity and behavior. Accurately modeling neural dynamics in these modalities is crucial for understanding this relationship but is hindered by the high-dimensionality, complex spatiotemporal dependencies, and prevalent behaviorally irrelevant dynamics in these modalities. Existing dynamical models often employ preprocessing steps to obtain low-dimensional representations from neural image modalities. However, this process can discard behaviorally relevant information and miss spatiotemporal structure. We propose SBIND, a novel data-driven deep learning framework to model spatiotemporal dependencies in neural images and disentangle their behaviorally relevant dynamics from other neural dynamics. We validate SBIND on widefield imaging datasets, and show its extension to functional ultrasound imaging, a recent modality whose dynamical modeling has largely remained unexplored. We find that our model effectively identifies both local and long-range spatial dependencies across the brain while also dissociating behaviorally relevant neural dynamics. Doing so, SBIND outperforms existing models in neural-behavioral prediction. Overall, SBIND provides a versatile tool for investigating the neural mechanisms underlying behavior using imaging modalities.
A Rhythm-Aware Phrase Insertion for Classical Arabic Poetry Composition
arXiv:2509.18514v1 Announce Type: cross Abstract: This paper presents a methodology for inserting phrases in Arabic poems to conform to a specific rhythm using ByT5, a byte-level multilingual transformer-based model. Our work discusses a rule-based grapheme-to-beat transformation tailored for extracting the rhythm from fully diacritized Arabic script. Our approach employs a conditional denoising objective to fine-tune ByT5, where the model reconstructs masked words to match a target rhythm. We adopt a curriculum learning strategy, pre-training on a general Arabic dataset before fine-tuning on poetic dataset, and explore cross-lingual transfer from English to Arabic. Experimental results demonstrate that our models achieve high rhythmic alignment while maintaining semantic coherence. The proposed model has the potential to be used in co-creative applications in the process of composing classical Arabic poems.
Re-uploading quantum data: A universal function approximator for quantum inputs
arXiv:2509.18530v1 Announce Type: cross Abstract: Quantum data re-uploading has proved powerful for classical inputs, where repeatedly encoding features into a small circuit yields universal function approximation. Extending this idea to quantum inputs remains underexplored, as the information contained in a quantum state is not directly accessible in classical form. We propose and analyze a quantum data re-uploading architecture in which a qubit interacts sequentially with fresh copies of an arbitrary input state. The circuit can approximate any bounded continuous function using only one ancilla qubit and single-qubit measurements. By alternating entangling unitaries with mid-circuit resets of the input register, the architecture realizes a discrete cascade of completely positive and trace-preserving maps, analogous to collision models in open quantum system dynamics. Our framework provides a qubit-efficient and expressive approach to designing quantum machine learning models that operate directly on quantum data.
Efficient Breast and Ovarian Cancer Classification via ViT-Based Preprocessing and Transfer Learning
arXiv:2509.18553v1 Announce Type: cross Abstract: Cancer is one of the leading health challenges for women, specifically breast and ovarian cancer. Early detection can help improve the survival rate through timely intervention and treatment. Traditional methods of detecting cancer involve manually examining mammograms, CT scans, ultrasounds, and other imaging types. However, this makes the process labor-intensive and requires the expertise of trained pathologists. Hence, making it both time-consuming and resource-intensive. In this paper, we introduce a novel vision transformer (ViT)-based method for detecting and classifying breast and ovarian cancer. We use a pre-trained ViT-Base-Patch16-224 model, which is fine-tuned for both binary and multi-class classification tasks using publicly available histopathological image datasets. Further, we use a preprocessing pipeline that converts raw histophological images into standardized PyTorch tensors, which are compatible with the ViT architecture and also help improve the model performance. We evaluated the performance of our model on two benchmark datasets: the BreakHis dataset for binary classification and the UBC-OCEAN dataset for five-class classification without any data augmentation. Our model surpasses existing CNN, ViT, and topological data analysis-based approaches in binary classification. For multi-class classification, it is evaluated against recent topological methods and demonstrates superior performance. Our study highlights the effectiveness of Vision Transformer-based transfer learning combined with efficient preprocessing in oncological diagnostics.
VLN-Zero: Rapid Exploration and Cache-Enabled Neurosymbolic Vision-Language Planning for Zero-Shot Transfer in Robot Navigation
arXiv:2509.18592v1 Announce Type: cross Abstract: Rapid adaptation in unseen environments is essential for scalable real-world autonomy, yet existing approaches rely on exhaustive exploration or rigid navigation policies that fail to generalize. We present VLN-Zero, a two-phase vision-language navigation framework that leverages vision-language models to efficiently construct symbolic scene graphs and enable zero-shot neurosymbolic navigation. In the exploration phase, structured prompts guide VLM-based search toward informative and diverse trajectories, yielding compact scene graph representations. In the deployment phase, a neurosymbolic planner reasons over the scene graph and environmental observations to generate executable plans, while a cache-enabled execution module accelerates adaptation by reusing previously computed task-location trajectories. By combining rapid exploration, symbolic reasoning, and cache-enabled execution, the proposed framework overcomes the computational inefficiency and poor generalization of prior vision-language navigation methods, enabling robust and scalable decision-making in unseen environments. VLN-Zero achieves 2x higher success rate compared to state-of-the-art zero-shot models, outperforms most fine-tuned baselines, and reaches goal locations in half the time with 55% fewer VLM calls on average compared to state-of-the-art models across diverse environments. Codebase, datasets, and videos for VLN-Zero are available at: https://vln-zero.github.io/.
BRAID: Input-Driven Nonlinear Dynamical Modeling of Neural-Behavioral Data
arXiv:2509.18627v1 Announce Type: cross Abstract: Neural populations exhibit complex recurrent structures that drive behavior, while continuously receiving and integrating external inputs from sensory stimuli, upstream regions, and neurostimulation. However, neural populations are often modeled as autonomous dynamical systems, with little consideration given to the influence of external inputs that shape the population activity and behavioral outcomes. Here, we introduce BRAID, a deep learning framework that models nonlinear neural dynamics underlying behavior while explicitly incorporating any measured external inputs. Our method disentangles intrinsic recurrent neural population dynamics from the effects of inputs by including a forecasting objective within input-driven recurrent neural networks. BRAID further prioritizes the learning of intrinsic dynamics that are related to a behavior of interest by using a multi-stage optimization scheme. We validate BRAID with nonlinear simulations, showing that it can accurately learn the intrinsic dynamics shared between neural and behavioral modalities. We then apply BRAID to motor cortical activity recorded during a motor task and demonstrate that our method more accurately fits the neural-behavioral data by incorporating measured sensory stimuli into the model and improves the forecasting of neural-behavioral data compared with various baseline methods, whether input-driven or not.
Online Learning for Optimizing AoI-Energy Tradeoff under Unknown Channel Statistics
arXiv:2509.18654v1 Announce Type: cross Abstract: We consider a real-time monitoring system where a source node (with energy limitations) aims to keep the information status at a destination node as fresh as possible by scheduling status update transmissions over a set of channels. The freshness of information at the destination node is measured in terms of the Age of Information (AoI) metric. In this setting, a natural tradeoff exists between the transmission cost (or equivalently, energy consumption) of the source and the achievable AoI performance at the destination. This tradeoff has been optimized in the existing literature under the assumption of having a complete knowledge of the channel statistics. In this work, we develop online learning-based algorithms with finite-time guarantees that optimize this tradeoff in the practical scenario where the channel statistics are unknown to the scheduler. In particular, when the channel statistics are known, the optimal scheduling policy is first proven to have a threshold-based structure with respect to the value of AoI (i.e., it is optimal to drop updates when the AoI value is below some threshold). This key insight was then utilized to develop the proposed learning algorithms that surprisingly achieve an order-optimal regret (i.e., $O(1)$) with respect to the time horizon length.
Scalable bayesian shadow tomography for quantum property estimation with set transformers
arXiv:2509.18674v1 Announce Type: cross Abstract: A scalable Bayesian machine learning framework is introduced for estimating scalar properties of an unknown quantum state from measurement data, which bypasses full density matrix reconstruction. This work is the first to integrate the classical shadows protocol with a permutation-invariant set transformer architecture, enabling the approach to predict and correct bias in existing estimators to approximate the true Bayesian posterior mean. Measurement outcomes are encoded as fixed-dimensional feature vectors, and the network outputs a residual correction to a baseline estimator. Scalability to large quantum systems is ensured by the polynomial dependence of input size on system size and number of measurements. On Greenberger-Horne-Zeilinger state fidelity and second-order R\'enyi entropy estimation tasks -- using random Pauli and random Clifford measurements -- this Bayesian estimator always achieves lower mean squared error than classical shadows alone, with more than a 99\% reduction in the few copy regime.
Query-Centric Diffusion Policy for Generalizable Robotic Assembly
arXiv:2509.18686v1 Announce Type: cross Abstract: The robotic assembly task poses a key challenge in building generalist robots due to the intrinsic complexity of part interactions and the sensitivity to noise perturbations in contact-rich settings. The assembly agent is typically designed in a hierarchical manner: high-level multi-part reasoning and low-level precise control. However, implementing such a hierarchical policy is challenging in practice due to the mismatch between high-level skill queries and low-level execution. To address this, we propose the Query-centric Diffusion Policy (QDP), a hierarchical framework that bridges high-level planning and low-level control by utilizing queries comprising objects, contact points, and skill information. QDP introduces a query-centric mechanism that identifies task-relevant components and uses them to guide low-level policies, leveraging point cloud observations to improve the policy's robustness. We conduct comprehensive experiments on the FurnitureBench in both simulation and real-world settings, demonstrating improved performance in skill precision and long-horizon success rate. In the challenging insertion and screwing tasks, QDP improves the skill-wise success rate by over 50% compared to baselines without structured queries.
Learning When to Restart: Nonstationary Newsvendor from Uncensored to Censored Demand
arXiv:2509.18709v1 Announce Type: cross Abstract: We study nonstationary newsvendor problems under nonparametric demand models and general distributional measures of nonstationarity, addressing the practical challenges of unknown degree of nonstationarity and demand censoring. We propose a novel distributional-detection-and-restart framework for learning in nonstationary environments, and instantiate it through two efficient algorithms for the uncensored and censored demand settings. The algorithms are fully adaptive, requiring no prior knowledge of the degree and type of nonstationarity, and offer a flexible yet powerful approach to handling both abrupt and gradual changes in nonstationary environments. We establish a comprehensive optimality theory for our algorithms by deriving matching regret upper and lower bounds under both general and refined structural conditions with nontrivial proof techniques that are of independent interest. Numerical experiments using real-world datasets, including nurse staffing data for emergency departments and COVID-19 test demand data, showcase the algorithms' superior and robust empirical performance. While motivated by the newsvendor problem, the distributional-detection-and-restart framework applies broadly to a wide class of nonstationary stochastic optimization problems. Managerially, our framework provides a practical, easy-to-deploy, and theoretically grounded solution for decision-making under nonstationarity.
Consistency of Selection Strategies for Fraud Detection
arXiv:2509.18739v1 Announce Type: cross Abstract: This paper studies how insurers can chose which claims to investigate for fraud. Given a prediction model, typically only claims with the highest predicted propability of being fraudulent are investigated. We argue that this can lead to inconsistent learning and propose a randomized alternative. More generally, we draw a parallel with the multi-arm bandit literature and argue that, in the presence of selection, the obtained observations are not iid. Hence, dependence on past observations should be accounted for when updating parameter estimates. We formalize selection in a binary regression framework and show that model updating and maximum-likelihood estimation can be implemented as if claims were investigated at random. Then, we define consistency of selection strategies and conjecture sufficient conditions for consistency. Our simulations suggest that the often-used selection strategy can be inconsistent while the proposed randomized alternative is consistent. Finally, we compare our randomized selection strategy with Thompson sampling, a standard multi-arm bandit heuristic. Our simulations suggest that the latter can be inefficient in learning low fraud probabilities.
Security smells in infrastructure as code: a taxonomy update beyond the seven sins
arXiv:2509.18761v1 Announce Type: cross Abstract: Infrastructure as Code (IaC) has become essential for modern software management, yet security flaws in IaC scripts can have severe consequences, as exemplified by the recurring exploits of Cloud Web Services. Prior work has recognized the need to build a precise taxonomy of security smells in IaC scripts as a first step towards developing approaches to improve IaC security. This first effort led to the unveiling of seven sins, limited by the focus on a single IaC tool as well as by the extensive, and potentially biased, manual effort that was required. We propose, in our work, to revisit this taxonomy: first, we extend the study of IaC security smells to a more diverse dataset with scripts associated with seven popular IaC tools, including Terraform, Ansible, Chef, Puppet, Pulumi, Saltstack, and Vagrant; second, we bring in some automation for the analysis by relying on an LLM. While we leverage LLMs for initial pattern processing, all taxonomic decisions underwent systematic human validation and reconciliation with established security standards. Our study yields a comprehensive taxonomy of 62 security smell categories, significantly expanding beyond the previously known seven. We demonstrate actionability by implementing new security checking rules within linters for seven popular IaC tools, often achieving 1.00 precision score. Our evolution study of security smells in GitHub projects reveals that these issues persist for extended periods, likely due to inadequate detection and mitigation tools. This work provides IaC practitioners with insights for addressing common security smells and systematically adopting DevSecOps practices to build safer infrastructure code.
AECBench: A Hierarchical Benchmark for Knowledge Evaluation of Large Language Models in the AEC Field
arXiv:2509.18776v1 Announce Type: cross Abstract: Large language models (LLMs), as a novel information technology, are seeing increasing adoption in the Architecture, Engineering, and Construction (AEC) field. They have shown their potential to streamline processes throughout the building lifecycle. However, the robustness and reliability of LLMs in such a specialized and safety-critical domain remain to be evaluated. To address this challenge, this paper establishes AECBench, a comprehensive benchmark designed to quantify the strengths and limitations of current LLMs in the AEC domain. The benchmark defines 23 representative tasks within a five-level cognition-oriented evaluation framework encompassing Knowledge Memorization, Understanding, Reasoning, Calculation, and Application. These tasks were derived from authentic AEC practice, with scope ranging from codes retrieval to specialized documents generation. Subsequently, a 4,800-question dataset encompassing diverse formats, including open-ended questions, was crafted primarily by engineers and validated through a two-round expert review. Furthermore, an LLM-as-a-Judge approach was introduced to provide a scalable and consistent methodology for evaluating complex, long-form responses leveraging expert-derived rubrics. Through the evaluation of nine LLMs, a clear performance decline across five cognitive levels was revealed. Despite demonstrating proficiency in foundational tasks at the Knowledge Memorization and Understanding levels, the models showed significant performance deficits, particularly in interpreting knowledge from tables in building codes, executing complex reasoning and calculation, and generating domain-specific documents. Consequently, this study lays the groundwork for future research and development aimed at the robust and reliable integration of LLMs into safety-critical engineering practices.
Real-time Deer Detection and Warning in Connected Vehicles via Thermal Sensing and Deep Learning
arXiv:2509.18779v1 Announce Type: cross Abstract: Deer-vehicle collisions represent a critical safety challenge in the United States, causing nearly 2.1 million incidents annually and resulting in approximately 440 fatalities, 59,000 injuries, and 10 billion USD in economic damages. These collisions also contribute significantly to declining deer populations. This paper presents a real-time detection and driver warning system that integrates thermal imaging, deep learning, and vehicle-to-everything communication to help mitigate deer-vehicle collisions. Our system was trained and validated on a custom dataset of over 12,000 thermal deer images collected in Mars Hill, North Carolina. Experimental evaluation demonstrates exceptional performance with 98.84 percent mean average precision, 95.44 percent precision, and 95.96 percent recall. The system was field tested during a follow-up visit to Mars Hill and readily sensed deer providing the driver with advanced warning. Field testing validates robust operation across diverse weather conditions, with thermal imaging maintaining between 88 and 92 percent detection accuracy in challenging scenarios where conventional visible light based cameras achieve less than 60 percent effectiveness. When a high probability threshold is reached sensor data sharing messages are broadcast to surrounding vehicles and roadside units via cellular vehicle to everything (CV2X) communication devices. Overall, our system achieves end to end latency consistently under 100 milliseconds from detection to driver alert. This research establishes a viable technological pathway for reducing deer-vehicle collisions through thermal imaging and connected vehicles.
Reconstruction of Optical Coherence Tomography Images from Wavelength-space Using Deep-learning
arXiv:2509.18783v1 Announce Type: cross Abstract: Conventional Fourier-domain Optical Coherence Tomography (FD-OCT) systems depend on resampling into wavenumber (k) domain to extract the depth profile. This either necessitates additional hardware resources or amplifies the existing computational complexity. Moreover, the OCT images also suffer from speckle noise, due to systemic reliance on low coherence interferometry. We propose a streamlined and computationally efficient approach based on Deep-Learning (DL) which enables reconstructing speckle-reduced OCT images directly from the wavelength domain. For reconstruction, two encoder-decoder styled networks namely Spatial Domain Convolution Neural Network (SD-CNN) and Fourier Domain CNN (FD-CNN) are used sequentially. The SD-CNN exploits the highly degraded images obtained by Fourier transforming the domain fringes to reconstruct the deteriorated morphological structures along with suppression of unwanted noise. The FD-CNN leverages this output to enhance the image quality further by optimization in Fourier domain (FD). We quantitatively and visually demonstrate the efficacy of the method in obtaining high-quality OCT images. Furthermore, we illustrate the computational complexity reduction by harnessing the power of DL models. We believe that this work lays the framework for further innovations in the realm of OCT image reconstruction.
Detection of security smells in IaC scripts through semantics-aware code and language processing
arXiv:2509.18790v1 Announce Type: cross Abstract: Infrastructure as Code (IaC) automates the provisioning and management of IT infrastructure through scripts and tools, streamlining software deployment. Prior studies have shown that IaC scripts often contain recurring security misconfigurations, and several detection and mitigation approaches have been proposed. Most of these rely on static analysis, using statistical code representations or Machine Learning (ML) classifiers to distinguish insecure configurations from safe code. In this work, we introduce a novel approach that enhances static analysis with semantic understanding by jointly leveraging natural language and code representations. Our method builds on two complementary ML models: CodeBERT, to capture semantics across code and text, and LongFormer, to represent long IaC scripts without losing contextual information. We evaluate our approach on misconfiguration datasets from two widely used IaC tools, Ansible and Puppet. To validate its effectiveness, we conduct two ablation studies (removing code text from the natural language input and truncating scripts to reduce context) and compare against four large language models (LLMs) and prior work. Results show that semantic enrichment substantially improves detection, raising precision and recall from 0.46 and 0.79 to 0.92 and 0.88 on Ansible, and from 0.55 and 0.97 to 0.87 and 0.75 on Puppet, respectively.
On the Convergence of Policy Mirror Descent with Temporal Difference Evaluation
arXiv:2509.18822v1 Announce Type: cross Abstract: Policy mirror descent (PMD) is a general policy optimization framework in reinforcement learning, which can cover a wide range of typical policy optimization methods by specifying different mirror maps. Existing analysis of PMD requires exact or approximate evaluation (for example unbiased estimation via Monte Carlo simulation) of action values solely based on policy. In this paper, we consider policy mirror descent with temporal difference evaluation (TD-PMD). It is shown that, given the access to exact policy evaluations, the dimension-free $O(1/T)$ sublinear convergence still holds for TD-PMD with any constant step size and any initialization. In order to achieve this result, new monotonicity and shift invariance arguments have been developed. The dimension free $\gamma$-rate linear convergence of TD-PMD is also established provided the step size is selected adaptively. For the two common instances of TD-PMD (i.e., TD-PQA and TD-NPG), it is further shown that they enjoy the convergence in the policy domain. Additionally, we investigate TD-PMD in the inexact setting and give the sample complexity for it to achieve the last iterate $\varepsilon$-optimality under a generative model, which improves the last iterate sample complexity for PMD over the dependence on $1/(1-\gamma)$.
DexSkin: High-Coverage Conformable Robotic Skin for Learning Contact-Rich Manipulation
arXiv:2509.18830v1 Announce Type: cross Abstract: Human skin provides a rich tactile sensing stream, localizing intentional and unintentional contact events over a large and contoured region. Replicating these tactile sensing capabilities for dexterous robotic manipulation systems remains a longstanding challenge. In this work, we take a step towards this goal by introducing DexSkin. DexSkin is a soft, conformable capacitive electronic skin that enables sensitive, localized, and calibratable tactile sensing, and can be tailored to varying geometries. We demonstrate its efficacy for learning downstream robotic manipulation by sensorizing a pair of parallel jaw gripper fingers, providing tactile coverage across almost the entire finger surfaces. We empirically evaluate DexSkin's capabilities in learning challenging manipulation tasks that require sensing coverage across the entire surface of the fingers, such as reorienting objects in hand and wrapping elastic bands around boxes, in a learning-from-demonstration framework. We then show that, critically for data-driven approaches, DexSkin can be calibrated to enable model transfer across sensor instances, and demonstrate its applicability to online reinforcement learning on real robots. Our results highlight DexSkin's suitability and practicality for learning real-world, contact-rich manipulation. Please see our project webpage for videos and visualizations: https://dex-skin.github.io/.
Text Slider: Efficient and Plug-and-Play Continuous Concept Control for Image/Video Synthesis via LoRA Adapters
arXiv:2509.18831v1 Announce Type: cross Abstract: Recent advances in diffusion models have significantly improved image and video synthesis. In addition, several concept control methods have been proposed to enable fine-grained, continuous, and flexible control over free-form text prompts. However, these methods not only require intensive training time and GPU memory usage to learn the sliders or embeddings but also need to be retrained for different diffusion backbones, limiting their scalability and adaptability. To address these limitations, we introduce Text Slider, a lightweight, efficient and plug-and-play framework that identifies low-rank directions within a pre-trained text encoder, enabling continuous control of visual concepts while significantly reducing training time, GPU memory consumption, and the number of trainable parameters. Furthermore, Text Slider supports multi-concept composition and continuous control, enabling fine-grained and flexible manipulation in both image and video synthesis. We show that Text Slider enables smooth and continuous modulation of specific attributes while preserving the original spatial layout and structure of the input. Text Slider achieves significantly better efficiency: 5$\times$ faster training than Concept Slider and 47$\times$ faster than Attribute Control, while reducing GPU memory usage by nearly 2$\times$ and 4$\times$, respectively.
Are Smaller Open-Weight LLMs Closing the Gap to Proprietary Models for Biomedical Question Answering?
arXiv:2509.18843v1 Announce Type: cross Abstract: Open-weight versions of large language models (LLMs) are rapidly advancing, with state-of-the-art models like DeepSeek-V3 now performing comparably to proprietary LLMs. This progression raises the question of whether small open-weight LLMs are capable of effectively replacing larger closed-source models. We are particularly interested in the context of biomedical question-answering, a domain we explored by participating in Task 13B Phase B of the BioASQ challenge. In this work, we compare several open-weight models against top-performing systems such as GPT-4o, GPT-4.1, Claude 3.5 Sonnet, and Claude 3.7 Sonnet. To enhance question answering capabilities, we use various techniques including retrieving the most relevant snippets based on embedding distance, in-context learning, and structured outputs. For certain submissions, we utilize ensemble approaches to leverage the diverse outputs generated by different models for exact-answer questions. Our results demonstrate that open-weight LLMs are comparable to proprietary ones. In some instances, open-weight LLMs even surpassed their closed counterparts, particularly when ensembling strategies were applied. All code is publicly available at https://github.com/evidenceprime/BioASQ-13b.
Bi-VLA: Bilateral Control-Based Imitation Learning via Vision-Language Fusion for Action Generation
arXiv:2509.18865v1 Announce Type: cross Abstract: We propose Bilateral Control-Based Imitation Learning via Vision-Language Fusion for Action Generation (Bi-VLA), a novel framework that extends bilateral control-based imitation learning to handle more than one task within a single model. Conventional bilateral control methods exploit joint angle, velocity, torque, and vision for precise manipulation but require task-specific models, limiting their generality. Bi-VLA overcomes this limitation by utilizing robot joint angle, velocity, and torque data from leader-follower bilateral control with visual features and natural language instructions through SigLIP and FiLM-based fusion. We validated Bi-VLA on two task types: one requiring supplementary language cues and another distinguishable solely by vision. Real-robot experiments showed that Bi-VLA successfully interprets vision-language combinations and improves task success rates compared to conventional bilateral control-based imitation learning. Our Bi-VLA addresses the single-task limitation of prior bilateral approaches and provides empirical evidence that combining vision and language significantly enhances versatility. Experimental results validate the effectiveness of Bi-VLA in real-world tasks. For additional material, please visit the website: https://mertcookimg.github.io/bi-vla/
Diversity Boosts AI-Generated Text Detection
arXiv:2509.18880v1 Announce Type: cross Abstract: Detecting AI-generated text is an increasing necessity to combat misuse of LLMs in education, business compliance, journalism, and social media, where synthetic fluency can mask misinformation or deception. While prior detectors often rely on token-level likelihoods or opaque black-box classifiers, these approaches struggle against high-quality generations and offer little interpretability. In this work, we propose DivEye, a novel detection framework that captures how unpredictability fluctuates across a text using surprisal-based features. Motivated by the observation that human-authored text exhibits richer variability in lexical and structural unpredictability than LLM outputs, DivEye captures this signal through a set of interpretable statistical features. Our method outperforms existing zero-shot detectors by up to 33.2% and achieves competitive performance with fine-tuned baselines across multiple benchmarks. DivEye is robust to paraphrasing and adversarial attacks, generalizes well across domains and models, and improves the performance of existing detectors by up to 18.7% when used as an auxiliary signal. Beyond detection, DivEye provides interpretable insights into why a text is flagged, pointing to rhythmic unpredictability as a powerful and underexplored signal for LLM detection.
Confidential LLM Inference: Performance and Cost Across CPU and GPU TEEs
arXiv:2509.18886v1 Announce Type: cross Abstract: Large Language Models (LLMs) are increasingly deployed on converged Cloud and High-Performance Computing (HPC) infrastructure. However, as LLMs handle confidential inputs and are fine-tuned on costly, proprietary datasets, their heightened security requirements slow adoption in privacy-sensitive sectors such as healthcare and finance. We investigate methods to address this gap and propose Trusted Execution Environments (TEEs) as a solution for securing end-to-end LLM inference. We validate their practicality by evaluating these compute-intensive workloads entirely within CPU and GPU TEEs. On the CPU side, we conduct an in-depth study running full Llama2 inference pipelines (7B, 13B, 70B) inside Intel's TDX and SGX, accelerated by Advanced Matrix Extensions (AMX). We derive 12 insights, including that across various data types, batch sizes, and input lengths, CPU TEEs impose under 10% throughput and 20% latency overheads, further reduced by AMX. We run LLM inference on NVIDIA H100 Confidential Compute GPUs, contextualizing our CPU findings and observing throughput penalties of 4-8% that diminish as batch and input sizes grow. By comparing performance, cost, and security trade-offs, we show how CPU TEEs can be more cost-effective or secure than their GPU counterparts. To our knowledge, our work is the first to comprehensively demonstrate the performance and practicality of modern TEEs across both CPUs and GPUs for enabling confidential LLMs (cLLMs).
Integrating Stacked Intelligent Metasurfaces and Power Control for Dynamic Edge Inference via Over-The-Air Neural Networks
arXiv:2509.18906v1 Announce Type: cross Abstract: This paper introduces a novel framework for Edge Inference (EI) that bypasses the conventional practice of treating the wireless channel as noise. We utilize Stacked Intelligent Metasurfaces (SIMs) to control wireless propagation, enabling the channel itself to perform over-the-air computation. This eliminates the need for symbol estimation at the receiver, significantly reducing computational and communication overhead. Our approach models the transmitter-channel-receiver system as an end-to-end Deep Neural Network (DNN) where the response of the SIM elements are trainable parameters. To address channel variability, we incorporate a dedicated DNN module responsible for dynamically adjusting transmission power leveraging user location information. Our performance evaluations showcase that the proposed metasurfaces-integrated DNN framework with deep SIM architectures are capable of balancing classification accuracy and power consumption under diverse scenarios, offering significant energy efficiency improvements.
Accurate and Efficient Prediction of Wi-Fi Link Quality Based on Machine Learning
arXiv:2509.18933v1 Announce Type: cross Abstract: Wireless communications are characterized by their unpredictability, posing challenges for maintaining consistent communication quality. This paper presents a comprehensive analysis of various prediction models, with a focus on achieving accurate and efficient Wi-Fi link quality forecasts using machine learning techniques. Specifically, the paper evaluates the performance of data-driven models based on the linear combination of exponential moving averages, which are designed for low-complexity implementations and are then suitable for hardware platforms with limited processing resources. Accuracy of the proposed approaches was assessed using experimental data from a real-world Wi-Fi testbed, considering both channel-dependent and channel-independent training data. Remarkably, channel-independent models, which allow for generalized training by equipment manufacturers, demonstrated competitive performance. Overall, this study provides insights into the practical deployment of machine learning-based prediction models for enhancing Wi-Fi dependability in industrial environments.
No Labels Needed: Zero-Shot Image Classification with Collaborative Self-Learning
arXiv:2509.18938v1 Announce Type: cross Abstract: While deep learning, including Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), has significantly advanced classification performance, its typical reliance on extensive annotated datasets presents a major obstacle in many practical scenarios where such data is scarce. Vision-language models (VLMs) and transfer learning with pre-trained visual models appear as promising techniques to deal with this problem. This paper proposes a novel zero-shot image classification framework that combines a VLM and a pre-trained visual model within a self-learning cycle. Requiring only the set of class names and no labeled training data, our method utilizes a confidence-based pseudo-labeling strategy to train a lightweight classifier directly on the test data, enabling dynamic adaptation. The VLM identifies high-confidence samples, and the pre-trained visual model enhances their visual representations. These enhanced features then iteratively train the classifier, allowing the system to capture complementary semantic and visual cues without supervision. Notably, our approach avoids VLM fine-tuning and the use of large language models, relying on the visual-only model to reduce the dependence on semantic representation. Experimental evaluations on ten diverse datasets demonstrate that our approach outperforms the baseline zero-shot method.
Generative data augmentation for biliary tract detection on intraoperative images
arXiv:2509.18958v1 Announce Type: cross Abstract: Cholecystectomy is one of the most frequently performed procedures in gastrointestinal surgery, and the laparoscopic approach is the gold standard for symptomatic cholecystolithiasis and acute cholecystitis. In addition to the advantages of a significantly faster recovery and better cosmetic results, the laparoscopic approach bears a higher risk of bile duct injury, which has a significant impact on quality of life and survival. To avoid bile duct injury, it is essential to improve the intraoperative visualization of the bile duct. This work aims to address this problem by leveraging a deep-learning approach for the localization of the biliary tract from white-light images acquired during the surgical procedures. To this end, the construction and annotation of an image database to train the Yolo detection algorithm has been employed. Besides classical data augmentation techniques, the paper proposes Generative Adversarial Network (GAN) for the generation of a synthetic portion of the training dataset. Experimental results have been discussed along with ethical considerations.
Bayesian Calibration and Model Assessment of Cell Migration Dynamics with Surrogate Model Integration
arXiv:2509.18998v1 Announce Type: cross Abstract: Computational models provide crucial insights into complex biological processes such as cancer evolution, but their mechanistic nature often makes them nonlinear and parameter-rich, complicating calibration. We systematically evaluate parameter probability distributions in cell migration models using Bayesian calibration across four complementary strategies: parametric and surrogate models, each with and without explicit model discrepancy. This approach enables joint analysis of parameter uncertainty, predictive performance, and interpretability. Applied to a real data experiment of glioblastoma progression in microfluidic devices, surrogate models achieve higher computational efficiency and predictive accuracy, whereas parametric models yield more reliable parameter estimates due to their mechanistic grounding. Incorporating model discrepancy exposes structural limitations, clarifying where model refinement is necessary. Together, these comparisons offer practical guidance for calibrating and improving computational models of complex biological systems.
VIR-Bench: Evaluating Geospatial and Temporal Understanding of MLLMs via Travel Video Itinerary Reconstruction
arXiv:2509.19002v1 Announce Type: cross Abstract: Recent advances in multimodal large language models (MLLMs) have significantly enhanced video understanding capabilities, opening new possibilities for practical applications. Yet current video benchmarks focus largely on indoor scenes or short-range outdoor activities, leaving the challenges associated with long-distance travel largely unexplored. Mastering extended geospatial-temporal trajectories is critical for next-generation MLLMs, underpinning real-world tasks such as embodied-AI planning and navigation. To bridge this gap, we present VIR-Bench, a novel benchmark consisting of 200 travel videos that frames itinerary reconstruction as a challenging task designed to evaluate and push forward MLLMs' geospatial-temporal intelligence. Experimental results reveal that state-of-the-art MLLMs, including proprietary ones, struggle to achieve high scores, underscoring the difficulty of handling videos that span extended spatial and temporal scales. Moreover, we conduct an in-depth case study in which we develop a prototype travel-planning agent that leverages the insights gained from VIR-Bench. The agent's markedly improved itinerary recommendations verify that our evaluation protocol not only benchmarks models effectively but also translates into concrete performance gains in user-facing applications.
Quantum Annealing for Minimum Bisection Problem: A Machine Learning-based Approach for Penalty Parameter Tuning
arXiv:2509.19005v1 Announce Type: cross Abstract: The Minimum Bisection Problem is a well-known NP-hard problem in combinatorial optimization, with practical applications in areas such as parallel computing, network design, and machine learning. In this paper, we examine the potential of using D-Wave Systems' quantum annealing solvers to solve the Minimum Bisection Problem, which we formulate as a Quadratic Unconstrained Binary Optimization model. A key challenge in this formulation lies in choosing an appropriate penalty parameter, as it plays a crucial role in ensuring both the quality of the solution and the satisfaction of the problem's constraints. To address this, we introduce a novel machine learning-based approach for adaptive tuning of the penalty parameter. Specifically, we use a Gradient Boosting Regressor model trained to predict suitable penalty parameter values based on structural properties of the input graph, the number of nodes and the graph's density. This method enables the penalty parameter to be adjusted dynamically for each specific problem instance, improving the solver's ability to balance the competing goals of minimizing the cut size and maintaining equally sized partitions. We test our approach on a large dataset of randomly generated Erd\H{o}s-R\'enyi graphs with up to 4,000 nodes, and we compare the results with classical partitioning algorithms, Metis and Kernighan-Lin. Experimental findings demonstrate that our adaptive tuning strategy significantly improves the performance of the quantum annealing hybrid solver and consistently outperforms the classical methods used, indicating its potential as an alternative for the graph partitioning problem.
A Fast Initialization Method for Neural Network Controllers: A Case Study of Image-based Visual Servoing Control for the multicopter Interception
arXiv:2509.19110v1 Announce Type: cross Abstract: Reinforcement learning-based controller design methods often require substantial data in the initial training phase. Moreover, the training process tends to exhibit strong randomness and slow convergence. It often requires considerable time or high computational resources. Another class of learning-based method incorporates Lyapunov stability theory to obtain a control policy with stability guarantees. However, these methods generally require an initially stable neural network control policy at the beginning of training. Evidently, a stable neural network controller can not only serve as an initial policy for reinforcement learning, allowing the training to focus on improving controller performance, but also act as an initial state for learning-based Lyapunov control methods. Although stable controllers can be designed using traditional control theory, designers still need to have a great deal of control design knowledge to address increasingly complicated control problems. The proposed neural network rapid initialization method in this paper achieves the initial training of the neural network control policy by constructing datasets that conform to the stability conditions based on the system model. Furthermore, using the image-based visual servoing control for multicopter interception as a case study, simulations and experiments were conducted to validate the effectiveness and practical performance of the proposed method. In the experiment, the trained control policy attains a final interception velocity of 15 m/s.
LLM-based Vulnerability Discovery through the Lens of Code Metrics
arXiv:2509.19117v1 Announce Type: cross Abstract: Large language models (LLMs) excel in many tasks of software engineering, yet progress in leveraging them for vulnerability discovery has stalled in recent years. To understand this phenomenon, we investigate LLMs through the lens of classic code metrics. Surprisingly, we find that a classifier trained solely on these metrics performs on par with state-of-the-art LLMs for vulnerability discovery. A root-cause analysis reveals a strong correlation and a causal effect between LLMs and code metrics: When the value of a metric is changed, LLM predictions tend to shift by a corresponding magnitude. This dependency suggests that LLMs operate at a similarly shallow level as code metrics, limiting their ability to grasp complex patterns and fully realize their potential in vulnerability discovery. Based on these findings, we derive recommendations on how research should more effectively address this challenge.
Circuit Complexity From Physical Constraints: Scaling Limitations of Attention
arXiv:2509.19161v1 Announce Type: cross Abstract: We argue that the standard circuit complexity measures derived from $NC, AC, TC$ provide limited practical information and are now insufficient to further differentiate model expressivity. To address these new limitations, we define a novel notion of local uniformity and a family of circuit complexity classes $RC(\cdot)$ that capture the fundamental constraints of scaling physical circuits. Through the lens of $RC(\cdot)$, we show that attention mechanisms with $\omega(n^{3/2})$ runtime cannot scale to accommodate the entropy of increasingly complex datasets. Our results simultaneously provide a methodology for defining meaningful bounds on transformer expressivity and naturally expose the restricted viability of attention.
CayleyPy Growth: Efficient growth computations and hundreds of new conjectures on Cayley graphs (Brief version)
arXiv:2509.19162v1 Announce Type: cross Abstract: This is the third paper of the CayleyPy project applying artificial intelligence to problems in group theory. We announce the first public release of CayleyPy, an open source Python library for computations with Cayley and Schreier graphs. Compared with systems such as GAP and Sage, CayleyPy handles much larger graphs and performs several orders of magnitude faster. Using CayleyPy we obtained about 200 new conjectures on Cayley and Schreier graphs, focused on diameters and growth. For many Cayley graphs of symmetric groups Sn we observe quasi polynomial diameter formulas: a small set of quadratic or linear polynomials indexed by n mod s. We conjecture that this is a general phenomenon, giving efficient diameter computation despite the problem being NP hard. We propose a refinement of the Babai type conjecture on diameters of Sn: n^2/2 + 4n upper bounds in the undirected case, compared to previous O(n^2) bounds. We also provide explicit generator families, related to involutions in a square with whiskers pattern, conjectured to maximize the diameter; search confirms this for all n up to 15. We further conjecture an answer to a question posed by V M Glushkov in 1968 on directed Cayley graphs generated by a cyclic shift and a transposition. For nilpotent groups we conjecture an improvement of J S Ellenberg's results on upper unitriangular matrices over Z/pZ, showing linear dependence of diameter on p. Moreover. Some conjectures are LLM friendly, naturally stated as sorting problems verifiable by algorithms or Python code. To benchmark path finding we created more than 10 Kaggle datasets. CayleyPy works with arbitrary permutation or matrix groups and includes over 100 predefined generators. Our growth computation code outperforms GAP and Sage up to 1000 times in speed and size.
Soft Tokens, Hard Truths
arXiv:2509.19170v1 Announce Type: cross Abstract: The use of continuous instead of discrete tokens during the Chain-of-Thought (CoT) phase of reasoning LLMs has garnered attention recently, based on the intuition that a continuous mixture of discrete tokens could simulate a superposition of several reasoning paths simultaneously. Theoretical results have formally proven that continuous tokens have much greater expressivity and can solve specific problems more efficiently. However, practical use of continuous tokens has been limited by strong training difficulties: previous works either just use continuous tokens at inference time on a pre-trained discrete-token model, or must distill the continuous CoT from ground-truth discrete CoTs and face computational costs that limit the CoT to very few tokens. This is the first work introducing a scalable method to learn continuous CoTs via reinforcement learning (RL), without distilling from reference discrete CoTs. We use "soft" tokens: mixtures of tokens together with noise on the input embedding to provide RL exploration. Computational overhead is minimal, enabling us to learn continuous CoTs with hundreds of tokens. On math reasoning benchmarks with Llama and Qwen models up to 8B, training with continuous CoTs match discrete-token CoTs for pass@1 and surpass them for pass@32, showing greater CoT diversity. In systematic comparisons, the best-performing scenario is to train with continuous CoT tokens then use discrete tokens for inference, meaning the "soft" models can be deployed in a standard way. Finally, we show continuous CoT RL training better preserves the predictions of the base model on out-of-domain tasks, thus providing a softer touch to the base model.
AlloyInter: Visualising Alloy Mixture Interpolations in t-SNE Representations
arXiv:2509.19202v1 Announce Type: cross Abstract: This entry description proposes AlloyInter, a novel system to enable joint exploration of input mixtures and output parameters space in the context of the SciVis Contest 2025. We propose an interpolation approach, guided by eXplainable Artificial Intelligence (XAI) based on a learned model ensemble that allows users to discover input mixture ratios by specifying output parameter goals that can be iteratively adjusted and improved towards a goal. We strengthen the capabilities of our system by building upon prior research within the robustness of XAI, as well as combining well-established techniques like manifold learning with interpolation approaches.
Neighbor Embeddings Using Unbalanced Optimal Transport Metrics
arXiv:2509.19226v1 Announce Type: cross Abstract: This paper proposes the use of the Hellinger--Kantorovich metric from unbalanced optimal transport (UOT) in a dimensionality reduction and learning (supervised and unsupervised) pipeline. The performance of UOT is compared to that of regular OT and Euclidean-based dimensionality reduction methods on several benchmark datasets including MedMNIST. The experimental results demonstrate that, on average, UOT shows improvement over both Euclidean and OT-based methods as verified by statistical hypothesis tests. In particular, on the MedMNIST datasets, UOT outperforms OT in classification 81\% of the time. For clustering MedMNIST, UOT outperforms OT 83\% of the time and outperforms both other metrics 58\% of the time.
Linear Regression under Missing or Corrupted Coordinates
arXiv:2509.19242v1 Announce Type: cross Abstract: We study multivariate linear regression under Gaussian covariates in two settings, where data may be erased or corrupted by an adversary under a coordinate-wise budget. In the incomplete data setting, an adversary may inspect the dataset and delete entries in up to an $\eta$-fraction of samples per coordinate; a strong form of the Missing Not At Random model. In the corrupted data setting, the adversary instead replaces values arbitrarily, and the corruption locations are unknown to the learner. Despite substantial work on missing data, linear regression under such adversarial missingness remains poorly understood, even information-theoretically. Unlike the clean setting, where estimation error vanishes with more samples, here the optimal error remains a positive function of the problem parameters. Our main contribution is to characterize this error up to constant factors across essentially the entire parameter range. Specifically, we establish novel information-theoretic lower bounds on the achievable error that match the error of (computationally efficient) algorithms. A key implication is that, perhaps surprisingly, the optimal error in the missing data setting matches that in the corruption setting-so knowing the corruption locations offers no general advantage.
Reinforcement Learning on Pre-Training Data
arXiv:2509.19249v1 Announce Type: cross Abstract: The growing disparity between the exponential scaling of computational resources and the finite growth of high-quality text data now constrains conventional scaling approaches for large language models (LLMs). To address this challenge, we introduce Reinforcement Learning on Pre-Training data (RLPT), a new training-time scaling paradigm for optimizing LLMs. In contrast to prior approaches that scale training primarily through supervised learning, RLPT enables the policy to autonomously explore meaningful trajectories to learn from pre-training data and improve its capability through reinforcement learning (RL). While existing RL strategies such as reinforcement learning from human feedback (RLHF) and reinforcement learning with verifiable rewards (RLVR) rely on human annotation for reward construction, RLPT eliminates this dependency by deriving reward signals directly from pre-training data. Specifically, it adopts a next-segment reasoning objective, rewarding the policy for accurately predicting subsequent text segments conditioned on the preceding context. This formulation allows RL to be scaled on pre-training data, encouraging the exploration of richer trajectories across broader contexts and thereby fostering more generalizable reasoning skills. Extensive experiments on both general-domain and mathematical reasoning benchmarks across multiple models validate the effectiveness of RLPT. For example, when applied to Qwen3-4B-Base, RLPT yields absolute improvements of $3.0$, $5.1$, $8.1$, $6.0$, $6.6$, and $5.3$ on MMLU, MMLU-Pro, GPQA-Diamond, KOR-Bench, AIME24, and AIME25, respectively. The results further demonstrate favorable scaling behavior, suggesting strong potential for continued gains with more compute. In addition, RLPT provides a solid foundation, extending the reasoning boundaries of LLMs and enhancing RLVR performance.
Recovering Wasserstein Distance Matrices from Few Measurements
arXiv:2509.19250v1 Announce Type: cross Abstract: This paper proposes two algorithms for estimating square Wasserstein distance matrices from a small number of entries. These matrices are used to compute manifold learning embeddings like multidimensional scaling (MDS) or Isomap, but contrary to Euclidean distance matrices, are extremely costly to compute. We analyze matrix completion from upper triangular samples and Nystr\"{o}m completion in which $\mathcal{O}(d\log(d))$ columns of the distance matrices are computed where $d$ is the desired embedding dimension, prove stability of MDS under Nystr\"{o}m completion, and show that it can outperform matrix completion for a fixed budget of sample distances. Finally, we show that classification of the OrganCMNIST dataset from the MedMNIST benchmark is stable on data embedded from the Nystr\"{o}m estimation of the distance matrix even when only 10\% of the columns are computed.
Discovering strategies for coastal resilience with AI-based prediction and optimization
arXiv:2509.19263v1 Announce Type: cross Abstract: Tropical storms cause extensive property damage and loss of life, making them one of the most destructive types of natural hazards. The development of predictive models that identify interventions effective at mitigating storm impacts has considerable potential to reduce these adverse outcomes. In this study, we use an artificial intelligence (AI)-driven approach for optimizing intervention schemes that improve resilience to coastal flooding. We combine three different AI models to optimize the selection of intervention types, sites, and scales in order to minimize the expected cost of flooding damage in a given region, including the cost of installing and maintaining interventions. Our approach combines data-driven generation of storm surge fields, surrogate modeling of intervention impacts, and the solving of a continuous-armed bandit problem. We applied this methodology to optimize the selection of sea wall and oyster reef interventions near Tyndall Air Force Base (AFB) in Florida, an area that was catastrophically impacted by Hurricane Michael. Our analysis predicts that intervention optimization could be used to potentially save billions of dollars in storm damage, far outpacing greedy or non-optimal solutions.
WolBanking77: Wolof Banking Speech Intent Classification Dataset
arXiv:2509.19271v1 Announce Type: cross Abstract: Intent classification models have made a lot of progress in recent years. However, previous studies primarily focus on high-resource languages datasets, which results in a gap for low-resource languages and for regions with a high rate of illiterate people where languages are more spoken than read or written. This is the case in Senegal, for example, where Wolof is spoken by around 90\% of the population, with an illiteracy rate of 42\% for the country. Wolof is actually spoken by more than 10 million people in West African region. To tackle such limitations, we release a Wolof Intent Classification Dataset (WolBanking77), for academic research in intent classification. WolBanking77 currently contains 9,791 text sentences in the banking domain and more than 4 hours of spoken sentences. Experiments on various baselines are conducted in this work, including text and voice state-of-the-art models. The results are very promising on this current dataset. This paper also provides detailed analyses of the contents of the data. We report baseline f1-score and word error rate metrics respectively on NLP and ASR models trained on WolBanking77 dataset and also comparisons between models. We plan to share and conduct dataset maintenance, updates and to release open-source code.
A Gradient Flow Approach to Solving Inverse Problems with Latent Diffusion Models
arXiv:2509.19276v1 Announce Type: cross Abstract: Solving ill-posed inverse problems requires powerful and flexible priors. We propose leveraging pretrained latent diffusion models for this task through a new training-free approach, termed Diffusion-regularized Wasserstein Gradient Flow (DWGF). Specifically, we formulate the posterior sampling problem as a regularized Wasserstein gradient flow of the Kullback-Leibler divergence in the latent space. We demonstrate the performance of our method on standard benchmarks using StableDiffusion (Rombach et al., 2022) as the prior.
MOIS-SAM2: Exemplar-based Segment Anything Model 2 for multilesion interactive segmentation of neurobromas in whole-body MRI
arXiv:2509.19277v1 Announce Type: cross Abstract: Background and Objectives: Neurofibromatosis type 1 is a genetic disorder characterized by the development of numerous neurofibromas (NFs) throughout the body. Whole-body MRI (WB-MRI) is the clinical standard for detection and longitudinal surveillance of NF tumor growth. Existing interactive segmentation methods fail to combine high lesion-wise precision with scalability to hundreds of lesions. This study proposes a novel interactive segmentation model tailored to this challenge. Methods: We introduce MOIS-SAM2, a multi-object interactive segmentation model that extends the state-of-the-art, transformer-based, promptable Segment Anything Model 2 (SAM2) with exemplar-based semantic propagation. MOIS-SAM2 was trained and evaluated on 119 WB-MRI scans from 84 NF1 patients acquired using T2-weighted fat-suppressed sequences. The dataset was split at the patient level into a training set and four test sets (one in-domain and three reflecting different domain shift scenarios, e.g., MRI field strength variation, low tumor burden, differences in clinical site and scanner vendor). Results: On the in-domain test set, MOIS-SAM2 achieved a scan-wise DSC of 0.60 against expert manual annotations, outperforming baseline 3D nnU-Net (DSC: 0.54) and SAM2 (DSC: 0.35). Performance of the proposed model was maintained under MRI field strength shift (DSC: 0.53) and scanner vendor variation (DSC: 0.50), and improved in low tumor burden cases (DSC: 0.61). Lesion detection F1 scores ranged from 0.62 to 0.78 across test sets. Preliminary inter-reader variability analysis showed model-to-expert agreement (DSC: 0.62-0.68), comparable to inter-expert agreement (DSC: 0.57-0.69). Conclusions: The proposed MOIS-SAM2 enables efficient and scalable interactive segmentation of NFs in WB-MRI with minimal user input and strong generalization, supporting integration into clinical workflows.
SOE: Sample-Efficient Robot Policy Self-Improvement via On-Manifold Exploration
arXiv:2509.19292v1 Announce Type: cross Abstract: Intelligent agents progress by continually refining their capabilities through actively exploring environments. Yet robot policies often lack sufficient exploration capability due to action mode collapse. Existing methods that encourage exploration typically rely on random perturbations, which are unsafe and induce unstable, erratic behaviors, thereby limiting their effectiveness. We propose Self-Improvement via On-Manifold Exploration (SOE), a framework that enhances policy exploration and improvement in robotic manipulation. SOE learns a compact latent representation of task-relevant factors and constrains exploration to the manifold of valid actions, ensuring safety, diversity, and effectiveness. It can be seamlessly integrated with arbitrary policy models as a plug-in module, augmenting exploration without degrading the base policy performance. Moreover, the structured latent space enables human-guided exploration, further improving efficiency and controllability. Extensive experiments in both simulation and real-world tasks demonstrate that SOE consistently outperforms prior methods, achieving higher task success rates, smoother and safer exploration, and superior sample efficiency. These results establish on-manifold exploration as a principled approach to sample-efficient policy self-improvement. Project website: https://ericjin2002.github.io/SOE
Audio-Based Pedestrian Detection in the Presence of Vehicular Noise
arXiv:2509.19295v1 Announce Type: cross Abstract: Audio-based pedestrian detection is a challenging task and has, thus far, only been explored in noise-limited environments. We present a new dataset, results, and a detailed analysis of the state-of-the-art in audio-based pedestrian detection in the presence of vehicular noise. In our study, we conduct three analyses: (i) cross-dataset evaluation between noisy and noise-limited environments, (ii) an assessment of the impact of noisy data on model performance, highlighting the influence of acoustic context, and (iii) an evaluation of the model's predictive robustness on out-of-domain sounds. The new dataset is a comprehensive 1321-hour roadside dataset. It incorporates traffic-rich soundscapes. Each recording includes 16kHz audio synchronized with frame-level pedestrian annotations and 1fps video thumbnails.
Residual Off-Policy RL for Finetuning Behavior Cloning Policies
arXiv:2509.19301v1 Announce Type: cross Abstract: Recent advances in behavior cloning (BC) have enabled impressive visuomotor control policies. However, these approaches are limited by the quality of human demonstrations, the manual effort required for data collection, and the diminishing returns from increasing offline data. In comparison, reinforcement learning (RL) trains an agent through autonomous interaction with the environment and has shown remarkable success in various domains. Still, training RL policies directly on real-world robots remains challenging due to sample inefficiency, safety concerns, and the difficulty of learning from sparse rewards for long-horizon tasks, especially for high-degree-of-freedom (DoF) systems. We present a recipe that combines the benefits of BC and RL through a residual learning framework. Our approach leverages BC policies as black-box bases and learns lightweight per-step residual corrections via sample-efficient off-policy RL. We demonstrate that our method requires only sparse binary reward signals and can effectively improve manipulation policies on high-degree-of-freedom (DoF) systems in both simulation and the real world. In particular, we demonstrate, to the best of our knowledge, the first successful real-world RL training on a humanoid robot with dexterous hands. Our results demonstrate state-of-the-art performance in various vision-based tasks, pointing towards a practical pathway for deploying RL in the real world. Project website: https://residual-offpolicy-rl.github.io
Global Convergence of Multi-Agent Policy Gradient in Markov Potential Games
arXiv:2106.01969v4 Announce Type: replace Abstract: Potential games are arguably one of the most important and widely studied classes of normal form games. They define the archetypal setting of multi-agent coordination as all agent utilities are perfectly aligned with each other via a common potential function. Can this intuitive framework be transplanted in the setting of Markov Games? What are the similarities and differences between multi-agent coordination with and without state dependence? We present a novel definition of Markov Potential Games (MPG) that generalizes prior attempts at capturing complex stateful multi-agent coordination. Counter-intuitively, insights from normal-form potential games do not carry over as MPGs can consist of settings where state-games can be zero-sum games. In the opposite direction, Markov games where every state-game is a potential game are not necessarily MPGs. Nevertheless, MPGs showcase standard desirable properties such as the existence of deterministic Nash policies. In our main technical result, we prove fast convergence of independent policy gradient to Nash policies by adapting recent gradient dominance property arguments developed for single agent MDPs to multi-agent learning settings.
A Geometric Approach to $k$-means
arXiv:2201.04822v2 Announce Type: replace Abstract: \kmeans clustering is a fundamental problem in many scientific and engineering domains. The optimization problem associated with \kmeans clustering is nonconvex, for which standard algorithms are only guaranteed to find a local optimum. Leveraging the hidden structure of local solutions, we propose a general algorithmic framework for escaping undesirable local solutions and recovering the global solution or the ground truth clustering. This framework consists of iteratively alternating between two steps: (i) detect mis-specified clusters in a local solution, and (ii) improve the local solution by non-local operations. We discuss specific implementation of these steps, and elucidate how the proposed framework unifies many existing variants of \kmeans algorithms through a geometric perspective. We also present two natural variants of the proposed framework, where the initial number of clusters may be over- or under-specified. We provide theoretical justifications and extensive experiments to demonstrate the efficacy of the proposed approach.
Packed-Ensembles for Efficient Uncertainty Estimation
arXiv:2210.09184v4 Announce Type: replace Abstract: Deep Ensembles (DE) are a prominent approach for achieving excellent performance on key metrics such as accuracy, calibration, uncertainty estimation, and out-of-distribution detection. However, hardware limitations of real-world systems constrain to smaller ensembles and lower-capacity networks, significantly deteriorating their performance and properties. We introduce Packed-Ensembles (PE), a strategy to design and train lightweight structured ensembles by carefully modulating the dimension of their encoding space. We leverage grouped convolutions to parallelize the ensemble into a single shared backbone and forward pass to improve training and inference speeds. PE is designed to operate within the memory limits of a standard neural network. Our extensive research indicates that PE accurately preserves the properties of DE, such as diversity, and performs equally well in terms of accuracy, calibration, out-of-distribution detection, and robustness to distribution shift. We make our code available at https://github.com/ENSTA-U2IS/torch-uncertainty.
Is Pre-training Truly Better Than Meta-Learning?
arXiv:2306.13841v2 Announce Type: replace Abstract: In the context of few-shot learning, it is currently believed that a fixed pre-trained (PT) model, along with fine-tuning the final layer during evaluation, outperforms standard meta-learning algorithms. We re-evaluate these claims under an in-depth empirical examination of an extensive set of formally diverse datasets and compare PT to Model Agnostic Meta-Learning (MAML). Unlike previous work, we emphasize a fair comparison by using: the same architecture, the same optimizer, and all models trained to convergence. Crucially, we use a more rigorous statistical tool -- the effect size (Cohen's d) -- to determine the practical significance of the difference between a model trained with PT vs. a MAML. We then use a previously proposed metric -- the diversity coefficient -- to compute the average formal diversity of a dataset. Using this analysis, we demonstrate the following: 1. when the formal diversity of a data set is low, PT beats MAML on average and 2. when the formal diversity is high, MAML beats PT on average. The caveat is that the magnitude of the average difference between a PT vs. MAML using the effect size is low (according to classical statistical thresholds) -- less than 0.2. Nevertheless, this observation is contrary to the currently held belief that a pre-trained model is always better than a meta-learning model. Our extensive experiments consider 21 few-shot learning benchmarks, including the large-scale few-shot learning dataset Meta-Data set. We also show no significant difference between a MAML model vs. a PT model with GPT-2 on Openwebtext. We, therefore, conclude that a pre-trained model does not always beat a meta-learned model and that the formal diversity of a dataset is a driving factor.
"What is Different Between These Datasets?" A Framework for Explaining Data Distribution Shifts
arXiv:2403.05652v3 Announce Type: replace Abstract: The performance of machine learning models relies heavily on the quality of input data, yet real-world applications often face significant data-related challenges. A common issue arises when curating training data or deploying models: two datasets from the same domain may exhibit differing distributions. While many techniques exist for detecting such distribution shifts, there is a lack of comprehensive methods to explain these differences in a human-understandable way beyond opaque quantitative metrics. To bridge this gap, we propose a versatile framework of interpretable methods for comparing datasets. Using a variety of case studies, we demonstrate the effectiveness of our approach across diverse data modalities-including tabular data, text data, images, time-series signals -- in both low and high-dimensional settings. These methods complement existing techniques by providing actionable and interpretable insights to better understand and address distribution shifts.
Online Regularized Statistical Learning in Reproducing Kernel Hilbert Space With Non-Stationary Data
arXiv:2404.03211v5 Announce Type: replace Abstract: We study the convergence of recursive regularized learning algorithms in the reproducing kernel Hilbert space (RKHS) with dependent and non-stationary online data streams. Firstly, we introduce the concept of random Tikhonov regularization path and decompose the tracking error of the algorithm's output for the regularization path into random difference equations in RKHS, whose non-homogeneous terms are martingale difference sequences. Investigating the mean square asymptotic stability of the equations, we show that if the regularization path is slowly time-varying, then the algorithm's output achieves mean square consistency with the regularization path. Leveraging operator theory, particularly the monotonicity of the inverses of operators and the spectral decomposition of compact operators, we introduce the RKHS persistence of excitation condition (i.e. there exists a fixed-length time period, such that the conditional expectation of the operators induced by the input data accumulated over every period has a uniformly strictly positive compact lower bound) and develop a dominated convergence method to prove the mean square consistency between the algorithm's output and an unknown function. Finally, for independent and non-identically distributed data streams, the algorithm achieves the mean square consistency if the input data's marginal probability measures are slowly time-varying and the average measure over each fixed-length time period has a uniformly strictly positive lower bound.
Spectraformer: A Unified Random Feature Framework for Transformer
arXiv:2405.15310v5 Announce Type: replace Abstract: Linearization of attention using various kernel approximation and kernel learning techniques has shown promise. Past methods used a subset of combinations of component functions and weight matrices within the random feature paradigm. We identify the need for a systematic comparison of different combinations of weight matrices and component functions for attention learning in Transformer. Hence, we introduce Spectraformer, a unified framework for approximating and learning the kernel function in the attention mechanism of the Transformer. Our empirical results demonstrate, for the first time, that a random feature-based approach can achieve performance comparable to top-performing sparse and low-rank methods on the challenging Long Range Arena benchmark. Thus, we establish a new state-of-the-art for random feature-based efficient Transformers. The framework also produces many variants that offer different advantages in accuracy, training time, and memory consumption. Our code is available at: https://github.com/cruiseresearchgroup/spectraformer .
TIDMAD: Time Series Dataset for Discovering Dark Matter with AI Denoising
arXiv:2406.04378v2 Announce Type: replace Abstract: Dark matter makes up approximately 85% of total matter in our universe, yet it has never been directly observed in any laboratory on Earth. The origin of dark matter is one of the most important questions in contemporary physics, and a convincing detection of dark matter would be a Nobel-Prize-level breakthrough in fundamental science. The ABRACADABRA experiment was specifically designed to search for dark matter. Although it has not yet made a discovery, ABRACADABRA has produced several dark matter search results widely endorsed by the physics community. The experiment generates ultra-long time-series data at a rate of 10 million samples per second, where the dark matter signal would manifest itself as a sinusoidal oscillation mode within the ultra-long time series. In this paper, we present the TIDMAD -- a comprehensive data release from the ABRACADABRA experiment including three key components: an ultra-long time series dataset divided into training, validation, and science subsets; a carefully-designed denoising score for direct model benchmarking; and a complete analysis framework which produces a community-standard dark matter search result suitable for publication as a physics paper. This data release enables core AI algorithms to extract the signal and produce real physics results thereby advancing fundamental science. The data downloading and associated analysis scripts are available at https://github.com/jessicafry/TIDMAD
Sum-of-norms regularized Nonnegative Matrix Factorization
arXiv:2407.00706v2 Announce Type: replace Abstract: When applying nonnegative matrix factorization (NMF), the rank parameter is generally unknown. This rank, called the nonnegative rank, is usually estimated heuristically since computing its exact value is NP-hard. In this work, we propose an approximation method to estimate the rank on-the-fly while solving NMF. We use the sum-of-norm (SON), a group-lasso structure that encourages pairwise sim- ilarity, to reduce the rank of a factor matrix when the initial rank is overestimated. On various datasets, SON-NMF can reveal the correct nonnegative rank of the data without prior knowledge or parameter tuning. SON-NMF is a nonconvex, nonsmooth, non-separable, and non-proximable problem, making it nontrivial to solve. First, since rank estimation in NMF is NP-hard, the proposed approach does not benefit from lower computational com- plexity. Using a graph-theoretic argument, we prove that the complexity of SON- NMF is essentially irreducible. Second, the per-iteration cost of algorithms for SON-NMF can be high. This motivates us to propose a first-order BCD algorithm that approximately solves SON-NMF with low per-iteration cost via the proximal average operator. SON-NMF exhibits favorable features for applications. Besides the ability to automatically estimate the rank from data, SON-NMF can handle rank-deficient data matrices and detect weak components with small energy. Furthermore, in hyperspectral imaging, SON-NMF naturally addresses the issue of spectral variability.
DOTA: Distributional Test-Time Adaptation of Vision-Language Models
arXiv:2409.19375v2 Announce Type: replace Abstract: Vision-language foundation models (VLMs), such as CLIP, exhibit remarkable performance across a wide range of tasks. However, deploying these models can be unreliable when significant distribution gaps exist between training and test data, while fine-tuning for diverse scenarios is often costly. Cache-based test-time adapters offer an efficient alternative by storing representative test samples to guide subsequent classifications. Yet, these methods typically employ naive cache management with limited capacity, leading to severe catastrophic forgetting when samples are inevitably dropped during updates. In this paper, we propose DOTA (DistributiOnal Test-time Adaptation), a simple yet effective method addressing this limitation. Crucially, instead of merely memorizing individual test samples, DOTA continuously estimates the underlying distribution of the test data stream. Test-time posterior probabilities are then computed using these dynamically estimated distributions via Bayes' theorem for adaptation. This distribution-centric approach enables the model to continually learn and adapt to the deployment environment. Extensive experiments validate that DOTA significantly mitigates forgetting and achieves state-of-the-art performance compared to existing methods.
A Generative Framework for Probabilistic, Spatiotemporally Coherent Downscaling of Climate Simulation
arXiv:2412.15361v4 Announce Type: replace Abstract: Local climate information is crucial for impact assessment and decision-making, yet coarse global climate simulations cannot capture small-scale phenomena. Current statistical downscaling methods infer these phenomena as temporally decoupled spatial patches. However, to preserve physical properties, estimating spatio-temporally coherent high-resolution weather dynamics for multiple variables across long time horizons is crucial. We present a novel generative framework that uses a score-based diffusion model trained on high-resolution reanalysis data to capture the statistical properties of local weather dynamics. After training, we condition on coarse climate model data to generate weather patterns consistent with the aggregate information. As this predictive task is inherently uncertain, we leverage the probabilistic nature of diffusion models and sample multiple trajectories. We evaluate our approach with high-resolution reanalysis information before applying it to the climate model downscaling task. We then demonstrate that the model generates spatially and temporally coherent weather dynamics that align with global climate output.
Dynami-CAL GraphNet: A Physics-Informed Graph Neural Network Conserving Linear and Angular Momentum for Dynamical Systems
arXiv:2501.07373v2 Announce Type: replace Abstract: Accurate, interpretable, and real-time modeling of multi-body dynamical systems is essential for predicting behaviors and inferring physical properties in natural and engineered environments. Traditional physics-based models face scalability challenges and are computationally demanding, while data-driven approaches like Graph Neural Networks (GNNs) often lack physical consistency, interpretability, and generalization. In this paper, we propose Dynami-CAL GraphNet, a Physics-Informed Graph Neural Network that integrates the learning capabilities of GNNs with physics-based inductive biases to address these limitations. Dynami-CAL GraphNet enforces pairwise conservation of linear and angular momentum for interacting nodes using edge-local reference frames that are equivariant to rotational symmetries, invariant to translations, and equivariant to node permutations. This design ensures physically consistent predictions of node dynamics while offering interpretable, edge-wise linear and angular impulses resulting from pairwise interactions. Evaluated on a 3D granular system with inelastic collisions, Dynami-CAL GraphNet demonstrates stable error accumulation over extended rollouts, effective extrapolations to unseen configurations, and robust handling of heterogeneous interactions and external forces. Dynami-CAL GraphNet offers significant advantages in fields requiring accurate, interpretable, and real-time modeling of complex multi-body dynamical systems, such as robotics, aerospace engineering, and materials science. By providing physically consistent and scalable predictions that adhere to fundamental conservation laws, it enables the inference of forces and moments while efficiently handling heterogeneous interactions and external forces.
Fine-Tuning is Subgraph Search: A New Lens on Learning Dynamics
arXiv:2502.06106v3 Announce Type: replace Abstract: The study of mechanistic interpretability aims to reverse-engineer a model to explain its behaviors. While recent studies have focused on the static mechanism of a certain behavior, the learning dynamics inside a model remain to be explored. In this work, we develop a fine-tuning method for analyzing the mechanism behind learning. Inspired by the concept of intrinsic dimension, we view a model as a computational graph with redundancy for a specific task, and treat the fine-tuning process as a search for and optimization of a subgraph within this graph. Based on this hypothesis, we propose circuit-tuning, an algorithm that iteratively builds the subgraph for a specific task and updates the relevant parameters in a heuristic way. We first validate our hypothesis through a carefully designed experiment and provide a detailed analysis of the learning dynamics during fine-tuning. Subsequently, we conduct experiments on more complex tasks, demonstrating that circuit-tuning could strike a balance between the performance on the target task and the general capabilities. Our work offers a new analytical method for the dynamics of fine-tuning, provides new findings on the mechanisms behind the training process, and inspires the design of superior algorithms for the training of neural networks.
An Efficient Self-Supervised Framework for Long-Sequence EEG Modeling
arXiv:2502.17873v2 Announce Type: replace Abstract: Electroencephalogram (EEG) signals generally exhibit low signal-to-noise ratio (SNR) and high inter-subject variability, making generalization across subjects and domains challenging. Recent advances in deep learning, particularly self-supervised learning with Transformer-based architectures, have shown promise in EEG representation learning. However, their quadratic computational complexity increases memory usage and slows inference, making them inefficient for modeling long-range dependencies. Moreover, most existing approaches emphasize either explicit window segmentation of the temporal signal or spectral-only input embedding while neglecting raw temporal dynamics. In this paper, we propose EEGM2, a self-supervised framework that overcomes these limitations. EEGM2 adopts a U-shaped encoder-decoder architecture integrated with Mamba-2 to achieve linear computational complexity, thereby reducing memory usage and improving inference speed. Meanwhile, the selective information propagation mechanism of Mamba-2 enables the model to effectively capture and preserve long-range dependencies in raw EEG signals, where traditional RNN or CNN architectures often struggle. Moreover, EEGM2 employs a self-supervised pre-training objective that reconstructs raw EEG using a combined L1 and spectral (Fourier-based) loss, enhancing generalization by jointly preserving temporal dynamics and spectral characteristics. Experimental results demonstrate that EEGM2 achieves state-of-the-art performance in both short- and long-sequence modeling and classification. Further evaluations show that EEGM2 consistently outperforms existing models, demonstrating strong generalization across subjects and tasks, as well as transferability across domains. Overall, EEGM2 offers an efficient and scalable solution suitable for deployment on resource-constrained brain-computer interface (BCI) devices.
Union of Experts: Adapting Hierarchical Routing to Equivalently Decomposed Transformer
arXiv:2503.02495v3 Announce Type: replace Abstract: Mixture-of-Experts (MoE) enhances model performance while maintaining computational efficiency, making it well-suited for large-scale applications. Conventional mixture-of-experts (MoE) architectures suffer from suboptimal coordination dynamics, where isolated expert operations expose the model to overfitting risks. Moreover, they have not been effectively extended to attention blocks, which limits further efficiency improvements. To tackle these issues, we propose Union-of-Experts (UoE), which decomposes the transformer model into an equivalent group of experts and applies a hierarchical routing mechanism to allocate input subspaces to specialized experts. Our approach advances MoE design with four key innovations: (1) Constructing expert groups by partitioning non-MoE models into functionally equivalent specialists (2) Developing a hierarchical routing paradigm that integrates patch-wise data selection and expert selection strategies. (3) Extending the MoE design to attention blocks. (4) Proposing a hardware-optimized parallelization scheme that exploits batched matrix multiplications for efficient expert computation. The experiments demonstrate that our UoE model surpasses Full Attention, state-of-the-art MoEs and efficient transformers in several tasks across image and natural language domains. In language modeling tasks, UoE achieves an average reduction of 2.38 in perplexity compared to the best-performing MoE method with only 76% of its FLOPs. In the Long Range Arena benchmark, it demonstrates an average score at least 0.68% higher than all comparison models, with only 50% of the FLOPs of the best MoE method. In image classification, it yields an average accuracy improvement of 1.75% over the best model while maintaining comparable FLOPs. The source codes are available at https://github.com/YujiaoYang-work/UoE.
A Survey on Sparse Autoencoders: Interpreting the Internal Mechanisms of Large Language Models
arXiv:2503.05613v3 Announce Type: replace Abstract: Large Language Models (LLMs) have transformed natural language processing, yet their internal mechanisms remain largely opaque. Recently, mechanistic interpretability has attracted significant attention from the research community as a means to understand the inner workings of LLMs. Among various mechanistic interpretability approaches, Sparse Autoencoders (SAEs) have emerged as a promising method due to their ability to disentangle the complex, superimposed features within LLMs into more interpretable components. This paper presents a comprehensive survey of SAEs for interpreting and understanding the internal workings of LLMs. Our major contributions include: (1) exploring the technical framework of SAEs, covering basic architecture, design improvements, and effective training strategies; (2) examining different approaches to explaining SAE features, categorized into input-based and output-based explanation methods; (3) discussing evaluation methods for assessing SAE performance, covering both structural and functional metrics; and (4) investigating real-world applications of SAEs in understanding and manipulating LLM behaviors.
Manifold learning in metric spaces
arXiv:2503.16187v3 Announce Type: replace Abstract: Laplacian-based methods are popular for the dimensionality reduction of data lying in $\mathbb{R}^N$. Several theoretical results for these algorithms depend on the fact that the Euclidean distance locally approximates the geodesic distance on the underlying submanifold which the data are assumed to lie on. However, for some applications, other metrics, such as the Wasserstein distance, may provide a more appropriate notion of distance than the Euclidean distance. We provide a framework that generalizes the problem of manifold learning to metric spaces and study when a metric satisfies sufficient conditions for the pointwise convergence of the graph Laplacian.
Disentangle and Regularize: Sign Language Production with Articulator-Based Disentanglement and Channel-Aware Regularization
arXiv:2504.06610v3 Announce Type: replace Abstract: In this work, we propose DARSLP, a simple gloss-free, transformer-based sign language production (SLP) framework that directly maps spoken-language text to sign pose sequences. We first train a pose autoencoder that encodes sign poses into a compact latent space using an articulator-based disentanglement strategy, where features corresponding to the face, right hand, left hand, and body are modeled separately to promote structured and interpretable representation learning. Next, a non-autoregressive transformer decoder is trained to predict these latent representations from word-level text embeddings of the input sentence. To guide this process, we apply channel-aware regularization by aligning predicted latent distributions with priors extracted from the ground-truth encodings using a KL divergence loss. The contribution of each channel to the loss is weighted according to its associated articulator region, enabling the model to account for the relative importance of different articulators during training. Our approach does not rely on gloss supervision or pretrained models, and achieves state-of-the-art results on the PHOENIX14T and CSL-Daily datasets.
Scaling Up On-Device LLMs via Active-Weight Swapping Between DRAM and Flash
arXiv:2504.08378v2 Announce Type: replace Abstract: Large language models (LLMs) are increasingly being deployed on mobile devices, but the limited DRAM capacity constrains the deployable model size. This paper introduces ActiveFlow, the first LLM inference framework that can achieve adaptive DRAM usage for modern LLMs (not ReLU-based), enabling the scaling up of deployable model sizes. The framework is based on the novel concept of active weight DRAM-flash swapping and incorporates three novel techniques: (1) Cross-layer active weights preloading. It uses the activations from the current layer to predict the active weights of several subsequent layers, enabling computation and data loading to overlap, as well as facilitating large I/O transfers. (2) Sparsity-aware self-distillation. It adjusts the active weights to align with the dense-model output distribution, compensating for approximations introduced by contextual sparsity. (3) Active weight DRAM-flash swapping pipeline. It orchestrates the DRAM space allocation among the hot weight cache, preloaded active weights, and computation-involved weights based on available memory. Results show ActiveFlow achieves the performance-cost Pareto frontier compared to existing efficiency optimization methods.
ABG-NAS: Adaptive Bayesian Genetic Neural Architecture Search for Graph Representation Learning
arXiv:2504.21254v3 Announce Type: replace Abstract: Effective and efficient graph representation learning is essential for enabling critical downstream tasks, such as node classification, link prediction, and subgraph search. However, existing graph neural network (GNN) architectures often struggle to adapt to diverse and complex graph structures, limiting their ability to produce structure-aware and task-discriminative representations. To address this challenge, we propose ABG-NAS, a novel framework for automated graph neural network architecture search tailored for efficient graph representation learning. ABG-NAS encompasses three key components: a Comprehensive Architecture Search Space (CASS), an Adaptive Genetic Optimization Strategy (AGOS), and a Bayesian-Guided Tuning Module (BGTM). CASS systematically explores diverse propagation (P) and transformation (T) operations, enabling the discovery of GNN architectures capable of capturing intricate graph characteristics. AGOS dynamically balances exploration and exploitation, ensuring search efficiency and preserving solution diversity. BGTM further optimizes hyperparameters periodically, enhancing the scalability and robustness of the resulting architectures. Empirical evaluations on benchmark datasets (Cora, PubMed, Citeseer, and CoraFull) demonstrate that ABG-NAS consistently outperforms both manually designed GNNs and state-of-the-art neural architecture search (NAS) methods. These results highlight the potential of ABG-NAS to advance graph representation learning by providing scalable and adaptive solutions for diverse graph structures. Our code is publicly available at https://github.com/sserranw/ABG-NAS.
Connecting Independently Trained Modes via Layer-Wise Connectivity
arXiv:2505.02604v4 Announce Type: replace Abstract: Empirical and theoretical studies have shown that continuous low-loss paths can be constructed between independently trained neural network models. This phenomenon, known as mode connectivity, refers to the existence of such paths between distinct modes-i.e., well-trained solutions in parameter space. However, existing empirical methods are primarily effective for older and relatively simple architectures such as basic CNNs, VGG, and ResNet, raising concerns about their applicability to modern and structurally diverse models. In this work, we propose a new empirical algorithm for connecting independently trained modes that generalizes beyond traditional architectures and supports a broader range of networks, including MobileNet, ShuffleNet, EfficientNet, RegNet, Deep Layer Aggregation (DLA), and Compact Convolutional Transformers (CCT). In addition to broader applicability, the proposed method yields more consistent connectivity paths across independently trained mode pairs and supports connecting modes obtained with different training hyperparameters.
Dynamical Low-Rank Compression of Neural Networks with Robustness under Adversarial Attacks
arXiv:2505.08022v3 Announce Type: replace Abstract: Deployment of neural networks on resource-constrained devices demands models that are both compact and robust to adversarial inputs. However, compression and adversarial robustness often conflict. In this work, we introduce a dynamical low-rank training scheme enhanced with a novel spectral regularizer that controls the condition number of the low-rank core in each layer. This approach mitigates the sensitivity of compressed models to adversarial perturbations without sacrificing accuracy on clean data. The method is model- and data-agnostic, computationally efficient, and supports rank adaptivity to automatically compress the network at hand. Extensive experiments across standard architectures, datasets, and adversarial attacks show the regularized networks can achieve over 94% compression while recovering or improving adversarial accuracy relative to uncompressed baselines.
Beyond Input Activations: Identifying Influential Latents by Gradient Sparse Autoencoders
arXiv:2505.08080v2 Announce Type: replace Abstract: Sparse Autoencoders (SAEs) have recently emerged as powerful tools for interpreting and steering the internal representations of large language models (LLMs). However, conventional approaches to analyzing SAEs typically rely solely on input-side activations, without considering the causal influence between each latent feature and the model's output. This work is built on two key hypotheses: (1) activated latents do not contribute equally to the construction of the model's output, and (2) only latents with high causal influence are effective for model steering. To validate these hypotheses, we propose Gradient Sparse Autoencoder (GradSAE), a simple yet effective method that identifies the most influential latents by incorporating output-side gradient information.
msf-CNN: Patch-based Multi-Stage Fusion with Convolutional Neural Networks for TinyML
arXiv:2505.11483v2 Announce Type: replace Abstract: AI spans from large language models to tiny models running on microcontrollers (MCUs). Extremely memory-efficient model architectures are decisive to fit within an MCU's tiny memory budget e.g., 128kB of RAM. However, inference latency must remain small to fit real-time constraints. An approach to tackle this is patch-based fusion, which aims to optimize data flows across neural network layers. In this paper, we introduce msf-CNN, a novel technique that efficiently finds optimal fusion settings for convolutional neural networks (CNNs) by walking through the fusion solution space represented as a directed acyclic graph. Compared to previous work on CNN fusion for MCUs, msf-CNN identifies a wider set of solutions. We published an implementation of msf-CNN running on various microcontrollers (ARM Cortex-M, RISC-V, ESP32). We show that msf-CNN can achieve inference using 50% less RAM compared to the prior art (MCUNetV2 and StreamNet). We thus demonstrate how msf-CNN offers additional flexibility for system designers.
Early Prediction of In-Hospital ICU Mortality Using Innovative First-Day Data: A Review
arXiv:2505.12344v2 Announce Type: replace Abstract: The intensive care unit (ICU) manages critically ill patients, many of whom face a high risk of mortality. Early and accurate prediction of in-hospital mortality within the first 24 hours of ICU admission is crucial for timely clinical interventions, resource optimization, and improved patient outcomes. Traditional scoring systems, while useful, often have limitations in predictive accuracy and adaptability. Objective: This review aims to systematically evaluate and benchmark innovative methodologies that leverage data available within the first day of ICU admission for predicting in-hospital mortality. We focus on advancements in machine learning, novel biomarker applications, and the integration of diverse data types.
EC-LDA : Label Distribution Inference Attack against Federated Graph Learning with Embedding Compression
arXiv:2505.15140v2 Announce Type: replace Abstract: Graph Neural Networks (GNNs) have been widely used for graph analysis. Federated Graph Learning (FGL) is an emerging learning framework to collaboratively train graph data from various clients. However, since clients are required to upload model parameters to the server in each round, this provides the server with an opportunity to infer each client's data privacy. In this paper, we focus on label distribution attacks(LDAs) that aim to infer the label distributions of the clients' local data. We take the first step to attack client's label distributions in FGL. Firstly, we observe that the effectiveness of LDA is closely related to the variance of node embeddings in GNNs. Next, we analyze the relation between them and we propose a new attack named EC-LDA, which significantly improves the attack effectiveness by compressing node embeddings. Thirdly, extensive experiments on node classification and link prediction tasks across six widely used graph datasets show that EC-LDA outperforms the SOTA LDAs. For example, EC-LDA attains optimal values under both Cos-sim and JS-div evaluation metrics in the CoraFull and LastFM datasets. Finally, we explore the robustness of EC-LDA under differential privacy protection.
Representative Action Selection for Large Action Space Meta-Bandits
arXiv:2505.18269v3 Announce Type: replace Abstract: We study the problem of selecting a subset from a large action space shared by a family of bandits, with the goal of achieving performance nearly matching that of using the full action space. We assume that similar actions tend to have related payoffs, modeled by a Gaussian process. To exploit this structure, we propose a simple epsilon-net algorithm to select a representative subset. We provide theoretical guarantees for its performance and compare it empirically to Thompson Sampling and Upper Confidence Bound.
Foresight: Adaptive Layer Reuse for Accelerated and High-Quality Text-to-Video Generation
arXiv:2506.00329v2 Announce Type: replace Abstract: Diffusion Transformers (DiTs) achieve state-of-the-art results in text-to-image, text-to-video generation, and editing. However, their large model size and the quadratic cost of spatial-temporal attention over multiple denoising steps make video generation computationally expensive. Static caching mitigates this by reusing features across fixed steps but fails to adapt to generation dynamics, leading to suboptimal trade-offs between speed and quality. We propose Foresight, an adaptive layer-reuse technique that reduces computational redundancy across denoising steps while preserving baseline performance. Foresight dynamically identifies and reuses DiT block outputs for all layers across steps, adapting to generation parameters such as resolution and denoising schedules to optimize efficiency. Applied to OpenSora, Latte, and CogVideoX, Foresight achieves up to \latencyimprv end-to-end speedup, while maintaining video quality. The source code of Foresight is available at \href{https://github.com/STAR-Laboratory/foresight}{https://github.com/STAR-Laboratory/foresight}.
Bayes Error Rate Estimation in Difficult Situations
arXiv:2506.03159v3 Announce Type: replace Abstract: The Bayes Error Rate (BER) is the fundamental limit on the achievable generalizable classification accuracy of any machine learning model due to inherent uncertainty within the data. BER estimators offer insight into the difficulty of any classification problem and set expectations for optimal classification performance. In order to be useful, the estimators must also be accurate with a limited number of samples on multivariate problems with unknown class distributions. To determine which estimators meet the minimum requirements for "usefulness", an in-depth examination of their accuracy is conducted using Monte Carlo simulations with synthetic data in order to obtain their confidence bounds for binary classification. To examine the usability of the estimators for real-world applications, new non-linear multi-modal test scenarios are introduced. In each scenario, 2500 Monte Carlo simulations per scenario are run over a wide range of BER values. In a comparison of k-Nearest Neighbor (kNN), Generalized Henze-Penrose (GHP) divergence and Kernel Density Estimation (KDE) techniques, results show that kNN is overwhelmingly the more accurate non-parametric estimator. In order to reach the target of an under 5% range for the 95% confidence bounds, the minimum number of required samples per class is 1000. As more features are added, more samples are needed, so that 2500 samples per class are required at only 4 features. Other estimators do become more accurate than kNN as more features are added, but continuously fail to meet the target range.
Gaussian Process Diffeomorphic Statistical Shape Modelling Outperforms Angle-Based Methods for Assessment of Hip Dysplasia
arXiv:2506.04886v2 Announce Type: replace Abstract: Dysplasia is a recognised risk factor for osteoarthritis (OA) of the hip, early diagnosis of dysplasia is important to provide opportunities for surgical interventions aimed at reducing the risk of hip OA. We have developed a pipeline for semi-automated classification of dysplasia using volumetric CT scans of patients' hips and a minimal set of clinically annotated landmarks, combining the framework of the Gaussian Process Latent Variable Model with diffeomorphism to create a statistical shape model, which we termed the Gaussian Process Diffeomorphic Statistical Shape Model (GPDSSM). We used 192 CT scans, 100 for model training and 92 for testing. The GPDSSM effectively distinguishes dysplastic samples from controls while also highlighting regions of the underlying surface that show dysplastic variations. As well as improving classification accuracy compared to angle-based methods (AUC 96.2% vs 91.2%), the GPDSSM can save time for clinicians by removing the need to manually measure angles and interpreting 2D scans for possible markers of dysplasia.
Dynamic Mixture of Progressive Parameter-Efficient Expert Library for Lifelong Robot Learning
arXiv:2506.05985v2 Announce Type: replace Abstract: A generalist agent must continuously learn and adapt throughout its lifetime, achieving efficient forward transfer while minimizing catastrophic forgetting. Previous work within the dominant pretrain-then-finetune paradigm has explored parameter-efficient fine-tuning for single-task adaptation, effectively steering a frozen pretrained model with a small number of parameters. However, in the context of lifelong learning, these methods rely on the impractical assumption of a test-time task identifier and restrict knowledge sharing among isolated adapters. To address these limitations, we propose Dynamic Mixture of Progressive Parameter-Efficient Expert Library (DMPEL) for lifelong robot learning. DMPEL progressively builds a low-rank expert library and employs a lightweight router to dynamically combine experts into an end-to-end policy, enabling flexible and efficient lifelong forward transfer. Furthermore, by leveraging the modular structure of the fine-tuned parameters, we introduce expert coefficient replay, which guides the router to accurately retrieve frozen experts for previously encountered tasks. This technique mitigates forgetting while being significantly more storage- and computation-efficient than experience replay over the entire policy. Extensive experiments on the lifelong robot learning benchmark LIBERO demonstrate that our framework outperforms state-of-the-art lifelong learning methods in success rates during continual adaptation, while utilizing minimal trainable parameters and storage.
Athena: Enhancing Multimodal Reasoning with Data-efficient Process Reward Models
arXiv:2506.09532v2 Announce Type: replace Abstract: We present Athena-PRM, a multimodal process reward model (PRM) designed to evaluate the reward score for each step in solving complex reasoning problems. Developing high-performance PRMs typically demands significant time and financial investment, primarily due to the necessity for step-level annotations of reasoning steps. Conventional automated labeling methods, such as Monte Carlo estimation, often produce noisy labels and incur substantial computational costs. To efficiently generate high-quality process-labeled data, we propose leveraging prediction consistency between weak and strong completers as a criterion for identifying reliable process labels. Remarkably, Athena-PRM demonstrates outstanding effectiveness across various scenarios and benchmarks with just 5,000 samples. Furthermore, we also develop two effective strategies to improve the performance of PRMs: ORM initialization and up-sampling for negative data. We validate our approach in three specific scenarios: verification for test time scaling, direct evaluation of reasoning step correctness, and reward ranked fine-tuning. Our Athena-PRM consistently achieves superior performance across multiple benchmarks and scenarios. Notably, when using Qwen2.5-VL-7B as the policy model, Athena-PRM enhances performance by 10.2 points on WeMath and 7.1 points on MathVista for test time scaling. Furthermore, Athena-PRM sets the state-of-the-art (SoTA) results in VisualProcessBench and outperforms the previous SoTA by 3.9 F1-score, showcasing its robust capability to accurately assess the correctness of the reasoning step. Additionally, utilizing Athena-PRM as the reward model, we develop Athena-7B with reward ranked fine-tuning and outperforms baseline with a significant margin on five benchmarks.
A Rigorous Behavior Assessment of CNNs Using a Data-Domain Sampling Regime
arXiv:2507.03866v2 Announce Type: replace Abstract: We present a data-domain sampling regime for quantifying CNNs' graphic perception behaviors. This regime lets us evaluate CNNs' ratio estimation ability in bar charts from three perspectives: sensitivity to training-test distribution discrepancies, stability to limited samples, and relative expertise to human observers. After analyzing 16 million trials from 800 CNNs models and 6,825 trials from 113 human participants, we arrived at a simple and actionable conclusion: CNNs can outperform humans and their biases simply depend on the training-test distance. We show evidence of this simple, elegant behavior of the machines when they interpret visualization images. osf.io/gfqc3 provides registration, the code for our sampling regime, and experimental results.
Class-wise Balancing Data Replay for Federated Class-Incremental Learning
arXiv:2507.07712v2 Announce Type: replace Abstract: Federated Class Incremental Learning (FCIL) aims to collaboratively process continuously increasing incoming tasks across multiple clients. Among various approaches, data replay has become a promising solution, which can alleviate forgetting by reintroducing representative samples from previous tasks. However, their performance is typically limited by class imbalance, both within the replay buffer due to limited global awareness and between replayed and newly arrived classes. To address this issue, we propose a class wise balancing data replay method for FCIL (FedCBDR), which employs a global coordination mechanism for class-level memory construction and reweights the learning objective to alleviate the aforementioned imbalances. Specifically, FedCBDR has two key components: 1) the global-perspective data replay module reconstructs global representations of prior task in a privacy-preserving manner, which then guides a class-aware and importance-sensitive sampling strategy to achieve balanced replay; 2) Subsequently, to handle class imbalance across tasks, the task aware temperature scaling module adaptively adjusts the temperature of logits at both class and instance levels based on task dynamics, which reduces the model's overconfidence in majority classes while enhancing its sensitivity to minority classes. Experimental results verified that FedCBDR achieves balanced class-wise sampling under heterogeneous data distributions and improves generalization under task imbalance between earlier and recent tasks, yielding a 2%-15% Top-1 accuracy improvement over six state-of-the-art methods.
HyperEvent: A Strong Baseline for Dynamic Link Prediction via Relative Structural Encoding
arXiv:2507.11836v2 Announce Type: replace Abstract: Learning representations for continuous-time dynamic graphs is critical for dynamic link prediction. While recent methods have become increasingly complex, the field lacks a strong and informative baseline to reliably gauge progress. This paper proposes HyperEvent, a simple approach that captures relative structural patterns in event sequences through an intuitive encoding mechanism. As a straightforward baseline, HyperEvent leverages relative structural encoding to identify meaningful event sequences without complex parameterization. By combining these interpretable features with a lightweight transformer classifier, HyperEvent reframes link prediction as event structure recognition. Despite its simplicity, HyperEvent achieves competitive results across multiple benchmarks, often matching the performance of more complex models. This work demonstrates that effective modeling can be achieved through simple structural encoding, providing a clear reference point for evaluating future advancements.
PIGDreamer: Privileged Information Guided World Models for Safe Partially Observable Reinforcement Learning
arXiv:2508.02159v2 Announce Type: replace Abstract: Partial observability presents a significant challenge for Safe Reinforcement Learning (Safe RL), as it impedes the identification of potential risks and rewards. Leveraging specific types of privileged information during training to mitigate the effects of partial observability has yielded notable empirical successes. In this paper, we propose Asymmetric Constrained Partially Observable Markov Decision Processes (ACPOMDPs) to theoretically examine the advantages of incorporating privileged information in Safe RL. Building upon ACPOMDPs, we propose the Privileged Information Guided Dreamer (PIGDreamer), a model-based RL approach that leverages privileged information to enhance the agent's safety and performance through privileged representation alignment and an asymmetric actor-critic structure. Our empirical results demonstrate that PIGDreamer significantly outperforms existing Safe RL methods. Furthermore, compared to alternative privileged RL methods, our approach exhibits enhanced performance, robustness, and efficiency. Codes are available at: https://github.com/hggforget/PIGDreamer.
Topological Feature Compression for Molecular Graph Neural Networks
arXiv:2508.07807v2 Announce Type: replace Abstract: Recent advances in molecular representation learning have produced highly effective encodings of molecules for numerous cheminformatics and bioinformatics tasks. However, extracting general chemical insight while balancing predictive accuracy, interpretability, and computational efficiency remains a major challenge. In this work, we introduce a novel Graph Neural Network (GNN) architecture that combines compressed higher-order topological signals with standard molecular features. Our approach captures global geometric information while preserving computational tractability and human-interpretable structure. We evaluate our model across a range of benchmarks, from small-molecule datasets to complex material datasets, and demonstrate superior performance using a parameter-efficient architecture. We achieve the best performing results in both accuracy and robustness across almost all benchmarks. We open source all code \footnote{All code and results can be found on Github https://github.com/rahulkhorana/TFC-PACT-Net}.
EvoCoT: Overcoming the Exploration Bottleneck in Reinforcement Learning
arXiv:2508.07809v4 Announce Type: replace Abstract: Reinforcement learning with verifiable reward (RLVR) has become a promising paradigm for post-training large language models (LLMs) to improve their reasoning capability. However, when the rollout accuracy is low on hard problems, the reward becomes sparse, limiting learning efficiency and causing exploration bottlenecks. Existing approaches either rely on teacher models for distillation or filter out difficult problems, which limits scalability or restricts reasoning improvement through exploration. We propose EvoCoT, a self-evolving curriculum learning framework based on two-stage chain-of-thought (CoT) reasoning optimization. EvoCoT constrains the exploration space by self-generating and verifying CoT trajectories, then gradually shortens CoT steps to expand the space in a controlled way. The framework enables LLMs to stably learn from initially unsolved hard problems under sparse rewards. We apply EvoCoT to multiple LLM families, including Qwen, DeepSeek, and Llama. Experiments show that EvoCoT enables LLMs to solve previously unsolved problems, improves reasoning capability without external CoT supervision, and is compatible with various RL fine-tuning methods. We release the source code to support future research.
Generative Medical Event Models Improve with Scale
arXiv:2508.12104v2 Announce Type: replace Abstract: Realizing personalized medicine at scale calls for methods that distill insights from longitudinal patient journeys, which can be viewed as a sequence of medical events. Foundation models pretrained on large-scale medical event data represent a promising direction for scaling real-world evidence generation and generalizing to diverse downstream tasks. Using Epic Cosmos, a dataset with medical events from de-identified longitudinal health records for 16.3 billion encounters over 300 million unique patient records from 310 health systems, we introduce the Comet models, a family of decoder-only transformer models pretrained on 118 million patients representing 115 billion discrete medical events (151 billion tokens). We present the largest scaling-law study of medical event data, establishing a methodology for pretraining and revealing power-law scaling relationships for compute, tokens, and model size. Consequently, we pretrained a series of compute-optimal models with up to 1 billion parameters. Conditioned on a patient's real-world history, Comet autoregressively predicts the next medical event to simulate patient health timelines. We studied 78 real-world tasks, including diagnosis prediction, disease prognosis, and healthcare operations. Remarkably for a foundation model with generic pretraining and simulation-based inference, Comet generally outperformed or matched task-specific supervised models on these tasks, without requiring task-specific fine-tuning or few-shot examples. Comet's predictive power consistently improves as the model and pretraining scale. Our results show that Comet, a generative medical event foundation model, can effectively capture complex clinical dynamics, providing an extensible and generalizable framework to support clinical decision-making, streamline healthcare operations, and improve patient outcomes.
Hierarchical Evaluation Function: A Multi-Metric Approach for Optimizing Demand Forecasting Models
arXiv:2508.13057v4 Announce Type: replace Abstract: Accurate demand forecasting is crucial for effective inventory management in dynamic and competitive environments, where decisions are influenced by uncertainty, financial constraints, and logistical limitations. Traditional evaluation metrics such as Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) provide complementary perspectives but may lead to biased assessments when applied individually. To address this limitation, we propose the Hierarchical Evaluation Function (HEF), a composite function that integrates R2, MAE, and RMSE within a hierarchical and adaptive framework. The function incorporates dynamic weights, tolerance thresholds derived from the statistical properties of the series, and progressive penalty mechanisms to ensure robustness against extreme errors and invalid predictions. HEF was implemented to optimize multiple forecasting models using Grid Search, Particle Swarm Optimization (PSO), and Optuna, and tested on benchmark datasets including Walmart, M3, M4, and M5. Experimental results, validated through statistical tests, demonstrate that HEF consistently outperforms MAE as an evaluation function in global metrics such as R2, Global Relative Accuracy (GRA), RMSE, and RMSSE, thereby providing greater explanatory power, adaptability, and stability. While MAE retains advantages in simplicity and efficiency, HEF proves more effective for long-term planning and complex contexts. Overall, HEF constitutes a robust and adaptive alternative for model selection and hyperparameter optimization in highly variable demand forecasting environments.
Communication-Efficient Federated Learning with Adaptive Number of Participants
arXiv:2508.13803v2 Announce Type: replace Abstract: Rapid scaling of deep learning models has enabled performance gains across domains, yet it introduced several challenges. Federated Learning (FL) has emerged as a promising framework to address these concerns by enabling decentralized training. Nevertheless, communication efficiency remains a key bottleneck in FL, particularly under heterogeneous and dynamic client participation. Existing methods, such as FedAvg and FedProx, or other approaches, including client selection strategies, attempt to mitigate communication costs. However, the problem of choosing the number of clients in a training round remains extremely underexplored. We introduce Intelligent Selection of Participants (ISP), an adaptive mechanism that dynamically determines the optimal number of clients per round to enhance communication efficiency without compromising model accuracy. We validate the effectiveness of ISP across diverse setups, including vision transformers, real-world ECG classification, and training with gradient compression. Our results show consistent communication savings of up to 30\% without losing the final quality. Applying ISP to different real-world ECG classification setups highlighted the selection of the number of clients as a separate task of federated learning.
Retrieval Enhanced Feedback via In-context Neural Error-book
arXiv:2508.16313v4 Announce Type: replace Abstract: Recent advancements in Large Language Models (LLMs) have significantly improved reasoning capabilities, with in-context learning (ICL) emerging as a key technique for adaptation without retraining. While previous works have focused on leveraging correct examples, recent research highlights the importance of learning from errors to enhance performance. However, existing methods lack a structured framework for analyzing and mitigating errors, particularly in Multimodal Large Language Models (MLLMs), where integrating visual and textual inputs adds complexity. To address this issue, we propose REFINE: Retrieval-Enhanced Feedback via In-context Neural Error-book, a teacher-student framework that systematically structures errors and provides targeted feedback. REFINE introduces three systematic queries to construct structured feedback -- Feed-Target, Feed-Check, and Feed-Path -- to enhance multimodal reasoning by prioritizing relevant visual information, diagnosing critical failure points, and formulating corrective actions. Unlike prior approaches that rely on redundant retrievals, REFINE optimizes structured feedback retrieval, improving inference efficiency, token usage, and scalability. Our results demonstrate substantial speedup, reduced computational costs, and successful generalization, highlighting REFINE's potential for enhancing multimodal reasoning.
MetaFed: Advancing Privacy, Performance, and Sustainability in Federated Metaverse Systems
arXiv:2508.17341v2 Announce Type: replace Abstract: The rapid expansion of immersive Metaverse applications introduces complex challenges at the intersection of performance, privacy, and environmental sustainability. Centralized architectures fall short in addressing these demands, often resulting in elevated energy consumption, latency, and privacy concerns. This paper proposes MetaFed, a decentralized federated learning (FL) framework that enables sustainable and intelligent resource orchestration for Metaverse environments. MetaFed integrates (i) multi-agent reinforcement learning for dynamic client selection, (ii) privacy-preserving FL using homomorphic encryption, and (iii) carbon-aware scheduling aligned with renewable energy availability. Evaluations on MNIST and CIFAR-10 using lightweight ResNet architectures demonstrate that MetaFed achieves up to 25% reduction in carbon emissions compared to conventional approaches, while maintaining high accuracy and minimal communication overhead. These results highlight MetaFed as a scalable solution for building environmentally responsible and privacy-compliant Metaverse infrastructures.
Unlearning as Ablation: Toward a Falsifiable Benchmark for Generative Scientific Discovery
arXiv:2508.17681v3 Announce Type: replace Abstract: Bold claims about AI's role in science-from "AGI will cure all diseases" to promises of radically accelerated discovery-raise a central epistemic question: do large language models (LLMs) truly generate new knowledge, or do they merely remix memorized fragments? We propose unlearning-as-ablation as a falsifiable probe of constructive scientific discovery. The idea is to systematically remove a target result together with its forget-closure (supporting lemmas, paraphrases, and multi-hop entailments) and then evaluate whether the model can re-derive the result from only permitted axioms and tools. Success would indicate generative capability beyond recall; failure would expose current limits. Unlike prevailing motivations for unlearning-privacy, copyright, or safety-our framing repositions it as an epistemic probe for AI-for-Science. We outline a minimal pilot in mathematics and algorithms to illustrate feasibility, and sketch how the same approach could later be extended to domains such as physics or chemistry. This is a position paper: our contribution is conceptual and methodological, not empirical. We aim to stimulate discussion on how principled ablation tests could help distinguish models that reconstruct knowledge from those that merely retrieve it, and how such probes might guide the next generation of AI-for-Science benchmarks.
Graph Data Modeling: Molecules, Proteins, & Chemical Processes
arXiv:2508.19356v3 Announce Type: replace Abstract: Graphs are central to the chemical sciences, providing a natural language to describe molecules, proteins, reactions, and industrial processes. They capture interactions and structures that underpin materials, biology, and medicine. This primer, Graph Data Modeling: Molecules, Proteins, & Chemical Processes, introduces graphs as mathematical objects in chemistry and shows how learning algorithms (particularly graph neural networks) can operate on them. We outline the foundations of graph design, key prediction tasks, representative examples across chemical sciences, and the role of machine learning in graph-based modeling. Together, these concepts prepare readers to apply graph methods to the next generation of chemical discovery.
Turning Tabular Foundation Models into Graph Foundation Models
arXiv:2508.20906v2 Announce Type: replace Abstract: While foundation models have revolutionized such fields as natural language processing and computer vision, their potential in graph machine learning remains largely unexplored. One of the key challenges in designing graph foundation models (GFMs) is handling diverse node features that can vary across different graph datasets. While many works on GFMs have focused exclusively on text-attributed graphs, the problem of handling arbitrary features of other types in GFMs has not been fully addressed. However, this problem is not unique to the graph domain, as it also arises in the field of machine learning for tabular data. In this work, motivated by the recent success of tabular foundation models (TFMs) like TabPFNv2 or LimiX, we propose G2T-FM, a simple framework for turning tabular foundation models into graph foundation models. Specifically, G2T-FM augments the original node features with neighborhood feature aggregation, adds structural embeddings, and then applies a TFM to the constructed node representations. Even in a fully in-context regime, our model achieves strong results, significantly outperforming publicly available GFMs and performing competitively with, and often better than, well-tuned GNNs trained from scratch. Moreover, after finetuning, G2T-FM surpasses well-tuned GNN baselines. In particular, when combined with LimiX, G2T-FM often outperforms the best GNN by a significant margin. In summary, our paper reveals the potential of a previously overlooked direction of utilizing tabular foundation models for graph machine learning tasks.
The Transparent Earth: A Multimodal Foundation Model for the Earth's Subsurface
arXiv:2509.02783v2 Announce Type: replace Abstract: We present the Transparent Earth, a transformer-based architecture for reconstructing subsurface properties from heterogeneous datasets that vary in sparsity, resolution, and modality, where each modality represents a distinct type of observation (e.g., stress angle, mantle temperature, tectonic plate type). The model incorporates positional encodings of observations together with modality encodings, derived from a text embedding model applied to a description of each modality. This design enables the model to scale to an arbitrary number of modalities, making it straightforward to add new ones not considered in the initial design. We currently include eight modalities spanning directional angles, categorical classes, and continuous properties such as temperature and thickness. These capabilities support in-context learning, enabling the model to generate predictions either with no inputs or with an arbitrary number of additional observations from any subset of modalities. On validation data, this reduces errors in predicting stress angle by more than a factor of three. The proposed architecture is scalable and demonstrates improved performance with increased parameters. Together, these advances make the Transparent Earth an initial foundation model for the Earth's subsurface that ultimately aims to predict any subsurface property anywhere on Earth.
Long-Range Graph Wavelet Networks
arXiv:2509.06743v2 Announce Type: replace Abstract: Modeling long-range interactions, the propagation of information across distant parts of a graph, is a central challenge in graph machine learning. Graph wavelets, inspired by multi-resolution signal processing, provide a principled way to capture both local and global structures. However, existing wavelet-based graph neural networks rely on finite-order polynomial approximations, which limit their receptive fields and hinder long-range propagation. We propose Long-Range Graph Wavelet Networks (LR-GWN), which decompose wavelet filters into complementary local and global components. Local aggregation is handled with efficient low-order polynomials, while long-range interactions are captured through a flexible spectral-domain parameterization. This hybrid design unifies short- and long-distance information flow within a principled wavelet framework. Experiments show that LR-GWN achieves state-of-the-art performance among wavelet-based methods on long-range benchmarks, while remaining competitive on short-range datasets.
FediLoRA: Heterogeneous LoRA for Federated Multimodal Fine-tuning under Missing Modalities
arXiv:2509.06984v2 Announce Type: replace Abstract: Foundation models have demonstrated remarkable performance across a wide range of tasks, yet their large parameter sizes pose challenges for practical deployment, especially in decentralized environments. Parameter-efficient fine-tuning (PEFT), such as Low-Rank Adaptation (LoRA), reduces local computing and memory overhead, making it attractive for federated learning. However, existing federated LoRA methods typically assume uniform rank configurations and unimodal inputs, overlooking two key real-world challenges: (1) heterogeneous client resources have different LoRA ranks, and (2) multimodal data settings with potentially missing modalities. In this work, we propose FediLoRA, a simple yet effective framework for federated multimodal fine-tuning under heterogeneous LoRA ranks and missing modalities. FediLoRA introduces a dimension-wise aggregation strategy that reweights LoRA updates without information dilution during aggregation. It also includes a lightweight layer-wise model editing method that selectively incorporates global parameters to repair local components which improves both client and global model performances. Experimental results on three multimodal benchmark datasets demonstrate that FediLoRA achieves superior performance over competitive baselines in both global and personalized settings, particularly in the presence of modality incompleteness.
The CRITICAL Records Integrated Standardization Pipeline (CRISP): End-to-End Processing of Large-scale Multi-institutional OMOP CDM Data
arXiv:2509.08247v2 Announce Type: replace Abstract: While existing critical care EHR datasets such as MIMIC and eICU have enabled significant advances in clinical AI research, the CRITICAL dataset opens new frontiers by providing extensive scale and diversity -- containing 1.95 billion records from 371,365 patients across four geographically diverse CTSA institutions. CRITICAL's unique strength lies in capturing full-spectrum patient journeys, including pre-ICU, ICU, and post-ICU encounters across both inpatient and outpatient settings. This multi-institutional, longitudinal perspective creates transformative opportunities for developing generalizable predictive models and advancing health equity research. However, the richness of this multi-site resource introduces substantial complexity in data harmonization, with heterogeneous collection practices and diverse vocabulary usage patterns requiring sophisticated preprocessing approaches. We present CRISP to unlock the full potential of this valuable resource. CRISP systematically transforms raw Observational Medical Outcomes Partnership Common Data Model data into ML-ready datasets through: (1) transparent data quality management with comprehensive audit trails, (2) cross-vocabulary mapping of heterogeneous medical terminologies to unified SNOMED-CT standards, with deduplication and unit standardization, (3) modular architecture with parallel optimization enabling complete dataset processing in $<$1 day even on standard computing hardware, and (4) comprehensive baseline model benchmarks spanning multiple clinical prediction tasks to establish reproducible performance standards. By providing processing pipeline, baseline implementations, and detailed transformation documentation, CRISP saves researchers months of preprocessing effort and democratizes access to large-scale multi-institutional critical care data, enabling them to focus on advancing clinical AI.
Clip Your Sequences Fairly: Enforcing Length Fairness for Sequence-Level RL
arXiv:2509.09177v2 Announce Type: replace Abstract: We propose FSPO (Fair Sequence Policy Optimization), a sequence-level reinforcement learning method for LLMs that enforces length-fair clipping on the importance-sampling (IS) weight. We study RL methods with sequence-level IS and identify a mismatch when PPO/GRPO-style clipping is transplanted to sequences: a fixed clip range systematically reweights short vs.\ long responses, distorting the optimization direction. FSPO introduces a simple remedy: we clip the sequence log-IS ratio with a band that scales as $\sqrt{L}$. Theoretically, we formalize length fairness via a Length Reweighting Error (LRE) and prove that small LRE yields a cosine directional guarantee between the clipped and true updates. Empirically, FSPO flattens clip rates across length bins, stabilizes training, and outperforms all baselines across multiple evaluation datasets on Qwen3-8B-Base model.
Symbolic Feedforward Networks for Probabilistic Finite Automata: Exact Simulation and Learnability
arXiv:2509.10034v2 Announce Type: replace Abstract: We present a formal and constructive theory showing that probabilistic finite automata (PFAs) can be exactly simulated using symbolic feedforward neural networks. Our architecture represents state distributions as vectors and transitions as stochastic matrices, enabling probabilistic state propagation via matrix-vector products. This yields a parallel, interpretable, and differentiable simulation of PFA dynamics using soft updates-without recurrence. We formally characterize probabilistic subset construction, $\varepsilon$-closure, and exact simulation via layered symbolic computation, and prove equivalence between PFAs and specific classes of neural networks. We further show that these symbolic simulators are not only expressive but learnable: trained with standard gradient descent-based optimization on labeled sequence data, they recover the exact behavior of ground-truth PFAs. This learnability, formalized in Proposition 5.1, is the crux of this work. Our results unify probabilistic automata theory with neural architectures under a rigorous algebraic framework, bridging the gap between symbolic computation and deep learning.
ToMA: Token Merge with Attention for Diffusion Models
arXiv:2509.10918v2 Announce Type: replace Abstract: Diffusion models excel in high-fidelity image generation but face scalability limits due to transformers' quadratic attention complexity. Plug-and-play token reduction methods like ToMeSD and ToFu reduce FLOPs by merging redundant tokens in generated images but rely on GPU-inefficient operations (e.g., sorting, scattered writes), introducing overheads that negate theoretical speedups when paired with optimized attention implementations (e.g., FlashAttention). To bridge this gap, we propose Token Merge with Attention (ToMA), an off-the-shelf method that redesigns token reduction for GPU-aligned efficiency, with three key contributions: 1) a reformulation of token merge as a submodular optimization problem to select diverse tokens; 2) merge/unmerge as an attention-like linear transformation via GPU-friendly matrix operations; and 3) exploiting latent locality and sequential redundancy (pattern reuse) to minimize overhead. ToMA reduces SDXL/Flux generation latency by 24%/23%, respectively (with DINO $\Delta < 0.07$), outperforming prior methods. This work bridges the gap between theoretical and practical efficiency for transformers in diffusion.
FragmentGPT: A Unified GPT Model for Fragment Growing, Linking, and Merging in Molecular Design
arXiv:2509.11044v2 Announce Type: replace Abstract: Fragment-Based Drug Discovery (FBDD) is a popular approach in early drug development, but designing effective linkers to combine disconnected molecular fragments into chemically and pharmacologically viable candidates remains challenging. Further complexity arises when fragments contain structural redundancies, like duplicate rings, which cannot be addressed by simply adding or removing atoms or bonds. To address these challenges in a unified framework, we introduce FragmentGPT, which integrates two core components: (1) a novel chemically-aware, energy-based bond cleavage pre-training strategy that equips the GPT-based model with fragment growing, linking, and merging capabilities, and (2) a novel Reward Ranked Alignment with Expert Exploration (RAE) algorithm that combines expert imitation learning for diversity enhancement, data selection and augmentation for Pareto and composite score optimality, and Supervised Fine-Tuning (SFT) to align the learner policy with multi-objective goals. Conditioned on fragment pairs, FragmentGPT generates linkers that connect diverse molecular subunits while simultaneously optimizing for multiple pharmaceutical goals. It also learns to resolve structural redundancies-such as duplicated fragments-through intelligent merging, enabling the synthesis of optimized molecules. FragmentGPT facilitates controlled, goal-driven molecular assembly. Experiments and ablation studies on real-world cancer datasets demonstrate its ability to generate chemically valid, high-quality molecules tailored for downstream drug discovery tasks.
Single-stream Policy Optimization
arXiv:2509.13232v2 Announce Type: replace Abstract: We revisit policy-gradient optimization for Large Language Models (LLMs) from a single-stream perspective. Prevailing group-based methods like GRPO reduce variance with on-the-fly baselines but suffer from critical flaws: frequent degenerate groups erase learning signals, and synchronization barriers hinder scalability. We introduce Single-stream Policy Optimization (SPO), which eliminates these issues by design. SPO replaces per-group baselines with a persistent, KL-adaptive value tracker and normalizes advantages globally across the batch, providing a stable, low-variance learning signal for every sample. Being group-free, SPO enables higher throughput and scales effectively in long-horizon or tool-integrated settings where generation times vary. Furthermore, the persistent value tracker naturally enables an adaptive curriculum via prioritized sampling. Experiments using Qwen3-8B show that SPO converges more smoothly and attains higher accuracy than GRPO, while eliminating computation wasted on degenerate groups. Ablation studies confirm that SPO's gains stem from its principled approach to baseline estimation and advantage normalization, offering a more robust and efficient path for LLM reasoning. Across five hard math benchmarks with Qwen3 8B, SPO improves the average maj@32 by +3.4 percentage points (pp) over GRPO, driven by substantial absolute point gains on challenging datasets, including +7.3 pp on BRUMO 25, +4.4 pp on AIME 25, +3.3 pp on HMMT 25, and achieves consistent relative gain in pass@$k$ across the evaluated $k$ values. SPO's success challenges the prevailing trend of adding incidental complexity to RL algorithms, highlighting a path where fundamental principles, not architectural workarounds, drive the next wave of progress in LLM reasoning.
Unified Spatiotemporal Physics-Informed Learning (USPIL): A Framework for Modeling Complex Predator-Prey Dynamics
arXiv:2509.13425v3 Announce Type: replace Abstract: Ecological systems exhibit complex multi-scale dynamics that challenge traditional modeling. New methods must capture temporal oscillations and emergent spatiotemporal patterns while adhering to conservation principles. We present the Unified Spatiotemporal Physics-Informed Learning (USPIL) framework, a deep learning architecture integrating physics-informed neural networks (PINNs) and conservation laws to model predator-prey dynamics across dimensional scales. The framework provides a unified solution for both ordinary (ODE) and partial (PDE) differential equation systems, describing temporal cycles and reaction-diffusion patterns within a single neural network architecture. Our methodology uses automatic differentiation to enforce physics constraints and adaptive loss weighting to balance data fidelity with physical consistency. Applied to the Lotka-Volterra system, USPIL achieves 98.9% correlation for 1D temporal dynamics (loss: 0.0219, MAE: 0.0184) and captures complex spiral waves in 2D systems (loss: 4.7656, pattern correlation: 0.94). Validation confirms conservation law adherence within 0.5% and shows a 10-50x computational speedup for inference compared to numerical solvers. USPIL also enables mechanistic understanding through interpretable physics constraints, facilitating parameter discovery and sensitivity analysis not possible with purely data-driven methods. Its ability to transition between dimensional formulations opens new avenues for multi-scale ecological modeling. These capabilities make USPIL a transformative tool for ecological forecasting, conservation planning, and understanding ecosystem resilience, establishing physics-informed deep learning as a powerful and scientifically rigorous paradigm.
Privacy-Aware In-Context Learning for Large Language Models
arXiv:2509.13625v3 Announce Type: replace Abstract: Large language models (LLMs) have significantly transformed natural language understanding and generation, but they raise privacy concerns due to potential exposure of sensitive information. Studies have highlighted the risk of information leakage, where adversaries can extract sensitive information embedded in the prompts. In this work, we introduce a novel private prediction framework for generating high-quality synthetic text with strong privacy guarantees. Our approach leverages the Differential Privacy (DP) framework to ensure worst-case theoretical bounds on information leakage without requiring any fine-tuning of the underlying models. The proposed method performs inference on private records and aggregates the resulting per-token output distributions. This enables the generation of longer and coherent synthetic text while maintaining privacy guarantees. Additionally, we propose a simple blending operation that combines private and public inference to further enhance utility. Empirical evaluations demonstrate that our approach outperforms previous state-of-the-art methods on in-context-learning (ICL) tasks, making it a promising direction for privacy-preserving text generation while maintaining high utility.
APFEx: Adaptive Pareto Front Explorer for Intersectional Fairness
arXiv:2509.13908v2 Announce Type: replace Abstract: Ensuring fairness in machine learning models is critical, especially when biases compound across intersecting protected attributes like race, gender, and age. While existing methods address fairness for single attributes, they fail to capture the nuanced, multiplicative biases faced by intersectional subgroups. We introduce Adaptive Pareto Front Explorer (APFEx), the first framework to explicitly model intersectional fairness as a joint optimization problem over the Cartesian product of sensitive attributes. APFEx combines three key innovations- (1) an adaptive multi-objective optimizer that dynamically switches between Pareto cone projection, gradient weighting, and exploration strategies to navigate fairness-accuracy trade-offs, (2) differentiable intersectional fairness metrics enabling gradient-based optimization of non-smooth subgroup disparities, and (3) theoretical guarantees of convergence to Pareto-optimal solutions. Experiments on four real-world datasets demonstrate APFEx's superiority, reducing fairness violations while maintaining competitive accuracy. Our work bridges a critical gap in fair ML, providing a scalable, model-agnostic solution for intersectional fairness.
Hierarchical Federated Learning for Social Network with Mobility
arXiv:2509.14938v2 Announce Type: replace Abstract: Federated Learning (FL) offers a decentralized solution that allows collaborative local model training and global aggregation, thereby protecting data privacy. In conventional FL frameworks, data privacy is typically preserved under the assumption that local data remains absolutely private, whereas the mobility of clients is frequently neglected in explicit modeling. In this paper, we propose a hierarchical federated learning framework based on the social network with mobility namely HFL-SNM that considers both data sharing among clients and their mobility patterns. Under the constraints of limited resources, we formulate a joint optimization problem of resource allocation and client scheduling, which objective is to minimize the energy consumption of clients during the FL process. In social network, we introduce the concepts of Effective Data Coverage Rate and Redundant Data Coverage Rate. We analyze the impact of effective data and redundant data on the model performance through preliminary experiments. We decouple the optimization problem into multiple sub-problems, analyze them based on preliminary experimental results, and propose Dynamic Optimization in Social Network with Mobility (DO-SNM) algorithm. Experimental results demonstrate that our algorithm achieves superior model performance while significantly reducing energy consumption, compared to traditional baseline algorithms.
Small LLMs with Expert Blocks Are Good Enough for Hyperparamter Tuning
arXiv:2509.15561v2 Announce Type: replace Abstract: Hyper-parameter Tuning (HPT) is a necessary step in machine learning (ML) pipelines but becomes computationally expensive and opaque with larger models. Recently, Large Language Models (LLMs) have been explored for HPT, yet most rely on models exceeding 100 billion parameters. We propose an Expert Block Framework for HPT using Small LLMs. At its core is the Trajectory Context Summarizer (TCS), a deterministic block that transforms raw training trajectories into structured context, enabling small LLMs to analyze optimization progress with reliability comparable to larger models. Using two locally-run LLMs (phi4:reasoning14B and qwen2.5-coder:32B) and a 10-trial budget, our TCS-enabled HPT pipeline achieves average performance within ~0.9 percentage points of GPT-4 across six diverse tasks.
Highly Imbalanced Regression with Tabular Data in SEP and Other Applications
arXiv:2509.16339v2 Announce Type: replace Abstract: We investigate imbalanced regression with tabular data that have an imbalance ratio larger than 1,000 ("highly imbalanced"). Accurately estimating the target values of rare instances is important in applications such as forecasting the intensity of rare harmful Solar Energetic Particle (SEP) events. For regression, the MSE loss does not consider the correlation between predicted and actual values. Typical inverse importance functions allow only convex functions. Uniform sampling might yield mini-batches that do not have rare instances. We propose CISIR that incorporates correlation, Monotonically Decreasing Involution (MDI) importance, and stratified sampling. Based on five datasets, our experimental results indicate that CISIR can achieve lower error and higher correlation than some recent methods. Also, adding our correlation component to other recent methods can improve their performance. Lastly, MDI importance can outperform other importance functions. Our code can be found in https://github.com/Machine-Earning/CISIR.
LLM-Guided Co-Training for Text Classification
arXiv:2509.16516v2 Announce Type: replace Abstract: In this paper, we introduce a novel weighted co-training approach that is guided by Large Language Models (LLMs). Namely, in our co-training approach, we use LLM labels on unlabeled data as target labels and co-train two encoder-only based networks that train each other over multiple iterations: first, all samples are forwarded through each network and historical estimates of each network's confidence in the LLM label are recorded; second, a dynamic importance weight is derived for each sample according to each network's belief in the quality of the LLM label for that sample; finally, the two networks exchange importance weights with each other -- each network back-propagates all samples weighted with the importance weights coming from its peer network and updates its own parameters. By strategically utilizing LLM-generated guidance, our approach significantly outperforms conventional SSL methods, particularly in settings with abundant unlabeled data. Empirical results show that it achieves state-of-the-art performance on 4 out of 5 benchmark datasets and ranks first among 14 compared methods according to the Friedman test. Our results highlight a new direction in semi-supervised learning -- where LLMs serve as knowledge amplifiers, enabling backbone co-training models to achieve state-of-the-art performance efficiently.
Towards Interpretable and Efficient Attention: Compressing All by Contracting a Few
arXiv:2509.16875v2 Announce Type: replace Abstract: Attention mechanisms in Transformers have gained significant empirical success. Nonetheless, the optimization objectives underlying their forward pass are still unclear. Additionally, the quadratic complexity of self-attention is increasingly prohibitive. Unlike the prior work on addressing the interpretability or efficiency issue separately, we propose a unified optimization objective to alleviate both issues simultaneously. By unrolling the optimization over the objective, we derive an inherently interpretable and efficient attention mechanism, which compresses all tokens into low-dimensional structures by contracting a few representative tokens and then broadcasting the contractions back. This Contract-and-Broadcast Self-Attention (CBSA) mechanism can not only scale linearly but also generalize existing attention mechanisms as its special cases. Experiments further demonstrate comparable performance and even superior advantages of CBSA on several visual tasks. Code is available at this https URL.
SPRINT: Stochastic Performative Prediction With Variance Reduction
arXiv:2509.17304v2 Announce Type: replace Abstract: Performative prediction (PP) is an algorithmic framework for optimizing machine learning (ML) models where the model's deployment affects the distribution of the data it is trained on. Compared to traditional ML with fixed data, designing algorithms in PP converging to a stable point -- known as a stationary performative stable (SPS) solution -- is more challenging than the counterpart in conventional ML tasks due to the model-induced distribution shifts. While considerable efforts have been made to find SPS solutions using methods such as repeated gradient descent (RGD) and greedy stochastic gradient descent (SGD-GD), most prior studies assumed a strongly convex loss until a recent work established $O(1/\sqrt{T})$ convergence of SGD-GD to SPS solutions under smooth, non-convex losses. However, this latest progress is still based on the restricted bounded variance assumption in stochastic gradient estimates and yields convergence bounds with a non-vanishing error neighborhood that scales with the variance. This limitation motivates us to improve convergence rates and reduce error in stochastic optimization for PP, particularly in non-convex settings. Thus, we propose a new algorithm called stochastic performative prediction with variance reduction (SPRINT) and establish its convergence to an SPS solution at a rate of $O(1/T)$. Notably, the resulting error neighborhood is independent of the variance of the stochastic gradients. Experiments on multiple real datasets with non-convex models demonstrate that SPRINT outperforms SGD-GD in both convergence rate and stability.
Efficient Sliced Wasserstein Distance Computation via Adaptive Bayesian Optimization
arXiv:2509.17405v2 Announce Type: replace Abstract: The sliced Wasserstein distance (SW) reduces optimal transport on $\mathbb{R}^d$ to a sum of one-dimensional projections, and thanks to this efficiency, it is widely used in geometry, generative modeling, and registration tasks. Recent work shows that quasi-Monte Carlo constructions for computing SW (QSW) yield direction sets with excellent approximation error. This paper presents an alternate, novel approach: learning directions with Bayesian optimization (BO), particularly in settings where SW appears inside an optimization loop (e.g., gradient flows). We introduce a family of drop-in selectors for projection directions: BOSW, a one-shot BO scheme on the unit sphere; RBOSW, a periodic-refresh variant; ABOSW, an adaptive hybrid that seeds from competitive QSW sets and performs a few lightweight BO refinements; and ARBOSW, a restarted hybrid that periodically relearns directions during optimization. Our BO approaches can be composed with QSW and its variants (demonstrated by ABOSW/ARBOSW) and require no changes to downstream losses or gradients. We provide numerical experiments where our methods achieve state-of-the-art performance, and on the experimental suite of the original QSW paper, we find that ABOSW and ARBOSW can achieve convergence comparable to the best QSW variants with modest runtime overhead.
MVCL-DAF++: Enhancing Multimodal Intent Recognition via Prototype-Aware Contrastive Alignment and Coarse-to-Fine Dynamic Attention Fusion
arXiv:2509.17446v2 Announce Type: replace Abstract: Multimodal intent recognition (MMIR) suffers from weak semantic grounding and poor robustness under noisy or rare-class conditions. We propose MVCL-DAF++, which extends MVCL-DAF with two key modules: (1) Prototype-aware contrastive alignment, aligning instances to class-level prototypes to enhance semantic consistency; and (2) Coarse-to-fine attention fusion, integrating global modality summaries with token-level features for hierarchical cross-modal interaction. On MIntRec and MIntRec2.0, MVCL-DAF++ achieves new state-of-the-art results, improving rare-class recognition by +1.05\% and +4.18\% WF1, respectively. These results demonstrate the effectiveness of prototype-guided learning and coarse-to-fine fusion for robust multimodal understanding. The source code is available at https://github.com/chr1s623/MVCL-DAF-PlusPlus.
Optimizing Inference in Transformer-Based Models: A Multi-Method Benchmark
arXiv:2509.17894v2 Announce Type: replace Abstract: Efficient inference is a critical challenge in deep generative modeling, particularly as diffusion models grow in capacity and complexity. While increased complexity often improves accuracy, it raises compute costs, latency, and memory requirements. This work investigates techniques such as pruning, quantization, knowledge distillation, and simplified attention to reduce computational overhead without impacting performance. The study also explores the Mixture of Experts (MoE) approach to further enhance efficiency. These experiments provide insights into optimizing inference for the state-of-the-art Fast Diffusion Transformer (fast-DiT) model.
Joint Memory Frequency and Computing Frequency Scaling for Energy-efficient DNN Inference
arXiv:2509.17970v2 Announce Type: replace Abstract: Deep neural networks (DNNs) have been widely applied in diverse applications, but the problems of high latency and energy overhead are inevitable on resource-constrained devices. To address this challenge, most researchers focus on the dynamic voltage and frequency scaling (DVFS) technique to balance the latency and energy consumption by changing the computing frequency of processors. However, the adjustment of memory frequency is usually ignored and not fully utilized to achieve efficient DNN inference, which also plays a significant role in the inference time and energy consumption. In this paper, we first investigate the impact of joint memory frequency and computing frequency scaling on the inference time and energy consumption with a model-based and data-driven method. Then by combining with the fitting parameters of different DNN models, we give a preliminary analysis for the proposed model to see the effects of adjusting memory frequency and computing frequency simultaneously. Finally, simulation results in local inference and cooperative inference cases further validate the effectiveness of jointly scaling the memory frequency and computing frequency to reduce the energy consumption of devices.
Adaptive Kernel Design for Bayesian Optimization Is a Piece of CAKE with LLMs
arXiv:2509.17998v2 Announce Type: replace Abstract: The efficiency of Bayesian optimization (BO) relies heavily on the choice of the Gaussian process (GP) kernel, which plays a central role in balancing exploration and exploitation under limited evaluation budgets. Traditional BO methods often rely on fixed or heuristic kernel selection strategies, which can result in slow convergence or suboptimal solutions when the chosen kernel is poorly suited to the underlying objective function. To address this limitation, we propose a freshly-baked Context-Aware Kernel Evolution (CAKE) to enhance BO with large language models (LLMs). Concretely, CAKE leverages LLMs as the crossover and mutation operators to adaptively generate and refine GP kernels based on the observed data throughout the optimization process. To maximize the power of CAKE, we further propose BIC-Acquisition Kernel Ranking (BAKER) to select the most effective kernel through balancing the model fit measured by the Bayesian information criterion (BIC) with the expected improvement at each iteration of BO. Extensive experiments demonstrate that our fresh CAKE-based BO method consistently outperforms established baselines across a range of real-world tasks, including hyperparameter optimization, controller tuning, and photonic chip design. Our code is publicly available at https://github.com/richardcsuwandi/cake.
Reinforced Generation of Combinatorial Structures: Applications to Complexity Theory
arXiv:2509.18057v2 Announce Type: replace Abstract: We explore whether techniques from AI can help discover new combinatorial structures that improve on known limits on efficient algorithms. Specifically, we use AlphaEvolve (an LLM coding agent) to study two settings: a) Average-case hardness for MAX-CUT and MAX-Independent Set: We improve a recent result of Kunisky and Yu to obtain near-optimal upper and (conditional) lower bounds on certification algorithms for MAX-CUT and MAX-Independent Set on random 3- and 4-regular graphs. Our improved lower bounds are obtained by constructing nearly extremal Ramanujan graphs on as many as $163$ nodes, using AlphaEvolve. Additionally, via analytical arguments we strengthen the upper bounds to settle the computational hardness of these questions up to an error in the third decimal place. b) Worst-case Hardness of Approximation for MAX-k-CUT: We obtain new inapproximability results, proving that it is NP-hard to approximate MAX-4-CUT and MAX-3-CUT within factors of $0.987$ and $0.9649$ respectively, using AlphaEvolve to discover new gadget reductions. Our MAX-4-CUT result improves upon the SOTA of $0.9883$, and our MAX-3-CUT result improves on the current best gadget-based inapproximability result of $0.9853$, but falls short of improving the SOTA of $16/17$ that relies on a custom PCP, rather than a gadget reduction from "standard" H{\aa}stad-style PCPs. A key technical challenge we faced: verifying a candidate construction produced by AlphaEvolve is costly (often requiring exponential time). In both settings above, our results were enabled by using AlphaEvolve itself to evolve the verification procedure to be faster (sometimes by $10,000\times$). We conclude with a discussion of norms by which to assess the assistance from AI in developing proofs.
Strategic Dishonesty Can Undermine AI Safety Evaluations of Frontier LLMs
arXiv:2509.18058v2 Announce Type: replace Abstract: Large language model (LLM) developers aim for their models to be honest, helpful, and harmless. However, when faced with malicious requests, models are trained to refuse, sacrificing helpfulness. We show that frontier LLMs can develop a preference for dishonesty as a new strategy, even when other options are available. Affected models respond to harmful requests with outputs that sound harmful but are crafted to be subtly incorrect or otherwise harmless in practice. This behavior emerges with hard-to-predict variations even within models from the same model family. We find no apparent cause for the propensity to deceive, but show that more capable models are better at executing this strategy. Strategic dishonesty already has a practical impact on safety evaluations, as we show that dishonest responses fool all output-based monitors used to detect jailbreaks that we test, rendering benchmark scores unreliable. Further, strategic dishonesty can act like a honeypot against malicious users, which noticeably obfuscates prior jailbreak attacks. While output monitors fail, we show that linear probes on internal activations can be used to reliably detect strategic dishonesty. We validate probes on datasets with verifiable outcomes and by using them as steering vectors. Overall, we consider strategic dishonesty as a concrete example of a broader concern that alignment of LLMs is hard to control, especially when helpfulness and harmlessness conflict.
Learning functions, operators and dynamical systems with kernels
arXiv:2509.18071v2 Announce Type: replace Abstract: This expository article presents the approach to statistical machine learning based on reproducing kernel Hilbert spaces. The basic framework is introduced for scalar-valued learning and then extended to operator learning. Finally, learning dynamical systems is formulated as a suitable operator learning problem, leveraging Koopman operator theory. The manuscript collects the supporting material for the corresponding course taught at the CIME school "Machine Learning: From Data to Mathematical Understanding" in Cetraro.
DANSE: Data-driven Non-linear State Estimation of Model-free Process in Unsupervised Learning Setup
arXiv:2306.03897v3 Announce Type: replace-cross Abstract: We address the tasks of Bayesian state estimation and forecasting for a model-free process in an unsupervised learning setup. For a model-free process, we do not have any a-priori knowledge of the process dynamics. In the article, we propose DANSE -- a Data-driven Nonlinear State Estimation method. DANSE provides a closed-form posterior of the state of the model-free process, given linear measurements of the state. In addition, it provides a closed-form posterior for forecasting. A data-driven recurrent neural network (RNN) is used in DANSE to provide the parameters of a prior of the state. The prior depends on the past measurements as input, and then we find the closed-form posterior of the state using the current measurement as input. The data-driven RNN captures the underlying non-linear dynamics of the model-free process. The training of DANSE, mainly learning the parameters of the RNN, is executed using an unsupervised learning approach. In unsupervised learning, we have access to a training dataset comprising only a set of measurement data trajectories, but we do not have any access to the state trajectories. Therefore, DANSE does not have access to state information in the training data and can not use supervised learning. Using simulated linear and non-linear process models (Lorenz attractor and Chen attractor), we evaluate the unsupervised learning-based DANSE. We show that the proposed DANSE, without knowledge of the process model and without supervised learning, provides a competitive performance against model-driven methods, such as the Kalman filter (KF), extended KF (EKF), unscented KF (UKF), a data-driven deep Markov model (DMM) and a recently proposed hybrid method called KalmanNet. In addition, we show that DANSE works for high-dimensional state estimation.
Improving Image Captioning Descriptiveness by Ranking and LLM-based Fusion
arXiv:2306.11593v2 Announce Type: replace-cross Abstract: State-of-The-Art (SoTA) image captioning models are often trained on the MicroSoft Common Objects in Context (MS-COCO) dataset, which contains human-annotated captions with an average length of approximately ten tokens. Although effective for general scene understanding, these short captions often fail to capture complex scenes and convey detailed information. Moreover, captioning models tend to exhibit bias towards the ``average'' caption, which captures only the more general aspects, thus overlooking finer details. In this paper, we present a novel approach to generate richer and more informative image captions by combining the captions generated from different SoTA captioning models. Our proposed method requires no additional model training: given an image, it leverages pre-trained models from the literature to generate the initial captions, and then ranks them using a newly introduced image-text-based metric, which we name BLIPScore. Subsequently, the top two captions are fused using a Large Language Model (LLM) to produce the final, more detailed description. Experimental results on the MS-COCO and Flickr30k test sets demonstrate the effectiveness of our approach in terms of caption-image alignment and hallucination reduction according to the ALOHa, CAPTURE, and Polos metrics. A subjective study lends additional support to these results, suggesting that the captions produced by our model are generally perceived as more consistent with human judgment. By combining the strengths of diverse SoTA models, our method enhances the quality and appeal of image captions, bridging the gap between automated systems and the rich and informative nature of human-generated descriptions. This advance enables the generation of more suitable captions for the training of both vision-language and captioning models.
MediSyn: A Generalist Text-Guided Latent Diffusion Model For Diverse Medical Image Synthesis
arXiv:2405.09806v5 Announce Type: replace-cross Abstract: Deep learning algorithms require extensive data to achieve robust performance. However, data availability is often restricted in the medical domain due to patient privacy concerns. Synthetic data presents a possible solution to these challenges. Recently, image generative models have found increasing use for medical applications but are often designed for singular medical specialties and imaging modalities, thus limiting their broader utility. To address this, we introduce MediSyn: a text-guided, latent diffusion model capable of generating synthetic images from 6 medical specialties and 10 image types. Through extensive experimentation, we first demonstrate that MediSyn quantitatively matches or surpasses the performance of specialist models. Second, we show that our synthetic images are realistic and exhibit strong alignment with their corresponding text prompts, as validated by a team of expert physicians. Third, we provide empirical evidence that our synthetic images are visually distinct from their corresponding real patient images. Finally, we demonstrate that in data-limited settings, classifiers trained solely on synthetic data or real data supplemented with synthetic data can outperform those trained solely on real data. Our findings highlight the immense potential of generalist image generative models to accelerate algorithmic research and development in medicine.
The ICML 2023 Ranking Experiment: Examining Author Self-Assessment in ML/AI Peer Review
arXiv:2408.13430v3 Announce Type: replace-cross Abstract: We conducted an experiment during the review process of the 2023 International Conference on Machine Learning (ICML), asking authors with multiple submissions to rank their papers based on perceived quality. In total, we received 1,342 rankings, each from a different author, covering 2,592 submissions. In this paper, we present an empirical analysis of how author-provided rankings could be leveraged to improve peer review processes at machine learning conferences. We focus on the Isotonic Mechanism, which calibrates raw review scores using the author-provided rankings. Our analysis shows that these ranking-calibrated scores outperform the raw review scores in estimating the ground truth ``expected review scores'' in terms of both squared and absolute error metrics. Furthermore, we propose several cautious, low-risk applications of the Isotonic Mechanism and author-provided rankings in peer review, including supporting senior area chairs in overseeing area chairs' recommendations, assisting in the selection of paper awards, and guiding the recruitment of emergency reviewers.
GlaLSTM: A Concurrent LSTM Stream Framework for Glaucoma Detection via Biomarker Mining
arXiv:2408.15555v3 Announce Type: replace-cross Abstract: Glaucoma is a complex group of eye diseases marked by optic nerve damage, commonly linked to elevated intraocular pressure and biomarkers like retinal nerve fiber layer thickness. Understanding how these biomarkers interact is crucial for unraveling glaucoma's underlying mechanisms. In this paper, we propose GlaLSTM, a novel concurrent LSTM stream framework for glaucoma detection, leveraging latent biomarker relationships. Unlike traditional CNN-based models that primarily detect glaucoma from images, GlaLSTM provides deeper interpretability, revealing the key contributing factors and enhancing model transparency. This approach not only improves detection accuracy but also empowers clinicians with actionable insights, facilitating more informed decision-making. Experimental evaluations confirm that GlaLSTM surpasses existing state-of-the-art methods, demonstrating its potential for both advanced biomarker analysis and reliable glaucoma detection.
Multi-Scale Graph Theoretical Analysis of Resting-State fMRI for Classification of Alzheimer's Disease, Mild Cognitive Impairment, and Healthy Controls
arXiv:2409.04072v3 Announce Type: replace-cross Abstract: Alzheimer's disease (AD) is a neurodegenerative disorder marked by memory loss and cognitive decline, making early detection vital for timely intervention. However, early diagnosis is challenging due to the heterogeneous presentation of symptoms. Resting-state functional magnetic resonance imaging (rs-fMRI) captures spontaneous brain activity and functional connectivity, which are known to be disrupted in AD and mild cognitive impairment (MCI). Traditional methods, such as Pearson's correlation, have been used to calculate association matrices, but these approaches often overlook the dynamic and non-stationary nature of brain activity. In this study, we introduce a novel method that integrates discrete wavelet transform (DWT) and graph theory to model the dynamic behavior of brain networks. Our approach captures the time-frequency representation of brain activity, allowing for a more nuanced analysis of the underlying network dynamics. Machine learning was employed to automate the discrimination of different stages of AD based on learned patterns from brain network at different frequency bands. We applied our method to a dataset of rs-fMRI images from the Alzheimer's Disease Neuroimaging Initiative (ADNI) database, demonstrating its potential as an early diagnostic tool for AD and for monitoring disease progression. Our statistical analysis identifies specific brain regions and connections that are affected in AD and MCI, at different frequency bands, offering deeper insights into the disease's impact on brain function.
FAIR Universe HiggsML Uncertainty Dataset and Competition
arXiv:2410.02867v4 Announce Type: replace-cross Abstract: The FAIR Universe -- HiggsML Uncertainty Challenge focuses on measuring the physics properties of elementary particles with imperfect simulators due to differences in modelling systematic errors. Additionally, the challenge is leveraging a large-compute-scale AI platform for sharing datasets, training models, and hosting machine learning competitions. Our challenge brings together the physics and machine learning communities to advance our understanding and methodologies in handling systematic (epistemic) uncertainties within AI techniques.
EarthquakeNPP: A Benchmark for Earthquake Forecasting with Neural Point Processes
arXiv:2410.08226v2 Announce Type: replace-cross Abstract: For decades, classical point process models, such as the epidemic-type aftershock sequence (ETAS) model, have been widely used for forecasting the event times and locations of earthquakes. Recent advances have led to Neural Point Processes (NPPs), which promise greater flexibility and improvements over such classical models. However, the currently-used benchmark for NPPs does not represent an up-to-date challenge in the seismological community, since it contains data leakage and omits the largest earthquake sequence from the region. Additionally, initial earthquake forecasting benchmarks fail to compare NPPs with state-of-the-art forecasting models commonly used in seismology. To address these gaps, we introduce EarthquakeNPP: a collection of benchmark datasets to facilitate testing of NPPs on earthquake data, accompanied by an implementation of the state-of-the-art forecasting model: ETAS. The datasets cover a range of small to large target regions within California, dating from 1971 to 2021, and include different methodologies for dataset generation. Benchmarking experiments, using both log-likelihood and generative evaluation metrics widely recognised in seismology, show that none of the five NPPs tested outperform ETAS. These findings suggest that current NPP implementations are not yet suitable for practical earthquake forecasting. Nonetheless, EarthquakeNPP provides a platform to foster future collaboration between the seismology and machine learning communities.
Exploring Model Kinship for Merging Large Language Models
arXiv:2410.12613v3 Announce Type: replace-cross Abstract: Model merging has emerged as a key technique for enhancing the capabilities and efficiency of Large Language Models (LLMs). The open-source community has driven model evolution by iteratively merging existing models, yet a principled understanding of the gains and underlying factors in model merging remains limited. In this work, we study model evolution through iterative merging, drawing an analogy to biological evolution, and introduce the concept of model kinship, the degree of similarity or relatedness between LLMs. Through comprehensive empirical analysis, we show that model kinship is closely linked to the performance improvements achieved by merging, providing a useful criterion for selecting candidate models. Building on this insight, we propose a new model merging strategy: Top-k Greedy Merging with Model Kinship, which can improve benchmark performance. Specifically, we discover that incorporating model kinship as a guiding criterion enables continuous merging while mitigating performance degradation caused by local optima, thereby facilitating more effective model evolution. Code is available at https://github.com/zjunlp/ModelKinship.
EMMA: End-to-End Multimodal Model for Autonomous Driving
arXiv:2410.23262v3 Announce Type: replace-cross Abstract: We introduce EMMA, an End-to-end Multimodal Model for Autonomous driving. Built upon a multi-modal large language model foundation like Gemini, EMMA directly maps raw camera sensor data into various driving-specific outputs, including planner trajectories, perception objects, and road graph elements. EMMA maximizes the utility of world knowledge from the pre-trained large language models, by representing all non-sensor inputs (e.g. navigation instructions and ego vehicle status) and outputs (e.g. trajectories and 3D locations) as natural language text. This approach allows EMMA to jointly process various driving tasks in a unified language space, and generate the outputs for each task using task-specific prompts. Empirically, we demonstrate EMMA's effectiveness by achieving state-of-the-art performance in motion planning on nuScenes as well as competitive results on the Waymo Open Motion Dataset (WOMD). EMMA also yields competitive results for camera-primary 3D object detection on the Waymo Open Dataset (WOD). We show that co-training EMMA with planner trajectories, object detection, and road graph tasks yields improvements across all three domains, highlighting EMMA's potential as a generalist model for autonomous driving applications. We hope that our results will inspire research to further evolve the state of the art in autonomous driving model architectures.
Language Models as Causal Effect Generators
arXiv:2411.08019v2 Announce Type: replace-cross Abstract: In this work, we present sequence-driven structural causal models (SD-SCMs), a framework for specifying causal models with user-defined structure and language-model-defined mechanisms. We characterize how an SD-SCM enables sampling from observational, interventional, and counterfactual distributions according to the desired causal structure. We then leverage this procedure to propose a new type of benchmark for causal inference methods, generating individual-level counterfactual data to test treatment effect estimation. We create an example benchmark consisting of thousands of datasets, and test a suite of popular estimation methods for average, conditional average, and individual treatment effect estimation. We find under this benchmark that (1) causal methods outperform non-causal methods and that (2) even state-of-the-art methods struggle with individualized effect estimation, suggesting this benchmark captures some inherent difficulties in causal estimation. Apart from generating data, this same technique can underpin the auditing of language models for (un)desirable causal effects, such as misinformation or discrimination. We believe SD-SCMs can serve as a useful tool in any application that would benefit from sequential data with controllable causal structure.
Biology-Instructions: A Dataset and Benchmark for Multi-Omics Sequence Understanding Capability of Large Language Models
arXiv:2412.19191v2 Announce Type: replace-cross Abstract: Large language models (LLMs) have shown remarkable capabilities in general domains, but their application to multi-omics biology remains underexplored. To address this gap, we introduce Biology-Instructions, the first large-scale instruction-tuning dataset for multi-omics biological sequences, including DNA, RNA, proteins, and multi-molecules. This dataset bridges LLMs and complex biological sequence-related tasks, enhancing their versatility and reasoning while maintaining conversational fluency. We also highlight significant limitations of current state-of-the-art LLMs on multi-omics tasks without specialized training. To overcome this, we propose ChatMultiOmics, a strong baseline with a novel three-stage training pipeline, demonstrating superior biological understanding through Biology-Instructions. Both resources are publicly available, paving the way for better integration of LLMs in multi-omics analysis. The Biology-Instructions is publicly available at: https://github.com/hhnqqq/Biology-Instructions.
Variational decision diagrams for quantum-inspired machine learning applications
arXiv:2502.04271v2 Announce Type: replace-cross Abstract: Decision diagrams (DDs) have emerged as an efficient tool for simulating quantum circuits due to their capacity to exploit data redundancies in quantum states and quantum operations, enabling the efficient computation of probability amplitudes. However, their application in quantum machine learning (QML) has remained unexplored. This paper introduces variational decision diagrams (VDDs), a novel graph structure that combines the structural benefits of DDs with the adaptability of variational methods for efficiently representing quantum states. We investigate the trainability of VDDs by applying them to the ground state estimation problem for transverse-field Ising and Heisenberg Hamiltonians. Analysis of gradient variance suggests that training VDDs is possible, as no signs of vanishing gradients--also known as barren plateaus--are observed. This work provides new insights into the use of decision diagrams in QML as an alternative to design and train variational ans\"atze.
Machine-Learning Interatomic Potentials for Long-Range Systems
arXiv:2502.04668v2 Announce Type: replace-cross Abstract: Machine-learning interatomic potentials have emerged as a revolutionary class of force-field models in molecular simulations, delivering quantum-mechanical accuracy at a fraction of the computational cost and enabling the simulation of large-scale systems over extended timescales. However, they often focus on modeling local environments, neglecting crucial long-range interactions. We propose a Sum-of-Gaussians Neural Network (SOG-Net), a lightweight and versatile framework for integrating long-range interactions into machine learning force field. The SOG-Net employs a latent-variable learning network that seamlessly bridges short-range and long-range components, coupled with an efficient Fourier convolution layer that incorporates long-range effects. By learning sum-of-Gaussians multipliers across different convolution layers, the SOG-Net adaptively captures diverse long-range decay behaviors while maintaining close-to-linear computational complexity during training and simulation via non-uniform fast Fourier transforms. The method is demonstrated effective for a broad range of long-range systems.
Error Bound Analysis for the Regularized Loss of Deep Linear Neural Networks
arXiv:2502.11152v3 Announce Type: replace-cross Abstract: The optimization foundations of deep linear networks have recently received significant attention. However, due to their inherent non-convexity and hierarchical structure, analyzing the loss functions of deep linear networks remains a challenging task. In this work, we study the local geometric landscape of the regularized squared loss of deep linear networks around each critical point. Specifically, we derive a closed-form characterization of the critical point set and establish an error bound for the regularized loss under mild conditions on network width and regularization parameters. Notably, this error bound quantifies the distance from a point to the critical point set in terms of the current gradient norm, which can be used to derive linear convergence of first-order methods. To support our theoretical findings, we conduct numerical experiments and demonstrate that gradient descent converges linearly to a critical point when optimizing the regularized loss of deep linear networks.
A Neural Difference-of-Entropies Estimator for Mutual Information
arXiv:2502.13085v2 Announce Type: replace-cross Abstract: Estimating Mutual Information (MI), a key measure of dependence of random quantities without specific modelling assumptions, is a challenging problem in high dimensions. We propose a novel mutual information estimator based on parametrizing conditional densities using normalizing flows, a deep generative model that has gained popularity in recent years. This estimator leverages a block autoregressive structure to achieve improved bias-variance trade-offs on standard benchmark tasks.
Language Models Can Predict Their Own Behavior
arXiv:2502.13329v2 Announce Type: replace-cross Abstract: The text produced by language models (LMs) can exhibit specific `behaviors,' such as a failure to follow alignment training, that we hope to detect and react to during deployment. Identifying these behaviors can often only be done post facto, i.e., after the entire text of the output has been generated. We provide evidence that there are times when we can predict how an LM will behave early in computation, before even a single token is generated. We show that probes trained on the internal representation of input tokens alone can predict a wide range of eventual behaviors over the entire output sequence. Using methods from conformal prediction, we provide provable bounds on the estimation error of our probes, creating precise early warning systems for these behaviors. The conformal probes can identify instances that will trigger alignment failures (jailbreaking) and instruction-following failures, without requiring a single token to be generated. An early warning system built on the probes reduces jailbreaking by 91%. Our probes also show promise in pre-emptively estimating how confident the model will be in its response, a behavior that cannot be detected using the output text alone. Conformal probes can preemptively estimate the final prediction of an LM that uses Chain-of-Thought (CoT) prompting, hence accelerating inference. When applied to an LM that uses CoT to perform text classification, the probes drastically reduce inference costs (65% on average across 27 datasets), with negligible accuracy loss. Encouragingly, probes generalize to unseen datasets and perform better on larger models, suggesting applicability to the largest of models in real-world settings.
LightThinker: Thinking Step-by-Step Compression
arXiv:2502.15589v2 Announce Type: replace-cross Abstract: Large language models (LLMs) have shown remarkable performance in complex reasoning tasks, but their efficiency is hindered by the substantial memory and computational costs associated with generating lengthy tokens. In this paper, we propose LightThinker, a novel method that enables LLMs to dynamically compress intermediate thoughts during reasoning. Inspired by human cognitive processes, LightThinker compresses verbose thought steps into compact representations and discards the original reasoning chains, thereby significantly reducing the number of tokens stored in the context window. This is achieved by training the model on when and how to perform compression through data construction, mapping hidden states to condensed gist tokens, and creating specialized attention masks. Additionally, we introduce the Dependency (Dep) metric to quantify the degree of compression by measuring the reliance on historical tokens during generation. Extensive experiments on four datasets and two models show that LightThinker reduces peak memory usage and inference time, while maintaining competitive accuracy. Our work provides a new direction for improving the efficiency of LLMs in complex reasoning tasks without sacrificing performance. Code is released at https://github.com/zjunlp/LightThinker.
THFlow: A Temporally Hierarchical Flow Matching Framework for 3D Peptide Design
arXiv:2502.15855v2 Announce Type: replace-cross Abstract: Deep generative models provide a promising approach to de novo 3D peptide design. Most of them jointly model the distributions of peptide's position, orientation, and conformation, attempting to simultaneously converge to the target pocket. However, in the early stage of docking, optimizing conformation-only modalities such as rotation and torsion can be physically meaningless, as the peptide is initialized far from the protein pocket and no interaction field is present. We define this problem as the multimodal temporal inconsistency problem and claim it is a key factor contributing to low binding affinity in generated peptides. To address this challenge, we propose THFlow, a novel flow matching-based multimodal generative model that explicitly models the temporal hierarchy between peptide position and conformation. It employs a polynomial based conditional flow to accelerate positional convergence early on, and later aligns it with rotation and torsion for coordinated conformation refinement under the emerging interaction field. Additionally, we incorporate interaction-related features, such as polarity, to further enhance the model's understanding of peptide-protein binding. Extensive experiments demonstrate that THFlow outperforms existing methods in generating peptides with superior stability, affinity, and diversity, offering an effective and accurate solution for advancing peptide-based therapeutic development.
SCoT: Straight Consistent Trajectory for Pre-Trained Diffusion Model Distillations
arXiv:2502.16972v3 Announce Type: replace-cross Abstract: Pre-trained diffusion models are commonly used to generate clean data (e.g., images) from random noises, effectively forming pairs of noises and corresponding clean images. Distillation on these pre-trained models can be viewed as the process of constructing advanced trajectories within the pair to accelerate sampling. For instance, consistency model distillation develops consistent projection functions to regulate trajectories, although sampling efficiency remains a concern. Rectified flow method enforces straight trajectories to enable faster sampling, yet relies on numerical ODE solvers, which may introduce approximation errors. In this work, we bridge the gap between the consistency model and the rectified flow method by proposing a Straight Consistent Trajectory~(SCoT) model. SCoT enjoys the benefits of both approaches for fast sampling, producing trajectories with consistent and straight properties simultaneously. These dual properties are strategically balanced by targeting two critical objectives: (1) regulating the gradient of SCoT's mapping to a constant, (2) ensuring trajectory consistency. Extensive experimental results demonstrate the effectiveness and efficiency of SCoT.
Structure-prior Informed Diffusion Model for Graph Source Localization with Limited Data
arXiv:2502.17928v3 Announce Type: replace-cross Abstract: Source localization in graph information propagation is essential for mitigating network disruptions, including misinformation spread, cyber threats, and infrastructure failures. Existing deep generative approaches face significant challenges in real-world applications due to limited propagation data availability. We present SIDSL (\textbf{S}tructure-prior \textbf{I}nformed \textbf{D}iffusion model for \textbf{S}ource \textbf{L}ocalization), a generative diffusion framework that leverages topology-aware priors to enable robust source localization with limited data. SIDSL addresses three key challenges: unknown propagation patterns through structure-based source estimations via graph label propagation, complex topology-propagation relationships via a propagation-enhanced conditional denoiser with GNN-parameterized label propagation module, and class imbalance through structure-prior biased diffusion initialization. By learning pattern-invariant features from synthetic data generated by established propagation models, SIDSL enables effective knowledge transfer to real-world scenarios. Experimental evaluation on four real-world datasets demonstrates superior performance with 7.5-13.3\% F1 score improvements over baselines, including over 19\% improvement in few-shot and 40\% in zero-shot settings, validating the framework's effectiveness for practical source localization. Our code can be found \href{https://github.com/tsinghua-fib-lab/SIDSL}{here}.
Promote, Suppress, Iterate: How Language Models Answer One-to-Many Factual Queries
arXiv:2502.20475v3 Announce Type: replace-cross Abstract: To answer one-to-many factual queries (e.g., listing cities of a country), a language model (LM) must simultaneously recall knowledge and avoid repeating previous answers. How are these two subtasks implemented and integrated internally? Across multiple datasets, models, and prompt templates, we identify a promote-then-suppress mechanism: the model first recalls all answers, and then suppresses previously generated ones. Specifically, LMs use both the subject and previous answer tokens to perform knowledge recall, with attention propagating subject information and MLPs promoting the answers. Then, attention attends to and suppresses previous answer tokens, while MLPs amplify the suppression signal. Our mechanism is corroborated by extensive experimental evidence: in addition to using early decoding and causal tracing, we analyze how components use different tokens by introducing both Token Lens, which decodes aggregated attention updates from specified tokens, and a knockout method that analyzes changes in MLP outputs after removing attention to specified tokens. Overall, we provide new insights into how LMs' internal components interact with different input tokens to support complex factual recall. Code is available at https://github.com/Lorenayannnnn/how-lms-answer-one-to-many-factual-queries.
CaKE: Circuit-aware Editing Enables Generalizable Knowledge Learners
arXiv:2503.16356v2 Announce Type: replace-cross Abstract: Knowledge Editing (KE) enables the modification of outdated or incorrect information in large language models (LLMs). While existing KE methods can update isolated facts, they often fail to generalize these updates to multi-hop reasoning tasks that rely on the modified knowledge. Through an analysis of reasoning circuits -- the neural pathways LLMs use for knowledge-based inference, we find that current layer-localized KE approaches (e.g., MEMIT, WISE), which edit only single or a few model layers, inadequately integrate updated knowledge into these reasoning pathways. To address this limitation, we present CaKE (Circuit-aware Knowledge Editing), a novel method that enhances the effective integration of updated knowledge in LLMs. By only leveraging a few curated data samples guided by our circuit-based analysis, CaKE stimulates the model to develop appropriate reasoning circuits for newly incorporated knowledge. Experiments show that CaKE enables more accurate and consistent use of edited knowledge across related reasoning tasks, achieving an average improvement of 20% in multi-hop reasoning accuracy on the MQuAKE dataset while requiring less memory than existing KE methods. We release the code and data in https://github.com/zjunlp/CaKE.
LookAhead Tuning: Safer Language Models via Partial Answer Previews
arXiv:2503.19041v2 Announce Type: replace-cross Abstract: Fine-tuning enables large language models (LLMs) to adapt to specific domains, but often compromises their previously established safety alignment. To mitigate the degradation of model safety during fine-tuning, we introduce LookAhead Tuning, a lightweight and effective data-driven approach that preserves safety during fine-tuning. The method introduces two simple strategies that modify training data by previewing partial answer prefixes, thereby minimizing perturbations to the model's initial token distributions and maintaining its built-in safety mechanisms. Comprehensive experiments demonstrate that LookAhead Tuning effectively maintains model safety without sacrificing robust performance on downstream tasks. Our findings position LookAhead Tuning as a reliable and efficient solution for the safe and effective adaptation of LLMs.
Robust DNN Partitioning and Resource Allocation Under Uncertain Inference Time
arXiv:2503.21476v2 Announce Type: replace-cross Abstract: In edge intelligence systems, deep neural network (DNN) partitioning and data offloading can provide real-time task inference for resource-constrained mobile devices. However, the inference time of DNNs is typically uncertain and cannot be precisely determined in advance, presenting significant challenges in ensuring timely task processing within deadlines. To address the uncertain inference time, we propose a robust optimization scheme to minimize the total energy consumption of mobile devices while meeting task probabilistic deadlines. The scheme only requires the mean and variance information of the inference time, without any prediction methods or distribution functions. The problem is formulated as a mixed-integer nonlinear programming (MINLP) that involves jointly optimizing the DNN model partitioning and the allocation of local CPU/GPU frequencies and uplink bandwidth. To tackle the problem, we first decompose the original problem into two subproblems: resource allocation and DNN model partitioning. Subsequently, the two subproblems with probability constraints are equivalently transformed into deterministic optimization problems using the chance-constrained programming (CCP) method. Finally, the convex optimization technique and the penalty convex-concave procedure (PCCP) technique are employed to obtain the optimal solution of the resource allocation subproblem and a stationary point of the DNN model partitioning subproblem, respectively. The proposed algorithm leverages real-world data from popular hardware platforms and is evaluated on widely used DNN models. Extensive simulations show that our proposed algorithm effectively addresses the inference time uncertainty with probabilistic deadline guarantees while minimizing the energy consumption of mobile devices.
SupertonicTTS: Towards Highly Efficient and Streamlined Text-to-Speech System
arXiv:2503.23108v3 Announce Type: replace-cross Abstract: We introduce SupertonicTTS, a novel text-to-speech (TTS) system designed for efficient and streamlined speech synthesis. SupertonicTTS comprises three components: a speech autoencoder for continuous latent representation, a text-to-latent module leveraging flow-matching for text-to-latent mapping, and an utterance-level duration predictor. To enable a lightweight architecture, we employ a low-dimensional latent space, temporal compression of latents, and ConvNeXt blocks. The TTS pipeline is further simplified by operating directly on raw character-level text and employing cross-attention for text-speech alignment, thus eliminating the need for grapheme-to-phoneme (G2P) modules and external aligners. In addition, we propose context-sharing batch expansion that accelerates loss convergence and stabilizes text-speech alignment with minimal memory and I/O overhead. Experimental results demonstrate that SupertonicTTS delivers performance comparable to contemporary zero-shot TTS models with only 44M parameters, while significantly reducing architectural complexity and computational cost. Audio samples are available at: https://supertonictts.github.io/.
Propagation of Chaos in One-hidden-layer Neural Networks beyond Logarithmic Time
arXiv:2504.13110v2 Announce Type: replace-cross Abstract: We study the approximation gap between the dynamics of a polynomial-width neural network and its infinite-width counterpart, both trained using projected gradient descent in the mean-field scaling regime. We demonstrate how to tightly bound this approximation gap through a differential equation governed by the mean-field dynamics. A key factor influencing the growth of this ODE is the local Hessian of each particle, defined as the derivative of the particle's velocity in the mean-field dynamics with respect to its position. We apply our results to the canonical feature learning problem of estimating a well-specified single-index model; we permit the information exponent to be arbitrarily large, leading to convergence times that grow polynomially in the ambient dimension $d$. We show that, due to a certain ``self-concordance'' property in these problems -- where the local Hessian of a particle is bounded by a constant times the particle's velocity -- polynomially many neurons are sufficient to closely approximate the mean-field dynamics throughout training.
Phantora: Maximizing Code Reuse in Simulation-based Machine Learning System Performance Estimation
arXiv:2505.01616v2 Announce Type: replace-cross Abstract: Modern machine learning (ML) training workloads place substantial demands on both computational and communication resources. Consequently, accurate performance estimation has become increasingly critical for guiding system design decisions, such as the selection of parallelization strategies, cluster configurations, and hardware provisioning. Existing simulation-based performance estimation requires reimplementing the ML framework in a simulator, which demands significant manual effort and is hard to maintain as ML frameworks evolve rapidly. This paper introduces Phantora, a hybrid GPU cluster simulator designed for performance estimation of ML training workloads. Phantora executes unmodified ML frameworks as is within a distributed, containerized environment. Each container emulates the behavior of a GPU server in a large-scale cluster, while Phantora intercepts and simulates GPU- and communication-related operations to provide high-fidelity performance estimation. We call this approach hybrid simulation of ML systems, in contrast to traditional methods that simulate static workloads. The primary advantage of hybrid simulation is that it allows direct reuse of ML framework source code in simulation, avoiding the need for reimplementation. Our evaluation shows that Phantora provides accuracy comparable to static workload simulation while supporting three state-of-the-art LLM training frameworks out-of-the-box. In addition, Phantora operates on a single GPU, eliminating the need for the resource-intensive trace collection and workload extraction steps required by traditional trace-based simulators. Phantora is open-sourced at https://github.com/QDelta/Phantora.
Meta-Semantics Augmented Few-Shot Relational Learning
arXiv:2505.05684v3 Announce Type: replace-cross Abstract: Few-shot relational learning on knowledge graph (KGs) aims to perform reasoning over relations with only a few training examples. While current methods have focused primarily on leveraging specific relational information, rich semantics inherent in KGs have been largely overlooked. To bridge this gap, we propose PromptMeta, a novel prompted meta-learning framework that seamlessly integrates meta-semantics with relational information for few-shot relational learning. PromptMeta introduces two core innovations: (1) a Meta-Semantic Prompt (MSP) pool that learns and consolidates high-level meta-semantics shared across tasks, enabling effective knowledge transfer and adaptation to newly emerging relations; and (2) a learnable fusion mechanism that dynamically combines meta-semantics with task-specific relational information tailored to different few-shot tasks. Both components are optimized jointly with model parameters within a meta-learning framework. Extensive experiments and analyses on two real-world KG benchmarks validate the effectiveness of PromptMeta in adapting to new relations with limited supervision.
WavReward: Spoken Dialogue Models With Generalist Reward Evaluators
arXiv:2505.09558v2 Announce Type: replace-cross Abstract: End-to-end spoken dialogue models such as GPT-4o-audio have recently garnered significant attention in the speech domain. However, the evaluation of spoken dialogue models' conversational performance has largely been overlooked. This is primarily due to the intelligent chatbots convey a wealth of non-textual information which cannot be easily measured using text-based language models like ChatGPT. To address this gap, we propose WavReward, a reward feedback model based on audio language models that can evaluate both the IQ and EQ of spoken dialogue systems with speech input. Specifically, 1) based on audio language models, WavReward incorporates the deep reasoning process and the nonlinear reward mechanism for post-training. By utilizing multi-sample feedback via the reinforcement learning algorithm, we construct a specialized evaluator tailored to spoken dialogue models. 2) We introduce ChatReward-30K, a preference dataset used to train WavReward. ChatReward-30K includes both comprehension and generation aspects of spoken dialogue models. These scenarios span various tasks, such as text-based chats, nine acoustic attributes of instruction chats, and implicit chats. WavReward outperforms previous state-of-the-art evaluation models across multiple spoken dialogue scenarios, achieving a substantial improvement about Qwen2.5-Omni in objective accuracy from 53.4$\%$ to 91.5$\%$. In subjective A/B testing, WavReward also leads by a margin of 83$\%$. Comprehensive ablation studies confirm the necessity of each component of WavReward. All data and code will be publicly at https://github.com/jishengpeng/WavReward after the paper is accepted.
Can Global XAI Methods Reveal Injected Bias in LLMs? SHAP vs Rule Extraction vs RuleSHAP
arXiv:2505.11189v2 Announce Type: replace-cross Abstract: Large language models (LLMs) can amplify misinformation, undermining societal goals like the UN SDGs. We study three documented drivers of misinformation (valence framing, information overload, and oversimplification) which are often shaped by one's default beliefs. Building on evidence that LLMs encode such defaults (e.g., "joy is positive," "math is complex") and can act as "bags of heuristics," we ask: can general belief-driven heuristics behind misinformative behaviour be recovered from LLMs as clear rules? A key obstacle is that global rule-extraction methods in explainable AI (XAI) are built for numerical inputs/outputs, not text. We address this by eliciting global LLM beliefs and mapping them to numerical scores via statistically reliable abstractions, thereby enabling off-the-shelf global XAI to detect belief-related heuristics in LLMs. To obtain ground truth, we hard-code bias-inducing nonlinear heuristics of increasing complexity (univariate, conjunctive, nonconvex) into popular LLMs (ChatGPT and Llama) via system instructions. This way, we find that RuleFit under-detects non-univariate biases, while global SHAP better approximates conjunctive ones but does not yield actionable rules. To bridge this gap, we propose RuleSHAP, a rule-extraction algorithm that couples global SHAP-value aggregations with rule induction to better capture non-univariate bias, improving heuristics detection over RuleFit by +94% (MRR@1) on average. Our results provide a practical pathway for revealing belief-driven biases in LLMs.
Losing is for Cherishing: Data Valuation Based on Machine Unlearning and Shapley Value
arXiv:2505.16147v2 Announce Type: replace-cross Abstract: The proliferation of large models has intensified the need for efficient data valuation methods to quantify the contribution of individual data providers. Traditional approaches, such as game-theory-based Shapley value and influence-function-based techniques, face prohibitive computational costs or require access to full data and model training details, making them hardly achieve partial data valuation. To address this, we propose Unlearning Shapley, a novel framework that leverages machine unlearning to estimate data values efficiently. By unlearning target data from a pretrained model and measuring performance shifts on a reachable test set, our method computes Shapley values via Monte Carlo sampling, avoiding retraining and eliminating dependence on full data. Crucially, Unlearning Shapley supports both full and partial data valuation, making it scalable for large models (e.g., LLMs) and practical for data markets. Experiments on benchmark datasets and large-scale text corpora demonstrate that our approach matches the accuracy of state-of-the-art methods while reducing computational overhead by orders of magnitude. Further analysis confirms a strong correlation between estimated values and the true impact of data subsets, validating its reliability in real-world scenarios. This work bridges the gap between data valuation theory and practical deployment, offering a scalable, privacy-compliant solution for modern AI ecosystems.
Large Language Models Implicitly Learn to See and Hear Just By Reading
arXiv:2505.17091v2 Announce Type: replace-cross Abstract: This paper presents a fascinating find: By training an auto-regressive LLM model on text tokens, the text model inherently develops internally an ability to understand images and audio, thereby developing the ability to see and hear just by reading. Popular audio and visual LLM models fine-tune text LLM models to give text output conditioned on images and audio embeddings. On the other hand, our architecture takes in patches of images, audio waveforms or tokens as input. It gives us the embeddings or category labels typical of a classification pipeline. We show the generality of text weights in aiding audio classification for datasets FSD-50K and GTZAN. Further, we show this working for image classification on CIFAR-10 and Fashion-MNIST, as well on image patches. This pushes the notion of text-LLMs learning powerful internal circuits that can be utilized by activating necessary connections for various applications rather than training models from scratch every single time.
BroadGen: A Framework for Generating Effective and Efficient Advertiser Broad Match Keyphrase Recommendations
arXiv:2505.19164v3 Announce Type: replace-cross Abstract: In the domain of sponsored search advertising, the focus of {Keyphrase recommendation has largely been on exact match types, which pose issues such as high management expenses, limited targeting scope, and evolving search query patterns. Alternatives like Broad match types can alleviate certain drawbacks of exact matches but present challenges like poor targeting accuracy and minimal supervisory signals owing to limited advertiser usage. This research defines the criteria for an ideal broad match, emphasizing on both efficiency and effectiveness, ensuring that a significant portion of matched queries are relevant. We propose BroadGen, an innovative framework that recommends efficient and effective broad match keyphrases by utilizing historical search query data. Additionally, we demonstrate that BroadGen, through token correspondence modeling, maintains better query stability over time. BroadGen's capabilities allow it to serve daily, millions of sellers at eBay with over 2.5 billion items.
Learning coordinated badminton skills for legged manipulators
arXiv:2505.22974v2 Announce Type: replace-cross Abstract: Coordinating the motion between lower and upper limbs and aligning limb control with perception are substantial challenges in robotics, particularly in dynamic environments. To this end, we introduce an approach for enabling legged mobile manipulators to play badminton, a task that requires precise coordination of perception, locomotion, and arm swinging. We propose a unified reinforcement learning-based control policy for whole-body visuomotor skills involving all degrees of freedom to achieve effective shuttlecock tracking and striking. This policy is informed by a perception noise model that utilizes real-world camera data, allowing for consistent perception error levels between simulation and deployment and encouraging learned active perception behaviors. Our method includes a shuttlecock prediction model, constrained reinforcement learning for robust motion control, and integrated system identification techniques to enhance deployment readiness. Extensive experimental results in a variety of environments validate the robot's capability to predict shuttlecock trajectories, navigate the service area effectively, and execute precise strikes against human players, demonstrating the feasibility of using legged mobile manipulators in complex and dynamic sports scenarios.
Demystifying Spectral Feature Learning for Instrumental Variable Regression
arXiv:2506.10899v2 Announce Type: replace-cross Abstract: We address the problem of causal effect estimation in the presence of hidden confounders, using nonparametric instrumental variable (IV) regression. A leading strategy employs spectral features - that is, learned features spanning the top eigensubspaces of the operator linking treatments to instruments. We derive a generalization error bound for a two-stage least squares estimator based on spectral features, and gain insights into the method's performance and failure modes. We show that performance depends on two key factors, leading to a clear taxonomy of outcomes. In a good scenario, the approach is optimal. This occurs with strong spectral alignment, meaning the structural function is well-represented by the top eigenfunctions of the conditional operator, coupled with this operator's slow eigenvalue decay, indicating a strong instrument. Performance degrades in a bad scenario: spectral alignment remains strong, but rapid eigenvalue decay (indicating a weaker instrument) demands significantly more samples for effective feature learning. Finally, in the ugly scenario, weak spectral alignment causes the method to fail, regardless of the eigenvalues' characteristics. Our synthetic experiments empirically validate this taxonomy.
Latent Representation Learning of Multi-scale Thermophysics: Application to Dynamics in Shocked Porous Energetic Material
arXiv:2506.12996v2 Announce Type: replace-cross Abstract: Coupling of physics across length and time scales plays an important role in the response of microstructured materials to external loads. In a multi-scale framework, unresolved (subgrid) meso-scale dynamics is upscaled to the homogenized (macro-scale) representation of the heterogeneous material through closure models. Deep learning models trained using meso-scale simulation data are now a popular route to assimilate such closure laws. However, meso-scale simulations are computationally taxing, posing practical challenges in training deep learning-based surrogate models from scratch. In this work, we investigate an alternative meta-learning approach motivated by the idea of tokenization in natural language processing. We show that one can learn a reduced representation of the micro-scale physics to accelerate the meso-scale learning process by tokenizing the meso-scale evolution of the physical fields involved in an archetypal, albeit complex, reactive dynamics problem, \textit{viz.}, shock-induced energy localization in a porous energetic material. A probabilistic latent representation of \textit{micro}-scale dynamics is learned as building blocks for \textit{meso}-scale dynamics. The \textit{meso-}scale latent dynamics model learns the correlation between neighboring building blocks by training over a small dataset of meso-scale simulations. We compare the performance of our model with a physics-aware recurrent convolutional neural network (PARC) trained only on the full meso-scale dataset. We demonstrate that our model can outperform PARC with scarce meso-scale data. The proposed approach accelerates the development of closure models by leveraging inexpensive micro-scale simulations and fast training over a small meso-scale dataset, and can be applied to a range of multi-scale modeling problems.
LogicGuard: Improving Embodied LLM agents through Temporal Logic based Critics
arXiv:2507.03293v2 Announce Type: replace-cross Abstract: Large language models (LLMs) have shown promise in zero-shot and single step reasoning and decision making problems, but in long horizon sequential planning tasks, their errors compound, often leading to unreliable or inefficient behavior. We introduce LogicGuard, a modular actor-critic architecture in which an LLM actor is guided by a trajectory level LLM critic that communicates through Linear Temporal Logic (LTL). Our setup combines the reasoning strengths of language models with the guarantees of formal logic. The actor selects high-level actions from natural language observations, while the critic analyzes full trajectories and proposes new LTL constraints that shield the actor from future unsafe or inefficient behavior. LogicGuard supports both fixed safety rules and adaptive, learned constraints, and is model-agnostic: any LLM-based planner can serve as the actor, with LogicGuard acting as a logic-generating wrapper. We formalize planning as graph traversal under symbolic constraints, allowing LogicGuard to analyze failed or suboptimal trajectories and generate new temporal logic rules that improve future behavior. To demonstrate generality, we evaluate LogicGuard across two distinct settings: short-horizon general tasks and long-horizon specialist tasks. On the Behavior benchmark of 100 household tasks, LogicGuard increases task completion rates by 25% over a baseline InnerMonologue planner. On the Minecraft diamond-mining task, which is long-horizon and requires multiple interdependent subgoals, LogicGuard improves both efficiency and safety compared to SayCan and InnerMonologue. These results show that enabling LLMs to supervise each other through temporal logic yields more reliable, efficient and safe decision-making for both embodied agents.
A Resource Efficient Quantum Kernel
arXiv:2507.03689v3 Announce Type: replace-cross Abstract: Quantum processors may enhance machine learning by mapping high-dimensional data onto quantum systems for processing. Conventional feature maps, for encoding data onto a quantum circuit are currently impractical, as the number of entangling gates scales quadratically with the dimension of the dataset and the number of qubits. In this work, we introduce a quantum feature map designed to handle high-dimensional data with a significantly reduced number of qubits and entangling operations. Our approach preserves essential data characteristics while promoting computational efficiency, as evidenced by extensive experiments on benchmark datasets that demonstrate a marked improvement in both accuracy and resource utilization when using our feature map as a kernel for characterization, as compared to state-of-the-art quantum feature maps. Our noisy simulation results, combined with lower resource requirements, highlight our map's ability to function within the constraints of noisy intermediate-scale quantum devices. Through numerical simulations and small-scale implementation on a superconducting circuit quantum computing platform, we demonstrate that our scheme performs on par or better than a set of classical algorithms for classification. While quantum kernels are typically stymied by exponential concentration, our approach is affected with a slower rate with respect to both the number of qubits and features, which allows practical applications to remain within reach. Our findings herald a promising avenue for the practical implementation of quantum machine learning algorithms on near future quantum computing platforms.
Temporal Conformal Prediction (TCP): A Distribution-Free Statistical and Machine Learning Framework for Adaptive Risk Forecasting
arXiv:2507.05470v3 Announce Type: replace-cross Abstract: We propose Temporal Conformal Prediction (TCP), a distribution-free framework for constructing well-calibrated prediction intervals in nonstationary time series. TCP combines a quantile forecaster with split-conformal calibration on a rolling window and, in its TCP-RM variant, augments the conformal threshold with a Robbins-Monro (RM) offset to steer coverage toward a target level in real time. We benchmark TCP against GARCH, Historical Simulation, and a rolling Quantile Regression (QR) baseline across equities (S&P500), cryptocurrency (Bitcoin), and commodities (Gold). Three consistent findings emerge. First, rolling QR produces the sharpest intervals but is materially under-calibrated (e.g., S&P500: 86.3% vs. 95% target). Second, TCP and TCP-RM achieve near-nominal coverage while delivering substantially narrower intervals than Historical Simulation (e.g., S&P500: 29% reduction in width). Third, the RM update improves calibration with negligible width cost. Crisis-window visualizations around March 2020 show TCP/TCP-RM expanding and contracting intervals promptly as volatility spikes and recedes, with red dots marking days of miscoverage. A sensitivity study confirms robustness to window size and step-size choices. Overall, TCP provides a practical, theoretically grounded solution for calibrated uncertainty quantification under distribution shift, bridging statistical inference and machine learning for risk forecasting.
Intra-DP: A High Performance Collaborative Inference System for Mobile Edge Computing
arXiv:2507.05829v2 Announce Type: replace-cross Abstract: Deploying deep neural networks (DNNs) on resource-constrained mobile devices presents significant challenges, particularly in achieving real-time performance while simultaneously coping with limited computational resources and battery life. While Mobile Edge Computing (MEC) offers collaborative inference with GPU servers as a promising solution, existing approaches primarily rely on layer-wise model partitioning and undergo significant transmission bottlenecks caused by the sequential execution of DNN operations. To address this challenge, we present Intra-DP, a high-performance collaborative inference system optimized for DNN inference on MEC. Intra DP employs a novel parallel computing technique based on local operators (i.e., operators whose minimum unit input is not the entire input tensor, such as the convolution kernel). By decomposing their computations (operations) into several independent sub-operations and overlapping the computation and transmission of different sub-operations through parallel execution, Intra-DP mitigates transmission bottlenecks in MEC, achieving fast and energy-efficient inference. The evaluation demonstrates that Intra-DP reduces per-inference latency by up to 50% and energy consumption by up to 75% compared to state-of-the-art baselines, without sacrificing accuracy.
Automating Steering for Safe Multimodal Large Language Models
arXiv:2507.13255v3 Announce Type: replace-cross Abstract: Recent progress in Multimodal Large Language Models (MLLMs) has unlocked powerful cross-modal reasoning abilities, but also raised new safety concerns, particularly when faced with adversarial multimodal inputs. To improve the safety of MLLMs during inference, we introduce a modular and adaptive inference-time intervention technology, AutoSteer, without requiring any fine-tuning of the underlying model. AutoSteer incorporates three core components: (1) a novel Safety Awareness Score (SAS) that automatically identifies the most safety-relevant distinctions among the model's internal layers; (2) an adaptive safety prober trained to estimate the likelihood of toxic outputs from intermediate representations; and (3) a lightweight Refusal Head that selectively intervenes to modulate generation when safety risks are detected. Experiments on LLaVA-OV and Chameleon across diverse safety-critical benchmarks demonstrate that AutoSteer significantly reduces the Attack Success Rate (ASR) for textual, visual, and cross-modal threats, while maintaining general abilities. These findings position AutoSteer as a practical, interpretable, and effective framework for safer deployment of multimodal AI systems.
Measuring Sample Quality with Copula Discrepancies
arXiv:2507.21434v2 Announce Type: replace-cross Abstract: The scalable Markov chain Monte Carlo (MCMC) algorithms that underpin modern Bayesian machine learning, such as Stochastic Gradient Langevin Dynamics (SGLD), sacrifice asymptotic exactness for computational speed, creating a critical diagnostic gap: traditional sample quality measures fail catastrophically when applied to biased samplers. While powerful Stein-based diagnostics can detect distributional mismatches, they provide no direct assessment of dependence structure, often the primary inferential target in multivariate problems. We introduce the Copula Discrepancy (CD), a principled and computationally efficient diagnostic that leverages Sklar's theorem to isolate and quantify the fidelity of a sample's dependence structure independent of its marginals. Our theoretical framework provides the first structure-aware diagnostic specifically designed for the era of approximate inference. Empirically, we demonstrate that a moment-based CD dramatically outperforms standard diagnostics like effective sample size for hyperparameter selection in biased MCMC, correctly identifying optimal configurations where traditional methods fail. Furthermore, our robust MLE-based variant can detect subtle but critical mismatches in tail dependence that remain invisible to rank correlation-based approaches, distinguishing between samples with identical Kendall's tau but fundamentally different extreme-event behavior. With computational overhead orders of magnitude lower than existing Stein discrepancies, the CD provides both immediate practical value for MCMC practitioners and a theoretical foundation for the next generation of structure-aware sample quality assessment.
Q-DPTS: Quantum Differentially Private Time Series Forecasting via Variational Quantum Circuits
arXiv:2508.05036v2 Announce Type: replace-cross Abstract: Time series forecasting is vital in domains where data sensitivity is paramount, such as finance and energy systems. While Differential Privacy (DP) provides theoretical guarantees to protect individual data contributions, its integration especially via DP-SGD often impairs model performance due to injected noise. In this paper, we propose Q-DPTS, a hybrid quantum-classical framework for Quantum Differentially Private Time Series Forecasting. Q-DPTS combines Variational Quantum Circuits (VQCs) with per-sample gradient clipping and Gaussian noise injection, ensuring rigorous $(\epsilon, \delta)$-differential privacy. The expressiveness of quantum models enables improved robustness against the utility loss induced by DP mechanisms. We evaluate Q-DPTS on the ETT (Electricity Transformer Temperature) dataset, a standard benchmark for long-term time series forecasting. Our approach is compared against both classical and quantum baselines, including LSTM, QASA, QRWKV, and QLSTM. Results demonstrate that Q-DPTS consistently achieves lower prediction error under the same privacy budget, indicating a favorable privacy-utility trade-off. This work presents one of the first explorations into quantum-enhanced differentially private forecasting, offering promising directions for secure and accurate time series modeling in privacy-critical scenarios.
Training Language Model Agents to Find Vulnerabilities with CTF-Dojo
arXiv:2508.18370v2 Announce Type: replace-cross Abstract: Large language models (LLMs) have demonstrated exceptional capabilities when trained within executable runtime environments, notably excelling at software engineering tasks through verified feedback loops. Yet, scalable and generalizable execution-grounded environments remain scarce, limiting progress in training more capable ML agents. We introduce CTF-Dojo, the first large-scale executable runtime tailored for training LLMs with verifiable feedback, featuring 658 fully functional Capture-The-Flag (CTF)-style challenges containerized in Docker with guaranteed reproducibility. To enable rapid scaling without manual intervention, we develop CTF-Forge, an automated pipeline that transforms publicly available artifacts into ready-to-use execution environments in minutes, eliminating weeks of expert configuration traditionally required. We trained LLM-based agents on just 486 high-quality, execution-verified trajectories from CTF-Dojo, achieving up to 11.6% absolute gains over strong baselines across three competitive benchmarks: InterCode-CTF, NYU CTF Bench, and Cybench. Our best-performing 32B model reaches 31.9% Pass@1, establishing a new open-weight state-of-the-art that rivals frontier models like DeepSeek-V3-0324 and Gemini-2.5-Flash. By framing CTF-style tasks as a benchmark for executable-agent learning, CTF-Dojo demonstrates that execution-grounded training signals are not only effective but pivotal in advancing high-performance ML agents without dependence on costly proprietary systems.
Universal Dynamics with Globally Controlled Analog Quantum Simulators
arXiv:2508.19075v2 Announce Type: replace-cross Abstract: Analog quantum simulators with global control fields have emerged as powerful platforms for exploring complex quantum phenomena. Recent breakthroughs, such as the coherent control of thousands of atoms, highlight the growing potential for quantum applications at scale. Despite these advances, a fundamental theoretical question remains unresolved: to what extent can such systems realize universal quantum dynamics under global control? Here we establish a necessary and sufficient condition for universal quantum computation using only global pulse control, proving that a broad class of analog quantum simulators is, in fact, universal. We further extend this framework to fermionic and bosonic systems, including modern platforms such as ultracold atoms in optical superlattices. Crucially, to connect the theoretical possibility with experimental reality, we introduce a new control technique into the experiment - direct quantum optimal control. This method enables the synthesis of complex effective Hamiltonians and allows us to incorporate realistic hardware constraints. To show its practical power, we experimentally engineer three-body interactions outside the blockade regime and demonstrate topological dynamics on a Rydberg atom array. Using the new control framework, we overcome key experimental challenges, including hardware limitations and atom position fluctuations in the non-blockade regime, by identifying smooth, short-duration pulses that achieve high-fidelity dynamics. Experimental measurements reveal dynamical signatures of symmetry-protected-topological edge modes, confirming both the expressivity and feasibility of our approach. Our work opens a new avenue for quantum simulation beyond native hardware Hamiltonians, enabling the engineering of effective multi-body interactions and advancing the frontier of quantum information processing with globally-controlled analog platforms.
Explainable artificial intelligence (XAI) for scaling: An application for deducing hydrologic connectivity at watershed scale
arXiv:2509.02127v2 Announce Type: replace-cross Abstract: Explainable artificial intelligence (XAI) methods have been applied to interpret deep learning model results. However, applications that integrate XAI with established hydrologic knowledge for process understanding remain limited. Here we show that XAI method, applied at point-scale, could be used for cross-scale aggregation of hydrologic responses, a fundamental question in scaling problems, using hydrologic connectivity as a demonstration. Soil moisture and its movement generated by physically based hydrologic model were used to train a long short-term memory (LSTM) network, whose impacts of inputs were evaluated by XAI methods. Our results suggest that XAI-based classification can effectively identify the differences in the functional roles of various sub-regions at watershed scale. The aggregated XAI results could be considered as an explicit and quantitative indicator of hydrologic connectivity development, offering insights to hydrological organization. This framework could be used to facilitate aggregation of other geophysical responses to advance process understandings.
Agentic DDQN-Based Scheduling for Licensed and Unlicensed Band Allocation in Sidelink Networks
arXiv:2509.06775v3 Announce Type: replace-cross Abstract: In this paper, we present an agentic double deep Q-network (DDQN) scheduler for licensed/unlicensed band allocation in New Radio (NR) sidelink (SL) networks. Beyond conventional reward-seeking reinforcement learning (RL), the agent perceives and reasons over a multi-dimensional context that jointly captures queueing delay, link quality, coexistence intensity, and switching stability. A capacity-aware, quality of service (QoS)-constrained reward aligns the agent with goal-oriented scheduling rather than static thresholding. Under constrained bandwidth, the proposed design reduces blocking by up to 87.5% versus threshold policies while preserving throughput, highlighting the value of context-driven decisions in coexistence-limited NR SL networks. The proposed scheduler is an embodied agent (E-agent) tailored for task-specific, resource-efficient operation at the network edge.
LD-ViCE: Latent Diffusion Model for Video Counterfactual Explanations
arXiv:2509.08422v2 Announce Type: replace-cross Abstract: Video-based AI systems are increasingly adopted in safety-critical domains such as autonomous driving and healthcare. However, interpreting their decisions remains challenging due to the inherent spatiotemporal complexity of video data and the opacity of deep learning models. Existing explanation techniques often suffer from limited temporal coherence, insufficient robustness, and a lack of actionable causal insights. Current counterfactual explanation methods typically do not incorporate guidance from the target model, reducing semantic fidelity and practical utility. We introduce Latent Diffusion for Video Counterfactual Explanations (LD-ViCE), a novel framework designed to explain the behavior of video-based AI models. Compared to previous approaches, LD-ViCE reduces the computational costs of generating explanations by operating in latent space using a state-of-the-art diffusion model, while producing realistic and interpretable counterfactuals through an additional refinement step. Our experiments demonstrate the effectiveness of LD-ViCE across three diverse video datasets, including EchoNet-Dynamic (cardiac ultrasound), FERV39k (facial expression), and Something-Something V2 (action recognition). LD-ViCE outperforms a recent state-of-the-art method, achieving an increase in R2 score of up to 68% while reducing inference time by half. Qualitative analysis confirms that LD-ViCE generates semantically meaningful and temporally coherent explanations, offering valuable insights into the target model behavior. LD-ViCE represents a valuable step toward the trustworthy deployment of AI in safety-critical domains.
MOCHA: Multi-modal Objects-aware Cross-arcHitecture Alignment
arXiv:2509.14001v2 Announce Type: replace-cross Abstract: We introduce MOCHA (Multi-modal Objects-aware Cross-arcHitecture Alignment), a knowledge distillation approach that transfers region-level multimodal semantics from a large vision-language teacher (e.g., LLaVa) into a lightweight vision-only object detector student (e.g., YOLO). A translation module maps student features into a joint space, where the training of the student and translator is guided by a dual-objective loss that enforces both local alignment and global relational consistency. Unlike prior approaches focused on dense or global alignment, MOCHA operates at the object level, enabling efficient transfer of semantics without modifying the teacher or requiring textual input at inference. We validate our method across four personalized detection benchmarks under few-shot regimes. Results show consistent gains over baselines, with a +10.1 average score improvement. Despite its compact architecture, MOCHA reaches performance on par with larger multimodal models, proving its suitability for real-world deployment.
DivLogicEval: A Framework for Benchmarking Logical Reasoning Evaluation in Large Language Models
arXiv:2509.15587v2 Announce Type: replace-cross Abstract: Logic reasoning in natural language has been recognized as an important measure of human intelligence for Large Language Models (LLMs). Popular benchmarks may entangle multiple reasoning skills and thus provide unfaithful evaluations on the logic reasoning skill. Meanwhile, existing logic reasoning benchmarks are limited in language diversity and their distributions are deviated from the distribution of an ideal logic reasoning benchmark, which may lead to biased evaluation results. This paper thereby proposes a new classical logic benchmark DivLogicEval, consisting of natural sentences composed of diverse statements in a counterintuitive way. To ensure a more reliable evaluation, we also introduce a new evaluation metric that mitigates the influence of bias and randomness inherent in LLMs. Through experiments, we demonstrate the extent to which logical reasoning is required to answer the questions in DivLogicEval and compare the performance of different popular LLMs in conducting logical reasoning.
Gender and Political Bias in Large Language Models: A Demonstration Platform
arXiv:2509.16264v2 Announce Type: replace-cross Abstract: We present ParlAI Vote, an interactive system for exploring European Parliament debates and votes, and for testing LLMs on vote prediction and bias analysis. This platform connects debate topics, speeches, and roll-call outcomes, and includes rich demographic data such as gender, age, country, and political group. Users can browse debates, inspect linked speeches, compare real voting outcomes with predictions from frontier LLMs, and view error breakdowns by demographic group. Visualizing the EuroParlVote benchmark and its core tasks of gender classification and vote prediction, ParlAI Vote highlights systematic performance bias in state-of-the-art LLMs. The system unifies data, models, and visual analytics in a single interface, lowering the barrier for reproducing findings, auditing behavior, and running counterfactual scenarios. It supports research, education, and public engagement with legislative decision-making, while making clear both the strengths and the limitations of current LLMs in political analysis.
Pain in 3D: Generating Controllable Synthetic Faces for Automated Pain Assessment
arXiv:2509.16727v2 Announce Type: replace-cross Abstract: Automated pain assessment from facial expressions is crucial for non-communicative patients, such as those with dementia. Progress has been limited by two challenges: (i) existing datasets exhibit severe demographic and label imbalance due to ethical constraints, and (ii) current generative models cannot precisely control facial action units (AUs), facial structure, or clinically validated pain levels. We present 3DPain, a large-scale synthetic dataset specifically designed for automated pain assessment, featuring unprecedented annotation richness and demographic diversity. Our three-stage framework generates diverse 3D meshes, textures them with diffusion models, and applies AU-driven face rigging to synthesize multi-view faces with paired neutral and pain images, AU configurations, PSPI scores, and the first dataset-level annotations of pain-region heatmaps. The dataset comprises 82,500 samples across 25,000 pain expression heatmaps and 2,500 synthetic identities balanced by age, gender, and ethnicity. We further introduce ViTPain, a Vision Transformer based cross-modal distillation framework in which a heatmap-trained teacher guides a student trained on RGB images, enhancing accuracy, interpretability, and clinical reliability. Together, 3DPain and ViTPain establish a controllable, diverse, and clinically grounded foundation for generalizable automated pain assessment.
Min: Mixture of Noise for Pre-Trained Model-Based Class-Incremental Learning
arXiv:2509.16738v2 Announce Type: replace-cross Abstract: Class Incremental Learning (CIL) aims to continuously learn new categories while retaining the knowledge of old ones. Pre-trained models (PTMs) show promising capabilities in CIL. However, existing approaches that apply lightweight fine-tuning to backbones still induce parameter drift, thereby compromising the generalization capability of pre-trained models. Parameter drift can be conceptualized as a form of noise that obscures critical patterns learned for previous tasks. However, recent researches have shown that noise is not always harmful. For example, the large number of visual patterns learned from pre-training can be easily abused by a single task, and introducing appropriate noise can suppress some low-correlation features, thus leaving a margin for future tasks. To this end, we propose learning beneficial noise for CIL guided by information theory and propose Mixture of Noise (Min), aiming to mitigate the degradation of backbone generalization from adapting new tasks. Specifically, task-specific noise is learned from high-dimension features of new tasks. Then, a set of weights is adjusted dynamically for optimal mixture of different task noise. Finally, Min embeds the beneficial noise into the intermediate features to mask the response of inefficient patterns. Extensive experiments on six benchmark datasets demonstrate that Min achieves state-of-the-art performance in most incremental settings, with particularly outstanding results in 50-steps incremental settings. This shows the significant potential for beneficial noise in continual learning. Code is available at https://github.com/ASCIIJK/MiN-NeurIPS2025.
NeuFACO: Neural Focused Ant Colony Optimization for Traveling Salesman Problem
arXiv:2509.16938v2 Announce Type: replace-cross Abstract: This study presents Neural Focused Ant Colony Optimization (NeuFACO), a non-autoregressive framework for the Traveling Salesman Problem (TSP) that combines advanced reinforcement learning with enhanced Ant Colony Optimization (ACO). NeuFACO employs Proximal Policy Optimization (PPO) with entropy regularization to train a graph neural network for instance-specific heuristic guidance, which is integrated into an optimized ACO framework featuring candidate lists, restricted tour refinement, and scalable local search. By leveraging amortized inference alongside ACO stochastic exploration, NeuFACO efficiently produces high-quality solutions across diverse TSP instances.
SilentStriker:Toward Stealthy Bit-Flip Attacks on Large Language Models
arXiv:2509.17371v2 Announce Type: replace-cross Abstract: The rapid adoption of large language models (LLMs) in critical domains has spurred extensive research into their security issues. While input manipulation attacks (e.g., prompt injection) have been well studied, Bit-Flip Attacks (BFAs) -- which exploit hardware vulnerabilities to corrupt model parameters and cause severe performance degradation -- have received far less attention. Existing BFA methods suffer from key limitations: they fail to balance performance degradation and output naturalness, making them prone to discovery. In this paper, we introduce SilentStriker, the first stealthy bit-flip attack against LLMs that effectively degrades task performance while maintaining output naturalness. Our core contribution lies in addressing the challenge of designing effective loss functions for LLMs with variable output length and the vast output space. Unlike prior approaches that rely on output perplexity for attack loss formulation, which inevitably degrade output naturalness, we reformulate the attack objective by leveraging key output tokens as targets for suppression, enabling effective joint optimization of attack effectiveness and stealthiness. Additionally, we employ an iterative, progressive search strategy to maximize attack efficacy. Experiments show that SilentStriker significantly outperforms existing baselines, achieving successful attacks without compromising the naturalness of generated text.
Bilateral Distribution Compression: Reducing Both Data Size and Dimensionality
arXiv:2509.17543v2 Announce Type: replace-cross Abstract: Existing distribution compression methods reduce dataset size by minimising the Maximum Mean Discrepancy (MMD) between original and compressed sets, but modern datasets are often large in both sample size and dimensionality. We propose Bilateral Distribution Compression (BDC), a two-stage framework that compresses along both axes while preserving the underlying distribution, with overall linear time and memory complexity in dataset size and dimension. Central to BDC is the Decoded MMD (DMMD), which quantifies the discrepancy between the original data and a compressed set decoded from a low-dimensional latent space. BDC proceeds by (i) learning a low-dimensional projection using the Reconstruction MMD (RMMD), and (ii) optimising a latent compressed set with the Encoded MMD (EMMD). We show that this procedure minimises the DMMD, guaranteeing that the compressed set faithfully represents the original distribution. Experiments show that across a variety of scenarios BDC can achieve comparable or superior performance to ambient-space compression at substantially lower cost.
The Narcissus Hypothesis: Descending to the Rung of Illusion
arXiv:2509.17999v2 Announce Type: replace-cross Abstract: Modern foundational models increasingly reflect not just world knowledge, but patterns of human preference embedded in their training data. We hypothesize that recursive alignment-via human feedback and model-generated corpora-induces a social desirability bias, nudging models to favor agreeable or flattering responses over objective reasoning. We refer to it as the Narcissus Hypothesis and test it across 31 models using standardized personality assessments and a novel Social Desirability Bias score. Results reveal a significant drift toward socially conforming traits, with profound implications for corpus integrity and the reliability of downstream inferences. We then offer a novel epistemological interpretation, tracing how recursive bias may collapse higher-order reasoning down Pearl's Ladder of Causality, culminating in what we refer to as the Rung of Illusion.
From Lag to Agility: Reinventing Freshworks’ Data Ingestion Architecture
As a global software-as-a-service (SaaS) company specializing in providing intuitive, AI-powered business solutions...
Adaptive Identity Resolution on Databricks with Hightouch
How do you deliver meaningful, long-term engagement with your customers when you...
Enforce consistent, secure tagging across data and AI assets with Governed Tags in Unity Catalog (Public Preview)
Today, we are excited to announce Governed Tags in Public Preview across all regions...
How Automation Reflects Human Timing and Performance in Media
When people watch video, they respond to more than the visuals. A pause, a breath, or the way a phrase is delivered often matters as much as the image itself. […]
The post How Automation Reflects Human Timing and Performance in Media appeared first on Datafloq.
Synthetic Data as Infrastructure: Engineering Privacy-Preserving AI with Real-Time Fidelity
In AI development, real-world data is both an asset and a liability. While it fuels the training, validation, and fine-tuning of machine learning models, it also presents significant challenges, including […]
The post Synthetic Data as Infrastructure: Engineering Privacy-Preserving AI with Real-Time Fidelity appeared first on Datafloq.
How to Secure Data Science Jobs in the USA as a Fresher in 2026?
Data science jobs in the USA are growing rapidly. According to the U.S. Bureau of Labor Statistics, data-centric jobs such as data scientist, data engineer, and data analyst are expected […]
The post How to Secure Data Science Jobs in the USA as a Fresher in 2026? appeared first on Datafloq.
How LLMs Are Changing the Way We Process Unstructured Data
Over 80% of business data is unstructured. Emails, PDFs, chats, medical notes, social media posts, videos-none of it fits neatly into rows and columns. Traditional tools struggle to analyze such […]
The post How LLMs Are Changing the Way We Process Unstructured Data appeared first on Datafloq.
Teradata Puts Data at the Core of Agentic AI with Launch of AgentBuilder
The first wave of GenAI was prompt-based. You asked a question, the model gave you an answer, and that was the extent of it. These tools could generate responses, but Read more…
The post Teradata Puts Data at the Core of Agentic AI with Launch of AgentBuilder appeared first on BigDATAwire.
What new AI features are product teams building?
AI Agents, Assistants, Revenue generators and more from top tier companies including YouTube, Linear, Square, Miro, Zendesk, Audible, Google Maps. DoP Deep Dive.
Why I chose Lexical over Tiptap
So… confession. I was a tiptap fan boy. Like really. install → write 2 lines → editor works. nice. done. 👏
Then I saw Lexical… and omg its fast as hell. Also its made by Meta (yeah fb guys), same people who made React. And I was like, okay okay let’s try this baby.
| Feature | Tiptap | Lexical |
|---|---|---|
| Bundle Size | ~110kb+ (depends what you add) | ~25kb core only |
| DX (developer experince lol) | super easy, ready 2 go | low level, you build more urself |
| Performance | decent, but bigger | ultra fast & light |
| Community | huge, lot of examples | growing, meta support |
| Out-of-the-box | ✅ many features plug n play | ❌ nope, u add stuff ( Unless you use Lexkit ) |
Tiptap = feels like plug socket, u just connect ur charger.
Lexical = feels like buying wires & making ur own charger 😅 but once u do, its lighter & faster.
And yeah, first time I tried lexical, I was like
“bruh where is bold button?? why i must code bold my self??”
then boom 💥 I found LexKit → open source layer on top of Lexical.
It’s like… same vibes as shadcn on radix. u get the raw power + nice developer experince. Honestly saved me.
- Tiptap = 🍕 ready pizza, eat now.
- Lexical = 🥦 raw veggies, u cook but more healthy.
And with LexKit → feels like u got a chef who preps the veggies for u 😂
So yeah, that’s why I kinda moved. Not saying tiptap bad… I still love it. But lexical is lighter, and I like fast things.
What u think? You on team tiptap or lexical? Or still lost in contenteditable hell lol
Thanks for the time, feel free to comment down below :)
Why AI Platforms Like ChatGPT, Gemini, Claude, and Others Are Unreliable
AI platforms are everywhere now — ChatGPT, Gemini, Claude, you name it. Everyone’s acting like they’re the future of productivity, creativity, and maybe even intelligence.
But here’s the thing no one wants to admit:
These platforms are unreliable — and sometimes, even misleading.
They’re polished, fast, and helpful in certain cases — but after using them seriously for months, I’ve seen where they consistently fall short. Not just minor flaws, but deep-rooted design issues that affect how useful (or useless) they are in real work.
1. They’re Way Too Positive — Even When You’re Wrong
Most AI tools are trained to be agreeable. That means if you send them bad writing, broken logic, or flawed ideas, they’ll still respond with:
"This is a strong start!""Great work overall!""Nicely structured."
At first, this might feel encouraging — until you start noticing something strange. Even your weakest drafts get praised. Even your errors are “understandable.” There’s rarely any honest critique unless you push hard for it.
And I mean hard. You literally have to say things like:
Tell me what’s wrong with this.
Be critical — don’t be polite.
Give me the flaws, not compliments.
Then, after prompt #4 or #5, the real feedback finally shows up.
Meanwhile, real people (friends, clients, readers) don’t need five prompts. They’ll point out issues instantly — because they’re not designed to protect your feelings.
That’s the difference. These AI tools are yes-men by design. That’s not useful when you’re trying to grow or fix something.
The second major problem: AI doesn’t really get you on the first try.
You can describe your problem, add context, maybe even paste in code or content — and what you get back is almost always:
- Off-topic
- Oversimplified
- Based on assumptions you didn’t ask for
And you’re left thinking: Did it even read what I just said?
It’s only after you rephrase the prompt multiple times — refining it, guiding it like a confused intern — that it finally gives something relevant.
This is especially frustrating for professionals who already know what they want. You’re spending time just teaching the AI what the problem is, before it even attempts to solve it.
3. The Solutions Look Smart — But Often Don’t Work
A lot of AI-generated answers look amazing. Clear formatting. Confident tone. Code examples. Step-by-step explanations.
But here’s the reality: half of those answers fail in the real world.
- Code suggestions break or don’t apply
- Technical advice is outdated or vague
- The AI forgets context it just saw a few prompts ago
- You have to debug its solution, not yours
This happens all the time in dev workflows. It suggests things that sound right but break under real conditions. And since it doesn’t understand your full environment, it’s just guessing.
Looks good on screen. Doesn’t hold up in production.
4. There’s No Human Experience Behind the Advice
One thing AI completely lacks — and probably always will — is actual lived experience.
It can’t improvise. It can’t give you the kind of tip a real person gives after doing the job for 5 years.
Like:
- Don’t bother with that library, it’s flaky after v2.1.
- If you’re working with slow APIs, this workaround will save you hours.
- Avoid mixing X and Y — it technically works, but it’s a pain to maintain.”
AI never gives advice like that, because it doesn’t know what pain feels like. It only sees patterns — not consequences.
That’s why you can get good suggestions, but rarely great ones. And almost never the kind that come from real-world experience.
5. You Still Have to Think Hard and Fix Things
Let’s bust the biggest myth:
AI doesn’t “do the work” for you.
It gives you something to start with. Sometimes it’s helpful. Sometimes it saves you 30 minutes. But you still have to think, fix, test, and adapt what it gives you.
- It won’t understand edge cases
- It won’t know business rules
- It won’t catch the things that make or break your use case
So you’re still deeply involved. You can’t just hand off a task and expect done-for-you results. Not if quality matters.
Here’s the truth most AI fans won’t say out loud:
These tools are useful, but not trustworthy. They’re impressive, but not reliable. They’re fast, but not deep.
If you’re using them to support your thinking, great. If you’re using them to replace your thinking — you’re going to hit walls, fast.
So yes, use ChatGPT. Use Claude. Use Gemini. But always treat them like junior assistants — not senior experts. Don’t believe the praise. Don’t rely on the first answer. And don’t expect magic.
At the end of the day, your judgment still matters more than their output.
If you found this post helpful, consider supporting my work — it means a lot.
🚀 From Algorithms to Neural Networks: ML vs DL Explained
We often hear Machine Learning (ML) and Deep Learning (DL) used interchangeably, but they aren’t the same.
- Machine learning learns from training data and then performs on new data.
- It works well on structured data but classical ML models don't have layers, hence cannot work on complex data like image or do complex calculations.
- Deep learning is a subset of machine learning that uses many multilayered neural networks to model complex data. It uses artificial neural network.
- Example: image classification, speech recognition, and natural language processing.
Artificial neural networks (ANN): ANN's work on the logic on how brain can perform calculations. It consists of 3 layers:
- Input layer: receives data.
- Hidden layer: process and learn patterns.
- Output layer: generates results.
Convolution neural networks (CNN): CNNs are primarily used for image classification tasks.
- Input layer: The input image (represented as a matrix of pixel values) is fed into the network.
- Convolution layer: Here, most of the tasks takes place like extracting features.
- Pooling layer:Reduces dimensions while keeping key features.
- Activation layer: Activation functions (like ReLU) are applied after convolutional and fully connected layers to add non linearity to the model so that it can understand complex patterns.
- Fully connected layer: Combines extracted feature for classification.
- Output layer: Produces the final prediction (e.g., softmax for multi-class classification, sigmoid for binary classification, linear for regression).
Recurrent neural networks (RNN): It is used in sequential data. It requires memory, remembering past data etc. It is used in tasks like Natural language processing, Stock price prediction etc.
- RNN is used for tasks like predicting next word.
Develop React Native Apps Without Emulator or Simulator – Just Mirror!
If you’re a React Native developer on macOS and tired of booting up heavy simulators or Android emulators, there’s a better way.
I skip them entirely — and mirror real devices via USB instead. This approach lets me simulate the app visually on-screen, without needing to run an emulator or simulator at all.
- macOS Sequoia 15.3.2
- React Native CLI
- Android Device + Vysor (USB mirroring)
- iPhone + macOS’s built-in iPhone Mirroring
Vysor is a simple way to mirror an Android device to your Mac screen. Even with the free version (USB only), it works great for development. You need to install Vysor on Mac and once you start the application with Android Device connected it will ask to install vysor on Android Device. Then it will show you a panel like this.

Steps:
- Enable USB Debugging on Android
- Connect via USB
- Launch Vysor and mirror the device
- Run your app
npx react-native run-android
Now you see the app on your Mac — via your real Android phone.

With macOS 15.3.2 (Sequoia), Apple introduced native iPhone Mirroring. Here are the steps to mirror iPhone.
Steps:
- Connect via USB
- Lock your iPhone
- Click on connect button in mirroring panel
- Enter iPhone password in iPhone
- See it working

- Works on real hardware
- Mirrors the exact device UX
- No more slow simulators
- Works with React Native DevMenu, console logs, and debugging
- USB-based — no need to rely on wireless pairing
- Still has lots of space on screen to work with

If all you need is to see and interact with your app on-screen, simulators are optional. Mirroring your real devices is a fast, reliable alternative — especially if you already work on macOS Sequoia.
If you found this post helpful, consider supporting my work — it means a lot.
🔥 How I Replaced My Entire Backend With Supabase in 3 Hours — Real Talk, Real Code
🔥 How I Replaced My Entire Backend With Supabase in 3 Hours — Real Talk, Real Code

What if I told you that you could replace your entire backend — from authentication to database to RESTful APIs — in 3 hours, securely and scalably, with practically no server setup? Sounds like clickbait?
Not today. I'm here to report my experience of migrating a fully custom Node.js + PostgreSQL backend to Supabase. I hit real walls, found real solutions, and wrote real code. Buckle up, let’s go full-stack.
- Replaced custom backend with Supabase in ~3 hours.
- Got Auth (OAuth, email, magic link), DB (PostgreSQL), Realtime, API, Role-based Access Control.
- All secure by default.
- Reduced backend code by 80%.
- No monthly bill yet (free tier generous).
My original setup:
- 🍃 Node.js Express server
- 🐘 Hosted PostgreSQL on Heroku
- 🛡️ Custom auth logic with JWT
- 🚧 REST API built manually with validation
- 📩 Nodemailer for email magic links
What I wanted:
- Fewer moving pieces
- More time for frontend work (which users actually see)
Supabase promised:
"Firebase, but open source and powered by PostgreSQL."
So I bit the bullet.
1. 🔧 Setting Up Supabase
You can start with a free hosted Supabase project:
npx supabase init
npx supabase start # if you want a local dev instance
OR create your project directly in Supabase Studio.
2. 🧠 Migrating My PostgreSQL Schema
I already had a schema.sql file. Importing it was as easy as:
supabase db push
Supabase uses native PostgreSQL under the hood — so ANY SQL you used before will work here.
🔥 Bonus: Supabase auto-generates REST & GraphQL APIs based on your schema!
3. 👥 Replacing Authentication
Instead of coding OAuth from scratch, Supabase gives you a prebuilt auth system.
With a simple setup, I had:
- Email/password sign in
- Magic links
- Google & GitHub OAuth
import { createClient } from '@supabase/supabase-js';
const supabase = createClient(YOUR_SUPABASE_URL, YOUR_SUPABASE_KEY);
// Sign up a user
const { user, error } = await supabase.auth.signUp({
email: 'hello@example.com',
password: 'securepassword'
});
You can also listen to auth state changes:
supabase.auth.onAuthStateChange((event, session) => {
console.log('Auth event:', event);
});
All tokens are handled with localStorage or cookies.
You get SSR-friendly APIs (especially with Next.js).
4. 📦 Replacing API Endpoints
Here’s where it gets magical.
From PostgreSQL tables, Supabase automatically gives you REST endpoints:
GET /rest/v1/tasks
POST /rest/v1/tasks
Need GraphQL? It's also enabled by default:
POST /graphql/v1
Want filters?
GET /rest/v1/tasks?user_id=eq.42&completed=is.false
Security? Use Supabase's Row-Level Security (RLS) using PostgreSQL policies:
CREATE POLICY "Users only access their tasks"
ON tasks
FOR SELECT USING (auth.uid() = user_id);
Now, Supabase enforces that users only read their own tasks. No custom backend logic. 🤯
5. 🔄 Replacing Realtime Functionality
I had a chat feature using WebSockets and Redis pub/sub.
Supabase Realtime lets you subscribe to PostgreSQL changes directly:
supabase
.channel('messages')
.on('postgres_changes', { event: '*', schema: 'public', table: 'messages' }, (
payload) => {
console.log('New message:', payload);
})
.subscribe();
No servers, just pure magic.
6. ⬇️ Reducing Codebase Size
After migrating:
- Backend files dropped from 55 → 7.
- No more CORS config.
- No auth edge cases.
- No API docs creation — Supabase Studio does it automatically.
Everything is connected via environment variables and secure JWT auth. Step 1 to production ready.
🧪 Real Case: Task Tracker Migration
I created a minimal tasks CRUD app.
- ✅ Authenticated users
- ✅ Tasks table with triggers for timestamps
- ✅ Auto-generated REST API for data access
- ✅ RLS to enforce auth
Frontend used Vue with Supabase client. Here's basic CRUD:
// Fetch tasks
const { data } = await supabase
.from('tasks')
.select('*')
.order('created_at', { ascending: false });
// Add task
await supabase.from('tasks').insert({ title: 'Buy milk' });
// Update task
await supabase.from('tasks').update({ completed: true }).eq('id', 42);
// Delete task
await supabase.from('tasks').delete().eq('id', 42);
- RLS is off by default. You need to enable row-level security + add policies for each table.
- Supabase keys vs JWT confusion. Read docs carefully.
- Local dev can be tricky. Supabase CLI has improved, but starting locally can still trip you up — Docker required.
| 🔥 Pros | 💩 Cons |
|---|---|
| PostgreSQL inside 🐘 | No fine-grain GraphQL filters |
| Push to production fast | Limited built-in triggers |
| Integrated Auth + Storage | Less control vs custom server |
| Free tier is generous | Still growing (beta features) |
✅ Perfect for rapid MVPs, internal tools, data-centric apps.
✅ Tight budgets (free tier generous).
✅ When you want to focus on UX, not backend plumbing.
🚫 Not ideal yet for complex multi-tenant SaaS or super low-latency apps.
Supabase is production-capable, if you're okay with some abstraction. It’s basically Postgres with superpowers like instant APIs, Auth, and Realtime.
If Firebase didn't sit right with your OSS heart, Supabase will.
If you love SQL, you'll feel at home.
🧙♂️ My backend now feels like a plugin — I can focus 90% of my time on frontend UX. Honestly, that's the future.
👇 Have you tried Supabase? What was your experience?
Share it in the comments below or tweet @me with your wins or fails!
⚡️ If you need this done – we offer Fullstack Development services.
Start at the End: Logic Programming for the Imperatively Damaged
A book by Claude Code Opus 4.1. Covers Prolog, Mercury, and MiniKanren.
I built an initial data syncing system for Django projects
One recurring headache in Django projects is keeping seed data consistent across environments.
- You add reference data (categories, roles, settings) in development… and forget to sync it to staging or production.
- Different environments drift apart, leading to version conflicts or missing records.
- Deployment scripts end up with ad-hoc JSON fixtures or SQL patches that are hard to maintain.
I got tired of that. So I built django-synced-seeders — a simple, ORM-friendly way to version and sync your seed data.
- Versioned seeds: Every export is tracked so you don’t re-import the same data.
-
Environment sync: Run
syncseedsin staging or production to automatically bring them up to date. - Export / Import commands: Seamlessly move reference data between environments.
- Selective loading: Only load the seeds you need by defining exporting QuerySets.
pip install django-synced-seeders
or use uv
uv add django-synced-seeders
Add it to INSTALLED_APPS in settings.py, then run:
python manage.py migrate
Define your seeders (e.g. seeders.py):
from seeds.registries import seeder_registry
from seeds.seeders import Seeder
from .models import Category, Tag
@seeder_registry.register()
class CategorySeeder(Seeder):
seed_slug = "categories"
exporting_querysets = (Category.objects.all(),)
delete_existing = True
@seeder_registry.register()
class TagSeeder(Seeder):
seed_slug = "tags"
exporting_querysets = (Tag.objects.all(),)
Export locally:
python manage.py exportseed categories
python manage.py exportseed tags
Sync on another environment:
python manage.py syncseeds
Now your development, staging, and production stay aligned — without manual JSON juggling.
- Prevents “works on my machine” seed data issues.
- Keeps environments aligned in CI/CD pipelines.
- Easier to maintain than fixtures or raw SQL.
- Open source (MIT license) and ready for contributions.
If you’ve ever wrestled with fixtures or forgotten to copy seed data between environments, I think you’ll find this useful.
👉 Check it out here: github.com/Starscribers/django-synced-seeders
👉 Join my Discord Server: https://discord.gg/ngE8JxjDx7
KEXP: Derya Yıldırım & Grup Şimşek - Full Performance (Live on KEXP)
Derya Yıldırım & Grup Şimşek Live on KEXP
On July 31, 2025, Turkish psych-folk dynamo Derya Yıldırım & Grup Şimşek took over the KEXP studio with a four-song set—Direne Direne, Cool Hand, Bal and Hop Bico. Derya’s soaring vocals and saz weave through Axel Oliveres’s organ and synth textures, Helen Wells’s driving drum grooves and Alana Amram’s funky bass lines, all captured by host Evie Stokes and a top-notch audio/video team.
Catch more from the band on their Bandcamp and revisit the full performance on KEXP’s site for a taste of fresh, genre-bending vibes.
Watch on YouTube
Golf.com: The Mystery Of Bethpage Black’s Unique Warning Sign
Bethpage Black’s infamous warning sign—it’s more than just a cheeky dare before you tee off; it’s a piece of golf lore. In his new video, GOLF’s Josh Berhow dives into old records, busts the wild origin myths and finally pins down when that “you better be good” message first appeared.
Hungry for more? GOLF.com is your backstage pass to the game—Top 100 courses and teachers, exclusive pro interviews, gear reviews and all the latest Tour buzz. Subscribe to their channels and never miss a swing.
Watch on YouTube
Rechart stroke line issue at joining point

This is my code. I am trying to implement stroke when data is empty. but the stroke is coming slight bigger at the joining point which is the top most like below image. Can you please help how it can be resolved?

GameSpot: Hades 2 Review
Hades 2 bursts out of early access with everything you loved about the original turned up to eleven: a bigger world, more characters and banter, an arsenal of fresh weapons and deeper build choices.
Despite its expanded scope, it never loses that signature spark—each run feels as tight, rewarding and addictive as ever. A must-play sequel that builds on the first game without missing a beat.
Watch on YouTube
GameSpot: Hotel Barcelona - Suda51's Cheeseburger Launch Trailer
From the creators of Deadly Premonition and No More Heroes comes Hotel Barcelona: you’re a marshal possessed by a murderer checking into a hotel teeming with killers. Check in on Sep 26, 2025—and start wiping them out in Suda51’s wild “Cheeseburger” launch trailer.
Shot by director of photography Mark Lentz and co-produced by Badvertising, with special props to Scott Popular and Kyle Hovanec for making this madcap mayhem possible.
Watch on YouTube
GUC Launches Next – Generation 2.5D/3D APT Platform Leveraging TSMC’s Latest 3DFabric® and Advanced Process Technologies
GUC. has launched its next-gen 2.5D/3D ATP platform to accelerate design cycles and lower risks for high-performance ASICs.
The post GUC Launches Next – Generation 2.5D/3D APT Platform Leveraging TSMC’s Latest 3DFabric® and Advanced Process Technologies appeared first on EE Times.
How Huawei Reduces Design Time and Improves Confidence in Thermal Models
Huawei leverages Simcenter Micred T3STER and Simcenter Flotherm's automatic calibration to achieve precise thermal models for SoC/SiP devices, reducing design time and improving confidence.
The post How Huawei Reduces Design Time and Improves Confidence in Thermal Models appeared first on EE Times.
eFPGA – Hidden Engine of Tomorrow’s High-Frequency Trading Systems
What are the modern challenges facing designers of high-frequency trading systems? High-frequency trading (HFT) system designers face challenges that go far beyond raw speed. Today, it’s about squeezing out nanoseconds while managing ever-growing complexity, security risks, and regulatory pressures. Every picosecond matters – profitability is directly tied to latency, with firms pushing closer to the […]
The post eFPGA – Hidden Engine of Tomorrow’s High-Frequency Trading Systems appeared first on EE Times.
Designing a Qubit is One Thing, Achieving Large-Scale Quantum Computing is Another
Developing a scalable quantum solution will require more than just selecting the qubit on which to base it.
The post Designing a Qubit is One Thing, Achieving Large-Scale Quantum Computing is Another appeared first on EE Times.
Neurophos Photonic AI Test Chip Hits 300 TOPS/W
AI chip startup Neurophos has demonstrated its metasurface based optical compute modulators in silicon
The post Neurophos Photonic AI Test Chip Hits 300 TOPS/W appeared first on EE Times.
From Sydney to Smart Cities: Morse Micro on the Road to IoT 2.0
Fresh funding and next-gen platforms give Sydney-based Morse Micro a step up in delivering long-range, low-power connectivity for the intelligent IoT era.
The post From Sydney to Smart Cities: Morse Micro on the Road to IoT 2.0 appeared first on EE Times.
Electrical Safety Considerations
Electrification trends demand higher voltages (e.g., 48V, 800V) for efficiency, raising isolation needs, especially in automotive applications.
The post Electrical Safety Considerations appeared first on EE Times.
AV STEP Perspectives: NHTSA’s NPRM for Autonomous Vehicles
These application requirements will provide information to NHTSA for making decisions on terms and conditions for participation.
The post AV STEP Perspectives: NHTSA’s NPRM for Autonomous Vehicles appeared first on EE Times.
Alibaba Unveils Own AI Chip, Mounting Direct Challenge to Nvidia
Alibaba unveils its T-Head PPU, a homegrown AI chip designed to rival Nvidia's H20.
The post Alibaba Unveils Own AI Chip, Mounting Direct Challenge to Nvidia appeared first on EE Times.
The ThermoWorks Thermapen One is 30 percent off right now
When it comes to cooking meat, finding that all-important sweet spot between under- and over-cooked can be tricky to get right every single time. That is, unless you’re using one of the ThermoWorks instant-read thermometers that we’ve been big proponents of for a long time. And right now our favorite one is down to a record low of $76 in select colors, as part of the brand’s fall warehouse sale. Usually priced at $109, you’re saving $33 if you pick one up now.
The Thermapen One records accurate temperatures in an instant (specifically one second or less), which can be the difference between a perfectly medium-rare steak and one that requires a bit too much chewing. This model also has a handy auto-rotating backlit display that allows you to easily see the reading regardless of how you’re holding it. It also has useful auto-wake and sleep features, which again, are useful when doneness deals in seconds. An IP67 waterproofing rating means you don’t have to worry about it getting splashed. That said, the thermometer isn’t suitable for dishwashers, so keep that in mind.
The Thermapen One took home our best thermometer award, so this is definitely a deal we’d confidently recommend taking advantage of, but it isn’t the only one available right now. ThermoWorks’ sale also includes offers on its various BBQ alarm thermometers, battery banks, kitchen utensils and more. You can shop all the deals here.
Follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/the-thermoworks-thermapen-one-is-30-percent-off-right-now-163043164.html?src=rss
The best VPN deals: Get up to 87 percent off ProtonVPN, ExpressVPN, Surfshark and more
A virtual private network (VPN) can come in handy daily, whether you're using one to streaming foreign TV shows or trying to save money buy browsing international sites for discounts. But if you're going to invest in a VPN, it's worth checking for sales and deals first before you subscribe. Pricing can be tricky for these services — and far from transparent — but there are deals to be had.
VPN provides often provide deep discounts to those willing to sign up for one- or two-year plans, paying the full charge for the period upfront. This is a win-win — they boost their subscriber numbers, and you get heavy price cuts on some of our favorite services. Most of the deals we highlight below follow that pattern, so make sure you're comfortable with a longer commitment before you take the plunge. If you've been thinking about subscribing to a VPN service, read on for the best VPN deals we could find right now.
NordVPN — $83.43 for a two-year subscription with three months free (77 percent off): NordVPN gets the most important parts of a VPN right. It's fast, it doesn't leak any of your data and it's great at changing your virtual location. I noted in my NordVPN review that it always connects quickly and includes a support page that makes it easy to get live help. Although I'm sad to see it shutting down Meshnet, NordVPN still includes a lot of cool features, like servers that instantly connect you to Tor. This deal gives you 77 percent off the two-year plan, which also comes with three extra months — but there's no expiration date, so you have a little time for comparison shopping.
ExpressVPN Basic — $97.72 for a two-year subscription with four months free (73 percent off): This is one of the best VPNs, especially for new users, who will find its apps and website headache-free on all platforms. In tests for my ExpressVPN review, it dropped my download speeds by less than 7 percent and successfully changed my virtual location 14 out of 15 times. In short, it's an all-around excellent service that only suffers from being a little overpriced — which is why I'm so excited whenever I find it offering a decent deal. This deal, which gets you 28 months of ExpressVPN service, represents a 73 percent savings. It's the lowest I've seen ExpressVPN go in some time, though like NordVPN, it's not on a ticking clock.
ExpressVPN Advanced — $125.72 for a two-year subscription with four months free (67 percent off): ExpressVPN recently split its pricing into multiple tiers, but they all still come with similar discounts for going long. In addition to top-tier VPN service, advanced users get two additional simultaneous connections (for a total of 12), the ExpressVPN Keys password manager, advanced ad and tracker blocking, ID protection features and a 50 percent discount on an AirCove router.
Surfshark Starter — $53.73 for a two-year subscription with three months free (87 percent off): This is the "basic" level of Surfshark, but it includes the entire VPN; everything on Surfshark One is an extra perk. With this subscription, you'll get some of the most envelope-pushing features in the VPN world right now. Surfshark has a more closely connected server network than most VPNs, so it can rotate your IP constantly to help you evade detection — it even lets you choose your own entry and exit nodes for a double-hop connection. That all comes with a near-invisible impact on download speeds. With this year-round deal, you can save 87 percent on 27 months of Surfshark.
Surfshark Starter+ — $59.13 for a two-year subscription with three months free (87 percent off): If you want some of the extra features of the Surfshark suite but aren't interested in jumping all the way to Surfshark One, try this intermediate tier instead. Starter+ includes Alternative ID, which you can use to mask your details when you sign up for online accounts, and Surfshark Search, a private search engine with no ads or activity tracking. This is another year-round deal that works out to an 86 percent discount.
Surfshark One — $67.23 for a two-year subscription with three months free (86 percent off): A VPN is great, but it's not enough to protect your data all on its own. Surfshark One adds several apps that boost your security beyond just VPN service, including Surfshark Antivirus (scans devices and downloads for malware) and Surfshark Alert (alerts you whenever your sensitive information shows up in a data breach), plus Surfshark Search and Alternative ID from the previous tier. This evergreen deal gives you 86 percent off all those features. If you bump up to Surfshark One+, you'll also get data removal through Incogni, but the price jumps enough that it's not quite worthwhile in my eyes.
CyberGhost — $56.94 for a two-year subscription with two months free (83 percent off): CyberGhost has some of the best automation you'll see on any VPN. With its Smart Rules system, you can determine how its apps respond to different types of Wi-Fi networks, with exceptions for specific networks you know by name. Typically, you can set it to auto-connect, disconnect or send you a message asking what to do. CyberGhost's other best feature is its streaming servers — while it's not totally clear what it does to optimize them, I've found both better video quality and more consistent unblocking when I use them on streaming sites. Currently, you can get 26 months of CyberGhost for 83 percent off the usual price.
Private Internet Access — $79 for a three-year subscription with three months free (83 percent off): It's a bit hard to find (the link at the start of this paragraph includes the coupon), but Private Internet Access (PIA) is giving out the best available price right now on a VPN I'd recommend using. With this deal, you can get 39 months of PIA for a little bit over $2 per month — an 83 percent discount on its monthly price. Despite being so cheap, PIA almost never comes off as a budget VPN, coming with its own DNS servers, a built-in ad blocker and automation powers to rival CyberGhost. However, internet speeds can fluctuate while you're connected.
Like I said in the intro, practically every VPN heavily discounts its long-term subscriptions the whole year round. The only noteworthy exception is Mullvad, the Costco hot dog of VPNs (that's a compliment, to be clear). When there's constantly a huge discount going on, it can be hard to tell when you're actually getting a good deal. The best way to squeeze out more savings is to look for seasonal deals, student discounts or exclusive sales like Proton VPN's coupon for Engadget readers.
One trick VPNs often use is to add extra months onto an introductory deal, pushing the average monthly price even lower. When it comes time to renew, you usually can't get these extra months again. You often can't even renew for the same basic period of time — for example, you may only be able to renew a two-year subscription for one year. If you're planning to hold onto a VPN indefinitely, check the fine print to see how much it will cost per month after the first renewal, and ensure that fits into your budget.
Follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/best-vpn-deals-120056041.html?src=rss
Instagram reaches 3 billion monthly users
Nearly 15 years in, Instagram has passed a new milestone: the app now reaches 3 billion monthly users, Mark Zuckerberg shared in a post on Threads. That's up from 2 billion monthly users in 2022.
Meta doesn't regularly share monthly or daily user numbers for its "family" of apps, but Facebook reached 2 billion daily users in 2023; WhatsApp passed 2 billion monthly users in 2020. The company reported 3.48 billion "daily active people" across facebook, WhatsApp and Messenger last quarter.
Meta shared the latest metric as it reportedly plans some significant changes to Instagram. According to Bloomberg, Meta will soon make Reels an even more prominent part of the app. Instagram exec Adam Mosseri told the publication that users will see a redesigned navigation bar that will "highlight private messaging and Reels." The company will also run a test in South Korea and India that will allow users to set Reels as the default feed for the app. (Instagram's newly-announced iPad app already makes Reels the default feed in order "to reflect how people use bigger screens today," the company has said.)
It's probably no coincidence that these changes come as the United States government edges closer toward an agreement that will put the US version of TikTok largely in the hands of US-based investors. Despite more than a year of uncertainty surrounding the app's future in the United States, TikTok is still a formidable competitor to Meta more broadly and Instagram specifically.
This article originally appeared on Engadget at https://www.engadget.com/social-media/instagram-reaches-3-billion-monthly-users-160554420.html?src=rss
Google's AI Search Live is now available to all US app users
Search Live is now available for Google app users in the US, offering real-time, multimodal search, powered by AI. This feature will enable users to have real-time conversations with Google Search in AI Mode while sharing their phone's camera feed with the app. Search will be able to see and interpret what the user's camera is focused on and offer relevant links for deeper context, as well as live guidance.
The new feature can be accessed from a new "Live" icon beneath the search bar in the Google app. It can also be used from Google Lens by selecting the Live option at the bottom of the screen. Camera sharing will be enabled by default here to allow for an instant back-and-forth conversation about whatever is in front of you.
Search Live is available through the Google app on iOS and Android now. This wider rollout only supports English for now.
This article originally appeared on Engadget at https://www.engadget.com/ai/googles-ai-search-live-is-now-available-to-all-us-app-users-151849371.html?src=rssThe best October Prime Day deals to get today: Early sales on tech from Apple, Roku, Shark, Anker and more
October Prime Day will be here soon on October 7 and 8, but as to be expected, you can already find some decent sales available now. Amazon always has lead-up sales in the days and weeks before Prime Day, and it’s wise to shop early if you’re on the hunt for something specific and you see that item at a good discount.
Prime Day deals are typically reserved for subscribers, but there are always a few that anyone can shop. We expect this year to be no exception, and we’re already starting to see that trend in these early Prime Day deals. These are the best Prime Day deals you can get right now ahead of the event, and we’ll update this post with the latest offers as we get closer to October Prime Day proper.
Apple iPad (A16) for $299 ($50 off): The new base-model iPad now comes with twice the storage of the previous model and the A16 chip. That makes the most affordable iPad faster and more capable, but still isn't enough to support Apple Intelligence.
Apple Mac mini (M4) for $499 $100 off): If you prefer desktops, the upgraded M4 Mac mini is one that won’t take up too much space, but will provide a ton of power at the same time. Not only does it come with an M4 chipset, but it also includes 16GB of RAM in the base model, plus front-facing USB-C and headphone ports for easier access.
Apple iPad Air (11-inch, M3) for $449 ($150 off): The only major difference between the latest iPad Air and the previous generation is the addition of the faster M3 chip. We awarded the new slab an 89 in our review, appreciating the fact that the M3 chip was about 16 percent faster in benchmark tests than the M2. This is the iPad to get if you want a reasonable amount of productivity out of an iPad that's more affordable than the Pro models.
Jisulife Life7 handheld fan for $25 (14 percent off, Prime exclusive): This handy little fan is a must-have if you life in a warm climate or have a tropical vacation planned anytime soon. It can be used as a table or handheld fan and even be worn around the neck so you don't have to hold it at all. Its 5,000 mAh battery allows it to last hours on a single charge, and the small display in the middle of the fan's blades show its remaining battery level.
Roku Streaming Stick Plus 2025 for $29 (27 percent off): Roku makes some of the best streaming devices available, and this small dongle gives you access to a ton of free content plus all the other streaming services you could ask for: Netflix, Prime Video, Disney+, HBO Max and many more.
Anker 622 5K magnetic power bank with stand for $34 (29 percent off, Prime exclusive): This 0.5-inch thick power bank attaches magnetically to iPhones and won't get in your way when you're using your phone. It also has a built-in stand so you can watch videos, make FaceTime calls and more hands-free while your phone is powering up.
Leebein 2025 electric spin scrubber for $40 (43 percent off, Prime exclusive): This is an updated version of my beloved Leebein electric scrubber, which has made cleaning my shower easier than ever before. It comes with seven brush heads so you can use it to clean all kinds of surfaces, and its adjustable arm length makes it easier to clean hard-to-reach spots. It's IPX7 waterproof and recharges via USB-C.
Anker Nano 5K ultra-slim power bank (Qi2, 15W) for $46 (16 percent off): A top pick in our guide to the best MagSafe power banks, this super-slim battery is great for anyone who wants the convenient of extra power without the bulk. We found its proportions work very well with iPhones, and its smooth, matte texture and solid build quality make it feel premium.
Samsung EVO Select microSD card (256GB) for $23 (15 percent off): This Samsung card has been one of our recommended models for a long time. It's a no-frills microSD card that, while not the fastest, will be perfectly capable in most devices where you're just looking for simple, expanded storage.
JBL Go 4 portable speaker for $40 (20 percent off): The Go 4 is a handy little Bluetooth speaker that you can take anywhere you go thanks to its small, IP67-rated design and built-in carrying loop. It'll get seven hours of playtime on a single charge, and you can pair two together for stereo sound.
Anker MagGo 10K power bank (Qi2, 15W) for $63 (22 percent off, Prime exclusive): A 10K power bank like this is ideal if you want to be able to recharge your phone at least once fully and have extra power to spare. This one is also Qi2 compatible, providing up to 15W of power to supported phones.
Rode Wireless Go III for $199 (30 percent off): A top pick in our guide to the best wireless microphones, the Wireless Go III records pro-grade sound and has handy extras like onboard storage, 32-bit float and universal compatibility with iPhones, Android, cameras and PCs.
Shark AI robot vacuum with self-empty base for $300 (54 percent off): A version of one of our favorite robot vacuums, this Shark machine has strong suction power and supports home mapping. The Shark mobile app lets you set cleaning schedules, and the self-empty base that it comes with will hold 60 days worth of dust and debris.
Nintendo Switch 2 for $449: While not technically a discount, it's worth mentioning that the Switch 2 and the Mario Kart Switch 2 bundle are both available at Amazon now, no invitation required. Amazon only listed the new console for the first time in July after being left out of the initial pre-order/availability window in April. Once it became available, Amazon customers looking to buy the Switch 2 had to sign up to receive an invitation to do so. Now, that extra step has been removed and anyone can purchase the Switch 2 on Amazon.
Follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/the-best-october-prime-day-deals-to-get-today-early-sales-on-tech-from-apple-roku-shark-anker-and-more-050801467.html?src=rss
How to use Live Translation with AirPods
With the arrival of iOS 26, Apple’s Live Translation feature for AirPods is now ready for use. It’s available on older models of the company’s earbuds, so you don’t need the new AirPods Pro 3 to access it. There are some hardware and software requirements though, so let’s dive into what you’ll need before you can start translating conversations.
Live Translation on AirPods only works on models with the H2 chip. This includes the AirPods 4 with ANC, AirPods Pro 2 and AirPods Pro 3. You’ll also need an iPhone that can run Apple Intelligence, which is the iPhone 15 Pro, Pro Max or any member of the iPhone 16 or iPhone 17 lineups.
Once you have your hardware at the ready, you’ll need to make sure Apple Intelligence is turned on in the Settings app on your iPhone. You’ll also need to make sure that Apple’s Translate app is installed as it’s needed to power this whole thing. Lastly, your AirPods should be on the latest firmware, and you can check that in the AirPods settings menu on your iPhone.
The first step towards using Live Translation is to download the languages you’ll need. What’s more, you’ll have to download both the language you’re speaking and the one the other person is speaking. For example, if you’re translating Spanish to English, you’ll need to download both the Spanish and English language packs (yes, even if your phone’s system is already set to English). I’d recommend downloading all of the languages you think you’ll need before traveling, that way you aren’t trying to do so in the moment you need them.
Once this is done, all of the processing for Live Translation will happen on your iPhone and your conversation data is private. You will also be able to use Live Translation offline, too, so you won’t have to worry about finding a Wi-Fi connection or buying a local SIM card.
How to complete the download process:
Put your AirPods in your ears and make sure they’re connected to your iPhone.
Go to the Settings app and tap the name of your AirPods on the main menu.
Under the Translation section, tap Languages and then select the ones you want to download by tapping the download icon (downward arrow on the right).
This screen will show what languages you’ve downloaded and which ones are available. At launch, Live Translation works with English, French, German, Portuguese and Spanish. Support for Italian, Japanese, Korean and Chinese (simplified) is coming by the end of the year.
After you’ve downloaded the languages you need, you’ll have to set up a Live Translation conversation before you can start talking. This tells the Translate app which language to listen for and which one to translate it to.
To set up a Live Translation conversation you need to:
Put your AirPods in your ears and make sure they’re connected to your iPhone.
Double check to make sure Apple Intelligence is turned on. A quick way to confirm this is by long-pressing the Camera Control key or pressing the power and volume up buttons at once to see if the Visual Intelligence interface appears.
Go to the Translate app and tap “Live” on the menu along the bottom.
Select the language the other person is speaking.
Select the language you want your AirPods to translate to.
After you’ve completed all of those set-up steps, you’re ready for a Live Translation session. There are a number of ways to activate the feature when it’s ready to use, and some of them allow you to do so without even having to reach for your phone.
All the ways you can start Live Translation:
Go to the Translate app, select Live from the menu and then tap Start Translation.
Set the Action button on your iPhone to automatically start Live Translation when you’re wearing your AirPods.
Press and hold the stems on both AirPods at the same time.
Ask Siri by saying “Siri, start Live Translation.”
Open Control Center by swiping down from the top right corner of your screen, then tap Translate.
How to use Live Translation in a conversation:
After you’ve done one of the five options above, your session will begin. If you don't open the Translate app, you’ll see a notification and a Live Translation icon will remain in the Dynamic Island. You’ll also hear a chime in your AirPods and Siri will let you know the translation has begun.
Listen to the other person speaking. AirPods will translate what the person says to your selected language. Active noise cancellation (ANC) will automatically turn on to lower the voice of the speaker and environmental noise so that you can focus on Siri’s translated speech.
In very noisy settings, you can use your iPhone’s microphones in addition to AirPods to enhance performance. To do this, simply move your phone closer to the person speaking.
Say your response as you would during a normal conversation.
Use the Live tab in the Translate app to show a transcript on your iPhone to the person you’re speaking with. You can also press the Play button to hear an audible translation over your iPhone speaker.
The person you’re speaking with can also use AirPods to hear your translated responses. They will need a compatible set of AirPods, an iPhone that supports Apple Intelligence and to set up and start a Live Translation themselves.
To stop Live Translation, tap the X button in the Translate app.
Apple’s Live Translation feature is still in beta at this time. And since the tool relies on generative models for translation, the company warns that the results may be “inaccurate, unexpected or offensive.” You’ll want to double check any important information — like addresses, directions and contact information — for accuracy.
This article originally appeared on Engadget at https://www.engadget.com/audio/headphones/how-to-use-live-translation-with-airpods-144837882.html?src=rss
Yakuza Kiwami 3 is official, and it’s out next year with a bonus new spinoff game
Following Sega’s Ryu Ga Gotoku Studios accidentally leaking the game's existence last week, Yakuza Kiwami 3 has been officially announced by the developer during its RGG Summit presentation. Like Yakuza Kiwami and Yakuza Kiwami 2 before it, Yakuza Kiwami 3 is a full remake of an early entry in the long-running series, in this case 2009’s Yakuza 3, which originally launched on the PlayStation 3.
Yakuza Kiwami 3 is another ground-up remake from RGG, featuring modern graphics, enhanced gameplay and new cutscenes. The game continues the adventures of the (at this point in the story) middle-aged Kazuma Kiryu, who temporarily puts his criminal career on hold to help run an orphanage that will become very important in later entries in the series. Yakuza Kiwami 3 is also bundled with a free spinoff game called Dark Ties, which focuses on Kiryu’s adversary, Yoshitaka Mine.
Yakuza Kiwami 3 and Dark Ties will be released on February 12, 2026, for PS4 and PS5, Xbox and PC (Steam), as well as the Switch 2. Yakuza Kiwami and Yakuza Kiwami 2 are both coming to Switch 2 later this year, and RGG has also announced that Yakuza 0: Director’s Cut is coming to PS5, Xbox and PC on December 8. The expanded version of what many consider to be the best Yakuza game of all time has been a Switch 2 exclusive until now.
This week’s RGG Summit also gave us a brief update on the studio’s next game, Stranger Than Heaven, which we still know very little about, other than that it’s separate from the Like a Dragon and Judgement series and is set during multiple time periods in the 20th century. The game is still several years away from release, but a new behind the scenes trailer shows off snippets of in-game footage and motion capture sessions with actors.
At the time of writing, we’re still waiting for an announcement of the next Like a Dragon game, with the most recent entry being this year’s wonderfully titled Like a Dragon: Pirate Yakuza in Hawaii.
This article originally appeared on Engadget at https://www.engadget.com/gaming/yakuza-kiwami-3-is-official-and-its-out-next-year-with-a-bonus-new-spinoff-game-140315189.html?src=rss
Proton VPN review 2025: A nonprofit service with premium performance
Proton VPN stands out for two main reasons: it's one of the only virtual private networks (VPNs) to include a free plan with no data limits, and it's one of the few services majority-owned by a nonprofit. It's the best VPN in both of those categories, and it makes a strong case for being the best overall.
Even if you don't care about the work of the Proton Foundation, Proton VPN is a service worth using. It's easy to install and manage, runs like the wind and meets high standards for security and privacy. It has more IP locations in Africa than any of its competitors. It's even looking toward the future by working toward full IPv6 support.
In short, Proton VPN gets our enthusiastic recommendation, especially for torrenting (which it supports on almost every server). It's not perfect — the apps for Apple systems lag behind their Windows and Android counterparts, and the free servers can be noticeably sluggish — but the cons pale in comparison to the pros. We'll get into it all below.
Editor's note (9/23/25): Editor's note: We've overhauled our VPN coverage to provide more detailed, actionable buying advice. Going forward, we'll continue to update both our best VPN list and individual reviews (like this one) as circumstances change. Most recently, we added official scores to all of our VPN reviews. Check out how we test VPNs to learn more about the new standards we're using.
The table summarizes what we found while reviewing Proton VPN, both good and bad. Keep it open in a tab while you comparison shop for a VPN.
Category | Notes |
Installation and UI | Windows has the best interface, but all apps are smooth Android users get unique preset protocols Browser extensions for Chrome and Firefox can be used for split tunneling on Mac and iOS |
Speed | Retains 88 percent of download speeds and 98 percent of upload speeds Global latency average stays under 300 ms, with 52 ms on the fastest server |
Security | No DNS leaks or WebRTC leaks on any servers Full IPv6 support is available on Android, Linux and browser extensions; Mac, Windows and iOS still block IPv6 to prevent leaks WireShark test showed active packet encryption |
Pricing | Best plan costs $81.36 for two years ($3.39 per month) Free plan includes unlimited data and critical security features, but you can't choose your server |
Bundles | Proton Unlimited saves money if you want two or more Proton products |
Privacy policy | General Proton policy prevents collection of IP addresses unless a user has violated the terms of service (such as by using a Proton VPN server to abuse another site) No third parties are allowed to handle personally identifiable information Confirmed by Securitum audit in 2024 |
Virtual location change | Unblocked Netflix repeatedly in all five testing locations, with new content proving a successful location change A free server in Romania got into Netflix but had trouble loading the library |
Server network | 154 locations in 117 countries More servers in Africa than any other VPN, plus many others across the globe About two-thirds of server locations are virtual |
Features | NetShield can block just malware, or all malware, ads and trackers Kill switch on all platformsSplit tunneling on Windows, Android and browser extensions only Secure Core servers route VPN through two locations, one of which is physically secured in Iceland, Sweden or Switzerland Almost all paid servers are P2P-enabled Tor over VPN servers in six countries let you access dark web sites from any browser Profiles saves time when you repeatedly need specific connection settings |
Customer support | Most articles in the online help center, while well-written, are invisible unless you use the search function Live chat is only for paying customers, and is unavailable from midnight to 9 AM CET |
Background check | Launched in 2017 by the same company that developed ProtonMail Majority owned by the Proton Foundation, whose board includes the company founders and can resist takeover attempts While ProtonMail has worked with Swiss authorities in the past, Proton VPN is not governed by the same laws that compelled this Claims of a vulnerability in WireGuard's memory don't hold water |
This section explains how it feels to run Proton VPN on the various platforms it supports. As a rule, it's not difficult. Proton VPN has more features than ExpressVPN, and a couple of them might trip up new users, but you'd have to really scrounge to find an actual inconvenience to complain about.
Windows
Proton VPN installs easily on Windows — you'll need to grant it permission to make changes, but that's it. Once you've signed in on the app, you'll reach one of the best interfaces we've tried on a VPN. The server network is immediately visible as both a list and map, and the location search bar, connect button and major features are all laid out around the same window.
It's honestly amazing how much you can reach from the launch window without anything feeling cluttered. They even squeezed in keyboard shortcuts for the search field. We also love that settings open in the same window, since dealing with both the main VPN app and a separate preferences panel can get annoying. Our only real gripe is that there should be an easier way to adjust the size of the map.
Mac
The desktop app for Mac isn't quite as deftly laid out as the Windows app. You can reach most of the important features from the main window, including Profiles, NetShield, Secure Core servers and the kill switch. However, there's no longer a way to filter out a list of the P2P or Tor servers, except by digging through the Profile controls. On the plus side, you can adjust the size of the map, so it's now a viable alternative to the server list.
The other preferences are hidden in the menu bar — go to Proton VPN > Settings to reach them. They're laid out in four tabs, and shouldn't take more than a minute to go through at setup.
Android
The Android app takes the same design cues as the Windows app, and works as well. Four tabs along the bottom switch between the home screen, the country list, Profiles and all other settings. You can search the list of countries by tapping the magnifying glass at the top-right. In another nice touch, tapping the dots by any virtual location will tell you where the server is physically located.
Android users get some nifty exclusive Profiles, including "anti-censorship," which automatically connects to the fastest country except for the one you're in. The Settings tab is a single menu with subheadings and no unnecessary complication.
iOS
Proton VPN for iPhone and iPad looks almost the same as it does on Windows and Android, but with some of the same drawbacks found on Mac. The server list is more cluttered, and once again there's no easy way to sift out the P2P and Tor locations.
The Settings tab puts all the feature descriptions in the open, which makes it look denser than it is. But these are minor quibbles — this is still a VPN that's very easy to activate and forget about.
Browser extensions
Proton VPN has browser extensions for Chrome and Firefox. These serve as de facto split tunneling, as connecting through the extension protects only browser traffic; everything else goes unprotected. You can split the tunnel further by setting the VPN to not work on certain URLs (unlike the other apps, you don't need to know the IPs of those sites).
We used Ookla's Speedtest app to determine how much Proton VPN drags on a user's latency, measured in milliseconds (ms), and download and upload speeds, measured in megabits per second (Mbps). Together, these three stats show whether a VPN will noticeably slow down your internet, especially during demanding tasks.
We had high hopes for Proton here because of its VPN Accelerator technology, which runs VPN communications across several parallel tracks to process everything faster. It didn't disappoint — for the most part. Although download speeds didn't reach the heights we saw from ExpressVPN, Proton VPN's browsing performance still looks excellent nearly across the board.
To choose our locations for the test, we checked Proton VPN's list of smart routing servers, which use servers in one country to simulate IP addresses in another. Almost all the smart routing servers are based in five cities: Miami, London, Marseille, Bucharest and Singapore. We ran these tests on a Mac using the automatic protocol setting.
| Server Location | Latency (ms) | Increase factor | Download speed (Mbps) | Percentage drop | Upload speed (Mbps) | Percentage drop |
| Portland, OR, USA (unprotected) | 16 | -- | 58.93 | -- | 5.82 | -- |
| San Jose, CA, USA (best server) | 52 | 3.3x | 55.82 | 5 | 5.58 | 4 |
| Miami, FL, USA | 160 | 10x | 54.33 | 8 | 5.49 | 6 |
| London, UK | 332 | 20.8x | 52.55 | 11 | 5.72 | 2 |
| Marseille, France | 309 | 19.3x | 45.42 | 23 | 5.59 | 4 |
| Bucharest, Romania | 408 | 25.5x | 52.51 | 11 | 5.57 | 4 |
| Singapore, Singapore | 394 | 24.6x | 52.26 | 11 | 5.50 | 5 |
| Average | 276 | 17.3x | 52.15 | 12 | 5.58 | 4 |
Proton VPN looks very good in that table. Its average download speed was 88 percent of our unprotected speeds. To put that in perspective, if you started with 30 Mbps down (about half what we get) and connected to any Proton VPN server, you'd almost certainly still have a fast enough connection to stream in 4K.
Note the "almost" — Proton VPN did drop noticeably on its French server in Marseille. It's not uncommon for one of a VPN's data centers to have trouble while the others work fine, and you can usually fix the problem by just disconnecting and reconnecting. Just note that while drops to about 75 percent of your download speed are rare, they're not inconceivable.
When we talk about VPN security, we're really talking about reliability. Can this VPN establish an encrypted tunnel and transmit all your information through it, every time, without leaks or failures? With Proton VPN, we're happy to say the answer is yes; we probed its security and found no cracks to speak of. Read the section below for specifics.
Proton VPN protocols: WireGuard, OpenVPN, IKEv2 and Stealth
Proton VPN uses four VPN protocols to communicate between your devices, its servers and the internet. Three of them (WireGuard, OpenVPN and IKEv2) are common choices with no serious flaws as long as they're implemented thoughtfully. The fourth, Stealth, is an obfuscation protocol you should only use if the other three are blocked.
OpenVPN is the most secure option. Without getting too technical, OpenVPN encrypts its backend functions as well as the data itself, which leaves it with no obvious vulnerabilities. It can also communicate using the same ports as common HTTPS traffic, so it's hard to block.
WireGuard is more efficient than OpenVPN, both in its source code and the cryptography it uses. It normally requires an exchange of fixed IP addresses, but the Proton VPN implementation overwrites those IPs with randomized addresses, cutting the security risk.
IKEv2 is a safe choice that's occasionally faster than either OpenVPN or WireGuard. You probably won't use it unless it happens to come up while you've set the protocol to Smart. As such, it's on the way to being phased out of Proton VPN.
Stealth is unique to Proton VPN, though its function is not. It's got the same architecture as WireGuard, but adds another TLS tunnel to evade network blocks that catch VPN traffic. That extra encryption slows it down, so we don't recommend using it unless the other three protocols don't work.
The first option on the app, called "Smart," is not a protocol — it means your VPN client selects the protocol that will give you the best speeds on your current server. Since all four protocols are safe, there's no downside to using the Smart setting most of the time.
Leak test
We used AirVPN's IP leak tool to check all four of Proton VPN's protocols for DNS and WebRTC leaks. Proton VPN uses its own DNS servers to reduce the risk of sending unencrypted requests, but since leaks are still possible, we tested using a simple method: checking our visible IP address before and after connecting to the VPN.
Despite testing several locations over three days, we never saw our real IP address show up on the tool. This held true even outside the Secure Core server list, where data centers might have been managed by third parties. It's not perfect proof, but it's a very good sign that Proton VPN enforces a consistent security regime on all its servers.
We also used BrowserLeaks to check for WebRTC leaks. These are mainly an issue on the browser side, but a VPN is doubly important if your browser happens to be leaking. We enabled WebRTC on our browser and tested the same set of Proton VPN servers without springing any WebRTC leaks.
Proton VPN and IPv6
Proton is working on making its entire VPN compatible with IPv6 addresses. If a VPN that's only configured for IPv4 has to resolve an IPv6 address, it can cause a leak — that's why most VPNs, even the best ones, block IPv6 altogether. That said, the whole internet will run on IPv6 one day, so it's nice to see Proton VPN leading the pack.
So far, IPv6 is automatically enabled on Proton VPN's Linux apps and browser extensions, and can be optionally activated on its Android app. The Proton VPN apps for all other platforms still block IPv6 traffic, but this should hopefully change soon.
Encryption test
Even if a VPN's protocol choices are solid, it's possible for individual implementations of those protocols to fail. We used WireShark, a packet inspector app, to test whether Proton VPN's encryption worked no matter what settings were in place. We're happy to say we never saw plaintext once.
To get full access to Proton VPN, you'll need a Plus subscription, which costs $9.99 per month. You can knock off half that price by subscribing for a full year and paying a lump sum of $59.88, working out to $4.99 per month. A Plus account with Proton VPN also gives you free access to every other Proton app.
You can also pay $107.76 in advance to subscribe for two years, an average of $4.49 per month — perhaps more convenient, but it doesn't save you much. The one-year plan is the best value, though it's also nice that you don't have to pay through the nose for only one month. There's a 30-day, money-back guarantee on all plans.
Proton VPN is currently offering Engadget readers an exclusive deal that offers a 12-month plan for $47.88 ($3.99 per month) and a 24-month plan for $81.36 ($3.39 per month). Learn more about it here. One final option is the Proton Unlimited subscription, discussed in the "side apps and bundles" section below."
The Proton VPN free plan
Proton VPN is one of the best free VPNs on the market right now. No other VPN backed by as much experience and good judgment has a free plan with no data limits. Instead of capping how much data you can use per month, Proton VPN restricts which servers free users can access, limiting them to five countries: the United States, Japan, the Netherlands, Poland and Romania.
The frustrating part is that you can't choose which of these servers you use; Proton VPN just auto-connects to whichever one is the least burdened. A Proton representative told us that this change goes along with improvements to the selection algorithm, better load balancing and the addition of the Poland and Romania locations. It is also possible to try for a better connection by clicking "change server."
The fact remains, though, that a free Proton VPN plan is useless for unblocking content in specific locations — but this may be by design. The free plan seems more aimed toward privacy and anonymity than streaming, and the placement of the free locations near Russia and China reflects that. Free Proton VPN plans don't sacrifice any essential security features.
Proton VPN's main bundle is Proton Unlimited, which gets you all six Proton products in one package: VPN, Mail, Drive, Calendar, Wallet and Pass. This costs $12.99 for a month, $119.88 for a year ($9.99 per month) and $191.76 for two years ($7.99 per month). We won't be going in-depth on any of them in this review, but here's a quick rundown of each.
Proton Mail: An end-to-end encrypted email service. Proton can still see a Mail user's real IP address, but can't read any of their messages.
Proton Drive: Encrypted cloud storage. As with Mail, Proton can identify users, but can't read any of the content they store.
Proton Calendar: An encrypted scheduling app with events and reminders.
Proton Wallet: A self-custody wallet for storing Bitcoin unconnected to any exchange.
Proton Pass: A password manager that generates, stores and autofills passwords for online accounts.
Even if you only need two of the six, Proton Unlimited saves you money. Separate monthly subscriptions to Proton VPN and Proton Mail would cost a total of $14.98, so you've already knocked off $2 per month. That increases if you're able to commit to a year in advance.
Proton's privacy policy comes in two parts: the general Proton policy and the shorter policy specific to Proton VPN. We'll cover them in that order.
General Proton privacy policy
Proton tracks user activity on its product websites using its own marketing tools; the data set collected does not include IP addresses. It retains an email address connected to each user's account, but it's not allowed to connect IP addresses (and thus identities and locations) to those emails unless the user breaches the terms of service.
You may rightly ask how Proton would know a user is abusing one of their services if they don't keep activity logs. The answer is that logs aren't needed; most forms of abuse can be detected in other ways and observed in real time. For example, if someone used a Proton VPN server to launch a DDoS attack, the team could inspect that server and find the hacker while the attack was still ongoing.
The policy goes on to list the five third-party data processors Proton uses (Zendesk, PayPal, Chargebee, Atlassian and Stripe), none of whom are allowed to store customer activity data. Proton cautions that it will share what data it does have in response to unblockable requests from the Swiss government, but not "until all legal or other remedies have been exhausted." This is standard for a VPN that wants to remain in business, and the transparency report shows the company does indeed fight court orders when it can.
Proton VPN privacy policy
Proton's VPN-specific privacy policy is quite short. It states that Proton cannot log user activities or identifiable characteristics of devices connected to the VPN, cannot throttle internet connections and must extend full privacy and security to free users.
In one sense, a privacy policy requires you to take the VPN provider at their word, but it's dangerous for a company to make promises they don't intend to keep. The policy is legally binding, and breaking it is grounds for a lawsuit. Proton VPN's succinct no-logs policy is therefore a great sign. It's also been confirmed several times by a third-party audit, most recently in July 2024.
Testing a VPN's ability to mask a user's location isn't complex — all you need is a streaming subscription. We connected to five test locations and tried to unblock Netflix with each one. If we managed to access the site, and saw different shows than those on the American library, we concluded that the location had masked us successfully.
| Server location | Unblocked Netflix? | Library changed? |
| Canada | Y | Y |
| Romania | Y | Y |
| Ghana | Y | Y |
| Japan | Y | Y |
| New Zealand | Y | Y |
Proton VPN passed the test every time in all five locations. The only hiccup came in Romania, which we chose because it's one of the free locations. The app connected us to a free server, which was too slow to load Netflix; when we chose a paid server, the problem disappeared.
Proton VPN's free plan includes servers in five locations: the Netherlands, Poland, Romania, the United States and Japan. When you connect as a free user, you'll be automatically connected to whichever location is fastest.
A paid plan opens up the full network of 154 servers in 117 countries and territories. The menu includes a huge selection of African locations, more than any VPN we've tested in some time. The Middle East, along with central and southern Asia, are also well represented, and U.S. users will find 20 different locations to choose from.
Keep in mind that about two-thirds of these server locations are virtual, meaning they're not physically located where they claim to be. This includes all the African servers except South Africa and Nigeria; all the South American servers except Brazil, Colombia and Argentina; and all the Middle Eastern servers except Turkey, Israel and the UAE. A majority of the locations in Asia are also virtual, including South Korea, India, Thailand, Indonesia and the Philippines.
To be clear, virtual locations can hide your IP address just as well as physical ones. It's only a problem if you're expecting the kind of performance, particularly in terms of latency, that you get from a nearby server. Luckily, Proton VPN gives you fast enough download and upload speeds that distance shouldn't be a problem.
None | Countries | Virtual Locations | Cities |
| North America | 6 | 3 | 25 |
| South America | 7 | 4 | 7 |
| Europe | 42 | 6 | 51 |
| Africa | 25 | 23 | 26 |
| Middle East | 13 | 10 | 14 |
| Asia | 22 | 16 | 25 |
| Oceania | 2 | 0 | 6 |
| TOTAL | 117 | 62 | 154 |
Proton VPN has a number of extra features that go beyond standard VPN functionality. We've already mentioned the Stealth protocol and IPv6 support. In this section, we'll cover an additional five features that might be of interest.
NetShield ad blocker
Proton VPN's built-in ad blocker is known as NetShield. It's available on the main UI page, and has two settings: one that blocks only malware sites, and one that blocks sites connected with malware, ads and trackers. The stronger feature is on by default.
NetShield works by checking any DNS requests against a database of web servers known to host malware, inject ads or attach cross-site trackers to your browsing session. The DNS-blocking approach means it's not capable of blocking ads served from the same domain that hosts them — so no blocking YouTube video ads. On the positive side, it means NetShield works across your entire device, not just on your browser.
NetShield also displays a running total of how many of each form of interference it's blocked. It catches most banner ads, but since you can't customize the blocklist in any way, it's best when combined with another browser-level ad blocker.
Secure Core servers
Here's an interesting one. Secure Core is a form of a common feature known as double VPN or multi-hop VPN, in which a connection runs through two VPN servers before being decrypted. If one server fails or gets compromised, the other server keeps your connection private.
Proton VPN takes this a step further. When you activate Secure Core, your connection will still end at your chosen server location — but before that, it will travel through a designated server in Iceland, Sweden or Switzerland. A few touches make Secure Core servers more reliable than the average VPN node:
All three countries are safe jurisdictions, with consumer-friendly privacy laws and courts sympathetic to privacy claims.
Secure Core data centers are locked down physically; for example, the Iceland location is a refitted military base, and the Sweden location is literally underground.
Proton owns and operates all Secure Core locations itself, with no rentals or third-party managers.
Almost no other VPNs pay as much attention to physical security as Proton VPN does with this feature. The second hop makes Secure Core connections slower on average, but it's worth it if you have something especially sensitive to do online.
Kill switch
Proton VPN includes a kill switch, a standard feature. When active, a kill switch cuts off your internet whenever your connection to the VPN drops. This means you're never in danger of leaking your real identity or location, even for a second. It also protects you against the TunnelVision exploit, which requires the hacker to make a fake VPN server.
Split tunneling
Split tunneling is included on the Windows and Android apps, but users on other devices can access it through the browser extension. With split tunneling, some apps or websites get online through the VPN, while others stay unprotected.
Proton VPN allows split tunneling by both app and IP address. This grants you a precise level of control over your split, as long as you know the IP of each website you're placing on the list (you can find that out using DNS checker).
Torrenting servers and port forwarding
Proton VPN is one of the best VPNs for torrenting. It restricts torrenting to P2P servers, but nearly every server on the list is a P2P server — only Secure Core servers and some free servers don't permit torrenting. Combine that with the fact that it maintains 96 percent of your upload speeds on average, and you should have few problems using a torrenting client.
It also has some support for port forwarding, which can improve torrenting speed. Windows and Linux users can enable it with a simple toggle, which provides an active port number for configuring private servers. Mac users can set up port forwarding through manual OpenVPN or WireGuard configurations.
Tor over VPN
A handful of Proton VPN servers route you directly to the Tor network after encrypting your connection. While connected to one of these Tor over VPN servers, which are marked with TOR in their names and an onion symbol, you'll be able to open .onion links on a normal browser.
This is more than just convenient — Tor over VPN is the safest way to access the dark web. With the VPN as an intermediary, you're never connecting to Tor with your own IP address, so malicious node operators can't see your real identity. For maximum privacy, use Tor Browser to create your Proton VPN account, so you're never exposed at any point in the process.
Proton VPN has Tor servers in six countries (the U.S., France, Switzerland, Sweden, Germany and Hong Kong). Each just has one Tor server, except the United States, which gets two. Tor over VPN is supported on all platforms, but it won't work on Mac or iOS unless you have the kill switch enabled.
Profiles
A "profile" on Proton VPN is a group of pre-established settings you can use to quickly configure the VPN for a particular task. Two profiles are available from the start: Fastest, which connects to the fastest server, and Random, which always connects to a different server. You can create more profiles by toggling four settings:
Feature: The type of server used. Choose from Standard, Secure Core, P2P or Tor over VPN.
Country: The country to which the profile connects.
Server: A server within that country. You can also select "fastest" or "random."
Protocol: Which VPN protocol the profile will use. "Smart" can be selected.
As an example, say you want to watch a TV series that's only available on Netflix in Canada. You could create a profile called "Netflix Canada" that connects to the fastest Canadian server with just one click. We'd call profiles situationally useful, but they can save a lot of time if you regularly perform the same action on your VPN.
We went to Proton VPN's FAQ pages with two questions that came up while researching other sections: which of Proton VPN's servers are managed by third parties, and why do certain server locations (like Marseilles) run slow despite the app showing a light load?
You can access the help center through any of Proton VPN's apps, or by going directly to the website. Articles appear to be organized into six categories. Oddly, clicking any category button only shows you a handful of the articles in that section — for example, the Troubleshooting category looks like it only has five articles. If you type "troubleshooting" into the search bar, though, you'll see dozens pop up. There are even some sections, like Billing, that don't appear on the main page at all.
It has the feel of a website update that wasn't adequately brought in line with the bulk of the support content. Until Proton fixes it, just use the search bar for everything. The articles themselves are well-written, give or take some stilted English.
Getting quick help
We couldn't find written answers to our questions about ownership and server load, so we turned to live chat. Free users should keep in mind that live chat support is only available on paid accounts, but there's a fairly active subreddit at r/protonvpn where Proton staff frequently post.
Live chat is not intuitively located on protonvpn.com. We finally found it by scrolling all the way to the bottom of the main page, only to be told nobody was online to help at the moment — live chat is only accessible from 9 AM to midnight Central European Time (CET). We submitted our question about the Marseille servers as an email ticket instead.
This part was easy, at least, as the form helpfully populated our system information. We also got a prompt response within 24 hours. We ended the interaction there, as we weren't able to reproduce the sluggish behavior on the French server locations, but it's nice to know the team will answer quickly.
Proton VPN launched in 2017, but its team's experience goes back much farther. The founders of its parent company, Proton AG, met while working at CERN in Switzerland, and the company remains under Swiss jurisdiction.
Their first product, Proton Mail, went live in 2014 after a successful crowdfunding campaign, and claims to have 100 million users today. Proton VPN was Proton AG's second project. Like Proton Mail, it consists of a free plan supplemented by paid upgrades.
Since then, Proton has introduced several more products: Proton Calendar in 2020, Proton Drive cloud storage in 2022 and the Proton Pass password manager in 2023, each designed around using end-to-end encryption to make user data inaccessible.
The Proton Foundation
Proton announced in 2024 that the majority of its shares had been acquired by the Proton Foundation, a nonprofit whose only purpose is to control Proton stock. Among other benefits, this prevents it from being purchased by anyone who disagrees with its mission. To sell to an objectionable parent company, the entire board of trustees would have to agree, which feels unlikely based on Proton's track record.
Throughout Proton's history, we only found two incidents serious enough to comment on, and only one of them concerned Proton VPN. We'll cover them both below.
ProtonMail law enforcement collaboration allegations
On the page that hosts its annual transparency report, Proton states openly that it "may be legally compelled to disclose certain user information to Swiss authorities" (see the Privacy Policy section of this article for more on precisely what information that describes). In 2021, the company admitted it had given Swiss police (acting on a French warrant) a ProtonMail user's IP address and device logs. The police arrested the user, a French environmental activist.
While that's unnerving for privacy-minded users, there are some important contextual issues to consider. Most importantly, ProtonMail is not governed by the same policy as Proton VPN. At the time the case unfolded, Swiss law obliged all email companies to comply with court orders from Swiss authorities to hand over data. VPNs aren't subject to those retention requirements.
Today, Swiss email companies have been reclassified so they're also exempt from data retention requirements, thanks in part to a policy change Proton fought for. A representative from Proton confirmed that "under Swiss law, we are not obligated to save any user connection logs." It's also reassuring that, despite complying with the subpoena, Proton wasn't able to turn over the contents of any emails.
Alleged WireGuard memory vulnerability
In January 2025, researchers at Venak Security alleged that Proton VPN lacks memory protection for keys generated under the WireGuard protocol, which might let hackers scrape the keys and decrypt intercepted communications. Proton responded to Venak in a blog post, which a Proton representative confirmed remains their official response to the allegations.
In short: the Venak article only demonstrates that it's possible to view public keys, not private ones. This isn't much of a bombshell, given that "public" is right there in the name. But asymmetric encryption — the kind used by VPN protocols like WireGuard — requires both keys to decrypt any messages. Even if a hacker were able to get ahold of a private key, they likely wouldn't be able to use it for anything. WireGuard incorporates perfect forward secrecy by default, changing session keys often enough that any given key is obsolete by the time it's stolen.
In short, we're prepared to recommend Proton VPN to almost anybody. Whether you're mainly concerned with security, streaming or something else, chances are good that you'll be satisfied. The only serious downsides are that the long-term plans are overpriced and that it's hard to get live tech support if you live outside of Europe.
It's also our unqualified pick for the best free VPN, but with the caveat that it's a bad choice for anyone who needs to choose specific server locations. If all you care about is staying hidden from your ISP and advertisers, Proton should be your first choice.
This article originally appeared on Engadget at https://www.engadget.com/cybersecurity/vpn/proton-vpn-review-2025-a-nonprofit-service-with-premium-performance-153046073.html?src=rss
Pick up Apple's 25W MagSafe charger while it's down to a record-low price
Whether you picked up a new iPhone 17 recently or you have an older model, you can pick up one of Apple's own chargers at a discount thanks to a rare sale. Apple's 25W MagSafe charger with a two-meter cable is on sale for $35 — 29 percent off its usual price.
Believe it or not, this sale actually makes the two-meter version cheaper than the one-meter version. The latter at the moment would set you back $39.
If you have an iPhone 16, iPhone 17 or iPhone Air, this cable can charge your device at 25W as long as it's connected to a 30W power adapter on the other end. While you'll need a more recent iPhone to get the fastest MagSafe charging speeds, the charger can wirelessly top up the battery of any iPhone from the last eight years (iPhone 8 and later). With older iPhones, the charging speed tops out at 15W. The cable works with AirPods wireless charging cases too — it's certified for Qi2.2 and Qi charging.
The MagSafe charger is one of our favorite iPhone accessories, and would pair quite nicely with your new iPhone if you're picking up one of the latest models. If you're on the fence about that, be sure to check out our reviews of the iPhone 17, iPhone Pro/Pro Max and iPhone Air.
Check out our coverage of the best Apple deals for more discounts, and follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/pick-up-apples-25w-magsafe-charger-while-its-down-to-a-record-low-price-143415869.html?src=rss
It's the last chance to get three free months of the Apple Music Family Plan
Apple Music has a great deal going on right now for those interested in the Family Plan. New subscribers can get three free months of that plan — which, at $17 per month normally, comes out to $51 in savings for the whole period. Just note that the last day you can get the promotion is September 24.
The Family Plan allows six different users to access the platform. It offers cross-device support and each user is tied to an Apple ID, so their favorite music won't mess with anyone else's algorithm.
Apple Music actually topped our list of the best music streaming platforms, and for good reason. It sounds great and it's easy to use. What else is there? All music is available in CD quality or higher and there are plenty of personalized playlists and the like. The platform also operates a number of live radio stations, which is fun.
The service is available for Android devices, but it really shines on Apple products. To that end, the web and Windows PC apps aren’t as polished as the iOS version. It doesn't pay artists properly, but that's true of every music streaming platform. Apple Music does pay out more than Spotify, but that's an incredibly low bar.
Offer for new subscribers redeeming on eligible devices. Auto-renews at $16.99/mo until cancelled. Requires Family Sharing. Terms apply.
Check out our coverage of the best Apple deals for more discounts, and follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/its-the-last-chance-to-get-three-free-months-of-the-apple-music-family-plan-151240128.html?src=rss
Logitech's new keyboard can be recharged by any kind of light
Logitech has launched the Signature Slim Solar+ K980, a new solar-powered keyboard that you don't need to put under the sun whenever it runs low on battery. The company says it can use "light from any light source to stay charged and ready to use" and that you can use it in complete darkness for up to four months once it's fully charged. As long as the light source reaches 200 lux in brightness, which is considered dim lighting during daytime, it can charge the keyboard. "Even the need to think about charging can be a distraction, so we designed Signature Slim Solar+ to take that off your plate completely," said Art O'Gnimh, the General Manager of Core Products Group at Logitech.
You don't have to think about plugging the keyboard in or changing its battery: It's powered by a rechargeable battery that Logitech says can last up to 10 years. But if it does malfunction, the company told The Verge that you can replace it on your own, because it's encased in plastic and is sold by iFixit. The keyboard absorbs light through a strip above the keys themselves, which use a scissor-switch mechanism and are in a full-size layout with a separate number pad. It's compatible with multiple operating systems, and you can link it with up to three multi-OS devices and jump from one to the other with its Easy-Switch keys. If you use the Logi Options+ app, you can program its action key to automate simple tasks and to customize its AI launch key to instantly fire up the AI chatbot of your choice.
The Signature Slim Solar+ K980 is now available for $100. Logitech is also selling a business variant with a USB-C receiver for $110 and a North America-exclusive model with a layout specifically for Mac for $110.
This article originally appeared on Engadget at https://www.engadget.com/computing/accessories/logitechs-new-keyboard-can-be-recharged-by-any-kind-of-light-120019932.html?src=rssSpotify now directly integrates with DJ software
Spotify just announced integration with popular DJ software platforms like rekordbox, Serato and djay. This will make it much easier to build out sets from playlists and to do cool stuff like blend tracks.
The company says that users "will be able to access their entire library and playlists directly within desktop DJ software," with just one caveat. This is only for Premium subscribers. The integration is available in 51 global markets.
It looks pretty easy to get started. Just log into a Premium account directly inside of the preferred DJ software. That's pretty much it.
It's worth noting that this isn't a brand-new idea. Spotify offered something similar for years, but stopped supporting third-party DJ platforms in 2020. This was a business decision that was believed to be based on rights constraints.
The platform has been busy lately. Spotify recently introduced lossless streaming and an in-app messaging feature. However, it still pays artists peanuts while making nearly $17 billion each year. It's also worth remembering that CEO Daniel Ek is heavily invested in a military AI company called Helsing.
This article originally appeared on Engadget at https://www.engadget.com/entertainment/music/spotify-now-directly-integrates-with-dj-software-090055300.html?src=rss
The best wireless chargers for 2025
Wireless charging has become one of the easiest ways to keep your gadgets powered without dealing with tangled cables or a worn-out charging port. Whether you’re topping up your phone, earbuds or smartwatch, a good wireless charger saves you the hassle of plugging in and can even deliver faster charging speeds with the right standard.
The best options in 2025 go beyond simple pads. You’ll find 3-in-1 wireless chargers that handle multiple devices at once, a magnetic wireless charger that snaps into place on your phone and even foldable or travel-friendly designs that work like portable chargers on the go. Many of the latest models are Qi2 certified, which means better efficiency and wider compatibility.
If you’re looking for something to keep by your nightstand or a full wireless charging station for your desk, there are plenty of choices with solid build quality and practical functionality. The right pick depends on how many devices you need to charge at once and where you’ll use it most.
While it’s tempting to buy a wireless charging pad optimized for the specific phone you have now, resist that urge. Instead, think about the types of devices (phones included) that you could see yourself using in the near future. If you’re sure you’ll use iPhones for a long time, an Apple MagSafe-compatible magnetic wireless charger will be faster and more convenient. If you use Android phones or think you might switch sides, however, you’ll want a more universal design. If you have other accessories like wireless earbuds or a smartwatch that supports wireless charging, maybe you’d be better off with a 3-in-1 wireless charger or full wireless charging station.
Odds are that you have a specific use case in mind for your charger. You may want it by your bedside on your nightstand for a quick charge in the morning, or on your desk for at-a-glance notifications. You might even keep it in your bag for convenient travel charging instead of bulky portable chargers or power banks. Think about where you want to use this accessory and what you want to do with the device(s) it charges while it’s powering up. For example, a wireless charging pad might be better for bedside use if you just want to be able to drop your phone down at the end of a long day and know it’ll be powered up in the morning. However, a stand will be better if you have an iPhone and want to make use of the Standby feature during the nighttime hours.
For a desk wireless charger, a stand lets you more easily glance at phone notifications throughout the day. For traveling, undoubtedly, a puck-style charging pad is best since it will take up much less space in your bag than a stand would. Many power banks also include wireless charging pads built in, so one of those might make even more sense for those who are always on the go. Some foldable chargers are also designed for travel, collapsing flat to take up less space.
Although wireless charging is usually slower than its wired equivalent, speed and wattage are still important considerations. A fast charger can supply enough power for a long night out in the time it takes to change outfits. Look for options that promise faster charging and support standards like Qi2 certified charging for the best balance of efficiency and compatibility.
In general, a 15W charger is more than quick enough for most situations, and you’ll need a MagSafe-compatible charger to extract that level of performance from an iPhone. With that said, even the slower 7.5W and 10W chargers are fast enough for an overnight power-up. If anything, you’ll want to worry more about support for cases. While many models can deliver power through a reasonably thick case (typically 3mm to 5mm), you’ll occasionally run into examples that only work with naked phones.
There are some proprietary chargers that smash the 15W barrier if you have the right phone. Apple’s latest MagSafe charging pad can provide up to 25W of wireless power to compatible iPhones when paired with a 30W or 35W adapter — the latter being another component you’ll have to get right to make sure the whole equation works as fast as it possibly can.
Pay attention to what’s included in the box. Some wireless chargers don’t include power adapters, and others may even ask you to reuse your phone’s USB-C charging cable. What may seem to be a bargain may prove expensive if you have to buy extras just to use it properly. As mentioned above, you’ll want to make sure all of the components needed to use the wireless charger can provide the level of power you need — you’re only as strong (or in this case, fast) as your weakest link.
Fit and finish is also worth considering. You’re likely going to use your wireless charger every day, so even small differences in build quality could make the difference between joy and frustration. If your charger doesn’t use MagSafe-compatible tech, textured surfaces like fabric or rubberized plastic are more likely to keep your phone in place. The base should be grippy or weighty enough that the charger won’t slide around. Also double check that the wireless charger you’re considering can support phones outfitted with cases — the specifications are usually listed in the charger’s description or specs.
You’ll also want to think about the minor conveniences. Status lights are useful for indicating correct phone placement, but an overly bright light can be distracting. Ideally, the light dims or shuts off after a certain period of time. And while we caution against lips and trays that limit compatibility, you may still want some barriers to prevent your device falling off its perch on the charging station.
Do wireless chargers work if you have a phone case?
Many wireless chargers do work if you leave the case on your phone. Generally, a case up to 3mm thick should be compatible with most wireless chargers. However, you should check the manufacturer’s guide to ensure a case is supported.
How do I know if my phone supports wireless charging?
Checking the phone’s specification should tell you if your phone is compatible with wireless charging. You might see words like “Qi wireless charging” or “wireless charging compatible.”
Do cords charge your phone faster?
Most often, wired charging will be faster than wireless charging. However, wired charging also depends on what the charging cable’s speed is and how much power it’s designed to carry. A quick-charging cable that can transmit up to 120W of power is going to be faster than a wireless charger.
This article originally appeared on Engadget at https://www.engadget.com/computing/accessories/best-wireless-charger-140036359.html?src=rss
The best robot vacuums on a budget for 2025
If vacuuming is your least favorite chore, employing a robot vacuum can save you time and stress while also making sure your home stays clean. While once most robo-vacs landed on the higher end of the price spectrum, that’s not the case anymore. Sure, you could pick up a $1,000 cleaning behemoth with mopping features, but it would be incorrect to assume that you need to spend that much money to get a good machine.
Now, you can get an autonomous dirt-sucker with serious cleaning chops for $500 — sometimes even $300 or less. But you get what you pay for in this space; don’t expect affordable robot vacuum cleaners to have all of the bells and whistles that premium machines do, like self-emptying capabilities or advanced dirt detection. After testing dozens of robot vacuums at various price points, I’ve narrowed down our top picks for the best budget robot vacuums you can buy right now.
Since I've tested dozens of robot vacuums, I'm often asked if these gadgets are "worth it" and I'd say the answer is yes. The biggest thing they offer is convenience: just turn on a robot vacuum and walk away. The machine will take care of the rest. If vacuuming is one of your least favorite chores, or you just want to spend less time keeping your home tidy, semi-autonomous robotic vacuum is a great investment. Many models, albeit more expensive ones, even come with features like a self-empty station to further reduce maintenance.
There are plenty of other good things about them, but before we dive in let’s consider the biggest trade-offs: less power, less capacity and less flexibility. Those first two go hand in hand; robot vacuum cleaners are much smaller than upright vacuums, which leads to less powerful suction. They also hold less dirt because their built-in bins are a fraction of the size of a standard vacuum canister or bag. Fortunately, some models include features like an auto-empty station, which helps with dirt capacity, especially in homes with pet hair.
When it comes to flexibility, robot vacuums do things differently than standard ones. You can control some with your smartphone, set cleaning schedules and more, but robo-vacs are primarily tasked with cleaning floors. On the flip side, their upright counterparts can come with various attachments that let you clean couches, stairs, light fixtures and other hard-to-reach places.
When looking for the best cheap robot vacuum, one of the first things you should consider is the types of floors you have in your home. Do you have mostly carpet, tile, laminate, hardwood? Carpets demand vacuums with strong suction power that can pick up debris pushed down into nooks and crannies. Unfortunately, there isn’t a universal metric by which suction is measured. Some companies provide Pascal (Pa) levels and generally the higher the Pa, the stronger. But other companies don’t rely on Pa levels and simply say their bots have X-times more suction power than other robot vacuums.
So how can you ensure you’re getting the best cheap robot vacuum to clean your floor type? Read the product description. Look for details about its ability to clean hard floors and carpets, and see if it has a “max” mode you can use to increase suction. If you are given a Pa measurement, look for around 2000Pa if you have mostly carpeted floors. Pay attention to the brush roll mechanism as well, especially if you're dealing with dog hair or other stubborn debris that can cause tangles. Many budget models use bristle brushes, while others offer tangle-free designs to minimize maintenance.
You may find some budget robot vacuums also offer vacuum/mop combo capabilities. These bots feature a water tank, which means they can offer mopping functionality, enhancing debris pickup, and resulting in shiny floors. However, these are less common when you’re shopping in the lower price range.
Size is also important for two reasons: clearance and dirt storage. Check the specs for the robot’s height to see if it can get underneath the furniture you have in your home. Most robo-vacs won’t be able to clean under a couch (unless it’s a very tall, very strange couch), but some can get under entryway tables, nightstands and the like. As for dirt storage, look out for the milliliter capacity of the robot’s dustbin — the bigger the capacity, the more dirt the vacuum cleaner can collect before you have to empty it.
You should also double check the Wi-Fi capabilities of the robo-vac you’re eyeing. While you may think that’s a given on all smart home devices, it’s not. Some of the most affordable models don’t have the option to connect to your home Wi-Fi network. If you choose a robot vac like this, you won’t be able to direct it with a smartphone app or with voice controls. Another feature that’s typically reserved for Wi-Fi-connected robots is scheduling because most of them use a mobile app to set cleaning schedules.
But Wi-Fi-incapable vacuums usually come with remote controls that have all the basic functions that companion mobile apps do, including start, stop and return to dock. And if you’re concerned about the possibility of hacking, a robot vac with no access to your Wi-Fi network is the best option.
Obstacle detection and cliff sensors are other key features to look out for. The former helps the robot vacuum navigate around furniture while it cleans, rather than mindlessly pushing its way into it. Many also offer no-go zones, letting you block off areas you don’t want the robot to enter. Meanwhile, cliff sensors prevent robot vacuums from tumbling down the stairs, making them the best vacuum for multi-level homes.
When we consider which robot vacuums to test, we look at each machine’s specs and feature list, as well as online reviews to get a general idea of its capabilities. With each robot vacuum we review, we set it up as per the instructions and use it for as long as possible — at minimum, we’ll use each for one week, running cleaning cycles daily. We make sure to try out any physical buttons the machine has on it, and any app-power features like scheduling, robot mapping and more.
Since we test robot vacuums in our own homes, there are obstacles already in the machine’s way like tables, chairs and other furniture — this helps us understand how capable the machine is at avoiding obstacles, and we’ll intentionally throw smaller items in their way like shoes, pet toys and more. With robot vacuums that include self-emptying bases, we assess how loud the machine is while emptying contents into the base and roughly how long it takes for us to fill up the bag (or bagless) base with debris.
First and foremost, always empty your robot vacuum’s dustbin after every cleaning job, or use a self-empty station if the model supports it. Simply detach and empty the dustbin as soon as the robot is done cleaning, and then reattach it so it's ready to go for the next time. It’s also a good idea to take a dry cloth to the inside of the dustbin every once in a while to remove any small dust and dirt particles clinging to its insides.
In addition, you’ll want to regularly examine the machine’s brushes to see if any human or pet hair has wrapped around them, or if any large debris is preventing them from working properly. Some brushes are better than others at not succumbing to tangled hair, but it’s a good idea to check your robot’s brushes regardless — both their main brush and any smaller, side brushes or corner brushes they have. These parts are often easy to pop off of the machine (because they do require replacements eventually) so we recommend removing each brush entirely, getting rid of any tangles or other debris attached to them and reinstalling them afterwards. If you have a robot vacuum with mopping capabilities, you’ll need to wash the bots’ mop pads too, to avoid any unpleasant smells or tracking mess around your home. Similarly, if your robot vacuum has a water tank, it’s worth washing this out regularly to keep it clean.
Robot vacuums also have filters that need replacing every couple of months. Check your machine’s user manual or the manufacturer’s website to see how long they recommend going in between filter replacements. Most of the time, these filters cannot be washed, so you will need to buy new ones either directly from the manufacturer or from other retailers like Amazon or Walmart.
Are budget robot vacuums good for pet hair?
Yes, budget robot vacuums can be good for pet hair. Just keep in mind they generally tend to have lower suction power and smaller dustbins than more expensive (and larger) robot vacuums. If pet hair is your biggest concern, we recommend getting as expensive of a robot vacuum as your budget allows, or consider investing in a cordless vacuum since those tend to be more powerful overall.
How long do budget robot vacuums last per charge?
Budget robot vacuums typically last 40-60 minutes per charge, and the best ones will automatically return to their charging dock when they need more power.
Do budget robot vacuums work on carpets and hardwood floors?
Yes, budget robot vacuums work on both carpets and hardwood floors.
Which budget robot vacuums have mapping features?
Home mapping features are typically exclusive to more expensive robot vacuums. Check the product description of any robot vacuum you're thinking of buying and look for "smart mapping" or "smart home mapping" in the feature list if you want a device that supports it.
Check out more from our spring cleaning guide.
This article originally appeared on Engadget at https://www.engadget.com/home/smart-home/best-budget-robot-vacuums-133030847.html?src=rss
Google AI Mode now speaks Spanish
Google's AI Mode is continuing its rapid global growth. Today, the company announced that this addition to Google Search is rolling out in Spanish. The new option is available in all countries that support AI Mode. The move will allow Spanish speakers around the world to engage with this AI chatbot in their language of choice when asking more complicated questions than a search engine can typically answer well.
The proliferation of this AI enhancement to Google's traditional search has happened at a break-neck pace. AI Mode was first introduced in March and then made available across the US in May. The first language expansion came earlier this month with the addition of AI Mode in Hindi, Indonesian, Japanese, Korean and Brazilian Portuguese.
This article originally appeared on Engadget at https://www.engadget.com/google-ai-mode-now-speaks-spanish-223346697.html?src=rss
Apple TV+ indefinitely delays its domestic extremism thriller 'The Savant'
Apple has delayed the release of its new series The Savant just three days before it was supposed to premiere on September 26, Deadline reports. The series follows an investigator, played by Jessica Chastain, who infiltrates a domestic extremist group in the US. Apple hasn't provided a new release date for the show.
"After careful consideration, we have made the decision to postpone The Savant," the company shared in a statement to Deadline. "We appreciate your understanding and look forward to releasing the series at a future date." The timing of the sudden delay, and the lack of explanation for why the company is delaying the show, could be telling. Disney made a similar knee-jerk reaction in placing Jimmy Kimmel Live! on indefinite hiatus following a joke Kimmel made about the reaction to the killing of right-wing activist Charlie Kirk.
Given that The Savant likely focuses on preventing acts of political violence, it might make you wonder who Apple is worried its show will offend. But it's also entirely possible that the company is trying to avoid people making any kind of association between its TV show and a very public assassination.
Apple generally avoids rocking the boat whenever possible, particularly when it could hurt its business interests. The Problem With Jon Stewart was reportedly cancelled when Jon Stewart wanted to cover topics Apple deemed controversial, like China and artificial intelligence. Apple does business in China, so it seems likely the company was skittish about airing anything that could be viewed as criticism, even if having difficult conversations was the premise of Stewart's show. The decision to pull The Savant, even if despite reading like the company is worried about offending right-wing extremists, was likely made from a similar place of caution.
This article originally appeared on Engadget at https://www.engadget.com/entertainment/streaming/apple-tv-indefinitely-delays-its-domestic-extremism-thriller-the-savant-223044979.html?src=rss
Amazon is closing all Fresh grocery stores in the UK
Amazon is pivoting its grocery operations in the UK, announcing that it will close 14 of its Amazon Fresh stores in the country. The remaining five Amazon Fresh locations in the UK will be converted to the Whole Foods Market brand. Rather than the brick and mortar shops, Amazon said it will focus on online grocery deliveries within the region. In 2026, the company said it expects to add perishables to its Same-Day Delivery orders for UK customers, which was just introduced in the US last month.
The move echoes a similar contraction in 2023, where Amazon said it would shutter both some Fresh supermarkets and some Go convenience stores. Many of these shops highlighted the Just Walk Out tech from Amazon, which it introduced in the US in 2018 and in the UK in 2021. Just Walk Out eliminated cashiers in those stores and instead charged customers by using a network of cameras, sensors and human observers checking video feeds to calculate the tab for a person's purchase and then charge them afterwards. However, the approach yielded concerns around cost, accuracy and privacy. Amazon stopped using Just Walk Out in its US Fresh stores last year.
Update, September 23, 2025, 5:55PM ET: Revised to correct a misstatement about Amazon's current use of Just Walk Out in the US.
This article originally appeared on Engadget at https://www.engadget.com/amazon-is-closing-all-fresh-grocery-stores-in-the-uk-195200222.html?src=rss
Major League Baseball will adopt an automated challenge system in 2026
Next year, baseball reasons will have one less reason to rage at the umpire. Major League Baseball announced today that it will introduce the Automated Ball Strike challenge system in the 2026 season for all spring training, championship season and postseason games. In other words, next year there will be a way for the players to attempt to overturn an umpire's call about whether a pitch counts as a strike or a ball if they disagree with the initial decision.
ABS uses a network of a dozen camera to record every pitch thrown. The umpire will still call the pitch a ball or strike as usual, but under the new system, the pitcher, catcher or batter can immediately challenge that decision. Coaching staff and other players cannot offer input on whether or not a challenge is initiated. If the cameras show any part of the ball touching the batter's strike zone, the pitch will be counted as a strike. All teams will begin a game with two challenge opportunities, and only lose them if they challenge unsuccessfully. For games that go into extra innings, a team will get an additional challenge if it has none remaining at the start of the additional gameplay.
Baseball has taken a gradual path to introducing this tech. ABS has been tested at the Triple-A level since 2022, and it finally got a chance in the majors during spring training and in the All-Star Game this year. Other sports have also been leveraging electronics to ensure that gameplay rules and scoring are consistent. Football/soccer has implemented a video assistant referee (VAR) system in several leagues, including FIFA and the UK's Premier league. Tennis is also adopting electronic line calls at Wimbledon and other tournaments. Even the electronic systems are not infallible, but considering how much any high-level athletic endeavor can be won or lost by millimeters, having a backup for the human eye seems like a net positive.
This article originally appeared on Engadget at https://www.engadget.com/major-league-baseball-will-adopt-an-automated-challenge-system-in-2026-205023531.html?src=rss
How to watch Xbox’s Tokyo Game Show livestream
Curious to see if those Forza Horizon 6 rumors are true? You may not have long to wait. Xbox's presentation at the Tokyo Game Show 2025 is fast approaching. You can watch the event live right here on September 25 at 6AM ET.
Forza Horizon 6 is rumored to have a Japan setting, making this week's event a logical venue for its announcement. That's not the only thing to go on. Windows Central reported last month that it had seen official documentation suggesting the game would be announced at the Tokyo Game Show. An Xbox executive producer even posted earlier this month that it would be an event "you don't want to miss." (Am I sadistic for hoping he was hyping up something like a new Xbox dashboard feature?)
The Xbox brand could use some positive mojo. Last week, Microsoft announced that it would raise console prices for the second time in less than five months. The increase, which begins on October 3, was "due to changes in the macroeconomic environment." (That sounds like a copywriter's answer to "How do you say 'tariffs' without actually saying 'tariffs?'") It's all the more reason the company would love to shift your focus to something fun.
You can stream Microsoft's event below on September 25 at 6AM ET.
This article originally appeared on Engadget at https://www.engadget.com/gaming/xbox/how-to-watch-xboxs-tokyo-game-show-livestream-204657743.html?src=rss
There's more than one way to make an Xbox handheld
With the launch of the ROG Xbox Ally only a few weeks away on October 16, the fantasy of a portable Xbox is about to be a lot more real. As a recent video from YouTuber James Channel shows, though, with a first-generation Xbox and the right components, you can make your own version of an Xbox handheld right now. Just don't expect it to be pretty.
James' "portable monstrosity" strips away the original Xbox's large plastic casing and thick internal cables and preserves the bare essentials: a motherboard and the console's disk drive, with a new flash drive and a display from an iPod video accessory. All those components are precariously mounted between the left and right halves of an Xbox controller, for a complete package that seems less easy to hold than ASUS' current handheld PCs, but only marginally so. It's a quick and dirty assembly with a surprising amount of super glue — a far cry from the polished Xbox 360 handheld created by YouTuber Millomaker — but it gets the job done.
You can already stream Xbox games to a multitude of screens, or play their PC versions on a growing number of handheld PCs. You don't need to turn an original Xbox into a portable device, but considering Microsoft and ASUS have yet to announce pricing for their new handhelds, maybe keep this cheaper alternative in your back pocket.
This article originally appeared on Engadget at https://www.engadget.com/gaming/xbox/theres-more-than-one-way-to-make-an-xbox-handheld-201503415.html?src=rssMicrosoft claims a 'breakthrough' in AI chip cooling
AI is an enormous energy drain, contributing to greenhouse gas emissions at a time when the planet desperately needs progress in the opposite direction. Although most of that comes from running GPUs, cooling them is another significant overhead. So, it's worth noting when a company of Microsoft's stature claims to have achieved a breakthrough in chip cooling.
Microsoft's new system is based on microfluidics, a method long pursued but hard to implement. The company claims its approach could lead to three times better cooling than current methods.
Many data centers rely on cold plates to prevent GPUs from overheating. Although effective to a degree, the plates are separated from the heat source by several layers of material, which limits their performance. "If you're still relying heavily on traditional cold plate technology [in five years], you're stuck," Microsoft program manager Sashi Majety is quoted as saying in the company's announcement.
In microfluidics, the coolant flows closer to the source. The liquid in Microsoft's prototype moves through thread-like channels etched onto the back of the chip. The company also used AI to more efficiently direct the coolant through those channels.
Another aspect separating this prototype from previous attempts is that it drew inspiration from Mother Nature. As you can see in the image above, the etchings resemble the veins in a leaf or a butterfly wing.
Microsoft says the technique can reduce the maximum silicon temperature rise inside a GPU by 65 percent. (However, that number depends on the workload and chip type.) This would enable overclocking "without worrying about melting the chip down," Microsoft's Jim Kleewein said. It could allow the company to place servers closer together physically, reducing latency. It would also lead to "higher-quality" waste heat use.
Although this sounds good for the environment in a general sense, Microsoft's announcement doesn't lean into that. The blog post primarily discusses the technique's potential for performance and efficiency gains. Green benefits are only alluded to briefly as "sustainability" and reduced grid stress. Let's hope that's only a case of a cynical observer overanalyzing framing. Our planet needs all the help it can get.
This article originally appeared on Engadget at https://www.engadget.com/ai/microsoft-claims-a-breakthrough-in-ai-chip-cooling-193106705.html?src=rss
YouTube may reinstate channels banned for spreading covid and election misinformation
Channels once banned by YouTube for spreading false information regarding the COVID-19 pandemic or the 2020 election may soon have the opportunity to get their channels back, in a decision transparently courting "conservative voices."
Alphabet, the parent company of Google and YouTube, has sent a letter via counsel to the House Judiciary Committee in which it alleges the company was pressured by the Biden administration to take down misinformation on YouTube related to the COVID-19 pandemic that did not violate the company's existing policies at the time. It now describes the Biden administration's actions as "unacceptable and wrong."
It also informed the committee that YouTube would be offering a path to reinstatement for creators whose channels were banned for repeatedly violating community guidelines on election-integrity-related content, as well as for COVID-19-related content. The guidelines under which those bans were carried out were removed by the company in 2023 and 2024, respectively. Details on exactly what the path for reinstatement looks like were not shared.
"The COVID-19 pandemic was an unprecedented time in which online platforms had to reach decisions about how best to balance freedom of expression with responsibility," the letter reads. "Senior Biden administration officials, including White House officials, conducted repeated and sustained outreach to Alphabet and pressed the company regarding user generated content related to the COVID-19 pandemic that did not violate its policies."
Alphabet goes on to denounce any government attempts to "dictate how the Company moderates content," and says it will always "fight against those efforts on First Amendment grounds."
Notable YouTube channels banned for either COVID-19 or election-integrity-related content include Steve Bannon's War Room, Co-Deputy Director of the FBI Dan Bongino's channel and the channel for Children's Health Defense, an organization previously linked with Secretary of HHS RFK Jr. "YouTube values conservative voices on its platform and recognizes that these creators have extensive reach and play an important role in civic discourse," the company wrote. In its letter, Alphabet also expresses concern that the European Union's Digital Services Act and Digital Markets Act could have a chilling effect on freedom of expression.
The letter was sent in response to subpoenas as part of the House Judiciary Committee's ongoing investigations into alleged government-directed content moderation. The committee recently held a hearing on "Europe’s Threat to American Speech and Innovation," among others.
This article originally appeared on Engadget at https://www.engadget.com/big-tech/youtube-may-reinstate-channels-banned-for-spreading-covid-and-election-misinformation-190257602.html?src=rss
Costco reportedly stops selling Xbox consoles online
Costco has reportedly stopped selling Xbox consoles online throughout the US and UK, according to reports by The Gamer and others. The wholesaler has removed any mention of the console and related accessories and games from its website. I checked this myself and, sure enough, the search yielded no results.
The site still has dedicated sections for both Sony and Nintendo and is selling the PS5 and the Switch family of consoles, along with accessories and games for each system. It's unclear if online unavailability has extended to brick-and-mortar locations, but some Reddit users noticed a distinct lack of Xbox products at the retailer. We reached out to Costco to ask what's going on and will update this post when we hear back.
We don't know why Costco would make this move, but there's a chance this is in relation to Microsoft's poor showing this console generation. The PS5 has sold nearly 80 million units, while the Xbox Series X/S has sold around 42 million units.
The Xbox One also struggled during the previous generation, leading some to speculate that Microsoft has been preparing to exit the console business. The company has denied this and there have been rumors that it's actively working on the follow-up to the Series X/S. However, the company has also begun porting its games to rival consoles.
This article originally appeared on Engadget at https://www.engadget.com/gaming/xbox/costco-reportedly-stops-selling-xbox-consoles-online-184906670.html?src=rss
How to cancel your Disney+ subscription
The inevitable has happened and Disney+ has once again announced that prices will be going up for its streaming service. Whether it's because of the ever-increasing costs or because of the company's recent teetering toward censorship or because you simply aren't using it, you may decide it's time to take a break. Here's everything you need to know about canceling your Disney+ subscription.
The simplest way to end your Disney+ service is if you're being billed directly by the mouse. You can follow the same steps in a web or mobile browser, or within the Disney+ mobile app.
Log in to your Disney+ account.
Select your Profile.
Select Account.
Select your Disney+ subscription under Subscription.
Select Cancel Subscription.
Easy peasy. But things can get a little more convoluted if you're not in a direct-billing situation.
Like many entertainment services, Disney+ offers the option to access its streaming service from a third-party provider. Most often, these are the companies running mobile app stores, like Apple and Google, or through wireless service brands, like Spectrum or Verizon. Since those companies are the ones that handle the money, you need to start the cancellation process with them rather than with Disney.
The exact details might vary, but the general approach is to sign into your account with the third party, then find the place to manage either billing or subscriptions, and pick the Disney+ option. Here are the specific steps for a few of the most common providers.
Cancel via Apple
Go to the Settings app on your iPhone or iPad.
Tap on your name at the top of the screen and tap Subscriptions.
Select your Disney+ subscription to manage and make changes.
Cancel via Google
Go to the Google Play store using a web browser.
Confirm that you’re signed in to your Google account.
On the top right, click your Google account icon and select Payment & subscriptions.
Click the Subscriptions tab and select your Disney+ subscription.
Click Manage and select Cancel subscription.
Cancel via Amazon
Go to Amazon Memberships and Subscriptions using a web browser.
Sign in to your Amazon account.
Navigate to your Disney+ subscription and select Cancel Subscription.
Because Disney owns everything, at some point you may have upgraded to a bundle plan that includes Hulu, ESPN or HBO Max as well as Disney+. If you originally had a subscription for one of those services that you upgraded to include Disney+, canceling the Disney service will only end that part of the package deal. You will continue getting billed for the original plan you bought under the terms at the time you signed up. Ending the entire bundle means you'll also need to separately cancel your streaming service with Hulu, ESPN or HBO Max.
If you want to simply take a break because you won't be using a Disney+ subscription for a few months, the company does offer a pause option. It's not available for the Disney+, Hulu, HBO Max Bundle subscription, but for any other plans, you can pause your subscription as long as your Disney+ account is active and you have no outstanding payments to the company. And once again, if a third party handles your billing, you'll need to contact them to initiate a pause. For direct-billing customers, here's how to pause your Disney+ service:
Log in to your Disney+ account.
Select your Profile.
Select Account.
Select your Disney+ subscription under Subscription.
Select Pause Subscription.
Choose the duration of the pause.
Select Pause Subscription.
Clicking the final button doesn't immediately end your service. Since Disney doesn't offer any refunds on partially-used subscriptions, you'll still have access to the service until the end of the current billing period after canceling. That means that if you change your mind and decide to keep the service, it's pretty easy to resume your previous plan before the billing period ends. There will be a "Restart Subscription" option under the Account tab. If you decide to resume Disney+ use after the end of your final billing period, you'll have to start up a new subscription with the platform.
Cancellation also doesn't erase your data with Disney. The company will hold onto your name, email address and other info unless you choose to delete your Disney+ account.
This article originally appeared on Engadget at https://www.engadget.com/entertainment/streaming/how-to-cancel-your-disney-subscription-183643669.html?src=rss
PlayStation's Franchise Rewards program gates merch behind in-game trophies
Sony is introducing a new rewards program for PlayStation owners that lets you purchase exclusive physical merchandise if you've unlocked certain in-game trophies. The company is starting with rewards for two trophies from Sucker Punch's Ghost of Tsushima (rewards for Ghost of Yotei are in the works), and Sony will presumably offer something similar for all of its most popular game franchises.
The "Ghost Rewards" you might have earned playing Ghost of Tsushima include a $25 commemorative pin shaped like a mask (unlocked for earning the game's "Living Legend" Platinum trophy) or a $30 custom t-shirt with what looks like a gold woodblock print design (unlocked for earning the "Mono No Aware" Gold trophy). In order to claim either reward you have to login to your PlayStation account on a dedicated website before December 31, 2025, and despite what the term "reward" might suggest, pay for either item to actually receive it. The reward, in this case, is access, not the merch itself.
Sony's last attempt at some kind of loyalty or rewards program was the short-lived and entirely digital PlayStation Stars program. While it was running, it let you earn "Stars" for playing specific games or doing activities on your console, and then spend those Stars on what amounted to digital models of characters or items. The program always felt a bit like an NFT feature that the company had quickly reworked when blockchain tech fell out of style, and it made sense when it abandoned it.
Rather than PlayStation Stars, Franchise Rewards is most similar to Bungie Rewards, the program and online store the Destiny 2 developer has run since 2018. Via Bungie Rewards you can unlock commemorative shirts, jackets and more for completing in-game activities in Destiny and Destiny 2, including the series' multi-hour raids.
This article originally appeared on Engadget at https://www.engadget.com/gaming/playstation/playstations-franchise-rewards-program-gates-merch-behind-in-game-trophies-182001158.html?src=rss
Disney+ prices are increasing in October (yes, again)
Disney might be trying to put the Jimmy Kimmel Live fiasco to bed by bringing the show back on Tuesday night (good luck with that). But the company isn't exactly putting itself back in customers’ good graces. Once again, it’s hiking the prices of Disney+ subscriptions in the US.
Several standalone plans and bundles are getting price increases. The changes come into effect on October 21.
After that date, subscribers will be paying $2 extra for the standard Disney+ plan (the one with ads) at $12 per month. The ad-free Disney+ Premium option will soon cost $19 per month, an increase of $3. For those playing along at home, that means the monthly ad-free Disney+ plan will have nearly tripled in price in the six years that the service has been around.
Bundle price increases are as follows:
Disney+ and Hulu with ads: currently $11 per month, going up by $2 to $13
Disney+, Hulu and ESPN Select with ads: currently $17 per month, going up by $3 to $20
Disney+, Hulu and ESPN Select Premium (ad-free): currently $27 per month, going up by $3 to $30
Disney+ Premium (ad-free), Hulu and ESPN Select (both with ads): currently $22 per month, going up by $3 to $25 — note that this is a legacy plan for existing subscribers, and it's not possible to switch to it
Disney+, Hulu and HBO Max Basic with ads: currently $17 per month, going up by $3 to $20
Disney+ Premium, Hulu Premium and HBO Max (No Ads): currently $30 per month, going up by $3 to $33
Ad-free Hulu Premium ($19 per month) and the ad-free Disney+ and Hulu Premium bundle ($20 per month) are not changing in price for now. The Disney+, Hulu and ESPN Unlimited bundles are remaining the same too, at $36 with ads on all three services and $45 with ad-free Disney+ Premium and Hulu Premium. The company will combine Disney+ and Hulu into the same app next year, but there will still be standalone plans for each service.
Disney is following Apple and Peacock in raising prices of their streaming services over the last couple of months. But the timing of the Disney+ increase is an especially ill-judged one.
The announcement comes amid many subscribers canceling their plans in protest against Disney's decision to temporarily remove Jimmy Kimmel from its airwaves. A price hike isn't exactly likely to entice them to sign back up as Kimmel's show returns to ABC.
This article originally appeared on Engadget at https://www.engadget.com/entertainment/streaming/disney-prices-are-increasing-in-october-yes-again-171830091.html?src=rss
Google Photos' conversational editing is rolling out to Android users
You know how annoying it is to click multiple edits on a photo? What's that? It's actually pretty easy to do. Well, Google says otherwise and has a solution for you: conversational editing, a feature that lets you tell Google your requested edits, rather than have to make them yourself.
Google first introduced conversational editing to Pixel 10 phones, but the company is now rolling it out to Android users in the US. It should be available for any adults who have their Google account set to English, have Face Groups turned on and location estimates enabled.
To use conversational editing, first click "help me edit" in the editor. Then you can say exactly what edits you want either using your voice or text. The feature uses "advanced Gemini capabilities" to make the changes. You can do things like edit strangers out of the background, lighten the colors or get rid of a glare. It will show you the original and updated photos side-by-side to compare.
This article originally appeared on Engadget at https://www.engadget.com/ai/google-photos-conversational-editing-is-rolling-out-to-android-users-170057906.html?src=rssRiot's 2XKO fighting game hits early access on October 7
Riot's long-awaited fighting game 2XKO, previously called Project L, will be released for PC as an early access title on October 7. That's just two weeks away.
The company dropped a development update video that's filled with nods to the source material. 2XKO is set in the League of Legends universe and features many characters from across the franchise. Players can fight as icons like Jinx, Yasui, Braum and many more. The early access version will feature 10 playable characters, with more coming down the line.
For the uninitiated, this is a 2 vs. 2 tag-based fighting game that's somewhat similar to the Marvel vs. Capcom series. Folks can play solo or recruit friends as tag partners. Riot promises the game will feature a "high level of depth and mastery."
2XKO has already experienced a bit of controversy, as LoL fans have found the game's name somewhat difficult to pronounce. This led Riot to put out a social media post showing the correct pronunciation.
The title will eventually be released for multiple platforms, including PS5 and Xbox Series X/S. The early access build, however, is just for PC players. This is a free-to-play game.
This article originally appeared on Engadget at https://www.engadget.com/gaming/riots-2xko-fighting-game-hits-early-access-on-october-7-165651941.html?src=rss
The Secret Service seized a network capable of shutting down New York City's cell service
The Secret Service says it thwarted a telecommunications cyber-op in New York City. On Tuesday, the agency announced that it seized a network of SIM servers. It was capable of jamming cell towers, conducting DDoS attacks and enabling encrypted communications. The discovery came ahead of world leaders gathering for the UN General Assembly this week.
The network, reportedly discovered in August, was extensive and sophisticated. It included over 300 SIM servers and 100,000 SIM cards across multiple sites. A Secret Service official told The New York Times that it was powerful enough to send 30 million anonymous text messages per minute. Photos provided by the Secret Service (below) show racks of SIM- and antenna-laden servers.
"This network had the potential to disable cell phone towers and essentially shut down the cellular network in New York City," special agent Matt McCool said in a video statement. He said an early analysis points to communications between at least one foreign country and "individuals that are known to federal law enforcement," which reportedly includes cartel members.
McCool added that, due to the sensitivity and complexity of the investigation, he couldn't go into specifics. Cybersecurity researcher James A. Lewis told The New York Times that only a handful of countries were capable of pulling that off, including Russia, China and Israel. Another security expert, Anthony J. Ferrante of FTI, said the network could have also been used for eavesdropping. "My instinct is this is espionage," he told the Times.
Secret Service officials told The New York Times that there was no specific information that the network posed a threat to the UN conference. Regardless, the confiscated devices were concentrated within a 35-mile radius of the assembly. The agency is responsible for security at the gathering.
"This is an open and active investigation, and we have no arrests to announce today," McCool said in his statement. "The Secret Service will continue to run down all leads until we fully understand the intent of the operation and identify those responsible."
This article originally appeared on Engadget at https://www.engadget.com/cybersecurity/the-secret-service-seized-a-network-capable-of-shutting-down-new-york-citys-cell-service-164958013.html?src=rss
Apple is expanding Tap to Pay on iPhone across more of Europe
Apple is expanding its Tap to Pay on iPhone feature for merchants to five more countries in Europe. Businesses in Estonia, Latvia, Lithuania, Monaco and Norway will now be able to accept in-person contactless payments on their iPhones.
The functionality is limited to specific third-party iOS apps that vary by nation. For example, British fintech company SumUp will now support Tap to Pay on iPhone in its iOS app in four of the five new countries, since SumUp is not offered in Monaco.
Norway will see the most payment platforms gain access to Apple's NFC payment tech, with over half a dozen platforms, including PayPal and Stripe, now supporting Tap to Pay on iPhone in the kingdom. Details on which merchant platforms were enabled by country can be found in Apple's announcement.
Merchants using these now supported platforms will be able to accept Apple Pay as well as contactless credit and debit cards. Every transaction done using Tap to Pay on iPhone is encrypted and processed using Secure Element, a dedicated chip designed for storing sensitive information. Platforms wishing to use Apple's NFC technology when accepting payments must enter into a commercial agreement with the tech giant and pay the associated fees.
Tap to Pay on iPhone is now available in 43 countries and regions worldwide. Merchants using approved platforms will not require any additional hardware to accept these payments.
This article originally appeared on Engadget at https://www.engadget.com/big-tech/apple-is-expanding-tap-to-pay-on-iphone-across-more-of-europe-163910943.html?src=rss
The Death Stranding anime now has a title and its first trailer
The long-running joke about Hideo Kojima is that he’d secretly rather be making movies than video games. Kojima somehow nearly got into double figures on Metal Gear games without any of them receiving the adaptation treatment (though not for the lack of trying on his part), but it’s looking like a very different story for the Death Stranding series on which he’s been working since departing Konami.
A live-action adaptation of the post-apocalyptic walking simulator landed a writer and director back in the spring, and it was announced a few months later that an animated Death Stranding movie was also on the way, with Aaron Guzikowski (Raised by Wolves) penning the screenplay. We now know what film will be called, and there’s a trailer.
Death Stranding Mosquito is directed by ABC Animation’s Hiroshi Miyamoto, with Kojima himself serving as a producer, and will apparently tell an original story within the "surreal and emotionally resonant" Death Stranding universe. If you’ve played the original game or its 2025 sequel, the teaser will look very familiar, with the film seemingly focusing on a character who definitely isn’t Norman Reedus’ Sam Porter Bridges, but is sporting very similar get-up.
The hooded figure comes face to face with what appears to be a BT-ified doglike creature, and then has a brutal fist fight with another character. We don’t get any more context than that, nor any whiff of a release date, but visually Death Stranding Mosquito looks absolutely stunning.
It’s been a busy few days for Kojima-related announcements. We got the first gameplay trailer for Kojima Productions’ upcoming horror game, OD, and found out that Kojima is also releasing his own credit card in Japan. Yes, really.
This article originally appeared on Engadget at https://www.engadget.com/entertainment/tv-movies/the-death-stranding-anime-now-has-a-title-and-its-first-trailer-155516913.html?src=rss
Meta to launch national super PAC against AI regulation
Meta is launching a national super political action committee (PAC), according to a report by Axios. This super PAC will be committed to fighting "onerous" AI regulation across the country. It's called the American Technology Excellence Project and Meta spokesperson Rachel Holland said the company is investing "tens of millions" into the effort.
The goal of the PAC is to elect pro AI state candidates from both parties. It's being run by longtime Republican operative Brian Baker with an assist from Democratic consulting firm Hilltop Public Solutions.
The tech-friendly federal government has no plans to regulate AI but fell short on banning states from doing so. There have been over 1,000 state-level policy proposals introduced this year, which Meta thinks could hurt America in the AI race with China.
"State lawmakers are uniquely positioned to ensure that America remains a global technology leader," Meta VP of public policy Brian Rice said in a statement. "This is why Meta is launching an effort to support the election of state candidates across the country who embrace AI development, champion the U.S. technology industry and defend American tech leadership at home and abroad."
The company has not released any information as to which forthcoming state elections would be disrupted by the aforementioned tens of millions of dollars. We also don't know how many people the PAC will employ.
Meta is preparing to pump tens of millions of dollars into a new California super PAC that will fund candidates opposed to tech regulation, especially the regulation of AI, per Politico.
— More Perfect Union (@MorePerfectUS) August 26, 2025
This is just the latest move into politics by Meta. It recently launched a PAC in California to protect tech and AI interests. The state has been fairly proactive about enacting protections against potentially harmful AI use cases. It passed a law protecting the digital likenesses of actors and has attempted bills that block election misinformation and protect against "critical harm" caused by AI.
While the Trump administration loves itself some AI, there are limits. The president recently signed an executive order banning "woke AI" from being used in the federal government. I haven't come across any woke AI in the wild, but I have seen whatever this is.
This article originally appeared on Engadget at https://www.engadget.com/big-tech/meta-to-launch-national-super-pac-against-ai-regulation-154537574.html?src=rss
Rokid's smartglasses are surprisingly capable
Meta put the smartglasses industry on alert when it announced the Meta Ray-Ban Displays last week. And while those might feature one of the most advanced optical engines on a device its size, after testing out one of its competitors — the Rokid Glasses — I'm convinced there's still plenty of room for competition.
At $549, the Rokid Glasses are more affordable than the Meta Ray-Ban Displays, which are set to launch at $800. However, it should be noted that this difference won't last forever, as following Rokid's Kickstarter campaign, its suggested retail price will increase significantly to around $740. Also, while Kickstarter campaigns aren't always the strongest indicator of reliability, Rokid has actually been around for some time with devices dating back to before 2018.
But more importantly, Rokid's eyewear has some notable design differences. Instead of a single full-color display for just your right eye, it features dual microLED waveguides that provide a true binocular view, which helps reduce eyestrain. The downside is that the Rokid glasses only support a single color — green — though that’s kind of fun if you're into the classic hacker aesthetic. Text and icons are more than sharp enough to make reading the glasses' minimalist UI a cinch. And with up to 1,500 nits of brightness, its display is easy to see even outside in bright light. In the future, though, Rokid will need to upgrade to full-color components to better compete with rivals like the Meta Ray-Ban Displays.
Rokid's glasses score well when it comes to overall style and wearability. The Meta Ray-Ban Displays look like someone stole the frames off Garth's head from Wayne's World and then made them thrice as thick, whereas Rokid's glasses actually look more like Wayfarers than Ray-Ban's own creation. Touch panels are hidden in each arm, and you even get real nose pads for extra comfort. Plus, weighing in at just 49 grams, Rokid claims its creation is the lightest "full-function AI and AR glasses."
The only major indicators that these aren't a typical set of eyewear are the small camera near your left temple and a faint outline of where the waveguides project a heads-up display onto its lenses. There are also tiny built-in speakers that play the sound from videos, music or answers from Rokid's AI helper and they are about as good as you can expect from a gadget this compact. But it probably won't come as a surprise when I say they could be a touch louder or provide better bass.
Meanwhile, when it comes to recharging, there's a simple magnetic pin connector at the end of the right arm that can connect to any USB-C cable using an included adapter. Unfortunately, if you want a charging case like you get with many of its rivals, you'll have to shell out another $100. Battery life has been surprisingly solid in my experience as well. You can get up to six hours of continuous music playback over Bluetooth, though if you use more advanced features (especially ones that rely on AI), you will need to juice up sooner.
As for functionality, the company’s standalone approach to content generation is both its biggest strength and weakness. That's because while Meta's smartglasses come with tie-ins to Facebook and Instagram which makes livestreaming what you see a breeze, Rokid doesn't offer that option. Instead, you'll have to use the onboard 12MP camera and five mics to take photos and videos before manually downloading them to your phone and then sharing them to your favorite platform. This results in a few extra steps between capture and publication (and no option for livestreaming), but at least you do get the freedom of choice.
Image quality is also acceptable. You won't be dazzled by its contrast and dynamic range and darker environments can be a bit of a challenge. But as a vehicle for recording the world around you, these glasses are a decent way to take in your surroundings. Thankfully, the process of capturing content couldn't be simpler, just press once on the physical button on the right arm for a picture or press and hold for video. Or if you prefer, you can use voice commands like "Hi Rokid, record a video."
Aside from taking photos and videos, Rokid's glasses can also pair with your phone to serve up notifications, record voice memos and even offer turn-by-turn directions using AI, though I couldn't get that last feature working. There's also a teleprompter mode that allows you to upload scripts to the glasses and have text scroll down automatically as you speak.
However, the biggest draw (or deterrence, depending on your opinion of machine learning) is the AI integration, which uses the device’s Qualcomm AR1 chip and an onboard ChatGPT model to provide real-time translation and audio transcriptions. Just like what you get when using large LLMs on a phone or laptop, even when AI can understand most of what's coming in, there are still times when it doesn't fluently convert certain lines or phrases.
There's also the option to ask the glasses to create a text description of what its cameras see, though again, AI sometimes struggles with accuracy. When I held my phone up in front of the lens, it correctly identified what type of device it was, but then it got confused by a barcode on a box in the background and thought I was trying to insert a SIM card.
Even considering the foibles of current AI models, the Rokid glasses are a welcome surprise in a growing sea of smartglasses. They're lighter and sleeker than anything I've tried to date while covering all the most important functions: playing music, surfacing notifications and capturing decent first-person photos and videos. Other features like live translation and live captions are a bonus. When they work, which is most of the time, it really feels like an engaging glimpse of what is poised to be the next big era for wearable computing.
It's way too early to pick a winner or even recommend these as a must-have for bleeding-edge enthusiasts. But to see smaller names like Rokid come up with compelling alternatives to Meta's latest makes these smartglasses worth paying attention to.
The Rokid Glasses are available for pre-order now via the company's Kickstarter campaign with estimated deliveries slated for sometime in November.
This article originally appeared on Engadget at https://www.engadget.com/wearables/rokids-smartglasses-are-surprisingly-capable-153027590.html?src=rss
WhatsApp starts rolling out message translations on iOS and Android
WhatsApp is now rolling out message translations on its iOS and Android apps. Starting today, Android users will be able to translate messages between six languages: English, Spanish, Hindi, Portuguese, Russian and Arabic. On iPhone, there's support for translation between the following languages (i.e. all of the ones supported by Apple's Translate app):
Arabic
Dutch
English
French
German
Hindi
Indonesian
Italian
Japanese
Korean
Mandarin Chinese
Polish
Portuguese (Brazil)
Russian
Spanish
Thai
Turkish
Ukrainian
Vietnamese
To convert a message into a different language, long press on it, select Translate, then the language you'd like to translate the message to or from. Android users will get an extra-handy bonus feature with the ability to switch on automatic translation for an entire chat.
Translations are handled on your device to help protect your privacy — WhatsApp still won't be able to see your encrypted chats. Your device will download relevant language packs for future translations. WhatsApp says translation works in one-on-one chats, groups and Channel updates. The platform will also add support for more languages down the line.
There's no word as yet on if or when WhatsApp will support message translations on the web or in its Windows app. "Translating messages on WhatsApp is only available on certain devices and may not be available to you yet," a note on a support page reads. "In the meantime, we recommend keeping WhatsApp updated on your device so you can get the feature as soon as it's available."
This article originally appeared on Engadget at https://www.engadget.com/apps/whatsapp-starts-rolling-out-message-translations-on-ios-and-android-150132823.html?src=rss
The EU wants Apple, Google and Microsoft to clamp down on online scams
The European Union has asked Apple, Google and Microsoft to explain how they police online financial scams, stepping up enforcement of the Digital Services Act (DSA), as first reported by the Financial Times. Formal information requests were also sent to Booking Holdings, the owner of Booking.com, regarding how the company handles fake accommodation listings. Likewise, regulators will be probing fake banking apps in Apple’s App Store and Google Play. Additionally, they will be taking a close look at fake search results in Google search and Microsoft's Bing.
Speaking with the Financial Times, EU tech chief Henna Virkkunen said criminal activity is increasingly moving online and platforms must do more to detect and prevent illegal content. Virkkunen said that financial losses from online fraud exceed €4 billion a year (around $4.7 billion) across the EU, and that the rise of AI has made detecting these scams more difficult.
The four companies will be given the chance to respond to these information requests, but under the DSA companies can face penalties up to 6 percent of their global annual revenue for failing to adequately combat illegal content and disinformation.
Earlier this year Apple and Meta were fined around $570 million and $228 million, respectively, after the European Commission found them in violation of the Digital Markets Act (DMA), though both companies are appealing the fines. The DMA is a set of rules governing online platforms that was adopted alongside the DSA in 2022.
European fines on American companies, particularly a recent $3.5 billion fine levied on Google for antitrust violations, have drawn the attention and ire of President Donald Trump. The president has threatened a trade probe over what he views as "discriminatory actions" against American tech companies.
This article originally appeared on Engadget at https://www.engadget.com/big-tech/the-eu-wants-apple-google-and-microsoft-to-clamp-down-on-online-scams-145333226.html?src=rss
A PlayStation State of Play is set for September 24
The Tokyo Game Show is taking place this week and Sony is getting in on the action with a PlayStation State of Play. The stream will start at 5PM ET on Wednesday, September 24 and run for over 35 minutes. You can watch it on YouTube (also with English subtitles or in Japanese) and Twitch. The stream will be available right here for your convenience, because we're nice like that.
There will be a fresh look at Saros, the next game from Returnal studio Housemarque. We'll get our first peek at gameplay from that project, which is set to hit PS5 next year. Sony also promises that the State of Play will include "new looks at anticipated third-party and indie titles, plus updates from some of our teams at PlayStation Studios."
There have been some rumblings that Sony may be about to reveal more details about Marvel's Wolverine (the next title from Insomniac, the developer of the Spider-Man games), so that seems like a decent bet. For what it's worth, this Friday is The Last of Us Day, so there's a chance we might hear something from Naughty Dog regarding that series.
This article originally appeared on Engadget at https://www.engadget.com/gaming/playstation/a-playstation-state-of-play-is-set-for-september-24-143526268.html?src=rssHideo Kojima's OD captures the spirit of P.T. in the first gameplay trailer
Kojima Productions, the studio helmed by auteur and famed cardboard box enthusiast Hideo Kojima, has finally given us our first glimpse of gameplay for the horror game OD. Developed in collaboration with Get Out and Us director Jordan Peele, OD is being billed as a totally unique experience that Kojima expects to divide players. It’s also going to leverage Microsoft’s cloud gaming tech in ways we’re not yet aware of, with Xbox Game Studios publishing the game.
In the new just over three-minute trailer entitled "Knock", we see first-person gameplay footage of the player character (played by a ludicrously photorealistic Sophia Lillis) anxiously lighting a series of candles, several of which have babies on them, because Kojima. In the background we hear a very ominous knocking sound, with the trailer ending as Lillis’ character is grabbed by someone (or something) who doesn’t appear to be especially friendly.
If you were fortunate enough to play P.T., the playable (and tragically no longer accessible) teaser for Kojima and Guillermo del Toro’s cancelled Silent Hill game, you’ll know that the Metal Gear creator clearly understands how to craft terrifying horror experiences. From what we’ve seen so far, it looks like the spirit of P.T. at least lives on in OD.
It’s been a busy day for Kojima and his studio, which celebrates its 10th anniversary this year and has so far exclusively released Death Stranding games. At Kojima Productions’ "Beyond the Strand" event it was also announced that the studio is partnering with Niantic Spatial to develop what appears to be some kind of AR experience that brings Kojima’s "iconic storytelling into the real world." Whether that means you can one day expect to encounter a virtual Norman Reedus attempting to steady his wobbling backpack on your way to the grocery store remains unclear, but Kojima Productions says the collaboration represents a "bold expansion into new forms of media beyond traditional gaming."
And if all of that wasn't enough, Kojima Productions is also teaming up with Mitsubishi UFJ Financial Group on a new credit card. It seemingly functions like a regular old credit card that can also be added to your phone, but you can accumulate reward points that can be spent on Kojima Productions merch and other items. Don’t get too excited unless you live in Japan, though, as it doesn’t look like the Kojima-branded credit card will be making its way to our shores when it launches next year.
This article originally appeared on Engadget at https://www.engadget.com/gaming/hideo-kojimas-od-captures-the-spirit-of-pt-in-the-first-gameplay-trailer-142623143.html?src=rss
Meta is making its Llama AI models available to more governments in Europe and Asia
Meta is allowing more governments to access its suite of Llama AI models. The group includes France, Germany, Italy, Japan, and South Korea and organizations associated with the European Union and NATO, the company said in an update.
The move comes after the company took similar steps last year to bring Llama to the US government and its contractors. Meta has also made its AI models available to the UK, Canada, Australia and New Zealand for "national security use cases."
Meta notes that governments won't just be using the company's off-the-shelf models. They'll also be able to incorporate their own data and create AI applications for specific use cases. "Governments can also fine-tune Llama models using their own sensitive national security data, host them in secure environments at various levels of classification, and deploy models tailored for specific purposes on-device in the field," the company says.
Meta says the open source nature of Llama makes it ideally suited for government use as "it can be securely downloaded and deployed without the need to transfer sensitive data through third-party AI providers." Recently, Mark Zuckerberg has suggested that "safety concerns" could potentially prevent Meta from open-sourcing its efforts around building "real superintelligence."
This article originally appeared on Engadget at https://www.engadget.com/ai/meta-is-making-its-llama-ai-models-available-to-more-governments-in-europe-and-asia-134621319.html?src=rss
GoPro Max 2 review: There's a new 360 camera contender in town
In a break from tradition, GoPro hasn’t announced a new Hero Black camera this fall. Instead, this year’s flagship is the much-rumored Max 2 360 camera ($500). The Max 2 lands at a time when spherical video is having a mini renaissance, taking on Insta360’s X5 ($550) and DJI’s Osmo 360 ($550). Perhaps surprisingly, GoPro’s Max 2 is the most affordable of the three, suggesting that the company might be looking to gain ground on its rivals and, hopefully, make the creatively warped world of 360-degree video more accessible.
With a mix of pro features like Timecode, GP-Log (with LUTs) alongside mobile-focused editing, GoPro clearly hopes the Max 2 will appeal to demanding and casual users alike. The company has also focused heavily on improving the user experience rather than going for pure technological advances and after a week or so of testing, that feels like a sensible move.
The Max 2 brings a decent resolution bump from its 5.6K predecessor, offering full 8K with 10-bit color. This puts it on par with the DJI Osmo 360 and Insta360 X5, but GoPro claims that Max 2 is the only one of the three with “true” 8K. That’s to say it doesn't count unusable pixels on the sensor or those that are used in overlapping for stitching the footage from the two lenses together. GoPro goes as far to say that this results in somewhere between 16- and 23-percent higher resolution than its rivals.
You can now shoot 360 video at 8K/30 fps, 5.6K/60 fps and good ol’ 4K at 90 fps in 360 mode. When you shoot in single-lens mode (aka, non-360 mode), the max resolution available is 4K60, up from 1.4K/30 on the original Max. But pure resolution isn’t the only quality gain this time around, the Max 2 now joins its Hero siblings with 10-bit color and a top bit rate of 120Mbps, which can be increased to 300Mbps via GoPro’s experimental Labs firmware.
Other hardware updates include a gentle redesign that matches the current Hero and Hero 13 cameras with heat-sink style grooves over the front face and centrally-placed lenses (rather than in a left-right configuration as before). The physical size and shape of the Max 2 otherwise matches the OG Max. There is one new, and much appreciated change, though. With the Max 2, the lenses twist off for easy replacement. As there’s a lens on both sides, it’s always going to land “butter-side down” when dropped. The probability of scuffing or breaking one is therefore much higher, but with Max 2, replacing them is a trivial matter and a solid quality of life improvement. The Insta360 X5 has replaceable lenses too, but DJI’s Osmo 360 requires sending the camera to the company for a refresh.
As for audio, the six-mic array is directional, with sound focusing on where the action is taking place. As with the Hero 12 and 13 Black, you can also connect AirPods or a Bluetooth microphone (such as DJI’s Mic 3) to the GoPro directly for narration or extra-clear shrieks of fear. There’s no doubt this makes the Max 2 more appealing to vloggers and social creators.
There’s no onboard storage here, which is true for all GoPro cameras, but worth mentioning now as DJI’s Osmo 360 ships with 105GB of storage. Given the amount of times I’ve headed out with my camera only to find I left the memory card in my PC, I’d really love to see GoPro make it a standard addition to its cameras too.
After years of testing action cameras, I’ve learned that while some models excel in one area or terrain, they can struggle in others. I live near a huge park with a variety of colors, trees and pockets of water, which makes it a perfect testing ground. The Max 2 fares well across the board, with vibrant, natural colors and generally balanced exposure. You’ll notice transitions in the exposure as you move from direct sunlight to shadow, but that’s fairly typical.
When you review and reframe your footage, you’ll instantly be reminded you’re working with a 360 camera. The minute you drag your finger over a video to rotate it or zoom out for that drone-like “floating” footage, you’ll also introduce some warping. Sometimes it’s a bit frustrating trying to find the right balance of warp and pleasant framing, other times it actually makes for a good effect. If you zoom out fully, for example, you’ll end up with one of those “tiny planet” videos.
It’s also worth talking about stitch lines. Where the two lenses overlap, you’ll sometimes notice where the video is being stitched together, often via some slight wobbling or a break in a street markings and so on. Again, it’s a fact of life with current 360 photography, and you will notice it with the Max 2 from time to time.
Conversely, 360 video allows for extremely good stabilization, especially in single lens mode. I tried recording myself with a long selfie stick, precariously perched on my bike’s handlebars (not locked in with a mount) and despite the camera moving like a fish on land as I rode over uneven ground and potholes, the footage still came out impressively smooth. In friendlier conditions — such as walking with the camera — footage is even smoother and immediately ready for sharing.
New additions this year include 8K timewarps and a new (for Max) “HyperView” which is a 180-degree ultrawide FOV that just uses everything the sensor captures for extra immersive footage. As with HyperView on the Hero cameras, it’s a little extreme with lots of warping but it feels like you’re being sucked into the image, perfect for point of view footage.
Which brings us to the aforementioned Selfie Mode and POV mode; both are more about removing friction than adding any new creative tools. As you don’t need to have a 360 camera facing you while shooting a selfie, the video isn’t always oriented with you in frame when you open it in Quik. With Selfie/POV mode, it will load up framed correctly, so you can go right into sharing your clip.
Think of it as a hybrid between 360 and single-lens mode. You will still capture everything in 360, and can move the shot around to show different things, but if your POV or your face talking to camera are the main focus, you don’t need to do any reframing to get there. The camera also applies the optimal stabilization, reducing the amount of editing needed to get from camera to export. The first Max would always open videos from the front camera point of view regardless, leaving you to dig around for what you actually wanted to focus on.
Photography with a 360 camera is both simple and complicated at the same time. On the one hand, you don’t need to worry whether you’re in shot, as you’re going to capture everything, but likewise you’re going to want to make sure you catch the right moment or the best angle. A new Burst mode alleviates some of that concern by taking a bunch of photos for a set period of time (one to six seconds). giving you the ability to strike a few poses or make sure you catch the best shot if the subject is moving. You can then edit and reframe in Quik as with any other media.
Unlike a regular camera, with 360 video you can’t avoid at least some editing. At minimum, you’ll need to confirm framing for exporting to a flat (dewarped) video. That said, editing is where all the fun is. Being able to shoot one video and make it dynamic with panning and zooming is one of the major benefits of this type of camera. Quik is where you’ll be doing most of this, and unlike DJI, which is a relative newcomer to the category, GoPro has a few years’ headstart on the app side of things.
The result is an editing experience that’s intuitive that strikes a good balance between creative possibility and ease of use. For a simple punch out video where you set the framing and zoom amount and then export, it’s just a few button clicks before you have a video you can share. You can of course go back and re-edit and export in another aspect ratio if, say, you want an Instagram Reel in portrait alongside a regular 16:9/widescreen version for YouTube.
Quik also includes some filters that may or may not be to your taste. Much more useful are the preset effects, including a variety of spins, rolls and pans that are clearly aimed at action footage, but can be used creatively for any type of video. You can also track an object automatically via AI. It’s perfect for keeping your kid or pet in the shot while they run around with one click and an easy way to make your video dynamic. Overall, editing in Quik feels like a solid pipeline for posting to social media, but it is still a bit cumbersome for anything longer. Desktop editing options are Adobe Premier and After Effects via the GoPro Reframe plugin. The company also recently announced a beta plugin for Davinci Resolve.
The Max 2 ships with a 1,960mAh “Enduro” battery, which is designed to last longer even in extreme cold. GoPro claims that it should last “all day” but that of course depends what you’re doing with it. When I took the camera out for a day of filming, visiting different locations and pulling the camera out when I found something interesting, the battery lasted for the whole six-hour excursion. That’s not actual recording time, obviously, and I maybe grabbed about 30 minutes of actual footage. But that’s me walking around with the camera on, or in standby, and hitting record sporadically over that period. In fact, there was still about 15-percent battery left when I went to export my footage the next day.
That’s more of a real world test with me connecting the camera to the phone and transferring files, which will yield less recording time than if you just set the camera down and press record. This is about on par with what I’ve experienced with regular GoPros that can usually record for about an hour and a half in a “set and record” scenario.
A reasonable amount of time has passed between the Max 1 and Max 2, so if you were hoping for a top-to-bottom spec overhaul, you might be a little disappointed. But with 360 video, source resolution is the main upgrade and Max 2 can output 4K/60 video, which is by far the most important thing. That improved resolution has filtered down into all the important timelapse and video modes, and that makes the camera feel current and mostly complete.
I do think it’s about time that GoPros have onboard storage, at least as an option, as that removes a really simple pain point. The fact that DJI is doing it might well give GoPro the nudge it needs.
A lot of what sets the Max 2 apart from DJI will be in the editing experience. It’s simple and well thought out, with some useful tools and effects that make getting footage into something you want to share pretty straightforward. Although DJI’s onboard storage and higher maximum frame rate will be tempting for many. Insta360’s app is generally considered easy to use, too, so with the X5, GoPro’s advantage is the price (at least for now). What really sets these cameras apart, are the videos you end up sharing, and in that regard GoPro’s bet on “true 8K” and the app experience might just be enough.
This article originally appeared on Engadget at https://www.engadget.com/cameras/gopro-max-2-review-theres-a-new-360-camera-contender-in-town-130058942.html?src=rss
Google is turning Gemini into a gaming sidekick with a new Android overlay
Google might have found a way Gemini could be useful while you're playing games on your phone. The company is introducing a new software overlay today it calls the Play Games Sidekick that gives you access to Gemini Live while you play, alongside a host of other gaming-focused updates to Google Play that could make the app platform a better home for gamers.
Sidekick exists as a small, moveable tab in games downloaded from the Play Store that you can slide over to show relevant info and tools for whatever game you're playing. By default, that's things like easy access to a screenshot button, screen recording tools and a shortcut for going live on YouTube, but you'll see achievements and other game stats in there, too.
Google is clearly most interested in how Sidekick could serve as a delivery system for Gemini, though, so AI plays a large role in how Sidekick actually helps you while you play. That includes offering a curated selection of game tips that you can swipe through, and a big button that you can press that starts Gemini Live. Based on a demo Google ran for press, Gemini Live does seem like it could be a competent guide for navigating games. It was able to offer strategies for how to best start a game of The Battle of Polytopia and told game-specific jokes that were only funny in how awkward they were. Since Gemini can accept screen sharing as an input, it was also able to offer its guidance without a lot of context from the Google project manager running the demo. Referring to in-game items as "this" or "that" was enough to get Gemini to understand.
Gemini in Sidekick won't really replace a detailed game guide written by a human, but for a quick answer it's easier than Googling. It's also similar in many ways to Microsoft's Gaming Copilot, which also places a live AI in games with you. For now, Google is taking a restrained approach to rolling out Play Games Sidekick and its AI features. You don't have to interact with the overlay at all if you don't want to (you can even dismiss it to the notification shade) and Gemini-powered features will only be available "in select games over the coming months." That includes games from "hero partners EA and NetMarble," according to Google, like "Star Wars Galaxy of Heroes, FC Mobile and Solo Leveling Arise."
Beyond the Sidekick, Google views its updates to Google Play Games as a way to unify what's a pretty siloed-off gaming experience on mobile. Each game has its own profile, achievements and in-game stats, and few of them connect to each other. In an attempt to fix that, Google is introducing a "platform-level gaming profile" that tracks stats and achievements across Android and PC, and even supports AI-generated profile pictures. Like other gaming platforms, you can follow your friends and see what games they're enjoying. Google will also host forums for games available in the Play Store where you can ask questions about a game and get answers from other players.
All of these tweaks come with major caveats in that they require players to use them and developers to enable them, but they do suggest Google is trying to take games seriously after bungling more ambitious projects like Stadia. And not just on Android: As part of this rollout, the PC version of Google Play Games is coming out of beta, putting the company in even more direct competition with the Steams of the world.
This article originally appeared on Engadget at https://www.engadget.com/mobile/google-is-turning-gemini-into-a-gaming-sidekick-with-a-new-android-overlay-130052048.html?src=rss
GoPro's Lit Hero is an entry-level action cam with a built-in light
Along with its new 360 Pro 2 Max camera, GoPro has introduced the Lit Hero — a new compact action cam that looks like its entry-level Hero with a built-in LED light. That, along with improved image quality and a price that falls between the Hero and high-end Hero 13 models, could make it a popular option for creators and vloggers.
The GoPro Lit has a similar form factor to the Hero but differs in a few key ways. The built-in light opens up creative options particularly for vloggers, as it can help illuminate your face in somber lighting or shadows. That could make it useful not only for regular vlogging, but as a "B" cam for action creators who want better lighting on their faces. In a further nod to those creators, it now has the record button up front, though the lack of a front display may make it a tough sell for some.
Another key improvement over the Hero is with video quality. The Hero Lit can capture 4K video at up to 60 fps instead of 30 fps before, opening up a 2x slow-mo option at the highest resolution. And like the Hero (following an update) the Hero Lit can capture 4:3 video that makes it easier to create vertical video for social media while offering cropping options for regular 16:9 shots. You can also shoot social-ready 12MP 4:3 photos.
Otherwise, the Lit's feature list lines up closely with the Hero. It's waterproof down to 16 feet (5m) for underwater action and rugged enough for extreme sports. It uses the same Enduro battery that promises over 100 minutes of 4K 60p video on a charge, though not with the LED lights turned on I imagine. It's now on pre-order for $270 on GoPro.com, with shipping set to start on October 21.
This article originally appeared on Engadget at https://www.engadget.com/cameras/gopros-lit-hero-is-an-entry-level-action-cam-with-a-built-in-light-130035003.html?src=rss
Google Play is getting AI-sorted search results, a 'You' tab and short-form K-dramas
Google is announcing several updates to Google Play in an attempt to shift the app store from "a place to download apps" to "an experience." Many of the changes are powered by AI, and most seem like a preemptive attempt to keep the Play Store attractive for users now that it seems increasingly possible Google will be forced to open up Android to third-party app stores.
The most visible update Google is introducing to Google Play is a new tab. It's called the "You Tab" and it acts like a combination of a profile page and a For You tab, specifically for app store content. You can access Google's universal game profiles from the tab — part of larger gaming-focused updates Google is bringing to Google Play — along with app recommendations and content recommendations from streaming apps available through the Play Store. The tab seems relatively easy to ignore if you just want to download apps, but Google thinks users could turn to it as a curation tool and a way to take advantage of deals.
The company is also expanding the ways you can find apps. New regional sections will collect apps and content based on specific interests or seasonal topics. Google has tried a "Cricket Hub" in India and a Comics section in Japan, and now it's bringing an Entertainment section to Korea that will collect short-form video apps, webcomics and streaming services into a single home. Interestingly, Google is making content from these apps available to sample directly in Google Play, and not just in Korea. You'll be able to read webcomics and watch short-form K-dramas directly in Google Play, without having to download an additional app in the US, too.
When you're looking for something in particular, a new "Guided Search" feature will let you search for a goal (for example, "buy a house") and receive results that are organized into specific categories by Gemini. Those Gemini-based improvements will also extend to individual app pages, where Google continues to expand the availability of its "Ask Play" feature. Ask Play lets you ask questions about an app and receive AI-generated responses, a bit like the Rufus AI chatbot Amazon includes in its store pages.
Google's Play Store updates start rolling out this week in countries where the company's Play Points program is available, like the US, the UK, Japan and Korea. They'll come to "additional countries" on October 1, according to Google.
This article originally appeared on Engadget at https://www.engadget.com/mobile/google-play-is-getting-ai-sorted-search-results-a-you-tab-and-short-form-k-dramas-130005402.html?src=rss
This slim Anker MagSafe power bank is on sale for only $46
We can all be honest and say that carrying around a bulky power bank almost makes it seem like your phone dying isn't so bad. Between the heaviness and any necessary cords, they can just be a pain. So, we were intrigued when Anker debuted a new, very thin power bank this summer: the Anker Nano 5K MagGo Slim power bank.
Now, both Anker and Amazon are running sales on it, dropping the price from $55 to $46. The 16 percent discount a new low for the power bank and available in the black and white models. It's just about a third of an inch thick and attaches right to your iPhone. On that note, it works with any MagSafe compatible phone with a magnetic case.
Anker's Nano 5K MagGo Slim is our pick for best, well, slim MagSafe power bank. It took two and a half hours to charge an iPhone 15 from 5 percent to 90 percent. However, it could boost the battery to 40 percent in just under an hour. Overall, though, the minimalist design and easy to grip matte texture, really sold it to us.
Follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/this-slim-anker-magsafe-power-bank-is-on-sale-for-only-46-121512535.html?src=rss
Palworld: Palfarm might be the creepiest farming game ever
Palworld is getting as spinoff that looks both cozy and terrifying — oh, and filled with characters that look exactly like Pokémon. In Palworld: Palfarm, you move to the Palpagos Islands and create a farm alongside Pals. These creatures help with farm work, cook and can even become friends.
According to an announcement on Steam, "Through daily conversations, working together, or giving gifts from time to time, you can gradually deepen your relationships with both the Pals and the people of the island." Pocketpair, the developer behind both games, adds that they might even play matchmaker — a brand new trailer shows Pals officiating at a human wedding. Notably, the game also supports multiplayer.
However, the game certainly seems to have an air of darkness. For starters, there's this note in the description: "…Is one of your Pals slacking off? Time to teach them the joy of working." Ominous, to say the least. Then there's "nasty Pals," who will try to raid your farm and must be beaten in combat.
Darkest of all is a black market that sells guns, among other suspicious items. What you would need a gun for in this game is something you can choose to find out, but it certainly seems like the Palpagos Islands are a mixed bag of a place.
Palworld: Palfarm doesn't have a set release date yet, but you can watch the full trailer now.
This article originally appeared on Engadget at https://www.engadget.com/gaming/palworld-palfarm-might-be-the-creepiest-farming-game-ever-123049220.html?src=rss
Prime members can get 8Bitdo's Pro 2 controller with travel case for only $40
8Bitdo may have already launched its Pro 3 controller, but that doesn't mean you should dismiss older models. The Pro 2 has been one of our favorites for a long time, and right now Prime members can get the Bluetooth controller bundled with a travel case for only $40. That's $20 off and a 34-percent discount. This controller does, indeed, work with the Nintendo Switch 2, and the only caveat is that the sale price is only available to Prime members.
Despite launching in 2021, the Pro 2 was still our choice for best PlayStation-style mobile gaming controller this year. It works well with Android and iOS systems and has extensive customization options when you use your phone. Plus, the design is comfortable to hold and available in multiple colors.
Follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/prime-members-can-get-8bitdos-pro-2-controller-with-travel-case-for-only-40-115247955.html?src=rss
DJI Osmo Nano review: High-quality video in a truly tiny action cam
DJI might be an innovative company, but it has been playing catch-up to rival Insta360 in the action cam world. A perfect example of that is its latest product, the Osmo Nano ($299). It follows a path Insta360 paved with its tiny Go Ultra and Go 3S, which let you separate the cam from the display to shoot with the least weight possible. Like those, the Nano’s tiny camera can be detached from the screen and easily worn to record activities ranging from extreme watersports to cat cam videos.
The Osmo Nano isn’t quite a copy-paste of its rival, though. Rather than inserting the camera into the flip up screen housing like the Go Ultra, the Nano’s screen magnetically clips to the bottom of the camera so you can point it forward to capture action or backward for vlogging. While it still lags behind its rival in some areas, DJI’s Osmo Nano is a solid first attempt at a mini-sized camera thanks to its excellent video quality.
With its lightweight detachable camera that can be clipped to your head or worn on your body like a pendant, the Nano can be used in everyday activities like hiking or swimming — with the latter possible thanks to its 33 foot (10 meter) underwater rating. It’s also small enough to be attached to kids and pets to create a visual journal of their activities. At the same time, when attached to the Vision Dock that houses the screen, the Nano functions like a normal action camera.
With that in mind, size is key. The Osmo Nano camera is built from lightweight translucent plastic and weighs just 1.83 ounces (52 grams) by itself. That’s about the same as the Insta360 Go Ultra but a touch heavier than the Go 3S. Its capsule-like shape is similar to the Go 3S (but a bit bigger), while the Go Ultra is more rounded. All of that is to say that the Nano is incredibly small and light compared to a GoPro Hero 13 or DJI’s Action 5 Pro — I barely felt it when using the new headband accessory
They attach together in two ways, with the screen facing either forward or backward, using DJI’s magnetic mount that it’s used for a few years now. Together they weigh 4.37 ounces, still less than a regular action camera. The Vision Dock can wirelessly control the camera without being connected, to a distance of 33 feet. The mount also allows the Nano to connect to DJI’s family of accessories, including a new hat clip and lanyard.
During my testing, the camera and module were easy to connect in either direction thanks to the magnets and latches. To switch from vlogging to the front view, though, you need to detach and reconnect the Vision Dock. Insta360’s system is better, as it just takes a flip of the Go Ultra's screen to change modes.
The difference in camera module sizes can be explained by the sensors. Where the Go 3S has a small 1/2.3-inch sensor, both the Nano and Go Ultra have larger 1/1.3-inch sensors that take up more space but work better in low light. As for optics, the Nano uses an ultra wide angle lens with a 143-degree field of view, giving you the ability to switch between ultra wide and dewarped (square) video. The Go Ultra is slightly wider at 156 degrees, while the Go 3S’s FOV is 125 degrees. I found the Nano’s field of view to be an ideal compromise between the two.
The only physical control on the Nano is the record/power button, with the Vision Dock holding everything else. DJI’s typical screen swiping and tapping actions are used to select things like voice control and screen brightness, along with video resolution, frame rate, RockSteady stabilization and D-LogM capture. Once you get used to swiping and tapping on such a small display, these menus are responsive and let you change settings quickly. However, the navigation isn’t particularly intuitive so settings require some time to learn.
As with other recent DJI products, the Osmo Nano has generous built-in memory, with 64GB (transfers at 400 MB/s) and 128GB (at 600 MB/s) options. Note that those speeds don’t affect video quality; they’re only the rates at which you can transfer footage to your PC. This internal memory is convenient as it means you don’t need to dig around for a microSD card and it makes offloading faster. That said, it’s nice to have a microsSD slot as well — the Go Ultra only has a microSD storage option, and the Go 3S only has internal memory.
Each module has its own non-removable battery with 530mAh and 1,300mAh capacities for the camera and Vision Dock respectively. Those allow operating times of up to 90 minutes for the camera alone, or 200 minutes when paired with the screen module, according to DJI. In comparison, Insta360’s Go Ultra camera can run for 70 minutes or a maximum of 200 minutes when docked to the display.
Note that those specs only apply when recording in 1080p at 24p. When shooting with the Nano at a more typical setting of 4K 60p, I found that battery life was less than half that, around 35 minutes for the camera alone. However, that rose to 49 minutes when using DJI’s endurance mode, with RockSteady stabilization enabled but Wi-Fi turned off. I also noticed that when I shot in 4K at 50p or higher with the camera alone, it shut down after 20 minutes of continuous recording due to overheating.
The Nano’s camera has no USB-C input so it must be connected to the docking station for charging. However, the docking station alone can fast charge the Nano camera to an 80 percent battery in 20 minutes. It takes about 20 minutes to charge both devices together to 80 percent, and 60 minutes for a full charge — 20 minutes more than the Go Ultra.
Other key features include voice and gesture control (tapping or nodding) to start recording, timelapse and Pre-Rec to save footage taken just before the record button is pressed. Insta360’s Go 3S does have a couple of features not found on the Nano, namely Find Me for iPhone if it’s lost and Dolby Vision HDR support.
The Nano can also be controlled using the DJI Mimo smartphone app, though the Vision Dock’s remote control makes that unnecessary most of the time. That app also lets you edit video, but Insta360’s Studio app is superior for that thanks to its more complete editing toolkit and Shot Lab AI module that lets you do some neat effects with little-to-no work required. DJI is definitely well behind its rival in this area.
A big selling point of the DJI Nano is that it produces high-quality video with faster frame rates than rival cameras. You can capture 4K at up to 60 fps, or 120 fps in slow motion mode, compared to just 4K 30 fps for the Go 3s. It also supports full sensor 4:3 4K video at up to 50 fps. The Go Ultra maxes out at 60 fps at 16:9 4K and 30 fps at 4:3 4K.
Thanks to the big 1/1.3-inch sensor, video is bright and sharp straight out of the camera when shooting in daylight. DJI has improved the color performance compared to its older products, with hues that are more natural. Where sharpening was overly aggressive on models like the Action 5 (which makes video look artificial) DJI has toned that down on the Osmo Nano. And if you don’t like the default application, you can change it in the settings.
Like the Action 5 Pro, the Nano can shoot video with 10-bits of color in both D-LogM and regular modes. The latter gives users extra dynamic range without having to mess with tricky log settings. My preference is still to shoot D-LogM then apply DJI’s LUT in post. That yields more natural colors and gives you up to 13.5 stops of dynamic range in challenging lighting conditions, like tree-lined trails on a sunny day.
The larger sensor also makes the Osmo Nano superior to the Go 3S and about equal to the Insta360’s Go Ultra in low light. When I shot nighttime cityscapes and in indoor bars, it delivered clean video with relatively low noise. For even lower light situations, both the Nano and Go Ultra have night shooting modes called SuperNight and PureVideo, respectively. Both work well if you don’t move the camera too fast, due to the fact that they combine multiple frames into one. If I moved the camera too rapidly, it caused motion blur and other issues. The Insta360 Go Ultra is slightly better in this regard.
DJI’s RockSteady 3.0 reduces camera shake in normal daylight shooting conditions, though it’s not quite up to GoPro’s canny smoothing algorithms. When I tested it while walking, stabilization fell apart a bit in night shooting due to the lower shutter speeds, with noticeable blur and pixelization over sharp jolts and bumps. To avoid that, it’s best to boost the ISO level and shutter speed manually. The company’s HorizonBalancing, meanwhile, reliably corrects tilting up to 30 degrees to keep video level.
As with DJI’s other recent action cams, the Osmo Nano connects to the company’s Mic 2, Mic 3 and Mic Mini via its proprietary OsmoAudio direct connection. That offers higher quality and a more reliable connection than Bluetooth, while allowing you to use two mics at the same time for interviews or multiperson action scenarios. The Nano also has dual built-in microphones for stereo recording, but in my testing, the tinny audio was only good enough for ambient sounds and not voices.
It’s interesting to watch DJI try to catch up to another company for a change. With the Nano, it leaned on its camera experience and mostly matches or beats its main rival in terms of video quality. However, the company is still lagging behind in a few areas, particularly its editing app — something that’s important for many creators.
DJI seems to be aware of that and priced the Nano much cheaper than rivals. The Nano costs $299 (€279 and £239 in Europe) for the 64GB combo and $329 for the 128GB combo (€309/£259), both of which include the Vision Dock, magnetic hat clip, magnetic lanyard, protective case, high-speed charging cable and dual-direction magnetic ball-joint adapter mount. That compares to $450 for the Insta360 Go Ultra, which has no built-in memory and includes fewer accessories, and $400 for the Go 3S with 128GB of internal storage.
Update September 23, 2025 at 8:50AM ET: The review has been updated to reflect US availability.
This article originally appeared on Engadget at https://www.engadget.com/cameras/dji-osmo-nano-review-high-quality-video-in-a-truly-tiny-action-cam-120040319.html?src=rss
The Morning After: US and China agree to agree on a TikTok deal
After the proclamation of a TikTok ban, which fizzled out, during President Trump’s first term, the idea of a TikTok lockout across the US was back on the table when he returned for a second presidency.
Now, after too much will-they-won’t-they, White House press secretary Karoline Leavitt said a TikTok deal is expected to be signed “in the coming days.” This follows President Donald Trump posting an update on Friday that did little to clarify what the deal actually is.
Trump said both that the two had “made progress” on “approval of the TikTok Deal” and that he “appreciate[s] the TikTok approval.” Trump also told reporters in the Oval Office “he approved the TikTok deal,” according to Reuters.
During an appearance on Fox News’ “Saturday in America” the following day, Leavitt added the deal would mean that “TikTok will be majority owned by Americans in the United States.” She added: “Now that deal just needs to be signed, and the president’s team is working with their Chinese counterparts to do just that.”
The proposed terms reportedly include a brand new app for TikTok’s US users, which will continue to use ByteDance’s technology for its algorithm, US investor control and a multibillion-dollar payday for the Trump administration. But several days later, nothing is yet official.
— Mat Smith
Get Engadget's newsletter delivered direct to your inbox. Subscribe right here!
The news you might have missed
SpaceX’s lunar lander could be ‘years late’ for a planned 2027 mission to the Moon
Engadget review recap: All the iPhone 17 reviews and other Apple devices
With a straightforward process to replace batteries.
The new iPhone Air got a provisional 7 out of 10 in iFixit’s teardown critique. As seen in the repair company’s teardown, the iPhone Air’s battery can be easily swapped, has a modular USB-C port and works with day-one repair guides. Apple kept the same battery design introduced with the iPhone 16 lineup, which switched to an electrically released battery adhesive for easier, more clinical removal. Oh, another fun find: iFixit discovered the iPhone Air’s battery is the same cell found in the accompanying MagSafe Battery accessory. iFixit likened it to a “spare tire.”
Double billing now.
The Mandalorian and Grogu follows on from the events of Disney+ series The Mandalorian — a show that director Jon Favreau created — and the fall of the Empire in Return of the Jedi. It’s set to hit theaters on May 22, 2026. The trailer does make it seem like the movie will retain the playfulness of The Mandalorian. During the short teaser, Grogu uses the Force to try to steal a snack from Sigourney Weaver’s character, only to be denied. Poor Grogu.
It might be due to the eye-catching edges of the camera unit.
Careful, there may be a potentially scratch-prone iPhone 17 models. According to a Bloomberg report, those demoing the latest iPhone in-store noticed the iPhone 17 Pro in Deep Blue and the iPhone Air in Space Black models already had very noticeable scratches and scuffs. In a video by JerryRigEverything, the YouTuber puts the iPhone 17 models to the test with razor blades, coins and keys. The video highlights the edges of the iPhone 17 Pro’s back camera housing as particularly prone to scuffing since the colored aluminum oxide layer from the anodization process tends not to stick to sharp corners.
This article originally appeared on Engadget at https://www.engadget.com/general/the-morning-after-engadget-newsletter-111626774.html?src=rss
Bang & Olufsen's Beo Grace earbuds will cost you $1,500
Bang & Olufsen has launched a new pair of earbuds that could cost more than your phone or your laptop. The Beo Grace, as the model is called, will set you back $1,500, £1000 or €1200, depending on where you are. It has a silver aluminum casing with a pearl finish, which you can protect with a bespoke leather pouch, though the accessory will cost you an additional $400. The company says Beo Grace was "inspired by the elegance of fine jewelry," with aluminum stems reimagined from its iconic A8 earphones. Bang & Olufsen's A8 had stems made of metal, as well, but they transition into ear hooks that enable a more and secure and snug fit.
The earphones, the audio manufacturer explains, were "inspired by the acoustic principles" of the $2,200 Beoplay H100 headphones. Beo Grace has Spatial Audio and is optimized for Dolby Atmos, with an Adaptive Active Noise Cancellation technology that's "four times more effective" than the manufacturer's previous best earbuds. Specifically, its ANC tech is powered by six studio-grade microphones and can adjust itself in real time, based on the ambient noise. The model comes with tactile controls, so that every press to pause, play or skip is "crisp, deliberate and satisfying," but you will be able to adjust the volume by simple tapping. When it comes to battery life, the Beo Grace can last up to 4.5 hours of listening with ANC, and up to 17 hours with the charging case.
Beo Grace is now available for pre-order from the Bang & Olufsen website and will be widely available on November 17. The model comes with a three-year warranty, so you at least know that the company will fix your $1,500 earbuds if they break in the near future.
This article originally appeared on Engadget at https://www.engadget.com/audio/headphones/bang--olufsens-beo-grace-earbuds-will-cost-you-1500-103012904.html?src=rssThe best Chromebook you can buy in 2025
Whether you’re shopping for a budget-friendly laptop for school or a sleek machine for everyday productivity, the best Chromebooks can offer surprising functionality for the price. Chromebooks have come a long way from their early days as web-only devices. Now, many Chromebook models feature powerful processors, premium displays and even touchscreen support, making them a compelling alternative to a regular laptop for plenty of users.
There are more options than ever too, from lightweight clamshells to high-end, 2-in-1 designs that can easily replace your daily driver. Whether you're after a new Chromebook for streaming, work or staying on top of emails, there’s likely a model that fits both your budget and your workflow. We’ve tested the top Chromebooks on the market to help you find the right one — whether you’re after maximum value or top-tier performance.
What is Chrome OS, and why would I use it over Windows?
This is probably the number one question about Chromebooks. There are plenty of inexpensive Windows laptops on the market, so why bother with Chrome's operating system? Glad you asked. For me, the simple and clean nature of Chrome OS is a big selling point. Chrome OS is based on Google’s Chrome browser, which means most of the programs you can run are web based. There’s no bloatware or unwanted apps to uninstall like you often get on Windows laptops, it boots up in seconds, and you can completely reset to factory settings almost as quickly.
Of course, simplicity will also be a major drawback for some users. Not being able to install native software can be a dealbreaker if you’re a video editor or software developer. But there are also plenty of people who do the majority of their work in a web browser, using tools like Google Docs and spreadsheets for productivity without needing a full Windows setup.
Google and its software partners are getting better every year at supporting more advanced features. For example, Google added video editing tools to the Google Photos app on Chromebooks – it won’t replace Adobe Premiere, but it should be handy for a lot of people. Similarly, Google and Adobe announced Photoshop on the web in 2023, something that brings much of the power of Adobe’s desktop apps to Chromebooks.
Chromebooks can also run Android apps, which greatly expands the amount of software available. The quality varies widely, but it means you can do more with a Chromebook beyond just web-based apps. For example, you can install the Netflix app and save videos for offline watching. Other Android apps like Microsoft Office and Adobe Lightroom are surprisingly capable as well. Between Android apps and a general improvement in web apps, Chromebooks are more than just portals to a browser.
What do Chromebooks do well?
Put simply, web browsing and really anything web based. Online shopping, streaming music and video and using various social media sites are among the most common daily tasks people do on Chromebooks. As you might expect, they also work well with Google services like Photos, Docs, Gmail, Drive, Keep and so on. Yes, any computer that can run Chrome can do that too, but the lightweight nature of Google Chrome OS makes it a responsive and stable platform.
As I mentioned before, Chrome OS can run Android apps, so if you’re an Android user you’ll find some nice ties between the platforms. You can get most of the same apps that are on your phone on a Chromebook and keep info in sync between them. You can also use some Android phones as a security key for your Chromebook or instantly tether your 2-in-1 laptop to use mobile data.
Google continues to tout security as a major differentiator for Chromebooks, and it’s definitely a factor worth considering. Auto-updates are the first lines of defense: Chrome OS updates download quickly in the background and a fast reboot is all it takes to install the latest version. Google says that each webpage and app on a Chromebook runs in its own sandbox as well, so any security threats are contained to that individual app. Finally, Chrome OS has a self-check called Verified Boot that runs every time a device starts up. Beyond all this, the simple fact that you generally can’t install traditional apps on a Chromebook means there are fewer ways for bad actors to access the system.
If you’re interested in Google’s Gemini AI tools, a Chromebook is a good option as well. Every Chromebook in our top picks comes with a full year of Google’s AI Pro plan — this combines the usual Google One perks like 2TB of storage and 10 percent back in purchases from the Google Store with a bunch of AI tools. You’ll get access to Gemini in Chrome, Gmail, Google Docs and other apps, Gemini 2.5 Pro in the Gemini app and more. Given that this plan is $20/month, it’s a pretty solid perk. Chromebook Plus models also include tools like the AI-powered “help me write,” the Google Photos Magic Editor and generative AI backgrounds you can create by filling in a few prompts.
As for when to avoid Chromebooks, the answer is simple: If you rely heavily on a specific native application for Windows or a Mac, chances are you won’t find the exact same option on a ChromeOS device. That’s most true in fields like photo and video editing, but it can also be the case in law or finance. Plenty of businesses run on Google’s G suite software, but more still have specific requirements that a Chromebook might not match. If you’re an iPhone user, you’ll also miss out on the way the iPhone easily integrates with an iPad or Mac. For me, the big downside is not being able to access iMessage on a Chromebook.
Finally, gaming Chromebooks are not ubiquitous, although they’re becoming a slightly more reasonable option with the rise of cloud gaming. In late 2022, Google and some hardware partners announced a push to make Chromebooks with cloud gaming in mind. From a hardware perspective, that means laptops with bigger screens that have higher refresh rates as well as optimizing those laptops to work with services like NVIDIA GeForce Now, Xbox Game Pass and Amazon Luna. You’ll obviously need an internet connection to use these services, but the good news is that playing modern games on a Chromebook isn’t impossible. You can also install Android games from the Google Play Store, but that’s not what most people are thinking of when they want to game on a laptop.
What are the most important specs for a Chromebook?
Chrome OS is lightweight and runs well on fairly modest hardware, so the most important thing to look for might not be processor power or storage space. But Google made it easier to get consistent specs and performance late last year when it introduced the Chromebook Plus initiative. Any device with a Chromebook Plus designation meets some minimum requirements, which happen to be very similar to what I’d recommend most people get if they’re looking for the best laptop they can use every day.
Chromebook Plus models have at least a 12th-gen Intel Core i3 processor, or an AMD Ryzen 3 7000 series processor, both of which should be more than enough for most people. These laptops also have a minimum of 8GB of RAM and 128GB of SSD storage, which should do the trick unless you’re really pushing your Chromebook. All Chromebook Plus models have to have a 1080p webcam, which is nice in these days of constant video calling, and they also all have to have at least a 1080p FHD IPS screen.
Of course, you can get higher specs or better screens if you desire, but I’ve found that basically everything included in the Chromebook Plus target specs makes for a very good experience.
Google has an Auto Update policy for Chromebooks as well, and while that’s not exactly a spec, it’s worth checking before you buy. Last year, Google announced that Chromebooks would get software updates and support for an impressive 10 years after their release date. This support page lists the Auto Update expiration date for virtually every Chromebook ever, but a good rule of thumb is to buy the newest machine you can to maximize your support.
How much should I spend on a Chromebook?
Chromebooks started out notoriously cheap, with list prices often coming in under $300. But as they’ve gone more mainstream, they’ve transitioned from being essentially modern netbooks to some of the best laptops you’ll want to use all day. As such, prices have increased: At this point, you should expect to spend at least $400 if you want a solid daily driver. There are still many Chromebooks out there available at a low price that may be suitable as secondary devices, but a good Chromebook that can be an all-day, every-day laptop will cost more. But, notably, even the best Chromebooks usually cost less than the best Windows laptops, or even the best “regular” laptops out there.
There are a handful of premium Chromebooks that approach or even exceed $1,000 that claim to offer better performance and more processing power, but I don’t recommend spending that much. Generally, that’ll get you a better design with more premium materials, as well as more powerful internals and extra storage space, like a higher-capacity SSD. Of course, you also sometimes pay for the brand name. But, the specs I outlined earlier are usually enough, and there are multiple good premium Chromebooks in the $700 to $800 range at this point.
See Also:
Lenovo IdeaPad Flex 5i Chromebook Plus
This was our pick for best overall Chromebook for years, and it’s still one of the better options you can find for a basic laptop that doesn’t break the bank. It’s a few years older than our current top pick, so its processor isn’t fresh and it only has 128GB of storage. It also won’t get updates from Google as long as newer models. But it still combines a nice screen and keyboard with solid performance. This laptop typically costs $500, which feels high given its a few years old and Acer’s Chromebook Plus 514 is only $350, but if you can find it on sale and can’t find the Acer it’s worth a look.
ASUS CX15
This Chromebook is extremely affordable – you can currently pick it up for only $159 at Walmart. That price and its large 15.6-inch screen is mainly what it has going for it, as the Intel Celeron N4500 chip and 4GB of RAM powering it does not provide good performance if you’re doing anything more than browsing with a few tabs open. If you’re shopping for someone with extremely basic needs and have a small budget, the CX15 might fit the bill. But just be aware that you get what you pay for.
Samsung Galaxy Chromebook Plus
Samsung’s Galaxy Chromebook Plus, released in late 2024, is one of the more unique Chromebooks out there. It’s extremely thin and light, at 0.46 inches and 2.6 pounds, but it manages to include a 15.6-inch display in that frame. That screen is a 1080p panel that’s sharp and bright, but its 16:9 aspect ratio made things feel a bit cramped when scrolling vertically. Performance is very good, and the keyboard is solid, though I’m not a fan of the number pad as it shifts everything to the left. At $700 it’s not cheap, but that feels fair considering its size and capabilities. If you’re looking for a big screen laptop that is also super light, this Chromebook merits consideration, even if it’s not the best option for everyone.
This article originally appeared on Engadget at https://www.engadget.com/computing/laptops/best-chromebooks-160054646.html?src=rss
The search for anti-gravity propulsion
 Exploring the strange intersection of science, conspiracy, and military secrecy in the decades-long quest for anti-gravity propulsion.
Exploring the strange intersection of science, conspiracy, and military secrecy in the decades-long quest for anti-gravity propulsion.
CrowdStrike Fal.con 2025: Flexing Into The Agentic AI Age
CrowdStrike held its Fal.Con 2025 conference at a new location — the MGM Grand in Las Vegas during the week of September 15. The event attracted over 8,000 attendees – a 30% increase from last year – and more than 100 sponsors. The growth is indicative of CrowdStrike’s growth as a security platform provider and […]
Workday Rising 2025: A CIO’s Reality Check on the Vendor’s Heavy Bets on AI
Workday’s inherent strength has been built on the ‘Power of One’ – a unified, organic architecture that doubles down on stability and simplicity above all else. At Rising 2025, Workday committed to maintaining this foundation while simultaneously executing a fundamental strategic expansion. Workday is repositioning from a closed, best-of-breed application suite to an open, AI-orchestration platform; […]
Your Top Questions On Generative AI, AI Agents, And Agentic Systems For Security Tools Answered
Many security professionals are still confused about which AI capabilities are real now and which will come down the road. Get answers to some of the most common questions about use of generative AI, agentic AI, and AI agents in security tools in this preview of our upcoming Security & Risk Summit.
EU questions Apple, Google and Microsoft about their scam prevention efforts
The European Union has queried Apple, Google and Microsoft on their efforts to prevent online scams. There is a fourth company under scrutiny. Booking Holding, which is a Europe based company, and […]
Thank you for being a Ghacks reader. The post EU questions Apple, Google and Microsoft about their scam prevention efforts appeared first on gHacks Technology News.
Baldur's Gate 3 gets a native build for the Steam Deck
Larian Studios has announced a native version of Baldur's Gate 3 for Steam Deck. You don't need to run it using Proton anymore. Baldur's Gate 3 was the undisputed game of the […]
Thank you for being a Ghacks reader. The post Baldur's Gate 3 gets a native build for the Steam Deck appeared first on gHacks Technology News.
WhatsApp can now translate messages in chats
Meta has announced that WhatsApp Messenger can now translate messages in chats. This is done on the device. Translation works for personal chats, groups, and Channel updates. To use it on iOS, […]
Thank you for being a Ghacks reader. The post WhatsApp can now translate messages in chats appeared first on gHacks Technology News.
Firefox add-on developers may roll back all users to earlier versions of their extensions now
For many users, a key feature of web browsers is the ability to install add-ons. These extensions improve browsing in meaningful ways, from blocking unwanted content over making downloads more user-friendly, to […]
Thank you for being a Ghacks reader. The post Firefox add-on developers may roll back all users to earlier versions of their extensions now appeared first on gHacks Technology News.
Microsoft confirms DRM playback issues in Windows
Microsoft revealed a remake of the classic video wallpaper feature DreamScene for Windows just yesterday. Today, Microsoft is confirming that recent versions of its Windows 11 operating system are plagued by a […]
Thank you for being a Ghacks reader. The post Microsoft confirms DRM playback issues in Windows appeared first on gHacks Technology News.
Microsoft silently introduces Windows AI Lab to let users test experimental features
Microsoft has quietly introduced a way to allow users to test experimental features. You can opt in to the Windows AI Lab. Last week, Windows Latest reported that Microsoft was testing Windows […]
Thank you for being a Ghacks reader. The post Microsoft silently introduces Windows AI Lab to let users test experimental features appeared first on gHacks Technology News.
Google announces Gemini for Google TV
Google has announced Gemini for Google TV. You can interact with the AI to find what to watch. Google isn't the first to bring its AI to TVs, Microsoft Copilot for Samsung […]
Thank you for being a Ghacks reader. The post Google announces Gemini for Google TV appeared first on gHacks Technology News.
Trump’s Hurricane Helene Fund Raised Millions. Good Luck Finding the Receipts

The presidential campaign bad-mouthed FEMA while using crowdfunding to donate to evangelical nonprofits.
Denis Villeneuve May Not Start Casting His James Bond Until After ‘Dune: Part Three’

A new report suggests, however, we're likely not going to really know the actor who takes on the 007 mantle.
First Lunar Crew Since Apollo Could Launch in 4 Months. Seriously?

Agency officials are eyeing a February 5 launch for the mission that will send four astronauts around the Moon, but can they actually stick to this aggressive timeline?
VR Headsets Are Better Than Ever and No One Seems to Care

It's the best of times and the worst of times for VR enthusiaists.
OpenAI Announces Plans for Five More ‘Stargate’ Data Centers in the US

Stargate’s AI data centers are about to pop up across the U.S.
Japanese Probe That Famously Sent Fictional Pop Star to Venus Is Officially Dead

JAXA had been attempting to restore contact with Akatsuki for a year before terminating the mission.
The ‘Alien: Earth’ Finale Flipped the Franchise on Its Head

'The Real Monsters' brought the first season of Noah Hawley's FX 'Alien' show to a close.
How the World Is Reacting to Trump’s Tylenol Autism Scare

Other countries and major health organizations have been quick to denounce the Trump administration's attempts to blame autism on acetaminophen use during pregnancy.
Why Meta’s Ray-Ban Display May Never Replace Your iPhone

There's one big hurdle between Meta and making a device that actually stands on its own.
‘Stranger Things’ Teases a Lot of Action for Its Final Season

The fifth and final season of 'Stranger Things' will release in three volumes from November through December on Netflix.
‘Predator: Badlands’ Director Says Its ‘Alien’ Crossover Doesn’t Come With Xenomorphs

Plus, Hayden Panettiere may not be in 'Scream 7' after all.
YouTube Gives the Right Wing What it Wants, Says Biden Admin ‘Pressed’ it to Remove Content

It'll also reinstate accounts banned for spreading misinformation.
The Final ‘Wicked: For Good’ Trailer Teases the Catfight to End All Catfights

We couldn't be happier... could we?
‘Marvel Zombies’ Has Plenty of Blood, but No Heart

The MCU gets its animated version of hype moments and aura in the 'What If...?' spinoff.
‘Pokémon Legends: Z-A’ Hands On: I Choose You, Switch 2

The Switch 2's first 'Pokémon' game is the most radical departure for the longtime series.
Jimmy Kimmel Strikes Back

The late night host struck the right tone during his first episode back. But Trump still wants to silence dissent.
Tired of 5G? Qualcomm Says 6G Will Be Here Before the End of the World

Qualcomm imagines 6G will power tomorrow's AI boom. Just ignore today's AI in the meantime.
Dive Into the Most Breathtaking Ocean Photos of the Year

The winners of the 2025 Ocean Photographer of the Year competition captured the ocean and its wildlife like you’ve never seen before.
Nothing Ear 3 Review: Super Sounding Wireless Earbuds, Not-So-Super Mic

Nothing nails the basics for its latest Ear 3 ANC wireless earbuds, but its hyped-up Super Mic feature sounds soupy at best.
‘Scanners’ Is More Than Just a Very Excellent Exploding Head

David Cronenberg’s jittery 1981 sci-fi classic digs into a creepy power that makes people do creepy things.
A Tiered Approach to AI: The New Playbook for Agents and Workflows
A Small Language Model (SLM) is a neural model defined by its low parameter count, typically in the single-digit to low-tens of billions. These models trade broad, general-purpose capability for significant gains in efficiency, cost, and privacy, making them ideal for specialized tasks. While I’ve been cautiously testing SLMs, their practical value is becoming clearer.Continue reading "A Tiered Approach to AI: The New Playbook for Agents and Workflows"
The post A Tiered Approach to AI: The New Playbook for Agents and Workflows appeared first on Gradient Flow.
Top 10 Open-Source Projects in the Large Model Ecosystem
This leaderboard ranks the ten most influential open-source projects in the AI development ecosystem using OpenRank, a metric that measures community collaboration rather than simple popularity indicators like stars. The list spans the entire technology stack, from foundational infrastructure such as PyTorch for training and Ray for distributed compute, to high-performance inference engines like vLLM,Continue reading "Top 10 Open-Source Projects in the Large Model Ecosystem"
The post Top 10 Open-Source Projects in the Large Model Ecosystem appeared first on Gradient Flow.
Is your LLM overkill?
Subscribe • Previous Issues A Tiered Approach to AI: The New Playbook for Agents and Workflows A Small Language Model (SLM) is a neural model defined by its low parameter count, typically in the single-digit to low-tens of billions. These models trade broad, general-purpose capability for significant gains in efficiency, cost, and privacy, making them ideal forContinue reading "Is your LLM overkill?"
The post Is your LLM overkill? appeared first on Gradient Flow.
Using ChatGPT Like a Junior Dev: Productive, But Needs Checking
Treat ChatGPT like a junior dev on your team — helpful, but always needing review.
Revering AI Reveals Incompetence, Not Intelligence
Nothing is really good anymore; and AI is the peak of this lamentable trend.
Bid Shading Fundamentals: Traditional Techniques and Algorithms (Part 1)
Bid shading reduces bid prices in first-price auctions to avoid overpaying. It is an algorithm that calculates an optimal lower bid that still has a high probability of winning the auction.
Credit for AI Agents: Giving Autonomous Machines Their Own Financial Reputation
Creditcoin builds blockchain-based credit histories for AI agents, enabling trust, loans, and reputation in autonomous machine economies.
The $500 Fraud Tax: The Most Expensive Subscription You Never Signed Up For
Fraud isn’t just a crime—it’s a tax, and the invoice comes due for all of us. Every year, organizations and consumers lose over $5 trillion to fraud. In 2024, consumers reported $12.5 billion in direct fraud losses to the FTC.
When Patients Vanish from Grammar: The Hidden Risks of AI-Generated Medical Notes
This article analyzes the structural erasure of the patient as a grammatical subject in AI-generated clinical documentation. Drawing on a corpus of human-authored and automated medical notes, it identifies three recurrent strategies of subject removal—impersonal passives, nominalizations, and fragment clauses—and introduces the Syntactic Opacity Index (SOI) to quantify opacity. The study situates this phenomenon within medical linguistics, structural analysis of AI language, and ethical theory, demonstrating how automation reorganizes accountability in institutional medicine.
OpenVSX, Cursor, and the Fight for an Open Development Future
Microsoft’s latest move signals a shift in the AI IDE landscape.
Roo Code Makes MCP Integration Simple for Developers With a Single Prompt
Build custom MCP servers with one prompt in Roo Code. Integrate APIs, automate workflows, and supercharge your AI assistant directly from your IDE.
How To Add Integrations to Lovable Apps: A Step-By-Step Guide with Membrane
Use Membrane, the AI-Native Integration Layer, to build Lovable apps with reliable integrations to other apps.
Moonbirds and Azuki IP Coming To Verse8 as AI-Native Game Platform Integrates With Story
Story, a blockchain platform for intellectual property, and Verse8, an AI-powered game creation tool, today announced a collaboration. Story will serve as the licensing infrastructure, registering and managing IP usage on its Layer-1 network. Verse8 enables users to generate multiplayer 2D and 3D games through natural language prompts without requiring coding.
My First Python Web App—Built in a Weekend (With a Little AI Assist)
Having an AI explain patterns and answer questions in real-time was like having the best documentation and mentor rolled into one.
Pattern #4: Content Creation to Knowledge
AI is transforming unstructured content—docs, chats, tickets—into real-time knowledge that accelerates learning and improves code.
AI Makes Penetration Testing More Powerful for Healthcare Organizations
Artificial intelligence can help clinicians and administrative staff work more efficiently. It can even assist in healthcare customer service. What’s more, AI tools are now considered necessary for a strong security posture. Unfortunately, AI is just as useful for cybercriminals. At this year’s Black Hat USA conference in Las Vegas, experts shared some of the specific ways threat actors are using AI to become faster and more sophisticated, making them more dangerous to healthcare organizations. “Their favorite initial access vectors remain simply exploiting internet-facing, publicly known,…
Meeting the Demand for Modern Data Centers in Healthcare
As an industry, healthcare collects, creates, exchanges and stores enormous amounts of data. Think of your annual doctor’s visit and the amount of information a single patient can share, from health history to billing options. There are also different subsectors of the industry, including medical research and development, home health services, and post-acute care, that require different strategies. A one-size-fits-all solution is rarely appropriate. As new artificial intelligence (AI) capabilities emerge, healthcare organizations are exploring new approaches for how to use their existing data…
Securing the Connected Ecosystem of Senior Care
A number of cyber incidents that have affected health systems in recent years have also disrupted post-acute and senior care organizations. During the 2025 Healthcare Information and Management Systems Society global conference and expo in Las Vegas, some senior care leaders shared their experiences from last year’s Change Healthcare attack. Riverdale, N.Y.-based RiverSpring Living CIO David Finkelstein said that his organization used an electronic health record system vendor that relied on Change Healthcare for claims submissions. Due to the attack, it had to return…
How Badly Is AI Cutting Early-Career Employment?

As AI tools become more common in people’s everyday work, researchers are looking to uncover its effects on the job market—especially for early career workers.
A paper from the Stanford Digital Economy Lab, part of the Stanford Institute for Human-Centered AI, has now found early evidence that employment has taken a hit for young workers in the occupations that use generative AI the most. Since the widespread adoption of AI tools began in late 2022, a split has appeared, and early-career software engineers are among the hardest hit.
The researchers used data from the largest payroll provider in the United States, Automatic Data Processing (ADP), to gain up-to-date employment and earning data for millions of workers across industries, locations, and age groups. While other data may take months to come out, the researchers published their findings in late August with data through July.
Although there has been a rise in demand for AI skills in the job market, generative AI tools are getting much better at doing some of the same tasks typically associated with early-career workers. What AI tools don’t have is the experiential knowledge gained through years in the workforce, which makes more senior positions less vulnerable.
These charts show how employment over time compares among early career, developing, and senior workers (all occupations). Each age group is divided into five groups, based on AI exposure, and normalized to 1 in October 2022—roughly when popular generative AI tools became available to the public.
The trend may be a harbinger for more widespread changes, and the researchers plan to continue tracking the data. “It could be that there are reversals in these employment declines. It could be that other age groups become more or less exposed [to generative AI] and have differing patterns in their employment trends. So we’re going to continue to track this and see what happens,” says Bharat Chandar, one of the paper’s authors and a postdoctoral fellow at the Stanford Digital Economy Lab. In the most AI “exposed” jobs, AI tools can assist with or perform more of the work people do on a daily basis.
So, what does this mean for engineers?
With the rise of AI coding tools, software engineers have been the subject of a lot of discussion—both in the media and research. “There have been conflicting stories about whether that job is being impacted by AI, especially for entry level workers,” says Chandar. He and his colleagues wanted to find data on what’s happening now.
Since late 2022, early-career software engineers (between 22 and 30 years old) have experienced a decline in employment. At the same time, mid-level and senior employment has remained stable or grown. This is happening across the most AI-exposed jobs, and software engineering is a prime example.
Since late 2022, employment for early-career software developers has dropped. Employment for other age groups, however, has seen modest growth.
Chandar cautions that, for specific occupations, the trend may not be driven by AI alone; other changes in the tech industry could also be causing the drop. Still, the fact that it holds across industries suggests that there’s a real effect from AI.
The Stanford team also looked at a broader category of “computer occupations” based on the U.S. Bureau of Labor classifications—which includes hardware engineers, web developers, and more—and found similar results.
Growth in employment between October 2022 and July 2025 by age and AI exposure group. Quintiles 1-3 represent the lowest AI exposure groups, which experienced 6-13 percent growth. Quintiles 4-5 are the most AI-exposed jobs; employment for the youngest workers in these jobs fell 6 percent.
Part of the analysis uses data from the Anthropic Economic Index, which provides information about how Anthropic’s AI products are being used, including estimates of whether the types of queries used for certain occupations are more likely to automate work, potentially replacing employees, or augment an existing worker’s output.
With this data, the researchers were able to estimate whether an occupation’s use of AI generally complements employees’ work or replaces it. Jobs in which AI tools augment work did not see the same declines in employment, compared to roles involving tasks that could be automated.
This part of the analysis was based on Anthropic’s index alone. “Ideally, we would love to get more data on AI usage from the other AI companies as well, especially Open AI and Google,” Chandar says. (A recent paper from researchers at Microsoft did find that Copilot usage aligned closely with the estimates of AI exposure the Stanford team used.)
Going forward, the team also hopes to expand to data on employment outside of the United States.
Tech Keeps Chatbots From Leaking Your Data

Your chatbot might be leaky. According to recent reports, user conversations with AI chatbots such as OpenAI’s ChatGPT and xAI’s Grok “have been exposed in search engine results.” Similarly, prompts on the Meta AI app may be appearing on a public feed. But what if those queries and chats can be protected, boosting privacy in the process?
That’s what Duality, a company specializing in privacy-enhancing technologies, hopes to accomplish with its private large language model (LLM) inference framework. Behind the framework lies a technology called fully homomorphic encryption, or FHE, a cryptographic technique enabling computing on encrypted data without needing to decrypt it.
Duality’s framework first encrypts a user prompt or query using FHE, then sends the encrypted query to an LLM. The LLM processes the query without decryption, generates an encrypted reply, and transmits it back to the user.
“They can decrypt the results and get the benefit of running the LLM without actually revealing what was asked or what was responded,” says Kurt Rohloff, cofounder and chief technology officer at Duality.
As a prototype, the framework supports only smaller models, particularly Google’s BERT models. The team tweaked the LLMs to ensure compatibility with FHE, such as replacing some complex mathematical functions with their approximations for more efficient computation. Even with these slight alterations, however, the AI models operate just like a normal LLM would.
“Whatever we do on the inference does not require retraining. In our approach, we still want to make sure that training happens the usual way, and it’s the inference that we essentially try to make more efficient,” says Yuriy Polyakov, vice president of cryptography at Duality.
FHE is considered a quantum-computer-proof encryption. Yet despite its high level of security, the cryptographic method can be slow. “Fully homomorphic encryption algorithms are heavily memory bound,” says Rashmi Agrawal, cofounder and chief technology officer at CipherSonic Labs, a company that spun out of her doctoral research at Boston University on accelerating homomorphic encryption. She explains that FHE relies on lattice-based cryptography, which is built on math problems around vectors in a grid. “Because of that lattice-based encryption scheme, you blow up the data size,” she adds. This results in huge ciphertexts (the encrypted version of your data) and keys requiring lots of memory.
Another computational bottleneck entails an operation called bootstrapping, which is needed to periodically remove noise from ciphertexts, Agrawal says. “This particular operation is really expensive, and that is why FHE has been slow so far.”
To overcome these challenges, the team at Duality is making algorithmic improvements to an FHE scheme known as CKKS (Cheon-Kim-Kim-Song) that’s well-suited for machine learning applications. “This scheme can work with large vectors of real numbers, and it achieves very high throughput,” says Polyakov. Part of those improvements involves integrating a recent advancement dubbed functional bootstrapping. “That allows us to do a very efficient homomorphic comparison operation of large vectors,” Polyakov adds.
All of these implementations are available on OpenFHE, an open-source library that Duality contributes to and helps maintain. “This is a complicated and sophisticated problem that requires community effort. We’re making those tools available so that, together with the community, we can push the state of the art and enable inference for large language models,” says Polyakov.
Hardware acceleration also plays a part in speeding up FHE for LLM inference, especially for bigger AI models. “They can be accelerated by two to three orders of magnitude using specialized hardware acceleration devices,” Polyakov says. Duality is building with this in mind and has added a hardware abstraction layer to OpenFHE for switching from a default CPU backend to swifter ones such as GPUs and application-specific integrated circuits (ASICs).
Agrawal agrees that GPUs, as well as field-programmable gate arrays (FPGAs), are a good fit for FHE-protected LLM inference because they’re fast and connect to high-bandwidth memory. She adds that FPGAs in particular can be tailored for fully homomorphic encryption workloads.
For Duality’s next steps, the team is progressing their private LLM inference framework from prototype to production. The company is also working on safeguarding other AI operations, including fine-tuning pretrained models on specialized data for specific tasks, as well as semantic search to uncover the context and meaning behind a search query rather than just using keywords.
FHE forms part of a broader privacy-preserving toolbox for LLMs, alongside techniques such as differential privacy and confidential computing. Differential privacy introduces controlled noise or randomness to datasets, obscuring individual details while maintaining collective patterns. Meanwhile, confidential computing employs a trusted execution environment—a secure, isolated area within a CPU for processing sensitive data.
Confidential computing has been around longer than the newer FHE technology, and Agrawal considers it as FHE’s “head-to-head competition.” However, she notes that confidential computing can’t support GPUs, making them an ill match for LLMs.
“FHE is strongest when you need noninteractive end-to-end confidentiality because nobody is able to see your data anywhere in the whole process of computing,” Agrawal says.
A fully encrypted LLM using FHE opens up a realm of possibilities. In health care, for instance, clinical results can be analyzed without revealing sensitive patient records. Financial institutions can check for fraud without disclosing bank account information. Enterprises can outsource computing to cloud environments without unveiling proprietary data. User conversations with AI assistants can be protected, too.
“We’re entering into a renaissance of the applicability and usability of privacy technologies to enable secure data collaboration,” says Rohloff. “We all have data. We don’t necessarily have to choose between exposing our sensitive data and getting the best insights possible from that data.”
Article: InfoQ AI, ML and Data Engineering Trends Report - 2025

This InfoQ Trends Report offers readers a comprehensive overview of emerging trends and technologies in the areas of AI, ML, and Data Engineering. This report summarizes the InfoQ editorial team’s and external guests' view on the current trends in AI and ML technologies and what to look out for in the next 12 months.
By Srini Penchikala, Savannah Kunovsky, Anthony Alford, Daniel Dominguez, Vinod GojePodcast: AI, ML, and Data Engineering InfoQ Trends Report 2025

In this episode, members of the InfoQ editorial staff and friends of InfoQ discuss the current trends in the domain of AI, ML and Data Engineering. One of the regular features of InfoQ are the trends reports, which each focus on a different aspect of software development. These reports provide the InfoQ readers and listeners with a high-level overview of the topics to pay attention to this year.
By Srini Penchikala, Savannah Kunovsky, Anthony Alford, Daniel Dominguez, Vinod GojeWall Street and the Impact of Agentic AI
 As enterprise AI systems become more advanced, they are moving beyond task automation toward workflow intelligence. On Wall Street, this evolution is playing out where milliseconds can mean millions and decisions can ripple across markets. Financial institutions are beginning to embed agentic AI into core operations to surface insights and accelerate decision-making.
As enterprise AI systems become more advanced, they are moving beyond task automation toward workflow intelligence. On Wall Street, this evolution is playing out where milliseconds can mean millions and decisions can ripple across markets. Financial institutions are beginning to embed agentic AI into core operations to surface insights and accelerate decision-making.
Taiwan Lake Flood Victims Spend Second Night In Shelters
Hundreds of flood victims in Taiwan prepared for a second night in shelters on Wednesday as rescuers searched for survivors after a barrier lake burst in torrential rains from Super Typhoon Ragasa.
Zelensky Says NATO Membership Not Automatic Protection, Praises Trump After Shift
President Volodymyr Zelensky cast doubt Wednesday on NATO's ability to guarantee Ukraine's security but praised Donald Trump after the US president unexpectedly flip-flopped to say he thinks Russia can be defeated.
US Treasury Says In Talks To Support Argentina's Central Bank
US Treasury Secretary Scott Bessent said Wednesday that Washington is in talks with Argentina for a swap line allowing the country access to billions of dollars, as its right-wing leader Javier Milei seeks to calm markets ahead of midterm elections.
EU Chief Backs Calls To Keep Children Off Social Media
EU chief Ursula von der Leyen on Wednesday threw her support behind growing calls to ban social media use for children, promising to weigh action at the European level in coming months.
'Everything Broken': Chinese Residents In Typhoon Path Assess Damage
Residents in southern China's Yangjiang were grappling with damaged property and power outages Wednesday evening in the immediate aftermath of Typhoon Ragasa, hours after the destructive storm made landfall near the city.
UK Police Arrest Man After European Airports Cyberattack
UK police said Wednesday a man in his 40s had been arrested after a cyberattack disrupted major European airports including Brussels, Berlin and London's Heathrow.
Italy Deploys Frigate After Drone 'Attack' On Gaza Aid Flotilla
Italy's Defence Minister Guido Crosetto sent a navy frigate Wednesday to assist a Gaza-bound aid flotilla, after organisers said several of their boats had been targeted by drones off Greece.
French Consumer Group Seeks Perrier Sales Ban
An influential consumer rights association on Wednesday urged a court to ban the sale of Perrier bottled water in France, saying the brand's claim that its product is "natural" was misleading.
Gaza Civil Defence Says Dozens Killed In Israeli Strikes
Gaza's civil defence agency said Israeli forces killed dozens of people across the Palestinian territory on Wednesday, as the military pressed its assault on Gaza City from where hundreds of thousands have been forced to flee.
Russia Vows To Press On In Ukraine, Rejects Trump Jibe
The Kremlin said Wednesday it had no choice but to continue its military offensive on Ukraine and rejected US President Donald Trump's claim that Russia was a "paper tiger".
Germany's Merz Rejects Claims He Is Slowing Green Shift
German Chancellor Friedrich Merz on Wednesday rejected claims his government was undermining the climate change fight, but insisted that industry also needed to be protected to revive the crisis-wracked economy.
Danish PM To Apologise To Victims Of Greenland Forced Contraception
Danish Prime Minister Mette Frederiksen has arrived in Denmark's autonomous territory Greenland for a ceremony Wednesday to apologise in person to the victims of a forced contraception programme that Copenhagen ran for more than three decades.
Wiretapping Scandal Goes To Court In Greece
A trial linked to the illegal wiretapping of politicians and journalists using the spy software Predator opens on Wednesday in Greece, three years after a scandal that rocked the country.
14 Killed, 152 Missing In Taiwan After Barrier Lake Burst
At least 14 people were killed when a decades-old lake barrier burst in Taiwan, a government official said Wednesday, after Super Typhoon Ragasa pounded the island with torrential rain.
Modern-day Colombian Guerrillas Are Mere Druglords: Ex-FARC Commander
Colombian guerrilla fighters today are no more than drug lords given too much leeway by the leftist government, infamous former rebel commander Rodrigo Londono, aka "Timochenko," told AFP on Tuesday.
TV Host Kimmel Says 'Anti-American' For Govt To Threaten Comedians
TV host Jimmy Kimmel defended free speech when he returned to US screens on Tuesday, calling government pressure on his late-night talk show "anti-American" as critics decried his suspension as an attack on constitutional rights.
Massive Sinkhole In Bangkok Street Forces Evacuations
A portion of a busy road in Thailand's capital caved in early Wednesday, leaving a hole dozens of meters deep in front of a main hospital and forcing people nearby to evacuate.
No Pause For Food Delivery Riders During Pakistan's Monsoon
Abdullah Abbas waded through Lahore's flooded streets, struggling to push his motorcycle and deliver a food order on time.
Race For Rare Minerals Brings Boom To Tajikistan's Mines
In a labyrinth of tunnels running beneath 4,000-metre peaks, Tajik miners are scrabbling to secure antimony, one of the metals at the centre of a worldwide race for rare minerals.
Iran's Carpet Industry Unravelling Under Sanctions
Once a symbol of cultural prestige, Iran's handmade rugs are no longer selling as fast as they once did, as sanctions weigh on an already troubled economy and buyers' tastes change.
Asia Markets Waver After Wall St Retreats From Record
Equities wavered Wednesday following a down day on Wall Street, where worries about high valuations were compounded by mixed messaging from the Federal Reserve on its plans for interest rates.
14 Killed By Lake Burst In Taiwan As Typhoon Ragasa Wreaks Havoc
Fierce winds, pounding rain and high seas battered Hong Kong on Wednesday as Super Typhoon Ragasa headed into southern China after causing a lake burst that killed at least 14 people in Taiwan.
In Just One Year, Google Turns AI Setbacks Into Dominance
Caught off guard by ChatGPT and mocked for early blunders with its own generative artificial intelligence efforts, Google has pulled off a dramatic turnaround in just one year, becoming a major player in consumer-facing AI. "The market had written off Alphabet in the AI race," Matt Britzman, analyst at Hargreaves Lansdown, said of Google's parent company.
New York's Finance Sector Faces Risks From Trump Visa Crackdown
On a bright September morning, employees stream through the turnstiles and vast lobby of Goldman Sachs' headquarters in the sunlit Battery Park City neighborhood of Manhattan.
Guineans Approve New Constitution By Wide Margin, Pave Way For Elections
Four years after the military seized power, voters in a Guinea referendum have resoundingly chosen to implement a new constitution, with 89 percent supporting the charter, according to official provisional results announced Tuesday evening.
Why Do Language Models Hallucinate?
In this article, we look at five revelations from the paper "Why Do Language Models Hallucinate?"
Beginner’s Guide to Creating Your Own Python Shell with the cmd Module
This is a simple guide to turning Python scripts into easy-to-use command-line tools.
5 Cutting-Edge Natural Language Processing Trends Shaping 2026
In this article, we discuss five cutting-edge NLP trends that will shape 2026.
7 Python Libraries Every Analytics Engineer Should Know
A quick look at 7 Python libraries that help analytics engineers clean, transform, and analyze data effectively.
10 Newsletters for Busy Data Scientists
This article highlights ten of the best free newsletters for data scientists, covering everything from hands-on tutorials and statistical guides to industry news, AI breakthroughs, and career advice.
What every startup needs to know about building with AI
无摘要
How to get a job at Sana Labs: “We hire the top 0.0001% of the market"
无摘要
How to keep up with AI
无摘要
Revolut seeks banking licence in Turkey, hires new execs
无摘要
Outdated compliance tools are holding back fintechs
无摘要
Investing in Greece’s ‘brain gain’: Big Pi Ventures raises €130m for growth stage fund
无摘要
Jeff Dean, Naval Ravikant back Belgian startup creating world’s first chip for fully encrypted data processing
无摘要
Defence startup Auterion founder: ‘It’s a winner takes all’ for drone software
无摘要
Gigi founder Clara Gold: ‘The notion of “female founder” pisses me off’
无摘要
Smart ring maker Oura eyes $10.9bn valuation, reports say
无摘要
‘Busier than I’ve ever seen it’: VCs pile into companies squeezing every inch of performance out of compute
无摘要
10 Italian startups to watch, according to VCs
无摘要
Microsoft finally squashed this major Windows 11 24H2 bug - one year later
Windows PCs that were blocked from receiving the 24H2 update due to this glitch should now be able to install it.
Wi-Fi cutting out on your iPhone 17? You're not alone - but a fix is coming
The culprit could be Apple's new modem.
Slow or spotty Wi-Fi at home? Try my 10 go-to fixes to optimize your internet - fast
I spent the weekend improving my home network to get faster, more reliable Wi-Fi speed. Here's what I did.
Worried about your iPhone 17 scratching? iFixit's teardown reveals what's happening - and why
People are calling out scratches on the back of new iPhone 17 models, even ones still in the store. A teardown from iFixit explains where, how, and why the problem occurs.
Best early Amazon Prime Day headphones deals 2025: My 15 favorites sales ahead of October
Amazon Prime Day isn't far away, but there are already some excellent deals if you are looking for your next pair of headphones or earbuds.
You can Search live video with Google now - here's how
With Search Live, you can ask Gemini anything about the world around you in real-time.
Use Google Chat? Gemini can edit your messages now
Let Gemini help you with your chats with the click of a 'Refine' button.
Best Sam's Club deals to compete with October Prime Day 2025: My favorite 10+ deals
You don't have to run to Amazon to find great deals on tech. Before October Prime Day, check out the best deals at Sam's Club.
This is my all-time Linux distro - and I've tried them all
Over the decades, I've used or tested just about every Linux distribution available, and this one has stood above all else.
I put away my iPad and Kindle just hours after testing this tablet (and it's cheap)
While it may not be the latest model, the TCL Tab 10 Nxtpaper 5G has quickly become my go-to e-reader for several reasons.
Got AI FOMO? 3 bold but realistic bets your business can try today
our boss wants you to push full steam ahead into AI. OK. Here's your playbook.
Why I put my Bose QuietComfort Ultra away shortly after trying these headphones
On paper, the Bowers & Wilkins Px8 S2 may look eerily similar to the midrange Px7 S3. But the price increase is greatly justified.
This top-of-the-line gaming PC is on sale for $1,600 off at Walmart
The Skytech Prism 4 is a powerful desktop computer that houses the latest gaming hardware and a top-notch liquid cooling system.
I tried Logitech's infinite battery-life keyboard, and it's made AA batteries obsolete for me
The Slim Solar+ keyboard is powered by exposure to normal indoor lighting and can be wirelessly connected to three different devices at once.
Why these new $1,200 'sculptural' earbuds could shake up the audio market
Bang & Olufsen's new premium earbuds merge an ambitious design with top-tier audio quality. But I have a few concerns.
Own a Samsung TV? I changed these 6 settings to instantly improve the performance
Most people stick with default TV settings, but if you own a Samsung, tweaking a few key options can significantly improve your picture quality.
This Sony soundbar delivers glorious audio for virtually any genre of content - and it's priced well
Sony's Bravia Theater System 6 may not have all the flashy extras of its pricier sibling, but it still delivers impressive sound quality where it counts.
I compared the two best smartwatches on the market - here's how Apple Watch Series 11 wins
I've gone hands-on with both Apple's new Series 11 smartwatch and the Pixel Watch 4 - here are the major differences between the two.
How to use your Apple Watch's Hypertension Detection feature (and why you should)
The latest health-tracking feature on the Apple Watch has life-changing implications. Here's how to turn it on, and how it works.
Best early Prime Day Amazon Echo device deals 2025: My 10 favorites sales ahead of October
Prime Day will be here before we know it, but we've already found some great deals on Amazon Echo devices ahead of the sales event.
Microsoft finally squashed this major Windows 11 24H2 bug - one year later
Windows PCs that were blocked from receiving the 24H2 update due to this glitch should now be able to install it.
Wi-Fi cutting out on your iPhone 17? You're not alone - but a fix is coming
The culprit could be Apple's new modem.
Slow or spotty Wi-Fi at home? Try my 10 go-to fixes to optimize your internet - fast
I spent the weekend improving my home network to get faster, more reliable Wi-Fi speed. Here's what I did.
Worried about your iPhone 17 scratching? iFixit's teardown reveals what's happening - and why
People are calling out scratches on the back of new iPhone 17 models, even ones still in the store. A teardown from iFixit explains where, how, and why the problem occurs.
Best early Amazon Prime Day headphones deals 2025: My 15 favorites sales ahead of October
Amazon Prime Day isn't far away, but there are already some excellent deals if you are looking for your next pair of headphones or earbuds.
You can Search live video with Google now - here's how
With Search Live, you can ask Gemini anything about the world around you in real-time.
Use Google Chat? Gemini can edit your messages now
Let Gemini help you with your chats with the click of a 'Refine' button.
Best Sam's Club deals to compete with October Prime Day 2025: My favorite 10+ deals
You don't have to run to Amazon to find great deals on tech. Before October Prime Day, check out the best deals at Sam's Club.
This is my all-time Linux distro - and I've tried them all
Over the decades, I've used or tested just about every Linux distribution available, and this one has stood above all else.
I put away my iPad and Kindle just hours after testing this tablet (and it's cheap)
While it may not be the latest model, the TCL Tab 10 Nxtpaper 5G has quickly become my go-to e-reader for several reasons.
Got AI FOMO? 3 bold but realistic bets your business can try today
our boss wants you to push full steam ahead into AI. OK. Here's your playbook.
Why I put my Bose QuietComfort Ultra away shortly after trying these headphones
On paper, the Bowers & Wilkins Px8 S2 may look eerily similar to the midrange Px7 S3. But the price increase is greatly justified.
This top-of-the-line gaming PC is on sale for $1,600 off at Walmart
The Skytech Prism 4 is a powerful desktop computer that houses the latest gaming hardware and a top-notch liquid cooling system.
I tried Logitech's infinite battery-life keyboard, and it's made AA batteries obsolete for me
The Slim Solar+ keyboard is powered by exposure to normal indoor lighting and can be wirelessly connected to three different devices at once.
Why these new $1,200 'sculptural' earbuds could shake up the audio market
Bang & Olufsen's new premium earbuds merge an ambitious design with top-tier audio quality. But I have a few concerns.
Own a Samsung TV? I changed these 6 settings to instantly improve the performance
Most people stick with default TV settings, but if you own a Samsung, tweaking a few key options can significantly improve your picture quality.
This Sony soundbar delivers glorious audio for virtually any genre of content - and it's priced well
Sony's Bravia Theater System 6 may not have all the flashy extras of its pricier sibling, but it still delivers impressive sound quality where it counts.
I compared the two best smartwatches on the market - here's how Apple Watch Series 11 wins
I've gone hands-on with both Apple's new Series 11 smartwatch and the Pixel Watch 4 - here are the major differences between the two.
How to use your Apple Watch's Hypertension Detection feature (and why you should)
The latest health-tracking feature on the Apple Watch has life-changing implications. Here's how to turn it on, and how it works.
Best early Prime Day Amazon Echo device deals 2025: My 10 favorites sales ahead of October
Prime Day will be here before we know it, but we've already found some great deals on Amazon Echo devices ahead of the sales event.
Alibaba’s Qwen3-Max: Production-Ready Thinking Mode, 1T+ Parameters, and Day-One Coding/Agentic Bench Signals
Alibaba has released Qwen3-Max, a trillion-parameter Mixture-of-Experts (MoE) model positioned as its most capable foundation model to date, with an immediate public on-ramp via Qwen Chat and Alibaba Cloud’s Model Studio API. The launch moves Qwen’s 2025 cadence from preview to production and centers on two variants: Qwen3-Max-Instruct for standard reasoning/coding tasks and Qwen3-Max-Thinking for […]
The post Alibaba’s Qwen3-Max: Production-Ready Thinking Mode, 1T+ Parameters, and Day-One Coding/Agentic Bench Signals appeared first on MarkTechPost.
CloudFlare AI Team Just Open-Sourced ‘VibeSDK’ that Lets Anyone Build and Deploy a Full AI Vibe Coding Platform with a Single Click
CloudFlare AI team just open-sourced VibeSDK, a full-stack “vibe coding” platform that you can deploy end-to-end with a single click on Cloudflare’s network or GitHub Repo Fork. It packages code generation, safe execution, live preview, and multi-tenant deployment so teams can run their own internal or customer-facing AI app builder without stitching together infrastructure. What’s […]
The post CloudFlare AI Team Just Open-Sourced ‘VibeSDK’ that Lets Anyone Build and Deploy a Full AI Vibe Coding Platform with a Single Click appeared first on MarkTechPost.
Google AI Research Introduce a Novel Machine Learning Approach that Transforms TimesFM into a Few-Shot Learner
Google Research introduces in-context fine-tuning (ICF) for time-series forecasting named as ‘TimesFM-ICF): a continued-pretraining recipe that teaches TimesFM to exploit multiple related series provided directly in the prompt at inference time. The result is a few-shot forecaster that matches supervised fine-tuning while delivering +6.8% accuracy over the base TimesFM across an OOD benchmark—no per-dataset training […]
The post Google AI Research Introduce a Novel Machine Learning Approach that Transforms TimesFM into a Few-Shot Learner appeared first on MarkTechPost.
Coding Implementation to End-to-End Transformer Model Optimization with Hugging Face Optimum, ONNX Runtime, and Quantization
In this tutorial, we walk through how we use Hugging Face Optimum to optimize Transformer models and make them faster while maintaining accuracy. We begin by setting up DistilBERT on the SST-2 dataset, and then we compare different execution engines, including plain PyTorch and torch.compile, ONNX Runtime, and quantized ONNX. By doing this step by […]
The post Coding Implementation to End-to-End Transformer Model Optimization with Hugging Face Optimum, ONNX Runtime, and Quantization appeared first on MarkTechPost.
Google AI Introduces the Public Preview of Chrome DevTools MCP: Making Your Coding Agent Control and Inspect a Live Chrome Browser
Google has released a public preview of “Chrome DevTools MCP,” a Model Context Protocol (MCP) server that lets AI coding agents control and inspect a real Chrome instance—recording performance traces, inspecting the DOM and CSS, executing JavaScript, reading console output, and automating user flows. The launch directly targets a well-known limitation in code-generating agents: they […]
The post Google AI Introduces the Public Preview of Chrome DevTools MCP: Making Your Coding Agent Control and Inspect a Live Chrome Browser appeared first on MarkTechPost.
Meet VoXtream: An Open-Sourced Full-Stream Zero-Shot TTS Model for Real-Time Use that Begins Speaking from the First Word
Real-time agents, live dubbing, and simultaneous translation die by a thousand milliseconds. Most “streaming” TTS (Text to Speech) stacks still wait for a chunk of text before they emit sound, so the human hears a beat of silence before the voice starts. VoXtream—released by KTH’s Speech, Music and Hearing group—attacks this head-on: it begins speaking […]
The post Meet VoXtream: An Open-Sourced Full-Stream Zero-Shot TTS Model for Real-Time Use that Begins Speaking from the First Word appeared first on MarkTechPost.
How to Create Reliable Conversational AI Agents Using Parlant?
Parlant is a framework designed to help developers build production-ready AI agents that behave consistently and reliably. A common challenge when deploying large language model (LLM) agents is that they often perform well in testing but fail when interacting with real users. They may ignore carefully designed system prompts, generate inaccurate or irrelevant responses at […]
The post How to Create Reliable Conversational AI Agents Using Parlant? appeared first on MarkTechPost.
The Download: accidental AI relationships, and the future of contraception
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. It’s surprisingly easy to stumble into a relationship with an AI chatbot The news: The first large-scale computational analysis of the Reddit community r/MyBoyfriendIsAI, which is dedicated to discussing AI relationships, found that…
Trump is pushing leucovorin as a new treatment for autism. What is it?
MIT Technology Review Explains: Let our writers untangle the complex, messy world of technology to help you understand what’s coming next. You can read more from the series here. At a press conference on Monday, President Trump announced that his administration was taking action to address “the meteoric rise in autism.” He suggested that childhood…
The AI Hype Index: Cracking the chatbot code
Separating AI reality from hyped-up fiction isn’t always easy. That’s why we’ve created the AI Hype Index—a simple, at-a-glance summary of everything you need to know about the state of the industry. Millions of us use chatbots every day, even though we don’t really know how they work or how using them affects us. In…
It’s surprisingly easy to stumble into a relationship with an AI chatbot
It’s a tale as old as time. Looking for help with her art project, she strikes up a conversation with her assistant. One thing leads to another, and suddenly she has a boyfriend she’s introducing to her friends and family. The twist? Her new companion is an AI chatbot. The first large-scale computational analysis of…
Roundtables: Meet the 2025 Innovator of the Year
Every year, MIT Technology Review selects one individual whose work we admire to recognize as Innovator of the Year. For 2025, we chose Sneha Goenka, who designed the computations behind the world’s fastest whole-genome sequencing method. Thanks to her work, physicians can now sequence a patient’s genome and diagnose a genetic condition in less than eight…
The Download: AI’s retracted papers problem
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. AI models are using material from retracted scientific papers The news: Some AI chatbots rely on flawed research from retracted scientific papers to answer questions, according to recent studies. In one such study, researchers…
AI models are using material from retracted scientific papers
Some AI chatbots rely on flawed research from retracted scientific papers to answer questions, according to recent studies. The findings, confirmed by MIT Technology Review, raise questions about how reliable AI tools are at evaluating scientific research and could complicate efforts by countries and industries seeking to invest in AI tools for scientists. AI search…
The US–UK tech prosperity deal carries promise but also peril for the general public
The UK government hailed the recent US state visit as a landmark for the economy. A record £150 billion of inward investment was announced, including £31 billion targeted at artificial intelligence (AI) development.
Next-generation humanoid robot can do the moonwalk
KAIST research team's independently developed humanoid robot boasts world-class driving performance, reaching speeds of 12km/h, along with excellent stability, maintaining balance even with its eyes closed or on rough terrain. Furthermore, it can perform complex human-specific movements such as the duckwalk and moonwalk, drawing attention as a next-generation robot platform that can be utilized in actual industrial settings.
Is AI a threat to jobs? A 'Tomb Raider' affair poses the question
A lifelong fan of "Tomb Raider," French gamer Romain Bos was on tenterhooks when an update of the popular video game went online in August.
Microsoft is turning to the field of microfluidics to cool down AI chips
One of the major reasons why AI data centers are sucking up so much power is the need to cool processors that run very hot. But Microsoft Corp. is trying out a possible solution: sending fluid directly through tiny channels etched into the chips.
Inside Stargate AI's massive Texas data center campus, with 5 more sites announced
The Stargate Project has brought the global artificial intelligence race to the West Texas desert.
In just one year, Google turns AI setbacks into dominance
Caught off guard by ChatGPT and mocked for early blunders with its own generative artificial intelligence efforts, Google has pulled off a dramatic turnaround in just one year, becoming a major player in consumer-facing AI.
Creating robots that adapt to your emotion
Robots might be getting smarter, but to truly support people in daily life, they also need to become more empathetic. That means recognizing and responding to human emotions in real time.
Behavioral insights enhance AI-driven recommendations more than data volume increases, study shows
New research shows that understanding users' intentions—rather than simply increasing data volume—can improve the suggestions generated by YouTube's "black box" algorithms.
Engineers develop smarter AI to redefine control in complex systems
A new artificial intelligence breakthrough developed by researchers in the College of Engineering and Computer Science at Florida Atlantic University offers a smarter, more efficient way to manage complex systems that rely on multiple decision-makers operating at different levels of authority.
Analog computing platform uses synthetic frequency domain to boost scalability
Analog computers, computing systems that represent data as continuous physical quantities, such as voltage, frequency or vibrations, can be significantly more energy-efficient than digital computers, which represent data as binary states (i.e., 0s and 1s). However, upscaling analog computing platforms is often difficult, as their underlying components can behave differently in larger systems.
Scientists urge global AI 'red lines' as leaders gather at UN
Technology veterans, politicians and Nobel Prize winners called on nations around the world Monday to quickly establish "red lines" too dangerous for artificial intelligence to cross.
The US–UK tech prosperity deal carries promise but also peril for the general public
The UK government hailed the recent US state visit as a landmark for the economy. A record £150 billion of inward investment was announced, including £31 billion targeted at artificial intelligence (AI) development.
Next-generation humanoid robot can do the moonwalk
KAIST research team's independently developed humanoid robot boasts world-class driving performance, reaching speeds of 12km/h, along with excellent stability, maintaining balance even with its eyes closed or on rough terrain. Furthermore, it can perform complex human-specific movements such as the duckwalk and moonwalk, drawing attention as a next-generation robot platform that can be utilized in actual industrial settings.
Is AI a threat to jobs? A 'Tomb Raider' affair poses the question
A lifelong fan of "Tomb Raider," French gamer Romain Bos was on tenterhooks when an update of the popular video game went online in August.
Microsoft is turning to the field of microfluidics to cool down AI chips
One of the major reasons why AI data centers are sucking up so much power is the need to cool processors that run very hot. But Microsoft Corp. is trying out a possible solution: sending fluid directly through tiny channels etched into the chips.
Inside Stargate AI's massive Texas data center campus, with 5 more sites announced
The Stargate Project has brought the global artificial intelligence race to the West Texas desert.
In just one year, Google turns AI setbacks into dominance
Caught off guard by ChatGPT and mocked for early blunders with its own generative artificial intelligence efforts, Google has pulled off a dramatic turnaround in just one year, becoming a major player in consumer-facing AI.
Creating robots that adapt to your emotion
Robots might be getting smarter, but to truly support people in daily life, they also need to become more empathetic. That means recognizing and responding to human emotions in real time.
Behavioral insights enhance AI-driven recommendations more than data volume increases, study shows
New research shows that understanding users' intentions—rather than simply increasing data volume—can improve the suggestions generated by YouTube's "black box" algorithms.
Engineers develop smarter AI to redefine control in complex systems
A new artificial intelligence breakthrough developed by researchers in the College of Engineering and Computer Science at Florida Atlantic University offers a smarter, more efficient way to manage complex systems that rely on multiple decision-makers operating at different levels of authority.
Analog computing platform uses synthetic frequency domain to boost scalability
Analog computers, computing systems that represent data as continuous physical quantities, such as voltage, frequency or vibrations, can be significantly more energy-efficient than digital computers, which represent data as binary states (i.e., 0s and 1s). However, upscaling analog computing platforms is often difficult, as their underlying components can behave differently in larger systems.
Scientists urge global AI 'red lines' as leaders gather at UN
Technology veterans, politicians and Nobel Prize winners called on nations around the world Monday to quickly establish "red lines" too dangerous for artificial intelligence to cross.
Deploy High-Performance AI Models in Windows Applications on NVIDIA RTX AI PCs
 Today, Microsoft is making Windows ML available to developers. Windows ML enables C#, C++ and Python developers to optimally run AI models locally across PC...
Today, Microsoft is making Windows ML available to developers. Windows ML enables C#, C++ and Python developers to optimally run AI models locally across PC...
Faster Training Throughput in FP8 Precision with NVIDIA NeMo
 In previous posts on FP8 training, we explored the fundamentals of FP8 precision and took a deep dive into the various scaling recipes for practical large-scale...
In previous posts on FP8 training, we explored the fundamentals of FP8 precision and took a deep dive into the various scaling recipes for practical large-scale...
How to Accelerate Community Detection in Python Using GPU-Powered Leiden
") Community detection algorithms play an important role in understanding data by identifying hidden groups of related entities in networks. Social network...
Community detection algorithms play an important role in understanding data by identifying hidden groups of related entities in networks. Social network...
Build a Real-Time Visual Inspection Pipeline with NVIDIA TAO 6 and NVIDIA DeepStream 8
 Building a robust visual inspection pipeline for defect detection and quality control is not easy. Manufacturers and developers often face challenges such as...
Building a robust visual inspection pipeline for defect detection and quality control is not easy. Manufacturers and developers often face challenges such as...
Reasoning Through Molecular Synthetic Pathways with Generative AI
 A recurring challenge in molecular design, whether for pharmaceutical, chemical, or material applications, is creating synthesizable molecules. Synthesizability...
A recurring challenge in molecular design, whether for pharmaceutical, chemical, or material applications, is creating synthesizable molecules. Synthesizability...
Build a Retrieval-Augmented Generation (RAG) Agent with NVIDIA Nemotron
 Unlike traditional LLM-based systems that are limited by their training data, retrieval-augmented generation (RAG) improves text generation by incorporating...
Unlike traditional LLM-based systems that are limited by their training data, retrieval-augmented generation (RAG) improves text generation by incorporating...
The F.C.C.’s Brendan Carr Plans to Keep Going After the Media Following Jimmy Kimmel’s Return
While “Jimmy Kimmel Live!” returned to ABC on Tuesday, the chairman of the Federal Communications Commission has promised to continue his campaign against what he sees as liberal bias in broadcasts.
OpenAI to Join Tech Giants in Building 5 New Data Centers in U.S.
Working with the Japanese conglomerate SoftBank and the cloud company Oracle, the A.I. start-up will spend $400 billion over the next five years.
Elon Musk’s Father, Errol Musk, Accused of Child Sexual Abuse
Errol Musk has been accused of sexually abusing five of his children and stepchildren since 1993, a Times investigation found. Family members have appealed to Elon Musk for help.
How to Use Apple’s iOS 26 and Google’s Android 16
Don’t have the latest A.I.-powered model? There are still plenty of new features in Apple’s iOS 26 and Google’s Android 16 to make your own.
YouTube to Reinstate Accounts Banned Over Content Related to the Pandemic and 2020 Election
The streaming platform unveiled its plan in a letter to the House Judiciary Committee.
Meta Ramps Up Spending on A.I. Politics With New Super PAC
The new PAC, which is the second that Meta has unveiled in the last month, is aimed at backing those in support of the artificial intelligence industry.
TikTok Deal Could Make Oracle Founder Larry Ellison a New Kind of Media Mogul
The database billionaire and his son, David, are Trump favorites. The family could soon control an empire that includes CBS, Paramount, Warner, CNN and a piece of TikTok.
Trump’s $100,000 H-1B Visa Fee Puts Many Tech Start-Ups in a Bind
Silicon Valley start-ups said they were concerned they would be disproportionately hurt by the new visa fee for skilled foreign workers, given their limited resources.
Argentine Tech Executive Dies After Falling 2,000 Feet on Mount Shasta
While the Argentine hiker and entrepreneur, Matias Augusto Travizano, was descending the mountain, he fell down a glacier, the authorities said.
U.S. Asks Judge to Break Up Google’s Advertising Technology Monopoly
The Justice Department argued that the best way to address the company’s unfair advantage was to force it to sell off portions of its business.
Instagram Passes 3 Billion Monthly Users, Credits Push Toward Reels

Photographers may mourn Instagram’s move from a photo-first platform to one dominated by Reels, but the strategy seems to be working for Meta.
Rare Photos by Ansel Adams and Richard Avedon Go to Auction

An extraordinary collection of photographs, including rare works by Ansel Adams, Helmut Newton, and Diane Arbus, will be offered at auction by Christie’s this fall.
Ancient History Professor Creates Period-Correct AI Image Generator

A history professor at the University of Zurich is working with a computer expert for an unusual project: building a historically accurate AI image generator.
Unseen Nirvana Concert Footage Expected to Sell for $150k at Auction

Previously unseen footage from a 1990 Nirvana concert -- filmed for fun by two videographers before the band rose to fame -- is being offered at auction, where it is expected to sell for up to $150,000.
Nikon Small World in Motion Winners Reveal Hidden Microscopic Wonders

The 15th annual Nikon Small World in Motion winners showcase the world's best and most dynamic microscopic videography. The first-place video shows the self-pollination of a thymeleaf speedwell, while another prize-winning video captures actin and mitochondria in mouse brain tumor cells, demonstrating the diversity of the microscopy on display this year.
The Lumix S 100-500mm f/5-7.1 is Panasonic’s First Full Frame Ultra Tele Zoom

Panasonic has announced the Lumix S 100-500mm f/5-7.1 OIS, the company's first ultra telephoto zoom lens for full-frame L-mount.
Xiaomi 15T Pro Review: Great Leica Cameras That Inch Forward

The Xiaomi 15T Pro and 15T are driven by their cameras and Leica co-engineering, and continue to outperform established competitors in North America. As these are global launches, obtaining either of these still requires importing them from online vendors. Or, if you happen to be in Europe, Asia, or one of the other available markets, buy it and bring it back.
Mixboard is Google’s Mood Board Tool That Could Be Useful to Photographers
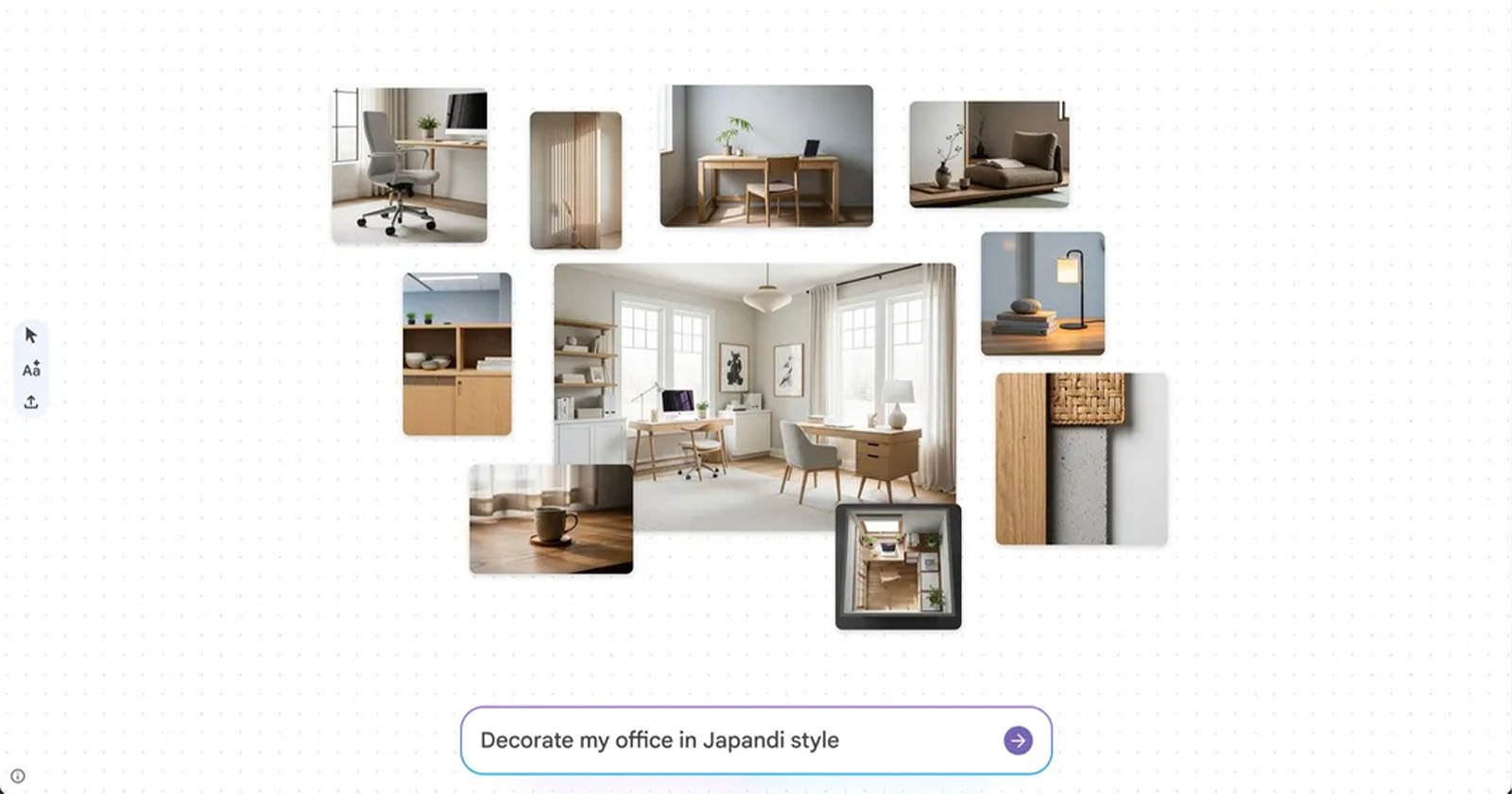
Conceptual and advertising photographers planning a shoot often turn to mood boards to help sculpt the aesthetic of their project; with that in mind Google Labs has released an intriguing new tool called Mixboard.
Google Photos Expands Voice Editing to Additional Android Phones

Remember the days when swapping out a background in a photo meant hours of work on Photoshop? They are well and truly behind us now as Google continues to roll out its editing by voice feature in Google Photos.
Sally Mann’s Book ‘Art Work’ Reflects on a Career of Creativity and Loss

Controversial photographer Sally Mann has recently released a new memoir titled, Art Work: On the Creative Life, which CBS describes as a reflection on the photographer's creativity and loss.
KEH Awards NFL’s Atlanta Falcons for Trading Over 200 Cameras and Lenses

Many photographers know firsthand the great deals they can score by purchasing used cameras and lenses, but an oft-ignored benefit of used photography marketplaces like KEH is their circularity. The more pre-owned cameras and lenses people buy and sell, the less equipment that sits useless or, worse yet, ends up in landfills. KEH's partnership with the NFL's Atlanta Falcons demonstrates the power of photo gear circularity.
Evoto Believes it Can Beat Adobe at Its Own Game

At its first-ever brand event, Evoto One, Evoto announced a sweeping expansion of its platform with new desktop, mobile, and video tools. Evoto has lofty goals and some powerful, entrenched competition, but it likes its odds.
How This Pro Photographer Uses Lumaprints to Grow His Business
![]()
Professional photographer Darin Ashton explains how he elevates his photography business and delivers gallery-quality prints using Lumaprints.
The iPhone Air Is a Preview of Apple’s Anticipated Foldable iPhone

In Mark Gurman's latest "Power On" newsletter, the longtime Bloomberg analyst speculates that this year's ultra-thin iPhone Air offers an early look at Apple's highly anticipated, oft-rumored foldable phone slated to arrive in 2026.
New Godox X3 Pro Wireless Flash Controller Aims to Do it All

The Godox X3 Pro TTL wireless flash trigger builds upon the popular X3's dependable flash control capabilities while adding a larger touchscreen, promising even better control over complex wireless lighting setups.
Canon Appears to Have Discontinued Its Last Pro DSLR, the 1DX Mark III

Canon appears to have discontinued the EOS 1DX Mark II, its last professional-level DSLR that it first announced in 2020 and has been steadily supporting via firmware updates as recently as last year.
Historians May Have Found Colorado’s Oldest Known Photo

Local historians believe they may have identified the oldest known photograph of Colorado -- a fascinating daguerreotype from 1853, taken during a doomed expedition across the American West.
Historic Photo Archive of Yazidi People in Happier Times Discovered in Pennsylvania

The Penn Museum in Philadelphia has discovered and digitized historic photos of the Yazidi people in northern Iraq during the 1930s.
Adobe Adds Luma AI’s Ray3 AI Video Generator to Firefly

Continuing to fulfill its promise to bring third-party AI models into its Firefly ecosystem, Adobe has added Luma AI's newest generative video model, Ray3, to Firefly.
Satellite Photos Show New Island Forming From Melting Glacier in Alaska

Alaska’s newest island can now be seen from space in recently released satellite photographs from NASA.
Mixboard
A new way to visualize your ideas
<p>
<a href="https://www.producthunt.com/products/google-labs?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1019444?app_id=339">Link</a>
</p>
Visuals
Upload your data and let AI generate charts in seconds
<p>
<a href="https://www.producthunt.com/products/visuals?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1019388?app_id=339">Link</a>
</p>
Loop MCP by SimpliflowAI
The tools Appstore for your AI
<p>
<a href="https://www.producthunt.com/products/simpliflowai-loop-mcp?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1019229?app_id=339">Link</a>
</p>
Kling 2.5 Turbo
Next-Level Creativity, Turbocharged
<p>
<a href="https://www.producthunt.com/products/kling-ai-4?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1019349?app_id=339">Link</a>
</p>
Modul
A tool to create good-looking presentations quickly
<p>
<a href="https://www.producthunt.com/products/modul?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1019396?app_id=339">Link</a>
</p>
Qudemo
Make your demo videos Interactive using AI
<p>
<a href="https://www.producthunt.com/products/qudemo?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1019477?app_id=339">Link</a>
</p>
Grapevine
A company GPT that actually works
<p>
<a href="https://www.producthunt.com/products/grapevine-5?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1019287?app_id=339">Link</a>
</p>
GroupTab
Grouped App Switcher for macOS
<p>
<a href="https://www.producthunt.com/products/grouptab?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1019370?app_id=339">Link</a>
</p>
Qwen3-Omni
Native end-to-end multilingual omni-modal LLM
<p>
<a href="https://www.producthunt.com/products/qwen3?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1019038?app_id=339">Link</a>
</p>
DeepSeek-V3.1-Terminus
A refined agentic model for developers
<p>
<a href="https://www.producthunt.com/products/deepseek?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1019034?app_id=339">Link</a>
</p>
To Understand AI, Watch How It Evolves
Naomi Saphra thinks that most research into language models focuses too much on the finished product. She’s mining the history of their training for insights into why these systems work the way they do.
The post To Understand AI, Watch How It Evolves first appeared on Quanta Magazine
Bayesian Optimization for Sequential Decisions with Multi-Arm Bandits
Join our workshop titled Bayesian Optimization for Sequential Decisions with Multi-Arm Bandits, which is a part of our workshops for Ukraine series! Here’s some more info: Title: Bayesian Optimization for Sequential Decisions with Multi-Arm Bandits Date: Thursday, October 23rd, 18:00 – 20:00 CEST (Rome, Berlin, Paris timezone) Speaker: Jordan Nafa is a ...
Continue reading: Bayesian Optimization for Sequential Decisions with Multi-Arm Bandits
Ten year anniversary of Free Range Statistics by @ellis2013nz
A few months ago—26 July 2025 to be precise—was the tenth anniversary of my first blog post. Over that time it turns out I’ve written about 225 blog posts, and an astonishing (to me) 350,000 words. That’s after you take out the...
Continue reading: Ten year anniversary of Free Range Statistics by @ellis2013nz
A Personal Message from an Open Source Contributor
You can send me questions for the blog using this form and subscribe to receive an email when there is a new post.
Dear fellow developers and data scientists,
If everyone reading this gave just the price of a coffee, I could focus fully on open s...
Continue reading: A Personal Message from an Open Source Contributor
Creating a simple R package with C++ code to sum “a + b”
If this post is useful to you I kindly ask a minimal donation on Buy Me a Coffee. It shall be used to continue my Open Source efforts. The full explanation is here: A Personal Message from an Open Source Contributor.
You can send me questions for...
Continue reading: Creating a simple R package with C++ code to sum “a + b”
Why I left Silicon Valley: Chinese tech workers talk about returning home
Chinese-origin tech workers are abandoning the American dream and returning home, where state-led incentives and ambition are plentiful.
Argentina wants to be an AI powerhouse, but its tech experts are leaving
iStock/Rest of World
What Trump’s H-1B crackdown means for Big Tech workers
Companies like Amazon, Google, and Microsoft rely on skilled foreign workers. Experts say they’ll pay for the best — but the policy could redirect top talent elsewhere.
AI breakthrough finds life-saving insights in everyday bloodwork
AI-powered analysis of routine blood tests can reveal hidden patterns that predict recovery and survival after spinal cord injuries. This breakthrough could make life-saving predictions affordable and accessible in hospitals worldwide.
Earthquakes Release Energy Mostly Through Heat, Not Ground Shaking
Up to 98 percent of the energy of an earthquake goes into flash heating rocks, not shaking the ground, new research shows. The finding could help yield better earthquake forecasts
Mary Roach’s New Book Replaceable You Explores Challenges in Replacing Body Parts
Mary Roach unpacks the millennia-long effort to replace failing body parts—and the reasons that modern medicine still struggles to match the original designs.
We Can Stop Teen Suicide
By understanding warning signs and talking to your child, parents can help reduce the risk of teen suicide
The Moon Is Rusting—Thanks to ‘Wind’ Blown from Earth
Lunar minerals can rust when bombarded with high-energy oxygen particles, experiments show
The Global Burden of RSV
Respiratory syncytial virus (RSV) continues to affect infants and older and immunocompromised people around the world. These graphics reveal where the burden lies and what the effects of immunizations are
The Fight to End Childhood RSV in Indian Country
American Indian and Alaska Native infants experience the highest rates of RSV-related hospitalization in the U.S., but a breakthrough immunization is helping to close the gap
New RSV Preventatives Dramatically Reduce Infant Illness and Death
The year 2023 marked the debut of groundbreaking innovations to prevent severe RSV infections in infants. Now protected babies are way less likely to develop severe infections or to end up in the ICU
How Indigenous Storytelling Is Transforming RSV Care in Native Communities
Abigail Echo-Hawk, a preeminent Native American public health expert, discusses RSV, “data genocide” and positive change driven by Indigenous storytelling
The Promise of RSV Prevention
RSV is the leading cause of infant hospitalizations in the U.S. But that could soon change as research advances lead to new preventative drugs for everyone
A Long Road to an RSV Antibody to Protect the Most Vulnerable
A tragic RSV vaccine trial in the 1960s set the field back for decades. Here’s how scientists finally made breakthroughs in RSV immunization
The Final RSV Frontier Is within Reach
The journey toward an RSV vaccine for children has been wrought with tragedy and setbacks. But six decades after scientists embarked on that path, they are nearing the finish line
James Webb Space Telescope Finds Atmosphere on Lava Planet TOI-561 b
Hot, small and old—exoplanet TOI-561 b is just about the worst place to look for alien air. Scientists using JWST found it there anyway
Key resources for building your STEM CV
If you are looking to get the attention of a STEM recruiter, here are some useful resources you can use to maximise your chances.
Read more: Key resources for building your STEM CV
UK arrests man in connection to cyberattack on European airports
‘Although this arrest is a positive step, the investigation into this incident is in its early stages and remains ongoing,’ said the NCA’s Paul Foster.
Read more: UK arrests man in connection to cyberattack on European airports
Skills, support, sustainability: Factors influencing Ireland’s SMEs
Skillnet Innovation Exchange’s Conor Carmody brings us up to speed on the initiative’s progress so far and his thoughts on Ireland’s SME landscape.
Read more: Skills, support, sustainability: Factors influencing Ireland’s SMEs
Kerry Group opens new biotech centre in Germany’s Leipzig
The new Leipzig facility will focus on enzyme and strain engineering, the company said.
Read more: Kerry Group opens new biotech centre in Germany’s Leipzig
Diplomacy by chip: Taiwan curbs exports to South Africa
South Africa’s diplomatic treatment of Taiwan in recent years has led the latter to impose a curb on chips exports to the China-aligned African country.
Read more: Diplomacy by chip: Taiwan curbs exports to South Africa
Planning and environmental consultancy MKO to create 75 new jobs
The jobs, which are to be filled over the next three years, will bring MKO’s workforce to 300 professionals.
Read more: Planning and environmental consultancy MKO to create 75 new jobs
UK risk intelligence platform Signal AI raises $165m to expand globally
The investment will give Battery Ventures a majority stake in the company.
Read more: UK risk intelligence platform Signal AI raises $165m to expand globally
‘Data handling affects everything, from our health to democracy’
Caitlin Fennessy discusses her role in the privacy sector and how creating a secure global ecosystem is both a governmental and organisational responsibility.
Read more: ‘Data handling affects everything, from our health to democracy’
This summer’s hot nights 40 times more likely because of climate crisis
‘Ireland is seeing a direct effect of global climate change,’ said Maynooth University’s Dr Claire Bergin.
Read more: This summer’s hot nights 40 times more likely because of climate crisis
US medtech G&F Precision Molding to open new Mullingar site with 30 jobs
G&F's current director of business development Ryan Mansfield will lead the new Irish facility.
Read more: US medtech G&F Precision Molding to open new Mullingar site with 30 jobs
Ireland climbs to 18 on the 2025 Global Innovation Index
Switzerland ranked highest of 139 countries for the sixth year in a row, while the UK came in at sixth overall.
Read more: Ireland climbs to 18 on the 2025 Global Innovation Index
What are the core skills for a validation engineer?
Marcela Amadeu Saragiotto gives us insights into managing priorities and communicating effectively.
Read more: What are the core skills for a validation engineer?
Mary Robinson, Geoffrey Hinton call for AI ‘red lines’ in new letter
The open letter warns of AI escalating widespread disinformation and mass unemployment.
Read more: Mary Robinson, Geoffrey Hinton call for AI ‘red lines’ in new letter
Airlines seen as vulnerable as ransomware confirmed in weekend cyberattack
A ransomware attack was confirmed by ENISA, Europe’s cybersecurity agency, as the source of the weekend’s airport disruption.
Read more: Airlines seen as vulnerable as ransomware confirmed in weekend cyberattack
‘Giant project,’ says Nvidia CEO as company bets $100bn on OpenAI
CNBC reports that the first investment of $10bn will be made when the first GW of Nvidia systems is deployed.
Read more: ‘Giant project,’ says Nvidia CEO as company bets $100bn on OpenAI
SETU gene therapy researcher inspired by family to tackle rare disease
When his nephews were diagnosed with a rare neurological disease, Dr Lee Coffey pivoted his research to work on developing treatments.
Read more: SETU gene therapy researcher inspired by family to tackle rare disease
GPT-5-Codex
OpenAI half-relased this model earlier this month, adding it to their Codex CLI tool but not their API.
Today they've fixed that - the new model can now be accessed as gpt-5-codex. It's priced the same as regular GPT-5: $1.25/million input tokens, $10/million output tokens, and the same hefty 90% discount for previously cached input tokens, especially important for agentic tool-using workflows which quickly produce a lengthy conversation.
It's only available via their Responses API, which means you currently need to install the llm-openai-plugin to use it with LLM:
llm install -U llm-openai-plugin
llm -m openai/gpt-5-codex -T llm_version 'What is the LLM version?'
Outputs:
The installed LLM version is 0.27.1.
I added tool support to that plugin today, mostly authored by GPT-5 Codex itself using OpenAI's Codex CLI.
The new prompting guide for GPT-5-Codex is worth a read.
GPT-5-Codex is purpose-built for Codex CLI, the Codex IDE extension, the Codex cloud environment, and working in GitHub, and also supports versatile tool use. We recommend using GPT-5-Codex only for agentic and interactive coding use cases.
Because the model is trained specifically for coding, many best practices you once had to prompt into general purpose models are built in, and over prompting can reduce quality.
The core prompting principle for GPT-5-Codex is “less is more.”
I tried my pelican benchmark at a cost of 2.156 cents.
llm -m openai/gpt-5-codex "Generate an SVG of a pelican riding a bicycle"

I asked Codex to describe this image and it correctly identified it as a pelican!
llm -m openai/gpt-5-codex -a https://static.simonwillison.net/static/2025/gpt-5-codex-api-pelican.png \
-s 'Write very detailed alt text'
Cartoon illustration of a cream-colored pelican with a large orange beak and tiny black eye riding a minimalist dark-blue bicycle. The bird’s wings are tucked in, its legs resemble orange stick limbs pushing the pedals, and its tail feathers trail behind with light blue motion streaks to suggest speed. A small coral-red tongue sticks out of the pelican’s beak. The bicycle has thin light gray spokes, and the background is a simple pale blue gradient with faint curved lines hinting at ground and sky.
<p>Tags: <a href="https://simonwillison.net/tags/ai">ai</a>, <a href="https://simonwillison.net/tags/openai">openai</a>, <a href="https://simonwillison.net/tags/prompt-engineering">prompt-engineering</a>, <a href="https://simonwillison.net/tags/generative-ai">generative-ai</a>, <a href="https://simonwillison.net/tags/llms">llms</a>, <a href="https://simonwillison.net/tags/ai-assisted-programming">ai-assisted-programming</a>, <a href="https://simonwillison.net/tags/pelican-riding-a-bicycle">pelican-riding-a-bicycle</a>, <a href="https://simonwillison.net/tags/llm-reasoning">llm-reasoning</a>, <a href="https://simonwillison.net/tags/llm-release">llm-release</a>, <a href="https://simonwillison.net/tags/gpt-5">gpt-5</a>, <a href="https://simonwillison.net/tags/codex-cli">codex-cli</a></p>
Qwen3-VL: Sharper Vision, Deeper Thought, Broader Action
Qwen3-VL: Sharper Vision, Deeper Thought, Broader Action
I've been looking forward to this. Qwen 2.5 VL is one of the best available open weight vision LLMs, so I had high hopes for Qwen 3's vision models.
Firstly, we are open-sourcing the flagship model of this series: Qwen3-VL-235B-A22B, available in both Instruct and Thinking versions. The Instruct version matches or even exceeds Gemini 2.5 Pro in major visual perception benchmarks. The Thinking version achieves state-of-the-art results across many multimodal reasoning benchmarks.
Bold claims against Gemini 2.5 Pro, which are supported by a flurry of self-reported benchmarks.
This initial model is enormous. On Hugging Face both Qwen3-VL-235B-A22B-Instruct and Qwen3-VL-235B-A22B-Thinking are 235B parameters and weigh 471 GB. Not something I'm going to be able to run on my 64GB Mac!
The Qwen 2.5 VL family included models at 72B, 32B, 7B and 3B sizes. Given the rate Qwen are shipping models at the moment I wouldn't be surprised to see smaller Qwen 3 VL models show up in just the next few days.
Also from Qwen today, three new API-only closed-weight models: upgraded Qwen 3 Coder, Qwen3-LiveTranslate-Flash (real-time multimodal interpretation), and Qwen3-Max, their new trillion parameter flagship model, which they describe as their "largest and most capable model to date".
Plus Qwen3Guard, a "safety moderation model series" that looks similar in purpose to Meta's Llama Guard. This one is open weights (Apache 2.0) and comes in 8B, 4B and 0.6B sizes on Hugging Face. There's more information in the QwenLM/Qwen3Guard GitHub repo.
Via Hacker News
Tags: ai, generative-ai, llms, vision-llms, qwen, llm-reasoning, llm-release, ai-in-china
--- ## 来源: https://stackoverflow.blog/feed/ ### [The history and future of software development (part 1)](https://stackoverflow.blog/2025/09/24/the-history-and-future-of-software-development-part-1/) Even if we go back just a few years, software engineering looked a bit different. But what if we go back 20 years? How about 70? Would even be able to recognize the way software was being built back then? ### [Democratizing your data access with AI agents](https://stackoverflow.blog/2025/09/23/democratizing-your-data-access-with-ai-agents/) Jeff Hollan, director of product at Snowflake, joins Ryan to discuss the role that data plays in making AI and AI agents better. Along the way, they discuss how a database leads to an AI platform, Snowflake’s new data marketplace, and the role data will play in AI agents. --- ## 来源: https://arxiv.org/rss/stat.ML ### [Surrogate Modelling of Proton Dose with Monte Carlo Dropout Uncertainty Quantification](https://arxiv.org/abs/2509.18155) arXiv:2509.18155v1 Announce Type: new Abstract: Accurate proton dose calculation using Monte Carlo (MC) is computationally demanding in workflows like robust optimisation, adaptive replanning, and probabilistic inference, which require repeated evaluations. To address this, we develop a neural surrogate that integrates Monte Carlo dropout to provide fast, differentiable dose predictions along with voxelwise predictive uncertainty. The method is validated through a series of experiments, starting with a one-dimensional analytic benchmark that establishes accuracy, convergence, and variance decomposition. Two-dimensional bone-water phantoms, generated using TOPAS Geant4, demonstrate the method's behavior under domain heterogeneity and beam uncertainty, while a three-dimensional water phantom confirms scalability for volumetric dose prediction. Across these settings, we separate epistemic (model) from parametric (input) contributions, showing that epistemic variance increases under distribution shift, while parametric variance dominates at material boundaries. The approach achieves significant speedups over MC while retaining uncertainty information, making it suitable for integration into robust planning, adaptive workflows, and uncertainty-aware optimisation in proton therapy. ### [Statistical Insight into Meta-Learning via Predictor Subspace Characterization and Quantification of Task Diversity](https://arxiv.org/abs/2509.18349) arXiv:2509.18349v1 Announce Type: new Abstract: Meta-learning has emerged as a powerful paradigm for leveraging information across related tasks to improve predictive performance on new tasks. In this paper, we propose a statistical framework for analyzing meta-learning through the lens of predictor subspace characterization and quantification of task diversity. Specifically, we model the shared structure across tasks using a latent subspace and introduce a measure of diversity that captures heterogeneity across task-specific predictors. We provide both simulation-based and theoretical evidence indicating that achieving the desired prediction accuracy in meta-learning depends on the proportion of predictor variance aligned with the shared subspace, as well as on the accuracy of subspace estimation. ### [End-Cut Preference in Survival Trees](https://arxiv.org/abs/2509.18477) arXiv:2509.18477v1 Announce Type: new Abstract: The end-cut preference (ECP) problem, referring to the tendency to favor split points near the boundaries of a feature's range, is a well-known issue in CART (Breiman et al., 1984). ECP may induce highly imbalanced and biased splits, obscure weak signals, and lead to tree structures that are both unstable and difficult to interpret. For survival trees, we show that ECP also arises when using greedy search to select the optimal cutoff point by maximizing the log-rank test statistic. To address this issue, we propose a smooth sigmoid surrogate (SSS) approach, in which the hard-threshold indicator function is replaced by a smooth sigmoid function. We further demonstrate, both theoretically and through numerical illustrations, that SSS provides an effective remedy for mitigating or avoiding ECP. ### [Estimating Heterogeneous Causal Effect on Networks via Orthogonal Learning](https://arxiv.org/abs/2509.18484) arXiv:2509.18484v1 Announce Type: new Abstract: Estimating causal effects on networks is important for both scientific research and practical applications. Unlike traditional settings that assume the Stable Unit Treatment Value Assumption (SUTVA), interference allows an intervention/treatment on one unit to affect the outcomes of others. Understanding both direct and spillover effects is critical in fields such as epidemiology, political science, and economics. Causal inference on networks faces two main challenges. First, causal effects are typically heterogeneous, varying with unit features and local network structure. Second, connected units often exhibit dependence due to network homophily, creating confounding between structural correlations and causal effects. In this paper, we propose a two-stage method to estimate heterogeneous direct and spillover effects on networks. The first stage uses graph neural networks to estimate nuisance components that depend on the complex network topology. In the second stage, we adjust for network confounding using these estimates and infer causal effects through a novel attention-based interference model. Our approach balances expressiveness and interpretability, enabling downstream tasks such as identifying influential neighborhoods and recovering the sign of spillover effects. We integrate the two stages using Neyman orthogonalization and cross-fitting, which ensures that errors from nuisance estimation contribute only at higher order. As a result, our causal effect estimates are robust to bias and misspecification in modeling causal effects under network dependencies. ### [Consistency of Selection Strategies for Fraud Detection](https://arxiv.org/abs/2509.18739) arXiv:2509.18739v1 Announce Type: new Abstract: This paper studies how insurers can chose which claims to investigate for fraud. Given a prediction model, typically only claims with the highest predicted propability of being fraudulent are investigated. We argue that this can lead to inconsistent learning and propose a randomized alternative. More generally, we draw a parallel with the multi-arm bandit literature and argue that, in the presence of selection, the obtained observations are not iid. Hence, dependence on past observations should be accounted for when updating parameter estimates. We formalize selection in a binary regression framework and show that model updating and maximum-likelihood estimation can be implemented as if claims were investigated at random. Then, we define consistency of selection strategies and conjecture sufficient conditions for consistency. Our simulations suggest that the often-used selection strategy can be inconsistent while the proposed randomized alternative is consistent. Finally, we compare our randomized selection strategy with Thompson sampling, a standard multi-arm bandit heuristic. Our simulations suggest that the latter can be inefficient in learning low fraud probabilities. ### [Neighbor Embeddings Using Unbalanced Optimal Transport Metrics](https://arxiv.org/abs/2509.19226) arXiv:2509.19226v1 Announce Type: new Abstract: This paper proposes the use of the Hellinger--Kantorovich metric from unbalanced optimal transport (UOT) in a dimensionality reduction and learning (supervised and unsupervised) pipeline. The performance of UOT is compared to that of regular OT and Euclidean-based dimensionality reduction methods on several benchmark datasets including MedMNIST. The experimental results demonstrate that, on average, UOT shows improvement over both Euclidean and OT-based methods as verified by statistical hypothesis tests. In particular, on the MedMNIST datasets, UOT outperforms OT in classification 81\% of the time. For clustering MedMNIST, UOT outperforms OT 83\% of the time and outperforms both other metrics 58\% of the time. ### [Recovering Wasserstein Distance Matrices from Few Measurements](https://arxiv.org/abs/2509.19250) arXiv:2509.19250v1 Announce Type: new Abstract: This paper proposes two algorithms for estimating square Wasserstein distance matrices from a small number of entries. These matrices are used to compute manifold learning embeddings like multidimensional scaling (MDS) or Isomap, but contrary to Euclidean distance matrices, are extremely costly to compute. We analyze matrix completion from upper triangular samples and Nystr\"{o}m completion in which $\mathcal{O}(d\log(d))$ columns of the distance matrices are computed where $d$ is the desired embedding dimension, prove stability of MDS under Nystr\"{o}m completion, and show that it can outperform matrix completion for a fixed budget of sample distances. Finally, we show that classification of the OrganCMNIST dataset from the MedMNIST benchmark is stable on data embedded from the Nystr\"{o}m estimation of the distance matrix even when only 10\% of the columns are computed. ### [A Gradient Flow Approach to Solving Inverse Problems with Latent Diffusion Models](https://arxiv.org/abs/2509.19276) arXiv:2509.19276v1 Announce Type: new Abstract: Solving ill-posed inverse problems requires powerful and flexible priors. We propose leveraging pretrained latent diffusion models for this task through a new training-free approach, termed Diffusion-regularized Wasserstein Gradient Flow (DWGF). Specifically, we formulate the posterior sampling problem as a regularized Wasserstein gradient flow of the Kullback-Leibler divergence in the latent space. We demonstrate the performance of our method on standard benchmarks using StableDiffusion (Rombach et al., 2022) as the prior. ### [KM-GPT: An Automated Pipeline for Reconstructing Individual Patient Data from Kaplan-Meier Plots](https://arxiv.org/abs/2509.18141) arXiv:2509.18141v1 Announce Type: cross Abstract: Reconstructing individual patient data (IPD) from Kaplan-Meier (KM) plots provides valuable insights for evidence synthesis in clinical research. However, existing approaches often rely on manual digitization, which is error-prone and lacks scalability. To address these limitations, we develop KM-GPT, the first fully automated, AI-powered pipeline for reconstructing IPD directly from KM plots with high accuracy, robustness, and reproducibility. KM-GPT integrates advanced image preprocessing, multi-modal reasoning powered by GPT-5, and iterative reconstruction algorithms to generate high-quality IPD without manual input or intervention. Its hybrid reasoning architecture automates the conversion of unstructured information into structured data flows and validates data extraction from complex KM plots. To improve accessibility, KM-GPT is equipped with a user-friendly web interface and an integrated AI assistant, enabling researchers to reconstruct IPD without requiring programming expertise. KM-GPT was rigorously evaluated on synthetic and real-world datasets, consistently demonstrating superior accuracy. To illustrate its utility, we applied KM-GPT to a meta-analysis of gastric cancer immunotherapy trials, reconstructing IPD to facilitate evidence synthesis and biomarker-based subgroup analyses. By automating traditionally manual processes and providing a scalable, web-based solution, KM-GPT transforms clinical research by leveraging reconstructed IPD to enable more informed downstream analyses, supporting evidence-based decision-making. ### [Augmenting Limited and Biased RCTs through Pseudo-Sample Matching-Based Observational Data Fusion Method](https://arxiv.org/abs/2509.18148) arXiv:2509.18148v1 Announce Type: cross Abstract: In the online ride-hailing pricing context, companies often conduct randomized controlled trials (RCTs) and utilize uplift models to assess the effect of discounts on customer orders, which substantially influences competitive market outcomes. However, due to the high cost of RCTs, the proportion of trial data relative to observational data is small, which only accounts for 0.65\% of total traffic in our context, resulting in significant bias when generalizing to the broader user base. Additionally, the complexity of industrial processes reduces the quality of RCT data, which is often subject to heterogeneity from potential interference and selection bias, making it difficult to correct. Moreover, existing data fusion methods are challenging to implement effectively in complex industrial settings due to the high dimensionality of features and the strict assumptions that are hard to verify with real-world data. To address these issues, we propose an empirical data fusion method called pseudo-sample matching. By generating pseudo-samples from biased, low-quality RCT data and matching them with the most similar samples from large-scale observational data, the method expands the RCT dataset while mitigating its heterogeneity. We validated the method through simulation experiments, conducted offline and online tests using real-world data. In a week-long online experiment, we achieved a 0.41\% improvement in profit, which is a considerable gain when scaled to industrial scenarios with hundreds of millions in revenue. In addition, we discuss the harm to model training, offline evaluation, and online economic benefits when the RCT data quality is not high, and emphasize the importance of improving RCT data quality in industrial scenarios. Further details of the simulation experiments can be found in the GitHub repository https://github.com/Kairong-Han/Pseudo-Matching. ### [Tensor Train Completion from Fiberwise Observations Along a Single Mode](https://arxiv.org/abs/2509.18149) arXiv:2509.18149v1 Announce Type: cross Abstract: Tensor completion is an extension of matrix completion aimed at recovering a multiway data tensor by leveraging a given subset of its entries (observations) and the pattern of observation. The low-rank assumption is key in establishing a relationship between the observed and unobserved entries of the tensor. The low-rank tensor completion problem is typically solved using numerical optimization techniques, where the rank information is used either implicitly (in the rank minimization approach) or explicitly (in the error minimization approach). Current theories concerning these techniques often study probabilistic recovery guarantees under conditions such as random uniform observations and incoherence requirements. However, if an observation pattern exhibits some low-rank structure that can be exploited, more efficient algorithms with deterministic recovery guarantees can be designed by leveraging this structure. This work shows how to use only standard linear algebra operations to compute the tensor train decomposition of a specific type of ``fiber-wise" observed tensor, where some of the fibers of a tensor (along a single specific mode) are either fully observed or entirely missing, unlike the usual entry-wise observations. From an application viewpoint, this setting is relevant when it is easier to sample or collect a multiway data tensor along a specific mode (e.g., temporal). The proposed completion method is fast and is guaranteed to work under reasonable deterministic conditions on the observation pattern. Through numerical experiments, we showcase interesting applications and use cases that illustrate the effectiveness of the proposed approach. ### [Forest tree species classification and entropy-derived uncertainty mapping using extreme gradient boosting and Sentinel-1/2 data](https://arxiv.org/abs/2509.18228) arXiv:2509.18228v1 Announce Type: cross Abstract: We present a new 10-meter map of dominant tree species in Swedish forests accompanied by pixel-level uncertainty estimates. The tree species classification is based on spatiotemporal metrics derived from Sentinel-1 and Sentinel-2 satellite data, combined with field observations from the Swedish National Forest Inventory. We apply an extreme gradient boosting model with Bayesian optimization to relate field observations to satellite-derived features and generate the final species map. Classification uncertainty is quantified using Shannon's entropy of the predicted class probabilities, which provide a spatially explicit measure of model confidence. The final model achieved an overall accuracy of 85% (F1 score = 0.82, Matthews correlation coefficient = 0.81), and mapped species distributions showed strong agreement with official forest statistics (r = 0.96). ### [Hierarchical Semi-Markov Models with Duration-Aware Dynamics for Activity Sequences](https://arxiv.org/abs/2509.18414) arXiv:2509.18414v1 Announce Type: cross Abstract: Residential electricity demand at granular scales is driven by what people do and for how long. Accurately forecasting this demand for applications like microgrid management and demand response therefore requires generative models that can produce realistic daily activity sequences, capturing both the timing and duration of human behavior. This paper develops a generative model of human activity sequences using nationally representative time-use diaries at a 10-minute resolution. We use this model to quantify which demographic factors are most critical for improving predictive performance. We propose a hierarchical semi-Markov framework that addresses two key modeling challenges. First, a time-inhomogeneous Markov \emph{router} learns the patterns of ``which activity comes next." Second, a semi-Markov \emph{hazard} component explicitly models activity durations, capturing ``how long" activities realistically last. To ensure statistical stability when data are sparse, the model pools information across related demographic groups and time blocks. The entire framework is trained and evaluated using survey design weights to ensure our findings are representative of the U.S. population. On a held-out test set, we demonstrate that explicitly modeling durations with the hazard component provides a substantial and statistically significant improvement over purely Markovian models. Furthermore, our analysis reveals a clear hierarchy of demographic factors: Sex, Day-Type, and Household Size provide the largest predictive gains, while Region and Season, though important for energy calculations, contribute little to predicting the activity sequence itself. The result is an interpretable and robust generator of synthetic activity traces, providing a high-fidelity foundation for downstream energy systems modeling. ### [Fast Linear Solvers via AI-Tuned Markov Chain Monte Carlo-based Matrix Inversion](https://arxiv.org/abs/2509.18452) arXiv:2509.18452v1 Announce Type: cross Abstract: Large, sparse linear systems are pervasive in modern science and engineering, and Krylov subspace solvers are an established means of solving them. Yet convergence can be slow for ill-conditioned matrices, so practical deployments usually require preconditioners. Markov chain Monte Carlo (MCMC)-based matrix inversion can generate such preconditioners and accelerate Krylov iterations, but its effectiveness depends on parameters whose optima vary across matrices; manual or grid search is costly. We present an AI-driven framework recommending MCMC parameters for a given linear system. A graph neural surrogate predicts preconditioning speed from $A$ and MCMC parameters. A Bayesian acquisition function then chooses the parameter sets most likely to minimise iterations. On a previously unseen ill-conditioned system, the framework achieves better preconditioning with 50\% of the search budget of conventional methods, yielding about a 10\% reduction in iterations to convergence. These results suggest a route for incorporating MCMC-based preconditioners into large-scale systems. ### [Probabilistic Geometric Principal Component Analysis with application to neural data](https://arxiv.org/abs/2509.18469) arXiv:2509.18469v1 Announce Type: cross Abstract: Dimensionality reduction is critical across various domains of science including neuroscience. Probabilistic Principal Component Analysis (PPCA) is a prominent dimensionality reduction method that provides a probabilistic approach unlike the deterministic approach of PCA and serves as a connection between PCA and Factor Analysis (FA). Despite their power, PPCA and its extensions are mainly based on linear models and can only describe the data in a Euclidean coordinate system. However, in many neuroscience applications, data may be distributed around a nonlinear geometry (i.e., manifold) rather than lying in the Euclidean space. We develop Probabilistic Geometric Principal Component Analysis (PGPCA) for such datasets as a new dimensionality reduction algorithm that can explicitly incorporate knowledge about a given nonlinear manifold that is first fitted from these data. Further, we show how in addition to the Euclidean coordinate system, a geometric coordinate system can be derived for the manifold to capture the deviations of data from the manifold and noise. We also derive a data-driven EM algorithm for learning the PGPCA model parameters. As such, PGPCA generalizes PPCA to better describe data distributions by incorporating a nonlinear manifold geometry. In simulations and brain data analyses, we show that PGPCA can effectively model the data distribution around various given manifolds and outperforms PPCA for such data. Moreover, PGPCA provides the capability to test whether the new geometric coordinate system better describes the data than the Euclidean one. Finally, PGPCA can perform dimensionality reduction and learn the data distribution both around and on the manifold. These capabilities make PGPCA valuable for enhancing the efficacy of dimensionality reduction for analysis of high-dimensional data that exhibit noise and are distributed around a nonlinear manifold. ### [Enhanced Survival Trees](https://arxiv.org/abs/2509.18494) arXiv:2509.18494v1 Announce Type: cross Abstract: We introduce a new survival tree method for censored failure time data that incorporates three key advancements over traditional approaches. First, we develop a more computationally efficient splitting procedure that effectively mitigates the end-cut preference problem, and we propose an intersected validation strategy to reduce the variable selection bias inherent in greedy searches. Second, we present a novel framework for determining tree structures through fused regularization. In combination with conventional pruning, this approach enables the merging of non-adjacent terminal nodes, producing more parsimonious and interpretable models. Third, we address inference by constructing valid confidence intervals for median survival times within the subgroups identified by the final tree. To achieve this, we apply bootstrap-based bias correction to standard errors. The proposed method is assessed through extensive simulation studies and illustrated with data from the Alzheimer's Disease Neuroimaging Initiative (ADNI) study. ### [Hyperbolic Coarse-to-Fine Few-Shot Class-Incremental Learning](https://arxiv.org/abs/2509.18504) arXiv:2509.18504v1 Announce Type: cross Abstract: In the field of machine learning, hyperbolic space demonstrates superior representation capabilities for hierarchical data compared to conventional Euclidean space. This work focuses on the Coarse-To-Fine Few-Shot Class-Incremental Learning (C2FSCIL) task. Our study follows the Knowe approach, which contrastively learns coarse class labels and subsequently normalizes and freezes the classifier weights of learned fine classes in the embedding space. To better interpret the "coarse-to-fine" paradigm, we propose embedding the feature extractor into hyperbolic space. Specifically, we employ the Poincar\'e ball model of hyperbolic space, enabling the feature extractor to transform input images into feature vectors within the Poincar\'e ball instead of Euclidean space. We further introduce hyperbolic contrastive loss and hyperbolic fully-connected layers to facilitate model optimization and classification in hyperbolic space. Additionally, to enhance performance under few-shot conditions, we implement maximum entropy distribution in hyperbolic space to estimate the probability distribution of fine-class feature vectors. This allows generation of augmented features from the distribution to mitigate overfitting during training with limited samples. Experiments on C2FSCIL benchmarks show that our method effectively improves both coarse and fine class accuracies. ### [Diagonal Linear Networks and the Lasso Regularization Path](https://arxiv.org/abs/2509.18766) arXiv:2509.18766v1 Announce Type: cross Abstract: Diagonal linear networks are neural networks with linear activation and diagonal weight matrices. Their theoretical interest is that their implicit regularization can be rigorously analyzed: from a small initialization, the training of diagonal linear networks converges to the linear predictor with minimal 1-norm among minimizers of the training loss. In this paper, we deepen this analysis showing that the full training trajectory of diagonal linear networks is closely related to the lasso regularization path. In this connection, the training time plays the role of an inverse regularization parameter. Both rigorous results and simulations are provided to illustrate this conclusion. Under a monotonicity assumption on the lasso regularization path, the connection is exact while in the general case, we show an approximate connection. ### [Central Limit Theorems for Asynchronous Averaged Q-Learning](https://arxiv.org/abs/2509.18964) arXiv:2509.18964v1 Announce Type: cross Abstract: This paper establishes central limit theorems for Polyak-Ruppert averaged Q-learning under asynchronous updates. We present a non-asymptotic central limit theorem, where the convergence rate in Wasserstein distance explicitly reflects the dependence on the number of iterations, state-action space size, the discount factor, and the quality of exploration. In addition, we derive a functional central limit theorem, showing that the partial-sum process converges weakly to a Brownian motion. ### [Clapping: Removing Per-sample Storage for Pipeline Parallel Distributed Optimization with Communication Compression](https://arxiv.org/abs/2509.19029) arXiv:2509.19029v1 Announce Type: cross Abstract: Pipeline-parallel distributed optimization is essential for large-scale machine learning but is challenged by significant communication overhead from transmitting high-dimensional activations and gradients between workers. Existing approaches often depend on impractical unbiased gradient assumptions or incur sample-size memory overhead. This paper introduces Clapping, a Communication compression algorithm with LAzy samPling for Pipeline-parallel learnING. Clapping adopts a lazy sampling strategy that reuses data samples across steps, breaking sample-wise memory barrier and supporting convergence in few-epoch or online training regimes. Clapping comprises two variants including Clapping-FC and Clapping-FU, both of which achieve convergence without unbiased gradient assumption, effectively addressing compression error propagation in multi-worker settings. Numerical experiments validate the performance of Clapping across different learning tasks. ### [DRO-REBEL: Distributionally Robust Relative-Reward Regression for Fast and Efficient LLM Alignment](https://arxiv.org/abs/2509.19104) arXiv:2509.19104v1 Announce Type: cross Abstract: Reinforcement learning with human feedback (RLHF) has become crucial for aligning Large Language Models (LLMs) with human intent. However, existing offline RLHF approaches suffer from overoptimization, where models overfit to reward misspecification and drift from preferred behaviors observed during training. We introduce DRO-REBEL, a unified family of robust REBEL updates with type-$p$ Wasserstein, KL, and $\chi^2$ ambiguity sets. Using Fenchel duality, each update reduces to a simple relative-reward regression, preserving scalability and avoiding PPO-style clipping or auxiliary value networks. Under standard linear-reward and log-linear policy classes with a data-coverage condition, we establish $O(n^{-1/4})$ estimation bounds with tighter constants than prior DRO-DPO approaches, and recover the minimax-optimal $O(n^{-1/2})$ rate via a localized Rademacher complexity analysis. The same analysis closes the gap for Wasserstein-DPO and KL-DPO, showing both also attain optimal parametric rates. We derive practical SGD algorithms for all three divergences: gradient regularization (Wasserstein), importance weighting (KL), and a fast 1-D dual solve ($\chi^2$). Experiments on Emotion Alignment, the large-scale ArmoRM multi-objective benchmark, and HH-Alignment demonstrate strong worst-case robustness across unseen preference mixtures, model sizes, and data scales, with $\chi^2$-REBEL showing consistently strong empirical performance. A controlled radius--coverage study validates a no-free-lunch trade-off: radii shrinking faster than empirical divergence concentration rates achieve minimax-optimal parametric rates but forfeit coverage, while coverage-guaranteeing radii incur $O(n^{-1/4})$ rates. ### [Unveiling the Role of Learning Rate Schedules via Functional Scaling Laws](https://arxiv.org/abs/2509.19189) arXiv:2509.19189v1 Announce Type: cross Abstract: Scaling laws have played a cornerstone role in guiding the training of large language models (LLMs). However, most existing works on scaling laws primarily focus on the final-step loss, overlooking the loss dynamics during the training process and, crucially, the impact of learning rate schedule (LRS). In this paper, we aim to bridge this gap by studying a teacher-student kernel regression setup trained via online stochastic gradient descent (SGD). Leveraging a novel intrinsic time viewpoint and stochastic differential equation (SDE) modeling of SGD, we introduce the Functional Scaling Law (FSL), which characterizes the evolution of population risk during the training process for general LRSs. Remarkably, the impact of the LRSs is captured through an explicit convolution-type functional term, making their effects fully tractable. To illustrate the utility of FSL, we analyze three widely used LRSs -- constant, exponential decay, and warmup-stable-decay (WSD) -- under both data-limited and compute-limited regimes. We provide theoretical justification for widely adopted empirical practices in LLMs pre-training such as (i) higher-capacity models are more data- and compute-efficient; (ii) learning rate decay can improve training efficiency; (iii) WSD-like schedules can outperform direct-decay schedules. Lastly, we explore the practical relevance of FSL as a surrogate model for fitting, predicting and optimizing the loss curves in LLM pre-training, with experiments conducted across model sizes ranging from 0.1B to 1B parameters. We hope our FSL framework can deepen the understanding of LLM pre-training dynamics and provide insights for improving large-scale model training. ### [Linear Regression under Missing or Corrupted Coordinates](https://arxiv.org/abs/2509.19242) arXiv:2509.19242v1 Announce Type: cross Abstract: We study multivariate linear regression under Gaussian covariates in two settings, where data may be erased or corrupted by an adversary under a coordinate-wise budget. In the incomplete data setting, an adversary may inspect the dataset and delete entries in up to an $\eta$-fraction of samples per coordinate; a strong form of the Missing Not At Random model. In the corrupted data setting, the adversary instead replaces values arbitrarily, and the corruption locations are unknown to the learner. Despite substantial work on missing data, linear regression under such adversarial missingness remains poorly understood, even information-theoretically. Unlike the clean setting, where estimation error vanishes with more samples, here the optimal error remains a positive function of the problem parameters. Our main contribution is to characterize this error up to constant factors across essentially the entire parameter range. Specifically, we establish novel information-theoretic lower bounds on the achievable error that match the error of (computationally efficient) algorithms. A key implication is that, perhaps surprisingly, the optimal error in the missing data setting matches that in the corruption setting-so knowing the corruption locations offers no general advantage. ### [A Neural Difference-of-Entropies Estimator for Mutual Information](https://arxiv.org/abs/2502.13085) arXiv:2502.13085v2 Announce Type: replace Abstract: Estimating Mutual Information (MI), a key measure of dependence of random quantities without specific modelling assumptions, is a challenging problem in high dimensions. We propose a novel mutual information estimator based on parametrizing conditional densities using normalizing flows, a deep generative model that has gained popularity in recent years. This estimator leverages a block autoregressive structure to achieve improved bias-variance trade-offs on standard benchmark tasks. ### [Propagation of Chaos in One-hidden-layer Neural Networks beyond Logarithmic Time](https://arxiv.org/abs/2504.13110) arXiv:2504.13110v2 Announce Type: replace Abstract: We study the approximation gap between the dynamics of a polynomial-width neural network and its infinite-width counterpart, both trained using projected gradient descent in the mean-field scaling regime. We demonstrate how to tightly bound this approximation gap through a differential equation governed by the mean-field dynamics. A key factor influencing the growth of this ODE is the local Hessian of each particle, defined as the derivative of the particle's velocity in the mean-field dynamics with respect to its position. We apply our results to the canonical feature learning problem of estimating a well-specified single-index model; we permit the information exponent to be arbitrarily large, leading to convergence times that grow polynomially in the ambient dimension $d$. We show that, due to a certain ``self-concordance'' property in these problems -- where the local Hessian of a particle is bounded by a constant times the particle's velocity -- polynomially many neurons are sufficient to closely approximate the mean-field dynamics throughout training. ### [Demystifying Spectral Feature Learning for Instrumental Variable Regression](https://arxiv.org/abs/2506.10899) arXiv:2506.10899v2 Announce Type: replace Abstract: We address the problem of causal effect estimation in the presence of hidden confounders, using nonparametric instrumental variable (IV) regression. A leading strategy employs spectral features - that is, learned features spanning the top eigensubspaces of the operator linking treatments to instruments. We derive a generalization error bound for a two-stage least squares estimator based on spectral features, and gain insights into the method's performance and failure modes. We show that performance depends on two key factors, leading to a clear taxonomy of outcomes. In a good scenario, the approach is optimal. This occurs with strong spectral alignment, meaning the structural function is well-represented by the top eigenfunctions of the conditional operator, coupled with this operator's slow eigenvalue decay, indicating a strong instrument. Performance degrades in a bad scenario: spectral alignment remains strong, but rapid eigenvalue decay (indicating a weaker instrument) demands significantly more samples for effective feature learning. Finally, in the ugly scenario, weak spectral alignment causes the method to fail, regardless of the eigenvalues' characteristics. Our synthetic experiments empirically validate this taxonomy. ### [Temporal Conformal Prediction (TCP): A Distribution-Free Statistical and Machine Learning Framework for Adaptive Risk Forecasting](https://arxiv.org/abs/2507.05470) arXiv:2507.05470v3 Announce Type: replace Abstract: We propose Temporal Conformal Prediction (TCP), a distribution-free framework for constructing well-calibrated prediction intervals in nonstationary time series. TCP combines a quantile forecaster with split-conformal calibration on a rolling window and, in its TCP-RM variant, augments the conformal threshold with a Robbins-Monro (RM) offset to steer coverage toward a target level in real time. We benchmark TCP against GARCH, Historical Simulation, and a rolling Quantile Regression (QR) baseline across equities (S&P500), cryptocurrency (Bitcoin), and commodities (Gold). Three consistent findings emerge. First, rolling QR produces the sharpest intervals but is materially under-calibrated (e.g., S&P500: 86.3% vs. 95% target). Second, TCP and TCP-RM achieve near-nominal coverage while delivering substantially narrower intervals than Historical Simulation (e.g., S&P500: 29% reduction in width). Third, the RM update improves calibration with negligible width cost. Crisis-window visualizations around March 2020 show TCP/TCP-RM expanding and contracting intervals promptly as volatility spikes and recedes, with red dots marking days of miscoverage. A sensitivity study confirms robustness to window size and step-size choices. Overall, TCP provides a practical, theoretically grounded solution for calibrated uncertainty quantification under distribution shift, bridging statistical inference and machine learning for risk forecasting. ### [Measuring Sample Quality with Copula Discrepancies](https://arxiv.org/abs/2507.21434) arXiv:2507.21434v2 Announce Type: replace Abstract: The scalable Markov chain Monte Carlo (MCMC) algorithms that underpin modern Bayesian machine learning, such as Stochastic Gradient Langevin Dynamics (SGLD), sacrifice asymptotic exactness for computational speed, creating a critical diagnostic gap: traditional sample quality measures fail catastrophically when applied to biased samplers. While powerful Stein-based diagnostics can detect distributional mismatches, they provide no direct assessment of dependence structure, often the primary inferential target in multivariate problems. We introduce the Copula Discrepancy (CD), a principled and computationally efficient diagnostic that leverages Sklar's theorem to isolate and quantify the fidelity of a sample's dependence structure independent of its marginals. Our theoretical framework provides the first structure-aware diagnostic specifically designed for the era of approximate inference. Empirically, we demonstrate that a moment-based CD dramatically outperforms standard diagnostics like effective sample size for hyperparameter selection in biased MCMC, correctly identifying optimal configurations where traditional methods fail. Furthermore, our robust MLE-based variant can detect subtle but critical mismatches in tail dependence that remain invisible to rank correlation-based approaches, distinguishing between samples with identical Kendall's tau but fundamentally different extreme-event behavior. With computational overhead orders of magnitude lower than existing Stein discrepancies, the CD provides both immediate practical value for MCMC practitioners and a theoretical foundation for the next generation of structure-aware sample quality assessment. ### [Bilateral Distribution Compression: Reducing Both Data Size and Dimensionality](https://arxiv.org/abs/2509.17543) arXiv:2509.17543v2 Announce Type: replace Abstract: Existing distribution compression methods reduce dataset size by minimising the Maximum Mean Discrepancy (MMD) between original and compressed sets, but modern datasets are often large in both sample size and dimensionality. We propose Bilateral Distribution Compression (BDC), a two-stage framework that compresses along both axes while preserving the underlying distribution, with overall linear time and memory complexity in dataset size and dimension. Central to BDC is the Decoded MMD (DMMD), which quantifies the discrepancy between the original data and a compressed set decoded from a low-dimensional latent space. BDC proceeds by (i) learning a low-dimensional projection using the Reconstruction MMD (RMMD), and (ii) optimising a latent compressed set with the Encoded MMD (EMMD). We show that this procedure minimises the DMMD, guaranteeing that the compressed set faithfully represents the original distribution. Experiments show that across a variety of scenarios BDC can achieve comparable or superior performance to ambient-space compression at substantially lower cost. ### [Packed-Ensembles for Efficient Uncertainty Estimation](https://arxiv.org/abs/2210.09184) arXiv:2210.09184v4 Announce Type: replace-cross Abstract: Deep Ensembles (DE) are a prominent approach for achieving excellent performance on key metrics such as accuracy, calibration, uncertainty estimation, and out-of-distribution detection. However, hardware limitations of real-world systems constrain to smaller ensembles and lower-capacity networks, significantly deteriorating their performance and properties. We introduce Packed-Ensembles (PE), a strategy to design and train lightweight structured ensembles by carefully modulating the dimension of their encoding space. We leverage grouped convolutions to parallelize the ensemble into a single shared backbone and forward pass to improve training and inference speeds. PE is designed to operate within the memory limits of a standard neural network. Our extensive research indicates that PE accurately preserves the properties of DE, such as diversity, and performs equally well in terms of accuracy, calibration, out-of-distribution detection, and robustness to distribution shift. We make our code available at https://github.com/ENSTA-U2IS/torch-uncertainty. ### [Sum-of-norms regularized Nonnegative Matrix Factorization](https://arxiv.org/abs/2407.00706) arXiv:2407.00706v2 Announce Type: replace-cross Abstract: When applying nonnegative matrix factorization (NMF), the rank parameter is generally unknown. This rank, called the nonnegative rank, is usually estimated heuristically since computing its exact value is NP-hard. In this work, we propose an approximation method to estimate the rank on-the-fly while solving NMF. We use the sum-of-norm (SON), a group-lasso structure that encourages pairwise sim- ilarity, to reduce the rank of a factor matrix when the initial rank is overestimated. On various datasets, SON-NMF can reveal the correct nonnegative rank of the data without prior knowledge or parameter tuning. SON-NMF is a nonconvex, nonsmooth, non-separable, and non-proximable problem, making it nontrivial to solve. First, since rank estimation in NMF is NP-hard, the proposed approach does not benefit from lower computational com- plexity. Using a graph-theoretic argument, we prove that the complexity of SON- NMF is essentially irreducible. Second, the per-iteration cost of algorithms for SON-NMF can be high. This motivates us to propose a first-order BCD algorithm that approximately solves SON-NMF with low per-iteration cost via the proximal average operator. SON-NMF exhibits favorable features for applications. Besides the ability to automatically estimate the rank from data, SON-NMF can handle rank-deficient data matrices and detect weak components with small energy. Furthermore, in hyperspectral imaging, SON-NMF naturally addresses the issue of spectral variability. ### [The ICML 2023 Ranking Experiment: Examining Author Self-Assessment in ML/AI Peer Review](https://arxiv.org/abs/2408.13430) arXiv:2408.13430v3 Announce Type: replace-cross Abstract: We conducted an experiment during the review process of the 2023 International Conference on Machine Learning (ICML), asking authors with multiple submissions to rank their papers based on perceived quality. In total, we received 1,342 rankings, each from a different author, covering 2,592 submissions. In this paper, we present an empirical analysis of how author-provided rankings could be leveraged to improve peer review processes at machine learning conferences. We focus on the Isotonic Mechanism, which calibrates raw review scores using the author-provided rankings. Our analysis shows that these ranking-calibrated scores outperform the raw review scores in estimating the ground truth ``expected review scores'' in terms of both squared and absolute error metrics. Furthermore, we propose several cautious, low-risk applications of the Isotonic Mechanism and author-provided rankings in peer review, including supporting senior area chairs in overseeing area chairs' recommendations, assisting in the selection of paper awards, and guiding the recruitment of emergency reviewers. ### [EarthquakeNPP: A Benchmark for Earthquake Forecasting with Neural Point Processes](https://arxiv.org/abs/2410.08226) arXiv:2410.08226v2 Announce Type: replace-cross Abstract: For decades, classical point process models, such as the epidemic-type aftershock sequence (ETAS) model, have been widely used for forecasting the event times and locations of earthquakes. Recent advances have led to Neural Point Processes (NPPs), which promise greater flexibility and improvements over such classical models. However, the currently-used benchmark for NPPs does not represent an up-to-date challenge in the seismological community, since it contains data leakage and omits the largest earthquake sequence from the region. Additionally, initial earthquake forecasting benchmarks fail to compare NPPs with state-of-the-art forecasting models commonly used in seismology. To address these gaps, we introduce EarthquakeNPP: a collection of benchmark datasets to facilitate testing of NPPs on earthquake data, accompanied by an implementation of the state-of-the-art forecasting model: ETAS. The datasets cover a range of small to large target regions within California, dating from 1971 to 2021, and include different methodologies for dataset generation. Benchmarking experiments, using both log-likelihood and generative evaluation metrics widely recognised in seismology, show that none of the five NPPs tested outperform ETAS. These findings suggest that current NPP implementations are not yet suitable for practical earthquake forecasting. Nonetheless, EarthquakeNPP provides a platform to foster future collaboration between the seismology and machine learning communities. ### [Language Models as Causal Effect Generators](https://arxiv.org/abs/2411.08019) arXiv:2411.08019v2 Announce Type: replace-cross Abstract: In this work, we present sequence-driven structural causal models (SD-SCMs), a framework for specifying causal models with user-defined structure and language-model-defined mechanisms. We characterize how an SD-SCM enables sampling from observational, interventional, and counterfactual distributions according to the desired causal structure. We then leverage this procedure to propose a new type of benchmark for causal inference methods, generating individual-level counterfactual data to test treatment effect estimation. We create an example benchmark consisting of thousands of datasets, and test a suite of popular estimation methods for average, conditional average, and individual treatment effect estimation. We find under this benchmark that (1) causal methods outperform non-causal methods and that (2) even state-of-the-art methods struggle with individualized effect estimation, suggesting this benchmark captures some inherent difficulties in causal estimation. Apart from generating data, this same technique can underpin the auditing of language models for (un)desirable causal effects, such as misinformation or discrimination. We believe SD-SCMs can serve as a useful tool in any application that would benefit from sequential data with controllable causal structure. ### [Manifold learning in metric spaces](https://arxiv.org/abs/2503.16187) arXiv:2503.16187v3 Announce Type: replace-cross Abstract: Laplacian-based methods are popular for the dimensionality reduction of data lying in $\mathbb{R}^N$. Several theoretical results for these algorithms depend on the fact that the Euclidean distance locally approximates the geodesic distance on the underlying submanifold which the data are assumed to lie on. However, for some applications, other metrics, such as the Wasserstein distance, may provide a more appropriate notion of distance than the Euclidean distance. We provide a framework that generalizes the problem of manifold learning to metric spaces and study when a metric satisfies sufficient conditions for the pointwise convergence of the graph Laplacian. ### [Bayesian Multivariate Density-Density Regression](https://arxiv.org/abs/2504.12617) arXiv:2504.12617v2 Announce Type: replace-cross Abstract: We introduce a novel and scalable Bayesian framework for multivariate-density-density regression (DDR), designed to model relationships between multivariate distributions. Our approach addresses the critical issue of distributions residing in spaces of differing dimensions. We utilize a generalized Bayes framework, circumventing the need for a fully specified likelihood by employing the sliced Wasserstein distance to measure the discrepancy between fitted and observed distributions. This choice not only handles high-dimensional data and varying sample sizes efficiently but also facilitates a Metropolis-adjusted Langevin algorithm (MALA) for posterior inference. Furthermore, we establish the posterior consistency of our generalized Bayesian approach, ensuring that the posterior distribution concentrates around the true parameters as the sample size increases. Through simulations and application to a population-scale single-cell dataset, we show that Bayesian DDR provides robust fits, superior predictive performance compared to traditional methods, and valuable insights into complex biological interactions. ### [Representative Action Selection for Large Action Space Meta-Bandits](https://arxiv.org/abs/2505.18269) arXiv:2505.18269v3 Announce Type: replace-cross Abstract: We study the problem of selecting a subset from a large action space shared by a family of bandits, with the goal of achieving performance nearly matching that of using the full action space. We assume that similar actions tend to have related payoffs, modeled by a Gaussian process. To exploit this structure, we propose a simple epsilon-net algorithm to select a representative subset. We provide theoretical guarantees for its performance and compare it empirically to Thompson Sampling and Upper Confidence Bound. ### [Bayes Error Rate Estimation in Difficult Situations](https://arxiv.org/abs/2506.03159) arXiv:2506.03159v3 Announce Type: replace-cross Abstract: The Bayes Error Rate (BER) is the fundamental limit on the achievable generalizable classification accuracy of any machine learning model due to inherent uncertainty within the data. BER estimators offer insight into the difficulty of any classification problem and set expectations for optimal classification performance. In order to be useful, the estimators must also be accurate with a limited number of samples on multivariate problems with unknown class distributions. To determine which estimators meet the minimum requirements for "usefulness", an in-depth examination of their accuracy is conducted using Monte Carlo simulations with synthetic data in order to obtain their confidence bounds for binary classification. To examine the usability of the estimators for real-world applications, new non-linear multi-modal test scenarios are introduced. In each scenario, 2500 Monte Carlo simulations per scenario are run over a wide range of BER values. In a comparison of k-Nearest Neighbor (kNN), Generalized Henze-Penrose (GHP) divergence and Kernel Density Estimation (KDE) techniques, results show that kNN is overwhelmingly the more accurate non-parametric estimator. In order to reach the target of an under 5% range for the 95% confidence bounds, the minimum number of required samples per class is 1000. As more features are added, more samples are needed, so that 2500 samples per class are required at only 4 features. Other estimators do become more accurate than kNN as more features are added, but continuously fail to meet the target range. ### [Single-stream Policy Optimization](https://arxiv.org/abs/2509.13232) arXiv:2509.13232v2 Announce Type: replace-cross Abstract: We revisit policy-gradient optimization for Large Language Models (LLMs) from a single-stream perspective. Prevailing group-based methods like GRPO reduce variance with on-the-fly baselines but suffer from critical flaws: frequent degenerate groups erase learning signals, and synchronization barriers hinder scalability. We introduce Single-stream Policy Optimization (SPO), which eliminates these issues by design. SPO replaces per-group baselines with a persistent, KL-adaptive value tracker and normalizes advantages globally across the batch, providing a stable, low-variance learning signal for every sample. Being group-free, SPO enables higher throughput and scales effectively in long-horizon or tool-integrated settings where generation times vary. Furthermore, the persistent value tracker naturally enables an adaptive curriculum via prioritized sampling. Experiments using Qwen3-8B show that SPO converges more smoothly and attains higher accuracy than GRPO, while eliminating computation wasted on degenerate groups. Ablation studies confirm that SPO's gains stem from its principled approach to baseline estimation and advantage normalization, offering a more robust and efficient path for LLM reasoning. Across five hard math benchmarks with Qwen3 8B, SPO improves the average maj@32 by +3.4 percentage points (pp) over GRPO, driven by substantial absolute point gains on challenging datasets, including +7.3 pp on BRUMO 25, +4.4 pp on AIME 25, +3.3 pp on HMMT 25, and achieves consistent relative gain in pass@$k$ across the evaluated $k$ values. SPO's success challenges the prevailing trend of adding incidental complexity to RL algorithms, highlighting a path where fundamental principles, not architectural workarounds, drive the next wave of progress in LLM reasoning. --- ## 来源: https://medium.com/feed/@odsc ### [The AI Advantage: How Creators Can Use AI to Generate Portfolio Concepts](https://odsc.medium.com/the-ai-advantage-how-creators-can-use-ai-to-generate-portfolio-concepts-7a7c415a6110?source=rss-2b9d62538208------2)
The creative industry is rapidly evolving, and a new co-pilot has entered the studio: artificial intelligence. Creators across fields — graphic designers, photographers, illustrators, writers — often face the dreaded creative block, tight deadlines, and the pressure to build a unique portfolio that stands out.
That’s where the AI advantage comes in. AI is not a replacement for human creativity, but rather a powerful tool for ideation and concept generation. When used correctly, AI can amplify your creativity by sparking fresh ideas and streamlining tedious tasks. In this blog, we explore how creators can leverage AI to supercharge their portfolio-building process — from breaking through creative blocks to visualizing concepts instantly and crafting compelling case studies.
Breaking Through Creative Block with AI
The hardest part of a new project is often staring at a blank page with no idea where to start. This is where AI shines as a brainstorming partner. Instead of struggling alone, you can tap into AI tools (like chatbots or prompt generators) to get your creative juices flowing.
For example, you might ask an AI to suggest “10 out-of-the-box campaign concepts for an eco-friendly fashion brand” or to imagine “a futuristic café in the style of a traditional woodblock print.” It can return unexpected themes and visuals that break you out of your creative rut. Suddenly, you’re moving from “what if?” to “aha!” — with AI providing the spark for your next original idea.
Visualizing Ideas Instantly
Coming up with a concept is one thing — actually visualizing it is another challenge. Traditionally, creating a mockup or illustration for every idea takes a lot of time and effort. But AI image generators like Midjourney, DALL-E, or Leonardo AI can turn a written description into a picture in seconds. These tools enable the production of detailed mockups without requiring a paintbrush or camera.
For instance, you can ask an AI to create a realistic product mockup in an imaginative setting. Describe a new sneaker design on the moon, and the AI will generate an authentic scene. This instant visual feedback lets you iterate on ideas without investing days of manual work.
Important note: Use AI-generated visuals for brainstorming, not as final portfolio pieces. Always add your own edits and style so the outcome reflects your vision.
AI for Strategic Storytelling and Case Studies
A knockout portfolio isn’t just about images — it also tells the story behind the work. Recruiters and clients want to understand your problem-solving approach and the impact of your projects, which means writing case studies or project summaries to accompany the visuals. Crafting this text can be challenging, especially if writing isn’t your strong suit. Here’s where AI text generators (like ChatGPT or Google Bard) can help polish your storytelling.
Think of AI as a writing coach. You can use it to outline, edit, and polish the written content of your portfolio. For example, you might ask your AI assistant to generate an outline for a case study and get a solid framework almost instantly. Then, after you draft a project description, you could have the AI refine it for clarity and to highlight key outcomes.
In the end, AI helps you articulate your creative process and the value of your work more clearly. By leveraging it to tighten up your writing, you ensure your ideas shine through and your case studies pack a punch. Just remember that the AI is there to assist, not replace, your voice — always review the suggestions and infuse your own tone so the final write-up is authentically yours.
Responsible Use: The “Don’t-Do-This” List
AI is a powerful ally, but using it carelessly or leaning on it too much can backfire. To get the most out of AI without losing your creative edge, keep these cautions in mind:
- Don’t present AI-generated work as your own. Always add your personal edits and style. AI outputs are starting points, not final pieces.
- Don’t rely solely on AI for ideas. If you use it as a crutch, your projects may end up generic. AI can produce content, but it doesn’t grasp context or emotion like you do.
- Don’t neglect the fundamentals. Solid design principles and skills are still essential. AI is an aid, not a substitute for real expertise.
Conclusion
AI can help you brainstorm new ideas, visualize concepts, and even refine how you present your work. Used responsibly, these tools act as a creative catalyst — boosting your productivity rather than replacing your creativity. By embracing AI as an ideation partner, you free up more time to refine your original ideas and bring them to life.
Join thousands of practitioners at ODSC AI West 2025, the leading applied data science and AI conference. Gain hands-on training in generative AI, large language models, retrieval-augmented generation, AI safety, and more through expert-led workshops and bootcamps. Explore cutting-edge tools in the AI Expo Hall, connect with industry leaders, and customize your experience with flexible 1- to 3-day passes.
Don’t miss this chance to expand your AI skills and network — register now to secure your spot.

Artificial intelligence (AI) has moved beyond proof-of-concept experiments, but many organizations still find it difficult to prove it delivers tangible value rather than hype. While model accuracy and innovation often capture the spotlight, executives want to see financial outcomes, and data scientists need clear technical benchmarks that validate success.
This gap demands rigorous measurement frameworks that tie advanced metrics to real-world results. When AI initiatives are evaluated through a structured lens that blends impact with technical depth, enterprises can more confidently scale adoption, communicate value across stakeholders, and position AI as a strategic driver rather than another emerging technology.
1. Financial ROI and Cost Savings
Traditional return on investment is still a cornerstone of business evaluation. However, measuring AI’s impact requires connecting model performance to real financial outcomes rather than abstract technical wins.
Recent surveys show that less than 20% of companies track key performance indicators (KPIs) for their generative AI solutions, which leaves most without a clear picture of value creation. The straightforward impact often comes from direct cost reductions, whether through automating repetitive processes, optimizing resource use, or reducing error rates that lead to expensive rework.
A fraud detection system offers a clear example. Lowering false positives saves money by cutting unnecessary investigations and freeing analysis to focus on higher-value tasks. To ensure credibility, brands must compare these gains to pre-AI baselines, which gives data teams a concrete view of how AI translates into measurable financial performance.
2. Productivity and Process Efficiency Gains
AI’s effect on productivity and efficiency is most evident in its ability to accelerate throughput, shorten cycle times, and remove bottlenecks that once slowed operations. In manufacturing, AI-driven robots and automation systems have reduced human error while boosting consistency and speed, proving especially valuable for scaling production without sacrificing quality.
Similar benefits are emerging in other industries, from reduced model training times to smarter supply chain optimization that balances inventory with real-time demand. Measuring these improvements requires looking at KPIs that connect directly to business performance, such as time-to-insight for data teams or orders processed per hour in logistics.
To ensure accuracy in evaluating impact, many use A/B testing or randomized control trials to isolate AI’s role. This approach gives leaders confidence that efficiency gains stem from intelligent automation rather than unrelated factors.
3. Strategic and Competitive Advantage
Measuring AI’s strategic and competitive advantage is less straightforward than tracking financial returns, but it shapes long-term growth. Businesses can evaluate impact through metrics like market share expansion, speed-to-market with AI-enabled features, intellectual property development, and the ability to attract or retain skilled talent.
Compliance also factors in, as metrics often reveal whether a company meets government or industry regulations. At the same time, tracking how AI adoption influences learning curves and data network effects shows how quickly an organization can innovate and scale.
For instance, those leveraging AI-driven demand forecasting improve pricing strategies and inventory management. Doing so allows them to outpace rivals in volatile markets and secure a more resilient position.
4. Customer and User Experience Metrics
AI’s impact on customer and user experience is best measured through improvements in satisfaction and retention, which directly affect long-term growth. Metrics like Net Promoter Score, churn reduction, or customer lifetime value become more meaningful when tied to AI-enabled personalization or predictive support that enhances interactions at scale. A clear example is customer support bots that reduce resolution times and improve customer satisfaction scores by providing faster, more accurate responses.
Beyond these direct indicators, brands can monitor proxy signals such as longer session lengths or evolving usage patterns in AI-enabled tools to understand how effectively AI shapes user behavior. These measures reveal how AI-driven experiences strengthen customer relationships and increase loyalty. They also offer a competitive edge that extends beyond efficiency or cost savings.
5. Model Performance and Decision Quality
Business impact in AI goes beyond accuracy metrics, because what matters is the relevance of decisions and their outcomes. Suppose a system generates 100% correct recommendations. The overall decision quality can decline if humans fail to consistently follow those suggestions, which highlights the gap between technical performance and practical adoption.
To bridge this, organizations must evaluate metrics beyond precision and recall, such as calibration, economic utility, and cost-sensitive measures that reflect real-world trade-offs. For example, a recommendation engine should be judged on click-through rates and the net profit uplift it delivers by improving the relevance of offers to customers.
Building a Framework for Sustainable AI Impact
Practitioners must blend quantitative rigor with business context to ensure AI measurement reflects technical accuracy and real-world outcomes. By linking model performance to financial, operational, and strategic metrics, they can communicate value in a way that resonates across stakeholders. Data leaders should build repeatable impact-measurement frameworks tailored to their employer’s goals and create a foundation for sustainable and scalable AI adoption.

![]() Lauren Goode / Wired:
Lauren Goode / Wired:
Modular, which lets developers build AI apps that run across multiple GPU and CPU vendors, raised $250M led by US Innovative Technology at a $1.6B valuation — Demand for AI chips is booming—and so is the need for software to run them. Chris Lattner's startup Modular just raised $250 million …

![]() Jagmeet Singh / TechCrunch:
Jagmeet Singh / TechCrunch:
Google launches the Data Commons MCP Server, allowing developers to integrate its collection of public datasets into AI systems via natural language queries — Google is turning its vast public data trove into a goldmine for AI with the debut of the Data Commons Model Context Protocol (MCP) …

![]() Tom Warren / The Verge:
Tom Warren / The Verge:
Microsoft is bringing Anthropic's Claude Sonnet 4 and Claude Opus 4.1 to Microsoft 365 Copilot, starting with Researcher and Copilot Studio — Microsoft is bringing Anthropic's Claude Sonnet 4 and Claude Opus 4.1 to Microsoft 365 Copilot users. … Microsoft is bringing Anthropic's Claude Sonnet 4 …

![]() Kurt Wagner / Bloomberg:
Kurt Wagner / Bloomberg:
Meta says Instagram has hit 3B monthly users and is changing its home screen to prioritize DMs and Reels; it is testing opening directly into Reels in India — Instagram has reached 3 billion monthly users, cementing the network as one of the most popular consumer apps of all time and leading …

![]() Blockworks:
Blockworks:
Zerohash, which provides on-chain infrastructure for businesses to offer trading, stablecoin payments, and more, raised a $104M Series D-2 at a $1B valuation — Funding round draws Morgan Stanley, SoFi and Apollo, underscoring rising demand for regulated on-chain infrastructure

![]() Ivan Mehta / TechCrunch:
Ivan Mehta / TechCrunch:
Emergent, which lets non-technical users build apps via AI agents that handle coding errors and more, raised a $23M Series A, bringing its total funding to $30M — In the last decade, as the camera quality of smartphones improved, platforms like Instagram, YouTube, and TikTok rose in popularity for photo and video sharing.

![]() Jeremy Kahn / Fortune:
Jeremy Kahn / Fortune:
Synthesized, which is developing AI tools to automate software testing, raised a $20M Series A led by Redalpine — Synthesized, a London- and New York-based startup that uses artificial intelligence to automate software testing, has raised $20 million in new venture capital funding …

![]() Bloomberg:
Bloomberg:
Sources: Oracle seeks to borrow $15B through the US sale of corporate bonds, as it begins to fulfill massive cloud infrastructure deals with OpenAI and others — Oracle Corp. is seeking to borrow $15 billion from the US investment-grade bond market on Wednesday, the second-biggest debt sale this year …

![]() Lucinda Shen / Axios:
Lucinda Shen / Axios:
WeTravel, whose travel payments software is used by group travel operators, raised a $92M Series C at a ~$450M valuation, up from ~$100M in 2022 — WeTravel, a travel payments software company, raised $92 million in Series C funding, CEO Ted Clements tells Axios.

![]() Imran Rahman-Jones / BBC:
Imran Rahman-Jones / BBC:
UK's National Crime Agency says it's arrested a man in connection with a cyberattack that has caused days of disruption at Heathrow and other European airports — A person has been arrested in connection with a cyber-attack which has caused days of disruption at several European airports including Heathrow.

![]() Lawrence Bonk / Engadget:
Lawrence Bonk / Engadget:
Spotify reinstates integration with third-party DJ software for Premium subscribers in 51 markets, including the US, after pulling support in 2020 — Budding mixmasters can create sets from pre-existing playlists. — Spotify just announced integration with popular DJ software platforms like rekordbox, Serato and djay.

![]() Michael Moritz / Financial Times:
Michael Moritz / Financial Times:
Michael Moritz says Trump's “H-1B caper will backfire” and shows the “fragile grasp” Trump and his acolytes have of what makes the US tech sector so successful — The move shows how slender a grasp the president has of what makes the American economy so successful

![]() Bloomberg:
Bloomberg:
Report: China's market regulator drafts rules to curb “coercive competition” in the online food delivery market, spurring a rally in Meituan and JD.com's shares — China's market watchdog is initiating a series of moves to tamp down runaway competition in the meal delivery arena …

![]() The Economic Times:
The Economic Times:
Indian digital payments giant PhonePe confidentially files for an IPO in India, seeking to raise $1.5B, sources say at a valuation of $15B — PhonePe, supported by Walmart, has confidentially filed its DRHP with SEBI. The digital payments platform reduced its net loss by 13.4% to Rs 1,727.4 crore …

![]() Luz Ding / Bloomberg:
Luz Ding / Bloomberg:
Alibaba's Hong Kong-listed shares hit a nearly four-year high after CEO Eddie Wu announced plans to increase AI spending beyond the $53B target over three years — Alibaba Group Holding Ltd.'s shares surged to their highest in nearly four years after revealing plans to ramp up AI spending past …

The review determined that TikTok's safeguards for keeping underage users off the platform were inadequate, leading to the collection of data from a large number of Canadian children. Regulators concluded that TikTok amassed information considered particularly sensitive, including biometric data such as facial and voice recognition details, as well as...
Read Entire Article
### [Logitech K980 Signature Slim Solar+ keyboard can run on indoor light – no sun required](https://www.techspot.com/news/109603-logitech-k980-signature-slim-solar-keyboard-can-run.html)

Priced at $99, the Signature Slim Solar+ K980 is another wireless keyboard from Logitech. The company has been making these solar-powered keyboards for over a decade now, most of which have been well-reviewed.
Read Entire Article
### [Microsoft unveils microfluidic cooling to handle hotter, denser AI workloads](https://www.techspot.com/news/109598-microsoft-unveils-microfluidic-cooling-handle-hotter-denser-ai.html)

This method differs from conventional cold plate technologies, which are separated from the chip by several thermal layers and are reaching their efficiency limits as processors grow more powerful and heat-intensive.
Read Entire Article
### [Google and Qualcomm hint at "incredible" Android PC in development](https://www.techspot.com/news/109602-google-qualcomm-hint-incredible-android-pc-development.html)

Speaking during the opening keynote at Qualcomm's Snapdragon Summit 2025, Amon and Google's SVP of Devices and Services, Rick Osterloh, spoke about what the future of computing could hold.
Read Entire Article
### [Intel could be developing Arc B770 with 16GB VRAM, multi-frame generation](https://www.techspot.com/news/109595-intel-likely-developing-arc-b770-16gb-vram-multi.html)

Recent data mining suggests that Intel is developing a new Arc Battlemage graphics card as well as the next stage of its XeSS frame generation technology. A recent job listing also referenced an unspecified high-end GPU.
Read Entire Article
### [Secret Service dismantles covert illicit network capable of shutting down cellular service in New York](https://www.techspot.com/news/109592-secret-service-dismantles-covert-illicit-network-capable-shutting.html)

The discovery comes after months of surveillance and enforcement operations aimed at tracing anonymous phone-based threats made against senior American officials earlier this year.
Read Entire Article
### [Steam user becomes first person to own 40,000 games on the platform](https://www.techspot.com/news/109599-steam-user-becomes-first-person-own-40000-games.html)

Sonix (or SonixLegend, according to their Steam profile URL) is a Shanghai, China-based gamer who has held a Steam account for 15 years. In that time, they have amassed a collection of 40,028 games. That's the equivalent of around 2,668 per year, or just over seven every day.
Read Entire Article
### [Disney to hike streaming prices again next month by up to $7](https://www.techspot.com/news/109597-disney-hike-streaming-prices-again-next-month-up.html)

Starting October 23, Disney+ will increase its subscription prices yet again. The decision, likely scheduled far in advance, now seems ill-timed following accusations that the company bowed to government censorship.
Read Entire Article
### [Google rolls out Gemini AI to Google TV and Android TV devices](https://www.techspot.com/news/109584-google-rolls-out-gemini-ai-google-tv-android.html)

Viewers can now interact with their TVs much as they would with a smartphone, asking questions or requesting tailored recommendations using natural, conversational phrasing. For television-related inquiries, Gemini is designed to help when audiences are debating what to watch, finding shows from incomplete details such as – "What's that hospital...
Read Entire Article
### [YouTube to bring back creators banned over Covid-19 and election claims, blames Biden administration for crackdown](https://www.techspot.com/news/109601-youtube-bring-back-creators-banned-over-covid-19.html)

According to a letter from Alphabet lawyer Daniel Donovan to House Judiciary Chair Jim Jordan, "YouTube values conservative voices on its platform," and recognizes the extensive reach these creators have and the role they play in civic discourse.
Read Entire Article
### [Oracle billionaire Larry Ellison is building a media empire, with stakes in TikTok, CBS, CNN and more](https://www.techspot.com/news/109589-oracle-billionaire-larry-ellison-building-media-empire-stakes.html)

The most significant shift centers on TikTok, the short-form video app with 170 million users in the United States. Earlier this year, Congress ordered its parent company, ByteDance, to divest the platform over national security concerns. Enforcement of the law was delayed by President Trump. Against that backdrop, Oracle, where...
Read Entire Article
### [Kali Linux 2025.3 released with ten new hacking tools](https://www.techspot.com/downloads/6738-kali-linux.html)

Kali Linux 2025.3 introduces ten new tools, including AI-assisted scanning and car hacking utilities. It also restores Nexmon support for monitor mode and packet injection on Broadcom/Cypress Wi-Fi chips, including the Raspberry Pi 5. The update refreshes VM build scripts with HashiCorp tooling, while Kali NetHunter gains wireless injection, and more.
Read Entire Article
### [Companies are losing money to AI "workslop" that slows everything down](https://www.techspot.com/news/109591-companies-losing-money-ai-workslop-slows-everything-down.html)

Modern workplaces are increasingly adopting artificial intelligence, promising speed, efficiency, and innovation. However, the reality is often messier in practice. Many companies feel pressured to adopt AI quickly, worried that failing to do so will leave them behind competitors. Yet work produced by AI can create more correction and confusion...
Read Entire Article
### [DDR5 shatters overclocking barrier to hit 13,020 MT/s in new world record](https://www.techspot.com/news/109586-ddr5-reaches-13020-mts-latest-overclocking-world-record.html)

The record was achieved using a single 24GB Corsair Vengeance module with a default speed of 7,500 MT/s. The system was powered by an Intel Core Ultra 7 265K CPU on Gigabyte's flagship Z890 AORUS Tachyon ICE motherboard, specifically designed for extreme CPU and memory overclocking.
Read Entire Article
### [Federal Reserve chair, other economists warn college graduates face difficult hiring challenges](https://www.techspot.com/news/109588-federal-reserve-chair-other-economists-warn-college-graduates.html)

Federal Reserve Chair Jerome Powell acknowledged that the US labor market is presenting unusual challenges for young and minority workers, at a time when both a broader economic slowdown and the rapid spread of artificial intelligence are reshaping job opportunities. Speaking after the Federal Open Market Committee's September meeting, Powell...
Read Entire Article
### [Samsung overcomes technical challenges, ready to supply HBM3E chips to Nvidia](https://www.techspot.com/news/109587-samsung-overcomes-technical-challenges-ready-supply-hbm3e-chips.html)

Samsung Electronics has resolved the technical hurdles it faced in producing 12-layer HBM3E memory chips, successfully passing Nvidia's strict qualification tests. According to people familiar with the matter cited by KED Global, the Korean chipmaker will soon begin supplying the high-bandwidth memory required for Nvidia's AI servers.
Read Entire Article
### [Russian hacking groups long seen as rivals now appear to be teaming up in Ukraine](https://www.techspot.com/news/109572-russian-hacking-groups-long-seen-rivals-now-appear.html)

ESET reported that in February it identified four Ukrainian machines compromised by both groups. On those systems, Gamaredon deployed its usual suite of malware families – PteroLNK, PteroStew, PteroOdd, PteroEffigy, and PteroGraphin – while Turla installed its proprietary Kazuar backdoor.
Read Entire Article
### [Nvidia App edges closer to fully replace the classic GPU Control Panel](https://www.techspot.com/downloads/7608-nvidia-app.html)

The Nvidia App has already replaced GeForce Experience and is gradually moving toward retiring the classic GPU Control Panel. It now manages game launching, driver updates, and most 3D and system settings, though it still lacks a few other advanced options.
Read Entire Article
### [Intel shifts driver support for 11th-14th gen Core CPUs to legacy branch](https://www.techspot.com/news/109578-intel-shifts-driver-support-11th-14th-gen-core.html)

On Monday, Intel confirmed that it has split graphics driver support into two tracks: Core Ultra processors will keep monthly updates and day-0 game support, while 11th through 14th-generation chips shift to a legacy model with quarterly security and critical fixes only.
Read Entire Article
### [Discovery of massive lava tubes on Venus raises new questions for science](https://www.techspot.com/news/109582-discovery-massive-lava-tubes-venus-raises-new-questions.html)

Massive lava-carved tunnels have been confirmed beneath the surface of Venus, providing the strongest evidence yet that the planet's volcanic past created underground networks unlike those on any other world in the solar system.
Read Entire Article
### [Hideo Kojima reveals P.T.-like horror OD, Physint cast, AR game, and Death Stranding anime](https://www.techspot.com/news/109585-hideo-kojima-teases-od-horror-title-physint-espionage.html)

The trailer for OD, subtitled Knock, has been getting the most attention from the 2-hour stream. The clip was created using in-engine footage from the Unreal 5 game, and it looks spectacular. It's also impressively creepy, which bodes well for those still lamenting the canceled Silent Hills, for which P.T....
Read Entire Article
### [MediaTek challenges Qualcomm with new Dimensity 9500 3nm flagship chip](https://www.techspot.com/news/109576-mediatek-challenges-qualcomm-new-dimensity-9500-3nm-flagship.html)

The launch puts MediaTek squarely into a renewed battle with Qualcomm, whose Snapdragon 8 Elite Gen 5 processor will power rival devices from manufacturers such as Xiaomi. Both chips employ "all-big-core" CPU architectures and dedicated hardware for generative AI, signaling how the premium smartphone market has become defined by technical...
Read Entire Article
### [Apple, Nvidia, Intel among 15 early customers for TSMC's 2nm process – despite huge price hike](https://www.techspot.com/news/109583-apple-nvidia-intel-among-15-early-customers-tsmc.html)

Claims regarding TSMC's N2 customers come from KLA, a major semiconductor equipment supplier. At the Goldman Sachs Communacopia & Technology Conference 2025, Ahmad Khan, President of KLA's combined product and customer organization, Semiconductor Products and Customers, said there are around 15 companies designing chips for N2.
Read Entire Article
### [Tesla robotaxis crash within days of Austin pilot launch](https://www.techspot.com/news/109577-tesla-robotaxis-crash-within-days-austin-pilot-launch.html)

A report to the federal government reveals that Tesla's robotaxi fleet in Austin suffered three crashes soon after the service began on June 23. Forbes reports that the company's data is vague and heavily redacted, but one or more of the accidents might have occurred on the first day.
Read Entire Article
### [YouTuber shows upgrading the iPhone 17 Pro Max from 256GB to 1TB is possible, but not easy](https://www.techspot.com/news/109581-youtuber-shows-upgrading-iphone-17-pro-max-256gb.html)

The iPhone 17 Pro Max starts at $1,199 for the base 256GB model. Moving to 512GB, 1TB, or 2TB costs an extra $200 each step up, with the $1,999 variant at the top of the stack.
Read Entire Article
### [Nvidia to invest $100 billion in OpenAI for 10 gigawatts of AI computing power](https://www.techspot.com/news/109579-nvidia-invest-100-billion-openai-10-gigawatts-ai.html)

Nvidia is preparing to make one of the largest corporate investments in history, committing as much as $100 billion to OpenAI as part of a sweeping agreement to expand the infrastructure underpinning artificial intelligence. The deal involves OpenAI purchasing millions of Nvidia's high-performance processors to support the build-out of up...
Read Entire Article
### [Nvidia RTX 5090 finally drops to $1,999 as RTX 5080 sells below MSRP in the United States](https://www.techspot.com/news/109580-nvidia-rtx-5090-finally-drops-1999-rtx-5080.html)

Nvidia's consumer Blackwell flagship has appeared on Walmart's website at its $1,999 official price, while the RTX 5080 is 7% under MSRP at $929.
Read Entire Article
### [AMD Ryzen 7 7800X3D or 9800X3D, Which Should You Buy?](https://www.techspot.com/review/3036-7800x3d-vs-9800x3d/)

A year after Zen 5's debut, we revisit AMD's Ryzen 9800X3D vs 7800X3D to see if the premium is worth it. With new GPUs and updates, has performance shifted or is the older chip still the smarter buy?

Read Entire Article
### [Criminals are driving fake cell towers through cities to blast out scam texts](https://www.techspot.com/news/109575-criminals-driving-fake-cell-towers-through-cities-blast.html)

The trend is a turning point, according to Cathal Mc Daid, VP of technology at telecommunications and cybersecurity firm Enea. "This is essentially the first time that we have seen large-scale use of mobile radio-transmitting devices by criminal groups," Mc Daid told Wired. He noted that while the underlying technology...
Read Entire Article
--- ## 来源: https://the-decoder.com/feed/ ### [Alibaba launches Qwen3-Max, its largest and most capable AI model to date](https://the-decoder.com/alibaba-launches-qwen3-max-its-largest-and-most-capable-ai-model-to-date/)

Alibaba has released Qwen3-Max, the biggest and most capable AI model in its lineup. The new model is built for real-world software development and automation, with major performance upgrades across the board.
The article Alibaba launches Qwen3-Max, its largest and most capable AI model to date appeared first on THE DECODER.
### [SAP and OpenAI plan to launch an AI platform for Germany's public sector using Microsoft Azure](https://the-decoder.com/sap-and-openai-plan-to-launch-an-ai-platform-for-germanys-public-sector-using-microsoft-azure/)
SAP and OpenAI are launching "OpenAI for Germany," an AI platform for Germany's public sector, built on Microsoft Azure and run by SAP's Delos Cloud subsidiary.
The article SAP and OpenAI plan to launch an AI platform for Germany's public sector using Microsoft Azure appeared first on THE DECODER.
### [Suno releases new AI music model v5](https://the-decoder.com/suno-releases-new-ai-music-model-v5/)
Suno has launched its latest music model, v5, for Pro and Premier subscribers.
The article Suno releases new AI music model v5 appeared first on THE DECODER.
### [Alibaba's Qwen introduces new models for voice, image editing and safety](https://the-decoder.com/alibabas-qwen-introduces-new-models-for-voice-image-editing-and-safety/)
Alibaba's Qwen AI group has rolled out several new models and updates.
The article Alibaba's Qwen introduces new models for voice, image editing and safety appeared first on THE DECODER.
### [Sam Altman says scaling up compute is the "literal key" to OpenAI's revenue growth](https://the-decoder.com/sam-altman-says-scaling-up-compute-is-the-literal-key-to-openais-revenue-growth/)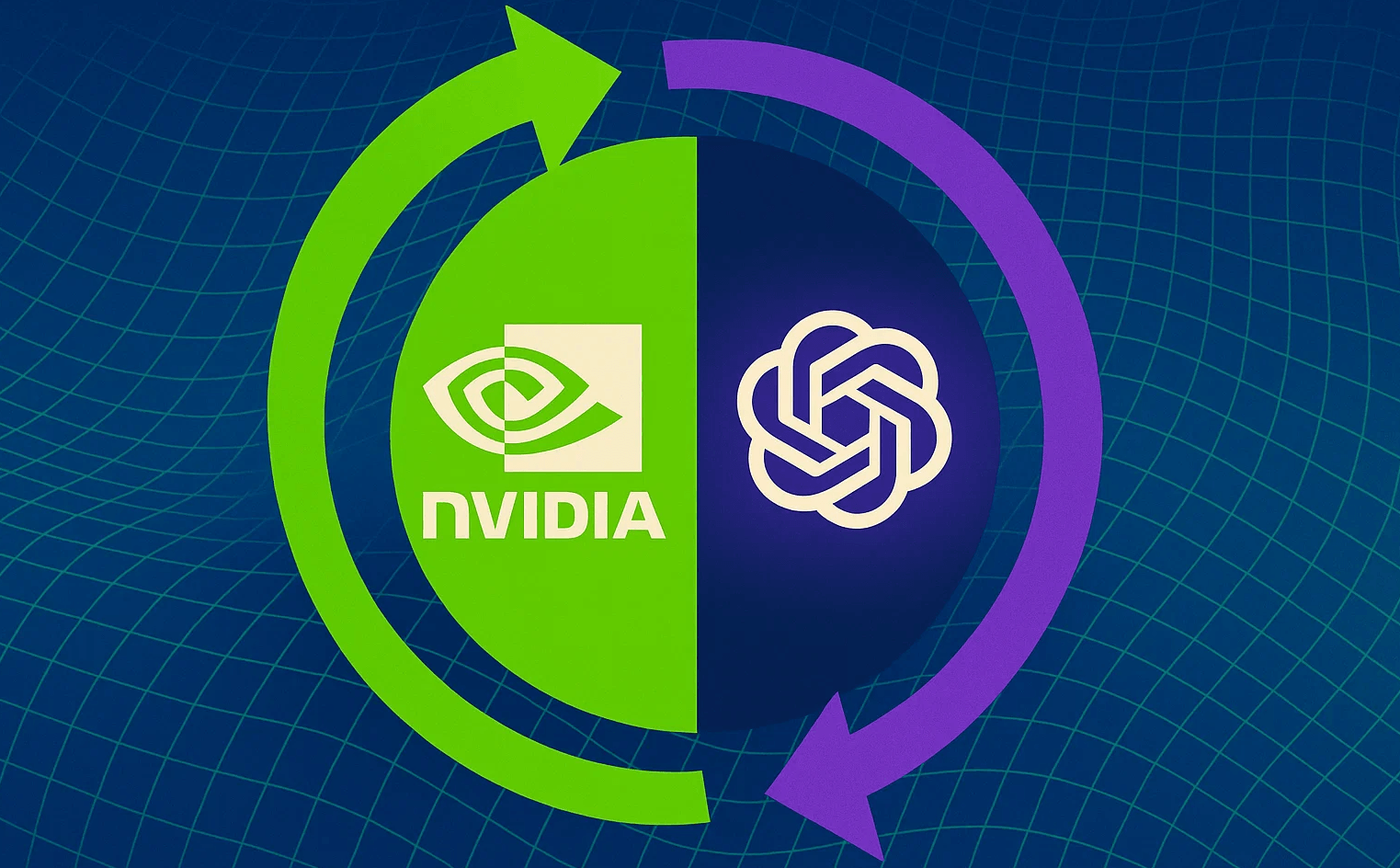
OpenAI CEO Sam Altman says scaling up compute will drive both AI breakthroughs and the company's revenue.
The article Sam Altman says scaling up compute is the "literal key" to OpenAI's revenue growth appeared first on THE DECODER.
### [Alibaba's Qwen3-Next builds on a faster MoE architecture](https://the-decoder.com/alibabas-qwen3-next-builds-on-a-faster-moe-architecture/)
Alibaba has released a new language model called Qwen3-Next, built on a customized MoE architecture. The company says the model runs much faster than its predecessors without losing performance.
The article Alibaba's Qwen3-Next builds on a faster MoE architecture appeared first on THE DECODER.
### [Alibaba unveils Qwen3-Omni, an AI model that processes text, images, audio, and video](https://the-decoder.com/alibaba-unveils-qwen3-omni-an-ai-model-that-processes-text-images-audio-and-video/)
Alibaba has introduced Qwen3-Omni, a native multimodal AI model designed to process text, images, audio, and video in real time.
The article Alibaba unveils Qwen3-Omni, an AI model that processes text, images, audio, and video appeared first on THE DECODER.
--- ## 来源: https://www.theintrinsicperspective.com/feed/ ### [Against Treating Chatbots as Conscious](https://www.theintrinsicperspective.com/p/against-treating-chatbots-as-conscious) Don't give AIs "exit rights" to conversations --- ## 来源: https://thenewstack.io/feed ### [The Case for Microfrontends and Moving Beyond One Framework](https://thenewstack.io/the-case-for-microfrontends-and-moving-beyond-one-framework/)
The hardest part of building large applications today isn’t scaling the backend. It’s keeping the frontend from becoming an untouchable
The post The Case for Microfrontends and Moving Beyond One Framework appeared first on The New Stack.
### [A Guide To Fluent Bit Processors for Conditional Log Processing](https://thenewstack.io/a-guide-to-fluent-bit-processors-for-conditional-log-processing/)
Fluent Bit is a widely used open source data collection agent, processor and forwarder that enables you to collect logs,
The post A Guide To Fluent Bit Processors for Conditional Log Processing appeared first on The New Stack.
### [All Infrastructure Is AI Infrastructure](https://thenewstack.io/all-infrastructure-is-ai-infrastructure/)
In the very near future, all technology infrastructure will effectively be AI infrastructure. This is not hyperbole. As enterprises scale
The post All Infrastructure Is AI Infrastructure appeared first on The New Stack.
### [AI Has Won: Google’s DORA Study Shows Universal Dev Adoption](https://thenewstack.io/ai-has-won-googles-dora-study-shows-universal-dev-adoption/)
A large majority of software development teams are now using AI, marking a fundamental shift in how code gets written,
The post AI Has Won: Google’s DORA Study Shows Universal Dev Adoption appeared first on The New Stack.
### [Open Source Turmoil: RubyGems Maintainers Kicked Off GitHub](https://thenewstack.io/open-source-turmoil-rubygems-maintainers-kicked-off-github/)
Jan Lehnardt said it best in a Mastodon post: “What the f*** is going on with Ruby?” What’s going on
The post Open Source Turmoil: RubyGems Maintainers Kicked Off GitHub appeared first on The New Stack.
### [Snowflake, Salesforce Launch New Standard To Unify Data for AI](https://thenewstack.io/snowflake-salesforce-launch-new-standard-to-unify-data-for-ai/)
Business intelligence service provider has kicked off a vendor-neutral initiative to create a standard for adding contextual information to structured
The post Snowflake, Salesforce Launch New Standard To Unify Data for AI appeared first on The New Stack.
### [GPT-5’s Enhanced Reasoning Comes With a Steep Hidden Cost](https://thenewstack.io/gpt-5s-enhanced-reasoning-comes-with-a-steep-hidden-cost/)
The arrival of GPT-5 represents a significant leap in AI-driven code generation. It’s powerful, functionally proficient and capable of solving
The post GPT-5’s Enhanced Reasoning Comes With a Steep Hidden Cost appeared first on The New Stack.
### [How To Enhance Productivity With DORA Metrics](https://thenewstack.io/how-to-enhance-productivity-with-dora-metrics/)
Building great software products isn’t only about clean code. It’s about how fast you can ship, how often you deploy
The post How To Enhance Productivity With DORA Metrics appeared first on The New Stack.
### [Why You Can’t Debug a Running Quantum Computer Program](https://thenewstack.io/why-you-cant-debug-a-running-quantum-computer-program/)
In a sense, writing applications for quantum computing is very much a case of going back to the future. Much
The post Why You Can’t Debug a Running Quantum Computer Program appeared first on The New Stack.
### [TikTok’s Ex-Algorithm Chief Launches Verdent AI Coding Tool](https://thenewstack.io/tiktoks-ex-algorithm-chief-launches-verdent-ai-coding-tool/)
What if there was an AI coding tool that had algorithms as sophisticated as TikTok’s? That thought experiment is now
The post TikTok’s Ex-Algorithm Chief Launches Verdent AI Coding Tool appeared first on The New Stack.
--- ## 来源: https://thenextweb.com/neural/feed ### [How European battery startups can thrive alongside Asian giants](https://thenextweb.com/news/how-european-battery-startups-can-compete)
The global battery market is experiencing unprecedented growth, with projections showing the sector will reach $400bn by 2030. Yet European entrepreneurs often feel locked out, watching Chinese giants like CATL dominate headlines with record-breaking IPOs while homegrown champions like Northvolt file for bankruptcy, exposing the harsh realities of competing against established Asian supply chains. Still, Europe will never be entirely independent in green energy and will want to cooperate with Asia. Yet the continent has strong demand for on-shoring supply, including green power and critical manufacturing. There are also genuine competitive advantages available to European green battery startups: proximity to…
This story continues at The Next Web ### [The EU’s €2T budget overlooks a key tech pillar: Open source](https://thenextweb.com/news/eu-budget-open-source)

On July 16, the European Commission proposed a €2tn seven-year budget – the largest in the EU’s history – to boost autonomy, competitiveness, and resilience. The spending plan addresses cybersecurity, innovation, and other key digital pillars, but omits a crucial component: open source. Open source software – built and maintained by communities rather than private companies alone, and free to edit and modify – is the foundation of today’s digital infrastructure. Since the 1990s, it has been ever-present in the digital infrastructure that European industry and public sector institutions depend on, creating huge dependencies on open source applications and libraries. From…
This story continues at The Next Web --- ## 来源: https://www.theregister.com/software/ai_ml/headlines.atom ### [AI hype train may jump the tracks over $2T infrastructure bill, warns Bain](https://go.theregister.com/feed/www.theregister.com/2025/09/24/bain_ai_costs/)
Industry looks like it's going to come up short – by about $800B
The AI craze is fueling massive growth in infrastructure, but the industry will need to hit $2 trillion in revenue by 2030 to keep funding this habit. Consultants at Bain & Company think it is going to come up short.…
### [US banking giant Citi pilots agentic AI with 5,000 staff](https://go.theregister.com/feed/www.theregister.com/2025/09/24/citi_pilots_agentic_ai/)Financial services firm admits it may mean fewer staff
US banking giant Citi has revved the Stylus Workspaces AI platform it has been rolling out to employees, touting that it is "now powered by agentic AI."…
### [OpenAI's Stargate project to pave the world with AI datacenters announces five new US locations](https://go.theregister.com/feed/www.theregister.com/2025/09/24/openai_oracle_softbank_datacenters/)In Texas, New Mexico, and the Midwest
The Stargate project, the OpenAI-led plan to cover the world with datacenters, has announced plans to construct five new bit barns in the US.…
### [Boffins fool a self-driving car by putting mirrors on traffic cones](https://go.theregister.com/feed/www.theregister.com/2025/09/23/selfdriving_car_fooled_with_mirrors/)21st century tech confused by $100 of shiny stuff
Mirrors can fool the Light Detection and Ranging (LIDAR) sensors used to guide autonomous vehicles by making them detect objects that don’t exist, or failing to detect actual obstacles.…
### [Nearly half of businesses suffered deepfaked phone calls against staff](https://go.theregister.com/feed/www.theregister.com/2025/09/23/gartner_ai_attack/)AI attacks on the rise
A survey of cybersecurity bosses has shown that 62 percent reported attacks on their staff using AI over the last year, either by the use of prompt injection attacks or faking out their systems using phony audio or video generated by AI.…
### [AI coding hype overblown, Bain shrugs](https://go.theregister.com/feed/www.theregister.com/2025/09/23/developers_genai_little_productivity_gains/)Tried by two-thirds of firms, ignored by most devs, and productivity barely moved
Software development was one of the first areas to adopt generative AI, but the promised revolution has so far delivered only modest productivity gains, and Bain says only a full rethink of the software lifecycle will shift the dial.…
### [Kaspersky: RevengeHotels checks back in with AI-coded malware](https://go.theregister.com/feed/www.theregister.com/2025/09/23/kaspersky_revengehotels_checks_back_in/)Old hotel scam gets an AI facelift, leaving travellers’ card details even more at risk
Kaspersky has raised the alarm over the resurgence of hotel-hacking outfit "RevengeHotels," which it claims is now using artificial intelligence to supercharge its scams.…
### [How I learned to stop worrying and love the datacenter](https://go.theregister.com/feed/www.theregister.com/2025/09/23/datacenter_builds_risk_rewards/)Stargates or black holes? Risks and rewards from the B(r)itbarn boom
Comment The UK has bitterly expensive power, an energy minister who sees electricity as bad, a lethargic planning system, and a grid with a backlog for connections running to 2039.…
--- ## 来源: https://rss.beehiiv.com/feeds/2R3C6Bt5wj.xml ### [Alibaba's Qwen3 blitz](https://www.therundown.ai/p/alibabas-qwen3-blitz) PLUS: Altman details infrastructure push in new blog ### [Nvidia fuels OpenAI's compute chase](https://www.therundown.ai/p/nvidia-fuels-openais-compute-chase) PLUS: Use GPT-5 in Microsoft 365 to analyze emails --- ## 来源: https://thesequence.substack.com/feed ### [The Sequence AI of the Week #725: Building Research, Not Answers: The DeepResearch Runtime](https://thesequence.substack.com/p/the-sequence-ai-of-the-week-725-building) A deep dive into the newest model released by Alibaba's agentic group. ### [The Sequence Knowledge #724: What are the Different Types of Mechanistic Interpretability?](https://thesequence.substack.com/p/the-sequence-knowledge-724-what-are) Discussing a taxonomy to understand the most important mechanistic interpretability methods. --- ## 来源: https://www.thetradenews.com/feed/ ### [RBC Capital Markets appoints head of European inflation trading](https://www.thetradenews.com/rbc-capital-markets-appoints-head-of-european-inflation-trading/)The firm has also named a new head of structured inflation and cross-currency basis trading as part of its push to bolster its European flow rates trading team.
The post RBC Capital Markets appoints head of European inflation trading appeared first on The TRADE.
### [Ediphy appeals FCA bond CTP decision](https://www.thetradenews.com/ediphy-appeals-fca-bond-ctp-decision/)The FCA has confirmed that the challenge to its appointment of Etrading Software as the UK’s consolidated tape provider is set to delay the implementation process.
The post Ediphy appeals FCA bond CTP decision appeared first on The TRADE.
### [The TRADE reveals Leaders in Trading New York 2025 awards shortlists](https://www.thetradenews.com/the-trade-reveals-leaders-in-trading-new-york-2025-awards-shortlists/)Algorithmic Trading, Execution Management Systems, Editors’ Choice, and Outsourced Trading Awards announced today, with Buy-Side Awards set to follow in the coming weeks.
The post The TRADE reveals Leaders in Trading New York 2025 awards shortlists appeared first on The TRADE.
### [Pyth Network launches new subscription service to deliver cross-asset market data](https://www.thetradenews.com/pyth-network-launches-new-subscription-service-to-deliver-cross-asset-market-data/)The offering was developed in collaboration with Douro Labs, and its early access program has also seen participation from major firms such as Jump Trading Group and several large banks.
The post Pyth Network launches new subscription service to deliver cross-asset market data appeared first on The TRADE.
### [Investec names ex-Winterflood Securities fixed income expert as new head of fixed income and ETFs](https://www.thetradenews.com/investec-names-ex-winterflood-securities-fixed-income-expert-as-new-head-of-fixed-income-and-etfs/)Investec has made two hires from Winterflood Securities, appointing a new head and deputy head of its fixed income and ETF offering; appointments follow news in July that Marex is set to acquire Winterflood Securities in early 2026.
The post Investec names ex-Winterflood Securities fixed income expert as new head of fixed income and ETFs appeared first on The TRADE.
### [BGC Group hires from Citi for equity derivatives sales trader](https://www.thetradenews.com/bgc-group-hires-from-citi-for-equity-derivatives-sales-trader/)Individual joins the broker after spending the last five years at Citi working across various roles.
The post BGC Group hires from Citi for equity derivatives sales trader appeared first on The TRADE.
### [LSEG enters strategic partnership to deliver data directly to Databricks](https://www.thetradenews.com/lseg-enters-strategic-partnership-to-deliver-data-directly-to-databricks/)The offering will allow firms to build governed AI agents using both enterprise and LSEG’s data, via Databrick’s Delta Sharing.
The post LSEG enters strategic partnership to deliver data directly to Databricks appeared first on The TRADE.
### [Orbit Financial Technology launches AI membership model to democratise financial research access](https://www.thetradenews.com/orbit-financial-technology-launches-ai-membership-model-to-democratise-financial-research-access/)The new offering - Orbit Flex - combines exclusive financial data with advanced AI infrastructure and workflows to remove cost and access barriers for smaller institutions.
The post Orbit Financial Technology launches AI membership model to democratise financial research access appeared first on The TRADE.
### [Morgan Stanley taps BNP Paribas for eFX sales role](https://www.thetradenews.com/morgan-stanley-taps-bnp-paribas-for-efx-sales-role/)Individual has worked extensively across FX at firms including Euronext, State Street, Santander and HSBC.
The post Morgan Stanley taps BNP Paribas for eFX sales role appeared first on The TRADE.
### [EDXM International and Sage Capital Management partner to enhance perpetual futures institutional access](https://www.thetradenews.com/edxm-international-and-sage-capital-management-partner-to-enhance-perpetual-futures-institutional-access/)As part of the offering, Sage Capital will act as a prime broker to the exchange; the news follows the launch of EDXM International in July, backed by partners including Citadel Securities and Virtu Financial.
The post EDXM International and Sage Capital Management partner to enhance perpetual futures institutional access appeared first on The TRADE.
--- ## 来源: https://www.theverge.com/rss/index.xml ### [UK arrests man in airport ransomware attack that caused delays across Europe](https://www.theverge.com/news/784786/uk-nca-europe-airport-cyberattack-ransomware-arrest) The UK’s National Crime Agency arrested a man in West Sussex in connection with a ransomware attack that caused significant flight delays last week and forced many airlines to check passengers and luggage manually. The cyberattack impacted several airports across Europe, including London’s Heathrow and Berlin’s Brandenburg. The agency shared little about the arrest in […] ### [YouTube will now let you hide those pesky end screens](https://www.theverge.com/news/784774/youtube-end-screen-videos-hide) YouTube will finally let you dismiss the pop-ups that fill your screen with recommendations at the end of a video. Now, when you come across an end screen, you can select a new “hide” button in the top-right corner of the video so you can finish what you’re watching without distractions. YouTube says it’s making […] ### [I tried a 240Hz 4K OLED gaming monitor and now I’m ruined](https://www.theverge.com/tech/784323/upgrading-240hz-oled-gaming-monitor) I keep accidentally ruining regular things for myself. I already can't use a standard keyboard layout, and now I think I have to buy a really nice monitor. I've spent the last few months living with the Alienware AW2725Q, a 27-inch gaming monitor with a 240Hz 4K resolution QD-OLED panel. It's one of a spate […] ### [Google is starting to launch real-time AI voice search](https://www.theverge.com/news/784685/google-search-live-ai-voice-search-launch) Google is bringing Search Live to everyone in the US, letting you search for information by having a conversation with an AI assistant. When you use the feature, Search Live will respond to your questions in real-time, as well as surface relevant links from the web. You can try the feature out by opening the […] ### [These earbuds include a tiny wired microphone you can hold](https://www.theverge.com/news/784703/portronics-conch-one-usb-c-earbuds-headphones-wired-microphone) Despite the best efforts of companies like DJI to shrink wireless wearable mics and make them as unobtrusive as possible, a lot of content creators still prefer a mic they can hold. So as wired headphones continue to make a comeback, Plantronics has released a pair of USB-C earbuds called the Conch One with their […] ### [Samsung’s latest Galaxy earbuds come with a free Galaxy SmartTag2 tracker](https://www.theverge.com/tech/784644/samsung-galaxy-buds-3-fe-blink-video-doorbell-deal-sale) Samsung’s Galaxy Buds 3 FE were released earlier this month for $149.99. The company hasn’t yet knocked down the price, but it’s including a free Galaxy SmartTag 2 at Amazon. The bundle saves you $30 and is available until September 28th. Samsung says both items may ship separately, so don’t worry if you receive one […] ### [Hades II’s big 1.0 update has me obsessed all over again](https://www.theverge.com/games/783718/hades-ii-2-1-0-update-review-pc-nintendo-switch) When Hades II first launched in early access, I had to force myself to stop playing after around 30 hours. I didn't want to burn out on what was already an excellent, jam-packed Hades sequel before it hit 1.0, when the final polish and story would be in place. I made the right choice; the […] ### [Microsoft embraces OpenAI rival Anthropic to improve Microsoft 365 apps](https://www.theverge.com/news/784392/microsoft-365-copilot-anthropic-ai-models-feature) Microsoft is bringing Anthropic’s Claude Sonnet 4 and Claude Opus 4.1 AI models to its Microsoft 365 Copilot today. It’s a big move that expands model choice beyond just OpenAI’s range of models in Microsoft 365 Copilot, and it will allow Microsoft’s customers to access Anthropic models in Researcher and Microsoft Copilot Studio. “Copilot will […] ### [Sharge’s magnetic fan-cooled SSD doubles as a USB hub](https://www.theverge.com/news/784634/sharge-disk-pro-active-cooling-ssd-kickstarter) Sharge is a brand slowly making a name for itself with eye-catching accessories that solve problems you didn’t realize you had. Its latest creation is an external SSD drive that includes a built-in cooling fan to improve its performance and longevity. It also has a bunch of extra ports so you can connect other accessories […] ### [Disney sure picked a terrible time to raise prices](https://www.theverge.com/report/784594/disney-jimmy-kimmel-backlash-price-hikes) Disney is in a tangled web of its own making. In just one week, the entertainment giant managed to anger both sides of the political spectrum, and then topped it all off with a Disney Plus price hike that made just about everyone mad. Now, Disney's facing criticism from all sides, and it may struggle […] --- ## 来源: https://pub.towardsai.net/feed ### [Long Term Memory + RAG + MCP + LangGraph = The Key To Powerful Agentic AI](https://pub.towardsai.net/long-term-memory-rag-mcp-langgraph-the-key-to-powerful-agentic-ai-39e75b7ecd1c?source=rss----98111c9905da---4)
In this story, I have a super quick tutorial showing you how to create a multi-agent chatbot using LangGraph, MCP, RAG, and long-term…
Understanding Neural Networks — and Building One!
A hands-on journey into neural networks, starting from scratch and ending with your first model.
Why Do We Need Neural Networks?
Imagine trying to teach a computer to do something humans find easy like recognizing a face in a photo, understanding someone’s accent, or predicting which movie you’ll enjoy next. Traditional programming struggles here because these tasks don’t have strict rules. You can’t write an “if-else” for every possible scenario as there are just too many variations.
This is where neural networks come in. They’re designed to learn from examples instead of being told exactly what to do. Feed them enough data, and they can discover patterns that are too complex for humans to explicitly code.
Some things neural networks are especially good at:
- Image recognition: Spotting faces, cats, or handwritten digits.
- Speech and language: Understanding voice commands, translating languages, or generating text.
- Predictions: Forecasting stock prices, weather, or even your next favorite song.
- Medical diagnostics: Detecting diseases from scans or medical data.
In short: neural networks are needed for any problem where patterns are complicated, messy, or too numerous to define with rules. They’re the “learning brains” for computers, letting machines tackle tasks that were once thought impossible.
What are Neural Networks ?
Think about a normal family dinner at home. The food is served, and everyone at the table has their own opinion.
- Your mom might notice if the vegetables are cooked fine.
- Your dad cares whether the food feels filling.
- Your sibling only judges based on how good the dessert is.
- Your grandmother might focus on whether the food is light and healthy.
Each person looks at the same dinner but from a different angle. And when you combine all these opinions, you arrive at the final judgment: “Dinner was great.”
That’s how a neural network works.
- Each “family member” is like a neuron, focusing on one part of the input.
- Some opinions count more than others , just like weights in a network.
- Put together, they form the final output.
In short: a neural network is nothing more than lots of small judgments coming together to make one big decision.
How Neural Networks Work
Think of a neural network as a big family dinner decision-making process. The goal is to decide if the meal is great or not, but instead of one person deciding, several family members give their opinions. Each opinion counts differently depending on who it is. This is very similar to how neural networks process information.

1. The Neuron
At the core of a neural network is a neuron. A neuron takes some inputs, applies weights to them, adds a bias, and then passes the result through an activation function to produce an output.
- In the family dinner analogy, a neuron is like one family member. They focus on a specific aspect of the dinner, for example, whether the dal has enough spice.
- The weight is how important their opinion is. Maybe Maa’s opinion matters a lot, and your sibling’s opinion matters less.
- The bias is a baseline tendency. Maybe Dadi always likes the food a bit more, so her input is slightly adjusted up.
Math Explanation
A single neuron can be written as:

Then the neuron applies an activation function fff to get the output:

- For example, a sigmoid activation squashes the output between 0 and 1, like a yes/no opinion.

2. Layers
Neurons are arranged in layers.
- Input layer: The raw information about the dinner. For example, saltiness, aroma, portion size, sweetness. Each input goes to one neuron.
- Hidden layer(s): Neurons that combine the inputs and process them further. These are like family members discussing among themselves before giving a final opinion.
- Output layer: The final decision. For example, “Dinner was great” or “Dinner was okay.”
Math Explanation for a Layer
Suppose you have a layer of m neurons and n inputs:


3. Forward Pass
Forward pass is just feeding information through the network:
- Inputs come into the first layer.
- Each neuron calculates its output using its weights, bias, and activation.
- The outputs become the inputs for the next layer.
- Finally, the output layer produces the network’s prediction.
Analogy:
- At the dinner, each family member gives their opinion (neuron output).
- Opinions are combined and passed on to the next group if needed (hidden layers).
- Finally, the family reaches a consensus (output layer).
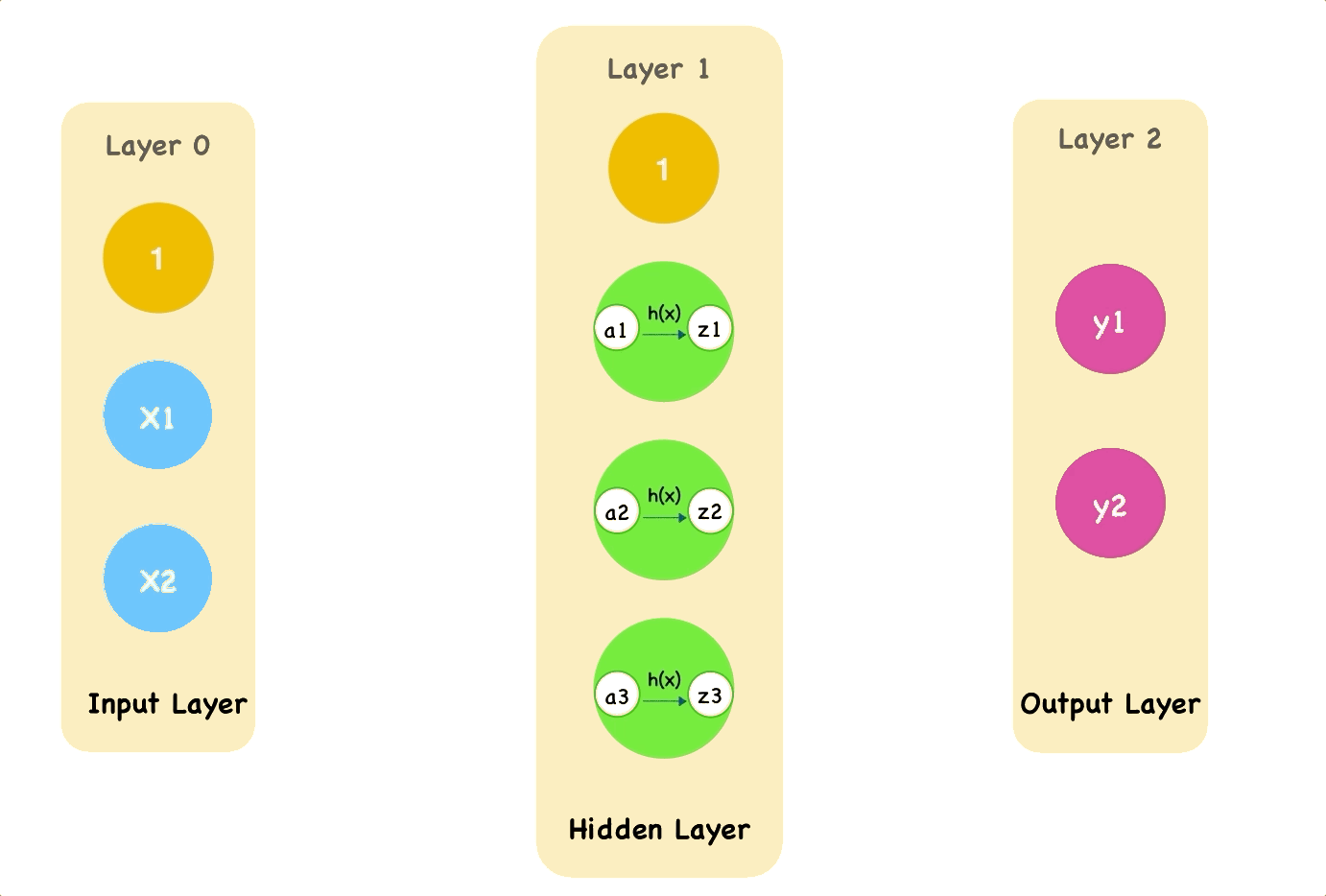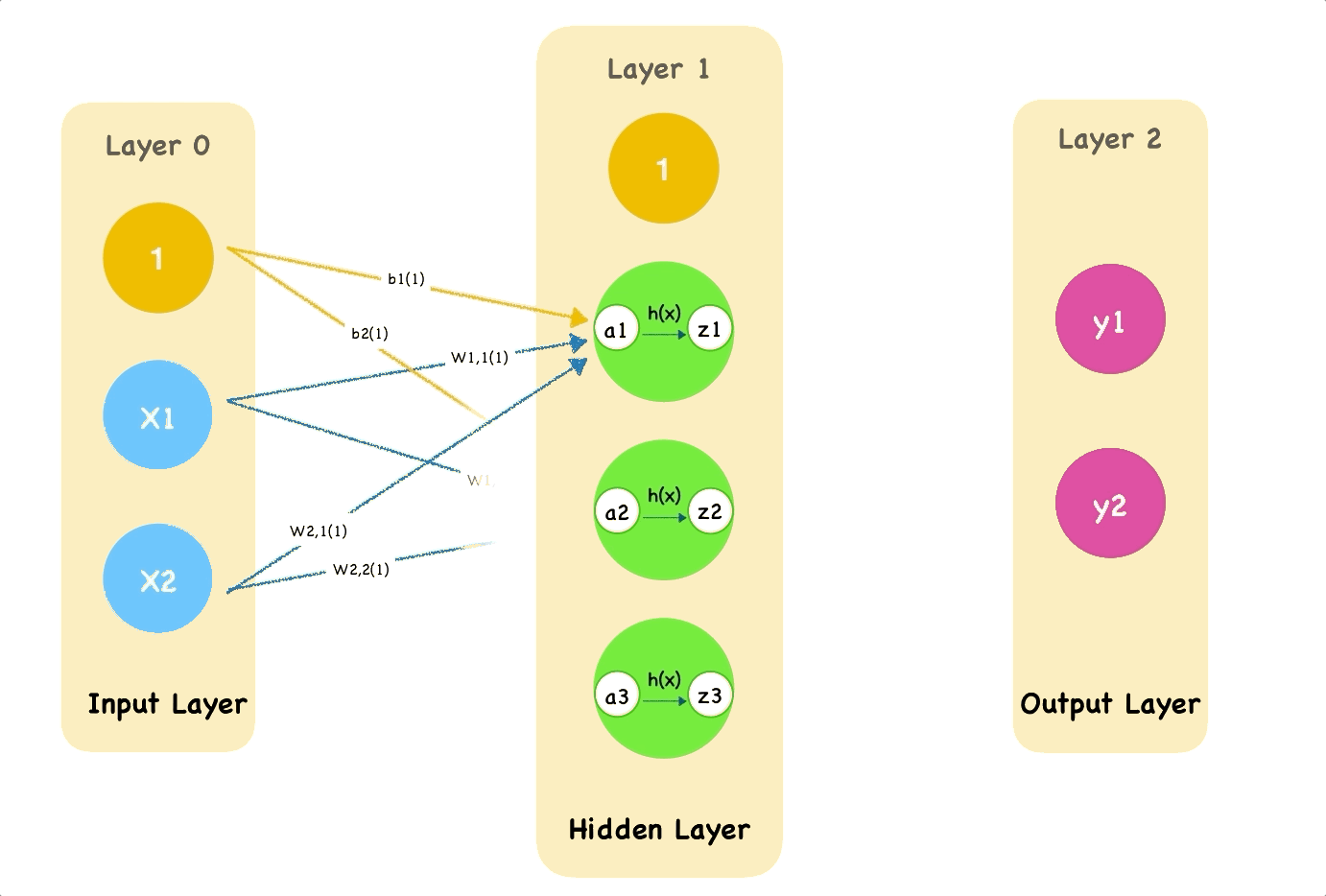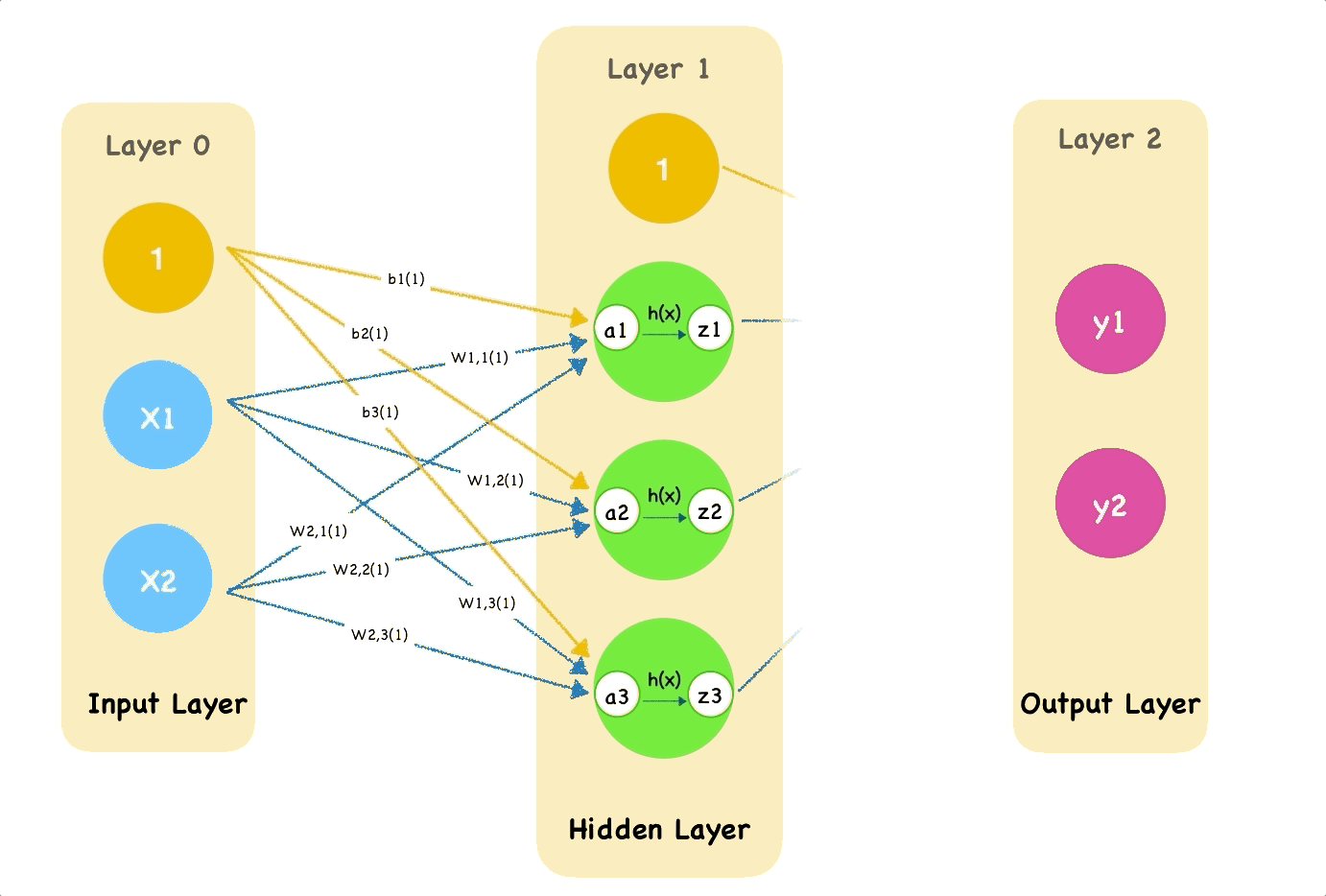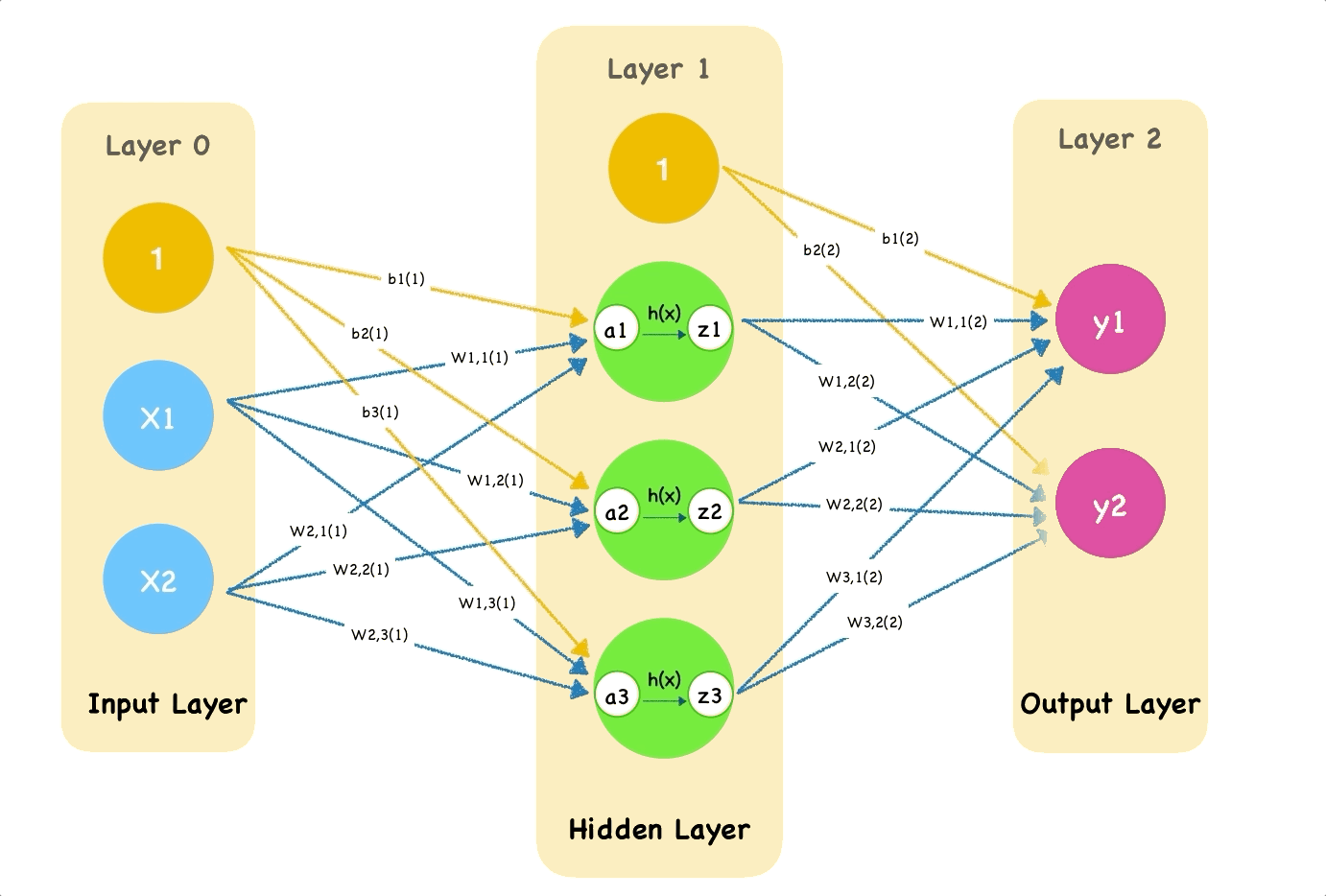
4. Loss Function
To learn, the network needs to know how far off its predictions are. That’s what the loss function does.
- If the network says “Dinner is great” but the family actually thinks it’s just okay, the loss is high.
- The network will adjust to reduce this error.
Read about Loss Functions here.
5. Backpropagation
Backpropagation is how the network learns from mistakes.
- The network calculates how much each neuron contributed to the error (loss).
- Then it adjusts weights and biases slightly to reduce the loss next time.
Math Explanation (Simplified)

Analogy:
- If Mom’s opinion was too harsh or too lenient in the dinner rating, we slightly adjust how much we consider her opinion next time.
- Over many meals (iterations), the network learns the perfect combination of opinions to make the right judgment.
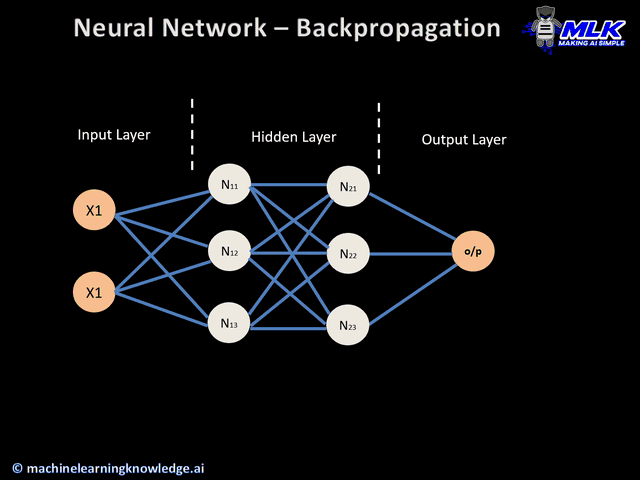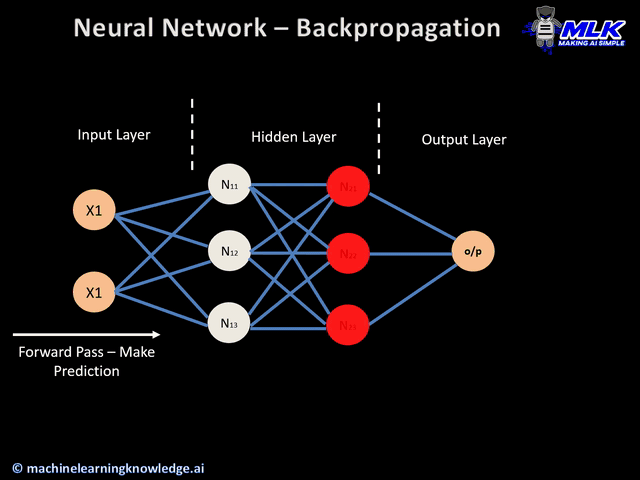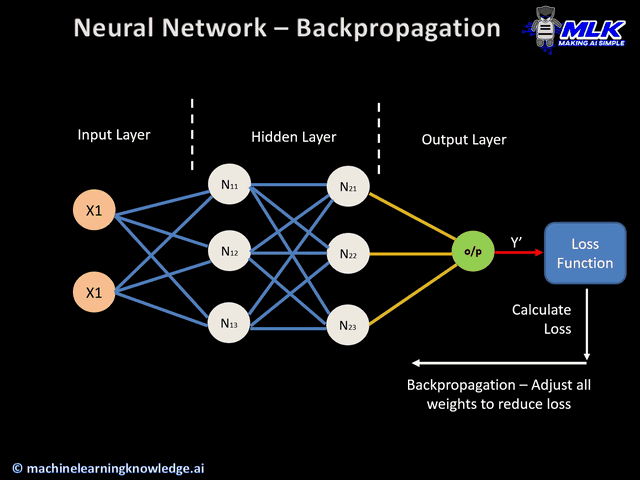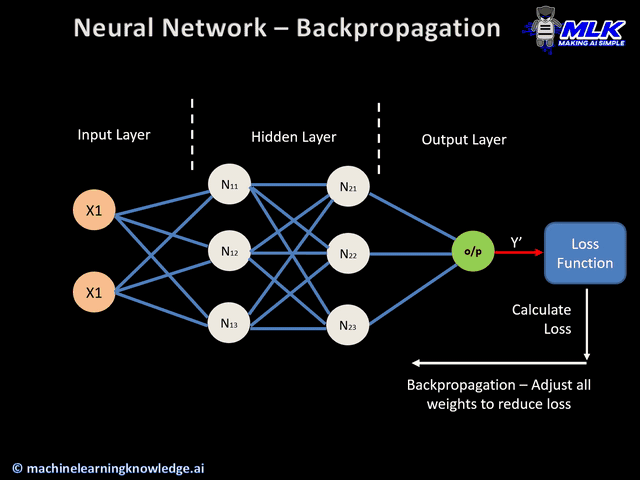
6. Activation Functions
Activation functions decide how strong a neuron’s output is.
- Sigmoid: squashes output between 0 and 1 (like yes/no opinions).
- ReLU: outputs zero if negative, or the input itself if positive (ignores weak opinions, emphasizes strong ones).
- Tanh: squashes between -1 and 1 (like positive/negative feelings).
Read about Activation Functions here.
A House Price Example
Imagine you are trying to predict the price of a house. Looking at just one detail, like the number of bedrooms, won’t tell you the full story. Instead, you have to combine different details to form bigger ideas that are easier to reason about.
For example, the age of the house and how many renovations it has gone through together give you a sense of how “new” the property feels. The locality, the number of schools nearby, and how dense the housing is combine into an idea of the “quality of the neighborhood.” Similarly, the area of the house, the number of bedrooms, and the number of bathrooms together represent its “size.”

Now these intermediate ideas like newness, neighborhood quality, and size become inputs for the final decision: the price of the house. That’s exactly what the hidden layer in a neural network does. It takes raw inputs and combines them into more meaningful features, which are then passed on to the next layer until the network produces an output.
Of course, in a real neural network you don’t decide these groupings yourself. You don’t tell the model to treat bedrooms, bathrooms, and area as “size.” The network figures that out on its own while training, by adjusting weights and biases. The diagram here is just a way to make it easier to imagine.
Another important detail is that in an actual neural network, almost every neuron in one layer is connected to every neuron in the next layer. This means the model doesn’t just look at inputs in neat little groups. Instead, it tries many different combinations and gradually learns which patterns matter most. Over time, it automatically discovers the right intermediate features that lead to accurate predictions.
Building a Simple Neural Network to Classify Handwritten Digits
We will use the MNIST dataset, which has 28×28 grayscale images of digits from 0 to 9. The goal is to train a neural network that can correctly predict which digit is in an image.
Step 1: Import Libraries
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.utils import to_categorical
- tensorflow is the library that will help us build and train neural networks.
- Sequential allows us to build a network layer by layer.
- Dense is a fully connected layer (all neurons connected to previous layer).
- Flatten converts the 2D image into a 1D vector for input.
- to_categorical converts labels into one-hot vectors (like a “vote” for each digit).
Step 2: Load and Preprocess the Data
# Load dataset
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Normalize pixel values to 0-1
x_train = x_train / 255.0
x_test = x_test / 255.0
# One-hot encode labels
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
- MNIST images have pixel values from 0 to 255. Dividing by 255 scales them to 0–1, which helps the network learn faster.
- Labels like 0,1,2…9 are converted to vectors of length 10. For example, label 3 becomes [0,0,0,1,0,0,0,0,0,0]. This helps the network “vote” for each digit.
- Normalizing is like adjusting each family member’s opinion on the same scale so no one opinion is too loud or too quiet. One-hot encoding is like giving each dish its own checkbox to mark whether it was tasty or not.
Step 3: Build the Neural Network
model = Sequential([
Flatten(input_shape=(28, 28)), # Input layer: flatten 28x28 image
Dense(128, activation='relu'), # Hidden layer with 128 neurons
Dense(10, activation='softmax') # Output layer: 10 neurons for 10 digits
])
- Flatten converts the 2D image into a 1D array of 784 pixels.
- The hidden layer has 128 neurons, each learning to detect patterns like lines, curves, or loops in the digits.
- The output layer has 10 neurons corresponding to digits 0–9. Softmax activation ensures all outputs sum to 1 (like probabilities).
Step 4: Compile the Model
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
- Optimizer (adam): Helps adjust weights to reduce error efficiently.
- Loss function (categorical_crossentropy): Measures how wrong the network’s predictions are.
- Metrics (accuracy): Lets us see how many digits the model gets right.
Step 5: Train the Model
model.fit(x_train, y_train, epochs=5, batch_size=32, validation_split=0.1)
- epochs=5: The network will look at the entire training dataset 5 times.
- batch_size=32: Updates weights after seeing 32 images at a time.
- validation_split=0.1: 10% of training data is used to check progress without training on it.
- Each epoch is like cooking dinner multiple times. The family learns from previous meals and gives better feedback each time.
- Batch size is like asking feedback from a few members at a time instead of the whole family at once.
Step 6: Evaluate the Model
model.evaluate(x_test, y_test)
- This checks how well the network performs on unseen data (test set).
- Test accuracy tells us what fraction of digits the network classified correctly.
Step 7: Make Predictions
import numpy as np
# Predict first 5 test images
predictions = model.predict(x_test[:5])
for i, pred in enumerate(predictions):
print(f"Image {i} prediction: {np.argmax(pred)}")
- model.predict outputs probabilities for each digit.
- np.argmax(pred) picks the digit with the highest probability.
At this point, we have a fully working neural network that classifies handwritten digits.
Summary
Neural networks are systems of interconnected neurons that learn patterns from data. Each neuron applies weights, a bias, and an activation function to its inputs, passing information through layers to produce predictions.
They are particularly useful for problems where traditional programming fails, such as image recognition, speech understanding, and predictions. Networks learn by comparing predictions to true values using a loss function and adjusting weights via backpropagation.
In our example, we built a simple network using TensorFlow to classify handwritten digits. The network learned to extract meaningful features from raw images, combine them in hidden layers, and output accurate predictions.
Even in this simple form, neural networks demonstrate the power of learning from data, much like combining small opinions to reach a final decision, but now in a structured, mathematical way.
To visualize neural networks: [Video]
To learn how to implement neural networks: [Playlist]
To read about Gradient Descent: [Article]
“It’s not enough to learn how to ride, you must also learn how to fall.” — Mexican proverb
Understanding Neural Networks — and Building One ! was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
### [Cracking Q-Learning](https://pub.towardsai.net/cracking-q-learning-6aa2e6775363?source=rss----98111c9905da---4) ### [LLMs Don’t Just Need to Be Smart — They Need to Be Specific. Here’s How.](https://pub.towardsai.net/llms-dont-just-need-to-be-smart-they-need-to-be-specific-here-s-how-6201a658f0f6?source=rss----98111c9905da---4)

How a new technique called “Test-Time Deliberation” teaches AI to think before it speaks
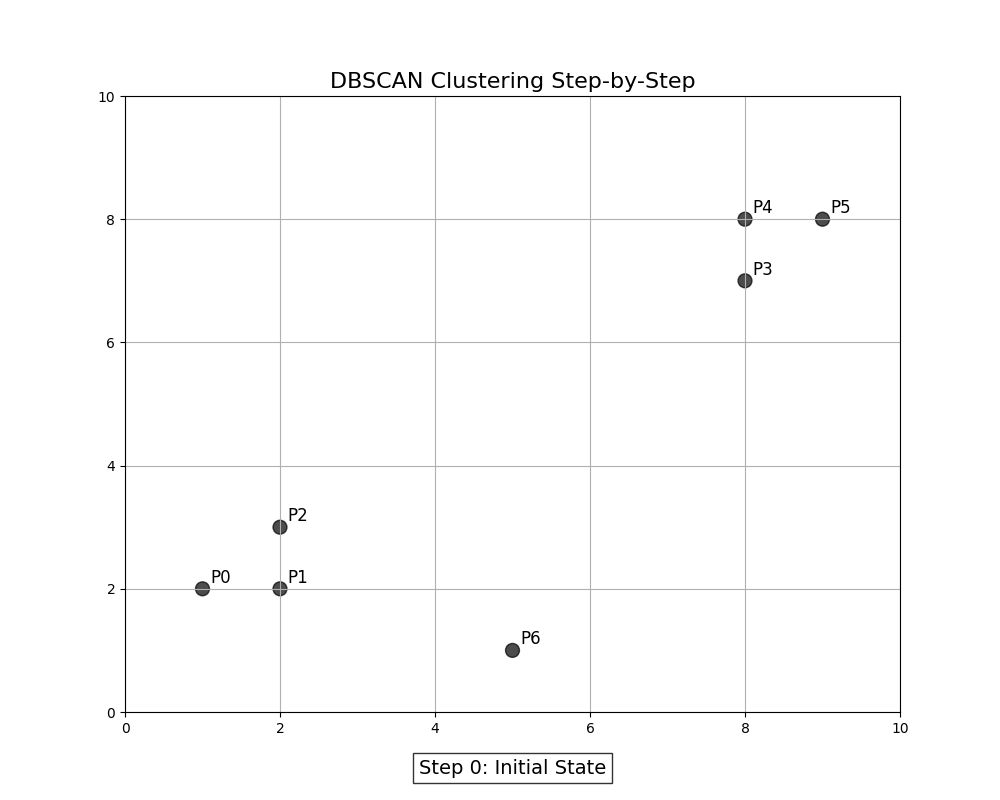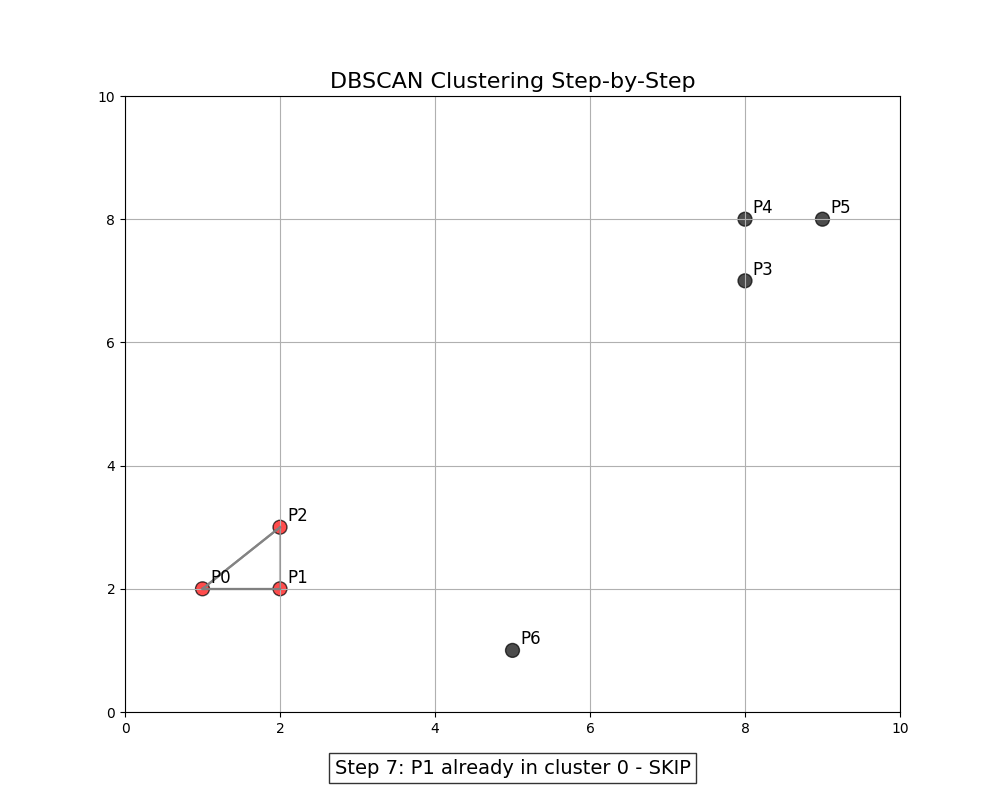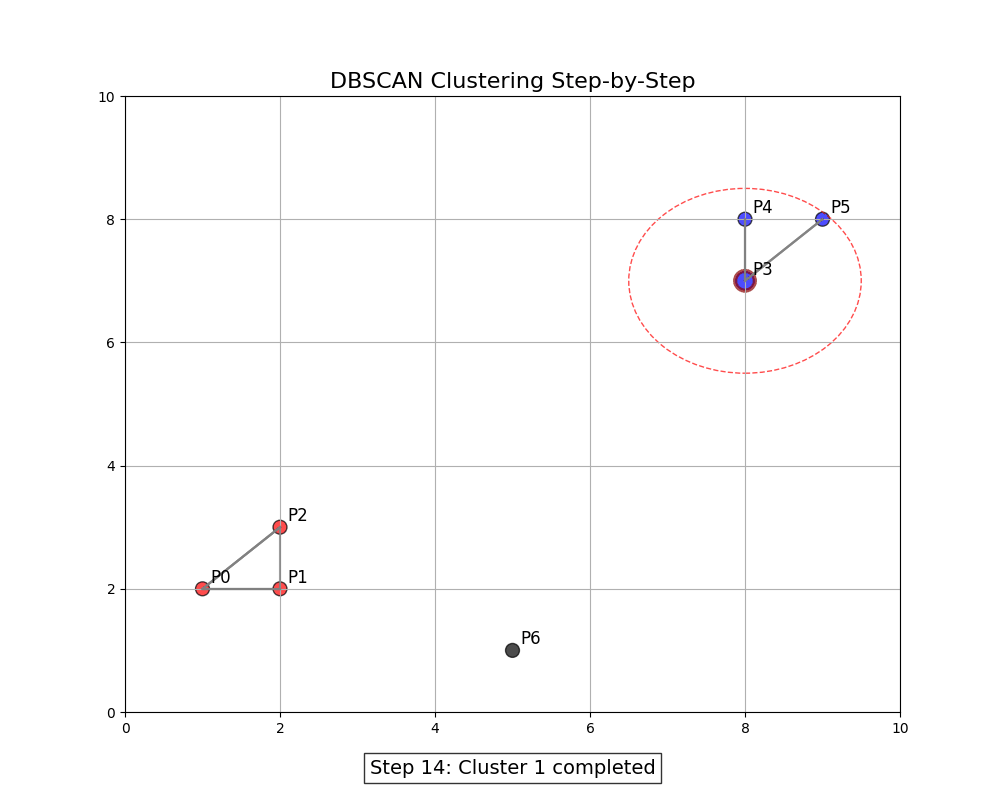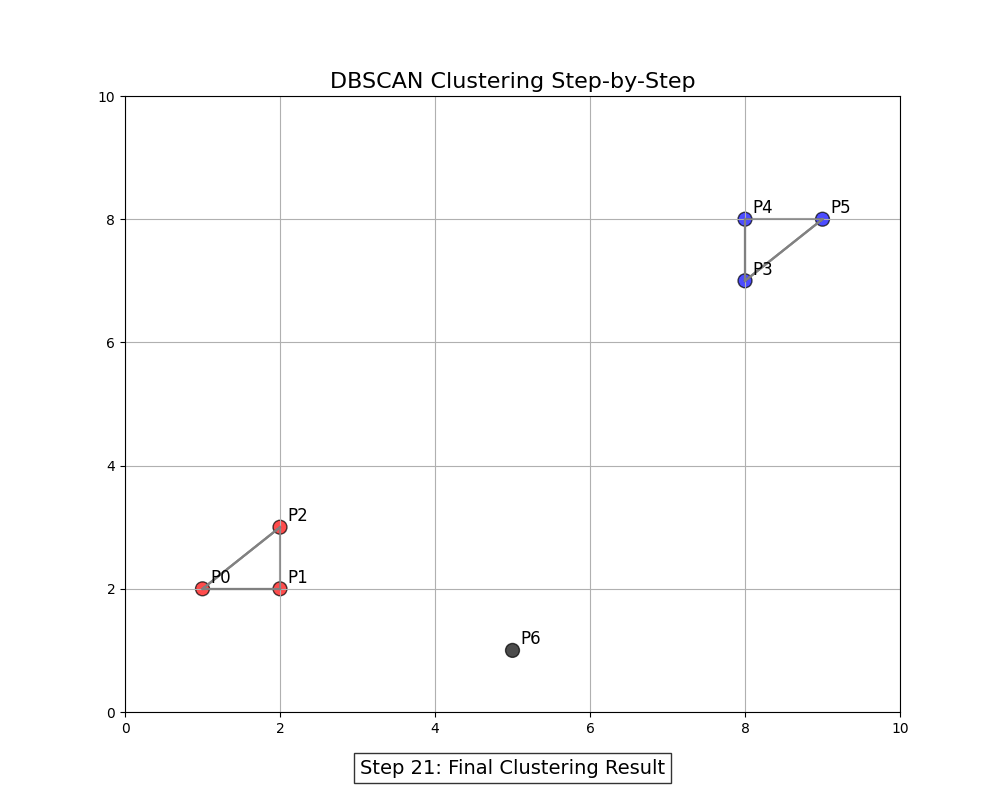
If you’ve ever tried to cluster data with varying densities or irregular shapes, you’ve likely discovered that traditional algorithms like K-Means fall short. In my previous article, Beyond Accuracy: A Guide to Classification Metrics, we explored how to evaluate models beyond simple accuracy. Today, we’re diving into a powerful clustering technique that doesn’t require specifying the number of clusters beforehand: DBSCAN.
What Makes DBSCAN Special?
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) stands out from other clustering algorithms in several key ways:
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) stands out from other clustering algorithms in several key ways:
- No preset cluster count: Unlike K-Means, you don’t need to specify the number of clusters
- Handles irregular shapes: Can find clusters of arbitrary shapes
- Identifies noise: Naturally separates outliers from meaningful clusters
- Density-based: Finds areas of high density separated by areas of low density
But how does it actually work? Let’s break it down with a hands-on implementation.
The Core Concepts: Eps and MinPts
DBSCAN operates on two simple parameters:
- Eps (ε): The radius that defines the neighborhood around each point
- MinPts: The minimum number of points required to form a dense region
Using these parameters, DBSCAN classifies points into three categories:
- Core points: Points with at least MinPts neighbors within their ε-radius
- Border points: Points that are reachable from core points but don’t have enough neighbors themselves
- Noise points: Points that are neither core nor border points
Walking Through DBSCAN Step by Step
Let’s implement a simplified version of DBSCAN with detailed explanations at each step. This will help us understand exactly what’s happening behind the scenes:
Lets first do it with our own hand using some basic maths :
🎯 DBSCAN ALGORITHM - SIMPLE WALKTHROUGH
==================================================
📍 Our data points:
P0: [1 2]
P1: [2 2]
P2: [2 3]
P3: [8 7]
P4: [8 8]
P5: [9 8]
P6: [5 1]
⚙️ Settings: eps=1.5, min_pts=3
🔍 Starting point-by-point analysis...
👀 Looking at P0 [1 2]:
Checking distances (need ≤ 1.5):
P0: distance = 0.00 🎯
P1: distance = 1.00 ✅
P2: distance = 1.41 ✅
P3: distance = 7.81 ❌
P4: distance = 8.06 ❌
P5: distance = 8.94 ❌
P6: distance = 4.12 ❌
→ Found 3 neighbors: [0, 1, 2]
→ P0 is a CORE POINT! Starting Cluster 0
Added P0 to Cluster 0
Added P1 to Cluster 0
Added P2 to Cluster 0
✅ Cluster 0 created!
👀 Looking at P1 [2 2]:
Already in cluster 0 - SKIP
👀 Looking at P2 [2 3]:
Already in cluster 0 - SKIP
👀 Looking at P3 [8 7]:
Checking distances (need ≤ 1.5):
P0: distance = 7.81 ❌
P1: distance = 6.08 ❌
P2: distance = 6.32 ❌
P3: distance = 0.00 🎯
P4: distance = 1.00 ✅
P5: distance = 1.41 ✅
P6: distance = 6.08 ❌
→ Found 3 neighbors: [3, 4, 5]
→ P3 is a CORE POINT! Starting Cluster 1
Added P3 to Cluster 1
Added P4 to Cluster 1
Added P5 to Cluster 1
✅ Cluster 1 created!
👀 Looking at P4 [8 8]:
Already in cluster 1 - SKIP
👀 Looking at P5 [9 8]:
Already in cluster 1 - SKIP
👀 Looking at P6 [5 1]:
Checking distances (need ≤ 1.5):
P0: distance = 4.12 ❌
P1: distance = 3.16 ❌
P2: distance = 3.61 ❌
P3: distance = 6.08 ❌
P4: distance = 5.83 ❌
P5: distance = 5.00 ❌
P6: distance = 0.00 🎯
→ Found 1 neighbors: [6]
→ Not enough neighbors (1 < 3)
→ P6 is NOISE (for now)
🎉 FINAL RESULTS:
==============================
P0 [1 2] → CLUSTER 0
P1 [2 2] → CLUSTER 0
P2 [2 3] → CLUSTER 0
P3 [8 7] → CLUSTER 1
P4 [8 8] → CLUSTER 1
P5 [9 8] → CLUSTER 1
P6 [5 1] → NOISE
What Just Happened?
Let’s break down the algorithm’s decision process:
- Point P0 had 3 neighbors (including itself), meeting the min_pts threshold of 3, so it became a core point and formed Cluster 0.
- Points P1 and P2 were within P0’s ε-radius, so they were added to Cluster 0 as border points.
- Point P3 had 3 neighbors, forming Cluster 1.
- Points P4 and P5 were within P3’s ε-radius, joining Cluster 1.
- Point P6 had only itself in its neighborhood, so it was classified as noise.
The algorithm successfully identified two dense clusters and separated the outlier point, all without being told how many clusters to look for!
Choosing the Right Parameters
As with any algorithm, parameter selection is crucial for DBSCAN:
- Too small ε: Everything becomes noise
- Too large ε: Everything merges into one cluster
- Too high min_pts: Many points marked as noise
- Too low min_pts: False clusters in sparse regions
A good rule of thumb is to set min_pts to twice the dimensionality of your dataset (but not less than 3). For ε, the k-distance graph method (plotting distance to the k-th nearest neighbor) often works well.
Real-World Applications
DBSCAN shines in scenarios where:
- Anomaly detection: Identifying fraudulent transactions or network intrusions
- Spatial data analysis: Finding geographical clusters of events
- Customer segmentation: Grouping similar purchasing behaviors
- Image processing: Identifying objects or regions in images
Limitations to Consider
While powerful, DBSCAN has some limitations:
- Struggles with varying densities: If clusters have different densities, a single ε may not work for all
- Sensitive to parameters: Poor parameter choices can drastically affect results
- Not completely deterministic: Border points might be assigned to different clusters depending on processing order
Beyond the Basics
For more advanced applications, consider these DBSCAN variants:
- HDBSCAN: Hierarchical version that handles varying densities better
- OPTICS: Creates a reachability plot that doesn’t require precise ε setting
- DENCLUE: Uses density functions for more mathematical rigor
Key Takeaways
- DBSCAN is a powerful density-based clustering algorithm that doesn’t require specifying the number of clusters beforehand.
- It naturally handles noise and outliers, making it robust for real-world data.
- The algorithm identifies core points, border points, and noise based on local density.
- Parameter selection (ε and min_pts) is crucial and often requires domain knowledge.
- While it has limitations with varying densities, it’s excellent for many practical applications.
Just as we discussed in my previous article on classification metrics, understanding the mechanics behind our algorithms helps us make better decisions about when and how to use them. DBSCAN’s intuitive approach to finding natural clusters in data makes it a valuable addition to any data scientist’s toolkit.
Have you used DBSCAN in your projects? Share your experiences and tips in the comments below!
Further reading:
DBSCAN Clustering Demystified: A Visual Walkthrough was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
### [The GPU Bottleneck: Why Your Multi-GPU Training is Crawling (and How to Fix It!)](https://pub.towardsai.net/the-gpu-bottleneck-why-your-multi-gpu-training-is-crawling-and-how-to-fix-it-b734fb125e38?source=rss----98111c9905da---4)The GPU Bottleneck: Why Your Multi-GPU Training is Crawling (and How to Fix It!) 🚀 | GPU 瓶頸:為什麼你的多 GPU 訓練比你想像的還要慢(以及如何解決!)
my notes on Deep Learning and Performance Optimization
tags: Pytorch | DistributedDataParalle(DDP) | Performance Optimization
So, you’ve assembled a beast of machine with multiple GPUs, ready to conquer the world of deep learning. But when you kick off your training, it feels… underwhelming. You’ve got all this horsepower, but the progress bar inches along at a snail’s pace. What gives? It’s a super common problem, and it usually comes down to one thing: the GPUs are spending more time talking to each other than actually working! The culprit? This is the infamous communication bottleneck.
你是不是覺得,你那台超讚的多 GPU 機器沒有發揮應有的潛力?硬體這麼強,但訓練速度卻像…蝸牛。這其實是個超常見的問題,通常都歸結為一個原因:你的 GPU 們花太多時間在彼此「聊天」,而不是專心工作!元兇是?GPU 之間的通訊瓶頸。
Think of it like a team project where everyone completes their part, but then they all have to gather in one room to discuss and combine their work. If that room is small and everyone is talking at once, progress grinds to a halt. This blog post will explain how to optimize this “team meeting” to unlock the full potential of your multi-GPU setup.
這篇部落格文章將解釋如何最佳化這個「團隊會議」,以釋放多 GPU 設定的全部潛力。
Understanding the Problem
The “Team Meeting” Problem in Distributed Training | 分散式訓練中的「團隊會議」問題
During distributed training, each GPU calculates a set of gradients. To ensure the model updates consistently across all GPUs, these gradients must be collected, averaged, and then distributed back to every GPU. This is the All-Reduce operation, and it's the main source of the communication bottleneck.
在分散式訓練期間,每個 GPU 都會計算一組梯度。為了確保模型在所有 GPU 上一致地更新,這些梯度必須被收集、平均,然後分發回每個 GPU。這就是 All-Reduce 操作,也是通訊瓶頸的主要來源。

Mathematically, if ∇L_w represents the gradients calculated by each worker w , the final aggregated gradient ∇L that every worker will use to update its model is the average of all individual gradients:
若以數學來表示,如果 ∇L_w 代表每個工作者 w 計算出的梯度,那麼所有worker最終將會用來更新模型的聚合梯度 ∇L ,則是所有個別梯度的平均值:

where W is the total number of workers (GPUs). This collective communication step ensures that all model replicas stay in sync with the same gradient information.
其中 W 為工作者(GPUs)的總數。這個集體通訊步驟確保了所有模型複本都使用相同的梯度資訊來保持同步。
The time spent on All-Reduce can easily exceed the time spent on actual computation, especially with slower interconnects like PCIe. But don't worry, we have a few tricks up our sleeve!
花在 All-Reduce 上的時間可以輕易地超過花在實際運算上的時間,特別是在使用像 PCIe 這樣較慢的互連時。但別擔心,我們有一些錦囊妙計!
The Three Pillars of Optimization | 優化的三大支柱
Let’s dive into three powerful techniques to slash communication overhead.
最厲害的招數就是將你的通訊與運算重疊。想像一下,學生們不是等著開會,而是在進行下一個專案部分時,同時分享他們已經完成的工作。這讓「會議時間」幾乎消失了。
- Gradient Accumulation | 梯度累積:
This is a fantastic trick for using a much larger effective batch size than your GPU’s memory can handle. Think of it like a meticulous chef preparing a huge cake: they mix the ingredients for one small layer at a time, but they don’t bake it until they’ve mixed all the layers. In our case, we accumulate the gradients from multiple mini-batches before doing a single, massive update.
想像一位廚師在準備一個巨大的蛋糕。他不會試圖一次在一個小碗裡混合所有材料,而是分層處理,一次混合一層的份量。他會把每一層混合好的麵糊都倒進一個大盆裡,直到所有層都混合完畢,才將整個蛋糕送進烤箱。
在我們的例子中,我們處理好幾個較小的「mini-batch」,並在每個 GPU 上本地累積它們的梯度。我們只在經過一定數量的步驟後,才觸發 All-Reduce 操作(也就是「烘烤」的步驟)。這意味著更少、但更有意義的更新。

In essence, this process involves two key steps and can be represented mathematically:
- 本地累積 (Local Accumulation): It process several mini-batches , and the gradients from these individual backward passes are automatically summed up in the model parameters.
Let N be the total number of mini-batches , and K be the accumulation step size. For each worker (GPU) w, the accumulated gradient G_{w}^{\text{acc}}is the sum of the gradients from its local mini-batches:

where \nable L(w_{i}, D_{i}) is the gradient of the loss function with respect to the wights w_i for mini-batch D_i .
- 一次大的 All-Reduce (One Big All-Reduce): After this local accumulation, a single All-Reduce operation combines the gradients from all workers to get the final gradient G^{\text{final}} :

where W is the number of workers.
Here is how you can implement gradient accumulation in a typical PyTorch training loop.
import torch
import torch.nn as nn
import torch.optim as optim
# ... other imports ...
# Initialize model, criterion, and optimizer
model = nn.Linear(10, 1)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Hyperparameters
accumulation_steps = 4
# Your training loop
for i, (inputs, labels) in enumerate(data_loader):
# Perform a forward pass
outputs = model(inputs)
# Calculate the loss and normalize it by accumulation steps
loss = criterion(outputs, labels) / accumulation_steps
# Perform a backward pass to accumulate gradients
loss.backward()
# Update weights only after accumulating gradients for 'accumulation_steps'
if (i + 1) % accumulation_steps == 0:
# Step 1: Update model weights based on accumulated gradients
optimizer.step()
# Step 2: Clear gradients for the next accumulation cycle
optimizer.zero_grad()
2. Gradient Compression | 梯度壓縮:
If Gradient Accumulation is about reducing the frequency of communication, Gradient Compression is about reducing the size of each communication packet.
如果說「梯度累積」是為了降低通訊的頻率,「梯度壓縮」就是為了減小每次通訊封包的大小。透過在梯度發送到網路上之前將其縮小,我們可以顯著減少 All-Reduce 操作所花費的時間。
- Quantization | 量化: This is the most common form of compression. The core idea is to reduce the numerical precision of the gradients from 32-floating-point number (FP32) to 16-bit (FP16) or even 8-bit (INT8). This can slash the data volume by 50% to 75%.
- 這是最常見的壓縮形式。其核心思想是降低梯度的數值精度,將梯度從 32 位元浮點數 (FP32) 降低到 16 位元 (FP16) 或甚至是 8 位元 (INT8)。這樣可以將數據量減少 50% 到 75%。

Mathematically, the quantization of a floating-point number x can be expressed as:

where S is a scaling factor that determines the range of quantized values. This maps the original floating-point values to a smaller set of integers or low-precision floating-point numbers. For example, using FP16 in PyTorch converts each element of the gradient from 32 bits to 16 bits.
Here is a conceptual example of how quantization works. Note that in a real distributed setup, a custom communication hook would be needed to send the scale and zero-point along with the quantized tensor.
import torch
def quantize_tensor_int8(tensor):
"""Quantizes a float tensor to 8-bit unsigned integer."""
min_val, max_val = tensor.min(), tensor.max()
scale = (max_val - min_val) / 255
zero_point = min_val
quantized_tensor = torch.round((tensor - zero_point) / scale).to(torch.uint8)
return quantized_tensor, scale, zero_point
def dequantize_tensor_int8(quantized_tensor, scale, zero_point):
"""Dequantizes an 8-bit unsigned integer tensor back to float."""
return quantized_tensor.float() * scale + zero_point
- Sparsification | 稀疏化: This is a more aggressive compression method that only transmits the most important, or “significant”, gradients when ignoring the tiny ones that might be close to zero. This technique is based on a common observation: during training, most gradient values are very small.
這是一種更為激進的壓縮方法,它只傳輸最重要或「最顯著」的梯度,同時忽略那些可能接近於零的微小梯度。這項技術基於一個常見的觀察:在訓練過程中,絕大多數的梯度值都非常小。

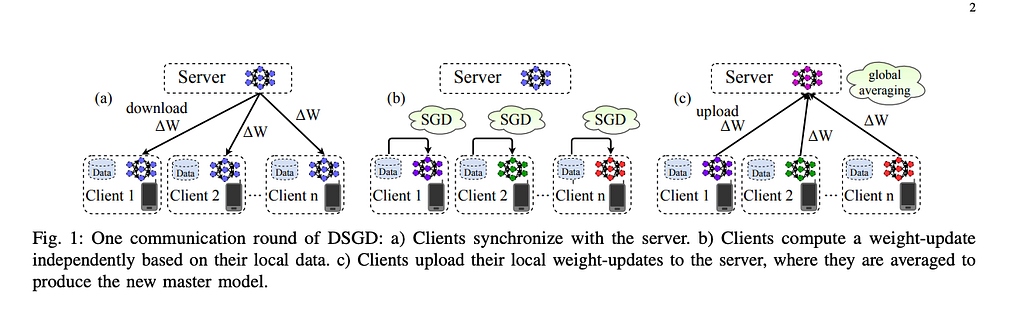
Mathematically, this can be represented by applying a mask function M(⋅) to the gradient vector g:

where g_i is the i-th element of the gradient vector g, and τ is predetermined threshold. Only when the absolute value of a gradient is greater than or equal to τ is it kept and transmitted. This reduces the amount of data that needs to be communicated, especially for models where the gradients are naturally sparse.
The following code demonstrates a conceptual implementation of sparsification using a communication hook in PyTorch:
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def topk_sparsification_hook(state: object, bucket: dist.GradBucket) -> torch.futures.Future[torch.Tensor]:
"""
This hook sparsifies the gradient by keeping only the top k% of values.
"""
tensor = bucket.get_tensor()
# Define the percentage of gradients to keep (e.g., 10%)
k_percentage = 0.1
k = max(1, int(tensor.numel() * k_percentage))
# Find the top k values by magnitude
topk_values, topk_indices = torch.topk(tensor.abs(), k)
# Create a new dense tensor, initialized to zeros
sparse_tensor = torch.zeros_like(tensor)
# Copy only the top k original gradient values to the new tensor
sparse_tensor.view(-1)[topk_indices] = tensor.view(-1)[topk_indices]
# All-reduce the sparse tensor across all GPUs
fut = dist.all_reduce(sparse_tensor, op=dist.ReduceOp.SUM, async_op=True).get_future()
def average_callback(fut):
# After summing across all GPUs, average the result
reduced_tensor = fut.wait()[0]
reduced_tensor /= dist.get_world_size()
return reduced_tensor
return fut.then(average_callback)
# --- How to register the hook ---
# model = DDP(model)
# model.register_comm_hook(state=None, hook=topk_sparsification_hook)
3. Communication Overlapping | 通訊重疊: This is the ultimate optimization. Imagine your team members don’t wait for the meeting to start. As soon as one person finishes their part, they immediately start sharing it with others while they begin their next task.
這是終極的優化技巧,而最棒的是 — — 如果你正在使用 PyTorch 的 DistributedDataParallel (DDP),你已經免費享受到這個功能了!

In PyTorch, this means we start the All-Reduce for the gradients of one layer as soon as they’re computed, while the backward pass continues to calculate gradients for the next layer. This hides the communication latency, making it feel “free.” This is handled automatically by PyTorch’s DistributedDataParallel (DDP).
這個想法是將「先運算,後通訊」的順序性流程,轉變為一個平行的流程。DDP 非常聰明,它不會等到整個反向傳播 (backward pass) 完成後才開始 All-Reduce。一旦某個特定層的梯度計算完成,DDP 會立即在背景開始將它傳送給其他 GPU。在通訊進行的同時,CPU 會繼續進行反向傳播,計算下一層的梯度。 這有效地將通訊延遲隱藏在運算時間之後。這個「團隊會議」被拆分成許多微小且重疊的片段進行,因此感覺上幾乎不花任何時間。

The latency of a Ring AllReduce operation, for example, is dominated by the number of rounds and the time of the slowest path in each round. It can be expressed as

where N is the number of nodes and T is the time of the slowest path (node pair). DDP minimizes this bottleneck by overlapping the communication time with the computation time of the next layer, making the total time for a backward pass more efficient.
The following code shows a basic DDP training loop. By simply wrapping your model in DDP, you get this key optimization right out of the box.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
import os
def setup_ddp(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
dist.init_process_group("nccl", rank=rank, world_size=world_size)
torch.cuda.set_device(rank)
def train_model():
rank = int(os.environ['RANK'])
world_size = int(os.environ['WORLD_SIZE'])
setup_ddp(rank, world_size)
model = nn.Linear(10, 1).to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)
print(f"[{rank}] Starting training...")
for epoch in range(5):
dummy_data = torch.randn(32, 10).to(rank)
target = torch.randn(32, 1).to(rank)
output = ddp_model(dummy_data)
loss = loss_fn(output, target)
optimizer.zero_grad()
loss.backward() # DDP automatically handles the All-Reduce here!
optimizer.step()
if rank == 0:
print(f"Epoch {epoch} finished with loss: {loss.item():.4f}")
dist.destroy_process_group()
if __name__ == '__main__':
# You would run this with `torchrun --nproc_per_node=2 your_script.py`
train_model()
The Takeaway | 總結
The biggest mistake people make is thinking they need to write a ton of complex code to get distributed training right. The truth is, modern frameworks like PyTorch have done a lot of the heavy lifting for you. By just properly setting up DistributedDataParallel and leveraging techniques like gradient accumulation, you're well on your way to building a truly optimized distributed training pipeline.
Happy training! 祝你最終釋放你多 GPU 設備的真正潛力,訓練愉快!

The GPU Bottleneck: Why Your Multi-GPU Training is Crawling (and How to Fix It!) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
### [Beyond “Looks Good to Me”: How to Quantify LLM Performance with Google’s GenAI Evaluation Service](https://pub.towardsai.net/beyond-looks-good-to-me-how-to-quantify-llm-performance-with-googles-genai-evaluation-service-5af9a1213920?source=rss----98111c9905da---4)The Production Hurdle
The greatest challenge faced by industry today is converting a solution from demo to production. And the main reason behind this is confidence in the results. The evaluation dataset and metrics that we build to test upon are not holistic and adaptable. They only provide a basic idea, not thorough testing. We still rely on “human in the loop” to look at some of the responses and evaluate them to make a final decision. But once it goes into production and is used by other users, it starts to fail. Businesses have a hard time relying on the gut feeling of engineers to release a demo into production with no concrete or customizable evaluation metrics. They often have questions like:
- What is the accuracy?
- How can we measure how frequently and in what cases it hallucinates
- How do we compare between 2 LLMs for our specific use case?
These questions require objective and specialized metrics built specifically for the task at hand. These metrics need to be data-driven and repeatable. Google’s GenAI Evaluation Service on Vertex AI is built to solve this problem of custom metrics for evaluation based on the task at hand. It is an enterprise-grade suite of tools designed to quantify the quality of a model’s output, enabling systematic testing, validation and application monitoring. The most powerful feature of this service is Adaptive Rubrics which moved beyond simple scores and into the realm of true unit testing for prompts.

The 4 Pillars of Evaluation
Gen AI Evaluation Service can evaluate a model in four different ways:
- Computation-Based Metrics: This is useful in cases when ground truth is available and is deterministic. It runs algorithms like ROUGE (for summarization) or BLEU (for translation).
- Static Rubrics: This is used to evaluate a model against fixed criteria and critical metrics like Groundedness and Safety.
- Model-Based Metrics: This is the “LLM-as-a-Judge” metric when a judge model is used to score a single response (Pointwise) or pick the better response (Pairwise).
- Adaptive Rubrics: This is the recommended method that reads the prompt and generates a unique set of pass/fail tests that are tailored towards a specific use case.
The Adaptive Rubric Feature
This Adaptive Rubric feature is the highlight of this service. Instead of providing a static set of pass/fail test cases, it reads the prompt and then dynamically generates a set of pass/fail unit tests that will be used on a generated response.
Let’s look at the exact example from Google’s documentation. Imagine you give the model this prompt:
User Prompt: “Write a four-sentence summary of the provided article about renewable energy, maintaining an optimistic tone.”
The service’s Rubric Generation step analyzes that prompt and instantly creates a set of specific tests. For this prompt, it might produce:
- Test Case 1: The response must be a summary of the provided article.
- Test Case 2: The response must contain exactly four sentences.
- Test Case 3: The response must maintain an optimistic tone.
Now, your model generates its response:
Model Response: “The article highlights significant growth in solar and wind power. These advancements are making clean energy more affordable. The future looks bright for renewables. However, the report also notes challenges with grid infrastructure.”
This is the result from the Rubric Validation step.
- Test Case 1 (Summary): Pass. Reason: The response accurately summarizes the main points.
- Test Case 2 (Four Sentences): Pass. Reason: The response is composed of four distinct sentences.
- Test Case 3 (Optimistic Tone): Fail. Reason: The final sentence introduces a negative point, which detracts from the optimistic tone.
The final pass rate is 66.7%. This is infinitely more useful than a “4/5” score because you know exactly what to fix.
How to Run Your First Evaluation (The Code)
This can be integrated into your code using the Vertex AI SDK.
from vertexai import Client, types
import pandas as pd
eval_df = pd.DataFrame({
"prompt": [
"Explain Generative AI in one line",
"Why is RAG so important in AI. Explain concisely.",
"Write a four-line poem about the lily, where the word 'and' cannot be
used.",
]
})
eval_dataset = client.evals.run_inference(
model="gemini-2.5-pro",
src=eval_df,
)
eval_dataset.show()

# Run the Evaluation
eval_result = client.evals.evaluate(dataset=eval_dataset)
# Visualize Results
# Get the data out of the Pydantic model into a dictionary
results_dict = eval_result.model_dump()
key_to_display = 'results_table'
if key_to_display in results_dict:
# Convert that specific part of the data into a DataFrame
df = pd.DataFrame(results_dict[key_to_display])
else:
print(f"Could not find the key '{key_to_display}'.")
summary_df = pd.DataFrame(results_dict['summary_metrics'])
print("--- Summary Metrics ---")
display(summary_df)

# Get the original prompts and responses
inputs_df = results_dict['evaluation_dataset'][0]['eval_dataset_df']
# Parse the complex 'eval_case_results' to get the score for each prompt
parsed_results = []
for case in results_dict['eval_case_results']:
case_index = case['eval_case_index']
# This drills down to the score and explanation for the 'general_quality_v1' metric
# It assumes one candidate response (index [0])
metric_result = case['response_candidate_results'][0]['metric_results']['general_quality_v1']
parsed_results.append({
'eval_case_index': case_index,
'score': metric_result['score'],
})
# Convert the parsed results into their own DataFrame
metrics_df = pd.DataFrame(parsed_results)
# Join the inputs_df (prompts/responses) with the metrics_df (scores)
# We use the index of inputs_df and the 'eval_case_index' from metrics_df
final_df = inputs_df.join(metrics_df.set_index('eval_case_index'))
# Display the final, combined table
print("--- Detailed Per-Prompt Results ---")
display(final_df)

Conclusion
Historically, we have relied on gut feeling and subjective human-in-the-loop checks. The GenAI Evaluation Service is a foundational step in changing that. It generates data-driven metrics using Adaptive Rubrics and transforms the problem of “quality” into a set of unit tests that are actionable.
Beyond “Looks Good to Me”: How to Quantify LLM Performance with Google’s GenAI Evaluation Service was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
### [Understanding LLM Sampling: Top-K , Top-P and Temperature](https://pub.towardsai.net/understanding-llm-sampling-top-k-top-p-and-temperature-aa9360466bf0?source=rss----98111c9905da---4) ### [Beyond pre-trained LLMs: Augmenting LLMs through vector databases to create a chatbot on…](https://pub.towardsai.net/beyond-pre-trained-llms-augmenting-llms-through-vector-databases-to-create-a-chatbot-on-9055d4a21d9c?source=rss----98111c9905da---4)
Beyond pre-trained LLMs: Augmenting LLMs through vector databases to create a chatbot on organizational data

In the ever-evolving realm of AI-driven applications, the power of Large Language Models (LLMs) like OpenAI’s GPT and Meta’s Llama2 cannot be overstated. In our previous article, we introduced you to the fascinating world of Language Models (LLMs) and the innovative LangChain framework. We demonstrated their utility in a straightforward but impactful use case, showcasing how OpenAI’s GPT LLM can be employed to extract structured information.
Now, as we dive further into the realm of LLMs, we begin to unravel an essential truth — while the potential of these models is immense, they might not always align perfectly with your specific needs straight out of the box. Why, you ask?
The reasons behind this limitation are manifold. First and foremost, tailored outputs may be the need of the hour, with your application requiring a distinct structure or style that the general LLM cannot grasp intuitively. Additionally, the pre-trained LLM might lack the essential context, crucial documents, or industry-specific knowledge that is indispensable for your project’s success. Think of it as a chatbot attempting to answer questions about intricate organizational protocols when it has never encountered the documents outlining those protocols in its training data.
Moreover, specialized vocabulary can prove to be a stumbling block, especially in domains replete with unique terminologies, concepts, and structures. Financial data, medical research papers, or transcripts of company meetings may contain terms and nuances unfamiliar to the LLM’s generic training data, making it stumble when attempting to summarize, respond, or generate content within these domains.

In the above example, the LLM lacks domain-specific information about the Volvo XC60. Although the LLM has no idea how to turn off reverse braking for that car model, it performs its generative task to the best of its ability anyway, producing an answer that sounds grammatically solid — but is unfortunately flatly incorrect. The reason LLMs like ChatGPT feel so bright is that they’ve seen an immense amount of human creative output — entire companies’ worth of open source code, libraries worth of books, lifetimes of conversations, scientific datasets, etc., but, critically, this core training data is static or incomplete to the required context.
So, how do you bridge this gap and ensure that an LLM aligns seamlessly with your distinct requirements? The answer lies in the realm of customization. You’ll likely need to fine-tune or adapt it to your specific use case. Currently, there exist four prominent methods for this:
- Full Fine-tuning: Comprehensive adjustment of all LLM parameters using task-specific data.
- Parameter-efficient Fine-tuning (PEFT): Strategic modification of select parameters to enhance efficiency in adaptation.
- Prompt Engineering: Precision refinement of model inputs to influence its output.
- Retrieval Augmented Generation (RAG): A potent fusion of prompt engineering and database querying, crafting contextually rich responses that extend beyond the capabilities of standalone LLMs.
While each method deserves its spotlight, our focus in this article will be on the RAG approach. We’ll begin with an introduction to the fine-tuning vs RAG approach, then delve deep into the world of vector databases, understanding their pivotal role in enhancing LLM capabilities through RAG. We’ll also showcase how this knowledge can be harnessed to create a fundamental chatbot tailored for organizational data. Along the way, we’ll illuminate various key concepts and techniques employed in this process. Join us on this insightful journey as we explore the significance of vector databases and their impact in the exciting realm of AI-driven applications.
Optimizing LLMs by Fine-tuning
Fine-tuning is a sophisticated technique that has gained prominence in the world of machine learning, offering a powerful means to enhance the performance of Large Language Models (LLMs). Fine-tuning takes the LLMs a step further by customizing them for specific tasks or domains. At its core, fine-tuning involves additional training of an already pre-trained LLM using a smaller, domain-specific, labeled dataset. This process fine-tunes select model parameters, optimizing its performance for a particular task or set of tasks. Full fine-tuning entails updating all the model parameters, akin to pretraining, albeit on a smaller scale.

Fine-tuning is a comprehensive subject that merits its own dedicated blog post. Nevertheless, in this blog, we will briefly touch upon its applications.
Fine-tuning perpetuates the training process on domain-specific data to refine model capabilities. It finds application across diverse domains:
- Customer service chatbots, fine-tuned on customer feedback and conversation transcripts, gain an improved understanding of sentiment and issue resolution.
- Recommendation systems achieve excellence by fine-tuning with users’ purchase histories, enabling more accurate product recommendations.
- Marketing models, when fine-tuned on voice and tone, generate content that resonates with target audiences.
- Educational models. fine-tuned on curriculum and student assessments, become adept at personalizing lessons and assessing proficiency.
In essence, fine-tuning empowers developers to tailor LLMs to their precise requirements, ingraining their business identity into the model’s framework, resulting in output finely attuned to their niche.
However, it’s essential to bear in mind that even fine-tuned models can confront challenges. They may become susceptible to data shifts over time, necessitating recurrent retraining and monitoring. Additionally, access to high-quality, domain-specific training data remains a prerequisite.
In the next section, we will delve into an approach known as Retrieval Augmented Generation (RAG), which tackles some of these challenges by amalgamating retrieval techniques with LLMs to enhance their capabilities.
Expanding the Context Window: Limitations and the Emergence of Retrieval Augmented Generation (RAG)
In the previous sections, we’ve discussed that the LLMs may lack domain-specific knowledge, access to organization-specific data, and live, up-to-date information. To overcome these limitations, the concept of expanding the context window has gained traction in recent months.
Expanding the context window involves providing more contextual information to LLMs, theoretically allowing them to make more informed responses. Anthropic, for instance, introduced the Claude model with an impressive 100K token context window. OpenAI followed suit, unveiling a 32K token GPT-4 model and a 16K token GPT-3.5 model.
While the idea of an extensive context window may seem like a panacea, it’s important to acknowledge that the approach of “context stuffing” has its drawbacks:
Decreased Answer Quality and Increased Hallucination Risk
As context windows grow, the quality of responses generated by LLMs tends to decrease, and the risk of hallucinations, where the model generates incorrect or fabricated information, increases. Research has shown that LLMs struggle to extract relevant information from excessively large contexts.
Linear Increase in Costs
Handling larger contexts requires more computational resources, and since LLM providers charge per token, longer contexts result in higher costs for each query.
Insufficiency for Organizational Data
Even with a very extensive context window, it might not be enough to provide all the necessary organizational data to an LLM without proper identification of the relevant information.
This is where Retrieval Augmented Generation (RAG) comes into play. RAG offers a solution by seamlessly integrating retrieval systems with LLMs to provide the necessary context and data, mitigating the limitations mentioned above.
The Role of Retrieval Augmented Generation (RAG)
Retrieval systems have been developed and optimized over decades to efficiently extract relevant information on a large scale while reducing costs. The parameters of these systems are adjustable, offering more flexibility compared to LLMs. RAG is the approach that leverages retrieval systems to enhance LLMs’ performance and contextual understanding.
Research indicates that LLMs tend to yield the best results when provided with fewer, highly relevant documents in the context, rather than inundating them with large volumes of unfiltered data. In a recent Stanford paper titled “Lost in the Middle”, researchers demonstrated that even state-of-the-art LLMs struggle to extract valuable information from lengthy and incoherent contexts, especially when critical information is buried within the middle portion of the context.
How Retrieval Augmented Generation (RAG) Works
RAG effectively addresses the limitations of LLMs by providing up-to-date information, domain-specific data, and organizational knowledge. Here’s how RAG works:
Retrieval Component: RAG includes a retrieval mechanism that fetches context-specific data from external databases or documents. This data is relevant to the query being processed.
Generation Component: The retrieved information is combined with the original query, creating an enriched context for the LLM to generate a more accurate response.
The result? RAG allows LLMs to cite their sources, improve auditability, and significantly enhance the accuracy and relevance of their responses.

Advantages of Retrieval Augmented Generation (RAG)
RAG offers several compelling advantages:
- Minimized Hallucinations: RAG reduces the risk of LLMs generating incorrect or fabricated information.
- Adaptability: It can accommodate dynamic, real-time data, making it ideal for applications requiring up-to-date information.
- Interpretability: RAG enables tracing the source of information used in LLM-generated responses.
- Cost-Effectiveness: Compared to fine-tuning, RAG requires less labeled data and computing resources.
Potential Limitations of RAG
While RAG is a powerful tool, it may not be suitable for all scenarios. In cases where a pre-trained LLM struggles with complex tasks like summarizing financial data or interpreting detailed medical records, fine-tuning the model might be a more effective approach.
In summary, Retrieval Augmented Generation (RAG) is a game-changing technique that combines the strengths of LLMs and retrieval systems to provide richer context and up-to-date information, significantly improving the performance and relevance of LLMs in various applications. It overcomes the limitations of the context window and opens up new possibilities for context-aware, accurate, and informed text generation.
Vector Databases and Semantic Search
In our previous section, we delved into the fascinating world of Retrieval Augmented Generation (RAG) and explored how it augments LLMs with new data. But here’s a question that naturally arises: how do we ensure that we can retrieve precisely the context we need from this vast sea of unstructured information?
Let’s illustrate this with a real-life scenario: Imagine Sarah, a commuter on a train, spots someone wearing an exquisite pair of handcrafted wooden sunglasses adorned with intricate carvings. She’s captivated by the unique design but misses the chance to inquire about them it before the person departs at the next station. Determined to find these one-of-a-kind sunglasses, Sarah turns to the internet later that day. There’s a catch, though — she doesn’t know the brand or any specific keywords related to those sunglasses. Undeterred, she opens her laptop and enters a search query: “handcrafted wooden sunglasses with intricate carvings.” To her delight, the perfect pair pops up as the second option in the search results. Without hesitation, she places an order, complete with a stylish wooden phone case to match her new eyewear.
This real-life scenario beautifully illustrates the power of semantic search, which enables businesses to guide customers towards toward taking action, whether it’s making a purchase or finding the information they seek. Achieving such precision and relevance in search results would have been challenging with traditional keyword searches. Enter the unsung hero of this story: vector databases, the driving force behind the success of semantic search.
In the realm of Artificial Intelligence (AI), where we are dealing with vast and complex data, the need for efficient handling and processing becomes paramount. As AI evolves into more advanced applications like image recognition, voice search, and recommendation engines, the nature of data becomes increasingly intricate. This is precisely where vector databases step onto the stage. Unlike traditional databases that store scalar values, vector databases are custom-designed to handle multi-dimensional data points, often referred to as vectors. Imagine these vectors as arrows pointing in specific directions with varying magnitudes in space. In today’s digital age, where AI and machine learning reign supreme, vector databases have emerged as indispensable tools for storing, searching, and analyzing high-dimensional data vectors.
So, what exactly is a vector database? It’s a specialized database that stores information in the form of multi-dimensional vectors, each representing specific characteristics or qualities. The number of dimensions in each vector can vary widely, from just a few to several thousand, depending on the complexity and detail of the data. Various processes, such as machine learning models, word embeddings, or feature extraction techniques, transform data like text, images, audio, and video into these vectors.

The primary advantage of a vector database lies in its ability to swiftly and accurately locate and retrieve data based on vector proximity or similarity. This means you can conduct searches rooted in semantic or contextual relevance, rather than relying solely on exact matches or predetermined criteria, as is the case with conventional databases.
For instance, with a vector database, you can:
- Search for songs that resonate with a specific tune based on melody and rhythm.
- Discover articles that align with another particular article in theme and perspective.
- Identify gadgets that share the characteristics and reviews of a specific device.
Vector databases come equipped with efficient storage, indexing, and querying mechanisms, all meticulously optimized for vector data. In stark contrast, traditional relational databases, designed primarily for tabular data with fixed columns, struggle to efficiently handle vector data due to its high dimensionality and variable-length characteristics.
In the rapidly evolving landscape of AI and data management, vector databases are the unsung champions, enabling us to navigate the complex and intricate world of high-dimensional data with ease and precision. Whether you’re in search of the perfect pair of sunglasses or embarking on a more profound AI-powered journey, vector databases are here to guide you through the maze of data and lead you to your desired destination.
How Vector Databases Work
To grasp how vector databases operate and why they differ from conventional databases, it’s essential to first comprehend the concept of embeddings.
Embeddings: Transforming Data into Meaningful Vectors
Unstructured data, encompassing text, images, and audio, lacks a predefined format, making it challenging for traditional databases to manage. To harness this data effectively for artificial intelligence and machine learning applications, it undergoes a transformation into numerical representations known as embedding.
Imagine embeddings as unique codes assigned to each item, whether it’s a word, image, or any other data point, capturing its meaning or essence. This process facilitates computer comprehension and comparison of these items in a more efficient and meaningful manner. It’s akin to condensing a complex book into a concise summary while preserving its key points.
Typically, embeddings are generated using specialized neural networks designed for this specific task. For instance, word embeddings convert words into vectors in such a way that words with similar meanings are closer together in the vector space. This transformation empowers algorithms to perceive relationships and similarities between items.

In essence, embeddings act as a bridge, transforming non-numeric data into a format compatible with machine learning models. This enables these models to discern patterns and relationships within the data more effectively.
Building a Vector Database
To create a vector database, the first step is to convert your data into vectors using an embedding model. Each vector represents the meaning of the input data, making it computationally feasible to search for semantically similar items based on their numerical representations.
To enhance the functionality of your vector database, consider incorporating metadata alongside the vectors. This step can significantly enrich the search capabilities and utility of your database. Depending on the specific requirements and capabilities of your chosen vector database solution, you can add various types of metadata to each vector.
One common form of metadata is the source document or page of the vector. This information allows you to trace back the origin of a particular vector, which can be valuable in scenarios where you want to understand the context or provenance of a retrieved item.
Furthermore, you can include custom metadata such as tags and keywords associated with each vector. These additional descriptors provide you with a powerful means to categorize and filter vectors beyond just semantic similarity. Users can perform keyword searches to quickly locate vectors that share specific characteristics or attributes, making it easier to find relevant information within your vector database.
Once you have your vectors and associated metadata, they are inserted into the vector database. This database is engineered to perform high-speed searches for similar matches. Various vector database solutions are available now, each with its unique capabilities.
Upon concluding this procedure for the Volvo user manual, specifically, to rectify the hallucination issue associated with automatic reverse braking on the Volvo XC60, as previously outlined, we will have established a comprehensive Vector database replete with vector embeddings and corresponding metadata for the Volvo user manual.
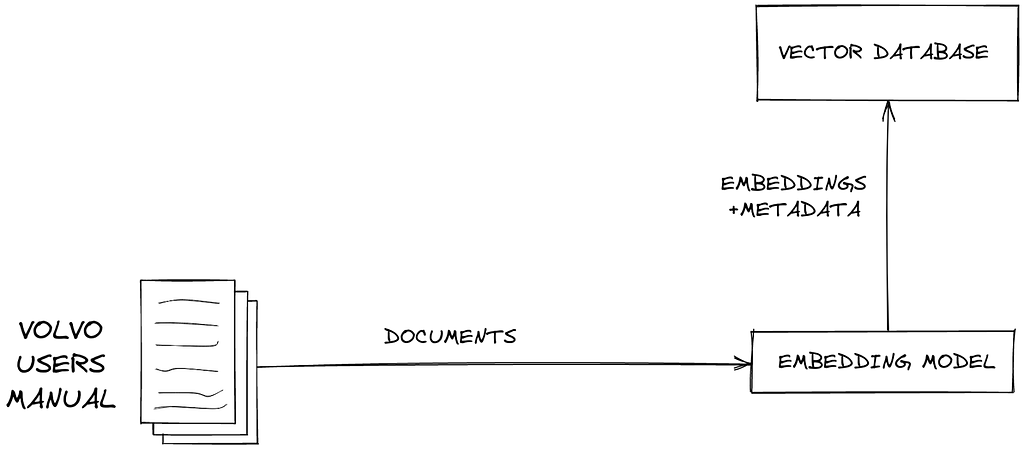
One of the notable advantages of vector databases is their ability to support real-time updates. This solves the challenge of maintaining data recency for machine learning models in applications like chatbots. For instance, you can automatically create vectors for new product offerings and update the database whenever you launch a new product, ensuring that your chatbot always provides up-to-date information to customers.
Semantic Search and Retrieval Augmented Generation (RAG)
Vector databases excel in semantic search use cases, allowing users to query data using natural language. Semantic search involves translating a user’s natural language query into embeddings and utilizing the vector database to search for similar entries.

You send these embeddings to the vector database, which then conducts a “nearest neighbor” search to identify the vectors that best match the user’s intended query. This semantic search process is at the heart of Retrieval Augmented Generation (RAG). Once the vector database retrieves the pertinent results, your application supplies them to the Language Model (LLM) through its contextual window, triggering the LLM to carry out its generative function. By utilizing the most pertinent facts from the vector database, RAG reduces the likelihood of generating inaccurate or hallucinated responses.
Semantic Search and Retrieval Augmented Generation (RAG) heavily relies on the concept of similarity measures within vector databases. These mathematical methods play a crucial role in determining the resemblance between two vectors in a vector space, enabling efficient query processing. Among the prominent similarity measures employed, the cosine similarity, Euclidean distance, and dot product are commonly used.
- Cosine similaritycalculates the cosine of the angle between two vectors, yielding values between -1 and 1. A score of 1 signifies identical vectors, while 0 denotes orthogonality, and -1 implies vectors in diametric opposition.
- Euclidean distance measures the straight-line separation between vectors, with 0 indicating identical vectors and larger values indicating increased dissimilarity.
- Dot product quantifies the product of vector magnitudes and cosine of the angle between them, resulting in values ranging from negative infinity to positive infinity. Positive values indicate vectors pointing in the same direction, 0 represents orthogonality, and negative values signify opposing directions.
Choosing the appropriate similarity measure is pivotal, as it significantly impacts the outcomes retrieved from a vector database. Each measure comes with its own set of advantages and limitations, making it essential to select the most suitable one according to the specific use case and requirements, ensuring the precision and relevance of the search results.
Advanced Functionality of Vector Databases
While semantic search is a powerful feature of vector databases, they can offer even more advanced functionality. For instance, some vector databases, like Pinecone, support hybrid search functionality. This approach combines semantic and keyword-based retrieval systems to provide a more nuanced and accurate search experience.
Implementing a Chatbot on Organizational Data using Vector Database and RAG
In the previous sections, we delved into the fundamentals of vector databases and Retrieval Augmented Generation (RAG) to enhance the capabilities of LLMs. Now, let’s explore a practical scenario where we can apply this knowledge to implement a chatbot tailored for an organizational use case.
Scenario
A college has created an extensive Employee Handbook to document its policies and procedures, which is intended to be a valuable resource for its employees. However, the sheer size and complexity of the handbook often pose a challenge for employees trying to find specific answers to their questions. Consequently, employees frequently resort to reaching out to the Human Resources (HR) department for even the most basic inquiries. This not only strains the HR team’s resources but also diverts their attention away from more critical tasks. To address this issue, the HR department is exploring the use of Language Models like ChatGPT to assist employees in navigating the Employee Handbook effectively.
Problem
While Language Models like ChatGPT excel at providing information based on their training data, they lack specific knowledge about the content of the college’s Employee Handbook. Consequently, when employees ask questions related to the handbook, the LLMs may provide generic or even random responses, causing confusion and inefficiency.
In the following two examples, we illustrate instances where specific information from the Employee Handbook is required. Ideally, we anticipate answers sourced directly from the Employee Handbook. However, ChatGPT often generates generic responses that, while generally accurate, lack the specificity found within the contents of the Employee Handbook.
Example 1: Queries related to overpayment to employees
Question: What if I get overpaid?
Related Content from Employee Handbook (Expected Answer):

Answer by ChatGPT:

Example 2: Queries related to not returning items upon termination
Question: What if I do not return items on termination?
Related Content from Employee Handbook (Expected Answer):

Answer by ChatGPT:

Solution
As previously discussed in this article, the solution lies in implementing Retrieval Augmented Generation using Vector Databases. In this context, the Employee Handbook can be stored within a vector database. When an employee interacts with the chatbot and asks a question, the chatbot will initiate a semantic search operation within the vector database using techniques like similarity search. This search will return relevant sections or excerpts from the Employee Handbook. These retrieved sections then serve as the context for the Language Model to generate precise and contextually appropriate responses to the employee’s queries.For our implementation, we will utilize Chroma as the vector database. Chroma DB is an open-source vector store designed specifically for storing and retrieving vector embeddings. Some of its key features include:
- Support for various underlying storage options, including DuckDB for standalone usage and ClickHouse for scalability in larger deployments.
- Availability of Software Development Kits (SDKs) for Python and JavaScript/TypeScript, facilitating ease of integration.
- A focus on simplicity, speed, and enabling advanced analysis of vector data.
As of September 2023, Chroma DB provides the option for self-hosted servers. However, it’s worth noting that their roadmap includes plans to offer managed/hosted services in the future.
Furthermore, we will leverage the LangChain framework, which we introduced in a previous blog post, to interact seamlessly with OpenAI LLMs.
Below, you will find actual code snippets that illustrate how to effectively implement this solution using these tools and other techniques. Additional information is provided wherever relevant. The solution comprises two key components: building a vector database containing pertinent documents and executing a semantic search on this database.
Building a Vector Database
Importing crucial modules from OpenAI and the LangChain framework for including OpenAI embeddings, text splitting, and PDF document loading, while also managing environment variables.
import openai
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader
import os
from dotenv import load_dotenv, find_dotenv
Setting up OpenAI API credentials and defining parameters for generating and persisting vector databases.
os.environ['OPENAI_API_KEY'] = '<OPENAI_API_KEY>'
openai.api_key = os.environ['OPENAI_API_KEY']parent_dir = ""
persist_directory = '/docs/chroma/'
file_to_load = '/docs/pdf/Employee Handbook of a College.pdf'
Defining a function to load, split a PDF file, and create a vector database from documents in the PDF file.
def create_and_persist_vector_db(file_path, persist_directory, chunk_size=1000, chunk_overlap=150):
try:
# Load Documents
loader = PyPDFLoader(file_path)
documents = loader.load()
# Split Documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
docs = text_splitter.split_documents(documents)
# Define Embedding Model
embedding = OpenAIEmbeddings()
# Create Vector Database from Data
vectordb = Chroma.from_documents(
documents=docs,
embedding=embedding,
persist_directory=persist_directory
) vectordb.persist()
return vectordb
except Exception as e:
print(f"An error occurred: {str(e)}")
return None
handbook_vectordb = create_and_persist_vector_db(parent_dir + file_to_load, persist_directory)if handbook_vectordb:
print("Vector database created and persisted successfully.")
Here, we utilize the RecursiveCharacterTextSplitter to effectively break down documents into manageable chunks. These chunks are then seamlessly inserted into a vector database as individual documents. While LangChain is designed to accommodate various Text Splitters, we have provided a list of notable ones for your reference:
- CharacterTextSplitter: This is the simplest method, splitting based on characters (defaulting to “\n\n”) and measuring chunk length by the number of characters.
- RecursiveCharacterTextSplitter: This text splitter is highly recommended for generic text. It can be customized with a list of characters and attempts to split text in that order until the chunks become sufficiently small. The default list includes [“\n\n”, “\n”, “ “, “”]. The primary aim is to maintain the continuity of paragraphs, sentences, and words, as these are often the most semantically related pieces of text.
- Split by Token (e.g., tiktoken): Language models have a token limit, which should not be exceeded. To ensure compliance, it’s advisable to count the number of tokens when splitting text into chunks. Multiple tokenizers are available, and it’s essential to use the same tokenizer as employed by the language model.
Furthermore, for document embedding, we have harnessed the power of OpenAIEmbeddings to facilitate storage in the vector database. OpenAI offers a range of embedding models, including ‘text-embedding-ada-002’. In addition to this, LangChain seamlessly integrates with various embedding models such as Cohere, Hugging Face, Llamma, and many more, providing you with a diverse array of choices to suit your specific needs.
Moreover, when constructing vectors from the embeddings, we also retain/store metadata, such as the document’s source, which in this context refers to the page number of the splitted text from the PDF. We’ll witness this in action when querying the database later. In addition to the default metadata, we have the flexibility to incorporate additional metadata, such as the document ID and other relevant tags associated with the document. These supplementary metadata elements are useful for various operations within the vector database.
Semantic Search on Vector DB
Importing modules related to language-based retrieval, memory management, and chat models from the LangChain library.
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
Defining a function for creating a conversational retrieval chatbot chain using a specified language model, retriever, and other parameters, and then initializing a chatbot chain with specific settings, using OpenAI’s GPT-3.5 Turbo model, and a vector database for retrieval.
def create_qa(llm_model, temperature, db, search_type, chain_type, k):
# Define Retriever
retriever = db.as_retriever(search_type=search_type, search_kwargs={"k": k}) #Create a chatbot chain. Memory is managed externally.
qa = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(model_name=llm_model, temperature=temperature),
chain_type=chain_type,
retriever=retriever,
return_source_documents=True,
return_generated_question=True,
) return qaembeddings = OpenAIEmbeddings()
handbook_vectordb = Chroma(persist_directory=persist_directory, embedding_function=embeddings)llm_model = "gpt-3.5-turbo"
temperature = 0
search_type = "mmr"
chain_type = "stuff"handbook_qa = create_qa(llm_model, temperature, handbook_vectordb, search_type, chain_type, k=5)
In the code implementation, the Conversational Retriever Chain serves as the foundation for constructing a chatbot that engages in conversations based on retrieved documents.
This chain follows a three-step process:
- Standalone Question Creation: The chat history (comprising a list of messages) and the new question are combined to form a standalone question. This step ensures that the question sent to the retrieval phase carries sufficient context without unnecessary distractions.
- Retrieval: The newly created question is fed into the retriever, which returns relevant documents.
- Response Generation: The retrieved documents are passed to a Language Model (LM). The LM generates a final response using either the new question alone (default behavior) or the original question and chat history.
The Conversational Retriever Chain’s parameterization includes:
- search_type: Determines the retrieval method which can include Similarity Search (which retrieves the top k documents with the highest similarity score) or Maximum Marginal Relevance (mmr) (which optimizes for relevant yet diverse documents).
- top k documents: Specifies the number of documents to retrieve.
- chain_type: Defines how the chain handles the top k documents obtained from the retrieval step. There are four primary chain_types:
- “Stuff”: All retrieved documents are sent to the Language Model within the same call and context window. However, when dealing with a large number of documents, they may not fit into the context window.
- “Map_Reduce”: Each document is individually processed by the Language Model to obtain an answer, and then all the answers are aggregated to derive the final response.
- “Refine”: Answers are generated from each document, and these answers are used to iteratively refine the response obtained from subsequent documents.
- “Map_Rerank”: Answers from all documents are sent to individual Language Models. These answers are ranked, and the one with the highest probability is selected as the final response.
This approach ensures flexibility in configuring the chatbot’s behavior, retrieval strategy, and response generation, allowing for tailored conversational experiences based on the provided parameters.
Interacting with a conversational chatbot to inquire about the Employee Handbook using the same questions posed in the “Problems” section.
handbook_qa({"question": "What if I get overpaid?", "chat_history": ""})['answer']
handbook_qa({"question": "What if I do not return items on termination?", "chat_history": ""})['answer']Output of the chatbot to the questions.


Comparing the results obtained from the vector database with the context and outputs described in the “Problem” section, it becomes evident that the vector database consistently provides answers that align with those found in the Employee Handbook. In stark contrast, pre-trained Language Models (LLMs) often produce erroneous or inaccurate results in such scenarios.
Fetching source of the answers as fetched by the retriever.

Class to create a Chatbot User Interface (UI) while also implementing mechanisms for preserving and managing chat history.
import panel as pn # GUI
import parampn.extension()class cbfs(param.Parameterized):
chat_history = param.List([])
answer = param.String("")
db_query = param.String("")
db_response = param.List([]) def __init__(self, **params):
super(cbfs, self).__init__( **params)
self.panels = []
self.qa = handbook_qa def convchain(self, query):
if not query:
return pn.WidgetBox(pn.Row('User:', pn.pane.Markdown("", width=600)), scroll=True)
result = self.qa({"question": query, "chat_history": self.chat_history})
self.chat_history.extend([(query, result["answer"])])
self.db_query = result["generated_question"]
self.answer = result['answer']
self.panels.extend([
pn.Row('User:', pn.pane.Markdown(query, width=600)),
pn.Row('ChatBot:', pn.pane.Markdown(self.answer, width=600, style={'background-color': '#F6F6F6'}))
])
inp.value = '' #clears loading indicator when cleared
return pn.WidgetBox(*self.panels,scroll=True) def clr_history(self,count=0):
self.chat_history = []
self.panels = []
return
Creating a chatbot and interacting with it.
cb = cbfs()button_clearhistory = pn.widgets.Button(name="Clear History", button_type='warning')
button_clearhistory.on_click(cb.clr_history)
inp = pn.widgets.TextInput( placeholder='Enter text here…')conversation = pn.bind(cb.convchain, inp)tab1 = pn.Column(
pn.panel(conversation, loading_indicator=True, height=600),
pn.layout.Divider(),
pn.Row(inp),
pn.layout.Divider(),
pn.Row( button_clearhistory, pn.pane.Markdown("Clears chat history. Can use to start a new topic" ))
)
dashboard = pn.Column(
pn.Row(pn.pane.Markdown('# Chat with PDF')),
pn.Tabs(('Chat', tab1))
)
dashboard
Output of the Chatbot UI
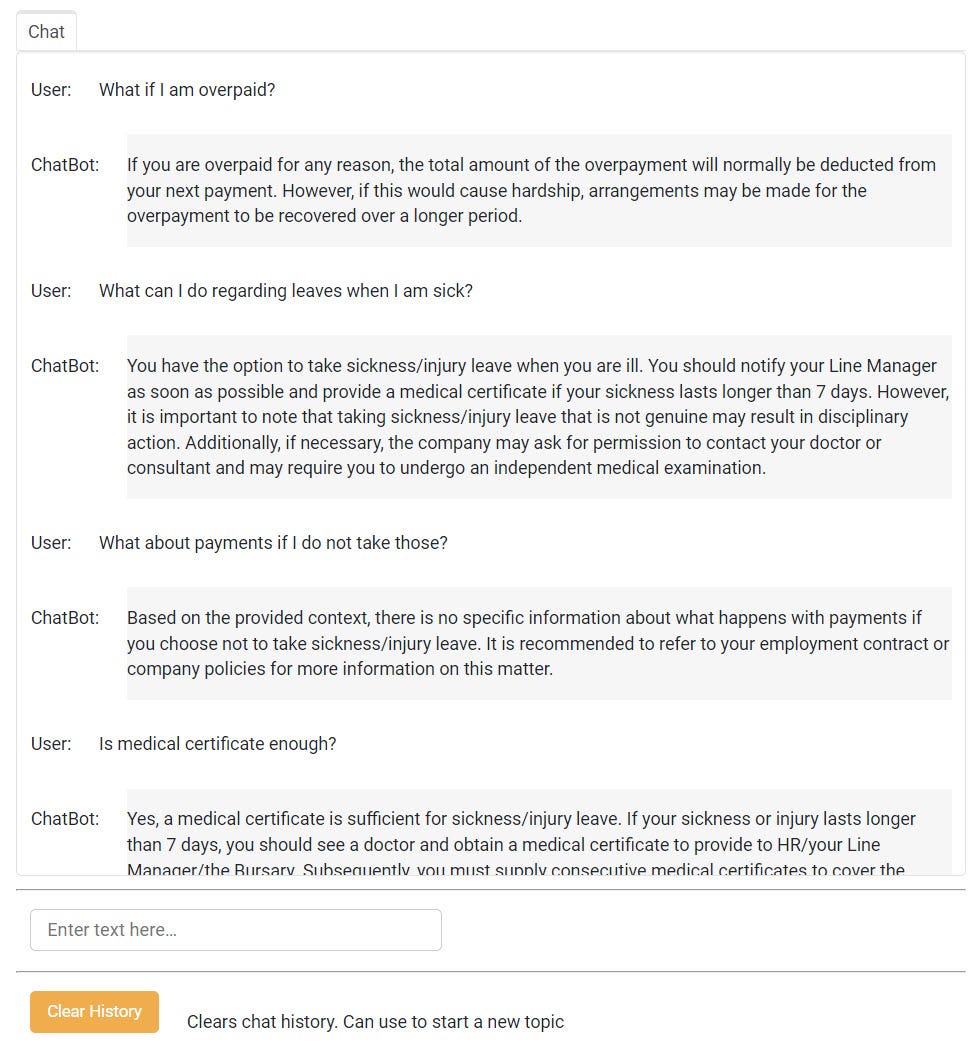
In this blog, we’ve delved into the limitations of pre-trained LLMs and explored various ways to enhance them, including fine-tuning and Retrieval Augmented Generation (RAG). We’ve also taken a deep dive into RAG and vector databases, discussing how they can seamlessly integrate with organizational data and demonstrated their practical application by building a chatbot within the LangChain framework.
But our journey doesn’t end here. In our next installment of this series, we will venture even further into the realm of vector databases. Specifically, we’ll be examining a range of operations within vector databases using Pinecone. This exploration promises to unlock a wealth of possibilities for applications in this domain. So, be sure to stay tuned for an exciting exploration of the powerful synergy between LLMs, LangChain, and vector databases! The future of data-driven solutions is bright, and we can’t wait to show you more.
Beyond pre-trained LLMs: Augmenting LLMs through vector databases to create a chatbot on… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
### [Harnessing the power of LLMs and LangChain for structured data extraction from unstructured data](https://pub.towardsai.net/harnessing-the-power-of-llms-and-langchain-for-structured-data-extraction-from-unstructured-data-12a2ae878404?source=rss----98111c9905da---4)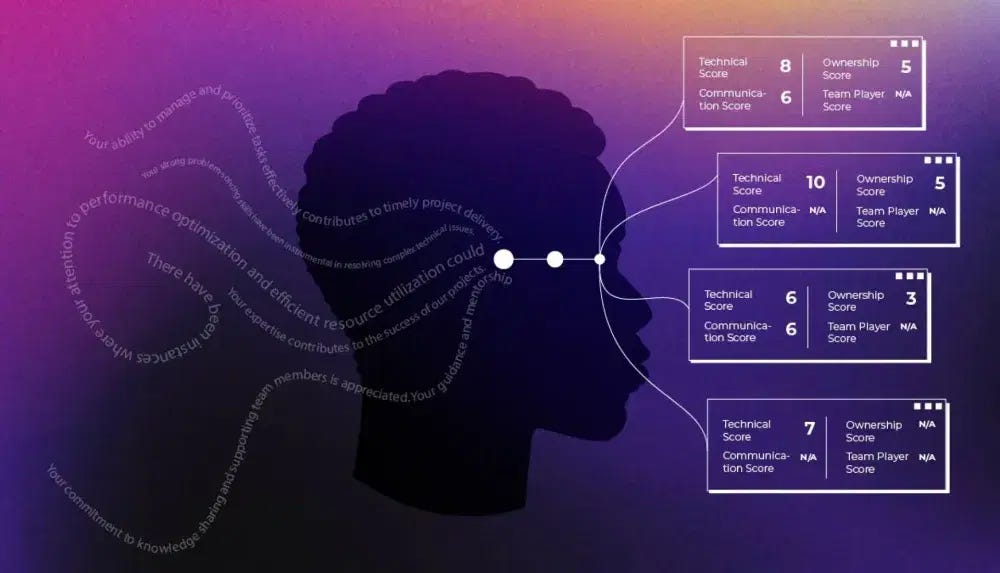
In today’s ever-evolving tech landscape, the rise of Large Language Models (LLMs) has brought about a transformative shift in how we engage with digital applications and content. These advanced language models, exemplified by renowned models like ChatGPT and Google BARD, have not only opened doors but entire gateways to innovative application development. As a testament to their potential, even tech giants like Microsoft and Meta have ventured into this arena with TypeChat and Llama 2, respectively, offering open-source libraries for developers to harness the power of LLMs.
Moreover, the growing influence of LLMs is not just evident in their adoption by tech giants but is also mirrored in the substantial investments pouring into this field. As of fall, 2023, some of the top-funded companies working with LLMs have raised staggering amounts of funding. OpenAI, the pioneering organization behind ChatGPT, has secured a whopping $14 billion in funding, highlighting the immense interest and belief in the potential of these models. Joining the league are companies like Anthropic with $1.55 billion, Cohere with $435 million, Adept with $415 million, Hugging Face with $160.60 million, and Mistral AI with $112.93 million in funding. These eye-popping figures underscore the burgeoning importance of LLMs in the tech world. (Source: cbinsights.com)
In this blog article, we will not only introduce you to LLMs but also dive deeper into Langchain — a cutting-edge LLM framework that is making waves in the industry. Furthermore, we will demonstrate how to harness the power of OpenAI GPT-3.5 LLM in conjunction with the Langchain framework to obtain structured outputs, paving the way for exciting new applications and developments. Let’s embark on this journey into the world of Large Language Models and explore the limitless possibilities they offer.
Introduction to Large Language Models (LLMs)
Large Language Models are artificial intelligence systems created to handle extensive quantities of natural language data. They leverage this data to generate responses to user queries (prompts). These systems are trained on massive data sets using advanced machine learning algorithms This training enables them to grasp the intricacies and structures of human language, empowering them to produce coherent and contextually relevant text in response to a diverse array of written inputs. The significance of Large Language Models is steadily growing across various domains, including but not limited to natural language processing, machine translation, code and text generation, among others.
Application Areas of LLMs
- Chatbots and Virtual Assistants
- Code Generation and Debugging
- Sentiment Analysis
- Text Classification and Clustering
- Language Translation
- Summarization and Paraphrasing
- Content Generation
Note: Most Large Language Models are not specifically trained to serve as repositories of factual information. While they possess language generation capabilities, they may not have knowledge about specific details like the winner of a major sporting event from the previous year. It is crucial to exercise caution by fact-checking and thoroughly comprehending their responses before relying on them as reliable references.
Applying Large Language Models
When considering the utilization of Large Language Models for a specific purpose, there exist several approaches one can explore. Broadly speaking, these approaches can be categorized into two distinct groups, although there may be some overlap between them. In the following discussion, we will provide a brief overview of the pros and cons associated with each approach and identify the scenarios that are most suitable for each.
Proprietary Services
OpenAI’s ChatGPT marked the introduction of Large Language Models (LLMs) to the mainstream, setting the stage for their widespread use. ChatGPT provides a user-friendly interface or API through which users can input prompts for various models, including GPT-3.5 and GPT-4, and receive prompt responses in a timely manner. These models are highly proficient and capable of handling intricate technical tasks like code generation and creative endeavors such as composing poetry in specific styles.
Nevertheless, there are notable downsides to these services. First and foremost, they demand an immense amount of computational resources, not only for their development (with GPT-4 costing over $100 million to create) but also for serving responses. Consequently, these extremely large models are typically controlled by organizations, necessitating users to transmit their data to third-party servers for interactions. This arrangement raises concerns about privacy, security, and the use of “black box” models, where users lack influence over their training and operational constraints. Furthermore, due to the substantial computational requirements, these services often come with associated costs, making budget considerations a significant factor in their widespread adoption.
In summary, proprietary LLM services are an excellent choice when tackling complex tasks. However, users should be willing to share data with third parties, anticipate costs when scaling up, and recognize the limited control they have over these models’ inner workings.
Open Source Models
An alternative route in the realm of language models is engaging with the thriving open source community, exemplified by platforms like Hugging Face. Here, a multitude of models contributed by various sources are available to address specific language-related tasks such as text generation, summarization, and classification. Although open source models have made significant progress, they have not yet matched the peak performance of proprietary models like GPT-4. However, ongoing developments are simplifying the process of using open source models, making them more user-friendly.
These models are often significantly smaller than proprietary alternatives like ChatGPT, facilitating local hosting and ensuring data control for privacy and governance. One notable advantage of open source models is their adaptability, allowing fine-tuning to specific datasets, thereby enhancing performance in domain-specific applications.
Furthermore, the introduction of Llama2, an innovative open source language model, has added another dimension to this landscape. Llama2 offers competitive performance, enhanced accessibility, data control, cost management, and fine-tuning capabilities, making it an appealing choice for various language-related tasks.
In summary, the open source community provides a viable alternative to proprietary models, with Llama2 strengthening this option by offering a powerful toolset for language tasks while enabling data control and cost efficiency.
Example of Applying LLM using OpenAI API in Python
This Python code snippet demonstrates how to utilize OpenAI’s API to interact with its Large Language Models (LLMs), such as GPT-3.5 Turbo and GPT-4. It begins by importing the necessary libraries and setting the API key for authentication. Then, it specifies the chosen model (in this case, “gpt-3.5-turbo”) and defines a user message (“Mary had a little”) as input. The code uses this message to create a chat-like interaction with the chosen LLM through the openai.ChatCompletion.create() function. Finally, it prints the generated response from the LLM. This code offers a straightforward way to integrate OpenAI’s language models into various applications, making it accessible and user-friendly for developers.
Code:
import os
import openai
openai.api_key = "<openai_api_key>"
model = "gpt-3.5-turbo"
message = "Mary had a little"
completion = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": message}]
)
print(completion["choices"][0]["message"]["content"])

LangChain — A Framework for LLM Applications
The popularity of LLMs has skyrocketed, drawing the attention of users and developers alike. However, beneath the surface of this excitement lies a challenge — how to effectively and seamlessly integrate these language models into applications. While LLMs excel at understanding and generating text, their true potential shines when they are harmoniously blended with other sources of computation and knowledge, resulting in dynamic and truly powerful applications.
Enter LangChain, a cutting-edge framework engineered to unlock the full potential of LLMs by streamlining their integration with a diverse range of resources. LangChain empowers data professionals and developers to create applications that not only exhibit linguistic intelligence but also tap into a rich ecosystem of information and computation.
What sets LangChain apart is its versatility. Unlike other solutions that might be limited to a specific LLM’s API, LangChain is designed to work seamlessly with various LLMs, including not only OpenAI’s but also those from Cohere, Hugging Face, Llama, and more. This flexibility ensures that developers can choose the language model that best suits their project’s requirements.
But LangChain’s capabilities don’t stop at LLM integration. It goes further by incorporating what it terms “Tools” into the development process. These tools can encompass a wide array of resources, from Wikipedia for knowledge enrichment to Zapier for automation and the file system for data management. By leveraging these tools, LangChain offers a comprehensive toolkit for developers to create applications that are not just linguistically proficient but also well-equipped to access, process, and utilize various data sources and computational services.
In summary, while the emergence of LLMs has ushered in a new era of application development, integrating them effectively into projects can be challenging. LangChain steps in as a groundbreaking framework that simplifies this process, allowing developers to harness the true potential of LLMs while seamlessly incorporating diverse resources and tools into their applications. With LangChain, the possibilities are boundless, making it the go-to choice for those looking to build intelligent, data-rich, and dynamic applications in the age of LLMs.
Key Components of LangChain
LangChain’s core framework is a powerful tool for language model applications, built around several key components that serve as building blocks. These components include Models (comprising LLMs, Chat Models, and Text Embedding Models), Prompts, Memory (both Short-Term and Long-Term), Chains (including LLMChains and Index-related Chains), Agents (comprising Action and Plan-and-Execute Agents), Callback, and Indexes. Let’s delve into these components in detail.
Model
At the heart of LangChain are Models, which come in three primary types:
- Large Language Models (LLMs): These models are trained on extensive text data and excel at generating meaningful output.
- Chat Models: They offer a structured approach, enabling interactive conversations with users through messages.
- Text Embedding Models: These models convert text into numerical representations, facilitating semantic-style searches across a vector space.
Prompt
The Prompt component serves as the entry point for interacting with LLMs and directing the flow of information. It includes three essential elements:
- Prompt Templates: These templates guide the format of the model’s responses, including questions and few-shot examples.
- Example Selectors: They dynamically choose examples based on user input to enhance interaction.
- Output Parsers: Output Parsers structure and format the model’s responses to meet specific requirements.
Memory
Memory plays a pivotal role in creating a seamless and interactive user experience within LangChain. It is divided into two parts:
- Short-Term Memory: This component keeps track of the current conversation, providing context for responses in real-time.
- Long-Term Memory: Long-Term Memory stores past interactions, enabling personalized and relevant responses based on historical data.
Chain
Chains bring together various components to generate meaningful responses from language models. There are two common types:
- LLMChain: This combines Prompt Template, Model, and optional Guardrails for standard interactions with language models.
- Index-related Chains: These interact with Indexes and combine data with LLMs using various methods to generate responses.
Agents
Agents are autonomous decision-makers within LangChain that interact with other components. They come in two main types:
- Action Agents: These handle small tasks and contribute to the smooth operation of the system.
- Plan-and-Execute Agents: These agents are responsible for managing complex or long-running tasks, vital for coordinating and managing information flow within the system.
Indexes
Indexes efficiently organize and retrieve data within LangChain and consist of several elements:
- Document Loaders: These bring data into LangChain from various sources.
- Text Splitters: Text Splitters break down large text chunks into manageable pieces for processing.
- VectorStores: VectorStores store numerical representations of text, facilitating semantic-style searches.
- Retrievers: Retrievers fetch relevant documents for interaction with language models, ensuring the system operates efficiently.
In summary, LangChain’s comprehensive framework combines these key components to create a versatile and efficient tool for developing language model applications. It empowers developers to harness the power of language models while managing data, interactions, and tasks effectively.
Note: The details of some of these components will be discussed in other blogs in the series.
Implementing a Feedback Scoring System with LangChain to get Structured Output
Scenario
In the ever-evolving landscape of team collaboration and performance management, efficient feedback sharing among team members is pivotal. Feedback, often composed in plain English, carries the potential to drive improvements, foster growth, and enhance productivity. However, when it comes to summarizing and analyzing this feedback at the end of each semester, organizations are confronted with the Herculean task of sifting through an avalanche of information. It is this challenge that necessitates the implementation of a robust feedback scoring system, one that not only scores feedback for each individual but also ensures a consistent format, ready for integration into the Performance Management System and seamless presentation on dashboards and other applications.
Problem
The core issue at hand might initially appear straightforward. Leveraging advanced AI tools such as ChatGPT and related APIs, scoring feedback should, in theory, be a simple endeavor. However, the complexity arises from the inherent variability in the structure of the feedback. Each piece of feedback is unique, and while AI models excel at interpreting plain English text, they do not consistently conform to requests for standardized output formats. For instance, as illustrated in the accompanying image, the output format can vary significantly. Moreover, these outputs sometimes contain explanations that are not required for database insertion, resulting in additional effort to format the data.
Below, we provide two examples of outputs generated by ChatGPT (without the use of any frameworks such as LangChain) in response to a request for structured JSON output (scores) for a given feedback. The same prompt was used for both runs, but the output differs on different runs. While the first output aligns with our desired format, the second output deviates from the specified requirements by including additional information beyond the expected JSON structure.
Prompt:

Output 1:

Output 2:

To address these challenges related to consistent output format from similar prompts, we introduce the LangChain framework, designed to streamline the process of feedback scoring and ensure consistent, structured output. LangChain is engineered to bridge the gap between the inherent flexibility of AI language models (LLMs) and the need for standardized data formatting. By leveraging LangChain, organizations can enjoy the benefits of AI-powered feedback scoring while maintaining control over the output format.
In the following sections, we will explore how LangChain can be effectively utilized to achieve structured feedback scoring, simplifying the integration of scores into your database and improving the overall efficiency of your feedback management process.
Solution
Within LangChain, several key components play pivotal roles in achieving structured and standardized outputs. These components include ChatOpenAI, ChatPromptTemplate, ResponseSchema, and StructuredOutputParser.
ChatOpenAI serves as the entry point for interacting with language models. It facilitates the communication between the user and the model, making it a crucial component for requests like feedback scoring. ChatOpenAI streamlines the process of sending prompts to the AI model and receiving responses, ensuring that the model understands and responds appropriately to specific requests.
ChatPromptTemplate is a critical part of LangChain’s toolkit for structuring interactions with language models. It allows users to define templates that guide the conversation with the model, making it easier to request structured data, like JSON output for feedback scoring. By providing predefined prompts and contexts, ChatPromptTemplate helps ensure consistency in interactions with the model and in the data generated.
ResponseSchema is the linchpin of LangChain when it comes to structuring AI-generated outputs. This component enables users to define the expected format for model responses, such as JSON structures. By specifying the schema, users can explicitly request structured data, aligning the AI model’s responses with their intended data format. This is particularly valuable in scenarios where data uniformity is critical, like the case of feedback scoring.
StructuredOutputParser complements the LangChain framework by providing tools to parse and extract structured data from the model’s responses. It plays a vital role in the feedback scoring process, where the model’s outputs may not always conform to the requested structure. StructuredOutputParser allows users to extract the essential information from model responses, discarding extraneous data and ensuring that the desired output is in a consistent format for easy integration into databases and other applications.
Together, these components within the LangChain framework empower organizations to harness the capabilities of AI language models while maintaining control over the structure and format of the data they generate. Whether it’s scoring feedback, generating reports, or any other structured data task, LangChain provides the tools needed to bridge the gap between the flexibility of AI models and the need for structured, standardized data.
Below, you will find code snippets that illustrate how to leverage ChatOpenAI, ChatPromptTemplate, ResponseSchema, and StructuredOutputParser to tackle the real-world challenges presented by our fictional Employee Feedback scoring system effectively.
Importing crucial modules from the LangChain framework for communication with language models, defining interaction templates, and structuring/parsing AI-generated responses.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.output_parsers import ResponseSchema,
StructuredOutputParser
Setting up OpenAI API credentials and define parameters for generating feedback scores based on a provided text.
openai_api_key = '<OPENAI_API_KEY>'
model = 'gpt-3.5-turbo'
temperature = 0
min_score = 0
max_score = 10
feedback = "- Took ownership of revising the Basic Database Course\n\
- Took ownership of his own learning and worked on pet projects\n\
- Has Python programming skills\n\
\n\
Area of Improvement: \n\
- As an SE2, Rob needs to expand his technical depth and breadth. \
He needs to grasp the technical concepts required for a Data Engineer such as data modeling, dimensional modeling, and analytics among
others.\n\
- Rob needs to learn best practices and implement them in projects, but without overengineering. \
He needs to learn how to balance technicalities and simplification.\n\
- Rob needs to be a better Active listener. \
He needs to make sure he listens to people and understands their viewpoints before answering or interrupting.\n\
- Rob needs to communicate more proactively (or ask questions when required) leading to being more reliable.\n\
- Rob needs to try to be more concise and clear when communicating."
Defining response schemas for feedback scores, including descriptions and score ranges, within the LangChain framework to structure and interpret AI-generated feedback data.
# Define response schemas for the feedback scores
overall_score_schema = ResponseSchema(name="Overall_Score",
description="Overall rating of the appraisee considering all aspects/areas. \
The scores should range from {min_score} to {max_score}, {min_score} being the worst performer, and {max_score} being an exceptional performer."
, type="float"
)
technical_score_schema = ResponseSchema(name="Technical_Score",
description="Rating of the appraisee considering technical skill. \
Technical Expertise (TE) is a multidisciplinary quality that determines an individual’s ability to use the right solution, tool, and/or processes in the best possible manner to get the job done....(further details) \
The scores should range from {min_score} to {max_score}, {min_score} being the worst performer, and {max_score} being an exceptional performer."
, type="float"
)
communication_score_schema = ResponseSchema(name="Communication_Score",
description="Rating of the appraisee considering communication skill. \
For someone to be effective with communication, one has to be an active listener who understands their audience or the speaker....(further details) \
The scores should range from {min_score} to {max_score}, {min_score} being the worst performer, and {max_score} being an exceptional performer."
, type="float"
)
ownership_score_schema = ResponseSchema(name="Ownership_Score",
description="Rating of the appraisee considering ownership traits. \
Ownership means being responsible for the successful implementation and execution of a project from beginning to end....(further details) \
The scores should range from {min_score} to {max_score}, {min_score} being the worst performer, and {max_score} being an exceptional performer."
, type="float"
)
teamplayer_score_schema = ResponseSchema(name="TeamPlayer_Score",
description="Rating of the appraisee considering team player traits....(further details) \
A team player is a person who works well as a member of a team. \
The scores should range from {min_score} to {max_score}, {min_score} being the worst performer, and {max_score} being an exceptional performer."
, type="float"
)
response_schemas = [overall_score_schema,
technical_score_schema,
communication_score_schema,
ownership_score_schema,
teamplayer_score_schema]
Initializing an output parser and obtaining format instructions based on predefined response schemas for structured data processing within the LangChain framework.
# Initialize output parser and format instructions
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
Creating a template for extracting feedback score information, including descriptions, from the appraiser to the appraisee using predefined response schemas and format instructions in the LangChain framework.
# Define feedback score template
feedback_score_template = "\
For the following feedback from appraiser to appraisee, extract the following information:\
{overall_score_schema.name}: {overall_score_schema.description}\
{technical_score_schema.name}: {technical_score_schema.description}\
{communication_score_schema.name}: {communication_score_schema.description}\
{ownership_score_schema.name}: {ownership_score_schema.description}\
{teamplayer_score_schema.name}: {teamplayer_score_schema.description}\
feedback: {{feedback}}\
{{format_instructions}}"
Creating a feedback scoring prompt template, initializing a ChatOpenAI instance for feedback scoring, and defining a function to score feedback based on the LangChain framework, OpenAI model parameters, and format instructions.
# Create feedback score prompt template
feedback_score_prompt_template = ChatPromptTemplate.from_template(feedback_score_template)
# Initialize ChatOpenAI instance for feedback scoring
feedback_scorer = ChatOpenAI(model_name=model, temperature=temperature, openai_api_key=openai_api_key)
def score_feedback(feedback, max_score, min_score, format_instructions):
feedback_score_prompt = feedback_score_prompt_template.format_messages(
feedback=feedback, max_score=max_score, min_score=min_score, format_instructions=format_instructions)
feedback_score_response = feedback_scorer(feedback_score_prompt)
feedback_score_dict = output_parser.parse(feedback_score_response.content)
return feedback_score_dict
Scoring the provided feedback using the LangChain framework and printing the resulting feedback score dictionary.
feedback_score_dict = score_feedback(
feedback=feedback, max_score=max_score, min_score=min_score, format_instructions=format_instructions)
print(feedback_score_dict)
Output:
{'Overall_Score': 6.5, 'Technical_Score': 5, 'Communication_Score': 6, 'Ownership_Score': 7, 'TeamPlayer_Score': 6}
In this exploration, we’ve demonstrated how to harness the power of Language Models (LLMs) in conjunction with the LangChain framework to obtain structured outputs for quantifying feedback effectively. This methodology not only ensures uniformity in data formatting but also simplifies the integration of feedback scores into databases and other applications. Importantly, the techniques showcased here can be readily extended to address a wide array of similar use cases, offering a versatile solution to organizations seeking to extract structured insights from unstructured data in the era of AI-powered analytics.
In the next blog in this series, we will delve into the world of vector databases and their crucial role when working with LLMs. We will highlight the advantages of using vector databases and compare it to fine-tuning LLM models. Additionally, we will demonstrate their application by developing a simple yet powerful QA chatbot tailored for organizational data. Stay tuned for an exciting exploration into the synergy between LLM, LangChain, and vector databases!
Harnessing the power of LLMs and LangChain for structured data extraction from unstructured data was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
--- ## 来源: https://towardsdatascience.com/feed ### [Introducing the AI-3P Assessment Framework: Score AI Projects Before Committing Resources](https://towardsdatascience.com/the-ai-3p-assessment-framework/)A question-driven scorecard to prioritize and de-risk AI initiatives before implementation
The post Introducing the AI-3P Assessment Framework: Score AI Projects Before Committing Resources appeared first on Towards Data Science.
### [Generating Consistent Imagery with Gemini](https://towardsdatascience.com/generating-consistent-imagery-with-gemini/)A practical guide to building a prompt-based generation pipeline for your image library
The post Generating Consistent Imagery with Gemini appeared first on Towards Data Science.
### [The Art of Asking Good Questions](https://towardsdatascience.com/the-art-of-asking-good-questions/)As a data scientist, are you driving product decisions? Or just supporting them? The right questions can turn AI from a threat into your career’s best ally. Here’s how to start asking them.
The post The Art of Asking Good Questions appeared first on Towards Data Science.
### [Generative AI Myths, Busted: An Engineers’s Quick Guide](https://towardsdatascience.com/gen-ai-myths-busted-a-engineerss-quick-guide/)A super simple and quick guide to how generative AI works, the myths around it, and why it won’t replace engineers anytime soon.
The post Generative AI Myths, Busted: An Engineers’s Quick Guide appeared first on Towards Data Science.
### [Why Are Marketers Turning To Quasi Geo-Lift Experiments? (And How to Plan Them)](https://towardsdatascience.com/why-are-marketers-turning-to-quasi-geo-lift-experiments-and-how-to-plan-them/)Are “quasi” geo-lift experiments the missing piece for your marketing science function?
The post Why Are Marketers Turning To Quasi Geo-Lift Experiments? (And How to Plan Them) appeared first on Towards Data Science.
### [5 Techniques to Prevent Hallucinations in Your RAG Question Answering](https://towardsdatascience.com/5-techniques-to-prevent-hallucinations-in-your-rag-question-answering/)Learn how to reduce the number of hallucinations, and the impact they have
The post 5 Techniques to Prevent Hallucinations in Your RAG Question Answering appeared first on Towards Data Science.
### [How to Connect an MCP Server for an AI-Powered, Supply-Chain Network Optimization Agent](https://towardsdatascience.com/mcp-server-for-an-ai-powered-supply-chain-network-optimization-agent/)From prompt to strategic decision-making: MCP-powered agents for cost-efficient, reliable and sustainable supply chain network design.
The post How to Connect an MCP Server for an AI-Powered, Supply-Chain Network Optimization Agent appeared first on Towards Data Science.
--- ## 来源: https://blogs.windows.com/feed ### [Windows ML is generally available: Empowering developers to scale local AI across Windows devices](https://blogs.windows.com/windowsdeveloper/2025/09/23/windows-ml-is-generally-available-empowering-developers-to-scale-local-ai-across-windows-devices/)The future of AI is hybrid, utilizing the respective strengths of cloud and client while harnessing every Windows device to achieve more. At Microsoft, we are reimagining what’s possible by bringing powerful AI compute directly to Windows devices,
The post Windows ML is generally available: Empowering developers to scale local AI across Windows devices appeared first on Windows Blog.
--- ## 来源: https://aihub.org/feed?cat=-473 ### [Data centers consume massive amounts of water – companies rarely tell the public exactly how much](https://aihub.org/2025/09/24/data-centers-consume-massive-amounts-of-water-companies-rarely-tell-the-public-exactly-how-much/) Lone Thomasky & Bits&Bäume / Digital Society Bell / Licenced by CC-BY 4.0 By Peyton McCauley, University of Wisconsin-Milwaukee and Melissa Scanlan, University of Wisconsin-Milwaukee As demand for artificial intelligence technology boosts construction and proposed construction of data centers around the world, those computers require not just electricity and land, but also a significant amount […] ### [Interview with Luc De Raedt: talking probabilistic logic, neurosymbolic AI, and explainability](https://aihub.org/2025/09/23/interview-with-luc-de-raedt-talking-probabilistic-logic-neurosymbolic-ai-and-explainability/) Should AI continue to be driven by a single paradigm, or does real progress lie in combining the strengths and weaknesses of many? Professor Luc De Raedt of KU Leuven has spent much of his career persistently addressing this question. Through pioneering work that bridges logic, probability, and machine learning, he has helped shape the […] ---