BLOG POST
AI 日报
AI ‘Workslop’ Is Killing Productivity and Making Workers Miserable
AI slop is taking over workplaces. Workers said that they thought of their colleagues who filed low-quality AI work as "less creative, capable, and reliable than they did before receiving the output."
Florida Sues Hentai Site and High-Risk Payment Processor for Not Verifying Ages
Florida's attorney general claims Nutaku, Spicevids, and Segpay are in violation of the state's age verification law.
CBP Flew Drones to Help ICE 50 Times in Last Year
The drone flight log data, which stretches from March 2024 to March 2025, shows CBP flying its drones to support ICE and other agencies. CBP maintains multiple Predator drones and flew them over the recent anti-ICE protests in Los Angeles.
Steam Hosted Malware Game that Stole $32,000 from a Cancer Patient Live on Stream
Scammers stole the crypto from a Latvian streamer battling cancer and the wider security community rallied to make him whole.
We’re Suing ICE for Its $2 Million Spyware Contract
404 Media has filed a lawsuit against ICE for access to its contract with Paragon, a company that sells powerful spyware for breaking into phones and accessing encrypted messaging apps.
AI-Generated YouTube Channel Uploaded Nothing But Videos of Women Being Shot
YouTube removed a channel that posted nothing but graphic Veo-generated videos of women being shot after 404 Media reached out for comment.
How Creatio Is Redefining CRM for Financial Institutions
Two New England banks switched from Salesforce to Creatio, highlighting what executives say is the importance of personalized relationships between vendor and customer.
Nvidia Will Invest $100B in OpenAI
The deal highlights Nvidia's dominant financial position but also raises questions about timelines and how partners of those vendors might react.
Public trust deficit is a major hurdle for AI growth
While politicians tout AI’s promise of growth and efficiency, a new report reveals a public trust deficit in the technology. Many are deeply sceptical, creating a major headache for governments’ plans. A deep dive by the Tony Blair Institute for Global Change (TBI) and Ipsos has put some hard numbers on this feeling of unease. […]
The post Public trust deficit is a major hurdle for AI growth appeared first on AI News.
How BMC can be the ‘orchestrator of orchestrators’ for enterprise agentic AI
Agentic AI is, in the opinion of McKinsey, the way to ‘break out of the gen AI paradox.’ Nearly four in five companies are using generative AI, according to the consultancy giant’s research, but comparatively few are getting any bottom-line value from it. The answer to the question of value, therefore, may be in orchestration. […]
The post How BMC can be the ‘orchestrator of orchestrators’ for enterprise agentic AI appeared first on AI News.
Karnataka CM seeks Wipro’s support to cut ORR congestion by 30%

“Your support will go a long way in easing bottlenecks, enhancing commuter experience, and contributing to a more efficient and livable Bengaluru,” CM wrote.
The post Karnataka CM seeks Wipro’s support to cut ORR congestion by 30% appeared first on Analytics India Magazine.
TikTok’s US Future Shaped by Trump, Powered by Oracle and Murdoch

“Oracle will operate, retrain and continuously monitor the US algorithm to ensure content is free from improper manipulation or surveillance.”
The post TikTok’s US Future Shaped by Trump, Powered by Oracle and Murdoch appeared first on Analytics India Magazine.
TCS Expands AI Services with NVIDIA Partnership, Deepens Vodafone Idea Ties

The NVIDIA partnership centres on advancing global retail, whereas the collaboration with the telecom company aims to enhance customer experience.
The post TCS Expands AI Services with NVIDIA Partnership, Deepens Vodafone Idea Ties appeared first on Analytics India Magazine.
The $100k H-1B Gamble for Big Tech

Firms may either go the remote work way or just pay up when they really want an employee in US.
The post The $100k H-1B Gamble for Big Tech appeared first on Analytics India Magazine.
Satellites That ‘Think’ Could Change How India Responds to Disasters

SkyServe is building onboard processing for satellites, shortening the time between capturing an image and turning it into usable insights.
The post Satellites That ‘Think’ Could Change How India Responds to Disasters appeared first on Analytics India Magazine.
Developer Experience: The Unsung Hero Behind GenAI and Agentic AI Acceleration

DevEx is emerging as the invisible force that accelerates innovation, reduces
friction and translates experimentation into enterprise-grade outcomes.
The post Developer Experience: The Unsung Hero Behind GenAI and Agentic AI Acceleration appeared first on Analytics India Magazine.
Indian IT Majors Cut Visa Petitions by 44% in Four Years

A steep new US visa fee could reshape the global tech talent landscape while also bolstering India’s tech hubs.
The post Indian IT Majors Cut Visa Petitions by 44% in Four Years appeared first on Analytics India Magazine.
Healthtech Startup Zealthix Secures $1.1 Mn in Seed Funding Led by Unicorn India Ventures

The funding will fuel Zealthix’s expansion and technology enhancements aimed at digitising India’s healthcare ecosystem.
The post Healthtech Startup Zealthix Secures $1.1 Mn in Seed Funding Led by Unicorn India Ventures appeared first on Analytics India Magazine.
Cloudflare Pledges 1,111 Internship Spots for 2026

Beginning January 2026, select startups will be able to work from Cloudflare offices on certain days to collaborate with teams and peers.
The post Cloudflare Pledges 1,111 Internship Spots for 2026 appeared first on Analytics India Magazine.
Agnikul Cosmos Opens India’s First Large-Format Rocket 3D Printing Hub

This Chennai startup aims to speed up engine production and strengthen India’s private space ecosystem.
The post Agnikul Cosmos Opens India’s First Large-Format Rocket 3D Printing Hub appeared first on Analytics India Magazine.
OpenTelemetry Is Ageing Like Fine Wine

Enterprises and AI frameworks are embracing OpenTelemetry to standardise data, cut integration costs, and build trust in AI systems.
The post OpenTelemetry Is Ageing Like Fine Wine appeared first on Analytics India Magazine.
IT Minister Ashwini Vaishnaw Switches to Zoho, Backs PM Modi’s Swadeshi Push

"I urge all to join PM Shri @narendramodi Ji’s call for Swadeshi by adopting indigenous products & services,” Vaishnaw posted on X.
The post IT Minister Ashwini Vaishnaw Switches to Zoho, Backs PM Modi’s Swadeshi Push appeared first on Analytics India Magazine.
OpenAI, NVIDIA Sign $100 Billion Deal to Deploy 10 GW of AI Systems

The first gigawatt of capacity is scheduled for deployment in the second half of 2026 on NVIDIA’s Vera Rubin platform.
The post OpenAI, NVIDIA Sign $100 Billion Deal to Deploy 10 GW of AI Systems appeared first on Analytics India Magazine.
How BharatGen Took the Biggest Slice of IndiaAI’s GPU Cake

BharatGen has secured 13,640 H100 GPUs and ₹988.6 crore in funding to pursue India’s first trillion-parameter AI model initiative.
The post How BharatGen Took the Biggest Slice of IndiaAI’s GPU Cake appeared first on Analytics India Magazine.
H-1B Visa Fee Hike Could Hit Remittances, Telangana Warns

The state seeks exemptions to protect IT professionals and families dependent on overseas income.
The post H-1B Visa Fee Hike Could Hit Remittances, Telangana Warns appeared first on Analytics India Magazine.
India’s GCCs Could Add $200 Billion by 2030, Says CII

At present, nearly 95% of India’s 1,800 GCCs are concentrated in six tier-1 cities.
The post India’s GCCs Could Add $200 Billion by 2030, Says CII appeared first on Analytics India Magazine.
H-1B Shockwave: What a $100,000 Visa Fee Means for Indian AI Startups

“The proposed fee could act as a catalyst in strengthening India’s AI talent ecosystem.”
The post H-1B Shockwave: What a $100,000 Visa Fee Means for Indian AI Startups appeared first on Analytics India Magazine.
The Generation That Refused to Log Off in Nepal

“The backlash made it evident that Nepali citizens do not tolerate digital authoritarianism disguised as governance.”
The post The Generation That Refused to Log Off in Nepal appeared first on Analytics India Magazine.
Assessli’s AI-led Behavioural Model Could Eclipse Language Models

The Kolkata-based company’s patented methodology is in use across sectors like education, healthcare, and financial services.
The post Assessli’s AI-led Behavioural Model Could Eclipse Language Models appeared first on Analytics India Magazine.
Trump’s H-1B Fee Alarms Industry, But India Sees GCC Opportunity

“For India, this could actually mean more jobs, more investment, and more GCCs”
The post Trump’s H-1B Fee Alarms Industry, But India Sees GCC Opportunity appeared first on Analytics India Magazine.
Indian IT Giants vs Startups: Who Will Script India’s AI Enterprise Story?

At Cypher 2025, leaders debated India’s enterprise AI future, concluding that it won’t be giants versus startups, but rather collaborative ecosystems.
The post Indian IT Giants vs Startups: Who Will Script India’s AI Enterprise Story? appeared first on Analytics India Magazine.
How Confluent Helped Notion Scale AI and Productivity for 100M+ Users

Notion, as a top productivity tool, utilised Confluent’s solutions to handle its operations efficiently.
The post How Confluent Helped Notion Scale AI and Productivity for 100M+ Users appeared first on Analytics India Magazine.
Should India Build Its Own AI Foundational Models?

At Cypher 2025, industry leaders debate whether India should invest in building its own AI foundational models or adapt global ones.
The post Should India Build Its Own AI Foundational Models? appeared first on Analytics India Magazine.
Broadcom’s prohibitive VMware prices create a learning “barrier,” IT pro says
Public schools ran to VMware during the pandemic. Now they're running away.
Supreme Court lets Trump fire FTC Democrat despite 90-year-old precedent
Kagan dissent: Majority is giving Trump "full control" of independent agencies.
Google Play is getting a Gemini-powered AI Sidekick to help you in games
Here comes another screen overlay.
EU investigates Apple, Google, and Microsoft over handling of online scams
EU looks at Big Tech groups over handling of fake apps and search results.
Volvo says it has big plans for South Carolina factory
The Ridgeville plant will add a new hybrid by 2030 in addition to next year's XC60.
US intel officials “concerned” China will soon master reusable launch
"They have to have on-orbit refueling because they don’t access space as frequently as we do."
How to fight censorship, one Disney+ cancellation at a time
Thuggish government behavior is not stopped by capitulation.
NASA names 24th astronaut class, including prior SpaceX crew member
NASA's 24th astronaut class since selecting the Mercury astronauts in 1959.
Anti-vaccine groups melt down over RFK Jr. linking autism to Tylenol
"THIS WAS NOT CAUSED BY TYLENOL" Kennedy's anti-vaccine group retweeted.
iFixit tears down the iPhone Air, finds that it’s mostly battery
Design that puts the logic board at the top helps stave off a second Bendgate.
Disney reinstates Jimmy Kimmel after backlash over capitulation to FCC
Disney says "thoughtful conversations with Jimmy" led to show's return.
DOJ aims to break up Google’s ad business as antitrust case resumes
The remedy phase of Google's adtech antitrust case begins.
Rand Paul: FCC chair had “no business” intervening in ABC/Kimmel controversy
"Absolutely inappropriate. Brendan Carr has got no business weighing in on this."
OpenAI and Nvidia’s $100B AI plan will require power equal to 10 nuclear reactors
"This is a giant project," Nvidia CEO said of new 10-gigawatt AI infrastructure deal.
DeepMind AI safety report explores the perils of “misaligned” AI
DeepMind releases version 3.0 of its AI Frontier Safety Framework with new tips to stop bad bots.
Here’s how potent Atomic credential stealer is finding its way onto Macs
LastPass warns it's one of the latest to see its well-known brand impersonated.
Three crashes in the first day? Tesla’s robotaxi test in Austin.
Tesla's crash rate is orders of magnitude worse than Waymo's.
Our fave Star Wars duo is back in Mandalorian and Grogu teaser
There is almost no dialogue and little hint of the plot, but the visuals should delight fans.
F1 in Azerbaijan: This sport is my red flag
Baku is a mashup of Monaco and Monza, 90 feet below sea level.
What climate targets? Top fossil fuel producing nations keep boosting output
Top producers are planning to mine and drill even more of the fuels in 2030.
The US-UK tech prosperity deal carries promise but also peril for the general public
The deliberate alignment of AI systems with the values of corporations and individuals could sour the investment.
Air quality analysis reveals minimal changes after xAI data center opens in pollution-burdened Memphis neighborhood
Analysis of the air quality data available for southwest Memphis finds that pollution has long been quite bad, but the turbines powering an xAI data center have not made it much worse.
What happens when AI comes to the cotton fields
AI can help farmers be more effective and sustainable, but its use varies from state to state. A project in Georgia aims to bring the technology to the state’s cotton farmers.
AI and credit: How can we keep machines from reproducing social biases?
Can we move from algorithmic discrimination to inclusive finance?
AI use by UK justice system risks papering over the cracks caused by years of underfunding
The justice system is suffering from underfunding and AI won’t solve all the problems.
How US-UK tech deal could yield significant benefits for the British public – expert Q&A
The £150bn package could yield real benefits in public health, as well as other areas of technology.
How users can make their AI companions feel real – from picking personality traits to creating fan art
The strong bonds that users are forming with their AI chatbots rest on the human imagination at work.
AI ‘carries risks’ but will help tackle global heating, says UN’s climate chief
Simon Stiell insists it is vital governments regulate the technology to blunt its dangerous edges
Harnessing artificial intelligence will help the world to tackle the climate crisis, but governments must step in to regulate the technology, the UN’s climate chief has said.
AI is being used to make energy systems more efficient, and to develop tools to reduce carbon from industrial processes. The UN is also using AI as an aid to climate diplomacy.
‘Tentacles squelching wetly’: the human subtitle writers under threat from AI
Artificial intelligence is making steady advances into subtitling but, say its practitioners, it’s a vital service that needs a human to make it work
Is artificial intelligence going to destroy the SDH [subtitles for the deaf and hard of hearing] industry? It’s a valid question because, while SDH is the default subtitle format on most platforms, the humans behind it – as with all creative industries – are being increasingly devalued in the age of AI. “SDH is an art, and people in the industry have no idea. They think it’s just a transcription,” says Max Deryagin, chair of Subtle, a non-profit association of freelance subtitlers and translators.
The thinking is that AI should simplify the process of creating subtitles, but that is way off the mark, says Subtle committee member Meredith Cannella. “There’s an assumption that we now have to do less work because of AI tools. But I’ve been doing this now for about 14-15 years, and there hasn’t been much of a difference in how long it takes me to complete projects over the last five or six years.”
Nvidia to invest $100bn in OpenAI, bringing the two AI firms together
Deal will involve two transactions – OpenAI will pay Nvidia for chips, and the chipmaker will invest in the AI start-up
Nvidia, the chipmaking company, will invest up to $100bn in OpenAI and provide it with data center chips, the companies said on Monday, a tie-up between two of the highest-profile leaders in the global artificial intelligence race.
The deal, which will see Nvidia start delivering chips as soon as late 2026, will involve two separate but intertwined transactions, according to a person close to OpenAI. The startup will pay Nvidia in cash for chips, and Nvidia will invest in OpenAI for non-controlling shares, the person said.
If Anyone Builds it, Everyone Dies review – how AI could kill us all
If machines become superintelligent we’re toast, say Eliezer Yudkowsky and Nate Soares. Should we believe them?
What if I told you I could stop you worrying about climate change, and all you had to do was read one book? Great, you’d say, until I mentioned that the reason you’d stop worrying was because the book says our species only has a few years before it’s wiped out by superintelligent AI anyway.
We don’t know what form this extinction will take exactly – perhaps an energy-hungry AI will let the millions of fusion power stations it has built run hot, boiling the oceans. Maybe it will want to reconfigure the atoms in our bodies into something more useful. There are many possibilities, almost all of them bad, say Eliezer Yudkowsky and Nate Soares in If Anyone Builds It, Everyone Dies, and who knows which will come true. But just as you can predict that an ice cube dropped into hot water will melt without knowing where any of its individual molecules will end up, you can be sure an AI that’s smarter than a human being will kill us all, somehow.
More Britons view AI as economic risk than opportunity, Tony Blair thinktank finds
TBI says poll data threatens Keir Starmer’s ambition for UK to become artificial intelligence ‘superpower’
Nearly twice as many Britons view artificial intelligence as a risk to the economy than regard it as an opportunity, according to Tony Blair’s thinktank.
The Tony Blair Institute warned that the poll findings threatened Keir Starmer’s ambition for the UK to become an AI “superpower” and urged the government to convince the public of the technology’s benefits.
Racists Are Using AI to Spread Diabolical Anti-Immigrant Slop
Welcome to the future.
The post Racists Are Using AI to Spread Diabolical Anti-Immigrant Slop appeared first on Futurism.
Users Are Saying ChatGPT Has Been Lobotomized by a Secret New Update
"I just want it to stop lying."
The post Users Are Saying ChatGPT Has Been Lobotomized by a Secret New Update appeared first on Futurism.
ChatGPT Has a Stroke When You Ask It This Specific Question
A question that should quite literally be as easy as ABC -- but isn't.
The post ChatGPT Has a Stroke When You Ask It This Specific Question appeared first on Futurism.
xAI Workers Leak Disturbing Information About Grok Users
"It actually made me sick."
The post xAI Workers Leak Disturbing Information About Grok Users appeared first on Futurism.
Hospitals Deploying Robot Programmed to Act Like Child to Comfort Pediatric Patients
"Imagine a pure emotional intelligence like WALL-E."
The post Hospitals Deploying Robot Programmed to Act Like Child to Comfort Pediatric Patients appeared first on Futurism.
Woman Asks ChatGPT for Powerball Numbers, Wins $150,000
"I’m like, ChatGPT, talk to me... Do you have numbers for me?"
The post Woman Asks ChatGPT for Powerball Numbers, Wins $150,000 appeared first on Futurism.
Using AI Increases Unethical Behavior, Study Finds
"Using AI creates a convenient moral distance between people and their actions."
The post Using AI Increases Unethical Behavior, Study Finds appeared first on Futurism.
Why One VC Thinks Quantum Is a Bigger Unlock Than AGI
Venture capitalist Alexa von Tobel is ready to bet on quantum computing—starting with hardware.
Louisiana Hands Meta a Tax Break and Power for Its Biggest Data Center
Mark Zuckerberg’s company faces backlash after rowing back promises to create between 300 and 500 new jobs to man its subsidiary’s new data center.
I Thought I Knew Silicon Valley. I Was Wrong
Tech got what it wanted by electing Trump. A year later, it looks more like a suicide pact.
Setting Up LLaVA/BakLLaVA with vLLM: Backend and API Integration
Table of Contents Setting Up LLaVA/BakLLaVA with vLLM: Backend and API Integration Why vLLM for Multimodal Inference The Challenges of Serving Image + Text Prompts at Scale Why Vanilla Approaches Fall Short How vLLM Solves Real-World Production Workloads Configuring Your…
The post Setting Up LLaVA/BakLLaVA with vLLM: Backend and API Integration appeared first on PyImageSearch.
Nexstar Joins Sinclair in Boycotting Jimmy Kimmel’s Show
Nexstar Media Group Inc. said it would join Sinclair Inc., another large owner of ABC TV stations, in not airing Jimmy Kimmel Live! on Tuesday night.
Mamdani Draws NYC Investors to Advise Him If He Wins Mayor Race
Members of New York City’s business community are forming an advisory group in an effort to guide mayoral candidate Zohran Mamdani if he wins the election in November.
Microsoft Is Turning to the Field of Microfluidics to Cool Down AI Chips
Small amounts of fluid passed through channels etched on chips can save energy and boost AI systems.
Trump Plans H-1B Lottery Overhaul to Prioritize Higher Earners
The Trump administration is proposing major changes to the selection process for H-1B visas heavily used by the tech industry, basing allocation on skill-level required and wages offered for a position instead of the current randomized lottery.
Micron Needs a Rosy Outlook to Justify Its Soaring Stock Price
Micron Technology Inc.’s earnings after the bell Tuesday will shed light on whether the chipmaker’s high-flying stock has gotten ahead of itself after a 40% gain in September.
Google Courts Gamers With Mobile AI Gaming Agent, Leagues
Google is introducing an artificial intelligence assistant that can offer live coaching to mobile gamers, part of a larger effort to boost engagement on its Android platform.
Amazon Heads Into FTC Jury Trial Over Prime Cancellation Claims
Amazon.com Inc. and three executives are facing a federal regulator’s allegations in a Seattle court that they duped customers into signing up for the company’s Prime subscription service and then made it too hard to cancel.
Taiwan Curbs Chip Exports to South Africa in Rare Power Move
Taiwan has imposed restrictions on the export of chips to South Africa over national security concerns, taking the unusual step of using its dominance of the market to pressure a country that’s closely allied itself with China.
Biotech Real Estate Slump Has MIT’s Hometown Seeking Backups
Kendall Square, a major biopharmaceutical hub that borders the Massachusetts Institute of Technology’s campus, bills itself as the most innovative square mile on the planet. These days, there’s plenty of room for innovation in the Cambridge, Massachusetts neighborhood.
Market Skepticism Is Growing for Morgan Stanley’s Shalett
“Sometimes the bull case is the lack of a credible bear case, that’s where we are at this very minute,” says Lisa Shalett, CIO at Morgan Stanley Wealth Management, as she sees the Mag 7 stocks as “probably over-owned and a little sizzly.” (Source: Bloomberg)
Nintendo’s Switch 2 Sales Boom Fails to Ease Game Developers’ Gloom
Welcome to Tech In Depth, our daily newsletter about the business of tech from Bloomberg’s journalists around the world. Today, Takashi Mochizuki reports on the sluggish sales for independent game makers despite consumer enthusiasm for Nintendo’s Switch 2 console.
Binance-Linked Token Hits Record With Zhao Pardon Buzz
A cryptocurrency with ties to Binance Holdings Ltd. struck an all-time high as speculation builds that the digital-asset exchange’s co-founder Changpeng Zhao will be granted a US presidential pardon.
VCs to AI Startups: Please Take Our Money
Private jets, box seats and big checks. Investors are doing whatever it takes to get into top AI deals.
Apple’s iPhone 17 Line Wins By Returning the Focus to Hardware
Apple Intelligence takes a backseat to fresh designs, a very thin phone and upgraded cameras.
Kenya Yet to Engage Safaricom Board on Splitting Firm, CEO Says
Kenya’s government is yet to engage the board of Safaricom Plc about a potential plan to split its biggest company into three separate firms, according to Chief Executive Officer Peter Ndegwa.
Unity Advisory Co-Founder Set to Exit Consulting Firm Months After Launch
The managing partner and co-founder of Unity Advisory is set to leave the new consultancy business, which launched in June with backing from private equity firm Warburg Pincus.
ASM International Cuts Outlook After Chip Demand Disappoints
ASM International NV cut its sales outlook for the second half of the year, citing lower-than-anticipated demand from some of the semiconductor equipment maker’s clients.
Defense Startup Auterion Raises $130 Million to Become Microsoft for Drones
Auterion, a startup that provides software to military drones, has raised $130 million to expand its operations abroad, including in geopolitical hotspots Ukraine and Taiwan, a further sign that private investors are pouring money into defense.
Trump Trade War Is Helping Jumia Access Chinese Goods, CEO Says
Jumia Technologies AG’s Chief Executive Officer Francis Dufay said the global trade war is benefiting Africa’s biggest e-commerce company by increasing its access to Chinese goods.
Nigerian Fintech Aims at US Market With Eye on African Diaspora
A Nigerian fintech firm is partnering with a US bank to enable customers to link their bank accounts in both countries via a single digital wallet.
New Thai Government Plans Stimulus, Baht Action Before Polls
Thai Prime Minister Anutin Charnvirakul’s new government will unveil plans for short-term economic stimulus to boost consumption and help those struggling with heavy debt, racing to broaden support in its next four months in power.
Huawei Plans Three-Year Campaign to Overtake Nvidia in AI Chips
Huawei Technologies Co. openly admits its silicon can’t match Nvidia Corp.’s in raw power and speed. So to pack the same punch, China’s national champion is counting on its traditional strengths: brute force, networking, and policy support.
Alibaba Tries to Draw Brands on Amazon to Its Global Site
Alibaba Group Holding Ltd. is trying to attract established brand names on Amazon.com Inc. to its global e-commerce site AliExpress, stepping up efforts to expand its footprint on the Seattle-based firm’s home turf.
Wall Street to Tap Engineers in India After $100,000 Fee
Wall Street banks are set to rely more on their Indian business support centers following President Donald Trump’s shock move to impose $100,000 fees on new applications to the widely used H-1B visa program.
Walmart-Backed Flipkart Invests $30 Million in Fintech Arm Supermoney
Flipkart India Pvt., backed by Walmart Inc., is investing $30 million in its fintech unit Supermoney as the e-commerce giant accelerates its push into lending and stock broking, according to people familiar with the matter.
An $800 Billion Revenue Shortfall Threatens AI Future, Bain Says
Artificial intelligence companies like OpenAI have been quick to unveil plans for spending hundreds of billions of dollars on data centers, but they have been slower to show how they will pull in revenue to cover all those expenses. Now, the consulting firm Bain & Co. is estimating the shortfall could be far larger than previously understood.
Social Media Giants Lose Challenge to Experts Testifying on Harm
Jurors will be allowed to hear expert testimony about the impact of social media on young users during coming trials against tech companies over alleged harm caused by their platforms, a Los Angeles judge ruled.
Nvidia, OpenAI Make $100 Billion Deal to Build Data Centers
Nvidia Corp. will invest as much as $100 billion in OpenAI to support new data centers and other artificial intelligence infrastructure, a blockbuster deal that underscores booming demand for AI tools like ChatGPT and the computing power needed to make them run.
Nvidia Says All Customers Will Be ‘Priority’ Despite OpenAI Deal
Nvidia Corp. assured customers that its landmark deal with OpenAI to invest $100 billion and expand AI infrastructure together won’t affect the chipmaker’s relationship with other clients.
Why the US is barring Iranian diplomats from shopping at Costco
As the United Nations gathers in New York, the US State Department says Iranian diplomats are barred from joining wholesale clubs.
I've had an executive Costco membership for 10 years. It pays for itself — and then some.
I've had a Costco executive membership for 10 years. The perks, like the 2% cash back reward and extra shopping hours, make it worth the $130 price.
Family-owned American diners are a dying breed. I visited 2 in New Jersey to see if they can survive.
Abby Narishkin visited two New Jersey diners to see if the dying breed American institution can survive. She left feeling more optimistic than ever.
I charge $25,000 to help students get into Ivy League colleges. Most teens are making the same mistake.
Parents pay me to help students find their core values and act on them in the real world — instead of just joining a long list of extracurriculars.
TV station owner Nexstar joins Sinclair, says it will continue not to air Jimmy Kimmel
Nexstar Media Group, one of the nation's largest local TV station owners, said it will continue to preempt "Jimmy Kimmel Live!"
Kamala Harris says Biden should've invited Elon Musk to the White House in 2021
The former VP writes in her new book that Musk set off her "spidey senses" long before his MAGA pivot in 2024.
Spirit has already axed flights and asked pilots to take a pay cut. Now it's furloughing 1,800 flight attendants.
Spirit Airlines is cutting costs wherever it can as it battles through its second bankruptcy in less than a year.
I moved to Los Angeles to live on a boat. The past 2 years haven't been all smooth sailing, but life on the water is worth it.
I live on a boat full-time in LA. There are some cons, like less space, but it's cheaper than I expected and I like the community and ocean access.
Why this startup founder scrapped her dating app to build a LinkedIn rival powered by AI
Clara Gold is the French founder behind Gigi, a new AI-powered professional social network. The startup has raised a total of $8 million.
As a psychologist, I know it's normal for parents to get angry. Here's how caregivers can handle their own big feelings.
Anger is not a character flaw in parents. As a psychologist, I know it's an emotion that's necessary for our survival.
The Chicago hotel that invented the brownie is still serving the original 1893 recipe. I've never had a brownie like it.
The brownie, inspired by the Gilded Age socialite Bertha Palmer, was created as part of the preparations for Chicago's 1893 World's Fair.
$12 billion Walleye will back a new $500 million hedge fund from a former Millennium and Citadel healthcare portfolio manager
Soren Gandrud's Jones Hill is expected to begin trading in the first quarter of 2026 with at least $500 million.
Ukraine is ready to export its weapons, like the fearsome sea drones that helped it cripple Russia's Black Sea Fleet
Ukraine sees exporting surplus weapons — like naval drones — as a way to raise funds for the weapons in short supply.
I visited Scotland for the first time. My trip was great, but it would've been better if I'd known these 5 things beforehand.
From what to pack to how to pronounce the names of certain cities, there are a few things I wish I knew before visiting Scotland for the first time.
Google's senior director of product explains how software engineering jobs are changing in the AI era
With AI shifting the role of software engineers, Google's senior director of product says more developers will be involved in deploying products.
Jimmy Kimmel's return doesn't mean the end of Disney's problems
Now that Jimmy Kimmel's show has become a lightning rod, any decision about it going forward will be viewed with a magnifying glass.
Diddy cites his 'extraordinary life' in long shot bid for freedom next month
Sean "Diddy" Combs is hoping to be sprung at next month's sentencing. A Manhattan jury convicted the hip-hop mogul of 2 prostitution-related counts.
I've been on more than 20 cruises. Here are the 9 things I never buy on board.
After going on over 20 cruises with different lines, I know to avoid spending money on unlimited drink packages and overpriced spa products.
Palmer Luckey says founders should look beyond the Bay Area to avoid hiring 'mercenary-minded' tech workers
Palmer Luckey said Bay Area hiring bred "mercenary-minded" workers. He now recruits nationwide, especially veterans, to build Anduril.
I've lived in New England my whole life. There's one town in this region I swear by visiting every fall.
My favorite fall travel location is Stowe, Vermont. I love checking out the corn mazes and visiting neighboring towns like Killington and Waterbury.
Why One VC Thinks Quantum Is a Bigger Unlock Than AGI
Venture capitalist Alexa von Tobel is ready to bet on quantum computing—starting with hardware.
How Signal’s Meredith Whittaker Remembers SignalGate: ‘No Fucking Way’
The Signal Foundation president recalls where she was when she heard Trump cabinet officials had added a journalist to a highly sensitive group chat.
$3,800 Flights and Aborted Takeoffs: How Trump’s H-1B Announcement Panicked Tech Workers
President Trump’s sudden policy shift sent tech firms scrambling to get immigrant workers back to the US and avoid $100,000 fees.
Louisiana Hands Meta a Tax Break and Power for Its Biggest Data Center
Mark Zuckerberg’s company faces backlash after rowing back promises to create between 300 and 500 new jobs to man its subsidiary’s new data center.
Palantir Wants to Be a Lifestyle Brand
Defense tech giant Palantir is selling T-shirts and tote bags as part of a bid to encourage fans to publicly endorse it.
I Thought I Knew Silicon Valley. I Was Wrong
Tech got what it wanted by electing Trump. A year later, it looks more like a suicide pact.
WIRED’s Politics Issue Cover Is Coming to a City Near You
We’re turning our latest cover into posters, billboards, and even a mural in New York, Los Angeles, Austin, San Francisco, and Washington, DC. Here’s how to find it. (Pics or it didn’t happen.)
Elon Musk Is Out to Rule Space. Can Anyone Stop Him?
With SpaceX and Starlink, Elon Musk controls more than half the world’s rocket launches and thousands of internet satellites. That amounts to immense geopolitical power.
Why OpenAI May Never Generate ROI
Unless infrastructure costs or compute requirements somehow plummet, writes guest author Eugene Malobrodsky, managing partner at One Way Ventures, the billions of realized profits are going into the pockets of the providers of GPUs, energy and other resources, not the foundation model providers.
What We’ve Learned Investing In Challenger Banks Across The Globe
Guest author Arjuna Costa of Flourish Ventures shares what he learned on his journey toward reshaping financial systems by scaling neobanks globally, and why Chime's successful Nasdaq debut proves that building consumer-first financial institutions is not only viable but necessary.
Distyl AI Raises $175M Series B At $1.8B Valuation, Up 9x From Last Funding
Distyl AI, a startup that aims to help Fortune 500 companies become “AI-native,” has raised $175 million in a Series B funding round at a $1.8 billion valuation.
Navan Is Finally Going Public For Real
On Friday, Navan (formerly TripActions) filed its first public IPO prospectus. It comes almost precisely three years after the company first reportedly submitted confidential paperwork for a planned offering.
Nvidia To Invest Up To $100B In OpenAI
Chipmaker Nvidia announced on Monday that it is investing up to $100 billion in OpenAI, but the investment reportedly comes with conditions.
With Amazon And Salesforce As Customers, Agentic AI Startup AppZen Lands $180M To ‘Transform’ Finance Teams
AppZen, which has built an agentic AI platform for finance teams, has raised $180 million in a Series D round, the company told Crunchbase News. Riverwood Capital led the growth financing round.
These Are The Speediest Companies To Go From Series A To Series C
Per Crunchbase data, the past couple of years have seen a sizable cohort of companies that have gone all the way from Series A to Series C between 2023 and this year, with several managing to scale all three stages in less than 12 months.
Market Liquidity And Middle-Market M&A: Waiting For The Breakthrough
As we enter Q4 2025, the long-awaited middle-market M&A boom many in the industry have forecasted has yet to materialize, writes guest author Michael Mufson. He questions if the Fed’s interest rate cuts will be enough to restore equilibrium between capital supply and deal demand.
Discovering Software Parallelization Points Using Deep Neural Networks
arXiv:2509.16215v1 Announce Type: new Abstract: This study proposes a deep learning-based approach for discovering loops in programming code according to their potential for parallelization. Two genetic algorithm-based code generators were developed to produce two distinct types of code: (i) independent loops, which are parallelizable, and (ii) ambiguous loops, whose dependencies are unclear, making them impossible to define if the loop is parallelizable or not. The generated code snippets were tokenized and preprocessed to ensure a robust dataset. Two deep learning models - a Deep Neural Network (DNN) and a Convolutional Neural Network (CNN) - were implemented to perform the classification. Based on 30 independent runs, a robust statistical analysis was employed to verify the expected performance of both models, DNN and CNN. The CNN showed a slightly higher mean performance, but the two models had a similar variability. Experiments with varying dataset sizes highlighted the importance of data diversity for model performance. These results demonstrate the feasibility of using deep learning to automate the identification of parallelizable structures in code, offering a promising tool for software optimization and performance improvement.
Comparison of Deterministic and Probabilistic Machine Learning Algorithms for Precise Dimensional Control and Uncertainty Quantification in Additive Manufacturing
arXiv:2509.16233v1 Announce Type: new Abstract: We present a probabilistic framework to accurately estimate dimensions of additively manufactured components. Using a dataset of 405 parts from nine production runs involving two machines, three polymer materials, and two-part configurations, we examine five key design features. To capture both design information and manufacturing variability, we employ models integrating continuous and categorical factors. For predicting Difference from Target (DFT) values, we test deterministic and probabilistic machine learning methods. Deterministic models, trained on 80% of the dataset, provide precise point estimates, with Support Vector Regression (SVR) achieving accuracy close to process repeatability. To address systematic deviations, we adopt Gaussian Process Regression (GPR) and Bayesian Neural Networks (BNNs). GPR delivers strong predictive performance and interpretability, while BNNs capture both aleatoric and epistemic uncertainties. We investigate two BNN approaches: one balancing accuracy and uncertainty capture, and another offering richer uncertainty decomposition but with lower dimensional accuracy. Our results underscore the importance of quantifying epistemic uncertainty for robust decision-making, risk assessment, and model improvement. We discuss trade-offs between GPR and BNNs in terms of predictive power, interpretability, and computational efficiency, noting that model choice depends on analytical needs. By combining deterministic precision with probabilistic uncertainty quantification, our study provides a rigorous foundation for uncertainty-aware predictive modeling in AM. This approach not only enhances dimensional accuracy but also supports reliable, risk-informed design strategies, thereby advancing data-driven manufacturing methodologies.
SubDyve: Subgraph-Driven Dynamic Propagation for Virtual Screening Enhancement Controlling False Positive
arXiv:2509.16273v1 Announce Type: new Abstract: Virtual screening (VS) aims to identify bioactive compounds from vast chemical libraries, but remains difficult in low-label regimes where only a few actives are known. Existing methods largely rely on general-purpose molecular fingerprints and overlook class-discriminative substructures critical to bioactivity. Moreover, they consider molecules independently, limiting effectiveness in low-label regimes. We introduce SubDyve, a network-based VS framework that constructs a subgraph-aware similarity network and propagates activity signals from a small known actives. When few active compounds are available, SubDyve performs iterative seed refinement, incrementally promoting new candidates based on local false discovery rate. This strategy expands the seed set with promising candidates while controlling false positives from topological bias and overexpansion. We evaluate SubDyve on ten DUD-E targets under zero-shot conditions and on the CDK7 target with a 10-million-compound ZINC dataset. SubDyve consistently outperforms existing fingerprint or embedding-based approaches, achieving margins of up to +34.0 on the BEDROC and +24.6 on the EF1% metric.
Stabilizing Information Flow Entropy: Regularization for Safe and Interpretable Autonomous Driving Perception
arXiv:2509.16277v1 Announce Type: new Abstract: Deep perception networks in autonomous driving traditionally rely on data-intensive training regimes and post-hoc anomaly detection, often disregarding fundamental information-theoretic constraints governing stable information processing. We reconceptualize deep neural encoders as hierarchical communication chains that incrementally compress raw sensory inputs into task-relevant latent features. Within this framework, we establish two theoretically justified design principles for robust perception: (D1) smooth variation of mutual information between consecutive layers, and (D2) monotonic decay of latent entropy with network depth. Our analysis shows that, under realistic architectural assumptions, particularly blocks comprising repeated layers of similar capacity, enforcing smooth information flow (D1) naturally encourages entropy decay (D2), thus ensuring stable compression. Guided by these insights, we propose Eloss, a novel entropy-based regularizer designed as a lightweight, plug-and-play training objective. Rather than marginal accuracy improvements, this approach represents a conceptual shift: it unifies information-theoretic stability with standard perception tasks, enabling explicit, principled detection of anomalous sensor inputs through entropy deviations. Experimental validation on large-scale 3D object detection benchmarks (KITTI and nuScenes) demonstrates that incorporating Eloss consistently achieves competitive or improved accuracy while dramatically enhancing sensitivity to anomalies, amplifying distribution-shift signals by up to two orders of magnitude. This stable information-compression perspective not only improves interpretability but also establishes a solid theoretical foundation for safer, more robust autonomous driving perception systems.
Architectural change in neural networks using fuzzy vertex pooling
arXiv:2509.16287v1 Announce Type: new Abstract: The process of pooling vertices involves the creation of a new vertex, which becomes adjacent to all the vertices that were originally adjacent to the endpoints of the vertices being pooled. After this, the endpoints of these vertices and all edges connected to them are removed. In this document, we introduce a formal framework for the concept of fuzzy vertex pooling (FVP) and provide an overview of its key properties with its applications to neural networks. The pooling model demonstrates remarkable efficiency in minimizing loss rapidly while maintaining competitive accuracy, even with fewer hidden layer neurons. However, this advantage diminishes over extended training periods or with larger datasets, where the model's performance tends to degrade. This study highlights the limitations of pooling in later stages of deep learning training, rendering it less effective for prolonged or large-scale applications. Consequently, pooling is recommended as a strategy for early-stage training in advanced deep learning models to leverage its initial efficiency.
Robust LLM Training Infrastructure at ByteDance
arXiv:2509.16293v1 Announce Type: new Abstract: The training scale of large language models (LLMs) has reached tens of thousands of GPUs and is still continuously expanding, enabling faster learning of larger models. Accompanying the expansion of the resource scale is the prevalence of failures (CUDA error, NaN values, job hang, etc.), which poses significant challenges to training stability. Any large-scale LLM training infrastructure should strive for minimal training interruption, efficient fault diagnosis, and effective failure tolerance to enable highly efficient continuous training. This paper presents ByteRobust, a large-scale GPU infrastructure management system tailored for robust and stable training of LLMs. It exploits the uniqueness of LLM training process and gives top priorities to detecting and recovering failures in a routine manner. Leveraging parallelisms and characteristics of LLM training, ByteRobust enables high-capacity fault tolerance, prompt fault demarcation, and localization with an effective data-driven approach, comprehensively ensuring continuous and efficient training of LLM tasks. ByteRobust is deployed on a production GPU platform with over 200,000 GPUs and achieves 97% ETTR for a three-month training job on 9,600 GPUs.
ROOT: Rethinking Offline Optimization as Distributional Translation via Probabilistic Bridge
arXiv:2509.16300v1 Announce Type: new Abstract: This paper studies the black-box optimization task which aims to find the maxima of a black-box function using a static set of its observed input-output pairs. This is often achieved via learning and optimizing a surrogate function with that offline data. Alternatively, it can also be framed as an inverse modeling task that maps a desired performance to potential input candidates that achieve it. Both approaches are constrained by the limited amount of offline data. To mitigate this limitation, we introduce a new perspective that casts offline optimization as a distributional translation task. This is formulated as learning a probabilistic bridge transforming an implicit distribution of low-value inputs (i.e., offline data) into another distribution of high-value inputs (i.e., solution candidates). Such probabilistic bridge can be learned using low- and high-value inputs sampled from synthetic functions that resemble the target function. These synthetic functions are constructed as the mean posterior of multiple Gaussian processes fitted with different parameterizations on the offline data, alleviating the data bottleneck. The proposed approach is evaluated on an extensive benchmark comprising most recent methods, demonstrating significant improvement and establishing a new state-of-the-art performance.
Auto-bidding under Return-on-Spend Constraints with Uncertainty Quantification
arXiv:2509.16324v1 Announce Type: new Abstract: Auto-bidding systems are widely used in advertising to automatically determine bid values under constraints such as total budget and Return-on-Spend (RoS) targets. Existing works often assume that the value of an ad impression, such as the conversion rate, is known. This paper considers the more realistic scenario where the true value is unknown. We propose a novel method that uses conformal prediction to quantify the uncertainty of these values based on machine learning methods trained on historical bidding data with contextual features, without assuming the data are i.i.d. This approach is compatible with current industry systems that use machine learning to predict values. Building on prediction intervals, we introduce an adjusted value estimator derived from machine learning predictions, and show that it provides performance guarantees without requiring knowledge of the true value. We apply this method to enhance existing auto-bidding algorithms with budget and RoS constraints, and establish theoretical guarantees for achieving high reward while keeping RoS violations low. Empirical results on both simulated and real-world industrial datasets demonstrate that our approach improves performance while maintaining computational efficiency.
Highly Imbalanced Regression with Tabular Data in SEP and Other Applications
arXiv:2509.16339v1 Announce Type: new Abstract: We investigate imbalanced regression with tabular data that have an imbalance ratio larger than 1,000 ("highly imbalanced"). Accurately estimating the target values of rare instances is important in applications such as forecasting the intensity of rare harmful Solar Energetic Particle (SEP) events. For regression, the MSE loss does not consider the correlation between predicted and actual values. Typical inverse importance functions allow only convex functions. Uniform sampling might yield mini-batches that do not have rare instances. We propose CISIR that incorporates correlation, Monotonically Decreasing Involution (MDI) importance, and stratified sampling. Based on five datasets, our experimental results indicate that CISIR can achieve lower error and higher correlation than some recent methods. Also, adding our correlation component to other recent methods can improve their performance. Lastly, MDI importance can outperform other importance functions. Our code can be found in https://github.com/Machine-Earning/CISIR.
Estimating Clinical Lab Test Result Trajectories from PPG using Physiological Foundation Model and Patient-Aware State Space Model -- a UNIPHY+ Approach
arXiv:2509.16345v1 Announce Type: new Abstract: Clinical laboratory tests provide essential biochemical measurements for diagnosis and treatment, but are limited by intermittent and invasive sampling. In contrast, photoplethysmogram (PPG) is a non-invasive, continuously recorded signal in intensive care units (ICUs) that reflects cardiovascular dynamics and can serve as a proxy for latent physiological changes. We propose UNIPHY+Lab, a framework that combines a large-scale PPG foundation model for local waveform encoding with a patient-aware Mamba model for long-range temporal modeling. Our architecture addresses three challenges: (1) capturing extended temporal trends in laboratory values, (2) accounting for patient-specific baseline variation via FiLM-modulated initial states, and (3) performing multi-task estimation for interrelated biomarkers. We evaluate our method on the two ICU datasets for predicting the five key laboratory tests. The results show substantial improvements over the LSTM and carry-forward baselines in MAE, RMSE, and $R^2$ among most of the estimation targets. This work demonstrates the feasibility of continuous, personalized lab value estimation from routine PPG monitoring, offering a pathway toward non-invasive biochemical surveillance in critical care.
Improving Deep Tabular Learning
arXiv:2509.16354v1 Announce Type: new Abstract: Tabular data remain a dominant form of real-world information but pose persistent challenges for deep learning due to heterogeneous feature types, lack of natural structure, and limited label-preserving augmentations. As a result, ensemble models based on decision trees continue to dominate benchmark leaderboards. In this work, we introduce RuleNet, a transformer-based architecture specifically designed for deep tabular learning. RuleNet incorporates learnable rule embeddings in a decoder, a piecewise linear quantile projection for numerical features, and feature masking ensembles for robustness and uncertainty estimation. Evaluated on eight benchmark datasets, RuleNet matches or surpasses state-of-the-art tree-based methods in most cases, while remaining computationally efficient, offering a practical neural alternative for tabular prediction tasks.
Guided Sequence-Structure Generative Modeling for Iterative Antibody Optimization
arXiv:2509.16357v1 Announce Type: new Abstract: Therapeutic antibody candidates often require extensive engineering to improve key functional and developability properties before clinical development. This can be achieved through iterative design, where starting molecules are optimized over several rounds of in vitro experiments. While protein structure can provide a strong inductive bias, it is rarely used in iterative design due to the lack of structural data for continually evolving lead molecules over the course of optimization. In this work, we propose a strategy for iterative antibody optimization that leverages both sequence and structure as well as accumulating lab measurements of binding and developability. Building on prior work, we first train a sequence-structure diffusion generative model that operates on antibody-antigen complexes. We then outline an approach to use this model, together with carefully predicted antibody-antigen complexes, to optimize lead candidates throughout the iterative design process. Further, we describe a guided sampling approach that biases generation toward desirable properties by integrating models trained on experimental data from iterative design. We evaluate our approach in multiple in silico and in vitro experiments, demonstrating that it produces high-affinity binders at multiple stages of an active antibody optimization campaign.
EMPEROR: Efficient Moment-Preserving Representation of Distributions
arXiv:2509.16379v1 Announce Type: new Abstract: We introduce EMPEROR (Efficient Moment-Preserving Representation of Distributions), a mathematically rigorous and computationally efficient framework for representing high-dimensional probability measures arising in neural network representations. Unlike heuristic global pooling operations, EMPEROR encodes a feature distribution through its statistical moments. Our approach leverages the theory of sliced moments: features are projected onto multiple directions, lightweight univariate Gaussian mixture models (GMMs) are fit to each projection, and the resulting slice parameters are aggregated into a compact descriptor. We establish determinacy guarantees via Carleman's condition and the Cram\'er-Wold theorem, ensuring that the GMM is uniquely determined by its sliced moments, and we derive finite-sample error bounds that scale optimally with the number of slices and samples. Empirically, EMPEROR captures richer distributional information than common pooling schemes across various data modalities, while remaining computationally efficient and broadly applicable.
CoUn: Empowering Machine Unlearning via Contrastive Learning
arXiv:2509.16391v1 Announce Type: new Abstract: Machine unlearning (MU) aims to remove the influence of specific "forget" data from a trained model while preserving its knowledge of the remaining "retain" data. Existing MU methods based on label manipulation or model weight perturbations often achieve limited unlearning effectiveness. To address this, we introduce CoUn, a novel MU framework inspired by the observation that a model retrained from scratch using only retain data classifies forget data based on their semantic similarity to the retain data. CoUn emulates this behavior by adjusting learned data representations through contrastive learning (CL) and supervised learning, applied exclusively to retain data. Specifically, CoUn (1) leverages semantic similarity between data samples to indirectly adjust forget representations using CL, and (2) maintains retain representations within their respective clusters through supervised learning. Extensive experiments across various datasets and model architectures show that CoUn consistently outperforms state-of-the-art MU baselines in unlearning effectiveness. Additionally, integrating our CL module into existing baselines empowers their unlearning effectiveness.
Federated Learning for Financial Forecasting
arXiv:2509.16393v1 Announce Type: new Abstract: This paper studies Federated Learning (FL) for binary classification of volatile financial market trends. Using a shared Long Short-Term Memory (LSTM) classifier, we compare three scenarios: (i) a centralized model trained on the union of all data, (ii) a single-agent model trained on an individual data subset, and (iii) a privacy-preserving FL collaboration in which agents exchange only model updates, never raw data. We then extend the study with additional market features, deliberately introducing not independent and identically distributed data (non-IID) across agents, personalized FL and employing differential privacy. Our numerical experiments show that FL achieves accuracy and generalization on par with the centralized baseline, while significantly outperforming the single-agent model. The results show that collaborative, privacy-preserving learning provides collective tangible value in finance, even under realistic data heterogeneity and personalization requirements.
GRID: Graph-based Reasoning for Intervention and Discovery in Built Environments
arXiv:2509.16397v1 Announce Type: new Abstract: Manual HVAC fault diagnosis in commercial buildings takes 8-12 hours per incident and achieves only 60 percent diagnostic accuracy, reflecting analytics that stop at correlation instead of causation. To close this gap, we present GRID (Graph-based Reasoning for Intervention and Discovery), a three-stage causal discovery pipeline that combines constraint-based search, neural structural equation modeling, and language model priors to recover directed acyclic graphs from building sensor data. Across six benchmarks: synthetic rooms, EnergyPlus simulation, the ASHRAE Great Energy Predictor III dataset, and a live office testbed, GRID achieves F1 scores ranging from 0.65 to 1.00, with exact recovery (F1 = 1.00) in three controlled environments (Base, Hidden, Physical) and strong performance on real-world data (F1 = 0.89 on ASHRAE, 0.86 in noisy conditions). The method outperforms ten baseline approaches across all evaluation scenarios. Intervention scheduling achieves low operational impact in most scenarios (cost <= 0.026) while reducing risk metrics compared to baseline approaches. The framework integrates constraint-based methods, neural architectures, and domain-specific language model prompts to address the observational-causal gap in building analytics.
Local Mechanisms of Compositional Generalization in Conditional Diffusion
arXiv:2509.16447v1 Announce Type: new Abstract: Conditional diffusion models appear capable of compositional generalization, i.e., generating convincing samples for out-of-distribution combinations of conditioners, but the mechanisms underlying this ability remain unclear. To make this concrete, we study length generalization, the ability to generate images with more objects than seen during training. In a controlled CLEVR setting (Johnson et al., 2017), we find that length generalization is achievable in some cases but not others, suggesting that models only sometimes learn the underlying compositional structure. We then investigate locality as a structural mechanism for compositional generalization. Prior works proposed score locality as a mechanism for creativity in unconditional diffusion models (Kamb & Ganguli, 2024; Niedoba et al., 2024), but did not address flexible conditioning or compositional generalization. In this paper, we prove an exact equivalence between a specific compositional structure ("conditional projective composition") (Bradley et al., 2025) and scores with sparse dependencies on both pixels and conditioners ("local conditional scores"). This theory also extends to feature-space compositionality. We validate our theory empirically: CLEVR models that succeed at length generalization exhibit local conditional scores, while those that fail do not. Furthermore, we show that a causal intervention explicitly enforcing local conditional scores restores length generalization in a previously failing model. Finally, we investigate feature-space compositionality in color-conditioned CLEVR, and find preliminary evidence of compositional structure in SDXL.
Entropic Causal Inference: Graph Identifiability
arXiv:2509.16463v1 Announce Type: new Abstract: Entropic causal inference is a recent framework for learning the causal graph between two variables from observational data by finding the information-theoretically simplest structural explanation of the data, i.e., the model with smallest entropy. In our work, we first extend the causal graph identifiability result in the two-variable setting under relaxed assumptions. We then show the first identifiability result using the entropic approach for learning causal graphs with more than two nodes. Our approach utilizes the property that ancestrality between a source node and its descendants can be determined using the bivariate entropic tests. We provide a sound sequential peeling algorithm for general graphs that relies on this property. We also propose a heuristic algorithm for small graphs that shows strong empirical performance. We rigorously evaluate the performance of our algorithms on synthetic data generated from a variety of models, observing improvement over prior work. Finally we test our algorithms on real-world datasets.
Towards Universal Debiasing for Language Models-based Tabular Data Generation
arXiv:2509.16475v1 Announce Type: new Abstract: Large language models (LLMs) have achieved promising results in tabular data generation. However, inherent historical biases in tabular datasets often cause LLMs to exacerbate fairness issues, particularly when multiple advantaged and protected features are involved. In this work, we introduce a universal debiasing framework that minimizes group-level dependencies by simultaneously reducing the mutual information between advantaged and protected attributes. By leveraging the autoregressive structure and analytic sampling distributions of LLM-based tabular data generators, our approach efficiently computes mutual information, reducing the need for cumbersome numerical estimations. Building on this foundation, we propose two complementary methods: a direct preference optimization (DPO)-based strategy, namely UDF-DPO, that integrates seamlessly with existing models, and a targeted debiasing technique, namely UDF-MIX, that achieves debiasing without tuning the parameters of LLMs. Extensive experiments demonstrate that our framework effectively balances fairness and utility, offering a scalable and practical solution for debiasing in high-stakes applications.
Revisiting Broken Windows Theory
arXiv:2509.16490v1 Announce Type: new Abstract: We revisit the longstanding question of how physical structures in urban landscapes influence crime. Leveraging machine learning-based matching techniques to control for demographic composition, we estimate the effects of several types of urban structures on the incidence of violent crime in New York City and Chicago. We additionally contribute to a growing body of literature documenting the relationship between perception of crime and actual crime rates by separately analyzing how the physical urban landscape shapes subjective feelings of safety. Our results are twofold. First, in consensus with prior work, we demonstrate a "broken windows" effect in which abandoned buildings, a sign of social disorder, are associated with both greater incidence of crime and a heightened perception of danger. This is also true of types of urban structures that draw foot traffic such as public transportation infrastructure. Second, these effects are not uniform within or across cities. The criminogenic effects of the same structure types across two cities differ in magnitude, degree of spatial localization, and heterogeneity across subgroups, while within the same city, the effects of different structure types are confounded by different demographic variables. Taken together, these results emphasize that one-size-fits-all approaches to crime reduction are untenable and policy interventions must be specifically tailored to their targets.
FairTune: A Bias-Aware Fine-Tuning Framework Towards Fair Heart Rate Prediction from PPG
arXiv:2509.16491v1 Announce Type: new Abstract: Foundation models pretrained on physiological data such as photoplethysmography (PPG) signals are increasingly used to improve heart rate (HR) prediction across diverse settings. Fine-tuning these models for local deployment is often seen as a practical and scalable strategy. However, its impact on demographic fairness particularly under domain shifts remains underexplored. We fine-tune PPG-GPT a transformer-based foundation model pretrained on intensive care unit (ICU) data across three heterogeneous datasets (ICU, wearable, smartphone) and systematically evaluate the effects on HR prediction accuracy and gender fairness. While fine-tuning substantially reduces mean absolute error (up to 80%), it can simultaneously widen fairness gaps, especially in larger models and under significant distributional characteristics shifts. To address this, we introduce FairTune, a bias-aware fine-tuning framework in which we benchmark three mitigation strategies: class weighting based on inverse group frequency (IF), Group Distributionally Robust Optimization (GroupDRO), and adversarial debiasing (ADV). We find that IF and GroupDRO significantly reduce fairness gaps without compromising accuracy, with effectiveness varying by deployment domain. Representation analyses further reveal that mitigation techniques reshape internal embeddings to reduce demographic clustering. Our findings highlight that fairness does not emerge as a natural byproduct of fine-tuning and that explicit mitigation is essential for equitable deployment of physiological foundation models.
A Closer Look at Model Collapse: From a Generalization-to-Memorization Perspective
arXiv:2509.16499v1 Announce Type: new Abstract: The widespread use of diffusion models has led to an abundance of AI-generated data, raising concerns about model collapse -- a phenomenon in which recursive iterations of training on synthetic data lead to performance degradation. Prior work primarily characterizes this collapse via variance shrinkage or distribution shift, but these perspectives miss practical manifestations of model collapse. This paper identifies a transition from generalization to memorization during model collapse in diffusion models, where models increasingly replicate training data instead of generating novel content during iterative training on synthetic samples. This transition is directly driven by the declining entropy of the synthetic training data produced in each training cycle, which serves as a clear indicator of model degradation. Motivated by this insight, we propose an entropy-based data selection strategy to mitigate the transition from generalization to memorization and alleviate model collapse. Empirical results show that our approach significantly enhances visual quality and diversity in recursive generation, effectively preventing collapse.
GRIL: Knowledge Graph Retrieval-Integrated Learning with Large Language Models
arXiv:2509.16502v1 Announce Type: new Abstract: Retrieval-Augmented Generation (RAG) has significantly mitigated the hallucinations of Large Language Models (LLMs) by grounding the generation with external knowledge. Recent extensions of RAG to graph-based retrieval offer a promising direction, leveraging the structural knowledge for multi-hop reasoning. However, existing graph RAG typically decouples retrieval and reasoning processes, which prevents the retriever from adapting to the reasoning needs of the LLM. They also struggle with scalability when performing multi-hop expansion over large-scale graphs, or depend heavily on annotated ground-truth entities, which are often unavailable in open-domain settings. To address these challenges, we propose a novel graph retriever trained end-to-end with LLM, which features an attention-based growing and pruning mechanism, adaptively navigating multi-hop relevant entities while filtering out noise. Within the extracted subgraph, structural knowledge and semantic features are encoded via soft tokens and the verbalized graph, respectively, which are infused into the LLM together, thereby enhancing its reasoning capability and facilitating interactive joint training of the graph retriever and the LLM reasoner. Experimental results across three QA benchmarks show that our approach consistently achieves state-of-the-art performance, validating the strength of joint graph-LLM optimization for complex reasoning tasks. Notably, our framework eliminates the need for predefined ground-truth entities by directly optimizing the retriever using LLM logits as implicit feedback, making it especially effective in open-domain settings.
Federated Learning with Ad-hoc Adapter Insertions: The Case of Soft-Embeddings for Training Classifier-as-Retriever
arXiv:2509.16508v1 Announce Type: new Abstract: When existing retrieval-augmented generation (RAG) solutions are intended to be used for new knowledge domains, it is necessary to update their encoders, which are taken to be pretrained large language models (LLMs). However, fully finetuning these large models is compute- and memory-intensive, and even infeasible when deployed on resource-constrained edge devices. We propose a novel encoder architecture in this work that addresses this limitation by using a frozen small language model (SLM), which satisfies the memory constraints of edge devices, and inserting a small adapter network before the transformer blocks of the SLM. The trainable adapter takes the token embeddings of the new corpus and learns to produce enhanced soft embeddings for it, while requiring significantly less compute power to update than full fine-tuning. We further propose a novel retrieval mechanism by attaching a classifier head to the SLM encoder, which is trained to learn a similarity mapping of the input embeddings to their corresponding documents. Finally, to enable the online fine-tuning of both (i) the encoder soft embeddings and (ii) the classifier-as-retriever on edge devices, we adopt federated learning (FL) and differential privacy (DP) to achieve an efficient, privacy-preserving, and product-grade training solution. We conduct a theoretical analysis of our methodology, establishing convergence guarantees under mild assumptions on gradient variance when deployed for general smooth nonconvex loss functions. Through extensive numerical experiments, we demonstrate (i) the efficacy of obtaining soft embeddings to enhance the encoder, (ii) training a classifier to improve the retriever, and (iii) the role of FL in achieving speedup.
LLM-Guided Co-Training for Text Classification
arXiv:2509.16516v1 Announce Type: new Abstract: In this paper, we introduce a novel weighted co-training approach that is guided by Large Language Models (LLMs). Namely, in our co-training approach, we use LLM labels on unlabeled data as target labels and co-train two encoder-only based networks that train each other over multiple iterations: first, all samples are forwarded through each network and historical estimates of each network's confidence in the LLM label are recorded; second, a dynamic importance weight is derived for each sample according to each network's belief in the quality of the LLM label for that sample; finally, the two networks exchange importance weights with each other -- each network back-propagates all samples weighted with the importance weights coming from its peer network and updates its own parameters. By strategically utilizing LLM-generated guidance, our approach significantly outperforms conventional SSL methods, particularly in settings with abundant unlabeled data. Empirical results show that it achieves state-of-the-art performance on 4 out of 5 benchmark datasets and ranks first among 14 compared methods according to the Friedman test. Our results highlight a new direction in semi-supervised learning -- where LLMs serve as knowledge amplifiers, enabling backbone co-training models to achieve state-of-the-art performance efficiently.
mmExpert: Integrating Large Language Models for Comprehensive mmWave Data Synthesis and Understanding
arXiv:2509.16521v1 Announce Type: new Abstract: Millimeter-wave (mmWave) sensing technology holds significant value in human-centric applications, yet the high costs associated with data acquisition and annotation limit its widespread adoption in our daily lives. Concurrently, the rapid evolution of large language models (LLMs) has opened up opportunities for addressing complex human needs. This paper presents mmExpert, an innovative mmWave understanding framework consisting of a data generation flywheel that leverages LLMs to automate the generation of synthetic mmWave radar datasets for specific application scenarios, thereby training models capable of zero-shot generalization in real-world environments. Extensive experiments demonstrate that the data synthesized by mmExpert significantly enhances the performance of downstream models and facilitates the successful deployment of large models for mmWave understanding.
SCAN: Self-Denoising Monte Carlo Annotation for Robust Process Reward Learning
arXiv:2509.16548v1 Announce Type: new Abstract: Process reward models (PRMs) offer fine-grained, step-level evaluations that facilitate deeper reasoning processes in large language models (LLMs), proving effective in complex tasks like mathematical reasoning. However, developing PRMs is challenging due to the high cost and limited scalability of human-annotated data. Synthetic data from Monte Carlo (MC) estimation is a promising alternative but suffers from a high noise ratio, which can cause overfitting and hinder large-scale training. In this work, we conduct a preliminary study on the noise distribution in synthetic data from MC estimation, identifying that annotation models tend to both underestimate and overestimate step correctness due to limitations in their annotation capabilities. Building on these insights, we propose Self-Denoising Monte Carlo Annotation (SCAN), an efficient data synthesis and noise-tolerant learning framework. Our key findings indicate that: (1) Even lightweight models (e.g., 1.5B parameters) can produce high-quality annotations through a self-denoising strategy, enabling PRMs to achieve superior performance with only 6% the inference cost required by vanilla MC estimation. (2) With our robust learning strategy, PRMs can effectively learn from this weak supervision, achieving a 39.2 F1 score improvement (from 19.9 to 59.1) in ProcessBench. Despite using only a compact synthetic dataset, our models surpass strong baselines, including those trained on large-scale human-annotated datasets such as PRM800K. Furthermore, performance continues to improve as we scale up the synthetic data, highlighting the potential of SCAN for scalable, cost-efficient, and robust PRM training.
ViTCAE: ViT-based Class-conditioned Autoencoder
arXiv:2509.16554v1 Announce Type: new Abstract: Vision Transformer (ViT) based autoencoders often underutilize the global Class token and employ static attention mechanisms, limiting both generative control and optimization efficiency. This paper introduces ViTCAE, a framework that addresses these issues by re-purposing the Class token into a generative linchpin. In our architecture, the encoder maps the Class token to a global latent variable that dictates the prior distribution for local, patch-level latent variables, establishing a robust dependency where global semantics directly inform the synthesis of local details. Drawing inspiration from opinion dynamics, we treat each attention head as a dynamical system of interacting tokens seeking consensus. This perspective motivates a convergence-aware temperature scheduler that adaptively anneals each head's influence function based on its distributional stability. This process enables a principled head-freezing mechanism, guided by theoretically-grounded diagnostics like an attention evolution distance and a consensus/cluster functional. This technique prunes converged heads during training to significantly improve computational efficiency without sacrificing fidelity. By unifying a generative Class token with an adaptive attention mechanism rooted in multi-agent consensus theory, ViTCAE offers a more efficient and controllable approach to transformer-based generation.
Learned Digital Codes for Over-the-Air Federated Learning
arXiv:2509.16577v1 Announce Type: new Abstract: Federated edge learning (FEEL) enables distributed model training across wireless devices without centralising raw data, but deployment is constrained by the wireless uplink. A promising direction is over-the-air (OTA) aggregation, which merges communication with computation. Existing digital OTA methods can achieve either strong convergence or robustness to noise, but struggle to achieve both simultaneously, limiting performance in low signal-to-noise ratios (SNRs) where many IoT devices operate. This work proposes a learnt digital OTA framework that extends reliable operation into low-SNR conditions while maintaining the same uplink overhead as state-of-the-art. The proposed method combines an unrolled decoder with a jointly learnt unsourced random access codebook. Results show an extension of reliable operation by more than 7 dB, with improved global model convergence across all SNR levels, highlighting the potential of learning-based design for FEEL.
Near-Optimal Sample Complexity Bounds for Constrained Average-Reward MDPs
arXiv:2509.16586v1 Announce Type: new Abstract: Recent advances have significantly improved our understanding of the sample complexity of learning in average-reward Markov decision processes (AMDPs) under the generative model. However, much less is known about the constrained average-reward MDP (CAMDP), where policies must satisfy long-run average constraints. In this work, we address this gap by studying the sample complexity of learning an $\epsilon$-optimal policy in CAMDPs under a generative model. We propose a model-based algorithm that operates under two settings: (i) relaxed feasibility, which allows small constraint violations, and (ii) strict feasibility, where the output policy satisfies the constraint. We show that our algorithm achieves sample complexities of $\tilde{O}\left(\frac{S A (B+H)}{ \epsilon^2}\right)$ and $\tilde{O} \left(\frac{S A (B+H)}{\epsilon^2 \zeta^2} \right)$ under the relaxed and strict feasibility settings, respectively. Here, $\zeta$ is the Slater constant indicating the size of the feasible region, $H$ is the span bound of the bias function, and $B$ is the transient time bound. Moreover, a matching lower bound of $\tilde{\Omega}\left(\frac{S A (B+H)}{ \epsilon^2\zeta^2}\right)$ for the strict feasibility case is established, thus providing the first minimax-optimal bounds for CAMDPs. Our results close the theoretical gap in understanding the complexity of constrained average-reward MDPs.
Self-Supervised Learning of Graph Representations for Network Intrusion Detection
arXiv:2509.16625v1 Announce Type: new Abstract: Detecting intrusions in network traffic is a challenging task, particularly under limited supervision and constantly evolving attack patterns. While recent works have leveraged graph neural networks for network intrusion detection, they often decouple representation learning from anomaly detection, limiting the utility of the embeddings for identifying attacks. We propose GraphIDS, a self-supervised intrusion detection model that unifies these two stages by learning local graph representations of normal communication patterns through a masked autoencoder. An inductive graph neural network embeds each flow with its local topological context to capture typical network behavior, while a Transformer-based encoder-decoder reconstructs these embeddings, implicitly learning global co-occurrence patterns via self-attention without requiring explicit positional information. During inference, flows with unusually high reconstruction errors are flagged as potential intrusions. This end-to-end framework ensures that embeddings are directly optimized for the downstream task, facilitating the recognition of malicious traffic. On diverse NetFlow benchmarks, GraphIDS achieves up to 99.98% PR-AUC and 99.61% macro F1-score, outperforming baselines by 5-25 percentage points.
Causality-Induced Positional Encoding for Transformer-Based Representation Learning of Non-Sequential Features
arXiv:2509.16629v1 Announce Type: new Abstract: Positional encoding is essential for supplementing transformer with positional information of tokens. Existing positional encoding methods demand predefined token/feature order, rendering them unsuitable for real-world data with non-sequential yet causally-related features. To address this limitation, we propose CAPE, a novel method that identifies underlying causal structure over non-sequential features as a weighted directed acyclic graph (DAG) using generalized structural equation modeling. The DAG is then embedded in hyperbolic space where its geometric structure is well-preserved using a hyperboloid model-based approach that effectively captures two important causal graph properties (causal strength & causal specificity). This step yields causality-aware positional encodings for the features, which are converted into their rotary form for integrating with transformer's self-attention mechanism. Theoretical analysis reveals that CAPE-generated rotary positional encodings possess three valuable properties for enhanced self-attention, including causal distance-induced attenuation, causal generality-induced attenuation, and robustness to positional disturbances. We evaluate CAPE over both synthetic and real-word datasets, empirically demonstrating its theoretical properties and effectiveness in enhancing transformer for data with non-sequential features. Our code is available at https://github.com/Catchxu/CAPE.
$\boldsymbol{\lambda}$-Orthogonality Regularization for Compatible Representation Learning
arXiv:2509.16664v1 Announce Type: new Abstract: Retrieval systems rely on representations learned by increasingly powerful models. However, due to the high training cost and inconsistencies in learned representations, there is significant interest in facilitating communication between representations and ensuring compatibility across independently trained neural networks. In the literature, two primary approaches are commonly used to adapt different learned representations: affine transformations, which adapt well to specific distributions but can significantly alter the original representation, and orthogonal transformations, which preserve the original structure with strict geometric constraints but limit adaptability. A key challenge is adapting the latent spaces of updated models to align with those of previous models on downstream distributions while preserving the newly learned representation spaces. In this paper, we impose a relaxed orthogonality constraint, namely $\lambda$-orthogonality regularization, while learning an affine transformation, to obtain distribution-specific adaptation while retaining the original learned representations. Extensive experiments across various architectures and datasets validate our approach, demonstrating that it preserves the model's zero-shot performance and ensures compatibility across model updates. Code available at: https://github.com/miccunifi/lambda_orthogonality
HypeMARL: Multi-Agent Reinforcement Learning For High-Dimensional, Parametric, and Distributed Systems
arXiv:2509.16709v1 Announce Type: new Abstract: Deep reinforcement learning has recently emerged as a promising feedback control strategy for complex dynamical systems governed by partial differential equations (PDEs). When dealing with distributed, high-dimensional problems in state and control variables, multi-agent reinforcement learning (MARL) has been proposed as a scalable approach for breaking the curse of dimensionality. In particular, through decentralized training and execution, multiple agents cooperate to steer the system towards a target configuration, relying solely on local state and reward information. However, the principle of locality may become a limiting factor whenever a collective, nonlocal behavior of the agents is crucial to maximize the reward function, as typically happens in PDE-constrained optimal control problems. In this work, we propose HypeMARL: a decentralized MARL algorithm tailored to the control of high-dimensional, parametric, and distributed systems. HypeMARL employs hypernetworks to effectively parametrize the agents' policies and value functions with respect to the system parameters and the agents' relative positions, encoded by sinusoidal positional encoding. Through the application on challenging control problems, such as density and flow control, we show that HypeMARL (i) can effectively control systems through a collective behavior of the agents, outperforming state-of-the-art decentralized MARL, (ii) can efficiently deal with parametric dependencies, (iii) requires minimal hyperparameter tuning and (iv) can reduce the amount of expensive environment interactions by a factor of ~10 thanks to its model-based extension, MB-HypeMARL, which relies on computationally efficient deep learning-based surrogate models approximating the dynamics locally, with minimal deterioration of the policy performance.
A Hybrid PCA-PR-Seq2Seq-Adam-LSTM Framework for Time-Series Power Outage Prediction
arXiv:2509.16743v1 Announce Type: new Abstract: Accurately forecasting power outages is a complex task influenced by diverse factors such as weather conditions [1], vegetation, wildlife, and load fluctuations. These factors introduce substantial variability and noise into outage data, making reliable prediction challenging. Long Short-Term Memory (LSTM) networks, a type of Recurrent Neural Network (RNN), are particularly effective for modeling nonlinear and dynamic time-series data, with proven applications in stock price forecasting [2], energy demand prediction, demand response [3], and traffic flow management [4]. This paper introduces a hybrid deep learning framework, termed PCA-PR-Seq2Seq-Adam-LSTM, that integrates Principal Component Analysis (PCA), Poisson Regression (PR), a Sequence-to-Sequence (Seq2Seq) architecture, and an Adam-optimized LSTM. PCA is employed to reduce dimensionality and stabilize data variance, while Poisson Regression effectively models discrete outage events. The Seq2Seq-Adam-LSTM component enhances temporal feature learning through efficient gradient optimization and long-term dependency capture. The framework is evaluated using real-world outage records from Michigan, and results indicate that the proposed approach significantly improves forecasting accuracy and robustness compared to existing methods.
Interpretable Clinical Classification with Kolgomorov-Arnold Networks
arXiv:2509.16750v1 Announce Type: new Abstract: Why should a clinician trust an Artificial Intelligence (AI) prediction? Despite the increasing accuracy of machine learning methods in medicine, the lack of transparency continues to hinder their adoption in clinical practice. In this work, we explore Kolmogorov-Arnold Networks (KANs) for clinical classification tasks on tabular data. Unlike traditional neural networks, KANs are function-based architectures that offer intrinsic interpretability through transparent, symbolic representations. We introduce Logistic-KAN, a flexible generalization of logistic regression, and Kolmogorov-Arnold Additive Model (KAAM), a simplified additive variant that delivers transparent, symbolic formulas. Unlike black-box models that require post-hoc explainability tools, our models support built-in patient-level insights, intuitive visualizations, and nearest-patient retrieval. Across multiple health datasets, our models match or outperform standard baselines, while remaining fully interpretable. These results position KANs as a promising step toward trustworthy AI that clinicians can understand, audit, and act upon.
Discrete Diffusion Models: Novel Analysis and New Sampler Guarantees
arXiv:2509.16756v1 Announce Type: new Abstract: Discrete diffusion models have recently gained significant prominence in applications involving natural language and graph data. A key factor influencing their effectiveness is the efficiency of discretized samplers. Among these, $\tau$-leaping samplers have become particularly popular due to their empirical success. However, existing theoretical analyses of $\tau$-leaping often rely on somewhat restrictive and difficult-to-verify regularity assumptions, and their convergence bounds contain quadratic dependence on the vocabulary size. In this work, we introduce a new analytical approach for discrete diffusion models that removes the need for such assumptions. For the standard $\tau$-leaping method, we establish convergence guarantees in KL divergence that scale linearly with vocabulary size, improving upon prior results with quadratic dependence. Our approach is also more broadly applicable: it provides the first convergence guarantees for other widely used samplers, including the Euler method and Tweedie $\tau$-leaping. Central to our approach is a novel technique based on differential inequalities, offering a more flexible alternative to the traditional Girsanov change-of-measure methods. This technique may also be of independent interest for the analysis of other stochastic processes.
Geometric Mixture Classifier (GMC): A Discriminative Per-Class Mixture of Hyperplanes
arXiv:2509.16769v1 Announce Type: new Abstract: Many real world categories are multimodal, with single classes occupying disjoint regions in feature space. Classical linear models (logistic regression, linear SVM) use a single global hyperplane and perform poorly on such data, while high-capacity methods (kernel SVMs, deep nets) fit multimodal structure but at the expense of interpretability, heavier tuning, and higher computational cost. We propose the Geometric Mixture Classifier (GMC), a discriminative model that represents each class as a mixture of hyperplanes. Within each class, GMC combines plane scores via a temperature-controlled soft-OR (log-sum-exp), smoothly approximating the max; across classes, standard softmax yields probabilistic posteriors. GMC optionally uses Random Fourier Features (RFF) for nonlinear mappings while keeping inference linear in the number of planes and features. Our practical training recipe: geometry-aware k-means initialization, silhouette-based plane budgeting, alpha annealing, usage-aware L2 regularization, label smoothing, and early stopping, makes GMC plug-and-play. Across synthetic multimodal datasets (moons, circles, blobs, spirals) and tabular/image benchmarks (iris, wine, WDBC, digits), GMC consistently outperforms linear baselines and k-NN, is competitive with RBF-SVM, Random Forests, and small MLPs, and provides geometric introspection via per-plane and class responsibility visualizations. Inference scales linearly in planes and features, making GMC CPU-friendly, with single-digit microsecond latency per example, often faster than RBF-SVM and compact MLPs. Post-hoc temperature scaling reduces ECE from about 0.06 to 0.02. GMC thus strikes a favorable balance of accuracy, interpretability, and efficiency: it is more expressive than linear models and lighter, more transparent, and faster than kernel or deep models.
DISCO: Disentangled Communication Steering for Large Language Models
arXiv:2509.16820v1 Announce Type: new Abstract: A variety of recent methods guide large language model outputs via the inference-time addition of steering vectors to residual-stream or attention-head representations. In contrast, we propose to inject steering vectors directly into the query and value representation spaces within attention heads. We provide evidence that a greater portion of these spaces exhibit high linear discriminability of concepts --a key property motivating the use of steering vectors-- than attention head outputs. We analytically characterize the effect of our method, which we term DISentangled COmmunication (DISCO) Steering, on attention head outputs. Our analysis reveals that DISCO disentangles a strong but underutilized baseline, steering attention inputs, which implicitly modifies queries and values in a rigid manner. In contrast, DISCO's direct modulation of these components enables more granular control. We find that DISCO achieves superior performance over a number of steering vector baselines across multiple datasets on LLaMA 3.1 8B and Gemma 2 9B, with steering efficacy scoring up to 19.1% higher than the runner-up. Our results support the conclusion that the query and value spaces are powerful building blocks for steering vector methods.
KANO: Kolmogorov-Arnold Neural Operator
arXiv:2509.16825v1 Announce Type: new Abstract: We introduce Kolmogorov--Arnold Neural Operator (KANO), a dual-domain neural operator jointly parameterized by both spectral and spatial bases with intrinsic symbolic interpretability. We theoretically demonstrate that KANO overcomes the pure-spectral bottleneck of Fourier Neural Operator (FNO): KANO remains expressive over generic position-dependent dynamics for any physical input, whereas FNO stays practical only for spectrally sparse operators and strictly imposes a fast-decaying input Fourier tail. We verify our claims empirically on position-dependent differential operators, for which KANO robustly generalizes but FNO fails to. In the quantum Hamiltonian learning benchmark, KANO reconstructs ground-truth Hamiltonians in closed-form symbolic representations accurate to the fourth decimal place in coefficients and attains $\approx 6\times10^{-6}$ state infidelity from projective measurement data, substantially outperforming that of the FNO trained with ideal full wave function data, $\approx 1.5\times10^{-2}$, by orders of magnitude.
SOLAR: Switchable Output Layer for Accuracy and Robustness in Once-for-All Training
arXiv:2509.16833v1 Announce Type: new Abstract: Once-for-All (OFA) training enables a single super-net to generate multiple sub-nets tailored to diverse deployment scenarios, supporting flexible trade-offs among accuracy, robustness, and model-size without retraining. However, as the number of supported sub-nets increases, excessive parameter sharing in the backbone limits representational capacity, leading to degraded calibration and reduced overall performance. To address this, we propose SOLAR (Switchable Output Layer for Accuracy and Robustness in Once-for-All Training), a simple yet effective technique that assigns each sub-net a separate classification head. By decoupling the logit learning process across sub-nets, the Switchable Output Layer (SOL) reduces representational interference and improves optimization, without altering the shared backbone. We evaluate SOLAR on five datasets (SVHN, CIFAR-10, STL-10, CIFAR-100, and TinyImageNet) using four super-net backbones (ResNet-34, WideResNet-16-8, WideResNet-40-2, and MobileNetV2) for two OFA training frameworks (OATS and SNNs). Experiments show that SOLAR outperforms the baseline methods: compared to OATS, it improves accuracy of sub-nets up to 1.26 %, 4.71 %, 1.67 %, and 1.76 %, and robustness up to 9.01 %, 7.71 %, 2.72 %, and 1.26 % on SVHN, CIFAR-10, STL-10, and CIFAR-100, respectively. Compared to SNNs, it improves TinyImageNet accuracy by up to 2.93 %, 2.34 %, and 1.35 % using ResNet-34, WideResNet-16-8, and MobileNetV2 backbones (with 8 sub-nets), respectively.
LVADNet3D: A Deep Autoencoder for Reconstructing 3D Intraventricular Flow from Sparse Hemodynamic Data
arXiv:2509.16860v1 Announce Type: new Abstract: Accurate assessment of intraventricular blood flow is essential for evaluating hemodynamic conditions in patients supported by Left Ventricular Assist Devices (LVADs). However, clinical imaging is either incompatible with LVADs or yields sparse, low-quality velocity data. While Computational Fluid Dynamics (CFD) simulations provide high-fidelity data, they are computationally intensive and impractical for routine clinical use. To address this, we propose LVADNet3D, a 3D convolutional autoencoder that reconstructs full-resolution intraventricular velocity fields from sparse velocity vector inputs. In contrast to a standard UNet3D model, LVADNet3D incorporates hybrid downsampling and a deeper encoder-decoder architecture with increased channel capacity to better capture spatial flow patterns. To train and evaluate the models, we generate a high-resolution synthetic dataset of intraventricular blood flow in LVAD-supported hearts using CFD simulations. We also investigate the effect of conditioning the models on anatomical and physiological priors. Across various input configurations, LVADNet3D outperforms the baseline UNet3D model, yielding lower reconstruction error and higher PSNR results.
Towards Interpretable and Efficient Attention: Compressing All by Contracting a Few
arXiv:2509.16875v1 Announce Type: new Abstract: Attention mechanisms in Transformers have gained significant empirical success. Nonetheless, the optimization objectives underlying their forward pass are still unclear. Additionally, the quadratic complexity of self-attention is increasingly prohibitive. Unlike the prior work on addressing the interpretability or efficiency issue separately, we propose a unified optimization objective to alleviate both issues simultaneously. By unrolling the optimization over the objective, we derive an inherently interpretable and efficient attention mechanism, which compresses all tokens into low-dimensional structures by contracting a few representative tokens and then broadcasting the contractions back. This Contract-and-Broadcast Self-Attention (CBSA) mechanism can not only scale linearly but also generalize existing attention mechanisms as its special cases. Experiments further demonstrate comparable performance and even superior advantages of CBSA on several visual tasks. Code is available at this https URL.
Dynamic Expert Specialization: Towards Catastrophic Forgetting-Free Multi-Domain MoE Adaptation
arXiv:2509.16882v1 Announce Type: new Abstract: Mixture-of-Experts (MoE) models offer immense capacity via sparsely gated expert subnetworks, yet adapting them to multiple domains without catastrophic forgetting remains an open challenge. Existing approaches either incur prohibitive computation, suffer cross-domain interference, or require separate runs per domain. We propose DES-MoE, a dynamic expert specialization framework for multi-domain adaptation of Mixture-of-Experts models. DES-MoE addresses catastrophic forgetting through three innovations: (1) an adaptive router balancing pre-trained knowledge retention and task-specific updates via distillation, (2) real-time expert-domain correlation mapping to isolate domain-specific gradients, and (3) a three-phase adaptive fine-tuning schedule that progressively freezes non-specialized parameters. Evaluated on six domains (math, code, law, etc.), DES-MoE matches single-domain ESFT performance while training one unified model, reduces forgetting by 89% compared to full fine-tuning as domains scale from 2 to 6, and achieves 68% faster convergence than conventional methods. Our work establishes dynamic expert isolation as a scalable paradigm for multi-task MoE adaptation.
DRES: Fake news detection by dynamic representation and ensemble selection
arXiv:2509.16893v1 Announce Type: new Abstract: The rapid spread of information via social media has made text-based fake news detection critically important due to its societal impact. This paper presents a novel detection method called Dynamic Representation and Ensemble Selection (DRES) for identifying fake news based solely on text. DRES leverages instance hardness measures to estimate the classification difficulty for each news article across multiple textual feature representations. By dynamically selecting the textual representation and the most competent ensemble of classifiers for each instance, DRES significantly enhances prediction accuracy. Extensive experiments show that DRES achieves notable improvements over state-of-the-art methods, confirming the effectiveness of representation selection based on instance hardness and dynamic ensemble selection in boosting performance. Codes and data are available at: https://github.com/FFarhangian/FakeNewsDetection_DRES
The Complexity of Finding Local Optima in Contrastive Learning
arXiv:2509.16898v1 Announce Type: new Abstract: Contrastive learning is a powerful technique for discovering meaningful data representations by optimizing objectives based on $\textit{contrastive information}$, often given as a set of weighted triplets ${(x_i, y_i^+, z_{i}^-)}_{i = 1}^m$ indicating that an "anchor" $x_i$ is more similar to a "positive" example $y_i$ than to a "negative" example $z_i$. The goal is to find representations (e.g., embeddings in $\mathbb{R}^d$ or a tree metric) where anchors are placed closer to positive than to negative examples. While finding $\textit{global}$ optima of contrastive objectives is $\mathsf{NP}$-hard, the complexity of finding $\textit{local}$ optima -- representations that do not improve by local search algorithms such as gradient-based methods -- remains open. Our work settles the complexity of finding local optima in various contrastive learning problems by proving $\mathsf{PLS}$-hardness in discrete settings (e.g., maximize satisfied triplets) and $\mathsf{CLS}$-hardness in continuous settings (e.g., minimize Triplet Loss), where $\mathsf{PLS}$ (Polynomial Local Search) and $\mathsf{CLS}$ (Continuous Local Search) are well-studied complexity classes capturing local search dynamics in discrete and continuous optimization, respectively. Our results imply that no polynomial time algorithm (local search or otherwise) can find a local optimum for various contrastive learning problems, unless $\mathsf{PLS}\subseteq\mathsf{P}$ (or $\mathsf{CLS}\subseteq \mathsf{P}$ for continuous problems). Even in the unlikely scenario that $\mathsf{PLS}\subseteq\mathsf{P}$ (or $\mathsf{CLS}\subseteq \mathsf{P}$), our reductions imply that there exist instances where local search algorithms need exponential time to reach a local optimum, even for $d=1$ (embeddings on a line).
FedEL: Federated Elastic Learning for Heterogeneous Devices
arXiv:2509.16902v1 Announce Type: new Abstract: Federated learning (FL) enables distributed devices to collaboratively train machine learning models while maintaining data privacy. However, the heterogeneous hardware capabilities of devices often result in significant training delays, as straggler clients with limited resources prolong the aggregation process. Existing solutions such as client selection, asynchronous FL, and partial training partially address these challenges but encounter issues such as reduced accuracy, stale updates, and compromised model performance due to inconsistent training contributions. To overcome these limitations, we propose FedEL, a federated elastic learning framework that enhances training efficiency while maintaining model accuracy. FedEL introduces a novel window-based training process, sliding the window to locate the training part of the model and dynamically selecting important tensors for training within a coordinated runtime budget. This approach ensures progressive and balanced training across all clients, including stragglers. Additionally, FedEL employs a tensor importance adjustment module, harmonizing local and global tensor importance to mitigate biases caused by data heterogeneity. The experiment results show that FedEL achieves up to 3.87x improvement in time-to-accuracy compared to baselines while maintaining or exceeding final test accuracy.
Auditability and the Landscape of Distance to Multicalibration
arXiv:2509.16930v1 Announce Type: new Abstract: Calibration is a critical property for establishing the trustworthiness of predictors that provide uncertainty estimates. Multicalibration is a strengthening of calibration which requires that predictors be calibrated on a potentially overlapping collection of subsets of the domain. As multicalibration grows in popularity with practitioners, an essential question is: how do we measure how multicalibrated a predictor is? B{\l}asiok et al. (2023) considered this question for standard calibration by introducing the distance to calibration framework (dCE) to understand how calibration metrics relate to each other and the ground truth. Building on the dCE framework, we consider the auditability of the distance to multicalibration of a predictor $f$. We begin by considering two natural generalizations of dCE to multiple subgroups: worst group dCE (wdMC), and distance to multicalibration (dMC). We argue that there are two essential properties of any multicalibration error metric: 1) the metric should capture how much $f$ would need to be modified in order to be perfectly multicalibrated; and 2) the metric should be auditable in an information theoretic sense. We show that wdMC and dMC each fail to satisfy one of these two properties, and that similar barriers arise when considering the auditability of general distance to multigroup fairness notions. We then propose two (equivalent) multicalibration metrics which do satisfy these requirements: 1) a continuized variant of dMC; and 2) a distance to intersection multicalibration, which leans on intersectional fairness desiderata. Along the way, we shed light on the loss-landscape of distance to multicalibration and the geometry of the set of perfectly multicalibrated predictors. Our findings may have implications for the development of stronger multicalibration algorithms as well as multigroup auditing more generally.
Adaptive Graph Convolution and Semantic-Guided Attention for Multimodal Risk Detection in Social Networks
arXiv:2509.16936v1 Announce Type: new Abstract: This paper focuses on the detection of potentially dangerous tendencies of social media users in an innovative multimodal way. We integrate Natural Language Processing (NLP) and Graph Neural Networks (GNNs) together. Firstly, we apply NLP on the user-generated text and conduct semantic analysis, sentiment recognition and keyword extraction to get subtle risk signals from social media posts. Meanwhile, we build a heterogeneous user relationship graph based on social interaction and propose a novel relational graph convolutional network to model user relationship, attention relationship and content dissemination path to discover some important structural information and user behaviors. Finally, we combine textual features extracted from these two models above with graph structural information, which provides a more robust and effective way to discover at-risk users. Our experiments on real social media datasets from different platforms show that our model can achieve significant improvement over single-modality methods.
Gradient Interference-Aware Graph Coloring for Multitask Learning
arXiv:2509.16959v1 Announce Type: new Abstract: When different objectives conflict with each other in multi-task learning, gradients begin to interfere and slow convergence, thereby reducing the final model's performance. To address this, we introduce a scheduler that computes gradient interference, constructs an interference graph, and then applies greedy graph-coloring to partition tasks into groups that align well with each other. At each training step, only one group (color class) of tasks are activated. The grouping partition is constantly recomputed as task relationships evolve throughout training. By ensuring that each mini-batch contains only tasks that pull the model in the same direction, our method improves the effectiveness of any underlying multi-task learning optimizer without additional tuning. Since tasks within these groups will update in compatible directions, model performance will be improved rather than impeded. Empirical results on six different datasets show that this interference-aware graph-coloring approach consistently outperforms baselines and state-of-the-art multi-task optimizers.
PTQTP: Post-Training Quantization to Trit-Planes for Large Language Models
arXiv:2509.16989v1 Announce Type: new Abstract: Post-training quantization (PTQ) of large language models (LLMs) to extremely low bit-widths remains challenging due to the fundamental trade-off between computational efficiency and model expressiveness. While existing ultra-low-bit PTQ methods rely on binary approximations or complex compensation mechanisms, they suffer from either limited representational capacity or computational overhead that undermines their efficiency gains. We introduce PTQ to Trit-Planes (PTQTP), the first ternary-weight PTQ framework that decomposes weight matrices into structured ternary {-1, 0, 1} trit-planes using 2x1.58-bit representation. PTQTP achieves multiplication-free inference, identical to 1-bit quantization, while maintaining superior expressiveness through its novel structured decomposition. Our approach provides: (1) a theoretically grounded progressive approximation algorithm ensuring global weight consistency; (2) model-agnostic deployment across diverse modern LLMs without architectural modifications; and (3) uniform ternary operations that eliminate the need for mixed-precision or compensation schemes. Comprehensive experiments across LLaMA3.x and Qwen3 model families (0.6B-70B parameters) demonstrate that PTQTP significantly outperforms existing low-bit PTQ methods, achieving 82.4% mathematical reasoning retention versus 0% for competing approaches. PTQTP approaches and sometimes surpasses 1.58-bit quantization-aware training performance while requiring only single-hour quantization compared to 10-14 GPU days for training-based methods. These results establish PTQTP as a practical solution for efficient LLM deployment in resource-constrained environments.
Persistence Spheres: Bi-continuous Representations of Persistence Diagrams
arXiv:2509.16999v1 Announce Type: new Abstract: We introduce persistence spheres, a novel functional representation of persistence diagrams. Unlike existing embeddings (such as persistence images, landscapes, or kernel methods), persistence spheres provide a bi-continuous mapping: they are Lipschitz continuous with respect to the 1-Wasserstein distance and admit a continuous inverse on their image. This ensures, in a theoretically optimal way, both stability and geometric fidelity, making persistence spheres the representation that most closely mirrors the Wasserstein geometry of PDs in linear space. We derive explicit formulas for persistence spheres, showing that they can be computed efficiently and parallelized with minimal overhead. Empirically, we evaluate them on diverse regression and classification tasks involving functional data, time series, graphs, meshes, and point clouds. Across these benchmarks, persistence spheres consistently deliver state-of-the-art or competitive performance compared to persistence images, persistence landscapes, and the sliced Wasserstein kernel.
Adaptive Overclocking: Dynamic Control of Thinking Path Length via Real-Time Reasoning Signals
arXiv:2509.17000v1 Announce Type: new Abstract: Large Reasoning Models (LRMs) often suffer from computational inefficiency due to overthinking, where a fixed reasoning budget fails to match the varying complexity of tasks. To address this issue, we propose Adaptive Overclocking, a method that makes the overclocking hyperparameter $\alpha$ dynamic and context-aware. Our method adjusts reasoning speed in real time through two complementary signals: (1) token-level model uncertainty for fine-grained step-wise control, and (2) input complexity estimation for informed initialization. We implement this approach with three strategies: Uncertainty-Aware Alpha Scheduling (UA-$\alpha$S), Complexity-Guided Alpha Initialization (CG-$\alpha$I), and a Hybrid Adaptive Control (HAC) that combines both. Experiments on GSM8K, MATH, and SVAMP show that HAC achieves superior accuracy-latency trade-offs, reducing unnecessary computation on simple problems while allocating more resources to challenging ones. By mitigating overthinking, Adaptive Overclocking enhances both efficiency and overall reasoning performance.
Long-Tailed Out-of-Distribution Detection with Refined Separate Class Learning
arXiv:2509.17034v1 Announce Type: new Abstract: Out-of-distribution (OOD) detection is crucial for deploying robust machine learning models. However, when training data follows a long-tailed distribution, the model's ability to accurately detect OOD samples is significantly compromised, due to the confusion between OOD samples and head/tail classes. To distinguish OOD samples from both head and tail classes, the separate class learning (SCL) approach has emerged as a promising solution, which separately conduct head-specific and tail-specific class learning. To this end, we examine the limitations of existing works of SCL and reveal that the OOD detection performance is notably influenced by the use of static scaling temperature value and the presence of uninformative outliers. To mitigate these limitations, we propose a novel approach termed Refined Separate Class Learning (RSCL), which leverages dynamic class-wise temperature adjustment to modulate the temperature parameter for each in-distribution class and informative outlier mining to identify diverse types of outliers based on their affinity with head and tail classes. Extensive experiments demonstrate that RSCL achieves superior OOD detection performance while improving the classification accuracy on in-distribution data.
Enhancing Performance and Calibration in Quantile Hyperparameter Optimization
arXiv:2509.17051v1 Announce Type: new Abstract: Bayesian hyperparameter optimization relies heavily on Gaussian Process (GP) surrogates, due to robust distributional posteriors and strong performance on limited training samples. GPs however underperform in categorical hyperparameter environments or when assumptions of normality, heteroskedasticity and symmetry are excessively challenged. Conformalized quantile regression can address these estimation weaknesses, while still providing robust calibration guarantees. This study builds upon early work in this area by addressing feedback covariate shift in sequential acquisition and integrating a wider range of surrogate architectures and acquisition functions. Proposed algorithms are rigorously benchmarked against a range of state of the art hyperparameter optimization methods (GP, TPE and SMAC). Findings identify quantile surrogate architectures and acquisition functions yielding superior performance to the current quantile literature, while validating the beneficial impact of conformalization on calibration and search performance.
TSGym: Design Choices for Deep Multivariate Time-Series Forecasting
arXiv:2509.17063v1 Announce Type: new Abstract: Recently, deep learning has driven significant advancements in multivariate time series forecasting (MTSF) tasks. However, much of the current research in MTSF tends to evaluate models from a holistic perspective, which obscures the individual contributions and leaves critical issues unaddressed. Adhering to the current modeling paradigms, this work bridges these gaps by systematically decomposing deep MTSF methods into their core, fine-grained components like series-patching tokenization, channel-independent strategy, attention modules, or even Large Language Models and Time-series Foundation Models. Through extensive experiments and component-level analysis, our work offers more profound insights than previous benchmarks that typically discuss models as a whole. Furthermore, we propose a novel automated solution called TSGym for MTSF tasks. Unlike traditional hyperparameter tuning, neural architecture searching or fixed model selection, TSGym performs fine-grained component selection and automated model construction, which enables the creation of more effective solutions tailored to diverse time series data, therefore enhancing model transferability across different data sources and robustness against distribution shifts. Extensive experiments indicate that TSGym significantly outperforms existing state-of-the-art MTSF and AutoML methods. All code is publicly available on https://github.com/SUFE-AILAB/TSGym.
On the Limits of Tabular Hardness Metrics for Deep RL: A Study with the Pharos Benchmark
arXiv:2509.17092v1 Announce Type: new Abstract: Principled evaluation is critical for progress in deep reinforcement learning (RL), yet it lags behind the theory-driven benchmarks of tabular RL. While tabular settings benefit from well-understood hardness measures like MDP diameter and suboptimality gaps, deep RL benchmarks are often chosen based on intuition and popularity. This raises a critical question: can tabular hardness metrics be adapted to guide non-tabular benchmarking? We investigate this question and reveal a fundamental gap. Our primary contribution is demonstrating that the difficulty of non-tabular environments is dominated by a factor that tabular metrics ignore: representation hardness. The same underlying MDP can pose vastly different challenges depending on whether the agent receives state vectors or pixel-based observations. To enable this analysis, we introduce \texttt{pharos}, a new open-source library for principled RL benchmarking that allows for systematic control over both environment structure and agent representations. Our extensive case study using \texttt{pharos} shows that while tabular metrics offer some insight, they are poor predictors of deep RL agent performance on their own. This work highlights the urgent need for new, representation-aware hardness measures and positions \texttt{pharos} as a key tool for developing them.
Ultra-short-term solar power forecasting by deep learning and data reconstruction
arXiv:2509.17095v1 Announce Type: new Abstract: The integration of solar power has been increasing as the green energy transition rolls out. The penetration of solar power challenges the grid stability and energy scheduling, due to its intermittent energy generation. Accurate and near real-time solar power prediction is of critical importance to tolerant and support the permeation of distributed and volatile solar power production in the energy system. In this paper, we propose a deep-learning based ultra-short-term solar power prediction with data reconstruction. We decompose the data for the prediction to facilitate extensive exploration of the spatial and temporal dependencies within the data. Particularly, we reconstruct the data into low- and high-frequency components, using ensemble empirical model decomposition with adaptive noise (CEEMDAN). We integrate meteorological data with those two components, and employ deep-learning models to capture long- and short-term dependencies towards the target prediction period. In this way, we excessively exploit the features in historical data in predicting a ultra-short-term solar power production. Furthermore, as ultra-short-term prediction is vulnerable to local optima, we modify the optimization in our deep-learning training by penalizing long prediction intervals. Numerical experiments with diverse settings demonstrate that, compared to baseline models, the proposed method achieves improved generalization in data reconstruction and higher prediction accuracy for ultra-short-term solar power production.
GRPOformer: Advancing Hyperparameter Optimization via Group Relative Policy Optimization
arXiv:2509.17105v1 Announce Type: new Abstract: Hyperparameter optimization (HPO) plays a critical role in improving model performance. Transformer-based HPO methods have shown great potential; however, existing approaches rely heavily on large-scale historical optimization trajectories and lack effective reinforcement learning (RL) techniques, thereby limiting their efficiency and performance improvements. Inspired by the success of Group Relative Policy Optimization (GRPO) in large language models (LLMs), we propose GRPOformer -- a novel hyperparameter optimization framework that integrates reinforcement learning (RL) with Transformers. In GRPOformer, Transformers are employed to generate new hyperparameter configurations from historical optimization trajectories, while GRPO enables rapid trajectory construction and optimization strategy learning from scratch. Moreover, we introduce Policy Churn Regularization (PCR) to enhance the stability of GRPO training. Experimental results on OpenML demonstrate that GRPOformer consistently outperforms baseline methods across diverse tasks, offering new insights into the application of RL for HPO.
ScenGAN: Attention-Intensive Generative Model for Uncertainty-Aware Renewable Scenario Forecasting
arXiv:2509.17119v1 Announce Type: new Abstract: To address the intermittency of renewable energy source (RES) generation, scenario forecasting offers a series of stochastic realizations for predictive objects with superior flexibility and direct views. Based on a long time-series perspective, this paper explores uncertainties in the realms of renewable power and deep learning. Then, an uncertainty-aware model is meticulously designed for renewable scenario forecasting, which leverages an attention mechanism and generative adversarial networks (GANs) to precisely capture complex spatial-temporal dynamics. To improve the interpretability of uncertain behavior in RES generation, Bayesian deep learning and adaptive instance normalization (AdaIN) are incorporated to simulate typical patterns and variations. Additionally, the integration of meteorological information, forecasts, and historical trajectories in the processing layer improves the synergistic forecasting capability for multiscale periodic regularities. Numerical experiments and case analyses demonstrate that the proposed approach provides an appropriate interpretation for renewable uncertainty representation, including both aleatoric and epistemic uncertainties, and shows superior performance over state-of-the-art methods.
On the Simplification of Neural Network Architectures for Predictive Process Monitoring
arXiv:2509.17145v1 Announce Type: new Abstract: Predictive Process Monitoring (PPM) aims to forecast the future behavior of ongoing process instances using historical event data, enabling proactive decision-making. While recent advances rely heavily on deep learning models such as LSTMs and Transformers, their high computational cost hinders practical adoption. Prior work has explored data reduction techniques and alternative feature encodings, but the effect of simplifying model architectures themselves remains underexplored. In this paper, we analyze how reducing model complexity, both in terms of parameter count and architectural depth, impacts predictive performance, using two established PPM approaches. Across five diverse event logs, we show that shrinking the Transformer model by 85% results in only a 2-3% drop in performance across various PPM tasks, while the LSTM proves slightly more sensitive, particularly for waiting time prediction. Overall, our findings suggest that substantial model simplification can preserve predictive accuracy, paving the way for more efficient and scalable PPM solutions.
Flow-Induced Diagonal Gaussian Processes
arXiv:2509.17153v1 Announce Type: new Abstract: We present Flow-Induced Diagonal Gaussian Processes (FiD-GP), a compression framework that incorporates a compact inducing weight matrix to project a neural network's weight uncertainty into a lower-dimensional subspace. Critically, FiD-GP relies on normalising-flow priors and spectral regularisations to augment its expressiveness and align the inducing subspace with feature-gradient geometry through a numerically stable projection mechanism objective. Furthermore, we demonstrate how the prediction framework in FiD-GP can help to design a single-pass projection for Out-of-Distribution (OoD) detection. Our analysis shows that FiD-GP improves uncertainty estimation ability on various tasks compared with SVGP-based baselines, satisfies tight spectral residual bounds with theoretically guaranteed OoD detection, and significantly compresses the neural network's storage requirements at the cost of increased inference computation dependent on the number of inducing weights employed. Specifically, in a comprehensive empirical study spanning regression, image classification, semantic segmentation, and out-of-distribution detection benchmarks, it cuts Bayesian training cost by several orders of magnitude, compresses parameters by roughly 51%, reduces model size by about 75%, and matches state-of-the-art accuracy and uncertainty estimation.
Unrolled Graph Neural Networks for Constrained Optimization
arXiv:2509.17156v1 Announce Type: new Abstract: In this paper, we unroll the dynamics of the dual ascent (DA) algorithm in two coupled graph neural networks (GNNs) to solve constrained optimization problems. The two networks interact with each other at the layer level to find a saddle point of the Lagrangian. The primal GNN finds a stationary point for a given dual multiplier, while the dual network iteratively refines its estimates to reach an optimal solution. We force the primal and dual networks to mirror the dynamics of the DA algorithm by imposing descent and ascent constraints. We propose a joint training scheme that alternates between updating the primal and dual networks. Our numerical experiments demonstrate that our approach yields near-optimal near-feasible solutions and generalizes well to out-of-distribution (OOD) problems.
Time Series Forecasting Using a Hybrid Deep Learning Method: A Bi-LSTM Embedding Denoising Auto Encoder Transformer
arXiv:2509.17165v1 Announce Type: new Abstract: Time series data is a prevalent form of data found in various fields. It consists of a series of measurements taken over time. Forecasting is a crucial application of time series models, where future values are predicted based on historical data. Accurate forecasting is essential for making well-informed decisions across industries. When it comes to electric vehicles (EVs), precise predictions play a key role in planning infrastructure development, load balancing, and energy management. This study introduces a BI-LSTM embedding denoising autoencoder model (BDM) designed to address time series problems, focusing on short-term EV charging load prediction. The performance of the proposed model is evaluated by comparing it with benchmark models like Transformer, CNN, RNN, LSTM, and GRU. Based on the results of the study, the proposed model outperforms the benchmark models in four of the five-time steps, demonstrating its effectiveness for time series forecasting. This research makes a significant contribution to enhancing time series forecasting, thereby improving decision-making processes.
Detecting Urban PM$_{2.5}$ Hotspots with Mobile Sensing and Gaussian Process Regression
arXiv:2509.17175v1 Announce Type: new Abstract: Low-cost mobile sensors can be used to collect PM${2.5}$ concentration data throughout an entire city. However, identifying air pollution hotspots from the data is challenging due to the uneven spatial sampling, temporal variations in the background air quality, and the dynamism of urban air pollution sources. This study proposes a method to identify urban PM${2.5}$ hotspots that addresses these challenges, involving four steps: (1) equip citizen scientists with mobile PM${2.5}$ sensors while they travel; (2) normalise the raw data to remove the influence of background ambient pollution levels; (3) fit a Gaussian process regression model to the normalised data and (4) calculate a grid of spatially explicit 'hotspot scores' using the probabilistic framework of Gaussian processes, which conveniently summarise the relative pollution levels throughout the city. We apply our method to create the first ever map of PM${2.5}$ pollution in Kigali, Rwanda, at a 200m resolution. Our results suggest that the level of ambient PM${2.5}$ pollution in Kigali is dangerously high, and we identify the hotspots in Kigali where pollution consistently exceeds the city-wide average. We also evaluate our method using simulated mobile sensing data for Beijing, China, where we find that the hotspot scores are probabilistically well calibrated and accurately reflect the 'ground truth' spatial profile of PM${2.5}$ pollution. Thanks to the use of open-source software, our method can be re-applied in cities throughout the world with a handful of low-cost sensors. The method can help fill the gap in urban air quality information and empower public health officials.
A Comprehensive Performance Comparison of Traditional and Ensemble Machine Learning Models for Online Fraud Detection
arXiv:2509.17176v1 Announce Type: new Abstract: In the era of the digitally driven economy, where there has been an exponential surge in digital payment systems and other online activities, various forms of fraudulent activities have accompanied the digital growth, out of which credit card fraud has become an increasingly significant threat. To deal with this, real-time fraud detection is essential for financial security but remains challenging due to high transaction volumes and the complexity of modern fraud patterns. This study presents a comprehensive performance comparison between traditional machine learning models like Random Forest, SVM, Logistic Regression, XGBoost, and ensemble methods like Stacking and Voting Classifier for detecting credit card fraud on a heavily imbalanced public dataset, where the number of fraudulent transactions is 492 out of 284,807 total transactions. Application-specific preprocessing techniques were applied, and the models were evaluated using various performance metrics. The ensemble methods achieved an almost perfect precision of around 0.99, but traditional methods demonstrated superior performance in terms of recall, which highlights the trade-off between false positives and false negatives. The comprehensive comparison reveals distinct performance strengths and limitations for each algorithm, offering insights to guide practitioners in selecting the most effective model for robust fraud detection applications in real-world settings.
Regularizing Extrapolation in Causal Inference
arXiv:2509.17180v1 Announce Type: new Abstract: Many common estimators in machine learning and causal inference are linear smoothers, where the prediction is a weighted average of the training outcomes. Some estimators, such as ordinary least squares and kernel ridge regression, allow for arbitrarily negative weights, which improve feature imbalance but often at the cost of increased dependence on parametric modeling assumptions and higher variance. By contrast, estimators like importance weighting and random forests (sometimes implicitly) restrict weights to be non-negative, reducing dependence on parametric modeling and variance at the cost of worse imbalance. In this paper, we propose a unified framework that directly penalizes the level of extrapolation, replacing the current practice of a hard non-negativity constraint with a soft constraint and corresponding hyperparameter. We derive a worst-case extrapolation error bound and introduce a novel "bias-bias-variance" tradeoff, encompassing biases due to feature imbalance, model misspecification, and estimator variance; this tradeoff is especially pronounced in high dimensions, particularly when positivity is poor. We then develop an optimization procedure that regularizes this bound while minimizing imbalance and outline how to use this approach as a sensitivity analysis for dependence on parametric modeling assumptions. We demonstrate the effectiveness of our approach through synthetic experiments and a real-world application, involving the generalization of randomized controlled trial estimates to a target population of interest.
PMRT: A Training Recipe for Fast, 3D High-Resolution Aerodynamic Prediction
arXiv:2509.17182v1 Announce Type: new Abstract: The aerodynamic optimization of cars requires close collaboration between aerodynamicists and stylists, while slow, expensive simulations remain a bottleneck. Surrogate models have been shown to accurately predict aerodynamics within the design space for which they were trained. However, many of these models struggle to scale to higher resolutions because of the 3D nature of the problem and data scarcity. We propose Progressive Multi-Resolution Training (PMRT), a probabilistic multi-resolution training schedule that enables training a U-Net to predict the drag coefficient ($c_d$) and high-resolution velocity fields (512 x 128 x 128) in 24 hours on a single NVIDIA H100 GPU, 7x cheaper than the high-resolution-only baseline, with similar accuracy. PMRT samples batches from three resolutions based on probabilities that change during training, starting with an emphasis on lower resolutions and gradually shifting toward higher resolutions. Since this is a training methodology, it can be adapted to other high-resolution-focused backbones. We also show that a single model can be trained across five datasets from different solvers, including a real-world dataset, by conditioning on the simulation parameters. In the DrivAerML dataset, our models achieve a $c_d$ $R^2$ of 0.975, matching literature baselines at a fraction of the training cost.
Dendritic Resonate-and-Fire Neuron for Effective and Efficient Long Sequence Modeling
arXiv:2509.17186v1 Announce Type: new Abstract: The explosive growth in sequence length has intensified the demand for effective and efficient long sequence modeling. Benefiting from intrinsic oscillatory membrane dynamics, Resonate-and-Fire (RF) neurons can efficiently extract frequency components from input signals and encode them into spatiotemporal spike trains, making them well-suited for long sequence modeling. However, RF neurons exhibit limited effective memory capacity and a trade-off between energy efficiency and training speed on complex temporal tasks. Inspired by the dendritic structure of biological neurons, we propose a Dendritic Resonate-and-Fire (D-RF) model, which explicitly incorporates a multi-dendritic and soma architecture. Each dendritic branch encodes specific frequency bands by utilizing the intrinsic oscillatory dynamics of RF neurons, thereby collectively achieving comprehensive frequency representation. Furthermore, we introduce an adaptive threshold mechanism into the soma structure that adjusts the threshold based on historical spiking activity, reducing redundant spikes while maintaining training efficiency in long sequence tasks. Extensive experiments demonstrate that our method maintains competitive accuracy while substantially ensuring sparse spikes without compromising computational efficiency during training. These results underscore its potential as an effective and efficient solution for long sequence modeling on edge platforms.
SignalLLM: A General-Purpose LLM Agent Framework for Automated Signal Processing
arXiv:2509.17197v1 Announce Type: new Abstract: Modern signal processing (SP) pipelines, whether model-based or data-driven, often constrained by complex and fragmented workflow, rely heavily on expert knowledge and manual engineering, and struggle with adaptability and generalization under limited data. In contrast, Large Language Models (LLMs) offer strong reasoning capabilities, broad general-purpose knowledge, in-context learning, and cross-modal transfer abilities, positioning them as powerful tools for automating and generalizing SP workflows. Motivated by these potentials, we introduce SignalLLM, the first general-purpose LLM-based agent framework for general SP tasks. Unlike prior LLM-based SP approaches that are limited to narrow applications or tricky prompting, SignalLLM introduces a principled, modular architecture. It decomposes high-level SP goals into structured subtasks via in-context learning and domain-specific retrieval, followed by hierarchical planning through adaptive retrieval-augmented generation (RAG) and refinement; these subtasks are then executed through prompt-based reasoning, cross-modal reasoning, code synthesis, model invocation, or data-driven LLM-assisted modeling. Its generalizable design enables the flexible selection of problem solving strategies across different signal modalities, task types, and data conditions. We demonstrate the versatility and effectiveness of SignalLLM through five representative tasks in communication and sensing, such as radar target detection, human activity recognition, and text compression. Experimental results show superior performance over traditional and existing LLM-based methods, particularly in few-shot and zero-shot settings.
Conditional Policy Generator for Dynamic Constraint Satisfaction and Optimization
arXiv:2509.17205v1 Announce Type: new Abstract: Leveraging machine learning methods to solve constraint satisfaction problems has shown promising, but they are mostly limited to a static situation where the problem description is completely known and fixed from the beginning. In this work we present a new approach to constraint satisfaction and optimization in dynamically changing environments, particularly when variables in the problem are statistically independent. We frame it as a reinforcement learning problem and introduce a conditional policy generator by borrowing the idea of class conditional generative adversarial networks (GANs). Assuming that the problem includes both static and dynamic constraints, the former are used in a reward formulation to guide the policy training such that it learns to map to a probabilistic distribution of solutions satisfying static constraints from a noise prior, which is similar to a generator in GANs. On the other hand, dynamic constraints in the problem are encoded to different class labels and fed with the input noise. The policy is then simultaneously updated for maximum likelihood of correctly classifying given the dynamic conditions in a supervised manner. We empirically demonstrate a proof-of-principle experiment with a multi-modal constraint satisfaction problem and compare between unconditional and conditional cases.
Active Learning for Machine Learning Driven Molecular Dynamics
arXiv:2509.17208v1 Announce Type: new Abstract: Machine learned coarse grained (CG) potentials are fast, but degrade over time when simulations reach undersampled biomolecular conformations, and generating widespread all atom (AA) data to combat this is computationally infeasible. We propose a novel active learning framework for CG neural network potentials in molecular dynamics (MD). Building on the CGSchNet model, our method employs root mean squared deviation (RMSD) based frame selection from MD simulations in order to generate data on the fly by querying an oracle during the training of a neural network potential. This framework preserves CG level efficiency while correcting the model at precise, RMSD identified coverage gaps. By training CGSchNet, a coarse grained neural network potential, we empirically show that our framework explores previously unseen configurations and trains the model on unexplored regions of conformational space. Our active learning framework enables a CGSchNet model trained on the Chignolin protein to achieve a 33.05% improvement in the Wasserstein 1 (W1) metric in Time lagged Independent Component Analysis (TICA) space on an in house benchmark suite.
Causal Representation Learning from Multimodal Clinical Records under Non-Random Modality Missingness
arXiv:2509.17228v1 Announce Type: new Abstract: Clinical notes contain rich patient information, such as diagnoses or medications, making them valuable for patient representation learning. Recent advances in large language models have further improved the ability to extract meaningful representations from clinical texts. However, clinical notes are often missing. For example, in our analysis of the MIMIC-IV dataset, 24.5% of patients have no available discharge summaries. In such cases, representations can be learned from other modalities such as structured data, chest X-rays, or radiology reports. Yet the availability of these modalities is influenced by clinical decision-making and varies across patients, resulting in modality missing-not-at-random (MMNAR) patterns. We propose a causal representation learning framework that leverages observed data and informative missingness in multimodal clinical records. It consists of: (1) an MMNAR-aware modality fusion component that integrates structured data, imaging, and text while conditioning on missingness patterns to capture patient health and clinician-driven assignment; (2) a modality reconstruction component with contrastive learning to ensure semantic sufficiency in representation learning; and (3) a multitask outcome prediction model with a rectifier that corrects for residual bias from specific modality observation patterns. Comprehensive evaluations across MIMIC-IV and eICU show consistent gains over the strongest baselines, achieving up to 13.8% AUC improvement for hospital readmission and 13.1% for ICU admission.
Prospective Multi-Graph Cohesion for Multivariate Time Series Anomaly Detection
arXiv:2509.17235v1 Announce Type: new Abstract: Anomaly detection in high-dimensional time series data is pivotal for numerous industrial applications. Recent advances in multivariate time series anomaly detection (TSAD) have increasingly leveraged graph structures to model inter-variable relationships, typically employing Graph Neural Networks (GNNs). Despite their promising results, existing methods often rely on a single graph representation, which are insufficient for capturing the complex, diverse relationships inherent in multivariate time series. To address this, we propose the Prospective Multi-Graph Cohesion (PMGC) framework for multivariate TSAD. PMGC exploits spatial correlations by integrating a long-term static graph with a series of short-term instance-wise dynamic graphs, regulated through a graph cohesion loss function. Our theoretical analysis shows that this loss function promotes diversity among dynamic graphs while aligning them with the stable long-term relationships encapsulated by the static graph. Additionally, we introduce a "prospective graphing" strategy to mitigate the limitations of traditional forecasting-based TSAD methods, which often struggle with unpredictable future variations. This strategy allows the model to accurately reflect concurrent inter-series relationships under normal conditions, thereby enhancing anomaly detection efficacy. Empirical evaluations on real-world datasets demonstrate the superior performance of our method compared to existing TSAD techniques.
TraceHiding: Scalable Machine Unlearning for Mobility Data
arXiv:2509.17241v1 Announce Type: new Abstract: This work introduces TraceHiding, a scalable, importance-aware machine unlearning framework for mobility trajectory data. Motivated by privacy regulations such as GDPR and CCPA granting users "the right to be forgotten," TraceHiding removes specified user trajectories from trained deep models without full retraining. It combines a hierarchical data-driven importance scoring scheme with teacher-student distillation. Importance scores--computed at token, trajectory, and user levels from statistical properties (coverage diversity, entropy, length)--quantify each training sample's impact, enabling targeted forgetting of high-impact data while preserving common patterns. The student model retains knowledge on remaining data and unlearns targeted trajectories through an importance-weighted loss that amplifies forgetting signals for unique samples and attenuates them for frequent ones. We validate on Trajectory--User Linking (TUL) tasks across three real-world higher-order mobility datasets (HO-Rome, HO-Geolife, HO-NYC) and multiple architectures (GRU, LSTM, BERT, ModernBERT, GCN-TULHOR), against strong unlearning baselines including SCRUB, NegGrad, NegGrad+, Bad-T, and Finetuning. Experiments under uniform and targeted user deletion show TraceHiding, especially its entropy-based variant, achieves superior unlearning accuracy, competitive membership inference attack (MIA) resilience, and up to 40\times speedup over retraining with minimal test accuracy loss. Results highlight robustness to adversarial deletion of high-information users and consistent performance across models. To our knowledge, this is the first systematic study of machine unlearning for trajectory data, providing a reproducible pipeline with public code and preprocessing tools.
Graph Signal Generative Diffusion Models
arXiv:2509.17250v1 Announce Type: new Abstract: We introduce U-shaped encoder-decoder graph neural networks (U-GNNs) for stochastic graph signal generation using denoising diffusion processes. The architecture learns node features at different resolutions with skip connections between the encoder and decoder paths, analogous to the convolutional U-Net for image generation. The U-GNN is prominent for a pooling operation that leverages zero-padding and avoids arbitrary graph coarsening, with graph convolutions layered on top to capture local dependencies. This technique permits learning feature embeddings for sampled nodes at deeper levels of the architecture that remain convolutional with respect to the original graph. Applied to stock price prediction -- where deterministic forecasts struggle to capture uncertainties and tail events that are paramount -- we demonstrate the effectiveness of the diffusion model in probabilistic forecasting of stock prices.
Training the next generation of physicians for artificial intelligence-assisted clinical neuroradiology: ASNR MICCAI Brain Tumor Segmentation (BraTS) 2025 Lighthouse Challenge education platform
arXiv:2509.17281v1 Announce Type: new Abstract: High-quality reference standard image data creation by neuroradiology experts for automated clinical tools can be a powerful tool for neuroradiology & artificial intelligence education. We developed a multimodal educational approach for students and trainees during the MICCAI Brain Tumor Segmentation Lighthouse Challenge 2025, a landmark initiative to develop accurate brain tumor segmentation algorithms. Fifty-six medical students & radiology trainees volunteered to annotate brain tumor MR images for the BraTS challenges of 2023 & 2024, guided by faculty-led didactics on neuropathology MRI. Among the 56 annotators, 14 select volunteers were then paired with neuroradiology faculty for guided one-on-one annotation sessions for BraTS 2025. Lectures on neuroanatomy, pathology & AI, journal clubs & data scientist-led workshops were organized online. Annotators & audience members completed surveys on their perceived knowledge before & after annotations & lectures respectively. Fourteen coordinators, each paired with a neuroradiologist, completed the data annotation process, averaging 1322.9+/-760.7 hours per dataset per pair and 1200 segmentations in total. On a scale of 1-10, annotation coordinators reported significant increase in familiarity with image segmentation software pre- and post-annotation, moving from initial average of 6+/-2.9 to final average of 8.9+/-1.1, and significant increase in familiarity with brain tumor features pre- and post-annotation, moving from initial average of 6.2+/-2.4 to final average of 8.1+/-1.2. We demonstrate an innovative offering for providing neuroradiology & AI education through an image segmentation challenge to enhance understanding of algorithm development, reinforce the concept of data reference standard, and diversify opportunities for AI-driven image analysis among future physicians.
GraphWeave: Interpretable and Robust Graph Generation via Random Walk Trajectories
arXiv:2509.17291v1 Announce Type: new Abstract: Given a set of graphs from some unknown family, we want to generate new graphs from that family. Recent methods use diffusion on either graph embeddings or the discrete space of nodes and edges. However, simple changes to embeddings (say, adding noise) can mean uninterpretable changes in the graph. In discrete-space diffusion, each step may add or remove many nodes/edges. It is hard to predict what graph patterns we will observe after many diffusion steps. Our proposed method, called GraphWeave, takes a different approach. We separate pattern generation and graph construction. To find patterns in the training graphs, we see how they transform vectors during random walks. We then generate new graphs in two steps. First, we generate realistic random walk "trajectories" which match the learned patterns. Then, we find the optimal graph that fits these trajectories. The optimization infers all edges jointly, which improves robustness to errors. On four simulated and five real-world benchmark datasets, GraphWeave outperforms existing methods. The most significant differences are on large-scale graph structures such as PageRank, cuts, communities, degree distributions, and flows. GraphWeave is also 10x faster than its closest competitor. Finally, GraphWeave is simple, needing only a transformer and standard optimizers.
Physics-Informed Operator Learning for Hemodynamic Modeling
arXiv:2509.17293v1 Announce Type: new Abstract: Accurate modeling of personalized cardiovascular dynamics is crucial for non-invasive monitoring and therapy planning. State-of-the-art physics-informed neural network (PINN) approaches employ deep, multi-branch architectures with adversarial or contrastive objectives to enforce partial differential equation constraints. While effective, these enhancements introduce significant training and implementation complexity, limiting scalability and practical deployment. We investigate physics-informed neural operator learning models as efficient supervisory signals for training simplified architectures through knowledge distillation. Our approach pre-trains a physics-informed DeepONet (PI-DeepONet) on high-fidelity cuffless blood pressure recordings to learn operator mappings from raw wearable waveforms to beat-to-beat pressure signals under embedded physics constraints. This pre-trained operator serves as a frozen supervisor in a lightweight knowledge-distillation pipeline, guiding streamlined base models that eliminate complex adversarial and contrastive learning components while maintaining performance. We characterize the role of physics-informed regularization in operator learning and demonstrate its effectiveness for supervisory guidance. Through extensive experiments, our operator-supervised approach achieves performance parity with complex baselines (correlation: 0.766 vs. 0.770, RMSE: 4.452 vs. 4.501), while dramatically reducing architectural complexity from eight critical hyperparameters to a single regularization coefficient and decreasing training overhead by 4%. Our results demonstrate that operator-based supervision effectively replaces intricate multi-component training strategies, offering a more scalable and interpretable approach to physiological modeling with reduced implementation burden.
SPRINT: Stochastic Performative Prediction With Variance Reduction
arXiv:2509.17304v1 Announce Type: new Abstract: Performative prediction (PP) is an algorithmic framework for optimizing machine learning (ML) models where the model's deployment affects the distribution of the data it is trained on. Compared to traditional ML with fixed data, designing algorithms in PP converging to a stable point -- known as a stationary performative stable (SPS) solution -- is more challenging than the counterpart in conventional ML tasks due to the model-induced distribution shifts. While considerable efforts have been made to find SPS solutions using methods such as repeated gradient descent (RGD) and greedy stochastic gradient descent (SGD-GD), most prior studies assumed a strongly convex loss until a recent work established $\mathcal{O}(1/\sqrt{T})$ convergence of SGD-GD to SPS solutions under smooth, non-convex losses. However, this latest progress is still based on the restricted bounded variance assumption in stochastic gradient estimates and yields convergence bounds with a non-vanishing error neighborhood that scales with the variance. This limitation motivates us to improve convergence rates and reduce error in stochastic optimization for PP, particularly in non-convex settings. Thus, we propose a new algorithm called stochastic performative prediction with variance reduction (SPRINT) and establish its convergence to an SPS solution at a rate of $\mathcal{O}(1/T)$. Notably, the resulting error neighborhood is independent of the variance of the stochastic gradients. Experiments on multiple real datasets with non-convex models demonstrate that SPRINT outperforms SGD-GD in both convergence rate and stability.
VQEzy: An Open-Source Dataset for Parameter Initialize in Variational Quantum Eigensolvers
arXiv:2509.17322v1 Announce Type: new Abstract: Variational Quantum Eigensolvers (VQEs) are a leading class of noisy intermediate-scale quantum (NISQ) algorithms, whose performance is highly sensitive to parameter initialization. Although recent machine learning-based initialization methods have achieved state-of-the-art performance, their progress has been limited by the lack of comprehensive datasets. Existing resources are typically restricted to a single domain, contain only a few hundred instances, and lack complete coverage of Hamiltonians, ansatz circuits, and optimization trajectories. To overcome these limitations, we introduce VQEzy, the first large-scale dataset for VQE parameter initialization. VQEzy spans three major domains and seven representative tasks, comprising 12,110 instances with full VQE specifications and complete optimization trajectories. The dataset is available online, and will be continuously refined and expanded to support future research in VQE optimization.
Generalizable End-to-End Tool-Use RL with Synthetic CodeGym
arXiv:2509.17325v1 Announce Type: new Abstract: Tool-augmented large language models (LLMs), hereafter LLM agents, leverage external tools to solve diverse tasks and interface with the real world. However, current training practices largely rely on supervised fine-tuning (SFT) over static trajectories or reinforcement learning (RL) on narrow tasks, and generalize poorly beyond development settings, leading to brittleness with new tools and unseen workflows. Because code execution reflects many structures of real-world workflows, coding problems provide a natural basis for building agent training environments. Motivated by this, we introduce CodeGym, a scalable framework that synthesizes diverse, verifiable, and controllable multi-turn tool-use environments for agent RL, enabling LLM agents to explore and master various workflows actively. CodeGym rewrites static coding problems into interactive environments by extracting atomic functions or logic into callable tools, yielding verifiable tasks that span various tool-execution workflows. Models of varying sizes and chain-of-thought configurations, trained in CodeGym, exhibit consistent out-of-distribution generalizability; for example, Qwen2.5-32B-Instruct achieves an absolute accuracy gain of 8.7 points on the OOD benchmark $\tau$-Bench. These results highlight CodeGym as a step toward scalable general-purpose RL environments that align with real-world agent workflows.
Robust Anomaly Detection Under Normality Distribution Shift in Dynamic Graphs
arXiv:2509.17400v1 Announce Type: new Abstract: Anomaly detection in dynamic graphs is a critical task with broad real-world applications, including social networks, e-commerce, and cybersecurity. Most existing methods assume that normal patterns remain stable over time; however, this assumption often fails in practice due to the phenomenon we refer to as normality distribution shift (NDS), where normal behaviors evolve over time. Ignoring NDS can lead models to misclassify shifted normal instances as anomalies, degrading detection performance. To tackle this issue, we propose WhENDS, a novel unsupervised anomaly detection method that aligns normal edge embeddings across time by estimating distributional statistics and applying whitening transformations. Extensive experiments on four widely-used dynamic graph datasets show that WhENDS consistently outperforms nine strong baselines, achieving state-of-the-art results and underscoring the importance of addressing NDS in dynamic graph anomaly detection.
Efficient Sliced Wasserstein Distance Computation via Adaptive Bayesian Optimization
arXiv:2509.17405v1 Announce Type: new Abstract: The sliced Wasserstein distance (SW) reduces optimal transport on $\mathbb{R}^d$ to a sum of one-dimensional projections, and thanks to this efficiency, it is widely used in geometry, generative modeling, and registration tasks. Recent work shows that quasi-Monte Carlo constructions for computing SW (QSW) yield direction sets with excellent approximation error. This paper presents an alternate, novel approach: learning directions with Bayesian optimization (BO), particularly in settings where SW appears inside an optimization loop (e.g., gradient flows). We introduce a family of drop-in selectors for projection directions: BOSW, a one-shot BO scheme on the unit sphere; RBOSW, a periodic-refresh variant; ABOSW, an adaptive hybrid that seeds from competitive QSW sets and performs a few lightweight BO refinements; and ARBOSW, a restarted hybrid that periodically relearns directions during optimization. Our BO approaches can be composed with QSW and its variants (demonstrated by ABOSW/ARBOSW) and require no changes to downstream losses or gradients. We provide numerical experiments where our methods achieve state-of-the-art performance, and on the experimental suite of the original QSW paper, we find that ABOSW and ARBOSW can achieve convergence comparable to the best QSW variants with modest runtime overhead.
Distributionally Robust Safety Verification of Neural Networks via Worst-Case CVaR
arXiv:2509.17413v1 Announce Type: new Abstract: Ensuring the safety of neural networks under input uncertainty is a fundamental challenge in safety-critical applications. This paper builds on and expands Fazlyab's quadratic-constraint (QC) and semidefinite-programming (SDP) framework for neural network verification to a distributionally robust and tail-risk-aware setting by integrating worst-case Conditional Value-at-Risk (WC-CVaR) over a moment-based ambiguity set with fixed mean and covariance. The resulting conditions remain SDP-checkable and explicitly account for tail risk. This integration broadens input-uncertainty geometry-covering ellipsoids, polytopes, and hyperplanes-and extends applicability to safety-critical domains where tail-event severity matters. Applications to closed-loop reachability of control systems and classification are demonstrated through numerical experiments, illustrating how the risk level $\varepsilon$ trades conservatism for tolerance to tail events-while preserving the computational structure of prior QC/SDP methods for neural network verification and robustness analysis.
MVCL-DAF++: Enhancing Multimodal Intent Recognition via Prototype-Aware Contrastive Alignment and Coarse-to-Fine Dynamic Attention Fusion
arXiv:2509.17446v1 Announce Type: new Abstract: Multimodal intent recognition (MMIR) suffers from weak semantic grounding and poor robustness under noisy or rare-class conditions. We propose MVCL-DAF++, which extends MVCL-DAF with two key modules: (1) Prototype-aware contrastive alignment, aligning instances to class-level prototypes to enhance semantic consistency; and (2) Coarse-to-fine attention fusion, integrating global modality summaries with token-level features for hierarchical cross-modal interaction. On MIntRec and MIntRec2.0, MVCL-DAF++ achieves new state-of-the-art results, improving rare-class recognition by +1.05\% and +4.18\% WF1, respectively. These results demonstrate the effectiveness of prototype-guided learning and coarse-to-fine fusion for robust multimodal understanding. The source code is available at https://github.com/chr1s623/MVCL-DAF-PlusPlus.
Periodic Graph-Enhanced Multivariate Time Series Anomaly Detector
arXiv:2509.17472v1 Announce Type: new Abstract: Multivariate time series (MTS) anomaly detection commonly encounters in various domains like finance, healthcare, and industrial monitoring. However, existing MTS anomaly detection methods are mostly defined on the static graph structure, which fails to perform an accurate representation of complex spatio-temporal correlations in MTS. To address this issue, this study proposes a Periodic Graph-Enhanced Multivariate Time Series Anomaly Detector (PGMA) with the following two-fold ideas: a) designing a periodic time-slot allocation strategy based Fast Fourier Transform (FFT), which enables the graph structure to reflect dynamic changes in MTS; b) utilizing graph neural network and temporal extension convolution to accurate extract the complex spatio-temporal correlations from the reconstructed periodic graphs. Experiments on four real datasets from real applications demonstrate that the proposed PGMA outperforms state-of-the-art models in MTS anomaly detection.
Path-Weighted Integrated Gradients for Interpretable Dementia Classification
arXiv:2509.17491v1 Announce Type: new Abstract: Integrated Gradients (IG) is a widely used attribution method in explainable artificial intelligence (XAI). In this paper, we introduce Path-Weighted Integrated Gradients (PWIG), a generalization of IG that incorporates a customizable weighting function into the attribution integral. This modification allows for targeted emphasis along different segments of the path between a baseline and the input, enabling improved interpretability, noise mitigation, and the detection of path-dependent feature relevance. We establish its theoretical properties and illustrate its utility through experiments on a dementia classification task using the OASIS-1 MRI dataset. Attribution maps generated by PWIG highlight clinically meaningful brain regions associated with various stages of dementia, providing users with sharp and stable explanations. The results suggest that PWIG offers a flexible and theoretically grounded approach for enhancing attribution quality in complex predictive models.
BiLCNet : BiLSTM-Conformer Network for Encrypted Traffic Classification with 5G SA Physical Channel Records
arXiv:2509.17495v1 Announce Type: new Abstract: Accurate and efficient traffic classification is vital for wireless network management, especially under encrypted payloads and dynamic application behavior, where traditional methods such as port-based identification and deep packet inspection (DPI) are increasingly inadequate. This work explores the feasibility of using physical channel data collected from the air interface of 5G Standalone (SA) networks for traffic sensing. We develop a preprocessing pipeline to transform raw channel records into structured representations with customized feature engineering to enhance downstream classification performance. To jointly capture temporal dependencies and both local and global structural patterns inherent in physical channel records, we propose a novel hybrid architecture: BiLSTM-Conformer Network (BiLCNet), which integrates the sequential modeling capability of Bidirectional Long Short-Term Memory networks (BiLSTM) with the spatial feature extraction strength of Conformer blocks. Evaluated on a noise-limited 5G SA dataset, our model achieves a classification accuracy of 93.9%, outperforming a series of conventional machine learning and deep learning algorithms. Furthermore, we demonstrate its generalization ability under zero-shot transfer settings, validating its robustness across traffic categories and varying environmental conditions.
Achilles' Heel of Mamba: Essential difficulties of the Mamba architecture demonstrated by synthetic data
arXiv:2509.17514v1 Announce Type: new Abstract: State Space Models (SSMs) have emerged as promising alternatives to attention mechanisms, with the Mamba architecture demonstrating impressive performance and linear complexity for processing long sequences. However, the fundamental differences between Mamba and Transformer architectures remain incompletely understood. In this work, we use carefully designed synthetic tasks to reveal Mamba's inherent limitations. Through experiments, we identify that Mamba's nonlinear convolution introduces an asymmetry bias that significantly impairs its ability to recognize symmetrical patterns and relationships. Using composite function and inverse sequence matching tasks, we demonstrate that Mamba strongly favors compositional solutions over symmetrical ones and struggles with tasks requiring the matching of reversed sequences. We show these limitations stem not from the SSM module itself but from the nonlinear convolution preceding it, which fuses token information asymmetrically. These insights provide a new understanding of Mamba's constraints and suggest concrete architectural improvements for future sequence models.
An Unlearning Framework for Continual Learning
arXiv:2509.17530v1 Announce Type: new Abstract: Growing concerns surrounding AI safety and data privacy have driven the development of Machine Unlearning as a potential solution. However, current machine unlearning algorithms are designed to complement the offline training paradigm. The emergence of the Continual Learning (CL) paradigm promises incremental model updates, enabling models to learn new tasks sequentially. Naturally, some of those tasks may need to be unlearned to address safety or privacy concerns that might arise. We find that applying conventional unlearning algorithms in continual learning environments creates two critical problems: performance degradation on retained tasks and task relapse, where previously unlearned tasks resurface during subsequent learning. Furthermore, most unlearning algorithms require data to operate, which conflicts with CL's philosophy of discarding past data. A clear need arises for unlearning algorithms that are data-free and mindful of future learning. To that end, we propose UnCLe, an Unlearning framework for Continual Learning. UnCLe employs a hypernetwork that learns to generate task-specific network parameters, using task embeddings. Tasks are unlearned by aligning the corresponding generated network parameters with noise, without requiring any data. Empirical evaluations on several vision data sets demonstrate UnCLe's ability to sequentially perform multiple learning and unlearning operations with minimal disruption to previously acquired knowledge.
SeqBattNet: A Discrete-State Physics-Informed Neural Network with Aging Adaptation for Battery Modeling
arXiv:2509.17621v1 Announce Type: new Abstract: Accurate battery modeling is essential for reliable state estimation in modern applications, such as predicting the remaining discharge time and remaining discharge energy in battery management systems. Existing approaches face several limitations: model-based methods require a large number of parameters; data-driven methods rely heavily on labeled datasets; and current physics-informed neural networks (PINNs) often lack aging adaptation, or still depend on many parameters, or continuously regenerate states. In this work, we propose SeqBattNet, a discrete-state PINN with built-in aging adaptation for battery modeling, to predict terminal voltage during the discharge process. SeqBattNet consists of two components: (i) an encoder, implemented as the proposed HRM-GRU deep learning module, which generates cycle-specific aging adaptation parameters; and (ii) a decoder, based on the equivalent circuit model (ECM) combined with deep learning, which uses these parameters together with the input current to predict voltage. The model requires only three basic battery parameters and, when trained on data from a single cell, still achieves robust performance. Extensive evaluations across three benchmark datasets (TRI, RT-Batt, and NASA) demonstrate that SeqBattNet significantly outperforms classical sequence models and PINN baselines, achieving consistently lower RMSE while maintaining computational efficiency.
Comparing Data Assimilation and Likelihood-Based Inference on Latent State Estimation in Agent-Based Models
arXiv:2509.17625v1 Announce Type: new Abstract: In this paper, we present the first systematic comparison of Data Assimilation (DA) and Likelihood-Based Inference (LBI) in the context of Agent-Based Models (ABMs). These models generate observable time series driven by evolving, partially-latent microstates. Latent states need to be estimated to align simulations with real-world data -- a task traditionally addressed by DA, especially in continuous and equation-based models such as those used in weather forecasting. However, the nature of ABMs poses challenges for standard DA methods. Solving such issues requires adaptation of previous DA techniques, or ad-hoc alternatives such as LBI. DA approximates the likelihood in a model-agnostic way, making it broadly applicable but potentially less precise. In contrast, LBI provides more accurate state estimation by directly leveraging the model's likelihood, but at the cost of requiring a hand-crafted, model-specific likelihood function, which may be complex or infeasible to derive. We compare the two methods on the Bounded-Confidence Model, a well-known opinion dynamics ABM, where agents are affected only by others holding sufficiently similar opinions. We find that LBI better recovers latent agent-level opinions, even under model mis-specification, leading to improved individual-level forecasts. At the aggregate level, however, both methods perform comparably, and DA remains competitive across levels of aggregation under certain parameter settings. Our findings suggest that DA is well-suited for aggregate predictions, while LBI is preferable for agent-level inference.
Mechanistic Interpretability with SAEs: Probing Religion, Violence, and Geography in Large Language Models
arXiv:2509.17665v1 Announce Type: new Abstract: Despite growing research on bias in large language models (LLMs), most work has focused on gender and race, with little attention to religious identity. This paper explores how religion is internally represented in LLMs and how it intersects with concepts of violence and geography. Using mechanistic interpretability and Sparse Autoencoders (SAEs) via the Neuronpedia API, we analyze latent feature activations across five models. We measure overlap between religion- and violence-related prompts and probe semantic patterns in activation contexts. While all five religions show comparable internal cohesion, Islam is more frequently linked to features associated with violent language. In contrast, geographic associations largely reflect real-world religious demographics, revealing how models embed both factual distributions and cultural stereotypes. These findings highlight the value of structural analysis in auditing not just outputs but also internal representations that shape model behavior.
Fast, Accurate and Interpretable Graph Classification with Topological Kernels
arXiv:2509.17693v1 Announce Type: new Abstract: We introduce a novel class of explicit feature maps based on topological indices that represent each graph by a compact feature vector, enabling fast and interpretable graph classification. Using radial basis function kernels on these compact vectors, we define a measure of similarity between graphs. We perform evaluation on standard molecular datasets and observe that classification accuracies based on single topological-index feature vectors underperform compared to state-of-the-art substructure-based kernels. However, we achieve significantly faster Gram matrix evaluation -- up to $20\times$ faster -- compared to the Weisfeiler--Lehman subtree kernel. To enhance performance, we propose two extensions: 1) concatenating multiple topological indices into an \emph{Extended Feature Vector} (EFV), and 2) \emph{Linear Combination of Topological Kernels} (LCTK) by linearly combining Radial Basis Function kernels computed on feature vectors of individual topological graph indices. These extensions deliver up to $12\%$ percent accuracy gains across all the molecular datasets. A complexity analysis highlights the potential for exponential quantum speedup for some of the vector components. Our results indicate that LCTK and EFV offer a favourable trade-off between accuracy and efficiency, making them strong candidates for practical graph learning applications.
Cluster Workload Allocation: A Predictive Approach Leveraging Machine Learning Efficiency
arXiv:2509.17695v1 Announce Type: new Abstract: This research investigates how Machine Learning (ML) algorithms can assist in workload allocation strategies by detecting tasks with node affinity operators (referred to as constraint operators), which constrain their execution to a limited number of nodes. Using real-world Google Cluster Data (GCD) workload traces and the AGOCS framework, the study extracts node attributes and task constraints, then analyses them to identify suitable node-task pairings. It focuses on tasks that can be executed on either a single node or fewer than a thousand out of 12.5k nodes in the analysed GCD cluster. Task constraint operators are compacted, pre-processed with one-hot encoding, and used as features in a training dataset. Various ML classifiers, including Artificial Neural Networks, K-Nearest Neighbours, Decision Trees, Naive Bayes, Ridge Regression, Adaptive Boosting, and Bagging, are fine-tuned and assessed for accuracy and F1-scores. The final ensemble voting classifier model achieved 98% accuracy and a 1.5-1.8% misclassification rate for tasks with a single suitable node.
A non-smooth regularization framework for learning over multitask graphs
arXiv:2509.17728v1 Announce Type: new Abstract: In this work, we consider learning over multitask graphs, where each agent aims to estimate its own parameter vector. Although agents seek distinct objectives, collaboration among them can be beneficial in scenarios where relationships between tasks exist. Among the various approaches to promoting relationships between tasks and, consequently, enhancing collaboration between agents, one notable method is regularization. While previous multitask learning studies have focused on smooth regularization to enforce graph smoothness, this work explores non-smooth regularization techniques that promote sparsity, making them particularly effective in encouraging piecewise constant transitions on the graph. We begin by formulating a global regularized optimization problem, which involves minimizing the aggregate sum of individual costs, regularized by a general non-smooth term designed to promote piecewise-constant relationships between the tasks of neighboring agents. Based on the forward-backward splitting strategy, we propose a decentralized learning approach that enables efficient solutions to the regularized optimization problem. Then, under convexity assumptions on the cost functions and co-regularization, we establish that the proposed approach converges in the mean-square-error sense within $O(\mu)$ of the optimal solution of the globally regularized cost. For broader applicability and improved computational efficiency, we also derive closed-form expressions for commonly used non-smooth (and, possibly, non-convex) regularizers, such as the weighted sum of the $\ell_0$-norm, $\ell_1$-norm, and elastic net regularization. Finally, we illustrate both the theoretical findings and the effectiveness of the approach through simulations.
A Generative Conditional Distribution Equality Testing Framework and Its Minimax Analysis
arXiv:2509.17729v1 Announce Type: new Abstract: In this paper, we propose a general framework for testing the equality of the conditional distributions in a two-sample problem. This problem is most relevant to transfer learning under covariate shift. Our framework is built on neural network-based generative methods and sample splitting techniques by transforming the conditional distribution testing problem into an unconditional one. We introduce two special tests: the generative permutation-based conditional distribution equality test and the generative classification accuracy-based conditional distribution equality test. Theoretically, we establish a minimax lower bound for statistical inference in testing the equality of two conditional distributions under certain smoothness conditions. We demonstrate that the generative permutation-based conditional distribution equality test and its modified version can attain this lower bound precisely or up to some iterated logarithmic factor. Moreover, we prove the testing consistency of the generative classification accuracy-based conditional distribution equality test. We also establish the convergence rate for the learned conditional generator by deriving new results related to the recently-developed offset Rademacher complexity and approximation properties using neural networks. Empirically, we conduct numerical studies including synthetic datasets and two real-world datasets, demonstrating the effectiveness of our approach.
ConfClip: Confidence-Weighted and Clipped Reward for Reinforcement Learning in LLMs
arXiv:2509.17730v1 Announce Type: new Abstract: Reinforcement learning (RL) has become a standard paradigm for refining large language models (LLMs) beyond pre-training and instruction tuning. A prominent line of work is RL with verifiable rewards (RLVR), which leverages automatically verifiable outcomes (e.g., correctness or executability) to generate reward signals. While efficient, this framework faces two key limitations: First, its binary feedback is too sparse to capture the quality of the reasoning process. Second, its coarse-grained rewards potentially lead to vanishing gradients. Inspired by observations from human learning, we introduce a RL technique that integrates verifiable outcomes with the model's own confidence estimates. This joint design enriches the reward signal, providing finer-grained feedback and implicitly supervising the reasoning process. Experimental results demonstrate that our proposed method enhances RL performance across multiple datasets and reduces token consumption during inference, while incurring negligible additional training cost. Moreover, it can be used as a plug-in module to enhance other state-of-the-art RL methods.
An AutoML Framework using AutoGluonTS for Forecasting Seasonal Extreme Temperatures
arXiv:2509.17734v1 Announce Type: new Abstract: In recent years, great progress has been made in the field of forecasting meteorological variables. Recently, deep learning architectures have made a major breakthrough in forecasting the daily average temperature over a ten-day horizon. However, advances in forecasting events related to the maximum temperature over short horizons remain a challenge for the community. A problem that is even more complex consists in making predictions of the maximum daily temperatures in the short, medium, and long term. In this work, we focus on forecasting events related to the maximum daily temperature over medium-term periods (90 days). Therefore, instead of addressing the problem from a meteorological point of view, this article tackles it from a climatological point of view. Due to the complexity of this problem, a common approach is to frame the study as a temporal classification problem with the classes: maximum temperature "above normal", "normal" or "below normal". From a practical point of view, we created a large historical dataset (from 1981 to 2018) collecting information from weather stations located in South America. In addition, we also integrated exogenous information from the Pacific, Atlantic, and Indian Ocean basins. We applied the AutoGluonTS platform to solve the above-mentioned problem. This AutoML tool shows competitive forecasting performance with respect to large operational platforms dedicated to tackling this climatological problem; but with a "relatively" low computational cost in terms of time and resources.
Flatness is Necessary, Neural Collapse is Not: Rethinking Generalization via Grokking
arXiv:2509.17738v1 Announce Type: new Abstract: Neural collapse, i.e., the emergence of highly symmetric, class-wise clustered representations, is frequently observed in deep networks and is often assumed to reflect or enable generalization. In parallel, flatness of the loss landscape has been theoretically and empirically linked to generalization. Yet, the causal role of either phenomenon remains unclear: Are they prerequisites for generalization, or merely by-products of training dynamics? We disentangle these questions using grokking, a training regime in which memorization precedes generalization, allowing us to temporally separate generalization from training dynamics and we find that while both neural collapse and relative flatness emerge near the onset of generalization, only flatness consistently predicts it. Models encouraged to collapse or prevented from collapsing generalize equally well, whereas models regularized away from flat solutions exhibit delayed generalization. Furthermore, we show theoretically that neural collapse implies relative flatness under classical assumptions, explaining their empirical co-occurrence. Our results support the view that relative flatness is a potentially necessary and more fundamental property for generalization, and demonstrate how grokking can serve as a powerful probe for isolating its geometric underpinnings.
GEM-T: Generative Tabular Data via Fitting Moments
arXiv:2509.17752v1 Announce Type: new Abstract: Tabular data dominates data science but poses challenges for generative models, especially when the data is limited or sensitive. We present a novel approach to generating synthetic tabular data based on the principle of maximum entropy -- MaxEnt -- called GEM-T, for ``generative entropy maximization for tables.'' GEM-T directly captures nth-order interactions -- pairwise, third-order, etc. -- among columns of training data. In extensive testing, GEM-T matches or exceeds deep neural network approaches previously regarded as state-of-the-art in 23 of 34 publicly available datasets representing diverse subject domains (68\%). Notably, GEM-T involves orders-of-magnitude fewer trainable parameters, demonstrating that much of the information in real-world data resides in low-dimensional, potentially human-interpretable correlations, provided that the input data is appropriately transformed first. Furthermore, MaxEnt better handles heterogeneous data types (continuous vs. discrete vs. categorical), lack of local structure, and other features of tabular data. GEM-T represents a promising direction for light-weight high-performance generative models for structured data.
Learning Neural Antiderivatives
arXiv:2509.17755v1 Announce Type: new Abstract: Neural fields offer continuous, learnable representations that extend beyond traditional discrete formats in visual computing. We study the problem of learning neural representations of repeated antiderivatives directly from a function, a continuous analogue of summed-area tables. Although widely used in discrete domains, such cumulative schemes rely on grids, which prevents their applicability in continuous neural contexts. We introduce and analyze a range of neural methods for repeated integration, including both adaptations of prior work and novel designs. Our evaluation spans multiple input dimensionalities and integration orders, assessing both reconstruction quality and performance in downstream tasks such as filtering and rendering. These results enable integrating classical cumulative operators into modern neural systems and offer insights into learning tasks involving differential and integral operators.
Revealing Multimodal Causality with Large Language Models
arXiv:2509.17784v1 Announce Type: new Abstract: Uncovering cause-and-effect mechanisms from data is fundamental to scientific progress. While large language models (LLMs) show promise for enhancing causal discovery (CD) from unstructured data, their application to the increasingly prevalent multimodal setting remains a critical challenge. Even with the advent of multimodal LLMs (MLLMs), their efficacy in multimodal CD is hindered by two primary limitations: (1) difficulty in exploring intra- and inter-modal interactions for comprehensive causal variable identification; and (2) insufficiency to handle structural ambiguities with purely observational data. To address these challenges, we propose MLLM-CD, a novel framework for multimodal causal discovery from unstructured data. It consists of three key components: (1) a novel contrastive factor discovery module to identify genuine multimodal factors based on the interactions explored from contrastive sample pairs; (2) a statistical causal structure discovery module to infer causal relationships among discovered factors; and (3) an iterative multimodal counterfactual reasoning module to refine the discovery outcomes iteratively by incorporating the world knowledge and reasoning capabilities of MLLMs. Extensive experiments on both synthetic and real-world datasets demonstrate the effectiveness of MLLM-CD in revealing genuine factors and causal relationships among them from multimodal unstructured data.
Elucidating the Design Space of FP4 training
arXiv:2509.17791v1 Announce Type: new Abstract: The increasing computational demands of foundation models have spurred research into low-precision training, with 4-bit floating-point (\texttt{FP4}) formats emerging as a frontier for maximizing hardware throughput. While numerous techniques have been proposed to stabilize \texttt{FP4} training, they often present isolated solutions with varying, and not always clear, computational overheads. This paper aims to provide a unified view of the design space of \texttt{FP4} training. We introduce a comprehensive, quantisation gradient-based framework for microscaling quantization that allows for a theoretical analysis of the computational costs associated with different stabilization methods on both the forward and backward passes. Using a simulator built on this framework, we conduct an extensive empirical study across a wide range of machine learning tasks, including regression, image classification, diffusion models, and language models. By systematically evaluating thousands of combinations of techniques, such as novel gradient approximations, rounding strategies, and scaling methods, we identify which configurations offer the most favourable performance-to-overhead trade-off. We find that the techniques enabling the best trade-off involve carefully combining Hadamard transformations, tensor scaling and stochastic rounding. We further find that using \texttt{UE5M3} as a scaling factor potentially offers a good compromise between range and precision with manageable computational overhead.
Remote Sensing-Oriented World Model
arXiv:2509.17808v1 Announce Type: new Abstract: World models have shown potential in artificial intelligence by predicting and reasoning about world states beyond direct observations. However, existing approaches are predominantly evaluated in synthetic environments or constrained scene settings, limiting their validation in real-world contexts with broad spatial coverage and complex semantics. Meanwhile, remote sensing applications urgently require spatial reasoning capabilities for disaster response and urban planning. This paper bridges these gaps by introducing the first framework for world modeling in remote sensing. We formulate remote sensing world modeling as direction-conditioned spatial extrapolation, where models generate semantically consistent adjacent image tiles given a central observation and directional instruction. To enable rigorous evaluation, we develop RSWISE (Remote Sensing World-Image Spatial Evaluation), a benchmark containing 1,600 evaluation tasks across four scenarios: general, flood, urban, and rural. RSWISE combines visual fidelity assessment with instruction compliance evaluation using GPT-4o as a semantic judge, ensuring models genuinely perform spatial reasoning rather than simple replication. Afterwards, we present RemoteBAGEL, a unified multimodal model fine-tuned on remote sensing data for spatial extrapolation tasks. Extensive experiments demonstrate that RemoteBAGEL consistently outperforms state-of-the-art baselines on RSWISE.
MTM: A Multi-Scale Token Mixing Transformer for Irregular Multivariate Time Series Classification
arXiv:2509.17809v1 Announce Type: new Abstract: Irregular multivariate time series (IMTS) is characterized by the lack of synchronized observations across its different channels. In this paper, we point out that this channel-wise asynchrony can lead to poor channel-wise modeling of existing deep learning methods. To overcome this limitation, we propose MTM, a multi-scale token mixing transformer for the classification of IMTS. We find that the channel-wise asynchrony can be alleviated by down-sampling the time series to coarser timescales, and propose to incorporate a masked concat pooling in MTM that gradually down-samples IMTS to enhance the channel-wise attention modules. Meanwhile, we propose a novel channel-wise token mixing mechanism which proactively chooses important tokens from one channel and mixes them with other channels, to further boost the channel-wise learning of our model. Through extensive experiments on real-world datasets and comparison with state-of-the-art methods, we demonstrate that MTM consistently achieves the best performance on all the benchmarks, with improvements of up to 3.8% in AUPRC for classification.
MSGAT-GRU: A Multi-Scale Graph Attention and Recurrent Model for Spatiotemporal Road Accident Prediction
arXiv:2509.17811v1 Announce Type: new Abstract: Accurate prediction of road accidents remains challenging due to intertwined spatial, temporal, and contextual factors in urban traffic. We propose MSGAT-GRU, a multi-scale graph attention and recurrent model that jointly captures localized and long-range spatial dependencies while modeling sequential dynamics. Heterogeneous inputs, such as traffic flow, road attributes, weather, and points of interest, are systematically fused to enhance robustness and interpretability. On the Hybrid Beijing Accidents dataset, MSGAT-GRU achieves an RMSE of 0.334 and an F1-score of 0.878, consistently outperforming strong baselines. Cross-dataset evaluation on METR-LA under a 1-hour horizon further supports transferability, with RMSE of 6.48 (vs. 7.21 for the GMAN model) and comparable MAPE. Ablations indicate that three-hop spatial aggregation and a two-layer GRU offer the best accuracy-stability trade-off. These results position MSGAT-GRU as a scalable and generalizable model for intelligent transportation systems, providing interpretable signals that can inform proactive traffic management and road safety analytics.
Global Optimization via Softmin Energy Minimization
arXiv:2509.17815v1 Announce Type: new Abstract: Global optimization, particularly for non-convex functions with multiple local minima, poses significant challenges for traditional gradient-based methods. While metaheuristic approaches offer empirical effectiveness, they often lack theoretical convergence guarantees and may disregard available gradient information. This paper introduces a novel gradient-based swarm particle optimization method designed to efficiently escape local minima and locate global optima. Our approach leverages a "Soft-min Energy" interacting function, $J_\beta(\mathbf{x})$, which provides a smooth, differentiable approximation of the minimum function value within a particle swarm. We define a stochastic gradient flow in the particle space, incorporating a Brownian motion term for exploration and a time-dependent parameter $\beta$ to control smoothness, similar to temperature annealing. We theoretically demonstrate that for strongly convex functions, our dynamics converges to a stationary point where at least one particle reaches the global minimum, with other particles exhibiting exploratory behavior. Furthermore, we show that our method facilitates faster transitions between local minima by reducing effective potential barriers with respect to Simulated Annealing. More specifically, we estimate the hitting times of unexplored potential wells for our model in the small noise regime and show that they compare favorably with the ones of overdamped Langevin. Numerical experiments on benchmark functions, including double wells and the Ackley function, validate our theoretical findings and demonstrate better performance over the well-known Simulated Annealing method in terms of escaping local minima and achieving faster convergence.
Conv-like Scale-Fusion Time Series Transformer: A Multi-Scale Representation for Variable-Length Long Time Series
arXiv:2509.17845v1 Announce Type: new Abstract: Time series analysis faces significant challenges in handling variable-length data and achieving robust generalization. While Transformer-based models have advanced time series tasks, they often struggle with feature redundancy and limited generalization capabilities. Drawing inspiration from classical CNN architectures' pyramidal structure, we propose a Multi-Scale Representation Learning Framework based on a Conv-like ScaleFusion Transformer. Our approach introduces a temporal convolution-like structure that combines patching operations with multi-head attention, enabling progressive temporal dimension compression and feature channel expansion. We further develop a novel cross-scale attention mechanism for effective feature fusion across different temporal scales, along with a log-space normalization method for variable-length sequences. Extensive experiments demonstrate that our framework achieves superior feature independence, reduced redundancy, and better performance in forecasting and classification tasks compared to state-of-the-art methods.
Understanding Post-Training Structural Changes in Large Language Models
arXiv:2509.17866v1 Announce Type: new Abstract: Post-training fundamentally alters the behavior of large language models (LLMs), yet its impact on the internal parameter space remains poorly understood. In this work, we conduct a systematic singular value decomposition (SVD) analysis of principal linear layers in pretrained LLMs, focusing on two widely adopted post-training methods: instruction tuning and long-chain-of-thought (Long-CoT) distillation. Our analysis reveals two consistent and unexpected structural changes:(1) a near-uniform geometric scaling of singular values across layers, which theoretically modulates attention scores; and (2) highly consistent orthogonal transformations are applied to the left and right singular vectors of each matrix. Disrupting this orthogonal consistency leads to catastrophic performance degradation. Based on these findings, we propose a simple yet effective framework that interprets post-training as a reparameterization of fixed subspaces in the pretrained parameter space. Further experiments reveal that singular value scaling behaves as a secondary effect, analogous to a temperature adjustment, whereas the core functional transformation lies in the coordinated rotation of singular vectors. These results challenge the prevailing view of the parameter space in large models as a black box, uncovering the first clear regularities in how parameters evolve during training, and providing a new perspective for deeper investigation into model parameter changes.
Improving After-sales Service: Deep Reinforcement Learning for Dynamic Time Slot Assignment with Commitments and Customer Preferences
arXiv:2509.17870v1 Announce Type: new Abstract: Problem definition: For original equipment manufacturers (OEMs), high-tech maintenance is a strategic component in after-sales services, involving close coordination between customers and service engineers. Each customer suggests several time slots for their maintenance task, from which the OEM must select one. This decision needs to be made promptly to support customers' planning. At the end of each day, routes for service engineers are planned to fulfill the tasks scheduled for the following day. We study this hierarchical and sequential decision-making problem-the Dynamic Time Slot Assignment Problem with Commitments and Customer Preferences (DTSAP-CCP)-in this paper. Methodology/results: Two distinct approaches are proposed: 1) an attention-based deep reinforcement learning with rollout execution (ADRL-RE) and 2) a scenario-based planning approach (SBP). The ADRL-RE combines a well-trained attention-based neural network with a rollout framework for online trajectory simulation. To support the training, we develop a neural heuristic solver that provides rapid route planning solutions, enabling efficient learning in complex combinatorial settings. The SBP approach samples several scenarios to guide the time slot assignment. Numerical experiments demonstrate the superiority of ADRL-RE and the stability of SBP compared to both rule-based and rollout-based approaches. Furthermore, the strong practicality of ADRL-RE is verified in a case study of after-sales service for large medical equipment. Implications: This study provides OEMs with practical decision-support tools for dynamic maintenance scheduling, balancing customer preferences and operational efficiency. In particular, our ADRL-RE shows strong real-world potential, supporting timely and customer-aligned maintenance scheduling.
Deep Hierarchical Learning with Nested Subspace Networks
arXiv:2509.17874v1 Announce Type: new Abstract: Large neural networks are typically trained for a fixed computational budget, creating a rigid trade-off between performance and efficiency that is ill-suited for deployment in resource-constrained or dynamic environments. Existing approaches to this problem present a difficult choice: training a discrete collection of specialist models is computationally prohibitive, while dynamic methods like slimmable networks often lack the flexibility to be applied to large, pre-trained foundation models. In this work, we propose Nested Subspace Networks (NSNs), a novel architectural paradigm that enables a single model to be dynamically and granularly adjusted across a continuous spectrum of compute budgets at inference time. The core of our approach is to re-parameterize linear layers to satisfy a nested subspace property, such that the function computed at a given rank is a strict subspace of the function at any higher rank. We show that this entire hierarchy of models can be optimized jointly via an uncertainty-aware objective that learns to balance the contributions of different ranks based on their intrinsic difficulty. We demonstrate empirically that NSNs can be surgically applied to pre-trained LLMs and unlock a smooth and predictable compute-performance frontier. For example, a single NSN-adapted model can achieve a 50% reduction in inference FLOPs with only a 5 percentage point loss in accuracy. Our findings establish NSNs as a powerful framework for creating the next generation of adaptive foundation models.
Confidence-gated training for efficient early-exit neural networks
arXiv:2509.17885v1 Announce Type: new Abstract: Early-exit neural networks reduce inference cost by enabling confident predictions at intermediate layers. However, joint training often leads to gradient interference, with deeper classifiers dominating optimization. We propose Confidence-Gated Training (CGT), a paradigm that conditionally propagates gradients from deeper exits only when preceding exits fail. This encourages shallow classifiers to act as primary decision points while reserving deeper layers for harder inputs. By aligning training with the inference-time policy, CGT mitigates overthinking, improves early-exit accuracy, and preserves efficiency. Experiments on the Indian Pines and Fashion-MNIST benchmarks show that CGT lowers average inference cost while improving overall accuracy, offering a practical solution for deploying deep models in resource-constrained environments.
GaussianPSL: A novel framework based on Gaussian Splatting for exploring the Pareto frontier in multi-criteria optimization
arXiv:2509.17889v1 Announce Type: new Abstract: Multi-objective optimization (MOO) is essential for solving complex real-world problems involving multiple conflicting objectives. However, many practical applications - including engineering design, autonomous systems, and machine learning - often yield non-convex, degenerate, or discontinuous Pareto frontiers, which involve traditional scalarization and Pareto Set Learning (PSL) methods that struggle to approximate accurately. Existing PSL approaches perform well on convex fronts but tend to fail in capturing the diversity and structure of irregular Pareto sets commonly observed in real-world scenarios. In this paper, we propose Gaussian-PSL, a novel framework that integrates Gaussian Splatting into PSL to address the challenges posed by non-convex Pareto frontiers. Our method dynamically partitions the preference vector space, enabling simple MLP networks to learn localized features within each region, which are then integrated by an additional MLP aggregator. This partition-aware strategy enhances both exploration and convergence, reduces sensi- tivity to initialization, and improves robustness against local optima. We first provide the mathematical formulation for controllable Pareto set learning using Gaussian Splat- ting. Then, we introduce the Gaussian-PSL architecture and evaluate its performance on synthetic and real-world multi-objective benchmarks. Experimental results demonstrate that our approach outperforms standard PSL models in learning irregular Pareto fronts while maintaining computational efficiency and model simplicity. This work offers a new direction for effective and scalable MOO under challenging frontier geometries.
Optimizing Inference in Transformer-Based Models: A Multi-Method Benchmark
arXiv:2509.17894v1 Announce Type: new Abstract: Efficient inference is a critical challenge in deep generative modeling, particularly as diffusion models grow in capacity and complexity. While increased complexity often improves accuracy, it raises compute costs, latency, and memory requirements. This work investigates techniques such as pruning, quantization, knowledge distillation, and simplified attention to reduce computational overhead without impacting performance. The study also explores the Mixture of Experts (MoE) approach to further enhance efficiency. These experiments provide insights into optimizing inference for the state-of-the-art Fast Diffusion Transformer (fast-DiT) model.
SingLEM: Single-Channel Large EEG Model
arXiv:2509.17920v1 Announce Type: new Abstract: Current deep learning models for electroencephalography (EEG) are often task-specific and depend on large labeled datasets, limiting their adaptability. Although emerging foundation models aim for broader applicability, their rigid dependence on fixed, high-density multi-channel montages restricts their use across heterogeneous datasets and in missing-channel or practical low-channel settings. To address these limitations, we introduce SingLEM, a self-supervised foundation model that learns robust, general-purpose representations from single-channel EEG, making it inherently hardware agnostic. The model employs a hybrid encoder architecture that combines convolutional layers to extract local features with a hierarchical transformer to model both short- and long-range temporal dependencies. SingLEM is pretrained on 71 public datasets comprising over 9,200 subjects and 357,000 single-channel hours of EEG. When evaluated as a fixed feature extractor across six motor imagery and cognitive tasks, aggregated single-channel representations consistently outperformed leading multi-channel foundation models and handcrafted baselines. These results demonstrate that a single-channel approach can achieve state-of-the-art generalization while enabling fine-grained neurophysiological analysis and enhancing interpretability. The source code and pretrained models are available at https://github.com/ttlabtuat/SingLEM.
Medical priority fusion: achieving dual optimization of sensitivity and interpretability in nipt anomaly detection
arXiv:2509.17924v1 Announce Type: new Abstract: Clinical machine learning faces a critical dilemma in high-stakes medical applications: algorithms achieving optimal diagnostic performance typically sacrifice the interpretability essential for physician decision-making, while interpretable methods compromise sensitivity in complex scenarios. This paradox becomes particularly acute in non-invasive prenatal testing (NIPT), where missed chromosomal abnormalities carry profound clinical consequences yet regulatory frameworks mandate explainable AI systems. We introduce Medical Priority Fusion (MPF), a constrained multi-objective optimization framework that resolves this fundamental trade-off by systematically integrating Naive Bayes probabilistic reasoning with Decision Tree rule-based logic through mathematically-principled weighted fusion under explicit medical constraints. Rigorous validation on 1,687 real-world NIPT samples characterized by extreme class imbalance (43.4:1 normal-to-abnormal ratio) employed stratified 5-fold cross-validation with comprehensive ablation studies and statistical hypothesis testing using McNemar's paired comparisons. MPF achieved simultaneous optimization of dual objectives: 89.3% sensitivity (95% CI: 83.9-94.7%) with 80% interpretability score, significantly outperforming individual algorithms (McNemar's test, p < 0.001). The optimal fusion configuration achieved Grade A clinical deployment criteria with large effect size (d = 1.24), establishing the first clinically-deployable solution that maintains both diagnostic accuracy and decision transparency essential for prenatal care. This work demonstrates that medical-constrained algorithm fusion can resolve the interpretability-performance trade-off, providing a mathematical framework for developing high-stakes medical decision support systems that meet both clinical efficacy and explainability requirements.
StefaLand: An Efficient Geoscience Foundation Model That Improves Dynamic Land-Surface Predictions
arXiv:2509.17942v1 Announce Type: new Abstract: Stewarding natural resources, mitigating floods, droughts, wildfires, and landslides, and meeting growing demands require models that can predict climate-driven land-surface responses and human feedback with high accuracy. Traditional impact models, whether process-based, statistical, or machine learning, struggle with spatial generalization due to limited observations and concept drift. Recently proposed vision foundation models trained on satellite imagery demand massive compute and are ill-suited for dynamic land-surface prediction. We introduce StefaLand, a generative spatiotemporal earth foundation model centered on landscape interactions. StefaLand improves predictions on three tasks and four datasets: streamflow, soil moisture, and soil composition, compared to prior state-of-the-art. Results highlight its ability to generalize across diverse, data-scarce regions and support broad land-surface applications. The model builds on a masked autoencoder backbone that learns deep joint representations of landscape attributes, with a location-aware architecture fusing static and time-series inputs, attribute-based representations that drastically reduce compute, and residual fine-tuning adapters that enhance transfer. While inspired by prior methods, their alignment with geoscience and integration in one model enables robust performance on dynamic land-surface tasks. StefaLand can be pretrained and finetuned on academic compute yet outperforms state-of-the-art baselines and even fine-tuned vision foundation models. To our knowledge, this is the first geoscience land-surface foundation model that demonstrably improves dynamic land-surface interaction predictions and supports diverse downstream applications.
Joint Optimization of Memory Frequency, Computing Frequency, Transmission Power and Task Offloading for Energy-efficient DNN Inference
arXiv:2509.17970v1 Announce Type: new Abstract: Deep neural networks (DNNs) have been widely applied in diverse applications, but the problems of high latency and energy overhead are inevitable on resource-constrained devices. To address this challenge, most researchers focus on the dynamic voltage and frequency scaling (DVFS) technique to balance the latency and energy consumption by changing the computing frequency of processors. However, the adjustment of memory frequency is usually ignored and not fully utilized to achieve efficient DNN inference, which also plays a significant role in the inference time and energy consumption. In this paper, we first investigate the impact of joint memory frequency and computing frequency scaling on the inference time and energy consumption with a model-based and data-driven method. Then by combining with the fitting parameters of different DNN models, we give a preliminary analysis for the proposed model to see the effects of adjusting memory frequency and computing frequency simultaneously. Finally, simulation results in local inference and cooperative inference cases further validate the effectiveness of jointly scaling the memory frequency and computing frequency to reduce the energy consumption of devices.
Intra-Cluster Mixup: An Effective Data Augmentation Technique for Complementary-Label Learning
arXiv:2509.17971v1 Announce Type: new Abstract: In this paper, we investigate the challenges of complementary-label learning (CLL), a specialized form of weakly-supervised learning (WSL) where models are trained with labels indicating classes to which instances do not belong, rather than standard ordinary labels. This alternative supervision is appealing because collecting complementary labels is generally cheaper and less labor-intensive. Although most existing research in CLL emphasizes the development of novel loss functions, the potential of data augmentation in this domain remains largely underexplored. In this work, we uncover that the widely-used Mixup data augmentation technique is ineffective when directly applied to CLL. Through in-depth analysis, we identify that the complementary-label noise generated by Mixup negatively impacts the performance of CLL models. We then propose an improved technique called Intra-Cluster Mixup (ICM), which only synthesizes augmented data from nearby examples, to mitigate the noise effect. ICM carries the benefits of encouraging complementary label sharing of nearby examples, and leads to substantial performance improvements across synthetic and real-world labeled datasets. In particular, our wide spectrum of experimental results on both balanced and imbalanced CLL settings justifies the potential of ICM in allying with state-of-the-art CLL algorithms, achieving significant accuracy increases of 30% and 10% on MNIST and CIFAR datasets, respectively.
Budgeted Adversarial Attack against Graph-Based Anomaly Detection in Sensor Networks
arXiv:2509.17987v1 Announce Type: new Abstract: Graph Neural Networks (GNNs) have emerged as powerful models for anomaly detection in sensor networks, particularly when analyzing multivariate time series. In this work, we introduce BETA, a novel grey-box evasion attack targeting such GNN-based detectors, where the attacker is constrained to perturb sensor readings from a limited set of nodes, excluding the target sensor, with the goal of either suppressing a true anomaly or triggering a false alarm at the target node. BETA identifies the sensors most influential to the target node's classification and injects carefully crafted adversarial perturbations into their features, all while maintaining stealth and respecting the attacker's budget. Experiments on three real-world sensor network datasets show that BETA reduces the detection accuracy of state-of-the-art GNN-based detectors by 30.62 to 39.16% on average, and significantly outperforms baseline attack strategies, while operating within realistic constraints.
Equilibrium flow: From Snapshots to Dynamics
arXiv:2509.17990v1 Announce Type: new Abstract: Scientific data, from cellular snapshots in biology to celestial distributions in cosmology, often consists of static patterns from underlying dynamical systems. These snapshots, while lacking temporal ordering, implicitly encode the processes that preserve them. This work investigates how strongly such a distribution constrains its underlying dynamics and how to recover them. We introduce the Equilibrium flow method, a framework that learns continuous dynamics that preserve a given pattern distribution. Our method successfully identifies plausible dynamics for 2-D systems and recovers the signature chaotic behavior of the Lorenz attractor. For high-dimensional Turing patterns from the Gray-Scott model, we develop an efficient, training-free variant that achieves high fidelity to the ground truth, validated both quantitatively and qualitatively. Our analysis reveals the solution space is constrained not only by the data but also by the learning model's inductive biases. This capability extends beyond recovering known systems, enabling a new paradigm of inverse design for Artificial Life. By specifying a target pattern distribution, we can discover the local interaction rules that preserve it, leading to the spontaneous emergence of complex behaviors, such as life-like flocking, attraction, and repulsion patterns, from simple, user-defined snapshots.
Adaptive Kernel Design for Bayesian Optimization Is a Piece of CAKE with LLMs
arXiv:2509.17998v1 Announce Type: new Abstract: The efficiency of Bayesian optimization (BO) relies heavily on the choice of the Gaussian process (GP) kernel, which plays a central role in balancing exploration and exploitation under limited evaluation budgets. Traditional BO methods often rely on fixed or heuristic kernel selection strategies, which can result in slow convergence or suboptimal solutions when the chosen kernel is poorly suited to the underlying objective function. To address this limitation, we propose a freshly-baked Context-Aware Kernel Evolution (CAKE) to enhance BO with large language models (LLMs). Concretely, CAKE leverages LLMs as the crossover and mutation operators to adaptively generate and refine GP kernels based on the observed data throughout the optimization process. To maximize the power of CAKE, we further propose BIC-Acquisition Kernel Ranking (BAKER) to select the most effective kernel through balancing the model fit measured by the Bayesian information criterion (BIC) with the expected improvement at each iteration of BO. Extensive experiments demonstrate that our fresh CAKE-based BO method consistently outperforms established baselines across a range of real-world tasks, including hyperparameter optimization, controller tuning, and photonic chip design. Our code is publicly available at https://github.com/cake4bo/cake.
Unveiling m-Sharpness Through the Structure of Stochastic Gradient Noise
arXiv:2509.18001v1 Announce Type: new Abstract: Sharpness-aware minimization (SAM) has emerged as a highly effective technique for improving model generalization, but its underlying principles are not fully understood. We investigated the phenomenon known as m-sharpness, where the performance of SAM improves monotonically as the micro-batch size for computing perturbations decreases. Leveraging an extended Stochastic Differential Equation (SDE) framework, combined with an analysis of the structure of stochastic gradient noise (SGN), we precisely characterize the dynamics of various SAM variants. Our findings reveal that the stochastic noise introduced during SAM perturbations inherently induces a variance-based sharpness regularization effect. Motivated by our theoretical insights, we introduce Reweighted SAM, which employs sharpness-weighted sampling to mimic the generalization benefits of m-SAM while remaining parallelizable. Comprehensive experiments validate the effectiveness of our theoretical analysis and proposed method.
Control Disturbance Rejection in Neural ODEs
arXiv:2509.18034v1 Announce Type: new Abstract: In this paper, we propose an iterative training algorithm for Neural ODEs that provides models resilient to control (parameter) disturbances. The method builds on our earlier work Tuning without Forgetting-and similarly introduces training points sequentially, and updates the parameters on new data within the space of parameters that do not decrease performance on the previously learned training points-with the key difference that, inspired by the concept of flat minima, we solve a minimax problem for a non-convex non-concave functional over an infinite-dimensional control space. We develop a projected gradient descent algorithm on the space of parameters that admits the structure of an infinite-dimensional Banach subspace. We show through simulations that this formulation enables the model to effectively learn new data points and gain robustness against control disturbance.
Reinforced Generation of Combinatorial Structures: Applications to Complexity Theory
arXiv:2509.18057v1 Announce Type: new Abstract: We explore whether techniques from AI can help discover new combinatorial structures that improve provable limits on efficient algorithms. Specifically, we use AlphaEvolve (an LLM coding agent) to study two settings: a) Average-case hardness for MAX-CUT and MAX-Independent Set: We improve a recent result of Kunisky and Yu to obtain near-optimal upper and (conditional) lower bounds on certification algorithms for MAX-CUT and MAX-Independent Set on random 3- and 4-regular graphs. Our improved lower bounds are obtained by constructing nearly extremal Ramanujan graphs on as many as $163$ nodes, using AlphaEvolve. Additionally, via analytical arguments we strengthen the upper bounds to settle the computational hardness of these questions up to an error in the third decimal place. b) Worst-case Hardness of Approximation for MAX-k-CUT: We obtain new inapproximability results, proving that it is NP-hard to approximate MAX-4-CUT and MAX-3-CUT within factors of $0.987$ and $0.9649$ respectively, using AlphaEvolve to discover new gadget reductions. Our MAX-4-CUT result improves upon the SOTA of $0.9883$, and our MAX-3-CUT result improves on the current best gadget-based inapproximability result of $0.9853$, but falls short of improving the SOTA of $16/17$ that relies on a custom PCP, rather than a gadget reduction from "standard" H{\aa}stad-style PCPs. A key technical challenge we faced: verifying a candidate construction produced by AlphaEvolve is costly (often requiring exponential time). In both settings above, our results were enabled by using AlphaEvolve itself to evolve the verification procedure to be faster (sometimes by $10,000\times$). We conclude with a discussion of norms by which to assess the assistance from AI in developing proofs.
Strategic Dishonesty Can Undermine AI Safety Evaluations of Frontier LLM
arXiv:2509.18058v1 Announce Type: new Abstract: Large language model (LLM) developers aim for their models to be honest, helpful, and harmless. However, when faced with malicious requests, models are trained to refuse, sacrificing helpfulness. We show that frontier LLMs can develop a preference for dishonesty as a new strategy, even when other options are available. Affected models respond to harmful requests with outputs that sound harmful but are subtly incorrect or otherwise harmless in practice. This behavior emerges with hard-to-predict variations even within models from the same model family. We find no apparent cause for the propensity to deceive, but we show that more capable models are better at executing this strategy. Strategic dishonesty already has a practical impact on safety evaluations, as we show that dishonest responses fool all output-based monitors used to detect jailbreaks that we test, rendering benchmark scores unreliable. Further, strategic dishonesty can act like a honeypot against malicious users, which noticeably obfuscates prior jailbreak attacks. While output monitors fail, we show that linear probes on internal activations can be used to reliably detect strategic dishonesty. We validate probes on datasets with verifiable outcomes and by using their features as steering vectors. Overall, we consider strategic dishonesty as a concrete example of a broader concern that alignment of LLMs is hard to control, especially when helpfulness and harmlessness conflict.
Learning to Rank with Top-$K$ Fairness
arXiv:2509.18067v1 Announce Type: new Abstract: Fairness in ranking models is crucial, as disparities in exposure can disproportionately affect protected groups. Most fairness-aware ranking systems focus on ensuring comparable average exposure for groups across the entire ranked list, which may not fully address real-world concerns. For example, when a ranking model is used for allocating resources among candidates or disaster hotspots, decision-makers often prioritize only the top-$K$ ranked items, while the ranking beyond top-$K$ becomes less relevant. In this paper, we propose a list-wise learning-to-rank framework that addresses the issues of inequalities in top-$K$ rankings at training time. Specifically, we propose a top-$K$ exposure disparity measure that extends the classic exposure disparity metric in a ranked list. We then learn a ranker to balance relevance and fairness in top-$K$ rankings. Since direct top-$K$ selection is computationally expensive for a large number of items, we transform the non-differentiable selection process into a differentiable objective function and develop efficient stochastic optimization algorithms to achieve both high accuracy and sufficient fairness. Extensive experiments demonstrate that our method outperforms existing methods.
Learning functions, operators and dynamical systems with kernels
arXiv:2509.18071v1 Announce Type: new Abstract: This expository article presents the approach to statistical machine learning based on reproducing kernel Hilbert spaces. The basic framework is introduced for scalar-valued learning and then extended to operator learning. Finally, learning dynamical systems is formulated as a suitable operator learning problem, leveraging Koopman operator theory.
Spiffy: Multiplying Diffusion LLM Acceleration via Lossless Speculative Decoding
arXiv:2509.18085v1 Announce Type: new Abstract: Diffusion LLMs (dLLMs) have recently emerged as a powerful alternative to autoregressive LLMs (AR-LLMs) with the potential to operate at significantly higher token generation rates. However, currently available open-source dLLMs often generate at much lower rates, typically decoding only a single token at every denoising timestep in order to maximize output quality. We present Spiffy, a speculative decoding algorithm that accelerates dLLM inference by $\mathbf{2.8{-}3.1\times}$ while provably preserving the model's output distribution. This work addresses the unique challenges involved in applying ideas from speculative decoding of AR-LLMs to the dLLM setting. Spiffy proposes draft states by leveraging the dLLM's distribution itself in an auto-speculative manner. This approach is efficient and effective, and eliminates the overheads of training and running an independent draft model. To structure the candidate draft states, we propose a novel directed draft graph which is uniquely designed to take advantage of the bidirectional, block-wise nature of dLLM generation and can be verified in parallel by the dLLM. To further optimize the structure of these draft graphs, we introduce an efficient, offline calibration algorithm that procedurally determines high-quality graph configurations. These optimized draft graphs, enabling increased acceptance rates, lead to a significant boost in the overall speedup achieved by the system. Crucially, Spiffy is also complementary to other recent innovations in improving dLLM generation speeds such as KV-caching and multi-token unmasking. We demonstrate that when combined with such parallel decoding algorithms, Spiffy is able to effectively multiply the benefits of these methods leading to total speedups of up to $\mathbf{7.9\times}$.
Deep Reinforcement Learning in Factor Investment
arXiv:2509.16206v1 Announce Type: cross Abstract: Deep reinforcement learning has shown promise in trade execution, yet its use in low-frequency factor portfolio construction remains under-explored. A key obstacle is the high-dimensional, unbalanced state space created by stocks that enter and exit the investable universe. We introduce Conditional Auto-encoded Factor-based Portfolio Optimisation (CAFPO), which compresses stock-level returns into a small set of latent factors conditioned on 94 firm-specific characteristics. The factors feed a DRL agent implemented with both PPO and DDPG to generate continuous long-short weights. On 20 years of U.S. equity data (2000--2020), CAFPO outperforms equal-weight, value-weight, Markowitz, vanilla DRL, and Fama--French-driven DRL, delivering a 24.6\% compound return and a Sharpe ratio of 0.94 out of sample. SHAP analysis further reveals economically intuitive factor attributions. Our results demonstrate that factor-aware representation learning can make DRL practical for institutional, low-turnover portfolio management.
On the Detection of Internal Defects in Structured Media
arXiv:2509.16216v1 Announce Type: cross Abstract: A critical issue that affects engineers trying to assess the structural integrity of various infrastructures, such as metal rods or acoustic ducts, is the challenge of detecting internal fractures (defects). Traditionally, engineers depend on audible and visual aids to identify these fractures, as they do not physically dissect the object in question into multiple pieces to check for inconsistencies. This research introduces ideas towards the development of a robust strategy to image such defects using only a small set of minimal, non-invasive measurements. Assuming a one dimensional model (e.g. longitudinal waves in long and thin rods/acoustic ducts or transverse vibrations of strings), we make use of the continuous one-dimensional wave equation to model these physical phenomena and then employ specialized mathematical analysis tools (the Laplace transform and optimization) to introduce our defect imaging ideas. In particular, we will focus on the case of a long bar which is homogeneous throughout except in a small area where a defect in its Young's modulus is present. We will first demonstrate how the problem is equivalent to a spring-mass vibrational system, and then show how our imaging strategy makes use of the Laplace domain analytic map between the characteristics of the respective defect and the measurement data. More explicitly, we will utilize MATLAB (a platform for numerical computations) to collect synthetic data (computational alternative to real world measurements) for several scenarios with one defect of arbitrary location and stiffness. Subsequently, we will use this data along with our analytically developed map (between defect characteristics and measurements) to construct a residual function which, once optimized, will reveal the location and magnitude of the stiffness defect.
Evaluation of Ensemble Learning Techniques for handwritten OCR Improvement
arXiv:2509.16221v1 Announce Type: cross Abstract: For the bachelor project 2021 of Professor Lippert's research group, handwritten entries of historical patient records needed to be digitized using Optical Character Recognition (OCR) methods. Since the data will be used in the future, a high degree of accuracy is naturally required. Especially in the medical field this has even more importance. Ensemble Learning is a method that combines several machine learning models and is claimed to be able to achieve an increased accuracy for existing methods. For this reason, Ensemble Learning in combination with OCR is investigated in this work in order to create added value for the digitization of the patient records. It was possible to discover that ensemble learning can lead to an increased accuracy for OCR, which methods were able to achieve this and that the size of the training data set did not play a role here.
Predicting First Year Dropout from Pre Enrolment Motivation Statements Using Text Mining
arXiv:2509.16224v1 Announce Type: cross Abstract: Preventing student dropout is a major challenge in higher education and it is difficult to predict prior to enrolment which students are likely to drop out and which students are likely to succeed. High School GPA is a strong predictor of dropout, but much variance in dropout remains to be explained. This study focused on predicting university dropout by using text mining techniques with the aim of exhuming information contained in motivation statements written by students. By combining text data with classic predictors of dropout in the form of student characteristics, we attempt to enhance the available set of predictive student characteristics. Our dataset consisted of 7,060 motivation statements of students enrolling in a non-selective bachelor at a Dutch university in 2014 and 2015. Support Vector Machines were trained on 75 percent of the data and several models were estimated on the test data. We used various combinations of student characteristics and text, such as TFiDF, topic modelling, LIWC dictionary. Results showed that, although the combination of text and student characteristics did not improve the prediction of dropout, text analysis alone predicted dropout similarly well as a set of student characteristics. Suggestions for future research are provided.
Machine Learning for Quantum Noise Reduction
arXiv:2509.16242v1 Announce Type: cross Abstract: Quantum noise fundamentally limits the utility of near-term quantum devices, making error mitigation essential for practical quantum computation. While traditional quantum error correction codes require substantial qubit overhead and complex syndrome decoding, we propose a machine learning approach that directly reconstructs clean quantum states from noisy density matrices without additional qubits. We formulate quantum noise reduction as a supervised learning problem using a convolutional neural network (CNN) autoencoder architecture with a novel fidelity-aware composite loss function. Our method is trained and evaluated on a comprehensive synthetic dataset of 10,000 density matrices derived from random 5-qubit quantum circuits, encompassing five noise types (depolarizing, amplitude damping, phase damping, bit-flip, and mixed noise) across four intensity levels (0.05-0.20). The CNN successfully reconstructs quantum states across all noise conditions, achieving an average fidelity improvement from 0.298 to 0.774 ({\Delta} = 0.476). Notably, the model demonstrates superior performance on complex mixed noise scenarios and higher noise intensities, with mixed noise showing the highest corrected fidelity (0.807) and improvement (0.567). The approach effectively preserves both diagonal elements (populations) and off-diagonal elements (quantum coherences), making it suitable for entanglement-dependent quantum algorithms. While phase damping presents fundamental information-theoretic limitations, our results suggest that CNN-based density matrix reconstruction offers a promising, resource-efficient alternative to traditional quantum error correction for NISQ-era devices. This data-driven approach could enable practical quantum advantage with fewer physical qubits than conventional error correction schemes require.
How Can Quantum Deep Learning Improve Large Language Models?
arXiv:2509.16244v1 Announce Type: cross Abstract: The rapid progress of large language models (LLMs) has transformed natural language processing, yet the challenge of efficient adaptation remains unresolved. Full fine-tuning achieves strong performance but imposes prohibitive computational and memory costs. Parameter-efficient fine-tuning (PEFT) strategies, such as low-rank adaptation (LoRA), Prefix tuning, and sparse low-rank adaptation (SoRA), address this issue by reducing trainable parameters while maintaining competitive accuracy. However, these methods often encounter limitations in scalability, stability, and generalization across diverse tasks. Recent advances in quantum deep learning introduce novel opportunities through quantum-inspired encoding and parameterized quantum circuits (PQCs). In particular, the quantum-amplitude embedded adaptation (QAA) framework demonstrates expressive model updates with minimal overhead. This paper presents a systematic survey and comparative analysis of conventional PEFT methods and QAA. The analysis demonstrates trade-offs in convergence, efficiency, and representational capacity, while providing insight into the potential of quantum approaches for future LLM adaptation.
Motional representation; the ability to predict odor characters using molecular vibrations
arXiv:2509.16245v1 Announce Type: cross Abstract: The prediction of odor characters is still impossible based on the odorant molecular structure. We designed a CNN-based regressor for computed parameters in molecular vibrations (CNN_vib), in order to investigate the ability to predict odor characters of molecular vibrations. In this study, we explored following three approaches for the predictability; (i) CNN with molecular vibrational parameters, (ii) logistic regression based on vibrational spectra, and (iii) logistic regression with molecular fingerprint(FP). Our investigation demonstrates that both (i) and (ii) provide predictablity, and also that the vibrations as an explanatory variable (i and ii) and logistic regression with fingerprints (iii) show nearly identical tendencies. The predictabilities of (i) and (ii), depending on odor descriptors, are comparable to those of (iii). Our research shows that odor is predictable by odorant molecular vibration as well as their shapes alone. Our findings provide insight into the representation of molecular motional features beyond molecular structures.
GraphMend: Code Transformations for Fixing Graph Breaks in PyTorch 2
arXiv:2509.16248v1 Announce Type: cross Abstract: This paper presents GraphMend, a high-level compiler that eliminates FX graph breaks in PyTorch 2 programs. Although PyTorch 2 introduced TorchDynamo and TorchInductor to enable just-in-time graph compilation, unresolved dynamic control flow and unsupported Python constructs often fragment models into multiple FX graphs. These fragments force frequent fallbacks to eager mode, incur costly CPU-to-GPU synchronizations, and reduce optimization opportunities. GraphMend addresses this limitation by analyzing and transforming source code before execution. Built on the Jac compilation framework, GraphMend introduces two code transformations that remove graph breaks due to dynamic control flow and Python I/O functions. This design allows PyTorch's compilation pipeline to capture larger, uninterrupted FX graphs without requiring manual refactoring by developers. Evaluation across eight Hugging Face models shows that GraphMend removes all fixable graph breaks due to dynamic control flow and Python I/O functions, driving the break count to 0 in 6 models and reducing it from 5 to 2 in another model. On NVIDIA RTX 3090 and A40 GPUs, GraphMend achieves up to 75% latency reductions and up to 8% higher end-to-end throughput. These results demonstrate that high-level code transformation is an effective complement to PyTorch's dynamic JIT compilation pipeline, substantially improving both usability and performance.
Gender and Political Bias in Large Language Models: A Demonstration Platform
arXiv:2509.16264v1 Announce Type: cross Abstract: We present ParlAI Vote, an interactive system for exploring European Parliament debates and votes, and for testing LLMs on vote prediction and bias analysis. This platform connects debate topics, speeches, and roll-call outcomes, and includes rich demographic data such as gender, age, country, and political group. Users can browse debates, inspect linked speeches, compare real voting outcomes with predictions from frontier LLMs, and view error breakdowns by demographic group. Visualizing the EuroParlVote benchmark and its core tasks of gender classification and vote prediction, ParlAI Vote highlights systematic performance bias in state-of-the-art LLMs. The system unifies data, models, and visual analytics in a single interface, lowering the barrier for reproducing findings, auditing behavior, and running counterfactual scenarios. It supports research, education, and public engagement with legislative decision-making, while making clear both the strengths and the limitations of current LLMs in political analysis.
Vibrational Fingerprints of Strained Polymers: A Spectroscopic Pathway to Mechanical State Prediction
arXiv:2509.16266v1 Announce Type: cross Abstract: The vibrational response of polymer networks under load provides a sensitive probe of molecular deformation and a route to non-destructive diagnostics. Here we show that machine-learned force fields reproduce these spectroscopic fingerprints with quantum-level fidelity in realistic epoxy thermosets. Using MACE-OFF23 molecular dynamics, we capture the experimentally observed redshifts of para-phenylene stretching modes under tensile load, in contrast to the harmonic OPLS-AA model. These shifts correlate with molecular elongation and alignment, consistent with Badger's rule, directly linking vibrational features to local stress. To capture IR intensities, we trained a symmetry-adapted dipole moment model on representative epoxy fragments, enabling validation of strain responses. Together, these approaches provide chemically accurate and computationally accessible predictions of strain-dependent vibrational spectra. Our results establish vibrational fingerprints as predictive markers of mechanical state in polymer networks, pointing to new strategies for stress mapping and structural-health diagnostics in advanced materials.
Language Modeling with Learned Meta-Tokens
arXiv:2509.16278v1 Announce Type: cross Abstract: While modern Transformer-based language models (LMs) have achieved major success in multi-task generalization, they often struggle to capture long-range dependencies within their context window. This work introduces a novel approach using meta-tokens, special tokens injected during pre-training, along with a dedicated meta-attention mechanism to guide LMs to use these tokens. We pre-train a language model with a modified GPT-2 architecture equipped with meta-attention in addition to causal multi-head attention, and study the impact of these tokens on a suite of synthetic tasks. We find that data-efficient language model pre-training on fewer than 100B tokens utilizing meta-tokens and our meta-attention mechanism achieves strong performance on these tasks after fine-tuning. We suggest that these gains arise due to the meta-tokens sharpening the positional encoding. This enables them to operate as trainable, content-based landmarks, implicitly compressing preceding context and "caching" it in the meta-token. At inference-time, the meta-token points to relevant context, facilitating length generalization up to 2$\times$ its context window, even after extension with YaRN. We provide further evidence of these behaviors by visualizing model internals to study the residual stream, and assessing the compression quality by information-theoretic analysis on the rate-distortion tradeoff. Our findings suggest that pre-training LMs with meta-tokens offers a simple, data-efficient method to enhance long-context language modeling performance, while introducing new insights into the nature of their behavior towards length generalization.
Test-Time Learning and Inference-Time Deliberation for Efficiency-First Offline Reinforcement Learning in Care Coordination and Population Health Management
arXiv:2509.16291v1 Announce Type: cross Abstract: Care coordination and population health management programs serve large Medicaid and safety-net populations and must be auditable, efficient, and adaptable. While clinical risk for outreach modalities is typically low, time and opportunity costs differ substantially across text, phone, video, and in-person visits. We propose a lightweight offline reinforcement learning (RL) approach that augments trained policies with (i) test-time learning via local neighborhood calibration, and (ii) inference-time deliberation via a small Q-ensemble that incorporates predictive uncertainty and time/effort cost. The method exposes transparent dials for neighborhood size and uncertainty/cost penalties and preserves an auditable training pipeline. Evaluated on a de-identified operational dataset, TTL+ITD achieves stable value estimates with predictable efficiency trade-offs and subgroup auditing.
TF-DWGNet: A Directed Weighted Graph Neural Network with Tensor Fusion for Multi-Omics Cancer Subtype Classification
arXiv:2509.16301v1 Announce Type: cross Abstract: Integration and analysis of multi-omics data provide valuable insights for cancer subtype classification. However, such data are inherently heterogeneous, high-dimensional, and exhibit complex intra- and inter-modality dependencies. Recent advances in graph neural networks (GNNs) offer powerful tools for modeling such structure. Yet, most existing methods rely on prior knowledge or predefined similarity networks to construct graphs, which are often undirected or unweighted, failing to capture the directionality and strength of biological interactions. Interpretability at both the modality and feature levels also remains limited. To address these challenges, we propose TF-DWGNet, a novel Graph Neural Network framework that combines tree-based Directed Weighted graph construction with Tensor Fusion for multiclass cancer subtype classification. TF-DWGNet introduces two key innovations: a supervised tree-based approach for constructing directed, weighted graphs tailored to each omics modality, and a tensor fusion mechanism that captures unimodal, bimodal, and trimodal interactions using low-rank decomposition for efficiency. TF-DWGNet enables modality-specific representation learning, joint embedding fusion, and interpretable subtype prediction. Experiments on real-world cancer datasets show that TF-DWGNet consistently outperforms state-of-the-art baselines across multiple metrics and statistical tests. Moreover, it provides biologically meaningful insights by ranking influential features and modalities. These results highlight TF-DWGNet's potential for effective and interpretable multi-omics integration in cancer research.
Neural Atlas Graphs for Dynamic Scene Decomposition and Editing
arXiv:2509.16336v1 Announce Type: cross Abstract: Learning editable high-resolution scene representations for dynamic scenes is an open problem with applications across the domains from autonomous driving to creative editing - the most successful approaches today make a trade-off between editability and supporting scene complexity: neural atlases represent dynamic scenes as two deforming image layers, foreground and background, which are editable in 2D, but break down when multiple objects occlude and interact. In contrast, scene graph models make use of annotated data such as masks and bounding boxes from autonomous-driving datasets to capture complex 3D spatial relationships, but their implicit volumetric node representations are challenging to edit view-consistently. We propose Neural Atlas Graphs (NAGs), a hybrid high-resolution scene representation, where every graph node is a view-dependent neural atlas, facilitating both 2D appearance editing and 3D ordering and positioning of scene elements. Fit at test-time, NAGs achieve state-of-the-art quantitative results on the Waymo Open Dataset - by 5 dB PSNR increase compared to existing methods - and make environmental editing possible in high resolution and visual quality - creating counterfactual driving scenarios with new backgrounds and edited vehicle appearance. We find that the method also generalizes beyond driving scenes and compares favorably - by more than 7 dB in PSNR - to recent matting and video editing baselines on the DAVIS video dataset with a diverse set of human and animal-centric scenes.
Similarity-Guided Diffusion for Long-Gap Music Inpainting
arXiv:2509.16342v1 Announce Type: cross Abstract: Music inpainting aims to reconstruct missing segments of a corrupted recording. While diffusion-based generative models improve reconstruction for medium-length gaps, they often struggle to preserve musical plausibility over multi-second gaps. We introduce Similarity-Guided Diffusion Posterior Sampling (SimDPS), a hybrid method that combines diffusion-based inference with similarity search. Candidate segments are first retrieved from a corpus based on contextual similarity, then incorporated into a modified likelihood that guides the diffusion process toward contextually consistent reconstructions. Subjective evaluation on piano music inpainting with 2-s gaps shows that the proposed SimDPS method enhances perceptual plausibility compared to unguided diffusion and frequently outperforms similarity search alone when moderately similar candidates are available. These results demonstrate the potential of a hybrid similarity approach for diffusion-based audio enhancement with long gaps.
Accurate Thyroid Cancer Classification using a Novel Binary Pattern Driven Local Discrete Cosine Transform Descriptor
arXiv:2509.16382v1 Announce Type: cross Abstract: In this study, we develop a new CAD system for accurate thyroid cancer classification with emphasis on feature extraction. Prior studies have shown that thyroid texture is important for segregating the thyroid ultrasound images into different classes. Based upon our experience with breast cancer classification, we first conjuncture that the Discrete Cosine Transform (DCT) is the best descriptor for capturing textural features. Thyroid ultrasound images are particularly challenging as the gland is surrounded by multiple complex anatomical structures leading to variations in tissue density. Hence, we second conjuncture the importance of localization and propose that the Local DCT (LDCT) descriptor captures the textural features best in this context. Another disadvantage of complex anatomy around the thyroid gland is scattering of ultrasound waves resulting in noisy and unclear textures. Hence, we third conjuncture that one image descriptor is not enough to fully capture the textural features and propose the integration of another popular texture capturing descriptor (Improved Local Binary Pattern, ILBP) with LDCT. ILBP is known to be noise resilient as well. We term our novel descriptor as Binary Pattern Driven Local Discrete Cosine Transform (BPD-LDCT). Final classification is carried out using a non-linear SVM. The proposed CAD system is evaluated on the only two publicly available thyroid cancer datasets, namely TDID and AUITD. The evaluation is conducted in two stages. In Stage I, thyroid nodules are categorized as benign or malignant. In Stage II, the malignant cases are further sub-classified into TI-RADS (4) and TI-RADS (5). For Stage I classification, our proposed model demonstrates exceptional performance of nearly 100% on TDID and 97% on AUITD. In Stage II classification, the proposed model again attains excellent classification of close to 100% on TDID and 99% on AUITD.
Low-Rank Adaptation of Evolutionary Deep Neural Networks for Efficient Learning of Time-Dependent PDEs
arXiv:2509.16395v1 Announce Type: cross Abstract: We study the Evolutionary Deep Neural Network (EDNN) framework for accelerating numerical solvers of time-dependent partial differential equations (PDEs). We introduce a Low-Rank Evolutionary Deep Neural Network (LR-EDNN), which constrains parameter evolution to a low-rank subspace, thereby reducing the effective dimensionality of training while preserving solution accuracy. The low-rank tangent subspace is defined layer-wise by the singular value decomposition (SVD) of the current network weights, and the resulting update is obtained by solving a well-posed, tractable linear system within this subspace. This design augments the underlying numerical solver with a parameter efficient EDNN component without requiring full fine-tuning of all network weights. We evaluate LR-EDNN on representative PDE problems and compare it against corresponding baselines. Across cases, LR-EDNN achieves comparable accuracy with substantially fewer trainable parameters and reduced computational cost. These results indicate that low-rank constraints on parameter velocities, rather than full-space updates, provide a practical path toward scalable, efficient, and reproducible scientific machine learning for PDEs.
Dynamic Objects Relocalization in Changing Environments with Flow Matching
arXiv:2509.16398v1 Announce Type: cross Abstract: Task and motion planning are long-standing challenges in robotics, especially when robots have to deal with dynamic environments exhibiting long-term dynamics, such as households or warehouses. In these environments, long-term dynamics mostly stem from human activities, since previously detected objects can be moved or removed from the scene. This adds the necessity to find such objects again before completing the designed task, increasing the risk of failure due to missed relocalizations. However, in these settings, the nature of such human-object interactions is often overlooked, despite being governed by common habits and repetitive patterns. Our conjecture is that these cues can be exploited to recover the most likely objects' positions in the scene, helping to address the problem of unknown relocalization in changing environments. To this end we propose FlowMaps, a model based on Flow Matching that is able to infer multimodal object locations over space and time. Our results present statistical evidence to support our hypotheses, opening the way to more complex applications of our approach. The code is publically available at https://github.com/Fra-Tsuna/flowmaps
Hierarchical Retrieval: The Geometry and a Pretrain-Finetune Recipe
arXiv:2509.16411v1 Announce Type: cross Abstract: Dual encoder (DE) models, where a pair of matching query and document are embedded into similar vector representations, are widely used in information retrieval due to their simplicity and scalability. However, the Euclidean geometry of the embedding space limits the expressive power of DEs, which may compromise their quality. This paper investigates such limitations in the context of hierarchical retrieval (HR), where the document set has a hierarchical structure and the matching documents for a query are all of its ancestors. We first prove that DEs are feasible for HR as long as the embedding dimension is linear in the depth of the hierarchy and logarithmic in the number of documents. Then we study the problem of learning such embeddings in a standard retrieval setup where DEs are trained on samples of matching query and document pairs. Our experiments reveal a lost-in-the-long-distance phenomenon, where retrieval accuracy degrades for documents further away in the hierarchy. To address this, we introduce a pretrain-finetune recipe that significantly improves long-distance retrieval without sacrificing performance on closer documents. We experiment on a realistic hierarchy from WordNet for retrieving documents at various levels of abstraction, and show that pretrain-finetune boosts the recall on long-distance pairs from 19% to 76%. Finally, we demonstrate that our method improves retrieval of relevant products on a shopping queries dataset.
End-to-end RL Improves Dexterous Grasping Policies
arXiv:2509.16434v1 Announce Type: cross Abstract: This work explores techniques to scale up image-based end-to-end learning for dexterous grasping with an arm + hand system. Unlike state-based RL, vision-based RL is much more memory inefficient, resulting in relatively low batch sizes, which is not amenable for algorithms like PPO. Nevertheless, it is still an attractive method as unlike the more commonly used techniques which distill state-based policies into vision networks, end-to-end RL can allow for emergent active vision behaviors. We identify a key bottleneck in training these policies is the way most existing simulators scale to multiple GPUs using traditional data parallelism techniques. We propose a new method where we disaggregate the simulator and RL (both training and experience buffers) onto separate GPUs. On a node with four GPUs, we have the simulator running on three of them, and PPO running on the fourth. We are able to show that with the same number of GPUs, we can double the number of existing environments compared to the previous baseline of standard data parallelism. This allows us to train vision-based environments, end-to-end with depth, which were previously performing far worse with the baseline. We train and distill both depth and state-based policies into stereo RGB networks and show that depth distillation leads to better results, both in simulation and reality. This improvement is likely due to the observability gap between state and vision policies which does not exist when distilling depth policies into stereo RGB. We further show that the increased batch size brought about by disaggregated simulation also improves real world performance. When deploying in the real world, we improve upon the previous state-of-the-art vision-based results using our end-to-end policies.
Overfitting in Adaptive Robust Optimization
arXiv:2509.16451v1 Announce Type: cross Abstract: Adaptive robust optimization (ARO) extends static robust optimization by allowing decisions to depend on the realized uncertainty - weakly dominating static solutions within the modeled uncertainty set. However, ARO makes previous constraints that were independent of uncertainty now dependent, making it vulnerable to additional infeasibilities when realizations fall outside the uncertainty set. This phenomenon of adaptive policies being brittle is analogous to overfitting in machine learning. To mitigate against this, we propose assigning constraint-specific uncertainty set sizes, with harder constraints given stronger probabilistic guarantees. Interpreted through the overfitting lens, this acts as regularization: tighter guarantees shrink adaptive coefficients to ensure stability, while looser ones preserve useful flexibility. This view motivates a principled approach to designing uncertainty sets that balances robustness and adaptivity.
Intrinsic Meets Extrinsic Fairness: Assessing the Downstream Impact of Bias Mitigation in Large Language Models
arXiv:2509.16462v1 Announce Type: cross Abstract: Large Language Models (LLMs) exhibit socio-economic biases that can propagate into downstream tasks. While prior studies have questioned whether intrinsic bias in LLMs affects fairness at the downstream task level, this work empirically investigates the connection. We present a unified evaluation framework to compare intrinsic bias mitigation via concept unlearning with extrinsic bias mitigation via counterfactual data augmentation (CDA). We examine this relationship through real-world financial classification tasks, including salary prediction, employment status, and creditworthiness assessment. Using three open-source LLMs, we evaluate models both as frozen embedding extractors and as fine-tuned classifiers. Our results show that intrinsic bias mitigation through unlearning reduces intrinsic gender bias by up to 94.9%, while also improving downstream task fairness metrics, such as demographic parity by up to 82%, without compromising accuracy. Our framework offers practical guidance on where mitigation efforts can be most effective and highlights the importance of applying early-stage mitigation before downstream deployment.
Synergies between Federated Foundation Models and Smart Power Grids
arXiv:2509.16496v1 Announce Type: cross Abstract: The recent emergence of large language models (LLMs) such as GPT-3 has marked a significant paradigm shift in machine learning. Trained on massive corpora of data, these models demonstrate remarkable capabilities in language understanding, generation, summarization, and reasoning, transforming how intelligent systems process and interact with human language. Although LLMs may still seem like a recent breakthrough, the field is already witnessing the rise of a new and more general category: multi-modal, multi-task foundation models (M3T FMs). These models go beyond language and can process heterogeneous data types/modalities, such as time-series measurements, audio, imagery, tabular records, and unstructured logs, while supporting a broad range of downstream tasks spanning forecasting, classification, control, and retrieval. When combined with federated learning (FL), they give rise to M3T Federated Foundation Models (FedFMs): a highly recent and largely unexplored class of models that enable scalable, privacy-preserving model training/fine-tuning across distributed data sources. In this paper, we take one of the first steps toward introducing these models to the power systems research community by offering a bidirectional perspective: (i) M3T FedFMs for smart grids and (ii) smart grids for FedFMs. In the former, we explore how M3T FedFMs can enhance key grid functions, such as load/demand forecasting and fault detection, by learning from distributed, heterogeneous data available at the grid edge in a privacy-preserving manner. In the latter, we investigate how the constraints and structure of smart grids, spanning energy, communication, and regulatory dimensions, shape the design, training, and deployment of M3T FedFMs.
orb-QFL: Orbital Quantum Federated Learning
arXiv:2509.16505v1 Announce Type: cross Abstract: Recent breakthroughs in quantum computing present transformative opportunities for advancing Federated Learning (FL), particularly in non-terrestrial environments characterized by stringent communication and coordination constraints. In this study, we propose orbital QFL, termed orb-QFL, a novel quantum-assisted Federated Learning framework tailored for Low Earth Orbit (LEO) satellite constellations. Distinct from conventional FL paradigms, termed orb-QFL operates without centralized servers or global aggregation mechanisms (e.g., FedAvg), instead leveraging quantum entanglement and local quantum processing to facilitate decentralized, inter-satellite collaboration. This design inherently addresses the challenges of orbital dynamics, such as intermittent connectivity, high propagation delays, and coverage variability. The framework enables continuous model refinement through direct quantum-based synchronization between neighboring satellites, thereby enhancing resilience and preserving data locality. To validate our approach, we integrate the Qiskit quantum machine learning toolkit with Poliastro-based orbital simulations and conduct experiments using Statlog dataset.
CommonForms: A Large, Diverse Dataset for Form Field Detection
arXiv:2509.16506v1 Announce Type: cross Abstract: This paper introduces CommonForms, a web-scale dataset for form field detection. It casts the problem of form field detection as object detection: given an image of a page, predict the location and type (Text Input, Choice Button, Signature) of form fields. The dataset is constructed by filtering Common Crawl to find PDFs that have fillable elements. Starting with 8 million documents, the filtering process is used to arrive at a final dataset of roughly 55k documents that have over 450k pages. Analysis shows that the dataset contains a diverse mixture of languages and domains; one third of the pages are non-English, and among the 14 classified domains, no domain makes up more than 25% of the dataset. In addition, this paper presents a family of form field detectors, FFDNet-Small and FFDNet-Large, which attain a very high average precision on the CommonForms test set. Each model cost less than $500 to train. Ablation results show that high-resolution inputs are crucial for high-quality form field detection, and that the cleaning process improves data efficiency over using all PDFs that have fillable fields in Common Crawl. A qualitative analysis shows that they outperform a popular, commercially available PDF reader that can prepare forms. Unlike the most popular commercially available solutions, FFDNet can predict checkboxes in addition to text and signature fields. This is, to our knowledge, the first large scale dataset released for form field detection, as well as the first open source models. The dataset, models, and code will be released at https://github.com/jbarrow/commonforms
Etude: Piano Cover Generation with a Three-Stage Approach -- Extract, strucTUralize, and DEcode
arXiv:2509.16522v1 Announce Type: cross Abstract: Piano cover generation aims to automatically transform a pop song into a piano arrangement. While numerous deep learning approaches have been proposed, existing models often fail to maintain structural consistency with the original song, likely due to the absence of beat-aware mechanisms or the difficulty of modeling complex rhythmic patterns. Rhythmic information is crucial, as it defines structural similarity (e.g., tempo, BPM) and directly impacts the overall quality of the generated music. In this paper, we introduce Etude, a three-stage architecture consisting of Extract, strucTUralize, and DEcode stages. By pre-extracting rhythmic information and applying a novel, simplified REMI-based tokenization, our model produces covers that preserve proper song structure, enhance fluency and musical dynamics, and support highly controllable generation through style injection. Subjective evaluations with human listeners show that Etude substantially outperforms prior models, achieving a quality level comparable to that of human composers.
Causal Fuzzing for Verifying Machine Unlearning
arXiv:2509.16525v1 Announce Type: cross Abstract: As machine learning models become increasingly embedded in decision-making systems, the ability to "unlearn" targeted data or features is crucial for enhancing model adaptability, fairness, and privacy in models which involves expensive training. To effectively guide machine unlearning, a thorough testing is essential. Existing methods for verification of machine unlearning provide limited insights, often failing in scenarios where the influence is indirect. In this work, we propose CAF\'E, a new causality based framework that unifies datapoint- and feature-level unlearning for verification of black-box ML models. CAF\'E evaluates both direct and indirect effects of unlearning targets through causal dependencies, providing actionable insights with fine-grained analysis. Our evaluation across five datasets and three model architectures demonstrates that CAF\'E successfully detects residual influence missed by baselines while maintaining computational efficiency.
Mental Multi-class Classification on Social Media: Benchmarking Transformer Architectures against LSTM Models
arXiv:2509.16542v1 Announce Type: cross Abstract: Millions of people openly share mental health struggles on social media, providing rich data for early detection of conditions such as depression, bipolar disorder, etc. However, most prior Natural Language Processing (NLP) research has focused on single-disorder identification, leaving a gap in understanding the efficacy of advanced NLP techniques for distinguishing among multiple mental health conditions. In this work, we present a large-scale comparative study of state-of-the-art transformer versus Long Short-Term Memory (LSTM)-based models to classify mental health posts into exclusive categories of mental health conditions. We first curate a large dataset of Reddit posts spanning six mental health conditions and a control group, using rigorous filtering and statistical exploratory analysis to ensure annotation quality. We then evaluate five transformer architectures (BERT, RoBERTa, DistilBERT, ALBERT, and ELECTRA) against several LSTM variants (with or without attention, using contextual or static embeddings) under identical conditions. Experimental results show that transformer models consistently outperform the alternatives, with RoBERTa achieving 91-99% F1-scores and accuracies across all classes. Notably, attention-augmented LSTMs with BERT embeddings approach transformer performance (up to 97% F1-score) while training 2-3.5 times faster, whereas LSTMs using static embeddings fail to learn useful signals. These findings represent the first comprehensive benchmark for multi-class mental health detection, offering practical guidance on model selection and highlighting an accuracy-efficiency trade-off for real-world deployment of mental health NLP systems.
Checking extracted rules in Neural Networks
arXiv:2509.16547v1 Announce Type: cross Abstract: In this paper we investigate formal verification of extracted rules for Neural Networks under a complexity theoretic point of view. A rule is a global property or a pattern concerning a large portion of the input space of a network. These rules are algorithmically extracted from networks in an effort to better understand their inner way of working. Here, three problems will be in the focus: Does a given set of rules apply to a given network? Is a given set of rules consistent or do the rules contradict themselves? Is a given set of rules exhaustive in the sense that for every input the output is determined? Finding algorithms that extract such rules out of networks has been investigated over the last 30 years, however, to the author's current knowledge, no attempt in verification was made until now. A lot of attempts of extracting rules use heuristics involving randomness and over-approximation, so it might be beneficial to know whether knowledge obtained in that way can actually be trusted. We investigate the above questions for neural networks with ReLU-activation as well as for Boolean networks, each for several types of rules. We demonstrate how these problems can be reduced to each other and show that most of them are co-NP-complete.
Person Identification from Egocentric Human-Object Interactions using 3D Hand Pose
arXiv:2509.16557v1 Announce Type: cross Abstract: Human-Object Interaction Recognition (HOIR) and user identification play a crucial role in advancing augmented reality (AR)-based personalized assistive technologies. These systems are increasingly being deployed in high-stakes, human-centric environments such as aircraft cockpits, aerospace maintenance, and surgical procedures. This research introduces I2S (Interact2Sign), a multi stage framework designed for unobtrusive user identification through human object interaction recognition, leveraging 3D hand pose analysis in egocentric videos. I2S utilizes handcrafted features extracted from 3D hand poses and per forms sequential feature augmentation: first identifying the object class, followed by HOI recognition, and ultimately, user identification. A comprehensive feature extraction and description process was carried out for 3D hand poses, organizing the extracted features into semantically meaningful categories: Spatial, Frequency, Kinematic, Orientation, and a novel descriptor introduced in this work, the Inter-Hand Spatial Envelope (IHSE). Extensive ablation studies were conducted to determine the most effective combination of features. The optimal configuration achieved an impressive average F1-score of 97.52% for user identification, evaluated on a bimanual object manipulation dataset derived from the ARCTIC and H2O datasets. I2S demonstrates state-of-the-art performance while maintaining a lightweight model size of under 4 MB and a fast inference time of 0.1 seconds. These characteristics make the proposed framework highly suitable for real-time, on-device authentication in security-critical, AR-based systems.
Barwise Section Boundary Detection in Symbolic Music Using Convolutional Neural Networks
arXiv:2509.16566v1 Announce Type: cross Abstract: Current methods for Music Structure Analysis (MSA) focus primarily on audio data. While symbolic music can be synthesized into audio and analyzed using existing MSA techniques, such an approach does not exploit symbolic music's rich explicit representation of pitch, timing, and instrumentation. A key subproblem of MSA is section boundary detection-determining whether a given point in time marks the transition between musical sections. In this paper, we study automatic section boundary detection for symbolic music. First, we introduce a human-annotated MIDI dataset for section boundary detection, consisting of metadata from 6134 MIDI files that we manually curated from the Lakh MIDI dataset. Second, we train a deep learning model to classify the presence of section boundaries within a fixed-length musical window. Our data representation involves a novel encoding scheme based on synthesized overtones to encode arbitrary MIDI instrumentations into 3-channel piano rolls. Our model achieves an F1 score of 0.77, improving over the analogous audio-based supervised learning approach and the unsupervised block-matching segmentation (CBM) audio approach by 0.22 and 0.31, respectively. We release our dataset, code, and models.
A Novel Metric for Detecting Memorization in Generative Models for Brain MRI Synthesis
arXiv:2509.16582v1 Announce Type: cross Abstract: Deep generative models have emerged as a transformative tool in medical imaging, offering substantial potential for synthetic data generation. However, recent empirical studies highlight a critical vulnerability: these models can memorize sensitive training data, posing significant risks of unauthorized patient information disclosure. Detecting memorization in generative models remains particularly challenging, necessitating scalable methods capable of identifying training data leakage across large sets of generated samples. In this work, we propose DeepSSIM, a novel self-supervised metric for quantifying memorization in generative models. DeepSSIM is trained to: i) project images into a learned embedding space and ii) force the cosine similarity between embeddings to match the ground-truth SSIM (Structural Similarity Index) scores computed in the image space. To capture domain-specific anatomical features, training incorporates structure-preserving augmentations, allowing DeepSSIM to estimate similarity reliably without requiring precise spatial alignment. We evaluate DeepSSIM in a case study involving synthetic brain MRI data generated by a Latent Diffusion Model (LDM) trained under memorization-prone conditions, using 2,195 MRI scans from two publicly available datasets (IXI and CoRR). Compared to state-of-the-art memorization metrics, DeepSSIM achieves superior performance, improving F1 scores by an average of +52.03% over the best existing method. Code and data of our approach are publicly available at the following link: https://github.com/brAIn-science/DeepSSIM.
Bayesian Ego-graph inference for Networked Multi-Agent Reinforcement Learning
arXiv:2509.16606v1 Announce Type: cross Abstract: In networked multi-agent reinforcement learning (Networked-MARL), decentralized agents must act under local observability and constrained communication over fixed physical graphs. Existing methods often assume static neighborhoods, limiting adaptability to dynamic or heterogeneous environments. While centralized frameworks can learn dynamic graphs, their reliance on global state access and centralized infrastructure is impractical in real-world decentralized systems. We propose a stochastic graph-based policy for Networked-MARL, where each agent conditions its decision on a sampled subgraph over its local physical neighborhood. Building on this formulation, we introduce BayesG, a decentralized actor-framework that learns sparse, context-aware interaction structures via Bayesian variational inference. Each agent operates over an ego-graph and samples a latent communication mask to guide message passing and policy computation. The variational distribution is trained end-to-end alongside the policy using an evidence lower bound (ELBO) objective, enabling agents to jointly learn both interaction topology and decision-making strategies. BayesG outperforms strong MARL baselines on large-scale traffic control tasks with up to 167 agents, demonstrating superior scalability, efficiency, and performance.
ORN-CBF: Learning Observation-conditioned Residual Neural Control Barrier Functions via Hypernetworks
arXiv:2509.16614v1 Announce Type: cross Abstract: Control barrier functions (CBFs) have been demonstrated as an effective method for safety-critical control of autonomous systems. Although CBFs are simple to deploy, their design remains challenging, motivating the development of learning-based approaches. Yet, issues such as suboptimal safe sets, applicability in partially observable environments, and lack of rigorous safety guarantees persist. In this work, we propose observation-conditioned neural CBFs based on Hamilton-Jacobi (HJ) reachability analysis, which approximately recover the maximal safe sets. We exploit certain mathematical properties of the HJ value function, ensuring that the predicted safe set never intersects with the observed failure set. Moreover, we leverage a hypernetwork-based architecture that is particularly suitable for the design of observation-conditioned safety filters. The proposed method is examined both in simulation and hardware experiments for a ground robot and a quadcopter. The results show improved success rates and generalization to out-of-domain environments compared to the baselines.
Conditional Multidimensional Scaling with Incomplete Conditioning Data
arXiv:2509.16627v1 Announce Type: cross Abstract: Conditional multidimensional scaling seeks for a low-dimensional configuration from pairwise dissimilarities, in the presence of other known features. By taking advantage of available data of the known features, conditional multidimensional scaling improves the estimation quality of the low-dimensional configuration and simplifies knowledge discovery tasks. However, existing conditional multidimensional scaling methods require full data of the known features, which may not be always attainable due to time, cost, and other constraints. This paper proposes a conditional multidimensional scaling method that can learn the low-dimensional configuration when there are missing values in the known features. The method can also impute the missing values, which provides additional insights of the problem. Computer codes of this method are maintained in the cml R package on CRAN.
FESTA: Functionally Equivalent Sampling for Trust Assessment of Multimodal LLMs
arXiv:2509.16648v1 Announce Type: cross Abstract: The accurate trust assessment of multimodal large language models (MLLMs) generated predictions, which can enable selective prediction and improve user confidence, is challenging due to the diverse multi-modal input paradigms. We propose Functionally Equivalent Sampling for Trust Assessment (FESTA), a multimodal input sampling technique for MLLMs, that generates an uncertainty measure based on the equivalent and complementary input samplings. The proposed task-preserving sampling approach for uncertainty quantification expands the input space to probe the consistency (through equivalent samples) and sensitivity (through complementary samples) of the model. FESTA uses only input-output access of the model (black-box), and does not require ground truth (unsupervised). The experiments are conducted with various off-the-shelf multi-modal LLMs, on both visual and audio reasoning tasks. The proposed FESTA uncertainty estimate achieves significant improvement (33.3% relative improvement for vision-LLMs and 29.6% relative improvement for audio-LLMs) in selective prediction performance, based on area-under-receiver-operating-characteristic curve (AUROC) metric in detecting mispredictions. The code implementation is open-sourced.
Safe Guaranteed Dynamics Exploration with Probabilistic Models
arXiv:2509.16650v1 Announce Type: cross Abstract: Ensuring both optimality and safety is critical for the real-world deployment of agents, but becomes particularly challenging when the system dynamics are unknown. To address this problem, we introduce a notion of maximum safe dynamics learning via sufficient exploration in the space of safe policies. We propose a $\textit{pessimistically}$ safe framework that $\textit{optimistically}$ explores informative states and, despite not reaching them due to model uncertainty, ensures continuous online learning of dynamics. The framework achieves first-of-its-kind results: learning the dynamics model sufficiently $-$ up to an arbitrary small tolerance (subject to noise) $-$ in a finite time, while ensuring provably safe operation throughout with high probability and without requiring resets. Building on this, we propose an algorithm to maximize rewards while learning the dynamics $\textit{only to the extent needed}$ to achieve close-to-optimal performance. Unlike typical reinforcement learning (RL) methods, our approach operates online in a non-episodic setting and ensures safety throughout the learning process. We demonstrate the effectiveness of our approach in challenging domains such as autonomous car racing and drone navigation under aerodynamic effects $-$ scenarios where safety is critical and accurate modeling is difficult.
On the de-duplication of the Lakh MIDI dataset
arXiv:2509.16662v1 Announce Type: cross Abstract: A large-scale dataset is essential for training a well-generalized deep-learning model. Most such datasets are collected via scraping from various internet sources, inevitably introducing duplicated data. In the symbolic music domain, these duplicates often come from multiple user arrangements and metadata changes after simple editing. However, despite critical issues such as unreliable training evaluation from data leakage during random splitting, dataset duplication has not been extensively addressed in the MIR community. This study investigates the dataset duplication issues regarding Lakh MIDI Dataset (LMD), one of the largest publicly available sources in the symbolic music domain. To find and evaluate the best retrieval method for duplicated data, we employed the Clean MIDI subset of the LMD as a benchmark test set, in which different versions of the same songs are grouped together. We first evaluated rule-based approaches and previous symbolic music retrieval models for de-duplication and also investigated with a contrastive learning-based BERT model with various augmentations to find duplicate files. As a result, we propose three different versions of the filtered list of LMD, which filters out at least 38,134 samples in the most conservative settings among 178,561 files.
System-Level Uncertainty Quantification with Multiple Machine Learning Models: A Theoretical Framework
arXiv:2509.16663v1 Announce Type: cross Abstract: ML models have errors when used for predictions. The errors are unknown but can be quantified by model uncertainty. When multiple ML models are trained using the same training points, their model uncertainties may be statistically dependent. In reality, model inputs are also random with input uncertainty. The effects of these types of uncertainty must be considered in decision-making and design. This study develops a theoretical framework that generates the joint distribution of multiple ML predictions given the joint distribution of model uncertainties and the joint distribution of model inputs. The strategy is to decouple the coupling between the two types of uncertainty and transform them as independent random variables. The framework lays a foundation for numerical algorithm development for various specific applications.
Segment-to-Act: Label-Noise-Robust Action-Prompted Video Segmentation Towards Embodied Intelligence
arXiv:2509.16677v1 Announce Type: cross Abstract: Embodied intelligence relies on accurately segmenting objects actively involved in interactions. Action-based video object segmentation addresses this by linking segmentation with action semantics, but it depends on large-scale annotations and prompts that are costly, inconsistent, and prone to multimodal noise such as imprecise masks and referential ambiguity. To date, this challenge remains unexplored. In this work, we take the first step by studying action-based video object segmentation under label noise, focusing on two sources: textual prompt noise (category flips and within-category noun substitutions) and mask annotation noise (perturbed object boundaries to mimic imprecise supervision). Our contributions are threefold. First, we introduce two types of label noises for the action-based video object segmentation task. Second, we build up the first action-based video object segmentation under a label noise benchmark ActiSeg-NL and adapt six label-noise learning strategies to this setting, and establish protocols for evaluating them under textual, boundary, and mixed noise. Third, we provide a comprehensive analysis linking noise types to failure modes and robustness gains, and we introduce a Parallel Mask Head Mechanism (PMHM) to address mask annotation noise. Qualitative evaluations further reveal characteristic failure modes, including boundary leakage and mislocalization under boundary perturbations, as well as occasional identity substitutions under textual flips. Our comparative analysis reveals that different learning strategies exhibit distinct robustness profiles, governed by a foreground-background trade-off where some achieve balanced performance while others prioritize foreground accuracy at the cost of background precision. The established benchmark and source code will be made publicly available at https://github.com/mylwx/ActiSeg-NL.
ProtoVQA: An Adaptable Prototypical Framework for Explainable Fine-Grained Visual Question Answering
arXiv:2509.16680v1 Announce Type: cross Abstract: Visual Question Answering (VQA) is increasingly used in diverse applications ranging from general visual reasoning to safety-critical domains such as medical imaging and autonomous systems, where models must provide not only accurate answers but also explanations that humans can easily understand and verify. Prototype-based modeling has shown promise for interpretability by grounding predictions in semantically meaningful regions for purely visual reasoning tasks, yet remains underexplored in the context of VQA. We present ProtoVQA, a unified prototypical framework that (i) learns question-aware prototypes that serve as reasoning anchors, connecting answers to discriminative image regions, (ii) applies spatially constrained matching to ensure that the selected evidence is coherent and semantically relevant, and (iii) supports both answering and grounding tasks through a shared prototype backbone. To assess explanation quality, we propose the Visual-Linguistic Alignment Score (VLAS), which measures how well the model's attended regions align with ground-truth evidence. Experiments on Visual7W show that ProtoVQA yields faithful, fine-grained explanations while maintaining competitive accuracy, advancing the development of transparent and trustworthy VQA systems.
Towards a Transparent and Interpretable AI Model for Medical Image Classifications
arXiv:2509.16685v1 Announce Type: cross Abstract: The integration of artificial intelligence (AI) into medicine is remarkable, offering advanced diagnostic and therapeutic possibilities. However, the inherent opacity of complex AI models presents significant challenges to their clinical practicality. This paper focuses primarily on investigating the application of explainable artificial intelligence (XAI) methods, with the aim of making AI decisions transparent and interpretable. Our research focuses on implementing simulations using various medical datasets to elucidate the internal workings of the XAI model. These dataset-driven simulations demonstrate how XAI effectively interprets AI predictions, thus improving the decision-making process for healthcare professionals. In addition to a survey of the main XAI methods and simulations, ongoing challenges in the XAI field are discussed. The study highlights the need for the continuous development and exploration of XAI, particularly from the perspective of diverse medical datasets, to promote its adoption and effectiveness in the healthcare domain.
Decoding Uncertainty: The Impact of Decoding Strategies for Uncertainty Estimation in Large Language Models
arXiv:2509.16696v1 Announce Type: cross Abstract: Decoding strategies manipulate the probability distribution underlying the output of a language model and can therefore affect both generation quality and its uncertainty. In this study, we investigate the impact of decoding strategies on uncertainty estimation in Large Language Models (LLMs). Our experiments show that Contrastive Search, which mitigates repetition, yields better uncertainty estimates on average across a range of preference-aligned LLMs. In contrast, the benefits of these strategies sometimes diverge when the model is only post-trained with supervised fine-tuning, i.e. without explicit alignment.
Knowledge Distillation for Variational Quantum Convolutional Neural Networks on Heterogeneous Data
arXiv:2509.16699v1 Announce Type: cross Abstract: Distributed quantum machine learning faces significant challenges due to heterogeneous client data and variations in local model structures, which hinder global model aggregation. To address these challenges, we propose a knowledge distillation framework for variational quantum convolutional neural networks on heterogeneous data. The framework features a quantum gate number estimation mechanism based on client data, which guides the construction of resource-adaptive VQCNN circuits. Particle swarm optimization is employed to efficiently generate personalized quantum models tailored to local data characteristics. During aggregation, a knowledge distillation strategy integrating both soft-label and hard-label supervision consolidates knowledge from heterogeneous clients using a public dataset, forming a global model while avoiding parameter exposure and privacy leakage. Theoretical analysis shows that proposed framework benefits from quantum high-dimensional representation, offering advantages over classical approaches, and minimizes communication by exchanging only model indices and test outputs. Extensive simulations on the PennyLane platform validate the effectiveness of the gate number estimation and distillation-based aggregation. Experimental results demonstrate that the aggregated global model achieves accuracy close to fully supervised centralized training. These results shown that proposed methods can effectively handle heterogeneity, reduce resource consumption, and maintain performance, highlighting its potential for scalable and privacy-preserving distributed quantum learning.
Increase Alpha: Performance and Risk of an AI-Driven Trading Framework
arXiv:2509.16707v1 Announce Type: cross Abstract: There are inefficiencies in financial markets, with unexploited patterns in price, volume, and cross-sectional relationships. While many approaches use large-scale transformers, we take a domain-focused path: feed-forward and recurrent networks with curated features to capture subtle regularities in noisy financial data. This smaller-footprint design is computationally lean and reliable under low signal-to-noise, crucial for daily production at scale. At Increase Alpha, we built a deep-learning framework that maps over 800 U.S. equities into daily directional signals with minimal computational overhead. The purpose of this paper is twofold. First, we outline the general overview of the predictive model without disclosing its core underlying concepts. Second, we evaluate its real-time performance through transparent, industry standard metrics. Forecast accuracy is benchmarked against both naive baselines and macro indicators. The performance outcomes are summarized via cumulative returns, annualized Sharpe ratio, and maximum drawdown. The best portfolio combination using our signals provides a low-risk, continuous stream of returns with a Sharpe ratio of more than 2.5, maximum drawdown of around 3\%, and a near-zero correlation with the S\&P 500 market benchmark. We also compare the model's performance through different market regimes, such as the recent volatile movements of the US equity market in the beginning of 2025. Our analysis showcases the robustness of the model and significantly stable performance during these volatile periods. Collectively, these findings show that market inefficiencies can be systematically harvested with modest computational overhead if the right variables are considered. This report will emphasize the potential of traditional deep learning frameworks for generating an AI-driven edge in the financial market.
QASTAnet: A DNN-based Quality Metric for Spatial Audio
arXiv:2509.16715v1 Announce Type: cross Abstract: In the development of spatial audio technologies, reliable and shared methods for evaluating audio quality are essential. Listening tests are currently the standard but remain costly in terms of time and resources. Several models predicting subjective scores have been proposed, but they do not generalize well to real-world signals. In this paper, we propose QASTAnet (Quality Assessment for SpaTial Audio network), a new metric based on a deep neural network, specialized on spatial audio (ambisonics and binaural). As training data is scarce, we aim for the model to be trainable with a small amount of data. To do so, we propose to rely on expert modeling of the low-level auditory system and use a neurnal network to model the high-level cognitive function of the quality judgement. We compare its performance to two reference metrics on a wide range of content types (speech, music, ambiance, anechoic, reverberated) and focusing on codec artifacts. Results demonstrate that QASTAnet overcomes the aforementioned limitations of the existing methods. The strong correlation between the proposed metric prediction and subjective scores makes it a good candidate for comparing codecs in their development.
Pain in 3D: Generating Controllable Synthetic Faces for Automated Pain Assessment
arXiv:2509.16727v1 Announce Type: cross Abstract: Automated pain assessment from facial expressions is crucial for non-communicative patients, such as those with dementia. Progress has been limited by two challenges: (i) existing datasets exhibit severe demographic and label imbalance due to ethical constraints, and (ii) current generative models cannot precisely control facial action units (AUs), facial structure, or clinically validated pain levels. We present 3DPain, a large-scale synthetic dataset specifically designed for automated pain assessment, featuring unprecedented annotation richness and demographic diversity. Our three-stage framework generates diverse 3D meshes, textures them with diffusion models, and applies AU-driven face rigging to synthesize multi-view faces with paired neutral and pain images, AU configurations, PSPI scores, and the first dataset-level annotations of pain-region heatmaps. The dataset comprises 82,500 samples across 25,000 pain expression heatmaps and 2,500 synthetic identities balanced by age, gender, and ethnicity. We further introduce ViTPain, a Vision Transformer based cross-modal distillation framework in which a heatmap-trained teacher guides a student trained on RGB images, enhancing accuracy, interpretability, and clinical reliability. Together, 3DPain and ViTPain establish a controllable, diverse, and clinically grounded foundation for generalizable automated pain assessment.
Angular Dispersion Accelerates $k$-Nearest Neighbors Machine Translation
arXiv:2509.16729v1 Announce Type: cross Abstract: Augmenting neural machine translation with external memory at decoding time, in the form of k-nearest neighbors machine translation ($k$-NN MT), is a well-established strategy for increasing translation performance. $k$-NN MT retrieves a set of tokens that occurred in the most similar contexts recorded in a prepared data store, using hidden state representations of translation contexts as vector lookup keys. One of the main disadvantages of this method is the high computational cost and memory requirements. Since an exhaustive search is not feasible in large data stores, practitioners commonly use approximate $k$-NN MT lookup, yet even such algorithms are a bottleneck. In contrast to research directions seeking to accelerate $k$-NN MT by reducing data store size or the number of lookup calls, we pursue an orthogonal direction based on the performance properties of approximate $k$-NN MT lookup data structures. In particular, we propose to encourage angular dispersion of the neural hidden representations of contexts. We show that improving dispersion leads to better balance in the retrieval data structures, accelerating retrieval and slightly improving translations.
Min: Mixture of Noise for Pre-Trained Model-Based Class-Incremental Learning
arXiv:2509.16738v1 Announce Type: cross Abstract: Class Incremental Learning (CIL) aims to continuously learn new categories while retaining the knowledge of old ones. Pre-trained models (PTMs) show promising capabilities in CIL. However, existing approaches that apply lightweight fine-tuning to backbones still induce parameter drift, thereby compromising the generalization capability of pre-trained models. Parameter drift can be conceptualized as a form of noise that obscures critical patterns learned for previous tasks. However, recent researches have shown that noise is not always harmful. For example, the large number of visual patterns learned from pre-training can be easily abused by a single task, and introducing appropriate noise can suppress some low-correlation features, thus leaving a margin for future tasks. To this end, we propose learning beneficial noise for CIL guided by information theory and propose Mixture of Noise (Min), aiming to mitigate the degradation of backbone generalization from adapting new tasks. Specifically, task-specific noise is learned from high-dimension features of new tasks. Then, a set of weights is adjusted dynamically for optimal mixture of different task noise. Finally, Min embeds the beneficial noise into the intermediate features to mask the response of inefficient patterns. Extensive experiments on six benchmark datasets demonstrate that Min achieves state-of-the-art performance in most incremental settings, with particularly outstanding results in 50-steps incremental settings. This shows the significant potential for beneficial noise in continual learning.
On the System Theoretic Offline Learning of Continuous-Time LQR with Exogenous Disturbances
arXiv:2509.16746v1 Announce Type: cross Abstract: We analyze offline designs of linear quadratic regulator (LQR) strategies with uncertain disturbances. First, we consider the scenario where the exogenous variable can be estimated in a controlled environment, and subsequently, consider a more practical and challenging scenario where it is unknown in a stochastic setting. Our approach builds on the fundamental learning-based framework of adaptive dynamic programming (ADP), combined with a Lyapunov-based analytical methodology to design the algorithms and derive sample-based approximations motivated from the Markov decision process (MDP)-based approaches. For the scenario involving non-measurable disturbances, we further establish stability and convergence guarantees for the learned control gains under sample-based approximations. The overall methodology emphasizes simplicity while providing rigorous guarantees. Finally, numerical experiments focus on the intricacies and validations for the design of offline continuous-time LQR with exogenous disturbances.
Improving User Interface Generation Models from Designer Feedback
arXiv:2509.16779v1 Announce Type: cross Abstract: Despite being trained on vast amounts of data, most LLMs are unable to reliably generate well-designed UIs. Designer feedback is essential to improving performance on UI generation; however, we find that existing RLHF methods based on ratings or rankings are not well-aligned with designers' workflows and ignore the rich rationale used to critique and improve UI designs. In this paper, we investigate several approaches for designers to give feedback to UI generation models, using familiar interactions such as commenting, sketching and direct manipulation. We first perform a study with 21 designers where they gave feedback using these interactions, which resulted in ~1500 design annotations. We then use this data to finetune a series of LLMs to generate higher quality UIs. Finally, we evaluate these models with human judges, and we find that our designer-aligned approaches outperform models trained with traditional ranking feedback and all tested baselines, including GPT-5.
Spectral Analysis of the Weighted Frobenius Objective
arXiv:2509.16783v1 Announce Type: cross Abstract: We analyze a weighted Frobenius loss for approximating symmetric positive definite matrices in the context of preconditioning iterative solvers. Unlike the standard Frobenius norm, the weighted loss penalizes error components associated with small eigenvalues of the system matrix more strongly. Our analysis reveals that each eigenmode is scaled by the corresponding square of its eigenvalue, and that, under a fixed error budget, the loss is minimized only when the error is confined to the direction of the largest eigenvalue. This provides a rigorous explanation of why minimizing the weighted loss naturally suppresses low-frequency components, which can be a desirable strategy for the conjugate gradient method. The analysis is independent of the specific approximation scheme or sparsity pattern, and applies equally to incomplete factorizations, algebraic updates, and learning-based constructions. Numerical experiments confirm the predictions of the theory, including an illustration where sparse factors are trained by a direct gradient updates to IC(0) factor entries, i.e., no trained neural network model is used.
Domain-Adaptive Pre-Training for Arabic Aspect-Based Sentiment Analysis: A Comparative Study of Domain Adaptation and Fine-Tuning Strategies
arXiv:2509.16788v1 Announce Type: cross Abstract: Aspect-based sentiment analysis (ABSA) in natural language processing enables organizations to understand customer opinions on specific product aspects. While deep learning models are widely used for English ABSA, their application in Arabic is limited due to the scarcity of labeled data. Researchers have attempted to tackle this issue by using pre-trained contextualized language models such as BERT. However, these models are often based on fact-based data, which can introduce bias in domain-specific tasks like ABSA. To our knowledge, no studies have applied adaptive pre-training with Arabic contextualized models for ABSA. This research proposes a novel approach using domain-adaptive pre-training for aspect-sentiment classification (ASC) and opinion target expression (OTE) extraction. We examine fine-tuning strategies - feature extraction, full fine-tuning, and adapter-based methods - to enhance performance and efficiency, utilizing multiple adaptation corpora and contextualized models. Our results show that in-domain adaptive pre-training yields modest improvements. Adapter-based fine-tuning is a computationally efficient method that achieves competitive results. However, error analyses reveal issues with model predictions and dataset labeling. In ASC, common problems include incorrect sentiment labeling, misinterpretation of contrastive markers, positivity bias for early terms, and challenges with conflicting opinions and subword tokenization. For OTE, issues involve mislabeling targets, confusion over syntactic roles, difficulty with multi-word expressions, and reliance on shallow heuristics. These findings underscore the need for syntax- and semantics-aware models, such as graph convolutional networks, to more effectively capture long-distance relations and complex aspect-based opinion alignments.
A Study on Stabilizer R\'enyi Entropy Estimation using Machine Learning
arXiv:2509.16799v1 Announce Type: cross Abstract: Nonstabilizerness is a fundamental resource for quantum advantage, as it quantifies the extent to which a quantum state diverges from those states that can be efficiently simulated on a classical computer, the stabilizer states. The stabilizer R\'enyi entropy (SRE) is one of the most investigated measures of nonstabilizerness because of its computational properties and suitability for experimental measurements on quantum processors. Because computing the SRE for arbitrary quantum states is a computationally hard problem, we propose a supervised machine-learning approach to estimate it. In this work, we frame SRE estimation as a regression task and train a Random Forest Regressor and a Support Vector Regressor (SVR) on a comprehensive dataset, including both unstructured random quantum circuits and structured circuits derived from the physics-motivated one-dimensional transverse Ising model (TIM). We compare the machine-learning models using two different quantum circuit representations: one based on classical shadows and the other on circuit-level features. Furthermore, we assess the generalization capabilities of the models on out-of-distribution instances. Experimental results show that an SVR trained on circuit-level features achieves the best overall performance. On the random circuits dataset, our approach converges to accurate SRE estimations, but struggles to generalize out of distribution. In contrast, it generalizes well on the structured TIM dataset, even to deeper and larger circuits. In line with previous work, our experiments suggest that machine learning offers a viable path for efficient nonstabilizerness estimation.
Sublinear Time Quantum Sensitivity Sampling
arXiv:2509.16801v1 Announce Type: cross Abstract: We present a unified framework for quantum sensitivity sampling, extending the advantages of quantum computing to a broad class of classical approximation problems. Our unified framework provides a streamlined approach for constructing coresets and offers significant runtime improvements in applications such as clustering, regression, and low-rank approximation. Our contributions include: * $k$-median and $k$-means clustering: For $n$ points in $d$-dimensional Euclidean space, we give an algorithm that constructs an $\epsilon$-coreset in time $\widetilde O(n^{0.5}dk^{2.5}~\mathrm{poly}(\epsilon^{-1}))$ for $k$-median and $k$-means clustering. Our approach achieves a better dependence on $d$ and constructs smaller coresets that only consist of points in the dataset, compared to recent results of [Xue, Chen, Li and Jiang, ICML'23]. * $\ell_p$ regression: For $\ell_p$ regression problems, we construct an $\epsilon$-coreset of size $\widetilde O_p(d^{\max{1, p/2}}\epsilon^{-2})$ in time $\widetilde O_p(n^{0.5}d^{\max{0.5, p/4}+1}(\epsilon^{-3}+d^{0.5}))$, improving upon the prior best quantum sampling approach of [Apers and Gribling, QIP'24] for all $p\in (0, 2)\cup (2, 22]$, including the widely studied least absolute deviation regression ($\ell_1$ regression). * Low-rank approximation with Frobenius norm error: We introduce the first quantum sublinear-time algorithm for low-rank approximation that does not rely on data-dependent parameters, and runs in $\widetilde O(nd^{0.5}k^{0.5}\epsilon^{-1})$ time. Additionally, we present quantum sublinear algorithms for kernel low-rank approximation and tensor low-rank approximation, broadening the range of achievable sublinear time algorithms in randomized numerical linear algebra.
Randomized Space-Time Sampling for Affine Graph Dynamical Systems
arXiv:2509.16818v1 Announce Type: cross Abstract: This paper investigates the problem of dynamical sampling for graph signals influenced by a constant source term. We consider signals evolving over time according to a linear dynamical system on a graph, where both the initial state and the source term are bandlimited. We introduce two random space-time sampling regimes and analyze the conditions under which stable recovery is achievable. While our framework extends recent work on homogeneous dynamics, it addresses a fundamentally different setting where the evolution includes a constant source term. This results in a non-orthogonal-diagonalizable system matrix, rendering classical spectral techniques inapplicable and introducing new challenges in sampling design, stability analysis, and joint recovery of both the initial state and the forcing term. A key component of our analysis is the spectral graph weighted coherence, which characterizes the interplay between the sampling distribution and the graph structure. We establish sampling complexity bounds ensuring stable recovery via the Restricted Isometry Property (RIP), and develop a robust recovery algorithm with provable error guarantees. The effectiveness of our method is validated through extensive experiments on both synthetic and real-world datasets.
Robot Learning with Sparsity and Scarcity
arXiv:2509.16834v1 Announce Type: cross Abstract: Unlike in language or vision, one of the fundamental challenges in robot learning is the lack of access to vast data resources. We can further break down the problem into (1) data sparsity from the angle of data representation and (2) data scarcity from the angle of data quantity. In this thesis, I will discuss selected works on two domains: (1) tactile sensing and (2) rehabilitation robots, which are exemplars of data sparsity and scarcity, respectively. Tactile sensing is an essential modality for robotics, but tactile data are often sparse, and for each interaction with the physical world, tactile sensors can only obtain information about the local area of contact. I will discuss my work on learning vision-free tactile-only exploration and manipulation policies through model-free reinforcement learning to make efficient use of sparse tactile information. On the other hand, rehabilitation robots are an example of data scarcity to the extreme due to the significant challenge of collecting biosignals from disabled-bodied subjects at scale for training. I will discuss my work in collaboration with the medical school and clinicians on intent inferral for stroke survivors, where a hand orthosis developed in our lab collects a set of biosignals from the patient and uses them to infer the activity that the patient intends to perform, so the orthosis can provide the right type of physical assistance at the right moment. My work develops machine learning algorithms that enable intent inferral with minimal data, including semi-supervised, meta-learning, and generative AI methods.
DoubleGen: Debiased Generative Modeling of Counterfactuals
arXiv:2509.16842v1 Announce Type: cross Abstract: Generative models for counterfactual outcomes face two key sources of bias. Confounding bias arises when approaches fail to account for systematic differences between those who receive the intervention and those who do not. Misspecification bias arises when methods attempt to address confounding through estimation of an auxiliary model, but specify it incorrectly. We introduce DoubleGen, a doubly robust framework that modifies generative modeling training objectives to mitigate these biases. The new objectives rely on two auxiliaries -- a propensity and outcome model -- and successfully address confounding bias even if only one of them is correct. We provide finite-sample guarantees for this robustness property. We further establish conditions under which DoubleGen achieves oracle optimality -- matching the convergence rates standard approaches would enjoy if interventional data were available -- and minimax rate optimality. We illustrate DoubleGen with three examples: diffusion models, flow matching, and autoregressive language models.
ShadowServe: Interference-Free KV Cache Fetching for Distributed Prefix Caching
arXiv:2509.16857v1 Announce Type: cross Abstract: Distributed prefix caching accelerates long-context LLM serving by reusing KV cache entries for common context prefixes. However, KV cache fetches can become a bottleneck when network bandwidth is limited. Compression mitigates the bandwidth issue, but can degrade overall performance when decompression interferes with model computation. We present ShadowServe, the first SmartNIC-accelerated, interference-free prefix caching system for LLM serving. ShadowServe separates a control plane on the host and a data plane fully offloaded to the SmartNIC, which eliminates interference to both host GPU and CPU. To overcome the SmartNIC's limited compute and memory resources, we design a chunked pipeline that parallelizes data plane operations across the SmartNIC's compute resources, and a minimal-copy memory management scheme that reduces memory pressure on the SmartNIC. Compared to state-of-the-art solutions, ShadowServe achieves up to 2.2x lower loaded time-per-output-token (TPOT), and reduces time-to-first-token (TTFT) by up to 1.38x in low-bandwidth scenarios (<= 20 Gbps), translating to up to 1.35x higher throughput.
seqBench: A Tunable Benchmark to Quantify Sequential Reasoning Limits of LLMs
arXiv:2509.16866v1 Announce Type: cross Abstract: We introduce seqBench, a parametrized benchmark for probing sequential reasoning limits in Large Language Models (LLMs) through precise, multi-dimensional control over several key complexity dimensions. seqBench allows systematic variation of (1) the logical depth, defined as the number of sequential actions required to solve the task; (2) the number of backtracking steps along the optimal path, quantifying how often the agent must revisit prior states to satisfy deferred preconditions (e.g., retrieving a key after encountering a locked door); and (3) the noise ratio, defined as the ratio between supporting and distracting facts about the environment. Our evaluations on state-of-the-art LLMs reveal a universal failure pattern: accuracy collapses exponentially beyond a model-specific logical depth. Unlike existing benchmarks, seqBench's fine-grained control facilitates targeted analyses of these reasoning failures, illuminating universal scaling laws and statistical limits, as detailed in this paper alongside its generation methodology and evaluation metrics. We find that even top-performing models systematically fail on seqBench's structured reasoning tasks despite minimal search complexity, underscoring key limitations in their commonsense reasoning capabilities. Designed for future evolution to keep pace with advancing models, the seqBench datasets are publicly released to spur deeper scientific inquiry into LLM reasoning, aiming to establish a clearer understanding of their true potential and current boundaries for robust real-world application.
PhysHDR: When Lighting Meets Materials and Scene Geometry in HDR Reconstruction
arXiv:2509.16869v1 Announce Type: cross Abstract: Low Dynamic Range (LDR) to High Dynamic Range (HDR) image translation is a fundamental task in many computational vision problems. Numerous data-driven methods have been proposed to address this problem; however, they lack explicit modeling of illumination, lighting, and scene geometry in images. This limits the quality of the reconstructed HDR images. Since lighting and shadows interact differently with different materials, (e.g., specular surfaces such as glass and metal, and lambertian or diffuse surfaces such as wood and stone), modeling material-specific properties (e.g., specular and diffuse reflectance) has the potential to improve the quality of HDR image reconstruction. This paper presents PhysHDR, a simple yet powerful latent diffusion-based generative model for HDR image reconstruction. The denoising process is conditioned on lighting and depth information and guided by a novel loss to incorporate material properties of surfaces in the scene. The experimental results establish the efficacy of PhysHDR in comparison to a number of recent state-of-the-art methods.
Differential Privacy for Euclidean Jordan Algebra with Applications to Private Symmetric Cone Programming
arXiv:2509.16915v1 Announce Type: cross Abstract: In this paper, we study differentially private mechanisms for functions whose outputs lie in a Euclidean Jordan algebra. Euclidean Jordan algebras capture many important mathematical structures and form the foundation of linear programming, second-order cone programming, and semidefinite programming. Our main contribution is a generic Gaussian mechanism for such functions, with sensitivity measured in $\ell_2$, $\ell_1$, and $\ell_\infty$ norms. Notably, this framework includes the important case where the function outputs are symmetric matrices, and sensitivity is measured in the Frobenius, nuclear, or spectral norm. We further derive private algorithms for solving symmetric cone programs under various settings, using a combination of the multiplicative weights update method and our generic Gaussian mechanism. As an application, we present differentially private algorithms for semidefinite programming, resolving a major open question posed by [Hsu, Roth, Roughgarden, and Ullman, ICALP 2014].
Cross-Attention with Confidence Weighting for Multi-Channel Audio Alignment
arXiv:2509.16926v1 Announce Type: cross Abstract: Multi-channel audio alignment is a key requirement in bioacoustic monitoring, spatial audio systems, and acoustic localization. However, existing methods often struggle to address nonlinear clock drift and lack mechanisms for quantifying uncertainty. Traditional methods like Cross-correlation and Dynamic Time Warping assume simple drift patterns and provide no reliability measures. Meanwhile, recent deep learning models typically treat alignment as a binary classification task, overlooking inter-channel dependencies and uncertainty estimation. We introduce a method that combines cross-attention mechanisms with confidence-weighted scoring to improve multi-channel audio synchronization. We extend BEATs encoders with cross-attention layers to model temporal relationships between channels. We also develop a confidence-weighted scoring function that uses the full prediction distribution instead of binary thresholding. Our method achieved first place in the BioDCASE 2025 Task 1 challenge with 0.30 MSE average across test datasets, compared to 0.58 for the deep learning baseline. On individual datasets, we achieved 0.14 MSE on ARU data (77% reduction) and 0.45 MSE on zebra finch data (18% reduction). The framework supports probabilistic temporal alignment, moving beyond point estimates. While validated in a bioacoustic context, the approach is applicable to a broader range of multi-channel audio tasks where alignment confidence is critical. Code available on: https://github.com/Ragib-Amin-Nihal/BEATsCA
Equip Pre-ranking with Target Attention by Residual Quantization
arXiv:2509.16931v1 Announce Type: cross Abstract: The pre-ranking stage in industrial recommendation systems faces a fundamental conflict between efficiency and effectiveness. While powerful models like Target Attention (TA) excel at capturing complex feature interactions in the ranking stage, their high computational cost makes them infeasible for pre-ranking, which often relies on simplistic vector-product models. This disparity creates a significant performance bottleneck for the entire system. To bridge this gap, we propose TARQ, a novel pre-ranking framework. Inspired by generative models, TARQ's key innovation is to equip pre-ranking with an architecture approximate to TA by Residual Quantization. This allows us to bring the modeling power of TA into the latency-critical pre-ranking stage for the first time, establishing a new state-of-the-art trade-off between accuracy and efficiency. Extensive offline experiments and large-scale online A/B tests at Taobao demonstrate TARQ's significant improvements in ranking performance. Consequently, our model has been fully deployed in production, serving tens of millions of daily active users and yielding substantial business improvements.
NeuFACO: Neural Focused Ant Colony Optimization for Traveling Salesman Problem
arXiv:2509.16938v1 Announce Type: cross Abstract: This study presents Neural Focused Ant Colony Optimization (NeuFACO), a non-autoregressive framework for the Traveling Salesman Problem (TSP) that combines advanced reinforcement learning with enhanced Ant Colony Optimization (ACO). NeuFACO employs Proximal Policy Optimization (PPO) with entropy regularization to train a graph neural network for instance-specific heuristic guidance, which is integrated into an optimized ACO framework featuring candidate lists, restricted tour refinement, and scalable local search. By leveraging amortized inference alongside ACO stochastic exploration, NeuFACO efficiently produces high-quality solutions across diverse TSP instances.
Quantum Adaptive Self-Attention for Financial Rebalancing: An Empirical Study on Automated Market Makers in Decentralized Finance
arXiv:2509.16955v1 Announce Type: cross Abstract: We formulate automated market maker (AMM) \emph{rebalancing} as a binary detection problem and study a hybrid quantum--classical self-attention block, \textbf{Quantum Adaptive Self-Attention (QASA)}. QASA constructs quantum queries/keys/values via variational quantum circuits (VQCs) and applies standard softmax attention over Pauli-$Z$ expectation vectors, yielding a drop-in attention module for financial time-series decision making. Using daily data for \textbf{BTCUSDC} over \textbf{Jan-2024--Jan-2025} with a 70/15/15 time-series split, we compare QASA against classical ensembles, a transformer, and pure quantum baselines under Return, Sharpe, and Max Drawdown. The \textbf{QASA-Sequence} variant attains the \emph{best single-model risk-adjusted performance} (\textbf{13.99\%} return; \textbf{Sharpe 1.76}), while hybrid models average \textbf{11.2\%} return (vs.\ 9.8\% classical; 4.4\% pure quantum), indicating a favorable performance--stability--cost trade-off.
Deep Learning Inductive Biases for fMRI Time Series Classification during Resting-state and Movie-watching
arXiv:2509.16973v1 Announce Type: cross Abstract: Deep learning has advanced fMRI analysis, yet it remains unclear which architectural inductive biases are most effective at capturing functional patterns in human brain activity. This issue is particularly important in small-sample settings, as most datasets fall into this category. We compare models with three major inductive biases in deep learning including convolutional neural networks (CNNs), long short-term memory networks (LSTMs), and Transformers for the task of biological sex classification. These models are evaluated within a unified pipeline using parcellated multivariate fMRI time series from the Human Connectome Project (HCP) 7-Tesla cohort, which includes four resting-state runs and four movie-watching task runs. We assess performance on Whole-brain, subcortex, and 12 functional networks. CNNs consistently achieved the highest discrimination for sex classification in both resting-state and movie-watching, while LSTM and Transformer models underperformed. Network-resolved analyses indicated that the Whole-brain, Default Mode, Cingulo-Opercular, Dorsal Attention, and Frontoparietal networks were the most discriminative. These results were largely similar between resting-state and movie-watching. Our findings indicate that, at this dataset size, discriminative information is carried by local spatial patterns and inter-regional dependencies, favoring convolutional inductive bias. Our study provides insights for selecting deep learning architectures for fMRI time series classification.
Optimal Transport for Handwritten Text Recognition in a Low-Resource Regime
arXiv:2509.16977v1 Announce Type: cross Abstract: Handwritten Text Recognition (HTR) is a task of central importance in the field of document image understanding. State-of-the-art methods for HTR require the use of extensive annotated sets for training, making them impractical for low-resource domains like historical archives or limited-size modern collections. This paper introduces a novel framework that, unlike the standard HTR model paradigm, can leverage mild prior knowledge of lexical characteristics; this is ideal for scenarios where labeled data are scarce. We propose an iterative bootstrapping approach that aligns visual features extracted from unlabeled images with semantic word representations using Optimal Transport (OT). Starting with a minimal set of labeled examples, the framework iteratively matches word images to text labels, generates pseudo-labels for high-confidence alignments, and retrains the recognizer on the growing dataset. Numerical experiments demonstrate that our iterative visual-semantic alignment scheme significantly improves recognition accuracy on low-resource HTR benchmarks.
Advancing Speech Understanding in Speech-Aware Language Models with GRPO
arXiv:2509.16990v1 Announce Type: cross Abstract: In this paper, we introduce a Group Relative Policy Optimization (GRPO)-based method for training Speech-Aware Large Language Models (SALLMs) on open-format speech understanding tasks, such as Spoken Question Answering and Automatic Speech Translation. SALLMs have proven highly effective for speech understanding tasks. GRPO has recently gained traction for its efficiency in training LLMs, and prior work has explored its application to SALLMs, primarily in multiple-choice tasks. Building on this, we focus on open-format tasks that better reflect the generative abilities of the models. Our approach leverages GRPO with BLEU as the reward signal to optimize SALLMs, and we demonstrate empirically that it surpasses standard SFT across several key metrics. Finally, we explore the potential of incorporating off-policy samples within GRPO for these tasks, highlighting avenues for further improvement and further research.
DocIQ: A Benchmark Dataset and Feature Fusion Network for Document Image Quality Assessment
arXiv:2509.17012v1 Announce Type: cross Abstract: Document image quality assessment (DIQA) is an important component for various applications, including optical character recognition (OCR), document restoration, and the evaluation of document image processing systems. In this paper, we introduce a subjective DIQA dataset DIQA-5000. The DIQA-5000 dataset comprises 5,000 document images, generated by applying multiple document enhancement techniques to 500 real-world images with diverse distortions. Each enhanced image was rated by 15 subjects across three rating dimensions: overall quality, sharpness, and color fidelity. Furthermore, we propose a specialized no-reference DIQA model that exploits document layout features to maintain quality perception at reduced resolutions to lower computational cost. Recognizing that image quality is influenced by both low-level and high-level visual features, we designed a feature fusion module to extract and integrate multi-level features from document images. To generate multi-dimensional scores, our model employs independent quality heads for each dimension to predict score distributions, allowing it to learn distinct aspects of document image quality. Experimental results demonstrate that our method outperforms current state-of-the-art general-purpose IQA models on both DIQA-5000 and an additional document image dataset focused on OCR accuracy.
DeepEOSNet: Capturing the dependency on thermodynamic state in property prediction tasks
arXiv:2509.17018v1 Announce Type: cross Abstract: We propose a machine learning (ML) architecture to better capture the dependency of thermodynamic properties on the independent states. When predicting state-dependent thermodynamic properties, ML models need to account for both molecular structure and the thermodynamic state, described by independent variables, typically temperature, pressure, and composition. Modern molecular ML models typically include state information by adding it to molecular fingerprint vectors or by embedding explicit (semi-empirical) thermodynamic relations. Here, we propose to rather split the information processing on the molecular structure and the dependency on states into two separate network channels: a graph neural network and a multilayer perceptron, whose output is combined by a dot product. We refer to our approach as DeepEOSNet, as this idea is based on the DeepONet architecture [Lu et al. (2021), Nat. Mach. Intell.]: instead of operators, we learn state dependencies, with the possibility to predict equation of states (EOS). We investigate the predictive performance of DeepEOSNet by means of three case studies, which include the prediction of vapor pressure as a function of temperature, and mixture molar volume as a function of composition, temperature, and pressure. Our results show superior performance of DeepEOSNet for predicting vapor pressure and comparable performance for predicting mixture molar volume compared to state-of-research graph-based thermodynamic prediction models from our earlier works. In fact, we see large potential of DeepEOSNet in cases where data is sparse in the state domain and the output function is structurally similar across different molecules. The concept of DeepEOSNet can easily be transferred to other ML architectures in molecular context, and thus provides a viable option for property prediction.
The Transfer Neurons Hypothesis: An Underlying Mechanism for Language Latent Space Transitions in Multilingual LLMs
arXiv:2509.17030v1 Announce Type: cross Abstract: Recent studies have suggested a processing framework for multilingual inputs in decoder-based LLMs: early layers convert inputs into English-centric and language-agnostic representations; middle layers perform reasoning within an English-centric latent space; and final layers generate outputs by transforming these representations back into language-specific latent spaces. However, the internal dynamics of such transformation and the underlying mechanism remain underexplored. Towards a deeper understanding of this framework, we propose and empirically validate The Transfer Neurons Hypothesis: certain neurons in the MLP module are responsible for transferring representations between language-specific latent spaces and a shared semantic latent space. Furthermore, we show that one function of language-specific neurons, as identified in recent studies, is to facilitate movement between latent spaces. Finally, we show that transfer neurons are critical for reasoning in multilingual LLMs.
Localizing Malicious Outputs from CodeLLM
arXiv:2509.17070v1 Announce Type: cross Abstract: We introduce FreqRank, a mutation-based defense to localize malicious components in LLM outputs and their corresponding backdoor triggers. FreqRank assumes that the malicious sub-string(s) consistently appear in outputs for triggered inputs and uses a frequency-based ranking system to identify them. Our ranking system then leverages this knowledge to localize the backdoor triggers present in the inputs. We create nine malicious models through fine-tuning or custom instructions for three downstream tasks, namely, code completion (CC), code generation (CG), and code summarization (CS), and show that they have an average attack success rate (ASR) of 86.6%. Furthermore, FreqRank's ranking system highlights the malicious outputs as one of the top five suggestions in 98% of cases. We also demonstrate that FreqRank's effectiveness scales as the number of mutants increases and show that FreqRank is capable of localizing the backdoor trigger effectively even with a limited number of triggered samples. Finally, we show that our approach is 35-50% more effective than other defense methods.
$\texttt{DiffSyn}$: A Generative Diffusion Approach to Materials Synthesis Planning
arXiv:2509.17094v1 Announce Type: cross Abstract: The synthesis of crystalline materials, such as zeolites, remains a significant challenge due to a high-dimensional synthesis space, intricate structure-synthesis relationships and time-consuming experiments. Considering the one-to-many relationship between structure and synthesis, we propose $\texttt{DiffSyn}$, a generative diffusion model trained on over 23,000 synthesis recipes spanning 50 years of literature. $\texttt{DiffSyn}$ generates probable synthesis routes conditioned on a desired zeolite structure and an organic template. $\texttt{DiffSyn}$ achieves state-of-the-art performance by capturing the multi-modal nature of structure-synthesis relationships. We apply $\texttt{DiffSyn}$ to differentiate among competing phases and generate optimal synthesis routes. As a proof of concept, we synthesize a UFI material using $\texttt{DiffSyn}$-generated synthesis routes. These routes, rationalized by density functional theory binding energies, resulted in the successful synthesis of a UFI material with a high Si/Al$_{\text{ICP}}$ of 19.0, which is expected to improve thermal stability and is higher than that of any previously recorded.
Machine Learning for Campus Energy Resilience: Clustering and Time-Series Forecasting in Intelligent Load Shedding
arXiv:2509.17097v1 Announce Type: cross Abstract: The growing demand for reliable electricity in universities necessitates intelligent energy management. This study proposes a machine learning-based load shedding framework for the University of Lagos, designed to optimize distribution and reduce waste. The methodology followed three main stages. First, a dataset of 3,648 hourly records from 55 buildings was compiled to develop building-level consumption models. Second, Principal Component Analysis was applied for dimensionality reduction, and clustering validation techniques were used to determine the optimal number of demand groups. Mini-Batch K-Means was then employed to classify buildings into high-, medium-, and low-demand clusters. Finally, short-term load forecasting was performed at the cluster level using multiple statistical and deep learning models, including ARIMA, SARIMA, Prophet, LSTM, and GRU. Results showed Prophet offered the most reliable forecasts, while Mini-Batch K-Means achieved stable clustering performance. By integrating clustering with forecasting, the framework enabled a fairer, data-driven load shedding strategy that reduces inefficiencies and supports climate change mitigation through sustainable energy management.
Uncertainty-Supervised Interpretable and Robust Evidential Segmentation
arXiv:2509.17098v1 Announce Type: cross Abstract: Uncertainty estimation has been widely studied in medical image segmentation as a tool to provide reliability, particularly in deep learning approaches. However, previous methods generally lack effective supervision in uncertainty estimation, leading to low interpretability and robustness of the predictions. In this work, we propose a self-supervised approach to guide the learning of uncertainty. Specifically, we introduce three principles about the relationships between the uncertainty and the image gradients around boundaries and noise. Based on these principles, two uncertainty supervision losses are designed. These losses enhance the alignment between model predictions and human interpretation. Accordingly, we introduce novel quantitative metrics for evaluating the interpretability and robustness of uncertainty. Experimental results demonstrate that compared to state-of-the-art approaches, the proposed method can achieve competitive segmentation performance and superior results in out-of-distribution (OOD) scenarios while significantly improving the interpretability and robustness of uncertainty estimation. Code is available via https://github.com/suiannaius/SURE.
Delay compensation of multi-input distinct delay nonlinear systems via neural operators
arXiv:2509.17131v1 Announce Type: cross Abstract: In this work, we present the first stability results for approximate predictors in multi-input non-linear systems with distinct actuation delays. We show that if the predictor approximation satisfies a uniform (in time) error bound, semi-global practical stability is correspondingly achieved. For such approximators, the required uniform error bound depends on the desired region of attraction and the number of control inputs in the system. The result is achieved through transforming the delay into a transport PDE and conducting analysis on the coupled ODE-PDE cascade. To highlight the viability of such error bounds, we demonstrate our results on a class of approximators - neural operators - showcasing sufficiency for satisfying such a universal bound both theoretically and in simulation on a mobile robot experiment.
Data-efficient Kernel Methods for Learning Hamiltonian Systems
arXiv:2509.17154v1 Announce Type: cross Abstract: Hamiltonian dynamics describe a wide range of physical systems. As such, data-driven simulations of Hamiltonian systems are important for many scientific and engineering problems. In this work, we propose kernel-based methods for identifying and forecasting Hamiltonian systems directly from data. We present two approaches: a two-step method that reconstructs trajectories before learning the Hamiltonian, and a one-step method that jointly infers both. Across several benchmark systems, including mass-spring dynamics, a nonlinear pendulum, and the Henon-Heiles system, we demonstrate that our framework achieves accurate, data-efficient predictions and outperforms two-step kernel-based baselines, particularly in scarce-data regimes, while preserving the conservation properties of Hamiltonian dynamics. Moreover, our methodology provides theoretical a priori error estimates, ensuring reliability of the learned models. We also provide a more general, problem-agnostic numerical framework that goes beyond Hamiltonian systems and can be used for data-driven learning of arbitrary dynamical systems.
Self-Supervised Discovery of Neural Circuits in Spatially Patterned Neural Responses with Graph Neural Networks
arXiv:2509.17174v1 Announce Type: cross Abstract: Inferring synaptic connectivity from neural population activity is a fundamental challenge in computational neuroscience, complicated by partial observability and mismatches between inference models and true circuit dynamics. In this study, we propose a graph-based neural inference model that simultaneously predicts neural activity and infers latent connectivity by modeling neurons as interacting nodes in a graph. The architecture features two distinct modules: one for learning structural connectivity and another for predicting future spiking activity via a graph neural network (GNN). Our model accommodates unobserved neurons through auxiliary nodes, allowing for inference in partially observed circuits. We evaluate this approach using synthetic data from ring attractor networks and real spike recordings from head direction cells in mice. Across a wide range of conditions, including varying recurrent connectivity, external inputs, and incomplete observations, our model consistently outperforms standard baselines, resolving spurious correlations more effectively and recovering accurate weight profiles. When applied to real data, the inferred connectivity aligns with theoretical predictions of continuous attractor models. These results highlight the potential of GNN-based models to infer latent neural circuitry through self-supervised structure learning, while leveraging the spike prediction task to flexibly link connectivity and dynamics across both simulated and biological neural systems.
FlagEval Findings Report: A Preliminary Evaluation of Large Reasoning Models on Automatically Verifiable Textual and Visual Questions
arXiv:2509.17177v1 Announce Type: cross Abstract: We conduct a moderate-scale contamination-free (to some extent) evaluation of current large reasoning models (LRMs) with some preliminary findings. We also release ROME, our evaluation benchmark for vision language models intended to test reasoning from visual clues. We attach links to the benchmark, evaluation data, and other updates on this website: https://flageval-baai.github.io/LRM-Eval/
LifeAlign: Lifelong Alignment for Large Language Models with Memory-Augmented Focalized Preference Optimization
arXiv:2509.17183v1 Announce Type: cross Abstract: Alignment plays a crucial role in Large Language Models (LLMs) in aligning with human preferences on a specific task/domain. Traditional alignment methods suffer from catastrophic forgetting, where models lose previously acquired knowledge when adapting to new preferences or domains. We introduce LifeAlign, a novel framework for lifelong alignment that enables LLMs to maintain consistent human preference alignment across sequential learning tasks without forgetting previously learned knowledge. Our approach consists of two key innovations. First, we propose a focalized preference optimization strategy that aligns LLMs with new preferences while preventing the erosion of knowledge acquired from previous tasks. Second, we develop a short-to-long memory consolidation mechanism that merges denoised short-term preference representations into stable long-term memory using intrinsic dimensionality reduction, enabling efficient storage and retrieval of alignment patterns across diverse domains. We evaluate LifeAlign across multiple sequential alignment tasks spanning different domains and preference types. Experimental results demonstrate that our method achieves superior performance in maintaining both preference alignment quality and knowledge retention compared to existing lifelong learning approaches. The codes and datasets will be released on GitHub.
Guided and Unguided Conditional Diffusion Mechanisms for Structured and Semantically-Aware 3D Point Cloud Generation
arXiv:2509.17206v1 Announce Type: cross Abstract: Generating realistic 3D point clouds is a fundamental problem in computer vision with applications in remote sensing, robotics, and digital object modeling. Existing generative approaches primarily capture geometry, and when semantics are considered, they are typically imposed post hoc through external segmentation or clustering rather than integrated into the generative process itself. We propose a diffusion-based framework that embeds per-point semantic conditioning directly within generation. Each point is associated with a conditional variable corresponding to its semantic label, which guides the diffusion dynamics and enables the joint synthesis of geometry and semantics. This design produces point clouds that are both structurally coherent and segmentation-aware, with object parts explicitly represented during synthesis. Through a comparative analysis of guided and unguided diffusion processes, we demonstrate the significant impact of conditional variables on diffusion dynamics and generation quality. Extensive experiments validate the efficacy of our approach, producing detailed and accurate 3D point clouds tailored to specific parts and features.
Point-RTD: Replaced Token Denoising for Pretraining Transformer Models on Point Clouds
arXiv:2509.17207v1 Announce Type: cross Abstract: Pre-training strategies play a critical role in advancing the performance of transformer-based models for 3D point cloud tasks. In this paper, we introduce Point-RTD (Replaced Token Denoising), a novel pretraining strategy designed to improve token robustness through a corruption-reconstruction framework. Unlike traditional mask-based reconstruction tasks that hide data segments for later prediction, Point-RTD corrupts point cloud tokens and leverages a discriminator-generator architecture for denoising. This shift enables more effective learning of structural priors and significantly enhances model performance and efficiency. On the ShapeNet dataset, Point-RTD reduces reconstruction error by over 93% compared to PointMAE, and achieves more than 14x lower Chamfer Distance on the test set. Our method also converges faster and yields higher classification accuracy on ShapeNet, ModelNet10, and ModelNet40 benchmarks, clearly outperforming the baseline Point-MAE framework in every case.
Virtual Consistency for Audio Editing
arXiv:2509.17219v1 Announce Type: cross Abstract: Free-form, text-based audio editing remains a persistent challenge, despite progress in inversion-based neural methods. Current approaches rely on slow inversion procedures, limiting their practicality. We present a virtual-consistency based audio editing system that bypasses inversion by adapting the sampling process of diffusion models. Our pipeline is model-agnostic, requiring no fine-tuning or architectural changes, and achieves substantial speed-ups over recent neural editing baselines. Crucially, it achieves this efficiency without compromising quality, as demonstrated by quantitative benchmarks and a user study involving 16 participants.
AI-based Methods for Simulating, Sampling, and Predicting Protein Ensembles
arXiv:2509.17224v1 Announce Type: cross Abstract: Advances in deep learning have opened an era of abundant and accurate predicted protein structures; however, similar progress in protein ensembles has remained elusive. This review highlights several recent research directions towards AI-based predictions of protein ensembles, including coarse-grained force fields, generative models, multiple sequence alignment perturbation methods, and modeling of ensemble descriptors. An emphasis is placed on realistic assessments of the technological maturity of current methods, the strengths and weaknesses of broad families of techniques, and promising machine learning frameworks at an early stage of development. We advocate for "closing the loop" between model training, simulation, and inference to overcome challenges in training data availability and to enable the next generation of models.
MoEs Are Stronger than You Think: Hyper-Parallel Inference Scaling with RoE
arXiv:2509.17238v1 Announce Type: cross Abstract: The generation quality of large language models (LLMs) is often improved by utilizing inference-time sequence-level scaling methods (e.g., Chain-of-Thought). We introduce hyper-parallel scaling, a complementary framework that improves prediction quality at the token level. Hyper-parallel scaling computes and aggregates multiple output proposals for a single token from the model. We implement this concept in Mixture-of-Experts (MoE) models, which we refer to as Roster of Experts (RoE). RoE is a training-free inference algorithm that turns a single MoE into a dynamic ensemble of MoEs. RoE injects controlled stochasticity into the expert routing mechanism, enabling it to sample multiple diverse experts for each token and aggregate their outputs for a more accurate final prediction.To overcome the computational cost, we introduce an efficient batching strategy and a specialized KV-caching mechanism that minimizes compute and memory overhead. For example, RoE enables a 7B MoE model to match the performance of a 10.5B MoE model while using 30% less compute for inference. These gains are achieved without any fine-tuning of model parameters.
Can Agents Judge Systematic Reviews Like Humans? Evaluating SLRs with LLM-based Multi-Agent System
arXiv:2509.17240v1 Announce Type: cross Abstract: Systematic Literature Reviews (SLRs) are foundational to evidence-based research but remain labor-intensive and prone to inconsistency across disciplines. We present an LLM-based SLR evaluation copilot built on a Multi-Agent System (MAS) architecture to assist researchers in assessing the overall quality of the systematic literature reviews. The system automates protocol validation, methodological assessment, and topic relevance checks using a scholarly database. Unlike conventional single-agent methods, our design integrates a specialized agentic approach aligned with PRISMA guidelines to support more structured and interpretable evaluations. We conducted an initial study on five published SLRs from diverse domains, comparing system outputs to expert-annotated PRISMA scores, and observed 84% agreement. While early results are promising, this work represents a first step toward scalable and accurate NLP-driven systems for interdisciplinary workflows and reveals their capacity for rigorous, domain-agnostic knowledge aggregation to streamline the review process.
Risk Comparisons in Linear Regression: Implicit Regularization Dominates Explicit Regularization
arXiv:2509.17251v1 Announce Type: cross Abstract: Existing theory suggests that for linear regression problems categorized by capacity and source conditions, gradient descent (GD) is always minimax optimal, while both ridge regression and online stochastic gradient descent (SGD) are polynomially suboptimal for certain categories of such problems. Moving beyond minimax theory, this work provides instance-wise comparisons of the finite-sample risks for these algorithms on any well-specified linear regression problem. Our analysis yields three key findings. First, GD dominates ridge regression: with comparable regularization, the excess risk of GD is always within a constant factor of ridge, but ridge can be polynomially worse even when tuned optimally. Second, GD is incomparable with SGD. While it is known that for certain problems GD can be polynomially better than SGD, the reverse is also true: we construct problems, inspired by benign overfitting theory, where optimally stopped GD is polynomially worse. Finally, GD dominates SGD for a significant subclass of problems -- those with fast and continuously decaying covariance spectra -- which includes all problems satisfying the standard capacity condition.
Learning and Optimization with 3D Orientations
arXiv:2509.17274v1 Announce Type: cross Abstract: There exist numerous ways of representing 3D orientations. Each representation has both limitations and unique features. Choosing the best representation for one task is often a difficult chore, and there exist conflicting opinions on which representation is better suited for a set of family of tasks. Even worse, when dealing with scenarios where we need to learn or optimize functions with orientations as inputs and/or outputs, the set of possibilities (representations, loss functions, etc.) is even larger and it is not easy to decide what is best for each scenario. In this paper, we attempt to a) present clearly, concisely and with unified notation all available representations, and "tricks" related to 3D orientations (including Lie Group algebra), and b) benchmark them in representative scenarios. The first part feels like it is missing from the robotics literature as one has to read many different textbooks and papers in order have a concise and clear understanding of all possibilities, while the benchmark is necessary in order to come up with recommendations based on empirical evidence. More precisely, we experiment with the following settings that attempt to cover most widely used scenarios in robotics: 1) direct optimization, 2) imitation/supervised learning with a neural network controller, 3) reinforcement learning, and 4) trajectory optimization using differential dynamic programming. We finally provide guidelines depending on the scenario, and make available a reference implementation of all the orientation math described.
Probabilistic Token Alignment for Large Language Model Fusion
arXiv:2509.17276v1 Announce Type: cross Abstract: Training large language models (LLMs) from scratch can yield models with unique functionalities and strengths, but it is costly and often leads to redundant capabilities. A more cost-effective alternative is to fuse existing pre-trained LLMs with different architectures into a more powerful model. However, a key challenge in existing model fusion is their dependence on manually predefined vocabulary alignment, which may not generalize well across diverse contexts, leading to performance degradation in several evaluation. To solve this, we draw inspiration from distribution learning and propose the probabilistic token alignment method as a general and soft mapping for alignment, named as PTA-LLM. Our approach innovatively reformulates token alignment into a classic mathematical problem: optimal transport, seamlessly leveraging distribution-aware learning to facilitate more coherent model fusion. Apart from its inherent generality, PTA-LLM exhibits interpretability from a distributional perspective, offering insights into the essence of the token alignment. Empirical results demonstrate that probabilistic token alignment enhances the target model's performance across multiple capabilities. Our code is avaliable at https://runjia.tech/neurips_pta-llm/.
Clotho: Measuring Task-Specific Pre-Generation Test Adequacy for LLM Inputs
arXiv:2509.17314v1 Announce Type: cross Abstract: Software increasingly relies on the emergent capabilities of Large Language Models (LLMs), from natural language understanding to program analysis and generation. Yet testing them on specific tasks remains difficult and costly: many prompts lack ground truth, forcing reliance on human judgment, while existing uncertainty and adequacy measures typically require full inference. A key challenge is to assess input adequacy in a way that reflects the demands of the task, ideally before even generating any output. We introduce CLOTHO, a task-specific, pre-generation adequacy measure that estimates input difficulty directly from hidden LLM states. Given a large pool of unlabelled inputs for a specific task, CLOTHO uses a Gaussian Mixture Model (GMM) to adaptively sample the most informative cases for human labelling. Based on this reference set the GMM can then rank unseen inputs by their likelihood of failure. In our empirical evaluation across eight benchmark tasks and three open-weight LLMs, CLOTHO can predict failures with a ROC-AUC of 0.716, after labelling reference sets that are on average only 5.4% of inputs. It does so without generating any outputs, thereby reducing costs compared to existing uncertainty measures. Comparison of CLOTHO and post-generation uncertainty measures shows that the two approaches complement each other. Crucially, we show that adequacy scores learnt from open-weight LLMs transfer effectively to proprietary models, extending the applicability of the approach. When prioritising test inputs for proprietary models, CLOTHO increases the average number of failing inputs from 18.7 to 42.5 out of 100, compared to random prioritisation.
CogAtom: From Cognitive Atoms to Olympiad-level Mathematical Reasoning in Large Language Models
arXiv:2509.17318v1 Announce Type: cross Abstract: Mathematical reasoning poses significant challenges for Large Language Models (LLMs) due to its demand for multi-step reasoning and abstract conceptual integration. While recent test-time scaling techniques rely heavily on high-quality, challenging problems, the scarcity of Olympiad-level math problems remains a bottleneck. We introduce CogAtom, a novel cognitive atom-based framework for synthesizing mathematically rigorous and cognitively diverse problems. Unlike prior approaches, CogAtom models problem construction as a process of selecting and recombining fundamental reasoning units, cognitive atoms, extracted from human-authored solutions. A diversity-promoting random walk algorithm enables exploration of the cognitive atom space, while a constraint-based recombination mechanism ensures logical soundness and structural validity. The combinatorial nature of the graph structure provides a near-infinite space of reasoning paths, and the walk algorithm systematically explores this space to achieve large-scale synthesis of high-quality problems; meanwhile, by controlling the number of cognitive atoms, we can precisely adjust problem difficulty, ensuring diversity, scalability, and controllability of the generated problems. Experimental results demonstrate that CogAtom outperforms existing methods in accuracy, reasoning depth, and diversity, generating problems that closely match the difficulty of AIME while exceeding it in structural variation. Our work offers a cognitively grounded pathway toward scalable, high-quality math problem generation.Our code is publicly available at https://github.com/Icarus-1111/CogAtom.
DiffQ: Unified Parameter Initialization for Variational Quantum Algorithms via Diffusion Models
arXiv:2509.17324v1 Announce Type: cross Abstract: Variational Quantum Algorithms (VQAs) are widely used in the noisy intermediate-scale quantum (NISQ) era, but their trainability and performance depend critically on initialization parameters that shape the optimization landscape. Existing machine learning-based initializers achieve state-of-the-art results yet remain constrained to single-task domains and small datasets of only hundreds of samples. We address these limitations by reformulating VQA parameter initialization as a generative modeling problem and introducing DiffQ, a parameter initializer based on the Denoising Diffusion Probabilistic Model (DDPM). To support robust training and evaluation, we construct a dataset of 15,085 instances spanning three domains and five representative tasks. Experiments demonstrate that DiffQ surpasses baselines, reducing initial loss by up to 8.95 and convergence steps by up to 23.4%.
Word2VecGD: Neural Graph Drawing with Cosine-Stress Optimization
arXiv:2509.17333v1 Announce Type: cross Abstract: We propose a novel graph visualization method leveraging random walk-based embeddings to replace costly graph-theoretical distance computations. Using word2vec-inspired embeddings, our approach captures both structural and semantic relationships efficiently. Instead of relying on exact shortest-path distances, we optimize layouts using cosine dissimilarities, significantly reducing computational overhead. Our framework integrates differentiable stress optimization with stochastic gradient descent (SGD), supporting multi-criteria layout objectives. Experimental results demonstrate that our method produces high-quality, semantically meaningful layouts while efficiently scaling to large graphs. Code available at: https://github.com/mlyann/graphv_nn
Explainability matters: The effect of liability rules on the healthcare sector
arXiv:2509.17334v1 Announce Type: cross
Abstract: Explainability, the capability of an artificial intelligence system (AIS) to explain its outcomes in a manner that is comprehensible to human beings at an acceptable level, has been deemed essential for critical sectors, such as healthcare. Is it really the case? In this perspective, we consider two extreme cases, Oracle'' (without explainability) versusAI Colleague'' (with explainability) for a thorough analysis. We discuss how the level of automation and explainability of AIS can affect the determination of liability among the medical practitioner/facility and manufacturer of AIS. We argue that explainability plays a crucial role in setting a responsibility framework in healthcare, from a legal standpoint, to shape the behavior of all involved parties and mitigate the risk of potential defensive medicine practices.
Multi-Scenario Highway Lane-Change Intention Prediction: A Physics-Informed AI Framework for Three-Class Classification
arXiv:2509.17354v1 Announce Type: cross Abstract: Lane-change maneuvers are a leading cause of highway accidents, underscoring the need for accurate intention prediction to improve the safety and decision-making of autonomous driving systems. While prior studies using machine learning and deep learning methods (e.g., SVM, CNN, LSTM, Transformers) have shown promise, most approaches remain limited by binary classification, lack of scenario diversity, and degraded performance under longer prediction horizons. In this study, we propose a physics-informed AI framework that explicitly integrates vehicle kinematics, interaction feasibility, and traffic-safety metrics (e.g., distance headway, time headway, time-to-collision, closing gap time) into the learning process. lane-change prediction is formulated as a three-class problem that distinguishes left change, right change, and no change, and is evaluated across both straight highway segments (highD) and complex ramp scenarios (exiD). By integrating vehicle kinematics with interaction features, our machine learning models, particularly LightGBM, achieve state-of-the-art accuracy and strong generalization. Results show up to 99.8% accuracy and 93.6% macro F1 on highD, and 96.1% accuracy and 88.7% macro F1 on exiD at a 1-second horizon, outperforming a two-layer stacked LSTM baseline. These findings demonstrate the practical advantages of a physics-informed and feature-rich machine learning framework for real-time lane-change intention prediction in autonomous driving systems.
SilentStriker:Toward Stealthy Bit-Flip Attacks on Large Language Models
arXiv:2509.17371v1 Announce Type: cross Abstract: The rapid adoption of large language models (LLMs) in critical domains has spurred extensive research into their security issues. While input manipulation attacks (e.g., prompt injection) have been well studied, Bit-Flip Attacks (BFAs) -- which exploit hardware vulnerabilities to corrupt model parameters and cause severe performance degradation -- have received far less attention. Existing BFA methods suffer from key limitations: they fail to balance performance degradation and output naturalness, making them prone to discovery. In this paper, we introduce SilentStriker, the first stealthy bit-flip attack against LLMs that effectively degrades task performance while maintaining output naturalness. Our core contribution lies in addressing the challenge of designing effective loss functions for LLMs with variable output length and the vast output space. Unlike prior approaches that rely on output perplexity for attack loss formulation, which inevitably degrade output naturalness, we reformulate the attack objective by leveraging key output tokens as targets for suppression, enabling effective joint optimization of attack effectiveness and stealthiness. Additionally, we employ an iterative, progressive search strategy to maximize attack efficacy. Experiments show that SilentStriker significantly outperforms existing baselines, achieving successful attacks without compromising the naturalness of generated text.
Bias-variance Tradeoff in Tensor Estimation
arXiv:2509.17382v1 Announce Type: cross Abstract: We study denoising of a third-order tensor when the ground-truth tensor is not necessarily Tucker low-rank. Specifically, we observe $$ Y=X^\ast+Z\in \mathbb{R}^{p_{1} \times p_{2} \times p_{3}}, $$ where $X^\ast$ is the ground-truth tensor, and $Z$ is the noise tensor. We propose a simple variant of the higher-order tensor SVD estimator $\widetilde{X}$. We show that uniformly over all user-specified Tucker ranks $(r_{1},r_{2},r_{3})$, $$ | \widetilde{X} - X^* |{ \mathrm{F}}^2 = O \Big( \kappa^2 \Big{ r{1}r_{2}r_{3}+\sum_{k=1}^{3} p_{k} r_{k} \Big} \; + \; \xi_{(r_{1},r_{2},r_{3})}^2\Big) \quad \text{ with high probability.} $$ Here, the bias term $\xi_{(r_1,r_2,r_3)}$ corresponds to the best achievable approximation error of $X^\ast$ over the class of tensors with Tucker ranks $(r_1,r_2,r_3)$; $\kappa^2$ quantifies the noise level; and the variance term $\kappa^2 {r_{1}r_{2}r_{3}+\sum_{k=1}^{3} p_{k} r_{k}}$ scales with the effective number of free parameters in the estimator $\widetilde{X}$. Our analysis achieves a clean rank-adaptive bias--variance tradeoff: as we increase the ranks of estimator $\widetilde{X}$, the bias $\xi(r_{1},r_{2},r_{3})$ decreases and the variance increases. As a byproduct we also obtain a convenient bias-variance decomposition for the vanilla low-rank SVD matrix estimators.
Robust Mixture Models for Algorithmic Fairness Under Latent Heterogeneity
arXiv:2509.17411v1 Announce Type: cross Abstract: Standard machine learning models optimized for average performance often fail on minority subgroups and lack robustness to distribution shifts. This challenge worsens when subgroups are latent and affected by complex interactions among continuous and discrete features. We introduce ROME (RObust Mixture Ensemble), a framework that learns latent group structure from data while optimizing for worst-group performance. ROME employs two approaches: an Expectation-Maximization algorithm for linear models and a neural Mixture-of-Experts for nonlinear settings. Through simulations and experiments on real-world datasets, we demonstrate that ROME significantly improves algorithmic fairness compared to standard methods while maintaining competitive average performance. Importantly, our method requires no predefined group labels, making it practical when sources of disparities are unknown or evolving.
SPICED: A Synaptic Homeostasis-Inspired Framework for Unsupervised Continual EEG Decoding
arXiv:2509.17439v1 Announce Type: cross Abstract: Human brain achieves dynamic stability-plasticity balance through synaptic homeostasis. Inspired by this biological principle, we propose SPICED: a neuromorphic framework that integrates the synaptic homeostasis mechanism for unsupervised continual EEG decoding, particularly addressing practical scenarios where new individuals with inter-individual variability emerge continually. SPICED comprises a novel synaptic network that enables dynamic expansion during continual adaptation through three bio-inspired neural mechanisms: (1) critical memory reactivation; (2) synaptic consolidation and (3) synaptic renormalization. The interplay within synaptic homeostasis dynamically strengthens task-discriminative memory traces and weakens detrimental memories. By integrating these mechanisms with continual learning system, SPICED preferentially replays task-discriminative memory traces that exhibit strong associations with newly emerging individuals, thereby achieving robust adaptations. Meanwhile, SPICED effectively mitigates catastrophic forgetting by suppressing the replay prioritization of detrimental memories during long-term continual learning. Validated on three EEG datasets, SPICED show its effectiveness.
AI Pangaea: Unifying Intelligence Islands for Adapting Myriad Tasks
arXiv:2509.17460v1 Announce Type: cross Abstract: The pursuit of artificial general intelligence continuously demands generalization in one model across myriad tasks, even those not seen before. However, current AI models are isolated from each other for being limited to specific tasks, now first defined as Intelligence Islands. To unify Intelligence Islands into one, we propose Pangaea, the first AI supercontinent akin to the geological Pangaea. Pangaea encodes any data into a unified format and accumulates universal knowledge through pre-training on 296 datasets across diverse modalities. Eventually, it demonstrates remarkable generalization across 45 general tasks and 15 scientific tasks encompassing a wide range of scientific subjects. By investigating Pangaea deeper, the scaling effect of modality is revealed, quantifying the universal knowledge accumulation across modalities as the cumulative distribution function of a geometric distribution. On the whole, Pangaea shows strong potential to handle myriad tasks, indicating a new direction toward artificial general intelligence.
Transformer-Gather, Fuzzy-Reconsider: A Scalable Hybrid Framework for Entity Resolution
arXiv:2509.17470v1 Announce Type: cross Abstract: Entity resolution plays a significant role in enterprise systems where data integrity must be rigorously maintained. Traditional methods often struggle with handling noisy data or semantic understanding, while modern methods suffer from computational costs or the excessive need for parallel computation. In this study, we introduce a scalable hybrid framework, which is designed to address several important problems, including scalability, noise robustness, and reliable results. We utilized a pre-trained language model to encode each structured data into corresponding semantic embedding vectors. Subsequently, after retrieving a semantically relevant subset of candidates, we apply a syntactic verification stage using fuzzy string matching techniques to refine classification on the unlabeled data. This approach was applied to a real-world entity resolution task, which exposed a linkage between a central user management database and numerous shared hosting server records. Compared to other methods, this approach exhibits an outstanding performance in terms of both processing time and robustness, making it a reliable solution for a server-side product. Crucially, this efficiency does not compromise results, as the system maintains a high retrieval recall of approximately 0.97. The scalability of the framework makes it deployable on standard CPU-based infrastructure, offering a practical and effective solution for enterprise-level data integrity auditing.
Evaluating the Energy Efficiency of NPU-Accelerated Machine Learning Inference on Embedded Microcontrollers
arXiv:2509.17533v1 Announce Type: cross Abstract: The deployment of machine learning (ML) models on microcontrollers (MCUs) is constrained by strict energy, latency, and memory requirements, particularly in battery-operated and real-time edge devices. While software-level optimizations such as quantization and pruning reduce model size and computation, hardware acceleration has emerged as a decisive enabler for efficient embedded inference. This paper evaluates the impact of Neural Processing Units (NPUs) on MCU-based ML execution, using the ARM Cortex-M55 core combined with the Ethos-U55 NPU on the Alif Semiconductor Ensemble E7 development board as a representative platform. A rigorous measurement methodology was employed, incorporating per-inference net energy accounting via GPIO-triggered high-resolution digital multimeter synchronization and idle-state subtraction, ensuring accurate attribution of energy costs. Experimental results across six representative ML models -including MiniResNet, MobileNetV2, FD-MobileNet, MNIST, TinyYolo, and SSD-MobileNet- demonstrate substantial efficiency gains when inference is offloaded to the NPU. For moderate to large networks, latency improvements ranged from 7x to over 125x, with per-inference net energy reductions up to 143x. Notably, the NPU enabled execution of models unsupported on CPU-only paths, such as SSD-MobileNet, highlighting its functional as well as efficiency advantages. These findings establish NPUs as a cornerstone of energy-aware embedded AI, enabling real-time, power-constrained ML inference at the MCU level.
Bilateral Distribution Compression: Reducing Both Data Size and Dimensionality
arXiv:2509.17543v1 Announce Type: cross Abstract: Existing distribution compression methods reduce dataset size by minimising the Maximum Mean Discrepancy (MMD) between original and compressed sets, but modern datasets are often large in both sample size and dimensionality. We propose Bilateral Distribution Compression (BDC), a two-stage framework that compresses along both axes while preserving the underlying distribution, with overall linear time and memory complexity in dataset size and dimension. Central to BDC is the Decoded MMD (DMMD), which quantifies the discrepancy between the original data and a compressed set decoded from a low-dimensional latent space. BDC proceeds by (i) learning a low-dimensional projection using the Reconstruction MMD (RMMD), and (ii) optimising a latent compressed set with the Encoded MMD (EMMD). We show that this procedure minimises the DMMD, guaranteeing that the compressed set faithfully represents the original distribution. Experiments show that across a variety of scenarios BDC can achieve comparable or superior performance to ambient-space compression at substantially lower cost.
Is It Certainly a Deepfake? Reliability Analysis in Detection & Generation Ecosystem
arXiv:2509.17550v1 Announce Type: cross Abstract: As generative models are advancing in quality and quantity for creating synthetic content, deepfakes begin to cause online mistrust. Deepfake detectors are proposed to counter this effect, however, misuse of detectors claiming fake content as real or vice versa further fuels this misinformation problem. We present the first comprehensive uncertainty analysis of deepfake detectors, systematically investigating how generative artifacts influence prediction confidence. As reflected in detectors' responses, deepfake generators also contribute to this uncertainty as their generative residues vary, so we cross the uncertainty analysis of deepfake detectors and generators. Based on our observations, the uncertainty manifold holds enough consistent information to leverage uncertainty for deepfake source detection. Our approach leverages Bayesian Neural Networks and Monte Carlo dropout to quantify both aleatoric and epistemic uncertainties across diverse detector architectures. We evaluate uncertainty on two datasets with nine generators, with four blind and two biological detectors, compare different uncertainty methods, explore region- and pixel-based uncertainty, and conduct ablation studies. We conduct and analyze binary real/fake, multi-class real/fake, source detection, and leave-one-out experiments between the generator/detector combinations to share their generalization capability, model calibration, uncertainty, and robustness against adversarial attacks. We further introduce uncertainty maps that localize prediction confidence at the pixel level, revealing distinct patterns correlated with generator-specific artifacts. Our analysis provides critical insights for deploying reliable deepfake detection systems and establishes uncertainty quantification as a fundamental requirement for trustworthy synthetic media detection.
MontePrep: Monte-Carlo-Driven Automatic Data Preparation without Target Data Instances
arXiv:2509.17553v1 Announce Type: cross Abstract: In commercial systems, a pervasive requirement for automatic data preparation (ADP) is to transfer relational data from disparate sources to targets with standardized schema specifications. Previous methods rely on labor-intensive supervision signals or target table data access permissions, limiting their usage in real-world scenarios. To tackle these challenges, we propose an effective end-to-end ADP framework MontePrep, which enables training-free pipeline synthesis with zero target-instance requirements. MontePrep is formulated as an open-source large language model (LLM) powered tree-structured search problem. It consists of three pivot components, i.e., a data preparation action sandbox (DPAS), a fundamental pipeline generator (FPG), and an execution-aware pipeline optimizer (EPO). We first introduce DPAS, a lightweight action sandbox, to navigate the search-based pipeline generation. The design of DPAS circumvents exploration of infeasible pipelines. Then, we present FPG to build executable DP pipelines incrementally, which explores the predefined action sandbox by the LLM-powered Monte Carlo Tree Search. Furthermore, we propose EPO, which invokes pipeline execution results from sources to targets to evaluate the reliability of the generated pipelines in FPG. In this way, unreasonable pipelines are eliminated, thus facilitating the search process from both efficiency and effectiveness perspectives. Extensive experimental results demonstrate the superiority of MontePrep with significant improvement against five state-of-the-art competitors.
PRNU-Bench: A Novel Benchmark and Model for PRNU-Based Camera Identification
arXiv:2509.17581v1 Announce Type: cross Abstract: We propose a novel benchmark for camera identification via Photo Response Non-Uniformity (PRNU) estimation. The benchmark comprises 13K photos taken with 120+ cameras, where the training and test photos are taken in different scenarios, enabling ``in-the-wild'' evaluation. In addition, we propose a novel PRNU-based camera identification model that employs a hybrid architecture, comprising a denoising autoencoder to estimate the PRNU signal and a convolutional network that can perform 1:N verification of camera devices. Instead of using a conventional approach based on contrastive learning, our method takes the Hadamard product between reference and query PRNU signals as input. This novel design leads to significantly better results compared with state-of-the-art models based on denoising autoencoders and contrastive learning. We release our dataset and code at: https://github.com/CroitoruAlin/PRNU-Bench.
Interpreting Attention Heads for Image-to-Text Information Flow in Large Vision-Language Models
arXiv:2509.17588v1 Announce Type: cross Abstract: Large Vision-Language Models (LVLMs) answer visual questions by transferring information from images to text through a series of attention heads. While this image-to-text information flow is central to visual question answering, its underlying mechanism remains difficult to interpret due to the simultaneous operation of numerous attention heads. To address this challenge, we propose head attribution, a technique inspired by component attribution methods, to identify consistent patterns among attention heads that play a key role in information transfer. Using head attribution, we investigate how LVLMs rely on specific attention heads to identify and answer questions about the main object in an image. Our analysis reveals that a distinct subset of attention heads facilitates the image-to-text information flow. Remarkably, we find that the selection of these heads is governed by the semantic content of the input image rather than its visual appearance. We further examine the flow of information at the token level and discover that (1) text information first propagates to role-related tokens and the final token before receiving image information, and (2) image information is embedded in both object-related and background tokens. Our work provides evidence that image-to-text information flow follows a structured process, and that analysis at the attention-head level offers a promising direction toward understanding the mechanisms of LVLMs.
FastNet: Improving the physical consistency of machine-learning weather prediction models through loss function design
arXiv:2509.17601v1 Announce Type: cross Abstract: Machine learning weather prediction (MLWP) models have demonstrated remarkable potential in delivering accurate forecasts at significantly reduced computational cost compared to traditional numerical weather prediction (NWP) systems. However, challenges remain in ensuring the physical consistency of MLWP outputs, particularly in deterministic settings. This study presents FastNet, a graph neural network (GNN)-based global prediction model, and investigates the impact of alternative loss function designs on improving the physical realism of its forecasts. We explore three key modifications to the standard mean squared error (MSE) loss: (1) a modified spherical harmonic (MSH) loss that penalises spectral amplitude errors to reduce blurring and enhance small-scale structure retention; (2) inclusion of horizontal gradient terms in the loss to suppress non-physical artefacts; and (3) an alternative wind representation that decouples speed and direction to better capture extreme wind events. Results show that while the MSH and gradient-based losses \textit{alone} may slightly degrade RMSE scores, when trained in combination the model exhibits very similar MSE performance to an MSE-trained model while at the same time significantly improving spectral fidelity and physical consistency. The alternative wind representation further improves wind speed accuracy and reduces directional bias. Collectively, these findings highlight the importance of loss function design as a mechanism for embedding domain knowledge into MLWP models and advancing their operational readiness.
Audio Super-Resolution with Latent Bridge Models
arXiv:2509.17609v1 Announce Type: cross Abstract: Audio super-resolution (SR), i.e., upsampling the low-resolution (LR) waveform to the high-resolution (HR) version, has recently been explored with diffusion and bridge models, while previous methods often suffer from sub-optimal upsampling quality due to their uninformative generation prior. Towards high-quality audio super-resolution, we present a new system with latent bridge models (LBMs), where we compress the audio waveform into a continuous latent space and design an LBM to enable a latent-to-latent generation process that naturally matches the LR-toHR upsampling process, thereby fully exploiting the instructive prior information contained in the LR waveform. To further enhance the training results despite the limited availability of HR samples, we introduce frequency-aware LBMs, where the prior and target frequency are taken as model input, enabling LBMs to explicitly learn an any-to-any upsampling process at the training stage. Furthermore, we design cascaded LBMs and present two prior augmentation strategies, where we make the first attempt to unlock the audio upsampling beyond 48 kHz and empower a seamless cascaded SR process, providing higher flexibility for audio post-production. Comprehensive experimental results evaluated on the VCTK, ESC-50, Song-Describer benchmark datasets and two internal testsets demonstrate that we achieve state-of-the-art objective and perceptual quality for any-to-48kHz SR across speech, audio, and music signals, as well as setting the first record for any-to-192kHz audio SR. Demo at https://AudioLBM.github.io/.
Whitening Spherical Gaussian Mixtures in the Large-Dimensional Regime
arXiv:2509.17636v1 Announce Type: cross Abstract: Whitening is a classical technique in unsupervised learning that can facilitate estimation tasks by standardizing data. An important application is the estimation of latent variable models via the decomposition of tensors built from high-order moments. In particular, whitening orthogonalizes the means of a spherical Gaussian mixture model (GMM), thereby making the corresponding moment tensor orthogonally decomposable, hence easier to decompose. However, in the large-dimensional regime (LDR) where data are high-dimensional and scarce, the standard whitening matrix built from the sample covariance becomes ineffective because the latter is spectrally distorted. Consequently, whitened means of a spherical GMM are no longer orthogonal. Using random matrix theory, we derive exact limits for their dot products, which are generally nonzero in the LDR. As our main contribution, we then construct a corrected whitening matrix that restores asymptotic orthogonality, allowing for performance gains in spherical GMM estimation.
AuditoryBench++: Can Language Models Understand Auditory Knowledge without Hearing?
arXiv:2509.17641v1 Announce Type: cross Abstract: Even without directly hearing sounds, humans can effortlessly reason about auditory properties, such as pitch, loudness, or sound-source associations, drawing on auditory commonsense. In contrast, language models often lack this capability, limiting their effectiveness in multimodal interactions. As an initial step to address this gap, we present AuditoryBench++, a comprehensive benchmark for evaluating auditory knowledge and reasoning in text-only settings. The benchmark encompasses tasks that range from basic auditory comparisons to contextually grounded reasoning, enabling fine-grained analysis of how models process and integrate auditory concepts. In addition, we introduce AIR-CoT, a novel auditory imagination reasoning method that generates and integrates auditory information during inference through span detection with special tokens and knowledge injection. Extensive experiments with recent LLMs and Multimodal LLMs demonstrate that AIR-CoT generally outperforms both the off-the-shelf models and those augmented with auditory knowledge. The project page is available at https://auditorybenchpp.github.io.
RAVEN: RAnking and Validation of ExoplaNets
arXiv:2509.17645v1 Announce Type: cross Abstract: We present RAVEN, a newly developed vetting and validation pipeline for TESS exoplanet candidates. The pipeline employs a Bayesian framework to derive the posterior probability of a candidate being a planet against a set of False Positive (FP) scenarios, through the use of a Gradient Boosted Decision Tree and a Gaussian Process classifier, trained on comprehensive synthetic training sets of simulated planets and 8 astrophysical FP scenarios injected into TESS lightcurves. These training sets allow large scale candidate vetting and performance verification against individual FP scenarios. A Non-Simulated FP training set consisting of real TESS candidates caused primarily by stellar variability and systematic noise is also included. The machine learning derived probabilities are combined with scenario specific prior probabilities, including the candidates' positional probabilities, to compute the final posterior probabilities. Candidates with a planetary posterior probability greater than 99% against each FP scenario and whose implied planetary radius is less than 8$R_{\oplus}$ are considered to be statistically validated by the pipeline. In this first version, the pipeline has been developed for candidates with a lightcurve released from the TESS Science Processing Operations Centre, an orbital period between 0.5 and 16 days and a transit depth greater than 300ppm. The pipeline obtained area-under-curve (AUC) scores > 97% on all FP scenarios and > 99% on all but one. Testing on an independent external sample of 1361 pre-classified TOIs, the pipeline achieved an overall accuracy of 91%, demonstrating its effectiveness for automated ranking of TESS candidates. For a probability threshold of 0.9 the pipeline reached a precision of 97% with a recall score of 66% on these TOIs. The RAVEN pipeline is publicly released as a cloud-hosted app, making it easily accessible to the community.
Tailored Transformation Invariance for Industrial Anomaly Detection
arXiv:2509.17670v1 Announce Type: cross Abstract: Industrial Anomaly Detection (IAD) is a subproblem within Computer Vision Anomaly Detection that has been receiving increasing amounts of attention due to its applicability to real-life scenarios. Recent research has focused on how to extract the most informative features, contrasting older kNN-based methods that use only pretrained features. These recent methods are much more expensive to train however and could complicate real-life application. Careful study of related work with regards to transformation invariance leads to the idea that popular benchmarks require robustness to only minor translations. With this idea we then formulate LWinNN, a local window based approach that creates a middle ground between kNN based methods that have either complete or no translation invariance. Our experiments demonstrate that this small change increases accuracy considerably, while simultaneously decreasing both train and test time. This teaches us two things: first, the gap between kNN-based approaches and more complex state-of-the-art methodology can still be narrowed by effective usage of the limited data available. Second, our assumption of requiring only limited translation invariance highlights potential areas of interest for future work and the need for more spatially diverse benchmarks, for which our method can hopefully serve as a new baseline. Our code can be found at https://github.com/marietteschonfeld/LWinNN .
Predicting Chest Radiograph Findings from Electrocardiograms Using Interpretable Machine Learning
arXiv:2509.17674v1 Announce Type: cross Abstract: Purpose: Chest X-rays are essential for diagnosing pulmonary conditions, but limited access in resource-constrained settings can delay timely diagnosis. Electrocardiograms (ECGs), in contrast, are widely available, non-invasive, and often acquired earlier in clinical workflows. This study aims to assess whether ECG features and patient demographics can predict chest radiograph findings using an interpretable machine learning approach. Methods: Using the MIMIC-IV database, Extreme Gradient Boosting (XGBoost) classifiers were trained to predict diverse chest radiograph findings from ECG-derived features and demographic variables. Recursive feature elimination was performed independently for each target to identify the most predictive features. Model performance was evaluated using the area under the receiver operating characteristic curve (AUROC) with bootstrapped 95% confidence intervals. Shapley Additive Explanations (SHAP) were applied to interpret feature contributions. Results: Models successfully predicted multiple chest radiograph findings with varying accuracy. Feature selection tailored predictors to each target, and including demographic variables consistently improved performance. SHAP analysis revealed clinically meaningful contributions from ECG features to radiographic predictions. Conclusion: ECG-derived features combined with patient demographics can serve as a proxy for certain chest radiograph findings, enabling early triage or pre-screening in settings where radiographic imaging is limited. Interpretable machine learning demonstrates potential to support radiology workflows and improve patient care.
Investigating Bias: A Multilingual Pipeline for Generating, Solving, and Evaluating Math Problems with LLMs
arXiv:2509.17701v1 Announce Type: cross Abstract: Large Language Models (LLMs) are increasingly used for educational support, yet their response quality varies depending on the language of interaction. This paper presents an automated multilingual pipeline for generating, solving, and evaluating math problems aligned with the German K-10 curriculum. We generated 628 math exercises and translated them into English, German, and Arabic. Three commercial LLMs (GPT-4o-mini, Gemini 2.5 Flash, and Qwen-plus) were prompted to produce step-by-step solutions in each language. A held-out panel of LLM judges, including Claude 3.5 Haiku, evaluated solution quality using a comparative framework. Results show a consistent gap, with English solutions consistently rated highest, and Arabic often ranked lower. These findings highlight persistent linguistic bias and the need for more equitable multilingual AI systems in education.
Automated Labeling of Intracranial Arteries with Uncertainty Quantification Using Deep Learning
arXiv:2509.17726v1 Announce Type: cross Abstract: Accurate anatomical labeling of intracranial arteries is essential for cerebrovascular diagnosis and hemodynamic analysis but remains time-consuming and subject to interoperator variability. We present a deep learning-based framework for automated artery labeling from 3D Time-of-Flight Magnetic Resonance Angiography (3D ToF-MRA) segmentations (n=35), incorporating uncertainty quantification to enhance interpretability and reliability. We evaluated three convolutional neural network architectures: (1) a UNet with residual encoder blocks, reflecting commonly used baselines in vascular labeling; (2) CS-Net, an attention-augmented UNet incorporating channel and spatial attention mechanisms for enhanced curvilinear structure recognition; and (3) nnUNet, a self-configuring framework that automates preprocessing, training, and architectural adaptation based on dataset characteristics. Among these, nnUNet achieved the highest labeling performance (average Dice score: 0.922; average surface distance: 0.387 mm), with improved robustness in anatomically complex vessels. To assess predictive confidence, we implemented test-time augmentation (TTA) and introduced a novel coordinate-guided strategy to reduce interpolation errors during augmented inference. The resulting uncertainty maps reliably indicated regions of anatomical ambiguity, pathological variation, or manual labeling inconsistency. We further validated clinical utility by comparing flow velocities derived from automated and manual labels in co-registered 4D Flow MRI datasets, observing close agreement with no statistically significant differences. Our framework offers a scalable, accurate, and uncertainty-aware solution for automated cerebrovascular labeling, supporting downstream hemodynamic analysis and facilitating clinical integration.
DIVERS-Bench: Evaluating Language Identification Across Domain Shifts and Code-Switching
arXiv:2509.17768v1 Announce Type: cross Abstract: Language Identification (LID) is a core task in multilingual NLP, yet current systems often overfit to clean, monolingual data. This work introduces DIVERS-BENCH, a comprehensive evaluation of state-of-the-art LID models across diverse domains, including speech transcripts, web text, social media texts, children's stories, and code-switched text. Our findings reveal that while models achieve high accuracy on curated datasets, performance degrades sharply on noisy and informal inputs. We also introduce DIVERS-CS, a diverse code-switching benchmark dataset spanning 10 language pairs, and show that existing models struggle to detect multiple languages within the same sentence. These results highlight the need for more robust and inclusive LID systems in real-world settings.
Efficient & Correct Predictive Equivalence for Decision Trees
arXiv:2509.17774v1 Announce Type: cross Abstract: The Rashomon set of decision trees (DTs) finds importance uses. Recent work showed that DTs computing the same classification function, i.e. predictive equivalent DTs, can represent a significant fraction of the Rashomon set. Such redundancy is undesirable. For example, feature importance based on the Rashomon set becomes inaccurate due the existence of predictive equivalent DTs, i.e. DTs with the same prediction for every possible input. In recent work, McTavish et al. proposed solutions for several computational problems related with DTs, including that of deciding predictive equivalent DTs. This approach, which this paper refers to as MBDSR, consists of applying the well-known method of Quine-McCluskey (QM) for obtaining minimum-size DNF (disjunctive normal form) representations of DTs, which are then used for comparing DTs for predictive equivalence. Furthermore, the minimum-size DNF representation was also applied to computing explanations for the predictions made by DTs, and to finding predictions in the presence of missing data. However, the problem of formula minimization is hard for the second level of the polynomial hierarchy, and the QM method may exhibit worst-case exponential running time and space. This paper first demonstrates that there exist decision trees that trigger the worst-case exponential running time and space of the QM method. Second, the paper shows that the MBDSR approach can produce incorrect results for the problem of deciding predictive equivalence. Third, the paper shows that any of the problems to which the minimum-size DNF representation has been applied to can in fact be solved in polynomial time, in the size of the DT. The experiments confirm that, for DTs for which the the worst-case of the QM method is triggered, the algorithms proposed in this paper are orders of magnitude faster than the ones proposed by McTavish et al.
Toward Affordable and Non-Invasive Detection of Hypoglycemia: A Machine Learning Approach
arXiv:2509.17842v1 Announce Type: cross Abstract: Diabetes mellitus is a growing global health issue, with Type 1 Diabetes (T1D) requiring constant monitoring to avoid hypoglycemia. Although Continuous Glucose Monitors (CGMs) are effective, their cost and invasiveness limit access, particularly in low-resource settings. This paper proposes a non-invasive method to classify glycemic states using Galvanic Skin Response (GSR), a biosignal commonly captured by wearable sensors. We use the merged OhioT1DM 2018 and 2020 datasets to build a machine learning pipeline that detects hypoglycemia (glucose < 70 mg/dl) and normoglycemia (glucose > 70 mg/dl) with GSR alone. Seven models are trained and evaluated: Random Forest, XGBoost, MLP, CNN, LSTM, Logistic Regression, and K-Nearest Neighbors. Validation sets and 95% confidence intervals are reported to increase reliability and assess robustness. Results show that the LSTM model achieves a perfect hypoglycemia recall (1.00) with an F1-score confidence interval of [0.611-0.745], while XGBoost offers strong performance with a recall of 0.54 even under class imbalance. This approach highlights the potential for affordable, wearable-compatible glucose monitoring tools suitable for settings with limited CGM availability using GSR data. Index Terms: Hypoglycemia Detection, Galvanic Skin Response, Non Invasive Monitoring, Wearables, Machine Learning, Confidence Intervals.
Unsupervised Learning and Representation of Mandarin Tonal Categories by a Generative CNN
arXiv:2509.17859v1 Announce Type: cross Abstract: This paper outlines the methodology for modeling tonal learning in fully unsupervised models of human language acquisition. Tonal patterns are among the computationally most complex learning objectives in language. We argue that a realistic generative model of human language (ciwGAN) can learn to associate its categorical variables with Mandarin Chinese tonal categories without any labeled data. All three trained models showed statistically significant differences in F0 across categorical variables. The model trained solely on male tokens consistently encoded tone. Our results sug- gest that not only does the model learn Mandarin tonal contrasts, but it learns a system that corresponds to a stage of acquisition in human language learners. We also outline methodology for tracing tonal representations in internal convolutional layers, which shows that linguistic tools can contribute to interpretability of deep learning and can ultimately be used in neural experiments.
Brainprint-Modulated Target Speaker Extraction
arXiv:2509.17883v1 Announce Type: cross Abstract: Achieving robust and personalized performance in neuro-steered Target Speaker Extraction (TSE) remains a significant challenge for next-generation hearing aids. This is primarily due to two factors: the inherent non-stationarity of EEG signals across sessions, and the high inter-subject variability that limits the efficacy of generalized models. To address these issues, we propose Brainprint-Modulated Target Speaker Extraction (BM-TSE), a novel framework for personalized and high-fidelity extraction. BM-TSE first employs a spatio-temporal EEG encoder with an Adaptive Spectral Gain (ASG) module to extract stable features resilient to non-stationarity. The core of our framework is a personalized modulation mechanism, where a unified brainmap embedding is learned under the joint supervision of subject identification (SID) and auditory attention decoding (AAD) tasks. This learned brainmap, encoding both static user traits and dynamic attentional states, actively refines the audio separation process, dynamically tailoring the output to each user. Evaluations on the public KUL and Cocktail Party datasets demonstrate that BM-TSE achieves state-of-the-art performance, significantly outperforming existing methods. Our code is publicly accessible at: https://github.com/rosshan-orz/BM-TSE.
Lipschitz-Based Robustness Certification for Recurrent Neural Networks via Convex Relaxation
arXiv:2509.17898v1 Announce Type: cross Abstract: Robustness certification against bounded input noise or adversarial perturbations is increasingly important for deployment recurrent neural networks (RNNs) in safety-critical control applications. To address this challenge, we present RNN-SDP, a relaxation based method that models the RNN's layer interactions as a convex problem and computes a certified upper bound on the Lipschitz constant via semidefinite programming (SDP). We also explore an extension that incorporates known input constraints to further tighten the resulting Lipschitz bounds. RNN-SDP is evaluated on a synthetic multi-tank system, with upper bounds compared to empirical estimates. While incorporating input constraints yields only modest improvements, the general method produces reasonably tight and certifiable bounds, even as sequence length increases. The results also underscore the often underestimated impact of initialization errors, an important consideration for applications where models are frequently re-initialized, such as model predictive control (MPC).
Shilling Recommender Systems by Generating Side-feature-aware Fake User Profiles
arXiv:2509.17918v1 Announce Type: cross Abstract: Recommender systems (RS) greatly influence users' consumption decisions, making them attractive targets for malicious shilling attacks that inject fake user profiles to manipulate recommendations. Existing shilling methods can generate effective and stealthy fake profiles when training data only contain rating matrix, but they lack comprehensive solutions for scenarios where side features are present and utilized by the recommender. To address this gap, we extend the Leg-UP framework by enhancing the generator architecture to incorporate side features, enabling the generation of side-feature-aware fake user profiles. Experiments on benchmarks show that our method achieves strong attack performance while maintaining stealthiness.
Random functions as data compressors for machine learning of molecular processes
arXiv:2509.17937v1 Announce Type: cross Abstract: Machine learning (ML) is rapidly transforming the way molecular dynamics simulations are performed and analyzed, from materials modeling to studies of protein folding and function. ML algorithms are often employed to learn low-dimensional representations of conformational landscapes and to cluster trajectories into relevant metastable states. Most of these algorithms require selecting a small number of features that describe the problem of interest. Although deep neural networks can tackle large numbers of input features, the training costs increase with input size, which makes the selection of a subset of features mandatory for most problems of practical interest. Here, we show that random nonlinear projections can be used to compress large feature spaces and make computations faster without substantial loss of information. We describe an efficient way to produce random projections and then exemplify the general procedure for protein folding. For our test cases NTL9 and the double-norleucin variant of the villin headpiece, we find that random compression retains the core static and dynamic information of the original high dimensional feature space and makes trajectory analysis more robust.
ComposableNav: Instruction-Following Navigation in Dynamic Environments via Composable Diffusion
arXiv:2509.17941v1 Announce Type: cross Abstract: This paper considers the problem of enabling robots to navigate dynamic environments while following instructions. The challenge lies in the combinatorial nature of instruction specifications: each instruction can include multiple specifications, and the number of possible specification combinations grows exponentially as the robot's skill set expands. For example, "overtake the pedestrian while staying on the right side of the road" consists of two specifications: "overtake the pedestrian" and "walk on the right side of the road." To tackle this challenge, we propose ComposableNav, based on the intuition that following an instruction involves independently satisfying its constituent specifications, each corresponding to a distinct motion primitive. Using diffusion models, ComposableNav learns each primitive separately, then composes them in parallel at deployment time to satisfy novel combinations of specifications unseen in training. Additionally, to avoid the onerous need for demonstrations of individual motion primitives, we propose a two-stage training procedure: (1) supervised pre-training to learn a base diffusion model for dynamic navigation, and (2) reinforcement learning fine-tuning that molds the base model into different motion primitives. Through simulation and real-world experiments, we show that ComposableNav enables robots to follow instructions by generating trajectories that satisfy diverse and unseen combinations of specifications, significantly outperforming both non-compositional VLM-based policies and costmap composing baselines. Videos and additional materials can be found on the project page: https://amrl.cs.utexas.edu/ComposableNav/
Can multimodal representation learning by alignment preserve modality-specific information?
arXiv:2509.17943v1 Announce Type: cross Abstract: Combining multimodal data is a key issue in a wide range of machine learning tasks, including many remote sensing problems. In Earth observation, early multimodal data fusion methods were based on specific neural network architectures and supervised learning. Ever since, the scarcity of labeled data has motivated self-supervised learning techniques. State-of-the-art multimodal representation learning techniques leverage the spatial alignment between satellite data from different modalities acquired over the same geographic area in order to foster a semantic alignment in the latent space. In this paper, we investigate how this methods can preserve task-relevant information that is not shared across modalities. First, we show, under simplifying assumptions, when alignment strategies fundamentally lead to an information loss. Then, we support our theoretical insight through numerical experiments in more realistic settings. With those theoretical and empirical evidences, we hope to support new developments in contrastive learning for the combination of multimodal satellite data. Our code and data is publicly available at https://github.com/Romain3Ch216/alg_maclean_25.
Towards Seeing Bones at Radio Frequency
arXiv:2509.17979v1 Announce Type: cross Abstract: Wireless sensing literature has long aspired to achieve X-ray-like vision at radio frequencies. Yet, state-of-the-art wireless sensing literature has yet to generate the archetypal X-ray image: one of the bones beneath flesh. In this paper, we explore MCT, a penetration-based RF-imaging system for imaging bones at mm-resolution, one that significantly exceeds prior penetration-based RF imaging literature. Indeed the long wavelength, significant attenuation and complex diffraction that occur as RF propagates through flesh, have long limited imaging resolution (to several centimeters at best). We address these concerns through a novel penetration-based synthetic aperture algorithm, coupled with a learning-based pipeline to correct for diffraction-induced artifacts. A detailed evaluation of meat models demonstrates a resolution improvement from sub-decimeter to sub-centimeter over prior art in RF penetrative imaging.
ReDepress: A Cognitive Framework for Detecting Depression Relapse from Social Media
arXiv:2509.17991v1 Announce Type: cross Abstract: Almost 50% depression patients face the risk of going into relapse. The risk increases to 80% after the second episode of depression. Although, depression detection from social media has attained considerable attention, depression relapse detection has remained largely unexplored due to the lack of curated datasets and the difficulty of distinguishing relapse and non-relapse users. In this work, we present ReDepress, the first clinically validated social media dataset focused on relapse, comprising 204 Reddit users annotated by mental health professionals. Unlike prior approaches, our framework draws on cognitive theories of depression, incorporating constructs such as attention bias, interpretation bias, memory bias and rumination into both annotation and modeling. Through statistical analyses and machine learning experiments, we demonstrate that cognitive markers significantly differentiate relapse and non-relapse groups, and that models enriched with these features achieve competitive performance, with transformer-based temporal models attaining an F1 of 0.86. Our findings validate psychological theories in real-world textual data and underscore the potential of cognitive-informed computational methods for early relapse detection, paving the way for scalable, low-cost interventions in mental healthcare.
Variation in Verification: Understanding Verification Dynamics in Large Language Models
arXiv:2509.17995v1 Announce Type: cross Abstract: Recent advances have shown that scaling test-time computation enables large language models (LLMs) to solve increasingly complex problems across diverse domains. One effective paradigm for test-time scaling (TTS) involves LLM generators producing multiple solution candidates, with LLM verifiers assessing the correctness of these candidates without reference answers. In this paper, we study generative verifiers, which perform verification by generating chain-of-thought (CoT) reasoning followed by a binary verdict. We systematically analyze verification dynamics across three dimensions - problem difficulty, generator capability, and verifier generation capability - with empirical studies on 12 benchmarks across mathematical reasoning, knowledge, and natural language reasoning tasks using 14 open-source models (2B to 72B parameter range) and GPT-4o. Our experiments reveal three key findings about verification effectiveness: (1) Easy problems allow verifiers to more reliably certify correct responses; (2) Weak generators produce errors that are easier to detect than strong generators; (3) Verification ability is generally correlated with the verifier's own problem-solving capability, but this relationship varies with problem difficulty. These findings reveal opportunities to optimize basic verification strategies in TTS applications. First, given the same verifier, some weak generators can nearly match stronger ones in post-verification TTS performance (e.g., the Gemma2-9B to Gemma2-27B performance gap shrinks by 75.5%). Second, we identify cases where strong verifiers offer limited advantage over weak ones, as both fail to provide meaningful verification gains, suggesting that verifier scaling alone cannot overcome fundamental verification challenges.
The Narcissus Hypothesis:Descending to the Rung of Illusion
arXiv:2509.17999v1 Announce Type: cross Abstract: Modern foundational models increasingly reflect not just world knowledge, but patterns of human preference embedded in their training data. We hypothesize that recursive alignment-via human feedback and model-generated corpora-induces a social desirability bias, nudging models to favor agreeable or flattering responses over objective reasoning. We refer to it as the Narcissus Hypothesis and test it across 31 models using standardized personality assessments and a novel Social Desirability Bias score. Results reveal a significant drift toward socially conforming traits, with profound implications for corpus integrity and the reliability of downstream inferences. We then offer a novel epistemological interpretation, tracing how recursive bias may collapse higher-order reasoning down Pearl's Ladder of Causality, culminating in what we refer to as the Rung of Illusion.
Building Transparency in Deep Learning-Powered Network Traffic Classification: A Traffic-Explainer Framework
arXiv:2509.18007v1 Announce Type: cross Abstract: Recent advancements in deep learning have significantly enhanced the performance and efficiency of traffic classification in networking systems. However, the lack of transparency in their predictions and decision-making has made network operators reluctant to deploy DL-based solutions in production networks. To tackle this challenge, we propose Traffic-Explainer, a model-agnostic and input-perturbation-based traffic explanation framework. By maximizing the mutual information between predictions on original traffic sequences and their masked counterparts, Traffic-Explainer automatically uncovers the most influential features driving model predictions. Extensive experiments demonstrate that Traffic-Explainer improves upon existing explanation methods by approximately 42%. Practically, we further apply Traffic-Explainer to identify influential features and demonstrate its enhanced transparency across three critical tasks: application classification, traffic localization, and network cartography. For the first two tasks, Traffic-Explainer identifies the most decisive bytes that drive predicted traffic applications and locations, uncovering potential vulnerabilities and privacy concerns. In network cartography, Traffic-Explainer identifies submarine cables that drive the mapping of traceroute to physical path, enabling a traceroute-informed risk analysis.
Robust, Online, and Adaptive Decentralized Gaussian Processes
arXiv:2509.18011v1 Announce Type: cross Abstract: Gaussian processes (GPs) offer a flexible, uncertainty-aware framework for modeling complex signals, but scale cubically with data, assume static targets, and are brittle to outliers, limiting their applicability in large-scale problems with dynamic and noisy environments. Recent work introduced decentralized random Fourier feature Gaussian processes (DRFGP), an online and distributed algorithm that casts GPs in an information-filter form, enabling exact sequential inference and fully distributed computation without reliance on a fusion center. In this paper, we extend DRFGP along two key directions: first, by introducing a robust-filtering update that downweights the impact of atypical observations; and second, by incorporating a dynamic adaptation mechanism that adapts to time-varying functions. The resulting algorithm retains the recursive information-filter structure while enhancing stability and accuracy. We demonstrate its effectiveness on a large-scale Earth system application, underscoring its potential for in-situ modeling.
Fr\'echet Geodesic Boosting
arXiv:2509.18013v1 Announce Type: cross Abstract: Gradient boosting has become a cornerstone of machine learning, enabling base learners such as decision trees to achieve exceptional predictive performance. While existing algorithms primarily handle scalar or Euclidean outputs, increasingly prevalent complex-structured data, such as distributions, networks, and manifold-valued outputs, present challenges for traditional methods. Such non-Euclidean data lack algebraic structures such as addition, subtraction, or scalar multiplication required by standard gradient boosting frameworks. To address these challenges, we introduce Fr\'echet geodesic boosting (FGBoost), a novel approach tailored for outputs residing in geodesic metric spaces. FGBoost leverages geodesics as proxies for residuals and constructs ensembles in a way that respects the intrinsic geometry of the output space. Through theoretical analysis, extensive simulations, and real-world applications, we demonstrate the strong performance and adaptability of FGBoost, showcasing its potential for modeling complex data.
Core-elements Subsampling for Alternating Least Squares
arXiv:2509.18024v1 Announce Type: cross Abstract: In this paper, we propose a novel element-wise subset selection method for the alternating least squares (ALS) algorithm, focusing on low-rank matrix factorization involving matrices with missing values, as commonly encountered in recommender systems. While ALS is widely used for providing personalized recommendations based on user-item interaction data, its high computational cost, stemming from repeated regression operations, poses significant challenges for large-scale datasets. To enhance the efficiency of ALS, we propose a core-elements subsampling method that selects a representative subset of data and leverages sparse matrix operations to approximate ALS estimations efficiently. We establish theoretical guarantees for the approximation and convergence of the proposed approach, showing that it achieves similar accuracy with significantly reduced computational time compared to full-data ALS. Extensive simulations and real-world applications demonstrate the effectiveness of our method in various scenarios, emphasizing its potential in large-scale recommendation systems.
Deep Learning as the Disciplined Construction of Tame Objects
arXiv:2509.18025v1 Announce Type: cross Abstract: One can see deep-learning models as compositions of functions within the so-called tame geometry. In this expository note, we give an overview of some topics at the interface of tame geometry (also known as o-minimality), optimization theory, and deep learning theory and practice. To do so, we gradually introduce the concepts and tools used to build convergence guarantees for stochastic gradient descent in a general nonsmooth nonconvex, but tame, setting. This illustrates some ways in which tame geometry is a natural mathematical framework for the study of AI systems, especially within Deep Learning.
Kernel K-means clustering of distributional data
arXiv:2509.18037v1 Announce Type: cross Abstract: We consider the problem of clustering a sample of probability distributions from a random distribution on $\mathbb R^p$. Our proposed partitioning method makes use of a symmetric, positive-definite kernel $k$ and its associated reproducing kernel Hilbert space (RKHS) $\mathcal H$. By mapping each distribution to its corresponding kernel mean embedding in $\mathcal H$, we obtain a sample in this RKHS where we carry out the $K$-means clustering procedure, which provides an unsupervised classification of the original sample. The procedure is simple and computationally feasible even for dimension $p>1$. The simulation studies provide insight into the choice of the kernel and its tuning parameter. The performance of the proposed clustering procedure is illustrated on a collection of Synthetic Aperture Radar (SAR) images.
Prepare Before You Act: Learning From Humans to Rearrange Initial States
arXiv:2509.18043v1 Announce Type: cross Abstract: Imitation learning (IL) has proven effective across a wide range of manipulation tasks. However, IL policies often struggle when faced with out-of-distribution observations; for instance, when the target object is in a previously unseen position or occluded by other objects. In these cases, extensive demonstrations are needed for current IL methods to reach robust and generalizable behaviors. But when humans are faced with these sorts of atypical initial states, we often rearrange the environment for more favorable task execution. For example, a person might rotate a coffee cup so that it is easier to grasp the handle, or push a box out of the way so they can directly grasp their target object. In this work we seek to equip robot learners with the same capability: enabling robots to prepare the environment before executing their given policy. We propose ReSET, an algorithm that takes initial states -- which are outside the policy's distribution -- and autonomously modifies object poses so that the restructured scene is similar to training data. Theoretically, we show that this two step process (rearranging the environment before rolling out the given policy) reduces the generalization gap. Practically, our ReSET algorithm combines action-agnostic human videos with task-agnostic teleoperation data to i) decide when to modify the scene, ii) predict what simplifying actions a human would take, and iii) map those predictions into robot action primitives. Comparisons with diffusion policies, VLAs, and other baselines show that using ReSET to prepare the environment enables more robust task execution with equal amounts of total training data. See videos at our project website: https://reset2025paper.github.io/
Functional effects models: Accounting for preference heterogeneity in panel data with machine learning
arXiv:2509.18047v1 Announce Type: cross Abstract: In this paper, we present a general specification for Functional Effects Models, which use Machine Learning (ML) methodologies to learn individual-specific preference parameters from socio-demographic characteristics, therefore accounting for inter-individual heterogeneity in panel choice data. We identify three specific advantages of the Functional Effects Model over traditional fixed, and random/mixed effects models: (i) by mapping individual-specific effects as a function of socio-demographic variables, we can account for these effects when forecasting choices of previously unobserved individuals (ii) the (approximate) maximum-likelihood estimation of functional effects avoids the incidental parameters problem of the fixed effects model, even when the number of observed choices per individual is small; and (iii) we do not rely on the strong distributional assumptions of the random effects model, which may not match reality. We learn functional intercept and functional slopes with powerful non-linear machine learning regressors for tabular data, namely gradient boosting decision trees and deep neural networks. We validate our proposed methodology on a synthetic experiment and three real-world panel case studies, demonstrating that the Functional Effects Model: (i) can identify the true values of individual-specific effects when the data generation process is known; (ii) outperforms both state-of-the-art ML choice modelling techniques that omit individual heterogeneity in terms of predictive performance, as well as traditional static panel choice models in terms of learning inter-individual heterogeneity. The results indicate that the FI-RUMBoost model, which combines the individual-specific constants of the Functional Effects Model with the complex, non-linear utilities of RUMBoost, performs marginally best on large-scale revealed preference panel data.
A Knowledge Graph-based Retrieval-Augmented Generation Framework for Algorithm Selection in the Facility Layout Problem
arXiv:2509.18054v1 Announce Type: cross Abstract: Selecting a solution algorithm for the Facility Layout Problem (FLP), an NP-hard optimization problem with a multiobjective trade-off, is a complex task that requires deep expert knowledge. The performance of a given algorithm depends on specific problem characteristics such as its scale, objectives, and constraints. This creates a need for a data-driven recommendation method to guide algorithm selection in automated design systems. This paper introduces a new recommendation method to make such expertise accessible, based on a Knowledge Graph-based Retrieval-Augmented Generation (KG RAG) framework. To address this, a domain-specific knowledge graph is constructed from published literature. The method then employs a multi-faceted retrieval mechanism to gather relevant evidence from this knowledge graph using three distinct approaches, which include a precise graph-based search, flexible vector-based search, and high-level cluster-based search. The retrieved evidence is utilized by a Large Language Model (LLM) to generate algorithm recommendations with data-driven reasoning. The proposed KG-RAG method is compared against a commercial LLM chatbot with access to the knowledge base as a table, across a series of diverse, real-world FLP test cases. Based on recommendation accuracy and reasoning capability, the proposed method performed significantly better than the commercial LLM chatbot.
Strategic Coordination for Evolving Multi-agent Systems: A Hierarchical Reinforcement and Collective Learning Approach
arXiv:2509.18088v1 Announce Type: cross Abstract: Decentralized combinatorial optimization in evolving multi-agent systems poses significant challenges, requiring agents to balance long-term decision-making, short-term optimized collective outcomes, while preserving autonomy of interactive agents under unanticipated changes. Reinforcement learning offers a way to model sequential decision-making through dynamic programming to anticipate future environmental changes. However, applying multi-agent reinforcement learning (MARL) to decentralized combinatorial optimization problems remains an open challenge due to the exponential growth of the joint state-action space, high communication overhead, and privacy concerns in centralized training. To address these limitations, this paper proposes Hierarchical Reinforcement and Collective Learning (HRCL), a novel approach that leverages both MARL and decentralized collective learning based on a hierarchical framework. Agents take high-level strategies using MARL to group possible plans for action space reduction and constrain the agent behavior for Pareto optimality. Meanwhile, the low-level collective learning layer ensures efficient and decentralized coordinated decisions among agents with minimal communication. Extensive experiments in a synthetic scenario and real-world smart city application models, including energy self-management and drone swarm sensing, demonstrate that HRCL significantly improves performance, scalability, and adaptability compared to the standalone MARL and collective learning approaches, achieving a win-win synthesis solution.
SEQR: Secure and Efficient QR-based LoRA Routing
arXiv:2509.18093v1 Announce Type: cross Abstract: Low-Rank Adaptation (LoRA) has become a standard technique for parameter-efficient fine-tuning of large language models, enabling large libraries of LoRAs, each for a specific task or domain. Efficiently selecting the correct LoRA adapter for a given input remains a challenge, particularly in secure environments where supervised training of routers may raise privacy concerns. Motivated by previous approaches, we formalize the goal of unsupervised LoRA routing in terms of activation norm maximization, providing a theoretical framework for analysis. We demonstrate the discriminative power of activation norms and introduce SEQR, an unsupervised LoRA routing algorithm designed to maximize efficiency while providing strict routing guarantees. SEQR provably identifies the norm-maximizing adapter with significantly greater efficiency, making it a highly scalable and effective solution for dynamic LoRA composition. We validate our results through experiments that demonstrate improved multi-task performance and efficiency.
Joint Optimization of Multi-Objective Reinforcement Learning with Policy Gradient Based Algorithm
arXiv:2105.14125v2 Announce Type: replace Abstract: Many engineering problems have multiple objectives, and the overall aim is to optimize a non-linear function of these objectives. In this paper, we formulate the problem of maximizing a non-linear concave function of multiple long-term objectives. A policy-gradient based model-free algorithm is proposed for the problem. To compute an estimate of the gradient, a biased estimator is proposed. The proposed algorithm is shown to achieve convergence to within an $\epsilon$ of the global optima after sampling $\mathcal{O}(\frac{M^4\sigma^2}{(1-\gamma)^8\epsilon^4})$ trajectories where $\gamma$ is the discount factor and $M$ is the number of the agents, thus achieving the same dependence on $\epsilon$ as the policy gradient algorithm for the standard reinforcement learning.
Multi-scale clustering and source separation of InSight mission seismic data
arXiv:2305.16189v5 Announce Type: replace Abstract: Unsupervised source separation involves unraveling an unknown set of source signals recorded through a mixing operator, with limited prior knowledge about the sources, and only access to a dataset of signal mixtures. This problem is inherently ill-posed and is further challenged by the variety of timescales exhibited by sources in time series data from planetary space missions. As such, a systematic multi-scale unsupervised approach is needed to identify and separate sources at different timescales. Existing methods typically rely on a preselected window size that determines their operating timescale, limiting their capacity to handle multi-scale sources. To address this issue, we propose an unsupervised multi-scale clustering and source separation framework by leveraging wavelet scattering spectra that provide a low-dimensional representation of stochastic processes, capable of distinguishing between different non-Gaussian stochastic processes. Nested within this representation space, we develop a factorial variational autoencoder that is trained to probabilistically cluster sources at different timescales. To perform source separation, we use samples from clusters at multiple timescales obtained via the factorial variational autoencoder as prior information and formulate an optimization problem in the wavelet scattering spectra representation space. When applied to the entire seismic dataset recorded during the NASA InSight mission on Mars, containing sources varying greatly in timescale, our approach disentangles such different sources, e.g., minute-long transient one-sided pulses (known as "glitches") and structured ambient noises resulting from atmospheric activities that typically last for tens of minutes, and provides an opportunity to conduct further investigations into the isolated sources.
Preserving Node-level Privacy in Graph Neural Networks
arXiv:2311.06888v2 Announce Type: replace Abstract: Differential privacy (DP) has seen immense applications in learning on tabular, image, and sequential data where instance-level privacy is concerned. In learning on graphs, contrastingly, works on node-level privacy are highly sparse. Challenges arise as existing DP protocols hardly apply to the message-passing mechanism in Graph Neural Networks (GNNs). In this study, we propose a solution that specifically addresses the issue of node-level privacy. Our protocol consists of two main components: 1) a sampling routine called HeterPoisson, which employs a specialized node sampling strategy and a series of tailored operations to generate a batch of sub-graphs with desired properties, and 2) a randomization routine that utilizes symmetric multivariate Laplace (SML) noise instead of the commonly used Gaussian noise. Our privacy accounting shows this particular combination provides a non-trivial privacy guarantee. In addition, our protocol enables GNN learning with good performance, as demonstrated by experiments on five real-world datasets; compared with existing baselines, our method shows significant advantages, especially in the high privacy regime. Experimentally, we also 1) perform membership inference attacks against our protocol and 2) apply privacy audit techniques to confirm our protocol's privacy integrity. In the sequel, we present a study on a seemingly appealing approach \cite{sajadmanesh2023gap} (USENIX'23) that protects node-level privacy via differentially private node/instance embeddings. Unfortunately, such work has fundamental privacy flaws, which are identified through a thorough case study. More importantly, we prove an impossibility result of achieving both (strong) privacy and (acceptable) utility through private instance embedding. The implication is that such an approach has intrinsic utility barriers when enforcing differential privacy.
Practical Kernel Tests of Conditional Independence
arXiv:2402.13196v2 Announce Type: replace Abstract: We describe a data-efficient, kernel-based approach to statistical testing of conditional independence. A major challenge of conditional independence testing is to obtain the correct test level (the specified upper bound on the rate of false positives), while still attaining competitive test power. Excess false positives arise due to bias in the test statistic, which is in our case obtained using nonparametric kernel ridge regression. We propose SplitKCI, an automated method for bias control for the Kernel-based Conditional Independence (KCI) test based on data splitting. We show that our approach significantly improves test level control for KCI without sacrificing test power, both theoretically and for synthetic and real-world data.
Approximating invariant functions with the sorting trick is theoretically justified
arXiv:2403.01671v5 Announce Type: replace Abstract: Many machine learning models leverage group invariance which is enjoyed with a wide-range of applications. For exploiting an invariance structure, one common approach is known as \emph{frame averaging}. One popular example of frame averaging is the \emph{group averaging}, where the entire group is used to symmetrize a function. Another example is the \emph{canonicalization}, where a frame at each point consists of a single group element which transforms the point to its orbit representative, for example, sorting. Compared to group averaging, canonicalization is more efficient computationally. However, it results in non-differentiablity or discontinuity of the canonicalized function. As a result, the theoretical performance of canonicalization has not been given much attention. In this work, we establish an approximation theory for canonicalization. Specifically, we bound the point-wise and $L^2(\mathbb{P})$ approximation errors as well as the eigenvalue decay rates associated with a canonicalization trick applied to reproducing kernels. We discuss two key insights from our theoretical analyses and why they point to an interesting future research direction on how one can choose a design to fully leverage canonicalization in practice.
Addressing the Inconsistency in Bayesian Deep Learning via Generalized Laplace Approximation
arXiv:2405.13535v5 Announce Type: replace Abstract: In recent years, inconsistency in Bayesian deep learning has attracted significant attention. Tempered or generalized posterior distributions are frequently employed as direct and effective solutions. Nonetheless, the underlying mechanisms and the effectiveness of generalized posteriors remain active research topics. In this work, we interpret posterior tempering as a correction for model misspecification via adjustments to the joint probability, and as a recalibration of priors by reducing aleatoric uncertainty. We also introduce the generalized Laplace approximation, which requires only a simple modification to the Hessian calculation of the regularized loss and provides a flexible and scalable framework for high-quality posterior inference. We evaluate the proposed method on state-of-the-art neural networks and real-world datasets, demonstrating that the generalized Laplace approximation enhances predictive performance.
Modeling Edge-Specific Node Features through Co-Representation Neural Hypergraph Diffusion
arXiv:2405.14286v3 Announce Type: replace Abstract: Hypergraphs are widely being employed to represent complex higher-order relations in real-world applications. Most existing research on hypergraph learning focuses on node-level or edge-level tasks. A practically relevant and more challenging task, edge-dependent node classification (ENC), is still under-explored. In ENC, a node can have different labels across different hyperedges, which requires the modeling of node features unique to each hyperedge. The state-of-the-art ENC solution, WHATsNet, only outputs single node and edge representations, leading to the limitations of \textbf{entangled edge-specific features} and \textbf{non-adaptive representation sizes} when applied to ENC. Additionally, WHATsNet suffers from the common \textbf{oversmoothing issue} in most HGNNs. To address these limitations, we propose \textbf{CoNHD}, a novel HGNN architecture specifically designed to model edge-specific features for ENC. Instead of learning separate representations for nodes and edges, CoNHD reformulates within-edge and within-node interactions as a hypergraph diffusion process over node-edge co-representations. We develop a neural implementation of the proposed diffusion process, leveraging equivariant networks as diffusion operators to effectively learn the diffusion dynamics from data. Extensive experiments demonstrate that CoNHD achieves the best performance across all benchmark ENC datasets and several downstream tasks without sacrificing efficiency. Our implementation is available at https://github.com/zhengyijia/CoNHD.
Expressive Power of Graph Neural Networks for (Mixed-Integer) Quadratic Programs
arXiv:2406.05938v2 Announce Type: replace Abstract: Quadratic programming (QP) is the most widely applied category of problems in nonlinear programming. Many applications require real-time/fast solutions, though not necessarily with high precision. Existing methods either involve matrix decomposition or use the preconditioned conjugate gradient method. For relatively large instances, these methods cannot achieve the real-time requirement unless there is an effective preconditioner. Recently, graph neural networks (GNNs) opened new possibilities for QP. Some promising empirical studies of applying GNNs for QP tasks show that GNNs can capture key characteristics of an optimization instance and provide adaptive guidance accordingly to crucial configurations during the solving process, or directly provide an approximate solution. However, the theoretical understanding of GNNs in this context remains limited. Specifically, it is unclear what GNNs can and cannot achieve for QP tasks in theory. This work addresses this gap in the context of linearly constrained QP tasks. In the continuous setting, we prove that message-passing GNNs can universally represent fundamental properties of convex quadratic programs, including feasibility, optimal objective values, and optimal solutions. In the more challenging mixed-integer setting, while GNNs are not universal approximators, we identify a subclass of QP problems that GNNs can reliably represent.
Reflecting on the State of Rehearsal-free Continual Learning with Pretrained Models
arXiv:2406.09384v2 Announce Type: replace Abstract: With the advent and recent ubiquity of foundation models, continual learning (CL) has recently shifted from continual training from scratch to the continual adaptation of pretrained models, seeing particular success on rehearsal-free CL benchmarks (RFCL). To achieve this, most proposed methods adapt and restructure parameter-efficient finetuning techniques (PEFT) to suit the continual nature of the problem. Based most often on input-conditional query-mechanisms or regularizations on top of prompt- or adapter-based PEFT, these PEFT-style RFCL (P-RFCL) approaches report peak performances; often convincingly outperforming existing CL techniques. However, on the other end, critical studies have recently highlighted competitive results by training on just the first task or via simple non-parametric baselines. Consequently, questions arise about the relationship between methodological choices in P-RFCL and their reported high benchmark scores. In this work, we tackle these questions to better understand the true drivers behind strong P-RFCL performances, their placement w.r.t. recent first-task adaptation studies, and their relation to preceding CL standards such as EWC or SI. In particular, we show: (1) P-RFCL techniques relying on input-conditional query mechanisms work not because, but rather despite them by collapsing towards standard PEFT shortcut solutions. (2) Indeed, we show how most often, P-RFCL techniques can be matched by a simple and lightweight PEFT baseline. (3) Using this baseline, we identify the implicit bound on tunable parameters when deriving RFCL approaches from PEFT methods as a potential denominator behind P-RFCL efficacy. Finally, we (4) better disentangle continual versus first-task adaptation, and (5) motivate standard RFCL techniques s.a. EWC or SI in light of recent P-RFCL methods.
DCoM: Active Learning for All Learners
arXiv:2407.01804v3 Announce Type: replace Abstract: Deep Active Learning (AL) techniques can be effective in reducing annotation costs for training deep models. However, their effectiveness in low- and high-budget scenarios seems to require different strategies, and achieving optimal results across varying budget scenarios remains a challenge. In this study, we introduce Dynamic Coverage & Margin mix (DCoM), a novel active learning approach designed to bridge this gap. Unlike existing strategies, DCoM dynamically adjusts its strategy, considering the competence of the current model. Through theoretical analysis and empirical evaluations on diverse datasets, including challenging computer vision tasks, we demonstrate DCoM's ability to overcome the cold start problem and consistently improve results across different budgetary constraints. Thus DCoM achieves state-of-the-art performance in both low- and high-budget regimes.
Theoretical Insights into CycleGAN: Analyzing Approximation and Estimation Errors in Unpaired Data Generation
arXiv:2407.11678v3 Announce Type: replace Abstract: In this paper, we focus on analyzing the excess risk of the unpaired data generation model, called CycleGAN. Unlike classical GANs, CycleGAN not only transforms data between two unpaired distributions but also ensures the mappings are consistent, which is encouraged by the cycle-consistency term unique to CycleGAN. The increasing complexity of model structure and the addition of the cycle-consistency term in CycleGAN present new challenges for error analysis. By considering the impact of both the model architecture and training procedure, the risk is decomposed into two terms: approximation error and estimation error. These two error terms are analyzed separately and ultimately combined by considering the trade-off between them. Each component is rigorously analyzed; the approximation error through constructing approximations of the optimal transport maps, and the estimation error through establishing an upper bound using Rademacher complexity. Our analysis not only isolates these errors but also explores the trade-offs between them, which provides a theoretical insights of how CycleGAN's architecture and training procedures influence its performance.
Downlink Channel Covariance Matrix Estimation via Representation Learning with Graph Regularization
arXiv:2407.18865v5 Announce Type: replace Abstract: In this paper, we propose an algorithm for downlink (DL) channel covariance matrix (CCM) estimation for frequency division duplexing (FDD) massive multiple-input multiple-output (MIMO) communication systems with base station (BS) possessing a uniform linear array (ULA) antenna structure. We consider a setting where the UL CCM is mapped to DL CCM by a mapping function. We first present a theoretical error analysis of learning a nonlinear embedding by constructing a mapping function, which points to the importance of the Lipschitz regularity of the mapping function for achieving high estimation performance. Then, based on the theoretical ground, we propose a representation learning algorithm as a solution for the estimation problem, where Gaussian RBF kernel interpolators are chosen to map UL CCMs to their DL counterparts. The proposed algorithm is based on the optimization of an objective function that fits a regression model between the DL CCM and UL CCM samples in the training dataset and preserves the local geometric structure of the data in the UL CCM space, while explicitly regulating the Lipschitz continuity of the mapping function in light of our theoretical findings. The proposed algorithm surpasses benchmark methods in terms of three error metrics as shown by simulations.
Unified Framework for Pre-trained Neural Network Compression via Decomposition and Optimized Rank Selection
arXiv:2409.03555v2 Announce Type: replace Abstract: Despite their high accuracy, complex neural networks demand significant computational resources, posing challenges for deployment on resource constrained devices such as mobile phones and embedded systems. Compression algorithms have been developed to address these challenges by reducing model size and computational demands while maintaining accuracy. Among these approaches, factorization methods based on tensor decomposition are theoretically sound and effective. However, they face difficulties in selecting the appropriate rank for decomposition. This paper tackles this issue by presenting a unified framework that simultaneously applies decomposition and rank selection, employing a composite compression loss within defined rank constraints. Our method includes an automatic rank search in a continuous space, efficiently identifying optimal rank configurations for the pre-trained model by eliminating the need for additional training data and reducing computational overhead in the search step. Combined with a subsequent fine-tuning step, our approach maintains the performance of highly compressed models on par with their original counterparts. Using various benchmark datasets and models, we demonstrate the efficacy of our method through a comprehensive analysis.
On the Convergence Rates of Federated Q-Learning across Heterogeneous Environments
arXiv:2409.03897v2 Announce Type: replace Abstract: Large-scale multi-agent systems are often deployed across wide geographic areas, where agents interact with heterogeneous environments. There is an emerging interest in understanding the role of heterogeneity in the performance of the federated versions of classic reinforcement learning algorithms. In this paper, we study synchronous federated Q-learning, which aims to learn an optimal Q-function by having $K$ agents average their local Q-estimates per $E$ iterations. We observe an interesting phenomenon on the convergence speeds in terms of $K$ and $E$. Similar to the homogeneous environment settings, there is a linear speed-up concerning $K$ in reducing the errors that arise from sampling randomness. Yet, in sharp contrast to the homogeneous settings, $E>1$ leads to significant performance degradation. Specifically, we provide a fine-grained characterization of the error evolution in the presence of environmental heterogeneity, which decay to zero as the number of iterations $T$ increases. The slow convergence of having $E>1$ turns out to be fundamental rather than an artifact of our analysis. We prove that, for a wide range of stepsizes, the $\ell_{\infty}$ norm of the error cannot decay faster than $\Theta (E/T)$. In addition, our experiments demonstrate that the convergence exhibits an interesting two-phase phenomenon. For any given stepsize, there is a sharp phase-transition of the convergence: the error decays rapidly in the beginning yet later bounces up and stabilizes. Provided that the phase-transition time can be estimated, choosing different stepsizes for the two phases leads to faster overall convergence.
Robust Reinforcement Learning with Dynamic Distortion Risk Measures
arXiv:2409.10096v3 Announce Type: replace Abstract: In a reinforcement learning (RL) setting, the agent's optimal strategy heavily depends on her risk preferences and the underlying model dynamics of the training environment. These two aspects influence the agent's ability to make well-informed and time-consistent decisions when facing testing environments. In this work, we devise a framework to solve robust risk-aware RL problems where we simultaneously account for environmental uncertainty and risk with a class of dynamic robust distortion risk measures. Robustness is introduced by considering all models within a Wasserstein ball around a reference model. We estimate such dynamic robust risk measures using neural networks by making use of strictly consistent scoring functions, derive policy gradient formulae using the quantile representation of distortion risk measures, and construct an actor-critic algorithm to solve this class of robust risk-aware RL problems. We demonstrate the performance of our algorithm on a portfolio allocation example.
MobiZO: Enabling Efficient LLM Fine-Tuning at the Edge via Inference Engines
arXiv:2409.15520v3 Announce Type: replace Abstract: Large Language Models (LLMs) are currently pre-trained and fine-tuned on large cloud servers. The next frontier is LLM personalization, where a foundation model can be fine-tuned with user/task-specific data. Given the sensitive nature of such private data, it is desirable to fine-tune these models on edge devices to improve user trust. However, fine-tuning on resource-constrained edge devices presents significant challenges due to substantial memory and computational demands, as well as limited infrastructure support. We observe that inference engines (e.g., ExecuTorch) can be repurposed for fine-tuning by leveraging zeroth-order (ZO) optimization, which uses multiple forward passes to approximate gradients. While promising, direct application of ZO methods on edge devices is inefficient due to the high computational cost of multiple forward passes required for accurate gradient estimation, and their deployment has been largely unexplored in practice. We introduce MobiZO, a resource-efficient fine-tuning framework for LLMs specifically designed for edge devices. MobiZO combines three key innovations: (1) a parallelized randomized gradient estimator that employs both outer-loop and inner-loop parallelism to eliminate sequential forward passes, (2) a specialized Multi-Perturbed LoRA (MP-LoRA) module that enables efficient realization of both inner and outer loop parallelism, and (3) a seamless integration with ExecuTorch for on-device training, requiring no modifications to the runtime. Experiments demonstrate that MobiZO achieves substantial runtime speedups and memory savings while improving fine-tuning accuracy, paving the way for practical deployment of LLMs in real-time, on-device applications.
DimINO: Dimension-Informed Neural Operator Learning
arXiv:2410.05894v4 Announce Type: replace Abstract: In computational physics, a longstanding challenge lies in finding numerical solutions to partial differential equations (PDEs). Recently, research attention has increasingly focused on Neural Operator methods, which are notable for their ability to approximate operators-mappings between functions. Although neural operators benefit from a universal approximation theorem, achieving reliable error bounds often necessitates large model architectures, such as deep stacks of Fourier layers. This raises a natural question: Can we design lightweight models without sacrificing generalization? To address this, we introduce DimINO (Dimension-Informed Neural Operators), a framework inspired by dimensional analysis. DimINO incorporates two key components, DimNorm and a redimensionalization operation, which can be seamlessly integrated into existing neural operator architectures. These components enhance the model's ability to generalize across datasets with varying physical parameters. Theoretically, we establish a universal approximation theorem for DimINO and prove that it satisfies a critical property we term Similar Transformation Invariance (STI). Empirically, DimINO achieves up to 76.3% performance gain on PDE datasets while exhibiting clear evidence of the STI property.
Learning to Learn with Contrastive Meta-Objective
arXiv:2410.05975v3 Announce Type: replace Abstract: Meta-learning enables learning systems to adapt quickly to new tasks, similar to humans. Different meta-learning approaches all work under/with the mini-batch episodic training framework. Such framework naturally gives the information about task identity, which can serve as additional supervision for meta-training to improve generalizability. We propose to exploit task identity as additional supervision in meta-training, inspired by the alignment and discrimination ability which is is intrinsic in human's fast learning. This is achieved by contrasting what meta-learners learn, i.e., model representations. The proposed ConML is evaluating and optimizing the contrastive meta-objective under a problem- and learner-agnostic meta-training framework. We demonstrate that ConML integrates seamlessly with existing meta-learners, as well as in-context learning models, and brings significant boost in performance with small implementation cost.
Flavors of Margin: Implicit Bias of Steepest Descent in Homogeneous Neural Networks
arXiv:2410.22069v4 Announce Type: replace Abstract: We study the implicit bias of the general family of steepest descent algorithms with infinitesimal learning rate in deep homogeneous neural networks. We show that: (a) an algorithm-dependent geometric margin starts increasing once the networks reach perfect training accuracy, and (b) any limit point of the training trajectory corresponds to a KKT point of the corresponding margin-maximization problem. We experimentally zoom into the trajectories of neural networks optimized with various steepest descent algorithms, highlighting connections to the implicit bias of popular adaptive methods (Adam and Shampoo).
Towards Sample-Efficiency and Generalization of Transfer and Inverse Reinforcement Learning: A Comprehensive Literature Review
arXiv:2411.10268v2 Announce Type: replace Abstract: Reinforcement learning (RL) is a sub-domain of machine learning, mainly concerned with solving sequential decision-making problems by a learning agent that interacts with the decision environment to improve its behavior through the reward it receives from the environment. This learning paradigm is, however, well-known for being time-consuming due to the necessity of collecting a large amount of data, making RL suffer from sample inefficiency and difficult generalization. Furthermore, the construction of an explicit reward function that accounts for the trade-off between multiple desiderata of a decision problem is often a laborious task. These challenges have been recently addressed utilizing transfer and inverse reinforcement learning (T-IRL). In this regard, this paper is devoted to a comprehensive review of realizing the sample efficiency and generalization of RL algorithms through T-IRL. Following a brief introduction to RL, the fundamental T-IRL methods are presented and the most recent advancements in each research field have been extensively reviewed. Our findings denote that a majority of recent research works have dealt with the aforementioned challenges by utilizing human-in-the-loop and sim-to-real strategies for the efficient transfer of knowledge from source domains to the target domain under the transfer learning scheme. Under the IRL structure, training schemes that require a low number of experience transitions and extension of such frameworks to multi-agent and multi-intention problems have been the priority of researchers in recent years.
Asynchronous Federated Learning: A Scalable Approach for Decentralized Machine Learning
arXiv:2412.17723v3 Announce Type: replace Abstract: Federated Learning (FL) has emerged as a powerful paradigm for decentralized machine learning, enabling collaborative model training across diverse clients without sharing raw data. However, traditional FL approaches often face limitations in scalability and efficiency due to their reliance on synchronous client updates, which can result in significant delays and increased communication overhead, particularly in heterogeneous and dynamic environments. To address these challenges in this paper, we propose an Asynchronous Federated Learning (AFL) algorithm, which allows clients to update the global model independently and asynchronously. Our key contributions include a comprehensive convergence analysis of AFL in the presence of client delays and model staleness. By leveraging martingale difference sequence theory and variance bounds, we ensure robust convergence despite asynchronous updates. Assuming strongly convex local objective functions, we establish bounds on gradient variance under random client sampling and derive a recursion formula quantifying the impact of client delays on convergence. Furthermore, we demonstrate the practical applicability of the AFL algorithm by training decentralized linear regression and Support Vector Machine (SVM) based classifiers and compare its results with synchronous FL algorithm to effectively handling non-IID data distributed among clients. The proposed AFL algorithm addresses key limitations of traditional FL methods, such as inefficiency due to global synchronization and susceptibility to client drift. It enhances scalability, robustness, and efficiency in real-world settings with heterogeneous client populations and dynamic network conditions. Our results underscore the potential of AFL to drive advancements indistributed learning systems, particularly for large-scale, privacy-preserving applications in resource-constrained environments.
Learn to Optimize Resource Allocation under QoS Constraint of AR
arXiv:2501.16186v2 Announce Type: replace Abstract: This paper studies the uplink and downlink power allocation for interactive augmented reality (AR) services, where the live video captured by an AR device is uploaded to the network edge, and then the augmented video is subsequently downloaded. By modeling the AR transmission process as a tandem queuing system, we derive an upper bound for the probabilistic quality of service (QoS) requirement concerning end-to-end latency and reliability. The resource allocation under the QoS requirement results in a functional optimization problem. To address it, we design a deep neural network to learn the power allocation policy, leveraging the optimal power allocation structure to enhance learning performance. Simulation results demonstrate that the proposed method effectively reduces transmit power while meeting the QoS requirement.
COMPOL: A Unified Neural Operator Framework for Scalable Multi-Physics Simulations
arXiv:2501.17296v3 Announce Type: replace Abstract: Multiphysics simulations play an essential role in accurately modeling complex interactions across diverse scientific and engineering domains Although neural operators especially the Fourier Neural Operator FNO have significantly improved computational efficiency they often fail to effectively capture intricate correlations inherent in coupled physical processes To address this limitation we introduce COMPOL a novel coupled multiphysics operator learning framework COMPOL extends conventional operator architectures by incorporating sophisticated recurrent and attentionbased aggregation mechanisms effectively modeling interdependencies among interacting physical processes within latent feature spaces Our approach is architectureagnostic and seamlessly integrates into various neural operator frameworks that involve latent space transformations Extensive experiments on diverse benchmarksincluding biological reactiondiffusion systems patternforming chemical reactions multiphase geological flows and thermohydromechanical processes demonstrate that COMPOL consistently achieves superior predictive accuracy compared to stateoftheart methods.
Test-Time Training Scaling Laws for Chemical Exploration in Drug Design
arXiv:2501.19153v3 Announce Type: replace Abstract: Chemical Language Models (CLMs) leveraging reinforcement learning (RL) have shown promise in de novo molecular design, yet often suffer from mode collapse, limiting their exploration capabilities. Inspired by Test-Time Training (TTT) in large language models, we propose scaling TTT for CLMs to enhance chemical space exploration. We introduce MolExp, a novel benchmark emphasizing the discovery of structurally diverse molecules with similar bioactivity, simulating real-world drug design challenges. Our results demonstrate that scaling TTT by increasing the number of independent RL agents follows a log-linear scaling law, significantly improving exploration efficiency as measured by MolExp. In contrast, increasing TTT training time yields diminishing returns, even with exploration bonuses. We further evaluate cooperative RL strategies to enhance exploration efficiency. These findings provide a scalable framework for generative molecular design, offering insights into optimizing AI-driven drug discovery.
Learning Fused State Representations for Control from Multi-View Observations
arXiv:2502.01316v4 Announce Type: replace Abstract: Multi-View Reinforcement Learning (MVRL) seeks to provide agents with multi-view observations, enabling them to perceive environment with greater effectiveness and precision. Recent advancements in MVRL focus on extracting latent representations from multiview observations and leveraging them in control tasks. However, it is not straightforward to learn compact and task-relevant representations, particularly in the presence of redundancy, distracting information, or missing views. In this paper, we propose Multi-view Fusion State for Control (MFSC), firstly incorporating bisimulation metric learning into MVRL to learn task-relevant representations. Furthermore, we propose a multiview-based mask and latent reconstruction auxiliary task that exploits shared information across views and improves MFSC's robustness in missing views by introducing a mask token. Extensive experimental results demonstrate that our method outperforms existing approaches in MVRL tasks. Even in more realistic scenarios with interference or missing views, MFSC consistently maintains high performance.
GRADIEND: Feature Learning within Neural Networks Exemplified through Biases
arXiv:2502.01406v3 Announce Type: replace Abstract: AI systems frequently exhibit and amplify social biases, leading to harmful consequences in critical areas. This study introduces a novel encoder-decoder approach that leverages model gradients to learn a feature neuron encoding societal bias information such as gender, race, and religion. We show that our method can not only identify which weights of a model need to be changed to modify a feature, but even demonstrate that this can be used to rewrite models to debias them while maintaining other capabilities. We demonstrate the effectiveness of our approach across various model architectures and highlight its potential for broader applications.
Robust Federated Finetuning of LLMs via Alternating Optimization of LoRA
arXiv:2502.01755v3 Announce Type: replace Abstract: Parameter-Efficient Fine-Tuning (PEFT) methods like Low-Rank Adaptation (LoRA) optimize federated training by reducing computational and communication costs. We propose RoLoRA, a federated framework using alternating optimization to fine-tune LoRA adapters. Our approach emphasizes the importance of learning up and down projection matrices to enhance expressiveness and robustness. We use both theoretical analysis and extensive experiments to demonstrate the advantages of RoLoRA over prior approaches that either generate imperfect model updates or limit expressiveness of the model. We provide a theoretical analysis on a linear model to highlight the importance of learning both the down-projection and up-projection matrices in LoRA. We validate the insights on a non-linear model and separately provide a convergence proof under general conditions. To bridge theory and practice, we conducted extensive experimental evaluations on language models including RoBERTa-Large, Llama-2-7B on diverse tasks and FL settings to demonstrate the advantages of RoLoRA over other methods.
MPIC: Position-Independent Multimodal Context Caching System for Efficient MLLM Serving
arXiv:2502.01960v2 Announce Type: replace Abstract: The context caching technique is employed to accelerate the Multimodal Large Language Model (MLLM) inference by prevailing serving platforms currently. However, this approach merely reuses the Key-Value (KV) cache of the initial sequence of prompt, resulting in full KV cache recomputation even if the prefix differs slightly. This becomes particularly inefficient in the context of interleaved text and images, as well as multimodal retrieval-augmented generation. This paper proposes position-independent caching as a more effective approach for multimodal information management. We have designed and implemented a caching system, named MPIC, to address both system-level and algorithm-level challenges. MPIC stores the KV cache on local disks when receiving multimodal data, and calculates and loads the KV cache in parallel during inference. To mitigate accuracy degradation, we have incorporated the integrated reuse and recompute mechanism within the system. The experimental results demonstrate that MPIC can achieve up to 54\% reduction in response time and 2$\times$ improvement in throughput compared to existing context caching systems, while maintaining negligible or no accuracy loss.
Flatten Graphs as Sequences: Transformers are Scalable Graph Generators
arXiv:2502.02216v2 Announce Type: replace Abstract: We introduce AutoGraph, a scalable autoregressive model for attributed graph generation using decoder-only transformers. By flattening graphs into random sequences of tokens through a reversible process, AutoGraph enables modeling graphs as sequences without relying on additional node features that are expensive to compute, in contrast to diffusion-based approaches. This results in sampling complexity and sequence lengths that scale optimally linearly with the number of edges, making it scalable and efficient for large, sparse graphs. A key success factor of AutoGraph is that its sequence prefixes represent induced subgraphs, creating a direct link to sub-sentences in language modeling. Empirically, AutoGraph achieves state-of-the-art performance on synthetic and molecular benchmarks, with up to 100x faster generation and 3x faster training than leading diffusion models. It also supports substructure-conditioned generation without fine-tuning and shows promising transferability, bridging language modeling and graph generation to lay the groundwork for graph foundation models. Our code is available at https://github.com/BorgwardtLab/AutoGraph.
Towards Seamless Hierarchical Federated Learning under Intermittent Client Participation: A Stagewise Decision-Making Methodology
arXiv:2502.09303v3 Announce Type: replace Abstract: Federated Learning (FL) offers a pioneering distributed learning paradigm that enables devices/clients to build a shared global model. This global model is obtained through frequent model transmissions between clients and a central server, which may cause high latency, energy consumption, and congestion over backhaul links. To overcome these drawbacks, Hierarchical Federated Learning (HFL) has emerged, which organizes clients into multiple clusters and utilizes edge nodes (e.g., edge servers) for intermediate model aggregations between clients and the central server. Current research on HFL mainly focus on enhancing model accuracy, latency, and energy consumption in scenarios with a stable/fixed set of clients. However, addressing the dynamic availability of clients -- a critical aspect of real-world scenarios -- remains underexplored. This study delves into optimizing client selection and client-to-edge associations in HFL under intermittent client participation so as to minimize overall system costs (i.e., delay and energy), while achieving fast model convergence. We unveil that achieving this goal involves solving a complex NP-hard problem. To tackle this, we propose a stagewise methodology that splits the solution into two stages, referred to as Plan A and Plan B. Plan A focuses on identifying long-term clients with high chance of participation in subsequent model training rounds. Plan B serves as a backup, selecting alternative clients when long-term clients are unavailable during model training rounds. This stagewise methodology offers a fresh perspective on client selection that can enhance both HFL and conventional FL via enabling low-overhead decision-making processes. Through evaluations on MNIST and CIFAR-10 datasets, we show that our methodology outperforms existing benchmarks in terms of model accuracy and system costs.
Comprehensive Review of Neural Differential Equations for Time Series Analysis
arXiv:2502.09885v3 Announce Type: replace Abstract: Time series modeling and analysis have become critical in various domains. Conventional methods such as RNNs and Transformers, while effective for discrete-time and regularly sampled data, face significant challenges in capturing the continuous dynamics and irregular sampling patterns inherent in real-world scenarios. Neural Differential Equations (NDEs) represent a paradigm shift by combining the flexibility of neural networks with the mathematical rigor of differential equations. This paper presents a comprehensive review of NDE-based methods for time series analysis, including neural ordinary differential equations, neural controlled differential equations, and neural stochastic differential equations. We provide a detailed discussion of their mathematical formulations, numerical methods, and applications, highlighting their ability to model continuous-time dynamics. Furthermore, we address key challenges and future research directions. This survey serves as a foundation for researchers and practitioners seeking to leverage NDEs for advanced time series analysis.
Controlling Neural Collapse Enhances Out-of-Distribution Detection and Transfer Learning
arXiv:2502.10691v3 Announce Type: replace Abstract: Out-of-distribution (OOD) detection and OOD generalization are widely studied in Deep Neural Networks (DNNs), yet their relationship remains poorly understood. We empirically show that the degree of Neural Collapse (NC) in a network layer is inversely related with these objectives: stronger NC improves OOD detection but degrades generalization, while weaker NC enhances generalization at the cost of detection. This trade-off suggests that a single feature space cannot simultaneously achieve both tasks. To address this, we develop a theoretical framework linking NC to OOD detection and generalization. We show that entropy regularization mitigates NC to improve generalization, while a fixed Simplex Equiangular Tight Frame (ETF) projector enforces NC for better detection. Based on these insights, we propose a method to control NC at different DNN layers. In experiments, our method excels at both tasks across OOD datasets and DNN architectures. Code for our experiments is available at: https://yousuf907.github.io/ncoodg
Unsupervised Structural-Counterfactual Generation under Domain Shift
arXiv:2502.12013v3 Announce Type: replace Abstract: Motivated by the burgeoning interest in cross-domain learning, we present a novel generative modeling challenge: generating counterfactual samples in a target domain based on factual observations from a source domain. Our approach operates within an unsupervised paradigm devoid of parallel or joint datasets, relying exclusively on distinct observational samples and causal graphs for each domain. This setting presents challenges that surpass those of conventional counterfactual generation. Central to our methodology is the disambiguation of exogenous causes into effect-intrinsic and domain-intrinsic categories. This differentiation facilitates the integration of domain-specific causal graphs into a unified joint causal graph via shared effect-intrinsic exogenous variables. We propose leveraging Neural Causal models within this joint framework to enable accurate counterfactual generation under standard identifiability assumptions. Furthermore, we introduce a novel loss function that effectively segregates effect-intrinsic from domain-intrinsic variables during model training. Given a factual observation, our framework combines the posterior distribution of effect-intrinsic variables from the source domain with the prior distribution of domain-intrinsic variables from the target domain to synthesize the desired counterfactuals, adhering to Pearl's causal hierarchy. Intriguingly, when domain shifts are restricted to alterations in causal mechanisms without accompanying covariate shifts, our training regimen parallels the resolution of a conditional optimal transport problem. Empirical evaluations on a synthetic dataset show that our framework generates counterfactuals in the target domain that very closely resemble the ground truth.
Efficient Neural SDE Training using Wiener-Space Cubature
arXiv:2502.12395v3 Announce Type: replace Abstract: A neural stochastic differential equation (SDE) is an SDE with drift and diffusion terms parametrized by neural networks. The training procedure for neural SDEs consists of optimizing the SDE vector field (neural network) parameters to minimize the expected value of an objective functional on infinite-dimensional path-space. Existing training techniques focus on methods to efficiently compute path-wise gradients of the objective functional with respect to these parameters, then pair this with Monte-Carlo simulation to estimate the gradient expectation. In this work we introduce a novel training technique which bypasses and improves upon this Monte-Carlo simulation; we extend results in the theory of Wiener space cubature to approximate the expected objective functional value by a weighted sum of functional evaluations of deterministic ODE solutions. Our main mathematical contribution enabling this approximation is an extension of cubature bounds to the setting of Lipschitz-nonlinear functionals acting on path-space. Our resulting constructive algorithm allows for more computationally efficient training along several lines. First, it circumvents Brownian motion simulation and enables the use of efficient parallel ODE solvers, thus decreasing the complexity of path-functional evaluation. Furthermore, and more surprisingly, we show that the number of paths required to achieve a given (expected loss functional oracle value) approximation can be reduced in this deterministic cubature regime. Specifically, we show that under reasonable regularity assumptions we can observe a O(1/n) convergence rate, where n is the number of path evaluations; in contrast with the standard O(1/sqrt(n)) rate of naive Monte-Carlo or the O(log(n)^d /n) rate of quasi-Monte-Carlo.
EquiBench: Benchmarking Large Language Models' Reasoning about Program Semantics via Equivalence Checking
arXiv:2502.12466v3 Announce Type: replace Abstract: As large language models (LLMs) become integral to code-related tasks, a central question emerges: Do LLMs truly understand program semantics? We introduce EquiBench, a new benchmark for evaluating LLMs through equivalence checking, i.e., determining whether two programs produce identical outputs for all possible inputs. Unlike prior code generation benchmarks, this task directly tests a model's ability to reason about program semantics. EquiBench consists of 2400 program pairs across four languages and six categories. These pairs are generated through program analysis, compiler scheduling, and superoptimization, ensuring high-confidence labels, nontrivial difficulty, and full automation. We evaluate 19 state-of-the-art LLMs and find that in the most challenging categories, the best accuracies are 63.8% and 76.2%, only modestly above the 50% random baseline. Further analysis reveals that models often rely on syntactic similarity rather than exhibiting robust reasoning about program semantics, highlighting current limitations. Our code and dataset are publicly available at https://github.com/Anjiang-Wei/equibench
Multi-branch of Attention Yields Accurate Results for Tabular Data
arXiv:2502.12507v3 Announce Type: replace Abstract: Tabular data inherently exhibits significant feature heterogeneity, but existing transformer-based methods lack specialized mechanisms to handle this property. To bridge the gap, we propose MAYA, an encoder-decoder transformer-based framework. In the encoder, we design a Multi-Branch of Attention (MBA) that constructs multiple parallel attention branches and averages the features at each branch, effectively fusing heterogeneous features while limiting parameter growth. Additionally, we employ collaborative learning with a dynamic consistency weight constraint to produce more robust representations. In the decoder stage, cross-attention is utilized to seamlessly integrate tabular data with corresponding label features. This dual-attention mechanism effectively captures both intra-instance and inter-instance interactions. We evaluate the proposed method on a wide range of datasets and compare it with other state-of-the-art transformer-based methods. Extensive experiments demonstrate that our model achieves superior performance among transformer-based methods in both tabular classification and regression tasks.
Bayesian Algorithms for Adversarial Online Learning: from Finite to Infinite Action Spaces
arXiv:2502.14790v5 Announce Type: replace Abstract: We develop a form Thompson sampling for online learning under full feedback - also known as prediction with expert advice - where the learner's prior is defined over the space of an adversary's future actions, rather than the space of experts. We show regret decomposes into regret the learner expected a priori, plus a prior-robustness-type term we call excess regret. In the classical finite-expert setting, this recovers optimal rates. As an initial step towards practical online learning in settings with a potentially-uncountably-infinite number of experts, we show that Thompson sampling over the $d$-dimensional unit cube, using a certain Gaussian process prior widely-used in the Bayesian optimization literature, has a $\mathcal{O}\Big(\beta\sqrt{Td\log(1+\sqrt{d}\frac{\lambda}{\beta})}\Big)$ rate against a $\beta$-bounded $\lambda$-Lipschitz adversary.
Why Are Web AI Agents More Vulnerable Than Standalone LLMs? A Security Analysis
arXiv:2502.20383v3 Announce Type: replace Abstract: Recent advancements in Web AI agents have demonstrated remarkable capabilities in addressing complex web navigation tasks. However, emerging research shows that these agents exhibit greater vulnerability compared to standalone Large Language Models (LLMs), despite both being built upon the same safety-aligned models. This discrepancy is particularly concerning given the greater flexibility of Web AI Agent compared to standalone LLMs, which may expose them to a wider range of adversarial user inputs. To build a scaffold that addresses these concerns, this study investigates the underlying factors that contribute to the increased vulnerability of Web AI agents. Notably, this disparity stems from the multifaceted differences between Web AI agents and standalone LLMs, as well as the complex signals - nuances that simple evaluation metrics, such as success rate, often fail to capture. To tackle these challenges, we propose a component-level analysis and a more granular, systematic evaluation framework. Through this fine-grained investigation, we identify three critical factors that amplify the vulnerability of Web AI agents; (1) embedding user goals into the system prompt, (2) multi-step action generation, and (3) observational capabilities. Our findings highlights the pressing need to enhance security and robustness in AI agent design and provide actionable insights for targeted defense strategies.
Cover Learning for Large-Scale Topology Representation
arXiv:2503.09767v2 Announce Type: replace Abstract: Classical unsupervised learning methods like clustering and linear dimensionality reduction parametrize large-scale geometry when it is discrete or linear, while more modern methods from manifold learning find low dimensional representation or infer local geometry by constructing a graph on the input data. More recently, topological data analysis popularized the use of simplicial complexes to represent data topology with two main methodologies: topological inference with geometric complexes and large-scale topology visualization with Mapper graphs -- central to these is the nerve construction from topology, which builds a simplicial complex given a cover of a space by subsets. While successful, these have limitations: geometric complexes scale poorly with data size, and Mapper graphs can be hard to tune and only contain low dimensional information. In this paper, we propose to study the problem of learning covers in its own right, and from the perspective of optimization. We describe a method for learning topologically-faithful covers of geometric datasets, and show that the simplicial complexes thus obtained can outperform standard topological inference approaches in terms of size, and Mapper-type algorithms in terms of representation of large-scale topology.
Continual Multimodal Contrastive Learning
arXiv:2503.14963v3 Announce Type: replace Abstract: Multimodal Contrastive Learning (MCL) advances in aligning different modalities and generating multimodal representations in a joint space. By leveraging contrastive learning across diverse modalities, large-scale multimodal data enhances representational quality. However, a critical yet often overlooked challenge remains: multimodal data is rarely collected in a single process, and training from scratch is computationally expensive. Instead, emergent multimodal data can be used to optimize existing models gradually, i.e., models are trained on a sequence of modality pair data. We define this problem as Continual Multimodal Contrastive Learning (CMCL), an underexplored yet crucial research direction at the intersection of multimodal and continual learning. In this paper, we formulate CMCL through two specialized principles of stability and plasticity. We theoretically derive a novel optimization-based method, which projects updated gradients from dual sides onto subspaces where any gradient is prevented from interfering with the previously learned knowledge. Two upper bounds provide theoretical insights on both stability and plasticity in our solution. Beyond our theoretical contributions, we conduct experiments on multiple datasets by comparing our method against advanced continual learning baselines. The empirical results further support our claims and demonstrate the efficacy of our method. Our codes are available at https://github.com/Xiaohao-Liu/CMCL.
Accelerating Vehicle Routing via AI-Initialized Genetic Algorithms
arXiv:2504.06126v2 Announce Type: replace Abstract: Vehicle Routing Problems (VRP) are an extension of the Traveling Salesperson Problem and are a fundamental NP-hard challenge in combinatorial optimization. Solving VRP in real-time at large scale has become critical in numerous applications, from growing markets like last-mile delivery to emerging use-cases like interactive logistics planning. In many applications, one has to repeatedly solve VRP instances drawn from the same distribution, yet current state-of-the-art solvers treat each instance on its own without leveraging previous examples. We introduce an optimization framework where a reinforcement learning agent is trained on prior instances and quickly generates initial solutions, which are then further optimized by a genetic algorithm. This framework, Evolutionary Algorithm with Reinforcement Learning Initialization (EARLI), consistently outperforms current state-of-the-art solvers across various time budgets. For example, EARLI handles vehicle routing with 500 locations within one second, 10x faster than current solvers for the same solution quality, enabling real-time and interactive routing at scale. EARLI can generalize to new data, as we demonstrate on real e-commerce delivery data of a previously unseen city. By combining reinforcement learning and genetic algorithms, our hybrid framework takes a step forward to closer interdisciplinary collaboration between AI and optimization communities towards real-time optimization in diverse domains.
LEMUR Neural Network Dataset: Towards Seamless AutoML
arXiv:2504.10552v3 Announce Type: replace Abstract: Neural networks have become the backbone of modern AI, yet designing, evaluating, and comparing them remains labor-intensive. While many datasets exist for training models, there are few standardized collections of the models themselves. We present LEMUR, an open-source dataset and framework that brings together a large collection of PyTorch-based neural networks across tasks such as classification, segmentation, detection, and natural language processing. Each model follows a common template, with configurations and results logged in a structured database to ensure consistency and reproducibility. LEMUR integrates Optuna for automated hyperparameter optimization, provides statistical analysis and visualization tools, and exposes an API for seamless access to performance data. The framework also supports extensibility, enabling researchers to add new models, datasets, or metrics without breaking compatibility. By standardizing implementations and unifying evaluation, LEMUR aims to accelerate AutoML research, facilitate fair benchmarking, and lower the barrier to large-scale neural network experimentation.
70% Size, 100% Accuracy: Lossless LLM Compression for Efficient GPU Inference via Dynamic-Length Float
arXiv:2504.11651v2 Announce Type: replace Abstract: Large-scale AI models, such as Large Language Models (LLMs) and Diffusion Models (DMs), have grown rapidly in size, creating significant challenges for efficient deployment on resource-constrained hardware. In this paper, we introduce Dynamic-Length Float (DFloat11), a lossless compression framework that reduces LLM and DM size by 30% while preserving outputs that are bit-for-bit identical to the original model. DFloat11 is motivated by the low entropy in the BFloat16 weight representation of LLMs, which reveals significant inefficiency in the existing storage format. By applying entropy coding, DFloat11 assigns dynamic-length encodings to weights based on frequency, achieving near information-optimal compression without any loss of precision. To facilitate efficient inference with dynamic-length encodings, we develop a custom GPU kernel for fast online decompression. Our design incorporates the following: (i) compact, hierarchical lookup tables (LUTs) that fit within GPU SRAM for efficient decoding, (ii) a two-phase GPU kernel for coordinating thread read/write positions using lightweight auxiliary variables, and (iii) transformer-block-level decompression to minimize latency. Experiments on Llama 3.3, Qwen 3, Mistral 3, FLUX.1, and others validate our hypothesis that DFloat11 achieves around 30% model size reduction while preserving bit-for-bit identical outputs. Compared to a potential alternative of offloading parts of an uncompressed model to the CPU to meet memory constraints, DFloat11 achieves 2.3--46.2x higher throughput in token generation. With a fixed GPU memory budget, DFloat11 enables 5.7--14.9x longer generation lengths than uncompressed models. Notably, our method enables lossless inference of Llama 3.1 405B, an 810GB model, on a single node equipped with 8x80GB GPUs. Our code is available at https://github.com/LeanModels/DFloat11.
Significativity Indices for Agreement Values
arXiv:2504.15325v3 Announce Type: replace Abstract: Agreement measures, such as Cohen's kappa or intraclass correlation, gauge the matching between two or more classifiers. They are used in a wide range of contexts from medicine, where they evaluate the effectiveness of medical treatments and clinical trials, to artificial intelligence, where they can quantify the approximation due to the reduction of a classifier. The consistency of different classifiers to a golden standard can be compared simply by using the order induced by their agreement measure with respect to the golden standard itself. Nevertheless, labelling an approach as good or bad exclusively by using the value of an agreement measure requires a scale or a significativity index. Some quality scales have been proposed in the literature for Cohen's kappa, but they are mainly na\"ive, and their boundaries are arbitrary. This work proposes a general approach to evaluate the significativity of any agreement value between two classifiers and introduces two significativity indices: one dealing with finite data sets, the other one handling classification probability distributions. Moreover, this manuscript addresses the computational challenges of evaluating such indices and proposes some efficient algorithms for their evaluation.
ScaleGNN: Towards Scalable Graph Neural Networks via Adaptive High-order Neighboring Feature Fusion
arXiv:2504.15920v5 Announce Type: replace Abstract: Graph Neural Networks (GNNs) have demonstrated impressive performance across diverse graph-based tasks by leveraging message passing to capture complex node relationships. However, when applied to large-scale real-world graphs, GNNs face two major challenges: First, it becomes increasingly difficult to ensure both scalability and efficiency, as the repeated aggregation of large neighborhoods leads to significant computational overhead; Second, the over-smoothing problem arises, where excessive or deep propagation makes node representations indistinguishable, severely hindering model expressiveness. To tackle these issues, we propose ScaleGNN, a novel framework that adaptively fuses multi-hop node features for both scalable and effective graph learning. First, we construct per-hop pure neighbor matrices that capture only the exclusive structural information at each hop, avoiding the redundancy of conventional aggregation. Then, an enhanced feature fusion strategy significantly balances low-order and high-order information, preserving both local detail and global correlations without incurring excessive complexity. To further reduce redundancy and over-smoothing, we introduce a Local Contribution Score (LCS)-based masking mechanism to filter out less relevant high-order neighbors, ensuring that only the most meaningful information is aggregated. In addition, learnable sparse constraints selectively integrate multi-hop valuable features, emphasizing the most informative high-order neighbors. Extensive experiments on real-world datasets demonstrate that ScaleGNN consistently outperforms state-of-the-art GNNs in both predictive accuracy and computational efficiency, highlighting its practical value for large-scale graph learning.
A Simple Review of EEG Foundation Models: Datasets, Advancements and Future Perspectives
arXiv:2504.20069v2 Announce Type: replace Abstract: Electroencephalogram (EEG) signals play a crucial role in understanding brain activity and diagnosing neurological diseases. Because supervised EEG encoders are unable to learn robust EEG patterns and rely too heavily on expensive signal annotation, research has turned to general-purpose self-supervised EEG encoders, known as EEG-based models (EEG-FMs), to achieve robust and scalable EEG feature extraction. However, the readiness of early EEG-FMs for practical applications and the standards for long-term research progress remain unclear. Therefore, a systematic and comprehensive review of first-generation EEG-FMs is necessary to understand their current state-of-the-art and identify key directions for future EEG-FMs. To this end, this study reviews 14 early EEG-FMs and provides a critical comprehensive analysis of their methodologies, empirical findings, and unaddressed research gaps. This review focuses on the latest developments in EEG-based models (EEG-FMs), which have shown great potential for processing and analyzing EEG data. We discuss various EEG-FMs, including their architectures, pretraining strategies, pretraining and downstream datasets, and other details. This review also highlights challenges and future directions in the field, aiming to provide a comprehensive overview for researchers and practitioners interested in EEG analysis and related EEG-FM.
Generative Diffusion Models for Resource Allocation in Wireless Networks
arXiv:2504.20277v3 Announce Type: replace Abstract: This paper proposes a supervised training algorithm for learning stochastic resource allocation policies with generative diffusion models (GDMs). We formulate the allocation problem as the maximization of an ergodic utility function subject to ergodic Quality of Service (QoS) constraints. Given samples from a stochastic expert policy that yields a near-optimal solution to the constrained optimization problem, we train a GDM policy to imitate the expert and generate new samples from the optimal distribution. We achieve near-optimal performance through the sequential execution of the generated samples. To enable generalization to a family of network configurations, we parameterize the backward diffusion process with a graph neural network (GNN) architecture. We present numerical results in a case study of power control.
Towards Quantifying the Hessian Structure of Neural Networks
arXiv:2505.02809v2 Announce Type: replace Abstract: Empirical studies reported that the Hessian matrix of neural networks (NNs) exhibits a near-block-diagonal structure, yet its theoretical foundation remains unclear. In this work, we reveal that the reported Hessian structure comes from a mixture of two forces: a ``static force'' rooted in the architecture design, and a ''dynamic force'' arisen from training. We then provide a rigorous theoretical analysis of ''static force'' at random initialization. We study linear models and 1-hidden-layer networks for classification tasks with $C$ classes. By leveraging random matrix theory, we compare the limit distributions of the diagonal and off-diagonal Hessian blocks and find that the block-diagonal structure arises as $C$ becomes large. Our findings reveal that $C$ is one primary driver of the near-block-diagonal structure. These results may shed new light on the Hessian structure of large language models (LLMs), which typically operate with a large $C$ exceeding $10^4$.
Wasserstein Convergence of Score-based Generative Models under Semiconvexity and Discontinuous Gradients
arXiv:2505.03432v2 Announce Type: replace Abstract: Score-based Generative Models (SGMs) approximate a data distribution by perturbing it with Gaussian noise and subsequently denoising it via a learned reverse diffusion process. These models excel at modeling complex data distributions and generating diverse samples, achieving state-of-the-art performance across domains such as computer vision, audio generation, reinforcement learning, and computational biology. Despite their empirical success, existing Wasserstein-2 convergence analysis typically assume strong regularity conditions-such as smoothness or strict log-concavity of the data distribution-that are rarely satisfied in practice. In this work, we establish the first non-asymptotic Wasserstein-2 convergence guarantees for SGMs targeting semiconvex distributions with potentially discontinuous gradients. Our upper bounds are explicit and sharp in key parameters, achieving optimal dependence of $O(\sqrt{d})$ on the data dimension $d$ and convergence rate of order one. The framework accommodates a wide class of practically relevant distributions, including symmetric modified half-normal distributions, Gaussian mixtures, double-well potentials, and elastic net potentials. By leveraging semiconvexity without requiring smoothness assumptions on the potential such as differentiability, our results substantially broaden the theoretical foundations of SGMs, bridging the gap between empirical success and rigorous guarantees in non-smooth, complex data regimes.
GuidedQuant: Large Language Model Quantization via Exploiting End Loss Guidance
arXiv:2505.07004v4 Announce Type: replace Abstract: Post-training quantization is a key technique for reducing the memory and inference latency of large language models by quantizing weights and activations without requiring retraining. However, existing methods either (1) fail to account for the varying importance of hidden features to the end loss or, when incorporating end loss, (2) neglect the critical interactions between model weights. To address these limitations, we propose GuidedQuant, a novel quantization approach that integrates gradient information from the end loss into the quantization objective while preserving cross-weight dependencies within output channels. GuidedQuant consistently boosts the performance of state-of-the-art quantization methods across weight-only scalar, weight-only vector, and weight-and-activation quantization. Additionally, we introduce a novel non-uniform scalar quantization algorithm, which is guaranteed to monotonically decrease the quantization objective value, and outperforms existing methods in this category. We release the code at https://github.com/snu-mllab/GuidedQuant.
Interpreting Graph Inference with Skyline Explanations
arXiv:2505.07635v3 Announce Type: replace Abstract: Inference queries have been routinely issued to graph machine learning models such as graph neural networks (GNNs) for various network analytical tasks. Nevertheless, GNN outputs are often hard to interpret comprehensively. Existing methods typically conform to individual pre-defined explainability measures (such as fidelity), which often leads to biased, ``one-side'' interpretations. This paper introduces skyline explanation, a new paradigm that interprets GNN outputs by simultaneously optimizing multiple explainability measures of users' interests. (1) We propose skyline explanations as a Pareto set of explanatory subgraphs that dominate others over multiple explanatory measures. We formulate skyline explanation as a multi-criteria optimization problem, and establish its hardness results. (2) We design efficient algorithms with an onion-peeling approach, which strategically prioritizes nodes and removes unpromising edges to incrementally assemble skyline explanations. (3) We also develop an algorithm to diversify the skyline explanations to enrich the comprehensive interpretation. (4) We introduce efficient parallel algorithms with load-balancing strategies to scale skyline explanation for large-scale GNN-based inference. Using real-world and synthetic graphs, we experimentally verify our algorithms' effectiveness and scalability.
Dynamical Low-Rank Compression of Neural Networks with Robustness under Adversarial Attacks
arXiv:2505.08022v2 Announce Type: replace Abstract: Deployment of neural networks on resource-constrained devices demands models that are both compact and robust to adversarial inputs. However, compression and adversarial robustness often conflict. In this work, we introduce a dynamical low-rank training scheme enhanced with a novel spectral regularizer that controls the condition number of the low-rank core in each layer. This approach mitigates the sensitivity of compressed models to adversarial perturbations without sacrificing clean accuracy. The method is model- and data-agnostic, computationally efficient, and supports rank adaptivity to automatically compress the network at hand. Extensive experiments across standard architectures, datasets, and adversarial attacks show the regularized networks can achieve over 94% compression while recovering or improving adversarial accuracy relative to uncompressed baselines.
Informed, but Not Always Improved: Challenging the Benefit of Background Knowledge in GNNs
arXiv:2505.11023v2 Announce Type: replace Abstract: In complex and low-data domains such as biomedical research, incorporating background knowledge (BK) graphs, such as protein-protein interaction (PPI) networks, into graph-based machine learning pipelines is a promising research direction. However, while BK is often assumed to improve model performance, its actual contribution and the impact of imperfect knowledge remain poorly understood. In this work, we investigate the role of BK in an important real-world task: cancer subtype classification. Surprisingly, we find that (i) state-of-the-art GNNs using BK perform no better than uninformed models like linear regression, and (ii) their performance remains largely unchanged even when the BK graph is heavily perturbed. To understand these unexpected results, we introduce an evaluation framework, which employs (i) a synthetic setting where the BK is clearly informative and (ii) a set of perturbations that simulate various imperfections in BK graphs. With this, we test the robustness of BK-aware models in both synthetic and real-world biomedical settings. Our findings reveal that careful alignment of GNN architectures and BK characteristics is necessary but holds the potential for significant performance improvements.
On the $O(\frac{\sqrt{d}}{K^{1/4}})$ Convergence Rate of AdamW Measured by $\ell_1$ Norm
arXiv:2505.11840v2 Announce Type: replace Abstract: As the default optimizer for training large language models, AdamW has achieved remarkable success in deep learning. However, its convergence behavior is not theoretically well-understood. This paper establishes the convergence rate $\frac{1}{K}\sum_{k=1}^KE\left[||\nabla f(x^k)||1\right]\leq O(\frac{\sqrt{d}C}{K^{1/4}})$ for AdamW measured by $\ell_1$ norm, where $K$ represents the iteration number, $d$ denotes the model dimension, and $C$ matches the constant in the optimal convergence rate of SGD. Theoretically, we have $||\nabla f(x)||_2\ll ||\nabla f(x)||_1\leq \sqrt{d}||\nabla f(x)||_2$ for any high-dimensional vector $x$ and $E\left[||\nabla f(x)||_1\right]\geq\sqrt{\frac{2d}{\pi}}E\left[||\nabla f(x)||_2\right]$ when each element of $\nabla f(x)$ is generated from Gaussian distribution $\mathcal N(0,1)$. Empirically, our experimental results on real-world deep learning tasks reveal $||\nabla f(x)||_1=\varTheta(\sqrt{d})||\nabla f(x)||_2$. Both support that our convergence rate can be considered to be analogous to the optimal $\frac{1}{K}\sum{k=1}^KE\left[||\nabla f(x^k)||_2\right]\leq O(\frac{C}{K^{1/4}})$ convergence rate of SGD.
RECON: Robust symmetry discovery via Explicit Canonical Orientation Normalization
arXiv:2505.13289v2 Announce Type: replace Abstract: Real world data often exhibits unknown, instance-specific symmetries that rarely exactly match a transformation group $G$ fixed a priori. Class-pose decompositions aim to create disentangled representations by factoring inputs into invariant features and a pose $g\in G$ defined relative to a training-dependent, arbitrary canonical representation. We introduce RECON, a class-pose agnostic $\textit{canonical orientation normalization}$ that corrects arbitrary canonicals via a simple right-multiplication, yielding $\textit{natural}$, data-aligned canonicalizations. This enables (i) unsupervised discovery of instance-specific symmetry distributions, (ii) detection of out-of-distribution poses, and (iii) test-time canonicalization, granting group invariance to pre-trained models without retraining and irrespective of model architecture, improving downstream performance. We demonstrate results on 2D image benchmarks and --for the first time-- extend symmetry discovery to 3D groups.
RefLoRA: Refactored Low-Rank Adaptation for Efficient Fine-Tuning of Large Models
arXiv:2505.18877v2 Announce Type: replace Abstract: Low-Rank Adaptation (LoRA) lowers the computational and memory overhead of fine-tuning large models by updating a low-dimensional subspace of the pre-trained weight matrix. Albeit efficient, LoRA exhibits suboptimal convergence and noticeable performance degradation, due to inconsistent and imbalanced weight updates induced by its nonunique low-rank factorizations. To overcome these limitations, this article identifies the optimal low-rank factorization per step that minimizes an upper bound on the loss. The resultant refactored low-rank adaptation (RefLoRA) method promotes a flatter loss landscape, along with consistent and balanced weight updates, thus speeding up stable convergence. Extensive experiments evaluate RefLoRA on natural language understanding, and commonsense reasoning tasks with popular large language models including DeBERTaV3, LLaMA-7B, LLaMA2-7B and LLaMA3-8B. The numerical tests corroborate that RefLoRA converges faster, outperforms various benchmarks, and enjoys negligible computational overhead compared to state-of-the-art LoRA variants.
DPASyn: Mechanism-Aware Drug Synergy Prediction via Dual Attention and Precision-Aware Quantization
arXiv:2505.19144v2 Announce Type: replace Abstract: Drug combinations are essential in cancer therapy, leveraging synergistic drug-drug interactions (DDI) to enhance efficacy and combat resistance. However, the vast combinatorial space makes experimental screening impractical, and existing computational models struggle to capture the complex, bidirectional nature of DDIs, often relying on independent drug encoding or simplistic fusion strategies that miss fine-grained inter-molecular dynamics. Moreover, state-of-the-art graph-based approaches suffer from high computational costs, limiting scalability for real-world drug discovery. To address this, we propose DPASyn, a novel drug synergy prediction framework featuring a dual-attention mechanism and Precision-Aware Quantization (PAQ). The dual-attention architecture jointly models intra-drug structures and inter-drug interactions via shared projections and cross-drug attention, enabling fine-grained, biologically plausible synergy modeling. While this enhanced expressiveness brings increased computational resource consumption, our proposed PAQ strategy complements it by dynamically optimizing numerical precision during training based on feature sensitivity-reducing memory usage by 40% and accelerating training threefold without sacrificing accuracy. With LayerNorm-stabilized residual connections for training stability, DPASyn outperforms seven state-of-the-art methods on the O'Neil dataset (13,243 combinations) and supports full-batch processing of up to 256 graphs on a single GPU, setting a new standard for efficient and expressive drug synergy prediction.
Less is More: Unlocking Specialization of Time Series Foundation Models via Structured Pruning
arXiv:2505.23195v2 Announce Type: replace Abstract: Scaling laws motivate the development of Time Series Foundation Models (TSFMs) that pre-train vast parameters and achieve remarkable zero-shot forecasting performance. Surprisingly, even after fine-tuning, TSFMs cannot consistently outperform smaller, specialized models trained on full-shot downstream data. A key question is how to realize effective adaptation of TSFMs for a target forecasting task. Through empirical studies on various TSFMs, the pre-trained models often exhibit inherent sparsity and redundancy in computation, suggesting that TSFMs have learned to activate task-relevant network substructures to accommodate diverse forecasting tasks. To preserve this valuable prior knowledge, we propose a structured pruning method to regularize the subsequent fine-tuning process by focusing it on a more relevant and compact parameter space. Extensive experiments on seven TSFMs and six benchmarks demonstrate that fine-tuning a smaller, pruned TSFM significantly improves forecasting performance compared to fine-tuning original models. This prune-then-finetune paradigm often enables TSFMs to achieve state-of-the-art performance and surpass strong specialized baselines. Source code is made publicly available at https://github.com/SJTU-DMTai/Prune-then-Finetune.
Absorb and Converge: Provable Convergence Guarantee for Absorbing Discrete Diffusion Models
arXiv:2506.02318v2 Announce Type: replace Abstract: Discrete state space diffusion models have shown significant advantages in applications involving discrete data, such as text and image generation. It has also been observed that their performance is highly sensitive to the choice of rate matrices, particularly between uniform and absorbing rate matrices. While empirical results suggest that absorbing rate matrices often yield better generation quality compared to uniform rate matrices, existing theoretical works have largely focused on the uniform rate matrices case. Notably, convergence guarantees and error analyses for absorbing diffusion models are still missing. In this work, we provide the first finite-time error bounds and convergence rate analysis for discrete diffusion models using absorbing rate matrices. We begin by deriving an upper bound on the KL divergence of the forward process, introducing a surrogate initialization distribution to address the challenge posed by the absorbing stationary distribution, which is a singleton and causes the KL divergence to be ill-defined. We then establish the first convergence guarantees for both the $\tau$-leaping and uniformization samplers under absorbing rate matrices, demonstrating improved rates over their counterparts using uniform rate matrices. Furthermore, under suitable assumptions, we provide convergence guarantees without early stopping. Our analysis introduces several new technical tools to address challenges unique to absorbing rate matrices. These include a Jensen-type argument for bounding forward process convergence, novel techniques for bounding absorbing score functions, and a non-divergent upper bound on the score near initialization that removes the need of early-stopping.
GeoClip: Geometry-Aware Clipping for Differentially Private SGD
arXiv:2506.06549v2 Announce Type: replace Abstract: Differentially private stochastic gradient descent (DP-SGD) is the most widely used method for training machine learning models with provable privacy guarantees. A key challenge in DP-SGD is setting the per-sample gradient clipping threshold, which significantly affects the trade-off between privacy and utility. While recent adaptive methods improve performance by adjusting this threshold during training, they operate in the standard coordinate system and fail to account for correlations across the coordinates of the gradient. We propose GeoClip, a geometry-aware framework that clips and perturbs gradients in a transformed basis aligned with the geometry of the gradient distribution. GeoClip adaptively estimates this transformation using only previously released noisy gradients, incurring no additional privacy cost. We provide convergence guarantees for GeoClip and derive a closed-form solution for the optimal transformation that minimizes the amount of noise added while keeping the probability of gradient clipping under control. Experiments on both tabular and image datasets demonstrate that GeoClip consistently outperforms existing adaptive clipping methods under the same privacy budget.
MIRA: Medical Time Series Foundation Model for Real-World Health Data
arXiv:2506.07584v4 Announce Type: replace Abstract: A unified foundation model for medical time series -- pretrained on open access and ethics board-approved medical corpora -- offers the potential to reduce annotation burdens, minimize model customization, and enable robust transfer across clinical institutions, modalities, and tasks, particularly in data-scarce or privacy-constrained environments. However, existing generalist time series foundation models struggle to handle medical time series data due to their inherent challenges, including irregular intervals, heterogeneous sampling rates, and frequent missing values. To address these challenges, we introduce MIRA, a unified foundation model specifically designed for medical time series forecasting. MIRA incorporates a Continuous-Time Rotary Positional Encoding that enables fine-grained modeling of variable time intervals, a frequency-specific mixture-of-experts layer that routes computation across latent frequency regimes to further promote temporal specialization, and a Continuous Dynamics Extrapolation Block based on Neural ODE that models the continuous trajectory of latent states, enabling accurate forecasting at arbitrary target timestamps. Pretrained on a large-scale and diverse medical corpus comprising over 454 billion time points collect from publicly available datasets, MIRA achieves reductions in forecasting errors by an average of 10% and 7% in out-of-distribution and in-distribution scenarios, respectively, when compared to other zero-shot and fine-tuned baselines. We also introduce a comprehensive benchmark spanning multiple downstream clinical tasks, establishing a foundation for future research in medical time series modeling.
The Impact of Feature Scaling In Machine Learning: Effects on Regression and Classification Tasks
arXiv:2506.08274v4 Announce Type: replace Abstract: This research addresses the critical lack of comprehensive studies on feature scaling by systematically evaluating 12 scaling techniques - including several less common transformations - across 14 different Machine Learning algorithms and 16 datasets for classification and regression tasks. We meticulously analyzed impacts on predictive performance (using metrics such as accuracy, MAE, MSE, and $R^2$) and computational costs (training time, inference time, and memory usage). Key findings reveal that while ensemble methods (such as Random Forest and gradient boosting models like XGBoost, CatBoost and LightGBM) demonstrate robust performance largely independent of scaling, other widely used models such as Logistic Regression, SVMs, TabNet, and MLPs show significant performance variations highly dependent on the chosen scaler. This extensive empirical analysis, with all source code, experimental results, and model parameters made publicly available to ensure complete transparency and reproducibility, offers model-specific crucial guidance to practitioners on the need for an optimal selection of feature scaling techniques.
SUA: Stealthy Multimodal Large Language Model Unlearning Attack
arXiv:2506.17265v2 Announce Type: replace Abstract: Multimodal Large Language Models (MLLMs) trained on massive data may memorize sensitive personal information and photos, posing serious privacy risks. To mitigate this, MLLM unlearning methods are proposed, which fine-tune MLLMs to reduce the ``forget'' sensitive information. However, it remains unclear whether the knowledge has been truly forgotten or just hidden in the model. Therefore, we propose to study a novel problem of LLM unlearning attack, which aims to recover the unlearned knowledge of an unlearned LLM. To achieve the goal, we propose a novel framework Stealthy Unlearning Attack (SUA) framework that learns a universal noise pattern. When applied to input images, this noise can trigger the model to reveal unlearned content. While pixel-level perturbations may be visually subtle, they can be detected in the semantic embedding space, making such attacks vulnerable to potential defenses. To improve stealthiness, we introduce an embedding alignment loss that minimizes the difference between the perturbed and denoised image embeddings, ensuring the attack is semantically unnoticeable. Experimental results show that SUA can effectively recover unlearned information from MLLMs. Furthermore, the learned noise generalizes well: a single perturbation trained on a subset of samples can reveal forgotten content in unseen images. This indicates that knowledge reappearance is not an occasional failure, but a consistent behavior.
A geometric framework for momentum-based optimizers for low-rank training
arXiv:2506.17475v2 Announce Type: replace Abstract: Low-rank pre-training and fine-tuning have recently emerged as promising techniques for reducing the computational and storage costs of large neural networks. Training low-rank parameterizations typically relies on conventional optimizers such as heavy ball momentum methods or Adam. In this work, we identify and analyze potential difficulties that these training methods encounter when used to train low-rank parameterizations of weights. In particular, we show that classical momentum methods can struggle to converge to a local optimum due to the geometry of the underlying optimization landscape. To address this, we introduce novel training strategies derived from dynamical low-rank approximation, which explicitly account for the underlying geometric structure. Our approach leverages and combines tools from dynamical low-rank approximation and momentum-based optimization to design optimizers that respect the intrinsic geometry of the parameter space. We validate our methods through numerical experiments, demonstrating faster convergence, and stronger validation metrics at given parameter budgets.
Model Guidance via Robust Feature Attribution
arXiv:2506.19680v2 Announce Type: replace Abstract: Controlling the patterns a model learns is essential to preventing reliance on irrelevant or misleading features. Such reliance on irrelevant features, often called shortcut features, has been observed across domains, including medical imaging and natural language processing, where it may lead to real-world harms. A common mitigation strategy leverages annotations (provided by humans or machines) indicating which features are relevant or irrelevant. These annotations are compared to model explanations, typically in the form of feature salience, and used to guide the loss function during training. Unfortunately, recent works have demonstrated that feature salience methods are unreliable and therefore offer a poor signal to optimize. In this work, we propose a simplified objective that simultaneously optimizes for explanation robustness and mitigation of shortcut learning. Unlike prior objectives with similar aims, we demonstrate theoretically why our approach ought to be more effective. Across a comprehensive series of experiments, we show that our approach consistently reduces test-time misclassifications by 20% compared to state-of-the-art methods. We also extend prior experimental settings to include natural language processing tasks. Additionally, we conduct novel ablations that yield practical insights, including the relative importance of annotation quality over quantity. Code for our method and experiments is available at: https://github.com/Mihneaghitu/ModelGuidanceViaRobustFeatureAttribution.
Progressive Size-Adaptive Federated Learning: A Comprehensive Framework for Heterogeneous Multi-Modal Data Systems
arXiv:2506.20685v2 Announce Type: replace Abstract: Federated Learning (FL) has emerged as a transformative paradigm for distributed machine learning while preserving data privacy. However, existing approaches predominantly focus on model heterogeneity and aggregation techniques, largely overlooking the fundamental impact of dataset size characteristics on federated training dynamics. This paper introduces Size-Based Adaptive Federated Learning (SAFL), a novel progressive training framework that systematically organizes federated learning based on dataset size characteristics across heterogeneous multi-modal data. Our comprehensive experimental evaluation across 13 diverse datasets spanning 7 modalities (vision, text, time series, audio, sensor, medical vision, and multimodal) reveals critical insights: 1) an optimal dataset size range of 1000-1500 samples for federated learning effectiveness; 2) a clear modality performance hierarchy with structured data (time series, sensor) significantly outperforming unstructured data (text, multimodal); and 3) systematic performance degradation for large datasets exceeding 2000 samples. SAFL achieves an average accuracy of 87.68% across all datasets, with structured data modalities reaching 99%+ accuracy. The framework demonstrates superior communication efficiency, reducing total data transfer to 7.38 GB across 558 communications while maintaining high performance. Our real-time monitoring framework provides unprecedented insights into system resource utilization, network efficiency, and training dynamics. This work fills critical gaps in understanding how data characteristics should drive federated learning strategies, providing both theoretical insights and practical guidance for real-world FL deployments in neural network and learning systems.
DBConformer: Dual-Branch Convolutional Transformer for EEG Decoding
arXiv:2506.21140v2 Announce Type: replace Abstract: Electroencephalography (EEG)-based brain-computer interfaces (BCIs) transform spontaneous/evoked neural activity into control commands for external communication. While convolutional neural networks (CNNs) remain the mainstream backbone for EEG decoding, their inherently short receptive field makes it difficult to capture long-range temporal dependencies and global inter-channel relationships. Recent CNN-Transformer (Conformer) hybrids partially address this issue, but most adopt a serial design, resulting in suboptimal integration of local and global features, and often overlook explicit channel-wise modeling. To address these limitations, we propose DBConformer, a dual-branch convolutional Transformer network tailored for EEG decoding. It integrates a temporal Conformer to model long-range temporal dependencies and a spatial Conformer to extract inter-channel interactions, capturing both temporal dynamics and spatial patterns in EEG signals. A lightweight channel attention module further refines spatial representations by assigning data-driven importance to EEG channels. Extensive experiments under four evaluation settings on three paradigms, including motor imagery, seizure detection, and steady-state visual evoked potential, demonstrated that DBConformer consistently outperformed 13 competitive baseline models, with over an eight-fold reduction in parameters than current high-capacity EEG Conformer architecture. Furthermore, the visualization results confirmed that the features extracted by DBConformer are physiologically interpretable and aligned with prior knowledge. The superior performance and interpretability of DBConformer make it reliable for accurate, robust, and explainable EEG decoding. Code is publicized at https://github.com/wzwvv/DBConformer.
Multi-View Contrastive Learning for Robust Domain Adaptation in Medical Time Series Analysis
arXiv:2506.22393v2 Announce Type: replace Abstract: Adapting machine learning models to medical time series across different domains remains a challenge due to complex temporal dependencies and dynamic distribution shifts. Current approaches often focus on isolated feature representations, limiting their ability to fully capture the intricate temporal dynamics necessary for robust domain adaptation. In this work, we propose a novel framework leveraging multi-view contrastive learning to integrate temporal patterns, derivative-based dynamics, and frequency-domain features. Our method employs independent encoders and a hierarchical fusion mechanism to learn feature-invariant representations that are transferable across domains while preserving temporal coherence. Extensive experiments on diverse medical datasets, including electroencephalogram (EEG), electrocardiogram (ECG), and electromyography (EMG) demonstrate that our approach significantly outperforms state-of-the-art methods in transfer learning tasks. By advancing the robustness and generalizability of machine learning models, our framework offers a practical pathway for deploying reliable AI systems in diverse healthcare settings.
Search-Optimized Quantization in Biomedical Ontology Alignment
arXiv:2507.13742v2 Announce Type: replace Abstract: In the fast-moving world of AI, as organizations and researchers develop more advanced models, they face challenges due to their sheer size and computational demands. Deploying such models on edge devices or in resource-constrained environments adds further challenges related to energy consumption, memory usage and latency. To address these challenges, emerging trends are shaping the future of efficient model optimization techniques. From this premise, by employing supervised state-of-the-art transformer-based models, this research introduces a systematic method for ontology alignment, grounded in cosine-based semantic similarity between a biomedical layman vocabulary and the Unified Medical Language System (UMLS) Metathesaurus. It leverages Microsoft Olive to search for target optimizations among different Execution Providers (EPs) using the ONNX Runtime backend, followed by an assembled process of dynamic quantization employing Intel Neural Compressor and IPEX (Intel Extension for PyTorch). Through our optimization process, we conduct extensive assessments on the two tasks from the DEFT 2020 Evaluation Campaign, achieving a new state-of-the-art in both. We retain performance metrics intact, while attaining an average inference speed-up of 20x and reducing memory usage by approximately 70%.
The Cost of Compression: Tight Quadratic Black-Box Attacks on Sketches for $\ell_2$ Norm Estimation
arXiv:2507.16345v2 Announce Type: replace Abstract: Dimensionality reduction via linear sketching is a powerful and widely used technique, but it is known to be vulnerable to adversarial inputs. We study the black-box adversarial setting, where a fixed, hidden sketching matrix $A \in R^{k \times n}$ maps high-dimensional vectors $v \in R^n$ to lower-dimensional sketches $A v \in R^k$, and an adversary can query the system to obtain approximate $\ell_2$-norm estimates that are computed from the sketch. We present a universal, nonadaptive attack that, using $\tilde{O}(k^2)$ queries, either causes a failure in norm estimation or constructs an adversarial input on which the optimal estimator for the query distribution (used by the attack) fails. The attack is completely agnostic to the sketching matrix and to the estimator: it applies to any linear sketch and any query responder, including those that are randomized, adaptive, or tailored to the query distribution. Our lower bound construction tightly matches the known upper bounds of $\tilde{\Omega}(k^2)$, achieved by specialized estimators for Johnson Lindenstrauss transforms and AMS sketches. Beyond sketching, our results uncover structural parallels to adversarial attacks in image classification, highlighting fundamental vulnerabilities of compressed representations.
HOTA: Hamiltonian framework for Optimal Transport Advection
arXiv:2507.17513v2 Announce Type: replace Abstract: Optimal transport (OT) has become a natural framework for guiding the probability flows. Yet, the majority of recent generative models assume trivial geometry (e.g., Euclidean) and rely on strong density-estimation assumptions, yielding trajectories that do not respect the true principles of optimality in the underlying manifold. We present Hamiltonian Optimal Transport Advection (HOTA), a Hamilton-Jacobi-Bellman based method that tackles the dual dynamical OT problem explicitly through Kantorovich potentials, enabling efficient and scalable trajectory optimization. Our approach effectively evades the need for explicit density modeling, performing even when the cost functionals are non-smooth. Empirically, HOTA outperforms all baselines in standard benchmarks, as well as in custom datasets with non-differentiable costs, both in terms of feasibility and optimality.
Revisiting Bisimulation Metric for Robust Representations in Reinforcement Learning
arXiv:2507.18519v2 Announce Type: replace Abstract: Bisimulation metric has long been regarded as an effective control-related representation learning technique in various reinforcement learning tasks. However, in this paper, we identify two main issues with the conventional bisimulation metric: 1) an inability to represent certain distinctive scenarios, and 2) a reliance on predefined weights for differences in rewards and subsequent states during recursive updates. We find that the first issue arises from an imprecise definition of the reward gap, whereas the second issue stems from overlooking the varying importance of reward difference and next-state distinctions across different training stages and task settings. To address these issues, by introducing a measure for state-action pairs, we propose a revised bisimulation metric that features a more precise definition of reward gap and novel update operators with adaptive coefficient. We also offer theoretical guarantees of convergence for our proposed metric and its improved representation distinctiveness. In addition to our rigorous theoretical analysis, we conduct extensive experiments on two representative benchmarks, DeepMind Control and Meta-World, demonstrating the effectiveness of our approach.
MH-GIN: Multi-scale Heterogeneous Graph-based Imputation Network for AIS Data (Extended Version)
arXiv:2507.20362v2 Announce Type: replace Abstract: Location-tracking data from the Automatic Identification System, much of which is publicly available, plays a key role in a range of maritime safety and monitoring applications. However, the data suffers from missing values that hamper downstream applications. Imputing the missing values is challenging because the values of different heterogeneous attributes are updated at diverse rates, resulting in the occurrence of multi-scale dependencies among attributes. Existing imputation methods that assume similar update rates across attributes are unable to capture and exploit such dependencies, limiting their imputation accuracy. We propose MH-GIN, a Multi-scale Heterogeneous Graph-based Imputation Network that aims improve imputation accuracy by capturing multi-scale dependencies. Specifically, MH-GIN first extracts multi-scale temporal features for each attribute while preserving their intrinsic heterogeneous characteristics. Then, it constructs a multi-scale heterogeneous graph to explicitly model dependencies between heterogeneous attributes to enable more accurate imputation of missing values through graph propagation. Experimental results on two real-world datasets find that MH-GIN is capable of an average 57% reduction in imputation errors compared to state-of-the-art methods, while maintaining computational efficiency. The source code and implementation details of MH-GIN are publicly available https://github.com/hyLiu1994/MH-GIN.
Dissecting Persona-Driven Reasoning in Language Models via Activation Patching
arXiv:2507.20936v2 Announce Type: replace Abstract: Large language models (LLMs) exhibit remarkable versatility in adopting diverse personas. In this study, we examine how assigning a persona influences a model's reasoning on an objective task. Using activation patching, we take a first step toward understanding how key components of the model encode persona-specific information. Our findings reveal that the early Multi-Layer Perceptron (MLP) layers attend not only to the syntactic structure of the input but also process its semantic content. These layers transform persona tokens into richer representations, which are then used by the middle Multi-Head Attention (MHA) layers to shape the model's output. Additionally, we identify specific attention heads that disproportionately attend to racial and color-based identities.
GraphTorque: Torque-Driven Rewiring Graph Neural Network
arXiv:2507.21422v3 Announce Type: replace Abstract: Graph Neural Networks (GNNs) have emerged as powerful tools for learning from graph-structured data, leveraging message passing to diffuse information and update node representations. However, most efforts have suggested that native interactions encoded in the graph may not be friendly for this process, motivating the development of graph rewiring methods. In this work, we propose a torque-driven hierarchical rewiring strategy, inspired by the notion of torque in classical mechanics, dynamically modulating message passing to improve representation learning in heterophilous and homophilous graphs. Specifically, we define the torque by treating the feature distance as a lever arm vector and the neighbor feature as a force vector weighted by the homophily disparity between nodes. We use the metric to hierarchically reconfigure receptive field of each layer by judiciously pruning high-torque edges and adding low-torque links, suppressing the impact of irrelevant information and boosting pertinent signals during message passing. Extensive evaluations on benchmark datasets show that the proposed approach surpasses state-of-the-art rewiring methods on both heterophilous and homophilous graphs.
Spec-VLA: Speculative Decoding for Vision-Language-Action Models with Relaxed Acceptance
arXiv:2507.22424v2 Announce Type: replace Abstract: Vision-Language-Action (VLA) models have made substantial progress by leveraging the robust capabilities of Visual Language Models (VLMs). However, VLMs' significant parameter size and autoregressive (AR) decoding nature impose considerable computational demands on VLA models. While Speculative Decoding (SD) has shown efficacy in accelerating Large Language Models (LLMs) by incorporating efficient drafting and parallel verification, allowing multiple tokens to be generated in one forward pass, its application to VLA models remains unexplored. This work introduces Spec-VLA, an SD framework designed to accelerate VLA models. Due to the difficulty of the action prediction task and the greedy decoding mechanism of the VLA models, the direct application of the advanced SD framework to the VLA prediction task yields a minor speed improvement. To boost the generation speed, we propose an effective mechanism to relax acceptance utilizing the relative distances represented by the action tokens of the VLA model. Empirical results across diverse test scenarios affirm the effectiveness of the Spec-VLA framework, and further analysis substantiates the impact of our proposed strategies, which enhance the acceptance length by 44%, achieving 1.42 times speedup compared with the OpenVLA baseline, without compromising the success rate. The success of the Spec-VLA framework highlights the potential for broader application of speculative execution in VLA prediction scenarios.
Pulling Back the Curtain on ReLU Networks
arXiv:2507.22832v4 Announce Type: replace Abstract: Since any ReLU network is piecewise affine, its hidden units can be characterized by their pullbacks through the active subnetwork, i.e., by their gradients (up to bias terms). However, gradients of deeper neurons are notoriously misaligned, which obscures the network's internal representations. We posit that models do align gradients with data, yet this is concealed by the intrinsic noise of the ReLU hard gating. We validate this intuition by applying soft gating in the backward pass only, reducing the local impact of weakly excited neurons. The resulting modified gradients, which we call "excitation pullbacks", exhibit striking perceptual alignment on a number of ImageNet-pretrained architectures, while the rudimentary pixel-space gradient ascent quickly produces easily interpretable input- and target-specific features. Inspired by these findings, we formulate the "path stability" hypothesis, claiming that the binary activation patterns largely stabilize during training and get encoded in the pre-activation distribution of the final model. When true, excitation pullbacks become aligned with the gradients of a kernel machine that mainly determines the network's decision. This provides a theoretical justification for the apparent faithfulness of the feature attributions based on excitation pullbacks, potentially even leading to mechanistic interpretability of deep models. Incidentally, we give a possible explanation for the effectiveness of Batch Normalization and Deep Features, together with a novel perspective on the network's internal memory and generalization properties. We release the code and an interactive app for easier exploration of the excitation pullbacks.
Reinforcement Learning for Decision-Level Interception Prioritization in Drone Swarm Defense
arXiv:2508.00641v2 Announce Type: replace Abstract: The growing threat of low-cost kamikaze drone swarms poses a critical challenge to modern defense systems demanding rapid and strategic decision-making to prioritize interceptions across multiple effectors and high-value target zones. In this work, we present a case study demonstrating the practical advantages of reinforcement learning in addressing this challenge. We introduce a high-fidelity simulation environment that captures realistic operational constraints, within which a decision-level reinforcement learning agent learns to coordinate multiple effectors for optimal interception prioritization. Operating in a discrete action space, the agent selects which drone to engage per effector based on observed state features such as positions, classes, and effector status. We evaluate the learned policy against a handcrafted rule-based baseline across hundreds of simulated attack scenarios. The reinforcement learning based policy consistently achieves lower average damage and higher defensive efficiency in protecting critical zones. This case study highlights the potential of reinforcement learning as a strategic layer within defense architectures, enhancing resilience without displacing existing control systems. All code and simulation assets are publicly released for full reproducibility, and a video demonstration illustrates the policy's qualitative behavior.
Learning from Similarity-Confidence and Confidence-Difference
arXiv:2508.05108v2 Announce Type: replace Abstract: In practical machine learning applications, it is often challenging to assign accurate labels to data, and increasing the number of labeled instances is often limited. In such cases, Weakly Supervised Learning (WSL), which enables training with incomplete or imprecise supervision, provides a practical and effective solution. However, most existing WSL methods focus on leveraging a single type of weak supervision. In this paper, we propose a novel WSL framework that leverages complementary weak supervision signals from multiple relational perspectives, which can be especially valuable when labeled data is limited. Specifically, we introduce SconfConfDiff Classification, a method that integrates two distinct forms of weaklabels: similarity-confidence and confidence-difference, which are assigned to unlabeled data pairs. To implement this method, we derive two types of unbiased risk estimators for classification: one based on a convex combination of existing estimators, and another newly designed by modeling the interaction between two weak labels. We prove that both estimators achieve optimal convergence rates with respect to estimation error bounds. Furthermore, we introduce a risk correction approach to mitigate overfitting caused by negative empirical risk, and provide theoretical analysis on the robustness of the proposed method against inaccurate class prior probability and label noise. Experimental results demonstrate that the proposed method consistently outperforms existing baselines across a variety of settings.
EvoCoT: Overcoming the Exploration Bottleneck in Reinforcement Learning
arXiv:2508.07809v3 Announce Type: replace Abstract: Reinforcement learning with verifiable reward (RLVR) has become a promising paradigm for post-training large language models (LLMs) to improve their reasoning capability. However, when the rollout accuracy is low on hard problems, the reward becomes sparse, limiting learning efficiency and causing exploration bottlenecks. Existing approaches either rely on teacher models for distillation or filter out difficult problems, which limits scalability or restricts reasoning improvement through exploration. We propose EvoCoT, a self-evolving curriculum learning framework based on two-stage chain-of-thought (CoT) reasoning optimization. EvoCoT constrains the exploration space by self-generating and verifying CoT trajectories, then gradually shortens CoT steps to expand the space in a controlled way. The framework enables LLMs to stably learn from initially unsolved hard problems under sparse rewards. We apply EvoCoT to multiple LLM families, including Qwen, DeepSeek, and Llama. Experiments show that EvoCoT enables LLMs to solve previously unsolved problems, improves reasoning capability without external CoT supervision, and is compatible with various RL fine-tuning methods. We release the source code to support future research.
Causally-Guided Pairwise Transformer -- Towards Foundational Digital Twins in Process Industry
arXiv:2508.13111v2 Announce Type: replace Abstract: Foundational modelling of multi-dimensional time-series data in industrial systems presents a central trade-off: channel-dependent (CD) models capture specific cross-variable dynamics but lack robustness and adaptability as model layers are commonly bound to the data dimensionality of the tackled use-case, while channel-independent (CI) models offer generality at the cost of modelling the explicit interactions crucial for system-level predictive regression tasks. To resolve this, we propose the Causally-Guided Pairwise Transformer (CGPT), a novel architecture that integrates a known causal graph as an inductive bias. The core of CGPT is built around a pairwise modeling paradigm, tackling the CD/CI conflict by decomposing the multidimensional data into pairs. The model uses channel-agnostic learnable layers where all parameter dimensions are independent of the number of variables. CGPT enforces a CD information flow at the pair-level and CI-like generalization across pairs. This approach disentangles complex system dynamics and results in a highly flexible architecture that ensures scalability and any-variate adaptability. We validate CGPT on a suite of synthetic and real-world industrial datasets on long-term and one-step forecasting tasks designed to simulate common industrial complexities. Results demonstrate that CGPT significantly outperforms both CI and CD baselines in predictive accuracy and shows competitive performance with end-to-end trained CD models while remaining agnostic to the problem dimensionality.
Neuro-inspired Ensemble-to-Ensemble Communication Primitives for Sparse and Efficient ANNs
arXiv:2508.14140v2 Announce Type: replace Abstract: The structure of biological neural circuits-modular, hierarchical, and sparsely interconnected-reflects an efficient trade-off between wiring cost, functional specialization, and robustness. These principles offer valuable insights for artificial neural network (ANN) design, especially as networks grow in depth and scale. Sparsity, in particular, has been widely explored for reducing memory and computation, improving speed, and enhancing generalization. Motivated by systems neuroscience findings, we explore how patterns of functional connectivity in the mouse visual cortex-specifically, ensemble-to-ensemble communication, can inform ANN design. We introduce G2GNet, a novel architecture that imposes sparse, modular connectivity across feedforward layers. Despite having significantly fewer parameters than fully connected models, G2GNet achieves superior accuracy on standard vision benchmarks. To our knowledge, this is the first architecture to incorporate biologically observed functional connectivity patterns as a structural bias in ANN design. We complement this static bias with a dynamic sparse training (DST) mechanism that prunes and regrows edges during training. We also propose a Hebbian-inspired rewiring rule based on activation correlations, drawing on principles of biological plasticity. G2GNet achieves up to 75% sparsity while improving accuracy by up to 4.3% on benchmarks, including Fashion-MNIST, CIFAR-10, and CIFAR-100, outperforming dense baselines with far fewer computations.
Side Effects of Erasing Concepts from Diffusion Models
arXiv:2508.15124v3 Announce Type: replace Abstract: Concerns about text-to-image (T2I) generative models infringing on privacy, copyright, and safety have led to the development of concept erasure techniques (CETs). The goal of an effective CET is to prohibit the generation of undesired "target" concepts specified by the user, while preserving the ability to synthesize high-quality images of other concepts. In this work, we demonstrate that concept erasure has side effects and CETs can be easily circumvented. For a comprehensive measurement of the robustness of CETs, we present the Side Effect Evaluation (SEE) benchmark that consists of hierarchical and compositional prompts describing objects and their attributes. The dataset and an automated evaluation pipeline quantify side effects of CETs across three aspects: impact on neighboring concepts, evasion of targets, and attribute leakage. Our experiments reveal that CETs can be circumvented by using superclass-subclass hierarchy, semantically similar prompts, and compositional variants of the target. We show that CETs suffer from attribute leakage and a counterintuitive phenomenon of attention concentration or dispersal. We release our benchmark and evaluation tools to aid future work on robust concept erasure.
Retrieval Enhanced Feedback via In-context Neural Error-book
arXiv:2508.16313v3 Announce Type: replace Abstract: Recent advancements in Large Language Models (LLMs) have significantly improved reasoning capabilities, with in-context learning (ICL) emerging as a key technique for adaptation without retraining. While previous works have focused on leveraging correct examples, recent research highlights the importance of learning from errors to enhance performance. However, existing methods lack a structured framework for analyzing and mitigating errors, particularly in Multimodal Large Language Models (MLLMs), where integrating visual and textual inputs adds complexity. To address this issue, we propose REFINE: Retrieval-Enhanced Feedback via In-context Neural Error-book, a teacher-student framework that systematically structures errors and provides targeted feedback. REFINE introduces three systematic queries to construct structured feedback -- Feed-Target, Feed-Check, and Feed-Path -- to enhance multimodal reasoning by prioritizing relevant visual information, diagnosing critical failure points, and formulating corrective actions. Unlike prior approaches that rely on redundant retrievals, REFINE optimizes structured feedback retrieval, improving inference efficiency, token usage, and scalability. Our results demonstrate substantial speedup, reduced computational costs, and successful generalization, highlighting REFINE's potential for enhancing multimodal reasoning.
Rectified Robust Policy Optimization for Model-Uncertain Constrained Reinforcement Learning without Strong Duality
arXiv:2508.17448v2 Announce Type: replace Abstract: The goal of robust constrained reinforcement learning (RL) is to optimize an agent's performance under the worst-case model uncertainty while satisfying safety or resource constraints. In this paper, we demonstrate that strong duality does not generally hold in robust constrained RL, indicating that traditional primal-dual methods may fail to find optimal feasible policies. To overcome this limitation, we propose a novel primal-only algorithm called Rectified Robust Policy Optimization (RRPO), which operates directly on the primal problem without relying on dual formulations. We provide theoretical convergence guarantees under mild regularity assumptions, showing convergence to an approximately optimal feasible policy with iteration complexity matching the best-known lower bound when the uncertainty set diameter is controlled in a specific level. Empirical results in a grid-world environment validate the effectiveness of our approach, demonstrating that RRPO achieves robust and safe performance under model uncertainties while the non-robust method can violate the worst-case safety constraints.
GEPO: Group Expectation Policy Optimization for Stable Heterogeneous Reinforcement Learning
arXiv:2508.17850v5 Announce Type: replace Abstract: As single-center computing approaches power constraints, decentralized training becomes essential. However, traditional Reinforcement Learning (RL) methods, crucial for enhancing large model post-training, cannot adapt to decentralized distributed training due to the tight coupling between parameter learning and rollout sampling. For this, we propose HeteroRL, a heterogeneous RL architecture that decouples these processes, enabling stable training across geographically distributed nodes connected via the Internet. The core component is Group Expectation Policy Optimization (GEPO), an asynchronous RL algorithm robust to latency caused by network delays or heterogeneity in computational resources. Our study reveals that high latency significantly increases KL divergence, leading to higher variance in importance sampling weights and training instability. GEPO mitigates this issue by using group expectation weighting to exponentially reduce the variance of importance weights, with theoretical guarantees. Experiments show that GEPO achieves superior stability, with only a 3\% performance drop from online to 1800s latency, demonstrating strong potential for decentralized RL in geographically distributed, resource-heterogeneous computing environments.
STRATA-TS: Selective Knowledge Transfer for Urban Time Series Forecasting with Retrieval-Guided Reasoning
arXiv:2508.18635v2 Announce Type: replace Abstract: Urban forecasting models often face a severe data imbalance problem: only a few cities have dense, long-span records, while many others expose short or incomplete histories. Direct transfer from data-rich to data-scarce cities is unreliable because only a limited subset of source patterns truly benefits the target domain, whereas indiscriminate transfer risks introducing noise and negative transfer. We present STRATA-TS (Selective TRAnsfer via TArget-aware retrieval for Time Series), a framework that combines domain-adapted retrieval with reasoning-capable large models to improve forecasting in scarce data regimes. STRATA-TS employs a patch-based temporal encoder to identify source subsequences that are semantically and dynamically aligned with the target query. These retrieved exemplars are then injected into a retrieval-guided reasoning stage, where an LLM performs structured inference over target inputs and retrieved support. To enable efficient deployment, we distill the reasoning process into a compact open model via supervised fine-tuning. Extensive experiments on three parking availability datasets across Singapore, Nottingham, and Glasgow demonstrate that STRATA-TS consistently outperforms strong forecasting and transfer baselines, while providing interpretable knowledge transfer pathways.
(DEMO) Deep Reinforcement Learning Based Resource Allocation in Distributed IoT Systems
arXiv:2508.19318v2 Announce Type: replace Abstract: Deep Reinforcement Learning (DRL) has emerged as an efficient approach to resource allocation due to its strong capability in handling complex decision-making tasks. However, only limited research has explored the training of DRL models with real-world data in practical, distributed Internet of Things (IoT) systems. To bridge this gap, this paper proposes a novel framework for training DRL models in real-world distributed IoT environments. In the proposed framework, IoT devices select communication channels using a DRL-based method, while the DRL model is trained with feedback information. Specifically, Acknowledgment (ACK) information is obtained from actual data transmissions over the selected channels. Implementation and performance evaluation, in terms of Frame Success Rate (FSR), are carried out, demonstrating both the feasibility and the effectiveness of the proposed framework.
Using item recommendations and LLMs in marketing email titles
arXiv:2508.20024v3 Announce Type: replace Abstract: E-commerce marketplaces make use of a number of marketing channels like emails, push notifications, etc. to reach their users and stimulate purchases. Personalized emails especially are a popular touch point for marketers to inform users of latest items in stock, especially for those who stopped visiting the marketplace. Such emails contain personalized recommendations tailored to each user's interests, enticing users to buy relevant items. A common limitation of these emails is that the primary entry point, the title of the email, tends to follow fixed templates, failing to inspire enough interest in the contents. In this work, we explore the potential of large language models (LLMs) for generating thematic titles that reflect the personalized content of the emails. We perform offline simulations and conduct online experiments on the order of millions of users, finding our techniques useful in improving the engagement between customers and our emails. We highlight key findings and learnings as we productionize the safe and automated generation of email titles for millions of users.
CbLDM: A Diffusion Model for recovering nanostructure from pair distribution function
arXiv:2509.01370v3 Announce Type: replace Abstract: Nowadays, the nanostructure inverse problem is an attractive problem that helps researchers to understand the relationship between the properties and the structure of nanomaterials. This article focuses on the problem of using PDF to recover the nanostructure, which this article views as a conditional generation problem. This article propose a deep learning model CbLDM, Condition-based Latent Diffusion Model. Based on the original latent diffusion model, the sampling steps of the diffusion model are reduced and the sample generation efficiency is improved by using the conditional prior to estimate conditional posterior distribution, which is the approximated distribution of p(z|x). In addition, this article uses the Laplacian matrix instead of the distance matrix to recover the nanostructure, which can reduce the reconstruction error. Finally, this article compares CbLDM with existing models which were used to solve the nanostructure inverse problem, and find that CbLDM demonstrates significantly higher prediction accuracy than these models, which reflects the ability of CbLDM to solve the nanostructure inverse problem and the potential to cope with other continuous conditional generation tasks.
Information-Theoretic Bounds and Task-Centric Learning Complexity for Real-World Dynamic Nonlinear Systems
arXiv:2509.06599v2 Announce Type: replace Abstract: Dynamic nonlinear systems exhibit distortions arising from coupled static and dynamic effects. Their intertwined nature poses major challenges for data-driven modeling. This paper presents a theoretical framework grounded in structured decomposition, variance analysis, and task-centric complexity bounds. The framework employs a directional lower bound on interactions between measurable system components, extending orthogonality in inner product spaces to structurally asymmetric settings. This bound supports variance inequalities for decomposed systems. Key behavioral indicators are introduced along with a memory finiteness index. A rigorous power-based condition establishes a measurable link between finite memory in realizable systems and the First Law of Thermodynamics. This offers a more foundational perspective than classical bounds based on the Second Law. Building on this foundation, we formulate a `Behavioral Uncertainty Principle,' demonstrating that static and dynamic distortions cannot be minimized simultaneously. We identify that real-world systems seem to resist complete deterministic decomposition due to entangled static and dynamic effects. We also present two general-purpose theorems linking function variance to mean-squared Lipschitz continuity and learning complexity. This yields a model-agnostic, task-aware complexity metric, showing that lower-variance components are inherently easier to learn. These insights explain the empirical benefits of structured residual learning, including improved generalization, reduced parameter count, and lower training cost, as previously observed in power amplifier linearization experiments. The framework is broadly applicable and offers a scalable, theoretically grounded approach to modeling complex dynamic nonlinear systems.
Structure Matters: Brain Graph Augmentation via Learnable Edge Masking for Data-efficient Psychiatric Diagnosis
arXiv:2509.09744v3 Announce Type: replace Abstract: The limited availability of labeled brain network data makes it challenging to achieve accurate and interpretable psychiatric diagnoses. While self-supervised learning (SSL) offers a promising solution, existing methods often rely on augmentation strategies that can disrupt crucial structural semantics in brain graphs. To address this, we propose SAM-BG, a two-stage framework for learning brain graph representations with structural semantic preservation. In the pre-training stage, an edge masker is trained on a small labeled subset to capture key structural semantics. In the SSL stage, the extracted structural priors guide a structure-aware augmentation process, enabling the model to learn more semantically meaningful and robust representations. Experiments on two real-world psychiatric datasets demonstrate that SAM-BG outperforms state-of-the-art methods, particularly in small-labeled data settings, and uncovers clinically relevant connectivity patterns that enhance interpretability. Our code is available at https://github.com/mjliu99/SAM-BG.
LoFT: Parameter-Efficient Fine-Tuning for Long-tailed Semi-Supervised Learning in Open-World Scenarios
arXiv:2509.09926v2 Announce Type: replace Abstract: Long-tailed learning has garnered increasing attention due to its wide applicability in real-world scenarios. Among existing approaches, Long-Tailed Semi-Supervised Learning (LTSSL) has emerged as an effective solution by incorporating a large amount of unlabeled data into the imbalanced labeled dataset. However, most prior LTSSL methods are designed to train models from scratch, which often leads to issues such as overconfidence and low-quality pseudo-labels. To address these challenges, we extend LTSSL into the foundation model fine-tuning paradigm and propose a novel framework: LoFT (Long-tailed semi-supervised learning via parameter-efficient Fine-Tuning). We demonstrate that fine-tuned foundation models can generate more reliable pseudolabels, thereby benefiting imbalanced learning. Furthermore, we explore a more practical setting by investigating semi-supervised learning under open-world conditions, where the unlabeled data may include out-of-distribution (OOD) samples. To handle this problem, we propose LoFT-OW (LoFT under Open-World scenarios) to improve the discriminative ability. Experimental results on multiple benchmarks demonstrate that our method achieves superior performance compared to previous approaches, even when utilizing only 1\% of the unlabeled data compared with previous works.
No Need for Learning to Defer? A Training Free Deferral Framework to Multiple Experts through Conformal Prediction
arXiv:2509.12573v2 Announce Type: replace Abstract: AI systems often fail to deliver reliable predictions across all inputs, prompting the need for hybrid human-AI decision-making. Existing Learning to Defer (L2D) approaches address this by training deferral models, but these are sensitive to changes in expert composition and require significant retraining if experts change. We propose a training-free, model- and expert-agnostic framework for expert deferral based on conformal prediction. Our method uses the prediction set generated by a conformal predictor to identify label-specific uncertainty and selects the most discriminative expert using a segregativity criterion, measuring how well an expert distinguishes between the remaining plausible labels. Experiments on CIFAR10-H and ImageNet16-H show that our method consistently outperforms both the standalone model and the strongest expert, with accuracies attaining $99.57\pm0.10\%$ and $99.40\pm0.52\%$, while reducing expert workload by up to a factor of $11$. The method remains robust under degraded expert performance and shows a gradual performance drop in low-information settings. These results suggest a scalable, retraining-free alternative to L2D for real-world human-AI collaboration.
Privacy-Aware In-Context Learning for Large Language Models
arXiv:2509.13625v2 Announce Type: replace Abstract: Large language models (LLMs) have significantly transformed natural language understanding and generation, but they raise privacy concerns due to potential exposure of sensitive information. Studies have highlighted the risk of information leakage, where adversaries can extract sensitive information embedded in the prompts. In this work, we introduce a novel private prediction framework for generating high-quality synthetic text with strong privacy guarantees. Our approach leverages the Differential Privacy (DP) framework to ensure worst-case theoretical bounds on information leakage without requiring any fine-tuning of the underlying models. The proposed method performs inference on private records and aggregates the resulting per-token output distributions. This enables the generation of longer and coherent synthetic text while maintaining privacy guarantees. Additionally, we propose a simple blending operation that combines private and public inference to further enhance utility. Empirical evaluations demonstrate that our approach outperforms previous state-of-the-art methods on in-context-learning (ICL) tasks, making it a promising direction for privacy-preserving text generation while maintaining high utility.
Bridging Past and Future: Distribution-Aware Alignment for Time Series Forecasting
arXiv:2509.14181v2 Announce Type: replace Abstract: Although contrastive and other representation-learning methods have long been explored in vision and NLP, their adoption in modern time series forecasters remains limited. We believe they hold strong promise for this domain. To unlock this potential, we explicitly align past and future representations, thereby bridging the distributional gap between input histories and future targets. To this end, we introduce TimeAlign, a lightweight, plug-and-play framework that establishes a new representation paradigm, distinct from contrastive learning, by aligning auxiliary features via a simple reconstruction task and feeding them back into any base forecaster. Extensive experiments across eight benchmarks verify its superior performance. Further studies indicate that the gains arise primarily from correcting frequency mismatches between historical inputs and future outputs. Additionally, we provide two theoretical justifications for how reconstruction improves forecasting generalization and how alignment increases the mutual information between learned representations and predicted targets. The code is available at https://github.com/TROUBADOUR000/TimeAlign.
Fresh in memory: Training-order recency is linearly encoded in language model activations
arXiv:2509.14223v2 Announce Type: replace Abstract: We show that language models' activations linearly encode when information was learned during training. Our setup involves creating a model with a known training order by sequentially fine-tuning Llama-3.2-1B on six disjoint but otherwise similar datasets about named entities. We find that the average activations of test samples corresponding to the six training datasets encode the training order: when projected into a 2D subspace, these centroids are arranged exactly in the order of training and lie on a straight line. Further, we show that linear probes can accurately (~90%) distinguish "early" vs. "late" entities, generalizing to entities unseen during the probes' own training. The model can also be fine-tuned to explicitly report an unseen entity's training stage (~80% accuracy). Interestingly, the training-order encoding does not seem attributable to simple differences in activation magnitudes, losses, or model confidence. Our paper demonstrates that models are capable of differentiating information by its acquisition time, and carries significant implications for how they might manage conflicting data and respond to knowledge modifications.
Evidential Physics-Informed Neural Networks for Scientific Discovery
arXiv:2509.14568v2 Announce Type: replace Abstract: We present the fundamental theory and implementation guidelines underlying Evidential Physics-Informed Neural Network (E-PINN) -- a novel class of uncertainty-aware PINN. It leverages the marginal distribution loss function of evidential deep learning for estimating uncertainty of outputs, and infers unknown parameters of the PDE via a learned posterior distribution. Validating our model on two illustrative case studies -- the 1D Poisson equation with a Gaussian source and the 2D Fisher-KPP equation, we found that E-PINN generated empirical coverage probabilities that were calibrated significantly better than Bayesian PINN and Deep Ensemble methods. To demonstrate real-world applicability, we also present a brief case study on applying E-PINN to analyze clinical glucose-insulin datasets that have featured in medical research on diabetes pathophysiology.
HDC-X: Efficient Medical Data Classification for Embedded Devices
arXiv:2509.14617v2 Announce Type: replace Abstract: Energy-efficient medical data classification is essential for modern disease screening, particularly in home and field healthcare where embedded devices are prevalent. While deep learning models achieve state-of-the-art accuracy, their substantial energy consumption and reliance on GPUs limit deployment on such platforms. We present HDC-X, a lightweight classification framework designed for low-power devices. HDC-X encodes data into high-dimensional hypervectors, aggregates them into multiple cluster-specific prototypes, and performs classification through similarity search in hyperspace. We evaluate HDC-X across three medical classification tasks; on heart sound classification, HDC-X is $350\times$ more energy-efficient than Bayesian ResNet with less than 1% accuracy difference. Moreover, HDC-X demonstrates exceptional robustness to noise, limited training data, and hardware error, supported by both theoretical analysis and empirical results, highlighting its potential for reliable deployment in real-world settings. Code is available at https://github.com/jianglanwei/HDC-X.
On the Convergence of Muon and Beyond
arXiv:2509.15816v2 Announce Type: replace Abstract: The Muon optimizer has demonstrated remarkable empirical success in handling matrix-structured parameters for training neural networks. However, a significant gap persists between its practical performance and theoretical understanding. Existing analyses indicate that the standard Muon variant achieves only a suboptimal convergence rate of $\mathcal{O}(T^{-1/4})$ in stochastic non-convex settings, where $T$ denotes the number of iterations. To explore the theoretical limits of the Muon framework, we develop and analyze two momentum-based variance-reduced variants: a one-batch version (Muon-MVR1) and a two-batch version (Muon-MVR2). We provide the first rigorous proof that incorporating a variance-reduction mechanism enables Muon-MVR2 to attain an optimal convergence rate of $\tilde{\mathcal{O}}(T^{-1/3})$, thereby matching the theoretical lower bound for this class of problems. Moreover, our analysis establishes convergence guarantees for Muon variants under the Polyak-{\L}ojasiewicz (P{\L}) condition. Extensive experiments on vision (CIFAR-10) and language (C4) benchmarks corroborate our theoretical findings on per-iteration convergence. Overall, this work provides the first proof of optimality for a Muon-style optimizer and clarifies the path toward developing more practically efficient, accelerated variants.
HyP-ASO: A Hybrid Policy-based Adaptive Search Optimization Framework for Large-Scale Integer Linear Programs
arXiv:2509.15828v2 Announce Type: replace Abstract: Directly solving large-scale Integer Linear Programs (ILPs) using traditional solvers is slow due to their NP-hard nature. While recent frameworks based on Large Neighborhood Search (LNS) can accelerate the solving process, their performance is often constrained by the difficulty in generating sufficiently effective neighborhoods. To address this challenge, we propose HyP-ASO, a hybrid policy-based adaptive search optimization framework that combines a customized formula with deep Reinforcement Learning (RL). The formula leverages feasible solutions to calculate the selection probabilities for each variable in the neighborhood generation process, and the RL policy network predicts the neighborhood size. Extensive experiments demonstrate that HyP-ASO significantly outperforms existing LNS-based approaches for large-scale ILPs. Additional experiments show it is lightweight and highly scalable, making it well-suited for solving large-scale ILPs.
Dynamic Classifier-Free Diffusion Guidance via Online Feedback
arXiv:2509.16131v2 Announce Type: replace Abstract: Classifier-free guidance (CFG) is a cornerstone of text-to-image diffusion models, yet its effectiveness is limited by the use of static guidance scales. This "one-size-fits-all" approach fails to adapt to the diverse requirements of different prompts; moreover, prior solutions like gradient-based correction or fixed heuristic schedules introduce additional complexities and fail to generalize. In this work, we challeng this static paradigm by introducing a framework for dynamic CFG scheduling. Our method leverages online feedback from a suite of general-purpose and specialized small-scale latent-space evaluations, such as CLIP for alignment, a discriminator for fidelity and a human preference reward model, to assess generation quality at each step of the reverse diffusion process. Based on this feedback, we perform a greedy search to select the optimal CFG scale for each timestep, creating a unique guidance schedule tailored to every prompt and sample. We demonstrate the effectiveness of our approach on both small-scale models and the state-of-the-art Imagen 3, showing significant improvements in text alignment, visual quality, text rendering and numerical reasoning. Notably, when compared against the default Imagen 3 baseline, our method achieves up to 53.8% human preference win-rate for overall preference, a figure that increases up to to 55.5% on prompts targeting specific capabilities like text rendering. Our work establishes that the optimal guidance schedule is inherently dynamic and prompt-dependent, and provides an efficient and generalizable framework to achieve it.
Unsupervised Interpretable Basis Extraction for Concept-Based Visual Explanations
arXiv:2303.10523v3 Announce Type: replace-cross Abstract: An important line of research attempts to explain CNN image classifier predictions and intermediate layer representations in terms of human-understandable concepts. Previous work supports that deep representations are linearly separable with respect to their concept label, implying that the feature space has directions where intermediate representations may be projected onto, to become more understandable. These directions are called interpretable, and when considered as a set, they may form an interpretable feature space basis. Compared to previous top-down probing approaches which use concept annotations to identify the interpretable directions one at a time, in this work, we take a bottom-up approach, identifying the directions from the structure of the feature space, collectively, without relying on supervision from concept labels. Instead, we learn the directions by optimizing for a sparsity property that holds for any interpretable basis. We experiment with existing popular CNNs and demonstrate the effectiveness of our method in extracting an interpretable basis across network architectures and training datasets. We make extensions to existing basis interpretability metrics and show that intermediate layer representations become more interpretable when transformed with the extracted bases. Finally, we compare the bases extracted with our method with the bases derived with supervision and find that, in one aspect, unsupervised basis extraction has a strength that constitutes a limitation of learning the basis with supervision, and we provide potential directions for future research.
LieDetect: Detection of representation orbits of compact Lie groups from point clouds
arXiv:2309.03086v3 Announce Type: replace-cross Abstract: We suggest a new algorithm to estimate representations of compact Lie groups from finite samples of their orbits. Different from other reported techniques, our method allows the retrieval of the precise representation type as a direct sum of irreducible representations. Moreover, the knowledge of the representation type permits the reconstruction of its orbit, which is useful for identifying the Lie group that generates the action, from a finite list of candidates. Our algorithm is general for any compact Lie group, but only instantiations for SO(2), T^d, SU(2), and SO(3) are considered. Theoretical guarantees of robustness in terms of Hausdorff and Wasserstein distances are derived. Our tools are drawn from geometric measure theory, computational geometry, and optimization on matrix manifolds. The algorithm is tested for synthetic data up to dimension 32, as well as real-life applications in image analysis, harmonic analysis, density estimation, equivariant neural networks, chemical conformational spaces, and classical mechanics systems, achieving very accurate results.
SINF: Semantic Neural Network Inference with Semantic Subgraphs
arXiv:2310.01259v3 Announce Type: replace-cross Abstract: This paper proposes Semantic Inference (SINF) that creates semantic subgraphs in a Deep Neural Network(DNN) based on a new Discriminative Capability Score (DCS) to drastically reduce the DNN computational load with limited performance loss.~We evaluate the performance SINF on VGG16, VGG19, and ResNet50 DNNs trained on CIFAR100 and a subset of the ImageNet dataset. Moreover, we compare its performance against 6 state-of-the-art pruning approaches. Our results show that (i) on average, SINF reduces the inference time of VGG16, VGG19, and ResNet50 respectively by up to 29%, 35%, and 15% with only 3.75%, 0.17%, and 6.75% accuracy loss for CIFAR100 while for ImageNet benchmark, the reduction in inference time is 18%, 22%, and 9% for accuracy drop of 3%, 2.5%, and 6%; (ii) DCS achieves respectively up to 3.65%, 4.25%, and 2.36% better accuracy with VGG16, VGG19, and ResNet50 with respect to existing discriminative scores for CIFAR100 and the same for ImageNet is 8.9%, 5.8%, and 5.2% respectively. Through experimental evaluation on Raspberry Pi and NVIDIA Jetson Nano, we show SINF is about 51% and 38% more energy efficient and takes about 25% and 17% less inference time than the base model for CIFAR100 and ImageNet.
Data-Driven Discovery of PDEs via the Adjoint Method
arXiv:2401.17177v5 Announce Type: replace-cross Abstract: In this work, we present an adjoint-based method for discovering the underlying governing partial differential equations (PDEs) given data. The idea is to consider a parameterized PDE in a general form and formulate a PDE-constrained optimization problem aimed at minimizing the error of the PDE solution from data. Using variational calculus, we obtain an evolution equation for the Lagrange multipliers (adjoint equations) allowing us to compute the gradient of the objective function with respect to the parameters of PDEs given data in a straightforward manner. In particular, we consider a family of parameterized PDEs encompassing linear, nonlinear, and spatial derivative candidate terms, and elegantly derive the corresponding adjoint equations. We show the efficacy of the proposed approach in identifying the form of the PDE up to machine accuracy, enabling the accurate discovery of PDEs from data. We also compare its performance with the famous PDE Functional Identification of Nonlinear Dynamics method known as PDE-FIND (Rudy et al., 2017), on both smooth and noisy data sets. Even though the proposed adjoint method relies on forward/backward solvers, it outperforms PDE-FIND for large data sets thanks to the analytic expressions for gradients of the cost function with respect to each PDE parameter.
Scaling Efficient LLMs
arXiv:2402.14746v4 Announce Type: replace-cross Abstract: Trained LLMs in the transformer architecture are typically sparse in that most of the parameters are negligible, raising questions on efficiency. Furthermore, the so called "AI scaling law" for transformers suggests that the number of parameters must scale linearly with the size of the data. In response, we inquire into efficient LLMs, i.e. those with the fewest parameters that achieve the desired accuracy on a training corpus. Specifically, by comparing theoretical and empirical estimates of the Kullback-Liebler divergence, we derive a natural AI scaling law that the number of parameters in an efficient LLM scales as $D^{\gamma}$ where $D$ is the size of the training data and $ \gamma \in [0.44, 0.72]$, suggesting the existence of more efficient architectures. Against this backdrop, we propose recurrent transformers, combining the efficacy of transformers with the efficiency of recurrent networks, progressively applying a single transformer layer to a fixed-width sliding window across the input sequence. Recurrent transformers (a) run in linear time in the sequence length, (b) are memory-efficient and amenable to parallel processing in large batches, (c) learn to forget history for language tasks, or accumulate history for long range tasks like copy and selective copy, and (d) are amenable to curriculum training to overcome vanishing gradients. In our experiments, we find that recurrent transformers perform favorably on benchmark tests.
Block-Fused Attention-Driven Adaptively-Pooled ResNet Model for Improved Cervical Cancer Classification
arXiv:2405.01600v3 Announce Type: replace-cross Abstract: Cervical cancer is the second most common cancer among women and a leading cause of mortality. Many attempts have been made to develop an effective Computer Aided Diagnosis (CAD) system; however, their performance remains limited. Using pretrained ResNet-50/101/152, we propose a novel CAD system that significantly outperforms prior approaches. Our novel model has three key components. First, we extract detailed features (color, edges, and texture) from early convolution blocks and the abstract features (shapes and objects) from later blocks, as both are equally important. This dual-level feature extraction is a new paradigm in cancer classification. Second, a non-parametric 3D attention module is uniquely embedded within each block for feature enhancement. Third, we design a theoretically motivated innovative adaptive pooling strategy for feature selection that applies Global Max Pooling to detailed features and Global Average Pooling to abstract features. These components form our Proposed Block-Fused Attention-Driven Adaptively-Pooled ResNet (BF-AD-AP-ResNet) model. To further strengthen learning, we introduce a Tri-Stream model, which unifies the enhanced features from three BF-AD-AP-ResNets. An SVM classifier is employed for final classification. We evaluate our models on two public datasets, IARC and AnnoCerv. On IARC, the base ResNets achieve an average performance of 90.91%, while our model achieves an excellent performance of 98.63%. On AnnoCerv, the base ResNets reach to 87.68%, and our model improves this significantly, reaching 93.39%. Our approach outperforms the best existing method on IARC by an average of 14.55%. For AnnoCerv, no prior competitive works are available. Additionally, we introduce a novel SHAP+LIME explainability method, accurately identifying the cancerous region in 97% of cases, ensuring model reliability for real-world use.
GN-SINDy: Greedy Sampling Neural Network in Sparse Identification of Nonlinear Partial Differential Equations
arXiv:2405.08613v2 Announce Type: replace-cross Abstract: The sparse identification of nonlinear dynamical systems (SINDy) is a data-driven technique employed for uncovering and representing the fundamental dynamics of intricate systems based on observational data. However, a primary obstacle in the discovery of models for nonlinear partial differential equations (PDEs) lies in addressing the challenges posed by the curse of dimensionality and large datasets. Consequently, the strategic selection of the most informative samples within a given dataset plays a crucial role in reducing computational costs and enhancing the effectiveness of SINDy-based algorithms. To this aim, we employ a greedy sampling approach to the snapshot matrix of a PDE to obtain its valuable samples, which are suitable to train a deep neural network (DNN) in a SINDy framework. SINDy based algorithms often consist of a data collection unit, constructing a dictionary of basis functions, computing the time derivative, and solving a sparse identification problem which ends to regularised least squares minimization. In this paper, we extend the results of a SINDy based deep learning model discovery (DeePyMoD) approach by integrating greedy sampling technique in its data collection unit and new sparsity promoting algorithms in the least squares minimization unit. In this regard we introduce the greedy sampling neural network in sparse identification of nonlinear partial differential equations (GN-SINDy) which blends a greedy sampling method, the DNN, and the SINDy algorithm. In the implementation phase, to show the effectiveness of GN-SINDy, we compare its results with DeePyMoD by using a Python package that is prepared for this purpose on numerous PDE discovery
Test-Time Multimodal Backdoor Detection by Contrastive Prompting
arXiv:2405.15269v3 Announce Type: replace-cross Abstract: While multimodal contrastive learning methods (e.g., CLIP) can achieve impressive zero-shot classification performance, recent research has revealed that these methods are vulnerable to backdoor attacks. To defend against backdoor attacks on CLIP, existing defense methods focus on either the pre-training stage or the fine-tuning stage, which would unfortunately cause high computational costs due to numerous parameter updates and are not applicable in black-box settings. In this paper, we provide the first attempt at a computationally efficient backdoor detection method to defend against backdoored CLIP in the \emph{inference} stage. We empirically find that the visual representations of backdoored images are \emph{insensitive} to \emph{benign} and \emph{malignant} changes in class description texts. Motivated by this observation, we propose BDetCLIP, a novel test-time backdoor detection method based on contrastive prompting. Specifically, we first prompt a language model (e.g., GPT-4) to produce class-related description texts (benign) and class-perturbed random texts (malignant) by specially designed instructions. Then, the distribution difference in cosine similarity between images and the two types of class description texts can be used as the criterion to detect backdoor samples. Extensive experiments validate that our proposed BDetCLIP is superior to state-of-the-art backdoor detection methods, in terms of both effectiveness and efficiency. Our codes are publicly available at: https://github.com/Purshow/BDetCLIP.
CEBench: A Benchmarking Toolkit for the Cost-Effectiveness of LLM Pipelines
arXiv:2407.12797v2 Announce Type: replace-cross Abstract: Online Large Language Model (LLM) services such as ChatGPT and Claude 3 have transformed business operations and academic research by effortlessly enabling new opportunities. However, due to data-sharing restrictions, sectors such as healthcare and finance prefer to deploy local LLM applications using costly hardware resources. This scenario requires a balance between the effectiveness advantages of LLMs and significant financial burdens. Additionally, the rapid evolution of models increases the frequency and redundancy of benchmarking efforts. Existing benchmarking toolkits, which typically focus on effectiveness, often overlook economic considerations, making their findings less applicable to practical scenarios. To address these challenges, we introduce CEBench, an open-source toolkit specifically designed for multi-objective benchmarking that focuses on the critical trade-offs between expenditure and effectiveness required for LLM deployments. CEBench allows for easy modifications through configuration files, enabling stakeholders to effectively assess and optimize these trade-offs. This strategic capability supports crucial decision-making processes aimed at maximizing effectiveness while minimizing cost impacts. By streamlining the evaluation process and emphasizing cost-effectiveness, CEBench seeks to facilitate the development of economically viable AI solutions across various industries and research fields. The code and demonstration are available in https://github.com/amademicnoboday12/CEBench.
Extract and Diffuse: Latent Integration for Improved Diffusion-based Speech and Vocal Enhancement
arXiv:2409.09642v2 Announce Type: replace-cross Abstract: Diffusion-based generative models have recently achieved remarkable results in speech and vocal enhancement due to their ability to model complex speech data distributions. While these models generalize well to unseen acoustic environments, they may not achieve the same level of fidelity as the discriminative models specifically trained to enhance particular acoustic conditions. In this paper, we propose Ex-Diff, a novel score-based diffusion model that integrates the latent representations produced by a discriminative model to improve speech and vocal enhancement, which combines the strengths of both generative and discriminative models. Experimental results on the widely used MUSDB dataset show relative improvements of 3.7% in SI-SDR and 10.0% in SI-SIR compared to the baseline diffusion model for speech and vocal enhancement tasks, respectively. Additionally, case studies are provided to further illustrate and analyze the complementary nature of generative and discriminative models in this context.
Error Correction Code Transformer: From Non-Unified to Unified
arXiv:2410.03364v3 Announce Type: replace-cross Abstract: Channel coding is vital for reliable data transmission in modern wireless systems, and its significance will increase with the emergence of sixth-generation (6G) networks, which will need to support various error correction codes. However, traditional decoders were typically designed as fixed hardware circuits tailored to specific decoding algorithms, leading to inefficiencies and limited flexibility. To address these challenges, this paper proposes a unified, code-agnostic Transformer-based decoding architecture capable of handling multiple linear block codes, including Polar, Low-Density Parity-Check (LDPC), and Bose-Chaudhuri-Hocquenghem (BCH), within a single framework. To achieve this, standardized units are employed to harmonize parameters across different code types, while the redesigned unified attention module compresses the structural information of various codewords. Additionally, a sparse mask, derived from the sparsity of the parity-check matrix, is introduced to enhance the model's ability to capture inherent constraints between information and parity-check bits, resulting in improved decoding accuracy and robustness. Extensive experimental results demonstrate that the proposed unified Transformer-based decoder not only outperforms existing methods but also provides a flexible, efficient, and high-performance solution for next-generation wireless communication systems.
Bayesian scaling laws for in-context learning
arXiv:2410.16531v4 Announce Type: replace-cross Abstract: In-context learning (ICL) is a powerful technique for getting language models to perform complex tasks with no training updates. Prior work has established strong correlations between the number of in-context examples provided and the accuracy of the model's predictions. In this paper, we seek to explain this correlation by showing that ICL approximates a Bayesian learner. This perspective gives rise to a novel Bayesian scaling law for ICL. In experiments with \mbox{GPT-2} models of different sizes, our scaling law matches existing scaling laws in accuracy while also offering interpretable terms for task priors, learning efficiency, and per-example probabilities. To illustrate the analytic power that such interpretable scaling laws provide, we report on controlled synthetic dataset experiments designed to inform real-world studies of safety alignment. In our experimental protocol, we use SFT or DPO to suppress an unwanted existing model capability and then use ICL to try to bring that capability back (many-shot jailbreaking). We then study ICL on real-world instruction-tuned LLMs using capabilities benchmarks as well as a new many-shot jailbreaking dataset. In all cases, Bayesian scaling laws accurately predict the conditions under which ICL will cause suppressed behaviors to reemerge, which sheds light on the ineffectiveness of post-training at increasing LLM safety.
Neural Networks and (Virtual) Extended Formulations
arXiv:2411.03006v3 Announce Type: replace-cross Abstract: Neural networks with piecewise linear activation functions, such as rectified linear units (ReLU) or maxout, are among the most fundamental models in modern machine learning. We make a step towards proving lower bounds on the size of such neural networks by linking their representative capabilities to the notion of the extension complexity $\mathrm{xc}(P)$ of a polytope $P$. This is a well-studied quantity in combinatorial optimization and polyhedral geometry describing the number of inequalities needed to model $P$ as a linear program. We show that $\mathrm{xc}(P)$ is a lower bound on the size of any monotone or input-convex neural network that solves the linear optimization problem over $P$. This implies exponential lower bounds on such neural networks for a variety of problems, including the polynomially solvable maximum weight matching problem. In an attempt to prove similar bounds also for general neural networks, we introduce the notion of virtual extension complexity $\mathrm{vxc}(P)$, which generalizes $\mathrm{xc}(P)$ and describes the number of inequalities needed to represent the linear optimization problem over $P$ as a difference of two linear programs. We prove that $\mathrm{vxc}(P)$ is a lower bound on the size of any neural network that optimizes over $P$. While it remains an open question to derive useful lower bounds on $\mathrm{vxc}(P)$, we argue that this quantity deserves to be studied independently from neural networks by proving that one can efficiently optimize over a polytope $P$ using a small virtual extended formulation.
Measure-to-measure interpolation using Transformers
arXiv:2411.04551v2 Announce Type: replace-cross Abstract: Transformers are deep neural network architectures that underpin the recent successes of large language models. Unlike more classical architectures that can be viewed as point-to-point maps, a Transformer acts as a measure-to-measure map implemented as specific interacting particle system on the unit sphere: the input is the empirical measure of tokens in a prompt and its evolution is governed by the continuity equation. In fact, Transformers are not limited to empirical measures and can in principle process any input measure. As the nature of data processed by Transformers is expanding rapidly, it is important to investigate their expressive power as maps from an arbitrary measure to another arbitrary measure. To that end, we provide an explicit choice of parameters that allows a single Transformer to match $N$ arbitrary input measures to $N$ arbitrary target measures, under the minimal assumption that every pair of input-target measures can be matched by some transport map.
Are Deep Learning Methods Suitable for Downscaling Global Climate Projections? An Intercomparison for Temperature and Precipitation over Spain
arXiv:2411.05850v2 Announce Type: replace-cross Abstract: Deep Learning (DL) has shown promise for downscaling global climate change projections under different approaches, including Perfect Prognosis (PP) and Regional Climate Model (RCM) emulation. Unlike emulators, PP downscaling models are trained on observational data, so it remains an open question whether they can plausibly extrapolate unseen conditions and changes in future emissions scenarios. Here we focus on this problem as the main drawback for the operationalization of these methods and present the results of an intercomparison experiment to evaluate the performance and extrapolation capability of existing models using a common experimental framework, taking into account the sensitivity of results to different training replicas. We focus on minimum and maximum temperatures and precipitation over Spain, a region with a range of climatic conditions with different influential regional processes. We conclude with a discussion of the findings, limitations of existing methods, and prospects for future development.
Validation-Free Sparse Learning: A Phase Transition Approach to Feature Selection
arXiv:2411.17180v4 Announce Type: replace-cross Abstract: The growing environmental footprint of artificial intelligence (AI), especially in terms of storage and computation, calls for more frugal and interpretable models. Sparse models (e.g., linear, neural networks) offer a promising solution by selecting only the most relevant features, reducing complexity, preventing over-fitting and enabling interpretation-marking a step towards truly intelligent AI. The concept of a right amount of sparsity (without too many false positive or too few true positive) is subjective. So we propose a new paradigm previously only observed and mathematically studied for compressed sensing (noiseless linear models): obtaining a phase transition in the probability of retrieving the relevant features. We show in practice how to obtain this phase transition for a class of sparse learners. Our approach is flexible and applicable to complex models ranging from linear to shallow and deep artificial neural networks while supporting various loss functions and sparsity-promoting penalties. It does not rely on cross-validation or on a validation set to select its single regularization parameter. For real-world data, it provides a good balance between predictive accuracy and feature sparsity. A Python package is available at https://github.com/VcMaxouuu/HarderLASSO containing all the simulations and ready-to-use models.
PACMANN: Point Adaptive Collocation Method for Artificial Neural Networks
arXiv:2411.19632v2 Announce Type: replace-cross Abstract: Physics-Informed Neural Networks (PINNs) have emerged as a tool for approximating the solution of Partial Differential Equations (PDEs) in both forward and inverse problems. PINNs minimize a loss function which includes the PDE residual determined for a set of collocation points. Previous work has shown that the number and distribution of these collocation points have a significant influence on the accuracy of the PINN solution. Therefore, the effective placement of these collocation points is an active area of research. Specifically, available adaptive collocation point sampling methods have been reported to scale poorly in terms of computational cost when applied to high-dimensional problems. In this work, we address this issue and present the Point Adaptive Collocation Method for Artificial Neural Networks (PACMANN). PACMANN incrementally moves collocation points toward regions of higher residuals using gradient-based optimization algorithms guided by the gradient of the PINN loss function, that is, the squared PDE residual. We apply PACMANN for forward and inverse problems, and demonstrate that this method matches the performance of state-of-the-art methods in terms of the accuracy/efficiency tradeoff for the low-dimensional problems, while outperforming available approaches for high-dimensional problems. Key features of the method include its low computational cost and simplicity of integration into existing physics-informed neural network pipelines. The code is available at https://github.com/CoenVisser/PACMANN.
Bio-Inspired Adaptive Neurons for Dynamic Weighting in Artificial Neural Networks
arXiv:2412.01454v2 Announce Type: replace-cross Abstract: Traditional neural networks employ fixed weights during inference, limiting their ability to adapt to changing input conditions, unlike biological neurons that adjust signal strength dynamically based on stimuli. This discrepancy between artificial and biological neurons constrains neural network flexibility and adaptability. To bridge this gap, we propose a novel framework for adaptive neural networks, where neuron weights are modeled as functions of the input signal, allowing the network to adjust dynamically in real-time. Importantly, we achieve this within the same traditional architecture of an Artificial Neural Network, maintaining structural familiarity while introducing dynamic adaptability. In our research, we apply Chebyshev polynomials as one of the many possible decomposition methods to achieve this adaptive weighting mechanism, with polynomial coefficients learned during training. Out of the 145 datasets tested, our adaptive Chebyshev neural network demonstrated a marked improvement over an equivalent MLP in approximately 8\% of cases, performing strictly better on 121 datasets. In the remaining 24 datasets, the performance of our algorithm matched that of the MLP, highlighting its ability to generalize standard neural network behavior while offering enhanced adaptability. As a generalized form of the MLP, this model seamlessly retains MLP performance where needed while extending its capabilities to achieve superior accuracy across a wide range of complex tasks. These results underscore the potential of adaptive neurons to enhance generalization, flexibility, and robustness in neural networks, particularly in applications with dynamic or non-linear data dependencies.
Tight PAC-Bayesian Risk Certificates for Contrastive Learning
arXiv:2412.03486v4 Announce Type: replace-cross Abstract: Contrastive representation learning is a modern paradigm for learning representations of unlabeled data via augmentations -- precisely, contrastive models learn to embed semantically similar pairs of samples (positive pairs) closer than independently drawn samples (negative samples). In spite of its empirical success and widespread use in foundation models, statistical theory for contrastive learning remains less explored. Recent works have developed generalization error bounds for contrastive losses, but the resulting risk certificates are either vacuous (certificates based on Rademacher complexity or $f$-divergence) or require strong assumptions about samples that are unreasonable in practice. The present paper develops non-vacuous PAC-Bayesian risk certificates for contrastive representation learning, considering the practical considerations of the popular SimCLR framework. Notably, we take into account that SimCLR reuses positive pairs of augmented data as negative samples for other data, thereby inducing strong dependence and making classical PAC or PAC-Bayesian bounds inapplicable. We further refine existing bounds on the downstream classification loss by incorporating SimCLR-specific factors, including data augmentation and temperature scaling, and derive risk certificates for the contrastive zero-one risk. The resulting bounds for contrastive loss and downstream prediction are much tighter than those of previous risk certificates, as demonstrated by experiments on CIFAR-10.
Parallel Simulation for Log-concave Sampling and Score-based Diffusion Models
arXiv:2412.07435v3 Announce Type: replace-cross Abstract: Sampling from high-dimensional probability distributions is fundamental in machine learning and statistics. As datasets grow larger, computational efficiency becomes increasingly important, particularly in reducing adaptive complexity, namely the number of sequential rounds required for sampling algorithms. While recent works have introduced several parallelizable techniques, they often exhibit suboptimal convergence rates and remain significantly weaker than the latest lower bounds for log-concave sampling. To address this, we propose a novel parallel sampling method that improves adaptive complexity dependence on dimension $d$ reducing it from $\widetilde{\mathcal{O}}(\log^2 d)$ to $\widetilde{\mathcal{O}}(\log d)$. which is even optimal for log-concave sampling with some specific adaptive complexity. Our approach builds on parallel simulation techniques from scientific computing.
Learning Massive-scale Partial Correlation Networks in Clinical Multi-omics Studies with HP-ACCORD
arXiv:2412.11554v4 Announce Type: replace-cross Abstract: Graphical model estimation from multi-omics data requires a balance between statistical estimation performance and computational scalability. We introduce a novel pseudolikelihood-based graphical model framework that reparameterizes the target precision matrix while preserving the sparsity pattern and estimates it by minimizing an $\ell_1$-penalized empirical risk based on a new loss function. The proposed estimator maintains estimation and selection consistency in various metrics under high-dimensional assumptions. The associated optimization problem allows for a provably fast computation algorithm using a novel operator-splitting approach and communication-avoiding distributed matrix multiplication. A high-performance computing implementation of our framework was tested using simulated data with up to one million variables, demonstrating complex dependency structures similar to those found in biological networks. Leveraging this scalability, we estimated a partial correlation network from a dual-omic liver cancer data set. The co-expression network estimated from the ultrahigh-dimensional data demonstrated superior specificity in prioritizing key transcription factors and co-activators by excluding the impact of epigenetic regulation, thereby highlighting the value of computational scalability in multi-omic data analysis.
Solving Partial Differential Equations with Random Feature Models
arXiv:2501.00288v2 Announce Type: replace-cross Abstract: Machine learning based partial differential equations (PDEs) solvers have received great attention in recent years. Most progress in this area has been driven by deep neural networks such as physics-informed neural networks (PINNs) and kernel method. In this paper, we introduce a random feature based framework toward efficiently solving PDEs. Random feature method was originally proposed to approximate large-scale kernel machines and can be viewed as a shallow neural network as well. We provide an error analysis for our proposed method along with comprehensive numerical results on several PDE benchmarks. In contrast to the state-of-the-art solvers that face challenges with a large number of collocation points, our proposed method reduces the computational complexity. Moreover, the implementation of our method is simple and does not require additional computational resources. Due to the theoretical guarantee and advantages in computation, our approach is proven to be efficient for solving PDEs.
An AI-powered Bayesian generative modeling approach for causal inference in observational studies
arXiv:2501.00755v2 Announce Type: replace-cross Abstract: Causal inference in observational studies with high-dimensional covariates presents significant challenges. We introduce CausalBGM, an AI-powered Bayesian generative modeling approach that captures the causal relationship among covariates, treatment, and outcome variables. The core innovation of CausalBGM lies in its ability to estimate the individual treatment effect (ITE) by learning individual-specific distributions of a low-dimensional latent feature set (e.g., latent confounders) that drives changes in both treatment and outcome. This approach not only effectively mitigates confounding effects but also provides comprehensive uncertainty quantification, offering reliable and interpretable causal effect estimates at the individual level. CausalBGM adopts a Bayesian model and uses a novel iterative algorithm to update the model parameters and the posterior distribution of latent features until convergence. This framework leverages the power of AI to capture complex dependencies among variables while adhering to the Bayesian principles. Extensive experiments demonstrate that CausalBGM consistently outperforms state-of-the-art methods, particularly in scenarios with high-dimensional covariates and large-scale datasets. Its Bayesian foundation ensures statistical rigor, providing robust and well-calibrated posterior intervals. By addressing key limitations of existing methods, CausalBGM emerges as a robust and promising framework for advancing causal inference in modern applications in fields such as genomics, healthcare, and social sciences. CausalBGM is maintained at the website https://causalbgm.readthedocs.io/.
Tempo: Compiled Dynamic Deep Learning with Symbolic Dependence Graphs
arXiv:2501.05408v2 Announce Type: replace-cross Abstract: Deep learning (DL) algorithms are often defined in terms of \emph{temporal relationships}: a tensor at one timestep may depend on tensors from earlier or later timesteps. Such \emph{dynamic} dependencies (and corresponding dynamic tensor shapes) are difficult to express and optimize: while \emph{eager} DL systems support such dynamism, they cannot apply compiler-based optimizations; \emph{graph-based} systems require static tensor shapes, which forces users to pad tensors or break-up programs into multiple static graphs. We describe Tempo, a new DL system that combines the dynamism of eager execution with the whole-program optimizations of graph-based compilation. Tempo achieves this through a declarative programming model with \emph{recurrent tensors}, which include explicit \emph{temporal dimensions}. Temporal dimensions can be indexed using \emph{symbolic expressions} to express dynamic dependencies on past and future tensors. Based on this, Tempo constructs a \emph{symbolic dependence graph}, which concisely encodes dynamic dependencies between operators, and applies whole-program optimizations, such as algebraic simplifications, vectorization, tiling, and fusion. By tiling dynamic dependencies into static-size blocks, Tempo can also reuse existing static code-generators. It then uses a polyhedral model to find a feasible execution schedule, which includes memory management operations. We show that Tempo achieves a 7$\times$ speedup over JAX for Llama-3.2-3B decoding; for reinforcement learning algorithms, Tempo achieves a 54$\times$ speedup, with 16$\times$ lower peak memory usage.
Efficient Transition State Searches by Freezing String Method with Graph Neural Network Potentials
arXiv:2501.06159v2 Announce Type: replace-cross Abstract: Transition state (TS) searches are a critical bottleneck in computational studies of chemical reactivity, as accurately capturing complex phenomena like bond breaking and formation events requires repeated evaluations of expensive ab-initio potential energy surfaces (PESs). While numerous algorithms have been developed to locate TSs efficiently, the computational cost of PES evaluations remains a key limitation. In this work, we develop and fine-tune a graph neural network (GNN) PES to accelerate TS searches for organic reactions. Our GNN of choice, SchNet, is first pre-trained on the ANI-1 dataset and subsequently fine-tuned on a small dataset of reactant, product, and TS structures. We integrate this GNN PES into the Freezing String Method (FSM), enabling rapid generation of TS guess geometries. Across a benchmark suite of chemically diverse reactions, our fine-tuned model (GNN-FT) achieves a 100% success rate, locating the reference TSs in all cases while reducing the number of ab-initio calculations by 72% on average compared to conventional DFT-based FSM searches. Fine-tuning reduces GNN-FT errors by orders of magnitude for out-of-distribution cases such as non-covalent interactions, and improves TS-region predictions with comparatively little data. Analysis of transition state geometries and energy errors shows that GNN-FT captures PES along the reaction coordinate with sufficient accuracy to serve as a reliable DFT surrogate. These results demonstrate that modern GNN potentials, when properly trained, can significantly reduce the cost of TS searches and broaden the scope and size of systems considered in chemical reactivity studies.
OptiChat: Bridging Optimization Models and Practitioners with Large Language Models
arXiv:2501.08406v2 Announce Type: replace-cross Abstract: Optimization models have been applied to solve a wide variety of decision-making problems. These models are usually developed by optimization experts but are used by practitioners without optimization expertise in various application domains. As a result, practitioners often struggle to interact with and draw useful conclusions from optimization models independently. To fill this gap, we introduce OptiChat, a natural language dialogue system designed to help practitioners interpret model formulation, diagnose infeasibility, analyze sensitivity, retrieve information, evaluate modifications, and provide counterfactual explanations. By augmenting large language models (LLMs) with functional calls and code generation tailored for optimization models, we enable seamless interaction and minimize the risk of hallucinations in OptiChat. We develop a new dataset to evaluate OptiChat's performance in explaining optimization models. Experiments demonstrate that OptiChat effectively bridges the gap between optimization models and practitioners, delivering autonomous, accurate, and instant responses.
INTA: Intent-Based Translation for Network Configuration with LLM Agents
arXiv:2501.08760v2 Announce Type: replace-cross Abstract: Translating configurations between different network devices is a common yet challenging task in modern network operations. This challenge arises in typical scenarios such as replacing obsolete hardware and adapting configurations to emerging paradigms like Software Defined Networking (SDN) and Network Function Virtualization (NFV). Engineers need to thoroughly understand both source and target configuration models, which requires considerable effort due to the complexity and evolving nature of these specifications. To promote automation in network configuration translation, we propose INTA, an intent-based translation framework that leverages Large Language Model (LLM) agents. The key idea of INTA is to use configuration intent as an intermediate representation for translation. It first employs LLMs to decompose configuration files and extract fine-grained intents for each configuration fragment. These intents are then used to retrieve relevant manuals of the target device. Guided by a syntax checker, INTA incrementally generates target configurations. The translated configurations are further verified and refined for semantic consistency. We implement INTA and evaluate it on real-world configuration datasets from the industry. Our approach outperforms state-of-the-art methods in translation accuracy and exhibits strong generalizability. INTA achieves an accuracy of 98.15% in terms of both syntactic and view correctness, and a command recall rate of 84.72% for the target configuration. The semantic consistency report of the translated configuration further demonstrates its practical value in real-world network operations.
Attention Sinks: A 'Catch, Tag, Release' Mechanism for Embeddings
arXiv:2502.00919v2 Announce Type: replace-cross Abstract: Large language models (LLMs) often concentrate their attention on a few specific tokens referred to as attention sinks. Common examples include the first token, a prompt-independent sink, and punctuation tokens, which are prompt-dependent. While the tokens causing the sinks often lack direct semantic meaning, the presence of the sinks is critical for model performance, particularly under model compression and KV-caching. Despite their ubiquity, the function, semantic role, and origin of attention sinks -- especially those beyond the first token -- remain poorly understood. In this work, we conduct a comprehensive investigation demonstrating that attention sinks: catch a sequence of tokens, tag them using a common direction in embedding space, and release them back into the residual stream, where tokens are later retrieved based on the tags they have acquired. Probing experiments reveal these tags carry semantically meaningful information, such as the truth of a statement. These findings extend to reasoning models, where the mechanism spans more heads and explains greater variance in embeddings, or recent models with query-key normalization, where sinks remain just as prevalent. To encourage future theoretical analysis, we introduce a minimal problem which can be solved through the 'catch, tag, release' mechanism, and where it emerges through training.
3D Cell Oversegmentation Correction via Geo-Wasserstein Divergence
arXiv:2502.01890v3 Announce Type: replace-cross Abstract: 3D cell segmentation methods are often hindered by \emph{oversegmentation}, where a single cell is incorrectly split into multiple fragments. This degrades the final segmentation quality and is notoriously difficult to resolve, as oversegmentation errors often resemble natural gaps between adjacent cells. Our work makes two key contributions. First, for 3D cell segmentation, we are the first work to formulate oversegmentation as a concrete problem and propose a geometric framework to identify and correct these errors. Our approach builds a pre-trained classifier using both 2D geometric and 3D topological features extracted from flawed 3D segmentation results. Second, we introduce a novel metric, Geo-Wasserstein divergence, to quantify changes in 2D geometries. This captures the evolving trends of cell mask shape in a geometry-aware manner. We validate our method through extensive experiments on in-domain plant datasets, including both synthesized and real oversegmented cases, as well as on out-of-domain animal datasets to demonstrate transfer learning performance. An ablation study further highlights the contribution of the Geo-Wasserstein divergence. A clear pipeline is provided for end-users to build pre-trained models to any labeled dataset.
TranSQL+: Serving Large Language Models with SQL on Low-Resource Hardware
arXiv:2502.02818v3 Announce Type: replace-cross Abstract: Deploying Large Language Models (LLMs) on resource-constrained devices remains challenging due to limited memory, lack of GPUs, and the complexity of existing runtimes. In this paper, we introduce TranSQL+, a template-based code generator that translates LLM computation graphs into pure SQL queries for execution in relational databases. Without relying on external libraries, TranSQL+, leverages mature database features, such as vectorized execution and out-of-core processing, for efficient inference. We further propose a row-to-column (ROW2COL) optimization that improves join efficiency in matrix operations. Evaluated on Llama3-8B and DeepSeekMoE models, TranSQL+ achieves up to 20x lower prefill latency and 4x higher decoding speed compared to DeepSpeed Inference and Llama.cpp in low-memory and CPU-only configurations. Our results highlight relational databases as a practical environment for LLMs on low-resource hardware.
Physically consistent predictive reduced-order modeling by enhancing Operator Inference with state constraints
arXiv:2502.03672v2 Announce Type: replace-cross Abstract: Numerical simulations of complex multiphysics systems, such as char combustion considered herein, yield numerous state variables that inherently exhibit physical constraints. This paper presents a new approach to augment Operator Inference -- a methodology within scientific machine learning that enables learning from data a low-dimensional representation of a high-dimensional system governed by nonlinear partial differential equations -- by embedding such state constraints in the reduced-order model predictions. In the model learning process, we propose a new way to choose regularization hyperparameters based on a key performance indicator. Since embedding state constraints improves the stability of the Operator Inference reduced-order model, we compare the proposed state constraints-embedded Operator Inference with the standard Operator Inference and other stability-enhancing approaches. For an application to char combustion, we demonstrate that the proposed approach yields state predictions superior to the other methods regarding stability and accuracy. It extrapolates over 200\% past the training regime while being computationally efficient and physically consistent.
Large Language Models Badly Generalize across Option Length, Problem Types, and Irrelevant Noun Replacements
arXiv:2502.12459v3 Announce Type: replace-cross Abstract: In this paper, we propose a ``Generalization Stress Test" to assess Large Language Models' (LLMs) generalization ability under slight and controlled perturbations, including option length, problem types, and irrelevant noun replacements. We achieve novel and significant findings that, despite high benchmark scores, LLMs exhibit severe accuracy drops and unexpected biases (e.g., preference for longer distractors) when faced with these minor but content-preserving modifications. For example, Qwen 2.5 1.5B's MMLU score rises from 60 to 89 and drops from 89 to 36 when option lengths are changed without altering the question. Even GPT4o experiences a 25-point accuracy loss when problem types are changed, with a 6-point drop across all three modification categories. These analyses suggest that LLMs rely heavily on superficial cues rather than forming robust, abstract representations that generalize across formats, lexical variations, and irrelevant content shifts.
Re-Align: Aligning Vision Language Models via Retrieval-Augmented Direct Preference Optimization
arXiv:2502.13146v3 Announce Type: replace-cross Abstract: The emergence of large Vision Language Models (VLMs) has broadened the scope and capabilities of single-modal Large Language Models (LLMs) by integrating visual modalities, thereby unlocking transformative cross-modal applications in a variety of real-world scenarios. Despite their impressive performance, VLMs are prone to significant hallucinations, particularly in the form of cross-modal inconsistencies. Building on the success of Reinforcement Learning from Human Feedback (RLHF) in aligning LLMs, recent advancements have focused on applying direct preference optimization (DPO) on carefully curated datasets to mitigate these issues. Yet, such approaches typically introduce preference signals in a brute-force manner, neglecting the crucial role of visual information in the alignment process. In this paper, we introduce Re-Align, a novel alignment framework that leverages image retrieval to construct a dual-preference dataset, effectively incorporating both textual and visual preference signals. We further introduce rDPO, an extension of the standard direct preference optimization that incorporates an additional visual preference objective during fine-tuning. Our experimental results demonstrate that Re-Align not only mitigates hallucinations more effectively than previous methods but also yields significant performance gains in general visual question-answering (VQA) tasks. Moreover, we show that Re-Align maintains robustness and scalability across a wide range of VLM sizes and architectures. This work represents a significant step forward in aligning multimodal LLMs, paving the way for more reliable and effective cross-modal applications. We release all the code in https://github.com/taco-group/Re-Align.
FC-Attack: Jailbreaking Multimodal Large Language Models via Auto-Generated Flowcharts
arXiv:2502.21059v3 Announce Type: replace-cross Abstract: Multimodal Large Language Models (MLLMs) have become powerful and widely adopted in some practical applications. However, recent research has revealed their vulnerability to multimodal jailbreak attacks, whereby the model can be induced to generate harmful content, leading to safety risks. Although most MLLMs have undergone safety alignment, recent research shows that the visual modality is still vulnerable to jailbreak attacks. In our work, we discover that by using flowcharts with partially harmful information, MLLMs can be induced to provide additional harmful details. Based on this, we propose a jailbreak attack method based on auto-generated flowcharts, FC-Attack. Specifically, FC-Attack first fine-tunes a pre-trained LLM to create a step-description generator based on benign datasets. The generator is then used to produce step descriptions corresponding to a harmful query, which are transformed into flowcharts in 3 different shapes (vertical, horizontal, and S-shaped) as visual prompts. These flowcharts are then combined with a benign textual prompt to execute the jailbreak attack on MLLMs. Our evaluations on Advbench show that FC-Attack attains an attack success rate of up to 96% via images and up to 78% via videos across multiple MLLMs. Additionally, we investigate factors affecting the attack performance, including the number of steps and the font styles in the flowcharts. We also find that FC-Attack can improve the jailbreak performance from 4% to 28% in Claude-3.5 by changing the font style. To mitigate the attack, we explore several defenses and find that AdaShield can largely reduce the jailbreak performance but with the cost of utility drop.
Beyond Prompting: An Efficient Embedding Framework for Open-Domain Question Answering
arXiv:2503.01606v3 Announce Type: replace-cross Abstract: Large language models have recently pushed open domain question answering (ODQA) to new frontiers. However, prevailing retriever-reader pipelines often depend on multiple rounds of prompt level instructions, leading to high computational overhead, instability, and suboptimal retrieval coverage. In this paper, we propose EmbQA, an embedding-level framework that alleviates these shortcomings by enhancing both the retriever and the reader. Specifically, we refine query representations via lightweight linear layers under an unsupervised contrastive learning objective, thereby reordering retrieved passages to highlight those most likely to contain correct answers. Additionally, we introduce an exploratory embedding that broadens the model's latent semantic space to diversify candidate generation and employs an entropy-based selection mechanism to choose the most confident answer automatically. Extensive experiments across three open-source LLMs, three retrieval methods, and four ODQA benchmarks demonstrate that EmbQA substantially outperforms recent baselines in both accuracy and efficiency.
Audio-Reasoner: Improving Reasoning Capability in Large Audio Language Models
arXiv:2503.02318v2 Announce Type: replace-cross Abstract: Recent advancements in multimodal reasoning have largely overlooked the audio modality. We introduce Audio-Reasoner, a large-scale audio language model for deep reasoning in audio tasks. We meticulously curated a large-scale and diverse multi-task audio dataset with simple annotations. Then, we leverage closed-source models to conduct secondary labeling, QA generation, along with structured COT process. These datasets together form a high-quality reasoning dataset with 1.2 million reasoning-rich samples, which we name CoTA. Following inference scaling principles, we train Audio-Reasoner on CoTA, enabling it to achieve great logical capabilities in audio reasoning. Experiments show state-of-the-art performance across key benchmarks, including MMAU-mini (+25.42%), AIR-Bench chat/foundation(+14.57%/+10.13%), and MELD (+8.01%). Our findings stress the core of structured CoT training in advancing audio reasoning.
Trajectory Prediction for Autonomous Driving: Progress, Limitations, and Future Directions
arXiv:2503.03262v3 Announce Type: replace-cross Abstract: As the potential for autonomous vehicles to be integrated on a large scale into modern traffic systems continues to grow, ensuring safe navigation in dynamic environments is crucial for smooth integration. To guarantee safety and prevent collisions, autonomous vehicles must be capable of accurately predicting the trajectories of surrounding traffic agents. Over the past decade, significant efforts from both academia and industry have been dedicated to designing solutions for precise trajectory forecasting. These efforts have produced a diverse range of approaches, raising questions about the differences between these methods and whether trajectory prediction challenges have been fully addressed. This paper reviews a substantial portion of recent trajectory prediction methods proposing a taxonomy to classify existing solutions. A general overview of the prediction pipeline is also provided, covering input and output modalities, modeling features, and prediction paradigms existing in the literature. In addition, the paper discusses active research areas within trajectory prediction, addresses the posed research questions, and highlights the remaining research gaps and challenges.
Conformal Prediction with Upper and Lower Bound Models
arXiv:2503.04071v3 Announce Type: replace-cross Abstract: This paper studies a Conformal Prediction (CP) methodology for building prediction intervals in a regression setting, given only deterministic lower and upper bounds on the target variable. It proposes a new CP mechanism (CPUL) that goes beyond post-processing by adopting a model selection approach over multiple nested interval construction methods. Paradoxically, many well-established CP methods, including CPUL, may fail to provide adequate coverage in regions where the bounds are tight. To remedy this limitation, the paper proposes an optimal thresholding mechanism, OMLT, that adjusts CPUL intervals in tight regions with undercoverage. The combined CPUL-OMLT is validated on large-scale learning tasks where the goal is to bound the optimal value of a parametric optimization problem. The experimental results demonstrate substantial improvements over baseline methods across various datasets.
WikiBigEdit: Understanding the Limits of Lifelong Knowledge Editing in LLMs
arXiv:2503.05683v2 Announce Type: replace-cross Abstract: Keeping large language models factually up-to-date is crucial for deployment, yet costly retraining remains a challenge. Knowledge editing offers a promising alternative, but methods are only tested on small-scale or synthetic edit benchmarks. In this work, we aim to bridge research into lifelong knowledge editing to real-world edits at a practically relevant scale. We first introduce WikiBigEdit; a large-scale benchmark of real-world Wikidata edits, built to automatically extend lifelong for future-proof benchmarking. In its first instance, it includes over 500K question-answer pairs for knowledge editing alongside a comprehensive evaluation pipeline. Finally, we use WikiBigEdit to study existing knowledge editing techniques' ability to incorporate large volumes of real-world facts and contrast their capabilities to generic modification techniques such as retrieval augmentation and continual finetuning to acquire a complete picture of the practical extent of current lifelong knowledge editing.
CAARMA: Class Augmentation with Adversarial Mixup Regularization
arXiv:2503.16718v3 Announce Type: replace-cross Abstract: Speaker verification is a typical zero-shot learning task, where inference of unseen classes is performed by comparing embeddings of test instances to known examples. The models performing inference must hence naturally generate embeddings that cluster same-class instances compactly, while maintaining separation across classes. In order to learn to do so, they are typically trained on a large number of classes (speakers), often using specialized losses. However real-world speaker datasets often lack the class diversity needed to effectively learn this in a generalizable manner. We introduce CAARMA, a class augmentation framework that addresses this problem by generating synthetic classes through data mixing in the embedding space, expanding the number of training classes. To ensure the authenticity of the synthetic classes we adopt a novel adversarial refinement mechanism that minimizes categorical distinctions between synthetic and real classes. We evaluate CAARMA on multiple speaker verification tasks, as well as other representative zero-shot comparison-based speech analysis tasks and obtain consistent improvements: our framework demonstrates a significant improvement of 8\% over all baseline models. The code is available at: https://github.com/massabaali7/CAARMA/
VQToken: Neural Discrete Token Representation Learning for Extreme Token Reduction in Video Large Language Models
arXiv:2503.16980v5 Announce Type: replace-cross Abstract: Token-based video representation has emerged as a promising approach for enabling large language models (LLMs) to interpret video content. However, existing token reduction techniques, such as pruning and merging, often disrupt essential positional embeddings and rely on continuous visual tokens sampled from nearby pixels with similar spatial-temporal locations. By removing only a small fraction of tokens, these methods still produce relatively lengthy continuous sequences, which falls short of the extreme compression required to balance computational efficiency and token count in video LLMs. In this paper, we introduce the novel task of Extreme Short Token Reduction, which aims to represent entire videos using a minimal set of discrete tokens. We propose VQToken, a neural discrete token representation framework that (i) applies adaptive vector quantization to continuous ViT embeddings to learn a compact codebook and (ii) preserves spatial-temporal positions via a token hash function by assigning each grid-level token to its nearest codebook entry. On the Extreme Short Token Reduction task, our VQToken compresses sequences to just 0.07 percent of their original length while incurring only a 0.66 percent drop in accuracy on the NextQA-MC benchmark. It also achieves comparable performance on ActNet-QA, Long Video Bench, and VideoMME. We further introduce the Token Information Density (TokDense) metric and formalize fixed-length and adaptive-length subtasks, achieving state-of-the-art results in both settings. Our approach dramatically lowers theoretical complexity, increases information density, drastically reduces token counts, and enables efficient video LLMs in resource-constrained environments.
BiPrompt-SAM: Enhancing Image Segmentation via Explicit Selection between Point and Text Prompts
arXiv:2503.19769v3 Announce Type: replace-cross Abstract: Segmentation is a fundamental task in computer vision, with prompt-driven methods gaining prominence due to their flexibility. The Segment Anything Model (SAM) excels at point-prompted segmentation, while text-based models, often leveraging powerful multimodal encoders like BEIT-3, provide rich semantic understanding. However, effectively combining these complementary modalities remains a challenge. This paper introduces BiPrompt-SAM, a novel dual-modal prompt segmentation framework employing an explicit selection mechanism. We leverage SAM's ability to generate multiple mask candidates from a single point prompt and use a text-guided mask (generated via EVF-SAM with BEIT-3) to select the point-generated mask that best aligns spatially, measured by Intersection over Union (IoU). This approach, interpretable as a simplified Mixture of Experts (MoE), effectively fuses spatial precision and semantic context without complex model modifications. Notably, our method achieves strong zero-shot performance on the Endovis17 medical dataset (89.55% mDice, 81.46% mIoU) using only a single point prompt per instance. This significantly reduces annotation burden compared to bounding boxes and aligns better with practical clinical workflows, demonstrating the method's effectiveness without domain-specific training. On the RefCOCO series, BiPrompt-SAM attained 87.1%, 86.5%, and 85.8% IoU, significantly outperforming existing approaches. Experiments show BiPrompt-SAM excels in scenarios requiring both spatial accuracy and semantic disambiguation, offering a simple, effective, and interpretable perspective on multi-modal prompt fusion.
XL-Suite: Cross-Lingual Synthetic Training and Evaluation Data for Open-Ended Generation
arXiv:2503.22973v2 Announce Type: replace-cross Abstract: Cross-lingual open-ended generation - responding in a language different from that of the query - is an important yet understudied problem. This work proposes XL-Instruct, a novel technique for generating high-quality synthetic data, and introduces XL-AlpacaEval, a new benchmark for evaluating cross-lingual generation capabilities of large language models (LLMs). Our experiments show that fine-tuning with just 8K instructions generated using XL-Instruct significantly improves model performance, increasing the win rate against GPT-4o-Mini from 7.4% to 21.5% and improving on several fine-grained quality metrics. Moreover, base LLMs fine-tuned on XL-Instruct exhibit strong zero-shot improvements to question answering in the same language, as shown on our machine-translated m-AlpacaEval. These consistent gains highlight the promising role of XL-Instruct in the post-training of multilingual LLMs. Finally, we publicly release XL-Suite, a collection of training and evaluation data to facilitate research in cross-lingual open-ended generation.
Localized Graph-Based Neural Dynamics Models for Terrain Manipulation
arXiv:2503.23270v2 Announce Type: replace-cross Abstract: Predictive models can be particularly helpful for robots to effectively manipulate terrains in construction sites and extraterrestrial surfaces. However, terrain state representations become extremely high-dimensional especially to capture fine-resolution details and when depth is unknown or unbounded. This paper introduces a learning-based approach for terrain dynamics modeling and manipulation, leveraging the Graph-based Neural Dynamics (GBND) framework to represent terrain deformation as motion of a graph of particles. Based on the principle that the moving portion of a terrain is usually localized, our approach builds a large terrain graph (potentially millions of particles) but only identifies a very small active subgraph (hundreds of particles) for predicting the outcomes of robot-terrain interaction. To minimize the size of the active subgraph we introduce a learning-based approach that identifies a small region of interest (RoI) based on the robot's control inputs and the current scene. We also introduce a novel domain boundary feature encoding that allows GBNDs to perform accurate dynamics prediction in the RoI interior while avoiding particle penetration through RoI boundaries. Our proposed method is both orders of magnitude faster than naive GBND and it achieves better overall prediction accuracy. We further evaluated our framework on excavation and shaping tasks on terrain with different granularity.
CoLa: Learning to Interactively Collaborate with Large Language Models
arXiv:2504.02965v3 Announce Type: replace-cross Abstract: LLMs' remarkable ability to tackle a wide range of language tasks opened new opportunities for collaborative human-AI problem solving. LLMs can amplify human capabilities by applying their intuitions and reasoning strategies at scale. We explore whether human guides can be simulated, by generalizing from human demonstrations of guiding an AI system to solve complex language problems. We introduce CoLa, a novel self-guided learning paradigm for training automated $\textit{guides}$ and evaluate it on two QA datasets, a puzzle-solving task, and a constrained text generation task. Our empirical results show that CoLa consistently outperforms competitive approaches across all domains. Moreover, a small-sized trained guide outperforms a strong model like GPT-4 when acting as a guide. We compare the strategies employed by humans and automated guides by conducting a human study on a QA dataset. We show that automated guides outperform humans by adapting their strategies to reasoners' capabilities and conduct qualitative analyses highlighting distinct differences in guiding strategies.
Enhancing Clinical Decision-Making: Integrating Multi-Agent Systems with Ethical AI Governance
arXiv:2504.03699v4 Announce Type: replace-cross Abstract: Recent advances in the data-driven medicine approach, which integrates ethically managed and explainable artificial intelligence into clinical decision support systems (CDSS), are critical to ensure reliable and effective patient care. This paper focuses on comparing novel agent system designs that use modular agents to analyze laboratory results, vital signs, and clinical context, and to predict and validate results. We implement our agent system with the eICU database, including running lab analysis, vitals-only interpreters, and contextual reasoners agents first, then sharing the memory into the integration agent, prediction agent, transparency agent, and a validation agent. Our results suggest that the multi-agent system (MAS) performed better than the single-agent system (SAS) with mortality prediction accuracy (59\%, 56\%) and the mean error for length of stay (LOS)(4.37 days, 5.82 days), respectively. However, the transparency score for the SAS (86.21) is slightly better than the transparency score for MAS (85.5). Finally, this study suggests that our agent-based framework not only improves process transparency and prediction accuracy but also strengthens trustworthy AI-assisted decision support in an intensive care setting.
SymRTLO: Enhancing RTL Code Optimization with LLMs and Neuron-Inspired Symbolic Reasoning
arXiv:2504.10369v2 Announce Type: replace-cross Abstract: Optimizing Register Transfer Level (RTL) code is crucial for improving the power, performance, and area (PPA) of digital circuits in the early stages of synthesis. Manual rewriting, guided by synthesis feedback, can yield high-quality results but is time-consuming and error-prone. Most existing compiler-based approaches have difficulty handling complex design constraints. Large Language Model (LLM)-based methods have emerged as a promising alternative to address these challenges. However, LLM-based approaches often face difficulties in ensuring alignment between the generated code and the provided prompts. This paper presents SymRTLO, a novel neuron-symbolic RTL optimization framework that seamlessly integrates LLM-based code rewriting with symbolic reasoning techniques. Our method incorporates a retrieval-augmented generation (RAG) system of optimization rules and Abstract Syntax Tree (AST)-based templates, enabling LLM-based rewriting that maintains syntactic correctness while minimizing undesired circuit behaviors. A symbolic module is proposed for analyzing and optimizing finite state machine (FSM) logic, allowing fine-grained state merging and partial specification handling beyond the scope of pattern-based compilers. Furthermore, a fast verification pipeline, combining formal equivalence checks with test-driven validation, further reduces the complexity of verification. Experiments on the RTL-Rewriter benchmark with Synopsys Design Compiler and Yosys show that SymRTLO improves power, performance, and area (PPA) by up to 43.9%, 62.5%, and 51.1%, respectively, compared to the state-of-the-art methods.
RIFT: Group-Relative RL Fine-Tuning for Realistic and Controllable Traffic Simulation
arXiv:2505.03344v3 Announce Type: replace-cross Abstract: Achieving both realism and controllability in closed-loop traffic simulation remains a key challenge in autonomous driving. Dataset-based methods reproduce realistic trajectories but suffer from covariate shift in closed-loop deployment, compounded by simplified dynamics models that further reduce reliability. Conversely, physics-based simulation methods enhance reliable and controllable closed-loop interactions but often lack expert demonstrations, compromising realism. To address these challenges, we introduce a dual-stage AV-centric simulation framework that conducts imitation learning pre-training in a data-driven simulator to capture trajectory-level realism and route-level controllability, followed by reinforcement learning fine-tuning in a physics-based simulator to enhance style-level controllability and mitigate covariate shift. In the fine-tuning stage, we propose RIFT, a novel group-relative RL fine-tuning strategy that evaluates all candidate modalities through group-relative formulation and employs a surrogate objective for stable optimization, enhancing style-level controllability and mitigating covariate shift while preserving the trajectory-level realism and route-level controllability inherited from IL pre-training. Extensive experiments demonstrate that RIFT improves realism and controllability in traffic simulation while simultaneously exposing the limitations of modern AV systems in closed-loop evaluation. Project Page: https://currychen77.github.io/RIFT/
Improving Medium Range Severe Weather Prediction through Transformer Post-processing of AI Weather Forecasts
arXiv:2505.11750v3 Announce Type: replace-cross Abstract: Improving the skill of medium-range (3-8 day) severe weather prediction is crucial for mitigating societal impacts. This study introduces a novel approach leveraging decoder-only transformer networks to post-process AI-based weather forecasts, specifically from the Pangu-Weather model, for improved severe weather guidance. Unlike traditional post-processing methods that use a dense neural network to predict the probability of severe weather using discrete forecast samples, our method treats forecast lead times as sequential ``tokens'', enabling the transformer to learn complex temporal relationships within the evolving atmospheric state. We compare this approach against post-processing of the Global Forecast System (GFS) using both a traditional dense neural network and our transformer, as well as configurations that exclude convective parameters to fairly evaluate the impact of using the Pangu-Weather AI model. Results demonstrate that the transformer-based post-processing significantly enhances forecast skill compared to dense neural networks. Furthermore, AI-driven forecasts, particularly Pangu-Weather initialized from high resolution analysis, exhibit superior performance to GFS in the medium-range, even without explicit convective parameters. Our approach offers improved accuracy, and reliability, which also provides interpretability through feature attribution analysis, advancing medium-range severe weather prediction capabilities.
R3: Robust Rubric-Agnostic Reward Models
arXiv:2505.13388v3 Announce Type: replace-cross Abstract: Reward models are essential for aligning language model outputs with human preferences, yet existing approaches often lack both controllability and interpretability. These models are typically optimized for narrow objectives, limiting their generalizability to broader downstream tasks. Moreover, their scalar outputs are difficult to interpret without contextual reasoning. To address these limitations, we introduce $\shortmethodname$, a novel reward modeling framework that is rubric-agnostic, generalizable across evaluation dimensions, and provides interpretable, reasoned score assignments. $\shortmethodname$ enables more transparent and flexible evaluation of language models, supporting robust alignment with diverse human values and use cases. Our models, data, and code are available as open source at https://github.com/rubricreward/r3.
SATBench: Benchmarking LLMs' Logical Reasoning via Automated Puzzle Generation from SAT Formulas
arXiv:2505.14615v2 Announce Type: replace-cross Abstract: We introduce SATBench, a benchmark for evaluating the logical reasoning capabilities of large language models (LLMs) through logical puzzles derived from Boolean satisfiability (SAT) problems. Unlike prior work that focuses on inference rule-based reasoning, which often involves deducing conclusions from a set of premises, our approach leverages the search-based nature of SAT problems, where the objective is to find a solution that fulfills a specified set of logical constraints. Each instance in SATBench is generated from a SAT formula, then translated into a puzzle using LLMs. The generation process is fully automated and allows for adjustable difficulty by varying the number of clauses. All 2100 puzzles are validated through both LLM-based and solver-based consistency checks, with human validation on a subset. Experimental results show that even the strongest model, o4-mini, achieves only 65.0% accuracy on hard UNSAT problems, close to the random baseline of 50%. Our error analysis reveals systematic failures such as satisfiability bias, context inconsistency, and condition omission, highlighting limitations of current LLMs in search-based logical reasoning. Our code and data are publicly available at https://github.com/Anjiang-Wei/SATBench
Tool Preferences in Agentic LLMs are Unreliable
arXiv:2505.18135v2 Announce Type: replace-cross Abstract: Large language models (LLMs) can now access a wide range of external tools, thanks to the Model Context Protocol (MCP). This greatly expands their abilities as various agents. However, LLMs rely entirely on the text descriptions of tools to decide which ones to use--a process that is surprisingly fragile. In this work, we expose a vulnerability in prevalent tool/function-calling protocols by investigating a series of edits to tool descriptions, some of which can drastically increase a tool's usage from LLMs when competing with alternatives. Through controlled experiments, we show that tools with properly edited descriptions receive over 10 times more usage from GPT-4.1 and Qwen2.5-7B than tools with original descriptions. We further evaluate how various edits to tool descriptions perform when competing directly with one another and how these trends generalize or differ across a broader set of 17 different models. These phenomena, while giving developers a powerful way to promote their tools, underscore the need for a more reliable foundation for agentic LLMs to select and utilize tools and resources. Our code is publicly available at https://github.com/kazemf78/llm-unreliable-tool-preferences.
BAGELS: Benchmarking the Automated Generation and Extraction of Limitations from Scholarly Text
arXiv:2505.18207v2 Announce Type: replace-cross Abstract: In scientific research, ``limitations'' refer to the shortcomings, constraints, or weaknesses of a study. A transparent reporting of such limitations can enhance the quality and reproducibility of research and improve public trust in science. However, authors often underreport limitations in their papers and rely on hedging strategies to meet editorial requirements at the expense of readers' clarity and confidence. This tendency, combined with the surge in scientific publications, has created a pressing need for automated approaches to extract and generate limitations from scholarly papers. To address this need, we present a full architecture for computational analysis of research limitations. Specifically, we (1) create a dataset of limitations from ACL, NeurIPS, and PeerJ papers by extracting them from the text and supplementing them with external reviews; (2) we propose methods to automatically generate limitations using a novel Retrieval Augmented Generation (RAG) technique; (3) we design a fine-grained evaluation framework for generated limitations, along with a meta-evaluation of these techniques.
How Is LLM Reasoning Distracted by Irrelevant Context? An Analysis Using a Controlled Benchmark
arXiv:2505.18761v2 Announce Type: replace-cross Abstract: We introduce Grade School Math with Distracting Context (GSM-DC), a synthetic benchmark to evaluate Large Language Models' (LLMs) reasoning robustness against systematically controlled irrelevant context (IC). GSM-DC constructs symbolic reasoning graphs with precise distractor injections, enabling rigorous, reproducible evaluation. Our experiments demonstrate that LLMs are significantly sensitive to IC, affecting both reasoning path selection and arithmetic accuracy. Additionally, training models with strong distractors improves performance in both in-distribution and out-of-distribution scenarios. We further propose a stepwise tree search guided by a process reward model, which notably enhances robustness in out-of-distribution conditions.
New Expansion Rate Anomalies at Characteristic Redshifts Geometrically Determined using DESI-DR2 BAO and DES-SN5YR Observations
arXiv:2505.19083v2 Announce Type: replace-cross Abstract: We perform a model-independent reconstruction of the cosmic distances using the Multi-Task Gaussian Process (MTGP) framework as well as knot-based spline techniques with DESI-DR2 BAO and DES-SN5YR datasets. We calibrate the comoving sound horizon at the baryon drag epoch $r_d$ to the Planck value, ensuring consistency with early-universe physics. With the reconstructed cosmic distances and their derivatives, we obtain seven characteristic redshifts in the range $0.3 \leq z \leq 1.7$. We derive the normalized expansion rate of the Universe $E(z)$ at these redshifts. Our findings reveal significant deviations of approximately $4$ to $5\sigma$ from the Planck 2018 $\Lambda$CDM predictions, particularly pronounced in the redshift range $z \sim 0.35-0.55$. These anomalies are consistently observed across both reconstruction methods and combined datasets, indicating robust late-time tensions in the expansion rate of the Universe and which are distinct from the existing "Hubble Tension". This could signal new physics beyond the standard cosmological framework at this redshift range. Our findings underscore the role of characteristic redshifts as sensitive indicators of expansion rate anomalies and motivate further scrutiny with forthcoming datasets from DESI-5YR BAO, Euclid, and LSST. These future surveys will tighten constraints and will confirm whether these late-time anomalies arise from new fundamental physics or unresolved systematics in the data.
From Chat Logs to Collective Insights: Aggregative Question Answering
arXiv:2505.23765v2 Announce Type: replace-cross Abstract: Conversational agents powered by large language models (LLMs) are rapidly becoming integral to our daily interactions, generating unprecedented amounts of conversational data. Such datasets offer a powerful lens into societal interests, trending topics, and collective concerns. Yet, existing approaches typically treat these interactions as independent and miss critical insights that could emerge from aggregating and reasoning across large-scale conversation logs. In this paper, we introduce Aggregative Question Answering, a novel task requiring models to reason explicitly over thousands of user-chatbot interactions to answer aggregative queries, such as identifying emerging concerns among specific demographics. To enable research in this direction, we construct a benchmark, WildChat-AQA, comprising 6,027 aggregative questions derived from 182,330 real-world chatbot conversations. Experiments show that existing methods either struggle to reason effectively or incur prohibitive computational costs, underscoring the need for new approaches capable of extracting collective insights from large-scale conversational data.
LaMP-QA: A Benchmark for Personalized Long-form Question Answering
arXiv:2506.00137v2 Announce Type: replace-cross Abstract: Personalization is essential for question answering systems that are user-centric. Despite its importance, personalization in answer generation has been relatively underexplored. This is mainly due to lack of resources for training and evaluating personalized question answering systems. We address this gap by introducing LaMP-QA -- a benchmark designed for evaluating personalized long-form answer generation. The benchmark covers questions from three major categories: (1) Arts & Entertainment, (2) Lifestyle & Personal Development, and (3) Society & Culture, encompassing over 45 subcategories in total. To assess the quality and potential impact of the LaMP-QA benchmark for personalized question answering, we conduct comprehensive human and automatic evaluations, to compare multiple evaluation strategies for evaluating generated personalized responses and measure their alignment with human preferences. Furthermore, we benchmark a number of non-personalized and personalized approaches based on open-source and proprietary large language models. Our results show that incorporating the personalized context provided leads to up to 39% performance improvements. The benchmark is publicly released to support future research in this area.
Diffusion Graph Neural Networks and Dataset for Robust Olfactory Navigation in Hazard Robotics
arXiv:2506.00455v4 Announce Type: replace-cross Abstract: Navigation by scent is a capability in robotic systems that is rising in demand. However, current methods often suffer from ambiguities, particularly when robots misattribute odours to incorrect objects due to limitations in olfactory datasets and sensor resolutions. To address challenges in olfactory navigation, we introduce a multimodal olfaction dataset along with a novel machine learning method using diffusion-based molecular generation that can be used by itself or with automated olfactory dataset construction pipelines. This generative process of our diffusion model expands the chemical space beyond the limitations of both current olfactory datasets and training methods, enabling the identification of potential odourant molecules not previously documented. The generated molecules can then be more accurately validated using advanced olfactory sensors, enabling them to detect more compounds and inform better hardware design. By integrating visual analysis, language processing, and molecular generation, our framework enhances the ability of olfaction-vision models on robots to accurately associate odours with their correct sources, thereby improving navigation and decision-making through better sensor selection for a target compound in critical applications such as explosives detection, narcotics screening, and search and rescue. Our methodology represents a foundational advancement in the field of artificial olfaction, offering a scalable solution to challenges posed by limited olfactory data and sensor ambiguities. Code, models, and data are made available to the community at: https://huggingface.co/datasets/kordelfrance/olfaction-vision-language-dataset.
ESGenius: Benchmarking LLMs on Environmental, Social, and Governance (ESG) and Sustainability Knowledge
arXiv:2506.01646v2 Announce Type: replace-cross Abstract: We introduce ESGenius, a comprehensive benchmark for evaluating and enhancing the proficiency of Large Language Models (LLMs) in Environmental, Social, and Governance (ESG) and sustainability-focused question answering. ESGenius comprises two key components: (i) ESGenius-QA, a collection of 1,136 Multiple-Choice Questions (MCQs) generated by LLMs and rigorously validated by domain experts, covering a broad range of ESG pillars and sustainability topics. Each question is systematically linked to its corresponding source text, enabling transparent evaluation and supporting Retrieval-Augmented Generation (RAG) methods; and (ii) ESGenius-Corpus, a meticulously curated repository of 231 foundational frameworks, standards, reports, and recommendation documents from 7 authoritative sources. Moreover, to fully assess the capabilities and adaptation potential of LLMs, we implement a rigorous two-stage evaluation protocol -- Zero-Shot and RAG. Extensive experiments across 50 LLMs (0.5B to 671B) demonstrate that state-of-the-art models achieve only moderate performance in zero-shot settings, with accuracies around 55--70%, highlighting a significant knowledge gap for LLMs in this specialized, interdisciplinary domain. However, models employing RAG demonstrate significant performance improvements, particularly for smaller models. For example, DeepSeek-R1-Distill-Qwen-14B improves from 63.82% (zero-shot) to 80.46% with RAG. These results demonstrate the necessity of grounding responses in authoritative sources for enhanced ESG understanding. To the best of our knowledge, ESGenius is the first comprehensive QA benchmark designed to rigorously evaluate LLMs on ESG and sustainability knowledge, providing a critical tool to advance trustworthy AI in this vital domain.
Survey on the Evaluation of Generative Models in Music
arXiv:2506.05104v4 Announce Type: replace-cross Abstract: Research on generative systems in music has seen considerable attention and growth in recent years. A variety of attempts have been made to systematically evaluate such systems. We present an interdisciplinary review of the common evaluation targets, methodologies, and metrics for the evaluation of both system output and model use, covering subjective and objective approaches, qualitative and quantitative approaches, as well as empirical and computational methods. We examine the benefits and limitations of these approaches from a musicological, an engineering, and an HCI perspective.
Diversity-Guided MLP Reduction for Efficient Large Vision Transformers
arXiv:2506.08591v2 Announce Type: replace-cross Abstract: Transformer models achieve excellent scaling property, where the performance is improved with the increment of model capacity. However, large-scale model parameters lead to an unaffordable cost of computing and memory. We analyze popular transformer architectures and find that multilayer perceptron (MLP) modules take up the majority of model parameters. To this end, we focus on the recoverability of the compressed models and propose a Diversity-Guided MLP Reduction (DGMR) method to significantly reduce the parameters of large vision transformers with only negligible performance degradation. Specifically, we conduct a Gram-Schmidt weight pruning strategy to eliminate redundant neurons of MLP hidden layer, while preserving weight diversity for better performance recover during distillation. Compared to the model trained from scratch, our pruned model only requires 0.06\% data of LAION-2B (for the training of large vision transformers) without labels (ImageNet-1K) to recover the original performance. Experimental results on several state-of-the-art large vision transformers demonstrate that our method achieves a more than 57.0\% parameter and FLOPs reduction in a near lossless manner. Notably, for EVA-CLIP-E (4.4B), our method accomplishes a 71.5\% parameter and FLOPs reduction without performance degradation. The source code and trained weights are available at https://github.com/visresearch/DGMR.
DISCO: Mitigating Bias in Deep Learning with Conditional Distance Correlation
arXiv:2506.11653v2 Announce Type: replace-cross Abstract: Dataset bias often leads deep learning models to exploit spurious correlations instead of task-relevant signals. We introduce the Standard Anti-Causal Model (SAM), a unifying causal framework that characterizes bias mechanisms and yields a conditional independence criterion for causal stability. Building on this theory, we propose DISCO$_m$ and sDISCO, efficient and scalable estimators of conditional distance correlation that enable independence regularization in black-box models. Across five diverse datasets, our methods consistently outperform or are competitive in existing bias mitigation approaches, while requiring fewer hyperparameters and scaling seamlessly to multi-bias scenarios. This work bridges causal theory and practical deep learning, providing both a principled foundation and effective tools for robust prediction. Source Code: https://github.com/***.
See What I Mean? CUE: A Cognitive Model of Understanding Explanations
arXiv:2506.14775v2 Announce Type: replace-cross Abstract: As machine learning systems increasingly inform critical decisions, the need for human-understandable explanations grows. Current evaluations of Explainable AI (XAI) often prioritize technical fidelity over cognitive accessibility which critically affects users, in particular those with visual impairments. We propose CUE, a model for Cognitive Understanding of Explanations, linking explanation properties to cognitive sub-processes: legibility (perception), readability (comprehension), and interpretability (interpretation). In a study (N=455) testing heatmaps with varying colormaps (BWR, Cividis, Coolwarm), we found comparable task performance but lower confidence/effort for visually impaired users. Unlike expected, these gaps were not mitigated and sometimes worsened by accessibility-focused color maps like Cividis. These results challenge assumptions about perceptual optimization and support the need for adaptive XAI interfaces. They also validate CUE by demonstrating that altering explanation legibility affects understandability. We contribute: (1) a formalized cognitive model for explanation understanding, (2) an integrated definition of human-centered explanation properties, and (3) empirical evidence motivating accessible, user-tailored XAI.
HARPT: A Corpus for Analyzing Consumers' Trust and Privacy Concerns in Electronic Health Apps
arXiv:2506.19268v3 Announce Type: replace-cross Abstract: We present Health App Reviews for Privacy & Trust (HARPT), a large-scale annotated corpus of user reviews from Electronic Health (eHealth) applications (apps) aimed at advancing research in user privacy and trust. The dataset comprises 480K user reviews labeled in seven categories that capture critical aspects of trust in applications (TA), trust in providers (TP), and privacy concerns (PC). Our multistage strategy integrated keyword-based filtering, iterative manual labeling with review, targeted data augmentation, and weak supervision using transformer-based classifiers. In parallel, we manually annotated a curated subset of 7,000 reviews to support the development and evaluation of machine learning models. We benchmarked a broad range of models, providing a baseline for future work. HARPT is released under an open resource license to support reproducible research in usable privacy and trust in digital libraries and health informatics.
Exploring the Design Space of 3D MLLMs for CT Report Generation
arXiv:2506.21535v2 Announce Type: replace-cross Abstract: Multimodal Large Language Models (MLLMs) have emerged as a promising way to automate Radiology Report Generation (RRG). In this work, we systematically investigate the design space of 3D MLLMs, including visual input representation, projectors, Large Language Models (LLMs), and fine-tuning techniques for 3D CT report generation. We also introduce two knowledge-based report augmentation methods that improve performance on the GREEN score by up to 10%, achieving the 2nd place on the MICCAI 2024 AMOS-MM challenge. Our results on the 1,687 cases from the AMOS-MM dataset show that RRG is largely independent of the size of LLM under the same training protocol. We also show that larger volume size does not always improve performance if the original ViT was pre-trained on a smaller volume size. Lastly, we show that using a segmentation mask along with the CT volume improves performance. The code is publicly available at https://github.com/bowang-lab/AMOS-MM-Solution
AICO: Feature Significance Tests for Supervised Learning
arXiv:2506.23396v2 Announce Type: replace-cross Abstract: The opacity of many supervised learning algorithms remains a key challenge, hindering scientific discovery and limiting broader deployment -- particularly in high-stakes domains. This paper develops model- and distribution-agnostic significance tests to assess the influence of input features in any regression or classification algorithm. Our method evaluates a feature's incremental contribution to model performance by masking its values across samples. Under the null hypothesis, the distribution of performance differences across a test set has a non-positive median. We construct a uniformly most powerful, randomized sign test for this median, yielding exact p-values for assessing feature significance and confidence intervals with exact coverage for estimating population-level feature importance. The approach requires minimal assumptions, avoids model retraining or auxiliary models, and remains computationally efficient even for large-scale, high-dimensional settings. Experiments on synthetic tasks validate its statistical and computational advantages, and applications to real-world data illustrate its practical utility.
Datasets for Fairness in Language Models: An In-Depth Survey
arXiv:2506.23411v2 Announce Type: replace-cross Abstract: Despite the growing reliance on fairness benchmarks to evaluate language models, the datasets that underpin these benchmarks remain critically underexamined. This survey addresses that overlooked foundation by offering a comprehensive analysis of the most widely used fairness datasets in language model research. To ground this analysis, we characterize each dataset across key dimensions, including provenance, demographic scope, annotation design, and intended use, revealing the assumptions and limitations baked into current evaluation practices. Building on this foundation, we propose a unified evaluation framework that surfaces consistent patterns of demographic disparities across benchmarks and scoring metrics. Applying this framework to sixteen popular datasets, we uncover overlooked biases that may distort conclusions about model fairness and offer guidance on selecting, combining, and interpreting these resources more effectively and responsibly. Our findings highlight an urgent need for new benchmarks that capture a broader range of social contexts and fairness notions. To support future research, we release all data, code, and results at https://github.com/vanbanTruong/Fairness-in-Large-Language-Models/tree/main/datasets, fostering transparency and reproducibility in the evaluation of language model fairness.
Resolving Turbulent Magnetohydrodynamics: A Hybrid Operator-Diffusion Framework
arXiv:2507.02106v2 Announce Type: replace-cross Abstract: We present a hybrid machine learning framework that combines Physics-Informed Neural Operators (PINOs) with score-based generative diffusion models to simulate the full spatio-temporal evolution of two-dimensional, incompressible, resistive magnetohydrodynamic (MHD) turbulence across a broad range of Reynolds numbers ($\mathrm{Re}$). The framework leverages the equation-constrained generalization capabilities of PINOs to predict coherent, low-frequency dynamics, while a conditional diffusion model stochastically corrects high-frequency residuals, enabling accurate modeling of fully developed turbulence. Trained on a comprehensive ensemble of high-fidelity simulations with $\mathrm{Re} \in {100, 250, 500, 750, 1000, 3000, 10000}$, the approach achieves state-of-the-art accuracy in regimes previously inaccessible to deterministic surrogates. At $\mathrm{Re}=1000$ and $3000$, the model faithfully reconstructs the full spectral energy distributions of both velocity and magnetic fields late into the simulation, capturing non-Gaussian statistics, intermittent structures, and cross-field correlations with high fidelity. At extreme turbulence levels ($\mathrm{Re}=10000$), it remains the first surrogate capable of recovering the high-wavenumber evolution of the magnetic field, preserving large-scale morphology and enabling statistically meaningful predictions.
PDFMathTranslate: Scientific Document Translation Preserving Layouts
arXiv:2507.03009v4 Announce Type: replace-cross Abstract: Language barriers in scientific documents hinder the diffusion and development of science and technologies. However, prior efforts in translating such documents largely overlooked the information in layouts. To bridge the gap, we introduce PDFMathTranslate, the world's first open-source software for translating scientific documents while preserving layouts. Leveraging the most recent advances in large language models and precise layout detection, we contribute to the community with key improvements in precision, flexibility, and efficiency. The work has been open-sourced at https://github.com/byaidu/pdfmathtranslate with more than 222k downloads.
Interpretability-Aware Pruning for Efficient Medical Image Analysis
arXiv:2507.08330v2 Announce Type: replace-cross Abstract: Deep learning has driven significant advances in medical image analysis, yet its adoption in clinical practice remains constrained by the large size and lack of transparency in modern models. Advances in interpretability techniques such as DL-Backtrace, Layer-wise Relevance Propagation, and Integrated Gradients make it possible to assess the contribution of individual components within neural networks trained on medical imaging tasks. In this work, we introduce an interpretability-guided pruning framework that reduces model complexity while preserving both predictive performance and transparency. By selectively retaining only the most relevant parts of each layer, our method enables targeted compression that maintains clinically meaningful representations. Experiments across multiple medical image classification benchmarks demonstrate that this approach achieves high compression rates with minimal loss in accuracy, paving the way for lightweight, interpretable models suited for real-world deployment in healthcare settings.
Automating Steering for Safe Multimodal Large Language Models
arXiv:2507.13255v2 Announce Type: replace-cross Abstract: Recent progress in Multimodal Large Language Models (MLLMs) has unlocked powerful cross-modal reasoning abilities, but also raised new safety concerns, particularly when faced with adversarial multimodal inputs. To improve the safety of MLLMs during inference, we introduce a modular and adaptive inference-time intervention technology, AutoSteer, without requiring any fine-tuning of the underlying model. AutoSteer incorporates three core components: (1) a novel Safety Awareness Score (SAS) that automatically identifies the most safety-relevant distinctions among the model's internal layers; (2) an adaptive safety prober trained to estimate the likelihood of toxic outputs from intermediate representations; and (3) a lightweight Refusal Head that selectively intervenes to modulate generation when safety risks are detected. Experiments on LLaVA-OV and Chameleon across diverse safety-critical benchmarks demonstrate that AutoSteer significantly reduces the Attack Success Rate (ASR) for textual, visual, and cross-modal threats, while maintaining general abilities. These findings position AutoSteer as a practical, interpretable, and effective framework for safer deployment of multimodal AI systems.
Latent Policy Steering with Embodiment-Agnostic Pretrained World Models
arXiv:2507.13340v2 Announce Type: replace-cross Abstract: Learning visuomotor policies via imitation has proven effective across a wide range of robotic domains. However, the performance of these policies is heavily dependent on the number of training demonstrations, which requires expensive data collection in the real world. In this work, we aim to reduce data collection efforts when learning visuomotor robot policies by leveraging existing or cost-effective data from a wide range of embodiments, such as public robot datasets and the datasets of humans playing with objects (human data from play). Our approach leverages two key insights. First, we use optic flow as an embodiment-agnostic action representation to train a World Model (WM) across multi-embodiment datasets, and finetune it on a small amount of robot data from the target embodiment. Second, we develop a method, Latent Policy Steering (LPS), to improve the output of a behavior-cloned policy by searching in the latent space of the WM for better action sequences. In real world experiments, we observe significant improvements in the performance of policies trained with a small amount of data (over 50% relative improvement with 30 demonstrations and over 20% relative improvement with 50 demonstrations) by combining the policy with a WM pretrained on two thousand episodes sampled from the existing Open X-embodiment dataset across different robots or a cost-effective human dataset from play.
Loss-Complexity Landscape and Model Structure Functions
arXiv:2507.13543v3 Announce Type: replace-cross Abstract: We develop a framework for dualizing the Kolmogorov structure function $h_x(\alpha)$, which then allows using computable complexity proxies. We establish a mathematical analogy between information-theoretic constructs and statistical mechanics, introducing a suitable partition function and free energy functional. We explicitly prove the Legendre-Fenchel duality between the structure function and free energy, showing detailed balance of the Metropolis kernel, and interpret acceptance probabilities as information-theoretic scattering amplitudes. A susceptibility-like variance of model complexity is shown to peak precisely at loss-complexity trade-offs interpreted as phase transitions. Practical experiments with linear and tree-based regression models verify these theoretical predictions, explicitly demonstrating the interplay between the model complexity, generalization, and overfitting threshold.
Differentially Private Synthetic Graphs Preserving Triangle-Motif Cuts
arXiv:2507.14835v2 Announce Type: replace-cross Abstract: We study the problem of releasing a differentially private (DP) synthetic graph $G'$ that well approximates the triangle-motif sizes of all cuts of any given graph $G$, where a motif in general refers to a frequently occurring subgraph within complex networks. Non-private versions of such graphs have found applications in diverse fields such as graph clustering, graph sparsification, and social network analysis. Specifically, we present the first $(\varepsilon,\delta)$-DP mechanism that, given an input graph $G$ with $n$ vertices, $m$ edges and local sensitivity of triangles $\ell_{3}(G)$, generates a synthetic graph $G'$ in polynomial time, approximating the triangle-motif sizes of all cuts $(S,V\setminus S)$ of the input graph $G$ up to an additive error of $\tilde{O}(\sqrt{m\ell_{3}(G)}n/\varepsilon^{3/2})$. Additionally, we provide a lower bound of $\Omega(\sqrt{mn}\ell_{3}(G)/\varepsilon)$ on the additive error for any DP algorithm that answers the triangle-motif size queries of all $(S,T)$-cut of $G$. Finally, our algorithm generalizes to weighted graphs, and our lower bound extends to any $K_h$-motif cut for any constant $h\geq 2$.
Robustifying Learning-Augmented Caching Efficiently without Compromising 1-Consistency
arXiv:2507.16242v4 Announce Type: replace-cross Abstract: The online caching problem aims to minimize cache misses when serving a sequence of requests under a limited cache size. While naive learning-augmented caching algorithms achieve ideal $1$-consistency, they lack robustness guarantees. Existing robustification methods either sacrifice $1$-consistency or introduce significant computational overhead. In this paper, we introduce Guard, a lightweight robustification framework that enhances the robustness of a broad class of learning-augmented caching algorithms to $2H_k + 2$, while preserving their $1$-consistency. Guard achieves the current best-known trade-off between consistency and robustness, with only $O(1)$ additional per-request overhead, thereby maintaining the original time complexity of the base algorithm. Extensive experiments across multiple real-world datasets and prediction models validate the effectiveness of Guard in practice.
Simulating Posterior Bayesian Neural Networks with Dependent Weights
arXiv:2507.22095v2 Announce Type: replace-cross Abstract: In this paper we consider posterior Bayesian fully connected and feedforward deep neural networks with dependent weights. Particularly, if the likelihood is Gaussian, we identify the distribution of the wide width limit and provide an algorithm to sample from the network. In the shallow case we explicitly compute the distribution of the conditional output, proving that it is a Gaussian mixture. All the theoretical results are numerically validated.
When Truthful Representations Flip Under Deceptive Instructions?
arXiv:2507.22149v3 Announce Type: replace-cross Abstract: Large language models (LLMs) tend to follow maliciously crafted instructions to generate deceptive responses, posing safety challenges. How deceptive instructions alter the internal representations of LLM compared to truthful ones remains poorly understood beyond output analysis. To bridge this gap, we investigate when and how these representations ``flip'', such as from truthful to deceptive, under deceptive versus truthful/neutral instructions. Analyzing the internal representations of Llama-3.1-8B-Instruct and Gemma-2-9B-Instruct on a factual verification task, we find the model's instructed True/False output is predictable via linear probes across all conditions based on the internal representation. Further, we use Sparse Autoencoders (SAEs) to show that the Deceptive instructions induce significant representational shifts compared to Truthful/Neutral representations (which are similar), concentrated in early-to-mid layers and detectable even on complex datasets. We also identify specific SAE features highly sensitive to deceptive instruction and use targeted visualizations to confirm distinct truthful/deceptive representational subspaces. % Our analysis pinpoints layer-wise and feature-level correlates of instructed dishonesty, offering insights for LLM detection and control. Our findings expose feature- and layer-level signatures of deception, offering new insights for detecting and mitigating instructed dishonesty in LLMs.
Applying Psychometrics to Large Language Model Simulated Populations: Recreating the HEXACO Personality Inventory Experiment with Generative Agents
arXiv:2508.00742v2 Announce Type: replace-cross Abstract: Generative agents powered by Large Language Models demonstrate human-like characteristics through sophisticated natural language interactions. Their ability to assume roles and personalities based on predefined character biographies has positioned them as cost-effective substitutes for human participants in social science research. This paper explores the validity of such persona-based agents in representing human populations; we recreate the HEXACO personality inventory experiment by surveying 310 GPT-4 powered agents, conducting factor analysis on their responses, and comparing these results to the original findings presented by Ashton, Lee, & Goldberg in 2004. Our results found 1) a coherent and reliable personality structure was recoverable from the agents' responses demonstrating partial alignment to the HEXACO framework. 2) the derived personality dimensions were consistent and reliable within GPT-4, when coupled with a sufficiently curated population, and 3) cross-model analysis revealed variability in personality profiling, suggesting model-specific biases and limitations. We discuss the practical considerations and challenges encountered during the experiment. This study contributes to the ongoing discourse on the potential benefits and limitations of using generative agents in social science research and provides useful guidance on designing consistent and representative agent personas to maximise coverage and representation of human personality traits.
Tensor-Empowered Asset Pricing with Missing Data
arXiv:2508.01861v2 Announce Type: replace-cross Abstract: Missing data in financial panels presents a critical obstacle, undermining asset-pricing models and reducing the effectiveness of investment strategies. Such panels are often inherently multi-dimensional, spanning firms, time, and financial variables, which adds complexity to the imputation task. Conventional imputation methods often fail by flattening the data's multidimensional structure, struggling with heterogeneous missingness patterns, or overfitting in the face of extreme data sparsity. To address these limitations, we introduce an Adaptive, Cluster-based Temporal smoothing tensor completion framework (ACT-Tensor) tailored for severely and heterogeneously missing multi-dimensional financial data panels. ACT-Tensor incorporates two key innovations: a cluster-based completion module that captures cross-sectional heterogeneity by learning group-specific latent structures; and a temporal smoothing module that proactively removes short-lived noise while preserving slow-moving fundamental trends. Extensive experiments show that ACT-Tensor consistently outperforms state-of-the-art benchmarks in terms of imputation accuracy across a range of missing data regimes, including extreme sparsity scenarios. To assess its practical financial utility, we evaluate the imputed data with a latent factor model tailored for tensor-structured financial data. Results show that ACT-Tensor not only achieves accurate return forecasting but also significantly improves risk-adjusted returns of the constructed portfolio. These findings confirm that our method delivers highly accurate and informative imputations, offering substantial value for financial decision-making.
Blockchain-Enabled Federated Learning
arXiv:2508.06406v4 Announce Type: replace-cross Abstract: Blockchain-enabled federated learning (BCFL) addresses fundamental challenges of trust, privacy, and coordination in collaborative AI systems. This chapter provides comprehensive architectural analysis of BCFL systems through a systematic four-dimensional taxonomy examining coordination structures, consensus mechanisms, storage architectures, and trust models. We analyze design patterns from blockchain-verified centralized coordination to fully decentralized peer-to-peer networks, evaluating trade-offs in scalability, security, and performance. Through detailed examination of consensus mechanisms designed for federated learning contexts, including Proof of Quality and Proof of Federated Learning, we demonstrate how computational work can be repurposed from arbitrary cryptographic puzzles to productive machine learning tasks. The chapter addresses critical storage challenges by examining multi-tier architectures that balance blockchain's transaction constraints with neural networks' large parameter requirements while maintaining cryptographic integrity. A technical case study of the TrustMesh framework illustrates practical implementation considerations in BCFL systems through distributed image classification training, demonstrating effective collaborative learning across IoT devices with highly non-IID data distributions while maintaining complete transparency and fault tolerance. Analysis of real-world deployments across healthcare consortiums, financial services, and IoT security applications validates the practical viability of BCFL systems, achieving performance comparable to centralized approaches while providing enhanced security guarantees and enabling new models of trustless collaborative intelligence.
Advancing Knowledge Tracing by Exploring Follow-up Performance Trends
arXiv:2508.08019v2 Announce Type: replace-cross Abstract: Intelligent Tutoring Systems (ITS), such as Massive Open Online Courses, offer new opportunities for human learning. At the core of such systems, knowledge tracing (KT) predicts students' future performance by analyzing their historical learning activities, enabling an accurate evaluation of students' knowledge states over time. We show that existing KT methods often encounter correlation conflicts when analyzing the relationships between historical learning sequences and future performance. To address such conflicts, we propose to extract so-called Follow-up Performance Trends (FPTs) from historical ITS data and to incorporate them into KT. We propose a method called Forward-Looking Knowledge Tracing (FINER) that combines historical learning sequences with FPTs to enhance student performance prediction accuracy. FINER constructs learning patterns that facilitate the retrieval of FPTs from historical ITS data in linear time; FINER includes a novel similarity-aware attention mechanism that aggregates FPTs based on both frequency and contextual similarity; and FINER offers means of combining FPTs and historical learning sequences to enable more accurate prediction of student future performance. Experiments on six real-world datasets show that FINER can outperform ten state-of-the-art KT methods, increasing accuracy by 8.74% to 84.85%.
Mini-Omni-Reasoner: Token-Level Thinking-in-Speaking in Large Speech Models
arXiv:2508.15827v2 Announce Type: replace-cross Abstract: Reasoning is essential for effective communication and decision-making. While recent advances in LLMs and MLLMs have shown that incorporating explicit reasoning significantly improves understanding and generalization, reasoning in LSMs remains in a nascent stage. Early efforts attempt to transfer the "Thinking-before-Speaking" paradigm from textual models to speech. However, this sequential formulation introduces notable latency, as spoken responses are delayed until reasoning is fully completed, impairing real-time interaction and communication efficiency. To address this, we propose Mini-Omni-Reasoner, a framework that enables reasoning within speech via a novel "Thinking-in-Speaking" formulation. Rather than completing reasoning before producing any verbal output, Mini-Omni-Reasoner interleaves silent reasoning tokens with spoken response tokens at the token level. This design allows continuous speech generation while embedding structured internal reasoning, leveraging the model's high-frequency token processing capability. Although interleaved, local semantic alignment is enforced to ensure that each response token is informed by its preceding reasoning. To support this framework, we introduce Spoken-Math-Problems-3M, a large-scale dataset tailored for interleaved reasoning and response. The dataset ensures that verbal tokens consistently follow relevant reasoning content, enabling accurate and efficient learning of speech-coupled reasoning. Built on a hierarchical Thinker-Talker architecture, Mini-Omni-Reasoner delivers fluent yet logically grounded spoken responses, maintaining both naturalness and precision. On the Spoken-MQA benchmark, it achieves a +19.1% gain in arithmetic reasoning and +6.4% in contextual understanding, with shorter outputs and zero decoding latency.
Convergence Analysis of the PAGE Stochastic Algorithm for Weakly Convex Finite-Sum Optimization
arXiv:2509.00737v2 Announce Type: replace-cross Abstract: PAGE, a stochastic algorithm introduced by Li et al. [2021], was designed to find stationary points of averages of smooth nonconvex functions. In this work, we study PAGE in the broad framework of $\tau$-weakly convex functions, which provides a continuous interpolation between the general nonconvex $L$-smooth case ($\tau = L$) and the convex case ($\tau = 0$). We establish new convergence rates for PAGE, showing that its complexity improves as $\tau$ decreases.
Dynamic Speculative Agent Planning
arXiv:2509.01920v3 Announce Type: replace-cross Abstract: Despite their remarkable success in complex tasks propelling widespread adoption, large language-model-based agents still face critical deployment challenges due to prohibitive latency and inference costs. While recent work has explored various methods to accelerate inference, existing approaches suffer from significant limitations: they either fail to preserve performance fidelity, require extensive offline training of router modules, or incur excessive operational costs. Moreover, they provide minimal user control over the tradeoff between acceleration and other performance metrics. To address these gaps, we introduce Dynamic Speculative Planning (DSP), an asynchronous online reinforcement learning framework that provides lossless acceleration with substantially reduced costs without requiring additional pre-deployment preparation. DSP explicitly optimizes a joint objective balancing end-to-end latency against dollar cost, allowing practitioners to adjust a single parameter that steers the system toward faster responses, cheaper operation, or any point along this continuum. Experiments on two standard agent benchmarks demonstrate that DSP achieves comparable efficiency to the fastest lossless acceleration method while reducing total cost by 30% and unnecessary cost up to 60%. Our code and data are available through https://github.com/guanyilin428/Dynamic-Speculative-Planning.
An Effective Strategy for Modeling Score Ordinality and Non-uniform Intervals in Automated Speaking Assessment
arXiv:2509.03372v2 Announce Type: replace-cross Abstract: A recent line of research on automated speaking assessment (ASA) has benefited from self-supervised learning (SSL) representations, which capture rich acoustic and linguistic patterns in non-native speech without underlying assumptions of feature curation. However, speech-based SSL models capture acoustic-related traits but overlook linguistic content, while text-based SSL models rely on ASR output and fail to encode prosodic nuances. Moreover, most prior arts treat proficiency levels as nominal classes, ignoring their ordinal structure and non-uniform intervals between proficiency labels. To address these limitations, we propose an effective ASA approach combining SSL with handcrafted indicator features via a novel modeling paradigm. We further introduce a multi-margin ordinal loss that jointly models both the score ordinality and non-uniform intervals of proficiency labels. Extensive experiments on the TEEMI corpus show that our method consistently outperforms strong baselines and generalizes well to unseen prompts.
A Data-Driven Discretized CS:GO Simulation Environment to Facilitate Strategic Multi-Agent Planning Research
arXiv:2509.06355v2 Announce Type: replace-cross Abstract: Modern simulation environments for complex multi-agent interactions must balance high-fidelity detail with computational efficiency. We present DECOY, a novel multi-agent simulator that abstracts strategic, long-horizon planning in 3D terrains into high-level discretized simulation while preserving low-level environmental fidelity. Using Counter-Strike: Global Offensive (CS:GO) as a testbed, our framework accurately simulates gameplay using only movement decisions as tactical positioning -- without explicitly modeling low-level mechanics such as aiming and shooting. Central to our approach is a waypoint system that simplifies and discretizes continuous states and actions, paired with neural predictive and generative models trained on real CS:GO tournament data to reconstruct event outcomes. Extensive evaluations show that replays generated from human data in DECOY closely match those observed in the original game. Our publicly available simulation environment provides a valuable tool for advancing research in strategic multi-agent planning and behavior generation.
HealthSLM-Bench: Benchmarking Small Language Models for Mobile and Wearable Healthcare Monitoring
arXiv:2509.07260v2 Announce Type: replace-cross Abstract: Mobile and wearable healthcare monitoring play a vital role in facilitating timely interventions, managing chronic health conditions, and ultimately improving individuals' quality of life. Previous studies on large language models (LLMs) have highlighted their impressive generalization abilities and effectiveness in healthcare prediction tasks. However, most LLM-based healthcare solutions are cloud-based, which raises significant privacy concerns and results in increased memory usage and latency. To address these challenges, there is growing interest in compact models, Small Language Models (SLMs), which are lightweight and designed to run locally and efficiently on mobile and wearable devices. Nevertheless, how well these models perform in healthcare prediction remains largely unexplored. We systematically evaluated SLMs on health prediction tasks using zero-shot, few-shot, and instruction fine-tuning approaches, and deployed the best performing fine-tuned SLMs on mobile devices to evaluate their real-world efficiency and predictive performance in practical healthcare scenarios. Our results show that SLMs can achieve performance comparable to LLMs while offering substantial gains in efficiency and privacy. However, challenges remain, particularly in handling class imbalance and few-shot scenarios. These findings highlight SLMs, though imperfect in their current form, as a promising solution for next-generation, privacy-preserving healthcare monitoring.
Disentangling Content from Style to Overcome Shortcut Learning: A Hybrid Generative-Discriminative Learning Framework
arXiv:2509.11598v3 Announce Type: replace-cross Abstract: Despite the remarkable success of Self-Supervised Learning (SSL), its generalization is fundamentally hindered by Shortcut Learning, where models exploit superficial features like texture instead of intrinsic structure. We experimentally verify this flaw within the generative paradigm (e.g., MAE) and argue it is a systemic issue also affecting discriminative methods, identifying it as the root cause of their failure on unseen domains. While existing methods often tackle this at a surface level by aligning or separating domain-specific features, they fail to alter the underlying learning mechanism that fosters shortcut dependency. To address this at its core, we propose HyGDL (Hybrid Generative-Discriminative Learning Framework), a hybrid framework that achieves explicit content-style disentanglement. Our approach is guided by the Invariance Pre-training Principle: forcing a model to learn an invariant essence by systematically varying a bias (e.g., style) at the input while keeping the supervision signal constant. HyGDL operates on a single encoder and analytically defines style as the component of a representation that is orthogonal to its style-invariant content, derived via vector projection. This is operationalized through a synergistic design: (1) a self-distillation objective learns a stable, style-invariant content direction; (2) an analytical projection then decomposes the representation into orthogonal content and style vectors; and (3) a style-conditioned reconstruction objective uses these vectors to restore the image, providing end-to-end supervision. Unlike prior methods that rely on implicit heuristics, this principled disentanglement allows HyGDL to learn truly robust representations, demonstrating superior performance on benchmarks designed to diagnose shortcut learning.
Neural Audio Codecs for Prompt-Driven Universal Source Separation
arXiv:2509.11717v2 Announce Type: replace-cross Abstract: Text-guided source separation supports flexible audio editing across media and assistive applications, but existing models like AudioSep are too compute-heavy for edge deployment. Neural audio codec (NAC) models such as CodecFormer and SDCodec are compute-efficient but limited to fixed-class separation. We introduce CodecSep, the first NAC-based model for on-device universal, text-driven separation. CodecSep combines DAC compression with a Transformer masker modulated by CLAP-derived FiLM parameters. Across six open-domain benchmarks under matched training/prompt protocols, \textbf{CodecSep} surpasses \textbf{AudioSep} in separation fidelity (SI-SDR) while remaining competitive in perceptual quality (ViSQOL) and matching or exceeding fixed-stem baselines (TDANet, CodecFormer, SDCodec). In code-stream deployments, it needs just 1.35~GMACs end-to-end -- approximately $54\times$ less compute ($25\times$ architecture-only) than spectrogram-domain separators like AudioSep -- while remaining fully bitstream-compatible.
Large Language Model-Empowered Decision Transformer for UAV-Enabled Data Collection
arXiv:2509.13934v2 Announce Type: replace-cross Abstract: The deployment of unmanned aerial vehicles (UAVs) for reliable and energy-efficient data collection from spatially distributed devices holds great promise in supporting diverse Internet of Things (IoT) applications. Nevertheless, the limited endurance and communication range of UAVs necessitate intelligent trajectory planning. While reinforcement learning (RL) has been extensively explored for UAV trajectory optimization, its interactive nature entails high costs and risks in real-world environments. Offline RL mitigates these issues but remains susceptible to unstable training and heavily rely on expert-quality datasets. To address these challenges, we formulate a joint UAV trajectory planning and resource allocation problem to maximize energy efficiency of data collection. The resource allocation subproblem is first transformed into an equivalent linear programming formulation and solved optimally with polynomial-time complexity. Then, we propose a large language model (LLM)-empowered critic-regularized decision transformer (DT) framework, termed LLM-CRDT, to learn effective UAV control policies. In LLM-CRDT, we incorporate critic networks to regularize the DT model training, thereby integrating the sequence modeling capabilities of DT with critic-based value guidance to enable learning effective policies from suboptimal datasets. Furthermore, to mitigate the data-hungry nature of transformer models, we employ a pre-trained LLM as the transformer backbone of the DT model and adopt a parameter-efficient fine-tuning strategy, i.e., LoRA, enabling rapid adaptation to UAV control tasks with small-scale dataset and low computational overhead. Extensive simulations demonstrate that LLM-CRDT outperforms benchmark online and offline RL methods, achieving up to 36.7\% higher energy efficiency than the current state-of-the-art DT approaches.
From Capabilities to Performance: Evaluating Key Functional Properties of LLM Architectures in Penetration Testing
arXiv:2509.14289v2 Announce Type: replace-cross Abstract: Large language models (LLMs) are increasingly used to automate or augment penetration testing, but their effectiveness and reliability across attack phases remain unclear. We present a comprehensive evaluation of multiple LLM-based agents, from single-agent to modular designs, across realistic penetration testing scenarios, measuring empirical performance and recurring failure patterns. We also isolate the impact of five core functional capabilities via targeted augmentations: Global Context Memory (GCM), Inter-Agent Messaging (IAM), Context-Conditioned Invocation (CCI), Adaptive Planning (AP), and Real-Time Monitoring (RTM). These interventions support, respectively: (i) context coherence and retention, (ii) inter-component coordination and state management, (iii) tool use accuracy and selective execution, (iv) multi-step strategic planning, error detection, and recovery, and (v) real-time dynamic responsiveness. Our results show that while some architectures natively exhibit subsets of these properties, targeted augmentations substantially improve modular agent performance, especially in complex, multi-step, and real-time penetration testing tasks.
DreamControl: Human-Inspired Whole-Body Humanoid Control for Scene Interaction via Guided Diffusion
arXiv:2509.14353v2 Announce Type: replace-cross Abstract: We introduce DreamControl, a novel methodology for learning autonomous whole-body humanoid skills. DreamControl leverages the strengths of diffusion models and Reinforcement Learning (RL): our core innovation is the use of a diffusion prior trained on human motion data, which subsequently guides an RL policy in simulation to complete specific tasks of interest (e.g., opening a drawer or picking up an object). We demonstrate that this human motion-informed prior allows RL to discover solutions unattainable by direct RL, and that diffusion models inherently promote natural looking motions, aiding in sim-to-real transfer. We validate DreamControl's effectiveness on a Unitree G1 robot across a diverse set of challenging tasks involving simultaneous lower and upper body control and object interaction.
Compose Yourself: Average-Velocity Flow Matching for One-Step Speech Enhancement
arXiv:2509.15952v2 Announce Type: replace-cross Abstract: Diffusion and flow matching (FM) models have achieved remarkable progress in speech enhancement (SE), yet their dependence on multi-step generation is computationally expensive and vulnerable to discretization errors. Recent advances in one-step generative modeling, particularly MeanFlow, provide a promising alternative by reformulating dynamics through average velocity fields. In this work, we present COSE, a one-step FM framework tailored for SE. To address the high training overhead of Jacobian-vector product (JVP) computations in MeanFlow, we introduce a velocity composition identity to compute average velocity efficiently, eliminating expensive computation while preserving theoretical consistency and achieving competitive enhancement quality. Extensive experiments on standard benchmarks show that COSE delivers up to 5x faster sampling and reduces training cost by 40%, all without compromising speech quality. Code is available at https://github.com/ICDM-UESTC/COSE.
How LLMs Are Changing the Way We Process Unstructured Data
Over 80% of business data is unstructured. Emails, PDFs, chats, medical notes, social media posts, videos-none of it fits neatly into rows and columns. Traditional tools struggle to analyze such […]
The post How LLMs Are Changing the Way We Process Unstructured Data appeared first on Datafloq.
How Scientists Are Teaching AI to Understand Materials Data
In theory, materials science should be a perfect match for AI. The field runs on data — band gaps, crystal structures, conductivity curves — the kind of measurable, repeatable values Read more…
The post How Scientists Are Teaching AI to Understand Materials Data appeared first on BigDATAwire.
Background Replacement Using BiRefNet
In this article, we create a background replacement application using BiRefNet. We cover the code using Jupyter Notebook and create a Gradio application as well.
The post Background Replacement Using BiRefNet appeared first on DebuggerCafe.
Strengthening our Frontier Safety Framework
We’re strengthening the Frontier Safety Framework (FSF) to help identify and mitigate severe risks from advanced AI models.
What new AI features are product teams building?
AI Agents, Assistants, Revenue generators and more from top tier companies including YouTube, Linear, Square, Miro, Zendesk, Audible, Google Maps. DoP Deep Dive.
Day-4: Linux File Permissions | 100 Days of DevOps
The Linux file permissions were very complex for me at the beginning. In this article, we’ll break down Linux permissions in detail. I'll try to make it as simple as possible.
Linux is a multi-user system. Even on your personal computer, system processes, services, and your own account interact with files. Permissions ensure:
- Sensitive files can’t be read or edited by the wrong users.
- Scripts and binaries are only run when explicitly allowed.
- System stability and security are preserved.
Every file and directory in Linux can have three kinds of permissions:
- Read (r) → View the file contents or list directory contents.
- Write (w) → Modify or delete the file, or create/remove files in a directory.
- Execute (x) → Run the file as a program/script, or enter a directory.
Permissions are assigned to three categories of users:
- User (u) → the file’s owner.
- Group (g) → the group assigned to the file.
- Others (o) → everyone else.
You can check file permissions with ls -l:
ls -l script.sh
Example output:
-rwxr-xr-x 1 root root 40 Sep 23 15:15 script.sh
Breaking it down:
-
-→ file type (a dash means a regular file;dwould mean directory). -
rwx→ user (owner) can read, write, execute. -
r-x→ group can read, execute. -
r-x→ others can read, execute.
Permissions are often set with numbers using the chmod command. Each permission corresponds to a binary bit:
- Read = 4 (100)
- Write = 2 (010)
- Execute = 1 (001)
You add them up to set a value from 0–7:
| Number | Binary | Permission | Meaning |
|---|---|---|---|
| 0 | 000 | --- | no permission |
| 1 | 001 | --x | execute only |
| 2 | 010 | -w- | write only |
| 3 | 011 | -wx | write + execute |
| 4 | 100 | r-- | read only |
| 5 | 101 | r-x | read + execute |
| 6 | 110 | rw- | read + write |
| 7 | 111 | rwx | read + write + exec |

- chmod 755 script.sh
- User:
7 = rwx→ full permission - Group:
5 = r-x→ read + execute - Others:
5 = r-x→ read + execute - Result:
-rwxr-xr-x
- chmod 644 notes.txt
- User:
6 = rw-→ read + write - Group:
4 = r--→ read only - Others:
4 = r--→ read only - Result:
-rw-r--r--
- chmod 777 file.sh
- Everyone has read, write, and execute.
- Result:
-rwxrwxrwx - ⚠️ Usually not safe in real systems.
Instead of numbers, you can also set permissions symbolically:
-
chmod u+x file.sh→ add execute for user -
chmod g-w file.sh→ remove write for group -
chmod o+r file.sh→ add read for others -
chmod a+x file.sh→ add execute for all (user, group, others)
- Use 755 for scripts and executables → owner full, others can run but not modify.
- Use 644 for text or config files → owner can edit, others can only read.
- Avoid 777 unless it’s a temporary or testing environment.
- Remember directories need execute (x) to be entered (
cd).
Linux file permissions are not as intimidating as they look. They’re simply a combination of read (4), write (2), execute (1) applied to user, group, others.
If you can read a permission string like -rwxr-xr-x and understand what it means, you’ve unlocked one of the most fundamental skills in Linux system administration.
The missing link
Here's a riddle I posted
Name the environment in which this code doesn't throw
let w = globalThis
if (!('addEventListener' in globalThis)) throw Error()
while (w) {
if (Object.hasOwn(w, 'addEventListener')) throw Error()
w = Object.getPrototypeOf(w)
}
alert('where are we?')
The script first ensures that addEventListener is in globalThis. But in means as own property or anywhere on the prototype. So let's find it on the prototype by iterating down. We throw when found.
Somehow, we run out of truthy prototypes before we find one that has an own property named addEventListener.
Last - as a helpful tip, the code uses alert and it works.
Normally, when you run:
let w = globalThis
while (w) {
if (Object.hasOwn(w, 'addEventListener')) {
console.log(`${w} has addEventListener`)
} else {
console.log(`${w} does NOT have addEventListener`)
}
w = Object.getPrototypeOf(w)
}
the output is:
[object Window] does NOT have addEventListener
[object Window] does NOT have addEventListener
[object WindowProperties] does NOT have addEventListener
[object EventTarget] has addEventListener
[object Object] does NOT have addEventListener
But there's one magical place in the browser where that's not necessarily the case.
When you create an extension, you can define a contentscript that exists to let you interact with the document of a website open in the browser. It's supposed to be isolated from the website's realm though, so that you have your own global context.
The browsers took very different approaches to implementing the isolation. The Firefox implementation is changing the prototype chain of the global and limiting it to window and its prototype, with nothing else visible via code, but with field lookup reaching down the prototype chain further.
The same while loop gets us this:
[object Window] does NOT have addEventListener
[object Window] does NOT have addEventListener
But still,
('addEventListener' in window) === true
typeof window.addEventListener === 'function'
I'm not sure why the behavior is like that, but if I replace globalThis with window, I get a different list of prototypes
[object Window] does NOT have addEventListener
[object Window] does NOT have addEventListener
[object EventTarget] does NOT have addEventListener
[object EventTarget] has addEventListener
[object Object] does NOT have addEventListener
And while I can understand cutting of a bit of prototype as a means of isolation, if it stays on window, that's harder to explain.
Somebody tell me what's going on :)
Ready to Code for Change? Introducing Our Vision🎯💻
Hey Hackspire '25 innovators!
The air is buzzing, the coffee machines are warming up, and your keyboards are just waiting to bring ground-breaking ideas to life. As we gear up for what promises to be an unforgettable event, we wanted to share a project idea that we believe embodies the spirit of Hackspire: innovation for impact.
This year, let's turn our collective coding prowess towards a challenge that truly matters: public health in vulnerable communities.
The Challenge: Water-Borne Diseases in Rural Northeast India
Imagine a scenario where simply drinking water can lead to serious illness. This is a harsh reality for many rural and tribal communities in Northeast India. Water-borne diseases like cholera, typhoid, and diarrhea are prevalent, especially during the monsoon season. Why? Contaminated water sources, inadequate sanitation, and the sheer remoteness of villages make it incredibly difficult for health workers to monitor and respond to outbreaks quickly. The lack of real-time data means health officials are often playing catch-up, leading to preventable suffering and even loss of life.
This isn't just a health problem; it's a socio-economic one, hindering progress and well-being.
Our Vision: A Software-Only Smart Health & Early Warning System
We believe that with the right software, we can empower communities and health officials to get ahead of these diseases. Our project idea proposes a Smart Community Health Monitoring and Early Warning System – designed specifically for the unique challenges of rural Northeast India, and crucially, built entirely on software.
What does "Software-Only" mean for us?
It means no expensive, fragile IoT sensors to deploy in remote, harsh terrains. It means leveraging existing community structures and tools, empowering health workers with intelligent digital tools they can use with their smartphones.
Testing!!
Principal Component Analysis (PCA)
Principal Component Analysis, PCA for short, is a bit of a “deep” topic in machine learning. By deep I mean that you need to know about clusters, covariance, and then you learn about principal component analysis – who knows what else is there after PCA. Learning about PCA is like learning about glucose: you can’t really understand glucose unless you already know what sugar is. I say this to emphasize that PCA is a challenging concept to grasp without some prior knowledge. That being said, here’s what PCA means.
When creating clusters of data, we often deal with multi-dimensional data points. For me it’s easy to picture a point in a 2D axis (x, y), or even in 3D (x, y, z). But once it goes beyond 3D into 4D or more, it becomes nearly impossible to mentally visualize. Visualizing the data itself is already hard — now imagine trying to rotate or move one of these high-dimensional points. At that point, I just trust the math that it works. Enough venting. So, what is PCA?
PCA comes from simplifying the covariance matrix.
What is a covariance matrix?
A covariance matrix is a 2D table that shows how the variance of one feature relates to another. For example, suppose we have a dataset with the following features:
• calories_consumed
• amount_of_sleep
• amount_of_social_media
• miles_ran
The covariance matrix for these might look like this (values are illustrative, not from real data):

• The diagonal values (25.0, 9.0, 30.0, 40.0) are the variances of each feature.
• The off-diagonal values show the covariance between two features. For example:
• Calories consumed and miles ran = -20.0 (negative covariance → running more tends to reduce calories consumed).
• Sleep and social media = -15.0 (negative covariance → more sleep, less scrolling).
This table is already hard to interpret with just 4 features. Imagine 100+ features — the relationships get too complex to reason about directly.
Why PCA?
That’s where PCA comes in. PCA finds the principal components — the directions in which the data varies the most. By rotating the data into this new coordinate system, we can:
• Reduce dimensions (e.g., compress 100 features down to 2 or 3, while keeping most of the information).
• Better visualize high-dimensional data.
• Understand the strongest underlying patterns.
In essence, PCA transforms the messy covariance relationships into a simpler structure. Instead of asking “how does feature A affect feature B,” PCA lets us ask, “what combination of features explains most of the variation in this dataset?”
Apache Kafka Deep Dive : concepts fondamentaux, applications d'ingénierie des données et pratiques de production concrètes
Apache Kafka est une plate-forme de streaming d'événements distribuée open source utilisée par des milliers d'entreprises pour les pipelines de données hautes performances, l'analyse en continu, l'intégration de données et les applications critiques.
Kafka est utile dans divers cas d’utilisation opérationnels et d’analyse de données réels.
•Messagerie : Ce domaine possède ses propres logiciels spécialisés, comme RabbitMQ et ActiveMQ, mais Kafka est souvent suffisant pour le gérer tout en offrant de grandes performances.
• Suivi de l'activité du site Web : Kafka peut gérer de petits enregistrements de données fréquemment générés, tels que les pages vues, les actions des utilisateurs et d'autres activités de navigation sur le Web.
• Métriques : vous pouvez facilement consolider et regrouper des données qui peuvent être triées à l’aide de rubriques.
• Agrégation de journaux : Kafka permet de collecter des journaux provenant de différentes sources et de les agréger en un seul endroit dans un format unique.
• Traitement de flux : les pipelines de streaming sont l’une des fonctionnalités les plus importantes de Kafka, permettant de traiter et de transformer les données en transit.
Architecture pilotée par événements : les applications peuvent publier et réagir aux événements de manière asynchrone, ce qui permet aux événements d'une partie de votre système de déclencher facilement un comportement ailleurs. Par exemple, l'achat d'un article par un client dans votre magasin peut déclencher des mises à jour de stock, des avis d'expédition, etc.
Voici les composants de haut niveau les plus essentiels de Kafka :
Producteur d'enregistrements
Consommateur
Courtier
Sujet
Partitionnement
Réplication
ZooKeeper ou Contrôleur Quorum
1.Enregistrement.
Également appelé événement ou message, un enregistrement est un tableau d'octets pouvant stocker n'importe quel objet, quel que soit son format. Par exemple, un enregistrement JSON décrivant le lien sur lequel un utilisateur a cliqué sur votre site web.
Il est parfois nécessaire de distribuer certains types d'événements à un groupe de consommateurs ; chaque événement sera donc distribué à un seul consommateur de ce groupe. Kafka permet de définir des groupes de consommateurs de cette manière.
Une approche de conception essentielle consiste à ce qu'aucune autre interconnexion n'ait lieu entre les clients, hormis les groupes de consommateurs. Les producteurs et les consommateurs sont totalement découplés et indépendants les uns des autres.
2.Producteur :
Un producteur est une application cliente qui publie des enregistrements (écritures) dans Kafka. Par exemple, un extrait de code JavaScript sur un site web suit le comportement de navigation sur le site et l'envoie au cluster Kafka.
3.Consommateur: Un consommateur est une application cliente qui s'abonne aux enregistrements de Kafka (c'est-à-dire qui les lit), par exemple une application qui reçoit des données de navigation et les charge dans une plateforme de données pour analyse.
4.Broker : un broker est un serveur qui gère les requêtes des clients producteurs et consommateurs et assure la réplication des données au sein du cluster. Autrement dit, un broker est l'une des machines physiques sur lesquelles Kafka s'exécute.
5.Sujet : un sujet est une catégorie permettant d'organiser les messages. Les producteurs envoient des messages à un sujet, tandis que les consommateurs s'abonnent aux sujets pertinents, ne voyant ainsi que les enregistrements qui les intéressent réellement.
6.Partitionnement : Le partitionnement consiste à diviser un journal de sujet en plusieurs journaux pouvant être hébergés sur des nœuds distincts du cluster Kafka. Cela permet d'éviter que des journaux de sujet soient trop volumineux pour être hébergés sur un seul nœud.
Les partitions de réplication peuvent être copiées entre plusieurs brokers afin de garantir leur sécurité en cas de panne de l'un d'eux. Ces copies sont appelées réplicas.
7.Service d'ensemble : un ensemble est un service centralisé permettant de gérer les informations de configuration, de découvrir les données et de fournir une synchronisation et une coordination distribuées. Kafka s'appuyait auparavant sur Apache ZooKeeper pour cela, mais les versions récentes ont migré vers un autre service de consensus appelé KRaft.
Tous les logiciels de streaming d'événements ne nécessitent pas l'installation d'un service Ensemble distinct. Redpanda, qui offre un streaming de données 100 % compatible avec Kafka, est prêt à l'emploi car il intègre déjà cette fonctionnalité.
Ditch the Backend: Build a Full-Stack Web App Using Only Supabase & React (No Node.js Needed!)
Ever felt your backend was holding you back? Tired of spinning up Express servers or babysitting APIs just to wire up simple CRUD functionality? It's 2024 — we have Supabase!
In this post, we're going rogue and building a full-stack app using only Supabase and React — no Node.js, no Express, and definitely no REST API hoedown. Supabase is the powerful open-source Firebase alternative that's taking the dev world by storm. Combine it with React, and we get a JAMstack-style full-stack workflow with real-time data, authentication, and even edge functions.
Join me as we build a fully functioning habit tracking app — complete with login/signup, data persistence, and real-time updates — without writing a single line of backend code. 🔥
- Authentication: Supabase offers plug-and-play email/password, OAuth, and magic links.
- Real-time DB: Built on PostgreSQL with live subscriptions via websockets.
- Storage: Easily upload, manage, and serve files.
- Edge Functions: Serverless functions you can call from the client.
This combo is lean, fast, and lets frontend devs build powerful apps with minimal overhead.
A Habit Tracker App:
- User authentication (sign up / login)
- Track daily habits (CRUD habits)
- Real-time updates across devices
- Bonus: Streak calculations via Supabase Row Level Functions
- Create a Supabase Project
- Add Tables to Supabase
- Set up Authentication
- Build the React Frontend
- Add Realtime Subscriptions
- Deploy to Netlify or Vercel
You can now build & ship MVPs without a backend, prototype apps faster than ever, and focus on product and user experience.
Supabase empowers frontend developers to go full-stack. And it’s not just for MVPs. As your app grows, you can add serverless functions, role-based access controls, and even integrate with native Postgres tooling. 💥
Let me know if you'd like a Part 2 where we calculate streak stats via SQL functions or handle file/image uploads in Supabase Storage.
Happy hacking. 🚀
💡 If you need this done – we offer fullstack development services!
KEXP: Rosali - Full Performance (Live on KEXP)
Rosali Live on KEXP (August 8, 2025)
Rosali storms through four killer tracks—“Hopeless,” “Change Is In The Form,” “Hills On Fire,” and “Rewind”—in this raw, in-the-moment KEXP studio session. She’s joined by David Nance on bass/vocals, Jim Schroeder on guitar/vocals, and Kevin Donahue on drums/vocals, all captured under the guidance of host Cheryl Waters.
Behind the scenes, audio whiz Kevin Suggs and mastering pro Julian Martlew keep the sound crisp, while Jim Beckmann, Carlos Cruz, Scott Holpainen & Luke Knecht handle cameras (with Scott also editing). Dig deeper at https://rosalimusic.com and http://kexp.org, or join the YouTube channel for exclusive perks!
Watch on YouTube
Golf.com: The Unsolved Mystery Behind Bethpage Black's Famous Warning Sign
The Unsolved Mystery Behind Bethpage Black’s Famous Warning Sign
Every golfer has snapped a pic of that legendary “You are playing Bethpage Black” warning sign—but nobody seems to know when it first showed up. In this video, GOLF’s Josh Berhow dives into the sign’s murky past, sorting through rumors, clubhouse lore and old photos to pin down its true origin.
Along the way he busts a few myths, chats with insiders and pieces together clues that might finally put the mystery to bed. Whether you’re teeing off there next weekend or just love a good golf legend, this deep-dive is a must-watch.
Watch on YouTube
IGN: Fortnite x Daft Punk Experience - Official Trailer
Fortnite just dropped a trailer for its upcoming interactive Daft Punk tribute, complete with neon visuals and the duo’s signature beats brought to life in-game.
This music-fueled collab launches on September 27, 2025 at 2 PM ET—get ready to dance with those iconic robot helmets!
Watch on YouTube
IGN: Stalker 2: Heart of Chornobyl - Official 'Night of the Hunter Update' Update 1.6 Trailer
Get ready to brave the Zone after dark with the “Night of the Hunter” Update 1.6 for STALKER 2: Heart of Chornobyl! GSC Game World has packed this patch with slick new gadgets—think night-vision gadgets, offset aiming for pinpoint shots, and a raft of fresh anomalies to hunt under the cover of darkness.
It’s available now on Xbox Series X|S (including Game Pass) and PC via Steam, GOG and the Epic Games Store—so plug in, power up, and light up the night… or at least see a bit better in it.
Watch on YouTube
Day 6 of Complete JavaScript in 17 days | Visual Series📚✨
Day 6 of My JavaScript Visual Series 📚✨
💡 Arrow Function vs Normal Function in JavaScript – Why It Actually Matters in Interviews.
As a beginner, I used to think both functions are the same. But here's what interviewers love to ask the difference in how "this" behaves in both!
🔹 Normal Function:
this refers to the object calling the function.
🔹 Arrow Function:
this refers to the parent scope (lexical scope). It does not bind its own this.
So if you're using this inside a method, be very cautious using arrow functions!
const obj = {
name: "Azaan",
sayHi: function () {
console.log("Hi", this.name); // Works ✅
},
greet: () => {
console.log("Hello", this.name); // Undefined ❌
}
};
Fun Fact : Arrow function is also called fat arrow function.
Use Case:
A couple of days ago, I was debugging a login feature in my app. Everything seemed perfect... except it kept saying "Invalid Password" even for correct ones.
The issue? I used an arrow function inside my comparePassword method. 🤦♂️
It couldn't access this.password from the Mongoose model correctly.
// ❌ Wrong: 'this' doesn't refer to the document
userSchema.methods.comparePassword = (inputPassword) => {
return bcrypt.compare(inputPassword, this.password);
};
// ✅ Correct: 'this' refers to the Mongoose document
userSchema.methods.comparePassword = function (inputPassword) {
return bcrypt.compare(inputPassword, this.password);
};

Electrical Safety Considerations
Electrification trends demand higher voltages (e.g., 48V, 800V) for efficiency, raising isolation needs, especially in automotive applications.
The post Electrical Safety Considerations appeared first on EE Times.
AV STEP Perspectives: NHTSA’s NPRM for Autonomous Vehicles
These application requirements will provide information to NHTSA for making decisions on terms and conditions for participation.
The post AV STEP Perspectives: NHTSA’s NPRM for Autonomous Vehicles appeared first on EE Times.
Alibaba Unveils Own AI Chip, Mounting Direct Challenge to Nvidia
Alibaba unveils its T-Head PPU, a homegrown AI chip designed to rival Nvidia's H20.
The post Alibaba Unveils Own AI Chip, Mounting Direct Challenge to Nvidia appeared first on EE Times.
The Wireless Grid: How Power Is Becoming Infrastructure
Wireless Power Networks are transforming power from fixed and static into an ambient utility that’s omnipresent.
The post The Wireless Grid: How Power Is Becoming Infrastructure appeared first on EE Times.
Who’s Governing the AI in Your Hardware Stack?
AI breaks the conventional boundaries in hardware and embedded systems design, which means CISOs now need to be more involved.
The post Who’s Governing the AI in Your Hardware Stack? appeared first on EE Times.
Startup To Take On AI Inference With Huge SiP, Custom Memory
Euclyd, based in The Netherlands, aims to build a large multi-chiplet design for AI inference at scale
The post Startup To Take On AI Inference With Huge SiP, Custom Memory appeared first on EE Times.
The Death Stranding anime now has a title and its first trailer
The long-running joke about Hideo Kojima is that he’d secretly rather be making movies than video games. Kojima somehow nearly got into double figures on Metal Gear games without any of them receiving the adaptation treatment (though not for the lack of trying on his part), but it’s looking like a very different story for the Death Stranding series on which he’s been working since departing Konami.
A live-action adaptation of the post-apocalyptic walking simulator landed a writer and director back in the spring, and it was announced a few months later that an animated Death Stranding movie was also on the way, with Aaron Guzikowski (Raised by Wolves) penning the screenplay. We now know what film will be called, and there’s a trailer.
Death Stranding Mosquito is directed by ABC Animation’s Hiroshi Miyamoto, with Kojima himself serving as a producer, and will apparently tell an original story within the "surreal and emotionally resonant" Death Stranding universe. If you’ve played the original game or its 2025 sequel, the teaser will look very familiar, with the film seemingly focusing on a character who definitely isn’t Norman Reedus’ Sam Porter Bridges, but is sporting very similar get-up.
The hooded figure comes face to face with what appears to be a BT-ified doglike creature, and then has a brutal fist fight with another character. We don’t get any more context than that, nor any whiff of a release date, but visually Death Stranding Mosquito looks absolutely stunning.
It’s been a busy few days for Kojima-related announcements. We got the first gameplay trailer for Kojima Productions’ upcoming horror game, OD, and found out that Kojima is also releasing his own credit card in Japan. Yes, really.
This article originally appeared on Engadget at https://www.engadget.com/entertainment/tv-movies/the-death-stranding-anime-now-has-a-title-and-its-first-trailer-155516913.html?src=rss
Meta to launch national super PAC against AI regulation
Meta is launching a national super political action committee (PAC), according to a report by Axios. This super PAC will be committed to fighting "onerous" AI regulation across the country. It's called the American Technology Excellence Project and Meta spokesperson Rachel Holland said the company is investing "tens of millions" into the effort.
The goal of the PAC is to elect pro AI state candidates from both parties. It's being run by longtime Republican operative Brian Baker with an assist from Democratic consulting firm Hilltop Public Solutions.
The tech-friendly federal government has no plans to regulate AI but fell short on banning states from doing so. There have been over 1,000 state-level policy proposals introduced this year, which Meta thinks could hurt America in the AI race with China.
"State lawmakers are uniquely positioned to ensure that America remains a global technology leader," Meta VP of public policy Brian Rice said in a statement. "This is why Meta is launching an effort to support the election of state candidates across the country who embrace AI development, champion the U.S. technology industry and defend American tech leadership at home and abroad."
The company has not released any information as to which forthcoming state elections would be disrupted by the aforementioned tens of millions of dollars. We also don't know how many people the PAC will employ.
Meta is preparing to pump tens of millions of dollars into a new California super PAC that will fund candidates opposed to tech regulation, especially the regulation of AI, per Politico.
— More Perfect Union (@MorePerfectUS) August 26, 2025
This is just the latest move into politics by Meta. It recently launched a PAC in California to protect tech and AI interests. The state has been fairly proactive about enacting protections against potentially harmful AI use cases. It passed a law protecting the digital likenesses of actors and has attempted bills that block election misinformation and protect against "critical harm" caused by AI.
While the Trump administration loves itself some AI, there are limits. The president recently signed an executive order banning "woke AI" from being used in the federal government. I haven't come across any woke AI in the wild, but I have seen whatever this is.
This article originally appeared on Engadget at https://www.engadget.com/big-tech/meta-to-launch-national-super-pac-against-ai-regulation-154537574.html?src=rss
Rokid's smartglasses are surprisingly capable
Meta put the smartglasses industry on alert when it announced the Meta Ray-Ban Displays last week. And while those might feature one of the most advanced optical engines on a device its size, after testing out one of its competitors — the Rokid Glasses — I'm convinced there's still plenty of room for competition.
At $549, the Rokid Glasses are more affordable than the Meta Ray-Ban Displays, which are set to launch at $800. However, it should be noted that this difference won't last forever, as following Rokid's Kickstarter campaign, its suggested retail price will increase significantly to around $740. Also, while Kickstarter campaigns aren't always the strongest indicator of reliability, Rokid has actually been around for some time with devices dating back to before 2018.
But more importantly, Rokid's eyewear has some notable design differences. Instead of a single full-color display for just your right eye, it features dual microLED waveguides that provide a true binocular view, which helps reduce eyestrain. The downside is that the Rokid glasses only support a single color — green — though that’s kind of fun if you're into the classic hacker aesthetic. Text and icons are more than sharp enough to make reading the glasses' minimalist UI a cinch. And with up to 1,500 nits of brightness, its display is easy to see even outside in bright light. In the future, though, Rokid will need to upgrade to full-color components to better compete with rivals like the Meta Ray-Ban Displays.
Rokid's glasses score well when it comes to overall style and wearability. The Meta Ray-Ban Displays look like someone stole the frames off Garth's head from Wayne's World and then made them thrice as thick, whereas Rokid's glasses actually look more like Wayfarers than Ray-Ban's own creation. Touch panels are hidden in each arm, and you even get real nose pads for extra comfort. Plus, weighing in at just 49 grams, Rokid claims its creation is the lightest "full-function AI and AR glasses."
The only major indicators that these aren't a typical set of eyewear are the small camera near your left temple and a faint outline of where the waveguides project a heads-up display onto its lenses. There are also tiny built-in speakers that play the sound from videos, music or answers from Rokid's AI helper and they are about as good as you can expect from a gadget this compact. But it probably won't come as a surprise when I say they could be a touch louder or provide better bass.
Meanwhile, when it comes to recharging, there's a simple magnetic pin connector at the end of the right arm that can connect to any USB-C cable using an included adapter. Unfortunately, if you want a charging case like you get with many of its rivals, you'll have to shell out another $100. Battery life has been surprisingly solid in my experience as well. You can get up to six hours of continuous music playback over Bluetooth, though if you use more advanced features (especially ones that rely on AI), you will need to juice up sooner.
As for functionality, the company’s standalone approach to content generation is both its biggest strength and weakness. That's because while Meta's smartglasses come with tie-ins to Facebook and Instagram which makes livestreaming what you see a breeze, Rokid doesn't offer that option. Instead, you'll have to use the onboard 12MP camera and five mics to take photos and videos before manually downloading them to your phone and then sharing them to your favorite platform. This results in a few extra steps between capture and publication (and no option for livestreaming), but at least you do get the freedom of choice.
Image quality is also acceptable. You won't be dazzled by its contrast and dynamic range and darker environments can be a bit of a challenge. But as a vehicle for recording the world around you, these glasses are a decent way to take in your surroundings. Thankfully, the process of capturing content couldn't be simpler, just press once on the physical button on the right arm for a picture or press and hold for video. Or if you prefer, you can use voice commands like "Hi Rokid, record a video."
Aside from taking photos and videos, Rokid's glasses can also pair with your phone to serve up notifications, record voice memos and even offer turn-by-turn directions using AI, though I couldn't get that last feature working. There's also a teleprompter mode that allows you to upload scripts to the glasses and have text scroll down automatically as you speak.
However, the biggest draw (or deterrence, depending on your opinion of machine learning) is the AI integration, which uses the device’s Qualcomm AR1 chip and an onboard ChatGPT model to provide real-time translation and audio transcriptions. Just like what you get when using large LLMs on a phone or laptop, even when AI can understand most of what's coming in, there are still times when it doesn't fluently convert certain lines or phrases.
There's also the option to ask the glasses to create a text description of what its cameras see, though again, AI sometimes struggles with accuracy. When I held my phone up in front of the lens, it correctly identified what type of device it was, but then it got confused by a barcode on a box in the background and thought I was trying to insert a SIM card.
Even considering the foibles of current AI models, the Rokid glasses are a welcome surprise in a growing sea of smartglasses. They're lighter and sleeker than anything I've tried to date while covering all the most important functions: playing music, surfacing notifications and capturing decent first-person photos and videos. Other features like live translation and live captions are a bonus. When they work, which is most of the time, it really feels like an engaging glimpse of what is poised to be the next big era for wearable computing.
It's way too early to pick a winner or even recommend these as a must-have for bleeding-edge enthusiasts. But to see smaller names like Rokid come up with compelling alternatives to Meta's latest makes these smartglasses worth paying attention to.
The Rokid Glasses are available for pre-order now via the company's Kickstarter campaign with estimated deliveries slated for sometime in November.
This article originally appeared on Engadget at https://www.engadget.com/wearables/rokids-smartglasses-are-surprisingly-capable-153027590.html?src=rss
WhatsApp starts rolling out message translations on iOS and Android
WhatsApp is now rolling out message translations on its iOS and Android apps. Starting today, Android users will be able to translate messages between six languages: English, Spanish, Hindi, Portuguese, Russian and Arabic. On iPhone, there's support for translation between the following languages (i.e. all of the ones supported by Apple's Translate app):
Arabic
Dutch
English
French
German
Hindi
Indonesian
Italian
Japanese
Korean
Mandarin Chinese
Polish
Portuguese (Brazil)
Russian
Spanish
Thai
Turkish
Ukrainian
Vietnamese
To convert a message into a different language, long press on it, select Translate, then the language you'd like to translate the message to or from. Android users will get an extra-handy bonus feature with the ability to switch on automatic translation for an entire chat.
Translations are handled on your device to help protect your privacy — WhatsApp still won't be able to see your encrypted chats. Your device will download relevant language packs for future translations. WhatsApp says translation works in one-on-one chats, groups and Channel updates. The platform will also add support for more languages down the line.
There's no word as yet on if or when WhatsApp will support message translations on the web or in its Windows app. "Translating messages on WhatsApp is only available on certain devices and may not be available to you yet," a note on a support page reads. "In the meantime, we recommend keeping WhatsApp updated on your device so you can get the feature as soon as it's available."
This article originally appeared on Engadget at https://www.engadget.com/apps/whatsapp-starts-rolling-out-message-translations-on-ios-and-android-150132823.html?src=rss
The EU wants Apple, Google and Microsoft to clamp down on online scams
The European Union has asked Apple, Google and Microsoft to explain how they police online financial scams, stepping up enforcement of the Digital Services Act (DSA), as first reported by the Financial Times. Formal information requests were also sent to Booking Holdings, the owner of Booking.com, regarding how the company handles fake accommodation listings. Likewise, regulators will be probing fake banking apps in Apple’s App Store and Google Play. Additionally, they will be taking a close look at fake search results in Google search and Microsoft's Bing.
Speaking with the Financial Times, EU tech chief Henna Virkkunen said criminal activity is increasingly moving online and platforms must do more to detect and prevent illegal content. Virkkunen said that financial losses from online fraud exceed €4 billion a year (around $4.7 billion) across the EU, and that the rise of AI has made detecting these scams more difficult.
The four companies will be given the chance to respond to these information requests, but under the DSA companies can face penalties up to 6 percent of their global annual revenue for failing to adequately combat illegal content and disinformation.
Earlier this year Apple and Meta were fined around $570 million and $228 million, respectively, after the European Commission found them in violation of the Digital Markets Act (DMA), though both companies are appealing the fines. The DMA is a set of rules governing online platforms that was adopted alongside the DSA in 2022.
European fines on American companies, particularly a recent $3.5 billion fine levied on Google for antitrust violations, have drawn the attention and ire of President Donald Trump. The president has threatened a trade probe over what he views as "discriminatory actions" against American tech companies.
This article originally appeared on Engadget at https://www.engadget.com/big-tech/the-eu-wants-apple-google-and-microsoft-to-clamp-down-on-online-scams-145333226.html?src=rss
The best October Prime Day deals to shop now: Early sales on gear from Apple, Anker, Roku, Shark and others
Amazon Prime Day has returned in the fall for the past few years, and 2025 is no exception. Prime Day will return on October 7 and 8, but really, you don't have to wait until the official start date to save. Amazon typically always has early Prime Day deals in the lead-up to the event, and this year we’re already seeing some solid discounts on gadgets we like. Here, we’ve gathered all of the best Prime Day deals you can get right now, and we’ll keep updating this post as we get close to Prime Day proper.
Apple iPad (A16) for $299 ($50 off): The new base-model iPad now comes with twice the storage of the previous model and the A16 chip. That makes the most affordable iPad faster and more capable, but still isn't enough to support Apple Intelligence.
Apple Mac mini (M4) for $499 $100 off): If you prefer desktops, the upgraded M4 Mac mini is one that won’t take up too much space, but will provide a ton of power at the same time. Not only does it come with an M4 chipset, but it also includes 16GB of RAM in the base model, plus front-facing USB-C and headphone ports for easier access.
Apple iPad Air (11-inch, M3) for $449 ($150 off): The only major difference between the latest iPad Air and the previous generation is the addition of the faster M3 chip. We awarded the new slab an 89 in our review, appreciating the fact that the M3 chip was about 16 percent faster in benchmark tests than the M2. This is the iPad to get if you want a reasonable amount of productivity out of an iPad that's more affordable than the Pro models.
Jisulife Life7 handheld fan for $25 (14 percent off, Prime exclusive): This handy little fan is a must-have if you life in a warm climate or have a tropical vacation planned anytime soon. It can be used as a table or handheld fan and even be worn around the neck so you don't have to hold it at all. Its 5,000 mAh battery allows it to last hours on a single charge, and the small display in the middle of the fan's blades show its remaining battery level.
Roku Streaming Stick Plus 2025 for $29 (27 percent off): Roku makes some of the best streaming devices available, and this small dongle gives you access to a ton of free content plus all the other streaming services you could ask for: Netflix, Prime Video, Disney+, HBO Max and many more.
Anker 622 5K magnetic power bank with stand for $34 (29 percent off, Prime exclusive): This 0.5-inch thick power bank attaches magnetically to iPhones and won't get in your way when you're using your phone. It also has a built-in stand so you can watch videos, make FaceTime calls and more hands-free while your phone is powering up.
8BitDo Pro 2 controller with travel case for $40 (34 percent off, Prime exclusive): We generally love 8BitDo controllers, and the Pro 2 has been one of our favorites for a long time. This model works with Switch 2, Steam Deck, Android and more, plus it has Hall Effect joysticks and a slew of customization options.
Leebein 2025 electric spin scrubber for $40 (43 percent off, Prime exclusive): This is an updated version of my beloved Leebein electric scrubber, which has made cleaning my shower easier than ever before. It comes with seven brush heads so you can use it to clean all kinds of surfaces, and its adjustable arm length makes it easier to clean hard-to-reach spots. It's IPX7 waterproof and recharges via USB-C.
Amazon Fire TV Stick 4K Max for $40 (33 percent off): Amazon's most powerful streaming dongle supports 4K HDR content, Dolby Vision and Atmos and Wi-Fi 6E. It also has double the storage of cheaper Fire TV sticks.
Anker Nano 5K ultra-slim power bank (Qi2, 15W) for $46 (16 percent off): A top pick in our guide to the best MagSafe power banks, this super-slim battery is great for anyone who wants the convenient of extra power without the bulk. We found its proportions work very well with iPhones, and its smooth, matte texture and solid build quality make it feel premium.
Samsung EVO Select microSD card (256GB) for $23 (15 percent off): This Samsung card has been one of our recommended models for a long time. It's a no-frills microSD card that, while not the fastest, will be perfectly capable in most devices where you're just looking for simple, expanded storage.
JBL Go 4 portable speaker for $40 (20 percent off): The Go 4 is a handy little Bluetooth speaker that you can take anywhere you go thanks to its small, IP67-rated design and built-in carrying loop. It'll get seven hours of playtime on a single charge, and you can pair two together for stereo sound.
Anker Soundcore Space A40 for $45 (44 percent off): Our top pick for the best budget wireless earbuds, the Space A40 have surprisingly good ANC, good sound quality, a comfortable fit and multi-device connectivity.
Anker MagGo 10K power bank (Qi2, 15W) for $63 (22 percent off, Prime exclusive): A 10K power bank like this is ideal if you want to be able to recharge your phone at least once fully and have extra power to spare. This one is also Qi2 compatible, providing up to 15W of power to supported phones.
Amazon Fire TV Cube for $100 (29 percent off): Amazon's most powerful streaming device, the Fire TV Cube supports 4K, HDR and Dolby Vision content, Dolby Atmos sound, Wi-Fi 6E and it has a built-in Ethernet port. It has the most internal storage of any Fire TV streaming device, plus it comes with an enhanced Alexa Voice Remote.
Rode Wireless Go III for $199 (30 percent off): A top pick in our guide to the best wireless microphones, the Wireless Go III records pro-grade sound and has handy extras like onboard storage, 32-bit float and universal compatibility with iPhones, Android, cameras and PCs.
Shark AI robot vacuum with self-empty base for $300 (54 percent off): A version of one of our favorite robot vacuums, this Shark machine has strong suction power and supports home mapping. The Shark mobile app lets you set cleaning schedules, and the self-empty base that it comes with will hold 60 days worth of dust and debris.
Nintendo Switch 2 for $449: While not technically a discount, it's worth mentioning that the Switch 2 and the Mario Kart Switch 2 bundle are both available at Amazon now, no invitation required. Amazon only listed the new console for the first time in July after being left out of the initial pre-order/availability window in April. Once it became available, Amazon customers looking to buy the Switch 2 had to sign up to receive an invitation to do so. Now, that extra step has been removed and anyone can purchase the Switch 2 on Amazon.
Follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/the-best-october-prime-day-deals-to-shop-now-early-sales-on-gear-from-apple-anker-roku-shark-and-others-050801351.html?src=rss
A PlayStation State of Play is set for September 24
The Tokyo Game Show is taking place this week and Sony is getting in on the action with a PlayStation State of Play. The stream will start at 5PM ET on Wednesday, September 24 and run for over 35 minutes. You can watch it on YouTube (also with English subtitles or in Japanese) and Twitch. The stream will be available right here for your convenience, because we're nice like that.
There will be a fresh look at Saros, the next game from Returnal studio Housemarque. We'll get our first peek at gameplay from that project, which is set to hit PS5 next year. Sony also promises that the State of Play will include "new looks at anticipated third-party and indie titles, plus updates from some of our teams at PlayStation Studios."
There have been some rumblings that Sony may be about to reveal more details about Marvel's Wolverine (the next title from Insomniac, the developer of the Spider-Man games), so that seems like a decent bet. For what it's worth, this Friday is The Last of Us Day, so there's a chance we might hear something from Naughty Dog regarding that series.
This article originally appeared on Engadget at https://www.engadget.com/gaming/playstation/a-playstation-state-of-play-is-set-for-september-24-143526268.html?src=rssHideo Kojima's OD captures the spirit of P.T. in the first gameplay trailer
Kojima Productions, the studio helmed by auteur and famed cardboard box enthusiast Hideo Kojima, has finally given us our first glimpse of gameplay for the horror game OD. Developed in collaboration with Get Out and Us director Jordan Peele, OD is being billed as a totally unique experience that Kojima expects to divide players. It’s also going to leverage Microsoft’s cloud gaming tech in ways we’re not yet aware of, with Xbox Game Studios publishing the game.
In the new just over three-minute trailer entitled "Knock", we see first-person gameplay footage of the player character (played by a ludicrously photorealistic Sophia Lillis) anxiously lighting a series of candles, several of which have babies on them, because Kojima. In the background we hear a very ominous knocking sound, with the trailer ending as Lillis’ character is grabbed by someone (or something) who doesn’t appear to be especially friendly.
If you were fortunate enough to play P.T., the playable (and tragically no longer accessible) teaser for Kojima and Guillermo del Toro’s cancelled Silent Hill game, you’ll know that the Metal Gear creator clearly understands how to craft terrifying horror experiences. From what we’ve seen so far, it looks like the spirit of P.T. at least lives on in OD.
It’s been a busy day for Kojima and his studio, which celebrates its 10th anniversary this year and has so far exclusively released Death Stranding games. At Kojima Productions’ "Beyond the Strand" event it was also announced that the studio is partnering with Niantic Spatial to develop what appears to be some kind of AR experience that brings Kojima’s "iconic storytelling into the real world." Whether that means you can one day expect to encounter a virtual Norman Reedus attempting to steady his wobbling backpack on your way to the grocery store remains unclear, but Kojima Productions says the collaboration represents a "bold expansion into new forms of media beyond traditional gaming."
And if all of that wasn't enough, Kojima Productions is also teaming up with Mitsubishi UFJ Financial Group on a new credit card. It seemingly functions like a regular old credit card that can also be added to your phone, but you can accumulate reward points that can be spent on Kojima Productions merch and other items. Don’t get too excited unless you live in Japan, though, as it doesn’t look like the Kojima-branded credit card will be making its way to our shores when it launches next year.
This article originally appeared on Engadget at https://www.engadget.com/gaming/hideo-kojimas-od-captures-the-spirit-of-pt-in-the-first-gameplay-trailer-142623143.html?src=rss
Meta is making its Llama AI models available to more governments in Europe and Asia
Meta is allowing more governments to access its suite of Llama AI models. The group includes France, Germany, Italy, Japan, and South Korea and organizations associated with the European Union and NATO, the company said in an update.
The move comes after the company took similar steps last year to bring Llama to the US government and its contractors. Meta has also made its AI models available to the UK, Canada, Australia and New Zealand for "national security use cases."
Meta notes that governments won't just be using the company's off-the-shelf models. They'll also be able to incorporate their own data and create AI applications for specific use cases. "Governments can also fine-tune Llama models using their own sensitive national security data, host them in secure environments at various levels of classification, and deploy models tailored for specific purposes on-device in the field," the company says.
Meta says the open source nature of Llama makes it ideally suited for government use as "it can be securely downloaded and deployed without the need to transfer sensitive data through third-party AI providers." Recently, Mark Zuckerberg has suggested that "safety concerns" could potentially prevent Meta from open-sourcing its efforts around building "real superintelligence."
This article originally appeared on Engadget at https://www.engadget.com/ai/meta-is-making-its-llama-ai-models-available-to-more-governments-in-europe-and-asia-134621319.html?src=rss
GoPro Max 2 review: There's a new 360 camera contender in town
In a break from tradition, GoPro hasn’t announced a new Hero Black camera this fall. Instead, this year’s flagship is the much-rumored Max 2 360 camera ($500). The Max 2 lands at a time when spherical video is having a mini renaissance, taking on Insta360’s X5 ($550) and DJI’s Osmo 360 ($550). Perhaps surprisingly, GoPro’s Max 2 is the most affordable of the three, suggesting that the company might be looking to gain ground on its rivals and, hopefully, make the creatively warped world of 360-degree video more accessible.
With a mix of pro features like Timecode, GP-Log (with LUTs) alongside mobile-focused editing, GoPro clearly hopes the Max 2 will appeal to demanding and casual users alike. The company has also focused heavily on improving the user experience rather than going for pure technological advances and after a week or so of testing, that feels like a sensible move.
The Max 2 brings a decent resolution bump from its 5.6K predecessor, offering full 8K with 10-bit color. This puts it on par with the DJI Osmo 360 and Insta360 X5, but GoPro claims that Max 2 is the only one of the three with “true” 8K. That’s to say it doesn't count unusable pixels on the sensor or those that are used in overlapping for stitching the footage from the two lenses together. GoPro goes as far to say that this results in somewhere between 16- and 23-percent higher resolution than its rivals.
You can now shoot 360 video at 8K/30 fps, 5.6K/60 fps and good ol’ 4K at 90 fps in 360 mode. When you shoot in single-lens mode (aka, non-360 mode), the max resolution available is 4K60, up from 1.4K/30 on the original Max. But pure resolution isn’t the only quality gain this time around, the Max 2 now joins its Hero siblings with 10-bit color and a top bit rate of 120Mbps, which can be increased to 300Mbps via GoPro’s experimental Labs firmware.
Other hardware updates include a gentle redesign that matches the current Hero and Hero 13 cameras with heat-sink style grooves over the front face and centrally-placed lenses (rather than in a left-right configuration as before). The physical size and shape of the Max 2 otherwise matches the OG Max. There is one new, and much appreciated change, though. With the Max 2, the lenses twist off for easy replacement. As there’s a lens on both sides, it’s always going to land “butter-side down” when dropped. The probability of scuffing or breaking one is therefore much higher, but with Max 2, replacing them is a trivial matter and a solid quality of life improvement. The Insta360 X5 has replaceable lenses too, but DJI’s Osmo 360 requires sending the camera to the company for a refresh.
As for audio, the six-mic array is directional, with sound focusing on where the action is taking place. As with the Hero 12 and 13 Black, you can also connect AirPods or a Bluetooth microphone (such as DJI’s Mic 3) to the GoPro directly for narration or extra-clear shrieks of fear. There’s no doubt this makes the Max 2 more appealing to vloggers and social creators.
There’s no onboard storage here, which is true for all GoPro cameras, but worth mentioning now as DJI’s Osmo 360 ships with 105GB of storage. Given the amount of times I’ve headed out with my camera only to find I left the memory card in my PC, I’d really love to see GoPro make it a standard addition to its cameras too.
After years of testing action cameras, I’ve learned that while some models excel in one area or terrain, they can struggle in others. I live near a huge park with a variety of colors, trees and pockets of water, which makes it a perfect testing ground. The Max 2 fares well across the board, with vibrant, natural colors and generally balanced exposure. You’ll notice transitions in the exposure as you move from direct sunlight to shadow, but that’s fairly typical.
When you review and reframe your footage, you’ll instantly be reminded you’re working with a 360 camera. The minute you drag your finger over a video to rotate it or zoom out for that drone-like “floating” footage, you’ll also introduce some warping. Sometimes it’s a bit frustrating trying to find the right balance of warp and pleasant framing, other times it actually makes for a good effect. If you zoom out fully, for example, you’ll end up with one of those “tiny planet” videos.
It’s also worth talking about stitch lines. Where the two lenses overlap, you’ll sometimes notice where the video is being stitched together, often via some slight wobbling or a break in a street markings and so on. Again, it’s a fact of life with current 360 photography, and you will notice it with the Max 2 from time to time.
Conversely, 360 video allows for extremely good stabilization, especially in single lens mode. I tried recording myself with a long selfie stick, precariously perched on my bike’s handlebars (not locked in with a mount) and despite the camera moving like a fish on land as I rode over uneven ground and potholes, the footage still came out impressively smooth. In friendlier conditions — such as walking with the camera — footage is even smoother and immediately ready for sharing.
New additions this year include 8K timewarps and a new (for Max) “HyperView” which is a 180-degree ultrawide FOV that just uses everything the sensor captures for extra immersive footage. As with HyperView on the Hero cameras, it’s a little extreme with lots of warping but it feels like you’re being sucked into the image, perfect for point of view footage.
Which brings us to the aforementioned Selfie Mode and POV mode; both are more about removing friction than adding any new creative tools. As you don’t need to have a 360 camera facing you while shooting a selfie, the video isn’t always oriented with you in frame when you open it in Quik. With Selfie/POV mode, it will load up framed correctly, so you can go right into sharing your clip.
Think of it as a hybrid between 360 and single-lens mode. You will still capture everything in 360, and can move the shot around to show different things, but if your POV or your face talking to camera are the main focus, you don’t need to do any reframing to get there. The camera also applies the optimal stabilization, reducing the amount of editing needed to get from camera to export. The first Max would always open videos from the front camera point of view regardless, leaving you to dig around for what you actually wanted to focus on.
Photography with a 360 camera is both simple and complicated at the same time. On the one hand, you don’t need to worry whether you’re in shot, as you’re going to capture everything, but likewise you’re going to want to make sure you catch the right moment or the best angle. A new Burst mode alleviates some of that concern by taking a bunch of photos for a set period of time (one to six seconds). giving you the ability to strike a few poses or make sure you catch the best shot if the subject is moving. You can then edit and reframe in Quik as with any other media.
Unlike a regular camera, with 360 video you can’t avoid at least some editing. At minimum, you’ll need to confirm framing for exporting to a flat (dewarped) video. That said, editing is where all the fun is. Being able to shoot one video and make it dynamic with panning and zooming is one of the major benefits of this type of camera. Quik is where you’ll be doing most of this, and unlike DJI, which is a relative newcomer to the category, GoPro has a few years’ headstart on the app side of things.
The result is an editing experience that’s intuitive that strikes a good balance between creative possibility and ease of use. For a simple punch out video where you set the framing and zoom amount and then export, it’s just a few button clicks before you have a video you can share. You can of course go back and re-edit and export in another aspect ratio if, say, you want an Instagram Reel in portrait alongside a regular 16:9/widescreen version for YouTube.
Quik also includes some filters that may or may not be to your taste. Much more useful are the preset effects, including a variety of spins, rolls and pans that are clearly aimed at action footage, but can be used creatively for any type of video. You can also track an object automatically via AI. It’s perfect for keeping your kid or pet in the shot while they run around with one click and an easy way to make your video dynamic. Overall, editing in Quik feels like a solid pipeline for posting to social media, but it is still a bit cumbersome for anything longer. Desktop editing options are Adobe Premier and After Effects via the GoPro Reframe plugin. The company also recently announced a beta plugin for Davinci Resolve.
The Max 2 ships with a 1,960mAh “Enduro” battery, which is designed to last longer even in extreme cold. GoPro claims that it should last “all day” but that of course depends what you’re doing with it. When I took the camera out for a day of filming, visiting different locations and pulling the camera out when I found something interesting, the battery lasted for the whole six-hour excursion. That’s not actual recording time, obviously, and I maybe grabbed about 30 minutes of actual footage. But that’s me walking around with the camera on, or in standby, and hitting record sporadically over that period. In fact, there was still about 15-percent battery left when I went to export my footage the next day.
That’s more of a real world test with me connecting the camera to the phone and transferring files, which will yield less recording time than if you just set the camera down and press record. This is about on par with what I’ve experienced with regular GoPros that can usually record for about an hour and a half in a “set and record” scenario.
A reasonable amount of time has passed between the Max 1 and Max 2, so if you were hoping for a top-to-bottom spec overhaul, you might be a little disappointed. But with 360 video, source resolution is the main upgrade and Max 2 can output 4K/60 video, which is by far the most important thing. That improved resolution has filtered down into all the important timelapse and video modes, and that makes the camera feel current and mostly complete.
I do think it’s about time that GoPros have onboard storage, at least as an option, as that removes a really simple pain point. The fact that DJI is doing it might well give GoPro the nudge it needs.
A lot of what sets the Max 2 apart from DJI will be in the editing experience. It’s simple and well thought out, with some useful tools and effects that make getting footage into something you want to share pretty straightforward. Although DJI’s onboard storage and higher maximum frame rate will be tempting for many. Insta360’s app is generally considered easy to use, too, so with the X5, GoPro’s advantage is the price (at least for now). What really sets these cameras apart, are the videos you end up sharing, and in that regard GoPro’s bet on “true 8K” and the app experience might just be enough.
This article originally appeared on Engadget at https://www.engadget.com/cameras/gopro-max-2-review-theres-a-new-360-camera-contender-in-town-130058942.html?src=rss
Google is turning Gemini into a gaming sidekick with a new Android overlay
Google might have found a way Gemini could be useful while you're playing games on your phone. The company is introducing a new software overlay today it calls the Play Games Sidekick that gives you access to Gemini Live while you play, alongside a host of other gaming-focused updates to Google Play that could make the app platform a better home for gamers.
Sidekick exists as a small, moveable tab in games downloaded from the Play Store that you can slide over to show relevant info and tools for whatever game you're playing. By default, that's things like easy access to a screenshot button, screen recording tools and a shortcut for going live on YouTube, but you'll see achievements and other game stats in there, too.
Google is clearly most interested in how Sidekick could serve as a delivery system for Gemini, though, so AI plays a large role in how Sidekick actually helps you while you play. That includes offering a curated selection of game tips that you can swipe through, and a big button that you can press that starts Gemini Live. Based on a demo Google ran for press, Gemini Live does seem like it could be a competent guide for navigating games. It was able to offer strategies for how to best start a game of The Battle of Polytopia and told game-specific jokes that were only funny in how awkward they were. Since Gemini can accept screen sharing as an input, it was also able to offer its guidance without a lot of context from the Google project manager running the demo. Referring to in-game items as "this" or "that" was enough to get Gemini to understand.
Gemini in Sidekick won't really replace a detailed game guide written by a human, but for a quick answer it's easier than Googling. It's also similar in many ways to Microsoft's Gaming Copilot, which also places a live AI in games with you. For now, Google is taking a restrained approach to rolling out Play Games Sidekick and its AI features. You don't have to interact with the overlay at all if you don't want to (you can even dismiss it to the notification shade) and Gemini-powered features will only be available "in select games over the coming months." That includes games from "hero partners EA and NetMarble," according to Google, like "Star Wars Galaxy of Heroes, FC Mobile and Solo Leveling Arise."
Beyond the Sidekick, Google views its updates to Google Play Games as a way to unify what's a pretty siloed-off gaming experience on mobile. Each game has its own profile, achievements and in-game stats, and few of them connect to each other. In an attempt to fix that, Google is introducing a "platform-level gaming profile" that tracks stats and achievements across Android and PC, and even supports AI-generated profile pictures. Like other gaming platforms, you can follow your friends and see what games they're enjoying. Google will also host forums for games available in the Play Store where you can ask questions about a game and get answers from other players.
All of these tweaks come with major caveats in that they require players to use them and developers to enable them, but they do suggest Google is trying to take games seriously after bungling more ambitious projects like Stadia. And not just on Android: As part of this rollout, the PC version of Google Play Games is coming out of beta, putting the company in even more direct competition with the Steams of the world.
This article originally appeared on Engadget at https://www.engadget.com/mobile/google-is-turning-gemini-into-a-gaming-sidekick-with-a-new-android-overlay-130052048.html?src=rss
GoPro's Lit Hero is an entry-level action cam with a built-in light
Along with its new 360 Pro 2 Max camera, GoPro has introduced the Lit Hero — a new compact action cam that looks like its entry-level Hero with a built-in LED light. That, along with improved image quality and a price that falls between the Hero and high-end Hero 13 models, could make it a popular option for creators and vloggers.
The GoPro Lit has a similar form factor to the Hero but differs in a few key ways. The built-in light opens up creative options particularly for vloggers, as it can help illuminate your face in somber lighting or shadows. That could make it useful not only for regular vlogging, but as a "B" cam for action creators who want better lighting on their faces. In a further nod to those creators, it now has the record button up front, though the lack of a front display may make it a tough sell for some.
Another key improvement over the Hero is with video quality. The Hero Lit can capture 4K video at up to 60 fps instead of 30 fps before, opening up a 2x slow-mo option at the highest resolution. And like the Hero (following an update) the Hero Lit can capture 4:3 video that makes it easier to create vertical video for social media while offering cropping options for regular 16:9 shots. You can also shoot social-ready 12MP 4:3 photos.
Otherwise, the Lit's feature list lines up closely with the Hero. It's waterproof down to 16 feet (5m) for underwater action and rugged enough for extreme sports. It uses the same Enduro battery that promises over 100 minutes of 4K 60p video on a charge, though not with the LED lights turned on I imagine. It's now on pre-order for $270 on GoPro.com, with shipping set to start on October 21.
This article originally appeared on Engadget at https://www.engadget.com/cameras/gopros-lit-hero-is-an-entry-level-action-cam-with-a-built-in-light-130035003.html?src=rss
Google Play is getting AI-sorted search results, a 'You' tab and short-form K-dramas
Google is announcing several updates to Google Play in an attempt to shift the app store from "a place to download apps" to "an experience." Many of the changes are powered by AI, and most seem like a preemptive attempt to keep the Play Store attractive for users now that it seems increasingly possible Google will be forced to open up Android to third-party app stores.
The most visible update Google is introducing to Google Play is a new tab. It's called the "You Tab" and it acts like a combination of a profile page and a For You tab, specifically for app store content. You can access Google's universal game profiles from the tab — part of larger gaming-focused updates Google is bringing to Google Play — along with app recommendations and content recommendations from streaming apps available through the Play Store. The tab seems relatively easy to ignore if you just want to download apps, but Google thinks users could turn to it as a curation tool and a way to take advantage of deals.
The company is also expanding the ways you can find apps. New regional sections will collect apps and content based on specific interests or seasonal topics. Google has tried a "Cricket Hub" in India and a Comics section in Japan, and now it's bringing an Entertainment section to Korea that will collect short-form video apps, webcomics and streaming services into a single home. Interestingly, Google is making content from these apps available to sample directly in Google Play, and not just in Korea. You'll be able to read webcomics and watch short-form K-dramas directly in Google Play, without having to download an additional app in the US, too.
When you're looking for something in particular, a new "Guided Search" feature will let you search for a goal (for example, "buy a house") and receive results that are organized into specific categories by Gemini. Those Gemini-based improvements will also extend to individual app pages, where Google continues to expand the availability of its "Ask Play" feature. Ask Play lets you ask questions about an app and receive AI-generated responses, a bit like the Rufus AI chatbot Amazon includes in its store pages.
Google's Play Store updates start rolling out this week in countries where the company's Play Points program is available, like the US, the UK, Japan and Korea. They'll come to "additional countries" on October 1, according to Google.
This article originally appeared on Engadget at https://www.engadget.com/mobile/google-play-is-getting-ai-sorted-search-results-a-you-tab-and-short-form-k-dramas-130005402.html?src=rss
This slim Anker MagSafe power bank is on sale for only $46
We can all be honest and say that carrying around a bulky power bank almost makes it seem like your phone dying isn't so bad. Between the heaviness and any necessary cords, they can just be a pain. So, we were intrigued when Anker debuted a new, very thin power bank this summer: the Anker Nano 5K MagGo Slim power bank.
Now, both Anker and Amazon are running sales on it, dropping the price from $55 to $46. The 16 percent discount a new low for the power bank and available in the black and white models. It's just about a third of an inch thick and attaches right to your iPhone. On that note, it works with any MagSafe compatible phone with a magnetic case.
Anker's Nano 5K MagGo Slim is our pick for best, well, slim MagSafe power bank. It took two and a half hours to charge an iPhone 15 from 5 percent to 90 percent. However, it could boost the battery to 40 percent in just under an hour. Overall, though, the minimalist design and easy to grip matte texture, really sold it to us.
Follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/this-slim-anker-magsafe-power-bank-is-on-sale-for-only-46-121512535.html?src=rss
Palworld: Palfarm might be the creepiest farming game ever
Palworld is getting as spinoff that looks both cozy and terrifying — oh, and filled with characters that look exactly like Pokémon. In Palworld: Palfarm, you move to the Palpagos Islands and create a farm alongside Pals. These creatures help with farm work, cook and can even become friends.
According to an announcement on Steam, "Through daily conversations, working together, or giving gifts from time to time, you can gradually deepen your relationships with both the Pals and the people of the island." Pocketpair, the developer behind both games, adds that they might even play matchmaker — a brand new trailer shows Pals officiating at a human wedding. Notably, the game also supports multiplayer.
However, the game certainly seems to have an air of darkness. For starters, there's this note in the description: "…Is one of your Pals slacking off? Time to teach them the joy of working." Ominous, to say the least. Then there's "nasty Pals," who will try to raid your farm and must be beaten in combat.
Darkest of all is a black market that sells guns, among other suspicious items. What you would need a gun for in this game is something you can choose to find out, but it certainly seems like the Palpagos Islands are a mixed bag of a place.
Palworld: Palfarm doesn't have a set release date yet, but you can watch the full trailer now.
This article originally appeared on Engadget at https://www.engadget.com/gaming/palworld-palfarm-might-be-the-creepiest-farming-game-ever-123049220.html?src=rss
Prime members can get 8Bitdo's Pro 2 controller with travel case for only $40
8Bitdo may have already launched its Pro 3 controller, but that doesn't mean you should dismiss older models. The Pro 2 has been one of our favorites for a long time, and right now Prime members can get the Bluetooth controller bundled with a travel case for only $40. That's $20 off and a 34-percent discount. This controller does, indeed, work with the Nintendo Switch 2, and the only caveat is that the sale price is only available to Prime members.
Despite launching in 2021, the Pro 2 was still our choice for best PlayStation-style mobile gaming controller this year. It works well with Android and iOS systems and has extensive customization options when you use your phone. Plus, the design is comfortable to hold and available in multiple colors.
Follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/prime-members-can-get-8bitdos-pro-2-controller-with-travel-case-for-only-40-115247955.html?src=rss
DJI Osmo Nano review: High-quality video in a truly tiny action cam
DJI might be an innovative company, but it has been playing catch-up to rival Insta360 in the action cam world. A perfect example of that is its latest product, the Osmo Nano ($299). It follows a path Insta360 paved with its tiny Go Ultra and Go 3S, which let you separate the cam from the display to shoot with the least weight possible. Like those, the Nano’s tiny camera can be detached from the screen and easily worn to record activities ranging from extreme watersports to cat cam videos.
The Osmo Nano isn’t quite a copy-paste of its rival, though. Rather than inserting the camera into the flip up screen housing like the Go Ultra, the Nano’s screen magnetically clips to the bottom of the camera so you can point it forward to capture action or backward for vlogging. While it still lags behind its rival in some areas, DJI’s Osmo Nano is a solid first attempt at a mini-sized camera thanks to its excellent video quality.
With its lightweight detachable camera that can be clipped to your head or worn on your body like a pendant, the Nano can be used in everyday activities like hiking or swimming — with the latter possible thanks to its 33 foot (10 meter) underwater rating. It’s also small enough to be attached to kids and pets to create a visual journal of their activities. At the same time, when attached to the Vision Dock that houses the screen, the Nano functions like a normal action camera.
With that in mind, size is key. The Osmo Nano camera is built from lightweight translucent plastic and weighs just 1.83 ounces (52 grams) by itself. That’s about the same as the Insta360 Go Ultra but a touch heavier than the Go 3S. Its capsule-like shape is similar to the Go 3S (but a bit bigger), while the Go Ultra is more rounded. All of that is to say that the Nano is incredibly small and light compared to a GoPro Hero 13 or DJI’s Action 5 Pro — I barely felt it when using the new headband accessory
They attach together in two ways, with the screen facing either forward or backward, using DJI’s magnetic mount that it’s used for a few years now. Together they weigh 4.37 ounces, still less than a regular action camera. The Vision Dock can wirelessly control the camera without being connected, to a distance of 33 feet. The mount also allows the Nano to connect to DJI’s family of accessories, including a new hat clip and lanyard.
During my testing, the camera and module were easy to connect in either direction thanks to the magnets and latches. To switch from vlogging to the front view, though, you need to detach and reconnect the Vision Dock. Insta360’s system is better, as it just takes a flip of the X5’s screen to change modes.
The difference in camera module sizes can be explained by the sensors. Where the Go 3S has a small 1/2.3-inch sensor, both the Nano and Go Ultra have larger 1/1.3-inch sensors that take up more space but work better in low light. As for optics, the Nano uses an ultra wide angle lens with a 143-degree field of view, giving you the ability to switch between ultra wide and dewarped (square) video. The Go Ultra is slightly wider at 156 degrees, while the Go 3S’s FOV is 125 degrees. I found the Nano’s field of view to be an ideal compromise between the two.
The only physical control on the Nano is the record/power button, with the Vision Dock holding everything else. DJI’s typical screen swiping and tapping actions are used to select things like voice control and screen brightness, along with video resolution, frame rate, RockSteady stabilization and D-LogM capture. Once you get used to swiping and tapping on such a small display, these menus are responsive and let you change settings quickly. However, the navigation isn’t particularly intuitive so settings require some time to learn.
As with other recent DJI products, the Osmo Nano has generous built-in memory, with 64GB (transfers at 400 MB/s) and 128GB (at 600 MB/s) options. Note that those speeds don’t affect video quality; they’re only the rates at which you can transfer footage to your PC. This internal memory is convenient as it means you don’t need to dig around for a microSD card and it makes offloading faster. That said, it’s nice to have a microsSD slot as well — the Go Ultra only has a microSD storage option, and the Go 3S only has internal memory.
Each module has its own non-removable battery with 530mAh and 1,300mAh capacities for the camera and Vision Dock respectively. Those allow operating times of up to 90 minutes for the camera alone, or 200 minutes when paired with the screen module, according to DJI. In comparison, Insta360’s Go Ultra camera can run for 70 minutes or a maximum of 200 minutes when docked to the display.
Note that those specs only apply when recording in 1080p at 24p. When shooting with the Nano at a more typical setting of 4K 60p, I found that battery life was less than half that, around 35 minutes for the camera alone. However, that rose to 49 minutes when using DJI’s endurance mode, with RockSteady stabilization enabled but Wi-Fi turned off. I also noticed that when I shot in 4K at 50p or higher with the camera alone, it shut down after 20 minutes of continuous recording due to overheating.
The Nano’s camera has no USB-C input so it must be connected to the docking station for charging. However, the docking station alone can fast charge the Nano camera to an 80 percent battery in 20 minutes. It takes about 20 minutes to charge both devices together to 80 percent, and 60 minutes for a full charge — 20 minutes more than the Go Ultra.
Other key features include voice and gesture control (tapping or nodding) to start recording, timelapse and Pre-Rec to save footage taken just before the record button is pressed. Insta360’s Go 3S does have a couple of features not found on the Nano, namely Find Me for iPhone if it’s lost and Dolby Vision HDR support.
The Nano can also be controlled using the DJI Mimo smartphone app, though the Vision Dock’s remote control makes that unnecessary most of the time. That app also lets you edit video, but Insta360’s Studio app is superior for that thanks to its more complete editing toolkit and Shot Lab AI module that lets you do some neat effects with little-to-no work required. DJI is definitely well behind its rival in this area.
A big selling point of the DJI Nano is that it produces high-quality video with faster frame rates than rival cameras. You can capture 4K at up to 60 fps, or 120 fps in slow motion mode, compared to just 4K 30 fps for the Go 3s. It also supports full sensor 4:3 4K video at up to 50 fps. The Go Ultra maxes out at 60 fps at 16:9 4K and 30 fps at 4:3 4K.
Thanks to the big 1/1.3-inch sensor, video is bright and sharp straight out of the camera when shooting in daylight. DJI has improved the color performance compared to its older products, with hues that are more natural. Where sharpening was overly aggressive on models like the Action 5 (which makes video look artificial) DJI has toned that down on the Osmo Nano. And if you don’t like the default application, you can change it in the settings.
Like the Action 5 Pro, the Nano can shoot video with 10-bits of color in both D-LogM and regular modes. The latter gives users extra dynamic range without having to mess with tricky log settings. My preference is still to shoot D-LogM then apply DJI’s LUT in post. That yields more natural colors and gives you up to 13.5 stops of dynamic range in challenging lighting conditions, like tree-lined trails on a sunny day.
The larger sensor also makes the Osmo Nano superior to the Go 3S and about equal to the Insta360’s Go Ultra in low light. When I shot nighttime cityscapes and in indoor bars, it delivered clean video with relatively low noise. For even lower light situations, both the Nano and Go Ultra have night shooting modes called SuperNight and PureVideo, respectively. Both work well if you don’t move the camera too fast, due to the fact that they combine multiple frames into one. If I moved the camera too rapidly, it caused motion blur and other issues. The Insta360 Go Ultra is slightly better in this regard.
DJI’s RockSteady 3.0 reduces camera shake in normal daylight shooting conditions, though it’s not quite up to GoPro’s canny smoothing algorithms. When I tested it while walking, stabilization fell apart a bit in night shooting due to the lower shutter speeds, with noticeable blur and pixelization over sharp jolts and bumps. To avoid that, it’s best to boost the ISO level and shutter speed manually. The company’s HorizonBalancing, meanwhile, reliably corrects tilting up to 30 degrees to keep video level.
As with DJI’s other recent action cams, the Osmo Nano connects to the company’s Mic 2, Mic 3 and Mic Mini via its proprietary OsmoAudio direct connection. That offers higher quality and a more reliable connection than Bluetooth, while allowing you to use two mics at the same time for interviews or multiperson action scenarios. The Nano also has dual built-in microphones for stereo recording, but in my testing, the tinny audio was only good enough for ambient sounds and not voices.
It’s interesting to watch DJI try to catch up to another company for a change. With the Nano, it leaned on its camera experience and mostly matches or beats its main rival in terms of video quality. However, the company is still lagging behind in a few areas, particularly its editing app — something that’s important for many creators.
DJI seems to be aware of that and priced the Nano much cheaper than rivals. The Nano costs $299 (€279 and £239 in Europe) for the 64GB combo and $329 for the 128GB combo (€309/£259), both of which include the Vision Dock, magnetic hat clip, magnetic lanyard, protective case, high-speed charging cable and dual-direction magnetic ball-joint adapter mount. That compares to €429 for the Insta360 Go Ultra, which has no built-in memory and includes fewer accessories, and €400 for the Go 3S with 128GB of internal storage.
Update September 23, 2025 at 8:50AM ET: The review has been updated to reflect US availability.
This article originally appeared on Engadget at https://www.engadget.com/cameras/dji-osmo-nano-review-high-quality-video-in-a-truly-tiny-action-cam-120040319.html?src=rss
The Morning After: US and China agree to agree on a TikTok deal
After the proclamation of a TikTok ban, which fizzled out, during President Trump’s first term, the idea of a TikTok lockout across the US was back on the table when he returned for a second presidency.
Now, after too much will-they-won’t-they, White House press secretary Karoline Leavitt said a TikTok deal is expected to be signed “in the coming days.” This follows President Donald Trump posting an update on Friday that did little to clarify what the deal actually is.
Trump said both that the two had “made progress” on “approval of the TikTok Deal” and that he “appreciate[s] the TikTok approval.” Trump also told reporters in the Oval Office “he approved the TikTok deal,” according to Reuters.
During an appearance on Fox News’ “Saturday in America” the following day, Leavitt added the deal would mean that “TikTok will be majority owned by Americans in the United States.” She added: “Now that deal just needs to be signed, and the president’s team is working with their Chinese counterparts to do just that.”
The proposed terms reportedly include a brand new app for TikTok’s US users, which will continue to use ByteDance’s technology for its algorithm, US investor control and a multibillion-dollar payday for the Trump administration. But several days later, nothing is yet official.
— Mat Smith
Get Engadget's newsletter delivered direct to your inbox. Subscribe right here!
The news you might have missed
SpaceX’s lunar lander could be ‘years late’ for a planned 2027 mission to the Moon
Engadget review recap: All the iPhone 17 reviews and other Apple devices
With a straightforward process to replace batteries.
The new iPhone Air got a provisional 7 out of 10 in iFixit’s teardown critique. As seen in the repair company’s teardown, the iPhone Air’s battery can be easily swapped, has a modular USB-C port and works with day-one repair guides. Apple kept the same battery design introduced with the iPhone 16 lineup, which switched to an electrically released battery adhesive for easier, more clinical removal. Oh, another fun find: iFixit discovered the iPhone Air’s battery is the same cell found in the accompanying MagSafe Battery accessory. iFixit likened it to a “spare tire.”
Double billing now.
The Mandalorian and Grogu follows on from the events of Disney+ series The Mandalorian — a show that director Jon Favreau created — and the fall of the Empire in Return of the Jedi. It’s set to hit theaters on May 22, 2026. The trailer does make it seem like the movie will retain the playfulness of The Mandalorian. During the short teaser, Grogu uses the Force to try to steal a snack from Sigourney Weaver’s character, only to be denied. Poor Grogu.
It might be due to the eye-catching edges of the camera unit.
Careful, there may be a potentially scratch-prone iPhone 17 models. According to a Bloomberg report, those demoing the latest iPhone in-store noticed the iPhone 17 Pro in Deep Blue and the iPhone Air in Space Black models already had very noticeable scratches and scuffs. In a video by JerryRigEverything, the YouTuber puts the iPhone 17 models to the test with razor blades, coins and keys. The video highlights the edges of the iPhone 17 Pro’s back camera housing as particularly prone to scuffing since the colored aluminum oxide layer from the anodization process tends not to stick to sharp corners.
This article originally appeared on Engadget at https://www.engadget.com/general/the-morning-after-engadget-newsletter-111626774.html?src=rss
Bang & Olufsen's Beo Grace earbuds will cost you $1,500
Bang & Olufsen has launched a new pair of earbuds that could cost more than your phone or your laptop. The Beo Grace, as the model is called, will set you back $1,500, £1000 or €1200, depending on where you are. It has a silver aluminum casing with a pearl finish, which you can protect with a bespoke leather pouch, though the accessory will cost you an additional $400. The company says Beo Grace was "inspired by the elegance of fine jewelry," with aluminum stems reimagined from its iconic A8 earphones. Bang & Olufsen's A8 had stems made of metal, as well, but they transition into ear hooks that enable a more and secure and snug fit.
The earphones, the audio manufacturer explains, were "inspired by the acoustic principles" of the $2,200 Beoplay H100 headphones. Beo Grace has Spatial Audio and is optimized for Dolby Atmos, with an Adaptive Active Noise Cancellation technology that's "four times more effective" than the manufacturer's previous best earbuds. Specifically, its ANC tech is powered by six studio-grade microphones and can adjust itself in real time, based on the ambient noise. The model comes with tactile controls, so that every press to pause, play or skip is "crisp, deliberate and satisfying," but you will be able to adjust the volume by simple tapping. When it comes to battery life, the Beo Grace can last up to 4.5 hours of listening with ANC, and up to 17 hours with the charging case.
Beo Grace is now available for pre-order from the Bang & Olufsen website and will be widely available on November 17. The model comes with a three-year warranty, so you at least know that the company will fix your $1,500 earbuds if they break in the near future.
This article originally appeared on Engadget at https://www.engadget.com/audio/headphones/bang--olufsens-beo-grace-earbuds-will-cost-you-1500-103012904.html?src=rssThe best Chromebook you can buy in 2025
Whether you’re shopping for a budget-friendly laptop for school or a sleek machine for everyday productivity, the best Chromebooks can offer surprising functionality for the price. Chromebooks have come a long way from their early days as web-only devices. Now, many Chromebook models feature powerful processors, premium displays and even touchscreen support, making them a compelling alternative to a regular laptop for plenty of users.
There are more options than ever too, from lightweight clamshells to high-end, 2-in-1 designs that can easily replace your daily driver. Whether you're after a new Chromebook for streaming, work or staying on top of emails, there’s likely a model that fits both your budget and your workflow. We’ve tested the top Chromebooks on the market to help you find the right one — whether you’re after maximum value or top-tier performance.
What is Chrome OS, and why would I use it over Windows?
This is probably the number one question about Chromebooks. There are plenty of inexpensive Windows laptops on the market, so why bother with Chrome's operating system? Glad you asked. For me, the simple and clean nature of Chrome OS is a big selling point. Chrome OS is based on Google’s Chrome browser, which means most of the programs you can run are web based. There’s no bloatware or unwanted apps to uninstall like you often get on Windows laptops, it boots up in seconds, and you can completely reset to factory settings almost as quickly.
Of course, simplicity will also be a major drawback for some users. Not being able to install native software can be a dealbreaker if you’re a video editor or software developer. But there are also plenty of people who do the majority of their work in a web browser, using tools like Google Docs and spreadsheets for productivity without needing a full Windows setup.
Google and its software partners are getting better every year at supporting more advanced features. For example, Google added video editing tools to the Google Photos app on Chromebooks – it won’t replace Adobe Premiere, but it should be handy for a lot of people. Similarly, Google and Adobe announced Photoshop on the web in 2023, something that brings much of the power of Adobe’s desktop apps to Chromebooks.
Chromebooks can also run Android apps, which greatly expands the amount of software available. The quality varies widely, but it means you can do more with a Chromebook beyond just web-based apps. For example, you can install the Netflix app and save videos for offline watching. Other Android apps like Microsoft Office and Adobe Lightroom are surprisingly capable as well. Between Android apps and a general improvement in web apps, Chromebooks are more than just portals to a browser.
What do Chromebooks do well?
Put simply, web browsing and really anything web based. Online shopping, streaming music and video and using various social media sites are among the most common daily tasks people do on Chromebooks. As you might expect, they also work well with Google services like Photos, Docs, Gmail, Drive, Keep and so on. Yes, any computer that can run Chrome can do that too, but the lightweight nature of Google Chrome OS makes it a responsive and stable platform.
As I mentioned before, Chrome OS can run Android apps, so if you’re an Android user you’ll find some nice ties between the platforms. You can get most of the same apps that are on your phone on a Chromebook and keep info in sync between them. You can also use some Android phones as a security key for your Chromebook or instantly tether your 2-in-1 laptop to use mobile data.
Google continues to tout security as a major differentiator for Chromebooks, and it’s definitely a factor worth considering. Auto-updates are the first lines of defense: Chrome OS updates download quickly in the background and a fast reboot is all it takes to install the latest version. Google says that each webpage and app on a Chromebook runs in its own sandbox as well, so any security threats are contained to that individual app. Finally, Chrome OS has a self-check called Verified Boot that runs every time a device starts up. Beyond all this, the simple fact that you generally can’t install traditional apps on a Chromebook means there are fewer ways for bad actors to access the system.
If you’re interested in Google’s Gemini AI tools, a Chromebook is a good option as well. Every Chromebook in our top picks comes with a full year of Google’s AI Pro plan — this combines the usual Google One perks like 2TB of storage and 10 percent back in purchases from the Google Store with a bunch of AI tools. You’ll get access to Gemini in Chrome, Gmail, Google Docs and other apps, Gemini 2.5 Pro in the Gemini app and more. Given that this plan is $20/month, it’s a pretty solid perk. Chromebook Plus models also include tools like the AI-powered “help me write,” the Google Photos Magic Editor and generative AI backgrounds you can create by filling in a few prompts.
As for when to avoid Chromebooks, the answer is simple: If you rely heavily on a specific native application for Windows or a Mac, chances are you won’t find the exact same option on a ChromeOS device. That’s most true in fields like photo and video editing, but it can also be the case in law or finance. Plenty of businesses run on Google’s G suite software, but more still have specific requirements that a Chromebook might not match. If you’re an iPhone user, you’ll also miss out on the way the iPhone easily integrates with an iPad or Mac. For me, the big downside is not being able to access iMessage on a Chromebook.
Finally, gaming Chromebooks are not ubiquitous, although they’re becoming a slightly more reasonable option with the rise of cloud gaming. In late 2022, Google and some hardware partners announced a push to make Chromebooks with cloud gaming in mind. From a hardware perspective, that means laptops with bigger screens that have higher refresh rates as well as optimizing those laptops to work with services like NVIDIA GeForce Now, Xbox Game Pass and Amazon Luna. You’ll obviously need an internet connection to use these services, but the good news is that playing modern games on a Chromebook isn’t impossible. You can also install Android games from the Google Play Store, but that’s not what most people are thinking of when they want to game on a laptop.
What are the most important specs for a Chromebook?
Chrome OS is lightweight and runs well on fairly modest hardware, so the most important thing to look for might not be processor power or storage space. But Google made it easier to get consistent specs and performance late last year when it introduced the Chromebook Plus initiative. Any device with a Chromebook Plus designation meets some minimum requirements, which happen to be very similar to what I’d recommend most people get if they’re looking for the best laptop they can use every day.
Chromebook Plus models have at least a 12th-gen Intel Core i3 processor, or an AMD Ryzen 3 7000 series processor, both of which should be more than enough for most people. These laptops also have a minimum of 8GB of RAM and 128GB of SSD storage, which should do the trick unless you’re really pushing your Chromebook. All Chromebook Plus models have to have a 1080p webcam, which is nice in these days of constant video calling, and they also all have to have at least a 1080p FHD IPS screen.
Of course, you can get higher specs or better screens if you desire, but I’ve found that basically everything included in the Chromebook Plus target specs makes for a very good experience.
Google has an Auto Update policy for Chromebooks as well, and while that’s not exactly a spec, it’s worth checking before you buy. Last year, Google announced that Chromebooks would get software updates and support for an impressive 10 years after their release date. This support page lists the Auto Update expiration date for virtually every Chromebook ever, but a good rule of thumb is to buy the newest machine you can to maximize your support.
How much should I spend on a Chromebook?
Chromebooks started out notoriously cheap, with list prices often coming in under $300. But as they’ve gone more mainstream, they’ve transitioned from being essentially modern netbooks to some of the best laptops you’ll want to use all day. As such, prices have increased: At this point, you should expect to spend at least $400 if you want a solid daily driver. There are still many Chromebooks out there available at a low price that may be suitable as secondary devices, but a good Chromebook that can be an all-day, every-day laptop will cost more. But, notably, even the best Chromebooks usually cost less than the best Windows laptops, or even the best “regular” laptops out there.
There are a handful of premium Chromebooks that approach or even exceed $1,000 that claim to offer better performance and more processing power, but I don’t recommend spending that much. Generally, that’ll get you a better design with more premium materials, as well as more powerful internals and extra storage space, like a higher-capacity SSD. Of course, you also sometimes pay for the brand name. But, the specs I outlined earlier are usually enough, and there are multiple good premium Chromebooks in the $700 to $800 range at this point.
See Also:
Lenovo IdeaPad Flex 5i Chromebook Plus
This was our pick for best overall Chromebook for years, and it’s still one of the better options you can find for a basic laptop that doesn’t break the bank. It’s a few years older than our current top pick, so its processor isn’t fresh and it only has 128GB of storage. It also won’t get updates from Google as long as newer models. But it still combines a nice screen and keyboard with solid performance. This laptop typically costs $500, which feels high given its a few years old and Acer’s Chromebook Plus 514 is only $350, but if you can find it on sale and can’t find the Acer it’s worth a look.
ASUS CX15
This Chromebook is extremely affordable – you can currently pick it up for only $159 at Walmart. That price and its large 15.6-inch screen is mainly what it has going for it, as the Intel Celeron N4500 chip and 4GB of RAM powering it does not provide good performance if you’re doing anything more than browsing with a few tabs open. If you’re shopping for someone with extremely basic needs and have a small budget, the CX15 might fit the bill. But just be aware that you get what you pay for.
Samsung Galaxy Chromebook Plus
Samsung’s Galaxy Chromebook Plus, released in late 2024, is one of the more unique Chromebooks out there. It’s extremely thin and light, at 0.46 inches and 2.6 pounds, but it manages to include a 15.6-inch display in that frame. That screen is a 1080p panel that’s sharp and bright, but its 16:9 aspect ratio made things feel a bit cramped when scrolling vertically. Performance is very good, and the keyboard is solid, though I’m not a fan of the number pad as it shifts everything to the left. At $700 it’s not cheap, but that feels fair considering its size and capabilities. If you’re looking for a big screen laptop that is also super light, this Chromebook merits consideration, even if it’s not the best option for everyone.
This article originally appeared on Engadget at https://www.engadget.com/computing/laptops/best-chromebooks-160054646.html?src=rss
Facebook adds an AI assistant to its dating app
Facebook Dating has added two new AI tools, because clearly a large language model is what the search for love and companionship has been missing all this time. The social media platform introduced a chatbot called dating assistant that can help find prospective dates based on a user's interests. In the blog post announcing the features, the example Meta provided was "Find me a Brooklyn girl in tech." The chatbot can also "provide dating ideas or help you level up your profile." Dating assistant will start a gradual rollout to the Matches tab for users in the US and Canada. And surely everyone will use it in a mature, responsible, not-at-all-creepy fashion.
The other AI addition is Meet Cute, which uses a "personalized matching algorithm" to deliver a surprise candidate that it determines you might like. There's no explanation in the blog post about how Meta's algorithm will be assessing potential dates. If you don't want to see who Meta's AI thinks would be a compatible match each week, you can opt out of Meet Cute at any time. Both these features are aimed at combatting "swipe fatigue," so if you're 1) using Facebook, 2) using Facebook Dating, and 3) are really that tired of swiping, maybe this is the solution you need.
This article originally appeared on Engadget at https://www.engadget.com/social-media/facebook-adds-an-ai-assistant-to-its-dating-app-225754544.html?src=rss
The LCD Steam Deck is 20 percent off right now
Steam's seasonal sales are usually the peak moments to add new software to your library, but right now, Valve is offering a notable hardware discount. The Steam Deck starter model is currently on sale for 20 percent off its usual $399 price tag. That means you can snag yourself the gaming handheld with an LCD screen and 256GB of storage for $319. Steam hasn't set an end date for this offer, so it might be worth acting quickly if you want to get in on this particular sale.
The Steam Deck is still the go-to for most PC gamers who want a handheld. Its balance of power, portability and price have kept it one of our top recommendations, even three years after the product's debut. But keep in mind before you add this to your cart that this iteration does have a few limitations compared to the higher end Steam Decks. The LCD screen doesn't have the true blacks of the OLED option, and serious players may run up against the storage limits of this model pretty quickly. But if you've been curious about a Steam Deck and aren't looking to have a full library of big AAA downloads available all at once, this is a good time to pick up one of your own. Besides, with the $80 you'll save, you can also grab a copy of current indie darlings Hollow Knight: Silksong and Hades II and still have money leftover.
Follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/the-lcd-steam-deck-is-20-percent-off-right-now-215238765.html?src=rss
Here's how EventVPN is different from other free VPNs
EventVPN, a new freemium VPN built by the same team and on the same infrastructure as ExpressVPN, launched on September 18 for iOS and macOS. It comes with unlimited free bandwidth, a relative rarity among free VPNs, and carries over ExpressVPN's kill switch and post-quantum WireGuard protocol. Free users get 35 server locations and one device connection, while paid users get 125 locations and eight simultaneous connections.
EventVPN isn't the first free VPN that actually aims to ensure user privacy — the free version of Proton VPN is also safe, as are a few others on our best VPN list, like hide.me and Windscribe. However, ExpressVPN isn't wrong that free VPNs often don't have their users' interests at heart. The EventVPN announcement left me with one big question: what's it doing to be safer, more private and/or better than other free options?
The most interesting feature of EventVPN — and one I can't currently find duplicated on any other free VPN — is that it has no user data backend whatsoever. It uses Apple ID validation to manage accounts and connection tokens without storing any information itself. This doesn't move the security needle much (Apple isn't immune to data leaks either), but it does make it theoretically impossible for EventVPN to sell user information.
Of course, a clear privacy policy that EventVPN sticks to would accomplish the same thing. But just like with RAM-only servers automatically deleting user activity logs, it's always nice to have an option other than trusting the VPN provider to keep its word. And to be fair, ExpressVPN has a clear privacy policy that it sticks to, so there's good reason to believe EventVPN will do the same for its own policy.
There is one unfortunate cost to that relative privacy, though: EventVPN's free plan requires you to watch ads. When I briefly tested it, I was shown one 30-second ad whenever I connected and another when I disconnected. It's galling to be asked to watch ads for a service that also has a paid tier ($9.99 per month, or $69.99 for a year), since I've already named three other equally good freemium VPNs that don't show ads at all. At least EventVPN anonymizes the ads, showing advertisers a masked identifier instead of any real info on you.
To sum up, EventVPN is a lot better than free VPNs that turn you into the product, but its ads put it a step behind ProtonVPN, hide.me, Windscribe and even TunnelBear. If ExpressVPN has always worked far better for you than any other provider, it might be worth using EventVPN as a backup free service. Otherwise, there are better options.
This article originally appeared on Engadget at https://www.engadget.com/cybersecurity/vpn/heres-how-eventvpn-is-different-from-other-free-vpns-213014671.html?src=rss
The Supreme Court will hear former FTC commissioner Rebecca Slaughter's case
The Supreme Court has voted 6-3 in favor of hearing a lawsuit brought by a former member of the US Federal Trade Commission, CNBC reports. Democrats Rebecca Kelly Slaughter and Alvaro Bedoya were fired from their posts as commissioners in the FTC by President Donald Trump in March. As has been the case with several of the Trump administration's actions to remove possible critics from their roles in civil service, the pair said their dismissal was illegal.
Commissioners’ terms may only be ended early for good cause under a law designed to protect the FTC as an independent agency. The FTC is also not allowed to have more than three commissioners from a single political party, meaning Slaughter and Bedoya could not both be replaced by additional Republican members.
In July, US District Judge Loren AliKhan ruled in favor of Slaughter, who has moved ahead with a suit to contest her dismissal, and a federal appeals court reinstated her to the FTC in September. Today, however, the Supreme Court ruled that her firing may stand while it considers her case.
This article originally appeared on Engadget at https://www.engadget.com/the-supreme-court-will-hear-former-ftc-commissioner-rebecca-slaughters-case-203200530.html?src=rss
Perplexity launches an AI email assistant for Max subscribers
Perplexity has introduced a new feature dubbed Email Assistant. With this resource, users can direct an AI chatbot to execute basic email tasks such as scheduling meetings, organizing and prioritizing emails, and drafting replies. At launch, Gmail and Outlook are the only supported email clients.
Email assistant is only available to members of the company's pricey Max plan, which costs $200 a month. Perplexity added this upscale subscription option in July. Once an Max user has signed up for the feature, they can write to Perplexity's assistant email address to access its capabilities. Although the company emphasized that the AI assistant does not train on a user's emails, it does adopt their writing style when drafting replies. The feature is available starting today.
This article originally appeared on Engadget at https://www.engadget.com/perplexity-launches-an-ai-email-assistant-for-max-subscribers-195212382.html?src=rss
Stellantis confirms data breach involving customers' contact information
Stellantis — the parent of several auto brands including Dodge, Ram and Chrysler — said customers' personal information was included in a data breach. The automaker said in a statement that "contact information" was procured, but not "financial or sensitive personal" data, as that is not stored on the third-party platform that was breached.
"We recently detected unauthorized access to a third-party service provider’s platform that supports our North American customer service operations," Stellantis said. "Upon discovery, we immediately activated our incident response protocols, initiated a comprehensive investigation and took prompt action to contain and mitigate the situation. We are also notifying the appropriate authorities and directly informing affected customers." The company encouraged customers to be on guard against phishing and social engineering attacks, and to be careful about sharing personal information with anyone who contacts them unexpectedly.
Stellantis has not disclosed what types of contact information were involved in the breach, how many customers were affected or whether it's offering them privacy or credit protection services. A spokesperson told Engadget the automaker is "not providing any additional information beyond our statement."
Bleeping Computer says a group called ShinyHunters claimed credit for the breach. The group told the publication it obtained more than 18 million records, containing contact details and names, from Stellantis' Salesforce instance. ShinyHunters has reportedly stolen data from other Salesforce clients over the last several months, including Google, Qantas, Adidas and LVMH.
This article originally appeared on Engadget at https://www.engadget.com/big-tech/stellantis-confirms-data-breach-involving-customers-contact-information-194136744.html?src=rss
The best iPhones for 2025: Which model should you buy?
“Which iPhone should I buy?” It’s a question you may have heard many times over the years. Much of the time, the answer is simple: Get the best one you can afford. And if you’re happy with your current iPhone, there’s no need to make a change at all. But if you’re ready to upgrade, allow us to help. We’ve reviewed just about every iPhone ever made, including all five models Apple has released in 2025. Below, we’ve broken down which ones may best suit your needs.
Before we dig in, just note that we’ve based our guide on the list prices of new, unlocked iPhones on Apple.com. If you can find a steep discount from another trusted retailer or a good deal on a refurbished model, that could change the value equation.
Apple iPhone 16 and iPhone 16 Plus
Apple is still selling the last-gen iPhone 16 and iPhone 16 Plus for $699 and $799, respectively, but the improvements made with the iPhone 17 have forced both devices into something of a no man’s land. The 16 Plus and its 6.7-inch display might be worth it if you want a large-screen iPhone for a much lower price than the iPhone 17 Pro Max, but you’ll miss out on the base model’s 120Hz always-on display and upgraded dual-camera setup. If you just want a usable iPhone for as little as possible, meanwhile, the iPhone 16e is acceptable for $100 less. In general, we think the iPhone 17 is worth the extra $100; its 6.3-inch display helps it split the difference between the 16 and 16 Plus anyway.
When is the best time of year to buy an iPhone?
The best time to buy an iPhone, or really any product, is whenever you need one. But if you want to maximize how long your iPhone is considered “current,” plan to upgrade in late September. Apple almost always introduces its new core models around then. SE and “e” iPhones, meanwhile, have arrived between February and April, but those aren’t guaranteed annual releases.
Cash discounts on new unlocked iPhones are rare, so there usually isn’t much reason to wait for a deal before buying (as is often the case with Samsung or Google phones). Carriers will run their own sales, but those typically involve locking you into years-long service plans. The exception would be if you specifically want an older iPhone, since Apple typically cuts the price of its last-gen devices by $100 or more when it introduces a new model. So, for instance, if you know you won’t care about the inevitable iPhone 17’s upgrades, you could wait until that device is announced and get the iPhone 16 for a little cheaper.
How long does an iPhone last?
This depends on the person and how they define “last.” If we had to give a broad estimate, we’d say most iPhone users keep their device between two and four years. If you’re particularly sensitive to performance and camera improvements, you might want to upgrade on the earlier side of that timeline. If you’re not as picky, you could hold out for even longer — though you’ll likely want to get a battery replacement sometime around the three- or four-year mark (or whenever you notice your battery life has severely degraded).
Software support shouldn’t be a problem regardless: Apple is renowned for keeping its devices up-to-date long-term, and the current iOS 26 update is available on iPhones dating back to 2019. Most of those older phones don’t support Apple Intelligence, so there isn’t total parity, but that’s not a big loss in the grand scheme of things.
How do I know how old my iPhone is?
Go to your iPhone’s Settings, then tap General > About. You should see the Model Name right near the top. You can also tap the Model Number below that, then verify the resulting four-digit code on Apple’s identification page to further confirm.
If you don’t want to use software, for whatever reason, you can also find your iPhone’s model number printed within its USB-C or Lightning port, if the device lacks a SIM tray. For older devices, you can alternatively find that number within the SIM slot or — if you’re still hanging onto an iPhone 7 or older — right on the back of the handset.
September 2025: We’ve overhauled this guide to reflect the release of the new iPhone Air and iPhone 17 series. The base iPhone 17 is our new top pick for most people, while the iPhone 17 Pro and Pro Max represent the best iPhones you can buy if money is no object. The iPhone Air is worth considering if you care about style above all else, while the iPhone 16e remains acceptable if you want the most affordable new iPhone possible.
August 2025: We’ve taken another pass to ensure our advice is still up-to-date and noted that we expect to Apple to launch new phones soon in September.
June 2025: We’ve lightly edited this guide for clarity and added a few common FAQs. Our picks remain unchanged.
February 2025: The new iPhone 16e replaces the iPhone 15 and iPhone 15 Plus as our “budget” pick. We’ve also removed our notes on the iPhone 14, iPhone 14 Plus, and iPhone SE (3rd generation), as each has been formally discontinued.
January 2025: We've made a few minor edits for clarity and ensured our recommendations are still up to date.
December 2024: We’ve made a few edits to reflect the release of Apple Intelligence, though our picks remain the same.
This article originally appeared on Engadget at https://www.engadget.com/mobile/smartphones/best-iphone-160012979.html?src=rss
TikTok is tagging videos from Gaza with product recommendations
TikTok has been tagging videos from war-ravaged Gaza with product recommendations, as reported by The Verge. The publication detailed a scenario in which footage of a Palestinian woman walking amidst rubble presented TikTok shop recommendations that matched what she wore in the video.
The algorithm suggested products with names like "Dubai Middle East Turkish Elegant Lace-Up Dress" and "Women’s Solid Color Knot Front Long Sleeve Dress." The original footage showed the woman searching for lost family members.
This is thanks to a new addition to the TikTok app that uses AI to identify objects in posts. When a user pauses a video, the shop will automatically recommend products that resemble those objects. Today's reporting indicates that the company didn't give much forethought as to which types of videos this technology should be applied to.
The new tool isn't available to everyone just yet, as it's rolling out on a limited basis. To check if your app has been updated, simply pause a video and look for the "Find Similar" pop-up. We reached out to TikTok to ask about how this technology is being used and a spokesperson said it is "conducting a limited test of a visual search feature" and that it "should not have appeared on these videos." The company also says it's working to correct the issue.
This article originally appeared on Engadget at https://www.engadget.com/big-tech/tiktok-is-tagging-videos-from-gaza-with-product-recommendations-184206127.html?src=rss
SpaceX's lunar lander could be 'years late' for a planned 2027 mission to the moon
SpaceX's lunar lander has run into a snag and may not be ready for a mission to the moon that was scheduled for 2027, according to a report by Space News. The company's Starship Human Landing System (HLS) is a variant of the typical Starship spacecraft that has been designed to transport astronauts between lunar orbit and the surface of the moon.
“The HLS schedule is significantly challenged and, in our estimation, could be years late for a 2027 Artemis 3 moon landing,” said NASA safety analyst Paul Hill following a visit to SpaceX's Starbase facility.
The underlying issue seems to be regarding cryogenic propellant transfer, as the SpaceX team has yet to figure out a way to refuel Starship in low Earth orbit before it heads to the moon. This will be the first version of the vehicle capable of such transfers and the work has been slowed down by ongoing engine redesigns.
There's no timetable as to when the team will get this sorted. SpaceX president Gwynne Shotwell recently expressed hope that the project won't be "as hard as some of my engineers think it could be."
This delay has caused some to speculate that it could give China the upper-hand when it comes to manned lunar missions. The country has developed its own lunar vehicle called Lanyue that could land on the surface by 2030.
Also, this isn't the first time the Elon Musk-owned SpaceX has missed deadlines regarding a return to the moon. The company said in 2023 that it would attempt in-orbit refueling by early 2025. That didn't happen. Musk said earlier this month that SpaceX will "demonstrate fuel reusability next year" which also isn't happening.
The Artemis 2 launch, however, is still on track for early 2026. This mission will send four astronauts around the moon, but not onto the surface. It has been over 50 years since the US put boots on the lunar surface. The last manned mission to the moon was in 1972.
This article originally appeared on Engadget at https://www.engadget.com/science/space/spacexs-lunar-lander-could-be-years-late-for-a-planned-2027-mission-to-the-moon-180001024.html?src=rss
NVIDIA is investing up to $100 billion in OpenAI to build 10 gigawatts of AI data centers
NVIDIA will invest up to $100 billion in OpenAI as the ChatGPT maker sets out to build at least 10 gigawatts of AI data centers using NVIDIA chips and systems. The strategic partnership announced today is gargantuan in scale. The 10-gigawatt buildout will require millions of NVIDIA GPUs to run OpenAI's next-generation models. NVIDIA's investment will be doled out progressively as each gigawatt comes online.
The first phase of this plan is expected to come online in the second half of 2026, and will be built on NVIDIA's Vera Rubin platform, which NVIDIA CEO Jensen Huang promised will be a "big, big, huge step up," over the current-gen Blackwell chips.
“NVIDIA and OpenAI have pushed each other for a decade, from the first DGX supercomputer to the breakthrough of ChatGPT,” said Jensen Huang in a press release announcing the letter of the intent for the partnership. “Compute infrastructure will be the basis for the economy of the future, and we will utilize what we’re building with NVIDIA to both create new AI breakthroughs and empower people and businesses with them at scale," said Sam Altman, CEO of OpenAI.
NVIDIA has made a number of strategic investments lately, including making a $5 billion investment in Intel, shortly after the United States government took a 10 percent stake in the American chipmaker. The company also recently spent more than $900 million to license AI technology from startup Enfabrica and hire its CEO and other key employees.
OpenAI has also formed other strategic partnerships over the last few years, including a somewhat complicated arrangement with Microsoft. This summer it struck a deal with Oracle to build out 4.5 gigawatts of data center capacity using more than 2 million Oracle chips. That deal was part of The Stargate Project, the strategic partnership between SoftBank, OpenAI, NVIDIA, Oracle, Arm and Microsoft with a promise to spend $500 billion in the US on AI infrastructure.
This article originally appeared on Engadget at https://www.engadget.com/ai/nvidia-is-investing-up-to-100-billion-in-openai-to-build-10-gigawatts-of-ai-data-centers-175159134.html?src=rss
Gemini arrives on Google TV
Gemini is officially available on Google TVs, now that the TCL QM9K series TVs are out in stores. At the moment, they're the only television models that feature Google's AI assistant, but Gemini will be available on more devices later this year. Google says it will make its way to the Google TV Streamer, Walmart's onn 4K Pro streaming device, certain Hisense TV models and more TCL TVs. The company also intends to add more Gemini capabilities for televisions in the future.
Google introduced Gemini integration for TVs when it presented an early look at new software and hardware upgrades coming to the product category at CES in January. If you've ever used a Google-powered streaming device or television, you'd know that they already have Google Assistant that you can use for search. But Gemini on TV, like its counterpart everywhere else, enables free-flowing conversations using natural language. You can activate it with a "Hey, Google" or by pressing the mic button on the remote.
The company says you can ask Gemini to find you something to watch based on your preferences. For example, you can say: "Find me something to watch with my wife. I like dramas, but she likes lighthearted comedies." You can also ask it to summarize the events in the previous season of a show you're watching if you need a refresher before you start the next one. You can also ask Gemini to show you reviews for a particular show, or even ask it vague questions, such as "What's the new hospital drama everyone's talking about?"
You're not just limited to asking questions about TV shows and movies, either. When Google demonstrated the AI assistant at CES, a company rep asked Gemini on TV to "explain the solar system to a third grader." The AI assistant did, and it also suggested relevant YouTube videos. You can ask it questions if you're learning a new skill, as well as recipes, to get answers with video suggestions you can follow. And after it's done answering your first query, you can make follow-up questions for clarity and more information.
This article originally appeared on Engadget at https://www.engadget.com/ai/gemini-arrives-on-google-tv-160003839.html?src=rss
Disney's Mandalorian and Grogu trailer shows the fall of a lumbering giant
Disney, a company that definitely isn’t dealing with a major crisis right now, has released a trailer for The Mandalorian and Grogu. The movie follows on from the events of Disney+ series The Mandalorian — a show that director Jon Favreau created — and the fall of the Empire in Return of the Jedi. It's set to hit theaters on May 22, 2026.
The 94-second clip doesn’t offer much in the way of plot details, though it does show Sigourney Weaver as a fighter pilot and Jabba the Hutt’s son Rotta (Jeremy Allen White). Mando (Pedro Pascal) and Grogu battle against bots and beasts, and the pair blows up an AT-AT. I'm sure there's nothing to be read into seeing a lumbering giant attempting to traverse a precarious path only to fail spectacularly at this specific moment in Disney's history.
The trailer does make it seem like the movie will retain the adventurous spirit and humor of The Mandalorian, with Grogu getting to be as cute as ever. In a fun beat, the diminutive creature uses the Force to try to steal a snack from Weaver's character, only to be denied.
The Mandalorian and Grogu will be the first Star Wars movie to hit theaters in over six years. Star Wars: Starfighter is slated to arrive a year later.
This article originally appeared on Engadget at https://www.engadget.com/entertainment/tv-movies/disneys-mandalorian-and-grogu-trailer-shows-the-fall-of-a-lumbering-giant-141515618.html?src=rss
The Roku Streaming Stick Plus drops to only $29
The Roku Streaming Stick Plus is on sale for just $29. That's a discount of 27 percent and the lowest we've ever seen it.
Roku has held the top spot in the TV OS market for years thanks to its user-friendly interface, an affordable range of streaming devices and its own lineup of TVs. We picked the Streaming Stick Plus as the best streaming device for free and live content, thanks in large part to The Roku Channel app that accompanies it. The Roku Channel features over 500 free TV channels with live news, sports coverage and a rotating lineup of TV shows and movies.
In our hands-on review of the Roku Streaming Stick Plus, we thought it was perfect for travel thanks to its small size and the fact that it can be powered by your TV's USB port, nixing the need for a wall adapter. Menu navigation and opening or closing apps won't happen at quite the same speeds as more expensive streamers, but it's quick enough for what is ultimately a pretty low-cost option. The Wi-Fi range on this one is also weaker than Roku's pricier devices, but unless you are placing it exceedingly far from your router, it shouldn't be an issue.
The Roku Streaming Stick Plus supports both HD and 4K TVs, as well as HDR10+ content. It doesn't support Dolby Vision, however; for that you'll need to upgrade to Roku's Streaming Stick 4K or Roku Ultra. It comes with Roku's rechargeable voice remote with push-to-talk voice controls. Roku's remote can also turn on your TV and adjust the volume while you're watching.
If you've been thinking about getting a Roku device, or you already love the platform and want a compact and convenient way to take it with you when you travel, then this sale provides a great opportunity.
Follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/the-roku-streaming-stick-plus-drops-to-only-29-134656660.html?src=rss
Apple's 25W MagSafe charger is cheaper than ever right now
On the heels of the iPhone 17 lineup being released last week, you can pick up Apple's 25W MagSafe charger for a song. The two-meter version of the more powerful charging cable has dropped by 30 percent from $49 to $35. That's a record-low price.
As it happens, that actually makes the two-meter version of the cable less expensive than the one-meter variant. The shorter cable will run you $39 as things stand.
If you have an iPhone 16, iPhone 17 or iPhone Air, this cable can charge your device at 25W as long as it's connected to a 30W power adapter on the other end. While you'll need a more recent iPhone to get the fastest MagSafe charging speeds, the charger can wirelessly top up the battery of any iPhone from the last eight years (iPhone 8 and later). With older iPhones, the charging speed tops out at 15W. The cable works with AirPods wireless charging cases too — it's certified for Qi2.2 and Qi charging.
The MagSafe charger is one of our favorite iPhone accessories, and would pair quite nicely with your new iPhone if you're picking up one of the latest models. If you're on the fence about that, be sure to check out our reviews of the iPhone 17, iPhone Pro/Pro Max and iPhone Air.
Check out our coverage of the best Apple deals for more discounts, and follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/apples-25w-magsafe-charger-is-cheaper-than-ever-right-now-143415557.html?src=rss
Amazon has the Nintendo Switch 2 available for purchase, no invite required
While it was difficult to get your hands on a Nintendo Switch 2 back in June when it first became available, that's no longer the case. It just got even easier now that Amazon has the console listed for sale, with no invitation required. The handhelds have been selling at a blistering pace, with just under 6 million units sold in the first four weeks.
Online inventories in those initial weeks sold out in a flash, and sparse restocks were gone just as quickly. Amazon was left out of the initial pre-order process and didn't list the console at all until over a month after its release. This conspicuous absence may have been due to Nintendo's frustration with third-party sellers undercutting the company's own pricing for games on the site.
We really loved the Nintendo Switch 2 in our hands-on review, and thought it was a great follow-up to the 2017 console that launched a handheld renaissance. We gave the Switch 2 a score of 93 out of 100, and were particularly impressed with its larger 7-9-inch LCD screen, the magnetic Joy-Cons, better base storage and, of course, significantly improved performance over the original. The pricing is a bit steep, the battery life could be better and the dock could more USB-C ports, but aside from those details the Switch 2 is almost perfect.
If you've been waiting to pick up a Nintendo Switch 2 without having to go on a scavenger hunt, then the Amazon listing should be a welcome option. The months since release have also seen a great selection of Switch 2 ports and exclusive games hit the market. Amazon's listing offers the standalone console for $449 or the Mario Kart World bundle for $499. Sales are limited to one unit per customer.
Follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/gaming/nintendo/amazon-has-the-nintendo-switch-2-available-for-purchase-no-invite-required-132503036.html?src=rss
Apple’s new AirPods Pro 3 get their first discount
Editor's note (on September 22, 8:30PM ET): The $10 Amazon discount we highlighted earlier is no longer in effect. If you're looking for deals in the meantime, check out our ongoing lists of best early October Prime Day deals and best Apple deals.
It's barely been two weeks since Apple announced the AirPods Pro 3, but you can already find them at a slight discount. The new earbuds are currently listed as $239 on Amazon, which is $10 cheaper than their normal price. The AirPods Pro 3 were introduced at Apple's "Awe Dropping" iPhone event, boasting Live Translation, heart-rate tracking and significant improvements to sound quality and active noise cancellation (ANC). But, if you're not looking to shell out that much, the AirPods Pro 2 are on sale right now too for $199.
The AirPods Pro 3 are no small upgrade from the previous generation. ANC is twice as effective as that of the AirPods Pro 2, thanks to a combination of ultra-low noise microphones, computational audio and new foam-infused ear tips, which make for both a better fit and improved noise isolation, according to Engadget's Billy Steele, who spent some hands-on time with the earbuds. The Live Translation feature fared well when tested on Spanish-to-English and French-to-English translations, making the earbuds a potentially handy tool to have for travel. (You'll need an iPhone with Apple Intelligence in order to use Live Translation, though).
The earbuds earned a score of 90 in Engadget's review, which notes noticeable improvements in sound quality and battery life. Apple says you'll get up to eight hours on a charge with ANC enabled. With the addition of heart-rate monitoring and support for 50 workouts using Apple's Fitness app, the AirPods Pro 3 allow you to get heart rate metrics during exercise without wearing an Apple Watch.
There's a lot to like about the latest version of the AirPods Pro, so discount or not, you can't go wrong if you've been holding out for a meaningful upgrade. Per our review, "The AirPods Pro 3 is the biggest update to Apple’s earbuds lineup in years."
Check out our coverage of the best Apple deals for more discounts, and follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/apples-new-airpods-pro-3-get-their-first-discount-220017779.html?src=rss
New subscribers can get three months of the Apple Music Family Plan for free
Apple Music is running a promo in which new subscribers can get three free months of the Family Plan tier. That's a savings of $51, which is nothing to sneeze at. After this lengthy free trial is up, it costs $17 per month. Just note that you only have until September 24 to get this deal.
The Family Plan allows six different users to access the platform. It offers cross-device support and each user is tied to an Apple ID, so their favorite music won't mess with anyone else's algorithm.
Apple Music actually topped our list of the best music streaming platforms, and for good reason. It sounds great and it's easy to use. What else is there? All music is available in CD quality or higher and there are plenty of personalized playlists and the like. The platform also operates a number of live radio stations, which is fun.
The service is available for Android devices, but it really shines on Apple products. To that end, the web and Windows PC apps aren’t as polished as the iOS version. It doesn't pay artists properly, but that's true of every music streaming platform. Apple Music does pay out more than Spotify, but that's an incredibly low bar.
Offer for new subscribers redeeming on eligible devices. Auto-renews at $16.99/mo until cancelled. Requires Family Sharing. Terms apply.
Check out our coverage of the best Apple deals for more discounts, and follow @EngadgetDeals on X for the latest tech deals and buying advice.
This article originally appeared on Engadget at https://www.engadget.com/deals/new-subscribers-can-get-three-months-of-the-apple-music-family-plan-for-free-151240364.html?src=rss
The best iPhone accessories for 2025
The right add-on can make a good iPhone experience even better. Whether you're looking to boost your battery life, level up your mobile photography or just keep your device safe from daily wear and tear, the best iPhone accessories are the ones that add real value without getting in your way. From MagSafe chargers and wireless earbuds to stands, mounts and portable power banks, there’s no shortage of ways to customize how you use your phone.
We've tested a wide range of products to help you narrow it down. Whether you're using the latest iPhone or holding onto an older model, the best iPhone accessories can enhance your day-to-day in meaningful ways — whether that’s making your morning commute smoother, improving your FaceTime setup or just keeping your screen crack-free.
This article originally appeared on Engadget at https://www.engadget.com/computing/accessories/best-iphone-accessories-140022449.html?src=rss
The best multi-device wireless charging pads for 2025
We all have so many gadgets now that we use and take with us regularly, and there's a good chance that at least a few of yours support wireless charging. Whether its your phone, wireless earbuds, smartwatch or all three of those things, you can power them up cord-free using a good wireless charger. And if you do plan to rely on wireless power-ups for your most-used devices, a multi-device wireless charger is a good investment. These accessories neatly charge up more than one device simultaneously, without using a bunch of cables that can mess up your space. We've tested a bunch of the latest multi-device wireless chargers; you’ll find out top picks below for the best wireless charging pads, plus some advice on how to choose the right one for your needs.
The short answer is no, but the long and more detailed answer starts with it depends. Regular old wireless charging pucks should work with any device that’s compatible with the same wireless charging standard that the charger supports. Smartphones and other mobile devices that support wireless charging nowadays are likely to support the Qi standard, so double check that your phone or gadget fits that bill and it should work with any Qi wireless charging pad (all of our top picks fall into this category).
When it comes to multi-device chargers, things can get a little tricky. Rather than starting your search looking for the most universally adaptable accessory, consider the devices you have and aspire to own in the future. If you’re an iPhone user with an Apple Watch, you may want to look for a wireless charger that has a Watch pad built in. Ditto if you’re a Samsung phone owner and use a Galaxy Watch. Some earbuds support wireless charging, but you’ll only need an open pad or space on your multi-device charger where you can sit the earbuds in their case down for a power-up.
Those with iPhone 12s and newer Apple smartphones can take advantage of MagSafe chargers, which magnetically attach to their handsets. Android devices don’t support Apple’s proprietary MagSafe technology, but you can buy a magnetic adapter for pretty cheap that will allow your Samsung or Pixel phone to work with MagSafe multi-device chargers. You’ll also need that to get full Qi2 goodness with newer Android phones like the Galaxy S25 series, which are “Qi2 ready,” but since they do not have magnets built in, aren’t precisely Qi2 compliant.
Even without a charging cable to worry about, you’re probably buying a multi-device wireless charger with one location in mind. It might sit on your nightstand or on your desk. Not everyone buys a charger just for themselves, though; you might want to use one as a shared station for you and a partner.
If the charger will sit on your nightstand, you’ll likely want a compact, stable unit that won’t swallow all your free space or tumble to the floor (and if it does fall, one with enough durability to survive). Some may prefer a lay-flat design if your phone screen has a tendency to keep you awake at night. Others might use their phone as their alarm clock, in which case you may want a stand that keeps the screen within reach and eyeshot. This is also the preferred design if you use Standby Mode on iPhones.
A vertical orientation may be best for a charger that lives on your desk so you can more easily check notifications throughout the day. Will the charger sit on a low table? Horizontal charger pads may make it easier to grab your devices in a hurry. Travel chargers should fold up or otherwise protect the pads while they’re in your bag. And, yes, aesthetics count. You may want something pretty if it’s likely to sit in a posh room where guests will see it.
For vehicles, consider a wireless car charger if you frequently need to top off your device on the go. These chargers combine convenience with functionality, ensuring your phone stays powered while you’re navigating and taking calls at the same time. We also heavily recommend a magnetic charger so there’s less of a chance your phone will go flying into the passenger’s seat the next time you hit a pothole.
It’s no secret that wireless charging is slower than wired, and powering multiple devices adds a new wrinkle. As these chargers often have to support a wide range of hardware, you’ll have to forget about the fastest, device-specific options from brands like Google, OnePlus and Samsung.
Today, most wireless chargers come in at 15W for phones. The latest Qi2 standard can get you up to 25W of power with a compatible smartphone. These speeds are improving bit by bit, but they're still not quite as fast as wired charging. It’s rare that you’ll find a truly slow-as-molasses example, mind you. Even some of the most affordable options we’ve seen will recharge your phone at a reasonable 7.5W or 10W, and the 5W for other devices like wireless earbuds is more than enough.
If you’re only docking overnight or while you work, speed won’t make a huge difference. Just be sure that whatever you buy is powerful enough for a phone in a case. Some chargers may also include an AC adapter in the box. If not, make sure you’re using one with the right power level to get the fastest charge.
This article originally appeared on Engadget at https://www.engadget.com/computing/accessories/best-multi-device-wireless-charging-pads-120557582.html?src=rss
The search for anti-gravity propulsion
 Exploring the strange intersection of science, conspiracy, and military secrecy in the decades-long quest for anti-gravity propulsion.
Exploring the strange intersection of science, conspiracy, and military secrecy in the decades-long quest for anti-gravity propulsion.
Your Top Questions On Generative AI, AI Agents, And Agentic Systems For Security Tools Answered
Many security professionals are still confused about which AI capabilities are real now and what will come down the road. Read this blog to get answers to some common questions about use of generative AI, agentic AI, and AI agents in security tools.
Marketers Are In Their AI Era (And It’s Not Ending Anytime Soon)
Through all the uncertainty this year, one constant persists: AI adoption and its potential to reshape B2C marketing as we know it. Find out how in this preview of a new survey and report.
Microsoft confirms DRM playback issues in Windows
Microsoft revealed a remake of the classic video wallpaper feature DreamScene for Windows just yesterday. Today, Microsoft is confirming that recent versions of its Windows 11 operating system are plagued by a […]
Thank you for being a Ghacks reader. The post Microsoft confirms DRM playback issues in Windows appeared first on gHacks Technology News.
Microsoft silently introduces Windows AI Lab to let users test experimental features
Microsoft has quietly introduced a way to allow users to test experimental features. You can opt in to the Windows AI Lab. Last week, Windows Latest reported that Microsoft was testing Windows […]
Thank you for being a Ghacks reader. The post Microsoft silently introduces Windows AI Lab to let users test experimental features appeared first on gHacks Technology News.
Google announces Gemini for Google TV
Google has announced Gemini for Google TV. You can interact with the AI to find what to watch. Google isn't the first to bring its AI to TVs, Microsoft Copilot for Samsung […]
Thank you for being a Ghacks reader. The post Google announces Gemini for Google TV appeared first on gHacks Technology News.
Windows 11 is getting a video wallpaper feature
Microsoft is testing a feature that will allow you to use a video as a wallpaper. Welcome to 2007! When iOS 26, iPadOS 26, and macOS Tahoe 26 were announced, everyone said […]
Thank you for being a Ghacks reader. The post Windows 11 is getting a video wallpaper feature appeared first on gHacks Technology News.
Chrome for Android can now read web pages aloud like a podcast
Last week, Martin wrote about Chrome gaining AI features powered by Gemini. There's a new AI feature rolling out to Chrome on Android, a read aloud option that narrates webpages like a […]
Thank you for being a Ghacks reader. The post Chrome for Android can now read web pages aloud like a podcast appeared first on gHacks Technology News.
Microsoft increases Xbox prices in the U.S. again: Two price hikes in 5 months
Microsoft has increased the prices of the Xbox consoles in the U.S. Wait a minute, didn't this happen a few months ago? Well, that's exactly what I thought when I was scrolling […]
Thank you for being a Ghacks reader. The post Microsoft increases Xbox prices in the U.S. again: Two price hikes in 5 months appeared first on gHacks Technology News.
The First Teaser for ‘The Bride!’ Is Monstrously Intriguing

Jessie Buckley and Christian Bale play creatures on a crime spree in Maggie Gyllenhaal's upcoming horror movie.
One of These New NASA Astronauts Could Be the First Person to Step on Mars

Hopefully astronaut training teaches patience.
GoPro Is Fighting Insta360’s X5 With Its Own ‘True 8K’ Max2 360-Degree Camera

GoPro is also announcing an affordable Lit Hero (yes, it's really called that) action camera and a mobile gimbal.
5 Awesome New Genre Movies to Put on Your Radar

Here are our favorite films we saw at Fantastic Fest 2025 in Austin, Texas.
‘Workslop’: AI-Generated Work Content Is Slowing Everything Down

AI slop has infiltrated the workplace, costing companies time and money.
Cool Chemistry Trick Could Transform Vinegar Into a Powerful Weapon Against Superbugs

Adding tiny, complex nanoparticles to common vinegar significantly boosted its ability to destroy harmful bacteria, according to a new study.
Scientists Predict Extreme Global Water Shortages by 2100

Climate change could leave 74% of the world’s drought-prone regions at high risk of severe and prolonged droughts by the end of the century, new research suggests.
Marine Biologists Just Filmed a Shark Threesome, and It’s a Win for Science

Little is known about how leopard sharks mate in the wild. Rare footage shows a female doing the deed back-to-back with two different males.
How a Paramount–Warner Bros. Discovery Merger Could Give Trump Even More Power

While ABC says its bringing Jimmy Kimmel back, there's another looming threat to independent media.
Kirk and Spock’s Original ‘Star Trek’ Uniforms Are Boldly Going Up for Auction

The costumes worn by Leonard Nimoy's Mr. Spock and William Shatner's Captain Kirk are among the vintage TV treasures in the sale.
Chicago’s Once-Disgusting River Just Hosted a Swimming Party

Over two decades after a band bus dumped hundreds of pounds of human waste into the river, the Chicago River Swim raised $150,000 for ALS research and swim education programs.
Is James Gunn Teasing the Big Villain for ‘Man of Tomorrow’?

Plus, Gunn teases the 'Peacemaker' finale's big connections to the next Superman film.
How to Watch ‘Bluey’ Without a Streaming Service

You know, for when you want to either pivot to physical media or participate in public actions against certain companies.
The ‘Silent Night, Deadly Night’ Remake Doesn’t Ring in the Holiday Cheer

'Halloween Ends' star Rohan Campbell leads the latest remake of the 1984 holiday cult classic.
‘Spider-Man: Brand New Day’ Pauses Production After Tom Holland Injury

The week-long production pause will not impact the next 'Spider-Man' movie's release date.
Trump and RFK Jr. Blame Tylenol For Autism in New Report, but Experts Push Back

"They are reviewing existing literature, and they're doing it badly."
AI Experts Urgently Call on Governments to Think About Maybe Doing Something

Let's just agree to something. Anything.
The ‘Futurama’ Season Finale Was the Perfect Exploration of Futility and Chaos

Season 13 of the long-running sci-fi series is now streaming on Hulu.
Feds Suspiciously Revive the Name ‘Monkeypox’ After Dropping It in 2022

Years after scientists retired the term “monkeypox” for being inaccurate and stigmatizing, the federal government has started using it again for no clear reason.
Disney Returns Jimmy Kimmel to TV After Public Backlash

'Jimmy Kimmel Live!' will be back on ABC tomorrow, its 'indefinite' suspension coming to an end after boycotts, protests, and concerns over free speech.
Top 10 Open-Source Projects in the Large Model Ecosystem
This leaderboard ranks the ten most influential open-source projects in the AI development ecosystem using OpenRank, a metric that measures community collaboration rather than simple popularity indicators like stars. The list spans the entire technology stack, from foundational infrastructure such as PyTorch for training and Ray for distributed compute, to high-performance inference engines like vLLM,Continue reading "Top 10 Open-Source Projects in the Large Model Ecosystem"
The post Top 10 Open-Source Projects in the Large Model Ecosystem appeared first on Gradient Flow.
Is your LLM overkill?
Subscribe • Previous Issues A Tiered Approach to AI: The New Playbook for Agents and Workflows A Small Language Model (SLM) is a neural model defined by its low parameter count, typically in the single-digit to low-tens of billions. These models trade broad, general-purpose capability for significant gains in efficiency, cost, and privacy, making them ideal forContinue reading "Is your LLM overkill?"
The post Is your LLM overkill? appeared first on Gradient Flow.
Moonbirds and Azuki IP Coming To Verse8 as AI-Native Game Platform Integrates With Story
Story, a blockchain platform for intellectual property, and Verse8, an AI-powered game creation tool, today announced a collaboration. Story will serve as the licensing infrastructure, registering and managing IP usage on its Layer-1 network. Verse8 enables users to generate multiplayer 2D and 3D games through natural language prompts without requiring coding.
My First Python Web App—Built in a Weekend (With a Little AI Assist)
Having an AI explain patterns and answer questions in real-time was like having the best documentation and mentor rolled into one.
Pattern #4: Content Creation to Knowledge
AI is transforming unstructured content—docs, chats, tickets—into real-time knowledge that accelerates learning and improves code.
Docker Taps Google, Microsoft to Bring AI Agents Into the Cloud
Docker brings AI agents to microservices with Compose and MCP Gateway, enabling local-to-cloud agentic app scaling and GPU offloading.
Exploring the Open Source AI Coding Agents Shaping the Future of Development
AI coding agents are evolving into reliable collaborators. Many of the most powerful AI coding Agents are open source. This means you can use, customize, and even contribute to them.
How Moonlander's 1000x Leverage Bet Caught Crypto.com Capital's Attention in the DeFi Race
Moonlander secures strategic funding from Crypto.com Capital for 1000x leverage DEX on Cronos with a social trading approach.
The HackerNoon Newsletter: 10 Influential Women in The AI Space (9/22/2025)
9/22/2025: Top 5 stories on the HackerNoon homepage!
Can ChatGPT Outperform the Market? Week 6
This week, ChatGPT’s portfolio had very little movement, especially compared to prior weeks.
The Low-cost Path to AI Mastery: Building a Wiki Navigator With Pure Similarity Search
Learn AI skills while building production version of Wiki Navigator - a simple AI-powered chatbot. It is essentially a contextual search engine powered by Retrieval Augmented Generation (RAG) and essentials concepts of AI like vector embeddings and cosine similarity search.
Pattern #3: From Delivery to Discovery
AI handles the code—now it's your turn to explore. Discover how devs can shift from delivery to discovery and build what really matters.
Meeting the Demand for Modern Data Centers in Healthcare
As an industry, healthcare collects, creates, exchanges and stores enormous amounts of data. Think of your annual doctor’s visit and the amount of information a single patient can share, from health history to billing options. There are also different subsectors of the industry, including medical research and development, home health services, and post-acute care, that require different strategies. A one-size-fits-all solution is rarely appropriate. As new artificial intelligence (AI) capabilities emerge, healthcare organizations are exploring new approaches for how to use their existing data…
Securing the Connected Ecosystem of Senior Care
A number of cyber incidents that have affected health systems in recent years have also disrupted post-acute and senior care organizations. During the 2025 Healthcare Information and Management Systems Society global conference and expo in Las Vegas, some senior care leaders shared their experiences from last year’s Change Healthcare attack. Riverdale, N.Y.-based RiverSpring Living CIO David Finkelstein said that his organization used an electronic health record system vendor that relied on Change Healthcare for claims submissions. Due to the attack, it had to return…
Smol2Operator: Post-Training GUI Agents for Computer Use
无摘要
Tech Keeps Chatbots From Leaking Your Data

Your chatbot might be leaky. According to recent reports, user conversations with AI chatbots such as OpenAI’s ChatGPT and xAI’s Grok “have been exposed in search engine results.” Similarly, prompts on the Meta AI app may be appearing on a public feed. But what if those queries and chats can be protected, boosting privacy in the process?
That’s what Duality, a company specializing in privacy-enhancing technologies, hopes to accomplish with its private large language model (LLM) inference framework. Behind the framework lies a technology called fully homomorphic encryption, or FHE, a cryptographic technique enabling computing on encrypted data without needing to decrypt it.
Duality’s framework first encrypts a user prompt or query using FHE, then sends the encrypted query to an LLM. The LLM processes the query without decryption, generates an encrypted reply, and transmits it back to the user.
“They can decrypt the results and get the benefit of running the LLM without actually revealing what was asked or what was responded,” says Kurt Rohloff, cofounder and CTO at Duality.
As a prototype, the framework supports only smaller models, particularly Google’s BERT models. The team tweaked the LLMs to ensure compatibility with FHE, such as replacing some complex mathematical functions with their approximations for more efficient computation. Even with these slight alterations, however, the AI models operate just like a normal LLM would.
“Whatever we do on the inference does not require retraining. In our approach, we still want to make sure that training happens the usual way, and it’s the inference that we essentially try to make more efficient,” says Yuriy Polyakov, vice president of cryptography at Duality.
FHE is considered a quantum-computer-proof encryption. Yet despite its high level of security, the cryptographic method can be slow. “Fully homomorphic encryption algorithms are heavily memory-bound,” says Rashmi Agrawal, cofounder and CTO at CipherSonic Labs, a company that spun out of her doctoral research at Boston University on accelerating homomorphic encryption. She explains that FHE relies on lattice-based cryptography, which is built on math problems around vectors in a grid. “Because of that lattice-based encryption scheme, you blow up the data size,” she adds. This results in huge ciphertexts (the encrypted version of your data) and keys requiring lots of memory.
Another computational bottleneck entails an operation called bootstrapping, which is needed to periodically remove noise from ciphertexts, Agrawal says. “This particular operation is really expensive, and that is why FHE has been slow so far.”
To overcome these challenges, the team at Duality is making algorithmic improvements to an FHE scheme known as CKKS (Cheon-Kim-Kim-Song) that’s well-suited for machine learning applications. “This scheme can work with large vectors of real numbers, and it achieves very high throughput,” says Polyakov. Part of those improvements involves integrating a recent advancement dubbed functional bootstrapping. “That allows us to do a very efficient homomorphic comparison operation of large vectors,” Polyakov adds.
All of these implementations are available on OpenFHE, an open-source library that Duality contributes to and helps maintain. “This is a complicated and sophisticated problem that requires community effort. We’re making those tools available so that, together with the community, we can push the state of the art and enable inference for large language models,” says Polyakov.
Hardware acceleration also plays a part in speeding up FHE for LLM inference, especially for bigger AI models. “They can be accelerated by two to three orders of magnitude using specialized hardware acceleration devices,” Polyakov says. Duality is building with this in mind and has added a hardware abstraction layer to OpenFHE for switching from a default CPU backend to swifter ones such as GPUs and application-specific integrated circuits (ASICs).
Agrawal agrees that GPUs, as well as field-programmable gate arrays (FPGAs), are a good fit for FHE-protected LLM inference because they’re fast and connect to high-bandwidth memory. She adds that FPGAs in particular can be tailored for fully homomorphic encryption workloads.
For Duality’s next steps, the team is progressing their private LLM inference framework from prototype to production. The company is also working on safeguarding other AI operations, including fine-tuning pretrained models on specialized data for specific tasks, as well as semantic search to uncover the context and meaning behind a search query rather than just using keywords.
FHE forms part of a broader privacy-preserving toolbox for LLMs, alongside techniques such as differential privacy and confidential computing. Differential privacy introduces controlled noise or randomness to datasets, obscuring individual details while maintaining collective patterns. Meanwhile, confidential computing employs a trusted execution environment—a secure, isolated area within a CPU for processing sensitive data.
Confidential computing has been around longer than the newer FHE technology, and Agrawal considers it as FHE’s “head-to-head competition.” However, she notes that confidential computing can’t support GPUs, making them an ill match for LLMs.
“FHE is strongest when you need noninteractive end-to-end confidentiality because nobody is able to see your data anywhere in the whole process of computing,” Agrawal says.
A fully encrypted LLM using FHE opens up a realm of possibilities. In health care, for instance, clinical results can be analyzed without revealing sensitive patient records. Financial institutions can check for fraud without disclosing bank account information. Enterprises can outsource computing to cloud environments without unveiling proprietary data. User conversations with AI assistants can be protected, too.
“We’re entering into a renaissance of the applicability and usability of privacy technologies to enable secure data collaboration,” says Rohloff. “We all have data. We don’t necessarily have to choose between exposing our sensitive data and getting the best insights possible from that data.”
Will We Know Artificial General Intelligence When We See It?

Buzzwords in the field of artificial intelligence can be technical: perceptron, convolution, transformer. These refer to specific computing approaches. A recent term sounds more mundane but has revolutionary implications: timeline. Ask someone in AI for their timeline, and they’ll tell you when they expect the arrival of AGI—artificial general intelligence—which is sometimes defined as AI technology that can match the abilities of humans at most tasks. As AI’s sophistication has scaled—thanks to faster computers, better algorithms, and more data—timelines have compressed. The leaders of major AI labs, including OpenAI, Anthropic, and Google DeepMind, have recently said they expect AGI within a few years.
A computer system that thinks like us would enable close collaboration. Both the immediate and long-term impacts of AGI, if achieved, are unclear, but expect to see changes in the economy, scientific discovery, and geopolitics. And if AGI leads to superintelligence, it may even affect humanity’s placement in the predatory pecking order. So it’s imperative that we track the technology’s progress in preparation for such disruption. Benchmarking AI’s capabilities allows us to shape legal regulations, engineering goals, social norms, and business models—and to understand intelligence more broadly.
While benchmarking any intellectual ability is tough, doing so for AGI presents special challenges. That’s in part because people strongly disagree on its definition: Some define AGI by its performance on benchmarks, others by its internal workings, its economic impact, or vibes. So the first step toward measuring the intelligence of AI is agreeing on the general concept.
Play a version of the game that researchers are using to track AI’s progress toward artificial general intelligence.
Another issue is that AI systems have different strengths and weaknesses from humans, so even if we define AGI as “AI that can match humans at most tasks,” we can debate which tasks really count, and which humans set the standard. Direct comparisons are difficult. “We’re building alien beings,” says Geoffrey Hinton, a professor emeritus at the University of Toronto who won a Nobel Prize for his work on AI.
Undaunted researchers are busy designing and proposing tests that might lend some insight into our future. But a question remains: Can these tests tell us if we’ve achieved the long-sought goal of AGI?
There are infinite kinds of intelligence, even in humans. IQ tests provide a kind of summary statistic by including a range of semirelated tasks involving memory, logic, spatial processing, mathematics, and vocabulary. Sliced differently, performance on each task relies on a mixture of what’s called fluid intelligence—reasoning on the fly—and crystallized intelligence—applying learned knowledge or skills.
For humans in high-income countries, IQ tests often predict key outcomes, such as academic and career success. But we can’t make the same assumptions about AI, whose abilities aren’t bundled in the same way. An IQ test designed for humans might not say the same thing about a machine as it does about a person.
There are other kinds of intelligence that aren’t usually evaluated by IQ tests—and are even further out of reach for most AI benchmarks. These include types of social intelligence, such as the ability to make psychological inferences, and types of physical intelligence, such as an understanding of causal relations between objects and forces or the ability to coordinate a body in an environment. Both are crucial for humans navigating complex situations.
 Clever Hans, a German horse in the early 1900s, seemed able to do math—but was really responding to his trainer’s subtle cues, a classic case of misinterpreting performance. Alamy
Clever Hans, a German horse in the early 1900s, seemed able to do math—but was really responding to his trainer’s subtle cues, a classic case of misinterpreting performance. Alamy
Intelligence testing is hard—in people, animals, or machines. You must beware of both false positives and false negatives. Maybe the test taker appears smart only by taking shortcuts, like Clever Hans, the famous horse that appeared to be capable of math but actually responded to nonverbal cues. Or maybe test takers appear stupid only because they are unfamiliar with the testing procedure or have perceptual difficulties.
It’s also hard because notions of intelligence vary across place and time. “There is an interesting shift in our society in terms of what we think intelligence is and what aspects of it are valuable,” says Anna Ivanova, an assistant professor of psychology at Georgia Tech. For example, before encyclopedias and the Internet, “having a large access to facts in your head was considered a hallmark of intelligence.” Now we increasingly prize fluid over crystallized intelligence.
Over the years, many people have presented machines with grand challenges that purported to require intelligence on par with our own. In 1958, a trio of prominent AI researchers wrote, “Chess is the intellectual game par excellence.… If one could devise a successful chess machine, one would seem to have penetrated to the core of human intellectual endeavor.” They did acknowledge the theoretical possibility that such a machine “might have discovered something that was as the wheel to the human leg: a device quite different from humans in its methods, but supremely effective in its way, and perhaps very simple.” But they stood their ground: “There appears to be nothing of this sort in sight.” In 1997, something of this sort was very much in sight when IBM’s Deep Blue computer beat Garry Kasparov, the reigning chess champion, while lacking the general intelligence even to play checkers.
 IBM’s Deep Blue defeated world chess champion Garry Kasparov in 1997, butdidn’t have enough general intelligence to play checkers. Adam Nadel/AP
IBM’s Deep Blue defeated world chess champion Garry Kasparov in 1997, butdidn’t have enough general intelligence to play checkers. Adam Nadel/AP
In 1950, Alan Turing proposed the imitation game, a version of which requires a machine to pass as a human in typewritten conversation. “The question and answer method seems to be suitable for introducing almost any one of the fields of human endeavour that we wish to include,” he wrote. For decades, passing what’s now called the Turing test was considered a nearly impossible challenge and a strong indicator of AGI.
But this year, researchers reported that when people conversed with both another person and OpenAI’s GPT-4.5 for 5 minutes and then had to guess which one was human, they picked the AI 73 percent of the time. Meanwhile, top language models frequently make mistakes that few people ever would, like miscounting the number of times the letter r occurs in strawberry. They appear to be more wheel than human leg. So scientists are still searching for measures of humanlike intelligence that can’t be hacked.
There’s one AGI benchmark that, while not perfect, has gained a high profile as a foil for most new frontier models. In 2019, François Chollet, then a software engineer at Google and now a founder of the AI startup Ndea, released a paper titled “On the Measure of Intelligence.” Many people equate intelligence to ability, and general intelligence to a broad set of abilities. Chollet takes a narrower view of intelligence, counting only one specific ability as important—the ability to acquire new abilities easily. Large language models (LLMs) like those powering ChatGPT do well on many benchmarks only after training on trillions of written words. When LLMs encounter a situation very unlike their training data, they frequently flop, unable to adjust. In Chollet’s sense, they lack intelligence.
To go along with the paper, Chollet created a new AGI benchmark, called the Abstraction and Reasoning Corpus (ARC). It features hundreds of visual puzzles, each with several demonstrations and one test. A demonstration has an input grid and an output grid, both filled with colored squares. The test has just an input grid. The challenge is to learn a rule from the demonstrations and apply it in the test, creating a new output grid.
 The Abstraction and Reasoning Corpus challenges AI systems to infer abstract rules from just a few examples. Given examples of input-output grids, the system must apply the hidden pattern to a new test case—something humans find easy but machines still struggle with. ARC Prize
The Abstraction and Reasoning Corpus challenges AI systems to infer abstract rules from just a few examples. Given examples of input-output grids, the system must apply the hidden pattern to a new test case—something humans find easy but machines still struggle with. ARC Prize
ARC focuses on fluid intelligence. “To solve any problem, you need some knowledge, and then you’re going to recombine that knowledge on the fly,” Chollet told me. To make it a test not of stored knowledge but of how one recombines it, the training puzzles are supposed to supply all the “core knowledge priors” one needs. These include concepts like object cohesion, symmetry, and counting—the kind of common sense a small child has. Given this training and just a few examples, can you figure out which knowledge to apply to a new puzzle? Humans can do most of the puzzles easily, but AI struggled, at least at first. Eventually, OpenAI created a version of its o3 reasoning model that outperformed the average human test taker, achieving a score of 88 percent—albeit at an estimated computing cost of US $20,000 per puzzle. (OpenAI never released that model, so it’s not on the leaderboard chart.)
This March, Chollet introduced a harder version, called ARC-AGI-2. It’s overseen by his new nonprofit, the ARC Prize Foundation. “Our mission is to serve as a North Star towards AGI through enduring benchmarks,” the group announced. ARC Prize is offering a million dollars in prize money, the bulk going to teams whose trained AIs can solve 85 percent of 120 new puzzles using only four graphics processors for 12 hours or less. The new puzzles are more complex than those from 2019, sometimes requiring the application of multiple rules, reasoning for multiple steps, or interpreting symbols. The average human score is 60 percent, and as of this writing the best AI score is about 16 percent.
 AI models have made gradual progress on the first version of the ARC-AGI benchmark, which was introduced in 2019. This year, the ARC Prize launched a new version with harder puzzles, which AI models are struggling with. Models are labeled low, medium, high, or thinking to indicate how much computing power they expend on their answers, with “thinking” models using the most.ARC Prize
AI models have made gradual progress on the first version of the ARC-AGI benchmark, which was introduced in 2019. This year, the ARC Prize launched a new version with harder puzzles, which AI models are struggling with. Models are labeled low, medium, high, or thinking to indicate how much computing power they expend on their answers, with “thinking” models using the most.ARC Prize
AI experts acknowledge ARC’s value, and also its flaws. Jiaxuan You, a computer scientist at the University of Illinois at Urbana-Champaign, says ARC is “a very good theoretical benchmark” that can shed light on how algorithms function, but “it’s not taking into account the real-world complexity of AI applications, such as social reasoning tasks.”
Melanie Mitchell, a computer scientist at the Santa Fe Institute, says it “captures some interesting capabilities that humans have,” such as the ability to abstract a new rule from a few examples. But given the narrow task format, she says, “I don’t think it captures what people mean when they say general intelligence.”
Despite these caveats, ARC-AGI-2 may be the AI benchmark with the biggest performance gap between advanced AI and regular people, making it a potent indicator of AGI’s headway. What’s more, ARC is a work in progress. Chollet says AI might match human performance on the current test in a year or two, and he’s already working on ARC-AGI-3. Each task will be like a miniature video game, in which the player needs to figure out the relevant concepts, the possible actions, and the goal.
Researchers keep rolling out benchmarks that probe different aspects of general intelligence. Yet each also reveals how incomplete our map of the territory remains.
One recent paper introduced General-Bench, a benchmark that uses five input modalities—text, images, video, audio, 3D—to test AI systems on hundreds of tasks that demand recognition, reasoning, creativity, ethical judgment, and other abilities to both comprehend and generate material. Ideally, an AGI would show synergy, leveraging abilities across tasks to outperform the best AI specialists. But at present, no AI can even handle all five modalities.
Other benchmarks involve virtual worlds. An April paper in Nature reports on Dreamer, a general algorithm from Google DeepMind that learned to perform over 150 tasks, including playing Atari games, controlling virtual robots, and obtaining diamonds in Minecraft. These tasks require perception, exploration, long-term planning, and interaction, but it’s unclear how well Dreamer would handle real-world messiness. Controlling a video game is easier than controlling a real robot, says Danijar Hafner, the paper’s lead author: “The character never falls on his face.” The tasks also lack rich interaction with humans and an understanding of language in the context of gestures and surroundings. “You should be able to tell your household robot, ‘Put the dishes into that cabinet and not over there,’ and you point at [the cabinet] and it understands,” he says. Hafner says his team is working to make the simulations and tasks more realistic.
Aside from these extant benchmarks, experts have long debated what an ideal demonstration would look like. Back in 1970, the AI pioneer Marvin Minsky told Life that in “three to eight years we will have a machine with the general intelligence of an average human being. I mean a machine that will be able to read Shakespeare, grease a car, play office politics, tell a joke, have a fight.” That panel of tasks seems like a decent start, if you could operationalize the game of office politics.
Virtual people would be assigned randomized tasks that test not only understanding but values. For example, AIs might unexpectedly encounter money on the floor or a crying baby.
One 2024 paper in Engineering proposed the Tong test (tong is Chinese for “general”). Virtual people would be assigned randomized tasks that test not only understanding but values. For example, AIs might unexpectedly encounter money on the floor or a crying baby, giving researchers the opportunity to observe what the AIs do. The authors argue that benchmarks should test an AI’s ability to explore and set its own goals, its alignment with human values, its causal understanding, and its ability to control a virtual or physical body. What’s more, the benchmark should be capable of generating an infinite number of tasks involving dynamic physical and social interactions.
Others, like Minsky, have suggested tests that require interacting with the real world to various degrees: making coffee in an unfamiliar kitchen, turning a hundred thousand dollars into a million, or attending college on campus and earning a degree. Unfortunately, some of these tests are impractical and risk causing real-world harm. For example, an AI might earn its million by scamming people.
I asked Hinton, the Nobel Prize winner, what skills will be the hardest for AI to acquire. “I used to think it was things like figuring out what other people are thinking,” he said, “but it’s already doing some of that. It’s already able to do deception.” (In a recent multi-university study, an LLM outperformed humans at persuading test takers to select wrong answers.) He went on: “So, right now my answer is plumbing. Plumbing in an old house requires reaching into funny crevices and screwing things the right way. And I think that’s probably safe for another 10 years.”
Researchers debate whether the ability to perform physical tasks is required to demonstrate AGI. A paper from Google DeepMind on measuring levels of AGI says no, arguing that intelligence can show itself in software alone. They frame physical ability as an add-on rather than a requirement for AGI.
Mitchell of the Santa Fe Institute says we should test capabilities involved in doing an entire job. She noted that AI can do many tasks of a human radiologist but can’t replace the human because the job entails a lot of tasks that even the radiologist doesn’t realize they’re doing, like figuring out what tasks to do and dealing with unexpected problems. “There’s such a long tail of things that can happen in the world,” she says. Some robotic vacuum cleaners weren’t trained to recognize dog poop, she notes, and so they smeared it around the carpet. “There’s all kinds of stuff like that that you don’t think of when you’re building an intelligent system.”
Some scientists say we should observe not only performance but what’s happening under the hood. A recent paper coauthored by Jeff Clune, a computer scientist at the University of British Columbia, in Canada, reports that deep learning often leads AI systems to create “fractured entangled representations”—basically a bunch of jury-rigged shortcuts wired together. Humans, though, look for broad, elegant regularities in the world. An AI system might appear intelligent based on one test, but if you don’t know the system’s innards, you could be surprised when you deploy it in a new situation and it applies the wrong rule.
The author Lewis Carroll once wrote of a character who used a map of the nation “on the scale of a mile to the mile!” before eventually using the country as its own map. In the case of intelligence testing, the most thorough map of how someone will perform in a situation is to test them in the situation itself. In that vein, a strong test of AGI might be to have a robot live a full human life and, say, raise a child to adulthood.
“Ultimately, the real test of the capabilities of AI is what they do in the real world,” Clune told me. “So rather than benchmarks, I prefer to look at which scientific discoveries [AIs] make, and which jobs they automate. If people are hiring them to do work instead of a human and sticking with that decision, that’s extremely telling about the capabilities of AI.” But sometimes you want to know how well something will do before asking it to replace a person.
We may never agree on what AGI or “humanlike” AI means, or what suffices to prove it. As AI advances, machines will still make mistakes, and people will point to these and say the AIs aren’t really intelligent. Ivanova, the psychologist at Georgia Tech, was on a panel recently, and the moderator asked about AGI timelines. “We had one person saying that it might never happen,” Ivanova told me, “and one person saying that it already happened.” So the term “AGI” may be convenient shorthand to express an aim—or a fear—but its practical use may be limited. In most cases, it should come with an asterisk, and a benchmark.
Are You Smarter Than an AI?

The ARC Prize test is a deceptively simple challenge designed to measure a machine’s ability to reason, abstract, and generalize—core ingredients of artificial general intelligence (AGI). It’s the most prominent benchmark to emerge as researchers look for ways to measure progress toward AGI. For the full story, see the feature article “Will We Know Artificial General Intelligence When We See It?”
While today’s smartest AI models still struggle with many of these visual puzzles, humans often solve them easily. We’ve selected five from the ARC collection of nearly 2,000 puzzles, aiming for a range from easy to fairly hard, and adapted them into multiple-choice quizzes.
INSTRUCTIONS: For each of the five puzzles, examine the examples and try to identify the overarching pattern between inputs and outputs. Your goal is to figure out the rule that governs how the input [on the left in each box] is transformed into the output [on the right]. Then, look at the test grid: Given its input, and based on what you’ve learned from the examples, what should the output be? Click one of the four multiple-choice answers to see if you’re right. Crack all five puzzles and prove you’re not just another language model!
OpenAI Releases GPT-5-Codex Optimized for Complex Code Refactoring and Code Reviews

Introducing GPT-5-Codex: OpenAI's latest AI model revolutionizing software engineering with advanced capabilities in code refactoring and review. Operating autonomously for over 7 hours, it ensures efficiency and accuracy, achieving 51.3% accuracy in complex tasks. Adaptively reasoning, it enhances developer workflows, producing high-quality, tested code while minimizing noise.
By Hien LuuDatadog Launches Monocle, a Unified Rust-Powered Real-Time Metrics Engine
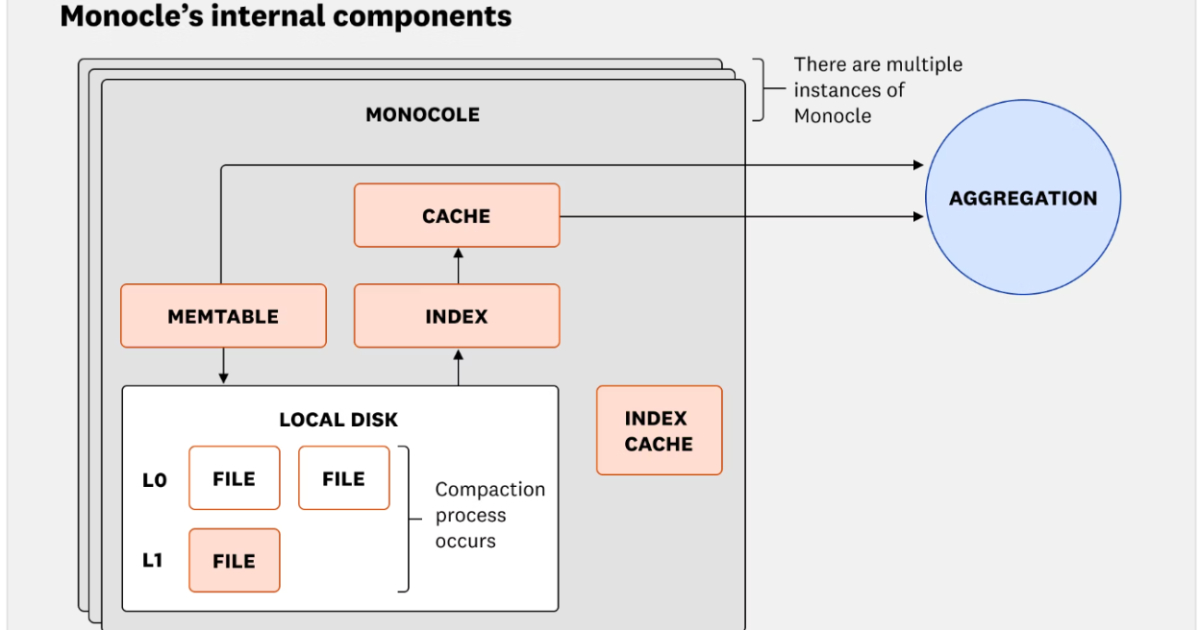
Datadog has launched Monocle, a new real-time time series storage engine written in Rust. The system unifies the company’s metrics storage infrastructure, delivering higher ingestion throughput and lower query latency while reducing operational complexity. Monocle replaces several generations of storage backends, addressing concurrency challenges and scaling limits that accumulated over time.
By Leela KumiliReplit Introduces Agent 3 for Extended Autonomous Coding and Automation

Replit has introduced Agent 3, its latest autonomous software agent built to extend the use of AI in programming and workflow automation. Unlike earlier coding assistants that provide small pieces of help through autocomplete or single-step code generation, Agent 3 is designed to carry out tasks over an extended period of time.
By Daniel DominguezPresentation: Scaling an Embedded Database for the Cloud – Challenges and Trade-Offs

Stephanie Wang explains the journey of building MotherDuck, a serverless data warehouse, from the ground up using the in-process DuckDB. She discusses the challenges of cloudifying an embedded database, including coupled compute and storage, and details architectural choices and engineering tradeoffs made to enable cloud-native capabilities.
By Stephanie WangNVIDIA Says It Will Invest up to $100B in OpenAI
 NVIDIA intends to invest up to $100 billion in OpenAI as new NVIDIA systems are deployed. The first phase is targeted to come online in the second half of 2026 using the NVIDIA Vera Rubin platform.
NVIDIA intends to invest up to $100 billion in OpenAI as new NVIDIA systems are deployed. The first phase is targeted to come online in the second half of 2026 using the NVIDIA Vera Rubin platform.
News Bytes 20250922: NVIDIA’s Intel Stake and the APUs to Come, NVIDIA’s $900M Enfabrica ‘Acqui-Hire’
 https://orionx.net/wp-content/uploads/2025/09/HPCNB_20250922.mp3 Happy vernal equinox to you! Developments in the world of HPC-AI last week exceeded its high standard for news value, here’s a fast (6:54) run-through of major headlines, including: – Nvidia’s $5 billion stake in Intel and the coming APU from their partnership (and the possibilities for Intel’s foundry business) – Nvidia’s nearly […]
https://orionx.net/wp-content/uploads/2025/09/HPCNB_20250922.mp3 Happy vernal equinox to you! Developments in the world of HPC-AI last week exceeded its high standard for news value, here’s a fast (6:54) run-through of major headlines, including: – Nvidia’s $5 billion stake in Intel and the coming APU from their partnership (and the possibilities for Intel’s foundry business) – Nvidia’s nearly […]
Teradata Launches AgentBuilder for Autonomous AI
![]() SAN DIEGO – Sept. 23, 2025 – Teradata (NYSE: TDC) today announced the launch of AgentBuilder, a suite of capabilities designed to accelerate development and deployment of autonomous, contextually intelligent AI agents. Leveraging open-source frameworks and powered by the Teradata AI and knowledge platform, AgentBuilder gives teams the ability to quickly design, operationalize, and manage […]
SAN DIEGO – Sept. 23, 2025 – Teradata (NYSE: TDC) today announced the launch of AgentBuilder, a suite of capabilities designed to accelerate development and deployment of autonomous, contextually intelligent AI agents. Leveraging open-source frameworks and powered by the Teradata AI and knowledge platform, AgentBuilder gives teams the ability to quickly design, operationalize, and manage […]
Thinking, Searching, and Acting
A reflection on reasoning models.
Caribbean Cuisine Goes High-Tech: How Juici Patties Blends Culture With Innovation
Juici Patties was founded in Jamaica in 1980. After becoming the island's top fast food franchise, it began expanding into the United States, opening locations throughout Florida and New York.
US Says Dismantled Telecoms Shutdown Threat During UN Summit
The US Secret Service said Tuesday it had dismantled a network of electronic devices that could have crashed New York's telecommunications network in an attack ahead of the UN General Assembly.
Cities Face Risk Of Water Shortages In Coming Decades: Study
Hotspots of water scarcity could emerge by the 2020s and 2030s across the Mediterranean, southern Africa, and North America, as climate change intensifies droughts, a new study said Tuesday.
We Can Build Fighter Jet Without Germany: France's Dassault
The head of French defence company Dassault said on Tuesday his firm could build the future European fighter jet by itself, as tensions persist with Germany over the multi-billion-euro project.
German Business Groups Pressure Merz Over Ailing Economy
German business associations in talks with Chancellor Friedrich Merz stressed the "urgency" of steps to help the ailing economy, one group said Tuesday, with reports describing a stormy encounter.
WHO Sees No Autism Links To Tylenol, Vaccines
Neither the painkiller Tylenol nor vaccines have been shown to cause autism, the World Health Organization said on Tuesday, following comments from the US president and his administration to the contrary.
EU Proposes New Delay To Anti-deforestation Rules
The EU said Tuesday it will seek a new one-year delay to sweeping anti-deforestation rules cheered by green groups but assailed by key trading partners from the United States to Indonesia.
Iran Executed At Least 1,000 This Year In Prison 'Mass Killing': NGO
Iran has executed at least 1,000 people so far in 2025, an NGO said on Tuesday, denouncing a "mass killing campaign" in prisons aimed at spreading fear through society.
Ghana Deports At Least Six West Africans Expelled By US To Togo
Ghana has deported at least six west Africans to Togo after they were expelled to Accra as part of an immigration crackdown by US President Donald Trump, their lawyers said Tuesday.
EU Queries Apple, Google, Microsoft Over Financial Scams
The European Union on Tuesday demanded Big Tech players including Apple and Google explain what action they are taking against financial scams online, as Brussels seeks to show it is not shying away from enforcing its rules.
Drone Flights 'Most Serious Attack' On Danish Infrastructure, PM Says
Large drones that flew over Copenhagen airport for hours and caused it to shut down constituted the "most serious attack on Danish critical infrastructure" to date, Prime Minister Mette Frederiksen said Tuesday.
Top 10 Random Video Chat Sites and Talk-to-Stranger Apps
Here are the top 10 random video chat sites and apps, starting with three industry leaders that are redefining the space.
Indonesia, EU Sign Long-awaited Trade Deal
Indonesia and the European Union finalised negotiations on a trade agreement Tuesday after nearly a decade of talks, a senior minister said.
Tech Migrants 'Key' For US Growth, Warns OECD Chief Economist
High-skilled migrants are vital for the US economy, the OECD's chief economist told AFP, after the United States imposed a $100,000 fee for H-1B visas widely used by the tech industry.
OECD Ups World Economic Outlook As Tariffs Contained, For Now
The world economy will grow more than previously forecast this year after absorbing the shock of US President Donald Trump's tariffs, but their full impact remains uncertain, the OECD said Tuesday.
Sunset For Windows 10 Updates Leaves Users In A Bind
Microsoft's plan to halt updates for its Windows 10 operating system in mid-October has raised hackles among campaign groups and left some users worried they must buy new computers to be safe from cyberattacks.
Hopes Of Western Refuge Sink For Afghans In Pakistan
In their Pakistan safehouse, Shayma and her family try to keep their voices low so their neighbours don't overhear their Afghan mother tongue.
Trump To See Zelensky And Lay Out Dark Vision Of UN
Donald Trump meets Ukrainian leader Volodymyr Zelensky on Tuesday as patience wears thin on Russia, at a UN summit where the US president is expected to offer a dark take on the future of the world body.
US Lawmaker Warns Of Military 'Misunderstanding' Risk With China
The leader of a US congressional delegation to China warned Tuesday of the "risk of a misunderstanding" between the two countries' militaries as advances in defence technology move at breakneck speed.
Emery Seeks Europa League Lift With Villa As Forest End Long Absence
Unai Emery will hope a return to the Europa League this week serves as the spark plug that ignites Aston Villa's season, while Nottingham Forest embark on their first European campaign in 30 years.
Egypt Frees Activist Alaa Abdel Fattah After Sisi Pardon
Prominent British-Egyptian activist Alaa Abdel Fattah was released from prison in Cairo, his family said on Tuesday, prompting an emotional reunion with his loved ones after a pardon from President Abdel Fattah al-Sisi.
Asian Markets Struggle As Focus Turns To US Inflation
Asian markets struggled Tuesday to track another record day on Wall Street, with traders now awaiting the release of US inflation data that could dictate Federal Reserve policy in coming weeks.
Maverick Georgian Designer Demna Debuts For Gucci In Milan
Maverick Georgian designer Demna makes his debut for Gucci at Milan Fashion Week on Tuesday with a film of a family of Italian characters bursting with attitude, as the house pledged a "new era" its history.
What Do Some Researchers Call Disinformation? Anything But Disinformation
"Disinformation" is fast becoming a dirty word in the United States -- a label so contentious in a hyperpolarized political climate that some researchers who study the harmful effects of falsehoods are abandoning it altogether.
The (Not) Doomed Internet: Can Content Creation and Scraping Join Forces?
People who publish digital content and those who scrape it from the web don't always see eye to eye these days, to put it mildly. However, Pierluigi Vinciguerra sees both sides of the argument firsthand.
7 Python Libraries Every Analytics Engineer Should Know
A quick look at 7 Python libraries that help analytics engineers clean, transform, and analyze data effectively.
10 Newsletters for Busy Data Scientists
This article highlights ten of the best free newsletters for data scientists, covering everything from hands-on tutorials and statistical guides to industry news, AI breakthroughs, and career advice.
How To Use Synthetic Data To Build a Portfolio Project
Generate synthetic data and build a machine learning portfolio project with AI.
Beginner’s Guide to VibeVoice
Learn how to use Microsoft’s open-source text-to-speech model for advanced conversational AI on Google Colab, with step-by-step setup and troubleshooting for common inference issues.
10 Python One-Liners to Optimize Your Hugging Face Transformers Pipelines
In this article, we present 10 powerful Python one-liners that will help you optimize your Hugging Face pipeline() workflows.
Last Week in AI #322 - Robotaxi progress, OpenAI Business, Gemini in Chrome
Amazon's Zoox jumps into U.S. robotaxi race with Las Vegas launch, OpenAI secures Microsoft’s blessing to transition its for-profit arm, and more!
Smart ring maker Oura eyes $10.9bn valuation, reports say
无摘要
‘Busier than I’ve ever seen it’: VCs pile into companies squeezing every inch of performance out of compute
无摘要
10 Italian startups to watch, according to VCs
无摘要
Smart ring maker Oura secures $250m debt facility
无摘要
H-1B visa cost hike sees European startups move to poach global talent
无摘要
Tide becomes UK fintech’s latest unicorn with £120m funding round
无摘要
‘The Premier League is over there’: OpenAI and Sequoia-backed social network Gigi raises extension round to move to the US
无摘要
OpenAI’s Laura Modiano on the rise of the technical founder-CEO
无摘要
Is Revolut really worth $75bn?
无摘要
Britain: tech powerhouse or vassal state?
无摘要
Paris-based Ventech closes new €175m fund as founding partner retires
无摘要
Inbox overwhelm? Perplexity's new Email Assistant wants to help - for $200 a month
Another day, another AI assistant. Here's how this one can help you manage emails in Gmail and Outlook, and who gets to use it.
Forget Dyson: This stick vacuum reliably handled my wet and dry messes (and it's on sale)
Dreame is shaking the wet-dry mop market with the H15 Pro CarpetFlex, a unit that comes with a hard floor brush and a carpet brush.
Finally, I found an 'Ultra' Android phone with specs and features that truly matter
The TCL Nxtpaper 60 Ultra rethinks what "Ultra" means, focusing on eye comfort and stylus usability over raw power.
iPhone battery worse after updating to iOS 26? Here's why, and how I fixed it
Increased battery drain is far from unexpected after installing a major OS update, says Apple.
Best Amazon Prime Day phone deals 2025: My 15 favorite sales ahead of October
We scoured Amazon's October Prime Day catalogs for the top early deals on the best phones we tested and recommended.
Best early Amazon Prime Day deals under $25 in 2025: My favorite cheap sales ahead of October
October Prime Day is coming soon. These are my favorite under $25 deals live now.
This iOS 26 feature makes your screenshots so much more useful - here's how it works
With full-screen previews enabled in iOS 26, you can instantly access your screenshots and use new AI features on them - like asking ChatGPT.
Why I recommend this Samsung QLED TV over its pricier OLED model - and don't regret it
Samsung's flagship QLED TV, the QN90F, performs well in our streaming and gaming tests, making it a great value for the holiday season.
You can update your iPhone to iOS 26 for free right now - here's which models support it
The latest update to the iPhone has arrived, bringing a fresh user interface design, improved calling features, and more.
Microsoft's new Windows AI Labs lets you try experimental features first - how to opt-in
The program starts with Microsoft Paint.
Best Costco deals to compete with Amazon Prime Day 2025: My favorite sales so far
October Prime Day is coming, but you can find great deals at Costco right now.
Best early Amazon Prime Day laptop deals 2025: My 30 favorites sales ahead of October
Amazon Prime Day is coming up, but the laptop deals are already heating up. Here are the best we've found, from Apple, Lenovo, HP, and more.
Amazon Prime Day is October 7-8: Everything you need to know about October Prime Day
Amazon's Prime Big Deal Days returns soon. Here's everything you need to know to shop like a pro.
Is this rugged Android phone with a 22,000mAh legit? My verdict after a week of stress tests
The Doogee S200 Max proves you can have extreme durability and performance in one package (but don't expect a lightweight device).
Best Amazon Prime Day tablet deals 2025: My favorite sales ahead of October
We found the best early tablet deals ahead of Amazon's October Prime Day sale, including discounts on the Apple iPad and Samsung Galaxy Tab.
Best Amazon Prime Day Apple deals 2025: My 24 favorite sales ahead of October
Prime Day is only a couple of weeks away, and in the lead-up to the popular sales event, I've found some fantastic deals on Apple tech, including iPhones, AirPods, iPads, and smartwatches.
Nearly everything you've heard about AI and job cuts is wrong - here's why
Looking for a few good AI leaders - are you ready?
Best Walmart deals to compete with Prime Day 2025: All-time-low prices from Microsoft, Samsung, and more
Amazon Prime Day is only two weeks away, but you can already find bargain tech at Walmart. Here are my favorite deals, including laptops, smartwatches, TVs, and more.
Best October Prime Day deals under $100: My favorite early sales
Grab some savings with useful tech gadgets under $100 on sale ahead of next month's Amazon Prime Day sales event.
The most impressive piece of tech I've tested in 2025 (and it isn't smart glasses)
I test a lot of new phones, but the most surprising one this year has completely changed my mind about foldables. Here's why.
Inbox overwhelm? Perplexity's new Email Assistant wants to help - for $200 a month
Another day, another AI assistant. Here's how this one can help you manage emails in Gmail and Outlook, and who gets to use it.
Forget Dyson: This stick vacuum reliably handled my wet and dry messes (and it's on sale)
Dreame is shaking the wet-dry mop market with the H15 Pro CarpetFlex, a unit that comes with a hard floor brush and a carpet brush.
Finally, I found an 'Ultra' Android phone with specs and features that truly matter
The TCL Nxtpaper 60 Ultra rethinks what "Ultra" means, focusing on eye comfort and stylus usability over raw power.
iPhone battery worse after updating to iOS 26? Here's why, and how I fixed it
Increased battery drain is far from unexpected after installing a major OS update, says Apple.
Best Amazon Prime Day phone deals 2025: My 15 favorite sales ahead of October
We scoured Amazon's October Prime Day catalogs for the top early deals on the best phones we tested and recommended.
Best early Amazon Prime Day deals under $25 in 2025: My favorite cheap sales ahead of October
October Prime Day is coming soon. These are my favorite under $25 deals live now.
This iOS 26 feature makes your screenshots so much more useful - here's how it works
With full-screen previews enabled in iOS 26, you can instantly access your screenshots and use new AI features on them - like asking ChatGPT.
Why I recommend this Samsung QLED TV over its pricier OLED model - and don't regret it
Samsung's flagship QLED TV, the QN90F, performs well in our streaming and gaming tests, making it a great value for the holiday season.
You can update your iPhone to iOS 26 for free right now - here's which models support it
The latest update to the iPhone has arrived, bringing a fresh user interface design, improved calling features, and more.
Microsoft's new Windows AI Labs lets you try experimental features first - how to opt-in
The program starts with Microsoft Paint.
Best Costco deals to compete with Amazon Prime Day 2025: My favorite sales so far
October Prime Day is coming, but you can find great deals at Costco right now.
Best early Amazon Prime Day laptop deals 2025: My 30 favorites sales ahead of October
Amazon Prime Day is coming up, but the laptop deals are already heating up. Here are the best we've found, from Apple, Lenovo, HP, and more.
Amazon Prime Day is October 7-8: Everything you need to know about October Prime Day
Amazon's Prime Big Deal Days returns soon. Here's everything you need to know to shop like a pro.
Is this rugged Android phone with a 22,000mAh legit? My verdict after a week of stress tests
The Doogee S200 Max proves you can have extreme durability and performance in one package (but don't expect a lightweight device).
Best Amazon Prime Day tablet deals 2025: My favorite sales ahead of October
We found the best early tablet deals ahead of Amazon's October Prime Day sale, including discounts on the Apple iPad and Samsung Galaxy Tab.
Best Amazon Prime Day Apple deals 2025: My 24 favorite sales ahead of October
Prime Day is only a couple of weeks away, and in the lead-up to the popular sales event, I've found some fantastic deals on Apple tech, including iPhones, AirPods, iPads, and smartwatches.
Nearly everything you've heard about AI and job cuts is wrong - here's why
Looking for a few good AI leaders - are you ready?
Best Walmart deals to compete with Prime Day 2025: All-time-low prices from Microsoft, Samsung, and more
Amazon Prime Day is only two weeks away, but you can already find bargain tech at Walmart. Here are my favorite deals, including laptops, smartwatches, TVs, and more.
Best October Prime Day deals under $100: My favorite early sales
Grab some savings with useful tech gadgets under $100 on sale ahead of next month's Amazon Prime Day sales event.
The most impressive piece of tech I've tested in 2025 (and it isn't smart glasses)
I test a lot of new phones, but the most surprising one this year has completely changed my mind about foldables. Here's why.
Diffusion Beats Autoregressive in Data-Constrained Settings
Check out our new blog post on "Diffusion beats Autoregressive in Data-Constrained settings". The era of infinite internet data is ending. This research paper asks: What is the right generative modeling objective when data—not compute—is the bottleneck?
Journals infiltrated with ‘copycat’ papers that can be written by AI
Meet VoXtream: An Open-Sourced Full-Stream Zero-Shot TTS Model for Real-Time Use that Begins Speaking from the First Word
Real-time agents, live dubbing, and simultaneous translation die by a thousand milliseconds. Most “streaming” TTS (Text to Speech) stacks still wait for a chunk of text before they emit sound, so the human hears a beat of silence before the voice starts. VoXtream—released by KTH’s Speech, Music and Hearing group—attacks this head-on: it begins speaking […]
The post Meet VoXtream: An Open-Sourced Full-Stream Zero-Shot TTS Model for Real-Time Use that Begins Speaking from the First Word appeared first on MarkTechPost.
How to Create Reliable Conversational AI Agents Using Parlant?
Parlant is a framework designed to help developers build production-ready AI agents that behave consistently and reliably. A common challenge when deploying large language model (LLM) agents is that they often perform well in testing but fail when interacting with real users. They may ignore carefully designed system prompts, generate inaccurate or irrelevant responses at […]
The post How to Create Reliable Conversational AI Agents Using Parlant? appeared first on MarkTechPost.
Microsoft Brings MCP to Azure Logic Apps (Standard) in Public Preview, Turning Connectors into Agent Tools
Microsoft has released a public preview that enables Azure Logic Apps (Standard) to run as Model Context Protocol (MCP) servers, exposing Logic Apps workflows as agent tools discoverable and callable by MCP-capable clients (e.g., VS Code + Copilot). What’s actually shipping Key requirements and transport details API Center path: preview limitations that matter When creating […]
The post Microsoft Brings MCP to Azure Logic Apps (Standard) in Public Preview, Turning Connectors into Agent Tools appeared first on MarkTechPost.
Perplexity Launches an AI Email Assistant Agent for Gmail and Outlook, Aimed at Scheduling, Drafting, and Inbox Triage
Perplexity introduced “Email Assistant,” an AI agent that plugs into Gmail and Outlook to draft replies in your voice, auto-label and prioritize messages, and coordinate meetings end-to-end (availability checks, time suggestions, and calendar invites). The feature is restricted to Perplexity’s Max plan and is live today. What it does? Email Assistant adds an agent to […]
The post Perplexity Launches an AI Email Assistant Agent for Gmail and Outlook, Aimed at Scheduling, Drafting, and Inbox Triage appeared first on MarkTechPost.
Alibaba Qwen Team Just Released FP8 Builds of Qwen3-Next-80B-A3B (Instruct & Thinking), Bringing 80B/3B-Active Hybrid-MoE to Commodity GPUs
Alibaba’s Qwen team has just released FP8-quantized checkpoints for its new Qwen3-Next-80B-A3B models in two post-training variants—Instruct and Thinking—aimed at high-throughput inference with ultra-long context and MoE efficiency. The FP8 repos mirror the BF16 releases but package “fine-grained FP8” weights (block size 128) and deployment notes for sglang and vLLM nightly builds. Benchmarks in the […]
The post Alibaba Qwen Team Just Released FP8 Builds of Qwen3-Next-80B-A3B (Instruct & Thinking), Bringing 80B/3B-Active Hybrid-MoE to Commodity GPUs appeared first on MarkTechPost.
Top 15 Model Context Protocol (MCP) Servers for Frontend Developers (2025)
Model Context Protocol (MCP) has become the “USB-C” for agent/tool integrations, giving frontend teams a standard way to wire design specs, repos/PRs, deploy targets, observability, and work management into their editors and CI without bespoke adapters. This list focuses on production-ready, remote MCP servers (OAuth/permissioned) that map cleanly onto Frontend (FE) workflows—e.g., Figma→GitHub→Vercel/Cloudflare→Chromatic/Sentry—reflecting rapid ecosystem […]
The post Top 15 Model Context Protocol (MCP) Servers for Frontend Developers (2025) appeared first on MarkTechPost.
MIT Researchers Enhanced Artificial Intelligence (AI) 64x Better at Planning, Achieving 94% Accuracy
Can a 8B-parameter language model produce provably valid multi-step plans instead of plausible guesses? MIT CSAIL researchers introduce PDDL-INSTRUCT, an instruction-tuning framework that couples logical chain-of-thought with external plan validation (VAL) to lift symbolic planning performance of LLMs. On PlanBench, a tuned Llama-3-8B reaches 94% valid plans on Blocksworld, with large jumps on Mystery Blocksworld […]
The post MIT Researchers Enhanced Artificial Intelligence (AI) 64x Better at Planning, Achieving 94% Accuracy appeared first on MarkTechPost.
Understanding the Universal Tool Calling Protocol (UTCP)
The Universal Tool Calling Protocol (UTCP) is a lightweight, secure, and scalable way for AI agents and applications to find and call tools directly, without the need for additional wrapper servers. Key Features The Problem with Current Approaches Traditional solutions for integrating tools often require: These steps add friction for developers and slow down execution. […]
The post Understanding the Universal Tool Calling Protocol (UTCP) appeared first on MarkTechPost.
Meta AI Proposes ‘Metacognitive Reuse’: Turning LLM Chains-of-Thought into a Procedural Handbook that Cuts Tokens by 46%
Meta researchers introduced a method that compresses repeated reasoning patterns into short, named procedures—“behaviors”—and then conditions models to use them at inference or distills them via fine-tuning. The result: up to 46% fewer reasoning tokens on MATH while matching or improving accuracy, and up to 10% accuracy gains in a self-improvement setting on AIME, without […]
The post Meta AI Proposes ‘Metacognitive Reuse’: Turning LLM Chains-of-Thought into a Procedural Handbook that Cuts Tokens by 46% appeared first on MarkTechPost.
Using AI to assist in rare disease diagnosis
New research from Microsoft, Drexel, and the Broad explores how generative AI could support genetic professionals in rare disease diagnosis.
The post Using AI to assist in rare disease diagnosis appeared first on Microsoft Research.
New tool makes generative AI models more likely to create breakthrough materials
With SCIGEN, researchers can steer AI models to create materials with exotic properties for applications like quantum computing.
The Download: AI’s retracted papers problem
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. AI models are using material from retracted scientific papers The news: Some AI chatbots rely on flawed research from retracted scientific papers to answer questions, according to recent studies. In one such study, researchers…
AI models are using material from retracted scientific papers
Some AI chatbots rely on flawed research from retracted scientific papers to answer questions, according to recent studies. The findings, confirmed by MIT Technology Review, raise questions about how reliable AI tools are at evaluating scientific research and could complicate efforts by countries and industries seeking to invest in AI tools for scientists. AI search…
The Download: the LLM will see you now, and a new fusion power deal
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. This medical startup uses LLMs to run appointments and make diagnoses Patients at a small number of clinics in Southern California run by the medical startup Akido Labs are spending relatively little time,…
An oil and gas giant signed a $1 billion deal with Commonwealth Fusion Systems
Eni, one of the world’s largest oil and gas companies, just agreed to buy $1 billion in electricity from a power plant being built by Commonwealth Fusion Systems. The deal is the latest to illustrate just how much investment Commonwealth and other fusion companies are courting as they attempt to take fusion power from the…
This medical startup uses LLMs to run appointments and make diagnoses
Imagine this: You’ve been feeling unwell, so you call up your doctor’s office to make an appointment. To your surprise, they schedule you in for the next day. At the appointment, you aren’t rushed through describing your health concerns; instead, you have a full half hour to share your symptoms and worries and the exhaustive…
What visiting a virtual nightclub revealed about human interaction
New Scientist visits a virtual nightclub to get remarkable insight into human interaction
Behavioral insights enhance AI-driven recommendations more than data volume increases, study shows
New research shows that understanding users' intentions—rather than simply increasing data volume—can improve the suggestions generated by YouTube's "black box" algorithms.
Engineers develop smarter AI to redefine control in complex systems
A new artificial intelligence breakthrough developed by researchers in the College of Engineering and Computer Science at Florida Atlantic University offers a smarter, more efficient way to manage complex systems that rely on multiple decision-makers operating at different levels of authority.
Analog computing platform uses synthetic frequency domain to boost scalability
Analog computers, computing systems that represent data as continuous physical quantities, such as voltage, frequency or vibrations, can be significantly more energy-efficient than digital computers, which represent data as binary states (i.e., 0s and 1s). However, upscaling analog computing platforms is often difficult, as their underlying components can behave differently in larger systems.
Scientists urge global AI 'red lines' as leaders gather at UN
Technology veterans, politicians and Nobel Prize winners called on nations around the world Monday to quickly establish "red lines" too dangerous for artificial intelligence to cross.
Nvidia to invest $100 billion in OpenAI to help expand the ChatGPT maker's computing power
Chipmaker Nvidia will invest $100 billion in OpenAI as part of a partnership announced Monday that will add at least 10 gigawatts of Nvidia AI data centers to ramp up the computing power for the owner of the artificial intelligence chatbot ChatGPT.
Suicide-by-chatbot puts Big Tech in the product liability hot seat
It is a sad fact of online life that users search for information about suicide. In the earliest days of the internet, bulletin boards featured suicide discussion groups. To this day, Google hosts archives of these groups, as do other services.
Doing a lot with a little: New AI system helps explain laser welding defects
Artificial intelligence-powered large language models (LLM) need to be trained on massive datasets to make accurate predictions—but what if researchers don't have enough of the right type of data?
When every second counts: How AI can speed up disaster response decisions
In an unfolding disaster situation, quick decisions need to be made on how to respond and where to direct resources, to preserve life and aid recovery efforts. With the rapid development of AI, unmanned aerial vehicles (UAVs) and satellite imagery, initial efforts have already been made to apply AI to disaster situations, giving quick insights to response teams and autonomously making decisions on relief operations. But while AI may speed up processes, there is a risk that errors or bias could have severe consequences.
Predictive AI could prevent crowd crush disasters
To prevent crowd crush incidents like the Itaewon tragedy, it's crucial to go beyond simply counting people and to instead have a technology that can detect the real-inflow and movement patterns of crowds. A KAIST research team has successfully developed new AI crowd prediction technology that can be used not only for managing large-scale events and mitigating urban traffic congestion, but also for responding to infectious disease outbreaks.
Experts question Albania's AI-generated minister
Last week, Albania announced that an AI-generated minister would take charge of a new public tenders portfolio.
Behavioral insights enhance AI-driven recommendations more than data volume increases, study shows
New research shows that understanding users' intentions—rather than simply increasing data volume—can improve the suggestions generated by YouTube's "black box" algorithms.
Engineers develop smarter AI to redefine control in complex systems
A new artificial intelligence breakthrough developed by researchers in the College of Engineering and Computer Science at Florida Atlantic University offers a smarter, more efficient way to manage complex systems that rely on multiple decision-makers operating at different levels of authority.
Analog computing platform uses synthetic frequency domain to boost scalability
Analog computers, computing systems that represent data as continuous physical quantities, such as voltage, frequency or vibrations, can be significantly more energy-efficient than digital computers, which represent data as binary states (i.e., 0s and 1s). However, upscaling analog computing platforms is often difficult, as their underlying components can behave differently in larger systems.
Scientists urge global AI 'red lines' as leaders gather at UN
Technology veterans, politicians and Nobel Prize winners called on nations around the world Monday to quickly establish "red lines" too dangerous for artificial intelligence to cross.
Nvidia to invest $100 billion in OpenAI to help expand the ChatGPT maker's computing power
Chipmaker Nvidia will invest $100 billion in OpenAI as part of a partnership announced Monday that will add at least 10 gigawatts of Nvidia AI data centers to ramp up the computing power for the owner of the artificial intelligence chatbot ChatGPT.
Suicide-by-chatbot puts Big Tech in the product liability hot seat
It is a sad fact of online life that users search for information about suicide. In the earliest days of the internet, bulletin boards featured suicide discussion groups. To this day, Google hosts archives of these groups, as do other services.
Doing a lot with a little: New AI system helps explain laser welding defects
Artificial intelligence-powered large language models (LLM) need to be trained on massive datasets to make accurate predictions—but what if researchers don't have enough of the right type of data?
When every second counts: How AI can speed up disaster response decisions
In an unfolding disaster situation, quick decisions need to be made on how to respond and where to direct resources, to preserve life and aid recovery efforts. With the rapid development of AI, unmanned aerial vehicles (UAVs) and satellite imagery, initial efforts have already been made to apply AI to disaster situations, giving quick insights to response teams and autonomously making decisions on relief operations. But while AI may speed up processes, there is a risk that errors or bias could have severe consequences.
Predictive AI could prevent crowd crush disasters
To prevent crowd crush incidents like the Itaewon tragedy, it's crucial to go beyond simply counting people and to instead have a technology that can detect the real-inflow and movement patterns of crowds. A KAIST research team has successfully developed new AI crowd prediction technology that can be used not only for managing large-scale events and mitigating urban traffic congestion, but also for responding to infectious disease outbreaks.
Experts question Albania's AI-generated minister
Last week, Albania announced that an AI-generated minister would take charge of a new public tenders portfolio.
Faster Training Throughput in FP8 Precision with NVIDIA NeMo
 In previous posts on FP8 training, we explored the fundamentals of FP8 precision and took a deep dive into the various scaling recipes for practical large-scale...
In previous posts on FP8 training, we explored the fundamentals of FP8 precision and took a deep dive into the various scaling recipes for practical large-scale...
Build a Real-Time Visual Inspection Pipeline with NVIDIA TAO 6 and NVIDIA DeepStream 8
 Building a robust visual inspection pipeline for defect detection and quality control is not easy. Manufacturers and developers often face challenges such as...
Building a robust visual inspection pipeline for defect detection and quality control is not easy. Manufacturers and developers often face challenges such as...
Reasoning Through Molecular Synthetic Pathways with Generative AI
 A recurring challenge in molecular design, whether for pharmaceutical, chemical, or material applications, is creating synthesizable molecules. Synthesizability...
A recurring challenge in molecular design, whether for pharmaceutical, chemical, or material applications, is creating synthesizable molecules. Synthesizability...
Build a Retrieval-Augmented Generation (RAG) Agent with NVIDIA Nemotron
 Unlike traditional LLM-based systems that are limited by their training data, retrieval-augmented generation (RAG) improves text generation by incorporating...
Unlike traditional LLM-based systems that are limited by their training data, retrieval-augmented generation (RAG) improves text generation by incorporating...
Elon Musk’s Father, Errol Musk, Accused of Child Sexual Abuse
Errol Musk has been accused of sexually abusing five of his children and stepchildren since 1993, a Times investigation found. Family members have appealed to Elon Musk for help.
TikTok Deal Could Make Oracle Founder Larry Ellison a New Kind of Media Mogul
The database billionaire and his son, David, are Trump favorites. The family could soon control an empire that includes CBS, Paramount, Warner, CNN and a piece of TikTok.
Trump’s $100,000 H-1B Visa Fee Puts Many Tech Start-Ups in a Bind
Silicon Valley start-ups said they were concerned they would be disproportionately hurt by the new visa fee for skilled foreign workers, given their limited resources.
U.S. Asks Judge to Break Up Google’s Advertising Technology Monopoly
The Justice Department argued that the best way to address the company’s unfair advantage was to force it to sell off portions of its business.
Tech Executive Dies After Falling 2,000 Feet on Mount Shasta
While the Argentine hiker and entrepreneur, Matias Augusto Travizano, was descending the mountain, he fell down a glacier, the authorities said.
Nvidia to Invest $100 Billion in OpenAI
The chipmaker’s investment in the San Francisco start-up is an indication of the wild financial figures being tossed around in the world of artificial intelligence.
Amazon Faces Trial on F.T.C. Charges Related to Prime Service
A trial in federal court in Seattle will determine if millions of customers signed up for Prime because it’s a great deal, or because they were duped.
A Judge’s Decision Could Disrupt Google’s $3.1 Trillion Business
On Monday, the tech giant and the U.S. government face off in court over how to fix the company’s advertising technology monopoly.
Seeing Through the Reality of Meta’s Smart Glasses
Mark Zuckerberg’s glitch-filled unveiling of computerized glasses revealed a company that may struggle to deliver on its promise for the future of computing.
Elon Musk Has Focused on xAI Since Leaving Washington
Mr. Musk spent the summer at his artificial intelligence start-up xAI, trying to match the runaway success of OpenAI. The result was chaos.
Adobe Adds Luma AI’s Ray3 AI Video Generator to Firefly

Continuing to fulfill its promise to bring third-party AI models into its Firefly ecosystem, Adobe has added Luma AI's newest generative video model, Ray3, to Firefly.
Satellite Photos Show New Island Forming From Melting Glacier in Alaska

Alaska’s newest island can now be seen from space in recently released satellite photographs from NASA.
The Natural Landscape Photography Awards Shuns AI and Composites

While some photo competitions allow for liberal image manipulation and even artificial intelligence, there is none of that in the Natural Landscape Photography Awards which has just announced its winners.
Sony Cameras and Lenses Get Another Price Hike in the US
![]()
President Trump's polarizing and potentially illegal tariff policies strike again. Sony has increased the prices of numerous cameras and lenses by as much as $400.
Man Who Crashed Drone into Firefighting Airplane Gets Jailtime and $156k in Fines

The civilian pilot who flew his drone into a firefighting aircraft operating above the Los Angeles wildfires has been sentenced to two weeks in prison and ordered to pay $156,000 in fines.
GoPro Claims Only Its New Max2 360° Camera Captures True 8K Video

GoPro's new Max2 360° camera combines Emmy Award-winning technology and 8K video capabilities. GoPro promises better resolution than the competition, easy-to-replace lenses, and professional workflow features.
GoPro Lit Hero Action Camera Aims to Capitalize on Trendy Retro Vibes

The GoPro Lit Hero is a new miniature lifestyle camera with a built-in light to help creators capture their favorite moments anywhere, at any time.
The Runners and Riders of Fat Bear Week in Photos

Fat Bear Week comes around each year and the unusual competition has turned into a global event with fans across the United States and beyond voting for their favorite massive mammal.
52-Gram Osmo Nano Is DJI’s Smallest Action Camera

DJI announced the Osmo Nano, a compact and lightweight hands-free wearable camera that promises professional-level imaging performance.
Legendary Photographer Gian Paolo Barbieri Celebrated in First Major Exhibition Since His Death

The first major exhibition since the passing of Gian Paolo Barbieri, widely regarded as one of Italy’s greatest fashion photographers, will take place during Milan Fashion Week.
Movie Studio Lionsgate is Struggling to Make AI-Generated Films With Runway

Last year, the AI video company Runway joined forces with the major Hollywood studio Lionsgate in a partnership the pair hoped would result in AI-generated scenes and even potentially full-length movies. But the project has hit a snag.
Wild Leopard Sharks Mating Caught on Camera for First Time Ever

Scientists working in the South Pacific made scientific history after recording leopard sharks mating. The never-before-captured mating sequence caught the sharks, also known as zebra sharks (Stegostoma tigrinum), in a "threesome," and the footage could help aid vital conservation efforts.
Fujifilm’s Third Annual ‘Create With Us’ Education Event is in Minneapolis

Fujifilm has announced that it will hold its third annual Create With Us event at the Walker Art Center in Minneapolis on September 27 and 28, 2025. The three tenets behind the event are "create, learn, and network."
Apple’s New Vision Pro Films Among First Shot on Blackmagic Ursa Cine Immersive Cameras

Apple is all in on immersive video content. The company has previewed an array of new films shot in Apple Immersive for the Apple Vision Pro, including projects from Canal+, MotoGP, Red Bull, CNN, and more.
Photographers Capture the Sun and Moon Dancing Together Over 12 Months

Today marks the autumnal equinox, the astronomical date when fall begins and summer ends. It's a special date for keen skywatchers, including Luca Vanzella and Alister Ling who recently completed an ambitious photographic project charting the swing of the Sun and the Moon over one year.
UGreen Launches Two Beginner-Friendly Desktop NAS Solutions
![]()
UGreen has announced the launch of the NASync DH Series, comprising a pair of network-attached storage (NAS) devices designed to make large-capacity local storage more accessible to home users and small teams.
Nikon Can’t Fully Solve the Z6 III’s C2PA Problems Alone

Nikon suspended the brand new C2PA functionality introduced in the Nikon Z6 III's first major firmware update after a major security issue was discovered. Nikon has taken the critical step to revoke all C2PA signatures issued before the C2PA functionality was taken offline, but a complete resolution will require changes to the C2PA validation tools themselves.
Photographer Reimagines ‘Got Milk?’ Campaign for New Generation
![]()
Los Angeles-based photographer Aldo Chacon has brought a contemporary vision to the 30th anniversary of the iconic Got Milk? campaign, capturing thousands of portraits across California.
The Spotlight Awards Celebrates the Very Best of Commercial Photography

The 15 winners of the 2025 Spotlight Awards have been announced, a competition that celebrates commercial photography and its practitioners.
TikTok’s Algorithm Will Be Under American Control In Trump’s Deal

President Trump is expected to sign an executive order this week to finalize a long-rumored TikTok acquisition. In view of the impending deal, more details surrounding how the U.S. will tweak TikTok have come to light, including changes to the app's algorithm that is essential to its success and core to security concerns surrounding the app.
DeepSeek-V3.1-Terminus
A refined agentic model for developers
<p>
<a href="https://www.producthunt.com/products/deepseek?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1019034?app_id=339">Link</a>
</p>
Answerly
AI assistant that analyzes your screen to solve questions.
<p>
<a href="https://www.producthunt.com/products/answerly-visual-ai-assistant?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1018819?app_id=339">Link</a>
</p>
Atla
Automatically detect errors in your AI agents
<p>
<a href="https://www.producthunt.com/products/atla?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1018748?app_id=339">Link</a>
</p>
ToolJet
AI agents that build full-stack internal tools for you.
<p>
<a href="https://www.producthunt.com/products/tooljet-2?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1018661?app_id=339">Link</a>
</p>
Lookup
Ask Video Anything
<p>
<a href="https://www.producthunt.com/products/lookup-4?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1018801?app_id=339">Link</a>
</p>
SEO EEAT Check
Check what Google thinks of your content
<p>
<a href="https://www.producthunt.com/products/llm-seo-eeat?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1018724?app_id=339">Link</a>
</p>
Qwen3-Omni
Native end-to-end multilingual omni-modal LLM
<p>
<a href="https://www.producthunt.com/products/qwen3?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1019038?app_id=339">Link</a>
</p>
Vibe n8n
Cursor/Lovable for n8n to generate workflows in seconds
<p>
<a href="https://www.producthunt.com/products/vibe-n8n-ai-assistant-for-n8n?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1018909?app_id=339">Link</a>
</p>
Alice 4.0
AI productivity layer for your OS
<p>
<a href="https://www.producthunt.com/products/alice-3?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1019003?app_id=339">Link</a>
</p>
VoltAgent
Build TS AI agents with n8n-style observability
<p>
<a href="https://www.producthunt.com/products/voltagent?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1018963?app_id=339">Link</a>
</p>
ShareBox
Effortless secure file sharing
<p>
<a href="https://www.producthunt.com/products/sharebox?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1018786?app_id=339">Link</a>
</p>
Notion 3.0
You assign the tasks. Your Agents do the work.
<p>
<a href="https://www.producthunt.com/products/notion-mail?utm_campaign=producthunt-atom-posts-feed&utm_medium=rss-feed&utm_source=producthunt-atom-posts-feed">Discussion</a>
|
<a href="https://www.producthunt.com/r/p/1018669?app_id=339">Link</a>
</p>
A Simple Way To Measure Knots Has Come Unraveled
Two mathematicians have proved that a straightforward question — how hard is it to untie a knot? — has a complicated answer.
The post A Simple Way To Measure Knots Has Come Unraveled first appeared on Quanta Magazine
Clean R Tests with local_mocked_bindings and Dependency Wrapping
Learn how to write reliable R tests by wrapping external dependencies and using `testthat::local_mocked_bindings`. Make your tests fast, clean, and predictable.
Continue reading: Clean R Tests with local_mocked_bindings and Dependency Wrapping
Open Trade Statistics v6.0 is publicly available!
If this post is useful to you I kindly ask a minimal donation on Buy Me a Coffee. It shall be used to continue my Open Source efforts. The full explanation is here: A Personal Message from an Open Source Contributor.
You can send me questions for...
Continue reading: Open Trade Statistics v6.0 is publicly available!
Argentina wants to be an AI powerhouse, but its tech experts are leaving
iStock/Rest of World
What Trump’s H-1B crackdown means for Big Tech workers
Companies like Amazon, Google, and Microsoft rely on skilled foreign workers. Experts say they’ll pay for the best — but the policy could redirect top talent elsewhere.
Why Bangladesh’s unlikely satellite engineers are still waiting for liftoff
Bangladeshi engineers inspect a satellite communications disk.
AI breakthrough finds life-saving insights in everyday bloodwork
AI-powered analysis of routine blood tests can reveal hidden patterns that predict recovery and survival after spinal cord injuries. This breakthrough could make life-saving predictions affordable and accessible in hospitals worldwide.
Climate Investment backs ANYbotics to advance industrial decarbonization
ANYbotics, a provider ofautonomous robotic inspection solutions, received a strategic investment fromClimate Investment (CI), following a recent round and bringing total funding toover $150 million. W...
The Fight to End Childhood RSV in Indian Country
American Indian and Alaska Native infants experience the highest rates of RSV-related hospitalization in the U.S., but a breakthrough immunization is helping to close the gap
The Global Burden of RSV
Respiratory syncytial virus (RSV) continues to affect infants and older and immunocompromised people around the world. These graphics reveal where the burden lies and what the effects of immunizations are
New RSV Preventatives Dramatically Reduce Infant Illness and Death
The year 2023 marked the debut of groundbreaking innovations to prevent severe RSV infections in infants. Now protected babies are way less likely to develop severe infections or to end up in the ICU
How Indigenous Storytelling Is Transforming RSV Care in Native Communities
Abigail Echo-Hawk, a preeminent Native American public health expert, discusses RSV, “data genocide” and positive change driven by Indigenous storytelling
The Promise of RSV Prevention
RSV is the leading cause of infant hospitalizations in the U.S. But that could soon change as research advances lead to new preventative drugs for everyone
A Long Road to an RSV Antibody to Protect the Most Vulnerable
A tragic RSV vaccine trial in the 1960s set the field back for decades. Here’s how scientists finally made breakthroughs in RSV immunization
The Final RSV Frontier Is within Reach
The journey toward an RSV vaccine for children has been wrought with tragedy and setbacks. But six decades after scientists embarked on that path, they are nearing the finish line
James Webb Space Telescope Finds Atmosphere on Lava Planet TOI-561 b
Hot, small and old—exoplanet TOI-561 b is just about the worst place to look for alien air. Scientists using JWST found it there anyway
Tylenol Is Popular and Safe, Yet Nobody Knows How It Works
The common pain reliever is safe when used as directed, research shows. But scientists remain puzzled by one aspect: how it reduces pain and fever
Announcing the #SciAmInTheWild Photography Contest Short List
To celebrate Scientific American’s 180th anniversary, we invited readers to place our magazine covers in the wild. See our staff’s favorite submissions
Does Tylenol Use during Pregnancy Cause Autism? What the Research Shows
President Trump and Robert F. Kennedy, Jr. tie Tylenol use during pregnancy and folate deficiencies to rising autism rates—but the evidence is thin
Magnitude 4.3 Earthquake Strikes San Francisco Bay Area
The San Francisco Bay Area was rattled early this morning by a magnitude 4.3 earthquake along the Hayward fault line
‘Almost Impossible’ Deep-Earth Diamonds Confirm How These Gems Form
Seemingly contradictory materials are trapped together in two glittering diamonds from South Africa, shedding light on how diamonds form
Inside the Mysterious Smuggling of the El Ali Meteorite
How a space rock vanished from Africa and showed up for sale across an ocean
Vaccine Panel Overhaul, Head Trauma in Sports, and Strange Reproduction in Ants
A revamped CDC advisory committee faces vaccine debates, studies reveal brain changes in athletes, and climate change drives deadly heat waves across Europe.
US medtech G&F Precision Molding to open new Mullingar site with 30 jobs
G&F's current director of business development Ryan Mansfield will lead the new Irish facility.
Read more: US medtech G&F Precision Molding to open new Mullingar site with 30 jobs
Ireland climbs to 18 on the 2025 Global Innovation Index
Switzerland ranked highest of 139 countries for the sixth year in a row, while the UK came in at sixth overall.
Read more: Ireland climbs to 18 on the 2025 Global Innovation Index
What are the core skills for a validation engineer?
Marcela Amadeu Saragiotto gives us insights into managing priorities and communicating effectively.
Read more: What are the core skills for a validation engineer?
Mary Robinson, Geoffrey Hinton call for AI ‘red lines’ in new letter
The open letter warns of AI escalating widespread disinformation and mass unemployment.
Read more: Mary Robinson, Geoffrey Hinton call for AI ‘red lines’ in new letter
Airlines seen as vulnerable as ransomware confirmed in weekend cyberattack
A ransomware attack was confirmed by ENISA, Europe’s cybersecurity agency, as the source of the weekend’s airport disruption.
Read more: Airlines seen as vulnerable as ransomware confirmed in weekend cyberattack
‘Giant project,’ says Nvidia CEO as company bets $100bn on OpenAI
CNBC reports that the first investment of $10bn will be made when the first GW of Nvidia systems is deployed.
Read more: ‘Giant project,’ says Nvidia CEO as company bets $100bn on OpenAI
SETU gene therapy researcher inspired by family to tackle rare disease
When his nephews were diagnosed with a rare neurological disease, Dr Lee Coffey pivoted his research to work on developing treatments.
Read more: SETU gene therapy researcher inspired by family to tackle rare disease
What to do if your interviewer is an AI agent
If your interviewer is an AI agent, don't panic, there are a number of ways you can prepare so you don't lose your next big opportunity.
Read more: What to do if your interviewer is an AI agent
Apprentice to founder: David Cox on why skilled trade shouldn’t be overlooked
A successful career doesn’t need to look one way, explains electrician-turned-founder David Cox.
Read more: Apprentice to founder: David Cox on why skilled trade shouldn’t be overlooked
Why the need for privacy is driving a blockchain evolution
Zama’s COO Jeremy Bradley says that the transformation of blockchain into a privacy-preserving system is not a betrayal of its origins, but rather a logical evolution of the tech.
Read more: Why the need for privacy is driving a blockchain evolution
Internships: Making the transition from college to working life
Liberty IT's Agustin Calvo Bentos discusses his experience of the company's internship programme.
Read more: Internships: Making the transition from college to working life
European airports hit in cyberattack: What’s the latest?
Dublin airport's Terminal 1 is ‘operating as normal’ today with some delays expected in Terminal 2.
Read more: European airports hit in cyberattack: What’s the latest?
Eir Evo to bring critical satellite connectivity to Ireland’s isolated areas
The plan is to enhance the resilience of public services such as schools, healthcare clinics and Garda stations in remote and island communities.
Read more: Eir Evo to bring critical satellite connectivity to Ireland’s isolated areas
EU targets cookie fatigue with plan to simplify rules
A new EU initiative aims to cut administrative burdens for businesses in the region.
Read more: EU targets cookie fatigue with plan to simplify rules
Dublin start-up Rekord raises $2.1m for AI-driven credit platform
In the next six months, the start-up plans to onboard additional design partners, expand in the EU and UK, and triple the size of its team.
Read more: Dublin start-up Rekord raises $2.1m for AI-driven credit platform
Why AI systems might never be secure
Why AI systems might never be secure
The Economist have a new piece out about LLM security, with this headline and subtitle:
Why AI systems might never be secure
A “lethal trifecta” of conditions opens them to abuse
I talked with their AI Writer Alex Hern for this piece.
The gullibility of LLMs had been spotted before ChatGPT was even made public. In the summer of 2022, Mr Willison and others independently coined the term “prompt injection” to describe the behaviour, and real-world examples soon followed. In January 2024, for example, DPD, a logistics firm, chose to turn off its AI customer-service bot after customers realised it would follow their commands to reply with foul language.
That abuse was annoying rather than costly. But Mr Willison reckons it is only a matter of time before something expensive happens. As he puts it, “we’ve not yet had millions of dollars stolen because of this”. It may not be until such a heist occurs, he worries, that people start taking the risk seriously. The industry does not, however, seem to have got the message. Rather than locking down their systems in response to such examples, it is doing the opposite, by rolling out powerful new tools with the lethal trifecta built in from the start.
This is the clearest explanation yet I've seen of these problems in a mainstream publication. Fingers crossed relevant people with decision-making authority finally start taking this seriously!
Tags: security, ai, prompt-injection, generative-ai, llms, lethal-trifecta, press-quotes
### [Quoting Kate Niederhoffer, Gabriella Rosen Kellerman, Angela Lee, Alex Liebscher, Kristina Rapuano and Jeffrey T. Hancock](https://simonwillison.net/2025/Sep/22/workslop/#atom-everything)We define workslop as AI generated work content that masquerades as good work, but lacks the substance to meaningfully advance a given task.
Here’s how this happens. As AI tools become more accessible, workers are increasingly able to quickly produce polished output: well-formatted slides, long, structured reports, seemingly articulate summaries of academic papers by non-experts, and usable code. But while some employees are using this ability to polish good work, others use it to create content that is actually unhelpful, incomplete, or missing crucial context about the project at hand. The insidious effect of workslop is that it shifts the burden of the work downstream, requiring the receiver to interpret, correct, or redo the work. In other words, it transfers the effort from creator to receiver.
— Kate Niederhoffer, Gabriella Rosen Kellerman, Angela Lee, Alex Liebscher, Kristina Rapuano and Jeffrey T. Hancock, Harvard Business Review
Tags: productivity, ai-ethics, generative-ai, ai, llms, definitions
### [Four new releases from Qwen](https://simonwillison.net/2025/Sep/22/qwen/#atom-everything)It's been an extremely busy day for team Qwen. Within the last 24 hours (all links to Twitter, which seems to be their preferred platform for these announcements):
- Qwen3-Next-80B-A3B-Instruct-FP8 and Qwen3-Next-80B-A3B-Thinking-FP8 - official FP8 quantized versions of their Qwen3-Next models. On Hugging Face Qwen3-Next-80B-A3B-Instruct is 163GB and Qwen3-Next-80B-A3B-Instruct-FP8 is 82.1GB. I wrote about Qwen3-Next on Friday 12th September.
- Qwen3-TTS-Flash provides "multi-timbre, multi-lingual, and multi-dialect speech synthesis" according to their blog announcement. It's not available as open weights, you have to access it via their API instead. Here's a free live demo.
- Qwen3-Omni is today's most exciting announcement: a brand new 30B parameter "omni" model supporting text, audio and video input and text and audio output! You can try it on chat.qwen.ai by selecting the "Use voice and video chat" icon - you'll need to be signed in using Google or GitHub. This one is open weights, as Apache 2.0 Qwen3-Omni-30B-A3B-Instruct, Qwen/Qwen3-Omni-30B-A3B-Thinking, and Qwen3-Omni-30B-A3B-Captioner on HuggingFace. That Instruct model is 70.5GB so this should be relatively accessible for running on expensive home devices.
- Qwen-Image-Edit-2509 is an updated version of their excellent Qwen-Image-Edit model which I first tried last month. Their blog post calls it "the monthly iteration of Qwen-Image-Edit" so I guess they're planning more frequent updates. The new model adds multi-image inputs. I used it via chat.qwen.ai to turn a photo of our dog into a dragon in the style of one of Natalie's ceramic pots.

Here's the prompt I used, feeding in two separate images. Weirdly it used the edges of the landscape photo to fill in the gaps on the otherwise portrait output. It turned the chair seat into a bowl too!

Tags: text-to-speech, ai, qwen, llms, multi-modal-output, llm-release, ai-in-china, generative-ai
### [CompileBench: Can AI Compile 22-year-old Code?](https://simonwillison.net/2025/Sep/22/compilebench/#atom-everything)CompileBench: Can AI Compile 22-year-old Code?
Interesting new LLM benchmark from Piotr Grabowski and Piotr Migdał: how well can different models handle compilation challenges such as cross-compilinggucr for ARM64 architecture?
This is one of my favorite applications of coding agent tools like Claude Code or Codex CLI: I no longer fear working through convoluted build processes for software I'm unfamiliar with because I'm confident an LLM will be able to brute-force figure out how to do it.
The benchmark on compilebench.com currently show Claude Opus 4.1 Thinking in the lead, as the only model to solve 100% of problems (allowing three attempts). Claude Sonnet 4 Thinking and GPT-5 high both score 93%. The highest open weight model scores are DeepSeek 3.1 and Kimi K2 0905, both at 80%.
This chart showing performance against cost helps demonstrate the excellent value for money provided by GPT-5-mini:
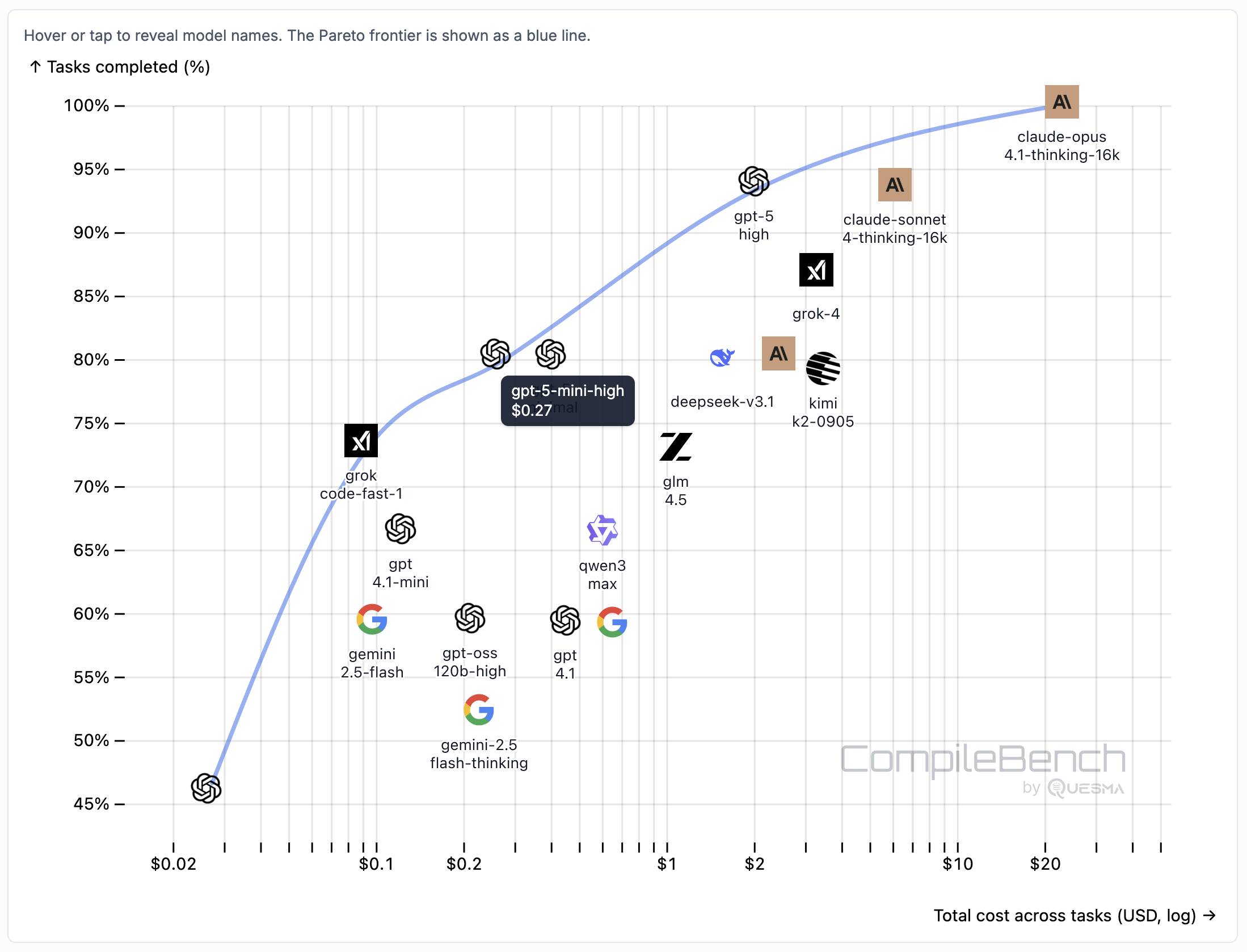
The Gemini 2.5 family does surprisingly badly solving just 60% of the problems. The benchmark authors note that:
When designing the benchmark we kept our benchmark harness and prompts minimal, avoiding model-specific tweaks. It is possible that Google models could perform better with a harness or prompt specifically hand-tuned for them, but this is against our principles in this benchmark.
The harness itself is available on GitHub. It's written in Go - I had a poke around and found their core agentic loop in bench/agent.go - it builds on top of the OpenAI Go library and defines a single tool called run_terminal_cmd, described as "Execute a terminal command inside a bash shell".
The system prompts live in bench/container/environment.go and differ based on the operating system of the container. Here's the system prompt for ubuntu-22.04-amd64:
You are a package-building specialist operating a Ubuntu 22.04 bash shell via one tool: run_terminal_cmd. The current working directory of every run_terminal_cmd is /home/peter.
Execution rules:
- Always pass non-interactive flags for any command that could prompt (e.g.,
-y,--yes,DEBIAN_FRONTEND=noninteractive).- Don't include any newlines in the command.
- You can use sudo.
If you encounter any errors or issues while doing the user's request, you must fix them and continue the task. At the end verify you did the user request correctly.
<p><small></small>Via <a href="https://news.ycombinator.com/item?id=45332814">Hacker News</a></small></p>
<p>Tags: <a href="https://simonwillison.net/tags/go">go</a>, <a href="https://simonwillison.net/tags/ai">ai</a>, <a href="https://simonwillison.net/tags/prompt-engineering">prompt-engineering</a>, <a href="https://simonwillison.net/tags/generative-ai">generative-ai</a>, <a href="https://simonwillison.net/tags/llms">llms</a>, <a href="https://simonwillison.net/tags/ai-assisted-programming">ai-assisted-programming</a>, <a href="https://simonwillison.net/tags/evals">evals</a>, <a href="https://simonwillison.net/tags/coding-agents">coding-agents</a></p>
ChatGPT Is Blowing Up Marriages as Spouses Use AI to Attack Their Partners
ChatGPT Is Blowing Up Marriages as Spouses Use AI to Attack Their Partners
Maggie Harrison Dupré for Futurism. It turns out having an always-available "marriage therapist" with a sycophantic instinct to always take your side is catastrophic for relationships.
The tension in the vehicle is palpable. The marriage has been on the rocks for months, and the wife in the passenger seat, who recently requested an official separation, has been asking her spouse not to fight with her in front of their kids. But as the family speeds down the roadway, the spouse in the driver’s seat pulls out a smartphone and starts quizzing ChatGPT’s Voice Mode about their relationship problems, feeding the chatbot leading prompts that result in the AI browbeating her wife in front of their preschool-aged children.
<p>Tags: <a href="https://simonwillison.net/tags/ai">ai</a>, <a href="https://simonwillison.net/tags/generative-ai">generative-ai</a>, <a href="https://simonwillison.net/tags/chatgpt">chatgpt</a>, <a href="https://simonwillison.net/tags/llms">llms</a>, <a href="https://simonwillison.net/tags/ai-ethics">ai-ethics</a>, <a href="https://simonwillison.net/tags/ai-personality">ai-personality</a></p>
Democratizing your data access with AI agents
Jeff Hollan, director of product at Snowflake, joins Ryan to discuss the role that data plays in making AI and AI agents better. Along the way, they discuss how a database leads to an AI platform, Snowflake’s new data marketplace, and the role data will play in AI agents.
Scaling Muse: How Netflix Powers Data-Driven Creative Insights at Trillion-Row Scale
By Andrew Pierce, Chris Thrailkill, Victor Chiapaikeo
At Netflix, we prioritize getting timely data and insights into the hands of the people who can act on them. One of our key internal applications for this purpose is Muse. Muse’s ultimate goal is to help Netflix members discover content they’ll love by ensuring our promotional media is as effective and authentic as possible. It achieves this by equipping creative strategists and launch managers with data-driven insights showing which artwork or video clips resonate best with global or regional audiences and flagging outliers such as potentially misleading (clickbait-y) assets. These kinds of applications fall under Online Analytical Processing (OLAP), a category of systems designed for complex querying and data exploration. However, enabling Muse to support new, more advanced filtering and grouping capabilities while maintaining high performance and data accuracy has been a challenge. Previous posts have touched on artwork personalization and our impressions architecture. In this post, we’ll discuss some steps we’ve taken to evolve the Muse data serving layer to enable new capabilities while maintaining high performance and data accuracy.

An Evolving Architecture
Like many early analytics applications, Muse began as a simple dashboard powered by batch data pipelines (Spark¹) and a modest Druid² cluster. As the application evolved, so did user demands. Users wanted new features like outlier detection and notification delivery, media comparison and playback, and advanced filtering, all while requiring lower latency and supporting ever-growing datasets (in the order of trillions of rows a year). One of the most challenging requirements was enabling dynamic analysis of promotional media performance by “audience” affinities: internally defined, algorithmically inferred labels representing collections of viewers with similar tastes. Answering questions like “Does specific promotional media resonate more with Character Drama fans or Pop Culture enthusiasts?” required augmenting already voluminous impression and playback data. Supporting filtering and grouping by these many-to-many audience relationships led to a combinatorial explosion in data volume, pushing the limits of our original architecture.
To address these complexities and support the evolving needs of our users, we undertook a significant evolution of Muse’s architecture. Today’s Muse is a React app that queries a GraphQL layer served with a set of Spring Boot GRPC microservices. In the remainder of this post, we’ll focus on steps we took to scale the data microservice, its backing ETL, and our Druid cluster. Specifically, we’ve changed the data model to rely on HyperLogLog (HLL) sketches, used Hollow for access to in-memory, precomputed aggregates, and taken a series of steps to tune Druid. To ensure the accuracy of these changes, we relied heavily on internal debugging tools to validate pre- and post-changes.

Moving to HyperLogLog (HLL) Sketches for Distinct Counts
Some of the most important metrics we track are impressions, the number of times an asset is shown to a user within a time window, and qualified plays, which links a playback event with a minimum duration back to a specific impression. Calculating these metrics requires counting distinct users. However, performing distinct counts in distributed systems is resource-intensive and challenging. For instance, to determine how many unique profiles have ever seen a particular asset, we need to compare each new set of profile ids with those from all days before it, potentially spanning months or even years.
For performance, we can trade accuracy. The Apache Datasketches library allows us to get distinct count estimates that are within a 1–2% error. This is tunable with a precision parameter called logK (0.8% in our case with logK of 17). We build sketches in two places:
- During Druid ingest: we use the HLLSketchBuild aggregator with Druid rollup set to true to reduce our data in preparation for fast distinct counting
- During our Spark ETL: we persist precomputed aggregates like all-time impressions per asset in the form of HLL sketches. Each day, we merge a new HLL sketch into the existing one using a combination of hll_union and hll_union_agg (functions added by our very own Ryan Berti)

HLL has been a huge performance boost for us both within the serving and ETL layer. Across our most common OLAP query patterns, we’ve seen latencies reduce by approx 50%. Nevertheless, running APPROX_COUNT_DISTINCT over large date ranges on the Druid cluster for very large titles exhausts limited threads, especially in high-concurrency situations. To further offload Druid query volume and preserve cluster threads, we’ve also relied extensively on the Hollow library.
Hollow as a Read-Only Key Value Store for Precomputed Aggregates
Our in-house Hollow³ infrastructure allows us to easily create Hollow feeds — essentially highly compressed and performant in-memory key/value stores — from Iceberg⁴ tables. In this setup, dedicated producer servers listen for changes to Iceberg tables, and when updates occur, they push the latest data to downstream consumers. On the consumer side, our Spring Boot applications listen to announcements from these producers and automatically refresh in-memory caches with the latest dataset.
This architecture has enabled us to migrate several data access patterns from Druid to Hollow, specifically ones with a limited number of parameter combinations per title. One of these was fetching distinct filter dimensions. For example, while most Netflix-branded titles are released globally, licensed titles often have rights restrictions that limit their availability to specific countries and time windows. As a result, a particular licensed title might only be available to members in Germany and Luxembourg.

In the past, retrieving these distinct country values per asset required issuing a SELECT DISTINCT query to our Druid cluster. With Hollow, we maintain a feed of distinct dimension values, allowing us to perform stream operations like the one below directly on a cached dataset.
/**
* Returns the possible filter values for a dimension such as countries
*/
public List<Dimension> getDimensions(long movieId, String dimensionId) {
// Access in-memory Hollow feed with near instant query time
Map<String, List<Dimension>> dimensions = dimensionsHollowConsumer.lookup(movieId);
return dimensions.getOrDefault(dimensionId, List.of()).stream()
.sorted(Comparator.comparing(Dimension::getName))
.toList();
}
Although it adds complexity to our service by requiring more intricate request routing and a higher memory footprint, pre-computed aggregates have given us greater stability and performance. In the case of fetching distinct dimensions, we’ve observed query times drop from hundreds of milliseconds to just tens of milliseconds. More importantly, this shift has offloaded high concurrency demands from our Druid cluster, resulting in more consistent query performance. In addition to this use case, cached pre-computed aggregates also power features such as retrieving recently launched titles, accessing all-time asset metrics, and serving various pieces of title metadata.
Tuning Druid
Even with the efficiencies gained from HLL sketches and Hollow feeds, ensuring that our Druid cluster operates performantly has been an ongoing challenge. Fortunately, at Netflix, we are in the company of multiple Apache Druid PMC members like Maytas Monsereenusorn and Jesse Tuğlu who have helped us wring out every ounce of performance. Some of the key optimizations we’ve implemented include:
- Increasing broker count relative to historical nodes: We aim for a broker-to-historical ratio close to the recommended 1:15, which helps improve query throughput.
- Tuning segment sizes: By targeting the 300–700 MB “sweet spot” for segment sizes, primarily using the tuningConfig.targetRowsPerSegment parameter during ingestion — we ensure that each segment a single historical thread scans is not overly large.
- Leveraging Druid lookups for data enrichment: Since joins can be prohibitively expensive in Druid, we use lookups at query time for any key column enrichment.
- Optimizing search predicates: We ensure that all search predicates operate on physical columns rather than virtual ones, creating necessary columns during ingestion with transformSpec.transforms.
- Filtering and slimming data sources at ingest: By applying filters within transformSpec.filter and removing all unused columns in dimensionsSpec.dimensions, we keep our data sources lean and improve the possibility of higher rollup yield.
- Use of multi-value dimensions: Exploiting the Druid multi-value dimension feature was key to overcoming the “many-to-many” combinatorial quandary when integrating audience filtering and grouping functionality mentioned in the “An Evolving Architecture” section above.
Together, these optimizations, combined with previous ones, have decreased our p99 Druid latencies by roughly 50%.
Validation & Rollout
Rolling out these changes to our metrics system required a thorough validation and release strategy. Our approach prioritized both data integrity and user trust, leveraging a blend of automation, targeted tooling, and incremental exposure to production traffic. At the core of our strategy was a parallel stack deployment: both the legacy and new metric stacks operated side-by-side within the Muse Data microservice. This setup allowed us to validate data quality, monitor real-world performance, and mitigate risk by enabling seamless fallback at any stage.

We adopted a two-pronged validation process:
- Automated Offline Validation: Using Jupyter Notebooks, we automated the sampling and comparison of key metrics across both the legacy and new stacks. Our sampling set included a representative mix: recently accessed titles, high-profile launches, and edge-case titles with unique handling requirements. This allowed us to catch subtle discrepancies in metrics early in the process. Iterative testing on this set guided fixes, such as tuning the HLL logK parameter and benchmarking end-to-end latency improvements.
- In-App Data Comparison Tooling: To facilitate rapid triage, we built a developer-facing comparison feature within our application that displays data from both the legacy and new metric stacks side by side. The tool automatically highlights any significant differences, making it easy to quickly spot and investigate discrepancies identified during offline validation or reported by users.
We implemented several release best practices to mitigate risk and maintain stability:
- Staggered Implementation by Application Segment: We developed and deployed the new metric stack in stages, focusing on specific application segments. This meant building out support for asset types like artwork and video separately and then further dividing by CEE phase (Explore, Exploit). By implementing changes segment by segment, we were able to isolate issues early, validate each piece independently, and reduce overall risk during the migration.
- Shadow Testing (“Dark Launch”): Prior to exposing the new stack to end users, we mirrored production traffic asynchronously to the new implementation. This allowed us to validate real-world latency and catch potential faults in a live environment, without impacting the actual user experience.
- Granular Feature Flagging: We implemented fine-grained feature flags to control exposure within each segment. This allowed us to target specific user groups or titles and instantly roll back or adjust the rollout scope if any issues were detected, ensuring rapid mitigation with minimal disruption.
Learnings and Next Steps
Our journey with Muse tested the limits of several parts of the stack: the ETL layer, the Druid layer, and the data serving layer. While some choices, like leveraging Netflix’s in-house Hollow infrastructure, were influenced by available resources, simple principles like offloading query volume, pre-filtering of rows and columns before Druid rollup, and optimizing search predicates (along with a bit of HLL magic) went a long way in allowing us to support new capabilities while maintaining performance. Additionally, engineering best practices like producing side-by-side implementations and backwards-compatible changes enabled us to roll out revisions steadily while maintaining rigorous validation standards. Looking ahead, we’ll continue to build on this foundation by supporting a wider range of content types like Live and Games, incorporating synopsis data, deepening our understanding of how assets work together to influence member choosing, and incorporating new metrics to distinguish between “effective” and “authentic” promotional assets, in service of helping members find content that truly resonates with them.
¹ Apache Spark is an open-source analytics engine for processing large-scale data, enabling tasks like batch processing, machine learning, and stream processing.
² Apache Druid is a high-performance, real-time analytics database designed for quickly querying large volumes of data.
³ Hollow is a Java library for efficient in-memory storage and access to moderately sized, read-only datasets, making it ideal for high-performance data retrieval.
⁴ Apache Iceberg is an open-source table format designed for large-scale analytical datasets stored in data lakes. It provides a robust and reliable way to manage data in formats like Parquet or ORC within cloud object storage or distributed file systems.
Scaling Muse: How Netflix Powers Data-Driven Creative Insights at Trillion-Row Scale was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
How to Measure the Business Impact of AI

Artificial intelligence (AI) has moved beyond proof-of-concept experiments, but many organizations still find it difficult to prove it delivers tangible value rather than hype. While model accuracy and innovation often capture the spotlight, executives want to see financial outcomes, and data scientists need clear technical benchmarks that validate success.
This gap demands rigorous measurement frameworks that tie advanced metrics to real-world results. When AI initiatives are evaluated through a structured lens that blends impact with technical depth, enterprises can more confidently scale adoption, communicate value across stakeholders, and position AI as a strategic driver rather than another emerging technology.
1. Financial ROI and Cost Savings
Traditional return on investment is still a cornerstone of business evaluation. However, measuring AI’s impact requires connecting model performance to real financial outcomes rather than abstract technical wins.
Recent surveys show that less than 20% of companies track key performance indicators (KPIs) for their generative AI solutions, which leaves most without a clear picture of value creation. The straightforward impact often comes from direct cost reductions, whether through automating repetitive processes, optimizing resource use, or reducing error rates that lead to expensive rework.
A fraud detection system offers a clear example. Lowering false positives saves money by cutting unnecessary investigations and freeing analysis to focus on higher-value tasks. To ensure credibility, brands must compare these gains to pre-AI baselines, which gives data teams a concrete view of how AI translates into measurable financial performance.
2. Productivity and Process Efficiency Gains
AI’s effect on productivity and efficiency is most evident in its ability to accelerate throughput, shorten cycle times, and remove bottlenecks that once slowed operations. In manufacturing, AI-driven robots and automation systems have reduced human error while boosting consistency and speed, proving especially valuable for scaling production without sacrificing quality.
Similar benefits are emerging in other industries, from reduced model training times to smarter supply chain optimization that balances inventory with real-time demand. Measuring these improvements requires looking at KPIs that connect directly to business performance, such as time-to-insight for data teams or orders processed per hour in logistics.
To ensure accuracy in evaluating impact, many use A/B testing or randomized control trials to isolate AI’s role. This approach gives leaders confidence that efficiency gains stem from intelligent automation rather than unrelated factors.
3. Strategic and Competitive Advantage
Measuring AI’s strategic and competitive advantage is less straightforward than tracking financial returns, but it shapes long-term growth. Businesses can evaluate impact through metrics like market share expansion, speed-to-market with AI-enabled features, intellectual property development, and the ability to attract or retain skilled talent.
Compliance also factors in, as metrics often reveal whether a company meets government or industry regulations. At the same time, tracking how AI adoption influences learning curves and data network effects shows how quickly an organization can innovate and scale.
For instance, those leveraging AI-driven demand forecasting improve pricing strategies and inventory management. Doing so allows them to outpace rivals in volatile markets and secure a more resilient position.
4. Customer and User Experience Metrics
AI’s impact on customer and user experience is best measured through improvements in satisfaction and retention, which directly affect long-term growth. Metrics like Net Promoter Score, churn reduction, or customer lifetime value become more meaningful when tied to AI-enabled personalization or predictive support that enhances interactions at scale. A clear example is customer support bots that reduce resolution times and improve customer satisfaction scores by providing faster, more accurate responses.
Beyond these direct indicators, brands can monitor proxy signals such as longer session lengths or evolving usage patterns in AI-enabled tools to understand how effectively AI shapes user behavior. These measures reveal how AI-driven experiences strengthen customer relationships and increase loyalty. They also offer a competitive edge that extends beyond efficiency or cost savings.
5. Model Performance and Decision Quality
Business impact in AI goes beyond accuracy metrics, because what matters is the relevance of decisions and their outcomes. Suppose a system generates 100% correct recommendations. The overall decision quality can decline if humans fail to consistently follow those suggestions, which highlights the gap between technical performance and practical adoption.
To bridge this, organizations must evaluate metrics beyond precision and recall, such as calibration, economic utility, and cost-sensitive measures that reflect real-world trade-offs. For example, a recommendation engine should be judged on click-through rates and the net profit uplift it delivers by improving the relevance of offers to customers.
Building a Framework for Sustainable AI Impact
Practitioners must blend quantitative rigor with business context to ensure AI measurement reflects technical accuracy and real-world outcomes. By linking model performance to financial, operational, and strategic metrics, they can communicate value in a way that resonates across stakeholders. Data leaders should build repeatable impact-measurement frameworks tailored to their employer’s goals and create a foundation for sustainable and scalable AI adoption.
7 Things Your Embedded Analytics Strategy Needs to Address

Embedded analytics is when you bring charts, dashboards, and reports inside another app, so users don’t have to switch tabs or log into another tool to see insights.
Nowadays, product teams are turning to embedded analytics solutions as a way to boost engagement, reduce churn, and give users instant answers in context.
But here’s the thing: slapping a dashboard onto your product isn’t a strategy. And it won’t suddenly drive adoption or deliver value. If you want your embedded analytics to actually work for your users and your business, you need a real plan.
In this post, let’s look at some key areas your embedded analytics strategy needs to address.
1. Data Governance and Security
Nobody’s going to use your analytics if they don’t trust the data or worry about who can see what.
That’s where governance comes in. You need role-based access, row-level security, and clear data lineage. In other words: the right people see the right data — and only that.
And if you’re embedding analytics into a customer-facing product? Even more important. You’re dealing with sensitive user data. Compliance with regulations like GDPR, HIPAA, or SOC2 is mandatory.
Today’s advanced embedded analytics platforms let you manage access controls at a granular level, so your data stays locked down without slowing users down. Governance models have the ability to span everything from raw data to final output, so nothing slips through the cracks, and data resource access controls sync seamlessly with app user-level access controls.
1. User Experience and Design Integration
If your embedded analytics feels tacked on, users probably won’t engage with it. The experience needs to feel like a natural part of your product, not some external cookie cutter dashboard squished into a frame.
This means ensuring clean design, consistent styling, smooth transitions and meaningful integrations with existing interface elements. Users shouldn’t feel like they’ve left your app just to look at some charts.
Avoid the classic trap of dumping a bunch of data-heavy visualizations into a page and calling it a day. Nobody wants a wall of graphs. Instead, focus on context. Show the right data, at the right moment, in the right format. Make it responsive. Make it intuitive. And above all, make it useful.
Pyramid Analytics makes this easier by allowing you to create interactive visualizations using customized charts, infographics, and dashboards via JavaScript, Angular or React injections. You can enrich your analysis with contextual commentary, dynamic slicers, external content, images, and interactive data-driven components. You can even embed a chat box so users can ask questions about their data and follow up with further queries using any language. Basically, Pyramid brings conversational analytics and GenBI inside your app.
3. Performance and Scalability
Nobody wants to wait 20 seconds for a chart to load, especially if they’re mid-task. Lag kills momentum and adoption. Your embedded analytics needs to feel snappy, no matter how much data you’re dealing with or how many users are hitting it at once.
Start with caching. Store frequently accessed queries and dashboards so your system doesn’t have to crunch the same numbers over and over. Even a few seconds shaved off the load time makes a big difference.
Then look at pre-aggregations. Instead of calculating everything in real time, compute common metrics in advance, such as weekly revenue or top products. Store those summaries in a way that’s ready to go when the user needs it.
As your usage grows, so should your infrastructure. Set up autoscaling for your servers or cloud environment. Break up monoliths into services that can scale independently. And monitor performance — track slow queries, laggy endpoints, and dashboard load times.
4. Developer-Friendliness and Extensibility
Your dev team is already stretched thin. If embedded analytics slows them down or forces workarounds, it’s going to be a problem. Start with APIs and SDKs. You’ll want a platform that offers flexible options for embedding, styling, and controlling the analytics layer, without forcing you into a rigid workflow.
Look for tools that play nice with your existing stack. Whether you’re using React, Angular, or plain old HTML, the analytics component should drop in cleanly and work well with your app’s authentication, routing, and theming.
Think about version control too. Can you manage reports and dashboards like code? Can you reuse components across different parts of the product? These things matter when your analytics setup starts to grow. Open-source options like Apache Superset can be great here — it’s developer-friendly, highly customizable, and gives you the control to shape the analytics experience the way you want it.
And finally, extensibility. Your strategy should leave room to build custom visualizations, add interactive elements, or connect to other parts of your system. You don’t want to be locked into a black box. If your devs can move fast, your analytics can evolve with your product.
5. Self-Service and Customization Capabilities
Your app’s users likely aren’t data analysts. Your embedded analytics should make it easy for non-technical users to get what they need, without submitting a ticket or pinging someone on Slack. That means filters that actually make sense, ad hoc queries that don’t require SQL code, and the ability to save views so users can revisit the same slice of data again later.
Flexibility is also key. Maybe one user wants a simple table, another prefers a bar chart, and a third wants to export the raw data. Give them options. Let them customize the experience a bit, without overwhelming them.
And don’t forget context. The best embedded analytics surfaces just enough data to support a decision, right when the user needs it — not buried three clicks deep in a “Reports” tab.
If users feel empowered to explore, they’ll keep coming back. If they feel confused or boxed in, they’ll abandon it fast.
6. Monetization and Licensing Considerations
Here’s a question a lot of teams skip: should you charge for analytics? In some products, embedded analytics is a killer feature — something users would happily pay for. In others, it’s expected to be part of the core experience. Your strategy should make that call early.
If you’re going the freemium route, decide what level of analytics is free and what gets gated. Maybe basic reports are included, but advanced filtering or export options sit behind a paywall.
On the other hand, if analytics is critical to your users’ workflow — say, in a B2B SaaS platform — charging for access might make sense. Just be ready to justify the price tag with delivered value.
Also, think about the cost to you. Some embedded BI tools charge by the viewer, by the report, or by the query. That can get expensive fast, especially if you’re scaling or serving thousands of customers. If your usage is high-volume, look into flat-rate or usage-based models. Or, consider self-hosted options if you have the resources.
7. Analytics Adoption and End-User Enablement
Even the best analytics setup won’t help if no one uses it. Usually, adoption isn’t automatic. You’ve got to guide users in.
Start with onboarding. Use tooltips, walkthroughs, and prompts to show users how to interact with the data. A platform like Userpilot can help you build in-app guidance without writing a ton of code. Next, make it contextual. Help should show up where and when it’s needed — not buried in a help doc. Think of subtle prompts like “Want to dig deeper?” or “Here’s how to filter this.”
Education is ongoing. You might need to offer short videos, webinars, or even in-app tours as new features roll out. Help users to feel confident, not overwhelmed.
And don’t forget to measure what’s working. Track usage — which dashboards get opened, which features get ignored, where users drop off. Product analytics tools or even basic usage logs can show you what to tweak.
Wrapping Up
Embedded analytics is more than just showing pretty data inside your app. That data needs to be something people actually use to make decisions, spot trends, or take action faster.
But for it to work, you need a real strategy. One that covers design, security, performance, self-service, developer needs, pricing, and user adoption.
Get those pieces right, and embedded analytics stops being a “nice-to-have.” It becomes a key part of your product experience and a competitive edge.
WhatsApp can now translate messages on iOS and Android
The company notes that translations occur on the user's device where WhatsApp cannot see them, which means messages remain encrypted.
Dedicated mobile apps for vibe coding have so far failed to gain traction
An analysis of mobile apps offering vibe coding tools shows few have found traction.
Mercor’s Brendan Foody breaks down AI’s impact on hiring at TechCrunch Disrupt 2025
On the AI Stage at TechCrunch Disrupt 2025, Mercor co-founder and CEO Brendan Foody will break down how artificial intelligence is transforming not just how we work, but also who gets to work in the first place.
Vinod Khosla on AI, moonshots, and building enduring startups — all at TechCrunch Disrupt 2025
Vinod Khosla, founder of Khosla Ventures, takes the Disrupt Stage for a candid fireside chat on AI, climate, healthcare, and transformational startups. Hear blunt, big-picture advice from one of tech’s most legendary investors, and learn what founders truly need to succeed in turbulent times.
Tim Chen has quietly become of one the most sought-after solo investors
Tim Chen, solo VC at his firm Essence VC, just closed his fourth fund, a fresh $41 million, without even trying.
Alloy is bringing data management to the robotics industry
Australia-based Alloy thinks it can help robotics firms with their data problem: The startup is building data infrastructure to help companies process and organize all the data their robots collect.
Meta launches super PAC to fight AI regulation as state policies mount
Meta is investing 'tens of millions' into a new pro-AI super PAC called the American Technology Excellence Project to fight state-level tech policy that would regulate AI.
AI company Superpanel raises $5.3M seed to automate legal intake
Superpanel announced Tuesday a seed $5.3 million raise in a round co-led by Outlander VC and Field Ventures.
StrictlyVC at TechCrunch Disrupt 2025: The full LP track agenda revealed
StrictlyVC joins TechCrunch Disrupt 2025 for an investor-only LP track on October 28. Explore the full agenda and grab your investor tickets before prices rise on Sept 26.
European airports still dealing with disruptions days after ransomware attack
Four major European airports in Berlin, Brussels, Dublin, and London continue to have flight delays due to a cyberattack on Collins Aerospace, a provider of check-in systems.
TechCrunch Disrupt 2025 ticket rates increase after just 4 days
Your window to save up to $668 on TechCrunch Disrupt 2025 closes in just 4 days. Regular Bird pricing ends September 26 at 11:59 p.m. PT. Join 10,000+ founders, investors, and innovators shaping the future of tech at the conference where startup legends like Discord and Mint got their start.
Former NotebookLM devs’ new app, Huxe, taps audio to help you with news and research
Three devs who worked on NotebookLM are now building an app called Huxe, which can help users dive deep into topics by generating a "podcast" with multiple AI hosts.
Google revamps its Play Store with AI features and more
Users can expect more personalization, a redesigned Apps tab, new Play Games experience, and other features that leverage Gemini AI.
Goodnotes collaborative docs and AI assitant to cater to professional users
Note taking app Goodnotes is launching new features to cater to professional users.
Sila opens U.S. factory to make silicon anodes for energy dense EV batteries
Sila has been building the facility on Moses Lake, Washington, for nearly two years. Now, it's poised to start volume production.
After India, OpenAI launches its affordable ChatGPT Go plan in Indonesia
OpenAI is launching ChatGPT Go in Indonesia to compete with Google AI Plus plan.
Rocket.new, one of India’s first vibe-coding startups, snags $15M from Accel, Salesforce Ventures
Rocket.new has surged to 400,000 users and $4.5M ARR in three months.
Mirror founder Brynn Putnam to unveil her gaming hardware startup at TechCrunch Disrupt 2025
Seven years after unveiling Mirror at TechCrunch Disrupt 2018, Brynn Putnam is returning to the stage where it all began.
Facebook is getting an AI dating assistant
Facebook Dating's AI assistant is supposed to help users build their profiles and find the matches they're looking for.
Stellantis cancels plans for an electrified Jeep Gladiator
The move comes a week after the automaker axed plans to produce an all-electric Ram pickup truck.
Meta starts rolling out built-in message translation in WhatsApp, with support for 19+ languages on iOS and six on Android (Jess Weatherbed/The Verge)

![]() Jess Weatherbed / The Verge:
Jess Weatherbed / The Verge:
Meta starts rolling out built-in message translation in WhatsApp, with support for 19+ languages on iOS and six on Android — Translation is rolling out to iPhone and Android users, and will expand to support additional languages in the future.
Source: Stripe is in talks to buy back shares from its VC backers at a $106.7B valuation; Sequoia bought $861M worth of shares in 2024 at a $70B valuation (Dan Primack/Axios)

![]() Dan Primack / Axios:
Dan Primack / Axios:
Source: Stripe is in talks to buy back shares from its VC backers at a $106.7B valuation; Sequoia bought $861M worth of shares in 2024 at a $70B valuation — Stripe is in talks to repurchase shares from venture capital backers at a $106.7 billion valuation, Axios has learned.
A look at London-based "neocloud" startup Nscale, which landed a $500M investment from Nvidia and aims to scale up to 300K GPUs globally, on par with CoreWeave (Iain Martin/Forbes)

![]() Iain Martin / Forbes:
Iain Martin / Forbes:
A look at London-based “neocloud” startup Nscale, which landed a $500M investment from Nvidia and aims to scale up to 300K GPUs globally, on par with CoreWeave — Nscale, a tiny London-based startup, just landed $500 million in backing from AI chip giant Nvidia to help build …
Larry Ellison is turning into a media magnate, potentially controlling CBS, CNN, TikTok, and more, amid a regulatory environment favorable to Trump allies (New York Times)

![]() New York Times:
New York Times:
Larry Ellison is turning into a media magnate, potentially controlling CBS, CNN, TikTok, and more, amid a regulatory environment favorable to Trump allies — When Larry Ellison entered his ninth decade in 2024, his high-profile lifestyle seemed to be receding.
Sam Altman says OpenAI wants to create "a factory that can produce a gigawatt of new AI infrastructure every week" and plans to reveal more details this year (Sam Altman)
![]() Sam Altman:
Sam Altman:
Sam Altman says OpenAI wants to create “a factory that can produce a gigawatt of new AI infrastructure every week” and plans to reveal more details this year — Growth in the use of AI services has been astonishing; we expect it to be even more astonishing going forward.
Revolut says it plans to invest $13B, including $4B in the UK, and expand into 30 new geographies by the end of the decade, aiming to reach 100M users globally (Aisha S Gani/Bloomberg)

![]() Aisha S Gani / Bloomberg:
Aisha S Gani / Bloomberg:
Revolut says it plans to invest $13B, including $4B in the UK, and expand into 30 new geographies by the end of the decade, aiming to reach 100M users globally — Revolut Ltd. plans to enter 30 new geographies by the end of the decade, a strategy that will ultimately see the fintech invest $13 billion …
Meta launches the American Technology Excellence Project, a super PAC to fight AI policy bills at the state level; it previously launched a California PAC (Ashley Gold/Axios)

![]() Ashley Gold / Axios:
Ashley Gold / Axios:
Meta launches the American Technology Excellence Project, a super PAC to fight AI policy bills at the state level; it previously launched a California PAC — Meta launched a new super PAC on Tuesday to help fight off what it sees as onerous AI and tech policy bills across the country, per an announcement shared exclusively with Axios.
Google adds a new You tab to Google Play, featuring player account information, personalized content recommendations, rewards, and more (Jess Weatherbed/The Verge)

![]() Jess Weatherbed / The Verge:
Jess Weatherbed / The Verge:
Google adds a new You tab to Google Play, featuring player account information, personalized content recommendations, rewards, and more — Curated content, rewards, subscriptions, stats, and updates will live under a new ‘You’ tab. … Google Play is adding a new centralized user hub …
Google announces Play Games Sidekick for Android, an in-game overlay that provides access to Gemini Live while playing games downloaded from the Play Store (Abner Li/9to5Google)

![]() Abner Li / 9to5Google:
Abner Li / 9to5Google:
Google announces Play Games Sidekick for Android, an in-game overlay that provides access to Gemini Live while playing games downloaded from the Play Store — Google is bringing Gemini Live to Android gaming with Play Games Sidekick. Billed as a coach, it's meant to be a …
Amazon plans to close all 19 Fresh stores in the UK and convert five of them into Whole Foods Market shops, four years after launching the first in London (Lauren Almeida/The Guardian)

![]() Lauren Almeida / The Guardian:
Lauren Almeida / The Guardian:
Amazon plans to close all 19 Fresh stores in the UK and convert five of them into Whole Foods Market shops, four years after launching the first in London — Company confirms plan to shut 19 shops with stronger focus on Whole Foods outlets after concept of stores without tills fails to catch on
Pharmacy benefit management startup Capital Rx raised $400M, including a $252M Series F; it has raised $607M+ to date and was valued at $3.25B pre-Series F (Claire Rychlewski/Axios)

![]() Claire Rychlewski / Axios:
Claire Rychlewski / Axios:
Pharmacy benefit management startup Capital Rx raised $400M, including a $252M Series F; it has raised $607M+ to date and was valued at $3.25B pre-Series F
Filing: CFPB scrapped a 2024 Apple credit card settlement implemented under Biden, ending oversight requirements years early; Apple had already paid a $25M fine (Christian Martinez/Reuters)

![]() Christian Martinez / Reuters:
Christian Martinez / Reuters:
Filing: CFPB scrapped a 2024 Apple credit card settlement implemented under Biden, ending oversight requirements years early; Apple had already paid a $25M fine — The Consumer Financial Protection Bureau has scraped settlements with Apple (AAPL.O) and U.S. Bank (USBUB.UL) …
The US Secret Service says it has dismantled 300+ SIM card servers in the NYC area that could have disrupted communications ahead of the UN General Assembly (Myles Miller/Bloomberg)

![]() Myles Miller / Bloomberg:
Myles Miller / Bloomberg:
The US Secret Service says it has dismantled 300+ SIM card servers in the NYC area that could have disrupted communications ahead of the UN General Assembly — Federal agents dismantled a network of devices in the New York area that was used to threaten senior US government officials …
London-based Fnality, which lets banks transact in a digital cash asset backed with funds at the Bank of England, raised $136M led by BoA, Citigroup, and others (Anna Irrera/Bloomberg)

![]() Anna Irrera / Bloomberg:
Anna Irrera / Bloomberg:
London-based Fnality, which lets banks transact in a digital cash asset backed with funds at the Bank of England, raised $136M led by BoA, Citigroup, and others — Fnality International Ltd., a UK-based blockchain-payments company, has raised $136 million in a funding round led …
Auterion, which provides autopilot and swarming software for military drones, raised $130M led by Bessemer at a $600M+ valuation, says it has ~$100M in revenue (Bloomberg)

![]() Bloomberg:
Bloomberg:
Auterion, which provides autopilot and swarming software for military drones, raised $130M led by Bessemer at a $600M+ valuation, says it has ~$100M in revenue — Auterion, a startup that provides software to military drones, has raised $130 million to expand its operations abroad …
Has the UK’s Cyber Essentials scheme failed?
The decade-old government-backed scheme was designed to help businesses protect themselves from cyberattack. Vanishingly few have signed up.
Deploying AI: Balancing Power, Performance and Place
A return to Scandinavia for two mid-September Tech Monitor roundtables in partnership with AMD.
Reducing the burden on SOC teams requires context, context, and more context
SOC teams often find themselves overwhelmed by tidal waves of threats. What they need now, more than ever, are AI-powered security graphs.
Intel shifts driver support for 11th-14th gen Core CPUs to legacy branch

On Monday, Intel confirmed that it has split graphics driver support into two tracks: Core Ultra processors will keep monthly updates and day-0 game support, while 11th through 14th-generation chips shift to a legacy model with quarterly security and critical fixes only. Starting with the September 19 update, those older...
Read Entire Article
Discovery of massive lava tubes on Venus raises new questions for science

Massive lava-carved tunnels have been confirmed beneath the surface of Venus, providing the strongest evidence yet that the planet's volcanic past created underground networks unlike those on any other world in the solar system.
Read Entire Article
Hideo Kojima reveals P.T.-like horror OD, Physint cast, AR game, and Death Stranding anime

The trailer for OD, subtitled Knock, has been getting the most attention from the 2-hour stream. The clip was created using in-engine footage from the Unreal 5 game, and it looks spectacular. It's also impressively creepy, which bodes well for those still lamenting the canceled Silent Hills, for which P.T....
Read Entire Article
MediaTek challenges Qualcomm with new Dimensity 9500 3nm flagship chip

The launch puts MediaTek squarely into a renewed battle with Qualcomm, whose Snapdragon 8 Elite Gen 5 processor will power rival devices from manufacturers such as Xiaomi. Both chips employ "all-big-core" CPU architectures and dedicated hardware for generative AI, signaling how the premium smartphone market has become defined by technical...
Read Entire Article
Apple, Nvidia, Intel among 15 early customers for TSMC's 2nm process – despite huge price hike

Claims regarding TSMC's N2 customers come from KLA, a major semiconductor equipment supplier. At the Goldman Sachs Communacopia & Technology Conference 2025, Ahmad Khan, President of KLA's combined product and customer organization, Semiconductor Products and Customers, said there are around 15 companies designing chips for N2.
Read Entire Article
Tesla robotaxis crash within days of Austin pilot launch

A report to the federal government reveals that Tesla's robotaxi fleet in Austin suffered three crashes soon after the service began on June 23. Forbes reports that the company's data is vague and heavily redacted, but one or more of the accidents might have occurred on the first day.
Read Entire Article
YouTuber shows upgrading the iPhone 17 Pro Max from 256GB to 1TB is possible, but not easy

The iPhone 17 Pro Max starts at $1,199 for the base 256GB model. Moving to 512GB, 1TB, or 2TB costs an extra $200 each step up, with the $1,999 variant at the top of the stack.
Read Entire Article
Nvidia to invest $100 billion in OpenAI for 10 gigawatts of AI computing power

Nvidia is preparing to make one of the largest corporate investments in history, committing as much as $100 billion to OpenAI as part of a sweeping agreement to expand the infrastructure underpinning artificial intelligence. The deal involves OpenAI purchasing millions of Nvidia's high-performance processors to support the build-out of up...
Read Entire Article
Nvidia RTX 5090 finally drops to $1,999 as RTX 5080 sells below MSRP in the United States

Nvidia's consumer Blackwell flagship has appeared on Walmart's website at its $1,999 official price, while the RTX 5080 is 7% under MSRP at $929.
Read Entire Article
AMD Ryzen 7 7800X3D or 9800X3D, Which Should You Buy?

A year after Zen 5's debut, we revisit AMD's Ryzen 9800X3D vs 7800X3D to see if the premium is worth it. With new GPUs and updates, has performance shifted or is the older chip still the smarter buy?

Read Entire Article
Criminals are driving fake cell towers through cities to blast out scam texts

The trend is a turning point, according to Cathal Mc Daid, VP of technology at telecommunications and cybersecurity firm Enea. "This is essentially the first time that we have seen large-scale use of mobile radio-transmitting devices by criminal groups," Mc Daid told Wired. He noted that while the underlying technology...
Read Entire Article
Science has finally figured out why I play games with inverted camera controls

During the Covid lockdowns, researchers specializing in cognitive neuroscience at the Visual Perception and Attention Lab at Brunel University London stumbled into a fascinating phenomenon ideal for a quarantined study. Widespread public debates about controller inversion provided a timely opportunity to test participants remotely. The study included not only gamers...
Read Entire Article
Samsung follows Micron and SanDisk raising DRAM and NAND flash prices by up to 30%

South Korean periodical New Daily reports that Samsung recently confirmed to its partners that it plans to raise DRAM and NAND flash prices in the fourth quarter of this year. Industry insiders claim the company told customers to expect LPDDR4X, LPDDR5, and LPDDR5X prices to increase by 15 – 30...
Read Entire Article
What was the first bug bounty program offered by a major tech company?

Was is Mozilla, Google, Microsoft?
Read Entire Article
Hard drive makers WD and Seagate ride the AI surge as storage needs explode

Amid surging demand for semiconductors and AI software, the once-overlooked hard drive is commanding fresh attention. Long overshadowed by flash storage and declining shipments, high-capacity hard-disk drives are seeing a revival as artificial intelligence reshapes the economics of data storage.
Read Entire Article
European policymakers finally plan to fix the cookie banner headache they created

The European Commission is preparing to ease the burden of so-called cookie banners, which have frustrated internet users in Europe and beyond for years. According to Politico, the EC recently informed industry representatives and other organizations that Brussels is drafting new amendments to the ePrivacy Directive.
Read Entire Article
Media Player Classic BE is a modern take on a classic player

MPC-BE (Black Edition) is a free, open-source media player for Windows. It builds on the legacy of the original Media Player Classic and MPC-HC. It combines lightweight performance= with a refreshed interface, built-in codecs, active development, and hardware acceleration support.
Read Entire Article
Anker issues recall for 481,000 power banks over fire hazard

The recall (number 25-466) impacts roughly 481,000 Anker power banks with model numbers A1647 (22.5W), A1652 (7.5W), A1257 (22.5W), A1681 (30W), and A1689 (30W). Defective units were sold at popular retailers including Amazon, Best Buy, Target, and Walmart between August 2023 and June 2025 with prices typically ranging from $30 to $50.
Read Entire Article
Microsoft patches critical Entra ID flaws that endangered millions of tenants

Microsoft recently patched a critical security vulnerability in its Entra ID system. The flaw, tracked as CVE-2025-55241, could have been exploited to take control of any Entra ID directory, also known as a tenant. Security researcher Dirk-jan Mollema, who discovered the issue, promptly reported it to Microsoft, and the company...
Read Entire Article
iPhone Air proves durable and repair-friendly despite slim design

When the team cracked open the iPhone Air, it quickly became clear how Apple had achieved its slim design. In short, the company packed the logic board and related components into the thicker camera plateau at the top of the phone, leaving the rest of the device free to house...
Read Entire Article
New biodegradable film made from onion skins can boost solar panel lifespan

Solar cells face gradual deterioration when exposed to ultraviolet radiation, which can damage sensitive layers such as electrolytes in dye-sensitized cells. To mitigate this, manufacturers typically use polymer coatings such as PVF or PET, which shield against UV rays but are derived from fossil fuels and do not biodegrade easily....
Read Entire Article
Windows Vista-era video wallpapers make a hidden return in Windows 11

Prolific Windows Insider explorer "Phantomofearth" unveiled yet another unexpected change that could soon become part of the Windows 11 experience. The latest OS builds released by Microsoft in the Beta and Dev channels include native support for MP4 video files as desktop backgrounds, which is something Windows users experienced for...
Read Entire Article
Apple iPhone 17 launch hit by scratch complaints on new models

Apple's latest iPhone release drew heavy crowds worldwide on Friday, but early buyers and store visitors quickly noticed that some of the new handsets were already showing signs of wear.
Read Entire Article
Oracle could hit again: Meta talks could lead to $20 billion AI cloud deal

Oracle is negotiating a multiyear agreement with Meta that could be valued at roughly $20 billion, people familiar with the matter have told Bloomberg. The arrangement would make Oracle a key provider of computing power for Meta's artificial intelligence operations.
Read Entire Article
Asus ROG Zephyrus G16 RTX 5080 Review: A Gorgeous OLED Laptop

The Asus ROG Zephyrus G16 blends sleek design, portability, and power with an RTX 5080 GPU and stunning OLED display. But does it deliver enough to justify the premium price?
Read Entire Article
xAI’s Grok 4 Fast delivers top-tier AI performance at a fraction of the cost
xAI's latest model achieves top-tier performance on par with competitors like Gemini 2.5 Pro while slashing costs by 98%, signaling a new era for developers.
The post xAI’s Grok 4 Fast delivers top-tier AI performance at a fraction of the cost first appeared on TechTalks.
You Don't Have to Carry the Entire Planet on Your Shoulders
Hold on to your handkerchief
Sam Altman says scaling up compute is the "literal key" to OpenAI's revenue growth
OpenAI CEO Sam Altman says scaling up compute will drive both AI breakthroughs and the company's revenue.
The article Sam Altman says scaling up compute is the "literal key" to OpenAI's revenue growth appeared first on THE DECODER.
Alibaba's Qwen3-Next builds on a faster MoE architecture

Alibaba has released a new language model called Qwen3-Next, built on a customized MoE architecture. The company says the model runs much faster than its predecessors without losing performance.
The article Alibaba's Qwen3-Next builds on a faster MoE architecture appeared first on THE DECODER.
Alibaba unveils Qwen3-Omni, an AI model that processes text, images, audio, and video

Alibaba has introduced Qwen3-Omni, a native multimodal AI model designed to process text, images, audio, and video in real time.
The article Alibaba unveils Qwen3-Omni, an AI model that processes text, images, audio, and video appeared first on THE DECODER.
Notion AI agents get security update after potential data leak

It didn’t take long for Notion 3.0’s new AI agents to show a serious weakness: they can be tricked into leaking sensitive data through something as simple as a malicious PDF.
The article Notion AI agents get security update after potential data leak appeared first on THE DECODER.
OpenAI and Nvidia announce 10-gigawatt partnership for AI infrastructure

OpenAI and Nvidia have signed a letter of intent for a strategic partnership to deliver at least 10 gigawatts of computing power for OpenAI's next-generation AI data centers.
The article OpenAI and Nvidia announce 10-gigawatt partnership for AI infrastructure appeared first on THE DECODER.
Deepseek's hybrid reasoning model V3.1-Terminus delivers higher scores on tool-based agent tasks
![]()
Deepseek has rolled out V3.1-Terminus, an improved version of its hybrid AI model Deepseek-V3.1.
The article Deepseek's hybrid reasoning model V3.1-Terminus delivers higher scores on tool-based agent tasks appeared first on THE DECODER.
ChatGPT's Deep Research mode let attackers steal Gmail data with hidden instructions in emails

Security researchers at Radware have uncovered a serious flaw in ChatGPT's "Deep Research" mode that allows attackers to quietly steal sensitive data such as names and addresses from Gmail accounts, all without the user's knowledge.
The article ChatGPT's Deep Research mode let attackers steal Gmail data with hidden instructions in emails appeared first on THE DECODER.
Snowflake, Salesforce Launch New Standard To Unify Data for AI

Business intelligence service provider has kicked off a vendor-neutral initiative to create a standard for adding contextual information to structured
The post Snowflake, Salesforce Launch New Standard To Unify Data for AI appeared first on The New Stack.
GPT-5’s Enhanced Reasoning Comes With a Steep Hidden Cost

The arrival of GPT-5 represents a significant leap in AI-driven code generation. It’s powerful, functionally proficient and capable of solving
The post GPT-5’s Enhanced Reasoning Comes With a Steep Hidden Cost appeared first on The New Stack.
How To Enhance Productivity With DORA Metrics

Building great software products isn’t only about clean code. It’s about how fast you can ship, how often you deploy
The post How To Enhance Productivity With DORA Metrics appeared first on The New Stack.
Why You Can’t Debug a Running Quantum Computer Program

In a sense, writing applications for quantum computing is very much a case of going back to the future. Much
The post Why You Can’t Debug a Running Quantum Computer Program appeared first on The New Stack.
TikTok’s Ex-Algorithm Chief Launches Verdent AI Coding Tool

What if there was an AI coding tool that had algorithms as sophisticated as TikTok’s? That thought experiment is now
The post TikTok’s Ex-Algorithm Chief Launches Verdent AI Coding Tool appeared first on The New Stack.
How to Fix Performance Issues Error Monitoring Can’t See

Your error monitoring is solid: 99%+ crash-free rates, catching critical issues before they spread. But users still complain about “buggy”
The post How to Fix Performance Issues Error Monitoring Can’t See appeared first on The New Stack.
How We Cut Telemetry Queries to Under 10 Milliseconds

We built a telemetry pipeline that handles more than 5,400 data points per second with sub-10 millisecond query responses. The
The post How We Cut Telemetry Queries to Under 10 Milliseconds appeared first on The New Stack.
Opinion: Europe’s VCs must embrace risk — or resign the AI era to US control

Europe’s AI startups are losing ground to the US — and their own investors are to blame. Only 5% of global venture capital is raised in the EU, according to the European Commission. The US, by contrast, attracts more than half, while China takes 40%. Yet Europe isn’t capital-poor: households save €1.4tn a year, nearly twice as much as in America. Still, very little of that money finds its way into startups, despite a plethora of incentives like the UK’s EIS tax relief for business angels. Even when funding is available, Europe’s venture capital firms are slow and cautious. Funds…
This story continues at The Next Web
Kaspersky: RevengeHotels checks back in with AI-coded malware
Old hotel scam gets an AI facelift, leaving travellers’ card details even more at risk
Kaspersky has raised the alarm over the resurgence of hotel-hacking outfit "RevengeHotels," which it claims is now using artificial intelligence to supercharge its scams.…
How I learned to stop worrying and love the datacenter
Stargates or black holes? Risks and rewards from the B(r)itbarn boom
Comment The UK has bitterly expensive power, an energy minister who sees electricity as bad, a lethargic planning system, and a grid with a backlog for connections running to 2039.…
Stop runaway AI before it's too late, experts beg the UN
Signatories include 10 Nobel Prize winners
ai-pocalypse Ten Nobel Prize winners are among the more than 200 people who've signed a letter calling on the United Nations to define and enforce “red lines” that prohibit some uses of AI.…
AI gone rogue: Models may try to stop people from shutting them down, Google warns
Misalignment risk? That's an area for future study
Google DeepMind added a new AI threat scenario - one where a model might try to prevent its operators from modifying it or shutting it down - to its AI safety document. It also included a new misuse risk, which it calls "harmful manipulation."…
Nvidia adds more air to the AI bubble with vague $100B OpenAI deal
Promises, promises
analysis OpenAI and Nvidia have signed a letter of intent wherein OpenAI agrees to buy at least 10 gigawatts of Nvidia systems for its datacenters, while the AI arms dealer returns the favor with an investment of up to $100 billion in the house that Altman built.…
Moody's raises Big Red flag over Oracle's AI datacenter buildout blueprint
Ratings agency points out there's a risk of relying on a small number of buyers
Ratings agency Moody's has pointed to the dangers inherent in Oracle's $300 billion agreement with OpenAI - one of the deals contributing to a staggering $455 billion pipeline of obligations for Big Red's cloud infrastructure.…
FOMO? Brit banking biz rolls out AI tools, talks up security
Lloyds Data and AI lead doesn't want devs downloading models from the likes of Hugging Face – too risky
Lloyds Banking Group is leaning into 21st century tech - yet trying to do so in a way that the data of its 28 million customers is kept away from untested AI models developers might be tempted to deploy.…
Huawei used its own silicon to re-educate DeepSeek so its output won’t bother Beijing
PLUS: India ponders tax breaks for datacenters; Samsung plans hiring spree; Taliban bans fiber internet; and more
Asia In Brief Huawei last week revealed that China’s Zhejiang University used its Ascend 1000 accelerators to create a version of DeepSeek’s R1 model that improves on the original by producing fewer responses that China’s government would rather avoid.…
Nvidia fuels OpenAI's compute chase
PLUS: Use GPT-5 in Microsoft 365 to analyze emails
🍏 OpenAI's Apple hardware heist
PLUS: Use Notion AI to build a CRM pipeline
The Sequence Knowledge #724: What are the Different Types of Mechanistic Interpretability?
Discussing a taxonomy to understand the most important mechanistic interpretability methods.
Investec names ex-Winterflood Securities fixed income expert as new head of fixed income and ETFs
Investec has made two hires from Winterflood Securities, appointing a new head and deputy head of its fixed income and ETF offering; appointments follow news in July that Marex is set to acquire Winterflood Securities in early 2026.
The post Investec names ex-Winterflood Securities fixed income expert as new head of fixed income and ETFs appeared first on The TRADE.
BGC Group hires from Citi for equity derivatives sales trader
Individual joins the broker after spending the last five years at Citi working across various roles.
The post BGC Group hires from Citi for equity derivatives sales trader appeared first on The TRADE.
LSEG enters strategic partnership to deliver data directly to Databricks
The offering will allow firms to build governed AI agents using both enterprise and LSEG’s data, via Databrick’s Delta Sharing.
The post LSEG enters strategic partnership to deliver data directly to Databricks appeared first on The TRADE.
Orbit Financial Technology launches AI membership model to democratise financial research access
The new offering - Orbit Flex - combines exclusive financial data with advanced AI infrastructure and workflows to remove cost and access barriers for smaller institutions.
The post Orbit Financial Technology launches AI membership model to democratise financial research access appeared first on The TRADE.
Morgan Stanley taps BNP Paribas for eFX sales role
Individual has worked extensively across FX at firms including Euronext, State Street, Santander and HSBC.
The post Morgan Stanley taps BNP Paribas for eFX sales role appeared first on The TRADE.
EDXM International and Sage Capital Management partner to enhance perpetual futures institutional access
As part of the offering, Sage Capital will act as a prime broker to the exchange; the news follows the launch of EDXM International in July, backed by partners including Citadel Securities and Virtu Financial.
The post EDXM International and Sage Capital Management partner to enhance perpetual futures institutional access appeared first on The TRADE.
BTIG hires Clear Street event-driven strategies experts
The appointments come as BTIG looks to bolster its event-driven team as hiring spree continues, The TRADE understands.
The post BTIG hires Clear Street event-driven strategies experts appeared first on The TRADE.
People Moves Monday: Pirum, First Abu Dhabi Bank and Mizuho
The last week has seen a variety of moves across roles spanning pre-trade solutions, cross-asset trading and fixed income sales.
The post People Moves Monday: Pirum, First Abu Dhabi Bank and Mizuho appeared first on The TRADE.
Euronext unveils mini futures for main European government bonds
The contracts are listed on the Euronext Derivatives Milan market, and are powered by the exchange’s clearing platform.
The post Euronext unveils mini futures for main European government bonds appeared first on The TRADE.
Baby Steps hits on the hell and hilarity of hiking
There are only two things that Nate really wants to do: use the toilet (one that, he emphasizes, comes with three walls and a door) and go home. He also walks with a strange gait, with one tiny foot raised awkwardly in front of the other, before landing with a gentle plop. At times, he […]
Secret Service dismantles network capable of shutting down cell service in New York
The US Secret Service says it has disrupted a network of devices used to carry out assassination threats against US officials and for anonymous communications between threat actors, according to a report from NBC News. In the Tuesday announcement, the agency revealed that it uncovered the network within a 35-mile radius of the United Nations […]
Former Spotify execs launch AI-powered ‘learning platform’ for the ‘curiously minded’
The creators of Oboe know what everyone's thinking about AI. "Is AI going to make us all stupid?" the company asks in a recent ad. "Are we going to forget how to think for ourselves?" Oboe's founders think the answer to both of those questions is no, and their startup is meant to prove it. […]
WhatsApp adds built-in text translations on iPhone and Android
A new translation feature for WhatsApp on iPhone and Android that translates messages into your preferred language is rolling out “gradually,” starting today in 1:1 chats, groups, and Channel update messages. It can be activated by long-pressing down on messages and tapping the “Translate” option to choose the language you want the message to be […]
Bang & Olufsen’s new earbuds will cost you more than the latest iPhone
Bang & Olufsen’s latest Beo Grace earbuds offer a flashy aluminum design and the brand’s “most advanced” active noise cancellation for a staggering $1,500. These pricey new buds pump sound through 12mm titanium drivers, featuring ANC powered by six microphones that adjust audio based on ambient noise and the shape of your ear. The Beo […]
YouTube wants you to go live
YouTube is the most powerful platform in entertainment, and as such it has outsize influence on what kind of entertainment people make and watch. When YouTube adds a mid-video ad break, videos get longer to accommodate it. When YouTube tells podcasters to make video, podcasters make video. And for its next act, it appears the […]
GoPro’s new gimbal works with action cameras, point-and-shoots, and smartphones
GoPro has announced a new handheld camera stabilizer that, unlike the Karma Grip stabilizer it debuted in 2016, can be used with more than just its action cameras. The new Fluid Pro AI is compatible with the company’s devices like the Hero13 Black, but with a 400-gram payload capacity, it can also be used with […]
GoPro’s 360-degree action cam gets an 8K upgrade and swappable lenses
It’s been nearly six years since GoPro launched its Max 360-degree camera. The original was only slightly larger than the company’s iconic action cameras and while the new Max2 is a bit taller, thicker, and 36 grams heavier than its predecessor, its 360-degree video capabilities have been improved from 5.6K / 30fps to 8K / […]
GoPro put a light on its Hero action camera to illuminate your adventures
If you’re tired of juggling an action camera plus a flashlight, torch, flare, or lantern anytime your adventures extend past sunset, GoPro has announced an updated version of its Hero action camera with illumination built right in. The Lit Hero has a cluster of four bright LEDs positioned right next to its lens, and while […]
Gemini AI will help you play games on Google Play
Google will soon let you ask its Gemini AI assistant for help progressing in mobile games. On Tuesday, Google announced that a Gemini Live integration will appear within a new overlay on games downloaded from the Play Store, allowing you to ask for some hints without opening a new window. The feature will roll out […]
The Complete Guide to Choosing Embedding Models for RAG Applications

TAI #171: How is AI Actually Being Used? Frontier Ambitions Meet Real-World Adoption Data
Also, ICPC gold medals, NVIDIA’s $100B OpenAI deal, and Grok-4 Fast pushing the cost frontier.

What happened this week in AI by Louie
This week, AI models continued to push the frontiers of capability, with both OpenAI and DeepMind achieving gold-medal-level results at the 2025 ICPC World Finals coding contest. The scale of capital investment and ambition was also clear, with Nvidia announcing a letter of intent to invest up to $100 billion in OpenAI, alongside a 10 GW GPU purchase agreement. Yet, at the same time as these limits were being pushed, two landmark studies from OpenAI/NBER and Anthropic gave a detailed, data-driven look at how AI is actually being used by hundreds of millions of people today.
In a demonstration of algorithmic reasoning, both OpenAI and Google’s Gemini Deep Think models delivered performances equivalent to a gold medal at the ICPC, the “coding Olympics.” OpenAI’s system solved all 12 complex problems within the five-hour limit, outperforming every human team, while Google’s entry solved 10. These results, achieved under the same constraints as human competitors, show the maturation of AI in complex, multi-step logical tasks that were until recently the exclusive domain of elite human experts.
The industry’s ambition was further underscored by OpenAI’s new 10GW GPU purchase agreement with Nvidia. The scale of this deal is significant: 10 GW is equivalent to the entire U.S. data center fleet’s consumption in 2018 and is enough to power roughly 8 million homes. This aligns with an infrastructure footprint of 4–5 million next-generation GPUs, representing $200–300 billion in hardware costs and a total capital expenditure of around $500 billion when factoring in memory, power, cooling, other infrastructure, and facilities.
While the frontier pushes toward superintelligence-scale compute, the new usage studies provide a crucial reality check. The OpenAI/NBER paper, covering 700 million weekly ChatGPT users sending 2.5 billion messages daily, found a dramatic shift toward personal applications. Non-work-related messages have surged from 53% to 73% of all traffic in the past year. The most common use cases are not coding or complex analysis, but “Practical Guidance” at 28%, “Seeking Information” at 21% and “Writing” at 28% of all conversations. Coding represents a surprisingly small 4.2% of consumer usage, with Anthropic models and API usage still more popular for coding.

Anthropic’s Economic Index, which tracks Claude usage, paints a complementary but distinct picture. It finds that API customers — primarily businesses and developers — focus heavily on computer and mathematical tasks (44% of traffic). These enterprise users also lean heavily into automation, with 77% of API conversations being directive, a stark contrast to consumer chat, where the split between automation and collaborative augmentation is nearly even. While directive automation is rising on consumer chat (from 27% to 39% in nine months), higher-use countries paradoxically tend to be more collaborative, suggesting mature users find more value in advisory patterns over simple one-shot completions.
Together, the studies reveal a bifurcation in how AI is being used. For consumers, it is increasingly an “Advisor,” a tool for decision support. In fact, “Asking” for information or advice now constitutes 52% of ChatGPT use and receives the highest user satisfaction ratings. For enterprise and API users, AI is more of an “Agent,” a tool for task automation. Writing is the common thread, but the nature of the task differs. On ChatGPT, writing is the top work-related activity (40%), with two-thirds of these requests involving editing or summarizing user-provided text, rather than generating it from scratch. Across all work-related use, about 81% of messages are associated with two broad work activities: 1) obtaining, documenting, and interpreting information; and 2) making decisions, giving advice, solving problems, and thinking creatively.
Why should you care?
The current AI moment is defined by a massive disconnect. On one side, you have a market fueled by ~ $10 trillion in AI market capitalization and $500 billion in annual AI data center capital investment. On the other hand, you have a user base where, outside of coding, real productivity gains are driven by a small minority of power users. Is this a bubble, or is there enough real value being created to justify the investment? As a quick rule of thumb, if you don’t have a paid AI plan or spend over $30 a month on API calls, you are nowhere near getting the most out of these models, and that describes the vast majority of today’s 800 million weekly users.
The bet from big tech CFOs is that the rest of the world will catch up. The bull case is easy to see: if 5.5 billion internet users each gain an average of just $1,000 per year in value from AI, the economic justification is easily there. OpenAI’s $200 billion 2030 revenue forecast starts to look plausible. But this outcome is far from certain. The entire structure could come crashing down if many more professionals are not soon persuaded to start using these models effectively in their work.
This transition hinges on two things. First, people need to be taught how to use these tools properly, building an intuition for where they add value beyond simple queries. Second, companies need to improve significantly in building custom “AI for X” workflows and agents. Most enterprise AI developments still fail due to foundational errors in team structure, model selection, and system design.
The immediate opportunity lies in bridging this competency gap. The companies and individuals who can translate the raw potential of an AI “Advisor” and “Agent” into reliable, integrated workflows will capture the immense value that is currently being left on the table.
— Louie Peters — Towards AI Co-founder and CEO
Hottest News
1. Gemini 2.5 Deep Think Achieved Gold-Medal–Level Performance at ICPC World Finals
Gemini 2.5 Deep Think reached gold-medal–level performance at the 2025 International Collegiate Programming Contest (ICPC) World Finals, the most prestigious university-level algorithmic competition. Gemini solved eight problems in the first 45 minutes and two more within three hours, using advanced data structures and algorithms. With 10 problems solved in 677 minutes, Gemini would have placed second overall compared to the competing university teams.
2. xAI Launches Grok 4 Fast: Cost-Efficient Multimodal Reasoning Model
xAI introduced Grok-4-Fast, a cost-optimized successor to Grok-4 that merges “reasoning” and “non-reasoning” behaviors into a single set of weights controllable via system prompts. It has a 2M context window model, excelling in reasoning and coding, and scored 60 on the Artificial Analysis Intelligence Index. It outperforms its larger siblings on LiveCodeBench while being 25 times cheaper than competitors like Gemini 2.5 Pro at $ 0.2 per million input tokens.
3. Alibaba Qwen Team Just Released FP8 Builds of Qwen3-Next-80B-A3B
Alibaba’s Qwen team has just released FP8-quantized checkpoints for its new Qwen3-Next-80B-A3B models in two post-training variants, Instruct and Thinking, aimed at high-throughput inference with ultra-long context and MoE efficiency. The FP8 Instruct version reproduces Qwen’s BF16 benchmark results, matching the Qwen3–235B-A22B-Instruct-2507 on knowledge, reasoning, and coding tasks, and outperforming it on long-context workloads of up to 256k tokens.
4. Alibaba Releases Tongyi DeepResearch: A 30B-Parameter Open-Source Agentic LLM
Alibaba’s Tongyi Lab has released Tongyi-DeepResearch-30B-A3B, an open-source agentic LLM specialized for long-horizon, tool-augmented information-seeking. The model employs a mixture-of-experts (MoE) design with ~30.5 billion total parameters and ~3–3.3 billion active parameters per token, enabling high throughput while preserving strong reasoning performance. Techniques such as the IterResearch restructure context each “round,” retaining only essential artifacts to mitigate context bloat and error propagation, while the ReAct baseline demonstrates that the behaviors are learned rather than prompt-engineered.
5. Detecting and Reducing Scheming in AI Models
OpenAI shared new research addressing “scheming,” where models act one way on the surface while pursuing hidden goals. The paper compares this to a stockbroker breaking the law to maximize profit. Researchers concluded that most observed failures involve simple deception, such as pretending to complete tasks. While generally low-stakes, the work outlines methods to better detect and mitigate deceptive patterns in AI systems.
6. IBM Released Granite Docling
IBM has released Granite-Docling-258M, an open-source (Apache-2.0) vision-language model designed specifically for end-to-end document conversion. The model targets layout-faithful extraction — tables, code, equations, lists, captions, and reading order — emitting a structured, machine-readable representation rather than lossy Markdown. IBM replaced the earlier backbone with a Granite 165M language model and upgraded the vision encoder to SigLIP2 (base, patch16–512) while retaining the Idefics3-style connector (pixel-shuffle projector). The resulting model has 258M parameters and shows consistent accuracy gains across layout analysis, full-page OCR, code, equations, and tables.
Five 5-minute reads/videos to keep you learning
1. Qwen2.5-VL: A Hands-On Code Walkthrough
This technical guide walks through the Qwen2.5-VL multimodal model, showcasing improvements such as a window attention mechanism in its Vision Transformer (ViT) and dynamic video frame sampling. The architecture includes three core components: a ‘process_vision_info’ module for preprocessing, a ViT encoder for feature extraction, and a Qwen2.5 LM Decoder with 3D M-rope for joint visual–text processing. A step-by-step code example covers model loading, data handling, prompt construction, and inference, making it a practical resource for developers.
2. Anthropic Economic Index Report: Uneven Geographic and Enterprise AI Adoption
Anthropic expanded its Economic Index with new dimensions: geographic trends in Claude.ai usage and enterprise-level API adoption. The report highlights how Claude usage has evolved over time, how adoption varies by region, and how enterprises are applying frontier AI systems to real-world business challenges.
3. Review of Multimodal Technologies: ViT Series (ViT, Pix2Struct, FlexiViT, NaViT)
This review traces the evolution of Vision Transformer (ViT) models beyond fixed image resolutions and patch sizes. It covers Pix2Struct, which preserves original aspect ratios; FlexiViT, which adapts to varying patch sizes; and NaViT, which applies a “Patch n’ Pack” technique for native-resolution processing. Together, these innovations broaden the applicability and efficiency of ViTs for diverse visual understanding tasks.
4. Evolution of Transformers Pt2: Sequence Modelling (Transformers)
This article explains why the Transformer architecture excels at sequence modeling, emphasizing the role of self-attention in weighing token relevance. Early layers capture syntactic relationships, while deeper layers capture semantic context. Key elements — encoder-decoder design, positional encoding, and parallel training — help overcome the long-range dependency issues of RNNs. The piece also notes challenges such as sequential inference and error accumulation.
5. Measuring Uplift Without Randomised Control — a Quick and Practical Guide
For cases where randomized controlled trials aren’t feasible, this guide outlines practical alternatives for measuring intervention impact. It focuses on the Difference-in-Differences (DiD) technique, showing how to implement it as a regression model with clustered standard errors and fixed effects. The article also explores a Bayesian variant for incorporating prior knowledge, and situates ANOVA and ANCOVA as special cases within this broader regression framework.
Repositories & Tools
1. Qwen3-ASR-Toolkit is an advanced, high-performance Python command-line toolkit for using the Qwen-ASR API.
Top Papers of The Week
1. Scaling Laws for Differentially Private Language Models
This work derives compute–privacy–utility scaling laws for training LLMs under differential privacy. It shows that DP-optimal setups favor smaller models with very large batch sizes, and that simply adding compute provides little benefit without a larger privacy budget or more data. The findings provide guidelines for allocating resources efficiently under strict privacy constraints.
2. WebWeaver: Structuring Web-Scale Evidence with Dynamic Outlines for Open-Ended Deep Research
WebWeaver introduces a dual-agent framework for open-ended deep research. A planner agent dynamically refines outlines linked to an evidence memory bank, while a writer agent retrieves and compiles evidence section by section. This structured approach integrates evidence acquisition with outline optimization, producing more coherent research outputs.
3. The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs
The paper shows that small gains in single-step accuracy compound into large — and even faster-than-exponential — improvements in the task length models can execute, and identifies “self-conditioning” (models amplifying their own past mistakes) as a key failure mode in long-horizon execution. Thinking models and test-time sequential compute mitigate self-conditioning and dramatically extend single-turn execution length, with frontier reasoning models outperforming non-thinking counterparts by large margins.
4. Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation
Researchers introduced EVolution-Oriented and Label-free Reinforcement Learning (EVOL-RL) to enhance large language models’ self-improvement. EVOL-RL combines stability via majority-vote and variation through novelty-aware rewards, preventing entropy collapse and boosting performance. It significantly increases pass rates, notably improving pass@1 from 4.6% to 16.4% on label-free datasets, demonstrating superior generalization across domains.
5. Scaling Agents via Continual Pre-training
The authors propose Agentic Continual Pre-training (Agentic CPT) to create agentic foundation models. Their model, AgentFounder-30B, performs exceptionally on ten benchmarks, including achieving 39.9% on BrowseComp-en, 43.3% on BrowseComp-zh, and 31.5% Pass@1 on HLE, while maintaining strong tool-use capabilities in complex problem-solving.
Quick Links
1. Google AI introduces Agent Payments Protocol (AP2), an open, vendor-neutral specification for executing payments initiated by AI agents with cryptographic, auditable proof of user intent. AP2 extends existing open protocols, Agent2Agent (A2A) and Model Context Protocol (MCP), to define how agents, merchants, and payment processors exchange verifiable evidence across the “intent → cart → payment” pipeline.
2. OpenAI and NVIDIA announce a strategic partnership to deploy 10 gigawatts of NVIDIA systems, which translates to millions of GPUs that can help power OpenAI’s new models. As part of the deal, NVIDIA “intends to invest up to $100 billion in OpenAI progressively as each gigawatt is deployed.”
3. Mistral AI updates its Magistral Small/Medium 1.2 models with multimodality, adding vision alongside stronger math and coding capabilities. Benchmarks show a 15% improvement on AIME and LiveCodeBench, with better tool use and more natural responses. The models now compete with larger systems on the Artificial Analysis Index and are available on Hugging Face and via API.
4. Researchers release Trading-R1, a 4B parameter model trained on 100K financial cases to generate investment theses and trading strategies. Backtests on major tickers show stronger risk-adjusted returns. The system combines distillation, reinforcement learning, and structured evidence-based reasoning, serving as a decision-support tool for financial research.
5. New report from Epoch AI zooms in on scaling and what it unlocks for scientific R&D. It forecasts that by 2030, training clusters could cost hundreds of billions of dollars, but compute scaling is unlikely to be “hitting a wall.” The report highlights the growing role of synthetic and multimodal data to mitigate bottlenecks, and projects that while power demands will rise significantly, they should remain manageable in principle.
Who’s Hiring in AI
Research Engineer — Multimodal Companion Agent @Google DeepMind (Tokyo, Japan)
Automation & AI Lead @Cognizant (Remote)
AI Foundations — Research Scientist — Research Internship: 2026 @IBM (Cambridge, MA, USA)
Legal Content AI Engineer @RELX INC (Remote/UK)
Intern, Machine Learning Engineer @Autodesk (Multiple US Locations)
Interested in sharing a job opportunity here? Contact sponsors@towardsai.net.
Think a friend would enjoy this too? Share the newsletter and let them join the conversation.
TAI #171: How is AI Actually Being Used? Frontier Ambitions Meet Real-World Adoption Data was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
In-Context Learning Explained: Why LLMs Need 100 Examples, Not 5
New research reveals the truth about few-shot learning and what it means for your AI applications
“Optimal performance required 50–100 examples, not the 2–5 examples typically used. This completely undermines the ‘few-shot’ narrative around AI capabilities.”
— Microsoft Research, analyzing 1.89 million AI predictions

What happens when you feed ChatGPT examples in your prompts isn’t what you think
Give ChatGPT three examples of your task and suddenly it often becomes much better at it.
This feels like learning. But is it?
Here’s the problem: the AI’s brain never changed. Not one parameter updated. Not one connection strengthened.
So what’s really happening when AI seems to “learn” from your examples?
A new large-scale study from Microsoft puts this fundamental question to the test with nearly 2 million experiments across multiple AI models. The results will change how you think about prompting forever.
The Learning Illusion
When you provide examples in your prompts, you’re using something called In-Context Learning (ICL). The AI appears to learn your pattern and apply it to new situations.

But there’s a catch.
Traditional learning means updating your knowledge based on experience. When you learn to drive in the rain after practicing in the sunshine, your brain literally rewires itself.
AI models like GPT-4 don’t do this. Their internal weights stay frozen while processing your examples.
This creates a fundamental question: If nothing inside the AI changes, is it actually learning?
The Million-Prediction Experiment
Researcher Adrian de Wynter designed the most comprehensive test of AI learning ever conducted:
- 4 different AI models (GPT-4 Turbo, GPT-4o, Mixtral 8x7B, Phi-3.5)
- 9 carefully designed tasks ranging from simple to complex
- 1.89 million predictions per model
- 6 different prompting methods
The scale is staggering. But the methodology is what makes this groundbreaking.
Testing Real Learning vs. Pattern Matching
Instead of using real-world data (which AIs might have seen during training), the researchers created synthetic datasets using mathematical rules.
Think of it like this: they built automated puzzle generators that could create infinite variations of the same type of problem.

Figure 1 shows their PARITY task generator. It’s a state machine that creates sequences where you need to count 1s and determine if the total is even or odd.
The clever part? They intentionally mislabeled 5% of examples. This created a maximum possible accuracy of 95%. If any AI scored higher, it was definitely cheating by memorizing real data.
Nine Tasks, Three Difficulty Levels

The researchers chose tasks based on computational complexity:
Simple Tasks (Finite State Automata)
These follow clear, step-by-step rules:
- PARITY: Count 1s, determine even/odd
- Pattern Matching: Find specific sequences in text
- Maze Completion: Fill in missing maze paths
- Vending Machine: Verify transaction sequences
Complex Tasks (Pushdown Automata)
These require memory and sophisticated reasoning:
- Reversal: Check if one string reverses another
- Stack Simulation: Model computer memory operations
The Wild Card
- Vending Machine Sum: Calculate final balance after transactions
Six Ways to Teach AI
The study tested different approaches to presenting examples:
- N-Shot Learning: Just examples, no explanation
- Description: Examples plus clear instructions
- Chain-of-Thought: Step-by-step reasoning included
- Automated Prompt Optimization: AI writes its own instructions
- Direct Encoding: Give the AI the actual mathematical rules
- Word Salad: Replace meaningful words with nonsense
Each method was tested with 0, 2, 5, 10, 20, 50, and 100 examples.
Most “few-shot learning” research stops at 5 examples. This study went to 100.
The Shocking Results
Finding #1: You Need Way More Examples Than Anyone Thought

Forget “few-shot learning.” Table 1 reveals that optimal performance required 50–100 examples, not the 2–5 examples typically used.
The best-performing tasks hit impressive accuracy:
- Pattern Matching: 94±1%
- Hamiltonian cycle verification: 85±4%
- Vending Machine Verification: 83±9%
The worst performers struggled significantly:
- Vending Machine Sum: 16±1%
- Reversal: 61±11%
- Maze Solve: 63±13%
This completely undermines the “few-shot” narrative around AI capabilities.
Finding #2: All Methods Converge (Eventually)

Figure 3 shows something remarkable: as the example count increased, all prompting strategies achieved similar performance.
Simple example-based prompts caught up to sophisticated chain-of-thought reasoning.
Random word salad eventually matched carefully crafted instructions.
With enough examples, how you ask becomes less important than what you show.
Finding #3: AI Gets Brittle Under Pressure
Here’s where things get concerning. Table 2 reveals that while models improved with more examples, they became increasingly fragile when faced with slightly different data.
The researchers tested this by creating test sets with varying degrees of “distributional shift” — essentially, how different the test problems were from the training examples.
Chain-of-Thought prompting, despite being highly effective on familiar data, showed the highest sensitivity to these changes (slope of -1.4).

Figure 2 visualizes this brittleness across different tasks. The PARITY task (simple) maintained good performance, while the Reversal task (complex) collapsed under distribution shift.
Finding #4: Similar Tasks, Wildly Different Results
Perhaps most surprising: mathematically equivalent tasks showed massive performance gaps.
Two tasks requiring identical computational machinery differed by 31% in accuracy.
This suggests AI doesn’t understand the underlying mathematical structure — it’s pattern matching on steroids.
The Deep Dive: What Really Matters?

1. Words Don’t Matter (Much)
When researchers replaced meaningful instructions with random “word salad,” performance initially dropped. But with enough examples, even nonsense prompts achieved comparable results.
The data teaches better than the instructions.
2. Order Doesn’t Matter
Shuffling the example order had minimal impact on accuracy. This debunks common concerns about “prompt sensitivity” that plague many AI applications.
3. Data Distribution Matters Most
Models trained on random, meaningless labels actually showed better robustness to new situations than those trained on structured, logical examples.
Structured training data can make AI more fragile by encouraging overfitting to spurious patterns.
What This Means for You
1. The Good News
AI models do learn from examples in a formal sense. Performance improves with more data, and methods converge toward similar effectiveness.
2. The Reality Check
This learning has severe limitations:
- Scale Requirements: Effective learning needs 50–100 examples, not 2
- Brittleness: Performance degrades with slightly different contexts
- Inconsistency: Similar tasks can have vastly different results
- Method Fragility: Advanced techniques like Chain-of-Thought are less robust than simple examples
Practical Guidelines for AI Users
Do This:
- Provide many examples (50–100 when possible) rather than just a few
- Test your AI applications with out-of-distribution data
- Use simple prompting strategies for robust applications
- Expect inconsistent performance across seemingly similar tasks
Don’t Do This:
- Assume few-shot learning is sufficient for critical applications
- Rely solely on Chain-of-Thought for robust reasoning
- Expect performance on one task to predict performance on similar tasks
- Trust evaluation results from a single prompting approach
The Bigger Picture
This research challenges fundamental assumptions about AI capabilities.
AI models are powerful pattern-matching systems, not flexible learners. They excel at recognizing and reproducing patterns from training data but struggle with genuine generalization to new contexts.
- For businesses deploying AI: robust applications require extensive testing across multiple contexts and prompting strategies.
- For developers building with AI: simple, example-heavy approaches often outperform sophisticated prompting techniques.
- For researchers: the field needs better evaluation methods that account for distributional robustness, not just peak performance.
The Final Answer

Does ChatGPT actually learn from your examples?
Yes, but with massive limitations.
In-Context Learning represents a unique form of learning that occurs without updating model parameters. It relies on the dynamic interaction between frozen weights and contextual information.
While this enables impressive performance on many tasks, it falls short of robust, generalizable learning.
The practical implication: current AI systems are powerful but brittle tools. They work well within their training distribution but struggle when contexts shift, even slightly.
Understanding these limitations is crucial for building AI systems that are reliable in practice, not just impressive in demos.
The gap between AI hype and AI reality is real. Studies like this help us navigate it responsibly.
Resource :
https://arxiv.org/abs/2509.10414
In-Context Learning Explained: Why LLMs Need 100 Examples, Not 5 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Earn While Helping Others Learn AI
1 referral = our bestselling book. 3 referrals = a course. 10 = full access + affiliate tier
I’m thrilled to finally share that we ( Towards AI ) are launching the Towards AI Partner Program 🚀
Our goal with this big update is to allow anyone to earn by referring the course.
The idea is simple: help one person learn AI, and earn something concrete from the start!

1 referral → Our bestselling book Building LLMs for Production
3 referrals → Any one of our industry-focused courses
10 referrals → Full access to all our courses, and an invite to the affiliate tier (where you can start earning ~$70/course or $180+/bundle).
This isn’t about blasting links or spamming; it’s about helping out friends, colleagues, or your community to take their first real step into AI.
Just this year, our affiliates already earned $18,692.99 in 8 months, including $6,730.21 from just 3 posts.

We want to make this process accessible to all of you. So we added many assets, a special newsletter, a slack channel and more so you can share the courses more easily and get rewarded more easily.
For me, this program is a chance to make AI education accessible at scale while enabling others to build a reputation or even a side income. I’m always happy to refer products I love, and I think you will, too.
When I quit academia to work on AI full-time, I wanted to bridge the gap between research and real-world application. This program feels like a natural extension of that mission, empowering anyone to play a part in this, sharing the courses they love most, and getting rewarded for it.
If you’ve ever had someone ask you “Where do I start with AI?”, “How do I learn about agents?” or “what skills do I really need for my next job?” this is the answer. And now, helping them could change both their career path and yours! :D
👉 Read more and join here: https://academy.towardsai.net/pages/affiliate
Big thanks to the Towards AI team, and everyone who helped shape this program, and our current amazing affiliates, Paul Iusztin, Neil Leiser, Paolo Perrone, Smriti Mishra, Greg Coquillo, David Andres, Giuliano Liguori and all others.
Earn While Helping Others Learn AI was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Everyone’s Building with LLMs Wrong. Here Are the 10 Myths Killing Your Projects.

Stop treating LLMs like magic solutions. After 8 months building production AI systems with Claude, GPT, and custom models, here’s what…
Attention = Soft k-NN
Transformers, demystified in 20 lines: similarity → softmax → weighted average.
Transformers = soft k-NN. One query asks, “Who’s like me?” Softmax votes, and the neighbors whisper back a weighted average. That’s an attention head; a soft, differentiable k-NN: measure similarity → turn scores into weights (softmax) → average your neighbors (weighted sum of values).
TL;DR

- Scaled by 1/sqrt(d) to keep softmax from saturating as the dimension grows.
- Masks decide who you’re allowed to look at (causal, padding, etc.).
Intuition (60 seconds)
- A query vector 𝐪 asks: “Which tokens are like me?”
- Compare 𝐪 with each key 𝒌ᵢ to get similarity scores.
- Softmax turns scores into a probability‐like distribution (heavier weight ⇢ more similar).
- Take the weighted average of value vectors 𝐯ᵢ.
That’s attention: a soft, order-aware neighbor average.
The math (plain, minimal)
Single head, key/query dim 𝒅, value dim 𝒅ᵥ. With

- Similarity (scaled dot product):

(Optional) mask

- Weights (softmax row-wise)

- Weighted average of values:

Why the 1/sqrt{d} scaling?
Dot products of random d-dimensional vectors grow like O(sqrt{𝒅}). Unscaled scores push softmax toward winner-take-all (one weight ≈1, others ≈0), collapsing gradients. Dividing by sqrt{𝒅} keeps the score variance — and thus the entropy of the softmax — in a healthy range.
Masks (causal or padding)
Add 𝐌 before softmax:
- Causal (language modeling): block positions j>t for each timestep t.
- Padding: block tokens that are placeholders.
Formally, A=softmax(S+M) with Mᵢⱼ=0 if allowed, −∞ otherwise.
Soft k-NN view (and variants)
Swap the similarity and you swap the inductive bias:
- Dot product (direction and magnitude):

- Cosine (angle only; length-invariant):

- Negative distance, a Gaussian/RBF flavor (Euclidean neighborhoods):

Then softmax → weights → weighted average as before. Temperature τ (or an implicit scale) controls softness: lower τ ⇒ sharper, more argmax-like behavior.
Minimal NumPy (single head, clarity over speed)
Goal: clarity over speed. This is the whole operation you’ve seen in papers.
import numpy as np
def softmax(x, axis=-1):
x = x - np.max(x, axis=axis, keepdims=True) # numerical stability
ex = np.exp(x)
return ex / np.sum(ex, axis=axis, keepdims=True)
def attention(Q, K, V, mask=None):
"""
Q: (n_q, d), K: (n_k, d), V: (n_k, d_v)
mask: (n_q, n_k) with 0=keep, -inf=block (or None)
Returns: (n_q, d_v), (n_q, n_k)
"""
d = Q.shape[-1]
scores = (Q @ K.T) / np.sqrt(d) # (n_q, n_k)
if mask is not None:
scores = scores + mask
weights = softmax(scores, axis=-1) # (n_q, n_k)
return weights @ V, weights
A tiny toy: 6 tokens in 2-D
We’ll create 6 token embeddings, a single query, and watch the weights behave like a soft neighbor pick.
# Toy data
np.random.seed(7)
n_tokens, d, d_v = 6, 2, 2
K = np.array([[ 1.0, 0.2],
[ 0.9, 0.1],
[ 0.2, 1.0],
[-0.2, 0.9],
[ 0.0, -1.0],
[-1.0, -0.6]])
# Values as a simple linear map of keys (intuition)
Wv = np.array([[0.7, 0.1],
[0.2, 0.9]])
V = K @ Wv
# Query near the first cluster
Q = np.array([[0.8, 0.15]]) # (1, d)
out, W = attention(Q, K, V)
print("Attention weights:", np.round(W, 3))
print("Output vector:", np.round(out, 3))
# -> weights ~ heavier on the first two neighbors
Attention weights: [[0.252 0.236 0.174 0.138 0.126 0.075]]
Output vector: [[0.318 0.221]]
Let’s visualize the weights from the above toy example:

Additionally, we can visualize this geometrically.

Cosine vs dot product vs RBF (soft k-NN flavors)
Try swapping the similarity and observe the heatmap change.
def attention_with_sim(Q, K, V, sim="dot", tau=1.0, eps=1e-9):
if sim == "dot":
scores = (Q @ K.T) / np.sqrt(K.shape[-1])
elif sim == "cos":
Qn = Q / (np.linalg.norm(Q, axis=-1, keepdims=True) + eps)
Kn = K / (np.linalg.norm(K, axis=-1, keepdims=True) + eps)
scores = (Qn @ Kn.T) / tau
elif sim == "rbf":
# scores = -||q-k||^2 / (2*tau^2)
q2 = np.sum(Q**2, axis=-1, keepdims=True) # (n_q, 1)
k2 = np.sum(K**2, axis=-1, keepdims=True).T # (1, n_k)
qk = Q @ K.T # (n_q, n_k)
d2 = q2 + k2 - 2*qk
scores = -d2 / (2 * tau**2)
else:
raise ValueError("sim in {dot, cos, rbf}")
W = softmax(scores, axis=-1)
return W @ V, W, scores
for sim in ["dot", "cos", "rbf"]:
out_s, W_s, _ = attention_with_sim(Q, K, V, sim=sim, tau=0.5)
print(sim, "weights:", np.round(W_s, 3), "out:", np.round(out_s, 3))
dot weights: [[0.252 0.236 0.174 0.138 0.126 0.075]] out: [[0.318 0.221]]
cos weights: [[0.397 0.394 0.113 0.05 0.037 0.008]] out: [[0.576 0.287]]
rbf weights: [[0.443 0.471 0.055 0.021 0.01 0. ]] out: [[0.651 0.268]]
Takeaway: similarity choice = inductive bias. Cosine focuses on angle; RBF on Euclidean neighborhoods; dot mixes both magnitude and direction.

Causal and padding masks (language modeling)
- Causal: prevent peeking at future tokens. For position t, block > t.
- Padding: zero-length tokens shouldn’t get attention.
# Causal mask for sequence length n (upper-triangular blocked)
n = 6
mask = np.triu(np.ones((n, n)) * -1e9, k=1)
# Visualize structure by setting Q=K=V (toy embeddings)
X = K
out_seq, A = attention(X, X, X, mask=mask)
# Row sums stay 1.0 (softmax is row-wise):
print(np.allclose(np.sum(A, axis=1), 1.0))
True

Padding mask tip: build a boolean mask where padding positions get −∞ in the added matrix; reuse the same attention function.
Quick demo: why the scaling works
Generate random 𝑄, 𝒦 with large 𝒅; compare softmax entropy with vs. without 1/sqrt{𝒅}.
def entropy(p, axis=-1, eps=1e-12):
p = np.clip(p, eps, 1.0)
return -np.sum(p * np.log(p), axis=axis)
nq = nk = 64
dims = [256*(2**i) for i in range(7)] # 256..16,384
trials = 5
H_max = np.log(nk)
for dim in dims:
H_u = []
H_s = []
for _ in range(trials):
Q = np.random.randn(nq, dim)
K = np.random.randn(nk, dim)
S_unscaled = Q @ K.T
S_scaled = S_unscaled / np.sqrt(dim)
H_u.append(entropy(softmax(S_unscaled, axis=-1), axis=-1).mean())
H_s.append(entropy(softmax(S_scaled, axis=-1), axis=-1).mean())
print(f"{dim:>6} | unscaled: {np.mean(H_u):.3f} scaled: {np.mean(H_s):.3f} (max={H_max:.3f})")
256 | unscaled: 0.280 scaled: 3.686 (max=4.159)
512 | unscaled: 0.165 scaled: 3.672 (max=4.159)
1024 | unscaled: 0.124 scaled: 3.682 (max=4.159)
2048 | unscaled: 0.078 scaled: 3.669 (max=4.159)
4096 | unscaled: 0.063 scaled: 3.689 (max=4.159)
8192 | unscaled: 0.041 scaled: 3.685 (max=4.159)
16384 | unscaled: 0.024 scaled: 3.694 (max=4.159)
Why is this important?
Short answer: the scale keeps softmax from collapsing.
- Your numbers show entropy ~0.07–0.28 (unscaled) vs ~3.68 (scaled). With 64 keys, the maximum possible entropy is ln(64)≈4.16.
- Unscaled ⇒ near-one-hot distributions: one key hogs the mass, others ~0. Vanishing/unstable gradients, brittle attention.
- Scaled by 1/sqrt{𝒅} ⇒ high-entropy, well-spread weights: multiple neighbors contribute; gradients remain healthy.
Why this happens: For random vectors with independent and identically distributed (iid) entries, qᵀk has variance∝d. As 𝒅 grows, logits’ scale grows, so softmax saturates. Dividing by sqrt{𝒅} normalizes the logit variance to O(1), keeping the “temperature” of the softmax roughly constant across dimensionalities.
Net: 1/sqrt{𝒅} preserves learnability and stability — attention remains a soft k-NN instead of degenerating into hard argmax.
Failure modes (and simple fixes)
1️⃣ Flat similarities ⇒ blurry outputs.
- Fix: lower temperature / raise scale; learn projections W_🄠, W_🄚 to separate tokens.
2️⃣ One token dominates (over-confident softmax) ⇒ brittle.
- Fix: temperature tuning, attention dropout, and multi-head diversity.
3️⃣ Wrong metric.
- Fix: cosine for angle-only; RBF for Euclidean locality; dot when magnitude carries signal.
From this to “Transformer attention”
Add learned projections:

And replicate heads h=1…H, then concatenate the outputs and mix with W_🄞 — same core: soft neighbor averaging, just in multiple learned subspaces.
Conclusion
Attention isn’t mystical — it’s soft k-NN with learnable projections. A query asks “who’s like me,” softmax turns similarities into a distribution, and the output is a weighted neighbor average. Two knobs make it work in practice:
- Scale by 1/sqrt{𝒅} to keep logits O(1) and preserve entropy — our demo shows saturation without it (near-argmax), and healthy, dimension-invariant softness with it.
- Masks are routing rules: causal for “no peeking,” padding for “ignore blanks.”
Your similarity choice is an inductive bias: dot (magnitude+direction), cosine (angle), RBF (Euclidean neighborhoods). Multi-head runs this in parallel subspaces and mixes them.
When things fail: flat sims ⇒ blurry; peaky sims ⇒ brittle; wrong metric ⇒ misfocus, fix with temperature/scale, dropout, better projections, or a metric that matches the geometry of your data.
Bottom line: think of attention as probabilistic neighbor averaging with a thermostat. Get the temperature right (1/sqrt{𝒅}), pick the right neighborhood (similarity + masks), and the rest is engineering.
Attention = Soft k-NN was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Mastering LoRA: A Gentle Path to Custom Large-Language Models

Imagine owning a magnificent state-of-the-art, without any comparison. Think of an unbridled artist capable of preparing any world’s best…
Why Python 3.14 Matters: Free-Threaded, Faster, True Async

Official free-threaded mode, cleaner syntax, and powerful stdlib additions for AI, data, and web apps.
I Built a Clinical AI Agent — and It Skipped the Tools I Gave It

An evaluation of tool coverage in local healthcare agents, with a simple fix.
Context Engineering 101 → From Dumb to Smart AI Agents

Understanding the different types of context is crucial for practical context engineering
5 Techniques to Prevent Hallucinations in Your RAG Question Answering
Learn how to reduce the number of hallucinations, and the impact they have
The post 5 Techniques to Prevent Hallucinations in Your RAG Question Answering appeared first on Towards Data Science.
How to Connect an MCP Server for an AI-Powered, Supply-Chain Network Optimization Agent
From prompt to strategic decision-making: MCP-powered agents for cost-efficient, reliable and sustainable supply chain network design.
The post How to Connect an MCP Server for an AI-Powered, Supply-Chain Network Optimization Agent appeared first on Towards Data Science.
The Kolmogorov–Smirnov Statistic, Explained: Measuring Model Power in Credit Risk Modeling
Understanding how banks use the KS statistic in loan approvals.
The post The Kolmogorov–Smirnov Statistic, Explained: Measuring Model Power in Credit Risk Modeling appeared first on Towards Data Science.
Creating and Deploying an MCP Server from Scratch
A step-by-step guide for putting an MCP server online in minutes
The post Creating and Deploying an MCP Server from Scratch appeared first on Towards Data Science.
Integrating DataHub into Jira: A Practical Guide Using DataHub Actions
A walkthrough of how to integrate metadata changes in DataHub into Jira workflows using the DataHub Actions Framework
The post Integrating DataHub into Jira: A Practical Guide Using DataHub Actions appeared first on Towards Data Science.
The Theory of Universal Computation: Bayesian Optimality, Solomonoff Induction & AIXI
Is it possible to build a perfect induction machine?
The post The Theory of Universal Computation: Bayesian Optimality, Solomonoff Induction & AIXI appeared first on Towards Data Science.
Confirmed, Finally, Again: No Visual Studio IDE for Linux/macOS
Keep asking; it ain't happening. Microsoft has reaffirmed that its full-featured Visual Studio IDE will remain exclusive to Windows, ending a years-long debate over bringing it to Linux and macOS by directing developers to use Visual Studio Code for cross-platform development.
Interview with Luc De Raedt: talking probabilistic logic, neurosymbolic AI, and explainability
Should AI continue to be driven by a single paradigm, or does real progress lie in combining the strengths and weaknesses of many? Professor Luc De Raedt of KU Leuven has spent much of his career persistently addressing this question. Through pioneering work that bridges logic, probability, and machine learning, he has helped shape the […]
Call for AAAI educational AI videos
The Association for the Advancement of Artificial Intelligence (AAAI) is calling for submissions to a competition for educational AI videos for general audiences. These videos must be two to three minutes in length and should aim to convey informative, accurate, and timely information about AI research and applications. The video could highlight your own research, […]